⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-11 更新
LLaVE: Large Language and Vision Embedding Models with Hardness-Weighted Contrastive Learning
Authors:Zhibin Lan, Liqiang Niu, Fandong Meng, Jie Zhou, Jinsong Su
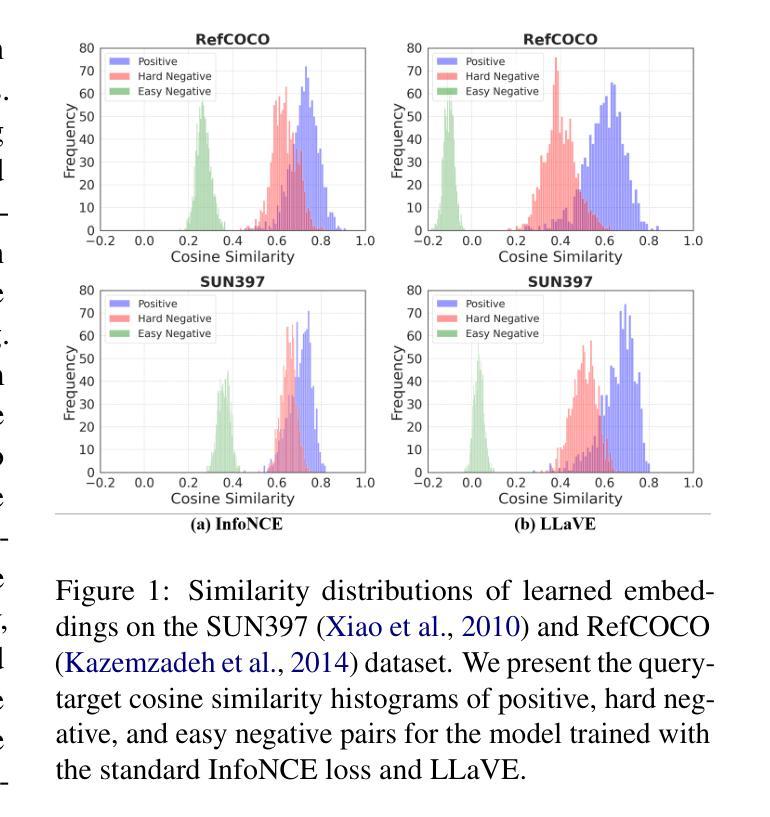
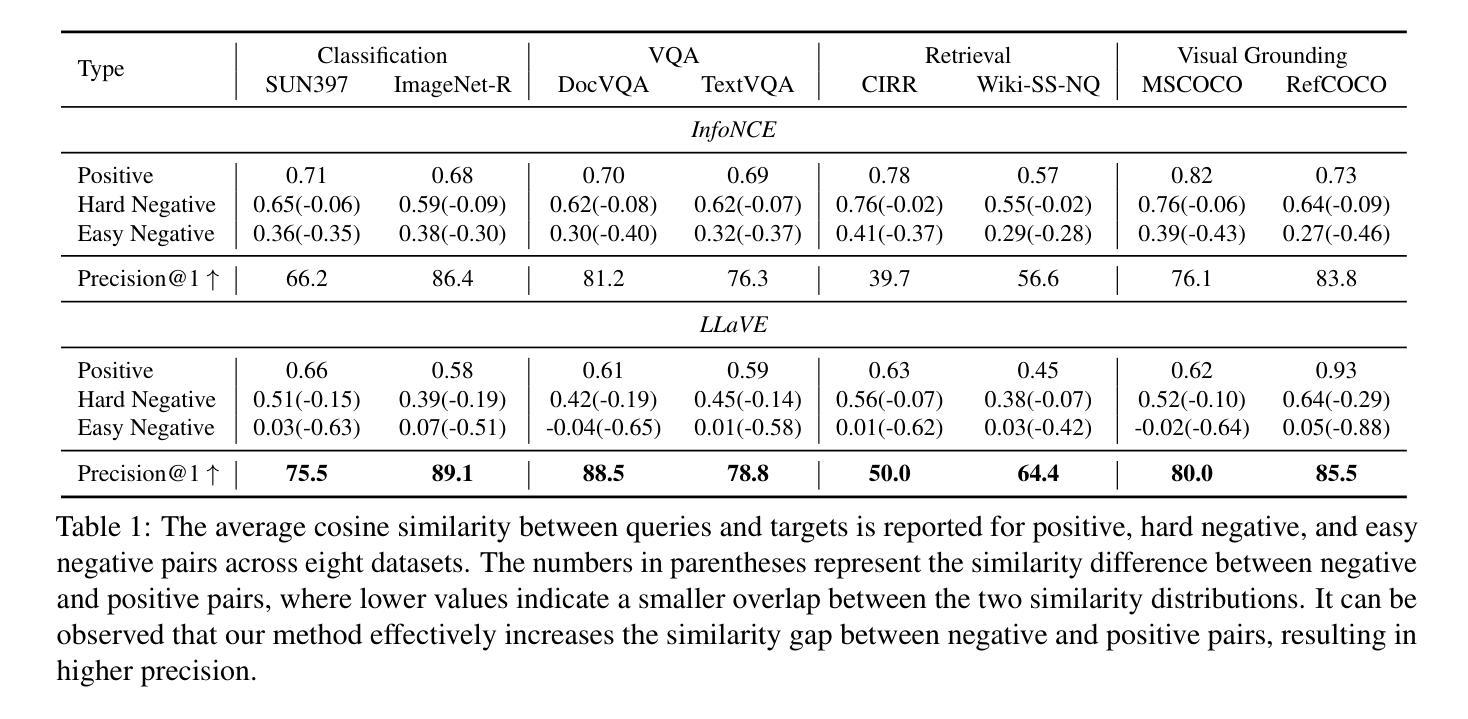
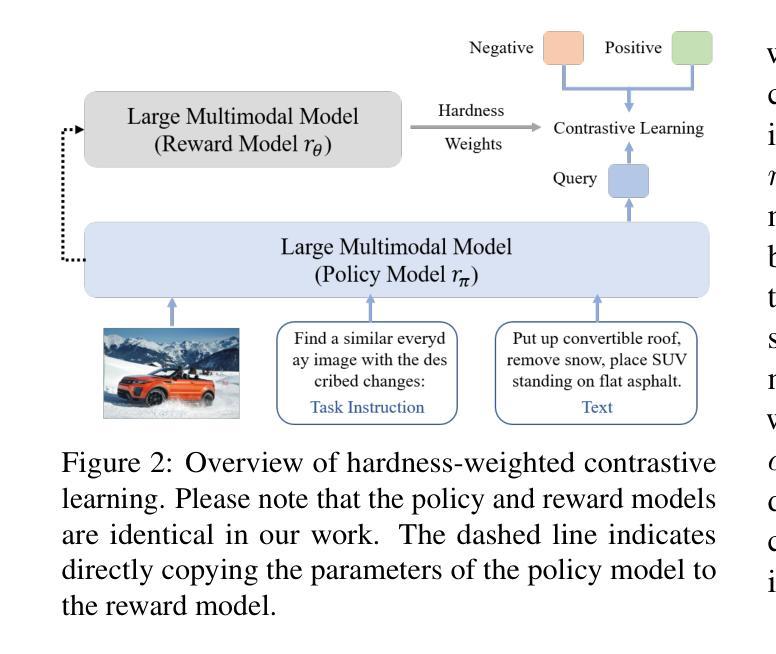
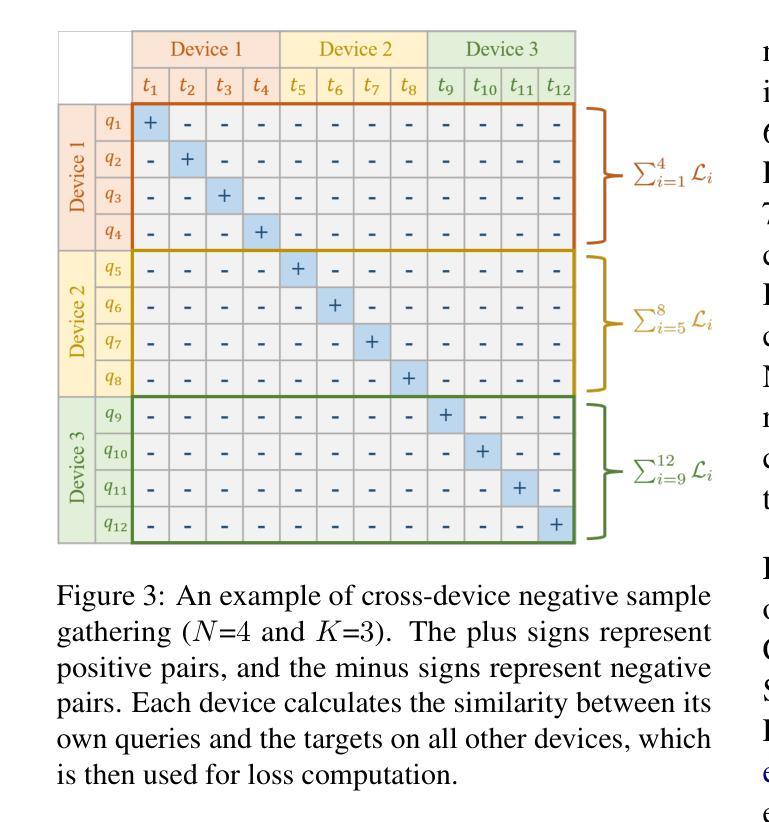
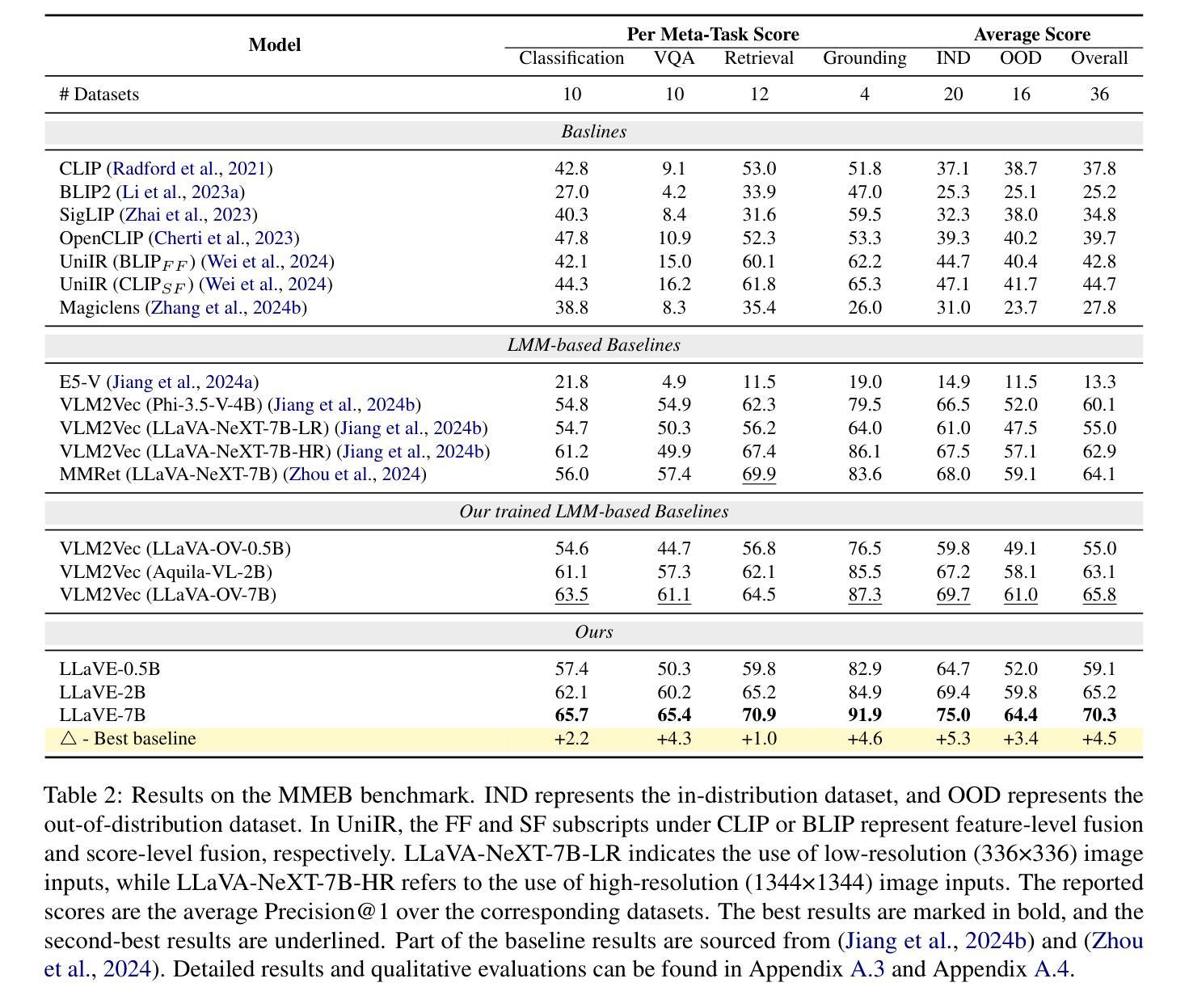
Universal multimodal embedding models play a critical role in tasks such as interleaved image-text retrieval, multimodal RAG, and multimodal clustering. However, our empirical results indicate that existing LMM-based embedding models trained with the standard InfoNCE loss exhibit a high degree of overlap in similarity distribution between positive and negative pairs, making it challenging to distinguish hard negative pairs effectively. To deal with this issue, we propose a simple yet effective framework that dynamically improves the embedding model’s representation learning for negative pairs based on their discriminative difficulty. Within this framework, we train a series of models, named LLaVE, and evaluate them on the MMEB benchmark, which covers 4 meta-tasks and 36 datasets. Experimental results show that LLaVE establishes stronger baselines that achieve state-of-the-art (SOTA) performance while demonstrating strong scalability and efficiency. Specifically, LLaVE-2B surpasses the previous SOTA 7B models, while LLaVE-7B achieves a further performance improvement of 6.2 points. Although LLaVE is trained on image-text data, it can generalize to text-video retrieval tasks in a zero-shot manner and achieve strong performance, demonstrating its remarkable potential for transfer to other embedding tasks.
通用多模态嵌入模型在交互图像文本检索、多模态RAG和多模态聚类等任务中扮演着至关重要的角色。然而,我们的实验结果表明,采用标准InfoNCE损失训练的现有基于LMM的嵌入模型在正负样本对的相似性分布上存在较高程度的重叠,这使得有效区分硬负样本对具有挑战性。为了解决这个问题,我们提出了一种简单有效的框架,该框架根据负样本的判别难度动态改进嵌入模型的特征表示学习。在该框架下,我们训练了一系列名为LLaVE的模型,并在涵盖4个元任务和36个数据集的MMEB基准测试集上进行评估。实验结果表明,LLaVE建立了更强的基线,实现了最先进的性能,同时展现了强大的可扩展性和效率。具体来说,LLaVE-2B超越了之前的7B模型SOTA,而LLaVE-7B进一步提高了性能达6.2点。尽管LLaVE是在图像文本数据上训练的,但它可以零样本的方式泛化到文本视频检索任务,并表现出强大的性能,显示出其在其他嵌入任务中的显著潜力。
论文及项目相关链接
PDF Preprint
Summary
本文介绍了通用多模态嵌入模型在多任务中的关键作用,如图像文本检索、多模态RAG和多模态聚类等。通过实验发现,基于现有LMM的嵌入模型使用标准的InfoNCE损失训练存在正负样本相似度分布重叠高的问题,难以有效区分硬负样本对。为此,提出一种简单有效的框架,根据判别难度动态改进负样本对的嵌入模型表示学习。在该框架下训练的LLaVE系列模型在MMEB基准测试上表现优异,实现了业界最佳水平,并展现出强大的可扩展性和效率。LLaVE模型在图像文本数据上训练,但可零样本泛化到文本视频检索任务,表现出卓越的可迁移性潜力。
Key Takeaways
- 通用多模态嵌入模型在多项任务中表现关键,如图像文本检索、多模态RAG和多模态聚类。
- 现有基于LMM的嵌入模型使用InfoNCE损失训练存在正负样本相似度分布重叠问题。
- 提出一种框架能够动态改进嵌入模型对负样本对的表示学习,基于其判别难度。
- LLaVE系列模型在MMEB基准测试上表现优异,达到业界最佳水平,并展示强大的可扩展性和效率。
- LLaVE模型在图像文本数据上训练,可零样本泛化至文本视频检索任务。
- LLaVE模型的出色表现证明了其对于其他嵌入任务的巨大潜力。
点此查看论文截图