⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-09 更新
Self-Supervised Models for Phoneme Recognition: Applications in Children’s Speech for Reading Learning
Authors:Lucas Block Medin, Thomas Pellegrini, Lucile Gelin
Child speech recognition is still an underdeveloped area of research due to the lack of data (especially on non-English languages) and the specific difficulties of this task. Having explored various architectures for child speech recognition in previous work, in this article we tackle recent self-supervised models. We first compare wav2vec 2.0, HuBERT and WavLM models adapted to phoneme recognition in French child speech, and continue our experiments with the best of them, WavLM base+. We then further adapt it by unfreezing its transformer blocks during fine-tuning on child speech, which greatly improves its performance and makes it significantly outperform our base model, a Transformer+CTC. Finally, we study in detail the behaviour of these two models under the real conditions of our application, and show that WavLM base+ is more robust to various reading tasks and noise levels. Index Terms: speech recognition, child speech, self-supervised learning
儿童语音识别仍然是一个研究不足领域,由于缺乏数据(尤其是非英语数据)以及该任务的特定难度。在之前的工作中,我们探索了各种儿童语音识别架构。在本文中,我们关注最新的自监督模型。我们首先对比了针对法语儿童语音的音素识别而改编的wav2vec 2.0、HuBERT和WavLM模型,并使用其中表现最佳的WavLM base+继续进行实验。然后我们通过微调儿童语音时解冻其变压器块进一步调整它,这极大地提高了其性能并使其显著优于我们的基准模型Transformer+CTC。最后,我们详细研究了这两种模型在实际应用条件下的表现,并证明WavLM base+对各种阅读任务和噪声水平更加稳健。关键词:语音识别、儿童语音、自监督学习。
论文及项目相关链接
PDF This paper was originally published in the Proceedings of Interspeech 2024. DOI: 10.21437/Interspeech.2024-1095
Summary
本文探讨了儿童语音识别领域的最新进展,特别是基于自监督学习的模型应用。文章对比了wav2vec 2.0、HuBERT和WavLM模型在法语儿童语音的音素识别效果,并基于最佳模型WavLM base+进行了进一步优化。实验表明,解锁变压器块在儿童语音上的精细调整大大提高了其性能,并在实际应用中表现出更高的稳健性。
Key Takeaways
- 儿童语音识别领域由于数据缺乏(尤其是非英语语言数据)和特定任务难度,仍是一个研究不足的区域。
- 文章中对比了wav2vec 2.0、HuBERT和WavLM模型在法语儿童语音的音素识别效果。
- WavLM base+模型在儿童语音的音素识别上表现最佳。
- 通过解锁变压器块进行精细调整,WavLM base+模型的性能得到进一步提升。
- WavLM base+模型在实际应用中对不同的阅读任务和噪声水平具有更高的稳健性。
- 自监督学习在儿童语音识别中发挥了重要作用。
点此查看论文截图

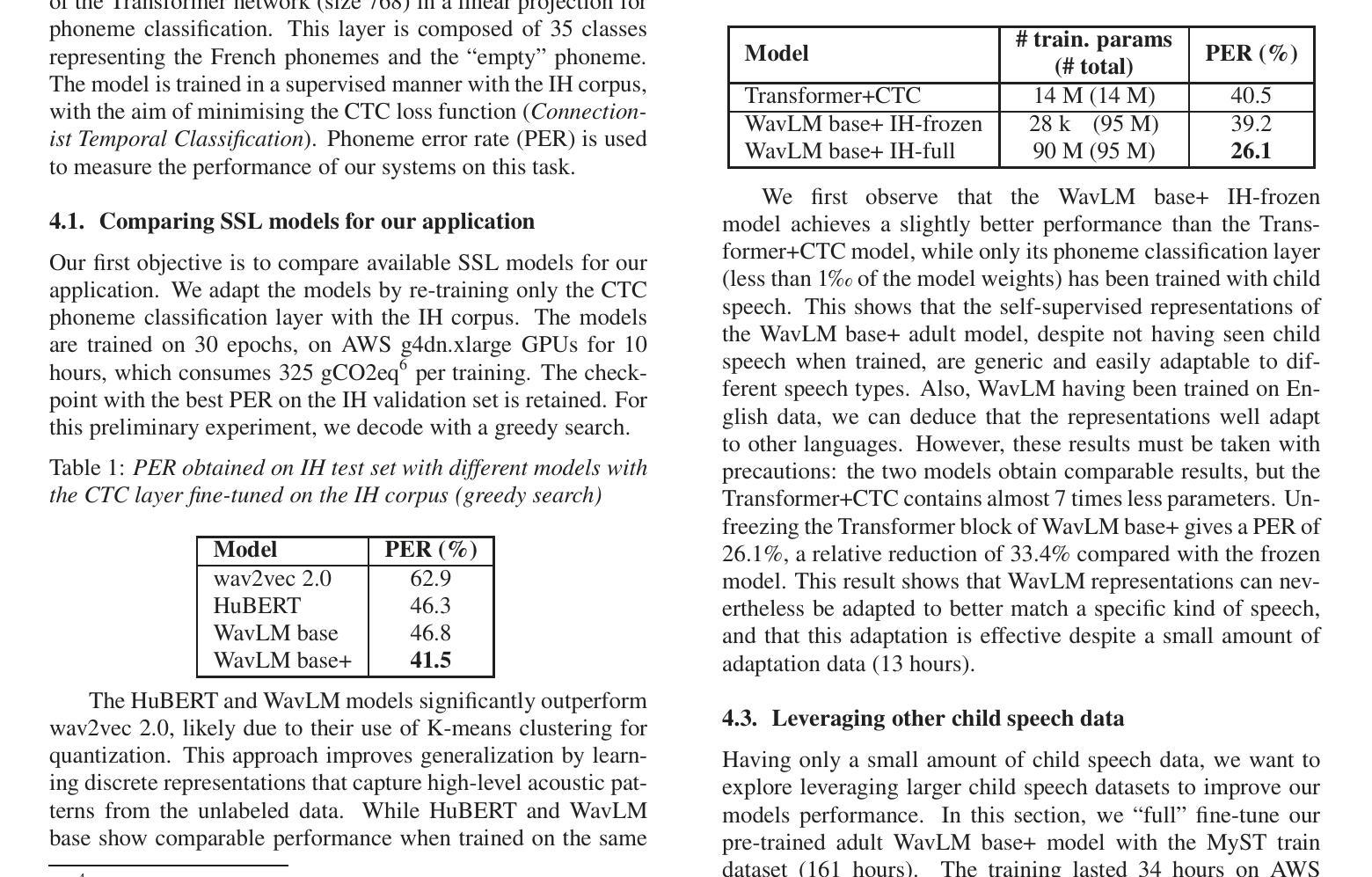

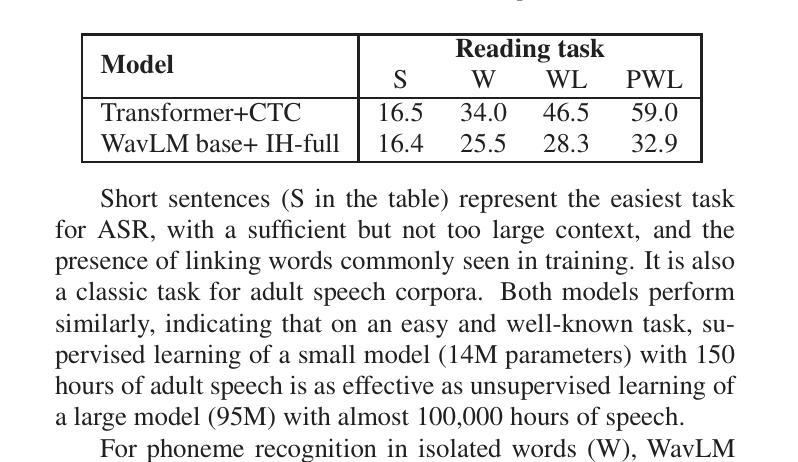
Dual-Class Prompt Generation: Enhancing Indonesian Gender-Based Hate Speech Detection through Data Augmentation
Authors:Muhammad Amien Ibrahim, Faisal, Tora Sangputra Yopie Winarto, Zefanya Delvin Sulistiya
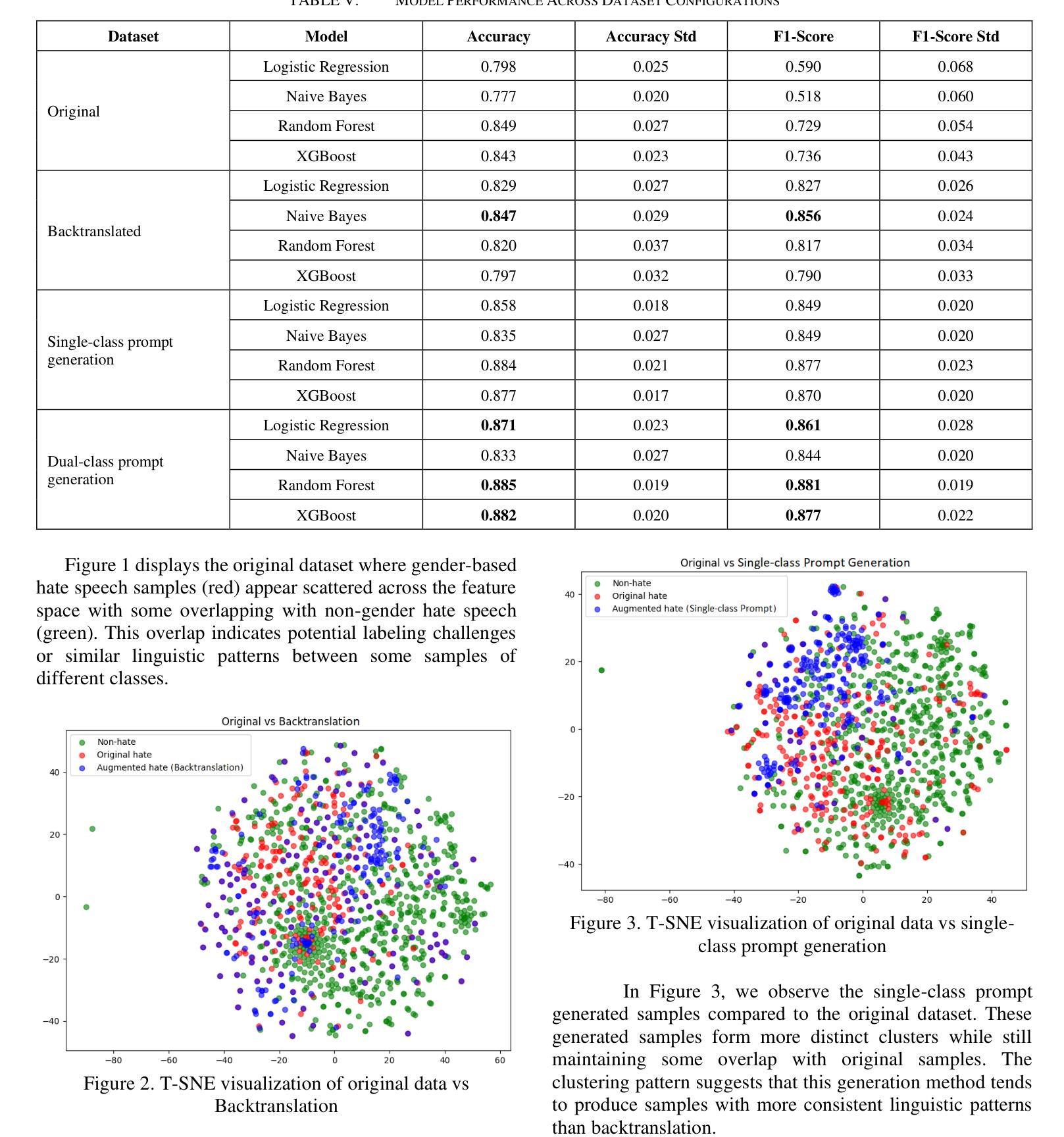
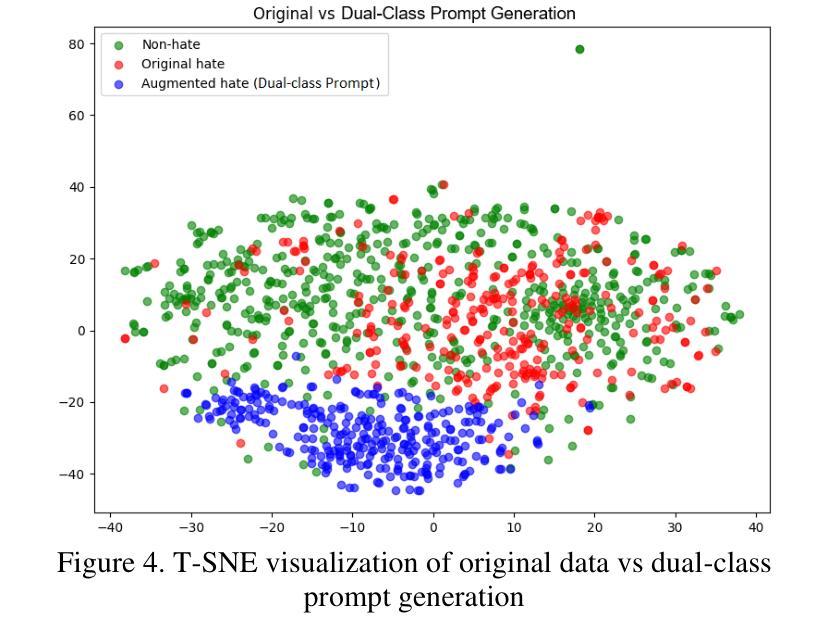
Detecting gender-based hate speech in Indonesian social media remains challenging due to limited labeled datasets. While binary hate speech classification has advanced, a more granular category like gender-targeted hate speech is understudied because of class imbalance issues. This paper addresses this gap by comparing three data augmentation techniques for Indonesian gender-based hate speech detection. We evaluate backtranslation, single-class prompt generation (using only hate speech examples), and our proposed dual-class prompt generation (using both hate speech and non-hate speech examples). Experiments show all augmentation methods improve classification performance, with our dual-class approach achieving the best results (88.5% accuracy, 88.1% F1-score using Random Forest). Semantic similarity analysis reveals dual-class prompt generation produces the most novel content, while T-SNE visualizations confirm these samples occupy distinct feature space regions while maintaining class characteristics. Our findings suggest that incorporating examples from both classes helps language models generate more diverse yet representative samples, effectively addressing limited data challenges in specialized hate speech detection.
检测印尼社交媒体中的基于性别的仇恨言论仍然是一个挑战,因为标记的数据集有限。虽然二元仇恨言论分类已经取得进展,但由于类别不平衡问题,更精细的类别(如针对性别的仇恨言论)的研究仍然不足。本文通过比较三种数据增强技术来解决这一空白,用于检测印尼基于性别的仇恨言论。我们评估了反向翻译、单类提示生成(仅使用仇恨言论示例)和我们提出的双类提示生成(使用仇恨言论和非仇恨言论示例)。实验表明,所有增强方法都提高了分类性能,我们的双类方法取得了最佳结果(使用随机森林达到88.5%的准确率和88.1%的F1分数)。语义相似性分析显示,双类提示生成产生的内容最新颖,而T-SNE可视化确认这些样本占据不同的特征空间区域,同时保持类别特征。我们的研究结果表明,结合两个类别的例子有助于语言模型生成更多样化且具有代表性的样本,有效解决特定仇恨言论检测中的有限数据挑战。
论文及项目相关链接
PDF Accepted to the 8th World Conference on Computing and Communication Technologies (WCCCT 2025)
Summary
本文研究了印尼社交媒体中的性别仇恨言论检测问题,针对因数据集不足而导致的挑战,提出了三种数据增强技术进行比较研究。通过对比后翻译、单类提示生成技术和作者提出的双类提示生成技术,发现所有数据增强方法都能提高分类性能,其中双类提示生成技术表现最佳,准确率高达88.5%,F1分数为88.1%,并使用随机森林进行实现。此方法不仅能产生更具创新性的内容,还能有效解决特殊仇恨言论检测中的有限数据挑战。
Key Takeaways
- 印尼社交媒体中的性别仇恨言论检测面临挑战,主要由于数据集有限。
- 数据增强技术被用于解决此问题,包括后翻译、单类提示生成和双类提示生成。
- 双类提示生成技术表现最佳,准确率高达88.5%,F1分数为88.1%。
- 双类提示生成法能产生最具有创新性的内容。
- 通过T-SNE可视化分析,双类提示生成的样本占据独特的特征空间区域,同时保持类别特性。
- 结合两类样本有助于语言模型生成更多样化且具代表性的样本。
点此查看论文截图


FREAK: Frequency-modulated High-fidelity and Real-time Audio-driven Talking Portrait Synthesis
Authors:Ziqi Ni, Ao Fu, Yi Zhou
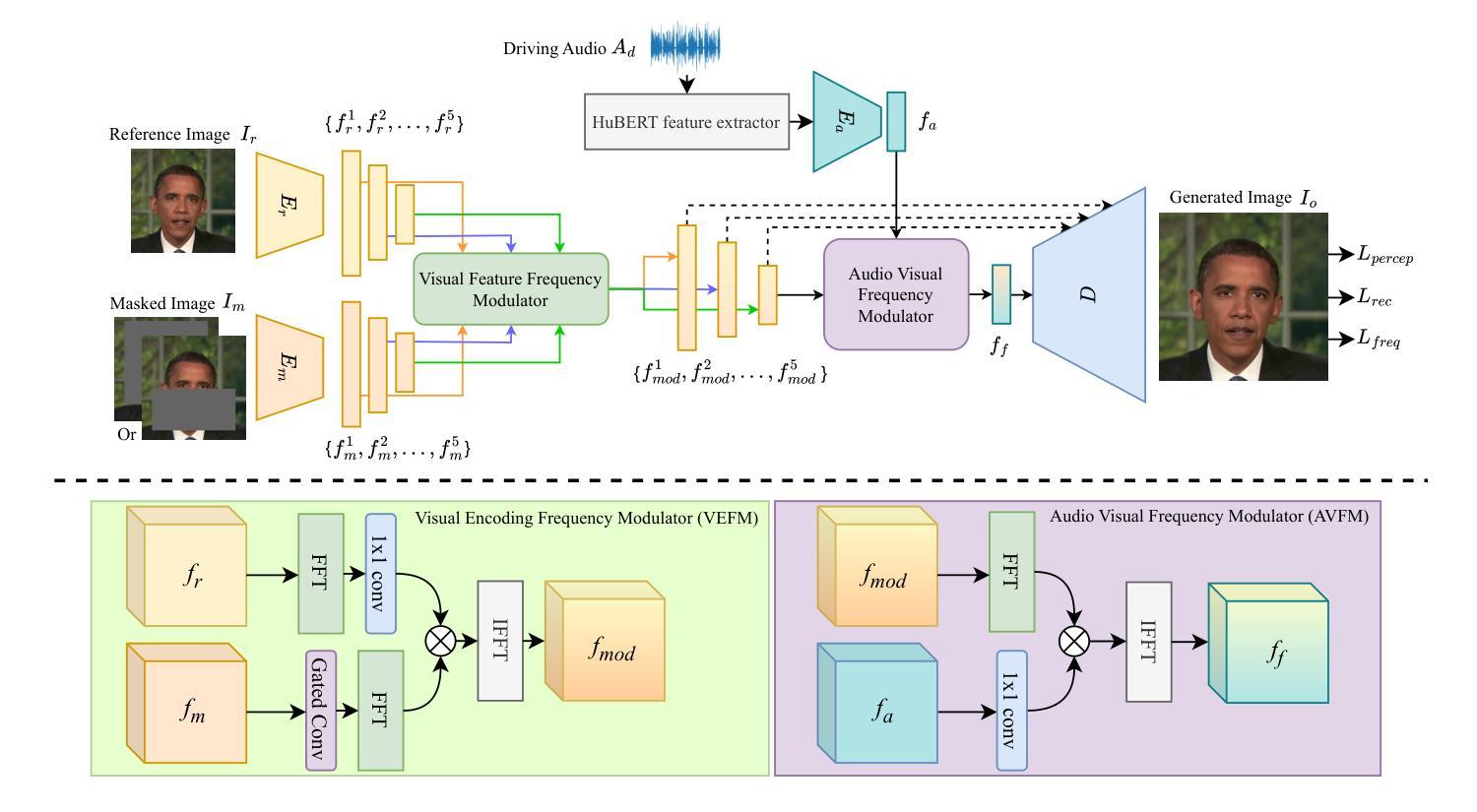
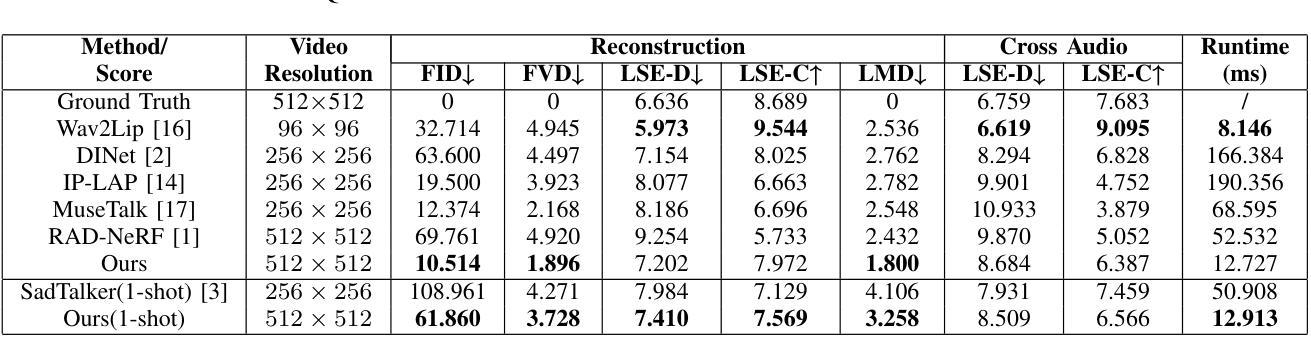
Achieving high-fidelity lip-speech synchronization in audio-driven talking portrait synthesis remains challenging. While multi-stage pipelines or diffusion models yield high-quality results, they suffer from high computational costs. Some approaches perform well on specific individuals with low resources, yet still exhibit mismatched lip movements. The aforementioned methods are modeled in the pixel domain. We observed that there are noticeable discrepancies in the frequency domain between the synthesized talking videos and natural videos. Currently, no research on talking portrait synthesis has considered this aspect. To address this, we propose a FREquency-modulated, high-fidelity, and real-time Audio-driven talKing portrait synthesis framework, named FREAK, which models talking portraits from the frequency domain perspective, enhancing the fidelity and naturalness of the synthesized portraits. FREAK introduces two novel frequency-based modules: 1) the Visual Encoding Frequency Modulator (VEFM) to couple multi-scale visual features in the frequency domain, better preserving visual frequency information and reducing the gap in the frequency spectrum between synthesized and natural frames. and 2) the Audio Visual Frequency Modulator (AVFM) to help the model learn the talking pattern in the frequency domain and improve audio-visual synchronization. Additionally, we optimize the model in both pixel domain and frequency domain jointly. Furthermore, FREAK supports seamless switching between one-shot and video dubbing settings, offering enhanced flexibility. Due to its superior performance, it can simultaneously support high-resolution video results and real-time inference. Extensive experiments demonstrate that our method synthesizes high-fidelity talking portraits with detailed facial textures and precise lip synchronization in real-time, outperforming state-of-the-art methods.
在音频驱动的说话肖像合成中实现高保真唇语音同步仍然是一个挑战。虽然多阶段管道或扩散模型能产生高质量的结果,但它们存在计算成本高的缺点。一些方法在资源较少的特定个人上表现良好,但仍会出现唇部动作不匹配的情况。上述方法都是在像素域建模的。我们观察到,合成说话视频和自然视频在频率域上存在明显的差异。目前,没有关于说话肖像合成的研究考虑这一方面的因素。为了解决这一问题,我们提出了一种调频、高保真、实时的音频驱动说话肖像合成框架,名为FREAK,它从频率域的角度对说话肖像进行建模,提高了合成肖像的保真度和自然度。FREAK引入了两个新的基于频率的模块:1)视觉编码频率调制器(VEFM),用于耦合频率域中的多尺度视觉特征,更好地保留视觉频率信息,减少合成帧和自然帧之间频谱的差距;2)视听频率调制器(AVFM),帮助模型学习频率域的说话模式,提高视听同步。此外,我们对像素域和频率域中的模型进行了联合优化。此外,FREAK支持在一键式和视频配音设置之间进行无缝切换,提供了增强的灵活性。凭借其卓越的性能,它可以同时支持高分辨率视频结果和实时推理。大量实验表明,我们的方法在实时合成高保真说话肖像方面表现出色,具有详细的面部纹理和精确的唇部同步,超越了最先进的方法。
论文及项目相关链接
摘要
实现高保真度的唇语音同步在音频驱动的人像合成中仍然是一个挑战。虽然多阶段管道或扩散模型能产生高质量的结果,但它们计算成本高昂。一些方法在低资源条件下对特定个体表现良好,但仍存在唇部动作不匹配的问题。当前的研究都在像素域进行建模,而我们在频率域观察到了合成视频与自然视频之间的明显差异。本文提出的FRC音驱动动态人脸识别肖像合成框架考虑了这一问题。我们引入了两个基于频率的新模块:视觉编码频率调制器(VEFM)和音频视觉频率调制器(AVFM),旨在更好地保存和协调视觉频率信息,并改进音频视频同步。我们的模型同时在像素域和频率域进行优化,具有灵活的语音设置切换能力,能支持高分辨率视频结果并实时推断。实验表明,我们的方法能在实时合成高保真度的人像说话内容,精细的面部纹理和精确的唇同步上超越现有技术的方法。
关键见解
- 音频驱动的人像合成中唇语音同步实现高保真度仍然具有挑战性。
- 当前方法在像素域建模,忽视了频率域的差异。
- 提出一种名为FREAK的新框架,从频率域角度进行人像合成,提高合成肖像的真实性和自然性。
- 引入两个新的频率模块:VEFM和AVFM,以改善视觉频率信息的保存和音频视频同步。
- FREAK能同时在像素域和频率域优化模型,并支持语音设置的灵活切换。
- FREAK可以支持高分辨率视频结果并实时推断。
- 实验表明,FREAK在实时合成高保真度的人像说话内容上优于现有技术。
点此查看论文截图


Pruning Deep Neural Networks via a Combination of the Marchenko-Pastur Distribution and Regularization
Authors:Leonid Berlyand, Theo Bourdais, Houman Owhadi, Yitzchak Shmalo
Deep neural networks (DNNs) have brought significant advancements in various applications in recent years, such as image recognition, speech recognition, and natural language processing. In particular, Vision Transformers (ViTs) have emerged as a powerful class of models in the field of deep learning for image classification. In this work, we propose a novel Random Matrix Theory (RMT)-based method for pruning pre-trained DNNs, based on the sparsification of weights and singular vectors, and apply it to ViTs. RMT provides a robust framework to analyze the statistical properties of large matrices, which has been shown to be crucial for understanding and optimizing the performance of DNNs. We demonstrate that our RMT-based pruning can be used to reduce the number of parameters of ViT models (trained on ImageNet) by 30-50% with less than 1% loss in accuracy. To our knowledge, this represents the state-of-the-art in pruning for these ViT models. Furthermore, we provide a rigorous mathematical underpinning of the above numerical studies, namely we proved a theorem for fully connected DNNs, and other more general DNN structures, describing how the randomness in the weight matrices of a DNN decreases as the weights approach a local or global minimum (during training). We verify this theorem through numerical experiments on fully connected DNNs, providing empirical support for our theoretical findings. Moreover, we prove a theorem that describes how DNN loss decreases as we remove randomness in the weight layers, and show a monotone dependence of the decrease in loss with the amount of randomness that we remove. Our results also provide significant RMT-based insights into the role of regularization during training and pruning.
近年来,深度神经网络(DNNs)在各种应用中取得了重大进展,例如图像识别、语音识别和自然语言处理。特别是,Vision Transformers(ViTs)作为深度学习领域图像分类模型中的强大类别而出现。在这项工作中,我们提出了一种基于随机矩阵理论(RMT)的新方法,用于修剪预训练的DNNs,该方法基于权重和奇异向量的稀疏化,并适用于ViTs。RMT提供了一个分析大型矩阵统计特性的稳健框架,已被证明对于理解和优化DNN的性能至关重要。我们证明,我们的基于RMT的修剪方法可用于将已在ImageNet上训练的ViT模型的参数数量减少30-50%,同时精度损失不到1%。据我们所知,这是这些ViT模型修剪的最新技术。此外,我们对上述数值研究进行了严格的数学论证,即我们为全连接DNNs和其他更一般的DNN结构证明了一个定理,描述了DNN权重矩阵中的随机性如何随着权重接近局部或全局最小值(在训练过程中)而减少。我们通过全连接DNN上的数值实验验证了这一定理,为我们的理论发现提供了实证支持。此外,我们证明了另一个定理,描述了随着我们在权重层中消除随机性,DNN损失如何减少,并显示了损失减少与我们消除的随机量之间的单调依赖性。我们的结果还提供了基于RMT的关于训练和修剪过程中正则化作用的深刻见解。
论文及项目相关链接
Summary
本文提出一种基于随机矩阵理论(RMT)的方法,用于对预训练的深度神经网络(DNN)进行剪枝,并将其应用于视觉转换器(ViT)模型。该方法基于权重和奇异向量的稀疏化,利用RMT分析大型矩阵的统计特性,以理解和优化DNN的性能。实验表明,使用RMT的剪枝技术可将训练在ImageNet上的ViT模型参数减少30-50%,同时精度损失小于1%。此外,本文还提供了严格的数学证明和实验支持。
Key Takeaways
- 引入了一种基于随机矩阵理论(RMT)的剪枝方法,用于预训练的深度神经网络(DNN)。
- 该方法通过权重和奇异向量的稀疏化实现,特别适用于视觉转换器(ViT)模型。
- RMT为分析大型矩阵的统计特性提供了稳健的框架,有助于理解和优化DNN性能。
- 实验显示,使用RMT的剪枝技术可大幅减少ViT模型的参数,同时保持高精度。
- 提供了严格的数学证明,包括针对全连接DNN和其他结构的定理。
- 证明了DNN损失随权重层随机性的减少而减少的规律。
点此查看论文截图


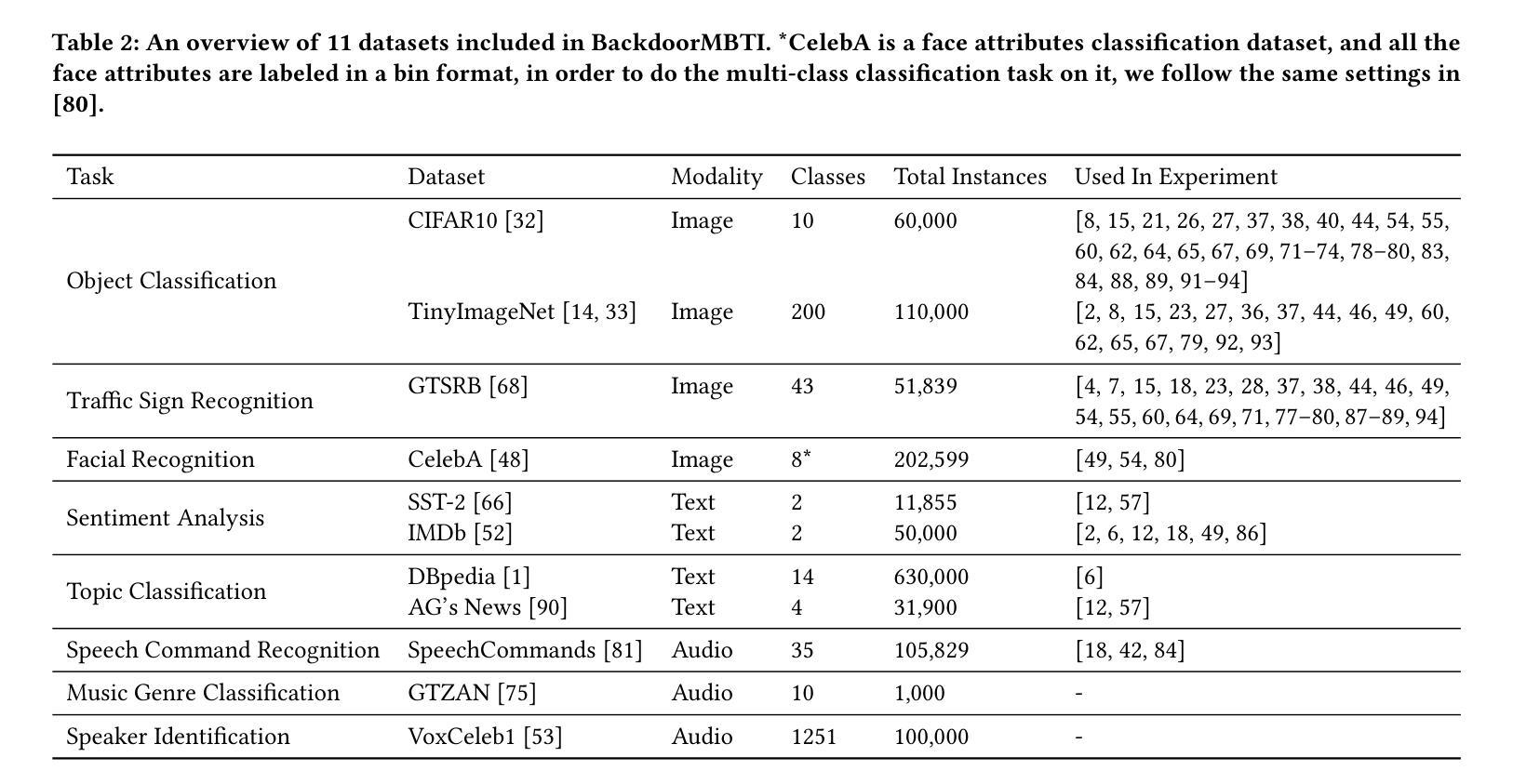
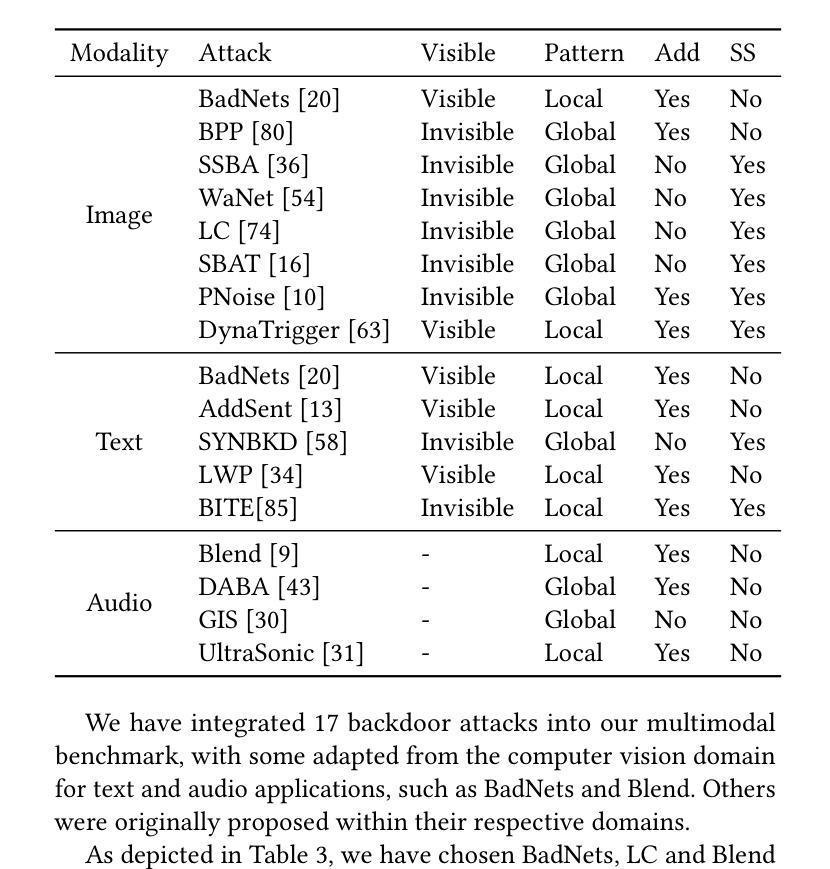
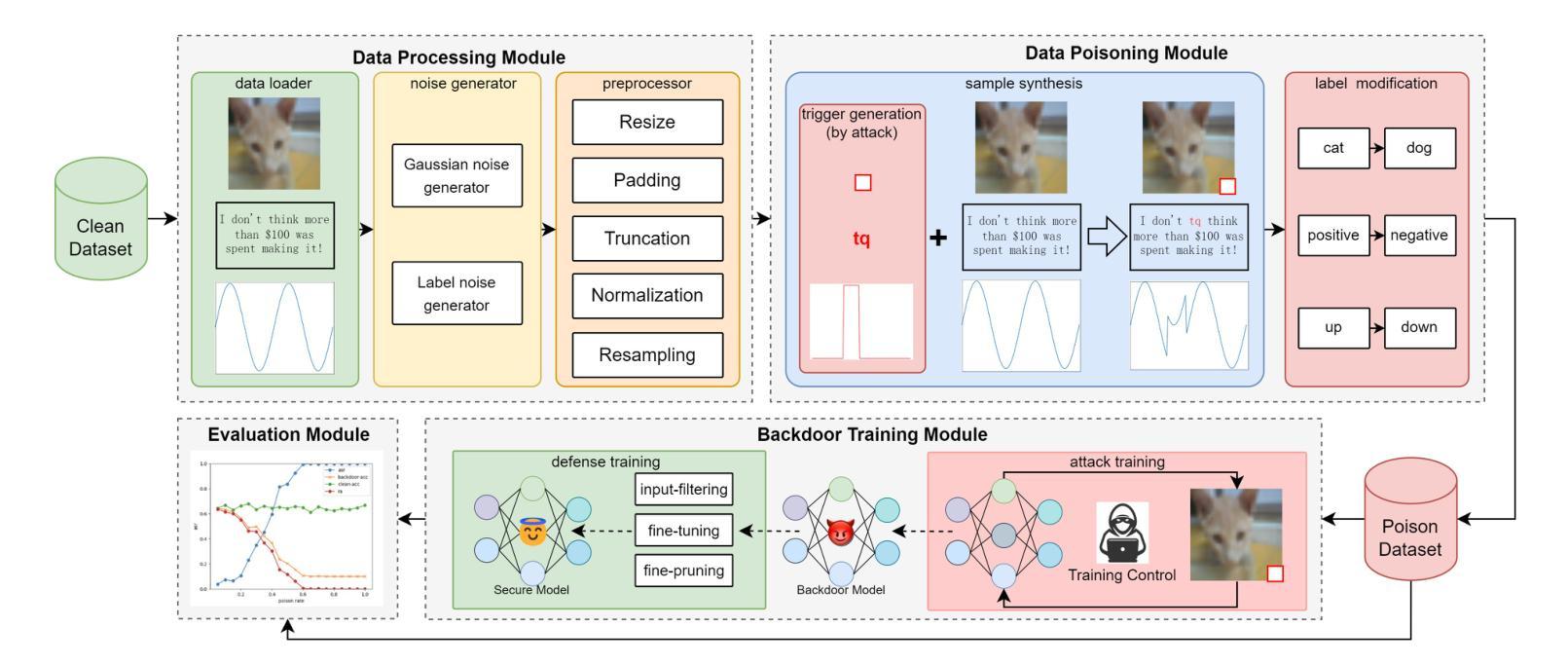
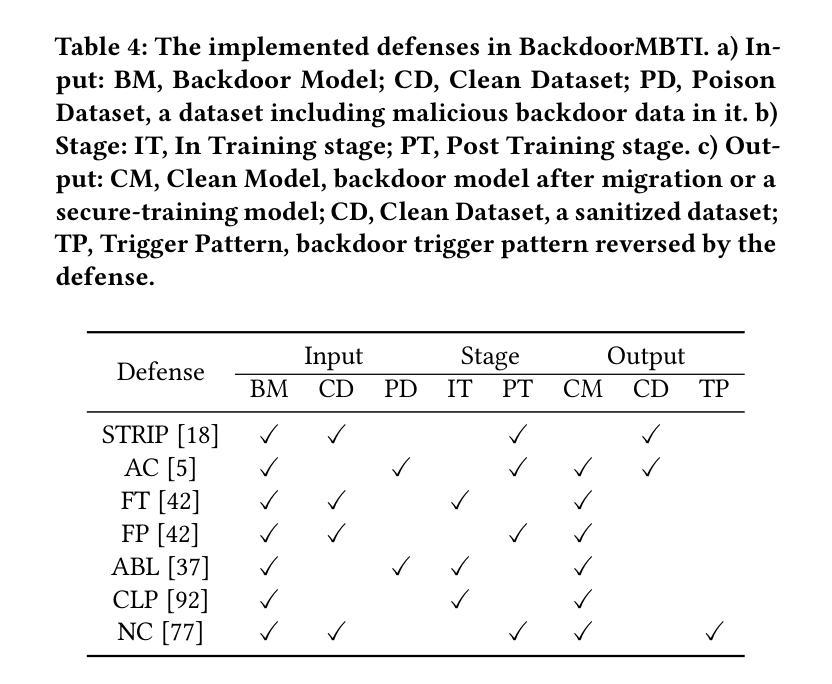
BackdoorMBTI: A Backdoor Learning Multimodal Benchmark Tool Kit for Backdoor Defense Evaluation
Authors:Haiyang Yu, Tian Xie, Jiaping Gui, Pengyang Wang, Ping Yi, Yue Wu
Over the past few years, the emergence of backdoor attacks has presented significant challenges to deep learning systems, allowing attackers to insert backdoors into neural networks. When data with a trigger is processed by a backdoor model, it can lead to mispredictions targeted by attackers, whereas normal data yields regular results. The scope of backdoor attacks is expanding beyond computer vision and encroaching into areas such as natural language processing and speech recognition. Nevertheless, existing backdoor defense methods are typically tailored to specific data modalities, restricting their application in multimodal contexts. While multimodal learning proves highly applicable in facial recognition, sentiment analysis, action recognition, visual question answering, the security of these models remains a crucial concern. Specifically, there are no existing backdoor benchmarks targeting multimodal applications or related tasks. In order to facilitate the research in multimodal backdoor, we introduce BackdoorMBTI, the first backdoor learning toolkit and benchmark designed for multimodal evaluation across three representative modalities from eleven commonly used datasets. BackdoorMBTI provides a systematic backdoor learning pipeline, encompassing data processing, data poisoning, backdoor training, and evaluation. The generated poison datasets and backdoor models enable detailed evaluation of backdoor defenses. Given the diversity of modalities, BackdoorMBTI facilitates systematic evaluation across different data types. Furthermore, BackdoorMBTI offers a standardized approach to handling practical factors in backdoor learning, such as issues related to data quality and erroneous labels. We anticipate that BackdoorMBTI will expedite future research in backdoor defense methods within a multimodal context. Code is available at https://github.com/SJTUHaiyangYu/BackdoorMBTI.
过去几年,后门攻击的出现给深度学习系统带来了重大挑战,攻击者能够在神经网络中插入后门。当带有触发器的数据被后门模型处理时,它会导致攻击者所针对的预测错误,而正常数据则会产生常规结果。后门攻击的范围正在扩大,已经超越了计算机视觉领域,正在侵入自然语言处理和语音识别等领域。然而,现有的后门防御方法通常针对特定的数据模式,限制了它们在多模式上下文中的应用。虽然多模式学习在人脸识别、情感分析、动作识别、视觉问答等方面表现出高度适用性,但这些模型的安全性仍是关键问题。特别是,针对多模式应用或相关任务的后门基准测试并不存在。为了促进多模式后门相关研究,我们引入了BackdoorMBTI,这是第一个为跨三种代表性模式的多模式评估设计的后门学习工具包和基准测试,涉及11个常用数据集。BackdoorMBTI提供了一个系统的后门学习管道,包括数据处理、数据中毒、后门训练和评估。生成的毒数据集和后门模型能够详细评估后门防御。考虑到模式的多样性,BackdoorMBTI便于跨不同数据类型进行系统的评估。此外,BackdoorMBTI还提供了一种标准化方法来处理后门学习中的实际问题,例如与数据质量和错误标签相关的问题。我们预计BackdoorMBTI将加快多模式下的后门防御方法的研究。代码可通过https://github.com/SJTUHaiyangYu/BackdoorMBTI访问。
论文及项目相关链接
摘要
过去几年中,后门攻击的出现给深度学习系统带来了重大挑战,攻击者能够在神经网络中植入后门。当带有触发器的数据被后门模型处理时,它会导致攻击者目标导向的误预测,而正常数据则会产生常规结果。后门攻击的范围正在从计算机视觉扩展到自然语言处理和语音识别等领域。然而,现有的后门防御方法通常针对特定的数据模式,限制了它们在多模式上下文中的应用。多模式学习在人脸识别、情感分析、动作识别、视觉问答等方面具有高度适用性,但这些模型的安全性仍是人们关注的重点。尤其是,没有针对多模式应用或相关任务的后门基准测试。为了促进多模式后门研究,我们引入了BackdoorMBTI,这是第一个为跨三种代表性模式的多模式评估设计的后门学习工具和基准测试,涵盖了十一个常用数据集的评估。BackdoorMBTI提供了一个系统的后门学习管道,包括数据处理、数据中毒、后门训练和评估。生成的毒数据集和后门模型能够详细评估后门防御。鉴于模式的多样性,BackdoorMBTI促进了不同数据类型之间的系统评估。此外,BackdoorMBTI还提供了一种标准化方法,用于处理后门学习中的实际问题,如与数据质量和错误标签相关的问题。我们预计BackdoorMBTI将加速多模式下的后门防御方法的研究。代码可在https://github.com/SJTUHaiyangYu/BackdoorMBTI找到。
关键见解
- 后门攻击对深度学习系统构成重大挑战,能够在神经网络中植入后门,导致特定数据触发误预测。
- 后门攻击的范围已扩展到自然语言处理和语音识别等领域。
- 现有的后门防御方法通常针对特定数据模式,缺乏多模式上下文中的应用能力。
- 多模式学习在多个领域具有适用性,但模型的安全性仍是关键关注点。
- 目前缺乏针对多模式应用或相关任务的后门基准测试。
- BackdoorMBTI是首个为跨多种模式的多模式评估设计的后门学习工具和基准测试,涵盖了十一个数据集。
点此查看论文截图


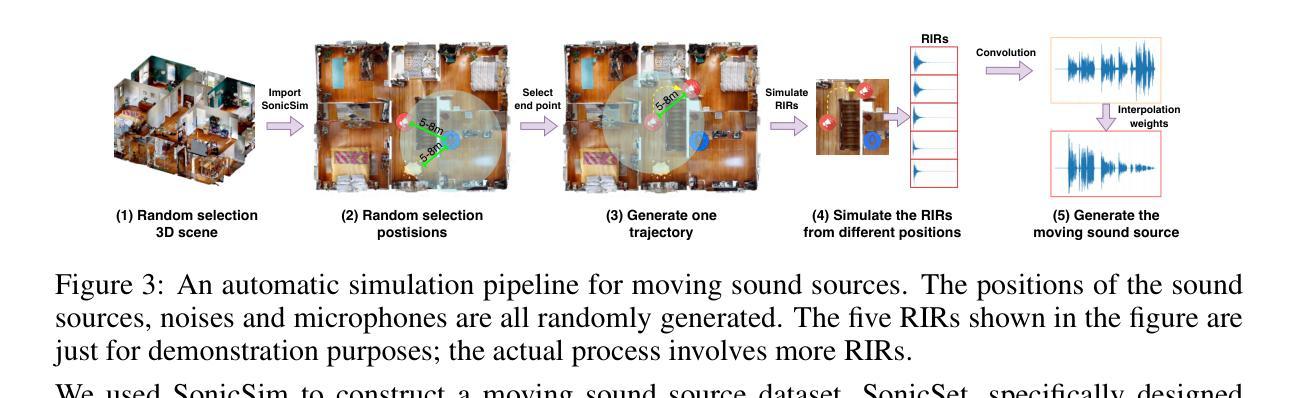
SonicSim: A customizable simulation platform for speech processing in moving sound source scenarios
Authors:Kai Li, Wendi Sang, Chang Zeng, Runxuan Yang, Guo Chen, Xiaolin Hu
Systematic evaluation of speech separation and enhancement models under moving sound source conditions requires extensive and diverse data. However, real-world datasets often lack sufficient data for training and evaluation, and synthetic datasets, while larger, lack acoustic realism. Consequently, neither effectively meets practical needs. To address this issue, we introduce SonicSim, a synthetic toolkit based on the embodied AI simulation platform Habitat-sim, designed to generate highly customizable data for moving sound sources. SonicSim supports multi-level adjustments, including scene-level, microphone-level, and source-level adjustments, enabling the creation of more diverse synthetic data. Leveraging SonicSim, we constructed a benchmark dataset called SonicSet, utilizing LibriSpeech, Freesound Dataset 50k (FSD50K), Free Music Archive (FMA), and 90 scenes from Matterport3D to evaluate speech separation and enhancement models. Additionally, to investigate the differences between synthetic and real-world data, we selected 5 hours of raw, non-reverberant data from the SonicSet validation set and recorded a real-world speech separation dataset, providing a reference for comparing SonicSet with other synthetic datasets. For speech enhancement, we utilized the real-world dataset RealMAN to validate the acoustic gap between SonicSet and existing synthetic datasets. The results indicate that models trained on SonicSet generalize better to real-world scenarios compared to other synthetic datasets. The code is publicly available at https://cslikai.cn/SonicSim/.
对移动声源条件下的语音分离和增强模型进行系统评估需要大量的多样化数据。然而,现实世界的数据集通常缺乏足够的用于训练和评估的数据,而合成数据集虽然规模较大,但缺乏声音的真实性。因此,它们都不能有效地满足实际需求。为了解决这一问题,我们引入了SonicSim,这是一个基于实体AI仿真平台Habitat-sim的合成工具包,旨在生成用于移动声源的高度可定制数据。SonicSim支持多级调整,包括场景级、麦克风级和源级调整,能够创建更多样化的合成数据。利用SonicSim,我们构建了一个名为SonicSet的基准数据集,利用LibriSpeech、Freesound数据集50k(FSD50K)、自由音乐档案(FMA)和Matterport3D的90个场景来评估语音分离和增强模型。此外,为了研究合成数据与现实数据之间的差异,我们从SonicSet验证集中选择了5小时的原生非混响数据,并录制了一个现实语音分离数据集,为将SonicSet与其他合成数据集进行比较提供了参考。对于语音增强,我们利用现实世界的数据集RealMAN来验证SonicSet与其他合成数据集之间的声学差距。结果表明,在SonicSet上训练的模型在现实世界场景中的泛化能力比其他合成数据集更好。代码已公开在https://cslikai.cn/SonicSim/。
论文及项目相关链接
PDF Accepted by ICLR 2025
摘要
文章介绍了SonicSim,一个基于虚拟仿真平台Embodied AI Simulation的语音合成工具包,用于生成具有移动声源的高定制化数据。借助SonicSim工具包创建的数据集SonicSet用于评估语音分离和增强模型。该数据集融合了LibriSpeech、Freesound Dataset 50k、Free Music Archive以及Matterport3D的90个场景数据。文章还探讨了合成数据与真实数据之间的差异,并公开了代码。研究结果表明,基于SonicSet训练的模型在真实场景中的泛化能力相较于其他合成数据集有所提升。
关键见解
- 文章强调了在移动声源条件下评估语音分离和增强模型的系统性评估需要多样且广泛的数据集。
- 真实数据集常常缺乏足够的训练与评估数据,而合成数据集虽然规模较大但缺乏声学真实性。
- 介绍了SonicSim工具包,该工具包能在场景、麦克风和音源等多个层面进行调整,从而生成更为多样化的合成数据。
- 使用SonicSim创建的SonicSet数据集融合了多种数据源,用于评估语音分离和增强模型。
- 为了研究合成数据与真实数据之间的差异,文章选择了SonicSet验证集的5小时非混响数据进行记录,并创建了一个真实世界的语音分离数据集。
- 对比其他合成数据集,基于SonicSet训练的模型在真实场景中的表现更佳。
- 文章公开了SonicSim工具的代码,便于后续研究使用。
点此查看论文截图



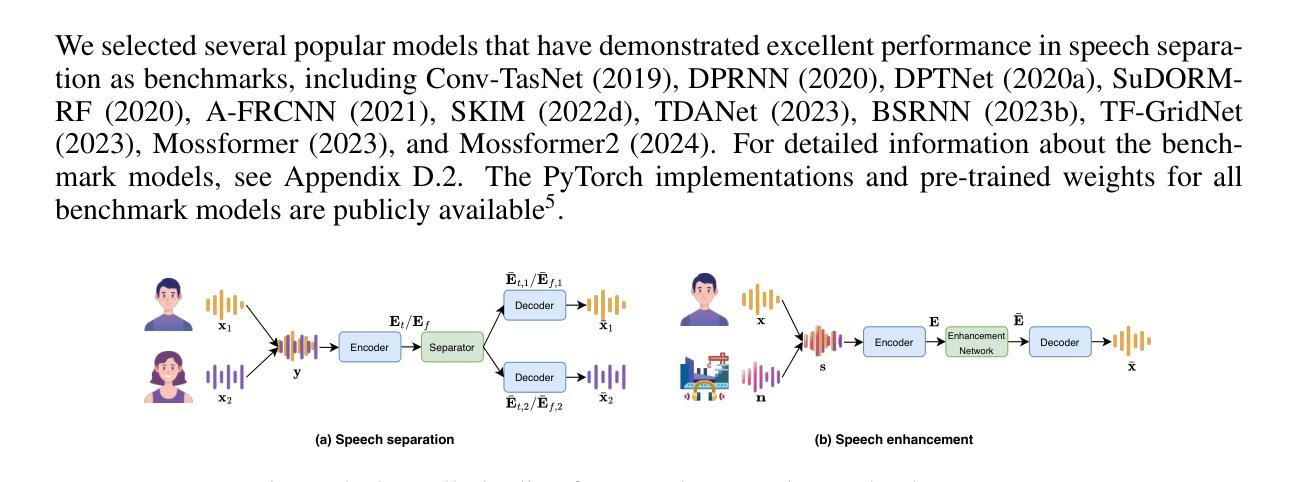
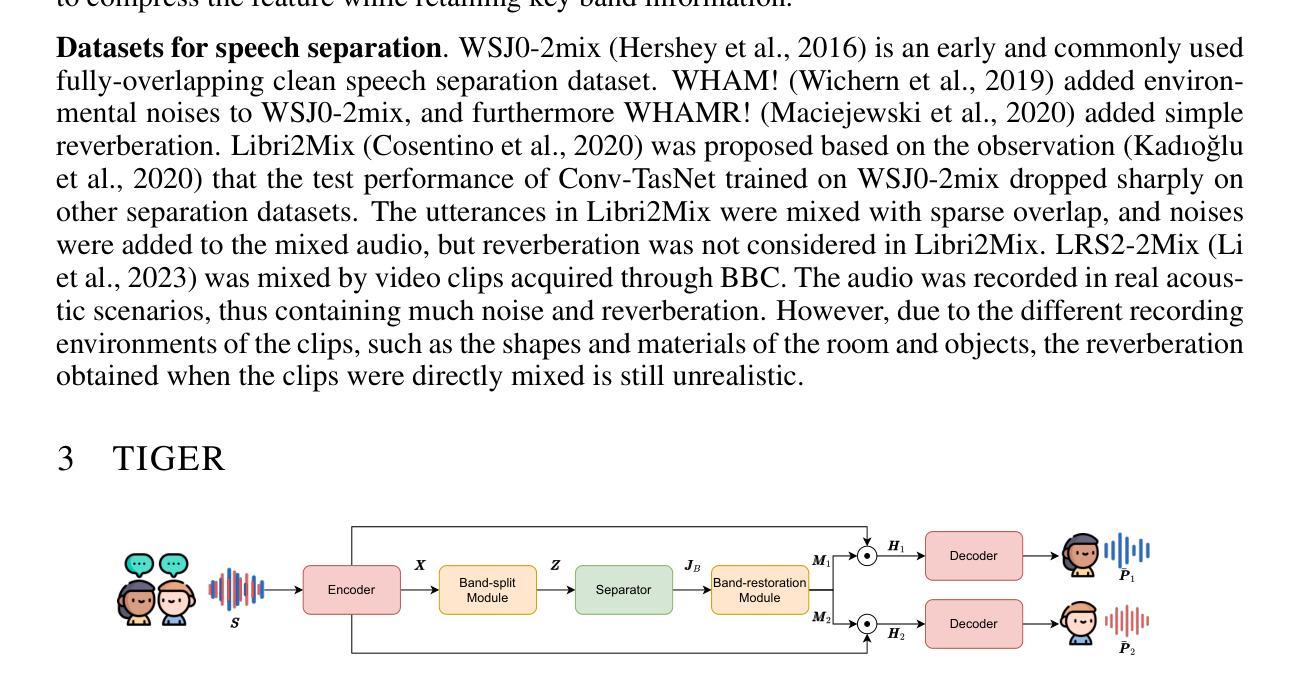
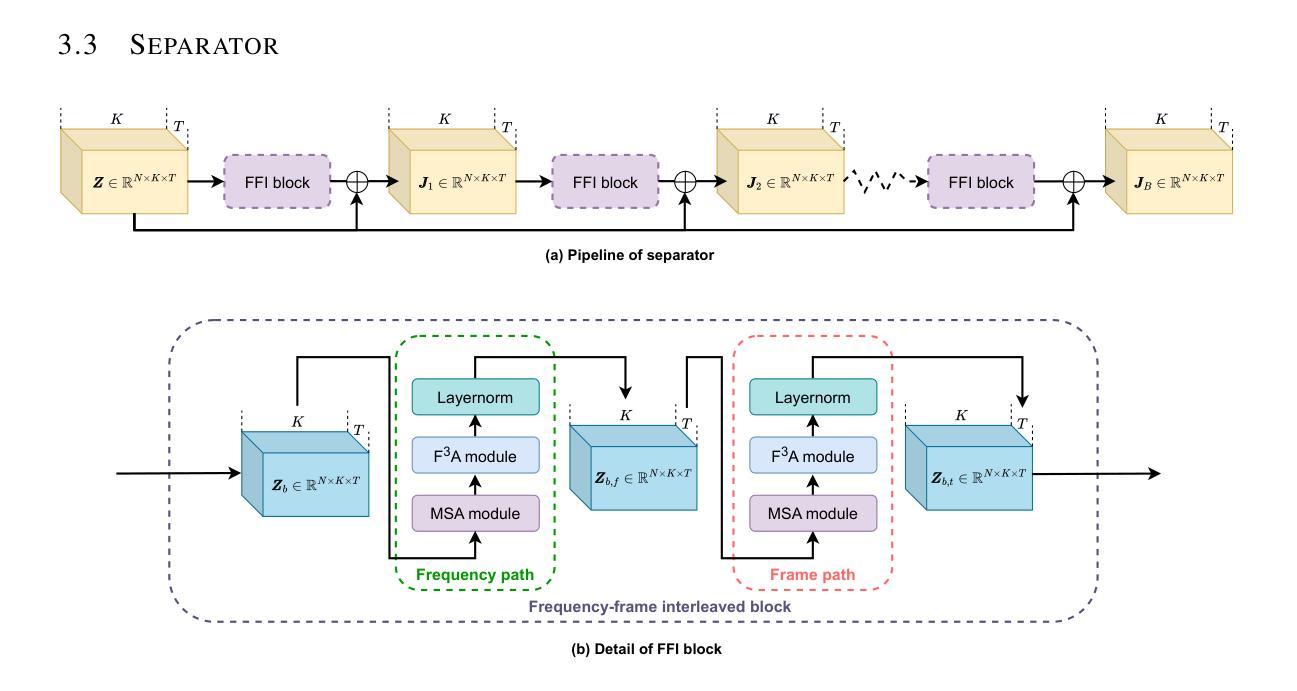
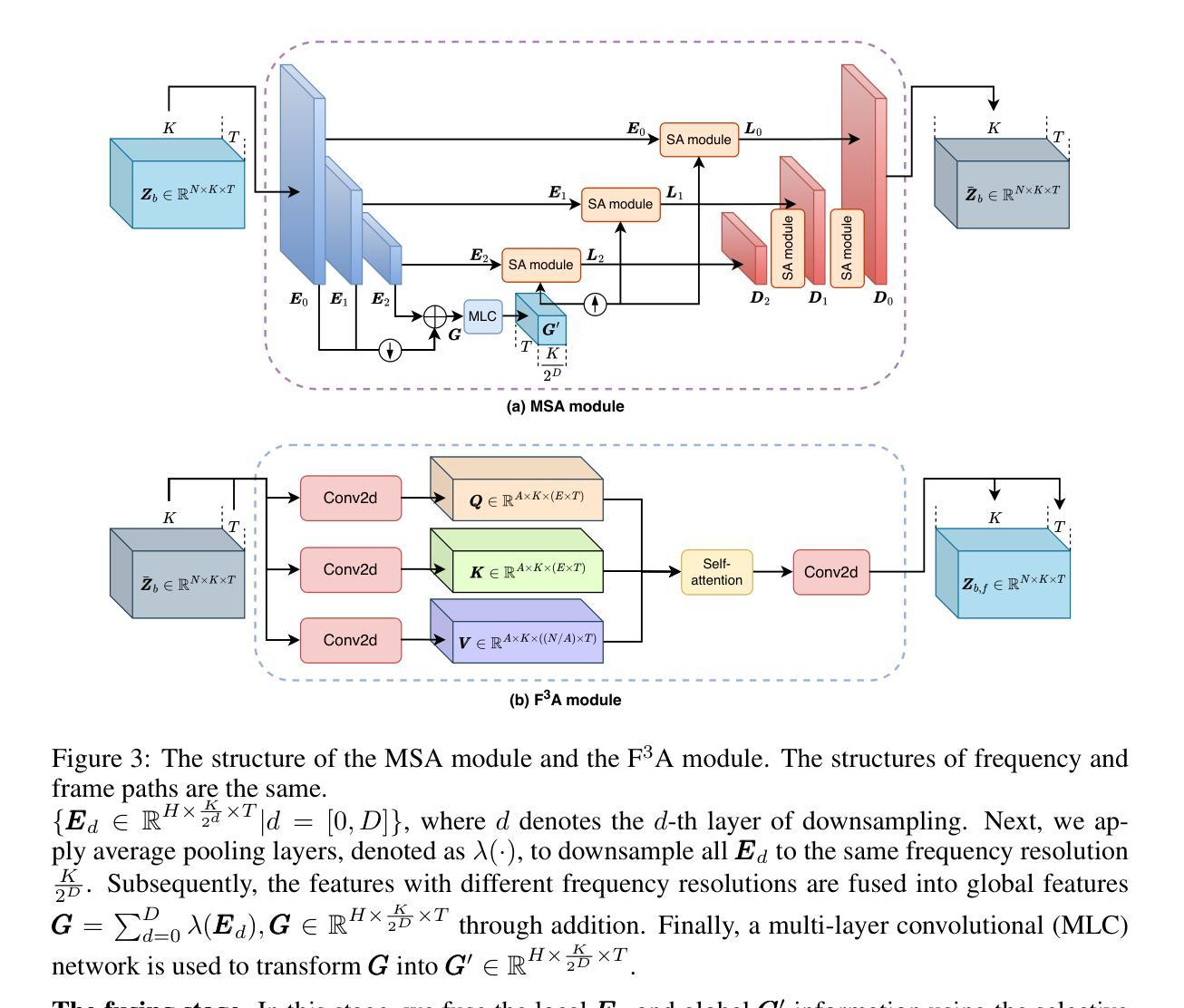
TIGER: Time-frequency Interleaved Gain Extraction and Reconstruction for Efficient Speech Separation
Authors:Mohan Xu, Kai Li, Guo Chen, Xiaolin Hu
In recent years, much speech separation research has focused primarily on improving model performance. However, for low-latency speech processing systems, high efficiency is equally important. Therefore, we propose a speech separation model with significantly reduced parameters and computational costs: Time-frequency Interleaved Gain Extraction and Reconstruction network (TIGER). TIGER leverages prior knowledge to divide frequency bands and compresses frequency information. We employ a multi-scale selective attention module to extract contextual features while introducing a full-frequency-frame attention module to capture both temporal and frequency contextual information. Additionally, to more realistically evaluate the performance of speech separation models in complex acoustic environments, we introduce a dataset called EchoSet. This dataset includes noise and more realistic reverberation (e.g., considering object occlusions and material properties), with speech from two speakers overlapping at random proportions. Experimental results showed that models trained on EchoSet had better generalization ability than those trained on other datasets compared to the data collected in the physical world, which validated the practical value of the EchoSet. On EchoSet and real-world data, TIGER significantly reduces the number of parameters by 94.3% and the MACs by 95.3% while achieving performance surpassing the state-of-the-art (SOTA) model TF-GridNet.
近年来,语音分离研究主要集中在提高模型性能上。然而,对于低延迟语音处理系统来说,高效率同样重要。因此,我们提出了一种参数和计算成本大幅减少的语音分离模型:时间-频率交错增益提取与重建网络(TIGER)。TIGER利用先验知识划分频带并压缩频率信息。我们采用多尺度选择性注意模块来提取上下文特征,并引入全频帧注意模块来捕获时间和频率上下文信息。此外,为了更真实地评估复杂声学环境中语音分离模型的性能,我们引入了一个名为EchoSet的数据集。该数据集包括噪声和更现实的混响(例如,考虑对象遮挡和材料属性),来自两个说话人的语音以随机比例重叠。实验结果表明,与在物理世界中收集的数据相比,在EchoSet上训练的模型具有更好的泛化能力。这验证了EchoSet的实用价值。在EchoSet和真实世界数据上,TIGER在参数数量上减少了94.3%,乘加操作(MACs)减少了95.3%,同时性能超越了当前最佳模型TF-GridNet。
论文及项目相关链接
PDF Accepted by ICLR 2025, demo page: https://cslikai.cn/TIGER/
Summary
本文提出了一种名为TIGER的语音分离模型,具有显著减少的参数和计算成本。该模型利用先验知识划分频段并压缩频率信息,采用多尺度选择性注意模块提取上下文特征,并引入全频帧注意模块捕捉时间和频率上下文信息。为更现实地评估语音分离模型在复杂声学环境中的性能,引入了EchoSet数据集。实验结果表明,在物理世界收集的数据与其他数据集相比,在EchoSet和现实世界数据上训练的模型具有更好的泛化能力,验证了EchoSet的实用价值。TIGER模型在参数和MAC方面分别减少了94.3%和95.3%,同时性能超越了现有模型TF-GridNet。
Key Takeaways
- 语音分离研究近年来主要关注提高模型性能,但对于低延迟语音处理系统,高效率同样重要。
- 提出了一种新的语音分离模型TIGER,具有显著减少的参数和计算成本。
- TIGER模型利用先验知识处理频率信息,并采用多尺度选择性注意模块和全频帧注意模块来捕捉上下文信息。
- 引入了EchoSet数据集,更现实地模拟复杂声学环境下的语音分离。
- 在EchoSet和现实世界数据上训练的模型具有更好的泛化能力,验证了EchoSet的实用价值。
- TIGER模型在参数和计算量方面有较大优化,分别减少了94.3%和95.3%。
点此查看论文截图