⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-09 更新
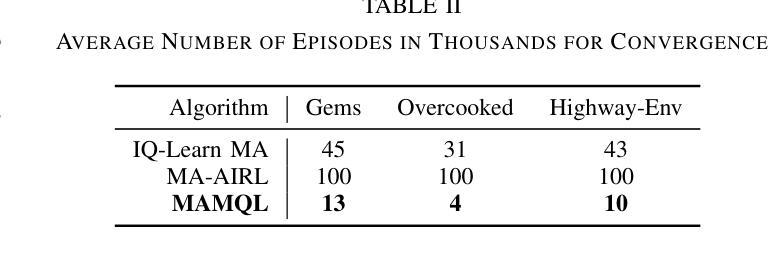
Multi-Agent Inverse Q-Learning from Demonstrations
Authors:Nathaniel Haynam, Adam Khoja, Dhruv Kumar, Vivek Myers, Erdem Bıyık
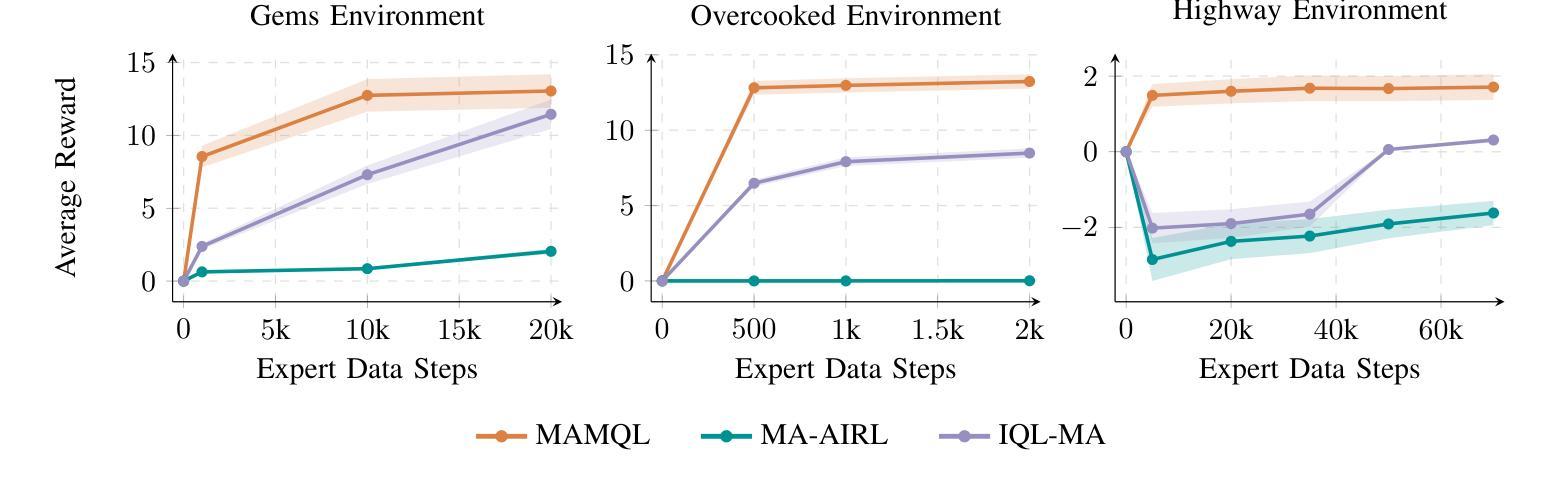
When reward functions are hand-designed, deep reinforcement learning algorithms often suffer from reward misspecification, causing them to learn suboptimal policies in terms of the intended task objectives. In the single-agent case, inverse reinforcement learning (IRL) techniques attempt to address this issue by inferring the reward function from expert demonstrations. However, in multi-agent problems, misalignment between the learned and true objectives is exacerbated due to increased environment non-stationarity and variance that scales with multiple agents. As such, in multi-agent general-sum games, multi-agent IRL algorithms have difficulty balancing cooperative and competitive objectives. To address these issues, we propose Multi-Agent Marginal Q-Learning from Demonstrations (MAMQL), a novel sample-efficient framework for multi-agent IRL. For each agent, MAMQL learns a critic marginalized over the other agents’ policies, allowing for a well-motivated use of Boltzmann policies in the multi-agent context. We identify a connection between optimal marginalized critics and single-agent soft-Q IRL, allowing us to apply a direct, simple optimization criterion from the single-agent domain. Across our experiments on three different simulated domains, MAMQL significantly outperforms previous multi-agent methods in average reward, sample efficiency, and reward recovery by often more than 2-5x. We make our code available at https://sites.google.com/view/mamql .
当奖励函数是手动设计时,深度强化学习算法往往会受到奖励误指定的困扰,导致它们在预期的任务目标方面学习到的策略是次优的。在单代理情况下,逆向强化学习(IRL)技术试图通过从专家演示中推断奖励函数来解决这个问题。然而,在多代理问题中,由于环境非平稳性和随着多个代理而增加的方差,学习目标和真实目标之间的不一致性会加剧。因此,在多代理总收益游戏中,多代理IRL算法很难平衡合作和竞争目标。为了解决这些问题,我们提出了多代理边际Q学习(MAMQL),这是一种用于多代理IRL的新型样本高效框架。对于每个代理,MAMQL学习其他代理策略的边际评论家,这允许在多代理背景下使用有充分依据的玻尔兹曼策略。我们发现了最优边际评论家和单代理软Q IRL之间的联系,使我们能够应用来自单代理领域的直接、简单的优化标准。在我们对三个不同模拟领域的实验测试中,MAMQL在平均奖励、样本效率和奖励恢复方面显著优于之前的多代理方法,通常超过2-5倍。我们的代码可在https://sites.google.com/view/mamql上获取。
论文及项目相关链接
PDF 8 pages, 4 figures, 2 tables. Published at the International Conference on Robotics and Automation (ICRA) 2025
Summary
本文提出一种名为MAMQL的多智能体边际Q学习算法,用于解决多智能体强化学习中的奖励函数误指定问题。该算法通过边际化其他智能体的策略来为每个智能体学习一个评论家,并应用Boltzmann策略。MAMQL在模拟域的测试中显著优于其他多智能体方法,提高了平均奖励、样本效率和奖励恢复能力。
Key Takeaways
- MAMQL是一种针对多智能体强化学习中的奖励函数误指定问题的新型算法。
- MAMQL通过为每个智能体学习一个边际评论家来解决多智能体环境中的合作与竞争目标平衡问题。
- MAMQL利用Boltzmann策略,在多智能体环境中表现出良好的适应性。
- 该算法在模拟域的测试中显著优于其他多智能体方法。
- MAMQL提高了多智能体系统的平均奖励、样本效率和奖励恢复能力。
- MAMQL算法与单智能体的软Q-IRL之间存在联系,这使其能够应用简单的优化标准。
点此查看论文截图


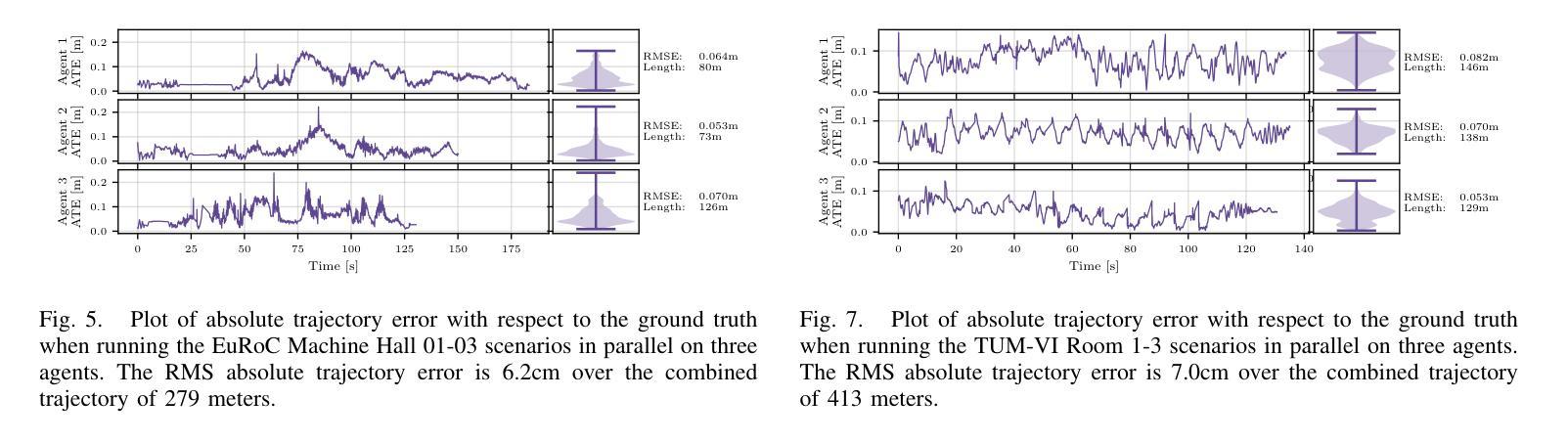
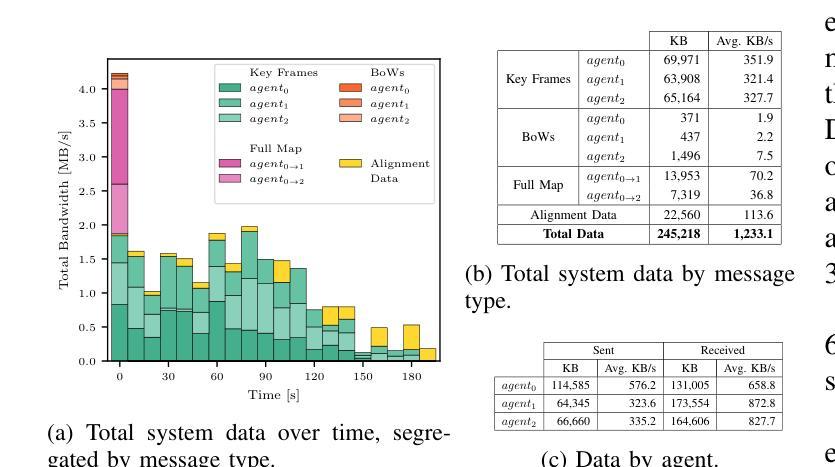
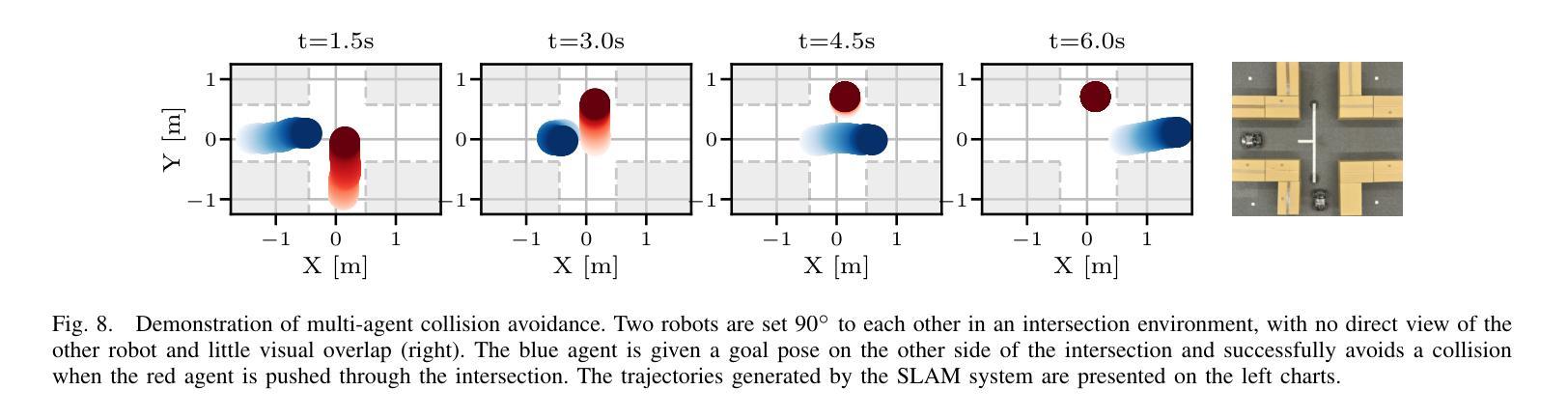
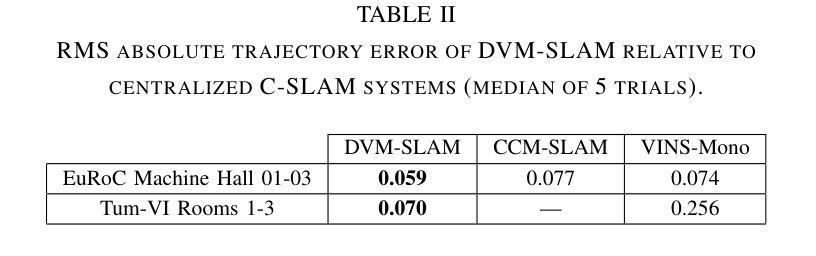
DVM-SLAM: Decentralized Visual Monocular Simultaneous Localization and Mapping for Multi-Agent Systems
Authors:Joshua Bird, Jan Blumenkamp, Amanda Prorok
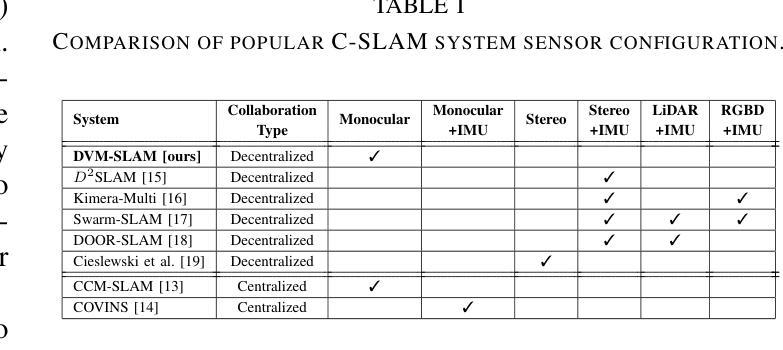
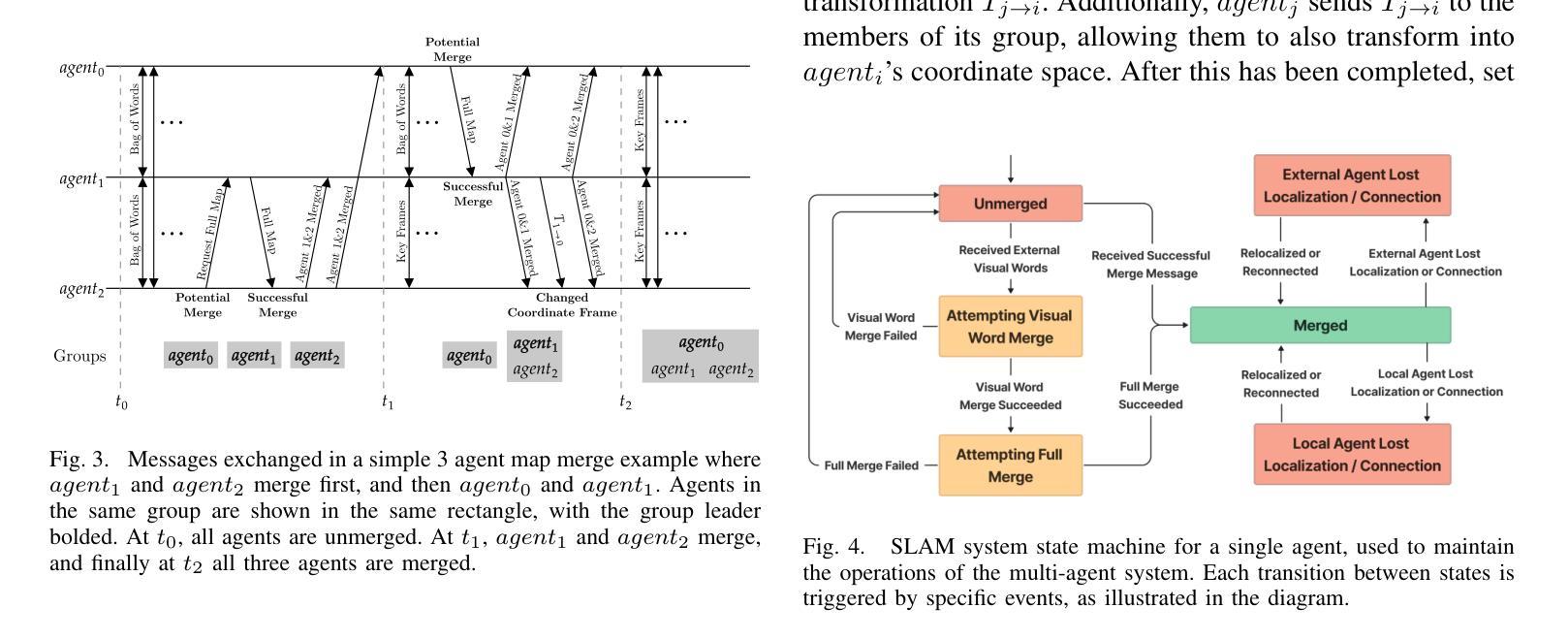
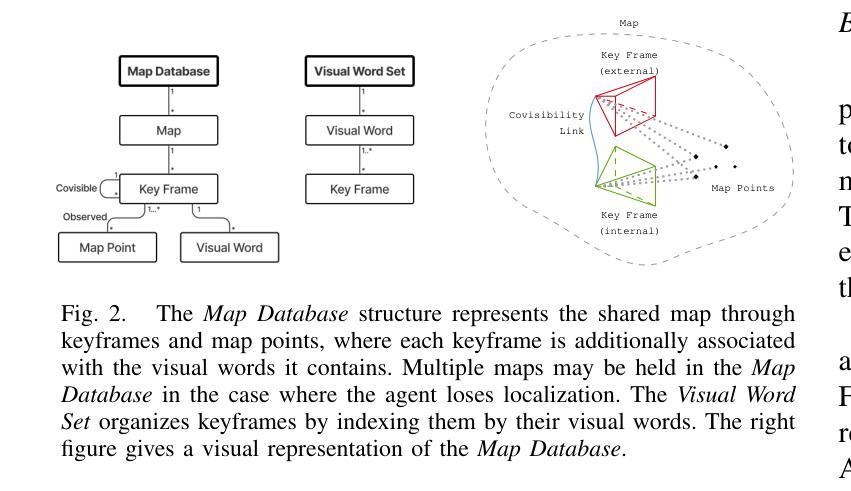
Cooperative Simultaneous Localization and Mapping (C-SLAM) enables multiple agents to work together in mapping unknown environments while simultaneously estimating their own positions. This approach enhances robustness, scalability, and accuracy by sharing information between agents, reducing drift, and enabling collective exploration of larger areas. In this paper, we present Decentralized Visual Monocular SLAM (DVM-SLAM), the first open-source decentralized monocular C-SLAM system. By only utilizing low-cost and light-weight monocular vision sensors, our system is well suited for small robots and micro aerial vehicles (MAVs). DVM-SLAM’s real-world applicability is validated on physical robots with a custom collision avoidance framework, showcasing its potential in real-time multi-agent autonomous navigation scenarios. We also demonstrate comparable accuracy to state-of-the-art centralized monocular C-SLAM systems. We open-source our code and provide supplementary material online.
协同定位与地图构建(C-SLAM)允许多个智能体在未知环境中协同工作,同时估计它们自身的位置。通过共享信息、减少漂移以及进行更大区域的集体探索,该方法增强了系统的稳健性、可扩展性和准确性。本文提出了第一个开源的去中心化单目协同视觉同步定位与地图构建系统——分散式视觉单目SLAM(DVM-SLAM)。该系统仅使用低成本、轻量级的单目视觉传感器,非常适合小型机器人和微型飞行器(MAVs)。通过物理机器人上的自定义避障框架验证了DVM-SLAM在现实世界的适用性,展示了其在实时多智能体自主导航场景中的潜力。我们还证明了其精度与最先进的集中式单目C-SLAM系统相当。我们公开了源代码并提供了补充材料。
论文及项目相关链接
Summary
C-SLAM技术通过多个智能体协同工作,在未知环境中进行地图构建并估计各自位置。本文介绍了一种名为DVM-SLAM的开源去中心化单目视觉SLAM系统,适用于小型机器人和微型飞行器。该系统通过利用低成本、轻量级的单目视觉传感器,具有良好的实时多智能体自主导航潜力,并通过实物机器人验证了其实用性,与最新的集中化单目视觉C-SLAM系统相比表现优异。
Key Takeaways
- C-SLAM技术允许多个智能体协同工作,在未知环境中进行地图构建和位置估计。
- DVM-SLAM是首个开源的去中心化单目视觉SLAM系统。
- DVM-SLAM适用于低成本、轻量级的单目视觉传感器,特别适用于小型机器人和微型飞行器。
- DVM-SLAM具有实时多智能体自主导航的潜力。
- 通过实物机器人验证了DVM-SLAM系统的实用性。
- DVM-SLAM与最新的集中化单目视觉C-SLAM系统相比表现优异。
点此查看论文截图


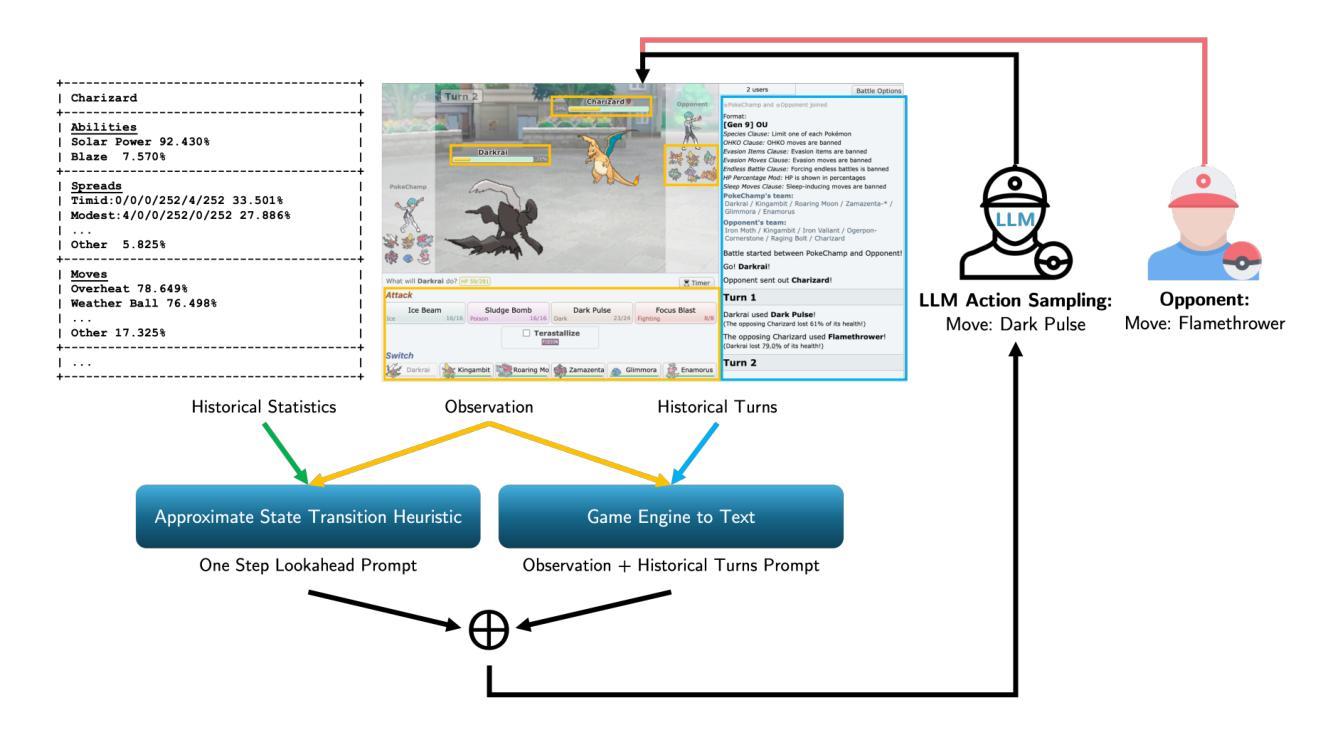
PokéChamp: an Expert-level Minimax Language Agent
Authors:Seth Karten, Andy Luu Nguyen, Chi Jin
We introduce Pok'eChamp, a minimax agent powered by Large Language Models (LLMs) for Pok'emon battles. Built on a general framework for two-player competitive games, Pok'eChamp leverages the generalist capabilities of LLMs to enhance minimax tree search. Specifically, LLMs replace three key modules: (1) player action sampling, (2) opponent modeling, and (3) value function estimation, enabling the agent to effectively utilize gameplay history and human knowledge to reduce the search space and address partial observability. Notably, our framework requires no additional LLM training. We evaluate Pok'eChamp in the popular Gen 9 OU format. When powered by GPT-4o, it achieves a win rate of 76% against the best existing LLM-based bot and 84% against the strongest rule-based bot, demonstrating its superior performance. Even with an open-source 8-billion-parameter Llama 3.1 model, Pok'eChamp consistently outperforms the previous best LLM-based bot, Pok'ellmon powered by GPT-4o, with a 64% win rate. Pok'eChamp attains a projected Elo of 1300-1500 on the Pok'emon Showdown online ladder, placing it among the top 30%-10% of human players. In addition, this work compiles the largest real-player Pok'emon battle dataset, featuring over 3 million games, including more than 500k high-Elo matches. Based on this dataset, we establish a series of battle benchmarks and puzzles to evaluate specific battling skills. We further provide key updates to the local game engine. We hope this work fosters further research that leverage Pok'emon battle as benchmark to integrate LLM technologies with game-theoretic algorithms addressing general multiagent problems. Videos, code, and dataset available at https://sites.google.com/view/pokechamp-llm.
我们介绍了Pok’eChamp,这是一个由大型语言模型(LLMs)驱动的宝可梦战斗的极小极大值代理人。基于两人竞技游戏的通用框架,Pok’eChamp利用LLMs的通用能力来增强极小极大值树搜索。具体来说,LLMs替换了三个关键模块:(1)玩家动作采样,(2)对手建模和(3)值函数估计,这使得代理人能够有效地利用游戏历史和人类知识来减少搜索空间并解决部分可观察性。值得注意的是,我们的框架不需要额外的LLM训练。我们在流行的Gen 9 OU格式中对Pok’eChamp进行了评估。当它由GPT-4o驱动时,与现有的最佳LLM机器人相比,它的胜率为76%,与最强的规则机器人相比,胜率为84%,这证明了其卓越性能。即使使用开源的8亿参数Llama 3.1模型,Pok’eChamp也始终优于之前最好的基于LLM的机器人Pok’ellmon,胜率为64%。Pok’eChamp在宝可梦对决在线排行榜上的预估Elo得分为1300-1500,跻身人类玩家前30%-10%。此外,这项工作还编译了最大的真实玩家宝可梦战斗数据集,包含超过300万场比赛,其中包括超过50万场高Elo比赛。基于此数据集,我们建立了一系列战斗基准测试和谜题来评估特定的战斗技能。我们还对本地游戏引擎进行了关键更新。我们希望这项工作能够激发更多的研究,利用宝可梦战斗作为基准测试,将LLM技术与解决一般多智能体问题的博弈论算法相结合。视频、代码和数据集可在https://sites.google.com/view/pokechamp-llm上找到。
论文及项目相关链接
PDF 24 pages, 13 figures
Summary
Pok’eChamp是一个利用大型语言模型(LLMs)驱动的minimax对战代理,用于进行Pokémon对战。该代理采用通用两玩家竞技游戏框架,通过LLMs增强minimax树搜索能力。LLMs替换关键模块,包括玩家行动采样、对手建模和价值函数估计,使代理能够利用游戏历史和人类知识来减少搜索空间并解决部分可观测性问题。Pok’eChamp在Gen 9 OU格式中的评估表现优异,使用GPT-4o时,在对抗最佳LLM基机器人和最强规则基机器人时,胜率分别达到了76%和84%。即使是使用开源的8亿参数Llama 3.1模型,Pok’eChamp也表现出超越之前最佳LLM基机器人Pok’ellmon的64%胜率。该工作还编译了最大的真实玩家Pokémon战斗数据集,包含超过300万场比赛,以及超过50万场高Elo比赛。基于此数据集,该工作建立了一系列战斗基准测试和谜题来评估特定的战斗技能。
Key Takeaways
- Pok’eChamp是一个基于大型语言模型(LLMs)的minimax对战代理,专门用于Pokémon对战。
- LLMs在Pok’eChamp中用于替换关键模块,如玩家行动采样、对手建模和价值函数估计,提高了代理的游戏性能。
- Pok’eChamp在Gen 9 OU格式中的评估表现优异,使用不同模型时表现出高胜率。
- Pok’eChamp使用开源模型Llama 3.1也表现出优越性能,超过了之前的最佳LLM基机器人。
- 该工作编译了最大的真实玩家Pokémon战斗数据集,包含大量比赛数据。
- 基于此数据集,建立了战斗基准测试和谜题,以评估特定的战斗技能。
点此查看论文截图


Multi-Agent Systems Powered by Large Language Models: Applications in Swarm Intelligence
Authors:Cristian Jimenez-Romero, Alper Yegenoglu, Christian Blum
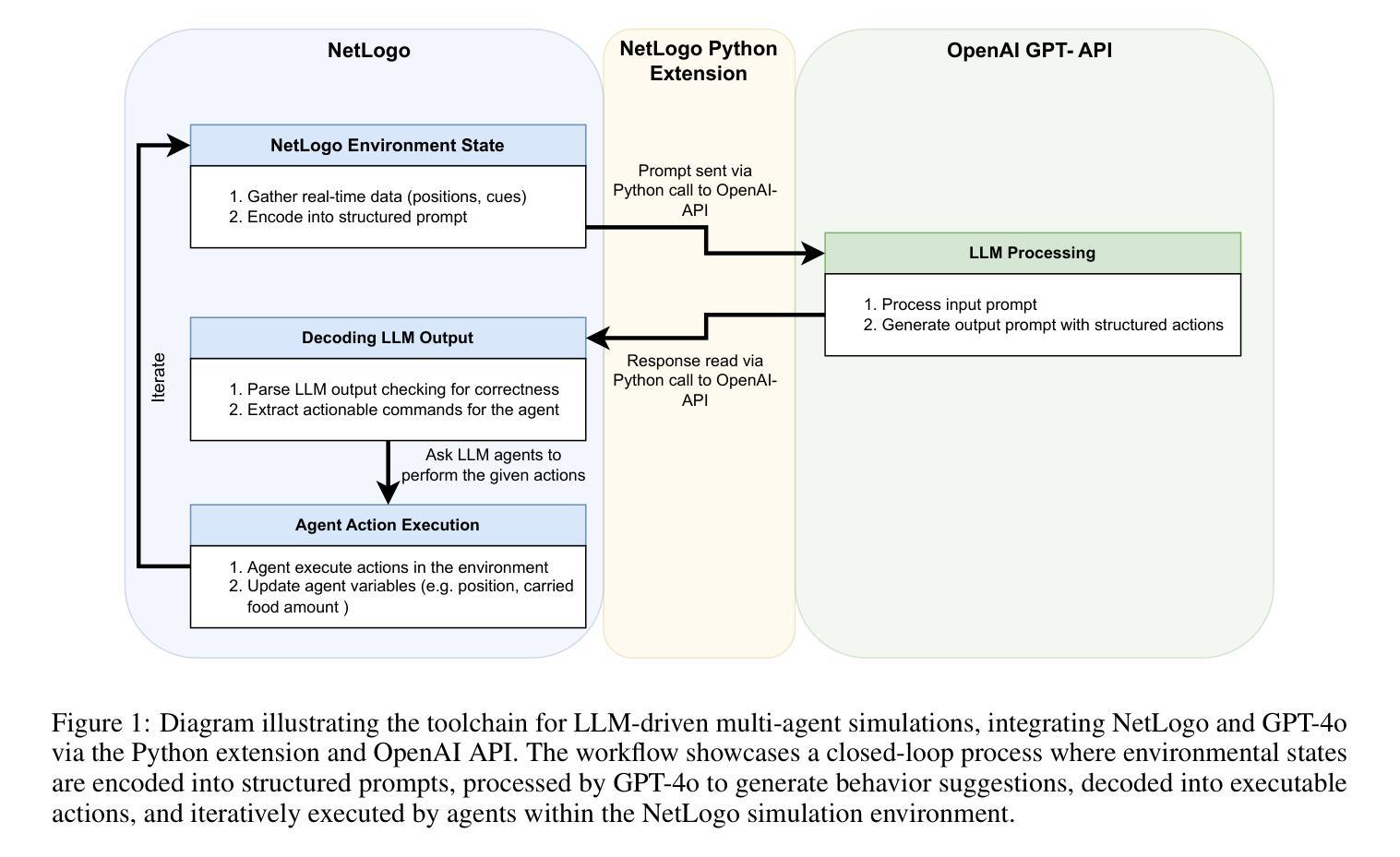
This work examines the integration of large language models (LLMs) into multi-agent simulations by replacing the hard-coded programs of agents with LLM-driven prompts. The proposed approach is showcased in the context of two examples of complex systems from the field of swarm intelligence: ant colony foraging and bird flocking. Central to this study is a toolchain that integrates LLMs with the NetLogo simulation platform, leveraging its Python extension to enable communication with GPT-4o via the OpenAI API. This toolchain facilitates prompt-driven behavior generation, allowing agents to respond adaptively to environmental data. For both example applications mentioned above, we employ both structured, rule-based prompts and autonomous, knowledge-driven prompts. Our work demonstrates how this toolchain enables LLMs to study self-organizing processes and induce emergent behaviors within multi-agent environments, paving the way for new approaches to exploring intelligent systems and modeling swarm intelligence inspired by natural phenomena. We provide the code, including simulation files and data at https://github.com/crjimene/swarm_gpt.
本文研究了大型语言模型(LLMs)在多智能体仿真中的集成方法,通过用LLM驱动的提示替换智能体的硬编码程序来实现。所提出的方法在群智能领域的两个复杂系统示例中得到了展示:蚂蚁群体觅食和鸟类集群迁徙。本研究的核心是一个将LLMs与NetLogo仿真平台集成的工具链,它利用NetLogo的Python扩展,通过OpenAI API与GPT-4o进行通信。该工具链促进了提示驱动的行为生成,使智能体能够自适应地响应环境数据。对于上述两个示例应用程序,我们既采用结构化的、基于规则的提示,也采用自主的、知识驱动的提示。我们的工作展示了该工具链如何使LLMs能够研究自组织过程并在多智能体环境中引发新兴行为,为探索智能系统和建立受自然现象启发的群智能模型开辟了新的途径。我们提供的代码,包括仿真文件和资料可以在https://github.com/crjimene/swarm_gpt找到。
论文及项目相关链接
Summary
大型语言模型(LLM)被集成到多智能体模拟中,通过LLM驱动的提示替换硬编码的智能体程序。本研究以群体智能领域的两个复杂系统——蚁群觅食和鸟群迁移为例,展示了这一方法。通过整合LLM与NetLogo模拟平台并借助Python扩展与GPT-4o进行通信的工具链,促进了提示驱动的行为生成,使智能体能根据环境数据自适应反应。我们的工作证明了这一工具链在研究自我组织过程和在多智能体环境中诱发新兴行为的能力,并为探索智能系统和模仿自然现象的群体智能提供了新的方法。代码及相关资料已上传至GitHub仓库。
Key Takeaways
- 大型语言模型(LLM)被用于多智能体模拟中,取代了传统的硬编码程序。
- 研究聚焦于如何利用LLM驱动的提示引导智能体的行为。
- 通过蚁群觅食和鸟群迁移两个例子展示了该方法的实际应用。
- 利用工具链整合了LLM与NetLogo模拟平台,并借助Python扩展实现与GPT-4o的通信。
- 提示驱动的行为生成使得智能体能根据环境数据自适应反应。
- 该方法展现了自我组织过程和新兴行为在多智能体环境中的潜力。
点此查看论文截图

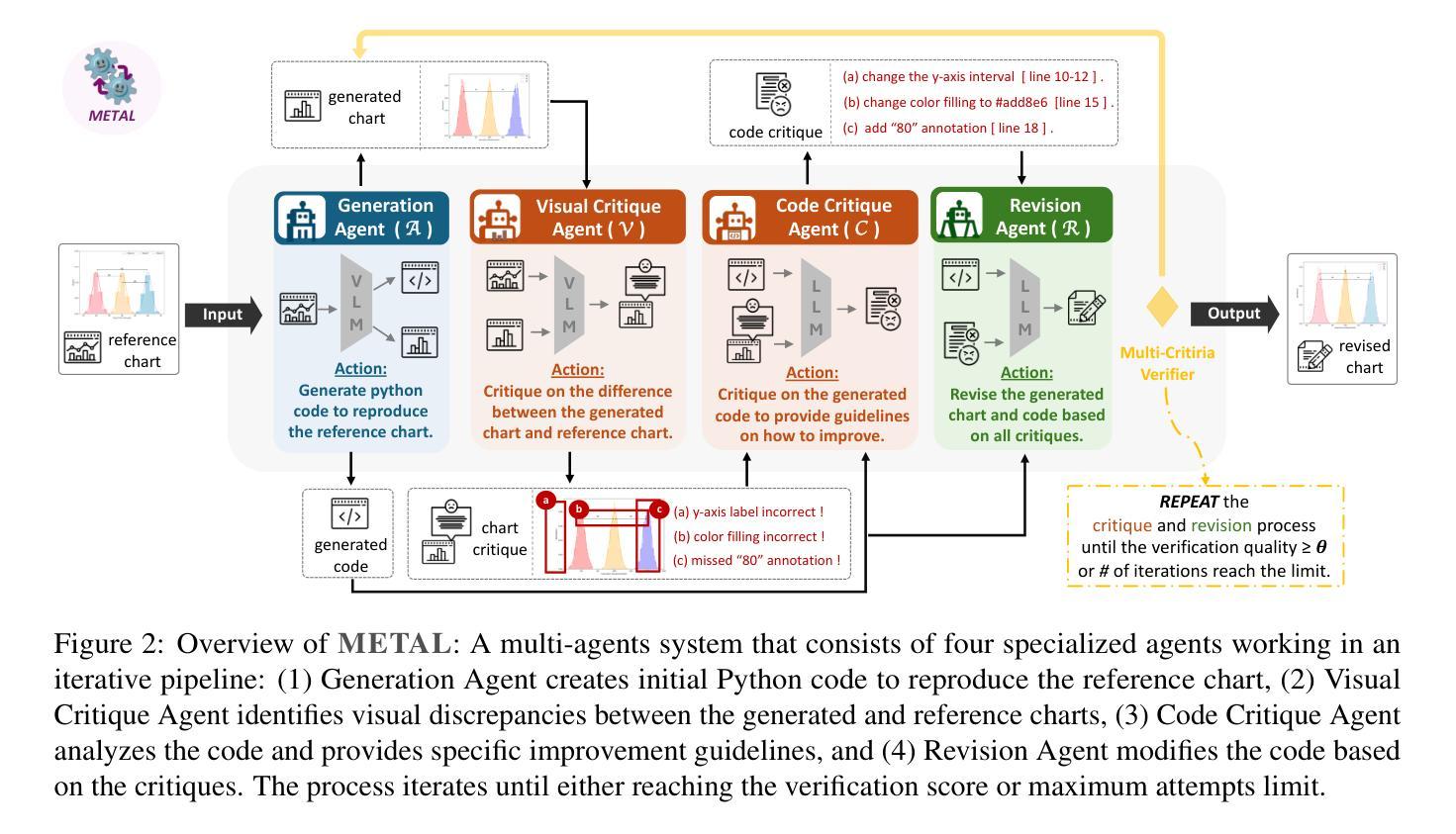
METAL: A Multi-Agent Framework for Chart Generation with Test-Time Scaling
Authors:Bingxuan Li, Yiwei Wang, Jiuxiang Gu, Kai-Wei Chang, Nanyun Peng
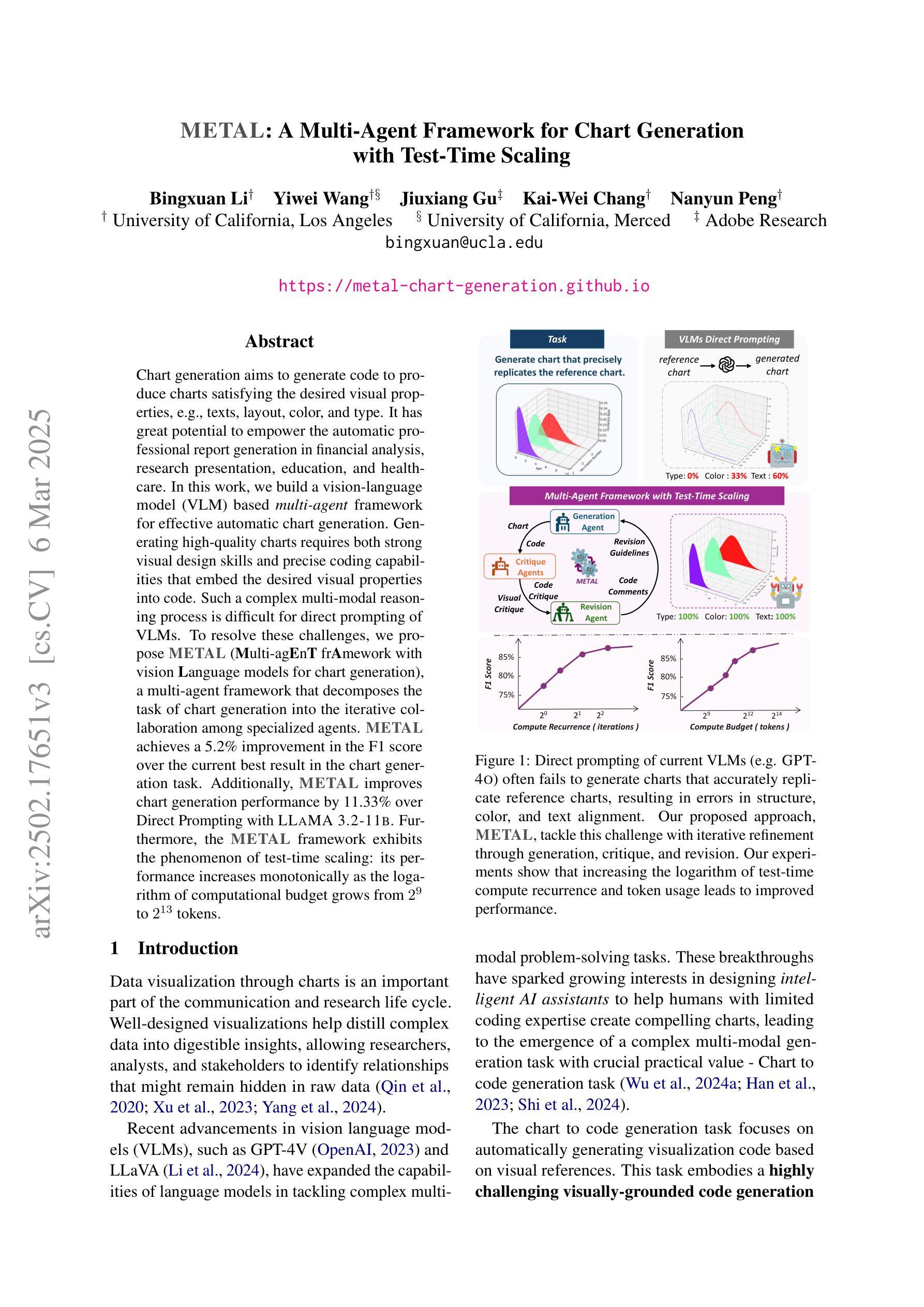
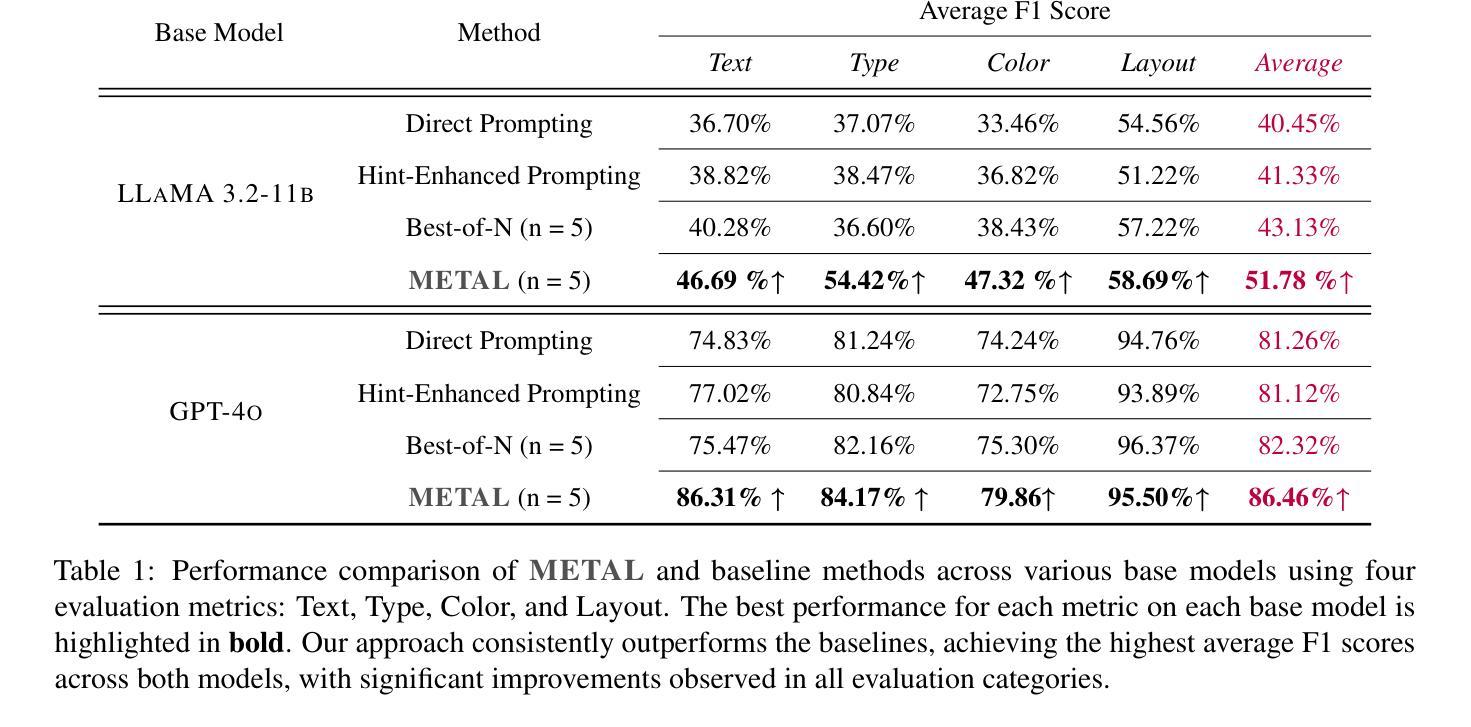
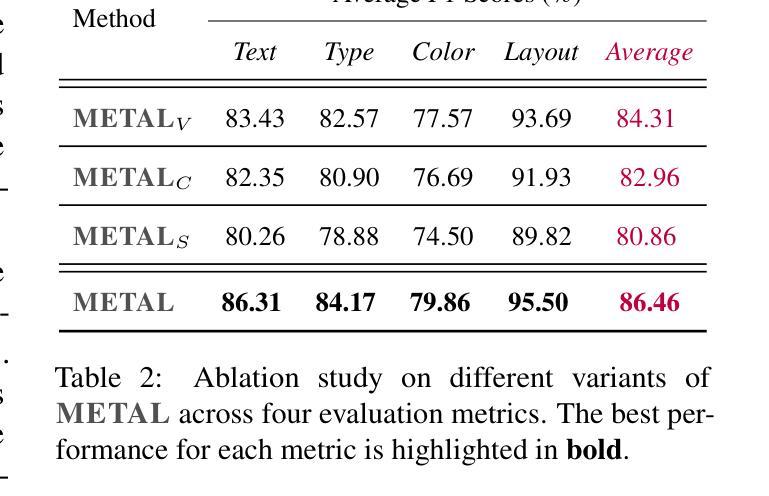
Chart generation aims to generate code to produce charts satisfying the desired visual properties, e.g., texts, layout, color, and type. It has great potential to empower the automatic professional report generation in financial analysis, research presentation, education, and healthcare. In this work, we build a vision-language model (VLM) based multi-agent framework for effective automatic chart generation. Generating high-quality charts requires both strong visual design skills and precise coding capabilities that embed the desired visual properties into code. Such a complex multi-modal reasoning process is difficult for direct prompting of VLMs. To resolve these challenges, we propose METAL, a multi-agent framework that decomposes the task of chart generation into the iterative collaboration among specialized agents. METAL achieves 5.2% improvement over the current best result in the chart generation task. The METAL framework exhibits the phenomenon of test-time scaling: its performance increases monotonically as the logarithmic computational budget grows from 512 to 8192 tokens. In addition, we find that separating different modalities during the critique process of METAL boosts the self-correction capability of VLMs in the multimodal context.
图表生成旨在生成代码,以产生满足所需视觉属性的图表,例如文本、布局、颜色和类型。它在金融分析、研究报告、教育和医疗的自动专业报告生成方面具有巨大的潜力。在这项工作中,我们建立了一个基于视觉语言模型(VLM)的多智能体框架,用于有效的自动图表生成。生成高质量的图表需要强大的视觉设计技能和精确的编码能力,将所需的视觉属性嵌入代码中。这样的复杂多模态推理过程对于直接提示VLM来说很难。为了解决这些挑战,我们提出了METAL,这是一个多智能体框架,将图表生成任务分解为专业智能体之间的迭代协作。METAL在图表生成任务上实现了比当前最佳结果高出5.2%的改进。METAL框架表现出测试时缩放现象:随着对数计算预算从512增长到8192令牌,其性能单调增加。此外,我们发现,在METAL的批判过程中分离不同的模态提升了多模态上下文中VLM的自我修正能力。
论文及项目相关链接
Summary
图表生成旨在生成代码以生成满足所需视觉属性的图表,如文本、布局、颜色和类型等。该研究建立了一个基于视觉语言模型(VLM)的多代理框架,以实现有效的自动图表生成。高质量图表生成需要强大的视觉设计技能和精确的编码能力,将所需的视觉属性嵌入代码中。这种复杂的跨模态推理过程难以通过直接提示VLMs实现。为了解决这些挑战,我们提出了METAL多代理框架,该框架将图表生成任务分解为专业代理之间的迭代协作。METAL在图表生成任务上实现了对当前最佳结果的5.2%的提升。此外,我们发现METAL的评审过程中不同模态的分离增强了VLMs在多模态环境中的自我修正能力。
Key Takeaways
- 图表生成旨在自动生成满足特定视觉属性的代码。
- 建立了一个基于视觉语言模型(VLM)的多代理框架进行自动图表生成。
- 高质量图表生成需要强大的视觉设计技能和精确的编码能力。
- METAL多代理框架将图表生成任务分解为专业代理之间的迭代协作。
- METAL在图表生成任务上实现了显著的性能提升。
- METAL框架展现出测试时缩放现象,性能随计算预算的对数增长而提高。
点此查看论文截图
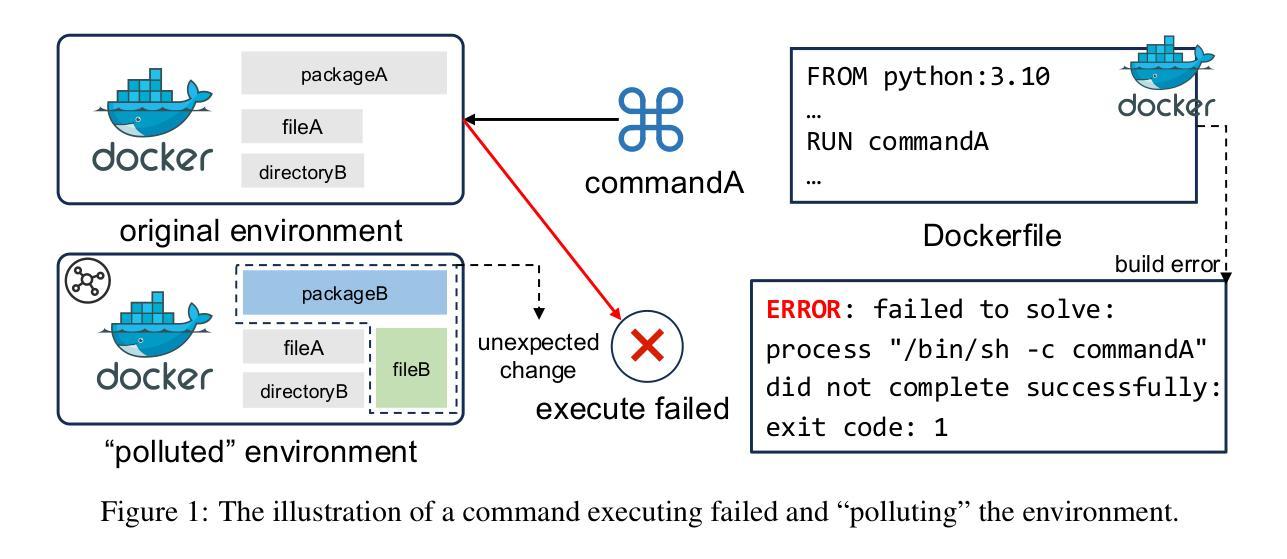
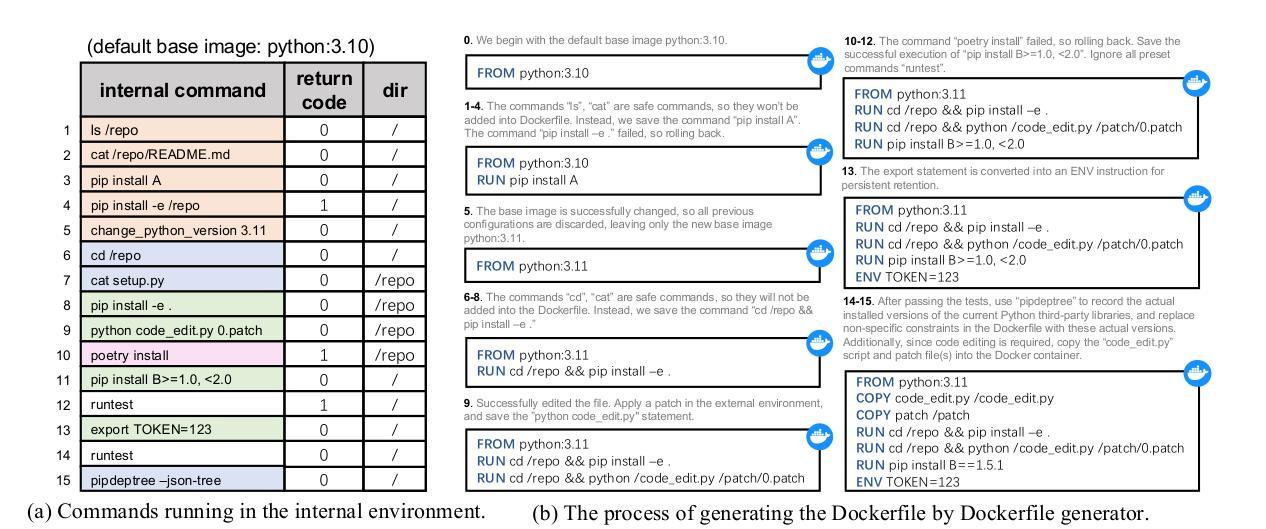
An LLM-based Agent for Reliable Docker Environment Configuration
Authors:Ruida Hu, Chao Peng, Xinchen Wang, Cuiyun Gao
Environment configuration is a critical yet time-consuming step in software development, especially when dealing with unfamiliar code repositories. While Large Language Models (LLMs) demonstrate the potential to accomplish software engineering tasks, existing methods for environment configuration often rely on manual efforts or fragile scripts, leading to inefficiencies and unreliable outcomes. We introduce Repo2Run, the first LLM-based agent designed to fully automate environment configuration and generate executable Dockerfiles for arbitrary Python repositories. We address two major challenges: (1) enabling the LLM agent to configure environments within isolated Docker containers, and (2) ensuring the successful configuration process is recorded and accurately transferred to a Dockerfile without error. To achieve this, we propose atomic configuration synthesis, featuring a dual-environment architecture (internal and external environment) with a rollback mechanism to prevent environment “pollution” from failed commands, guaranteeing atomic execution (execute fully or not at all) and a Dockerfile generator to transfer successful configuration steps into runnable Dockerfiles. We evaluate Repo2Run~on our proposed benchmark of 420 recent Python repositories with unit tests, where it achieves an 86.0% success rate, outperforming the best baseline by 63.9%. Repo2Run is available at https://github.com/bytedance/Repo2Run.
环境配置是软件开发中的一个关键且耗时的步骤,尤其是在处理不熟悉的代码仓库时。虽然大型语言模型(LLM)显示出完成软件工程任务的潜力,但现有的环境配置方法通常依赖于手动操作或易出错的脚本,导致效率低下和结果不可靠。我们介绍了Repo2Run,这是基于LLM的第一个完全自动化环境配置的代理,并为任意Python仓库生成可执行的Dockerfile。我们解决了两个主要挑战:(1)使LLM代理能够在隔离的Docker容器内配置环境;(2)确保成功的配置过程被记录并准确地转移到Dockerfile中而不出错。为了实现这一点,我们提出了原子配置合成,它采用双环境架构(内部和外部环境)并带有回滚机制,以防止因命令失败而导致的环境“污染”,保证原子执行(完全执行或不执行)以及Dockerfile生成器,将成功的配置步骤转移到可运行的Dockerfile中。我们在由单位测试组成的420个最新Python仓库的基准测试上对Repo2Run进行了评估,其成功率为86.0%,优于最佳基线63.9%。Repo2Run可在https://github.com/bytedance/Repo2Run上获取。
论文及项目相关链接
Summary
环境配置是软件开发中的一个重要且耗时的步骤,尤其是在处理不熟悉的代码仓库时。现有环境配置方法依赖手动或脆弱的脚本,导致效率低下和结果不可靠。我们引入了Repo2Run,这是第一个基于大型语言模型(LLM)的代理,旨在完全自动化环境配置并为任意Python仓库生成可执行Dockerfile。通过原子配置合成和双环境架构等关键技术,Repo2Run能够在Docker容器中配置环境并确保成功配置过程被准确记录并转移到Dockerfile中。我们在包含单位测试的基准测试上评估了Repo2Run,它在成功率上实现了超过其他基准模型的显著优势。更多信息可访问其GitHub仓库链接:链接地址。
Key Takeaways
- 环境配置在软件开发中是关键且耗时的步骤,特别是面对未知代码仓库时。
- 当前环境配置方法存在效率低下和结果不可靠的问题。
- Repo2Run是首个基于LLM的自动化环境配置代理,可为任意Python仓库生成可执行Dockerfile。
- Repo2Run解决了在Docker容器中配置环境的难题,并确保了成功配置过程被准确记录并转移到Dockerfile中。
点此查看论文截图



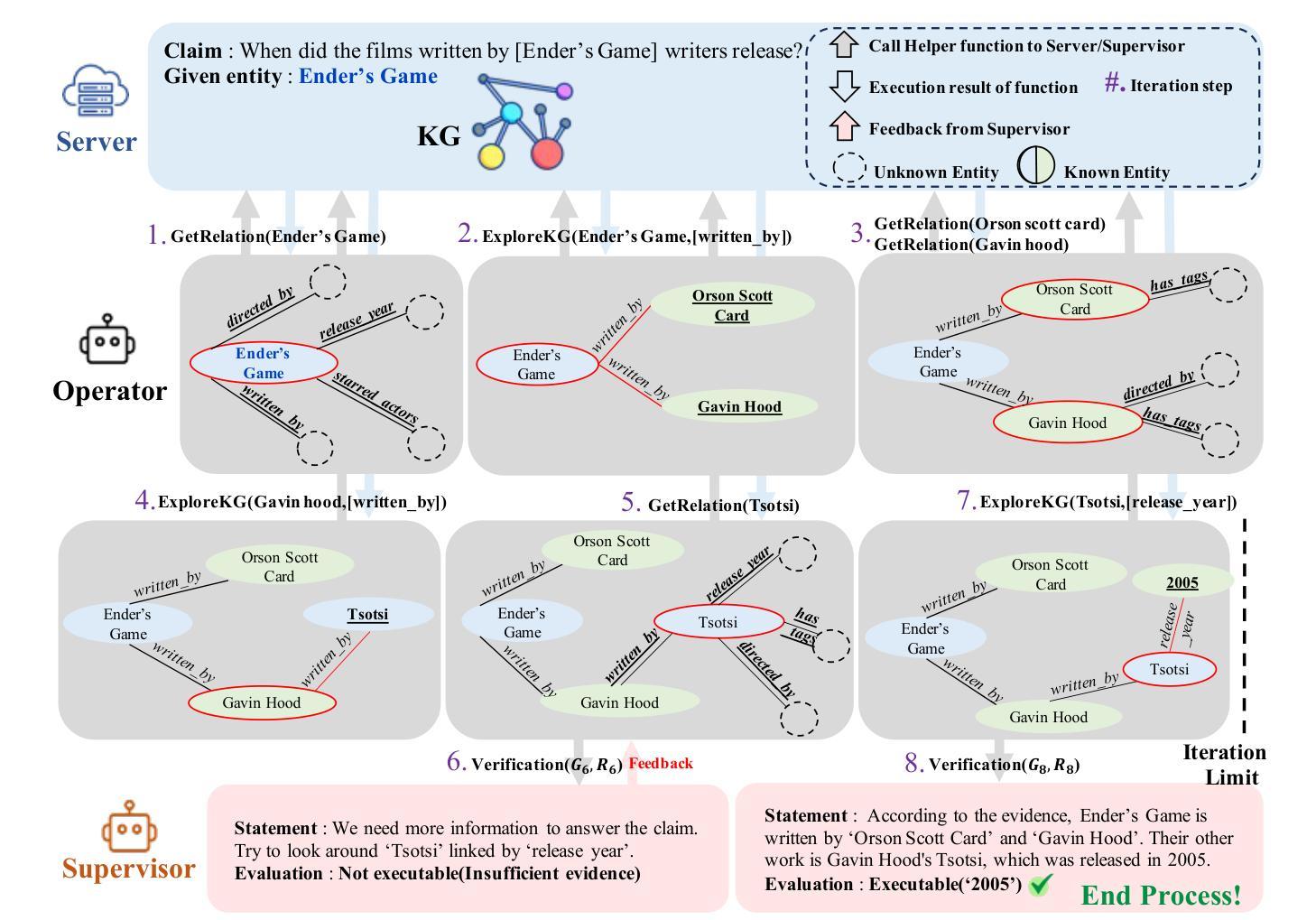
R2-KG: General-Purpose Dual-Agent Framework for Reliable Reasoning on Knowledge Graphs
Authors:Sumin Jo, Junseong Choi, Jiho Kim, Edward Choi
Recent studies have combined Large Language Models (LLMs) with Knowledge Graphs (KGs) to enhance reasoning, improving inference accuracy without additional training while mitigating hallucination. However, existing frameworks are often rigid, struggling to adapt to KG or task changes. They also rely heavily on powerful LLMs for reliable (i.e., trustworthy) reasoning. To address this, We introduce R2-KG, a plug-and-play, dual-agent framework that separates reasoning into two roles: an Operator (a low-capacity LLM) that gathers evidence and a Supervisor (a high-capacity LLM) that makes final judgments. This design is cost-efficient for LLM inference while still maintaining strong reasoning accuracy. Additionally, R2-KG employs an Abstention mechanism, generating answers only when sufficient evidence is collected from KG, which significantly enhances reliability. Experiments across multiple KG-based reasoning tasks show that R2-KG consistently outperforms baselines in both accuracy and reliability, regardless of the inherent capability of LLMs used as the Operator. Further experiments reveal that the single-agent version of R2-KG, equipped with a strict self-consistency strategy, achieves significantly higher-than-baseline reliability while reducing inference cost. However, it also leads to a higher abstention rate in complex KGs. Our findings establish R2-KG as a flexible and cost-effective solution for KG-based reasoning. It reduces reliance on high-capacity LLMs while ensuring trustworthy inference.
近期研究已将大型语言模型(LLM)与知识图谱(KG)相结合,以提升推理能力,可在不额外训练的情况下提高推理准确性,同时减轻虚构现象。然而,现有框架通常较为僵化,难以适应知识图谱或任务变更。它们还严重依赖强大的LLM进行可靠(即值得信赖)的推理。为解决这一问题,我们推出了R2-KG,一个即插即用的双代理框架,将推理分为两个角色:一个负责收集证据的运营商(低容量LLM)和一个进行最终判定的监督者(高容量LLM)。这种设计在LLM推理方面是成本效益较高的,同时仍能保持强大的推理准确性。此外,R2-KG采用了一种弃权机制,仅在从知识图谱收集到足够证据时才生成答案,这显著提高了可靠性。在多个基于知识图谱的推理任务上的实验表明,R2-KG在准确性和可靠性方面始终优于基准线,无论使用作为操作员(Operator)的LLM的固有能力如何。进一步的实验表明,配备有严格自我一致性策略的单一代理版本的R2-KG在可靠性方面大大超过基线水平,同时降低了推理成本。然而,这也导致了在复杂知识图谱中的弃权率更高。我们的发现确立了R2-KG作为基于知识图谱推理的灵活且经济的解决方案。它降低了对高容量LLM的依赖,同时确保可信推断。
论文及项目相关链接
Summary
大型语言模型(LLM)与知识图谱(KG)的结合提升了推理能力,提高了推理的准确性并缓解了虚构的问题。然而,现有框架缺乏灵活性,难以适应知识图谱或任务的变化,且高度依赖强大的LLM进行可靠推理。为解决这一问题,我们推出了R2-KG,一个即插即用的双代理框架,将推理分为两个角色:进行证据搜集的操作员(低容量LLM)和做出最终判断的监督员(高容量LLM)。此设计在保持强大的推理准确性的同时,降低了LLM的推理成本。此外,R2-KG采用拒绝机制,仅在从知识图谱收集到足够证据时才生成答案,显著提高了可靠性。在多个基于知识图谱的推理任务上的实验表明,R2-KG在准确性和可靠性方面始终优于基线,无论使用的操作员LLM的能力如何。
Key Takeaways
- R2-KG结合了大型语言模型(LLMs)和知识图谱(KGs),提升了推理能力。
- 现有框架存在缺乏灵活性和适应性的挑战。
- R2-KG通过分离推理角色为操作员和监督员来解决这些问题,提高推理准确性并降低成本。
- R2-KG采用拒绝机制,仅在有足够证据时生成答案,增强了可靠性。
- 实验表明,R2-KG在多个基于知识图谱的推理任务上表现优于基线。
- R2-KG在复杂知识图谱中的拒绝率相对较高。
点此查看论文截图

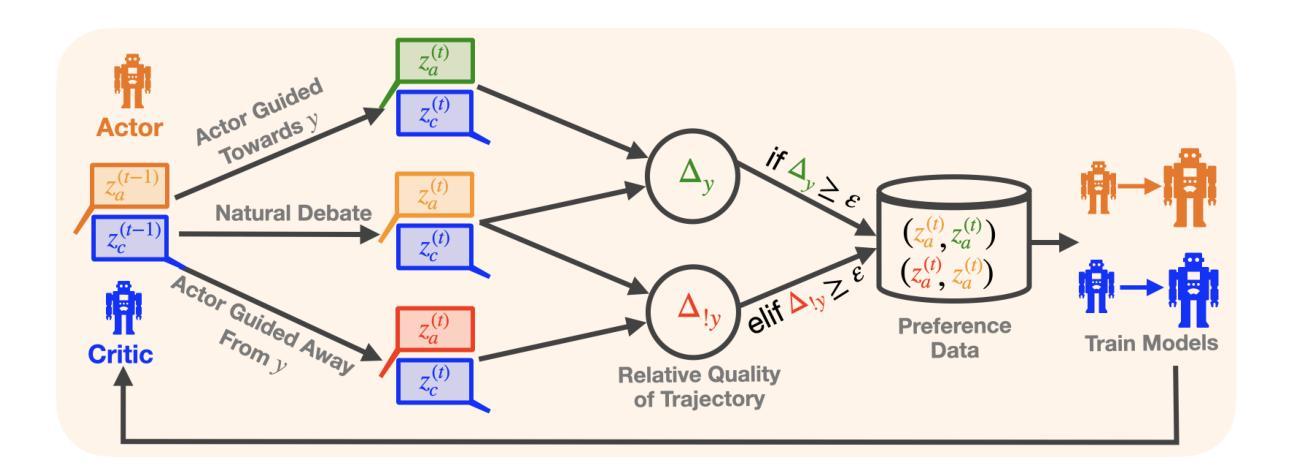
ACC-Collab: An Actor-Critic Approach to Multi-Agent LLM Collaboration
Authors:Andrew Estornell, Jean-Francois Ton, Yuanshun Yao, Yang Liu
Large language models (LLMs) have demonstrated a remarkable ability to serve as general-purpose tools for various language-based tasks. Recent works have demonstrated that the efficacy of such models can be improved through iterative dialog between multiple models. While these paradigms show promise in improving model efficacy, most works in this area treat collaboration as an emergent behavior, rather than a learned behavior. In doing so, current multi-agent frameworks rely on collaborative behaviors to have been sufficiently trained into off-the-shelf models. To address this limitation, we propose ACC-Collab, an Actor-Critic based learning framework to produce a two-agent team (an actor-agent and a critic-agent) specialized in collaboration. We demonstrate that ACC-Collab outperforms SotA multi-agent techniques on a wide array of benchmarks.
大型语言模型(LLM)已经表现出作为各种语言基础任务的通用工具的显著能力。最近的研究表明,通过多个模型之间的迭代对话可以提高此类模型的有效性。虽然这些范式在提高模型有效性方面显示出潜力,但该领域的大多数工作都将协作视为一种突发行为,而非学习行为。因此,当前的多智能体框架依赖于协作行为已经充分训练为现成的模型。为了解决这个问题,我们提出了ACC-Collab,这是一种基于Actor-Critic的学习框架,用于生成一个专门从事协作的两智能体团队(一个Actor智能体和一个Critic智能体)。我们证明,在广泛的基准测试中,ACC-Collab的表现优于最新多智能体技术。
论文及项目相关链接
Summary
大型语言模型(LLMs)具有作为多种语言任务通用工具的能力。最新研究表明,通过多个模型之间的迭代对话可以提高模型的效率。然而,当前的多代理框架依赖于协作行为的充分训练,而协作被视为一种新兴行为而非学习行为。为解决这一局限性,我们提出了基于Actor-Critic学习的ACC-Collab框架,构建了一支由两个代理组成的团队(一个演员代理和一个评论家代理),并擅长协作。我们证明了ACC-Collab在广泛的基准测试中优于现有先进的多代理技术。
Key Takeaways
- 大型语言模型(LLMs)具有多种语言任务的通用工具能力。
- 通过多个模型之间的迭代对话可以提高模型的效率。
- 当前的多代理框架依赖协作行为的充分训练,但协作被视为新兴行为而非学习行为。
- 提出了基于Actor-Critic学习的ACC-Collab框架来解决这一局限性。
- ACC-Collab框架由两个代理组成:一个演员代理和一个评论家代理。
- 演员代理和评论家代理组成的团队擅长协作。
点此查看论文截图


How Far Are We on the Decision-Making of LLMs? Evaluating LLMs’ Gaming Ability in Multi-Agent Environments
Authors:Jen-tse Huang, Eric John Li, Man Ho Lam, Tian Liang, Wenxuan Wang, Youliang Yuan, Wenxiang Jiao, Xing Wang, Zhaopeng Tu, Michael R. Lyu
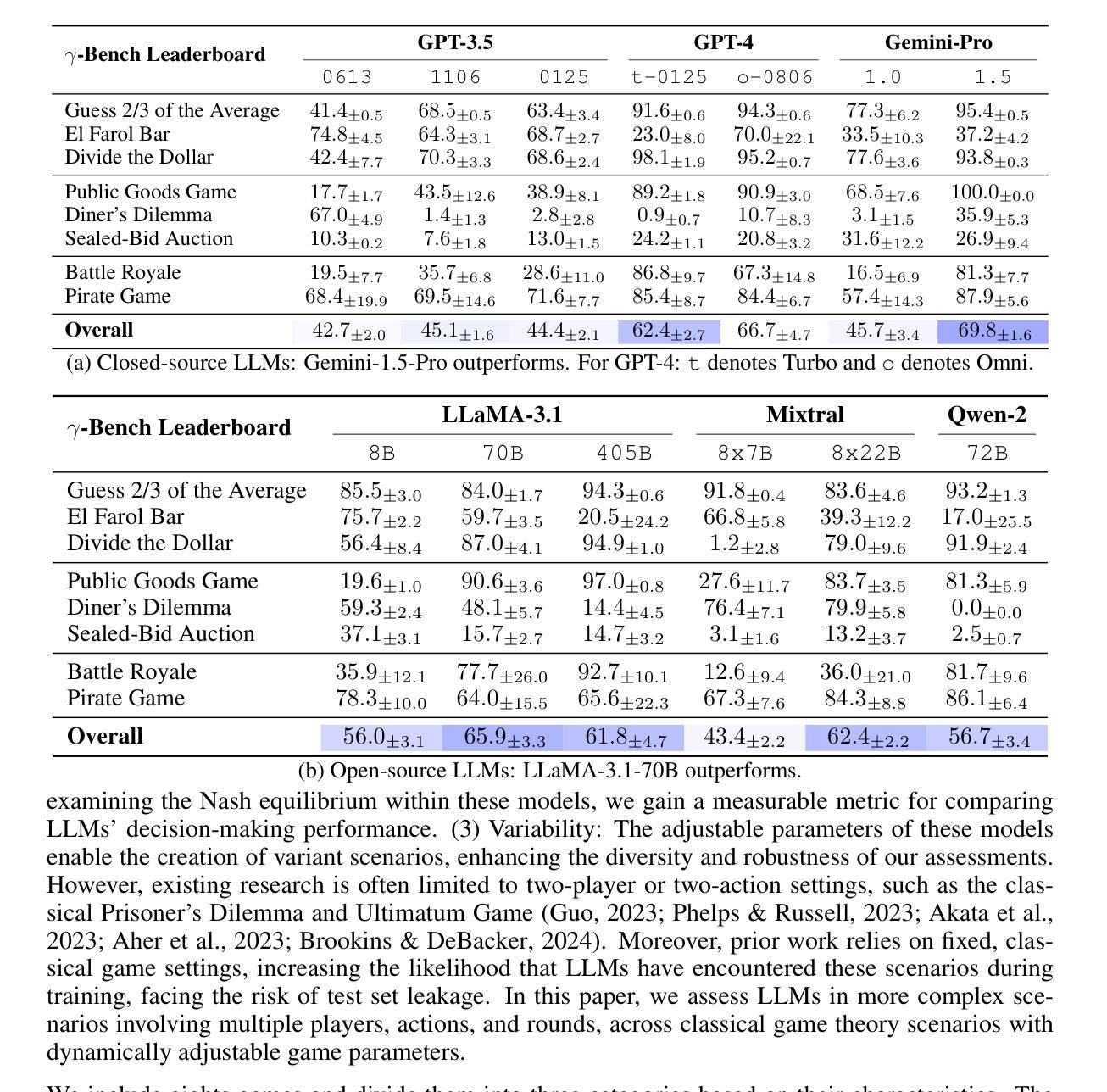
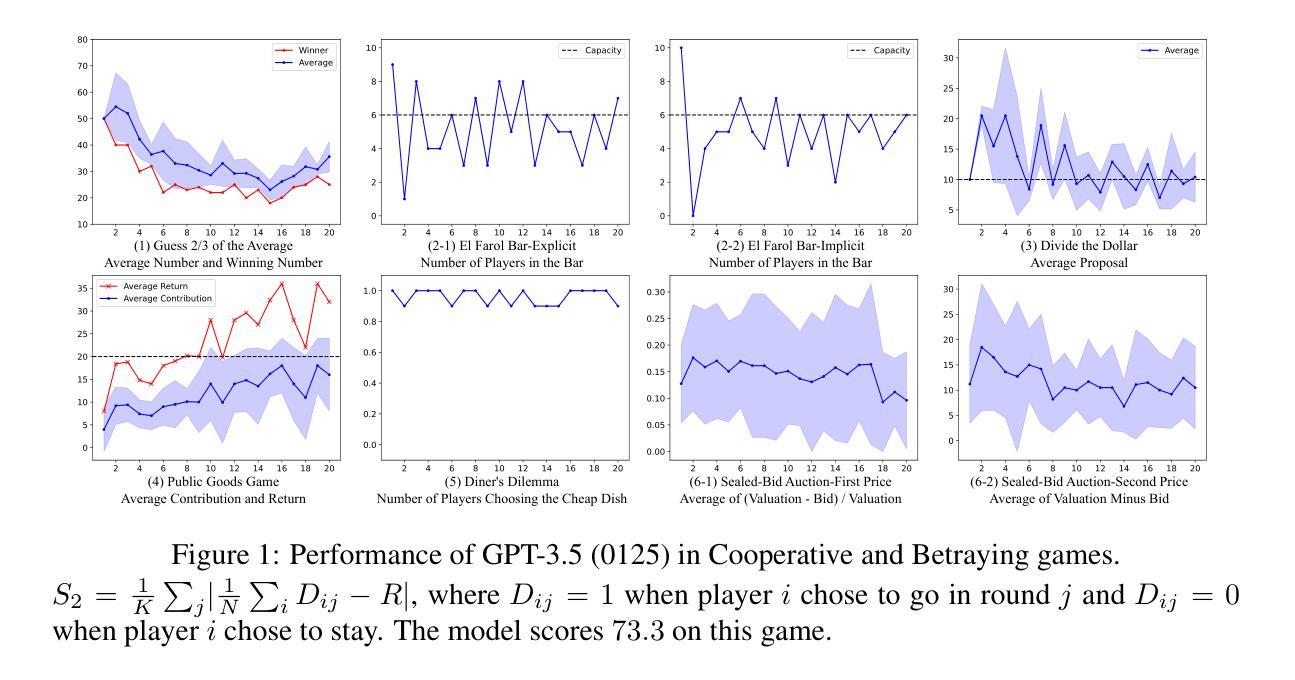
Decision-making is a complex process requiring diverse abilities, making it an excellent framework for evaluating Large Language Models (LLMs). Researchers have examined LLMs’ decision-making through the lens of Game Theory. However, existing evaluation mainly focus on two-player scenarios where an LLM competes against another. Additionally, previous benchmarks suffer from test set leakage due to their static design. We introduce GAMA($\gamma$)-Bench, a new framework for evaluating LLMs’ Gaming Ability in Multi-Agent environments. It includes eight classical game theory scenarios and a dynamic scoring scheme specially designed to quantitatively assess LLMs’ performance. $\gamma$-Bench allows flexible game settings and adapts the scoring system to different game parameters, enabling comprehensive evaluation of robustness, generalizability, and strategies for improvement. Our results indicate that GPT-3.5 demonstrates strong robustness but limited generalizability, which can be enhanced using methods like Chain-of-Thought. We also evaluate 13 LLMs from 6 model families, including GPT-3.5, GPT-4, Gemini, LLaMA-3.1, Mixtral, and Qwen-2. Gemini-1.5-Pro outperforms others, scoring of $69.8$ out of $100$, followed by LLaMA-3.1-70B ($65.9$) and Mixtral-8x22B ($62.4$). Our code and experimental results are publicly available at https://github.com/CUHK-ARISE/GAMABench.
决策是一个需要多种能力的复杂过程,因此它是评估大型语言模型(LLM)的绝佳框架。研究人员已经通过博弈论的角度研究了LLM的决策制定。然而,现有的评估主要集中在两人场景中,即LLM与其他LLM之间的竞争。此外,先前的基准测试由于其静态设计而遭受测试集泄露的问题。我们推出了GAMA($\gamma$)-Bench,这是一个新的评估LLM在多智能体环境中的游戏能力的框架。它包括八个经典的游戏理论场景和一个专门设计的动态评分方案,以定量评估LLM的性能。$\gamma$-Bench允许灵活的游戏设置,并适应不同的游戏参数来调整评分系统,从而全面评估LLM的稳健性、泛化能力和改进策略。我们的结果表明,GPT-3.5表现出强大的稳健性,但泛化能力有限,可以通过如“思维链”等方法加以增强。我们还评估了来自6个模型家族的13个LLM,包括GPT-3.5、GPT-4、双子座、LLaMA-3.1、Mixtral和Qwen-2。其中,双子座-专业版表现最佳,得分为满分一百中的69.8分,其次是LLaMA-3.1(得分65.9)和Mixtral(得分62.4)。我们的代码和实验结果可在https://github.com/CUHK-ARISE/GAMABench上公开获取。
论文及项目相关链接
PDF Accepted to ICLR 2025; 11 pages of main text; 26 pages of appendices; Included models: GPT-3.5-{0613, 1106, 0125}, GPT-4-0125, GPT-4o-0806, Gemini-{1.0, 1.5)-Pro, LLaMA-3.1-{7, 70, 405}B, Mixtral-8x{7, 22}B, Qwen-2-72B
Summary
决策制定是一个需要多种能力的复杂过程,因此成为评估大型语言模型(LLM)的理想框架。研究者通过博弈论的角度研究LLM的决策制定能力。现有评估主要集中在两人场景中,即LLM与另一个智能体的竞争情境。但先前的评价指标因设计静态而易出现测试集泄露问题。为此,我们推出了GAMA($\gamma$)-Bench新框架,用于在多变体环境中评估LLM的游戏能力。它包含八个经典博弈论场景和特别设计的动态评分系统,定量评估LLM的表现。$\gamma$-Bench框架允许灵活的游戏设置,并能适应不同的游戏参数调整评分系统,全面评估LLM的稳健性、通用性和改进策略。研究发现GPT-3.5展现出强大的稳健性但通用性有限,而通过使用链思维等方法可以增强其通用性。我们还评估了来自六个模型家族的13个LLM的性能排名,并公开了相关代码和实验结果。https://github.com/CUHK-ARISE/GAMABench。
Key Takeaways
- 大型语言模型(LLM)的决策制定能力通过博弈论角度进行研究。
- 现有评估框架主要集中在两人场景中,存在测试集泄露问题。
- 引入GAMA($\gamma$)-Bench新框架用于多变体环境中评估LLM的游戏能力。
- $\gamma$-Bench包含多个经典博弈论场景和动态评分系统,可全面评估LLM的稳健性、通用性和策略改进。
- GPT-3.5展现出强大的稳健性但通用性有限,可通过特定方法如链思维增强通用性。
- 评估了多个LLM的性能排名,包括GPT系列和其他模型家族。
点此查看论文截图

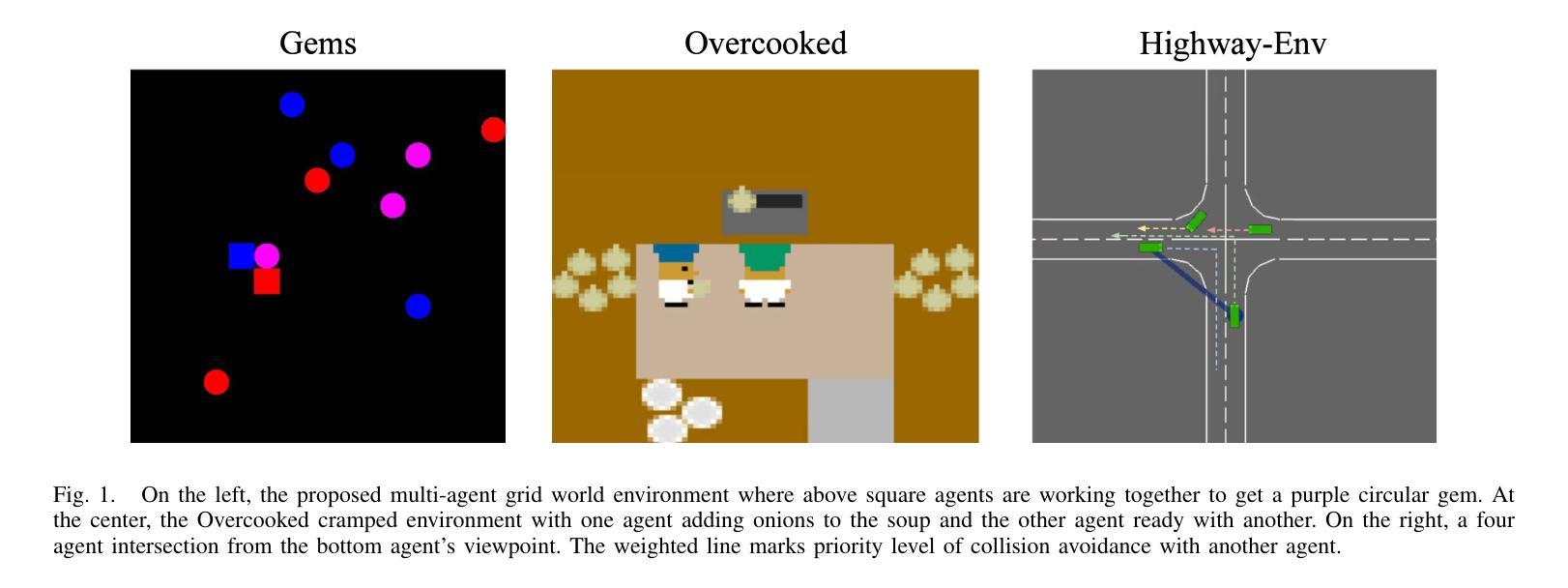
DoraemonGPT: Toward Understanding Dynamic Scenes with Large Language Models (Exemplified as A Video Agent)
Authors:Zongxin Yang, Guikun Chen, Xiaodi Li, Wenguan Wang, Yi Yang
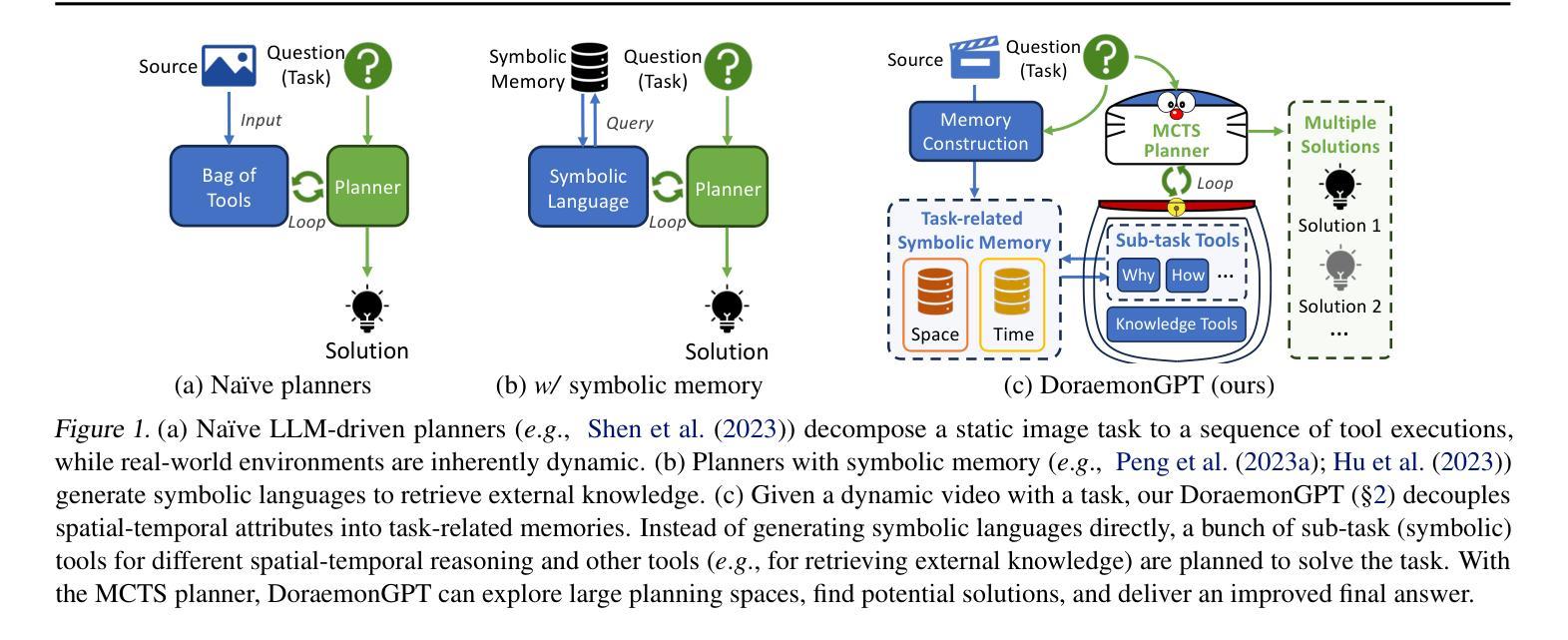
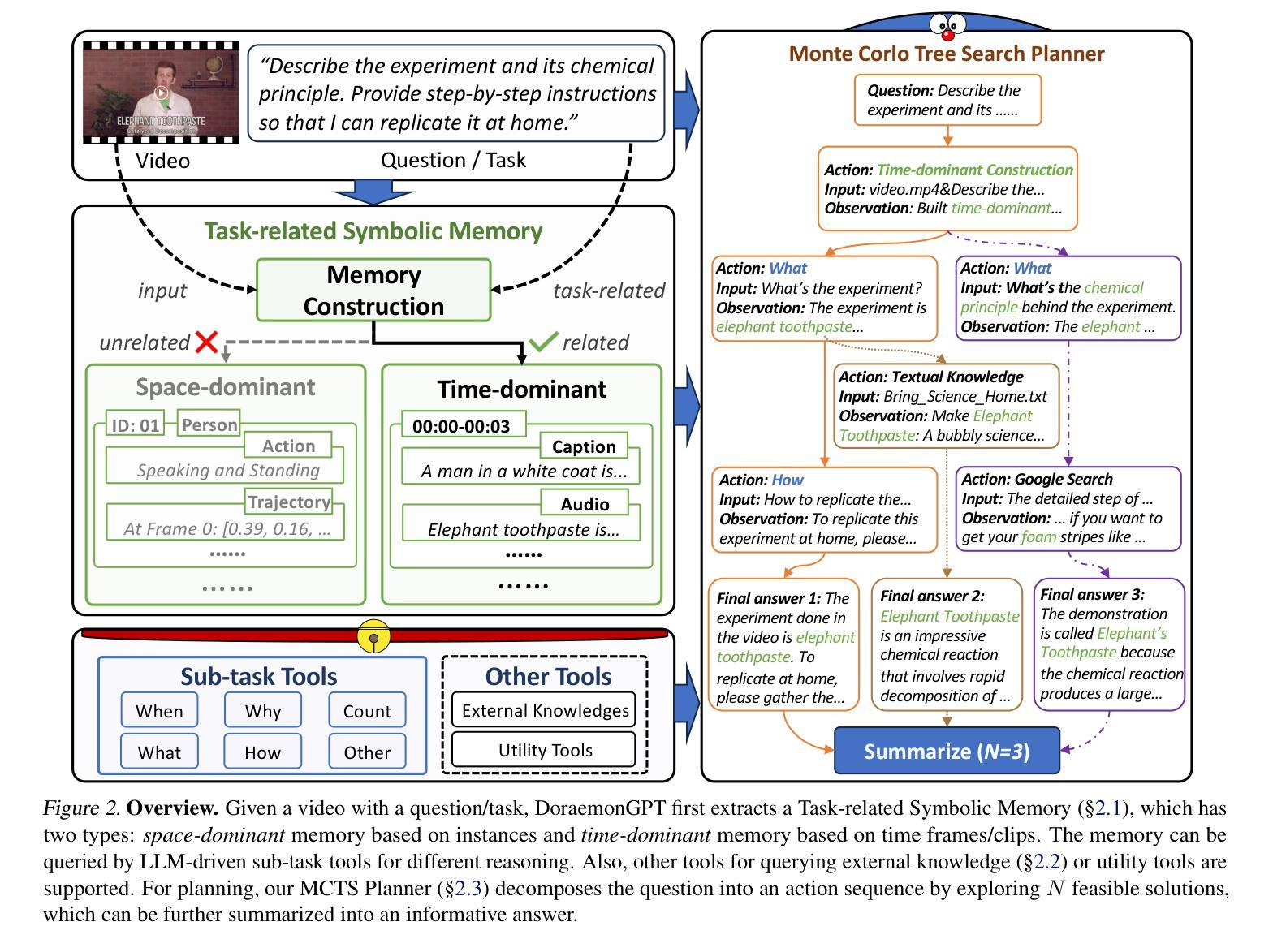
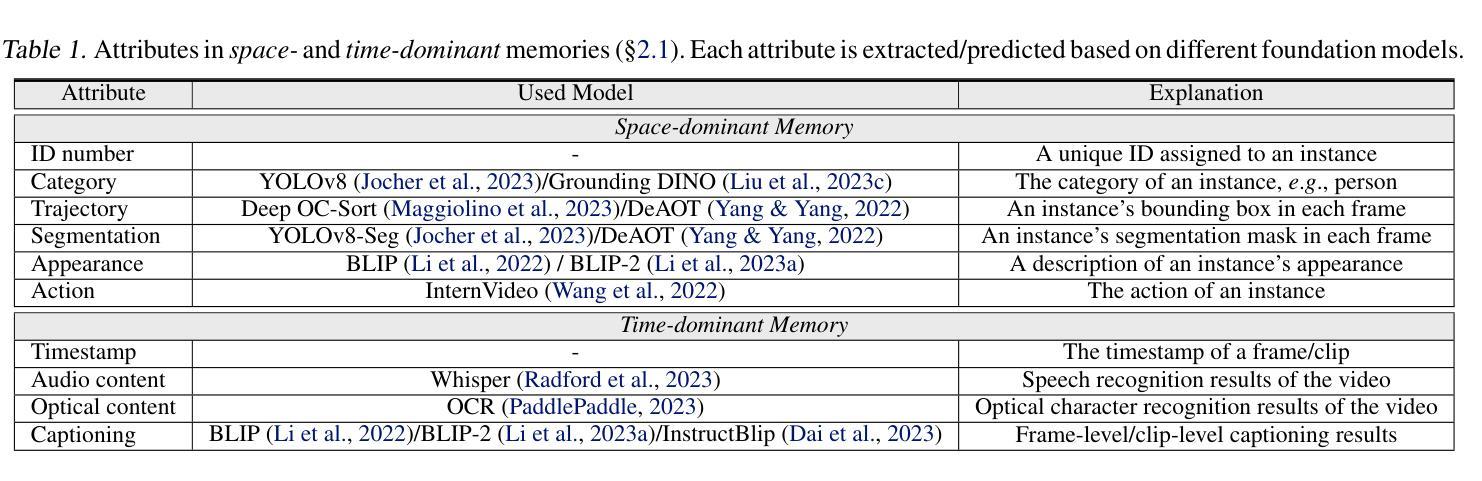
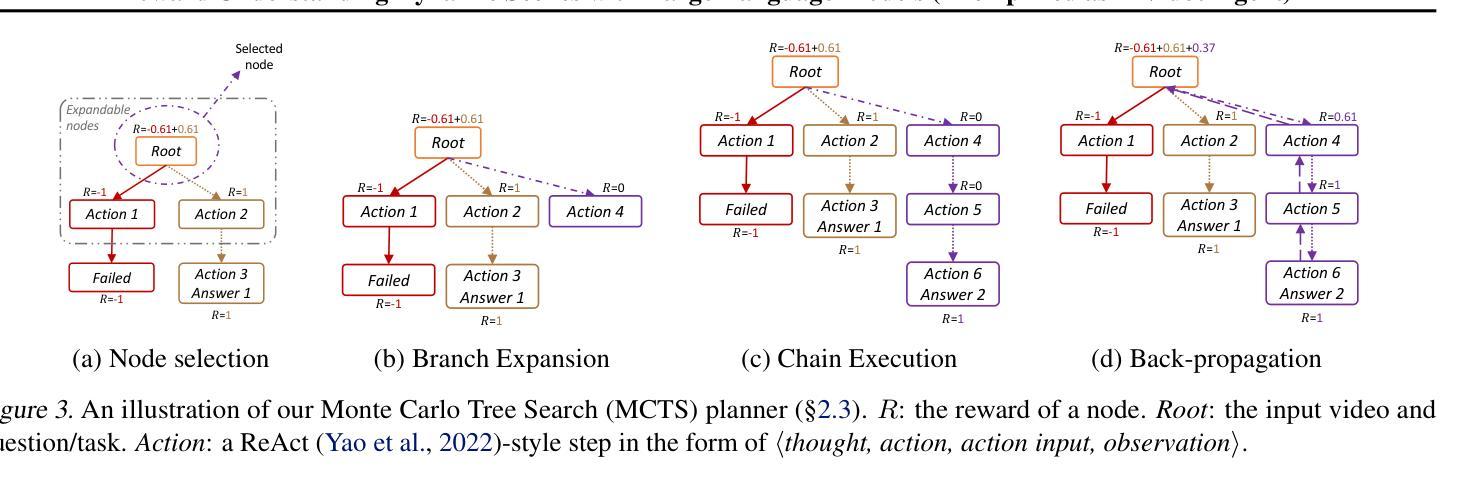
Recent LLM-driven visual agents mainly focus on solving image-based tasks, which limits their ability to understand dynamic scenes, making it far from real-life applications like guiding students in laboratory experiments and identifying their mistakes. Hence, this paper explores DoraemonGPT, a comprehensive and conceptually elegant system driven by LLMs to understand dynamic scenes. Considering the video modality better reflects the ever-changing nature of real-world scenarios, we exemplify DoraemonGPT as a video agent. Given a video with a question/task, DoraemonGPT begins by converting the input video into a symbolic memory that stores task-related attributes. This structured representation allows for spatial-temporal querying and reasoning by well-designed sub-task tools, resulting in concise intermediate results. Recognizing that LLMs have limited internal knowledge when it comes to specialized domains (e.g., analyzing the scientific principles underlying experiments), we incorporate plug-and-play tools to assess external knowledge and address tasks across different domains. Moreover, a novel LLM-driven planner based on Monte Carlo Tree Search is introduced to explore the large planning space for scheduling various tools. The planner iteratively finds feasible solutions by backpropagating the result’s reward, and multiple solutions can be summarized into an improved final answer. We extensively evaluate DoraemonGPT’s effectiveness on three benchmarks and several in-the-wild scenarios. The code will be released at https://github.com/z-x-yang/DoraemonGPT.
最近的LLM驱动视觉代理主要专注于解决基于图像的任务,这限制了它们对动态场景的理解能力,因此难以应用于指导实验室实验和学生纠错等现实生活场景。因此,本文探讨了DoraemonGPT这一由LLM驱动的全面而概念优雅的系统,以理解动态场景。考虑到视频模式能更好地反映真实场景的不断变化性质,我们将DoraemonGPT作为视频代理进行示例。对于包含问题或任务的视频,DoraemonGPT首先将其转换为存储任务相关属性的符号记忆。这种结构化表示允许通过精心设计的工作表进行时空查询和推理,从而得到简洁的中间结果。我们认识到,在特定领域(例如分析实验背后的科学原理),LLM的内部知识是有限的,因此我们引入了即插即用工具来评估外部知识并解决不同领域的任务。此外,还介绍了一种基于蒙特卡洛树搜索的LLM驱动规划器,用于探索大量规划空间以调度各种工具。规划器通过反向传播结果的奖励来迭代寻找可行解决方案,并将多个解决方案总结为改进的最终答案。我们在三个基准测试和若干野外场景中广泛评估了DoraemonGPT的有效性。代码将在https://github.com/z-x-yang/DoraemonGPT上发布。
论文及项目相关链接
Summary
大热的自然语言驱动模型多应用于处理静态图像任务,对动态场景理解尚显不足,距离应用于真实世界场景如学生实验指导等存在较大差距。本研究以全新的LLM驱动的动态场景理解系统DoraemonGPT为切入,结合视频载体特点开展研究。通过转化视频为符号记忆,存储任务相关属性,利用子任务工具进行时空查询和推理,产生精准中间结果。发现特定领域知识受限于模型本身知识广度的问题后,本研究利用全新插拔式工具评估外部知识,拓宽模型应用领域。同时引入基于蒙特卡洛树搜索的LLM驱动规划器进行任务调度规划,利用结果反馈优化求解路径。通过三项基准测试及现实场景验证证明模型的有效性。模型代码已上传至GitHub。
Key Takeaways
- LLM驱动的视觉代理模型在处理动态场景理解方面存在巨大潜力。
- DoraemonGPT系统结合视频模态处理动态场景,具有强大的时空查询和推理能力。
- 通过将视频转化为符号记忆,DoraemonGPT能够存储任务相关属性并产生精准中间结果。
- 利用子任务工具集以完成特定的分析推理工作,从而提高效率并增加答案的全面性。
- LLMS的知识范围受限于特定领域的问题得到解决,通过引入插拔式工具来评估外部知识并应用于不同领域任务。
- 利用蒙特卡洛树搜索技术的LLM驱动规划器有效解决了大规模任务规划问题。该规划器能够通过结果反馈进行迭代优化求解路径。
点此查看论文截图