⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-11 更新
Ensemble Debiasing Across Class and Sample Levels for Fairer Prompting Accuracy
Authors:Ruixi Lin, Ziqiao Wang, Yang You
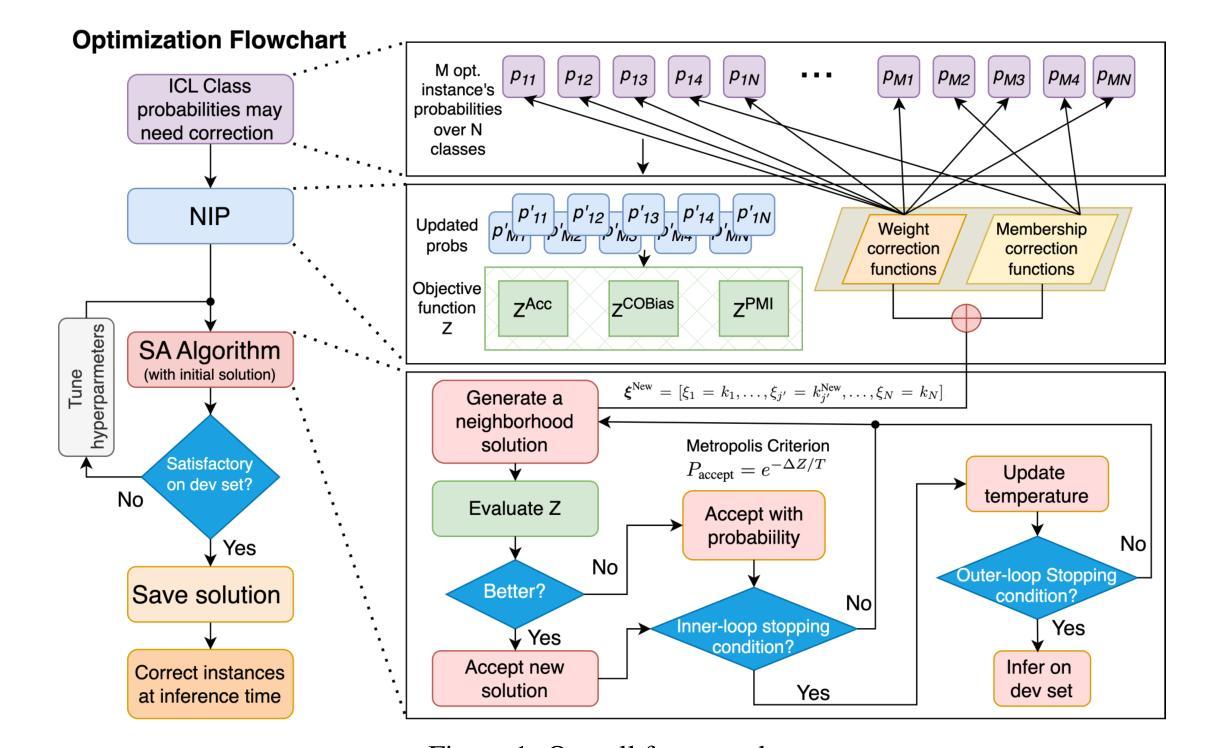
Language models are strong few-shot learners and achieve good overall accuracy in text classification tasks, masking the fact that their results suffer from great class accuracy imbalance. We believe that the pursuit of overall accuracy should not come from enriching the strong classes, but from raising up the weak ones. To address the imbalance, we propose a post-hoc nonlinear integer programming based debiasing method that ensembles weight correction and membership correction to enable flexible rectifications of class probabilities at both class and sample levels, enhancing the performance of LLMs directly from their outputs. Evaluations with Llama-2-13B on seven text classification benchmarks show that our approach achieves state-of-the-art overall accuracy gains with balanced class accuracies. The resulted probability correction scheme demonstrates that sample-level corrections are necessary to elevate weak classes. In addition, due to effectively correcting weak classes, our method also brings significant performance gains to Llama-2-70B, especially on a biomedical domain task, demonstrating its effectiveness across both small and large model variants.
语言模型是强大的少样本学习者,在文本分类任务中总体准确率较高,但存在类别准确率严重失衡的问题。我们认为追求总体准确率不应通过增强强类别来实现,而应通过提升弱类别来实现。为了解决不平衡问题,我们提出了一种基于事后非线性整数规划的去偏方法,通过集成权重修正和成员修正,能够在类和样本级别灵活地校正类概率,直接提升LLM的输出性能。使用Llama-2-13B在七个文本分类基准测试上的评估表明,我们的方法实现了最先进的总体准确率增益,同时类别准确率保持平衡。所得的概率校正方案表明,样本级校正对于提升弱类别是必要的。此外,由于有效地校正了弱类别,我们的方法还为Llama-2-70B带来了显著的性能提升,特别是在生物医学领域任务上,这证明了其在小型和大型模型变体中的有效性。
论文及项目相关链接
Summary
语言模型在少样本学习上表现出色,文本分类任务总体准确度较高,但存在类别准确度失衡的问题。为提高弱类别的性能,提出一种基于非线性整数规划的后期去偏方法,通过权重修正和成员修正来灵活调整类别概率,提高LLM的性能。在Llama-2-13B模型上的七个文本分类基准测试显示,该方法实现了最先进的总体精度增益,平衡了类别精度。概率校正方案表明,样本级别的校正对于提升弱类别是必要的。此外,该方法对Llama-2-70B模型也有显著的性能提升,尤其在生物医学领域任务中表现突出,证明其适用于不同规模的模型。
Key Takeaways
- 语言模型在少样本学习上有良好表现,但存在类别准确度失衡问题。
- 提出一种基于非线性整数规划的后期去偏方法,通过权重和成员修正来解决类别概率失衡问题。
- 这种方法提高了LLM的性能,特别是在弱类别上。
- 在多个文本分类基准测试中,该方法实现了最佳的总体精度和平衡类别精度。
- 概率校正方案表明样本级别的校正对提升弱类别性能至关重要。
- 该方法适用于不同规模的模型,包括大型语言模型如Llama-2-70B。
点此查看论文截图

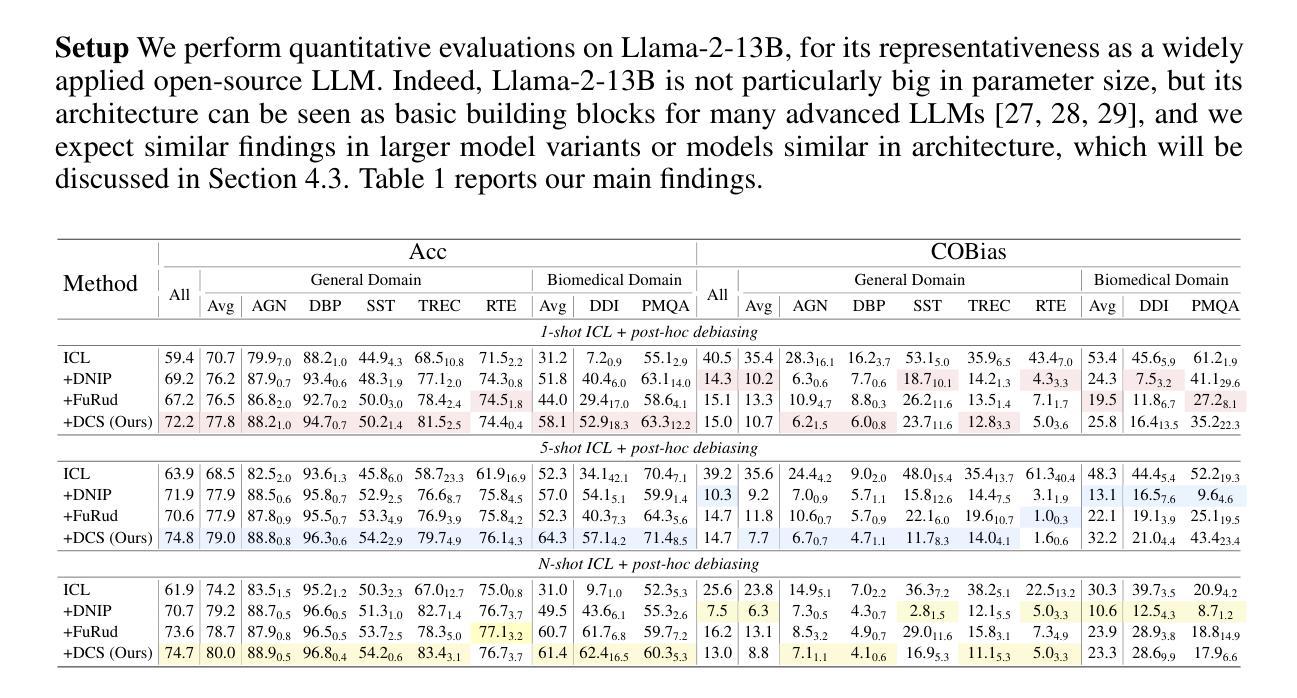
Leveraging Domain Knowledge at Inference Time for LLM Translation: Retrieval versus Generation
Authors:Bryan Li, Jiaming Luo, Eleftheria Briakou, Colin Cherry
While large language models (LLMs) have been increasingly adopted for machine translation (MT), their performance for specialist domains such as medicine and law remains an open challenge. Prior work has shown that LLMs can be domain-adapted at test-time by retrieving targeted few-shot demonstrations or terminologies for inclusion in the prompt. Meanwhile, for general-purpose LLM MT, recent studies have found some success in generating similarly useful domain knowledge from an LLM itself, prior to translation. Our work studies domain-adapted MT with LLMs through a careful prompting setup, finding that demonstrations consistently outperform terminology, and retrieval consistently outperforms generation. We find that generating demonstrations with weaker models can close the gap with larger model’s zero-shot performance. Given the effectiveness of demonstrations, we perform detailed analyses to understand their value. We find that domain-specificity is particularly important, and that the popular multi-domain benchmark is testing adaptation to a particular writing style more so than to a specific domain.
虽然大型语言模型(LLM)在机器翻译(MT)中的采用率越来越高,但它们在医学和法律等特定领域的表现仍然是一个挑战。先前的工作已经表明,可以通过在测试时检索有针对性的少量演示或术语来将LLM适应特定领域,并将其包含在提示中。同时,对于通用LLM MT,最近的研究发现,在翻译之前从LLM本身生成同样有用的领域知识是成功的。我们的工作通过精心设计的提示来研究LLM的域适应MT,发现演示始终优于术语,检索始终优于生成。我们发现,使用较弱模型生成演示可以缩小与大型模型的零射击性能差距。考虑到演示的有效性,我们进行详细的分析来理解它们的价值。我们发现领域特异性特别重要,流行的多领域基准测试更多的是测试对特定写作风格的适应,而不是对特定领域的适应。
论文及项目相关链接
Summary
大型语言模型(LLM)在机器翻译(MT)领域的应用日益广泛,但在医学、法律等专业领域的性能仍面临挑战。本文研究了通过精心设计的提示来进行领域适应的MT,发现演示始终优于术语,检索始终优于生成。利用较弱的模型生成演示可以缩小与大型模型的零样本性能的差距。本文还详细分析了演示的价值,发现领域特异性尤为重要,流行的多领域基准测试更多的是测试对特定写作风格的适应,而非特定领域的适应。
Key Takeaways
- 大型语言模型在机器翻译领域的表现逐渐受到重视,尤其在专业领域的表现尤为关键。
- 通过有针对性的少镜头演示和术语的检索可以实现对模型的领域适应。
- 演示效果优于术语检索,生成演示能够缩小与大型模型零样本性能的差距。
- 演示的价值在于其领域特异性,对于特定领域的适应至关重要。
- 多领域基准测试更多地是测试模型对特定写作风格的适应,而非特定领域的适应。
- 本文强调了仔细设计提示的重要性,对于提高模型在特定领域的性能至关重要。
点此查看论文截图

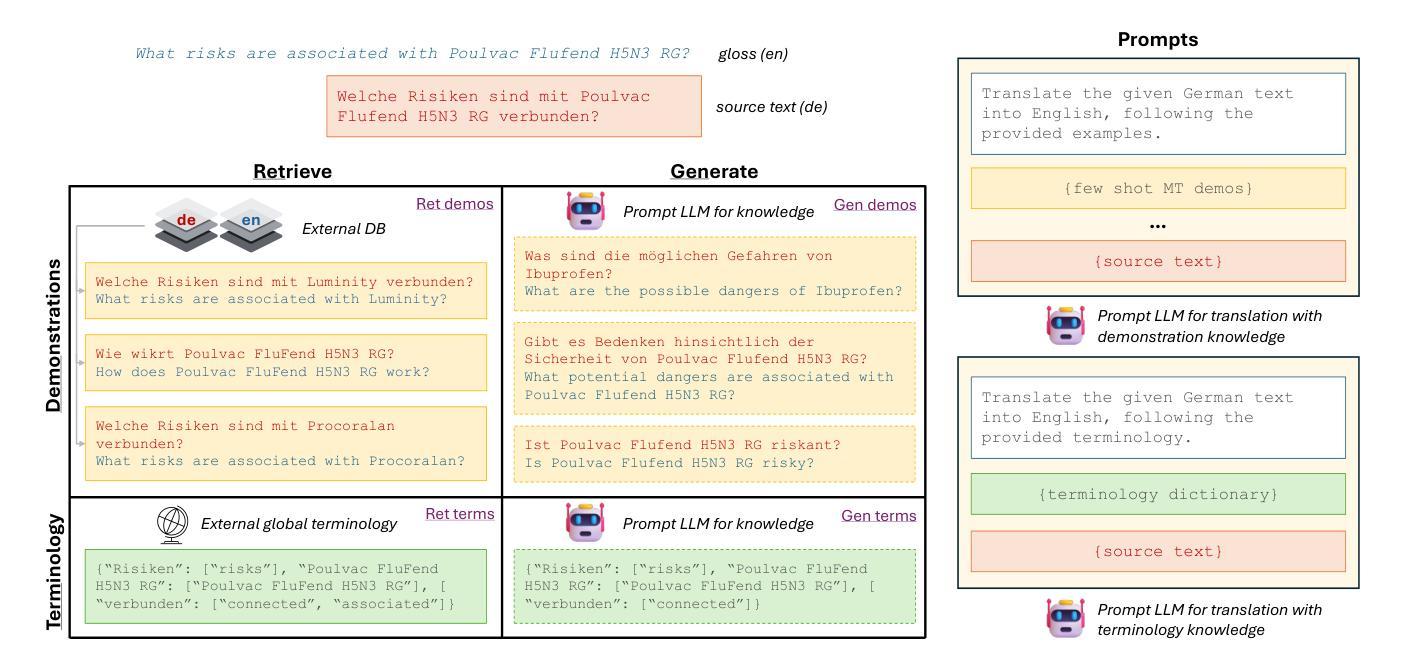

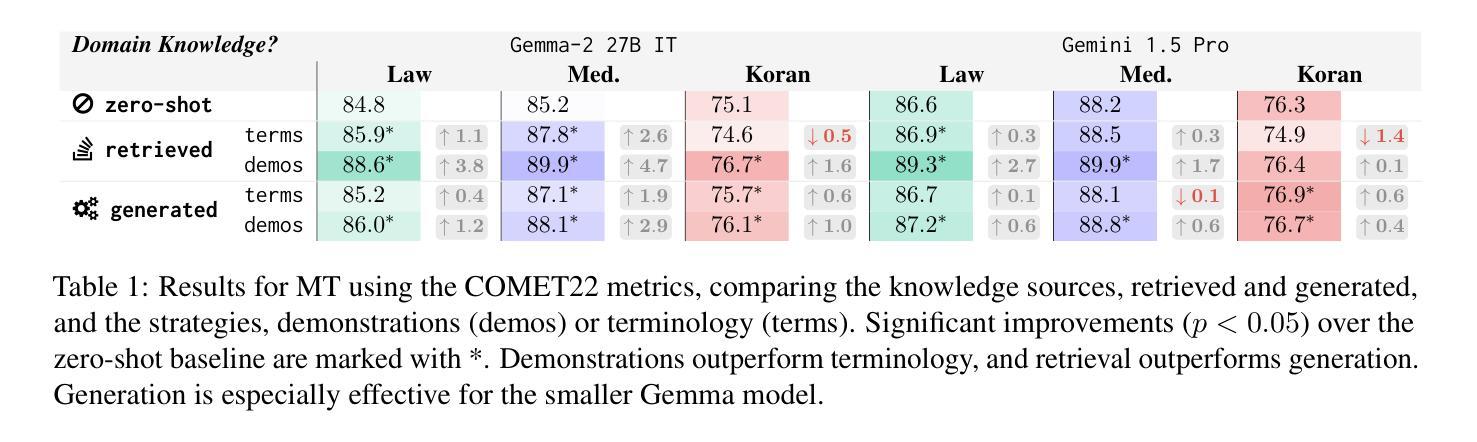
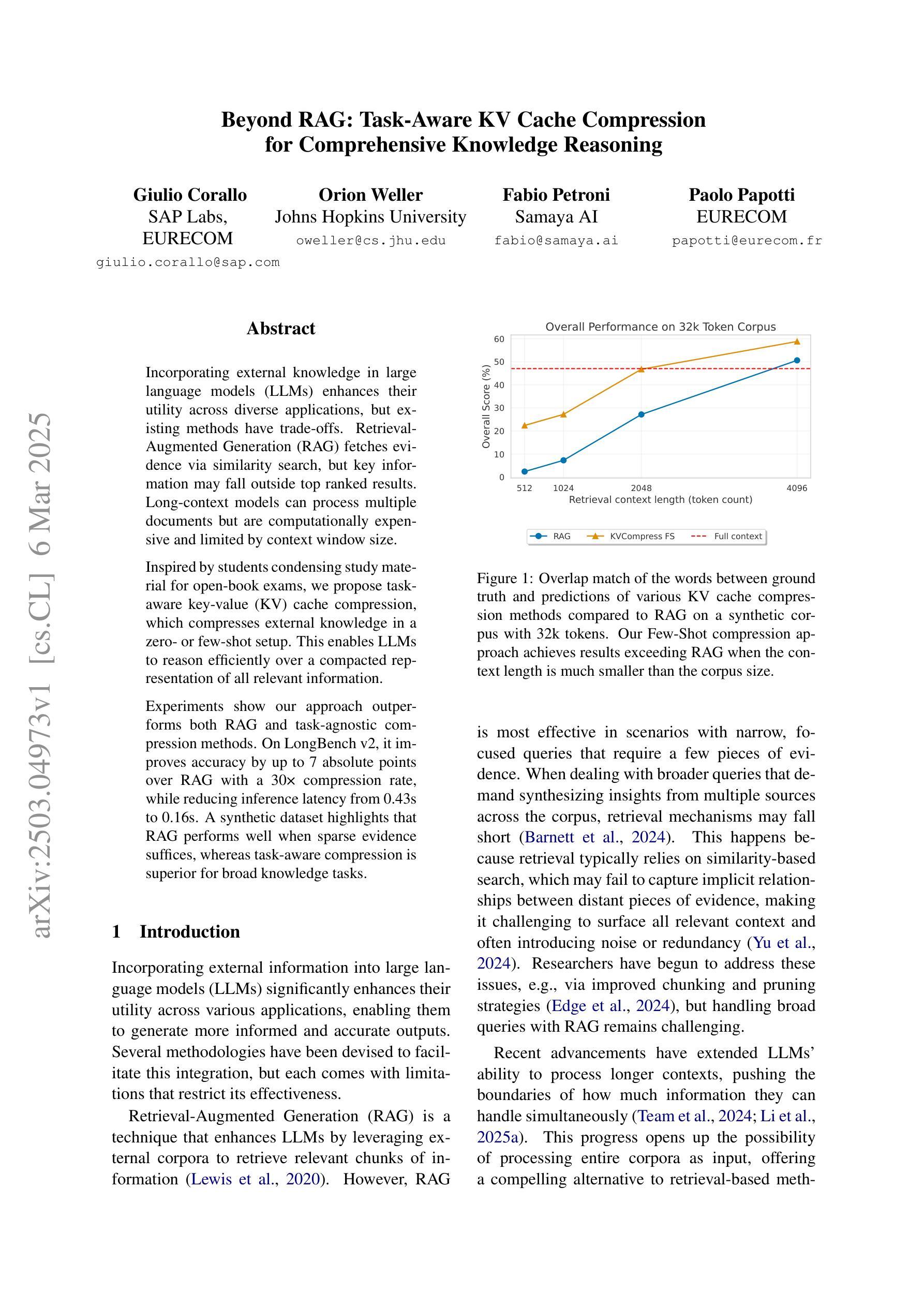
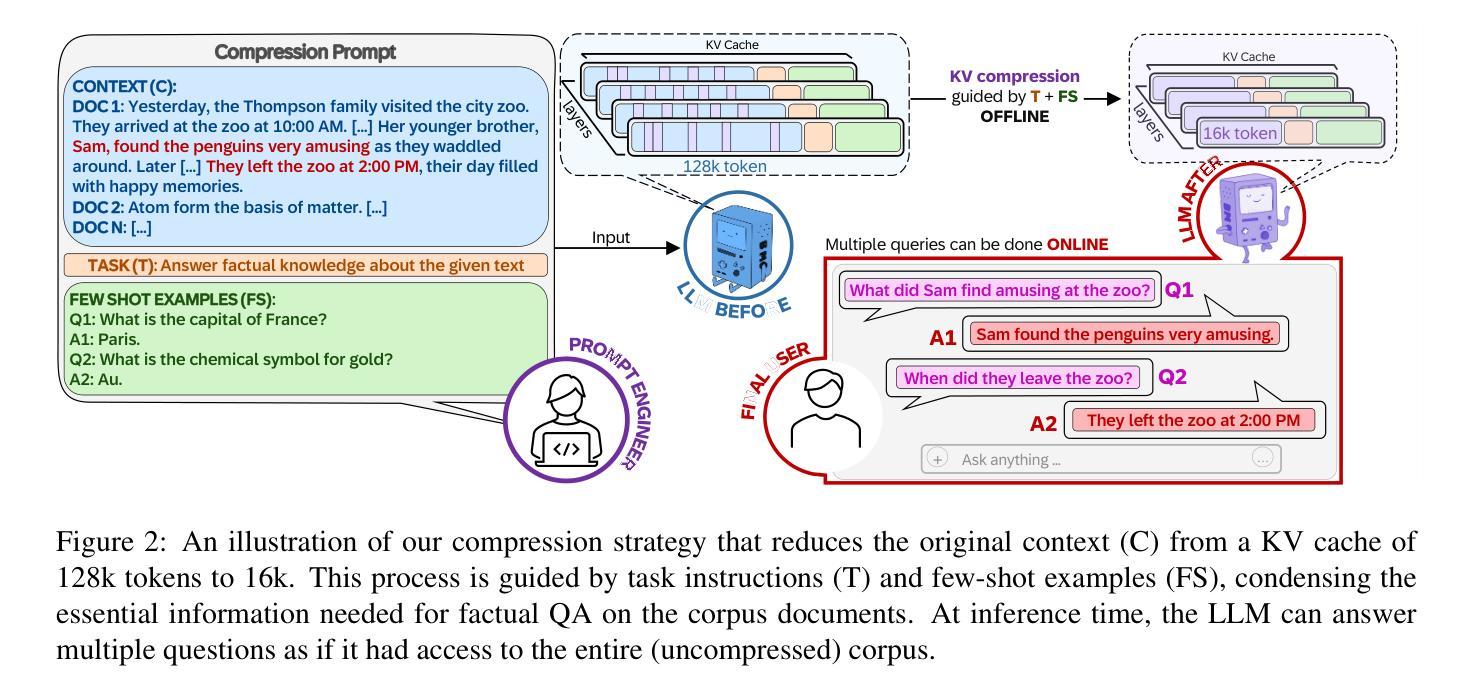
Beyond RAG: Task-Aware KV Cache Compression for Comprehensive Knowledge Reasoning
Authors:Giulio Corallo, Orion Weller, Fabio Petroni, Paolo Papotti
Incorporating external knowledge in large language models (LLMs) enhances their utility across diverse applications, but existing methods have trade-offs. Retrieval-Augmented Generation (RAG) fetches evidence via similarity search, but key information may fall outside top ranked results. Long-context models can process multiple documents but are computationally expensive and limited by context window size. Inspired by students condensing study material for open-book exams, we propose task-aware key-value (KV) cache compression, which compresses external knowledge in a zero- or few-shot setup. This enables LLMs to reason efficiently over a compacted representation of all relevant information. Experiments show our approach outperforms both RAG and task-agnostic compression methods. On LongBench v2, it improves accuracy by up to 7 absolute points over RAG with a 30x compression rate, while reducing inference latency from 0.43s to 0.16s. A synthetic dataset highlights that RAG performs well when sparse evidence suffices, whereas task-aware compression is superior for broad knowledge tasks.
将大型语言模型(LLM)中的外部知识相结合,可以在各种应用程序中增强其效用,但现有方法存在权衡。检索增强生成(RAG)通过相似性搜索获取证据,但关键信息可能不在排名靠前的结果中。长上下文模型可以处理多个文档,但计算成本高昂,且受限于上下文窗口大小。通过借鉴学生为开卷考试浓缩学习材料的方法,我们提出了任务感知的键值(KV)缓存压缩,它可以在零次或少数镜头设置中对外部知识进行压缩。这使得LLM能够在压缩后表示的所有相关信息上进行高效推理。实验表明,我们的方法优于RAG和任务无关压缩方法。在LongBench v2上,它在压缩率为30倍的情况下,较RAG提高了高达7个绝对点的准确性,同时将推理延迟从0.43秒减少到0.16秒。合成数据集的重点是,当稀疏证据足够时,RAG表现良好,而对于广泛的知识任务,任务感知压缩表现更优。
论文及项目相关链接
Summary
在大型语言模型中融入外部知识可提升其跨不同应用的实用性,但现有方法存在权衡。本文提出一种任务感知键值缓存压缩方法,该方法通过零次或少数次设置压缩外部知识,使语言模型能够在紧凑的表示形式中高效地处理所有相关信息。实验表明,该方法优于检索增强生成方法和任务无关压缩方法,在长榜数据集上准确度提高最多达7个百分点,且实现了高达三十倍的压缩率和减少了推理延迟。研究指出任务感知的压缩对于大量知识任务更占优势,而检索增强生成方法则更适合稀疏证据的情况。
Key Takeaways
- 大型语言模型融入外部知识可以提高其实用性。
- 现有融入方法存在权衡。如检索增强生成法可以获取证据,但可能遗漏关键信息;长语境模型可以处理多文档但计算成本较高并受限于语境窗口大小。
- 本文提出了一种任务感知键值缓存压缩方法,实现零次或少数次设置下的外部知识压缩。
- 该方法允许语言模型在紧凑的信息表示中高效推理。
- 实验显示此方法优于其他方法,在长榜数据集上准确度提高显著,同时实现高压缩率和减少推理延迟。
点此查看论文截图


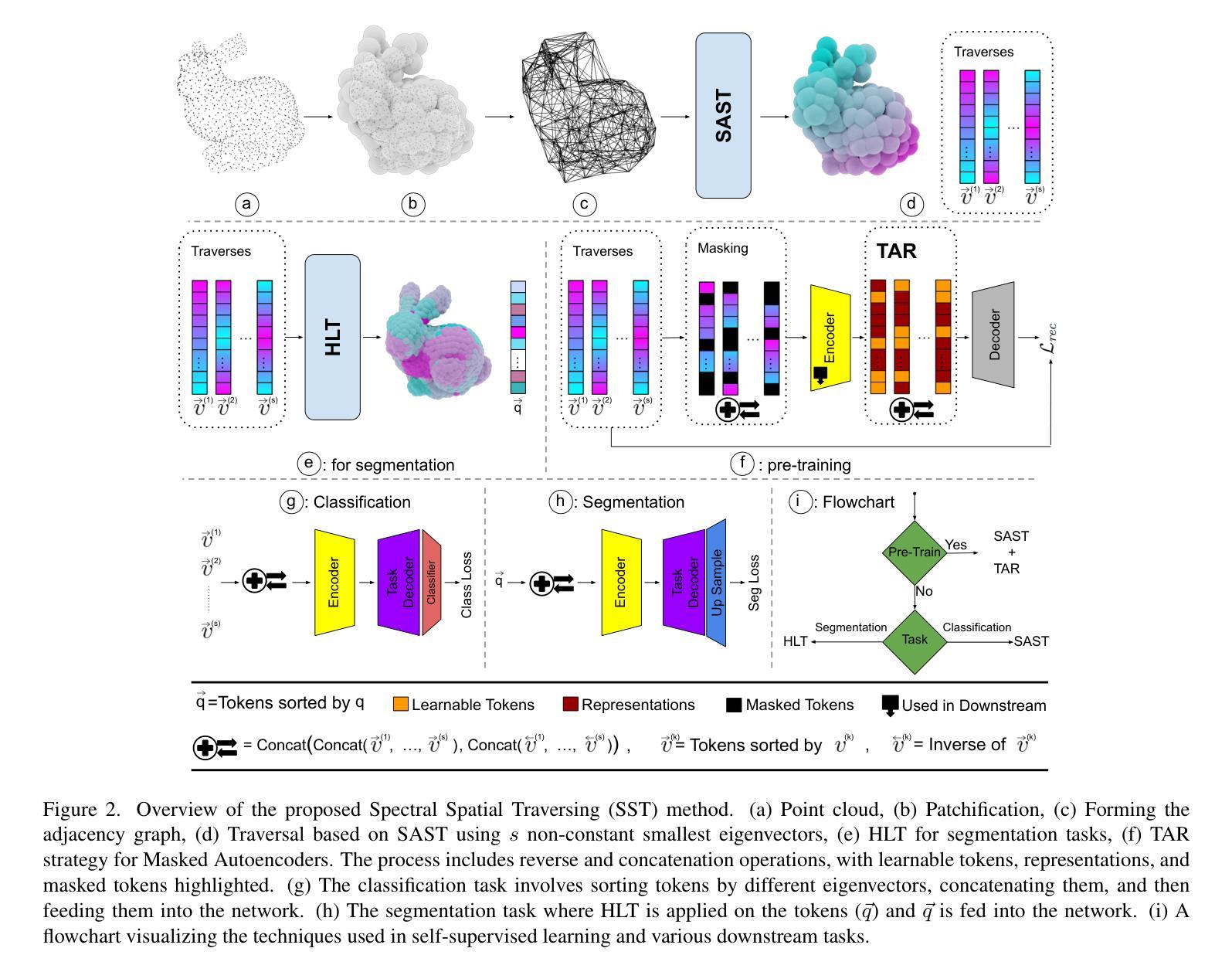
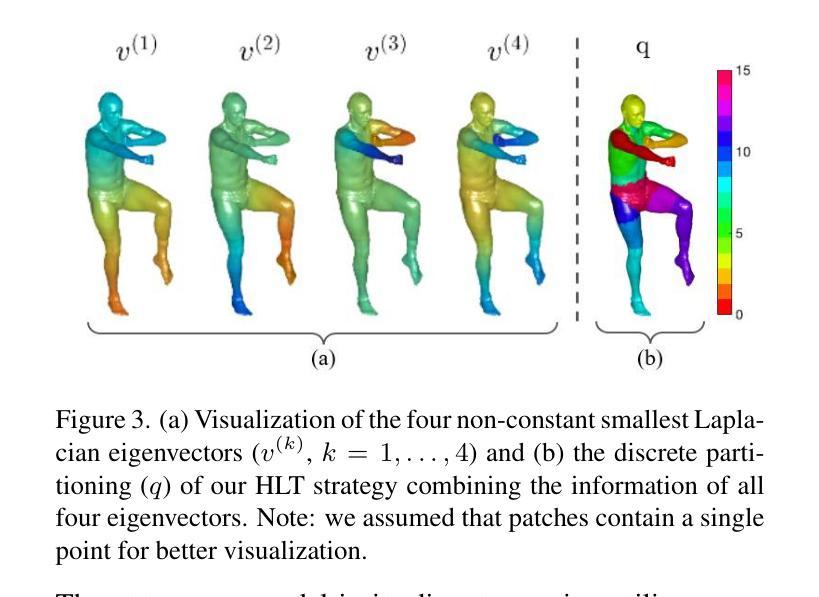
Spectral Informed Mamba for Robust Point Cloud Processing
Authors:Ali Bahri, Moslem Yazdanpanah, Mehrdad Noori, Sahar Dastani, Milad Cheraghalikhani, David Osowiechi, Gustavo Adolfo Vargas Hakim, Farzad Beizaee, Ismail Ben Ayed, Christian Desrosiers
State space models have shown significant promise in Natural Language Processing (NLP) and, more recently, computer vision. This paper introduces a new methodology leveraging Mamba and Masked Autoencoder networks for point cloud data in both supervised and self-supervised learning. We propose three key contributions to enhance Mamba’s capability in processing complex point cloud structures. First, we exploit the spectrum of a graph Laplacian to capture patch connectivity, defining an isometry-invariant traversal order that is robust to viewpoints and better captures shape manifolds than traditional 3D grid-based traversals. Second, we adapt segmentation via a recursive patch partitioning strategy informed by Laplacian spectral components, allowing finer integration and segment analysis. Third, we address token placement in Masked Autoencoder for Mamba by restoring tokens to their original positions, which preserves essential order and improves learning. Extensive experiments demonstrate the improvements of our approach in classification, segmentation, and few-shot tasks over state-of-the-art baselines.
状态空间模型在自然语言处理(NLP)中显示出巨大的潜力,最近在计算机视觉领域也受到了广泛关注。本文介绍了一种新的方法,利用Mamba和Masked Autoencoder网络对点云数据进行有监督和自监督学习。我们提出了三项关键贡献,以增强Mamba处理复杂点云结构的能力。首先,我们利用图拉普拉斯算子的谱来捕捉斑块连接性,定义了一个等距不变遍历顺序,该顺序对视角具有鲁棒性,并且比传统的基于三维网格的遍历更好地捕捉形状流形。其次,我们通过拉普拉斯谱分量进行递归斑块分割策略来适应分割,这允许更精细的集成和分段分析。第三,我们通过将令牌恢复到其原始位置来解决Mamba中的Masked Autoencoder的令牌放置问题,这保留了重要的顺序并提高了学习效果。大量实验表明,我们的方法在分类、分割和少样本任务上的表现优于最先进的基线方法。
论文及项目相关链接
Summary
本文介绍了一种新的利用Mamba和Masked Autoencoder网络处理点云数据的方法,包括监督学习和自监督学习。文章提出了三个主要贡献以增强Mamba处理复杂点云结构的能力:利用图拉普拉斯谱捕捉斑块连接性;通过递归斑块分区策略进行分段;以及在Masked Autoencoder中为Mamba恢复令牌位置。实验证明,该方法在分类、分割和少样本任务上均优于现有技术基线。
Key Takeaways
- 引入了一种新的利用Mamba和Masked Autoencoder网络处理点云数据的方法,适用于NLP和计算机视觉领域。
- 通过利用图拉普拉斯谱,增强了对点云数据的处理能力,能更准确地捕捉形状流形信息。
- 提出了一种基于拉普拉斯谱的递归斑块分区策略,实现了更精细的集成和分段分析。
- 通过恢复令牌到其原始位置,解决了Masked Autoencoder中的令牌放置问题,保留了重要的顺序信息,提高了学习效果。
- 与现有的技术基线相比,该方法在分类、分割和少样本任务上均表现出优势。
- 该方法具有处理复杂点云结构的能力,可以应用于不同的领域,如医疗、遥感等。
点此查看论文截图

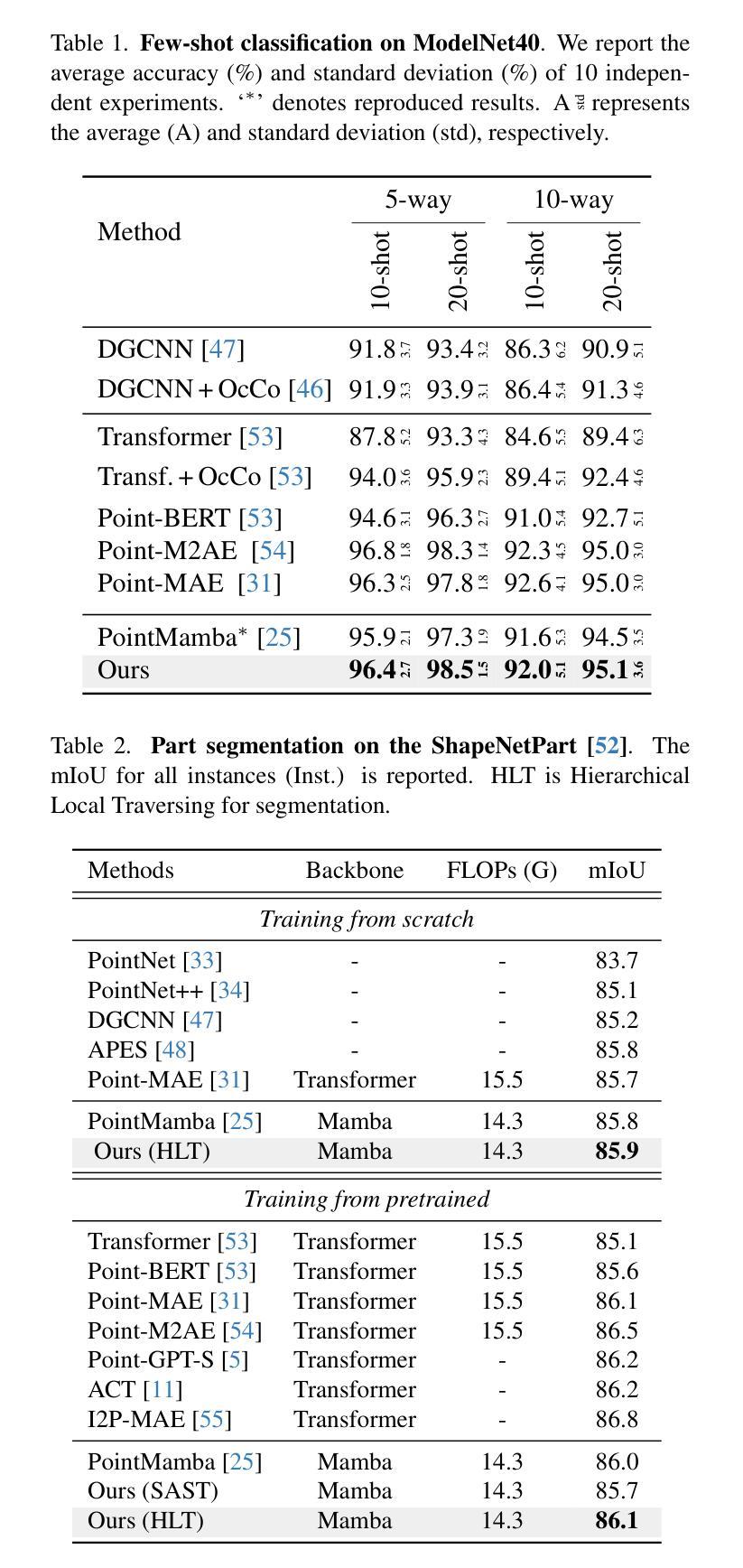
HILGEN: Hierarchically-Informed Data Generation for Biomedical NER Using Knowledgebases and Large Language Models
Authors:Yao Ge, Yuting Guo, Sudeshna Das, Swati Rajwal, Selen Bozkurt, Abeed Sarker
We present HILGEN, a Hierarchically-Informed Data Generation approach that combines domain knowledge from the Unified Medical Language System (UMLS) with synthetic data generated by large language models (LLMs), specifically GPT-3.5. Our approach leverages UMLS’s hierarchical structure to expand training data with related concepts, while incorporating contextual information from LLMs through targeted prompts aimed at automatically generating synthetic examples for sparsely occurring named entities. The performance of the HILGEN approach was evaluated across four biomedical NER datasets (MIMIC III, BC5CDR, NCBI-Disease, and Med-Mentions) using BERT-Large and DANN (Data Augmentation with Nearest Neighbor Classifier) models, applying various data generation strategies, including UMLS, GPT-3.5, and their best ensemble. For the BERT-Large model, incorporating UMLS led to an average F1 score improvement of 40.36%, while using GPT-3.5 resulted in a comparable average increase of 40.52%. The Best-Ensemble approach using BERT-Large achieved the highest improvement, with an average increase of 42.29%. DANN model’s F1 score improved by 22.74% on average using the UMLS-only approach. The GPT-3.5-based method resulted in a 21.53% increase, and the Best-Ensemble DANN model showed a more notable improvement, with an average increase of 25.03%. Our proposed HILGEN approach improves NER performance in few-shot settings without requiring additional manually annotated data. Our experiments demonstrate that an effective strategy for optimizing biomedical NER is to combine biomedical knowledge curated in the past, such as the UMLS, and generative LLMs to create synthetic training instances. Our future research will focus on exploring additional innovative synthetic data generation strategies for further improving NER performance.
我们提出了HILGEN方法,这是一种结合统一医学语言系统(UMLS)领域知识和由大型语言模型(尤其是GPT-3.5)生成合成数据分层信息的数据生成方法。我们的方法利用UMLS的层次结构来扩展训练数据的相关概念,同时通过有针对性的提示融入大型语言模型的上下文信息,旨在自动生成稀疏命名实体的合成示例。HILGEN方法在四个生物医学命名实体识别数据集(MIMIC III、BC5CDR、NCBI-Disease和Med-Mentions)上的性能表现通过使用BERT-Large和DANN(基于最近邻分类器的数据增强)模型进行了评估,并应用了各种数据生成策略,包括UMLS、GPT-3.5及其最佳组合。对于BERT-Large模型,结合UMLS平均F1分数提高了40.36%,而使用GPT-3.5也实现了相当的平均增幅40.52%。使用BERT-Large的最佳组合方法实现了最高的改进,平均提高了42.29%。对于DANN模型,使用仅UMLS的方法平均F1分数提高了22.74%,GPT-3.5的方法导致提高了21.53%,最佳组合DANN模型显示出更显著的改进,平均提高了25.03%。我们提出的HILGEN方法提高了少样本设置中的命名实体识别性能,无需额外手动注释的数据。我们的实验表明,优化生物医学命名实体识别的有效策略是结合过去整理好的生物医学知识(如UMLS)和生成式大型语言模型来创建合成训练实例。我们未来的研究将专注于探索更多创新合成数据生成策略,以进一步提高命名实体识别的性能。
论文及项目相关链接
Summary
基于统一医学语言系统(UMLS)的层次结构信息和大型语言模型(特别是GPT-3.5)生成的合成数据,我们提出了HILGEN方法。该方法利用UMLS的层次结构来扩展训练数据,并通过有针对性的提示自动生成稀疏命名实体的合成示例。在四个生物医学命名实体识别数据集上进行的评估表明,该方法在不额外需要手动注释数据的情况下提高了命名实体识别的性能。我们的实验表明,结合过去整理的生物医学知识和生成式LLM来创建合成训练实例是一种优化生物医学命名实体识别的有效策略。
Key Takeaways
- HILGEN方法结合了UMLS的层次结构信息和GPT-3.5生成的合成数据。
- UMLS的层次结构用于扩展训练数据,并生成与特定概念相关的合成示例。
- 在四个生物医学NER数据集上评估,使用BERT-Large模型,结合UMLS和GPT-3.5的方法分别提高了平均F1分数40.36%和40.52%。
- 最佳组合方法(使用BERT-Large)的平均F1分数提高了42.29%。
- DANN模型的F1分数使用UMLS方法平均提高了22.74%,GPT-3.5方法提高了21.53%。
- 无需额外手动注释数据,HILGEN方法即可提高NER性能。
点此查看论文截图


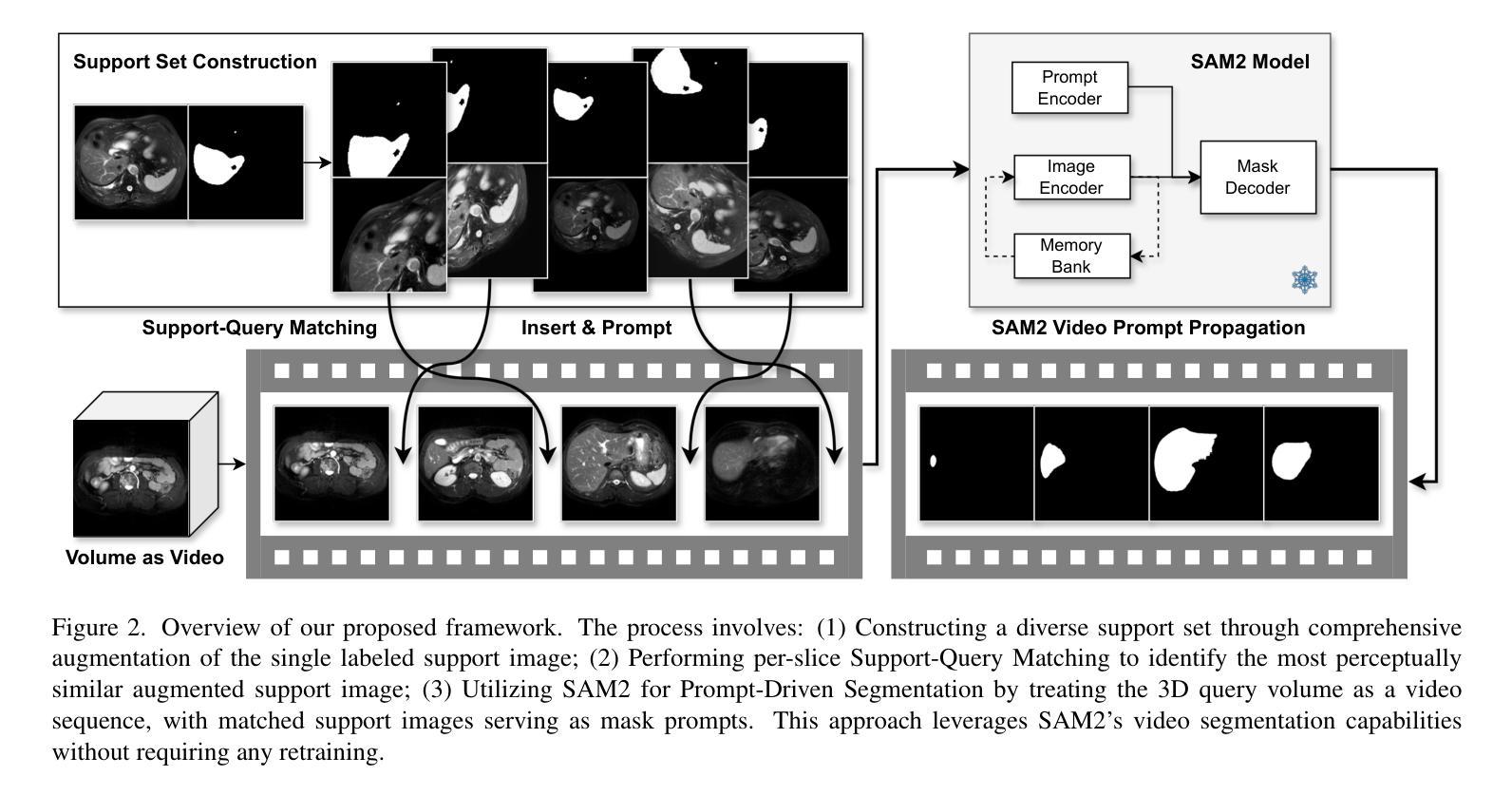
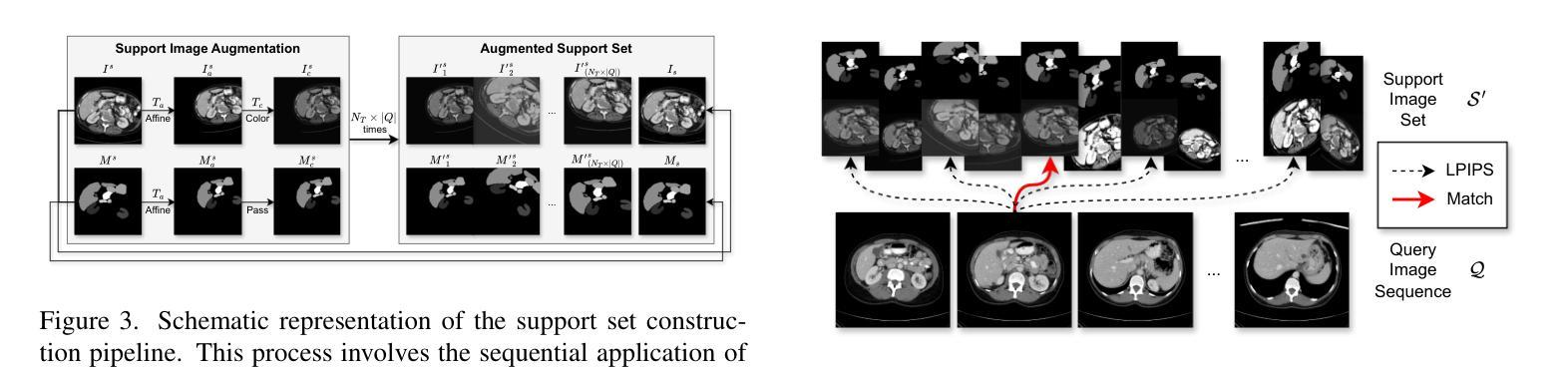
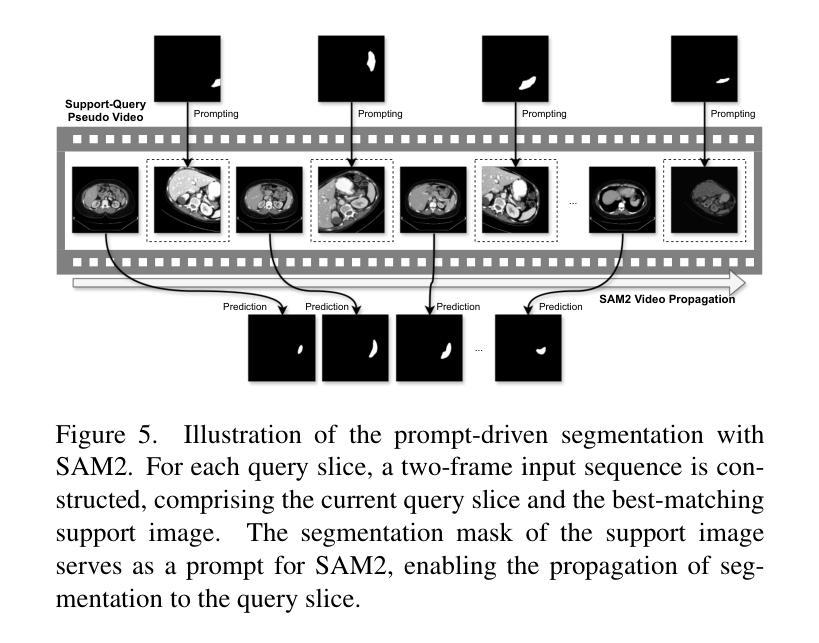
Rethinking Few-Shot Medical Image Segmentation by SAM2: A Training-Free Framework with Augmentative Prompting and Dynamic Matching
Authors:Haiyue Zu, Jun Ge, Heting Xiao, Jile Xie, Zhangzhe Zhou, Yifan Meng, Jiayi Ni, Junjie Niu, Linlin Zhang, Li Ni, Huilin Yang
The reliance on large labeled datasets presents a significant challenge in medical image segmentation. Few-shot learning offers a potential solution, but existing methods often still require substantial training data. This paper proposes a novel approach that leverages the Segment Anything Model 2 (SAM2), a vision foundation model with strong video segmentation capabilities. We conceptualize 3D medical image volumes as video sequences, departing from the traditional slice-by-slice paradigm. Our core innovation is a support-query matching strategy: we perform extensive data augmentation on a single labeled support image and, for each frame in the query volume, algorithmically select the most analogous augmented support image. This selected image, along with its corresponding mask, is used as a mask prompt, driving SAM2’s video segmentation. This approach entirely avoids model retraining or parameter updates. We demonstrate state-of-the-art performance on benchmark few-shot medical image segmentation datasets, achieving significant improvements in accuracy and annotation efficiency. This plug-and-play method offers a powerful and generalizable solution for 3D medical image segmentation.
在医学图像分割中,对大量标记数据集的依赖构成了一大挑战。小样本学习提供了一个潜在的解决方案,但现有方法通常仍然需要大量的训练数据。本文提出了一种利用Segment Anything Model 2(SAM2)的新方法,这是一个具有强大视频分割能力的视觉基础模型。我们将3D医学图像体积概念化为视频序列,摒弃了传统的逐片处理模式。我们的核心创新之处在于支持查询匹配策略:我们对单个标记的支持图像进行大量数据增强,并针对查询体积中的每一帧,算法选择最类似的增强支持图像。所选图像及其相应的掩膜被用作掩膜提示,驱动SAM2的视频分割。这种方法完全避免了模型重新训练或参数更新。我们在基准的少量医学图像分割数据集上展示了卓越的性能,在准确性和注释效率方面取得了显著的提升。这种即插即用的方法为3D医学图像分割提供了强大且通用的解决方案。
论文及项目相关链接
Summary
该文提出了一种利用Segment Anything Model 2(SAM2)进行医学图像分割的新方法,通过把3D医学图像体积概念化为视频序列,实现了对单一标记支持图像的大规模数据增强,提高了少样本医学图像分割的准确性和标注效率。
Key Takeaways
- 医学图像分割对大量标记数据集存在依赖,少样本学习为解决此问题提供了潜在方案。
- 本文提出了一个利用Segment Anything Model 2 (SAM2)的新方法,这是一个具有强大视频分割能力的视觉基础模型。
- 将传统的切片-by-切片模式转变为将3D医学图像体积概念化为视频序列的方法。
- 核心创新在于支持查询匹配策略:对单一标记的支持图像进行大规模数据增强,并对于查询体积中的每一帧,算法选择最类似的增强支持图像。
- 选定的图像及其对应的掩膜被用作掩膜提示,推动SAM2的视频分割。
- 此方法避免了模型重新训练或参数更新,实现了即插即用。
点此查看论文截图

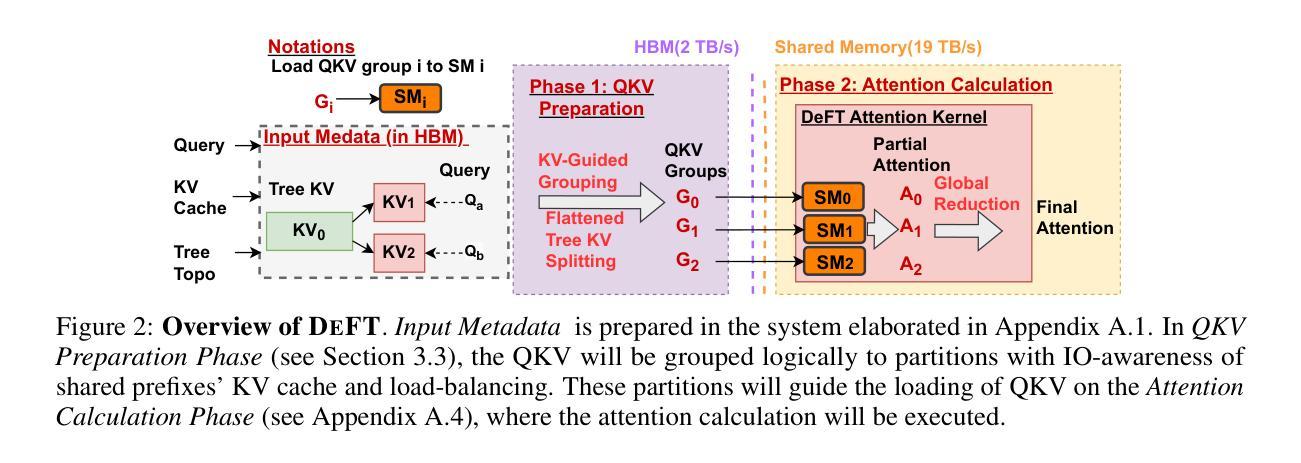
DeFT: Decoding with Flash Tree-attention for Efficient Tree-structured LLM Inference
Authors:Jinwei Yao, Kaiqi Chen, Kexun Zhang, Jiaxuan You, Binhang Yuan, Zeke Wang, Tao Lin
Large language models (LLMs) are increasingly employed for complex tasks that process multiple generation calls in a tree structure with shared prefixes of tokens, including few-shot prompting, multi-step reasoning, speculative decoding, etc. However, existing inference systems for tree-based applications are inefficient due to improper partitioning of queries and KV cache during attention calculation. This leads to two main issues: (1) a lack of memory access (IO) reuse for KV cache of shared prefixes, and (2) poor load balancing.As a result, there is redundant KV cache IO between GPU global memory and shared memory, along with low GPU utilization. To address these challenges, we propose DeFT(Decoding with Flash Tree-Attention), a hardware-efficient attention algorithm with prefix-aware and load-balanced KV cache partitions. DeFT reduces the number of read/write operations of KV cache during attention calculation through KV-Guided Grouping, a method that avoids repeatedly loading KV cache of shared prefixes in attention computation. Additionally, we propose Flattened Tree KV Splitting, a mechanism that ensures even distribution of the KV cache across partitions with little computation redundancy, enhancing GPU utilization during attention computations. By reducing 73-99% KV cache IO and nearly 100% IO for partial results during attention calculation, DeFT achieves up to 2.23/3.59x speedup in the end-to-end/attention latency across three practical tree-based workloads compared to state-of-the-art attention algorithms. Our code is available at https://github.com/LINs-lab/DeFT.
大型语言模型(LLM)越来越多地被用于处理树结构中的多代呼叫的复杂任务,这些任务具有共享前缀的令牌,包括少量提示、多步推理、推测解码等。然而,基于树的现有推理系统由于在注意力计算过程中的查询和KV缓存划分不当,导致效率不高。这引发了两个问题:(1)共享前缀的KV缓存缺乏内存访问(IO)重用;(2)负载不均衡。因此,存在GPU全局内存和共享内存之间的冗余KV缓存IO,以及GPU利用率低。为了解决这些挑战,我们提出了DeFT(带有闪电树注意力的解码),这是一种硬件高效的注意力算法,具有前缀感知和负载平衡的KV缓存分区。DeFT通过KV引导的分组方法,减少了注意力计算过程中KV缓存的读写操作次数,避免了重复加载共享前缀的KV缓存。此外,我们提出了扁平树KV拆分机制,确保KV缓存均匀分布在各分区内,计算冗余度低,提高了注意力计算时的GPU利用率。通过减少73-99%的KV缓存IO和近100%的注意力计算过程中部分结果的IO,DeFT在实际的树结构工作负载上实现了端到端延迟/注意力延迟最高达2.23倍/3.59倍的加速效果。我们的代码可在https://github.com/LINs-lab/DeFT获取。
论文及项目相关链接
PDF Update DeFT-v4, accepted by ICLR’25 (https://openreview.net/forum?id=2c7pfOqu9k). Our code is available at https://github.com/LINs-lab/DeFT
Summary
该文介绍了大型语言模型在处理具有共享前缀的令牌树结构中的多代呼叫任务时面临的挑战。为解决现有推理系统在注意力计算中的不当查询分区和KV缓存问题,提出了名为DeFT的硬件高效注意力算法,具有前缀感知和负载均衡的KV缓存分区。DeFT通过KV缓存的读/写操作次数减少了注意力计算过程中的冗余操作,实现了高效的树结构处理速度提升。
Key Takeaways
- 大型语言模型在处理包含共享前缀的令牌树结构中的多代调用任务时面临效率挑战。
- 现存推理系统在注意力计算中的查询分区和KV缓存存在问题,导致内存访问(IO)复用不足和负载不均衡。
- DeFT是一种硬件高效的注意力算法,具有前缀感知和负载均衡的KV缓存分区,旨在解决上述问题。
- DeFT通过KV缓存的读/写操作次数减少了冗余操作,提高了注意力计算效率。
- DeFT实现了对实际树结构工作负载的端到端和注意力延迟高达2.23倍和3.59倍的速度提升。
- DeFT代码已公开发布在https://github.com/LINs-lab/DeFT。
点此查看论文截图