⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-10 更新
Synthetic Data is an Elegant GIFT for Continual Vision-Language Models
Authors:Bin Wu, Wuxuan Shi, Jinqiao Wang, Mang Ye
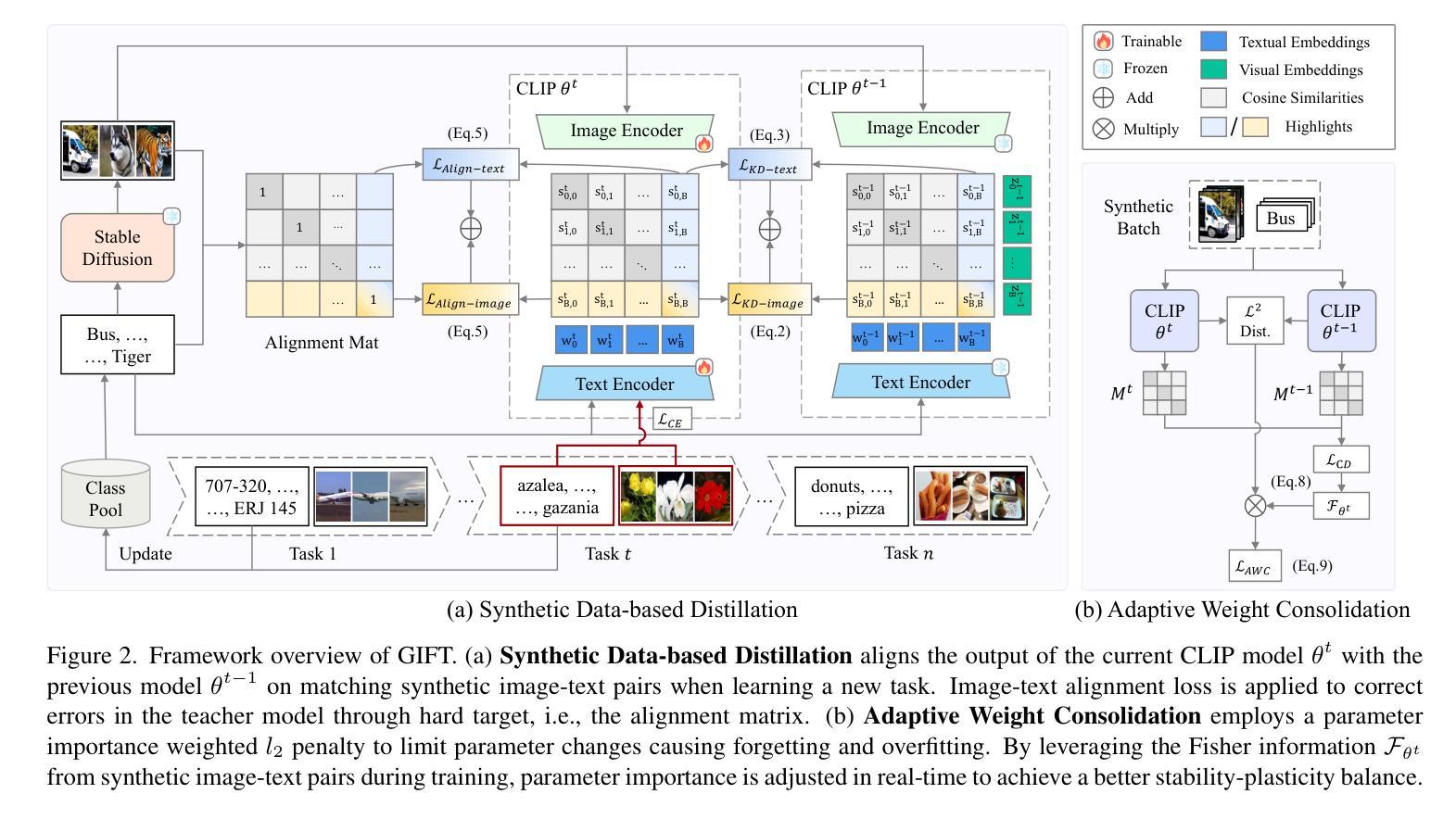
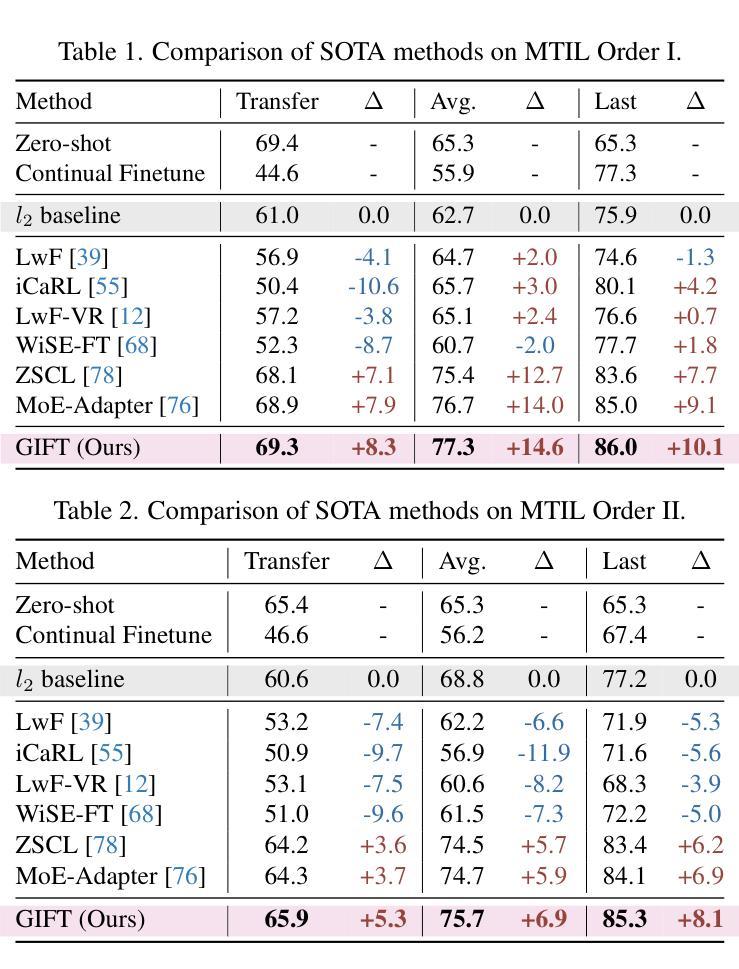
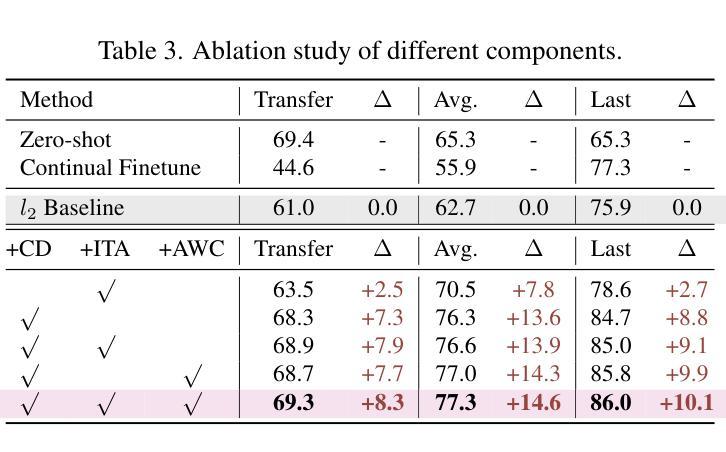
Pre-trained Vision-Language Models (VLMs) require Continual Learning (CL) to efficiently update their knowledge and adapt to various downstream tasks without retraining from scratch. However, for VLMs, in addition to the loss of knowledge previously learned from downstream tasks, pre-training knowledge is also corrupted during continual fine-tuning. This issue is exacerbated by the unavailability of original pre-training data, leaving VLM’s generalization ability degrading. In this paper, we propose GIFT, a novel continual fine-tuning approach that utilizes synthetic data to overcome catastrophic forgetting in VLMs. Taking advantage of recent advances in text-to-image synthesis, we employ a pre-trained diffusion model to recreate both pre-training and learned downstream task data. In this way, the VLM can revisit previous knowledge through distillation on matching diffusion-generated images and corresponding text prompts. Leveraging the broad distribution and high alignment between synthetic image-text pairs in VLM’s feature space, we propose a contrastive distillation loss along with an image-text alignment constraint. To further combat in-distribution overfitting and enhance distillation performance with limited amount of generated data, we incorporate adaptive weight consolidation, utilizing Fisher information from these synthetic image-text pairs and achieving a better stability-plasticity balance. Extensive experiments demonstrate that our method consistently outperforms previous state-of-the-art approaches across various settings.
预训练视觉语言模型(VLMs)需要持续学习(CL)来有效地更新其知识,并适应各种下游任务,而无需从头开始重新训练。然而,对于VLMs而言,除了从下游任务中学到的知识丢失之外,预训练知识在持续微调过程中也会被破坏。由于原始预训练数据不可用,这一问题更加严重,导致VLM的泛化能力下降。在本文中,我们提出了一种新型的持续微调方法GIFT,它利用合成数据来克服VLM中的灾难性遗忘问题。我们借助最新的文本到图像合成技术,利用预训练的扩散模型重新创建预训练和已学习的下游任务数据。通过这种方式,VLM可以通过对匹配的扩散生成图像和相应的文本提示进行蒸馏来回顾以前的知识。凭借合成图像-文本对在VLM特征空间中的广泛分布和高对齐度,我们提出了一种对比蒸馏损失以及图像-文本对齐约束。为了进一步对抗内部分布过拟合并增强有限生成数据的蒸馏性能,我们结合了自适应权重整合,利用这些合成图像-文本对的Fisher信息,实现了更好的稳定性-可塑性平衡。大量实验表明,我们的方法在各种设置下始终优于先前的方法。
论文及项目相关链接
PDF This work is accepted by CVPR 2025. Modifications may be performed
Summary
本文提出一种新型的持续微调方法GIFT,利用合成数据克服视觉语言模型(VLMs)在持续学习中的灾难性遗忘问题。通过利用预训练的扩散模型重新创建预训练及已学习的下游任务数据,使VLM能够通过匹配生成的扩散图像和相应的文本提示进行知识蒸馏。同时,利用合成图像-文本对在VLM特征空间中的广泛分布和高度对齐特性,提出了对比蒸馏损失和图像-文本对齐约束。为进一步解决内部分布过拟合问题并增强有限生成数据的蒸馏性能,融入自适应权重整合策略,利用这些合成图像-文本对的Fisher信息,实现更好的稳定-可塑性平衡。实验表明,该方法在各种设置下均表现优于先前的主流方法。
Key Takeaways
- GIFT是一种针对视觉语言模型(VLMs)的持续微调方法,旨在解决灾难性遗忘问题。
- 利用预训练的扩散模型重新创建预训练及下游任务数据,使VLM能够通过知识蒸馏复习旧知识。
- 通过合成图像-文本对在VLM特征空间中的广泛分布和高度对齐特性,引入对比蒸馏损失和图像-文本对齐约束。
- 为解决内部分布过拟合问题并增强有限生成数据的性能,采用自适应权重整合策略。
- 结合合成图像-文本对的Fisher信息,实现稳定-可塑性之间的平衡。
- 实验表明,GIFT方法在各种设置下均优于先前的主流方法。
点此查看论文截图

Underlying Semantic Diffusion for Effective and Efficient In-Context Learning
Authors:Zhong Ji, Weilong Cao, Yan Zhang, Yanwei Pang, Jungong Han, Xuelong Li
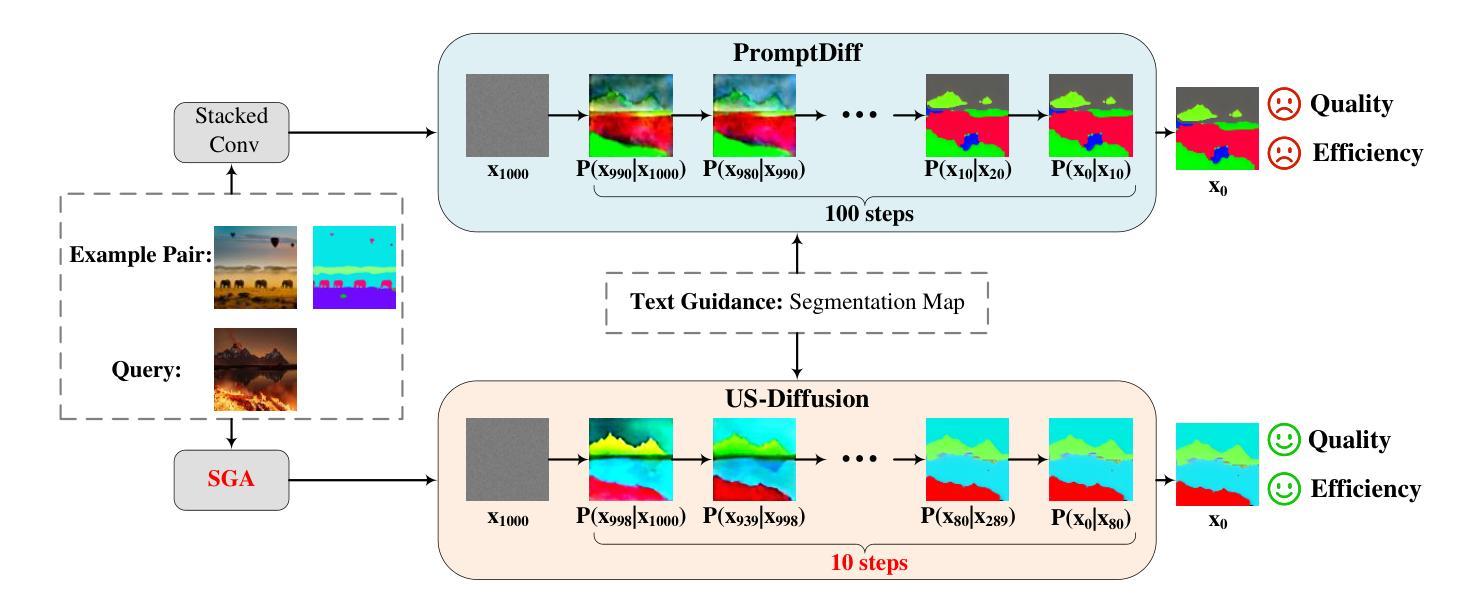
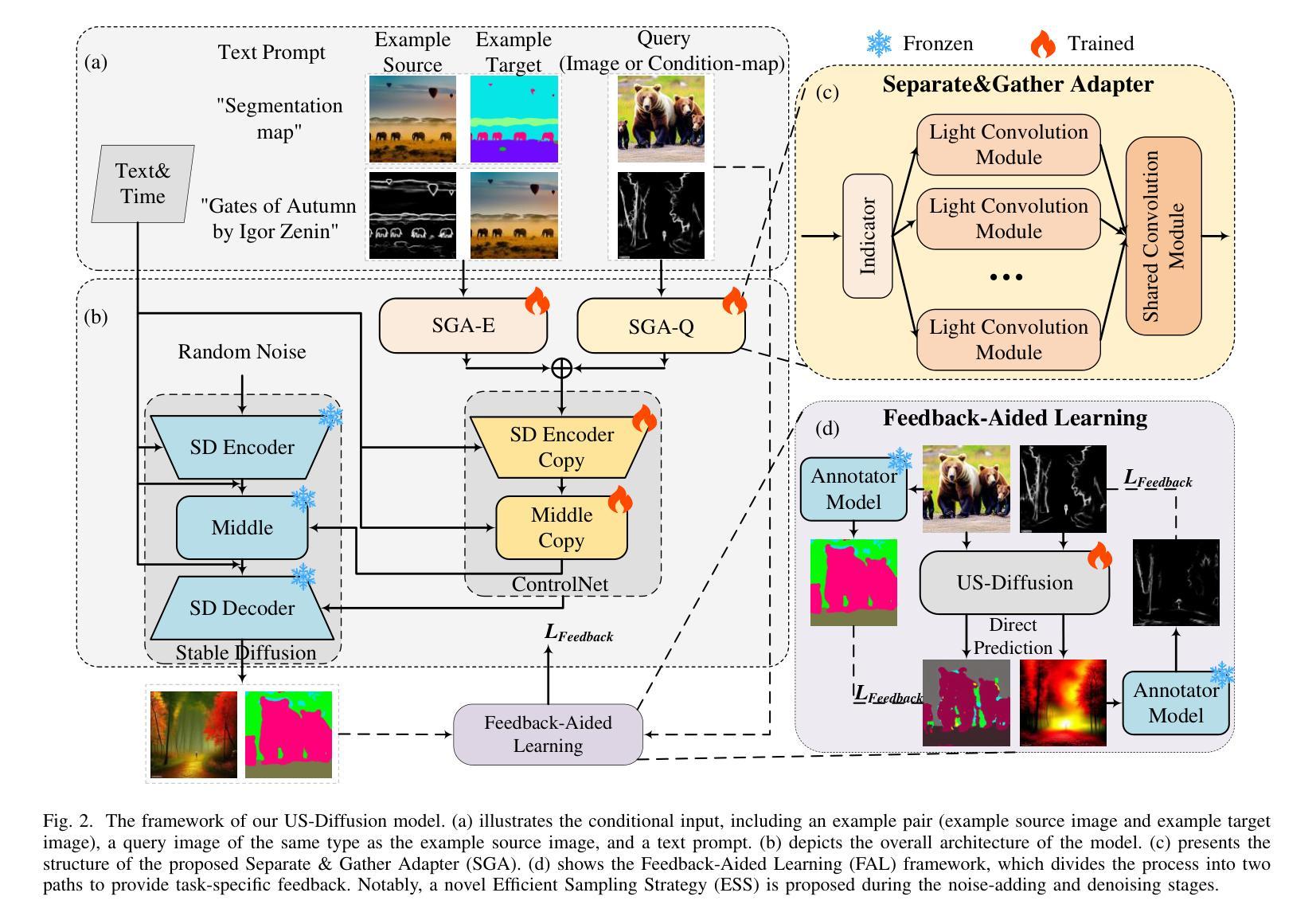
Diffusion models has emerged as a powerful framework for tasks like image controllable generation and dense prediction. However, existing models often struggle to capture underlying semantics (e.g., edges, textures, shapes) and effectively utilize in-context learning, limiting their contextual understanding and image generation quality. Additionally, high computational costs and slow inference speeds hinder their real-time applicability. To address these challenges, we propose Underlying Semantic Diffusion (US-Diffusion), an enhanced diffusion model that boosts underlying semantics learning, computational efficiency, and in-context learning capabilities on multi-task scenarios. We introduce Separate & Gather Adapter (SGA), which decouples input conditions for different tasks while sharing the architecture, enabling better in-context learning and generalization across diverse visual domains. We also present a Feedback-Aided Learning (FAL) framework, which leverages feedback signals to guide the model in capturing semantic details and dynamically adapting to task-specific contextual cues. Furthermore, we propose a plug-and-play Efficient Sampling Strategy (ESS) for dense sampling at time steps with high-noise levels, which aims at optimizing training and inference efficiency while maintaining strong in-context learning performance. Experimental results demonstrate that US-Diffusion outperforms the state-of-the-art method, achieving an average reduction of 7.47 in FID on Map2Image tasks and an average reduction of 0.026 in RMSE on Image2Map tasks, while achieving approximately 9.45 times faster inference speed. Our method also demonstrates superior training efficiency and in-context learning capabilities, excelling in new datasets and tasks, highlighting its robustness and adaptability across diverse visual domains.
扩散模型已经成为图像可控生成和密集预测等任务的重要框架。然而,现有模型往往难以捕捉底层语义(如边缘、纹理、形状),并有效地利用上下文学习,从而限制了其上下文理解和图像生成质量。此外,较高的计算成本和缓慢的推理速度阻碍了其在实时应用中的适用性。为了解决这些挑战,我们提出了底层语义扩散(US-Diffusion),这是一种增强的扩散模型,可以在多任务场景下提高底层语义学习、计算效率和上下文学习能力。我们引入了分离与聚合适配器(SGA),它解耦了不同任务的输入条件,同时共享架构,从而实现了更好的上下文学习和跨不同视觉领域的泛化能力。我们还提出了反馈辅助学习(FAL)框架,该框架利用反馈信号来指导模型捕捉语义细节并根据任务特定的上下文线索进行动态适应。此外,我们还提出了一种即插即用的高效采样策略(ESS),用于在较高噪声水平的时间步长上进行密集采样,旨在优化训练和推理效率,同时保持强大的上下文学习性能。实验结果表明,US-Diffusion在Map2Image任务上的FID平均降低了7.47,在Image2Map任务上的RMSE平均降低了0.026,同时推理速度提高了约9.45倍。我们的方法还展示了卓越的训练效率和上下文学习能力,在新的数据集和任务中表现出色,突显其在不同视觉领域的稳健性和适应性。
论文及项目相关链接
摘要
扩散模型已成为图像可控生成和密集预测等任务中的强大框架。然而,现有模型在捕捉底层语义(如边缘、纹理、形状)和有效利用上下文学习方面存在不足,限制了其上下文理解和图像生成质量。针对这些挑战,我们提出Underlying Semantic Diffusion(US-Diffusion)扩散模型增强底层语义学习、计算效率和多任务的上下文学习能力。引入分离聚集适配器(SGA),它允许对不同任务进行解耦输入条件,同时共享架构,实现了更好的上下文学习和跨不同视觉领域的泛化能力。我们还提出了反馈辅助学习(FAL)框架,利用反馈信号指导模型捕捉语义细节并根据任务特定上下文动态调整。此外,我们提出了即插即用的高效采样策略(ESS),针对高噪声水平的时间步长进行密集采样,旨在优化训练和推理效率,同时保持强大的上下文学习能力。实验结果表明,US-Diffusion在Map2Image任务上平均减少了7.47的FID分数,在Image2Map任务上平均减少了0.026的RMSE分数,同时推理速度提高了约9.45倍。我们的方法还展示了出色的训练效率和上下文学习能力,在新数据集和任务中表现出色,凸显其在不同视觉领域的稳健性和适应性。
要点分析
- 扩散模型已成为图像生成和预测任务的重要工具。但现有模型存在语义捕捉和上下文学习的局限性。
- US-Diffusion模型旨在解决这些挑战,通过增强底层语义学习、计算效率和上下文学习能力。
- 引入分离聚集适配器(SGA)以解耦不同任务的输入条件并共享架构,实现更好的上下文学习和跨领域泛化。
- 反馈辅助学习(FAL)框架利用反馈信号来指导模型捕捉语义细节并适应任务特定的上下文。
- 提出高效采样策略(ESS),旨在优化训练和推理效率,同时保持上下文学习能力。
点此查看论文截图

TextDoctor: Unified Document Image Inpainting via Patch Pyramid Diffusion Models
Authors:Wanglong Lu, Lingming Su, Jingjing Zheng, Vinícius Veloso de Melo, Farzaneh Shoeleh, John Hawkin, Terrence Tricco, Hanli Zhao, Xianta Jiang
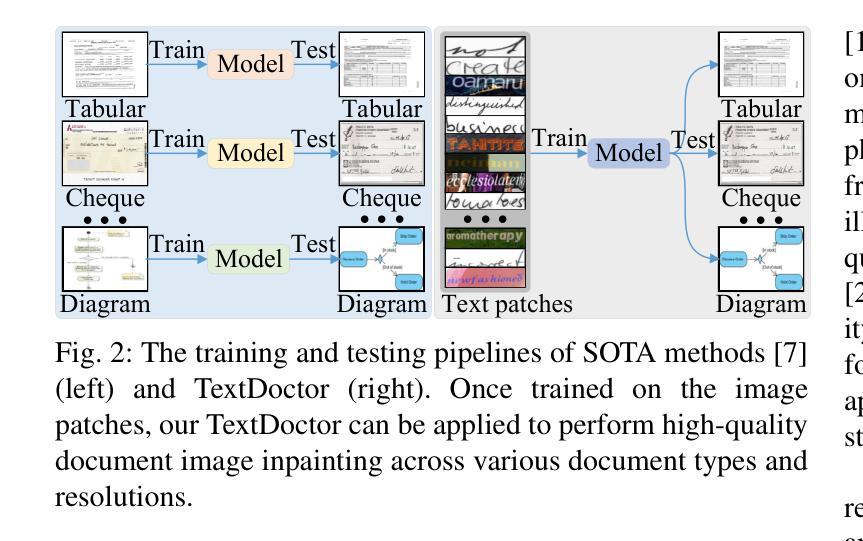
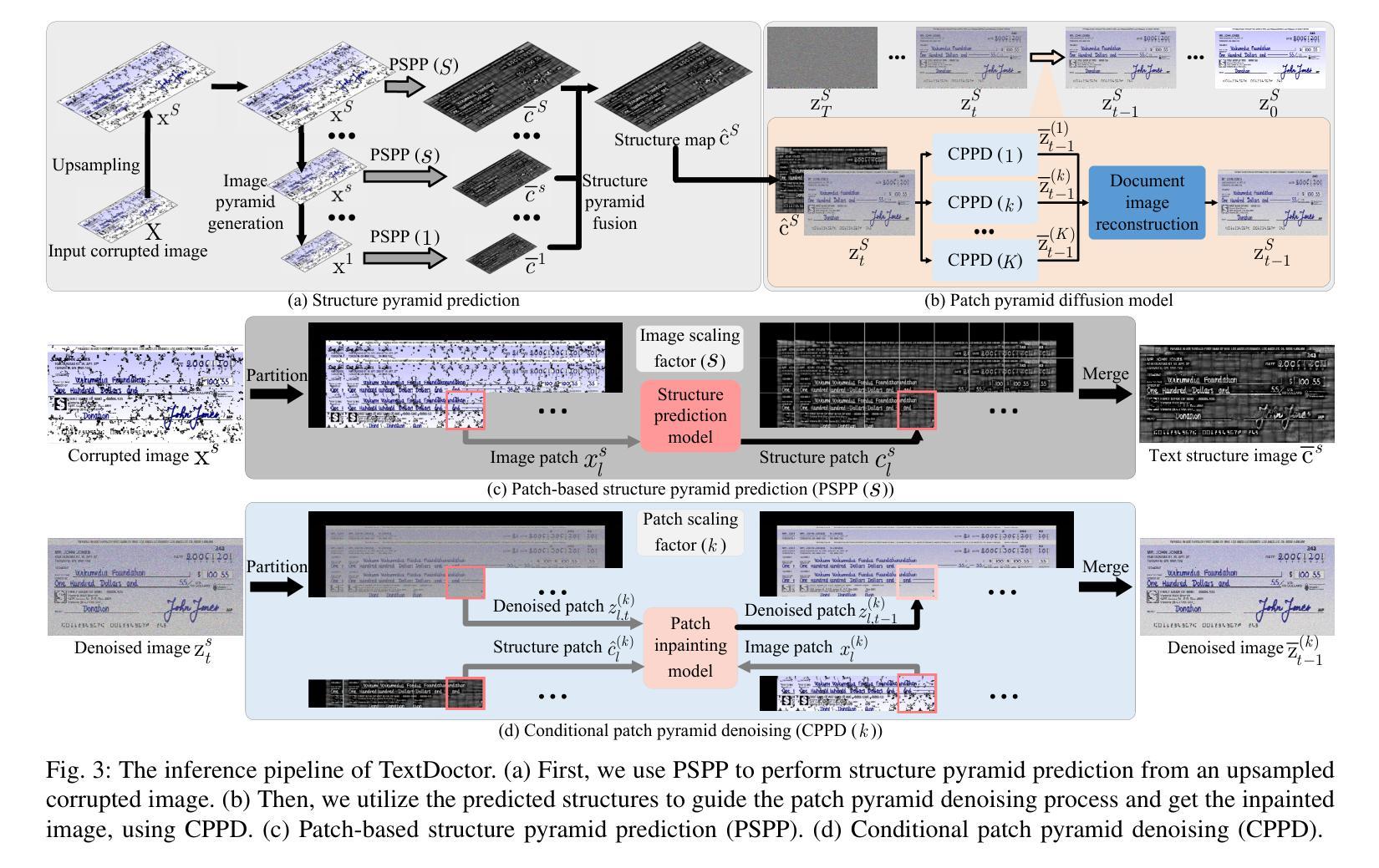
Digital versions of real-world text documents often suffer from issues like environmental corrosion of the original document, low-quality scanning, or human interference. Existing document restoration and inpainting methods typically struggle with generalizing to unseen document styles and handling high-resolution images. To address these challenges, we introduce TextDoctor, a novel unified document image inpainting method. Inspired by human reading behavior, TextDoctor restores fundamental text elements from patches and then applies diffusion models to entire document images instead of training models on specific document types. To handle varying text sizes and avoid out-of-memory issues, common in high-resolution documents, we propose using structure pyramid prediction and patch pyramid diffusion models. These techniques leverage multiscale inputs and pyramid patches to enhance the quality of inpainting both globally and locally. Extensive qualitative and quantitative experiments on seven public datasets validated that TextDoctor outperforms state-of-the-art methods in restoring various types of high-resolution document images.
现实世界文本文件的数字版本通常面临原始文件环境腐蚀、扫描质量低或人为干扰等问题。现有的文档恢复和修复方法通常在推广到未见过的文档风格和处理高分辨率图像时遇到困难。为了解决这些挑战,我们引入了TextDoctor,这是一种新颖的统一文档图像修复方法。TextDoctor受人类阅读行为的启发,首先恢复文本的基本元素,然后对整个文档图像应用扩散模型,而不是在特定文档类型上训练模型。为了处理不同的文本大小并避免高分辨率文档中常见的内存不足问题,我们建议使用结构金字塔预测和补丁金字塔扩散模型。这些技术利用多尺度输入和金字塔补丁来提高全局和局部修复的质量。在七个公共数据集上进行的大量定性和定量实验验证了TextDoctor在恢复各种类型的高分辨率文档图像方面优于最先进的方法。
论文及项目相关链接
PDF 28 pages, 25 figures
Summary
文本DocumentDoctor针对数字版现实世界文本文件存在的问题,如原始文档的环境腐蚀、扫描质量低或人为干扰等,提出了一种新的统一文档图像修复方法。该方法受到人类阅读行为的启发,从补丁中恢复基本文本元素,然后应用扩散模型于整个文档图像,而不是针对特定文档类型训练模型。针对高分辨率文档中常见的文本大小不同和内存不足问题,我们提出了结构金字塔预测和补丁金字塔扩散模型等解决方案。这些方法利用多尺度输入和金字塔补丁,提高了全局和局部修复的质量。在七个公共数据集上的广泛定性和定量实验验证了TextDoctor在恢复各种类型的高分辨率文档图像方面优于现有技术。
Key Takeaways
- TextDoctor是一种新的文档图像修复方法,旨在解决数字版现实世界文本文件存在的问题。
- 该方法能够从补丁中恢复基本文本元素,并应用扩散模型于整个文档图像。
- TextDoctor的灵感来源于人类阅读行为,能够处理不同的文档类型。
- 为了应对高分辨率文档中常见的文本大小不同和内存不足问题,TextDoctor采用了结构金字塔预测和补丁金字塔扩散模型等技术。
- 这些技术利用多尺度输入和金字塔补丁,提高了修复质量,既全局又局部。
- TextDoctor在七个公共数据集上进行了广泛的实验,证明了其在恢复高分辨率文档图像方面的优越性。
点此查看论文截图


Positive-Unlabeled Diffusion Models for Preventing Sensitive Data Generation
Authors:Hiroshi Takahashi, Tomoharu Iwata, Atsutoshi Kumagai, Yuuki Yamanaka, Tomoya Yamashita
Diffusion models are powerful generative models but often generate sensitive data that are unwanted by users, mainly because the unlabeled training data frequently contain such sensitive data. Since labeling all sensitive data in the large-scale unlabeled training data is impractical, we address this problem by using a small amount of labeled sensitive data. In this paper, we propose positive-unlabeled diffusion models, which prevent the generation of sensitive data using unlabeled and sensitive data. Our approach can approximate the evidence lower bound (ELBO) for normal (negative) data using only unlabeled and sensitive (positive) data. Therefore, even without labeled normal data, we can maximize the ELBO for normal data and minimize it for labeled sensitive data, ensuring the generation of only normal data. Through experiments across various datasets and settings, we demonstrated that our approach can prevent the generation of sensitive images without compromising image quality.
扩散模型是一种强大的生成模型,但经常会生成用户不需要的敏感数据,这主要是因为未标记的训练数据经常包含这种敏感数据。由于在大规模未标记的训练数据中标记所有敏感数据是不切实际的,我们通过使用少量标记的敏感数据来解决这个问题。在本文中,我们提出了正负未标记扩散模型,该模型使用未标记和敏感数据来防止敏感数据的生成。我们的方法可以使用仅未标记的(正常)(阴性)数据来近似正常数据的证据下限(ELBO),因此,即使没有标记的正常数据,我们也可以最大化正常数据的ELBO并最小化标记敏感数据的ELBO,确保只生成正常数据。通过在不同数据集和设置上的实验,我们证明了我们的方法可以防止生成敏感图像,同时不会损害图像质量。
论文及项目相关链接
PDF Accepted at ICLR2025. Code is available at https://github.com/takahashihiroshi/pudm
Summary
扩散模型通过少量标记敏感数据生成正向未标记扩散模型,防止生成敏感数据。此方法无需标记正常数据,即可最大化正常数据的证据下限(ELBO),最小化标记敏感数据的ELBO,确保仅生成正常数据。实验证明,该方法能有效防止生成敏感图像,同时保证图像质量不受影响。
Key Takeaways
- 扩散模型能够生成强大的生成模型,但可能会生成用户不需要的敏感数据。
- 敏感数据经常出现在未标记的训练数据中。
- 使用少量标记敏感数据来解决这一问题。
- 提出正向未标记扩散模型,利用未标记和敏感数据防止生成敏感数据。
- 通过最大化正常数据的证据下限(ELBO)和最小化标记敏感数据的ELBO来实现。
- 无需标记正常数据即可实现。
点此查看论文截图

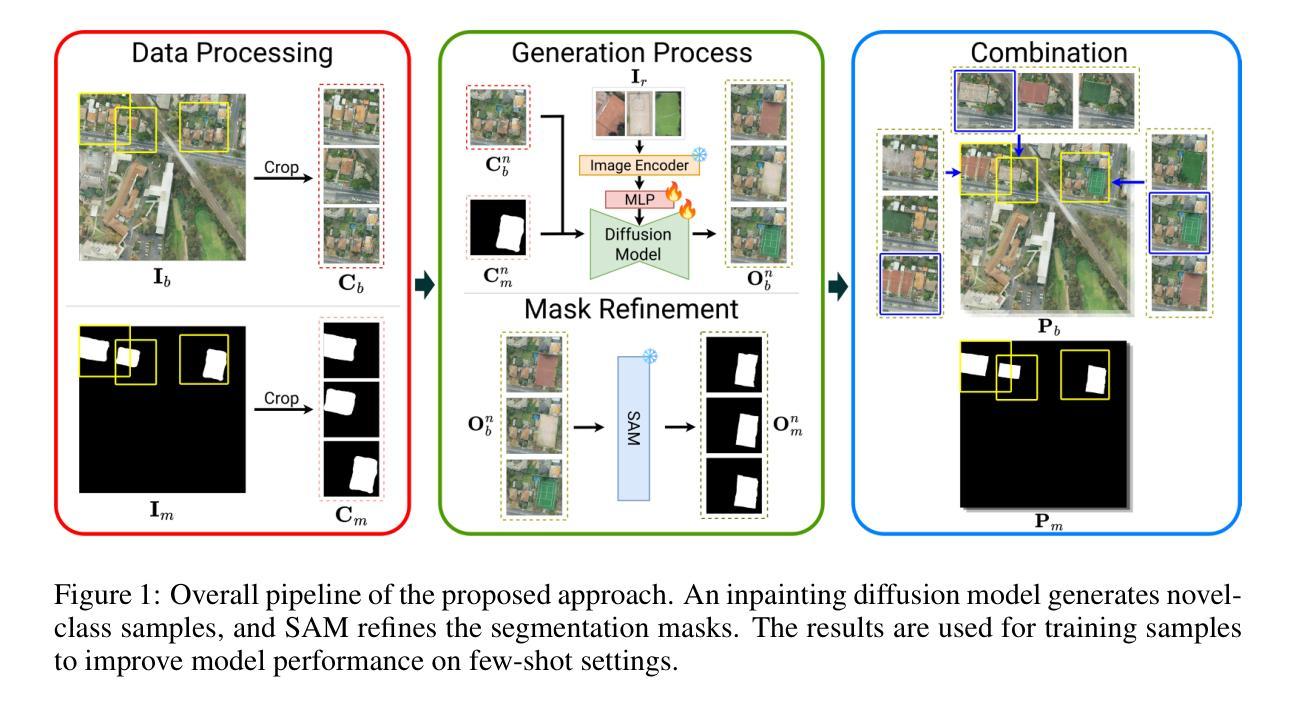
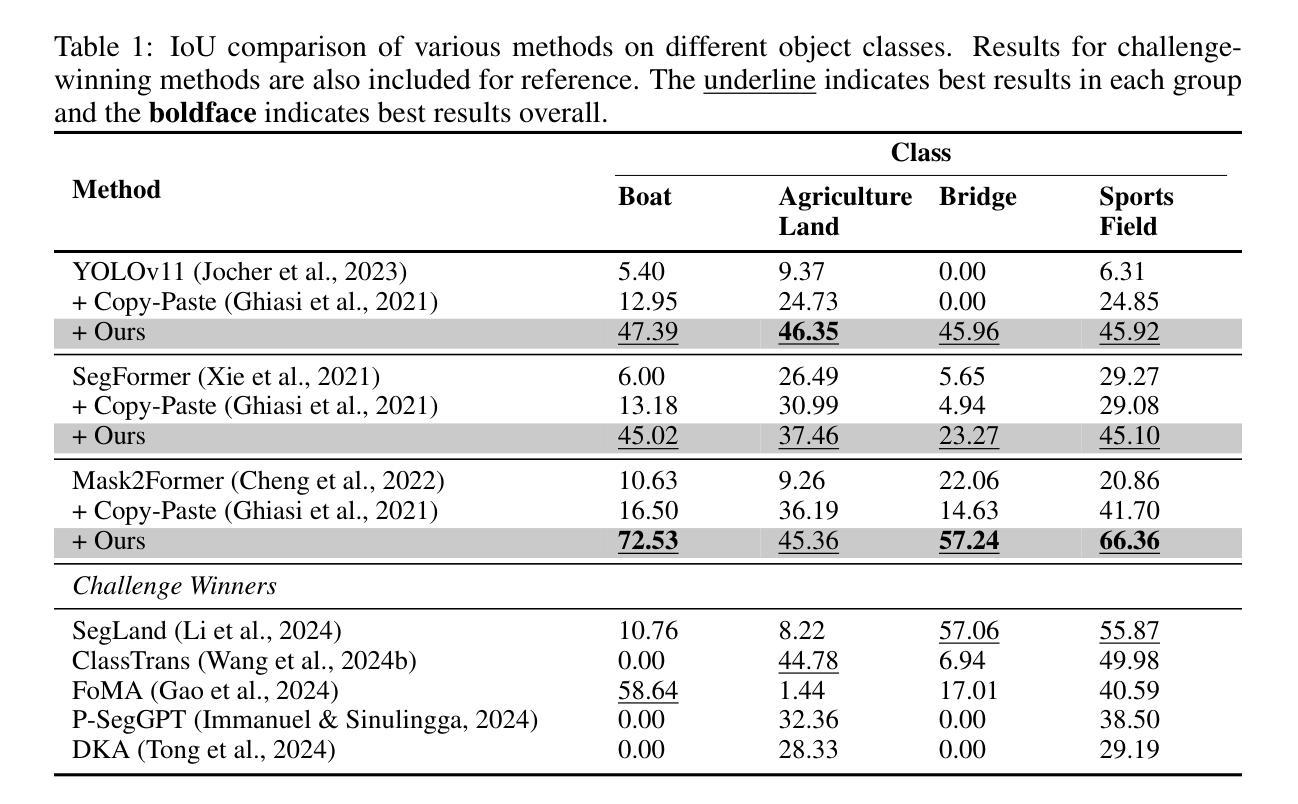
Tackling Few-Shot Segmentation in Remote Sensing via Inpainting Diffusion Model
Authors:Steve Andreas Immanuel, Woojin Cho, Junhyuk Heo, Darongsae Kwon
Limited data is a common problem in remote sensing due to the high cost of obtaining annotated samples. In the few-shot segmentation task, models are typically trained on base classes with abundant annotations and later adapted to novel classes with limited examples. However, this often necessitates specialized model architectures or complex training strategies. Instead, we propose a simple approach that leverages diffusion models to generate diverse variations of novel-class objects within a given scene, conditioned by the limited examples of the novel classes. By framing the problem as an image inpainting task, we synthesize plausible instances of novel classes under various environments, effectively increasing the number of samples for the novel classes and mitigating overfitting. The generated samples are then assessed using a cosine similarity metric to ensure semantic consistency with the novel classes. Additionally, we employ Segment Anything Model (SAM) to segment the generated samples and obtain precise annotations. By using high-quality synthetic data, we can directly fine-tune off-the-shelf segmentation models. Experimental results demonstrate that our method significantly enhances segmentation performance in low-data regimes, highlighting its potential for real-world remote sensing applications.
在遥感领域,由于获取标注样本的成本高昂,数据有限是一个常见问题。在少量分割任务中,模型通常会在基础类别上进行训练,这些基础类别拥有丰富的标注,然后适应具有有限示例的新类别。然而,这通常需要专门的模型架构或复杂的训练策略。相反,我们提出了一种简单的方法,利用扩散模型在给定场景内生成多种新型类别对象的变体,这些变体以新类别的有限示例为条件。通过将问题构造成图像修复任务,我们在各种环境下合成新类别的合理实例,有效地增加了新类别的样本数量,并减轻了过拟合。生成的样本使用余弦相似度度量进行评估,以确保与新类别语义一致。此外,我们还采用任意分割模型(SAM)对生成的样本进行分割,以获得精确标注。通过使用高质量的合成数据,我们可以直接对现成的分割模型进行微调。实验结果表明,我们的方法在数据稀少的情况下显著提高了分割性能,突显其在现实世界遥感应用中的潜力。
论文及项目相关链接
PDF Accepted to ICLRW 2025 (Oral)
Summary
利用扩散模型,针对遥感领域有限数据的问题,提出了一种简单的方法。该方法通过生成场景中新型物体多样化的变体,以有限的样本为条件,解决了样本量较少的问题。通过将问题转化为图像补全任务,合成各种环境下新型物体的合理实例,增加了新型样本的数量,有效缓解了过拟合现象。生成的样本使用余弦相似性度量进行评估,确保与新型类语义的一致性。同时,采用分段模型对生成样本进行精确标注,并可直接对货架上的分割模型进行微调。实验结果证明,该方法在低数据环境下显著提高分割性能,突显其在现实遥感应用中的潜力。
Key Takeaways
- 扩散模型用于生成新型物体多样化的变体,解决遥感领域有限数据问题。
- 方法将问题转化为图像补全任务,合成各种环境下的新型物体实例。
- 生成样本通过余弦相似性度量评估,确保与新型类的语义一致性。
- 采用Segment Anything Model(SAM)对生成样本进行精确标注。
- 使用高质量合成数据可直接微调货架上的分割模型。
- 实验结果证明该方法在低数据环境下显著提高分割性能。
点此查看论文截图


Efficient Diversity-Preserving Diffusion Alignment via Gradient-Informed GFlowNets
Authors:Zhen Liu, Tim Z. Xiao, Weiyang Liu, Yoshua Bengio, Dinghuai Zhang
While one commonly trains large diffusion models by collecting datasets on target downstream tasks, it is often desired to align and finetune pretrained diffusion models with some reward functions that are either designed by experts or learned from small-scale datasets. Existing post-training methods for reward finetuning of diffusion models typically suffer from lack of diversity in generated samples, lack of prior preservation, and/or slow convergence in finetuning. Inspired by recent successes in generative flow networks (GFlowNets), a class of probabilistic models that sample with the unnormalized density of a reward function, we propose a novel GFlowNet method dubbed Nabla-GFlowNet (abbreviated as \methodname), the first GFlowNet method that leverages the rich signal in reward gradients, together with an objective called \graddb plus its variant \resgraddb designed for prior-preserving diffusion finetuning. We show that our proposed method achieves fast yet diversity- and prior-preserving finetuning of Stable Diffusion, a large-scale text-conditioned image diffusion model, on different realistic reward functions.
通常,人们通过收集目标下游任务的数据集来训练大型扩散模型,但人们常常希望通过与专家设计或从小型数据集中学习得到的奖励函数对齐并微调预训练的扩散模型。现有的用于扩散模型奖励微调的后期训练方法通常存在生成样本缺乏多样性、缺乏先验保留以及微调收敛缓慢等问题。受最近生成流网络(GFlowNets)成功的启发,GFlowNets是一类以奖励函数的未归一化密度进行采样的概率模型。我们提出了一种新的GFlowNet方法,称为Nabla-GFlowNet(简称\methodname),它是第一个利用奖励梯度丰富信号的GFlowNet方法,以及一个称为\graddb的目标及其变体\resgraddb,专为保留先验的扩散微调设计。我们展示,所提方法能够在不同的现实奖励函数上快速且多样、保留先验地对大规模文本条件图像扩散模型Stable Diffusion进行微调。
论文及项目相关链接
PDF Technical Report (35 pages, 31 figures), Accepted at ICLR 2025
Summary
预训练的扩散模型可以通过与专家设计或从小规模数据集中学习的奖励函数进行对齐和微调,来提高其性能。现有的扩散模型奖励微调的后训练方法通常存在生成样本缺乏多样性、缺乏先验知识保留以及微调收敛缓慢的问题。受生成流网络(GFlowNets)近期成功的启发,我们提出了一种新的GFlowNet方法,名为Nabla-GFlowNet,它是第一个利用奖励梯度丰富信号的GFlowNet方法,配合称为\graddb的目标及其变体\resgraddb,用于先验保留的扩散微调。实验表明,所提方法在不同的真实奖励函数上,实现了对大规模文本条件图像扩散模型Stable Diffusion的快速、多样性和先验知识保留的微调。
Key Takeaways
- 扩散模型可以通过与奖励函数对齐和微调来提高性能。
- 现有方法存在生成样本缺乏多样性和先验知识保留的问题。
- Nabla-GFlowNet是一种新的GFlowNet方法,利用奖励梯度丰富信号。
- Nabla-GFlowNet配合\graddb及其变体\resgraddb,用于先验保留的扩散微调。
- 所提方法在不同真实奖励函数上实现了对Stable Diffusion模型的快速、多样性和先验知识保留的微调。
- Stable Diffusion是一个大规模文本条件图像扩散模型。
- Nabla-GFlowNet方法具有潜在的应用价值,可推广到其他领域的扩散模型微调。
点此查看论文截图


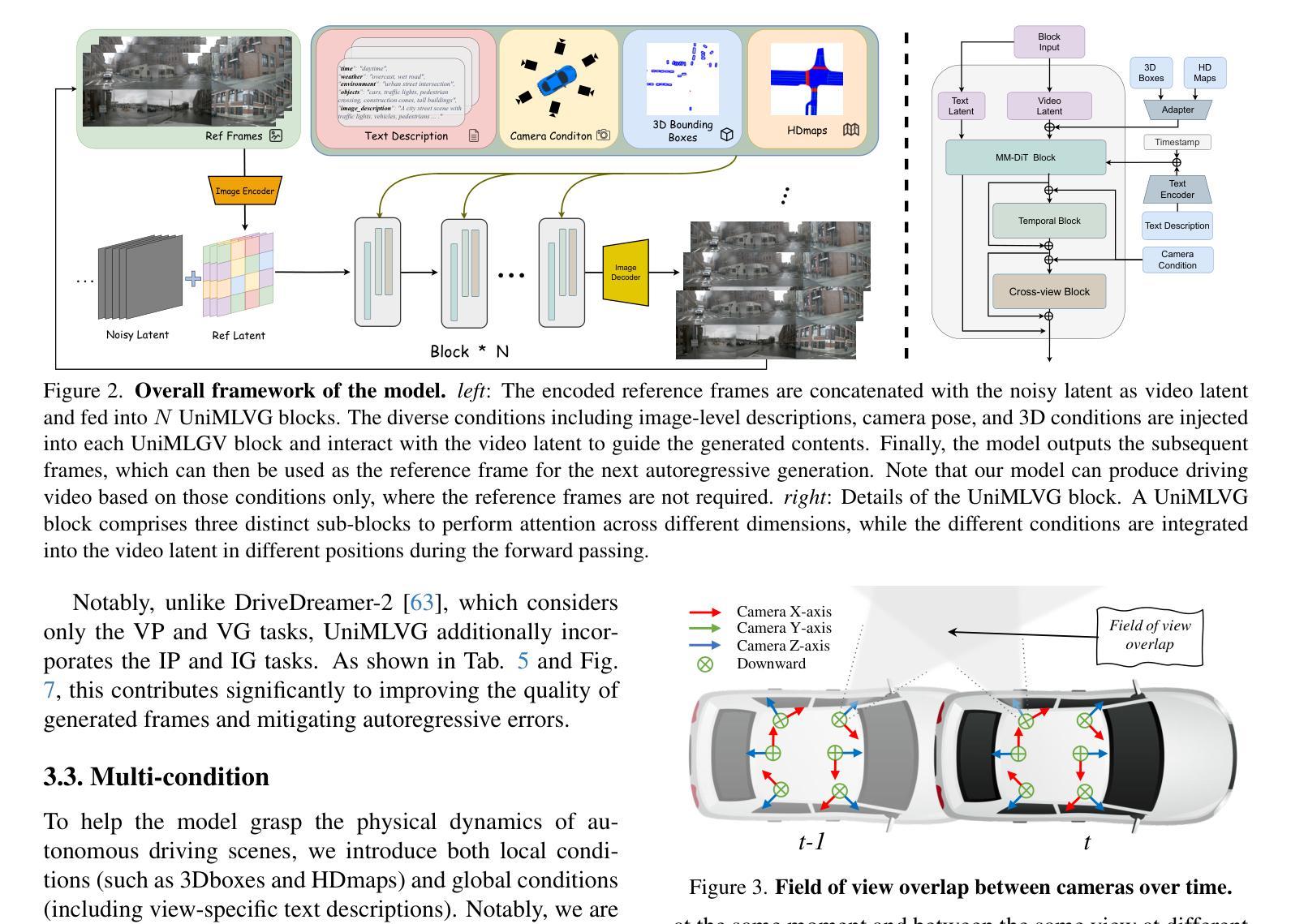
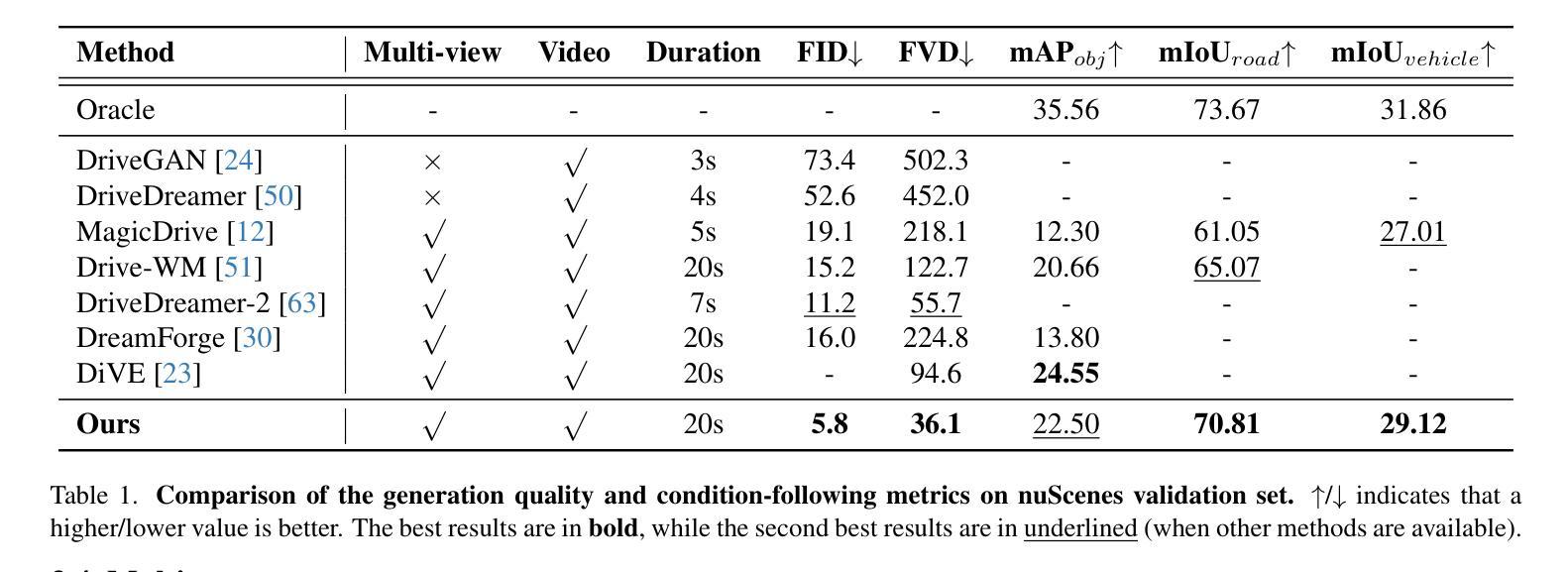
UniMLVG: Unified Framework for Multi-view Long Video Generation with Comprehensive Control Capabilities for Autonomous Driving
Authors:Rui Chen, Zehuan Wu, Yichen Liu, Yuxin Guo, Jingcheng Ni, Haifeng Xia, Siyu Xia
The creation of diverse and realistic driving scenarios has become essential to enhance perception and planning capabilities of the autonomous driving system. However, generating long-duration, surround-view consistent driving videos remains a significant challenge. To address this, we present UniMLVG, a unified framework designed to generate extended street multi-perspective videos under precise control. By integrating single- and multi-view driving videos into the training data, our approach updates a DiT-based diffusion model equipped with cross-frame and cross-view modules across three stages with multi training objectives, substantially boosting the diversity and quality of generated visual content. Importantly, we propose an innovative explicit viewpoint modeling approach for multi-view video generation to effectively improve motion transition consistency. Capable of handling various input reference formats (e.g., text, images, or video), our UniMLVG generates high-quality multi-view videos according to the corresponding condition constraints such as 3D bounding boxes or frame-level text descriptions. Compared to the best models with similar capabilities, our framework achieves improvements of 48.2% in FID and 35.2% in FVD.
创建多样且逼真的驾驶场景对于提升自动驾驶系统的感知和规划能力至关重要。然而,生成长时间、全景一致的驾驶视频仍然是一项重大挑战。为了解决这一问题,我们推出了UniMLVG,这是一个统一框架,旨在在精确控制下生成扩展街道多视角视频。我们的方法通过将单视角和多视角驾驶视频融入训练数据,更新了一个配备跨帧和跨视角模块的三阶段DiT扩散模型,通过多训练目标大幅提升了生成视觉内容的多样性和质量。重要的是,我们提出了一种创新的多视角视频生成的显式视点建模方法,有效提高运动过渡的一致性。我们的UniMLVG能够处理各种输入参考格式(如文本、图像或视频),根据相应的条件约束(如3D边界框或帧级文本描述)生成高质量的多视角视频。与具有类似能力的最佳模型相比,我们的框架在FID上提高了48.2%,在FVD上提高了35.2%。
论文及项目相关链接
Summary
自动驾驶系统的感知和规划能力的提升离不开多样化且真实的驾驶场景的生成。为此,本文推出UniMLVG统一框架,旨在生成扩展街道多视角视频。该框架集成单视角和多视角驾驶视频到训练数据中,通过更新基于DiT的扩散模型并配备跨帧和跨视模块,在三个阶段进行多任务训练,显著提高生成视频内容的多样性和质量。此外,提出明确的多视角视频生成视点建模方法,有效改善动作过渡一致性。UniMLVG能够处理多种输入参考格式,如文本、图像或视频等,并根据条件约束生成高质量的多视角视频。相较于其他类似能力模型,该框架在FID和FVD指标上分别提升了48.2%和35.2%。
Key Takeaways
- 生成多样化且真实的驾驶场景对提升自动驾驶系统的感知和规划能力至关重要。
- UniMLVG框架旨在生成扩展街道多视角视频,集成单视角和多视角驾驶视频到训练数据中。
- 通过更新基于DiT的扩散模型并配备跨帧和跨视模块,提高生成视频内容的多样性和质量。
- UniMLVG框架具备处理多种输入参考格式的能力,如文本、图像或视频等。
- 创新的明确视点建模方法用于多视角视频生成,改善动作过渡一致性。
- UniMLVG框架能够根据条件约束生成高质量的多视角视频。
点此查看论文截图



VISION-XL: High Definition Video Inverse Problem Solver using Latent Image Diffusion Models
Authors:Taesung Kwon, Jong Chul Ye
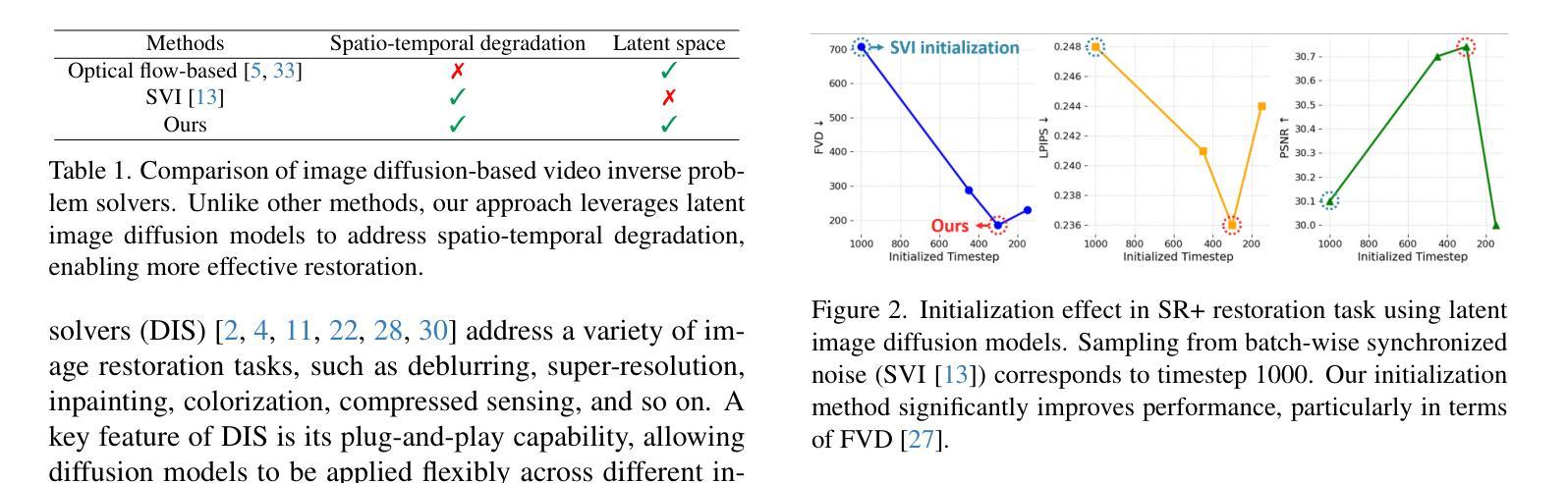
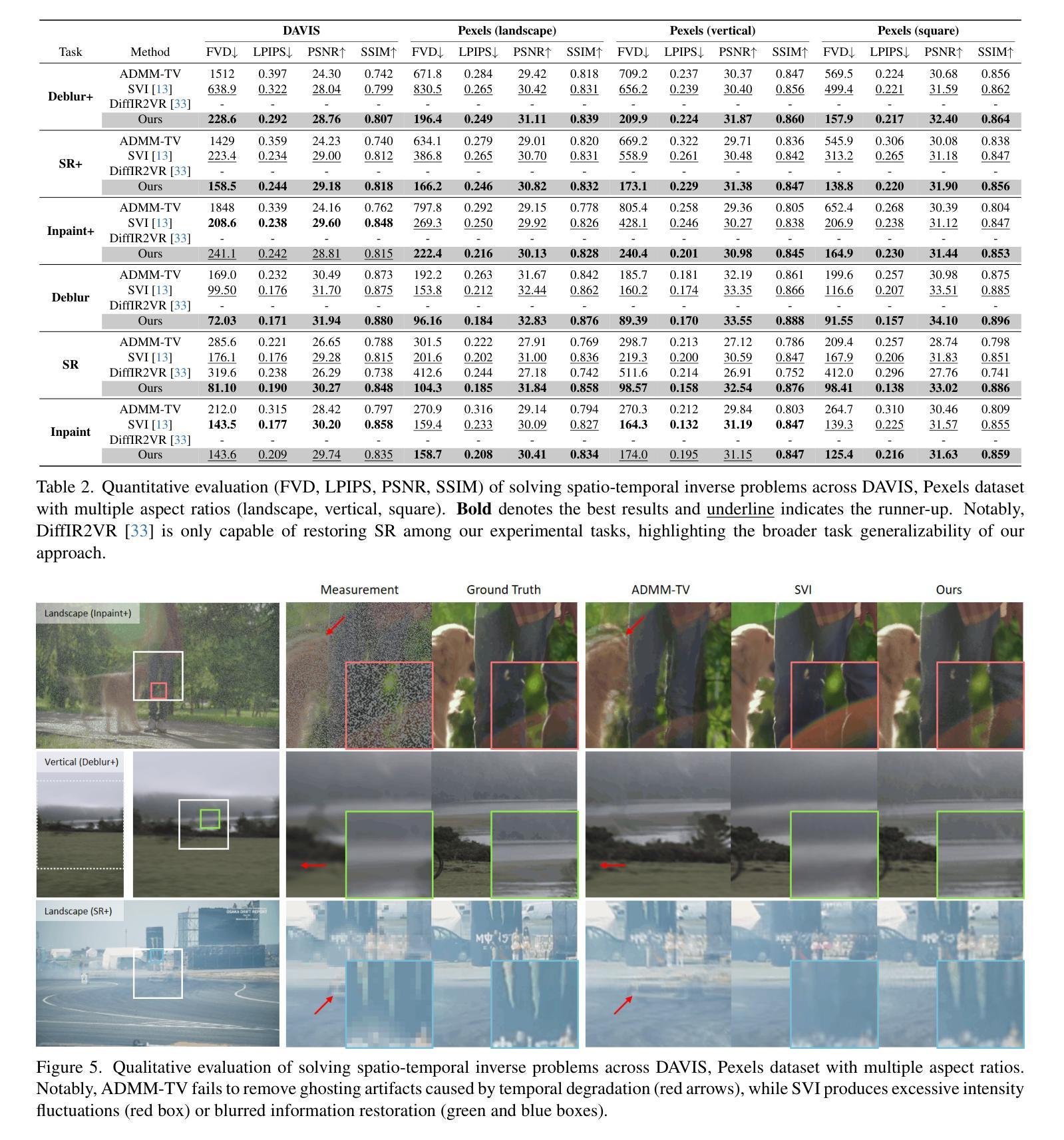
In this paper, we propose a novel framework for solving high-definition video inverse problems using latent image diffusion models. Building on recent advancements in spatio-temporal optimization for video inverse problems using image diffusion models, our approach leverages latent-space diffusion models to achieve enhanced video quality and resolution. To address the high computational demands of processing high-resolution frames, we introduce a pseudo-batch consistent sampling strategy, allowing efficient operation on a single GPU. Additionally, to improve temporal consistency, we present pseudo-batch inversion, an initialization technique that incorporates informative latents from the measurement. By integrating with SDXL, our framework achieves state-of-the-art video reconstruction across a wide range of spatio-temporal inverse problems, including complex combinations of frame averaging and various spatial degradations, such as deblurring, super-resolution, and inpainting. Unlike previous methods, our approach supports multiple aspect ratios (landscape, vertical, and square) and delivers HD-resolution reconstructions (exceeding 1280x720) in under 6 seconds per frame on a single NVIDIA 4090 GPU.
在这篇论文中,我们提出了一种利用潜在图像扩散模型解决高清视频反问题的新型框架。我们的方法建立在最近利用图像扩散模型解决视频反问题的时空优化进展之上,通过利用潜在空间扩散模型来提高视频质量和分辨率。为了解决处理高分辨率帧的高计算需求,我们引入了一种伪批量一致采样策略,该策略可在单个GPU上实现高效操作。此外,为了提高时间一致性,我们提出了伪批量反转初始化技术,该技术结合了测量中的信息潜在因素。通过与SDXL集成,我们的框架在广泛的时空反问题中实现了最先进的视频重建,包括帧平均值的复杂组合和各种空间退化,如去模糊、超分辨率和图像修复。不同于以前的方法,我们的方法支持多种纵横比(横屏、竖屏和正方形),并在单个NVIDIA 4090 GPU上以每秒不到6帧的速度实现高清分辨率重建(超过1280x720)。
论文及项目相关链接
PDF Project page: https://vision-xl.github.io/
Summary
基于图像扩散模型的时空优化进展,提出一种解决高清视频逆问题的新型框架。利用潜在空间扩散模型提高了视频质量和分辨率,并引入伪批次一致采样策略,实现了在单个GPU上的高效操作。结合伪批次反转初始化技术,提高了时间一致性。结合SDXL技术,该框架在多种时空逆问题中实现了视频重建的最佳效果。与传统方法不同,该方法支持多种纵横比,并在单个NVIDIA 4090 GPU上实现了超过1280x720分辨率的重建,每帧处理时间不到6秒。
Key Takeaways
- 利用潜在图像扩散模型解决高清视频逆问题。
- 引入伪批次一致采样策略,实现高效单GPU操作。
- 提出伪批次反转初始化技术,提高时间一致性。
- 结合SDXL技术实现先进视频重建。
- 支持多种纵横比的视频重建。
- 在单个NVIDIA 4090 GPU上实现快速高清分辨率重建(超过1280x720)。
- 每帧处理时间少于6秒。
点此查看论文截图



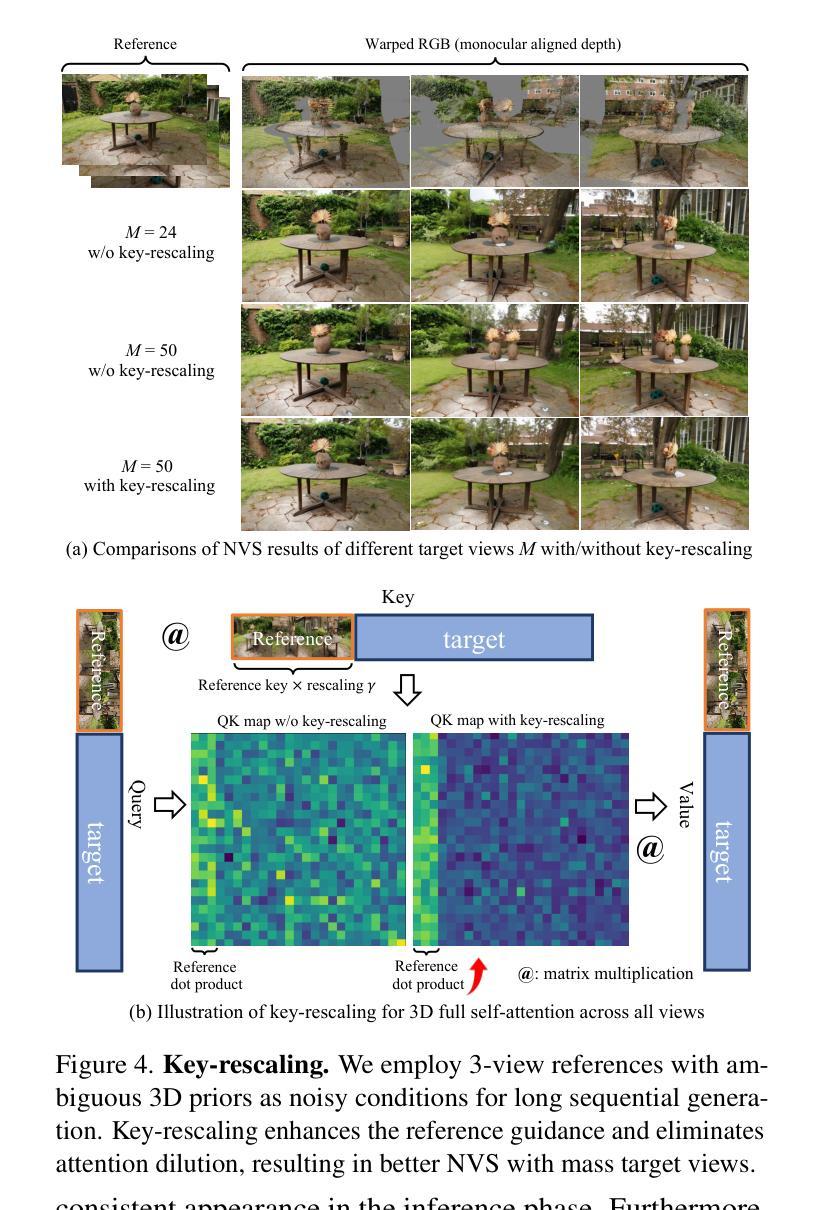
MVGenMaster: Scaling Multi-View Generation from Any Image via 3D Priors Enhanced Diffusion Model
Authors:Chenjie Cao, Chaohui Yu, Shang Liu, Fan Wang, Xiangyang Xue, Yanwei Fu
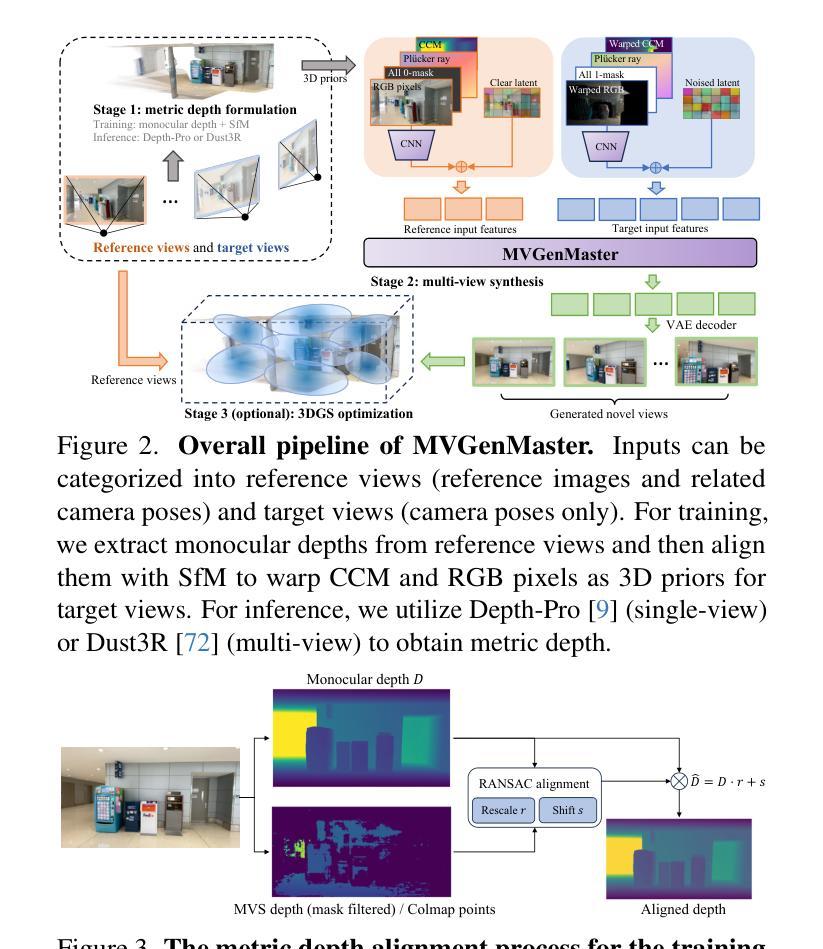
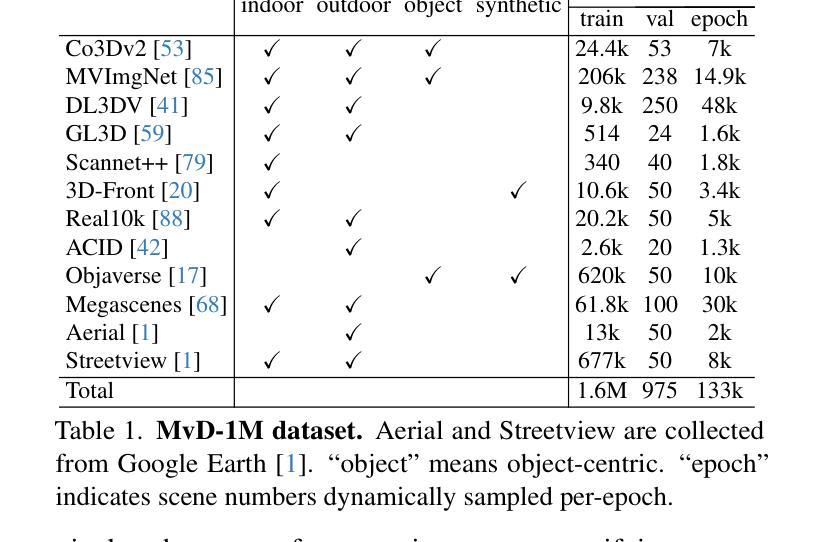
We introduce MVGenMaster, a multi-view diffusion model enhanced with 3D priors to address versatile Novel View Synthesis (NVS) tasks. MVGenMaster leverages 3D priors that are warped using metric depth and camera poses, significantly enhancing both generalization and 3D consistency in NVS. Our model features a simple yet effective pipeline that can generate up to 100 novel views conditioned on variable reference views and camera poses with a single forward process. Additionally, we have developed a comprehensive large-scale multi-view image dataset called MvD-1M, comprising up to 1.6 million scenes, equipped with well-aligned metric depth to train MVGenMaster. Moreover, we present several training and model modifications to strengthen the model with scaled-up datasets. Extensive evaluations across in- and out-of-domain benchmarks demonstrate the effectiveness of our proposed method and data formulation. Models and codes will be released at https://github.com/ewrfcas/MVGenMaster/.
我们介绍了MVGenMaster,这是一个多视图扩散模型,通过加入3D先验知识来应对多样化的新型视图合成(NVS)任务。MVGenMaster利用通过度量深度和相机姿态进行变形的3D先验知识,显著提高了NVS中的通用性和3D一致性。我们的模型采用简单有效的管道,只需一次前向过程,就可以根据可变的参考视图和相机姿态生成多达100个新型视图。此外,我们还开发了一个名为MvD-1M的大规模多视图图像数据集,包含高达160万个场景,配备对齐良好的度量深度以训练MVGenMaster。而且,我们对训练和模型进行了几次修改,以通过扩展数据集来加强模型。在内部和外部基准测试的大量评估表明了我们提出的方法和数据制定的有效性。模型和代码将在https://github.com/ewrfcas/MVGenMaster/发布。
论文及项目相关链接
PDF Accepted by CVPR2025. Models and codes will be released at https://github.com/ewrfcas/MVGenMaster/. The project page is at https://ewrfcas.github.io/MVGenMaster/
Summary
MVGenMaster是一款利用多视角扩散模型结合3D先验技术的通用型新视角合成(NVS)解决方案。它通过利用基于度量深度和相机姿态的3D先验知识,显著提高了NVS的通用性和3D一致性。MVGenMaster拥有简洁高效的流程,能够在单一前向过程中,根据多种参考视角和相机姿态生成多达100个新视角。此外,研究团队还开发了一个名为MvD-1M的大规模多视角图像数据集,包含160万场景,配备对齐的度量深度以训练MVGenMaster模型。该论文也介绍了一些通过扩展数据集加强模型性能的训练和模型修改方法。评估和实验结果表明,该方法及数据构建方式非常有效。模型和代码将公开发布在链接。
Key Takeaways
- MVGenMaster是一款多视角扩散模型,结合了3D先验技术用于新视角合成(NVS)。
- 利用了基于度量深度和相机姿态的3D先验知识,增强了模型的通用性和3D一致性。
- MVGenMaster可以基于多种参考视角和相机姿态生成多个新视角。
- 研究团队开发了一个大规模的多视角图像数据集MvD-1M,用于训练MVGenMaster模型。
- 该模型可以通过扩展数据集来加强性能,包括训练和模型的修改方法。
- MVGenMaster经过广泛评估和实验验证,证明其有效性。
点此查看论文截图

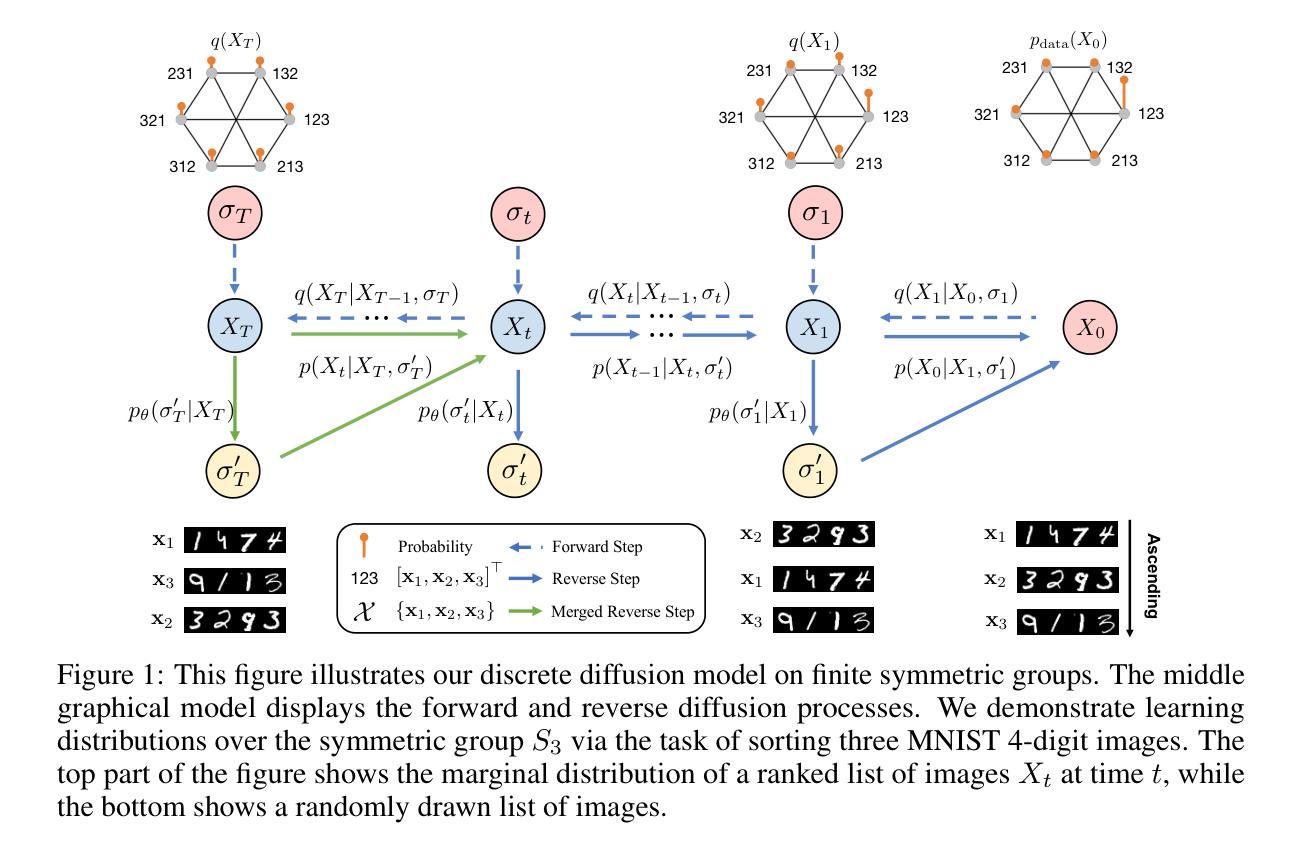
SymmetricDiffusers: Learning Discrete Diffusion on Finite Symmetric Groups
Authors:Yongxing Zhang, Donglin Yang, Renjie Liao
Finite symmetric groups $S_n$ are essential in fields such as combinatorics, physics, and chemistry. However, learning a probability distribution over $S_n$ poses significant challenges due to its intractable size and discrete nature. In this paper, we introduce SymmetricDiffusers, a novel discrete diffusion model that simplifies the task of learning a complicated distribution over $S_n$ by decomposing it into learning simpler transitions of the reverse diffusion using deep neural networks. We identify the riffle shuffle as an effective forward transition and provide empirical guidelines for selecting the diffusion length based on the theory of random walks on finite groups. Additionally, we propose a generalized Plackett-Luce (PL) distribution for the reverse transition, which is provably more expressive than the PL distribution. We further introduce a theoretically grounded “denoising schedule” to improve sampling and learning efficiency. Extensive experiments show that our model achieves state-of-the-art or comparable performances on solving tasks including sorting 4-digit MNIST images, jigsaw puzzles, and traveling salesman problems. Our code is released at https://github.com/DSL-Lab/SymmetricDiffusers.
有限对称群$S_n$在组合学、物理学和化学等领域中具有重要意义。然而,学习$S_n$上的概率分布面临着巨大的挑战,主要是由于其难以处理的大小和离散性质。在本文中,我们介绍了SymmetricDiffusers,这是一种新型离散扩散模型,它通过分解学习反向扩散的更简单转换来简化学习$S_n$上复杂分布的任务,这些转换使用深度神经网络完成。我们确定了riffle洗牌作为一种有效的正向转换,并根据有限群上的随机游走理论提供了选择扩散长度的经验指南。此外,我们提出了一种广义的Plackett-Luce(PL)分布用于反向转换,该分布被证明比PL分布更具表现力。我们还引入了一个理论基础的“降噪时间表”,以提高采样和学习效率。大量实验表明,我们的模型在解决包括排序4位MNIST图像、拼图和旅行推销员问题在内的任务时达到了最新或相当的性能。我们的代码已发布在https://github.com/DSL-Lab/SymmetricDiffusers。
论文及项目相关链接
PDF ICLR 2025 Oral
Summary
本文介绍了一种新的离散扩散模型——SymmetricDiffusers,该模型能够简化学习有限对称群$S_n$上的复杂分布的任务。它通过分解复杂的分布学习过程为更简单反向扩散过渡来实现这一目标,利用深度神经网络进行反向过渡学习。研究过程中采用了有效的正向过渡方法——洗牌,并基于随机有限群理论提供了选择扩散长度的经验指南。此外,提出了一种广义的Plackett-Luce分布用于反向过渡,提高了模型的表达能力。同时引入了理论基础的“去噪计划”以提高采样和学习效率。实验证明,该模型在排序、拼图和旅行商问题等多项任务上取得了领先水平。
Key Takeaways
- SymmetricDiffusers是一种针对有限对称群$S_n$上的复杂分布的离散扩散模型。
- 它通过分解复杂分布学习过程为更简单反向扩散过渡来实现学习。
- 深度神经网络用于进行反向过渡学习。
- 有效的正向过渡方法是洗牌,基于随机有限群理论选择扩散长度。
- 提出了一种广义的Plackett-Luce分布用于反向过渡,提高了模型的表达能力。
- 引入了理论基础的“去噪计划”以提高采样和学习效率。
点此查看论文截图

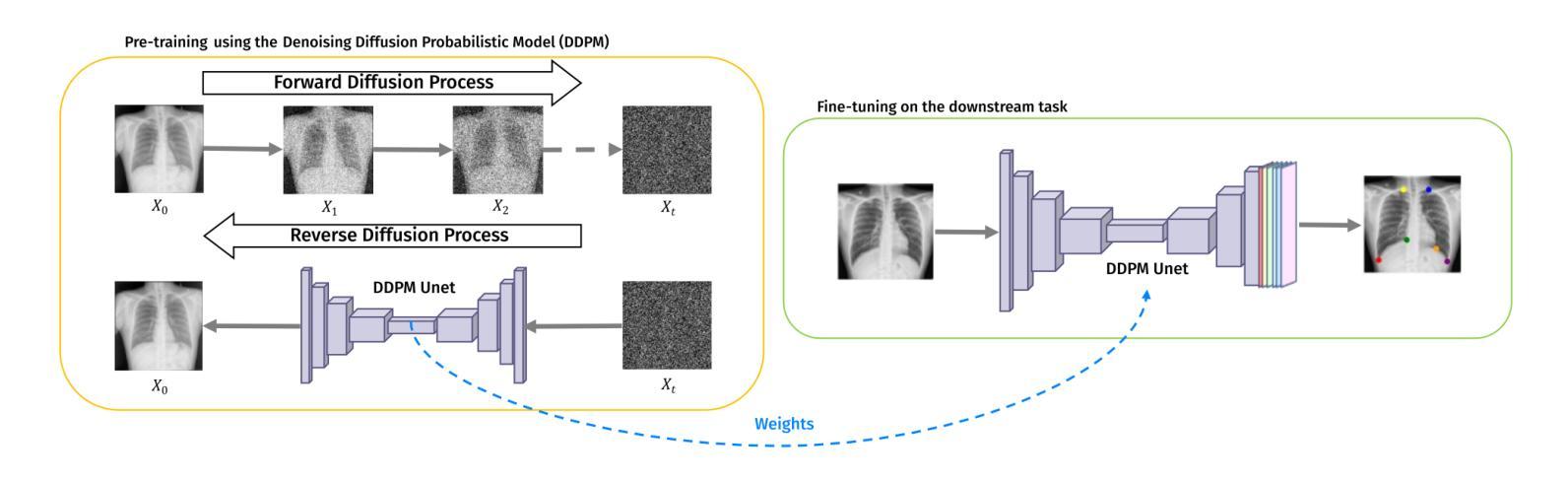
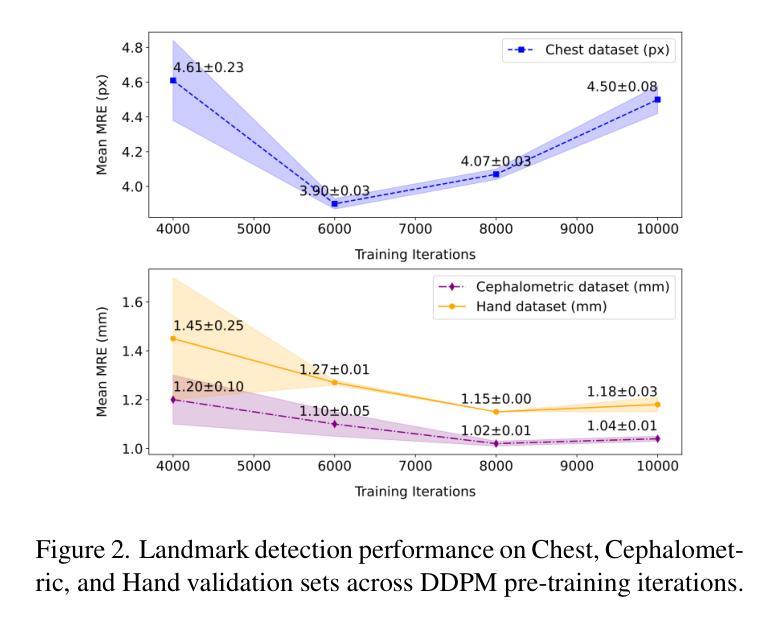
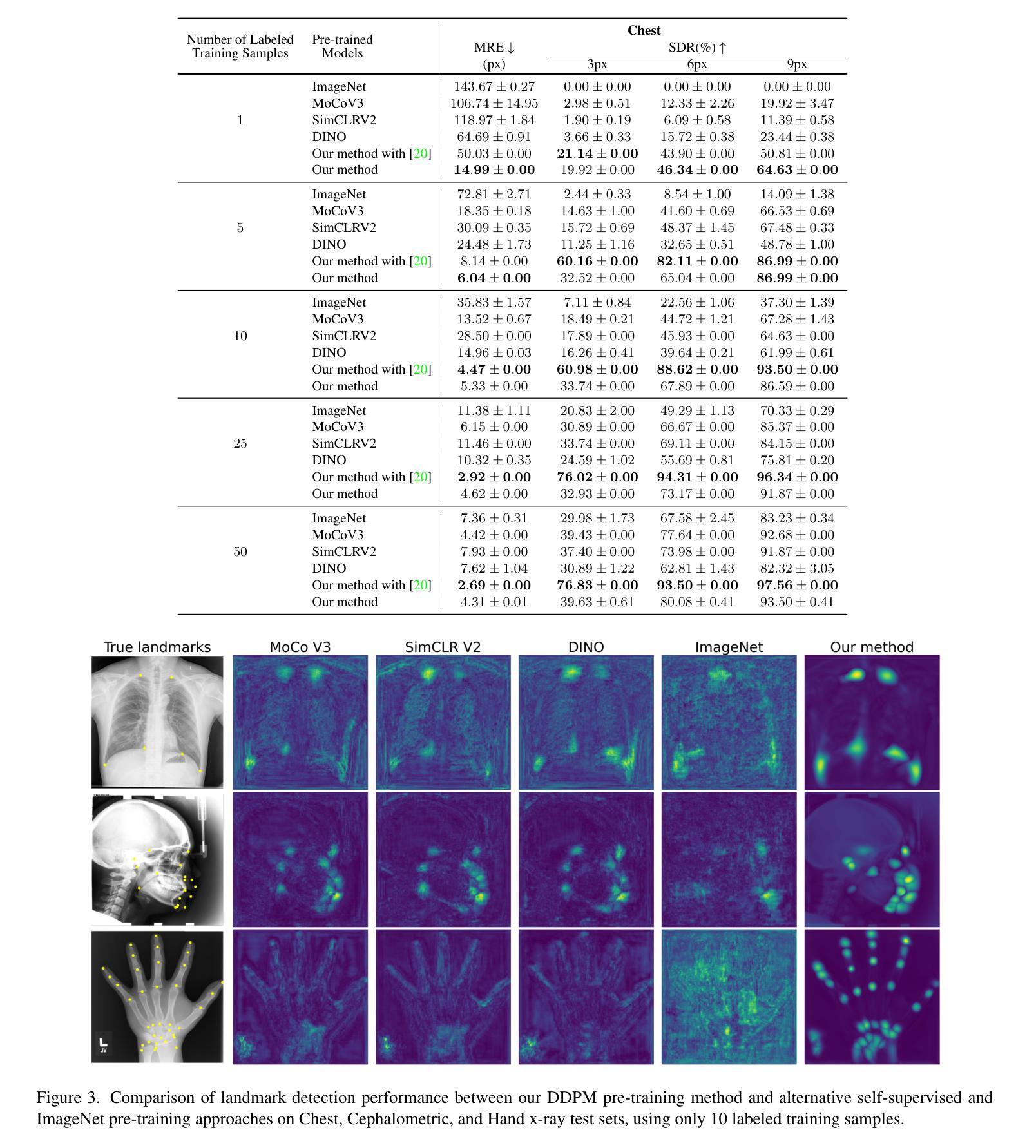
Self-supervised pre-training with diffusion model for few-shot landmark detection in x-ray images
Authors:Roberto Di Via, Francesca Odone, Vito Paolo Pastore
Deep neural networks have been extensively applied in the medical domain for various tasks, including image classification, segmentation, and landmark detection. However, their application is often hindered by data scarcity, both in terms of available annotations and images. This study introduces a novel application of denoising diffusion probabilistic models (DDPMs) to the landmark detection task, specifically addressing the challenge of limited annotated data in x-ray imaging. Our key innovation lies in leveraging DDPMs for self-supervised pre-training in landmark detection, a previously unexplored approach in this domain. This method enables accurate landmark detection with minimal annotated training data (as few as 50 images), surpassing both ImageNet supervised pre-training and traditional self-supervised techniques across three popular x-ray benchmark datasets. To our knowledge, this work represents the first application of diffusion models for self-supervised learning in landmark detection, which may offer a valuable pre-training approach in few-shot regimes, for mitigating data scarcity.
深度神经网络已广泛应用于医疗领域的各种任务,包括图像分类、分割和关键点检测。然而,其在实际应用中常受到数据稀缺的限制,包括可用的标注和图像。本研究首次将去噪扩散概率模型(DDPMs)应用于关键点检测任务,专门解决X射线成像中标注数据有限带来的挑战。我们的主要创新之处在于利用DDPMs进行关键点检测的自监督预训练,这是该领域之前未被探索的方法。该方法能够在极少的标注训练数据(仅50张图像)下实现准确的关键点检测,超越了ImageNet监督预训练和传统自监督技术在三个流行的X射线基准数据集上的表现。据我们所知,这项工作代表了扩散模型在关键点检测自监督学习中的首次应用,这可能为缓解数据稀缺问题提供有价值的预训练方法,特别是在小样本情况下。
论文及项目相关链接
PDF Accepted at WACV 2025
Summary
扩散模型在医学领域的应用研究。文章针对X射线成像中的地标检测任务,引入去噪扩散概率模型(DDPMs)进行自监督预训练,解决了标注数据有限的问题。此方法在仅使用少量(如50张)标注图像的情况下仍可实现准确的地标检测,并在三个公共X射线数据集上超越ImageNet监督预训练和传统自监督技术。此为扩散模型在自监督学习中的首次应用于地标检测,为解决数据稀缺问题提供了一种有价值的预训练方法。
Key Takeaways
- 研究背景涉及深度神经网络在医学领域的广泛应用及其在面对数据稀缺挑战时的局限性。
- 提出利用去噪扩散概率模型(DDPMs)解决地标检测任务中标注数据有限的问题。
- 核心创新点在于使用DDPMs进行自监督预训练,这是一种在医学图像地标检测领域尚未探索的方法。
- 该方法可在仅使用少量标注图像的情况下实现准确的地标检测。
- 此方法在三个流行的X射线数据集上的表现超越了ImageNet监督预训练和传统自监督技术。
- 这是首次将扩散模型应用于自监督学习的地标检测,为解决数据稀缺问题提供了有价值的预训练方法。
点此查看论文截图