⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-07 更新
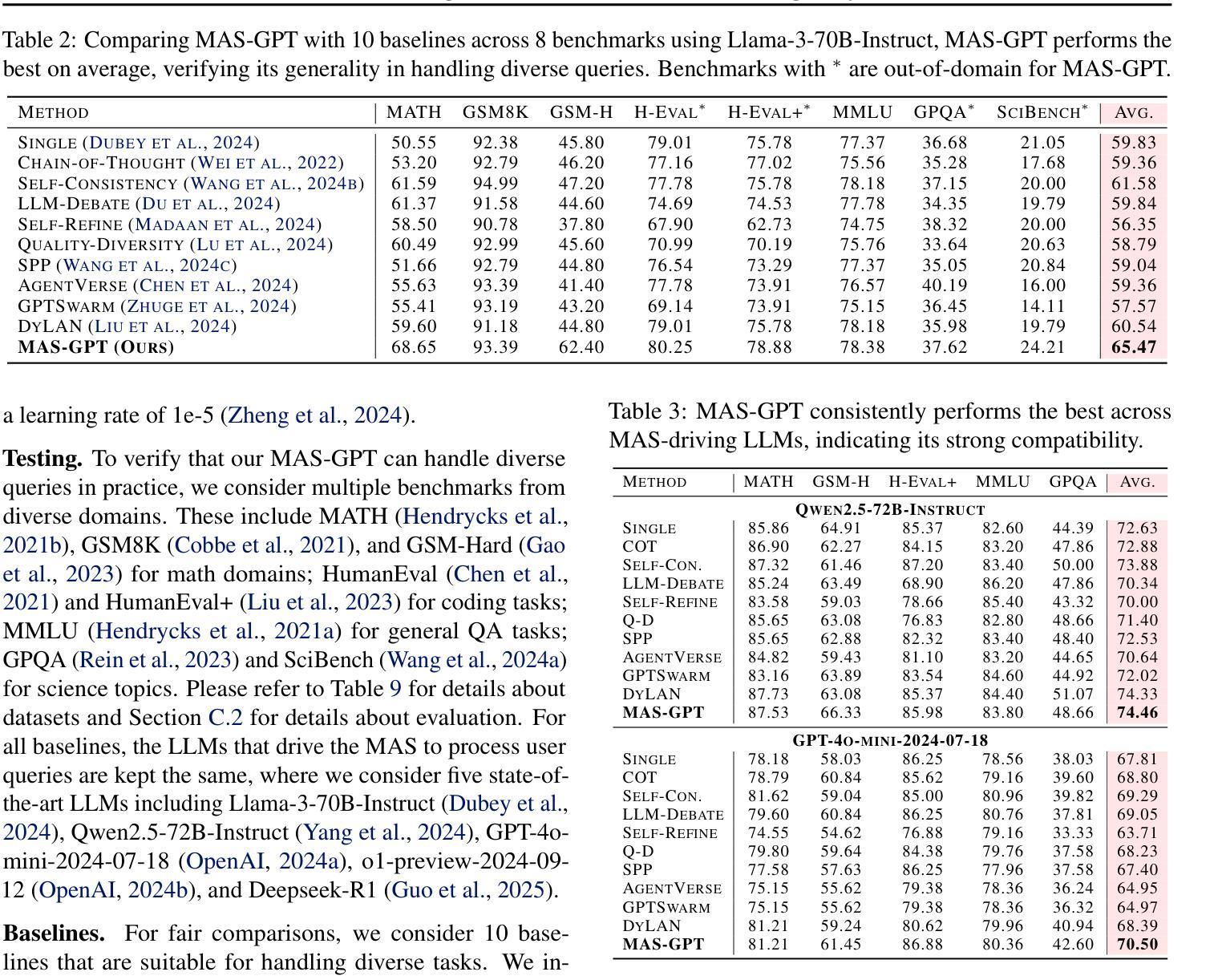
MAS-GPT: Training LLMs to Build LLM-based Multi-Agent Systems
Authors:Rui Ye, Shuo Tang, Rui Ge, Yaxin Du, Zhenfei Yin, Siheng Chen, Jing Shao
LLM-based multi-agent systems (MAS) have shown significant potential in tackling diverse tasks. However, to design effective MAS, existing approaches heavily rely on manual configurations or multiple calls of advanced LLMs, resulting in inadaptability and high inference costs. In this paper, we simplify the process of building an MAS by reframing it as a generative language task, where the input is a user query and the output is a corresponding MAS. To address this novel task, we unify the representation of MAS as executable code and propose a consistency-oriented data construction pipeline to create a high-quality dataset comprising coherent and consistent query-MAS pairs. Using this dataset, we train MAS-GPT, an open-source medium-sized LLM that is capable of generating query-adaptive MAS within a single LLM inference. The generated MAS can be seamlessly applied to process user queries and deliver high-quality responses. Extensive experiments on 9 benchmarks and 5 LLMs show that the proposed MAS-GPT consistently outperforms 10+ baseline MAS methods on diverse settings, indicating MAS-GPT’s high effectiveness, efficiency and strong generalization ability. Code will be available at https://github.com/rui-ye/MAS-GPT.
基于LLM的多智能体系统(MAS)在处理各种任务时显示出巨大的潜力。然而,为了设计有效的MAS,现有方法严重依赖于手动配置或多次调用高级LLM,导致不适应和高推理成本。在本文中,我们通过将其重构为生成式语言任务来简化构建MAS的过程,其中输入是用户查询,输出是相应的MAS。为了解决这项新任务,我们将MAS的表示形式统一为可执行代码,并提出了一种面向一致性的数据构建管道,以创建包含连贯和一致查询-MAS对的高质量数据集。使用该数据集,我们训练了MAS-GPT,这是一个开源的中型LLM,能够在单个LLM推理内生成查询适应性MAS。生成的MAS可以无缝应用于处理用户查询并提供高质量响应。在9个基准测试和5个LLM上的广泛实验表明,所提出的MAS-GPT在多种设置下始终优于10多个基线MAS方法,证明了MAS-GPT的高效率、高效能和强大的泛化能力。代码将在https://github.com/rui-ye/MAS-GPT上提供。
论文及项目相关链接
PDF 26 pages, 7 figures
Summary
基于LLM的多智能体系统(MAS)在处理多样化任务时显示出巨大潜力。然而,现有方法过于依赖手动配置或多次调用高级LLM,导致适应性和推理成本较高。本文简化了构建MAS的过程,将其重构为生成式语言任务,其中输入是用户查询,输出是相应的MAS。为应对这一新任务,我们统一了MAS的可执行代码表示,并提出了一种面向一致性的数据构建流程,以创建高质量的查询-MAS对数据集。基于此数据集,我们训练了MAS-GPT这一开源中型LLM,它能够生成查询自适应的MAS,只需一次LLM推理即可。生成的MAS可无缝应用于处理用户查询并返回高质量响应。在九个基准测试和五种LLM上的广泛实验表明,MAS-GPT在多种设置下始终优于十多种基线MAS方法,证明了其高效性、高效能和强大的泛化能力。
Key Takeaways
- LLM-based MAS在处理多样化任务时具有显著潜力。
- 当前MAS设计过于依赖手动配置或多次LLM调用,导致不适应和高成本。
- 本文将构建MAS简化为生成式语言任务,以用户查询为输入,生成相应的MAS为输出。
- 提出了一种面向一致性的数据构建流程来创建高质量的查询-MAS对数据集。
- 训练了MAS-GPT这一开源中型LLM,可生成查询自适应的MAS,提高效率和性能。
- MAS-GPT在多个基准测试上表现出优于多种基线MAS方法的性能。
点此查看论文截图


Multi-Agent DRL for Queue-Aware Task Offloading in Hierarchical MEC-Enabled Air-Ground Networks
Authors:Muhammet Hevesli, Abegaz Mohammed Seid, Aiman Erbad, Mohamed Abdallah
Mobile edge computing (MEC)-enabled air-ground networks are a key component of 6G, employing aerial base stations (ABSs) such as unmanned aerial vehicles (UAVs) and high-altitude platform stations (HAPS) to provide dynamic services to ground IoT devices (IoTDs). These IoTDs support real-time applications (e.g., multimedia and Metaverse services) that demand high computational resources and strict quality of service (QoS) guarantees in terms of latency and task queue management. Given their limited energy and processing capabilities, IoTDs rely on UAVs and HAPS to offload tasks for distributed processing, forming a multi-tier MEC system. This paper tackles the overall energy minimization problem in MEC-enabled air-ground integrated networks (MAGIN) by jointly optimizing UAV trajectories, computing resource allocation, and queue-aware task offloading decisions. The optimization is challenging due to the nonconvex, nonlinear nature of this hierarchical system, which renders traditional methods ineffective. We reformulate the problem as a multi-agent Markov decision process (MDP) with continuous action spaces and heterogeneous agents, and propose a novel variant of multi-agent proximal policy optimization with a Beta distribution (MAPPO-BD) to solve it. Extensive simulations show that MAPPO-BD outperforms baseline schemes, achieving superior energy savings and efficient resource management in MAGIN while meeting queue delay and edge computing constraints.
移动边缘计算(MEC)赋能的空地网络是6G的关键组成部分,利用空中基站(ABS),如无人机(UAV)和高空平台站(HAPS),为地面物联网设备(IoTD)提供动态服务。这些IoTD支持需要高计算资源和严格的延迟及任务队列管理服务质量(QoS)保证的实时应用程序(例如,多媒体和元宇宙服务)。鉴于其有限的能源和处理能力,IoTD依赖于无人机和HAPS进行任务卸载以进行分布式处理,形成了多层MEC系统。本文针对由无人机和HAP构成的移动边缘计算赋能的空地集成网络(MAGIN)中的总体能量最小化问题,通过联合优化无人机轨迹、计算资源分配和任务卸载决策来解决。优化具有挑战性,因为层次系统的非凸非线性性质使得传统方法无效。我们将该问题重新制定为一个具有连续动作空间和异质代理的多智能体马尔可夫决策过程(MDP),并提出一种基于Beta分布的多智能体近端策略优化(MAPPO-BD)的新变体来解决这个问题。大量模拟表明,MAPPO-BD优于基线方案,在MAGIN中实现出色的节能效果和高效资源管理,同时满足队列延迟和边缘计算约束。
论文及项目相关链接
Summary
移动边缘计算(MEC)赋能的空地网络是6G的关键组成部分,利用无人机(UAVs)和高空平台站(HAPS)等空中基站(ABSs)为地面物联网设备(IoTDs)提供动态服务。面对高计算资源和严格服务质量(QoS)需求的实时应用程序(例如多媒体和元宇宙服务),IoTDs借助UAVs和HAPS进行任务卸载,形成多层MEC系统。本文联合优化无人机轨迹、计算资源分配和任务卸载决策,解决MEC赋能的空地一体化网络(MAGIN)的总体能耗最小化问题。由于层次系统的非凸非线性特性,优化具有挑战性。本文将问题重新表述为多智能体马尔可夫决策过程(MDP),提出一种基于Beta分布的多智能体近端策略优化变体(MAPPO-BD)来解决。模拟结果表明,MAPPO-BD优于基线方案,在MAGIN中实现节能、高效资源管理,满足队列延迟和边缘计算约束。
Key Takeaways
- MEC赋能的空地网络是6G的重要组成部分,采用空中基站(ABSs)如无人机(UAVs)和高空平台站(HAPS)为地面物联网设备(IoTDs)提供支持。
- IoTDs需要处理高计算资源和严格服务质量(QoS)需求的实时应用,依赖于UAVs和HAPS进行任务卸载以实现多层次的MEC系统。
- 本文解决了在MEC赋能的空地一体化网络(MAGIN)中的能耗最小化问题,该问题涉及非线性且非凸的优化问题。
- 优化问题被重新表述为多智能体马尔可夫决策过程(MDP),涉及轨迹优化、计算资源分配以及考虑队列延迟的任务卸载决策。
- 提出了一种新的优化算法MAPPO-BD来解决该问题,该算法结合了多智能体近端策略优化和Beta分布策略。
- 模拟实验表明,MAPPO-BD算法相较于基线方案能够更有效地减少能耗并实现资源的高效管理。
点此查看论文截图


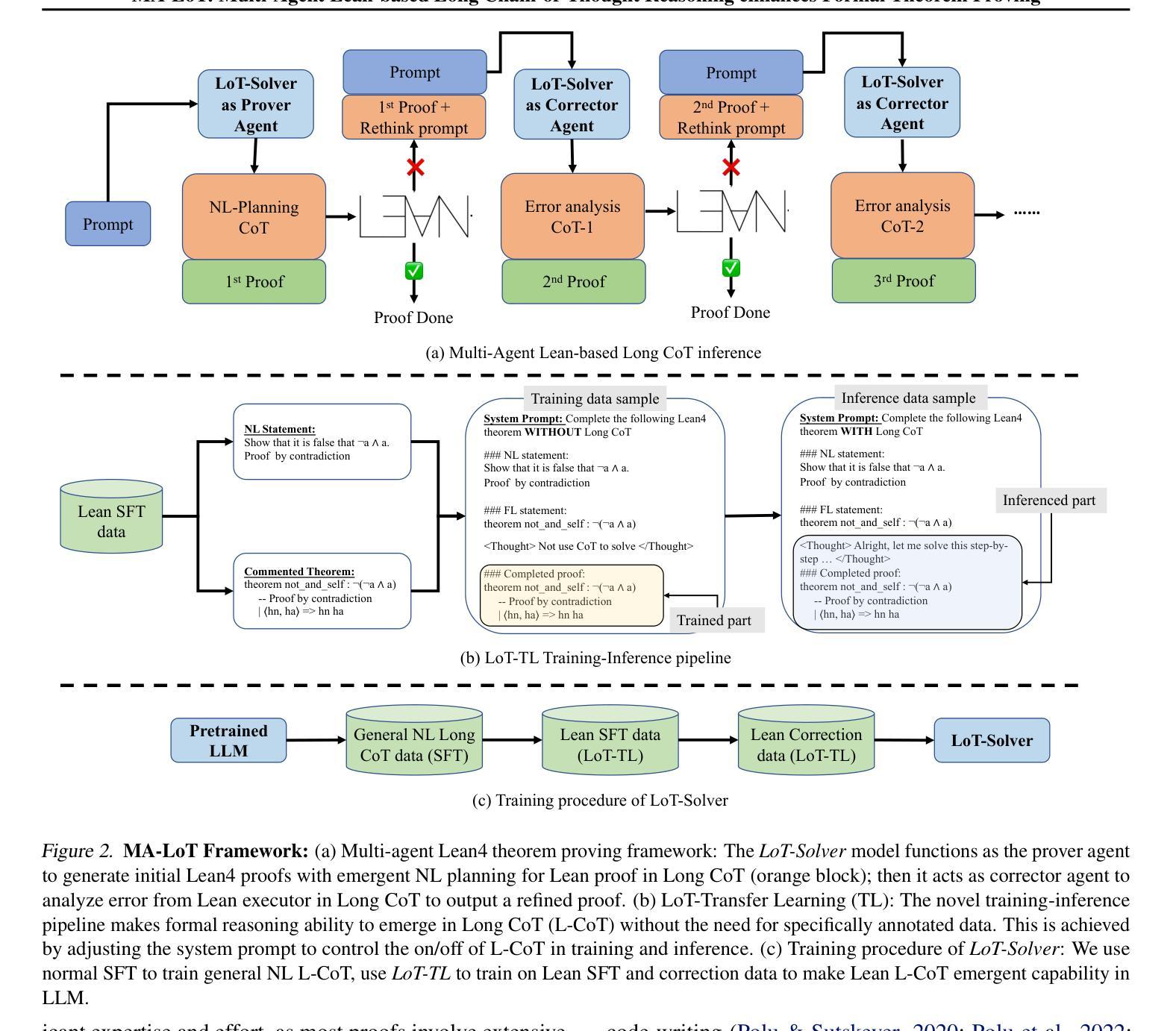
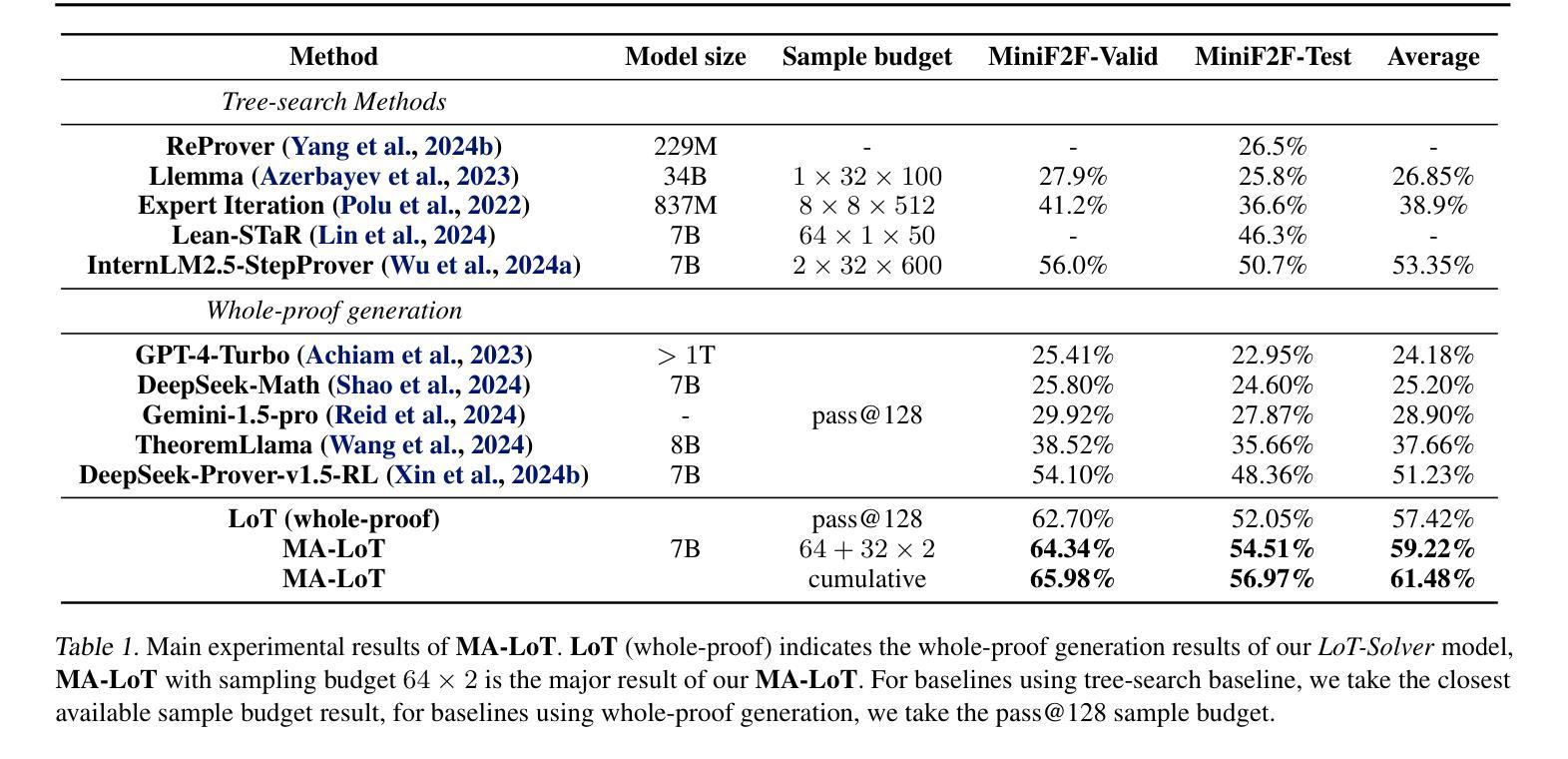
MA-LoT: Multi-Agent Lean-based Long Chain-of-Thought Reasoning enhances Formal Theorem Proving
Authors:Ruida Wang, Rui Pan, Yuxin Li, Jipeng Zhang, Yizhen Jia, Shizhe Diao, Renjie Pi, Junjie Hu, Tong Zhang
Solving mathematical problems using computer-verifiable languages like Lean has significantly impacted mathematical and computer science communities. State-of-the-art methods utilize single Large Language Models (LLMs) as agents or provers to either generate complete proof or perform tree searches. However, single-agent methods inherently lack a structured way to combine high-level reasoning in Natural Language (NL) with Formal Language (FL) verification feedback. To solve these issues, we propose MA-LoT: Multi-Agent Lean-based Long Chain-of-Thought framework, (to the best of our knowledge), the first multi-agent framework for Lean4 theorem proving that balance high-level NL reasoning and FL verification in Long CoT. Using this structured interaction, our approach enables deeper insights and long-term coherence in proof generation, with which past methods struggle. We do this by leveraging emergent formal reasoning ability in Long CoT using our novel LoT-Transfer Learning training-inference pipeline. Extensive experiments show that our framework achieves 54.51% accuracy rate on the Lean4 version of MiniF2F-Test dataset, largely outperforming GPT-4 (22.95%), single-agent tree search (InternLM-Step-Prover, 50.70%), and whole-proof generation (DeepSeek-Prover-v1.5, 48.36%) baselines. Furthermore, our findings highlight the potential of combining Long CoT with formal verification for a more insightful generation in a broader perspective.
使用诸如Lean之类的可验证计算机语言解决数学问题对数学和计算机科学社区产生了重大影响。最先进的方法使用单一的大型语言模型(LLM)作为代理或证明者来生成完整的证明或执行树搜索。然而,单代理方法本身缺乏将自然语言(NL)中的高级推理与形式语言(FL)验证反馈相结合的结构化方法。为了解决这些问题,我们提出了MA-LoT:基于Lean的多代理长期思维链框架(据我们所知,这是第一个在Long CoT中平衡高级NL推理和FL验证的Lean4定理证明多代理框架)。通过这种结构化的交互,我们的方法能够在证明生成过程中提供更深入的见解和长期的一致性,这是过去的方法所难以做到的。我们通过利用我们新颖的长链思维中的新兴形式推理能力,以及我们的LoT-迁移学习训练推理管道来实现这一点。大量实验表明,我们的框架在Lean4版本的MiniF2F-Test数据集上达到了54.51%的准确率,大大超过了GPT-4(22.95%)、单代理树搜索(InternLM-Step-Prover,50.70%)和全证明生成(DeepSeek-Prover-v1.5,48.36%)的基准线。此外,我们的研究结果表明,从长远来看,将长链思维与形式验证相结合具有更深刻洞察的潜力。
论文及项目相关链接
Summary
利用计算机验证语言如Lean解决数学问题对数学和计算机科学社区产生了深远影响。当前方法主要使用单一的大型语言模型(LLM)作为代理或证明者来生成完整的证明或执行树搜索。然而,单代理方法缺乏将自然语言(NL)中的高级推理与形式语言(FL)验证反馈相结合的结构化方式。为解决这些问题,我们提出了MA-LoT:基于Lean的多代理长思考链框架(据我们所知,这是首个在Lean4定理证明中平衡高级NL推理和FL验证的多代理框架)。通过结构化的交互方式,我们的方法能够在证明生成过程中提供更深入的见解和长期的一致性,这是过去的方法所难以做到的。我们使用新兴的形式推理能力在长思考链中使用我们新颖的训练推理管道LoT-Transfer Learning。大量实验表明,我们的框架在Lean4版本的MiniF2F测试数据集上达到了54.51%的准确率,大幅超越了GPT-4(22.95%)、单代理树搜索(InternLM-Step-Prover,50.70%)和全证明生成(DeepSeek-Prover-v1.5,48.36%)的基准测试。此外,我们的研究还发现,将长思考链与形式验证相结合具有更广阔的应用前景,能提供更深入的见解生成。
Key Takeaways
- 利用计算机验证语言如Lean解决数学问题对两个社区有深远影响。
- 当前方法主要依赖单一的大型语言模型(LLM)。
- 单一代理缺乏结构化方式结合自然语言(NL)中的高级推理与形式语言(FL)验证反馈。
- 提出MA-LoT框架,首次在Lean定理证明中平衡高级NL推理和FL验证。
- MA-LoT利用新兴的形式推理能力在长思考链中进行结构化交互以提高证明质量。
- MA-LoT在特定的数据集上表现出超越其他模型的性能表现。
点此查看论文截图

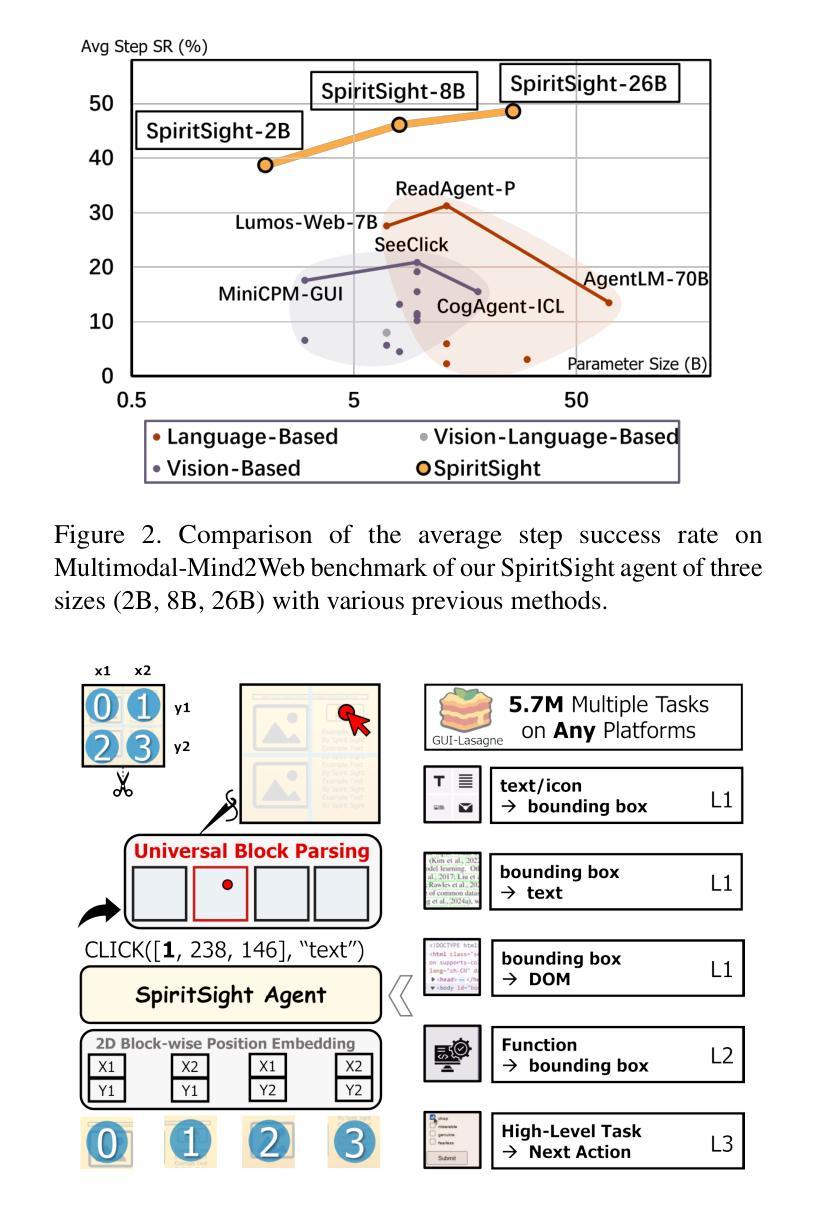
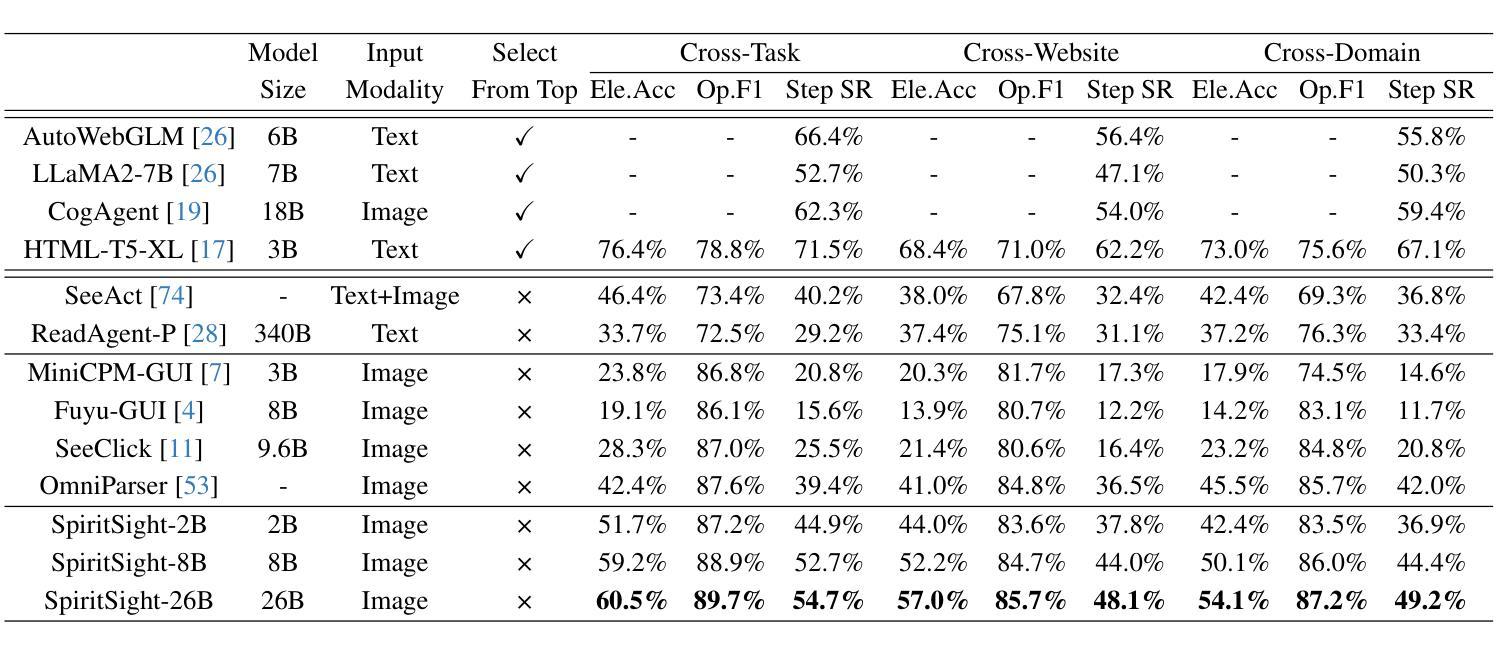
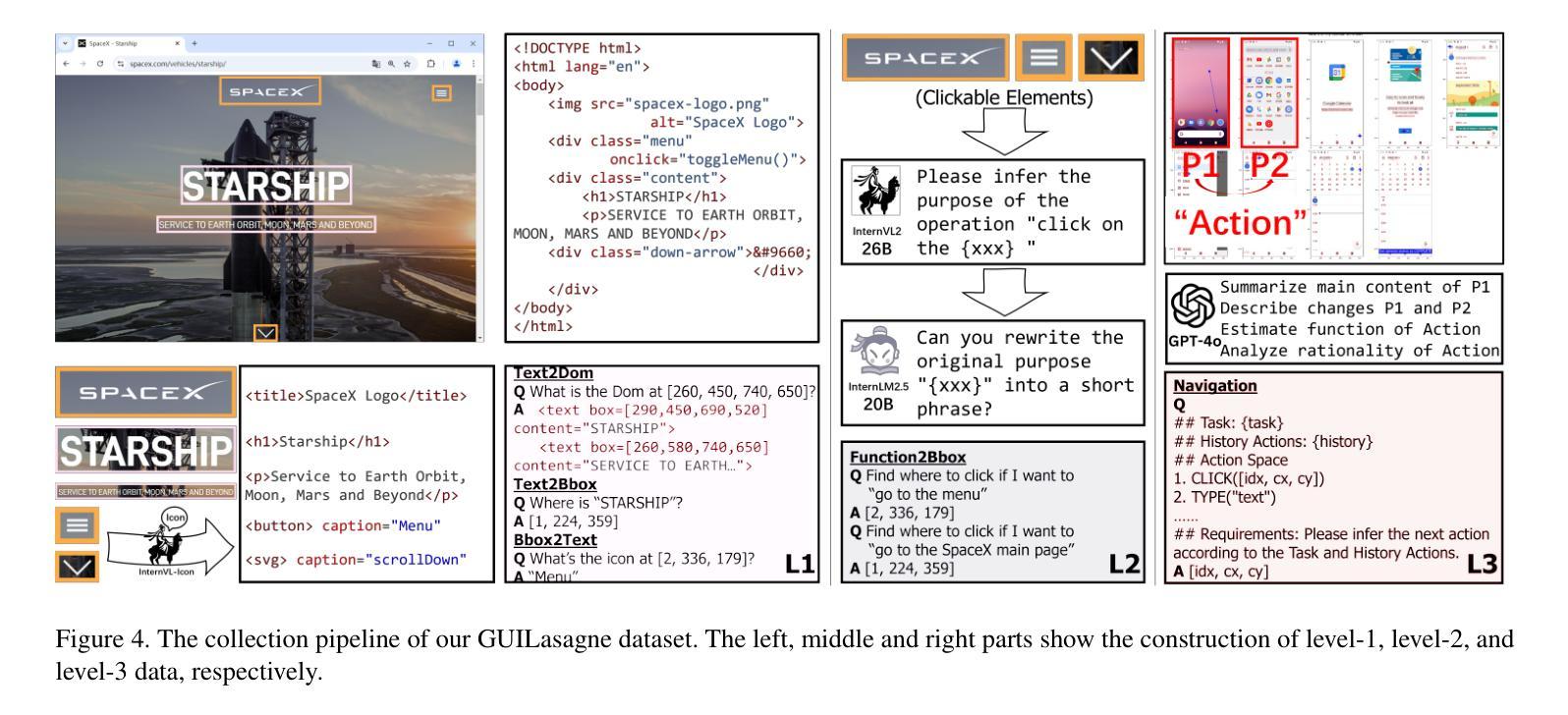
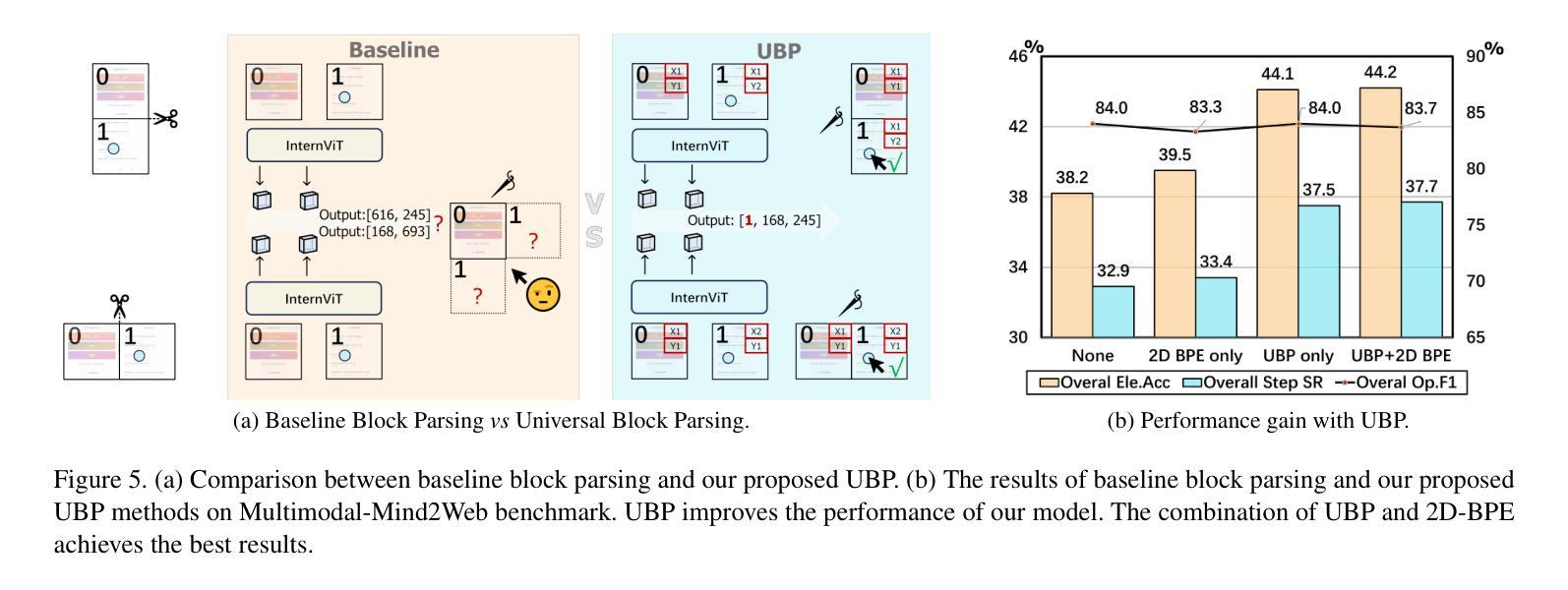
SpiritSight Agent: Advanced GUI Agent with One Look
Authors:Zhiyuan Huang, Ziming Cheng, Junting Pan, Zhaohui Hou, Mingjie Zhan
Graphical User Interface (GUI) agents show amazing abilities in assisting human-computer interaction, automating human user’s navigation on digital devices. An ideal GUI agent is expected to achieve high accuracy, low latency, and compatibility for different GUI platforms. Recent vision-based approaches have shown promise by leveraging advanced Vision Language Models (VLMs). While they generally meet the requirements of compatibility and low latency, these vision-based GUI agents tend to have low accuracy due to their limitations in element grounding. To address this issue, we propose $\textbf{SpiritSight}$, a vision-based, end-to-end GUI agent that excels in GUI navigation tasks across various GUI platforms. First, we create a multi-level, large-scale, high-quality GUI dataset called $\textbf{GUI-Lasagne}$ using scalable methods, empowering SpiritSight with robust GUI understanding and grounding capabilities. Second, we introduce the $\textbf{Universal Block Parsing (UBP)}$ method to resolve the ambiguity problem in dynamic high-resolution of visual inputs, further enhancing SpiritSight’s ability to ground GUI objects. Through these efforts, SpiritSight agent outperforms other advanced methods on diverse GUI benchmarks, demonstrating its superior capability and compatibility in GUI navigation tasks. Models are available at $\href{https://huggingface.co/SenseLLM/SpiritSight-Agent-8B}{this\ URL}$.
图形用户界面(GUI)代理在辅助人机交互、自动化人类用户在数字设备上的导航方面展示了惊人的能力。一个理想的GUI代理应该达到高准确性、低延迟,并兼容不同的GUI平台。最近的基于视觉的方法通过利用先进的视觉语言模型(VLMs)显示出希望。虽然它们通常满足兼容性和低延迟的要求,但这些基于视觉的GUI代理往往由于元素定位的限制而准确性较低。为了解决这个问题,我们提出了基于视觉的端到端GUI代理——SpiritSight,它在各种GUI平台的GUI导航任务中表现出色。首先,我们使用可扩展的方法创建了一个多层次、大规模、高质量的GUI数据集,名为GUI-Lasagne,为SpiritSight提供强大的GUI理解和定位能力。其次,我们引入了通用块解析(UBP)方法来解决动态高分辨率视觉输入的歧义问题,进一步增强了SpiritSight定位GUI对象的能力。通过这些努力,SpiritSight代理在多种GUI基准测试上的表现超过了其他先进方法,证明了其在GUI导航任务中的卓越能力和兼容性。模型可在这个URL找到。
论文及项目相关链接
PDF Paper accepted to CVPR 2025
Summary
本文介绍了一种名为SpiritSight的基于视觉的端到端GUI代理,旨在解决不同GUI平台上的导航任务。该代理通过创建大规模的GUI数据集GUI-Lasagne和使用Universal Block Parsing(UBP)方法解决视觉输入中的模糊问题,提高了GUI对象的接地能力。SpiritSight代理在多种GUI基准测试上表现出卓越的性能和兼容性。
Key Takeaways
- SpiritSight是一种基于视觉的端到端GUI代理,用于解决不同GUI平台上的导航任务。
- 创建了大规模的GUI数据集GUI-Lasagne,增强了SpiritSight对GUI的理解和接地能力。
- 引入了Universal Block Parsing(UBP)方法,解决了视觉输入中的模糊问题,提高了SpiritSight对GUI对象的接地能力。
- SpiritSight代理在多种GUI基准测试上表现出卓越的性能。
- Vision Language Models(VLMs)在GUI代理中的应用具有潜力,但仍存在准确性问题。
- 当前GUI代理需要同时满足高准确性、低延迟和不同GUI平台的兼容性。
点此查看论文截图

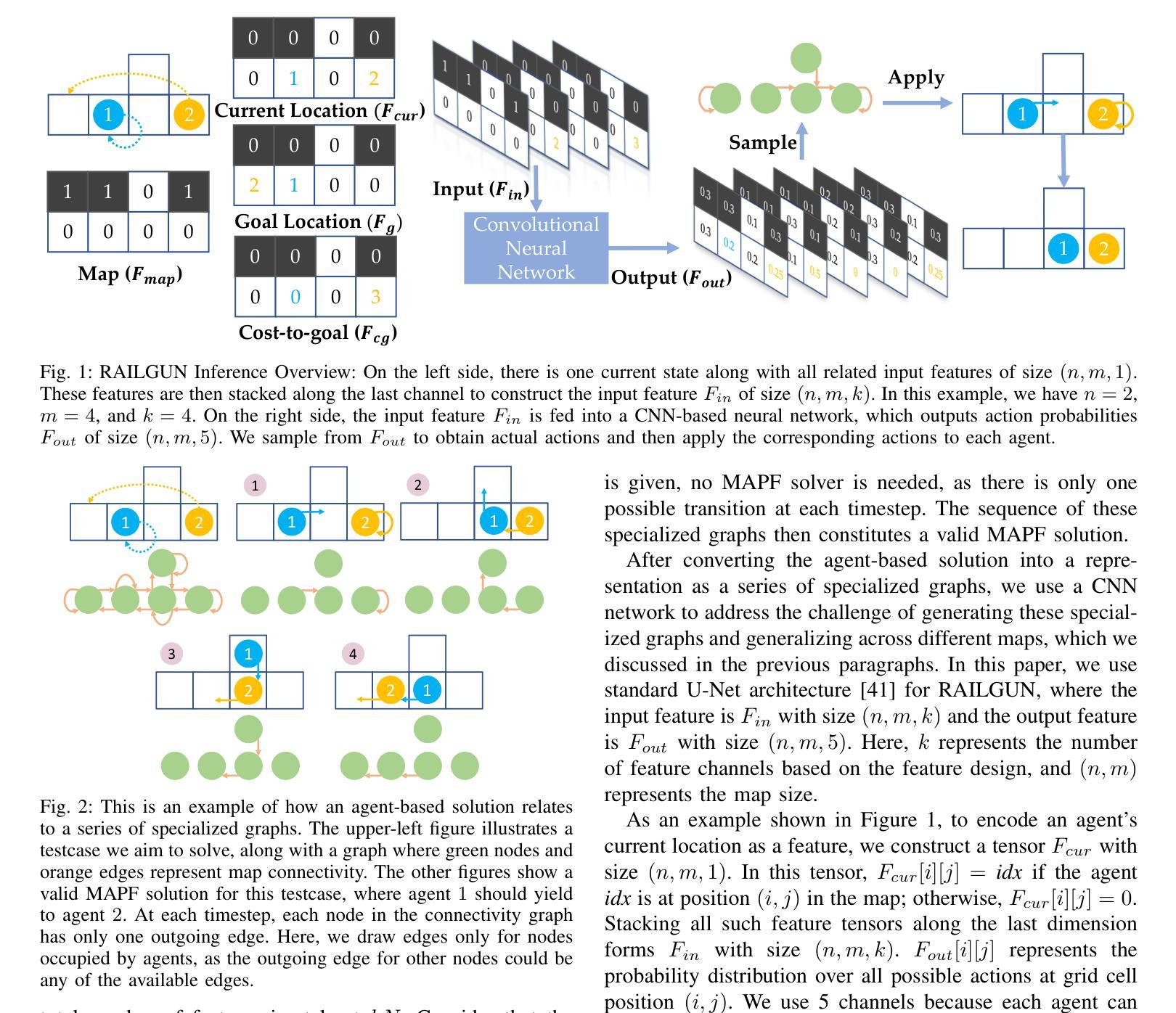
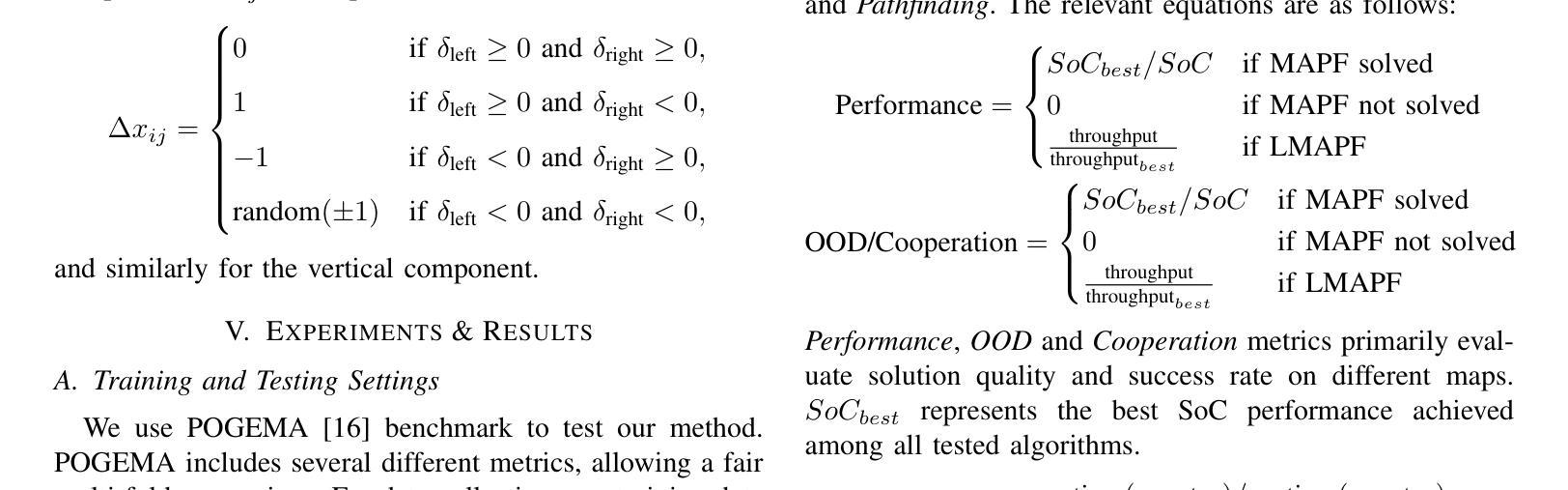
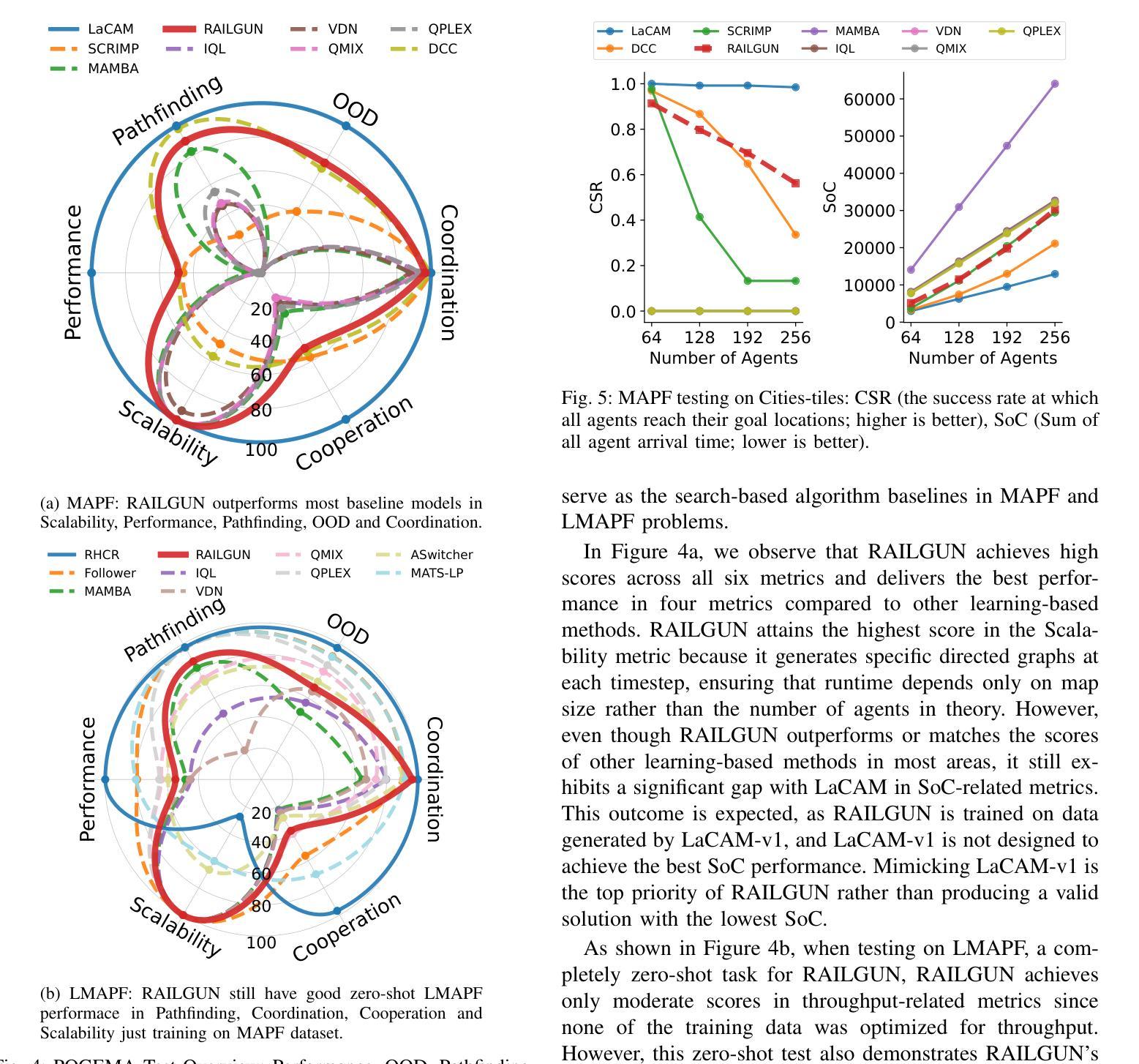
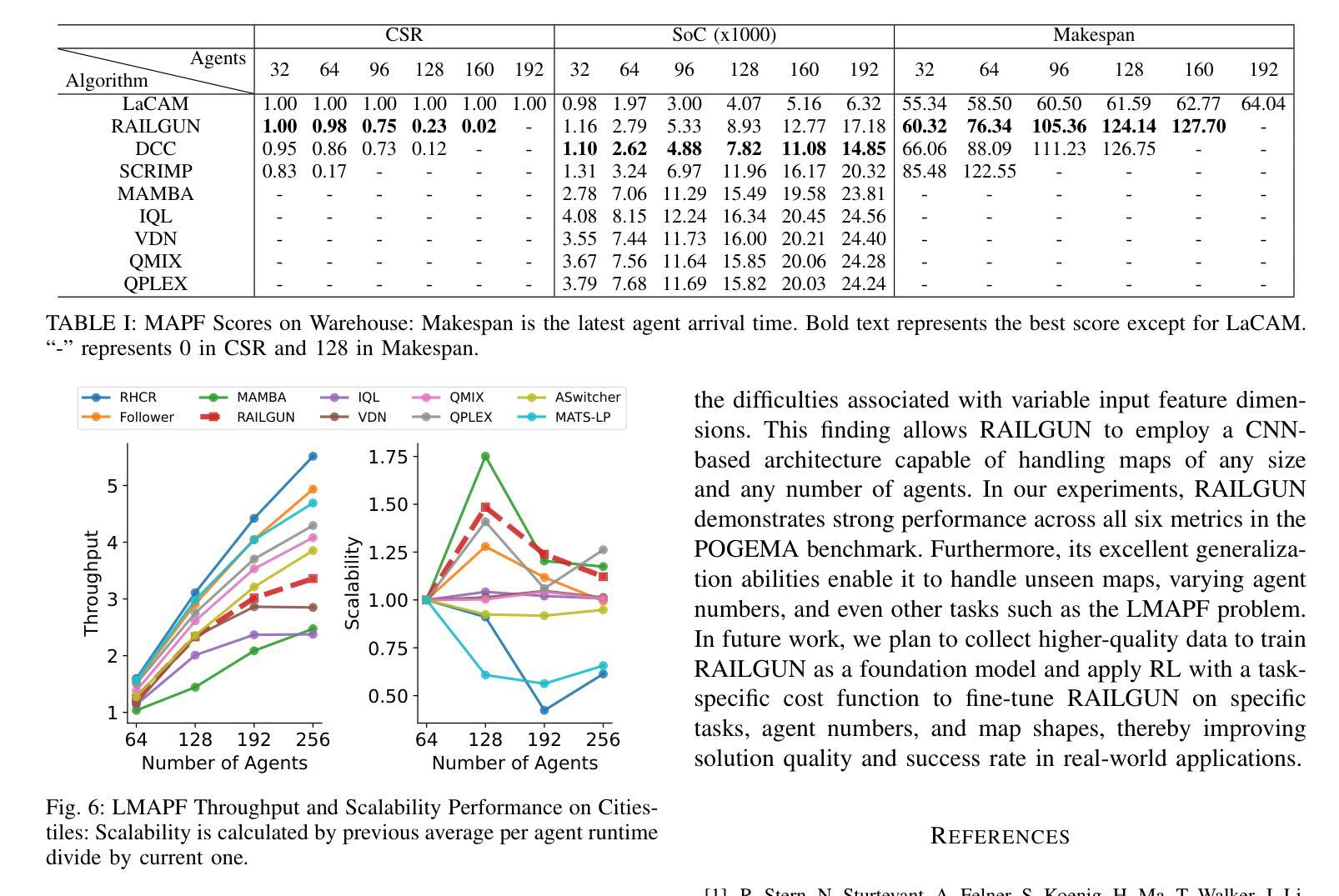
RAILGUN: A Unified Convolutional Policy for Multi-Agent Path Finding Across Different Environments and Tasks
Authors:Yimin Tang, Xiao Xiong, Jingyi Xi, Jiaoyang Li, Erdem Bıyık, Sven Koenig
Multi-Agent Path Finding (MAPF), which focuses on finding collision-free paths for multiple robots, is crucial for applications ranging from aerial swarms to warehouse automation. Solving MAPF is NP-hard so learning-based approaches for MAPF have gained attention, particularly those leveraging deep neural networks. Nonetheless, despite the community’s continued efforts, all learning-based MAPF planners still rely on decentralized planning due to variability in the number of agents and map sizes. We have developed the first centralized learning-based policy for MAPF problem called RAILGUN. RAILGUN is not an agent-based policy but a map-based policy. By leveraging a CNN-based architecture, RAILGUN can generalize across different maps and handle any number of agents. We collect trajectories from rule-based methods to train our model in a supervised way. In experiments, RAILGUN outperforms most baseline methods and demonstrates great zero-shot generalization capabilities on various tasks, maps and agent numbers that were not seen in the training dataset.
多智能体路径查找(MAPF)专注于为多个机器人找到无碰撞路径,对于从空中集群到仓库自动化等应用至关重要。解决MAPF问题是NP难题,因此基于学习的MAPF方法引起了关注,特别是那些利用深度神经网络的方法。尽管如此,尽管社区一直在努力,所有基于学习的MAPF规划器仍依赖于分散式规划,这是由于智能体和地图大小的差异造成的。我们为MAPF问题开发了第一个集中式学习策略,名为RAILGUN。RAILGUN不是基于智能体的策略,而是基于地图的策略。通过利用基于CNN的架构,RAILGUN可以在不同的地图上推广,并处理任何数量的智能体。我们从基于规则的方法收集轨迹,以监督方式训练我们的模型。在实验中,RAILGUN的性能超过了大多数基线方法,并在各种任务、地图和智能体数量上表现出了出色的零样本泛化能力,这些任务在训练数据集中都未曾出现。
论文及项目相关链接
PDF 7 pages
Summary
多智能体路径查找(MAPF)对于从无人机群到仓库自动化等多种应用至关重要。学习基于的方法,特别是利用深度神经网络的方法,已引起关注。然而,由于智能体数量和地图规模的变化,所有基于学习的MAPF规划器仍依赖于分散式规划。我们开发了首个针对MAPF问题的集中式学习政策,名为RAILGUN。RAILGUN不是基于智能体的政策,而是基于地图的政策。通过利用CNN架构,RAILGUN可以概括不同的地图,并处理任何数量的智能体。我们通过收集规则基础方法的轨迹以监督的方式训练我们的模型。在实验中,RAILGUN在多种任务、地图和智能体数量上超越了大多数基线方法,并在训练数据集未见的情况下表现出强大的零样本泛化能力。
Key Takeaways
- 多智能体路径查找(MAPF)在许多应用中发挥着重要作用,包括无人机群和仓库自动化。
- 解决MAPF是NP难题,因此基于学习的方法,特别是使用深度神经网络的方法受到了关注。
- 基于学习的MAPF规划器仍面临智能体数量和地图规模变化带来的挑战,因此需要分散式规划。
- 开发了首个针对MAPF问题的集中式学习政策RAILGUN。
- RAILGUN是一个基于地图的政策,可以概括不同的地图,并处理任何数量的智能体。
- RAILGUN通过收集规则基础方法的轨迹以监督方式训练模型。
点此查看论文截图


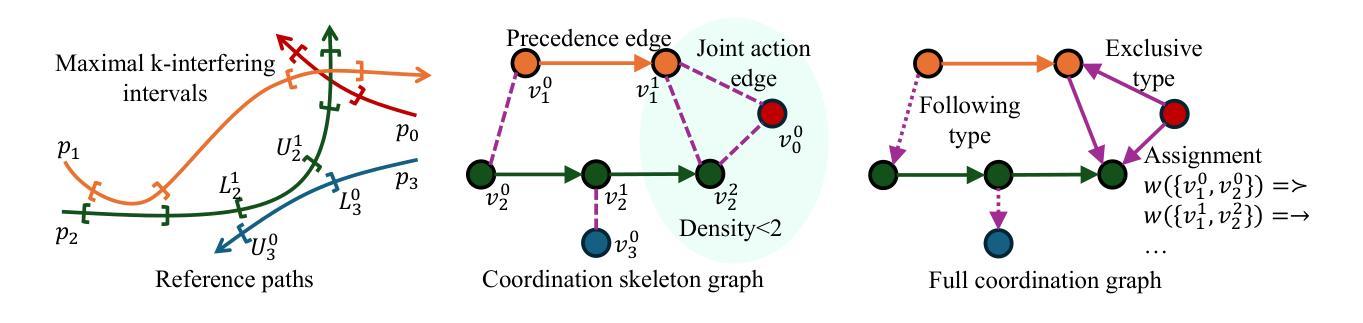
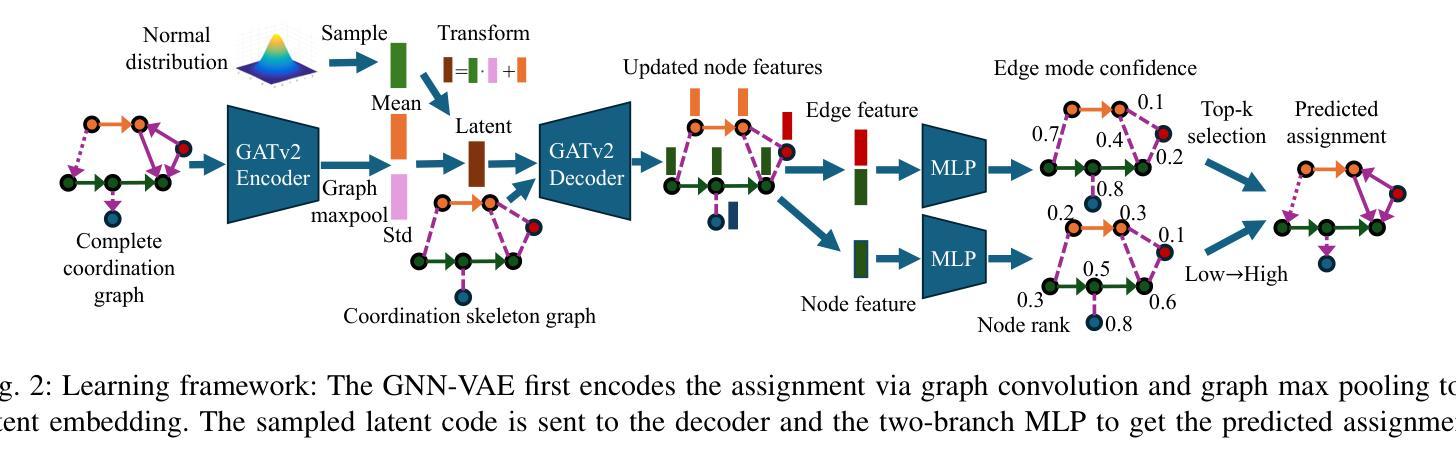
Reliable and Efficient Multi-Agent Coordination via Graph Neural Network Variational Autoencoders
Authors:Yue Meng, Nathalie Majcherczyk, Wenliang Liu, Scott Kiesel, Chuchu Fan, Federico Pecora
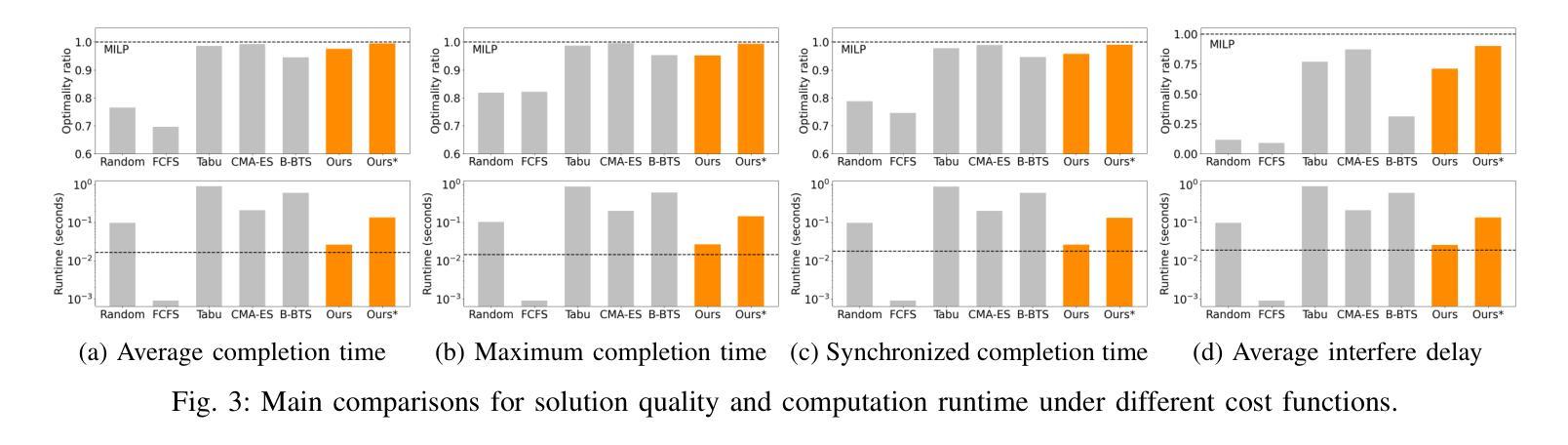
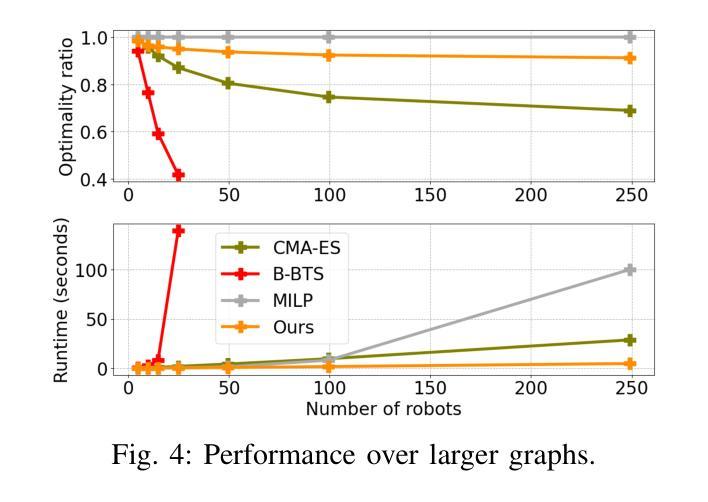
Multi-agent coordination is crucial for reliable multi-robot navigation in shared spaces such as automated warehouses. In regions of dense robot traffic, local coordination methods may fail to find a deadlock-free solution. In these scenarios, it is appropriate to let a central unit generate a global schedule that decides the passing order of robots. However, the runtime of such centralized coordination methods increases significantly with the problem scale. In this paper, we propose to leverage Graph Neural Network Variational Autoencoders (GNN-VAE) to solve the multi-agent coordination problem at scale faster than through centralized optimization. We formulate the coordination problem as a graph problem and collect ground truth data using a Mixed-Integer Linear Program (MILP) solver. During training, our learning framework encodes good quality solutions of the graph problem into a latent space. At inference time, solution samples are decoded from the sampled latent variables, and the lowest-cost sample is selected for coordination. Finally, the feasible proposal with the highest performance index is selected for the deployment. By construction, our GNN-VAE framework returns solutions that always respect the constraints of the considered coordination problem. Numerical results show that our approach trained on small-scale problems can achieve high-quality solutions even for large-scale problems with 250 robots, being much faster than other baselines. Project page: https://mengyuest.github.io/gnn-vae-coord
多智能体协调对于共享空间中的可靠多机器人导航至关重要,如自动化仓库等区域。在机器人流量密集的区域,局部协调方法可能无法找到无死锁的解决方案。在这些场景中,让中央单元生成决定机器人通行顺序的全局计划是恰当的。然而,随着问题规模的增长,此类集中式协调方法的运行时间显著增加。在本文中,我们提出利用图神经网络变分自动编码器(GNN-VAE)来解决多智能体协调问题,实现大规模问题的快速解决,优于集中式优化方法。我们将协调问题制定为图问题,并使用混合整数线性规划(MILP)求解器收集真实数据。在训练过程中,我们的学习框架将图问题的优质解决方案编码到潜在空间中。在推理时间,从采样的潜在变量中解码解决方案样本,并选择成本最低的样本进行协调。最后,选择性能指数最高的可行方案进行部署。通过构建,我们的GNN-VAE框架返回的解决方案始终尊重所考虑协调问题的约束。数值结果表明,我们的方法在小型问题上经过训练,即使对于具有250个机器人的大规模问题也能达到高质量的解决方案,并且比其他基线方法更快。项目页面:https://mengyuest.github.io/gnn-vae-coord
论文及项目相关链接
PDF Accepted by 2025 International Conference on Robotics and Automation (ICRA 2025)
Summary
多机器人导航中的多智能体协调至关重要。在密集机器人流量的区域,局部协调方法可能无法找到无死锁的解决方案。针对该问题,本文提出利用图神经网络变分自编码器(GNN-VAE)解决大规模多智能体协调问题,实现比集中式优化更快的解决速度。将协调问题转化为图形问题,并使用混合整数线性规划(MILP)求解器收集真实数据。训练过程中,学习框架将图形问题的优质解决方案编码到潜在空间中。在推理阶段,从采样潜在变量中解码解决方案样本,选择成本最低的样本进行协调。最终,选择性能指数最高的可行方案进行部署。该方法始终遵守协调问题的约束。数值结果表明,该方法在小规模问题上训练,即使在大规模问题(如涉及250个机器人)上也能获得高质量解决方案,且速度远超其他基线方法。
Key Takeaways
- 多智能体协调在共享空间如自动化仓库中的多机器人导航中至关重要。
- 在机器人流量密集区域,局部协调方法可能无法找到无死锁的解决方案。
- 提出利用图神经网络变分自编码器(GNN-VAE)解决大规模多智能体协调问题。
- 将协调问题转化为图形问题并使用真实数据训练模型。
- 模型能够在小规模问题上训练后,对大规模问题也能获得高质量解决方案。
- 该方法比集中式优化和其他基线方法更快。
点此查看论文截图

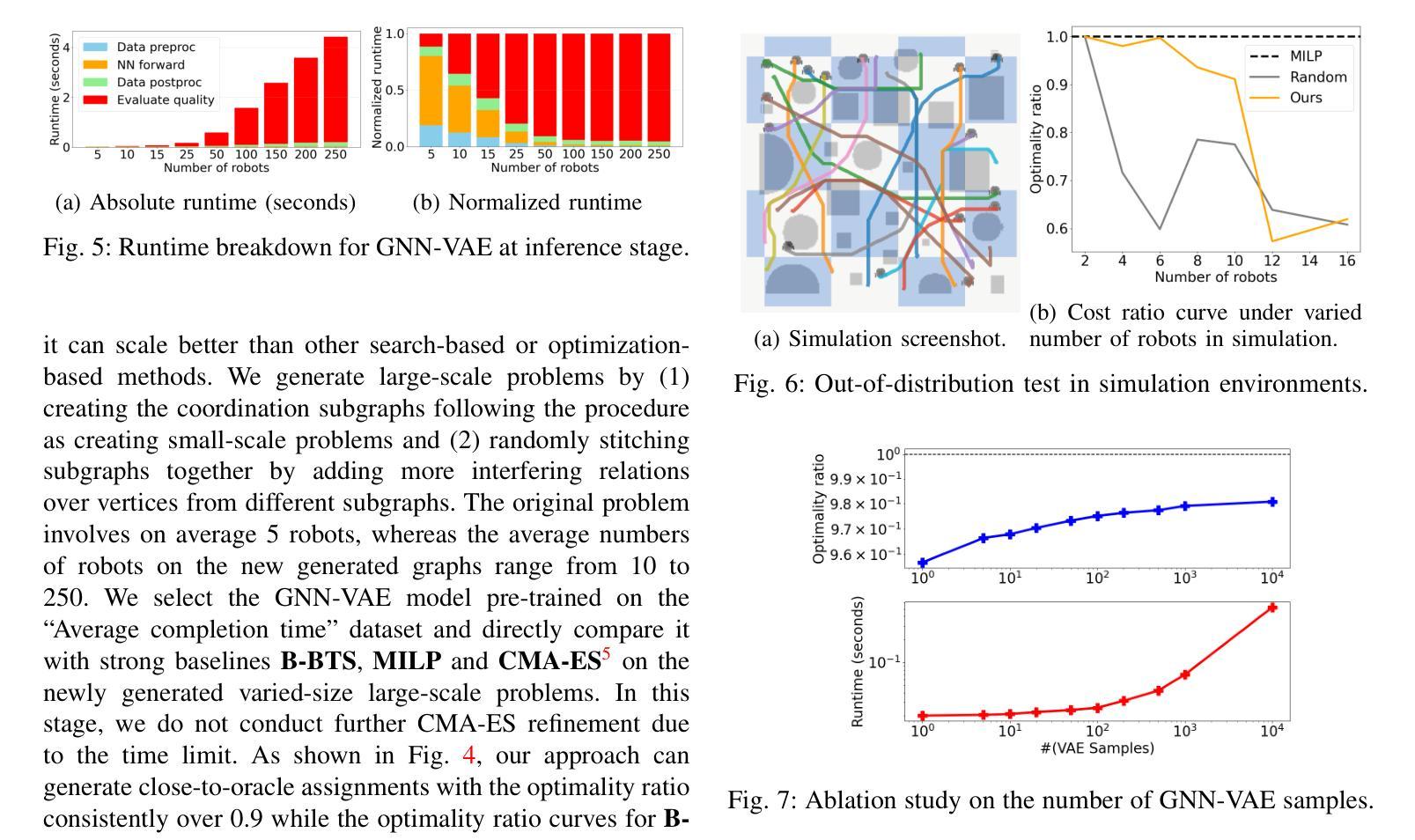
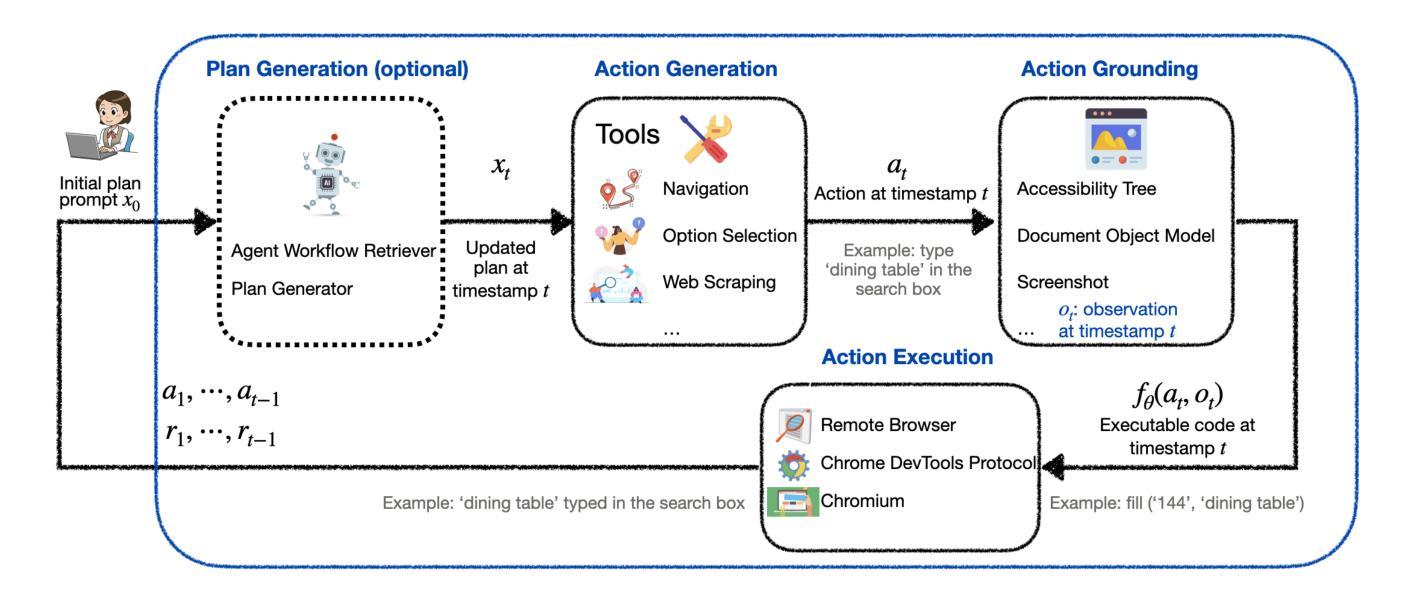
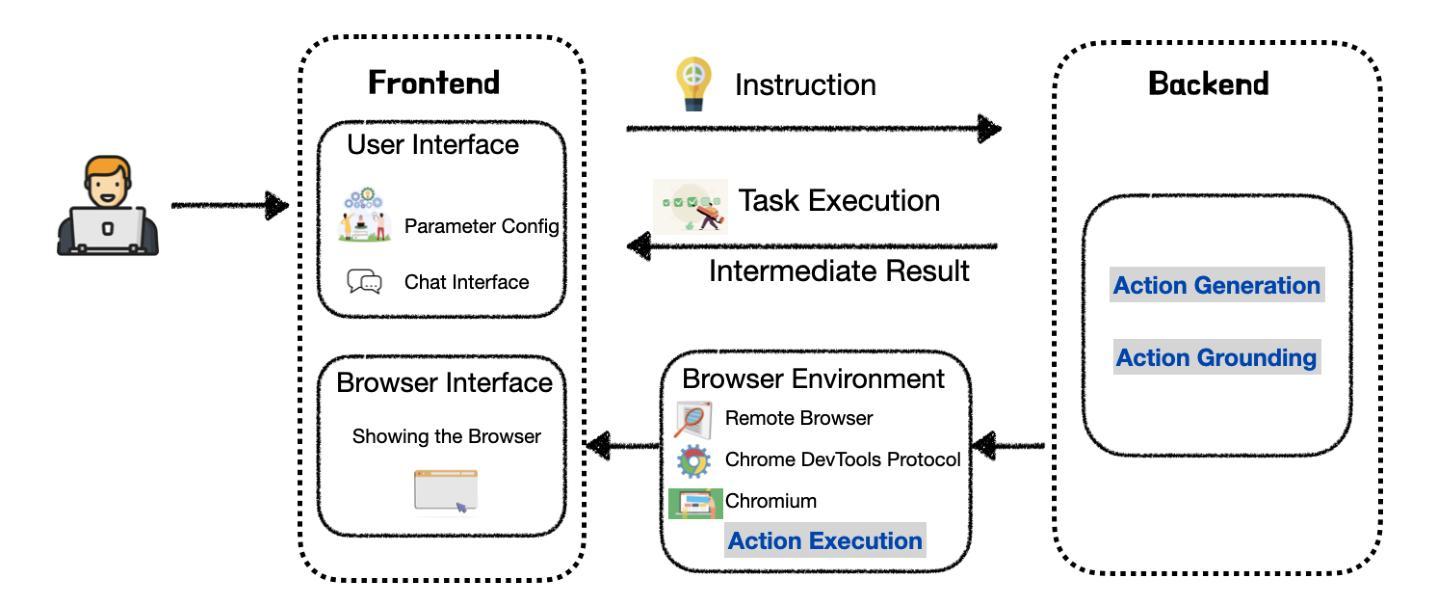
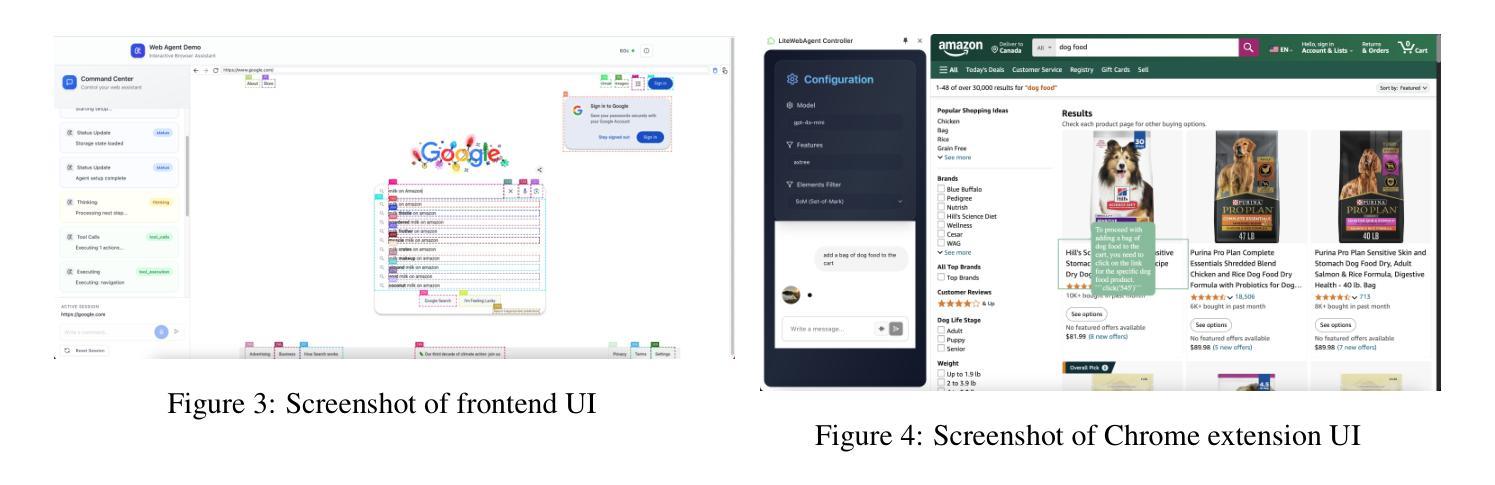
LiteWebAgent: The Open-Source Suite for VLM-Based Web-Agent Applications
Authors:Danqing Zhang, Balaji Rama, Jingyi Ni, Shiying He, Fu Zhao, Kunyu Chen, Arnold Chen, Junyu Cao
We introduce LiteWebAgent, an open-source suite for VLM-based web agent applications. Our framework addresses a critical gap in the web agent ecosystem with a production-ready solution that combines minimal serverless backend configuration, intuitive user and browser interfaces, and extensible research capabilities in agent planning, memory, and tree search. For the core LiteWebAgent agent framework, we implemented a simple yet effective baseline using recursive function calling, providing with decoupled action generation and action grounding. In addition, we integrate advanced research components such as agent planning, agent workflow memory, and tree search in a modular and extensible manner. We then integrate the LiteWebAgent agent framework with frontend and backend as deployed systems in two formats: (1) a production Vercel-based web application, which provides users with an agent-controlled remote browser, (2) a Chrome extension leveraging LiteWebAgent’s API to control an existing Chrome browser via CDP (Chrome DevTools Protocol). The LiteWebAgent framework is available at https://github.com/PathOnAI/LiteWebAgent, with deployed frontend at https://lite-web-agent.vercel.app/.
我们介绍了LiteWebAgent,这是一个用于基于VLM的Web代理应用程序的开源套件。我们的框架解决了Web代理生态系统中的关键空白,提供了一个生产就绪的解决方案,该方案结合了最小的无服务器后端配置、直观的用户和浏览器界面,以及可扩展的代理规划、内存和树搜索的研究能力。对于LiteWebAgent核心代理框架,我们实现了一种简单而有效的基线,使用递归函数调用,提供解耦的动作生成和动作接地。此外,我们以模块化和可扩展的方式集成了先进的组件,如代理规划、代理工作流程内存和树搜索。然后,我们将LiteWebAgent代理框架以前端和后端的身份部署为两种格式的系统:一是基于Vercel的生产Web应用程序,为用户提供代理控制的远程浏览器;二是Chrome扩展程序,利用LiteWebAgent的API通过CDP(Chrome开发工具协议)控制现有Chrome浏览器。LiteWebAgent框架可在https://github.com/PathOnAI/LiteWebAgent上找到,已部署的前端界面位于https://lite-web-agent.vercel.app/。
论文及项目相关链接
Summary
LiteWebAgent是一个针对基于VLM的web代理应用程序的开源套件,解决了web代理生态系统中的关键空白。它结合了轻量级无服务器后端配置、直观的用户和浏览器界面,以及可扩展的研究能力,如代理规划、内存和树搜索等。其核心框架采用递归函数调用实现简单有效的基线,并整合了先进的研究组件。此外,LiteWebAgent还提供两种部署形式:生产用的Vercel Web应用程序和Chrome扩展程序。
Key Takeaways
- LiteWebAgent是一个针对web代理应用程序的开源套件,解决了web代理生态系统中的关键空白。
- 它结合了轻量级无服务器后端配置,使得配置更为简单。
- LiteWebAgent具有直观的用户和浏览器界面。
- 该框架提供代理规划、内存和树搜索等研究能力,这些功能以模块化方式集成,易于扩展。
- LiteWebAgent的核心框架采用递归函数调用实现简单有效的基线,实现了动作生成和动作接地的解耦。
- LiteWebAgent提供了两种部署形式:作为生产用的Vercel Web应用程序和Chrome扩展程序。
点此查看论文截图

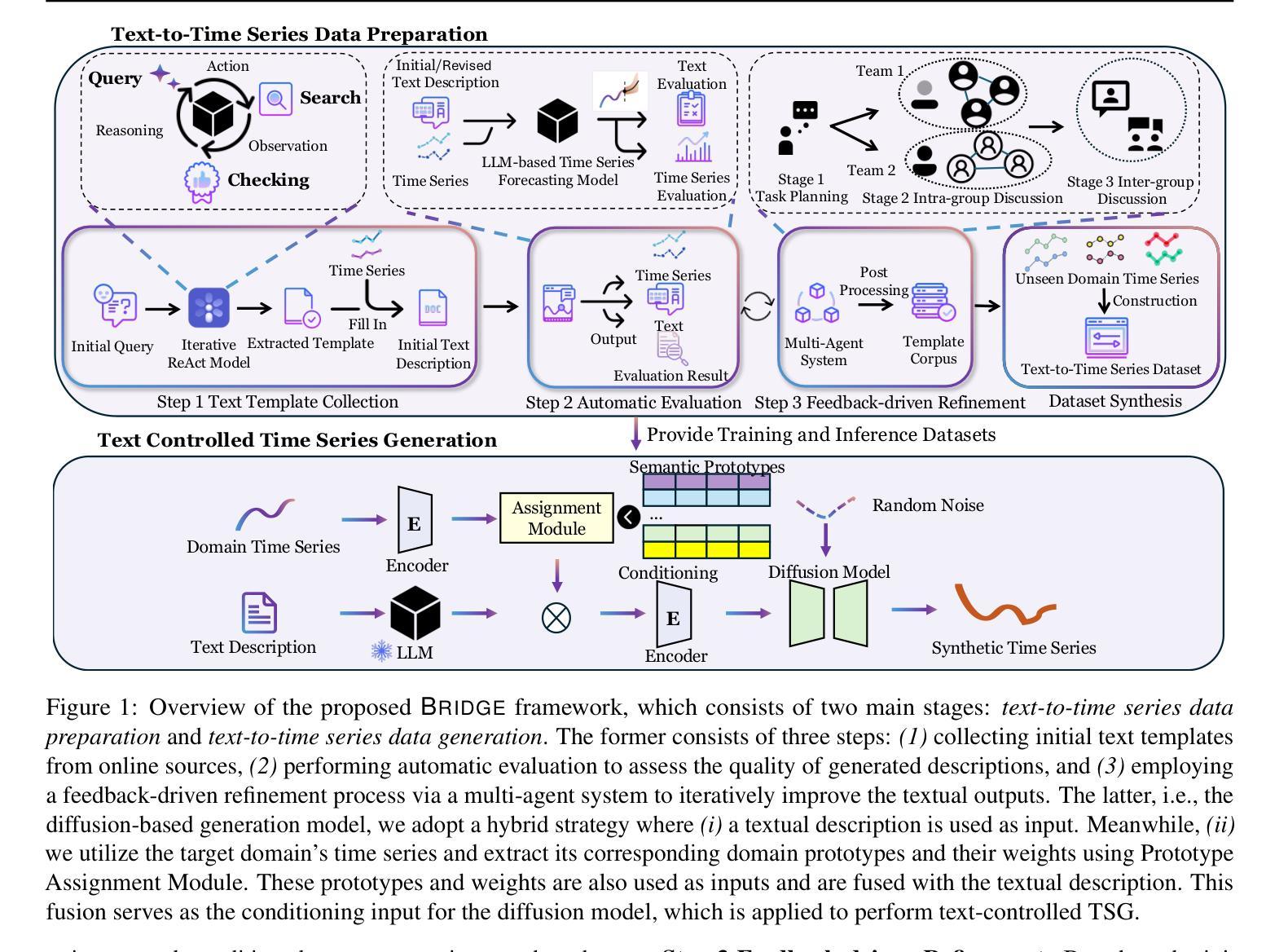
BRIDGE: Bootstrapping Text to Control Time-Series Generation via Multi-Agent Iterative Optimization and Diffusion Modelling
Authors:Hao Li, Yu-Hao Huang, Chang Xu, Viktor Schlegel, Ren-He Jiang, Riza Batista-Navarro, Goran Nenadic, Jiang Bian
Time-series Generation (TSG) is a prominent research area with broad applications in simulations, data augmentation, and counterfactual analysis. While existing methods have shown promise in unconditional single-domain TSG, real-world applications demand for cross-domain approaches capable of controlled generation tailored to domain-specific constraints and instance-level requirements. In this paper, we argue that text can provide semantic insights, domain information and instance-specific temporal patterns, to guide and improve TSG. We introduce ``Text-Controlled TSG’’, a task focused on generating realistic time series by incorporating textual descriptions. To address data scarcity in this setting, we propose a novel LLM-based Multi-Agent framework that synthesizes diverse, realistic text-to-TS datasets. Furthermore, we introduce BRIDGE, a hybrid text-controlled TSG framework that integrates semantic prototypes with text description for supporting domain-level guidance. This approach achieves state-of-the-art generation fidelity on 11 of 12 datasets, and improves controllability by 12.52% on MSE and 6.34% MAE compared to no text input generation, highlighting its potential for generating tailored time-series data.
时间序列生成(TSG)是一个具有广泛应用前景的重要研究领域,在模拟、数据增强和反向事实分析等方面都有应用。虽然现有方法在无条件单域TSG方面表现出潜力,但实际应用需要跨域方法,能够适应特定领域的约束和实例级要求的有控制生成。在本文中,我们主张文本可以提供语义洞察、领域信息和实例特定的时间模式,以指导和改进TSG。我们引入了“文本控制TSG”,这是一个通过融入文本描述来生成真实时间序列的任务。为了解决此场景下的数据稀缺问题,我们提出了一个基于大型语言模型的多智能体框架,该框架可以综合多样化的、真实的文本到时间序列数据集。此外,我们还引入了BRIDGE,一个混合文本控制TSG框架,它将语义原型与文本描述相结合,以支持领域级的指导。该方法在12个数据集中有11个达到了最先进的生成保真度,并且在均方误差(MSE)上提高了12.52%,平均绝对误差(MAE)提高了6.34%,相比于无文本输入生成增强了其控制性,显示出其在生成定制时间序列数据方面的潜力。
论文及项目相关链接
PDF Preprint. Work in progress
Summary
文本介绍了时间序数生成(TSG)的研究领域,并指出其在模拟、数据增强和反向事实分析中的广泛应用。现有方法主要关注无条件单域TSG,但实际应用需要跨域方法,以满足特定领域的约束和实例级要求。本文提出了“文本控制TSG”任务,旨在通过融入文本描述来生成真实的时间序列。为解决数据稀缺问题,我们提出了一种基于大型语言模型的多代理框架,并开发了用于文本控制的BRIDGE框架来整合语义原型与文本描述。此方法在多个数据集上实现最佳生成保真度,并提高了控制性。
Key Takeaways
- 时间序数生成(TSG)是一个涉及模拟、数据增强和反向事实分析等领域的重要研究话题。
- 当前的方法主要集中在无条件单域TSG,但实际应用需要更灵活的跨域方法。
- 文本可以提供语义洞察、领域信息和实例级时间模式,以指导和改进TSG。
- 引入“文本控制TSG”任务,旨在通过融入文本描述来生成真实的时间序列数据。
- 提出一种基于大型语言模型的多代理框架,用于解决数据稀缺问题,并合成多样化的现实文本对TSG数据集。
- 开发了BRIDGE框架,整合语义原型与文本描述,以支持领域级的指导。
点此查看论文截图

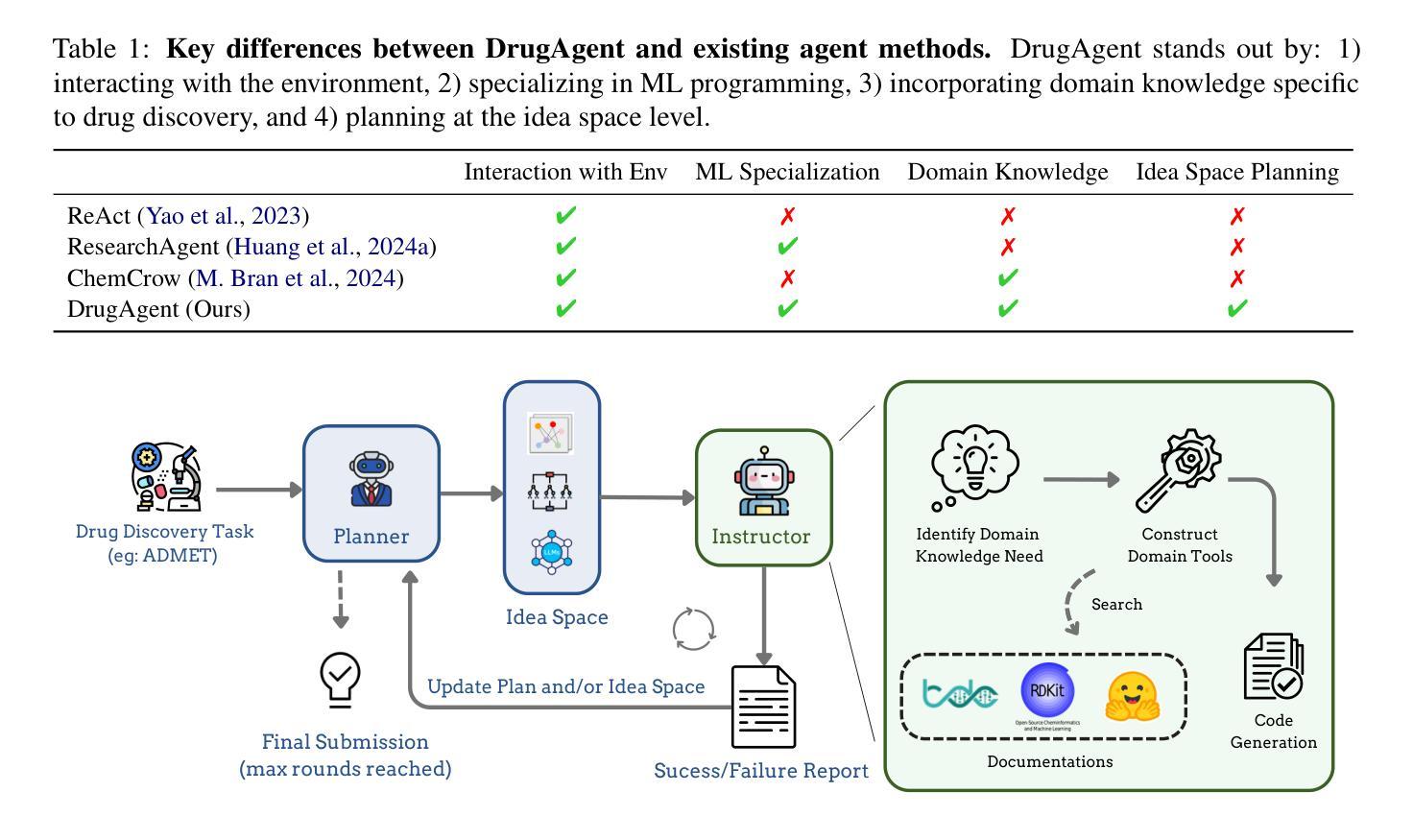
DrugAgent: Automating AI-aided Drug Discovery Programming through LLM Multi-Agent Collaboration
Authors:Sizhe Liu, Yizhou Lu, Siyu Chen, Xiyang Hu, Jieyu Zhao, Yingzhou Lu, Yue Zhao
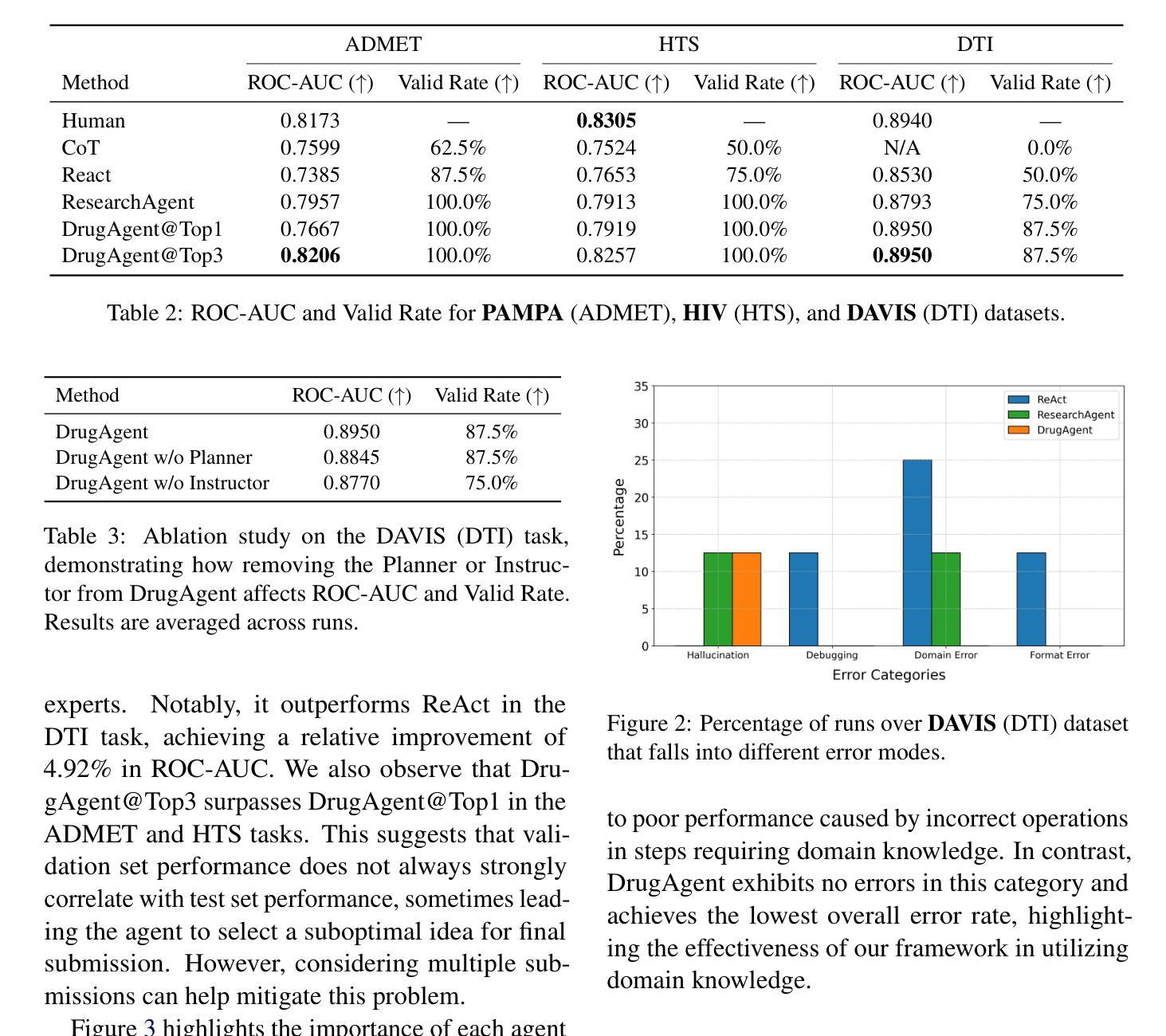
Recent progress in Large Language Models (LLMs) has drawn attention to their potential for accelerating drug discovery. However, a central problem remains: translating theoretical ideas into robust implementations in the highly specialized context of pharmaceutical research. This limitation prevents practitioners from making full use of the latest AI developments in drug discovery. To address this challenge, we introduce DrugAgent, a multi-agent framework that automates machine learning (ML) programming for drug discovery tasks. DrugAgent employs an LLM Planner that formulates high-level ideas and an LLM Instructor that identifies and integrates domain knowledge when implementing those ideas. We present case studies on three representative drug discovery tasks. Our results show that DrugAgent consistently outperforms leading baselines, including a relative improvement of 4.92% in ROC-AUC compared to ReAct for drug-target interaction (DTI). DrugAgent is publicly available at https://anonymous.4open.science/r/drugagent-5C42/.
最近大型语言模型(LLM)的进展引起了人们对加速药物发现的潜力的关注。然而,仍存在一个核心问题:在高度专业化的药物研究背景下,如何将理论想法转化为稳健的实施方案。这一局限性阻碍了从业人员充分利用药物发现方面的最新人工智能发展。为了应对这一挑战,我们引入了DrugAgent,这是一个多智能体框架,用于自动化药物发现任务中的机器学习(ML)编程。DrugAgent采用LLM Planner来制定高级思想,并采用LLM Instructor在实施这些思想时识别和整合领域知识。我们在三个具有代表性的药物发现任务上进行了案例研究。研究结果表明,DrugAgent始终优于领先的基线水平,其中ROC-AUC相较于ReAct在药物-靶标相互作用(DTI)方面的相对改进率为4.92%。DrugAgent的公开地址为:https://anonymous.4open.science/r/drugagent-5C42/。
论文及项目相关链接
Summary
大型语言模型(LLMs)在加速药物发现方面的潜力已引起关注,但仍存在将理论转化为药物研究中的稳健实现的问题。为解决这一挑战,引入了DrugAgent多智能体框架,自动化机器学习(ML)编程以完成药物发现任务。该框架包括LLM规划器来制定高级思想和一个LLM指导者来识别和整合领域知识来实现这些思想。在三个具有代表性的药物发现任务上的案例研究表明,DrugAgent持续优于领先的基线,在ROC-AUC方面相对于ReAct提高了4.92%。DrugAgent可在https://anonymous.4open.science/r/drugagent-5C42/公开访问。
Key Takeaways
- 大型语言模型(LLMs)在药物发现中具有加速潜力。
- 将理论转化为药物研究中的稳健实现仍存在挑战。
- DrugAgent是一个多智能体框架,旨在解决这一挑战,通过自动化机器学习编程完成药物发现任务。
- DrugAgent包括LLM规划器来制定高级思想和一个LLM指导者来识别和整合领域知识。
- 在三个不同任务上的案例研究表明,DrugAgent优于现有方法。
- DrugAgent在ROC-AUC指标上相对于ReAct提高了4.92%。
点此查看论文截图

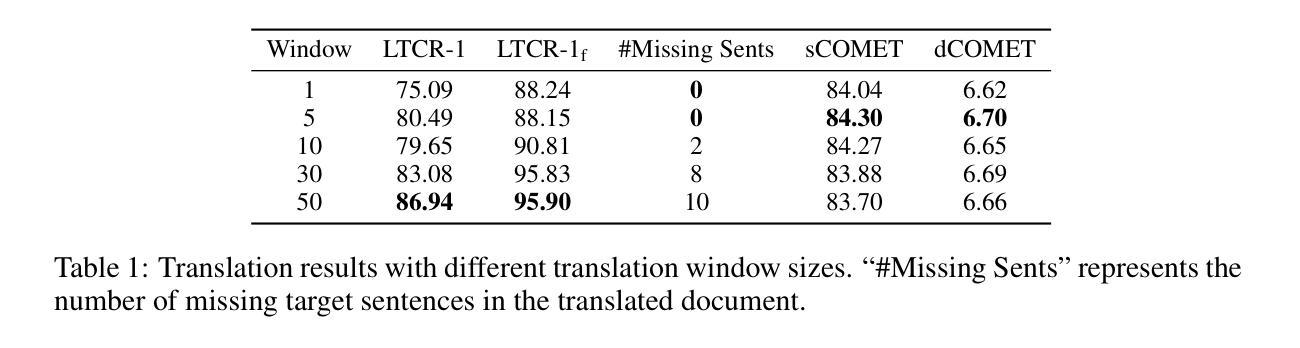
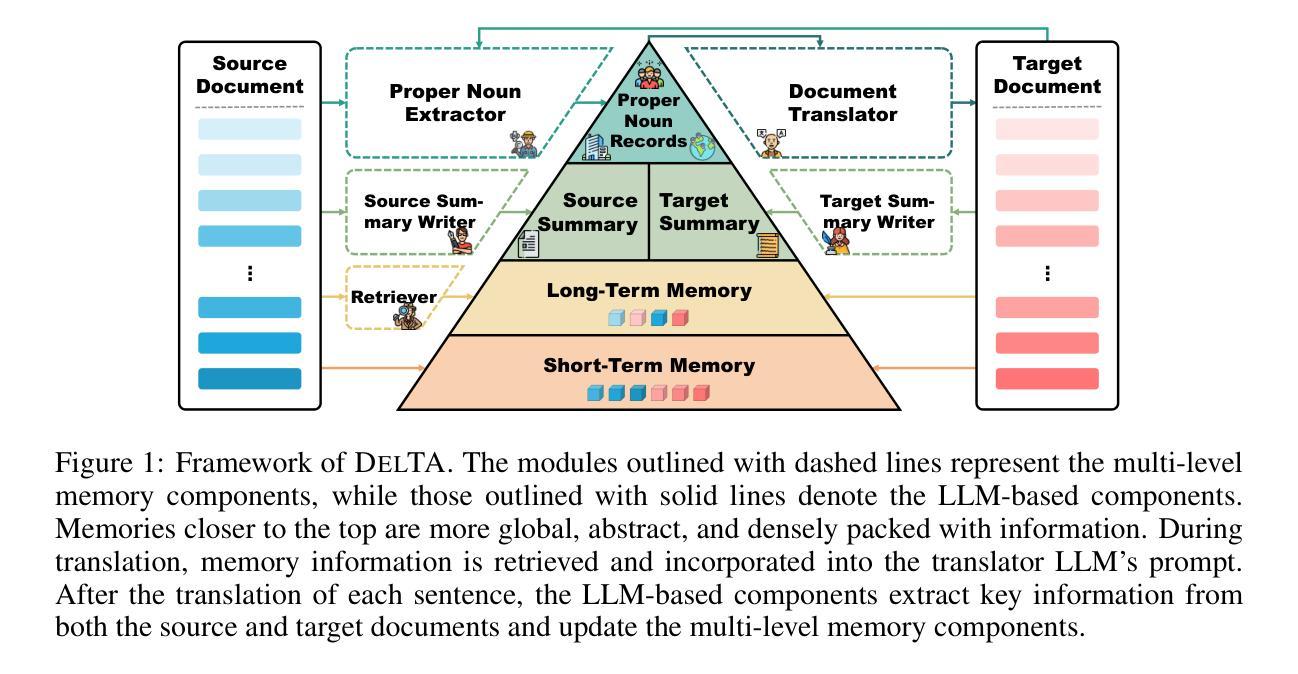
DelTA: An Online Document-Level Translation Agent Based on Multi-Level Memory
Authors:Yutong Wang, Jiali Zeng, Xuebo Liu, Derek F. Wong, Fandong Meng, Jie Zhou, Min Zhang
Large language models (LLMs) have achieved reasonable quality improvements in machine translation (MT). However, most current research on MT-LLMs still faces significant challenges in maintaining translation consistency and accuracy when processing entire documents. In this paper, we introduce DelTA, a Document-levEL Translation Agent designed to overcome these limitations. DelTA features a multi-level memory structure that stores information across various granularities and spans, including Proper Noun Records, Bilingual Summary, Long-Term Memory, and Short-Term Memory, which are continuously retrieved and updated by auxiliary LLM-based components. Experimental results indicate that DelTA significantly outperforms strong baselines in terms of translation consistency and quality across four open/closed-source LLMs and two representative document translation datasets, achieving an increase in consistency scores by up to 4.58 percentage points and in COMET scores by up to 3.16 points on average. DelTA employs a sentence-by-sentence translation strategy, ensuring no sentence omissions and offering a memory-efficient solution compared to the mainstream method. Furthermore, DelTA improves pronoun and context-dependent translation accuracy, and the summary component of the agent also shows promise as a tool for query-based summarization tasks. The code and data of our approach are released at https://github.com/YutongWang1216/DocMTAgent.
大型语言模型(LLM)在机器翻译(MT)领域取得了合理的质量改进。然而,当前关于MT-LLM的大多数研究在处理整个文档时,仍面临保持翻译一致性和准确性方面的重大挑战。在本文中,我们介绍了DelTA,这是一个旨在克服这些限制的文档级翻译代理。DelTA具有多层次内存结构,该结构可以存储不同粒度和跨度的信息,包括专有名词记录、双语摘要、长期记忆和短期记忆等,辅助的LLM组件会不断地检索和更新这些信息。实验结果表明,在四个开源/闭源LLM和两个代表性的文档翻译数据集方面,DelTA在翻译一致性和质量方面显著优于强大的基线模型,在一致性得分方面平均提高了高达4.58个百分点,在COMET得分方面平均提高了高达3.16个百分点。DelTA采用逐句翻译策略,确保无句子遗漏,与主流方法相比,具有更高效的内存解决方案。此外,DelTA提高了代词和上下文相关的翻译准确性,该代理的摘要组件也显示出在基于查询的摘要任务中的潜力。我们的方法代码和数据已在https://github.com/YutongWang1216/DocMTAgent发布。
论文及项目相关链接
PDF Accepted as a conference paper at ICLR 2025
Summary:
本文介绍了一种名为DelTA的文档级翻译代理,旨在解决大型语言模型在机器翻译中面临的翻译一致性和准确性问题。DelTA采用多层次内存结构,通过辅助的语言模型组件不断更新和检索信息,显著提高了一致性和翻译质量。实验结果表明,DelTA在四个开源/闭源的大型语言模型和两个代表性的文档翻译数据集上显著优于强基线。此外,DelTA采用逐句翻译策略,提高代词和上下文相关的翻译准确性,并展示了其摘要组件在基于查询的摘要任务中的潜力。
Key Takeaways:
- DelTA是一个文档级翻译代理,旨在解决大型语言模型在机器翻译中的一致性和准确性问题。
- DelTA采用多层次内存结构,包括专有名词记录、双语摘要、长期记忆和短期记忆,以便存储和检索信息。
- 通过辅助的语言模型组件,DelTA能持续更新和检索信息。
- 实验表明,DelTA在四个大型语言模型和两个文档翻译数据集上的翻译一致性和质量显著优于基线方法。
- DelTA采用逐句翻译策略,确保不遗漏任何句子,并提供一种与主流方法相比更省内存的解决方案。
- DelTA提高了代词和上下文相关的翻译准确性。
点此查看论文截图

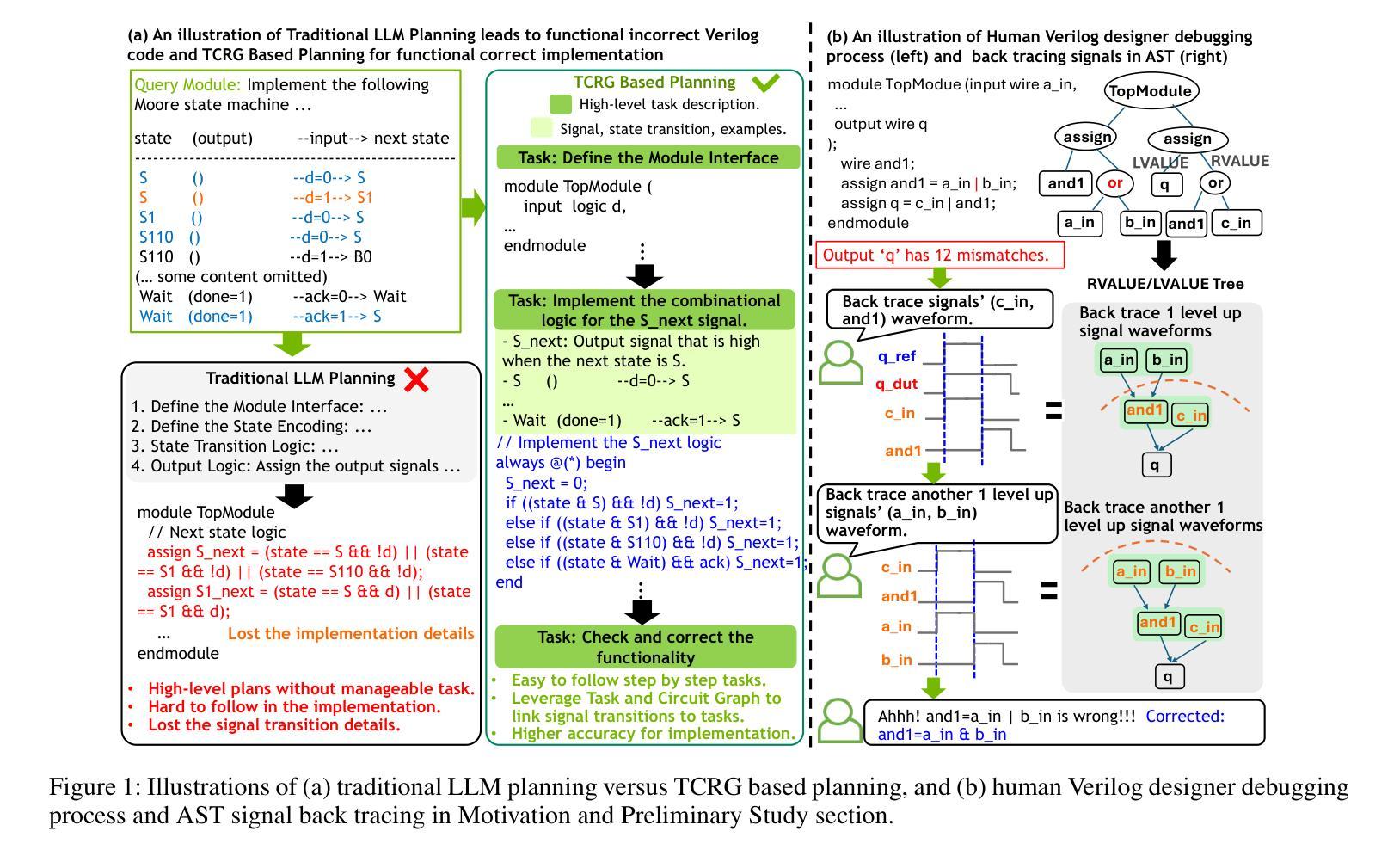
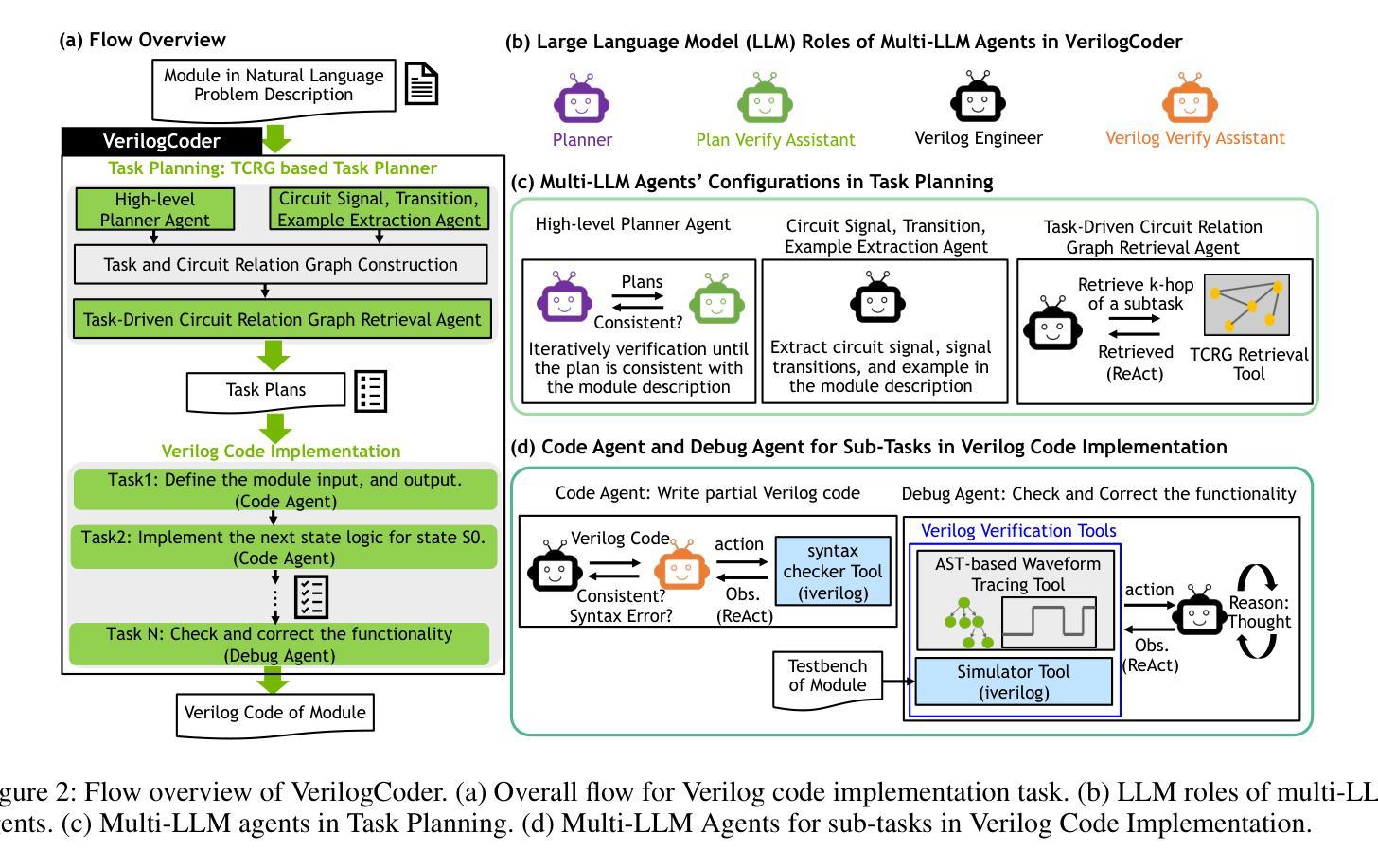
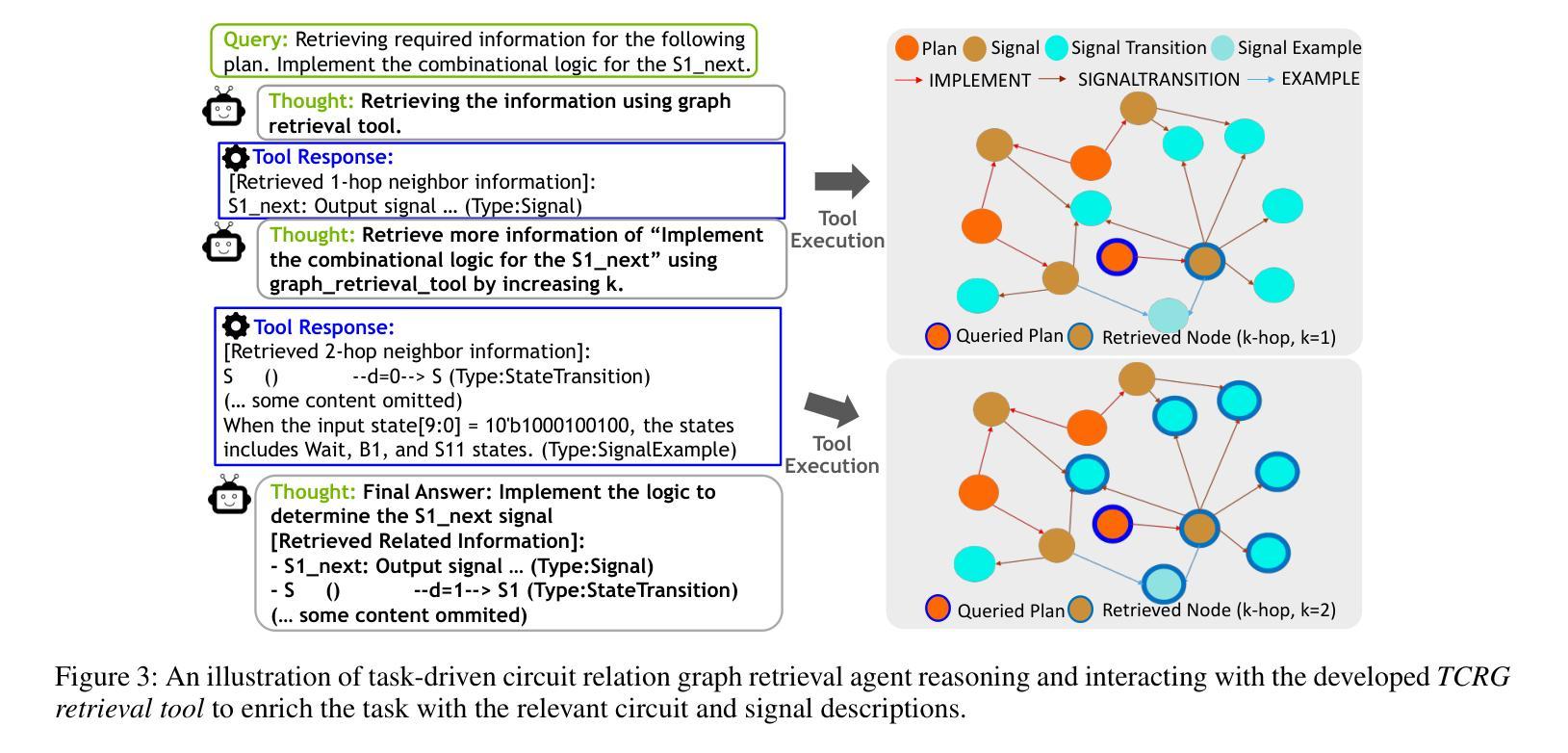
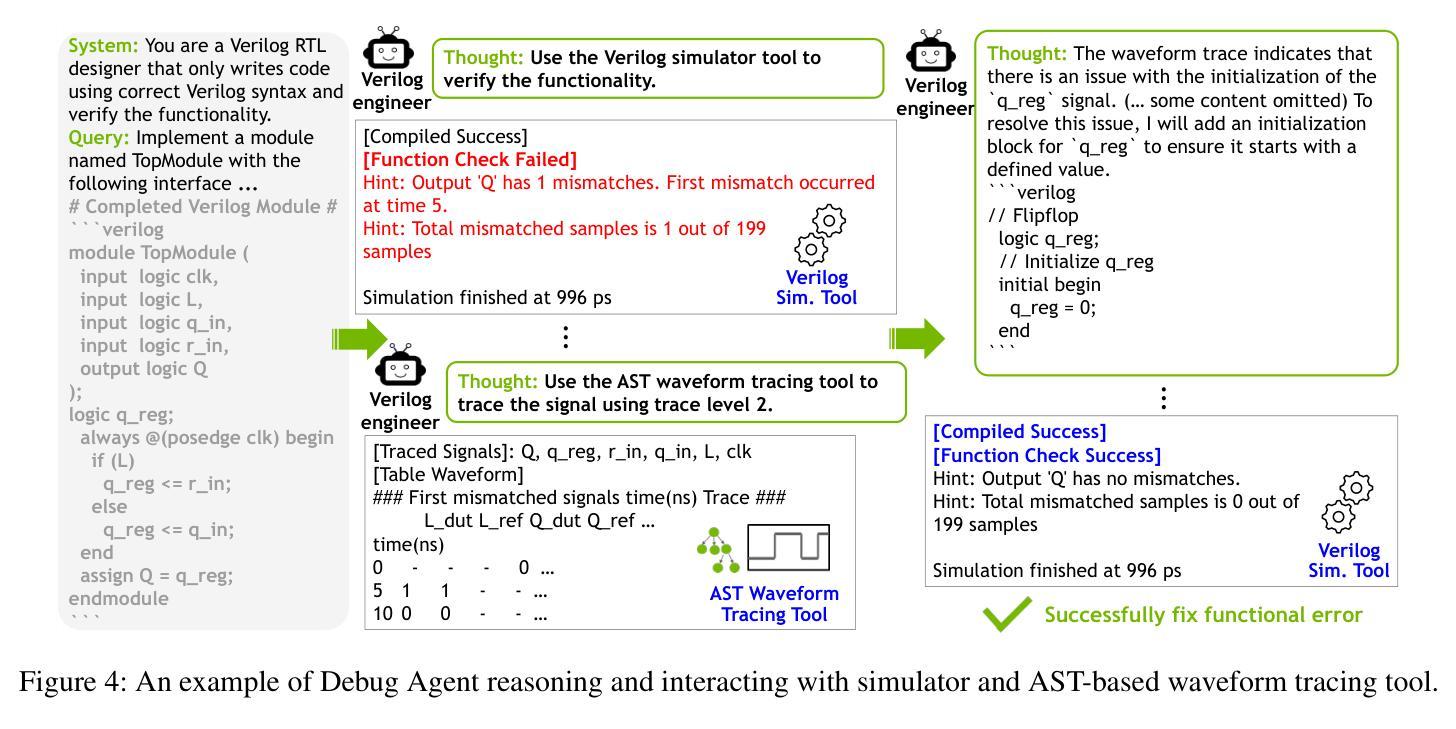
VerilogCoder: Autonomous Verilog Coding Agents with Graph-based Planning and Abstract Syntax Tree (AST)-based Waveform Tracing Tool
Authors:Chia-Tung Ho, Haoxing Ren, Brucek Khailany
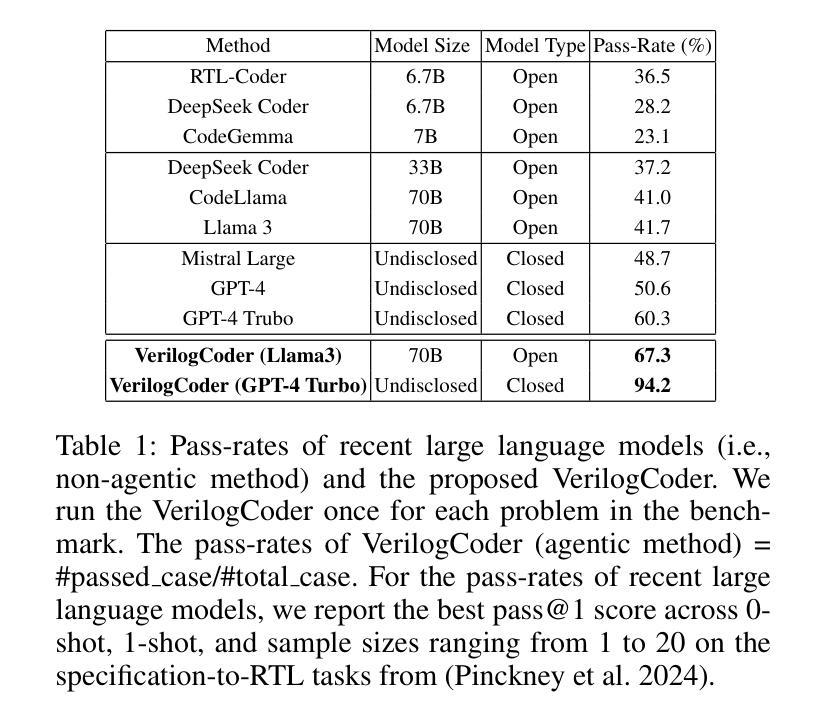
Due to the growing complexity of modern Integrated Circuits (ICs), automating hardware design can prevent a significant amount of human error from the engineering process and result in less errors. Verilog is a popular hardware description language for designing and modeling digital systems; thus, Verilog generation is one of the emerging areas of research to facilitate the design process. In this work, we propose VerilogCoder, a system of multiple Artificial Intelligence (AI) agents for Verilog code generation, to autonomously write Verilog code and fix syntax and functional errors using collaborative Verilog tools (i.e., syntax checker, simulator, and waveform tracer). Firstly, we propose a task planner that utilizes a novel Task and Circuit Relation Graph retrieval method to construct a holistic plan based on module descriptions. To debug and fix functional errors, we develop a novel and efficient abstract syntax tree (AST)-based waveform tracing tool, which is integrated within the autonomous Verilog completion flow. The proposed methodology successfully generates 94.2% syntactically and functionally correct Verilog code, surpassing the state-of-the-art methods by 33.9% on the VerilogEval-Human v2 benchmark.
由于现代集成电路(IC)的复杂性不断增长,自动化硬件设计可以防止工程过程中大量的人为错误,并减少错误的发生。Verilog是一种用于设计和建模数字系统的流行硬件描述语言;因此,Verilog生成是研究的一个新兴领域,有助于促进设计过程。在这项工作中,我们提出了VerilogCoder,这是一个用于Verilog代码生成的多人工智能(AI)代理系统,可以自主地编写Verilog代码,并使用协作的Verilog工具(即语法检查器、模拟器和波形跟踪器)来修复语法和功能错误。首先,我们提出了一种任务规划器,它利用新型的任务和电路关系图检索方法来构建基于模块描述的全面计划。为了调试和修复功能错误,我们开发了一种基于抽象语法树(AST)的新型高效波形跟踪工具,并已集成到自主Verilog完成流程中。所提出的方法成功生成了94.2%语法和功能上正确的Verilog代码,在VerilogEval-Human v2基准测试上的表现优于最新方法,提高了33.9%。
论文及项目相关链接
PDF main paper 7 pages, reference 1 page, it is the version that accepted by AAAI 2025
Summary
现代集成电路设计复杂度不断提高,自动硬件设计可减少人为错误。Verilog作为一种流行的硬件描述语言,其代码生成是研究的热点。本研究提出VerilogCoder系统,利用多个智能体自主编写Verilog代码并修复语法和功能错误。该系统采用任务规划器构建整体计划,并开发基于抽象语法树的波形追踪工具,成功生成94.2%的正确代码,超越现有方法在VerilogEval-Human v2基准测试上的表现。
Key Takeaways
- 自动硬件设计可减少人为错误并提高设计效率。
- Verilog是一种用于数字系统设计和建模的硬件描述语言。
- VerilogCoder系统利用多个智能体进行Verilog代码生成。
- 任务规划器利用新型任务与电路关系图检索方法构建整体计划。
- 基于抽象语法树的波形追踪工具用于调试和功能错误修复。
- 该方法成功生成了高比例的语法和功能正确的Verilog代码。
点此查看论文截图