⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-07 更新
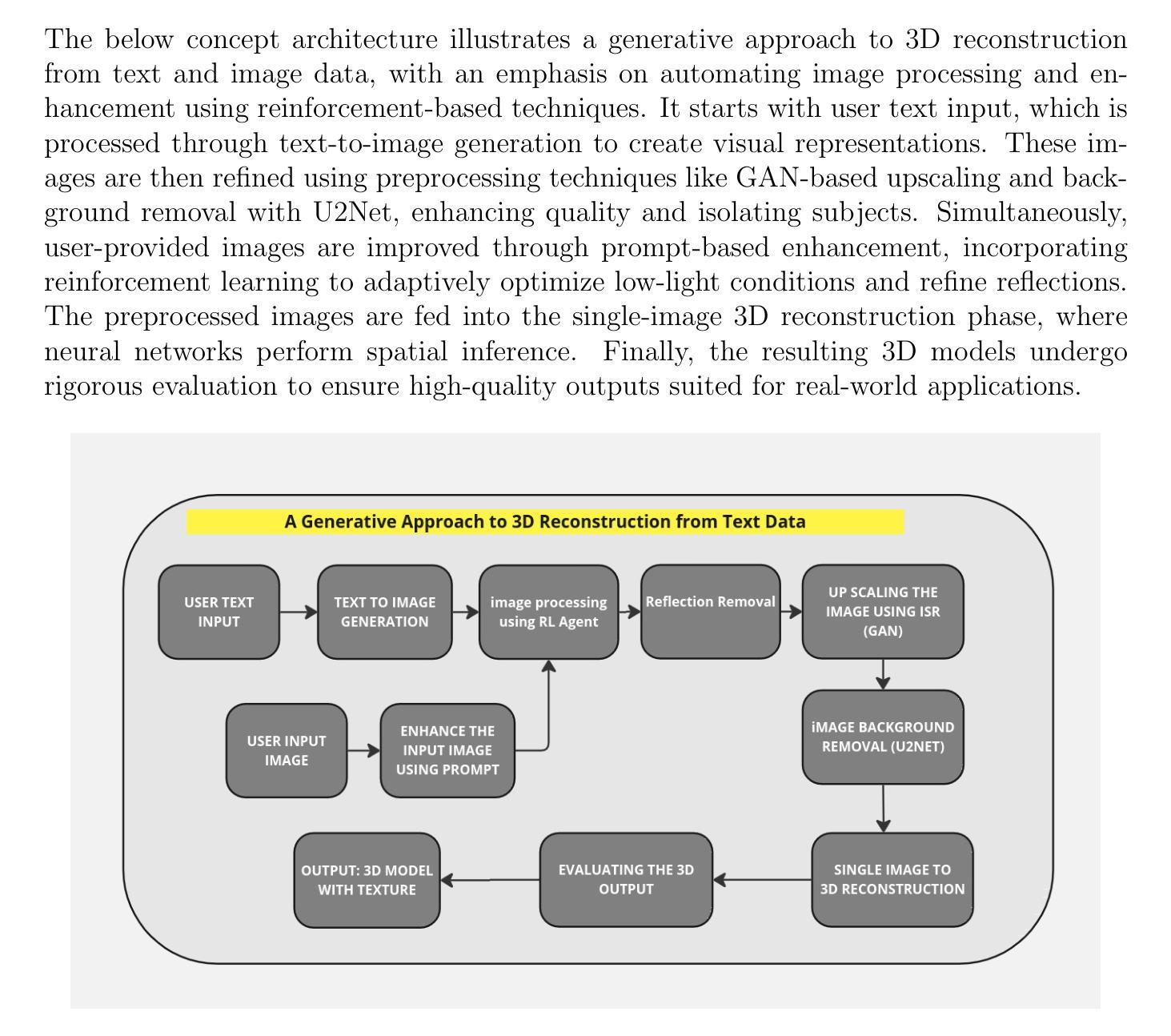
A Generative Approach to High Fidelity 3D Reconstruction from Text Data
Authors:Venkat Kumar R, Deepak Saravanan
The convergence of generative artificial intelligence and advanced computer vision technologies introduces a groundbreaking approach to transforming textual descriptions into three-dimensional representations. This research proposes a fully automated pipeline that seamlessly integrates text-to-image generation, various image processing techniques, and deep learning methods for reflection removal and 3D reconstruction. By leveraging state-of-the-art generative models like Stable Diffusion, the methodology translates natural language inputs into detailed 3D models through a multi-stage workflow. The reconstruction process begins with the generation of high-quality images from textual prompts, followed by enhancement by a reinforcement learning agent and reflection removal using the Stable Delight model. Advanced image upscaling and background removal techniques are then applied to further enhance visual fidelity. These refined two-dimensional representations are subsequently transformed into volumetric 3D models using sophisticated machine learning algorithms, capturing intricate spatial relationships and geometric characteristics. This process achieves a highly structured and detailed output, ensuring that the final 3D models reflect both semantic accuracy and geometric precision. This approach addresses key challenges in generative reconstruction, such as maintaining semantic coherence, managing geometric complexity, and preserving detailed visual information. Comprehensive experimental evaluations will assess reconstruction quality, semantic accuracy, and geometric fidelity across diverse domains and varying levels of complexity. By demonstrating the potential of AI-driven 3D reconstruction techniques, this research offers significant implications for fields such as augmented reality (AR), virtual reality (VR), and digital content creation.
生成式人工智能和先进计算机视觉技术的融合,开创了一种将文本描述转换为三维表示的方法。本研究提出了一种全自动流程管道,该管道无缝集成了文本到图像生成、各种图像处理技术和深度学习去除反射和三维重建的方法。通过利用最先进的生成模型(如Stable Diffusion),该方法通过多阶段工作流程将自然语言输入转换为详细的3D模型。重建过程首先从文本提示生成高质量图像开始,然后通过强化学习代理进行增强,并使用Stable Delight模型去除反射。随后应用先进的图像放大和背景去除技术,进一步提高视觉保真度。这些经过精细处理的二维表示随后使用复杂的机器学习算法转换为体积三维模型,捕捉复杂的空间关系和几何特征。这一过程实现了高度结构化且详细的输出,确保最终的3D模型既具有语义准确性又具有几何精度。这种方法解决了生成重建中的关键挑战,如保持语义连贯性、管理几何复杂性以及保留详细的视觉信息。综合实验评估将评估不同领域和不同层次复杂性的重建质量、语义准确性和几何保真度。该研究展示了人工智能驱动的3D重建技术潜力,对增强现实(AR)、虚拟现实(VR)和数字内容创建等领域具有重大影响。
论文及项目相关链接
摘要
生成式人工智能与先进计算机视觉技术的融合,为实现从文本描述到三维表征的转换带来了突破性的方法。该研究提出了一种全自动流程,该流程无缝集成了文本到图像生成、各种图像处理技术和深度学习反射去除及三维重建方法。通过利用如Stable Diffusion等最先进的生成模型,该方法通过多阶段工作流程将自然语言输入转换为详细的3D模型。重建过程从根据文本提示生成高质量图像开始,随后通过强化学习代理进行增强,并使用Stable Delight模型去除反射。高级图像放大和背景移除技术可进一步提高视觉保真度。这些经过精细处理的二维表示随后通过先进的机器学习算法转换为体积三维模型,捕捉复杂的空间关系和几何特征。这一过程实现了高度结构和详细的输出,确保最终的三维模型反映语义准确性和几何精度。此方法解决了生成重建中的关键挑战,如保持语义连贯性、管理几何复杂性以及保留详细的视觉信息。全面的实验评估将评估不同领域和不同程度复杂性的重建质量、语义准确性和几何保真度。该研究为增强现实(AR)、虚拟现实(VR)和数字内容创建等领域带来了人工智能驱动的三维重建技术的巨大潜力。
关键见解
- 生成式人工智能与计算机视觉技术的融合为实现文本到三维模型的转换提供了新方法。
- 研究提出了一种全自动流程,包括文本到图像生成、图像处理、深度学习等方法。
- 利用最新生成模型(如Stable Diffusion)实现自然语言到详细3D模型的转换。
- 重建流程包括去除反射、图像增强、背景移除和高级图像放大技术。
- 通过机器学习算法将二维表示转换为三维模型,实现高度结构和详细的输出。
- 该方法解决了语义连贯性、几何复杂性等生成重建中的关键挑战。
点此查看论文截图


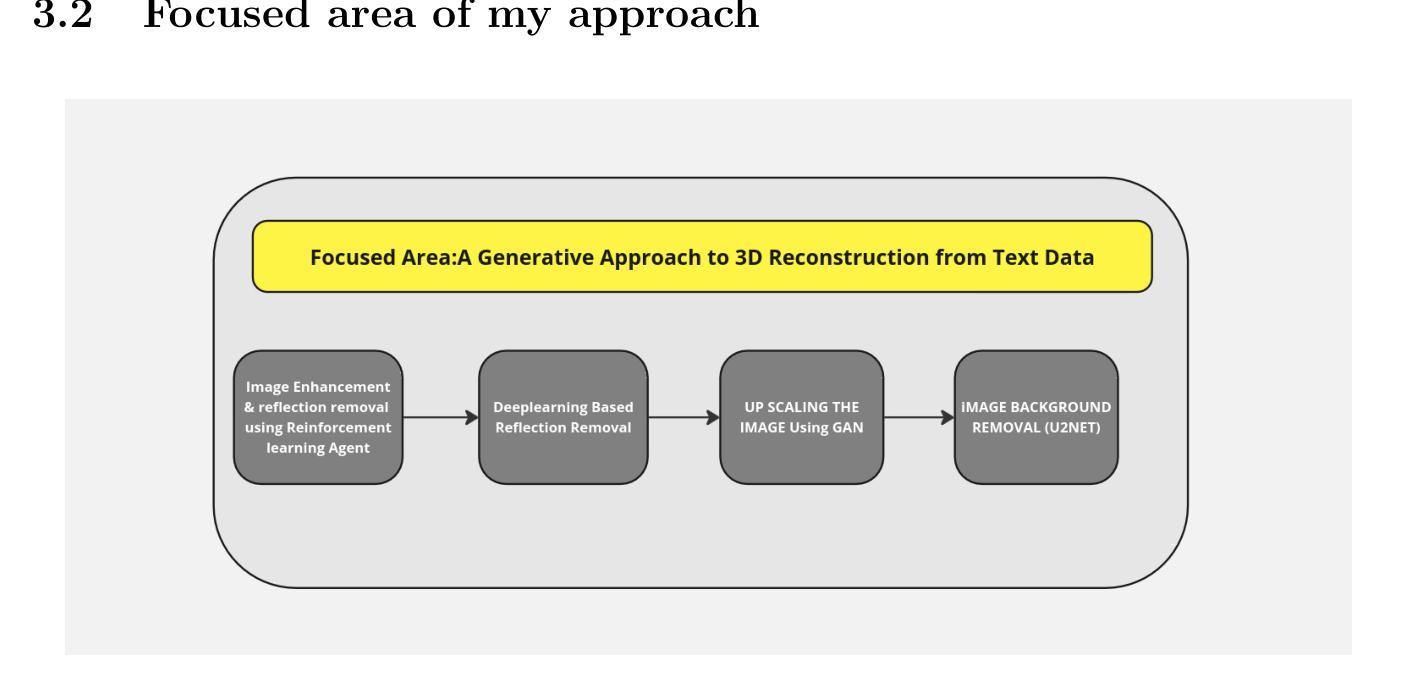

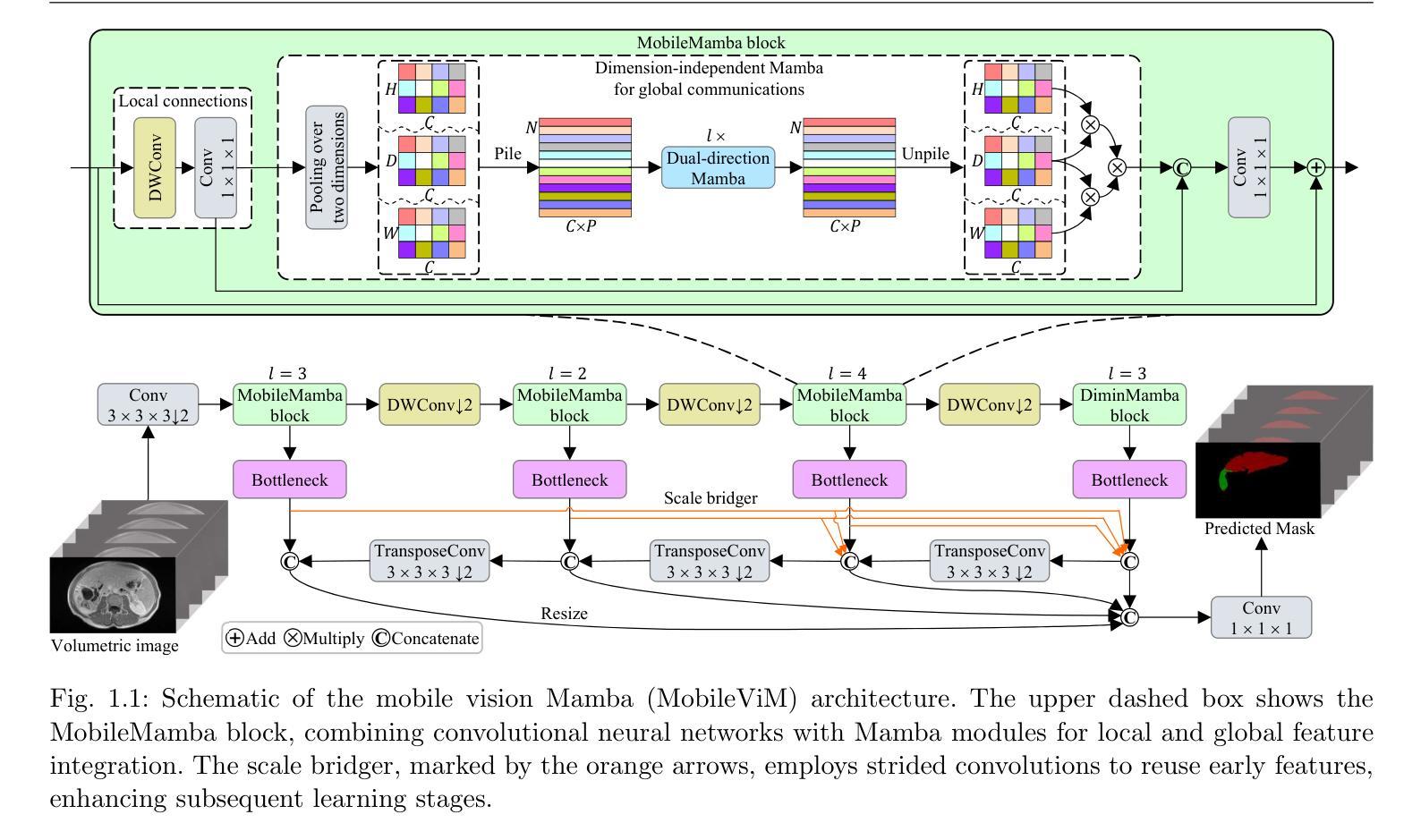
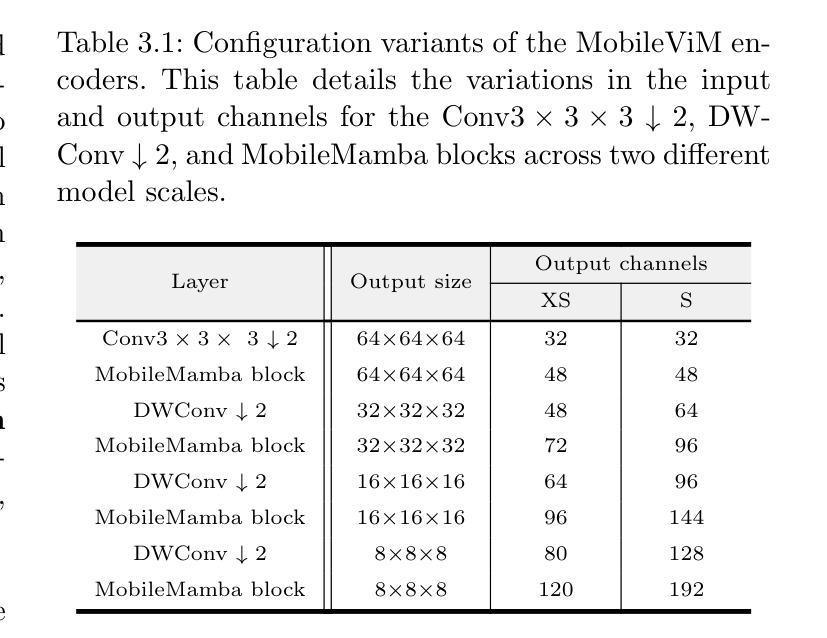
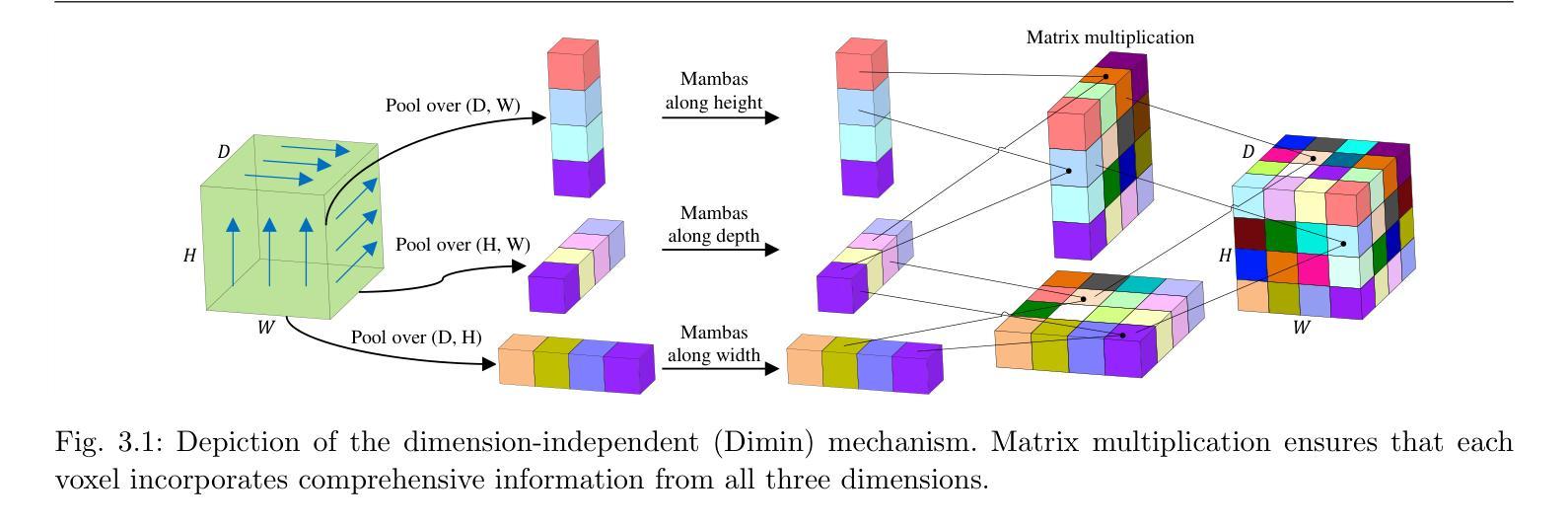
MobileViM: A Light-weight and Dimension-independent Vision Mamba for 3D Medical Image Analysis
Authors:Wei Dai, Jun Liu
Efficient evaluation of three-dimensional (3D) medical images is crucial for diagnostic and therapeutic practices in healthcare. Recent years have seen a substantial uptake in applying deep learning and computer vision to analyse and interpret medical images. Traditional approaches, such as convolutional neural networks (CNNs) and vision transformers (ViTs), face significant computational challenges, prompting the need for architectural advancements. Recent efforts have led to the introduction of novel architectures like the ``Mamba’’ model as alternative solutions to traditional CNNs or ViTs. The Mamba model excels in the linear processing of one-dimensional data with low computational demands. However, Mamba’s potential for 3D medical image analysis remains underexplored and could face significant computational challenges as the dimension increases. This manuscript presents MobileViM, a streamlined architecture for efficient segmentation of 3D medical images. In the MobileViM network, we invent a new dimension-independent mechanism and a dual-direction traversing approach to incorporate with a vision-Mamba-based framework. MobileViM also features a cross-scale bridging technique to improve efficiency and accuracy across various medical imaging modalities. With these enhancements, MobileViM achieves segmentation speeds exceeding 90 frames per second (FPS) on a single graphics processing unit (i.e., NVIDIA RTX 4090). This performance is over 24 FPS faster than the state-of-the-art deep learning models for processing 3D images with the same computational resources. In addition, experimental evaluations demonstrate that MobileViM delivers superior performance, with Dice similarity scores reaching 92.72%, 86.69%, 80.46%, and 77.43% for PENGWIN, BraTS2024, ATLAS, and Toothfairy2 datasets, respectively, which significantly surpasses existing models.
高效评估三维(3D)医学影像对于医疗诊断和治疗实践至关重要。近年来,深度学习和计算机视觉在医学图像分析和解释方面的应用有了显著增长。传统的卷积神经网络(CNN)和视觉变压器(ViT)面临重大的计算挑战,这促使了架构上的进步需求。最近的努力导致了诸如“Mamba”模型等新架构的引入,作为传统CNN或ViT的替代解决方案。Mamba模型在处理一维数据的线性处理方面表现出色,且计算需求较低。然而,Mamba在3D医学图像分析方面的潜力尚未得到充分探索,随着维度的增加,可能会面临重大的计算挑战。本文提出了MobileViM,这是一个用于高效分割3D医学影像的简化架构。在MobileViM网络中,我们发明了一种新的维度独立机制和一种双向遍历方法,将其融入基于视觉Mamba的框架中。MobileViM还采用跨尺度桥接技术,以提高各种医学影像模态的效率和准确性。通过这些增强功能,MobileViM在单个图形处理单元(例如NVIDIA RTX 4090)上实现了超过每秒90帧(FPS)的分割速度。此性能比使用相同计算资源处理3D图像的最先进深度学习模型的帧数快24 FPS以上。此外,实验评估表明,MobileViM的性能卓越,在PENGWIN、BraTS2024、ATLAS和Toothfairy2数据集上的Dice相似度得分分别达到92.72%、86.69%、80.46%和77.43%,显著超越了现有模型。
论文及项目相关链接
Summary
本文提出一种针对三维医学图像高效分割的流线型架构——MobileViM。该架构结合了Mamba模型的优点,通过引入新的维度独立机制和双向遍历方法,实现了对三维医学图像的快速和准确分割。此外,MobileViM还采用了跨尺度桥接技术,以提高在各种医学影像模态下的效率和准确性。实验结果表明,MobileViM在单一GPU上达到了超过每秒90帧的分割速度,并且在实际数据集上的表现也超过了现有模型。
Key Takeaways
- MobileViM是一种用于高效三维医学图像分割的流线型架构。
- MobileViM结合了Mamba模型的优点,适用于处理一维数据,并通过对三维医学图像进行线性处理来实现高效计算。
- MobileViM引入了新的维度独立机制和双向遍历方法,以提高分割速度和准确性。
- MobileViM采用跨尺度桥接技术,以应对不同医学影像模态的挑战。
- MobileViM在单一GPU上实现了超过每秒90帧的分割速度,比现有模型更快。
- 实验结果表明,MobileViM在实际数据集上的表现优于现有模型。
点此查看论文截图

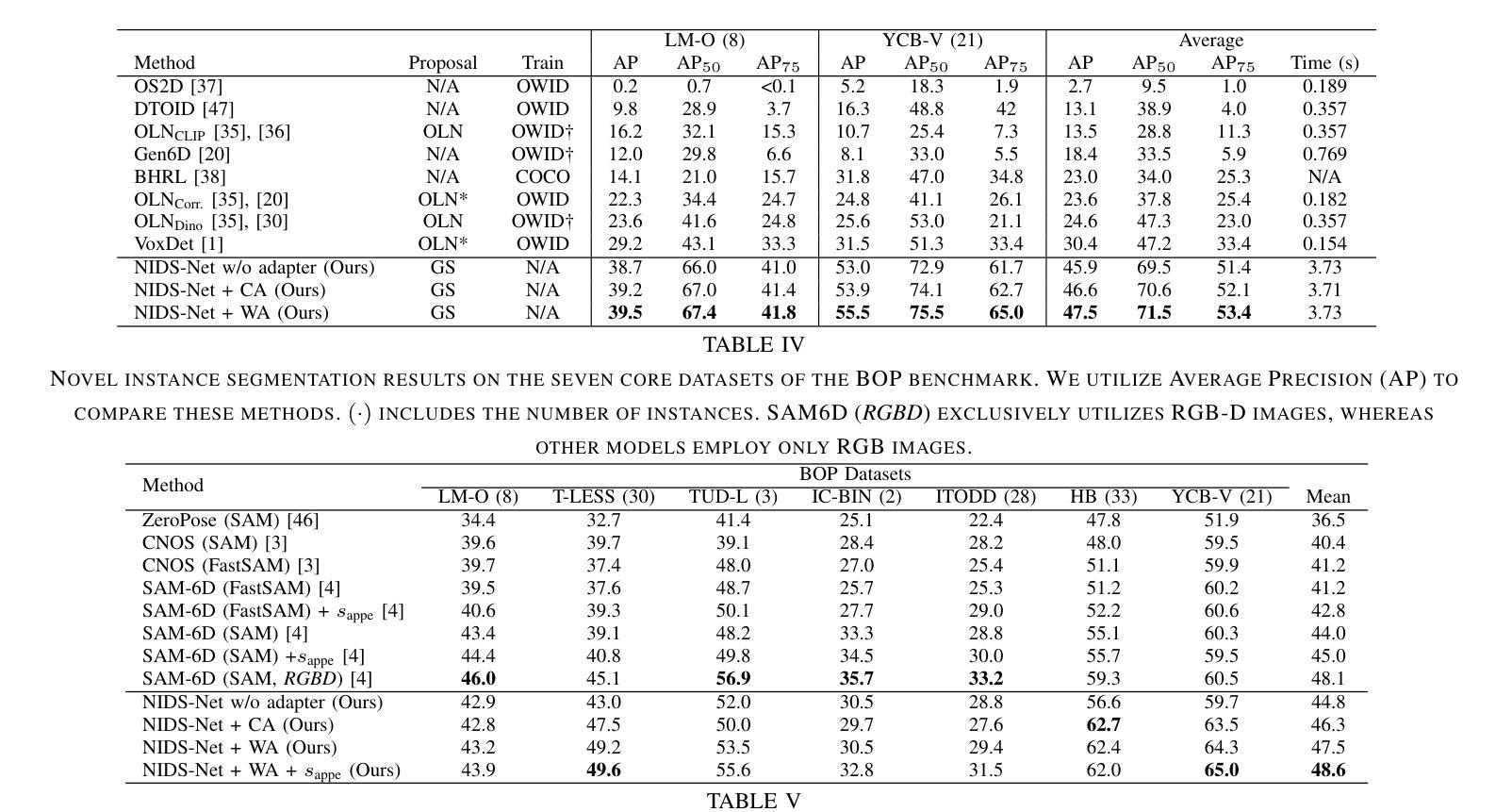
Adapting Pre-Trained Vision Models for Novel Instance Detection and Segmentation
Authors:Yangxiao Lu, Jishnu Jaykumar P, Yunhui Guo, Nicholas Ruozzi, Yu Xiang
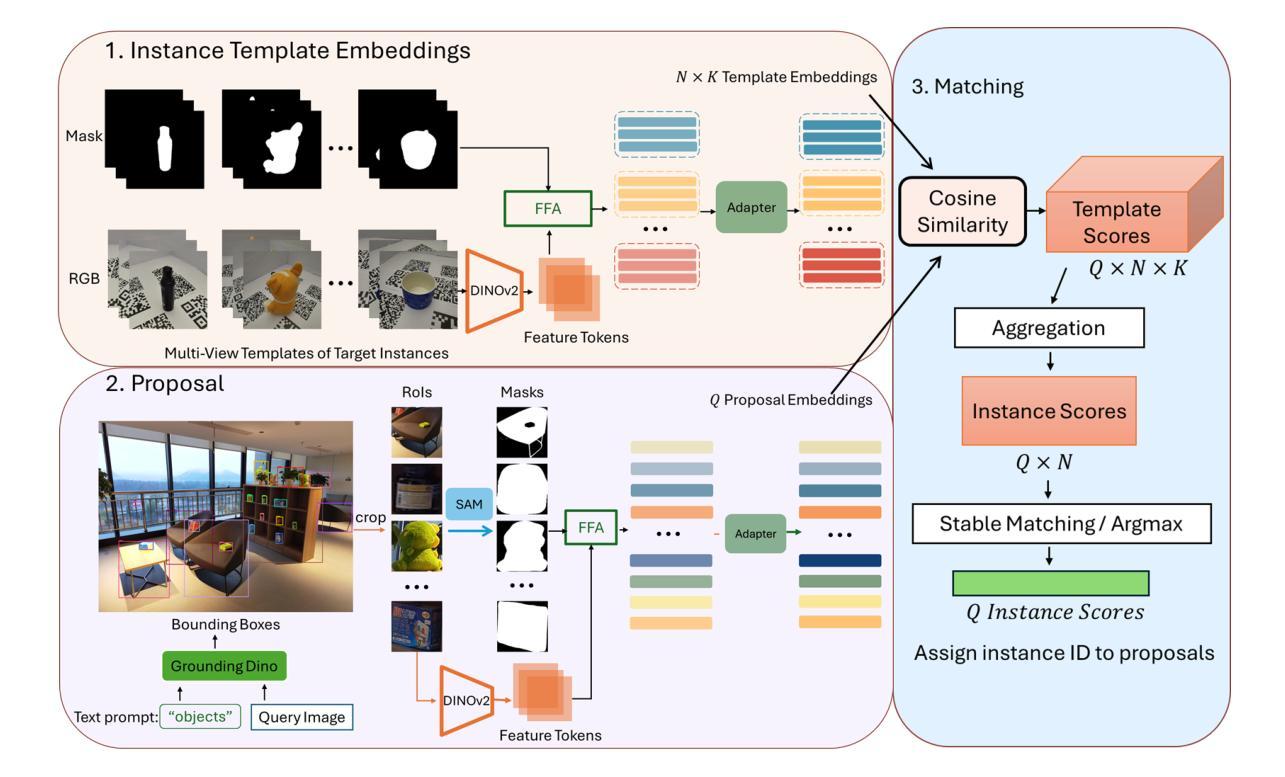
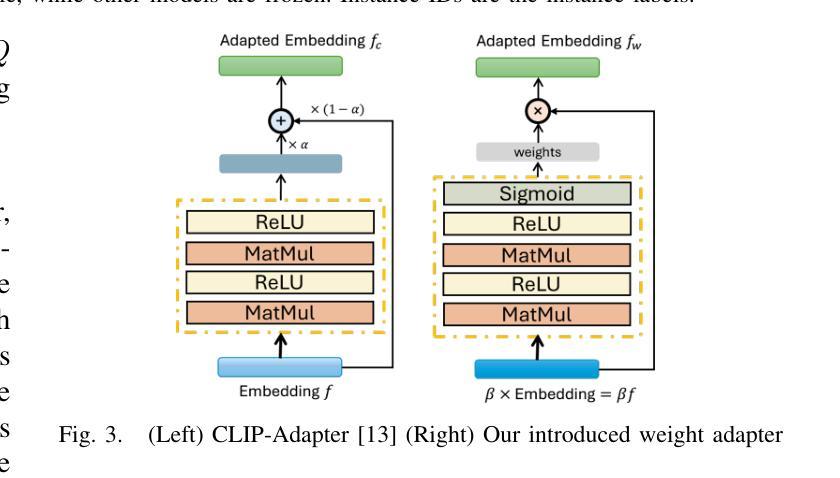
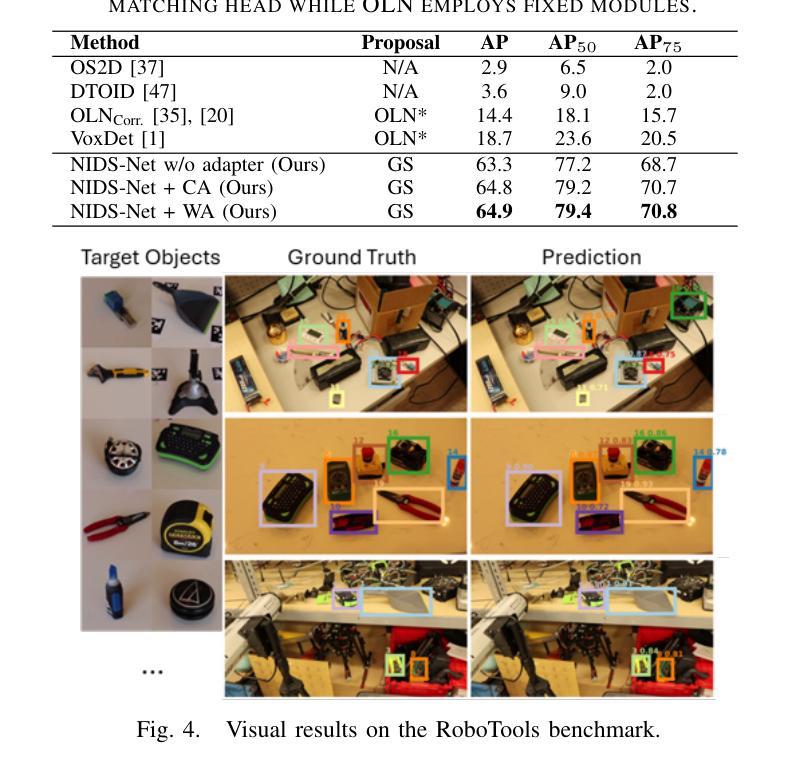
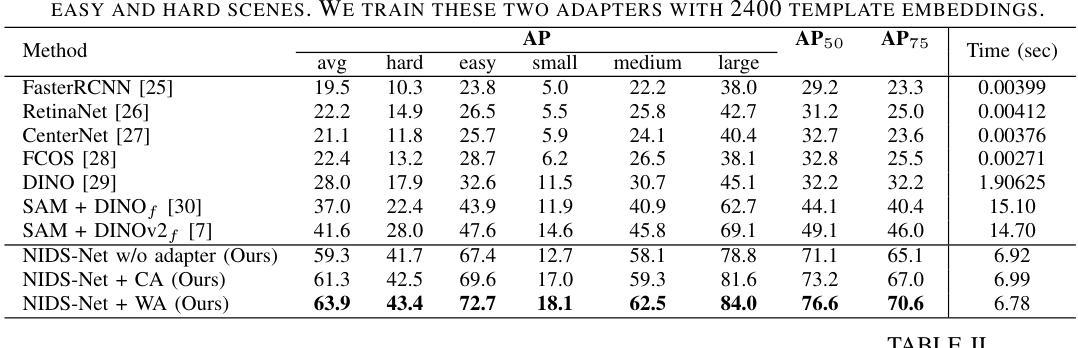
Novel Instance Detection and Segmentation (NIDS) aims at detecting and segmenting novel object instances given a few examples of each instance. We propose a unified, simple, yet effective framework (NIDS-Net) comprising object proposal generation, embedding creation for both instance templates and proposal regions, and embedding matching for instance label assignment. Leveraging recent advancements in large vision methods, we utilize Grounding DINO and Segment Anything Model (SAM) to obtain object proposals with accurate bounding boxes and masks. Central to our approach is the generation of high-quality instance embeddings. We utilized foreground feature averages of patch embeddings from the DINOv2 ViT backbone, followed by refinement through a weight adapter mechanism that we introduce. We show experimentally that our weight adapter can adjust the embeddings locally within their feature space and effectively limit overfitting in the few-shot setting. Furthermore, the weight adapter optimizes weights to enhance the distinctiveness of instance embeddings during similarity computation. This methodology enables a straightforward matching strategy that results in significant performance gains. Our framework surpasses current state-of-the-art methods, demonstrating notable improvements in four detection datasets. In the segmentation tasks on seven core datasets of the BOP challenge, our method outperforms the leading published RGB methods and remains competitive with the best RGB-D method. We have also verified our method using real-world images from a Fetch robot and a RealSense camera. Project Page: https://irvlutd.github.io/NIDSNet/
新型实例检测与分割(NIDS)旨在针对每个实例的几个示例进行新型对象实例的检测和分割。我们提出了一个统一、简单、有效的框架(NIDS-Net),它包括对象提案生成、为实例模板和提案区域创建嵌入,以及用于实例标签分配的嵌入匹配。我们利用最新的大型视觉方法进展,使用Grounding DINO和Segment Anything Model(SAM)获得具有准确边界框和掩码的对象提案。我们的方法的核心是生成高质量实例嵌入。我们使用DINOv2 ViT backbone的补丁嵌入的前景特征平均值,然后通过我们引入的重量适配器机制进行改进。实验表明,我们的重量适配器可以在其特征空间内局部调整嵌入,并有效地限制小样本设置中的过拟合。此外,重量适配器优化权重,以提高实例嵌入在相似度计算中的独特性。这种方法使简单的匹配策略能够在性能方面取得重大收益。我们的框架超越了当前最先进的方法,在四个检测数据集上取得了显著的改进。在BOP挑战的七个核心数据集上的分割任务中,我们的方法优于领先的已发布RGB方法,并与最佳的RGB-D方法保持竞争力。我们还使用Fetch机器人和RealSense相机的真实世界图像验证了我们的方法。项目页面:https://irvlutd.github.io/NIDSnet/
论文及项目相关链接
PDF Project Page: https://irvlutd.github.io/NIDSNet/
Summary
本文提出了一种针对新实例检测和分割(NIDS)的统一、简单而有效的框架(NIDS-Net)。该框架包括生成对象提案、创建实例模板和提案区域嵌入,以及进行嵌入匹配以分配实例标签。利用最近的视觉方法进展,通过Grounding DINO和Segment Anything Model (SAM)获得带有精确边界框和遮罩的对象提案。核心在于生成高质量实例嵌入,通过前景特征平均法从DINOv2 ViT骨干网生成补丁嵌入,并通过引入的重量适配器机制进行改进。实验表明,重量适配器可以在特征空间内局部调整嵌入,有效限制小样本设置中的过拟合。此外,重量适配器优化权重,以提高实例嵌入在相似度计算中的独特性。该方法使得简单的匹配策略能够带来显著的性能提升。在四个检测数据集上,该框架超过了当前的最先进方法,并在BOP挑战的七个核心数据集上的分割任务中表现出卓越性能。该项目已通过Fetch机器人和RealSense相机的真实图像进行了验证。
Key Takeaways
- NIDS-Net框架旨在解决新实例的检测和分割问题,包含对象提案生成、实例模板和提案区域嵌入创建以及嵌入匹配。
- 利用Grounding DINO和Segment Anything Model (SAM)获得精确的对象提案。
- 高质量的实例嵌入生成是关键,采用前景特征平均法并结合重量适配器机制进行改进。
- 重量适配器能够在特征空间内局部调整嵌入,有效限制小样本过拟合问题。
- 重量适配器优化权重,提高实例嵌入在相似度计算中的独特性,使得简单的匹配策略表现卓越。
- 在多个检测数据集上的性能超过了当前最先进的方法。
- 在BOP挑战的七个核心数据集上的分割任务表现出卓越性能,且已通过真实图像验证。
点此查看论文截图