⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-09 更新
Token-Efficient Long Video Understanding for Multimodal LLMs
Authors:Jindong Jiang, Xiuyu Li, Zhijian Liu, Muyang Li, Guo Chen, Zhiqi Li, De-An Huang, Guilin Liu, Zhiding Yu, Kurt Keutzer, Sungjin Ahn, Jan Kautz, Hongxu Yin, Yao Lu, Song Han, Wonmin Byeon
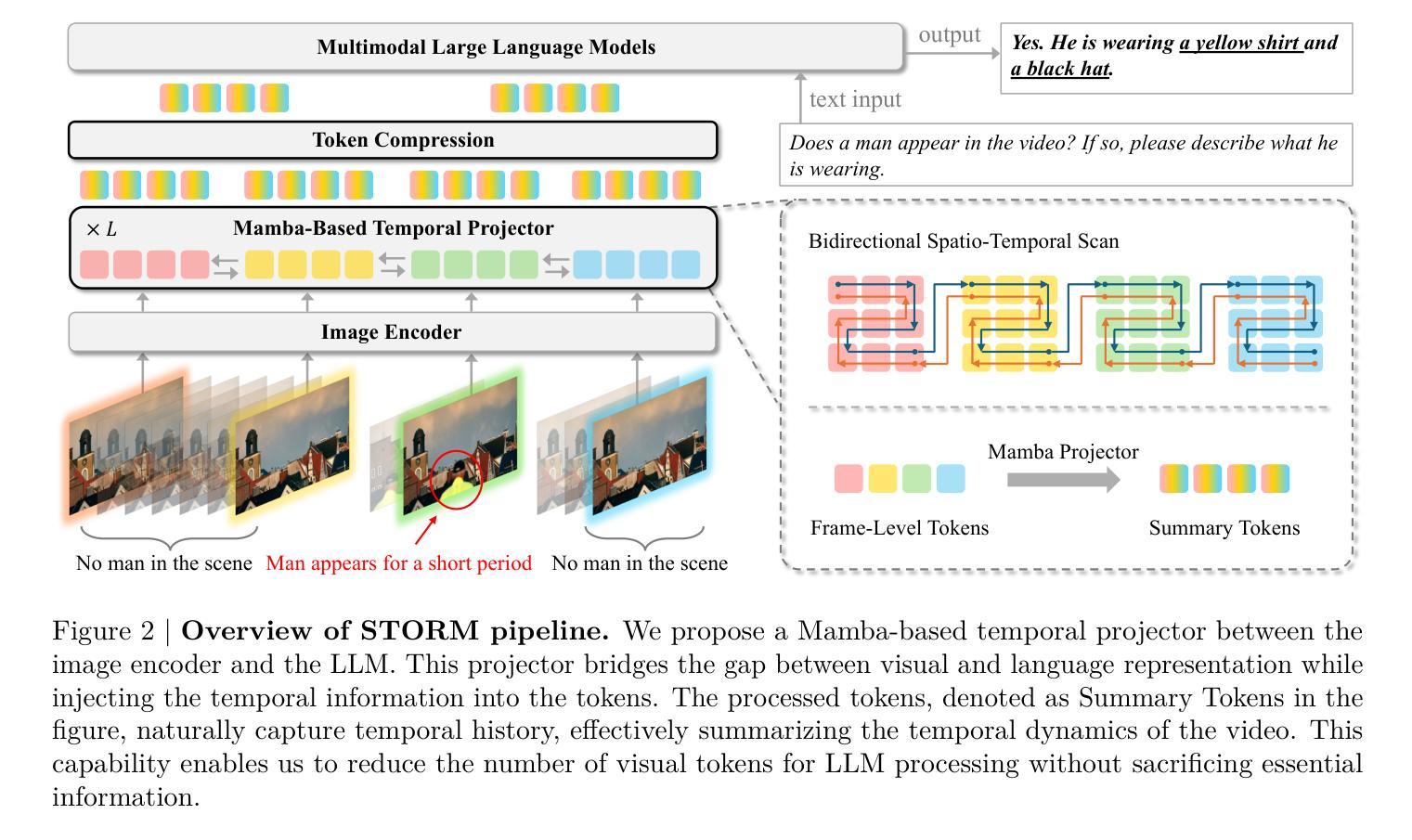
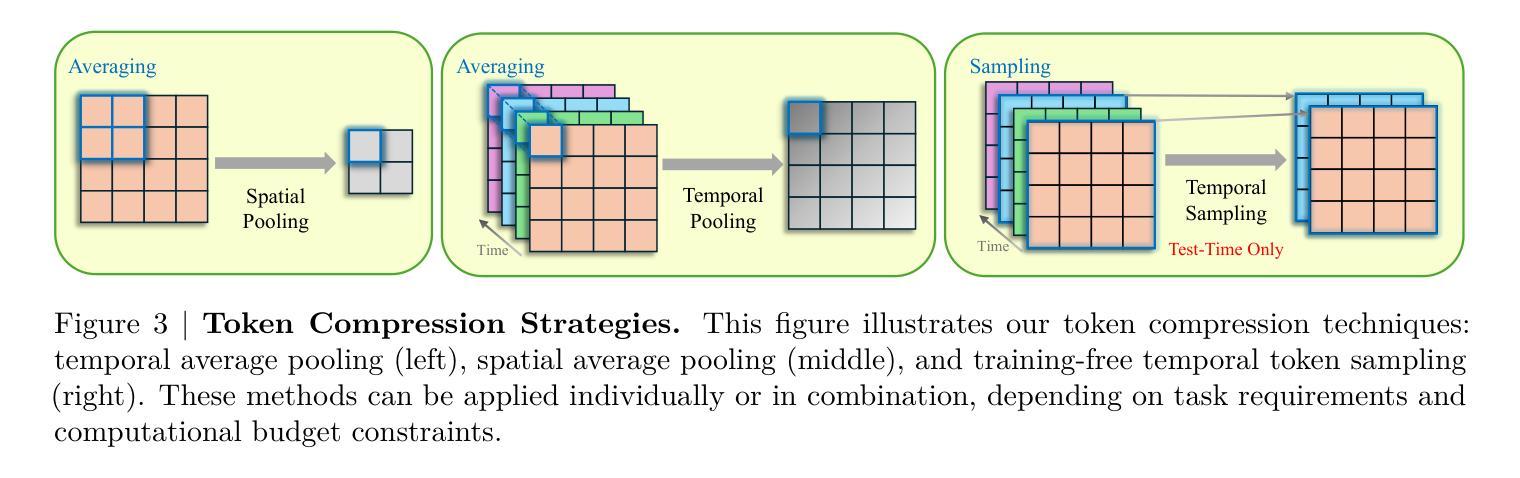
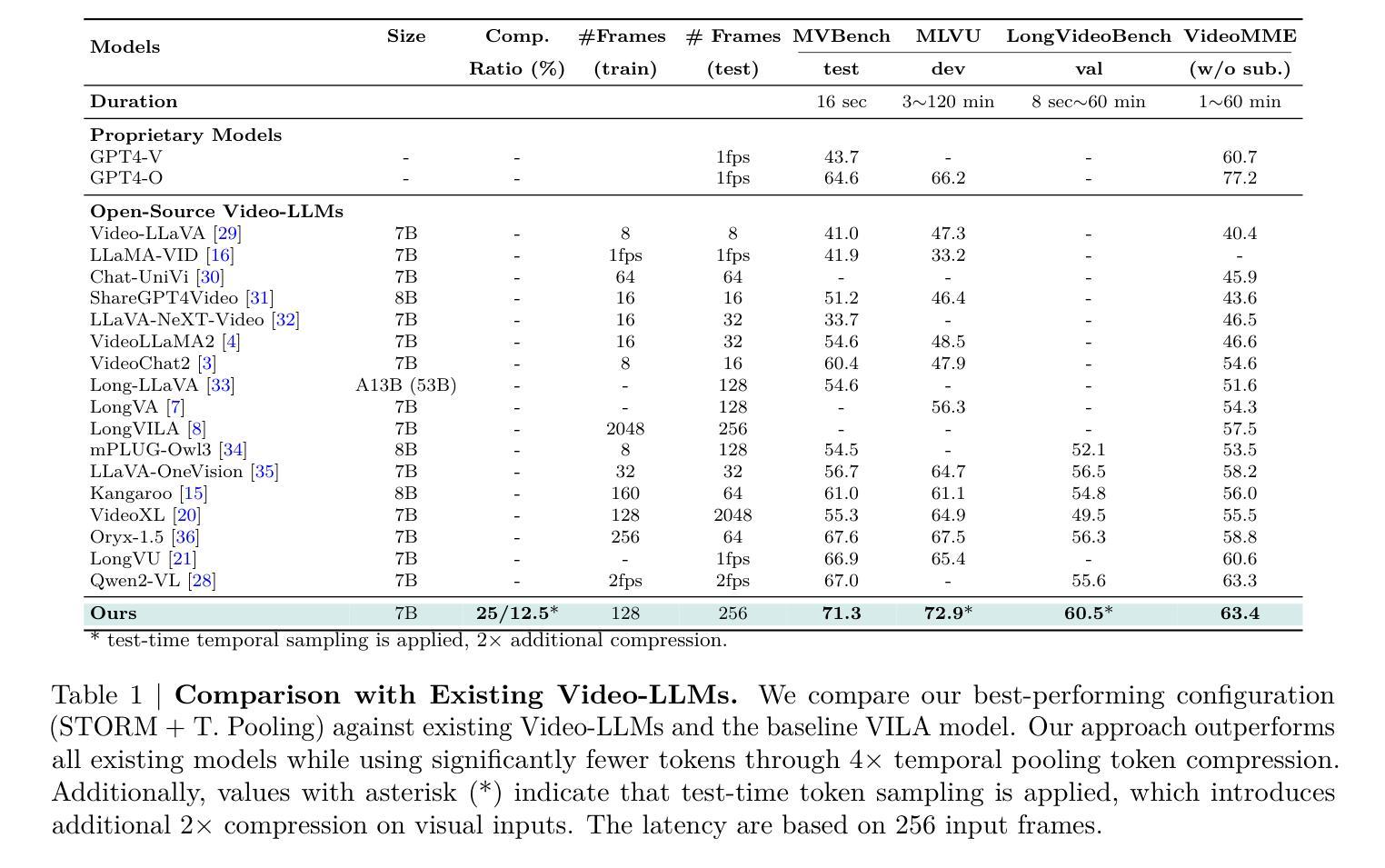
Recent advances in video-based multimodal large language models (Video-LLMs) have significantly improved video understanding by processing videos as sequences of image frames. However, many existing methods treat frames independently in the vision backbone, lacking explicit temporal modeling, which limits their ability to capture dynamic patterns and efficiently handle long videos. To address these limitations, we introduce STORM (\textbf{S}patiotemporal \textbf{TO}ken \textbf{R}eduction for \textbf{M}ultimodal LLMs), a novel architecture incorporating a dedicated temporal encoder between the image encoder and the LLM. Our temporal encoder leverages the Mamba State Space Model to integrate temporal information into image tokens, generating enriched representations that preserve inter-frame dynamics across the entire video sequence. This enriched encoding not only enhances video reasoning capabilities but also enables effective token reduction strategies, including test-time sampling and training-based temporal and spatial pooling, substantially reducing computational demands on the LLM without sacrificing key temporal information. By integrating these techniques, our approach simultaneously reduces training and inference latency while improving performance, enabling efficient and robust video understanding over extended temporal contexts. Extensive evaluations show that STORM achieves state-of-the-art results across various long video understanding benchmarks (more than 5% improvement on MLVU and LongVideoBench) while reducing the computation costs by up to $8\times$ and the decoding latency by 2.4-2.9$\times$ for the fixed numbers of input frames. Project page is available at https://research.nvidia.com/labs/lpr/storm
基于视频的多媒体大型语言模型(Video-LLMs)的最新进展通过处理视频作为图像帧序列显著提高了视频理解能力。然而,许多现有方法在视觉主干网络中独立处理帧,缺乏明确的时空建模,这限制了它们捕捉动态模式和有效处理长视频的能力。为了解决这些局限性,我们引入了STORM(用于多媒体LLM的时空令牌缩减(\textbf{S}patiotemporal \textbf{TO}ken \textbf{R}eduction for \textbf{M}ultimodal LLMs)),这是一种结合图像编码器与LLM之间的专用时空编码器的新型架构。我们的时空编码器利用Mamba状态空间模型将时空信息集成到图像令牌中,生成丰富的表示形式,这些表示形式可以保留整个视频序列中的帧间动态。这种丰富的编码不仅增强了视频推理能力,还实现了有效的令牌缩减策略,包括测试时采样和基于训练的时空池化,在不影响关键时空信息的情况下,大大降低了LLM的计算需求。通过整合这些技术,我们的方法能够在提高性能的同时,同时减少训练和推理延迟,实现在扩展的时空背景下的高效且稳健的视频理解。全面评估表明,STORM在各种长视频理解基准测试中达到了最新水平(在MLVU和LongVideoBench上的改进幅度超过5%),同时计算成本降低了高达8倍,对于固定数量的输入帧,解码延迟减少了2.4-2.9倍。项目页面可在https://research.nvidia.com/labs/lpr/storm上找到。
论文及项目相关链接
Summary
本文介绍了针对视频理解的新方法——STORM架构,它通过引入专门的时序编码器,将时序信息融入图像标记中,生成包含跨帧动态信息的丰富表示。这种方法提高了视频推理能力,并实现了有效的标记缩减策略,减少了大型语言模型的计算需求,同时不损失关键时序信息。这使得训练与推理时间延迟减少,同时在处理长视频时性能有所提升。
Key Takeaways
- STORM架构结合了时空信息,增强了视频理解能力。
- 通过引入专门的时序编码器,生成包含跨帧动态信息的丰富表示。
- 实现有效的标记缩减策略,降低大型语言模型的计算需求。
- 减少了训练与推理的时间延迟。
- 在处理长视频时性能有所提升。
6.STORM在多个长视频理解基准测试中达到了最新技术成果。
点此查看论文截图


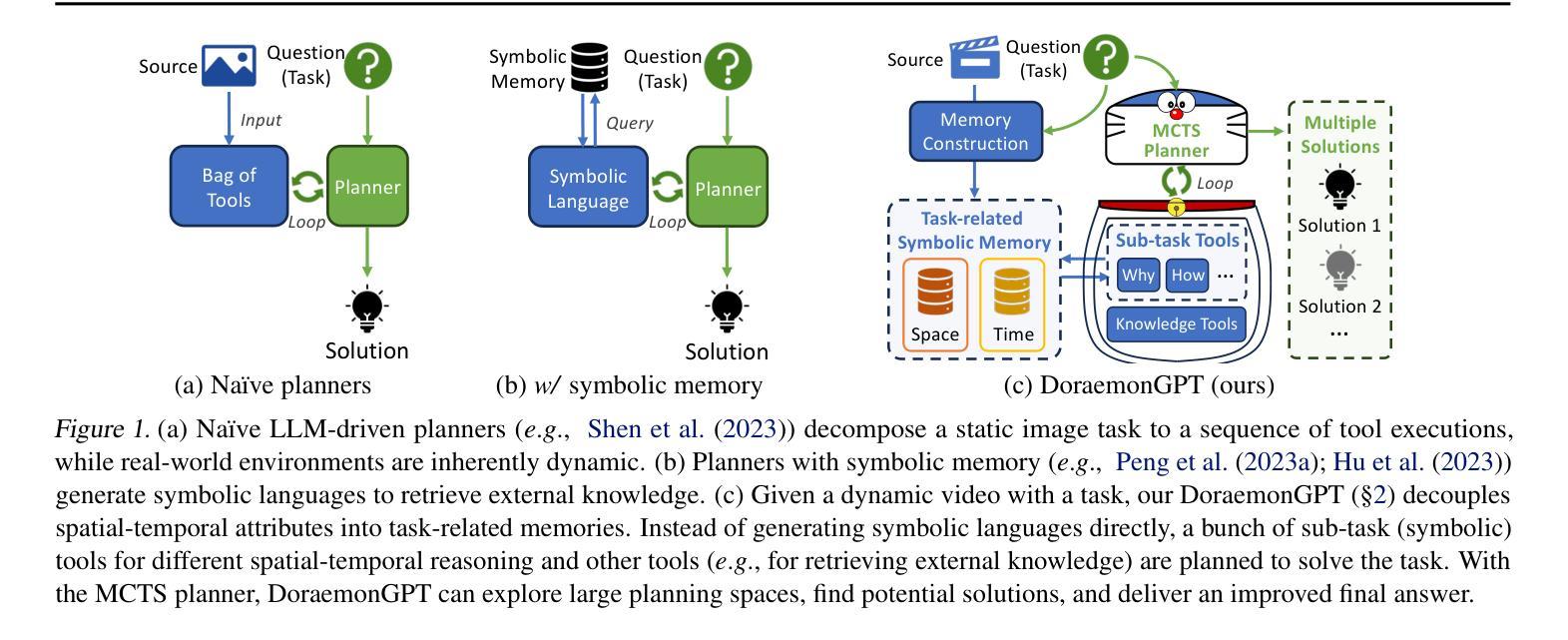
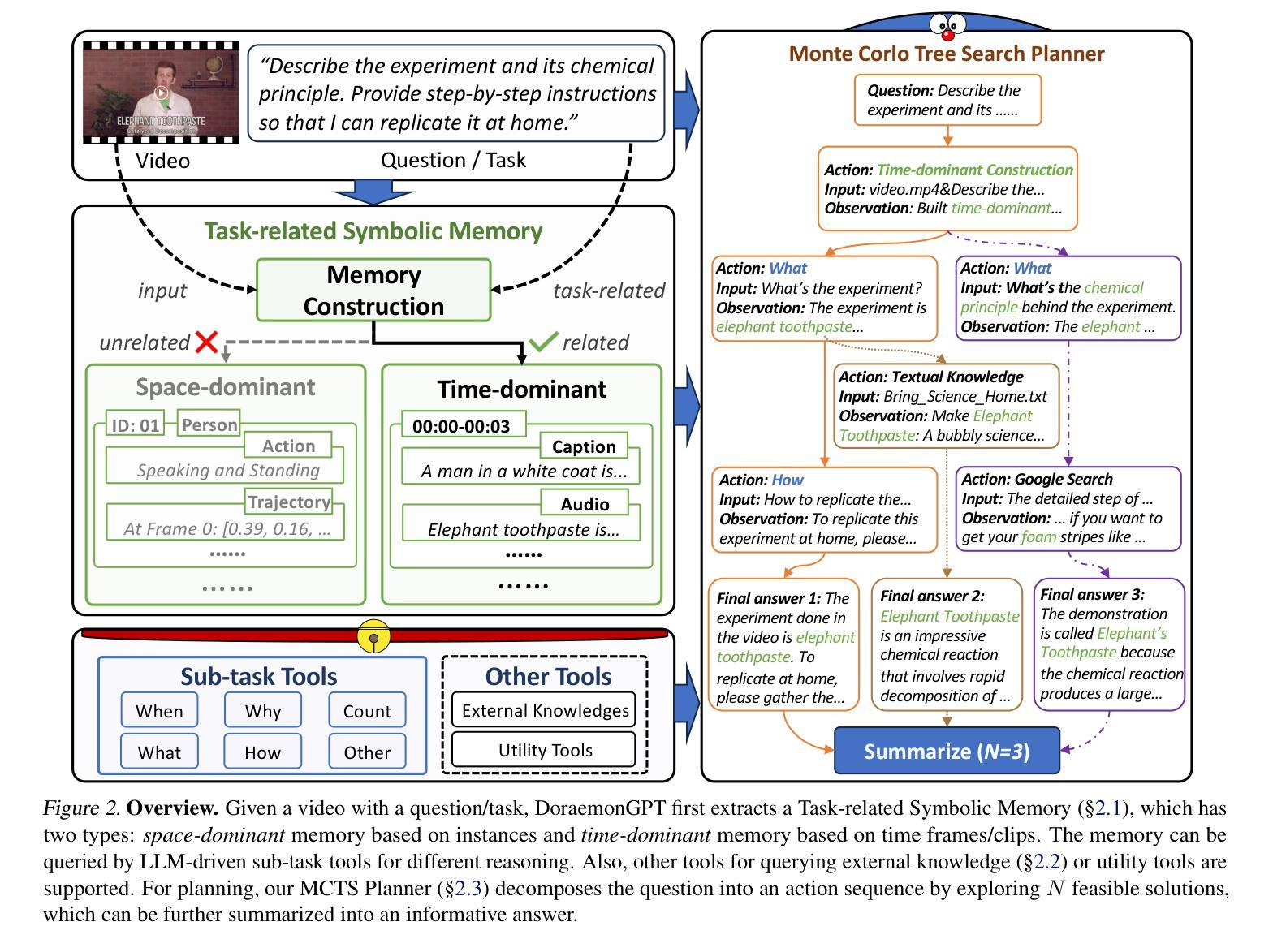
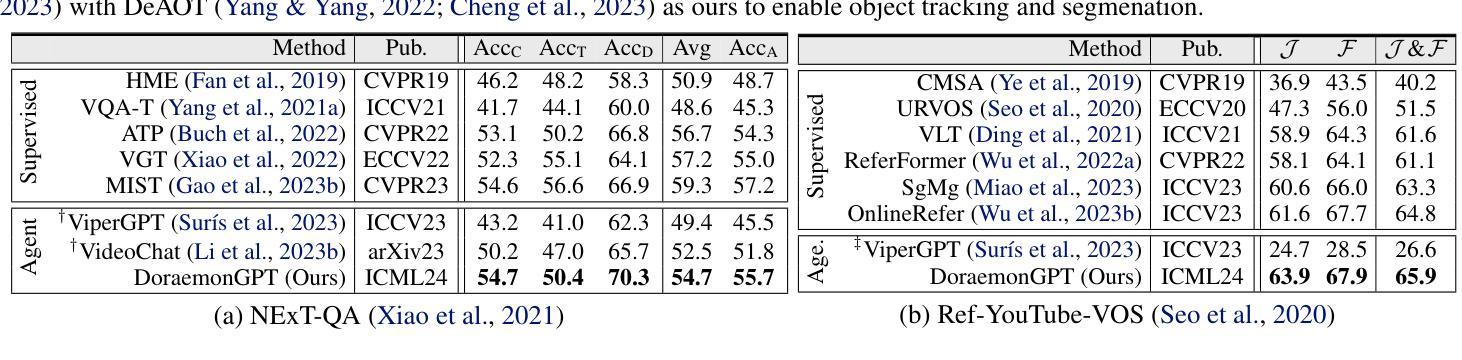
DoraemonGPT: Toward Understanding Dynamic Scenes with Large Language Models (Exemplified as A Video Agent)
Authors:Zongxin Yang, Guikun Chen, Xiaodi Li, Wenguan Wang, Yi Yang
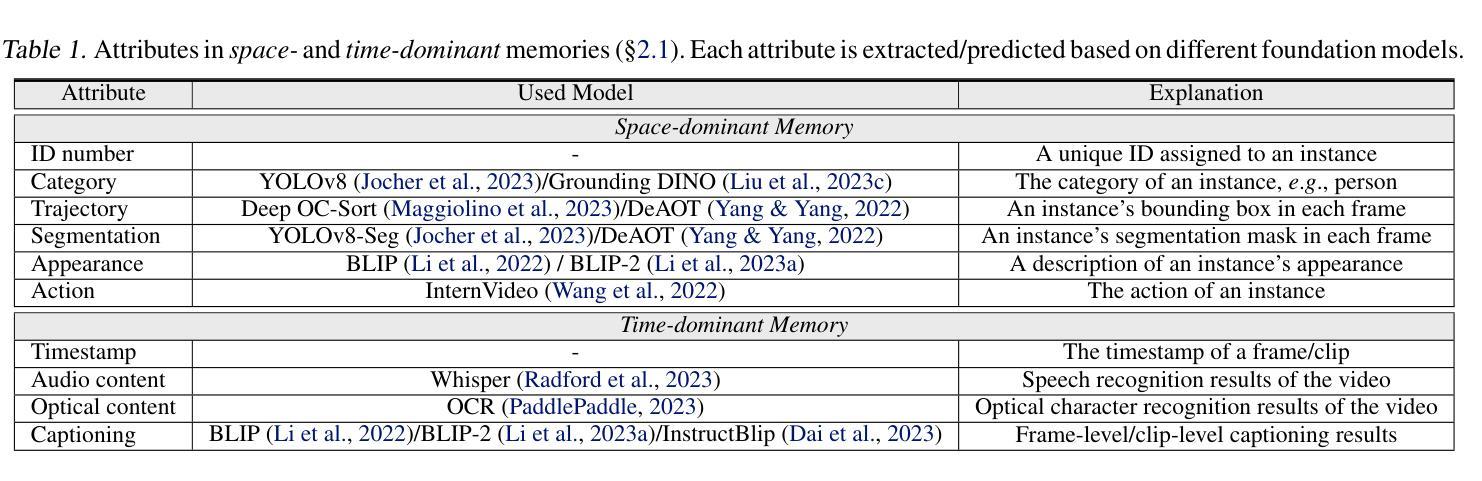
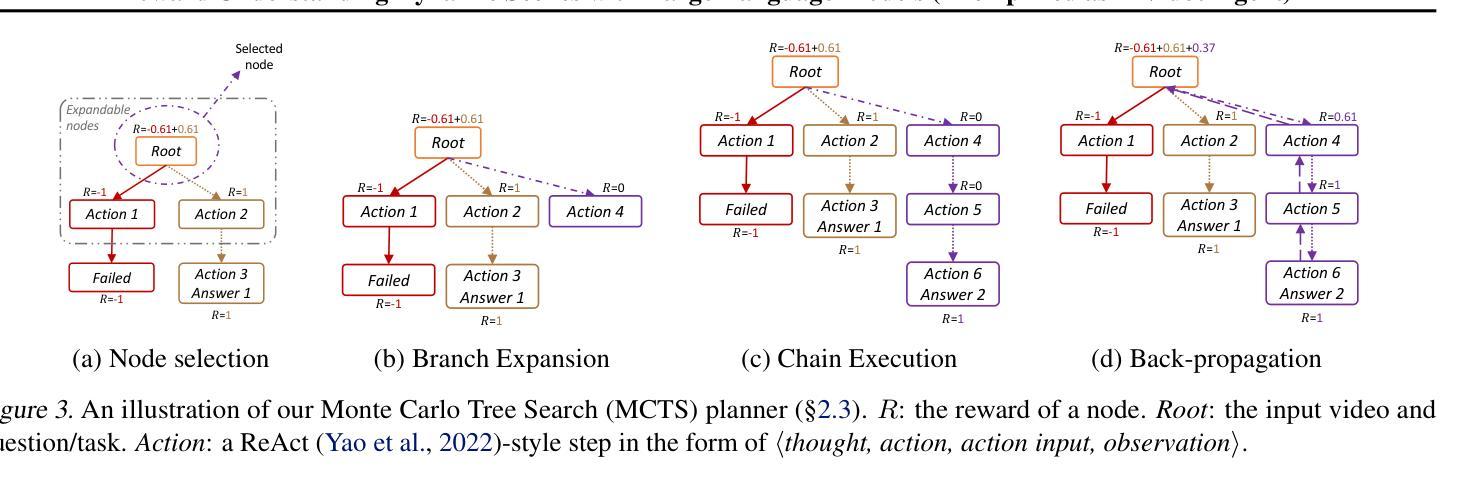
Recent LLM-driven visual agents mainly focus on solving image-based tasks, which limits their ability to understand dynamic scenes, making it far from real-life applications like guiding students in laboratory experiments and identifying their mistakes. Hence, this paper explores DoraemonGPT, a comprehensive and conceptually elegant system driven by LLMs to understand dynamic scenes. Considering the video modality better reflects the ever-changing nature of real-world scenarios, we exemplify DoraemonGPT as a video agent. Given a video with a question/task, DoraemonGPT begins by converting the input video into a symbolic memory that stores task-related attributes. This structured representation allows for spatial-temporal querying and reasoning by well-designed sub-task tools, resulting in concise intermediate results. Recognizing that LLMs have limited internal knowledge when it comes to specialized domains (e.g., analyzing the scientific principles underlying experiments), we incorporate plug-and-play tools to assess external knowledge and address tasks across different domains. Moreover, a novel LLM-driven planner based on Monte Carlo Tree Search is introduced to explore the large planning space for scheduling various tools. The planner iteratively finds feasible solutions by backpropagating the result’s reward, and multiple solutions can be summarized into an improved final answer. We extensively evaluate DoraemonGPT’s effectiveness on three benchmarks and several in-the-wild scenarios. The code will be released at https://github.com/z-x-yang/DoraemonGPT.
最近的大型语言模型(LLM)驱动的视觉代理主要关注基于图像的任务解决,这限制了它们对动态场景的理解能力,使其远离诸如指导实验室实验和学生识别错误等实际应用。因此,本文探讨了DoraemonGPT这一由LLM驱动的综合而概念优雅的系统,以理解动态场景。考虑到视频模式能更好地反映真实场景的不断变化性质,我们将DoraemonGPT作为视频代理进行示例。对于带有问题或任务的视频,DoraemonGPT首先将其转换为符号记忆,该记忆存储与任务相关的属性。这种结构化表示允许通过精心设计的子任务工具进行时空查询和推理,从而产生简洁的中间结果。我们认识到,当涉及到专业领域时(例如分析实验背后的科学原理),LLM的内部知识是有限的。因此,我们引入了即插即用工具来评估外部知识并应对不同领域的任务。此外,还介绍了一种基于蒙特卡洛树搜索的新型LLM驱动规划器,用于探索各种工具的大规模规划空间。规划器通过反向传播结果的奖励来迭代寻找可行解决方案,多个解决方案可以总结为改进的最终答案。我们在三个基准测试和若干野外场景中对DoraemonGPT的有效性进行了广泛评估。代码将在https://github.com/z-x-yang/DoraemonGPT上发布。
论文及项目相关链接
Summary
基于大型语言模型(LLM)驱动的视觉智能体近期主要关注图像任务的处理,这限制了它们在理解动态场景方面的能力,无法应对如实验室实验指导和学生错误识别等实际应用场景。因此,本文介绍了DoraemonGPT系统,这是一个由LLM驱动的、全面且概念优雅的理解动态场景的系统。考虑到视频模式能更好地反映现实世界的不断变化,我们以视频智能体为例介绍DoraemonGPT。给定一个带有问题或任务的视频,DoraemonGPT首先将输入视频转换为符号记忆,存储与任务相关的属性。这种结构化表示允许通过精心设计的子任务工具进行时空查询和推理,从而得到简洁的中间结果。为了弥补大型语言模型在特定领域知识的不足(如分析实验的科学原理),我们引入了插件式工具来评估外部知识并处理不同领域的任务。此外,还介绍了一种基于蒙特卡洛树搜索的LLM驱动规划器,用于探索各种工具的大型规划空间。规划器通过反向传播结果奖励来寻找可行解决方案,并将多个解决方案总结为改进的最终答案。我们在三个基准测试和若干野外场景中广泛评估了DoraemonGPT的有效性。相关代码将发布在https://github.com/z-x-yang/DoraemonGPT上。
Key Takeaways
- 近期LLM驱动的视觉智能体主要关注图像任务处理,但在理解动态场景方面存在局限性。
- DoraemonGPT系统通过结合LLM和符号记忆技术来强化处理动态场景的能力。
- 符号记忆可以存储任务相关属性,支持时空查询和推理。
- 利用插件式工具弥补大型语言模型在特定领域知识的不足。
- 基于蒙特卡洛树搜索的LLM驱动规划器用于探索多种工具间的规划空间。
- 评估结果表明DoraemonGPT在多个基准测试和野外场景中表现出有效性。
点此查看论文截图