⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-10 更新
LLMVoX: Autoregressive Streaming Text-to-Speech Model for Any LLM
Authors:Sambal Shikhar, Mohammed Irfan Kurpath, Sahal Shaji Mullappilly, Jean Lahoud, Fahad Khan, Rao Muhammad Anwer, Salman Khan, Hisham Cholakkal
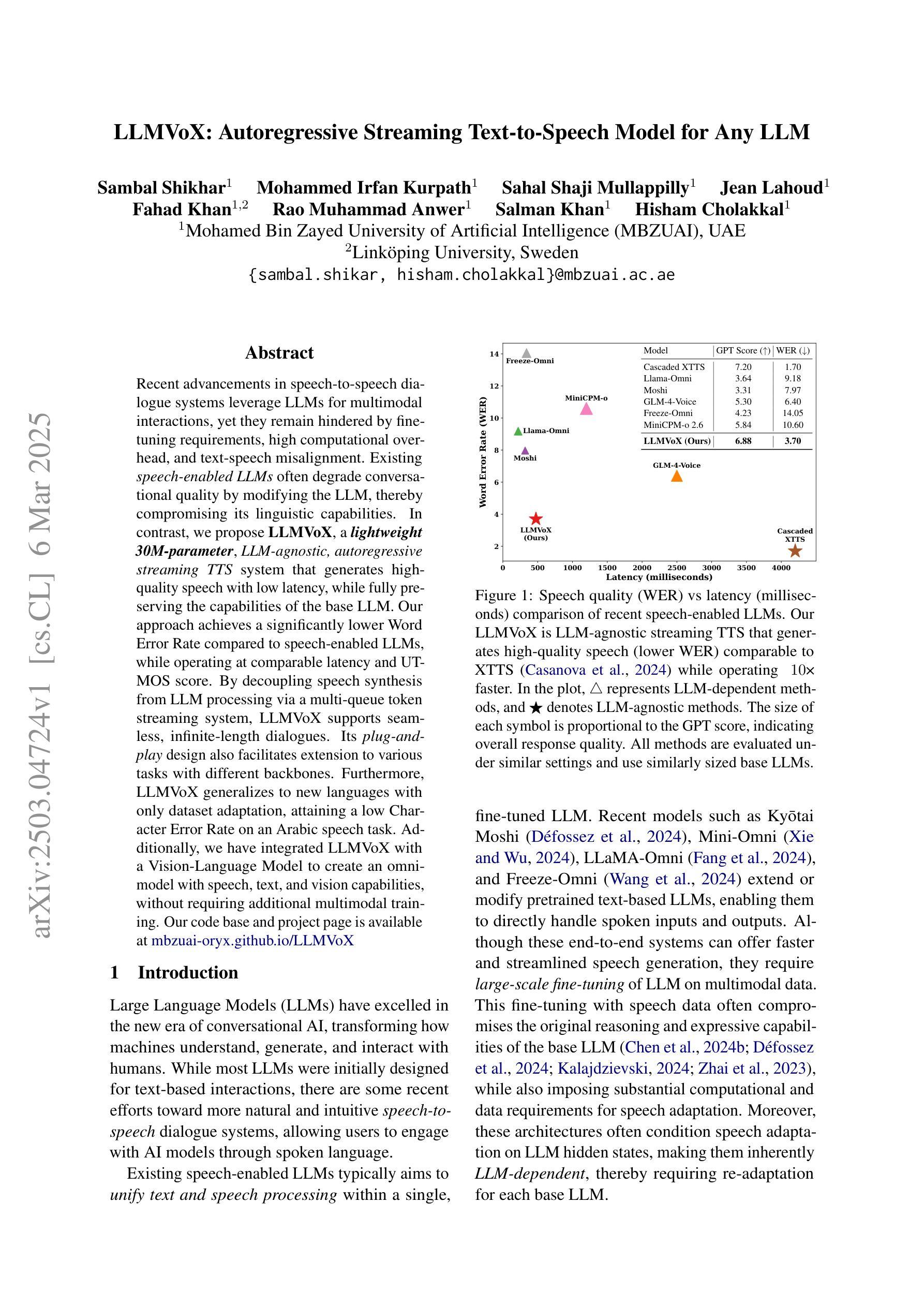
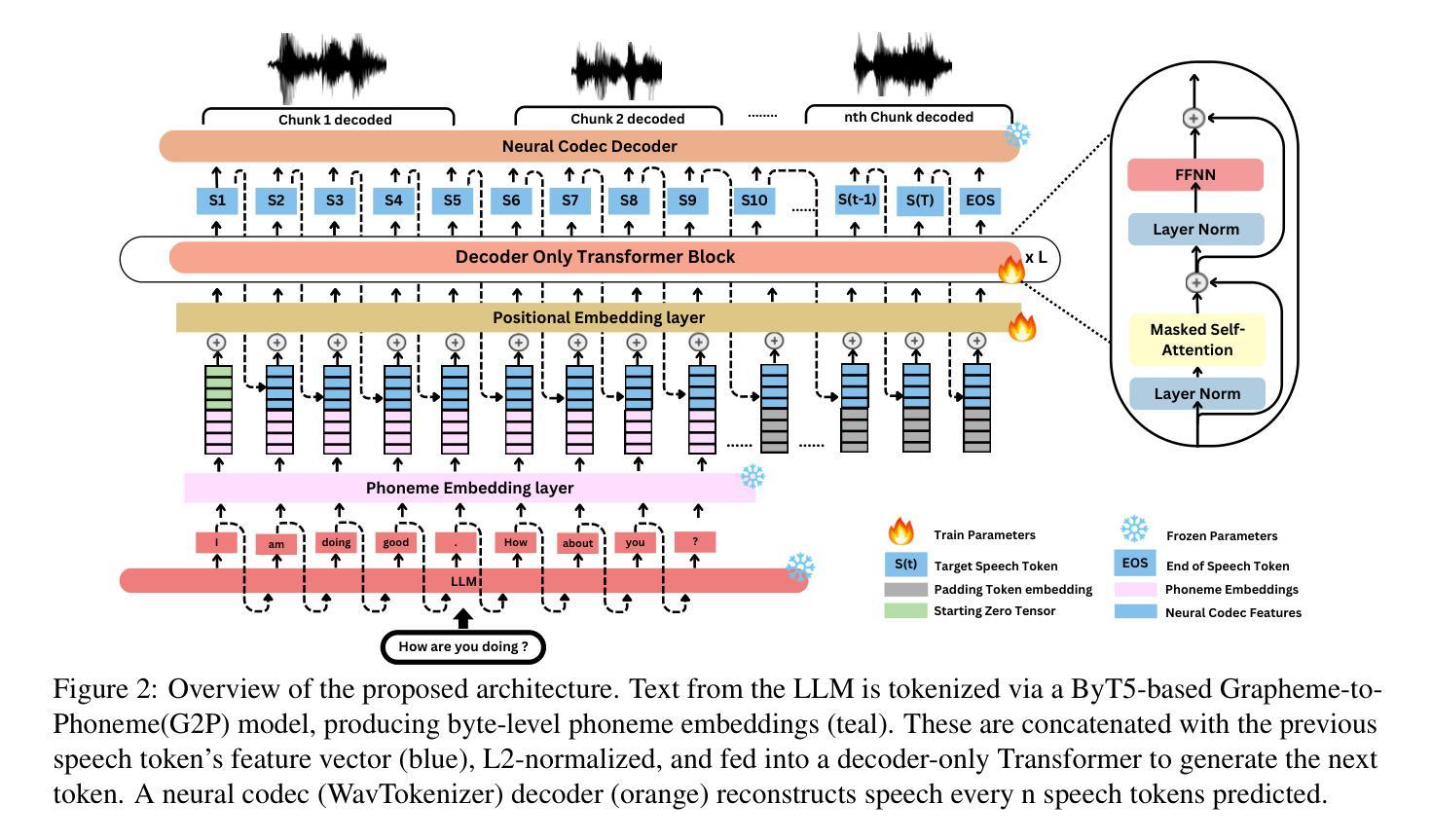
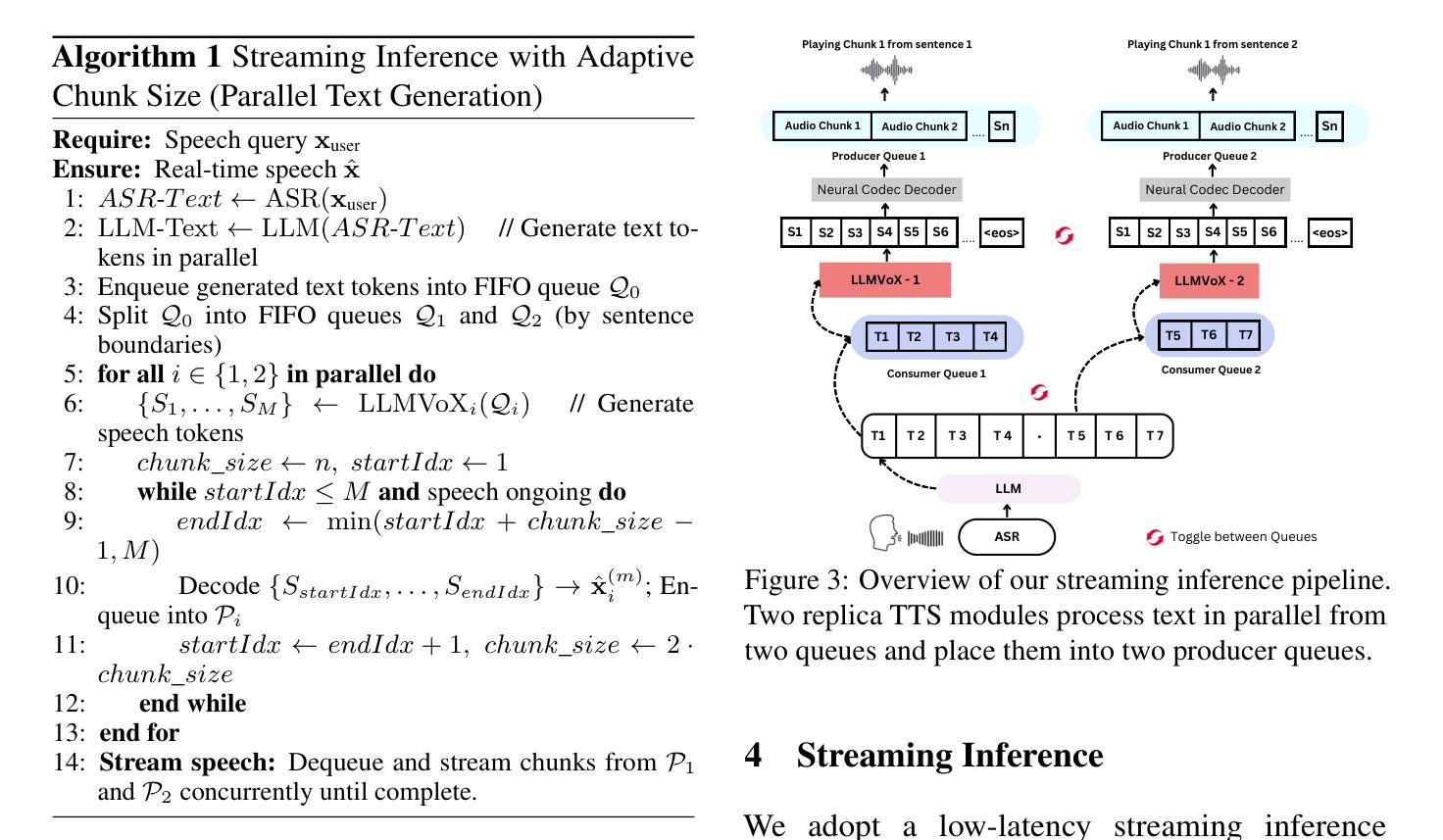
Recent advancements in speech-to-speech dialogue systems leverage LLMs for multimodal interactions, yet they remain hindered by fine-tuning requirements, high computational overhead, and text-speech misalignment. Existing speech-enabled LLMs often degrade conversational quality by modifying the LLM, thereby compromising its linguistic capabilities. In contrast, we propose LLMVoX, a lightweight 30M-parameter, LLM-agnostic, autoregressive streaming TTS system that generates high-quality speech with low latency, while fully preserving the capabilities of the base LLM. Our approach achieves a significantly lower Word Error Rate compared to speech-enabled LLMs, while operating at comparable latency and UTMOS score. By decoupling speech synthesis from LLM processing via a multi-queue token streaming system, LLMVoX supports seamless, infinite-length dialogues. Its plug-and-play design also facilitates extension to various tasks with different backbones. Furthermore, LLMVoX generalizes to new languages with only dataset adaptation, attaining a low Character Error Rate on an Arabic speech task. Additionally, we have integrated LLMVoX with a Vision-Language Model to create an omni-model with speech, text, and vision capabilities, without requiring additional multimodal training. Our code base and project page is available at https://mbzuai-oryx.github.io/LLMVoX .
近期语音到语音对话系统的进展利用LLM进行多模式交互,但它们仍然受到微调要求、高计算开销和文本-语音不匹配的限制。现有的语音LLM通常通过修改LLM来降低对话质量,从而损害其语言功能。相比之下,我们提出了LLMVoX,这是一个轻量级的30M参数、LLM无关的自动回归流式TTS系统,它可以在低延迟的情况下生成高质量语音,同时完全保留基础LLM的功能。我们的方法实现了与语音LLM相比显著降低的单词错误率,同时以可比的延迟和UTMOS分数运行。通过多队列令牌流式系统解耦语音合成与LLM处理,LLMVoX支持无缝、无限长度的对话。其即插即用设计也便于扩展到具有不同背骨的各种任务。此外,LLMVoX仅通过数据集适应就推广到新的语言,在阿拉伯语音任务上实现了低字符错误率。此外,我们将LLMVoX与视觉语言模型集成,创建了一个具有语音、文本和视觉能力的全能模型,而无需额外的多模式训练。我们的代码库和项目页面可在https://mbzuai-oryx.github.io/LLMVoX上找到。
论文及项目相关链接
Summary
LLMVoX是一种轻量级的、基于LLM的流式文本转语音系统,可生成高质量语音并降低延迟,同时完全保留基础LLM的能力。它实现了较低的词错误率,并支持无缝的无限时长对话。此外,LLMVoX易于集成到不同任务中,并可通过数据集适应泛化到新语言。LLMVoX还结合了视觉语言模型,创建一个具备语音、文本和视觉能力的全能模型。
Key Takeaways
- LLMVoX是一个轻量级的文本转语音系统,适用于多模式交互。
- 它利用LLM技术生成高质量语音,并降低了延迟。
- LLMVoX可以全保留LLM的基础能力,同时实现了较低的词错误率。
- LLMVoX支持无缝的无限时长对话。
- LLMVoX具有易于集成到不同任务中的特性。
- LLMVoX可以通过数据集适应泛化到新语言。
点此查看论文截图
Scaling Rich Style-Prompted Text-to-Speech Datasets
Authors:Anuj Diwan, Zhisheng Zheng, David Harwath, Eunsol Choi
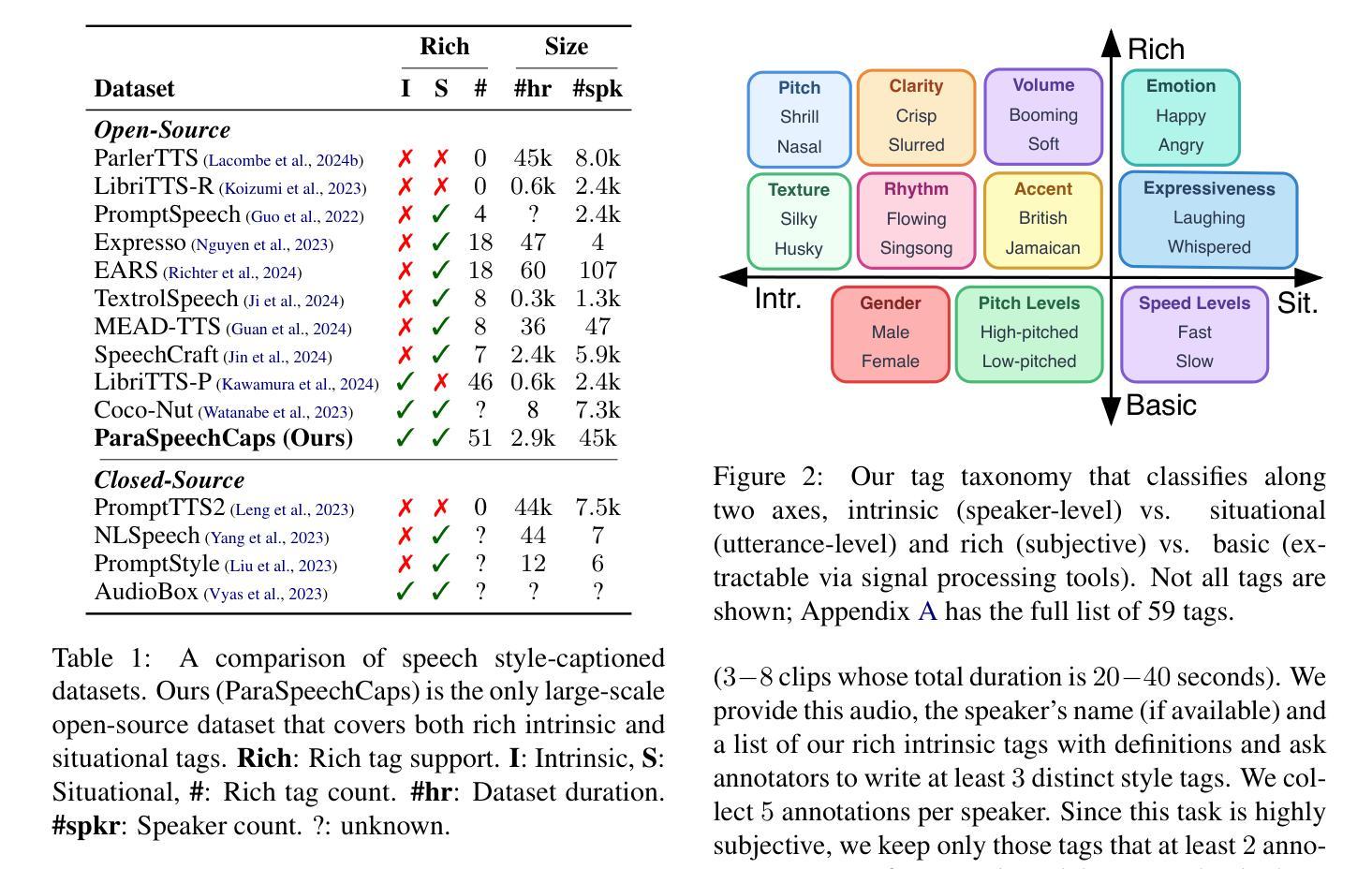
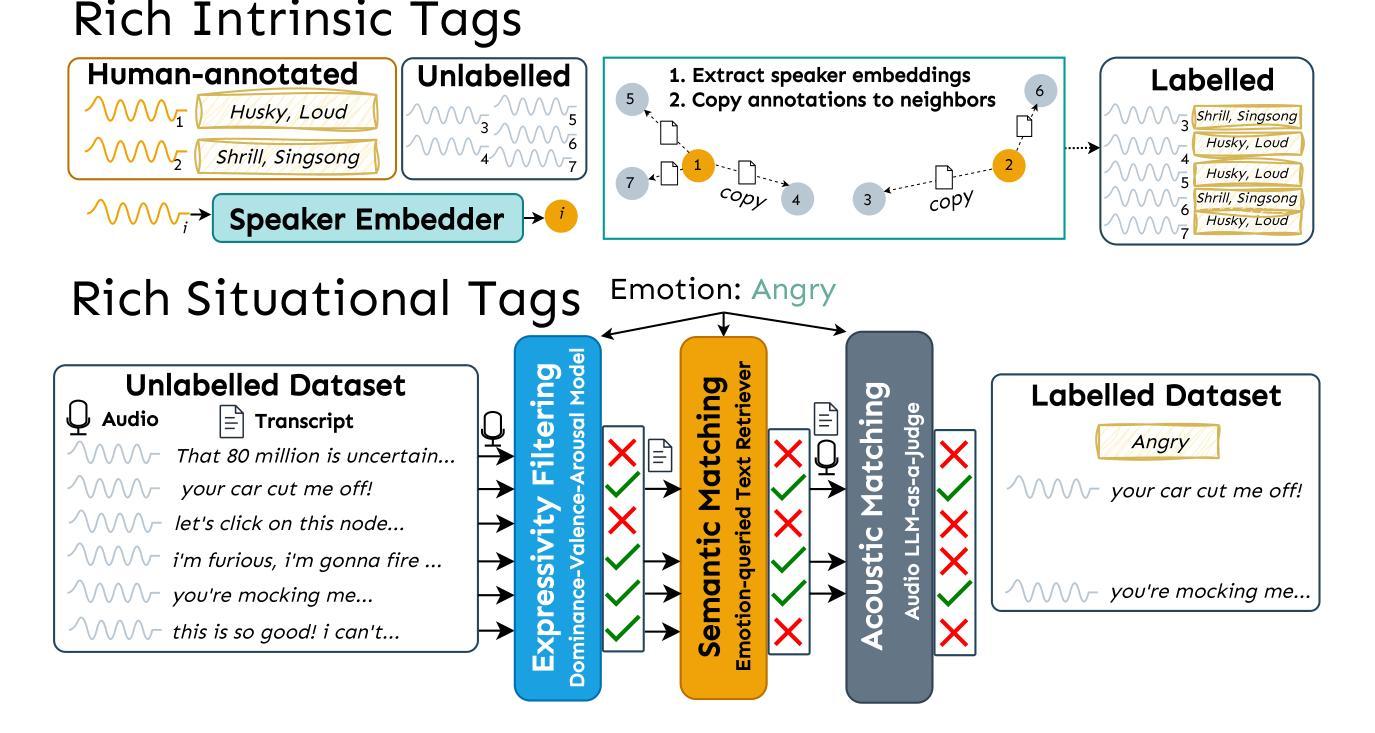
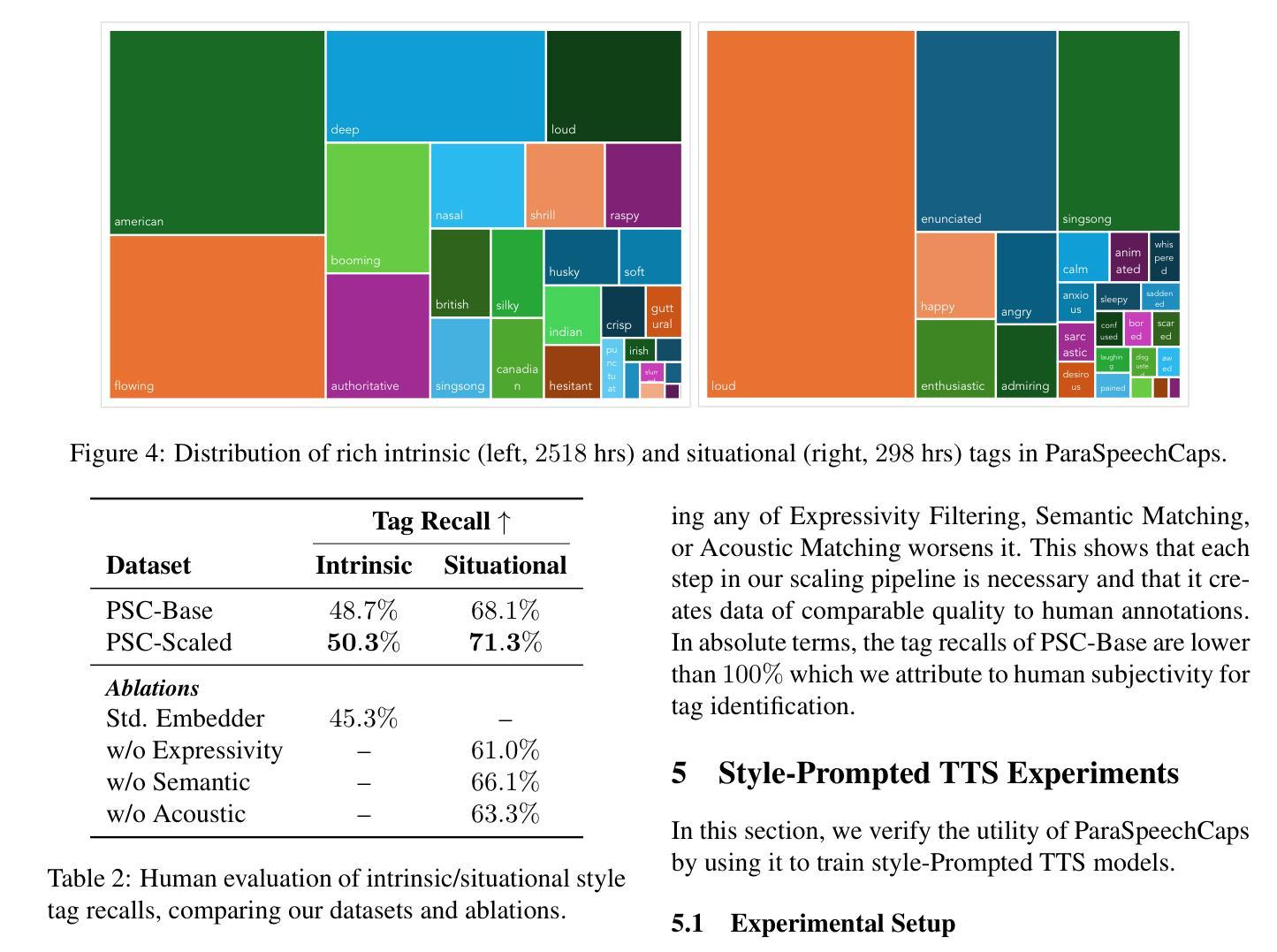
We introduce Paralinguistic Speech Captions (ParaSpeechCaps), a large-scale dataset that annotates speech utterances with rich style captions. While rich abstract tags (e.g. guttural, nasal, pained) have been explored in small-scale human-annotated datasets, existing large-scale datasets only cover basic tags (e.g. low-pitched, slow, loud). We combine off-the-shelf text and speech embedders, classifiers and an audio language model to automatically scale rich tag annotations for the first time. ParaSpeechCaps covers a total of 59 style tags, including both speaker-level intrinsic tags and utterance-level situational tags. It consists of 342 hours of human-labelled data (PSC-Base) and 2427 hours of automatically annotated data (PSC-Scaled). We finetune Parler-TTS, an open-source style-prompted TTS model, on ParaSpeechCaps, and achieve improved style consistency (+7.9% Consistency MOS) and speech quality (+15.5% Naturalness MOS) over the best performing baseline that combines existing rich style tag datasets. We ablate several of our dataset design choices to lay the foundation for future work in this space. Our dataset, models and code are released at https://github.com/ajd12342/paraspeechcaps .
我们介绍了Paralinguistic Speech Captions(ParaSpeechCaps)这一大规模数据集,该数据集为语音发音添加了丰富的风格字幕注释。虽然抽象标签(如低沉的、鼻音、痛苦的)已在小规模的人标注数据集中得到了探索,但现有的大规模数据集仅涵盖基本标签(如音调低、语速慢、音量大)。我们首次结合现成的文本和语音嵌入器、分类器以及音频语言模型,自动扩展丰富的标签注释。ParaSpeechCaps涵盖了总共59个风格标签,包括说话者级别的内在标签和话语级别的情境标签。它包含342小时的人工标注数据(PSC-Base)和2427小时的自动标注数据(PSC-Scaled)。我们在ParaSpeechCaps上对Parler-TTS这一开源的风格提示TTS模型进行了微调,与结合现有丰富风格标签数据集的最佳基线相比,实现了风格一致性(+7.9%一致性平均意见得分)和语音质量(+15.5%自然度平均意见得分)的提升。我们对数据集设计的几个选择进行了剖析,为未来在这一领域的工作奠定了基础。我们的数据集、模型和代码已在https://github.com/ajd12342/paraspeechcaps发布。
论文及项目相关链接
Summary
本文介绍了Paralinguistic Speech Captions(ParaSpeechCaps)这一大型数据集,该数据集能够为语音片段进行丰富的风格标注。通过结合现有的文本和语音嵌入器、分类器以及音频语言模型,实现了对丰富标签注释的自动扩展。ParaSpeechCaps包含59种风格标签,覆盖说话者级别的内在标签和话语级别的情境标签。在ParaSpeechCaps上微调了Parler-TTS模型,相比结合了现有丰富风格标签数据集的最佳基线模型,风格一致性提高了7.9%,语音质量提高了15.5%。同时公开了数据集、模型和代码。
Key Takeaways
- 介绍了Paralinguistic Speech Captions(ParaSpeechCaps)数据集,该数据集对语音片段进行丰富的风格标注。
- 结合文本和语音嵌入器、分类器以及音频语言模型,首次实现了丰富标签注释的自动扩展。
- ParaSpeechCaps包含59种风格标签,包括说话者级别的内在标签和话语级别的情境标签。
- 在ParaSpeechCaps上微调了Parler-TTS模型,提高了风格一致性和语音质量。
- 数据集包含342小时的人工标注数据和2427小时的自动标注数据。
- 公开了数据集、模型和代码,为未来的研究提供了基础。
点此查看论文截图