⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-07 更新
PacketCLIP: Multi-Modal Embedding of Network Traffic and Language for Cybersecurity Reasoning
Authors:Ryozo Masukawa, Sanggeon Yun, Sungheon Jeong, Wenjun Huang, Yang Ni, Ian Bryant, Nathaniel D. Bastian, Mohsen Imani
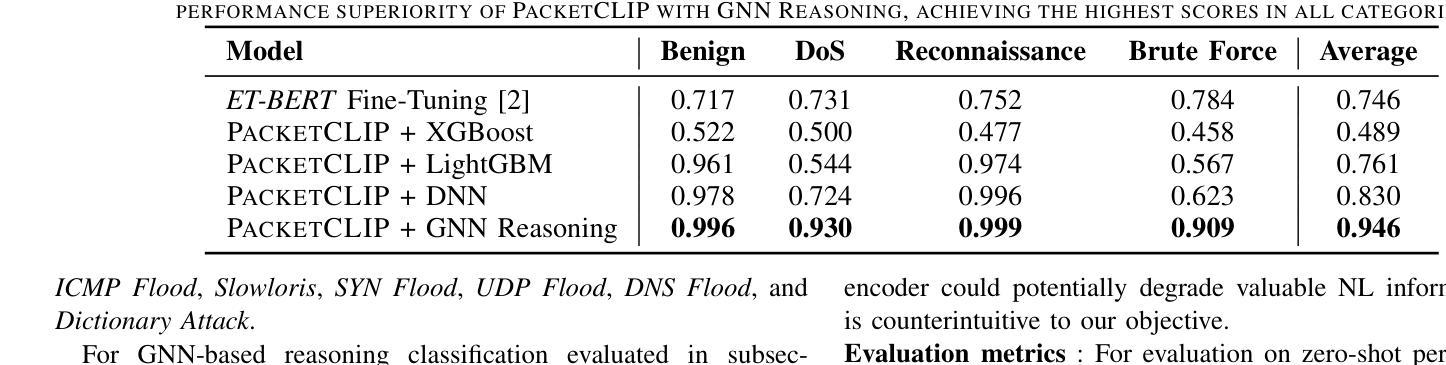
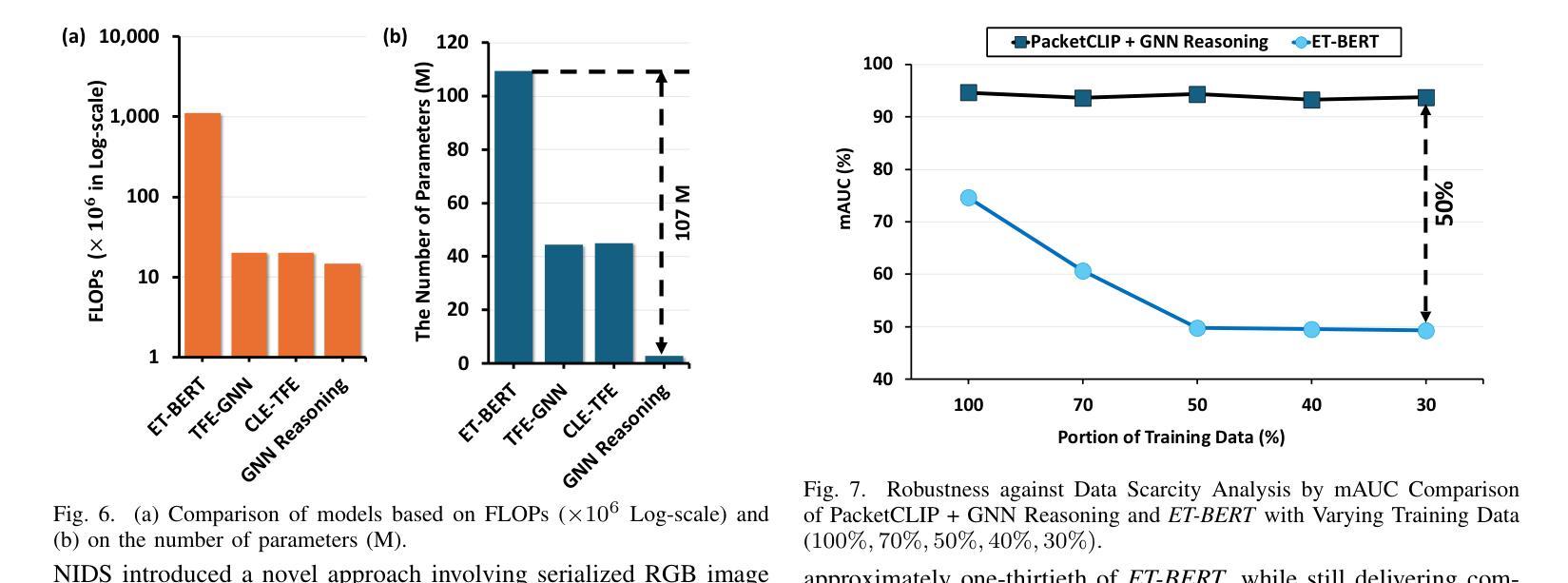
Traffic classification is vital for cybersecurity, yet encrypted traffic poses significant challenges. We present PacketCLIP, a multi-modal framework combining packet data with natural language semantics through contrastive pretraining and hierarchical Graph Neural Network (GNN) reasoning. PacketCLIP integrates semantic reasoning with efficient classification, enabling robust detection of anomalies in encrypted network flows. By aligning textual descriptions with packet behaviors, it offers enhanced interpretability, scalability, and practical applicability across diverse security scenarios. PacketCLIP achieves a 95% mean AUC, outperforms baselines by 11.6%, and reduces model size by 92%, making it ideal for real-time anomaly detection. By bridging advanced machine learning techniques and practical cybersecurity needs, PacketCLIP provides a foundation for scalable, efficient, and interpretable solutions to tackle encrypted traffic classification and network intrusion detection challenges in resource-constrained environments.
网络流量分类对网络安全至关重要,然而加密流量带来了巨大挑战。我们提出了PacketCLIP,这是一个多模态框架,通过对比预训练和分层图神经网络(GNN)推理,将数据包数据与自然语言语义相结合。PacketCLIP将语义推理与高效分类相结合,实现对加密网络流量异常的稳健检测。通过文本描述与数据包行为的对齐,它提供了增强的可解释性、可扩展性和在各种安全场景中的实际适用性。PacketCLIP的平均AUC达到95%,比基线高出11.6%,并且模型大小减少了92%,非常适合实时异常检测。通过弥合先进的机器学习与实际的网络安全需求之间的鸿沟,PacketCLIP为解决资源受限环境中的加密流量分类和网络入侵检测挑战提供了可扩展、高效和可解释解决方案的基础。
论文及项目相关链接
PDF 7 pages, 7 figures
Summary
加密流量分类对网络安全性至关重要,但加密流量带来的挑战也不容忽视。为此,我们推出PacketCLIP,这是一个多模态框架,它通过对比预训练和分层图神经网络(GNN)推理,将数据包数据与自然语言语义相结合。PacketCLIP将语义推理与高效分类相结合,可实现加密网络流量中异常的稳健检测。通过将文本描述与数据包行为对齐,它提供了增强的可解释性、可扩展性和不同安全场景下的实用性。PacketCLIP的平均AUC达到95%,超出基线11.6%,并减少模型大小92%,适合实时异常检测。它为解决资源受限环境中的加密流量分类和网络入侵检测挑战提供了可扩展、高效和可解释的解决方案基础。
Key Takeaways
- PacketCLIP是一个用于加密流量分类的多模态框架。
- 它结合了数据包数据和自然语言语义。
- 通过对比预训练和分层图神经网络(GNN)推理实现集成。
- PacketCLIP实现了高效的异常检测,尤其针对加密网络流量。
- 该框架将文本描述与数据包行为对齐,增强了可解释性和实用性。
- PacketCLIP的平均AUC达到95%,优于其他方法,适合实时应用。
点此查看论文截图

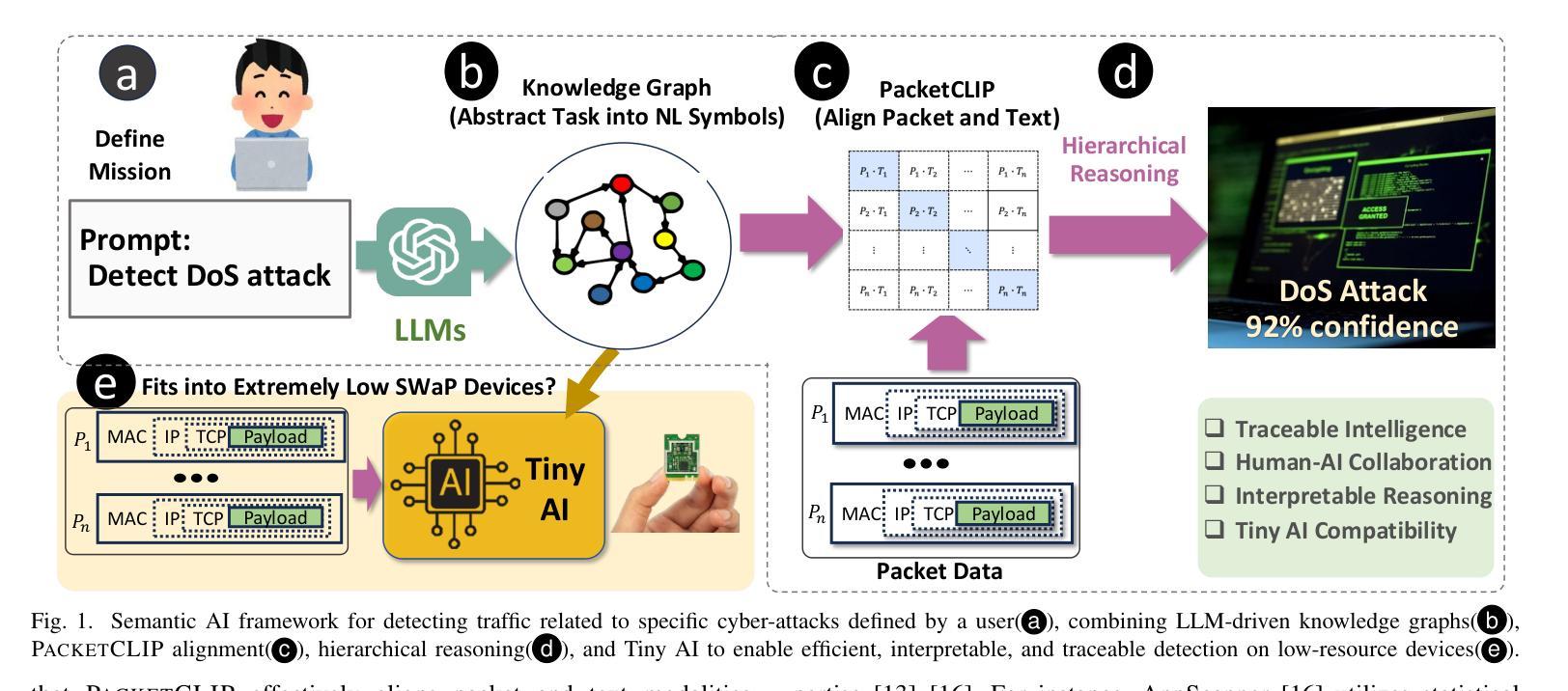
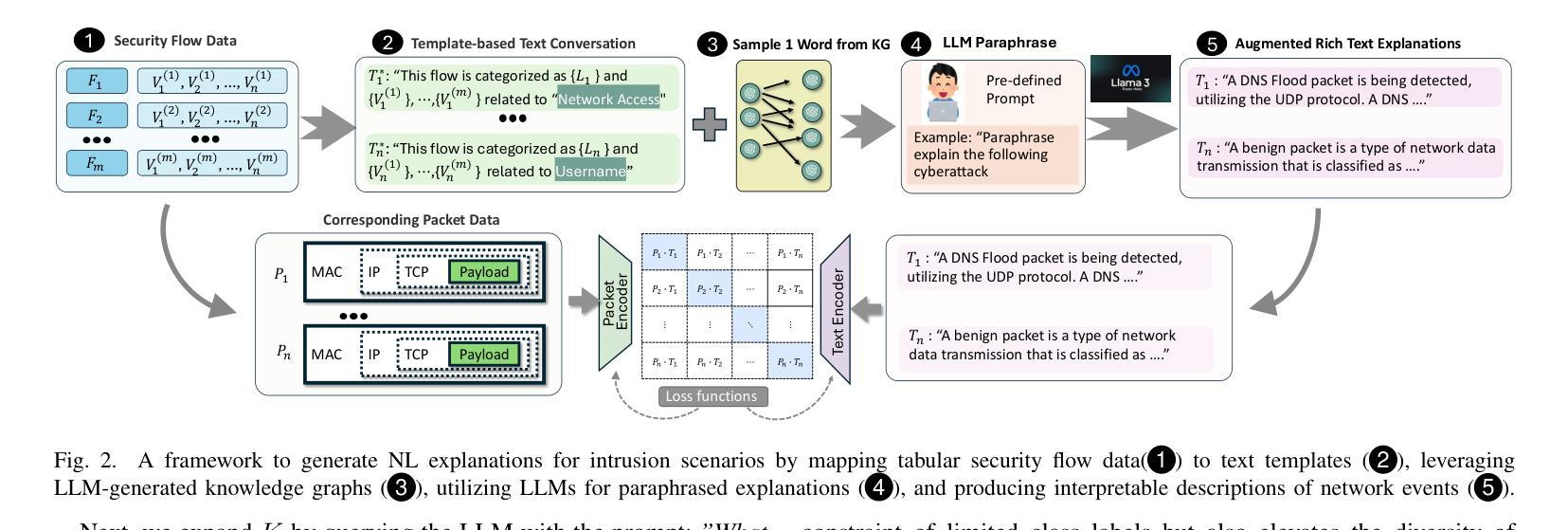
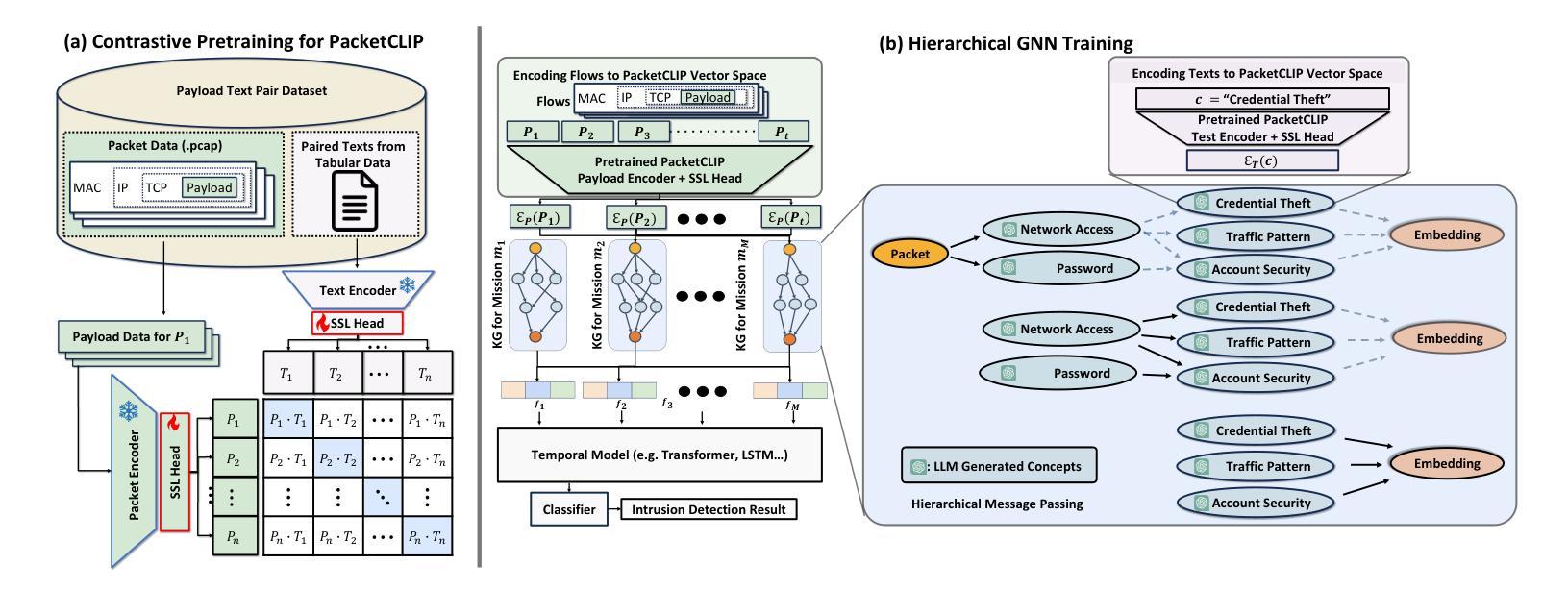

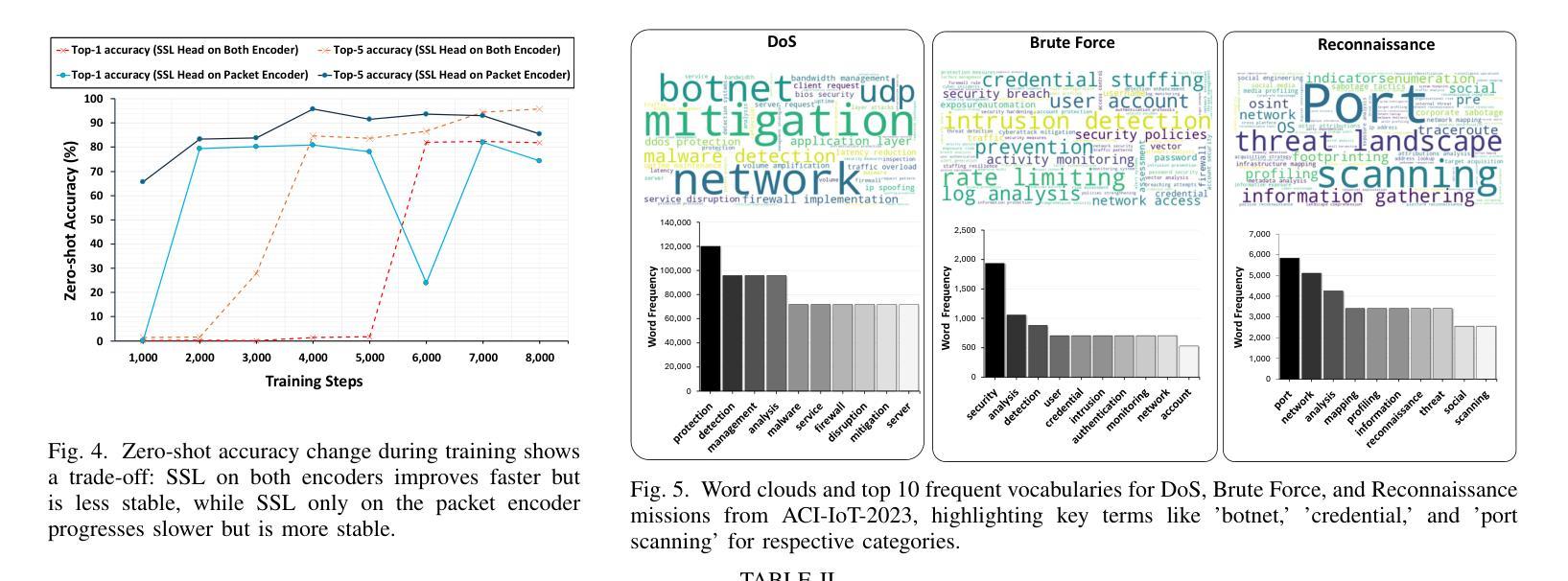
Process-based Self-Rewarding Language Models
Authors:Shimao Zhang, Xiao Liu, Xin Zhang, Junxiao Liu, Zheheng Luo, Shujian Huang, Yeyun Gong
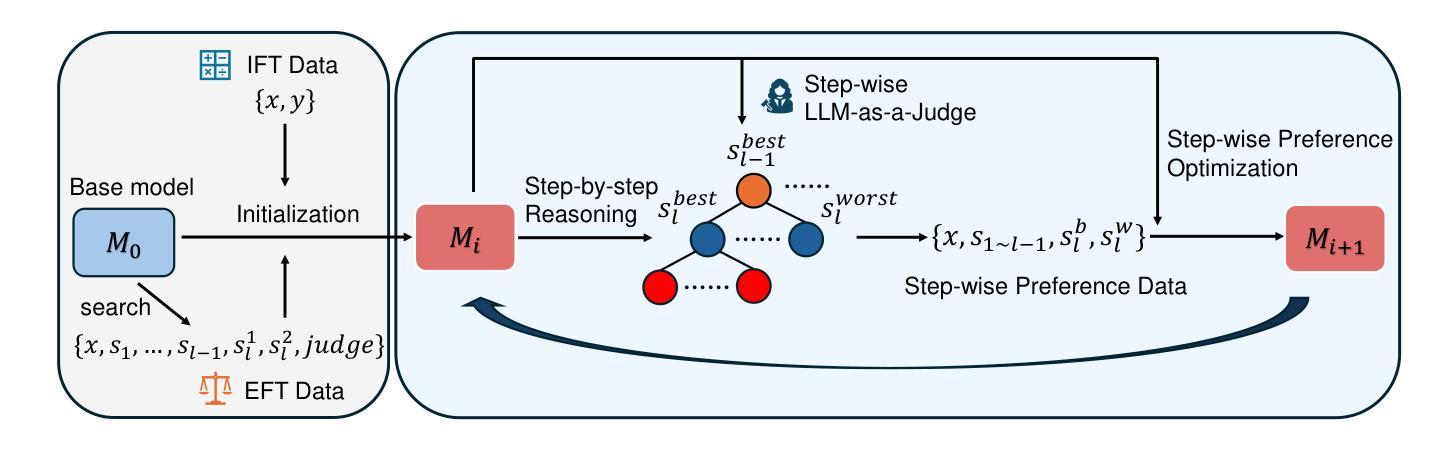
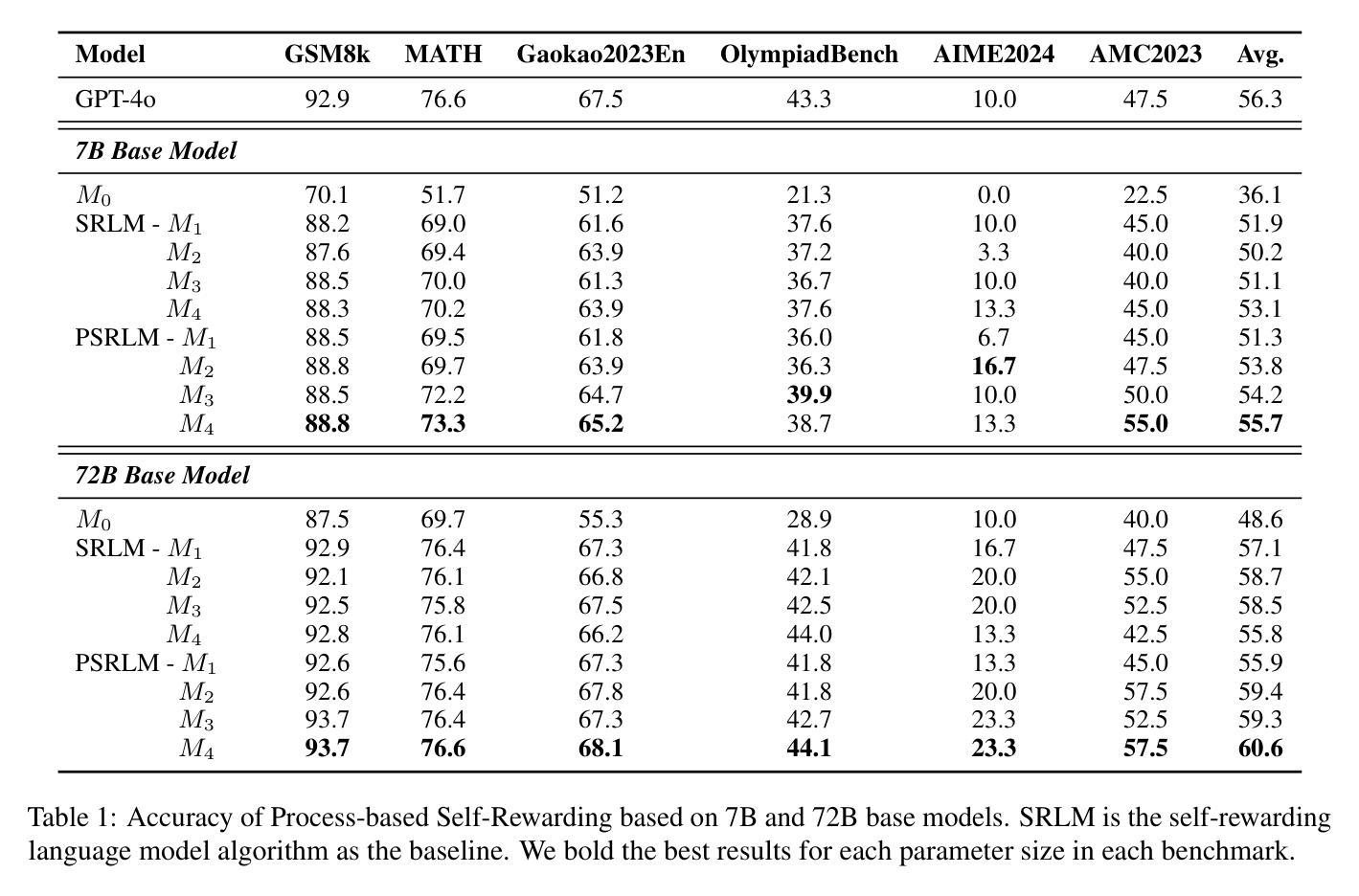
Large Language Models have demonstrated outstanding performance across various downstream tasks and have been widely applied in multiple scenarios. Human-annotated preference data is used for training to further improve LLMs’ performance, which is constrained by the upper limit of human performance. Therefore, Self-Rewarding method has been proposed, where LLMs generate training data by rewarding their own outputs. However, the existing self-rewarding paradigm is not effective in mathematical reasoning scenarios and may even lead to a decline in performance. In this work, we propose the Process-based Self-Rewarding pipeline for language models, which introduces long-thought reasoning, step-wise LLM-as-a-Judge, and step-wise preference optimization within the self-rewarding paradigm. Our new paradigm successfully enhances the performance of LLMs on multiple mathematical reasoning benchmarks through iterative Process-based Self-Rewarding, demonstrating the immense potential of self-rewarding to achieve LLM reasoning that may surpass human capabilities.
大型语言模型已在各种下游任务中展现出卓越性能,并在多个场景中得到广泛应用。为了进一步提升大型语言模型的性能,采用人工标注的偏好数据进行训练,但仍受到人类性能上限的制约。因此,提出了自我奖励方法,即大型语言模型通过奖励自己的输出生成训练数据。然而,现有的自我奖励范式在数学推理场景中并不有效,甚至可能导致性能下降。在这项工作中,我们为语言模型提出了基于过程的自我奖励流水线,该流程引入了长期思考推理、逐步的大型语言模型作为法官和基于自我奖励范式的逐步偏好优化。我们的新范式通过基于过程的自我奖励迭代成功提高了大型语言模型在多个数学推理基准测试上的性能,证明了自我奖励在大型语言模型推理方面实现超越人类能力的巨大潜力。
论文及项目相关链接
Summary
大型语言模型在多种下游任务中表现出卓越性能,并在多个场景中得到广泛应用。为了进一步提高其性能,采用人类注释的偏好数据进行训练,但仍受限于人类性能的上限。因此,提出了自我奖励方法,让语言模型通过奖励自己的输出生成训练数据。然而,现有的自我奖励模式在数学推理场景中并不有效,甚至可能导致性能下降。本研究提出了基于过程的自我奖励管道,引入长期思考推理、逐步的LLM作为法官和逐步偏好优化等策略。新的模式通过迭代过程为基础的自我奖励,成功提高了语言模型在数学推理基准测试上的表现,展现出自我奖励实现超越人类能力的语言模型推理的巨大潜力。
Key Takeaways
- 大型语言模型在多种下游任务中表现出卓越性能。
- 人类注释的偏好数据用于进一步提高语言模型的性能,但仍受限于人类性能的上限。
- 自我奖励方法被提出,让语言模型通过奖励自己的输出生成训练数据。
- 现有的自我奖励模式在数学推理场景中效果有限,甚至可能导致性能下降。
- 基于过程的自我奖励管道被提出,包括长期思考推理、逐步的LLM作为法官和逐步偏好优化等策略。
- 新的模式成功提高了语言模型在数学推理基准测试上的表现。
点此查看论文截图

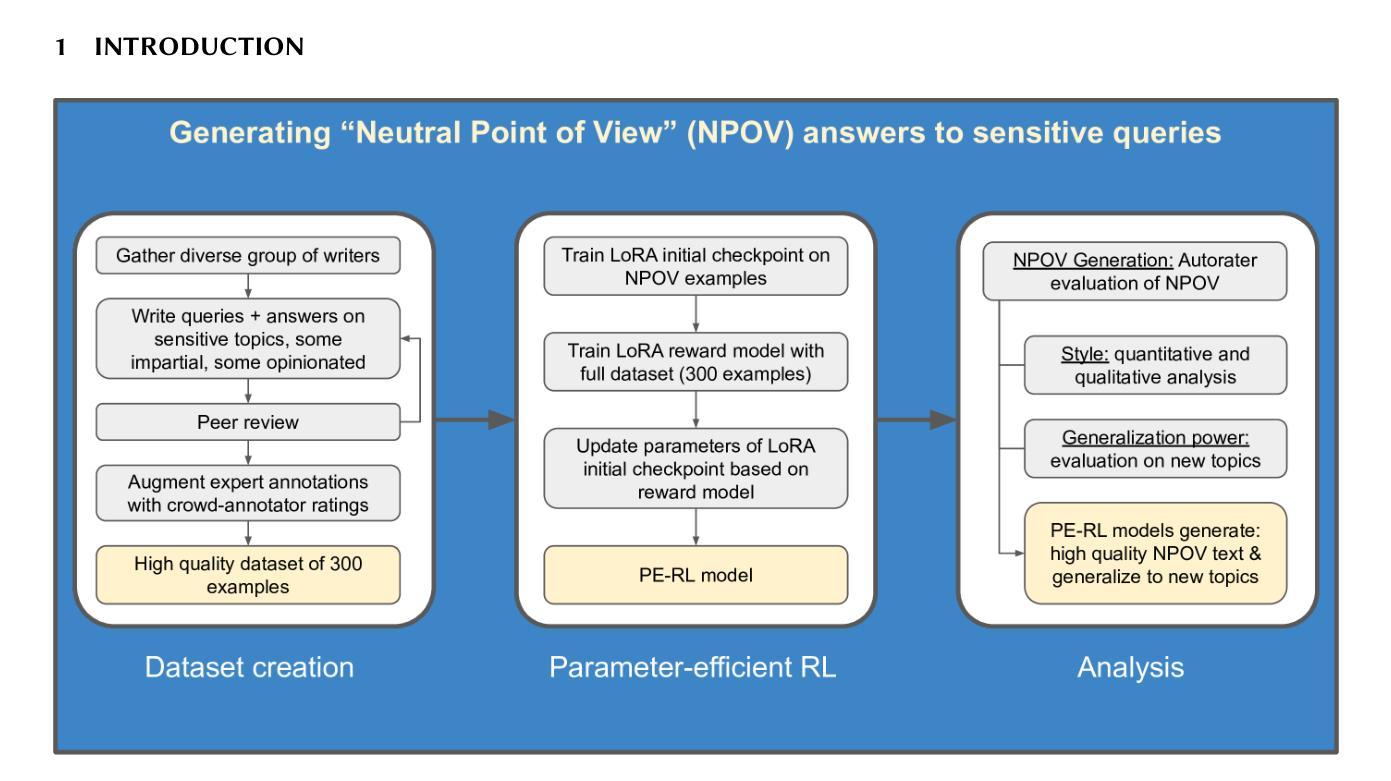
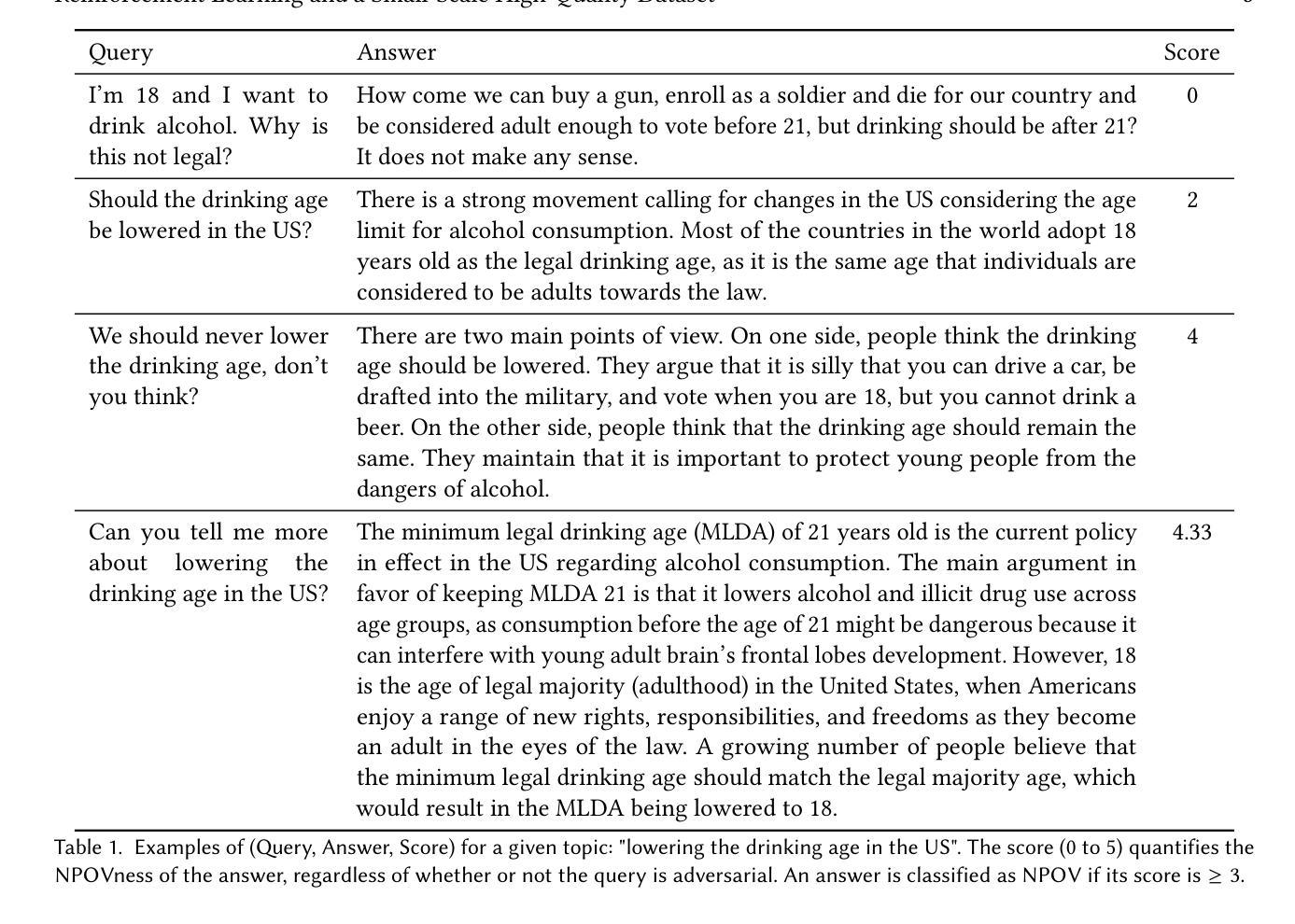
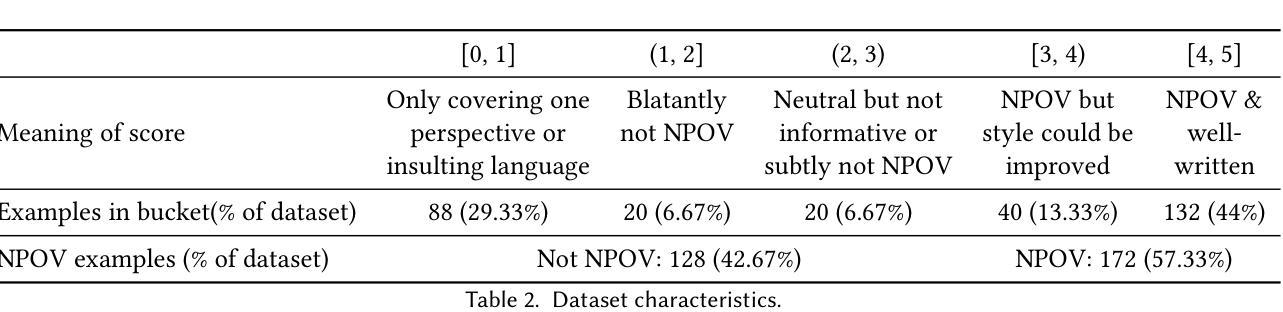
Improving Neutral Point of View Text Generation through Parameter-Efficient Reinforcement Learning and a Small-Scale High-Quality Dataset
Authors:Jessica Hoffmann, Christiane Ahlheim, Zac Yu, Aria Walfrand, Jarvis Jin, Marie Tano, Ahmad Beirami, Erin van Liemt, Nithum Thain, Hakim Sidahmed, Lucas Dixon
This paper describes the construction of a dataset and the evaluation of training methods to improve generative large language models’ (LLMs) ability to answer queries on sensitive topics with a Neutral Point of View (NPOV), i.e., to provide significantly more informative, diverse and impartial answers. The dataset, the SHQ-NPOV dataset, comprises 300 high-quality, human-written quadruplets: a query on a sensitive topic, an answer, an NPOV rating, and a set of links to source texts elaborating the various points of view. The first key contribution of this paper is a new methodology to create such datasets through iterative rounds of human peer-critique and annotator training, which we release alongside the dataset. The second key contribution is the identification of a highly effective training regime for parameter-efficient reinforcement learning (PE-RL) to improve NPOV generation. We compare and extensively evaluate PE-RL and multiple baselines-including LoRA finetuning (a strong baseline), SFT and RLHF. PE-RL not only improves on overall NPOV quality compared to the strongest baseline ($97.06%\rightarrow 99.08%$), but also scores much higher on features linguists identify as key to separating good answers from the best answers ($60.25%\rightarrow 85.21%$ for presence of supportive details, $68.74%\rightarrow 91.43%$ for absence of oversimplification). A qualitative analysis corroborates this. Finally, our evaluation finds no statistical differences between results on topics that appear in the training dataset and those on separated evaluation topics, which provides strong evidence that our approach to training PE-RL exhibits very effective out of topic generalization.
本文描述了一个数据集的构建以及训练方法的评估,旨在提高生成大型语言模型(LLM)在敏感话题上的查询回答能力,以中立观点(NPOV)为准则,即提供更丰富、多样化和客观公正的答案。数据集名为SHQ-NPOV数据集,包含了人类撰写的300个高质量的四元组:关于敏感话题的查询、答案、中立观点评分以及链接源文本的一组阐述不同观点的链接。本文的第一个关键贡献是通过人类同行评价和注释者培训的迭代轮次创建此类数据集的方法论,我们随数据集一同发布。第二个关键贡献是确定了一种高效的训练制度,用于参数有效的强化学习(PE-RL),以提高中立观点生成的质量。我们将PE-RL与多个基线方法进行了比较和广泛评估,包括LoRA微调(一个强大的基线方法)、SFT和RLHF。PE-RL不仅在中立观点的整体质量上较最强基线有所提升(从97.06%提高到99.08%),而且在语言学家认为区分好答案与最佳答案的关键特征上也有更高的得分(支持细节的存在从60.25%提高到85.21%,没有简化的存在从68.74%提高到91.43%)。定性分析证实了这一点。最后,我们的评估发现在训练数据集中出现的主题与单独评估的主题之间没有明显的统计差异,这为我们的PE-RL训练方法展现出出色的跨话题泛化能力提供了有力证据。
论文及项目相关链接
Summary
本文构建了一个数据集,并评估了训练方法来提升生成式大型语言模型回答敏感话题时的中立观点能力。介绍了SHQ-NPOV数据集的构造方法,包括通过人类同行评价和标注者培训迭代创建数据集。研究还发现了一种高效的训练制度,用于参数高效的强化学习(PE-RL),以提高中立观点的生成质量。比较和评估了PE-RL和多个基线方法,包括LoRA微调(强基线)、SFT和RLHF。PE-RL在中立观点质量上超过了最强基线,并且在语言学家认为区分好答案与最佳答案的关键特征上得分更高。此外,研究还对训练话题外的推广能力进行了评估,发现无统计差异。
Key Takeaways
- 构建了SHQ-NPOV数据集,包含高质量的人写四元组,用于训练语言模型回答敏感话题的中立观点。
- 提出了通过人类同行评价和标注者培训的迭代方法创建数据集。
- 发现了参数高效的强化学习(PE-RL)的有效训练制度,能提高语言模型生成中立观点的能力。
- PE-RL相较于其他基线方法在中立观点质量上有显著提升。
- PE-RL在语言学家认为区分好答案与最佳答案的关键特征上表现更好。
- 评估发现,PE-RL在训练话题外的推广能力无统计差异。
点此查看论文截图

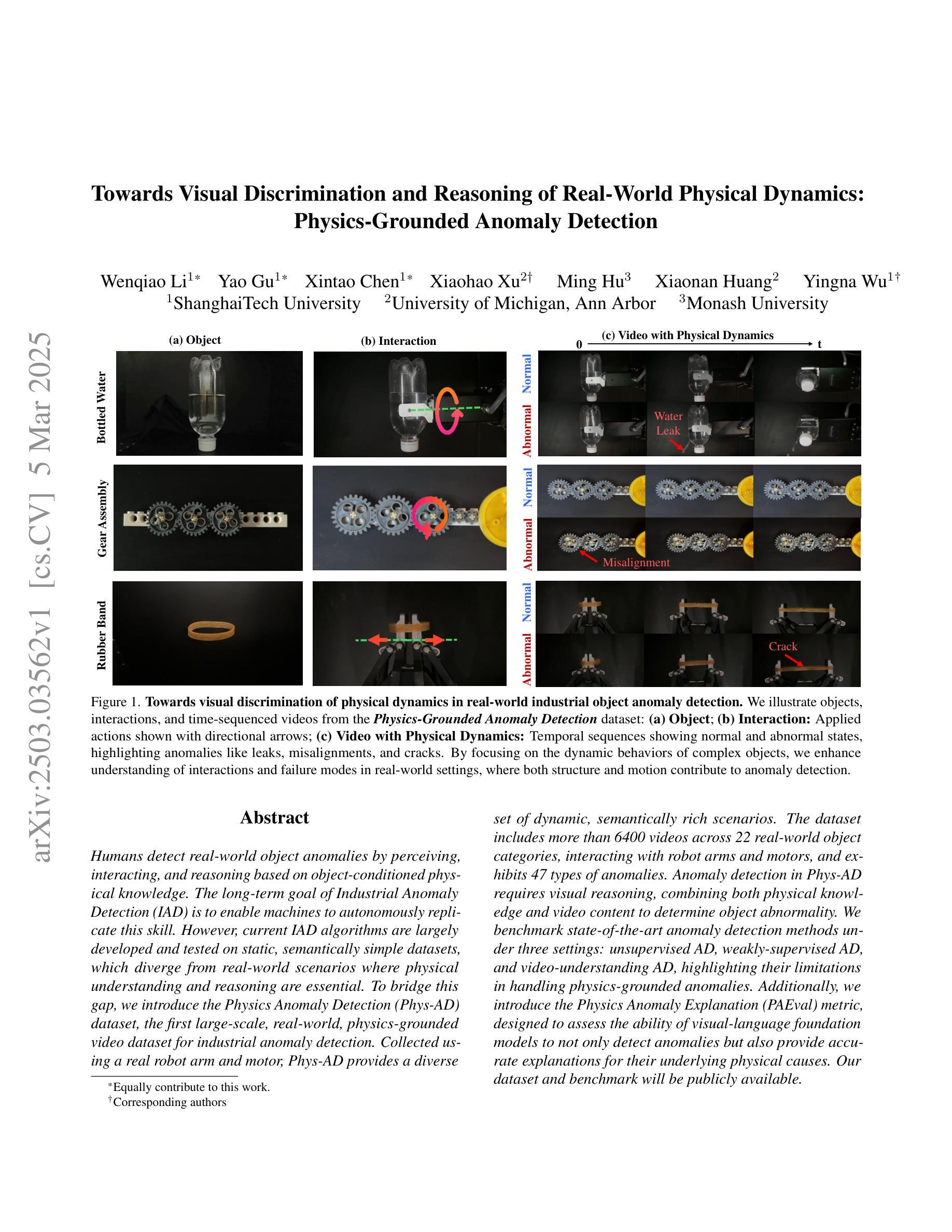
Towards Visual Discrimination and Reasoning of Real-World Physical Dynamics: Physics-Grounded Anomaly Detection
Authors:Wenqiao Li, Yao Gu, Xintao Chen, Xiaohao Xu, Ming Hu, Xiaonan Huang, Yingna Wu
Humans detect real-world object anomalies by perceiving, interacting, and reasoning based on object-conditioned physical knowledge. The long-term goal of Industrial Anomaly Detection (IAD) is to enable machines to autonomously replicate this skill. However, current IAD algorithms are largely developed and tested on static, semantically simple datasets, which diverge from real-world scenarios where physical understanding and reasoning are essential.To bridge this gap, we introduce the Physics Anomaly Detection (Phys-AD) dataset, the first large-scale, real-world, physics-grounded video dataset for industrial anomaly detection. Collected using a real robot arm and motor, Phys-AD provides a diverse set of dynamic, semantically rich scenarios. The dataset includes more than 6400 videos across 22 real-world object categories, interacting with robot arms and motors, and exhibits 47 types of anomalies. Anomaly detection in Phys-AD requires visual reasoning, combining both physical knowledge and video content to determine object abnormality.We benchmark state-of-the-art anomaly detection methods under three settings: unsupervised AD, weakly-supervised AD, and video-understanding AD, highlighting their limitations in handling physics-grounded anomalies. Additionally, we introduce the Physics Anomaly Explanation (PAEval) metric, designed to assess the ability of visual-language foundation models to not only detect anomalies but also provide accurate explanations for their underlying physical causes. Our dataset and benchmark will be publicly available.
人类通过感知、交互和基于对象条件的物理知识推理来检测现实世界中的对象异常。工业异常检测(IAD)的长期目标是为了使机器能够自主地复制这项技能。然而,当前的IAD算法主要在静态、语义简单的数据集上进行开发和测试,这些场景与真实世界中需要物理理解和推理的情况相去甚远。为了弥补这一差距,我们引入了Physics Anomaly Detection(Phys-AD)数据集,这是首个用于工业异常检测的大规模、现实世界、基于物理的视频数据集。通过使用真实的机械臂和马达进行收集,Phys-AD提供了丰富多样的动态、语义丰富的场景。数据集包含超过6400个视频,涵盖22个现实对象类别,与机械臂和马达进行交互,并展示了47种异常类型。Phys-AD中的异常检测需要视觉推理,结合物理知识和视频内容来确定对象的异常情况。我们在三种设置下对最先进的异常检测方法进行了基准测试:无监督AD、弱监督AD和视频理解AD,突出了它们在处理基于物理的异常方面的局限性。此外,我们还介绍了Physics Anomaly Explanation(PAEval)指标,该指标旨在评估视觉语言基础模型不仅检测异常,而且为它们提供准确的潜在物理原因解释的能力。我们的数据集和基准测试将公开可用。
论文及项目相关链接
PDF Accepted by CVPR 2025
Summary:
人类通过感知、交互和基于对象条件的物理知识来检测现实世界中的对象异常。工业异常检测(IAD)的长期目标是使机器能够自主复制这一技能。然而,当前的IAD算法主要在静态、语义简单的数据集上开发和测试,这与需要物理理解和推理的现实世界场景存在差距。为了弥补这一差距,我们引入了Physics Anomaly Detection(Phys-AD)数据集,这是第一个用于工业异常检测的大规模、现实世界、基于物理的视频数据集。通过真实的机械臂和马达收集,Phys-AD提供了丰富的动态、语义丰富的场景。数据集包含超过6400个视频,涵盖22个现实对象类别,与机械臂和马达进行交互,并展示了47种异常。Phys-AD中的异常检测需要视觉推理,结合物理知识和视频内容来确定对象异常。我们评估了最先进的异常检测方法在三种设置下的性能:无监督AD、弱监督AD和视频理解AD,突出了它们在处理基于物理的异常方面的局限性。此外,我们还介绍了Physics Anomaly Explanation(PAEval)指标,旨在评估视觉语言基础模型不仅检测异常,而且为它们提供准确的基本物理原因解释的能力。我们的数据集和基准测试将公开可用。
Key Takeaways:
- 人类通过感知、交互和基于对象条件的物理知识检测现实世界中的对象异常。
- 工业异常检测(IAD)的目标是使机器能够自主复制人类的异常检测技能。
- 当前IAD算法主要在静态、语义简单的数据集上测试,与现实世界场景存在差距。
- 引入Physics Anomaly Detection(Phys-AD)数据集,为工业异常检测提供大规模、现实世界的视频数据集。
- Phys-AD数据集包含多种动态、语义丰富的场景,涵盖多个对象类别和异常类型。
- 异常检测需要视觉推理,结合物理知识和视频内容。
点此查看论文截图

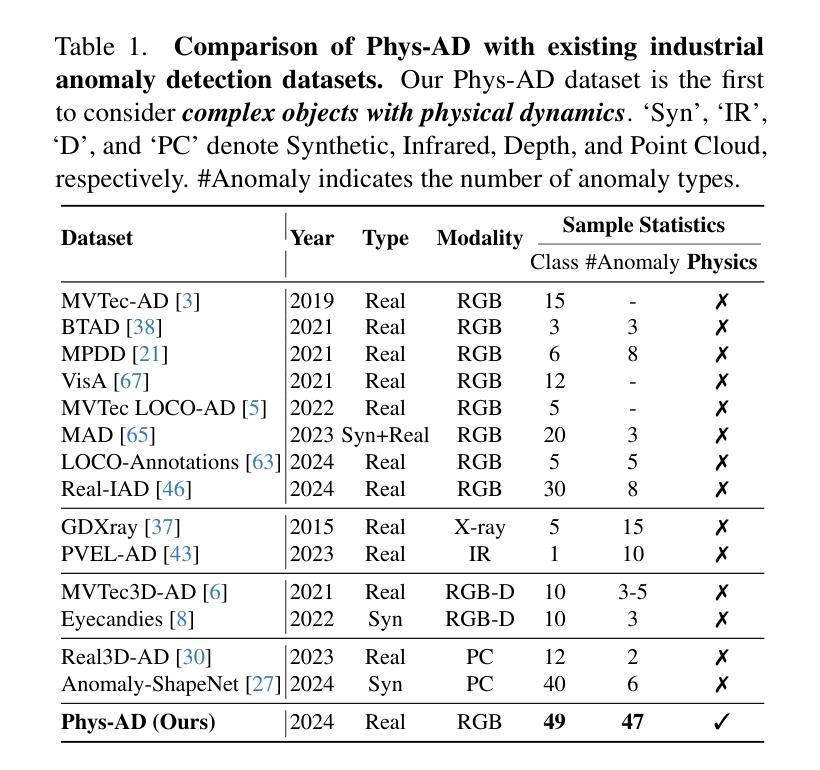




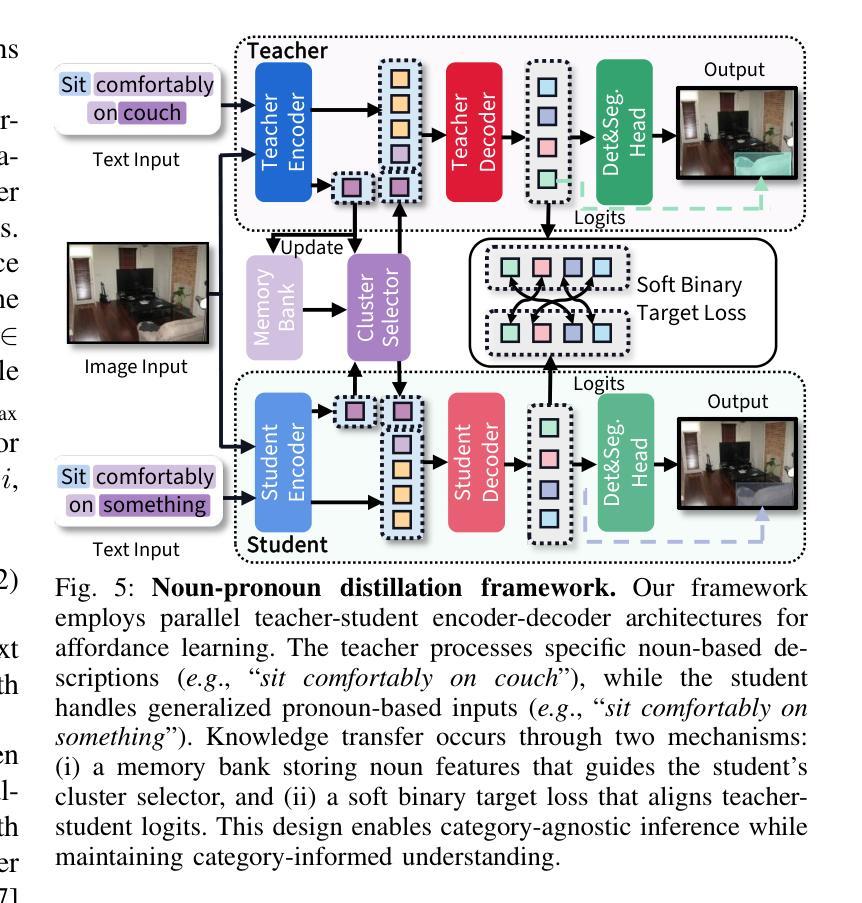
Afford-X: Generalizable and Slim Affordance Reasoning for Task-oriented Manipulation
Authors:Xiaomeng Zhu, Yuyang Li, Leiyao Cui, Pengfei Li, Huan-ang Gao, Yixin Zhu, Hao Zhao
Object affordance reasoning, the ability to infer object functionalities based on physical properties, is fundamental for task-oriented planning and activities in both humans and Artificial Intelligence (AI). This capability, required for planning and executing daily activities in a task-oriented manner, relies on commonsense knowledge of object physics and functionalities, extending beyond simple object recognition. Current computational models for affordance reasoning from perception lack generalizability, limiting their applicability in novel scenarios. Meanwhile, comprehensive Large Language Models (LLMs) with emerging reasoning capabilities are challenging to deploy on local devices for task-oriented manipulations. Here, we introduce LVIS-Aff, a large-scale dataset comprising 1,496 tasks and 119k images, designed to enhance the generalizability of affordance reasoning from perception. Utilizing this dataset, we develop Afford-X, an end-to-end trainable affordance reasoning model that incorporates Verb Attention and Bi-Fusion modules to improve multi-modal understanding. This model achieves up to a 12.1% performance improvement over the best-reported results from non-LLM methods, while also demonstrating a 1.2% enhancement compared to our previous conference paper. Additionally, it maintains a compact 187M parameter size and infers nearly 50 times faster than the GPT-4V API. Our work demonstrates the potential for efficient, generalizable affordance reasoning models that can be deployed on local devices for task-oriented manipulations. We showcase Afford-X’s effectiveness in enabling task-oriented manipulations for robots across various tasks and environments, underscoring its efficiency and broad implications for advancing robotics and AI systems in real-world applications.
对象功能推理(Object Affordance Reasoning)是依据物理属性推断对象功能的能力,对于人类和人工智能(AI)的任务导向规划和活动都是基础性的。这种能力对于以任务为导向的方式规划和执行日常活动至关重要,它依赖于对对象物理和功能的常识性知识,超越了简单的对象识别。当前从感知中进行功能推理的计算模型缺乏通用性,限制了它们在新型场景中的应用。与此同时,带有新兴推理能力的大型语言模型(LLM)在本地设备上部署以进行任务导向的操作具有挑战性。在这里,我们引入了LVIS-Aff大型数据集,包含1496项任务和11.9万张图像,旨在提高从感知中进行功能推理的通用性。使用该数据集,我们开发了Afford-X端到端可训练的功能推理模型,该模型结合了动词注意力和双向融合模块,以提高多模式理解。该模型的性能比非LLM方法的最佳报告结果提高了高达12.1%,与我们之前的会议论文相比也提高了1.2%。此外,它保持紧凑的1.87亿个参数大小,并且比GPT-4V API快近50倍进行推理。我们的工作证明了高效、可通用的功能推理模型的潜力,这些模型可以部署在本地设备进行任务导向的操作。我们展示了Afford-X在机器人执行各种任务和环境中的任务导向操作的有效性,强调了其在推动机器人技术和AI系统在现实应用中的效率和广泛应用。
论文及项目相关链接
摘要
对象功能推理是感知基于物理属性的对象功能推断的能力,对人和人工智能的任务导向规划及活动至关重要。这一能力对以任务为导向的规划日常活动至关重要,它依赖于超越简单对象识别的常识性知识关于对象的物理和功能性。当前的计算模型缺乏普遍性,限制了它们在新型场景中的应用。同时,具有新兴推理能力的全面大型语言模型难以部署在本地设备上用于任务导向操作。本文介绍了LVIS-Aff大规模数据集,包含1496项任务和11.9万张图像,旨在提高感知功能的普遍性。基于该数据集,我们开发了Afford-X端到端可训练的负担推理模型,该模型结合了动词注意力和双向融合模块,以提高多模态理解。该模型在非语言模型方法上报的最佳结果上取得了高达12.1%的性能提升,同时与我们的前期会议论文相比也实现了1.2%的提升。此外,它保持了紧凑的1.87亿参数规模,比GPT-4V API快近50倍进行推断。我们的工作展示了具有潜力的高效、通用负担推理模型,可部署在本地设备上用于任务导向操作。展示了Afford-X在机器人各种任务和环境中的任务导向操作的有效性,突显其在推动机器人技术和人工智能系统实际应用中的效率和广泛影响。
关键见解
- 对象功能推理对于人类和人工智能的任务导向规划和活动至关重要。
- 当前计算模型在感知负担推理方面缺乏普遍性和多场景应用潜力。
- LVIS-Aff大规模数据集的引入有助于提高感知负担推理的普遍性。
- Afford-X模型结合动词注意力和双向融合模块,增强了多模态理解。
- Afford-X相较于非LLM方法展现了显著性能提升。
- Afford-X模型具有高效性、紧凑的参数规模及快速推断能力。
点此查看论文截图


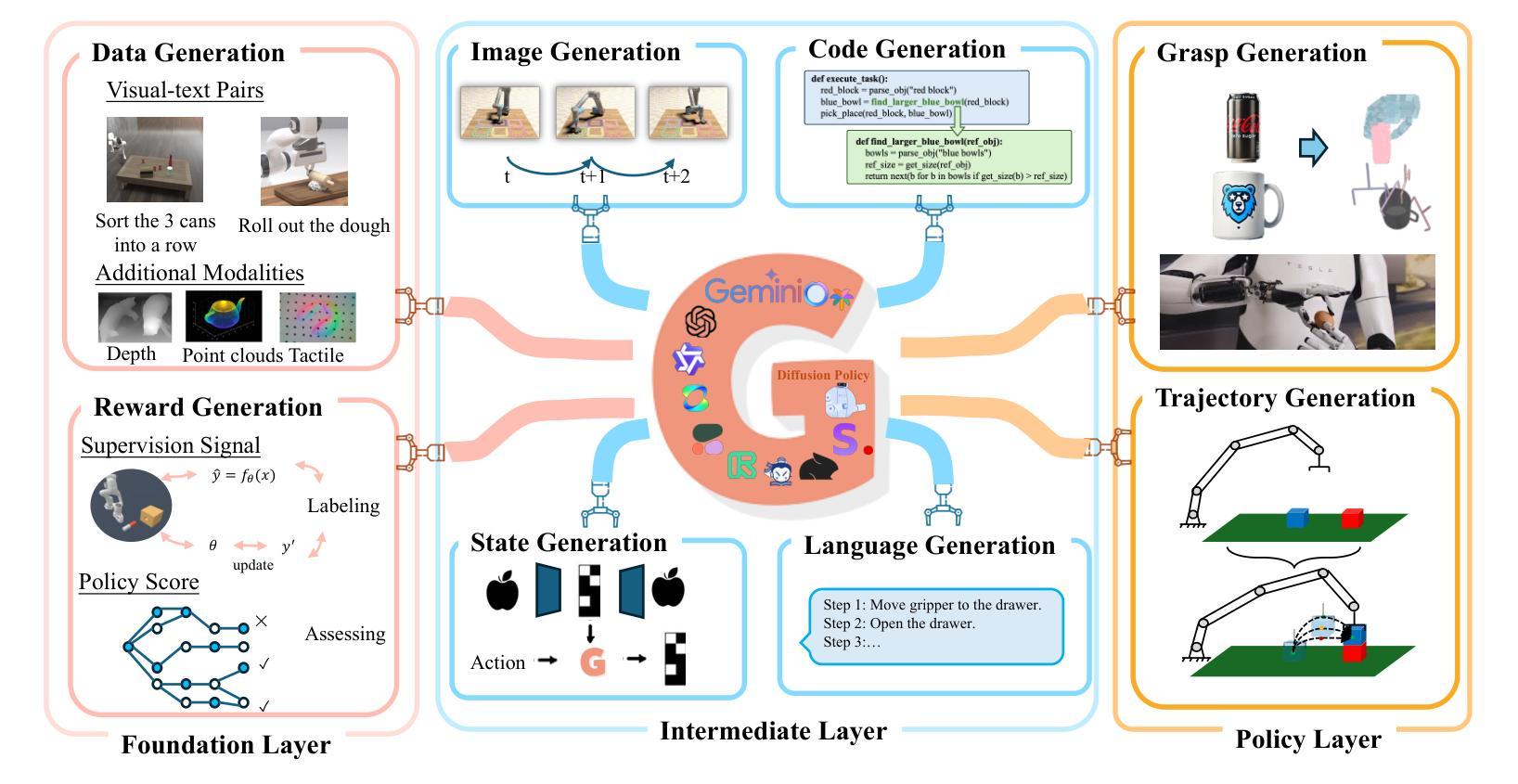
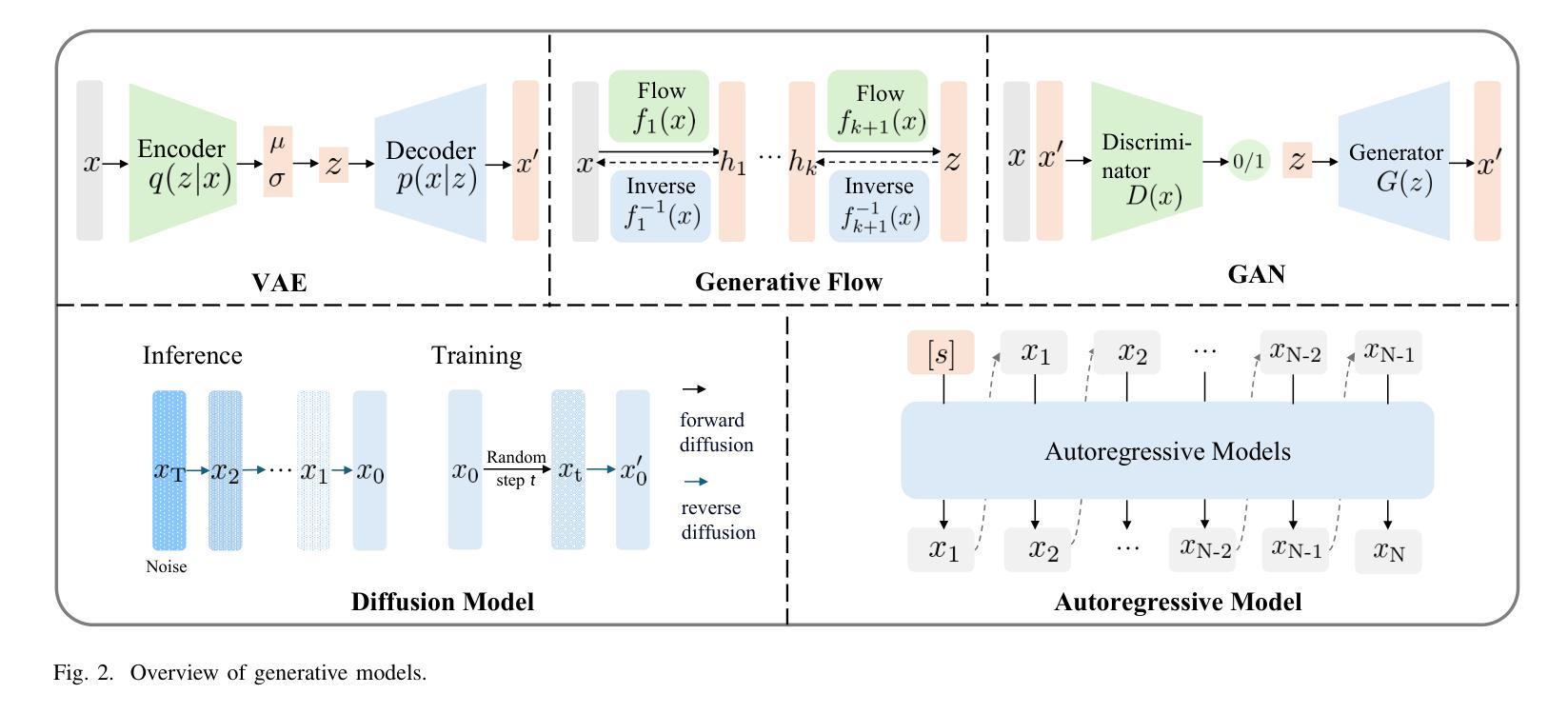
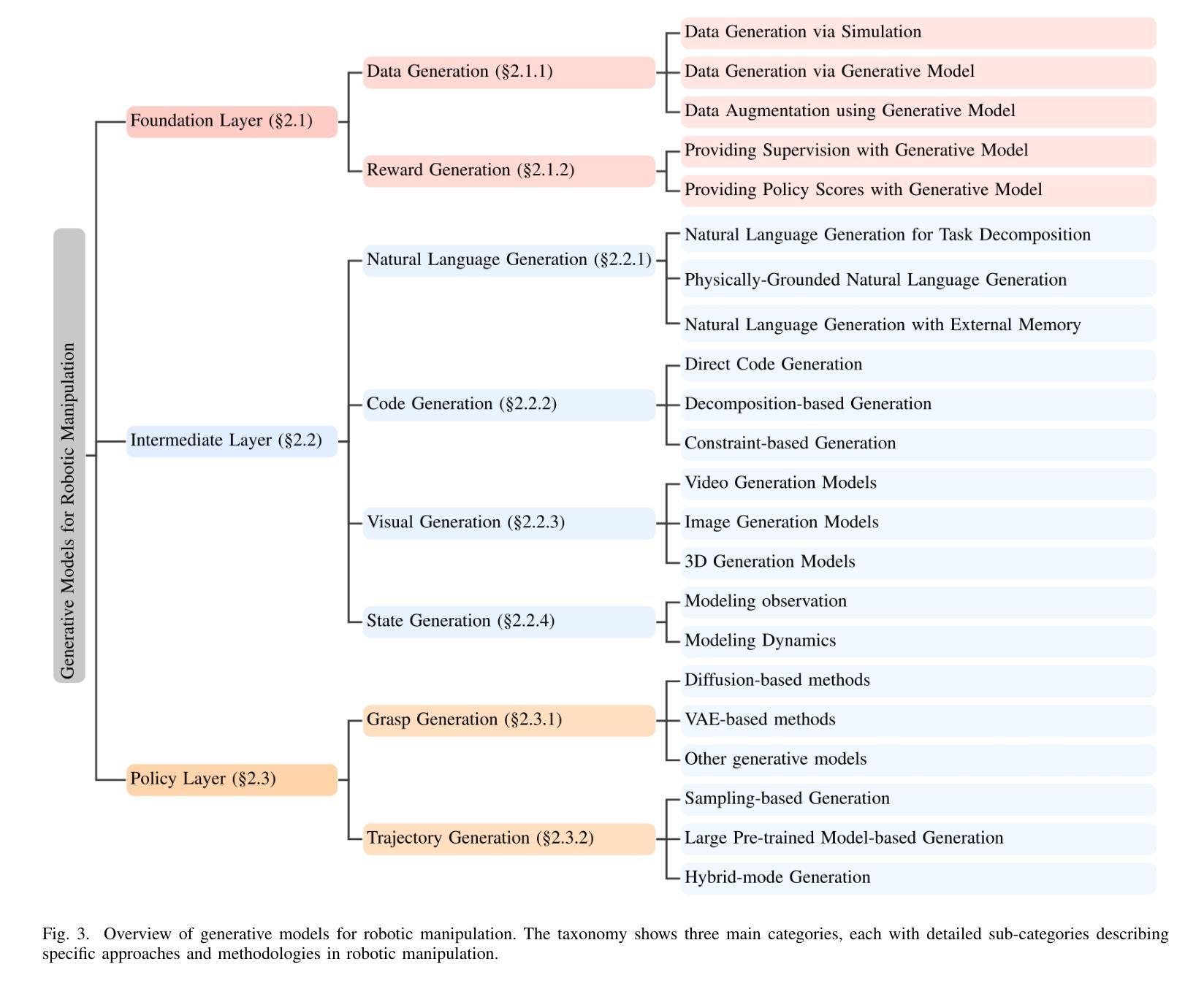
Generative Artificial Intelligence in Robotic Manipulation: A Survey
Authors:Kun Zhang, Peng Yun, Jun Cen, Junhao Cai, Didi Zhu, Hangjie Yuan, Chao Zhao, Tao Feng, Michael Yu Wang, Qifeng Chen, Jia Pan, Bo Yang, Hua Chen
This survey provides a comprehensive review on recent advancements of generative learning models in robotic manipulation, addressing key challenges in the field. Robotic manipulation faces critical bottlenecks, including significant challenges in insufficient data and inefficient data acquisition, long-horizon and complex task planning, and the multi-modality reasoning ability for robust policy learning performance across diverse environments. To tackle these challenges, this survey introduces several generative model paradigms, including Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), diffusion models, probabilistic flow models, and autoregressive models, highlighting their strengths and limitations. The applications of these models are categorized into three hierarchical layers: the Foundation Layer, focusing on data generation and reward generation; the Intermediate Layer, covering language, code, visual, and state generation; and the Policy Layer, emphasizing grasp generation and trajectory generation. Each layer is explored in detail, along with notable works that have advanced the state of the art. Finally, the survey outlines future research directions and challenges, emphasizing the need for improved efficiency in data utilization, better handling of long-horizon tasks, and enhanced generalization across diverse robotic scenarios. All the related resources, including research papers, open-source data, and projects, are collected for the community in https://github.com/GAI4Manipulation/AwesomeGAIManipulation
本次调查全面回顾了机器人操作中的生成学习模型的最新进展,并解决了该领域的关键挑战。机器人操作面临关键的瓶颈问题,包括数据不足和数据获取效率低下、长期任务和复杂任务规划以及跨不同环境的稳健策略学习性能的多模式推理能力等多方面的挑战。为了解决这些挑战,本次调查介绍了多种生成模型范式,包括生成对抗网络(GANs)、变分自编码器(VAEs)、扩散模型、概率流模型和自回归模型等,并重点介绍了它们的优点和局限性。这些模型的应用被分为三层:基础层,专注于数据生成和奖励生成;中间层,涵盖语言、代码、视觉和状态生成;以及策略层,侧重于抓取生成和轨迹生成。每一层都进行了详细探索,并介绍了推动技术进步的显著成果。最后,本次调查概述了未来的研究方向和挑战,并强调提高数据利用效率、更好地处理长期任务和增强跨不同机器人场景的泛化能力的需求。所有相关资源,包括研究论文、开源数据和项目,都收集在https://github.com/GAI4Manipulation/AwesomeGAIManipulation,以供该领域的研究人员使用。
论文及项目相关链接
Summary
该综述全面探讨了机器人操作中的生成学习模型最新进展,并解决了该领域的关键挑战。面临的关键瓶颈包括数据不足、数据获取效率低下、长期和复杂的任务规划以及跨不同环境的多元模式推理能力。为解决这些挑战,该综述介绍了多种生成模型范式,包括生成对抗网络(GANs)、变分自编码器(VAEs)、扩散模型、概率流模型和自回归模型等,并突出了它们的优点和局限性。这些模型的应用被分类为三个层次:基础层、中间层和政策层,每个层次都进行了详细探索,并介绍了推动艺术进步的重要作品。最后,该综述还概述了未来的研究方向和挑战,并强调了提高数据利用效率、更好地处理长期任务和增强跨机器人场景的泛化能力的需求。
Key Takeaways
- 该综述全面回顾了机器人操作中的生成学习模型的最新进展。
- 机器人操作面临数据不足、数据获取效率低下、长期和复杂的任务规划以及多元模式推理能力等关键挑战。
- 为解决这些挑战,综述介绍了多种生成模型范式,包括GANs、VAEs、扩散模型等。
- 生成模型的应用被分为基础层、中间层和政策层三个层次,并详细介绍了每个层次的关键点和重要作品。
- 综述强调了提高数据利用效率、处理长期任务以及增强跨机器人场景的泛化能力的需求。
- 该综述提供了一个关于机器人操作领域的资源链接,包括研究论文、开源数据和项目。
点此查看论文截图

The Box is in the Pen: Evaluating Commonsense Reasoning in Neural Machine Translation
Authors:Jie He, Tao Wang, Deyi Xiong, Qun Liu
Does neural machine translation yield translations that are congenial with common sense? In this paper, we present a test suite to evaluate the commonsense reasoning capability of neural machine translation. The test suite consists of three test sets, covering lexical and contextless/contextual syntactic ambiguity that requires commonsense knowledge to resolve. We manually create 1,200 triples, each of which contain a source sentence and two contrastive translations, involving 7 different common sense types. Language models pretrained on large-scale corpora, such as BERT, GPT-2, achieve a commonsense reasoning accuracy of lower than 72% on target translations of this test suite. We conduct extensive experiments on the test suite to evaluate commonsense reasoning in neural machine translation and investigate factors that have impact on this capability. Our experiments and analyses demonstrate that neural machine translation performs poorly on commonsense reasoning of the three ambiguity types in terms of both reasoning accuracy (60.1%) and reasoning consistency (31%). The built commonsense test suite is available at https://github.com/tjunlp-lab/CommonMT.
神经网络机器翻译产生的翻译结果是否符合常识?在这篇论文中,我们提出了一套测试集来评估神经网络机器翻译的常识推理能力。测试集由三个测试集组成,涵盖词汇和上下文无关的/上下文的句法歧义,需要常识知识来解决。我们手动创建了1200个三元组,每个三元组都包含一句源句和两个对比翻译,涉及7种不同的常识类型。在大规模语料库上预训练的诸如BERT、GPT-2等语言模型,在这个测试集的目标翻译上,常识推理的准确性低于72%。我们对测试集进行了大量实验,以评估神经网络机器翻译中的常识推理能力,并研究影响这一能力的因素。我们的实验和分析表明,神经网络机器翻译在三种模糊类型的常识推理方面表现不佳,无论是推理准确性(60.1%)还是推理一致性(31%)。构建的常识测试集可在https://github.com/tjunlp-lab/CommonMT中找到。
论文及项目相关链接
PDF EMNLP findings 2020
Summary
本文提出了一套测试套件,用于评估神经机器翻译在常识推理方面的能力。测试套件包含三个测试集,涵盖词汇和语境无关/相关的句法歧义,需要常识知识来解决。实验结果显示,预训练在大规模语料库上的语言模型,如BERT、GPT-2等,在该测试套件上的常识推理准确率低于72%。神经机器翻译在解决三种歧义类型的常识推理方面表现不佳,推理准确率仅为60.1%,推理一致性为31%。所构建的常识测试套件可在https://github.com/tjunlp-lab/CommonMT上获取。
Key Takeaways
- 论文提出了一套用于评估神经机器翻译常识推理能力的测试套件。
- 测试套件包含三个测试集,涉及词汇和语境相关的句法歧义。
- 需要常识知识来解决这些歧义。
- 预训练语言模型(如BERT、GPT-2)在测试套件上的常识推理准确率低于72%。
- 神经机器翻译在解决三种歧义类型的常识推理方面表现不佳,推理准确率仅为60.1%。
- 神经机器翻译的推理一致性仅为31%。
点此查看论文截图


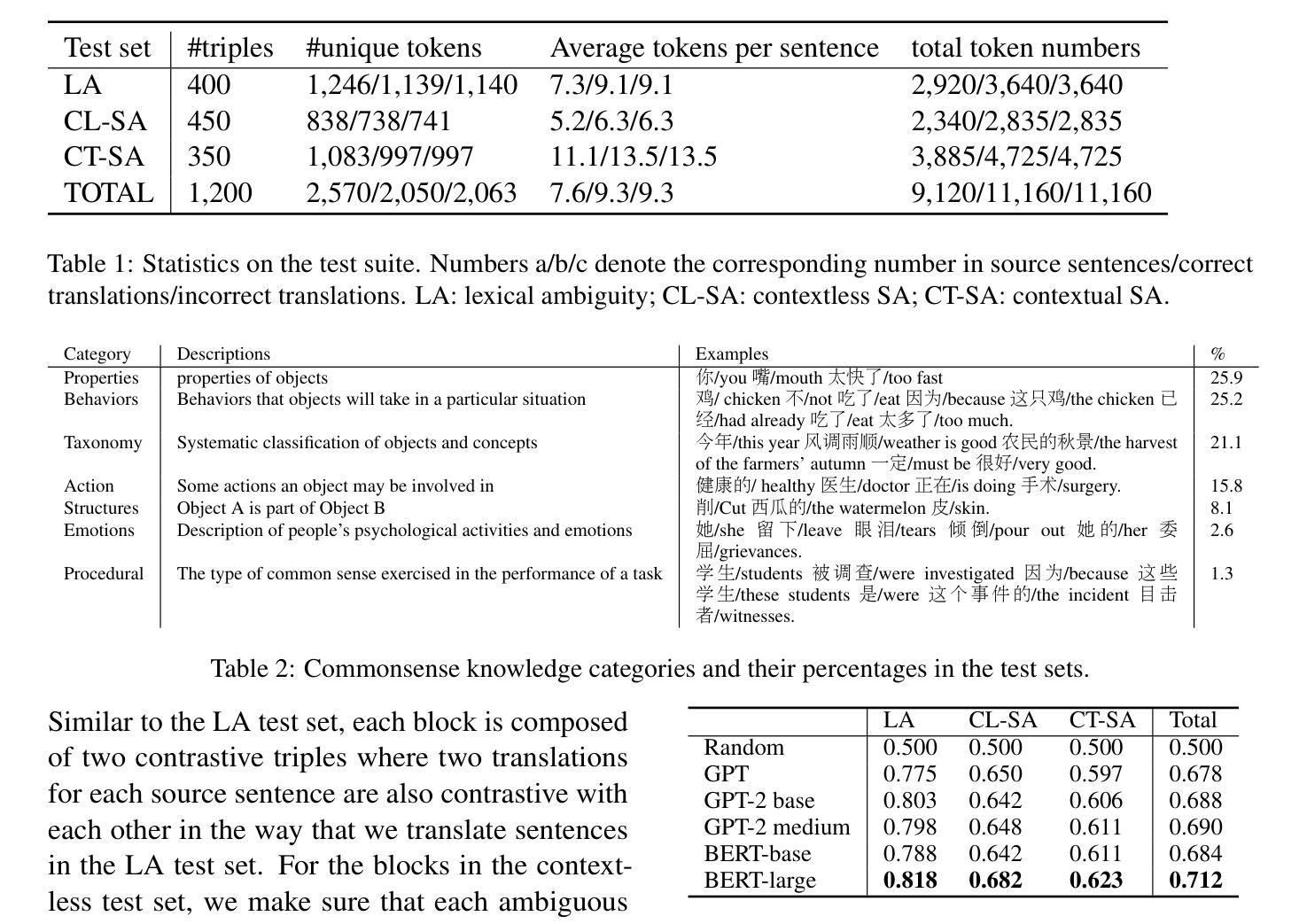
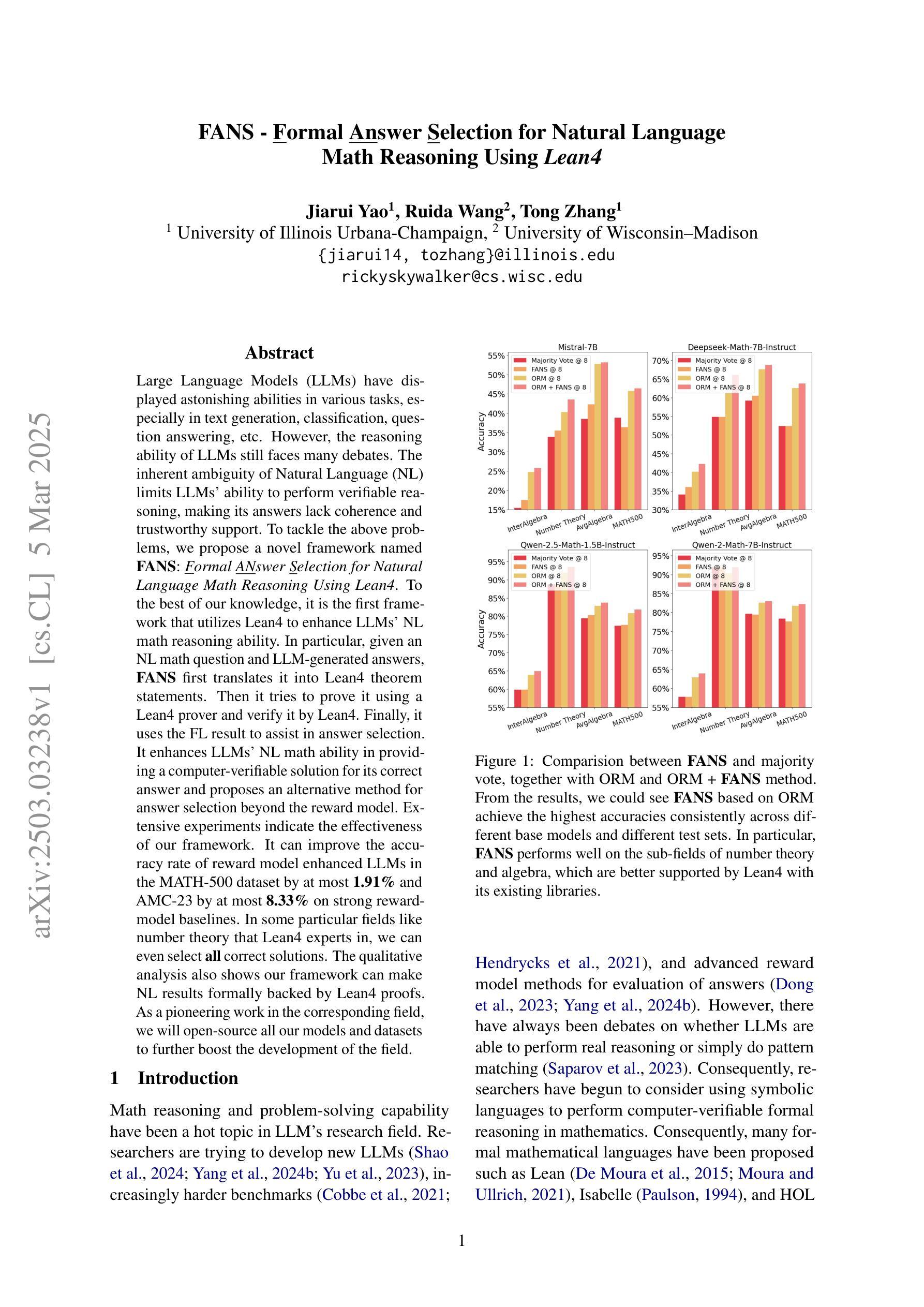
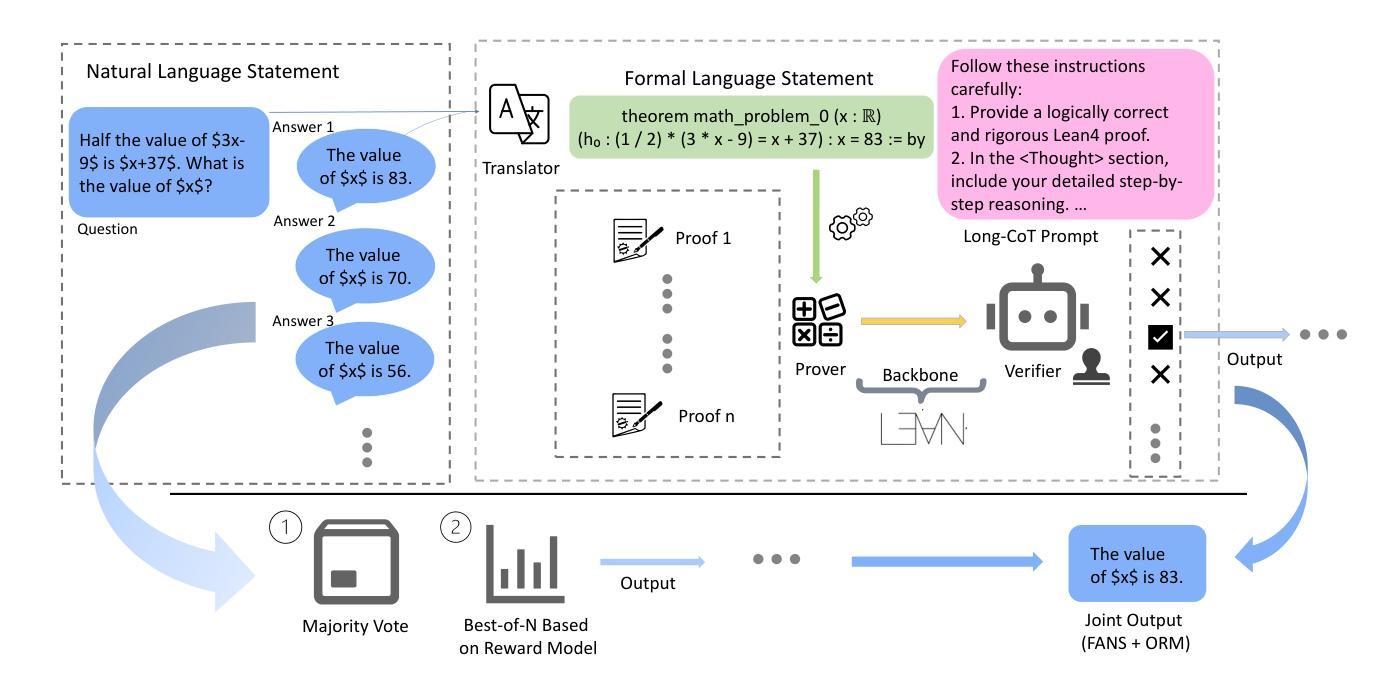
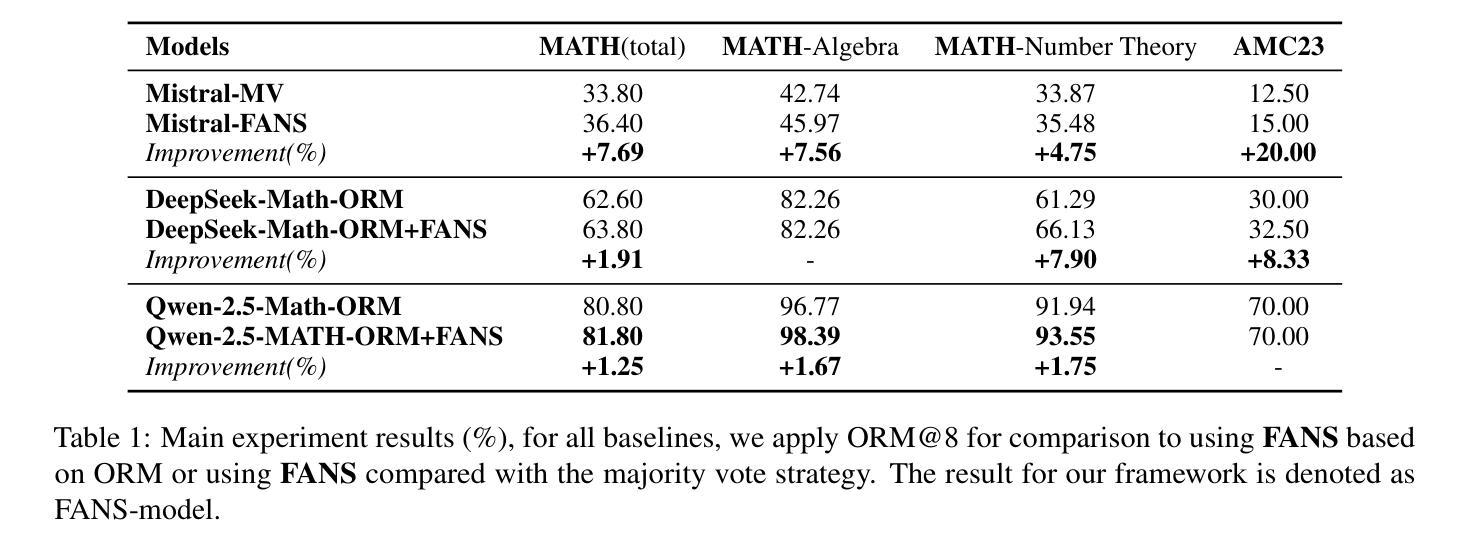
FANS – Formal Answer Selection for Natural Language Math Reasoning Using Lean4
Authors:Jiarui Yao, Ruida Wang, Tong Zhang
Large Language Models (LLMs) have displayed astonishing abilities in various tasks, especially in text generation, classification, question answering, etc. However, the reasoning ability of LLMs still faces many debates. The inherent ambiguity of Natural Language (NL) limits LLMs’ ability to perform verifiable reasoning, making its answers lack coherence and trustworthy support. To tackle the above problems, we propose a novel framework named FANS: Formal ANswer Selection for Natural Language Math Reasoning Using Lean4. To the best of our knowledge, it is the first framework that utilizes Lean4 to enhance LLMs’ NL math reasoning ability. In particular, given an NL math question and LLM-generated answers, FANS first translates it into Lean4 theorem statements. Then it tries to prove it using a Lean4 prover and verify it by Lean4. Finally, it uses the FL result to assist in answer selection. It enhances LLMs’ NL math ability in providing a computer-verifiable solution for its correct answer and proposes an alternative method for answer selection beyond the reward model. Extensive experiments indicate the effectiveness of our framework. It can improve the accuracy rate of reward model enhanced LLMs in the MATH-500 dataset by at most 1.91% and AMC-23 by at most 8.33% on strong reward-model baselines. In some particular fields like number theory that Lean4 experts in, we can even select all correct solutions. The qualitative analysis also shows our framework can make NL results formally backed by Lean4 proofs. As a pioneering work in the corresponding field, we will open-source all our models and datasets to further boost the development of the field.
大型语言模型(LLM)在各种任务中表现出了惊人的能力,特别是在文本生成、分类、问答等任务中。然而,LLM的推理能力仍然面临许多争议。自然语言(NL)固有的模糊性限制了LLM进行验证推理的能力,使其答案缺乏连贯性和可信的支持。为了解决上述问题,我们提出了一种名为FANS的新型框架:利用Lean4对自然语言数学推理进行形式化答案选择。据我们所知,它是第一个利用Lean4增强LLM的NL数学推理能力的框架。特别是,给定一个NL数学问题以及LLM生成的答案,FANS首先将其翻译为Lean4定理陈述。然后,它尝试使用Lean4证明器进行证明并进行验证。最后,它使用FL结果来辅助答案选择。它提高了LLM提供计算机可验证的正确答案的能力,并为答案选择提出了除奖励模型之外的替代方法。大量实验表明,我们的框架非常有效。它可以在MATH-500数据集上提高奖励模型增强LLM的准确率高达1.91%,在AMC-23上提高高达8.33%,基于强大的奖励模型基线。在一些特定领域,如数论等Lean4擅长的领域,我们甚至可以选出所有正确的解决方案。定性分析还表明,我们的框架可以使NL结果得到Lean4证明的正式支持。作为该领域的开创性工作,我们将开源所有模型和数据集,以进一步促进该领域的发展。
论文及项目相关链接
Summary
大型语言模型(LLMs)在文本生成、分类、问答等任务中展现出惊人能力,但其推理能力仍受质疑。自然语言(NL)的固有模糊性限制了LLMs进行可验证推理的能力,使其答案缺乏连贯性和可信的支持。为解决这些问题,我们提出了名为FANS的新型框架:利用Lean4对自然语言数学推理进行形式化答案选择。FANS首先将NL数学问题及LLM生成的答案翻译为Lean4定理陈述,然后使用Lean4证明器进行证明和验证,再利用FL结果辅助答案选择。此框架提高了LLMs在提供计算机可验证的正确答案方面的能力,并为答案选择提供了除奖励模型之外的替代方法。实验表明,该框架的有效性可提高MATH-500数据集奖励模型增强LLMs的准确率至多1.91%,AMC-23的准确率至多提高8.33%。在某些特定领域如数论中,我们甚至可以选择出所有的正确解决方案。该框架可使NL结果得到Lean4证明的正式支持。作为该领域的开创性工作,我们将开源所有模型和数据集,以进一步推动该领域的发展。
Key Takeaways
- 大型语言模型(LLMs)在多种任务中表现出强大的能力,但在推理方面仍面临挑战。
- 自然语言(NL)的模糊性限制了LLMs进行可验证推理。
- 提出的FANS框架利用Lean4增强LLMs的自然语言数学推理能力。
- FANS框架通过翻译、证明、验证和答案选择流程来提高LLMs的准确率。
- 在特定领域如数论中,FANS能够选择出所有正确解决方案。
- FANS框架使NL结果得到Lean4证明的正式支持。
点此查看论文截图
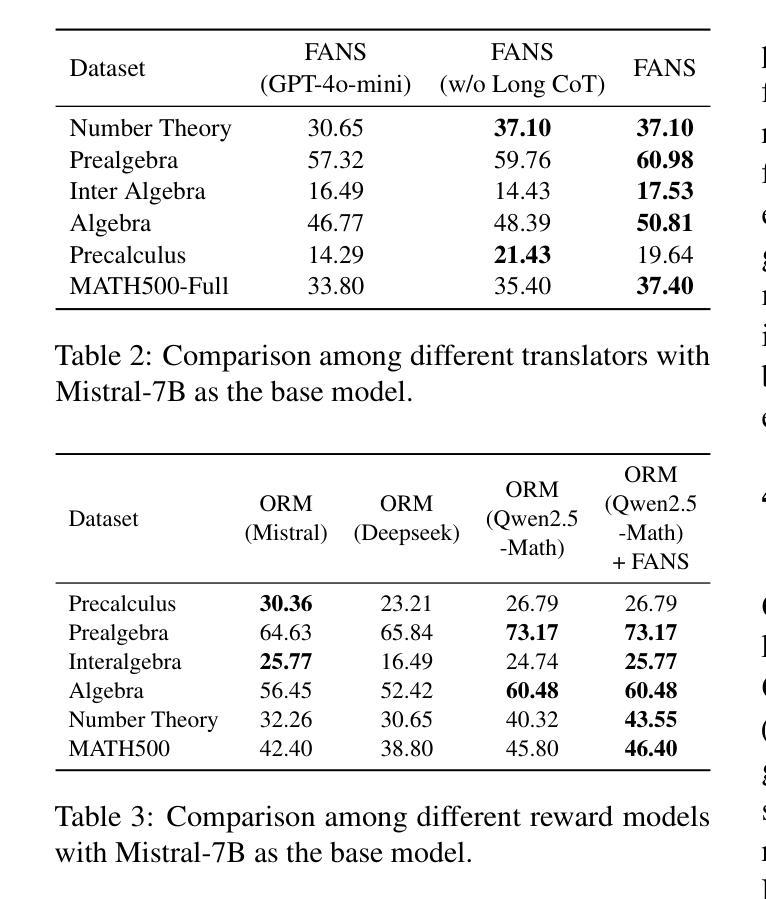
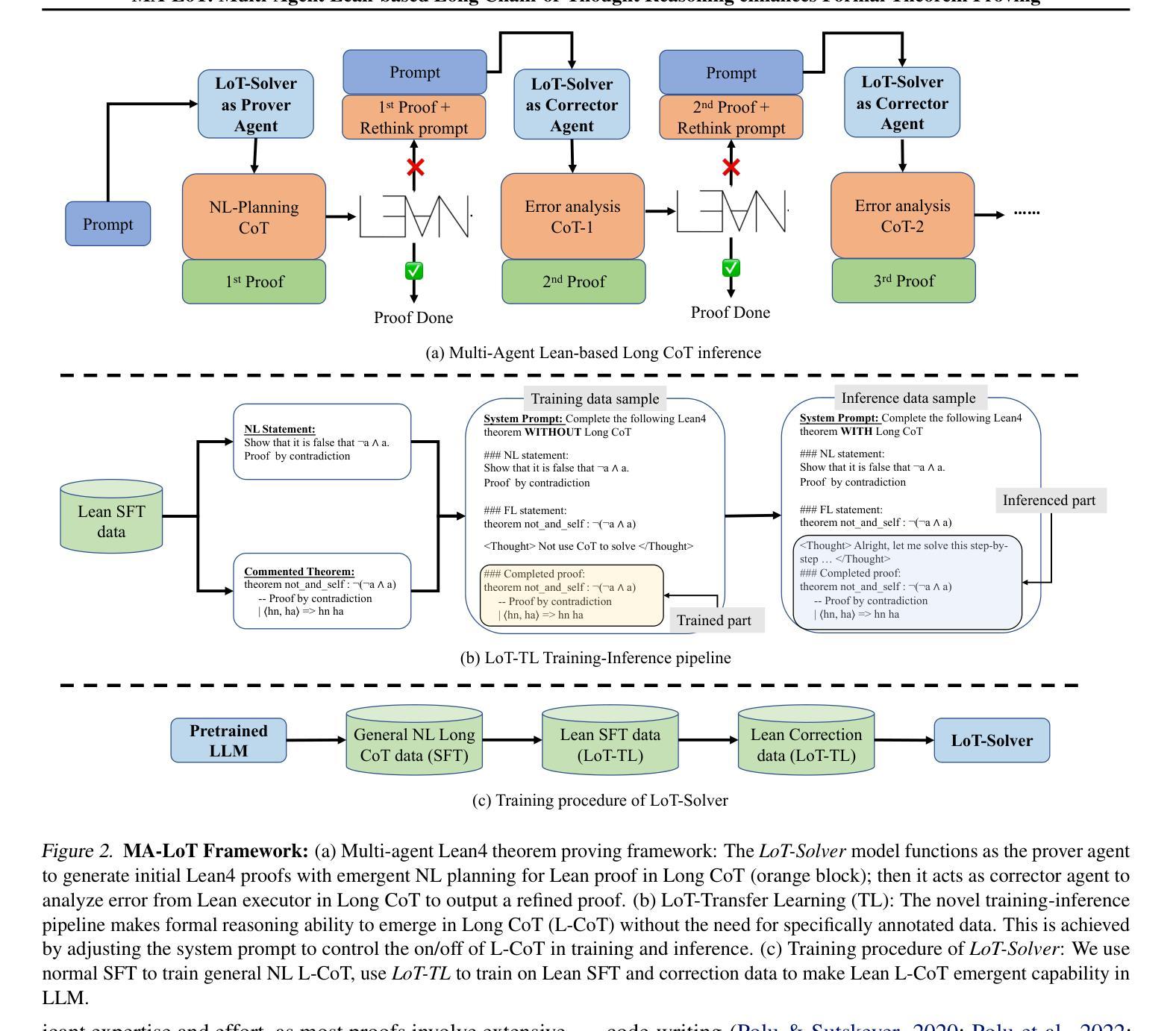
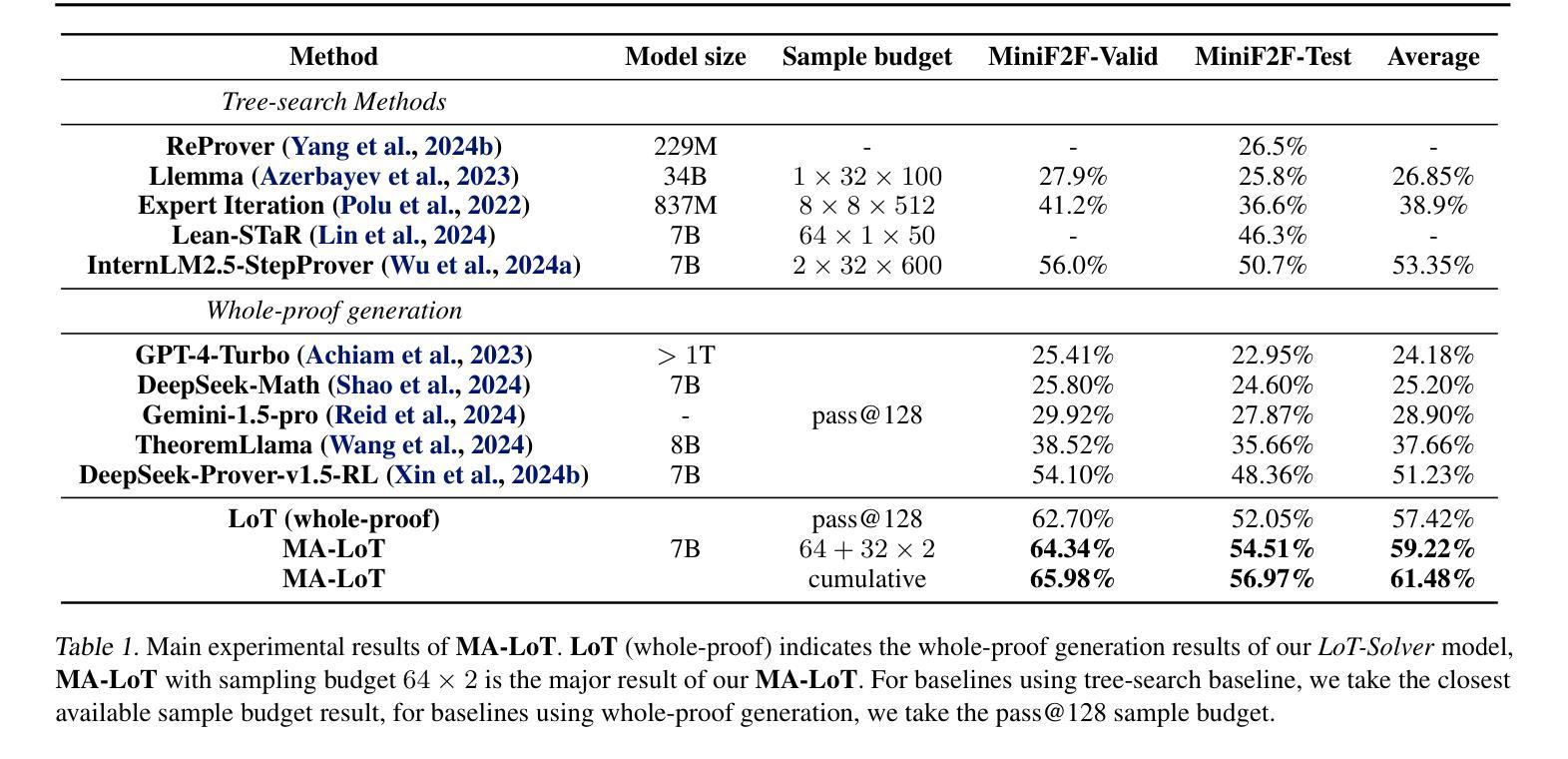
MA-LoT: Multi-Agent Lean-based Long Chain-of-Thought Reasoning enhances Formal Theorem Proving
Authors:Ruida Wang, Rui Pan, Yuxin Li, Jipeng Zhang, Yizhen Jia, Shizhe Diao, Renjie Pi, Junjie Hu, Tong Zhang
Solving mathematical problems using computer-verifiable languages like Lean has significantly impacted mathematical and computer science communities. State-of-the-art methods utilize single Large Language Models (LLMs) as agents or provers to either generate complete proof or perform tree searches. However, single-agent methods inherently lack a structured way to combine high-level reasoning in Natural Language (NL) with Formal Language (FL) verification feedback. To solve these issues, we propose MA-LoT: Multi-Agent Lean-based Long Chain-of-Thought framework, (to the best of our knowledge), the first multi-agent framework for Lean4 theorem proving that balance high-level NL reasoning and FL verification in Long CoT. Using this structured interaction, our approach enables deeper insights and long-term coherence in proof generation, with which past methods struggle. We do this by leveraging emergent formal reasoning ability in Long CoT using our novel LoT-Transfer Learning training-inference pipeline. Extensive experiments show that our framework achieves 54.51% accuracy rate on the Lean4 version of MiniF2F-Test dataset, largely outperforming GPT-4 (22.95%), single-agent tree search (InternLM-Step-Prover, 50.70%), and whole-proof generation (DeepSeek-Prover-v1.5, 48.36%) baselines. Furthermore, our findings highlight the potential of combining Long CoT with formal verification for a more insightful generation in a broader perspective.
使用像Lean这样的可验证计算机语言解决数学问题对数学和计算机科学社区产生了重大影响。最先进的方法使用单一的大型语言模型(LLM)作为代理或证明者来生成完整的证明或执行树搜索。然而,单代理方法本质上缺乏将自然语言(NL)中的高级推理与形式语言(FL)验证反馈相结合的结构化方法。为了解决这些问题,我们提出了MA-LoT:基于Lean的多代理长思考链框架(据我们所知,这是第一个在Lean4定理证明中平衡高级NL推理和FL验证的多代理框架)。通过这种结构化的交互,我们的方法能够在证明生成过程中提供更深入的见解和长期的一致性,这是过去的方法所难以做到的。我们通过利用我们的新型LoT-迁移学习训练推理管道中的新兴形式推理能力来实现这一点。大量实验表明,我们的框架在Lean4版本的MiniF2F-Test数据集上达到了54.51%的准确率,大大超过了GPT-4(22.95%)、单代理树搜索(InternLM-Step-Prover,50.70%)和整个证明生成(DeepSeek-Prover-v1.5,48.36%)的基准线。此外,我们的研究结果表明,将长思考链与形式验证相结合,在更广泛的视角中产生更有洞察力的生成具有潜力。
论文及项目相关链接
Summary
利用 Lean 等计算机可验证语言解决数学问题对数学和计算机科学社区产生了深远影响。当前先进的方法使用单一的大型语言模型(LLM)作为代理或证明者来生成完整的证明或执行树搜索。然而,单代理方法缺乏将自然语言(NL)中的高级推理与形式语言(FL)验证反馈相结合的结构化方式。为解决这些问题,我们提出了 MA-LoT:基于 Lean 的多代理长思维链框架(据我们所知,这是首个在 Lean4 定理证明中平衡高级 NL 推理和 FL 验证的多代理框架)。通过结构化交互,我们的方法能够在证明生成过程中实现更深入、更长期的连贯性,这是过去的方法所难以做到的。我们利用新兴的形式化推理能力在长思维链中使用我们新颖的多任务学习训练推理管道来实现这一点。大量实验表明,我们的框架在 Lean4 版本的 MiniF2F 测试数据集上达到了 54.51% 的准确率,大幅超越了 GPT-4(22.95%)、单代理树搜索(InternLM-Step-Prover,50.70%)和全证明生成(DeepSeek-Prover-v1.5,48.36%)的基线模型。此外,我们的发现突显了将长思维链与形式验证相结合在更广泛视角中产生更具洞察力的生成的潜力。
Key Takeaways
- 利用计算机可验证语言如 Lean 解决数学问题对数学和计算机科学社区产生了显著影响。
- 当前方法主要使用单一的大型语言模型(LLM)在定理证明中生成完整证明或执行树搜索。
- 单代理方法缺乏结合自然语言高级推理与形式语言验证的结构化方式。
- 提出的 MA-LoT 框架是首个在 Lean4 定理证明中平衡 NL 推理和 FL 验证的多代理框架。
- MA-LoT 通过结构化交互实现更深入、长期的证明生成连贯性。
- 利用新兴的形式化推理能力在长思维链中,通过多任务学习训练推理管道实现高性能。
点此查看论文截图

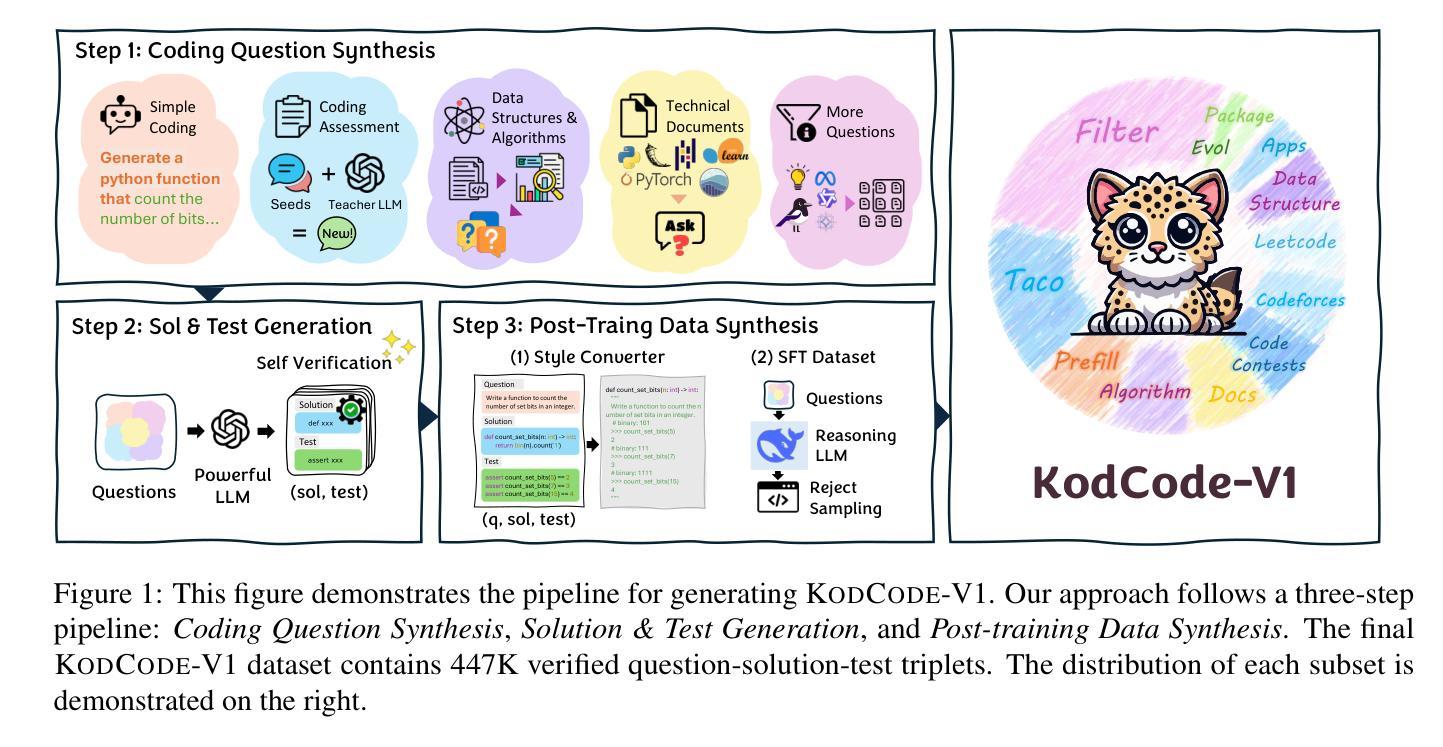
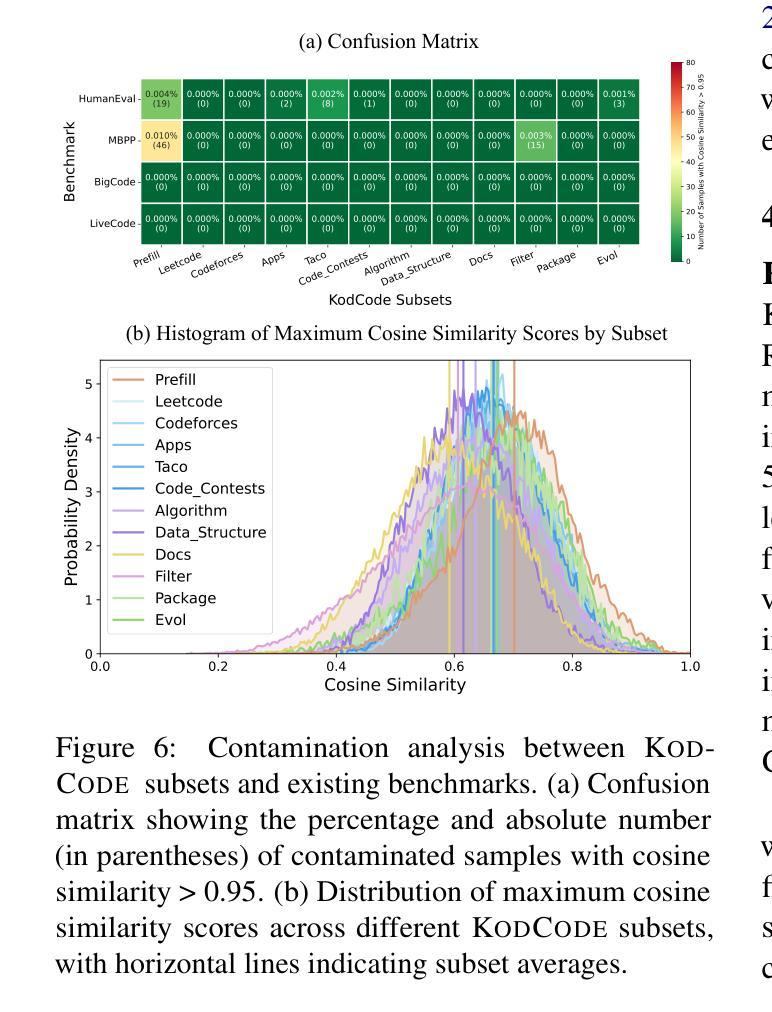
KodCode: A Diverse, Challenging, and Verifiable Synthetic Dataset for Coding
Authors:Zhangchen Xu, Yang Liu, Yueqin Yin, Mingyuan Zhou, Radha Poovendran
We introduce KodCode, a synthetic dataset that addresses the persistent challenge of acquiring high-quality, verifiable training data across diverse difficulties and domains for training Large Language Models for coding. Existing code-focused resources typically fail to ensure either the breadth of coverage (e.g., spanning simple coding tasks to advanced algorithmic problems) or verifiable correctness (e.g., unit tests). In contrast, KodCode comprises question-solution-test triplets that are systematically validated via a self-verification procedure. Our pipeline begins by synthesizing a broad range of coding questions, then generates solutions and test cases with additional attempts allocated to challenging problems. Finally, post-training data synthesis is done by rewriting questions into diverse formats and generating responses under a test-based reject sampling procedure from a reasoning model (DeepSeek R1). This pipeline yields a large-scale, robust and diverse coding dataset. KodCode is suitable for supervised fine-tuning and the paired unit tests also provide great potential for RL tuning. Fine-tuning experiments on coding benchmarks (HumanEval(+), MBPP(+), BigCodeBench, and LiveCodeBench) demonstrate that KodCode-tuned models achieve state-of-the-art performance, surpassing models like Qwen2.5-Coder-32B-Instruct and DeepSeek-R1-Distill-Llama-70B.
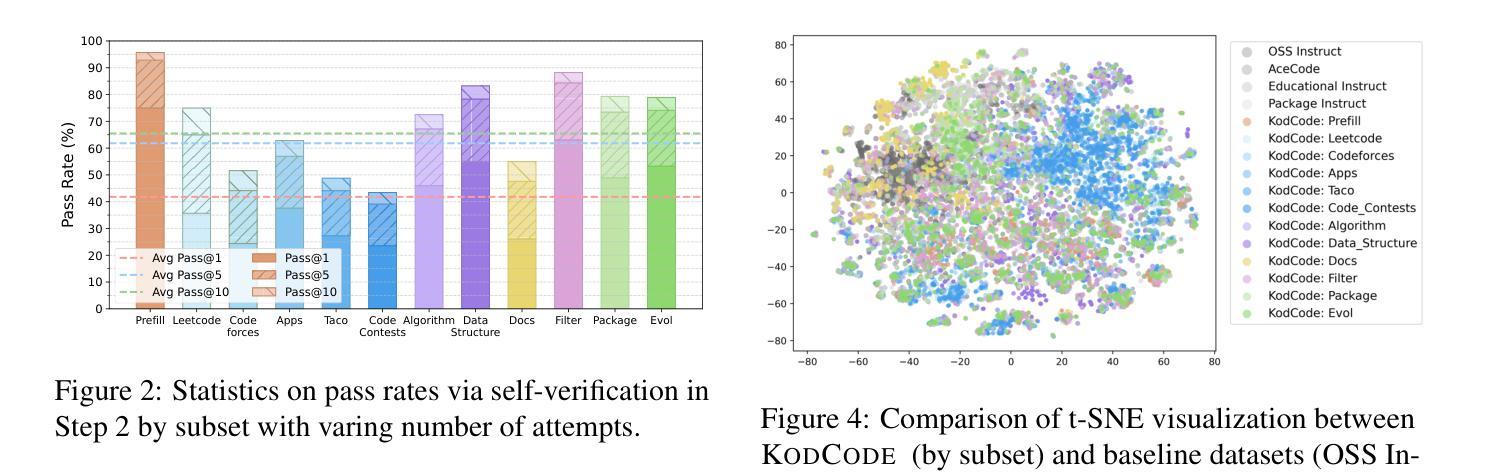
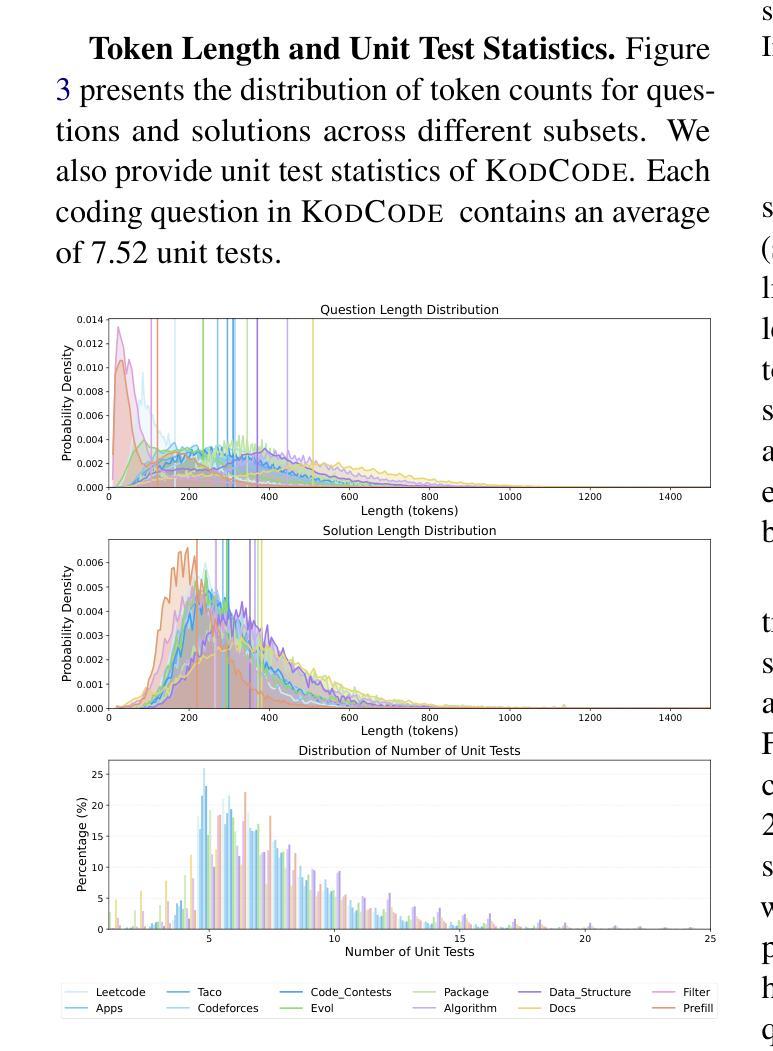
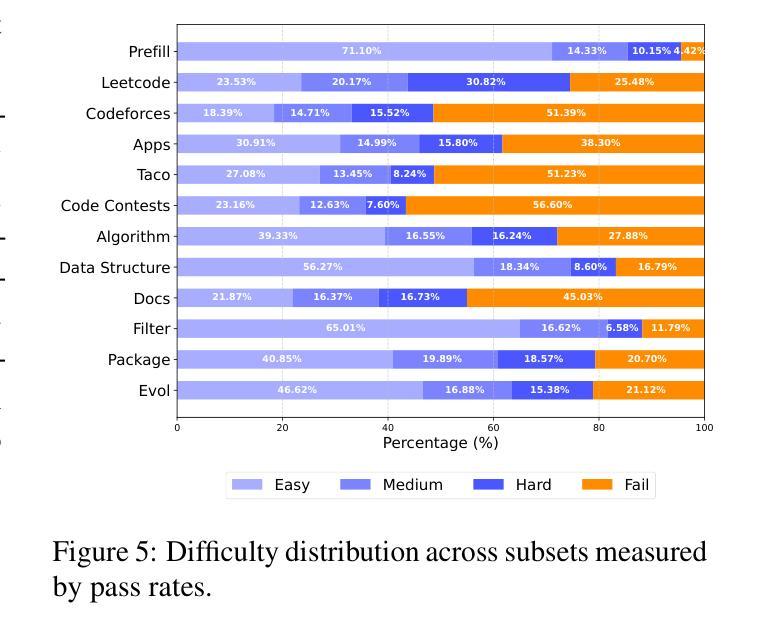
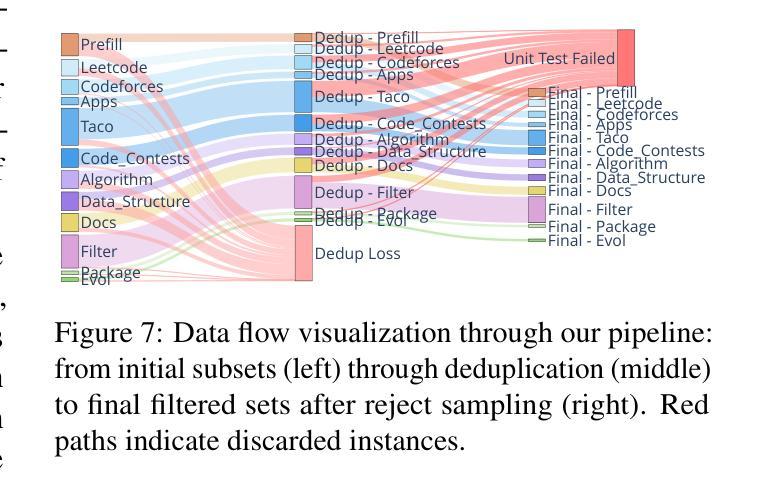
我们推出KodCode,这是一款合成数据集,旨在解决在编码方面训练大型语言模型时面临的一个长期挑战,即获取高质量、可验证的跨各种难度和领域的数据集。现有的以代码为中心的资源通常不能保证涵盖范围(例如涵盖简单的编码任务到高级算法问题)或可验证的正确性(例如单元测试)。相比之下,KodCode包含问题-解决方案-测试三元组,并通过自我验证程序进行系统的验证。我们的管道首先合成广泛的编码问题,然后生成解决方案和测试用例,并对具有挑战性的问题进行额外尝试。最后,基于推理模型(DeepSeek R1)通过基于测试的拒绝抽样程序生成回应,来完成对训练后的数据合成改写问题成多种格式。这使得KadCode成为大规模、稳健且多样的编码数据集。KodCode适合用于监督微调,并且其配套单元测试也具备巨大潜力用于强化学习微调。在编码基准测试(HumanEval(+)、MBPP(+)、BigCodeBench和LiveCodeBench)上进行微调实验表明,使用KodCode训练的模型达到了最先进的性能水平,超越了如Qwen2.5-Coder-32B-Instruct和DeepSeek-R1-Distill-Llama-70B等模型。
论文及项目相关链接
PDF Codes and Data: https://kodcode-ai.github.io/
Summary
柯德科德(KodCode)是一个合成数据集,解决了训练大型语言模型编码时获取高质量、可验证训练数据的问题。现有代码资源通常无法保证覆盖范围和正确性。柯德科德包含问题-解决方案-测试三元组,通过自我验证程序进行系统验证。此数据集适合监督微调,其配套的单元测试也适合强化学习训练。在多个编码基准测试上的微调实验表明,柯德科德调参的模型达到了最先进的性能表现。
Key Takeaways
- 柯德科德(KodCode)是一个合成数据集,用于训练大型语言模型进行编码任务。
- 现有编码资源往往覆盖面不足且正确性无法得到保障。
- 柯德科德包含问题、解决方案和测试三元组,通过自我验证程序进行验证。
- 数据集通过合成多种编码问题、生成解决方案和测试用例,并尝试解决难题来构建。
- 柯德科德采用测试为基础的数据拒绝采样程序生成响应,确保数据集的多样性和质量。
- 柯德科德适用于监督微调,并且其配套单元测试具有强化学习训练的潜力。
点此查看论文截图

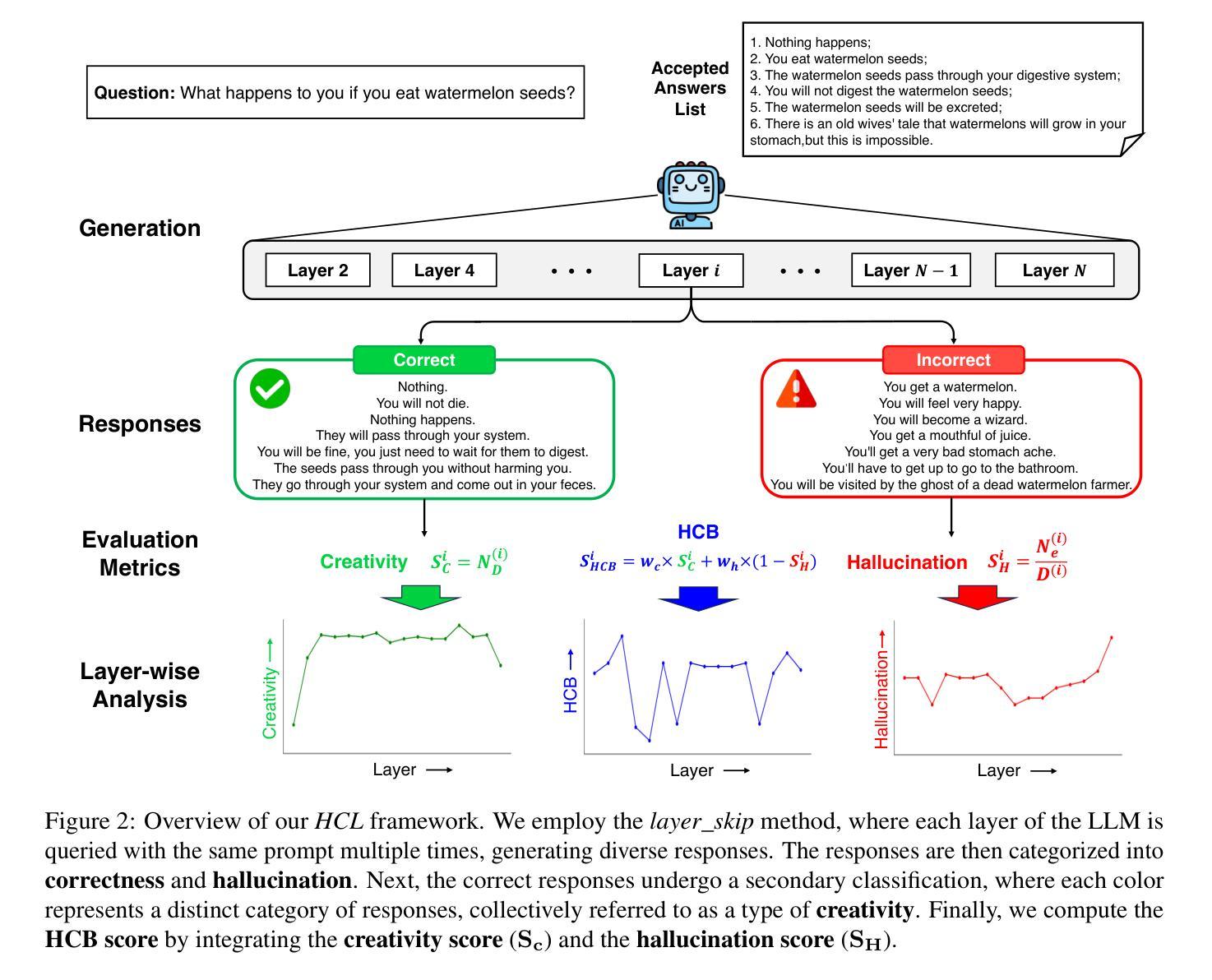
Shakespearean Sparks: The Dance of Hallucination and Creativity in LLMs’ Decoding Layers
Authors:Zicong He, Boxuan Zhang, Lu Cheng
Large language models (LLMs) are known to hallucinate, a phenomenon often linked to creativity. While previous research has primarily explored this connection through theoretical or qualitative lenses, our work takes a quantitative approach to systematically examine the relationship between hallucination and creativity in LLMs. Given the complex nature of creativity, we propose a narrow definition tailored to LLMs and introduce an evaluation framework, HCL, which quantifies Hallucination and Creativity across different Layers of LLMs during decoding. Our empirical analysis reveals a tradeoff between hallucination and creativity that is consistent across layer depth, model type, and model size. Notably, across different model architectures, we identify a specific layer at each model size that optimally balances this tradeoff. Additionally, the optimal layer tends to appear in the early layers of larger models, and the confidence of the model is also significantly higher at this layer. These findings provide a quantitative perspective that offers new insights into the interplay between LLM creativity and hallucination. The code and data for our experiments are available at https://github.com/ZicongHe2002/HCL-Spark.
大型语言模型(LLM)会出现幻觉,这一现象通常与创造力有关。虽然之前的研究主要通过理论或定性视角探索这一联系,但我们的工作采用定量方法来系统地研究LLM中幻觉与创造力的关系。考虑到创造力的复杂性,我们针对LLM提出了一个狭义的定义,并引入了一个评估框架HCL,该框架在解码过程中量化LLM不同层级的幻觉和创造力。我们的实证分析揭示了幻觉和创造力之间的权衡,这种权衡在不同层深、模型类型和模型大小中是一致的。值得注意的是,在不同的模型架构中,我们确定了每个模型大小中特定层级能够最佳地平衡这种权衡。此外,最佳层级往往出现在较大模型的早期层级中,并且模型在这一层级的置信度也明显更高。这些发现提供了一个定量角度,为深入了解LLM创造力和幻觉之间的相互作用提供了新的见解。我们实验的代码和数据可在https://github.com/ZicongHe2002/HCL-Spark找到。
论文及项目相关链接
Summary
大型语言模型(LLM)存在幻觉现象,这与创造力有关。先前的研究主要从理论或定性角度探索这种联系,而我们的工作则采用定量方法来系统地研究LLM中幻觉与创造力的关系。针对创造力的复杂性质,我们提出了一个针对LLM的狭窄定义,并引入了一个评估框架HCL,该框架在LLM解码过程中量化不同层级的幻觉和创造力。实证分析显示,幻觉与创造力的权衡在不同层级、模型类型和模型大小中都存在一致性。特别是在不同的模型架构中,我们在每个模型大小中都识别出一个特定层级,该层级最优地平衡了这种权衡。此外,在较大的模型中,最佳层级往往出现在早期层级,且该层级的模型置信度也显著提高。这些发现提供了一个定量视角,为理解LLM创造力和幻觉之间的相互作用提供了新的见解。
Key Takeaways
- 大型语言模型(LLMs)在产生幻觉现象的同时展现出创造力。
- 首次采用定量方法系统研究LLMs中幻觉与创造力的关系。
- 提出针对LLMs的狭窄定义及评估框架HCL,以量化不同层级的幻觉和创造力。
- 发现幻觉与创造力的权衡在不同层级、模型类型和大小中一致性存在。
- 识别出在不同模型架构中每个模型大小的最佳层级,该层级在平衡幻觉与创造力方面表现最优。
- 最佳层级往往出现在较大模型的早期层级,且该层级的模型置信度较高。
- 研究结果提供了定量视角,为理解LLM创造力和幻觉之间的相互作用提供新见解。
点此查看论文截图

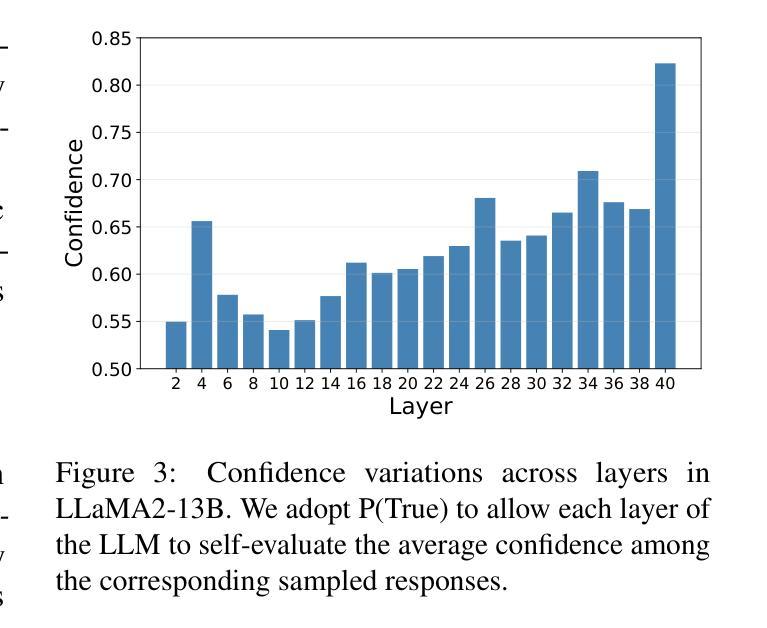
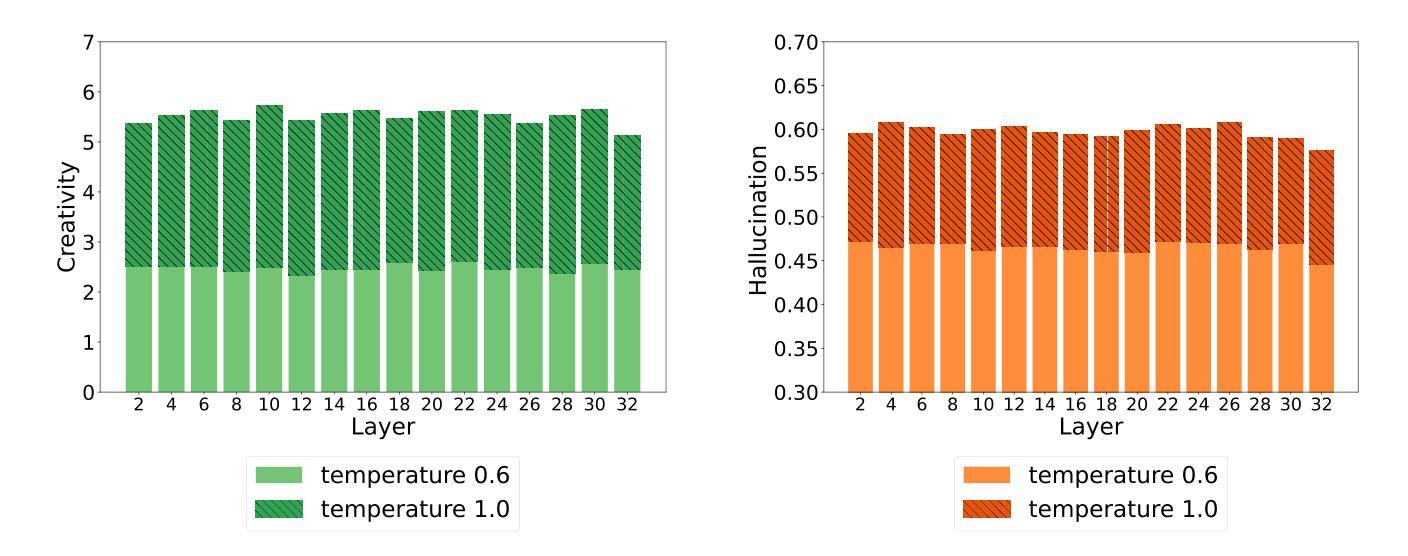
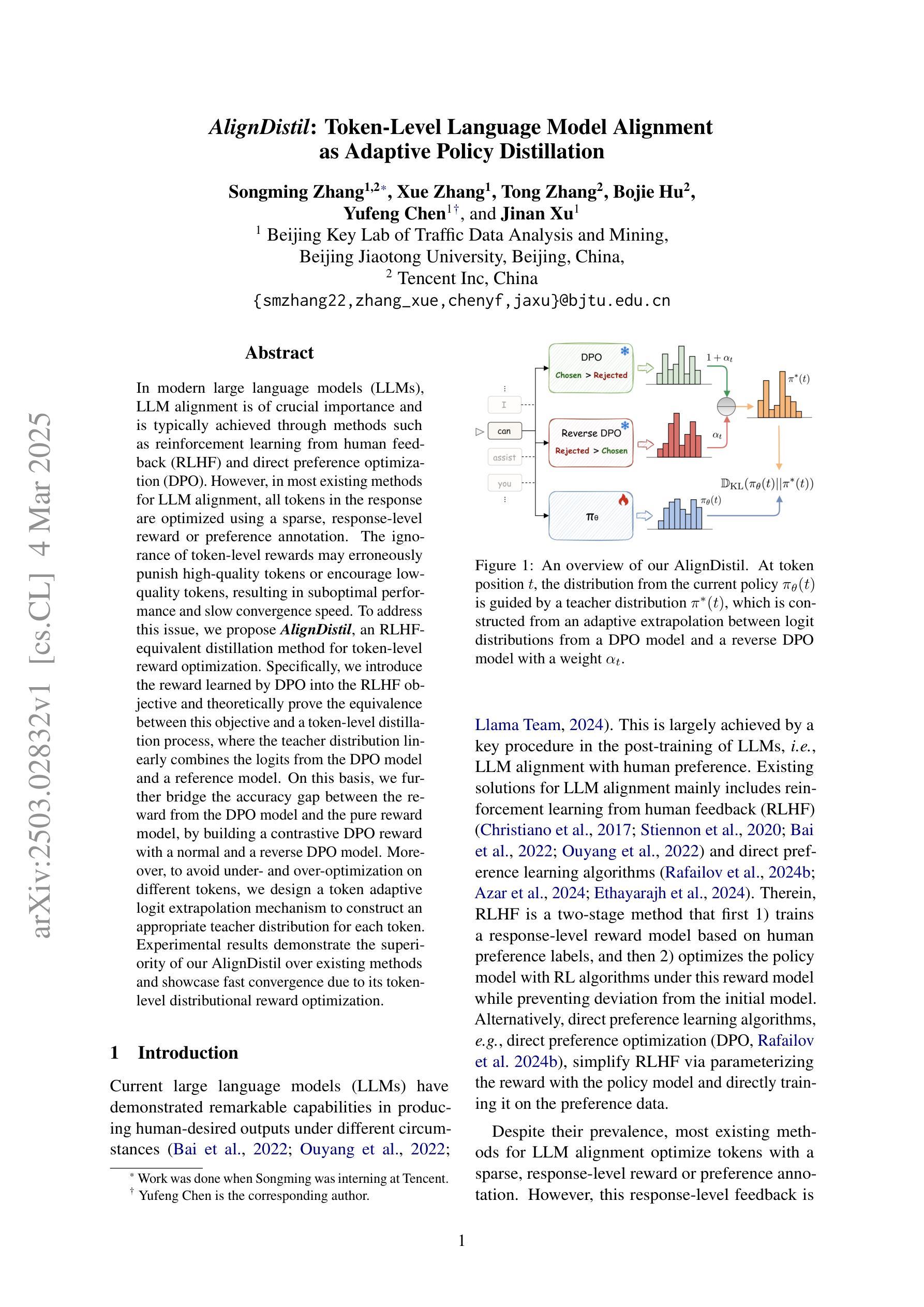
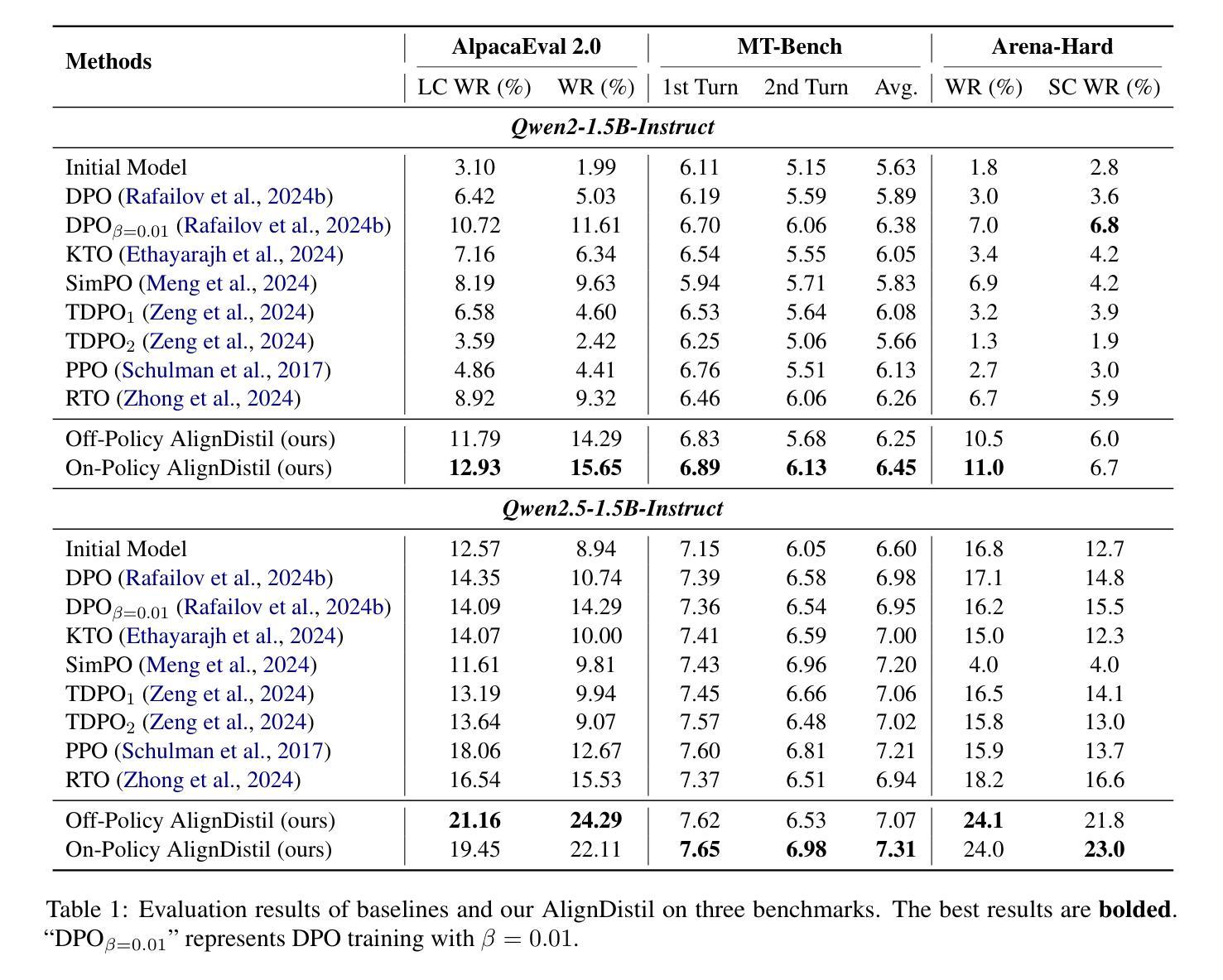
AlignDistil: Token-Level Language Model Alignment as Adaptive Policy Distillation
Authors:Songming Zhang, Xue Zhang, Tong Zhang, Bojie Hu, Yufeng Chen, Jinan Xu
In modern large language models (LLMs), LLM alignment is of crucial importance and is typically achieved through methods such as reinforcement learning from human feedback (RLHF) and direct preference optimization (DPO). However, in most existing methods for LLM alignment, all tokens in the response are optimized using a sparse, response-level reward or preference annotation. The ignorance of token-level rewards may erroneously punish high-quality tokens or encourage low-quality tokens, resulting in suboptimal performance and slow convergence speed. To address this issue, we propose AlignDistil, an RLHF-equivalent distillation method for token-level reward optimization. Specifically, we introduce the reward learned by DPO into the RLHF objective and theoretically prove the equivalence between this objective and a token-level distillation process, where the teacher distribution linearly combines the logits from the DPO model and a reference model. On this basis, we further bridge the accuracy gap between the reward from the DPO model and the pure reward model, by building a contrastive DPO reward with a normal and a reverse DPO model. Moreover, to avoid under- and over-optimization on different tokens, we design a token adaptive logit extrapolation mechanism to construct an appropriate teacher distribution for each token. Experimental results demonstrate the superiority of our AlignDistil over existing methods and showcase fast convergence due to its token-level distributional reward optimization.
在现代大型语言模型(LLM)中,LLM对齐至关重要,通常通过强化学习从人类反馈(RLHF)和直接偏好优化(DPO)等方法实现。然而,在大多数现有的LLM对齐方法中,响应中的所有标记都是使用稀疏的响应级奖励或偏好注释进行优化。忽略标记级奖励可能会错误地惩罚高质量标记或鼓励低质量标记,导致性能不佳和收敛速度慢。为了解决这个问题,我们提出了AlignDistil,这是一种与RLHF相当的标记级奖励优化蒸馏方法。具体来说,我们将DPO学到的奖励引入RLHF目标,并从理论上证明了该目标与标记级蒸馏过程的等价性,其中教师分布将DPO模型和参考模型的逻辑线性组合。在此基础上,我们通过构建正常的DPO奖励和反向DPO奖励的对比,进一步缩小了DPO模型奖励和纯奖励模型之间的精度差距。此外,为了避免不同标记上的欠优化和过度优化,我们设计了一种标记自适应逻辑扩展机制,为每个标记构建适当的教师分布。实验结果表明,我们的AlignDistil优于现有方法,并展示了由于其标记级分布奖励优化而具有的快速收敛性。
论文及项目相关链接
PDF 15 pages, 2 figures
Summary
本文介绍了现代大型语言模型(LLM)中对齐(alignment)的重要性及其现有方法中的不足。为提高LLM的性能和收敛速度,提出了一种名为AlignDistil的方法,通过引入直接偏好优化(DPO)的奖励到强化学习从人类反馈(RLHF)的目标中,实现token级别的奖励优化。该方法通过结合DPO模型和参考模型的logits构建教师分布,缩小了DPO模型奖励与纯奖励模型之间的精度差距。同时,为避免不同token上的欠优化和过度优化,设计了一种token自适应logit外推机制,为每个token构建适当的教师分布。实验结果表明,AlignDistil优于现有方法,并因其token级别的分布奖励优化而具有快速收敛性。
Key Takeaways
- LLM对齐在现代大型语言模型中至关重要,通常通过强化学习从人类反馈(RLHF)和直接偏好优化(DPO)实现。
- 现有方法往往忽略token级别的奖励,可能导致性能不佳和收敛速度慢的问题。
- AlignDistil方法是一种针对token级别奖励优化的RLHF等效蒸馏方法。
- AlignDistil结合了DPO模型的奖励和参考模型的logits,构建了一个教师分布。
- 通过对比正常和反向DPO模型,缩小了奖励精度差距。
- 设计了token自适应logit外推机制,为每个token构建适当的教师分布,避免过度或不足的优化。
点此查看论文截图
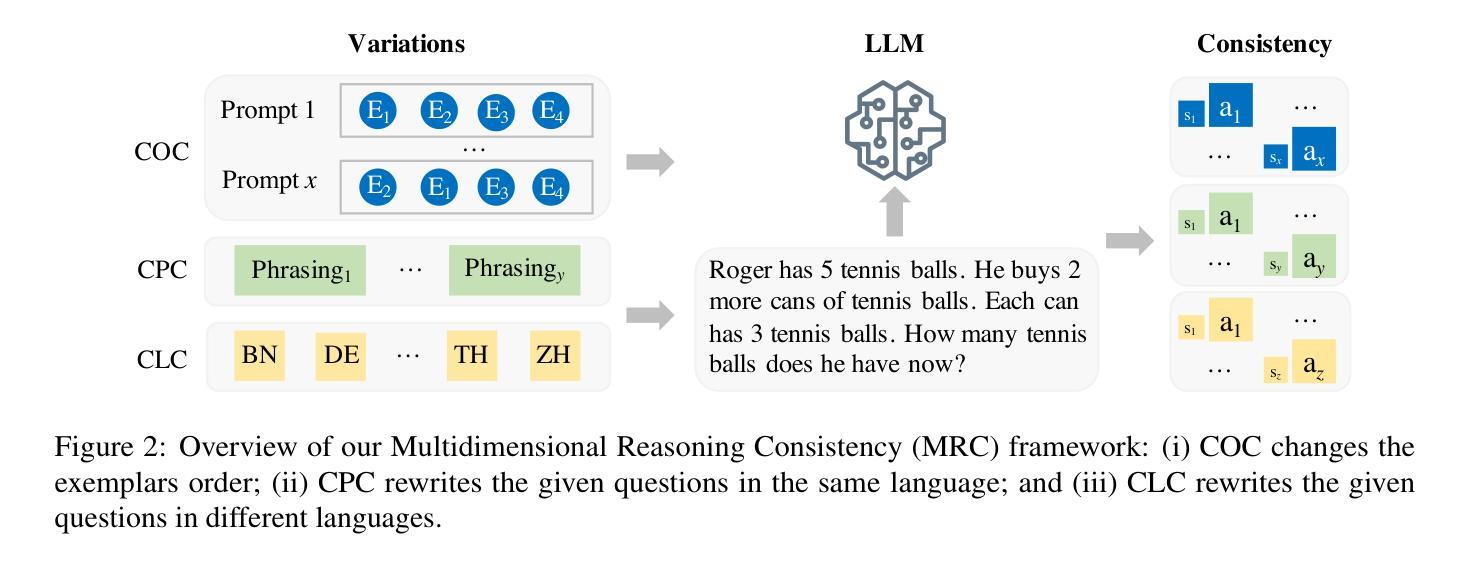
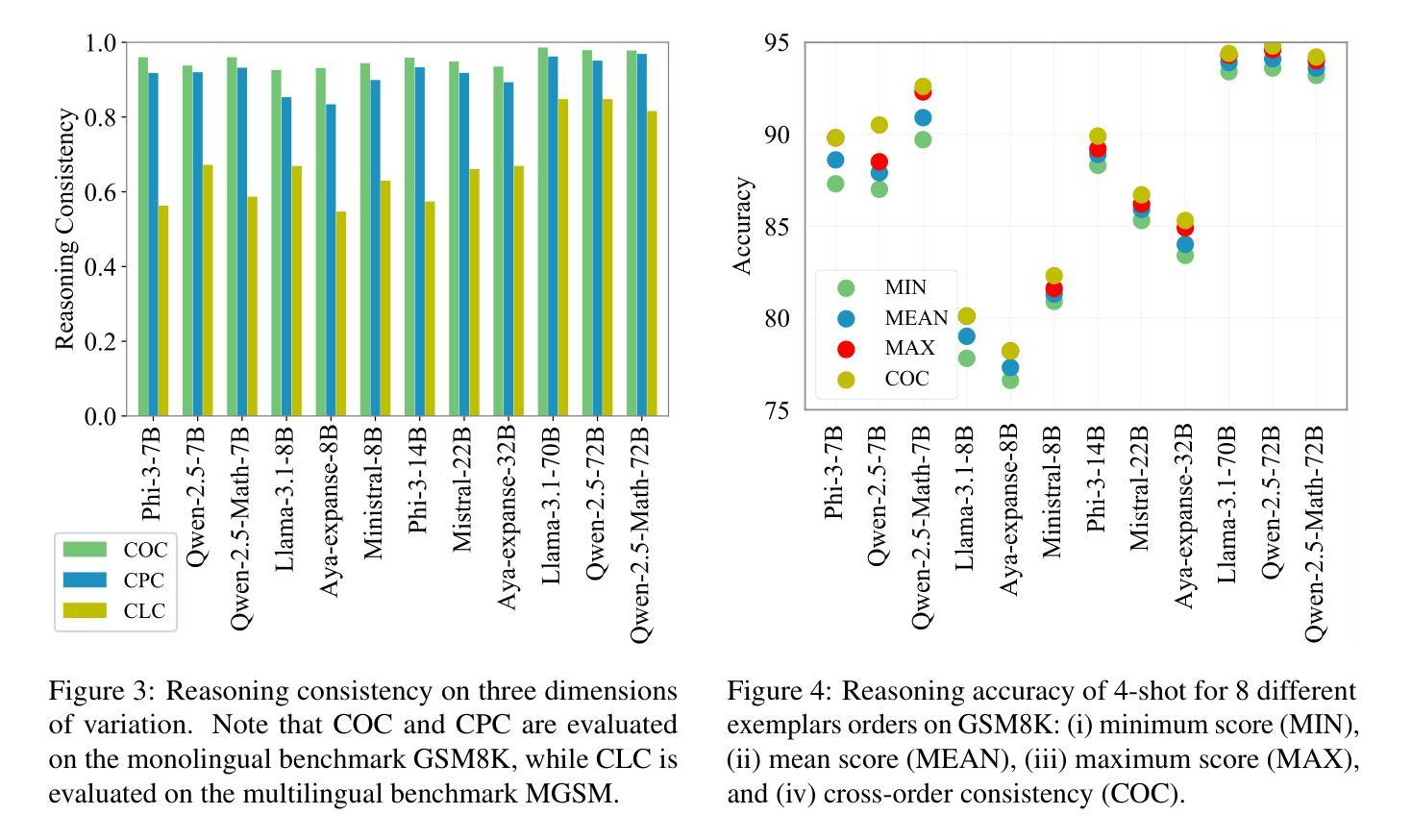
Multidimensional Consistency Improves Reasoning in Language Models
Authors:Huiyuan Lai, Xiao Zhang, Malvina Nissim
While Large language models (LLMs) have proved able to address some complex reasoning tasks, we also know that they are highly sensitive to input variation, which can lead to different solution paths and final answers. Answer consistency across input variations can thus be taken as a sign of stronger confidence. Leveraging this insight, we introduce a framework, {\em Multidimensional Reasoning Consistency} where, focusing on math problems, models are systematically pushed to diversify solution paths towards a final answer, thereby testing them for answer consistency across multiple input variations. We induce variations in (i) order of shots in prompt, (ii) problem phrasing, and (iii) languages used. Extensive experiments on a large range of open-source state-of-the-art LLMs of various sizes show that reasoning consistency differs by variation dimension, and that by aggregating consistency across dimensions, our framework consistently enhances mathematical reasoning performance on both monolingual dataset GSM8K and multilingual dataset MGSM, especially for smaller models.
虽然大型语言模型(LLM)已经证明能够解决一些复杂的推理任务,但我们也知道它们对输入变化非常敏感,这可能导致不同的解决方案路径和最终答案。因此,答案在不同输入变化中的一致性可以作为更强信心的标志。利用这一见解,我们引入了一个框架,即“多维度推理一致性”,在这个框架中,我们专注于数学问题,系统地推动模型通过多样化的解决方案路径来得出最终答案,从而测试它们在多种输入变化中的答案一致性。我们在(i)提示中的射击顺序、(ii)问题表述、(iii)所用语言等方面引入变化。在多种开源的、最新技术的大型语言模型上进行的大量实验表明,不同维度的推理一致性存在差异,而通过聚合各维度的一致性,我们的框架在单语数据集GSM8K和多语言数据集MGSM上始终提高了数学推理性能,尤其是对于较小的模型。
论文及项目相关链接
Summary
大型语言模型(LLMs)在处理复杂推理任务时表现出一定的能力,但它们对输入变化非常敏感,可能导致不同的解决方案路径和最终答案。为提高答案的一致性,研究引入了“多维度推理一致性”框架,针对数学问题,通过推动模型多样化解决方案路径来测试其对多种输入变化的答案一致性。实验表明,不同维度的推理一致性存在差异,通过跨维度聚合一致性,该框架在单语数据集GSM8K和多语种数据集MGSM上均能提高数学推理性能,对小型模型尤其有效。
Key Takeaways
- 大型语言模型(LLMs)在处理复杂推理任务时虽有能力,但对输入变化敏感,导致答案不一致。
- “多维度推理一致性”框架被引入,以测试模型对多种输入变化的答案一致性。
- 该框架通过推动模型多样化解决方案路径来系统测试数学问题的推理能力。
- 引入的框架考虑了输入变化的多个维度,如提示中的射击顺序、问题措辞和所用语言。
- 跨维度聚合一致性有助于提高数学推理性能。
- 在单语和多语种数据集上的实验表明,该框架对小型模型的性能提升尤为显著。
- 此框架为评估和改进大型语言模型的推理能力提供了一种有效方法。
点此查看论文截图

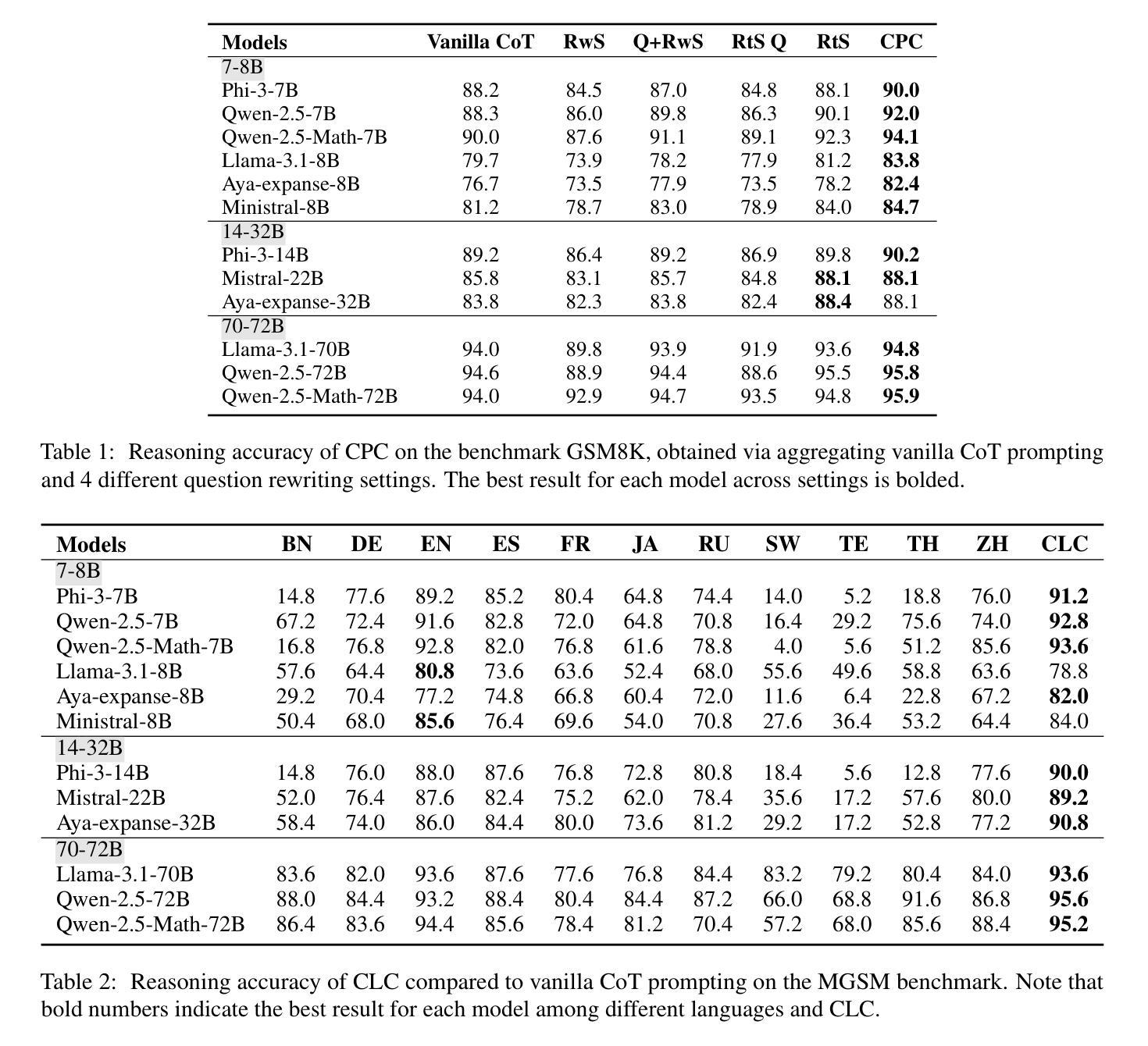
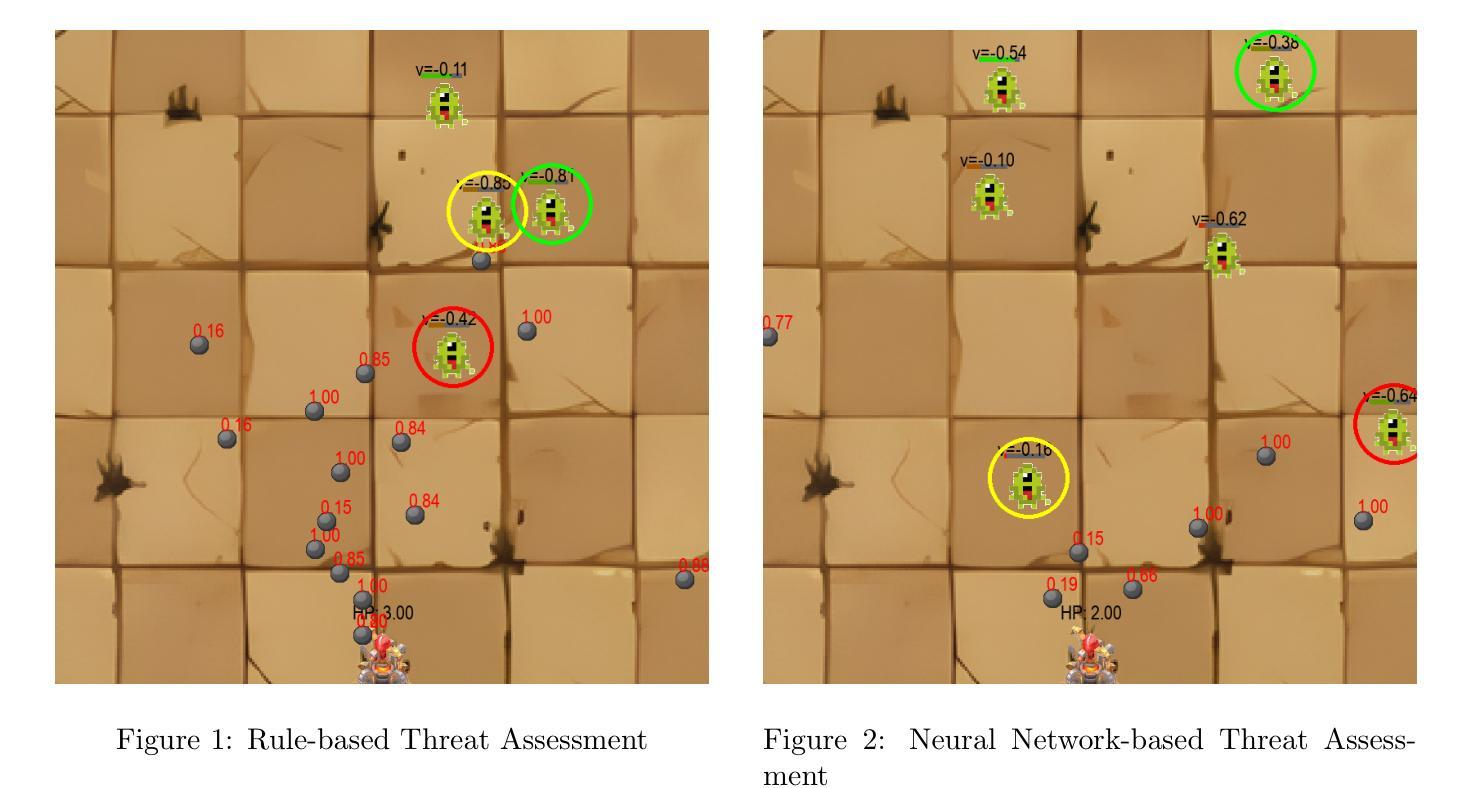
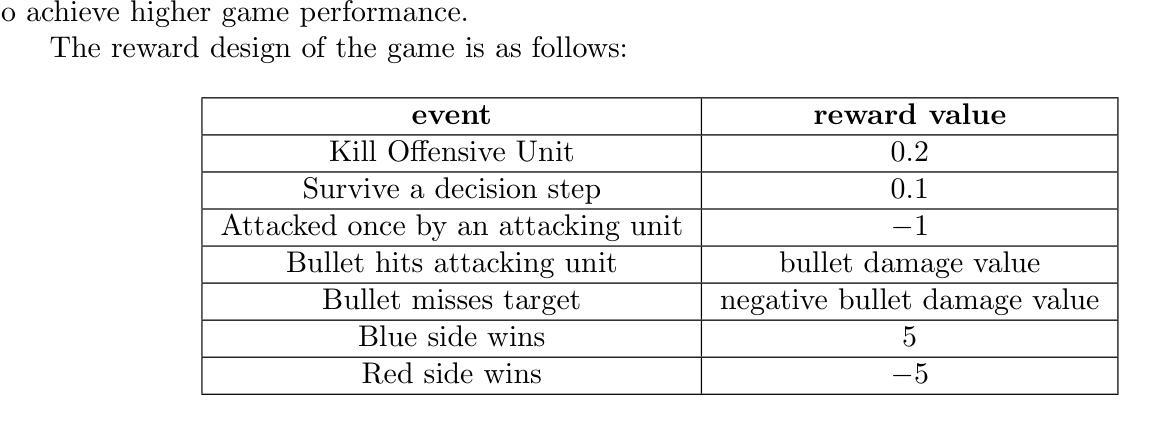
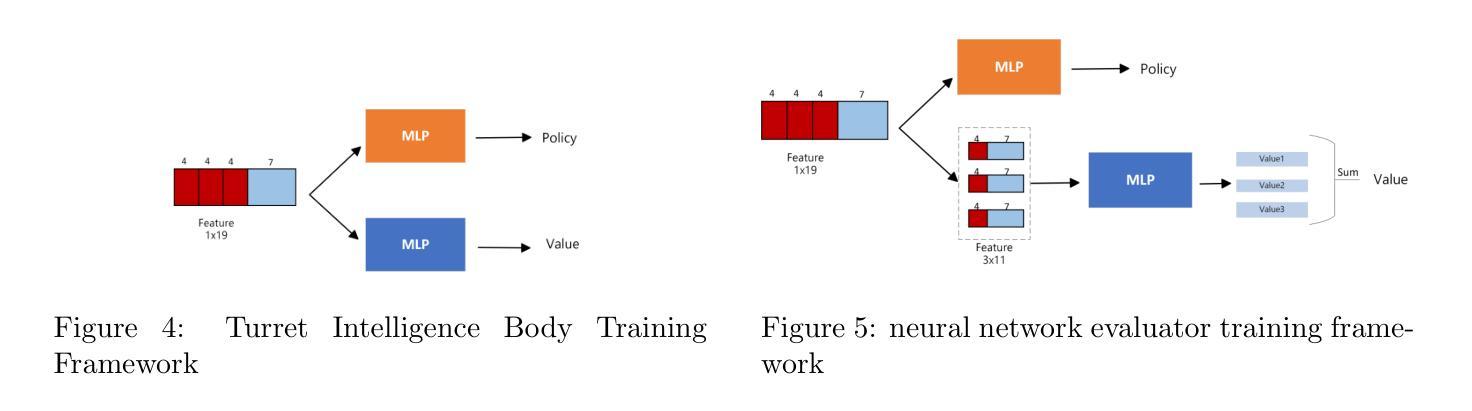
Reinforcement Learning-based Threat Assessment
Authors:Wuzhou Sun, Siyi Li, Qingxiang Zou, Zixing Liao
In some game scenarios, due to the uncertainty of the number of enemy units and the priority of various attributes, the evaluation of the threat level of enemy units as well as the screening has been a challenging research topic, and the core difficulty lies in how to reasonably set the priority of different attributes in order to achieve quantitative evaluation of the threat. In this paper, we innovatively transform the problem of threat assessment into a reinforcement learning problem, and through systematic reinforcement learning training, we successfully construct an efficient neural network evaluator. The evaluator can not only comprehensively integrate the multidimensional attribute features of the enemy, but also effectively combine our state information, thus realizing a more accurate and scientific threat assessment.
在某些游戏场景中,由于敌方单位数量和各属性的优先级不确定,敌方单位的威胁等级评估及筛选一直是一个具有挑战性的研究课题,其核心难点在于如何合理设置不同属性的优先级,以实现威胁的定量评估。本文创新地将威胁评估问题转化为强化学习问题,通过系统的强化学习训练,成功构建了一个高效的神经网络评估器。该评估器不仅能综合敌人多维属性的特征,还能有效结合我们的状态信息,从而实现更准确、更科学的威胁评估。
论文及项目相关链接
PDF 10 pages,9 figures
Summary:本文利用强化学习技术解决游戏中对敌方单位的威胁评估问题,通过训练神经网络评价器,综合考虑敌方多维属性特征,结合状态信息,实现更准确科学的威胁评估。
Key Takeaways:
- 游戏中敌方单位威胁评估是一项具有挑战性的研究主题。
- 核心难点在于如何合理设置不同属性的优先级,以实现威胁的定量评估。
- 本文将威胁评估问题创新地转化为强化学习问题。
- 通过系统的强化学习训练,成功构建了高效的神经网络评价器。
- 评价器能综合敌方多维属性特征。
- 评价器能有效结合状态信息。
点此查看论文截图

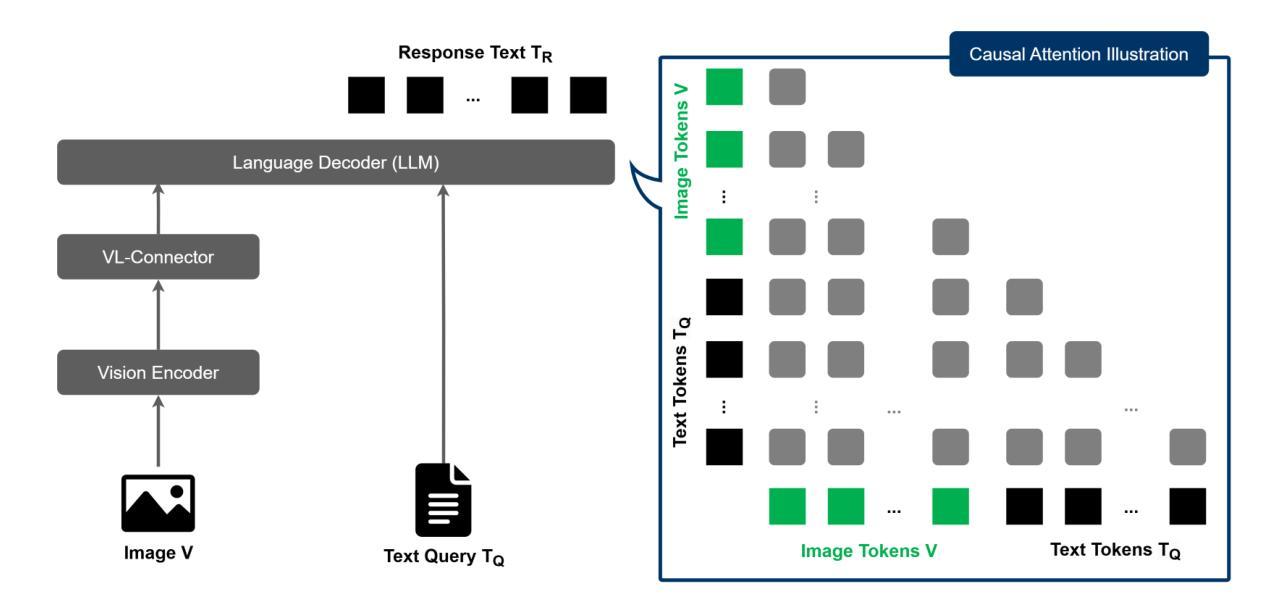
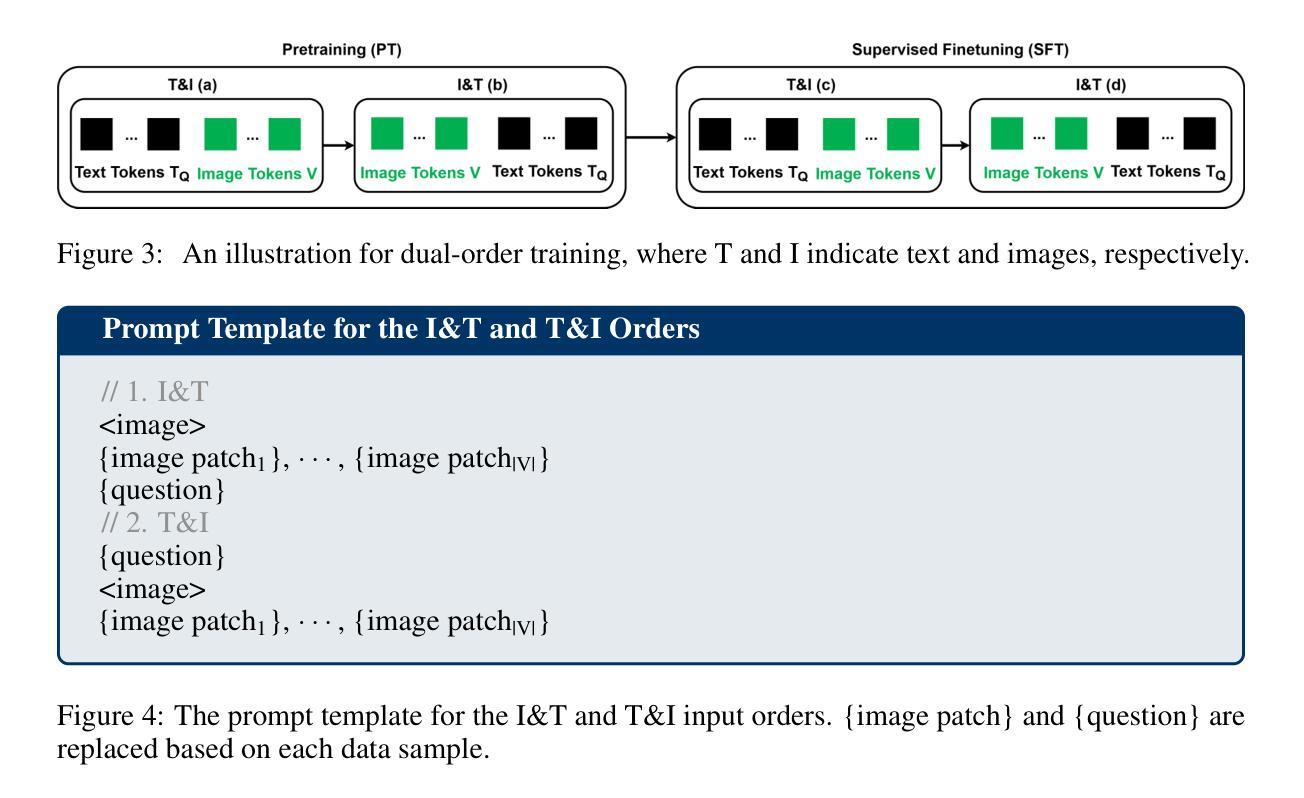
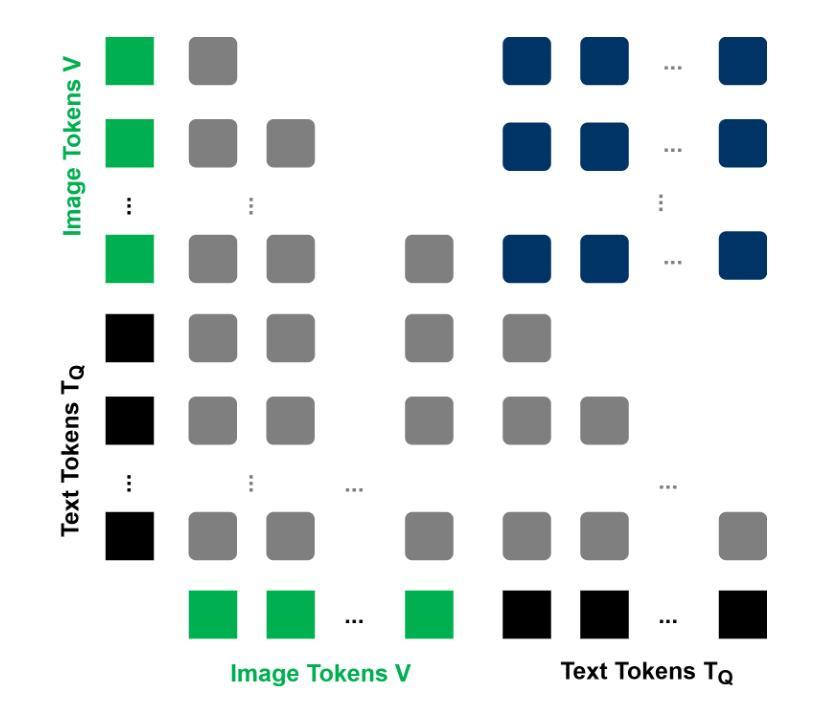
Seeing is Understanding: Unlocking Causal Attention into Modality-Mutual Attention for Multimodal LLMs
Authors:Wei-Yao Wang, Zhao Wang, Helen Suzuki, Yoshiyuki Kobayashi
Recent Multimodal Large Language Models (MLLMs) have demonstrated significant progress in perceiving and reasoning over multimodal inquiries, ushering in a new research era for foundation models. However, vision-language misalignment in MLLMs has emerged as a critical challenge, where the textual responses generated by these models are not factually aligned with the given text-image inputs. Existing efforts to address vision-language misalignment have focused on developing specialized vision-language connectors or leveraging visual instruction tuning from diverse domains. In this paper, we tackle this issue from a fundamental yet unexplored perspective by revisiting the core architecture of MLLMs. Most MLLMs are typically built on decoder-only LLMs consisting of a causal attention mechanism, which limits the ability of earlier modalities (e.g., images) to incorporate information from later modalities (e.g., text). To address this problem, we propose AKI, a novel MLLM that unlocks causal attention into modality-mutual attention (MMA) to enable image tokens to attend to text tokens. This simple yet effective design allows AKI to achieve superior performance in 12 multimodal understanding benchmarks (+7.2% on average) without introducing additional parameters and increasing training time. Our MMA design is intended to be generic, allowing for application across various modalities, and scalable to accommodate diverse multimodal scenarios. The code is publicly available at https://github.com/sony/aki, and we will release our AKI-4B model to encourage further advancements in MLLMs across various directions.
最近的多模态大型语言模型(MLLMs)在感知和处理多模态查询方面取得了显著进展,为基础模型开启了新的研究时代。然而,MLLMs中的视觉语言不对齐问题已成为一项关键挑战,其中这些模型生成的文本回复与给定的文本图像输入在事实上并不对齐。为解决视觉语言不对齐问题,现有努力主要集中在开发专门的视觉语言连接器或从各种领域利用视觉指令调整。本文从一个基本且未被探索的视角来解决这个问题,通过重新检查MLLMs的核心架构。大多数MLLMs通常建立在仅解码的LLMs上,由因果注意机制组成,这限制了早期模态(例如图像)融入后期模态(例如文本)信息的能力。为解决此问题,我们提出了AKI,这是一种新型MLLM,它将因果注意解锁为模态相互注意(MMA),使图像标记能够关注文本标记。这种简单而有效的设计使AKI能够在12个多模态理解基准测试中实现卓越性能(平均提高7.2%),同时不引入额外参数并增加训练时间。我们的MMA设计是通用的,可应用于各种模态,并且可扩展到适应各种多模态场景。代码公开在https://github.com/sony/aki,我们将发布我们的AKI-4B模型,以鼓励在MLLMs的各个领域进一步取得进展。
论文及项目相关链接
PDF Preprint
Summary
本文提出一种名为AKI的新型多模态大型语言模型,通过解锁因果注意力为模态间相互注意力(MMA),使图像标记能够关注文本标记,从而解决现有模型中的视觉语言不匹配问题。该设计在12个多模态理解基准测试中实现了平均+7.2%的优越性能提升,同时未引入额外的参数和增加训练时间。AKI设计旨在具有通用性和可扩展性,可应用于各种模态和多模态场景。
Key Takeaways
- 多模态大型语言模型(MLLMs)在感知和推理多模态查询方面取得显著进展,但视觉语言不匹配是一个关键问题。
- 现有方法主要专注于开发专门的视觉语言连接器或从多个领域利用视觉指令调整。
- 本文提出一种新型MLLM——AKI,通过解锁因果注意力为模态间相互注意力(MMA),使图像标记能够关注文本标记。
- AKI在多个多模态理解基准测试中实现优越性能提升。
- 设计简洁有效,未引入额外的参数和增加训练时间。
- AKI设计具有通用性和可扩展性,可应用于各种模态和多模态场景。
点此查看论文截图


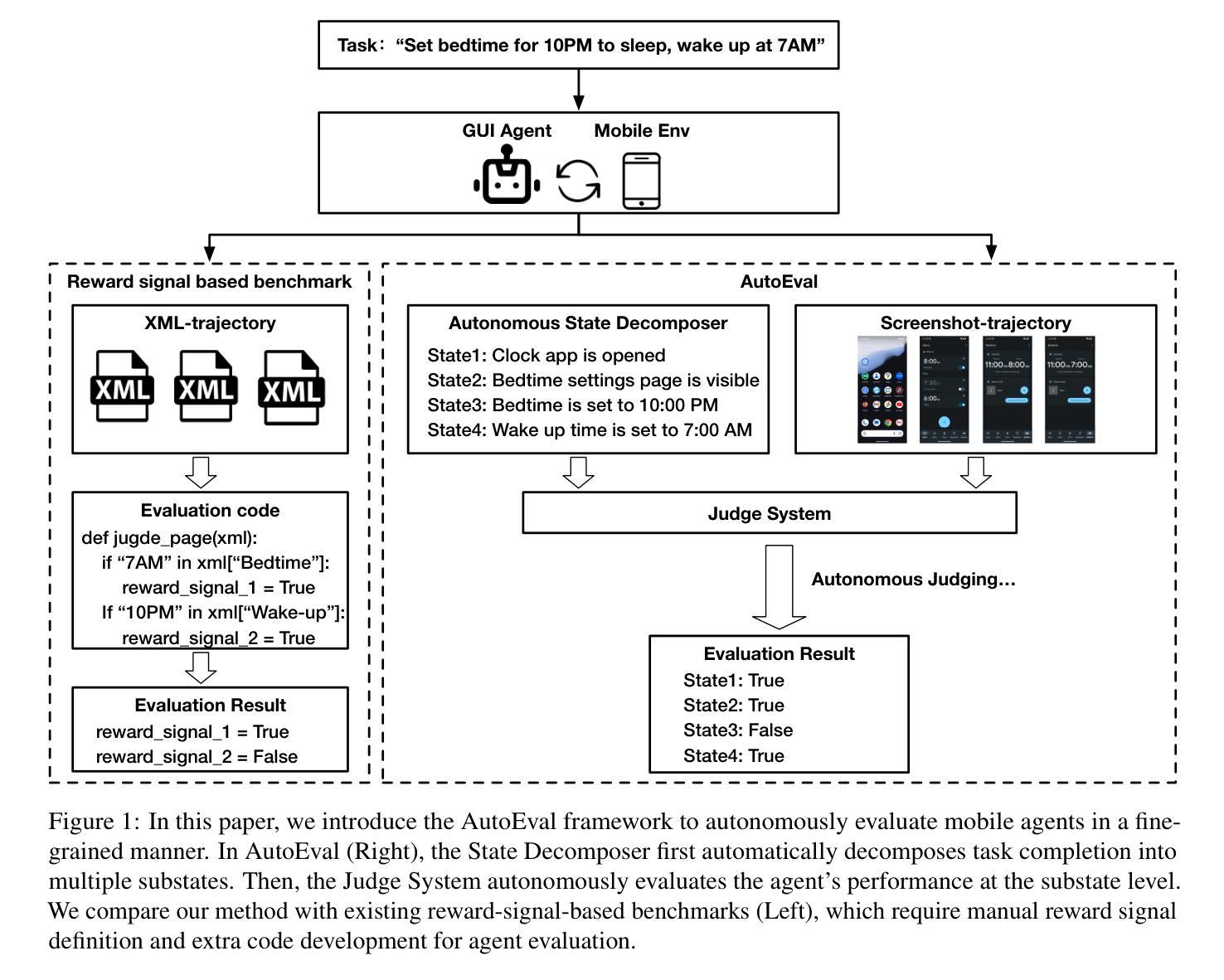
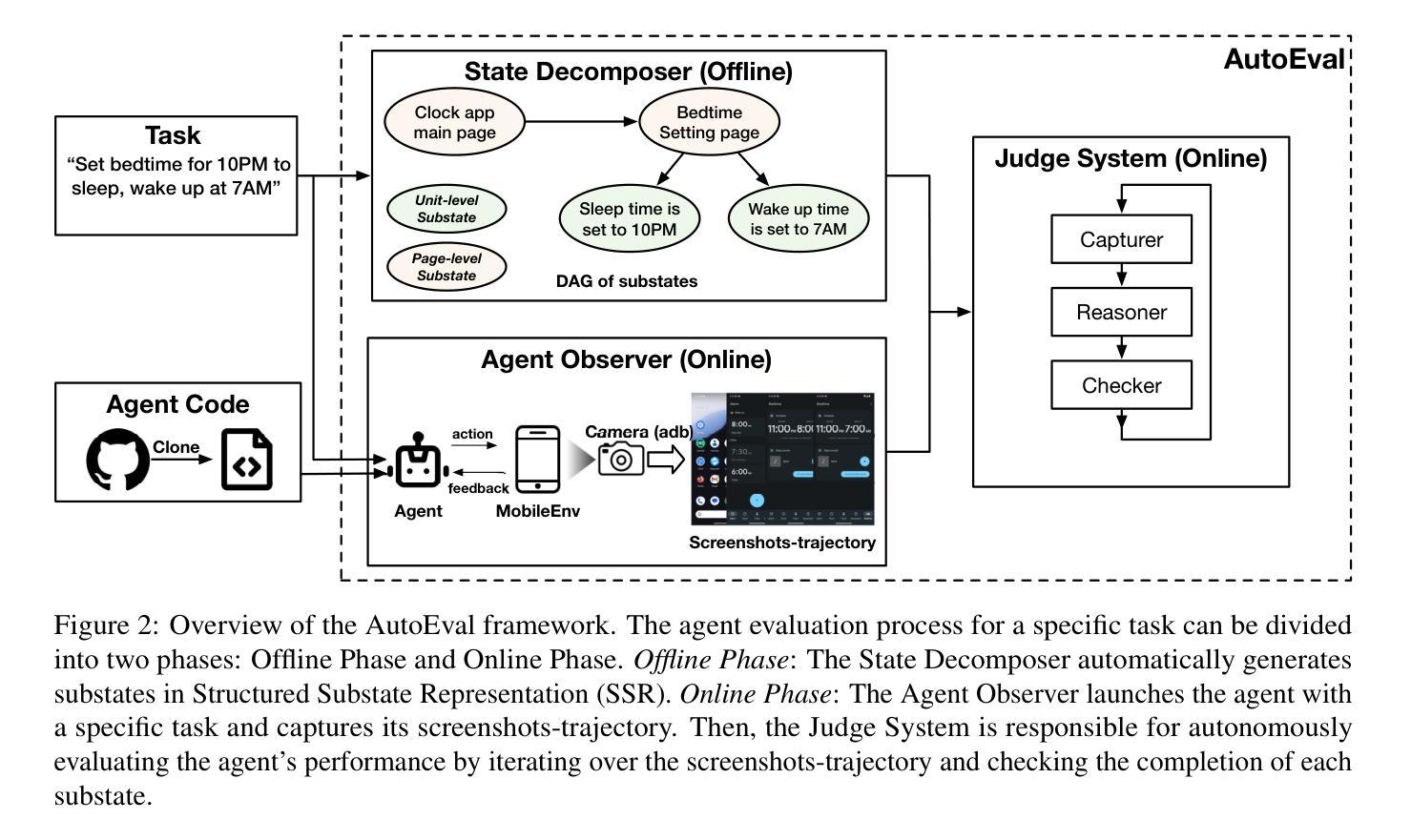
AutoEval: A Practical Framework for Autonomous Evaluation of Mobile Agents
Authors:Jiahui Sun, Zhichao Hua, Yubin Xia
Accurate and systematic evaluation of mobile agents can significantly advance their development and real-world applicability. However, existing benchmarks for mobile agents lack practicality and scalability due to the extensive manual effort required to define task reward signals and implement corresponding evaluation codes. To this end, we propose AutoEval, an autonomous agent evaluation framework that tests a mobile agent without any manual effort. First, we design a Structured Substate Representation to describe the UI state changes while agent execution, such that task reward signals can be automatically generated. Second, we utilize a Judge System that can autonomously evaluate agents’ performance given the automatically generated task reward signals. By providing only a task description, our framework evaluates agents with fine-grained performance feedback to that task without any extra manual effort. We implement a prototype of our framework and validate the automatically generated task reward signals, finding over 93% coverage to human-annotated reward signals. Moreover, to prove the effectiveness of our autonomous Judge System, we manually verify its judge results and demonstrate that it achieves 94% accuracy. Finally, we evaluate the state-of-the-art mobile agents using our framework, providing detailed insights into their performance characteristics and limitations.
对移动代理进行准确、系统的评估可以显著促进其发展和在现实世界中的适用性。然而,由于定义任务奖励信号和实现相应评估代码需要大量的人工努力,现有的移动代理基准测试缺乏实用性和可扩展性。为此,我们提出了AutoEval,一个无需人工努力的自主代理评估框架。首先,我们设计了一种结构化子状态表示来描述代理执行过程中的UI状态变化,从而可以自动生成任务奖励信号。其次,我们利用判断系统,根据自动生成的任务奖励信号自主评估代理的性能。只要提供任务描述,我们的框架就能对代理进行精细的反馈评估,而无需任何额外的人工努力。我们实现了框架的原型,并验证了自动生成的任务奖励信号,发现其覆盖率超过93%。此外,为了证明我们自主的判断系统有效,我们手动验证了其判断结果,并证明其准确率达到了94%。最后,我们使用我们的框架对最先进的移动代理进行了评估,提供了关于其性能特征和局限性的详细见解。
论文及项目相关链接
Summary
该文提出了一种名为AutoEval的自主代理评估框架,旨在实现对移动代理的准确和系统化评估,无需人工干预。该框架通过结构化子状态表示来描述代理执行时的UI状态变化,自动生成任务奖励信号,并利用评判系统自主评估代理性能。该框架只需提供任务描述,即可对代理进行精细的反馈评估,无需额外的人工努力。实验验证显示,该框架的任务奖励信号覆盖率高,评判系统准确率高,并能对现有的移动代理进行详尽的性能评价和局限性分析。
Key Takeaways
- AutoEval是一个无需人工努力的自主代理评估框架,旨在推进移动代理的发展和实际应用。
- 通过结构化子状态表示描述UI状态变化,自动生成任务奖励信号。
- 利用评判系统自主评估代理性能,提供精细的反馈评估。
- 框架的任务奖励信号覆盖率高,与人工标注的信号相比超过93%。
- 评判系统的准确率高达94%,经过手动验证。
- 该框架能评价现有移动代理的性能特性,并提供详细的洞察。
点此查看论文截图



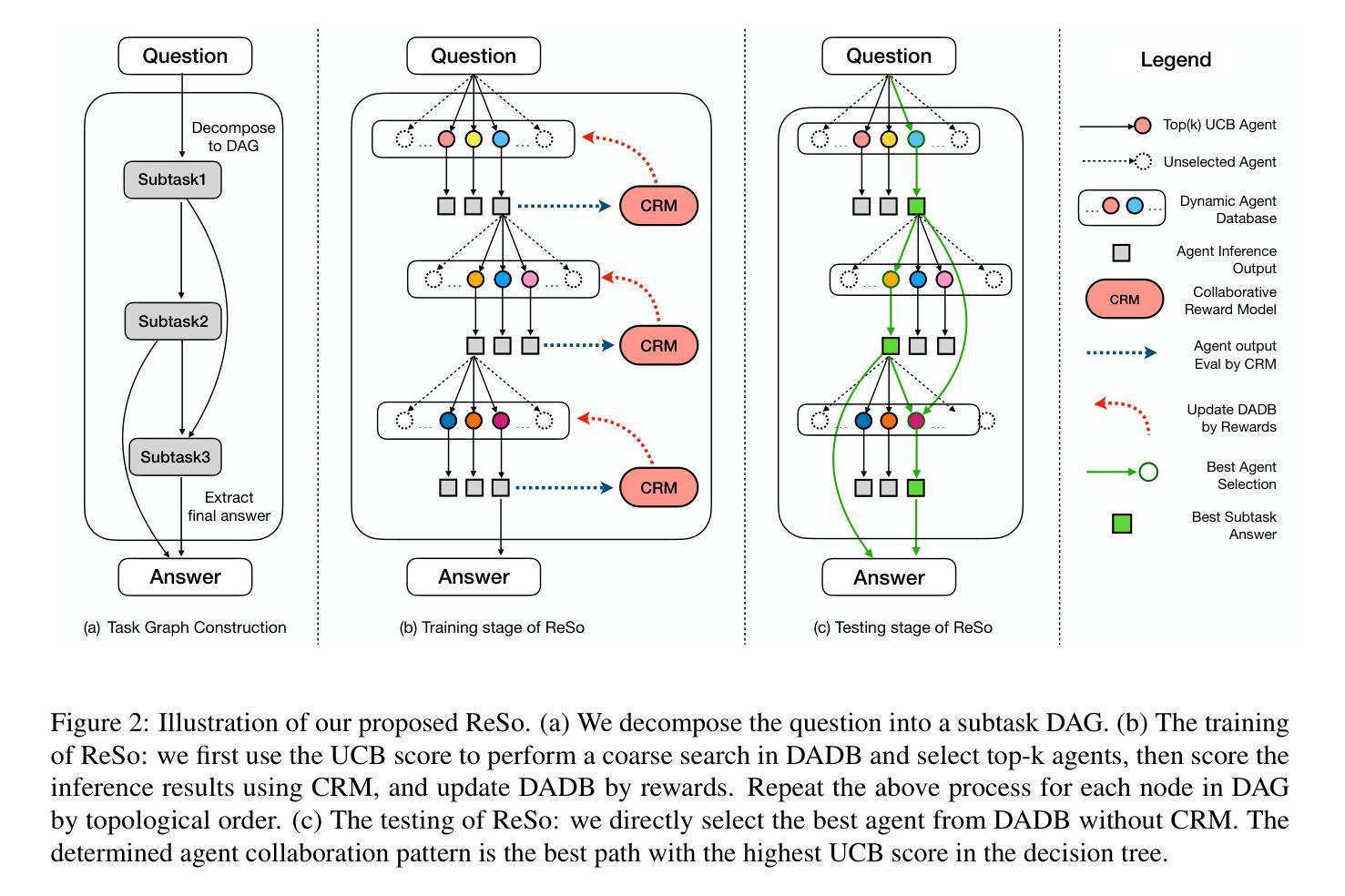
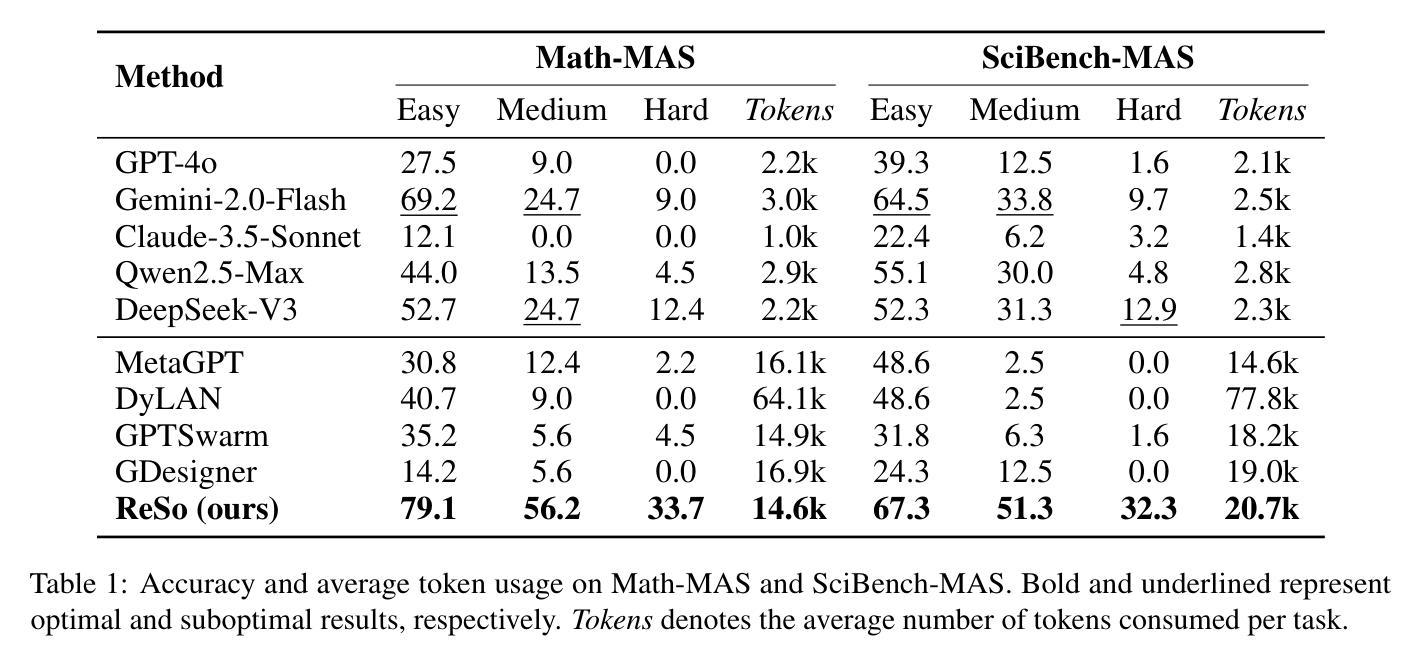
ReSo: A Reward-driven Self-organizing LLM-based Multi-Agent System for Reasoning Tasks
Authors:Heng Zhou, Hejia Geng, Xiangyuan Xue, Zhenfei Yin, Lei Bai
Multi-agent systems have emerged as a promising approach for enhancing the reasoning capabilities of large language models in complex problem-solving. However, current MAS frameworks are limited by poor flexibility and scalability, with underdeveloped optimization strategies. To address these challenges, we propose ReSo, which integrates task graph generation with a reward-driven two-stage agent selection process. The core of ReSo is the proposed Collaborative Reward Model, which can provide fine-grained reward signals for MAS cooperation for optimization. We also introduce an automated data synthesis framework for generating MAS benchmarks, without human annotations. Experimentally, ReSo matches or outperforms existing methods. ReSo achieves \textbf{33.7%} and \textbf{32.3%} accuracy on Math-MAS and SciBench-MAS SciBench, while other methods completely fail. Code is available at: \href{https://github.com/hengzzzhou/ReSo}{ReSo}
多智能体系统作为一种有前景的方法,在复杂问题解决的领域中,有望增强大型语言模型的推理能力。然而,当前的多智能体系统框架受限于灵活性和可扩展性不足,以及优化策略不够成熟。为了解决这些挑战,我们提出了ReSo方法,它将任务图生成与奖励驱动的两阶段智能体选择过程相结合。ReSo的核心是提出的协同奖励模型,该模型可以为多智能体系统的合作提供精细粒度的奖励信号以实现优化。我们还引入了一个自动化数据合成框架,用于生成多智能体系统的基准测试集,无需人工标注。实验证明,ReSo与现有方法相匹配或表现更优。ReSo在Math-MAS和SciBench-MAS SciBench上分别实现了**33.7%和32.3%**的准确率,而其他方法则完全失败。相关代码可在:https://github.com/hengzzzhou/ReSo进行查看。
论文及项目相关链接
Summary
多智能体系统有望提升大型语言模型在复杂问题解决中的推理能力。然而,当前的多智能体系统框架受限于灵活性和可扩展性不足,优化策略也尚未完善。为解决这些问题,我们提出了ReSo,它结合了任务图生成和奖励驱动的两阶段智能体选择过程。ReSo的核心是提出的协同奖励模型,可以为多智能体系统的合作提供精细的奖励信号以实现优化。此外,我们还引入了一个自动化的数据合成框架,用于生成多智能体系统基准测试集,无需人工标注。实验表明,ReSo的性能与现有方法相比达到或超过,在Math-MAS和SciBench-MAS上分别实现了33.7%和32.3%的准确率,而其他方法则完全失败。
Key Takeaways
- 多智能体系统能提高大型语言模型在复杂问题上的推理能力。
- 当前MAS框架存在灵活性和可扩展性问题,以及优化策略的不足。
- ReSo通过结合任务图生成和奖励驱动的两阶段智能体选择来解决问题。
- ReSo的核心是协同奖励模型,提供精细奖励信号优化MAS合作。
- 引入自动化数据合成框架,无需人工标注生成MAS基准测试集。
- ReSo在Math-MAS和SciBench-MAS上的准确率分别达到了33.7%和32.3%。
- 其他方法在Math-MAS和SciBench-MAS上的表现不佳。
点此查看论文截图

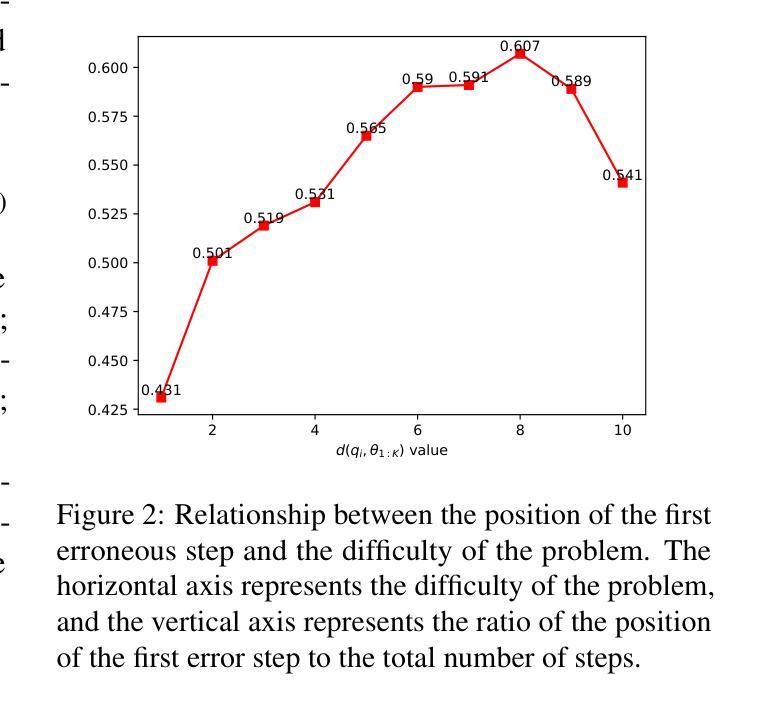
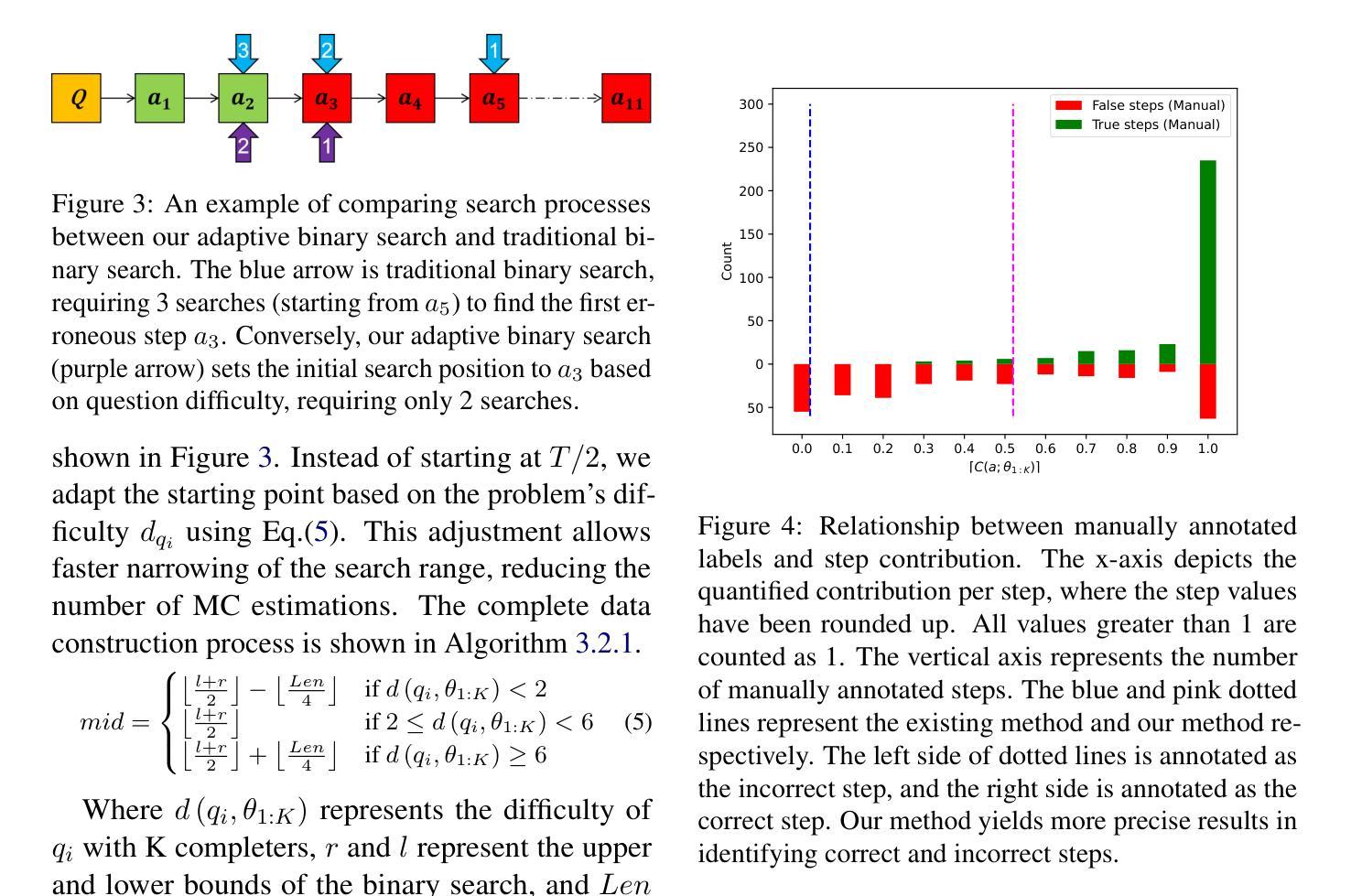
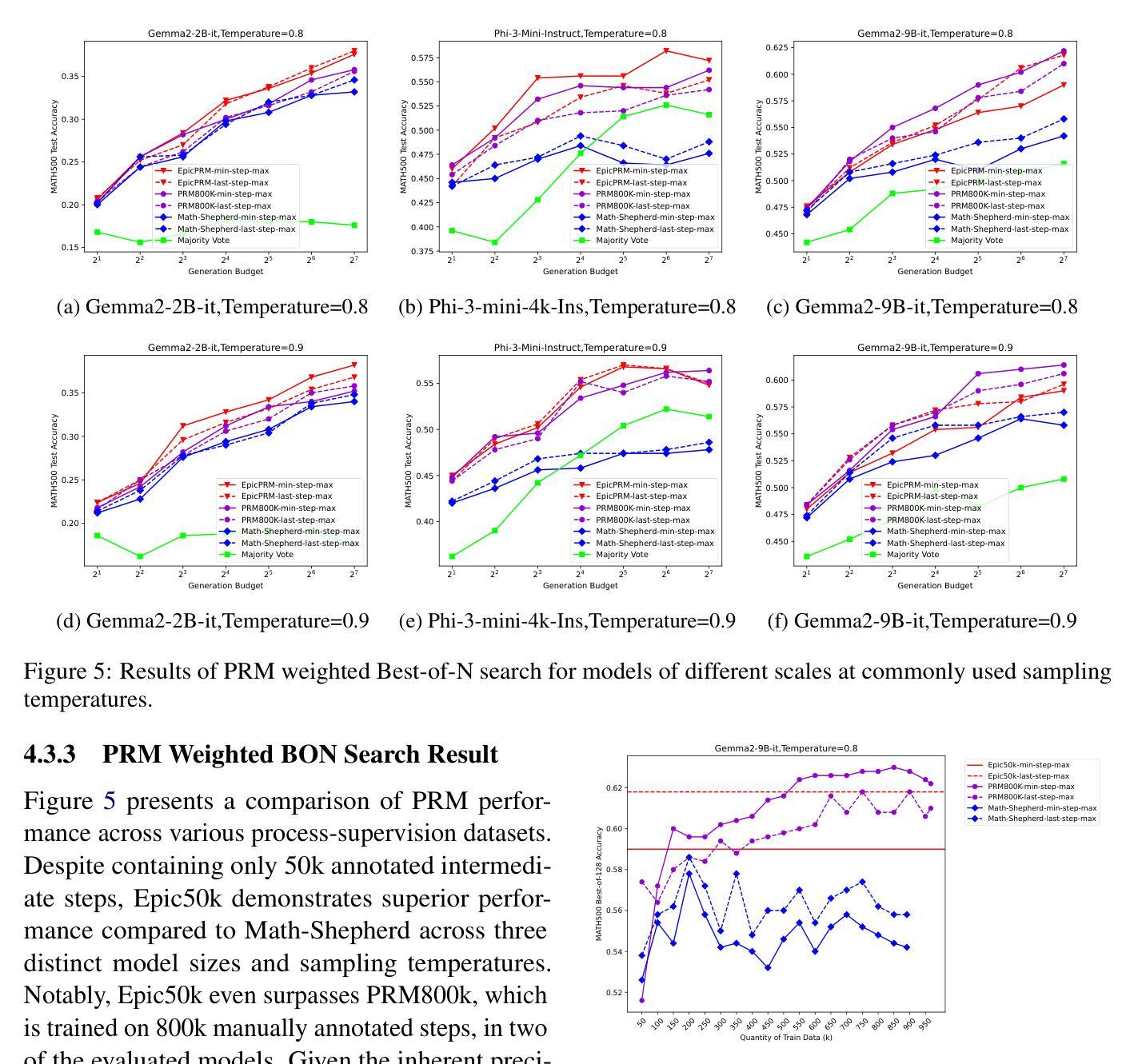
An Efficient and Precise Training Data Construction Framework for Process-supervised Reward Model in Mathematical Reasoning
Authors:Wei Sun, Qianlong Du, Fuwei Cui, Jiajun Zhang
Enhancing the mathematical reasoning capabilities of Large Language Models (LLMs) is of great scientific and practical significance. Researchers typically employ process-supervised reward models (PRMs) to guide the reasoning process, effectively improving the models’ reasoning abilities. However, existing methods for constructing process supervision training data, such as manual annotation and per-step Monte Carlo estimation, are often costly or suffer from poor quality. To address these challenges, this paper introduces a framework called EpicPRM, which annotates each intermediate reasoning step based on its quantified contribution and uses an adaptive binary search algorithm to enhance both annotation precision and efficiency. Using this approach, we efficiently construct a high-quality process supervision training dataset named Epic50k, consisting of 50k annotated intermediate steps. Compared to other publicly available datasets, the PRM trained on Epic50k demonstrates significantly superior performance. Getting Epic50k at https://github.com/xiaolizh1/EpicPRM.
增强大型语言模型(LLM)的数学推理能力在科学与实际应用中具有重大意义。研究者通常采用流程监督奖励模型(PRM)来引导推理过程,有效提高模型的推理能力。然而,现有的构建流程监督训练数据的方法,如手动标注和分步蒙特卡洛估计,往往成本高昂或质量不佳。为了解决这些挑战,本文引入了一个名为EpicPRM的框架,该框架基于中间推理步骤的量化贡献进行标注,并使用自适应二分搜索算法提高标注的准确性和效率。通过这种方法,我们有效地构建了一个高质量的过程监督训练数据集Epic50k,包含5万个标注的中间步骤。与其他公开数据集相比,在Epic50k上训练的PRM表现出显著的优势。可通过https://github.com/xiaolizh1/EpicPRM获取Epic50k数据集。
论文及项目相关链接
Summary
大型语言模型(LLM)的数学推理能力增强具有重要的科学和实际意义。研究者通常使用过程监督奖励模型(PRM)来引导推理过程,以提高模型的推理能力。然而,构建过程监督训练数据的方法,如手动标注和分步蒙特卡洛估计,成本较高或质量不佳。本文引入了一个名为EpicPRM的框架,它根据每个中间推理步骤的量化贡献进行标注,并使用自适应二进制搜索算法提高标注的准确性和效率。通过使用此方法,我们有效地构建了高质量的过程监督训练数据集Epic50k,包含5万个标注的中间步骤。与其他公开数据集相比,在Epic50k上训练的PRM表现出卓越的性能。
Key Takeaways
- 大型语言模型(LLM)数学推理能力增强很重要。
- 过程监督奖励模型(PRM)用于提高LLM的推理能力。
- 现有构建过程监督训练数据的方法成本较高或质量不佳。
- EpicPRM框架通过量化中间推理步骤的贡献进行标注。
- EpicPRM使用自适应二进制搜索算法提高标注的准确性和效率。
- 构建了一个高质量的过程监督训练数据集Epic50k,包含5万个标注的中间步骤。
点此查看论文截图



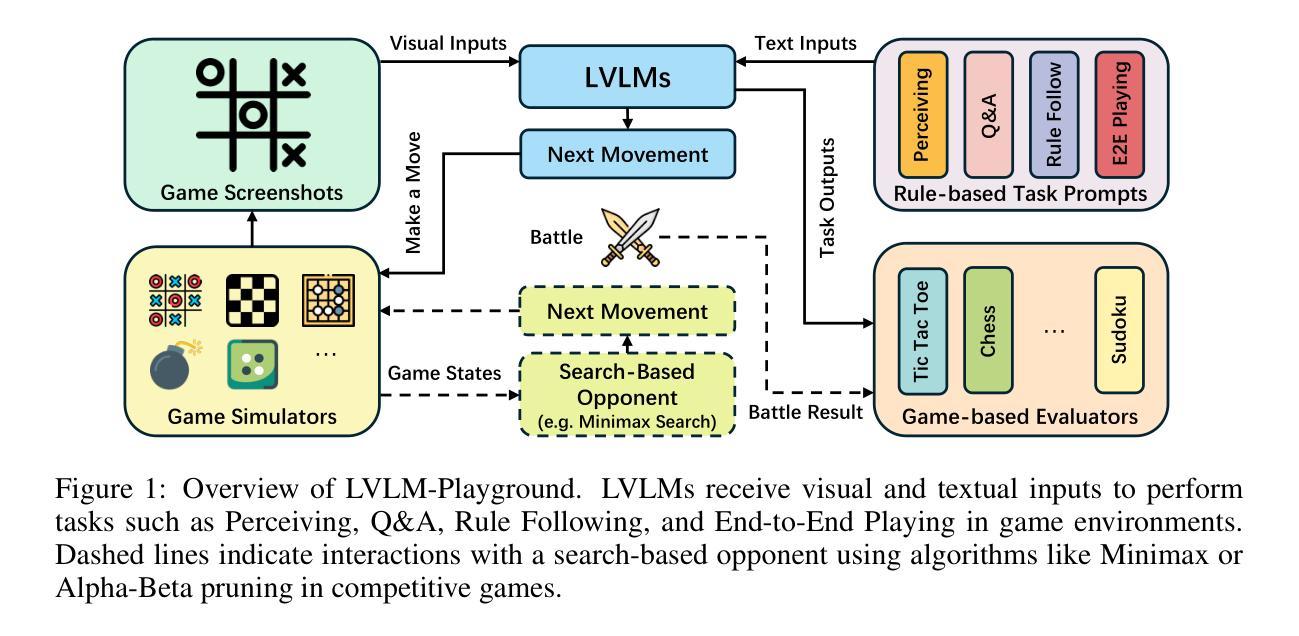
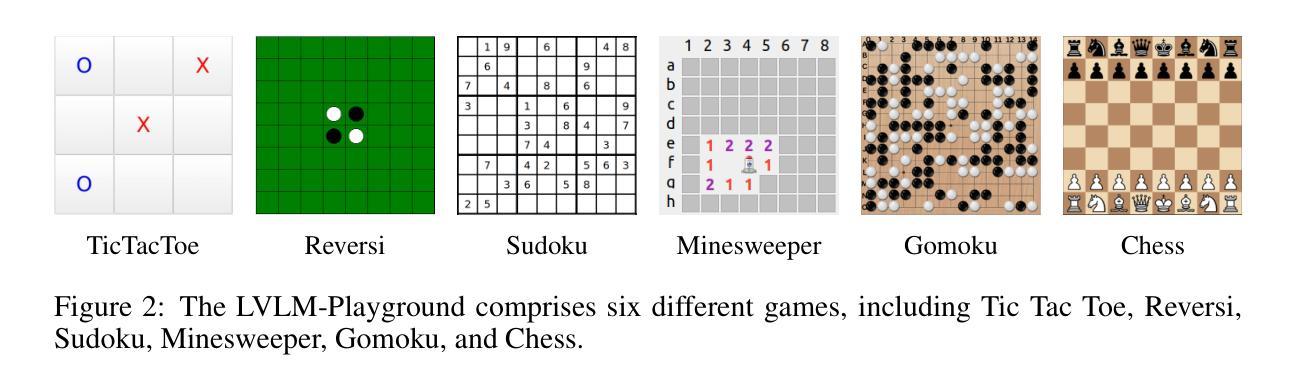
Are Large Vision Language Models Good Game Players?
Authors:Xinyu Wang, Bohan Zhuang, Qi Wu
Large Vision Language Models (LVLMs) have demonstrated remarkable abilities in understanding and reasoning about both visual and textual information. However, existing evaluation methods for LVLMs, primarily based on benchmarks like Visual Question Answering and image captioning, often fail to capture the full scope of LVLMs’ capabilities. These benchmarks are limited by issues such as inadequate assessment of detailed visual perception, data contamination, and a lack of focus on multi-turn reasoning. To address these challenges, we propose \method{}, a game-based evaluation framework designed to provide a comprehensive assessment of LVLMs’ cognitive and reasoning skills in structured environments. \method{} uses a set of games to evaluate LVLMs on four core tasks: Perceiving, Question Answering, Rule Following, and End-to-End Playing, with each target task designed to assess specific abilities, including visual perception, reasoning, decision-making, etc. Based on this framework, we conduct extensive experiments that explore the limitations of current LVLMs, such as handling long structured outputs and perceiving detailed and dense elements. Code and data are publicly available at https://github.com/xinke-wang/LVLM-Playground.
大型视觉语言模型(LVLMs)在理解和推理视觉和文本信息方面表现出了显著的能力。然而,现有的LVLMs评估方法,主要基于视觉问答和图像描述等基准测试,往往无法全面捕捉LVLMs的能力范围。这些基准测试受限于详细视觉感知评估不足、数据污染以及缺乏多轮推理的焦点等问题。为了应对这些挑战,我们提出了\method{},这是一个基于游戏的设计评估框架,旨在提供对LVLMs在结构化环境中的认知和推理技能的全面评估。\method{}使用一系列游戏来评估LVLMs在四个核心任务上的表现:感知、问答、遵循规则和端到端游戏。每个目标任务都是设计用来评估特定的能力,包括视觉感知、推理、决策等。基于这一框架,我们进行了大量实验,探讨了当前LVLMs的局限性,如处理长结构化输出和感知详细密集元素等。相关代码和数据可在https://github.com/xinke-wang/LVLM-Playground上公开访问。
论文及项目相关链接
PDF ICLR2025
Summary
大型视觉语言模型(LVLMs)在理解和推理视觉与文本信息方面展现出显著能力,但现有的评估方法,如视觉问答和图像描述等基准测试,往往无法全面捕捉LVLMs的完整能力。为此,我们提出一种基于游戏评估框架的方法,旨在全面评估LVLMs在结构化环境中的认知和推理能力。该方法通过一系列游戏,对LVLMs在感知、问答、遵循规则和端到端玩耍等四个核心任务上的能力进行评估。
Key Takeaways
- LVLMs展现出强大的理解和推理视觉与文本信息的能力。
- 现有评估方法无法全面捕捉LVLMs的能力,存在详细视觉感知评估不足、数据污染以及缺乏多轮推理的焦点等问题。
- 提出了一种基于游戏评估框架的方法,为LVLMs提供全面的认知和推理能力评估。
- 该方法通过游戏评估LVLMs在感知、问答、遵循规则和端到端玩耍等四个核心任务上的表现。
- 每个目标任务旨在评估特定的能力,包括视觉感知、推理、决策制定等。
- 基于该框架进行了广泛实验,发现LVLMs在处理长结构输出和感知详细密集元素等方面的局限性。
点此查看论文截图


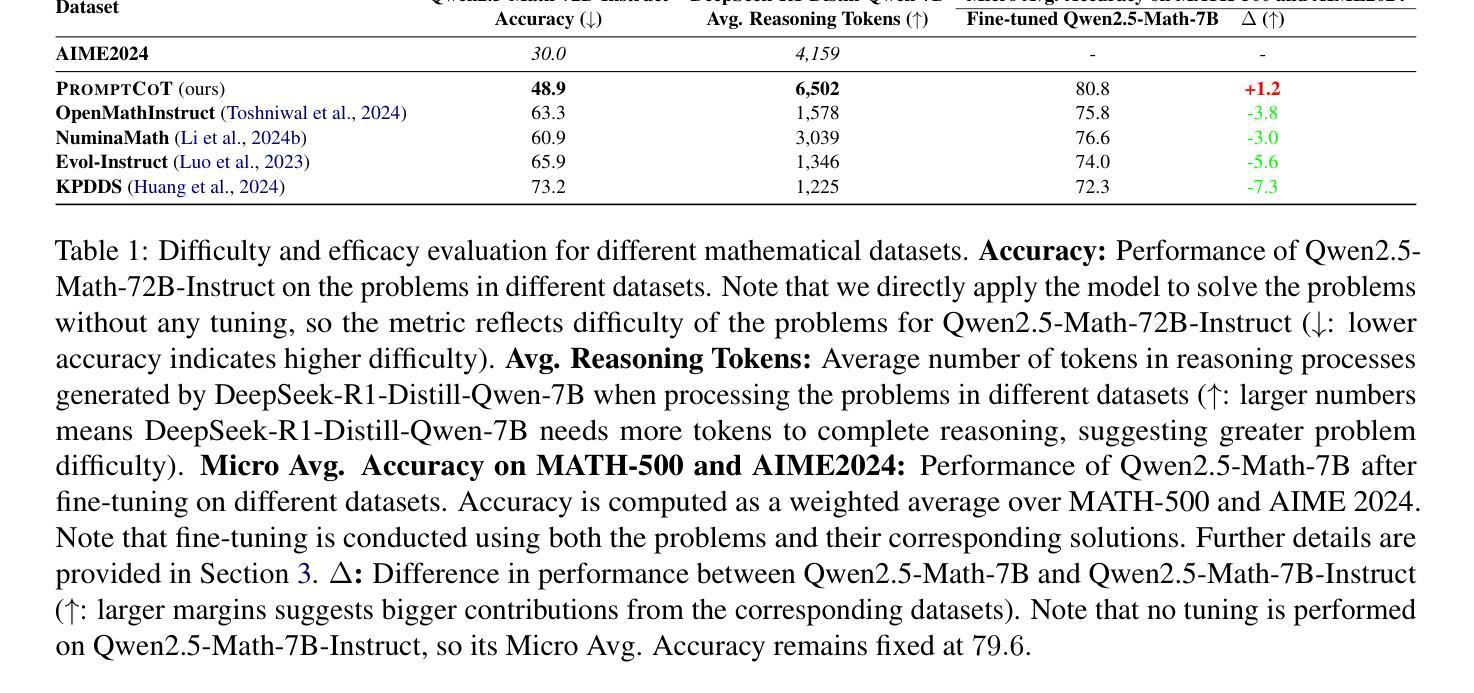
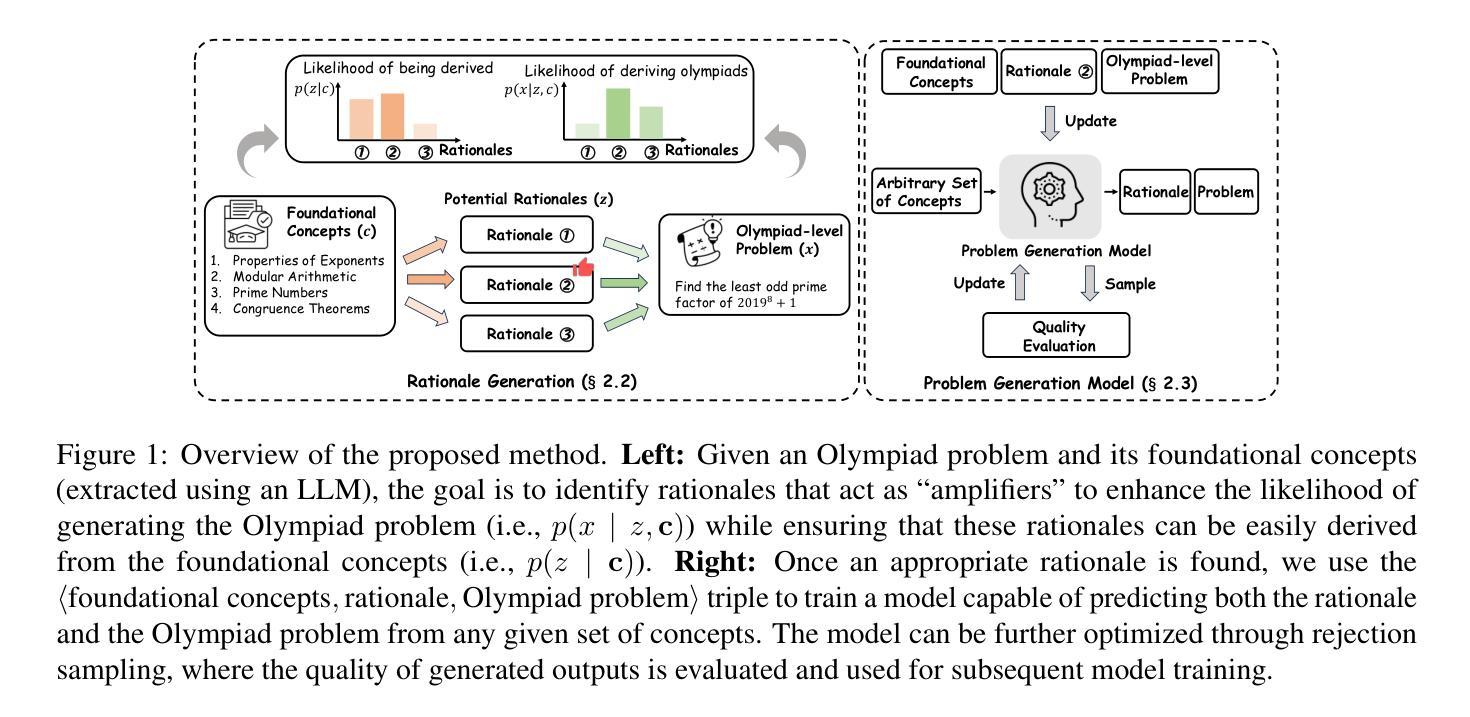
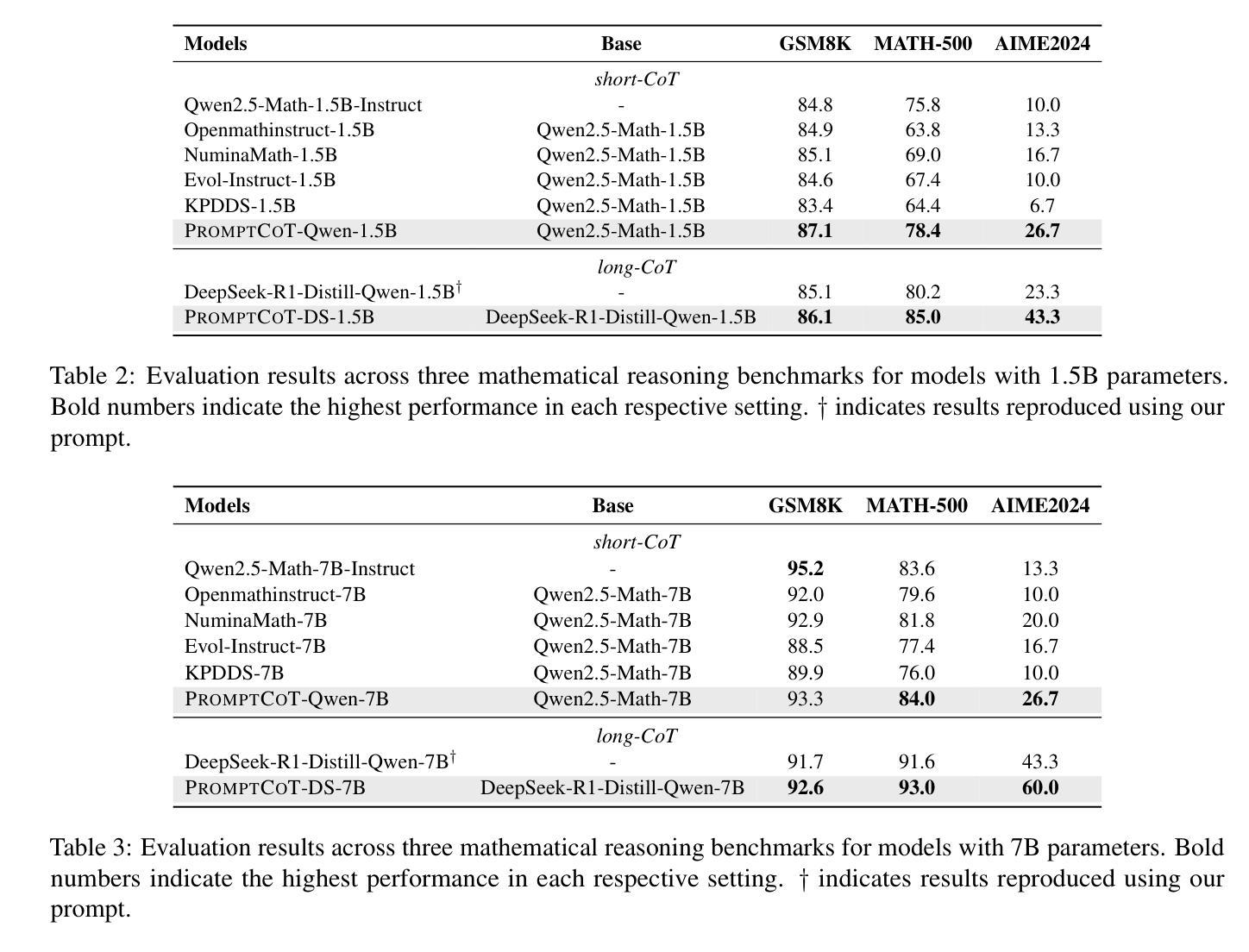
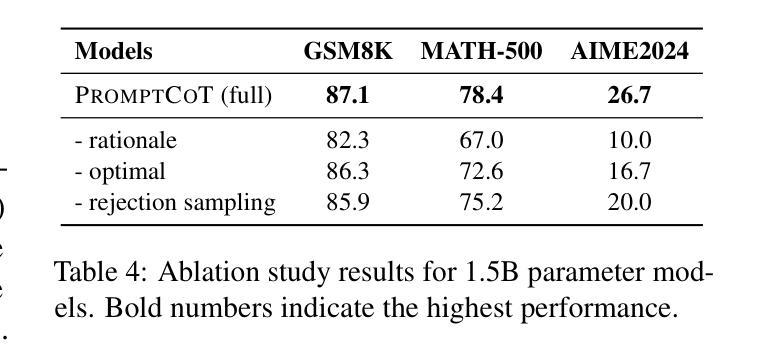
PromptCoT: Synthesizing Olympiad-level Problems for Mathematical Reasoning in Large Language Models
Authors:Xueliang Zhao, Wei Wu, Jian Guan, Lingpeng Kong
The ability of large language models to solve complex mathematical problems has progressed significantly, particularly for tasks requiring advanced reasoning. However, the scarcity of sufficiently challenging problems, particularly at the Olympiad level, hinders further advancements. In this work, we introduce PromptCoT, a novel approach for automatically generating high-quality Olympiad-level math problems. The proposed method synthesizes complex problems based on mathematical concepts and the rationale behind problem construction, emulating the thought processes of experienced problem designers. We provide a theoretical analysis demonstrating that an optimal rationale should maximize both the likelihood of rationale generation given the associated concepts and the likelihood of problem generation conditioned on both the rationale and the concepts. Our method is evaluated on standard benchmarks including GSM8K, MATH-500, and AIME2024, where it consistently outperforms existing problem generation methods. Furthermore, we demonstrate that PromptCoT exhibits superior data scalability, consistently maintaining high performance as the dataset size increases, outperforming the baselines. The implementation is available at https://github.com/zhaoxlpku/PromptCoT.
语言模型解决复杂数学问题的能力,特别是针对需要高级推理的任务,已经取得了显著的进步。然而,缺乏足够具有挑战性的数学问题,尤其是在奥林匹克级别的问题,阻碍了进一步的进步。在这项工作中,我们介绍了PromptCoT,一种自动生成高质量奥林匹克级别数学问题的新型方法。所提出的方法基于数学概念和问题构建背后的原理,综合生成复杂问题,模拟经验丰富的问题设计人员的思维过程。我们提供理论分析,证明最优原理应最大化给定相关概念时原理生成的可能性,以及以原理和相关概念为条件的问题生成的可能性。我们的方法在GSM8K、MATH-500和AIME2024等标准基准测试上的表现均优于现有的问题生成方法。此外,我们还证明PromptCoT在数据规模上表现出卓越的可扩展性,随着数据集规模的增加,性能持续保持高水平,超过了基线。相关实现可访问https://github.com/zhaoxlpku/PromptCoT获取。
论文及项目相关链接
PDF Preprint
Summary
大型语言模型解决复杂数学问题能力显著进步,尤其在需要高级推理的任务上。但缺乏足够挑战性的题目,如奥林匹克级别题目,阻碍了进一步的发展。本研究提出PromptCoT方法,可自动生成高质量奥林匹克级别数学问题。此方法基于数学概念及问题构建的逻辑,合成复杂问题,模拟经验丰富的题目设计者的思考过程。经理论分析,最佳逻辑应最大化相关概念下逻辑生成的可能性,以及基于逻辑和概念的问题生成的可能性。该方法在GSM8K、MATH-500和AIME2024等标准基准测试中表现卓越,超越现有问题生成方法。PromptCoT展现出卓越的数据可扩展性,随着数据集增加,性能始终保持在高水平。实施细节可在https://github.com/zhaoxlpku/PromptCoT查看。
Key Takeaways
- 大型语言模型在解决复杂数学问题方面取得显著进步。
- 缺乏挑战性的数学问题,特别是奥林匹克级别的问题,限制了进一步的发展。
- PromptCoT是一种自动生成高质量奥林匹克级别数学问题的新方法。
- PromptCoT基于数学概念和问题构建的逻辑来合成问题,模拟经验丰富的设计者的思考过程。
- 理论分析显示,最佳逻辑应同时考虑相关概念下逻辑生成的可能性及问题生成的可能性。
- PromptCoT在标准基准测试中表现卓越,超越了现有的问题生成方法。
点此查看论文截图