⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-09 更新
Compositional Translation: A Novel LLM-based Approach for Low-resource Machine Translation
Authors:Armel Zebaze, Benoît Sagot, Rachel Bawden
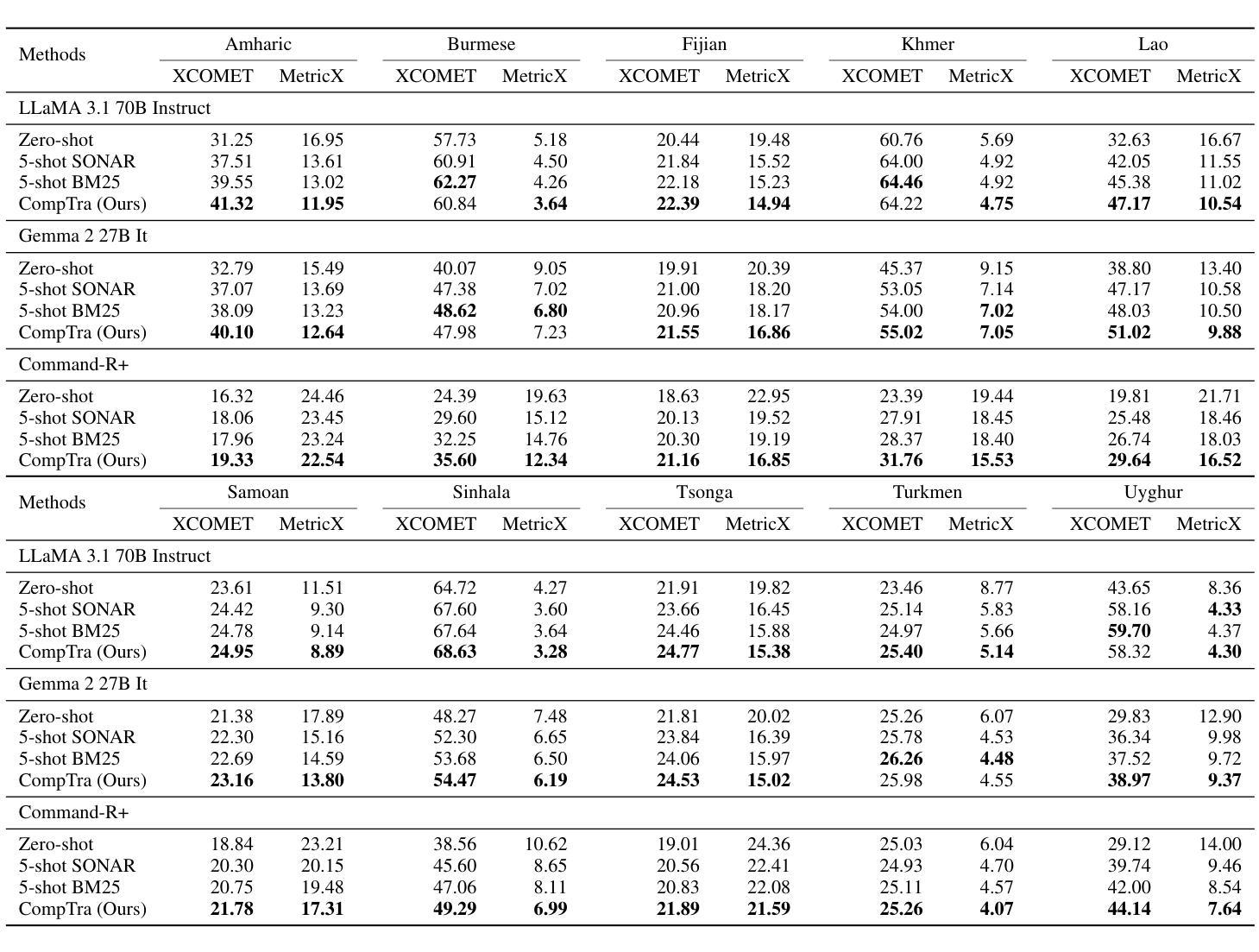
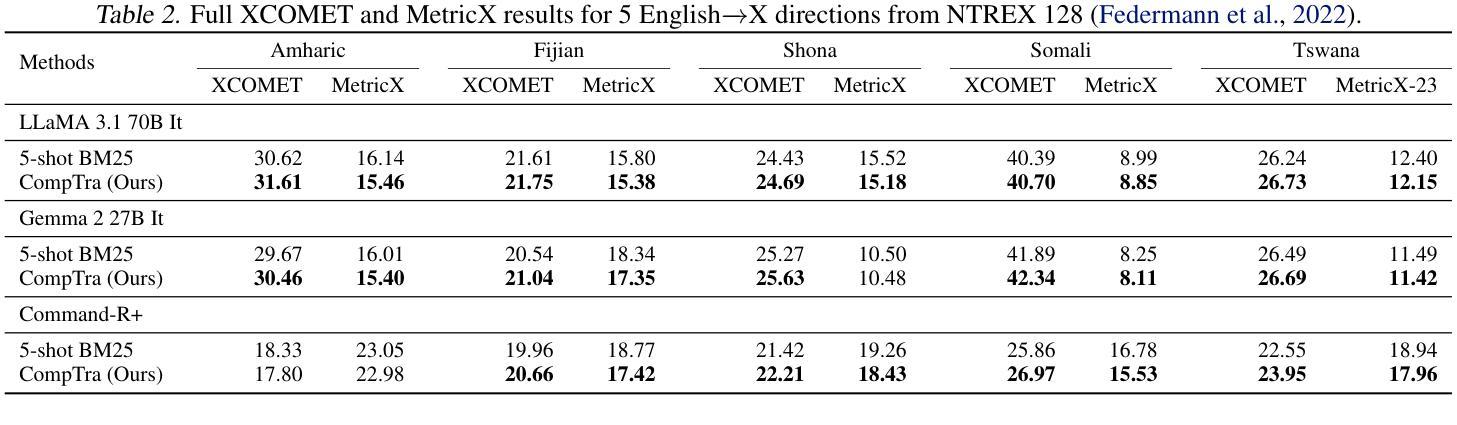
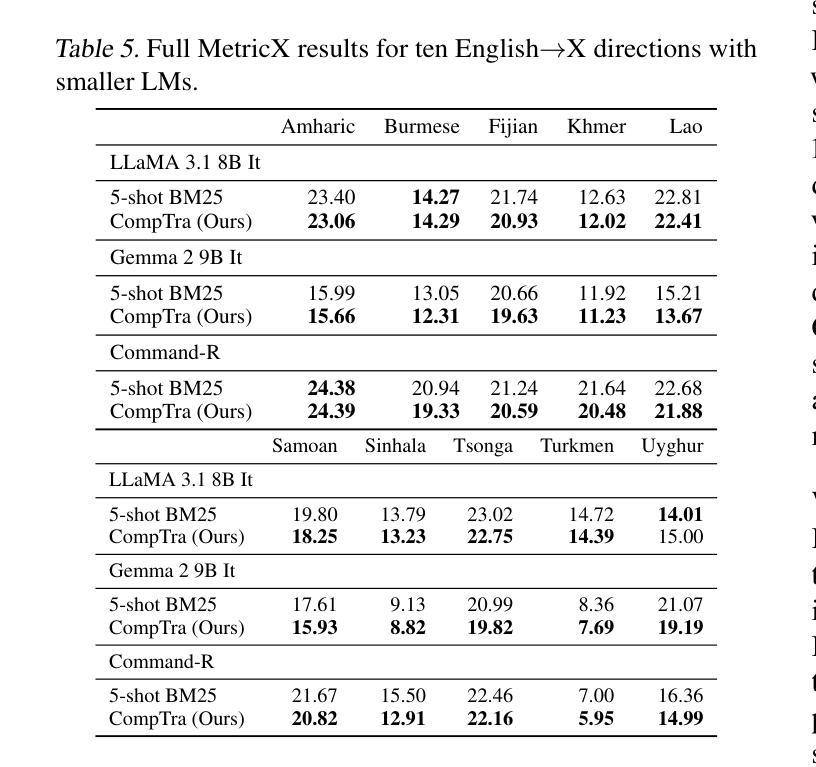
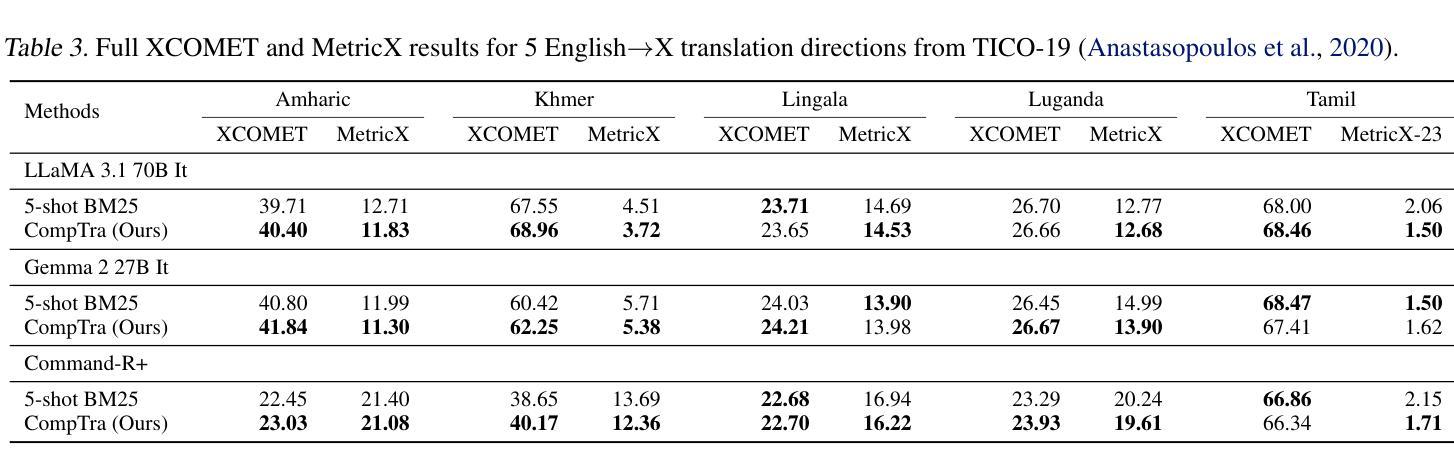
The ability of generative large language models (LLMs) to perform in-context learning has given rise to a large body of research into how best to prompt models for various natural language processing tasks. Machine Translation (MT) has been shown to benefit from in-context examples, in particular when they are semantically similar to the sentence to translate. In this paper, we propose a new LLM-based translation paradigm, compositional translation, to replace naive few-shot MT with similarity-based demonstrations. An LLM is used to decompose a sentence into simpler phrases, and then to translate each phrase with the help of retrieved demonstrations. Finally, the LLM is prompted to translate the initial sentence with the help of the self-generated phrase-translation pairs. Our intuition is that this approach should improve translation because these shorter phrases should be intrinsically easier to translate and easier to match with relevant examples. This is especially beneficial in low-resource scenarios, and more generally whenever the selection pool is small or out of domain. We show that compositional translation boosts LLM translation performance on a wide range of popular MT benchmarks, including FLORES 200, NTREX 128 and TICO-19. Code and outputs are available at https://github.com/ArmelRandy/compositional-translation
大型生成式语言模型(LLM)在上下文学习中的能力引发了大量关于如何最好地提示模型进行各种自然语言处理任务的研究。机器翻译(MT)显示从上下文示例中受益,特别是当它们与待翻译的句子语义相似时。在本文中,我们提出了一种基于LLM的新翻译范式——组合翻译,以用基于相似度的演示来替代简单的几次机器翻译。LLM被用来将句子分解成更简单的短语,然后借助检索到的演示来翻译每个短语。最后,在生成的短语翻译对的帮助下,LLM被提示翻译原始句子。我们的直觉是,这种方法应该能够改进翻译,因为这些较短的短语本质上更容易翻译和与相关的例子相匹配。这在低资源场景中尤其有益,而且在选择池较小或超出范围的情况下也更为普遍。我们证明了组合翻译提高了LLM在包括FLORES 200、NTREX 128和TICO-19等多个流行的机器翻译基准测试上的翻译性能。代码和输出可在https://github.com/ArmelRandy/compositional-translation找到。
简化版翻译
论文及项目相关链接
Summary
生成式大型语言模型(LLM)能够在上下文学习环境中表现出卓越性能,已引发大量研究如何更有效地对各类自然语言处理任务进行模型提示。本文提出一种新型基于LLM的翻译模式——组合翻译,旨在取代基于相似度演示的简单小样本机器翻译(MT)。该模式利用LLM将句子分解成更简单的短语,并借助检索到的演示来翻译每个短语。最后,借助生成的短语翻译对,LLM被提示翻译原始句子。我们的直觉是,这种方法能提高翻译质量,因为这些较短的短语本质上更容易翻译和匹配相关示例。这在低资源场景以及选择池较小或超出范围的情况下尤为有益。我们在广泛的流行机器翻译基准测试上展示了组合翻译对LLM翻译性能的提升,包括FLORES 200、NTREX 128和TICO-19。
Key Takeaways
- 生成式大型语言模型(LLM)能够通过上下文学习环境完成多种自然语言处理任务。
- 组合翻译是一种新型的基于LLM的翻译模式,旨在改进小样本机器翻译(MT)。
- 组合翻译通过分解句子为简单短语,并借助检索到的演示进行翻译来提高翻译质量。
- 该方法特别适用于低资源场景,以及选择池较小或超出范围的情况。
- 组合翻译在多个流行的机器翻译基准测试上表现出对LLM翻译性能的提升。
- 研究的代码和输出可在指定的GitHub仓库中找到。
- 该研究为机器翻译领域提供了新的思路和方法。
点此查看论文截图

Knowledge-Decoupled Synergetic Learning: An MLLM based Collaborative Approach to Few-shot Multimodal Dialogue Intention Recognition
Authors:Bin Chen, Yu Zhang, Hongfei Ye, Ziyi Huang, Hongyang Chen
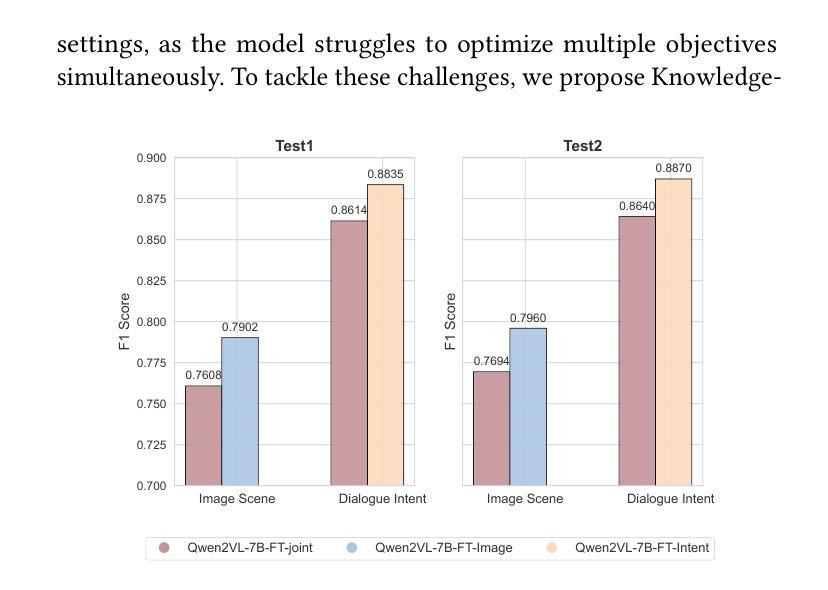
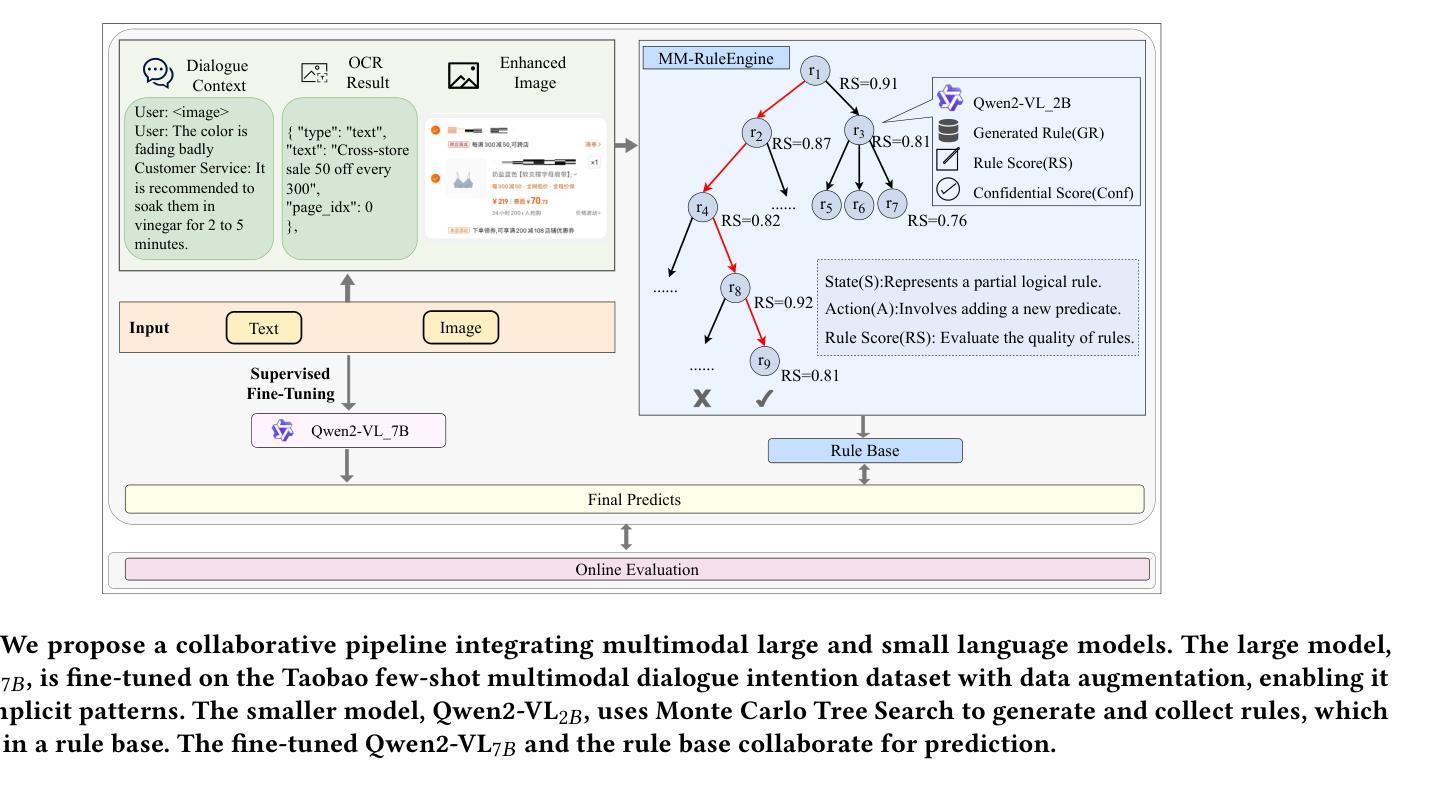
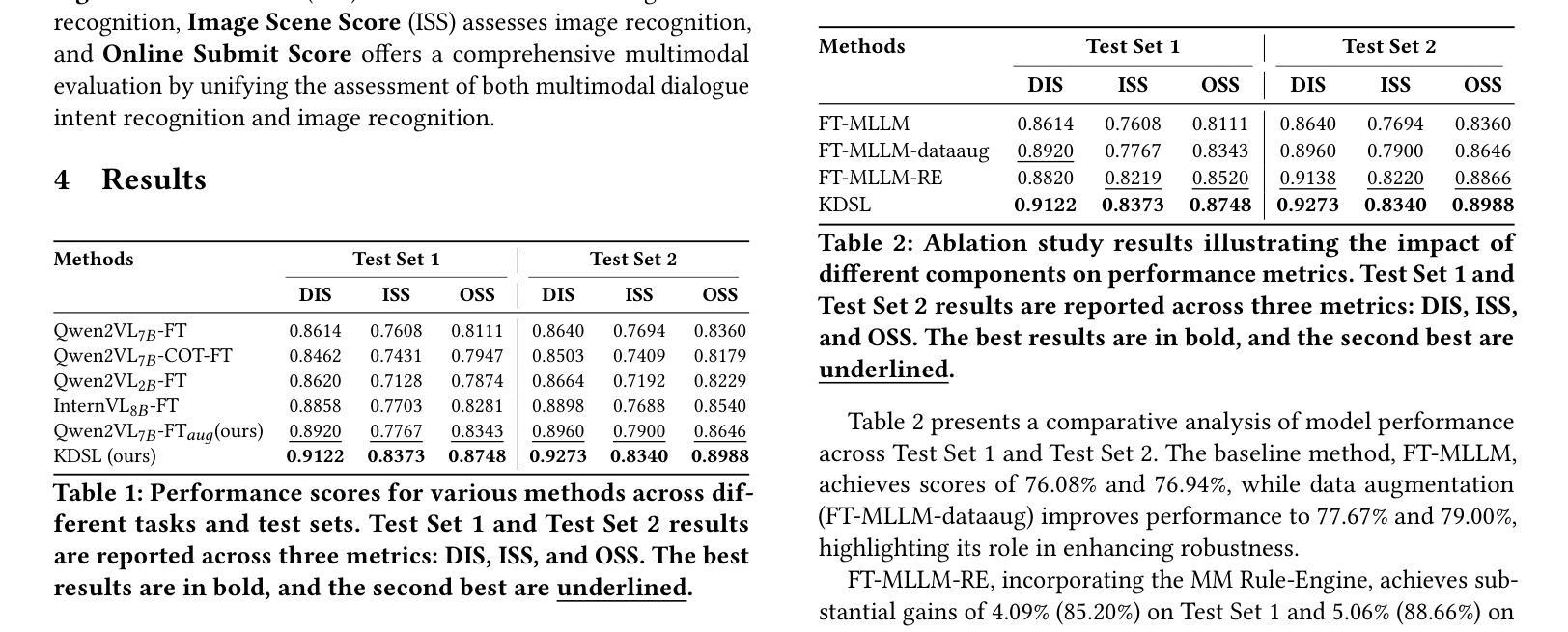
Few-shot multimodal dialogue intention recognition is a critical challenge in the e-commerce domainn. Previous methods have primarily enhanced model classification capabilities through post-training techniques. However, our analysis reveals that training for few-shot multimodal dialogue intention recognition involves two interconnected tasks, leading to a seesaw effect in multi-task learning. This phenomenon is attributed to knowledge interference stemming from the superposition of weight matrix updates during the training process. To address these challenges, we propose Knowledge-Decoupled Synergetic Learning (KDSL), which mitigates these issues by utilizing smaller models to transform knowledge into interpretable rules, while applying the post-training of larger models. By facilitating collaboration between the large and small multimodal large language models for prediction, our approach demonstrates significant improvements. Notably, we achieve outstanding results on two real Taobao datasets, with enhancements of 6.37% and 6.28% in online weighted F1 scores compared to the state-of-the-art method, thereby validating the efficacy of our framework.
在电子商务领域,小样本多模态对话意图识别是一项关键挑战。之前的方法主要通过后训练技术增强模型的分类能力。然而,我们的分析表明,训练用于小样本多模态对话意图识别的过程涉及两个相互关联的任务,导致多任务学习中的摇摆效应。这种现象归因于训练过程中权重矩阵更新叠加产生的知识干扰。为了解决这些挑战,我们提出了知识解耦协同学习(KDSL),通过利用较小的模型将知识转化为可解释的规则,同时应用较大模型的后期训练来缓解这些问题。通过促进大小多模态大型语言模型之间的预测协作,我们的方法取得了显著的改进。值得注意的是,我们在两个真实的淘宝数据集上取得了出色的结果,与最先进的方法相比,在线加权F1分数提高了6.37%和6.28%,从而验证了我们框架的有效性。
论文及项目相关链接
Summary
在电子商务领域中,少样本多模态对话意图识别是一项重要挑战。以往的方法主要通过后训练技术增强模型分类能力,但我们的分析发现,训练过程中涉及两个相互关联的任务,导致多任务学习中的跷跷板效应。针对这一问题,我们提出知识解耦协同学习(KDSL)方法,通过利用小型模型将知识转化为可解释的规则,同时应用大型模型的后训练,促进大型和小型多模态语言模型的预测协作,取得了显著改进。在真实淘宝数据集上,与现有最佳方法相比,我们的框架在加权F1分数上分别提高了6.37%和6.28%,验证了其有效性。
Key Takeaways
- 少样本多模态对话意图识别是电子商务领域的核心挑战。
- 现有方法主要通过后训练增强模型分类能力。
- 训练过程中涉及两个相互关联的任务,导致多任务学习的跷跷板效应。
- 知识解耦协同学习(KDSL)方法被提出以解决这个问题。
- KDSL利用小型模型转化知识为可解释的规则。
- KDSL结合大型模型的后训练,促进模型预测协作。
点此查看论文截图

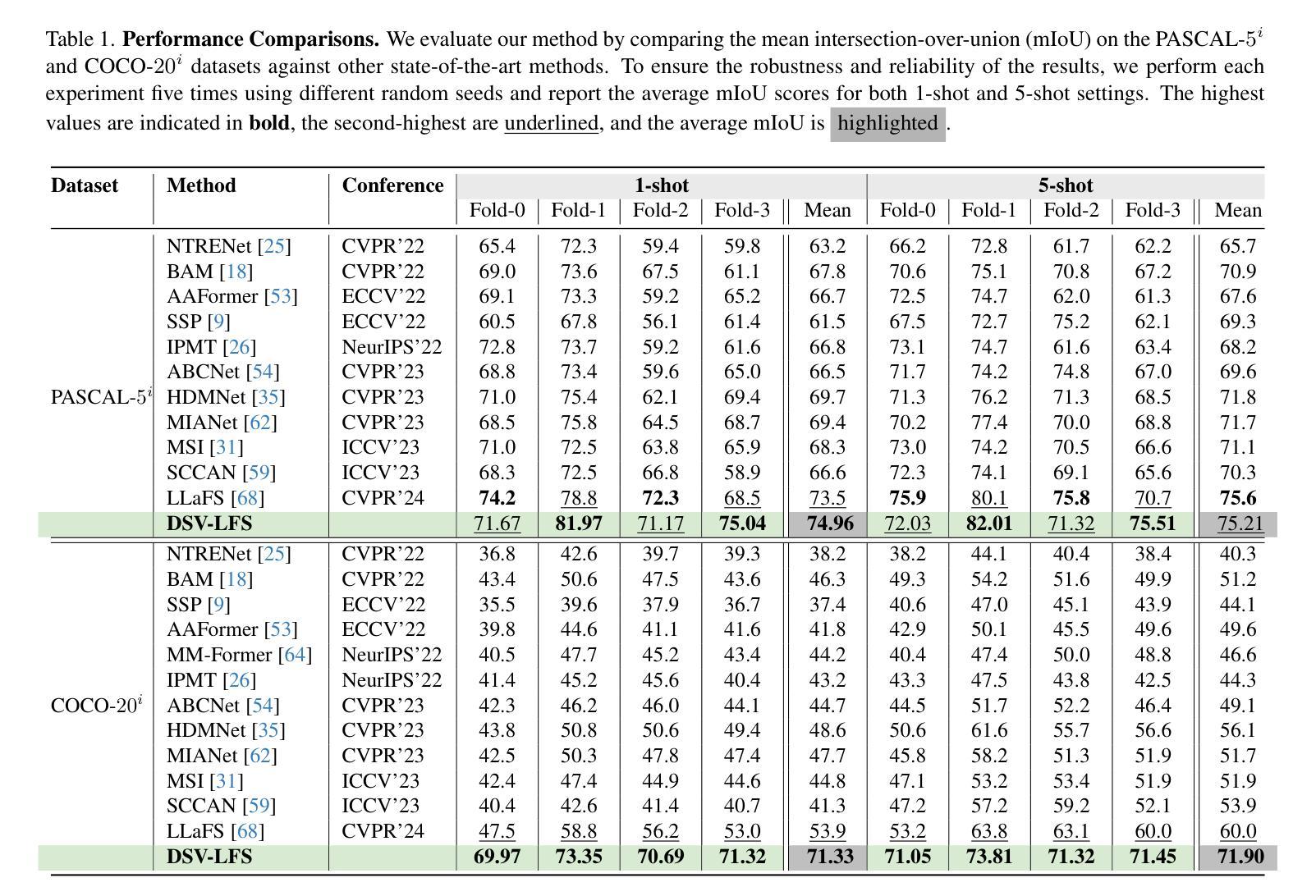
DSV-LFS: Unifying LLM-Driven Semantic Cues with Visual Features for Robust Few-Shot Segmentation
Authors:Amin Karimi, Charalambos Poullis
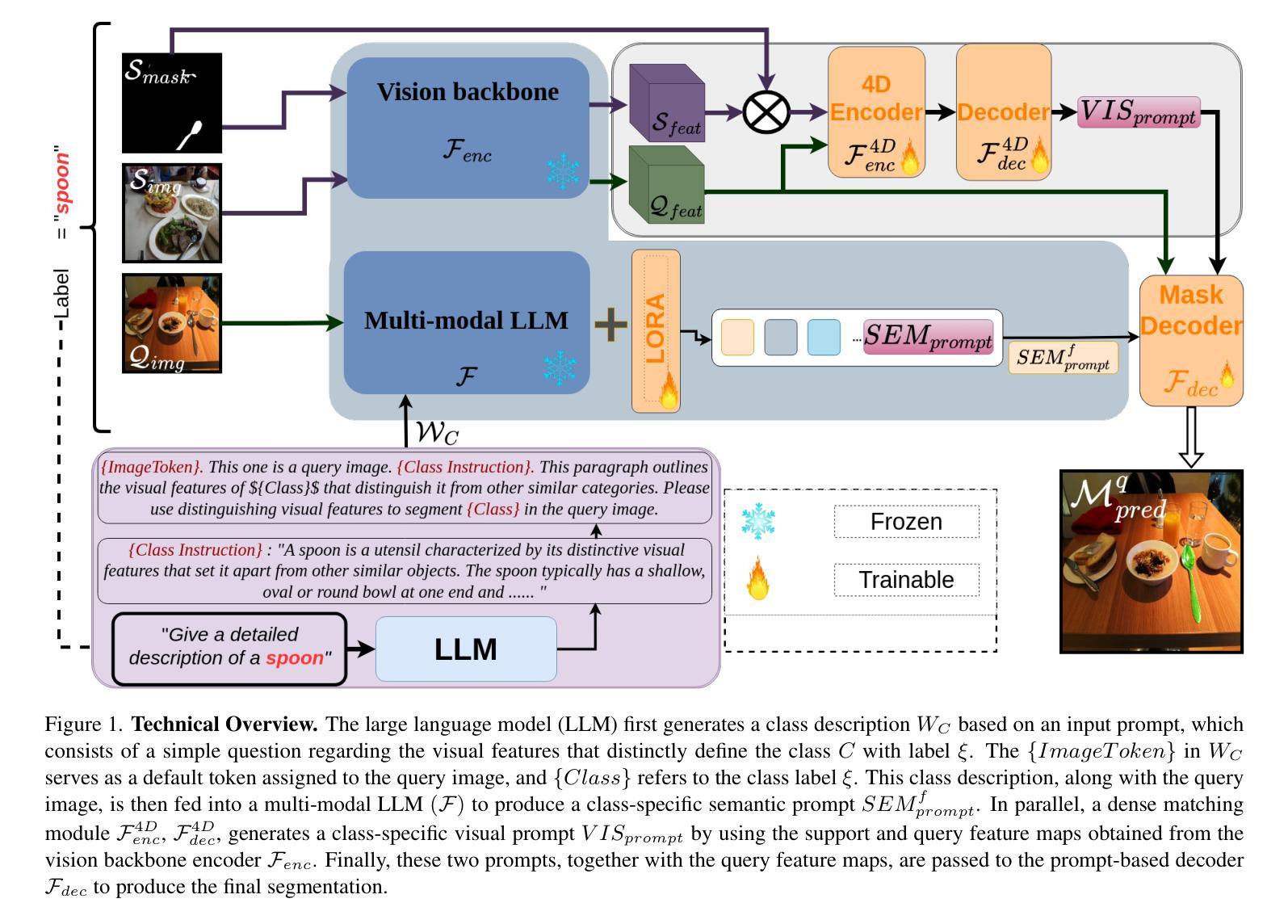
Few-shot semantic segmentation (FSS) aims to enable models to segment novel/unseen object classes using only a limited number of labeled examples. However, current FSS methods frequently struggle with generalization due to incomplete and biased feature representations, especially when support images do not capture the full appearance variability of the target class. To improve the FSS pipeline, we propose a novel framework that utilizes large language models (LLMs) to adapt general class semantic information to the query image. Furthermore, the framework employs dense pixel-wise matching to identify similarities between query and support images, resulting in enhanced FSS performance. Inspired by reasoning-based segmentation frameworks, our method, named DSV-LFS, introduces an additional token into the LLM vocabulary, allowing a multimodal LLM to generate a “semantic prompt” from class descriptions. In parallel, a dense matching module identifies visual similarities between the query and support images, generating a “visual prompt”. These prompts are then jointly employed to guide the prompt-based decoder for accurate segmentation of the query image. Comprehensive experiments on the benchmark datasets Pascal-$5^{i}$ and COCO-$20^{i}$ demonstrate that our framework achieves state-of-the-art performance-by a significant margin-demonstrating superior generalization to novel classes and robustness across diverse scenarios. The source code is available at \href{https://github.com/aminpdik/DSV-LFS}{https://github.com/aminpdik/DSV-LFS}
少样本语义分割(FSS)旨在使模型能够仅使用有限数量的标记示例来分割新的/未见过的对象类别。然而,由于表示不完整和特征偏见,当前的FSS方法经常面临泛化困难的问题,特别是当支持图像没有捕获目标类别的完整外观变化时。为了提高FSS管道的性能,我们提出了一种利用大型语言模型(LLM)来适应通用类语义信息到查询图像的新框架。此外,该框架采用密集像素级匹配来识别查询图像和支持图像之间的相似性,从而提高了FSS的性能。我们的方法受到基于推理的分割框架的启发,被命名为DSV-LFS。该方法在LLM词汇表中引入了一个额外的令牌,允许多模态LLM从类别描述生成“语义提示”。同时,密集匹配模块识别查询图像和支持图像之间的视觉相似性,生成“视觉提示”。然后,这些提示被共同用来引导基于提示的解码器,对查询图像进行准确的分割。在Pascal-$5^{i}$和COCO-$20^{i}$基准数据集上的综合实验表明,我们的框架达到了最先进的性能水平,并且在新的类别中表现出优越的泛化能力和在不同场景中的稳健性。源代码可在https://github.com/aminpdik/DSV-LFS获取。
论文及项目相关链接
Summary
本文提出了一种基于大语言模型的少样本语义分割框架DSV-LFS,该框架旨在通过利用通用类语义信息来改进少样本语义分割的性能。通过引入语义提示和视觉提示,结合密集像素匹配模块,DSV-LFS框架提高了对新型类别的泛化能力和在多种场景下的稳健性,实现了在Pascal-$5^{i}$和COCO-$20^{i}$等基准数据集上的最佳性能。
Key Takeaways
- 提出了一种基于大语言模型的少样本语义分割框架DSV-LFS。
- DSV-LFS框架利用通用类语义信息适应查询图像,以提高少样本语义分割的性能。
- 通过密集像素匹配模块识别查询图像和支持图像之间的相似性。
- 引入语义提示和视觉提示,增强了框架对新型类别的泛化能力。
- DSV-LFS在多种场景下的稳健性得到了提高。
- 在Pascal-$5^{i}$和COCO-$20^{i}$等基准数据集上实现了最佳性能。
点此查看论文截图

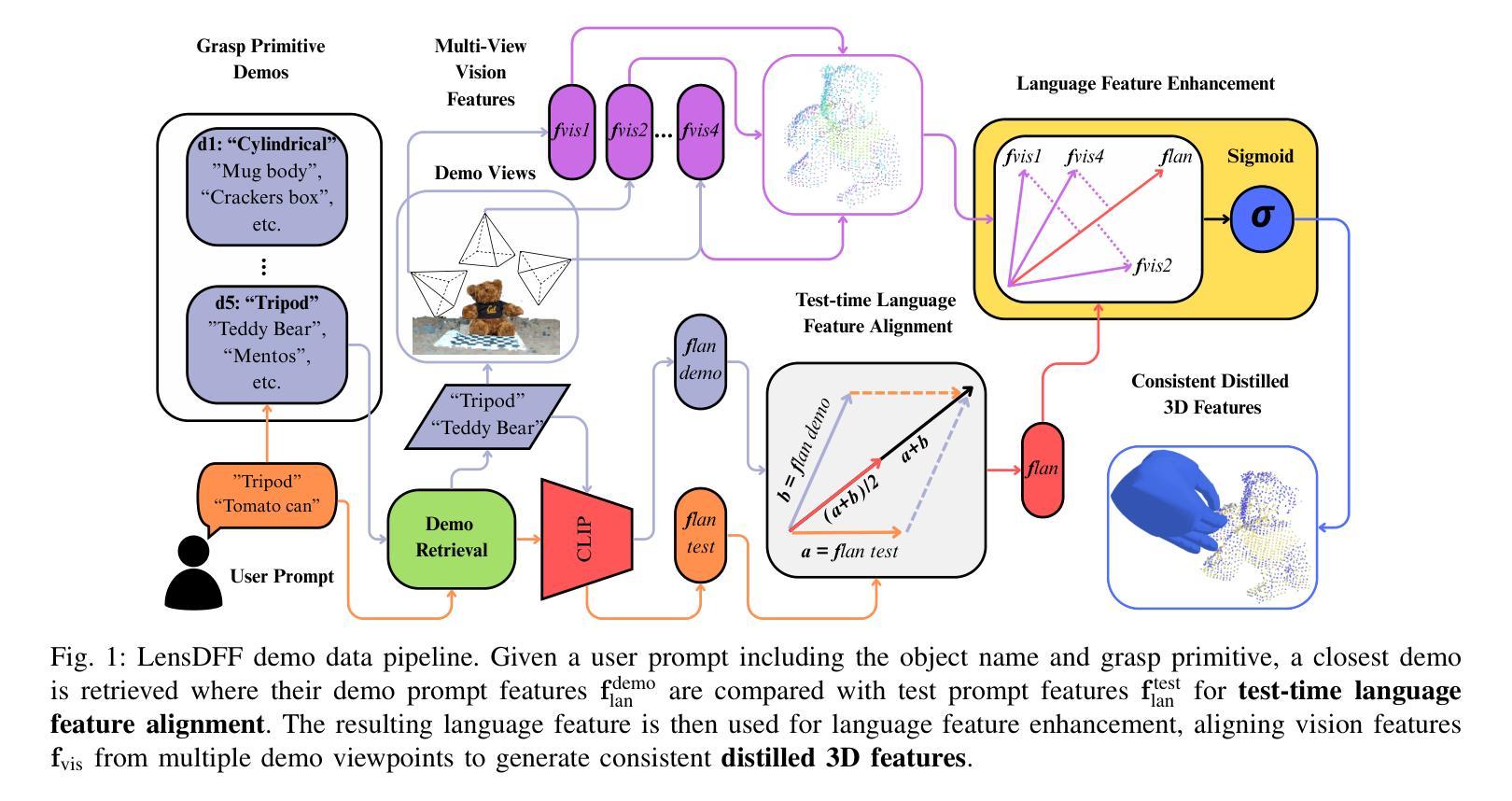
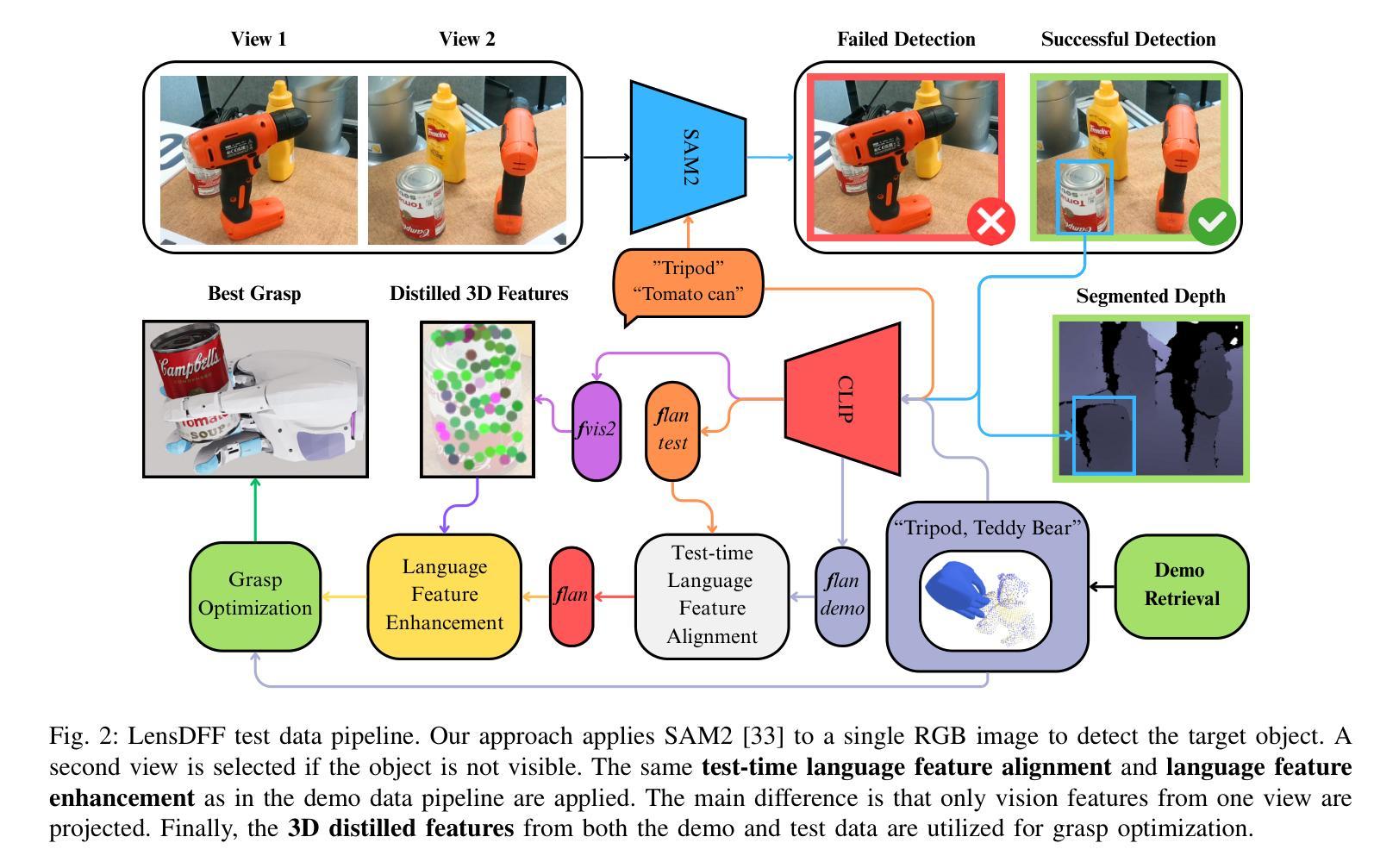
LensDFF: Language-enhanced Sparse Feature Distillation for Efficient Few-Shot Dexterous Manipulation
Authors:Qian Feng, David S. Martinez Lema, Jianxiang Feng, Zhaopeng Chen, Alois Knoll
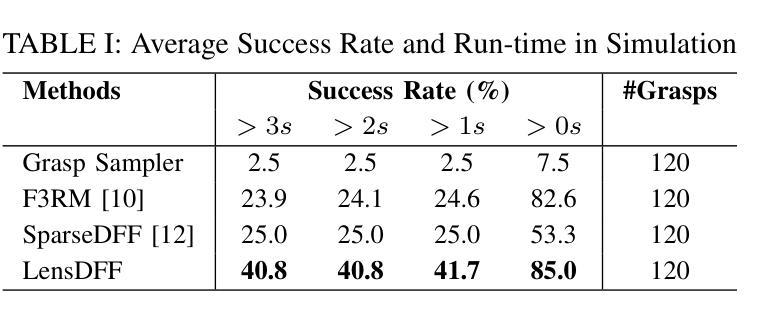
Learning dexterous manipulation from few-shot demonstrations is a significant yet challenging problem for advanced, human-like robotic systems. Dense distilled feature fields have addressed this challenge by distilling rich semantic features from 2D visual foundation models into the 3D domain. However, their reliance on neural rendering models such as Neural Radiance Fields (NeRF) or Gaussian Splatting results in high computational costs. In contrast, previous approaches based on sparse feature fields either suffer from inefficiencies due to multi-view dependencies and extensive training or lack sufficient grasp dexterity. To overcome these limitations, we propose Language-ENhanced Sparse Distilled Feature Field (LensDFF), which efficiently distills view-consistent 2D features onto 3D points using our novel language-enhanced feature fusion strategy, thereby enabling single-view few-shot generalization. Based on LensDFF, we further introduce a few-shot dexterous manipulation framework that integrates grasp primitives into the demonstrations to generate stable and highly dexterous grasps. Moreover, we present a real2sim grasp evaluation pipeline for efficient grasp assessment and hyperparameter tuning. Through extensive simulation experiments based on the real2sim pipeline and real-world experiments, our approach achieves competitive grasping performance, outperforming state-of-the-art approaches.
从少量演示中学习灵巧操作对于先进的人形机器人系统来说是一个重要且具有挑战性的任务。密集蒸馏特征场通过将从二维视觉基础模型中提炼的丰富语义特征蒸馏到三维领域来解决这一挑战。然而,它们对神经渲染模型的依赖(例如神经辐射场(NeRF)或高斯喷射)导致了较高的计算成本。相比之下,基于稀疏特征场的早期方法要么因多视图依赖和大量训练而导致效率低下,要么缺乏足够的抓握灵巧性。为了克服这些局限性,我们提出了语言增强稀疏蒸馏特征场(LensDFF),它通过我们新颖的语言增强特征融合策略,有效地将视图一致的二维特征蒸馏到三维点上,从而实现单视图小样本泛化。基于LensDFF,我们进一步引入了一种小样本灵巧操作框架,该框架将抓取原语集成到演示中,以生成稳定和高度灵巧的抓取。此外,我们为高效抓取评估和超参数调整提供了一个real2sim抓取评估流程。通过基于real2sim流程和真实世界实验的广泛仿真实验,我们的方法实现了具有竞争力的抓取性能,优于现有先进技术。
论文及项目相关链接
PDF 8 pages
Summary
基于少量演示数据实现高级人形机器人的灵巧操控是一项重大挑战。为解决这一问题,研究提出语言增强稀疏蒸馏特征场(LensDFF)技术,它通过新颖的跨视角语言增强特征融合策略实现二维特征的精准提取并转译为三维模型中的高效姿态操作。该技术结合了演示中的抓取动作原始信息,生成稳定且高度灵活的抓取动作。此外,研究还建立了一个用于高效抓取评估和参数调整的真实模拟抓取评估流程。通过模拟实验和真实世界实验验证,该方法表现出出色的抓取性能,优于现有技术。
Key Takeaways
- 学习从少量演示中进行灵巧操控对于高级人形机器人系统是重要的挑战。
- Dense distilled feature fields通过将二维视觉特征模型中的丰富语义特征蒸馏到三维领域来解决这一挑战。
- 当前方法存在计算成本高或操作不够灵巧的问题。
- 提出了一种新的方法——语言增强稀疏蒸馏特征场(LensDFF),它通过跨视角的语言增强特征融合策略将二维特征有效地蒸馏到三维点上。
- LensDFF实现了单视角的少量示范推广能力。
- 基于LensDFF,研究引入了包含抓取动作原始信息的灵巧操控框架,用于生成稳定和高度灵活的抓取动作。
点此查看论文截图


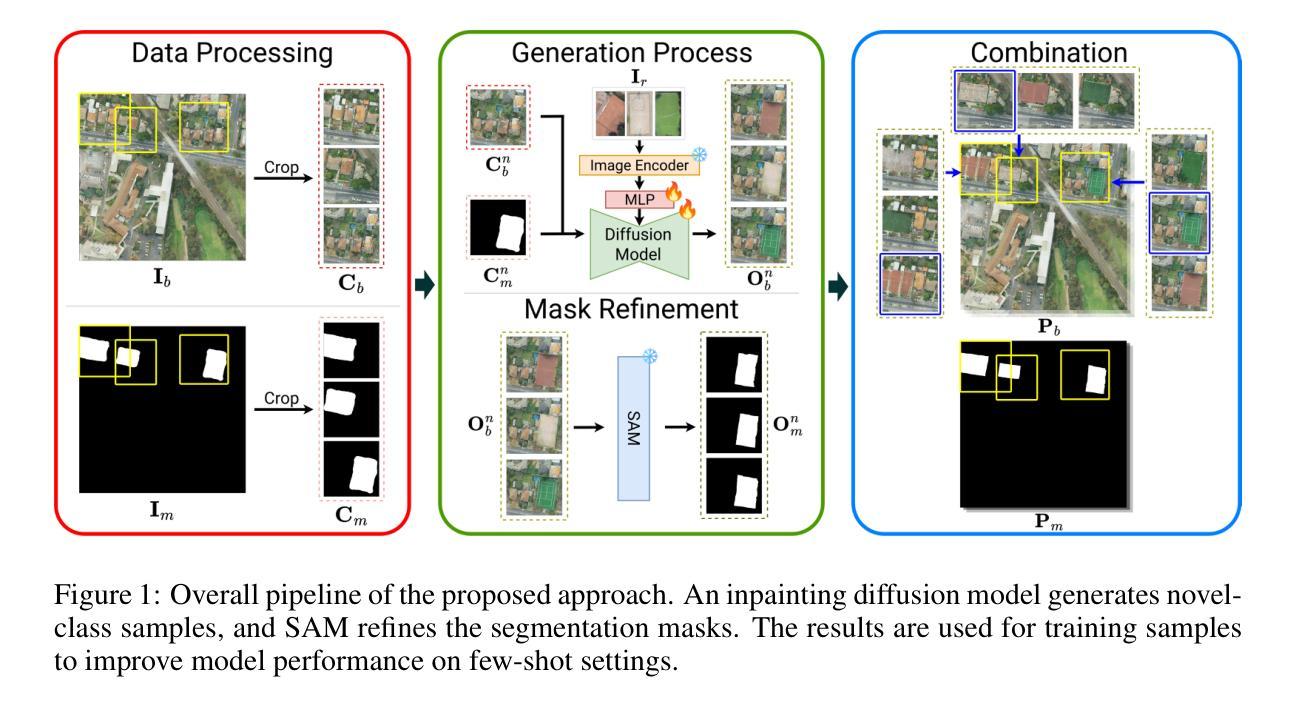
Tackling Few-Shot Segmentation in Remote Sensing via Inpainting Diffusion Model
Authors:Steve Andreas Immanuel, Woojin Cho, Junhyuk Heo, Darongsae Kwon
Limited data is a common problem in remote sensing due to the high cost of obtaining annotated samples. In the few-shot segmentation task, models are typically trained on base classes with abundant annotations and later adapted to novel classes with limited examples. However, this often necessitates specialized model architectures or complex training strategies. Instead, we propose a simple approach that leverages diffusion models to generate diverse variations of novel-class objects within a given scene, conditioned by the limited examples of the novel classes. By framing the problem as an image inpainting task, we synthesize plausible instances of novel classes under various environments, effectively increasing the number of samples for the novel classes and mitigating overfitting. The generated samples are then assessed using a cosine similarity metric to ensure semantic consistency with the novel classes. Additionally, we employ Segment Anything Model (SAM) to segment the generated samples and obtain precise annotations. By using high-quality synthetic data, we can directly fine-tune off-the-shelf segmentation models. Experimental results demonstrate that our method significantly enhances segmentation performance in low-data regimes, highlighting its potential for real-world remote sensing applications.
在遥感领域,由于获取标注样本的成本高昂,有限的数据是一个常见问题。在少量分割任务中,模型通常会在具有丰富注释的基础类上进行训练,然后适应具有有限例子的新类。然而,这通常需要专门的模型架构或复杂的训练策略。相反,我们提出了一种简单的方法,利用扩散模型在给定场景内生成新类对象的各种变体,以有限的例子为条件。通过将问题构造成图像修复任务,我们在各种环境下合成新类的合理实例,有效地增加了新类的样本数量,并减轻了过拟合。然后,我们使用余弦相似度度量法对生成的样本进行评估,以确保其与新类的语义一致性。此外,我们还采用了分割任何模型(SAM)来对生成的样本进行分割,以获得精确的注释。通过使用高质量合成数据,我们可以直接微调现成的分割模型。实验结果表明,我们的方法在数据稀缺的情况下显著提高了分割性能,突显了其在现实世界遥感应用中的潜力。
论文及项目相关链接
PDF Accepted to ICLRW 2025 (Oral)
Summary
基于有限数据的常见远程感应问题,文章提出了一个利用扩散模型的方法,以在给定场景中生成多样化、受限实例条件下新颖类对象的不同变体。通过将问题框架化为图像修复任务,该方法在多种环境下合成合理的新颖类实例,有效增加了样本数量并减轻了过拟合现象。使用余弦相似性度量评估生成的样本以确保与新颖类的语义一致性。实验结果表明,该方法在低数据状态下显著提高分割性能,具有现实遥感应用的潜力。
Key Takeaways
- 面对遥感中的有限数据问题,提出了一个基于扩散模型的解决方案。
- 方法生成多样化、基于实例条件的新颖类对象变体。
- 将问题框架化为图像修复任务,合成合理的新颖类实例。
- 通过增加样本数量减轻过拟合现象。
- 使用余弦相似性度量评估生成的样本以确保与新颖类的语义一致性。
- 使用合成的高品质数据直接微调现成的分割模型。
点此查看论文截图

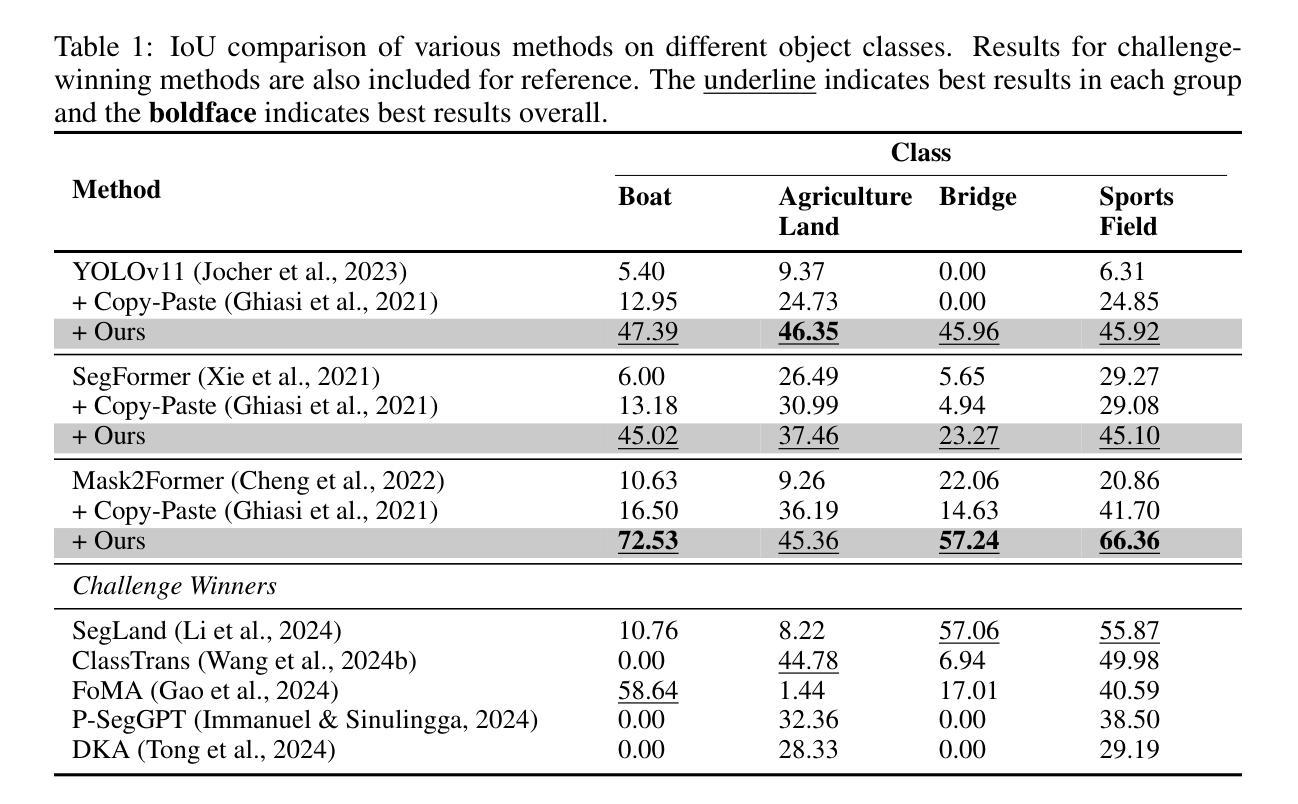

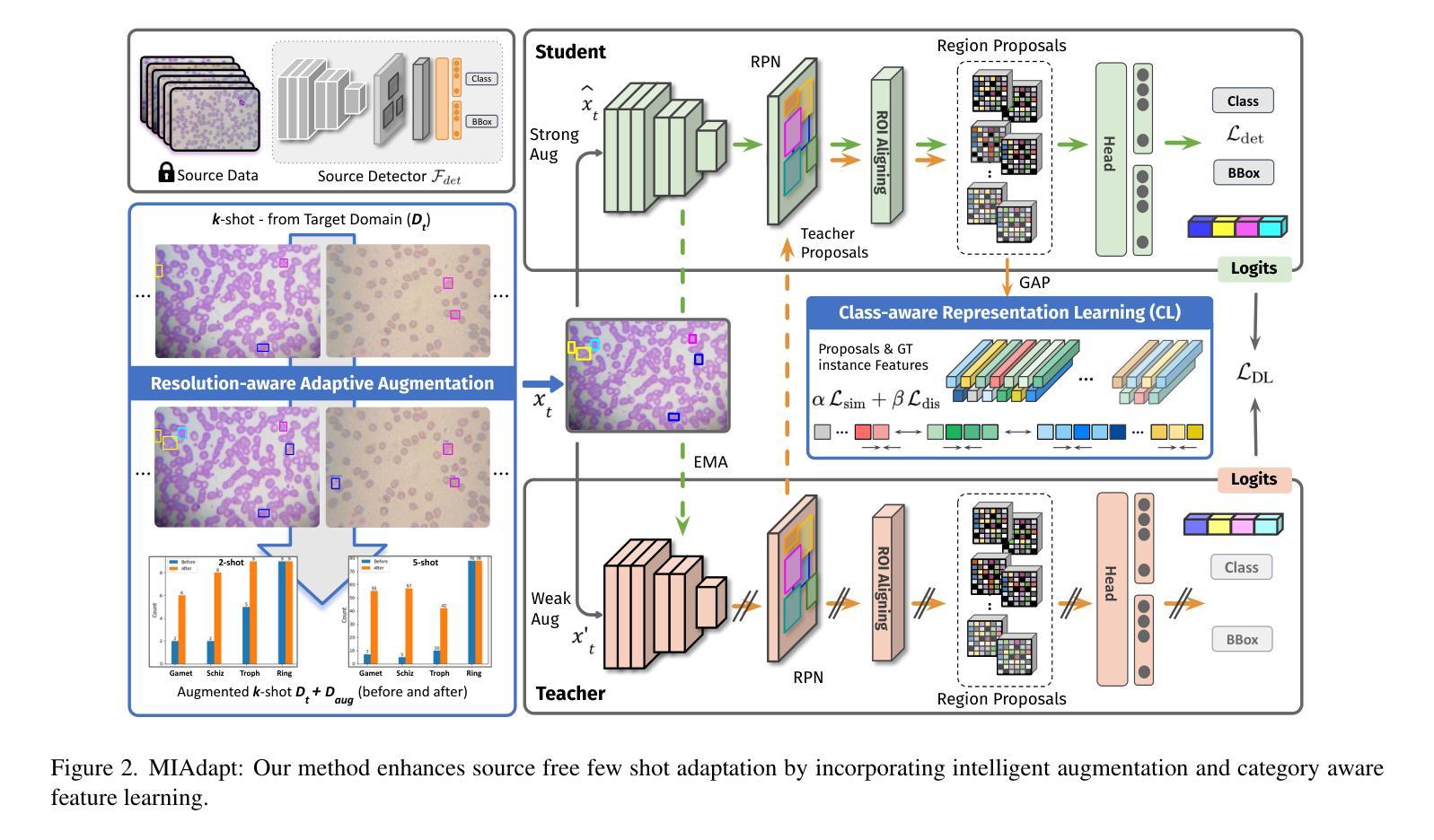
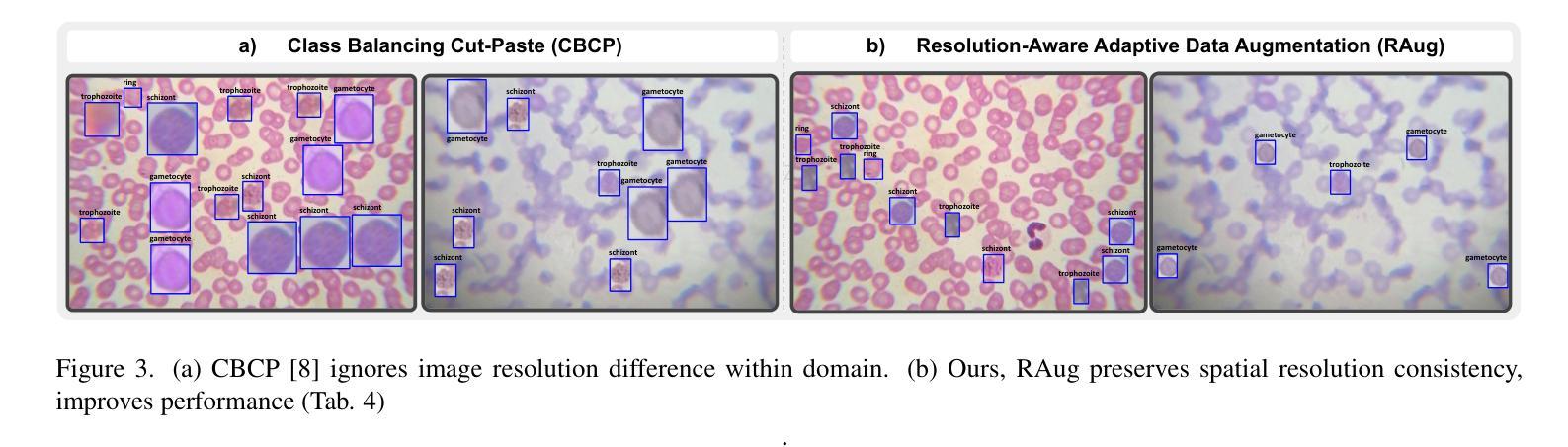
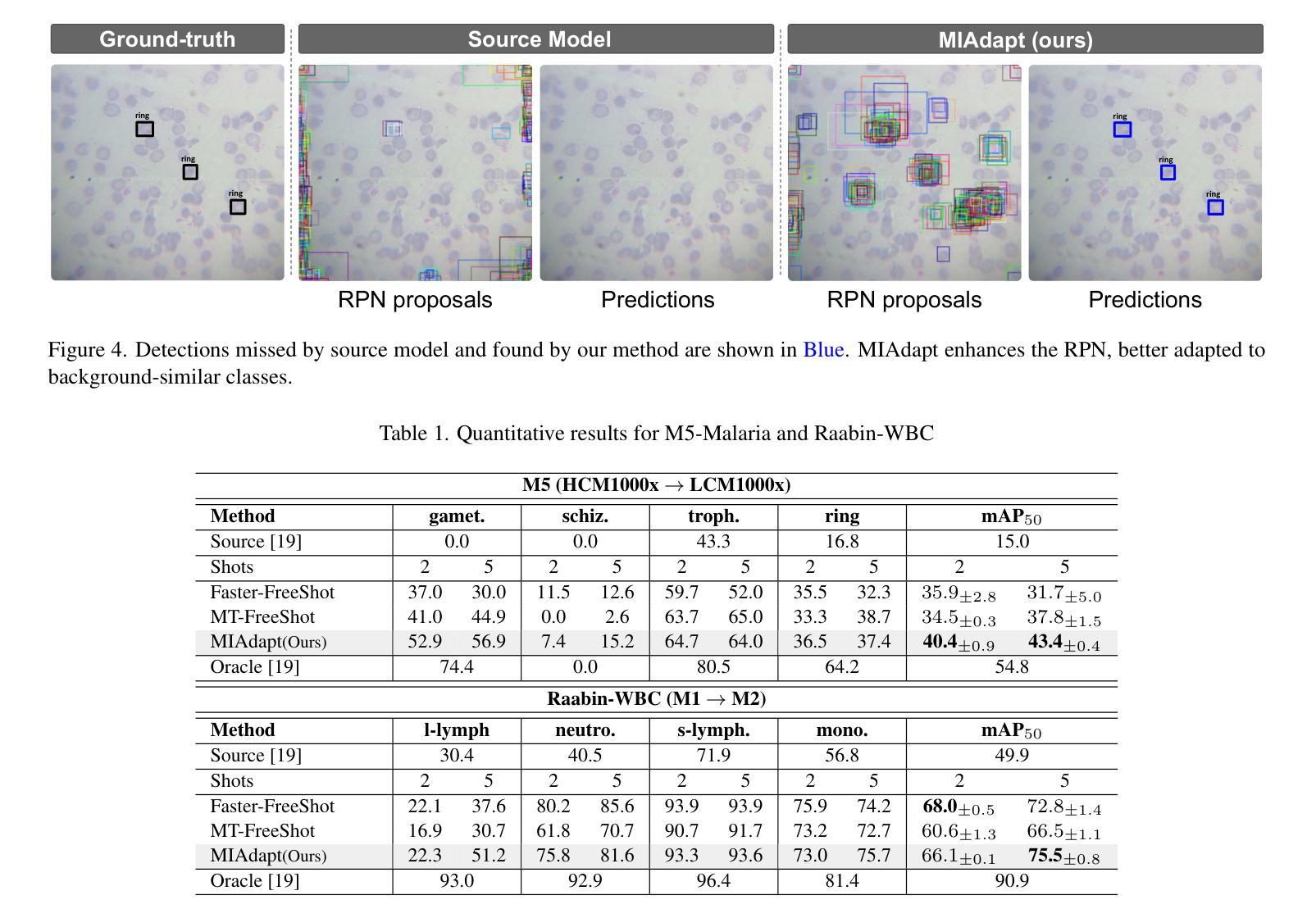
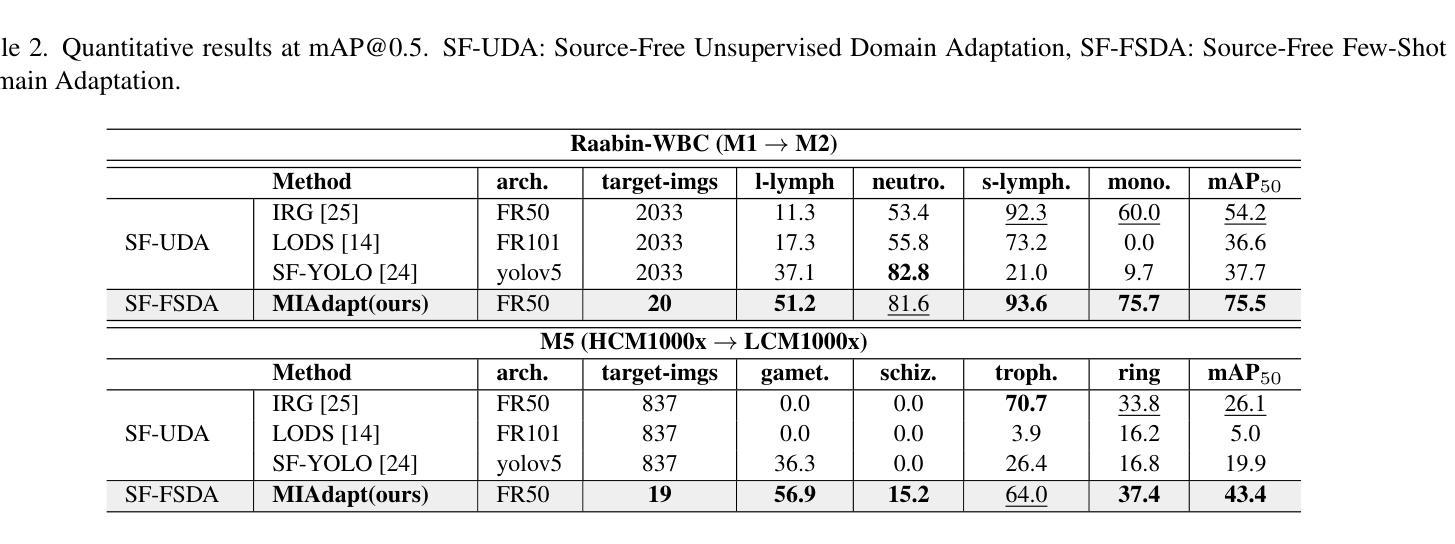
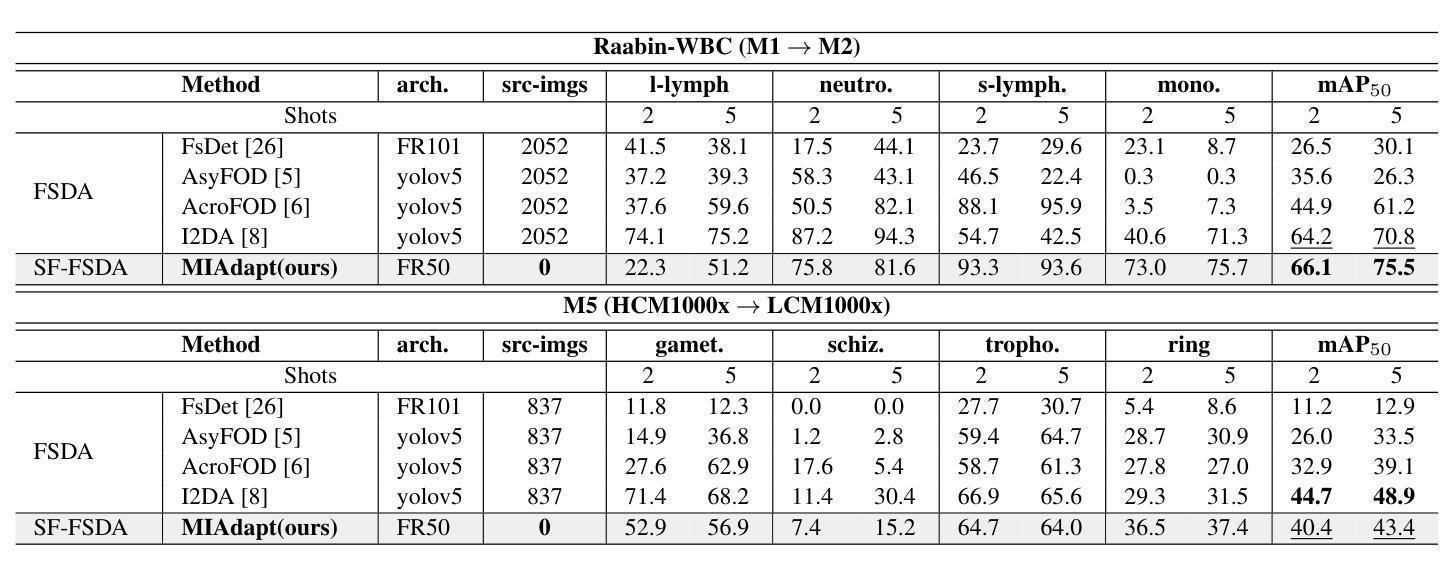
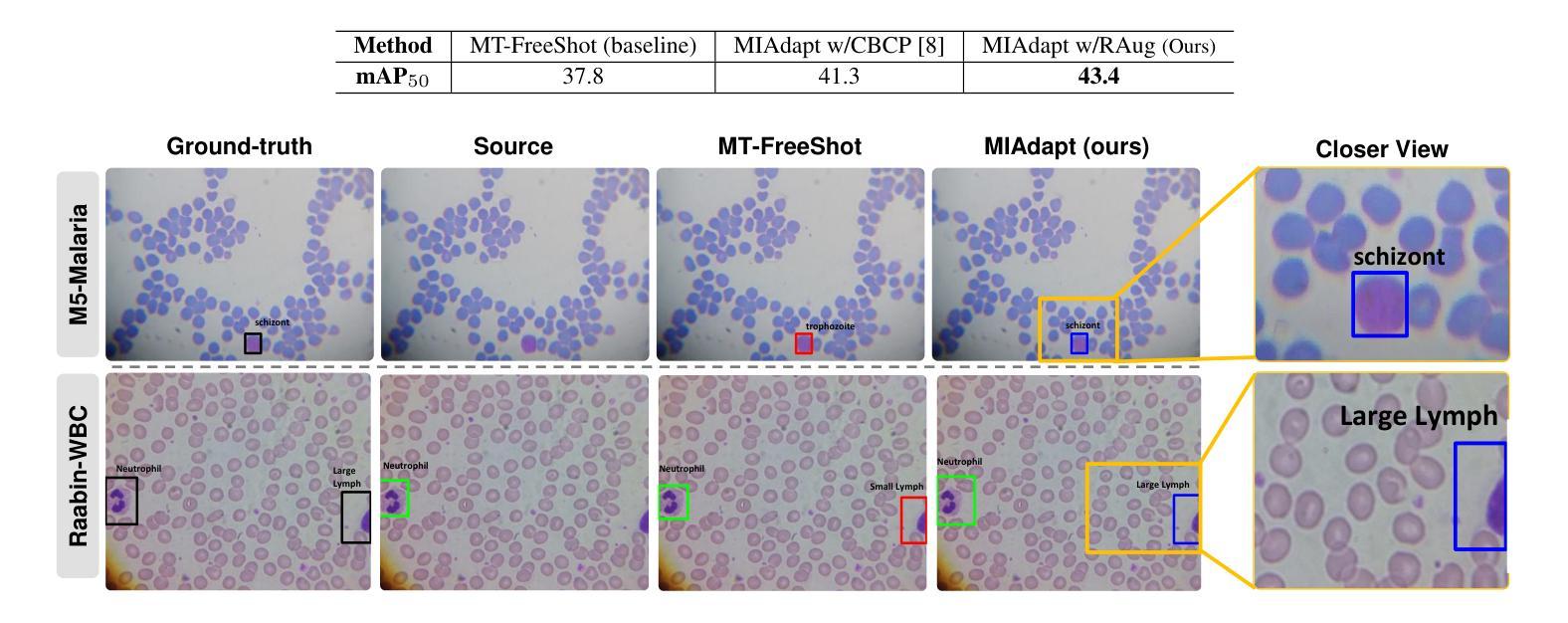
MIAdapt: Source-free Few-shot Domain Adaptive Object Detection for Microscopic Images
Authors:Nimra Dilawar, Sara Nadeem, Javed Iqbal, Waqas Sultani, Mohsen Ali
Existing generic unsupervised domain adaptation approaches require access to both a large labeled source dataset and a sufficient unlabeled target dataset during adaptation. However, collecting a large dataset, even if unlabeled, is a challenging and expensive endeavor, especially in medical imaging. In addition, constraints such as privacy issues can result in cases where source data is unavailable. Taking in consideration these challenges, we propose MIAdapt, an adaptive approach for Microscopic Imagery Adaptation as a solution for Source-free Few-shot Domain Adaptive Object detection (SF-FSDA). We also define two competitive baselines (1) Faster-FreeShot and (2) MT-FreeShot. Extensive experiments on the challenging M5-Malaria and Raabin-WBC datasets validate the effectiveness of MIAdapt. Without using any image from the source domain MIAdapt surpasses state-of-the-art source-free UDA (SF-UDA) methods by +21.3% mAP and few-shot domain adaptation (FSDA) approaches by +4.7% mAP on Raabin-WBC. Our code and models will be publicly available.
现有的通用无监督域自适应方法要求在适应过程中访问大量有标签的源数据集和足够的无标签目标数据集。然而,收集大量数据集,即使是未标记的,也是一项具有挑战性和昂贵的任务,特别是在医学影像领域。此外,隐私等问题可能导致源数据无法使用。考虑到这些挑战,我们提出了MIAdapt,这是一种针对显微镜图像适应的自适应方法,作为源自由少域自适应目标检测(SF-FSDA)的解决方案。我们还定义了两个有竞争力的基线模型:(1)Faster-FreeShot和(2)MT-FreeShot。在具有挑战性的M5疟疾和Raabin-WBC数据集上进行的广泛实验验证了MIAdapt的有效性。MIAdapt在不使用源域中的任何图像的情况下,在Raabin-WBC数据集上的平均精度(mAP)超过了最新的源自由UDA(SF-UDA)方法+21.3%,并超过了少域自适应目标检测(FSDA)的方法+4.7%。我们的代码和模型将公开可用。
论文及项目相关链接
PDF 6 pages, 5 figures
Summary
本文介绍了MIAdapt方法,这是一种针对显微图像自适应的源自由少镜头域自适应目标检测(SF-FSDA)的适应性方法。由于收集大量数据集(即使是无标签的)具有挑战性和昂贵性,尤其是医学成像领域,因此该方法考虑了无需源数据的挑战。通过定义两条竞争性基线(Faster-FreeShot和MT-FreeShot),并在具有挑战性的M5-Malaria和Raabin-WBC数据集上进行广泛实验,验证了MIAdapt的有效性。在源域图像未使用的情况下,MIAdapt的性能超过了现有的源自由UDA(SF-UDA)方法和少镜头域自适应方法。我们的代码和模型将公开可用。
Key Takeaways
- MIAdapt是一种针对显微图像自适应的源自由少镜头域自适应目标检测方法。
- 与其他方法相比,MIAdapt不需要使用大量标注的源数据集或无标签的目标数据集进行适配。
- 由于隐私等问题,可能会出现无法获得源数据的情况,MIAdapt考虑到了这一点。
- 在M5-Malaria和Raabin-WBC数据集上的实验验证了MIAdapt的有效性。
- MIAdapt的性能优于现有的源自由UDA方法和少镜头域自适应方法。具体来说,它在不使用源域图像的情况下超过了这些方法的性能。
- 代码和模型将公开可用,便于其他人进行研究和应用。
点此查看论文截图

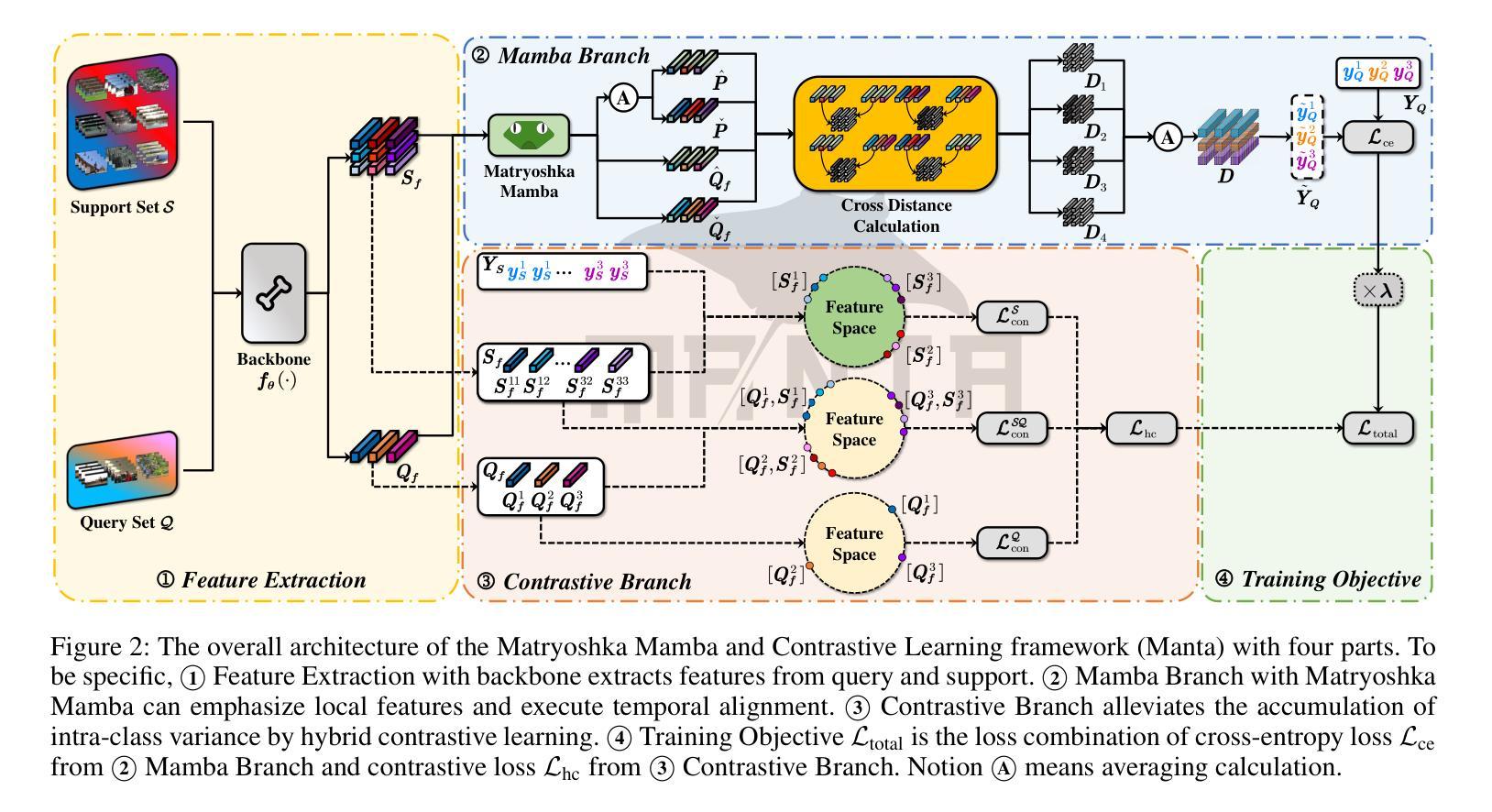
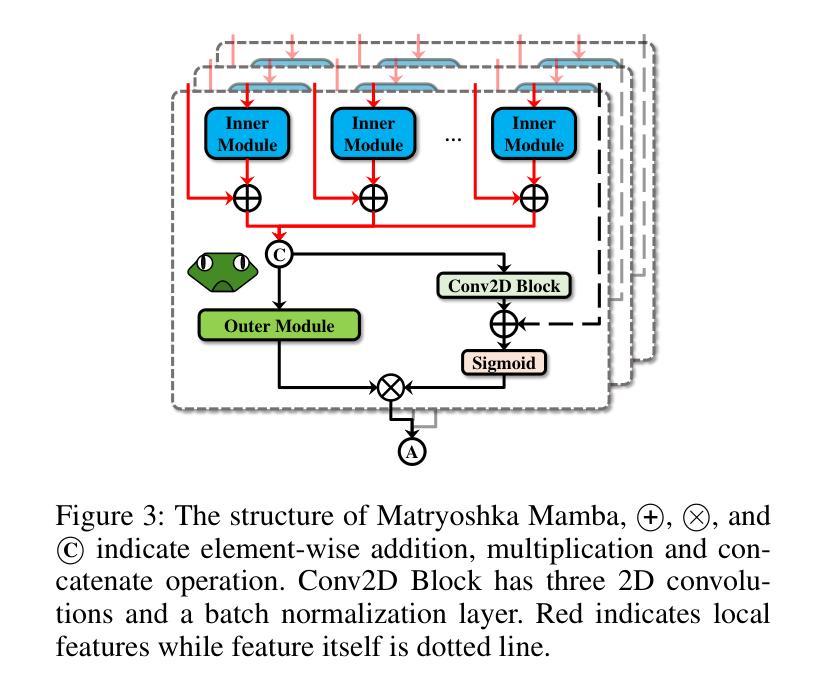
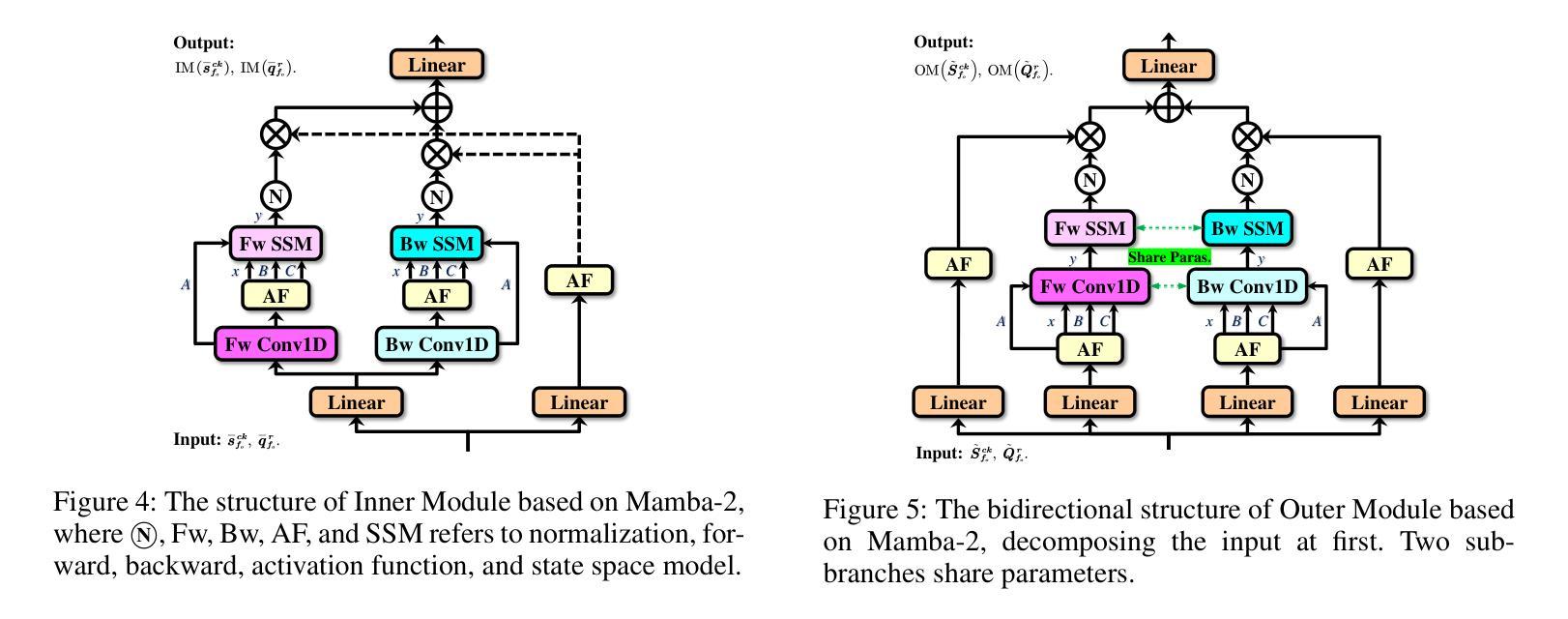
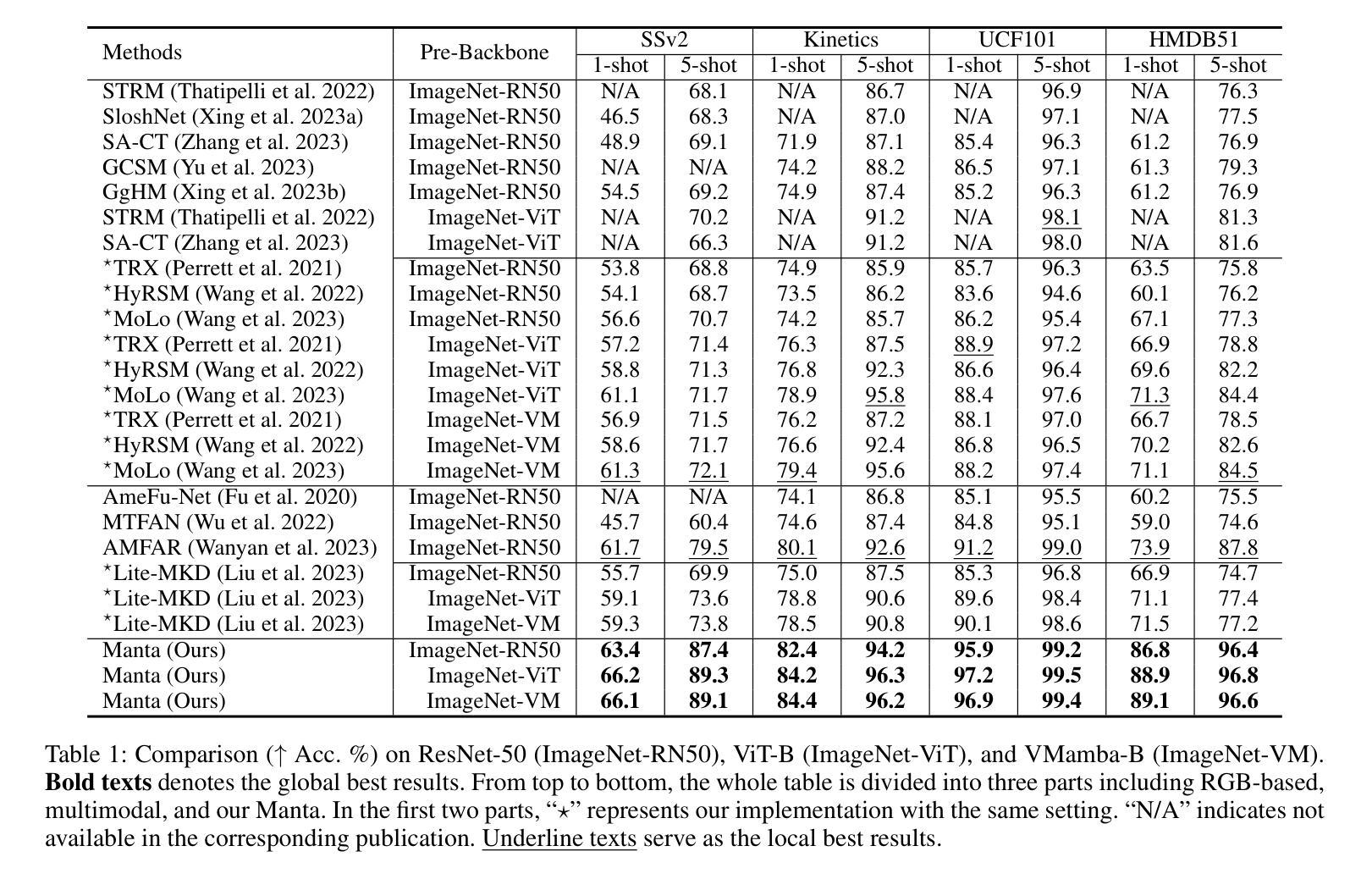
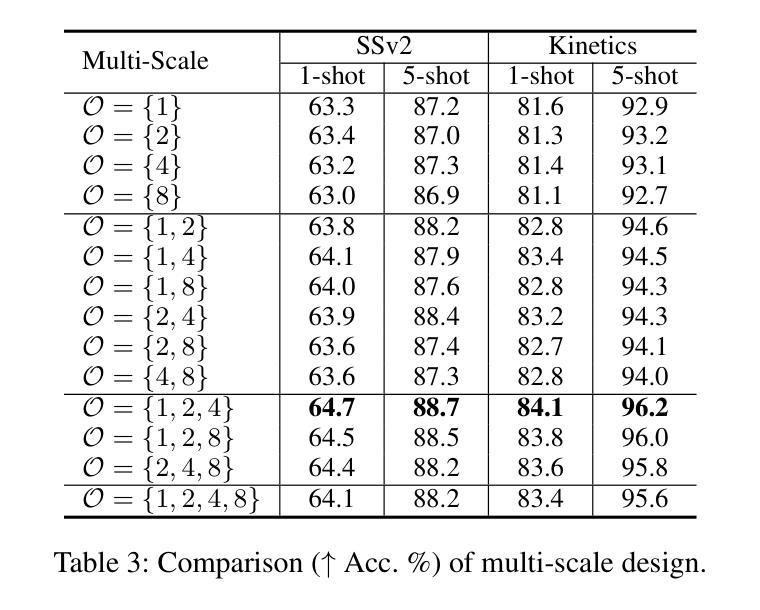
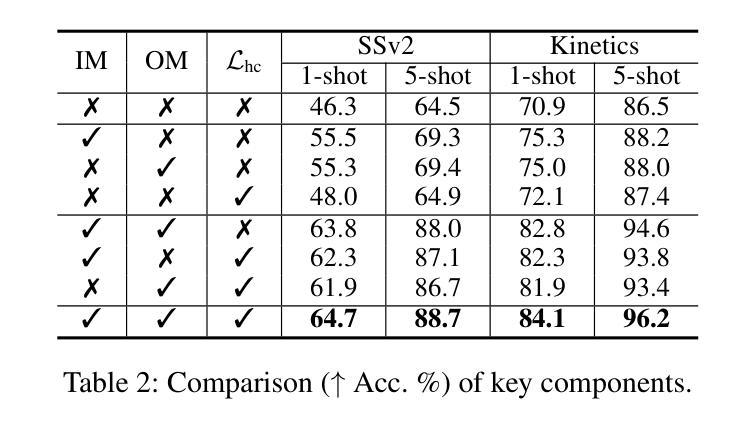
Manta: Enhancing Mamba for Few-Shot Action Recognition of Long Sub-Sequence
Authors:Wenbo Huang, Jinghui Zhang, Guang Li, Lei Zhang, Shuoyuan Wang, Fang Dong, Jiahui Jin, Takahiro Ogawa, Miki Haseyama
In few-shot action recognition (FSAR), long sub-sequences of video naturally express entire actions more effectively. However, the high computational complexity of mainstream Transformer-based methods limits their application. Recent Mamba demonstrates efficiency in modeling long sequences, but directly applying Mamba to FSAR overlooks the importance of local feature modeling and alignment. Moreover, long sub-sequences within the same class accumulate intra-class variance, which adversely impacts FSAR performance. To solve these challenges, we propose a Matryoshka MAmba and CoNtrasTive LeArning framework (Manta). Firstly, the Matryoshka Mamba introduces multiple Inner Modules to enhance local feature representation, rather than directly modeling global features. An Outer Module captures dependencies of timeline between these local features for implicit temporal alignment. Secondly, a hybrid contrastive learning paradigm, combining both supervised and unsupervised methods, is designed to mitigate the negative effects of intra-class variance accumulation. The Matryoshka Mamba and the hybrid contrastive learning paradigm operate in two parallel branches within Manta, enhancing Mamba for FSAR of long sub-sequence. Manta achieves new state-of-the-art performance on prominent benchmarks, including SSv2, Kinetics, UCF101, and HMDB51. Extensive empirical studies prove that Manta significantly improves FSAR of long sub-sequence from multiple perspectives.
在少样本动作识别(FSAR)中,视频的长子序列更自然地表达了整个动作。然而,主流基于Transformer的方法的高计算复杂度限制了其应用。最近的Mamba在建模长序列方面展示了效率,但直接将Mamba应用于FSAR忽略了局部特征建模和对齐的重要性。此外,同一类别内的长子序列会累积类内方差,这对FSAR性能产生不利影响。为了解决这些挑战,我们提出了Matryoshka Mamba和对比学习框架(Manta)。首先,Matryoshka Mamba引入了多个内部模块来增强局部特征表示,而不是直接建模全局特征。外部模块捕获这些局部特征之间时间线的依赖性,以进行隐式时间对齐。其次,结合有监督和无监督方法的混合对比学习范式旨在减轻类内方差累积的负面影响。Matryoshka Mamba和混合对比学习范式在Manta的两个并行分支中运行,增强了Mamba对长子序列的FSAR能力。Manta在SSv2、Kinetics、UCF101和HMDB51等主流基准测试中实现了最新性能。大量实证研究证明,Manta从多个角度显著提高了长子序列的FSAR性能。
论文及项目相关链接
PDF Accepted by AAAI 2025
Summary
本文介绍了针对少样本动作识别(FSAR)的新框架Manta。该框架解决了长序列动作识别的挑战,通过引入Matryoshka Mamba和混合对比学习范式,提高局部特征建模和对齐的能力,同时减少类内方差积累对FSAR性能的影响。Manta在多个基准测试集上实现了卓越的性能。
Key Takeaways
- Matryoshka Mamba被引入以强化局部特征表示,通过多个Inner Modules建模局部特征,而非直接建模全局特征。
- Outer Module用于捕捉这些局部特征的时间线依赖性,实现隐式的时间对齐。
- 提出了混合对比学习范式,结合监督和无监督方法,以减轻类内方差积累带来的负面影响。
- Manta框架中,Matryoshka Mamba和混合对比学习范式在两个并行分支中运行,增强了Mamba对长子序列的FSAR性能。
- Manta在SSv2、Kinetics、UCF101和HMDB51等主流基准测试集上实现了最新 state-of-the-art 性能。
- 广泛的实证研究证明,Manta从多个角度显著提高了长序列动作的FSAR性能。
点此查看论文截图

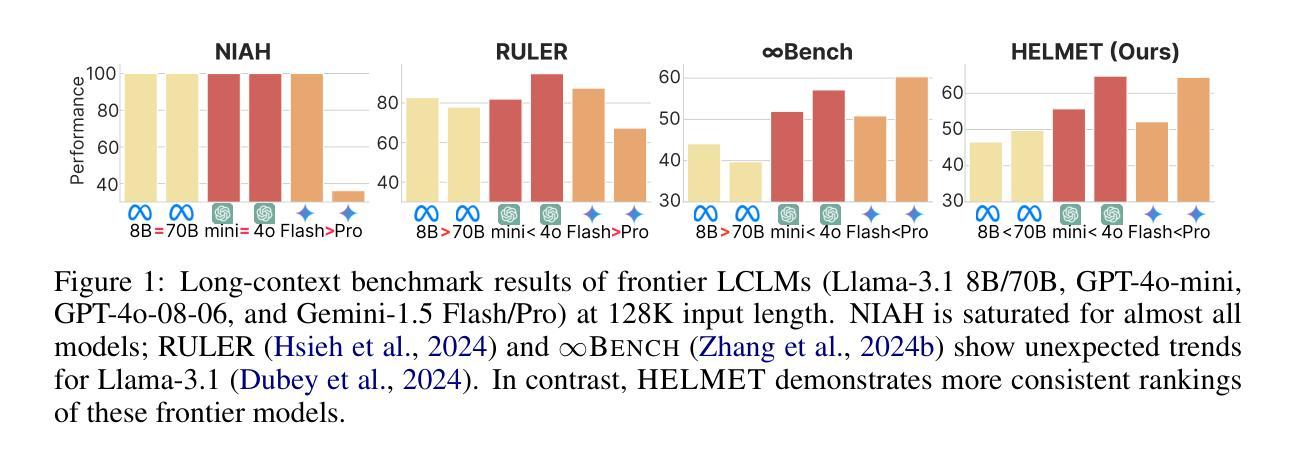
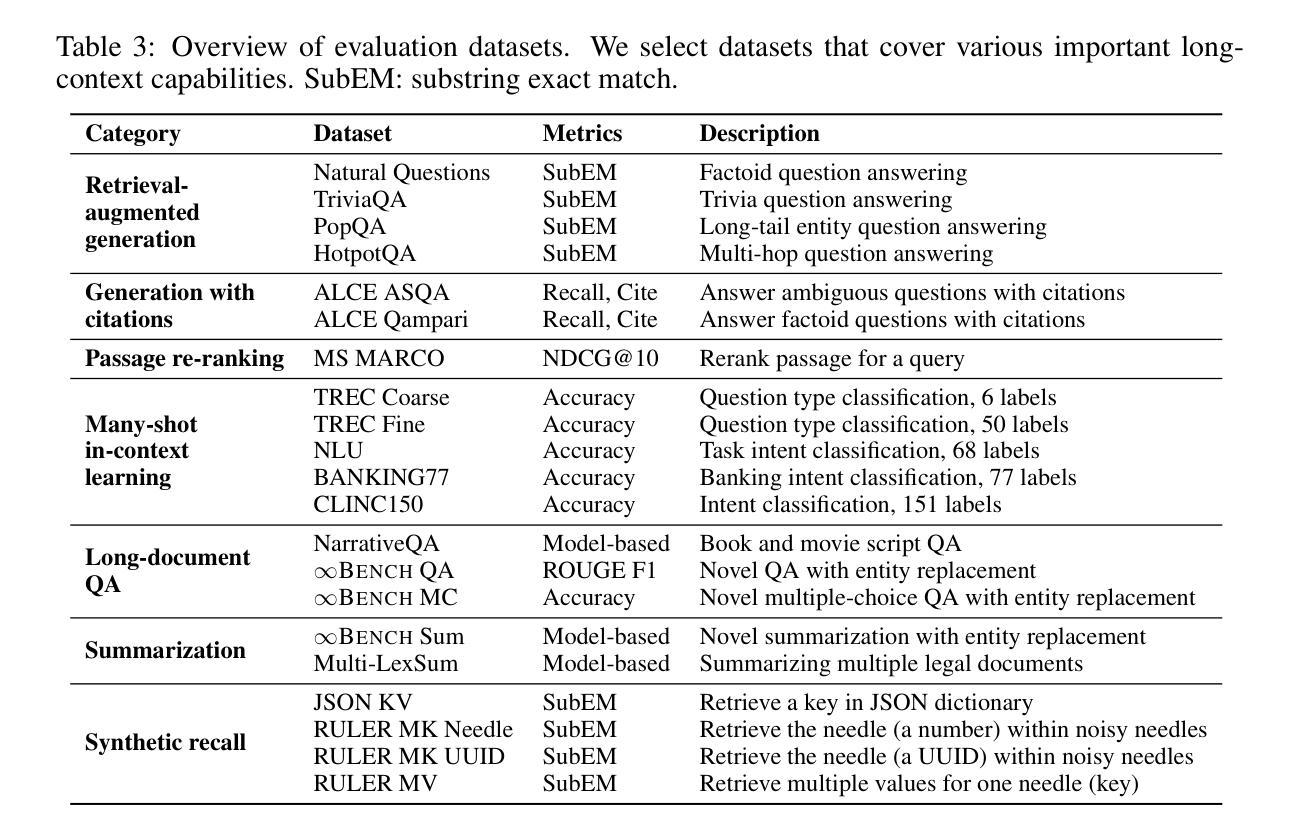
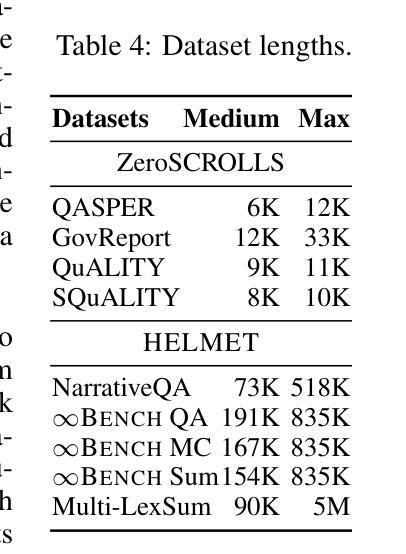
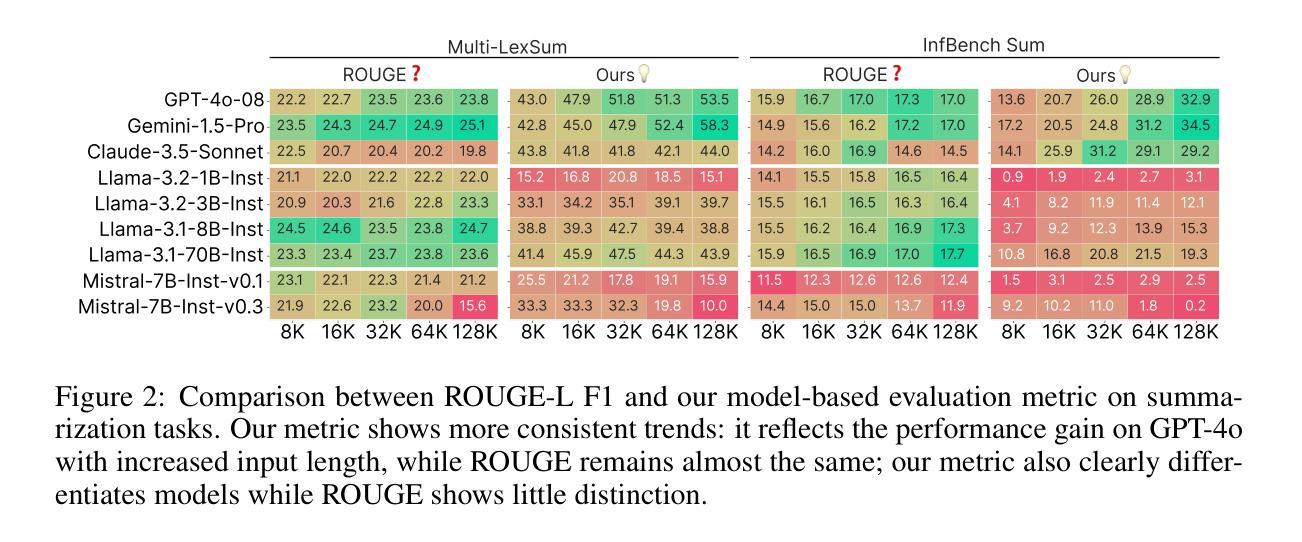
HELMET: How to Evaluate Long-Context Language Models Effectively and Thoroughly
Authors:Howard Yen, Tianyu Gao, Minmin Hou, Ke Ding, Daniel Fleischer, Peter Izsak, Moshe Wasserblat, Danqi Chen
Many benchmarks exist for evaluating long-context language models (LCLMs), yet developers often rely on synthetic tasks such as needle-in-a-haystack (NIAH) or an arbitrary subset of tasks. However, it remains unclear whether these benchmarks reflect the diverse downstream applications of LCLMs, and such inconsistencies further complicate model comparison. We investigate the underlying reasons behind these practices and find that existing benchmarks often provide noisy signals due to limited coverage of applications, insufficient context lengths, unreliable metrics, and incompatibility with base models. In this work, we introduce HELMET (How to Evaluate Long-context Models Effectively and Thoroughly), a comprehensive benchmark encompassing seven diverse, application-centric categories. We also address several issues in previous benchmarks by adding controllable lengths up to 128K tokens, model-based evaluation for reliable metrics, and few-shot prompting for robustly evaluating base models. Consequently, we demonstrate that HELMET offers more reliable and consistent rankings of frontier LCLMs. Through a comprehensive study of 59 LCLMs, we find that (1) synthetic tasks like NIAH do not reliably predict downstream performance; (2) the diverse categories in HELMET exhibit distinct trends and low correlations with each other; and (3) while most LCLMs achieve perfect NIAH scores, open-source models significantly lag behind closed ones when tasks require full-context reasoning or following complex instructions – the gap widens as length increases. Finally, we recommend using our RAG tasks for fast model development, as they are easy to run and better predict other downstream performance; ultimately, we advocate for a holistic evaluation across diverse tasks.
针对长语境语言模型(LCLM)的评估存在许多基准测试,但开发人员通常依赖于合成任务,如“大海捞针”(NIAH)或一系列任意任务。然而,尚不清楚这些基准测试是否反映了LCLM的多样化下游应用,并且这种不一致性进一步加剧了模型比较的难度。我们调查了这些实践背后的根本原因,并发现现有基准测试通常由于应用覆盖有限、上下文长度不足、指标不可靠以及与基础模型不兼容而提供嘈杂的信号。在这项工作中,我们引入了全面的基准测试HELMET(如何有效且彻底地评估长语境模型),包含七个多样化、以应用为中心的类别。我们还通过增加可控长度(最多达128K令牌)、基于模型的评估以获取可靠指标以及少样本提示来解决先前基准测试中的几个问题,从而稳健地评估基础模型。因此,我们证明了HELMET为前沿LCLM提供了更可靠且一致性的排名。通过对59个LCLM的综合研究,我们发现:(1)像NIAH这样的合成任务无法可靠地预测下游性能;(2)HELMET中的不同类别呈现出不同的趋势,彼此间低相关性;(3)虽然大多数LCLM在NIAH得分上表现完美,但在需要全语境推理或遵循复杂指令的任务上,开源模型与封闭模型的性能差距显著拉大,且随着长度的增加而扩大。最后,我们建议使用我们的RAG任务进行快速模型开发,因为它们易于运行并可以更好地预测其他下游性能;最终,我们主张在多样化任务上进行整体评估。
论文及项目相关链接
PDF ICLR 2025. Project page: https://princeton-nlp.github.io/HELMET/
Summary
该文探讨了对长文本语境模型(LCLM)的评估问题。现有评估基准测试存在诸多不足,如覆盖应用有限、语境长度不足、评价指标不可靠等。为此,作者提出了HELMET基准测试,该测试包含七个应用类别,并解决了以往基准测试中的问题,如可控的语境长度、基于模型的可靠评价指标和少样本提示等。研究结果表明,HELMET为前沿LCLM提供了更可靠和一致的排名。
Key Takeaways
- 现有评估基准测试在反映LCLM的多样下游应用方面存在不足。
- 开发者常依赖合成任务如“海底捞针”,但这些任务不能可靠预测下游性能。
- HELMET基准测试包含七个应用类别,更全面地评估LCLM。
- HELMET解决了以往基准测试中的问题,如语境长度、评价指标的可靠性等。
- 研究发现,合成任务不能反映LCLM的真实性能,不同类别之间的趋势各异且关联度低。
- 虽然许多LCLM在合成任务上表现完美,但在需要全语境推理或遵循复杂指令的任务上,开源模型与封闭模型之间存在显著差距,且差距随长度增加而扩大。
点此查看论文截图


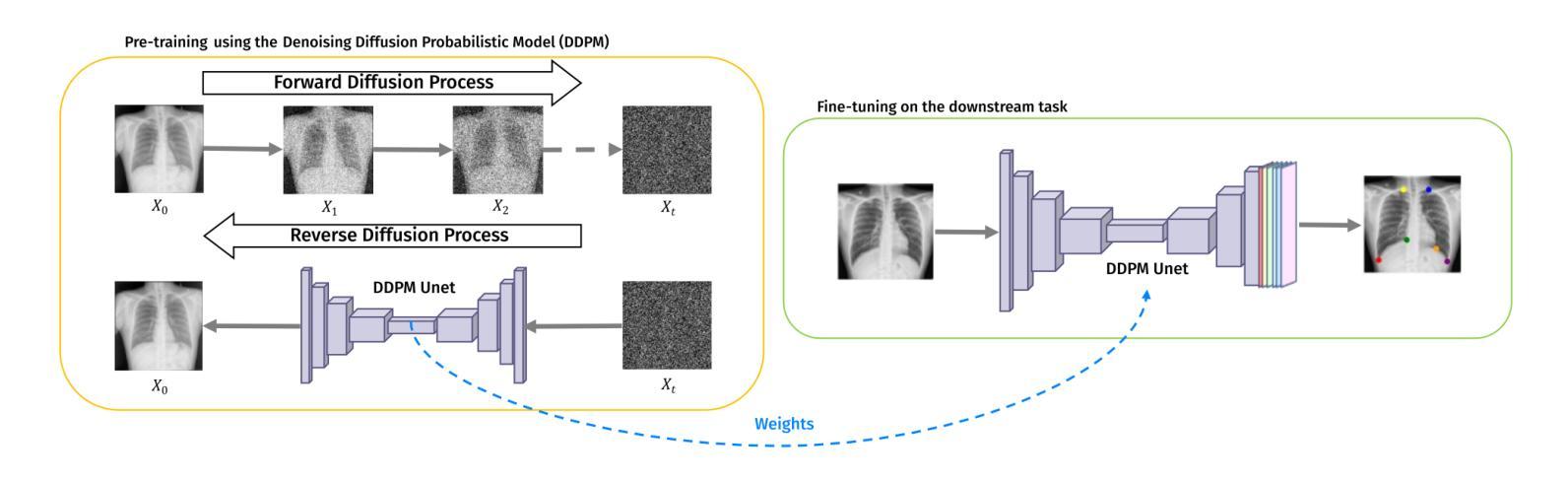
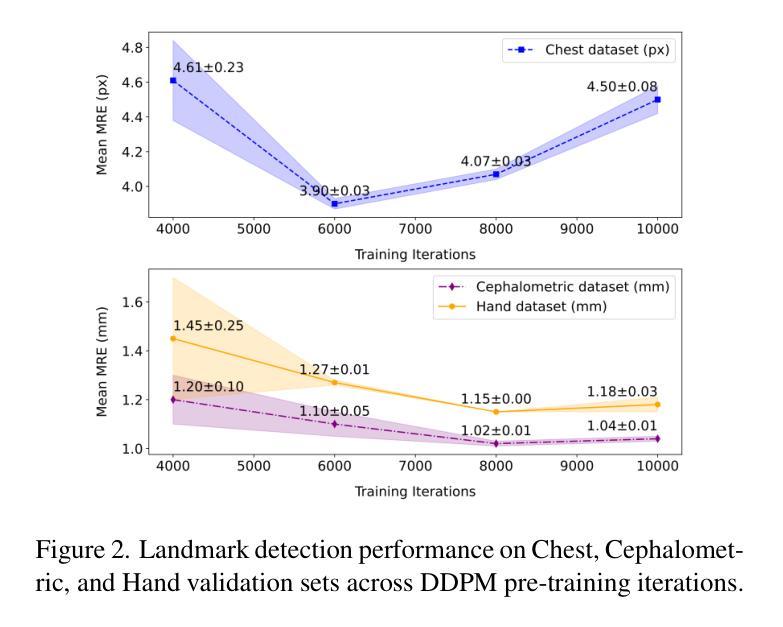
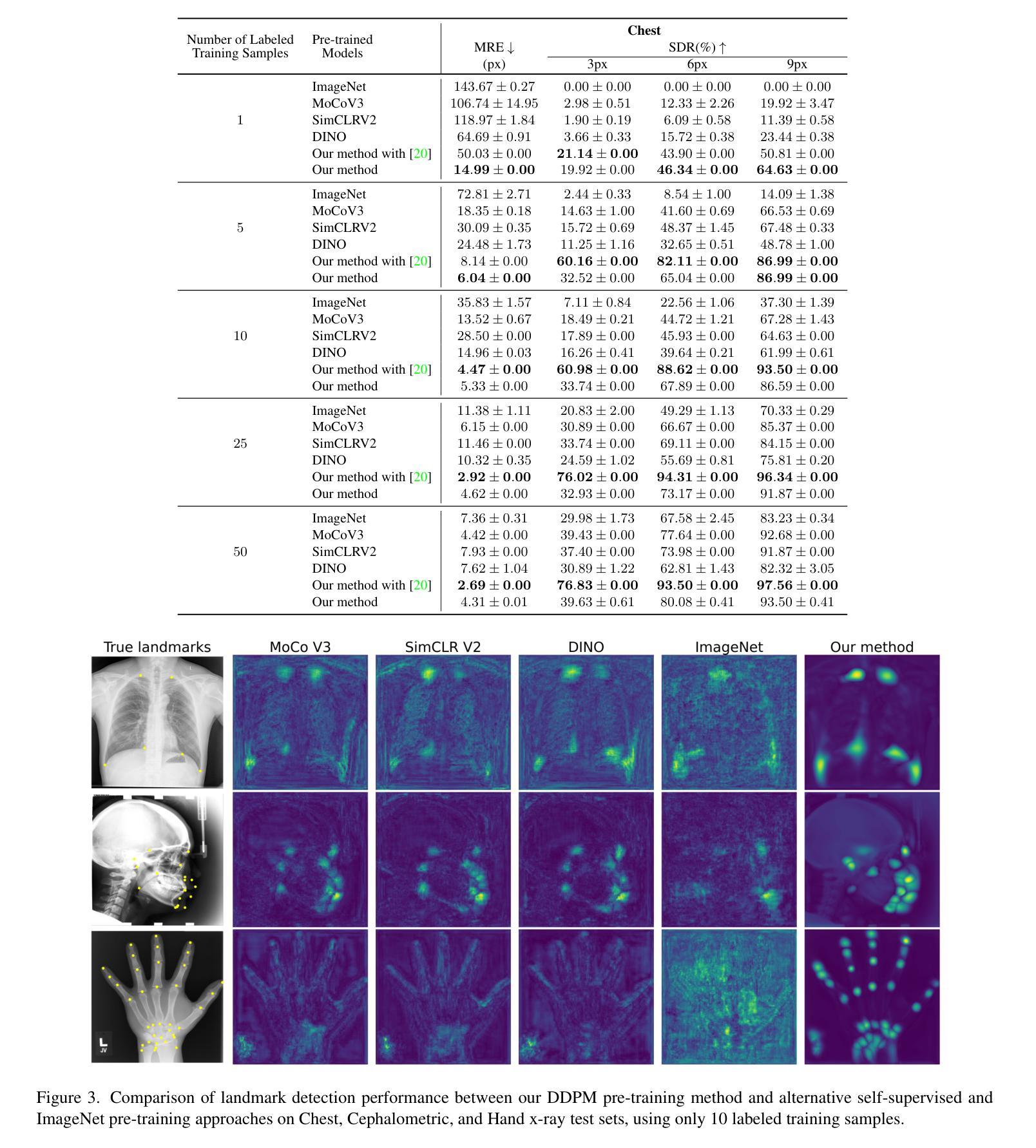
Self-supervised pre-training with diffusion model for few-shot landmark detection in x-ray images
Authors:Roberto Di Via, Francesca Odone, Vito Paolo Pastore
Deep neural networks have been extensively applied in the medical domain for various tasks, including image classification, segmentation, and landmark detection. However, their application is often hindered by data scarcity, both in terms of available annotations and images. This study introduces a novel application of denoising diffusion probabilistic models (DDPMs) to the landmark detection task, specifically addressing the challenge of limited annotated data in x-ray imaging. Our key innovation lies in leveraging DDPMs for self-supervised pre-training in landmark detection, a previously unexplored approach in this domain. This method enables accurate landmark detection with minimal annotated training data (as few as 50 images), surpassing both ImageNet supervised pre-training and traditional self-supervised techniques across three popular x-ray benchmark datasets. To our knowledge, this work represents the first application of diffusion models for self-supervised learning in landmark detection, which may offer a valuable pre-training approach in few-shot regimes, for mitigating data scarcity.
深度神经网络在医疗领域得到了广泛应用,用于各种任务,包括图像分类、分割和地标检测。然而,其应用往往受到数据和可用标注图像匮乏的制约。本研究引入去噪扩散概率模型(DDPMs)的新应用,专门解决X射线成像中标注数据有限带来的挑战。我们的主要创新之处在于利用DDPMs进行地标检测的自我监督预训练,这是该领域之前未探索过的方法。该方法能够在极少的标注训练数据(仅50张图像)下实现准确的地标检测,超越了ImageNet监督预训练和传统自我监督技术在三个流行的X射线基准数据集上的表现。据我们所知,这项工作代表了扩散模型在自我监督学习中的首次应用于地标检测,这可能为数据稀缺情况下提供有价值的预训练方法,特别是在小样例情况下。
论文及项目相关链接
PDF Accepted at WACV 2025
Summary
本文介绍了将去噪扩散概率模型(DDPMs)应用于医学领域地标检测任务的新应用,解决了在X射线成像中有限标注数据的挑战。通过自我监督预训练DDPMs,该方法在仅少量(如50张)标注图像的情况下实现了准确的地标检测,超越了ImageNet监督预训练和传统自我监督技术,在三个流行的X射线基准数据集上表现优异。这是首次将扩散模型应用于地标检测中的自我监督学习,为缓解数据稀缺问题提供了一种有价值的预训练方案。
Key Takeaways
- 研究将去噪扩散概率模型(DDPMs)应用于医学领域的地标检测任务。
- 面对医学图像标注和图像数据稀缺的挑战,DDPMs通过自我监督预训练实现了准确的地标检测。
- 在仅少量标注图像(如50张)的情况下,DDPMs表现超越ImageNet监督预训练和传统自我监督技术。
- 此方法在三个流行的X射线基准数据集上进行了验证并表现优异。
- 这是首次将扩散模型应用于医学图像地标检测中的自我监督学习。
- 该方法可能为缓解医学图像数据稀缺问题的预训练方案提供新的思路。
- 该研究为深度神经网络在医学领域的应用提供了新的可能性,特别是在数据稀缺的情况下。
点此查看论文截图