⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-09 更新
Omnidirectional Multi-Object Tracking
Authors:Kai Luo, Hao Shi, Sheng Wu, Fei Teng, Mengfei Duan, Chang Huang, Yuhang Wang, Kaiwei Wang, Kailun Yang
Panoramic imagery, with its 360{\deg} field of view, offers comprehensive information to support Multi-Object Tracking (MOT) in capturing spatial and temporal relationships of surrounding objects. However, most MOT algorithms are tailored for pinhole images with limited views, impairing their effectiveness in panoramic settings. Additionally, panoramic image distortions, such as resolution loss, geometric deformation, and uneven lighting, hinder direct adaptation of existing MOT methods, leading to significant performance degradation. To address these challenges, we propose OmniTrack, an omnidirectional MOT framework that incorporates Tracklet Management to introduce temporal cues, FlexiTrack Instances for object localization and association, and the CircularStatE Module to alleviate image and geometric distortions. This integration enables tracking in large field-of-view scenarios, even under rapid sensor motion. To mitigate the lack of panoramic MOT datasets, we introduce the QuadTrack dataset–a comprehensive panoramic dataset collected by a quadruped robot, featuring diverse challenges such as wide fields of view, intense motion, and complex environments. Extensive experiments on the public JRDB dataset and the newly introduced QuadTrack benchmark demonstrate the state-of-the-art performance of the proposed framework. OmniTrack achieves a HOTA score of 26.92% on JRDB, representing an improvement of 3.43%, and further achieves 23.45% on QuadTrack, surpassing the baseline by 6.81%. The dataset and code will be made publicly available at https://github.com/xifen523/OmniTrack.
全景影像以其360°的视野,为捕捉周围物体的空间和时间关系以支持多目标跟踪(MOT)提供了全面的信息。然而,大多数MOT算法都是针对视野有限的针孔图像定制的,在全景环境中会降低其有效性。此外,全景图像的失真,如分辨率损失、几何变形和光线不均,阻碍了现有MOT方法的直接应用,导致性能显著下降。为了解决这些挑战,我们提出了OmniTrack,一个全向MOT框架,它结合了轨迹管理以引入时间线索、FlexiTrack实例进行目标定位和关联,以及CircularStatE模块来缓解图像和几何失真。这种整合使得在大视野场景中,即使在传感器快速运动的情况下也能进行追踪。为了缓解全景MOT数据集的缺乏,我们引入了QuadTrack数据集——一个由四足机器人收集的全方位全景数据集,具有广阔的视野、强烈的运动和复杂环境等多样挑战。在公共JRDB数据集和新引入的QuadTrack基准测试上的大量实验表明,所提出的框架具有最先进的性能。OmniTrack在JRDB上的HOTA得分为26.92%,提高了3.42%,并在QuadTrack上实现了23.45%,超过了基准线6.81%。数据集和代码将在https://github.com/xifen523/OmniTrack上公开发布。
论文及项目相关链接
PDF Accepted to CVPR 2025. The dataset and code will be made publicly available at https://github.com/xifen523/OmniTrack
Summary:全景成像技术可为多目标跟踪(MOT)提供丰富的空间和时间信息,但在全景环境下,大多数MOT算法受限于视角范围,性能受限。此外,全景图像的畸变(如分辨率损失、几何变形和光照不均)给现有MOT方法的直接应用带来困难。为此,我们提出OmniTrack框架,结合轨迹管理引入时间线索、FlexiTrack进行目标定位和关联,以及CircularStatE模块缓解图像和几何畸变。该框架可在大视野场景下实现跟踪,甚至在快速传感器运动下也能保持性能。此外,我们还引入了QuadTrack数据集,该数据集由四足机器人收集,具有宽视野、强烈运动和复杂环境等多重挑战。实验表明,OmniTrack在公开JRDB数据集和新引入的QuadTrack基准测试上均表现优异。
Key Takeaways:
- 全景成像技术提供丰富的空间和时间信息支持多目标跟踪(MOT)。
- 大多数现有的MOT算法在全景环境下性能受限,需要新的算法来解决挑战。
- OmniTrack框架结合轨迹管理、FlexiTrack和CircularStatE模块,实现全景环境下有效的多目标跟踪。
- OmniTrack框架可在大视野场景下运行,甚至在快速传感器运动下也能保持性能。
- 引入QuadTrack数据集,具有宽视野、强烈运动和复杂环境等多重挑战。
- 实验表明OmniTrack在公开数据集和QuadTrack基准测试上表现优异。
点此查看论文截图

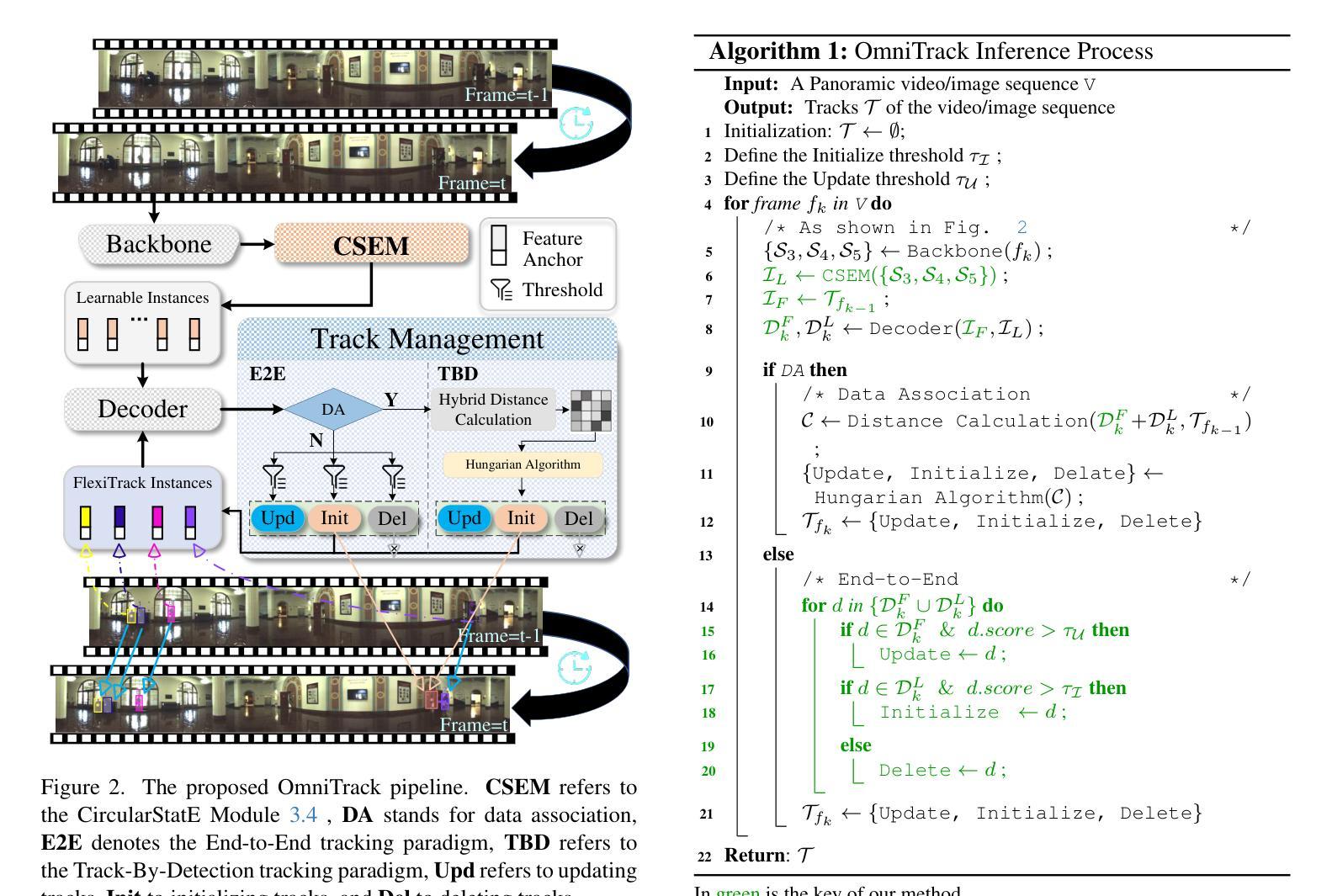
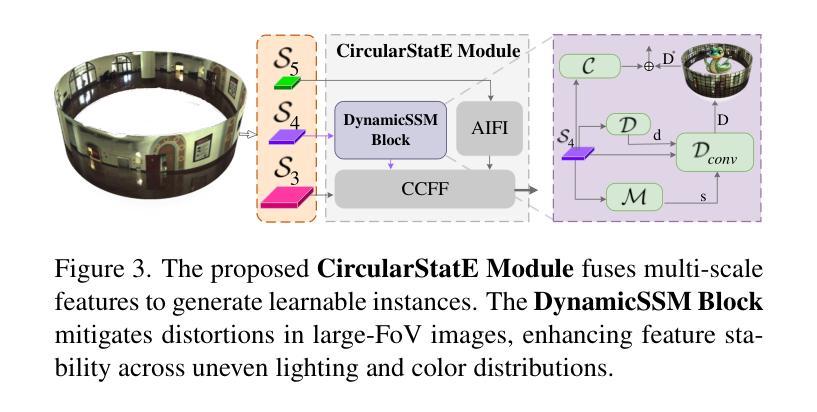
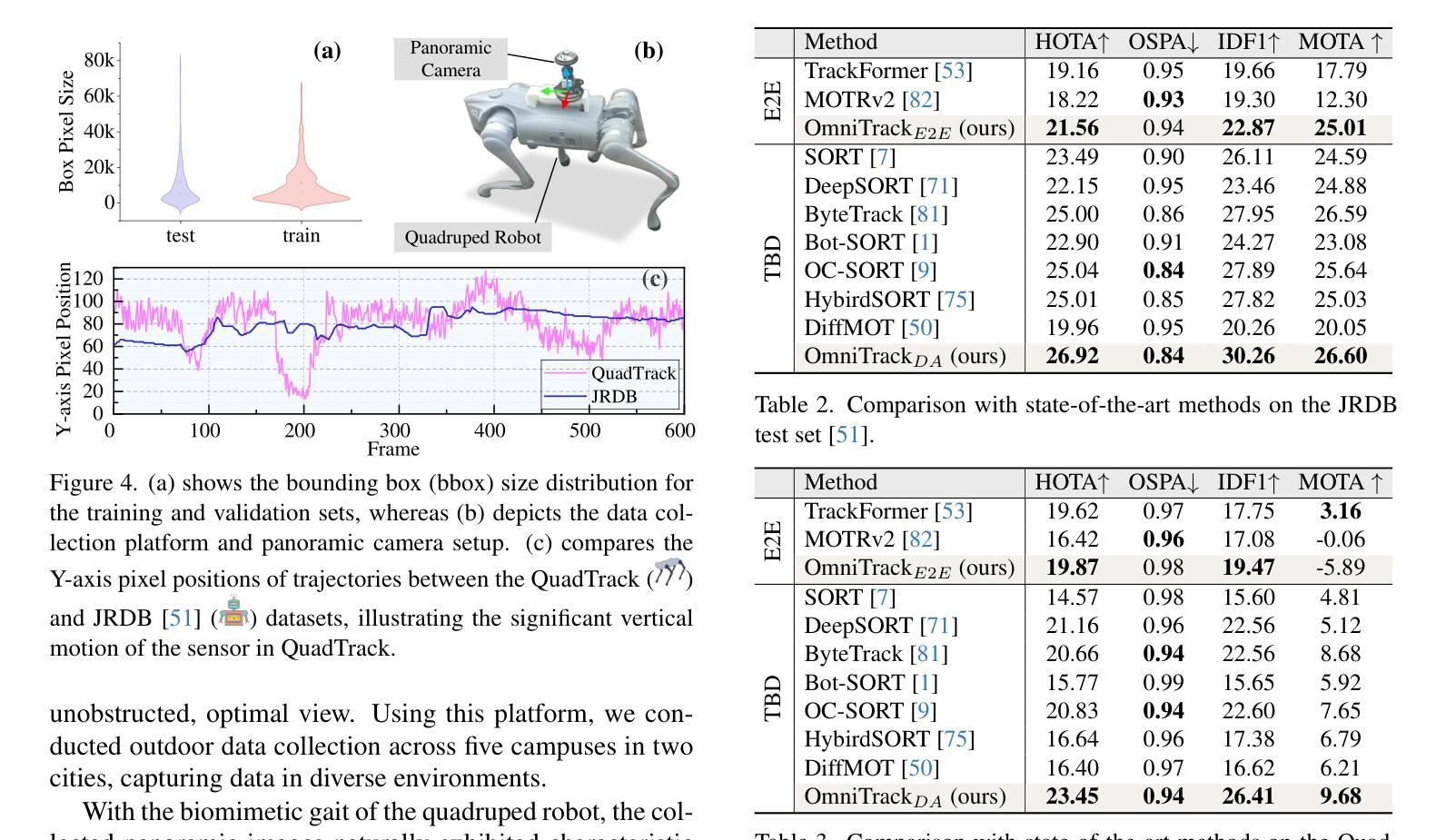
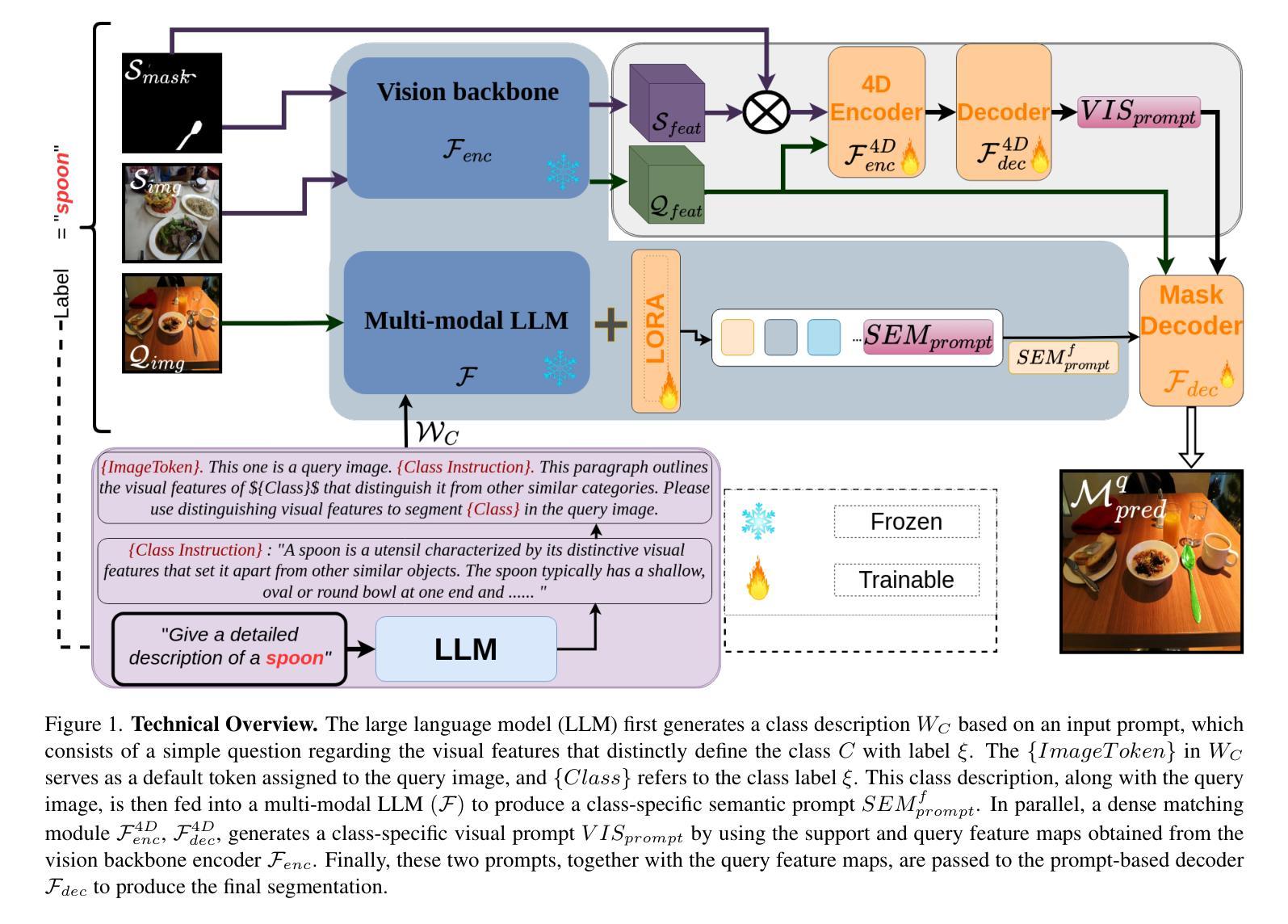
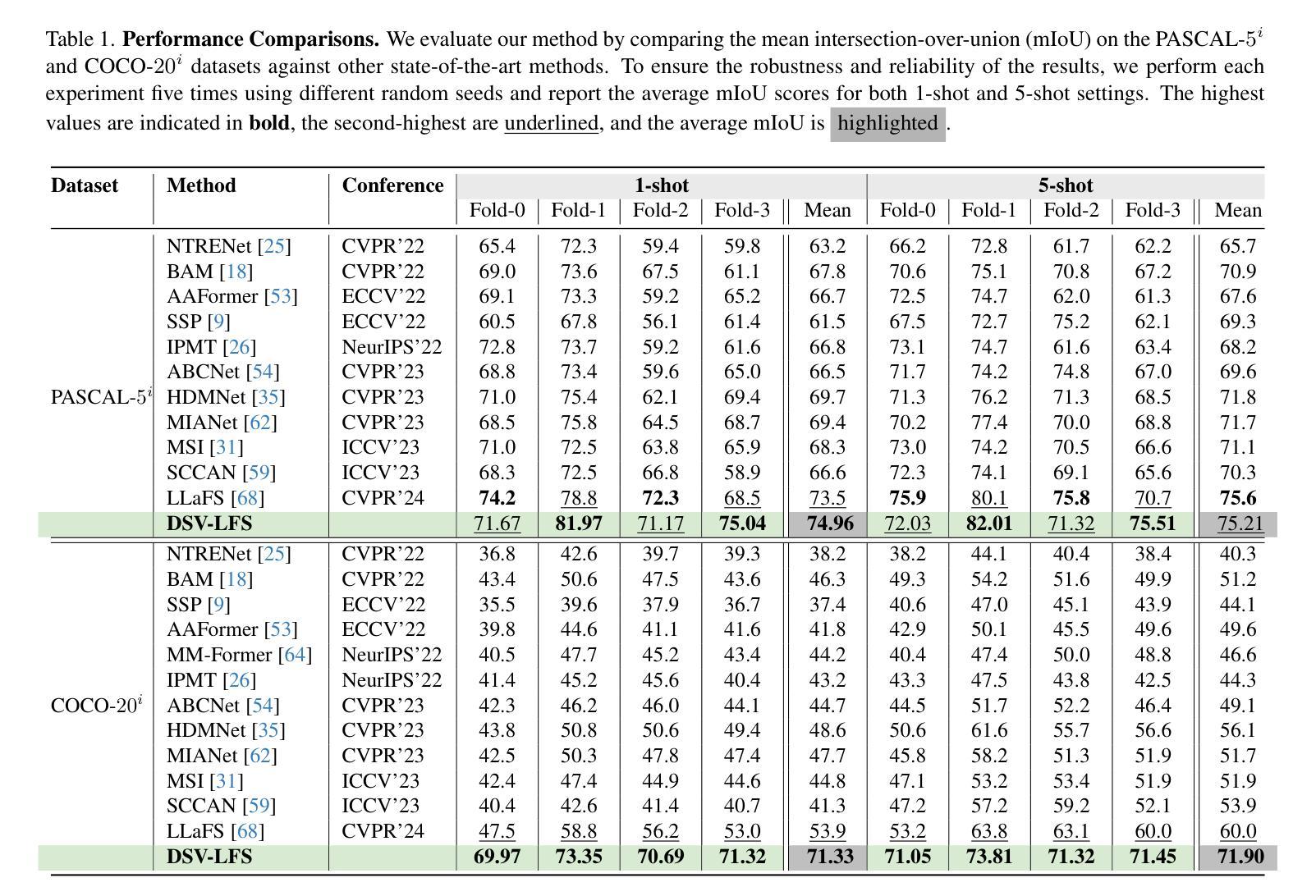
DSV-LFS: Unifying LLM-Driven Semantic Cues with Visual Features for Robust Few-Shot Segmentation
Authors:Amin Karimi, Charalambos Poullis
Few-shot semantic segmentation (FSS) aims to enable models to segment novel/unseen object classes using only a limited number of labeled examples. However, current FSS methods frequently struggle with generalization due to incomplete and biased feature representations, especially when support images do not capture the full appearance variability of the target class. To improve the FSS pipeline, we propose a novel framework that utilizes large language models (LLMs) to adapt general class semantic information to the query image. Furthermore, the framework employs dense pixel-wise matching to identify similarities between query and support images, resulting in enhanced FSS performance. Inspired by reasoning-based segmentation frameworks, our method, named DSV-LFS, introduces an additional token into the LLM vocabulary, allowing a multimodal LLM to generate a “semantic prompt” from class descriptions. In parallel, a dense matching module identifies visual similarities between the query and support images, generating a “visual prompt”. These prompts are then jointly employed to guide the prompt-based decoder for accurate segmentation of the query image. Comprehensive experiments on the benchmark datasets Pascal-$5^{i}$ and COCO-$20^{i}$ demonstrate that our framework achieves state-of-the-art performance-by a significant margin-demonstrating superior generalization to novel classes and robustness across diverse scenarios. The source code is available at \href{https://github.com/aminpdik/DSV-LFS}{https://github.com/aminpdik/DSV-LFS}
少量语义分割(FSS)旨在使模型能够仅使用有限数量的标记示例来对新型/未见过的对象类别进行分割。然而,当前的FSS方法由于特征表示不完整和存在偏见,在推广时经常遇到困难,特别是当支持图像没有捕捉到目标类别的完整外观变化时。为了改进FSS管道,我们提出了一种利用大型语言模型(LLM)来适应通用类别语义信息到查询图像的新框架。此外,该框架采用密集像素级匹配来识别查询图像和支持图像之间的相似性,从而提高了FSS的性能。我们的方法受到基于推理的分割框架的启发,被称为DSV-LFS,它引入了LLM词汇中的一个附加令牌,允许多模态LLM从类别描述生成“语义提示”。同时,密集匹配模块识别查询图像和支持图像之间的视觉相似性,生成“视觉提示”。然后这些提示被共同用来引导基于提示的解码器,对查询图像进行准确的分割。在Pascal-$5^{i}$和COCO-$20^{i}$基准数据集上的综合实验表明,我们的框架实现了最先进的性能,并显示出对新型类别的优越推广能力和在不同场景中的稳健性。源代码可在https://github.com/aminpdik/DSV-LFS获取。
论文及项目相关链接
Summary
本文提出了一种新的少样本语义分割(FSS)框架,该框架利用大型语言模型(LLM)来适应通用类语义信息到查询图像,并采用密集像素级匹配来识别查询图像和支持图像之间的相似性,从而提高FSS性能。该方法通过引入语义提示和视觉提示,实现了对查询图像的准确分割,并在基准数据集上取得了最先进的性能。
Key Takeaways
- 提出了一种新的少样本语义分割(FSS)框架,旨在使用有限数量的标记示例对新型/未见过的对象类别进行分割。
- 利用大型语言模型(LLM)适应通用类语义信息到查询图像,改善特征表示的不完整和偏见问题。
- 通过密集像素级匹配识别查询图像和支持图像之间的相似性,提高FSS性能。
- 引入语义提示和视觉提示,通过模态LLM生成语义提示,密集匹配模块生成视觉提示。
- 联合使用语义和视觉提示,引导基于提示的解码器对查询图像进行准确分割。
- 在Pascal-$5^{i}$和COCO-$20^{i}$基准数据集上的综合实验表明,该框架实现了显著的先进性能,对新型类具有优越泛化能力,并在各种场景中表现出稳健性。
点此查看论文截图

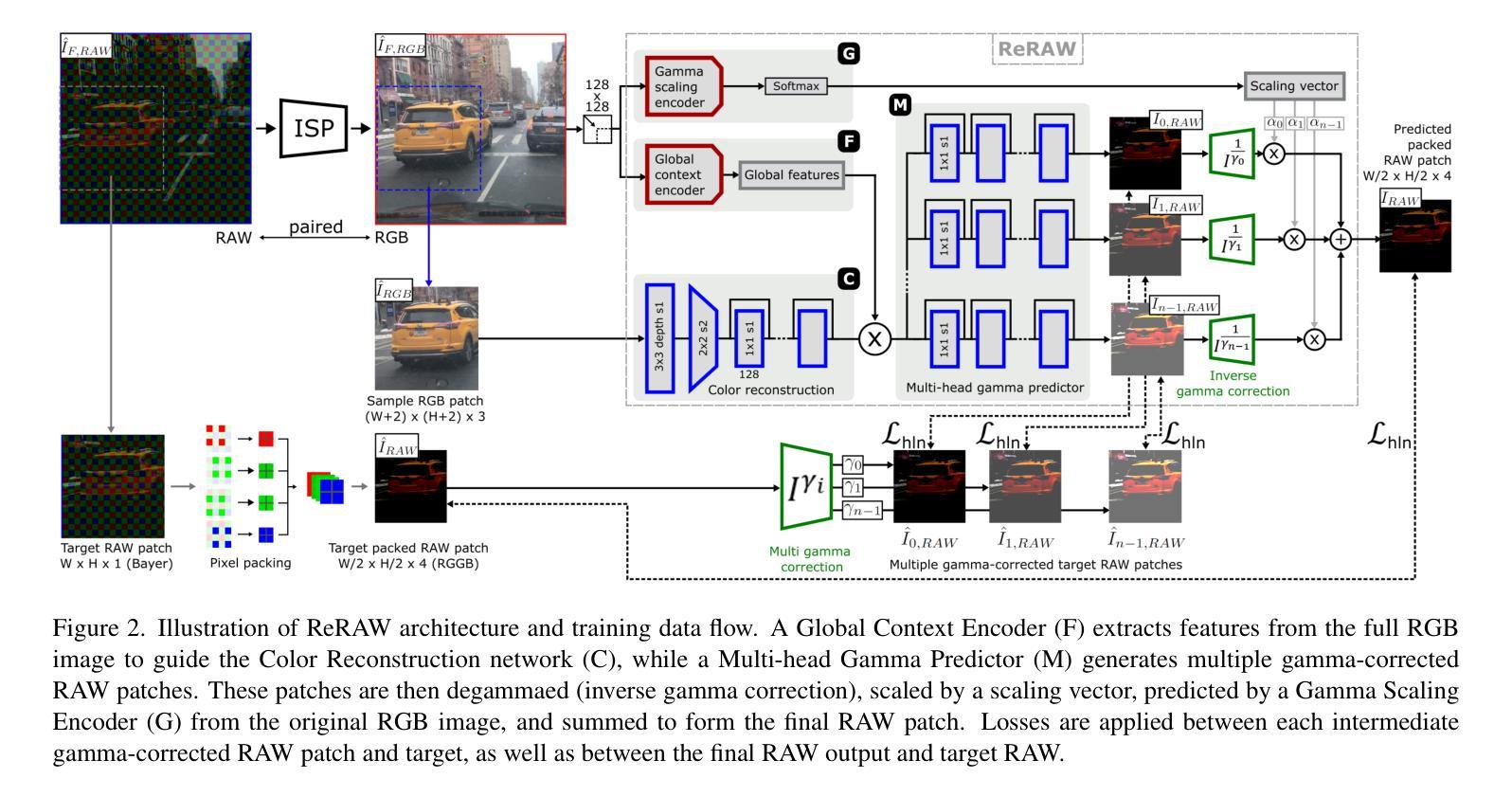
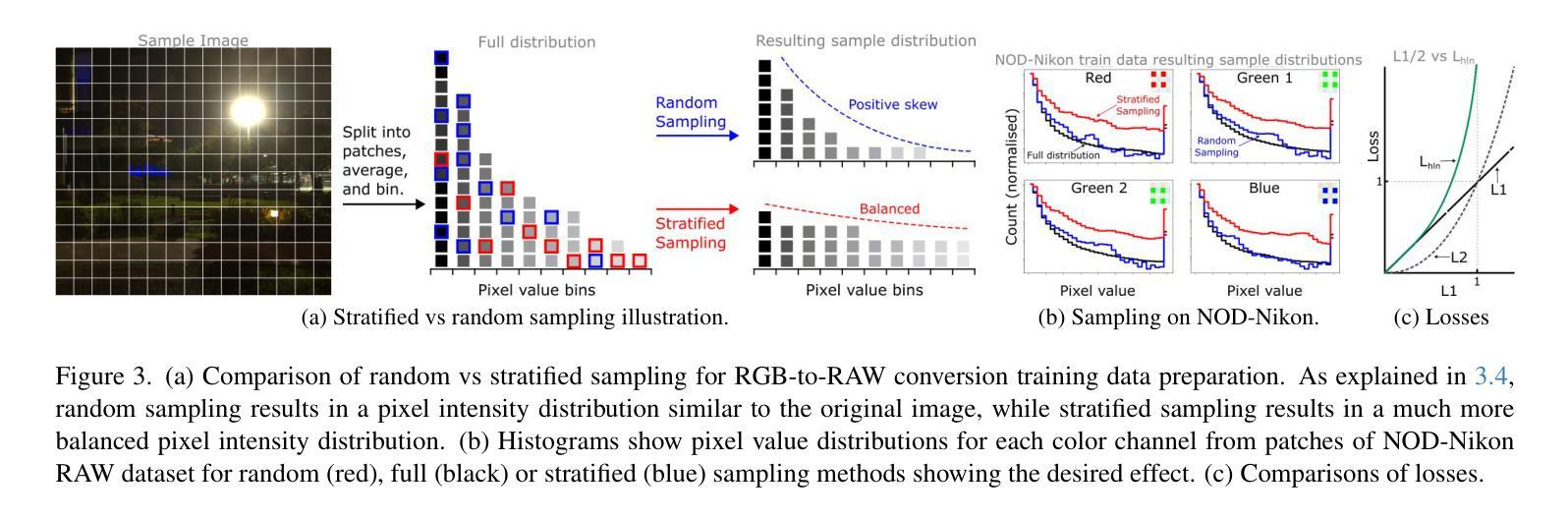
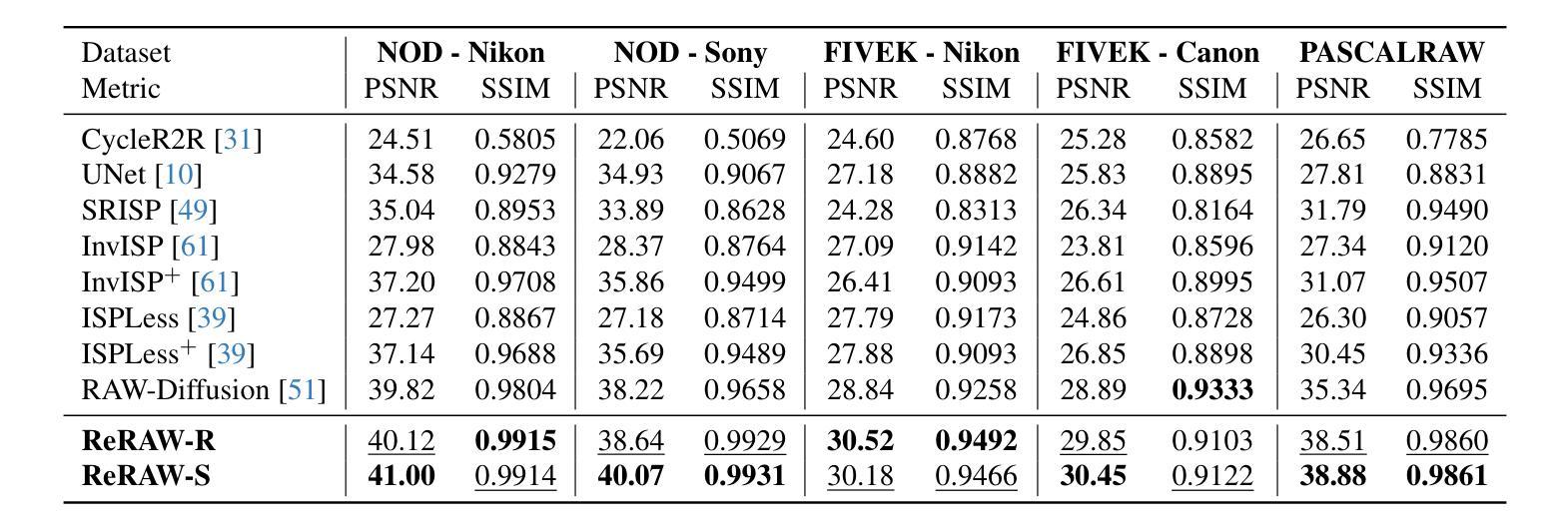
ReRAW: RGB-to-RAW Image Reconstruction via Stratified Sampling for Efficient Object Detection on the Edge
Authors:Radu Berdan, Beril Besbinar, Christoph Reinders, Junji Otsuka, Daisuke Iso
Edge-based computer vision models running on compact, resource-limited devices benefit greatly from using unprocessed, detail-rich RAW sensor data instead of processed RGB images. Training these models, however, necessitates large labeled RAW datasets, which are costly and often impractical to obtain. Thus, converting existing labeled RGB datasets into sensor-specific RAW images becomes crucial for effective model training. In this paper, we introduce ReRAW, an RGB-to-RAW conversion model that achieves state-of-the-art reconstruction performance across five diverse RAW datasets. This is accomplished through ReRAW’s novel multi-head architecture predicting RAW image candidates in gamma space. The performance is further boosted by a stratified sampling-based training data selection heuristic, which helps the model better reconstruct brighter RAW pixels. We finally demonstrate that pretraining compact models on a combination of high-quality synthetic RAW datasets (such as generated by ReRAW) and ground-truth RAW images for downstream tasks like object detection, outperforms both standard RGB pipelines, and RAW fine-tuning of RGB-pretrained models for the same task.
基于边缘的计算机视觉模型在紧凑、资源受限的设备上运行,与使用经过处理的RGB图像相比,使用未加工、细节丰富的原始传感器数据(RAW数据)将大有裨益。然而,训练这些模型需要大型标记原始数据集,这些数据集获取成本高昂且往往不切实际。因此,将现有的标记RGB数据集转换为特定传感器所需的RAW图像对于有效模型训练至关重要。在本文中,我们介绍了ReRAW,一种RGB到RAW的转换模型,它在五个不同的RAW数据集上实现了最先进的重建性能。这是通过ReRAW的新型多头架构实现的,该架构在伽马空间中预测RAW图像候选对象。通过分层采样基础上的训练数据选择启发式策略,进一步提高了性能,这有助于模型更好地重建明亮的RAW像素。最后,我们证明在高质量合成RAW数据集(如由ReRAW生成)和地面真实RAW图像上预训练紧凑模型,用于对象检测等下游任务,既优于标准的RGB管道,也优于对同一任务使用RGB预训练模型的RAW微调。
论文及项目相关链接
PDF Accepted at CVPR 2025
Summary
在资源受限的设备上运行的基于边缘的计算机视觉模型,使用未加工的、细节丰富的原始传感器数据代替经过处理的RGB图像,可以大大提高性能。然而,训练这些模型需要庞大的标记原始数据集,这既昂贵又不切实际。因此,将现有的标记RGB数据集转换为传感器特定的原始图像对于有效的模型训练至关重要。本文介绍了ReRAW,一种RGB到RAW的转换模型,它通过在伽马空间预测RAW图像候选者,实现了跨越五个不同原始数据集的最新重建性能。性能的提升还得益于分层抽样基础上的训练数据选择策略,有助于模型更好地重建明亮的原始像素。最后证明,在高质量合成原始数据集(如由ReRAW生成)和地面真实原始图像的组合上预训练紧凑模型,用于执行对象检测等下游任务,优于标准的RGB管道以及相同任务的RGB预训练模型的原始微调。
Key Takeaways
- 使用原始传感器数据代替RGB图像能提高边缘计算机视觉模型的性能。
- 庞大的标记原始数据集对于模型训练至关重要,但其获取成本高昂且不切实际。
- ReRAW模型能够通过RGB到RAW转换,实现优秀的图像重建性能。
- ReRAW模型采用多头架构预测原始图像候选者,并在伽马空间完成此操作。
- 分层抽样策略有助于模型更好地重建明亮的原始像素。
- 结合高质量合成原始数据集和真实原始图像预训练模型,能在下游任务上获得最佳性能。
点此查看论文截图


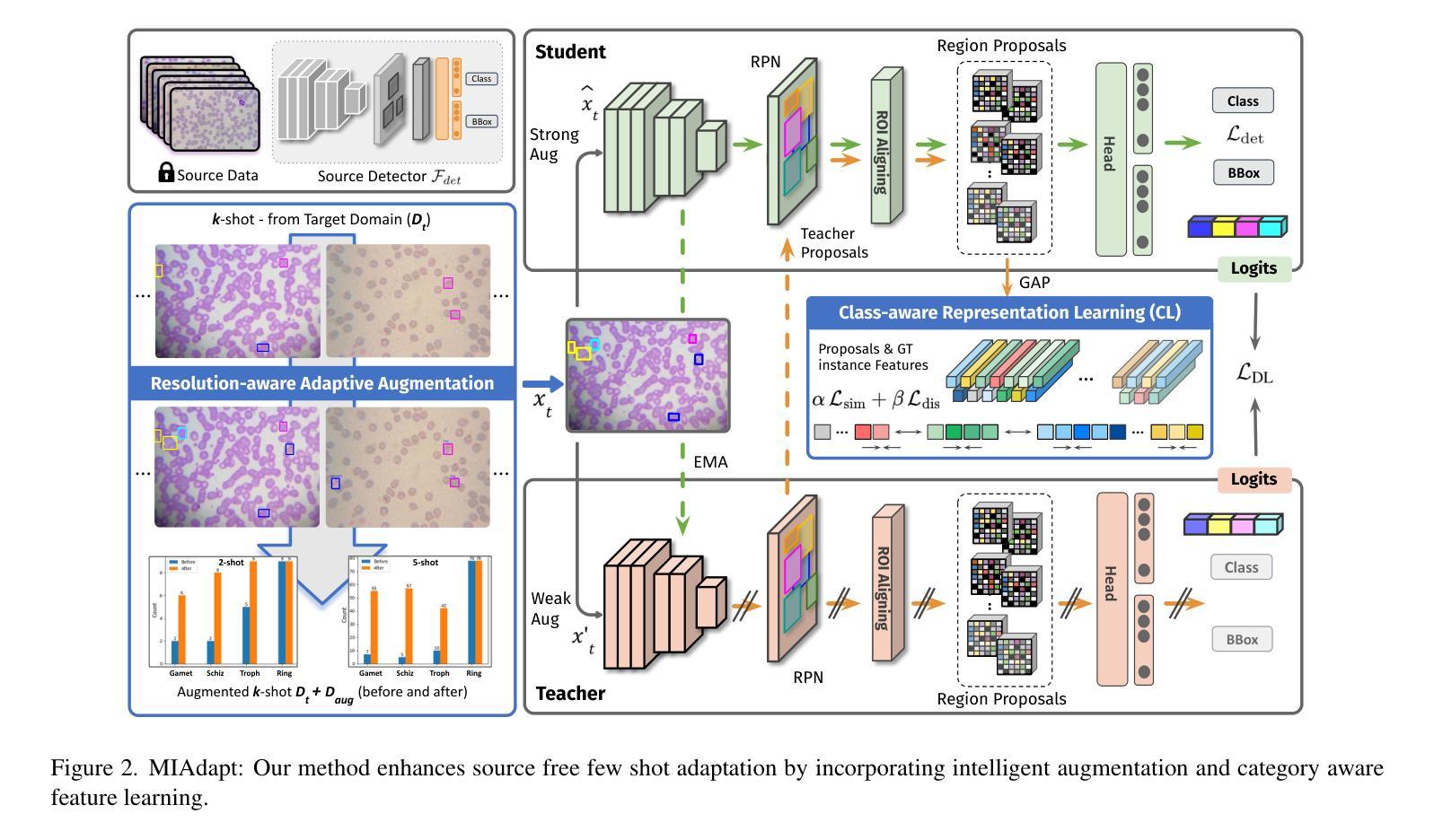
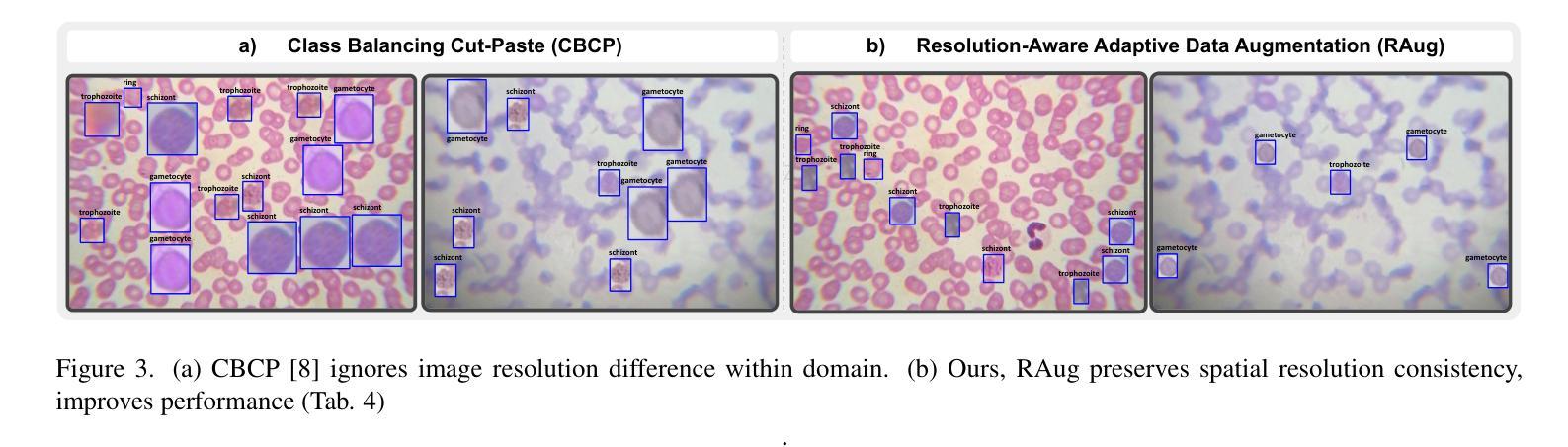
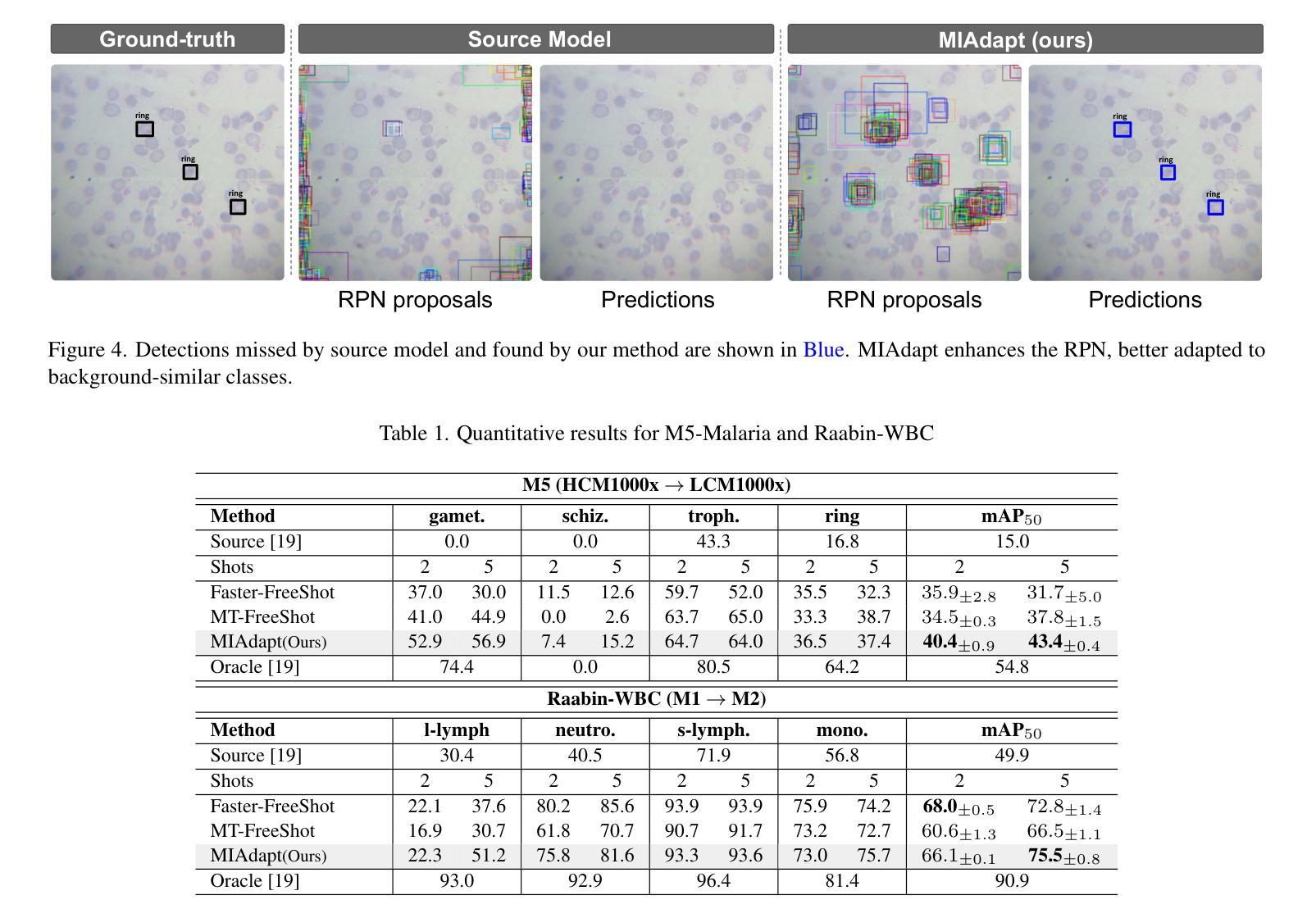
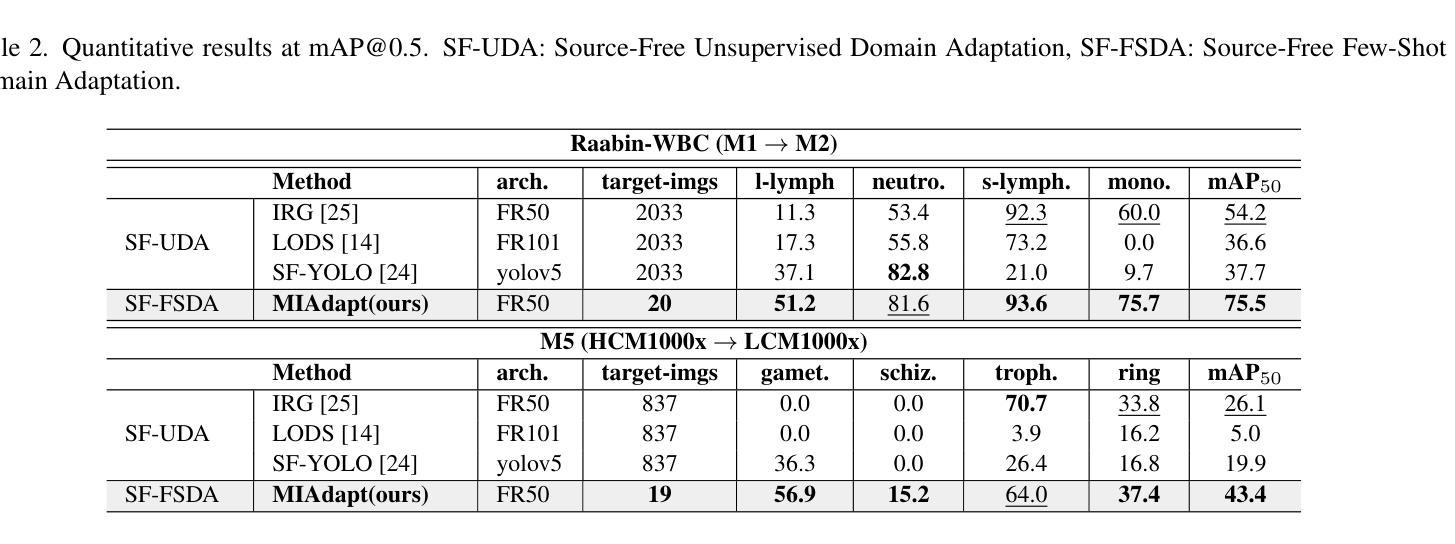
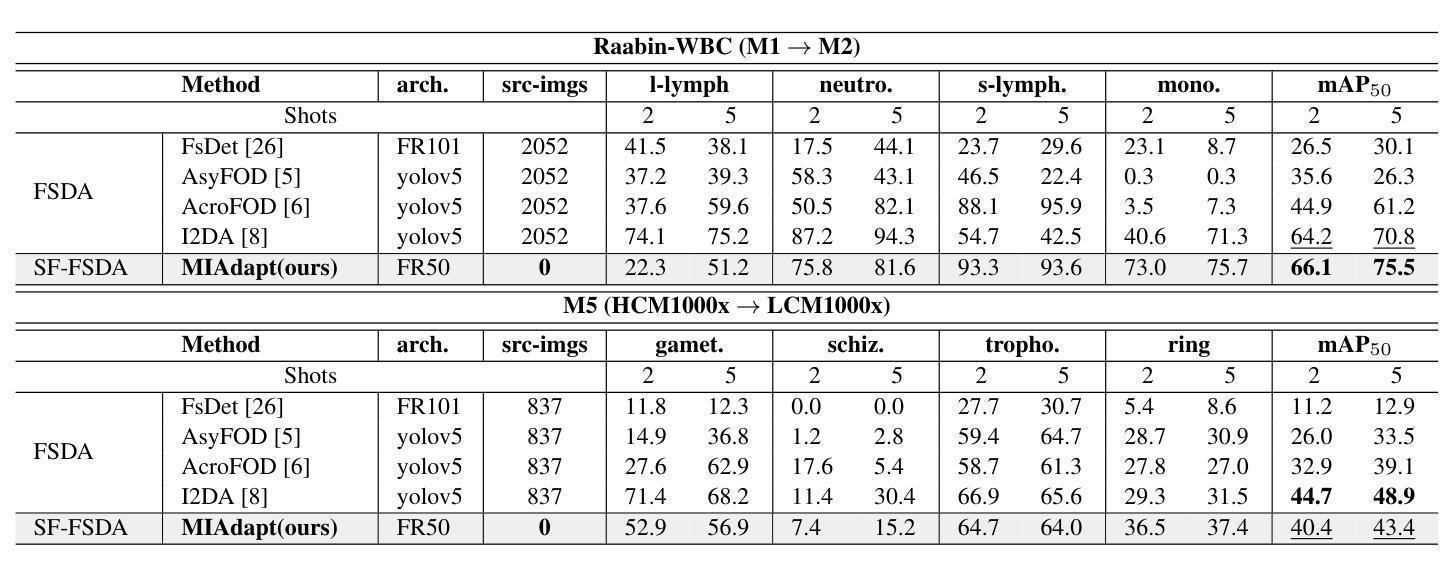
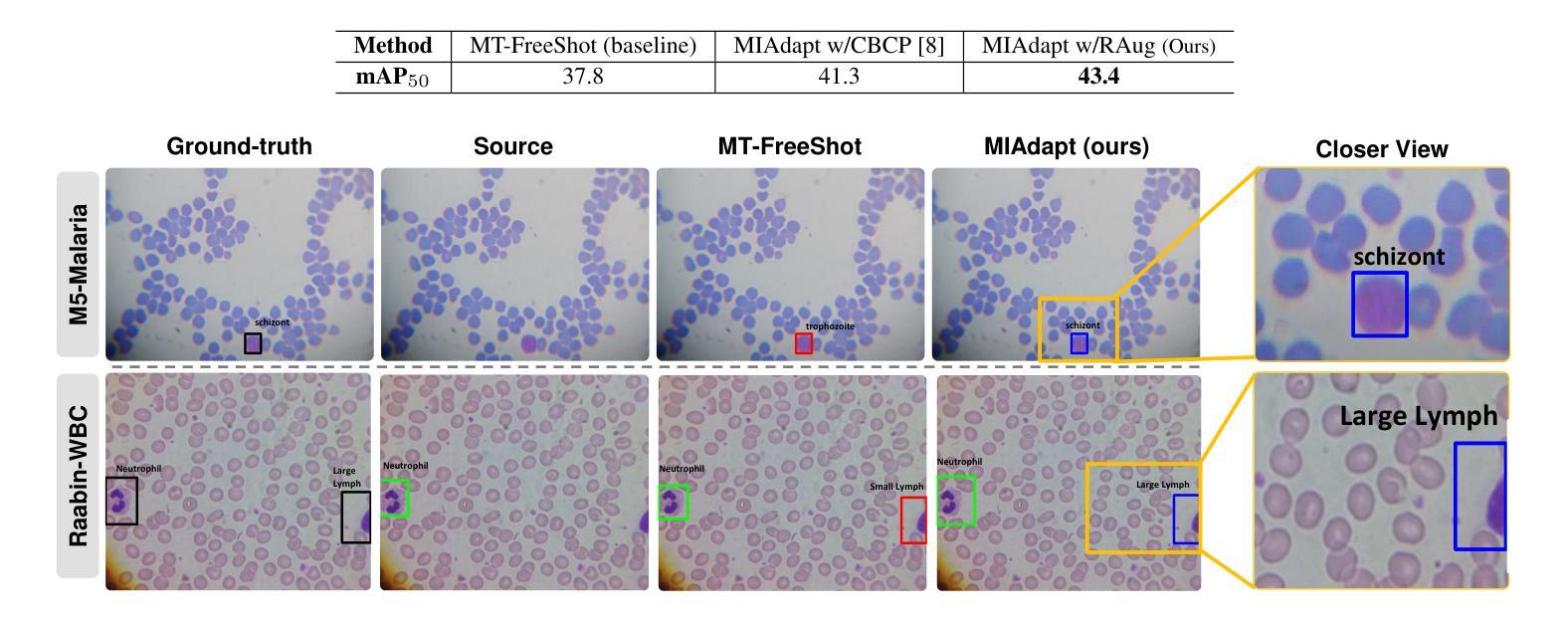
MIAdapt: Source-free Few-shot Domain Adaptive Object Detection for Microscopic Images
Authors:Nimra Dilawar, Sara Nadeem, Javed Iqbal, Waqas Sultani, Mohsen Ali
Existing generic unsupervised domain adaptation approaches require access to both a large labeled source dataset and a sufficient unlabeled target dataset during adaptation. However, collecting a large dataset, even if unlabeled, is a challenging and expensive endeavor, especially in medical imaging. In addition, constraints such as privacy issues can result in cases where source data is unavailable. Taking in consideration these challenges, we propose MIAdapt, an adaptive approach for Microscopic Imagery Adaptation as a solution for Source-free Few-shot Domain Adaptive Object detection (SF-FSDA). We also define two competitive baselines (1) Faster-FreeShot and (2) MT-FreeShot. Extensive experiments on the challenging M5-Malaria and Raabin-WBC datasets validate the effectiveness of MIAdapt. Without using any image from the source domain MIAdapt surpasses state-of-the-art source-free UDA (SF-UDA) methods by +21.3% mAP and few-shot domain adaptation (FSDA) approaches by +4.7% mAP on Raabin-WBC. Our code and models will be publicly available.
现有的通用无监督域适应方法要求在适应过程中同时访问大量有标签的源数据集和足够的无标签的目标数据集。然而,在医疗成像等领域,即使是无标签的数据集,收集也是一个具有挑战性和成本高昂的任务。此外,隐私问题等约束条件可能导致无法使用源数据。考虑到这些挑战,我们提出了MIAdapt,这是一种用于显微镜图像适应的自适应方法,作为无源少镜头域自适应目标检测(SF-FSDA)的解决方案。我们还定义了两个有竞争力的基线方法:(1)Faster-FreeShot和(2)MT-FreeShot。在具有挑战性的M5疟疾和Raabin-WBC数据集上的大量实验验证了MIAdapt的有效性。MIAdapt在不使用任何源域图像的情况下,超过了最新的无源UDA(SF-UDA)方法的mAP+21.3%,并在Raabin-WBC数据集上超过了少镜头域适应(FSDA)方法的mAP+4.7%。我们的代码和模型将公开可用。
论文及项目相关链接
PDF 6 pages, 5 figures
Summary
本文提出一种针对显微镜图像自适应的MIAdapt方法,用于解决源数据缺失下的少量样本域自适应目标检测问题。在M5-Malaria和Raabin-WBC数据集上的实验验证了MIAdapt的有效性,相较于现有的源数据缺失下的无监督域自适应方法和少量样本域自适应方法,MIAdapt分别提高了21.3%和4.7%的平均精度。
Key Takeaways
- 现有通用无监督域自适应方法需要大量标注的源数据集和足够的未标注目标数据集进行适应,这在医学成像中尤其具有挑战性和成本高昂。
- 针对这些挑战,提出了MIAdapt方法,用于显微镜图像的域适应。
- MIAdapt是一种针对源数据缺失下的少量样本域自适应目标检测(SF-FSDA)的解决方案。
- 在M5-Malaria和Raabin-WBC数据集上进行了广泛的实验验证,证明了MIAdapt的有效性。
- MIAdapt相较于现有方法显著提高了平均精度(mAP)。
点此查看论文截图

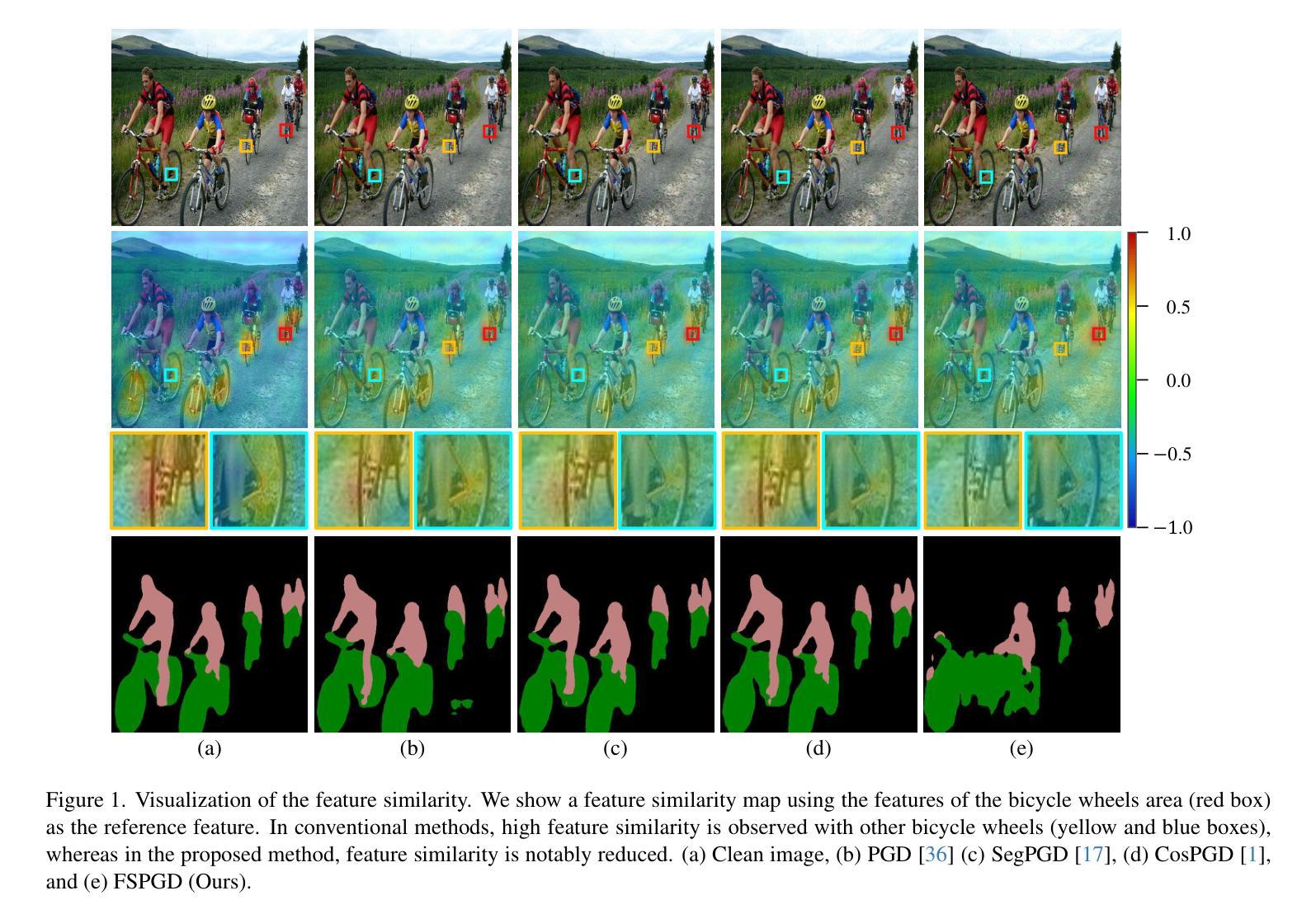
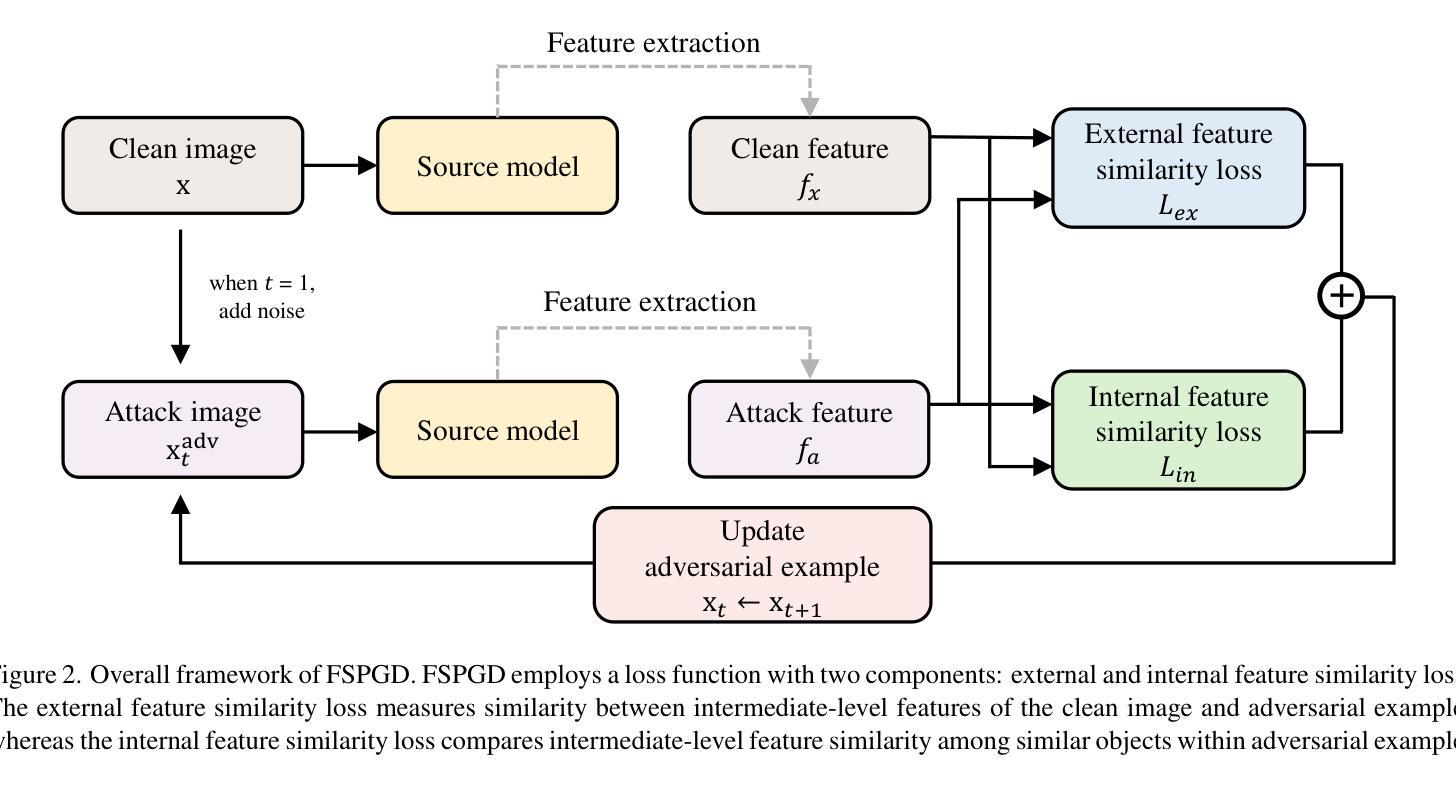
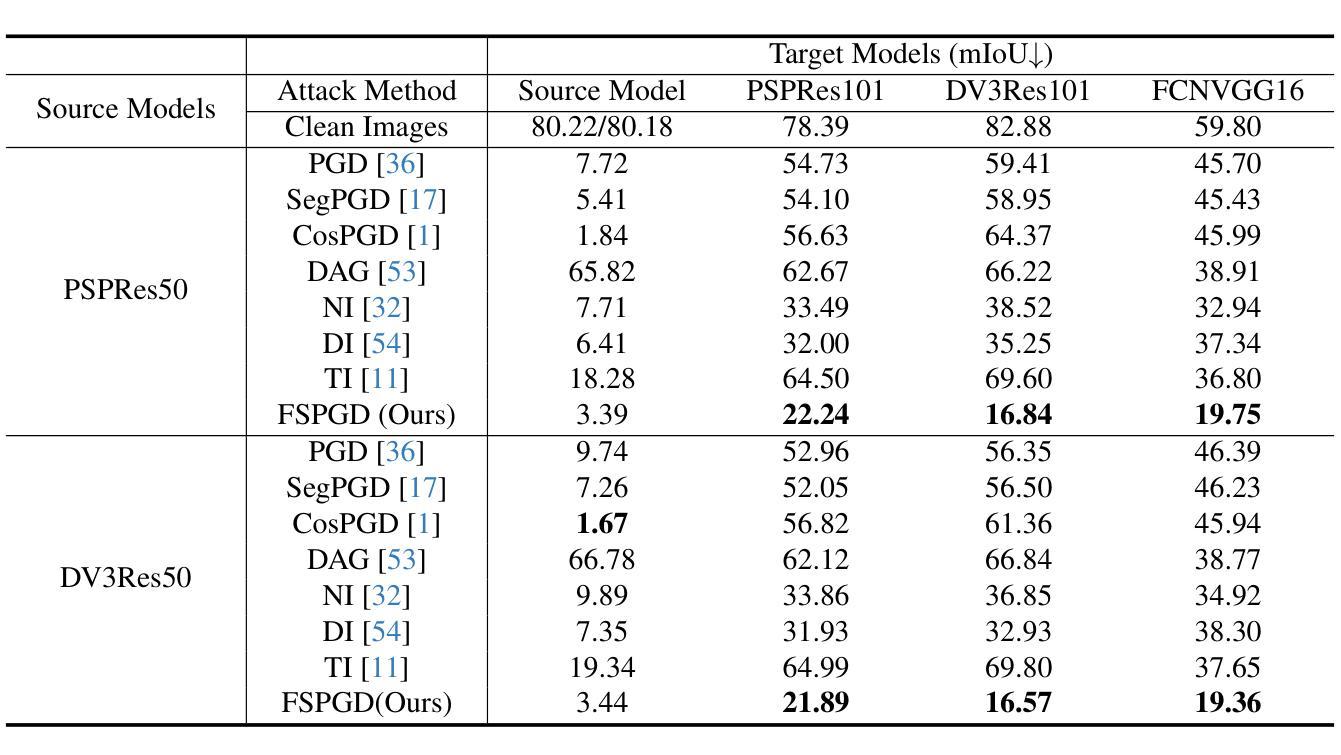
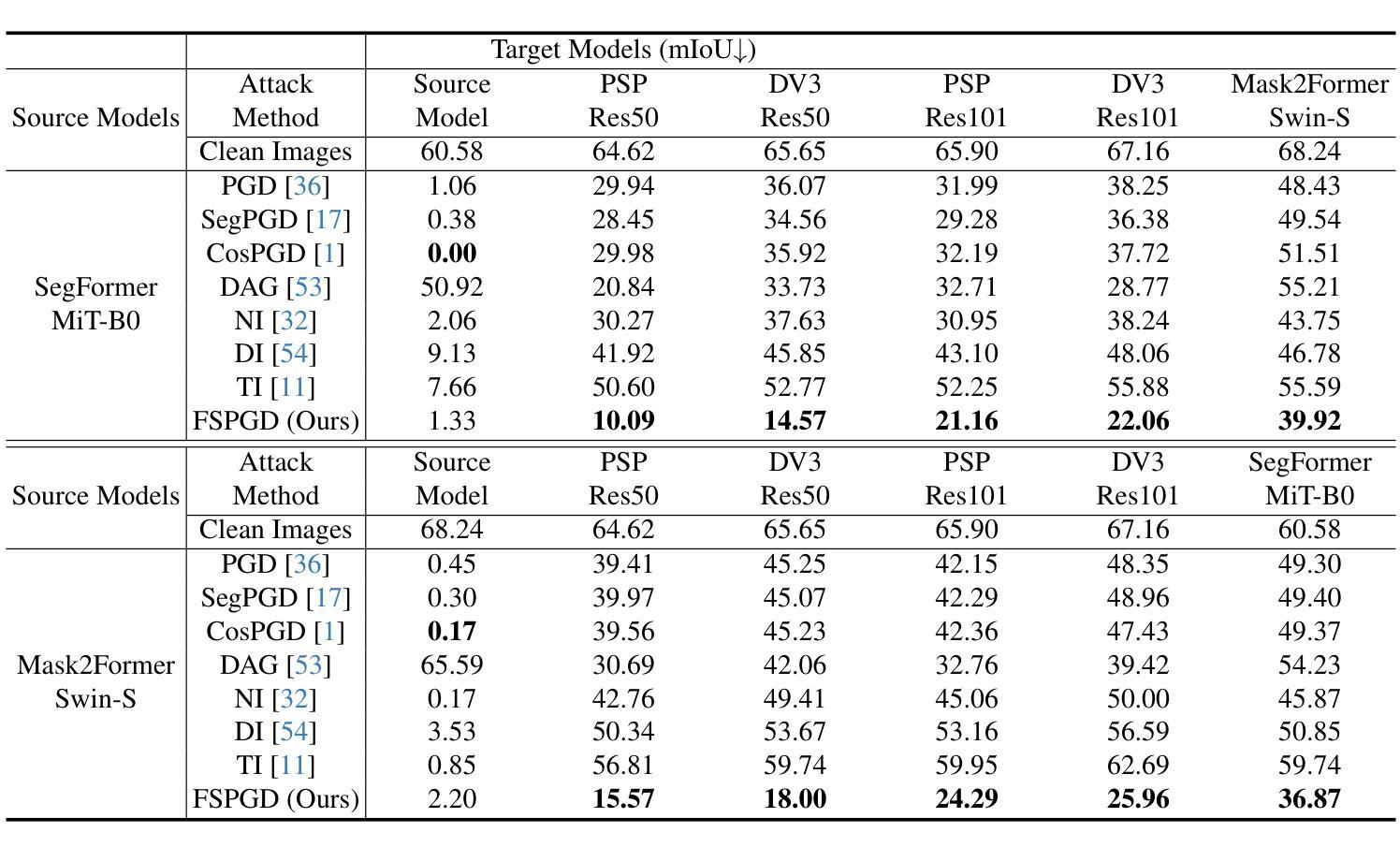
FSPGD: Rethinking Black-box Attacks on Semantic Segmentation
Authors:Eun-Sol Park, MiSo Park, Seung Park, Yong-Goo Shin
Transferability, the ability of adversarial examples crafted for one model to deceive other models, is crucial for black-box attacks. Despite advancements in attack methods for semantic segmentation, transferability remains limited, reducing their effectiveness in real-world applications. To address this, we introduce the Feature Similarity Projected Gradient Descent (FSPGD) attack, a novel black-box approach that enhances both attack performance and transferability. Unlike conventional segmentation attacks that rely on output predictions for gradient calculation, FSPGD computes gradients from intermediate layer features. Specifically, our method introduces a loss function that targets local information by comparing features between clean images and adversarial examples, while also disrupting contextual information by accounting for spatial relationships between objects. Experiments on Pascal VOC 2012 and Cityscapes datasets demonstrate that FSPGD achieves superior transferability and attack performance, establishing a new state-of-the-art benchmark. Code is available at https://github.com/KU-AIVS/FSPGD.
迁移性是指为某一模型制作的对抗样本欺骗其他模型的能力,对于黑盒攻击至关重要。尽管语义分割的攻击方法已经有所发展,但迁移性仍然有限,降低了其在现实世界应用中的有效性。为了解决这一问题,我们引入了特征相似性投影梯度下降(FSPGD)攻击,这是一种新型的黑盒攻击方法,既能提高攻击性能,又能增强迁移性。与传统的依赖输出预测进行梯度计算的分割攻击不同,FSPGD从中间层特征计算梯度。具体来说,我们的方法引入了一个损失函数,该函数通过比较干净图像和对抗样本之间的特征来定位局部信息,同时通过考虑对象之间的空间关系来破坏上下文信息。在Pascal VOC 2012和Cityscapes数据集上的实验表明,FSPGD在迁移性和攻击性能上达到了领先水平,树立了新的基准。代码可通过https://github.com/KU-AIVS/FSPGD获取。
论文及项目相关链接
Summary
本研究指出在语义分割领域的攻击方法中转移性的重要性及其对现实应用的影响。为提高攻击性能和转移性,研究者提出了特征相似性投影梯度下降(FSPGD)攻击方法。该方法通过引入损失函数,针对局部信息和空间关系进行梯度计算,实现了对中间层特征的利用。实验证明,FSPGD在Pascal VOC 2012和Cityscapes数据集上取得了更高的转移性和攻击性能,达到业界最新水平。
Key Takeaways
- 转移性是黑盒攻击中对抗性实例的关键能力,对于语义分割领域的攻击方法尤为重要。
- 当前攻击方法在转移性方面存在局限性,限制了其在现实应用中的有效性。
- FSPGD攻击是一种新型黑盒方法,旨在提高攻击性能和转移性。
- FSPGD通过引入损失函数并利用中间层特征来计算梯度,特别关注局部信息和空间关系。
- 实验证明,FSPGD在Pascal VOC 2012和Cityscapes数据集上的攻击性能和转移性均表现优异。
点此查看论文截图

Modulating CNN Features with Pre-Trained ViT Representations for Open-Vocabulary Object Detection
Authors:Xiangyu Gao, Yu Dai, Benliu Qiu, Lanxiao Wang, Heqian Qiu, Hongliang Li
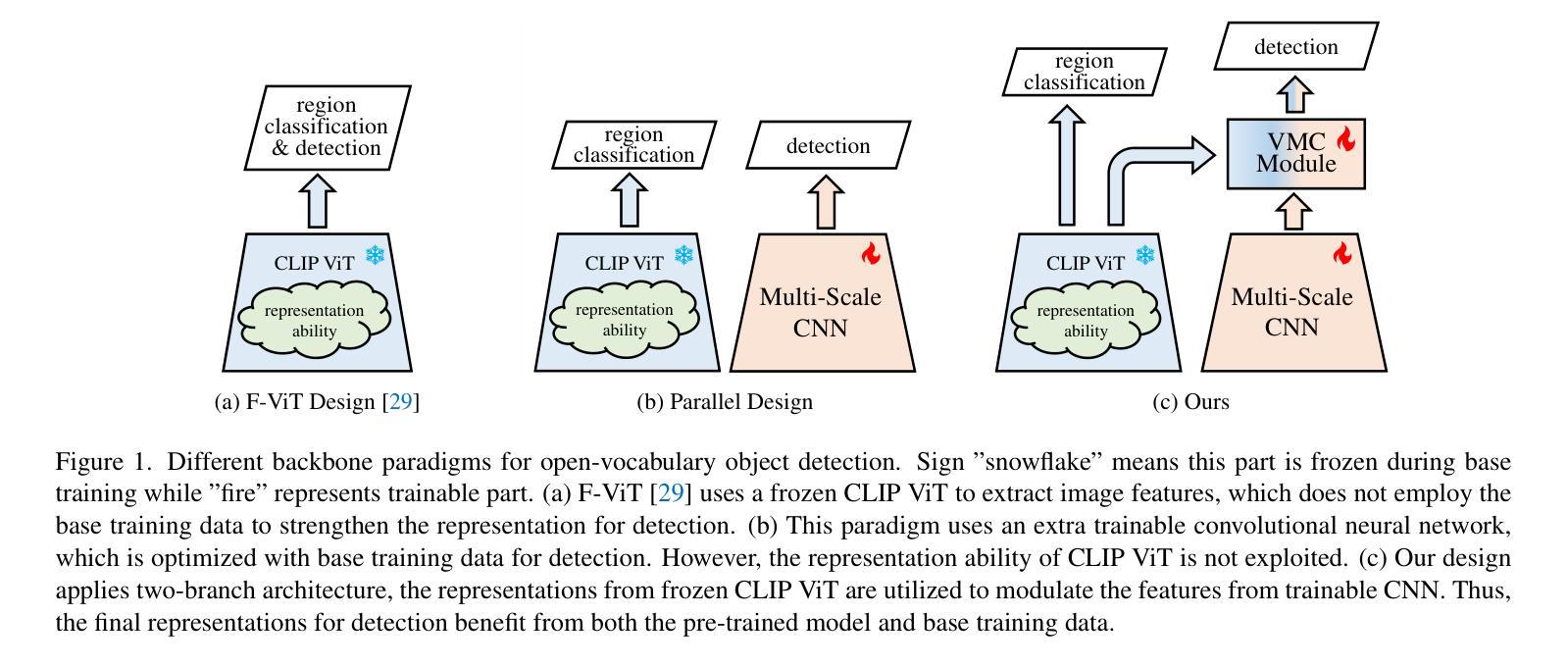
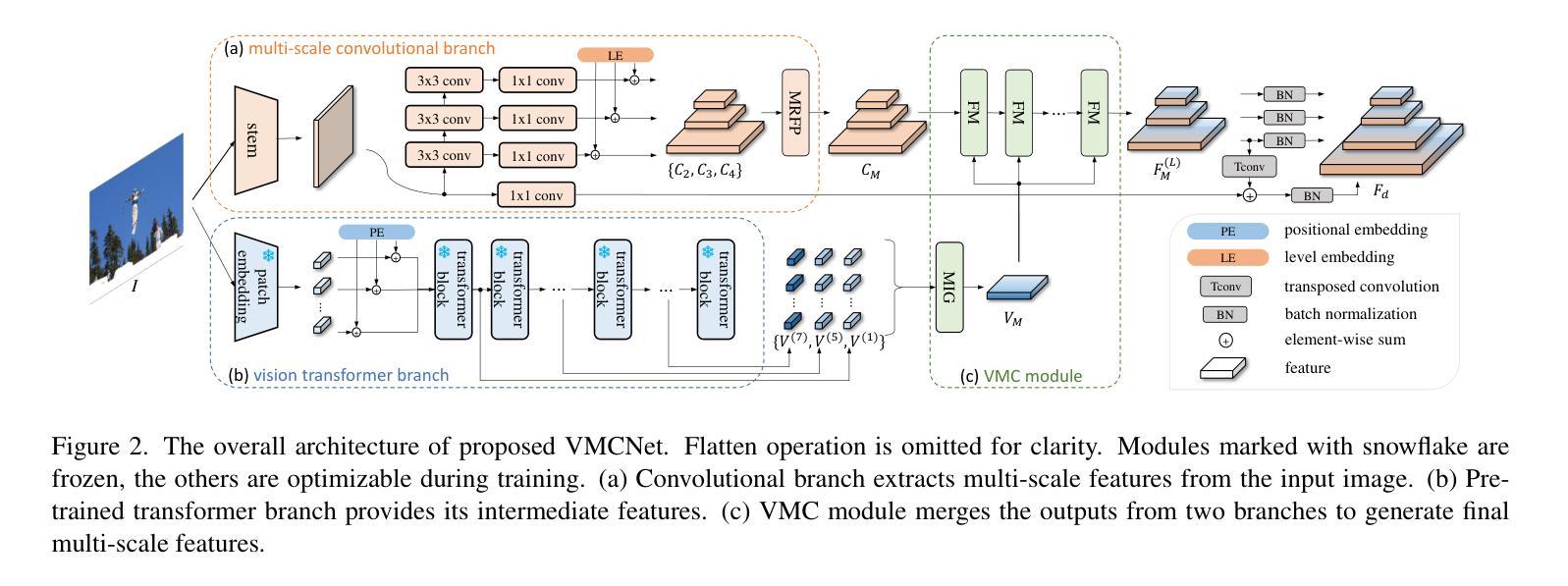
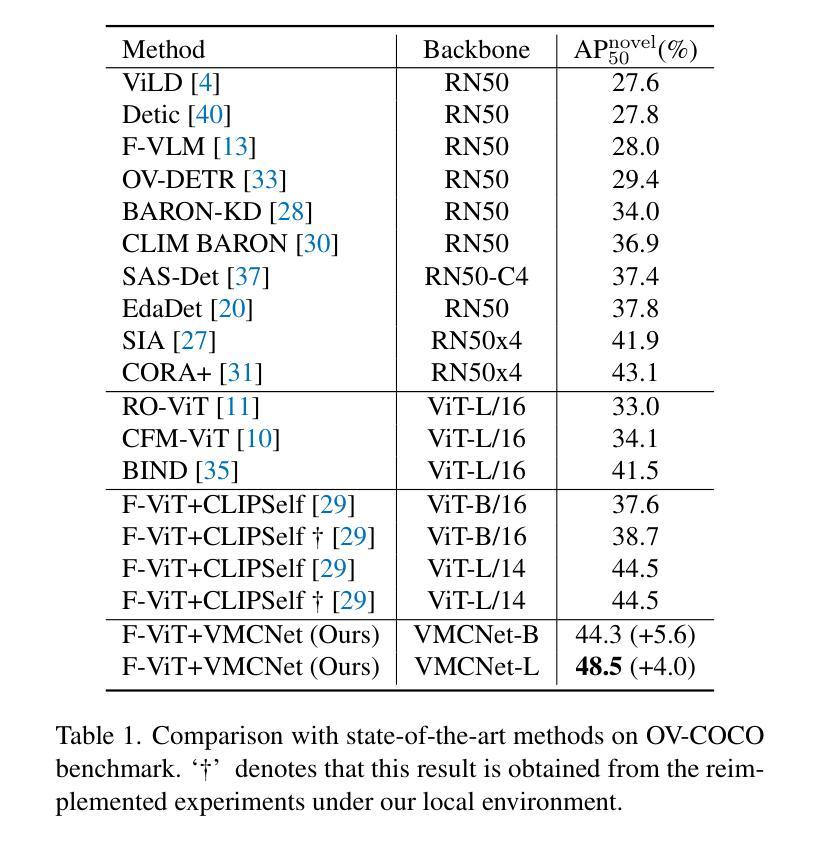
Owing to large-scale image-text contrastive training, pre-trained vision language model (VLM) like CLIP shows superior open-vocabulary recognition ability. Most existing open-vocabulary object detectors attempt to utilize the pre-trained VLMs to attain generalized representation. F-ViT uses the pre-trained visual encoder as the backbone network and freezes it during training. However, its frozen backbone doesn’t benefit from the labeled data to strengthen the representation for detection. Therefore, we propose a novel two-branch backbone network, named as \textbf{V}iT-Feature-\textbf{M}odulated Multi-Scale \textbf{C}onvolutional Network (VMCNet), which consists of a trainable convolutional branch, a frozen pre-trained ViT branch and a VMC module. The trainable CNN branch could be optimized with labeled data while the frozen pre-trained ViT branch could keep the representation ability derived from large-scale pre-training. Then, the proposed VMC module could modulate the multi-scale CNN features with the representations from ViT branch. With this proposed mixed structure, the detector is more likely to discover objects of novel categories. Evaluated on two popular benchmarks, our method boosts the detection performance on novel category and outperforms state-of-the-art methods. On OV-COCO, the proposed method achieves 44.3 AP${50}^{\mathrm{novel}}$ with ViT-B/16 and 48.5 AP${50}^{\mathrm{novel}}$ with ViT-L/14. On OV-LVIS, VMCNet with ViT-B/16 and ViT-L/14 reaches 27.8 and 38.4 mAP$_{r}$.
由于大规模图像文本对比训练,像CLIP这样的预训练视觉语言模型(VLM)表现出卓越的开放词汇识别能力。大多数现有的开放词汇对象检测器试图利用预训练的VLMs来获得通用表示。F-ViT使用预训练的视觉编码器作为主干网络,并在训练期间冻结它。然而,其冻结的主干网络并不能从标记数据中受益,以增强检测表示。因此,我们提出了一种新型的两分支主干网络,名为ViT特征调制多尺度卷积网络(VMCNet),它由可训练的卷积分支、冻结的预训练ViT分支和VMC模块组成。可训练的CNN分支可以利用标记数据进行优化,而冻结的预训练ViT分支可以保持从大规模预训练中学到的表示能力。然后,所提出的VMC模块可以调制来自ViT分支的多尺度CNN特征。通过这种混合结构,检测器更有可能发现新型类别的对象。在两个流行的基准测试上进行评估,我们的方法在新型类别检测性能上有所提升,并超越了最先进的方法。在OV-COCO上,所提方法使用ViT-B/16达到44.3 AP50novel,使用ViT-L/14达到48.5 AP50novel。在OV-LVIS上,VMCNet与ViT-B/16和ViT-L/ 点石即成金赋予了更强的开放性语意描述和更大的信息量上做出了明显的提升。通过使用我们提出的VMCNet结构,不仅提高了检测性能,而且显著提升了模型对新型类别对象的检测能力。该论文的主要贡献在于结合预训练视觉语言模型和卷积神经网络的优势,提出了一种混合结构的主干网络,实现了开放词汇下的高效对象检测。
论文及项目相关链接
Summary
基于大规模图像文本对比训练,预训练视觉语言模型(如CLIP)展现出卓越的开箱词汇识别能力。现有开箱词汇目标检测器大多尝试利用预训练视觉语言模型获得通用表示。F-ViT使用预训练的视觉编码器作为骨干网络并在训练期间冻结它。然而,其冻结骨干网并未受益于标注数据来强化检测表示。因此,我们提出了一种新型的两分支骨干网络,名为ViT特征调制多尺度卷积网络(VMCNet),包括一个可训练卷积分支、一个冻结的预训练ViT分支和VMC模块。可训练的CNN分支可以利用标注数据进行优化,而冻结的预训练ViT分支则能够保持从大规模预训练中获得的表示能力。随后,所提出的VMC模块可以调制来自ViT分支的表示与多尺度CNN特征。通过这种混合结构,检测器更有可能发现新型类别的目标。在流行的基准测试上评估,我们的方法在新型类别检测性能上有所提升并超越了最先进的方法。在OV-COCO上,所提方法使用ViT-B/16达到44.3 AP50novel,使用ViT-L/14达到48.5 AP50novel。在OV-LVIS上,VMCNet使用ViT-B/16和ViT-L/14分别达到了27.8和38.4的mAPr。
Key Takeaways
- 大规模图像文本对比训练使预训练视觉语言模型(如CLIP)具有卓越的开箱词汇识别能力。
- 现有开箱词汇目标检测器倾向于利用预训练视觉语言模型获取通用表示。
- F-ViT利用预训练视觉编码器作为骨干网络,但在训练过程中无法充分利用标注数据。
- 提出的VMCNet通过结合可训练的卷积分支和冻结的预训练ViT分支,旨在优化检测性能。
- VMC模块能够调制来自ViT分支和CNN分支的特征,增强检测器对新型类别目标的发现能力。
- 在OV-COCO和OV-LVIS基准测试上,VMCNet显著提升了检测性能。
点此查看论文截图