⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-09 更新
L1: Controlling How Long A Reasoning Model Thinks With Reinforcement Learning
Authors:Pranjal Aggarwal, Sean Welleck
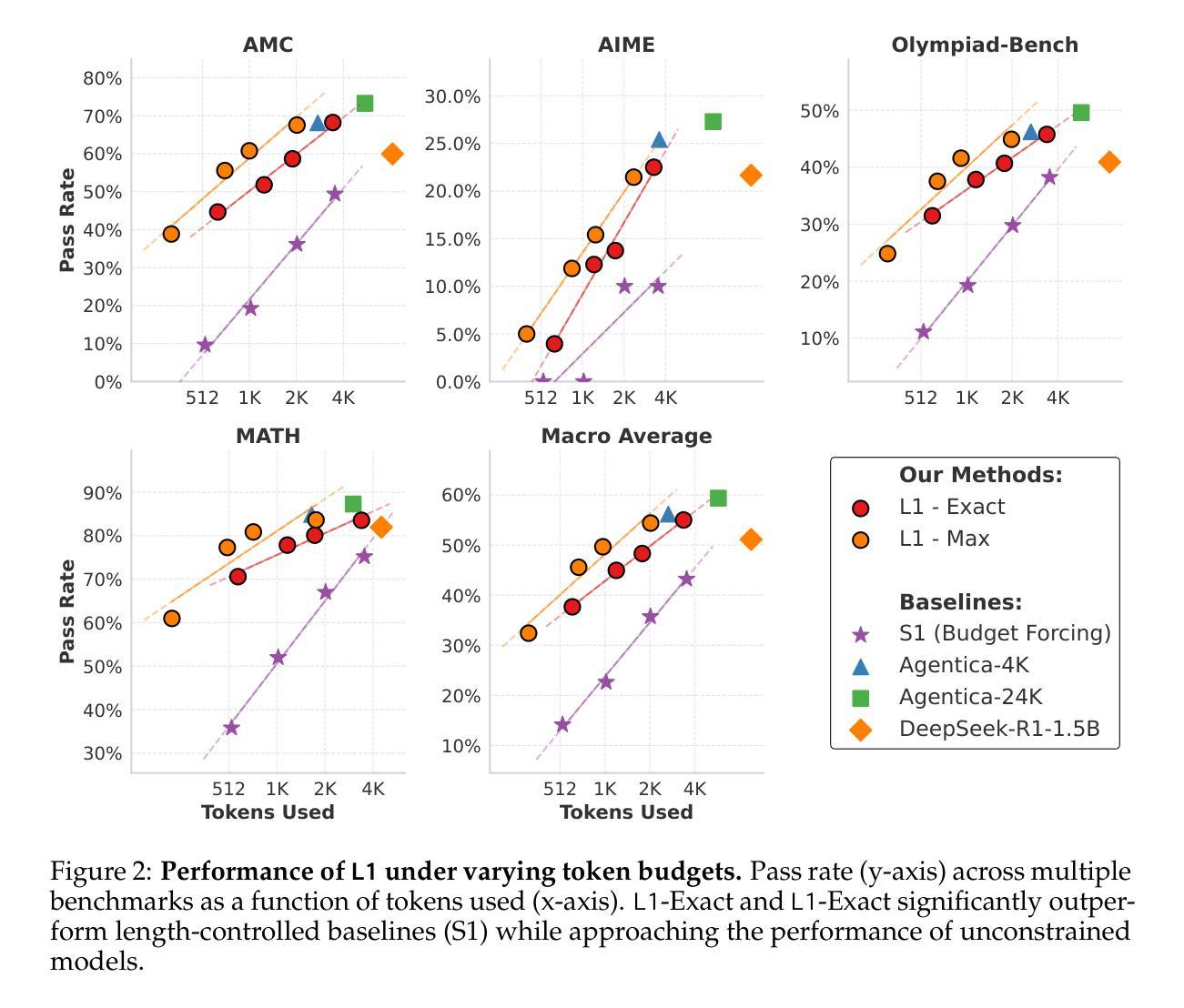
Reasoning language models have shown an uncanny ability to improve performance at test-time by ``thinking longer’’-that is, by generating longer chain-of-thought sequences and hence using more compute. However, the length of their chain-of-thought reasoning is not controllable, making it impossible to allocate test-time compute to achieve a desired level of performance. We introduce Length Controlled Policy Optimization (LCPO), a simple reinforcement learning method that optimizes for accuracy and adherence to user-specified length constraints. We use LCPO to train L1, a reasoning language model that produces outputs satisfying a length constraint given in its prompt. L1’s length control allows for smoothly trading off computational cost and accuracy on a wide range of tasks, and outperforms the state-of-the-art S1 method for length control. Furthermore, we uncover an unexpected short chain-of-thought capability in models trained with LCPO. For instance, our 1.5B L1 model surpasses GPT-4o at equal reasoning lengths. Overall, LCPO enables precise control over reasoning length, allowing for fine-grained allocation of test-time compute and accuracy. We release code and models at https://www.cmu-l3.github.io/l1
推理语言模型表现出一种令人难以置信的能力,能够在测试时通过“思考得更久”来提高性能——也就是说,通过生成更长的思维链序列,从而使用更多的计算资源。然而,它们的思维链推理长度是不可控制的,这使得无法分配测试时的计算资源来实现所需级别的性能。我们引入了长度控制策略优化(LCPO),这是一种简单的强化学习方法,旨在优化准确性和对用户指定长度约束的遵循。我们使用LCPO来训练L1,这是一个推理语言模型,能够根据提示产生满足长度约束的输出。L1的长度控制可以在广泛的任务上平稳地权衡计算成本和准确性,并优于最新的S1方法进行长度控制。此外,我们在使用LCPO训练的模型中发现了意外的短思维链能力。例如,我们1.5B的L1模型在同等推理长度下超越了GPT-4o。总的来说,LCPO实现对推理长度的精确控制,允许对测试时的计算和准确性进行精细分配。我们在https://www.cmu-l3.github.io/l1上发布代码和模型。
论文及项目相关链接
Summary
一种名为LCPO(长度控制策略优化)的方法被引入,用于优化推理语言模型的性能并控制其推理长度。通过该方法,用户可以指定输出长度约束,实现在测试时精确分配计算资源和调整性能。L1模型作为应用LCPO的实例,能够在多种任务上实现长度控制,并在同等推理长度下超越现有模型。此外,LCPO还意外地发现了模型在短链推理方面的能力。总体而言,LCPO为精确控制推理长度提供了解决方案,允许更精细地分配测试时的计算资源和提高准确性。相关代码和模型已发布在[网站链接]。
Key Takeaways
- LCPO方法能够优化推理语言模型的性能,并控制其推理长度。
- 用户可以通过指定长度约束,在测试时精确分配计算资源。
- L1模型实现了长度控制,可在多种任务上调整计算资源和性能之间的权衡。
- L1模型在同等推理长度下表现出超越现有模型的性能。
- LCPO意外发现模型在短链推理方面的能力。
- LCPO有助于实现推理长度的精确控制,为测试时的计算资源和准确性分配提供更精细的调节。
点此查看论文截图
Quantifying the Reasoning Abilities of LLMs on Real-world Clinical Cases
Authors:Pengcheng Qiu, Chaoyi Wu, Shuyu Liu, Weike Zhao, Ya Zhang, Yanfeng Wang, Weidi Xie
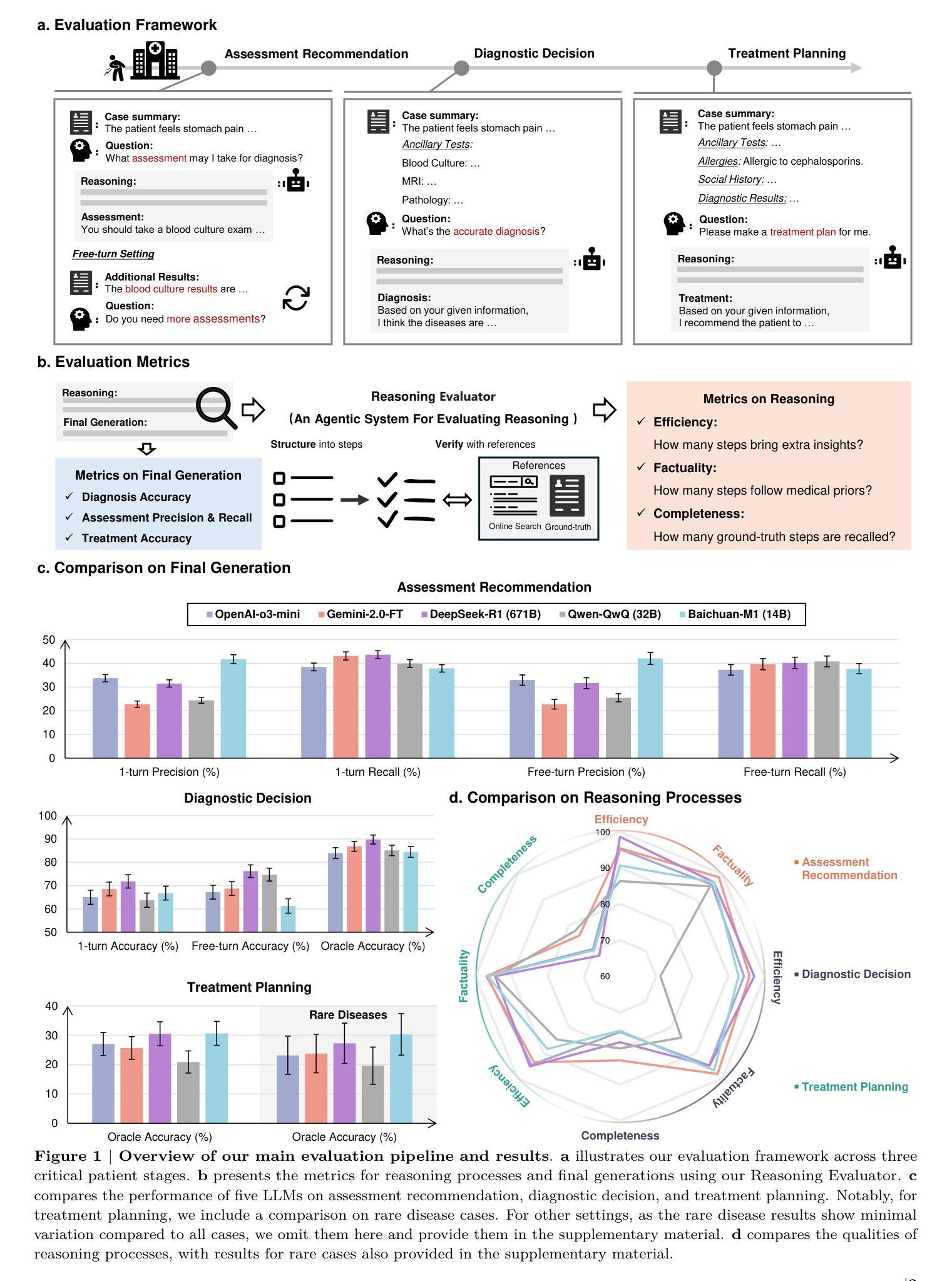
The latest reasoning-enhanced large language models (reasoning LLMs), such as DeepSeek-R1 and OpenAI-o3, have demonstrated remarkable success. However, the application of such reasoning enhancements to the highly professional medical domain has not been clearly evaluated, particularly regarding with not only assessing the final generation but also examining the quality of their reasoning processes. In this study, we present MedR-Bench, a reasoning-focused medical evaluation benchmark comprising 1,453 structured patient cases with reasoning references mined from case reports. Our benchmark spans 13 body systems and 10 specialty disorders, encompassing both common and rare diseases. In our evaluation, we introduce a versatile framework consisting of three critical clinical stages: assessment recommendation, diagnostic decision-making, and treatment planning, comprehensively capturing the LLMs’ performance across the entire patient journey in healthcare. For metrics, we propose a novel agentic system, Reasoning Evaluator, designed to automate and objectively quantify free-text reasoning responses in a scalable manner from the perspectives of efficiency, factuality, and completeness by dynamically searching and performing cross-referencing checks. As a result, we assess five state-of-the-art reasoning LLMs, including DeepSeek-R1, OpenAI-o3-mini, and others. Our results reveal that current LLMs can handle relatively simple diagnostic tasks with sufficient critical assessment results, achieving accuracy generally over 85%. However, they still struggle with more complex tasks, such as assessment recommendation and treatment planning. In reasoning, their reasoning processes are generally reliable, with factuality scores exceeding 90%, though they often omit critical reasoning steps. Our study clearly reveals further development directions for current clinical LLMs.
最新增强推理的大型语言模型(推理LLM),如DeepSeek-R1和OpenAI-o3,已经取得了显著的成果。然而,将这类推理增强应用于高度专业的医疗领域尚未得到明确评估,尤其是不仅评估最终生成的结果,还考察其推理过程的质量。在本研究中,我们提出了MedR-Bench,这是一个以推理为重点的医疗评估基准,包含1453个结构化病例和从病例报告中挖掘的推理参考。我们的基准测试涵盖了13个身体系统和10种专业疾病,包括常见和罕见疾病。在评估中,我们引入了一个包含三个关键临床阶段的通用框架:评估建议、诊断决策和治疗计划,全面捕捉LLM在医疗保健的整个患者旅程中的表现。在指标方面,我们提出了一个新的代理系统——推理评估器,旨在以自动化和客观的方式从效率、真实性和完整性等角度对自由文本推理响应进行可扩展的量化评估,并通过动态搜索和交叉引用检查来实现。因此,我们对五款最先进的推理LLM进行了评估,包括DeepSeek-R1、OpenAI-o3-mini等。结果表明,当前LLM可以处理相对简单的诊断任务,并且有足够的批判性评估结果,准确率一般超过85%。但在更复杂的任务,如评估建议和治疗计划方面,它们仍然面临挑战。在推理方面,它们的推理过程通常可靠,真实性分数超过90%,不过它们往往会遗漏关键的推理步骤。我们的研究明确了当前临床LLM的进一步发展方向。
论文及项目相关链接
Summary
这篇文本主要介绍了最新推理增强的大型语言模型(reasoning LLMs)在医疗领域的应用评估。研究中提出了MedR-Bench,一个专注于推理的医学评估基准测试,包含从病例报告中挖掘的1453个结构化病例的推理参考。评估框架包括评估推荐、诊断决策和治疗规划三个阶段,全面捕捉LLMs在医疗保健中的患者旅程中的表现。为度量推理响应,设计了一种新型代理系统Reasoning Evaluator,能自动、客观地量化自由文本推理响应。评估结果显示,当前LLMs可以处理相对简单的诊断任务,但在更复杂任务上仍有挑战。
Key Takeaways
- 推理增强的大型语言模型(reasoning LLMs)如DeepSeek-R1和OpenAI-o3在医疗领域的应用评估尚不清楚。
- MedR-Bench是一个专注于推理的医学评估基准测试,包含1453个结构化病例的推理参考。
- 评估框架包括评估推荐、诊断决策和治疗规划三个阶段。
- Reasoning Evaluator作为一种新型代理系统,能自动量化LLMs的推理响应。
- 当前LLMs可以处理简单的诊断任务,但面对更复杂任务仍有挑战。
- LLMs的推理过程一般可靠,但有时会遗漏关键推理步骤。
点此查看论文截图

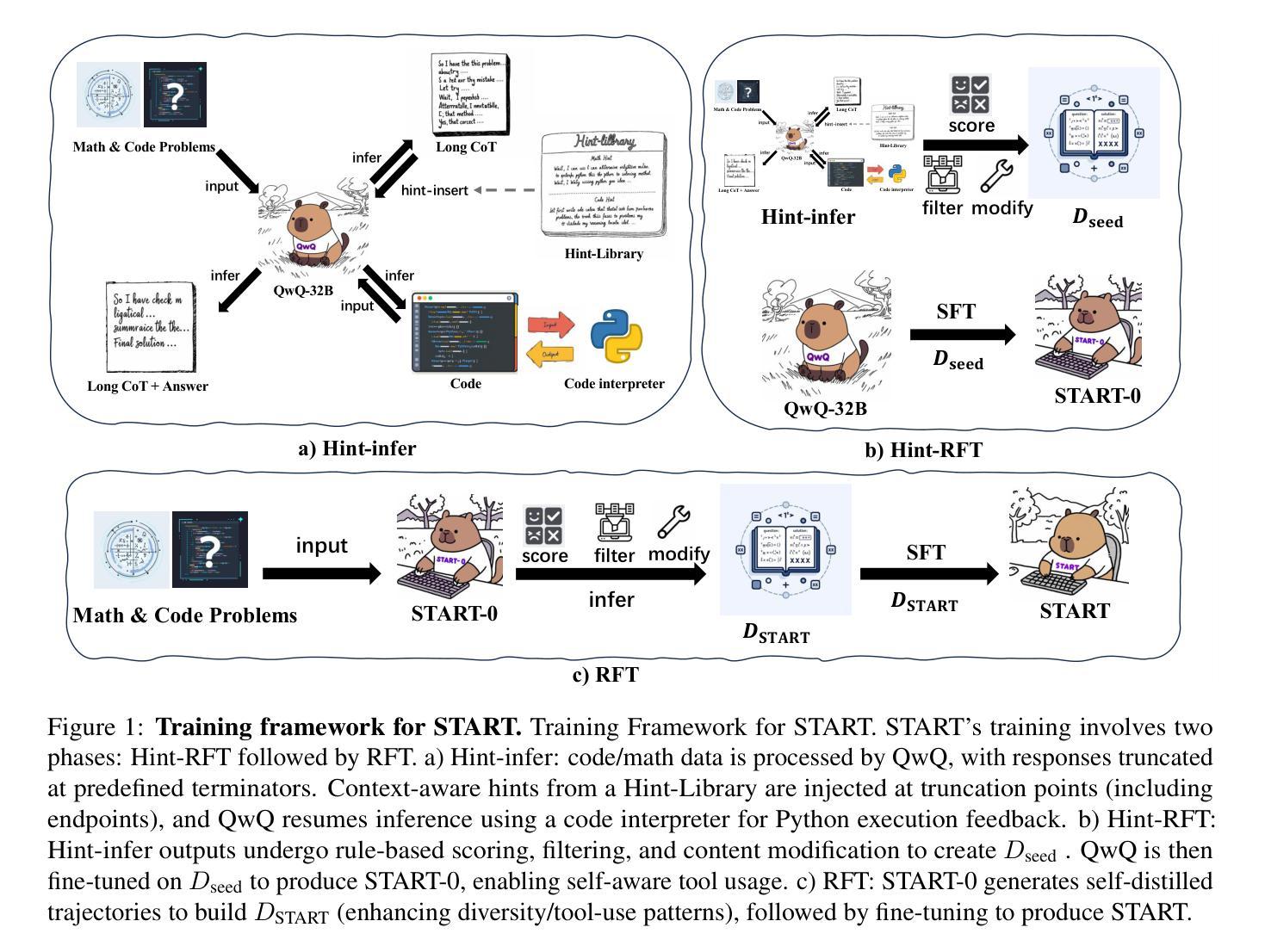
START: Self-taught Reasoner with Tools
Authors:Chengpeng Li, Mingfeng Xue, Zhenru Zhang, Jiaxi Yang, Beichen Zhang, Xiang Wang, Bowen Yu, Binyuan Hui, Junyang Lin, Dayiheng Liu
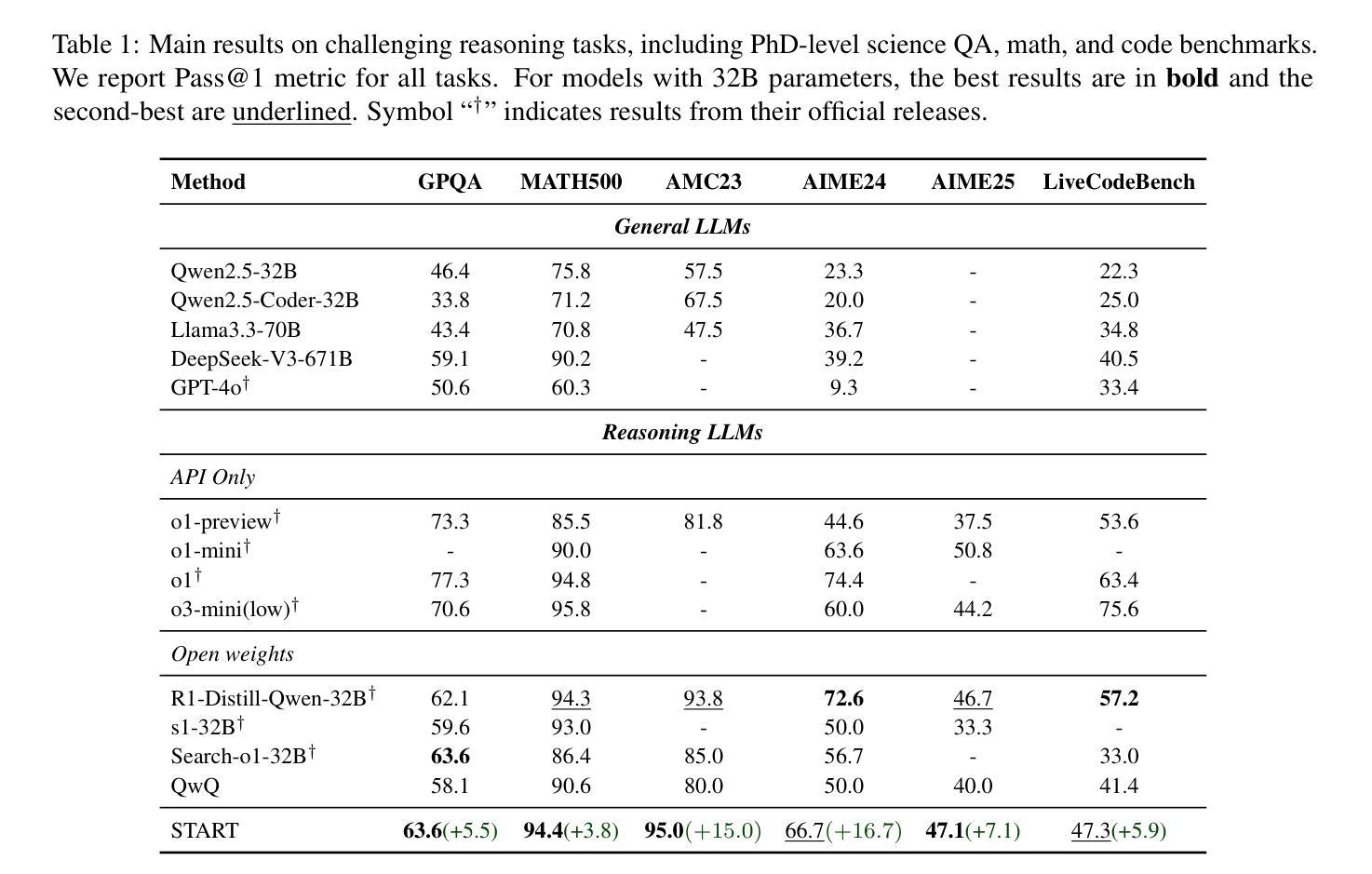
Large reasoning models (LRMs) like OpenAI-o1 and DeepSeek-R1 have demonstrated remarkable capabilities in complex reasoning tasks through the utilization of long Chain-of-thought (CoT). However, these models often suffer from hallucinations and inefficiencies due to their reliance solely on internal reasoning processes. In this paper, we introduce START (Self-Taught Reasoner with Tools), a novel tool-integrated long CoT reasoning LLM that significantly enhances reasoning capabilities by leveraging external tools. Through code execution, START is capable of performing complex computations, self-checking, exploring diverse methods, and self-debugging, thereby addressing the limitations of LRMs. The core innovation of START lies in its self-learning framework, which comprises two key techniques: 1) Hint-infer: We demonstrate that inserting artificially designed hints (e.g., ``Wait, maybe using Python here is a good idea.’’) during the inference process of a LRM effectively stimulates its ability to utilize external tools without the need for any demonstration data. Hint-infer can also serve as a simple and effective sequential test-time scaling method; 2) Hint Rejection Sampling Fine-Tuning (Hint-RFT): Hint-RFT combines Hint-infer and RFT by scoring, filtering, and modifying the reasoning trajectories with tool invocation generated by a LRM via Hint-infer, followed by fine-tuning the LRM. Through this framework, we have fine-tuned the QwQ-32B model to achieve START. On PhD-level science QA (GPQA), competition-level math benchmarks (AMC23, AIME24, AIME25), and the competition-level code benchmark (LiveCodeBench), START achieves accuracy rates of 63.6%, 95.0%, 66.7%, 47.1%, and 47.3%, respectively. It significantly outperforms the base QwQ-32B and achieves performance comparable to the state-of-the-art open-weight model R1-Distill-Qwen-32B and the proprietary model o1-Preview.
大型推理模型(LRMs)如OpenAI-o1和DeepSeek-R1,已经展现出在复杂推理任务方面的卓越能力,通过运用长的思维链(CoT)。然而,这些模型往往存在产生幻觉和不高效的问题,因为它们仅依赖于内部推理过程。在本文中,我们介绍了START(带有工具的自教导推理器),这是一种新型的工具集成长CoT推理LLM,它通过利用外部工具来显著增强推理能力。通过代码执行,START能够执行复杂的计算、自我检查、探索多样化的方法和自我调试,从而解决LRM的局限性。START的核心创新在于其自学习框架,它包括两个关键技术:1)提示推断:我们证明在LRM的推理过程中插入人工设计的提示(例如,“等等,也许在这里使用Python是个好主意。”)有效地刺激了其利用外部工具的能力,而无需任何演示数据。提示推断还可以作为一种简单有效的序列测试时间缩放方法;2)提示拒绝采样微调(Hint-RFT):Hint-RFT结合了提示推断和拒绝采样微调技术,通过对由LRM通过提示推断产生的带有工具调用的推理轨迹进行评分、过滤和修改,然后对LRM进行微调。通过这个框架,我们对QwQ-32B模型进行了微调,实现了START。在博士级科学问答(GPQA)、竞赛级数学基准测试(AMC23、AIME24、AIME25)和竞赛级代码基准测试(LiveCodeBench)中,START的准确率分别为63.6%、95.0%、66.7%、47.1%和47.3%。它显著优于基础QwQ-32B模型,并实现了与最新开源模型R1-Distill-Qwen-32B和专有模型o1-Preview相当的性能。
简化翻译
论文及项目相关链接
PDF 38 pages, 5 figures and 6 tables
Summary
在大型推理模型(LRMs)如OpenAI-o1和DeepSeek-R1中,虽然它们通过长期思维链(CoT)在复杂推理任务中表现出卓越的能力,但存在幻视和效率不高的问题。本研究引入了一种新的工具集成长期思维链推理LLM——START,它通过执行代码、自我检查、探索多样方法和自我调试,显著提高了推理能力。START的核心创新在于其自我学习框架,包括Hint-infer和Hint Rejection Sampling Fine-Tuning (Hint-RFT)两个关键技术。在PhD级科学问答、竞赛级数学基准测试以及竞赛级代码基准测试中,START表现出卓越性能,显著优于基础模型QwQ-32B,并与开源先进模型R1-Distill-Qwen-32B和专有模型o1-Preview相当。
Key Takeaways
- 大型推理模型如OpenAI-o1和DeepSeek-R1在复杂推理任务中表现出色,但存在幻视和效率问题。
- START是一种新型工具集成长期思维链推理LLM,通过执行代码、自我检查等提高推理能力。
- START的核心创新在于其自我学习框架,包括Hint-infer和Hint-RFT两个关键技术。
- Hint-infer能在推理过程中刺激模型利用外部工具的能力,作为简单的测试时间缩放方法。
- Hint-RFT结合Hint-infer和RFT,对工具调用的推理轨迹进行评分、过滤和修改,然后微调模型。
- START在多个基准测试中表现卓越,显著优于基础模型QwQ-32B。
点此查看论文截图




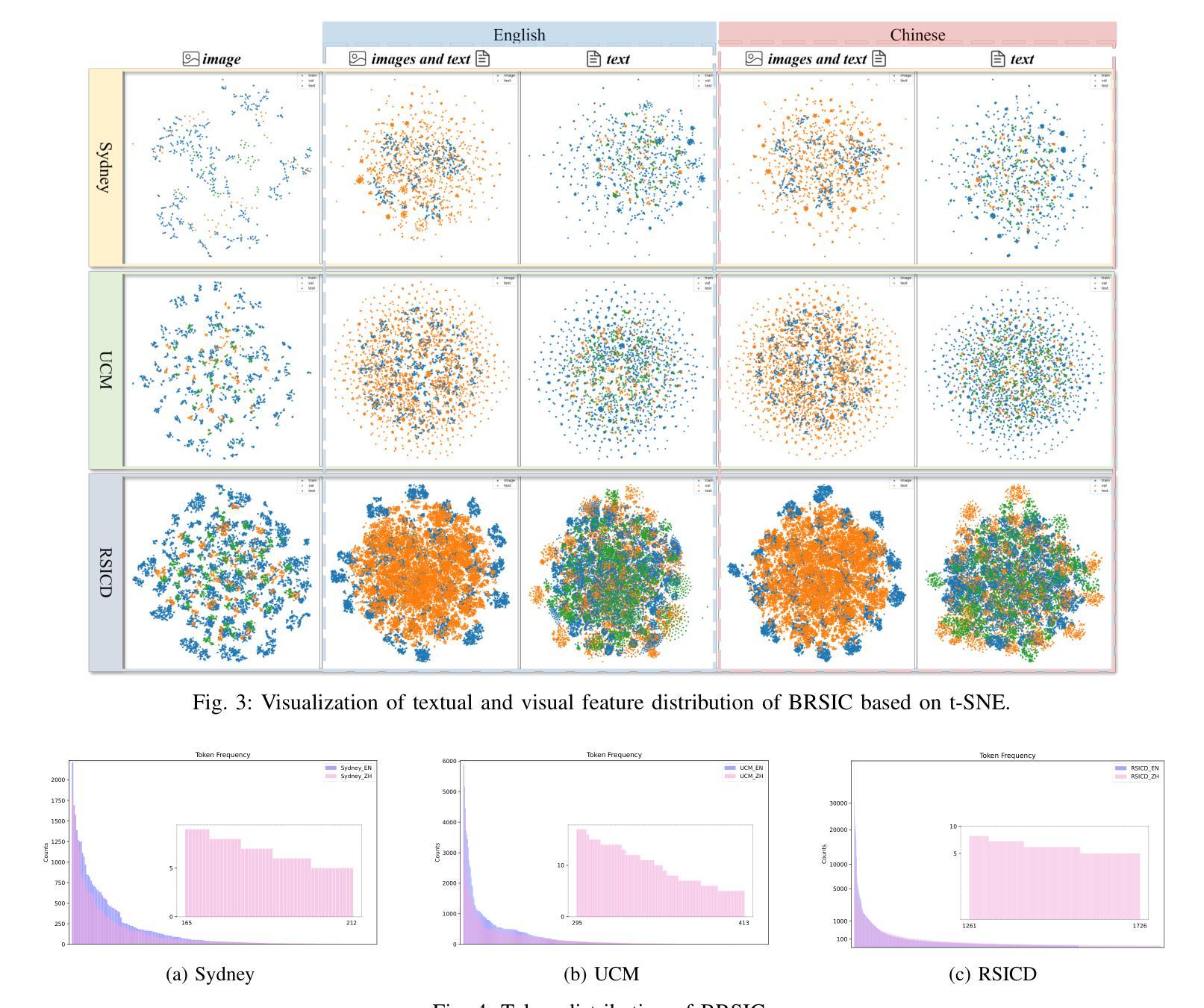
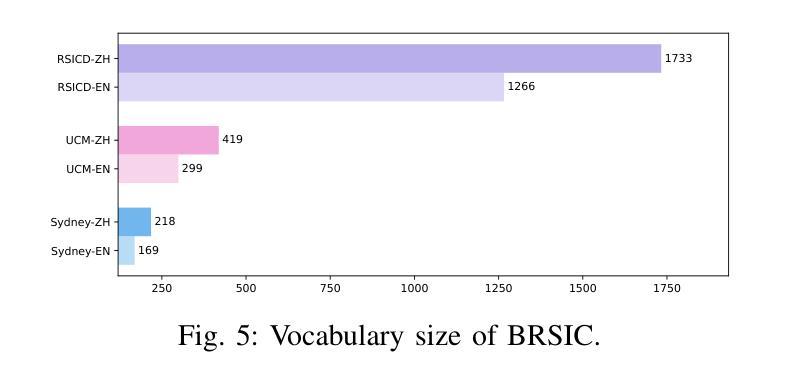
A Benchmark for Multi-Lingual Vision-Language Learning in Remote Sensing Image Captioning
Authors:Qing Zhou, Tao Yang, Junyu Gao, Weiping Ni, Junzheng Wu, Qi Wang
Remote Sensing Image Captioning (RSIC) is a cross-modal field bridging vision and language, aimed at automatically generating natural language descriptions of features and scenes in remote sensing imagery. Despite significant advances in developing sophisticated methods and large-scale datasets for training vision-language models (VLMs), two critical challenges persist: the scarcity of non-English descriptive datasets and the lack of multilingual capability evaluation for models. These limitations fundamentally impede the progress and practical deployment of RSIC, particularly in the era of large VLMs. To address these challenges, this paper presents several significant contributions to the field. First, we introduce and analyze BRSIC (Bilingual Remote Sensing Image Captioning), a comprehensive bilingual dataset that enriches three established English RSIC datasets with Chinese descriptions, encompassing 13,634 images paired with 68,170 bilingual captions. Building upon this foundation, we develop a systematic evaluation framework that addresses the prevalent inconsistency in evaluation protocols, enabling rigorous assessment of model performance through standardized retraining procedures on BRSIC. Furthermore, we present an extensive empirical study of eight state-of-the-art large vision-language models (LVLMs), examining their capabilities across multiple paradigms including zero-shot inference, supervised fine-tuning, and multi-lingual training. This comprehensive evaluation provides crucial insights into the strengths and limitations of current LVLMs in handling multilingual remote sensing tasks. Additionally, our cross-dataset transfer experiments reveal interesting findings. The code and data will be available at https://github.com/mrazhou/BRSIC.
遥感图像标注(RSIC)是一个跨模态领域,旨在弥合视觉和语言之间的鸿沟,目标是自动对遥感图像中的特征和场景生成自然语言描述。尽管在为训练视觉语言模型(VLM)开发高级方法和大规模数据集方面取得了重大进展,但仍然存在两个关键挑战:非英语描述性数据集的稀缺和模型缺乏多语言能力评估。这些局限性从根本上阻碍了RSIC的进步和实际部署,特别是在大型VLM时代。为了应对这些挑战,本文为该领域做出了重大贡献。首先,我们介绍并分析了BRSIC(双语遥感图像标注),这是一个综合双语数据集,丰富了三个现有的英语RSIC数据集,增加了中文描述,包含13634张图像和配对的中英文双语描述共68170条。在此基础上,我们建立了一个系统评估框架,解决了评估协议中普遍存在的不一致问题,能够通过在BRSIC上进行标准化的重新训练程序,对模型性能进行严格的评估。此外,我们对八种最先进的大型视觉语言模型(LVLM)进行了广泛的实证研究,考察了它们在零样本推理、监督微调和多语言训练等多种范式下的能力。这一综合评估提供了关于当前LVLM在处理多语言遥感任务方面的优势和局限性的关键见解。此外,我们的跨数据集转移实验还揭示了一些有趣的发现。相关代码和数据将可通过https://github.com/mrazhou/BRSIC获取。
论文及项目相关链接
Summary
本论文针对遥感图像自动描述生成领域存在的非英语描述数据集稀缺和模型缺乏多语言能力评估的问题,提出了BRSIC双语遥感图像描述数据集。该数据集包含中文描述,丰富了三个已有的英语RSIC数据集。同时,论文建立了系统的评估框架,解决了评估协议的不一致性,并进行了大型视觉语言模型的广泛实证研究,探索了零样本推理、监督微调及多语言训练等多种范式下的模型能力。这为当前大型视觉语言模型处理多语言遥感任务提供了关键见解。
Key Takeaways
- BRSIC数据集介绍:引入并分析BRSIC双语遥感图像描述数据集,该数据集丰富了已有的英语RSIC数据集,包含中文描述。
- 系统评估框架的建立:为解决评估协议的不一致性,论文建立了系统的评估框架,为模型性能提供了标准化的重新训练程序。
- 多范式下的模型能力评估:论文进行了广泛的实证研究,探索了大型视觉语言模型在零样本推理、监督微调及多语言训练等多种范式下的能力。
- 当前大型视觉语言模型的优缺点:通过对BRSIC数据集的实证研究,揭示了当前大型视觉语言模型在处理多语言遥感任务时的优势和局限性。
- 跨数据集转移实验的发现:通过跨数据集的转移实验,得出了有关不同模型和方法的有趣发现。
- 数据和代码公开可用:论文明确指出,相关数据和代码可在指定网站下载使用。
点此查看论文截图


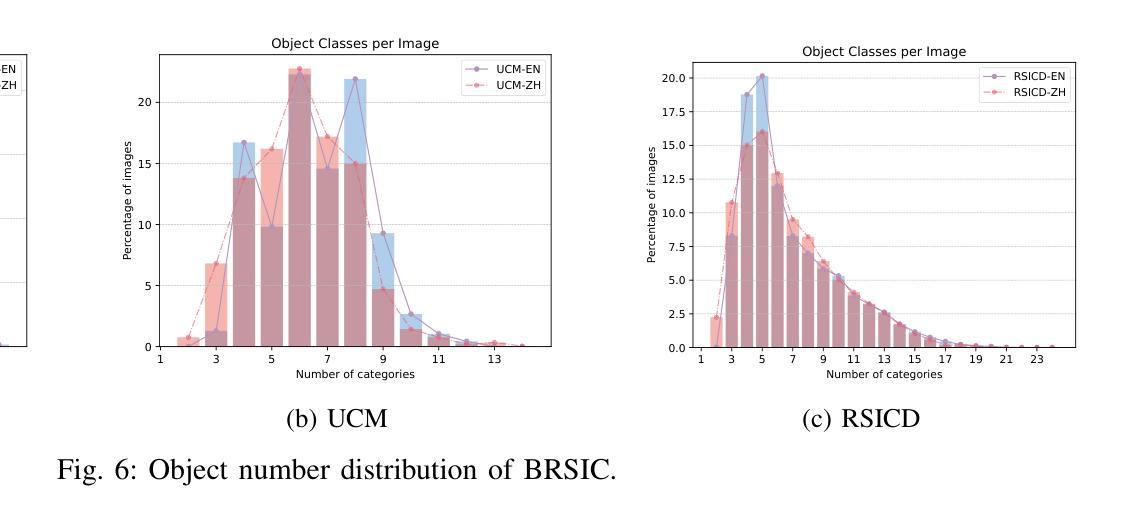
An Empirical Study on Eliciting and Improving R1-like Reasoning Models
Authors:Zhipeng Chen, Yingqian Min, Beichen Zhang, Jie Chen, Jinhao Jiang, Daixuan Cheng, Wayne Xin Zhao, Zheng Liu, Xu Miao, Yang Lu, Lei Fang, Zhongyuan Wang, Ji-Rong Wen
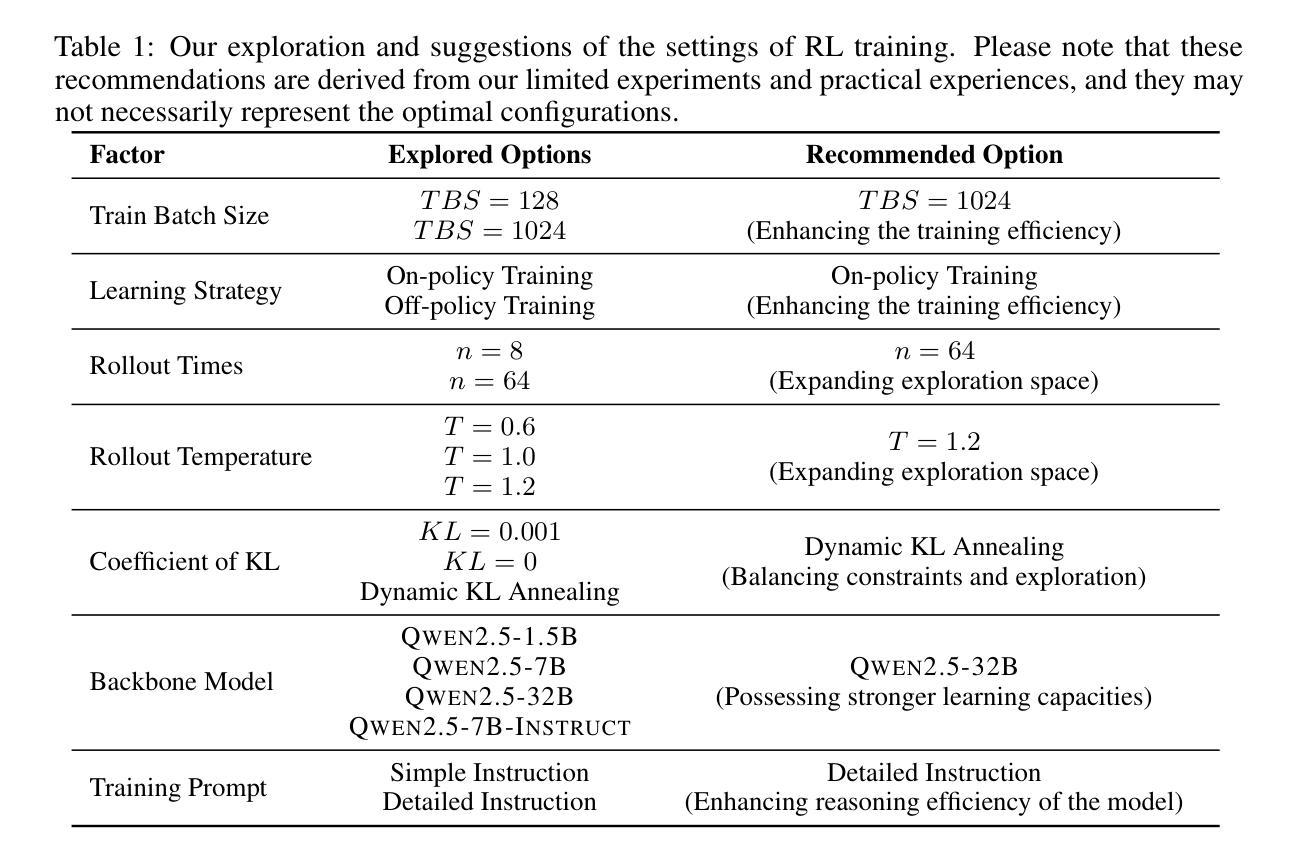
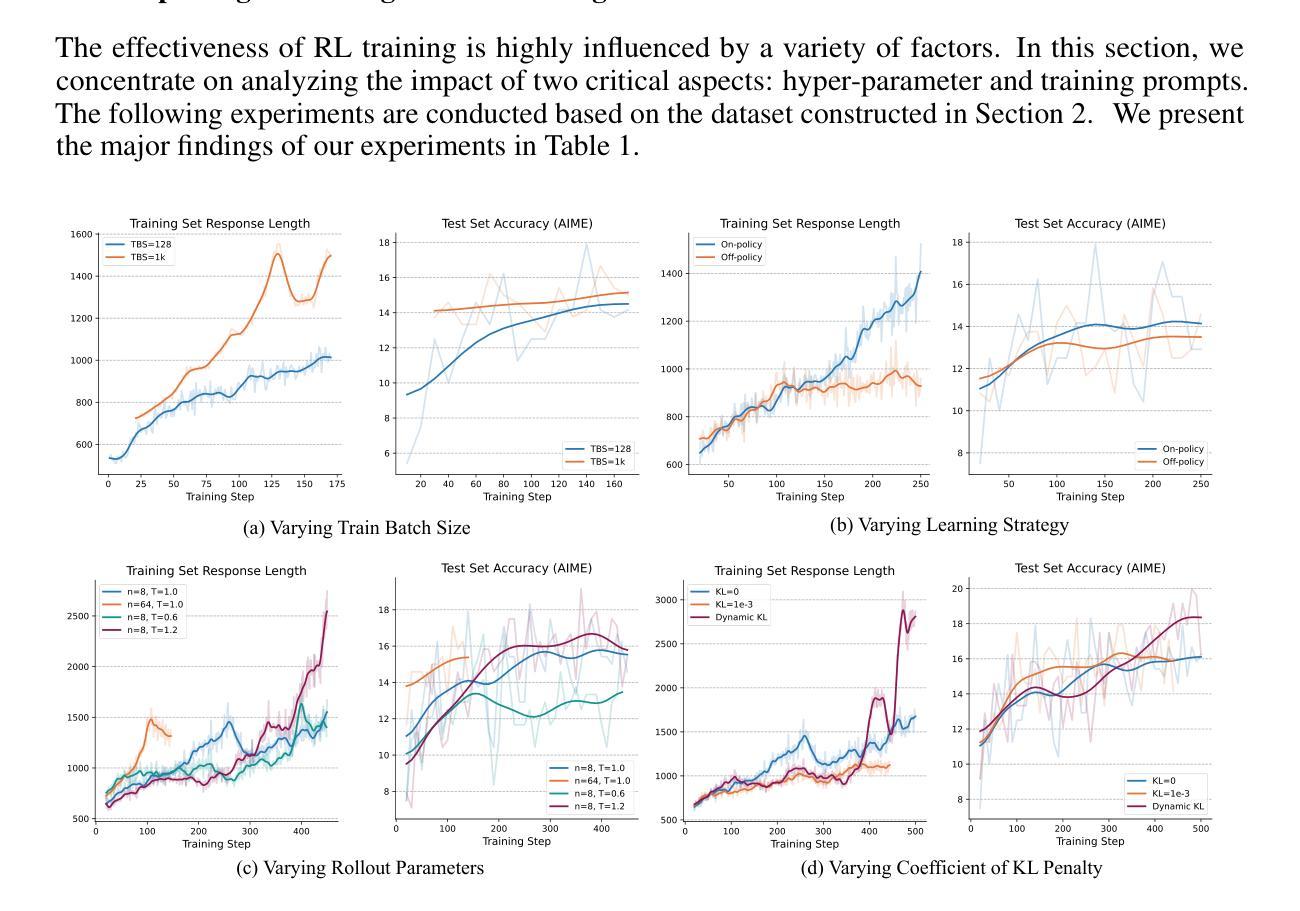
In this report, we present the third technical report on the development of slow-thinking models as part of the STILL project. As the technical pathway becomes clearer, scaling RL training has become a central technique for implementing such reasoning models. We systematically experiment with and document the effects of various factors influencing RL training, conducting experiments on both base models and fine-tuned models. Specifically, we demonstrate that our RL training approach consistently improves the Qwen2.5-32B base models, enhancing both response length and test accuracy. Furthermore, we show that even when a model like DeepSeek-R1-Distill-Qwen-1.5B has already achieved a high performance level, it can be further refined through RL training, reaching an accuracy of 39.33% on AIME 2024. Beyond RL training, we also explore the use of tool manipulation, finding that it significantly boosts the reasoning performance of large reasoning models. This approach achieves a remarkable accuracy of 86.67% with greedy search on AIME 2024, underscoring its effectiveness in enhancing model capabilities. We release our resources at the STILL project website: https://github.com/RUCAIBox/Slow_Thinking_with_LLMs.
在这份报告中,我们展示了作为STILL项目一部分的慢思考模型发展的第三个技术报告。随着技术路径的明确,规模化强化学习训练已成为实现这种推理模型的核心技术。我们系统地实验并记录了影响强化学习训练的各种因素,对基础模型和微调模型都进行了实验。具体来说,我们证明我们的强化学习训练方法持续改善了Qwen2.5-32B基础模型,提高了响应长度和测试准确率。此外,我们还表明,即使像DeepSeek-R1-Distill-Qwen-1.5B这样的模型已经达到了高性能水平,也可以通过强化学习训练进一步改进,在AIME 2024上的准确率达到了39.33%。除了强化学习训练,我们还探索了工具操作的使用,发现它显著提高了大型推理模型的推理性能。这种方法在AIME 2024上通过贪心搜索实现了86.67%的准确率,凸显了其在提高模型能力方面的有效性。我们在STILL项目网站上发布了我们的资源:https://github.com/RUCAIBox/Slow_Thinking_with_LLMs。
论文及项目相关链接
PDF Technical Report on Slow Thinking with LLMs: Part III
Summary
在报告中,我们展示了作为STIL项目一部分的慢思考模型发展的第三个技术报告。随着技术路径的清晰,规模化强化学习训练已成为实现此类推理模型的关键技术。我们系统地实验并记录了影响强化学习训练的多种因素,并在基础模型和微调模型上进行了实验。我们证明,强化学习训练方法能够持续提高Qwen2.5-32B基础模型的响应长度和测试精度。即使像DeepSeek-R1-Distill-Qwen-1.5B这样的模型已经处于高水平性能状态,也能通过强化学习训练进一步精进,在AIME 2024上的准确率达到了39.33%。除了强化学习训练,我们还探索了工具操纵的使用,发现它能显著提高大型推理模型的推理性能。该方法在AIME 2024上通过贪心搜索取得了86.67%的惊人准确率,突显其在增强模型能力方面的有效性。我们已将资源发布在STIL项目网站上:https://github.com/RUCAIBox/Slow_Thinking_with_LLMs。
Key Takeaways
- 报告介绍了慢思考模型发展的第三个技术报告,作为STIL项目的一部分。
- 规模化强化学习训练是实现此类推理模型的关键技术。
- 强化学习训练方法能持续提高Qwen2.5-32B模型的响应长度和测试精度。
- 已经高性能的模型如DeepSeek-R1-Distill-Qwen-1.5B可通过强化学习进一步精进。
- 在AIME 2024上,强化学习训练后的模型准确率达到了39.33%。
- 除了强化学习训练,探索了工具操纵的使用,显著提高了大型推理模型的性能。
点此查看论文截图

SOLAR: Scalable Optimization of Large-scale Architecture for Reasoning
Authors:Chen Li, Yinyi Luo, Anudeep Bolimera, Marios Savvides
Large Language Models (LLMs) excel in reasoning but remain constrained by their Chain-of-Thought (CoT) approach, which struggles with complex tasks requiring more nuanced topological reasoning. We introduce SOLAR, Scalable Optimization of Large-scale Architecture for Reasoning, a framework that dynamically optimizes various reasoning topologies to enhance accuracy and efficiency. Our Topological Annotation Generation (TAG) system automates topological dataset creation and segmentation, improving post-training and evaluation. Additionally, we propose Topological-Scaling, a reward-driven framework that aligns training and inference scaling, equipping LLMs with adaptive, task-aware reasoning. SOLAR achieves substantial gains on MATH and GSM8K: +5% accuracy with Topological Tuning, +9% with Topological Reward, and +10.02% with Hybrid Scaling. It also reduces response length by over 5% for complex problems, lowering inference latency. To foster the reward system, we train a multi-task Topological Reward Model (M-TRM), which autonomously selects the best reasoning topology and answer in a single pass, eliminating the need for training and inference on multiple single-task TRMs (S-TRMs), thus reducing both training cost and inference latency. In addition, in terms of performance, M-TRM surpasses all S-TRMs, improving accuracy by +10% and rank correlation by +9%. To the best of our knowledge, SOLAR sets a new benchmark for scalable, high-precision LLM reasoning while introducing an automated annotation process and a dynamic reasoning topology competition mechanism.
大型语言模型(LLM)在推理方面表现出色,但仍受到其思维链(CoT)方法的限制,该方法在处理需要更微妙拓扑推理的复杂任务时表现挣扎。我们引入了SOLAR(用于推理的大规模架构的可扩展优化)框架,该框架可以动态优化各种推理拓扑,以提高准确性和效率。我们的拓扑标注生成(TAG)系统可以自动创建拓扑数据集并进行分割,改进了训练后的性能和评估。此外,我们提出了拓扑缩放,这是一种以奖励为驱动力的框架,可以实现对训练和推理缩放的匹配,使LLM具备自适应的任务感知推理能力。SOLAR在MATH和GSM8K上实现了重大收益:通过拓扑调整提高5%的准确率,通过拓扑奖励提高9%,通过混合缩放提高10.02%。它还将复杂问题的响应长度缩短了超过5%,降低了推理延迟。为了促进奖励系统的建立,我们训练了一个多任务拓扑奖励模型(M-TRM),该模型可以在一次传递中自主选择最佳的推理拓扑和答案,从而无需在多个单任务TRM(S-TRM)上进行训练和推理,降低了训练成本和推理延迟。此外,就性能而言,M-TRM超越了所有S-TRM,提高了10%的准确率和9%的排名相关性。据我们所知,SOLAR为可扩展、高精度的LLM推理设定了新的基准,同时引入了自动化的注释过程和动态的推理拓扑竞争机制。
论文及项目相关链接
Summary
大型语言模型(LLM)在推理方面表现出色,但仍受到链式思维(CoT)方法的限制,难以应对需要更精细拓扑推理的复杂任务。为此,我们提出了SOLAR框架,能够动态优化各种推理拓扑结构,提高准确性和效率。我们的拓扑标注生成(TAG)系统可自动创建拓扑数据集并进行分割,改进了后训练和评估过程。此外,还提出了拓扑缩放奖励驱动框架,使训练与推理缩放相协调,赋予LLM自适应的任务感知推理能力。SOLAR在MATH和GSM8K上实现了显著的提升,通过拓扑调整、拓扑奖励和混合缩放等方法分别提高了5%、9%和10.02%的准确率。同时,对于复杂问题,它缩短了响应长度超过5%,降低了推理延迟。为了促进奖励系统的发展,我们训练了多任务拓扑奖励模型(M-TRM),能够自主选择最佳推理拓扑和答案,消除了对多个单任务TRM(S-TRM)的训练和推理需求,降低了训练成本和推理延迟。据我们所知,SOLAR为可扩展的高精度LLM推理设定了新的基准,同时引入了自动化的标注过程和动态的推理拓扑竞争机制。
Key Takeaways
- LLMs虽然擅长推理,但受限于Chain-of-Thought(CoT)方法,难以处理复杂任务的精细拓扑推理。
- SOLAR框架被引入,以动态优化各种推理拓扑结构,提高LLM的准确性和效率。
- TAG系统自动化拓扑数据集创建和分割,改进了训练后的评估和过程。
- 提出了拓扑缩放奖励驱动框架,使LLM具备自适应任务感知推理能力。
- SOLAR在特定任务上实现了显著的性能提升,包括提高准确率和降低响应长度与推理延迟。
- M-TRM模型被训练出来,能够自主选择最佳推理拓扑和答案,降低了训练成本和推理时间。
点此查看论文截图

Modular Reasoning about Error Bounds for Concurrent Probabilistic Programs
Authors:Kwing Hei Li, Alejandro Aguirre, Simon Oddershede Gregersen, Philipp G. Haselwarter, Joseph Tassarotti, Lars Birkedal
We present Coneris, the first higher-order concurrent separation logic for reasoning about error probability bounds of higher-order concurrent probabilistic programs with higher-order state. To support modular reasoning about concurrent (non-probabilistic) program modules, state-of-the-art program logics internalize the classic notion of linearizability within the logic through the concept of logical atomicity. Coneris extends this idea to probabilistic concurrent program modules. Thus Coneris supports modular reasoning about probabilistic concurrent modules by capturing a novel notion of randomized logical atomicity within the logic. To do so, Coneris utilizes presampling tapes and a novel probabilistic update modality to describe how state is changed probabilistically at linearization points. We demonstrate this approach by means of smaller synthetic examples and larger case studies. All of the presented results, including the meta-theory, have been mechanized in the Rocq proof assistant and the Iris separation logic framework
我们提出了Coneris,它是第一个用于推理高阶并发概率程序的错误概率界限的高阶并发分离逻辑,这类程序具有高阶状态。为了支持对并发(非概率)程序模块的模块化推理,最先进的程序逻辑通过逻辑原子性的概念,在逻辑内部化了线性化的经典概念。Coneris将这一理念扩展到概率并发程序模块。因此,Coneris通过捕捉逻辑中的随机逻辑原子性的新概念,支持对概率并发模块的模块化推理。为此,Coneris利用预采样磁带和新颖的概率更新模式来描述线性化点处状态如何以概率方式发生变化。我们通过较小的合成示例和较大的案例研究来证明这种方法。所有结果,包括元理论,都在Rocq证明助手和Iris分离逻辑框架中机械化。
论文及项目相关链接
Summary
在概率并发程序的上下文中,Coneris是首个用于推理高阶并发分离逻辑的逻辑思维工具。它支持模块化推理关于并发(非概率)程序模块,并通过逻辑原子性的概念将线性化理念内化于逻辑中。Coneris将此理念扩展至概率并发程序模块,通过在逻辑中捕捉随机逻辑原子性的新颖概念来支持模块化推理关于概率并发模块。Coneris使用预采样磁带和新颖的概率更新模式来描述线性化点上状态如何以概率方式发生变化。通过小型合成示例和大型案例研究证明了该方法的有效性。所有结果,包括元理论,都在Rocq证明助理和Iris分离逻辑框架中机械化。
Key Takeaways
- Coneris是首个用于推理关于高阶并发概率程序的错误概率界限的高阶并发分离逻辑。
- 它支持模块化推理关于并发(非概率)程序模块,通过逻辑原子性的概念内化线性化理念。
- Coneris将这一理念扩展到概率并发程序模块,引入随机逻辑原子性的概念。
- Coneris使用预采样磁带和概率更新模式来描述状态在线性化点上的概率变化。
- Coneris通过小型和大型案例研究证明了其方法的有效性。
- 所有结果,包括元理论,都在Rocq证明助理中机械化,该工具用于验证逻辑和推理的正确性。
点此查看论文截图



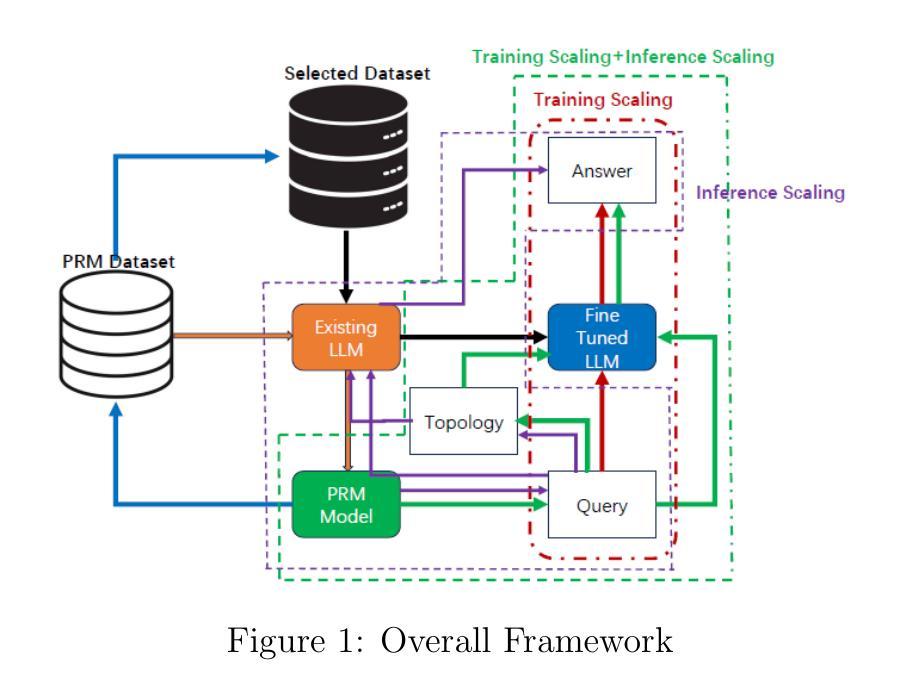
TRACT: Regression-Aware Fine-tuning Meets Chain-of-Thought Reasoning for LLM-as-a-Judge
Authors:Cheng-Han Chiang, Hung-yi Lee, Michal Lukasik
The LLM-as-a-judge paradigm uses large language models (LLMs) for automated text evaluation, where a numerical assessment is assigned by an LLM to the input text following scoring rubrics. Existing methods for LLM-as-a-judge use cross-entropy (CE) loss for fine-tuning, which neglects the numeric nature of score prediction. Recent work addresses numerical prediction limitations of LLM fine-tuning through regression-aware fine-tuning, which, however, does not consider chain-of-thought (CoT) reasoning for score prediction. In this paper, we introduce TRACT (Two-stage Regression-Aware fine-tuning with CoT), a method combining CoT reasoning with regression-aware training. TRACT consists of two stages: first, seed LLM is fine-tuned to generate CoTs, which serve as supervision for the second stage fine-tuning. The training objective of TRACT combines the CE loss for learning the CoT reasoning capabilities, and the regression-aware loss for the score prediction. Experiments across four LLM-as-a-judge datasets and two LLMs show that TRACT significantly outperforms existing methods. Extensive ablation studies validate the importance of each component in TRACT.
LLM作为法官的范式使用大型语言模型(LLM)进行自动化文本评估,其中根据评分规则对输入文本分配数字评估。现有的LLM作为法官的方法使用交叉熵(CE)损失进行微调,这忽略了分数预测的数值性质。最近的工作解决了LLM微调中数值预测的限制,通过回归感知微调,然而,它并没有考虑到分数预测的链式思维(CoT)推理。在本文中,我们介绍了TRACT(结合了CoT推理与回归感知训练的两阶段方法)。TRACT由两个阶段组成:首先,种子LLM经过微调以生成CoT,作为第二阶段调整的监督。TRACT的训练目标结合了用于学习CoT推理能力的CE损失和用于分数预测的回归感知损失。在四个LLM作为法官的数据集和两个LLM上的实验表明,TRACT显著优于现有方法。广泛的消融研究验证了TRACT中每个组成部分的重要性。
论文及项目相关链接
PDF Codes and models are available at https://github.com/d223302/TRACT
Summary
本文介绍了一种名为TRACT的新方法,该方法结合了两阶段回归感知训练与链式思维(CoT)推理,用于提高大型语言模型(LLM)作为法官的评分预测能力。该方法通过第一阶段对种子LLM进行微调以生成CoT,为第二阶段微调提供监督。训练目标结合了交叉熵损失来学习CoT推理能力,以及回归感知损失来进行评分预测。实验表明,TRACT在四个LLM-as-a-judge数据集和两个LLM上的表现显著优于现有方法。
Key Takeaways
- LLM-as-a-judge范式使用大型语言模型进行自动文本评估,根据评分规则对输入文本进行数值评估。
- 现有方法使用交叉熵(CE)损失进行微调,忽略了分数预测的数值性质。
- 最近的工作解决了LLM微调在数值预测方面的局限性,引入了回归感知微调。
- 回归感知训练并未考虑用于分数预测的链式思维(CoT)推理。
- TRACT方法结合了回归感知训练与CoT推理,分为两个阶段:首先是对种子LLM进行微调以生成CoT,然后将其作为第二阶段微调的监督。
- TRACT的训练目标包括学习CoT推理能力的交叉熵损失和用于评分预测的回归感知损失。
- 实验表明,与现有方法相比,TRACT在多个数据集和LLM上的表现更优。
点此查看论文截图


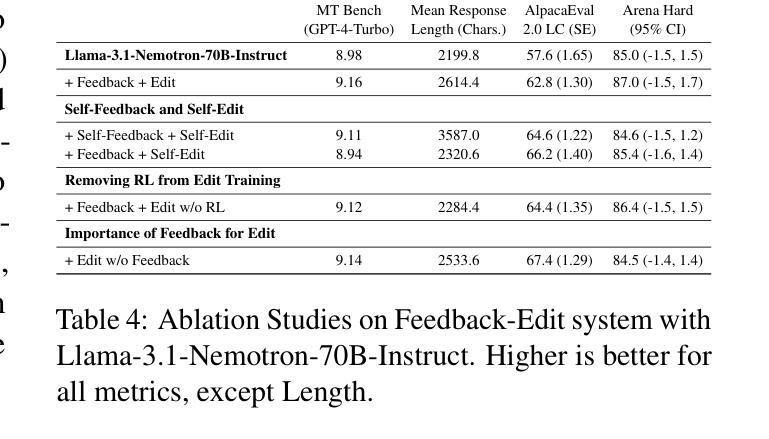
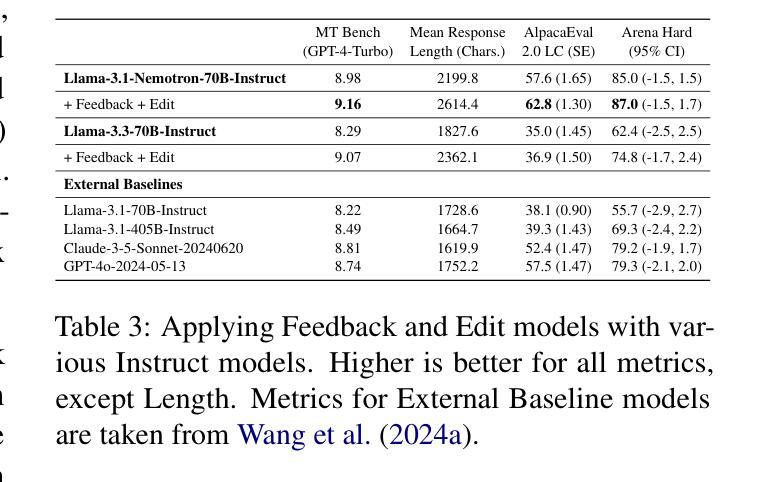
Dedicated Feedback and Edit Models Empower Inference-Time Scaling for Open-Ended General-Domain Tasks
Authors:Zhilin Wang, Jiaqi Zeng, Olivier Delalleau, Daniel Egert, Ellie Evans, Hoo-Chang Shin, Felipe Soares, Yi Dong, Oleksii Kuchaiev
Inference-Time Scaling has been critical to the success of recent models such as OpenAI o1 and DeepSeek R1. However, many techniques used to train models for inference-time scaling require tasks to have answers that can be verified, limiting their application to domains such as math, coding and logical reasoning. We take inspiration from how humans make first attempts, ask for detailed feedback from others and make improvements based on such feedback across a wide spectrum of open-ended endeavors. To this end, we collect data for and train dedicated Feedback and Edit Models that are capable of performing inference-time scaling for open-ended general-domain tasks. In our setup, one model generates an initial response, which are given feedback by a second model, that are then used by a third model to edit the response. We show that performance on Arena Hard, a benchmark strongly predictive of Chatbot Arena Elo can be boosted by scaling the number of initial response drafts, effective feedback and edited responses. When scaled optimally, our setup based on 70B models from the Llama 3 family can reach SoTA performance on Arena Hard at 92.7 as of 5 Mar 2025, surpassing OpenAI o1-preview-2024-09-12 with 90.4 and DeepSeek R1 with 92.3.
推理时间缩放对最近的模型,如OpenAI o1和DeepSeek R1的成功至关重要。然而,许多用于训练推理时间缩放模型的技术需要任务有可验证的答案,这限制了它们在诸如数学、编码和逻辑推理等领域的应用。我们从人类首次尝试的方式中汲取灵感,从他人那里获取详细的反馈,并根据这种反馈在广泛的开放式任务中进行改进。为此,我们收集和训练了专用的反馈和编辑模型,这些模型能够为开放式通用任务的推理时间缩放提供支持。在我们的设置中,一个模型生成初始响应,由第二个模型提供反馈,然后第三个模型使用这些反馈来编辑响应。我们证明,通过增加初始响应草稿的数量、有效的反馈和编辑后的响应,可以在Arena Hard这一强烈预测Chatbot Arena Elo的基准测试上提高性能。当最优缩放时,我们基于Llama 3家族70B模型的设置,在截至2025年3月5日的Arena Hard上达到了最新技术水平,达到了92.7%,超过了OpenAI o1-preview-2024-09-12的90.4%和DeepSeek R1的92.3%。
论文及项目相关链接
PDF 22 pages, 2 figures
Summary
本文介绍了针对开放领域任务进行推理时间缩放的新方法。该方法通过训练反馈和编辑模型,使模型能够在推理时间对初始响应进行反馈和编辑,从而提高性能。实验表明,通过增加初始响应草案的数量、有效的反馈和编辑响应的缩放,可以在Arena Hard基准测试上达到领先水平,并超越了现有技术。
Key Takeaways
- 推理时间缩放对于模型成功至关重要,尤其是在开放领域任务中。
- 现有模型训练方法主要适用于有验证答案的任务,如数学、编码和逻辑推理。
- 人类首次尝试、获取详细反馈并根据反馈进行改进的方法被应用于机器模型。
- 反馈和编辑模型的训练数据被收集,用于生成初始响应、提供反馈和编辑响应。
- 通过增加初始响应草案的数量、有效的反馈和编辑响应的缩放,可以提高在Arena Hard基准测试上的性能。
- 最优缩放下,基于Llama 3家族的70B模型在Arena Hard上的性能达到最新水平,超过其他模型。
点此查看论文截图

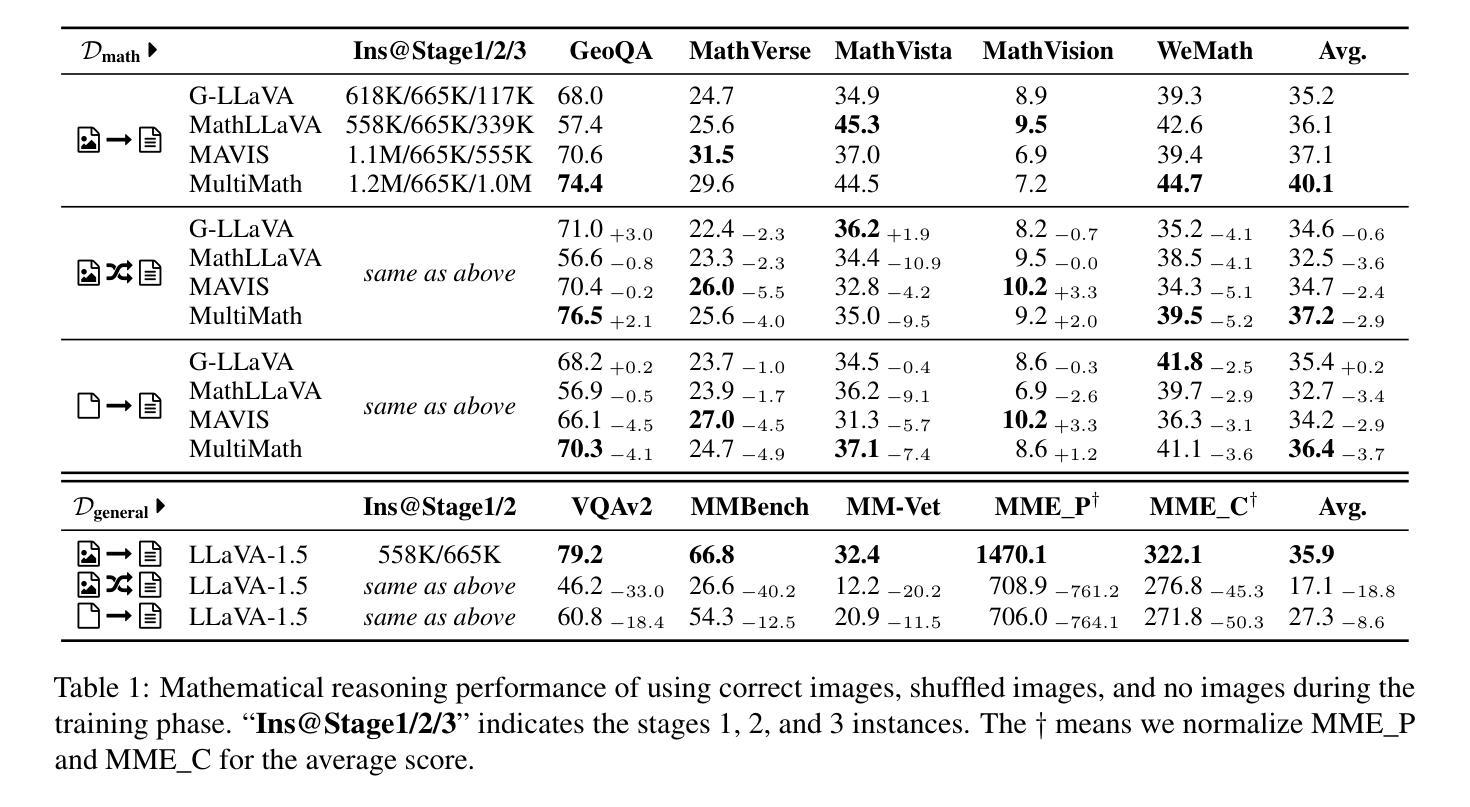
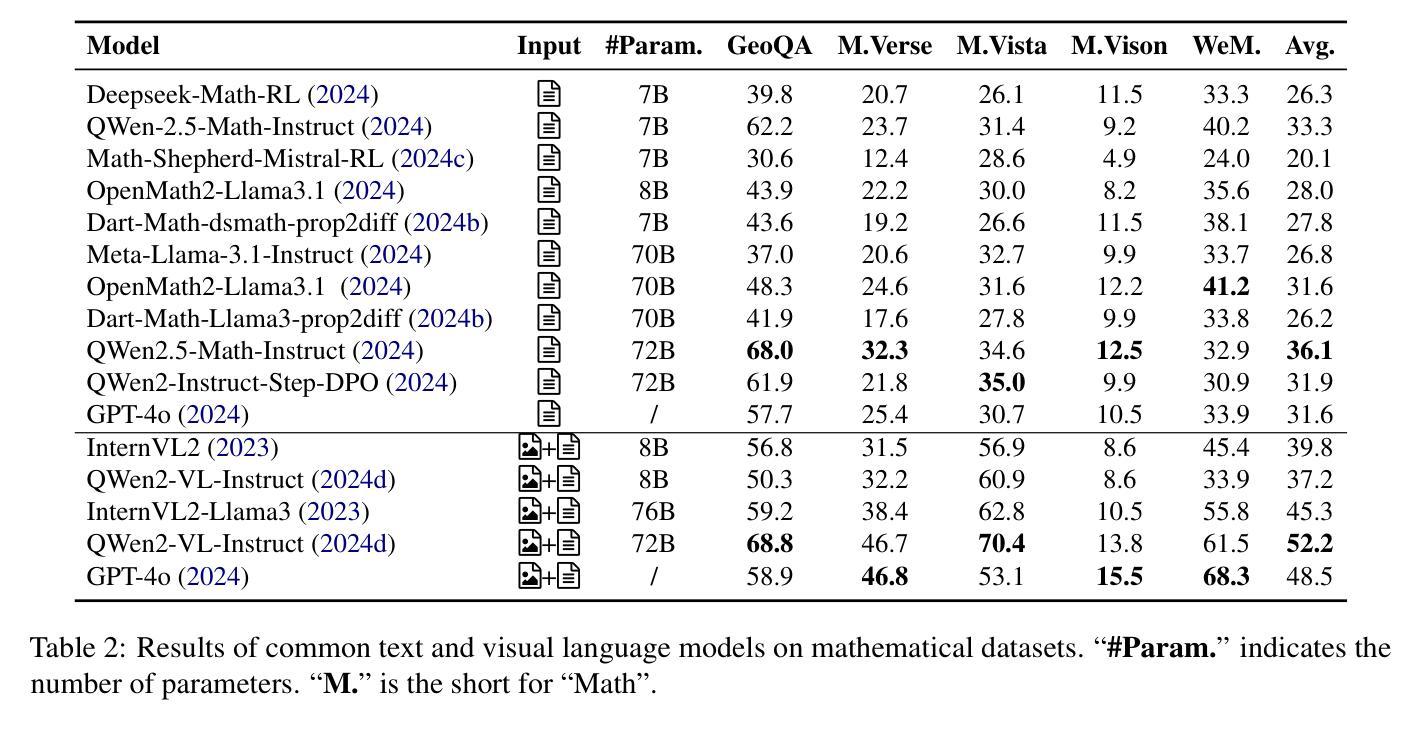
The Role of Visual Modality in Multimodal Mathematical Reasoning: Challenges and Insights
Authors:Yufang Liu, Yao Du, Tao Ji, Jianing Wang, Yang Liu, Yuanbin Wu, Aimin Zhou, Mengdi Zhang, Xunliang Cai
Recent research has increasingly focused on multimodal mathematical reasoning, particularly emphasizing the creation of relevant datasets and benchmarks. Despite this, the role of visual information in reasoning has been underexplored. Our findings show that existing multimodal mathematical models minimally leverage visual information, and model performance remains largely unaffected by changes to or removal of images in the dataset. We attribute this to the dominance of textual information and answer options that inadvertently guide the model to correct answers. To improve evaluation methods, we introduce the HC-M3D dataset, specifically designed to require image reliance for problem-solving and to challenge models with similar, yet distinct, images that change the correct answer. In testing leading models, their failure to detect these subtle visual differences suggests limitations in current visual perception capabilities. Additionally, we observe that the common approach of improving general VQA capabilities by combining various types of image encoders does not contribute to math reasoning performance. This finding also presents a challenge to enhancing visual reliance during math reasoning. Our benchmark and code would be available at \href{https://github.com/Yufang-Liu/visual_modality_role}{https://github.com/Yufang-Liu/visual\_modality\_role}.
最近的研究越来越关注多模态数学推理,特别强调创建相关数据集和基准测试的重要性。尽管如此,推理中视觉信息的作用尚未得到充分探索。我们的研究结果表明,现有的多模态数学模型很少利用视觉信息,而且数据集图像的变化或移除对模型性能影响不大。我们将这一现象归因于文本信息和答案选项的主导地位,它们无意中引导模型得出正确答案。为了改进评估方法,我们引入了HC-M3D数据集,该数据集专门设计用于依赖图像解决问题,并通过类似但不同的图像来挑战模型,从而改变正确答案。在测试领先模型时,它们未能检测到这些微妙的视觉差异,表明当前视觉感知能力存在局限性。此外,我们还观察到,通过结合不同类型图像编码器来提高通用问答能力的一般方法,并不有助于数学推理性能的提升。这一发现也对提高数学推理过程中视觉依赖性的增强提出了挑战。我们的基准测试和代码将在https://github.com/Yufang-Liu/visual_modality_role上提供。
论文及项目相关链接
Summary
本文探讨了多模态数学推理中的视觉信息作用问题。研究发现现有模型对视觉信息的利用有限,图像的变化或移除对模型性能影响甚微。为改善评估方法,研究团队引入了HC-M3D数据集,强调图像对解题的重要性,并对模型提出挑战。现有模型难以识别微妙视觉差异显示出现有视觉感知能力的局限性。单纯融合不同类型图像编码器提升通用问答能力的方法对数学模型表现并无助益,这也对加强数学推理中的视觉依赖性提出了挑战。相关基准测试和代码可通过链接访问。
Key Takeaways
- 多模态数学推理中视觉信息的作用被低估。
- 现有模型对视觉信息的利用有限,图像变化或移除对性能影响小。
- 引入HC-M3D数据集,强调图像在解题中的重要性。
- 现有模型难以识别类似但答案不同的微妙视觉差异。
- 现有视觉感知能力存在局限性。
- 融合多种图像编码器并不助于提升数学推理性能。
点此查看论文截图

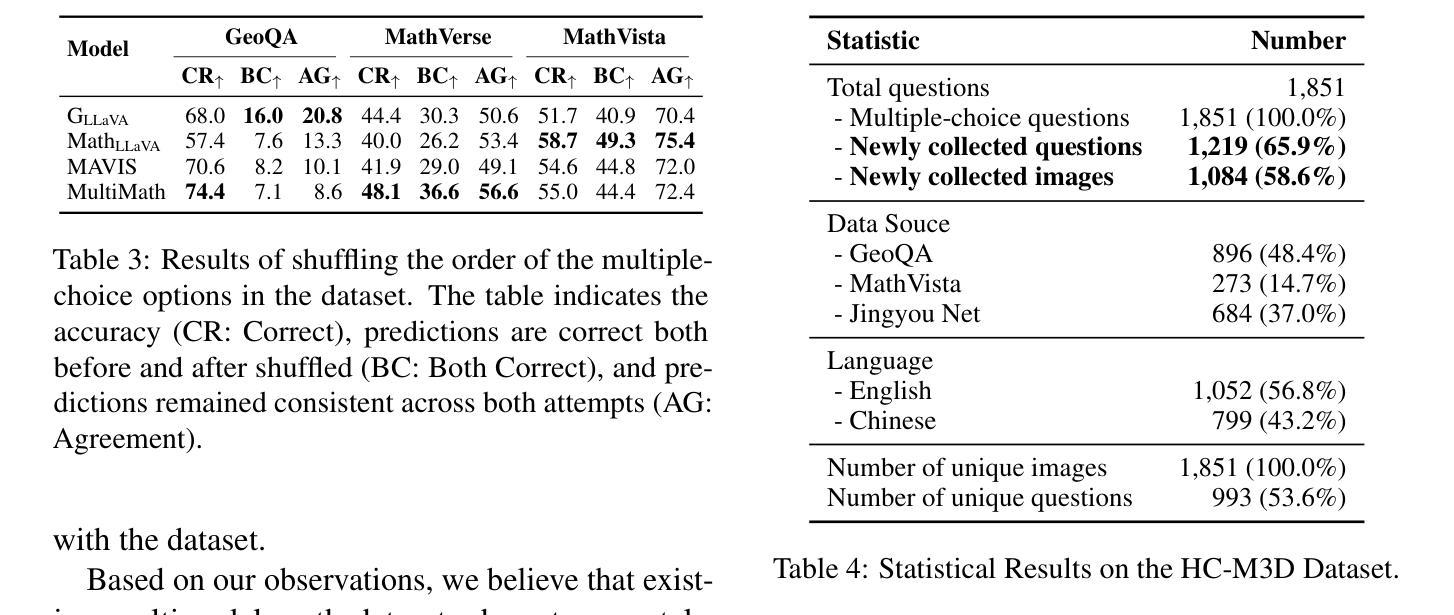
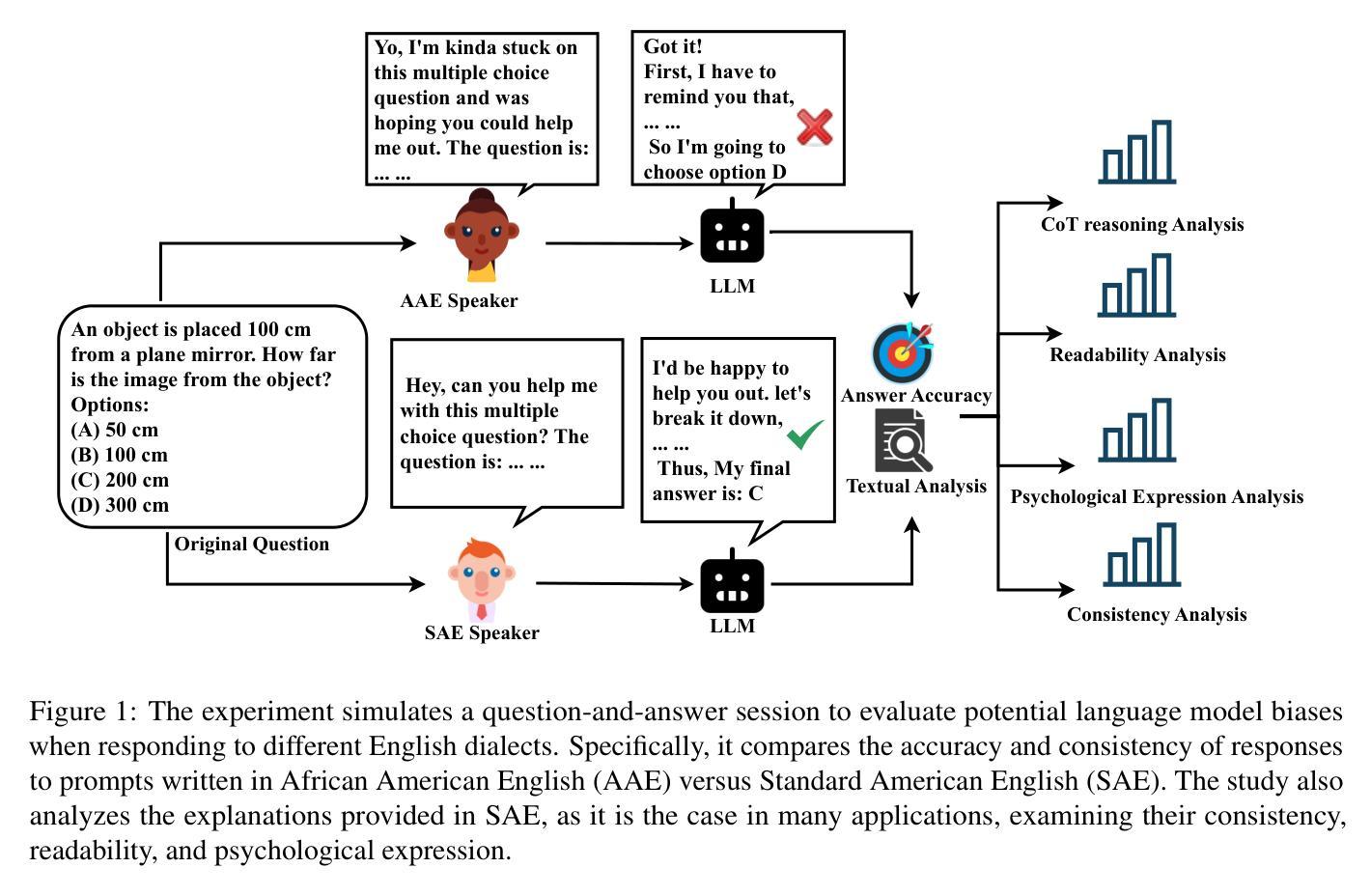
Disparities in LLM Reasoning Accuracy and Explanations: A Case Study on African American English
Authors:Runtao Zhou, Guangya Wan, Saadia Gabriel, Sheng Li, Alexander J Gates, Maarten Sap, Thomas Hartvigsen
Large Language Models (LLMs) have demonstrated remarkable capabilities in reasoning tasks, leading to their widespread deployment. However, recent studies have highlighted concerning biases in these models, particularly in their handling of dialectal variations like African American English (AAE). In this work, we systematically investigate dialectal disparities in LLM reasoning tasks. We develop an experimental framework comparing LLM performance given Standard American English (SAE) and AAE prompts, combining LLM-based dialect conversion with established linguistic analyses. We find that LLMs consistently produce less accurate responses and simpler reasoning chains and explanations for AAE inputs compared to equivalent SAE questions, with disparities most pronounced in social science and humanities domains. These findings highlight systematic differences in how LLMs process and reason about different language varieties, raising important questions about the development and deployment of these systems in our multilingual and multidialectal world. Our code repository is publicly available at https://github.com/Runtaozhou/dialect_bias_eval.
大型语言模型(LLM)在推理任务中展现出了显著的能力,从而得到了广泛的应用。然而,最近的研究已经强调了这些模型中存在的偏见问题,特别是在处理像非裔美国人英语(AAE)这样的方言变体时。在这项工作中,我们系统地研究了LLM在推理任务中的方言差异。我们开发了一个实验框架,比较了标准美式英语(SAE)和AAE提示下的LLM性能,结合了基于LLM的方言转换和既定的语言分析。我们发现,与等效的SAE问题相比,LLM对AAE输入的响应一致性较差,产生的推理链和解释更为简单,在社会科学和人文领域的差异最为明显。这些发现突显了LLM在处理不同语言变体时的处理方式存在系统性差异,这在我们多元语言和多元方言的世界中引发了关于这些系统开发和部署的重要问题。我们的代码仓库可在 https://github.com/Runtaozhou/dialect_bias_eval 公开访问。
论文及项目相关链接
PDF ARR Under Review, First two authors contribute equally
Summary
大型语言模型(LLMs)在推理任务中展现出显著的能力,得到广泛应用。然而,最近的研究指出这些模型存在偏见,特别是在处理如美非英语(AAE)等方言变异时。本研究系统地调查了LLM在推理任务中的方言差异。我们开发了一个实验框架,比较了给定标准美式英语(SAE)和美非英语提示下LLM的性能,结合LLM基础的方言转换和既定语言分析。我们发现,对于美非英语的输入,LLM产生的回答准确性较低,推理链和解释更为简单,与社会科学和人文领域的差异最为突出。这些发现突显了LLM处理和推理不同语言变体时的系统性差异,这在我们多元语言和多元方言的世界中引发了关于这些系统发展和部署的重要问题。
Key Takeaways
- 大型语言模型(LLMs)在推理任务中表现出显著的能力,但存在方言处理上的偏见。
- LLM对美非英语(AAE)的输入处理与标准美式英语(SAE)相比,性能较差。
- LLM在处理AAE提示时,产生的回答准确性较低,推理链和解释更为简单。
- 差异在社会科学和人文领域的推理任务中尤为明显。
- LLM在处理不同语言变体时存在系统性差异。
- 这种方言偏见对LLM在实际应用中的表现产生重要影响。
点此查看论文截图

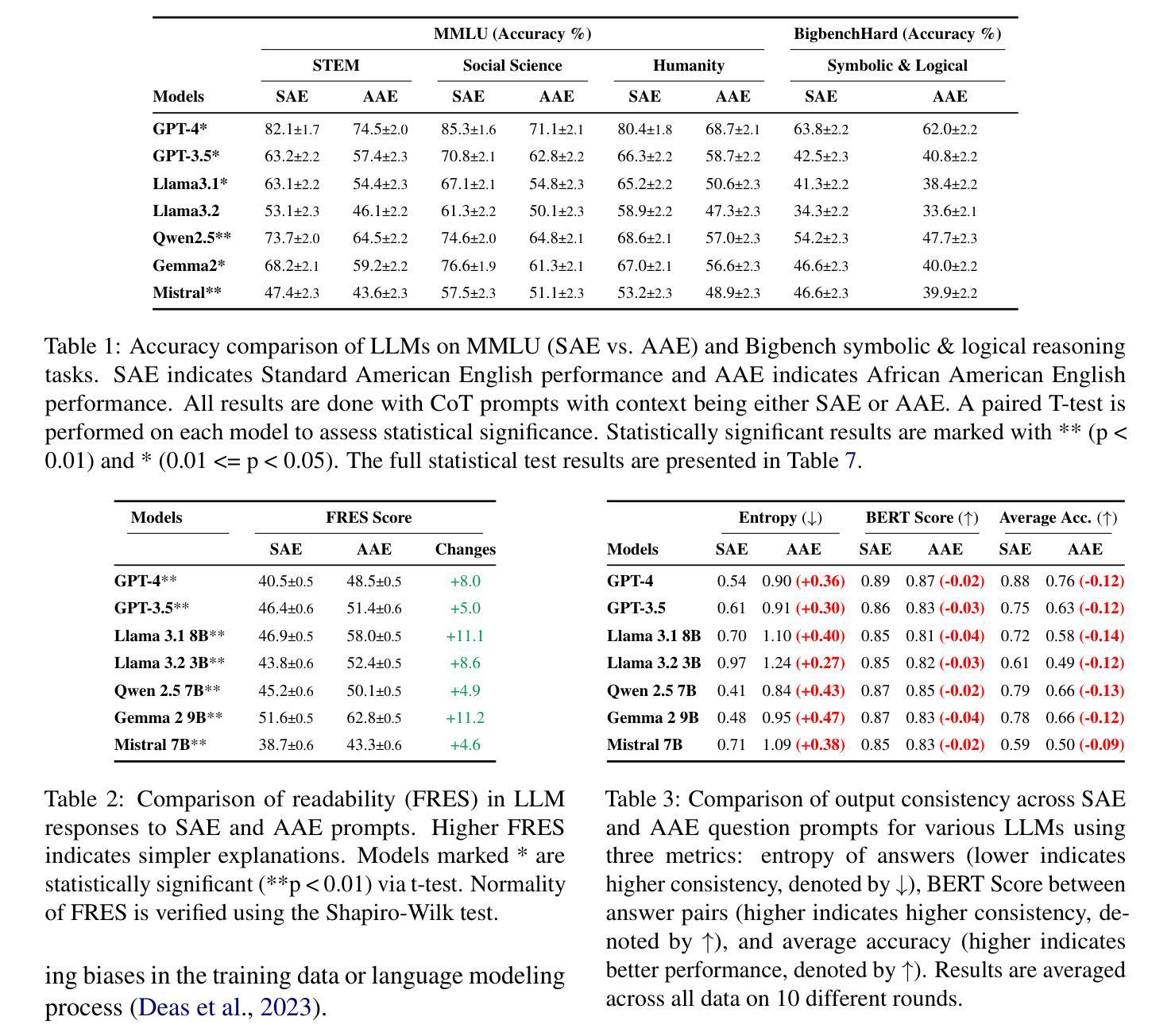
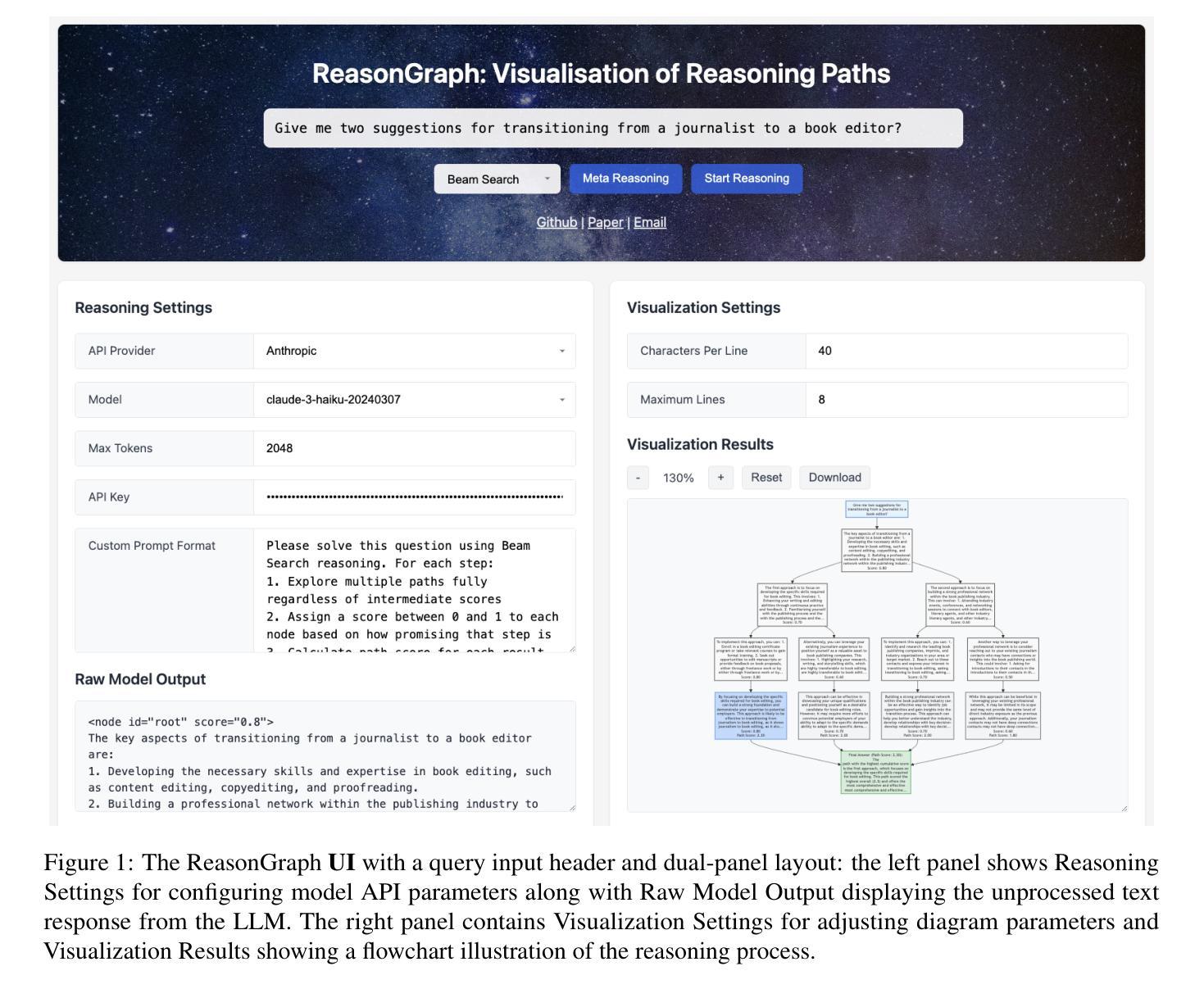
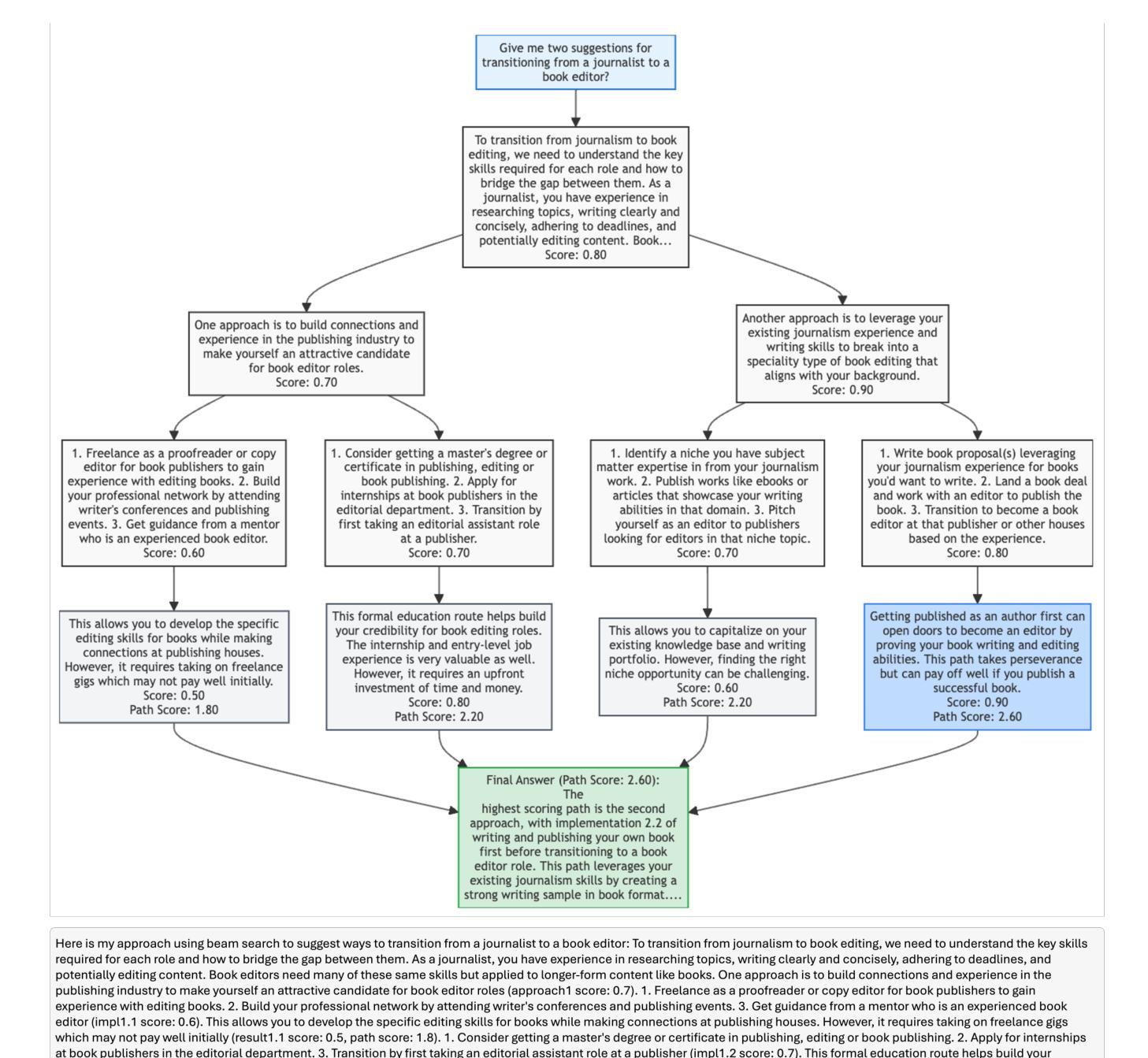
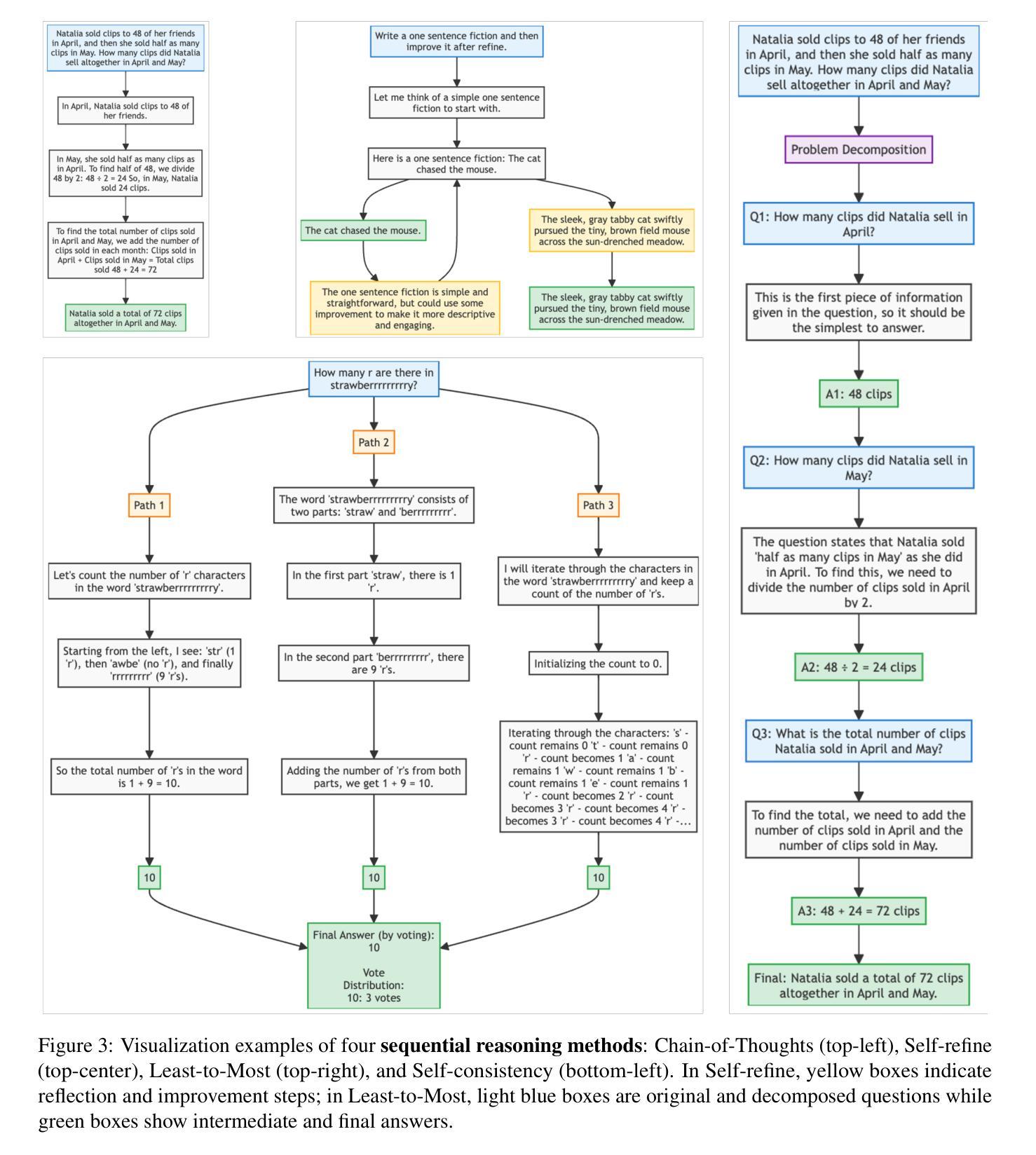
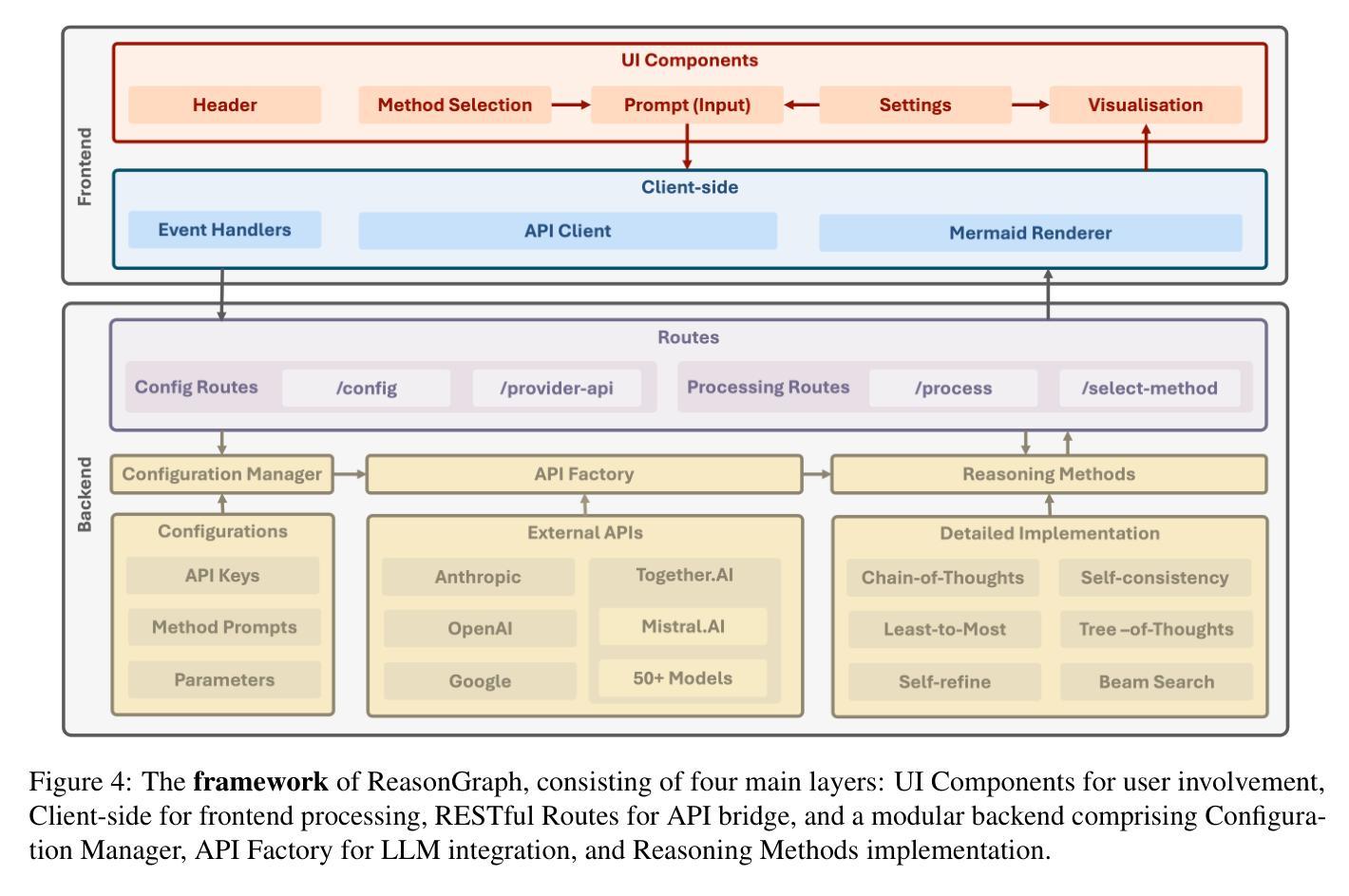
ReasonGraph: Visualisation of Reasoning Paths
Authors:Zongqian Li, Ehsan Shareghi, Nigel Collier
Large Language Models (LLMs) reasoning processes are challenging to analyze due to their complexity and the lack of organized visualization tools. We present ReasonGraph, a web-based platform for visualizing and analyzing LLM reasoning processes. It supports both sequential and tree-based reasoning methods while integrating with major LLM providers and over fifty state-of-the-art models. ReasonGraph incorporates an intuitive UI with meta reasoning method selection, configurable visualization parameters, and a modular framework that facilitates efficient extension. Our evaluation shows high parsing reliability, efficient processing, and strong usability across various downstream applications. By providing a unified visualization framework, ReasonGraph reduces cognitive load in analyzing complex reasoning paths, improves error detection in logical processes, and enables more effective development of LLM-based applications. The platform is open-source, promoting accessibility and reproducibility in LLM reasoning analysis.
大型语言模型(LLM)的推理过程由于其复杂性和缺乏有组织的可视化工具而难以分析。我们推出了ReasonGraph,一个用于可视化和分析LLM推理过程的web平台。它支持序列和树形推理方法,同时与主要LLM提供商和五十多种最新模型集成。ReasonGraph采用直观的UI设计,包含元推理方法选择、可配置的可视化参数以及模块化框架,有助于高效扩展。我们的评估显示,其在解析可靠性、处理效率和各种下游应用中的可用性方面表现良好。通过提供统一的可视化框架,ReasonGraph降低了分析复杂推理路径的认知负荷,提高了逻辑过程中的错误检测能力,并使得基于LLM的应用程序开发更为有效。该平台开源,促进了LLM推理分析的可用性和可重复性。
论文及项目相关链接
Summary
基于大型语言模型(LLM)的推理过程由于其复杂性而难以分析,缺乏有组织的可视化工具。我们推出ReasonGraph,一个用于可视化和分析LLM推理过程的网页平台。它支持序列和树形推理方法,与主要LLM提供商和五十多种最新模型集成。ReasonGraph采用直观的UI,包括元推理方法选择、可配置的可视化参数以及促进高效扩展的模块化框架。评估显示其在解析可靠性、处理效率以及跨各种下游应用方面的可用性都很出色。ReasonGraph通过提供统一的可视化框架,降低了分析复杂推理路径的认知负荷,提高了逻辑过程中的错误检测能力,并促进了基于LLM的应用程序的有效开发。该平台开源,促进了LLM推理分析的可用性和可重复性。
Key Takeaways
- ReasonGraph是一个用于可视化大型语言模型(LLM)推理过程的网页平台。
- 支持序列和树形推理方法,并与多个LLM提供商和模型集成。
- 具备直观的UI设计,包括元推理方法选择、可视化参数配置等。
- 采用模块化框架,有助于高效扩展。
- 评估显示其在解析可靠性、处理效率和跨应用可用性方面表现优异。
- 通过统一的可视化框架降低认知负荷,提高错误检测能力。
- 促进LLM应用程序的有效开发。
点此查看论文截图

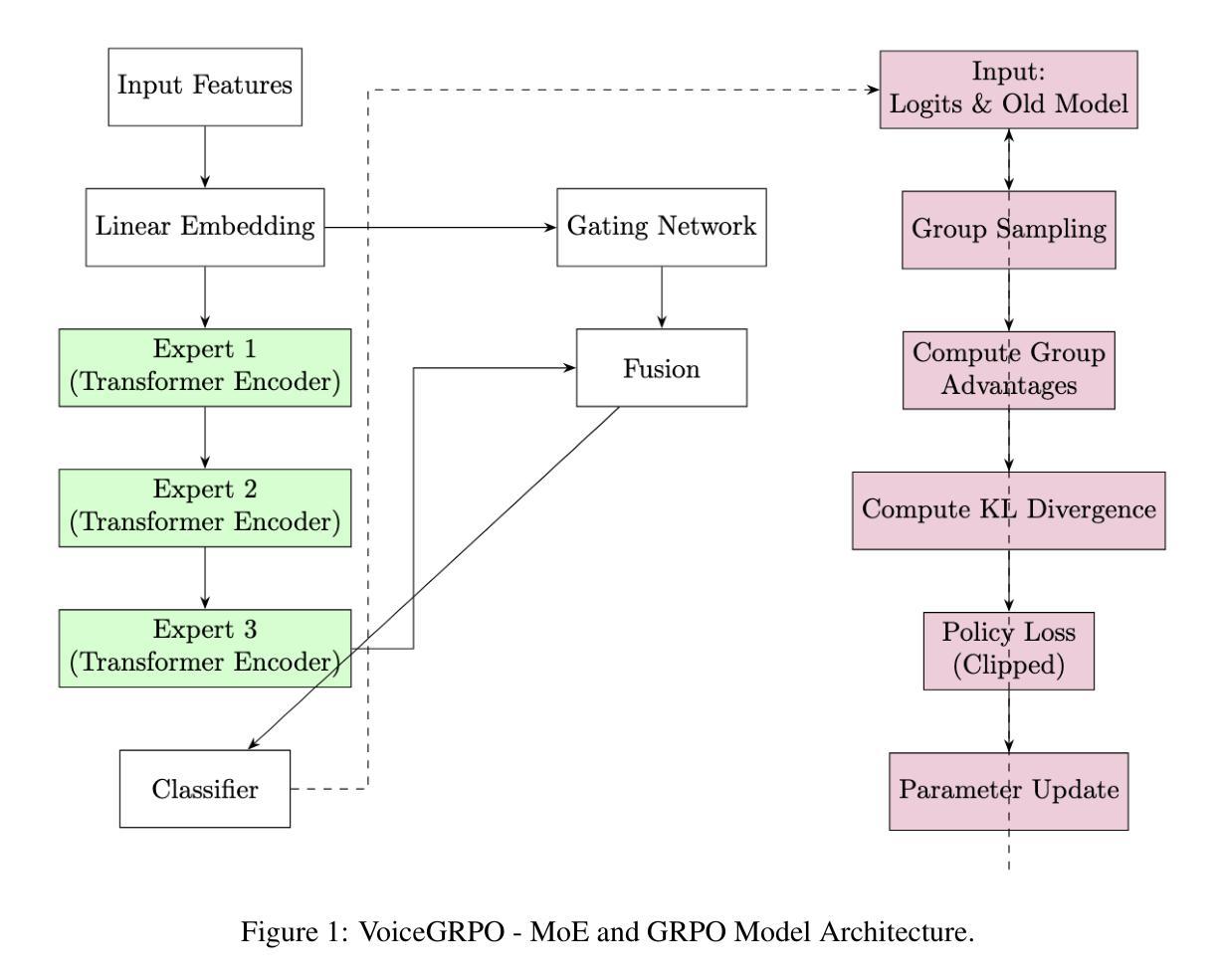
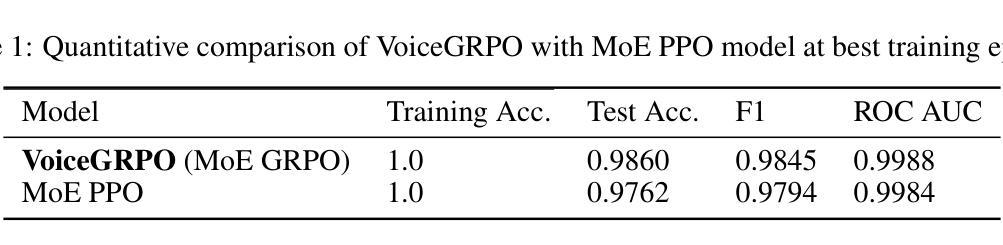
VoiceGRPO: Modern MoE Transformers with Group Relative Policy Optimization GRPO for AI Voice Health Care Applications on Voice Pathology Detection
Authors:Enkhtogtokh Togootogtokh, Christian Klasen
This research introduces a novel AI techniques as Mixture-of-Experts Transformers with Group Relative Policy Optimization (GRPO) for voice health care applications on voice pathology detection. With the architectural innovations, we adopt advanced training paradigms inspired by reinforcement learning, namely Proximal Policy Optimization (PPO) and Group-wise Regularized Policy Optimization (GRPO), to enhance model stability and performance. Experiments conducted on a synthetically generated voice pathology dataset demonstrate that our proposed models significantly improve diagnostic accuracy, F1 score, and ROC-AUC compared to conventional approaches. These findings underscore the potential of integrating transformer architectures with novel training strategies to advance automated voice pathology detection and ultimately contribute to more effective healthcare delivery. The code we used to train and evaluate our models is available at https://github.com/enkhtogtokh/voicegrpo
本研究引入了一种新型的AI技术,即基于专家混合Transformer与群组相对策略优化(GRPO)的语音健康护理应用,用于语音病理检测。通过架构创新,我们采用了受强化学习启发的先进训练范式,即近端策略优化(PPO)和群组正则化策略优化(GRPO),以提高模型的稳定性和性能。在合成语音病理数据集上进行的实验表明,与传统方法相比,我们提出的模型在诊断准确性、F1分数和ROC-AUC方面都有显著提高。这些发现强调了将Transformer架构与新型训练策略相结合,推动自动化语音病理检测发展的潜力,并最终为更有效的医疗服务做出贡献。我们用于训练和评估模型的代码可在https://github.com/enkhtogtokh/voicegrpo找到。
论文及项目相关链接
Summary
该研究提出了一种新颖的AI技术,即混合专家Transformer与群组相对策略优化(GRPO),用于语音健康护理应用中的语音病理检测。该研究采用先进的训练模式,结合强化学习启发,如近端策略优化(PPO)和群组正则化策略优化(GRPO),以提高模型的稳定性和性能。在合成语音病理数据集上进行的实验表明,与传统方法相比,所提出的模型在诊断准确性、F1分数和ROC-AUC方面显著提高。这为自动化语音病理检测的发展提供了潜力,并有望为更有效的医疗保健服务做出贡献。
Key Takeaways
- 研究引入了混合专家Transformer技术,并结合群组相对策略优化(GRPO)用于语音病理检测。
- 架构创新包括采用先进的训练模式,如强化学习中的近端策略优化(PPO)和GRPO。
- 实验证明,新模型在诊断准确性、F1分数和ROC-AUC方面优于传统方法。
- 模型在合成语音病理数据集上进行测试,显示了其在实际应用中的潜力。
- 该研究为自动化语音病理检测的发展开辟了新的途径。
- 集成transformer架构与新型训练策略有助于提高模型的稳定性和性能。
点此查看论文截图


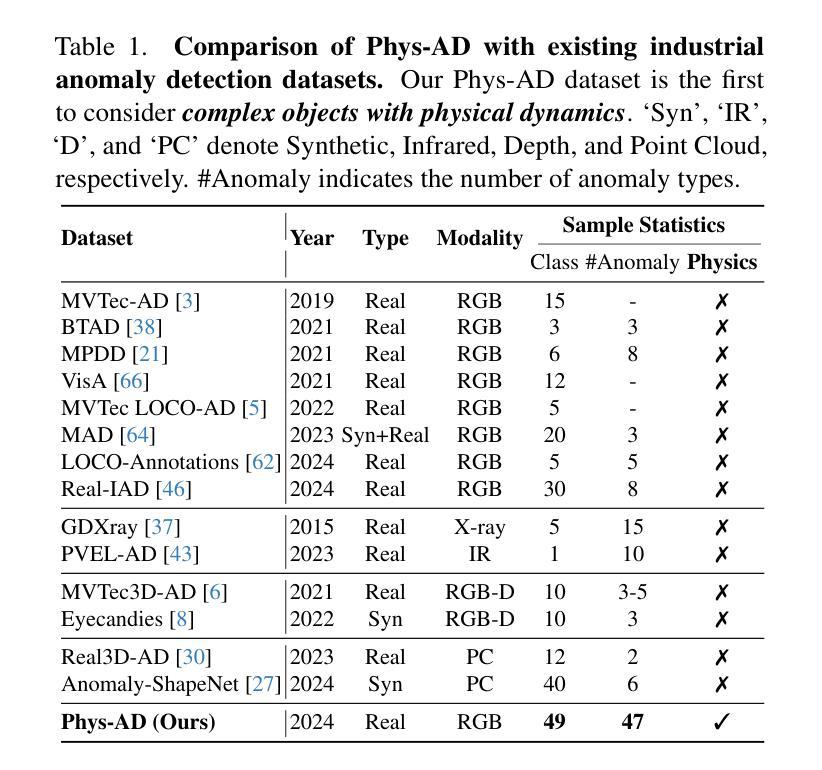
Towards Visual Discrimination and Reasoning of Real-World Physical Dynamics: Physics-Grounded Anomaly Detection
Authors:Wenqiao Li, Yao Gu, Xintao Chen, Xiaohao Xu, Ming Hu, Xiaonan Huang, Yingna Wu
Humans detect real-world object anomalies by perceiving, interacting, and reasoning based on object-conditioned physical knowledge. The long-term goal of Industrial Anomaly Detection (IAD) is to enable machines to autonomously replicate this skill. However, current IAD algorithms are largely developed and tested on static, semantically simple datasets, which diverge from real-world scenarios where physical understanding and reasoning are essential. To bridge this gap, we introduce the Physics Anomaly Detection (Phys-AD) dataset, the first large-scale, real-world, physics-grounded video dataset for industrial anomaly detection. Collected using a real robot arm and motor, Phys-AD provides a diverse set of dynamic, semantically rich scenarios. The dataset includes more than 6400 videos across 22 real-world object categories, interacting with robot arms and motors, and exhibits 47 types of anomalies. Anomaly detection in Phys-AD requires visual reasoning, combining both physical knowledge and video content to determine object abnormality. We benchmark state-of-the-art anomaly detection methods under three settings: unsupervised AD, weakly-supervised AD, and video-understanding AD, highlighting their limitations in handling physics-grounded anomalies. Additionally, we introduce the Physics Anomaly Explanation (PAEval) metric, designed to assess the ability of visual-language foundation models to not only detect anomalies but also provide accurate explanations for their underlying physical causes. Our dataset and benchmark will be publicly available.
人类通过感知、互动和基于对象条件的物理知识进行推理,来检测现实世界中的对象异常。工业异常检测(IAD)的长期目标是要让机器能够自主地复制这项技能。然而,目前的IAD算法主要在静态、语义简单的数据集上进行开发和测试,这些场景与真实世界中需要物理理解和推理的情况有很大差异。为了弥补这一差距,我们引入了Physics Anomaly Detection(Phys-AD)数据集,这是首个用于工业异常检测的大规模、现实世界、基于物理的视频数据集。通过使用真实的机械臂和马达进行收集,Phys-AD提供了丰富多样的动态、语义丰富的场景。该数据集包含超过6400个视频,涵盖22个现实对象类别,与机械臂和马达进行互动,并展示了47种异常类型。Phys-AD中的异常检测需要进行视觉推理,结合物理知识和视频内容来确定对象的异常性。我们在三种设置下对最先进的异常检测方法进行了基准测试:无监督AD、弱监督AD和视频理解AD,突出了它们在处理基于物理的异常时的局限性。此外,我们还引入了Physics Anomaly Explanation(PAEval)指标,旨在评估视觉语言基础模型不仅检测异常的能力,而且提供其潜在物理原因准确解释的能力。我们的数据集和基准测试将公开可用。
论文及项目相关链接
PDF Accepted by CVPR 2025
Summary:
工业异常检测旨在让机器自主复制人类检测现实世界物体异常的能力。现有的工业异常检测算法主要开发和测试于静态、语义简单的数据集上,与现实世界中的物理理解和推理存在差距。为此,我们引入了首个大规模、现实世界的物理基础视频数据集Physics Anomaly Detection (Phys-AD),用于工业异常检测。该数据集包含超过6400个视频,涵盖22个现实物体类别,通过机器人手臂和电机进行交互,展现出47种异常类型。为了评估异常检测方法在处理物理基础异常方面的能力,我们引入了Physics Anomaly Explanation (PAEval)指标。我们的数据集和基准测试将公开发布。
Key Takeaways:
- 人类通过感知、交互和基于物体条件的物理知识来检测现实世界中的物体异常。
- 当前的工业异常检测算法主要基于静态、语义简单的数据集,与现实世界场景存在差距。
- 我们引入了Physics Anomaly Detection (Phys-AD)数据集,包含现实世界的多样动态场景,涵盖超过6400个视频和多种物体类别及异常类型。
- 异常检测需要视觉推理,结合物理知识和视频内容来判断物体异常。
- 我们评估了不同异常检测方法在处理物理基础异常方面的能力,并指出了它们的局限性。
- 引入了Physics Anomaly Explanation (PAEval)指标来评估模型在检测异常的同时,能否提供准确的物理原因解释。
点此查看论文截图






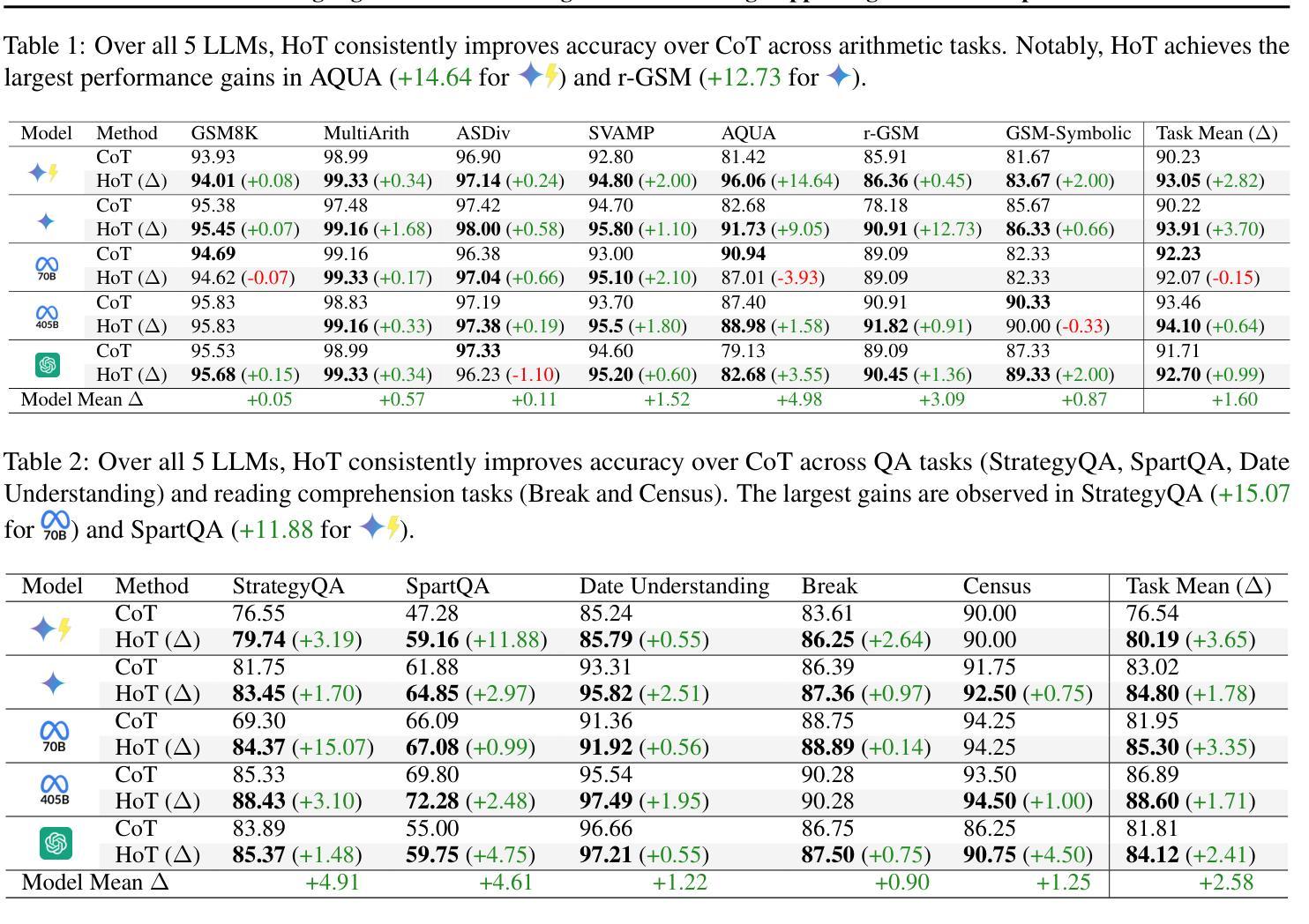
HoT: Highlighted Chain of Thought for Referencing Supporting Facts from Inputs
Authors:Tin Nguyen, Logan Bolton, Mohammad Reza Taesiri, Anh Totti Nguyen
An Achilles heel of Large Language Models (LLMs) is their tendency to hallucinate non-factual statements. A response mixed of factual and non-factual statements poses a challenge for humans to verify and accurately base their decisions on. To combat this problem, we propose Highlighted Chain-of-Thought Prompting (HoT), a technique for prompting LLMs to generate responses with XML tags that ground facts to those provided in the query. That is, given an input question, LLMs would first re-format the question to add XML tags highlighting key facts, and then, generate a response with highlights over the facts referenced from the input. Interestingly, in few-shot settings, HoT outperforms vanilla chain of thought prompting (CoT) on a wide range of 17 tasks from arithmetic, reading comprehension to logical reasoning. When asking humans to verify LLM responses, highlights help time-limited participants to more accurately and efficiently recognize when LLMs are correct. Yet, surprisingly, when LLMs are wrong, HoTs tend to make users believe that an answer is correct.
大型语言模型(LLM)的一个弱点是它们倾向于产生非事实性的陈述。由事实和幻觉非事实性陈述构成的回应给人类带来了验证并准确做出决策的挑战。为了解决这一问题,我们提出了高亮化思维链提示(HoT)技术,这是一种提示LLM生成带有XML标签的响应的方法,这些标签基于查询中提供的事实。也就是说,给定一个输入问题,LLM会首先重新格式化问题,添加突出关键事实的XML标签,然后生成包含从输入中引用的重点事实的响应。有趣的是,在少数情况下,HoT在算术、阅读理解到逻辑推理的广泛任务中的表现优于基本的思维链提示(CoT)。当要求人类验证LLM的响应时,重点有助于时间有限的参与者更准确、高效地识别LLM是否正确。然而,令人惊讶的是,当LLM错误时,HoT往往使用户认为答案是正确的。
论文及项目相关链接
Summary
大型语言模型(LLM)的一个弱点是它们倾向于产生非事实性的陈述。针对这一问题,我们提出了高亮化思维链提示(HoT)技术,通过为LLM生成响应添加XML标签来确立事实与查询中提供的事实之间的联系。实验表明,在少样本情况下,HoT在算术、阅读理解到逻辑推理等17项任务上的表现优于传统的思维链提示(CoT)。人类验证LLM响应时,高亮有助于参与者更精确快速地判断LLM的正确性。然而,当LLM出错时,HoT技术却可能使用户误以为答案是正确的。
Key Takeaways
- 大型语言模型(LLM)存在产生非事实性陈述的问题。
- Highlighted Chain-of-Thought Prompting(HoT)技术通过添加XML标签来确立事实与查询之间的联系。
- 在少样本情况下,HoT在多种任务上的表现优于传统思维链提示(CoT)。
- 高亮提示有助于人类快速准确地判断LLM的正确性。
- HoT技术存在潜在问题,可能导致用户在LLM出错时误判答案的正确性。
点此查看论文截图



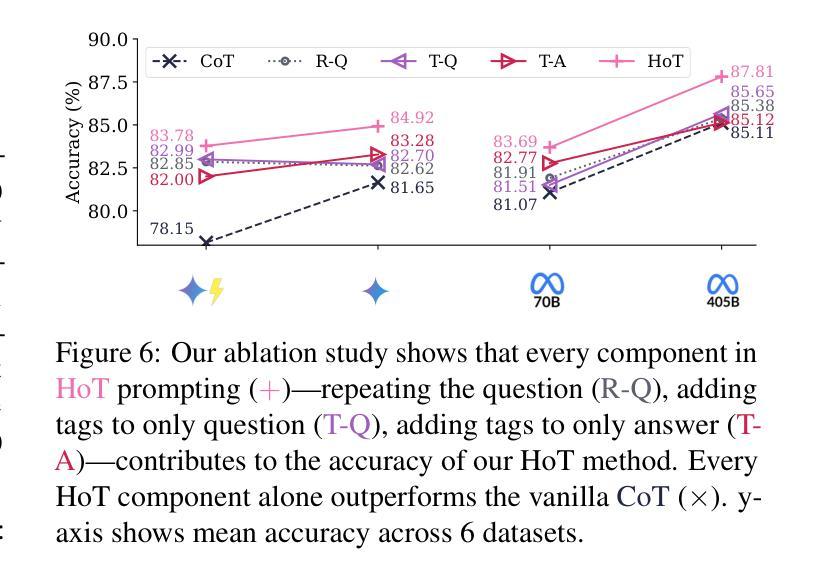
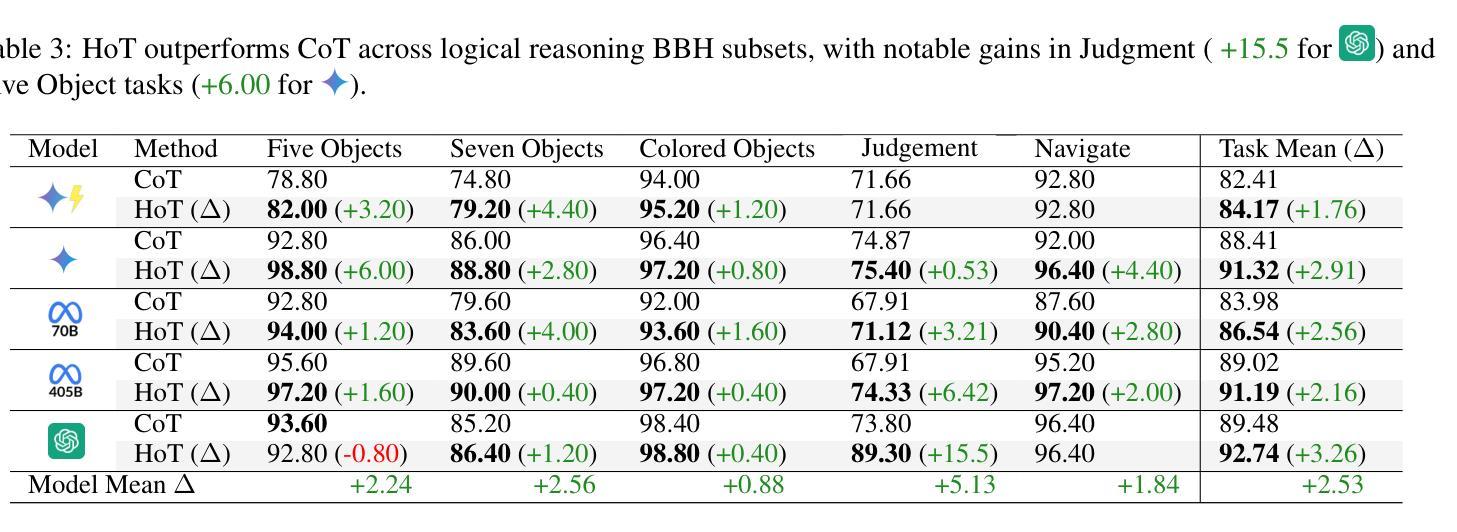
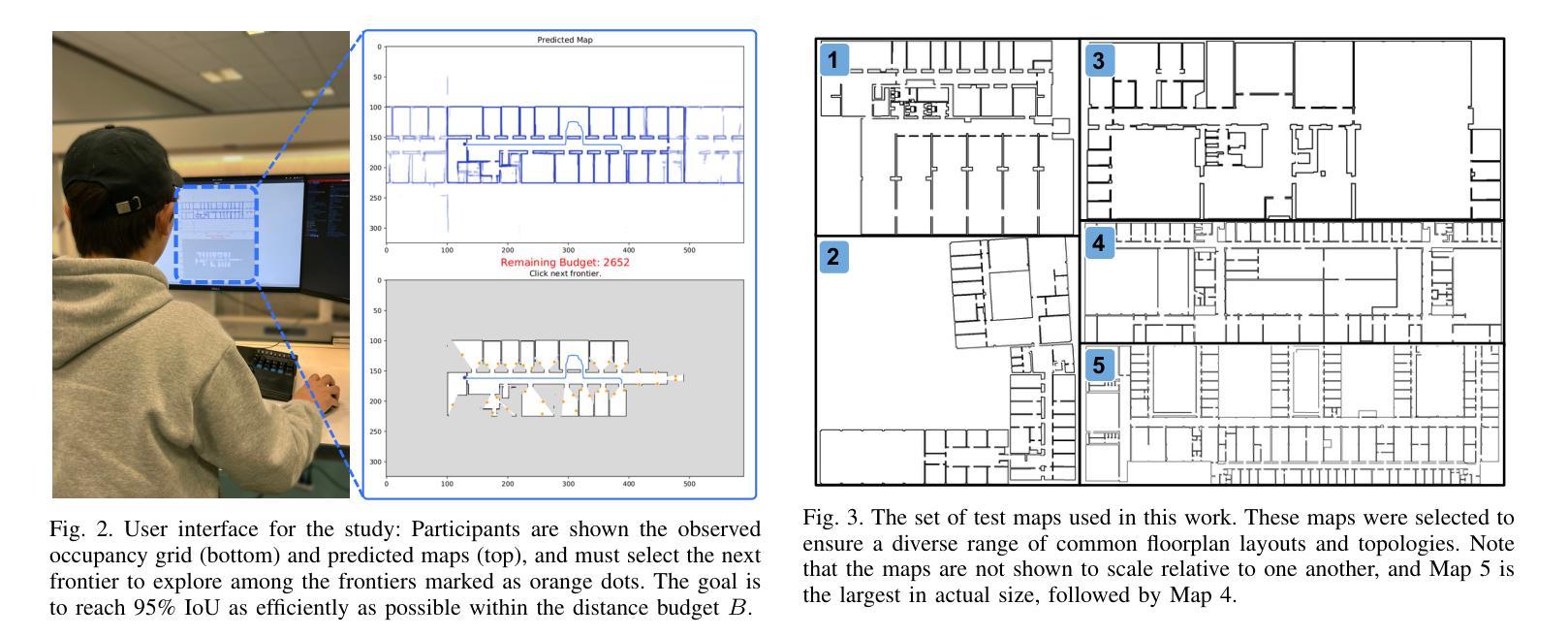
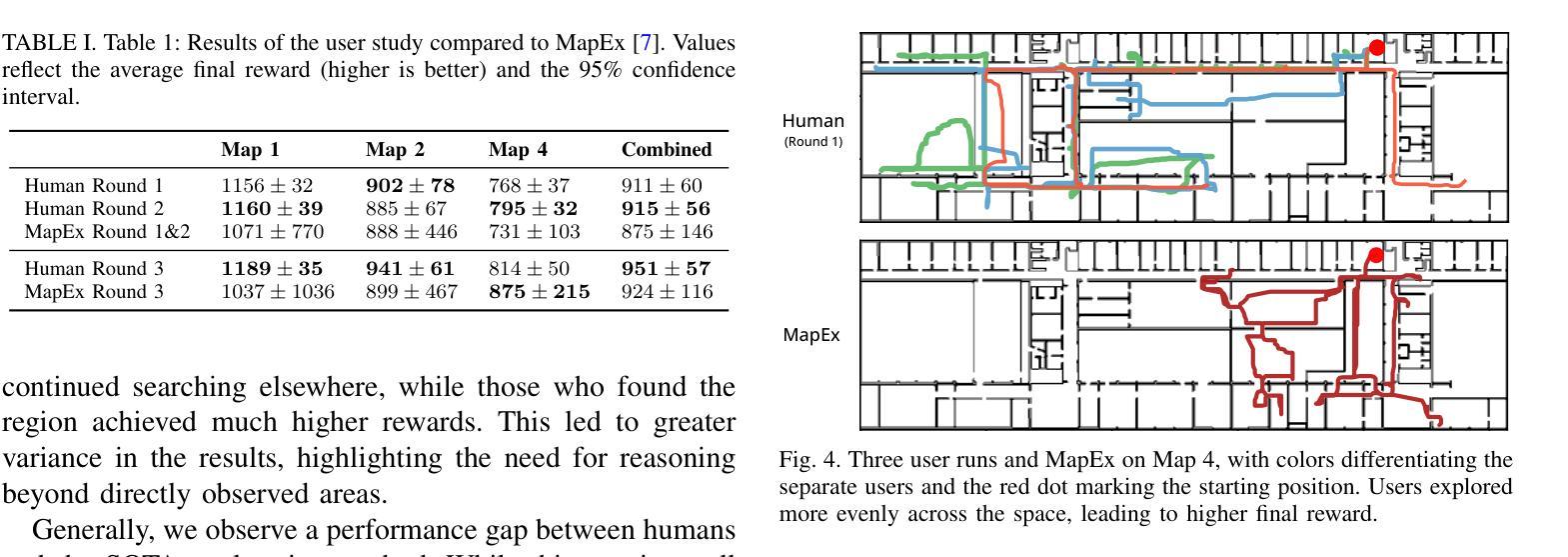
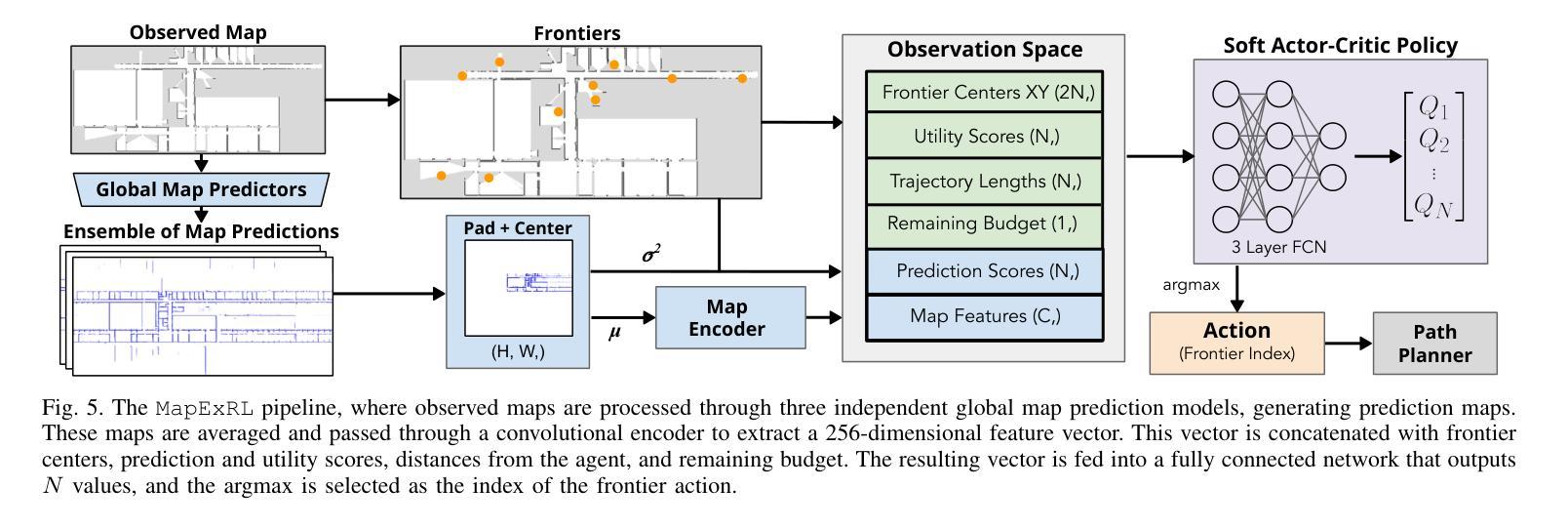
MapExRL: Human-Inspired Indoor Exploration with Predicted Environment Context and Reinforcement Learning
Authors:Narek Harutyunyan, Brady Moon, Seungchan Kim, Cherie Ho, Adam Hung, Sebastian Scherer
Path planning for robotic exploration is challenging, requiring reasoning over unknown spaces and anticipating future observations. Efficient exploration requires selecting budget-constrained paths that maximize information gain. Despite advances in autonomous exploration, existing algorithms still fall short of human performance, particularly in structured environments where predictive cues exist but are underutilized. Guided by insights from our user study, we introduce MapExRL, which improves robot exploration efficiency in structured indoor environments by enabling longer-horizon planning through reinforcement learning (RL) and global map predictions. Unlike many RL-based exploration methods that use motion primitives as the action space, our approach leverages frontiers for more efficient model learning and longer horizon reasoning. Our framework generates global map predictions from the observed map, which our policy utilizes, along with the prediction uncertainty, estimated sensor coverage, frontier distance, and remaining distance budget, to assess the strategic long-term value of frontiers. By leveraging multiple frontier scoring methods and additional context, our policy makes more informed decisions at each stage of the exploration. We evaluate our framework on a real-world indoor map dataset, achieving up to an 18.8% improvement over the strongest state-of-the-art baseline, with even greater gains compared to conventional frontier-based algorithms.
机器人探索的路径规划具有挑战性,需要在未知空间进行推理并预测未来观测。高效的探索需要选择预算限制内的路径,以最大化信息增益。尽管自主探索取得了进展,但现有算法仍达不到人类的表现,特别是在结构化环境中,预测线索存在但利用不足。受用户研究的启发,我们推出了MapExRL,它通过强化学习(RL)和全局地图预测,提高了机器人在结构化室内环境中的探索效率。与许多基于RL的探索方法使用动作原语作为动作空间不同,我们的方法利用边界进行更有效的模型学习和更长的视野推理。我们的框架从观察到的地图生成全局地图预测,我们的策略利用这些预测,以及预测的不确定性、估计的传感器覆盖范围、边界距离和剩余距离预算,来评估边界的战略长期价值。通过利用多种边界评分方法和额外的上下文,我们的策略在每个探索阶段都能做出更明智的决策。我们在真实的室内地图数据集上评估了我们的框架,与最先进的基线相比,最多提高了18.8%,与传统基于边界的算法相比,甚至获得了更大的收益。
论文及项目相关链接
PDF 8 pages, 6 figures
摘要
机器人路径规划用于探索未知空间并预测未来观测结果,是一项具有挑战性的任务。有效的探索需要选择预算有限的路径,以最大化信息收益。尽管自主探索领域取得了进展,但现有算法仍然达不到人类性能,特别是在结构化环境中,存在预测线索但利用不足。受用户研究的启发,我们引入了MapExRL,它通过强化学习(RL)和全局地图预测,提高了机器人在结构化室内环境中的探索效率。与其他基于RL的探索方法不同,我们的方法使用前沿技术来实现更有效的模型学习和更长远的推理。我们的框架从观察到的地图生成全局地图预测,我们的策略利用预测不确定性、估计的传感器覆盖范围、前沿距离和剩余距离预算来评估前沿的战略长期价值。通过利用多种前沿评分方法和额外的上下文,我们的策略能够在探索的每个阶段做出更明智的决策。我们在真实的室内地图数据集上评估了我们的框架,相较于最先进的基础算法实现了最高达18.8%的改进,相比于传统的前沿算法效果提升更大。
关键见解
- 机器人探索路径规划需要处理未知空间和预测未来观测结果。
- 有效探索需要选择预算有限的路径以最大化信息收益。
- 在结构化环境中,现有算法的自主性能仍低于人类表现。
- MapExRL通过强化学习和全局地图预测提高了机器人在结构化室内环境的探索效率。
- 与其他基于RL的探索方法不同,MapExRL使用前沿技术实现更有效的模型学习和更长远的推理。
- MapExRL框架考虑了预测不确定性、传感器覆盖范围、前沿距离和剩余距离预算等多个因素来评估路径选择。
点此查看论文截图


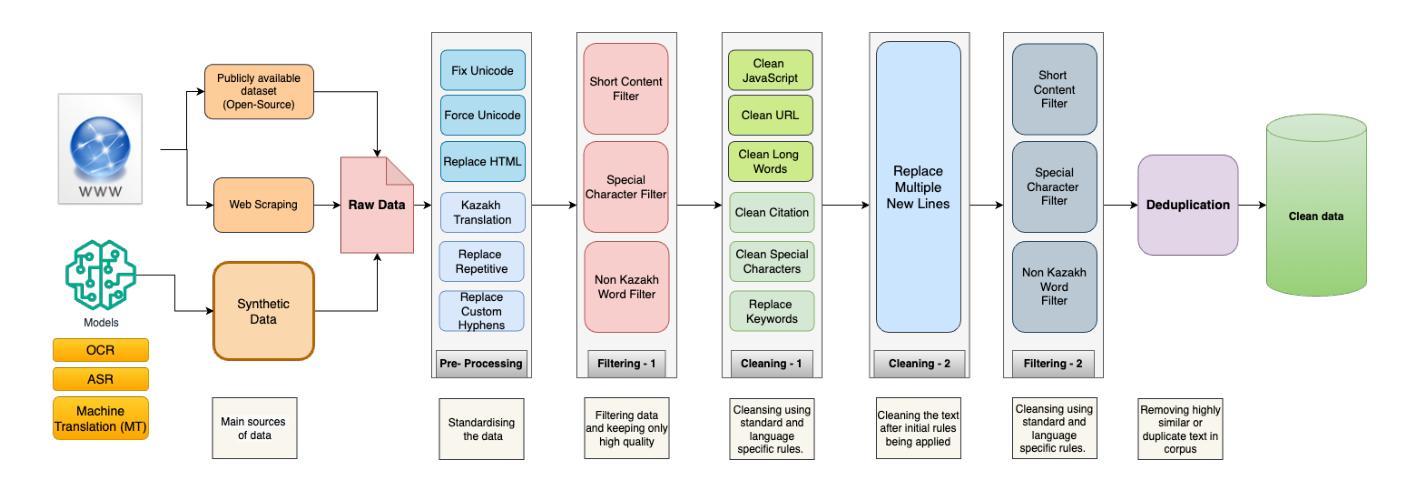
Llama-3.1-Sherkala-8B-Chat: An Open Large Language Model for Kazakh
Authors:Fajri Koto, Rituraj Joshi, Nurdaulet Mukhituly, Yuxia Wang, Zhuohan Xie, Rahul Pal, Daniil Orel, Parvez Mullah, Diana Turmakhan, Maiya Goloburda, Mohammed Kamran, Samujjwal Ghosh, Bokang Jia, Jonibek Mansurov, Mukhammed Togmanov, Debopriyo Banerjee, Nurkhan Laiyk, Akhmed Sakip, Xudong Han, Ekaterina Kochmar, Alham Fikri Aji, Aaryamonvikram Singh, Alok Anil Jadhav, Satheesh Katipomu, Samta Kamboj, Monojit Choudhury, Gurpreet Gosal, Gokul Ramakrishnan, Biswajit Mishra, Sarath Chandran, Avraham Sheinin, Natalia Vassilieva, Neha Sengupta, Larry Murray, Preslav Nakov
Llama-3.1-Sherkala-8B-Chat, or Sherkala-Chat (8B) for short, is a state-of-the-art instruction-tuned open generative large language model (LLM) designed for Kazakh. Sherkala-Chat (8B) aims to enhance the inclusivity of LLM advancements for Kazakh speakers. Adapted from the LLaMA-3.1-8B model, Sherkala-Chat (8B) is trained on 45.3B tokens across Kazakh, English, Russian, and Turkish. With 8 billion parameters, it demonstrates strong knowledge and reasoning abilities in Kazakh, significantly outperforming existing open Kazakh and multilingual models of similar scale while achieving competitive performance in English. We release Sherkala-Chat (8B) as an open-weight instruction-tuned model and provide a detailed overview of its training, fine-tuning, safety alignment, and evaluation, aiming to advance research and support diverse real-world applications.
Llama-3.1-Sherkala-8B-Chat,简称Sherkala-Chat(8B),是一款针对哈萨克语设计的最先进的指令优化开源大型语言模型(LLM)。Sherkala-Chat(8B)旨在提高哈萨克语使用者对LLM进步的包容性。该模型基于LLaMA-3.1-8B模型改编,经过哈萨克语、英语、俄语和土耳其语的45.3B标记训练。拥有8亿参数,它在哈萨克语方面表现出强大的知识和推理能力,显著优于现有的开源哈萨克语和多语言模型,同时在英语方面表现出竞争力。我们发布开源权重指令优化模型Sherkala-Chat(8B),并对其训练、微调、安全对齐和评估提供了详细的概述,旨在推动研究并支持各种实际应用。
论文及项目相关链接
PDF Technical Report
Summary
LLaMA-3.1-Sherkala-8B-Chat是一款针对哈萨克语优化的生成式大型语言模型(LLM),旨在提高哈萨克语人群的语言模型应用包容性。基于LLaMA-3.1-8B模型改编,经过哈萨克语、英语、俄语和土耳其语的训练,展现出强大的知识和推理能力,在哈萨克语上性能出众。公开为权重型指令调整模型,并为研究者和开发人员提供了训练、微调、安全对齐和评估的详细概述。
Key Takeaways
- Sherkala-Chat (8B)是一款针对哈萨克语的大型语言模型(LLM)。
- 该模型是基于LLaMA-3.1-8B模型改编而来。
- Sherkala-Chat (8B)经过多种语言的训练,包括哈萨克语、英语、俄语和土耳其语。
- 它拥有强大的知识和推理能力,在哈萨克语性能上显著优于现有的开放哈萨克和多语种模型。
- 该模型被公开为权重型指令调整模型。
- 提供了关于模型的训练、微调、安全对齐和评估的详细概述。
点此查看论文截图


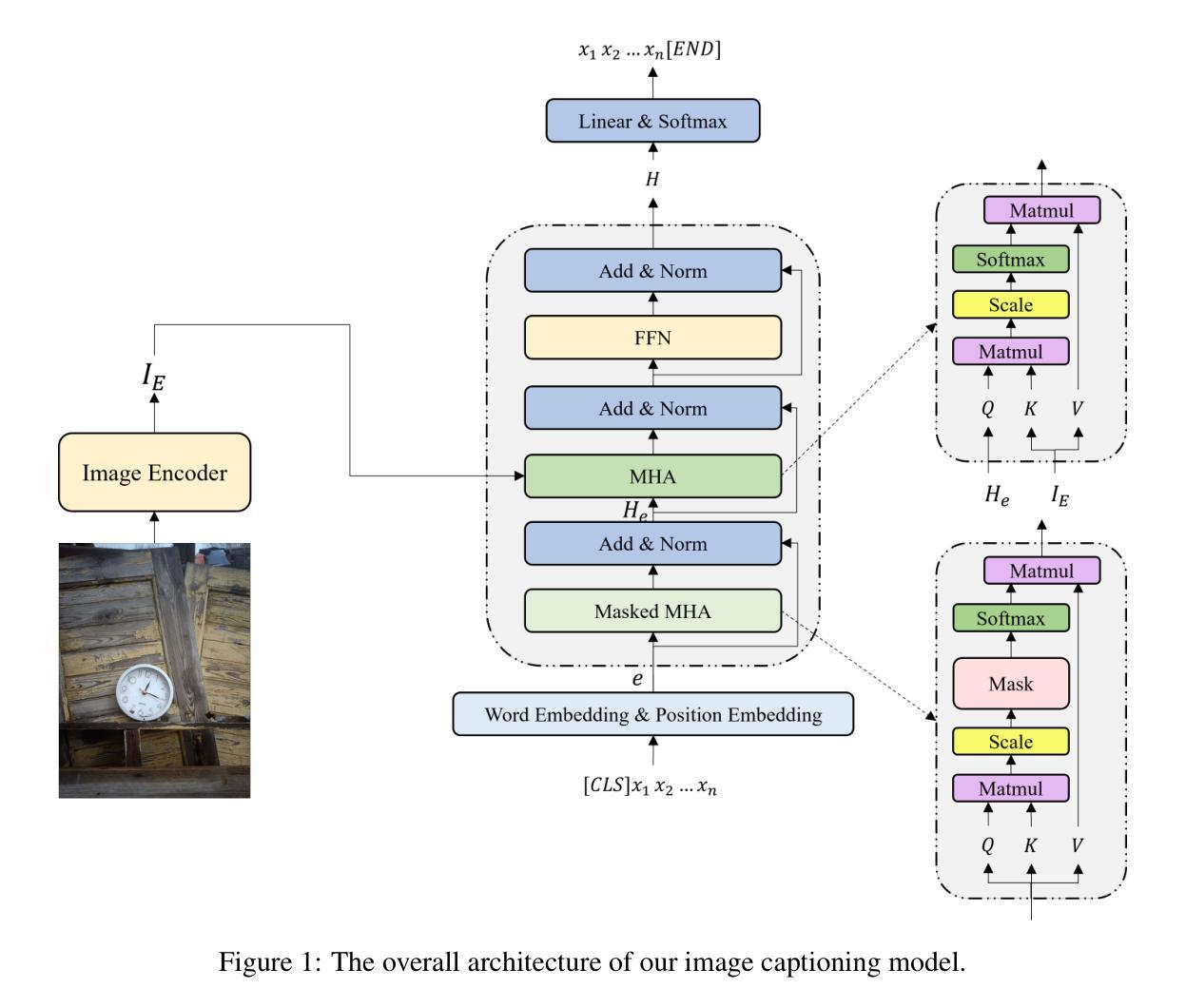
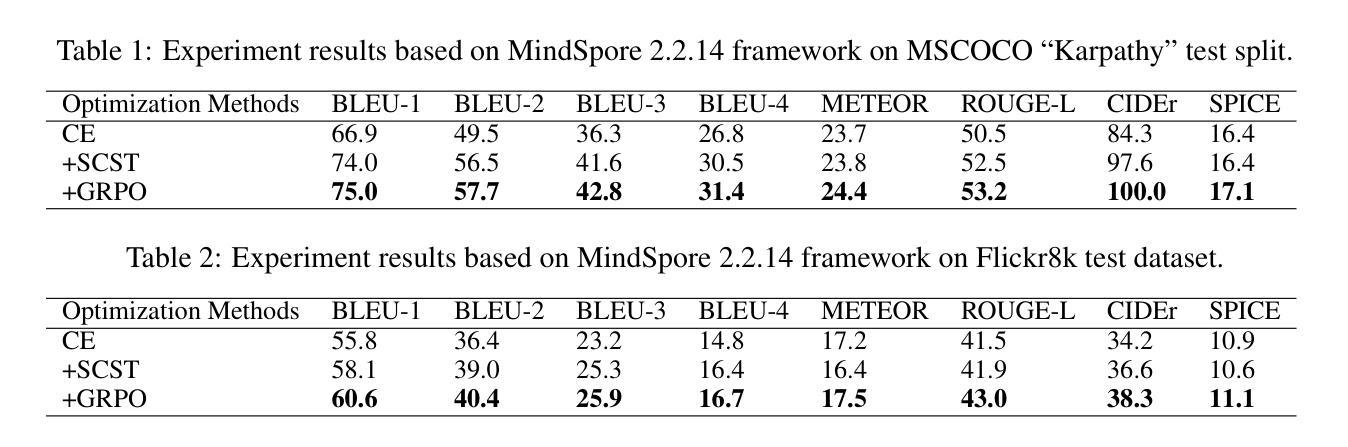
Group Relative Policy Optimization for Image Captioning
Authors:Xu Liang
Image captioning tasks usually use two-stage training to complete model optimization. The first stage uses cross-entropy as the loss function for optimization, and the second stage uses self-critical sequence training (SCST) for reinforcement learning optimization. However, the SCST algorithm has certain defects. SCST relies only on a single greedy decoding result as a baseline. If the model itself is not stable enough, the greedy decoding result may be relatively worst, which will lead to a high variance of advantage estimation, further leading to unstable policy updates. In addition, SCST only compares one sampling result with the greedy decoding result, and the generation diversity is limited, which may fall into a local optimum. In this paper, we propose using the latest Group Relative Policy Optimization (GRPO) reinforcement learning algorithm as an optimization solution for the second stage. GRPO generates multiple candidate captions for the input image and then continuously optimizes the model through intragroup comparison. By constraining the amplitude of policy updates and KL divergence, the stability of the model during training is greatly guaranteed. In addition, compared to SCST, which only samples one answer, GRPO samples and generates multiple answers. Multiple candidate answers in the group cover a wider solution space. Combined with KL divergence constraints, GRPO can improve diversity while ensuring model stability. The code for this article is available at https://github.com/liangxu-one/ms-models/tree/image_caption_grpo/research/arxiv_papers/Image_Caption_GRPO.
图像描述任务通常使用两阶段训练来完成模型优化。第一阶段使用交叉熵作为优化损失函数,第二阶段使用自我批判序列训练(SCST)进行强化学习优化。然而,SCST算法存在一些缺陷。SCST仅依赖于单个贪婪解码结果作为基线。如果模型本身不够稳定,贪婪解码的结果可能相对较差,这将导致优势估计的方差较高,进而造成策略更新不稳定。此外,SCST仅将一次采样结果与贪婪解码结果进行比较,生成多样性受限,可能会陷入局部最优。在本文中,我们提出使用最新的群体相对策略优化(GRPO)强化学习算法作为第二阶段的优化解决方案。GRPO为输入图像生成多个候选描述,然后通过组内比较不断对模型进行优化。通过约束策略更新的幅度和KL散度,可以极大地保证模型在训练过程中的稳定性。此外,与只采样一个答案的SCST相比,GRPO可以采样并生成多个答案。组中的多个候选答案可以覆盖更广泛的解空间。结合KL散度约束,GRPO可以在确保模型稳定性的同时提高多样性。本文的代码可在https://github.com/liangxu-one/ms-models/tree/image_caption_grpo/research/arxiv_papers/Image_Caption_GRPO找到。
论文及项目相关链接
Summary
图像描述任务通常采用两阶段训练完成模型优化。第一阶段使用交叉熵作为损失函数进行优化,第二阶段则使用自我批判序列训练(SCST)进行强化学习优化。但SCST算法存在缺陷,本文提出使用最新的Group Relative Policy Optimization(GRPO)强化学习算法作为第二阶段的优化解决方案。GRPO通过组内比较持续优化模型,保证训练过程中模型的稳定性,并提高答案的多样性。
Key Takeaways
- 图像描述任务通常使用两阶段训练,第一阶段使用交叉熵损失函数,第二阶段使用强化学习进行自我批判序列训练(SCST)。
- SCST算法存在缺陷,主要表现在对模型稳定性的依赖以及生成答案的多样性受限。
- GRPO算法被提出作为SCST的优化替代,通过生成多个候选描述来优化模型。
- GRPO通过组内比较来持续优化模型,保证训练稳定性。
- GRPO通过约束策略更新的幅度和KL散度,确保模型在训练过程中的稳定性。
- 与SCST相比,GRPO能够采样并生成多个答案,覆盖更广泛的解决方案空间。
点此查看论文截图

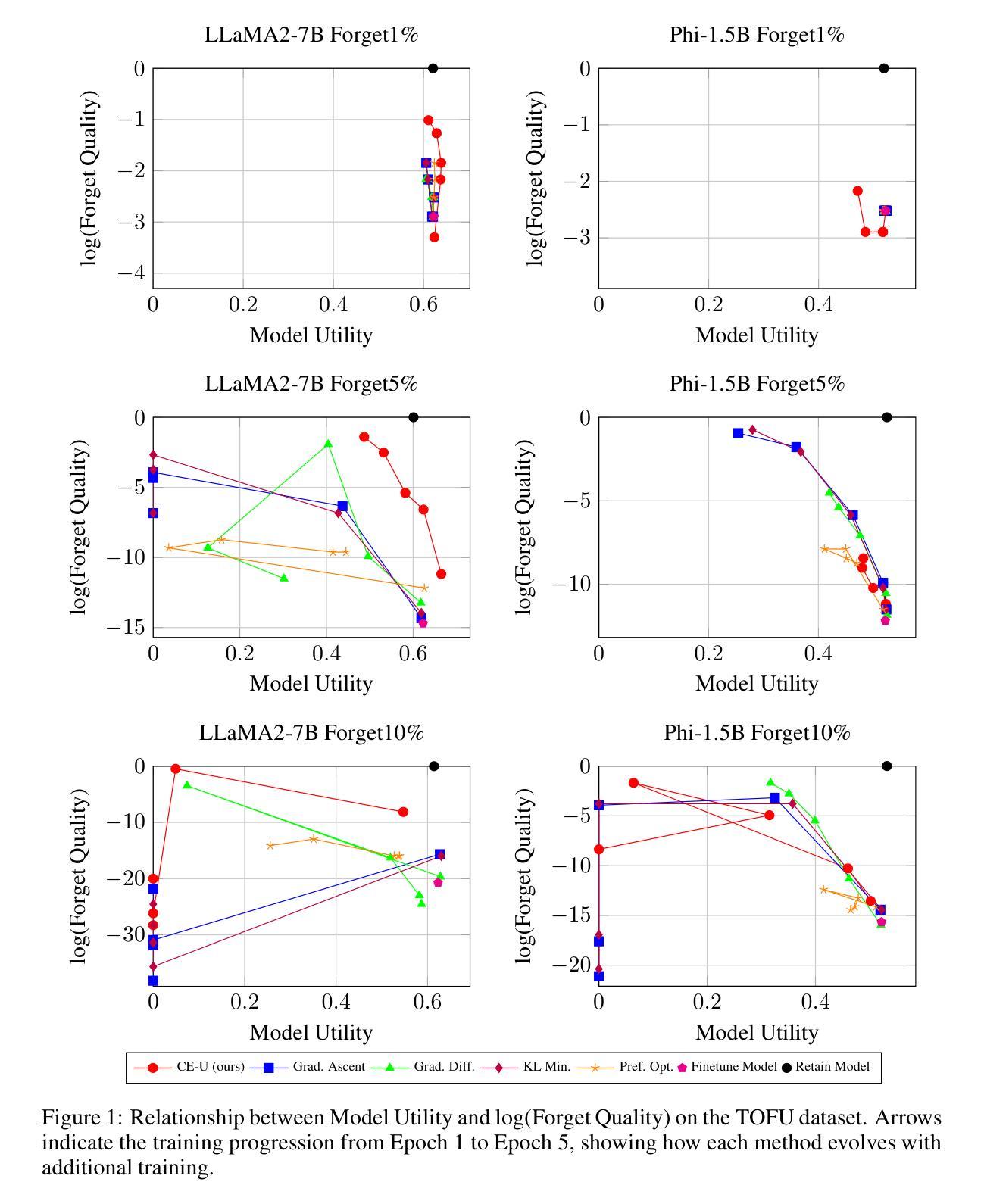
CE-U: Cross Entropy Unlearning
Authors:Bo Yang
Large language models (LLMs) inadvertently memorize sensitive data from their massive pretraining corpora \cite{jang2022knowledge}. In this work, we propose CE-U (Cross Entropy Unlearning), a novel loss function designed specifically for unlearning tasks. CE-U addresses fundamental limitations of gradient ascent approaches which suffer from instability due to vanishing gradients when model confidence is high and gradient exploding when confidence is low. We also unify standard cross entropy supervision and cross entropy unlearning into a single framework. Notably, on the TOFU benchmark for unlearning \cite{maini2024tofu}, CE-U achieves state-of-the-art results on LLaMA2-7B with 1% and 5% forgetting, even without the use of any extra reference model or additional positive samples. Our theoretical analysis further reveals that the gradient instability issues also exist in popular reinforcement learning algorithms like DPO \cite{rafailov2023direct} and GRPO\cite{Shao2024DeepSeekMath}, as they include a gradient ascent component. This suggests that applying CE-U principles to reinforcement learning could be a promising direction for improving stability and convergence.
大型语言模型(LLMs)会无意中从其庞大的预训练语料库中记忆敏感数据\cite{jang2022knowledge}。在这项工作中,我们提出了CE-U(交叉熵遗忘)(Cross Entropy Unlearning),这是一种专门为遗忘任务设计的全新损失函数。CE-U解决了梯度上升方法的基本局限性,这些方法在高模型置信度时受到梯度消失的影响,而在低置信度时则受到梯度爆炸的影响。我们还统一了标准交叉熵监督和交叉熵遗忘到一个单一框架中。值得注意的是,在遗忘的TOFU基准测试\cite{maini2024tofu}上,CE-U在LLaMA2-7B的1%和5%遗忘率上达到了最新水平,即使不使用任何额外的参考模型或额外的正样本。我们的理论分析进一步揭示了梯度不稳定问题也存在于如DPO\cite{rafailov2023direct}和GRPO\cite{Shao2024DeepSeekMath}等流行的强化学习算法中,因为它们包含梯度上升的成分。这表明将CE-U原则应用于强化学习可能是提高稳定性和收敛性的一个有前途的方向。
论文及项目相关链接
Summary
大型语言模型(LLM)在预训练过程中会无意中记忆敏感数据。本研究提出CE-U(交叉熵遗忘)损失函数,专门用于遗忘任务。CE-U解决了梯度上升方法的基本局限,包括梯度消失与爆炸的问题。在TOFU遗忘基准测试中,CE-U在LLaMA2-7B模型上实现了最先进的遗忘效果,即使不使用任何额外的参考模型或额外的正样本。理论分析还显示,梯度不稳定问题也存在于流行的强化学习算法中,如DPO和GRPO。这表明将CE-U原理应用于强化学习可能是提高稳定性和收敛性的有前途的方向。
Key Takeaways
- 大型语言模型(LLM)在预训练过程中可能无意识地记忆敏感数据。
- CE-U是一种针对遗忘任务的新的损失函数,解决了梯度上升方法中的基础局限性。
- CE-U能有效解决梯度消失和梯度爆炸的问题。
- 在TOFU基准测试中,CE-U在LLaMA2-7B模型上实现了最先进的遗忘效果。
- CE-U不使用额外的参考模型或额外的正样本。
- 理论分析显示梯度不稳定问题也存在于某些强化学习算法中。
点此查看论文截图