⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-07 更新
Look, Listen, and Answer: Overcoming Biases for Audio-Visual Question Answering
Authors:Jie Ma, Min Hu, Pinghui Wang, Wangchun Sun, Lingyun Song, Hongbin Pei, Jun Liu, Youtian Du
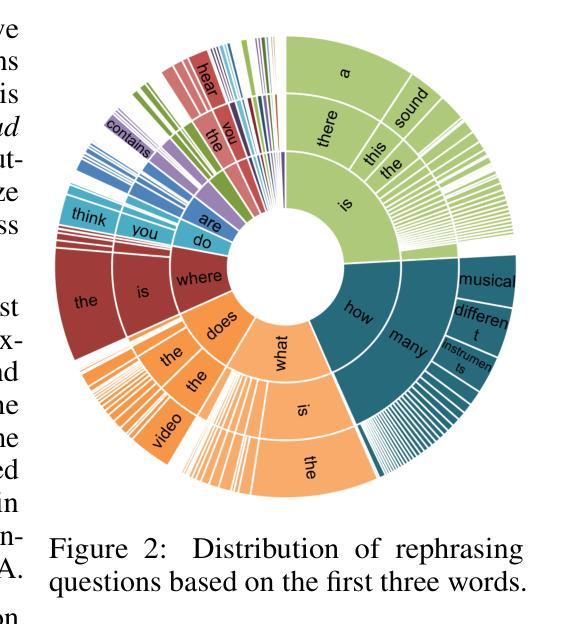
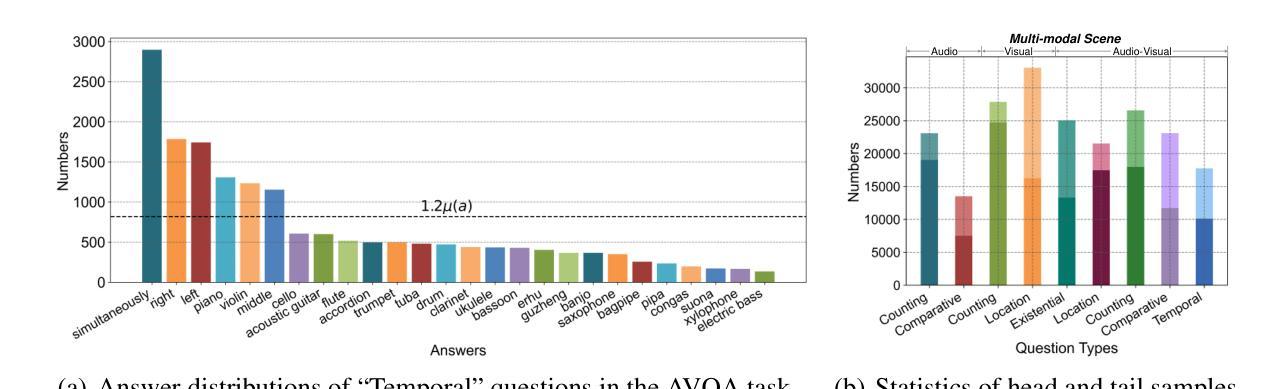
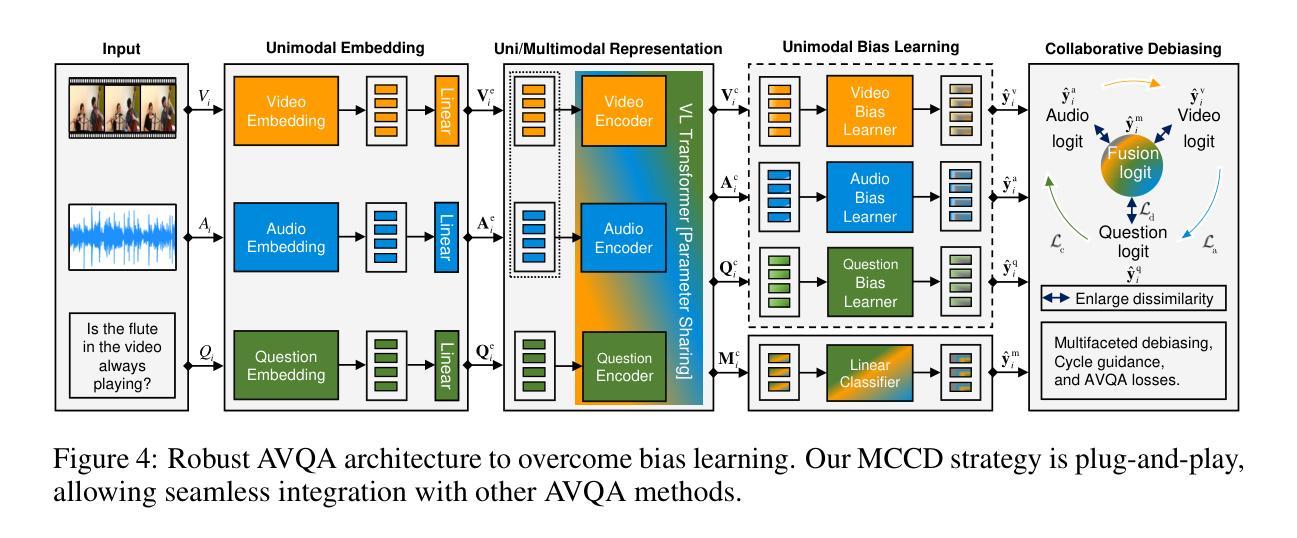
Audio-Visual Question Answering (AVQA) is a complex multi-modal reasoning task, demanding intelligent systems to accurately respond to natural language queries based on audio-video input pairs. Nevertheless, prevalent AVQA approaches are prone to overlearning dataset biases, resulting in poor robustness. Furthermore, current datasets may not provide a precise diagnostic for these methods. To tackle these challenges, firstly, we propose a novel dataset, MUSIC-AVQA-R, crafted in two steps: rephrasing questions within the test split of a public dataset (MUSIC-AVQA) and subsequently introducing distribution shifts to split questions. The former leads to a large, diverse test space, while the latter results in a comprehensive robustness evaluation on rare, frequent, and overall questions. Secondly, we propose a robust architecture that utilizes a multifaceted cycle collaborative debiasing strategy to overcome bias learning. Experimental results show that this architecture achieves state-of-the-art performance on MUSIC-AVQA-R, notably obtaining a significant improvement of 9.32%. Extensive ablation experiments are conducted on the two datasets mentioned to analyze the component effectiveness within the debiasing strategy. Additionally, we highlight the limited robustness of existing multi-modal QA methods through the evaluation on our dataset. We also conduct experiments combining various baselines with our proposed strategy on two datasets to verify its plug-and-play capability. Our dataset and code are available at https://github.com/reml-group/MUSIC-AVQA-R.
音频视觉问答(AVQA)是一项复杂的跨模态推理任务,要求智能系统根据音视频输入对自然语言查询进行准确响应。然而,流行的AVQA方法容易过度学习数据集偏见,导致稳健性较差。此外,当前的数据集可能无法为这些方法提供精确的诊断。为了应对这些挑战,首先,我们提出了一个新的数据集MUSIC-AVQA-R,它分为两个步骤构建:在公开数据集(MUSIC-AVQA)的测试分割中重新表述问题,然后引入分布偏移来分割问题。前者导致了一个大型、多样化的测试空间,而后者则对罕见、频繁和总体问题进行了全面的稳健性评估。其次,我们提出了一种稳健的架构,该架构利用多方面的循环协同去偏策略来克服偏见学习。实验结果表明,该架构在MUSIC-AVQA-R上达到了最新性能,显著提高了9.32%。对这两个数据集进行了广泛的消融实验,以分析去偏策略中的组件有效性。此外,我们通过在本数据集上进行评估,强调了现有多模态问答方法的有限稳健性。为了验证其即插即用能力,我们还在两个数据集上进行了将各种基线与我们提出的策略相结合的实验。我们的数据集和代码可在https://github.com/reml-group/MUSIC-AVQA-R找到。
论文及项目相关链接
PDF Accepted by NeurIPS 2024
Summary
该文本介绍了音频视觉问答(AVQA)任务面临的挑战,包括数据集偏差和缺乏精确的诊断数据集。为此,提出了一个新的数据集MUSIC-AVQA-R,采用两步构建:在公共数据集(MUSIC-AVQA)的测试集中重新表述问题并引入分布偏移来拆分问题。此外,还提出了一种利用多面循环协作去偏策略的强大架构。实验结果证明了该架构在MUSIC-AVQA-R上的卓越性能,并显著提高了9.32%。同时,通过评估现有多模态问答方法的有限稳健性,验证了所提出策略的插件和可玩性能力。
Key Takeaways
- 音频视觉问答(AVQA)是一个复杂的跨模态推理任务,要求智能系统基于音视频输入对自然语言查询做出准确响应。
- 当前AVQA方法容易过度学习数据集偏差,导致稳健性较差。
- 提出了新的数据集MUSIC-AVQA-R,通过重新表述问题和引入分布偏移来增强测试空间的多样性和综合稳健性评估。
- 提出了一种利用多面循环协作去偏策略的强大架构,取得了显著的性能提升。
- 实验结果表明,新架构在MUSIC-AVQA-R上实现了最先进的性能。
- 通过对现有多模态问答方法的评估,凸显了其有限稳健性。
点此查看论文截图