⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-11 更新
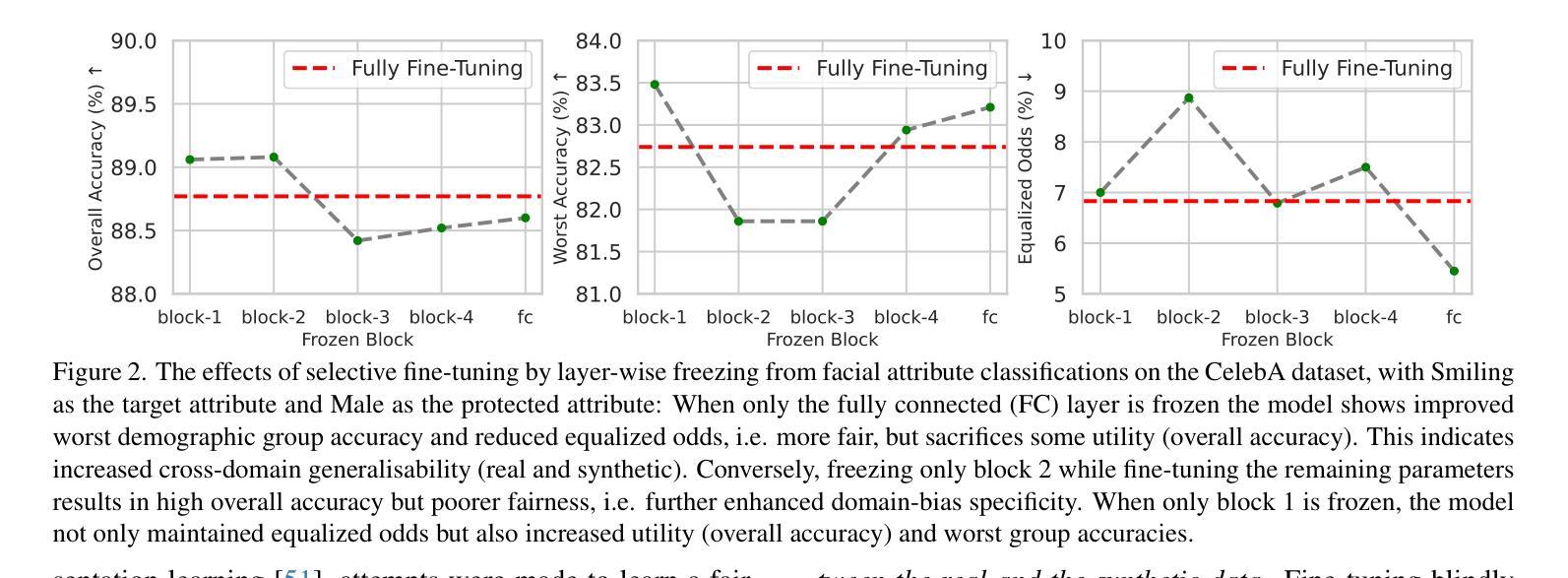
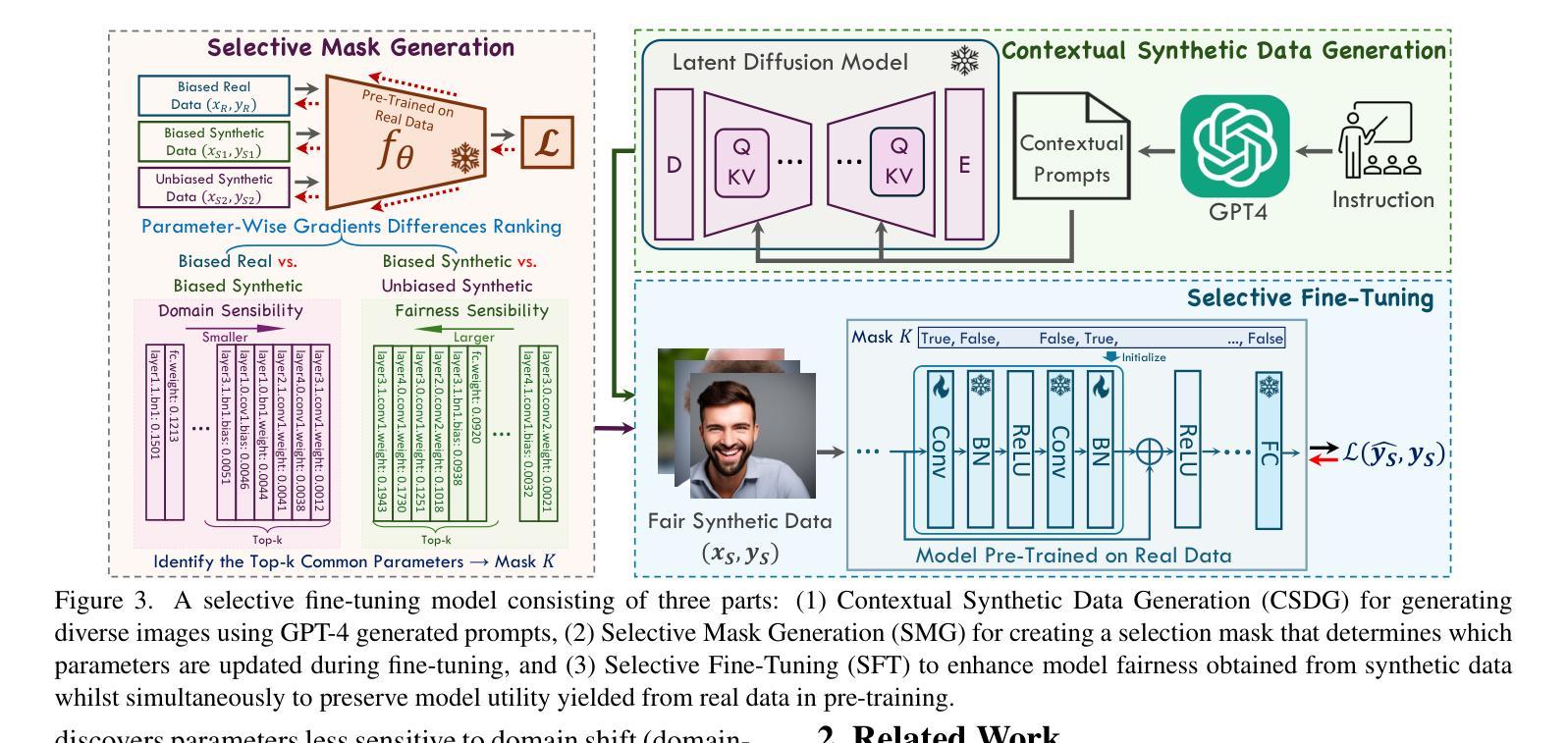
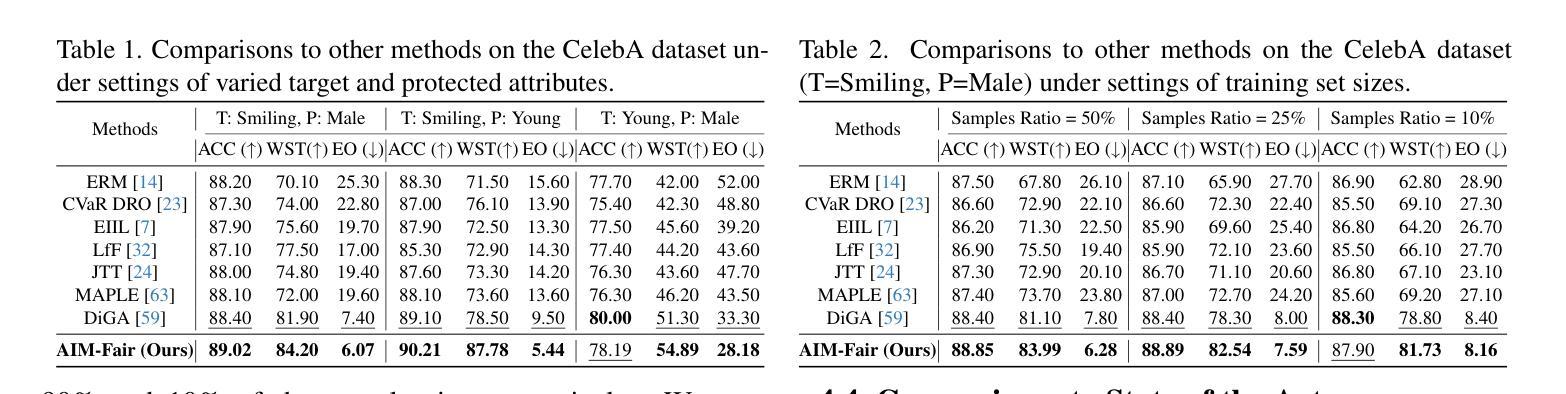
AIM-Fair: Advancing Algorithmic Fairness via Selectively Fine-Tuning Biased Models with Contextual Synthetic Data
Authors:Zengqun Zhao, Ziquan Liu, Yu Cao, Shaogang Gong, Ioannis Patras
Recent advances in generative models have sparked research on improving model fairness with AI-generated data. However, existing methods often face limitations in the diversity and quality of synthetic data, leading to compromised fairness and overall model accuracy. Moreover, many approaches rely on the availability of demographic group labels, which are often costly to annotate. This paper proposes AIM-Fair, aiming to overcome these limitations and harness the potential of cutting-edge generative models in promoting algorithmic fairness. We investigate a fine-tuning paradigm starting from a biased model initially trained on real-world data without demographic annotations. This model is then fine-tuned using unbiased synthetic data generated by a state-of-the-art diffusion model to improve its fairness. Two key challenges are identified in this fine-tuning paradigm, 1) the low quality of synthetic data, which can still happen even with advanced generative models, and 2) the domain and bias gap between real and synthetic data. To address the limitation of synthetic data quality, we propose Contextual Synthetic Data Generation (CSDG) to generate data using a text-to-image diffusion model (T2I) with prompts generated by a context-aware LLM, ensuring both data diversity and control of bias in synthetic data. To resolve domain and bias shifts, we introduce a novel selective fine-tuning scheme in which only model parameters more sensitive to bias and less sensitive to domain shift are updated. Experiments on CelebA and UTKFace datasets show that our AIM-Fair improves model fairness while maintaining utility, outperforming both fully and partially fine-tuned approaches to model fairness.
近期生成模型领域的进展激发了关于使用AI生成数据提高模型公平性的研究。然而,现有方法通常在合成数据的多样性和质量方面存在局限,导致公平性和整体模型准确度受损。此外,许多方法依赖于人口统计群体标签的可用性,这些标签的标注成本往往很高。本文针对这些局限性,提出了一种名为AIM-Fair的方法,旨在利用最前沿生成模型的潜力来促进算法公平性。研究了一种微调模式,从最初在真实世界数据上训练的带有偏见的模型开始,该模型没有人口统计注释。然后,使用由最先进扩散模型生成的公正合成数据对此模型进行微调,以提高其公平性。在此微调模式中确定了两个关键挑战:1)即使使用先进的生成模型,合成数据的质量仍然可能很低;2)真实数据和合成数据之间的领域和偏见差距。为了解决合成数据质量的局限性,我们提出了基于上下文合成数据生成(CSDG)的方法,使用文本到图像扩散模型(T2I)生成数据,并通过上下文感知LLM生成提示,确保合成数据的多样性和偏见的控制。为了解决领域和偏见转移问题,我们引入了一种新型选择性微调方案,其中只更新对偏见更敏感并且对领域转移不太敏感的部分模型参数。在CelebA和UTKFace数据集上的实验表明,我们的AIM-Fair方法在维持效用的同时提高了模型的公平性,并且优于完全和部分微调模型公平性的方法。
论文及项目相关链接
PDF Accepted at CVPR 2025. Github: https://github.com/zengqunzhao/AIM-Fair. Project page: https://zengqunzhao.github.io/AIMFair
Summary
随着生成模型的最新发展,提高模型公平性的研究愈发重要。本文提出了AIM-Fair方法,旨在克服现有方法的局限性并充分利用先进生成模型在促进算法公平性方面的潜力。该方法从一个基于现实数据但带有偏见的初始模型开始,然后使用由最先进的扩散模型生成的无偏见合成数据进行微调。为应对合成数据质量低的挑战,提出了基于文本到图像的扩散模型(T2I)与语境感知的大型语言模型(LLM)相结合生成数据的语境合成数据生成方法(CSDG),保证数据多样性和合成数据的偏见控制。同时采用选择性微调策略,仅更新对偏见敏感但对领域转移不敏感的模型参数来解决领域和偏见转移问题。实验表明,AIM-Fair在保持模型效用的同时提高了模型的公平性。
Key Takeaways
- 生成模型的进步引发了对提高模型公平性的研究关注。
- 现有方法面临合成数据多样性和质量上的局限性,影响模型的公平性和准确性。
- 提出AIM-Fair方法,旨在利用先进生成模型促进算法公平性。
- 使用合成数据微调初始模型以提高公平性。
- 针对合成数据质量低的问题,采用基于文本到图像的扩散模型和语境感知的大型语言模型的结合生成数据。
- 采用选择性微调策略来解决领域和偏见转移问题。
点此查看论文截图


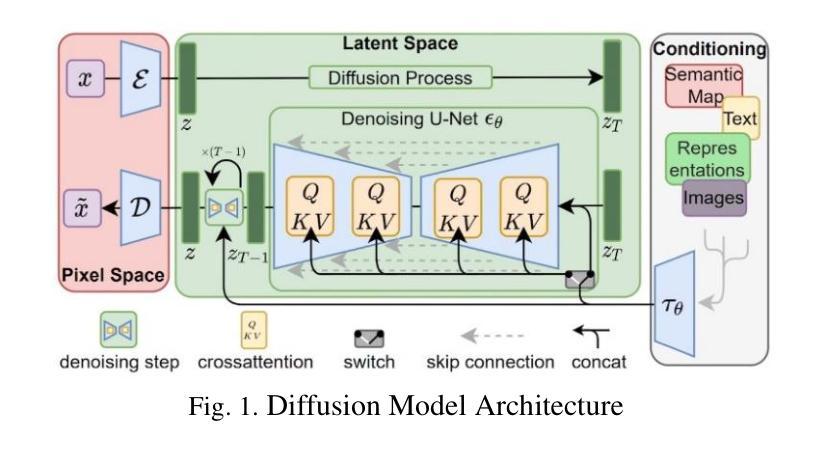
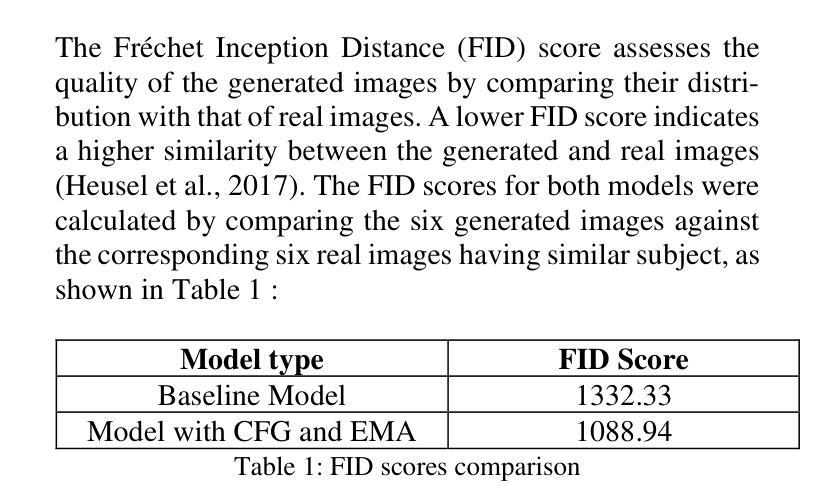
Development and Enhancement of Text-to-Image Diffusion Models
Authors:Rajdeep Roshan Sahu
This research focuses on the development and enhancement of text-to-image denoising diffusion models, addressing key challenges such as limited sample diversity and training instability. By incorporating Classifier-Free Guidance (CFG) and Exponential Moving Average (EMA) techniques, this study significantly improves image quality, diversity, and stability. Utilizing Hugging Face’s state-of-the-art text-to-image generation model, the proposed enhancements establish new benchmarks in generative AI. This work explores the underlying principles of diffusion models, implements advanced strategies to overcome existing limitations, and presents a comprehensive evaluation of the improvements achieved. Results demonstrate substantial progress in generating stable, diverse, and high-quality images from textual descriptions, advancing the field of generative artificial intelligence and providing new foundations for future applications. Keywords: Text-to-image, Diffusion model, Classifier-free guidance, Exponential moving average, Image generation.
本文重点研究文本到图像降噪扩散模型的发展和改进,解决样本多样性有限和训练不稳定等关键挑战。通过融入无分类器引导(CFG)和指数移动平均(EMA)技术,该研究显著提高了图像质量、多样性和稳定性。利用Hugging Face最先进的文本到图像生成模型,所提出的改进在生成式人工智能领域建立了新的基准。这项工作探索了扩散模型的基本原理,实施了先进的策略来克服现有局限性,并全面评估了所取得的改进。结果证明,在从文本来生成稳定、多样且高质量的图像方面取得了实质性进展,为生成人工智能领域提供了新的基础和未来应用的可能性。关键词:文本到图像、扩散模型、无分类器引导、指数移动平均、图像生成。
论文及项目相关链接
Summary
本文研究了文本到图像去噪扩散模型的发展和改进,通过融入Classifier-Free Guidance(CFG)和Exponential Moving Average(EMA)技术,提高了图像质量、多样性和稳定性。该研究利用Hugging Face的先进文本到图像生成模型,建立了生成式人工智能的新基准。
Key Takeaways
- 研究聚焦于文本到图像去噪扩散模型的发展和改进。
- 借助Classifier-Free Guidance(CFG)和Exponential Moving Average(EMA)技术,克服了样本多样性有限和训练不稳定等关键挑战。
- 利用Hugging Face的先进文本到图像生成模型,实现了生成式人工智能的新突破。
4.该研究深入探讨了扩散模型的基本原理,实施了高级策略来克服现有局限性。 - 实现了对改进的全面评估,证明了在生成稳定、多样、高质量的图像方面的显著进展。
6.该研究为文本描述生成图像的技术提供了新基础,推动了生成人工智能领域的发展。
点此查看论文截图



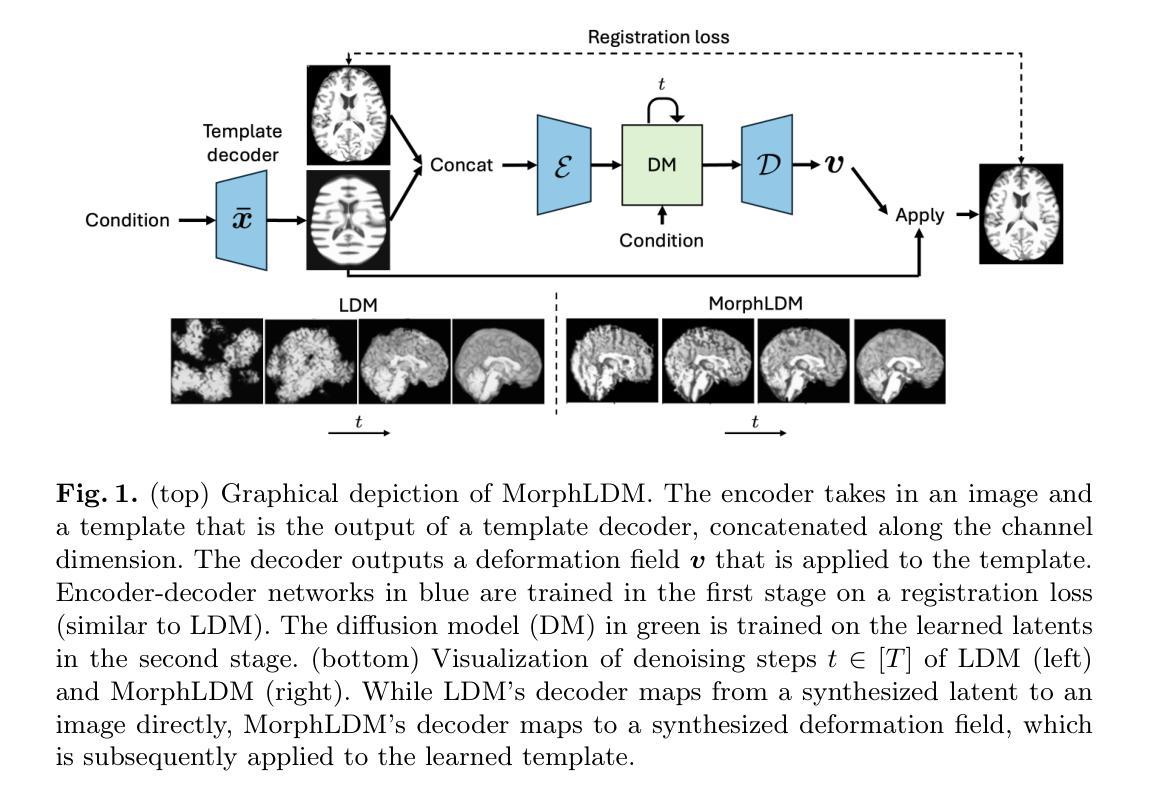
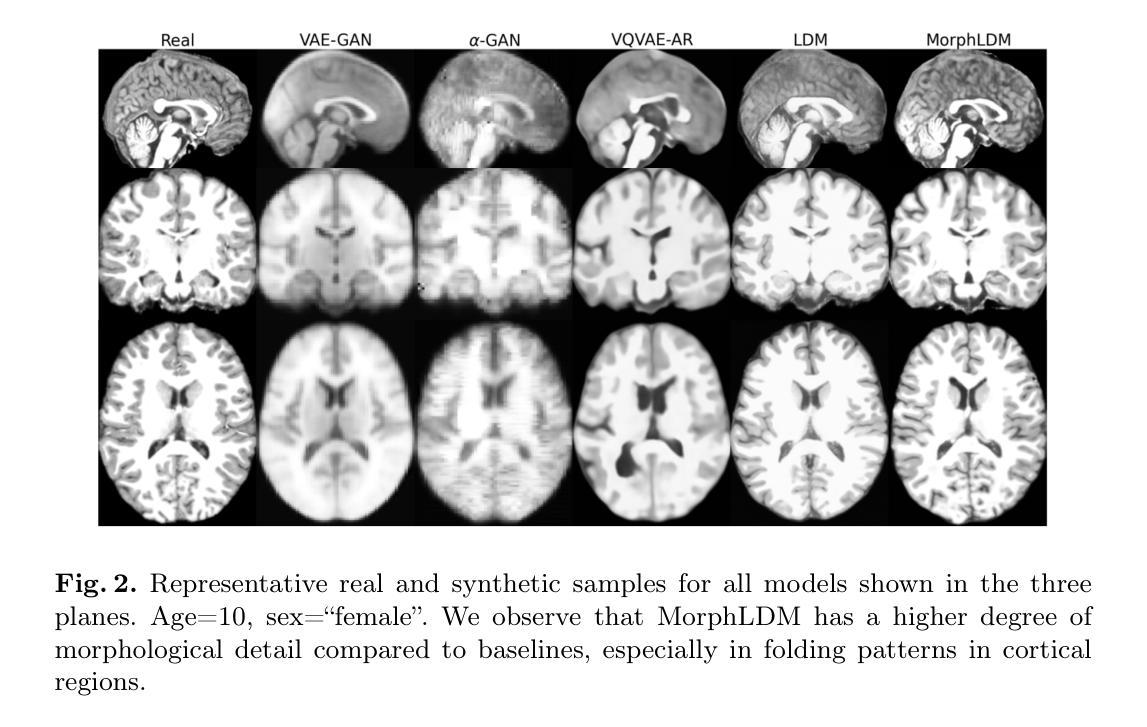
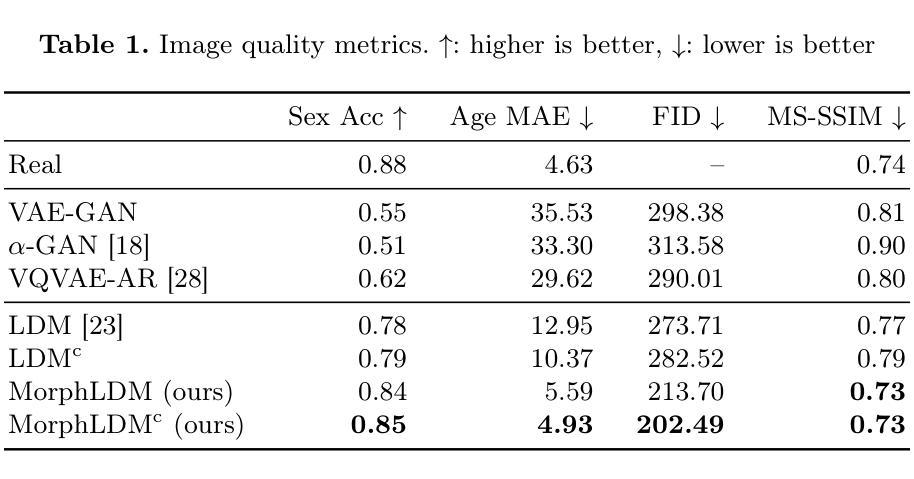
Generating Novel Brain Morphology by Deforming Learned Templates
Authors:Alan Q. Wang, Fangrui Huang, Bailey Trang, Wei Peng, Mohammad Abbasi, Kilian Pohl, Mert Sabuncu, Ehsan Adeli
Designing generative models for 3D structural brain MRI that synthesize morphologically-plausible and attribute-specific (e.g., age, sex, disease state) samples is an active area of research. Existing approaches based on frameworks like GANs or diffusion models synthesize the image directly, which may limit their ability to capture intricate morphological details. In this work, we propose a 3D brain MRI generation method based on state-of-the-art latent diffusion models (LDMs), called MorphLDM, that generates novel images by applying synthesized deformation fields to a learned template. Instead of using a reconstruction-based autoencoder (as in a typical LDM), our encoder outputs a latent embedding derived from both an image and a learned template that is itself the output of a template decoder; this latent is passed to a deformation field decoder, whose output is applied to the learned template. A registration loss is minimized between the original image and the deformed template with respect to the encoder and both decoders. Empirically, our approach outperforms generative baselines on metrics spanning image diversity, adherence with respect to input conditions, and voxel-based morphometry. Our code is available at https://github.com/alanqrwang/morphldm.
设计针对3D结构性脑MRI的生成模型,以合成形态上合理且具有特定属性(例如年龄、性别、疾病状态)的样本是一个研究热点。现有的基于GAN或扩散模型等框架的方法直接合成图像,这可能限制了它们捕捉复杂形态细节的能力。在这项工作中,我们提出了一种基于最先进的潜在扩散模型(LDMs)的3D脑MRI生成方法,称为MorphLDM。它通过应用合成变形场到一个学习到的模板来生成新的图像。我们的编码器输出的潜在嵌入来源于图像和学习到的模板(其本身也是模板解码器的输出),这个潜在嵌入被传递给变形场解码器,其输出被应用到学习到的模板上。通过最小化原始图像和变形模板之间的注册损失,同时优化编码器和两个解码器。经验上,我们的方法在图像多样性、符合输入条件的坚持性以及基于体素的形态测量等指标上的表现均超过了生成基线。我们的代码可在https://github.com/alanqrwang/morphldm上找到。
论文及项目相关链接
Summary
基于潜在扩散模型(LDM)的3D脑MRI生成方法已成为研究热点。MorphLDM作为基于先进LDM的新方法,通过合成变形场对所学模板进行操作生成新的图像。与典型的LDM使用的重建式自编码器不同,MorphLDM的编码器输出的是来自图像和所学模板两者的潜在嵌入,此潜在嵌入被传递给变形场解码器,其输出应用于所学模板。经过最小化原始图像和变形模板之间的注册损失后,其表现超出现在的主要生成模型。代码已公开在GitHub上。
Key Takeaways
- 研究焦点在于设计用于合成形态合理且属性特定的(如年龄、性别、疾病状态)3D结构脑MRI样本的生成模型。
- 当前方法基于潜在扩散模型(LDM)。
- 提出一种新方法MorphLDM,它通过合成变形场对所学模板进行操作来生成图像。
- 与典型LDM不同,MorphLDM的编码器输出结合了图像和模板信息的潜在嵌入。
- 使用变形场解码器处理潜在嵌入并应用于模板。
- 通过最小化注册损失来优化模型性能,该损失考虑了原始图像和变形模板之间的差异。
- 该方法在图像多样性、符合输入条件以及体素形态测量方面超越了现有生成模型的基准测试。
点此查看论文截图

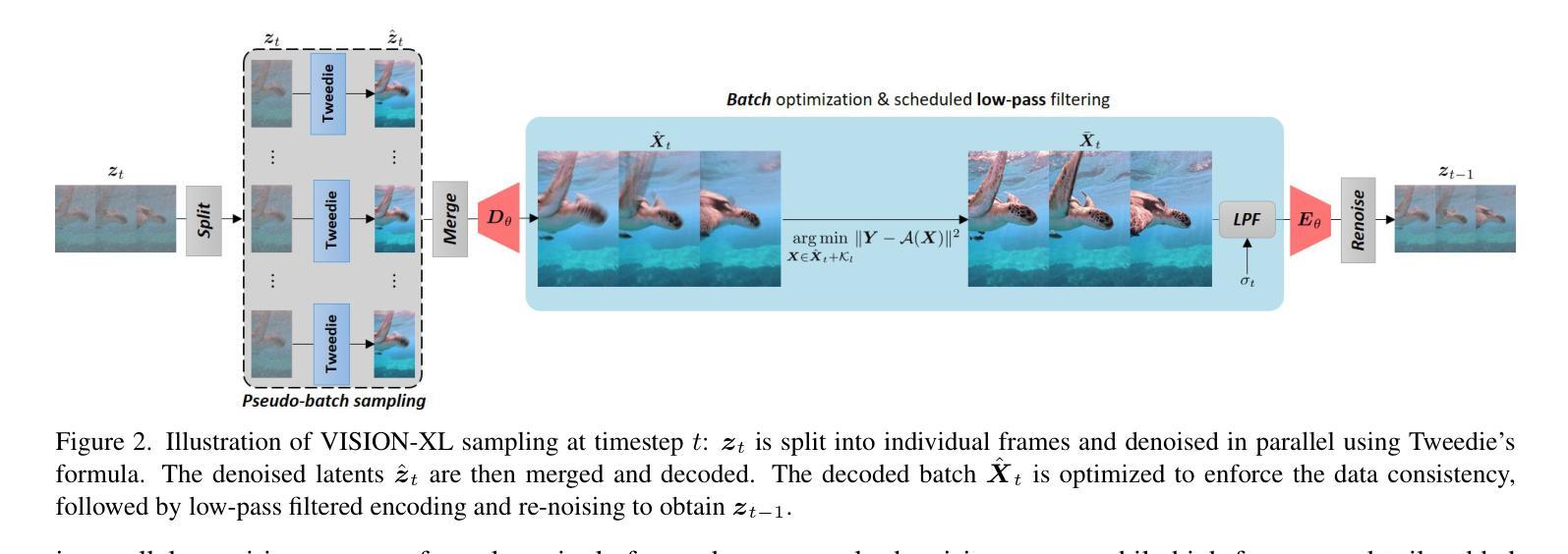
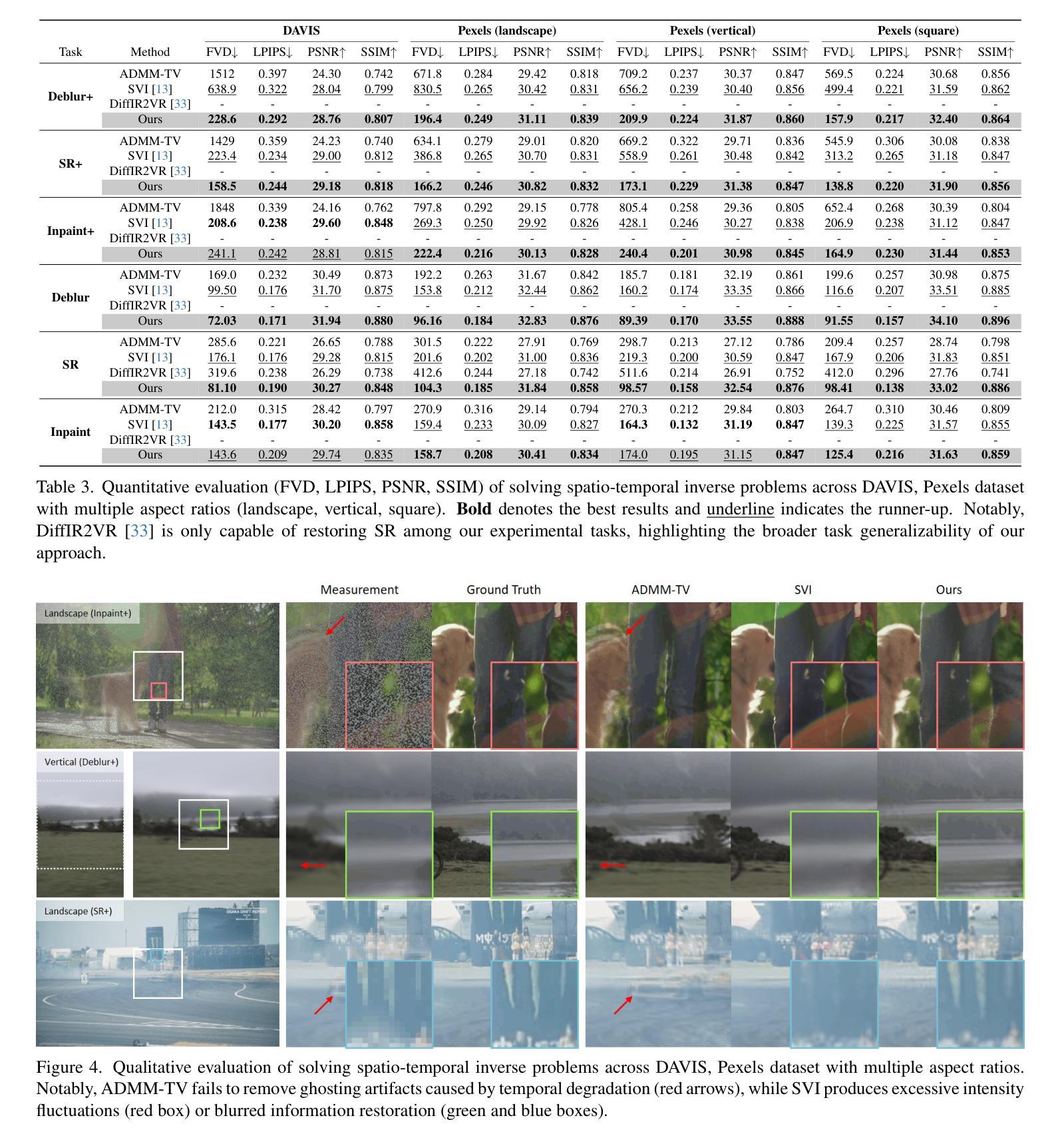
VISION-XL: High Definition Video Inverse Problem Solver using Latent Image Diffusion Models
Authors:Taesung Kwon, Jong Chul Ye
In this paper, we propose a novel framework for solving high-definition video inverse problems using latent image diffusion models. Building on recent advancements in spatio-temporal optimization for video inverse problems using image diffusion models, our approach leverages latent-space diffusion models to achieve enhanced video quality and resolution. To address the high computational demands of processing high-resolution frames, we introduce a pseudo-batch consistent sampling strategy, allowing efficient operation on a single GPU. Additionally, to improve temporal consistency, we present pseudo-batch inversion, an initialization technique that incorporates informative latents from the measurement. By integrating with SDXL, our framework achieves state-of-the-art video reconstruction across a wide range of spatio-temporal inverse problems, including complex combinations of frame averaging and various spatial degradations, such as deblurring, super-resolution, and inpainting. Unlike previous methods, our approach supports multiple aspect ratios (landscape, vertical, and square) and delivers HD-resolution reconstructions (exceeding 1280x720) in under 6 seconds per frame on a single NVIDIA 4090 GPU.
本文提出了一种基于潜在图像扩散模型解决高清视频逆问题的新型框架。我们的方法建立在最近基于图像扩散模型的视频逆问题时空优化的进展之上,利用潜在空间扩散模型实现增强视频质量和分辨率。为了解决处理高分辨率帧的高计算需求,我们引入了一种伪批量一致采样策略,该策略可在单个GPU上进行高效操作。此外,为了提高时间一致性,我们提出了伪批次反演初始化技术,该技术结合了测量中的信息潜在变量。通过与SDXL集成,我们的框架在广泛的时空逆问题中实现了最先进的视频重建效果,包括帧平均和各种空间退化的复杂组合,如去模糊、超分辨率和图像修复等。与之前的方法不同,我们的方法支持多种纵横比(横屏、竖屏和正方形),并在单个NVIDIA 4090 GPU上以每秒超过6帧的速度实现高清分辨率重建(超过1280x720)。
论文及项目相关链接
PDF Project page: https://vision-xl.github.io/
Summary
本文提出了一种基于潜在图像扩散模型的高清视频逆问题解决方案框架。该框架利用时空优化技术,通过潜在空间扩散模型增强视频质量和分辨率。为解决高分辨率帧的高计算需求,引入伪批次一致采样策略,可在单个GPU上实现高效操作。通过伪批次反转初始化技术,提高时间一致性。结合SDXL,该框架在广泛的时空逆问题中实现了最先进的视频重建效果,包括帧平均和各种空间退化如去模糊、超分辨率和修复等。与以前的方法不同,该方法支持多种纵横比,并在单个NVIDIA 4090 GPU上实现高清分辨率重建(超过1280x720),每帧处理时间不到6秒。
Key Takeaways
- 提出了基于潜在图像扩散模型的高清视频逆问题解决方案框架。
- 利用时空优化技术和潜在空间扩散模型增强视频质量和分辨率。
- 引入伪批次一致采样策略,满足高计算需求,实现高效操作。
- 通过伪批次反转初始化技术,提高时间一致性。
- 结合SDXL,在多种时空逆问题中实现最先进的视频重建效果。
- 支持多种纵横比的视频处理。
点此查看论文截图



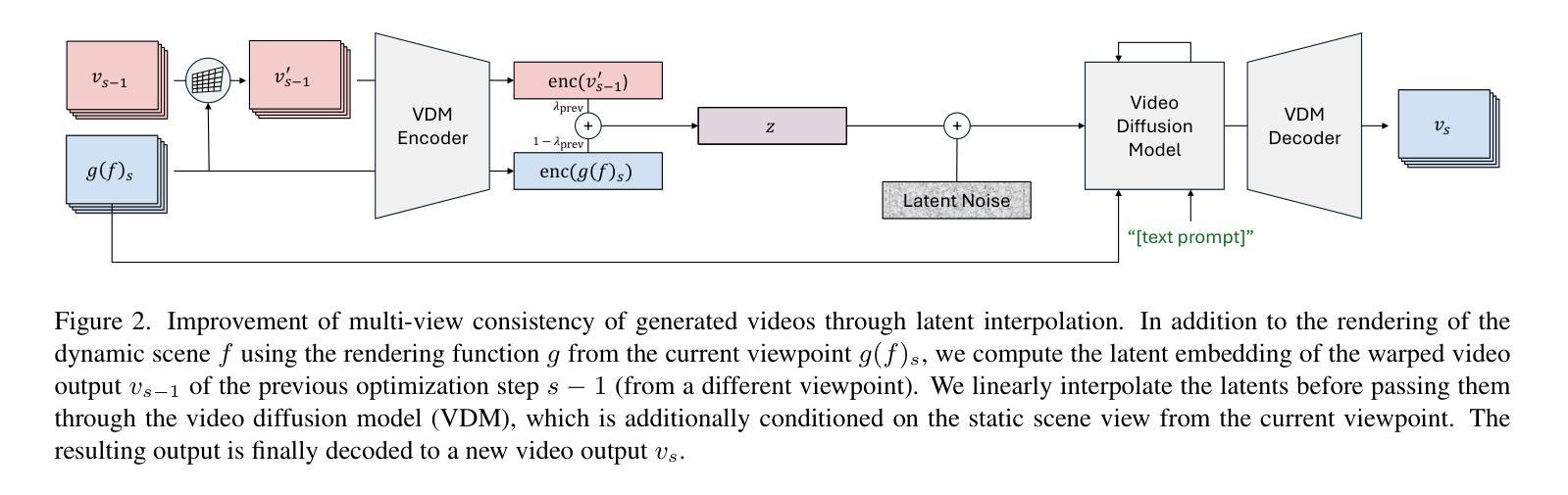
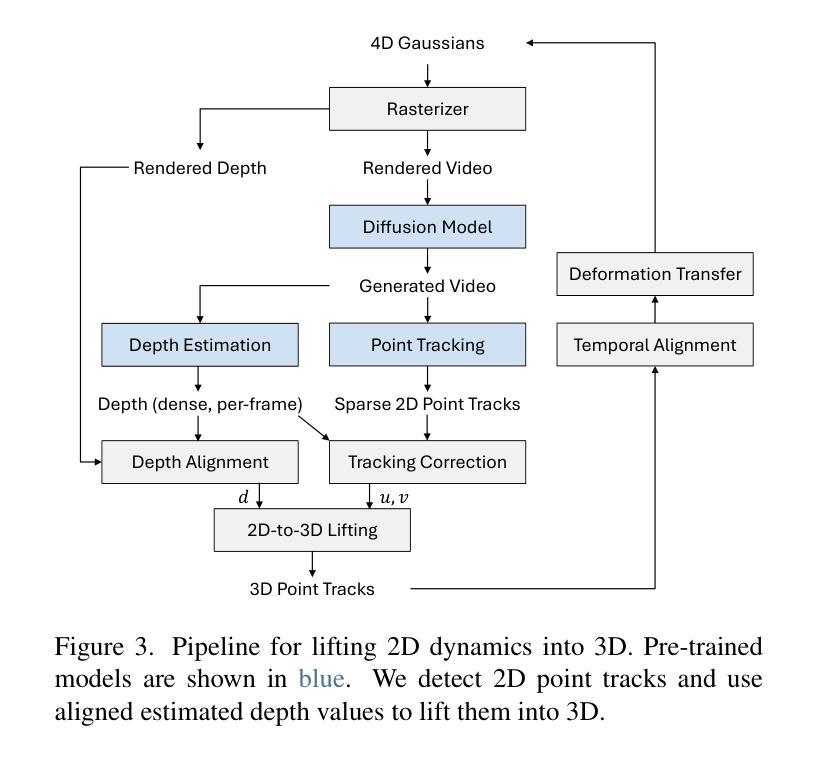
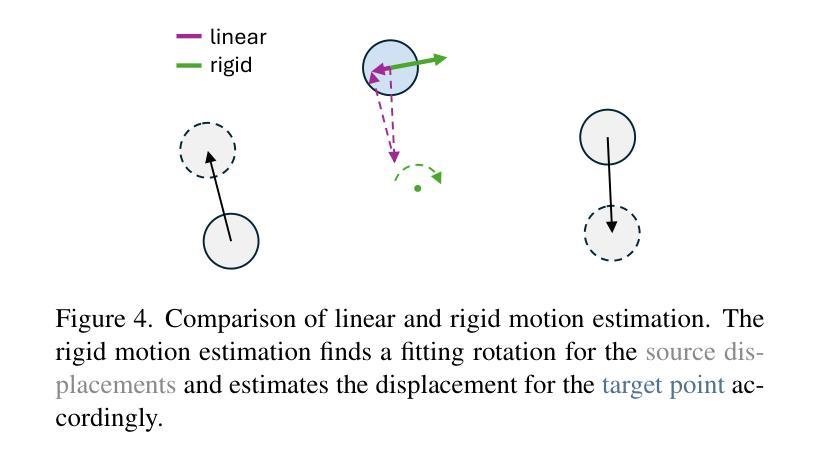
Gaussians-to-Life: Text-Driven Animation of 3D Gaussian Splatting Scenes
Authors:Thomas Wimmer, Michael Oechsle, Michael Niemeyer, Federico Tombari
State-of-the-art novel view synthesis methods achieve impressive results for multi-view captures of static 3D scenes. However, the reconstructed scenes still lack “liveliness,” a key component for creating engaging 3D experiences. Recently, novel video diffusion models generate realistic videos with complex motion and enable animations of 2D images, however they cannot naively be used to animate 3D scenes as they lack multi-view consistency. To breathe life into the static world, we propose Gaussians2Life, a method for animating parts of high-quality 3D scenes in a Gaussian Splatting representation. Our key idea is to leverage powerful video diffusion models as the generative component of our model and to combine these with a robust technique to lift 2D videos into meaningful 3D motion. We find that, in contrast to prior work, this enables realistic animations of complex, pre-existing 3D scenes and further enables the animation of a large variety of object classes, while related work is mostly focused on prior-based character animation, or single 3D objects. Our model enables the creation of consistent, immersive 3D experiences for arbitrary scenes.
最新先进的新型视图合成方法对于静态三维场景的多视图捕获取得了令人印象深刻的结果。然而,重建的场景仍然缺乏“生动性”,这是创建吸引人的三维体验的关键要素。最近,新型视频扩散模型能够生成具有复杂运动的现实视频并为二维图像提供动画效果,但它们不能直接用于动画三维场景,因为缺乏多视图一致性。为了给静态世界注入生命力,我们提出了Gaussians2Life方法,这是一种以高斯拼贴表示法来动画高质量三维场景部分的方法。我们的核心思想是利用强大的视频扩散模型作为我们模型的生产组件,并将其与一种将二维视频提升到有意义的三维运动的技术相结合。我们发现,与之前的工作相比,这能够实现对复杂预存三维场景的逼真动画,并进一步实现对各种对象类别的动画,而相关工作主要集中在基于先验的角色动画或单个三维对象上。我们的模型能够为任意场景创建连贯、沉浸式的三维体验。
论文及项目相关链接
PDF Project website at https://wimmerth.github.io/gaussians2life.html. Accepted to 3DV 2025
Summary
本文提出一种名为Gaussians2Life的方法,该方法利用视频扩散模型为高质量3D场景的部分内容注入活力。通过结合强大的视频扩散模型和将2D视频提升到有意义的3D运动的技术,实现了对复杂预存3D场景的真实动画渲染,并能对各种对象类别进行动画处理,与先前的工作相比,具有更大的灵活性和广泛的应用性。
Key Takeaways
- 当前先进的新视图合成方法在静态3D场景的多视图捕捉方面取得了令人印象深刻的结果,但重建的场景缺乏”生动性”,这是创建吸引入的3D体验的关键要素。
- 新的视频扩散模型可以生成具有复杂运动的真实视频并使2D图像动画化,但它们不能简单地用于动画化3D场景,缺乏多视图一致性。
- Gaussians2Life方法利用视频扩散模型为高质量3D场景注入活力,实现复杂预存3D场景的真实动画渲染。
- Gaussians2Life方法能将2D视频提升到有意义的3D运动,使得对任意场景的3D体验更加一致和沉浸式。
- 该方法不仅适用于基于先验的角色动画,还适用于单个3D物体的动画,具有更广泛的应用范围。
- 与先前的工作相比,Gaussians2Life方法具有更大的灵活性,能够处理更广泛的物体类别和场景。
点此查看论文截图

Reward Fine-Tuning Two-Step Diffusion Models via Learning Differentiable Latent-Space Surrogate Reward
Authors:Zhiwei Jia, Yuesong Nan, Huixi Zhao, Gengdai Liu
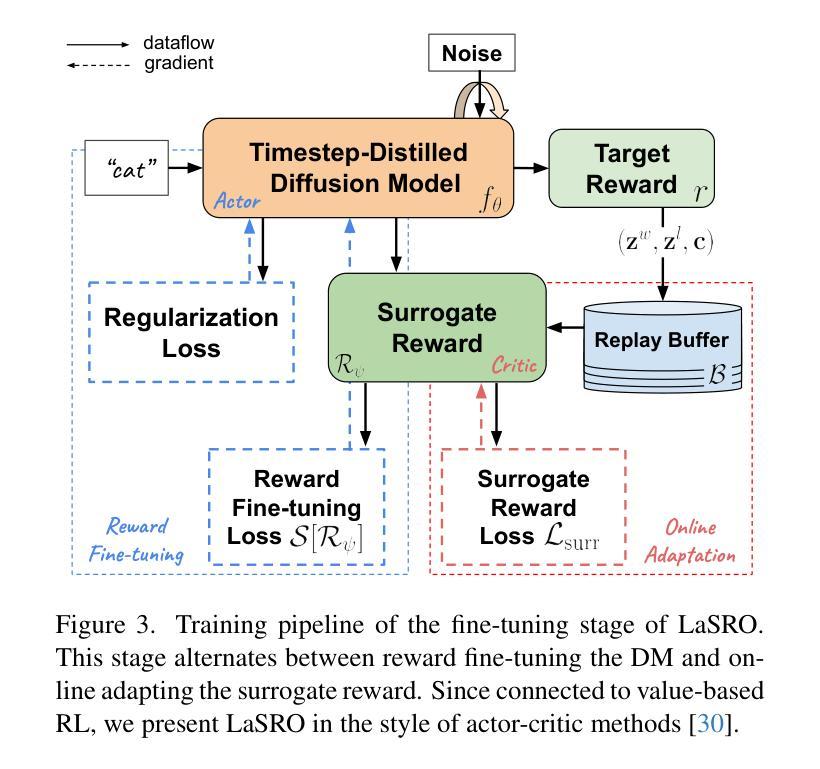
Recent research has shown that fine-tuning diffusion models (DMs) with arbitrary rewards, including non-differentiable ones, is feasible with reinforcement learning (RL) techniques, enabling flexible model alignment. However, applying existing RL methods to timestep-distilled DMs is challenging for ultra-fast ($\le2$-step) image generation. Our analysis suggests several limitations of policy-based RL methods such as PPO or DPO toward this goal. Based on the insights, we propose fine-tuning DMs with learned differentiable surrogate rewards. Our method, named LaSRO, learns surrogate reward models in the latent space of SDXL to convert arbitrary rewards into differentiable ones for efficient reward gradient guidance. LaSRO leverages pre-trained latent DMs for reward modeling and specifically targets image generation $\le2$ steps for reward optimization, enhancing generalizability and efficiency. LaSRO is effective and stable for improving ultra-fast image generation with different reward objectives, outperforming popular RL methods including PPO and DPO. We further show LaSRO’s connection to value-based RL, providing theoretical insights. See our webpage at https://sites.google.com/view/lasro.
最近的研究表明,利用强化学习(RL)技术对扩散模型(DMs)进行微调,接受任意奖励(包括不可区分的奖励)是可行的,从而实现灵活的模型对齐。然而,将现有强化学习方法应用于时间步蒸馏的扩散模型在超快速(≤2步)图像生成方面存在挑战。我们的分析指出了基于政策的强化学习方法(如PPO或DPO)在此目标上的局限性。基于这些见解,我们提出了利用学习到的可区分替代奖励对扩散模型进行微调的方法。我们的方法名为LaSRO,它在SDXL的潜在空间中学习替代奖励模型,将任意奖励转换为可区分的奖励,以实现有效的奖励梯度指导。LaSRO利用预训练的潜在扩散模型进行奖励建模,并针对奖励优化专门设定图像生成≤2步,从而提高通用性和效率。LaSRO在具有不同奖励目标的超快速图像生成方面非常有效且稳定,优于包括PPO和DPO在内的流行强化学习方法。我们还展示了LaSRO与价值型强化学习之间的联系,提供了理论见解。更多信息请访问我们的网页:https://sites.google.com/view/lasro。
论文及项目相关链接
PDF CVPR 2025
Summary
扩散模型使用强化学习技术进行任意奖励的微调,具有灵活模型对齐的能力。然而,在超快速(≤2步)图像生成方面,应用现有的强化学习方法具有挑战性。为此,我们提出了使用可学习的可分化替代奖励来微调扩散模型的方法——LaSRO。它在SDXL的潜在空间中学习替代奖励模型,将任意奖励转化为可区分的奖励,提供有效的奖励梯度指导。LaSRO利用预训练的潜在扩散模型进行奖励建模,专门针对≤2步的图像生成进行奖励优化,提高了通用性和效率。对于不同的奖励目标,LaSRO在改进超快速图像生成方面表现出色,超越了包括PPO和DPO在内的流行强化学习方法。此外,我们还展示了LaSRO与价值型强化学习之间的联系,提供了理论见解。有关详细信息,请访问我们的网页:https://sites.google.com/view/lasro。
Key Takeaways
- 扩散模型可以通过强化学习技术微调,以灵活对齐模型,即使使用非可分化奖励也可实现。
- 在超快速图像生成(≤2步)方面,现有强化学习方法存在挑战。
- LaSRO方法通过学习在潜在空间中的可分化替代奖励来解决这一问题,将任意奖励转化为可区分的奖励。
- LaSRO利用预训练的潜在扩散模型进行奖励建模,优化图像生成的奖励目标。
- LaSRO提高了图像生成的通用性和效率,在不同奖励目标下表现优异。
- LaSRO超越了流行的强化学习方法,如PPO和DPO。
点此查看论文截图




Modification Takes Courage: Seamless Image Stitching via Reference-Driven Inpainting
Authors:Ziqi Xie, Xiao Lai, Weidong Zhao, Siqi Jiang, Xianhui Liu, Wenlong Hou
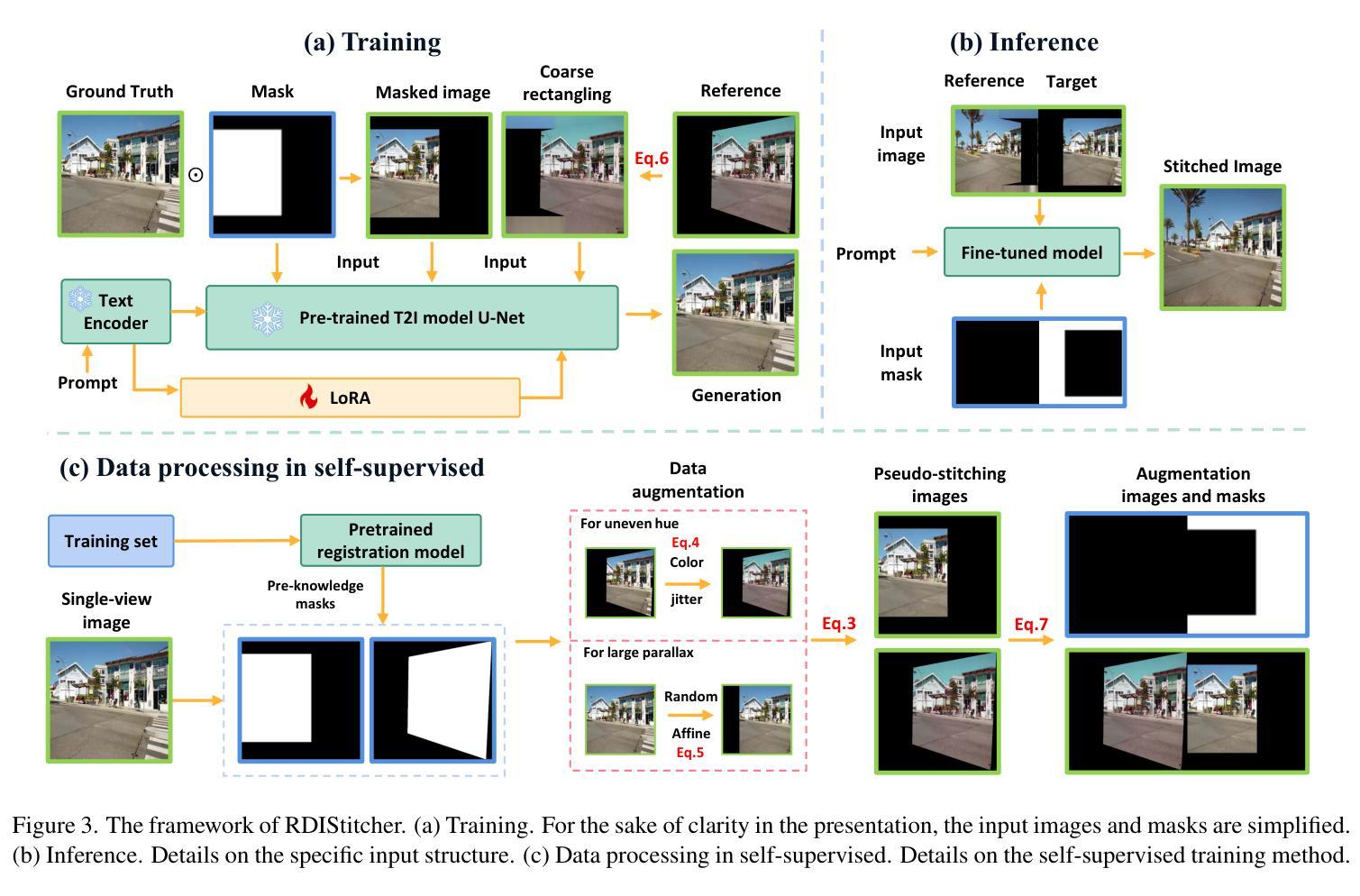
Current image stitching methods often produce noticeable seams in challenging scenarios such as uneven hue and large parallax. To tackle this problem, we propose the Reference-Driven Inpainting Stitcher (RDIStitcher), which reformulates the image fusion and rectangling as a reference-based inpainting model, incorporating a larger modification fusion area and stronger modification intensity than previous methods. Furthermore, we introduce a self-supervised model training method, which enables the implementation of RDIStitcher without requiring labeled data by fine-tuning a Text-to-Image (T2I) diffusion model. Recognizing difficulties in assessing the quality of stitched images, we present the Multimodal Large Language Models (MLLMs)-based metrics, offering a new perspective on evaluating stitched image quality. Compared to the state-of-the-art (SOTA) method, extensive experiments demonstrate that our method significantly enhances content coherence and seamless transitions in the stitched images. Especially in the zero-shot experiments, our method exhibits strong generalization capabilities. Code: https://github.com/yayoyo66/RDIStitcher
当前图像拼接方法往往在具有挑战性的场景中产生明显的接缝,如色调不均匀和较大视差。为了解决这个问题,我们提出了基于参考驱动的填充拼接器(RDIStitcher),它将图像融合和矩形框重新定义为基于参考的填充模型,并融入了比以往更大的修改融合区域和更强的修改强度。此外,我们引入了一种自监督模型训练方法,通过微调文本到图像(T2I)扩散模型,使RDIStitcher的实现无需标记数据。由于拼接图像的质量评估难度大,我们提出基于多模态大型语言模型(MLLMs)的度量标准,为评估拼接图像质量提供了新的视角。与最新方法相比,大量实验表明,我们的方法在拼接图像的内容连贯性和无缝过渡方面有了显著的提升。特别是在零样本实验中,我们的方法表现出强大的泛化能力。代码链接:https://github.com/yayoyo66/RDIStitcher
论文及项目相关链接
PDF 18 pages, 10 figures
摘要
针对现有图像拼接方法在处理不均匀色调和大视差等复杂场景时产生的明显接缝问题,我们提出了基于参考驱动的图像填充拼接器(RDIStitcher)。该方法将图像融合和矩形化重新构建为基于参考的填充模型,并引入更大的修改融合区域和更强的修改强度。此外,我们采用了一种自监督模型训练方法,通过微调文本到图像(T2I)扩散模型,无需标注数据即可实现RDIStitcher。同时,我们认识到评估拼接图像质量存在困难,因此提出了基于多模态大型语言模型(MLLMs)的评估指标,为评估拼接图像质量提供了新的视角。相较于现有最先进的(SOTA)方法,大量实验证明我们的方法显著提高了拼接图像的内容连贯性和无缝过渡效果,尤其在零样本实验中,我们的方法展现出强大的泛化能力。
关键见解
- RDIStitcher方法针对图像拼接中的明显接缝问题进行了优化,特别在复杂场景如不均匀色调和大视差情况下表现更优秀。
- RDIStitcher将图像融合和矩形化重构为基于参考的填充模型,扩大了修改融合区域并增强了修改强度。
- 通过微调文本到图像(T2I)扩散模型,实现了RDIStitcher的自监督模型训练,无需标注数据。
- 提出了基于多模态大型语言模型(MLLMs)的评估指标,为评估拼接图像质量提供了新视角。
- 与现有最先进的图像拼接方法相比,RDIStitcher在内容连贯性和无缝过渡方面有明显提升。
- RDIStitcher在零样本实验中表现出强大的泛化能力。
点此查看论文截图



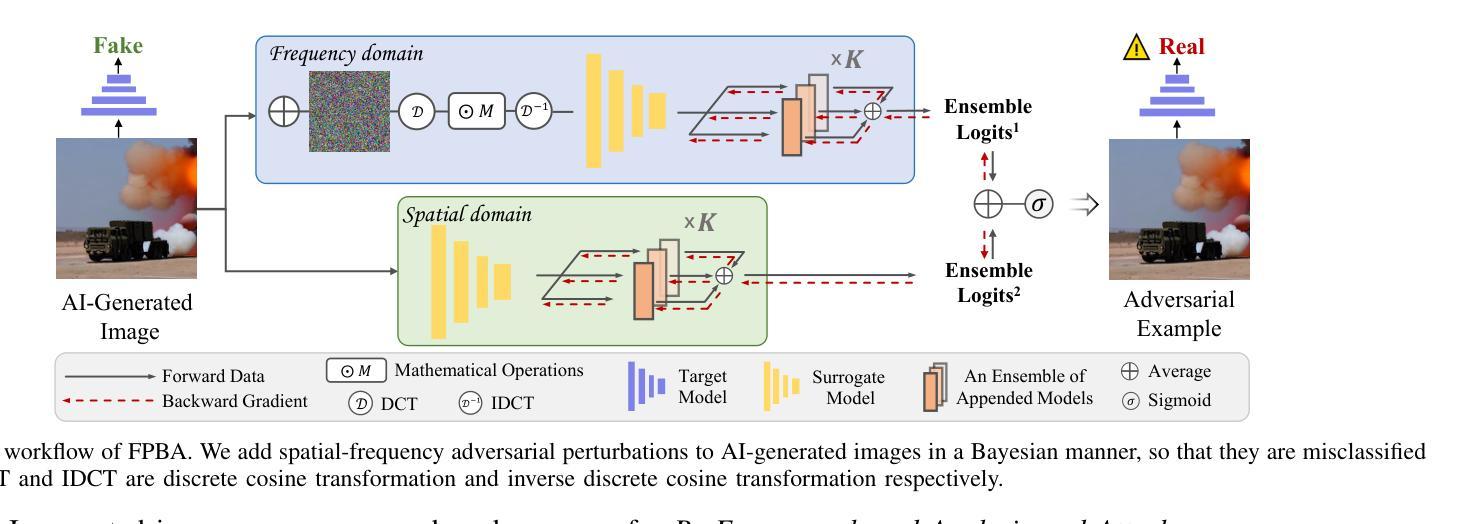
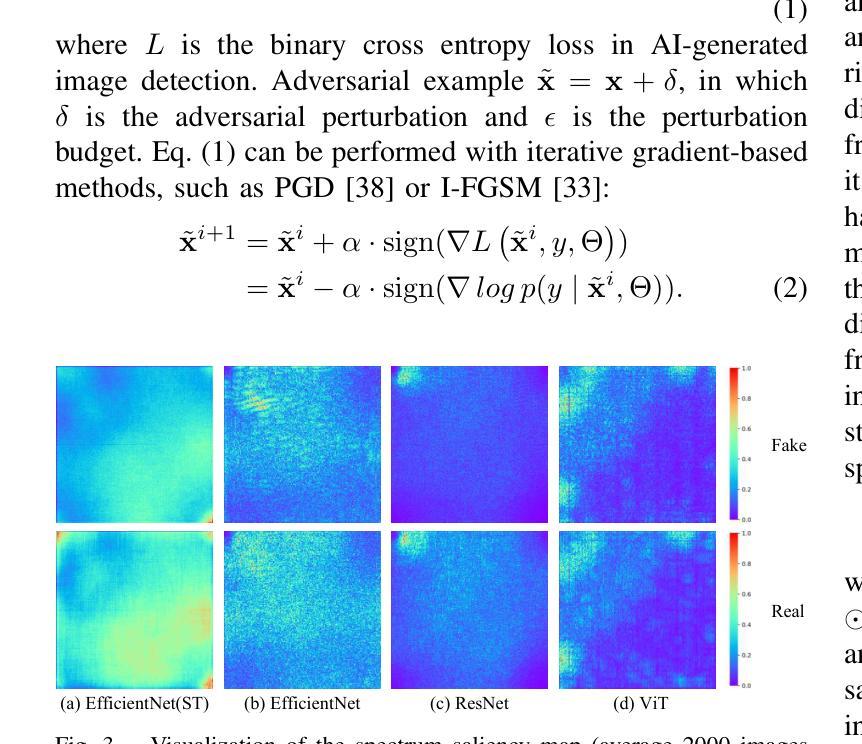
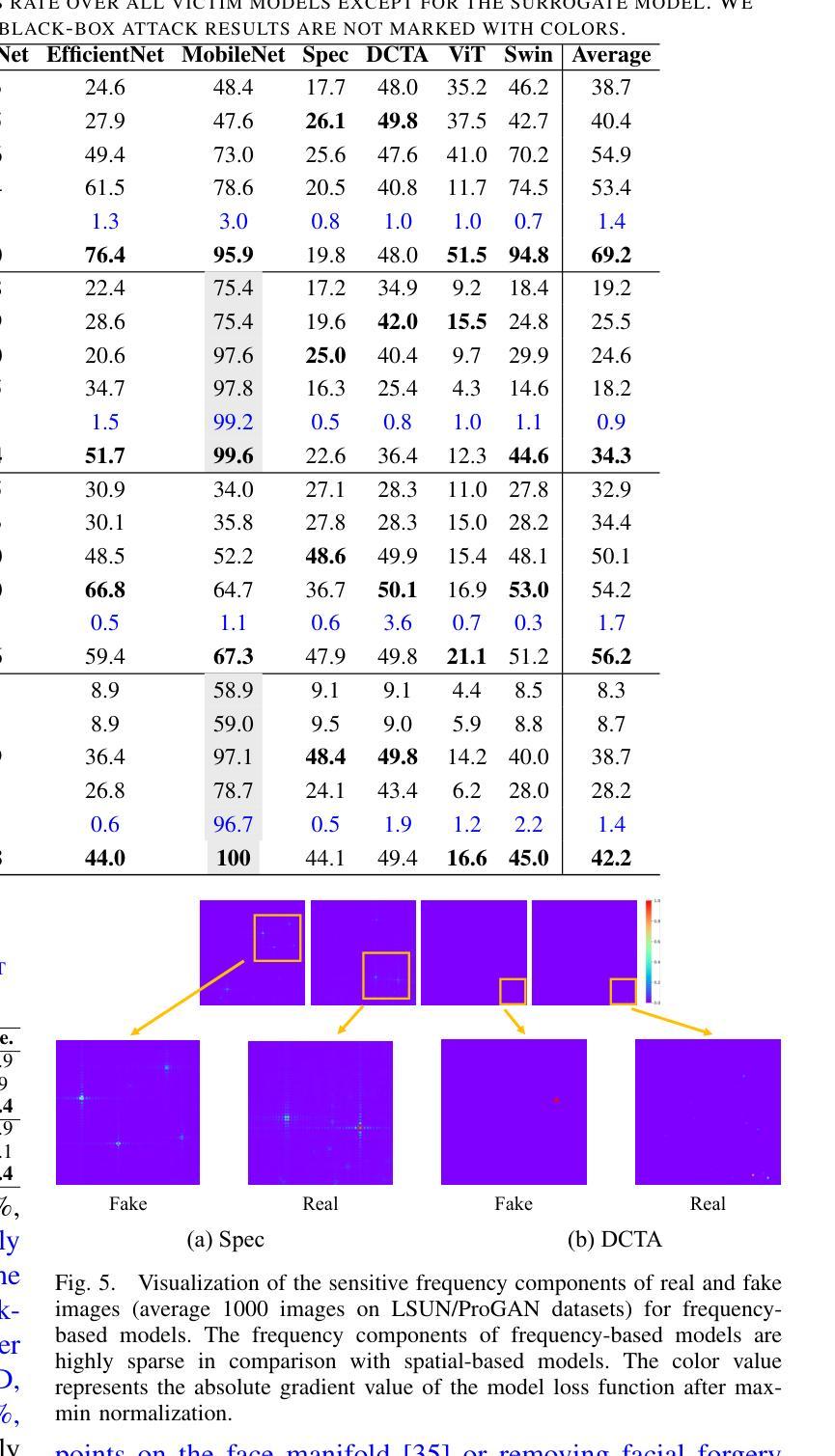
Vulnerabilities in AI-generated Image Detection: The Challenge of Adversarial Attacks
Authors:Yunfeng Diao, Naixin Zhai, Changtao Miao, Zitong Yu, Xingxing Wei, Xun Yang, Meng Wang
Recent advancements in image synthesis, particularly with the advent of GAN and Diffusion models, have amplified public concerns regarding the dissemination of disinformation. To address such concerns, numerous AI-generated Image (AIGI) Detectors have been proposed and achieved promising performance in identifying fake images. However, there still lacks a systematic understanding of the adversarial robustness of AIGI detectors. In this paper, we examine the vulnerability of state-of-the-art AIGI detectors against adversarial attack under white-box and black-box settings, which has been rarely investigated so far. To this end, we propose a new method to attack AIGI detectors. First, inspired by the obvious difference between real images and fake images in the frequency domain, we add perturbations under the frequency domain to push the image away from its original frequency distribution. Second, we explore the full posterior distribution of the surrogate model to further narrow this gap between heterogeneous AIGI detectors, e.g. transferring adversarial examples across CNNs and ViTs. This is achieved by introducing a novel post-train Bayesian strategy that turns a single surrogate into a Bayesian one, capable of simulating diverse victim models using one pre-trained surrogate, without the need for re-training. We name our method as Frequency-based Post-train Bayesian Attack, or FPBA. Through FPBA, we show that adversarial attack is truly a real threat to AIGI detectors, because FPBA can deliver successful black-box attacks across models, generators, defense methods, and even evade cross-generator detection, which is a crucial real-world detection scenario. The code will be shared upon acceptance.
近期图像合成领域的进展,特别是生成对抗网络(GAN)和扩散模型的出现,加剧了公众对传播虚假信息的担忧。为了应对这些担忧,已经提出了许多人工智能生成的图像(AIGI)检测器,并在识别虚假图像方面取得了令人鼓舞的性能。然而,目前对于AIGI检测器的对抗性稳健性仍缺乏系统的理解。
论文及项目相关链接
摘要
近期图像合成技术的进展,特别是GAN和Diffusion模型的出现,加剧了公众对假信息传播的担忧。为应对这些担忧,已经提出了许多AI生成的图像(AIGI)检测器,它们在识别虚假图像方面表现出良好的性能。然而,对于AIGI检测器的对抗性稳健性,仍缺乏系统的理解。本文研究了最先进的AIGI检测器在白盒和黑盒设置下对抗攻击的脆弱性,这一领域的研究迄今为止仍很少见。为此,我们提出了一种新的方法来攻击AIGI检测器。首先,受真实图像和虚假图像在频域上明显差异的启发,我们在频域中添加扰动使图像偏离其原始频率分布。其次,我们探索了代理模型的后验分布,以进一步缩小不同AIGI检测器之间的鸿沟。通过引入一种新的后训练贝叶斯策略,我们将单一代理转变为贝叶斯代理,能够模拟多种受害者模型,使用预训练的单一代理而无需重新训练即可实现这一目标。我们称我们的方法为基于频率的后训练贝叶斯攻击(FPBA)。通过FPBA,我们证明了对抗性攻击确实对AIGI检测器构成了真正的威胁。我们的方法成功实现了跨模型、生成器、防御方法的黑盒攻击,并能逃避跨生成器检测,这是真实世界检测场景中的关键能力。代码将在接受后共享。
关键见解
- AIGI检测器面临着对抗性攻击的威胁,这对其在实际应用中的稳健性提出了挑战。
- 提出了一种新的攻击方法FPBA,能够在频域中添加扰动来影响检测器的性能。
- FPBA能够模拟多种受害者模型,使用预训练的单一代理模型进行攻击,无需重新训练。
- FPBA攻击能够跨模型、生成器、防御方法进行黑盒攻击,显示出其强大的攻击能力。
- FPBA能够逃避跨生成器检测,这在真实世界的检测场景中是一个重要的能力。
- 本文的研究强调了对抗性攻击的严重性,并提醒研究人员需要进一步提高AIGI检测器的稳健性。
点此查看论文截图