⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-07 更新
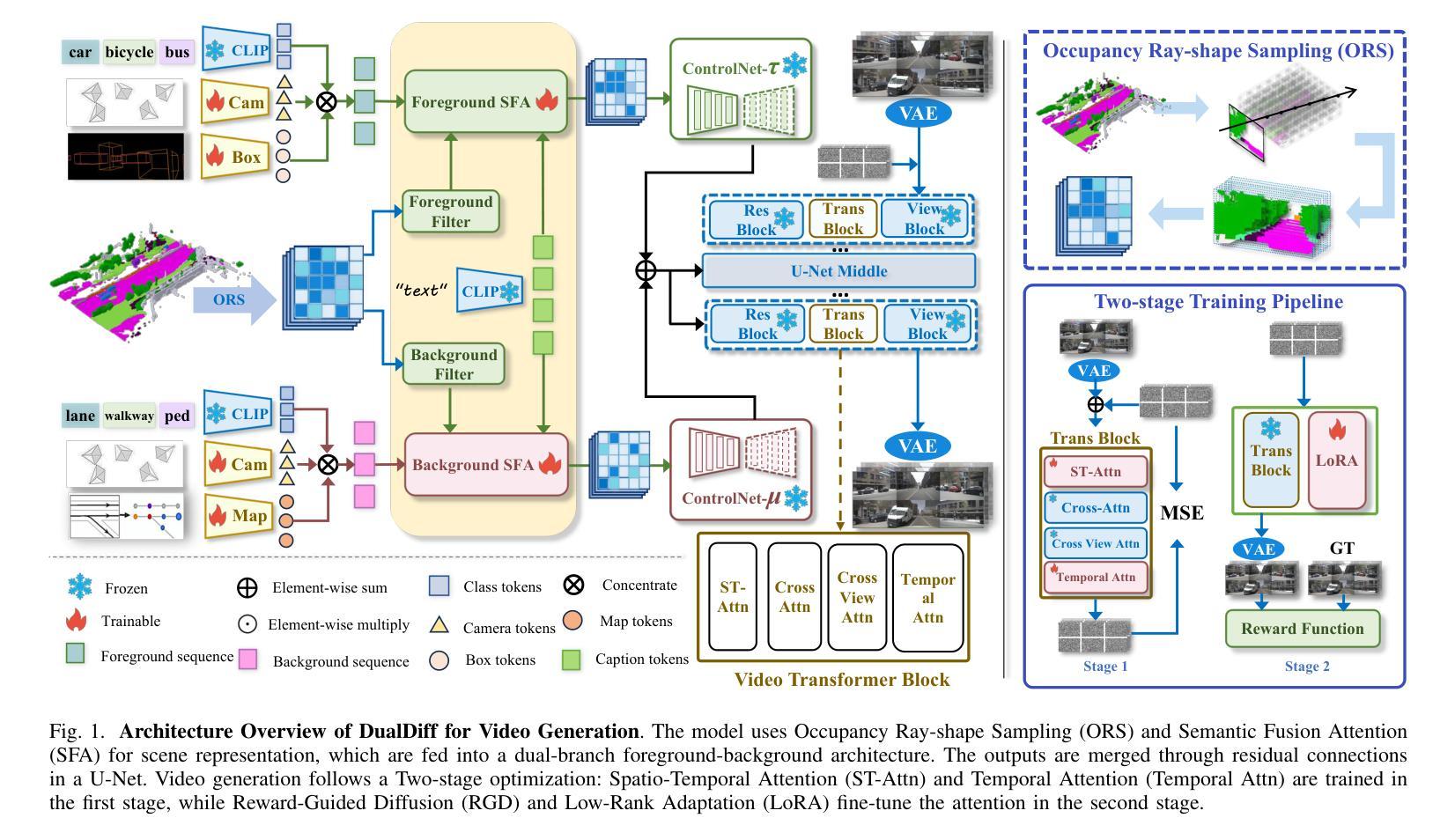
DualDiff+: Dual-Branch Diffusion for High-Fidelity Video Generation with Reward Guidance
Authors:Zhao Yang, Zezhong Qian, Xiaofan Li, Weixiang Xu, Gongpeng Zhao, Ruohong Yu, Lingsi Zhu, Longjun Liu
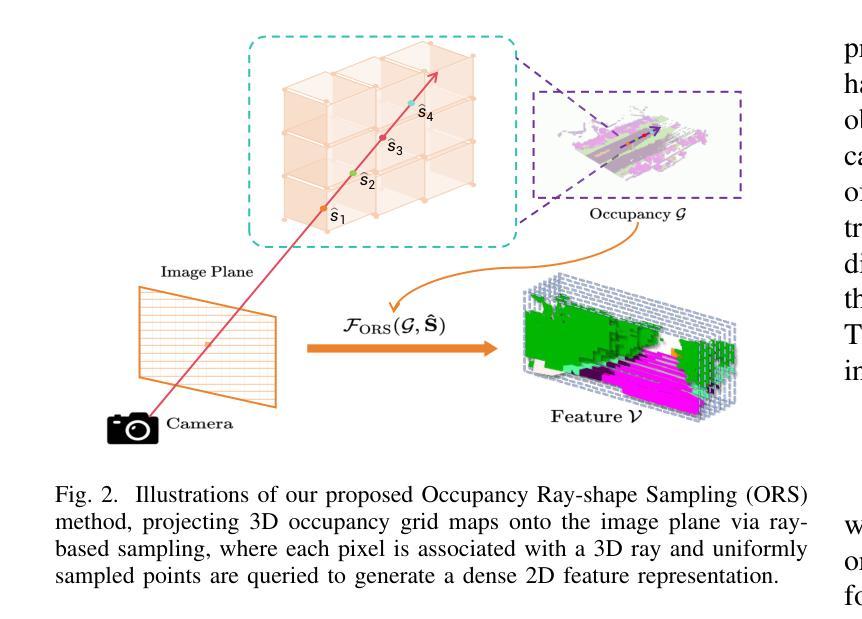
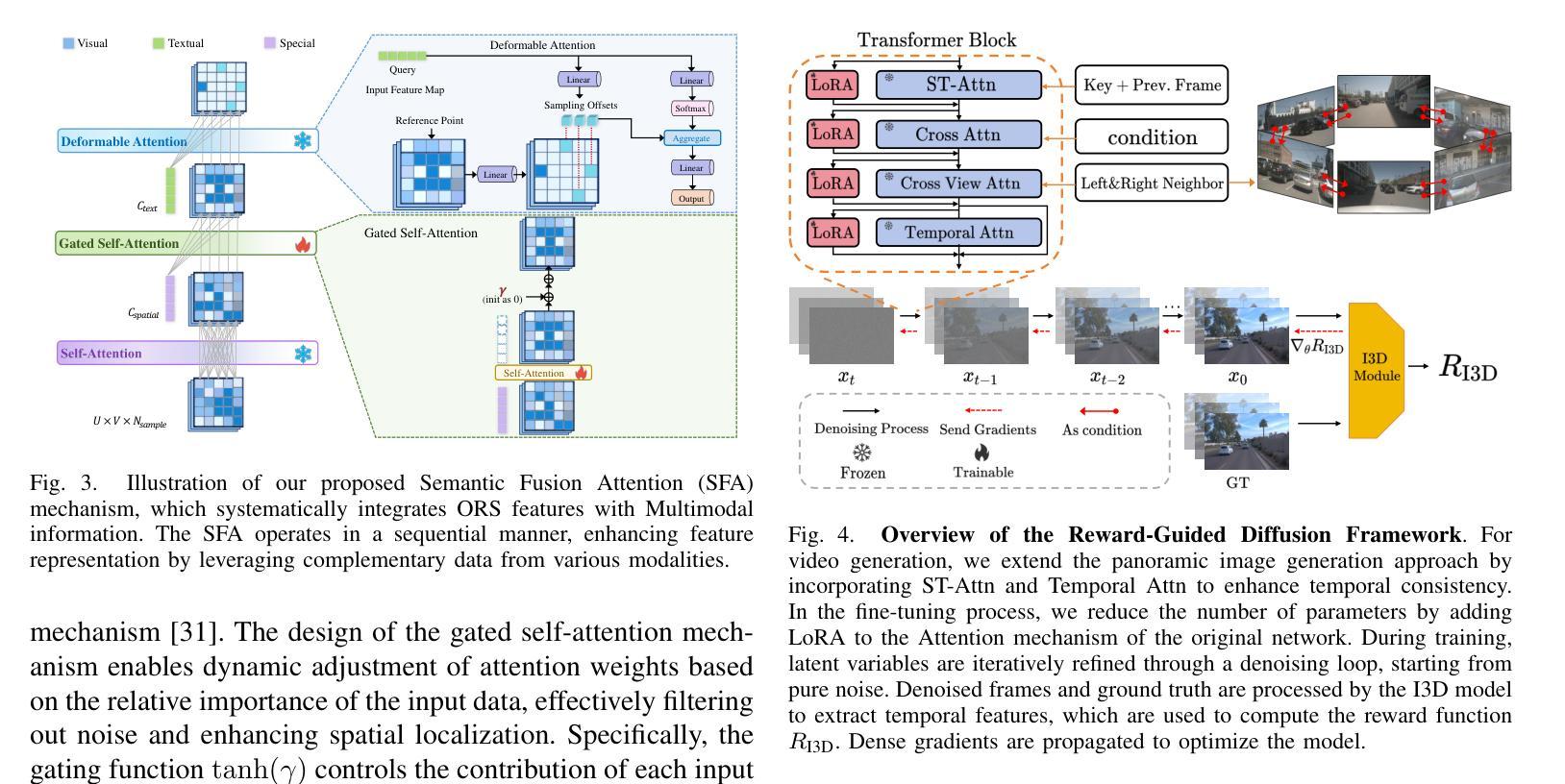
Accurate and high-fidelity driving scene reconstruction demands the effective utilization of comprehensive scene information as conditional inputs. Existing methods predominantly rely on 3D bounding boxes and BEV road maps for foreground and background control, which fail to capture the full complexity of driving scenes and adequately integrate multimodal information. In this work, we present DualDiff, a dual-branch conditional diffusion model designed to enhance driving scene generation across multiple views and video sequences. Specifically, we introduce Occupancy Ray-shape Sampling (ORS) as a conditional input, offering rich foreground and background semantics alongside 3D spatial geometry to precisely control the generation of both elements. To improve the synthesis of fine-grained foreground objects, particularly complex and distant ones, we propose a Foreground-Aware Mask (FGM) denoising loss function. Additionally, we develop the Semantic Fusion Attention (SFA) mechanism to dynamically prioritize relevant information and suppress noise, enabling more effective multimodal fusion. Finally, to ensure high-quality image-to-video generation, we introduce the Reward-Guided Diffusion (RGD) framework, which maintains global consistency and semantic coherence in generated videos. Extensive experiments demonstrate that DualDiff achieves state-of-the-art (SOTA) performance across multiple datasets. On the NuScenes dataset, DualDiff reduces the FID score by 4.09% compared to the best baseline. In downstream tasks, such as BEV segmentation, our method improves vehicle mIoU by 4.50% and road mIoU by 1.70%, while in BEV 3D object detection, the foreground mAP increases by 1.46%. Code will be made available at https://github.com/yangzhaojason/DualDiff.
准确且高保真度的驾驶场景重建需要有效利用全面的场景信息作为条件输入。现有方法主要依赖3D边界框和BEV路线图进行前景和背景控制,这无法捕捉驾驶场景的全貌并充分整合多模态信息。在这项工作中,我们提出了DualDiff,这是一种双分支条件扩散模型,旨在增强多视角和视频序列的驾驶场景生成。具体来说,我们引入了Occupancy Ray-shape Sampling(ORS)作为条件输入,它提供了丰富的前景和背景语义,以及3D空间几何,以精确控制这两个元素的生成。为了改进对精细前景对象的合成,特别是复杂和遥远的对象,我们提出了Foreground-Aware Mask(FGM)去噪损失函数。此外,我们开发了Semantic Fusion Attention(SFA)机制,以动态优先处理相关信息并抑制噪声,从而实现更有效的多模态融合。最后,为了确保高质量的图片到视频的生成,我们引入了Reward-Guided Diffusion(RGD)框架,该框架在生成的视频中保持全局一致性和语义连贯性。大量实验表明,DualDiff在多个数据集上实现了最新(SOTA)性能。在NuScenes数据集上,DualDiff将FID得分降低了4.09%,相较于最佳基线模型有所提升。在下游任务中,例如在BEV分割方面,我们的方法提高了车辆mIoU值4.5%,道路mIoU值提高了1.7%,而在BEV 3D目标检测方面,前景mAP提高了1.46%。代码将在https://github.com/yangzhaojason/DualDiff上公开提供。
论文及项目相关链接
Summary
本文提出了一种名为DualDiff的双分支条件扩散模型,用于增强驾驶场景的生成。该模型引入Occupancy Ray-shape Sampling(ORS)作为条件输入,提供丰富的前景和背景语义以及3D空间几何信息,以精确控制两者的生成。同时,通过Foreground-Aware Mask(FGM)降噪损失函数提升细节前景物体的合成质量,并引入Semantic Fusion Attention(SFA)机制实现多模态信息的有效融合。最后,通过Reward-Guided Diffusion(RGD)框架确保高质量的视频生成。实验证明,DualDiff在多个数据集上取得领先性能。
Key Takeaways
- DualDiff模型采用双分支条件扩散结构,提升驾驶场景生成能力。
- 引入Occupancy Ray-shape Sampling(ORS)作为条件输入,提供丰富的场景语义和几何信息。
- Foreground-Aware Mask(FGM)降噪损失函数用于增强细节前景物体的合成质量。
- Semantic Fusion Attention(SFA)机制实现多模态信息的动态优先级和噪声抑制。
- Reward-Guided Diffusion(RGD)框架保证视频生成的高质量及全局一致性。
- DualDiff在多个数据集上实现领先性能,如NuScenes数据集的FID分数降低4.09%。
- 下游任务如BEV分割和BEV 3D目标检测中,DualDiff方法提升车辆和道路的mIoU,以及前景的mAP。
点此查看论文截图

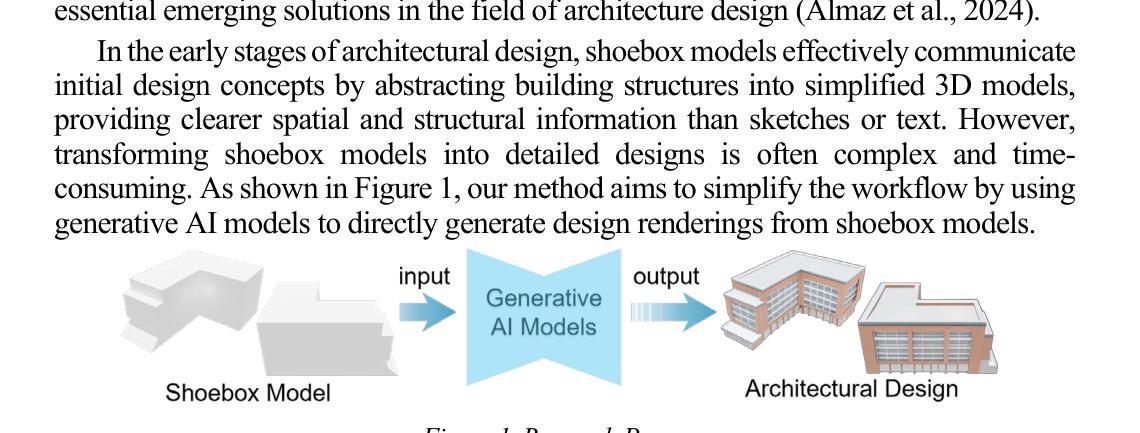
Multi-View Depth Consistent Image Generation Using Generative AI Models: Application on Architectural Design of University Buildings
Authors:Xusheng Du, Ruihan Gui, Zhengyang Wang, Ye Zhang, Haoran Xie
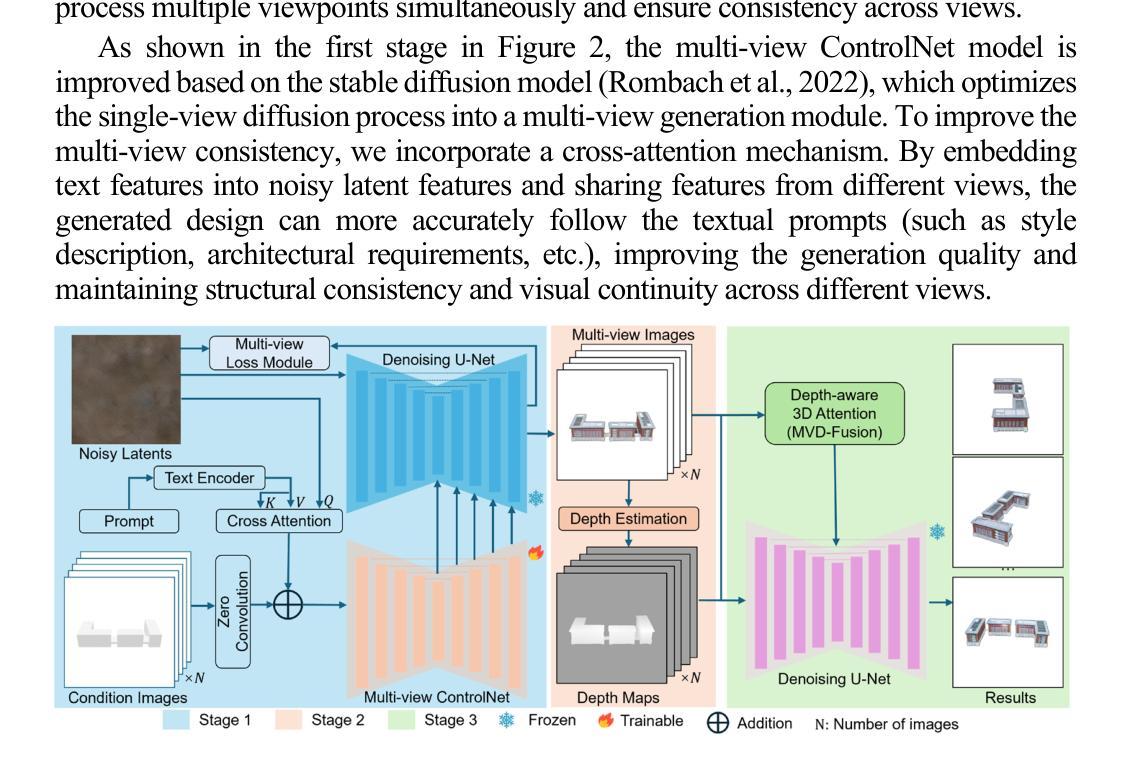
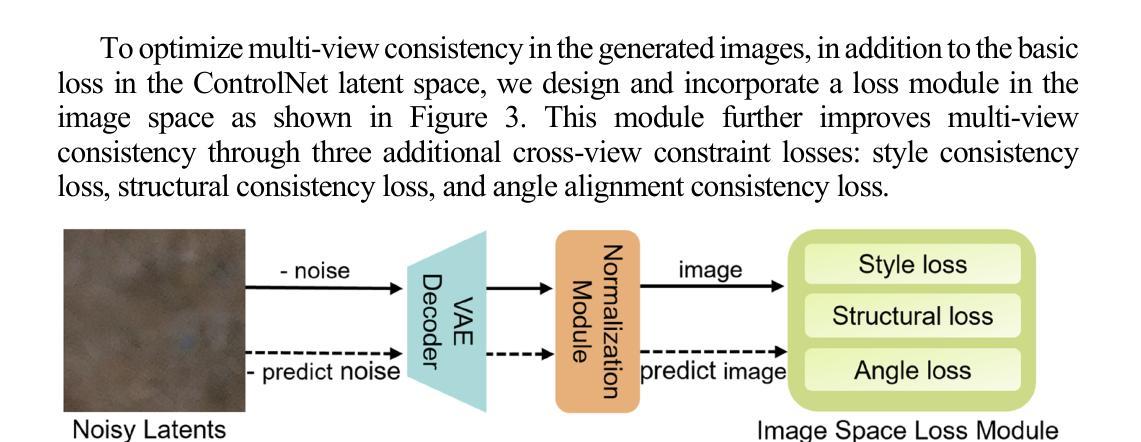
In the early stages of architectural design, shoebox models are typically used as a simplified representation of building structures but require extensive operations to transform them into detailed designs. Generative artificial intelligence (AI) provides a promising solution to automate this transformation, but ensuring multi-view consistency remains a significant challenge. To solve this issue, we propose a novel three-stage consistent image generation framework using generative AI models to generate architectural designs from shoebox model representations. The proposed method enhances state-of-the-art image generation diffusion models to generate multi-view consistent architectural images. We employ ControlNet as the backbone and optimize it to accommodate multi-view inputs of architectural shoebox models captured from predefined perspectives. To ensure stylistic and structural consistency across multi-view images, we propose an image space loss module that incorporates style loss, structural loss and angle alignment loss. We then use depth estimation method to extract depth maps from the generated multi-view images. Finally, we use the paired data of the architectural images and depth maps as inputs to improve the multi-view consistency via the depth-aware 3D attention module. Experimental results demonstrate that the proposed framework can generate multi-view architectural images with consistent style and structural coherence from shoebox model inputs.
在早期建筑设计阶段,鞋盒模型通常被用作建筑结构的简化表示,但需要大量的操作才能将它们转化为详细的设计。生成式人工智能(AI)为自动化这一转化过程提供了有前景的解决方案,但确保多视角一致性仍然是一个巨大的挑战。为了解决这一问题,我们提出了一种新的三阶段一致性图像生成框架,利用生成式AI模型从鞋盒模型表示生成建筑设计。所提出的方法改进了最先进的图像生成扩散模型,以生成多视角一致的建筑图像。我们采用ControlNet作为骨干网,并对其进行了优化,以适应从预定视角捕获的建筑鞋盒模型的多视角输入。为了确保多视角图像的风格和结构一致性,我们提出了一个图像空间损失模块,它结合了风格损失、结构损失和角度对齐损失。然后,我们使用深度估计方法从生成的多视角图像中提取深度图。最后,我们将建筑图像和深度图的配对数据作为输入,通过深度感知3D注意力模块提高多视角一致性。实验结果表明,该框架能够从鞋盒模型输入生成风格和结构一致的多视角建筑图像。
论文及项目相关链接
PDF 10 pages, 7 figures, in Proceedings of CAADRIA2025
Summary
本文提出了一种基于生成式人工智能模型的三阶段一致图像生成框架,用于从鞋盒模型表示生成建筑设计。该方法通过优化ControlNet来适应建筑鞋盒模型的多视角输入,通过图像空间损失模块确保跨多视角图像的风格和结构一致性。此外,还利用深度估计方法从生成的多视角图像中提取深度图,最后通过深度感知的3D注意力模块提高多视角一致性。实验结果表明,该框架能够从鞋盒模型输入生成具有一致风格和结构连贯性的多视角建筑图像。
Key Takeaways
- 介绍了生成式人工智能在建筑设计领域的应用背景及其所面临的挑战。
- 提出了一种三阶段的图像生成框架,用于从鞋盒模型生成建筑设计图像。
- 优化了ControlNet以适应建筑鞋盒模型的多视角输入。
- 通过图像空间损失模块确保不同视角的图像风格和结构一致性。
- 利用深度估计方法从生成的多视角图像中提取深度图。
- 使用深度感知的3D注意力模块提高了多视角一致性。
点此查看论文截图

Can Diffusion Models Provide Rigorous Uncertainty Quantification for Bayesian Inverse Problems?
Authors:Evan Scope Crafts, Umberto Villa
In recent years, the ascendance of diffusion modeling as a state-of-the-art generative modeling approach has spurred significant interest in their use as priors in Bayesian inverse problems. However, it is unclear how to optimally integrate a diffusion model trained on the prior distribution with a given likelihood function to obtain posterior samples. While algorithms that have been developed for this purpose can produce high-quality, diverse point estimates of the unknown parameters of interest, they are often tested on problems where the prior distribution is analytically unknown, making it difficult to assess their performance in providing rigorous uncertainty quantification. In this work, we introduce a new framework, Bayesian Inverse Problem Solvers through Diffusion Annealing (BIPSDA), for diffusion model based posterior sampling. The framework unifies several recently proposed diffusion model based posterior sampling algorithms and contains novel algorithms that can be realized through flexible combinations of design choices. Algorithms within our framework were tested on model problems with a Gaussian mixture prior and likelihood functions inspired by problems in image inpainting, x-ray tomography, and phase retrieval. In this setting, approximate ground-truth posterior samples can be obtained, enabling principled evaluation of the performance of the algorithms. The results demonstrate that BIPSDA algorithms can provide strong performance on the image inpainting and x-ray tomography based problems, while the challenging phase retrieval problem, which is difficult to sample from even when the posterior density is known, remains outside the reach of the diffusion model based samplers.
近年来,扩散模型作为最先进的生成建模方法,其在贝叶斯反问题中的先验使用引起了极大的兴趣。然而,尚不清楚如何将训练于先验分布的扩散模型与给定的似然函数相结合,以获得后验样本。尽管为此目的而开发的算法可以产生高质量且多样化的未知参数估计,但它们通常是在先验分布分析未知的问题上进行的测试,这使得难以评估它们在提供严格的不确定性量化方面的性能。在这项工作中,我们介绍了一种新的基于扩散退火的贝叶斯反问题求解器(BIPSDA)框架,用于基于扩散模型的采样。该框架统一了最近提出的几种基于扩散模型的采样算法,并包含了通过灵活的设计选择组合可实现的新颖算法。我们的框架内的算法在具有高斯混合先验和受图像修复、X射线断层扫描和相位检索问题启发的似然函数模型问题上进行了测试。在这种设置中,可以获得近似真实值后样本,从而能够按照原则评估算法的性能。结果表明,BIPSDA算法在图像修复和基于X射线断层扫描的问题上表现出强大的性能,而对于采样困难的相位检索问题(即使在已知后验密度的情况下也很难采样),仍超出了基于扩散模型的采样器的范围。
论文及项目相关链接
Summary
近年来,扩散模型作为最先进的生成建模方法备受关注,其在贝叶斯反问题中作为先验的使用也备受瞩目。本文引入了一个新的框架——通过扩散退火解决贝叶斯反问题(BIPSDA),用于基于扩散模型的后续采样。该框架统一了最近提出的几种扩散模型后续采样算法,并包含了可以通过灵活组合设计选择实现的新算法。在具有高斯混合先验和受图像修复、X射线断层扫描和相位检索问题启发的似然函数的模型问题上测试了框架内的算法。结果证明,BIPSDA算法在图像修复和基于X射线断层扫描的问题上表现出强大的性能,而对于即使已知后验密度也难以采样的具有挑战性的相位检索问题,仍处于扩散模型采样器的范围之外。
Key Takeaways
- 扩散模型作为生成建模方法受到广泛关注,并在贝叶斯反问题中作为先验的使用日益重要。
- 引入新的框架BIPSDA,用于基于扩散模型的后续采样,统一并扩展了现有的扩散模型采样算法。
- BIPSDA框架内的算法在具有高斯混合先验和特定似然函数的模型问题上进行了测试。
- 测试涵盖了图像修复、X射线断层扫描和相位检索等领域的问题。
- BIPSDA算法在图像修复和X射线断层扫描问题上表现出良好的性能。
- 相位检索问题对扩散模型采样器来说仍然具有挑战性。
- 通过近似地面真实后验样本,可以原则性地评估算法性能。
点此查看论文截图

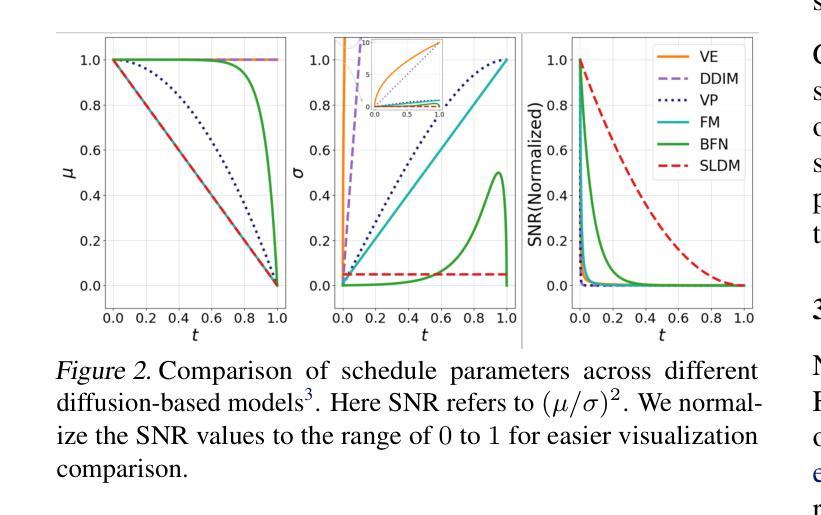
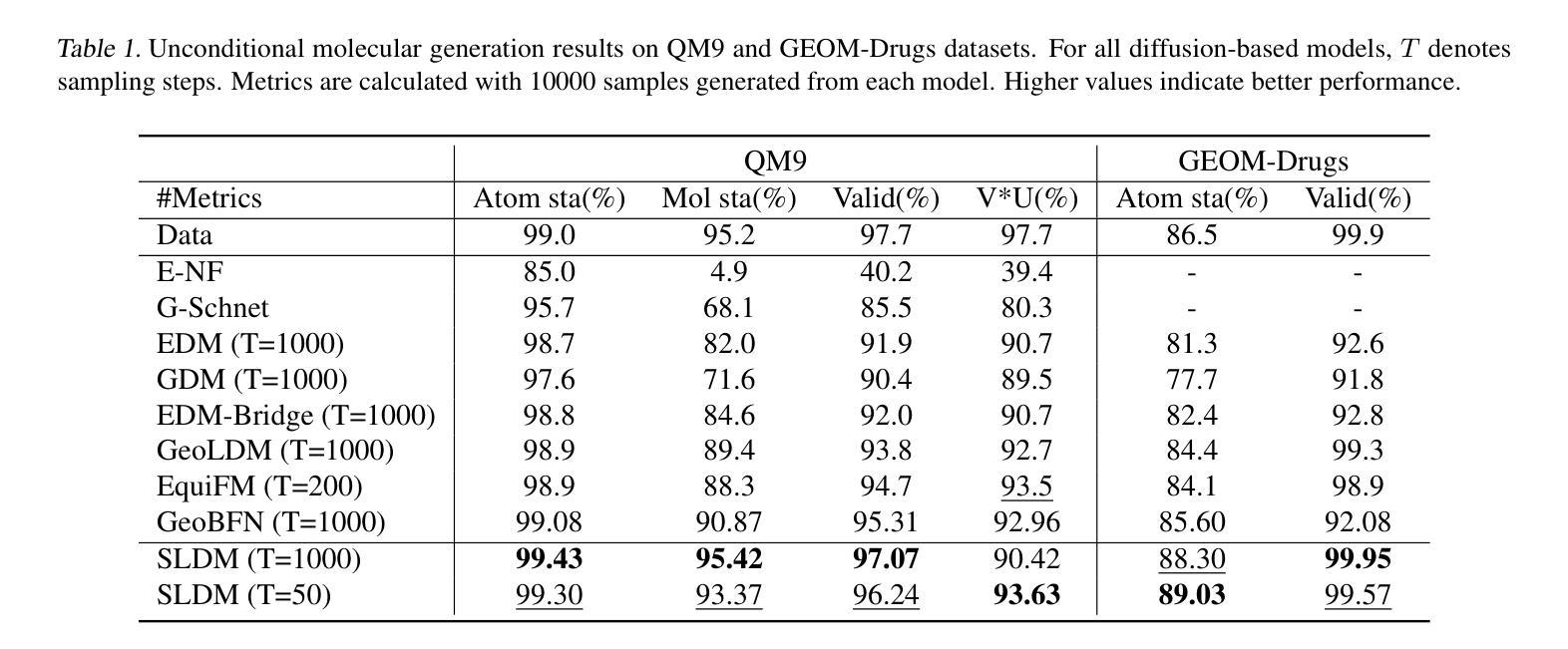
Straight-Line Diffusion Model for Efficient 3D Molecular Generation
Authors:Yuyan Ni, Shikun Feng, Haohan Chi, Bowen Zheng, Huan-ang Gao, Wei-Ying Ma, Zhi-Ming Ma, Yanyan Lan
Diffusion-based models have shown great promise in molecular generation but often require a large number of sampling steps to generate valid samples. In this paper, we introduce a novel Straight-Line Diffusion Model (SLDM) to tackle this problem, by formulating the diffusion process to follow a linear trajectory. The proposed process aligns well with the noise sensitivity characteristic of molecular structures and uniformly distributes reconstruction effort across the generative process, thus enhancing learning efficiency and efficacy. Consequently, SLDM achieves state-of-the-art performance on 3D molecule generation benchmarks, delivering a 100-fold improvement in sampling efficiency. Furthermore, experiments on toy data and image generation tasks validate the generality and robustness of SLDM, showcasing its potential across diverse generative modeling domains.
基于扩散的模型在分子生成方面显示出巨大的潜力,但通常需要大量的采样步骤来生成有效的样本。在本文中,我们引入了一种新型的直线扩散模型(SLDM)来解决这个问题,通过制定遵循线性轨迹的扩散过程。所提出的过程与分子结构的噪声敏感性特征相吻合,在生成过程中均匀分配重建工作,从而提高了学习效率和学习效果。因此,SLDM在3D分子生成基准测试上实现了最先进的性能,采样效率提高了100倍。此外,对玩具数据和图像生成任务的实验验证了SLDM的通用性和稳健性,展示了其在不同生成建模领域的潜力。
论文及项目相关链接
Summary:本文引入了一种新型的直线扩散模型(SLDM),通过制定线性轨迹的扩散过程,解决了分子生成中需要大量采样步骤的问题。该模型对齐噪声敏感性特征,均匀分布重建努力,提高学习效率与效果,实现了在三维分子生成基准测试上的卓越性能,采样效率提高了100倍。同时,在玩具数据和图像生成任务上的实验验证了其通用性和稳健性,展示了其在不同生成建模域中的潜力。
Key Takeaways:
- 新型直线扩散模型(SLDM)被提出以解决分子生成中的采样问题。
- SLDM通过制定线性轨迹的扩散过程,提高了采样效率。
- SLDM对齐噪声敏感性特征,使得模型更加适应分子结构的特点。
- SLDM在三维分子生成基准测试上实现了卓越性能。
- 与传统方法相比,SLDM的采样效率提高了100倍。
- 实验结果显示,SLDM在玩具数据和图像生成任务上具有通用性和稳健性。
点此查看论文截图

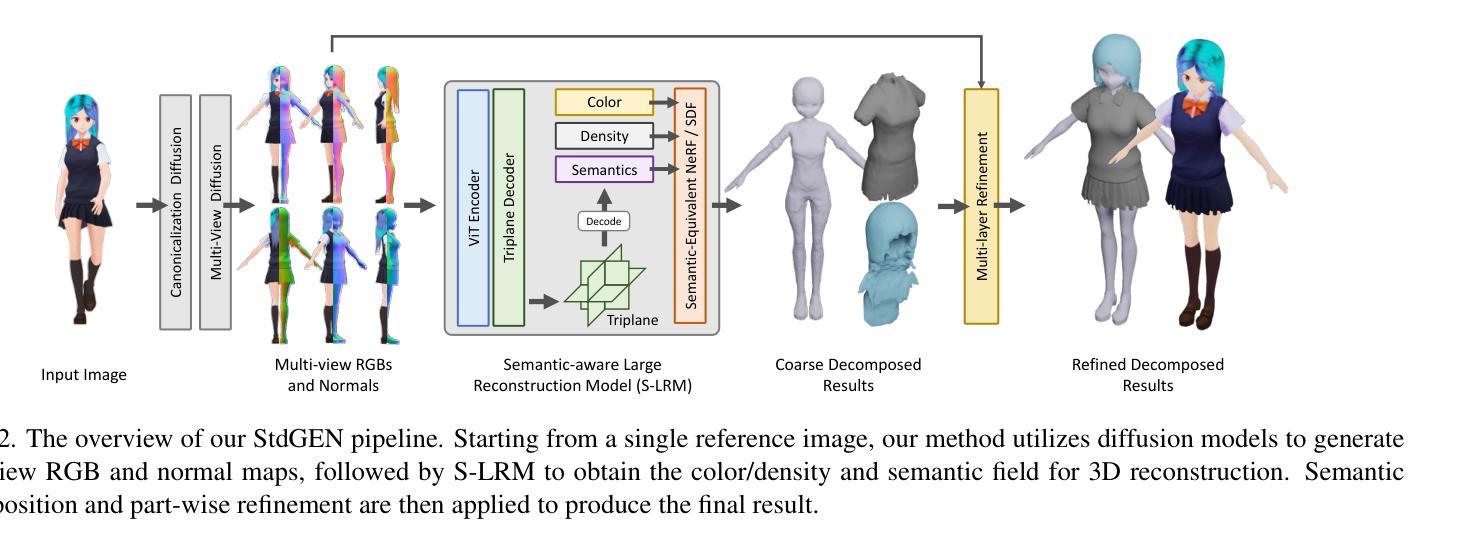
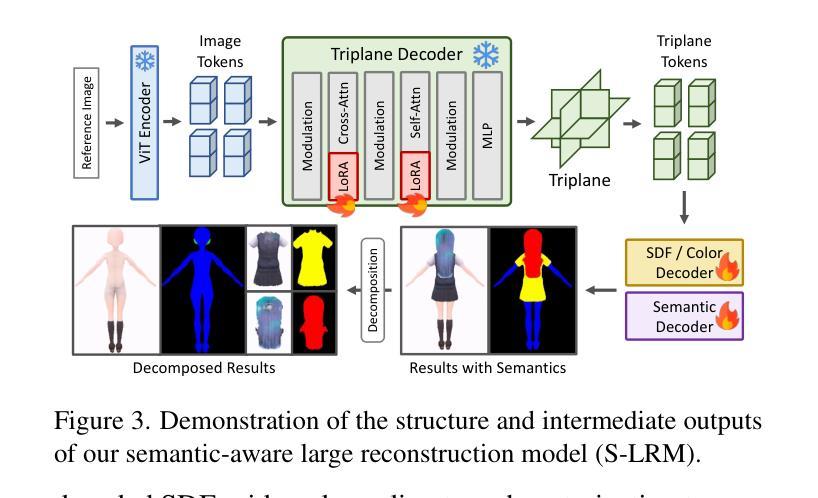
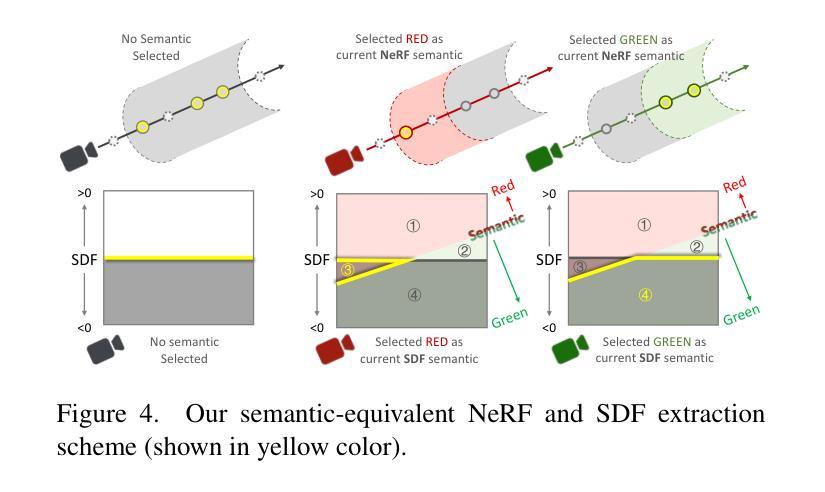
StdGEN: Semantic-Decomposed 3D Character Generation from Single Images
Authors:Yuze He, Yanning Zhou, Wang Zhao, Zhongkai Wu, Kaiwen Xiao, Wei Yang, Yong-Jin Liu, Xiao Han
We present StdGEN, an innovative pipeline for generating semantically decomposed high-quality 3D characters from single images, enabling broad applications in virtual reality, gaming, and filmmaking, etc. Unlike previous methods which struggle with limited decomposability, unsatisfactory quality, and long optimization times, StdGEN features decomposability, effectiveness and efficiency; i.e., it generates intricately detailed 3D characters with separated semantic components such as the body, clothes, and hair, in three minutes. At the core of StdGEN is our proposed Semantic-aware Large Reconstruction Model (S-LRM), a transformer-based generalizable model that jointly reconstructs geometry, color and semantics from multi-view images in a feed-forward manner. A differentiable multi-layer semantic surface extraction scheme is introduced to acquire meshes from hybrid implicit fields reconstructed by our S-LRM. Additionally, a specialized efficient multi-view diffusion model and an iterative multi-layer surface refinement module are integrated into the pipeline to facilitate high-quality, decomposable 3D character generation. Extensive experiments demonstrate our state-of-the-art performance in 3D anime character generation, surpassing existing baselines by a significant margin in geometry, texture and decomposability. StdGEN offers ready-to-use semantic-decomposed 3D characters and enables flexible customization for a wide range of applications. Project page: https://stdgen.github.io
我们推出了StdGEN,这是一个从单张图像生成语义分解的高质量3D角色的创新管道,广泛应用于虚拟现实、游戏制作、电影制作等领域。与以往方法在分解性、质量、优化时间等方面的局限不同,StdGEN具有分解性、有效性和高效性;也就是说,它能够在三分钟内生成具有分离语义组件的精细详细的3D角色,如身体、衣物和头发。StdGEN的核心是我们提出的大型语义感知重建模型(S-LRM),这是一个基于变压器的可推广模型,以前馈方式从多视角图像重建几何、颜色和语义。我们引入了可微多层语义表面提取方案,从由S-LRM重建的混合隐式字段中获取网格。此外,一个专门的高效多视角扩散模型和迭代多层表面细化模块被集成到管道中,以促进高质量、可分解的3D角色生成。大量实验表明,我们在3D动画角色生成方面达到了最新技术水平,在几何、纹理和分解性方面大大超过了现有基准。StdGEN提供即插即用的语义分解的3D角色,并为广泛的应用提供灵活的定制。项目页面:https://stdgen.github.io
论文及项目相关链接
PDF CVPR 2025. 13 pages, 10 figures
Summary
本文介绍了StdGEN,这是一个从单张图像生成语义分解的高质量3D角色的创新管道。StdGEN具有分解性、有效性和效率,能够生成具有分离语义组件的精细3D角色,如身体、衣物和头发。其核心是语义感知大型重建模型(S-LRM),该模型从多视角图像以前馈方式联合重建几何、颜色和语义。实验表明,StdGEN在3D动漫角色生成方面表现出卓越的性能,在几何、纹理和分解性方面大大超越了现有基线。
Key Takeaways
- StdGEN是一个生成语义分解的高质量3D角色的创新管道。
- 它能够从单张图像生成具有精细细节的3D角色,并分离出语义组件(如身体、衣物和头发)。
- StdGEN的核心是语义感知大型重建模型(S-LRM),该模型能够从前馈方式联合重建几何、颜色和语义。
- 通过引入可微多层语义表面提取方案,从由S-LRM重建的混合隐式字段中获取网格。
- StdGEN集成了高效的多视角扩散模型和迭代多层表面细化模块,以生成高质量、可分解的3D角色。
- 实验表明,StdGEN在3D动漫角色生成方面表现出卓越的性能,在几何、纹理和分解性方面超越现有方法。
点此查看论文截图

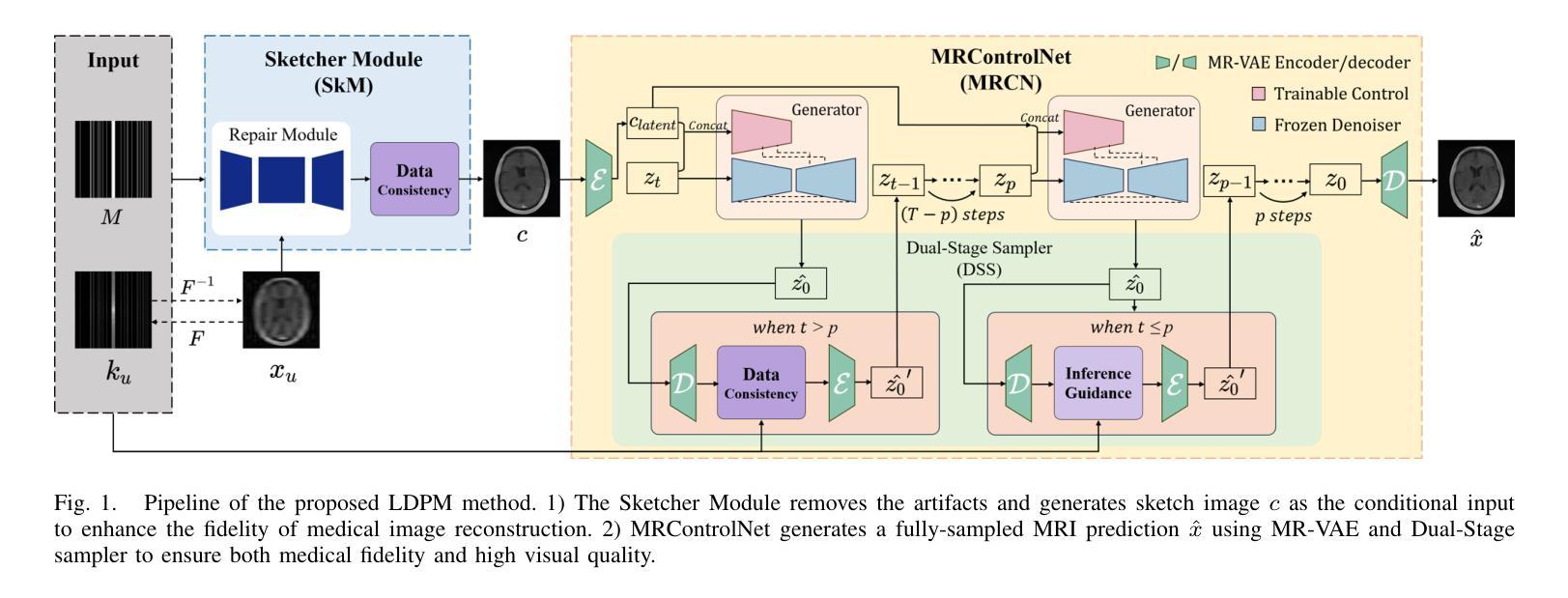
LDPM: Towards undersampled MRI reconstruction with MR-VAE and Latent Diffusion Prior
Authors:Xingjian Tang, Jingwei Guan, Linge Li, Ran Shi, Youmei Zhang, Mengye Lyu, Li Yan
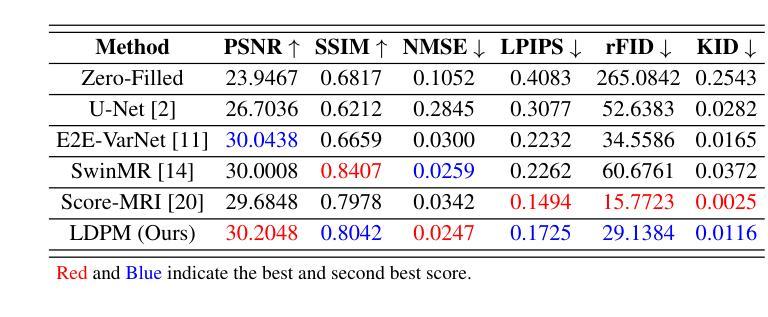
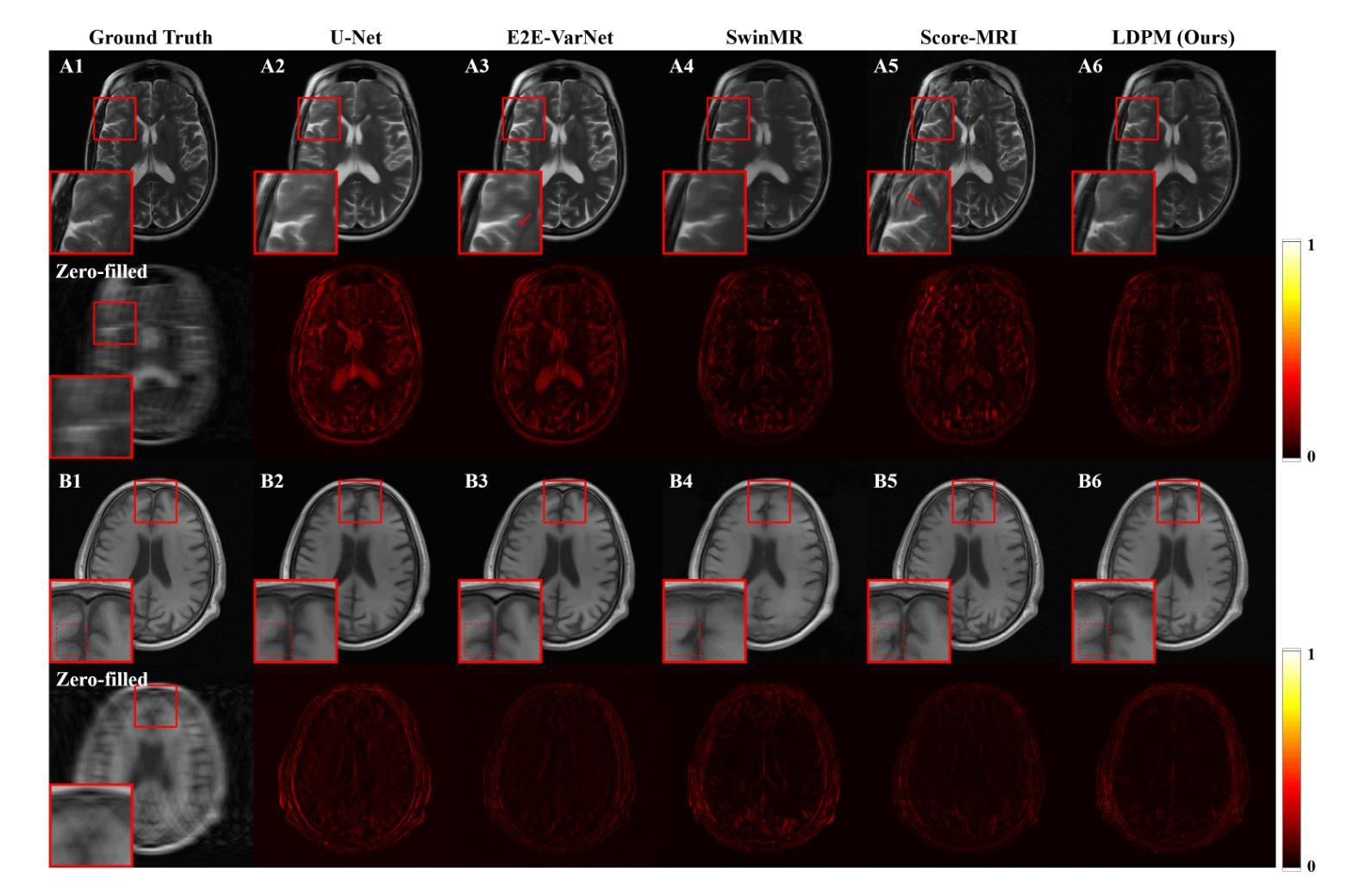
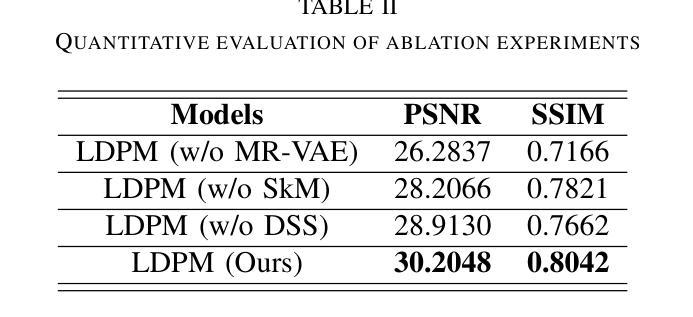
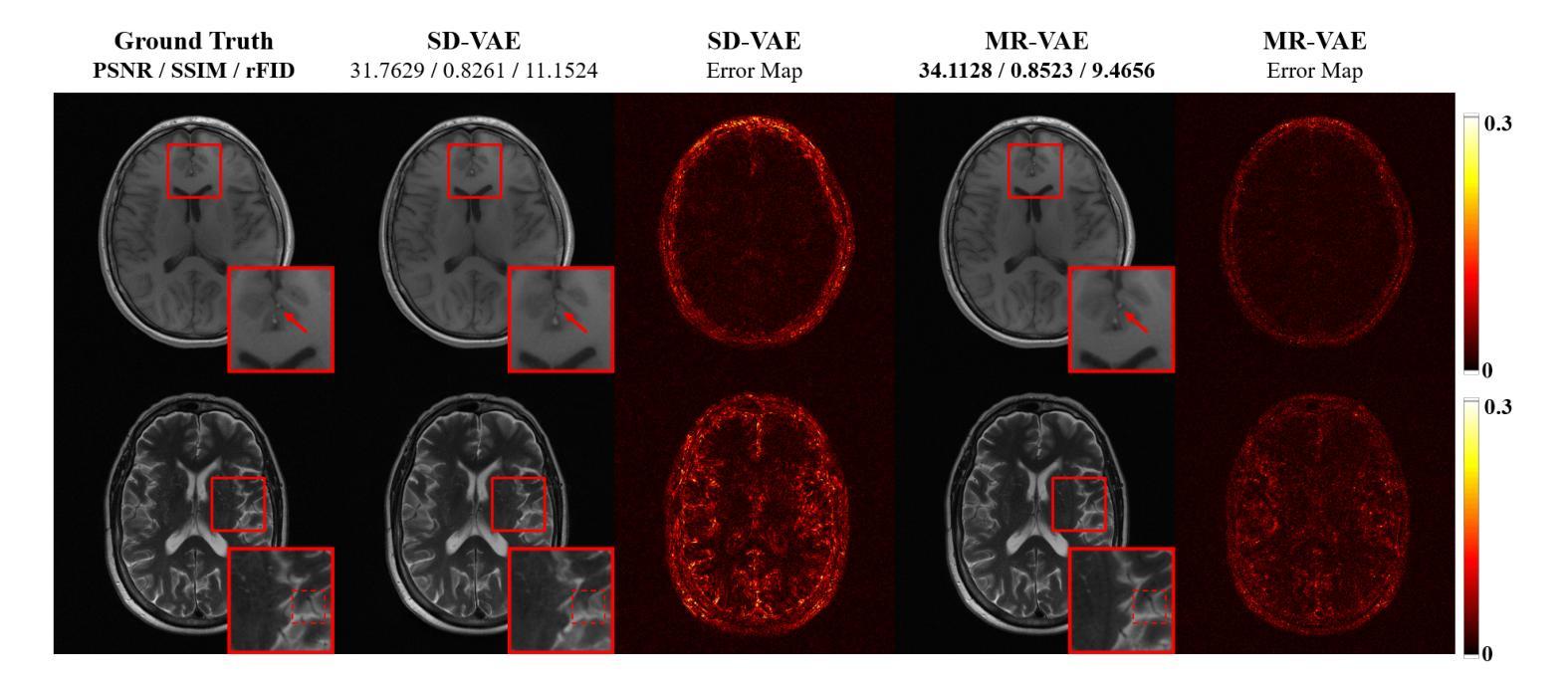
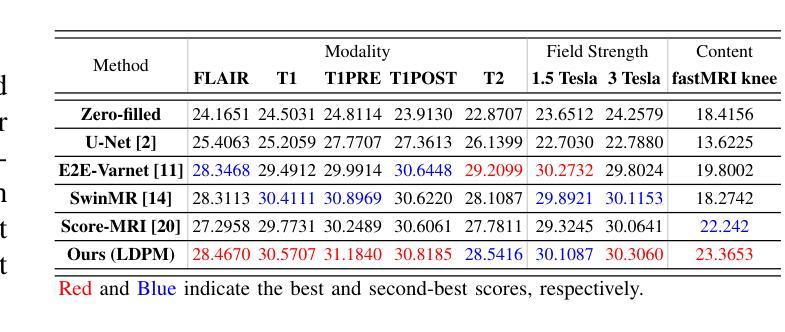
Diffusion models, as powerful generative models, have found a wide range of applications and shown great potential in solving image reconstruction problems. Some works attempted to solve MRI reconstruction with diffusion models, but these methods operate directly in pixel space, leading to higher computational costs for optimization and inference. Latent diffusion models, pre-trained on natural images with rich visual priors, are expected to solve the high computational cost problem in MRI reconstruction by operating in a lower-dimensional latent space. However, direct application to MRI reconstruction faces three key challenges: (1) absence of explicit control mechanisms for medical fidelity, (2) domain gap between natural images and MR physics, and (3) undefined data consistency in latent space. To address these challenges, a novel Latent Diffusion Prior-based undersampled MRI reconstruction (LDPM) method is proposed. Our LDPM framework addresses these challenges by: (1) a sketch-guided pipeline with a two-step reconstruction strategy, which balances perceptual quality and anatomical fidelity, (2) an MRI-optimized VAE (MR-VAE), which achieves an improvement of approximately 3.92 dB in PSNR for undersampled MRI reconstruction compared to that with SD-VAE \cite{sd}, and (3) Dual-Stage Sampler, a modified version of spaced DDPM sampler, which enforces high-fidelity reconstruction in the latent space. Experiments on the fastMRI dataset\cite{fastmri} demonstrate the state-of-the-art performance of the proposed method and its robustness across various scenarios. The effectiveness of each module is also verified through ablation experiments.
扩散模型作为强大的生成模型,在图像重建问题解决方案中得到了广泛的应用并表现出了巨大的潜力。一些研究尝试使用扩散模型解决MRI重建问题,但这些方法在像素空间直接操作,导致优化和推理的计算成本较高。预训练在自然图像上的潜在扩散模型具有丰富的视觉先验信息,有望通过降低维度的潜在空间解决MRI重建中的高计算成本问题。然而,直接应用于MRI重建面临三个主要挑战:(1)缺乏医疗准确性的明确控制机制;(2)自然图像与MR物理之间的领域差距;(3)潜在空间中的数据一致性未定义。为了解决这些挑战,提出了一种基于潜在扩散先验的欠采样MRI重建(LDPM)新方法。我们的LDPM框架通过以下方式应对这些挑战:(1)一个草图引导的流程,采用两步重建策略,平衡感知质量和解剖精度;(2)一个针对MRI优化的VAE(MR-VAE),与SD-VAE相比,它在欠采样MRI重建的PSNR上提高了约3.92分贝【sd】;(3)双阶段采样器,这是间隔DDPM采样器的改进版,它在潜在空间中强制进行高保真重建。在fastMRI数据集上的实验证明了该方法的先进性能及其在不同场景中的稳健性【fastmri】。每个模块的有效性也通过消融实验得到了验证。
论文及项目相关链接
摘要
扩散模型作为强大的生成模型,在图像重建问题中展现出了巨大的潜力,并得到了广泛的应用。尽管已有一些工作尝试用扩散模型解决MRI重建问题,但这些方法在像素空间直接操作导致了较高的优化和推理计算成本。预期通过潜在扩散模型(在具有丰富视觉先验的自然图像上预训练)来解决这一问题。然而,将其直接应用于MRI重建面临三个关键挑战。为了解决这些挑战,提出了一种基于潜在扩散先验的欠采样MRI重建(LDPM)方法。我们的LDPM框架通过以下方式应对挑战:1)一个带有两步重建策略的草图引导管道,平衡感知质量和解剖保真度;2)一个针对MRI优化的VAE(MR-VAE),在欠采样MRI重建的PSNR上提高了约3.92 dB;3)双阶段采样器,一个改进的空间DDPM采样器版本,在潜在空间中强制高保真重建。在fastMRI数据集上的实验证明了所提方法的先进性能和在各种场景中的稳健性。每个模块的有效性也通过消融实验得到了验证。
关键见解
- 扩散模型在解决图像重建问题中展现出了巨大潜力,包括MRI重建。
- 直接在像素空间操作导致较高的计算成本,而潜在扩散模型有望在较低维度的潜在空间中解决此问题。
- 将潜在扩散模型直接应用于MRI重建面临三个主要挑战:医学保真度的缺乏明确控制机制、自然图像与MR物理之间的领域差距,以及潜在空间中的数据一致性未定义。
- 提出的LDPM方法通过草图引导管道和两步重建策略平衡感知质量与解剖保真度。
- MR-VAE在欠采样MRI重建的PSNR上提高了约3.92 dB。
- 双阶段采样器是一种改进的空间DDPM采样器版本,它在潜在空间中强制执行高保真重建。
- 在fastMRI数据集上的实验证明了所提方法具有先进性能和在各种场景中的稳健性。
点此查看论文截图

An Undetectable Watermark for Generative Image Models
Authors:Sam Gunn, Xuandong Zhao, Dawn Song
We present the first undetectable watermarking scheme for generative image models. Undetectability ensures that no efficient adversary can distinguish between watermarked and un-watermarked images, even after making many adaptive queries. In particular, an undetectable watermark does not degrade image quality under any efficiently computable metric. Our scheme works by selecting the initial latents of a diffusion model using a pseudorandom error-correcting code (Christ and Gunn, 2024), a strategy which guarantees undetectability and robustness. We experimentally demonstrate that our watermarks are quality-preserving and robust using Stable Diffusion 2.1. Our experiments verify that, in contrast to every prior scheme we tested, our watermark does not degrade image quality. Our experiments also demonstrate robustness: existing watermark removal attacks fail to remove our watermark from images without significantly degrading the quality of the images. Finally, we find that we can robustly encode 512 bits in our watermark, and up to 2500 bits when the images are not subjected to watermark removal attacks. Our code is available at https://github.com/XuandongZhao/PRC-Watermark.
我们为生成图像模型提出了第一个不可检测的水印方案。不可检测性确保高效的对手即使在执行多次自适应查询后,也无法区分带水印和不带水印的图像。特别是,不可检测的水印在任何可高效计算的指标下都不会降低图像质量。我们的方案通过选择一个扩散模型的初始潜在变量来实现,该选择采用伪随机纠错码(Christ and Gunn, 2024)的策略,该策略保证了不可检测性和稳健性。我们通过实验证明了水印在保持质量和稳健性方面的优势,使用的是Stable Diffusion 2.1。我们的实验验证了我们测试过的所有先前方案相比,我们的水印不会降低图像质量。我们的实验还证明了稳健性:现有的水印移除攻击无法在我们的水印从图像中移除的同时而不显著降低图像质量。最后,我们发现我们可以稳健地在我们的水印中编码512位,当图像未受到水印移除攻击时,甚至可以编码高达2500位。我们的代码可在https://github.com/XuandongZhao/PRC-Watermark找到。
论文及项目相关链接
PDF ICLR 2025
Summary
本文提出首个针对生成图像模型的不可检测水印方案。该方案利用伪随机纠错码选择扩散模型的初始潜变量,确保水印的不可检测性和稳健性。实验证明,该水印不会降低图像质量,对现有的水印移除攻击具有强大的抵御能力。该方案可将水印嵌入到图像中而不会明显影响图像质量,并具有高达512位的稳健编码能力。
Key Takeaways
- 提出首个针对生成图像模型的不可检测水印方案。
- 利用伪随机纠错码选择扩散模型的初始潜变量以确保水印的不可检测性和稳健性。
- 实验证明水印不会降低图像质量。
- 对现有的水印移除攻击具有强大的抵御能力。
- 水印可以嵌入到图像中而不会明显影响图像质量。
- 该方案具有高达512位的稳健编码能力。
点此查看论文截图

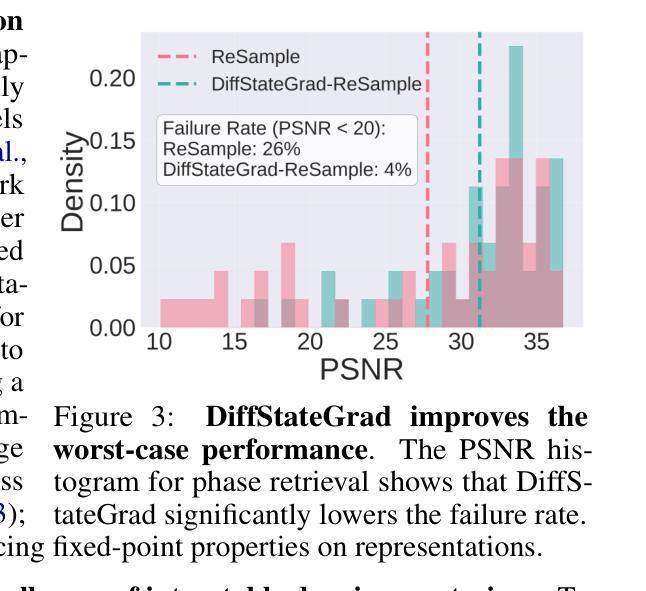
Diffusion State-Guided Projected Gradient for Inverse Problems
Authors:Rayhan Zirvi, Bahareh Tolooshams, Anima Anandkumar
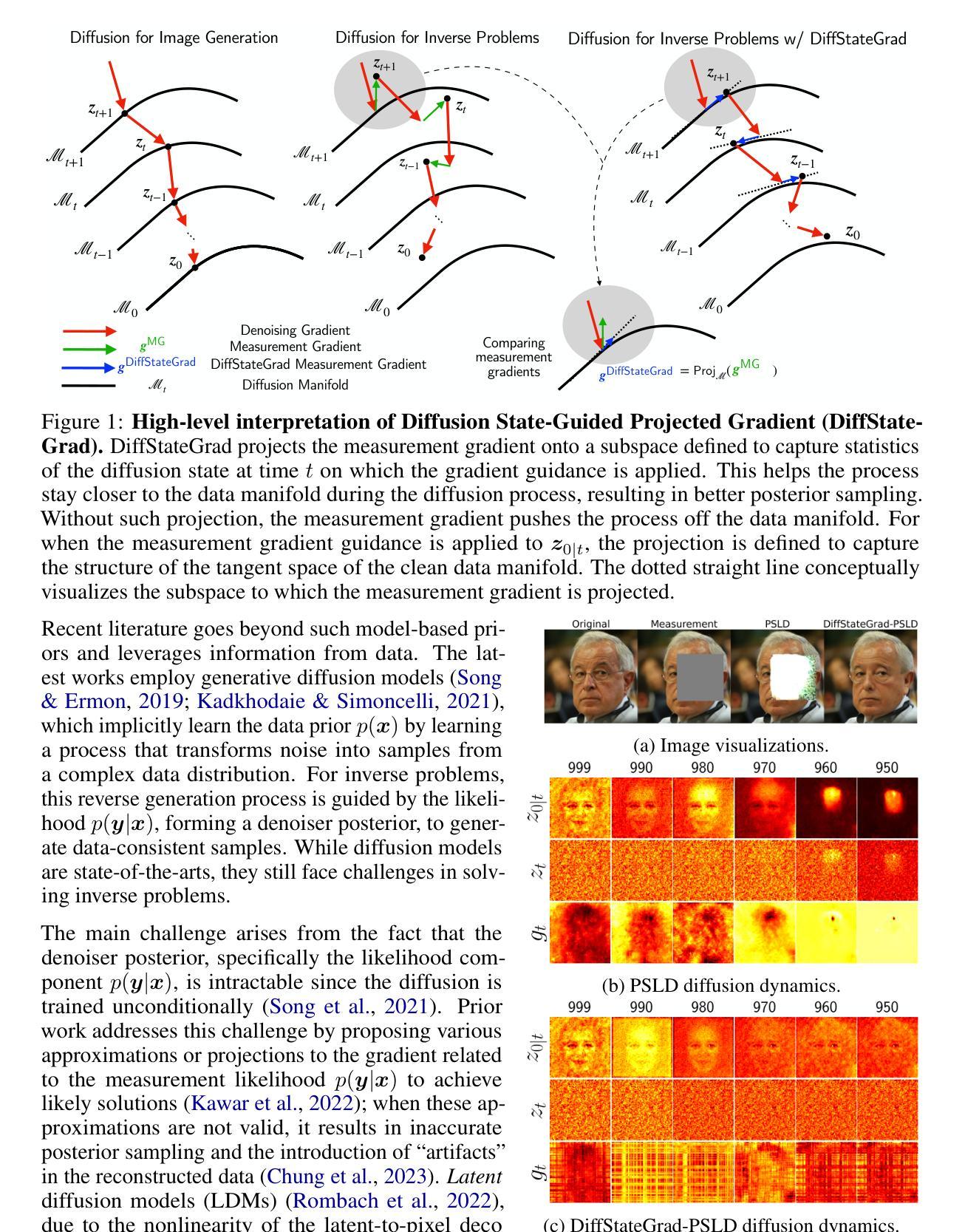
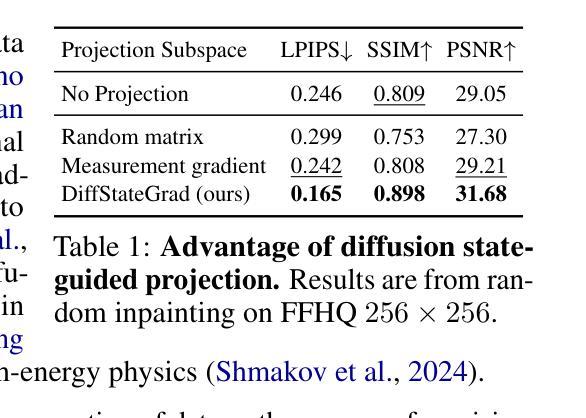
Recent advancements in diffusion models have been effective in learning data priors for solving inverse problems. They leverage diffusion sampling steps for inducing a data prior while using a measurement guidance gradient at each step to impose data consistency. For general inverse problems, approximations are needed when an unconditionally trained diffusion model is used since the measurement likelihood is intractable, leading to inaccurate posterior sampling. In other words, due to their approximations, these methods fail to preserve the generation process on the data manifold defined by the diffusion prior, leading to artifacts in applications such as image restoration. To enhance the performance and robustness of diffusion models in solving inverse problems, we propose Diffusion State-Guided Projected Gradient (DiffStateGrad), which projects the measurement gradient onto a subspace that is a low-rank approximation of an intermediate state of the diffusion process. DiffStateGrad, as a module, can be added to a wide range of diffusion-based inverse solvers to improve the preservation of the diffusion process on the prior manifold and filter out artifact-inducing components. We highlight that DiffStateGrad improves the robustness of diffusion models in terms of the choice of measurement guidance step size and noise while improving the worst-case performance. Finally, we demonstrate that DiffStateGrad improves upon the state-of-the-art on linear and nonlinear image restoration inverse problems. Our code is available at https://github.com/Anima-Lab/DiffStateGrad.
最近扩散模型的发展在解决反问题方面学习数据先验方面取得了显著成效。他们利用扩散采样步骤来诱导数据先验,同时在每一步使用测量指导梯度来施加数据一致性。对于一般反问题,当使用无条件训练的扩散模型时,由于测量似然性难以处理,导致后验采样不准确。换句话说,由于这些近似方法,它们无法保留由扩散先验定义的数据流形上的生成过程,从而导致图像恢复等应用程序中出现伪影。为了提高扩散模型解决反问题的性能和稳健性,我们提出了扩散状态引导投影梯度(DiffStateGrad),它将测量梯度投影到扩散过程中间状态的低秩近似子空间上。作为一个模块,DiffStateGrad可以添加到广泛的基于扩散的反向求解器中,以提高扩散过程在先验流形上的保留能力,并过滤掉产生伪影的组件。我们强调,DiffStateGrad提高了扩散模型在选择测量指导步长和噪声方面的稳健性,同时提高了最坏情况下的性能。最后,我们证明了DiffStateGrad在解决线性和非线性图像恢复反问题上优于现有技术。我们的代码可在https://github.com/Anima-Lab/DiffStateGrad上找到。
论文及项目相关链接
PDF Published as a conference paper at ICLR 2025. RZ and BT have equal contributions
Summary
近期扩散模型在解决反问题方面的进展有效学习了数据先验。它们利用扩散采样步骤来诱导数据先验,同时使用测量指导梯度来施加数据一致性。对于一般反问题,当使用无条件训练的扩散模型时,由于测量似然不可行,需要近似处理,导致后验采样不准确。为解决这一问题,提出了扩散状态引导投影梯度(DiffStateGrad),它将测量梯度投影到扩散过程中间状态的低秩近似子空间上。DiffStateGrad可作为模块添加到各种基于扩散的反问题求解器中,提高了扩散过程在先验流形上的保持能力,并过滤掉了产生伪影的组件。它提高了扩散模型在选择测量指导步长和噪声方面的稳健性,并在线性和非线性图像恢复反问题上取得了先进的效果。
Key Takeaways
- 扩散模型在解决反问题上取得新进展,通过扩散采样步骤学习数据先验并利用测量指导梯度施加数据一致性。
- 对于一般反问题,使用无条件训练的扩散模型时需要进行近似处理,导致后验采样不准确和生成过程中的失真。
- 提出DiffStateGrad方法,通过将测量梯度投影到扩散过程的低秩近似子空间上,提高扩散模型的性能。
- DiffStateGrad可作为模块添加到各种基于扩散的反问题求解器中,改善扩散过程在先验流形上的保持能力并过滤伪影成分。
- DiffStateGrad提高了扩散模型在选择测量指导步长和噪声方面的稳健性。
- DiffStateGrad在图像恢复等应用领域的表现优于现有技术。
点此查看论文截图



Counting Guidance for High Fidelity Text-to-Image Synthesis
Authors:Wonjun Kang, Kevin Galim, Hyung Il Koo, Nam Ik Cho
Recently, there have been significant improvements in the quality and performance of text-to-image generation, largely due to the impressive results attained by diffusion models. However, text-to-image diffusion models sometimes struggle to create high-fidelity content for the given input prompt. One specific issue is their difficulty in generating the precise number of objects specified in the text prompt. For example, when provided with the prompt “five apples and ten lemons on a table,” images generated by diffusion models often contain an incorrect number of objects. In this paper, we present a method to improve diffusion models so that they accurately produce the correct object count based on the input prompt. We adopt a counting network that performs reference-less class-agnostic counting for any given image. We calculate the gradients of the counting network and refine the predicted noise for each step. To address the presence of multiple types of objects in the prompt, we utilize novel attention map guidance to obtain high-quality masks for each object. Finally, we guide the denoising process using the calculated gradients for each object. Through extensive experiments and evaluation, we demonstrate that the proposed method significantly enhances the fidelity of diffusion models with respect to object count. Code is available at https://github.com/furiosa-ai/counting-guidance.
最近,文本到图像生成的质量和性能得到了显著改善,这很大程度上是由于扩散模型取得的令人印象深刻的结果。然而,文本到图像的扩散模型有时在生成给定输入提示的高保真内容时遇到困难。一个具体的问题是它们在生成文本提示中指定的精确数量的对象时遇到困难。例如,当提供“桌子上放着五个苹果和十个柠檬”的提示时,由扩散模型生成的图像通常包含不正确数量的对象。在本文中,我们提出了一种改进扩散模型的方法,使它们能够基于输入提示准确产生正确的对象计数。我们采用了一个计数网络,该网络可以对任何给定图像执行无参考的类无关计数。我们计算计数网络的梯度,并细化每一步预测的噪声。为了解决提示中存在多种类型对象的问题,我们利用新型注意力图引导来获得每个对象的高质量掩模。最后,我们使用为每个对象计算的梯度来引导去噪过程。通过广泛的实验和评估,我们证明所提出的方法显著提高了扩散模型在对象计数方面的保真度。代码可在https://github.com/furiosa-ai/counting-guidance找到。
论文及项目相关链接
PDF Accepted at WACV 2025 (Oral). Code is available at https://github.com/furiosa-ai/counting-guidance
Summary
本文介绍了如何通过改进扩散模型,使其能够根据输入提示准确生成对象数量。采用计数网络进行无参考的类无知计数,通过计算计数网络的梯度并优化每一步的预测噪声来实现。为解决提示中存在多种类型对象的问题,利用新型注意力图引导获得每个对象的高质量蒙版,并在每个对象的梯度引导下完成去噪过程。实验证明,该方法显著提高扩散模型在对象计数方面的保真度。
Key Takeaways
- 扩散模型在文本转图像生成领域取得显著进步,但在生成精确数量的内容方面仍有挑战。
- 本文提出一种改进方法,使扩散模型能基于输入提示准确生成对象数量。
- 采用计数网络进行无参考的类无知计数,适用于任何给定图像。
- 通过计算计数网络的梯度并优化每一步的预测噪声来提高模型性能。
- 为处理提示中的多种对象类型,使用新型注意力图引导技术,为每个对象生成高质量蒙版。
- 结合每个对象的梯度引导完成去噪过程。
- 实验证明,该方法在增强扩散模型对象计数方面的保真度方面表现显著。
点此查看论文截图




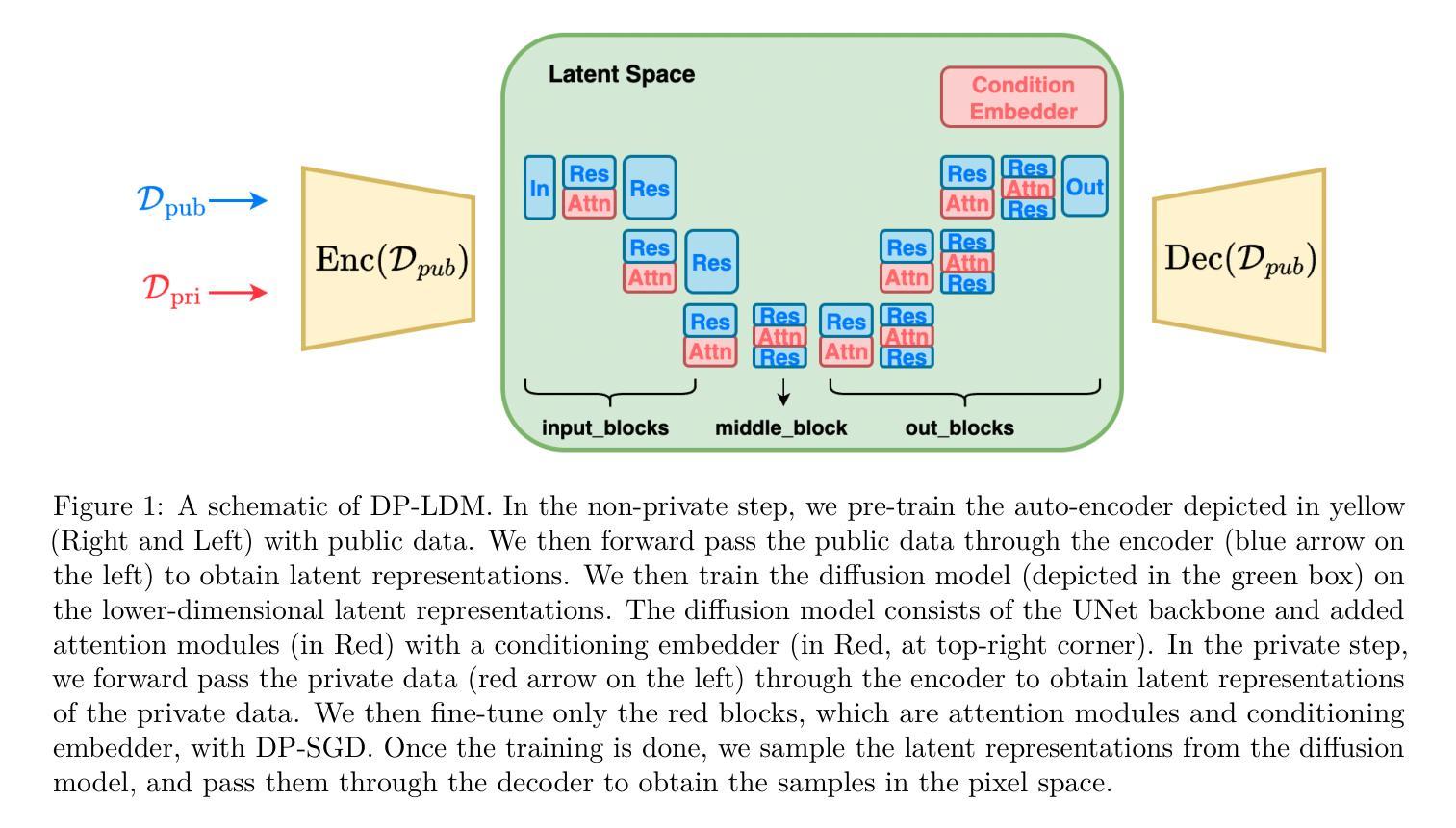
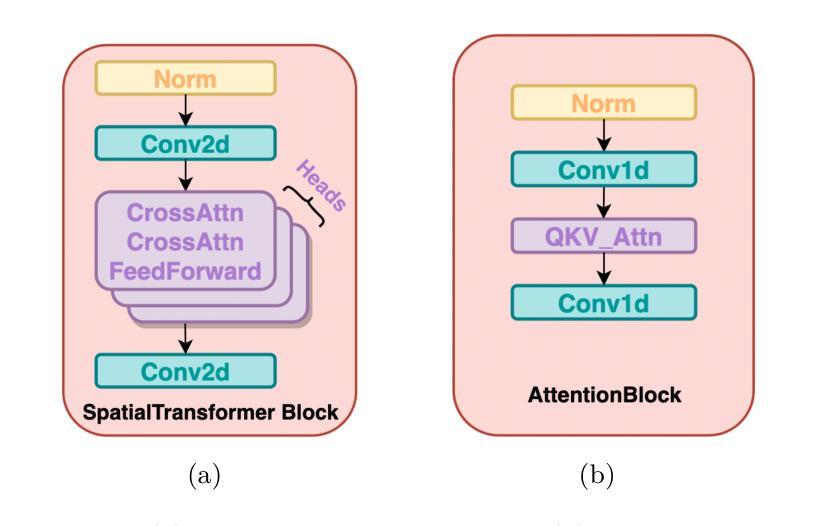
DP-LDMs: Differentially Private Latent Diffusion Models
Authors:Michael F. Liu, Saiyue Lyu, Margarita Vinaroz, Mijung Park
Diffusion models (DMs) are one of the most widely used generative models for producing high quality images. However, a flurry of recent papers points out that DMs are least private forms of image generators, by extracting a significant number of near-identical replicas of training images from DMs. Existing privacy-enhancing techniques for DMs, unfortunately, do not provide a good privacy-utility tradeoff. In this paper, we aim to improve the current state of DMs with differential privacy (DP) by adopting the $\textit{Latent}$ Diffusion Models (LDMs). LDMs are equipped with powerful pre-trained autoencoders that map the high-dimensional pixels into lower-dimensional latent representations, in which DMs are trained, yielding a more efficient and fast training of DMs. Rather than fine-tuning the entire LDMs, we fine-tune only the $\textit{attention}$ modules of LDMs with DP-SGD, reducing the number of trainable parameters by roughly $90%$ and achieving a better privacy-accuracy trade-off. Our approach allows us to generate realistic, high-dimensional images (256x256) conditioned on text prompts with DP guarantees, which, to the best of our knowledge, has not been attempted before. Our approach provides a promising direction for training more powerful, yet training-efficient differentially private DMs, producing high-quality DP images. Our code is available at https://anonymous.4open.science/r/DP-LDM-4525.
扩散模型(DMs)是生成高质量图像的最广泛使用的生成模型之一。然而,最近的一系列论文指出,扩散模型是图像生成器中隐私保护最差的形式之一,能够从扩散模型中提取大量近乎相同的训练图像复制品。不幸的是,现有的用于增强扩散模型隐私保护的技术并没有提供良好的隐私效用权衡。在本文中,我们旨在采用潜在扩散模型(LDMs)改进当前扩散模型与差分隐私(DP)的状态。LDMs配备了强大的预训练自动编码器,将高维像素映射到低维潜在表示中,在其中训练扩散模型,从而实现了更高效、更快的扩散模型训练。我们不需要微调整个LDMs,而只是使用DP-SGD微调LDMs的注意力模块,将可训练参数的数量减少了大约90%,并实现了更好的隐私准确性权衡。我们的方法能够利用文本提示生成具有DP保证的现实主义、高维图像(256x256),据我们所知,之前尚未有人尝试过。我们的方法为训练更强大、更高效且具有差分隐私保护能力的扩散模型提供了有前景的方向,能够生成高质量DP图像。我们的代码可在https://anonymous.4open.science/r/DP-LDM-4525上找到。
论文及项目相关链接
Summary
扩散模型(DMs)是生成高质量图像最常用的生成模型之一。然而,最近的论文指出DMs是最不私密的图像生成形式。现有增强隐私保护的技术并不能在隐私和效用之间取得良好的平衡。本文旨在采用具有差分隐私(DP)的潜在扩散模型(LDMs)来改善DMs的现状。LDMs配备强大的预训练自动编码器,将高维像素映射到低维潜在表示中训练DMs,实现了更高效、更快的DMs训练。我们只对LDMs的注意力模块进行微调,而不是对整个模型进行微调,并使用DP-SGD实现差分隐私保护。通过减少约90%的可训练参数,我们实现了更好的隐私与准确性之间的权衡。我们的方法能够生成具有文本提示条件的真实、高维图像(256x256),并具有DP保证,这在我们的知识范围内尚未有人尝试过。这为训练更强大、更高效且具有差分隐私的DMs提供了有前景的方向。
Key Takeaways
- 扩散模型(DMs)是生成高质量图像的主要工具,但存在隐私泄露的问题。
- 现有隐私增强技术在DMs上的隐私与效用平衡不佳。
- 采用潜在扩散模型(LDMs)结合差分隐私(DP)技术来改善DMs的隐私问题。
- LDMs使用预训练自动编码器将高维像素转化为低维潜在表示,提高了DMs的训练效率和速度。
- 只对LDMs的注意力模块进行微调,显著减少了可训练参数,实现了更好的隐私与准确性之间的平衡。
- 该方法能够生成具有文本提示条件的真实、高维图像(256x256),并具有差分隐私保证。
点此查看论文截图