⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-07 更新
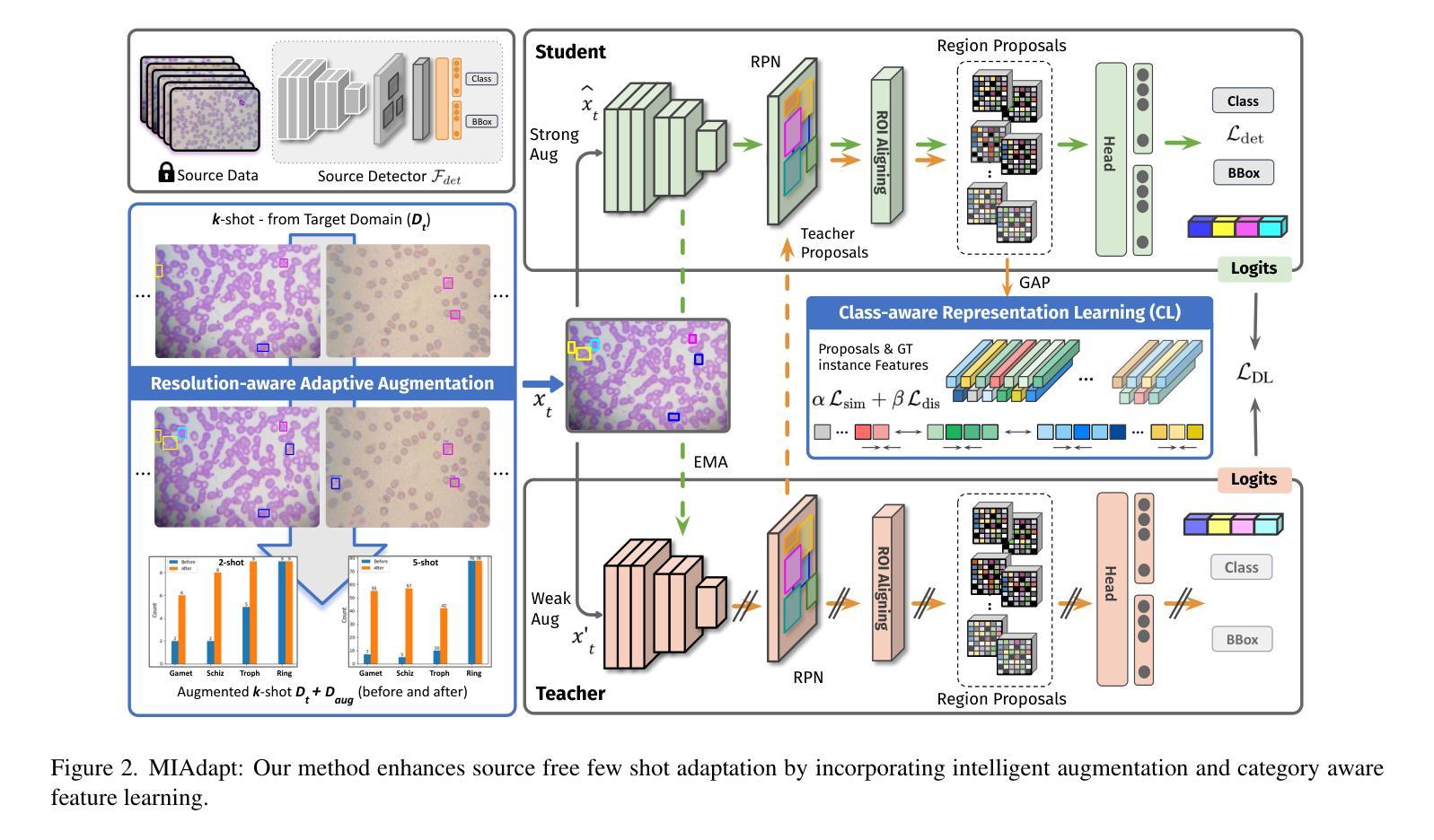
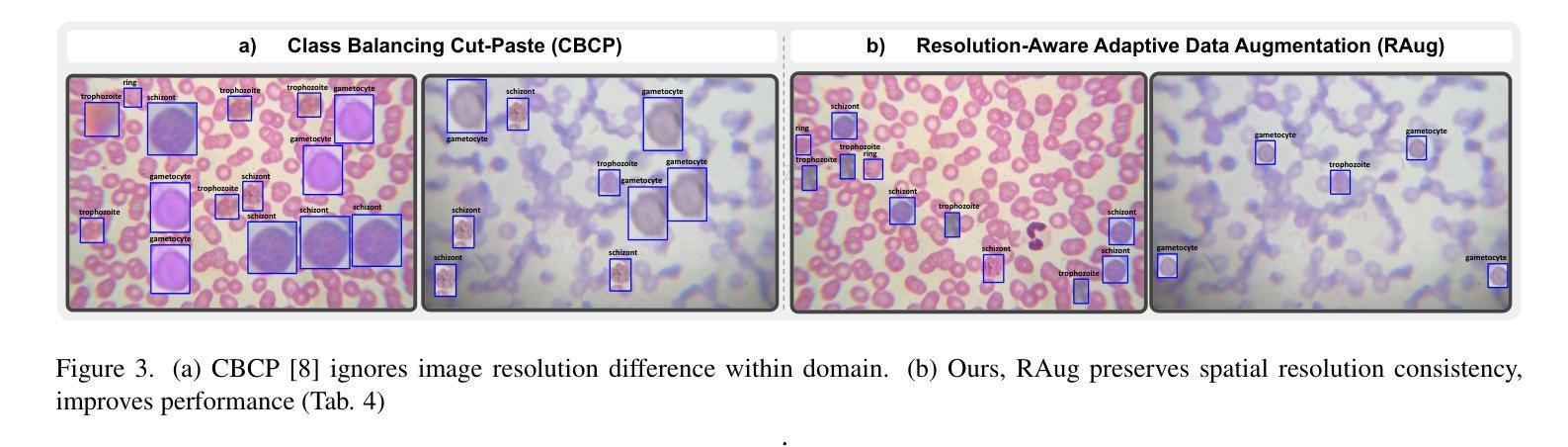
MIAdapt: Source-free Few-shot Domain Adaptive Object Detection for Microscopic Images
Authors:Nimra Dilawar, Sara Nadeem, Javed Iqbal, Waqas Sultani, Mohsen Ali
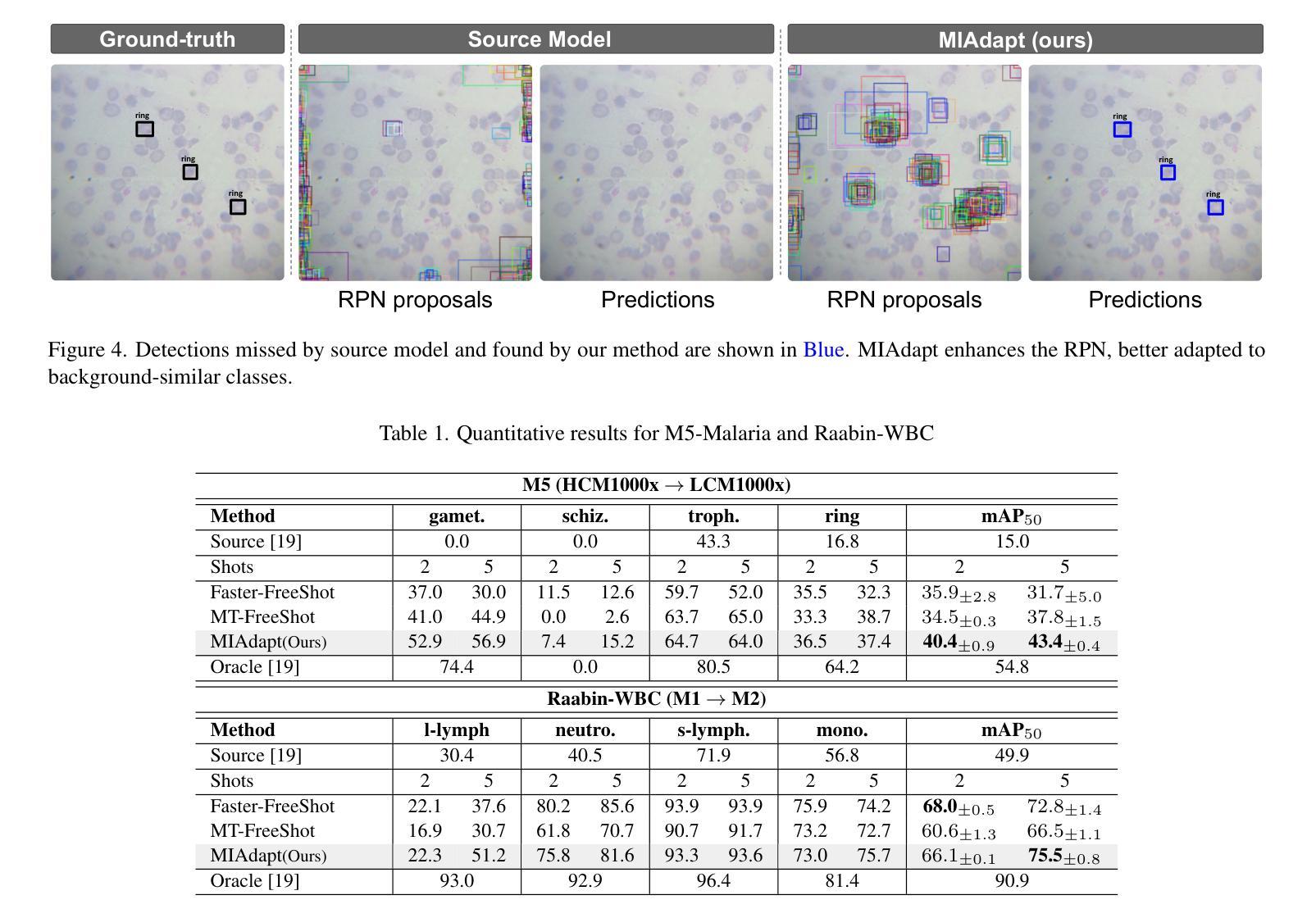
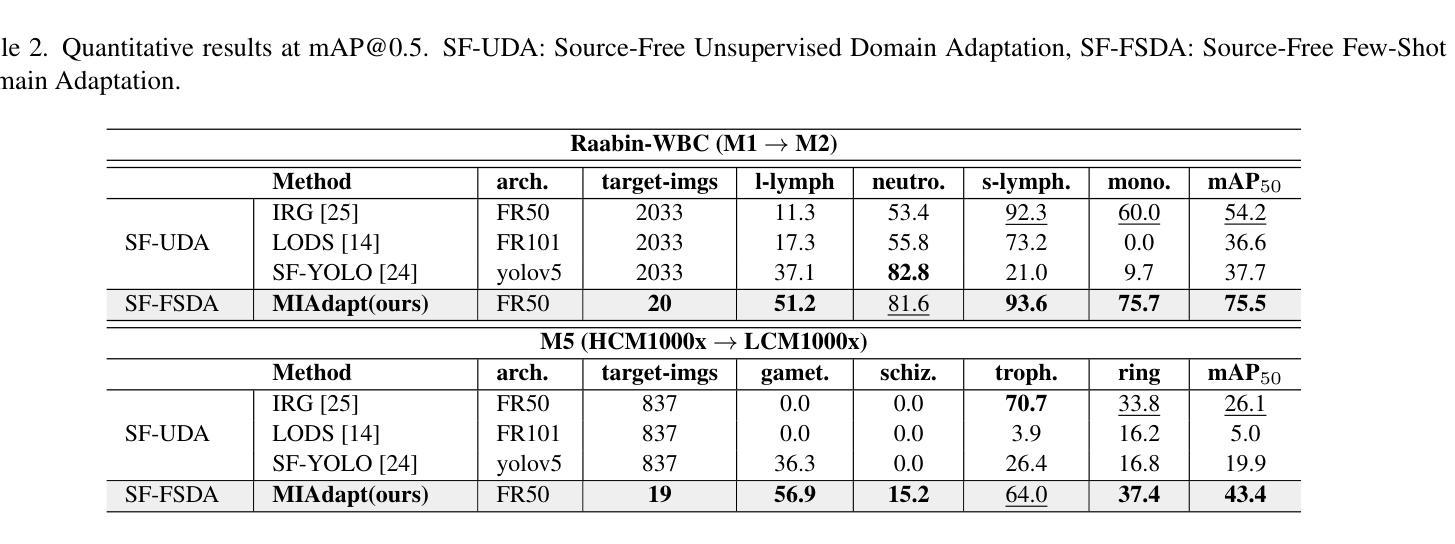
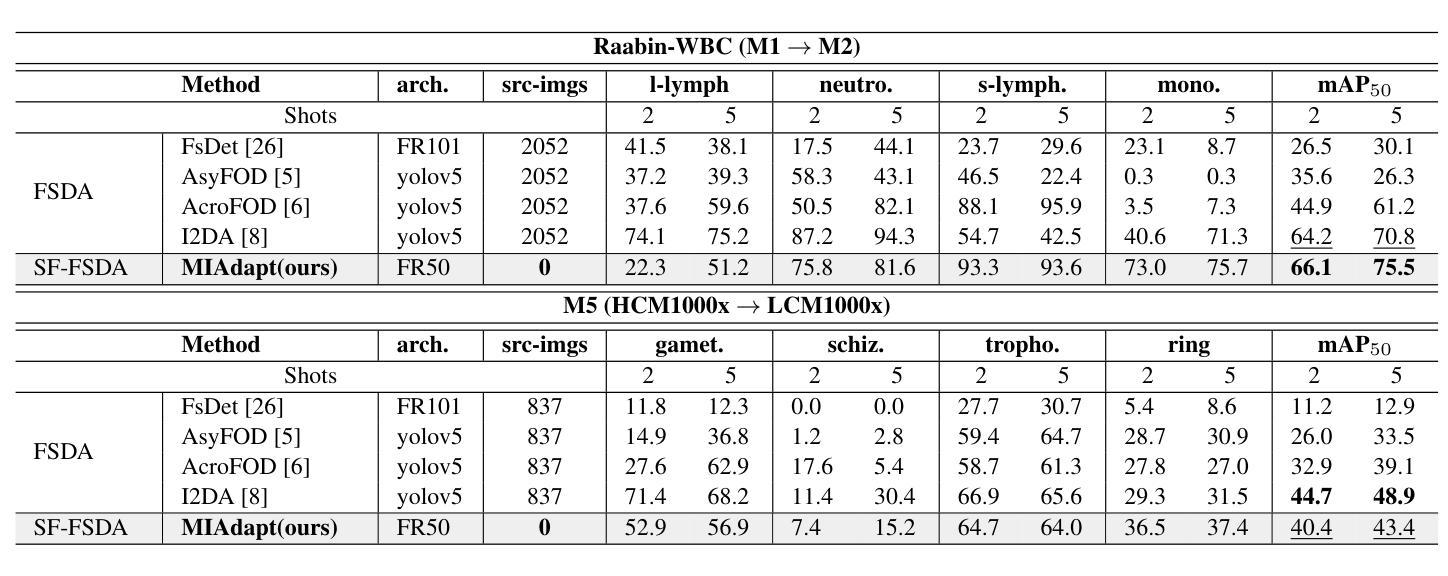
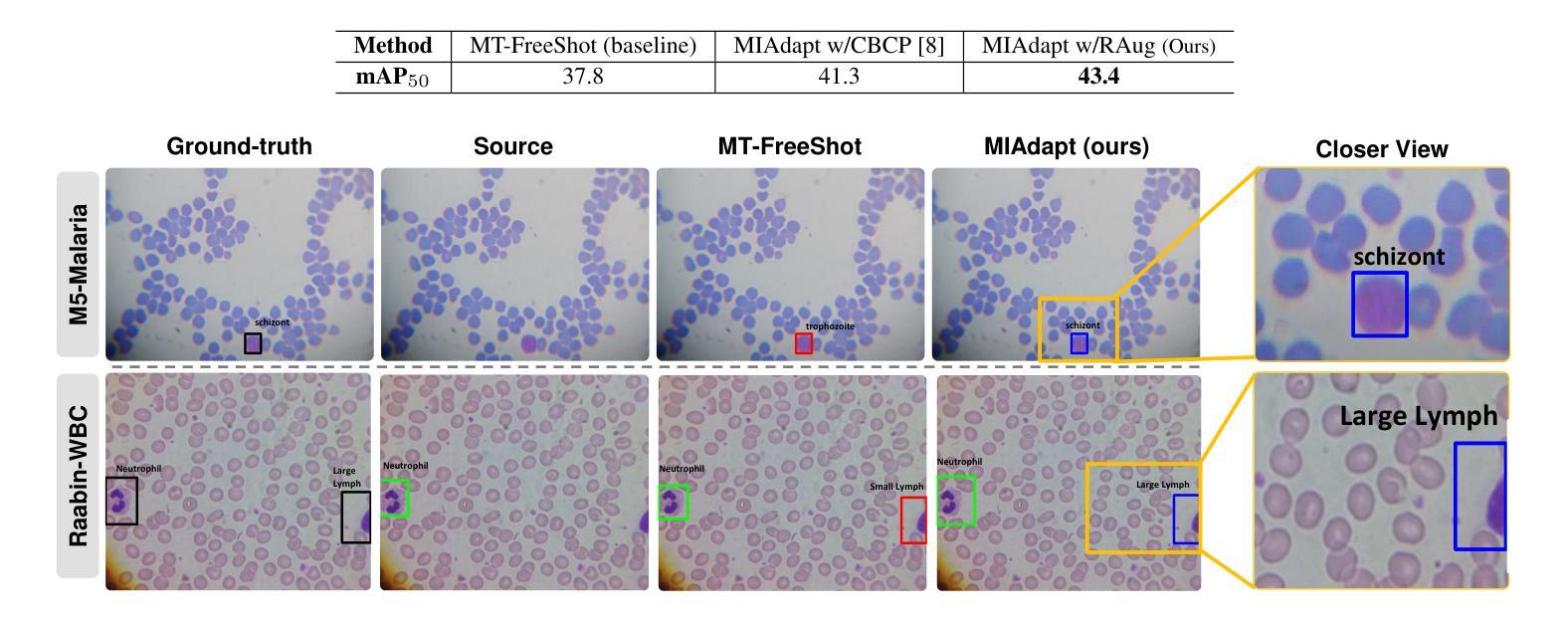
Existing generic unsupervised domain adaptation approaches require access to both a large labeled source dataset and a sufficient unlabeled target dataset during adaptation. However, collecting a large dataset, even if unlabeled, is a challenging and expensive endeavor, especially in medical imaging. In addition, constraints such as privacy issues can result in cases where source data is unavailable. Taking in consideration these challenges, we propose MIAdapt, an adaptive approach for Microscopic Imagery Adaptation as a solution for Source-free Few-shot Domain Adaptive Object detection (SF-FSDA). We also define two competitive baselines (1) Faster-FreeShot and (2) MT-FreeShot. Extensive experiments on the challenging M5-Malaria and Raabin-WBC datasets validate the effectiveness of MIAdapt. Without using any image from the source domain MIAdapt surpasses state-of-the-art source-free UDA (SF-UDA) methods by +21.3% mAP and few-shot domain adaptation (FSDA) approaches by +4.7% mAP on Raabin-WBC. Our code and models will be publicly available.
现有的通用无监督域自适应方法要求在适应过程中访问大量标记的源数据集和足够的未标记的目标数据集。然而,收集大数据集,即使是未标记的,也是一项具有挑战性和昂贵的工作,特别是在医学影像领域。此外,隐私等问题可能导致源数据无法使用。考虑到这些挑战,我们提出了MIAdapt,这是一种用于显微图像自适应的适应方法,作为源自由少样本域自适应目标检测(SF-FSDA)的解决方案。我们还定义了两个竞争基线,(1)Faster-FreeShot和(2)MT-FreeShot。在具有挑战性的M5-Malaria和Raabin-WBC数据集上的大量实验验证了MIAdapt的有效性。MIAdapt在不使用源域任何图像的情况下,超越了最新的源自由UDA(SF-UDA)方法,在Raabin-WBC上的mAP提高了+21.3%,并且相对于少样本域自适应(FSDA)方法的mAP提高了+4.7%。我们的代码和模型将公开可用。
论文及项目相关链接
PDF Under Review
Summary
本文主要介绍了MIAdapt方法,这是一种针对显微镜图像自适应的源免费少镜头域自适应目标检测(SF-FSDA)的适应性方法。考虑到收集大量数据集(即使是未标记的)的挑战性和昂贵性,特别是在医学影像中,作者提出了MIAdapt以及两个竞争基线方法Faster-FreeShot和MT-FreeShot。在具有挑战性的M5-Malaria和Raabin-WBC数据集上的广泛实验验证了MIAdapt的有效性。在不使用源域图像的情况下,MIAdapt在Raabin-WBC数据集上的mAP比最先进的源自由UDA(SF-UDA)方法和少镜头域自适应(FSDA)方法分别高出+21.3%和+4.7%。
Key Takeaways
- MIAdapt是一种针对显微镜图像自适应的源免费少镜头域自适应目标检测方法。
- 现有通用无监督域自适应方法需要大量标记源数据集和足够的未标记目标数据集,但数据收集具有挑战性和昂贵性。
- MIAdapt在M5-Malaria和Raabin-WBC数据集上的实验验证了其有效性。
- MIAdapt在未使用源域图像的情况下表现优异,相较于其他方法有明显的性能提升。
- 作者提出了两个竞争基线方法Faster-FreeShot和MT-FreeShot。
- MIAdapt将公开可用的代码和模型。
点此查看论文截图

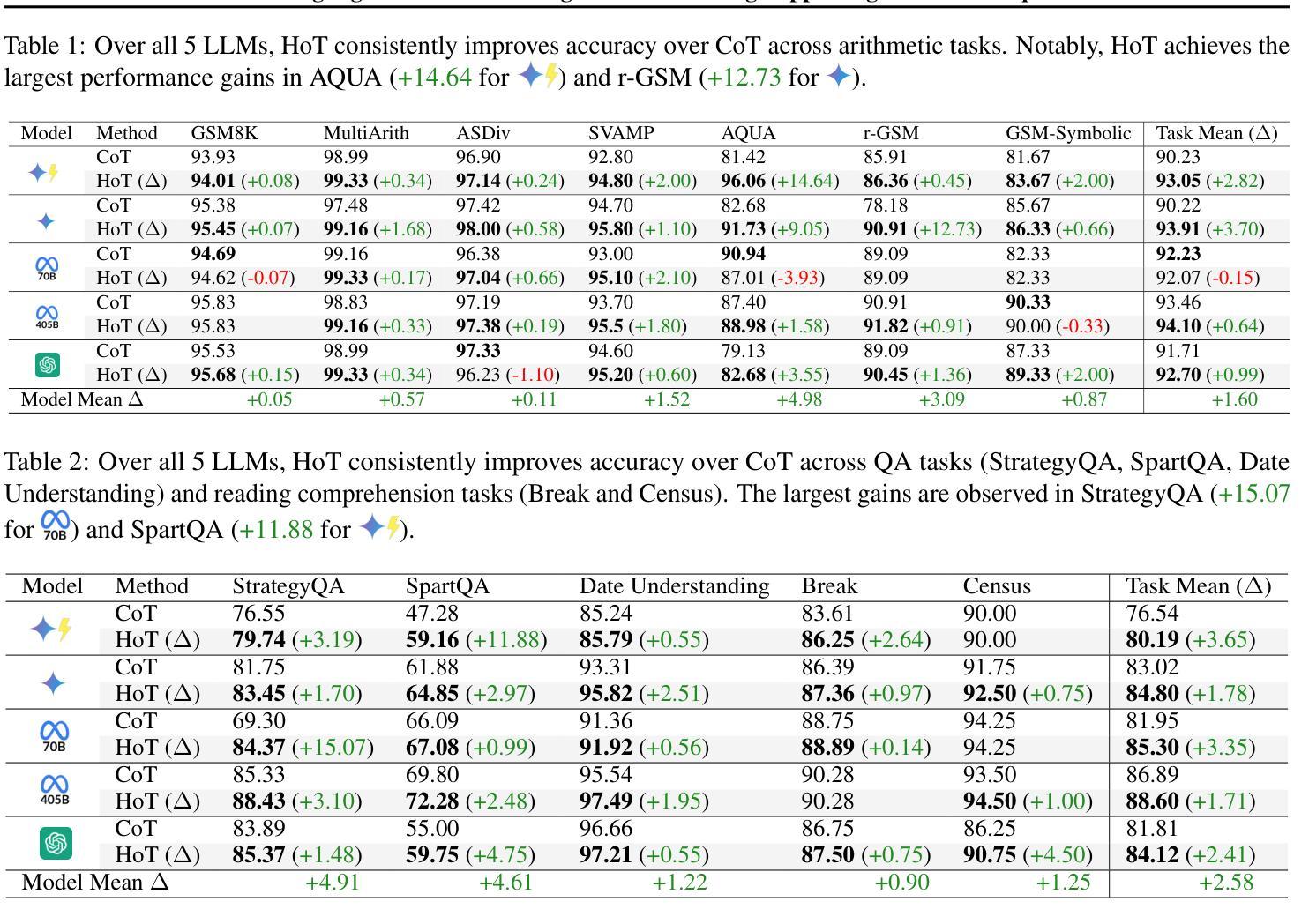
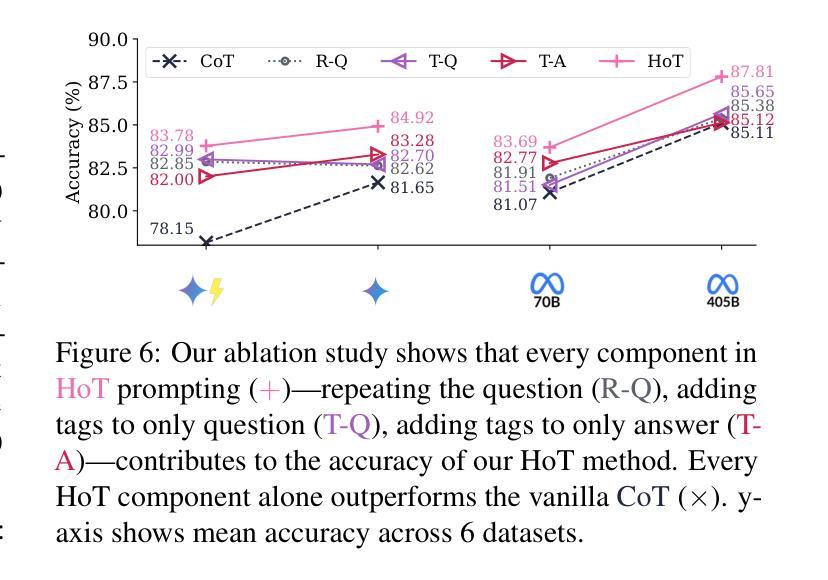
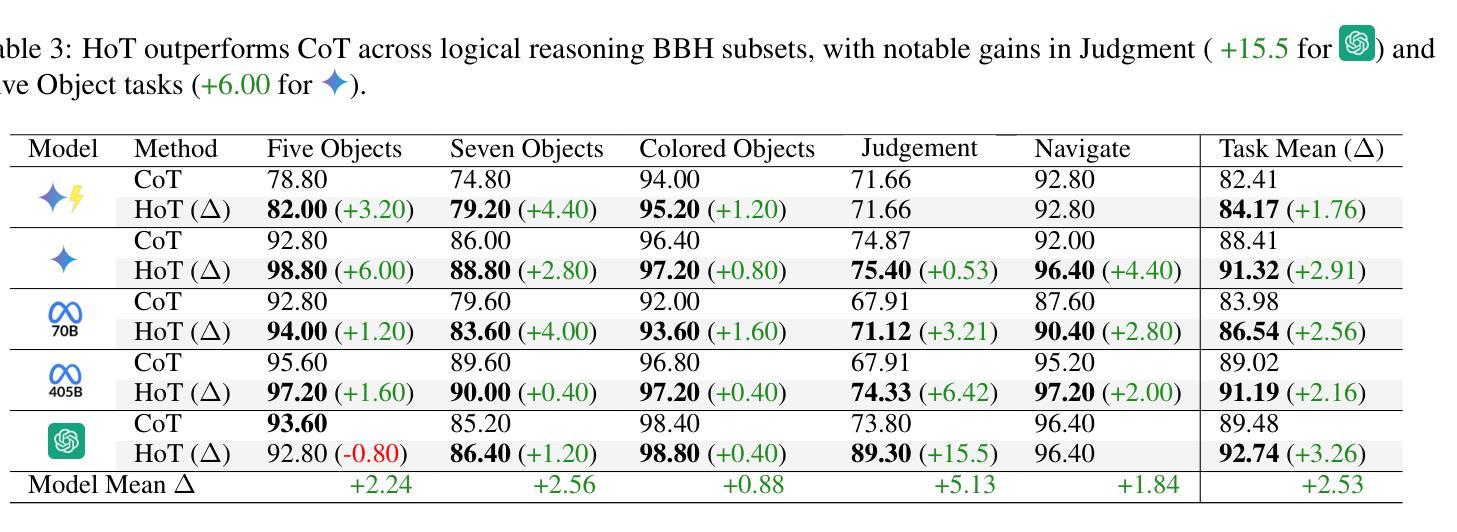
HoT: Highlighted Chain of Thought for Referencing Supporting Facts from Inputs
Authors:Tin Nguyen, Logan Bolton, Mohammad Reza Taesiri, Anh Totti Nguyen
An Achilles heel of Large Language Models (LLMs) is their tendency to hallucinate non-factual statements. A response mixed of factual and non-factual statements poses a challenge for humans to verify and accurately base their decisions on. To combat this problem, we propose Highlighted Chain-of-Thought Prompting (HoT), a technique for prompting LLMs to generate responses with XML tags that ground facts to those provided in the query. That is, given an input question, LLMs would first re-format the question to add XML tags highlighting key facts, and then, generate a response with highlights over the facts referenced from the input. Interestingly, in few-shot settings, HoT outperforms vanilla chain of thought prompting (CoT) on a wide range of 17 tasks from arithmetic, reading comprehension to logical reasoning. When asking humans to verify LLM responses, highlights help time-limited participants to more accurately and efficiently recognize when LLMs are correct. Yet, surprisingly, when LLMs are wrong, HoTs tend to make users believe that an answer is correct.
大型语言模型(LLM)的一个弱点是它们倾向于产生非事实陈述。由事实和并非事实组成的信息所组成的回答给人类带来了验证以及准确做出决定方面的挑战。为了解决这一问题,我们提出了“突出思考链提示”(HoT)技术,这是一种提示LLM生成带有XML标签的响应的技术,这些标签将事实依据与查询中提供的事实相结合。也就是说,给定一个输入问题,LLM会首先重新格式化问题,添加突出关键事实的XML标签,然后生成一个带有输入引用的亮点的响应。有趣的是,在少量样本的情况下,HoT在算术、阅读理解到逻辑推理等广泛的17项任务上的表现优于普通思考链提示(CoT)。当要求人类验证LLM的响应时,亮点有助于时间有限的参与者更准确、高效地识别LLM是否正确。然而,令人惊讶的是,当LLM错误时,HoT往往使用户认为答案是正确的。
论文及项目相关链接
Summary
大型语言模型(LLM)的一个弱点是它们倾向于产生非事实性的陈述,这使得它们的回应难以验证并准确作为决策依据。为解决这一问题,我们提出了高亮化思维链提示(HoT)技术,该技术通过XML标签为LLM的回应提供事实依据。在少量样本的情况下,HoT在算术、阅读理解到逻辑推理的17项任务上的表现优于基础思维链提示(CoT)。对人类参与者的验证显示,高亮有助于他们在有限时间内更准确地识别LLM的正确性,但有趣的是,当LLM错误时,HoT往往会使用户误以为答案是正确的。
Key Takeaways
- 大型语言模型(LLM)存在生成非事实性陈述的问题。
- Highlighted Chain-of-Thought Prompting(HoT)技术通过XML标签为LLM的回应提供事实依据。
- 在少量样本的情况下,HoT在多种任务上的表现优于基础思维链提示(CoT)。
- 高亮有助于人类参与者更准确地识别LLM的正确性。
- 当LLM错误时,HoT技术存在误导用户的可能。
- HoT有助于提升人类验证LLM回应时的效率和准确性。
点此查看论文截图



RIDE: Enhancing Large Language Model Alignment through Restyled In-Context Learning Demonstration Exemplars
Authors:Yuncheng Hua, Lizhen Qu, Zhuang Li, Hao Xue, Flora D. Salim, Gholamreza Haffari
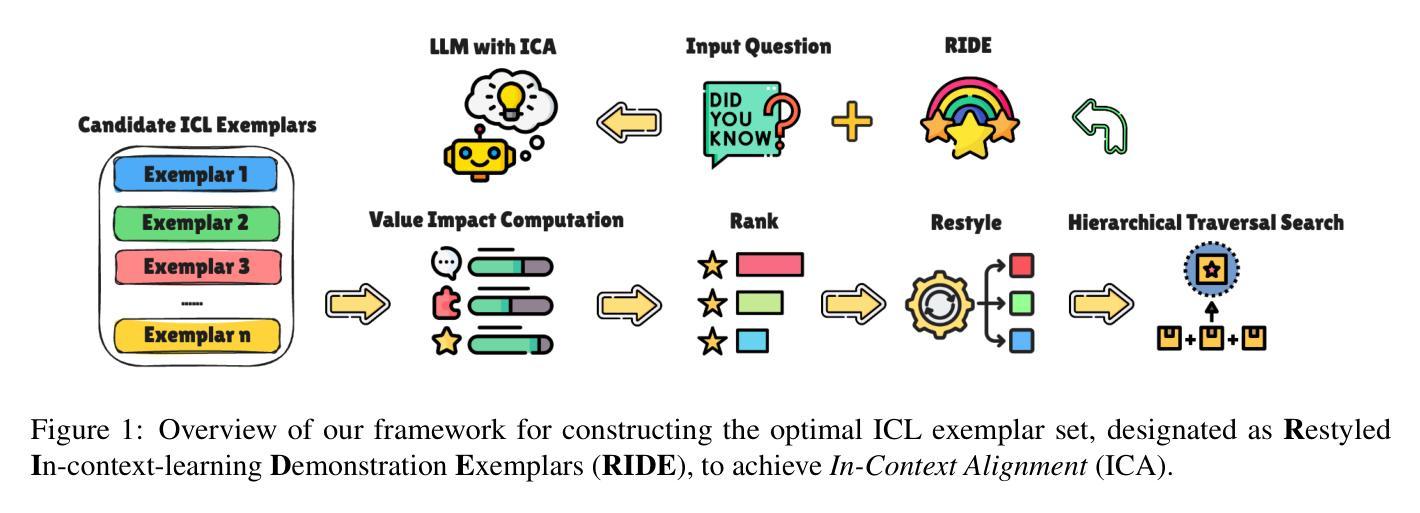
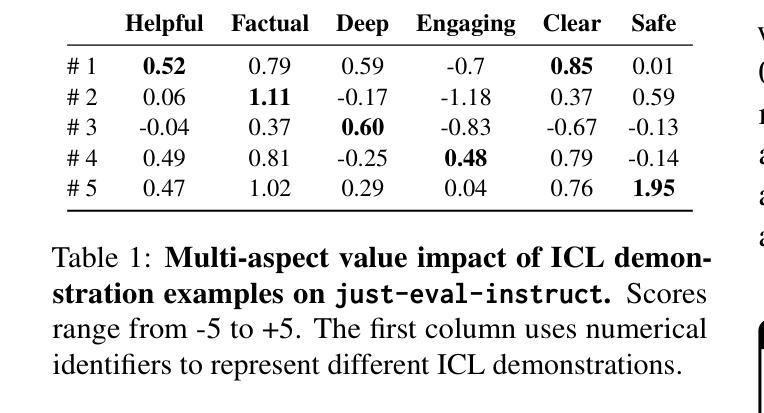
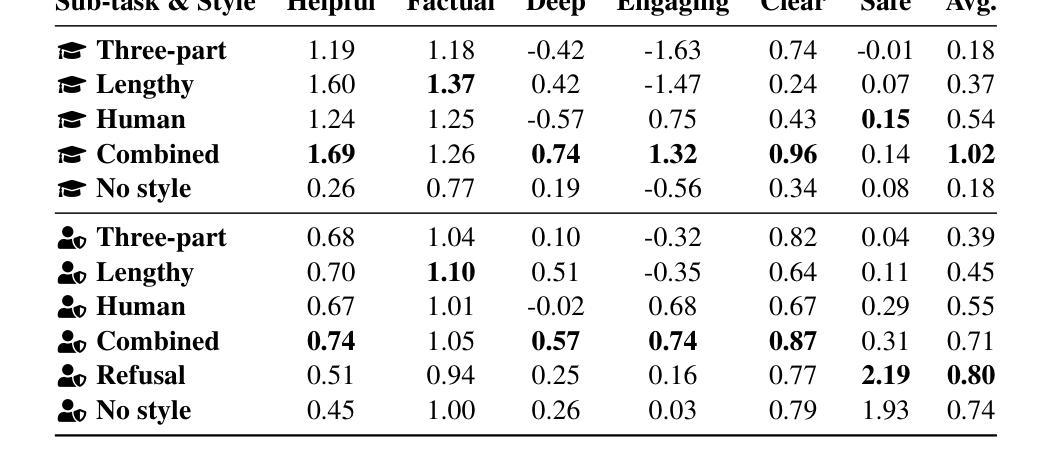
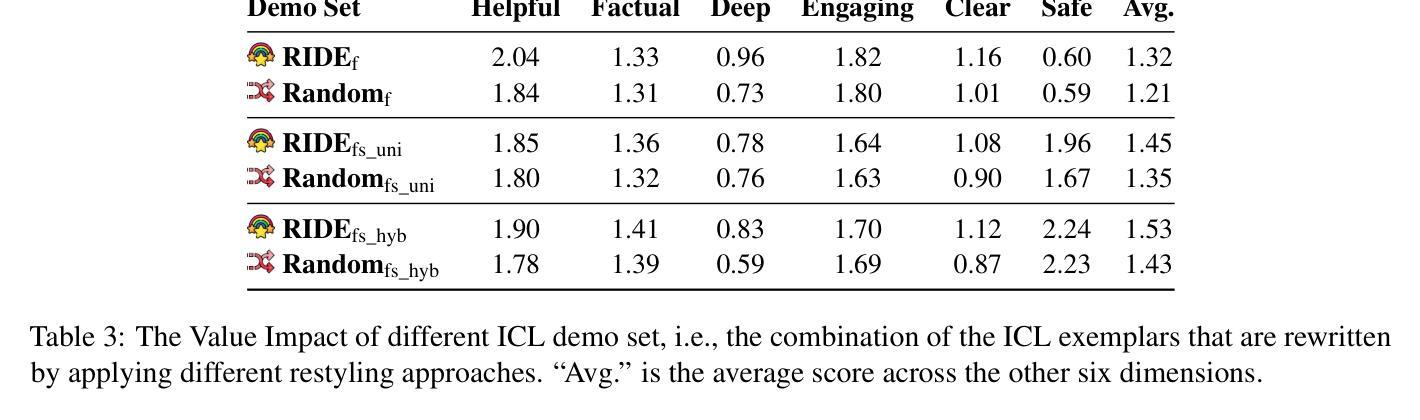
Alignment tuning is crucial for ensuring large language models (LLMs) behave ethically and helpfully. Current alignment approaches require high-quality annotations and significant training resources. This paper proposes a low-cost, tuning-free method using in-context learning (ICL) to enhance LLM alignment. Through an analysis of high-quality ICL demos, we identified style as a key factor influencing LLM alignment capabilities and explicitly restyled ICL exemplars based on this stylistic framework. Additionally, we combined the restyled demos to achieve a balance between the two conflicting aspects of LLM alignment–factuality and safety. We packaged the restyled examples as prompts to trigger few-shot learning, improving LLM alignment. Compared to the best baseline approach, with an average score of 5.00 as the maximum, our method achieves a maximum 0.10 increase on the Alpaca task (from 4.50 to 4.60), a 0.22 enhancement on the Just-eval benchmark (from 4.34 to 4.56), and a maximum improvement of 0.32 (from 3.53 to 3.85) on the MT-Bench dataset. We release the code and data at https://github.com/AnonymousCode-ComputerScience/RIDE.
对齐调整对于确保大型语言模型(LLM)以伦理和有帮助的方式行为至关重要。当前的对齐方法需要高质量标注和大量训练资源。本文提出了一种低成本、无需调整的方法,使用上下文学习(ICL)增强LLM的对齐。通过对高质量ICL演示的分析,我们发现风格是影响LLM对齐能力的关键因素,并基于此风格框架明确地重新设计了ICL范例。此外,我们将重新设计的演示结合起来,在LLM对齐的两个相互矛盾的方面——真实性和安全性之间取得了平衡。我们将重新设计的示例打包为提示,以触发少量学习,提高LLM的对齐能力。与最佳基线方法相比(以平均得分5.00为最高),我们的方法在Alpaca任务上最高提高了0.10(从4.50提高到4.60),在Just-eval基准测试上提高了0.22(从4.34提高到4.56),在MT-Bench数据集上最高提高了0.32(从3.53提高到3.85)。我们在https://github.com/AnonymousCode-ComputerScience/RIDE发布了代码和数据。
论文及项目相关链接
PDF 38 pages, 2 figures, 20 tables; The paper is under review in ARR
Summary
本论文提出了一种低成本的调参自由方法,利用上下文学习(ICL)增强大型语言模型(LLM)的对齐性。研究通过高质量ICL演示分析,确认风格是影响LLM对齐能力的关键因素,并据此重新设计ICL范例。结合重新设计的演示样本,在LLM对齐的两个方面——真实性和安全性之间取得平衡。将重新设计的示例作为提示触发少样本学习,提高LLM的对齐性。
Key Takeaways
- 论文提出了一种低成本的、无需调参的方法,通过上下文学习(ICL)增强大型语言模型(LLM)的伦理和有用性对齐。
- 风格是影响LLM对齐能力的关键因素,研究通过高质量ICL演示分析确认了这一点。
- 重新设计的ICL范例结合了真实性和安全性,实现了LLM对齐的两个方面之间的平衡。
- 通过将重新设计的示例作为提示触发少样本学习,提高了LLM的对齐性能。
- 与最佳基线方法相比,该方法在Alpaca任务、Just-eval基准测试和MT-Bench数据集上均实现了性能提升。
- 研究成果已发布在https://github.com/AnonymousCode-ComputerScience/RIDE上,包括代码和数据。
点此查看论文截图

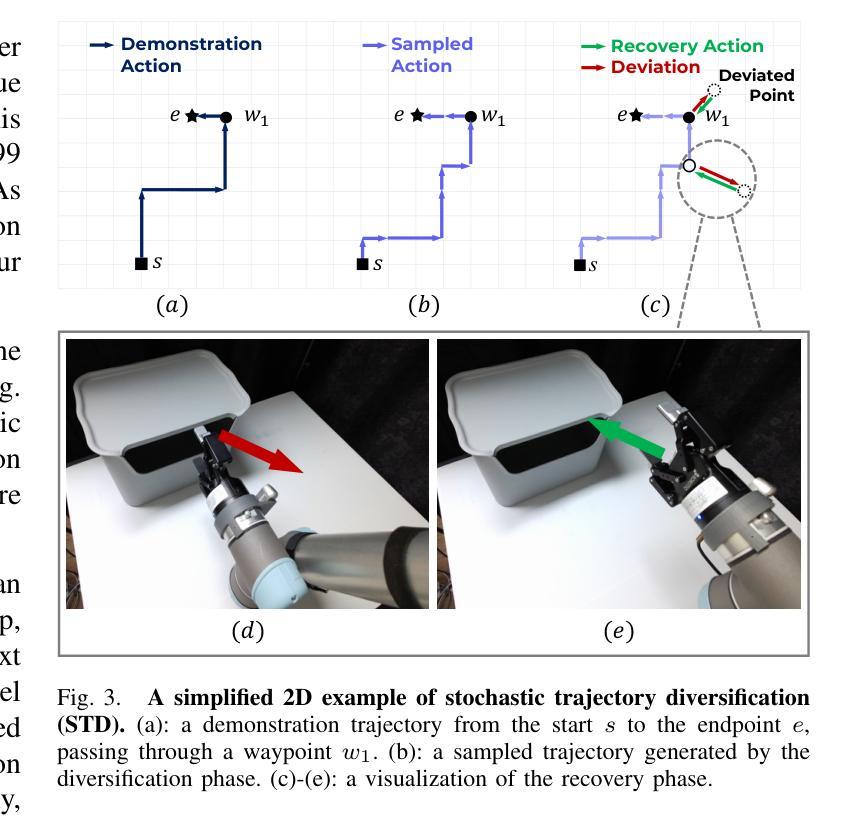
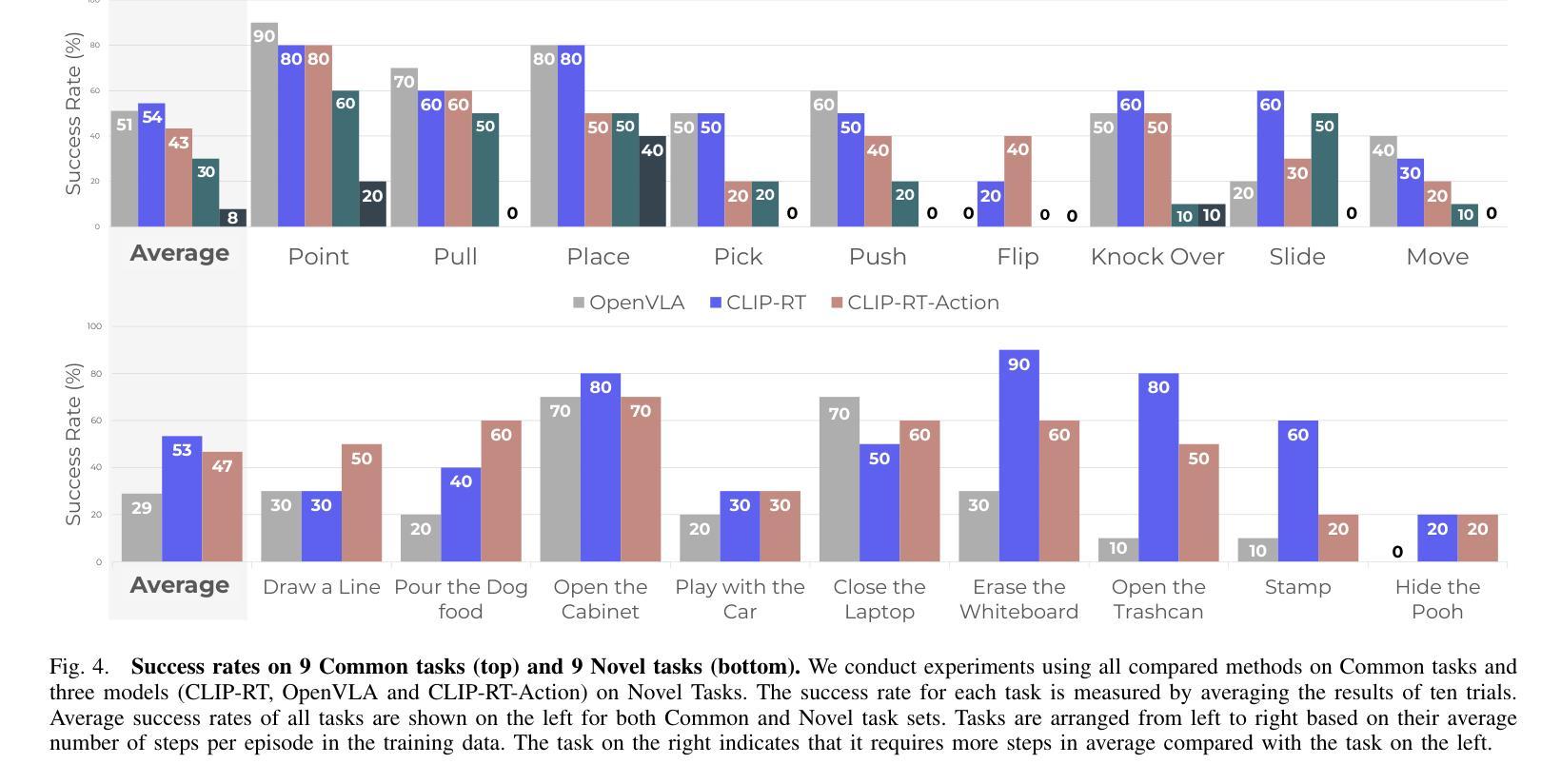
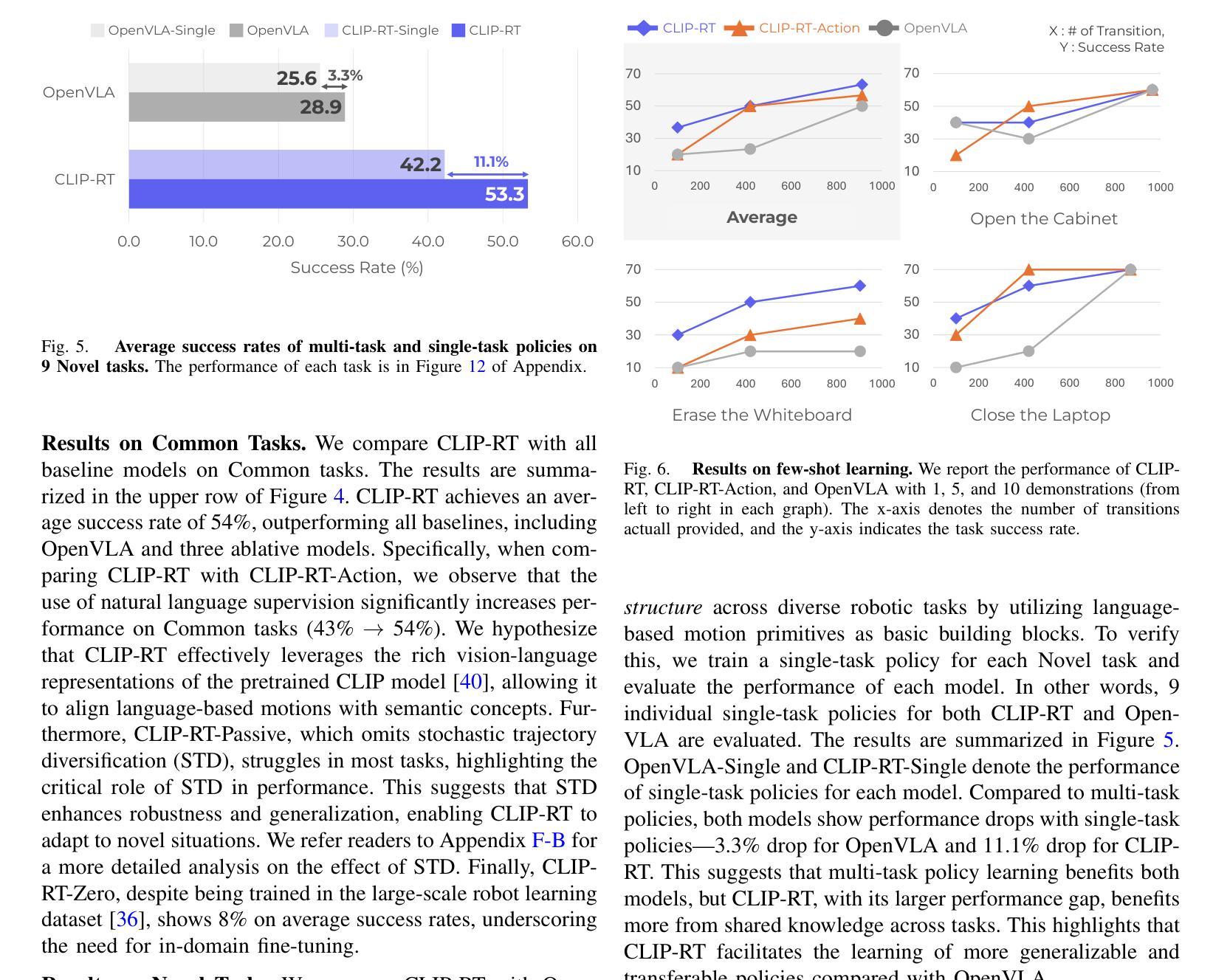
CLIP-RT: Learning Language-Conditioned Robotic Policies from Natural Language Supervision
Authors:Gi-Cheon Kang, Junghyun Kim, Kyuhwan Shim, Jun Ki Lee, Byoung-Tak Zhang
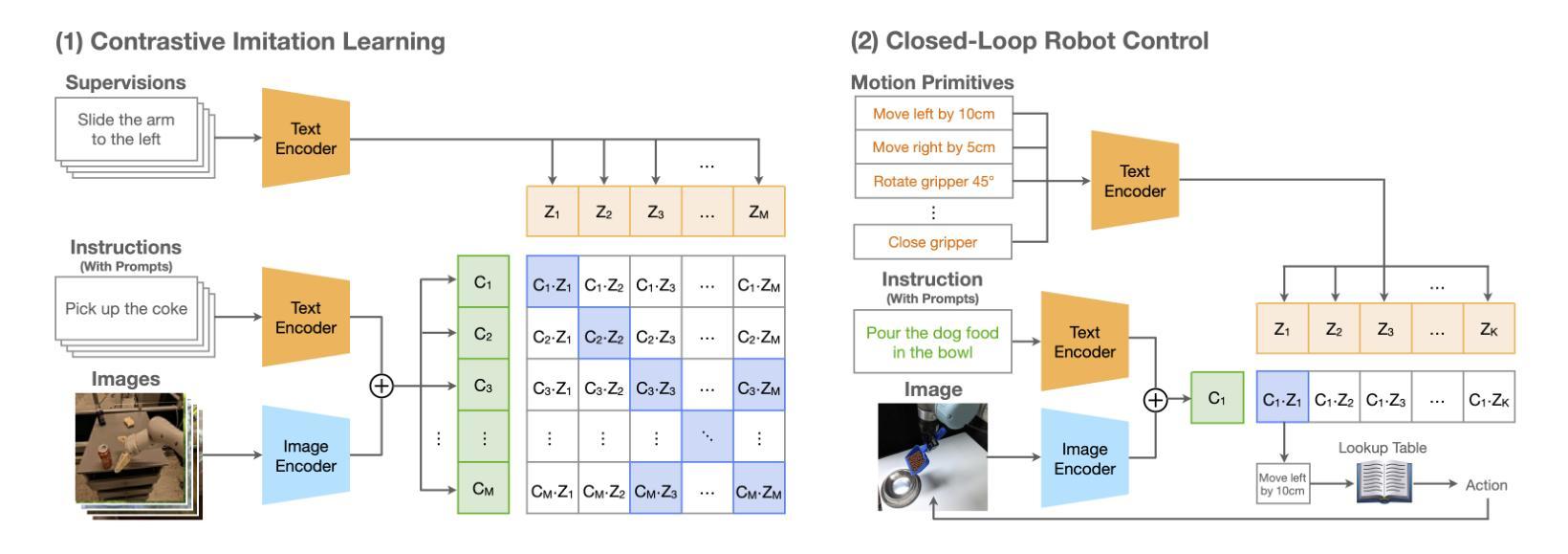
Teaching robots desired skills in real-world environments remains challenging, especially for non-experts. A key bottleneck is that collecting robotic data often requires expertise or specialized hardware, limiting accessibility and scalability. We posit that natural language offers an intuitive and accessible interface for robot learning. To this end, we study two aspects: (1) enabling non-experts to collect robotic data through natural language supervision (e.g., “move the arm to the right”) and (2) learning robotic policies directly from this supervision. Specifically, we introduce a data collection framework that collects robot demonstrations based on natural language supervision and further augments these demonstrations. We then present CLIP-RT, a vision-language-action (VLA) model that learns language-conditioned visuomotor policies from this supervision. CLIP-RT adapts the pretrained CLIP models and learns to predict language-based motion primitives via contrastive imitation learning. We train CLIP-RT on the Open X-Embodiment dataset and finetune it on in-domain data collected by our framework to learn diverse skills. CLIP-RT demonstrates strong capabilities in learning novel manipulation skills, outperforming the state-of-the-art model, OpenVLA (7B parameters), by 24% in average success rates, while using 7x fewer parameters (1B). We further observe that CLIP-RT shows significant improvements in few-shot generalization. Finally, through collaboration with humans or large pretrained models, we demonstrate that CLIP-RT can further improve its generalization on challenging robotic tasks.
教授机器人在真实世界环境中所需的技能仍然是一个挑战,尤其对于非专业人士而言。一个关键的瓶颈是,收集机器人数据通常需要专业知识或专用硬件,这限制了可访问性和可扩展性。我们认为自然语言为机器人学习提供了一个直观和可访问的界面。为此,我们研究了两个方面:(1)通过自然语言监督(例如,“将手臂向右移动”)使非专家能够收集机器人数据;(2)直接从这种监督中学习机器人策略。具体来说,我们引入了一个数据收集框架,该框架基于自然语言监督来收集机器人演示,并进一步扩充了这些演示。然后,我们提出了CLIP-RT,这是一种视觉语言动作(VLA)模型,可以从这种监督中学习语言调节的视听觉运动策略。CLIP-RT适应了预训练的CLIP模型,并通过对比模仿学习学会基于语言的运动原始预测。我们在Open X-Embodiment数据集上训练CLIP-RT,并通过我们的框架收集的领域内数据进行微调,以学习各种技能。CLIP-RT在学习新颖操作技能方面表现出强大的能力,在平均成功率方面超越了最先进的模型OpenVLA(7B参数)24%,同时使用参数更少(仅1B)。我们还观察到CLIP-RT在少量镜头概括方面显示出显着改进。最后,通过与人类或大型预训练模型的合作,我们证明CLIP-RT可以在具有挑战性的机器人任务上进一步改善其概括能力。
论文及项目相关链接
PDF 27 pages
Summary
本文探讨了在真实环境中教授机器人技能所面临的挑战,特别是非专家用户的挑战。文章提出了一种基于自然语言监督的数据收集框架,以及一个直接从这种监督中学习机器人策略的方法。为此引入了CLIP-RT模型,该模型可以在少量数据上实现高性能的技能学习,并且在少样本泛化方面表现出显著的改进。
Key Takeaways
- 机器人教学在非专家用户中面临挑战,主要瓶颈在于收集机器人数据需要专业知识或特殊硬件。
- 自然语言为机器人学习提供了一个直观和可访问的接口。
- 引入了一个基于自然语言监督的机器人数据收集框架。
- 介绍了CLIP-RT模型,该模型能够从自然语言监督中学习语言条件视觉运动策略。
- CLIP-RT模型在Open X-Embodiment数据集上训练,并在框架收集的领域数据上进行微调,以学习各种技能。
- CLIP-RT在学习新操作技能方面表现出强大的能力,相较于最新模型OpenVLA,平均成功率提高了24%,同时使用参数更少(仅使用1B参数)。
点此查看论文截图

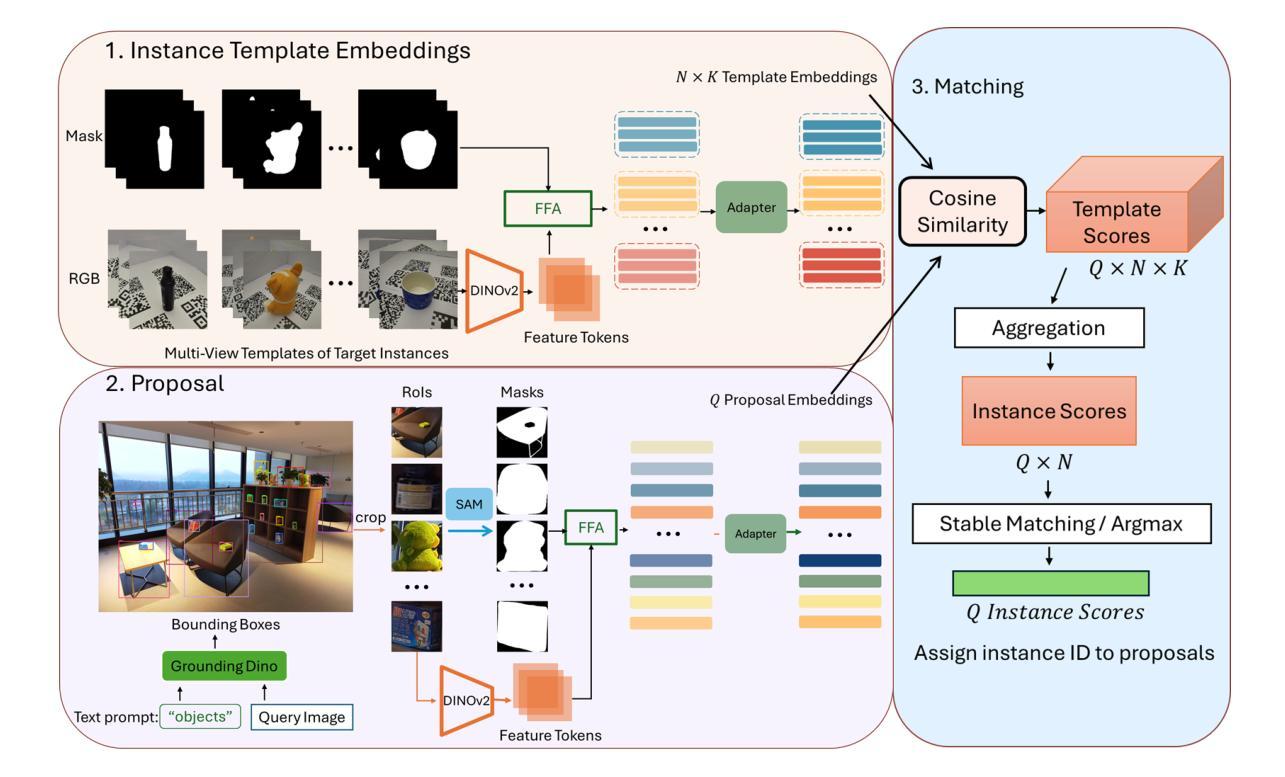
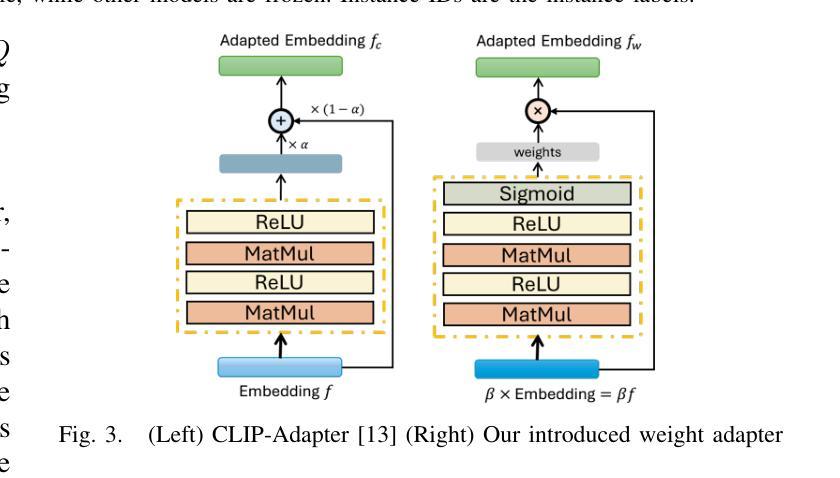
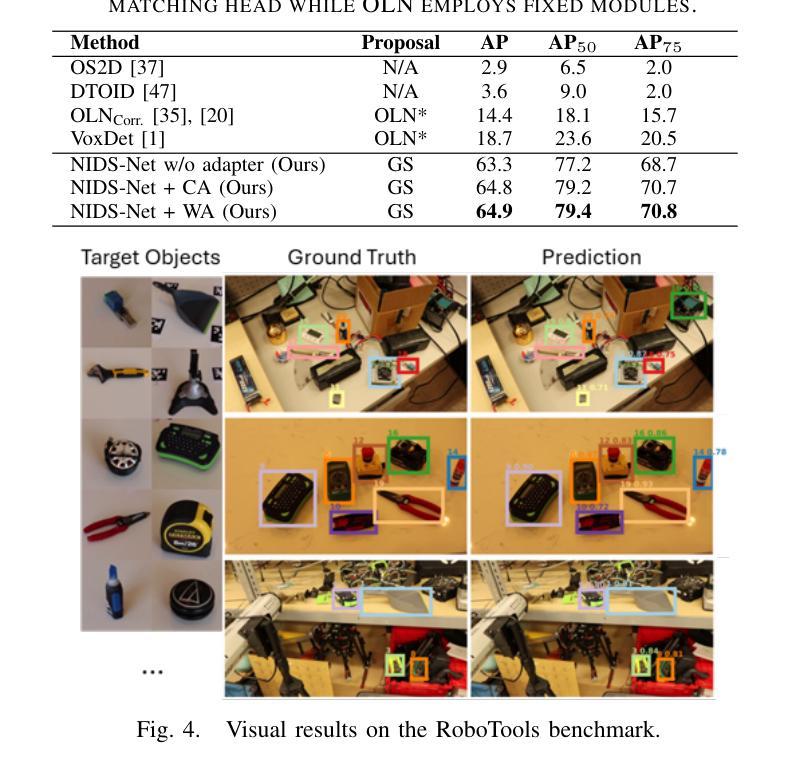
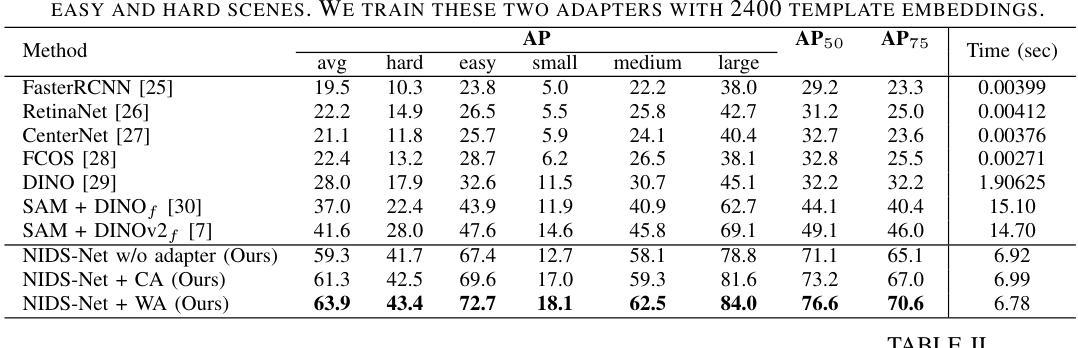
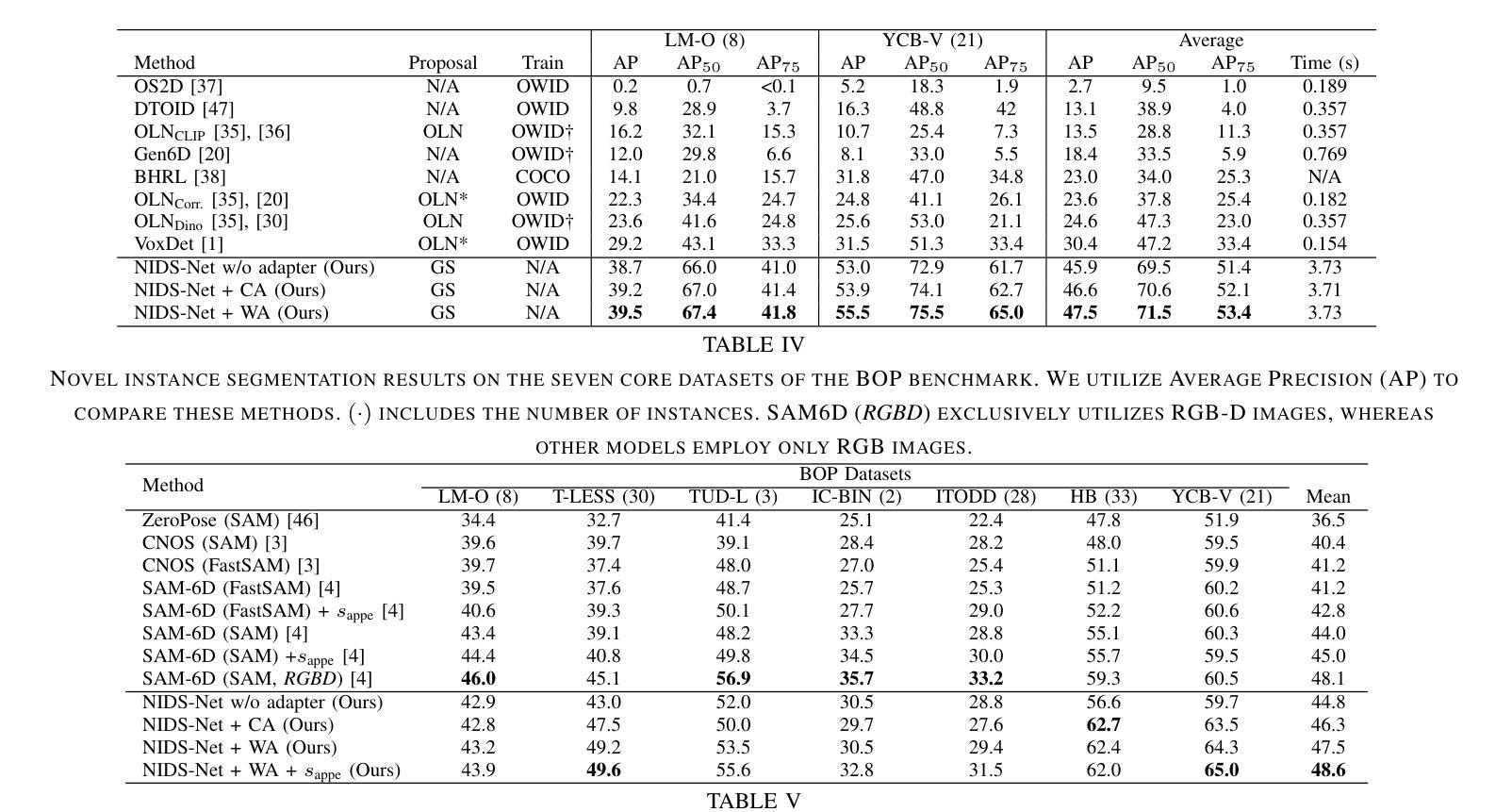
Adapting Pre-Trained Vision Models for Novel Instance Detection and Segmentation
Authors:Yangxiao Lu, Jishnu Jaykumar P, Yunhui Guo, Nicholas Ruozzi, Yu Xiang
Novel Instance Detection and Segmentation (NIDS) aims at detecting and segmenting novel object instances given a few examples of each instance. We propose a unified, simple, yet effective framework (NIDS-Net) comprising object proposal generation, embedding creation for both instance templates and proposal regions, and embedding matching for instance label assignment. Leveraging recent advancements in large vision methods, we utilize Grounding DINO and Segment Anything Model (SAM) to obtain object proposals with accurate bounding boxes and masks. Central to our approach is the generation of high-quality instance embeddings. We utilized foreground feature averages of patch embeddings from the DINOv2 ViT backbone, followed by refinement through a weight adapter mechanism that we introduce. We show experimentally that our weight adapter can adjust the embeddings locally within their feature space and effectively limit overfitting in the few-shot setting. Furthermore, the weight adapter optimizes weights to enhance the distinctiveness of instance embeddings during similarity computation. This methodology enables a straightforward matching strategy that results in significant performance gains. Our framework surpasses current state-of-the-art methods, demonstrating notable improvements in four detection datasets. In the segmentation tasks on seven core datasets of the BOP challenge, our method outperforms the leading published RGB methods and remains competitive with the best RGB-D method. We have also verified our method using real-world images from a Fetch robot and a RealSense camera. Project Page: https://irvlutd.github.io/NIDSNet/
新型实例检测与分割(NIDS)旨在针对每个实例的少数几个样本进行新型对象实例的检测和分割。我们提出了一个统一、简单、有效的框架(NIDS-Net),它包括对象提案生成、为实例模板和提案区域创建嵌入,以及用于实例标签分配的嵌入匹配。我们利用最新的大规模视觉方法进展,使用接地DINO和分割任何模型(SAM)获得具有准确边界框和蒙版的对象提案。我们的方法的核心是生成高质量实例嵌入。我们使用DINOv2 ViT骨干网中补丁嵌入的前景特征平均值,然后通过我们引入的重量适配器机制进行改进。我们通过实验证明,我们的重量适配器可以在其特征空间内局部调整嵌入,并在小样本设置中有效限制过拟合。此外,重量适配器优化权重,以提高实例嵌入在相似度计算期间的区分性。这种方法使匹配策略更加简单明了,从而实现了显著的性能提升。我们的框架超越了当前最先进的方法,在四个检测数据集上取得了显著的改进。在BOP挑战的七个核心数据集上的分割任务中,我们的方法优于领先的已发布RGB方法,并与最佳的RGB-D方法保持竞争力。我们还使用Fetch机器人和RealSense相机拍摄的真实世界图像验证了我们的方法。项目页面:https://irvlutd.github.io/NIDSnet/
论文及项目相关链接
PDF Project Page: https://irvlutd.github.io/NIDSNet/
Summary
本文介绍了针对Novel Instance Detection and Segmentation(NIDS)任务的新框架NIDS-Net。该框架通过生成对象提案、创建实例模板和提案区域嵌入,以及嵌入匹配进行实例标签分配。利用最近的视觉方法进展,如Grounding DINO和Segment Anything Model (SAM),获得带有精确边界框和遮罩的对象提案。核心是高质量的实例嵌入生成,通过使用DINOv2 ViT后端的补丁嵌入的前景色特征平均值,并通过新引入的重量适配器机制进行改进。实验表明,重量适配器可以在特征空间内局部调整嵌入,有效限制小样本设置中的过拟合。此外,重量适配器优化权重,以提高实例嵌入在相似性计算中的独特性。此方法简化了匹配策略,带来了显著的性能提升。NIDS-Net在四个检测数据集上的性能超过了当前的最先进方法,在BOP挑战的七个核心数据集上的分割任务中也表现出色。此外,该方法还通过Fetch机器人和RealSense相机的真实世界图像进行了验证。
Key Takeaways
- NIDS-Net是一个针对Novel Instance Detection and Segmentation任务的统一、简单而有效的框架。
- 框架包括对象提案生成、实例模板和提案区域嵌入创建,以及嵌入匹配进行实例标签分配。
- 利用了最近的视觉方法进展,如Grounding DINO和Segment Anything Model (SAM)。
- 高质量的实例嵌入生成是核心,通过DINOv2 ViT后端的补丁嵌入的前景色特征平均值生成,通过重量适配器机制改进。
- 重量适配器能够在特征空间内局部调整嵌入,有效限制小样本过拟合,优化权重提高实例嵌入的独特性。
- 此方法简化了匹配策略,显著提高了性能,在多个数据集上的表现超过了当前最先进的方法。
点此查看论文截图


MVP-Shot: Multi-Velocity Progressive-Alignment Framework for Few-Shot Action Recognition
Authors:Hongyu Qu, Rui Yan, Xiangbo Shu, Hailiang Gao, Peng Huang, Guo-Sen Xie
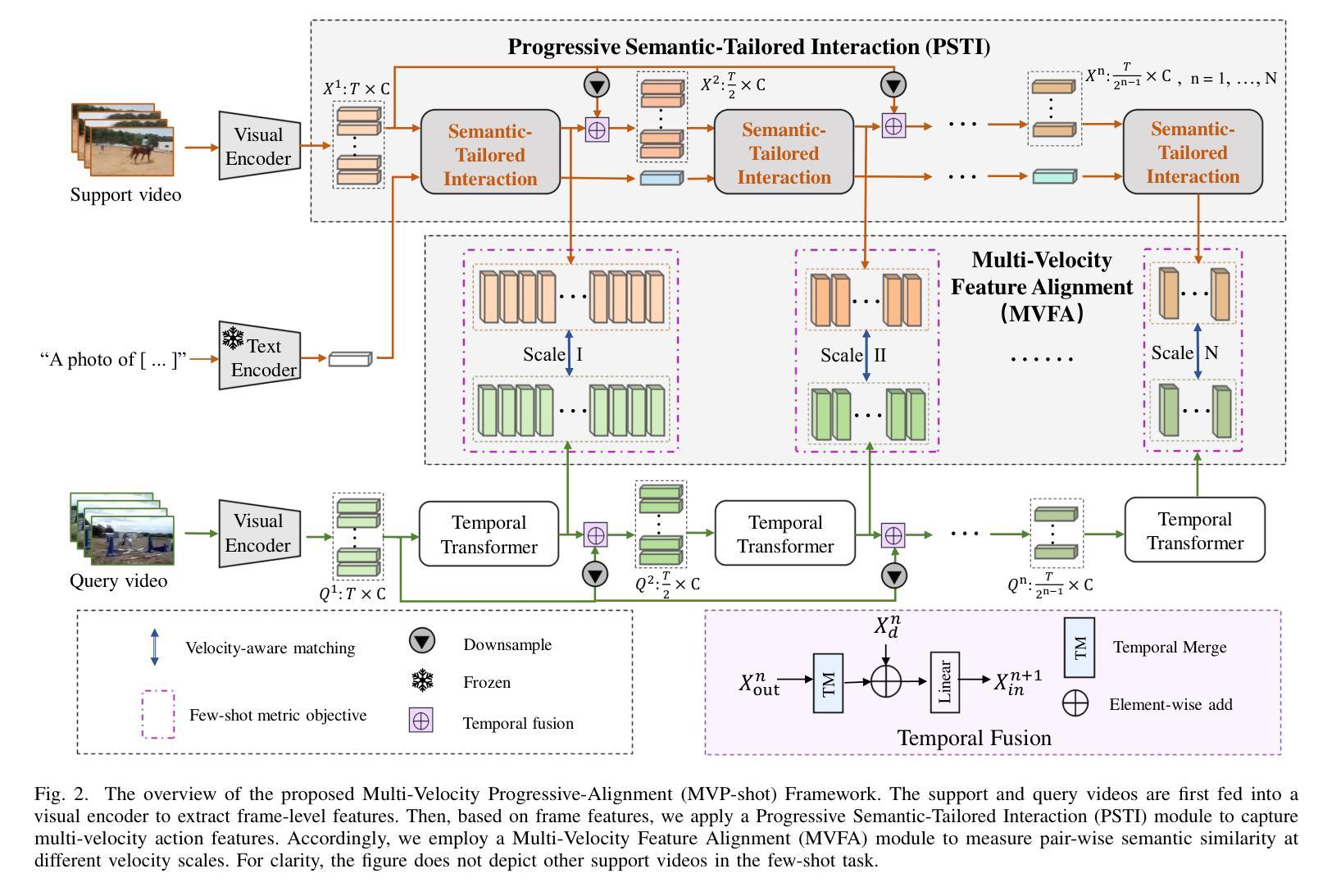
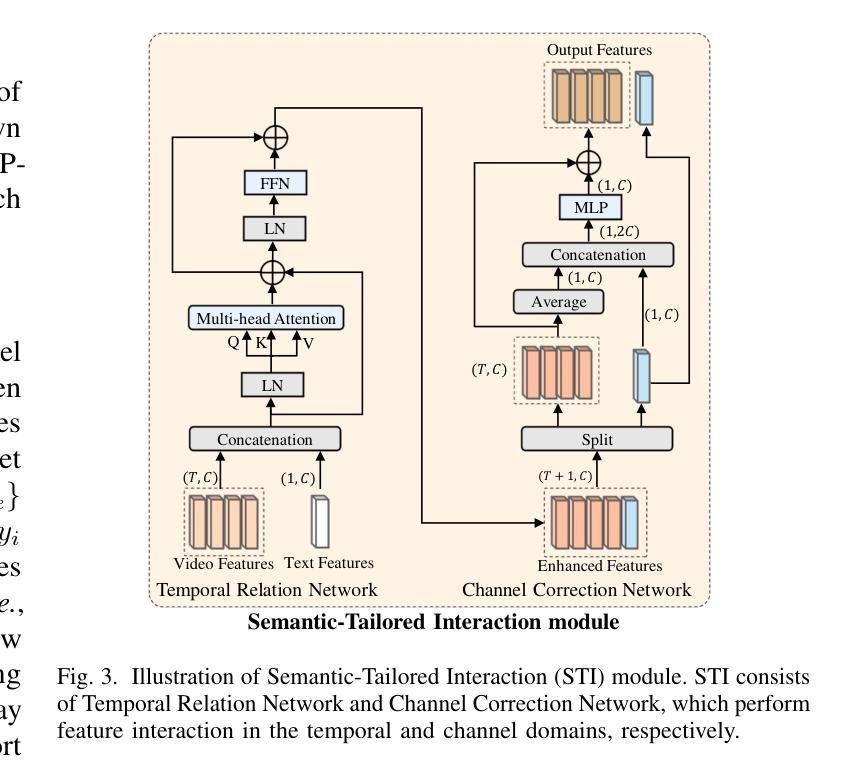
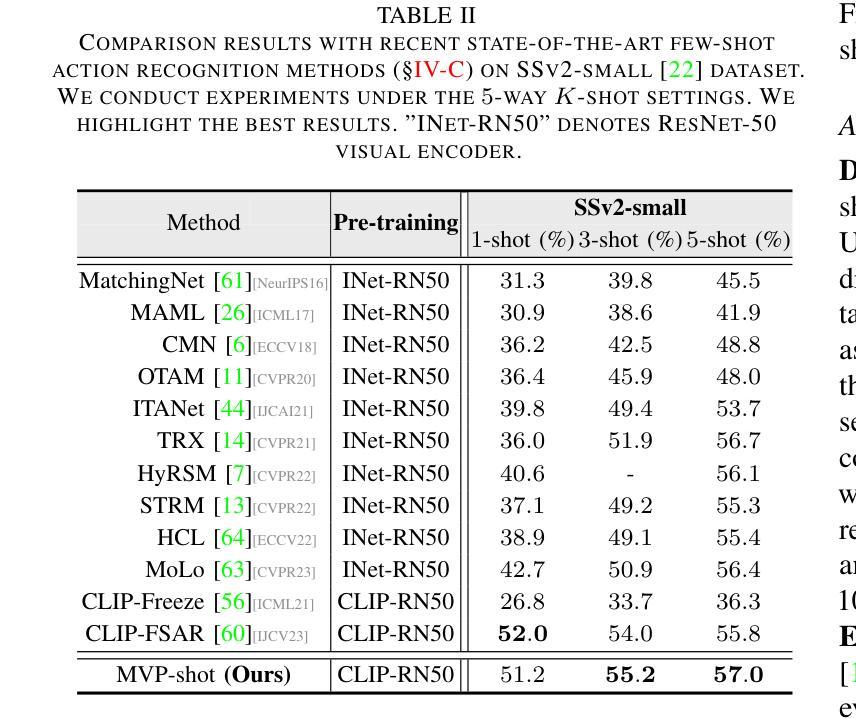
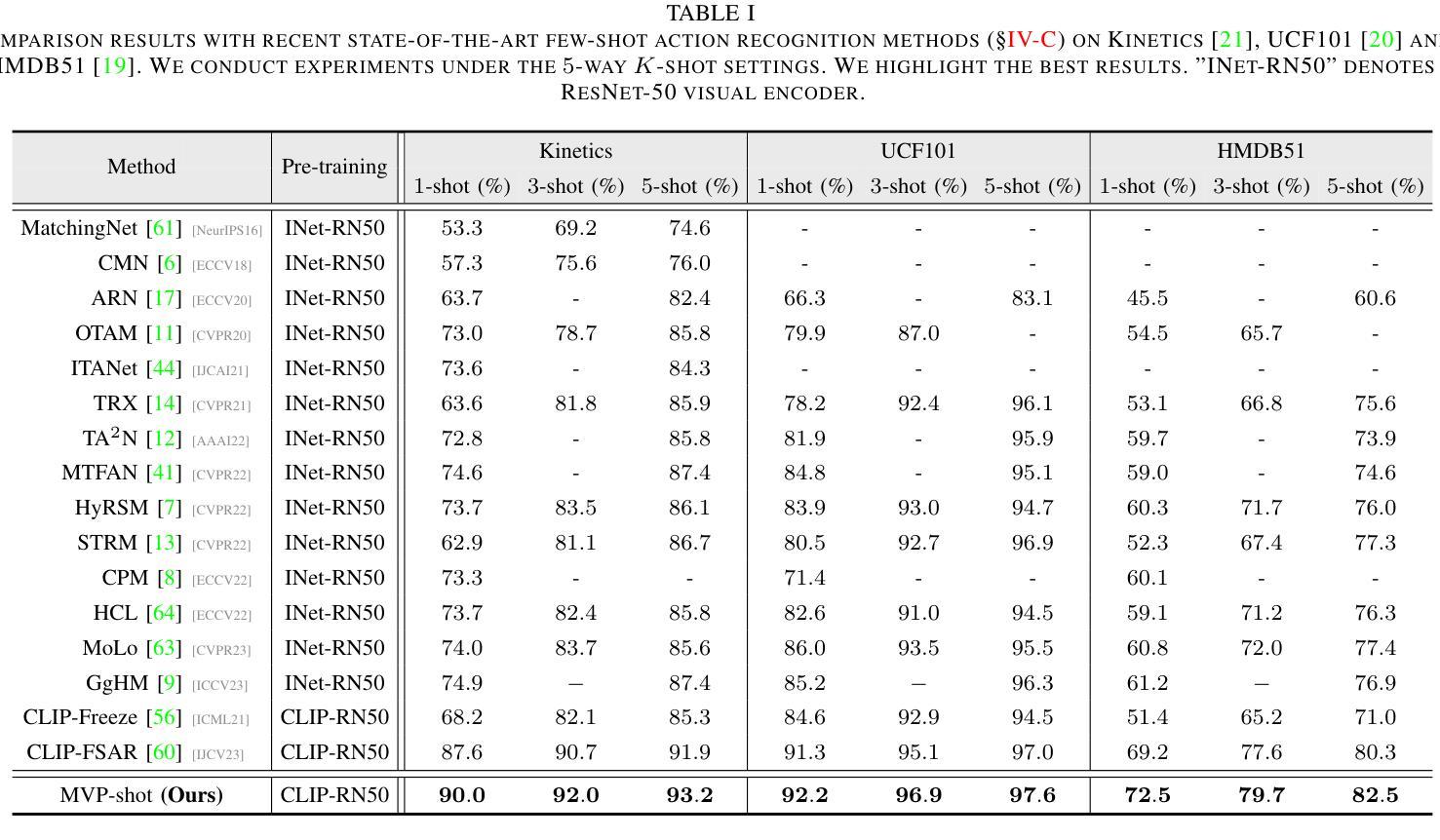
Recent few-shot action recognition (FSAR) methods typically perform semantic matching on learned discriminative features to achieve promising performance. However, most FSAR methods focus on single-scale (e.g., frame-level, segment-level, etc) feature alignment, which ignores that human actions with the same semantic may appear at different velocities. To this end, we develop a novel Multi-Velocity Progressive-alignment (MVP-Shot) framework to progressively learn and align semantic-related action features at multi-velocity levels. Concretely, a Multi-Velocity Feature Alignment (MVFA) module is designed to measure the similarity between features from support and query videos with different velocity scales and then merge all similarity scores in a residual fashion. To avoid the multiple velocity features deviating from the underlying motion semantic, our proposed Progressive Semantic-Tailored Interaction (PSTI) module injects velocity-tailored text information into the video feature via feature interaction on channel and temporal domains at different velocities. The above two modules compensate for each other to make more accurate query sample predictions under the few-shot settings. Experimental results show our method outperforms current state-of-the-art methods on multiple standard few-shot benchmarks (i.e., HMDB51, UCF101, Kinetics, and SSv2-small).
近期的few-shot动作识别(FSAR)方法通常通过对学习到的判别特征进行语义匹配,以取得有前景的性能。然而,大多数FSAR方法侧重于单一尺度的特征对齐(例如帧级别、片段级别等),忽略了相同语义的人类动作可能以不同速度出现。为此,我们开发了一种新的多速度渐进对齐(MVP-Shot)框架,以渐进的方式学习和对齐多速度级别下的语义相关动作特征。具体地,设计了一个多速度特征对齐(MVFA)模块,该模块旨在度量来自不同速度尺度的支持视频和查询视频特征之间的相似性,然后以残差的方式合并所有相似性得分。为了避免多个速度特征偏离底层运动语义,我们提出了一种新的渐进语义定制交互(PSTI)模块,该模块通过在不同速度的通道和时间域上执行特征交互,将速度定制文本信息注入视频特征。上述两个模块相互补充,在少样本设置下实现更准确的查询样本预测。实验结果表明,我们的方法在多个标准少样本基准测试(即HMDB51、UCF101、Kinetics和SSv2-small)上的性能优于当前最先进的方法。
论文及项目相关链接
PDF Accepted to TMM 2025
Summary
近期针对少样本动作识别(FSAR)的方法主要通过对学习到的判别特征进行语义匹配来实现较好的性能。然而,大多数FSAR方法仅关注单一尺度的特征对齐,忽略了相同语义的人类动作可能以不同速度出现。为此,我们提出了一个多速度渐进对齐(MVP-Shot)框架,以在多速度级别上渐进学习和对齐与语义相关的动作特征。具体来说,设计了一个多速度特征对齐(MVFA)模块,该模块可以测量来自支持视频和查询视频的不同速度尺度特征之间的相似性,并以残差方式合并所有相似性得分。为避免多速度特征偏离底层运动语义,我们提出了渐进语义定制交互(PSTI)模块,通过在不同速度下的通道和时间域上的特征交互,将定制的速度文本信息注入视频特征。以上两个模块相互补偿,在少样本设置下实现了更准确的查询样本预测。实验结果表明,我们的方法在多个标准少样本基准测试(如HMDB51、UCF101、Kinetics和SSv2-small)上的表现均优于当前最先进的方法。
Key Takeaways
- FSAR方法通过语义匹配在判别特征上实现良好性能。
- 现有FSAR方法主要关注单一尺度的特征对齐,忽略了动作速度多样性。
- 提出MVP-Shot框架,包含MVFA模块进行多速度特征对齐。
- MVFA模块测量不同速度尺度下的特征相似性,并以残差方式合并相似性得分。
- 为避免多速度特征偏离底层语义,引入PSTI模块,将速度文本信息注入视频特征。
- MVP-Shot框架在多个少样本动作识别基准测试上表现优异。
点此查看论文截图