⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-10 更新
LLM-guided Plan and Retrieval: A Strategic Alignment for Interpretable User Satisfaction Estimation in Dialogue
Authors:Sangyeop Kim, Sohhyung Park, Jaewon Jung, Jinseok Kim, Sungzoon Cho
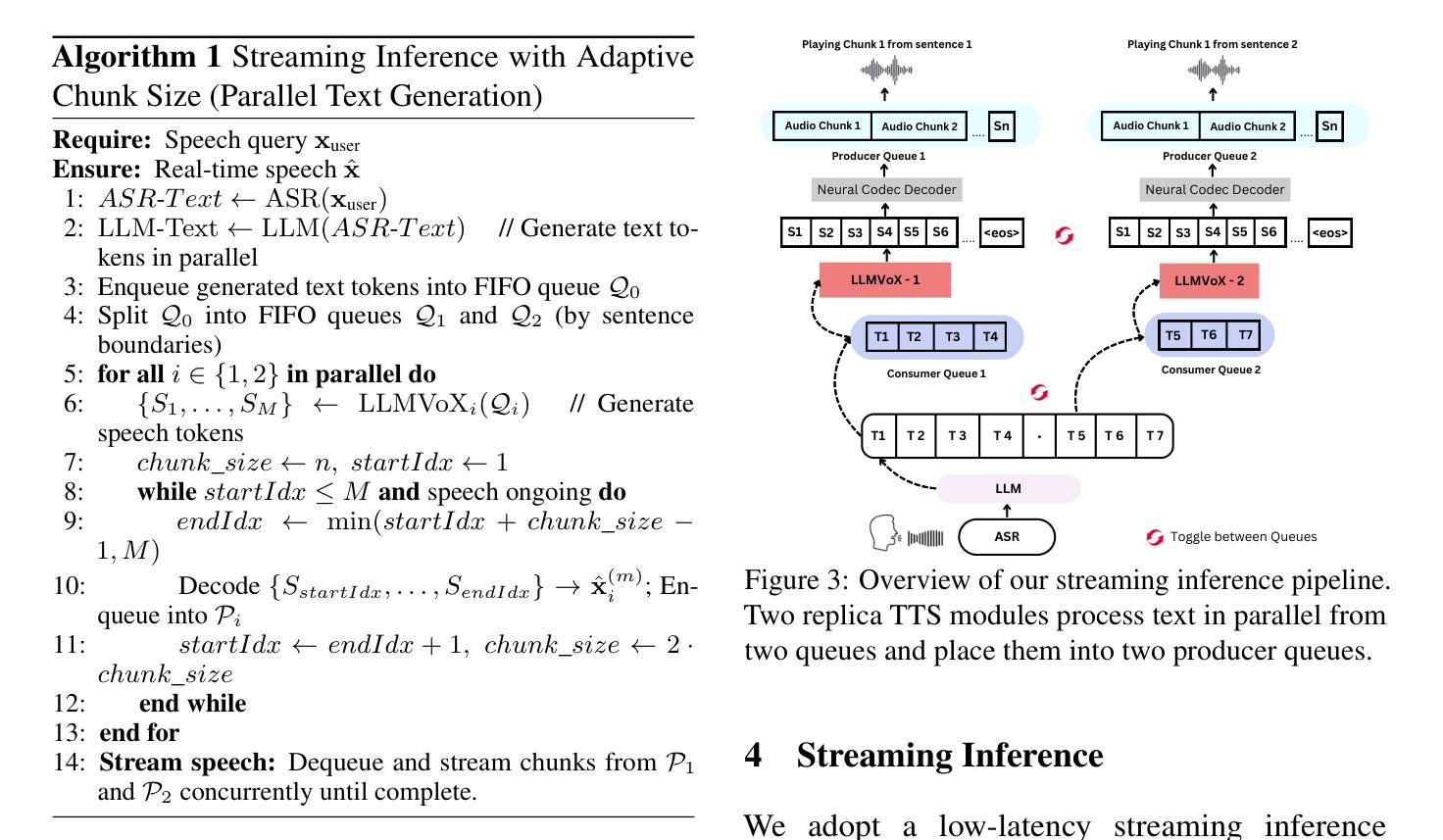
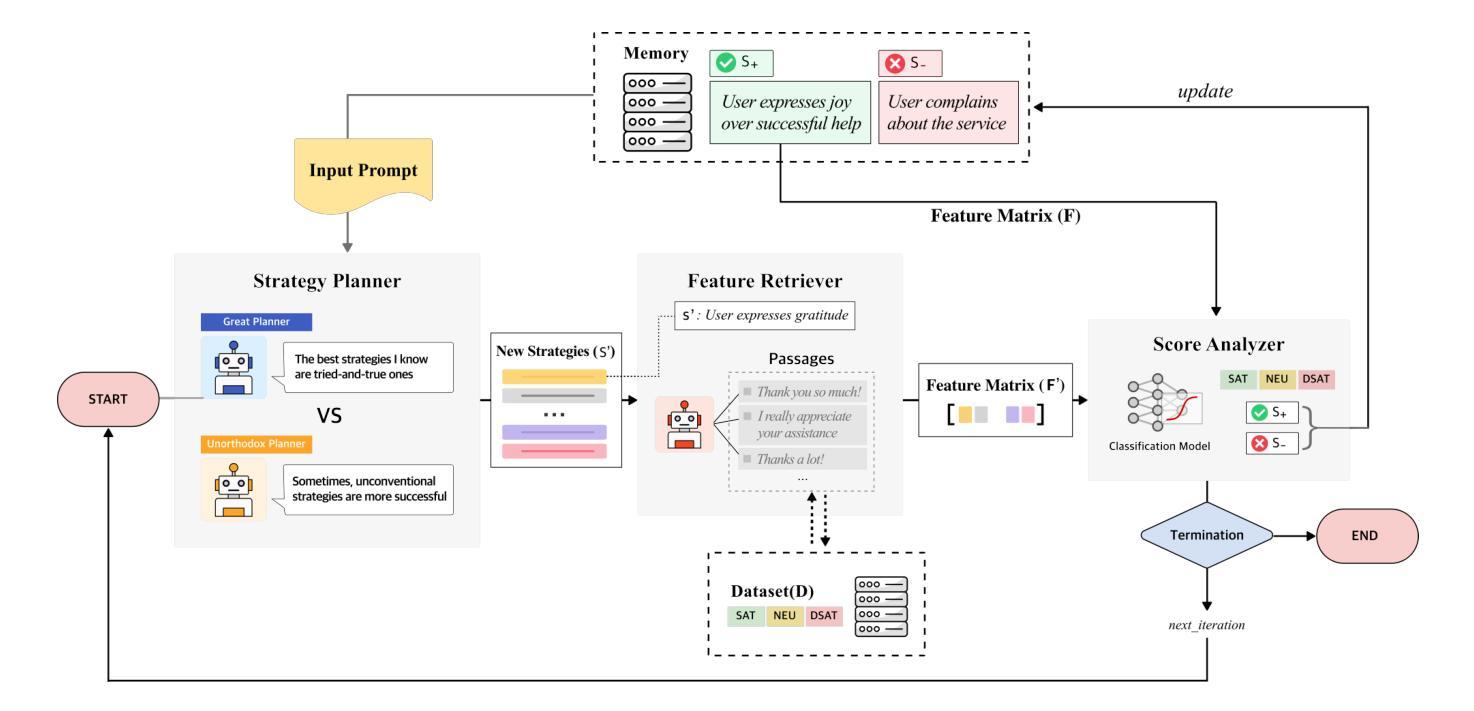
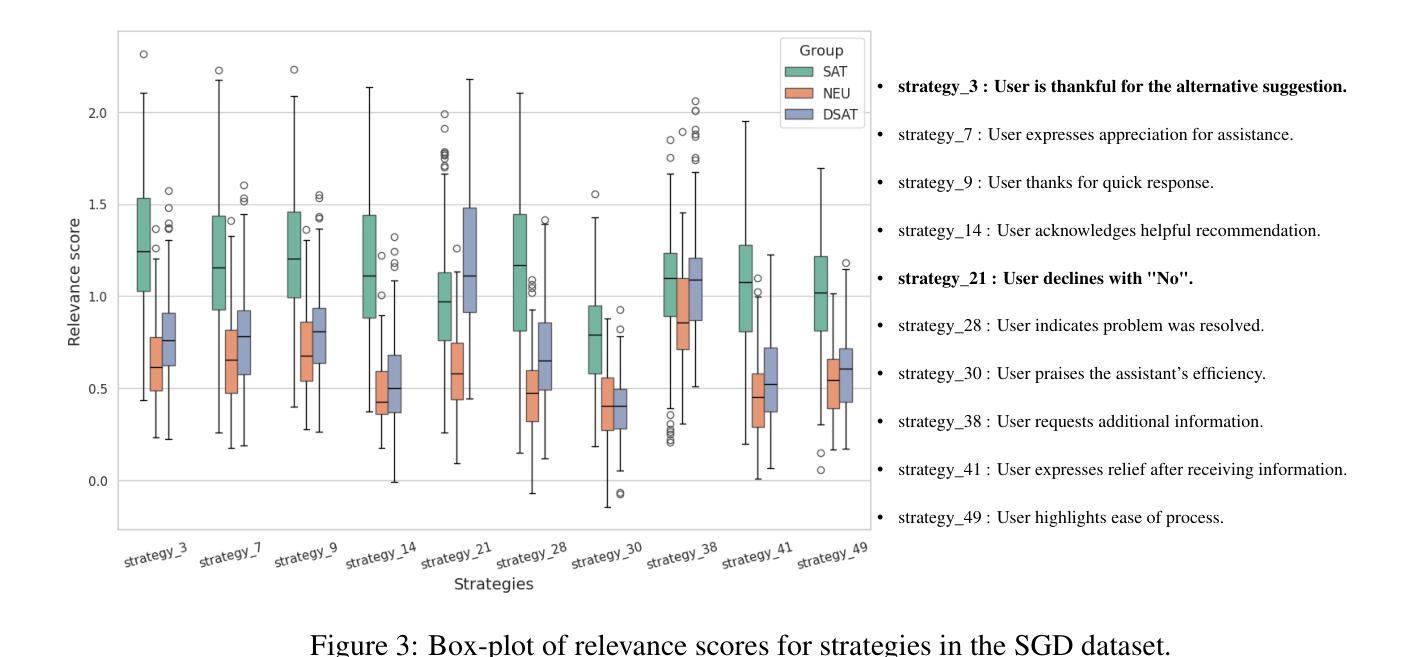
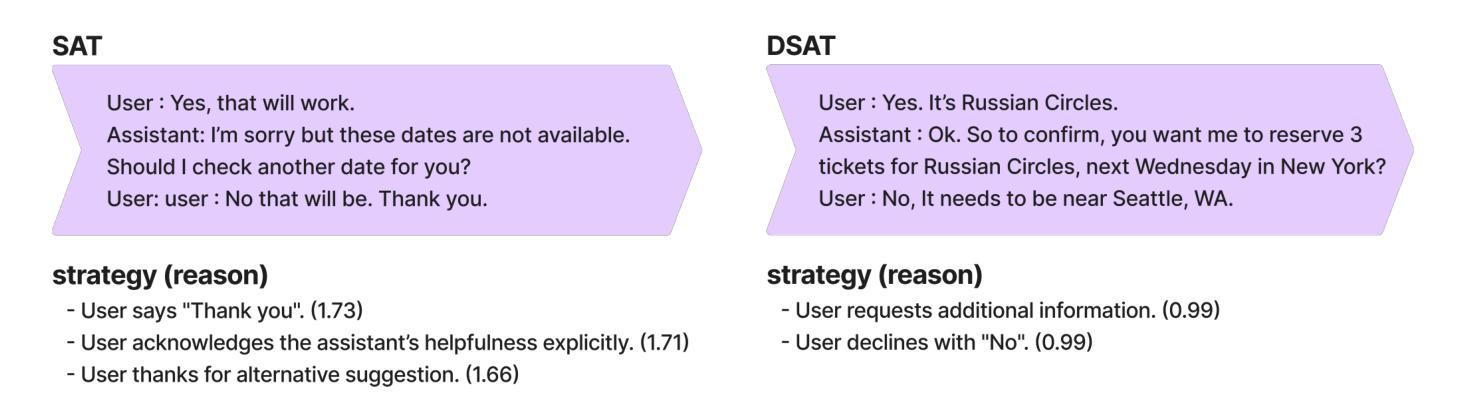
Understanding user satisfaction with conversational systems, known as User Satisfaction Estimation (USE), is essential for assessing dialogue quality and enhancing user experiences. However, existing methods for USE face challenges due to limited understanding of underlying reasons for user dissatisfaction and the high costs of annotating user intentions. To address these challenges, we propose PRAISE (Plan and Retrieval Alignment for Interpretable Satisfaction Estimation), an interpretable framework for effective user satisfaction prediction. PRAISE operates through three key modules. The Strategy Planner develops strategies, which are natural language criteria for classifying user satisfaction. The Feature Retriever then incorporates knowledge on user satisfaction from Large Language Models (LLMs) and retrieves relevance features from utterances. Finally, the Score Analyzer evaluates strategy predictions and classifies user satisfaction. Experimental results demonstrate that PRAISE achieves state-of-the-art performance on three benchmarks for the USE task. Beyond its superior performance, PRAISE offers additional benefits. It enhances interpretability by providing instance-level explanations through effective alignment of utterances with strategies. Moreover, PRAISE operates more efficiently than existing approaches by eliminating the need for LLMs during the inference phase.
理解用户对对话系统的满意度,也称为用户满意度估计(USE),对于评估对话质量和提升用户体验至关重要。然而,现有的USE方法面临着挑战,因为对用户不满的潜在原因理解有限,以及标注用户意图的成本高昂。为了解决这些挑战,我们提出了PRAISE(面向可解释满意度估计的计划与检索对齐)框架,这是一个可有效预测用户满意度的可解释框架。PRAISE通过三个关键模块进行操作。策略规划器制定分类用户满意度的自然语言标准。特征检索器然后结合大型语言模型(LLM)中的用户满意度知识,并从言论中检索相关特征。最后,分数分析器评估策略预测并分类用户满意度。实验结果表明,PRAISE在USE任务的三个基准测试中达到了最新技术水平。除了卓越的性能外,PRAISE还提供了其他好处。它通过提供与策略有效的言论对齐来实现实例级别的解释,从而增强了可解释性。此外,PRAISE在推理阶段不需要LLM,因此比现有方法运行得更高效。
论文及项目相关链接
PDF Accepted by NAACL 2025
Summary
用户满意度估计是评估对话质量和提升用户体验的关键环节。现有方法面临挑战,包括对用户不满意原因理解有限和标注用户意图成本高昂。为应对这些挑战,提出PRAISE(面向可解释满意度估计的计划与检索对齐)框架,实现有效的用户满意度预测。PRAISE通过策略规划器、特征检索器和评分分析器三个核心模块进行操作。实验结果表明,PRAISE在USE任务的三项基准测试中达到最佳性能。此外,PRAISE通过实例级的解释和对策略的有效对齐,提高了可解释性,且在推理阶段无需使用大型语言模型,操作更为高效。
Key Takeaways
- 用户满意度估计是评估对话质量和提升用户体验的重要环节。
- 现有方法面临理解用户不满意原因有限和标注用户意图成本高昂的挑战。
- PRAISE框架包括策略规划器、特征检索器和评分分析器三个核心模块。
- 策略规划器负责开发分类用户满意度的自然语言标准。
- 特征检索器负责从大型语言模型中获取用户满意度的知识,并检索与发言相关的特征。
- 评分分析器负责评估策略预测并对用户满意度进行分类。
点此查看论文截图



Knowledge-Decoupled Synergetic Learning: An MLLM based Collaborative Approach to Few-shot Multimodal Dialogue Intention Recognition
Authors:Bin Chen, Yu Zhang, Hongfei Ye, Ziyi Huang, Hongyang Chen
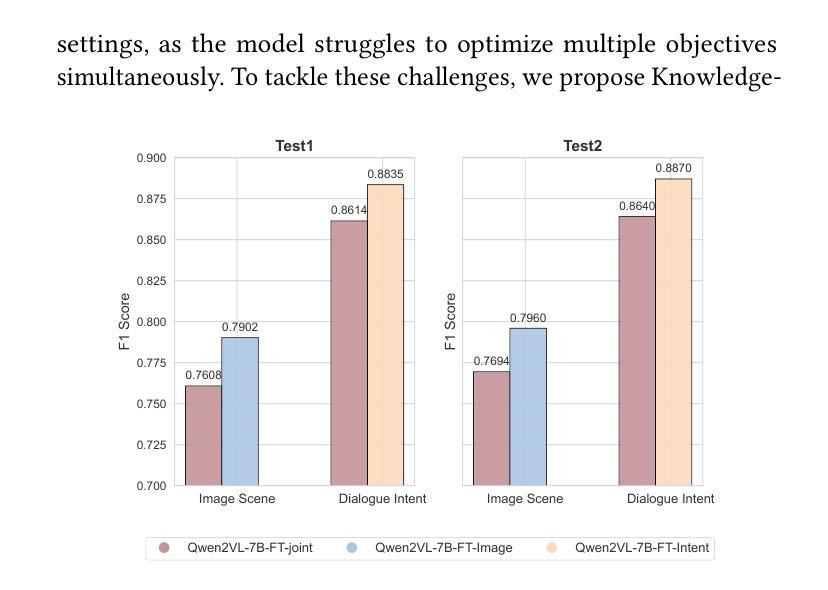
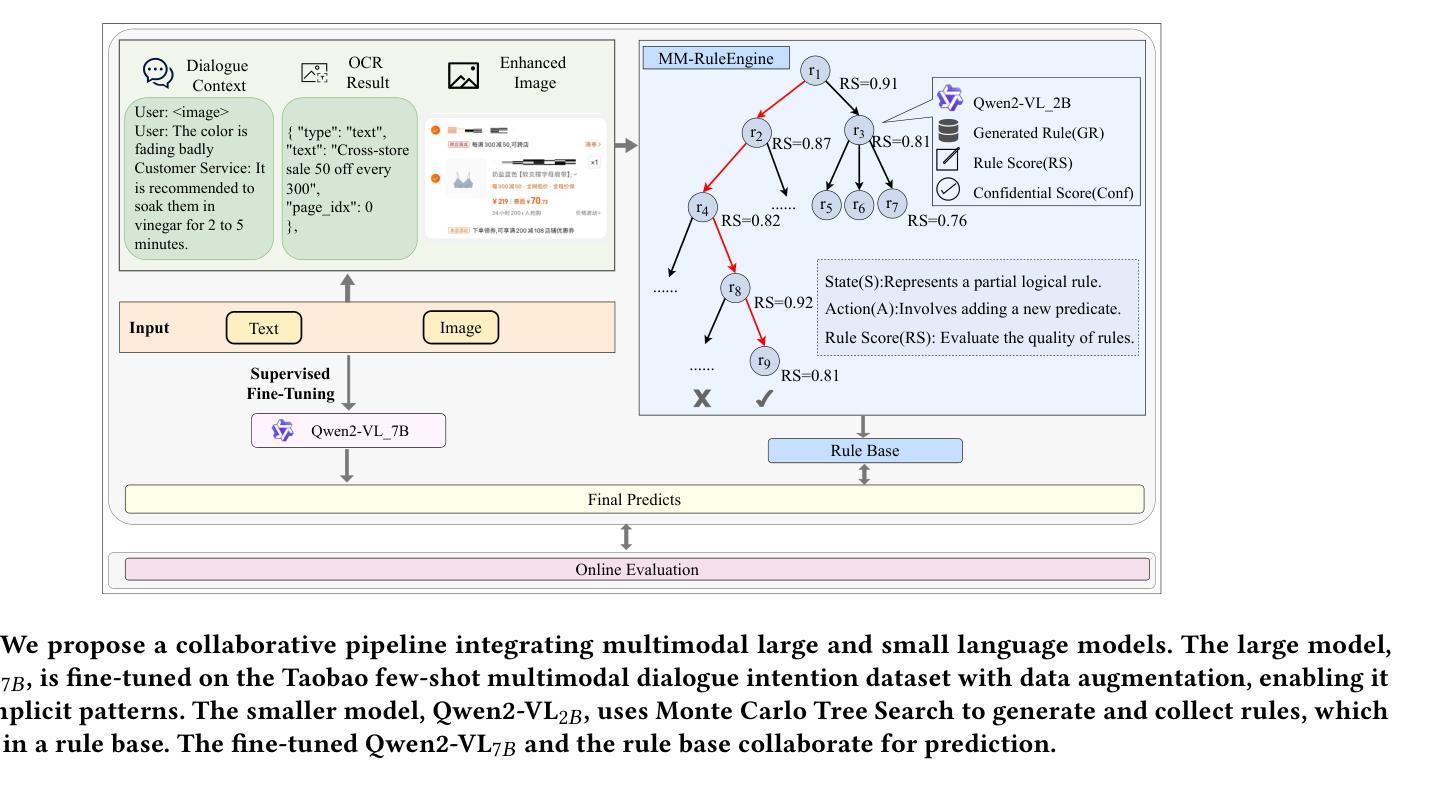
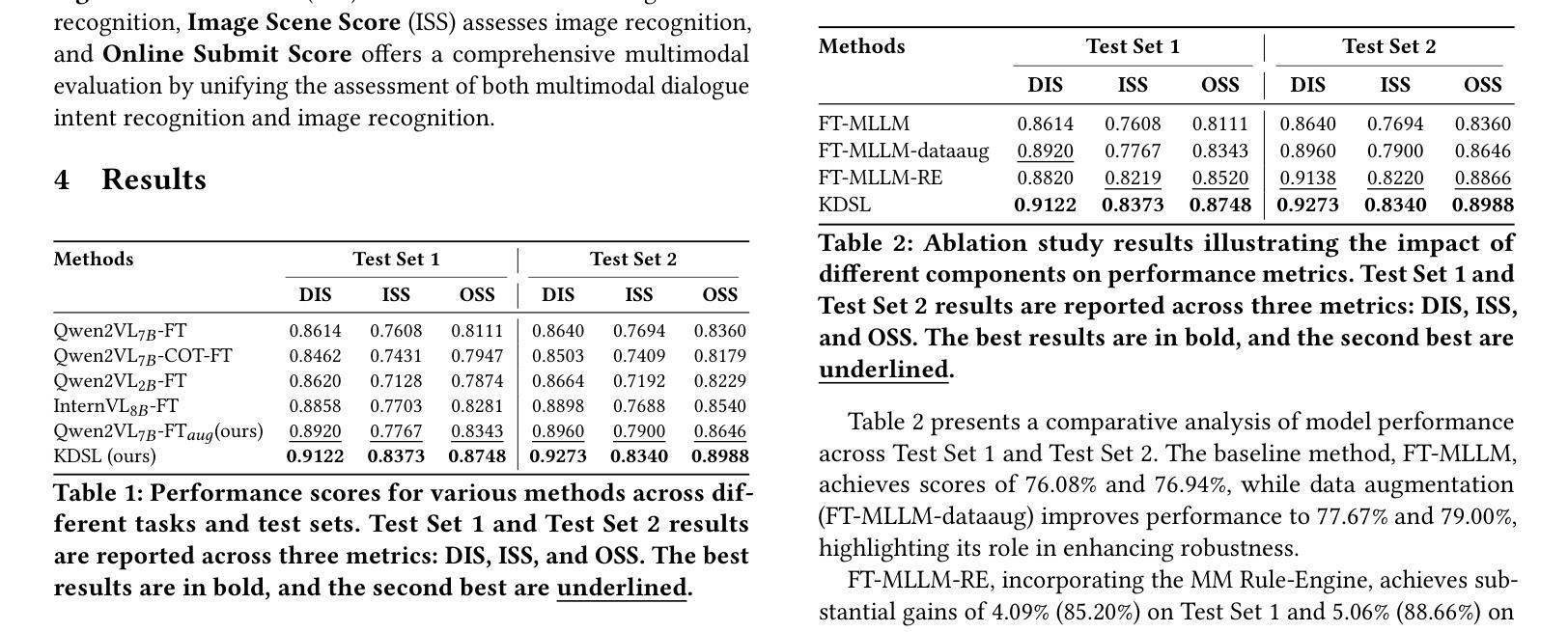
Few-shot multimodal dialogue intention recognition is a critical challenge in the e-commerce domainn. Previous methods have primarily enhanced model classification capabilities through post-training techniques. However, our analysis reveals that training for few-shot multimodal dialogue intention recognition involves two interconnected tasks, leading to a seesaw effect in multi-task learning. This phenomenon is attributed to knowledge interference stemming from the superposition of weight matrix updates during the training process. To address these challenges, we propose Knowledge-Decoupled Synergetic Learning (KDSL), which mitigates these issues by utilizing smaller models to transform knowledge into interpretable rules, while applying the post-training of larger models. By facilitating collaboration between the large and small multimodal large language models for prediction, our approach demonstrates significant improvements. Notably, we achieve outstanding results on two real Taobao datasets, with enhancements of 6.37% and 6.28% in online weighted F1 scores compared to the state-of-the-art method, thereby validating the efficacy of our framework.
少样本多模态对话意图识别是电子商务领域的一个关键挑战。之前的方法主要通过后训练技术增强模型的分类能力。然而,我们的分析发现,少样本多模态对话意图识别的训练涉及两个相互关联的任务,导致多任务学习中的摆动效应。这种现象归因于训练过程中权重矩阵更新叠加所带来的知识干扰。为了解决这些挑战,我们提出了知识解耦协同学习(KDSL),通过利用较小的模型将知识转化为可解释的规则,同时应用较大模型的后期训练,来缓解这些问题。通过促进大小多模态大型语言模型之间的预测协作,我们的方法取得了显著的改进。值得注意的是,我们在两个真实的淘宝数据集上取得了出色的结果,与最先进的方法相比,在线加权F1分数提高了6.37%和6.28%,从而验证了我们框架的有效性。
论文及项目相关链接
Summary
本文研究了电商领域中的小样本多模态对话意图识别挑战。现有方法主要通过后训练技术增强模型分类能力,但存在多任务学习中的知识干扰问题,影响模型性能。为此,本文提出知识解耦协同学习(KDSL)框架,利用小型模型将知识转化为可解释规则,同时应用大型模型的后训练技术。通过大小多模态语言模型的预测协作,显著提高性能,并在真实淘宝数据集上取得了出色的结果,相较于最新方法在线加权F1得分提高了6.37%和6.28%。
Key Takeaways
- 小样本多模态对话意图识别是电商领域的关键挑战。
- 现有方法主要通过后训练技术增强模型分类能力,但存在知识干扰问题。
- 知识解耦协同学习(KDSL)框架被提出以解决知识干扰问题。
- KDSL利用小型模型将知识转化为可解释规则。
- KDSL框架结合大型模型的后训练技术,显著提高性能。
- 在真实淘宝数据集上的实验验证了KDSL框架的有效性。
点此查看论文截图