⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-11 更新
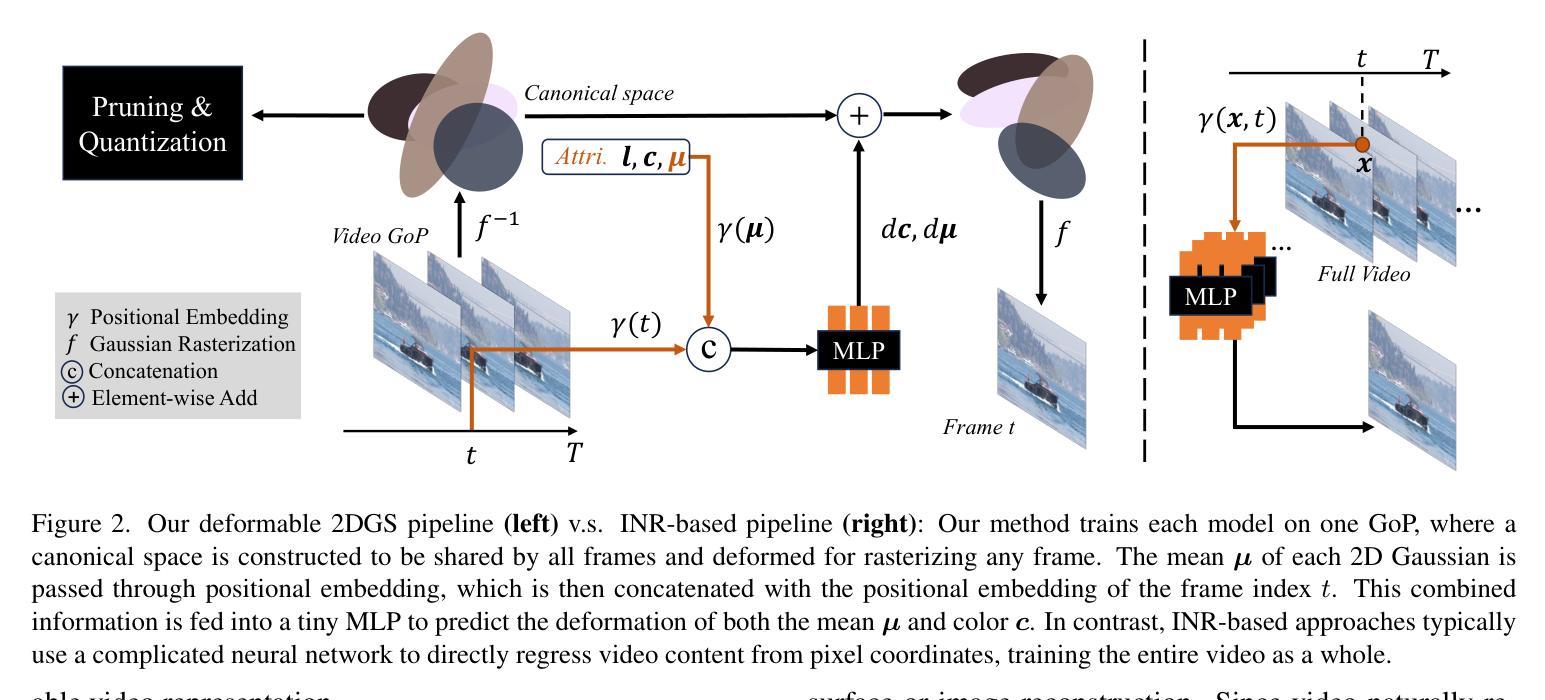
D2GV: Deformable 2D Gaussian Splatting for Video Representation in 400FPS
Authors:Mufan Liu, Qi Yang, Miaoran Zhao, He Huang, Le Yang, Zhu Li, Yiling Xu
Implicit Neural Representations (INRs) have emerged as a powerful approach for video representation, offering versatility across tasks such as compression and inpainting. However, their implicit formulation limits both interpretability and efficacy, undermining their practicality as a comprehensive solution. We propose a novel video representation based on deformable 2D Gaussian splatting, dubbed D2GV, which aims to achieve three key objectives: 1) improved efficiency while delivering superior quality; 2) enhanced scalability and interpretability; and 3) increased friendliness for downstream tasks. Specifically, we initially divide the video sequence into fixed-length Groups of Pictures (GoP) to allow parallel training and linear scalability with video length. For each GoP, D2GV represents video frames by applying differentiable rasterization to 2D Gaussians, which are deformed from a canonical space into their corresponding timestamps. Notably, leveraging efficient CUDA-based rasterization, D2GV converges fast and decodes at speeds exceeding 400 FPS, while delivering quality that matches or surpasses state-of-the-art INRs. Moreover, we incorporate a learnable pruning and quantization strategy to streamline D2GV into a more compact representation. We demonstrate D2GV’s versatility in tasks including video interpolation, inpainting and denoising, underscoring its potential as a promising solution for video representation. Code is available at: https://github.com/Evan-sudo/D2GV.
隐式神经表示(INR)已经成为一种强大的视频表示方法,它可以在压缩和补全等任务中发挥出色的通用性。然而,其隐式表示形式限制了可解释性和有效性,破坏了它们作为全面解决方案的实用性。我们提出了一种基于二维高斯贴图可变形技术的新型视频表示方法,称为D2GV,旨在实现三个关键目标:1)提高效率同时保证卓越质量;2)增强可扩展性和可解释性;以及3)增强下游任务的友好性。具体来说,我们首先将视频序列划分为固定长度的图像组(GoP),以实现并行训练和线性可扩展的视频长度。对于每个GoP,D2GV通过应用二维高斯的可微栅格化来表示视频帧,这些帧从规范空间变形到对应的时间戳。值得注意的是,借助高效的CUDA基于栅格化的方法,D2GV能够快速收敛,解码速度超过每秒400帧,同时提供与最先进的INR相匹配或超越其的质量。此外,我们引入了一种可学习的剪枝和量化策略,以简化D2GV为更紧凑的表示形式。我们在视频插值、补全和去噪等任务中展示了D2GV的通用性,突显其在视频表示方面的潜力。相关代码可通过以下链接获取:https://github.com/Evan-sudo/D2GV。
论文及项目相关链接
摘要
基于二维高斯点云变形技术的视频表示法(D2GV)被提出,旨在解决隐式神经表示(INR)在视频表示中的局限性问题。D2GV通过固定长度的图像组(GoP)进行视频序列分割,并采用可微分的二维高斯点云变形技术来实现视频帧的表示。该方法具有高效性、高质量、可解释性强以及下游任务友好性等优点。此外,D2GV还具有快速收敛和高速解码的能力,同时采用可学习的剪枝和量化策略来优化表示。D2GV在视频插值、修复和去噪等任务中展示了其潜力。
关键见解
- 隐式神经表示(INR)虽然为视频表示提供了强大的方法,但其隐式特性限制了其解释性和有效性。
- 提出了基于二维高斯点云变形的视频表示法(D2GV),以改进效率、质量、可解释性和下游任务友好性。
- D2GV通过将视频序列划分为固定长度的图像组(GoP)来实现并行训练和线性可扩展性。
- D2GV通过使用可微分的二维高斯点云变形技术来表示视频帧。
- D2GV具有快速收敛和高速解码的能力,并且可以通过结合可学习的剪枝和量化策略进行优化。
- D2GV在视频插值、修复和去噪等任务中展示了其有效性和潜力。
- D2GV的代码已公开可用,为进一步研究和应用提供了基础。
点此查看论文截图



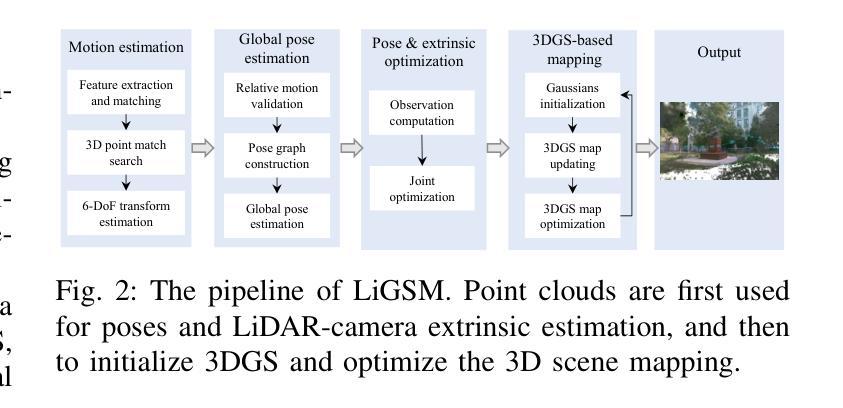
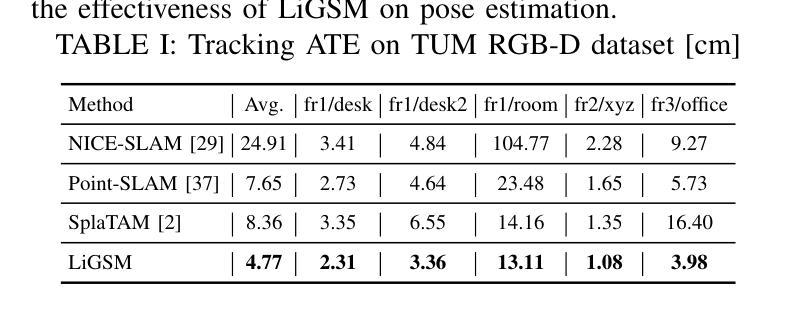
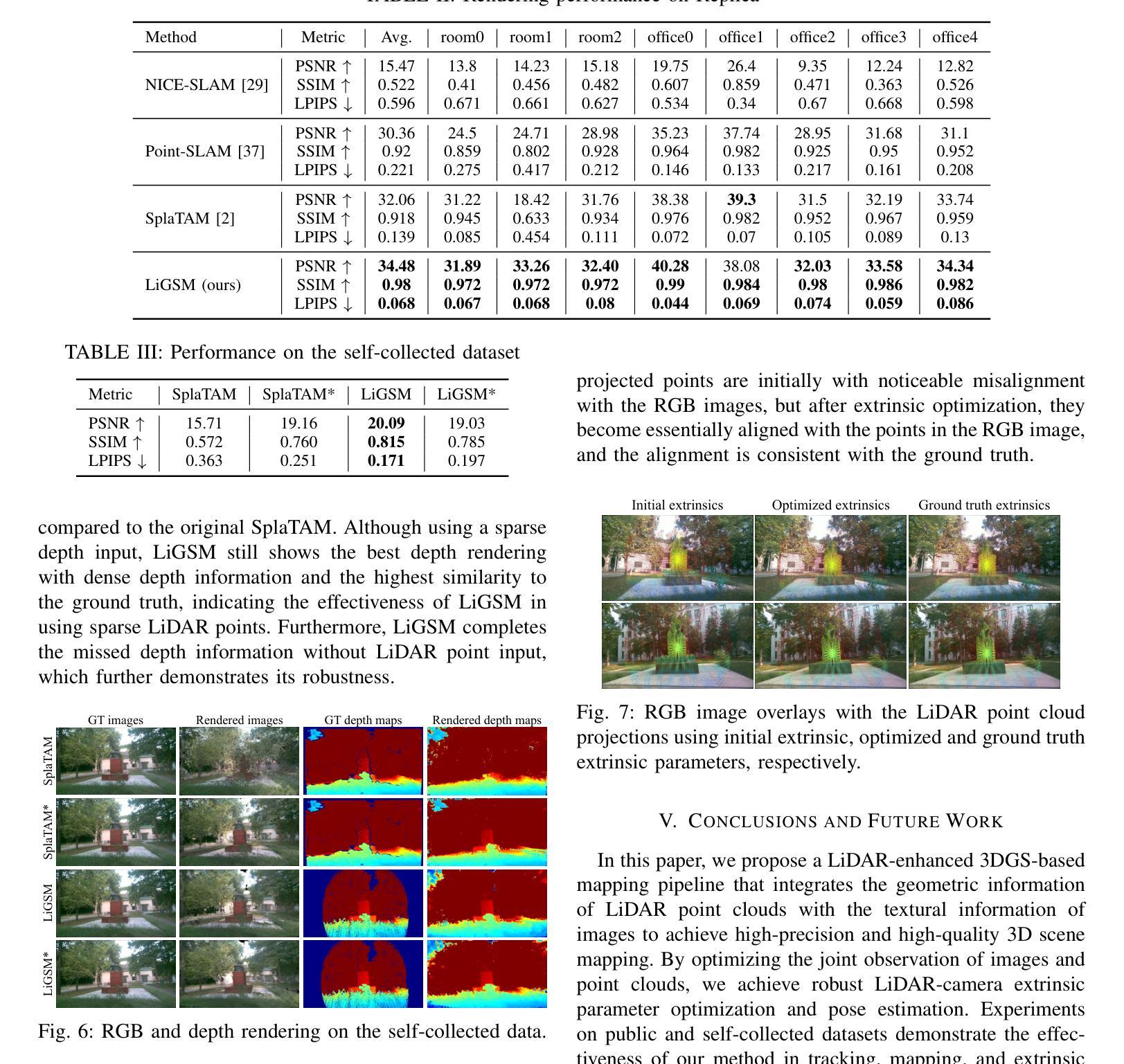
LiDAR-enhanced 3D Gaussian Splatting Mapping
Authors:Jian Shen, Huai Yu, Ji Wu, Wen Yang, Gui-Song Xia
This paper introduces LiGSM, a novel LiDAR-enhanced 3D Gaussian Splatting (3DGS) mapping framework that improves the accuracy and robustness of 3D scene mapping by integrating LiDAR data. LiGSM constructs joint loss from images and LiDAR point clouds to estimate the poses and optimize their extrinsic parameters, enabling dynamic adaptation to variations in sensor alignment. Furthermore, it leverages LiDAR point clouds to initialize 3DGS, providing a denser and more reliable starting points compared to sparse SfM points. In scene rendering, the framework augments standard image-based supervision with depth maps generated from LiDAR projections, ensuring an accurate scene representation in both geometry and photometry. Experiments on public and self-collected datasets demonstrate that LiGSM outperforms comparative methods in pose tracking and scene rendering.
本文介绍了LiGSM,这是一种新型的激光雷达增强型三维高斯模糊映射(3DGS)框架。它通过集成激光雷达数据提高了三维场景映射的准确性和鲁棒性。LiGSM通过图像和激光雷达点云构建联合损失来估计姿态并优化其外在参数,从而实现传感器对齐变化的动态适应。此外,它利用激光雷达点云进行初始化三维高斯模糊映射,与稀疏的SfM点相比,提供了更密集、更可靠的起点。在场景渲染方面,该框架增加了基于激光雷达投影生成的深度图的标准图像监督,确保场景在几何和光度方面的准确表示。在公共和自我收集的数据集上的实验表明,LiGSM在姿态跟踪和场景渲染方面的表现优于比较方法。
论文及项目相关链接
PDF Accepted by ICRA 2025
Summary
本文介绍了LiGSM,一种新型基于激光雷达增强的3D高斯喷涂(3DGS)映射框架。它通过集成激光雷达数据提高了3D场景映射的准确性和稳健性。LiGSM通过构建图像和激光雷达点云的联合损失来估计姿态并优化其外在参数,实现对传感器对齐变化的动态适应。此外,它利用激光雷达点云初始化3DGS,与稀疏SfM点相比,提供更密集、更可靠的起始点。在场景渲染方面,该框架增加了基于激光雷达投影生成的深度图的标准图像监督,确保场景在几何和光度上的准确表示。在公共和自我收集的数据集上的实验表明,LiGSM在姿态跟踪和场景渲染方面的性能优于比较方法。
Key Takeaways
- LiGSM是一个基于激光雷达增强的3D高斯喷涂(3DGS)映射框架,旨在提高3D场景映射的准确性和稳健性。
- 通过集成激光雷达数据,LiGSM构建联合损失来估计姿态并优化外在参数,实现传感器对齐变化的动态适应。
- LiGSM利用激光雷达点云初始化3DGS,提供比稀疏SfM点更密集、更可靠的起始点。
- 在场景渲染中,LiGSM结合了图像和激光雷达生成的深度图,确保场景的准确表示。
- LiGSM框架在公共和自我收集的数据集上进行了实验验证,展示了其在姿态跟踪和场景渲染方面的优越性。
- LiGSM框架能够动态适应不同的传感器对齐变化,提高了3D场景映射的鲁棒性。
点此查看论文截图



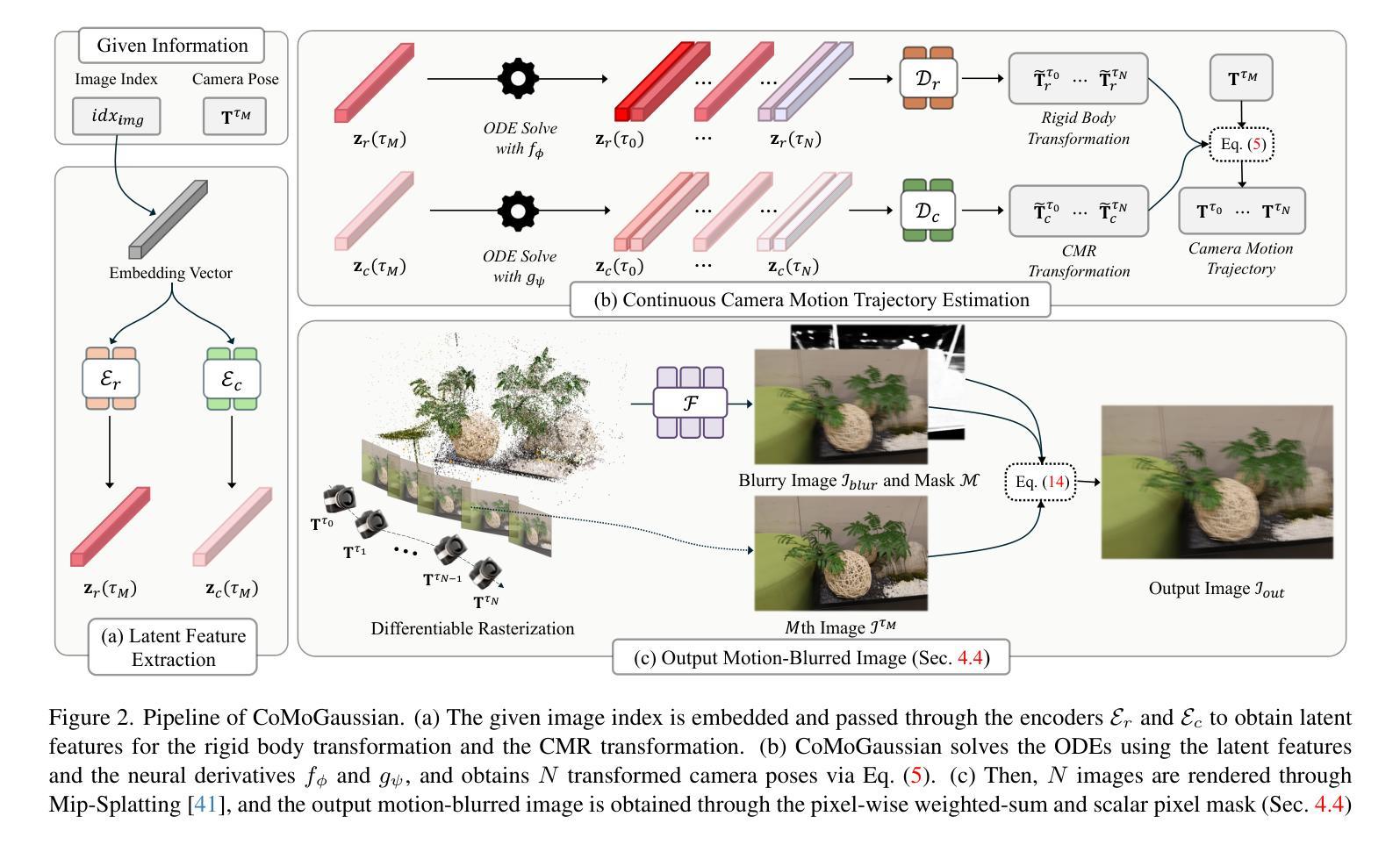
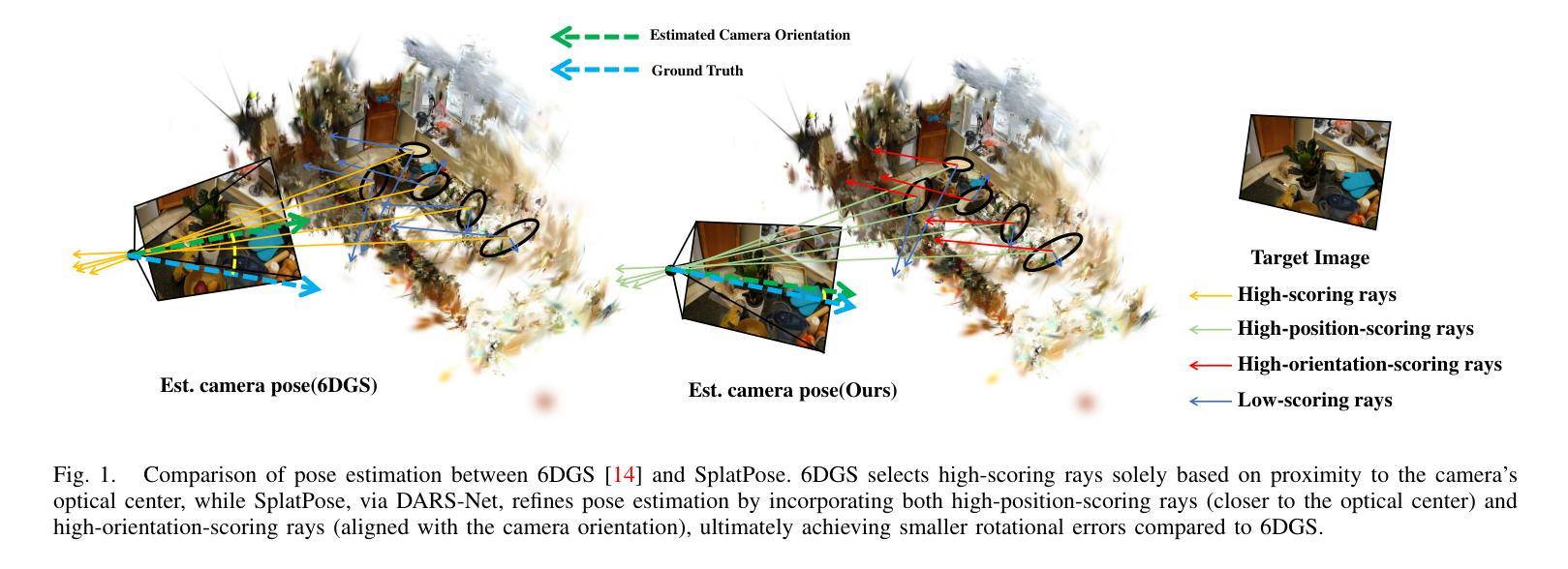
CoMoGaussian: Continuous Motion-Aware Gaussian Splatting from Motion-Blurred Images
Authors:Jungho Lee, Donghyeong Kim, Dogyoon Lee, Suhwan Cho, Minhyeok Lee, Wonjoon Lee, Taeoh Kim, Dongyoon Wee, Sangyoun Lee
3D Gaussian Splatting (3DGS) has gained significant attention for their high-quality novel view rendering, motivating research to address real-world challenges. A critical issue is the camera motion blur caused by movement during exposure, which hinders accurate 3D scene reconstruction. In this study, we propose CoMoGaussian, a Continuous Motion-Aware Gaussian Splatting that reconstructs precise 3D scenes from motion-blurred images while maintaining real-time rendering speed. Considering the complex motion patterns inherent in real-world camera movements, we predict continuous camera trajectories using neural ordinary differential equations (ODEs). To ensure accurate modeling, we employ rigid body transformations, preserving the shape and size of the object but rely on the discrete integration of sampled frames. To better approximate the continuous nature of motion blur, we introduce a continuous motion refinement (CMR) transformation that refines rigid transformations by incorporating additional learnable parameters. By revisiting fundamental camera theory and leveraging advanced neural ODE techniques, we achieve precise modeling of continuous camera trajectories, leading to improved reconstruction accuracy. Extensive experiments demonstrate state-of-the-art performance both quantitatively and qualitatively on benchmark datasets, which include a wide range of motion blur scenarios, from moderate to extreme blur.
3D高斯映射技术(3DGS)因其高质量的新型视图渲染而受到广泛关注,这激发了解决现实世界挑战的研究动力。一个关键问题是由于曝光过程中的移动导致的相机运动模糊,这阻碍了准确的3D场景重建。本研究提出了CoMoGaussian,一种连续运动感知高斯映射技术,能够从运动模糊图像重建精确的3D场景,同时保持实时渲染速度。考虑到真实世界相机移动所固有的复杂运动模式,我们使用神经常微分方程(ODEs)预测连续的相机轨迹。为了确保准确建模,我们采用刚体变换,保持物体的形状和大小,但依赖于采样帧的离散积分。为了更好地近似运动模糊的连续性,我们引入了连续运动细化(CMR)变换,通过引入额外的可学习参数来改进刚体变换。我们重新研究了基本的相机理论,并利用先进的神经常微分方程技术,实现了连续相机轨迹的精确建模,从而提高了重建精度。大量实验表明,在包括从轻度到重度模糊的广泛运动模糊场景中,我们的方法在基准数据集上实现了定量和定性的最先进的性能。
论文及项目相关链接
PDF Revised Version of CRiM-GS, Github: https://github.com/Jho-Yonsei/CoMoGaussian
Summary
这篇论文介绍了针对运动模糊图像进行精确三维场景重建的技术。通过提出一种名为“CoMoGaussian”的连续运动感知高斯融合方法,该方法能够在保持实时渲染速度的同时,从运动模糊图像中重建出精确的三维场景。论文采用神经网络常微分方程预测连续相机轨迹,并使用刚体变换对物体进行准确建模,引入了连续运动优化技术进一步修正轨迹预测,以提高重建准确性。在多个基准数据集上的实验结果表明,该技术在处理不同运动模糊场景下都能实现定量和定性的最佳性能。
Key Takeaways
- 论文关注于解决相机运动模糊问题,这是影响准确三维场景重建的挑战之一。
- 提出了一种名为“CoMoGaussian”的连续运动感知高斯融合方法,能够从运动模糊图像中重建出精确的三维场景。
- 采用神经网络常微分方程预测连续相机轨迹,为准确建模提供了基础。
- 使用刚体变换对物体进行建模,保持物体的形状和大小不变。
- 引入了连续运动优化技术(CMR),通过引入额外的可学习参数,提高了对物体运动的建模精度。
- 论文对相机理论进行了深入研究,结合了先进的神经网络常微分方程技术。
点此查看论文截图

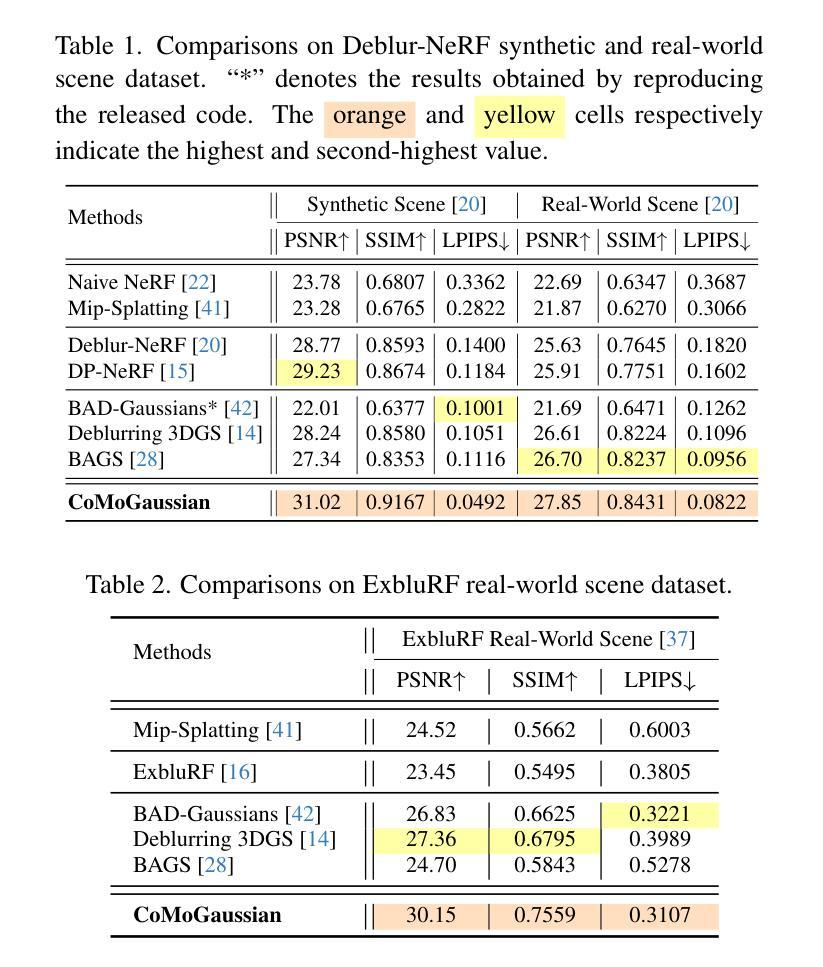
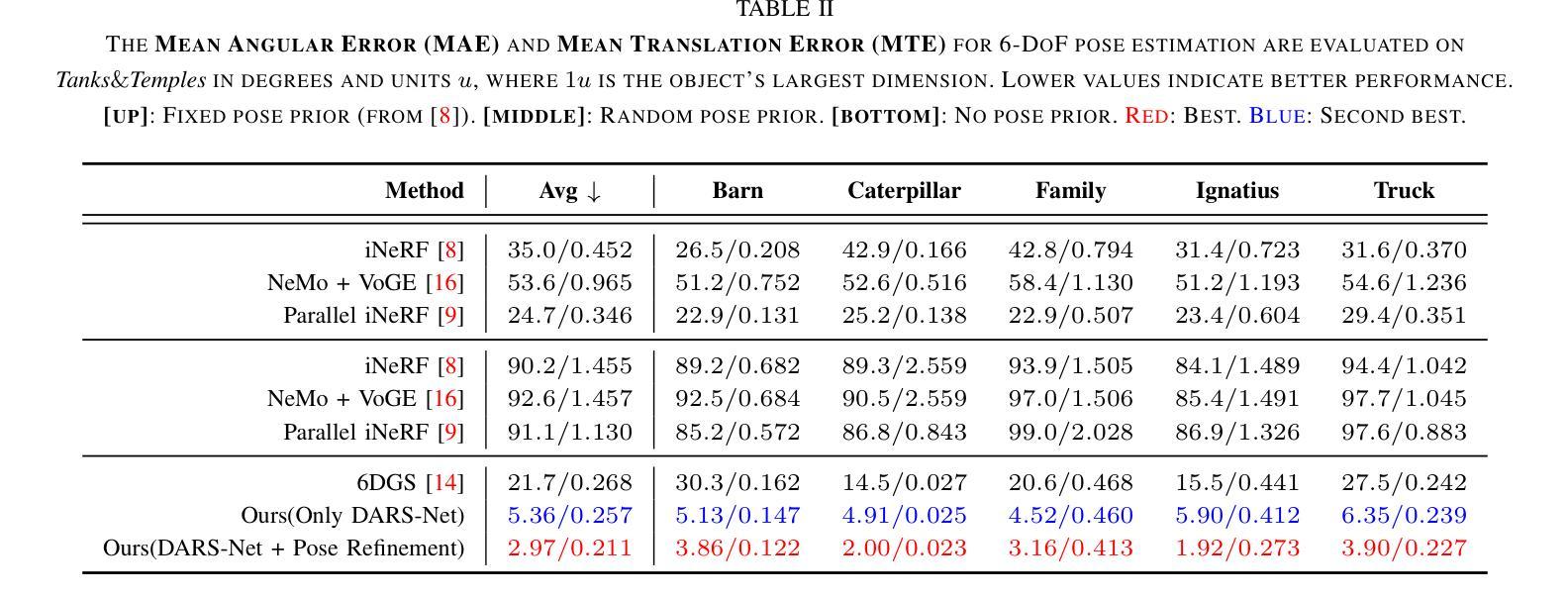
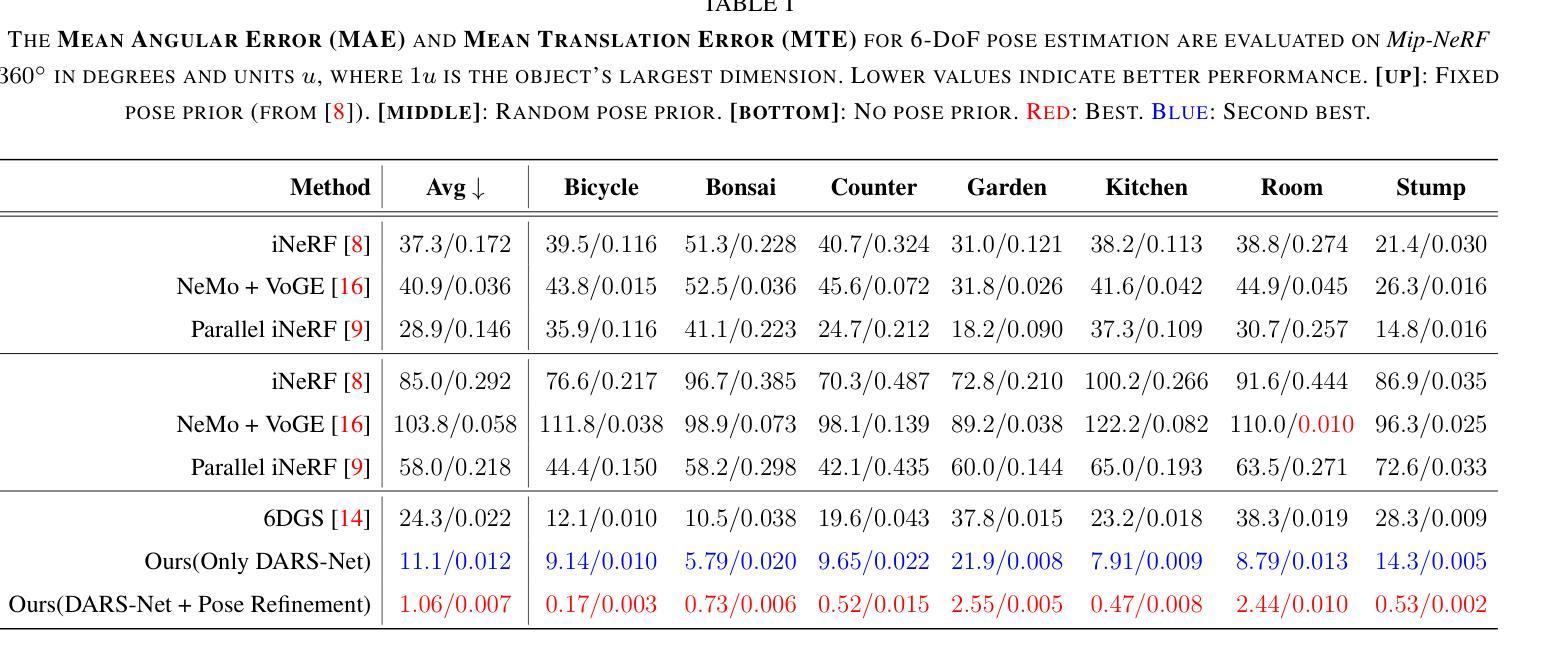
SplatPose: Geometry-Aware 6-DoF Pose Estimation from Single RGB Image via 3D Gaussian Splatting
Authors:Linqi Yang, Xiongwei Zhao, Qihao Sun, Ke Wang, Ao Chen, Peng Kang
6-DoF pose estimation is a fundamental task in computer vision with wide-ranging applications in augmented reality and robotics. Existing single RGB-based methods often compromise accuracy due to their reliance on initial pose estimates and susceptibility to rotational ambiguity, while approaches requiring depth sensors or multi-view setups incur significant deployment costs. To address these limitations, we introduce SplatPose, a novel framework that synergizes 3D Gaussian Splatting (3DGS) with a dual-branch neural architecture to achieve high-precision pose estimation using only a single RGB image. Central to our approach is the Dual-Attention Ray Scoring Network (DARS-Net), which innovatively decouples positional and angular alignment through geometry-domain attention mechanisms, explicitly modeling directional dependencies to mitigate rotational ambiguity. Additionally, a coarse-to-fine optimization pipeline progressively refines pose estimates by aligning dense 2D features between query images and 3DGS-synthesized views, effectively correcting feature misalignment and depth errors from sparse ray sampling. Experiments on three benchmark datasets demonstrate that SplatPose achieves state-of-the-art 6-DoF pose estimation accuracy in single RGB settings, rivaling approaches that depend on depth or multi-view images.
6自由度(6-DoF)姿态估计是计算机视觉中的一项基本任务,在增强现实和机器人技术中有广泛的应用。现有的基于单一RGB的方法往往由于依赖初始姿态估计和易于受到旋转模糊的影响而牺牲准确性。而需要深度传感器或多视角设置的方法又会带来显著的实施成本。为了解决这些限制,我们引入了SplatPose,这是一个结合3D高斯展布(3DGS)和双重分支神经网络的新框架,仅使用单个RGB图像即可实现高精度姿态估计。我们的方法的核心是双重注意力射线评分网络(DARS-Net),它通过几何域注意力机制创新地解耦了位置和对齐角度,通过显式建模方向依赖性来缓解旋转模糊。此外,从粗到细的优化管道通过对比查询图像和3DGS合成视图之间的密集2D特征,逐步精细调整姿态估计,有效校正特征错位和由稀疏射线采样引起的深度误差。在三个基准数据集上的实验表明,SplatPose在单一RGB设置中实现了最先进的6-DoF姿态估计精度,与依赖深度或多视角图像的方法不相上下。
论文及项目相关链接
PDF Submitted to IROS 2025
Summary
本文介绍了一种名为SplatPose的新型框架,它结合了3D高斯绘图(3DGS)和双分支神经网络,仅使用单张RGB图像即可实现高精度姿态估计。该框架通过Dual-Attention Ray Scoring Network(DARS-Net)创新地解决了位置与角度对齐的问题,并通过粗到细的优化管道逐步修正特征错位和由稀疏射线采样引起的深度误差。在三个基准数据集上的实验表明,SplatPose在仅使用RGB图像的情况下实现了最先进的6自由度(6-DoF)姿态估计精度,与依赖深度或多视角图像的方法相比具有竞争力。
Key Takeaways
- SplatPose框架结合了3D高斯绘图(3DGS)和双分支神经网络,实现了仅使用单张RGB图像的高精度姿态估计。
- Dual-Attention Ray Scoring Network(DARS-Net)通过解决位置与角度对齐的问题,提高了姿态估计的准确性。
- 粗到细的优化管道用于逐步修正特征错位和由稀疏射线采样引起的深度误差。
- SplatPose解决了现有RGB方法依赖初始姿态估计和易受到旋转模糊影响的问题。
- 与依赖深度或多视角图像的方法相比,SplatPose在基准数据集上实现了具有竞争力的姿态估计精度。
- SplatPose框架具有广泛的应用前景,特别是在增强现实和机器人领域。
点此查看论文截图



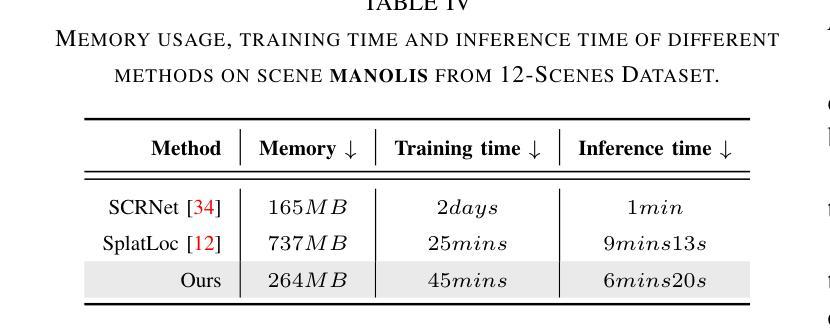
EvolvingGS: High-Fidelity Streamable Volumetric Video via Evolving 3D Gaussian Representation
Authors:Chao Zhang, Yifeng Zhou, Shuheng Wang, Wenfa Li, Degang Wang, Yi Xu, Shaohui Jiao
We have recently seen great progress in 3D scene reconstruction through explicit point-based 3D Gaussian Splatting (3DGS), notable for its high quality and fast rendering speed. However, reconstructing dynamic scenes such as complex human performances with long durations remains challenging. Prior efforts fall short of modeling a long-term sequence with drastic motions, frequent topology changes or interactions with props, and resort to segmenting the whole sequence into groups of frames that are processed independently, which undermines temporal stability and thereby leads to an unpleasant viewing experience and inefficient storage footprint. In view of this, we introduce EvolvingGS, a two-stage strategy that first deforms the Gaussian model to coarsely align with the target frame, and then refines it with minimal point addition/subtraction, particularly in fast-changing areas. Owing to the flexibility of the incrementally evolving representation, our method outperforms existing approaches in terms of both per-frame and temporal quality metrics while maintaining fast rendering through its purely explicit representation. Moreover, by exploiting temporal coherence between successive frames, we propose a simple yet effective compression algorithm that achieves over 50x compression rate. Extensive experiments on both public benchmarks and challenging custom datasets demonstrate that our method significantly advances the state-of-the-art in dynamic scene reconstruction, particularly for extended sequences with complex human performances.
我们通过明确的点基三维高斯模型技术(Gaussian Splatting, 3DGS)在三维场景重建方面取得了巨大的进步,以其高质量和快速的渲染速度而受到瞩目。然而,对于重建持续时间较长的动态场景,如复杂的人类行为表现等,仍然是一个挑战。之前的努力在模拟具有剧烈运动、频繁拓扑变化或与道具互动的长时间序列时显得不足。他们通常将整段序列分割成独立处理的帧组,这损害了时间稳定性,从而导致观影体验不佳和存储效率低下。鉴于此,我们引入了EvolvingGS,这是一个两阶段的策略,首先变形高斯模型以粗略地与目标帧对齐,然后通过最小限度的增加或减少点进行细化,特别是在快速变化的区域。由于增量进化表示的灵活性,我们的方法在每帧和时间质量指标方面都优于现有方法,同时通过其纯粹的显式表示保持了快速渲染。此外,通过利用连续帧之间的时间连贯性,我们提出了一种简单有效的压缩算法,实现了超过50倍的压缩率。在公共基准测试和具有挑战性的自定义数据集上的大量实验表明,我们的方法在动态场景重建方面取得了重大进展,特别是对于包含复杂人类行为的扩展序列。
论文及项目相关链接
Summary
近期,基于显式点云的3D高斯喷涂技术(3DGS)在三维场景重建方面取得了巨大进展,以其高质量和快速渲染速度而受到关注。然而,对于重建如复杂人类表演等长时间动态场景仍面临挑战。针对长期序列中大幅度动作、频繁拓扑变化以及与道具的互动建模难题,现有方法常常分割序列独立处理帧组,牺牲了时序稳定性,导致观看体验不佳和存储效率低下。为此,我们提出EvolvingGS,一个两阶段策略。首先通过高斯模型变形与目标帧大致对齐,然后进行精细调整,尽量减少快速变化区域的点增减。由于增量演化表示的灵活性,我们的方法在帧质量和时序质量指标上均优于现有方法,同时通过纯粹的显式表示维持快速渲染。此外,我们利用连续帧之间的时间一致性,提出了一种简单有效的压缩算法,实现了超过50倍的压缩率。在公共基准测试和具有挑战性的自定义数据集上的广泛实验表明,我们的方法在动态场景重建方面取得了显著进展,尤其是在复杂人类表演的长时间序列上。
Key Takeaways
- 3DGS技术在三维场景重建中取得显著进展,但重建长时间动态场景如复杂人类表演仍有挑战。
- 现有方法在处理具有频繁动作变化的长时间序列时,难以保持时序稳定性。
- EvolvingGS策略通过两阶段处理,实现高斯模型的粗略对齐和精细调整,提高了重建质量。
- 方法结合了增量演化表示和纯粹的显式表示,既提高了渲染质量又维持了快速渲染。
- 利用时间一致性提出了高效的压缩算法,实现了高压缩率。
- 广泛实验证明,新方法在动态场景重建方面优于现有技术,特别是在处理复杂人类表演的长时间序列时。
- 该方法有望改善动态场景重建的观看体验和存储效率。
点此查看论文截图

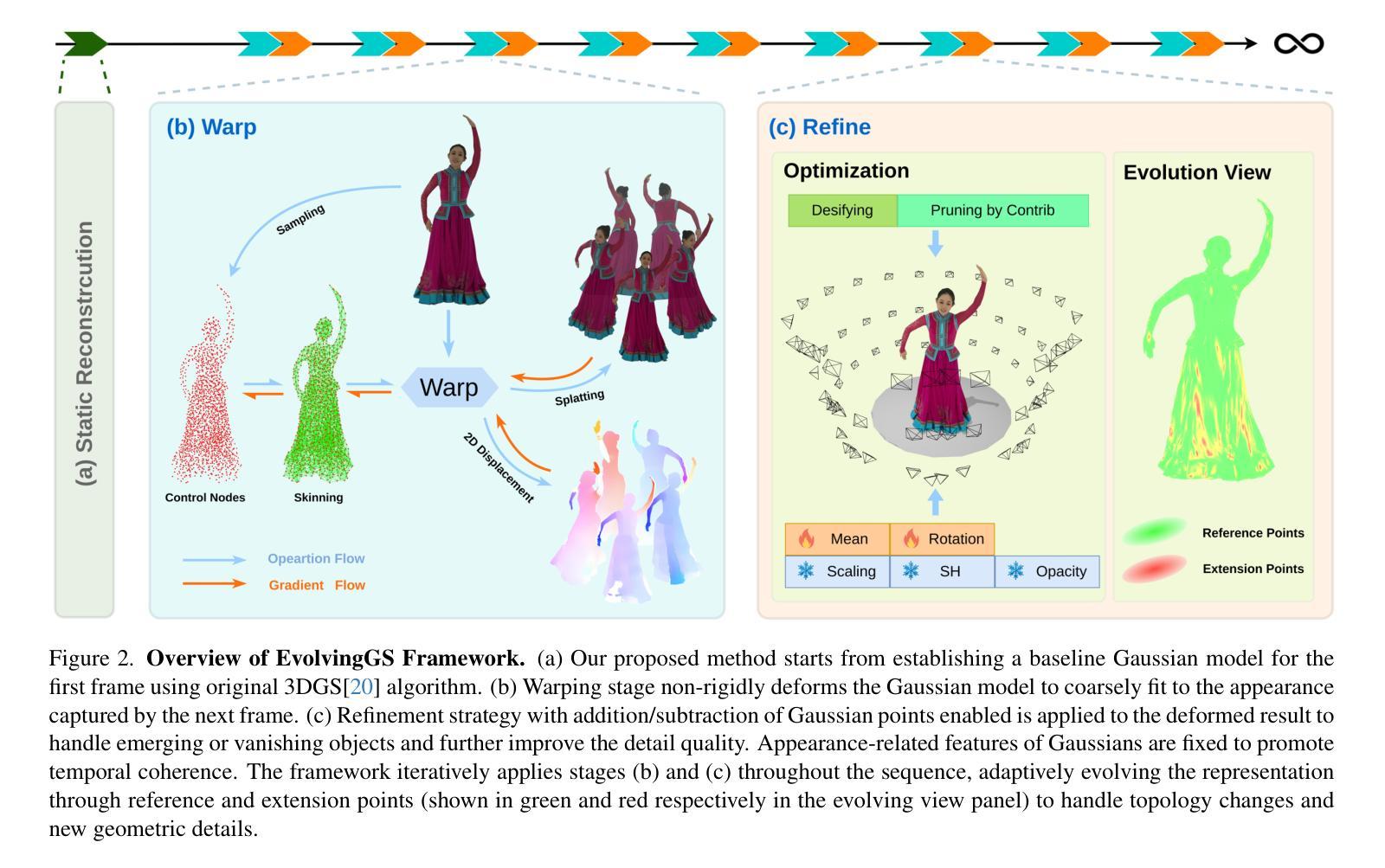
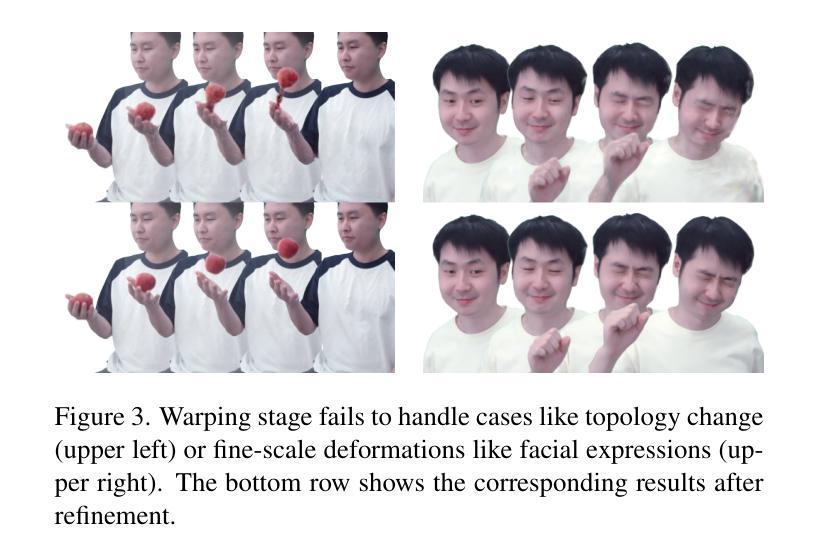
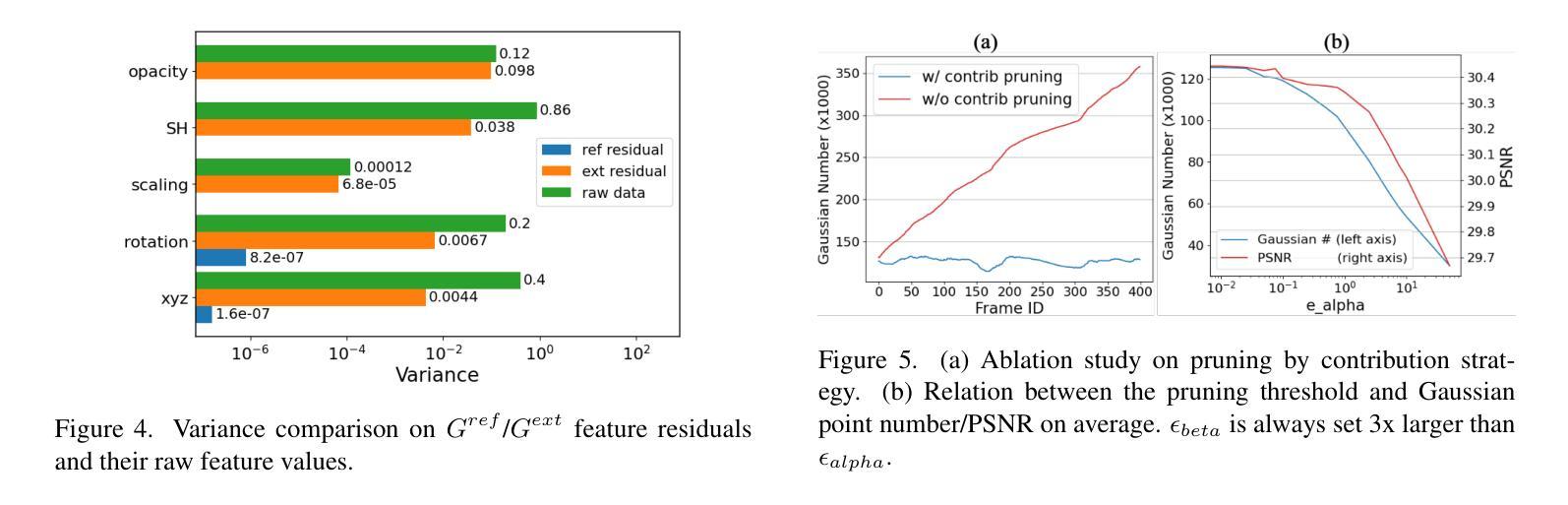
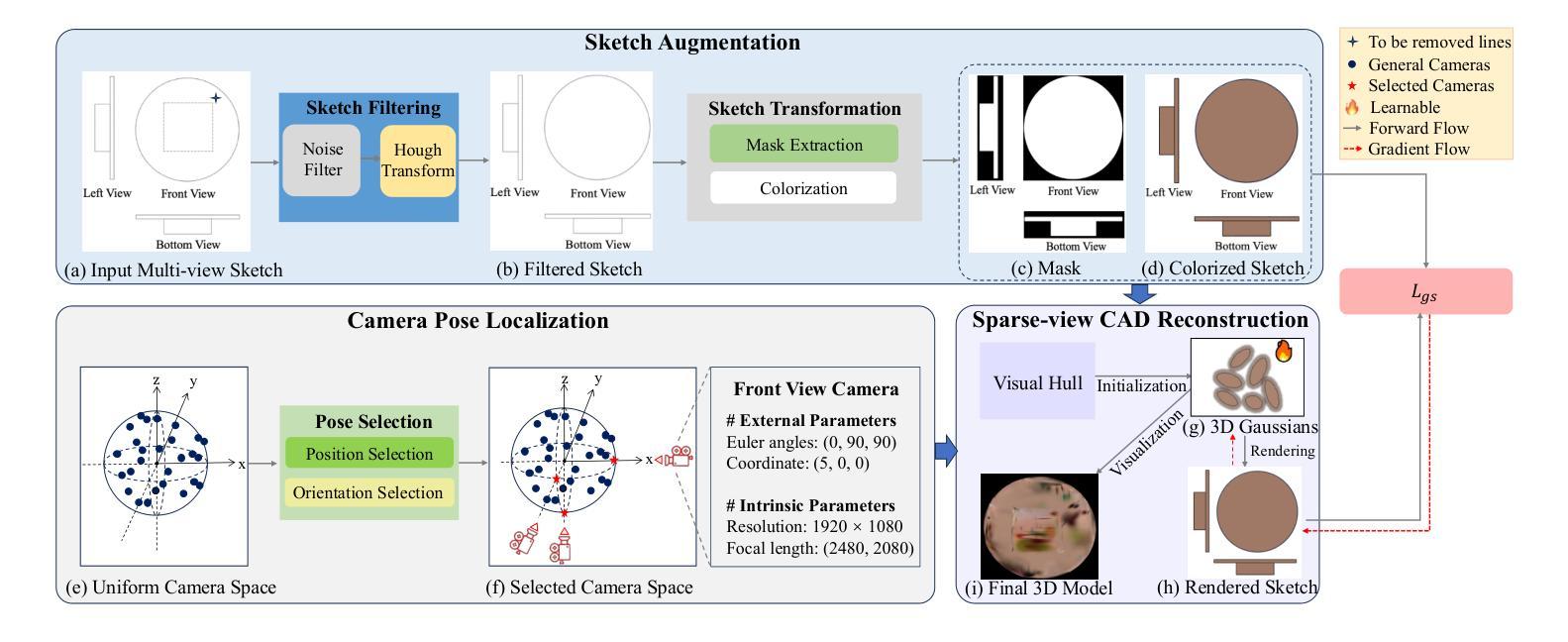
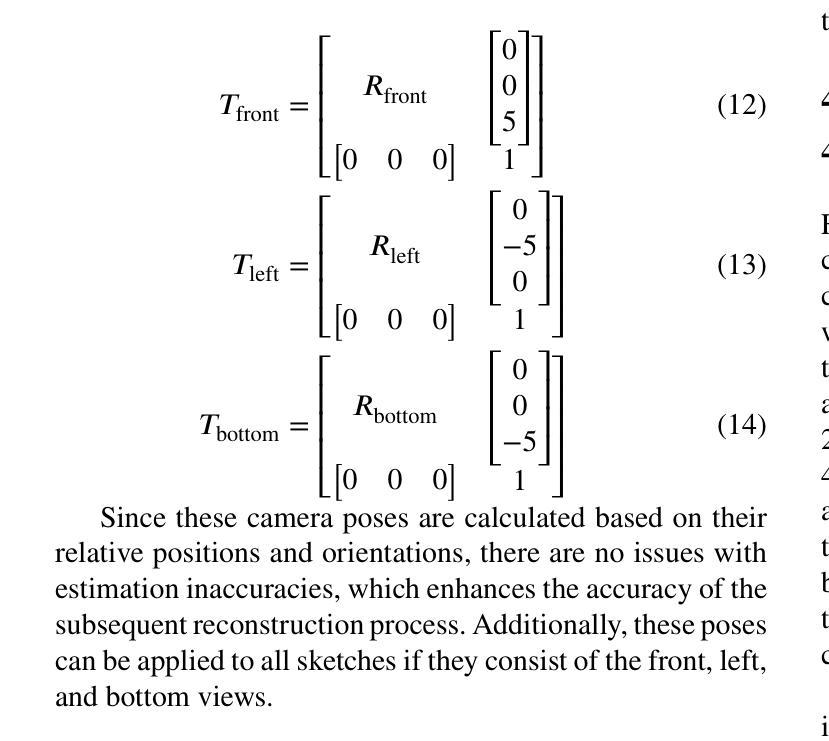
GaussianCAD: Robust Self-Supervised CAD Reconstruction from Three Orthographic Views Using 3D Gaussian Splatting
Authors:Zheng Zhou, Zhe Li, Bo Yu, Lina Hu, Liang Dong, Zijian Yang, Xiaoli Liu, Ning Xu, Ziwei Wang, Yonghao Dang, Jianqin Yin
The automatic reconstruction of 3D computer-aided design (CAD) models from CAD sketches has recently gained significant attention in the computer vision community. Most existing methods, however, rely on vector CAD sketches and 3D ground truth for supervision, which are often difficult to be obtained in industrial applications and are sensitive to noise inputs. We propose viewing CAD reconstruction as a specific instance of sparse-view 3D reconstruction to overcome these limitations. While this reformulation offers a promising perspective, existing 3D reconstruction methods typically require natural images and corresponding camera poses as inputs, which introduces two major significant challenges: (1) modality discrepancy between CAD sketches and natural images, and (2) difficulty of accurate camera pose estimation for CAD sketches. To solve these issues, we first transform the CAD sketches into representations resembling natural images and extract corresponding masks. Next, we manually calculate the camera poses for the orthographic views to ensure accurate alignment within the 3D coordinate system. Finally, we employ a customized sparse-view 3D reconstruction method to achieve high-quality reconstructions from aligned orthographic views. By leveraging raster CAD sketches for self-supervision, our approach eliminates the reliance on vector CAD sketches and 3D ground truth. Experiments on the Sub-Fusion360 dataset demonstrate that our proposed method significantly outperforms previous approaches in CAD reconstruction performance and exhibits strong robustness to noisy inputs.
在计算机视觉领域,从CAD草图自动重建3D计算机辅助设计(CAD)模型已引起广泛关注。然而,大多数现有方法依赖于矢量CAD草图和3D真实数据来进行监督,这在工业应用中往往难以获得,并且对噪声输入很敏感。为了解决这些问题,我们提出将CAD重建视为稀疏视图3D重建的一个特定实例。虽然这种重新表述提供了一个有前景的视角,但现有的3D重建方法通常需要自然图像和相应的相机姿态作为输入,这带来了两个主要挑战:(1)CAD草图与自然图像之间的模态差异;(2)为CAD草图准确估计相机姿态的难度。为了解决这些问题,我们首先需要将CAD草图转换为类似于自然图像的表示形式,并提取相应的掩码。接下来,我们手动计算正视图对应的相机姿态,以确保在三维坐标系内的准确对齐。最后,我们采用定制的稀疏视图3D重建方法,从对齐的正视图中实现高质量的重建。通过利用光栅CAD草图进行自监督,我们的方法消除了对矢量CAD草图和三维真实数据的依赖。在Sub-Fusion360数据集上的实验表明,我们的方法在CAD重建性能上显著优于以前的方法,并且对噪声输入表现出强大的稳健性。
论文及项目相关链接
Summary
本文提出一种基于稀疏视角的3D重建方法,将计算机辅助设计(CAD)重建视为特殊案例,以解决现有方法依赖难以获取的向量CAD草图与3D真实数据标注的问题。该方法通过将CAD草图转换为与自然图像相似的表现形式,提取相应的掩膜,手动计算正视图相机姿态,实现高质量重建。实验证明,该方法在Sub-Fusion360数据集上显著优于传统方法,对噪声输入具有较强的鲁棒性。
Key Takeaways
- 本文将CAD重建视为稀疏视角的3D重建特例,以克服对难以获取的向量CAD草图与真实数据标注的依赖。
- 通过转换CAD草图至类似自然图像的表现形式并提取掩膜,解决草图与真实数据间的差异问题。
- 手动计算正视图相机姿态,确保在三维坐标系内的准确对齐。
- 利用定制的稀疏视角3D重建方法实现高质量重建。
- 利用栅格化CAD草图进行自监督学习,减少对矢量CAD草图和真实数据标注的需求。
- 实验证明,该方法在Sub-Fusion360数据集上表现优异,显著优于传统方法。
点此查看论文截图



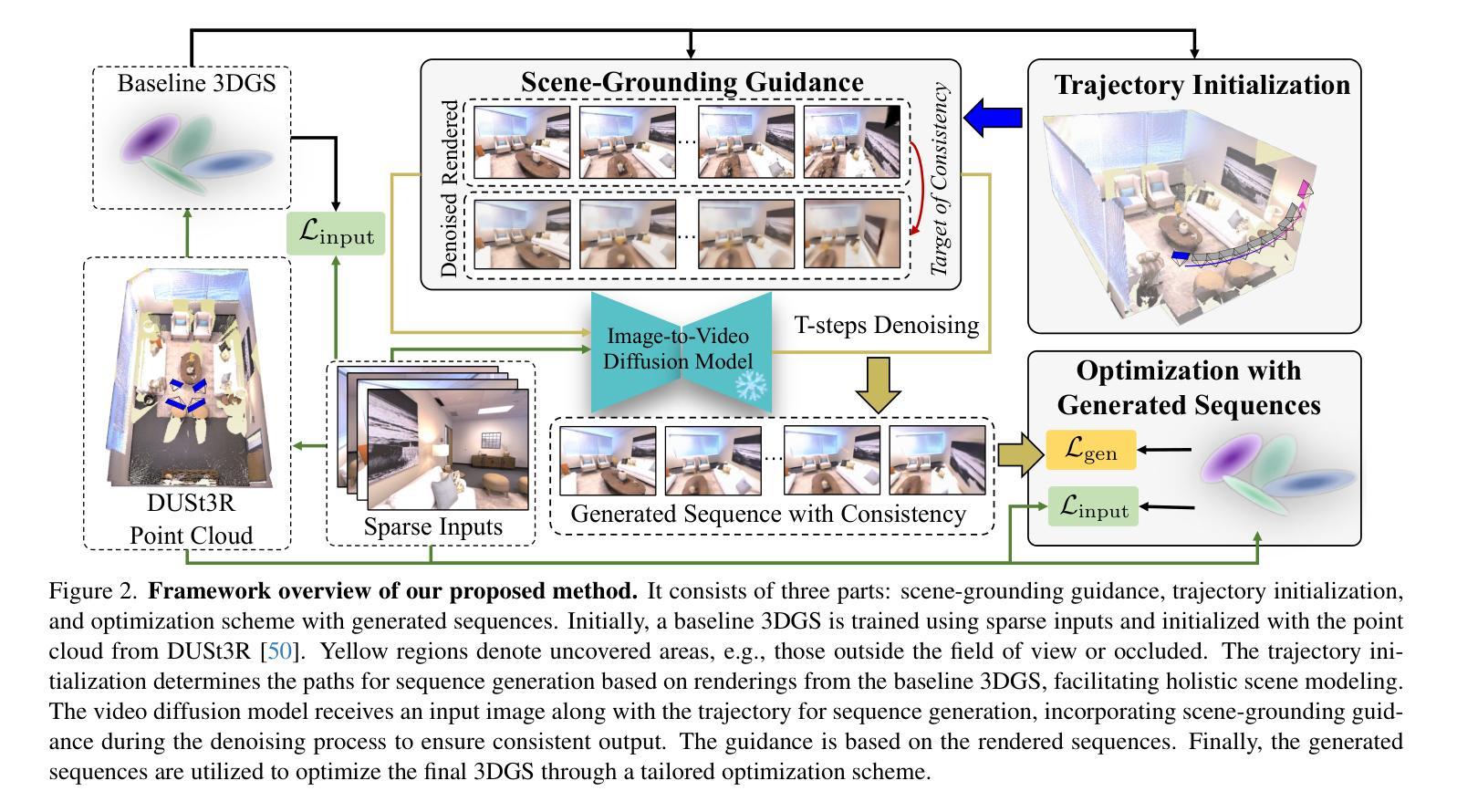
Taming Video Diffusion Prior with Scene-Grounding Guidance for 3D Gaussian Splatting from Sparse Inputs
Authors:Yingji Zhong, Zhihao Li, Dave Zhenyu Chen, Lanqing Hong, Dan Xu
Despite recent successes in novel view synthesis using 3D Gaussian Splatting (3DGS), modeling scenes with sparse inputs remains a challenge. In this work, we address two critical yet overlooked issues in real-world sparse-input modeling: extrapolation and occlusion. To tackle these issues, we propose to use a reconstruction by generation pipeline that leverages learned priors from video diffusion models to provide plausible interpretations for regions outside the field of view or occluded. However, the generated sequences exhibit inconsistencies that do not fully benefit subsequent 3DGS modeling. To address the challenge of inconsistencies, we introduce a novel scene-grounding guidance based on rendered sequences from an optimized 3DGS, which tames the diffusion model to generate consistent sequences. This guidance is training-free and does not require any fine-tuning of the diffusion model. To facilitate holistic scene modeling, we also propose a trajectory initialization method. It effectively identifies regions that are outside the field of view and occluded. We further design a scheme tailored for 3DGS optimization with generated sequences. Experiments demonstrate that our method significantly improves upon the baseline and achieves state-of-the-art performance on challenging benchmarks.
尽管最近使用3D高斯拼贴(3DGS)在新型视图合成方面取得了一些成功,但使用稀疏输入进行场景建模仍然是一个挑战。在这项工作中,我们解决了真实世界稀疏输入建模中的两个关键但被忽视的问题:外推和遮挡。为了解决这些问题,我们提出了一种通过生成式重建的流水线,它利用从视频扩散模型中学习的先验知识来对视野之外或被遮挡的区域提供合理的解释。然而,生成的序列存在不一致性,并不能完全有益于随后的3DGS建模。为了解决不一致性的挑战,我们引入了一种基于优化3DGS的渲染序列的新型场景定位指导,它驯化了扩散模型以生成一致的序列。这种指导是独立于训练的,并且不需要对扩散模型进行任何微调。为了促进整体场景建模,我们还提出了一种轨迹初始化方法。它有效地识别了视野之外和被遮挡的区域。我们还为使用生成序列的3DGS优化设计了一种定制方案。实验表明,我们的方法显著改进了基线方法,并在具有挑战性的基准测试上达到了最先进的性能。
论文及项目相关链接
PDF Accepted by CVPR2025. The project page is available at https://zhongyingji.github.io/guidevd-3dgs/
Summary
这篇论文针对使用3D高斯喷溅(3DGS)进行新型视图合成时面临的挑战进行了深入研究。针对真实世界稀疏输入建模中的外推和遮挡问题,提出了利用视频扩散模型的先验知识进行重建生成管道的方案。然而,生成的序列存在不一致性,不利于后续的3DGS建模。为解决这一问题,引入了基于优化3DGS渲染序列的场景接地指导,可训练扩散模型生成一致的序列。此外,还提出了一种轨迹初始化方法,能有效识别视野外的区域和遮挡区域。整体而言,该研究提高了基线方法的性能,并在具有挑战性的基准测试中达到了最先进的水平。
Key Takeaways
- 论文解决了在真实世界稀疏输入建模中的外推和遮挡问题。
- 提出了利用视频扩散模型的先验知识进行重建生成的方法。
- 生成的序列存在不一致性问题,影响了后续的3DGS建模。
- 引入了基于优化3DGS渲染序列的场景接地指导来解决不一致性问题。
- 该方法是一种训练免费的方法,不需要对扩散模型进行微调。
- 论文提出了一种轨迹初始化方法,能有效识别视野外的区域和遮挡区域。
点此查看论文截图




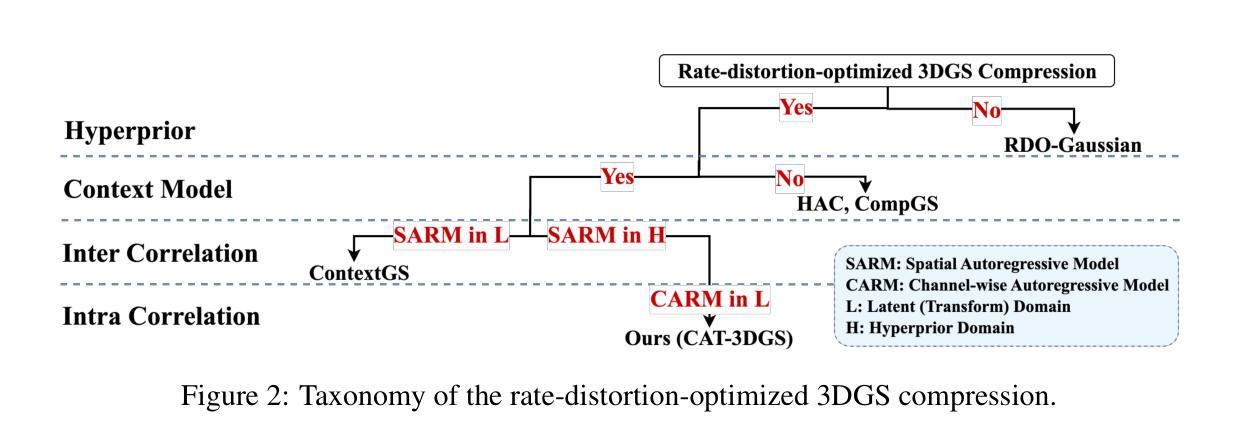
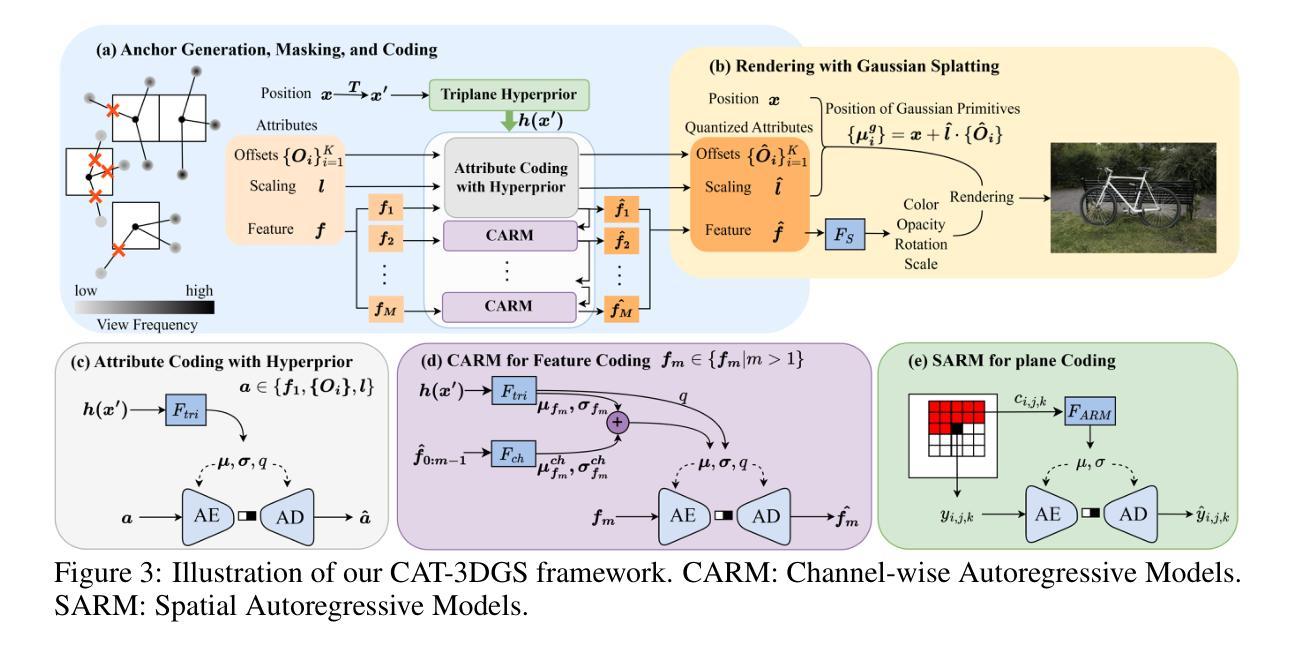
CAT-3DGS: A Context-Adaptive Triplane Approach to Rate-Distortion-Optimized 3DGS Compression
Authors:Yu-Ting Zhan, Cheng-Yuan Ho, Hebi Yang, Yi-Hsin Chen, Jui Chiu Chiang, Yu-Lun Liu, Wen-Hsiao Peng
3D Gaussian Splatting (3DGS) has recently emerged as a promising 3D representation. Much research has been focused on reducing its storage requirements and memory footprint. However, the needs to compress and transmit the 3DGS representation to the remote side are overlooked. This new application calls for rate-distortion-optimized 3DGS compression. How to quantize and entropy encode sparse Gaussian primitives in the 3D space remains largely unexplored. Few early attempts resort to the hyperprior framework from learned image compression. But, they fail to utilize fully the inter and intra correlation inherent in Gaussian primitives. Built on ScaffoldGS, this work, termed CAT-3DGS, introduces a context-adaptive triplane approach to their rate-distortion-optimized coding. It features multi-scale triplanes, oriented according to the principal axes of Gaussian primitives in the 3D space, to capture their inter correlation (i.e. spatial correlation) for spatial autoregressive coding in the projected 2D planes. With these triplanes serving as the hyperprior, we further perform channel-wise autoregressive coding to leverage the intra correlation within each individual Gaussian primitive. Our CAT-3DGS incorporates a view frequency-aware masking mechanism. It actively skips from coding those Gaussian primitives that potentially have little impact on the rendering quality. When trained end-to-end to strike a good rate-distortion trade-off, our CAT-3DGS achieves the state-of-the-art compression performance on the commonly used real-world datasets.
3D高斯喷溅(3DGS)作为一种有前景的3D表示方法最近崭露头角。许多研究都集中在降低其存储需求和内存占用上。然而,将3DGS表示进行压缩和传输到远程地点的需求却被忽视了。这种新应用要求对3DGS压缩进行速率失真优化。在3D空间中如何对稀疏的高斯基本元素进行量化和熵编码仍很大程度上未被探索。早期的少数尝试采用从学习图像压缩中的超先验框架,但它们未能充分利用高斯基本元素固有的内部和外部相关性。基于ScaffoldGS,这项工作被称为CAT-3DGS,引入了一种针对其速率失真优化编码的上下文自适应三平面方法。它采用多尺度三平面,根据高斯基本元素的主轴在3D空间中进行定向,以捕获其外部相关性(即空间相关性)用于投影平面上的空间自回归编码。使用这些三平面作为超先验,我们进一步执行通道自回归编码,以利用每个高斯基元内部的内部相关性。我们的CAT-3DGS采用了视图频率感知掩蔽机制。它积极跳过那些可能对渲染质量影响较小的高斯基元编码。当针对常见的现实世界数据集进行端到端的训练以达到良好的速率失真折衷时,我们的CAT-3DGS达到了最先进的压缩性能。
论文及项目相关链接
PDF Accepted for Publication in International Conference on Learning Representations (ICLR)
Summary
3DGS的存储需求和传输问题被忽视,因此需要研究其压缩技术。新的CAT-3DGS方法采用上下文自适应三平面技术,结合ScaffoldGS框架,对高斯原语进行率失真优化编码。该方法通过多尺度三平面捕捉高斯原语的空间相关性,并在投影的二维平面上进行空间自回归编码。此外,还利用通道自适应编码技术捕捉高斯原语内的相关性。CAT-3DGS还包括视图频率感知掩蔽机制,可跳过对渲染质量影响较小的高斯原语编码。经过端到端的训练,CAT-3DGS在常用真实数据集上实现了领先的压缩性能。
Key Takeaways
- 3DGS的存储和传输需求成为研究焦点,需要研究其压缩技术。
- CAT-3DGS方法采用上下文自适应三平面技术进行率失真优化编码。
- 多尺度三平面捕捉高斯原语的空间相关性。
- 通道自适应编码技术用于捕捉高斯原语内的相关性。
- CAT-3DGS包括视图频率感知掩蔽机制,可跳过对渲染质量影响较小的部分编码。
- 该方法在真实数据集上实现了领先的压缩性能。
点此查看论文截图

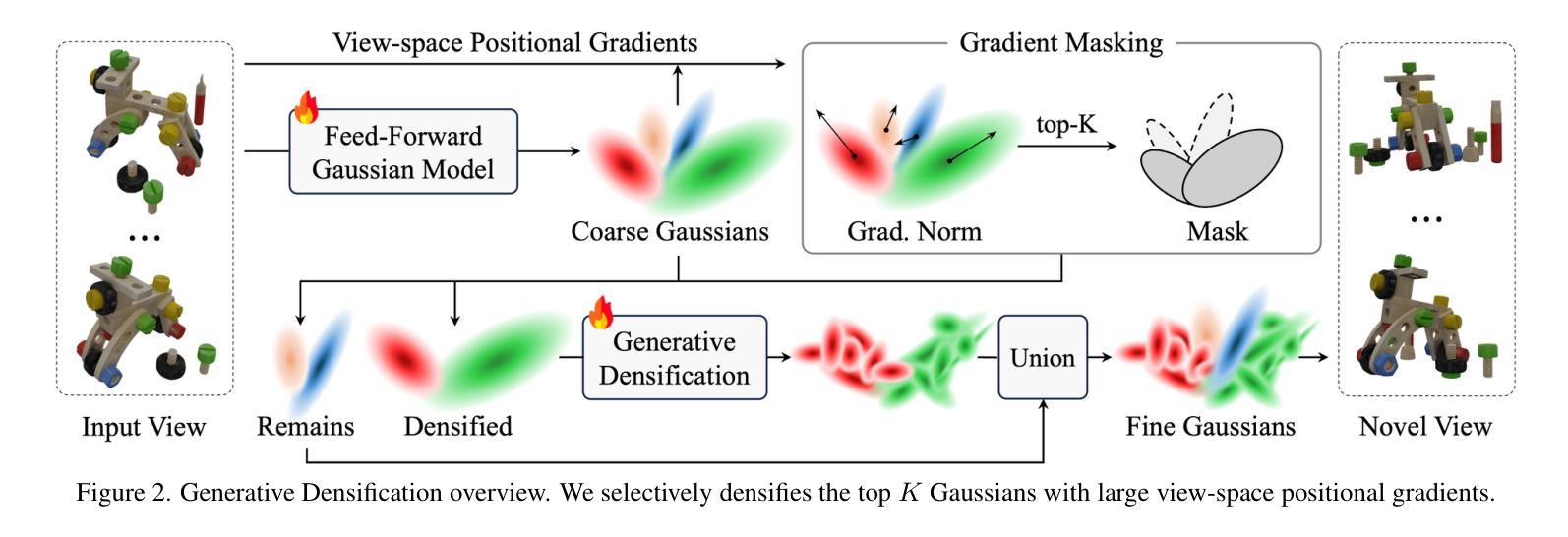
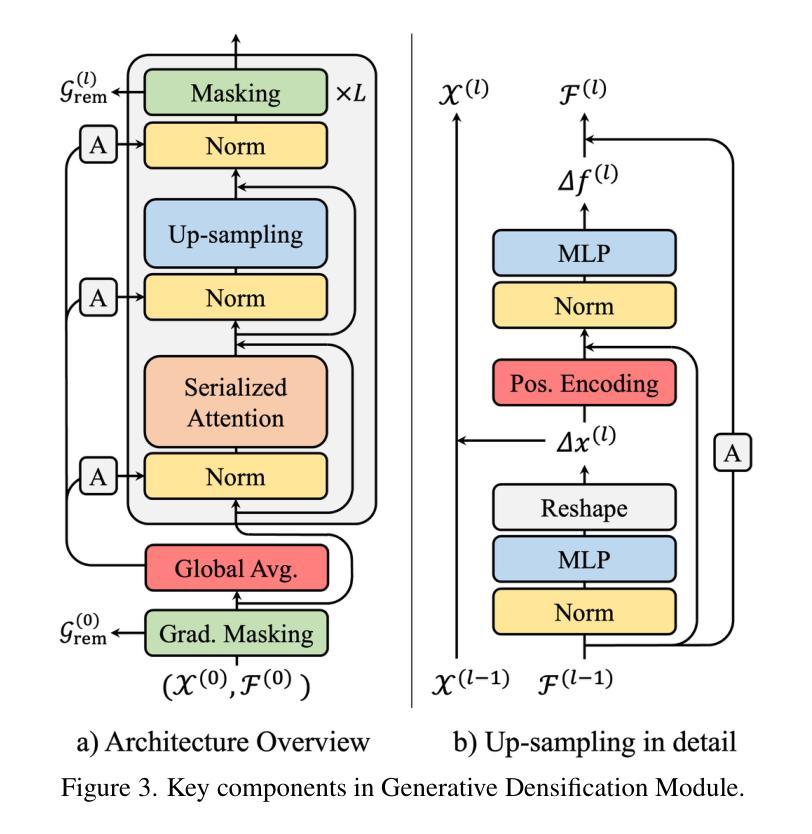
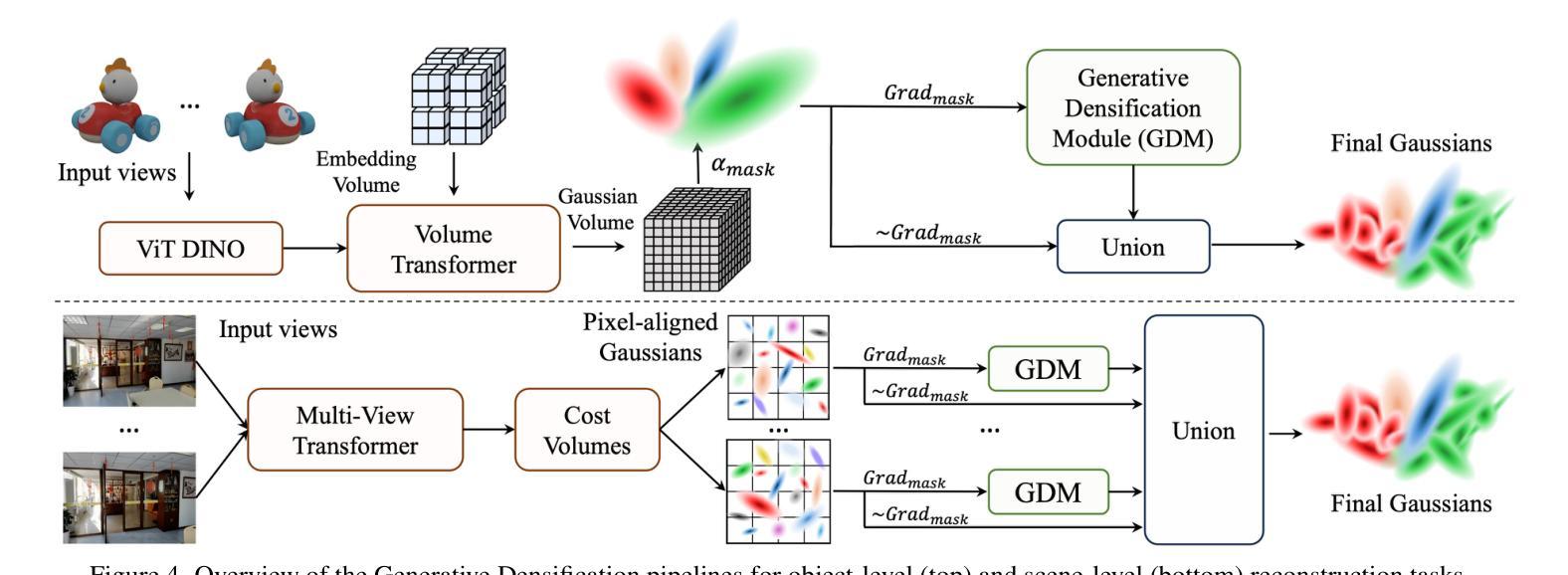
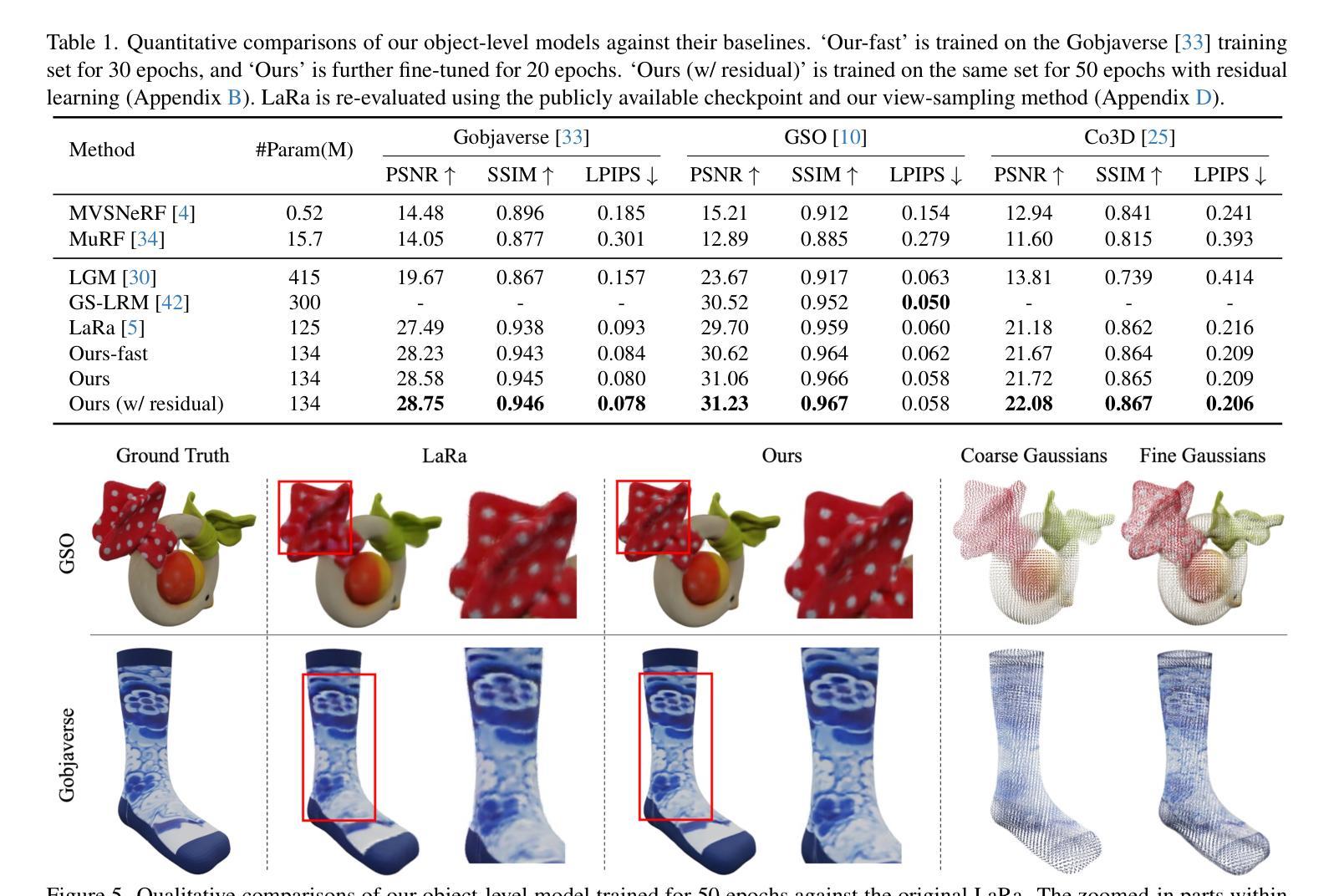
Generative Densification: Learning to Densify Gaussians for High-Fidelity Generalizable 3D Reconstruction
Authors:Seungtae Nam, Xiangyu Sun, Gyeongjin Kang, Younggeun Lee, Seungjun Oh, Eunbyung Park
Generalized feed-forward Gaussian models have achieved significant progress in sparse-view 3D reconstruction by leveraging prior knowledge from large multi-view datasets. However, these models often struggle to represent high-frequency details due to the limited number of Gaussians. While the densification strategy used in per-scene 3D Gaussian splatting (3D-GS) optimization can be adapted to the feed-forward models, it may not be ideally suited for generalized scenarios. In this paper, we propose Generative Densification, an efficient and generalizable method to densify Gaussians generated by feed-forward models. Unlike the 3D-GS densification strategy, which iteratively splits and clones raw Gaussian parameters, our method up-samples feature representations from the feed-forward models and generates their corresponding fine Gaussians in a single forward pass, leveraging the embedded prior knowledge for enhanced generalization. Experimental results on both object-level and scene-level reconstruction tasks demonstrate that our method outperforms state-of-the-art approaches with comparable or smaller model sizes, achieving notable improvements in representing fine details.
广义前馈高斯模型通过利用大型多视角数据集中的先验知识,在稀疏视角3D重建方面取得了显著进展。然而,由于高斯数量的限制,这些模型往往难以表示高频细节。虽然场景3D高斯拼贴(3D-GS)优化中使用的密集化策略可以适应前馈模型,但可能并不适合通用场景。在本文中,我们提出了生成密集化(Generative Densification),这是一种有效且通用的方法来密集化前馈模型产生的高斯。与3D-GS密集化策略不同,我们的方法不需要迭代地分裂和克隆原始高斯参数,而是对前馈模型的特性表示进行上采样,并在单次前向传递中生成其对应的精细高斯,利用嵌入的先验知识来提高泛化能力。在对象级和场景级的重建任务上的实验结果表明,我们的方法在具有相当或更小模型大小的最先进方法中表现更好,在表示细节方面取得了显著的改进。
论文及项目相关链接
PDF Project page: https://stnamjef.github.io/GenerativeDensification/
Summary
本文提出了基于广义前馈高斯模型的生成型稠化方法,用于稀疏视角的3D重建。该方法能有效提升前馈模型的高频细节表示能力,通过一次前向传播生成精细的高斯,提高了模型的泛化性能。实验结果表明,该方法在物体级和场景级的重建任务上均优于现有技术,且模型大小相当或更小。
Key Takeaways
- 广义前馈高斯模型在稀疏视角的3D重建中取得了显著进展,利用大规模多视角数据集的先验知识。
- 这些模型因高斯数量有限,难以表示高频细节。
- 现有方法如3D-GS优化中的稠化策略虽可适应前馈模型,但可能不适用于通用场景。
- 本文提出了生成型稠化方法,通过一次前向传播生成对应的高斯,提高了模型的泛化能力。
- 实验结果表明,该方法在物体级和场景级的重建任务上表现出优异的性能。
- 与现有技术相比,该方法在模型大小相当或更小的情况下实现了显著的性能提升。
点此查看论文截图

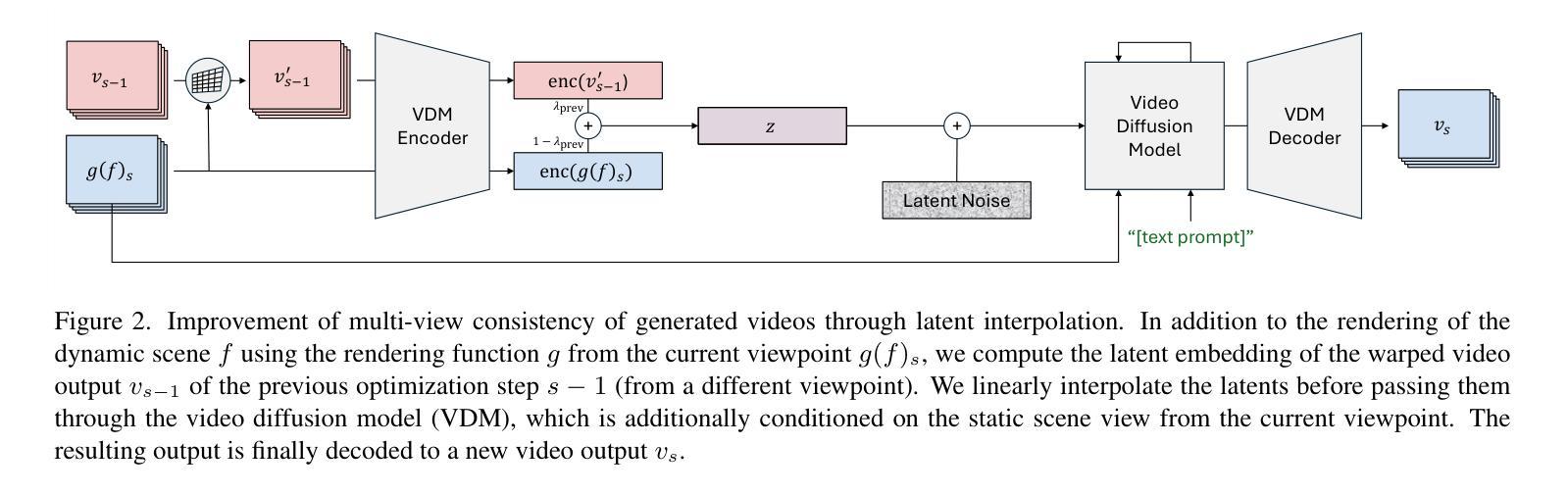
Gaussians-to-Life: Text-Driven Animation of 3D Gaussian Splatting Scenes
Authors:Thomas Wimmer, Michael Oechsle, Michael Niemeyer, Federico Tombari
State-of-the-art novel view synthesis methods achieve impressive results for multi-view captures of static 3D scenes. However, the reconstructed scenes still lack “liveliness,” a key component for creating engaging 3D experiences. Recently, novel video diffusion models generate realistic videos with complex motion and enable animations of 2D images, however they cannot naively be used to animate 3D scenes as they lack multi-view consistency. To breathe life into the static world, we propose Gaussians2Life, a method for animating parts of high-quality 3D scenes in a Gaussian Splatting representation. Our key idea is to leverage powerful video diffusion models as the generative component of our model and to combine these with a robust technique to lift 2D videos into meaningful 3D motion. We find that, in contrast to prior work, this enables realistic animations of complex, pre-existing 3D scenes and further enables the animation of a large variety of object classes, while related work is mostly focused on prior-based character animation, or single 3D objects. Our model enables the creation of consistent, immersive 3D experiences for arbitrary scenes.
当前先进的新型视图合成方法在静态3D场景的多视图捕获方面取得了令人印象深刻的结果。然而,重建的场景仍然缺乏“生动性”,这是创建吸引人的3D体验的关键要素。最近,新型视频扩散模型能够生成具有复杂运动的现实视频,并使2D图像实现动画效果,但它们不能直接用于动画化3D场景,因为缺乏多视图一致性。为了给静态世界注入生命力,我们提出了Gaussians2Life方法,这是一种以高斯贴图表示对高质量3D场景部分进行动画化的方法。我们的主要思想是利用强大的视频扩散模型作为我们模型生成的部分,并将其与一种可靠的技术相结合,将2D视频提升到有意义的3D运动中。我们发现,与之前的工作相比,这能够实现复杂的预存3D场景的逼真动画,并进一步实现各种对象类的动画,而相关工作主要集中在基于先验的角色动画或单个3D对象上。我们的模型能够为任意场景创建一致、沉浸式的3D体验。
论文及项目相关链接
PDF Project website at https://wimmerth.github.io/gaussians2life.html. Accepted to 3DV 2025
摘要
提出一种名为Gaussians2Life的方法,为高质量3D场景动画带来生命力。该方法结合视频扩散模型和2D视频提升技术,生成逼真的复杂预存场景动画,并能对不同种类的物体进行动画设计,打破了以往方法的局限。该方法实现了具有一致性的沉浸式3D体验。
关键要点
- 当前的新视角合成方法在静态3D场景的多视角捕捉上表现卓越,但重建的场景缺乏生命力,对于创建吸引人的3D体验而言是关键缺失。
- 新型的扩散模型能够为复杂运动生成逼真的视频并使二维图像动画化,但对于动态化3D场景缺乏多视角一致性。
- Gaussians2Life方法利用强大的视频扩散模型作为生成组件,结合技术将二维视频提升到有意义的3D运动中,从而实现对高质量3D场景部分的动画化。
- Gaussians2Life实现了对复杂预存场景的逼真动画化,并扩展了对各种物体类别的动画设计能力,超越了以往主要基于角色动画或单一3D物体的相关研究工作。
- 该方法实现了具有一致性的沉浸式3D体验,对于任意场景均能创建逼真的动画效果。
点此查看论文截图