⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-11 更新
Impoola: The Power of Average Pooling for Image-Based Deep Reinforcement Learning
Authors:Raphael Trumpp, Ansgar Schäfftlein, Mirco Theile, Marco Caccamo
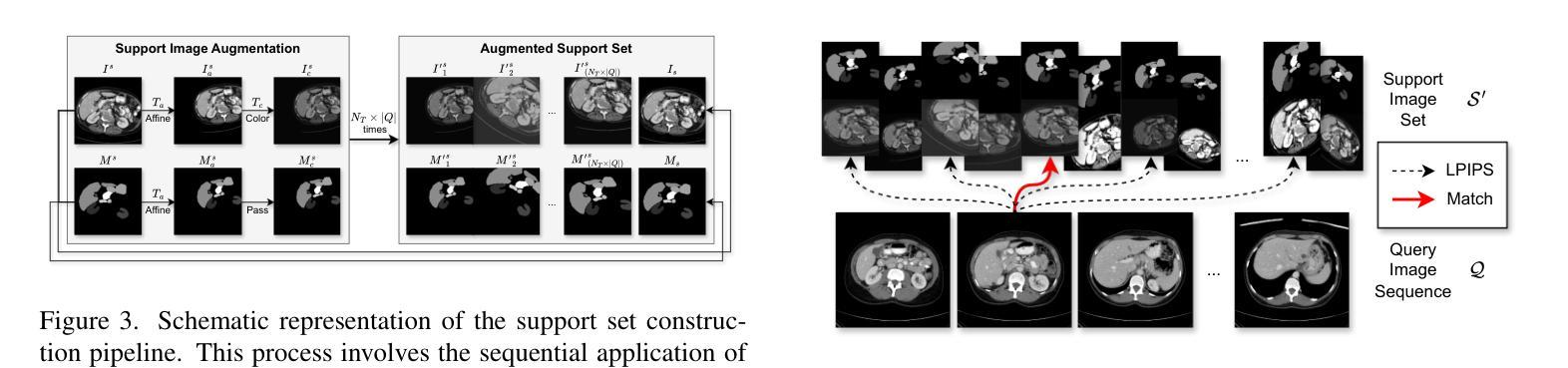
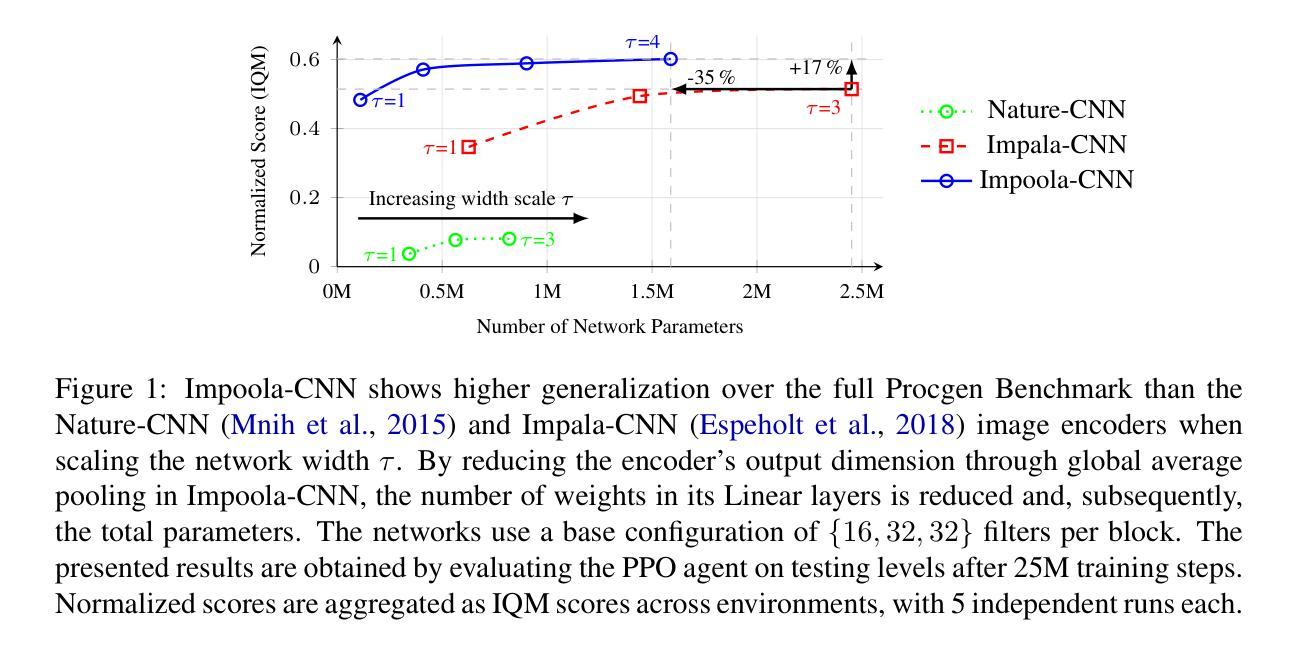
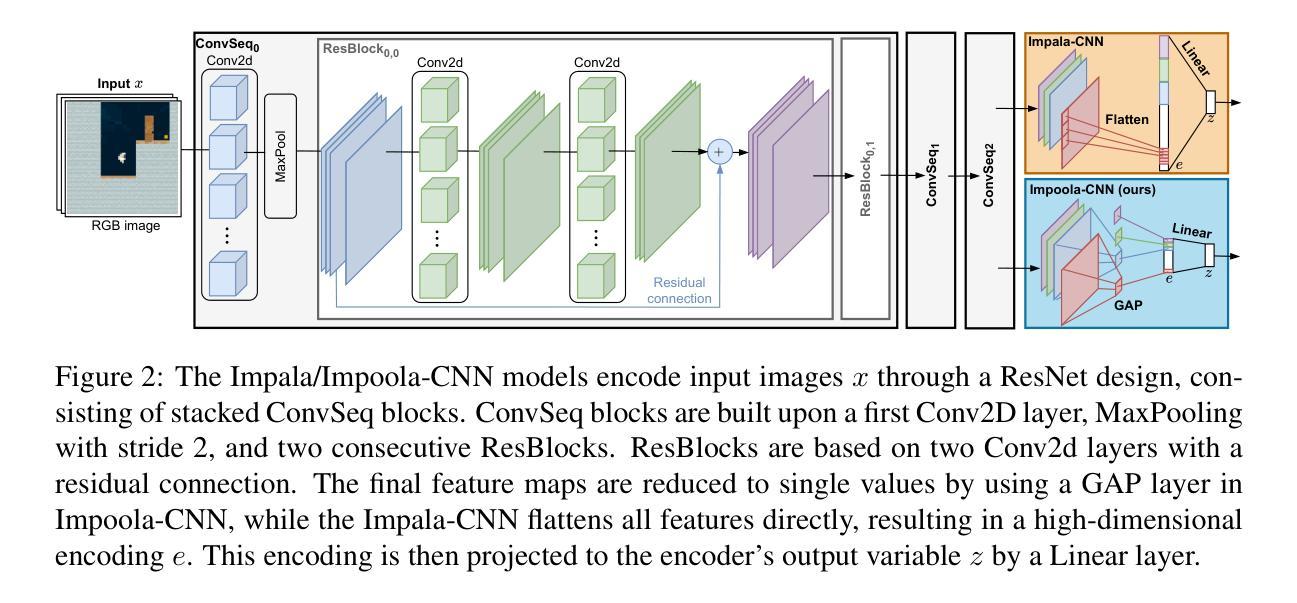
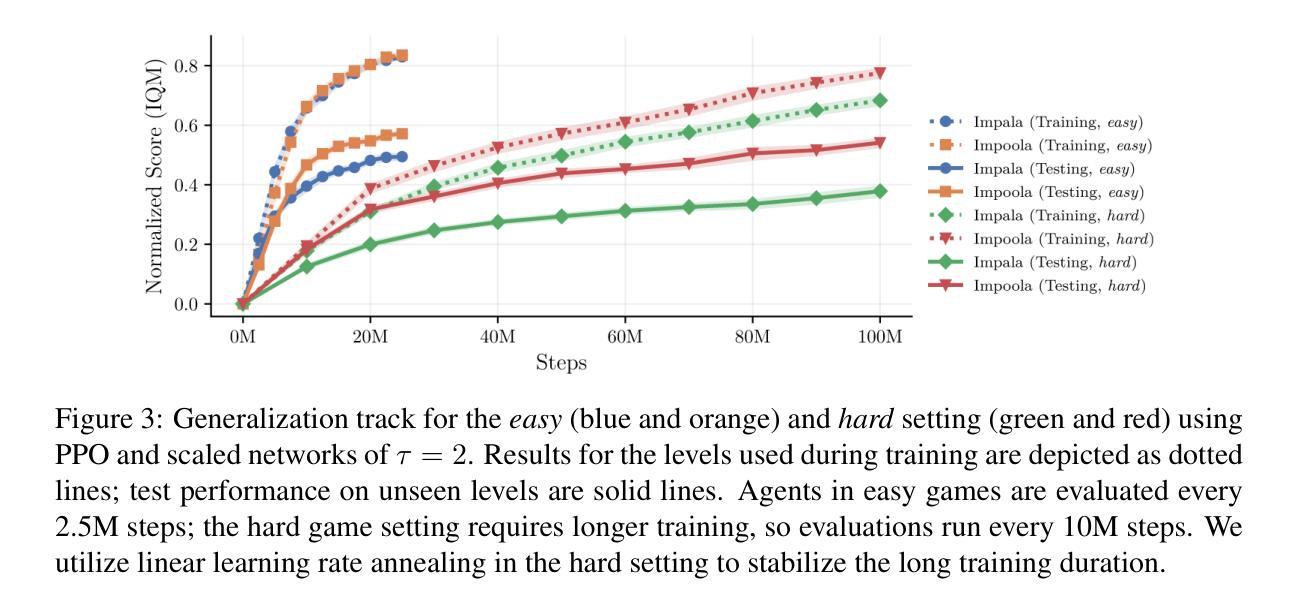
As image-based deep reinforcement learning tackles more challenging tasks, increasing model size has become an important factor in improving performance. Recent studies achieved this by focusing on the parameter efficiency of scaled networks, typically using Impala-CNN, a 15-layer ResNet-inspired network, as the image encoder. However, while Impala-CNN evidently outperforms older CNN architectures, potential advancements in network design for deep reinforcement learning-specific image encoders remain largely unexplored. We find that replacing the flattening of output feature maps in Impala-CNN with global average pooling leads to a notable performance improvement. This approach outperforms larger and more complex models in the Procgen Benchmark, particularly in terms of generalization. We call our proposed encoder model Impoola-CNN. A decrease in the network’s translation sensitivity may be central to this improvement, as we observe the most significant gains in games without agent-centered observations. Our results demonstrate that network scaling is not just about increasing model size - efficient network design is also an essential factor.
随着基于图像的深度强化学习处理更具挑战性的任务,模型规模的增加已成为提高性能的重要因素。最近的研究通过关注扩展网络的参数效率来实现这一点,通常使用Impala-CNN(一种受ResNet启发的15层网络)作为图像编码器。然而,虽然Impala-CNN明显优于较旧的CNN架构,但深度强化学习特定图像编码器的网络设计潜在进展却鲜有探索。我们发现,用全局平均池化代替Impala-CNN中的输出特征图平铺会导致性能显著改进。这种方法在Procgen基准测试中优于更大、更复杂的模型,特别是在泛化方面。我们将我们提出的编码器模型称为Impoola-CNN。网络翻译敏感性的降低可能是这种改进的核心,因为我们在没有以代理为中心观察的游戏中观察到最大的收益。我们的结果表明,网络扩展不仅仅关乎增加模型规模——高效的网络设计也是一个重要因素。
论文及项目相关链接
Summary
随着图像深度强化学习应对更具挑战性的任务,模型规模的增加已成为提高性能的重要因素。最近的研究通过关注扩展网络的参数效率来实现这一点,通常使用Impala-CNN作为图像编码器。然而,Impala-CNN虽然优于旧的CNN架构,但在深度强化学习专用图像编码器的网络设计方面仍有潜在的进步空间。研究发现,用全局平均池化替换Impala-CNN中的输出特征映射的平铺,能显著提高性能。该方法在Procgen Benchmark上的表现优于更大、更复杂的模型,特别是在泛化方面。我们称所提出的编码器模型为Impoola-CNN。网络翻译敏感性的降低可能是这一改进的核心,因为我们在非以代理为中心的观测游戏中观察到最大的收益。结果表明,网络扩展不仅仅关乎模型规模的增加——有效的网络设计也是一个重要因素。
Key Takeaways
- 图像深度强化学习面临更复杂的任务时,模型规模的增加对于提高性能至关重要。
- 最近的研究通过提高网络的参数效率来扩大模型规模,常用Impala-CNN作为图像编码器。
- Impala-CNN虽然性能优越,但在网络设计方面仍有改进空间。
- 用全局平均池化替换Impala-CNN中的特征映射平铺能显著提高性能。
- Impoola-CNN在Procgen Benchmark上的表现优于其他更大、更复杂的模型,特别是在泛化方面。
- 网络翻译敏感性的降低可能是性能提升的关键,特别是在非以代理为中心的观测游戏中。
点此查看论文截图

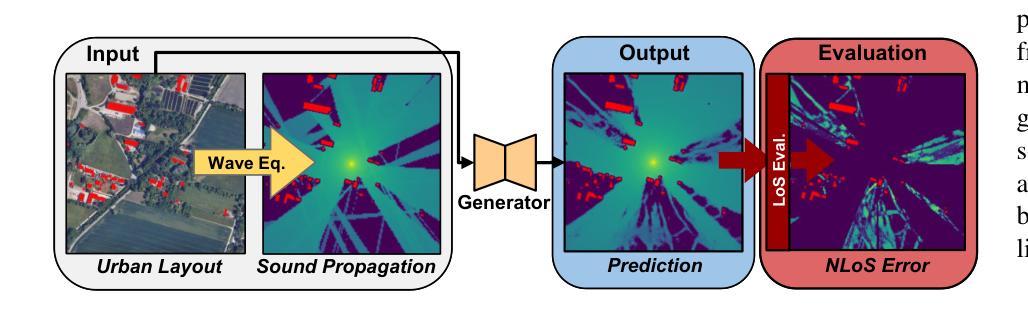
PhysicsGen: Can Generative Models Learn from Images to Predict Complex Physical Relations?
Authors:Martin Spitznagel, Jan Vaillant, Janis Keuper
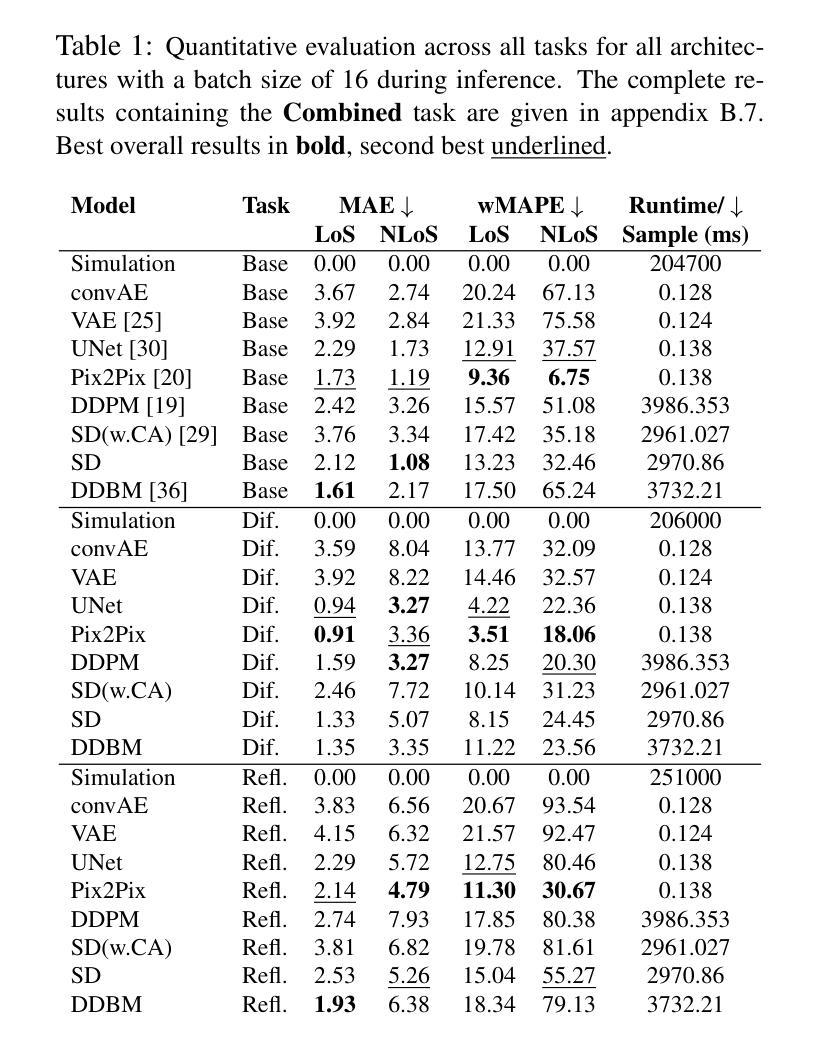
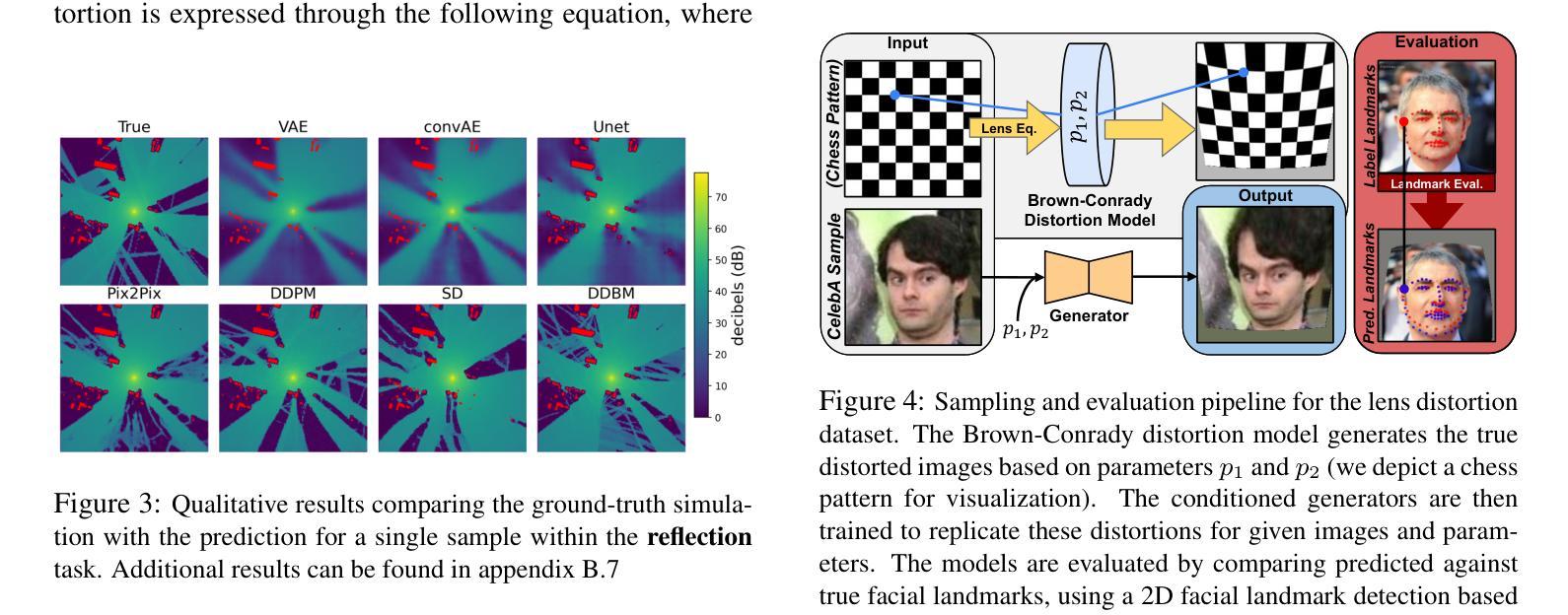
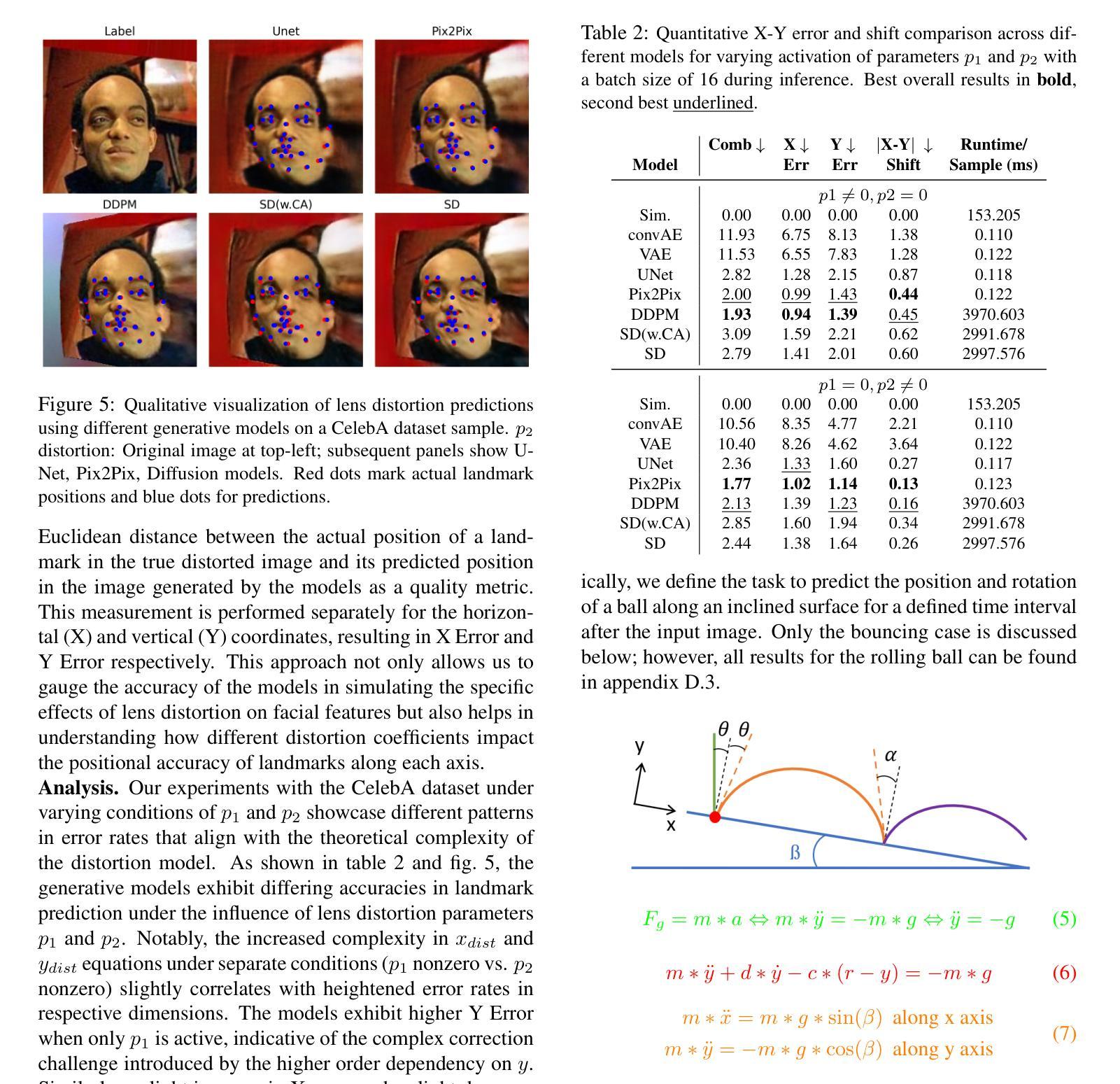
The image-to-image translation abilities of generative learning models have recently made significant progress in the estimation of complex (steered) mappings between image distributions. While appearance based tasks like image in-painting or style transfer have been studied at length, we propose to investigate the potential of generative models in the context of physical simulations. Providing a dataset of 300k image-pairs and baseline evaluations for three different physical simulation tasks, we propose a benchmark to investigate the following research questions: i) are generative models able to learn complex physical relations from input-output image pairs? ii) what speedups can be achieved by replacing differential equation based simulations? While baseline evaluations of different current models show the potential for high speedups (ii), these results also show strong limitations toward the physical correctness (i). This underlines the need for new methods to enforce physical correctness. Data, baseline models and evaluation code http://www.physics-gen.org.
生成学习模型的图像到图像翻译能力最近在估计图像分布之间的复杂(导向)映射方面取得了重大进展。虽然基于外观的任务(如图像修复或风格转换)已经得到了深入研究,我们提议研究生成模型在物理模拟方面的潜力。我们提供了30万张图像对的数据集和三个不同物理模拟任务的基准评估,提出一个基准测试来探讨以下研究问题:i)生成模型是否能从输入-输出图像对中学习复杂的物理关系?ii)通过替换基于微分方程的模拟,可以实现哪些加速?当前不同模型的基准评估结果显示出实现高加速的潜力(ii),但这些结果也显示出在物理正确性方面存在强烈限制(i)。这强调了需要新的方法来强制实施物理正确性的必要性。数据、基准模型和评估代码:物理-gen.org。
论文及项目相关链接
Summary
基于生成学习模型的图像到图像翻译能力,最近在估计图像分布之间的复杂(定向)映射方面取得了显著进展。尽管基于外观的任务(如图像修复或风格转换)已被深入研究,但本文旨在探讨生成模型在物理模拟方面的潜力。通过提供30万张图像对和三项不同物理模拟任务的基准评估,本文提出了一个基准测试来探讨以下问题:i)生成模型是否能够从输入输出图像对中学习复杂的物理关系?ii)通过替换基于微分方程的模拟,可以实现哪些加速?基准评估结果虽然显示出实现高加速率的潜力,但同时也显示出物理正确性方面的强烈局限性。这强调了需要新的方法来强制实施物理正确性的必要性。
Key Takeaways
- 生成学习模型在估计图像分布之间的复杂映射方面取得显著进展。
- 生成模型在物理模拟方面的潜力值得进一步探讨。
- 提供了一个包含30万张图像对的基准测试数据集,以及三项不同物理模拟任务的基准评估。
- 基准评估显示生成模型具有实现高加速率的潜力。
- 目前的结果表明在物理正确性方面存在强烈局限性。
- 需要新的方法来强制实施物理正确性。
点此查看论文截图