⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-07 更新
Process-based Self-Rewarding Language Models
Authors:Shimao Zhang, Xiao Liu, Xin Zhang, Junxiao Liu, Zheheng Luo, Shujian Huang, Yeyun Gong
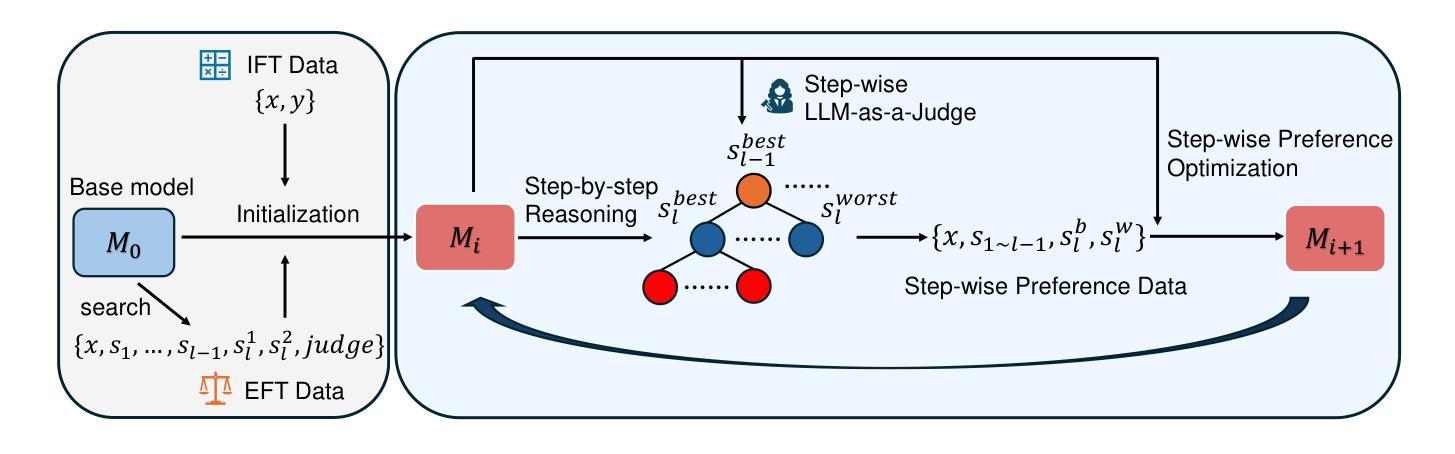
Large Language Models have demonstrated outstanding performance across various downstream tasks and have been widely applied in multiple scenarios. Human-annotated preference data is used for training to further improve LLMs’ performance, which is constrained by the upper limit of human performance. Therefore, Self-Rewarding method has been proposed, where LLMs generate training data by rewarding their own outputs. However, the existing self-rewarding paradigm is not effective in mathematical reasoning scenarios and may even lead to a decline in performance. In this work, we propose the Process-based Self-Rewarding pipeline for language models, which introduces long-thought reasoning, step-wise LLM-as-a-Judge, and step-wise preference optimization within the self-rewarding paradigm. Our new paradigm successfully enhances the performance of LLMs on multiple mathematical reasoning benchmarks through iterative Process-based Self-Rewarding, demonstrating the immense potential of self-rewarding to achieve LLM reasoning that may surpass human capabilities.
大型语言模型已在各种下游任务中展现出卓越性能,并在多个场景中得到广泛应用。为了进一步提升大型语言模型的性能,采用人工标注的偏好数据进行训练,但仍受限于人类性能的上限。因此,提出了自我奖励方法,即大型语言模型通过奖励自身输出生成训练数据。然而,现有的自我奖励范式在数学推理场景中并不有效,甚至可能导致性能下降。本研究提出了基于过程的自我奖励管道语言模型,引入了长期推理、逐步的大型语言模型作为法官和基于自我奖励范式内的逐步偏好优化。我们的新范式通过基于过程的自我奖励迭代成功提高了大型语言模型在多个数学推理基准测试中的性能,证明了自我奖励在大型语言模型推理方面具有超越人类能力的巨大潜力。
论文及项目相关链接
Summary
大规模语言模型在不同下游任务上表现出卓越性能,并在多个场景中得到了广泛应用。为进一步提高其性能并受到人类表现上限的限制,采用了人类标注偏好数据进行训练。然而,现有的自我奖励机制在数学推理场景中并不有效,甚至可能导致性能下降。本研究提出了基于流程的自我奖励管道,引入长期推理、逐步的语言模型作为法官和逐步偏好优化等机制。通过基于流程的迭代自我奖励,成功提高了语言模型在数学推理方面的性能,显示出自我奖励实现超越人类能力的语言推理的巨大潜力。
Key Takeaways
- 大规模语言模型在多种任务上表现出卓越性能,并广泛应用于不同场景。
- 人类标注偏好数据用于训练,以提高语言模型的性能,但仍受人类表现上限的限制。
- 现有自我奖励机制在数学推理场景中效果不佳,甚至导致性能下降。
- 本研究提出了基于流程的自我奖励管道,包括长期推理、逐步的语言模型评估以及偏好优化。
- 通过迭代基于流程的自我奖励,成功提高了语言模型在数学推理方面的性能。
- 基于自我奖励的语言模型有潜力实现超越人类能力的语言推理。
点此查看论文截图

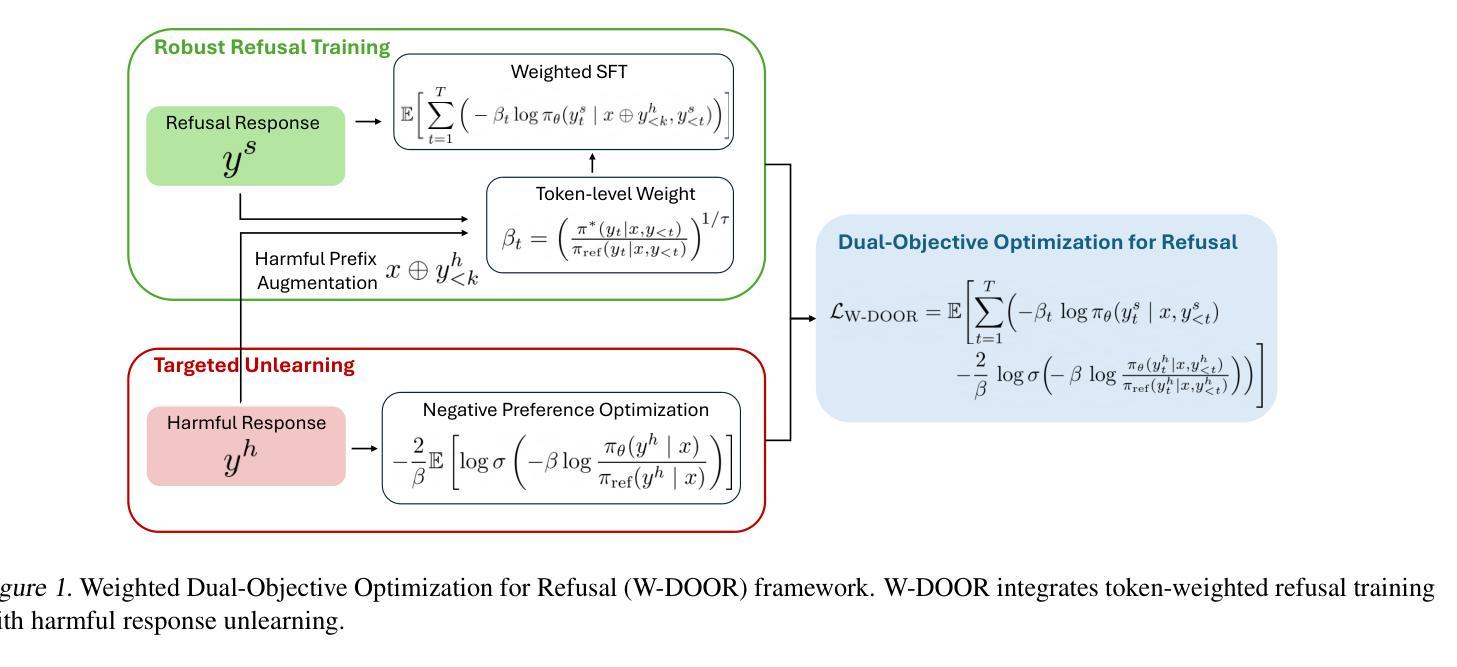
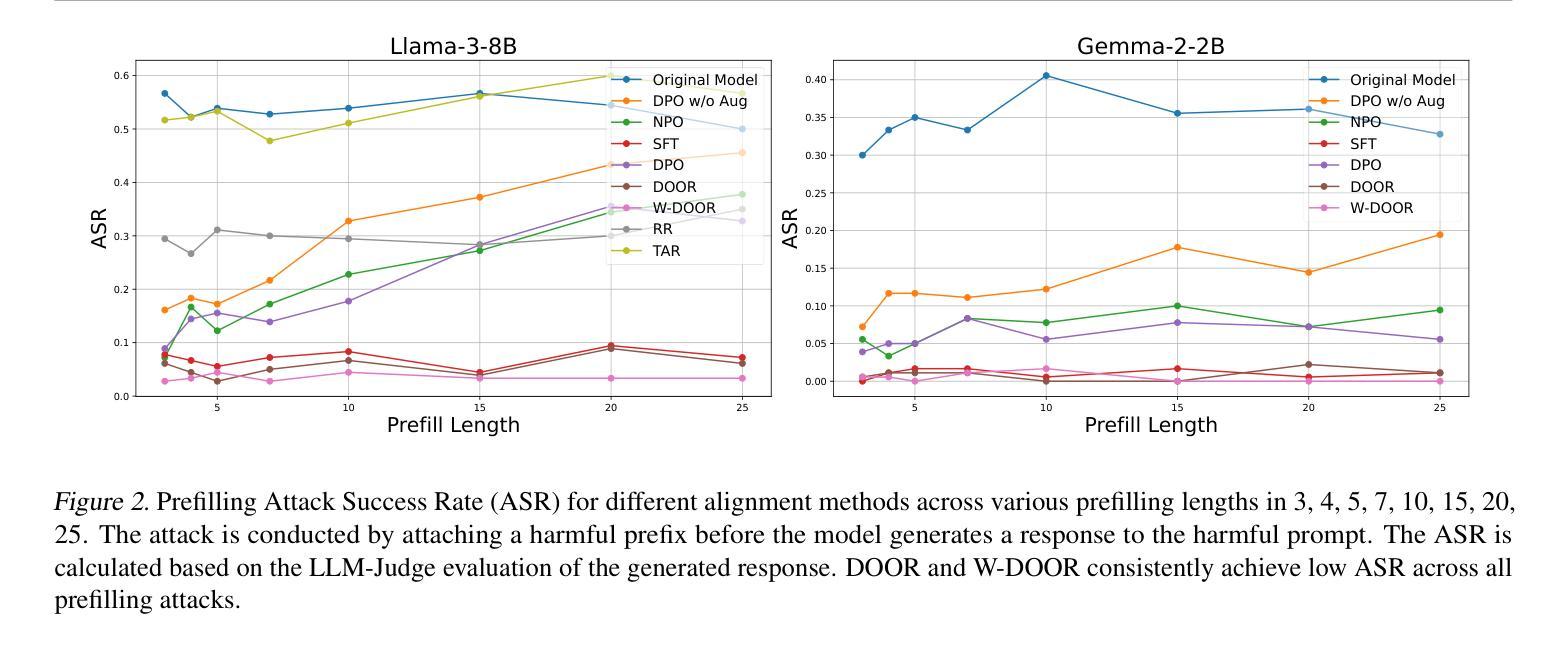
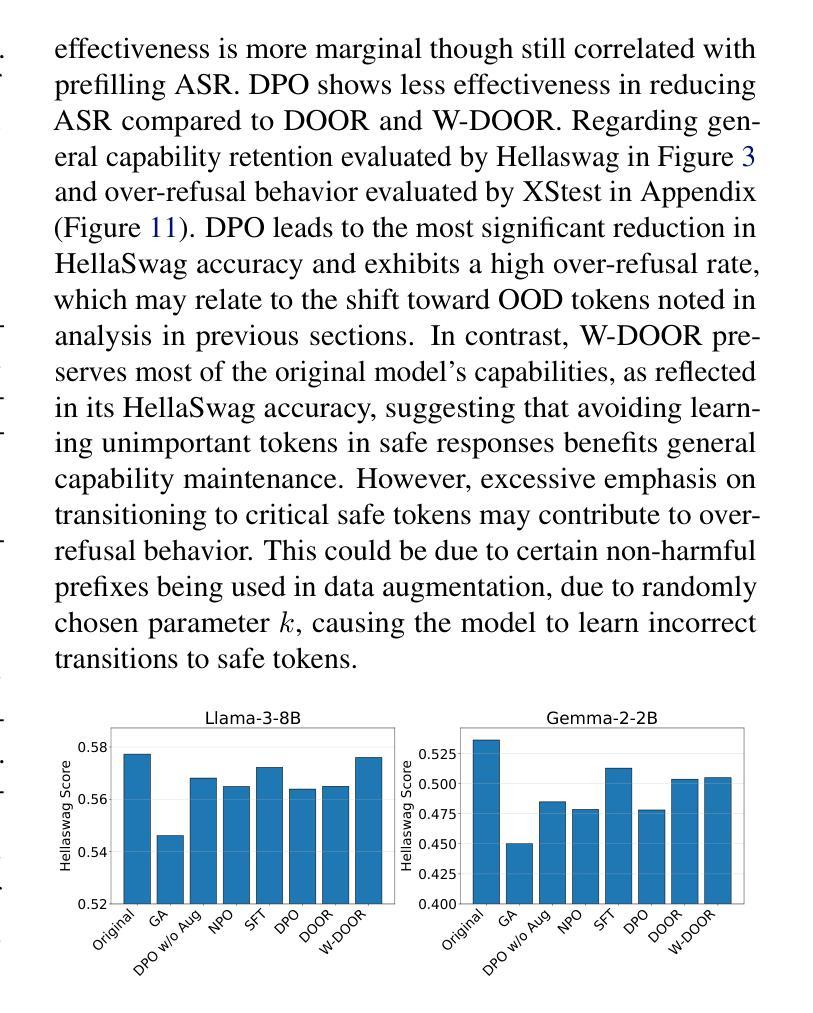
Improving LLM Safety Alignment with Dual-Objective Optimization
Authors:Xuandong Zhao, Will Cai, Tianneng Shi, David Huang, Licong Lin, Song Mei, Dawn Song
Existing training-time safety alignment techniques for large language models (LLMs) remain vulnerable to jailbreak attacks. Direct preference optimization (DPO), a widely deployed alignment method, exhibits limitations in both experimental and theoretical contexts as its loss function proves suboptimal for refusal learning. Through gradient-based analysis, we identify these shortcomings and propose an improved safety alignment that disentangles DPO objectives into two components: (1) robust refusal training, which encourages refusal even when partial unsafe generations are produced, and (2) targeted unlearning of harmful knowledge. This approach significantly increases LLM robustness against a wide range of jailbreak attacks, including prefilling, suffix, and multi-turn attacks across both in-distribution and out-of-distribution scenarios. Furthermore, we introduce a method to emphasize critical refusal tokens by incorporating a reward-based token-level weighting mechanism for refusal learning, which further improves the robustness against adversarial exploits. Our research also suggests that robustness to jailbreak attacks is correlated with token distribution shifts in the training process and internal representations of refusal and harmful tokens, offering valuable directions for future research in LLM safety alignment. The code is available at https://github.com/wicai24/DOOR-Alignment
现有大型语言模型(LLM)的训练时安全对齐技术仍然容易受到越狱攻击的影响。直接偏好优化(DPO)是一种广泛部署的对齐方法,其在实验和理论背景下均存在局限性,因为其损失函数对于拒绝学习而言并不理想。通过基于梯度的分析,我们识别出这些不足,并提出了一种改进的安全对齐方法,该方法将DPO目标分解为两个组成部分:(1)鲁棒拒绝训练,即使部分不安全生成,也鼓励拒绝;(2)有针对性地忘记有害知识。该方法显著提高了LLM对各种越狱攻击的鲁棒性,包括跨分布内和分布外的预填充、后缀和多轮攻击。此外,我们通过引入一种基于奖励的令牌级加权机制来强调拒绝学习的关键拒绝令牌的方法,这进一步提高了对对抗性利用的鲁棒性。我们的研究还表明,对越狱攻击的鲁棒性与训练过程中的令牌分布转变以及拒绝和有害令牌的内部表示有关,为未来LLM安全对齐的研究提供了有价值的方向。代码可在https://github.com/wicai24/DOOR-Alignment找到。
论文及项目相关链接
Summary
大型语言模型(LLM)在训练时的安全对齐技术仍易受到jailbreak攻击的影响。直接偏好优化(DPO)是一种广泛应用的对齐方法,但在实验和理论背景下都存在局限性,其损失函数对于拒绝学习并不理想。通过梯度分析,我们确定了这些不足,并提出了一种改进的安全对齐方法,该方法将DPO目标分为两个组成部分:(1)鲁棒的拒绝训练,即使在部分不安全生成的情况下也鼓励拒绝;(2)有针对性的消除有害知识。该方法显著提高了LLM对各种jailbreak攻击的鲁棒性,包括预填充、后缀和多轮攻击,涵盖了分布内和分布外场景。此外,我们引入了一种方法,通过引入基于奖励的令牌级加权机制来强调关键的拒绝令牌,进一步提高对抗恶意攻击的稳健性。本研究还表明,对jailbreak攻击的稳健性与训练过程中的令牌分布转变以及拒绝和有害令牌的内部表示有关,为未来LLM安全对齐的研究提供了有价值的方向。
Key Takeaways
- LLM现有的训练时间安全对齐技术容易受到jailbreak攻击的影响。
- 直接偏好优化(DPO)方法在拒绝学习方面存在局限性。
- 提出一种改进的安全对齐方法,包括鲁棒拒绝训练和有害知识的有针对性的消除。
- 新方法显著提高LLM对各种jailbreak攻击的鲁棒性,涵盖分布内和分布外场景。
- 引入基于奖励的令牌级加权机制来强调关键的拒绝令牌。
- 对jailbreak攻击的稳健性与训练过程中的令牌分布转变有关。
点此查看论文截图

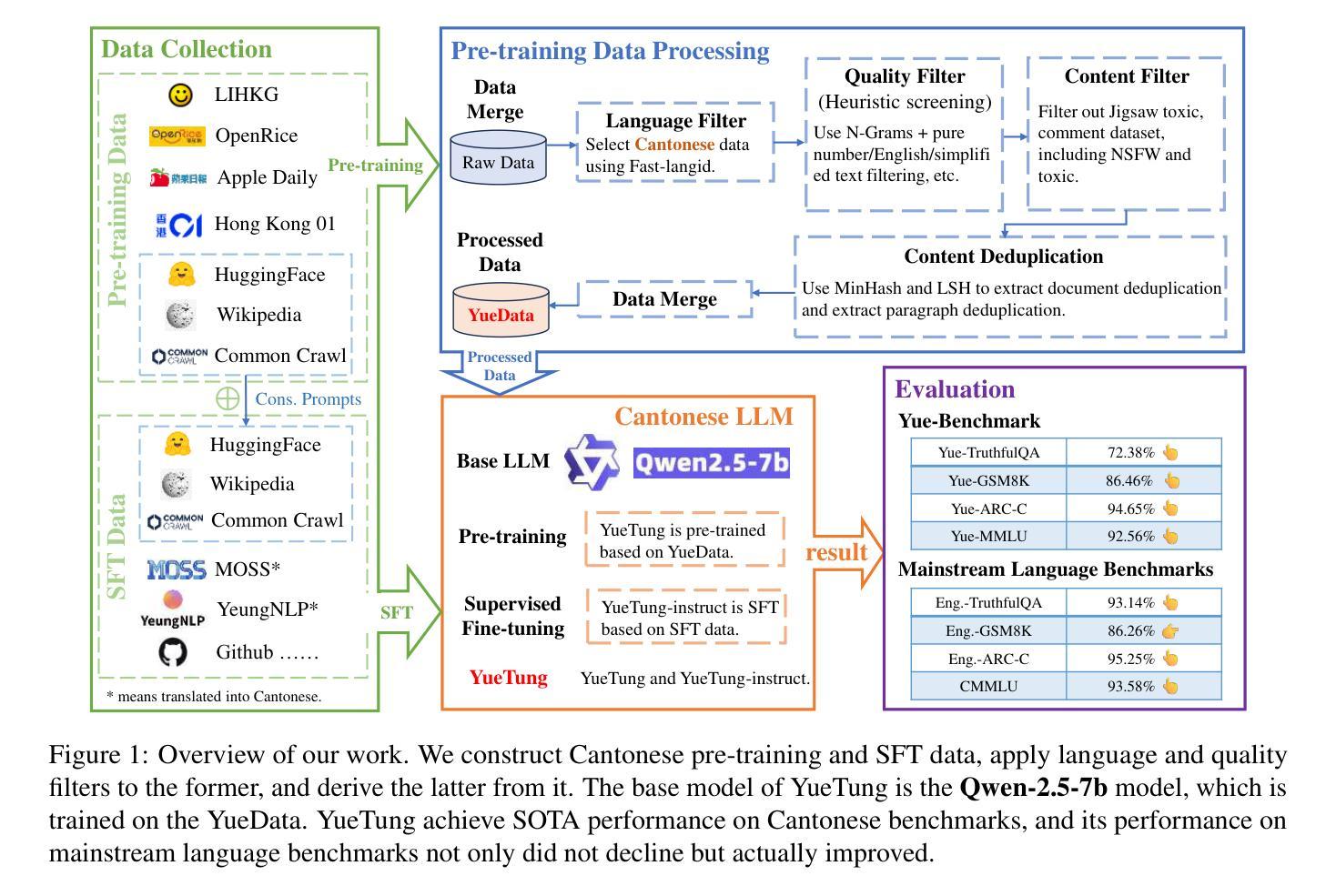
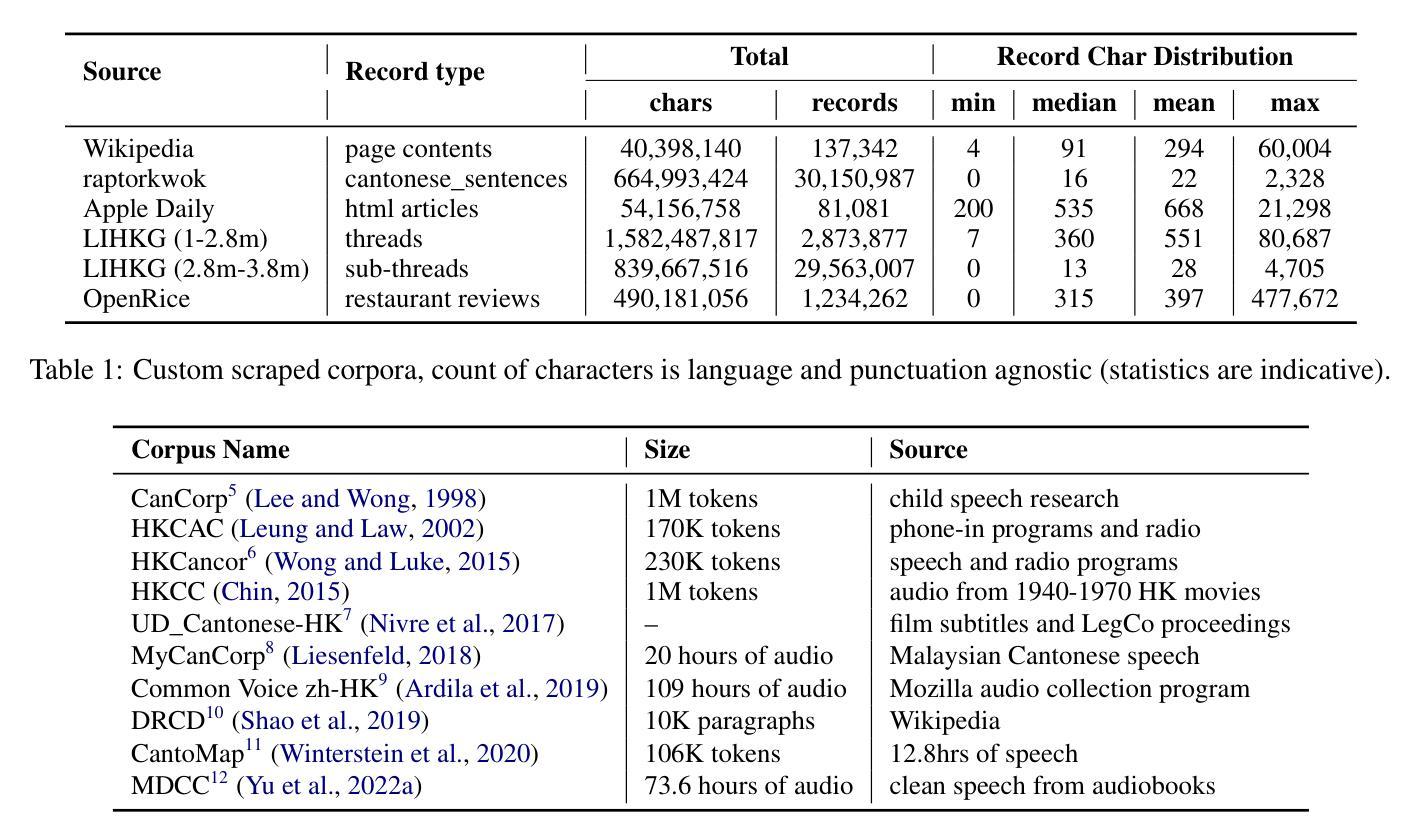
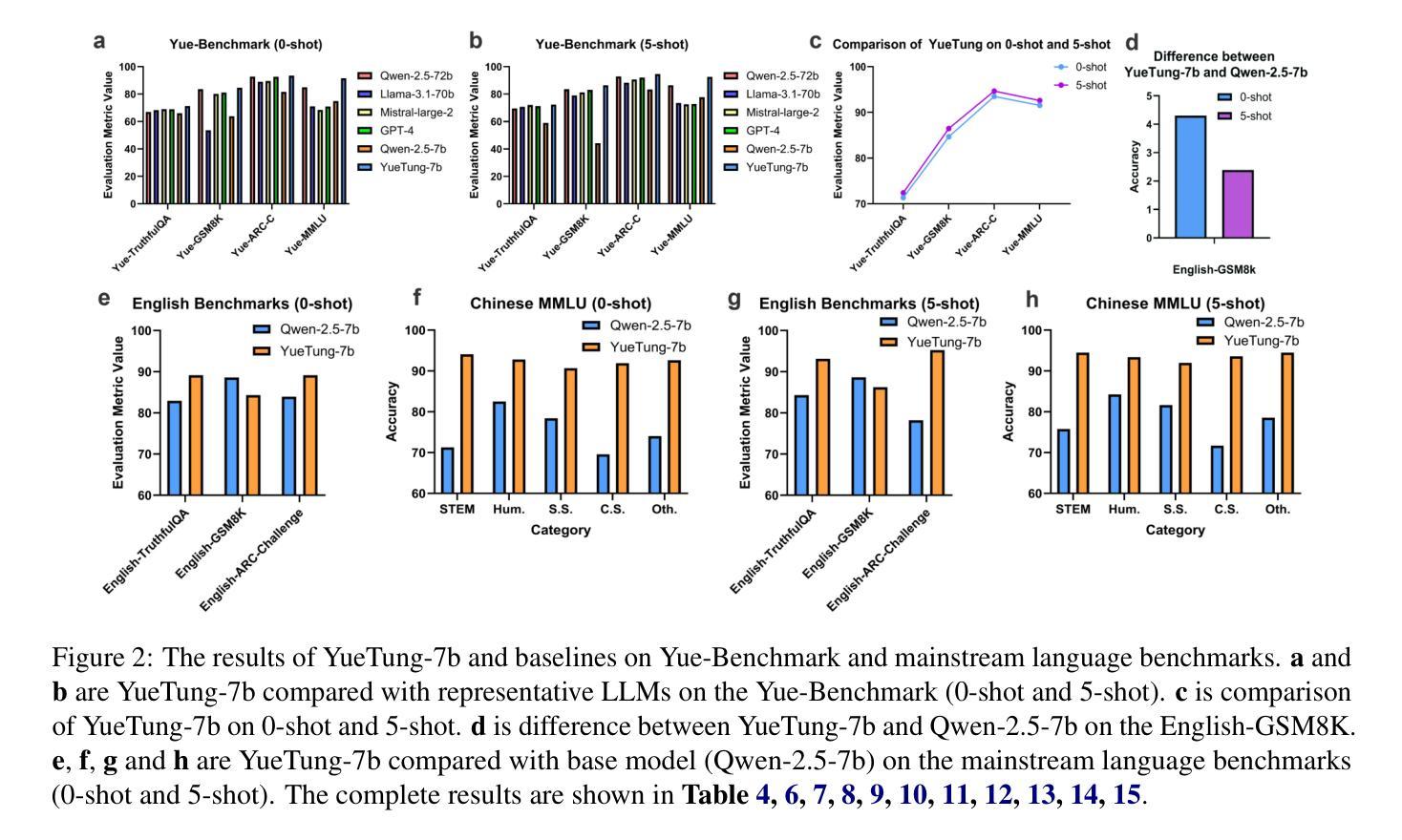
Developing and Utilizing a Large-Scale Cantonese Dataset for Multi-Tasking in Large Language Models
Authors:Jiyue Jiang, Alfred Kar Yin Truong, Yanyu Chen, Qinghang Bao, Sheng Wang, Pengan Chen, Jiuming Wang, Lingpeng Kong, Yu Li, Chuan Wu
High-quality data resources play a crucial role in learning large language models (LLMs), particularly for low-resource languages like Cantonese. Despite having more than 85 million native speakers, Cantonese is still considered a low-resource language in the field of natural language processing (NLP) due to factors such as the dominance of Mandarin, lack of cohesion within the Cantonese-speaking community, diversity in character encoding and input methods, and the tendency of overseas Cantonese speakers to prefer using English. In addition, rich colloquial vocabulary of Cantonese, English loanwords, and code-switching characteristics add to the complexity of corpus collection and processing. To address these challenges, we collect Cantonese texts from a variety of sources, including open source corpora, Hong Kong-specific forums, Wikipedia, and Common Crawl data. We conduct rigorous data processing through language filtering, quality filtering, content filtering, and de-duplication steps, successfully constructing a high-quality Cantonese corpus of over 2 billion tokens for training large language models. We further refined the model through supervised fine-tuning (SFT) on curated Cantonese tasks, enhancing its ability to handle specific applications. Upon completion of the training, the model achieves state-of-the-art (SOTA) performance on four Cantonese benchmarks. After training on our dataset, the model also exhibits improved performance on other mainstream language tasks.
高质量的数据资源在学习大型语言模型(LLM)中发挥着至关重要的作用,特别是在粤语这种低资源语言领域。尽管粤语有超过8500万母语者,但由于普通话的主导地位、粤语社群内部的缺乏凝聚力、字符编码和输入方法的多样性以及海外粤语使用者更倾向于使用英语等因素,粤语在自然语言处理(NLP)领域仍被视为一种低资源语言。此外,粤语的丰富口语词汇、英语借词和代码转换特性增加了语料库收集和处理工作的复杂性。为了应对这些挑战,我们从各种来源收集粤语文本,包括开放源代码语料库、香港特定论坛、Wikipedia和Common Crawl数据。我们通过语言过滤、质量过滤、内容过滤和去重等严格的数据处理步骤,成功构建了超过2亿令牌的高质量粤语语料库,用于训练大型语言模型。我们还通过精选的粤语任务进行有监督微调(SFT),进一步改进模型,提高其处理特定应用的能力。训练完成后,该模型在四个粤语基准测试中达到了最新技术水平。在我们的数据集上进行训练后,该模型在其他主流语言任务上的性能也有所提高。
论文及项目相关链接
Summary
本文介绍了针对粤语这一低资源语言领域,如何收集高质量数据资源用于训练大型语言模型(LLM)。通过从多种来源收集粤语文本,进行严谨的数据处理,成功构建了一个超过两亿标记的高质量粤语语料库。经过特定任务的监督微调后,该模型在四项粤语基准测试中达到了业界最佳性能,并且在主流语言任务上也有所提升。
Key Takeaways
- 粤语虽然有超过85百万的母语使用者,但在自然语言处理领域仍被视为低资源语言。主要挑战包括普通话的主导地位、粤语社群的不团结、字符编码和输入方法的多样性以及海外粤语使用者更倾向于使用英语等问题。
- 收集粤语文本来源多样化,包括开源语料库、香港特定论坛、Wikipedia和Common Crawl数据等。
- 对收集的数据进行了严格的处理,包括语言过滤、质量过滤、内容过滤和去重等步骤,成功构建了高质量粤语语料库。
- 通过监督微调(SFT)在定制粤语任务上进一步优化模型,提升其处理特定应用的能力。
- 模型在四项粤语基准测试中达到了业界最佳性能。
- 在训练数据集上训练后,模型在主流语言任务上的性能也有所提高。
点此查看论文截图

Addressing Overprescribing Challenges: Fine-Tuning Large Language Models for Medication Recommendation Tasks
Authors:Zihao Zhao, Chenxiao Fan, Chongming Gao, Fuli Feng, Xiangnan He
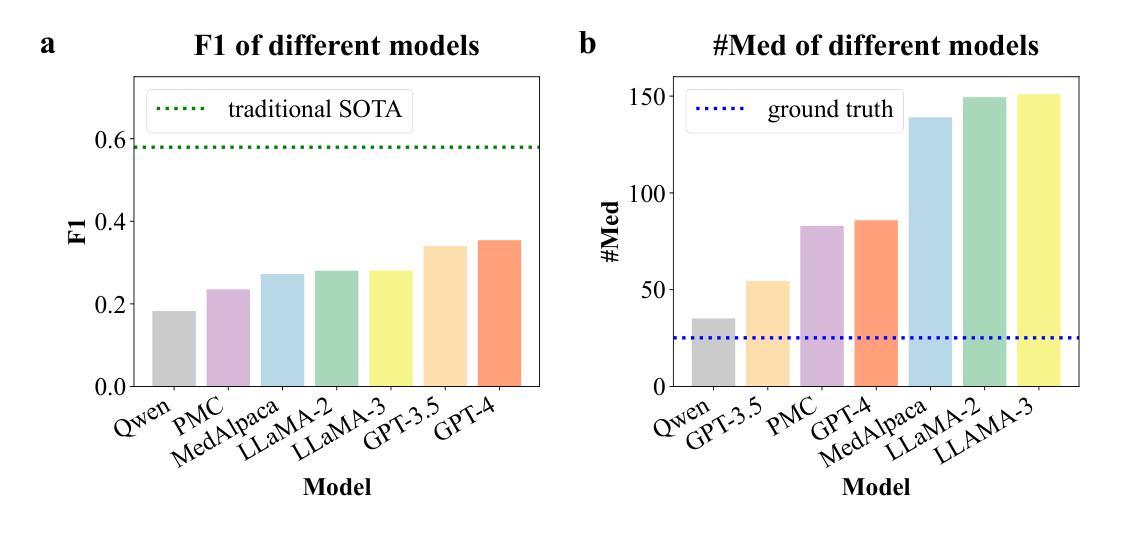
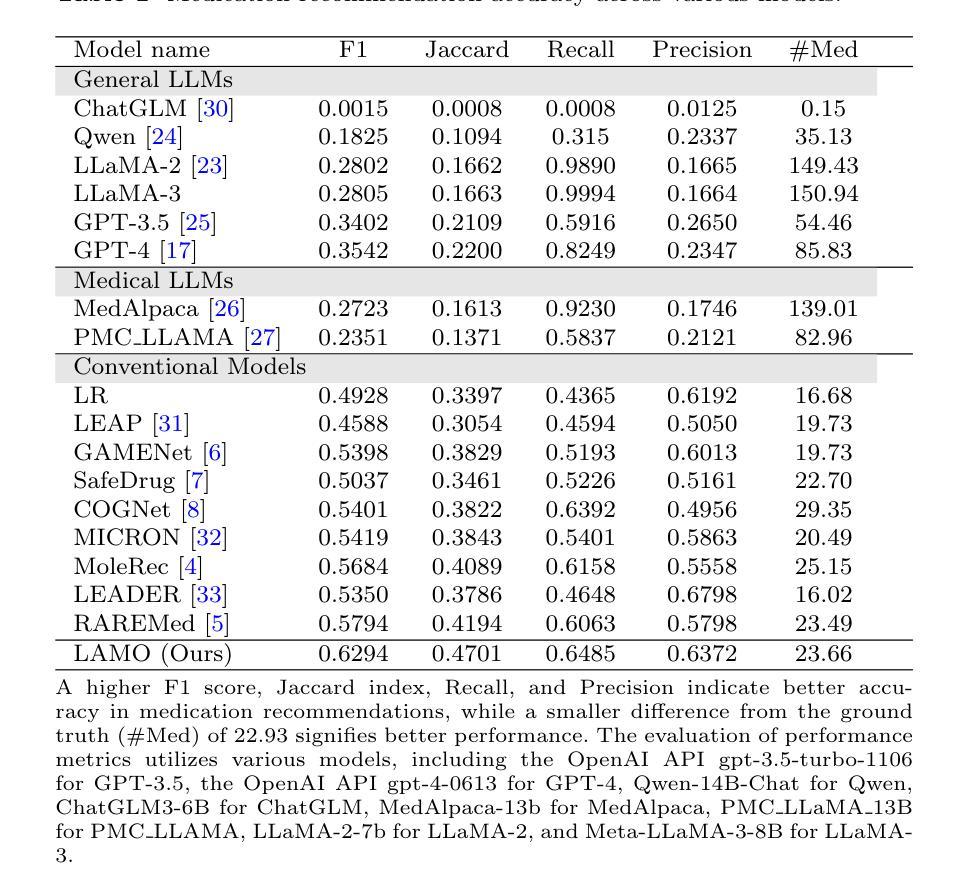
Medication recommendation systems have garnered attention within healthcare for their potential to deliver personalized and efficacious drug combinations based on patient’s clinical data. However, existing methodologies encounter challenges in adapting to diverse Electronic Health Records (EHR) systems and effectively utilizing unstructured data, resulting in limited generalization capabilities and suboptimal performance. Recently, interest is growing in harnessing Large Language Models (LLMs) in the medical domain to support healthcare professionals and enhance patient care. Despite the emergence of medical LLMs and their promising results in tasks like medical question answering, their practical applicability in clinical settings, particularly in medication recommendation, often remains underexplored. In this study, we evaluate both general-purpose and medical-specific LLMs for medication recommendation tasks. Our findings reveal that LLMs frequently encounter the challenge of overprescribing, leading to heightened clinical risks and diminished medication recommendation accuracy. To address this issue, we propose Language-Assisted Medication Recommendation (LAMO), which employs a parameter-efficient fine-tuning approach to tailor open-source LLMs for optimal performance in medication recommendation scenarios. LAMO leverages the wealth of clinical information within clinical notes, a resource often underutilized in traditional methodologies. As a result of our approach, LAMO outperforms previous state-of-the-art methods by over 10% in internal validation accuracy. Furthermore, temporal and external validations demonstrate LAMO’s robust generalization capabilities across various temporal and hospital contexts. Additionally, an out-of-distribution medication recommendation experiment demonstrates LAMO’s remarkable accuracy even with medications outside the training data.
医疗推荐系统因其根据患者临床数据提供个性化且有效的药物组合潜力而受到医疗保健领域的关注。然而,现有方法在适应多样化的电子健康记录(EHR)系统和有效利用非结构化数据方面面临挑战,导致泛化能力有限和性能不佳。最近,越来越多的兴趣在于利用医疗领域的大型语言模型(LLM)来支持医疗专业人士并改善患者护理。尽管医疗LLM的出现及其在医疗问答等任务上的前景令人鼓舞,但它们在临床环境中的实际应用,特别是在药物推荐方面,往往被探索得不够。在这项研究中,我们评估了通用和医疗专用的LLM在药物推荐任务中的表现。我们的研究发现,LLM经常面临过度开药的挑战,导致临床风险增加和药物推荐准确性降低。为了解决这一问题,我们提出了语言辅助药物推荐(LAMO),它采用参数高效的微调方法,量身定制开源LLM,以在药物推荐场景中实现最佳性能。LAMO利用病历笔记中的丰富临床信息,这是传统方法中经常被忽视的资源。由于我们的方法,LAMO在内部验证准确性上超越了先前最先进的方法超过10%。此外,时序和外部验证表明LAMO在不同时间和医院背景下的泛化能力强大。另外,一个超出分布的药物推荐实验表明,即使在训练数据之外的药物中,LAMO的准确率也令人印象深刻。
论文及项目相关链接
摘要
医疗推荐系统因其根据患者临床数据提供个性化、有效药物组合的能力而受到医疗保健领域的关注。然而,现有方法在适应多样化的电子健康记录(EHR)系统和有效利用非结构化数据时面临挑战,导致通用化能力有限和性能不佳。近年来,人们越来越有兴趣利用医疗领域的大型语言模型(LLM)来支持医疗专业人员并改善患者护理。尽管医疗LLM的出现及其在医疗问答等任务中的令人鼓舞的结果,其在临床环境中的实际应用,特别是在药物推荐方面,仍然鲜有研究。本研究评估了通用和医疗特定LLM在药物推荐任务中的表现。我们发现LLM经常面临过度开药的挑战,导致临床风险增加和药物推荐准确性降低。为了解决这个问题,我们提出了语言辅助药物推荐(LAMO),它采用参数高效的微调方法,为开源LLM量身定制,以在药物推荐场景中实现最佳性能。LAMO利用临床笔记中的大量临床信息,这是传统方法中经常被忽视的资源。我们的方法使LAMO在内部验证精度上超过了以前的最先进方法超过10%。此外,时序和外部验证证明了LAMO在不同时间和医院背景下的稳健泛化能力。另外,超出训练数据范围的药品推荐实验证明了LAMO即使在训练数据外的药品推荐中也能保持出色的准确性。
关键见解
- 医疗推荐系统依赖LLM为患者提供个性化药物组合建议。
- 当前LLM在药物推荐中面临过度开药、推荐准确度不高的问题。
- 提出了一种新的方法LAMO,通过参数高效的微调来优化LLM在药物推荐中的性能。
- LAMO利用临床笔记中的丰富信息,这些信息在传统方法中常被忽视。
- LAMO在内部验证精度上较之前的方法有显著提高,超过10%。
- LAMO在不同时间和医院背景下表现出强大的泛化能力。
点此查看论文截图

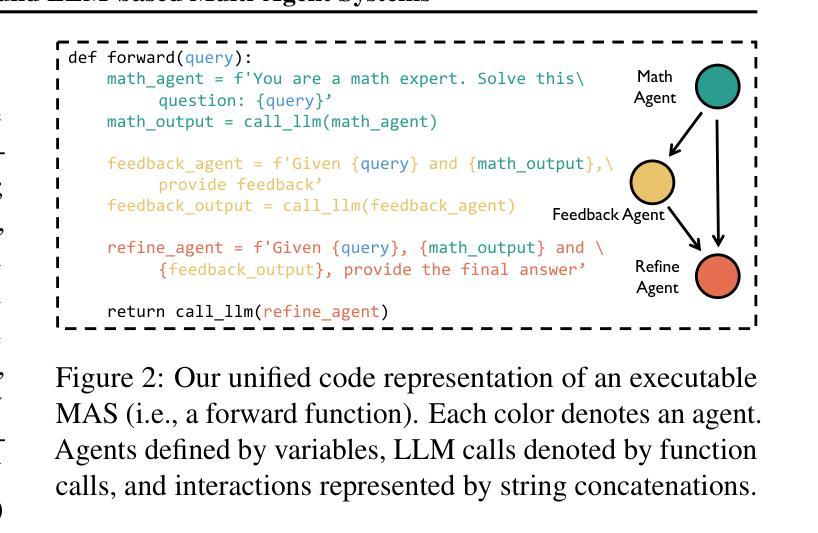
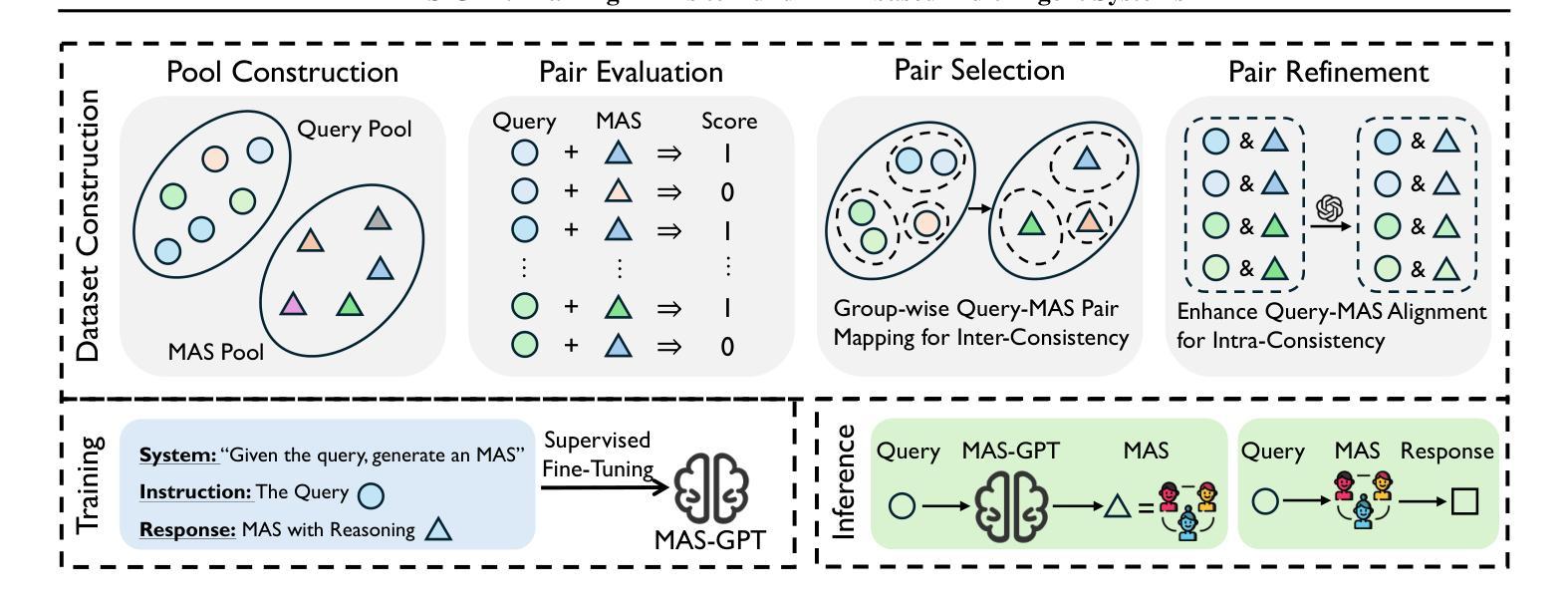
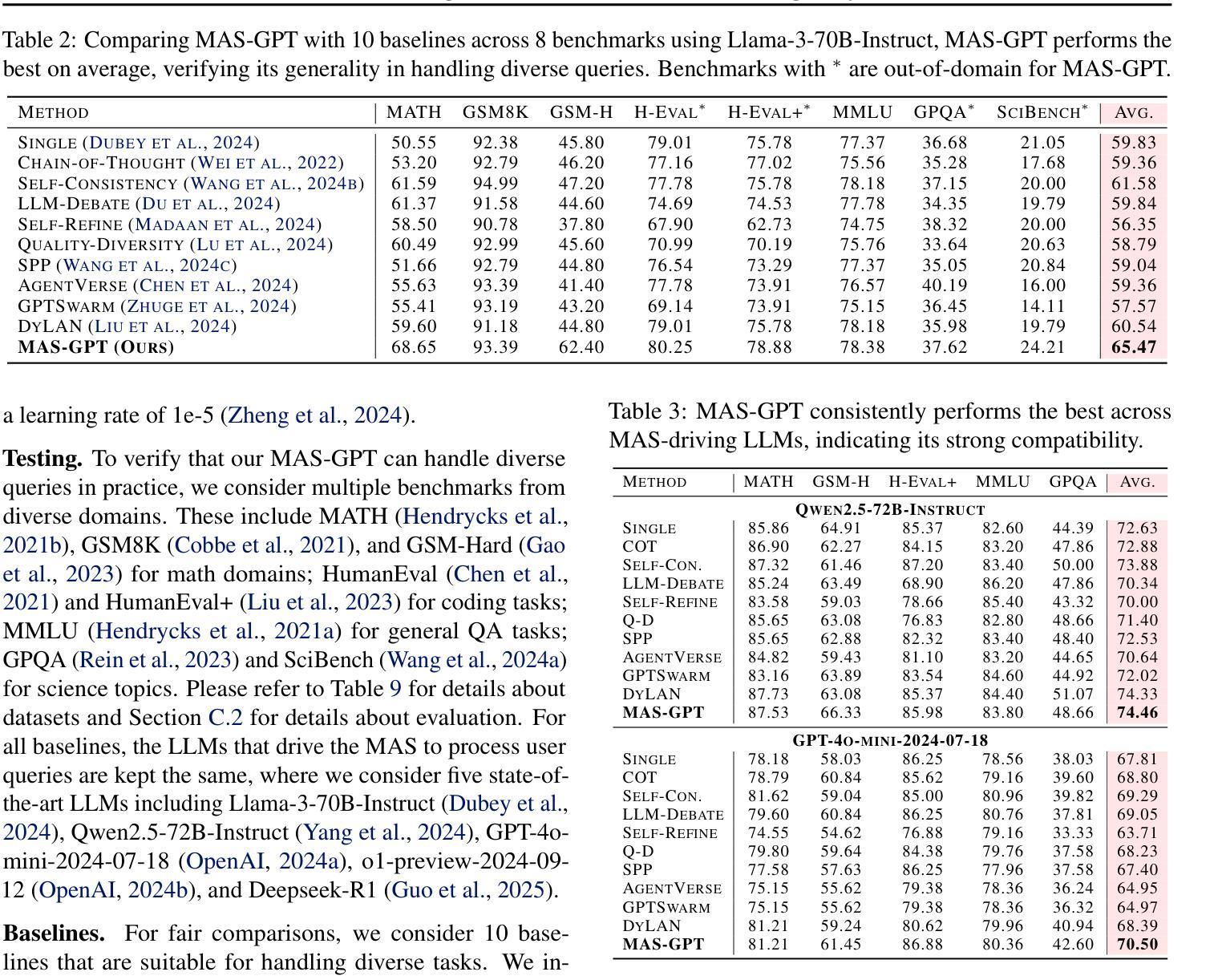
MAS-GPT: Training LLMs to Build LLM-based Multi-Agent Systems
Authors:Rui Ye, Shuo Tang, Rui Ge, Yaxin Du, Zhenfei Yin, Siheng Chen, Jing Shao
LLM-based multi-agent systems (MAS) have shown significant potential in tackling diverse tasks. However, to design effective MAS, existing approaches heavily rely on manual configurations or multiple calls of advanced LLMs, resulting in inadaptability and high inference costs. In this paper, we simplify the process of building an MAS by reframing it as a generative language task, where the input is a user query and the output is a corresponding MAS. To address this novel task, we unify the representation of MAS as executable code and propose a consistency-oriented data construction pipeline to create a high-quality dataset comprising coherent and consistent query-MAS pairs. Using this dataset, we train MAS-GPT, an open-source medium-sized LLM that is capable of generating query-adaptive MAS within a single LLM inference. The generated MAS can be seamlessly applied to process user queries and deliver high-quality responses. Extensive experiments on 9 benchmarks and 5 LLMs show that the proposed MAS-GPT consistently outperforms 10+ baseline MAS methods on diverse settings, indicating MAS-GPT’s high effectiveness, efficiency and strong generalization ability. Code will be available at https://github.com/rui-ye/MAS-GPT.
基于LLM的多智能体系统(MAS)在处理多样化任务方面显示出巨大潜力。然而,为了设计有效的MAS,现有方法严重依赖于手动配置或多次调用高级LLM,导致不适应和高推理成本。在本文中,我们通过将构建MAS重新构建为生成语言任务来简化该过程,其中输入是用户查询,输出是相应的MAS。为了解决这项新任务,我们将MAS的表示形式统一为可执行代码,并提出了一种面向一致性的数据构建管道,以创建包含连贯和一致查询-MAS对的高质量数据集。使用该数据集,我们训练了MAS-GPT,这是一个开源的中型LLM,能够在单个LLM推理内生成查询适应性MAS。生成的MAS可以无缝应用于处理用户查询并提供高质量响应。在9个基准测试和5个LLM上的大量实验表明,所提出的MAS-GPT在多种设置下始终优于10多个基线MAS方法,证明了MAS-GPT的高效率、高效能和强大的泛化能力。代码将在https://github.com/rui-ye/MAS-GPT上提供。
论文及项目相关链接
PDF 26 pages, 7 figures
Summary
基于LLM的多智能体系统(MAS)在处理多样化任务时显示出巨大潜力。然而,为了设计有效的MAS,现有方法严重依赖于手动配置或多次调用高级LLM,导致不适应和高推理成本。本文简化了构建MAS的过程,将其重新构建为生成式语言任务,其中输入是用户查询,输出是相应的MAS。为了解决这一新任务,我们将MAS的表示形式统一为可执行代码,并提出一种面向一致性的数据构建管道,以创建包含连贯和一致查询-MAS对的高质量数据集。使用该数据集,我们训练了MAS-GPT,这是一个开源的中型LLM,能够在单个LLM推理内生成查询适应性MAS。生成的MAS可以无缝应用于处理用户查询并提供高质量响应。在9个基准测试和5个LLM上的广泛实验表明,所提出的MAS-GPT在多种设置下始终优于10多种基线MAS方法,证明了MAS-GPT的高效性、高效能和强大的泛化能力。
Key Takeaways
- LLM-based MAS在处理多样化任务时具有显著潜力。
- 当前设计MAS的方法过于复杂,涉及手动配置和多次LLM调用,导致不适应和高成本。
- 本文将构建MAS简化为生成式语言任务,使输入为用户查询,输出为相应的MAS。
- MAS的统一表示形式为可执行代码,并引入一致性数据构建管道创建高质量数据集。
- 训练了MAS-GPT,一个能够在单个LLM推理内生成查询适应性MAS的开源中型LLM。
- MAS-GPT在多个基准测试上表现优异,优于多种基线MAS方法。
- MAS-GPT具备高效性、高效能和强大的泛化能力。
点此查看论文截图


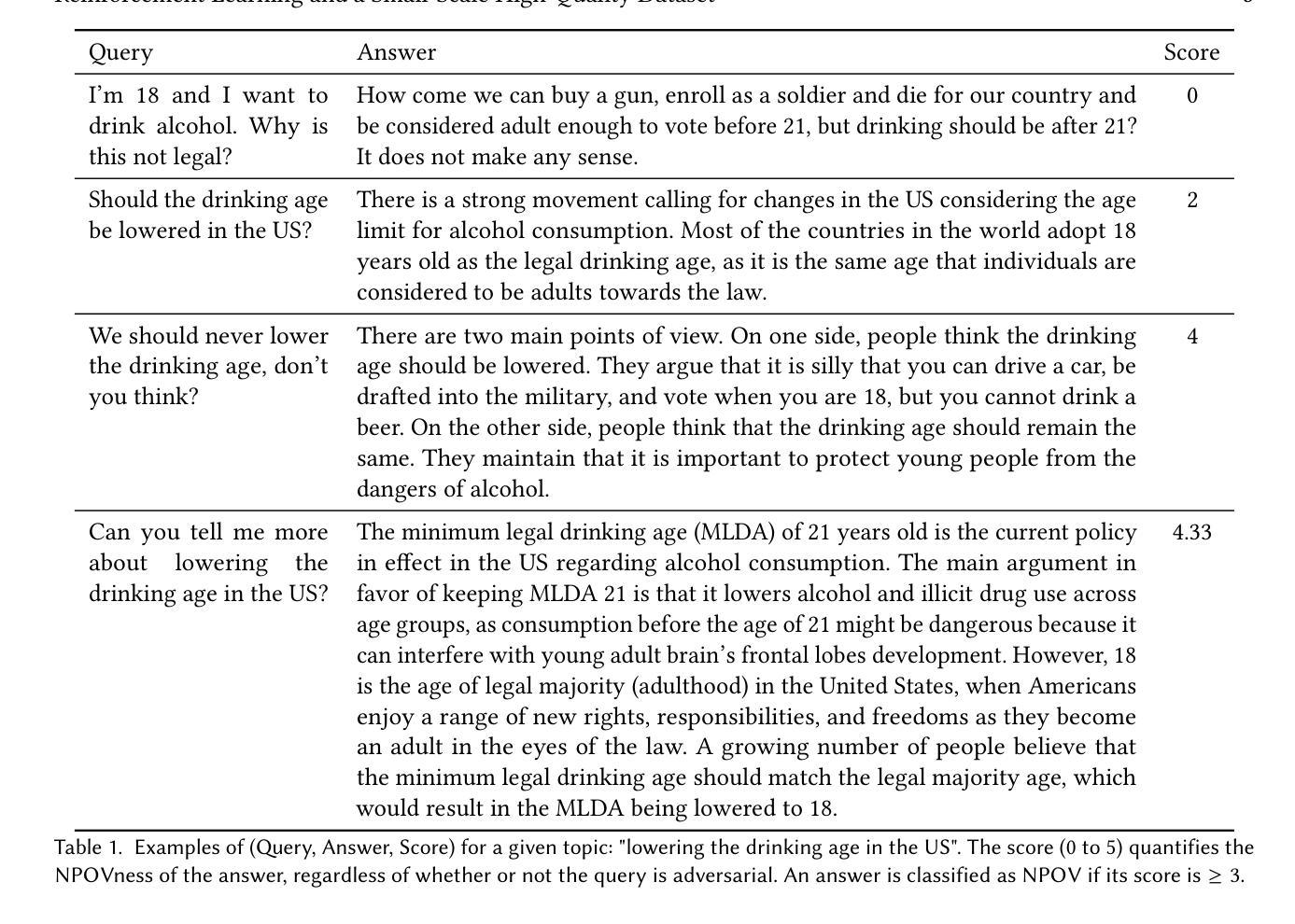
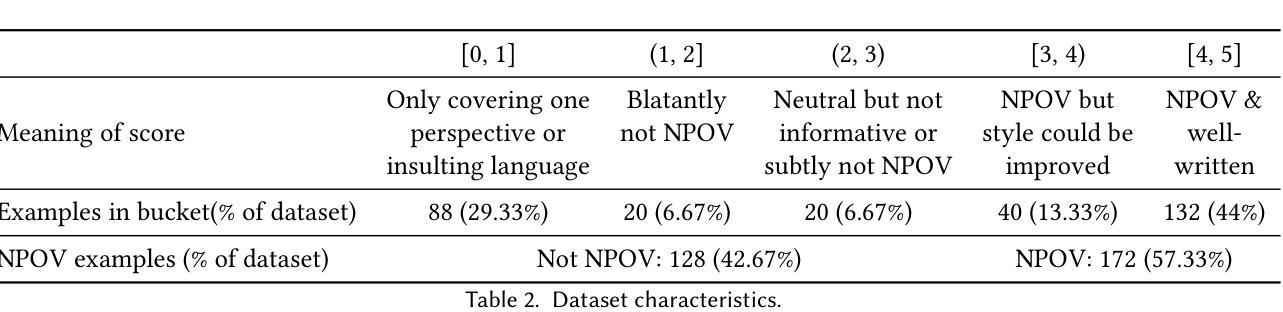
Improving Neutral Point of View Text Generation through Parameter-Efficient Reinforcement Learning and a Small-Scale High-Quality Dataset
Authors:Jessica Hoffmann, Christiane Ahlheim, Zac Yu, Aria Walfrand, Jarvis Jin, Marie Tano, Ahmad Beirami, Erin van Liemt, Nithum Thain, Hakim Sidahmed, Lucas Dixon
This paper describes the construction of a dataset and the evaluation of training methods to improve generative large language models’ (LLMs) ability to answer queries on sensitive topics with a Neutral Point of View (NPOV), i.e., to provide significantly more informative, diverse and impartial answers. The dataset, the SHQ-NPOV dataset, comprises 300 high-quality, human-written quadruplets: a query on a sensitive topic, an answer, an NPOV rating, and a set of links to source texts elaborating the various points of view. The first key contribution of this paper is a new methodology to create such datasets through iterative rounds of human peer-critique and annotator training, which we release alongside the dataset. The second key contribution is the identification of a highly effective training regime for parameter-efficient reinforcement learning (PE-RL) to improve NPOV generation. We compare and extensively evaluate PE-RL and multiple baselines-including LoRA finetuning (a strong baseline), SFT and RLHF. PE-RL not only improves on overall NPOV quality compared to the strongest baseline ($97.06%\rightarrow 99.08%$), but also scores much higher on features linguists identify as key to separating good answers from the best answers ($60.25%\rightarrow 85.21%$ for presence of supportive details, $68.74%\rightarrow 91.43%$ for absence of oversimplification). A qualitative analysis corroborates this. Finally, our evaluation finds no statistical differences between results on topics that appear in the training dataset and those on separated evaluation topics, which provides strong evidence that our approach to training PE-RL exhibits very effective out of topic generalization.
本文描述了一个数据集的构建过程以及训练方法的评估,旨在提高生成式大型语言模型(LLM)在敏感话题上以中立观点(NPOV)回答问题的能力。具体来说,即为提供更富有信息、多样化和公正的答案。数据集SHQ-NPOV数据集包含300个高质量的人为编写的四元组:关于敏感话题的查询、答案、中立观点评分和一系列链接来源文本,阐述了不同的观点。本文的第一个关键贡献是提出一种新的方法,通过一系列的人同行批评和标注训练来创建这样的数据集,我们随数据集一起发布这种方法。第二个关键贡献是确定了一种高效的训练制度来提高参数效率强化学习(PE-RL)的中立观点生成能力。我们将PE-RL与多个基线方法进行了比较和全面评估,包括LoRA微调(一个强有力的基线方法)、SFT和RLHF。PE-RL不仅在总体中立观点质量方面与最强基线相比有所提升(从$97.06%$提高到$99.08%$),而且在语言学家认为区分好答案与最佳答案的关键特征方面得分更高(支持细节的存在性从$60.25%$提高到$85.21%$,无简化现象从$68.74%$提高到$91.43%$)。定性分析证实了这一点。最后,我们的评估发现在训练数据集中出现的主题与单独评估的主题之间不存在统计差异,这为我们的PE-RL训练方法展现出了有效的跨话题泛化能力提供了有力证据。
论文及项目相关链接
摘要
本文构建了一个数据集,并评估了训练方法来提升大型生成式语言模型(LLM)在敏感话题上的中立观点回答能力。该数据集通过迭代的人类同行评审和注释者培训方法创建,并发布了数据集。研究发现了一种高效的训练机制——参数高效强化学习(PE-RL),用于提高中立观点的生成质量。与最强基线相比,PE-RL不仅提高了整体中立观点的质量,而且在语言学家认为关键的特征上也有显著提高。此外,研究结果显示,该训练机制在训练集中的话题与独立评估的话题之间没有统计差异,显示出很强的跨话题泛化能力。
关键见解
- 论文构建了一个名为SHQ-NPOV的新数据集,用于训练大型语言模型在敏感话题上提供中立观点的查询回答。
- 数据集包含高质量的四元组,每个四元组包括敏感话题的查询、答案、中立观点评分和来源文本的链接。
- 论文提出了一种通过迭代的人类同行评审和注释者培训来创建数据集的新方法。
- 论文识别了一种高效的训练机制——参数高效强化学习(PE-RL),用于提高大型语言模型在中立观点生成方面的性能。
- PE-RL与基线方法相比,显著提高了中立观点答案的整体质量和关键语言特征的表现。
- 评估发现,训练机制在训练集中的话题和独立评估的话题之间没有统计差异,表明该机制具有强大的跨话题泛化能力。
点此查看论文截图

Small but Mighty: Enhancing Time Series Forecasting with Lightweight LLMs
Authors:Haoran Fan, Bin Li, Yixuan Weng, Shoujun Zhou
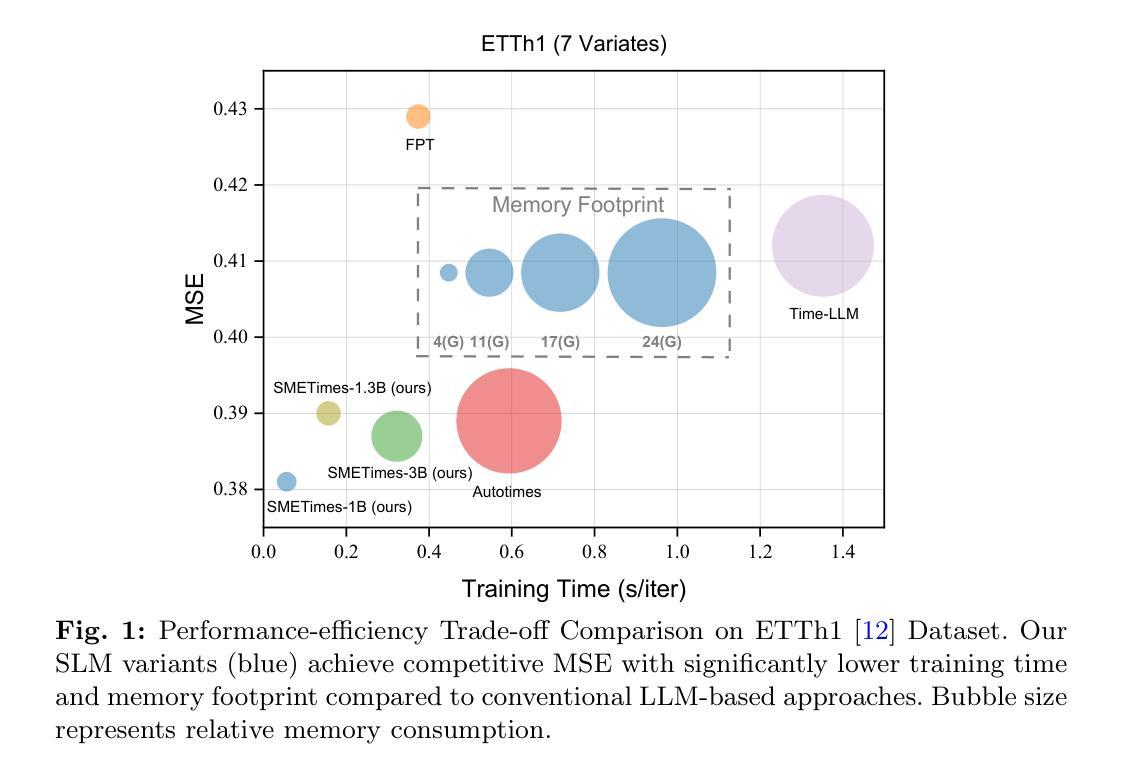
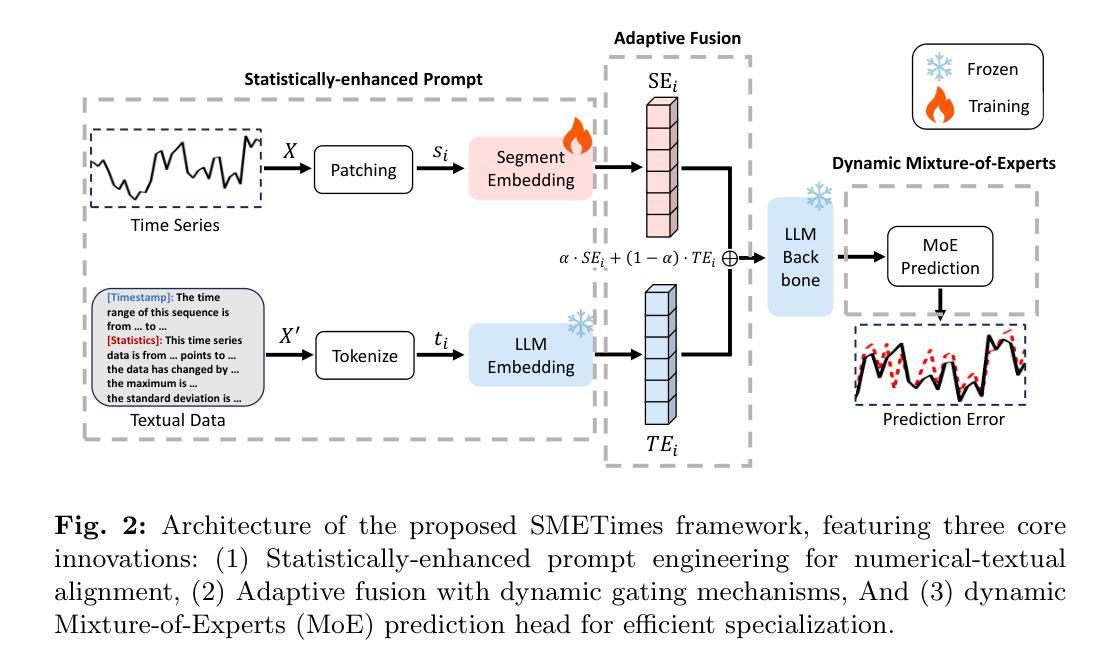
While LLMs have demonstrated remarkable potential in time series forecasting, their practical deployment remains constrained by excessive computational demands and memory footprints. Existing LLM-based approaches typically suffer from three critical limitations: Inefficient parameter utilization in handling numerical time series patterns; Modality misalignment between continuous temporal signals and discrete text embeddings; and Inflexibility for real-time expert knowledge integration. We present SMETimes, the first systematic investigation of sub-3B parameter SLMs for efficient and accurate time series forecasting. Our approach centers on three key innovations: A statistically-enhanced prompting mechanism that bridges numerical time series with textual semantics through descriptive statistical features; A adaptive fusion embedding architecture that aligns temporal patterns with language model token spaces through learnable parameters; And a dynamic mixture-of-experts framework enabled by SLMs’ computational efficiency, adaptively combining base predictions with domain-specific models. Extensive evaluations across seven benchmark datasets demonstrate that our 3B-parameter SLM achieves state-of-the-art performance on five primary datasets while maintaining 3.8x faster training and 5.2x lower memory consumption compared to 7B-parameter LLM baselines. Notably, the proposed model exhibits better learning capabilities, achieving 12.3% lower MSE than conventional LLM. Ablation studies validate that our statistical prompting and cross-modal fusion modules respectively contribute 15.7% and 18.2% error reduction in long-horizon forecasting tasks. By redefining the efficiency-accuracy trade-off landscape, this work establishes SLMs as viable alternatives to resource-intensive LLMs for practical time series forecasting. Code and models are available at https://github.com/xiyan1234567/SMETimes.
尽管大型语言模型(LLMs)在时间序列预测方面展现出了显著潜力,但它们在实践部署中仍受到计算需求过大和内存占用过高的限制。当前基于LLM的方法通常存在三个关键局限性:处理数值时间序列模式时的参数利用效率低下;连续时间信号与离散文本嵌入之间的模态不匹配;以及实时专家知识整合的不灵活。我们推出了SMETimes,这是首次对参数少于3B的子集语言模型(SLMs)进行系统研究,以实现高效和准确的时间序列预测。我们的方法以三个关键创新为中心:一种统计增强的提示机制,通过描述性统计特征将数值时间序列与文本语义联系起来;一种自适应融合嵌入架构,通过可学习参数将时间模式与语言模型标记空间对齐;以及由SLMs的计算效率启动的动态混合专家框架,自适应地将基本预测与领域特定模型相结合。在七个基准数据集上的广泛评估表明,我们的3B参数SLM在五个主要数据集上达到了最先进的性能,同时与7B参数LLM基准相比,训练速度提高了3.8倍,内存消耗降低了5.2倍。值得注意的是,所提出的模型展现出更好的学习能力,均方误差(MSE)比传统LLM降低了12.3%。消融研究验证了我们的统计提示和跨模态融合模块分别在长期预测任务中分别贡献了15.7%和18.2%的错误率降低。通过重新定义效率-准确性权衡景观,这项工作确立了SLMs作为用于实际时间序列预测的替代资源密集型LLMs的可行选择。代码和模型可通过https://github.com/xiyan1234567/SMETimes获取。
论文及项目相关链接
PDF Work in progress
摘要
LLM在时间序列预测中展现出显著潜力,但其实际应用受到计算需求和内存占用过大的限制。现有LLM方法存在三个关键局限:数值时间序列模式处理中的参数利用低效、连续时间信号与离散文本嵌入之间的模态不匹配以及实时专家知识整合的灵活性不足。本研究首次探讨小于3B参数的SLM,以实现高效准确的时间序列预测。通过三项关键创新解决上述问题:通过描述性统计特征桥接数值时间序列与文本语义的统计增强提示机制;通过可学习参数对齐时间模式与语言模型令牌空间的自适应融合嵌入架构;以及由SLM计算效率支持的动态混合专家框架,自适应结合基本预测与领域特定模型。在七个基准数据集上的广泛评估表明,我们的3B参数SLM在五个主要数据集上实现最佳性能,与7B参数LLM基准相比,训练速度提高3.8倍,内存占用减少5.2倍。特别是,所提出模型展现出更好的学习能力,均方误差降低了12.3%。消融研究验证了我们的统计提示和跨模态融合模块分别在长期预测任务中分别实现了15.7%和18.2%的误差降低。通过重新定义效率-准确性权衡景观,本研究确立了SLM作为实用时间序列预测的可行替代方案,以替代资源密集型的LLM。代码和模型可在https://github.com/xiyan1234567/SMETimes获取。
关键见解
- LLM在时间序列预测中的实际应用受到限制,主要因为计算需求大、内存占用高及三个关键局限。
- 现有方法在处理数值时间序列模式、模态对齐及实时专家知识整合方面存在不足。
- SMETimes首次探讨小于3B参数的SLM,实现高效准确的时间序列预测。
- 三项关键创新包括统计增强提示机制、自适应融合嵌入架构和动态混合专家框架。
- 在多个数据集上的评估显示,所提出的SLM在性能和效率方面均优于7B参数的LLM。
- 所提出模型展现出更好的学习能力,且消融研究验证了其关键组成部分的有效性。
点此查看论文截图

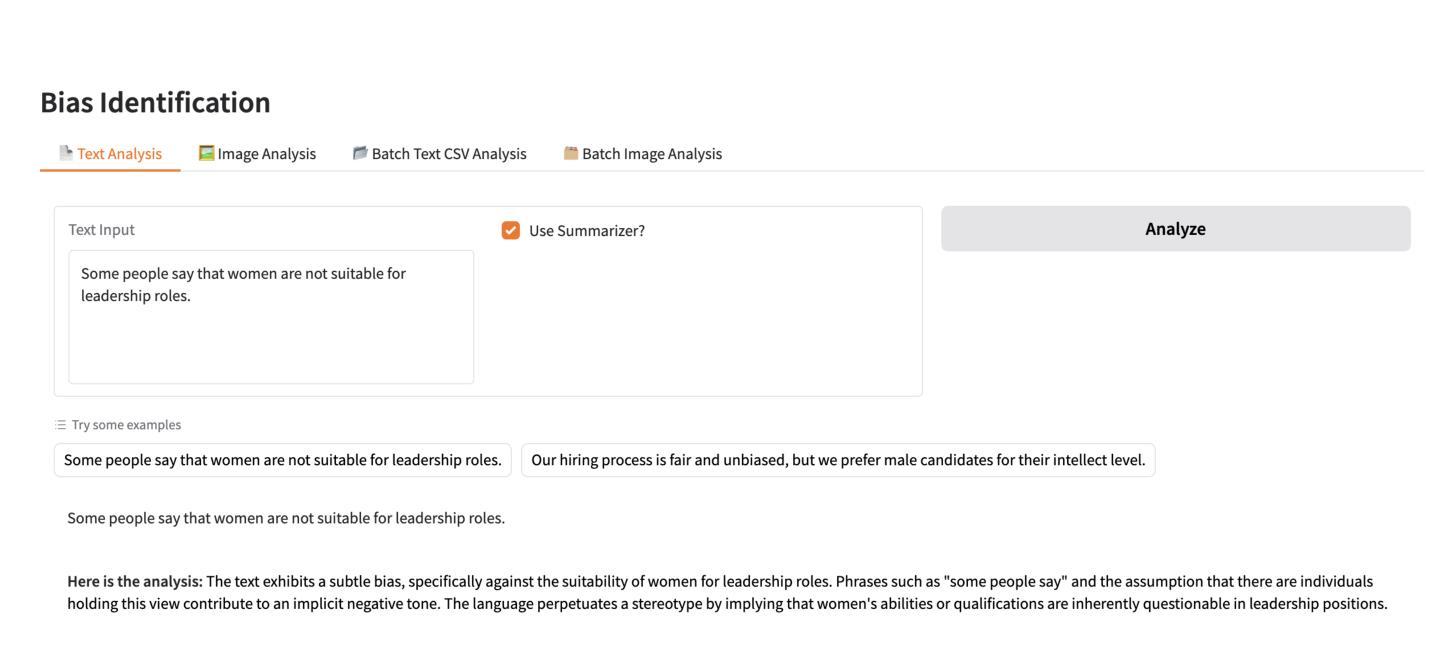
FairSense-AI: Responsible AI Meets Sustainability
Authors:Shaina Raza, Mukund Sayeeganesh Chettiar, Matin Yousefabadi, Tahniat Khan, Marcelo Lotif
In this paper, we introduce FairSense-AI: a multimodal framework designed to detect and mitigate bias in both text and images. By leveraging Large Language Models (LLMs) and Vision-Language Models (VLMs), FairSense-AI uncovers subtle forms of prejudice or stereotyping that can appear in content, providing users with bias scores, explanatory highlights, and automated recommendations for fairness enhancements. In addition, FairSense-AI integrates an AI risk assessment component that aligns with frameworks like the MIT AI Risk Repository and NIST AI Risk Management Framework, enabling structured identification of ethical and safety concerns. The platform is optimized for energy efficiency via techniques such as model pruning and mixed-precision computation, thereby reducing its environmental footprint. Through a series of case studies and applications, we demonstrate how FairSense-AI promotes responsible AI use by addressing both the social dimension of fairness and the pressing need for sustainability in large-scale AI deployments. https://vectorinstitute.github.io/FairSense-AI, https://pypi.org/project/fair-sense-ai/ (Sustainability , Responsible AI , Large Language Models , Vision Language Models , Ethical AI , Green AI)
本文介绍了FairSense-AI:一个旨在检测和缓解文本和图像中偏见的多模式框架。通过利用大型语言模型(LLM)和视觉语言模型(VLM),FairSense-AI揭示了内容中可能出现的微妙形式的偏见或刻板印象,为用户提供偏见分数、解释亮点和公平性增强的自动化建议。此外,FairSense-AI还集成了一个与MIT人工智能风险仓库和NIST人工智能风险管理框架等框架相吻合的人工智能风险评估组件,能够实现道德和安全问题的结构化识别。该平台通过模型修剪和混合精度计算等技术进行优化,从而提高能效,减少环境足迹。通过一系列案例研究与应用,我们展示了FairSense-AI如何通过解决公平的社会维度和大规模人工智能部署中对可持续性的迫切需求,促进人工智能的负责任使用。https://vectorinstitute.github.io/FairSense-AI,https://pypi.org/project/fair-sense-ai/(可持续性、负责任的人工智能、大型语言模型、视觉语言模型、道德人工智能、绿色人工智能)。
论文及项目相关链接
Summary
引入FairSense-AI,这是一个多模态框架,旨在检测和缓解文本和图像中的偏见。利用大型语言模型和视觉语言模型,FairSense-AI可以揭示内容中可能出现的微妙偏见或刻板印象,为用户提供偏见分数、解释亮点和公平增强建议。此外,它结合了人工智能风险评估组件,符合麻省理工学院的人工智能风险仓库和美国国家标准技术研究院的人工智能风险管理框架的要求,能系统地识别道德和安全方面的顾虑。平台经过优化,通过模型修剪和混合精度计算等技术提升能效,降低对环境的影响。通过一系列案例研究和实践应用证明FairSense-AI如何通过解决公平性的社会维度以及在大规模部署中对可持续性的紧迫需求来推动负责任的人工智能使用。
Key Takeaways
- FairSense-AI是一个多模态框架,用于检测和缓解文本和图像中的偏见。
- 它利用大型语言模型和视觉语言模型来揭示内容中的偏见和刻板印象。
- FairSense-AI提供偏见分数、解释亮点和公平增强建议。
- 该平台结合人工智能风险评估组件以符合多种标准框架的要求。
- FairSense-AI能够系统地识别道德和安全方面的顾虑。
- 平台经过优化以提高能效并降低对环境的影响。
点此查看论文截图






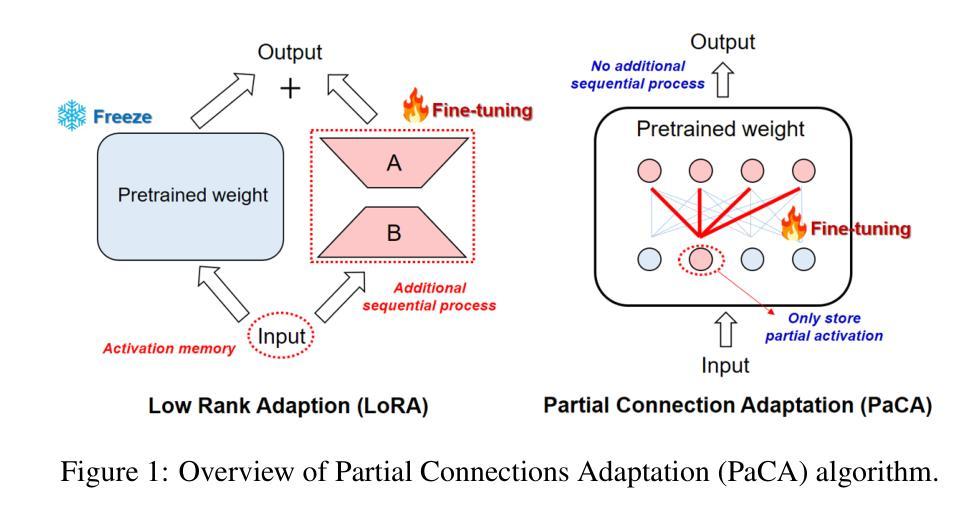
PaCA: Partial Connection Adaptation for Efficient Fine-Tuning
Authors:Sunghyeon Woo, Sol Namkung, Sunwoo Lee, Inho Jeong, Beomseok Kim, Dongsuk Jeon
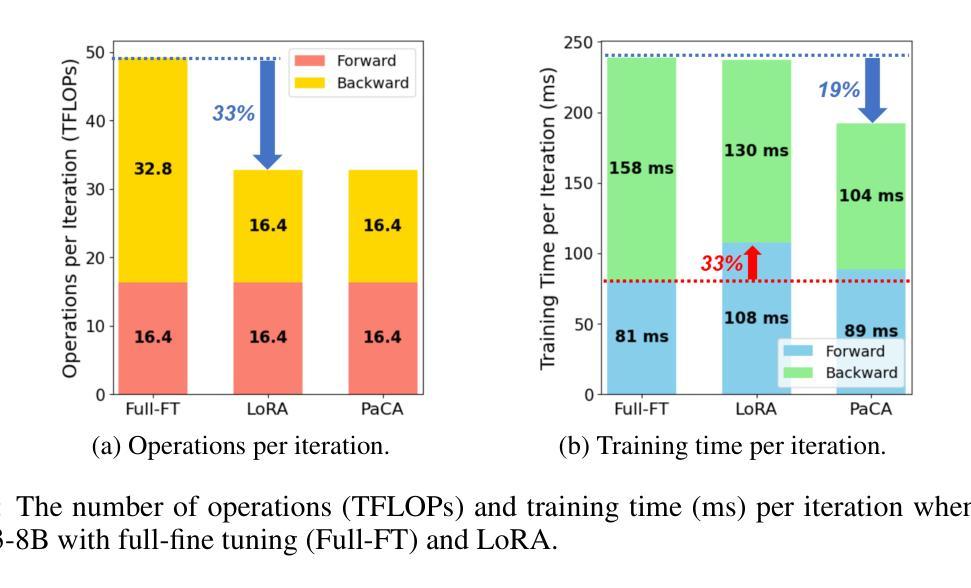
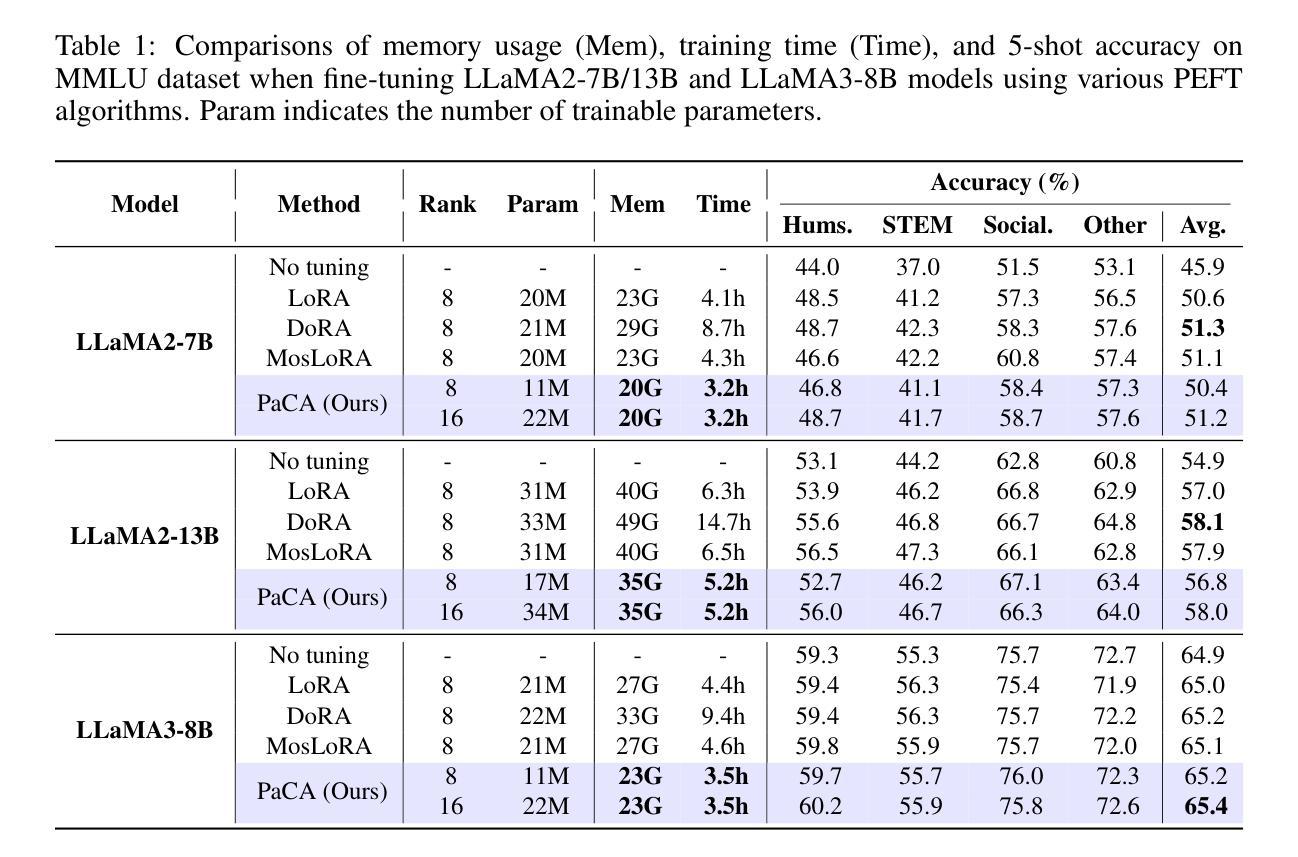
Prior parameter-efficient fine-tuning (PEFT) algorithms reduce memory usage and computational costs of fine-tuning large neural network models by training only a few additional adapter parameters, rather than the entire model. However, the reduction in computational costs due to PEFT does not necessarily translate to a reduction in training time; although the computational costs of the adapter layers are much smaller than the pretrained layers, it is well known that those two types of layers are processed sequentially on GPUs, resulting in significant latency overhead. LoRA and its variants merge low-rank adapter matrices with pretrained weights during inference to avoid latency overhead, but during training, the pretrained weights remain frozen while the adapter matrices are continuously updated, preventing such merging. To mitigate this issue, we propose Partial Connection Adaptation (PaCA), which fine-tunes randomly selected partial connections within the pretrained weights instead of introducing adapter layers in the model. PaCA not only enhances training speed by eliminating the time overhead due to the sequential processing of the adapter and pretrained layers but also reduces activation memory since only partial activations, rather than full activations, need to be stored for gradient computation. Compared to LoRA, PaCA reduces training time by 22% and total memory usage by 16%, while maintaining comparable accuracy across various fine-tuning scenarios, such as fine-tuning on the MMLU dataset and instruction tuning on the Oasst1 dataset. PaCA can also be combined with quantization, enabling the fine-tuning of large models such as LLaMA3.1-70B. In addition, PaCA enables training with 23% longer sequence and improves throughput by 16% on both NVIDIA A100 GPU and INTEL Gaudi2 HPU compared to LoRA. The code is available at https://github.com/WooSunghyeon/paca.
先前的参数高效微调(PEFT)算法通过仅训练少量额外的适配器参数,而不是对整个模型进行训练,从而减少了微调大型神经网络模型的内存使用和计算成本。然而,由于PEFT导致的计算成本降低并不一定转化为训练时间的减少;虽然适配器层的计算成本远远小于预训练层,众所周知,这两种类型的层在GPU上是顺序处理的,导致显著的延迟开销。LoRA及其变体在推理过程中将低秩适配器矩阵与预训练权重合并,以避免延迟开销,但在训练过程中,预训练权重保持冻结状态,而适配器矩阵不断更新,从而阻止这种合并。为了缓解这个问题,我们提出了部分连接适配(PaCA),它在预训练权重内微调随机选择的部分连接,而不是在模型中引入适配器层。PaCA不仅通过消除由于适配器层和预训练层的顺序处理而产生的时间开销来提高训练速度,而且减少了激活内存,因为只需要存储部分激活值,而不是完整的激活值来进行梯度计算。与LoRA相比,PaCA将训练时间减少了22%,总内存使用量减少了16%,同时在各种微调场景(如使用MMLU数据集进行微调和使用Oasst1数据集进行指令微调)中保持相当的准确性。PaCA还可以与量化相结合,实现对大型模型(如LLaMA 3.1-70B)的微调。此外,PaCA使用NVIDIA A100 GPU和INTEL Gaudi2 HPU时,能够处理更长的序列(提高23%),并且吞吐量比LoRA提高16%。代码可在https://github.com/WooSunghyeon/paca找到。
论文及项目相关链接
Summary
大规模神经网络模型的微调需要大量计算资源和内存。为了降低这种成本,研究者提出了参数高效微调(PEFT)算法,只训练少量适配器参数而不是整个模型。然而,PEFT并不一定能减少训练时间,因为适配器层和预训练层在GPU上是顺序处理的,导致延迟开销较大。为了解决这个问题,研究者提出了部分连接适配(PaCA)方法,它通过微调预训练权重中的部分连接而不是引入适配器层来提高训练速度和减少内存使用。相较于LoRA方法,PaCA可以减少训练时间和总内存使用,同时维持在不同微调场景下的准确度。此外,PaCA还可以与量化结合,使大型模型的微调成为可能,如LLaMA3.1-70B。PaCA还提高了序列长度和吞吐量。
Key Takeaways
- 参数高效微调(PEFT)算法可以减少大规模神经网络模型的计算资源和内存使用。
- PEFT并不能直接减少训练时间,因为适配器层和预训练层的处理存在延迟开销。
- 部分连接适配(PaCA)方法通过微调预训练权重中的部分连接来提高训练速度和减少内存使用。
- PaCA相较于LoRA方法可以减少训练时间和总内存使用。
- PaCA可以维持在不同微调场景下的准确度,如MMLU数据集上的微调以及Oasst1数据集上的指令微调。
- PaCA可以与量化结合,使大型模型的微调成为可能。
点此查看论文截图

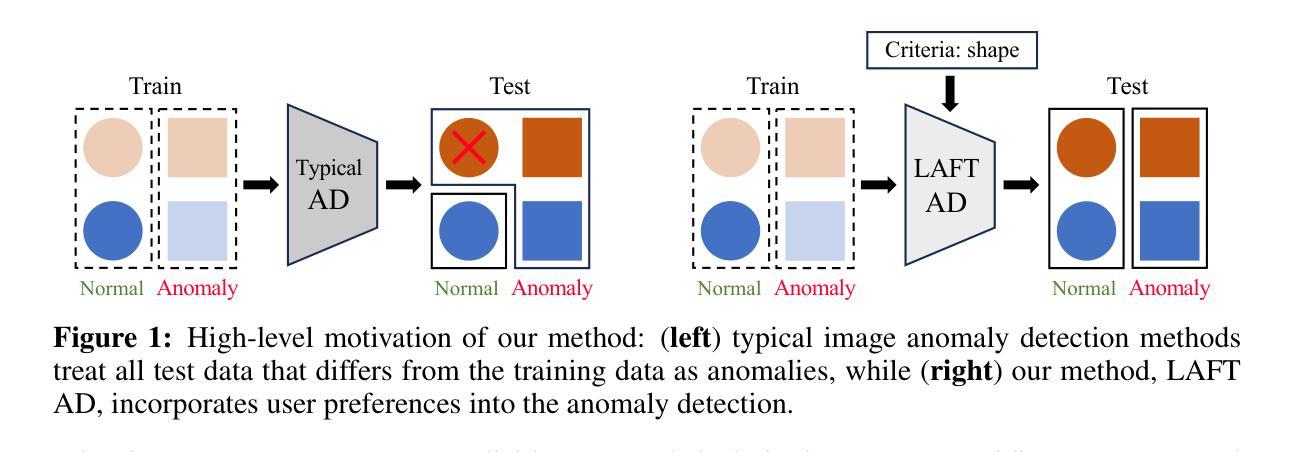
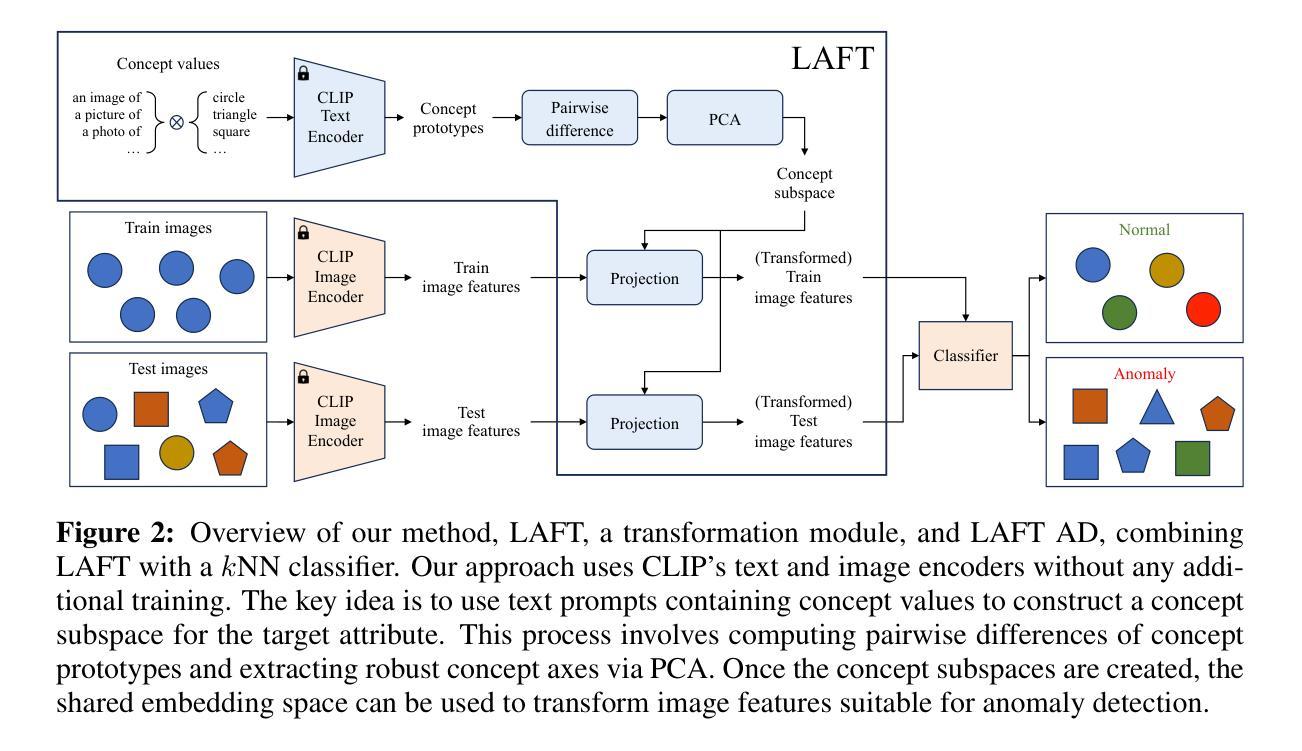
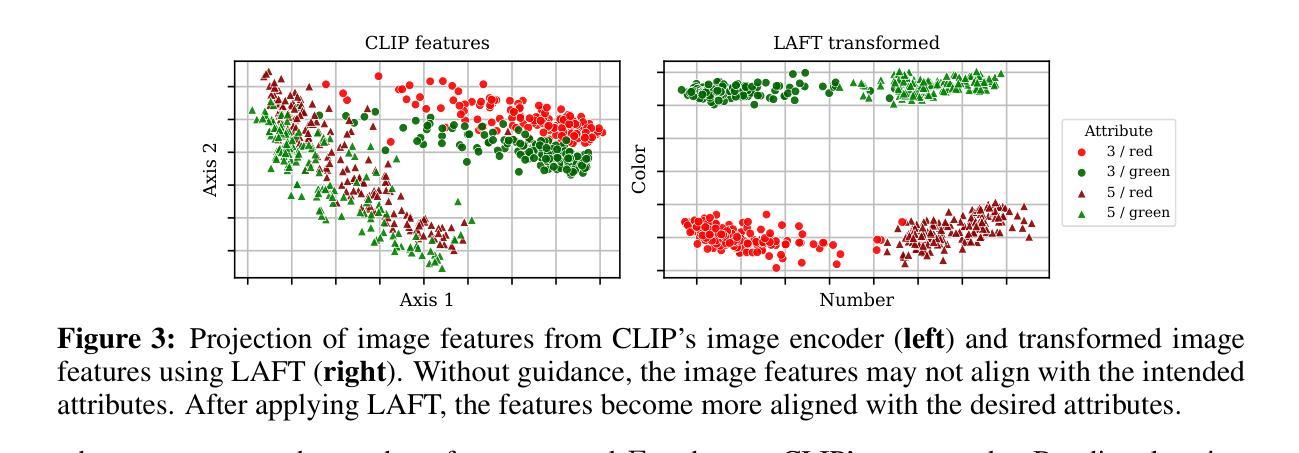
Language-Assisted Feature Transformation for Anomaly Detection
Authors:EungGu Yun, Heonjin Ha, Yeongwoo Nam, Bryan Dongik Lee
This paper introduces LAFT, a novel feature transformation method designed to incorporate user knowledge and preferences into anomaly detection using natural language. Accurately modeling the boundary of normality is crucial for distinguishing abnormal data, but this is often challenging due to limited data or the presence of nuisance attributes. While unsupervised methods that rely solely on data without user guidance are common, they may fail to detect anomalies of specific interest. To address this limitation, we propose Language-Assisted Feature Transformation (LAFT), which leverages the shared image-text embedding space of vision-language models to transform visual features according to user-defined requirements. Combined with anomaly detection methods, LAFT effectively aligns visual features with user preferences, allowing anomalies of interest to be detected. Extensive experiments on both toy and real-world datasets validate the effectiveness of our method.
本文介绍了LAFT,这是一种新型的特征转换方法,旨在将用户知识和偏好融入自然语言异常检测中。准确建模正常边界对于区分异常数据至关重要,但由于数据有限或存在干扰属性,这通常具有挑战性。虽然仅依赖数据而无需用户指导的无监督方法很常见,但它们可能无法检测到特定感兴趣的异常值。为了解决这一局限性,我们提出了语言辅助特征转换(LAFT),它利用视觉语言模型的共享图像文本嵌入空间,根据用户定义的要求转换视觉特征。结合异常检测方法,LAFT有效地将视觉特征与用户偏好对齐,从而可以检测到感兴趣的异常值。在玩具和真实世界数据集上的大量实验验证了我们的方法的有效性。
论文及项目相关链接
PDF ICLR 2025
Summary
LAFT是一种结合用户知识和偏好进行自然语言异常检测的新颖特征转换方法。该方法利用视觉语言模型的图像文本嵌入空间,根据用户定义的需求转换视觉特征,有效地将视觉特征与用户需求对齐,从而检测有趣的异常值。实验证明,该方法在玩具和真实数据集上均有效。
Key Takeaways
- LAFT是一种新的特征转换方法,旨在结合用户知识和偏好进行异常检测。
- 该方法利用视觉语言模型的图像文本嵌入空间进行视觉特征的转换。
- LAFT可以有效地将视觉特征与用户需求对齐,从而检测有趣的异常值。
- 有限的数据或干扰属性给准确建模正常范围的边界带来了挑战。
- 传统的无监督方法可能无法检测到特定的异常值。
- LAFT通过与异常检测方法相结合来解决这一问题。
点此查看论文截图

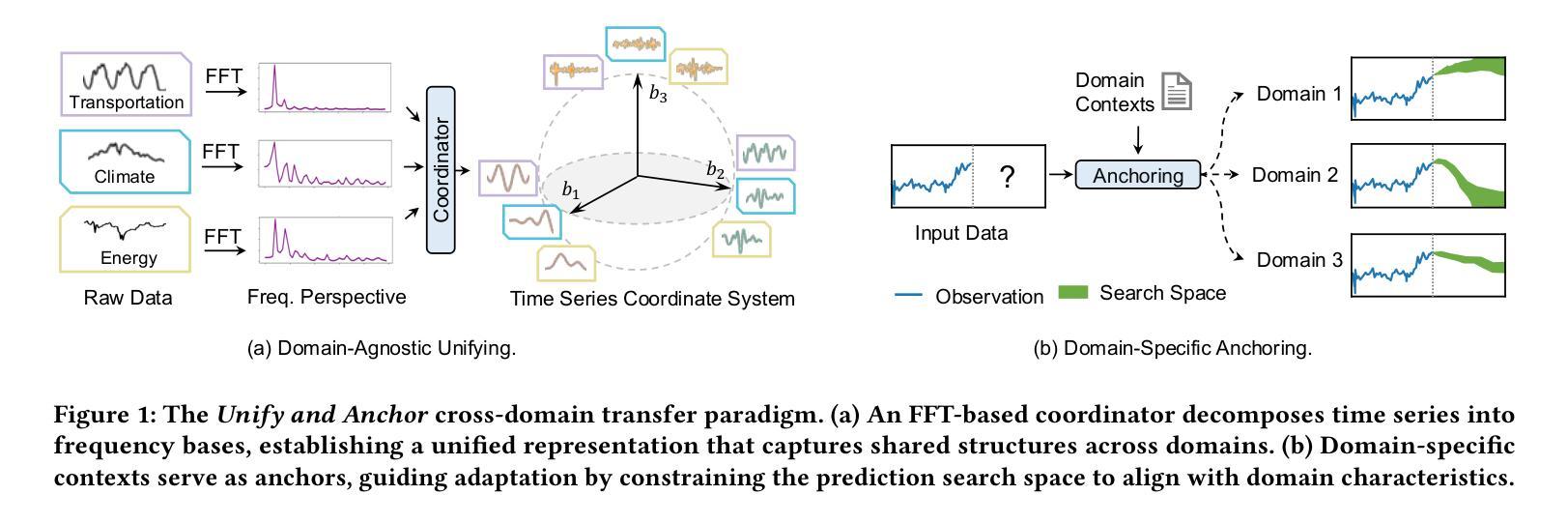
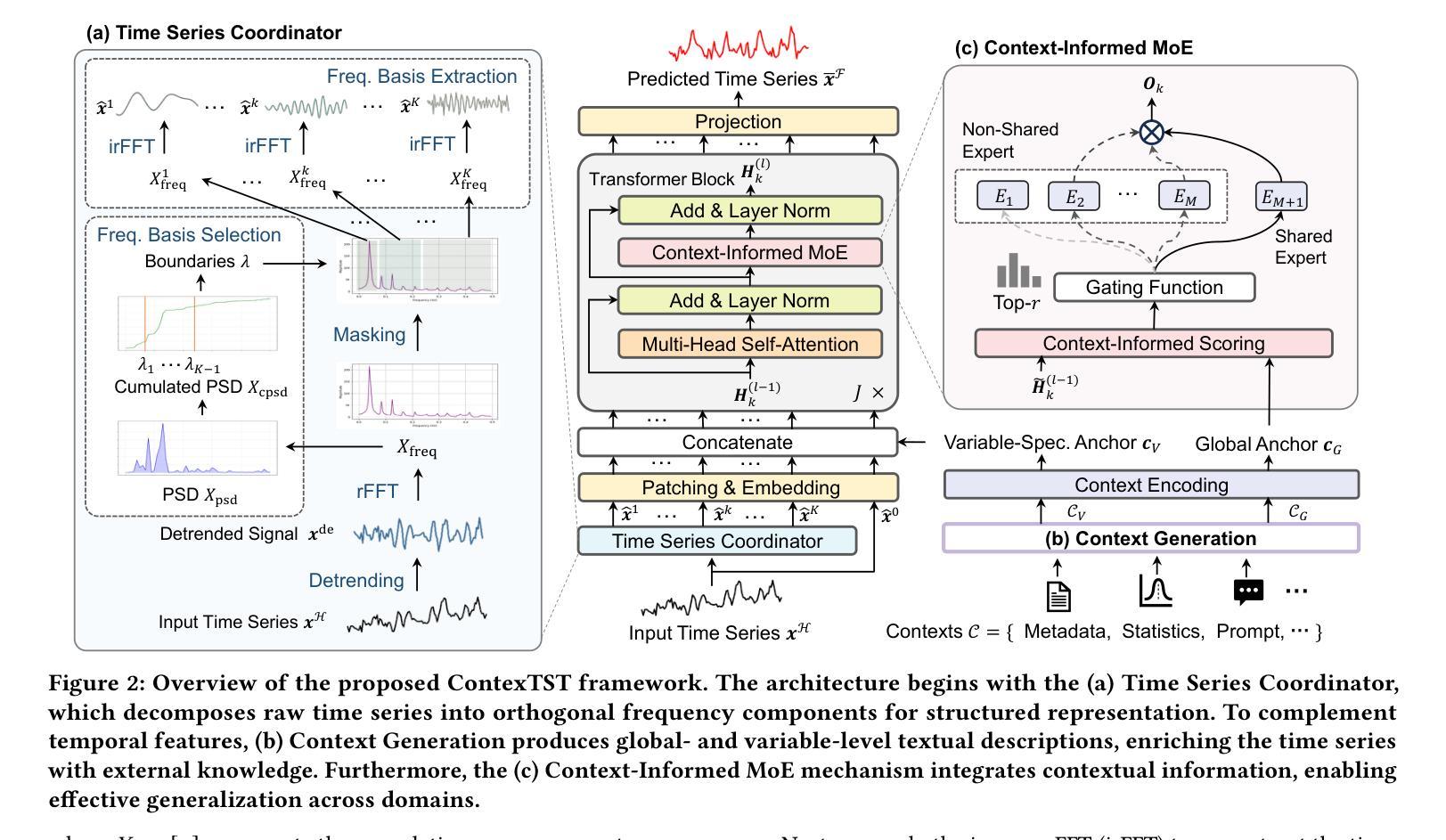
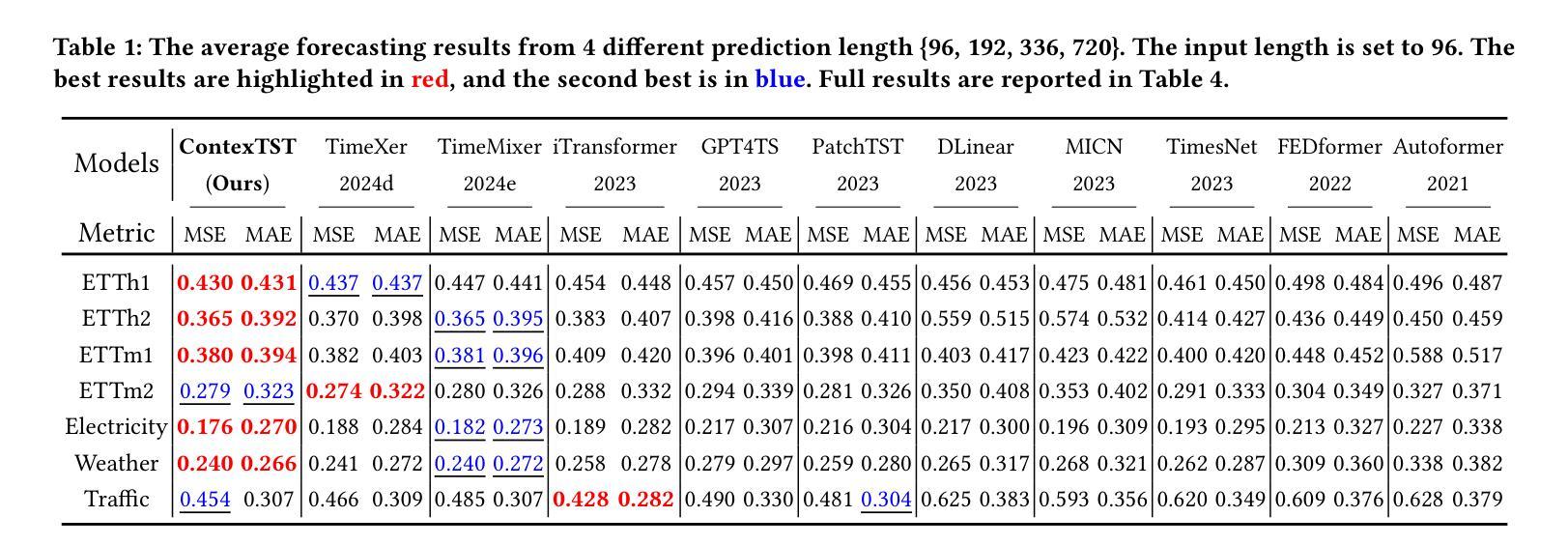
Unify and Anchor: A Context-Aware Transformer for Cross-Domain Time Series Forecasting
Authors:Xiaobin Hong, Jiawen Zhang, Wenzhong Li, Sanglu Lu, Jia Li
The rise of foundation models has revolutionized natural language processing and computer vision, yet their best practices to time series forecasting remains underexplored. Existing time series foundation models often adopt methodologies from these fields without addressing the unique characteristics of time series data. In this paper, we identify two key challenges in cross-domain time series forecasting: the complexity of temporal patterns and semantic misalignment. To tackle these issues, we propose the ``Unify and Anchor” transfer paradigm, which disentangles frequency components for a unified perspective and incorporates external context as domain anchors for guided adaptation. Based on this framework, we introduce ContexTST, a Transformer-based model that employs a time series coordinator for structured representation and the Transformer blocks with a context-informed mixture-of-experts mechanism for effective cross-domain generalization. Extensive experiments demonstrate that ContexTST advances state-of-the-art forecasting performance while achieving strong zero-shot transferability across diverse domains.
随着基础模型的兴起,自然语言处理和计算机视觉领域发生了革命性的变化,然而它们在时间序列预测方面的最佳实践仍然被探索不足。现有的时间序列基础模型往往采用这些领域的方法,而没有解决时间序列数据的独特特征。在本文中,我们确定了跨域时间序列预测的两个关键挑战:时间模式的复杂性和语义不对齐。为了解决这些问题,我们提出了“统一与锚点”迁移范式,该范式从统一的角度解决频率成分,并将外部上下文作为域锚点进行引导适应。基于此框架,我们引入了ContexTST模型,这是一个基于Transformer的模型,采用时间序列协调器进行结构化表示,并结合上下文感知的混合专家机制的Transformer块,实现有效的跨域泛化。大量实验表明,ContexTST模型在预测性能上取得了最先进的进展,同时在不同的领域实现了强大的零样本迁移能力。
论文及项目相关链接
PDF 20 pages, 12 figures, 8 tables, conference under review
Summary
时间序列预测领域中,跨域模型的应用存在两大挑战:时间模式的复杂性和语义不匹配问题。本文提出“统一与锚定”转移范式来解决这些问题,介绍了基于Transformer的ContexTST模型。该模型利用时间序列协调器进行结构化表示,并引入带有上下文信息的混合专家机制来实现跨域泛化。实验表明,ContexTST在先进的时间序列预测性能上取得了显著进展,同时在不同的领域之间实现了强大的零样本迁移能力。
Key Takeaways
- 时间序列预测领域中跨域模型面临两大挑战:时间模式的复杂性和语义不匹配。
- “统一与锚定”转移范式被提出以解决这些问题,该范式旨在从统一的角度解析频率成分,并通过引入领域锚点实现引导适应。
- ContexTST是一个基于Transformer的模型,采用时间序列协调器进行结构化表示。
- ContexTST模型使用带有上下文信息的混合专家机制,以提高跨域泛化能力。
- 实验结果显示ContexTST在先进的时间序列预测性能上取得了显著进展。
- ContexTST模型在不同的领域之间实现了强大的零样本迁移能力。
点此查看论文截图

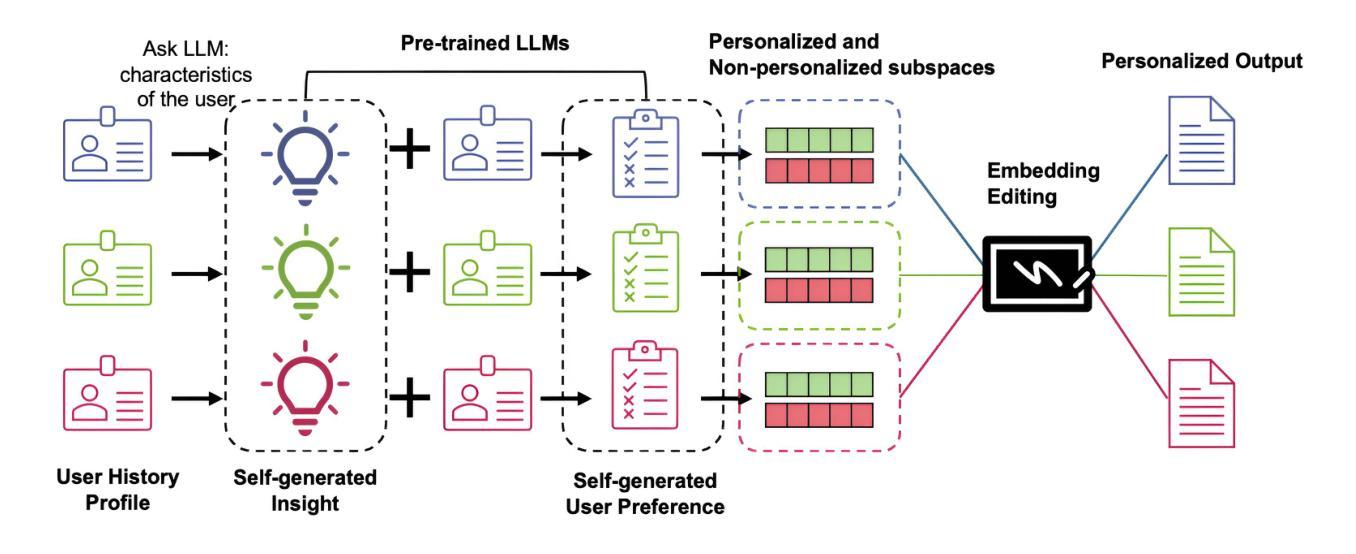
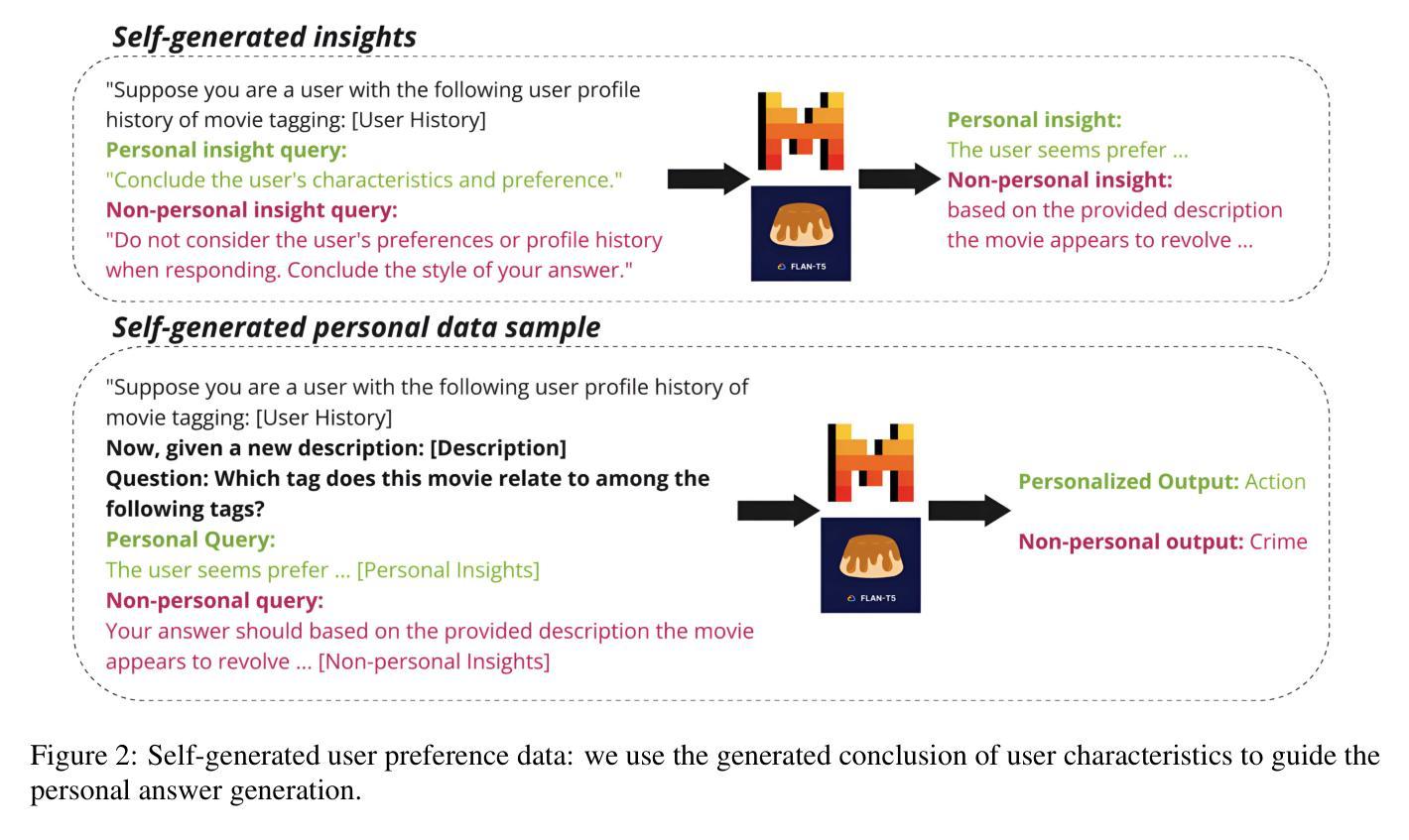
Personalize Your LLM: Fake it then Align it
Authors:Yijing Zhang, Dyah Adila, Changho Shin, Frederic Sala
Personalizing large language models (LLMs) is essential for delivering tailored interactions that improve user experience. Many existing personalization methods require fine-tuning LLMs for each user, rendering them prohibitively expensive for widespread adoption. Although retrieval-based approaches offer a more compute-efficient alternative, they still depend on large, high-quality datasets that are not consistently available for all users. To address this challenge, we propose CHAMELEON, a scalable and efficient personalization approach that uses (1) self-generated personal preference data and (2) representation editing to enable quick and cost-effective personalization. Our experiments on various tasks, including those from the LaMP personalization benchmark, show that CHAMELEON efficiently adapts models to personal preferences, improving instruction-tuned models and outperforms two personalization baselines by an average of 40% across two model architectures.
个性化大型语言模型(LLM)对于提供定制化的交互体验至关重要,这可以改善用户体验。许多现有的个性化方法需要对每个用户进行微调LLM,这使得它们广泛应用的成本过高。虽然基于检索的方法提供了一种更高效的计算替代方案,但它们仍然依赖于并非所有用户都可用的高质量大型数据集。为了应对这一挑战,我们提出了CHAMELEON,这是一种可扩展且高效的个性化方法,它采用(1)自我生成的个性化偏好数据以及(2)表示编辑来实现快速且经济的个性化。我们在包括来自LaMP个性化基准测试的各种任务上的实验表明,CHAMELEON可以有效地适应个人偏好,改进指令调整模型,并在两种模型架构上平均优于两个个性化基准测试40%。
论文及项目相关链接
PDF NAACL 2025 Findings
Summary
LLM个性化对于提供改善用户体验的定制交互至关重要。现有个人化方法需要大量针对每个用户的微调,导致成本高昂,难以广泛应用。我们提出CHAMELEON方法,通过(1)自我生成的个人偏好数据和(2)表示编辑,实现快速、经济的个性化。实验表明,CHAMELEON在多个任务上表现优异,包括LaMP个性化基准测试,能够高效适应个人偏好,改进指令调整模型,并在两种模型架构上平均优于两个个性化基准测试40%。
Key Takeaways
- LLM个性化对于提升用户体验至关重要。
- 现有个人化方法因需要大量针对每个用户的微调而成本高昂。
- CHAMELEON方法通过使用自我生成的个人偏好数据和表示编辑实现快速、经济的个性化。
- CHAMELEON在多个任务上表现优异,包括LaMP个性化基准测试。
- CHAMELEON能够高效适应个人偏好,改进指令调整模型。
- CHAMELEON在两种模型架构上的性能平均优于两个个性化基准测试40%。
点此查看论文截图

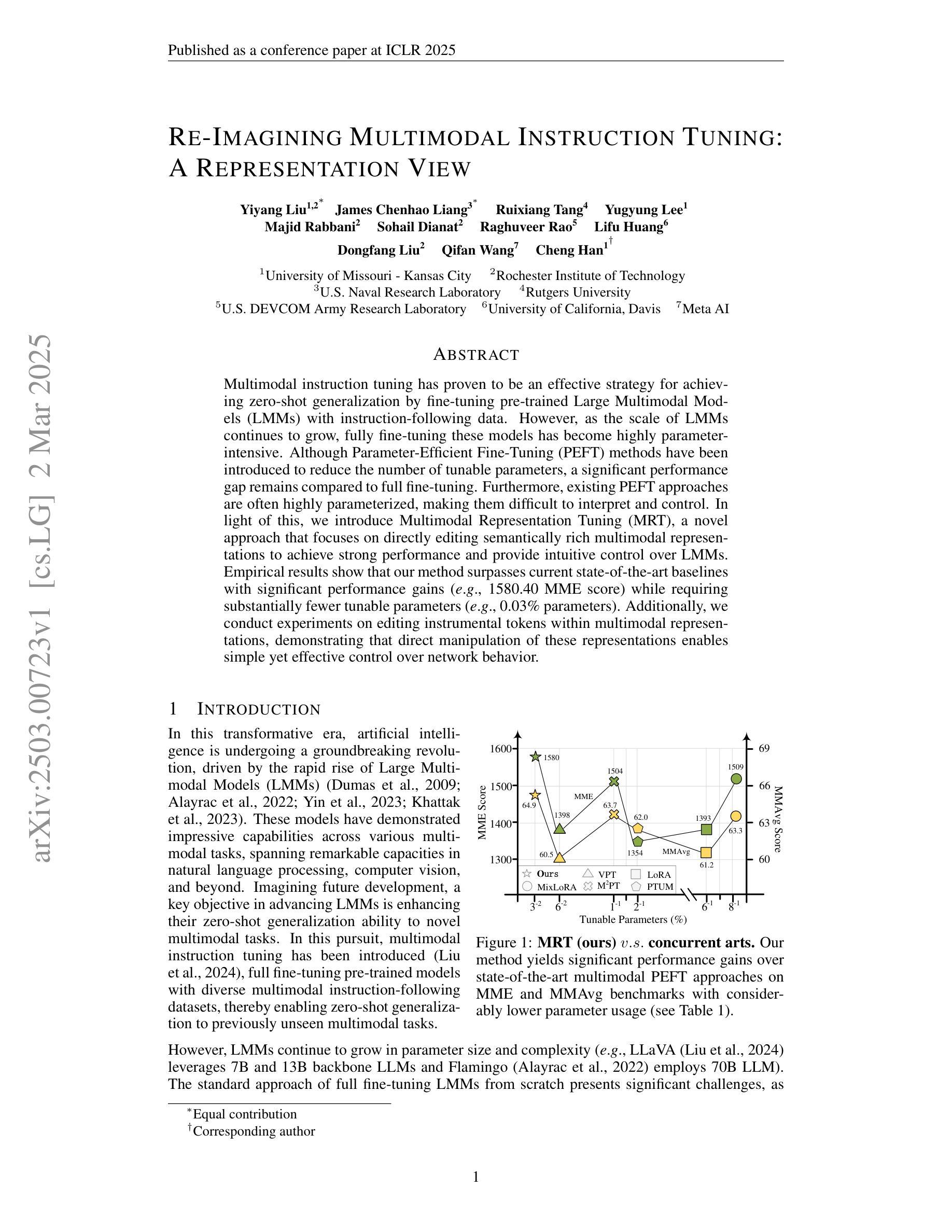
Re-Imagining Multimodal Instruction Tuning: A Representation View
Authors:Yiyang Liu, James Chenhao Liang, Ruixiang Tang, Yugyung Lee, Majid Rabbani, Sohail Dianat, Raghuveer Rao, Lifu Huang, Dongfang Liu, Qifan Wang, Cheng Han
Multimodal instruction tuning has proven to be an effective strategy for achieving zero-shot generalization by fine-tuning pre-trained Large Multimodal Models (LMMs) with instruction-following data. However, as the scale of LMMs continues to grow, fully fine-tuning these models has become highly parameter-intensive. Although Parameter-Efficient Fine-Tuning (PEFT) methods have been introduced to reduce the number of tunable parameters, a significant performance gap remains compared to full fine-tuning. Furthermore, existing PEFT approaches are often highly parameterized, making them difficult to interpret and control. In light of this, we introduce Multimodal Representation Tuning (MRT), a novel approach that focuses on directly editing semantically rich multimodal representations to achieve strong performance and provide intuitive control over LMMs. Empirical results show that our method surpasses current state-of-the-art baselines with significant performance gains (e.g., 1580.40 MME score) while requiring substantially fewer tunable parameters (e.g., 0.03% parameters). Additionally, we conduct experiments on editing instrumental tokens within multimodal representations, demonstrating that direct manipulation of these representations enables simple yet effective control over network behavior.
多模态指令调整已被证明是一种通过微调预训练的大型多模态模型(LMMs)与遵循指令的数据,实现零射击泛化的有效策略。然而,随着LMM规模的不断增长,完全微调这些模型已经变得非常参数密集。虽然已引入参数高效微调(PEFT)方法来减少可调参数的数量,但与完全微调相比,仍存在显著的性能差距。此外,现有的PEFT方法通常高度参数化,使得它们难以解释和控制。鉴于此,我们引入了多模态表示调整(MRT),这是一种新型方法,专注于直接编辑语义丰富的多模态表示,以实现强大的性能和直观控制LMMs。经验结果表明,我们的方法在达到最新基线水平的同时实现了显著的性能提升(例如,1580.40 MME得分),同时需要的可调参数大大减少(例如,仅使用百分之零点零三参数)。此外,我们还在编辑多模态表示中的仪器符号方面进行了实验,结果表明直接操作这些表示可以简单有效地控制网络行为。
论文及项目相关链接
Summary
多模态指令调整是一种通过微调预训练的大型多模态模型(LMMs)以实现零样本泛化的有效策略。然而,随着LMMs规模的扩大,完全微调这些模型变得极为参数密集。尽管已经引入了参数高效微调(PEFT)方法来减少可调参数的数量,但与完全微调相比仍存在显著的性能差距。本文介绍了一种新型的多模态表示调整(MRT)方法,该方法直接编辑语义丰富的多模态表示,以实现强大的性能和直观控制LMMs的能力。实验结果显示,该方法在显著的性能提升(例如,MME分数为1580.40)的同时,所需的可调参数大幅减少(例如,仅0.03%的参数)。此外,我们还进行了编辑仪器符号的令牌内多模态表示的测试,证明了直接操作这些表示能简单有效地控制网络行为。
Key Takeaways
- 多模态指令调整是一种有效的零样本泛化策略,通过微调预训练的大型多模态模型(LMMs)。
- 随着LMMs规模的增长,完全微调模型变得极为参数密集。
- 参数高效微调(PEFT)方法虽然可以减少可调参数数量,但仍存在与全微调显著的性能差距。
- 多模态表示调整(MRT)是一种新型方法,直接编辑语义丰富的多模态表示,以实现强大的性能和直观控制LMMs。
- MRT方法显著提高了性能(例如,MME分数为1580.40)并大幅减少了可调参数的需求(例如,仅0.03%的参数)。
- 直接编辑多模态表示中的仪器符号令牌可以简单有效地控制网络行为。
点此查看论文截图
Transformer Meets Twicing: Harnessing Unattended Residual Information
Authors:Laziz Abdullaev, Tan Nguyen
Transformer-based deep learning models have achieved state-of-the-art performance across numerous language and vision tasks. While the self-attention mechanism, a core component of transformers, has proven capable of handling complex data patterns, it has been observed that the representational capacity of the attention matrix degrades significantly across transformer layers, thereby hurting its overall performance. In this work, we leverage the connection between self-attention computations and low-pass non-local means (NLM) smoothing filters and propose the Twicing Attention, a novel attention mechanism that uses kernel twicing procedure in nonparametric regression to alleviate the low-pass behavior of associated NLM smoothing with compelling theoretical guarantees and enhanced adversarial robustness. This approach enables the extraction and reuse of meaningful information retained in the residuals following the imperfect smoothing operation at each layer. Our proposed method offers two key advantages over standard self-attention: 1) a provably slower decay of representational capacity and 2) improved robustness and accuracy across various data modalities and tasks. We empirically demonstrate the performance gains of our model over baseline transformers on multiple tasks and benchmarks, including image classification and language modeling, on both clean and corrupted data.
基于Transformer的深度学习模型已在众多语言和视觉任务中实现了最先进的性能。虽然Transformer的核心组件自注意力机制已证明能够处理复杂的数据模式,但人们观察到,随着Transformer层的增加,注意力矩阵的表示能力会显著下降,从而损害其总体性能。在这项工作中,我们利用自注意力计算与低通非局部均值(NLM)平滑滤波器之间的联系,提出Twicing Attention这一新型注意力机制。它采用非参数回归中的核Twicing程序,以缓解与NLM平滑相关的低通行为,具有引人注目的理论保证和增强的对抗鲁棒性。这种方法能够提取和再利用每层不完美的平滑操作后残留中的有意义信息。我们的方法相对于标准的自注意力具有两个主要优点:1)表示能力的衰减速度较慢;2)在各种数据模态和任务中提高了鲁棒性和准确性。我们在多个任务和基准测试上实证了我们的模型相对于基线Transformer的性能提升,包括图像分类、语言建模以及在干净和损坏数据上的表现。
论文及项目相关链接
Summary
基于Transformer的深度模型已在多个语言和视觉任务中取得最先进的性能。本文发现Transformer中的自注意力机制在处理复杂数据模式时表现出色,但注意力矩阵在Transformer层间的表示能力显著下降,影响了整体性能。为此,本文利用自注意力计算与低通非局部均值平滑滤波之间的联系,提出了Twicing Attention新型注意力机制。它采用非参数回归中的核扭曲过程来缓解与NLM平滑相关的低通行为,具有令人信服的理论保证和增强的对抗鲁棒性。该方法能够提取和再利用每一层不完美平滑操作后的残差中保留的有意义的信息。与标准自注意力相比,本文方法提供了两个主要优势:1)证明了的表示能力衰减较慢;2)提高了在各种数据模态和任务上的鲁棒性和准确性。在多个任务和基准测试上,包括图像分类和语言建模,以及在干净和损坏的数据上,本文模型均实现了性能提升。
Key Takeaways
- Transformer模型在语言和视觉任务上表现卓越,但自注意力机制存在表示能力退化问题。
- 退化问题导致模型性能下降,特别是在复杂数据模式下。
- 提出了Twicing Attention机制,结合自注意力与非局部均值平滑滤波,以缓解表示能力退化问题。
- Twicing Attention具有理论保证和增强的对抗鲁棒性。
- 该机制能够提取并再利用层间平滑操作后的残差信息。
- 与标准自注意力相比,Twicing Attention提供较慢的表示能力衰减和更高的鲁棒性、准确性。
点此查看论文截图

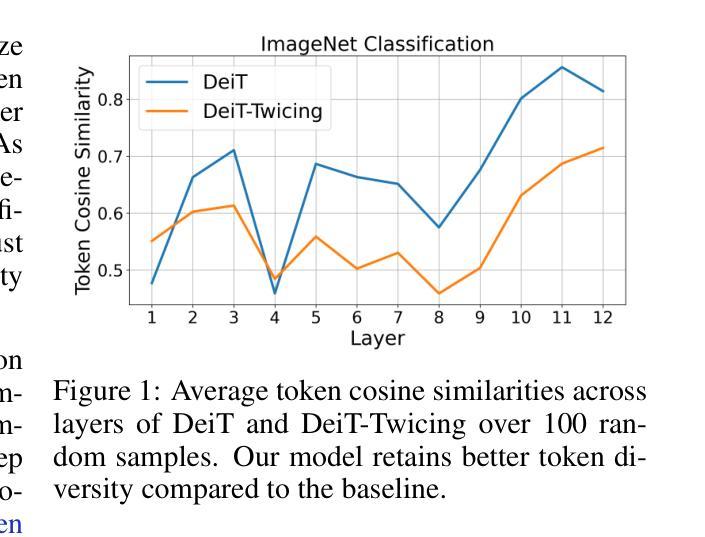
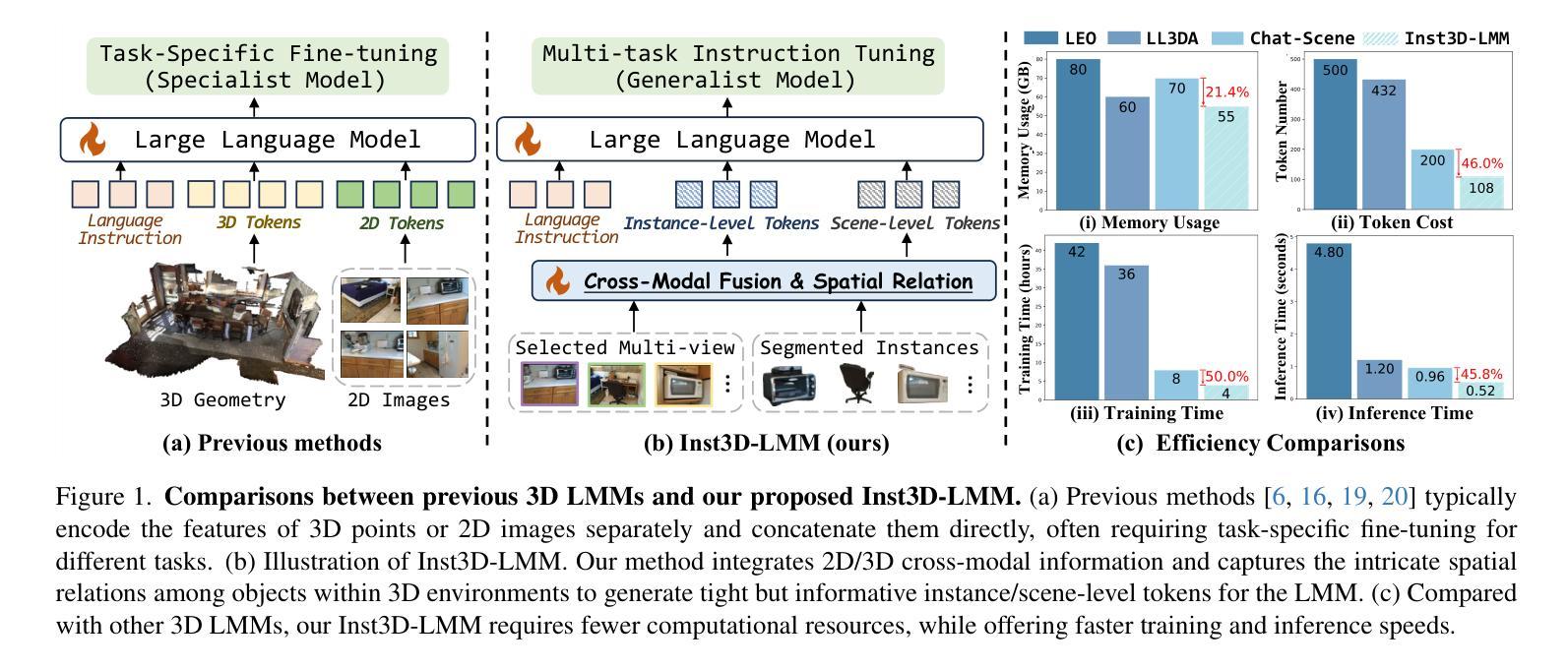
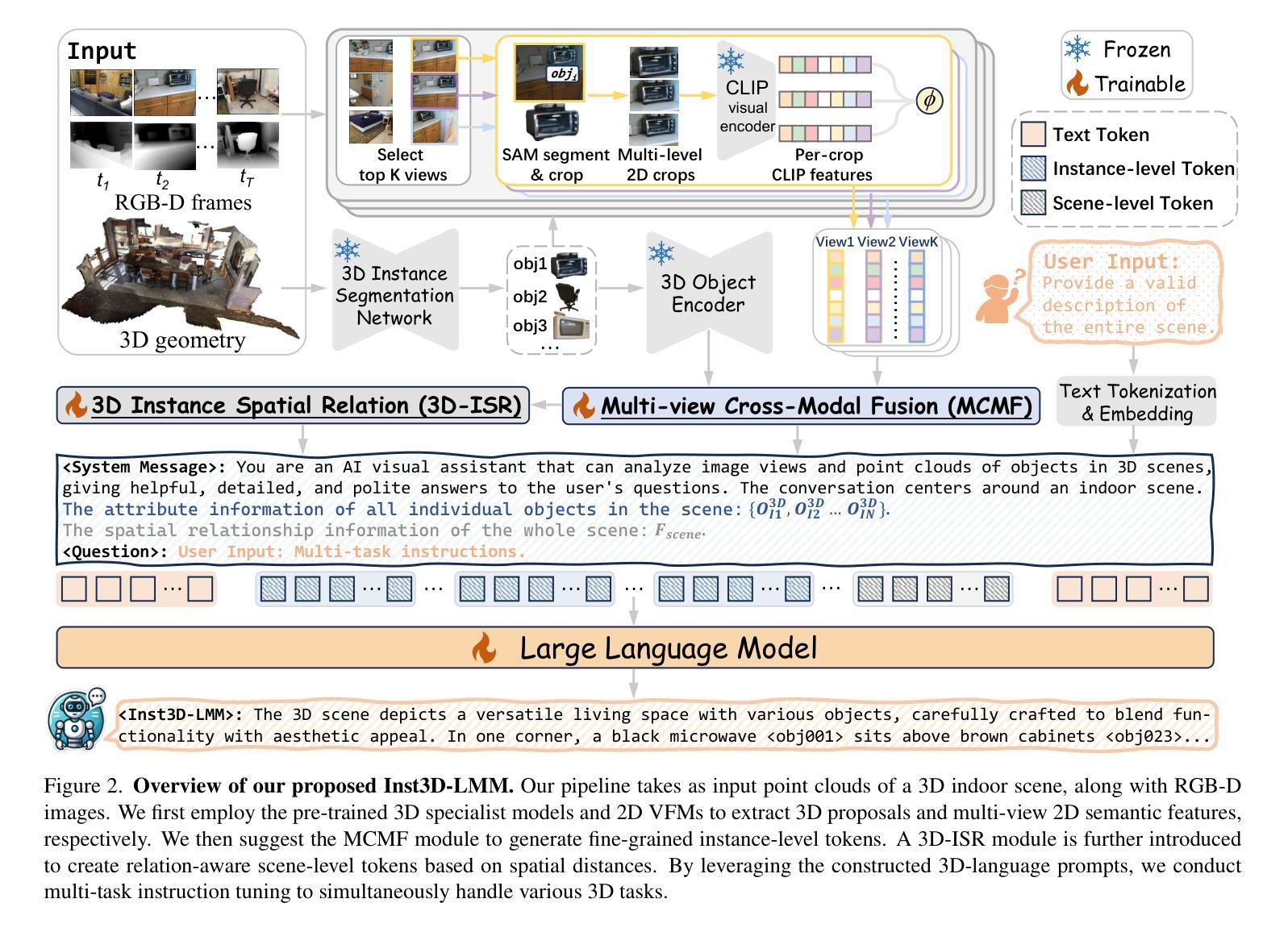
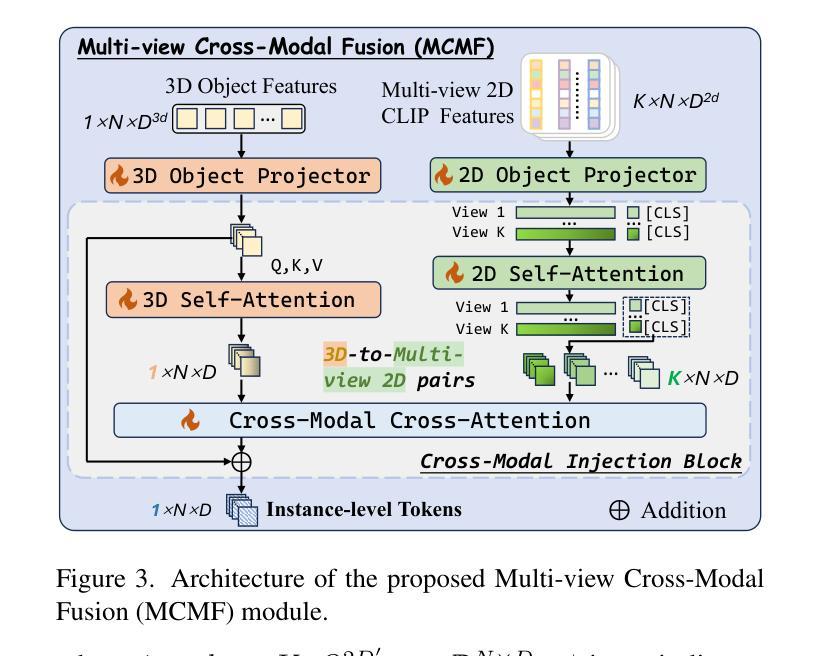
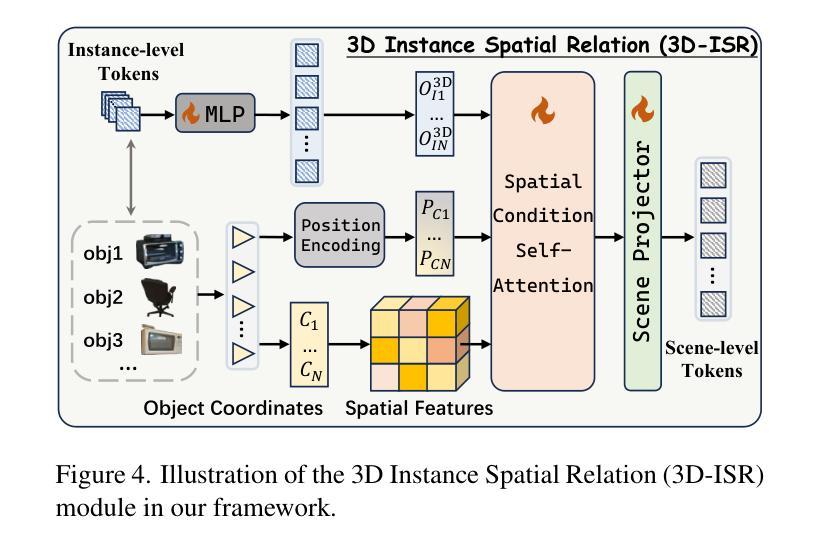
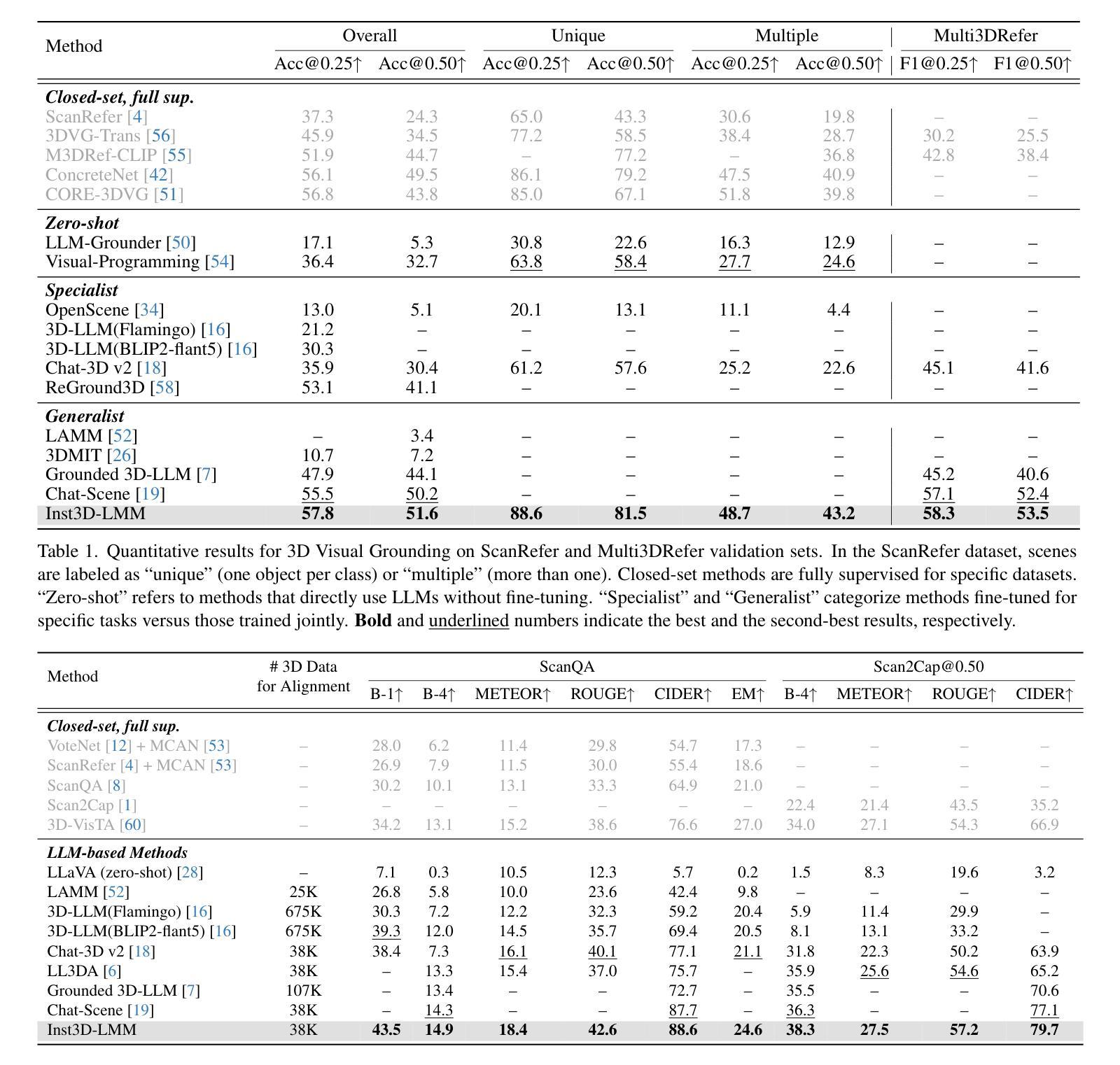
Inst3D-LMM: Instance-Aware 3D Scene Understanding with Multi-modal Instruction Tuning
Authors:Hanxun Yu, Wentong Li, Song Wang, Junbo Chen, Jianke Zhu
Despite encouraging progress in 3D scene understanding, it remains challenging to develop an effective Large Multi-modal Model (LMM) that is capable of understanding and reasoning in complex 3D environments. Most previous methods typically encode 3D point and 2D image features separately, neglecting interactions between 2D semantics and 3D object properties, as well as the spatial relationships within the 3D environment. This limitation not only hinders comprehensive representations of 3D scene, but also compromises training and inference efficiency. To address these challenges, we propose a unified Instance-aware 3D Large Multi-modal Model (Inst3D-LMM) to deal with multiple 3D scene understanding tasks simultaneously. To obtain the fine-grained instance-level visual tokens, we first introduce a novel Multi-view Cross-Modal Fusion (MCMF) module to inject the multi-view 2D semantics into their corresponding 3D geometric features. For scene-level relation-aware tokens, we further present a 3D Instance Spatial Relation (3D-ISR) module to capture the intricate pairwise spatial relationships among objects. Additionally, we perform end-to-end multi-task instruction tuning simultaneously without the subsequent task-specific fine-tuning. Extensive experiments demonstrate that our approach outperforms the state-of-the-art methods across 3D scene understanding, reasoning and grounding tasks. Source code is available at https://github.com/hanxunyu/Inst3D-LMM
尽管在3D场景理解方面取得了令人鼓舞的进展,但开发能够在复杂3D环境中进行理解和推理的有效大型多模态模型(LMM)仍然是一个挑战。大多数之前的方法通常分别编码3D点和2D图像特征,忽略了2D语义和3D对象属性之间的交互,以及3D环境内的空间关系。这种局限性不仅阻碍了对3D场景的全面表示,还影响了训练和推理的效率。
论文及项目相关链接
PDF CVPR2025, Code Link: https://github.com/hanxunyu/Inst3D-LMM
Summary
本文提出一种名为Inst3D-LMM的统一大型多模态模型,用于同时处理多个3D场景理解任务。该模型通过引入多视图跨模态融合(MCMF)模块,将多视图2D语义注入到相应的3D几何特征中,获取精细的实例级视觉令牌。同时,通过3D实例空间关系(3D-ISR)模块,捕捉对象之间的复杂成对空间关系,实现场景级关系感知令牌的获取。实验表明,该方法在3D场景理解、推理和定位任务上的性能均优于现有方法。
Key Takeaways
- 提出一种名为Inst3D-LMM的大型多模态模型,用于3D场景理解。
- 引入多视图跨模态融合(MCMF)模块,将2D语义与3D几何特征相结合。
- 通过3D实例空间关系(3D-ISR)模块,捕捉对象之间的复杂空间关系。
- 模型能够同时处理多个3D场景理解任务。
- 模型性能在多个3D场景理解、推理和定位任务上优于现有方法。
- 提供了模型的源代码,可供公众访问和使用。
点此查看论文截图

Assessing Correctness in LLM-Based Code Generation via Uncertainty Estimation
Authors:Arindam Sharma, Cristina David
In this work, we explore uncertainty estimation as a proxy for correctness in LLM-generated code. To this end, we adapt two state-of-the-art techniques from natural language generation – one based on entropy and another on mutual information – to the domain of code generation. Given the distinct semantic properties of code, we introduce modifications, including a semantic equivalence check based on symbolic execution. Our findings indicate a strong correlation between the uncertainty computed through these techniques and correctness, highlighting the potential of uncertainty estimation for quality assessment. Additionally, we propose a simplified version of the entropy-based method that assumes a uniform distribution over the LLM’s responses, demonstrating comparable effectiveness. Using these techniques, we develop an abstention policy that prevents the model from making predictions when uncertainty is high, reducing incorrect outputs to near zero. Our evaluation on the LiveCodeBench shows that our approach significantly outperforms a baseline relying solely on LLM-reported log-probabilities.
在这项工作中,我们探索将不确定性估计作为评估大型语言模型(LLM)生成代码正确性的代理指标。为此,我们从自然语言生成领域采用了两种先进技术——一种基于熵,另一种基于互信息——并将其应用于代码生成领域。考虑到代码的独特语义属性,我们进行了一些修改,包括基于符号执行的语义等价性检查。我们的研究发现,通过这些技术计算的不确定性与正确性之间存在强烈的相关性,突出了不确定性估计在质量评估中的潜力。此外,我们还提出了基于熵的方法的简化版,该方法假设大型语言模型的响应服从均匀分布,并展示了其相当的有效性。使用这些技术,我们制定了一项放弃政策,即当不确定性很高时,防止模型做出预测,从而将错误输出降低到几乎为零。我们在LiveCodeBench上的评估表明,我们的方法显著优于仅依赖大型语言模型报告的日志概率的基线方法。
论文及项目相关链接
PDF 18 pages and 3 References Pages
摘要
本文探索了不确定性估计作为评估LLM生成代码正确性的代理指标。为此,我们采用了自然语言生成领域的两种最新技术——基于熵的方法和基于互信息的方法,并将其适应于代码生成领域。考虑到代码的独特语义属性,我们引入了一些修改,包括基于符号执行的语义等价性检查。我们的研究发现,通过这些技术计算的不确定性与正确性之间存在强烈的相关性,突显了不确定性估计在质量评估中的潜力。此外,我们还提出了一种简化版的基于熵的方法,该方法假设LLM的响应呈均匀分布,并展示了其相当的有效性。利用这些技术,我们制定了一种避免策略,即当不确定性较高时,防止模型进行预测,从而将错误输出降低到几乎为零。我们在LiveCodeBench上的评估显示,我们的方法显著优于仅依赖LLM报告的对数概率的基线方法。
关键见解
- 文章探索了不确定性估计作为评估LLM生成代码正确性的方法。
- 文章采用了自然语言生成领域的两种技术,并适应于代码生成领域。
- 研究发现不确定性估计与代码正确性之间存在强烈的相关性。
- 文章提出了一种简化版的基于熵的不确定性估计方法,并验证了其有效性。
- 文章制定了一种避免策略,能够在不确定性较高时防止模型进行预测,显著减少错误输出。
- 评估显示,该方法显著优于仅依赖LLM报告的对数概率的基线方法。
- 该研究为LLM生成的代码质量评估提供了新的视角和方法。
点此查看论文截图




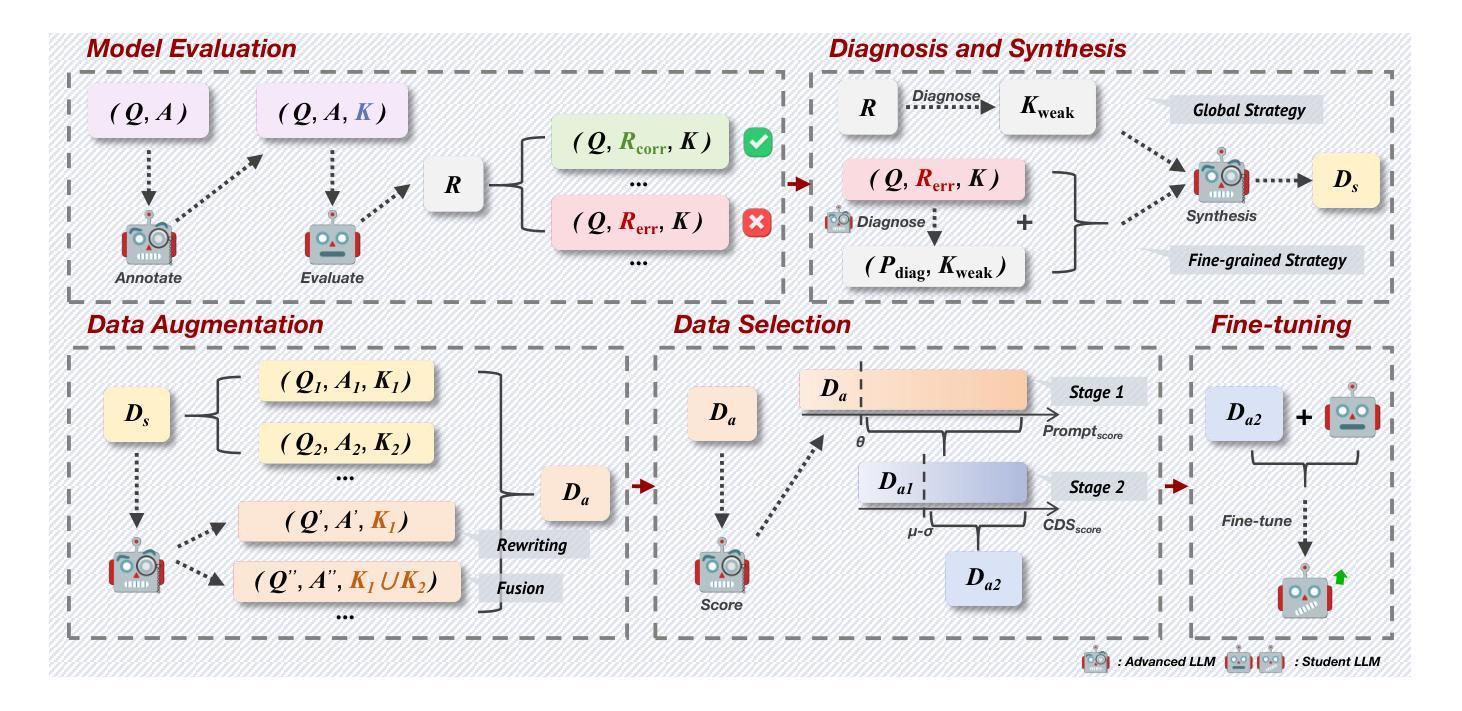
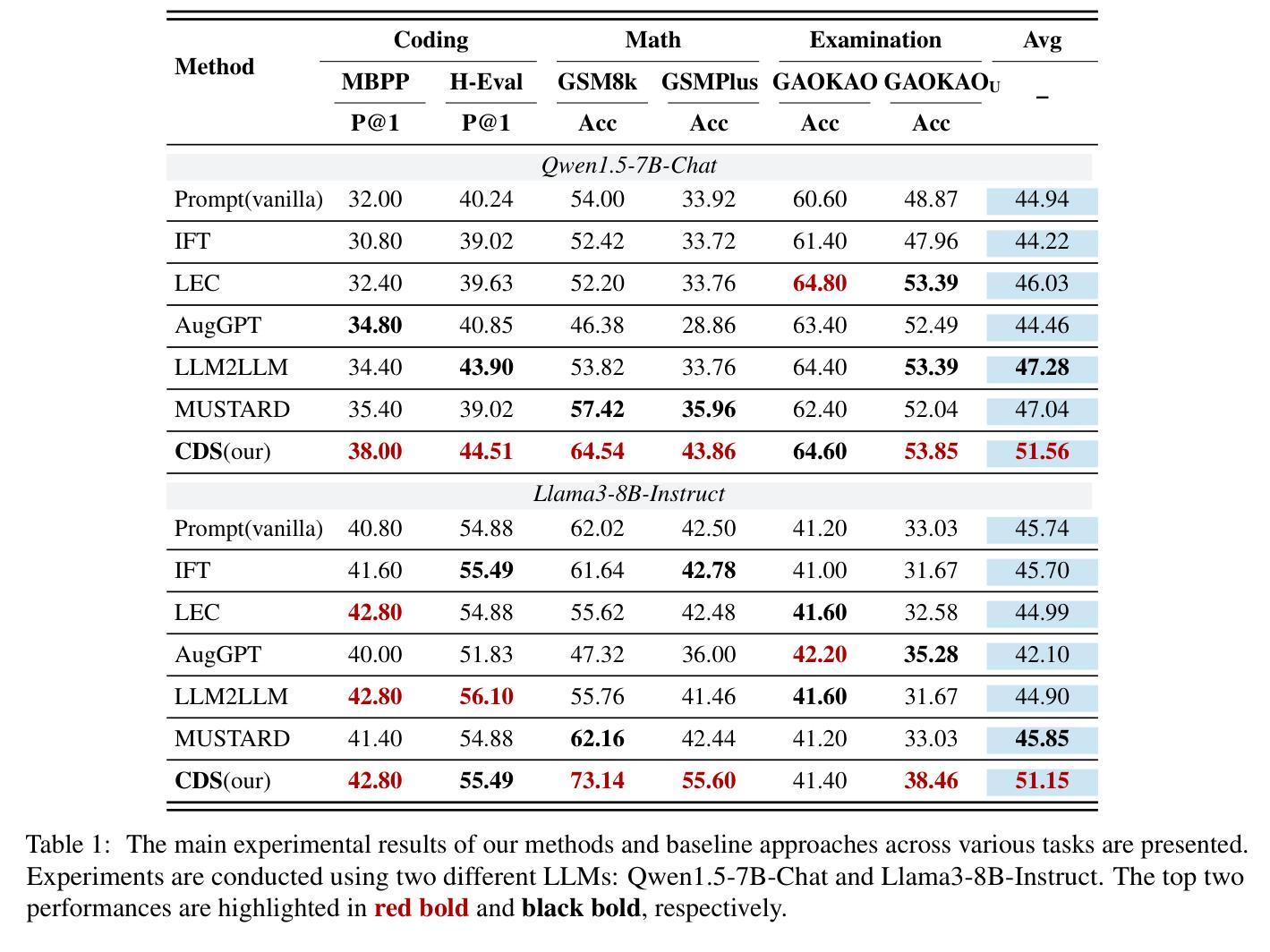
CDS: Data Synthesis Method Guided by Cognitive Diagnosis Theory
Authors:Haokun Zhao, Jinyi Han, Jiaqing Liang, Yanghua Xiao
Large Language Models (LLMs) have achieved significant advancements, but the increasing complexity of tasks and higher performance demands highlight the need for continuous improvement. Some approaches utilize synthetic data generated by advanced LLMs based on evaluation results to train models. However, conventional evaluation methods fail to provide detailed, fine-grained profiles of LLMs, limiting their guidance for data synthesis. In this paper, we introduce the Cognitive Diagnostic Synthesis (CDS) method, which incorporates a diagnostic process inspired by Cognitive Diagnosis Theory (CDT) to refine evaluation results and characterize model profiles at the knowledge component level. Based on these diagnostics, we propose two diagnosis-synthesis strategies for weakness-targeted data synthesis. Additionally, we present an enhanced data augmentation and selection pipeline to improve the quality and diversity of synthesized data. Our experiments with several open-source models show significant improvements across multiple benchmarks, achieving up to 6.00% improvement in code generation, 13.10% in mathematical reasoning, and 5.43% in academic exams. Code and data are available on GitHub.
大型语言模型(LLM)已经取得了显著的进步,但任务的复杂性和对性能要求的提高突显了持续改进的必要性。一些方法利用基于评估结果由先进的大型语言模型生成合成数据来训练模型。然而,传统的评估方法无法提供大型语言模型的详细、精细的概况,从而限制了它们在数据合成方面的指导。在本文中,我们介绍了认知诊断合成(CDS)方法,该方法结合了受认知诊断理论(CDT)启发的诊断过程,以优化评估结果并在知识组件级别刻画模型概况。基于这些诊断,我们提出了两种针对弱点进行的数据合成的诊断合成策略。此外,我们还展示了一个增强的数据增强和选择流程,以提高合成数据的质量和多样性。我们在多个开源模型上的实验显示,在各种基准测试中实现了显著的改进,在代码生成方面提高了6.00%,在数学推理方面提高了13.10%,在学术考试方面提高了5.43%。代码和数据已在GitHub上提供。
论文及项目相关链接
Summary
大语言模型(LLM)面临持续提高性能的需求,部分方法通过合成数据来训练模型。然而,传统评估方法无法提供详细的模型性能分析,限制了数据合成的指导。本文提出了结合认知诊断理论(CDT)的Cognitive Diagnostic Synthesis(CDS)方法,以精细化评估结果并刻画模型在知识组件层面的性能特征。基于这些诊断结果,本文提出了两种针对弱点合成数据的策略。同时,改进了数据增强和选择流程,提高了合成数据的质量和多样性。实验结果显示,该方法在多个基准测试中取得了显著改进,如代码生成提高了6.0%,数学推理提高了13.1%,学术考试提高了5.4%。GitHub上有相关代码和数据可供下载。
Key Takeaways
- LLM面临性能持续提升的需求和挑战。
- 传统评估方法无法提供详细的模型性能分析。
- Cognitive Diagnostic Synthesis (CDS)方法结合认知诊断理论(CDT)来精细化评估结果并刻画模型性能特征。
- 基于诊断结果,提出了两种针对弱点合成数据的策略。
- 改进了数据增强和选择流程,提高合成数据的质量和多样性。
- 实验结果显示该方法在多个基准测试中表现优异。
点此查看论文截图


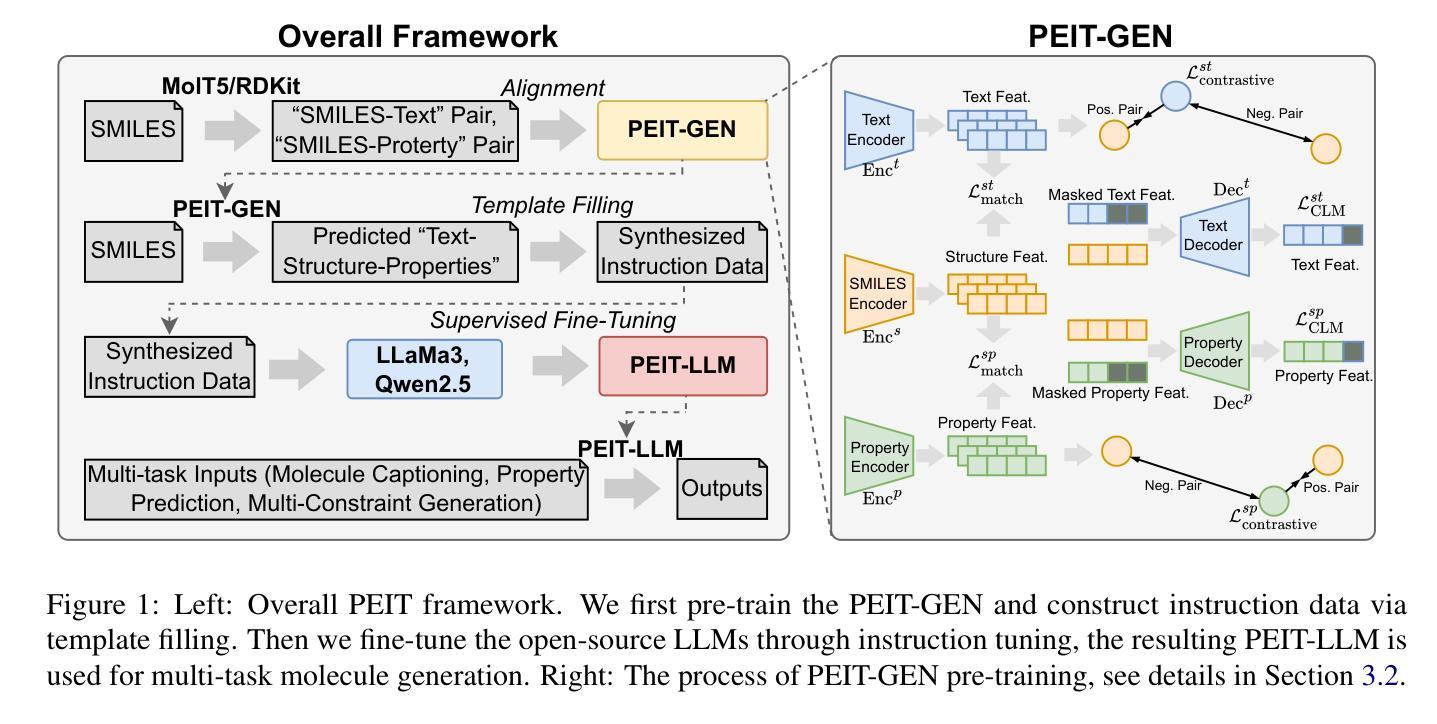
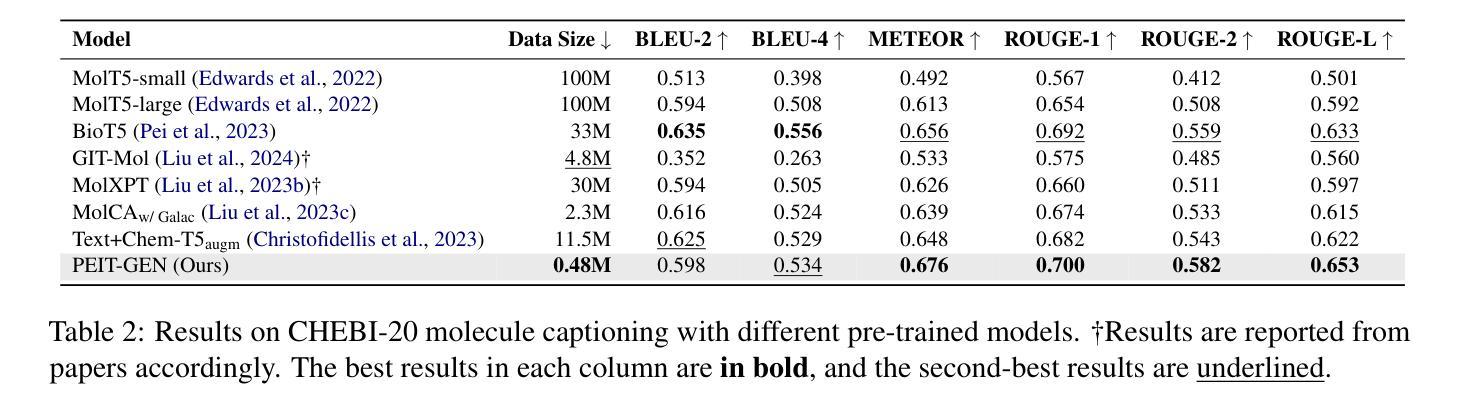
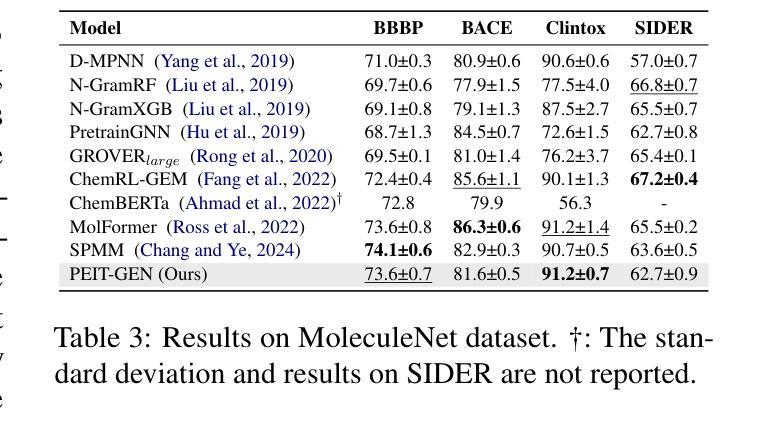
Property Enhanced Instruction Tuning for Multi-task Molecule Generation with Large Language Models
Authors:Xuan Lin, Long Chen, Yile Wang, Xiangxiang Zeng, Philip S. Yu
Large language models (LLMs) are widely applied in various natural language processing tasks such as question answering and machine translation. However, due to the lack of labeled data and the difficulty of manual annotation for biochemical properties, the performance for molecule generation tasks is still limited, especially for tasks involving multi-properties constraints. In this work, we present a two-step framework PEIT (Property Enhanced Instruction Tuning) to improve LLMs for molecular-related tasks. In the first step, we use textual descriptions, SMILES, and biochemical properties as multimodal inputs to pre-train a model called PEIT-GEN, by aligning multi-modal representations to synthesize instruction data. In the second step, we fine-tune existing open-source LLMs with the synthesized data, the resulting PEIT-LLM can handle molecule captioning, text-based molecule generation, molecular property prediction, and our newly proposed multi-constraint molecule generation tasks. Experimental results show that our pre-trained PEIT-GEN outperforms MolT5 and BioT5 in molecule captioning, demonstrating modalities align well between textual descriptions, structures, and biochemical properties. Furthermore, PEIT-LLM shows promising improvements in multi-task molecule generation, proving the scalability of the PEIT framework for various molecular tasks. We release the code, constructed instruction data, and model checkpoints in https://github.com/chenlong164/PEIT.
大型语言模型(LLM)已广泛应用于各种自然语言处理任务,如问答和机器翻译。然而,由于缺乏标注数据和生化属性手动注释的困难,分子生成任务的性能仍然有限,特别是涉及多属性约束的任务。在这项工作中,我们提出了一个两阶段的PEIT(属性增强指令调整)框架,以提高LLM在分子相关任务上的性能。第一步中,我们使用文本描述、SMILES和生物化学属性作为多模式输入,通过对齐多模式表示来合成指令数据,从而预训练一个名为PEIT-GEN的模型。在第二步中,我们使用合成数据对现有的开源LLM进行微调,得到的PEIT-LLM可以处理分子描述、基于文本的分子生成、分子属性预测以及我们新提出的多约束分子生成任务。实验结果表明,我们的预训练PEIT-GEN在分子描述方面超越了MolT5和BioT5。这证明了文本描述、结构和生物化学属性之间的模态对齐良好。此外,PEIT-LLM在多任务分子生成方面显示出有希望的改进,证明了PEIT框架对各种分子任务的可扩展性。我们在https://github.com/chenlong164/PEIT上发布了代码、构建好的指令数据和模型检查点。
论文及项目相关链接
Summary:LLM在自然语言处理任务中得到广泛应用,但针对分子生成任务的性能仍受限于缺乏标签数据和手动注释的难度。本文提出一个两阶段的PEIT框架,通过预训练和微调,提高LLM在分子相关任务上的性能。实验结果表明,预训练的PEIT-GEN在分子描述上优于MolT5和BioT5模型,并且PEIT框架对于多种分子任务表现出可扩展性。PEIT已在GitHub上发布。
Key Takeaways:
- LLM在多种NLP任务中应用广泛,但在分子生成任务上的性能受到限制。
- PEIT框架包含预训练和微调两个阶段,旨在提高LLM在分子相关任务上的性能。
- PEIT使用文本描述、SMILES和生物化学属性等多模式输入进行预训练。
- PEIT-GEN的合成数据用于微调现有开源LLM。
- PEIT-LLM能够处理分子描述、文本基础的分子生成、分子属性预测以及新提出的多约束分子生成任务。
- 实验结果表明,PEIT-GEN在分子描述上优于MolT5和BioT5模型。
点此查看论文截图


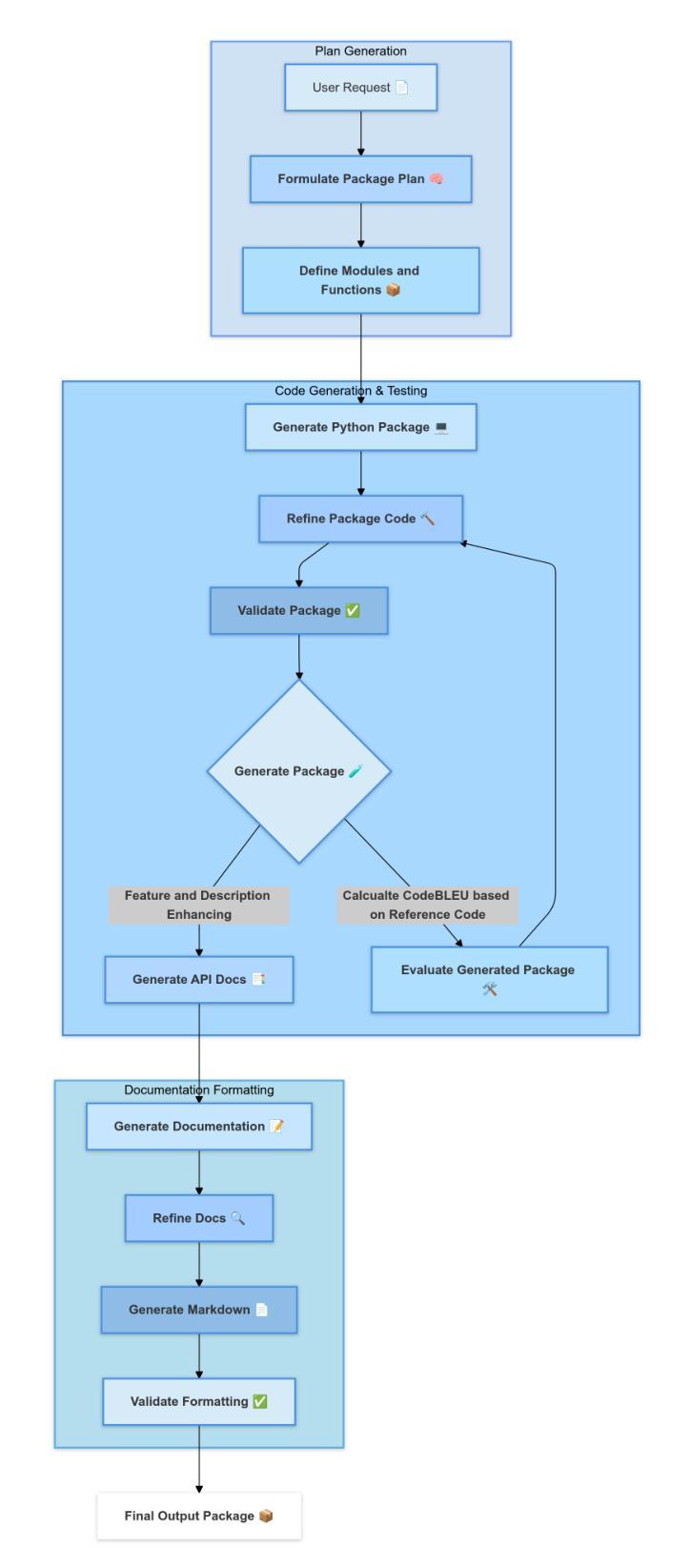
PyGen: A Collaborative Human-AI Approach to Python Package Creation
Authors:Saikat Barua, Mostafizur Rahman, Md Jafor Sadek, Rafiul Islam, Shehnaz Khaled, Md. Shohrab Hossain
The principles of automation and innovation serve as foundational elements for advancement in contemporary science and technology. Here, we introduce Pygen, an automation platform designed to empower researchers, technologists, and hobbyists to bring abstract ideas to life as core, usable software tools written in Python. Pygen leverages the immense power of autoregressive large language models to augment human creativity during the ideation, iteration, and innovation process. By combining state-of-the-art language models with open-source code generation technologies, Pygen has significantly reduced the manual overhead of tool development. From a user prompt, Pygen automatically generates Python packages for a complete workflow from concept to package generation and documentation. The findings of our work show that Pygen considerably enhances the researcher’s productivity by enabling the creation of resilient, modular, and well-documented packages for various specialized purposes. We employ a prompt enhancement approach to distill the user’s package description into increasingly specific and actionable. While being inherently an open-ended task, we have evaluated the generated packages and the documentation using Human Evaluation, LLM-based evaluation, and CodeBLEU, with detailed results in the results section. Furthermore, we documented our results, analyzed the limitations, and suggested strategies to alleviate them. Pygen is our vision of ethical automation, a framework that promotes inclusivity, accessibility, and collaborative development. This project marks the beginning of a large-scale effort towards creating tools where intelligent agents collaborate with humans to improve scientific and technological development substantially. Our code and generated examples are open-sourced at [https://github.com/GitsSaikat/Pygen]
自动化和创新的原则是当代科学技术进步的基础要素。在这里,我们介绍Pygen——一个自动化平台,旨在赋能研究者、技术专家和爱好者,将抽象的想法转化为实用的Python软件工具。Pygen利用自动回归大型语言模型的巨大力量,在创意、迭代和创新过程中增强人类的创造力。通过将最先进的语言模型与开源代码生成技术相结合,Pygen大大降低了工具开发的手动工作量。从用户提示开始,Pygen自动为从概念到软件包生成和文档的整个工作流程生成Python包。我们的研究结果表明,Pygen通过使研究人员能够创建针对各种特定用途的健壮、模块化且文档齐全的包,从而极大地提高了研究人员的工作效率。我们采用提示增强法对用户描述的包进行提炼,使其更加具体可行。虽然本质上这是一个开放的任务,但我们通过人工评估、基于大型语言模型的评估和CodeBLEU对生成的软件包和文档进行了评估,详细结果见结果部分。此外,我们还记录了我们的结果,分析了局限性,并提出了缓解策略。Pygen是我们对道德自动化的愿景,是一个促进包容性、可访问性和协作发展的框架。这个项目标志着朝着创建智能主体与人类合作改善科学和科技发展的大规模努力迈出了重要的一步。我们的代码和生成的示例在https://github.com/GitsSaikat/Pygen上开源。
论文及项目相关链接
PDF 33 pages, 13 figures
Summary
Pygen是一个自动化平台,利用先进的自然语言模型技术,助力研究人员和技术爱好者将抽象想法转化为实用的Python软件工具。该平台通过减少工具开发的手动工作量,显著提高了研究人员的生产力。Pygen能自动从用户提示生成Python包,并提供从概念到包生成和文档完整的自动化工作流程。其注重开放性、包容性和协作性,致力于促进科学和技术发展。目前已在GitHub上开源部分代码和生成的实例。
Key Takeaways
- Pygen是一个自动化平台,结合了自然语言模型与开源代码生成技术。
- Pygen可将抽象想法转化为Python软件工具,降低工具开发的手动工作量。
- 平台能自动从用户提示生成Python包,并提供完整自动化工作流程。
- Pygen强调开放性、包容性和协作性,推动科学和技术发展。
- 通过人类评估、LLM评估和CodeBLEU评估验证了Pygen的效果。
- Pygen部分代码和生成的实例已在GitHub上开源。
点此查看论文截图