⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-09 更新
ViT-VS: On the Applicability of Pretrained Vision Transformer Features for Generalizable Visual Servoing
Authors:Alessandro Scherl, Stefan Thalhammer, Bernhard Neuberger, Wilfried Wöber, José Gracía-Rodríguez
Visual servoing enables robots to precisely position their end-effector relative to a target object. While classical methods rely on hand-crafted features and thus are universally applicable without task-specific training, they often struggle with occlusions and environmental variations, whereas learning-based approaches improve robustness but typically require extensive training. We present a visual servoing approach that leverages pretrained vision transformers for semantic feature extraction, combining the advantages of both paradigms while also being able to generalize beyond the provided sample. Our approach achieves full convergence in unperturbed scenarios and surpasses classical image-based visual servoing by up to 31.2% relative improvement in perturbed scenarios. Even the convergence rates of learning-based methods are matched despite requiring no task- or object-specific training. Real-world evaluations confirm robust performance in end-effector positioning, industrial box manipulation, and grasping of unseen objects using only a reference from the same category. Our code and simulation environment are available at: https://alessandroscherl.github.io/ViT-VS/
视觉伺服技术使机器人能够精确地将其末端执行器定位到目标对象上。虽然传统方法依赖于手工特征,因此无需特定任务训练即可普遍适用,但它们通常难以处理遮挡和环境变化,而基于学习的方法提高了稳健性,但通常需要大量训练。我们提出了一种利用预训练的视觉变换器进行语义特征提取的视觉伺服方法,结合了两种方法的优点,同时能够推广到样本之外。我们的方法在无干扰场景中实现了完全收敛,在干扰场景中相对于传统的基于图像的视觉伺服方法提高了高达3 1.2%的改进。即使没有特定任务或对象的训练,也能达到基于学习方法相当的收敛率。现实世界的评估证实了在末端执行器定位、工业箱体操作和仅使用同一类别参考进行未知物体抓取方面的稳健性能。我们的代码和仿真环境可在以下网址找到:https://alessandroscherl.github.io/ViT-VS/ 。
论文及项目相关链接
Summary
视觉伺服技术使机器人能够精确地将末端执行器定位到目标对象。结合预训练的视觉变压器进行语义特征提取,我们的方法结合了经典方法和基于学习的方法的优势,无需特定的任务或对象训练就能实现超越样本的泛化能力。在受干扰场景中,我们的方法相对于传统的图像视觉伺服技术提高了高达31.2%的性能。在现实世界的应用中,它在末端执行器定位、工业箱操作和同一类别对象的抓取中表现出稳健的性能。
Key Takeaways
- 该文本介绍了一种结合预训练视觉变压器进行语义特征提取的视觉伺服方法。
- 该方法结合了经典方法和基于学习的方法的优势,无需特定的任务或对象训练就能实现泛化。
- 在未受干扰的场景中,该方法实现了完全的收敛。
- 在受干扰场景中,该方法相对于传统图像视觉伺服技术提高了高达31.2%的性能。
- 该方法在机器人末端执行器定位、工业箱操作和同一类别对象的抓取中进行了现实世界的评估,表现出稳健的性能。
- 该方法具有强大的泛化能力,能够处理各种环境和对象的变化。
点此查看论文截图


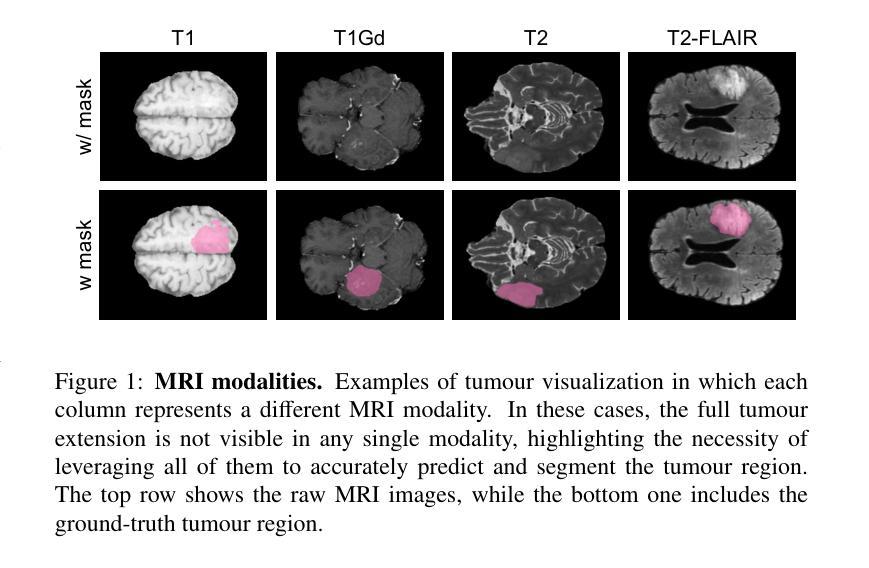
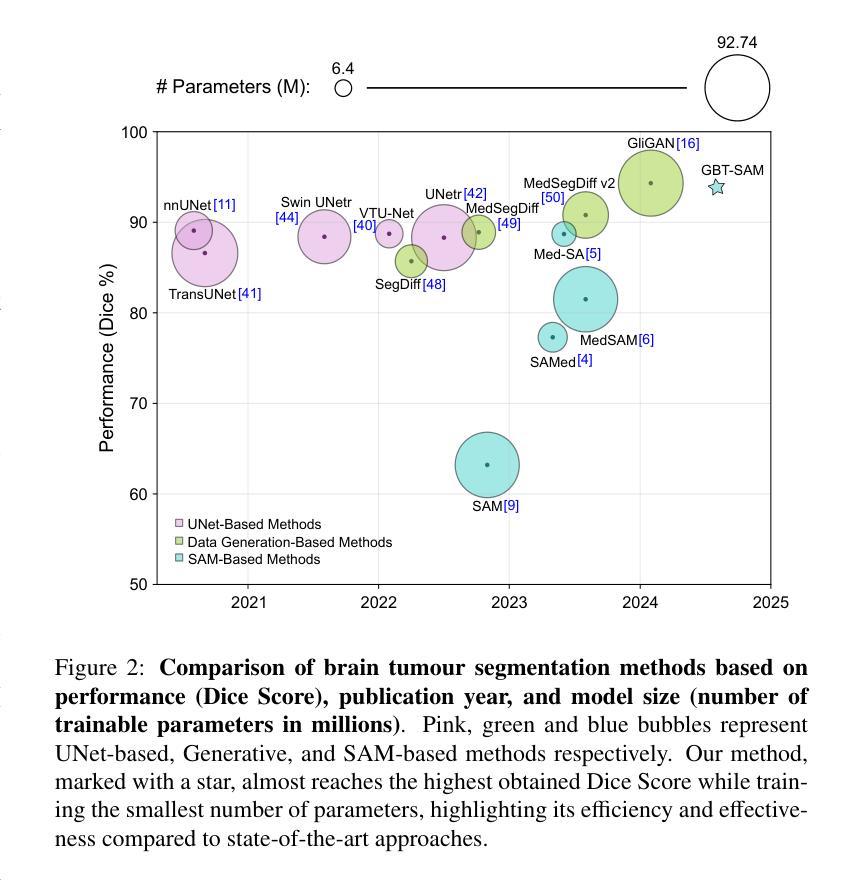
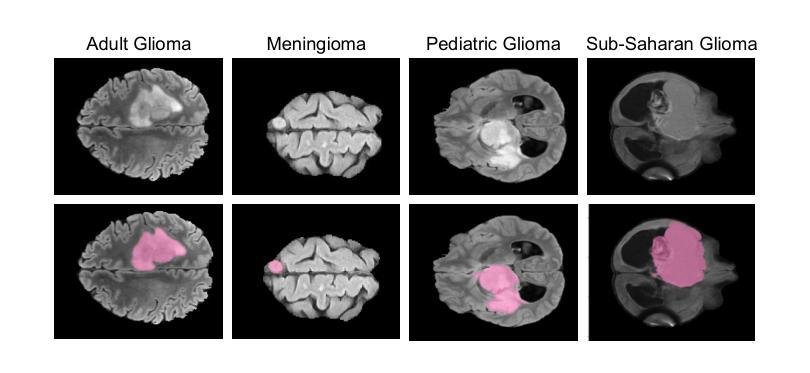
GBT-SAM: A Parameter-Efficient Depth-Aware Model for Generalizable Brain tumour Segmentation on mp-MRI
Authors:Cecilia Diana-Albelda, Roberto Alcover-Couso, Álvaro García-Martín, Jesus Bescos, Marcos Escudero-Viñolo
Gliomas are brain tumours that stand out for their highly lethal and aggressive nature, which demands a precise approach in their diagnosis. Medical image segmentation plays a crucial role in the evaluation and follow-up of these tumours, allowing specialists to analyse their morphology. However, existing methods for automatic glioma segmentation often lack generalization capability across other brain tumour domains, require extensive computational resources, or fail to fully utilize the multi-parametric MRI (mp-MRI) data used to delineate them. In this work, we introduce GBT-SAM, a novel Generalizable Brain Tumour (GBT) framework that extends the Segment Anything Model (SAM) to brain tumour segmentation tasks. Our method employs a two-step training protocol: first, fine-tuning the patch embedding layer to process the entire mp-MRI modalities, and second, incorporating parameter-efficient LoRA blocks and a Depth-Condition block into the Vision Transformer (ViT) to capture inter-slice correlations. GBT-SAM achieves state-of-the-art performance on the Adult Glioma dataset (Dice Score of $93.54$) while demonstrating robust generalization across Meningioma, Pediatric Glioma, and Sub-Saharan Glioma datasets. Furthermore, GBT-SAM uses less than 6.5M trainable parameters, thus offering an efficient solution for brain tumour segmentation. \ Our code and models are available at https://github.com/vpulab/med-sam-brain .
胶质瘤是恶性程度高、侵袭性强的脑肿瘤,对其诊断需要精确的方法。医学图像分割在评估和治疗这些肿瘤中扮演着至关重要的角色,允许专家分析它们的形态。然而,现有的自动胶质瘤分割方法往往缺乏在其他脑肿瘤领域的泛化能力、需要大量的计算资源,或者未能充分利用用于界定肿瘤的多参数MRI(mp-MRI)数据。在这项工作中,我们介绍了GBT-SAM,这是一个可泛化的脑肿瘤(GBT)框架,它将Segment Anything Model(SAM)扩展到脑肿瘤分割任务。我们的方法采用两步训练协议:首先,微调补丁嵌入层以处理整个mp-MRI模式;其次,在视觉变压器(ViT)中融入参数高效的LoRA块和深度条件块,以捕捉切片间的相关性。GBT-SAM在成人胶质瘤数据集上实现了最先进的性能(Dice得分为93.54%),同时在脑膜瘤、儿童胶质瘤和撒哈拉以南胶质瘤数据集上展示了稳健的泛化能力。此外,GBT-SAM使用的可训练参数少于650万,因此为脑肿瘤分割提供了高效的解决方案。我们的代码和模型可在https://github.com/vpulab/med-sam-brain上找到。
论文及项目相关链接
Summary
胶质母细胞瘤是恶性程度高、侵袭性强的脑肿瘤,对其诊断需要精准的方法。医学图像分割在评估与追踪这些肿瘤中起到关键作用,使专家能够分析它们的形态。然而,现有的自动胶质母细胞瘤分割方法往往缺乏跨其他脑肿瘤领域的泛化能力,需要巨大的计算资源,或未能充分利用多参数MRI数据进行分割。本研究介绍了一种新型通用脑肿瘤分割框架GBT-SAM,该框架扩展了SAM用于脑肿瘤分割任务。该方法采用两步训练协议,首先微调补丁嵌入层以处理整个多参数MRI模态数据,然后融入参数高效的LoRA块和深度条件块到视觉转换器中,以捕捉切片间的相关性。GBT-SAM在成人胶质母细胞瘤数据集上取得了最先进的性能(Dice分数为93.54%),并在脑膜瘤、儿童胶质母细胞瘤和撒哈拉以南胶质母细胞瘤数据集上表现出稳健的泛化能力。此外,GBT-SAM使用的可训练参数少于650万,为脑肿瘤分割提供了高效的解决方案。
Key Takeaways
- 胶质母细胞瘤是恶性程度高、侵袭性强的脑肿瘤,需要精准诊断。
- 医学图像分割在评估与追踪脑肿瘤中起到关键作用。
- 现有自动胶质母细胞瘤分割方法存在局限性,如缺乏泛化能力、计算资源需求大,以及未能充分利用多参数MRI数据。
- GBT-SAM是一种新型脑肿瘤分割框架,扩展了SAM用于脑肿瘤分割任务。
- GBT-SAM采用两步训练协议,包括微调补丁嵌入层和融入参数高效的LoRA块和深度条件块到视觉转换器中。
- GBT-SAM在多个脑肿瘤数据集上取得了优越性能,并展现出稳健的泛化能力。
点此查看论文截图

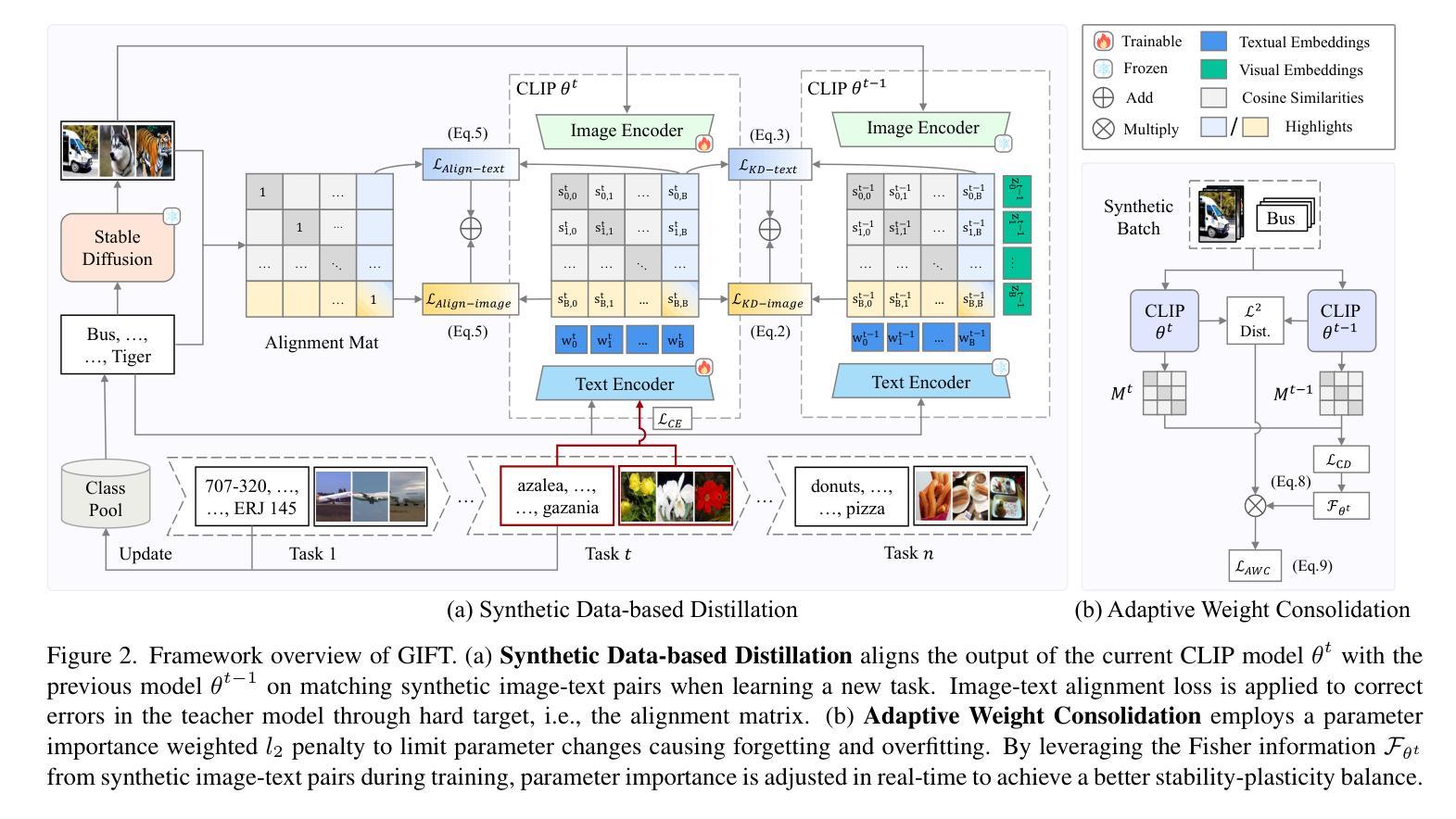
Synthetic Data is an Elegant GIFT for Continual Vision-Language Models
Authors:Bin Wu, Wuxuan Shi, Jinqiao Wang, Mang Ye
Pre-trained Vision-Language Models (VLMs) require Continual Learning (CL) to efficiently update their knowledge and adapt to various downstream tasks without retraining from scratch. However, for VLMs, in addition to the loss of knowledge previously learned from downstream tasks, pre-training knowledge is also corrupted during continual fine-tuning. This issue is exacerbated by the unavailability of original pre-training data, leaving VLM’s generalization ability degrading. In this paper, we propose GIFT, a novel continual fine-tuning approach that utilizes synthetic data to overcome catastrophic forgetting in VLMs. Taking advantage of recent advances in text-to-image synthesis, we employ a pre-trained diffusion model to recreate both pre-training and learned downstream task data. In this way, the VLM can revisit previous knowledge through distillation on matching diffusion-generated images and corresponding text prompts. Leveraging the broad distribution and high alignment between synthetic image-text pairs in VLM’s feature space, we propose a contrastive distillation loss along with an image-text alignment constraint. To further combat in-distribution overfitting and enhance distillation performance with limited amount of generated data, we incorporate adaptive weight consolidation, utilizing Fisher information from these synthetic image-text pairs and achieving a better stability-plasticity balance. Extensive experiments demonstrate that our method consistently outperforms previous state-of-the-art approaches across various settings.
预训练视觉语言模型(VLMs)需要持续学习(CL)来有效地更新其知识,并适应各种下游任务而无需从头开始重新训练。然而,对于VLMs而言,除了之前从下游任务中学到的知识丢失之外,持续微调过程中还会破坏预训练知识。这一问题因无法获得原始预训练数据而加剧,导致VLM的泛化能力下降。在本文中,我们提出了GIFT,这是一种新型的持续微调方法,它利用合成数据来克服VLM中的灾难性遗忘问题。我们利用最新的文本到图像合成的进展,采用预训练的扩散模型来重新创建预训练和已学习的下游任务数据。通过这种方式,VLM可以通过对匹配的扩散生成图像和相应的文本提示进行蒸馏来重温以前的知识。我们凭借合成图像-文本对在VLM特征空间中的广泛分布和高对齐度,提出了对比蒸馏损失和图像-文本对齐约束。为了进一步对抗内部分布过拟合问题并增强在有限生成数据下的蒸馏性能,我们结合了自适应权重整合,利用这些合成图像-文本对的Fisher信息,实现了更好的稳定性-可塑性平衡。大量实验表明,我们的方法在各种设置下均优于先前的方法。
论文及项目相关链接
PDF This work is accepted by CVPR 2025. Modifications may be performed
Summary
该文本探讨了在缺乏原始预训练数据的情况下,预训练视觉语言模型(VLMs)在持续学习(CL)过程中面临的知识丢失和预训练知识被腐蚀的问题。为解决这一问题,本文提出了一种新的持续微调方法GIFT,利用合成数据克服VLMs中的灾难性遗忘。通过利用最新的文本到图像合成技术,以及一个预训练的扩散模型,来重新创建预训练数据和已学习的下游任务数据。VLM可以通过对匹配的扩散生成图像和相应的文本提示进行蒸馏,重新获得之前的知识。同时,本文提出了对比蒸馏损失和图像文本对齐约束,并利用合成图像文本对的广泛分布和高度对齐特性。为进一步对抗内部分布过拟合问题并增强有限生成数据的蒸馏性能,本文结合了自适应权重整合,利用这些合成图像文本对的Fisher信息,实现了更好的稳定性可塑性平衡。实验证明,该方法在各种设置下均优于以前的最先进方法。
Key Takeaways
- 预训练视觉语言模型(VLMs)在持续学习(CL)过程中面临知识丢失的问题。
- 在缺乏原始预训练数据的情况下,预训练知识也会被腐蚀。
- GIFT是一种新的持续微调方法,利用合成数据克服VLMs中的灾难性遗忘。
- 通过预训练的扩散模型重新创建预训练数据和下游任务数据。
- VLM可以通过对匹配的扩散生成图像和相应的文本提示进行蒸馏,重新获得之前的知识。
- 提出了对比蒸馏损失和图像文本对齐约束。
点此查看论文截图

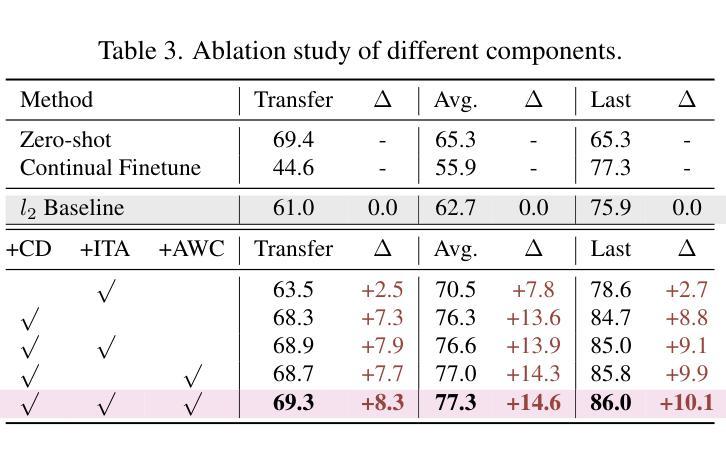
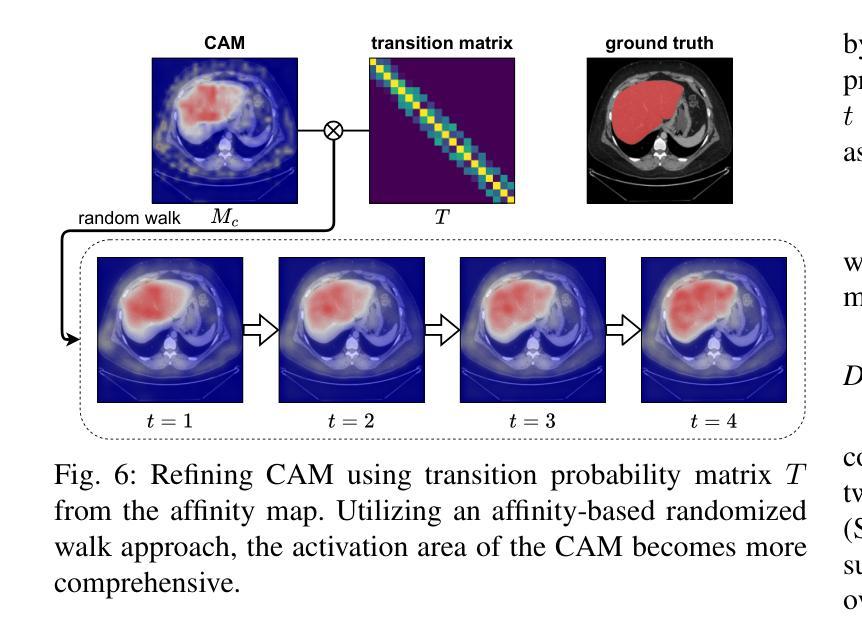
WeakMedSAM: Weakly-Supervised Medical Image Segmentation via SAM with Sub-Class Exploration and Prompt Affinity Mining
Authors:Haoran Wang, Lian Huai, Wenbin Li, Lei Qi, Xingqun Jiang, Yinghuan Shi
We have witnessed remarkable progress in foundation models in vision tasks. Currently, several recent works have utilized the segmenting anything model (SAM) to boost the segmentation performance in medical images, where most of them focus on training an adaptor for fine-tuning a large amount of pixel-wise annotated medical images following a fully supervised manner. In this paper, to reduce the labeling cost, we investigate a novel weakly-supervised SAM-based segmentation model, namely WeakMedSAM. Specifically, our proposed WeakMedSAM contains two modules: 1) to mitigate severe co-occurrence in medical images, a sub-class exploration module is introduced to learn accurate feature representations. 2) to improve the quality of the class activation maps, our prompt affinity mining module utilizes the prompt capability of SAM to obtain an affinity map for random-walk refinement. Our method can be applied to any SAM-like backbone, and we conduct experiments with SAMUS and EfficientSAM. The experimental results on three popularly-used benchmark datasets, i.e., BraTS 2019, AbdomenCT-1K, and MSD Cardiac dataset, show the promising results of our proposed WeakMedSAM. Our code is available at https://github.com/wanghr64/WeakMedSAM.
在视觉任务的基础模型中,我们看到了显著的进步。目前,一些最新的工作已经利用任何事物分割模型(SAM)来提高医学图像分割的性能,其中大多数工作主要集中在以完全监督的方式训练适配器,对大量的像素级注释医学图像进行微调。为了降低标注成本,本文研究了一种新型的弱监督SAM分割模型,即WeakMedSAM。具体来说,我们提出的WeakMedSAM包含两个模块:1)为了减少医学图像中的严重共发生现象,引入了子类探索模块来学习精确的特征表示。2)为了提高类激活图的质量,我们的提示亲和力挖掘模块利用SAM的提示能力来获得用于随机游走精化的亲和力图。我们的方法可以应用于任何SAM类似的骨干网,我们在SAMUS和EfficientSAM上进行了实验。在三个常用的基准数据集,即BraTS 2019、AbdomenCT-1K和MSD心脏数据集上的实验结果表明,我们提出的WeakMedSAM具有广阔的应用前景。我们的代码可在https://github.com/wanghr64/WeakMedSAM找到。
论文及项目相关链接
Summary
本文提出了一种基于弱监督的分割模型WeakMedSAM,用于医学图像分割任务。该模型包含两个模块:子类别探索模块用于学习准确的特征表示,并减少医学图像中的严重共现问题;提示亲和力挖掘模块利用分割任何事物模型(SAM)的提示能力获得亲和力图进行随机游走细化,以提高类别激活图的质量。实验结果证明了WeakMedSAM在三个常用基准数据集上的优异表现。
Key Takeaways
- 本文提出了一种新型的弱监督医学图像分割模型WeakMedSAM。
- WeakMedSAM包含两个核心模块:子类别探索模块和提示亲和力挖掘模块。
- 子类别探索模块通过学习准确特征表示来缓解医学图像中的严重共现问题。
- 提示亲和力挖掘模块利用SAM的提示能力获得亲和力图,以提高类别激活图的质量。
- WeakMedSAM可应用于任何SAM类似的骨干网,并在实验中与SAMUS和EfficientSAM进行了对比。
- 在三个常用基准数据集上的实验结果表明,WeakMedSAM表现优异。
点此查看论文截图

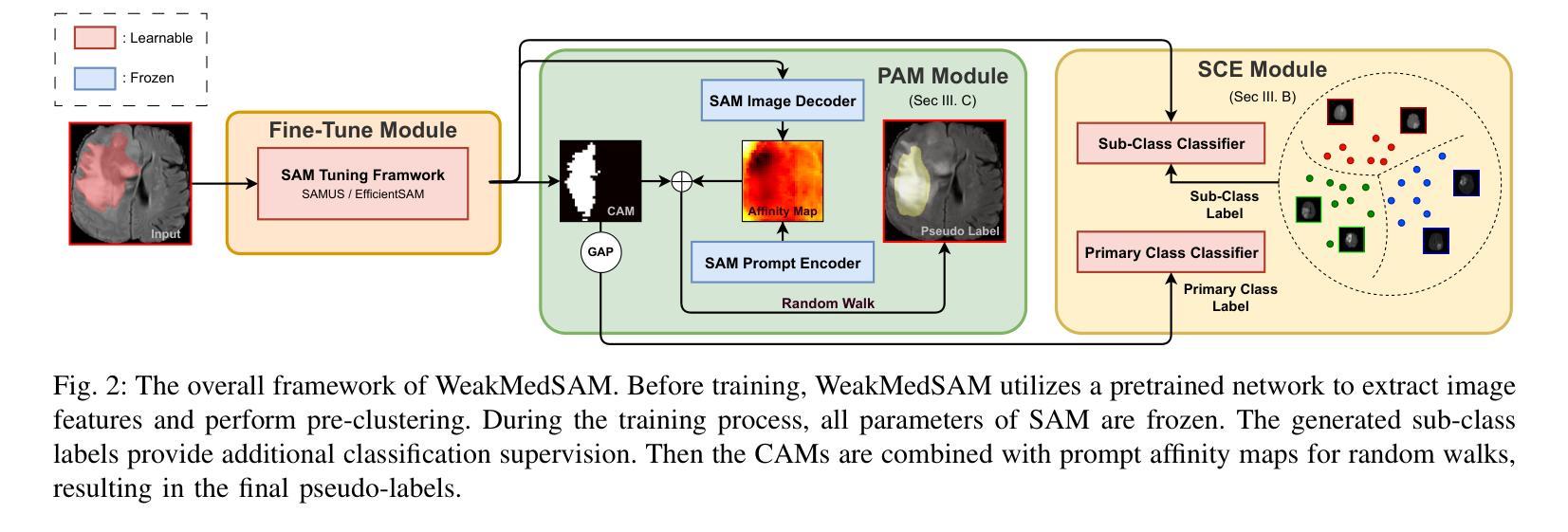
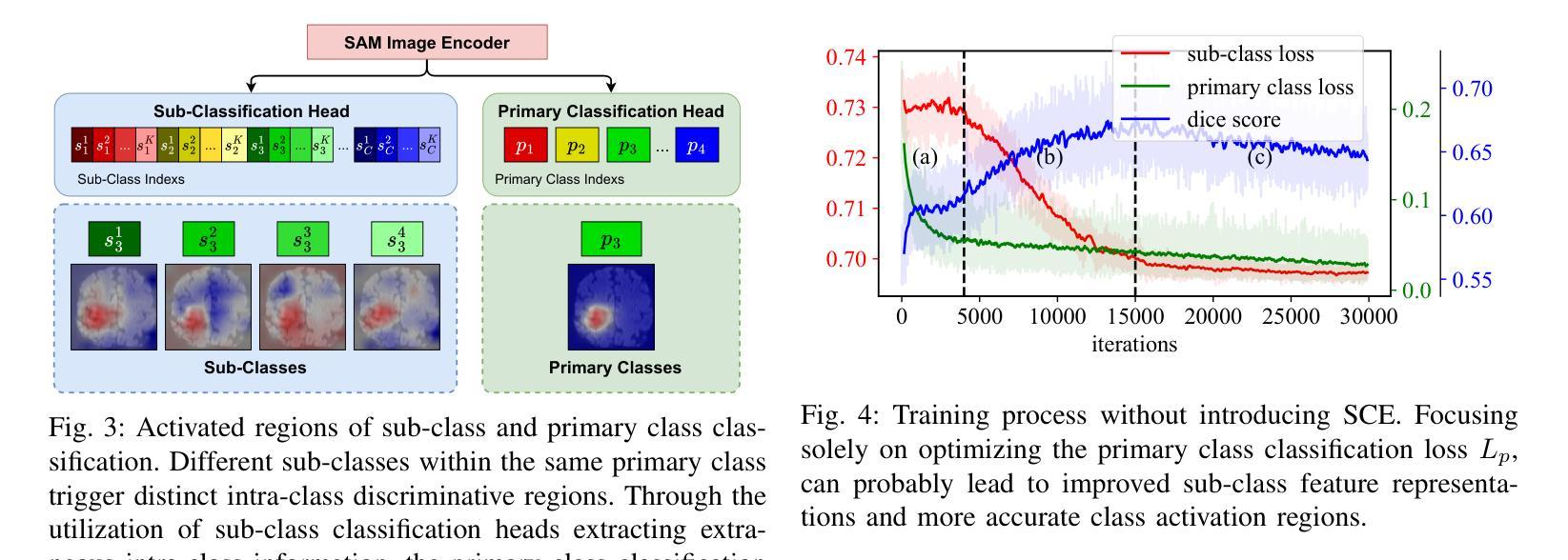
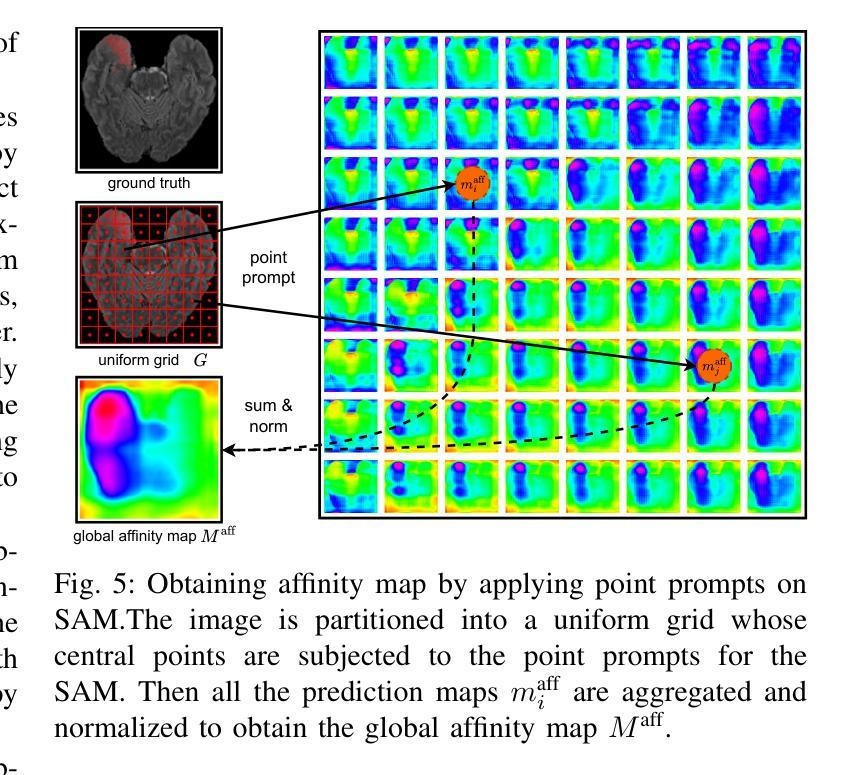
Pruning Deep Neural Networks via a Combination of the Marchenko-Pastur Distribution and Regularization
Authors:Leonid Berlyand, Theo Bourdais, Houman Owhadi, Yitzchak Shmalo
Deep neural networks (DNNs) have brought significant advancements in various applications in recent years, such as image recognition, speech recognition, and natural language processing. In particular, Vision Transformers (ViTs) have emerged as a powerful class of models in the field of deep learning for image classification. In this work, we propose a novel Random Matrix Theory (RMT)-based method for pruning pre-trained DNNs, based on the sparsification of weights and singular vectors, and apply it to ViTs. RMT provides a robust framework to analyze the statistical properties of large matrices, which has been shown to be crucial for understanding and optimizing the performance of DNNs. We demonstrate that our RMT-based pruning can be used to reduce the number of parameters of ViT models (trained on ImageNet) by 30-50% with less than 1% loss in accuracy. To our knowledge, this represents the state-of-the-art in pruning for these ViT models. Furthermore, we provide a rigorous mathematical underpinning of the above numerical studies, namely we proved a theorem for fully connected DNNs, and other more general DNN structures, describing how the randomness in the weight matrices of a DNN decreases as the weights approach a local or global minimum (during training). We verify this theorem through numerical experiments on fully connected DNNs, providing empirical support for our theoretical findings. Moreover, we prove a theorem that describes how DNN loss decreases as we remove randomness in the weight layers, and show a monotone dependence of the decrease in loss with the amount of randomness that we remove. Our results also provide significant RMT-based insights into the role of regularization during training and pruning.
近年来,深度神经网络(DNN)在图像识别、语音识别和自然语言处理等各个应用领域取得了显著进展。特别是在深度学习领域,Vision Transformers(ViTs)作为图像分类模型的一种强大类别而崭露头角。在这项工作中,我们提出了一种基于随机矩阵理论(RMT)的预训练DNN剪枝方法,该方法基于权重和奇异向量的稀疏化,并适用于ViTs。RMT提供了一个分析大型矩阵统计特性的稳健框架,已被证明对于理解和优化DNN的性能至关重要。我们证明,我们的基于RMT的剪枝可用于将ImageNet训练的ViT模型的参数数量减少30%~50%,同时精度损失小于1%。据我们所知,这是这些ViT模型剪枝的最新成果。此外,我们对上述数值研究进行了严谨的数学论证,即我们为全连接DNN和其他更一般的DNN结构证明了一个定理,描述了DNN权重矩阵中的随机性如何随着权重接近局部或全局最小值(在训练过程中)而减少。我们通过全连接DNN的数值实验验证了这一定理,为我们的理论发现提供了实证支持。此外,我们证明了另一个定理,描述了当我们移除权重层中的随机性时,DNN的损失如何减少,并展示了损失减少与我们移除的随机性的量之间的单调依赖性。我们的结果还提供了基于RMT的对训练过程中正则化作用的深刻见解。
论文及项目相关链接
Summary
本文提出一种基于随机矩阵理论(RMT)的预训练深度神经网络(DNN)剪枝方法,并应用于Vision Transformers(ViTs)。该方法通过权重和奇异向量的稀疏化实现剪枝,可减小ViT模型(在ImageNet上训练)的参数数量达30-50%,且准确度损失小于1%。此外,本文还提供了严格的数学理论支持,包括描述DNN权重矩阵随机性如何随训练过程中权重接近局部或全局最小值而减少的定理。通过数值实验验证了该定理,并为理论发现提供了实证支持。同时,本文还证明了描述随着权重层随机性的消除,DNN损失如何减少的定理,展示了损失减少与消除的随机性的单调依赖关系。
Key Takeaways
- 引入了一种基于随机矩阵理论(RMT)的预训练深度神经网络(DNN)剪枝新方法,特别适用于Vision Transformers(ViTs)。
- 通过权重和奇异向量的稀疏化,显著减少了ViT模型的参数数量,同时保持较高的准确度。
- 提供了严格的数学理论支持,包括描述DNN权重矩阵随机性变化的定理,并通过数值实验验证了该定理。
- 证明了描述DNN损失随权重层随机性减少而减少的定理,展示了损失减少与随机性消除之间的单调关系。
- 该方法可以实现高达30-50%的参数缩减,代表了ViT模型的最新剪枝成果。
- 结果对训练过程中的正则化作用提供了重要的RMT见解。
- 该研究为深度神经网络性能优化和理论分析提供了新的视角和方法。
点此查看论文截图


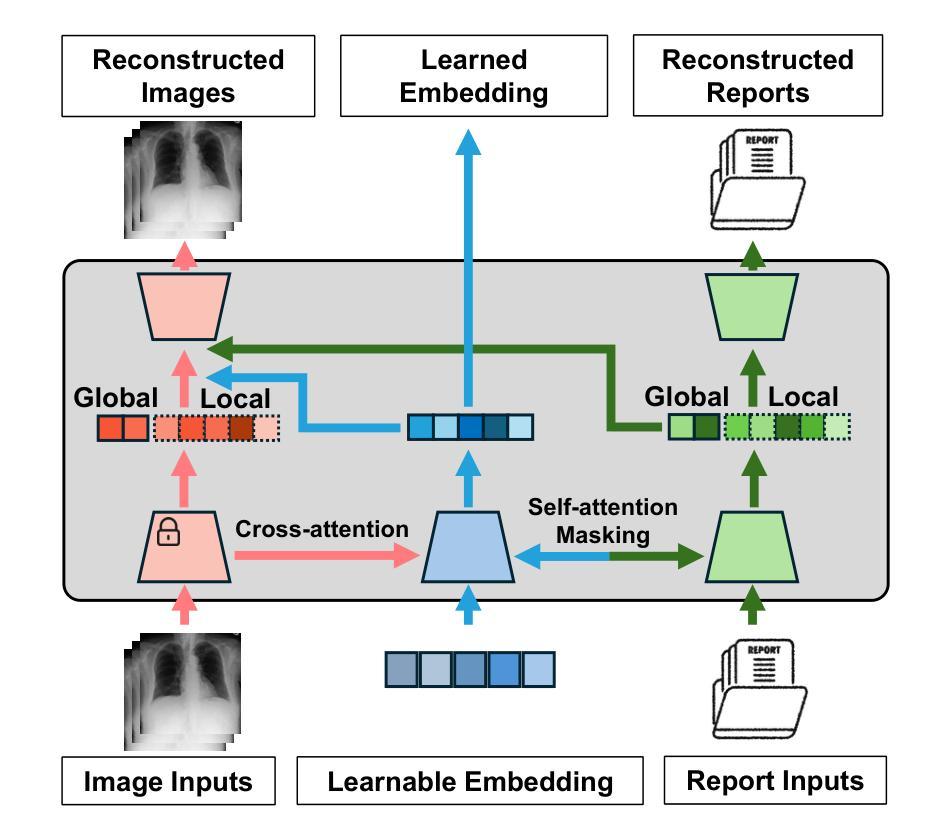
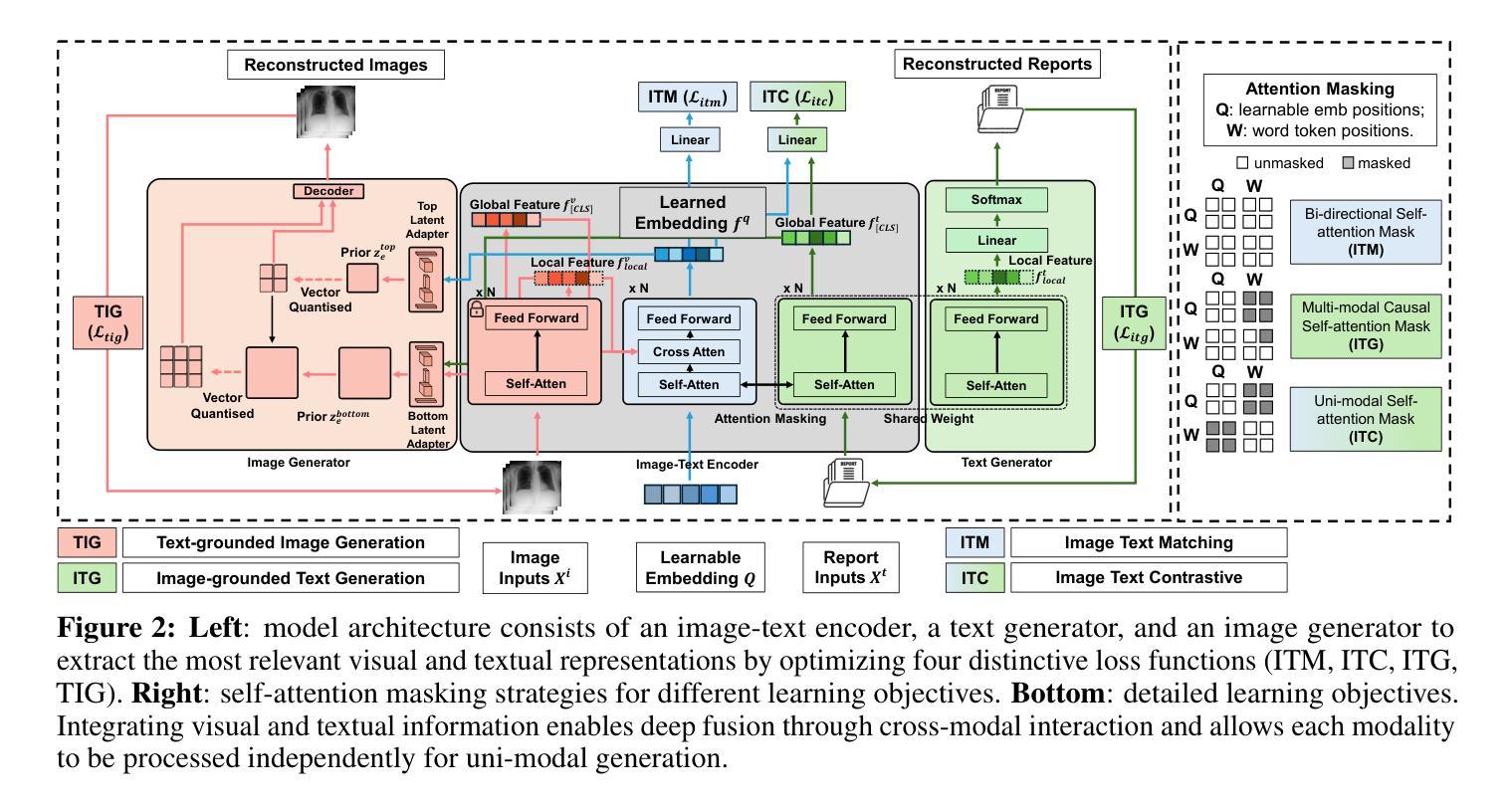
MedUnifier: Unifying Vision-and-Language Pre-training on Medical Data with Vision Generation Task using Discrete Visual Representations
Authors:Ziyang Zhang, Yang Yu, Yucheng Chen, Xulei Yang, Si Yong Yeo
Despite significant progress in Vision-Language Pre-training (VLP), current approaches predominantly emphasize feature extraction and cross-modal comprehension, with limited attention to generating or transforming visual content. This gap hinders the model’s ability to synthesize coherent and novel visual representations from textual prompts, thereby reducing the effectiveness of multi-modal learning. In this work, we propose MedUnifier, a unified VLP framework tailored for medical data. MedUnifier seamlessly integrates text-grounded image generation capabilities with multi-modal learning strategies, including image-text contrastive alignment, image-text matching and image-grounded text generation. Unlike traditional methods that reply on continuous visual representations, our approach employs visual vector quantization, which not only facilitates a more cohesive learning strategy for cross-modal understanding but also enhances multi-modal generation quality by effectively leveraging discrete representations. Our framework’s effectiveness is evidenced by the experiments on established benchmarks, including uni-modal tasks (supervised fine-tuning), cross-modal tasks (image-text retrieval and zero-shot image classification), and multi-modal tasks (medical report generation, image synthesis), where it achieves state-of-the-art performance across various tasks. MedUnifier also offers a highly adaptable tool for a wide range of language and vision tasks in healthcare, marking advancement toward the development of a generalizable AI model for medical applications.
尽管视觉语言预训练(VLP)取得了显著进展,但当前的方法主要侧重于特征提取和跨模态理解,对生成或转换视觉内容的关注有限。这一差距阻碍了模型从文本提示中合成连贯且新颖的视觉表示的能力,从而降低了多模态学习的有效性。在这项工作中,我们提出了针对医疗数据的统一VLP框架MedUnifier。MedUnifier无缝集成了基于文本的图像生成能力与多模态学习策略,包括图像文本对比对齐、图像文本匹配和基于图像的文本生成。与传统的依赖于连续视觉表示的方法不同,我们的方法采用视觉向量量化,这不仅有助于更连贯的跨模态理解学习策略,而且通过有效利用离散表示,提高了多模态生成质量。我们的框架在公认的标准基准测试上的实验证明了其有效性,包括单模态任务(监督微调)、跨模态任务(图像文本检索和零样本图像分类)和多模态任务(医疗报告生成、图像合成)。它在各种任务上实现了最先进的性能。MedUnifier还为医疗领域中的多种语言和视觉任务提供了高度适应的工具,标志着朝着开发用于医疗应用的可推广人工智能模型的发展进步。
论文及项目相关链接
PDF To be pubilshed in CVPR 2025
Summary
本文提出了一种针对医疗数据的统一视觉语言预训练框架MedUnifier。该框架融合了文本驱动图像生成能力与多模态学习策略,包括图像文本对比对齐、图像文本匹配和图像驱动文本生成。与传统的依赖于连续视觉表征的方法不同,MedUnifier采用视觉向量量化,不仅促进了跨模态理解的更连贯学习策略,而且通过有效利用离散表征提高了多模态生成质量。在多个基准测试上,MedUnifier实现了各种任务的最佳性能,并为医疗健康领域中的语言和视觉任务提供了高度可适应的工具,标志着医疗应用通用人工智能模型开发的进步。
Key Takeaways
- 当前视觉语言预训练(VLP)主要关注特征提取和跨模态理解,忽视了视觉内容的生成或转换。
- MedUnifier框架填补了这一空白,融合了文本驱动的图像生成与多模态学习策略。
- MedUnifier采用视觉向量量化,有效促进跨模态理解的连贯学习策略及多模态生成质量的提高。
- 相较于传统方法,MedUnifier在多种基准测试上实现最佳性能,包括单模态、跨模态和多模态任务。
- MedUnifier框架具有高度的适应性,可广泛应用于医疗健康领域的语言和视觉任务。
- MedUnifier为医疗应用通用人工智能模型的开发提供了重要进步。
点此查看论文截图

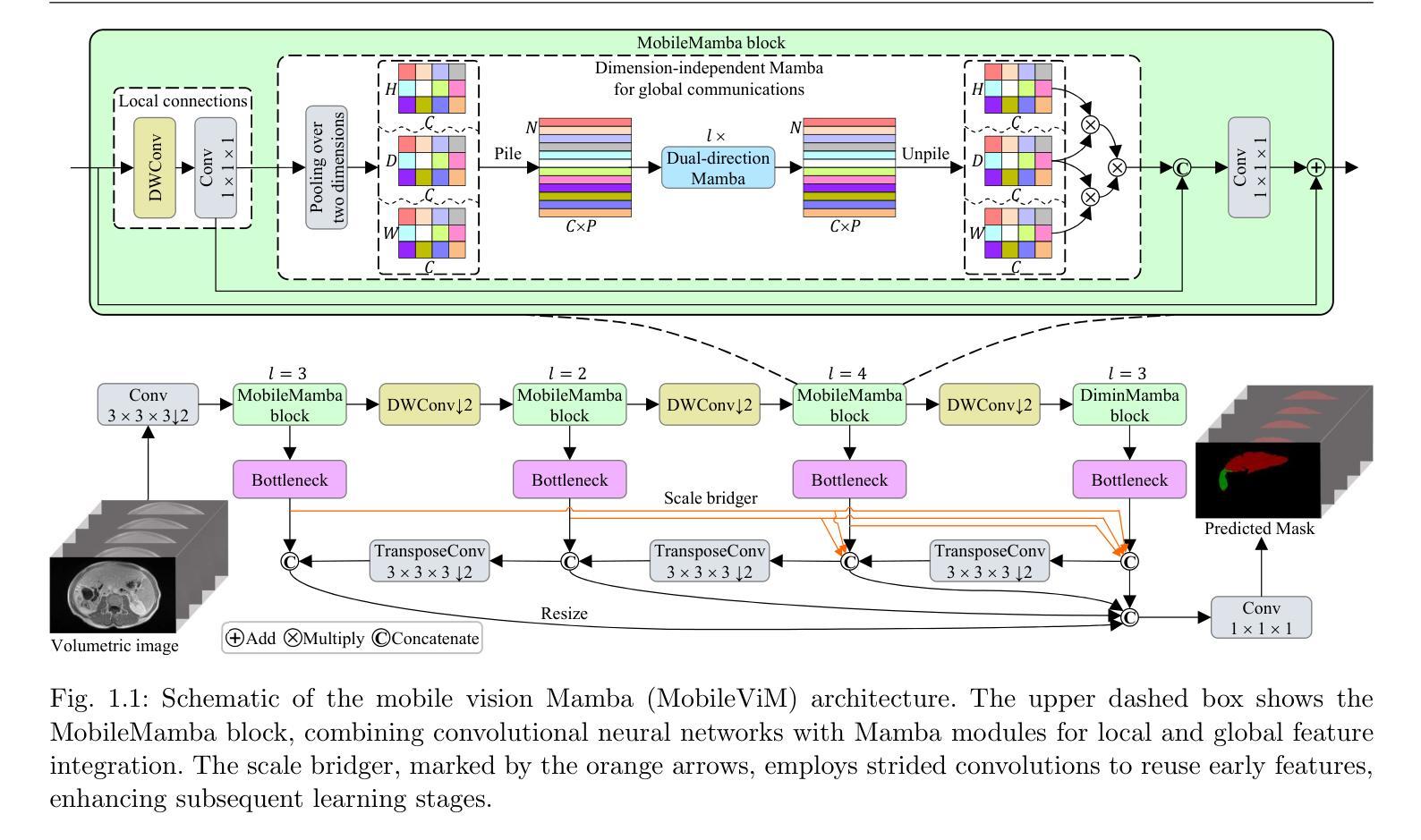
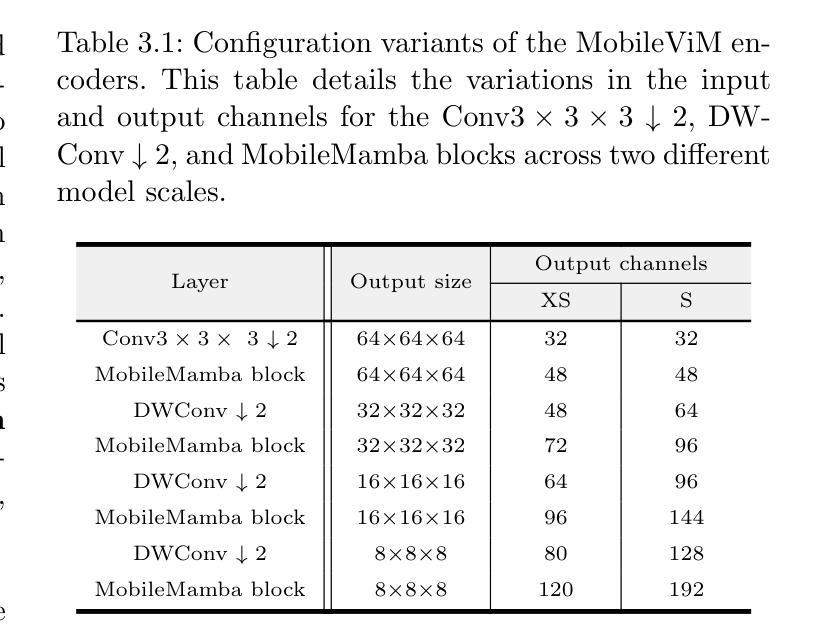
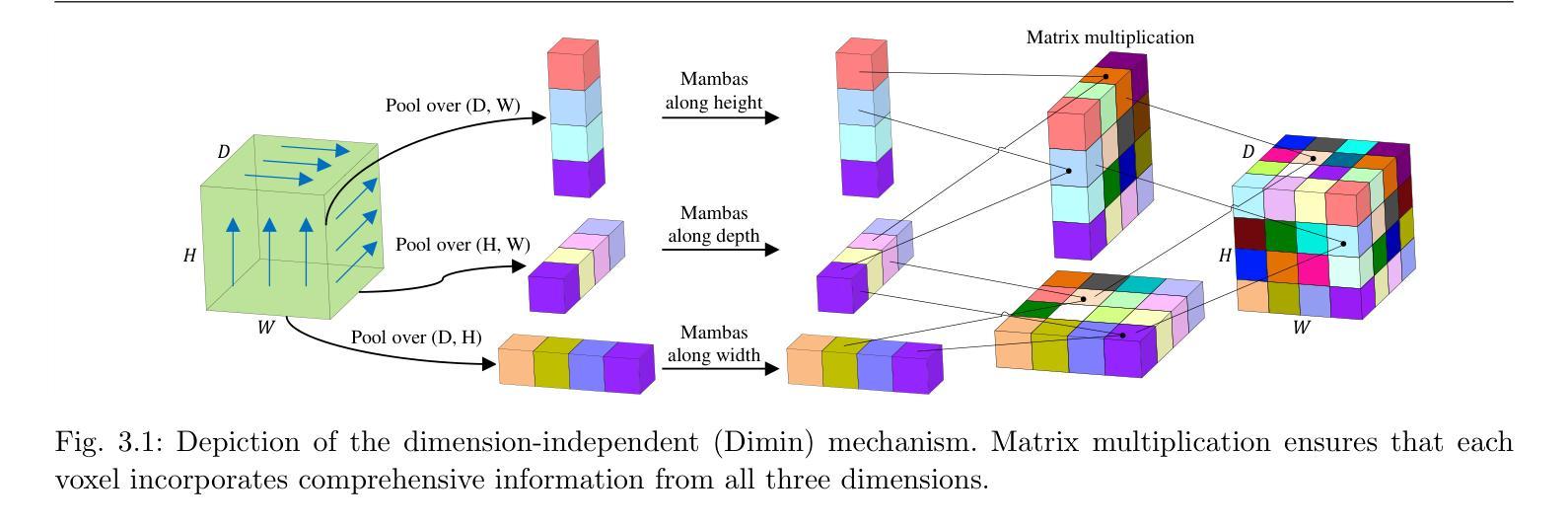
MobileViM: A Light-weight and Dimension-independent Vision Mamba for 3D Medical Image Analysis
Authors:Wei Dai, Jun Liu
Efficient evaluation of three-dimensional (3D) medical images is crucial for diagnostic and therapeutic practices in healthcare. Recent years have seen a substantial uptake in applying deep learning and computer vision to analyse and interpret medical images. Traditional approaches, such as convolutional neural networks (CNNs) and vision transformers (ViTs), face significant computational challenges, prompting the need for architectural advancements. Recent efforts have led to the introduction of novel architectures like the ``Mamba’’ model as alternative solutions to traditional CNNs or ViTs. The Mamba model excels in the linear processing of one-dimensional data with low computational demands. However, Mamba’s potential for 3D medical image analysis remains underexplored and could face significant computational challenges as the dimension increases. This manuscript presents MobileViM, a streamlined architecture for efficient segmentation of 3D medical images. In the MobileViM network, we invent a new dimension-independent mechanism and a dual-direction traversing approach to incorporate with a vision-Mamba-based framework. MobileViM also features a cross-scale bridging technique to improve efficiency and accuracy across various medical imaging modalities. With these enhancements, MobileViM achieves segmentation speeds exceeding 90 frames per second (FPS) on a single graphics processing unit (i.e., NVIDIA RTX 4090). This performance is over 24 FPS faster than the state-of-the-art deep learning models for processing 3D images with the same computational resources. In addition, experimental evaluations demonstrate that MobileViM delivers superior performance, with Dice similarity scores reaching 92.72%, 86.69%, 80.46%, and 77.43% for PENGWIN, BraTS2024, ATLAS, and Toothfairy2 datasets, respectively, which significantly surpasses existing models.
高效评估三维(3D)医学影像对于医疗诊断和治疗实践至关重要。近年来,深度学习和计算机视觉在医学图像分析和解释方面的应用得到了广泛接纳。传统的卷积神经网络(CNN)和视觉变压器(ViT)面临重大的计算挑战,这促使了架构发展的必要性。最近的努力导致了类似“Mamba”模型等新架构的引入,作为对传统CNN或ViT的替代解决方案。Mamba模型在处理一维数据的线性方面表现出色,计算需求较低。然而,Mamba在3D医学图像分析方面的潜力尚未得到充分探索,随着维度的增加,可能会面临重大的计算挑战。本手稿提出了MobileViM,这是一个用于高效分割3D医学影像的精简架构。在MobileViM网络中,我们创造了一种新的维度独立机制和一种双向遍历方法与基于视觉Mamba的框架相结合。MobileViM还采用跨尺度桥接技术,以提高不同医学影像模态的效率和准确性。通过这些增强功能,MobileViM在单个图形处理单元(即NVIDIA RTX 4090)上实现了超过每秒90帧(FPS)的分割速度。此性能比使用相同计算资源的现有深度学习模型处理3D图像的速度快24 FPS以上。此外,实验评估表明,MobileViM的性能卓越,在PENGWIN、BraTS2024、ATLAS和Toothfairy2数据集上的Dice相似度得分分别达到了92.72%、86.69%、80.46%和77.43%,显著超越了现有模型。
论文及项目相关链接
PDF The corresponding author disagrees with the manuscript submitted to arXiv
Summary
本文提出了MobileViM架构,用于高效处理三维医学图像分割。该架构结合了Mamba模型的优点,采用新的维度独立机制和双向遍历方法,并引入了跨尺度桥接技术。MobileViM实现了超过每秒90帧的速度,超越了现有深度学习模型。实验评估显示其在多个数据集上的优异性能。
Key Takeaways
- MobileViM是一个针对三维医学图像分割的高效架构。
- 结合了Mamba模型的优点,并采用新的维度独立机制和双向遍历方法。
- 引入了跨尺度桥接技术以提高效率和准确性。
- MobileViM实现了每秒超过90帧的速度,显著超越了现有模型。
- 在多个数据集上实现了优异的性能,Dice相似度得分高。
- MobileViM架构适用于多种医学成像模态。
点此查看论文截图

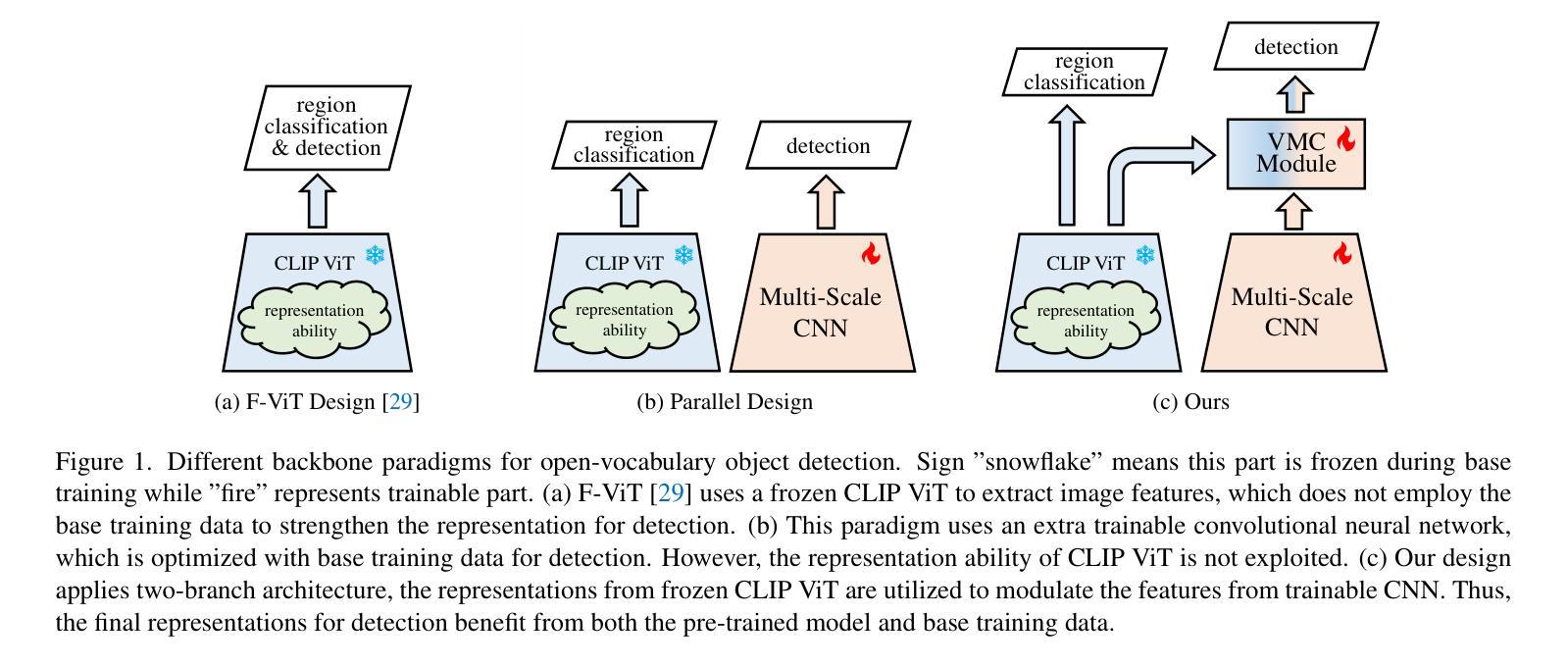
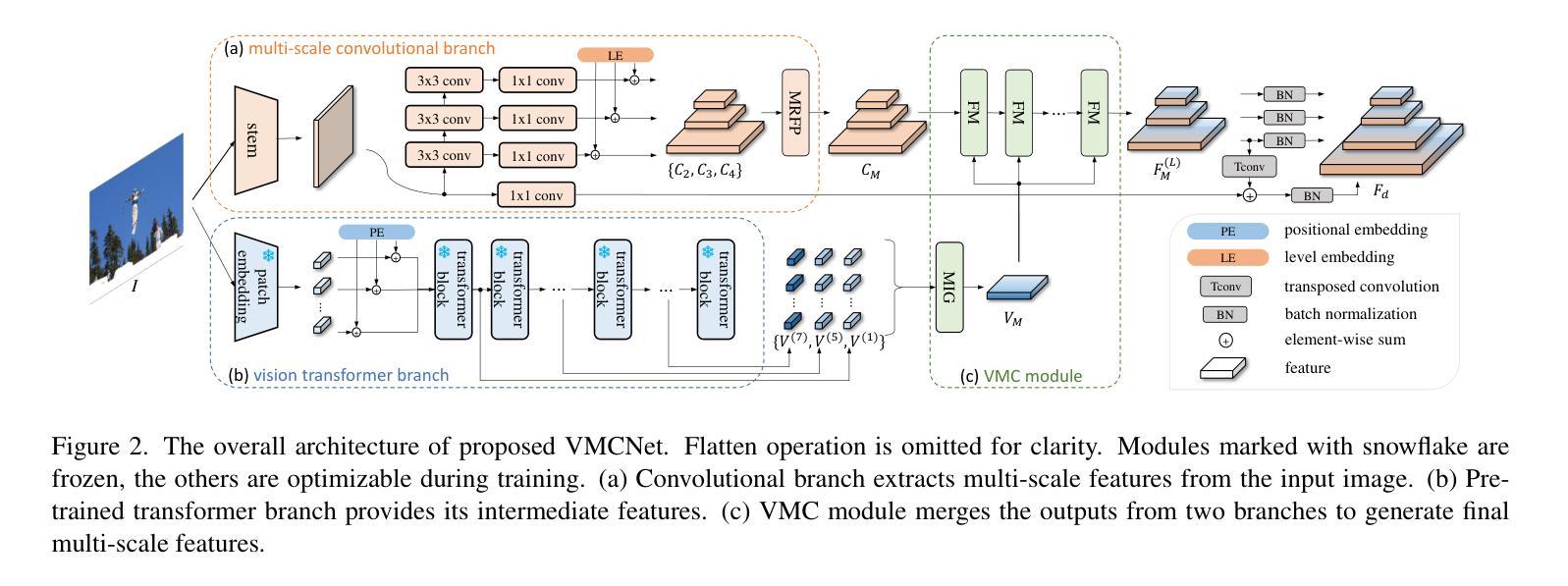
Modulating CNN Features with Pre-Trained ViT Representations for Open-Vocabulary Object Detection
Authors:Xiangyu Gao, Yu Dai, Benliu Qiu, Lanxiao Wang, Heqian Qiu, Hongliang Li
Owing to large-scale image-text contrastive training, pre-trained vision language model (VLM) like CLIP shows superior open-vocabulary recognition ability. Most existing open-vocabulary object detectors attempt to utilize the pre-trained VLMs to attain generalized representation. F-ViT uses the pre-trained visual encoder as the backbone network and freezes it during training. However, its frozen backbone doesn’t benefit from the labeled data to strengthen the representation for detection. Therefore, we propose a novel two-branch backbone network, named as \textbf{V}iT-Feature-\textbf{M}odulated Multi-Scale \textbf{C}onvolutional Network (VMCNet), which consists of a trainable convolutional branch, a frozen pre-trained ViT branch and a VMC module. The trainable CNN branch could be optimized with labeled data while the frozen pre-trained ViT branch could keep the representation ability derived from large-scale pre-training. Then, the proposed VMC module could modulate the multi-scale CNN features with the representations from ViT branch. With this proposed mixed structure, the detector is more likely to discover objects of novel categories. Evaluated on two popular benchmarks, our method boosts the detection performance on novel category and outperforms state-of-the-art methods. On OV-COCO, the proposed method achieves 44.3 AP${50}^{\mathrm{novel}}$ with ViT-B/16 and 48.5 AP${50}^{\mathrm{novel}}$ with ViT-L/14. On OV-LVIS, VMCNet with ViT-B/16 and ViT-L/14 reaches 27.8 and 38.4 mAP$_{r}$.
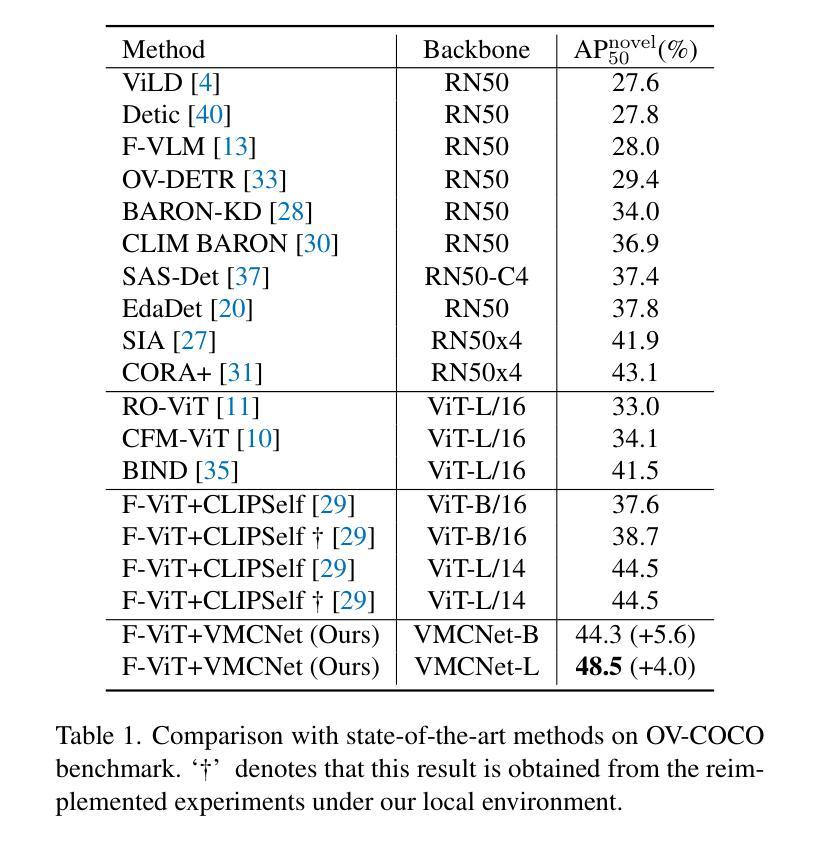
由于大规模图文对比训练,预训练的视觉语言模型(如CLIP)表现出卓越的开词汇识别能力。现有的大多数开放词汇对象检测器都试图利用预训练的VLMs来获得通用表示。F-ViT使用预训练的视觉编码器作为主干网络,并在训练过程中冻结它。然而,其冻结的主干网络无法从标记数据中受益,以增强检测表示。因此,我们提出了一种新的双分支主干网络,名为ViT特征调制多尺度卷积网络(VMCNet),它由一个可训练卷积分支、一个冻结的预训练ViT分支和VMC模块组成。可训练的CNN分支可以利用标记数据进行优化,而冻结的预训练ViT分支可以保持从大规模预训练中学到的表示能力。然后,所提出的VMC模块可以调制来自ViT分支的多尺度CNN特征。通过这种混合结构,检测器更有可能发现新型类别的对象。在两个流行的基准测试上进行评估,我们的方法在新型类别检测性能上有所提升,并超越了最新技术方法。在OV-COCO上,所提出的方法使用ViT-B/16实现了44.3的AP50novel,使用ViT-L/14实现了48.5的AP50novel。在OV-LVIS上,VMCNet与ViT-B/16和ViT-L/14分别达到了27.8和38.4的mAPr。
论文及项目相关链接
Summary
本文介绍了一种名为VMCNet的新型两分支骨干网络,用于开放词汇表对象检测。该网络结合了预训练的视觉语言模型(VLM)和卷积神经网络(CNN)的优势,通过混合结构提高检测性能。在大型预训练的基础上,VMCNet能够在新型类别对象检测任务中取得优异性能。
Key Takeaways
- 利用大规模图像文本对比训练,预训练的视觉语言模型(VLM)如CLIP展现出优越的开放词汇识别能力。
- F-ViT使用预训练视觉编码器作为骨干网络,但在训练过程中冻结该网络,无法从标记数据中获益以增强检测表示。
- 提出了一种新型的两分支骨干网络VMCNet,包括可训练的卷积分支、冻结的预训练ViT分支和VMC模块。
- 可训练的CNN分支可优化标记数据,而冻结的预训练ViT分支则保持从大规模预训练得到的表示能力。
- VMC模块能够调制多尺度CNN特征与ViT分支的表示,使检测器更可能发现新型类别的对象。
- 在两个流行基准上的评估表明,该方法在新型类别检测性能方面有所提升,并优于现有先进技术。
点此查看论文截图


Pathfinder for Low-altitude Aircraft with Binary Neural Network
Authors:Kaijie Yin, Tian Gao, Hui Kong
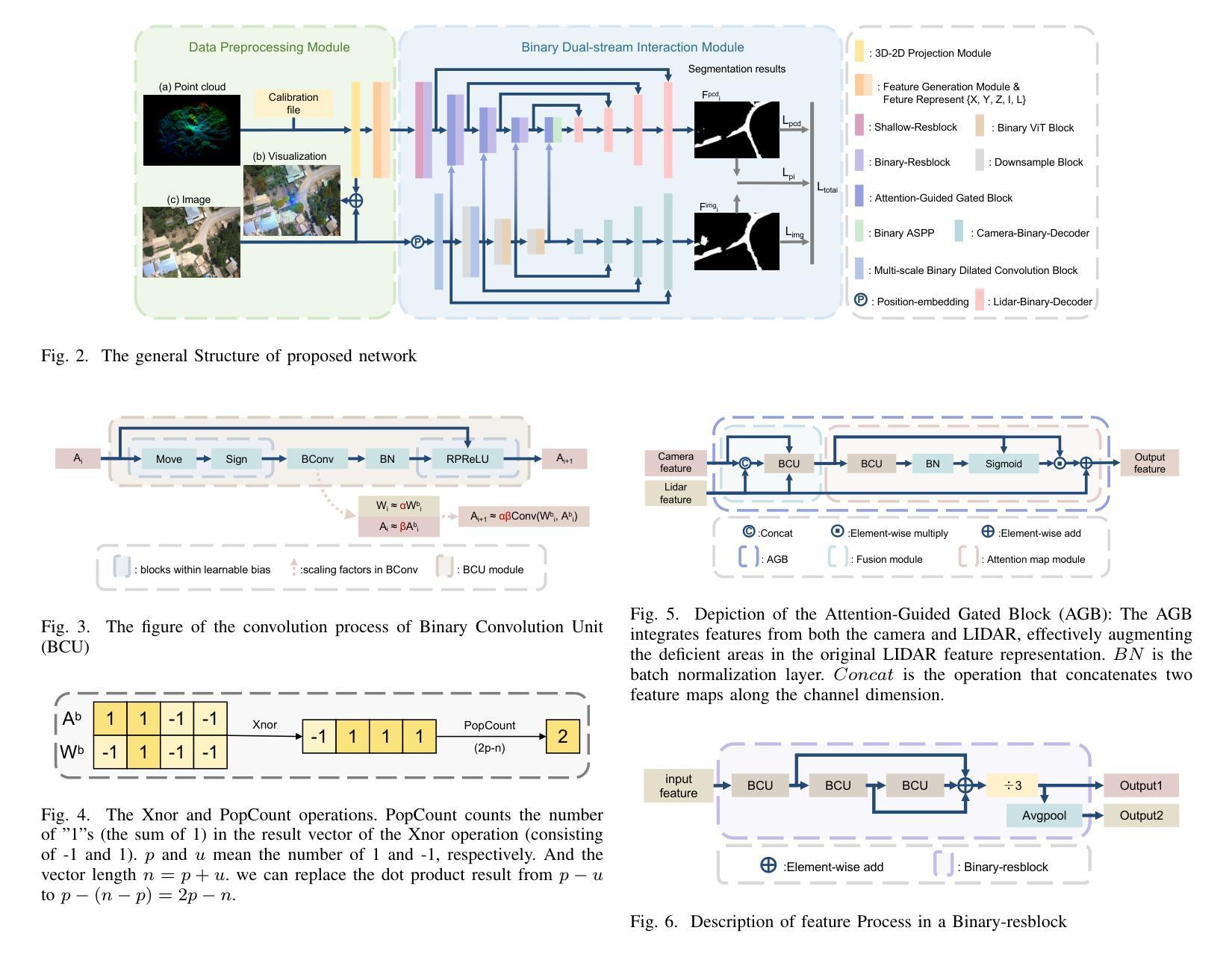
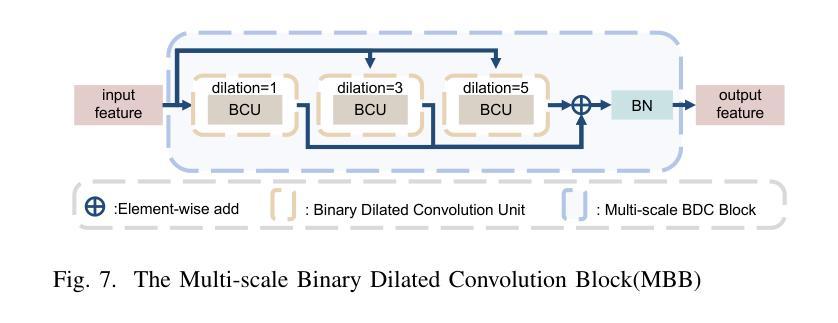
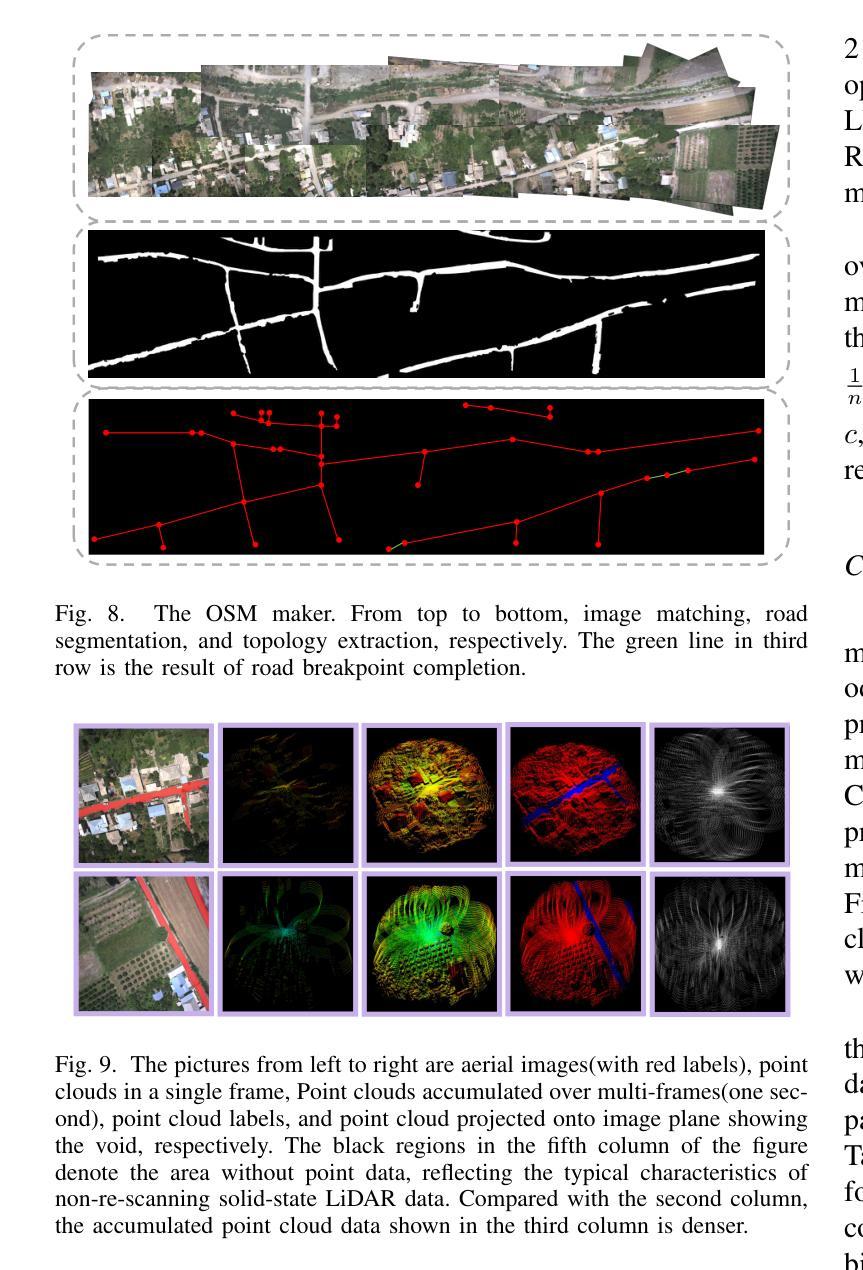
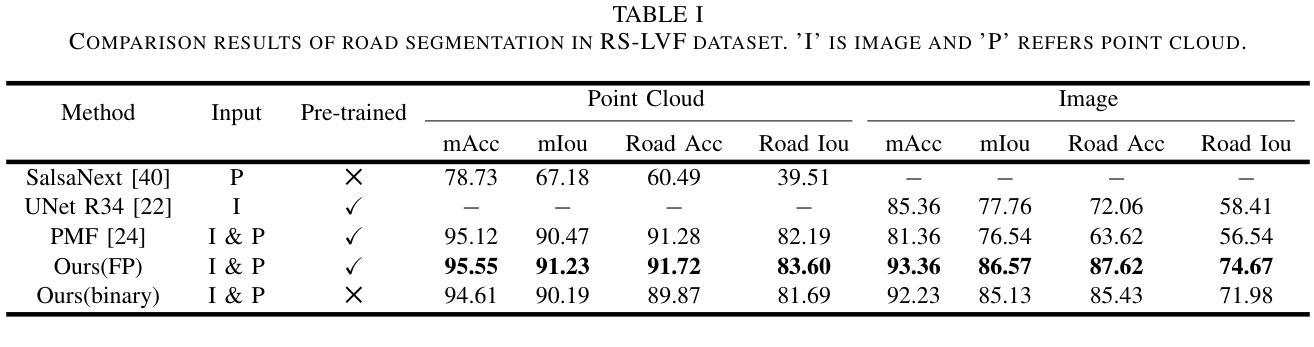
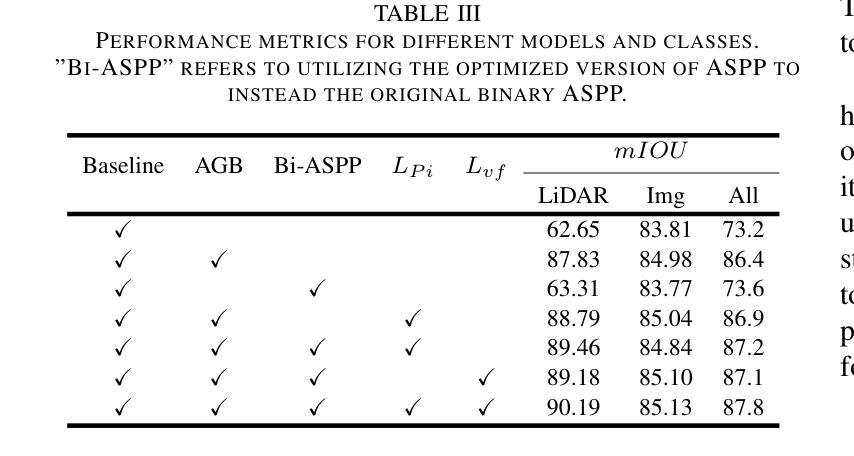
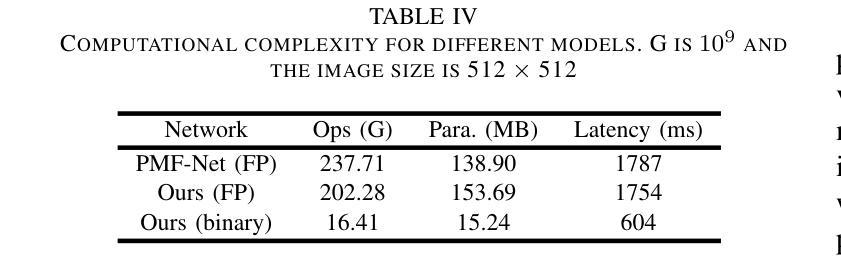
A prior global topological map (e.g., the OpenStreetMap, OSM) can boost the performance of autonomous mapping by a ground mobile robot. However, the prior map is usually incomplete due to lacking labeling in partial paths. To solve this problem, this paper proposes an OSM maker using airborne sensors carried by low-altitude aircraft, where the core of the OSM maker is a novel efficient pathfinder approach based on LiDAR and camera data, i.e., a binary dual-stream road segmentation model. Specifically, a multi-scale feature extraction based on the UNet architecture is implemented for images and point clouds. To reduce the effect caused by the sparsity of point cloud, an attention-guided gated block is designed to integrate image and point-cloud features. To optimize the model for edge deployment that significantly reduces storage footprint and computational demands, we propose a binarization streamline to each model component, including a variant of vision transformer (ViT) architecture as the encoder of the image branch, and new focal and perception losses to optimize the model training. The experimental results on two datasets demonstrate that our pathfinder method achieves SOTA accuracy with high efficiency in finding paths from the low-level airborne sensors, and we can create complete OSM prior maps based on the segmented road skeletons. Code and data are available at: \href{https://github.com/IMRL/Pathfinder}{https://github.com/IMRL/Pathfinder}.
先前的全局拓扑地图(例如,OpenStreetMap,OSM)可以通过地面移动机器人提升自主测绘的性能。然而,由于部分路径缺乏标注,先前的地图通常是不完整的。为了解决这一问题,本文提出了一种使用低空飞机携带的机载传感器的OSM制作方法。该OSM制作的核心是一种基于激光雷达和相机数据的新型高效路径查找方法,即二进制双流道路分割模型。具体而言,基于UNet架构实现了多尺度特征提取,用于图像和点云。为了减少点云稀疏造成的影响,设计了一个注意力引导的门控块来整合图像和点云特征。为了优化模型在边缘部署,显著降低存储空间和计算需求,我们对模型的每个组件都进行了二值化处理,包括使用变种视觉转换器(ViT)架构作为图像分支的编码器,以及新的焦点和感知损失来优化模型训练。在两个数据集上的实验结果表明,我们的路径查找方法实现了高效且高精度的路径查找,从低级别机载传感器出发,并可以基于分割的道路骨架构建完整的OSM先验地图。相关代码和数据可通过以下链接获取:https://github.com/IMRL/Pathfinder。
论文及项目相关链接
Summary
基于全球拓扑地图(如OpenStreetMap,OSM)可以显著提升地面移动机器人的自主绘图性能。但先前地图常常因为部分路径缺乏标注而不完整。本文提出了一种使用低空飞机携带的机载传感器的OSM制作方法,其核心是一种基于激光雷达和相机数据的新型高效路径查找方法,即二进制双流道路分割模型。该研究实现了基于UNet架构的多尺度特征提取用于图像和点云。为降低点云稀疏造成的影响,设计了注意力引导门控块来整合图像和点云特征。为优化模型在边缘部署时的存储和计算需求,该研究对每个模型组件进行二进制化流线处理,包括使用视觉变压器(ViT)架构作为图像分支的编码器,以及新的焦点和感知损失来优化模型训练。实验结果表明,该方法在寻找路径方面达到了高准确率和高效率,并可根据分割的道路骨架生成完整的OSM先验地图。
Key Takeaways
- 全球拓扑地图(如OpenStreetMap)能增强自主绘图性能。
- 现有地图因部分路径缺乏标注而不完整。
- 提出使用低空飞机携带的机载传感器制作OSM地图。
- 采用基于LiDAR和相机数据的新型高效路径查找方法。
- 实现多尺度特征提取,整合图像和点云信息。
- 通过注意力引导门控块解决点云稀疏问题。
点此查看论文截图