⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-07 更新
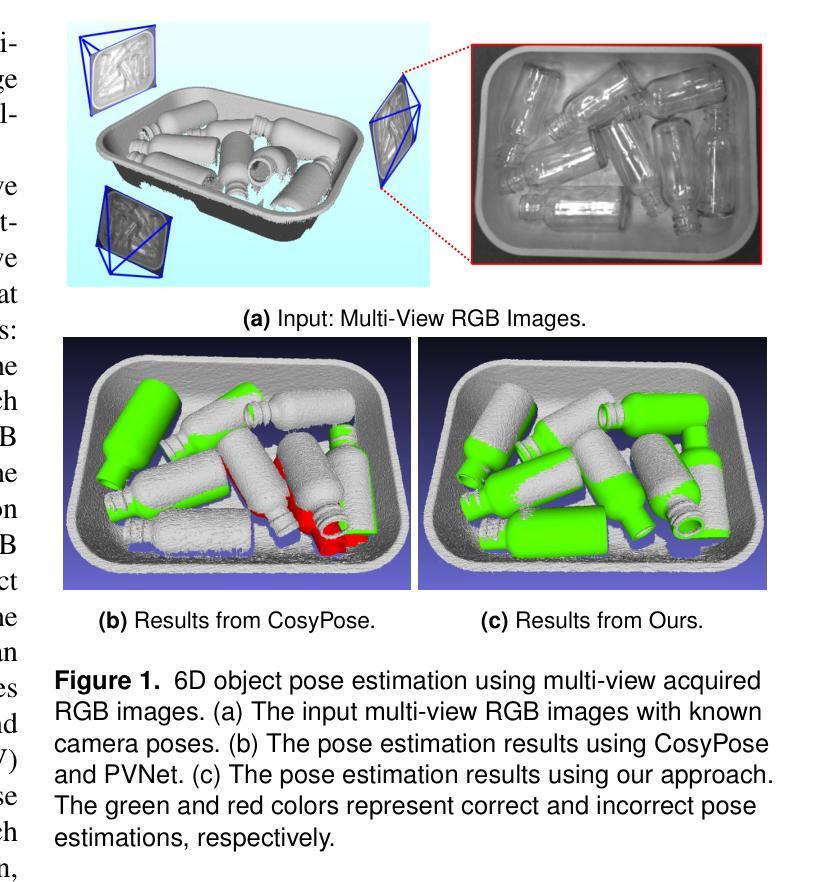
Active 6D Pose Estimation for Textureless Objects using Multi-View RGB Frames
Authors:Jun Yang, Wenjie Xue, Sahar Ghavidel, Steven L. Waslander
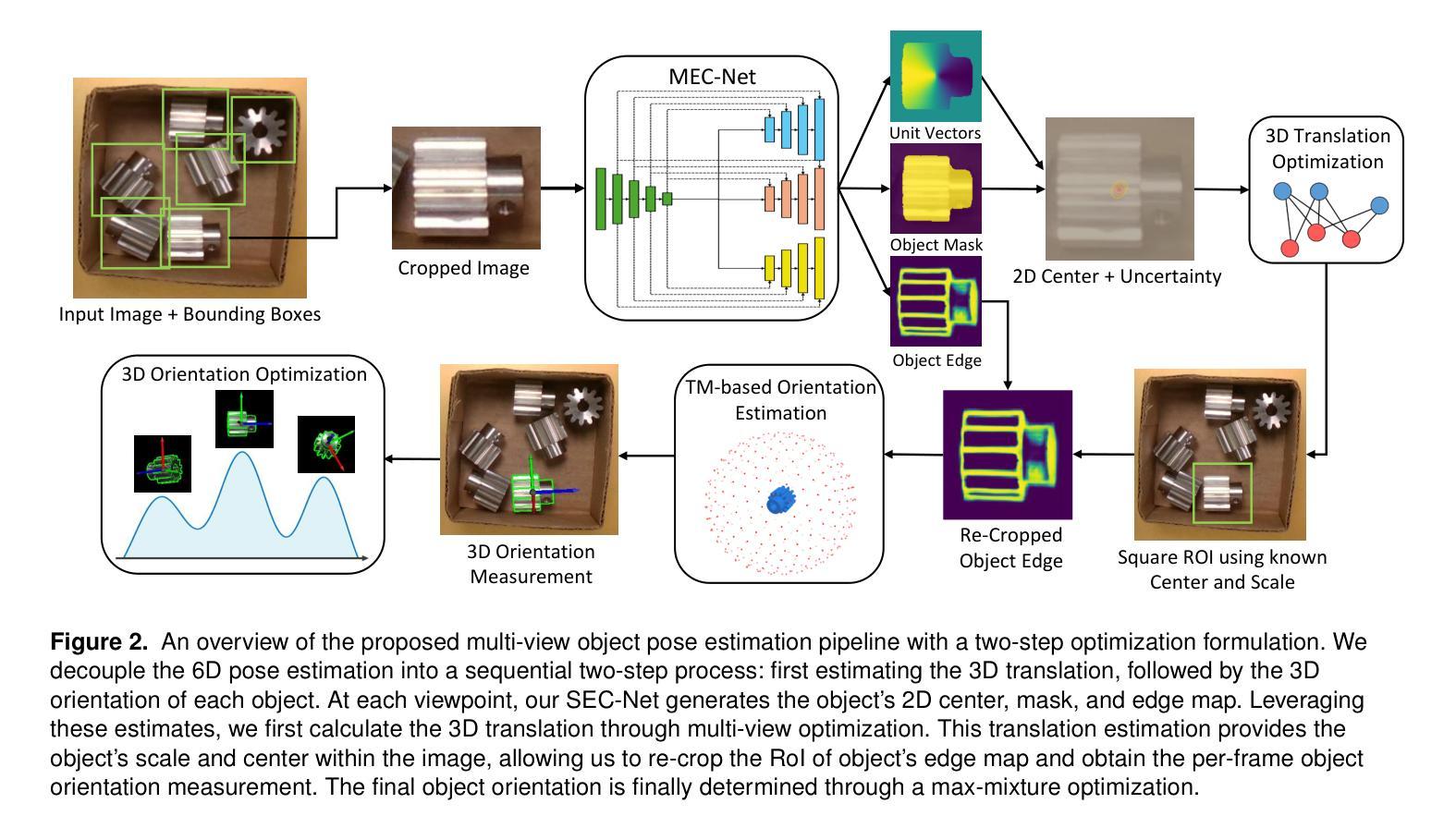
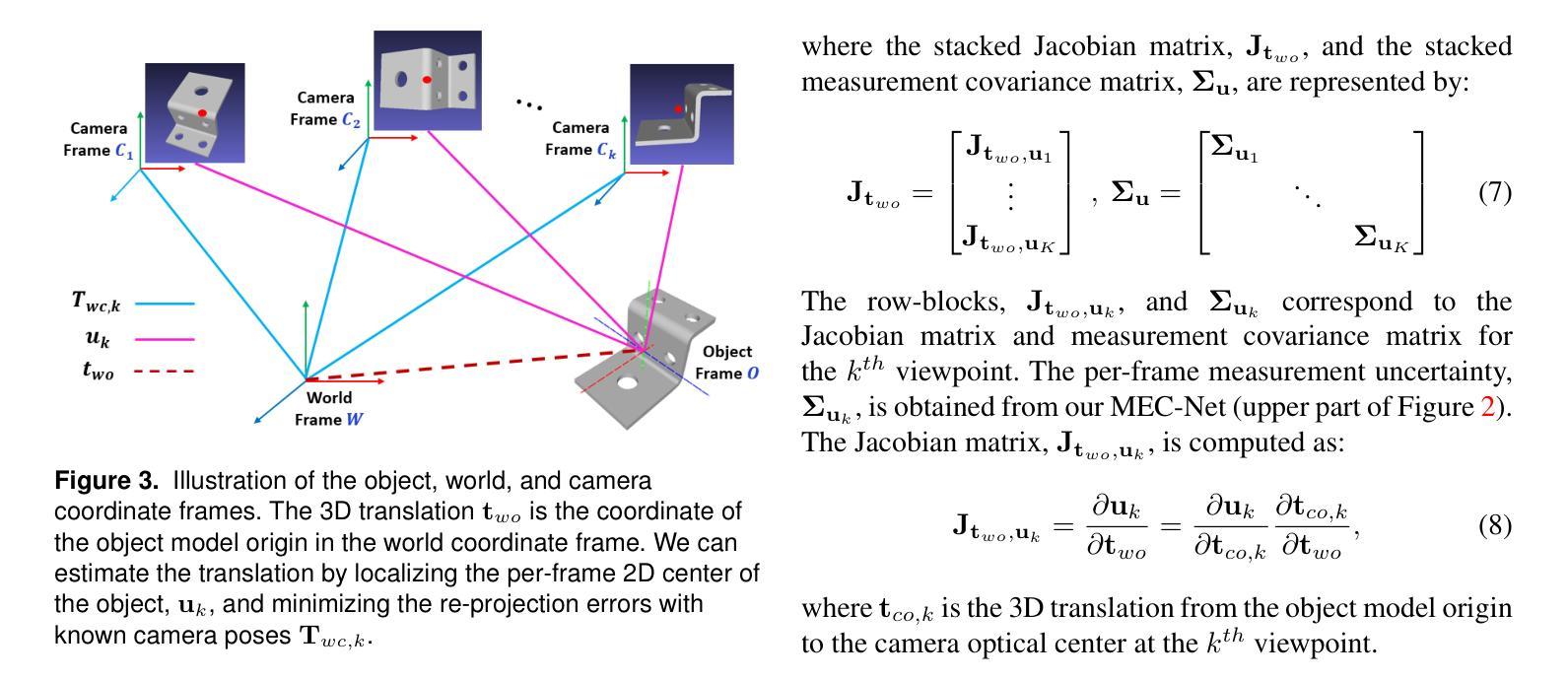
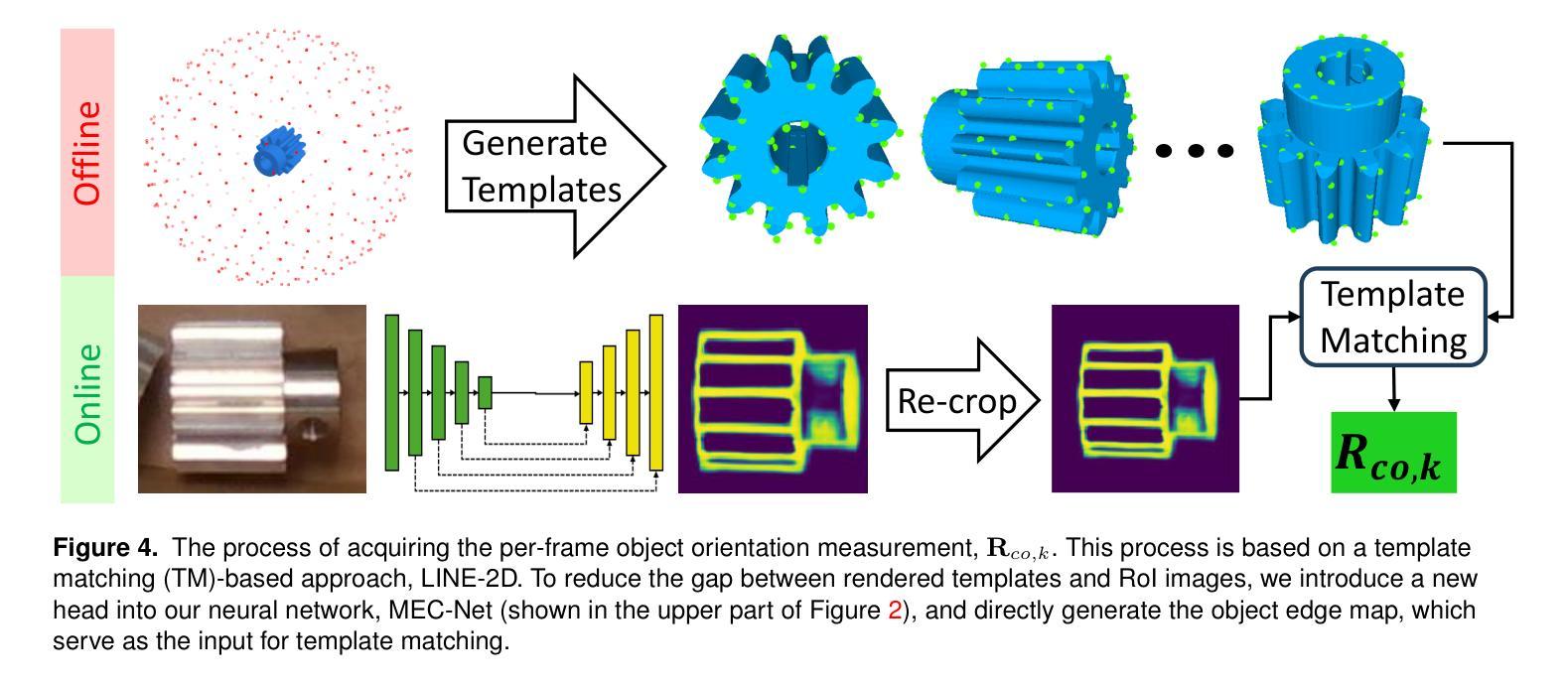
Estimating the 6D pose of textureless objects from RBG images is an important problem in robotics. Due to appearance ambiguities, rotational symmetries, and severe occlusions, single-view based 6D pose estimators are still unable to handle a wide range of objects, motivating research towards multi-view pose estimation and next-best-view prediction that addresses these limitations. In this work, we propose a comprehensive active perception framework for estimating the 6D poses of textureless objects using only RGB images. Our approach is built upon a key idea: decoupling the 6D pose estimation into a sequential two-step process can greatly improve both accuracy and efficiency. First, we estimate the 3D translation of each object, resolving scale and depth ambiguities inherent to RGB images. These estimates are then used to simplify the subsequent task of determining the 3D orientation, which we achieve through canonical scale template matching. Building on this formulation, we then introduce an active perception strategy that predicts the next best camera viewpoint to capture an RGB image, effectively reducing object pose uncertainty and enhancing pose accuracy. We evaluate our method on the public ROBI dataset as well as on a transparent object dataset that we created. When evaluated using the same camera viewpoints, our multi-view pose estimation significantly outperforms state-of-the-art approaches. Furthermore, by leveraging our next-best-view strategy, our method achieves high object pose accuracy with substantially fewer viewpoints than heuristic-based policies.
估计无纹理物体的RGB图像的6D姿态是机器人技术中的重要问题。由于外观模糊性、旋转对称性和严重的遮挡,基于单视角的6D姿态估计器仍然无法处理广泛的物体,这推动了多视角姿态估计和最佳视角预测的研究,以解决这些局限性。在这项工作中,我们提出了一个全面的主动感知框架,仅使用RGB图像来估计无纹理物体的6D姿态。我们的方法基于一个关键思想:将6D姿态估计解耦为顺序的两步过程可以大大提高准确性和效率。首先,我们估计每个物体的3D平移,解决RGB图像固有的尺度和深度模糊性。这些估计值随后用于简化后续确定3D方向的任务,我们通过规范尺度模板匹配来实现这一点。在此基础上,我们引入了一种主动感知策略,预测下一个最佳的相机视角以捕获RGB图像,这有效地减少了物体姿态的不确定性,提高了姿态的准确性。我们在公共的ROBI数据集和我们自己创建的透明物体数据集上评估了我们的方法。在相同的相机视角下进行评估时,我们的多视角姿态估计显著优于最新技术方法。此外,通过利用我们的最佳视角策略,我们的方法在视点数量上远少于基于启发式的方法,实现了较高的物体姿态准确性。
论文及项目相关链接
Summary
本文提出一种基于主动感知的框架,用于仅使用RGB图像估计无纹理物体的6D姿态。通过将6D姿态估计解耦为两步过程,先估计3D平移解决RGB图像的尺度和深度歧义,再简化后续的确定3D方向的任务。此外,还引入了一种主动感知策略,预测下一个最佳相机视角来捕捉RGB图像,提高物体姿态的准确性。
Key Takeaways
- 提出了一个针对无纹理物体6D姿态估计的主动感知框架。
- 通过将6D姿态估计分为两步,提高了准确性和效率。
- 先估计3D平移,解决RGB图像的尺度和深度歧义。
- 通过简化确定3D方向的任务,实现了高效姿态估计。
- 引入了一种主动感知策略,预测最佳的相机视角来提高物体姿态的准确性。
- 在公共ROBI数据集和自制透明物体数据集上的评估表明,该方法在多视角姿态估计方面显著优于最新技术。
点此查看论文截图

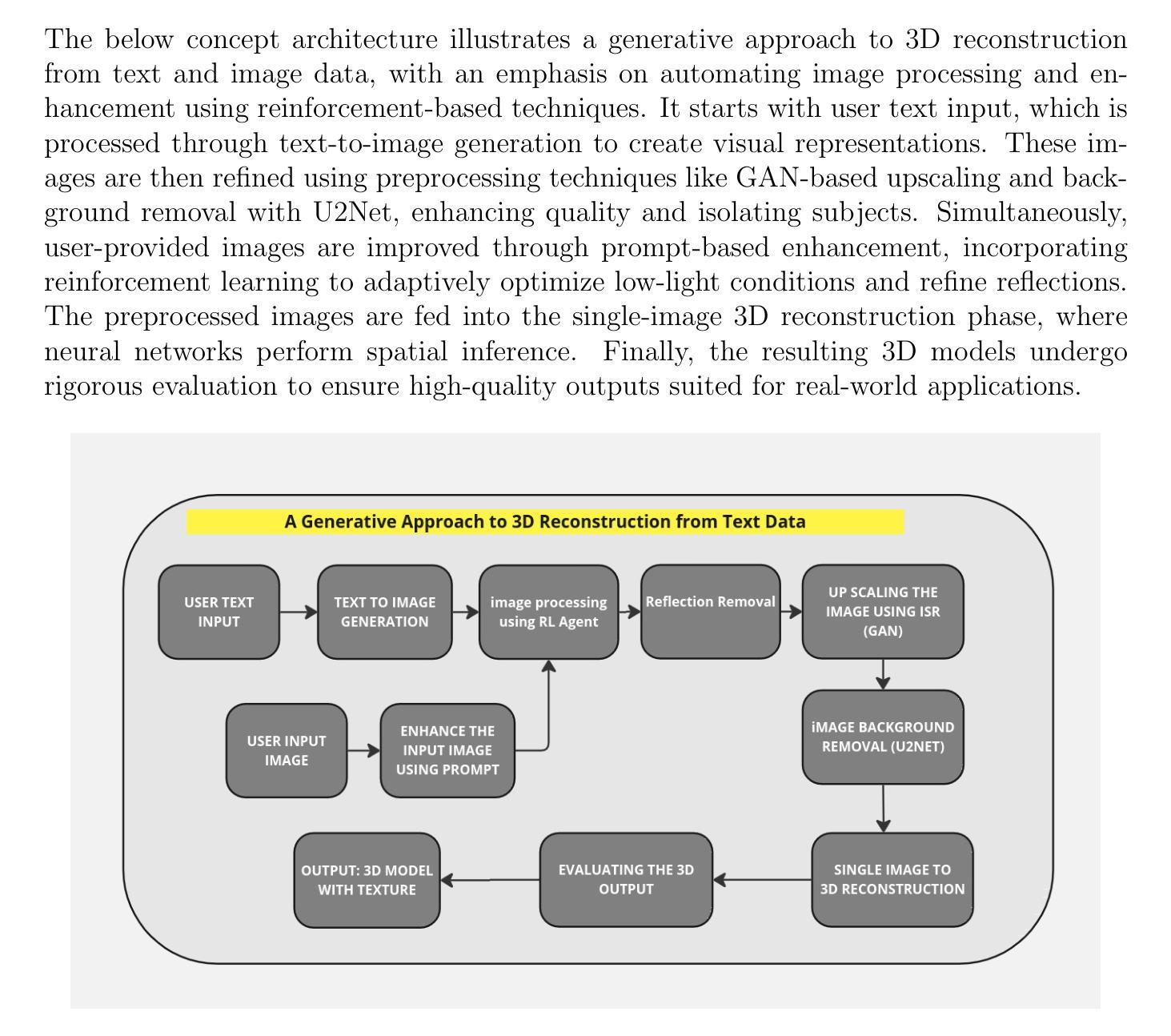
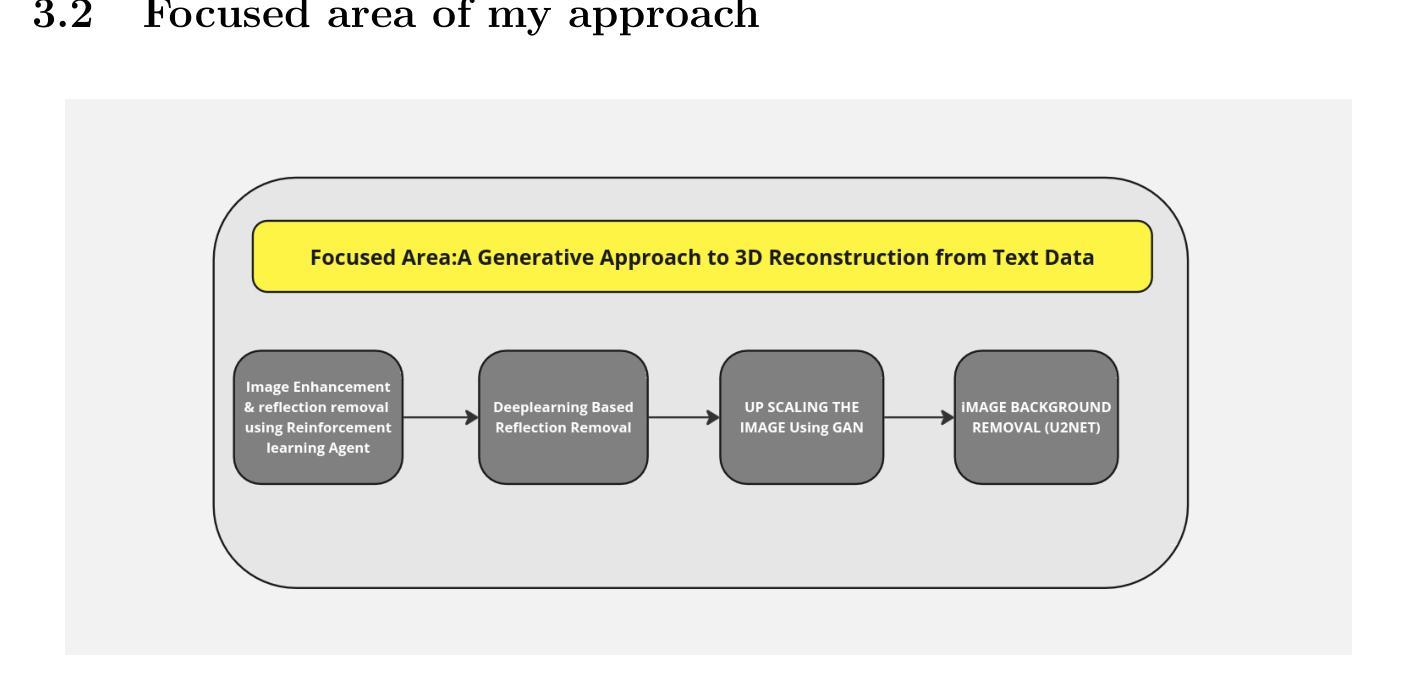
A Generative Approach to High Fidelity 3D Reconstruction from Text Data
Authors:Venkat Kumar R, Deepak Saravanan
The convergence of generative artificial intelligence and advanced computer vision technologies introduces a groundbreaking approach to transforming textual descriptions into three-dimensional representations. This research proposes a fully automated pipeline that seamlessly integrates text-to-image generation, various image processing techniques, and deep learning methods for reflection removal and 3D reconstruction. By leveraging state-of-the-art generative models like Stable Diffusion, the methodology translates natural language inputs into detailed 3D models through a multi-stage workflow. The reconstruction process begins with the generation of high-quality images from textual prompts, followed by enhancement by a reinforcement learning agent and reflection removal using the Stable Delight model. Advanced image upscaling and background removal techniques are then applied to further enhance visual fidelity. These refined two-dimensional representations are subsequently transformed into volumetric 3D models using sophisticated machine learning algorithms, capturing intricate spatial relationships and geometric characteristics. This process achieves a highly structured and detailed output, ensuring that the final 3D models reflect both semantic accuracy and geometric precision. This approach addresses key challenges in generative reconstruction, such as maintaining semantic coherence, managing geometric complexity, and preserving detailed visual information. Comprehensive experimental evaluations will assess reconstruction quality, semantic accuracy, and geometric fidelity across diverse domains and varying levels of complexity. By demonstrating the potential of AI-driven 3D reconstruction techniques, this research offers significant implications for fields such as augmented reality (AR), virtual reality (VR), and digital content creation.
生成式人工智能和先进计算机视觉技术的融合,为将文本描述转换为三维表示提供了一种突破性的方法。本研究提出了一种全自动流程管道,该管道无缝集成了文本到图像生成、各种图像处理技术和深度学习方法,用于去除反射和三维重建。通过利用最新的生成模型(如Stable Diffusion),该方法通过多阶段工作流程将自然语言输入转换为详细的3D模型。重建过程首先从文本提示生成高质量图像开始,随后通过强化学习代理进行增强,并使用Stable Delight模型去除反射。然后应用先进的图像放大和背景去除技术,以进一步提高视觉保真度。这些经过精细处理的二维表示随后使用复杂的机器学习算法转换为体积三维模型,捕捉复杂的空间关系和几何特征。这一过程实现了高度结构化且详细的输出,确保最终的3D模型既具有语义准确性又具有几何精度。这种方法解决了生成重建中的关键挑战,如保持语义连贯性、管理几何复杂性以及保留详细的视觉信息。综合实验评估将评估不同领域和不同程度复杂性的重建质量、语义准确性和几何保真度。本研究展示了人工智能驱动的3D重建技术对增强现实(AR)、虚拟现实(VR)和数字内容创建等领域的重要影响。
论文及项目相关链接
Summary
文本描述与三维图像转化的创新融合通过先进的计算机视觉技术和生成式人工智能实现了重大突破。该研究提出了全自动流程,无缝集成了文本到图像生成、各种图像处理技术和深度学习反射去除和三维重建方法。借助Stable Diffusion等最新生成模型,该方法通过多阶段工作流程将自然语言输入转化为详细的3D模型。这一过程从根据文本提示生成高质量图像开始,通过强化学习代理进行增强,并使用Stable Delight模型去除反射。然后应用先进的图像放大和背景去除技术,进一步提高视觉保真度。这些精炼的二维表示随后通过先进的机器学习算法转化为体积三维模型,捕捉复杂的空间关系和几何特征。该研究解决了生成重建中的关键挑战,如保持语义连贯性、管理几何复杂性以及保留详细的视觉信息。综合实验评估将评估不同领域和不同层次复杂性的重建质量、语义准确性和几何保真度。本研究为增强现实(AR)、虚拟现实(VR)和数字内容创建等领域提供了人工智能驱动的3D重建技术的巨大潜力。
Key Takeaways
- 生成式人工智能与计算机视觉技术的融合推动了文本到三维图像转化的创新突破。
- 研究提出了一个全自动流程,集成了多种技术,包括文本到图像生成、图像处理技术和深度学习方法。
- 利用最新生成模型如Stable Diffusion实现自然语言输入到详细三维模型的转化。
- 流程包括多个阶段,如高质量图像生成、增强、反射去除、图像放大、背景去除以及体积三维模型的转化。
- 该方法解决了生成重建中的关键挑战,如保持语义连贯性和几何复杂性。
- 综合实验评估将测试该方法的重建质量、语义准确性和几何保真度。
点此查看论文截图



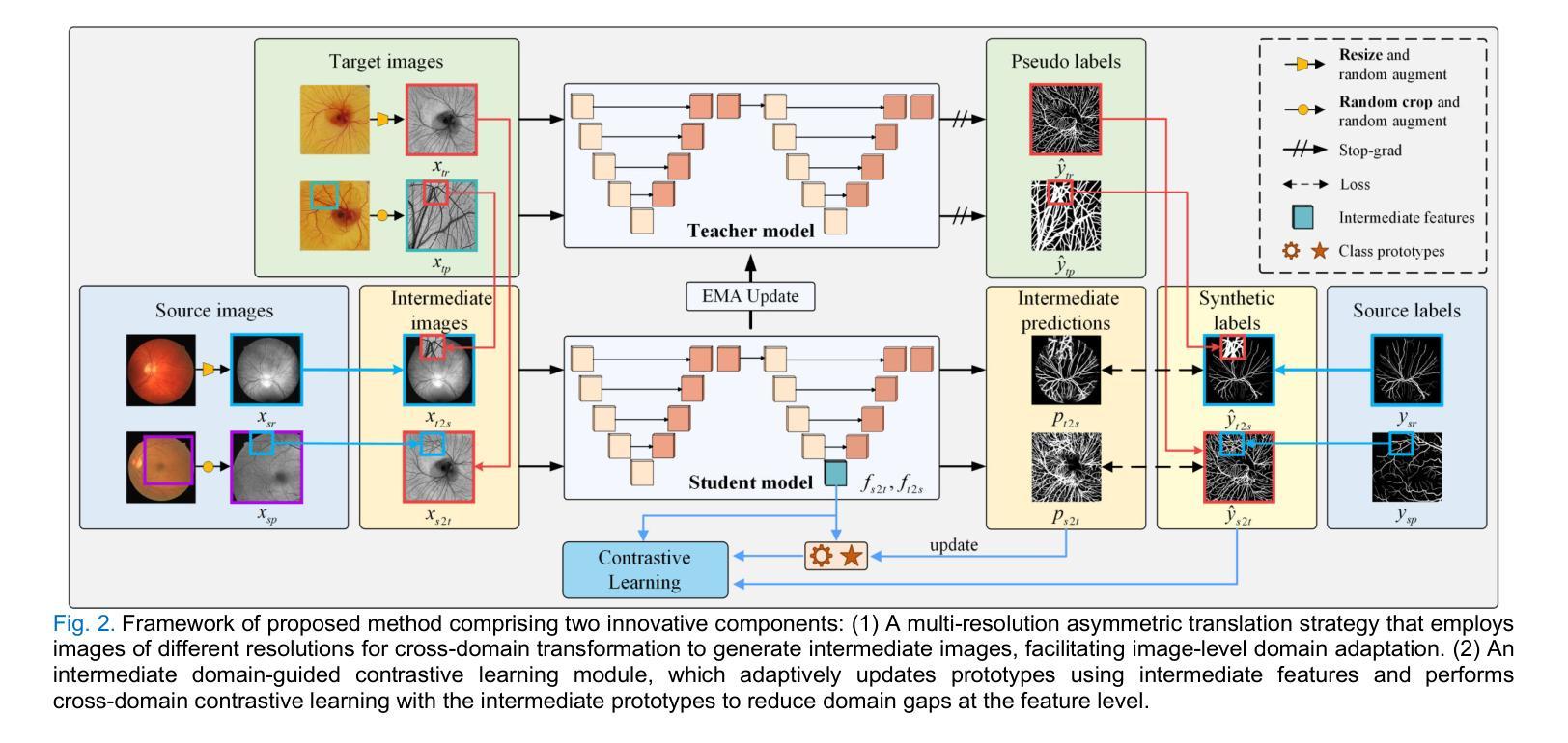
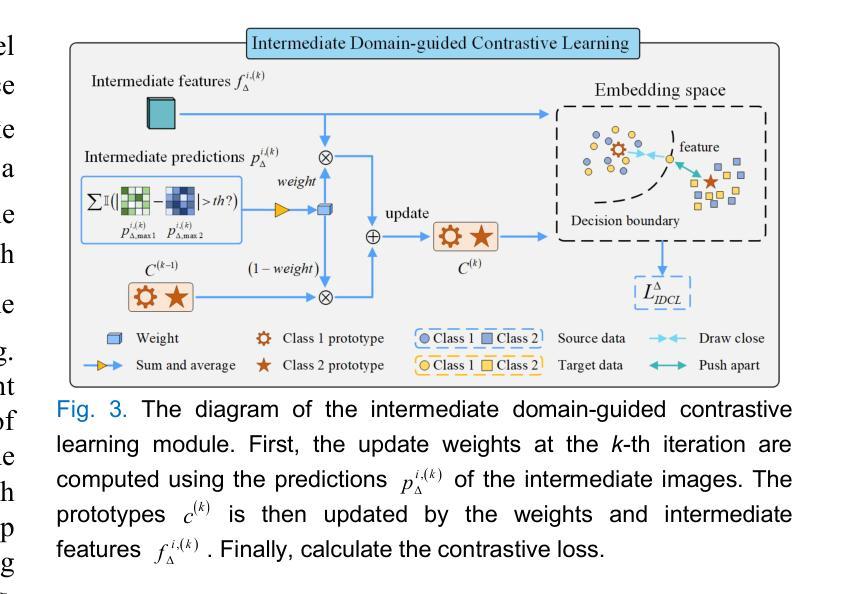
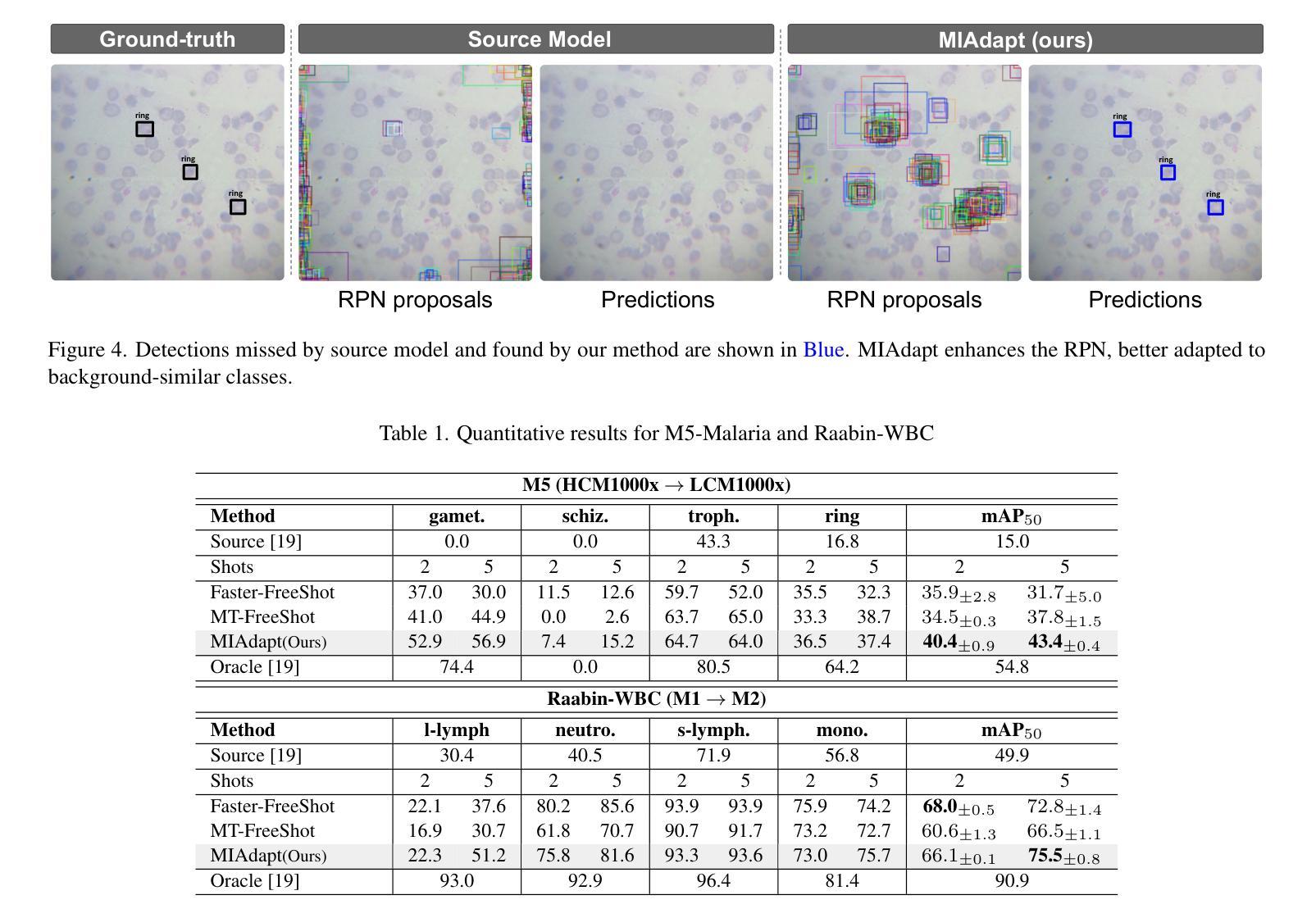
Intermediate Domain-guided Adaptation for Unsupervised Chorioallantoic Membrane Vessel Segmentation
Authors:Pengwu Song, Liang Xu, Peng Yao, Shuwei Shen, Pengfei Shao, Mingzhai Sun, Ronald X. Xu
The chorioallantoic membrane (CAM) model is widely employed in angiogenesis research, and distribution of growing blood vessels is the key evaluation indicator. As a result, vessel segmentation is crucial for quantitative assessment based on topology and morphology. However, manual segmentation is extremely time-consuming, labor-intensive, and prone to inconsistency due to its subjective nature. Moreover, research on CAM vessel segmentation algorithms remains limited, and the lack of public datasets contributes to poor prediction performance. To address these challenges, we propose an innovative Intermediate Domain-guided Adaptation (IDA) method, which utilizes the similarity between CAM images and retinal images, along with existing public retinal datasets, to perform unsupervised training on CAM images. Specifically, we introduce a Multi-Resolution Asymmetric Translation (MRAT) strategy to generate intermediate images to promote image-level interaction. Then, an Intermediate Domain-guided Contrastive Learning (IDCL) module is developed to disentangle cross-domain feature representations. This method overcomes the limitations of existing unsupervised domain adaptation (UDA) approaches, which primarily concentrate on directly source-target alignment while neglecting intermediate domain information. Notably, we create the first CAM dataset to validate the proposed algorithm. Extensive experiments on this dataset show that our method outperforms compared approaches. Moreover, it achieves superior performance in UDA tasks across retinal datasets, highlighting its strong generalization capability. The CAM dataset and source codes are available at https://github.com/PWSong-ustc/IDA.
胎盘绒毛膜膜(CAM)模型在血管生成研究中得到广泛应用,生长血管分布是关键评价指标。因此,基于拓扑和形态的定量评估,血管分割至关重要。然而,手动分割耗时费力,且由于主观性容易不一致。此外,CAM血管分割算法的研究仍然有限,缺乏公共数据集导致预测性能不佳。为了解决这些挑战,我们提出了一种创新的中域引导适配(IDA)方法,该方法利用CAM图像和视网膜图像之间的相似性,以及现有的公共视网膜数据集,对CAM图像进行无监督训练。具体来说,我们引入了一种多分辨率对称翻译(MRAT)策略来生成中间图像,以促进图像级别的交互。然后,开发了一个中间域引导对比学习(IDCL)模块来解开跨域特征表示。该方法克服了现有无监督域自适应(UDA)方法的局限性,这些方法主要集中在直接源目标对齐上,而忽略了中间域信息。值得注意的是,我们创建了第一个CAM数据集来验证所提出的算法。在该数据集上的大量实验表明,我们的方法优于比较方法。此外,它在视网膜数据集上的UDA任务中实现了卓越的性能,凸显了其强大的泛化能力。CAM数据集和源代码可在[https://github.com/PWSong-ustc/IDA找到。]
论文及项目相关链接
摘要
本文提出了中间域引导适应(IDA)方法,解决了CAM(胚胎绒毛膜尿囊膜)血管分割中的挑战性问题。该方法利用CAM图像与视网膜图像的相似性,结合现有公共视网膜数据集进行CAM图像的无监督训练。通过引入多分辨率不对称翻译(MRAT)策略生成中间图像促进图像级别的交互作用,并开发中间域引导对比学习(IDCL)模块以分离跨域特征表示。此方法克服了现有无监督域适应(UDA)方法的局限性,这些主要集中于直接源目标对齐而忽视了中间域的信息。本文创建了首个CAM数据集验证算法,并通过广泛的实验展示了该方法的优势,以及在视网膜数据集上的强大通用性。数据集及源代码公开在链接:https://github.com/PWSong-ustc/IDA。
关键见解
- CAM模型被广泛用于血管生成研究,其中血管分布是主要评估指标,因此血管分割对于基于拓扑和形态学的定量评估至关重要。
- 手动分割血管耗时、劳力密集且易出现不一致,因此研究CAM血管分割算法至关重要。
- 提出了一种新的中间域引导适应(IDA)方法,利用CAM图像与视网膜图像的相似性进行无监督训练。
- 通过引入多分辨率不对称翻译(MRAT)策略生成中间图像,促进图像级别的交互作用。
- 开发中间域引导对比学习(IDCL)模块以分离跨域特征表示,克服现有UDA方法的局限性。
- 创建首个CAM数据集验证算法的有效性,并进行广泛实验证明所提方法性能优越。
点此查看论文截图