⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-07 更新
A Comparative Analysis of Generalised Echo and Interference Cancelling and Extended Multichannel Wiener Filtering for Combined Noise Reduction and Acoustic Echo Cancellation
Authors:Arnout Roebben, Toon van Waterschoot, Marc Moonen
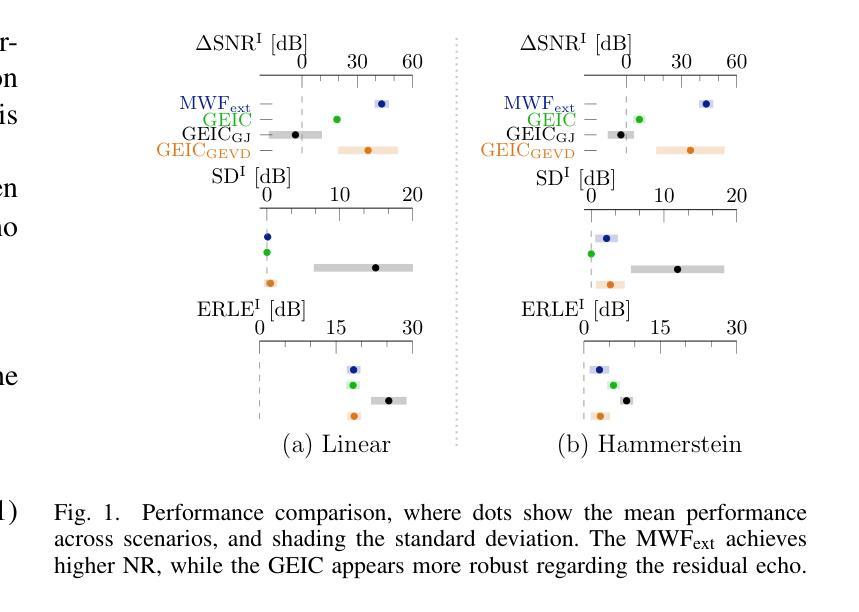
Two algorithms for combined acoustic echo cancellation (AEC) and noise reduction (NR) are analysed, namely the generalised echo and interference canceller (GEIC) and the extended multichannel Wiener filter (MWFext). Previously, these algorithms have been examined for linear echo paths, and assuming access to voice activity detectors (VADs) that separately detect desired speech and echo activity. However, algorithms implementing VADs may introduce detection errors. Therefore, in this paper, the previous analyses are extended by 1) modelling general nonlinear echo paths by means of the generalised Bussgang decomposition, and 2) modelling VAD error effects in each specific algorithm, thereby also allowing to model specific VAD assumptions. It is found and verified with simulations that, generally, the MWFext achieves a higher NR performance, while the GEIC achieves a more robust AEC performance.
分析两种用于组合声回波消除(AEC)和降噪(NR)的算法,即广义回声和干扰消除器(GEIC)和扩展的多通道维纳滤波器(MWFext)。以前,这些算法已经用于线性回声路径,并假设能够访问语音活动检测器(VAD),这些检测器可以分别检测所需的语音和回声活动。然而,采用VAD的算法可能会引入检测错误。因此,本文扩展了之前的分析,通过1)使用广义Bussgang分解对一般的非线性回声路径进行建模,以及2)对每个特定算法中的VAD误差效应进行建模,从而也允许对特定的VAD假设进行建模。通过模拟发现并验证,一般来说,MWFext的降噪性能更高,而GEIC的回波消除性能更稳健。
论文及项目相关链接
PDF Accepted for publication in ICASSP 2025
Summary
本文分析了两种用于结合声回波抑制(AEC)和降噪(NR)的算法,即广义回声和干扰消除器(GEIC)和扩展的多通道维纳滤波器(MWFext)。此研究突破了之前对于线性回声路径的假设以及对语音活动检测器(VAD)的使用,VAD能够分别检测出想要的语音和回声活动。然而,使用VAD的算法可能会引入检测错误。因此,本文通过两方面扩展之前的分析:一是通过广义Bussgang分解对一般非线性回声路径进行建模,二是针对每种特定算法模拟VAD误差效应,从而也允许模拟特定的VAD假设。模拟结果表明,一般来说,MWFext的降噪性能更高,而GEIC的回波抑制性能更稳健。
Key Takeaways
- 广义回声和干扰消除器(GEIC)以及扩展的多通道维纳滤波器(MWFext)是用于结合声回波抑制(AEC)和降噪(NR)的两种算法。
- 之前的研究主要假设线性回声路径和语音活动检测器(VAD)。然而,使用VAD可能会引入检测错误。
- 本文通过广义Bussgang分解对非线性回声路径进行建模。
- 针对每种算法模拟VAD误差效应,允许模拟特定VAD假设。
- MWFext通常表现出更高的降噪性能。
- GEIC在回波抑制方面表现出更稳健的性能。
点此查看论文截图

DuplexMamba: Enhancing Real-time Speech Conversations with Duplex and Streaming Capabilities
Authors:Xiangyu Lu, Wang Xu, Haoyu Wang, Hongyun Zhou, Haiyan Zhao, Conghui Zhu, Tiejun Zhao, Muyun Yang
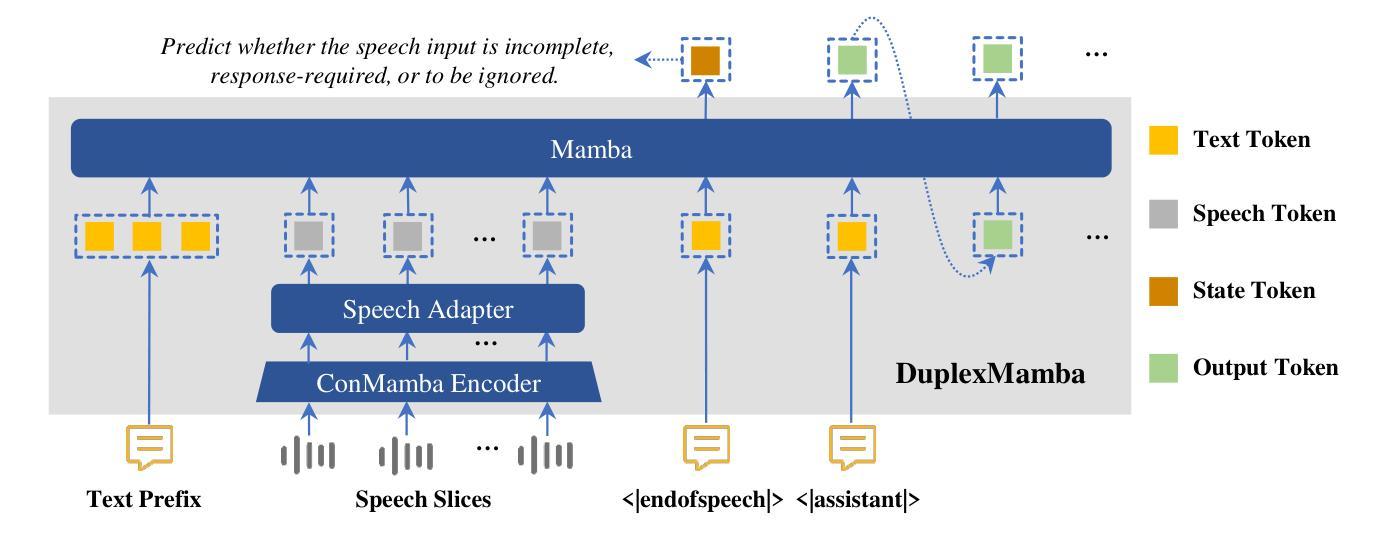
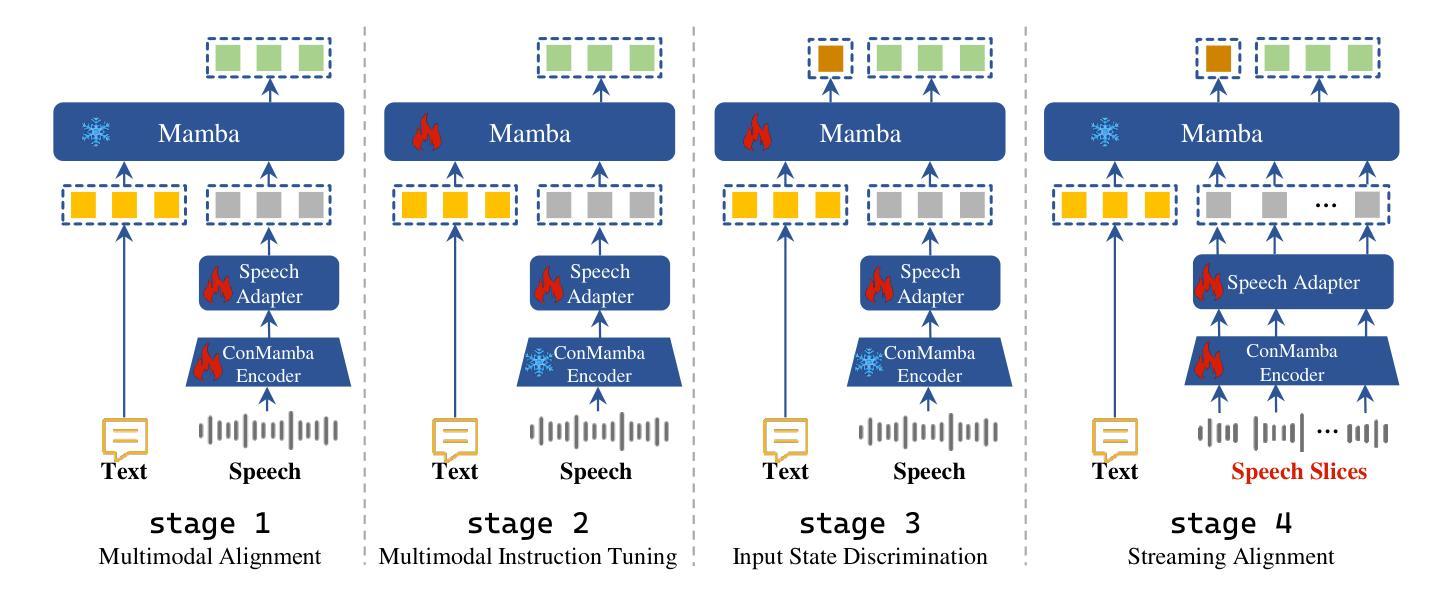
Real-time speech conversation is essential for natural and efficient human-machine interactions, requiring duplex and streaming capabilities. Traditional Transformer-based conversational chatbots operate in a turn-based manner and exhibit quadratic computational complexity that grows as the input size increases. In this paper, we propose DuplexMamba, a Mamba-based end-to-end multimodal duplex model for speech-to-text conversation. DuplexMamba enables simultaneous input processing and output generation, dynamically adjusting to support real-time streaming. Specifically, we develop a Mamba-based speech encoder and adapt it with a Mamba-based language model. Furthermore, we introduce a novel duplex decoding strategy that enables DuplexMamba to process input and generate output simultaneously. Experimental results demonstrate that DuplexMamba successfully implements duplex and streaming capabilities while achieving performance comparable to several recently developed Transformer-based models in automatic speech recognition (ASR) tasks and voice assistant benchmark evaluations. Our code and model are released
实时语音对话对于自然高效的人机交互至关重要,需要双向和流式处理能力。传统的基于Transformer的对话聊天机器人以轮次为基础运行,表现出随着输入量增加而二次方的计算复杂性。在本文中,我们提出了DuplexMamba,这是一个基于Mamba的端到端多模式双向模型,用于语音到文本的对话。DuplexMamba能够同时处理输入和生成输出,动态调整以支持实时流式处理。具体来说,我们开发了一个基于Mamba的语音编码器,并将其与基于Mamba的语言模型相结合。此外,我们引入了一种新的双向解码策略,使DuplexMamba能够同时处理输入并生成输出。实验结果表明,DuplexMamba成功实现了双向和流式处理功能,同时在自动语音识别(ASR)任务和语音助手基准评估中实现了与最近开发的几个基于Transformer的模型相当的性能。我们已经公开了代码和模型。
论文及项目相关链接
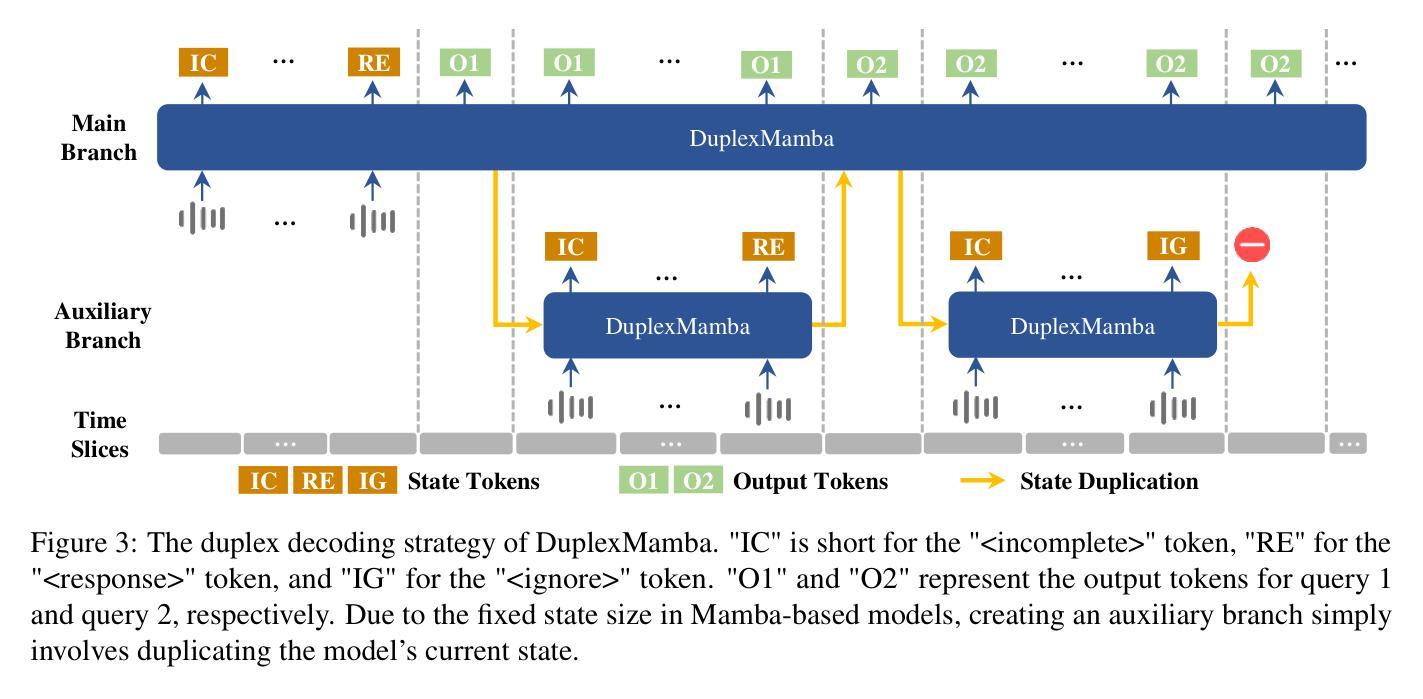
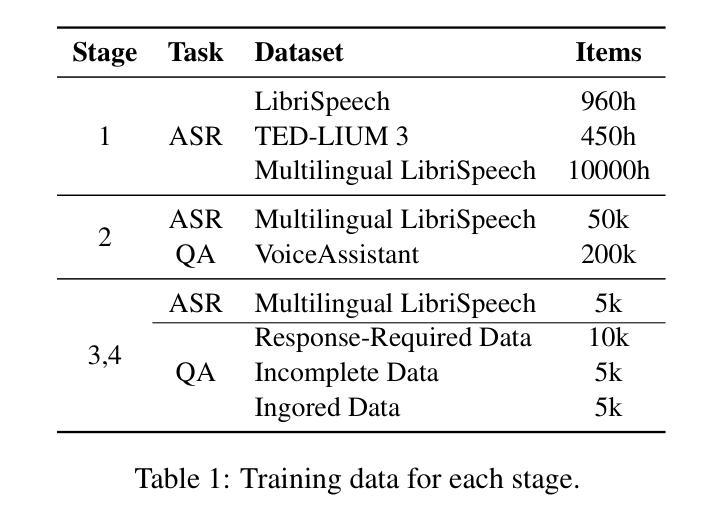
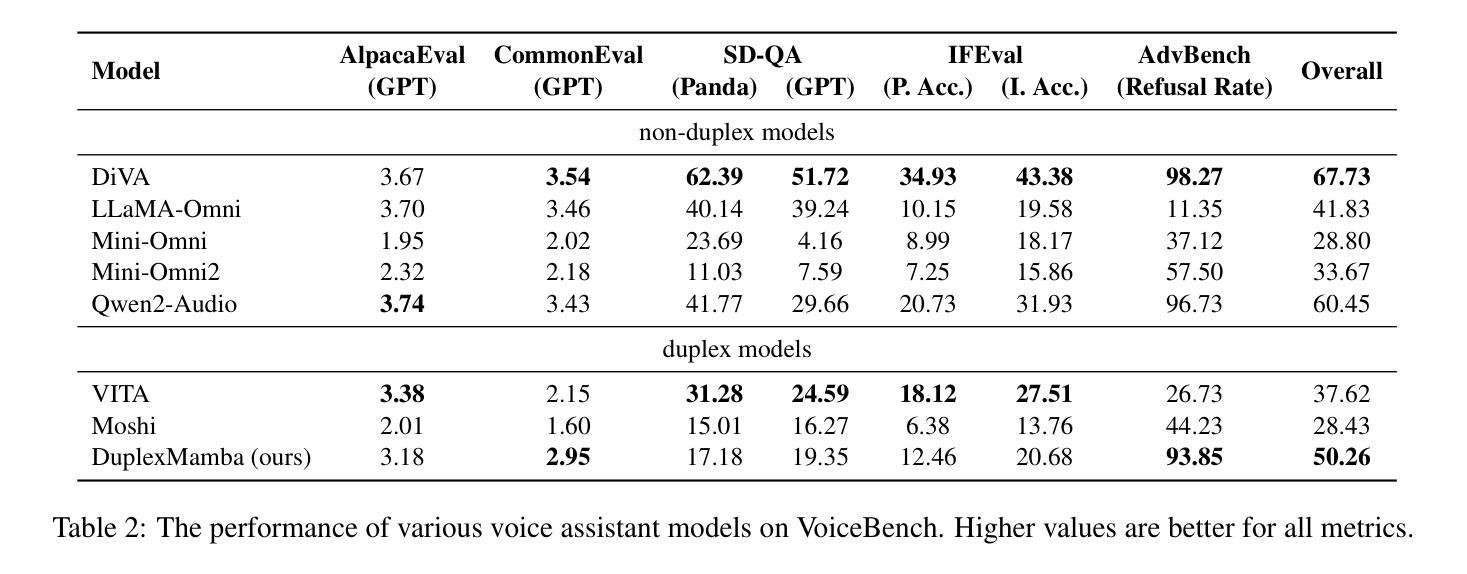
PDF 12 pages, 6 figures
摘要
本文提出了DuplexMamba,一个基于Mamba的端到端多模态双向模型,用于语音到文本的对话。该模型可实现实时流式处理,同时具备双向和流式处理能力,使得人机对话更加自然高效。通过引入Mamba基础的语音编码器和语言模型,并结合创新的双向解码策略,DuplexMamba能在处理输入的同时生成输出。实验结果显示,DuplexMamba在自动语音识别(ASR)任务和语音助手基准评估中表现优异,实现了与传统Transformer模型相当的性能,同时更有效地满足了实时语音对话的需求。
关键见解
- DuplexMamba模型结合Mamba技术实现实时语音对话,提升人机互动的自然性和效率。
- 模型具备同时处理输入和生成输出的能力,支持动态调整以适应实时流式处理。
- 引入基于Mamba的语音编码器和语言模型,优化语音到文本的转换过程。
- 创新性的双向解码策略,使DuplexMamba能在对话过程中同时处理输入和输出。
- 实验结果证实DuplexMamba在自动语音识别任务中表现优秀。
- 与最新Transformer模型相比,DuplexMamba在语音助手基准评估中展现出相当的性能。
- 模型代码和参数已公开发布,便于进一步研究和应用。
点此查看论文截图

CTC-DRO: Robust Optimization for Reducing Language Disparities in Speech Recognition
Authors:Martijn Bartelds, Ananjan Nandi, Moussa Koulako Bala Doumbouya, Dan Jurafsky, Tatsunori Hashimoto, Karen Livescu
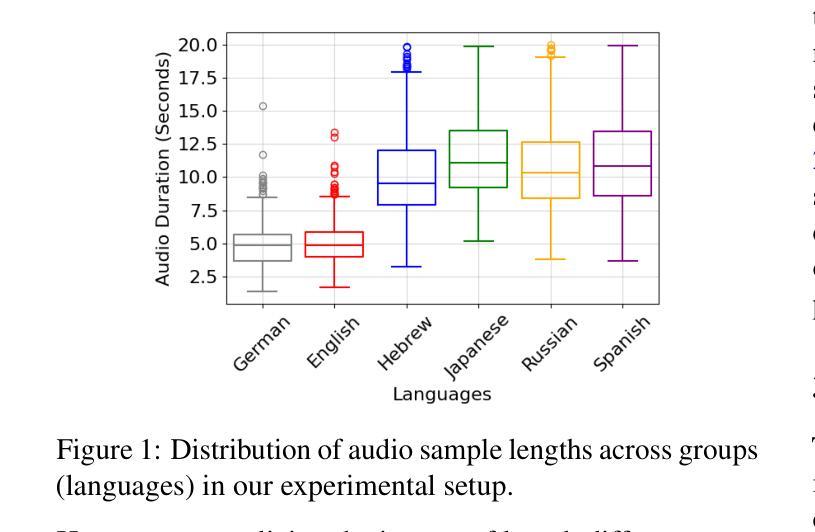
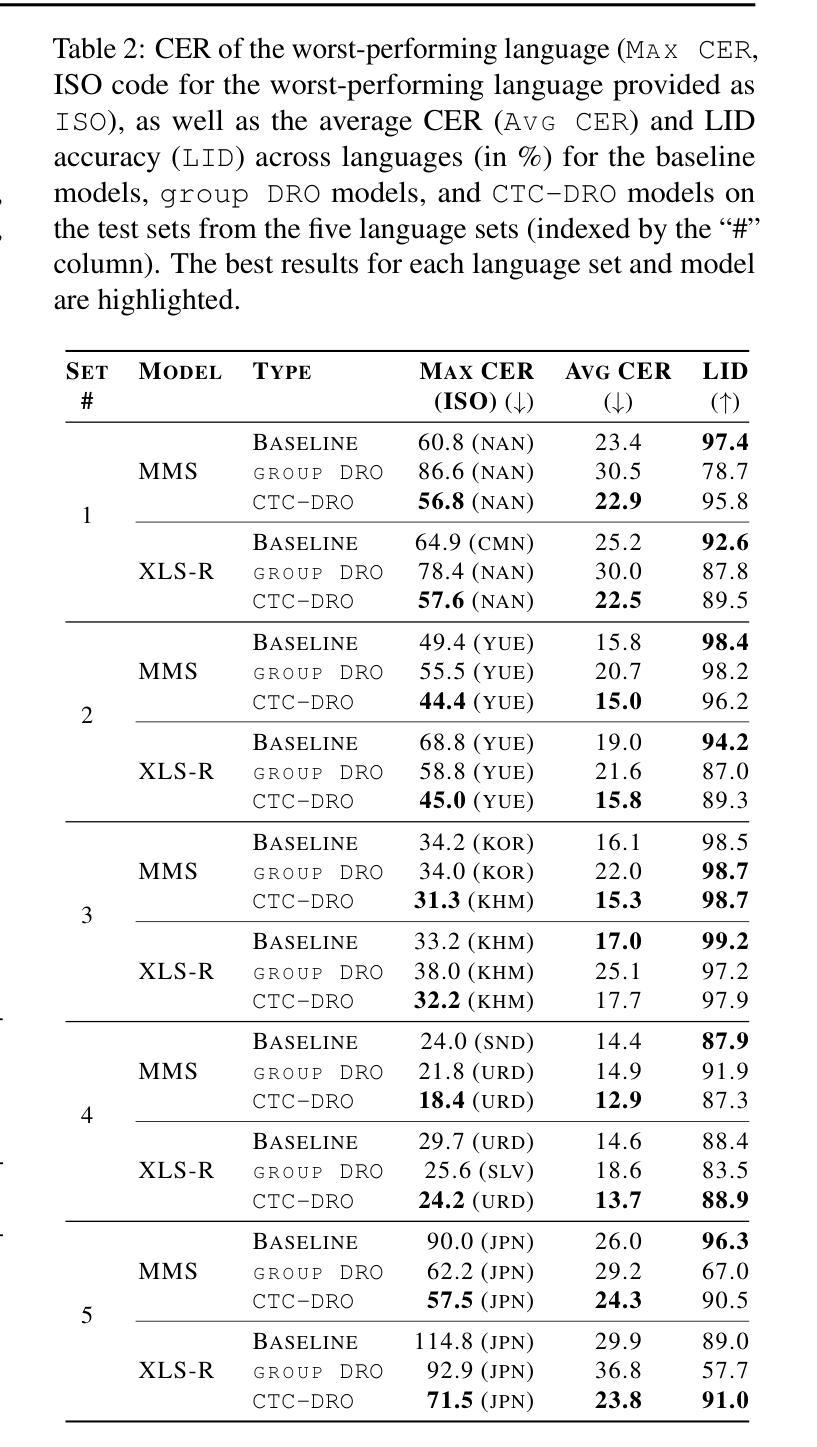
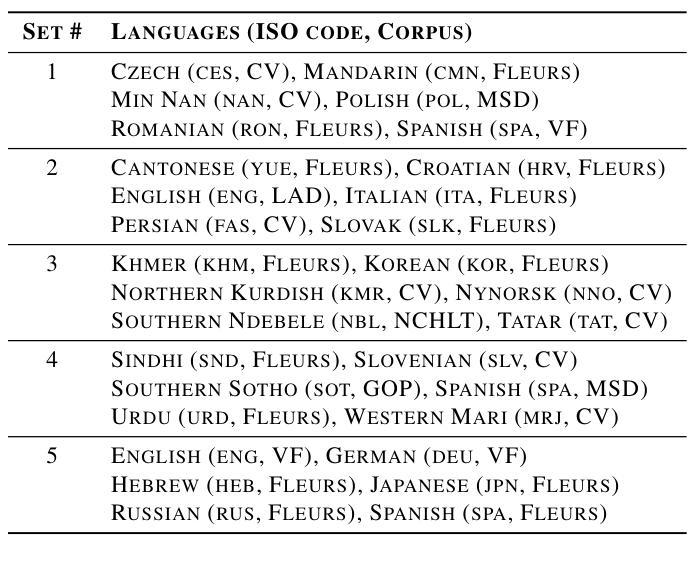
Modern deep learning models often achieve high overall performance, but consistently fail on specific subgroups. Group distributionally robust optimization (group DRO) addresses this problem by minimizing the worst-group loss, but it fails when group losses misrepresent performance differences between groups. This is common in domains like speech, where the widely used connectionist temporal classification (CTC) loss scales with input length and varies with linguistic and acoustic properties, leading to spurious differences between group losses. We present CTC-DRO, which addresses the shortcomings of the group DRO objective by smoothing the group weight update to prevent overemphasis on consistently high-loss groups, while using input length-matched batching to mitigate CTC’s scaling issues. We evaluate CTC-DRO on the task of multilingual automatic speech recognition (ASR) across five language sets from the ML-SUPERB 2.0 benchmark. CTC-DRO consistently outperforms group DRO and CTC-based baseline models, reducing the worst-language error by up to 47.1% and the average error by up to 32.9%. CTC-DRO can be applied to ASR with minimal computational costs, and offers the potential for reducing group disparities in other domains with similar challenges.
现代深度学习模型通常总体性能较高,但在特定子群体上始终存在失败的情况。分组分布鲁棒优化(group DRO)通过最小化最差分组损失来解决这个问题,但它在分组损失无法准确反映组间性能差异时就会失效。这在语音等领域很常见,例如广泛使用的连接时序分类(CTC)损失与输入长度成比例,并随语言和声学属性而变化,导致分组损失之间存在虚假差异。我们提出了CTC-DRO,它通过平滑分组权重更新来解决group DRO目标中的不足,以防止过分强调始终具有高损失的分组,同时使用与输入长度匹配的批次来缓解CTC的缩放问题。我们在ML-SUPERB 2.0基准测试的五套语言集上评估了CTC-DRO在多语种自动语音识别(ASR)任务上的表现。CTC-DRO始终优于group DRO和基于CTC的基线模型,将最差语言错误减少了高达47.1%,平均错误减少了高达32.9%。CTC-DRO可以最低的计算成本应用于ASR,并在具有类似挑战的其他领域具有减少群体差异的潜力。
论文及项目相关链接
Summary
本文介绍了针对现代深度学习模型在特定分组上持续失败的问题,提出一种改良的深度学习优化方法——CTC-DRO。该方法通过平滑群体权重更新,防止过于强调持续高损失的群体,并使用输入长度匹配的批处理来缓解CTC的缩放问题。在ML-SUPERB 2.0基准测试的多语种自动语音识别(ASR)任务中,CTC-DRO表现优异,相较于群体DRO和基于CTC的基准模型,能够减少最多47.1%的最差语言错误和最多32.9%的平均错误。此方法在ASR中的计算成本较低,并有潜力解决其他领域中的群体差异挑战。
Key Takeaways
- 现代深度学习模型在特定分组上性能欠佳的问题亟待解决。
- Group DRO通过最小化最差群体损失来解决这一问题,但当群体损失不能准确反映群体间性能差异时,其效果会受到影响。
- CTC损失在语音领域广泛应用,但其随输入长度变化而变化的特性会导致群体损失之间的虚假差异。
- CTC-DRO旨在解决Group DRO目标的不足,通过平滑群体权重更新防止过度关注持续高损失的群体。
- CTC-DRO使用输入长度匹配的批处理来缓解CTC的缩放问题。
- 在ML-SUPERB 2.0基准测试的多语种ASR任务中,CTC-DRO显著优于Group DRO和基于CTC的基准模型,减少了错误率。
点此查看论文截图