⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-09 更新
GaussianVideo: Efficient Video Representation and Compression by Gaussian Splatting
Authors:Inseo Lee, Youngyoon Choi, Joonseok Lee
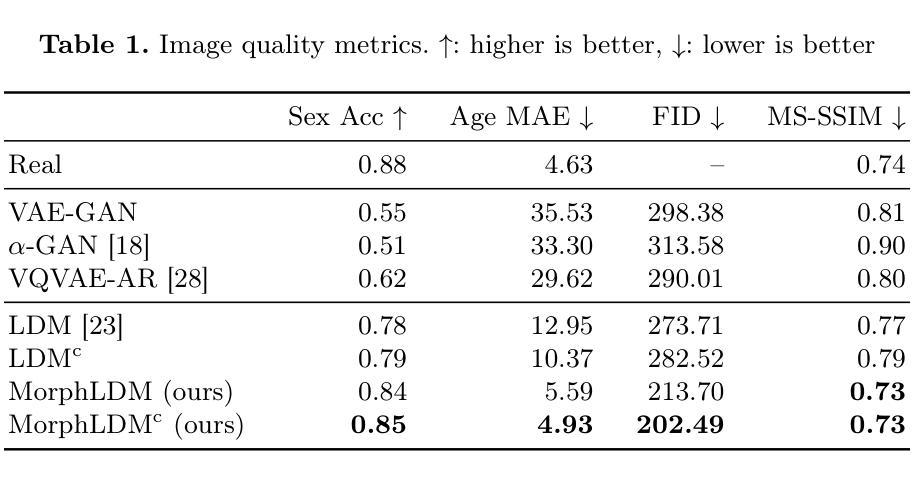
Implicit Neural Representation for Videos (NeRV) has introduced a novel paradigm for video representation and compression, outperforming traditional codecs. As model size grows, however, slow encoding and decoding speed and high memory consumption hinder its application in practice. To address these limitations, we propose a new video representation and compression method based on 2D Gaussian Splatting to efficiently handle video data. Our proposed deformable 2D Gaussian Splatting dynamically adapts the transformation of 2D Gaussians at each frame, significantly reducing memory cost. Equipped with a multi-plane-based spatiotemporal encoder and a lightweight decoder, it predicts changes in color, coordinates, and shape of initialized Gaussians, given the time step. By leveraging temporal gradients, our model effectively captures temporal redundancy at negligible cost, significantly enhancing video representation efficiency. Our method reduces GPU memory usage by up to 78.4%, and significantly expedites video processing, achieving 5.5x faster training and 12.5x faster decoding compared to the state-of-the-art NeRV methods.
隐式神经网络表示(NeRV)为视频表示和压缩引入了一种新的范式,超越了传统编码器的性能。然而,随着模型规模的扩大,编码和解码速度较慢以及内存消耗较高,阻碍了其在实践中的应用。为了解决这些局限性,我们提出了一种基于二维高斯平铺的新型视频表示和压缩方法,以有效地处理视频数据。我们提出的可变形二维高斯平铺能够动态适应每一帧的二维高斯变换,从而显著降低内存成本。通过配备基于多平面的时空编码器以及轻量级解码器,在给定的时间步长内,它可以预测初始化的高斯的颜色、坐标和形状的变化。通过利用时间梯度,我们的模型有效地捕获了时间冗余性,在几乎不增加成本的情况下显著提高了视频表示的效率。我们的方法将GPU内存使用率降低了高达78.4%,并大大加快了视频处理速度,与最先进的NeRV方法相比,训练速度提高了5.5倍,解码速度提高了12.5倍。
论文及项目相关链接
Summary
该文本介绍了基于隐式神经网络表示的视频技术(NeRV)的一种新方法,该方法使用二维高斯拼接技术有效地处理视频数据。此方法动态适应每一帧的二维高斯变换,显著降低内存成本,并通过多平面时空编码器和轻量级解码器预测初始化的高斯的颜色、坐标和形状的变化。该技术利用时间梯度有效地捕获时间冗余信息,大幅提高视频表示效率,降低GPU内存使用率和加速视频处理速度。与现有的NeRV方法相比,该方法在GPU内存使用率上降低了高达78.4%,训练和解码速度分别提高了5.5倍和12.5倍。
Key Takeaways
- NeRV技术引入了一种新的视频表示和压缩方法,基于二维高斯拼接技术处理视频数据。
- 动态适应每一帧的二维高斯变换能显著降低内存成本。
- 多平面时空编码器和轻量级解码器预测初始化的高斯参数的变化。
- 利用时间梯度捕获时间冗余信息,提高视频表示效率。
- 与现有NeRV方法相比,新方法在GPU内存使用率上降低78.4%。
- 训练速度提高5.5倍,解码速度提高12.5倍。
点此查看论文截图

S2Gaussian: Sparse-View Super-Resolution 3D Gaussian Splatting
Authors:Yecong Wan, Mingwen Shao, Yuanshuo Cheng, Wangmeng Zuo
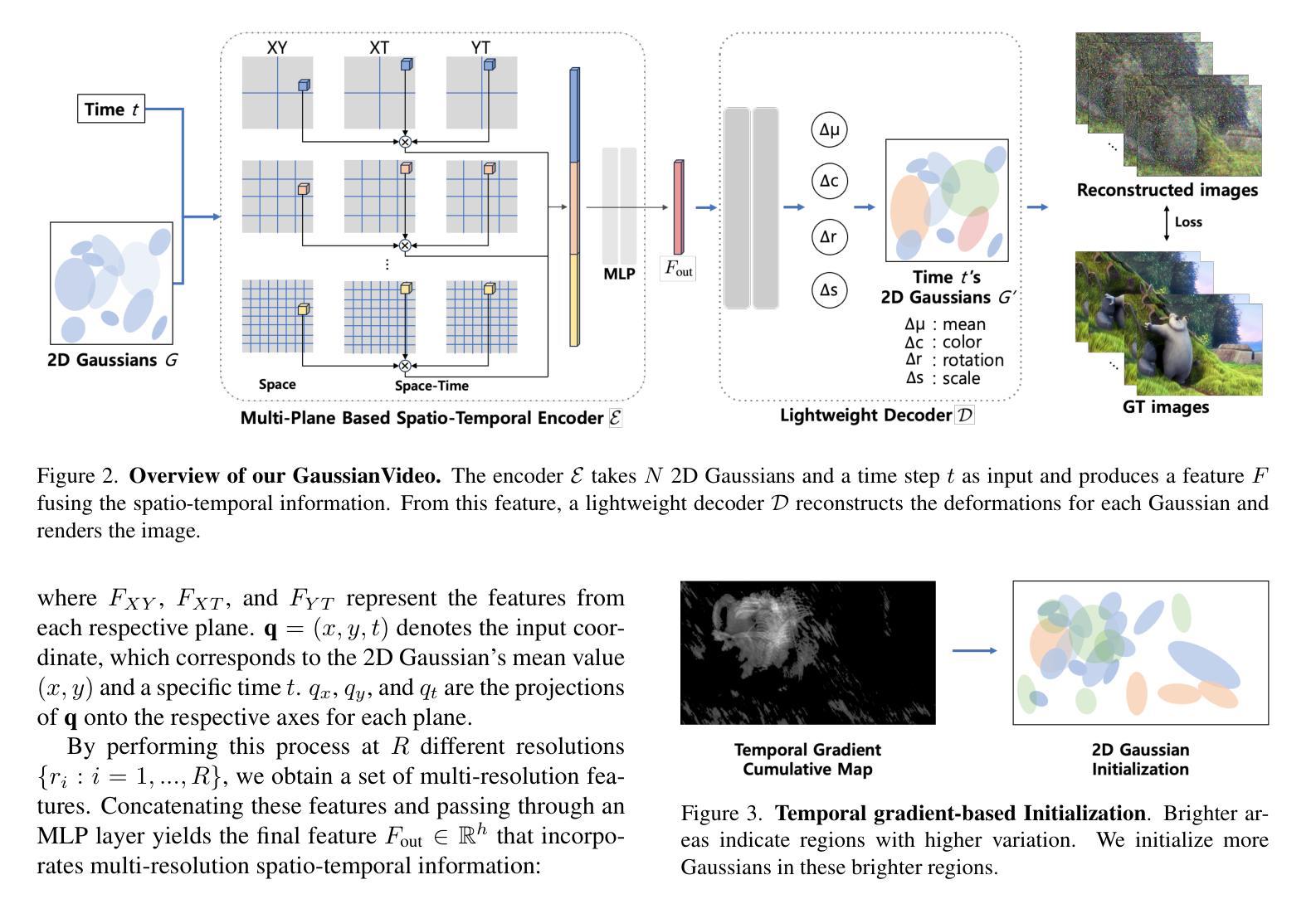
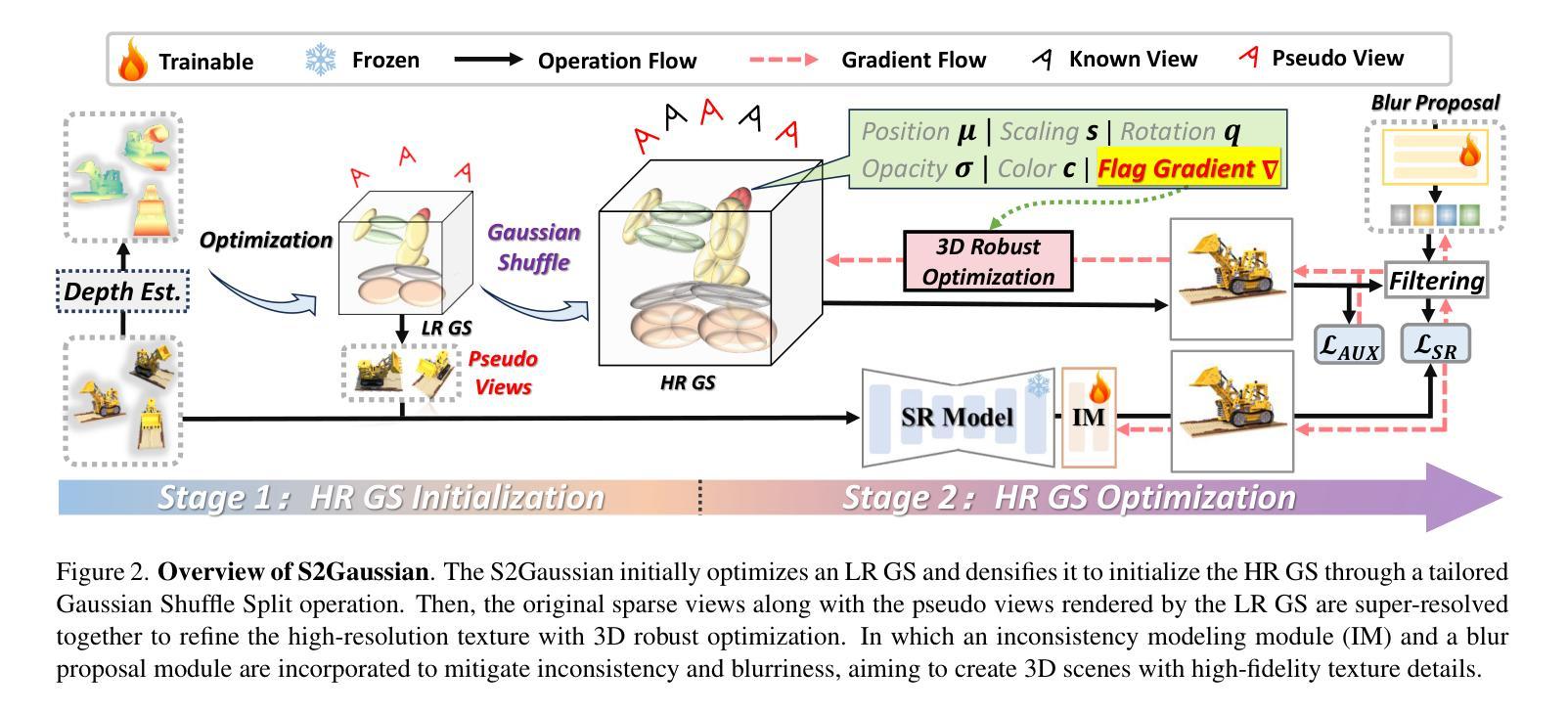
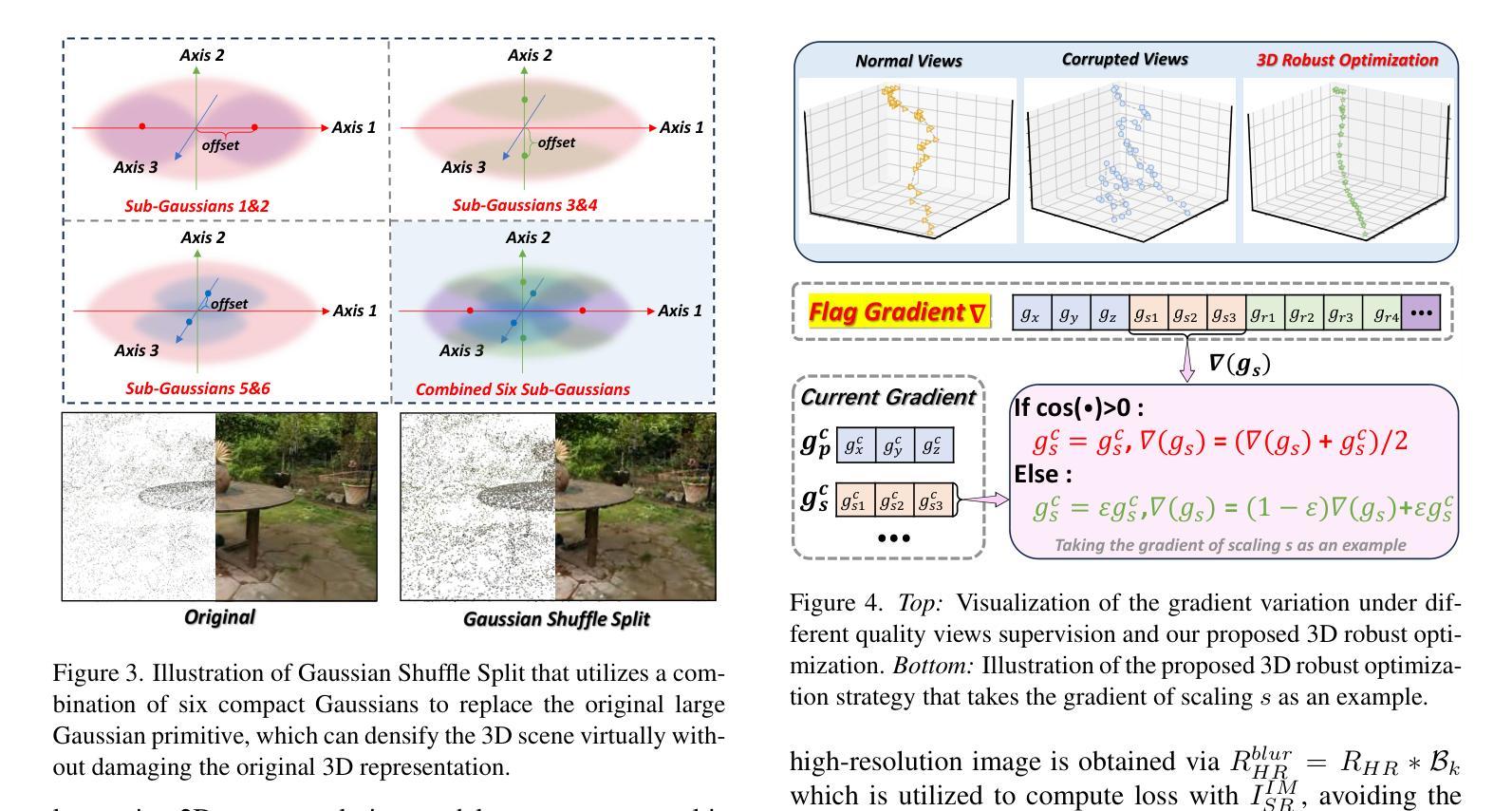
In this paper, we aim ambitiously for a realistic yet challenging problem, namely, how to reconstruct high-quality 3D scenes from sparse low-resolution views that simultaneously suffer from deficient perspectives and clarity. Whereas existing methods only deal with either sparse views or low-resolution observations, they fail to handle such hybrid and complicated scenarios. To this end, we propose a novel Sparse-view Super-resolution 3D Gaussian Splatting framework, dubbed S2Gaussian, that can reconstruct structure-accurate and detail-faithful 3D scenes with only sparse and low-resolution views. The S2Gaussian operates in a two-stage fashion. In the first stage, we initially optimize a low-resolution Gaussian representation with depth regularization and densify it to initialize the high-resolution Gaussians through a tailored Gaussian Shuffle Split operation. In the second stage, we refine the high-resolution Gaussians with the super-resolved images generated from both original sparse views and pseudo-views rendered by the low-resolution Gaussians. In which a customized blur-free inconsistency modeling scheme and a 3D robust optimization strategy are elaborately designed to mitigate multi-view inconsistency and eliminate erroneous updates caused by imperfect supervision. Extensive experiments demonstrate superior results and in particular establishing new state-of-the-art performances with more consistent geometry and finer details.
本文旨在解决一个现实且具有挑战性的课题,即如何从稀疏的低分辨率视角重建高质量的三维场景,这些视角既缺乏足够的视角又缺乏清晰度。现有的方法只处理稀疏视图或低分辨率观测,无法应对这种混合且复杂的场景。为此,我们提出了一种新型的稀疏视图超分辨率三维高斯喷绘框架,称为S2Gaussian,它仅利用稀疏和低分辨率的视图就能重建结构准确、细节真实的三维场景。S2Gaussian以两阶段的方式运行。在第一阶段,我们首先对低分辨率的高斯表示进行深度正则化优化,并通过定制的高斯洗牌分割操作将其密集化以初始化高分辨率高斯。在第二阶段,我们用来自原始稀疏视图和由低分辨率高斯渲染的伪视图生成的超分辨率图像来完善高分辨率高斯。其中,我们精心设计了一种无模糊的不一致性建模方案和一个稳健的三维优化策略,以减轻多视图的不一致性并消除由不完美的监督引起的错误更新。大量实验表明,结果优越,尤其是建立了新的最先进的性能,具有更一致的结构和更精细的细节。
论文及项目相关链接
PDF CVPR 2025
Summary
本文旨在解决一个现实且具挑战性的难题,即从稀疏的低分辨率视角重建高质量的三维场景。针对现有方法无法处理这种混合复杂场景的问题,提出了名为S2Gaussian的稀疏视图超分辨率3D高斯摊铺框架。该框架能在仅使用稀疏、低分辨率视图的情况下,重建出结构准确、细节真实的三维场景。S2Gaussian采用两阶段工作方式,首先优化低分辨率高斯表示并进行深度正则化,然后通过定制的高斯洗牌分割操作初始化高分辨率高斯。在第二阶段,使用来自原始稀疏视图和由低分辨率高斯渲染的伪视图的超分辨率图像来精细调整高分辨率高斯。设计了一种定制的无模糊不一致性建模方案和一种稳健的3D优化策略,以减轻多视图不一致性并消除由不完美的监督引起的错误更新。大量实验表明,该方法具有卓越的性能,特别是建立了一流的性能,具有更一致的几何和更精细的细节。
Key Takeaways
- 本文解决的是从稀疏的低分辨率视角重建高质量三维场景的现实难题。
- 提出了名为S2Gaussian的稀疏视图超分辨率3D高斯摊铺框架,能够处理复杂的混合场景。
- S2Gaussian通过两阶段工作方式,首先优化低分辨率高斯表示并进行深度正则化,然后初始化并精细调整高分辨率高斯。
- 定制了高斯洗牌分割操作以适应稀疏视图和超分辨率的需求。
- 通过超分辨率图像和定制的模糊不一致性建模方案来精细调整模型。
- 采用3D优化策略来减轻多视图不一致性并消除错误更新。
点此查看论文截图

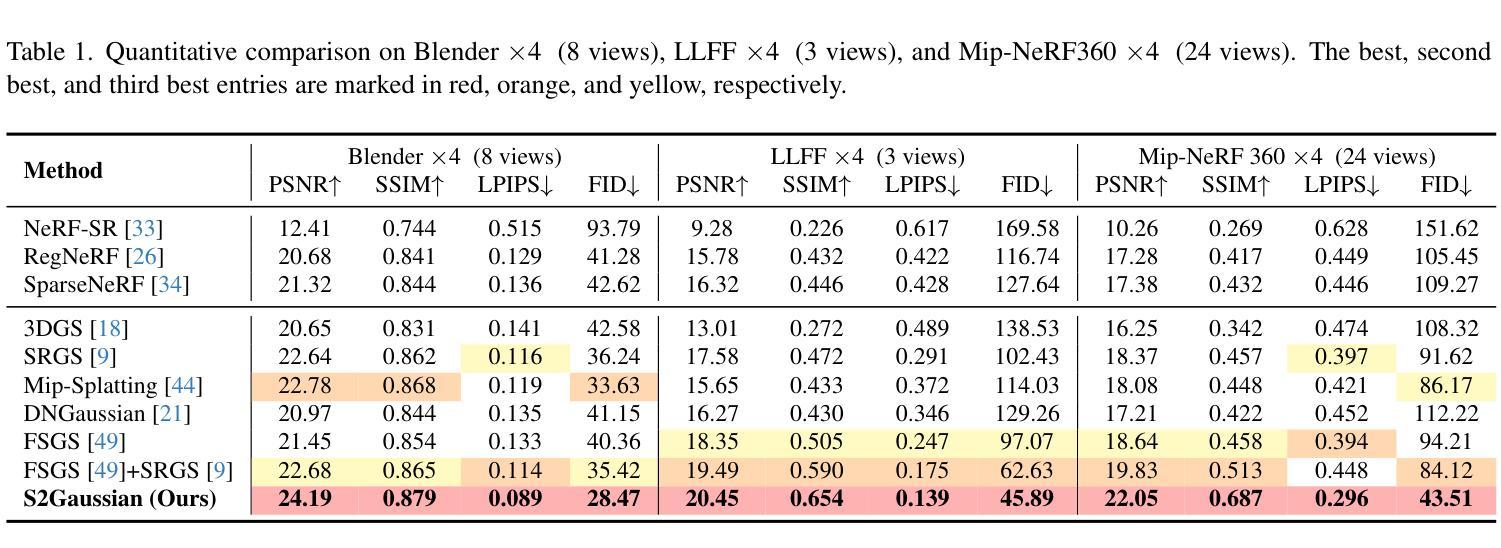
Instrument-Splatting: Controllable Photorealistic Reconstruction of Surgical Instruments Using Gaussian Splatting
Authors:Shuojue Yang, Zijian Wu, Mingxuan Hong, Qian Li, Daiyun Shen, Septimiu E. Salcudean, Yueming Jin
Real2Sim is becoming increasingly important with the rapid development of surgical artificial intelligence (AI) and autonomy. In this work, we propose a novel Real2Sim methodology, \textit{Instrument-Splatting}, that leverages 3D Gaussian Splatting to provide fully controllable 3D reconstruction of surgical instruments from monocular surgical videos. To maintain both high visual fidelity and manipulability, we introduce a geometry pre-training to bind Gaussian point clouds on part mesh with accurate geometric priors and define a forward kinematics to control the Gaussians as flexible as real instruments. Afterward, to handle unposed videos, we design a novel instrument pose tracking method leveraging semantics-embedded Gaussians to robustly refine per-frame instrument poses and joint states in a render-and-compare manner, which allows our instrument Gaussian to accurately learn textures and reach photorealistic rendering. We validated our method on 2 publicly released surgical videos and 4 videos collected on ex vivo tissues and green screens. Quantitative and qualitative evaluations demonstrate the effectiveness and superiority of the proposed method.
随着手术人工智能和自主技术的快速发展,Real2Sim变得越来越重要。在这项工作中,我们提出了一种新型的Real2Sim方法——仪器分裂(Instrument-Splatting),它利用3D高斯分裂(Gaussian Splatting)技术,从单目手术视频中实现手术仪器的全可控3D重建。为了保持高视觉保真度和可操作性,我们引入了几何预训练,将高斯点云与部分网格绑定,并引入准确的几何先验来定义前向运动学,以使高斯像真实仪器一样灵活可控。随后,为了处理未定位的视频,我们设计了一种新的仪器姿态跟踪方法,利用语义嵌入的高斯来稳健地优化每帧的仪器姿态和关节状态,以渲染和比较的方式,使仪器高斯能够准确学习纹理并实现逼真的渲染。我们在2个公开发布的手术视频和4个在离体组织和绿幕上收集的视频上验证了我们的方法。定量和定性评估证明了所提出方法的有效性和优越性。
论文及项目相关链接
PDF 11 pages, 5 figures
Summary
针对手术人工智能(AI)及自主性领域的迅速发展,本研究提出一种新型Real2Sim方法——仪器分裂法(Instrument-Splatting),结合3D高斯分裂技术,实现从单目手术视频中实现可控的精准手术仪器重建。为确保高质量视觉效果及操控性,本研究引入了几何预训练机制来精准模拟几何特征并控制高斯分布的灵活性如真实仪器一般。同时设计一种新颖仪器姿态追踪方法,对未标定视频进行处理,准确学习纹理并达到逼真的渲染效果。在公开及自制视频数据集上的定量与定性评估证明了该方法的有效性和优越性。
Key Takeaways
- 提出了一种新型Real2Sim方法——仪器分裂法(Instrument-Splatting),利用3D高斯分裂技术实现手术仪器的精准重建。
- 通过几何预训练机制确保高视觉保真度和操控性,模拟真实仪器的几何特征和控制灵活性。
- 设计了一种新颖的仪器姿态追踪方法,利用语义嵌入的高斯分布来精确优化每帧的仪器姿态和关节状态。
- 方法能够在未标定视频中进行渲染和比较,准确学习纹理并实现逼真的渲染效果。
- 方法在公开和自制视频数据集上经过定量和定性评估,证明了其有效性和优越性。
- 为手术人工智能和自主性领域的发展提供了有效的工具和方法,有助于推动相关领域的技术进步。
点此查看论文截图

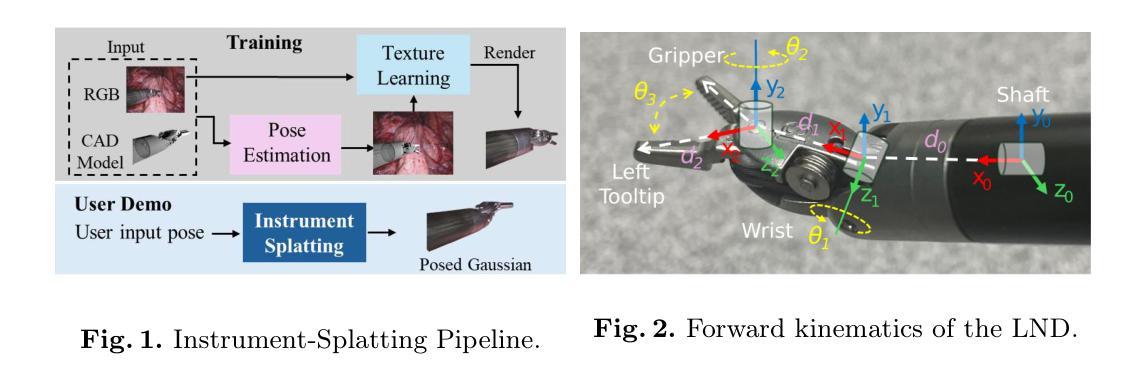
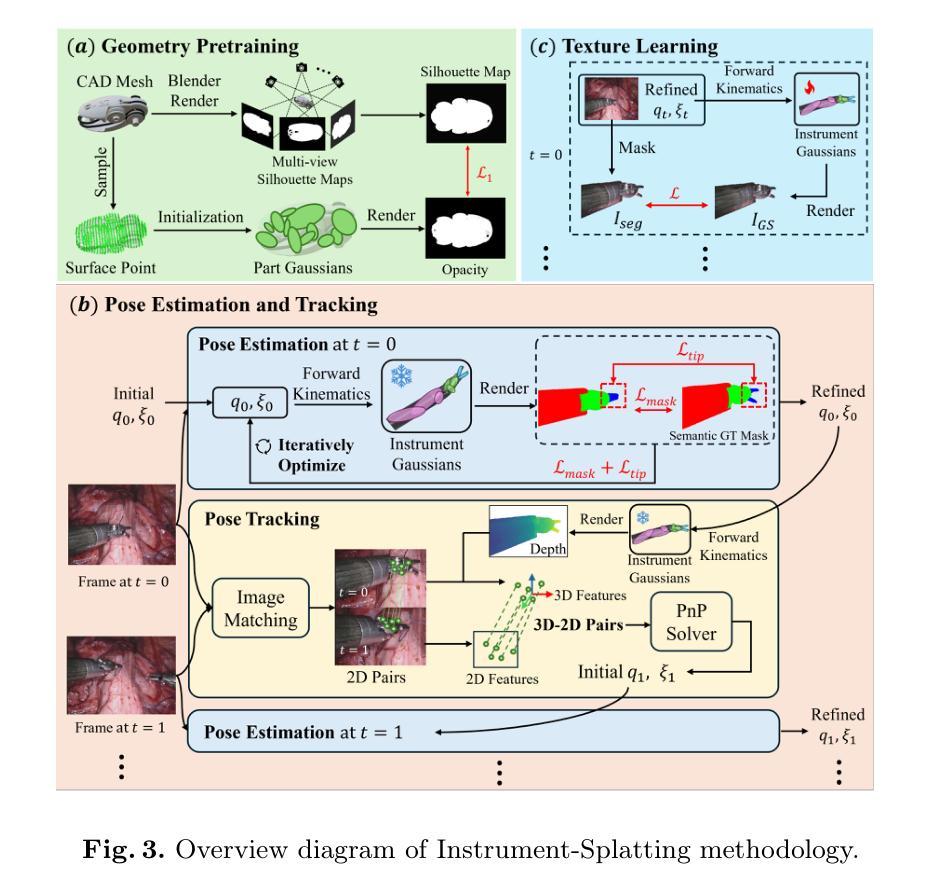
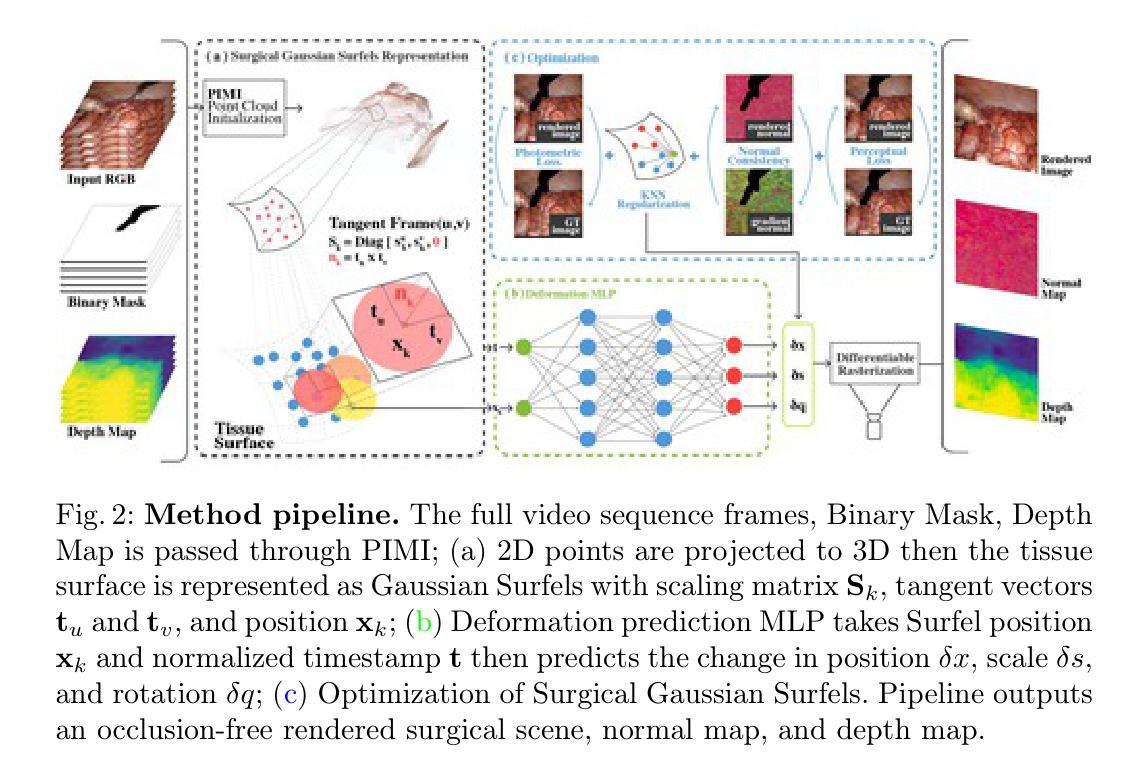
Surgical Gaussian Surfels: Highly Accurate Real-time Surgical Scene Rendering
Authors:Idris O. Sunmola, Zhenjun Zhao, Samuel Schmidgall, Yumeng Wang, Paul Maria Scheikl, Axel Krieger
Accurate geometric reconstruction of deformable tissues in monocular endoscopic video remains a fundamental challenge in robot-assisted minimally invasive surgery. Although recent volumetric and point primitive methods based on neural radiance fields (NeRF) and 3D Gaussian primitives have efficiently rendered surgical scenes, they still struggle with handling artifact-free tool occlusions and preserving fine anatomical details. These limitations stem from unrestricted Gaussian scaling and insufficient surface alignment constraints during reconstruction. To address these issues, we introduce Surgical Gaussian Surfels (SGS), which transforms anisotropic point primitives into surface-aligned elliptical splats by constraining the scale component of the Gaussian covariance matrix along the view-aligned axis. We predict accurate surfel motion fields using a lightweight Multi-Layer Perceptron (MLP) coupled with locality constraints to handle complex tissue deformations. We use homodirectional view-space positional gradients to capture fine image details by splitting Gaussian Surfels in over-reconstructed regions. In addition, we define surface normals as the direction of the steepest density change within each Gaussian surfel primitive, enabling accurate normal estimation without requiring monocular normal priors. We evaluate our method on two in-vivo surgical datasets, where it outperforms current state-of-the-art methods in surface geometry, normal map quality, and rendering efficiency, while remaining competitive in real-time rendering performance. We make our code available at https://github.com/aloma85/SurgicalGaussianSurfels
在单目内窥镜视频中,可变形组织的精确几何重建仍然是机器人辅助微创手术中的一项基本挑战。尽管最近基于神经辐射场(NeRF)和三维高斯原始点的体积和点方法已经有效地呈现了手术场景,但它们仍然在处理无工具遮挡和保留精细解剖细节方面存在困难。这些局限性源于高斯缩放的无限制性和重建过程中表面对齐约束的不足。为了解决这些问题,我们引入了手术高斯表面元素(Surgical Gaussian Surfels,SGS),通过将高斯协方差矩阵的尺度成分沿视图对齐轴进行约束,将各向异性点原始元素转换为与表面对齐的椭圆片。我们使用轻量级的多层感知器(MLP)结合局部约束来预测准确的表面运动场,以处理复杂的组织变形。我们使用同方向视图空间位置梯度来捕捉精细图像细节,通过在高重建区域分割高斯表面元素来实现。此外,我们将表面法线定义为每个高斯表面元素内密度变化最陡峭的方向,无需单眼法线先验即可实现准确的法线估计。我们在两个体内手术数据集上评估了我们的方法,在表面几何、法线图质量和渲染效率方面优于当前最先进的方法,同时在实时渲染性能上保持竞争力。我们的代码可在https://github.com/aloma85/SurgicalGaussianSurfels找到。
论文及项目相关链接
Summary
本文介绍了在机器人辅助微创手术中,针对单目内窥镜视频的可变形组织的精确几何重建仍然是一个基本挑战。文章提出了一种新的方法——Surgical Gaussian Surfels(SGS),通过约束高斯协方差矩阵的尺度成分和视图对齐轴,将各向异性点原始转换为表面对齐的椭圆片。使用局部约束的轻量级多层感知器(MLP)预测准确的表面运动场,处理复杂的组织变形。通过分割高斯曲面在过度重建区域捕捉图像细节,并定义表面法线为每个高斯曲面体素内密度变化最陡峭的方向,实现准确的无单目法线先验的正常估计。在两个体内手术数据集上的评估表明,该方法在表面几何、正常映射质量和渲染效率方面优于当前最先进的方法,同时在实时渲染性能方面保持竞争力。
Key Takeaways
- 单目内窥镜视频下的可变形组织几何重建是机器人辅助微创手术中的核心挑战。
- 现有方法如基于神经辐射场和3D高斯原始的方法虽能渲染手术场景,但在处理工具遮挡和保留精细解剖细节方面存在局限性。
- Surgical Gaussian Surfels (SGS)方法通过将各向异性点原始转换为表面对齐的椭圆片来解决这些问题。
- 通过约束高斯协方差矩阵的尺度成分和视图对齐轴实现转换。
- 使用轻量级多层感知器(MLP)结合局部约束预测准确的表面运动场来应对复杂组织变形。
- 利用高斯曲面在过度重建区域进行分裂来捕捉图像细节,并提供准确的无单目法线先验的正常估计。
点此查看论文截图

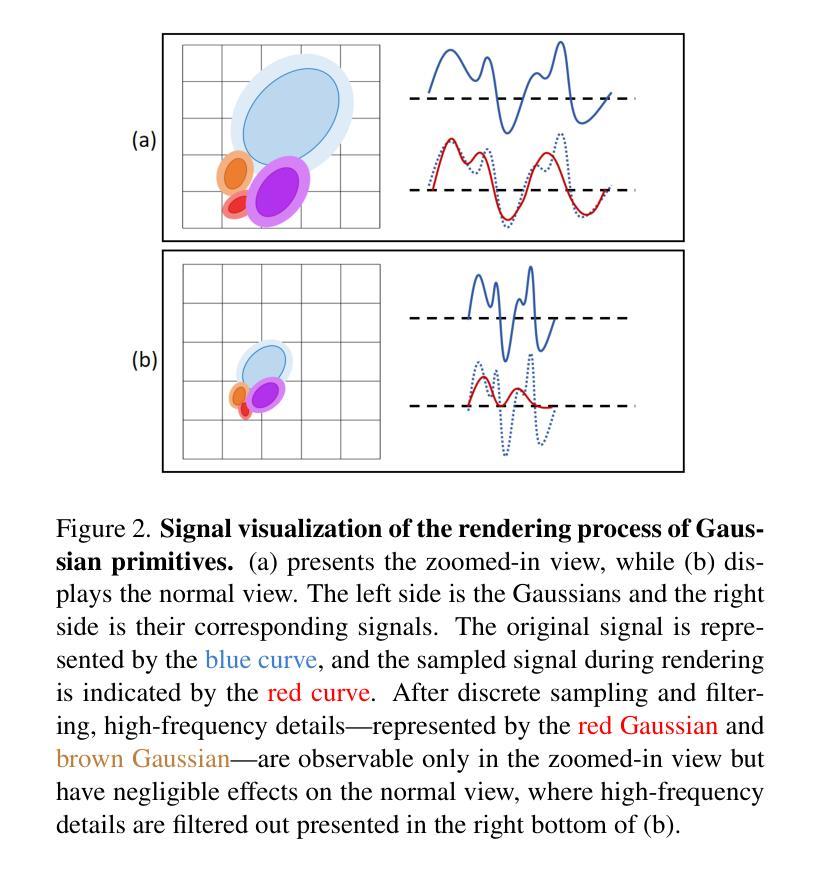
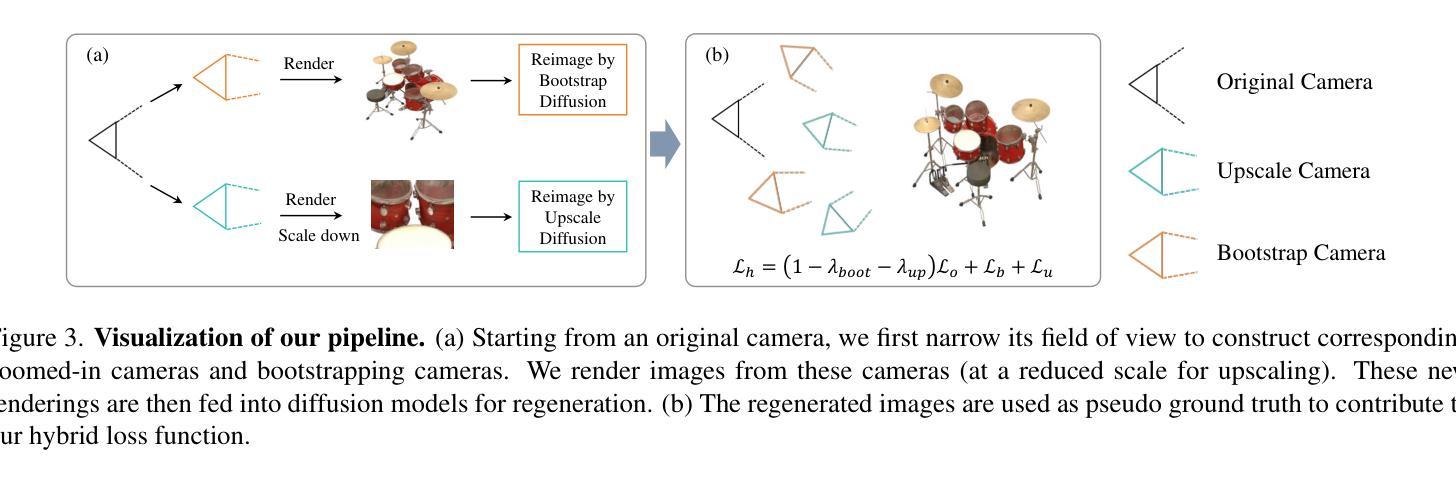
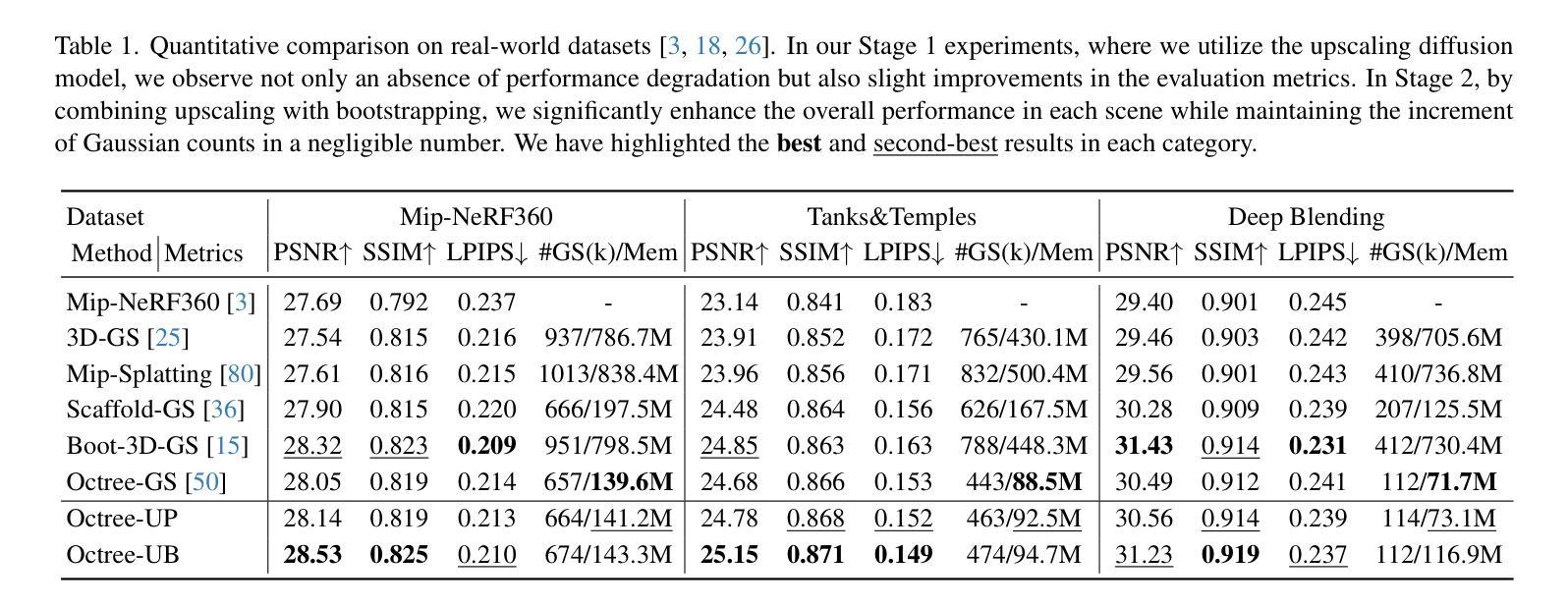
Beyond Existance: Fulfill 3D Reconstructed Scenes with Pseudo Details
Authors:Yifei Gao, Jun Huang, Lei Wang, Ruiting Dai, Jun Cheng
The emergence of 3D Gaussian Splatting (3D-GS) has significantly advanced 3D reconstruction by providing high fidelity and fast training speeds across various scenarios. While recent efforts have mainly focused on improving model structures to compress data volume or reduce artifacts during zoom-in and zoom-out operations, they often overlook an underlying issue: training sampling deficiency. In zoomed-in views, Gaussian primitives can appear unregulated and distorted due to their dilation limitations and the insufficient availability of scale-specific training samples. Consequently, incorporating pseudo-details that ensure the completeness and alignment of the scene becomes essential. In this paper, we introduce a new training method that integrates diffusion models and multi-scale training using pseudo-ground-truth data. This approach not only notably mitigates the dilation and zoomed-in artifacts but also enriches reconstructed scenes with precise details out of existing scenarios. Our method achieves state-of-the-art performance across various benchmarks and extends the capabilities of 3D reconstruction beyond training datasets.
3D高斯拼贴(3D-GS)的出现极大地推动了3D重建的发展,为各种场景提供了高保真和快速的训练速度。虽然近期的研究主要集中在改进模型结构以压缩数据量或减少放大和缩小操作时的伪影,但它们往往忽视了一个基本问题:训练采样不足。在放大视图中,由于膨胀限制和特定尺度训练样本的不足,高斯基元可能会出现无序和失真。因此,融入伪细节以确保场景的完整性和对齐性变得至关重要。在本文中,我们引入了一种新的训练方法,该方法结合了扩散模型和伪真实数据的多尺度训练。这种方法不仅显著减轻了膨胀和放大伪影,而且利用现有场景丰富了重建场景的精确细节。我们的方法在多个基准测试中实现了卓越的性能,并扩展了3D重建的能力,超越了训练数据集。
论文及项目相关链接
摘要
三维高斯映射(3DGS)的兴起为三维重建提供了高度保真和快速训练速度的优势。虽然近期的研究主要集中在改进模型结构以压缩数据量或减少放大缩小操作时的伪影,但它们往往忽略了底层问题:训练采样不足。在放大视图中,由于高斯原始体的膨胀限制和特定尺度训练样本的缺乏,高斯原始体可能会出现不规则和失真。因此,融入伪细节以确保场景的完整性和对齐性变得至关重要。本文介绍了一种新的训练方法,该方法结合了扩散模型和基于伪地面真实数据的多尺度训练。这种方法不仅显著减轻了膨胀和放大伪影问题,而且为重建的场景增添了精确细节。我们的方法在多个基准测试中实现了最先进的性能,并扩展了三维重建的能力,超越了训练数据集的限制。
要点掌握
- 3DGS的出现促进了三维重建的发展,提供了高度保真和快速训练的优势。
- 近期研究主要集中在改进模型结构,但往往忽略了训练采样不足的问题。
- 在放大视图中,高斯原始体可能出现不规则和失真。
- 融入伪细节对于确保场景的完整性和对齐性至关重要。
- 新的训练方法结合了扩散模型和基于伪地面真实数据的多尺度训练。
- 该方法显著减轻了膨胀和放大伪影问题。
点此查看论文截图


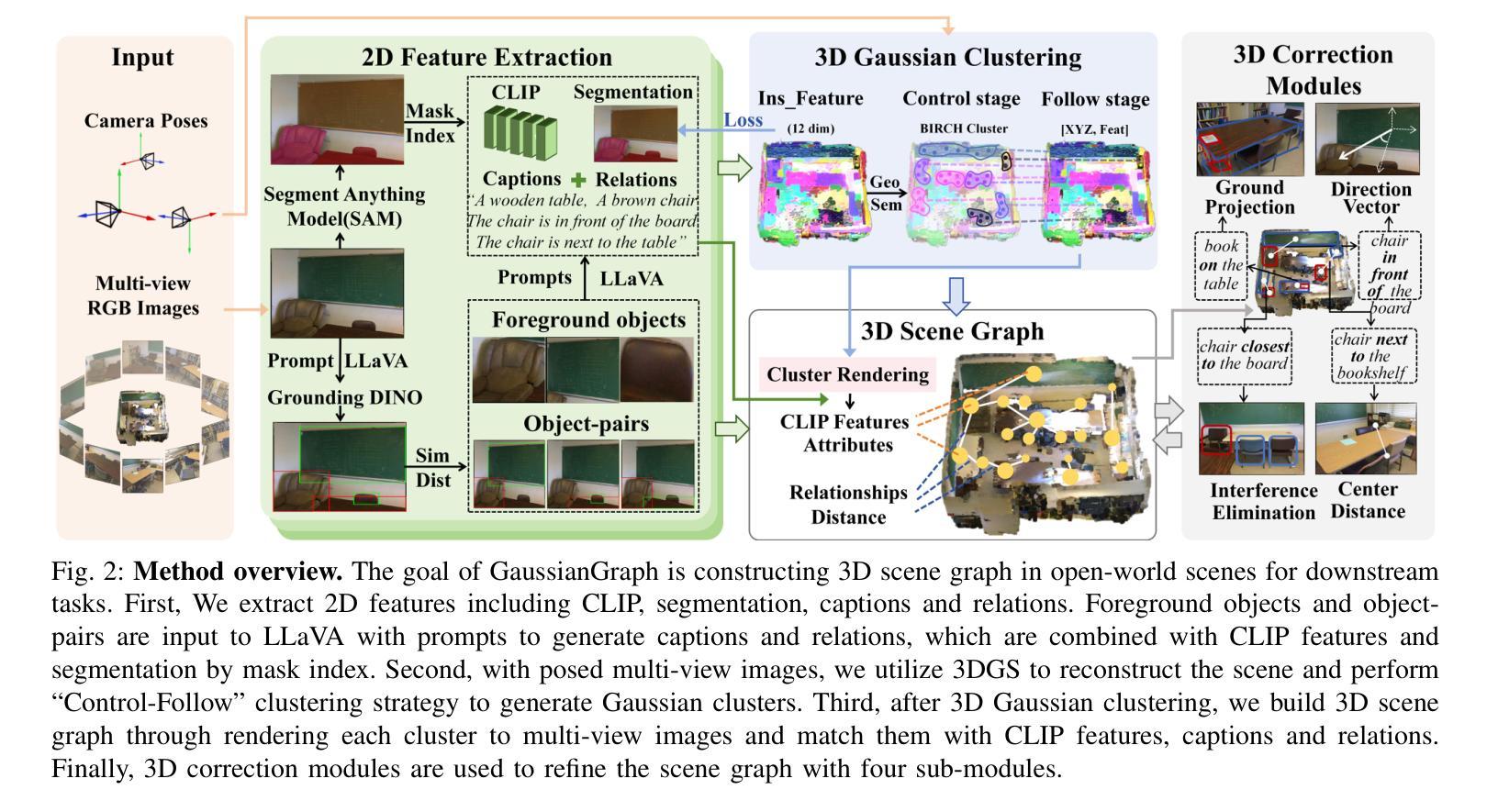
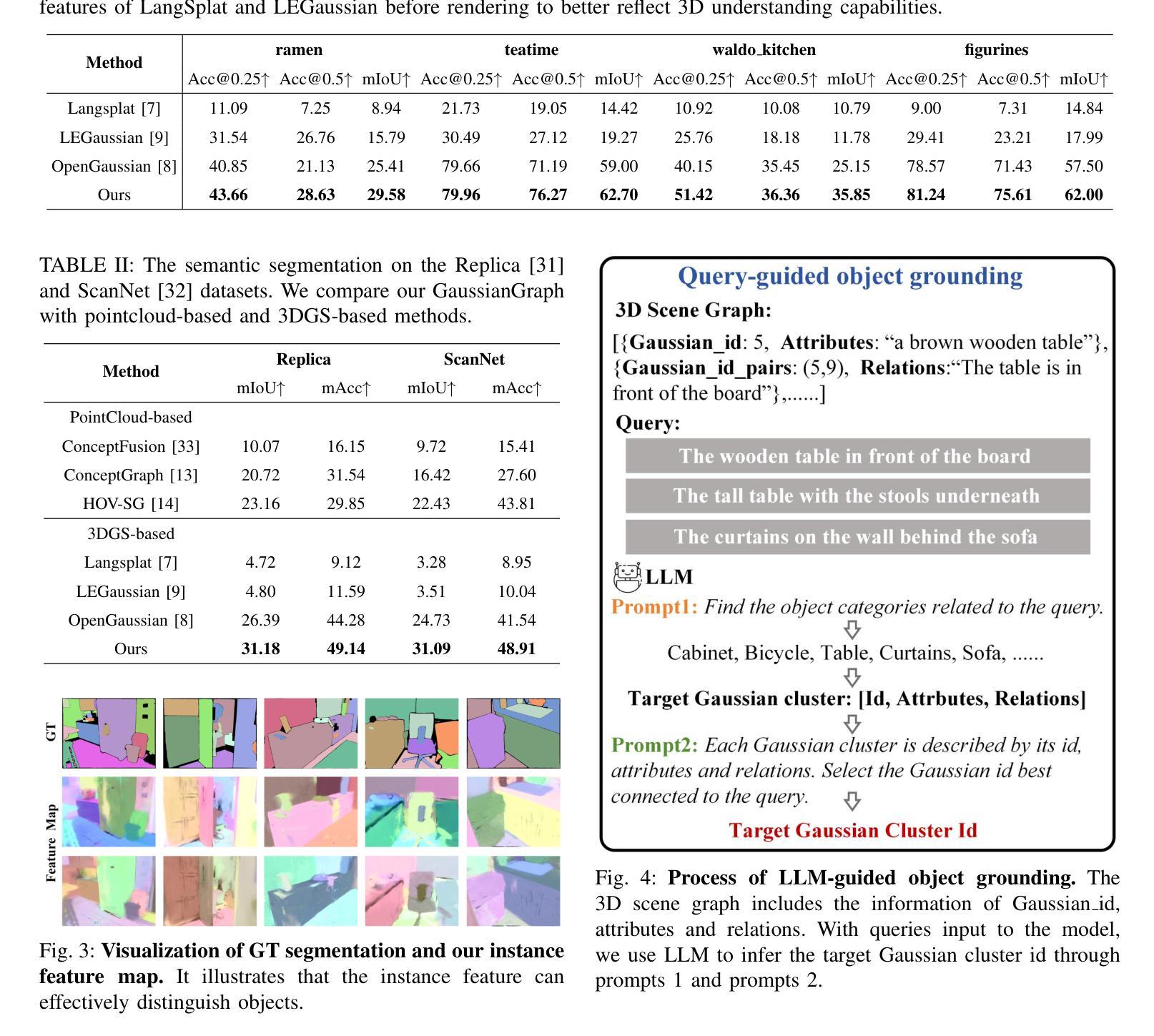
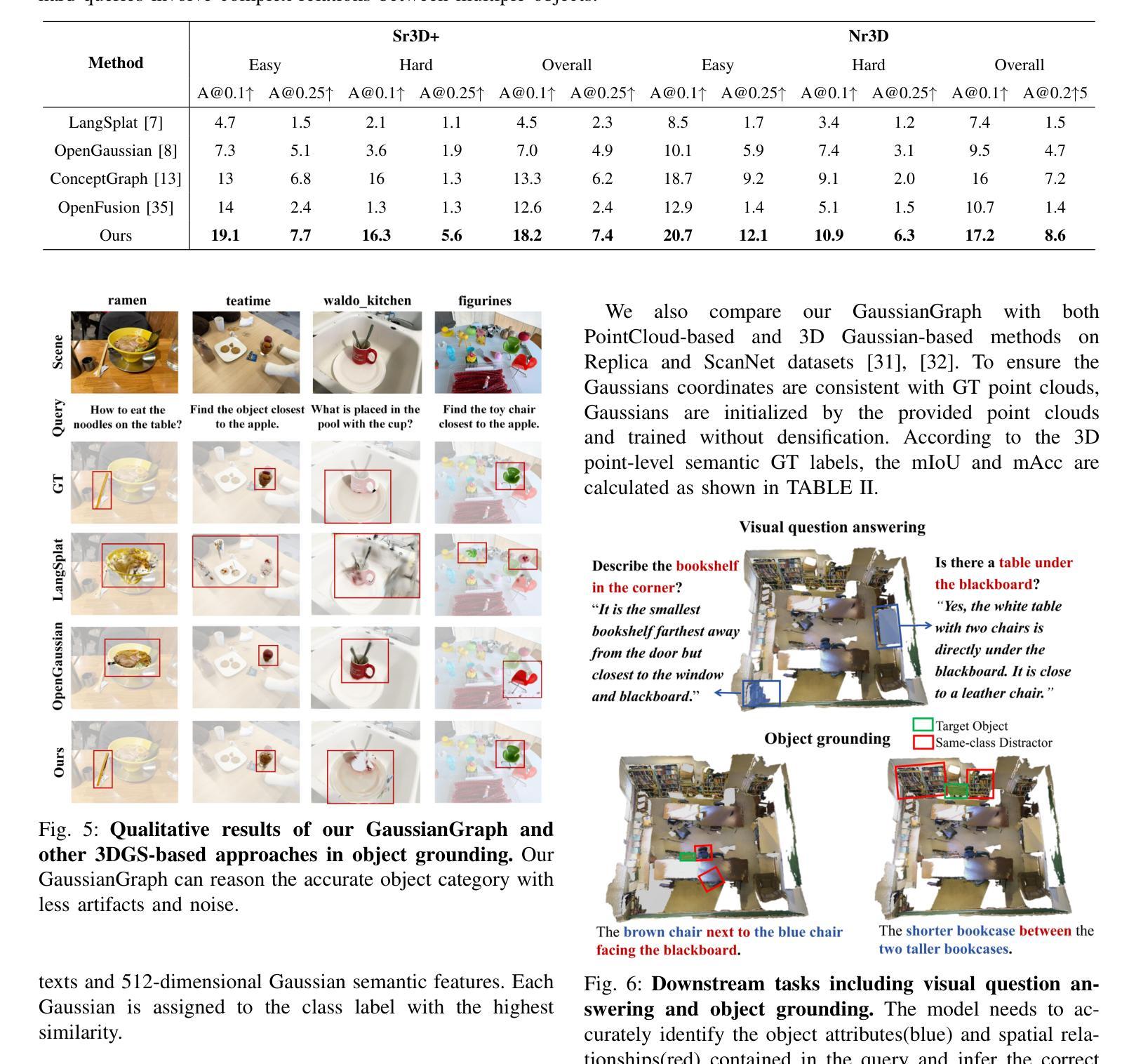
GaussianGraph: 3D Gaussian-based Scene Graph Generation for Open-world Scene Understanding
Authors:Xihan Wang, Dianyi Yang, Yu Gao, Yufeng Yue, Yi Yang, Mengyin Fu
Recent advancements in 3D Gaussian Splatting(3DGS) have significantly improved semantic scene understanding, enabling natural language queries to localize objects within a scene. However, existing methods primarily focus on embedding compressed CLIP features to 3D Gaussians, suffering from low object segmentation accuracy and lack spatial reasoning capabilities. To address these limitations, we propose GaussianGraph, a novel framework that enhances 3DGS-based scene understanding by integrating adaptive semantic clustering and scene graph generation. We introduce a “Control-Follow” clustering strategy, which dynamically adapts to scene scale and feature distribution, avoiding feature compression and significantly improving segmentation accuracy. Additionally, we enrich scene representation by integrating object attributes and spatial relations extracted from 2D foundation models. To address inaccuracies in spatial relationships, we propose 3D correction modules that filter implausible relations through spatial consistency verification, ensuring reliable scene graph construction. Extensive experiments on three datasets demonstrate that GaussianGraph outperforms state-of-the-art methods in both semantic segmentation and object grounding tasks, providing a robust solution for complex scene understanding and interaction.
近期3D高斯映射技术(3DGS)的进步极大地提高了对场景语义的理解,使得可以通过自然语言查询来定位场景中的物体。然而,现有方法主要集中在将压缩的CLIP特征嵌入到3D高斯中,存在物体分割精度低和缺乏空间推理能力的问题。为了解决这些局限性,我们提出了GaussianGraph这一新型框架,它通过融合自适应语义聚类和场景图生成,增强了基于3DGS的场景理解。我们引入了一种“Control-Follow”聚类策略,该策略能动态适应场景规模和特征分布,避免了特征压缩,并显著提高了分割精度。此外,我们通过整合从二维基础模型中提取的对象属性和空间关系,丰富了场景表示。为了解决空间关系中的不准确问题,我们提出了3D校正模块,通过空间一致性验证来过滤不可能的关系,确保可靠地构建场景图。在三个数据集上的大量实验表明,GaussianGraph在语义分割和对象定位任务上均优于最新方法,为复杂场景的理解和交互提供了稳健的解决方案。
论文及项目相关链接
Summary
3DGS领域的新进展通过引入GaussianGraph框架,提升了语义场景理解。该框架结合自适应语义聚类和场景图生成,通过动态适应场景规模和特征分布的“Control-Follow”聚类策略,改善了对象分割准确度和空间推理能力。此外,它集成了对象属性和从二维基础模型中提取的空间关系,以过滤不可能的、确保可靠的场景图构建和空间一致性验证。在多个数据集上的实验证明GaussianGraph在语义分割和对象定位任务上的性能超越了现有技术。
Key Takeaways
- 3DGS的近期进展已提高了语义场景理解的能力,允许通过自然语言查询定位场景中的物体。
- 当前方法主要使用压缩的CLIP特征嵌入到三维高斯中,存在对象分割准确度低和空间推理能力缺失的问题。
- GaussianGraph框架通过结合自适应语义聚类和场景图生成,增强了基于3DGS的场景理解。
- 引入的“Control-Follow”聚类策略可动态适应场景规模和特征分布,避免特征压缩并提高分割准确度。
- 通过集成对象属性和从二维基础模型中提取的空间关系,丰富了场景表示。
- 为解决空间关系的不准确问题,提出了3D修正模块,通过空间一致性验证过滤不可能的关系。
点此查看论文截图

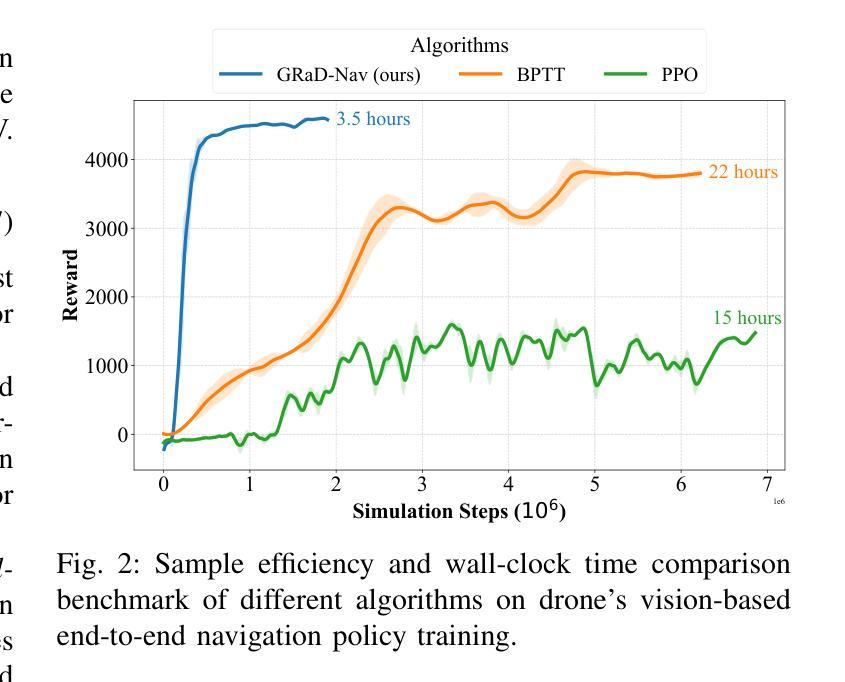
GRaD-Nav: Efficiently Learning Visual Drone Navigation with Gaussian Radiance Fields and Differentiable Dynamics
Authors:Qianzhong Chen, Jiankai Sun, Naixiang Gao, JunEn Low, Timothy Chen, Mac Schwager
Autonomous visual navigation is an essential element in robot autonomy. Reinforcement learning (RL) offers a promising policy training paradigm. However existing RL methods suffer from high sample complexity, poor sim-to-real transfer, and limited runtime adaptability to navigation scenarios not seen during training. These problems are particularly challenging for drones, with complex nonlinear and unstable dynamics, and strong dynamic coupling between control and perception. In this paper, we propose a novel framework that integrates 3D Gaussian Splatting (3DGS) with differentiable deep reinforcement learning (DDRL) to train vision-based drone navigation policies. By leveraging high-fidelity 3D scene representations and differentiable simulation, our method improves sample efficiency and sim-to-real transfer. Additionally, we incorporate a Context-aided Estimator Network (CENet) to adapt to environmental variations at runtime. Moreover, by curriculum training in a mixture of different surrounding environments, we achieve in-task generalization, the ability to solve new instances of a task not seen during training. Drone hardware experiments demonstrate our method’s high training efficiency compared to state-of-the-art RL methods, zero shot sim-to-real transfer for real robot deployment without fine tuning, and ability to adapt to new instances within the same task class (e.g. to fly through a gate at different locations with different distractors in the environment).
自主视觉导航是机器人自主性的关键要素。强化学习(RL)提供了一个有前景的策略训练范式。然而,现有的RL方法存在样本复杂性高、模拟到真实的转移性能差以及在训练期间未见到的导航场景中的运行时适应性有限等问题。对于具有复杂非线性和不稳定动力学以及控制和感知之间强烈动态耦合的无人机来说,这些问题更具挑战性。在本文中,我们提出了一种新颖框架,该框架将三维高斯融合(3DGS)与可微深度强化学习(DDRL)相结合,以训练基于视觉的无人机导航策略。通过利用高保真三维场景表示和可微分模拟,我们的方法提高了样本效率和模拟到真实的转移能力。此外,我们结合了上下文辅助估计网络(CENet)以适应运行时的环境变化。而且,通过在不同周围环境的混合中进行课程训练,我们实现了任务内泛化,即解决在训练期间未见到的任务新实例的能力。无人机硬件实验表明,与最新的RL方法相比,我们的方法具有高度的训练效率、零射击模拟到真实转移的能力(用于真实机器人部署而无需微调),以及适应同一任务类别中新实例的能力(例如,在不同的位置飞过带有不同干扰物的门)。
论文及项目相关链接
Summary
基于强化学习的自主视觉导航是机器人自主性的重要环节。然而,现有方法存在样本复杂性高、模拟到现实的转移性差以及训练时对环境变化的适应性有限等问题。本文提出了一种结合三维高斯融合(3DGS)和可微深度强化学习(DDRL)的新框架,用于训练基于视觉的无人机导航策略。该框架利用高精度三维场景表示和可微分模拟,提高了样本效率和模拟到现实的转移能力。此外,还结合了环境辅助估计网络(CENet),以适应环境中的实时变化。通过在不同环境混合的课程训练,实现了任务内泛化能力,即解决未见过的任务新实例的能力。无人机硬件实验表明,该方法相较于最新强化学习方法具有更高的训练效率、零适应模拟到现实转移能力以及适应新任务实例的能力。
Key Takeaways
- 自主视觉导航是机器人技术中的关键环节,强化学习在该领域具有广阔应用前景。
- 现有强化学习方法存在样本复杂性高、模拟到现实的转移性差等问题。
- 本文提出结合3DGS和DDRL的新框架,提高了样本效率和模拟到现实的转移能力。
- 引入了环境辅助估计网络(CENet),增强了无人机对环境中实时变化的适应性。
- 通过课程训练,实现了任务内泛化能力,即解决未见过的任务新实例的能力。
- 无人机硬件实验验证了该方法相较于其他方法的高效性、适应性和零适应模拟到现实的能力。
点此查看论文截图



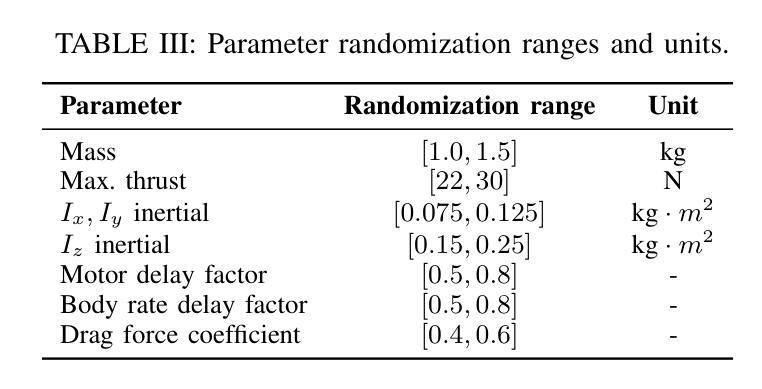
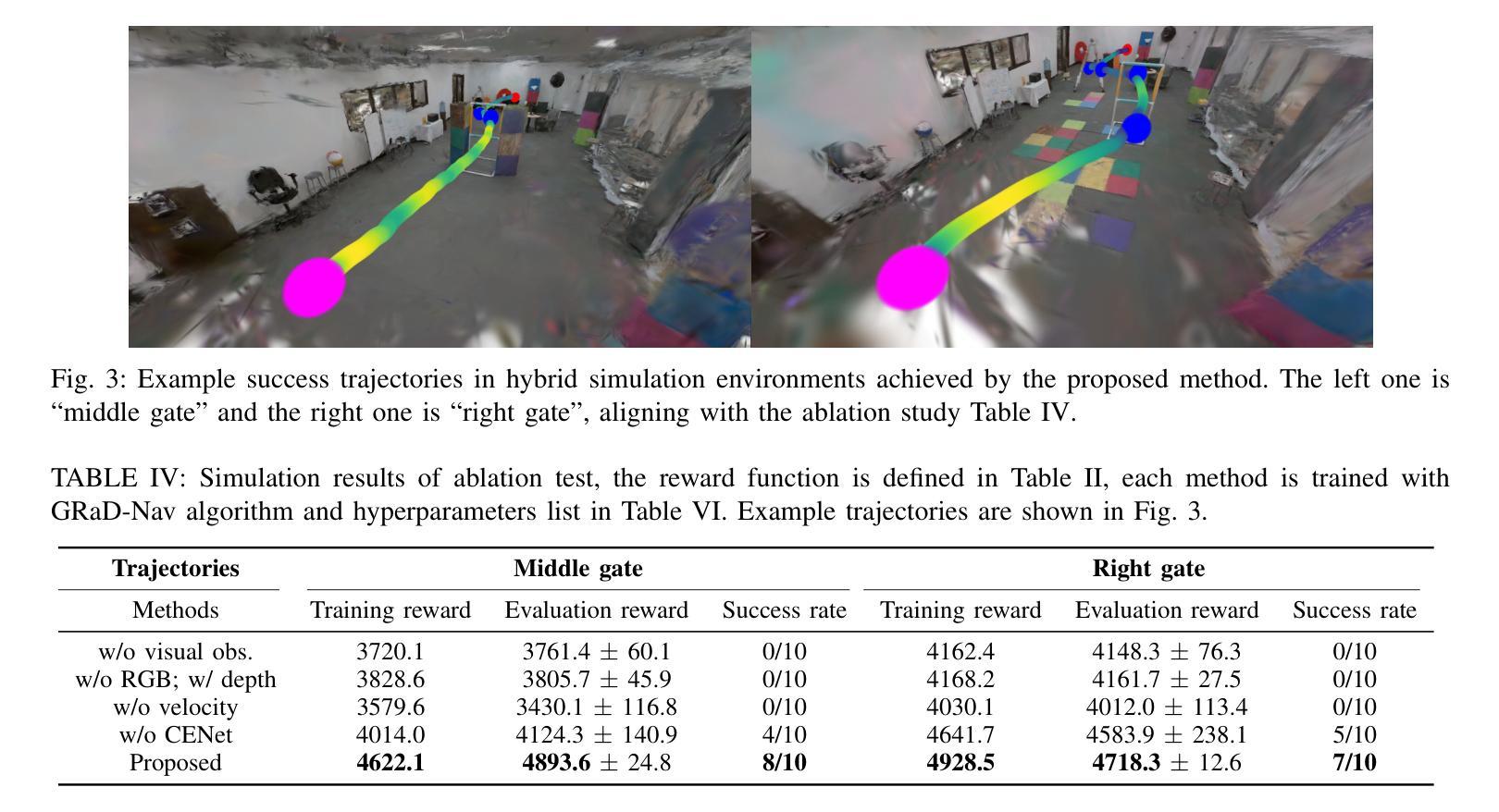
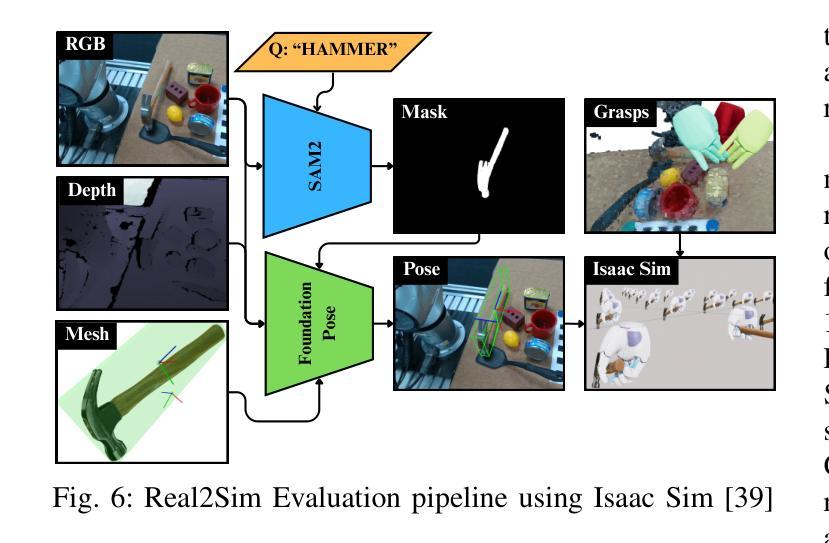
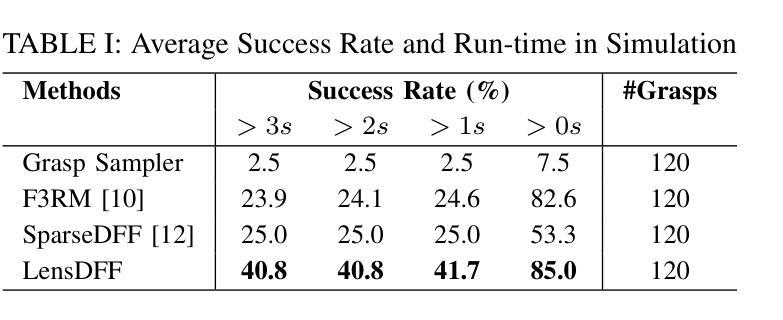
LensDFF: Language-enhanced Sparse Feature Distillation for Efficient Few-Shot Dexterous Manipulation
Authors:Qian Feng, David S. Martinez Lema, Jianxiang Feng, Zhaopeng Chen, Alois Knoll
Learning dexterous manipulation from few-shot demonstrations is a significant yet challenging problem for advanced, human-like robotic systems. Dense distilled feature fields have addressed this challenge by distilling rich semantic features from 2D visual foundation models into the 3D domain. However, their reliance on neural rendering models such as Neural Radiance Fields (NeRF) or Gaussian Splatting results in high computational costs. In contrast, previous approaches based on sparse feature fields either suffer from inefficiencies due to multi-view dependencies and extensive training or lack sufficient grasp dexterity. To overcome these limitations, we propose Language-ENhanced Sparse Distilled Feature Field (LensDFF), which efficiently distills view-consistent 2D features onto 3D points using our novel language-enhanced feature fusion strategy, thereby enabling single-view few-shot generalization. Based on LensDFF, we further introduce a few-shot dexterous manipulation framework that integrates grasp primitives into the demonstrations to generate stable and highly dexterous grasps. Moreover, we present a real2sim grasp evaluation pipeline for efficient grasp assessment and hyperparameter tuning. Through extensive simulation experiments based on the real2sim pipeline and real-world experiments, our approach achieves competitive grasping performance, outperforming state-of-the-art approaches.
从少数演示中学习灵巧操作对于先进的人形机器人系统来说是一个重大且具有挑战性的课题。密集蒸馏特征场通过将二维视觉基础模型的丰富语义特征蒸馏到三维领域来解决这一挑战。然而,它们依赖于神经渲染模型,如神经辐射场(NeRF)或高斯拼贴,导致计算成本高昂。相比之下,基于稀疏特征场的早期方法要么因多视图依赖和大量训练而导致效率低下,要么缺乏足够的抓握灵巧性。为了克服这些局限性,我们提出了语言增强稀疏蒸馏特征场(LensDFF),它通过我们新颖的语言增强特征融合策略,有效地将视图一致的二维特征蒸馏到三维点上,从而实现单视图少数演示的泛化。基于LensDFF,我们进一步引入了一种少数演示灵巧操作框架,该框架将抓握原始动作集成到演示中,以产生稳定和高度灵巧的抓握动作。此外,我们为高效抓握评估和超参数调整,提出了一种real2sim抓握评估管道。通过基于real2sim管道的大规模仿真实验和真实世界实验,我们的方法达到了有竞争力的抓握性能,超越了现有最新方法。
论文及项目相关链接
PDF 8 pages
Summary
这篇文本介绍了学习少数演示的灵巧操作对于高级人形机器人系统的重要意义及其所面临的挑战。文章提出一种基于语言增强的稀疏蒸馏特征场(LensDFF)的方法,通过新颖的语言增强特征融合策略,有效地将二维特征蒸馏到三维点上,实现了单视角的少数演示泛化。基于LensDFF,文章进一步引入了一种少数演示灵巧操作框架,该框架将抓取原始知识融入演示中,生成稳定且高度灵巧的抓取动作。此外,文章还提出了一种用于高效抓取评估和超参数调整的实到模拟抓取评估管道。通过基于实到模拟管道和真实世界实验的仿真实验,该方法在抓取性能上具有竞争力,超越了现有技术。
Key Takeaways
以下是七个关于该文本的关键见解:
- 学习少数演示的灵巧操作对高级人形机器人系统是重要且具有挑战性的课题。
- Dense distilled feature fields已成功通过蒸馏二维视觉基础模型的丰富语义特征到三维领域来解决此挑战。然而,它对神经渲染模型的依赖导致了高计算成本。
- 之前的稀疏特征场方法存在多视角依赖和广泛训练的低效问题或缺乏足够的抓取灵巧性。
- LensDFF(语言增强稀疏蒸馏特征场)方法通过新颖的语言增强特征融合策略解决了上述问题,实现了单视角的少数演示泛化。
- 基于LensDFF,引入了一种少数演示灵巧操作框架,该框架集成了抓取原始知识以生成稳定和高度灵巧的抓取动作。
- 提出了一种实到模拟的抓取评估管道,用于高效的抓取评估和超参数调整。
点此查看论文截图


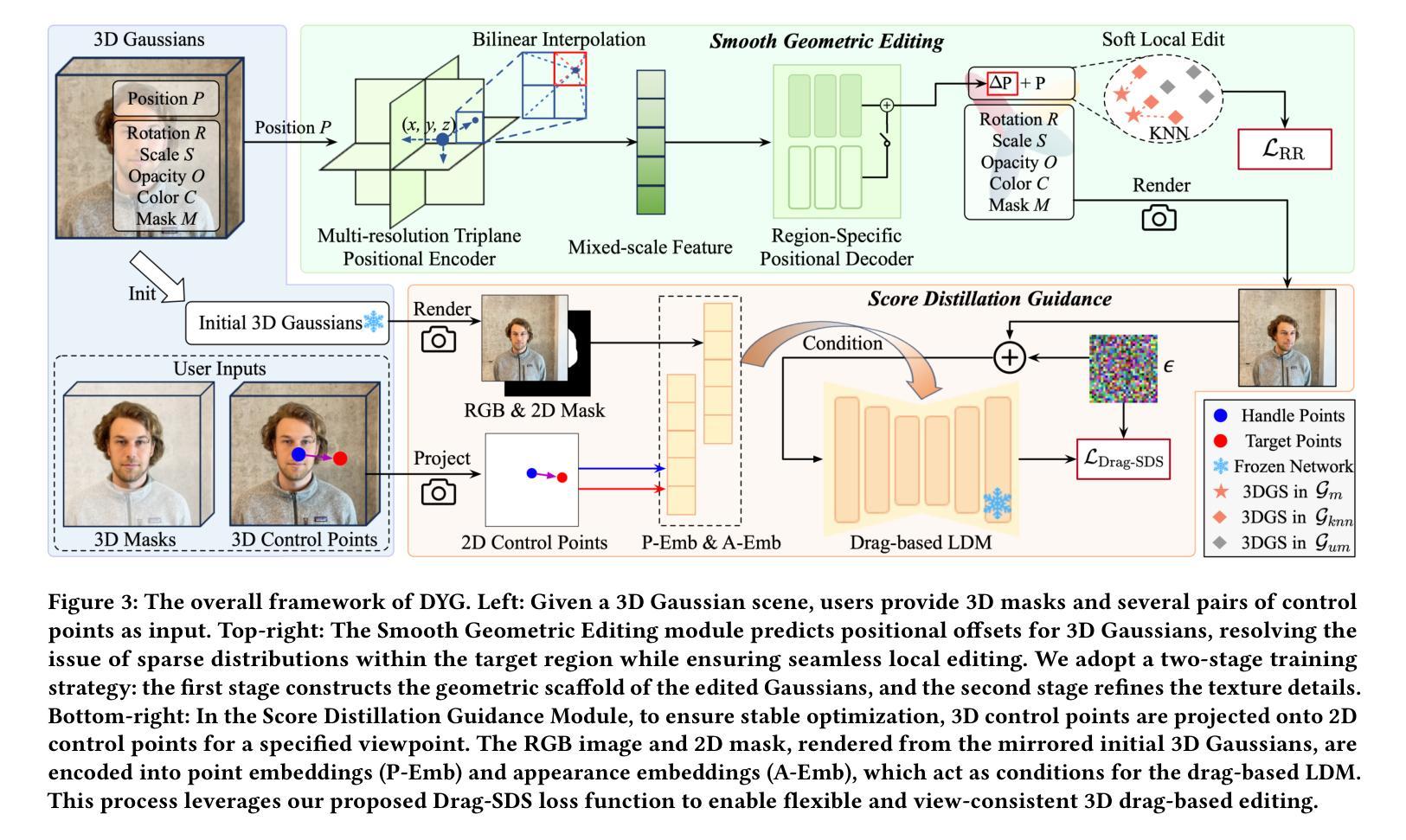
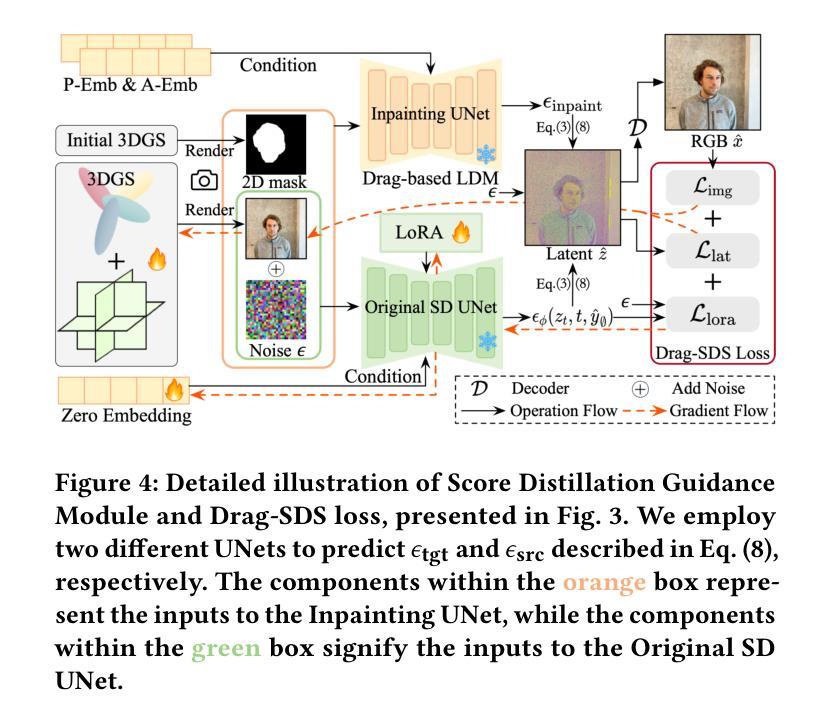
Drag Your Gaussian: Effective Drag-Based Editing with Score Distillation for 3D Gaussian Splatting
Authors:Yansong Qu, Dian Chen, Xinyang Li, Xiaofan Li, Shengchuan Zhang, Liujuan Cao, Rongrong Ji
Recent advancements in 3D scene editing have been propelled by the rapid development of generative models. Existing methods typically utilize generative models to perform text-guided editing on 3D representations, such as 3D Gaussian Splatting (3DGS). However, these methods are often limited to texture modifications and fail when addressing geometric changes, such as editing a character’s head to turn around. Moreover, such methods lack accurate control over the spatial position of editing results, as language struggles to precisely describe the extent of edits. To overcome these limitations, we introduce DYG, an effective 3D drag-based editing method for 3D Gaussian Splatting. It enables users to conveniently specify the desired editing region and the desired dragging direction through the input of 3D masks and pairs of control points, thereby enabling precise control over the extent of editing. DYG integrates the strengths of the implicit triplane representation to establish the geometric scaffold of the editing results, effectively overcoming suboptimal editing outcomes caused by the sparsity of 3DGS in the desired editing regions. Additionally, we incorporate a drag-based Latent Diffusion Model into our method through the proposed Drag-SDS loss function, enabling flexible, multi-view consistent, and fine-grained editing. Extensive experiments demonstrate that DYG conducts effective drag-based editing guided by control point prompts, surpassing other baselines in terms of editing effect and quality, both qualitatively and quantitatively. Visit our project page at https://quyans.github.io/Drag-Your-Gaussian.
近年来,三维场景编辑的进展得益于生成模型的快速发展。现有方法通常利用生成模型对三维表示进行文本引导编辑,例如三维高斯平铺(3DGS)。然而,这些方法通常仅限于纹理修改,在应对几何变化时往往会失效,比如编辑角色头部以进行旋转。此外,这些方法在控制编辑结果的空间位置方面缺乏准确性,因为语言很难精确描述编辑的程度。为了克服这些限制,我们引入了DYG,这是一种针对三维高斯平铺的有效三维拖拽编辑方法。它使用户可以通过输入三维掩码和控制点对,方便地指定所需的编辑区域和拖拽方向,从而实现编辑程度的精确控制。DYG结合了隐式triplane表示的优势,建立编辑结果的三维骨架,有效克服了在所需编辑区域中3DGS稀疏导致的次优编辑结果。此外,我们通过提出的Drag-SDS损失函数,将基于拖拽的潜在扩散模型融入我们的方法,实现灵活、多视角一致、精细的编辑。大量实验表明,DYG通过控制点提示进行有效的拖拽编辑,在编辑效果和品质方面超越其他基线方法,定性和定量评估均如此。请访问我们的项目页面:https://quyans.github.io/Drag-Your-Gaussian了解详情。
论文及项目相关链接
PDF Visit our project page at https://quyans.github.io/Drag-Your-Gaussian
Summary
本文介绍了基于3D拖放编辑方法的进展,该方法针对3D高斯展开(3DGS)的局限性进行了改进。通过引入DYG方法,用户可以方便地指定编辑区域和拖动方向,实现精确的编辑控制。该方法结合隐式triplane表示和拖放式潜在扩散模型,实现优质、多视角一致的精细编辑。实验证明,DYG在编辑效果和品质上超越了其他基线方法。
Key Takeaways
- 3D场景编辑的进展得益于生成模型的快速发展。
- 现有方法主要利用生成模型在3D表示上进行文本引导编辑,但存在对几何变化的局限性。
- DYG方法引入拖放编辑,方便用户指定编辑区域和拖动方向。
- DYG结合隐式triplane表示建立几何骨架,提升编辑质量。
- 通过引入拖放式潜在扩散模型,DYG实现灵活、多视角一致和精细的编辑。
- 实验证明DYG在编辑效果和品质上超越其他方法。
点此查看论文截图



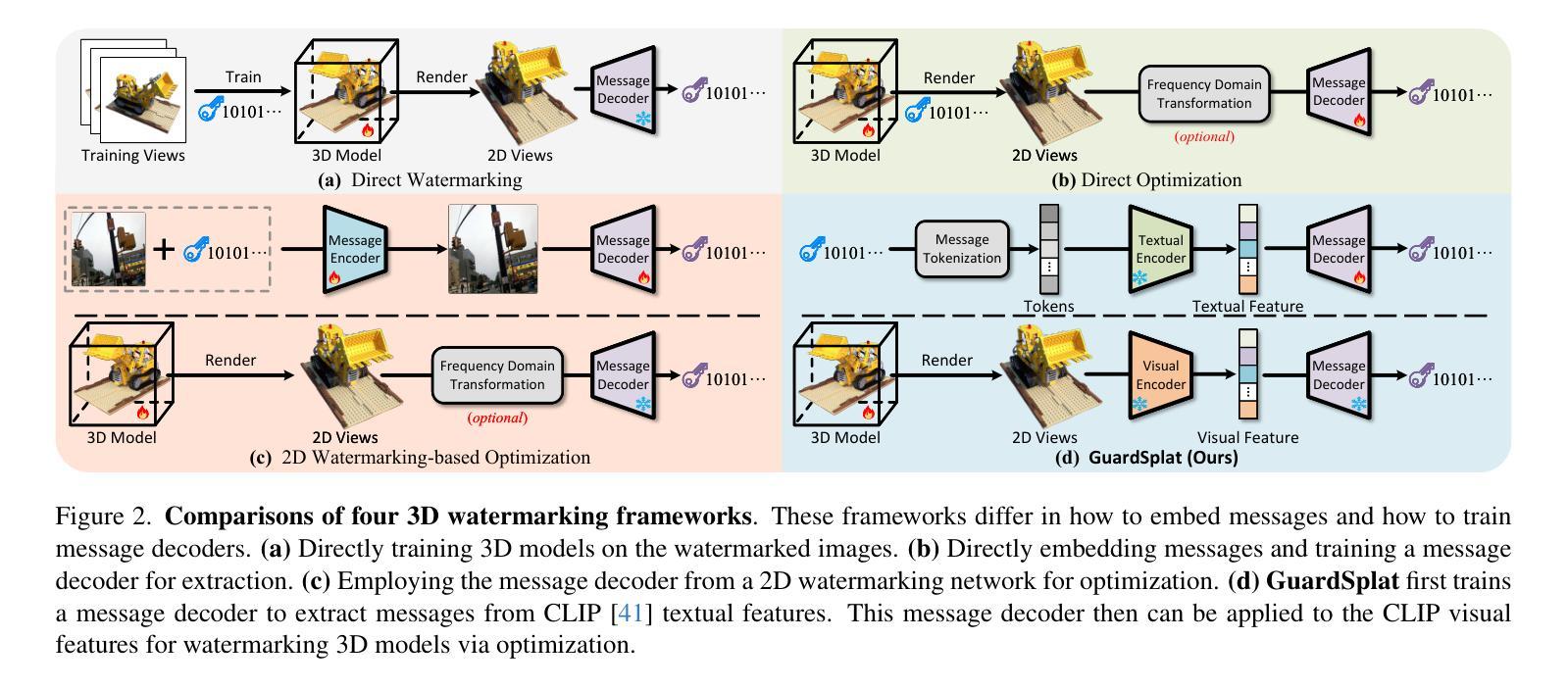
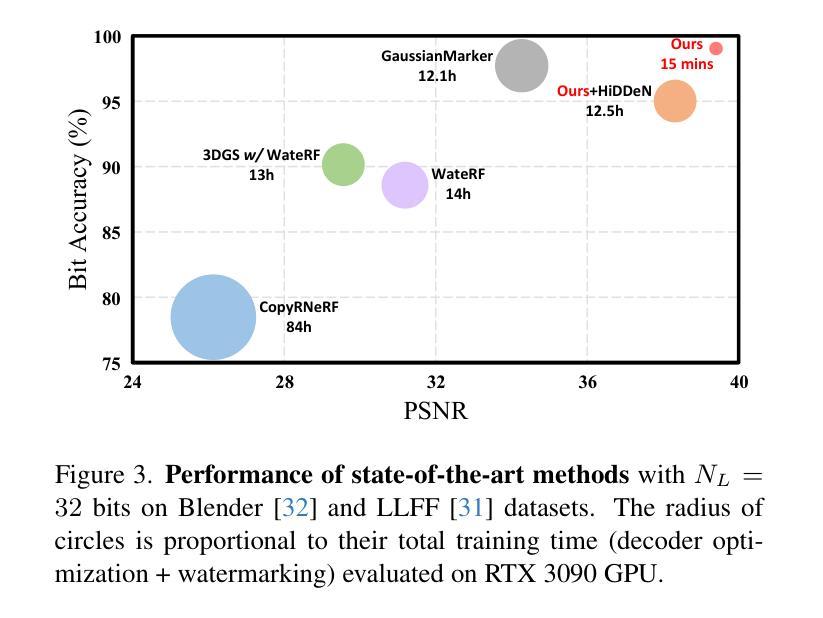
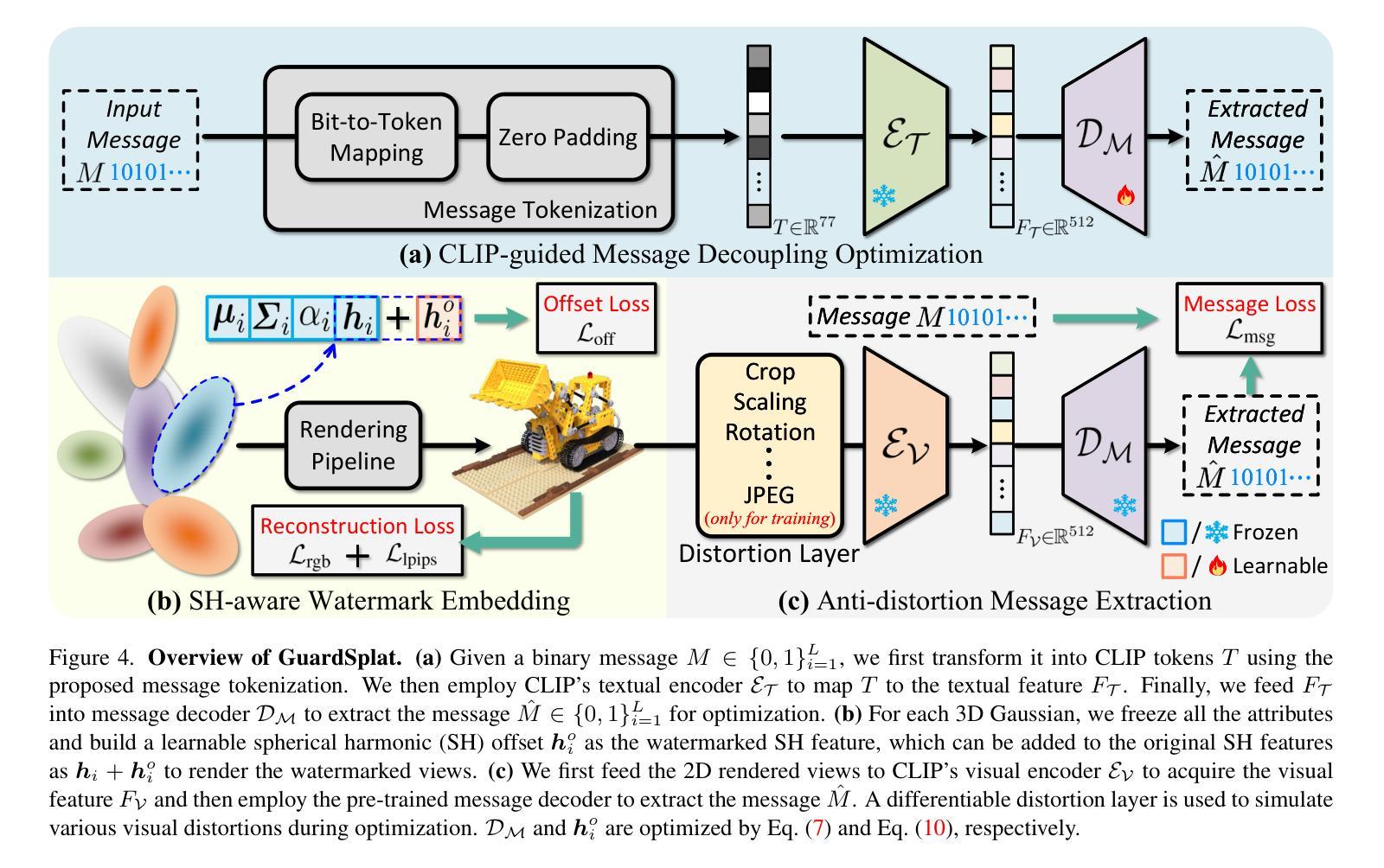
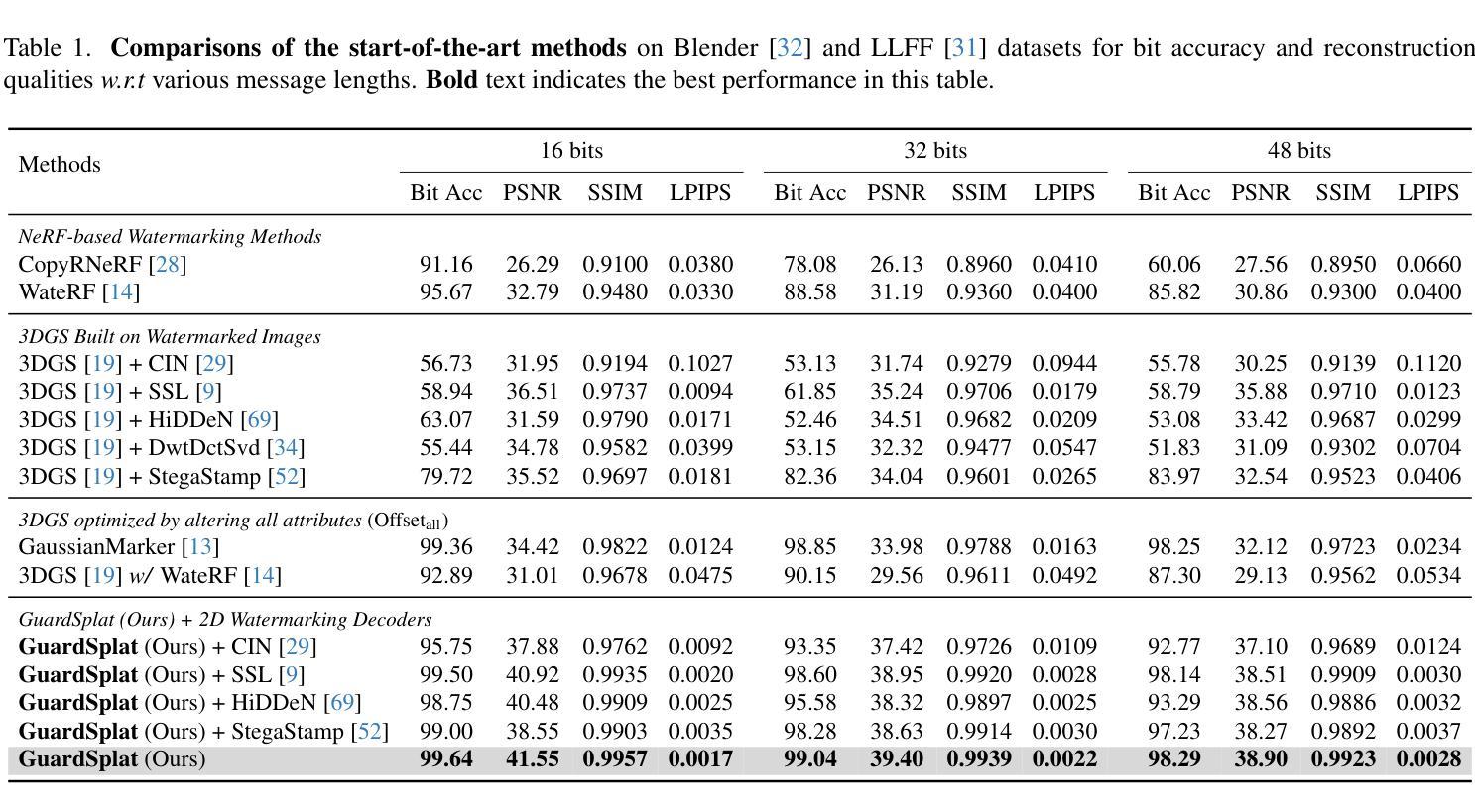
GuardSplat: Efficient and Robust Watermarking for 3D Gaussian Splatting
Authors:Zixuan Chen, Guangcong Wang, Jiahao Zhu, Jianhuang Lai, Xiaohua Xie
3D Gaussian Splatting (3DGS) has recently created impressive 3D assets for various applications. However, the copyright of these assets is not well protected as existing watermarking methods are not suited for the 3DGS rendering pipeline considering security, capacity, and invisibility. Besides, these methods often require hours or even days for optimization, limiting the application scenarios. In this paper, we propose GuardSplat, an innovative and efficient framework that effectively protects the copyright of 3DGS assets. Specifically, 1) We first propose a CLIP-guided Message Decoupling Optimization module for training the message decoder, leveraging CLIP’s aligning capability and rich representations to achieve a high extraction accuracy with minimal optimization costs, presenting exceptional capacity and efficiency. 2) Then, we propose a Spherical-harmonic-aware (SH-aware) Message Embedding module tailored for 3DGS, which employs a set of SH offsets to seamlessly embed the message into the SH features of each 3D Gaussian while maintaining the original 3D structure. It enables the 3DGS assets to be watermarked with minimal fidelity trade-offs and also prevents malicious users from removing the messages from the model files, meeting the demands for invisibility and security. 3) We further propose an Anti-distortion Message Extraction module to improve robustness against various visual distortions. Extensive experiments demonstrate that GuardSplat outperforms state-of-the-art and achieves fast optimization speed. Project page: https://narcissusex.github.io/GuardSplat, and Code: https://github.com/NarcissusEx/GuardSplat.
三维高斯延展(3DGS)最近为各种应用创建了令人印象深刻的三维资产。然而,这些资产的版权并未得到很好的保护,因为现有的水印方法并不适合考虑安全性、容量和隐蔽性的3DGS渲染流程。此外,这些方法需要数小时甚至数天的优化时间,限制了应用场景。在本文中,我们提出了GuardSplat,这是一个创新且高效的水印框架,能够有效地保护三维高斯延展资产(3DGS)的版权。具体来说,首先,我们提出了CLIP引导的消息解耦优化模块,用于训练消息解码器。利用CLIP的对齐能力和丰富的表示形式,我们可以在极低的优化成本下实现高提取精度,表现出卓越的容量和效率。其次,我们针对三维高斯延展提出了球面谐波感知(SH感知)消息嵌入模块,该模块使用一组SH偏移来无缝地将消息嵌入到每个三维高斯(3D Gaussian)的SH特征中,同时保持原始的三维结构。它允许在几乎不影响保真度的前提下对三维高斯延展资产进行水印处理,防止恶意用户从模型文件中移除消息,满足了隐蔽性和安全性的需求。最后,我们进一步提出了抗畸变消息提取模块,以提高对各种视觉畸变的鲁棒性。大量实验表明,GuardSplat超越了最新的技术,实现了快速优化速度。项目页面:https://narcissusex.github.io/GuardSplat,代码:https://github.com/NarcissusEx/GuardSplat。
论文及项目相关链接
PDF This paper is accepted by the IEEE/CVF International Conference on Computer Vision and Pattern Recognition (CVPR), 2025
Summary
本文提出GuardSplat框架,用于高效保护3D Gaussian Splatting(3DGS)资产版权。采用CLIP指导的消息解耦优化模块、球形谐波感知消息嵌入模块和抗失真消息提取模块,实现高提取精度、低优化成本、高容量和效率,同时满足隐形和安全需求。
Key Takeaways
- GuardSplat是一个用于保护3D Gaussian Splatting(3DGS)资产版权的创新框架。
- 采用CLIP指导的消息解耦优化模块,实现高提取精度和快速优化。
- 球形谐波感知消息嵌入模块将消息无缝嵌入到每个3D高斯函数的球谐特征中,保持原始3D结构。
- 抗失真消息提取模块提高了对各种视觉失真的鲁棒性。
- GuardSplat优于现有技术,实现了快速优化速度。
点此查看论文截图

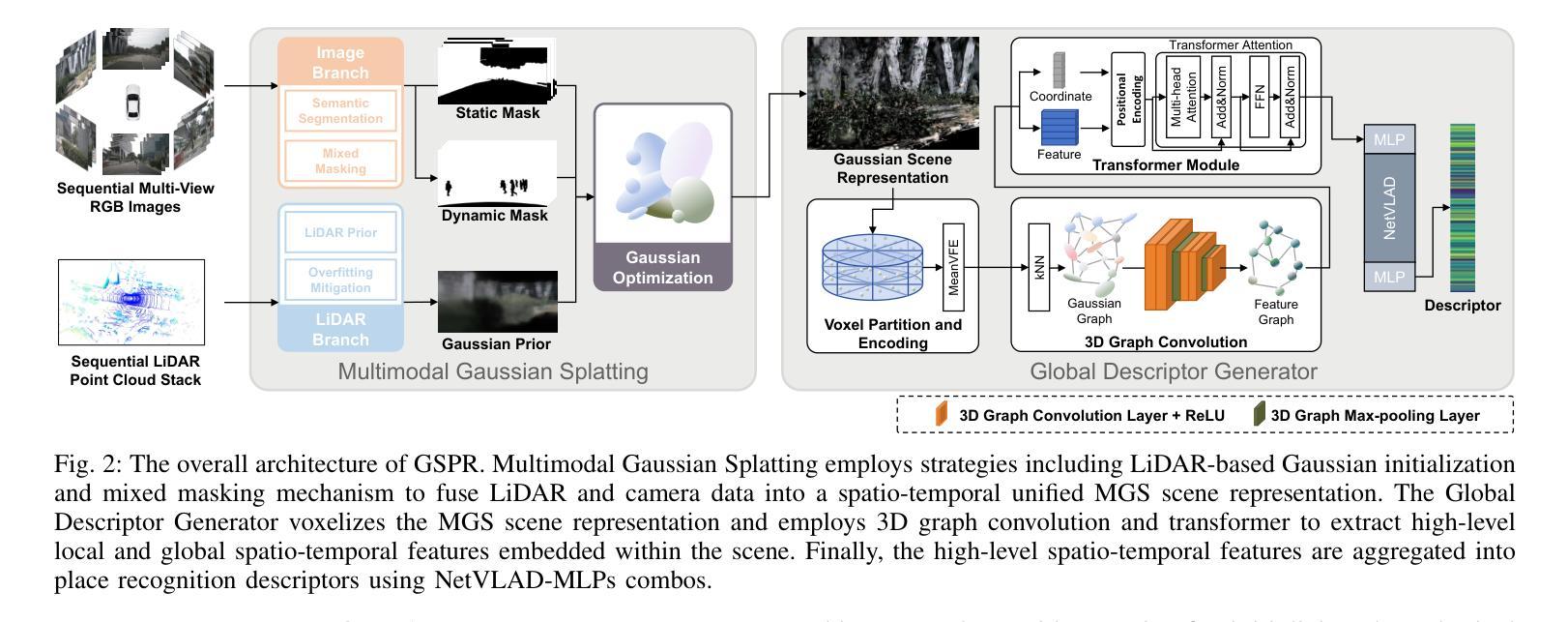
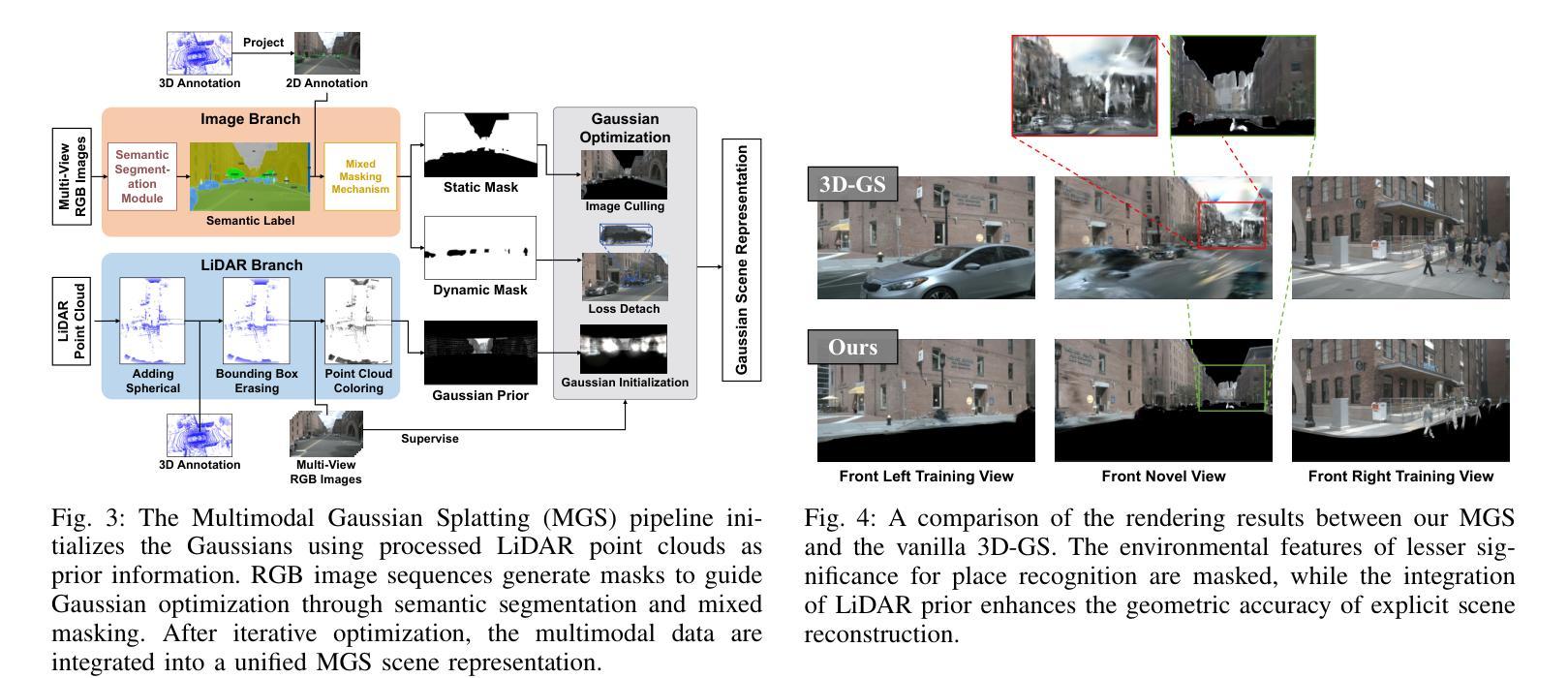
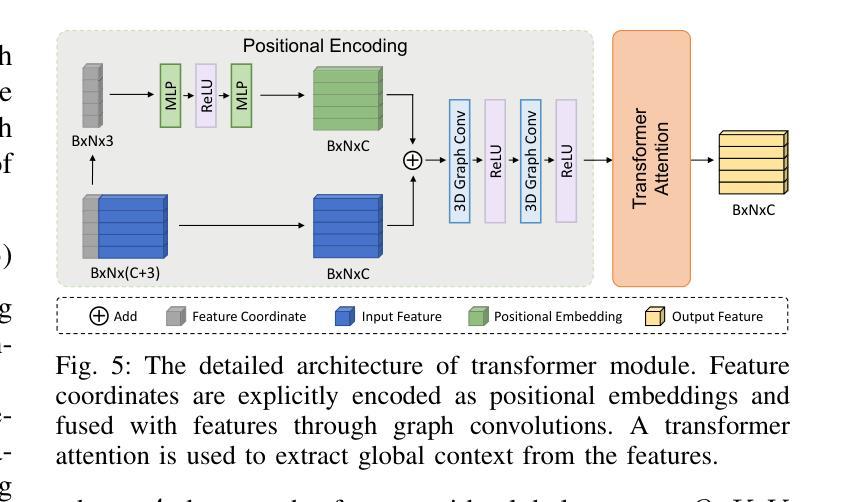
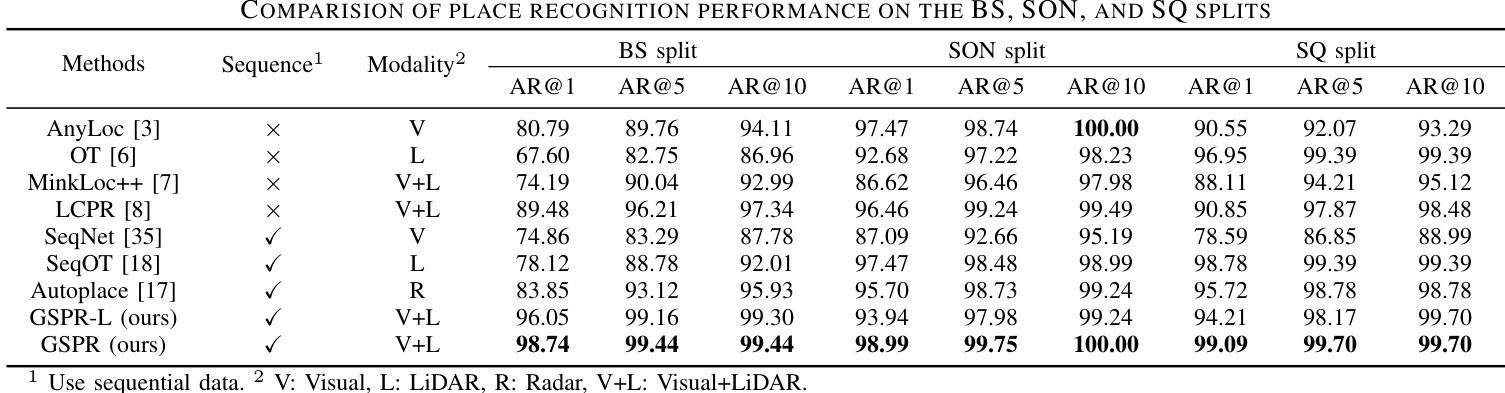
GSPR: Multimodal Place Recognition Using 3D Gaussian Splatting for Autonomous Driving
Authors:Zhangshuo Qi, Junyi Ma, Jingyi Xu, Zijie Zhou, Luqi Cheng, Guangming Xiong
Place recognition is a crucial component that enables autonomous vehicles to obtain localization results in GPS-denied environments. In recent years, multimodal place recognition methods have gained increasing attention. They overcome the weaknesses of unimodal sensor systems by leveraging complementary information from different modalities. However, most existing methods explore cross-modality correlations through feature-level or descriptor-level fusion, suffering from a lack of interpretability. Conversely, the recently proposed 3D Gaussian Splatting provides a new perspective on multimodal fusion by harmonizing different modalities into an explicit scene representation. In this paper, we propose a 3D Gaussian Splatting-based multimodal place recognition network dubbed GSPR. It explicitly combines multi-view RGB images and LiDAR point clouds into a spatio-temporally unified scene representation with the proposed Multimodal Gaussian Splatting. A network composed of 3D graph convolution and transformer is designed to extract spatio-temporal features and global descriptors from the Gaussian scenes for place recognition. Extensive evaluations on three datasets demonstrate that our method can effectively leverage complementary strengths of both multi-view cameras and LiDAR, achieving SOTA place recognition performance while maintaining solid generalization ability. Our open-source code will be released at https://github.com/QiZS-BIT/GSPR.
场景识别是自主车辆在GPS拒绝环境中获得定位结果的关键组件。近年来,多模态场景识别方法受到了越来越多的关注。它们通过利用不同模态的互补信息来克服单模态传感器系统的弱点。然而,大多数现有方法通过特征级或描述符级融合探索跨模态相关性,存在缺乏可解释性的问题。相反,最近提出的3D高斯喷涂技术为多模态融合提供了新的视角,通过将不同的模态和谐地转化为明确的场景表示。在本文中,我们提出了一种基于3D高斯喷涂技术的多模态场景识别网络,名为GSPR。它将多视角RGB图像和激光雷达点云显式地结合成一个时空统一的场景表示,并提出了多模态高斯喷涂技术。设计了一个由3D图卷积和变压器组成的网络,用于从高斯场景中提取时空特征和全局描述符,以进行场景识别。在三个数据集上的广泛评估表明,我们的方法可以有效地利用多视角相机和激光雷达的互补优势,实现最先进的场景识别性能,同时保持稳健的泛化能力。我们的开源代码将在https://github.com/QiZS-BIT/GSPR上发布。
论文及项目相关链接
PDF 8 pages, 6 figures
Summary
本文提出一种基于3D高斯点云(Gaussian Splatting)的多模态地方识别网络(GSPR)。该方法能结合多视角RGB图像和激光雷达点云,形成时空统一场景表示。通过3D图卷积和Transformer网络提取时空特征和全局描述符,实现地方识别。在三个数据集上的评估表明,该方法能充分利用多视角相机和激光雷达的互补优势,达到先进的地方识别性能,同时保持良好的泛化能力。
Key Takeaways
- 多模态地方识别对于自主车辆在GPS信号缺失环境中的定位至关重要。
- 当前方法主要通过特征级别或描述符级别的融合探索跨模态相关性,但缺乏可解释性。
- 3D高斯点云(Gaussian Splatting)为多模态融合提供了新视角,将不同模态和谐统一到明确的场景表示中。
- GSPR网络结合多视角RGB图像和激光雷达点云,形成时空统一场景表示。
- GSPR使用3D图卷积和Transformer网络提取时空特征和全局描述符用于地方识别。
- 在三个数据集上的评估显示,GSPR能充分利用多模态数据的互补优势,达到先进的地方识别性能。
点此查看论文截图