⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-11 更新
ARbiter: Generating Dialogue Options and Communication Support in Augmented Reality
Authors:Julián Méndez, Marc Satkowski
In this position paper, we propose researching the combination of Augmented Reality (AR) and Artificial Intelligence (AI) to support conversations, inspired by the interfaces of dialogue systems commonly found in videogames. AR-capable devices are becoming more powerful and conventional in looks, as seen in head-mounted displays (HMDs) like the Snapchat Spectacles, the XREAL glasses, or the recently presented Meta Orion. This development reduces possible ergonomic, appearance, and runtime concerns, thus allowing a more straightforward integration and extended use of AR in our everyday lives, both in private and at work. At the same time, we can observe an immense surge in AI development (also at CHI). Recently notorious Large Language Models (LLMs) like OpenAI’s o3-mini or DeepSeek-R1 soar over their precursors in their ability to sustain conversations, provide suggestions, and handle complex topics in (almost) real time. In combination with natural language recognition systems, which are nowadays a standard component of smartphones and similar devices (including modern AR-HMDs), it is easy to imagine a combined system that integrates into daily conversations and provides various types of assistance. Such a system would enable many opportunities for research in AR+AI, which, as stated by Hirzle et al., remains scarce. In the following, we describe how the design of a conversational AR+AI system can learn from videogame dialogue systems, and we propose use cases and research questions that can be investigated thanks to this AR+AI combination.
在这篇立场论文中,我们受到电子游戏中对谈系统界面的启发,提出研究增强现实(AR)和人工智能(AI)的结合来支持对话。随着头戴式显示器(如Snapchat的Spectacles、XREAL眼镜或最近推出的Meta Orion)等AR设备的性能和外观越来越强大和常规,这一发展减少了可能的人体工程学、外观和运行时的担忧,从而允许更直接地集成和扩展AR在我们日常生活和工作中的使用。同时,我们可以观察到人工智能发展的巨大浪潮(也在CHI中)。最近备受关注的大型语言模型(如OpenAI的o3-mini或DeepSeek-R1)在维持对话、提供建议和处理复杂话题的能力上超越了其前身,(几乎)实时进行。结合如今智能手机和类似设备(包括现代AR头戴式显示器)的标准组件自然语言识别系统,很容易想象出一个集成到日常对话中并提供各种类型帮助的联合系统。这样的系统将为AR+AI的研究带来许多机会,正如Hirzle等人所指出的那样,目前这方面的研究仍然很少。接下来,我们将描述如何从电子游戏对话系统中学习设计对话式AR+AI系统,并提出由于这种AR+AI组合而可以进行调查的使用案例和研究问题。
论文及项目相关链接
PDF This work has been accepted for the ACM CHI 2025 Workshop “Everyday AR through AI-in-the-Loop” (see https://xr-and-ai.github.io/)
Summary
增强现实(AR)与人工智能(AI)结合支持对话的研究被提出,受到电子游戏对话系统界面的启发。随着AR设备的日益普及和性能提升,如头戴式显示器(HMDs),结合AI的发展,特别是大型语言模型(LLMs)和自然语言识别系统,为AR+AI结合系统提供了广阔的研究机会。该系统可融入日常对话,提供各类协助。
Key Takeaways
- AR和AI结合支持对话的研究受到启发,源于电子游戏对话系统的界面设计。
- AR设备的普及和性能提升,为日常对话融入AR+AI系统提供了可能。
- 大型语言模型(LLMs)和自然语言识别系统的结合,增强了系统的对话能力。
- AR+AI系统能够提供各类协助,如提供建议、处理复杂话题等。
- AR+AI的结合为研究领域提供了许多机会,尤其是在设计和应用方面。
- 该系统能够从电子游戏对话系统中学习并应用于现实场景。
点此查看论文截图

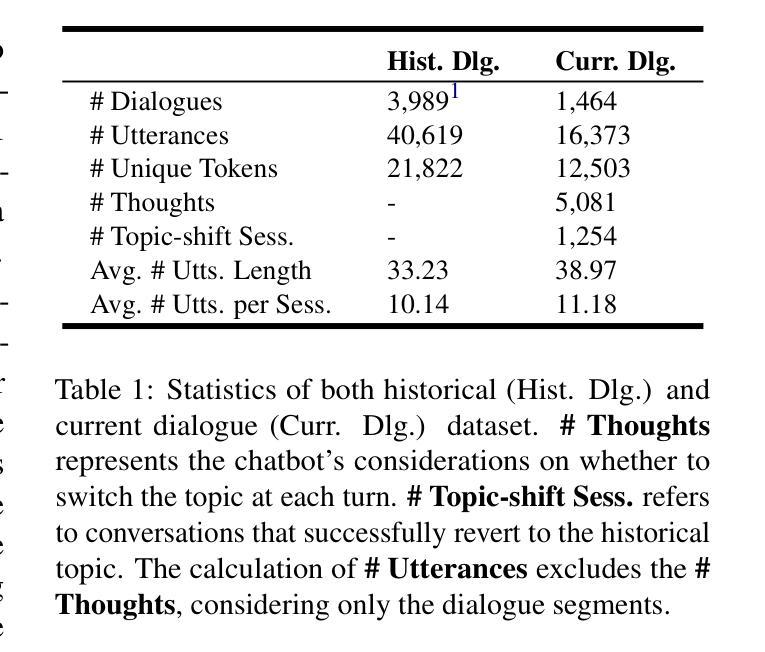
Interpersonal Memory Matters: A New Task for Proactive Dialogue Utilizing Conversational History
Authors:Bowen Wu, Wenqing Wang, Haoran Li, Ying Li, Jingsong Yu, Baoxun Wang
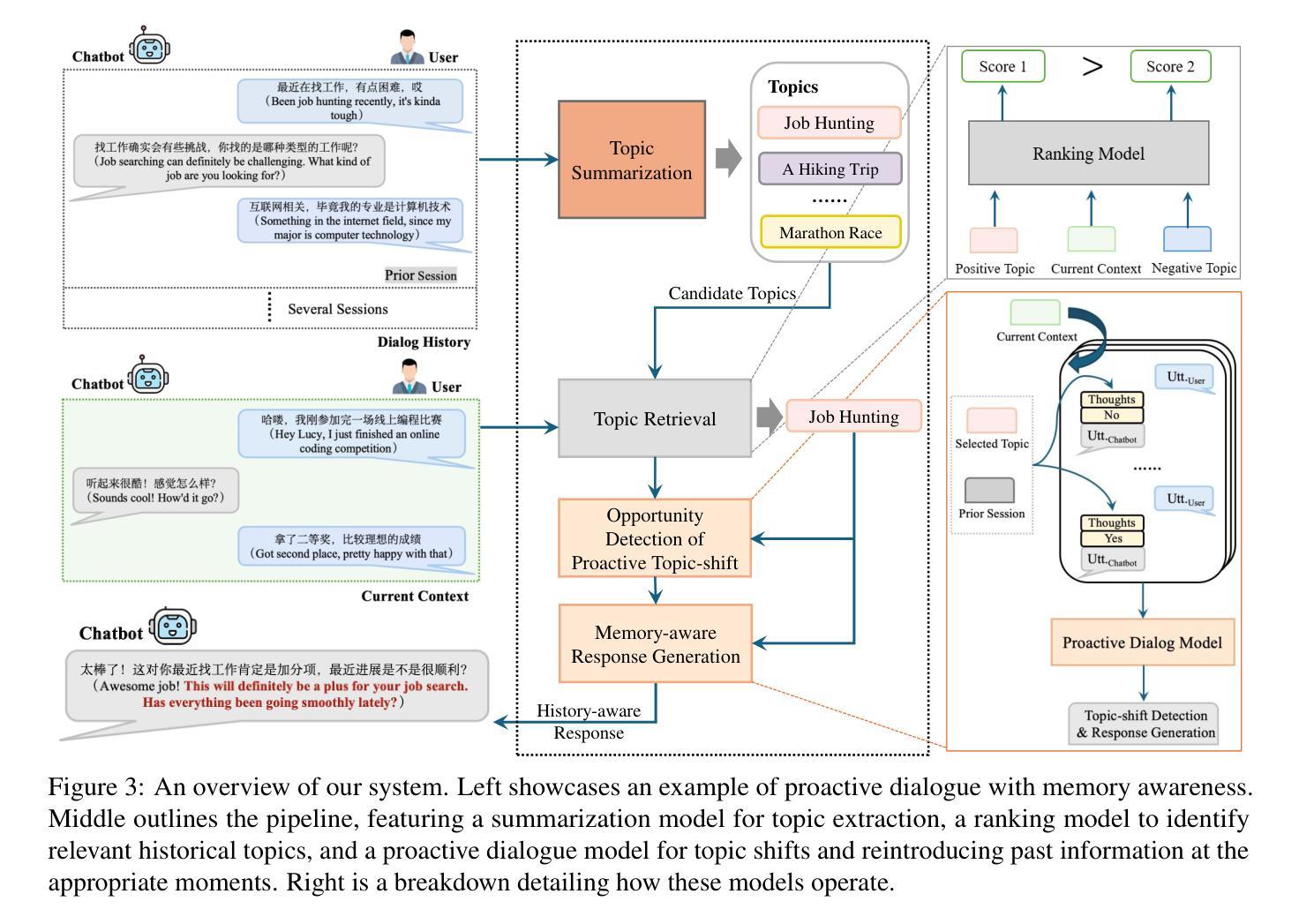
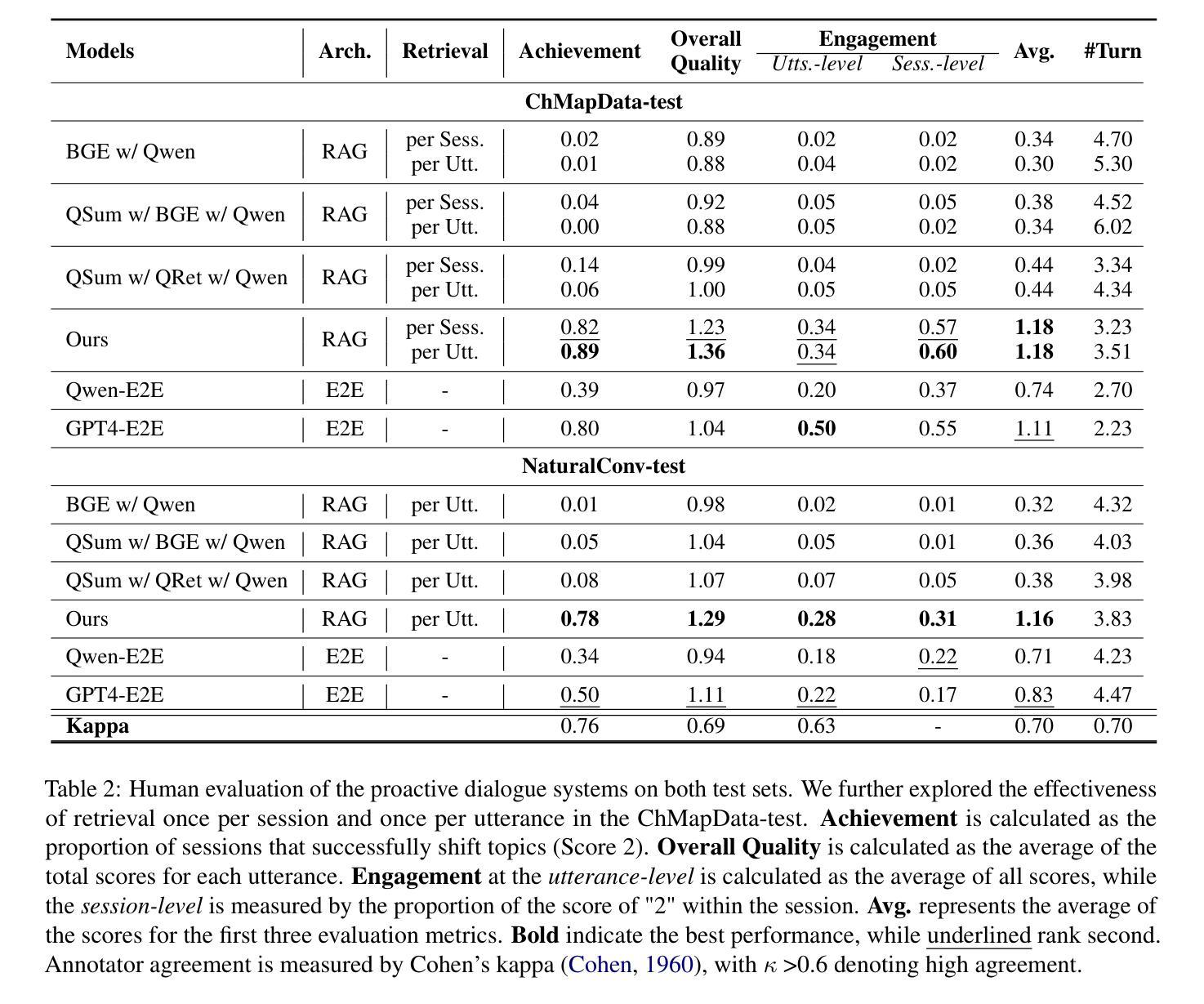
Proactive dialogue systems aim to empower chatbots with the capability of leading conversations towards specific targets, thereby enhancing user engagement and service autonomy. Existing systems typically target pre-defined keywords or entities, neglecting user attributes and preferences implicit in dialogue history, hindering the development of long-term user intimacy. To address these challenges, we take a radical step towards building a more human-like conversational agent by integrating proactive dialogue systems with long-term memory into a unified framework. Specifically, we define a novel task named Memory-aware Proactive Dialogue (MapDia). By decomposing the task, we then propose an automatic data construction method and create the first Chinese Memory-aware Proactive Dataset (ChMapData). Furthermore, we introduce a joint framework based on Retrieval Augmented Generation (RAG), featuring three modules: Topic Summarization, Topic Retrieval, and Proactive Topic-shifting Detection and Generation, designed to steer dialogues towards relevant historical topics at the right time. The effectiveness of our dataset and models is validated through both automatic and human evaluations. We release the open-source framework and dataset at https://github.com/FrontierLabs/MapDia.
主动对话系统的目标是赋予聊天机器人引导对话朝特定目标进行的能力,从而提高用户参与度和服务自主性。现有的系统通常针对预定义的关键字或实体,忽略了对话历史中隐含的用户属性和偏好,阻碍了与用户长期亲密感的发展。为了解决这些挑战,我们朝着构建更像人类的对话代理迈出了重要一步,通过将主动对话系统与长期记忆集成到一个统一框架中。具体来说,我们定义了一个名为记忆感知主动对话(MapDia)的新任务。通过分解任务,我们提出了一种自动数据构建方法,并创建了首个中文记忆感知主动数据集(ChMapData)。此外,我们引入了一个基于检索增强生成(RAG)的联合框架,包含三个模块:主题摘要、主题检索和主动话题转换检测与生成,旨在在合适的时间引导对话走向与历史主题相关的话题。我们的数据集和模型的有效性已通过自动和人工评估得到验证。我们在https://github.com/FrontierLabs/MapDia上发布了开源框架和数据集。
论文及项目相关链接
Summary
主动对话系统致力于增强聊天机器人引导对话走向特定目标的能力,从而提升用户参与度与服务自主性。为应对现有系统忽视对话历史中的用户属性与偏好,无法实现长期用户亲密度的提升等挑战,我们朝着构建更具人类特性的对话代理迈出了重要一步。我们提出将主动对话系统与长期记忆集成到一个统一框架中,并定义了名为MapDia的新任务。通过任务分解,我们提出了一种自动数据构建方法,并创建了首个中文记忆感知主动数据集(ChMapData)。此外,我们引入了基于检索增强生成(RAG)的联合框架,包含主题摘要、主题检索和主动话题转移检测与生成三个模块,旨在在合适的时间引导对话走向与历史主题相关。数据集和模型的有效性已通过自动和人类评估得到验证。我们已在https://github.com/Frontierlabs/MapDia开放源代码框架和数据集供公众使用。
Key Takeaways
- 主动对话系统的目标是增强聊天机器人的对话引导能力,提升用户参与度和服务自主性。
- 现有系统存在的问题是忽视用户属性和对话历史中的偏好,影响长期用户亲密度的提升。
- 为解决这些问题,提出将主动对话系统与长期记忆集成,并定义了名为MapDia的新任务。
- 提出了自动数据构建方法,创建了首个中文记忆感知主动数据集(ChMapData)。
- 引入了基于检索增强生成的联合框架,包含主题摘要、主题检索和主动话题转移检测与生成三个模块。
- 该框架能够在合适的时间引导对话走向相关的历史主题。
点此查看论文截图

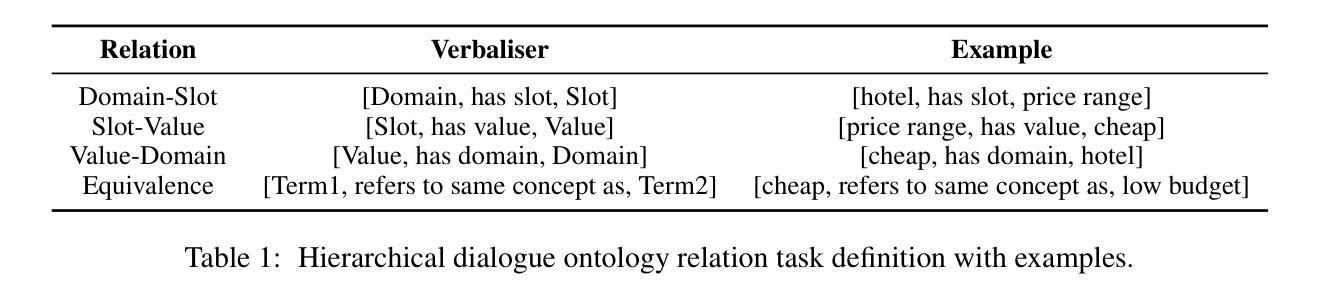
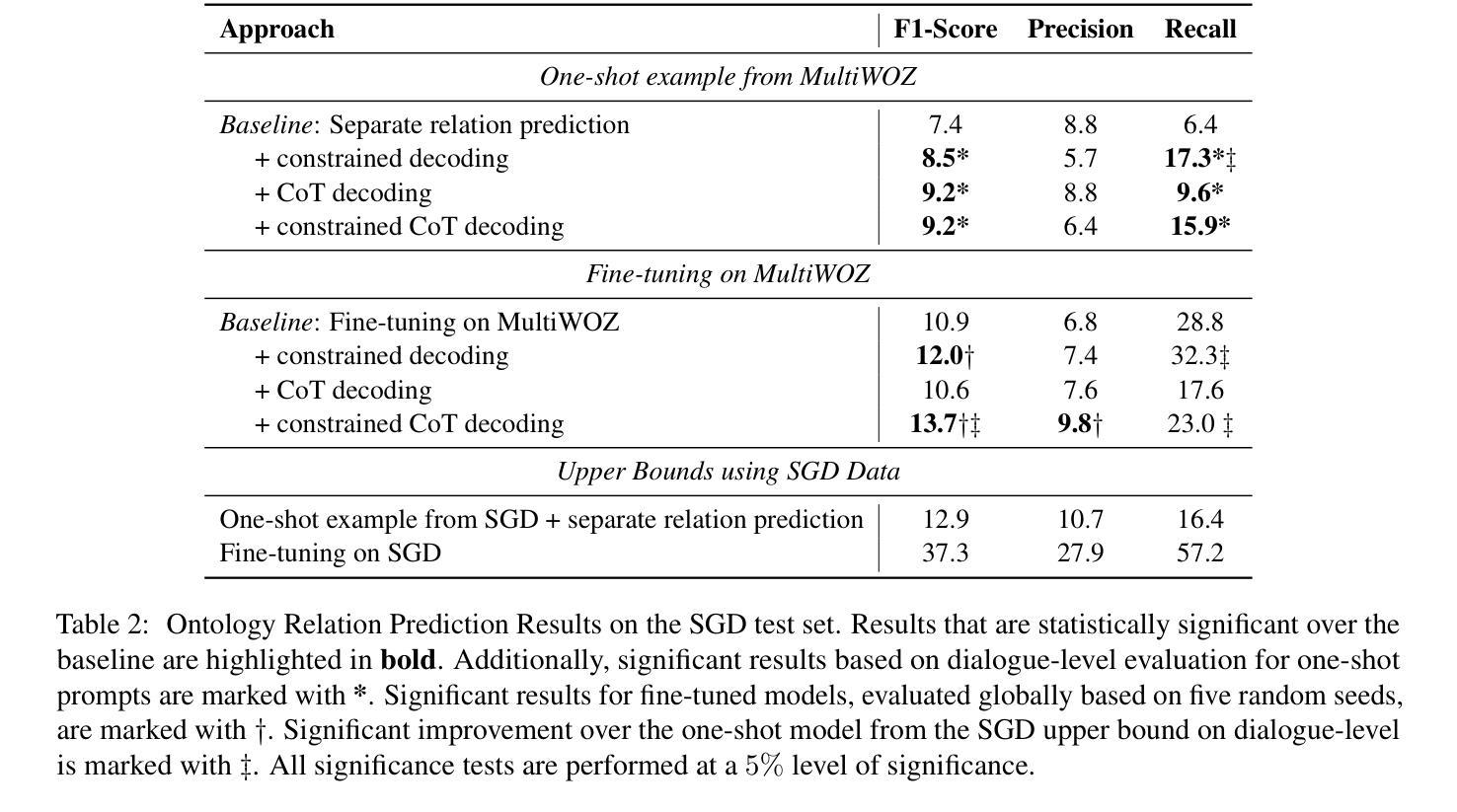
Dialogue Ontology Relation Extraction via Constrained Chain-of-Thought Decoding
Authors:Renato Vukovic, David Arps, Carel van Niekerk, Benjamin Matthias Ruppik, Hsien-Chin Lin, Michael Heck, Milica Gašić
State-of-the-art task-oriented dialogue systems typically rely on task-specific ontologies for fulfilling user queries. The majority of task-oriented dialogue data, such as customer service recordings, comes without ontology and annotation. Such ontologies are normally built manually, limiting the application of specialised systems. Dialogue ontology construction is an approach for automating that process and typically consists of two steps: term extraction and relation extraction. In this work, we focus on relation extraction in a transfer learning set-up. To improve the generalisation, we propose an extension to the decoding mechanism of large language models. We adapt Chain-of-Thought (CoT) decoding, recently developed for reasoning problems, to generative relation extraction. Here, we generate multiple branches in the decoding space and select the relations based on a confidence threshold. By constraining the decoding to ontology terms and relations, we aim to decrease the risk of hallucination. We conduct extensive experimentation on two widely used datasets and find improvements in performance on target ontology for source fine-tuned and one-shot prompted large language models.
当前先进的任务导向型对话系统通常依赖于特定任务的本体来完成用户查询。大部分任务导向型对话数据,如客户服务录音,都没有本体和注释。这些本体通常是手动构建的,限制了专用系统的应用。对话本体构建是一种自动化该过程的方法,通常包括两个步骤:术语提取和关系提取。在这项工作中,我们专注于迁移学习设置中的关系提取。为了提高通用性,我们提出了对大型语言模型解码机制的扩展。我们采用最近为推理问题开发的思维链(CoT)解码,将其适应于生成式关系提取。在此,我们在解码空间中生成多个分支,并根据置信阈值选择关系。通过约束解码以符合本体术语和关系,我们旨在降低幻想的风险。我们在两个广泛应用的数据集上进行了大量实验,发现在针对源微调和一次性提示的大型语言模型的目标本体上,性能有所提高。
论文及项目相关链接
PDF Accepted to appear at SIGDIAL 2024. 9 pages, 4 figures
Summary:
先进的任务导向型对话系统通常依赖于特定的任务本体来完成用户查询。大量的任务导向型对话数据,如客户服务录音,并没有本体和注释。本体通常是手动构建的,这限制了专业系统的应用。对话本体构建是一种自动化该过程的方法,主要包括术语提取和关系提取两个步骤。在这项工作中,我们专注于迁移学习设置中的关系提取。为了提高通用性,我们对大型语言模型的解码机制提出了扩展。我们适应最近为推理问题开发的Chain-of-Thought(CoT)解码,将其用于生成关系提取。在此,我们在解码空间中生成多个分支,并根据置信阈值选择关系。通过限制解码为本体术语和关系,我们旨在降低幻想的风险。我们在两个广泛使用的数据集上进行了大量实验,发现在针对源微调模型和一触式提示的大型语言模型的目标本体上提高了性能。
Key Takeaways:
- 任务导向型对话系统依赖任务特定本体完成用户查询。
- 大部分任务导向型对话数据并没有本体和注释。
- 对话本体构建旨在自动化该过程,包括术语提取和关系提取。
- 研究人员提出在迁移学习环境下改进关系提取的方法。
- 通过扩展大型语言模型的解码机制,采用Chain-of-Thought(CoT)解码来提高关系提取的通用性。
- 在解码过程中生成多个分支并选择基于置信阈值的关系。
点此查看论文截图