⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-09 更新
Enhancing SAM with Efficient Prompting and Preference Optimization for Semi-supervised Medical Image Segmentation
Authors:Aishik Konwer, Zhijian Yang, Erhan Bas, Cao Xiao, Prateek Prasanna, Parminder Bhatia, Taha Kass-Hout
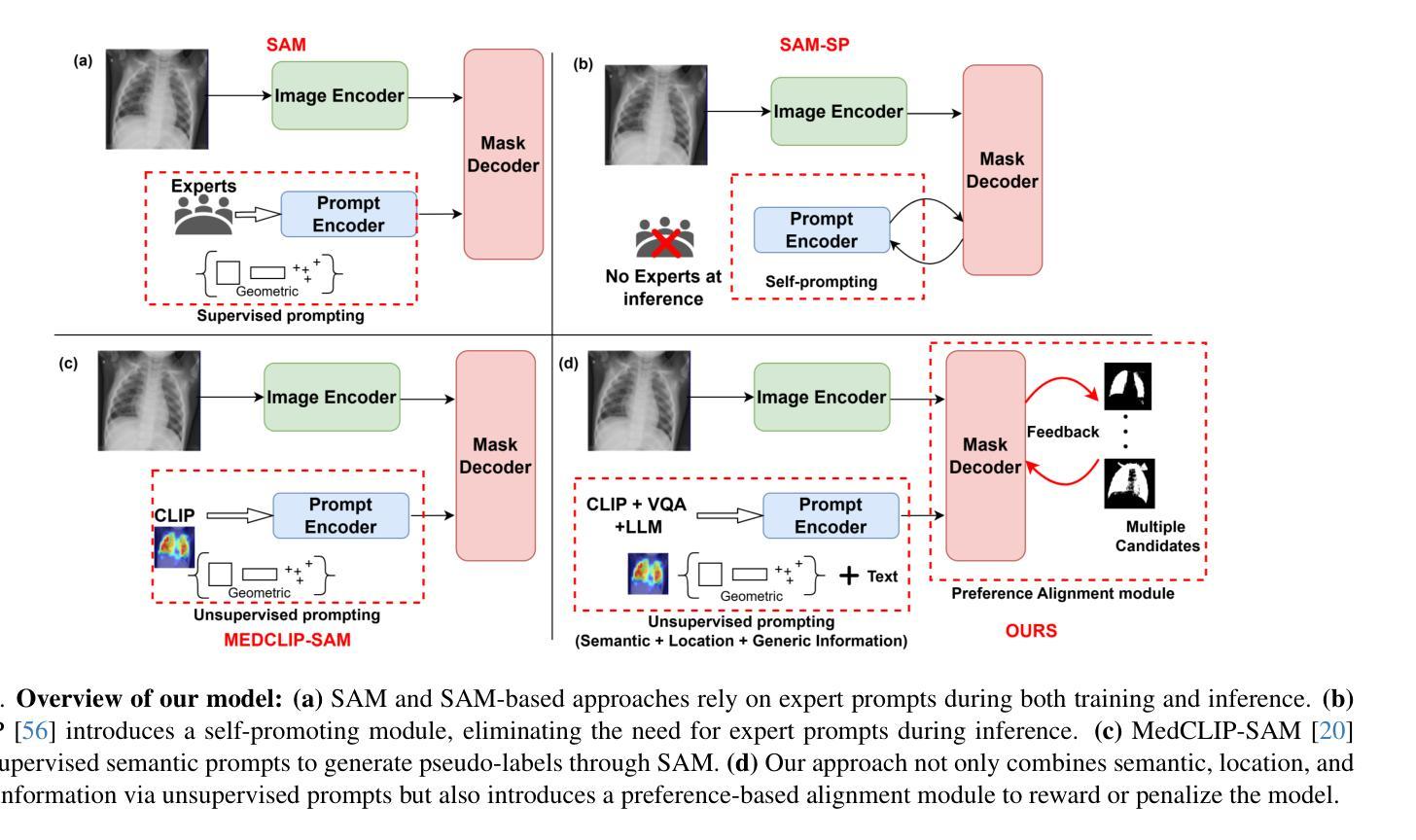
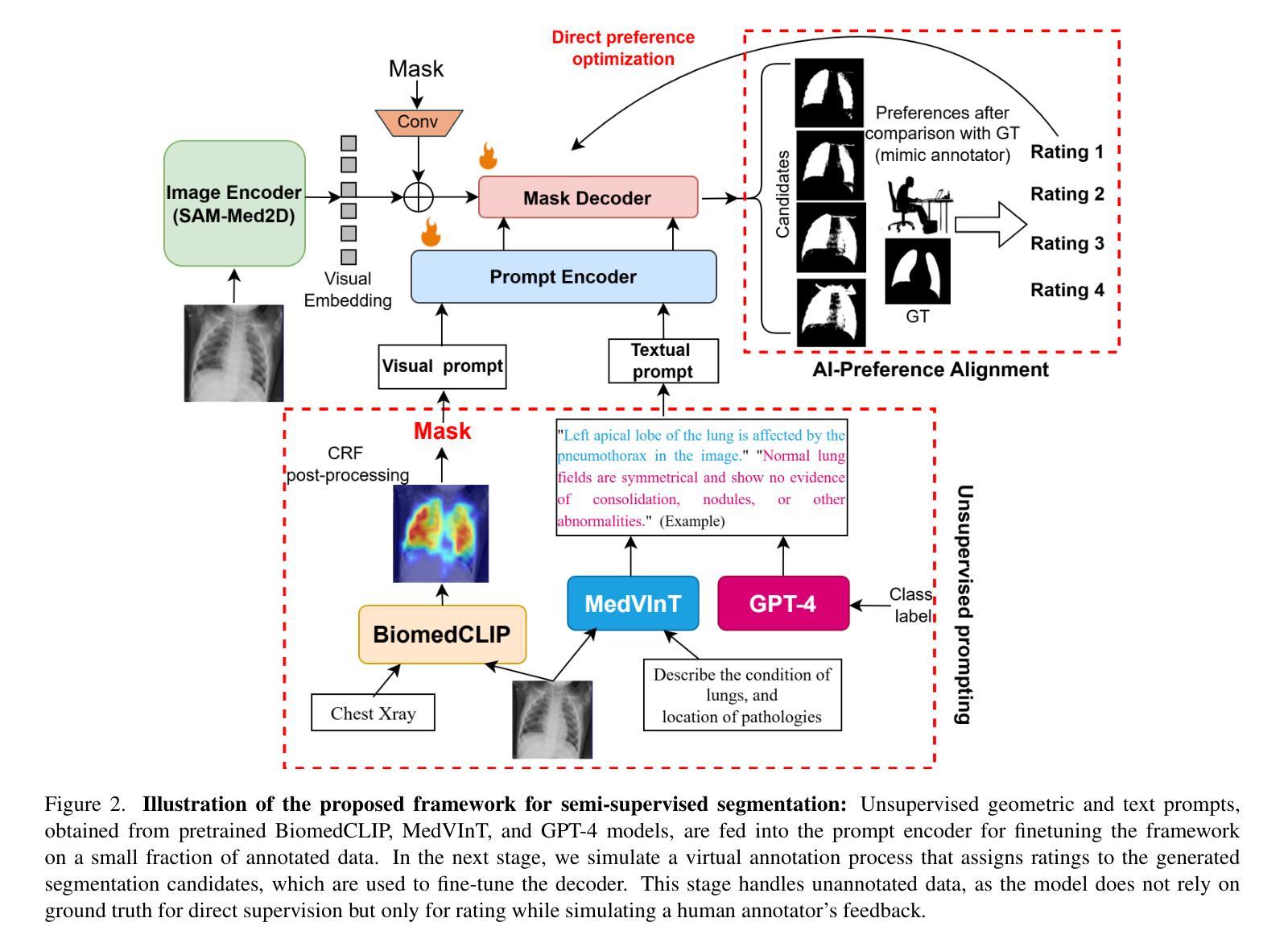
Foundational models such as the Segment Anything Model (SAM) are gaining traction in medical imaging segmentation, supporting multiple downstream tasks. However, such models are supervised in nature, still relying on large annotated datasets or prompts supplied by experts. Conventional techniques such as active learning to alleviate such limitations are limited in scope and still necessitate continuous human involvement and complex domain knowledge for label refinement or establishing reward ground truth. To address these challenges, we propose an enhanced Segment Anything Model (SAM) framework that utilizes annotation-efficient prompts generated in a fully unsupervised fashion, while still capturing essential semantic, location, and shape information through contrastive language-image pretraining and visual question answering. We adopt the direct preference optimization technique to design an optimal policy that enables the model to generate high-fidelity segmentations with simple ratings or rankings provided by a virtual annotator simulating the human annotation process. State-of-the-art performance of our framework in tasks such as lung segmentation, breast tumor segmentation, and organ segmentation across various modalities, including X-ray, ultrasound, and abdominal CT, justifies its effectiveness in low-annotation data scenarios.
像Segment Anything Model(SAM)这样的基础模型在医学影像分割领域正受到越来越多的关注,支持多种下游任务。然而,此类模型本质上是受监督的,仍然依赖于大量标注数据集或专家提供的提示。为了缓解这些限制,采用主动学习的传统技术范围有限,仍然需要持续的人工参与和复杂的领域知识来进行标签细化或建立奖励基准真实值。为了解决这些挑战,我们提出了一种增强的Segment Anything Model(SAM)框架,该框架利用以完全无监督的方式生成的标注效率提示,同时仍通过对比语言图像预训练和视觉问答捕获关键的语义、位置和形状信息。我们采用直接偏好优化技术来设计最佳策略,使模型能够利用模拟人类标注过程的虚拟标注者提供的简单评分或排名来生成高保真分割。我们的框架在肺分割、乳腺肿瘤分割以及包括X光、超声和腹部CT在内的多模态器官分割任务中的最新表现,证明了它在低标注数据场景中的有效性。
论文及项目相关链接
PDF Accepted to CVPR 2025
Summary
医学图像分割领域正在引入基于模型的方法,如Segment Anything Model(SAM),以支持多项下游任务。然而,这些方法本质上是监督学习,依赖于大量标注数据集或专家提供的提示。为缓解这些问题,我们提出了一种增强的SAM框架,采用无监督方式生成标注有效的提示,同时通过对比语言图像预训练和视觉问答捕捉关键的语义、位置和形状信息。我们采用直接偏好优化技术设计最佳策略,使模型能够利用虚拟注释模拟器提供简单评级或排名生成高保真分割。该框架在肺分割、乳腺肿瘤分割和器官分割等任务中表现出卓越性能,在各种模态(包括X射线、超声和腹部CT)中均有效适用于低标注数据场景。
Key Takeaways
- Segment Anything Model (SAM)在医学图像分割中受到关注,支持多种下游任务。
- 现有模型主要依赖大量标注数据集或专家提示,存在局限性。
- 提出的增强SAM框架采用无监督方式生成标注有效的提示。
- 通过对比语言图像预训练和视觉问答,框架能捕捉关键的语义、位置和形状信息。
- 采用直接偏好优化技术,模型能在简单评级或排名的基础上生成高保真分割。
- 该框架在多种医学图像分割任务中表现优异,包括肺分割、乳腺肿瘤分割和器官分割等。
点此查看论文截图