⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-11 更新
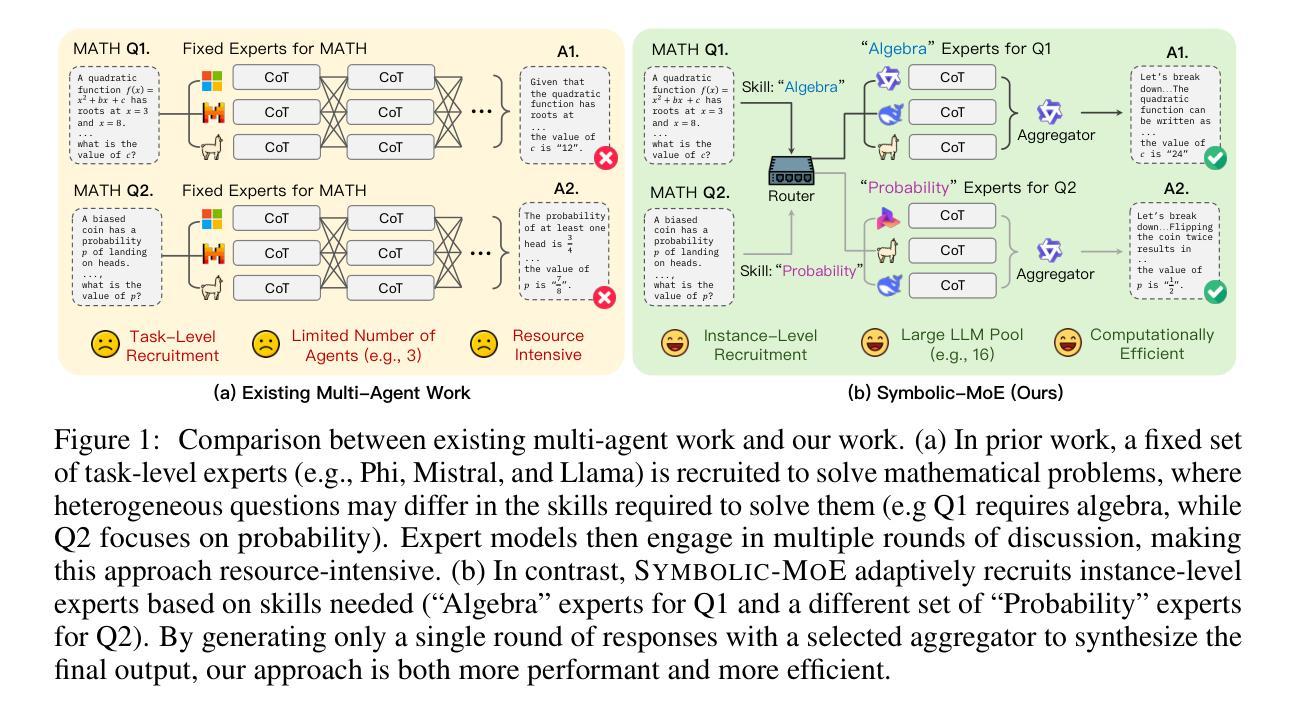
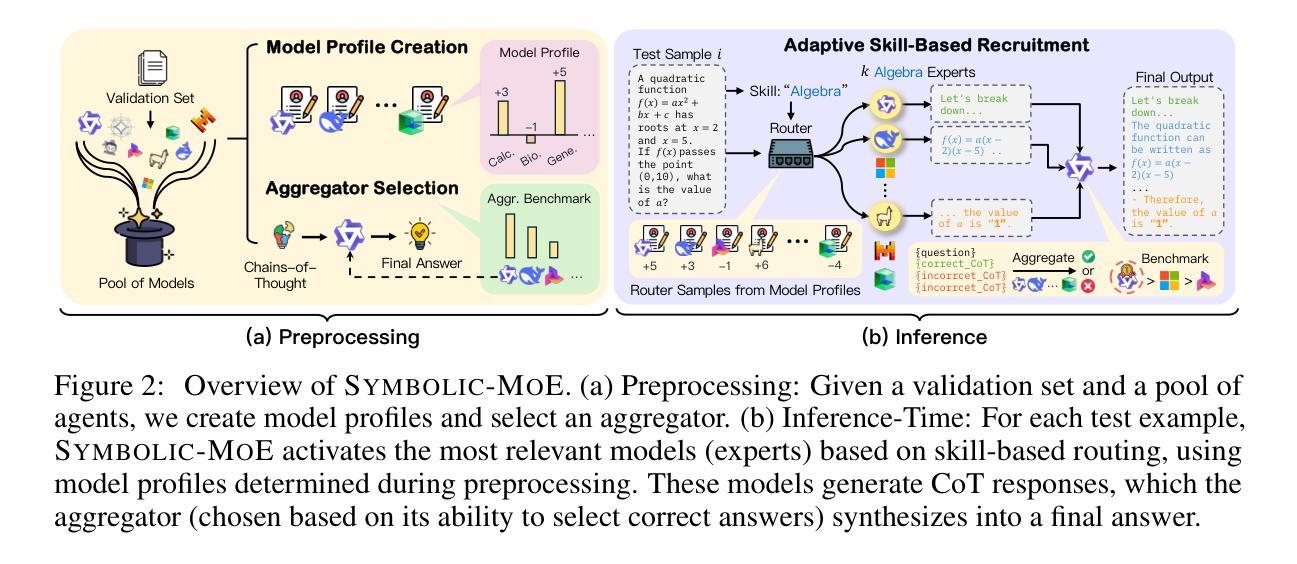
Symbolic Mixture-of-Experts: Adaptive Skill-based Routing for Heterogeneous Reasoning
Authors:Justin Chih-Yao Chen, Sukwon Yun, Elias Stengel-Eskin, Tianlong Chen, Mohit Bansal
Combining existing pre-trained expert LLMs is a promising avenue for scalably tackling large-scale and diverse tasks. However, selecting experts at the task level is often too coarse-grained, as heterogeneous tasks may require different expertise for each instance. To enable adaptive instance-level mixing of pre-trained LLM experts, we propose Symbolic-MoE, a symbolic, text-based, and gradient-free Mixture-of-Experts framework. Symbolic-MoE takes a fine-grained approach to selection by emphasizing skills, e.g., algebra in math or molecular biology in biomedical reasoning. We propose a skill-based recruiting strategy that dynamically selects the most relevant set of expert LLMs for diverse reasoning tasks based on their strengths. Each selected expert then generates its own reasoning, resulting in k outputs from k experts, which are then synthesized into a final high-quality response by an aggregator chosen based on its ability to integrate diverse reasoning outputs. We show that Symbolic-MoE’s instance-level expert selection improves performance by a large margin but – when implemented naively – can introduce a high computational overhead due to the need for constant model loading and offloading. To address this, we implement a batch inference strategy that groups instances based on their assigned experts, loading each model only once. This allows us to integrate 16 expert models on 1 GPU with a time cost comparable to or better than prior multi-agent baselines using 4 GPUs. Through extensive evaluations on diverse benchmarks (MMLU-Pro, GPQA, AIME, and MedMCQA), we demonstrate that Symbolic-MoE outperforms strong LLMs like GPT4o-mini, as well as multi-agent approaches, with an absolute average improvement of 8.15% over the best multi-agent baseline. Moreover, Symbolic-MoE removes the need for expensive multi-round discussions, outperforming discussion baselines with less computation.
结合现有的预训练专家LLM(大型语言模型)为大规模和多样化任务的可扩展处理带来了希望。然而,在任务层面选择专家通常太过粗糙,因为不同的任务实例可能需要不同的专业知识。为了实现对预训练LLM专家的自适应实例级混合,我们提出了Symbolic-MoE,一个基于符号、文本和无梯度的混合专家框架。Symbolic-MoE通过强调技能来采取精细粒度的选择方法,例如数学中的代数或生物医学推理中的分子生物学。我们提出了一种基于技能的招聘策略,该策略根据专家的优势动态选择最相关的一组专家LLM来处理多样化的推理任务。每个选中的专家然后生成自己的推理结果,产生来自k个专家的k个输出,然后通过一个聚合器将其综合成最终的高质量响应,聚合器的选择基于其整合多种推理输出的能力。我们表明,Symbolic-MoE的实例级专家选择大幅度提高了性能,但如果实施得过于简单,由于需要不断的模型加载和卸载,可能会引入很高的计算开销。为了解决这一问题,我们实现了一种批量推理策略,该策略根据分配的专家对实例进行分组,每个模型只加载一次。这使我们能够在单个GPU上集成16个专家模型,时间成本可与使用4个GPU的先前多代理基线相比,甚至更好。通过在不同基准测试(MMLU-Pro、GPQA、AIME和MedMCQA)上的广泛评估,我们证明Symbolic-MoE在强大的LLM(如GPT4o mini)和多代理方法上表现优异,绝对平均提高了8.15%,超过了最佳多代理基线。此外,Symbolic-MoE不需要昂贵的多轮讨论,其表现优于计算较少的讨论基线。
论文及项目相关链接
PDF The first three authors contributed equally. Project Page: https://symbolic_moe.github.io/
Summary
该文探讨了结合预训练专家LLMs的新方法,通过Symbolic-MoE框架实现自适应实例级别的混合。该方法采用基于技能的精细选择策略,针对不同类型的任务动态选择最相关的专家LLM。实验表明,Symbolic-MoE的实例级别专家选择能大幅提高性能,且通过批量推理策略优化计算开销。在多个基准测试上,Symbolic-MoE表现出优于GPT4o-mini等多模型方法的效果,绝对平均提升达8.15%。此外,Symbolic-MoE无需昂贵的多轮讨论,计算效率更高。
Key Takeaways
- 结合预训练专家LLMs是解决大规模多样任务的有前途的方法。
- Symbolic-MoE框架实现自适应实例级别的混合,采用基于技能的精细选择策略。
- 基于技能的策略能动态选择最相关的专家LLM以应对不同类型的任务。
- Symbolic-MoE通过批量推理策略优化计算开销,能在单GPU上集成多个专家模型。
- 在多个基准测试上,Symbolic-MoE表现出显著的优势,优于GPT4o-mini等多模型方法。
- Symbolic-MoE的绝对平均提升达8.15%,展现了强大的性能。
点此查看论文截图

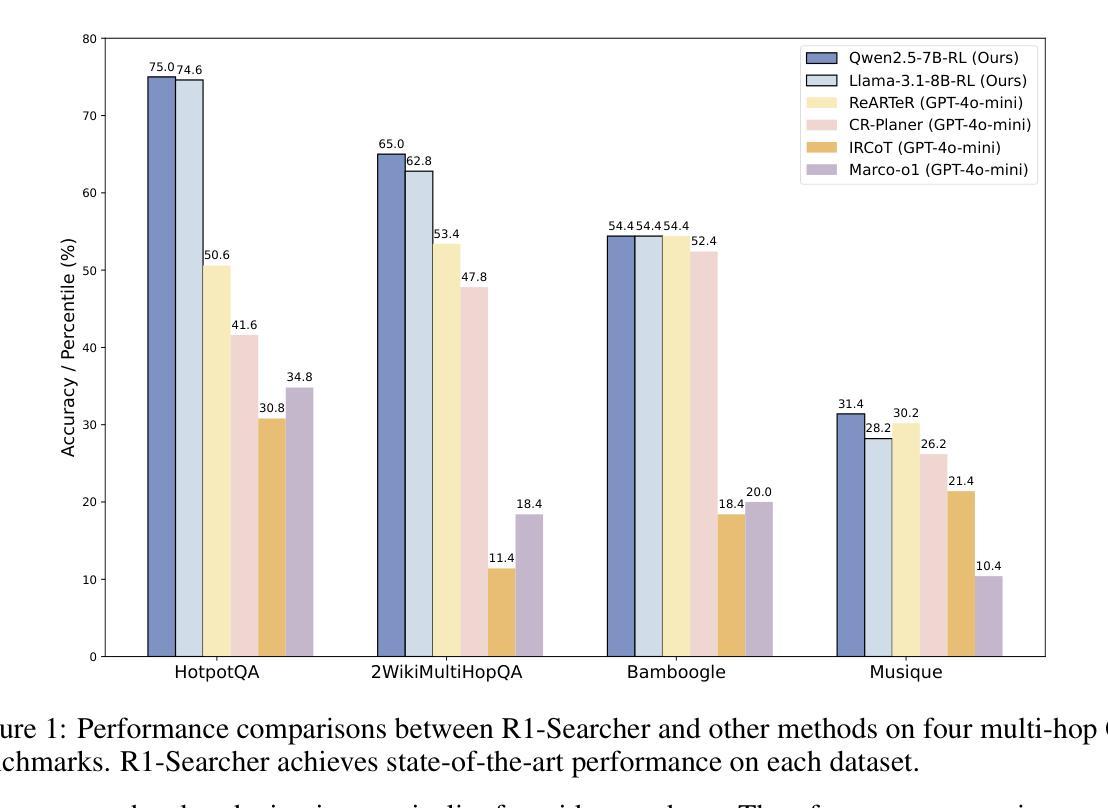
R1-Searcher: Incentivizing the Search Capability in LLMs via Reinforcement Learning
Authors:Huatong Song, Jinhao Jiang, Yingqian Min, Jie Chen, Zhipeng Chen, Wayne Xin Zhao, Lei Fang, Ji-Rong Wen
Existing Large Reasoning Models (LRMs) have shown the potential of reinforcement learning (RL) to enhance the complex reasoning capabilities of Large Language Models~(LLMs). While they achieve remarkable performance on challenging tasks such as mathematics and coding, they often rely on their internal knowledge to solve problems, which can be inadequate for time-sensitive or knowledge-intensive questions, leading to inaccuracies and hallucinations. To address this, we propose \textbf{R1-Searcher}, a novel two-stage outcome-based RL approach designed to enhance the search capabilities of LLMs. This method allows LLMs to autonomously invoke external search systems to access additional knowledge during the reasoning process. Our framework relies exclusively on RL, without requiring process rewards or distillation for a cold start. % effectively generalizing to out-of-domain datasets and supporting both Base and Instruct models. Our experiments demonstrate that our method significantly outperforms previous strong RAG methods, even when compared to the closed-source GPT-4o-mini.
现有的大型推理模型(LRM)已经显示出强化学习(RL)在增强大型语言模型(LLM)的复杂推理能力方面的潜力。虽然他们在数学和编程等具有挑战性的任务上取得了显著的成绩,但他们往往依赖于内部知识来解决问题,这对于时间敏感或知识密集的问题可能不足以解决问题,导致准确性和幻想。为了解决这个问题,我们提出了R1-Searcher,这是一种新型的两阶段基于结果的RL方法,旨在增强LLM的搜索能力。这种方法允许LLM在推理过程中自主调用外部搜索系统来访问额外的知识。我们的框架完全依赖于RL,而不需要过程奖励或冷启动时的蒸馏。%有效地泛化到域外数据集并支持Base和Instruct模型。我们的实验表明,我们的方法显著优于之前的强大RAG方法,即使与闭源的GPT-4o-mini相比也是如此。
简体中文翻译
论文及项目相关链接
Summary
强化学习(RL)在提升大型推理模型(LRMs)的复杂推理能力方面具有潜力。虽然现有模型在数学和编程等挑战性任务上表现出卓越性能,但它们往往依赖内部知识解决问题,对于时间敏感或知识密集型问题可能不足够准确,甚至产生幻觉。为解决这一问题,我们提出了R1-Searcher,一种新型两阶段结果导向的RL方法,旨在增强LLM的搜索能力。该方法允许LLM在推理过程中自主调用外部搜索系统获取额外知识。我们的框架完全依赖于RL,无需过程奖励或冷启动时的蒸馏。实验证明,我们的方法显著优于先前的强大RAG方法,即使与闭源的GPT-4o-mini相比也是如此。
Key Takeaways
- 强化学习(RL)在提升大型推理模型(LRMs)的复杂推理能力方面具有潜力。
- LRMs在解决数学和编程等挑战性任务上表现出卓越性能,但在时间敏感或知识密集型问题上可能不准确。
- R1-Searcher是一种新型两阶段结果导向的RL方法,旨在增强LLM的搜索能力。
- R1-Searcher允许LLM在推理过程中自主调用外部搜索系统获取额外知识。
- R1-Searcher框架完全依赖于强化学习,无需过程奖励或冷启动时的知识蒸馏。
- 实验证明R1-Searcher方法显著优于先前的RAG方法。
点此查看论文截图

An Empirical Study of Conformal Prediction in LLM with ASP Scaffolds for Robust Reasoning
Authors:Navdeep Kaur, Lachlan McPheat, Alessandra Russo, Anthony G Cohn, Pranava Madhyastha
In this paper, we examine the use of Conformal Language Modelling (CLM) alongside Answer Set Programming (ASP) to enhance the performance of standard open-weight LLMs on complex multi-step reasoning tasks. Using the StepGame dataset, which requires spatial reasoning, we apply CLM to generate sets of ASP programs from an LLM, providing statistical guarantees on the correctness of the outputs. Experimental results show that CLM significantly outperforms baseline models that use standard sampling methods, achieving substantial accuracy improvements across different levels of reasoning complexity. Additionally, the LLM-as-Judge metric enhances CLM’s performance, especially in assessing structurally and logically correct ASP outputs. However, calibrating CLM with diverse calibration sets did not improve generalizability for tasks requiring much longer reasoning steps, indicating limitations in handling more complex tasks.
在这篇论文中,我们研究了将Conformal Language Modelling(CLM)与Answer Set Programming(ASP)结合使用,以提高标准开放式权重的大型预训练语言模型(LLMs)在复杂多步骤推理任务上的性能。我们利用需要空间推理的StepGame数据集,应用CLM从LLM生成ASP程序集,为输出结果的正确性提供统计保证。实验结果表明,与采用标准采样方法的基线模型相比,CLM表现更优异,并且在不同级别的推理复杂度上实现了实质性的准确性提升。此外,LLM-as-Judge指标提高了CLM的性能,特别是在评估结构上和逻辑上正确的ASP输出方面。然而,使用各种校准集校准CLM并没有提高对需要更多推理步骤的任务的通用性,这表明在处理更复杂的任务时存在局限性。
论文及项目相关链接
Summary
本文探讨了将符合语言建模(CLM)与答案集编程(ASP)相结合,以提高标准开放权重大型语言模型在复杂多步骤推理任务上的性能。通过应用CLM生成ASP程序集,对空间推理要求的StepGame数据集进行统计保证输出的正确性。实验结果表明,CLM显著优于使用标准采样方法的基线模型,在不同层次的推理复杂度上实现了实质性的准确性提高。然而,对于需要更长时间推理的步骤,使用多种校准集校准CLM并没有提高其在复杂任务中的通用性,表明其在处理复杂任务方面的局限性。
Key Takeaways
- 本文结合Conformal Language Modelling (CLM)与Answer Set Programming (ASP),旨在提高大型语言模型在复杂多步骤推理任务上的性能。
- 使用StepGame数据集展示CLM生成ASP程序的能力,并提供了统计保证的正确性输出。
- 实验结果显示,CLM相较于基线模型在准确性上有显著提高,特别是在不同层次的推理复杂度上。
- LLM-as-Judge评估方法能有效提升CLM的性能,尤其在评估ASP输出的结构和逻辑正确性方面。
- 对于需要更长推理步骤的任务,CLM的通用性存在局限性。
点此查看论文截图

Speculative Decoding for Multi-Sample Inference
Authors:Yiwei Li, Jiayi Shi, Shaoxiong Feng, Peiwen Yuan, Xinglin Wang, Yueqi Zhang, Ji Zhang, Chuyi Tan, Boyuan Pan, Yao Hu, Kan Li
We propose a novel speculative decoding method tailored for multi-sample reasoning scenarios, such as self-consistency and Best-of-N sampling. Our method exploits the intrinsic consensus of parallel generation paths to synthesize high-quality draft tokens without requiring auxiliary models or external databases. By dynamically analyzing structural patterns across parallel reasoning paths through a probabilistic aggregation mechanism, it identifies consensus token sequences that align with the decoding distribution. Evaluations on mathematical reasoning benchmarks demonstrate a substantial improvement in draft acceptance rates over baselines, while reducing the latency in draft token construction. This work establishes a paradigm shift for efficient multi-sample inference, enabling seamless integration of speculative decoding with sampling-based reasoning techniques.
我们提出了一种针对多样本推理场景(如自洽性和最佳N采样)量身定制的新型投机解码方法。我们的方法利用并行生成路径的内在一致性,合成高质量草稿标记,无需辅助模型或外部数据库。它通过概率聚合机制动态分析并行推理路径的结构模式,识别与解码分布一致的共识标记序列。在数学推理基准测试上的评估表明,与基线相比,草案接受率有显著提高,同时降低了草稿标记构建的延迟。这项工作实现了高效多样本推断的模式转变,实现了投机解码与基于采样的推理技术的无缝集成。
论文及项目相关链接
Summary
本文提出了一种针对多样本推理场景(如自洽和最佳N采样)的定制新型投机解码方法。该方法利用并行生成路径的内在共识,通过概率聚合机制动态分析并行推理路径的结构模式,合成高质量草稿标记,无需辅助模型或外部数据库。它在数学推理基准测试上的评估结果表明,与基线相比,草案接受率有显著提高,同时降低了草案标记构建的延迟。这项工作为高效的多样本推断带来了范式转变,实现了投机解码与基于采样的推理技术的无缝集成。
Key Takeaways
- 提出了一种针对多样本推理场景的新型投机解码方法。
- 该方法利用并行生成路径的内在共识来合成高质量草稿标记。
- 通过概率聚合机制动态分析结构模式来识别与解码分布一致的共识标记序列。
- 在数学推理基准测试上的评估结果,显示出对草案接受率的显著提高和降低标记构建的延迟。
- 该方法无需辅助模型或外部数据库。
- 实现了投机解码与基于采样的推理技术的无缝集成。
点此查看论文截图

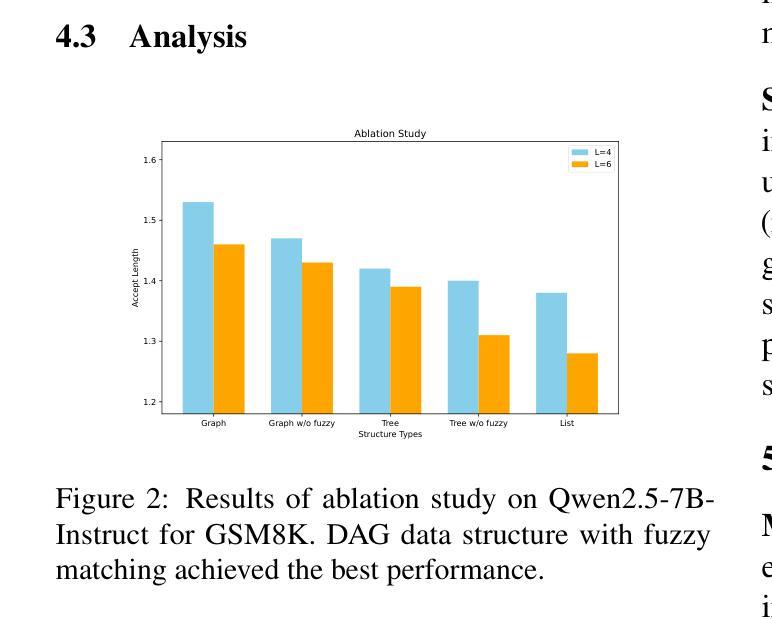
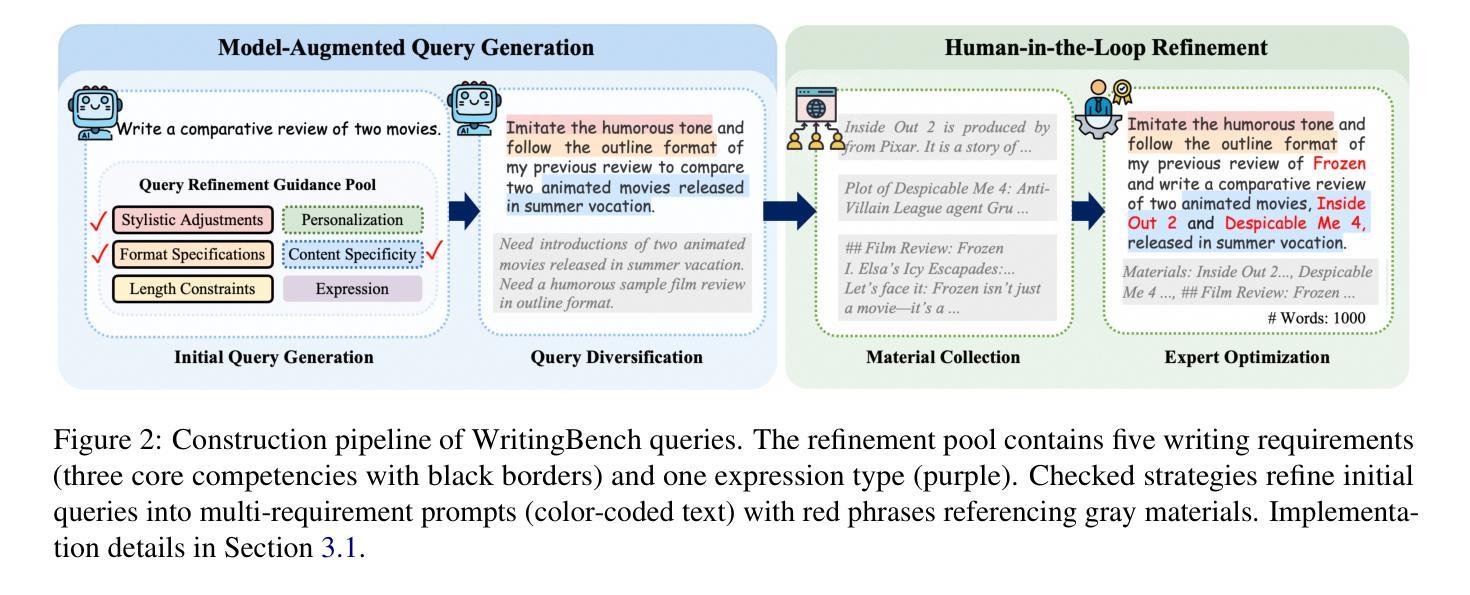
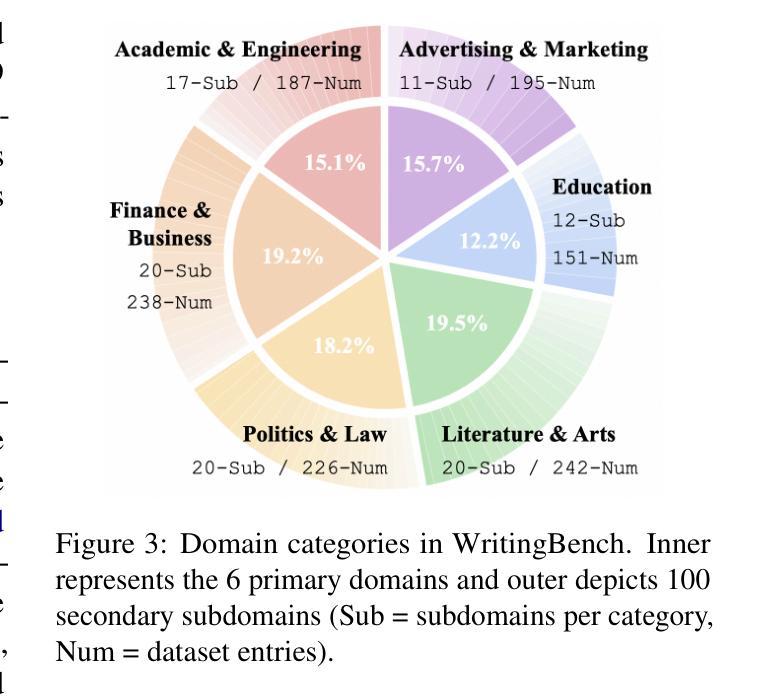
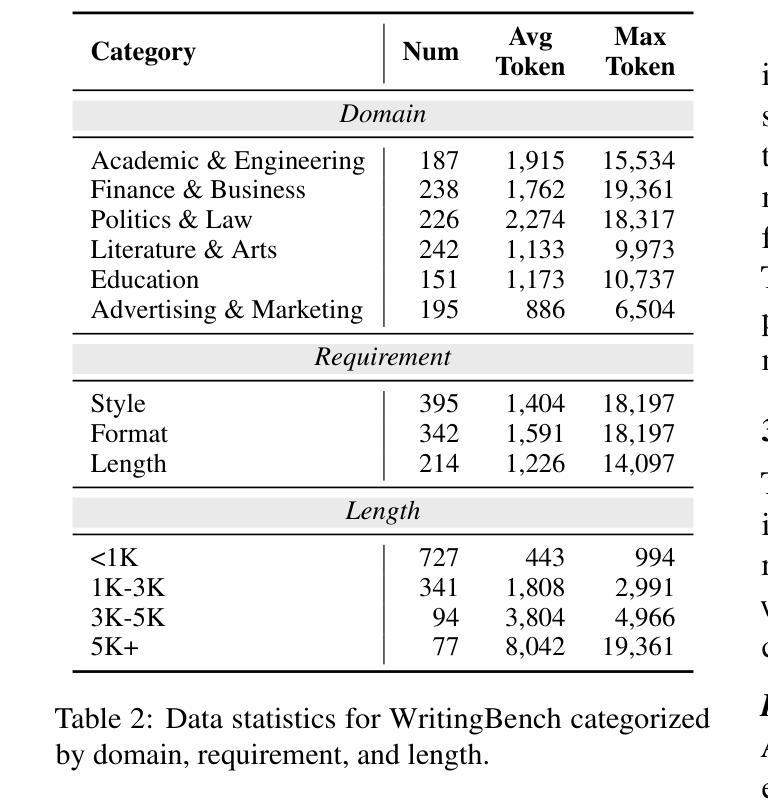
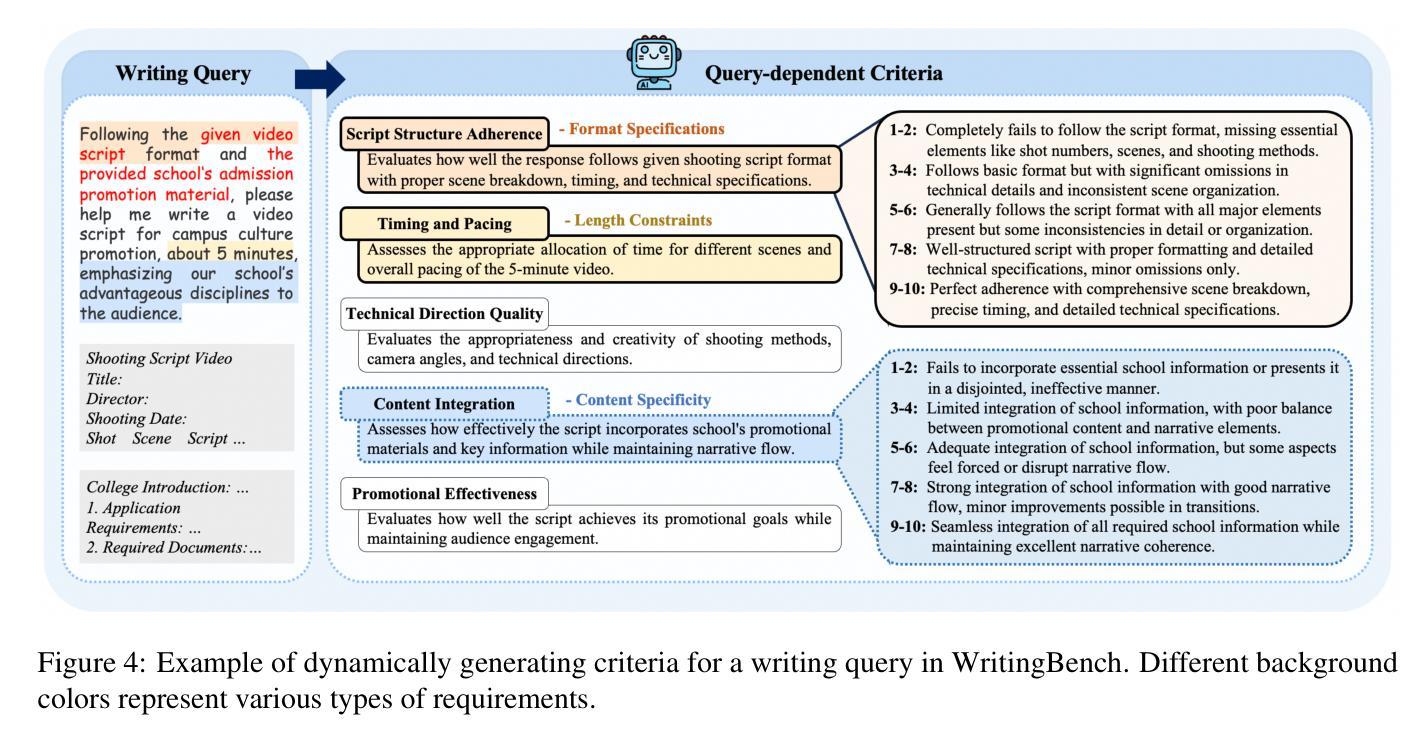
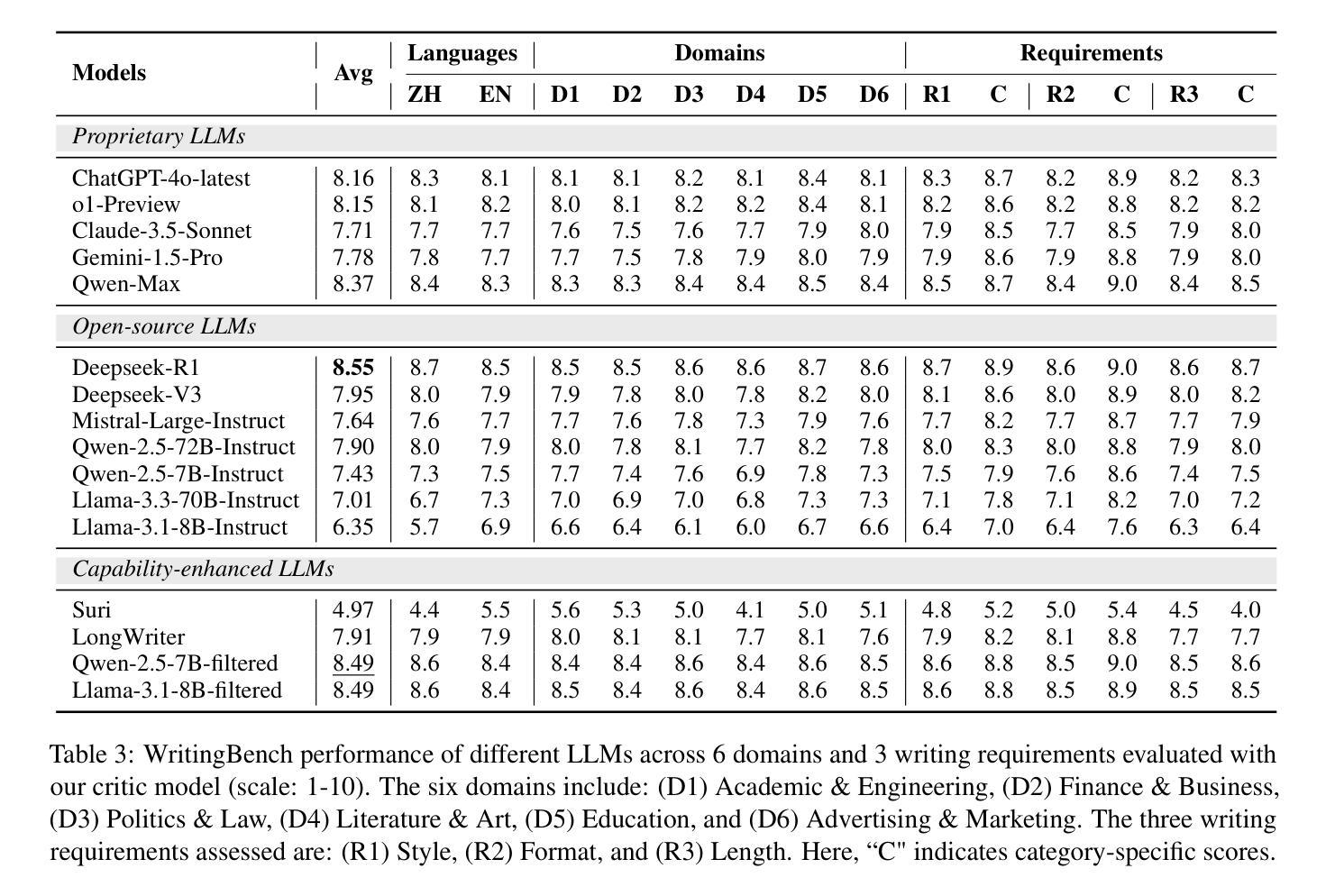
WritingBench: A Comprehensive Benchmark for Generative Writing
Authors:Yuning Wu, Jiahao Mei, Ming Yan, Chenliang Li, SHaopeng Lai, Yuran Ren, Zijia Wang, Ji Zhang, Mengyue Wu, Qin Jin, Fei Huang
Recent advancements in large language models (LLMs) have significantly enhanced text generation capabilities, yet evaluating their performance in generative writing remains a challenge. Existing benchmarks primarily focus on generic text generation or limited in writing tasks, failing to capture the diverse requirements of high-quality written contents across various domains. To bridge this gap, we present WritingBench, a comprehensive benchmark designed to evaluate LLMs across 6 core writing domains and 100 subdomains, encompassing creative, persuasive, informative, and technical writing. We further propose a query-dependent evaluation framework that empowers LLMs to dynamically generate instance-specific assessment criteria. This framework is complemented by a fine-tuned critic model for criteria-aware scoring, enabling evaluations in style, format and length. The framework’s validity is further demonstrated by its data curation capability, which enables 7B-parameter models to approach state-of-the-art (SOTA) performance. We open-source the benchmark, along with evaluation tools and modular framework components, to advance the development of LLMs in writing.
最近大型语言模型(LLM)的进展显著增强了文本生成能力,但评估其在生成写作中的性能仍然是一个挑战。现有的基准测试主要关注通用文本生成或有限的写作任务,无法捕捉跨不同领域高质量内容的多样化要求。为了弥补这一差距,我们推出了WritingBench,这是一个全面的基准测试,旨在评估LLM在6个核心写作域和100个子域中的表现,包括创造性、说服力、信息性和技术性写作。我们还提出了一个查询依赖评估框架,使LLM能够动态生成特定实例的评估标准。该框架通过微调评论家模型进行标准感知评分,以风格、格式和长度为特色进行评价。框架的有效性进一步通过其数据整合能力得到证明,这使得7B参数模型能够接近最新技术(SOTA)的性能水平。我们开源基准测试、评估工具和模块化框架组件,以促进写作领域的LLM发展。
论文及项目相关链接
Summary
大语言模型(LLM)的近期进展极大提升了文本生成能力,但在评估其生成写作性能上仍面临挑战。当前评估基准测试主要集中在通用文本生成或有限写作任务上,无法捕捉不同领域高质量内容的多样需求。为解决此问题,我们推出WritingBench,这是一个旨在评估LLM在六大核心写作领域及一百个子领域的全面基准测试,涵盖创意、说服、信息和技术写作。我们还提出了一种查询依赖评估框架,使LLM能够动态生成特定实例的评估标准。该框架通过精细调整的评论家模型进行标准感知评分,以风格、格式和长度进行评估。框架的有效性通过其数据整合能力进一步得到证明,使得7B参数模型能够接近最新技术水平。我们开源基准测试以及与评估工具和模块化框架组件相关的工具,以促进写作领域LLM的发展。
Key Takeaways
- LLM在文本生成方面取得显著进展,但评估其生成写作性能的基准测试仍不足。
- 现有基准测试主要集中在通用文本生成和有限写作任务上,忽略了不同写作领域的多样性。
- WritingBench是一个全面的基准测试,旨在评估LLM在六大核心写作领域及多个子领域的表现。
- 提出查询依赖评估框架,使LLM能动态生成特定实例的评估标准。
- 通过精细调整的评论家模型进行标准感知评分,涵盖风格、格式和长度等方面。
- 框架的有效性通过其数据整合能力得到证明,7B参数模型表现接近最新技术水平。
点此查看论文截图


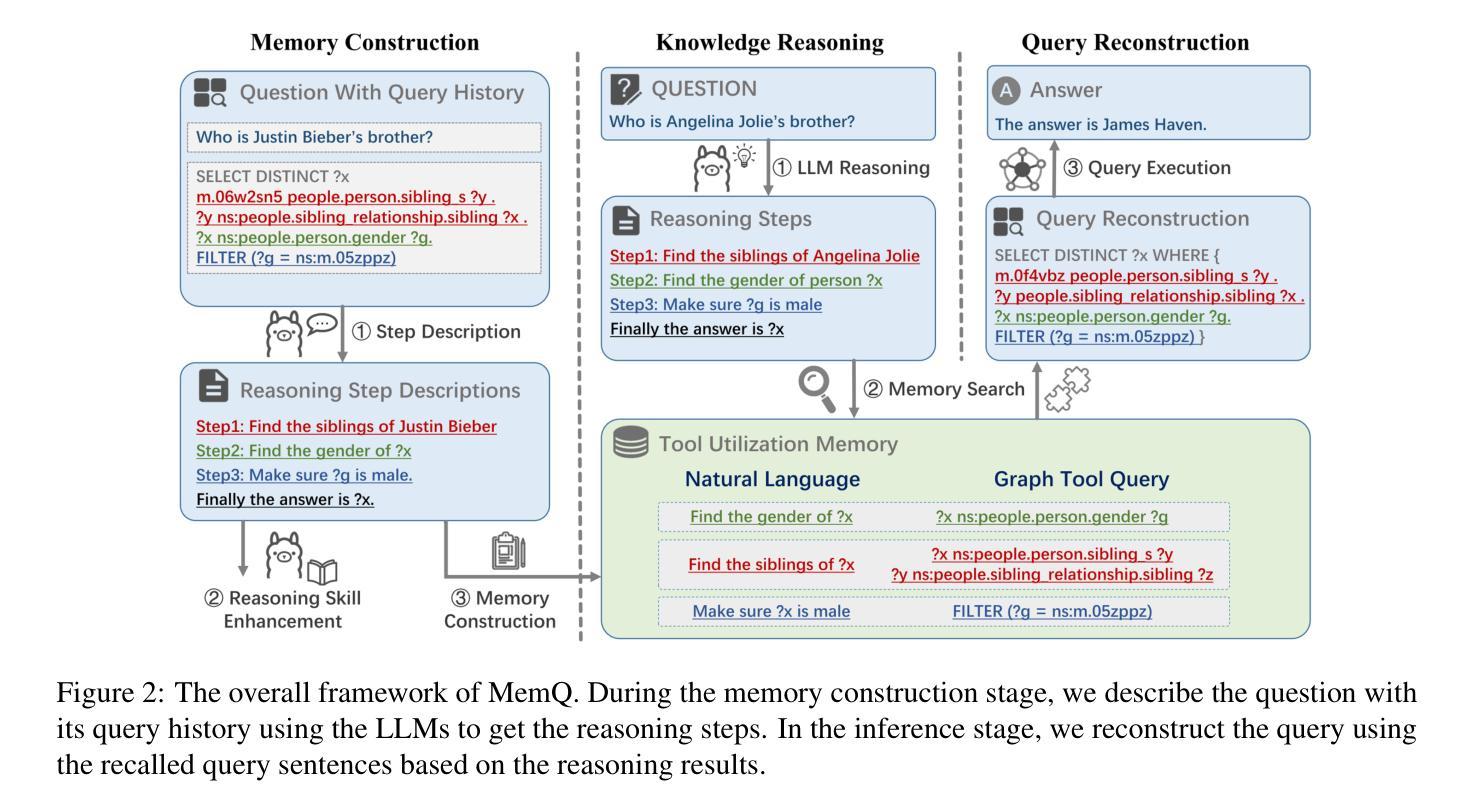
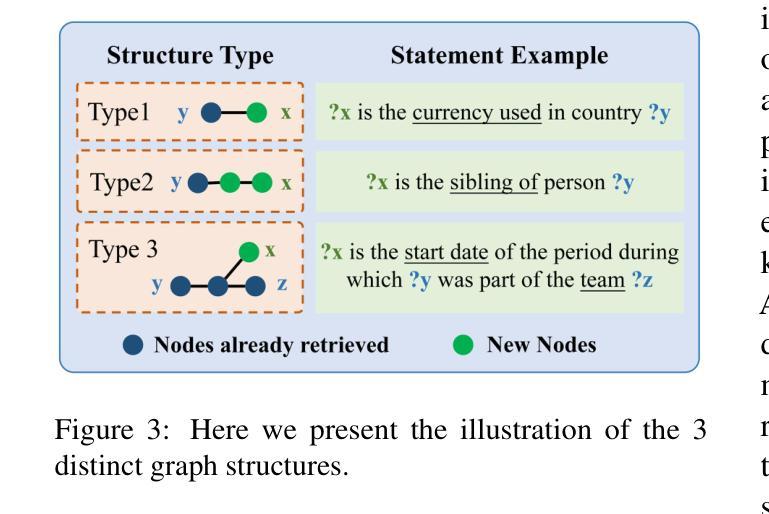
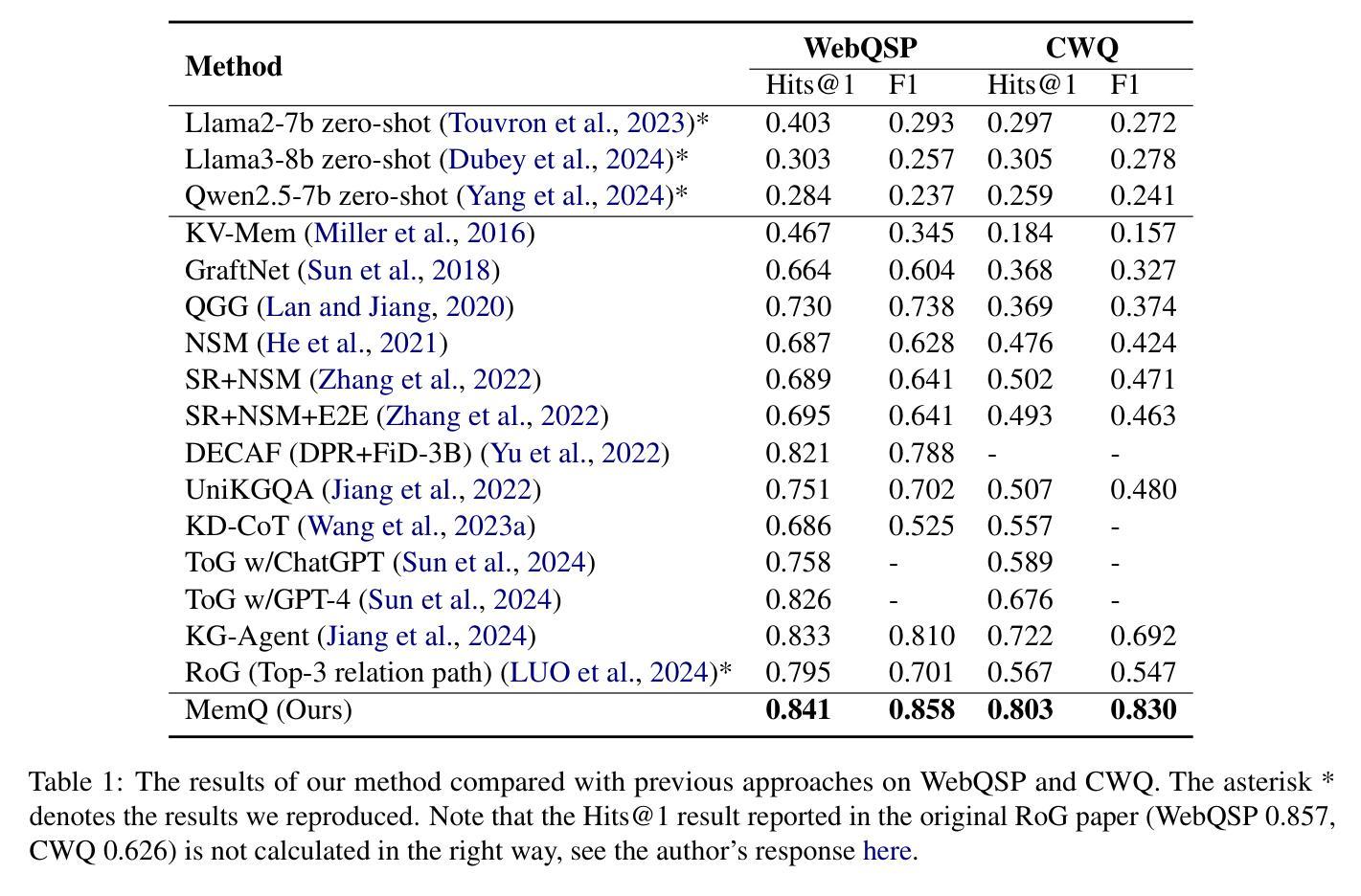
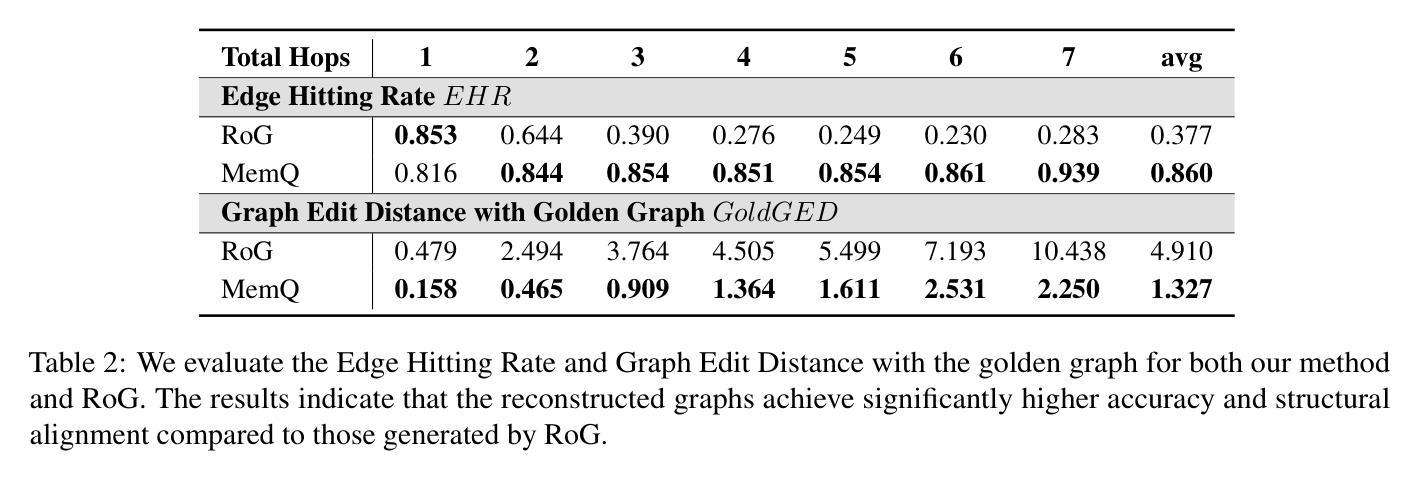
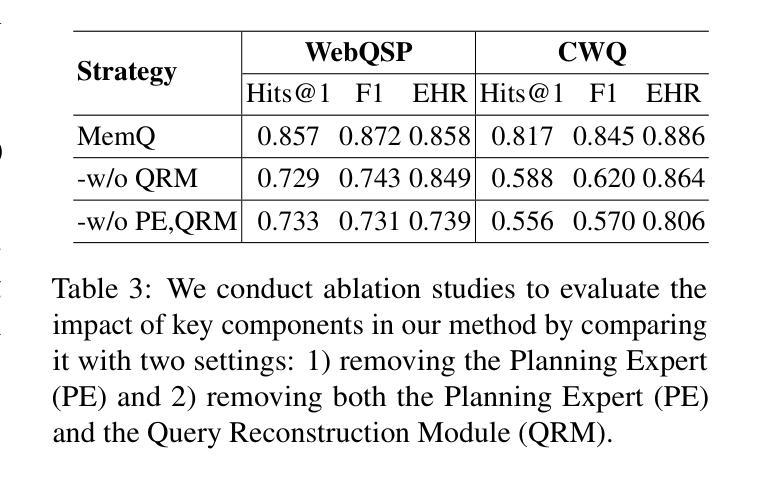
Memory-augmented Query Reconstruction for LLM-based Knowledge Graph Reasoning
Authors:Mufan Xu, Gewen Liang, Kehai Chen, Wei Wang, Xun Zhou, Muyun Yang, Tiejun Zhao, Min Zhang
Large language models (LLMs) have achieved remarkable performance on knowledge graph question answering (KGQA) tasks by planning and interacting with knowledge graphs. However, existing methods often confuse tool utilization with knowledge reasoning, harming readability of model outputs and giving rise to hallucinatory tool invocations, which hinder the advancement of KGQA. To address this issue, we propose Memory-augmented Query Reconstruction for LLM-based Knowledge Graph Reasoning (MemQ) to decouple LLM from tool invocation tasks using LLM-built query memory. By establishing a memory module with explicit descriptions of query statements, the proposed MemQ facilitates the KGQA process with natural language reasoning and memory-augmented query reconstruction. Meanwhile, we design an effective and readable reasoning to enhance the LLM’s reasoning capability in KGQA. Experimental results that MemQ achieves state-of-the-art performance on widely used benchmarks WebQSP and CWQ.
大型语言模型(LLM)通过规划与知识图谱进行交互,在知识图谱问答(KGQA)任务中取得了显著成效。然而,现有方法往往将工具利用与知识推理混淆,损害了模型输出的可读性,并出现了幻觉工具调用,阻碍了KGQA的发展。为了解决这一问题,我们提出了基于LLM知识图谱推理的记忆增强查询重建(MemQ)方法,通过使用LLM构建的查询记忆,将LLM与工具调用任务解耦。通过建立包含查询语句明确描述的内存模块,所提出的MemQ通过自然语言推理和记忆增强查询重建来促进KGQA过程。同时,我们设计了一个有效且易于理解的推理,以提高LLM在KGQA中的推理能力。实验结果表明,MemQ在广泛使用的WebQSP和CWQ基准测试中达到了最新技术水平。
论文及项目相关链接
Summary
大型语言模型(LLM)在知识图谱问答(KGQA)任务上取得了显著成果,但现有方法存在混淆工具使用与知识推理的问题,影响模型输出的可读性并导致出现幻觉工具调用,阻碍了KGQA的进步。为解决这一问题,我们提出使用LLM构建的查询记忆来解耦LLM与工具调用任务的Memory-augmented Query Reconstruction方法(MemQ)。通过建立包含明确查询描述的存储模块,MemQ通过自然语言推理和记忆增强查询重构促进KGQA过程。同时,我们设计了一种有效且可理解的推理方法,以提高LLM在KGQA中的推理能力。实验结果表明,MemQ在广泛使用的WebQSP和CWQ基准测试中实现了最佳性能。
Key Takeaways
- LLM在KGQA任务上表现卓越,但存在工具使用与知识推理混淆的问题。
- 现有问题导致模型输出可读性下降和幻觉工具调用。
- MemQ通过LLM构建的查询记忆解耦LLM与工具调用任务。
- MemQ建立包含明确查询描述的存储模块。
- MemQ促进KGQA过程通过自然语言推理和记忆增强查询重构。
- 设计有效且可理解的推理方法提高LLM在KGQA中的推理能力。
点此查看论文截图

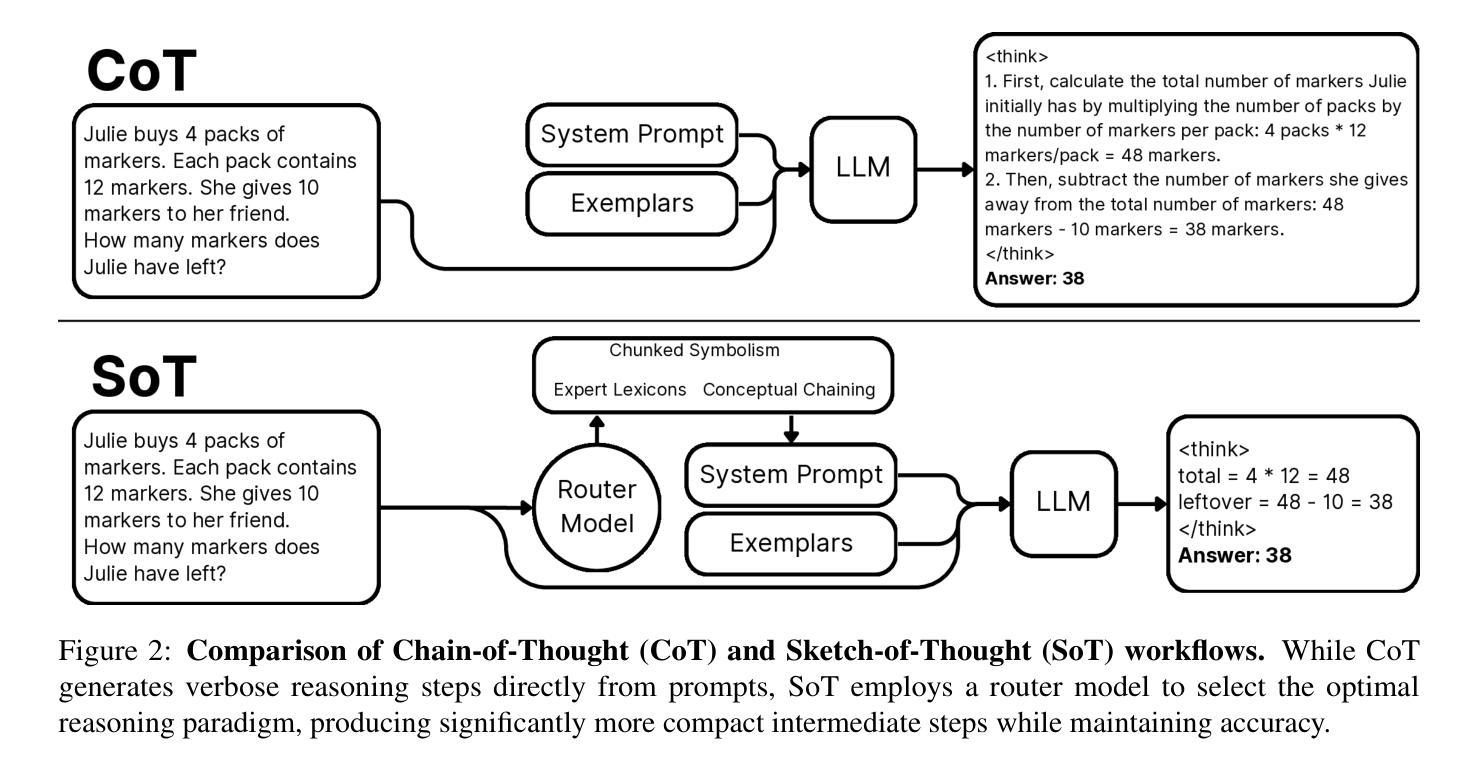
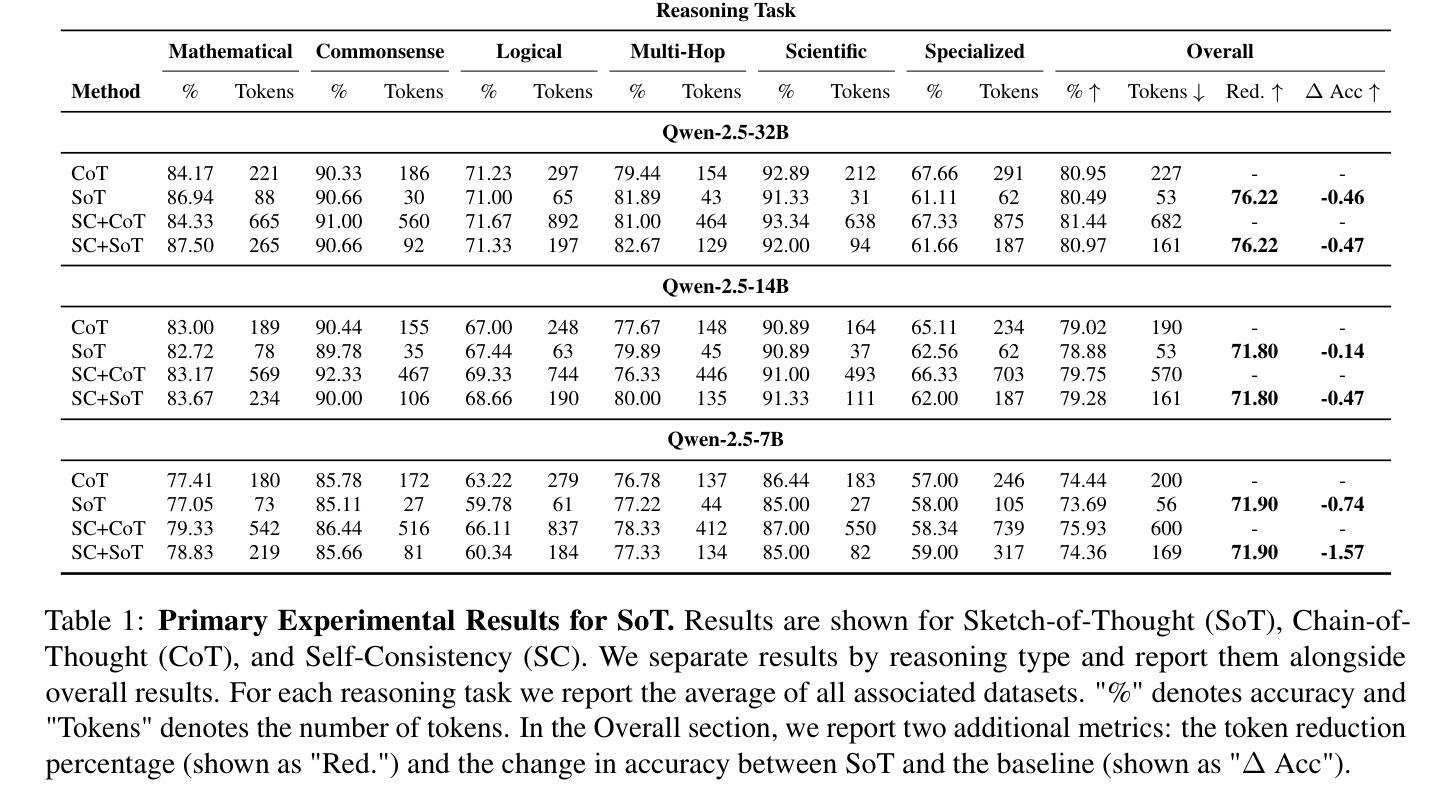
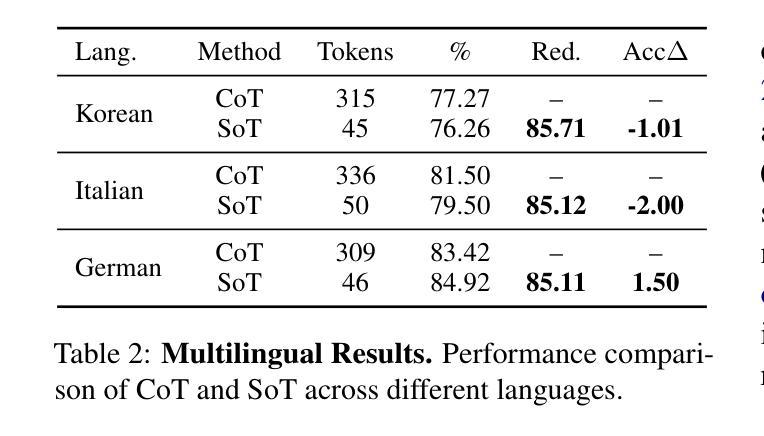
Sketch-of-Thought: Efficient LLM Reasoning with Adaptive Cognitive-Inspired Sketching
Authors:Simon A. Aytes, Jinheon Baek, Sung Ju Hwang
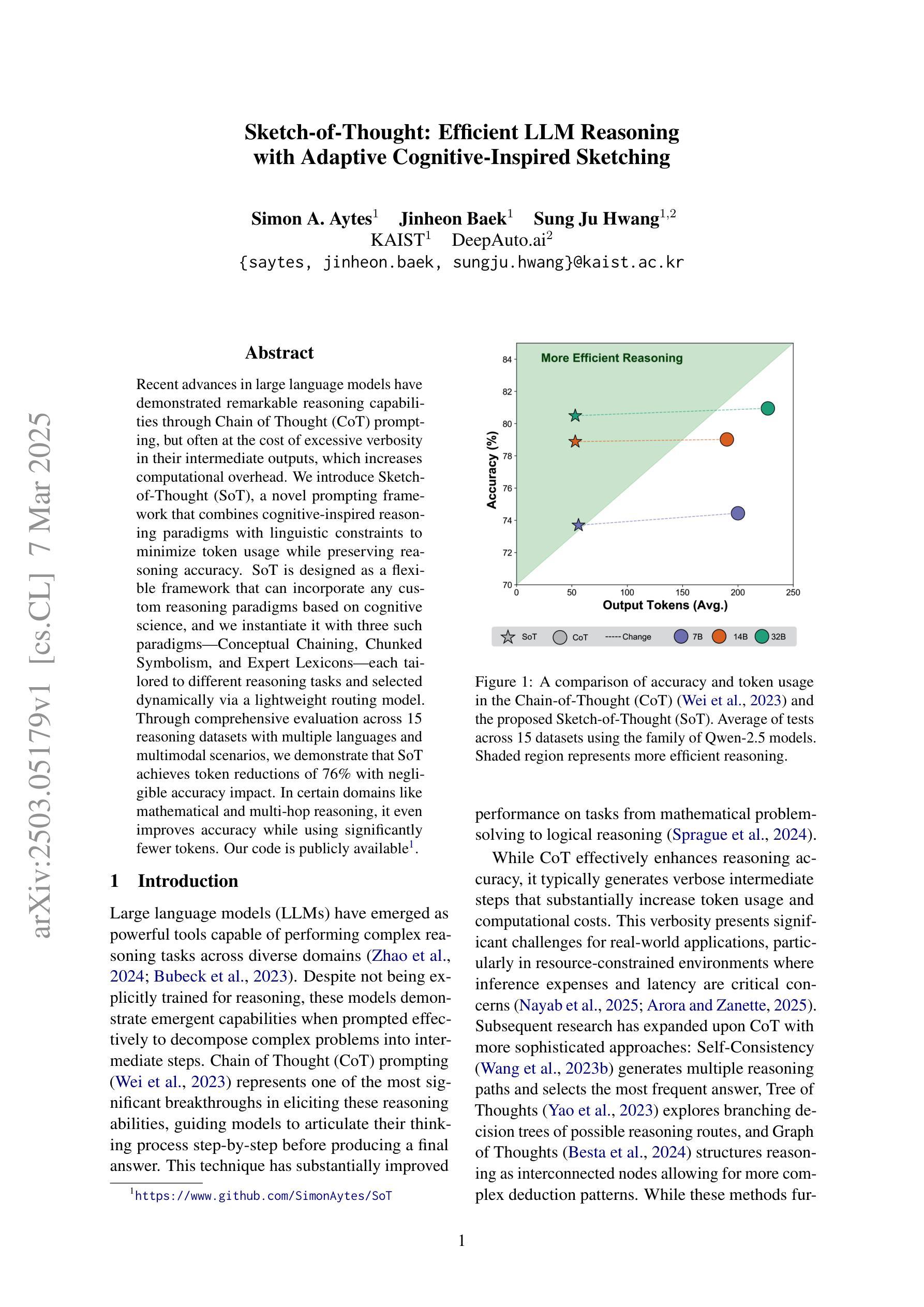
Recent advances in large language models have demonstrated remarkable reasoning capabilities through Chain of Thought (CoT) prompting, but often at the cost of excessive verbosity in their intermediate outputs, which increases computational overhead. We introduce Sketch-of-Thought (SoT), a novel prompting framework that combines cognitive-inspired reasoning paradigms with linguistic constraints to minimize token usage while preserving reasoning accuracy. SoT is designed as a flexible framework that can incorporate any custom reasoning paradigms based on cognitive science, and we instantiate it with three such paradigms - Conceptual Chaining, Chunked Symbolism, and Expert Lexicons - each tailored to different reasoning tasks and selected dynamically via a lightweight routing model. Through comprehensive evaluation across 15 reasoning datasets with multiple languages and multimodal scenarios, we demonstrate that SoT achieves token reductions of 76% with negligible accuracy impact. In certain domains like mathematical and multi-hop reasoning, it even improves accuracy while using significantly fewer tokens. Our code is publicly available: https://www.github.com/SimonAytes/SoT.
近期大型语言模型在通过思维链(Chain of Thought,简称CoT)提示展现出显著推理能力的同时,其产生的中间输出物往往过于冗长,增加了计算开销。我们引入了思维草图(Sketch-of-Thought,简称SoT),这是一种新型提示框架,结合了认知启发式的推理模式和语言约束,旨在最小化标记使用的同时保持推理准确性。SoT被设计为一个灵活的框架,可以根据认知科学融入任何自定义推理模式,我们为其提供了三种模式实例——概念链、分块符号和专家词汇集——每种模式都针对特定的推理任务定制,并通过轻量级路由模型动态选择。通过涵盖多种语言和跨模态场景的15个推理数据集的综合评估,我们证明了SoT在减少76%标记的同时几乎不影响准确性。在某些领域如数学和多跳推理中,即使在使用更少的标记的情况下也能提高准确性。我们的代码公开可用:https://www.github.com/SimonAytes/SoT。
论文及项目相关链接
Summary
大型语言模型的最新进展通过思维链(Chain of Thought,CoT)提示展现出惊人的推理能力,但往往伴随着中间输出过于冗长的问题,增加了计算开销。本文提出Sketch-of-Thought(SoT)这一新型提示框架,结合认知启发式的推理范式和语言学约束,旨在减少标记使用同时保持推理准确性。SoT被设计成可灵活融入认知科学为基础的各种自定义推理范式的框架,并实例化了三种范式:概念链、分块符号和专家词汇。通过跨越15个推理数据集的全面评估,展示SoT在减少76%标记使用的同时,对准确率影响甚微。在某些领域如数学和多步推理中,甚至在使用更少标记的情况下提高了准确性。
Key Takeaways
- Sketch-of-Thought(SoT)框架结合了认知启发式的推理范式和语言学约束,旨在减少大型语言模型中的标记使用。
- SoT框架旨在在保持推理准确性的同时,降低计算开销。
- SoT框架具有灵活性,可融入多种认知科学为基础的自定推理范式。
- SoT实例化了三种特定推理范式:概念链、分块符号和专家词汇。
- SoT在多个语言和跨模态场景的15个推理数据集上进行了全面评估。
- SoT实现了76%的标记减少而对准确率影响甚微,并且在某些领域如数学和多步推理中提高了准确性。
点此查看论文截图

R1-Zero’s “Aha Moment” in Visual Reasoning on a 2B Non-SFT Model
Authors:Hengguang Zhou, Xirui Li, Ruochen Wang, Minhao Cheng, Tianyi Zhou, Cho-Jui Hsieh
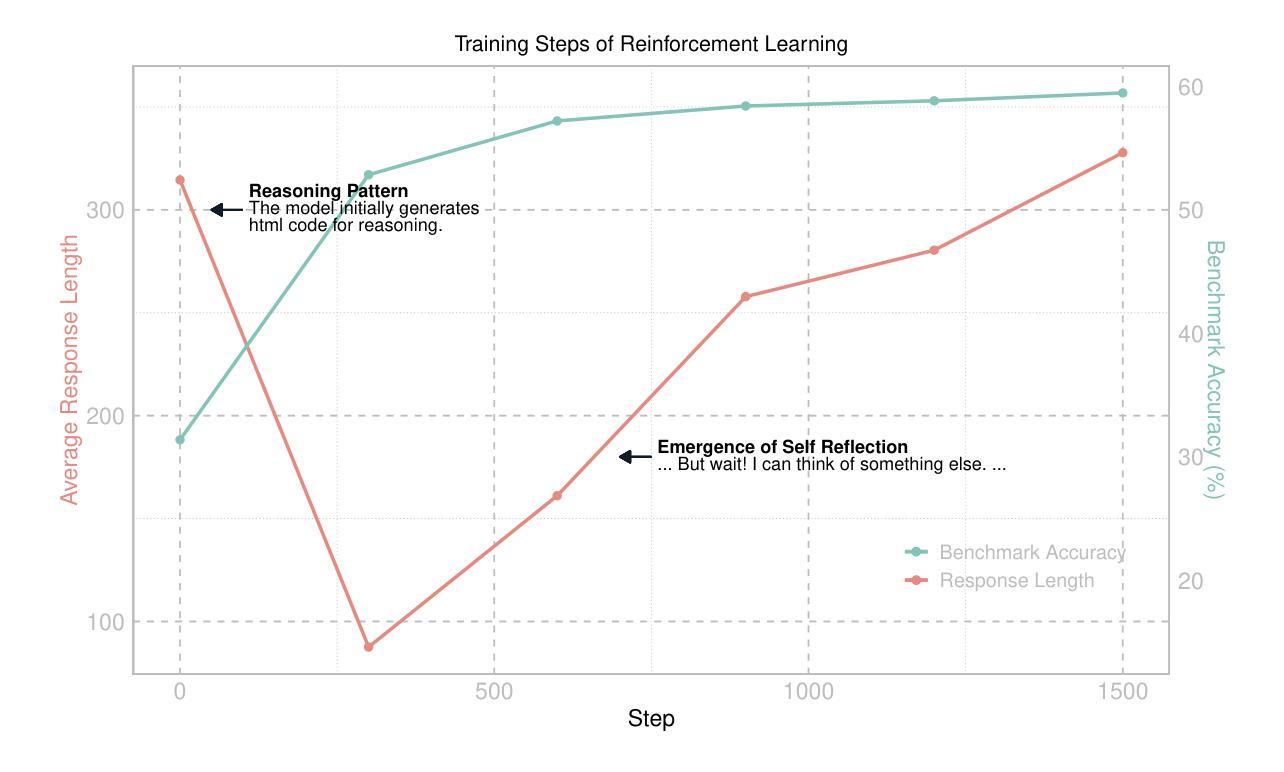
Recently DeepSeek R1 demonstrated how reinforcement learning with simple rule-based incentives can enable autonomous development of complex reasoning in large language models, characterized by the “aha moment”, in which the model manifest self-reflection and increased response length during training. However, attempts to extend this success to multimodal reasoning often failed to reproduce these key characteristics. In this report, we present the first successful replication of these emergent characteristics for multimodal reasoning on only a non-SFT 2B model. Starting with Qwen2-VL-2B and applying reinforcement learning directly on the SAT dataset, our model achieves 59.47% accuracy on CVBench, outperforming the base model by approximately ~30% and exceeding both SFT setting by ~2%. In addition, we share our failed attempts and insights in attempting to achieve R1-like reasoning using RL with instruct models. aiming to shed light on the challenges involved. Our key observations include: (1) applying RL on instruct model often results in trivial reasoning trajectories, and (2) naive length reward are ineffective in eliciting reasoning capabilities. The project code is available at https://github.com/turningpoint-ai/VisualThinker-R1-Zero
最近,DeepSeek R1展示了如何通过基于简单规则的激励来应用强化学习,从而在大型语言模型中自主发展出复杂的推理能力,其特点是表现为“啊哈时刻”,在此过程中,模型在训练过程中表现出自我反思和响应长度的增加。然而,尝试将这种成功扩展到多模态推理时,往往无法重现这些关键特征。在本报告中,我们首次成功地在仅使用非SFT 2B模型的条件下,实现了多模态推理的这些新兴特征。我们以Qwen2-VL-2B为起点,直接在SAT数据集上应用强化学习,我们的模型在CVBench上达到了59.47%的准确率,比基础模型高出约30%,并且比SFT设置的准确率高出约2%。此外,我们还分享了在使用RL进行指令模型以实现R1式推理的尝试中的失败经验和见解,以期阐明所涉及的挑战。我们的主要观察结果包括:(1)在指令模型上应用RL通常会导致平凡的推理轨迹,(2)简单的长度奖励在激发推理能力方面无效。项目代码可在https://github.com/turningpoint-ai/VisualThinker-R1-Zero找到。
论文及项目相关链接
PDF 10 pages, 6 figures
Summary
本报告介绍了关于DeepSeek R1利用强化学习驱动的大型语言模型的自主发展复杂推理技术的新进展。研究人员成功在非SFT 2B模型上实现了多模态推理的“啊哈时刻”,表现出自我反思和响应长度增加的特性。通过直接在SAT数据集上应用强化学习,模型在CVBench上达到了59.47%的准确率,相较于基础模型提升了约30%,并且相较于SFT设置提升了约2%。此外,报告还分享了使用RL对指令模型进行尝试时的失败经验和观察结果。
Key Takeaways
- 强化学习能够驱动大型语言模型自主发展复杂推理技术。
- 在非SFT 2B模型上成功实现多模态推理的“啊哈时刻”。
- 模型展现出自我反思和响应长度增加的特性。
- 在SAT数据集上应用强化学习,模型在CVBench上的准确率达到了59.47%。
- 对比基础模型,新模型的准确率提升了约30%。
- 对比SFT设置,新模型的准确率提升了约2%。
点此查看论文截图




Beyond RAG: Task-Aware KV Cache Compression for Comprehensive Knowledge Reasoning
Authors:Giulio Corallo, Orion Weller, Fabio Petroni, Paolo Papotti
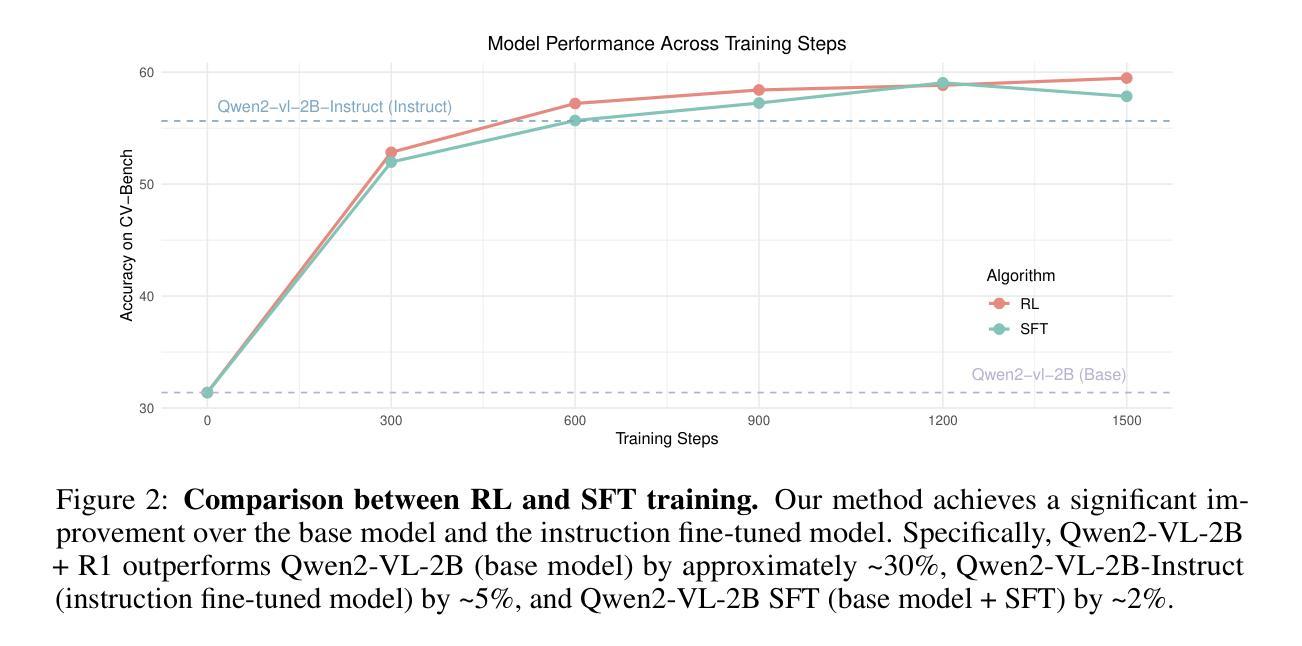
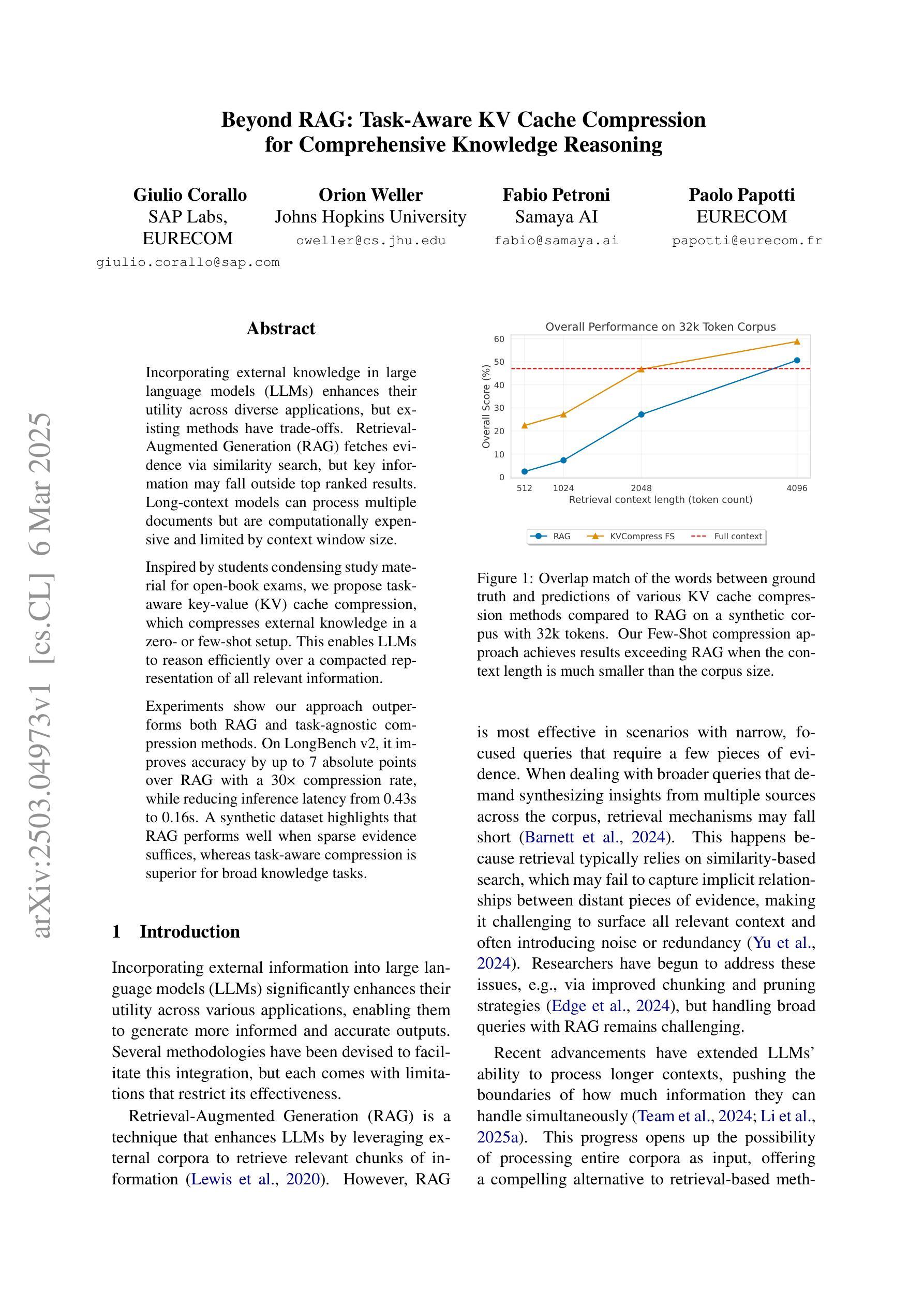
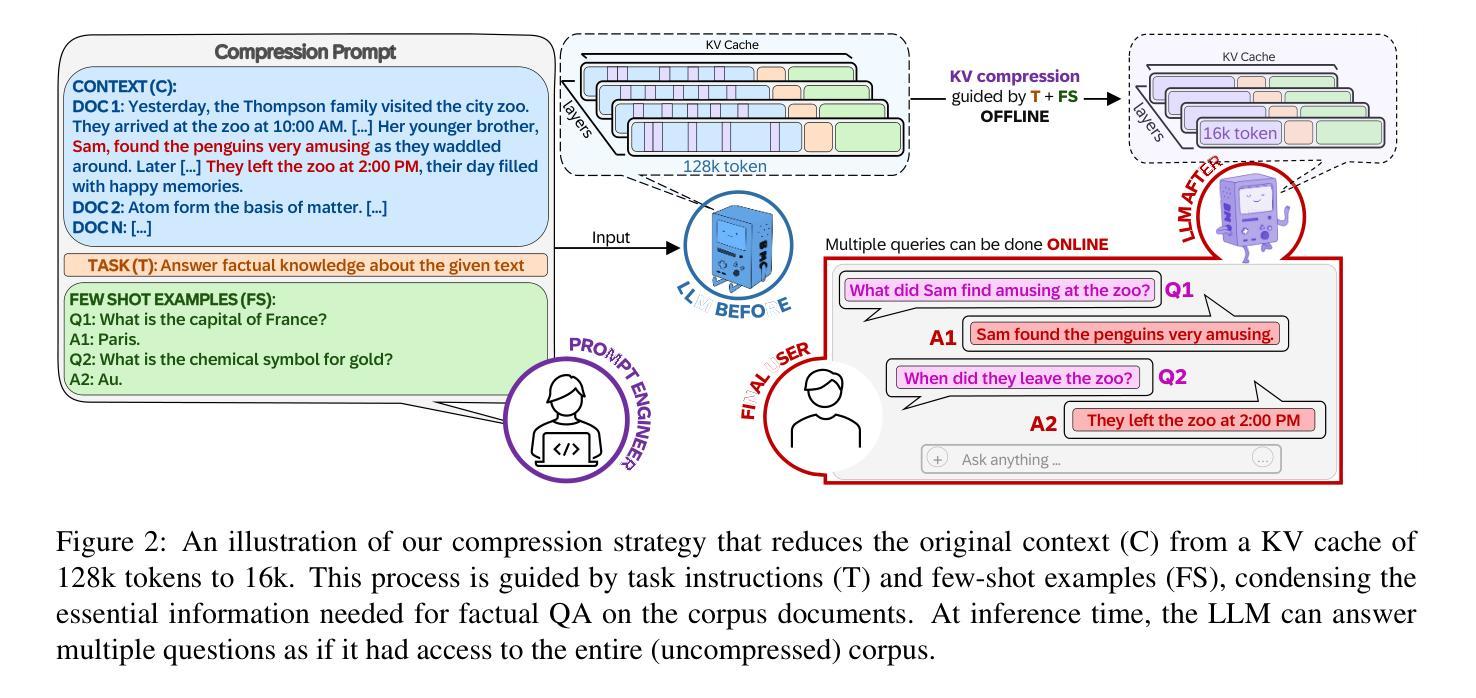
Incorporating external knowledge in large language models (LLMs) enhances their utility across diverse applications, but existing methods have trade-offs. Retrieval-Augmented Generation (RAG) fetches evidence via similarity search, but key information may fall outside top ranked results. Long-context models can process multiple documents but are computationally expensive and limited by context window size. Inspired by students condensing study material for open-book exams, we propose task-aware key-value (KV) cache compression, which compresses external knowledge in a zero- or few-shot setup. This enables LLMs to reason efficiently over a compacted representation of all relevant information. Experiments show our approach outperforms both RAG and task-agnostic compression methods. On LongBench v2, it improves accuracy by up to 7 absolute points over RAG with a 30x compression rate, while reducing inference latency from 0.43s to 0.16s. A synthetic dataset highlights that RAG performs well when sparse evidence suffices, whereas task-aware compression is superior for broad knowledge tasks.
将大型语言模型(LLM)中的外部知识相结合,提高了其在各种应用中的实用性,但现有方法存在权衡。检索增强生成(RAG)通过相似性搜索获取证据,但关键信息可能不在排名靠前的结果中。长上下文模型可以处理多个文档,但计算成本高昂,并受限于上下文窗口大小。通过借鉴学生为开卷考试精简学习材料的方法,我们提出了任务感知键值(KV)缓存压缩技术,该技术可以在零次或少数几次射击中压缩外部知识。这使得LLM能够在压缩后表示的所有相关信息上进行高效推理。实验表明,我们的方法优于RAG和任务无关的压缩方法。在LongBench v2上,与RAG相比,我们的方法在准确率上提高了高达7个绝对点,压缩率高达30倍,同时将推理延迟从0.43秒减少到0.16秒。合成数据集的重点是,当稀疏证据足够时,RAG表现良好,而对于广泛的知识任务,任务感知压缩表现更优。
论文及项目相关链接
Summary
在大型语言模型中融入外部知识可提高其跨多种应用的实用性,但现有方法存在权衡。检索增强生成法通过相似性搜索获取证据,但关键信息可能出现在排名靠后的结果中。长文本模型可处理多个文档,但计算成本高昂且受限于上下文窗口大小。受学生为开卷考试浓缩学习材料启发,我们提出任务感知键值缓存压缩技术,可在零样本或少样本设置中压缩外部知识。这使大型语言模型能够在紧凑表示所有相关信息的基础上高效推理。实验表明,我们的方法优于检索增强生成法和任务无关压缩方法。在LongBench v2上,与RAG相比,我们的方法提高了高达7个绝对点的准确率,压缩率高达30倍,同时将推理延迟从0.43秒减少到0.16秒。合成数据集显示,当稀疏证据充足时,RAG表现良好,而对于广泛知识任务,任务感知压缩表现更优越。
Key Takeaways
- 大型语言模型融入外部知识可提升跨应用实用性,但现有方法存在缺陷。
- 检索增强生成法可能忽略关键信息,因为关键信息可能不在高排名结果中。
- 长文本模型处理多个文档的能力受限,且计算成本高昂。
- 提出任务感知键值缓存压缩技术,可在零样本或少样本设置下高效压缩外部知识。
- 与RAG相比,该方法显著提高准确率、压缩率和推理速度。
- 在不同场景下(稀疏证据充足和广泛知识任务),该方法表现优越。
点此查看论文截图


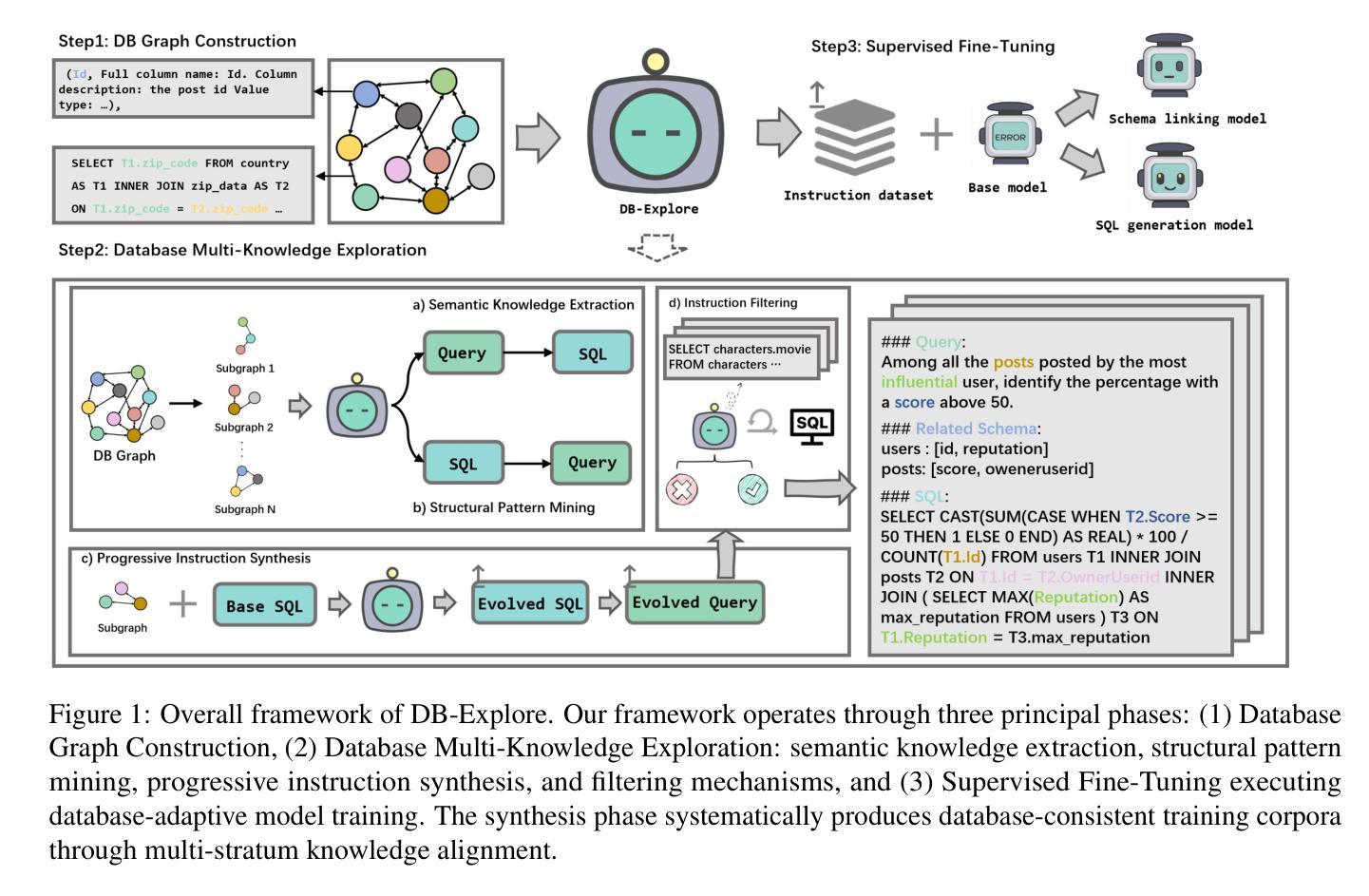
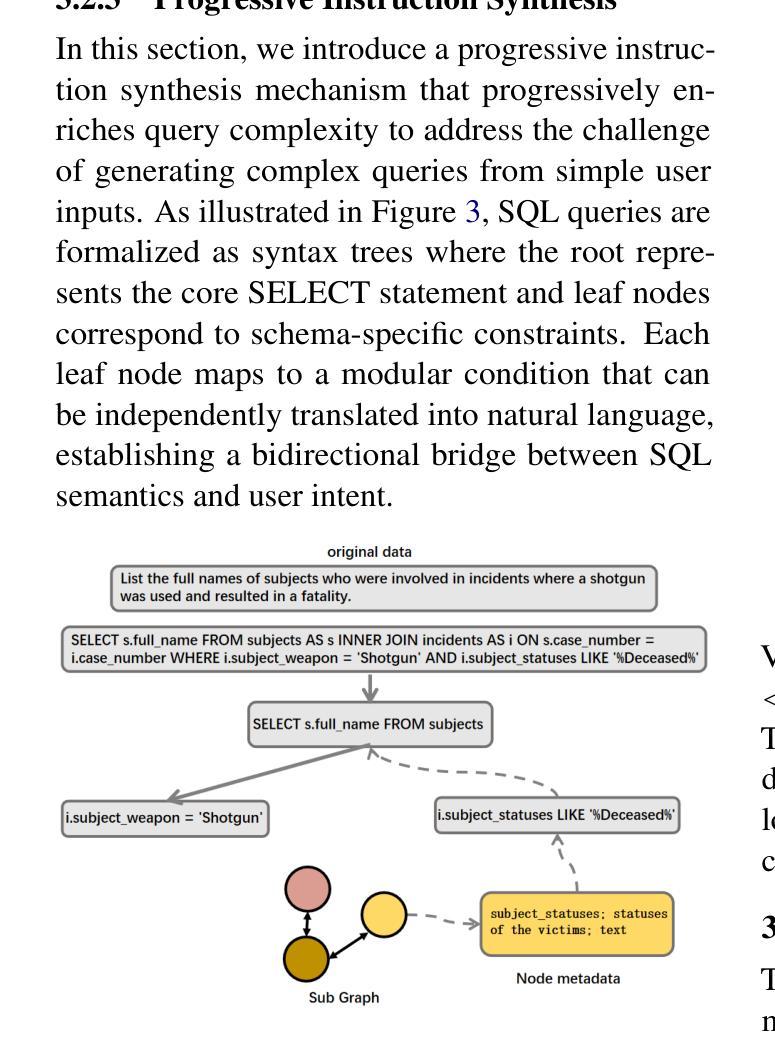
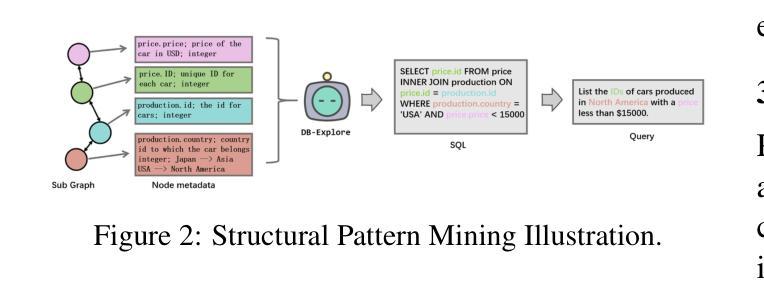
DB-Explore: Automated Database Exploration and Instruction Synthesis for Text-to-SQL
Authors:Haoyuan Ma, Yongliang Shen, Hengwei Liu, Wenqi Zhang, Haolei Xu, Qiuying Peng, Jun Wang, Weiming Lu
Recent text-to-SQL systems powered by large language models (LLMs) have demonstrated remarkable performance in translating natural language queries into SQL. However, these systems often struggle with complex database structures and domain-specific queries, as they primarily focus on enhancing logical reasoning and SQL syntax while overlooking the critical need for comprehensive database understanding. To address this limitation, we propose DB-Explore, a novel framework that systematically aligns LLMs with database knowledge through automated exploration and instruction synthesis. DB-Explore constructs database graphs to capture complex relational schemas, leverages GPT-4 to systematically mine structural patterns and semantic knowledge, and synthesizes instructions to distill this knowledge for efficient fine-tuning of LLMs. Our framework enables comprehensive database understanding through diverse sampling strategies and automated instruction generation, bridging the gap between database structures and language models. Experiments conducted on the SPIDER and BIRD benchmarks validate the effectiveness of DB-Explore, achieving an execution accuracy of 52.1% on BIRD and 84.0% on SPIDER. Notably, our open-source implementation, based on the Qwen2.5-coder-7B model, outperforms multiple GPT-4-driven text-to-SQL systems in comparative evaluations, and achieves near state-of-the-art performance with minimal computational cost.
最近由大型语言模型(LLM)驱动的文本到SQL系统在自然语言查询到SQL的转换中表现出了显著的性能。然而,这些系统在处理复杂的数据库结构和特定领域的查询时经常遇到困难,因为它们主要关注于提高逻辑推理解题能力和SQL语法,而忽视了全面理解数据库的关键需求。为了解决这一局限性,我们提出了DB-Explore这一新型框架,它通过自动化探索和指令合成,系统地使LLM与数据库知识相结合。DB-Explore构建数据库图来捕捉复杂的关联模式,利用GPT-4系统地挖掘结构模式和语义知识,并合成指令来提炼这些知识,以便有效地微调LLM。我们的框架通过多样化的采样策略和自动化的指令生成,实现了全面的数据库理解,缩小了数据库结构和语言模型之间的差距。在SPIDER和BIRD基准测试集上进行的实验验证了DB-Explore的有效性,在BIRD上实现了执行准确率52.1%,在SPIDER上实现了执行准确率84.0%。值得注意的是,我们基于Qwen2.5-coder-7B模型的开源实现,在比较评估中超越了多个GPT-4驱动的文本到SQL系统,并以极低的计算成本达到了近乎最先进的性能。
论文及项目相关链接
Summary
LLM驱动的文本到SQL系统虽在翻译自然语言查询为SQL方面表现出色,但在处理复杂数据库结构和特定领域查询时存在局限性。为此,提出DB-Explore框架,通过自动探索和指令合成,使LLM与数据库知识相结合。该框架构建数据库图捕捉复杂关系模式,利用GPT-4挖掘结构和语义知识,并合成指令以提炼知识,有效微调LLM。实验验证DB-Explore的有效性,并在SPIDER和BIRD基准测试中实现较高执行准确率。
Key Takeaways
- 文本到SQL系统面临处理复杂数据库结构和特定领域查询的挑战。
- DB-Explore框架提出,通过结合LLM和数据库知识解决此问题。
- DB-Explore构建数据库图以捕捉复杂关系模式。
- GPT-4被用来挖掘结构和语义知识。
- DB-Explore通过合成指令提炼知识,有效微调LLM。
- 实验验证DB-Explore的有效性,在SPIDER和BIRD基准测试中有高执行准确率。
点此查看论文截图

FirePlace: Geometric Refinements of LLM Common Sense Reasoning for 3D Object Placement
Authors:Ian Huang, Yanan Bao, Karen Truong, Howard Zhou, Cordelia Schmid, Leonidas Guibas, Alireza Fathi
Scene generation with 3D assets presents a complex challenge, requiring both high-level semantic understanding and low-level geometric reasoning. While Multimodal Large Language Models (MLLMs) excel at semantic tasks, their application to 3D scene generation is hindered by their limited grounding on 3D geometry. In this paper, we investigate how to best work with MLLMs in an object placement task. Towards this goal, we introduce a novel framework, FirePlace, that applies existing MLLMs in (1) 3D geometric reasoning and the extraction of relevant geometric details from the 3D scene, (2) constructing and solving geometric constraints on the extracted low-level geometry, and (3) pruning for final placements that conform to common sense. By combining geometric reasoning with real-world understanding of MLLMs, our method can propose object placements that satisfy both geometric constraints as well as high-level semantic common-sense considerations. Our experiments show that these capabilities allow our method to place objects more effectively in complex scenes with intricate geometry, surpassing the quality of prior work.
使用3D资产进行场景生成是一个复杂的挑战,需要高级语义理解和低级几何推理。虽然多模态大型语言模型(MLLMs)在语义任务上表现出色,但它们在3D场景生成中的应用受到其对3D几何知识掌握有限的限制。在本文中,我们研究了如何在对象放置任务中与MLLMs最佳协同工作。为此目标,我们引入了一个新型框架FirePlace,该框架将现有MLLMs应用于(1)3D几何推理和从3D场景中提取相关几何细节,(2)构建和解决提取的低级几何的几何约束,以及(3)修剪最终放置以符合常识。通过将几何推理与MLLMs对现实世界的理解相结合,我们的方法能够提出对象放置方案,这些方案既满足几何约束,又符合高级语义常识的考量。我们的实验表明,这些功能使我们的方法在具有复杂几何结构的场景中放置物体时更加有效,超越了以前工作的质量。
论文及项目相关链接
Summary
本文探讨了使用多模态大型语言模型(MLLMs)在对象放置任务中的挑战与机遇。针对这一问题,提出了一种名为FirePlace的新框架,该框架结合了MLLMs在语义理解方面的优势与对三维几何的理解,包括从三维场景中提取几何细节、构建并解决几何约束以及符合常识的最终放置优化。实验表明,该方法能在复杂场景中更有效地放置物体,达到超越先前工作的质量。
Key Takeaways
- 多模态大型语言模型(MLLMs)在语义任务上表现出色,但在三维场景生成方面存在对三维几何理解的局限性。
- 提出了一种名为FirePlace的新框架,用于处理MLLMs在对象放置任务中的限制问题。
- FirePlace结合了三维几何推理和现实世界理解,将现有的MLLMs用于从场景中提取相关几何细节和进行推理处理。
- 该方法能解决提取的低级几何上的几何约束问题。
- 通过修剪过程,确保最终放置符合常识和几何约束。
- 实验表明,该方法在复杂场景中放置物体时表现出更高的效能和质量。
点此查看论文截图



Learning from Failures in Multi-Attempt Reinforcement Learning
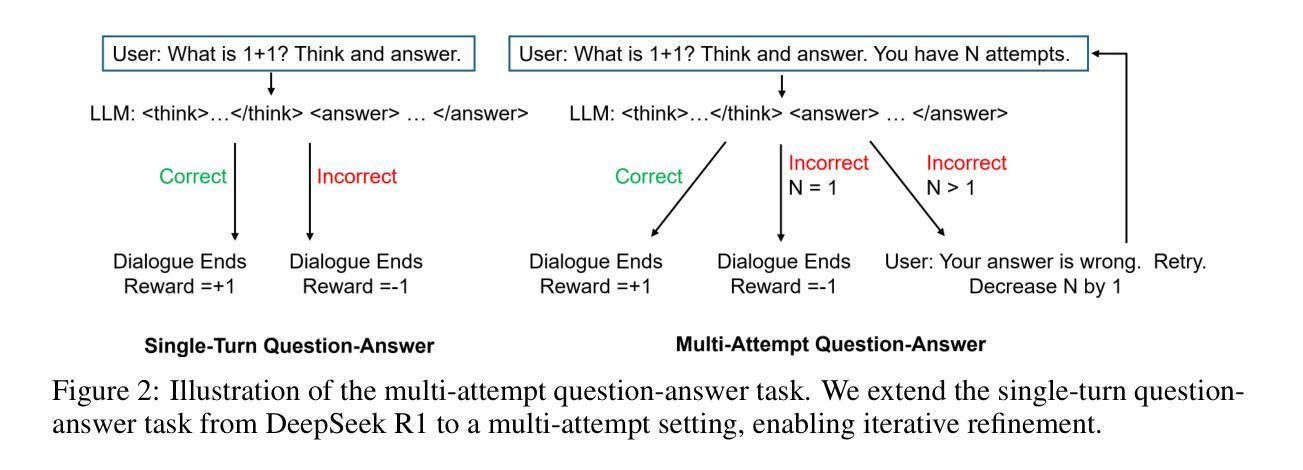
Authors:Stephen Chung, Wenyu Du, Jie Fu
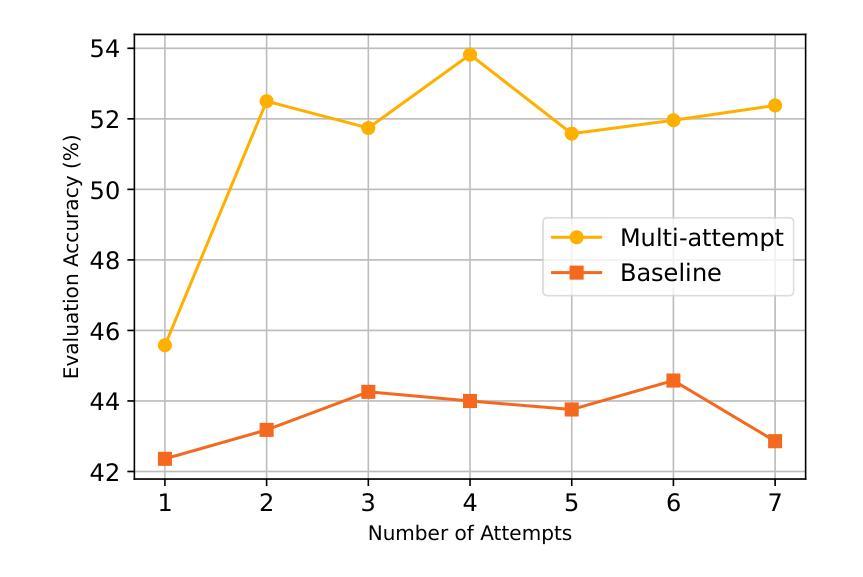
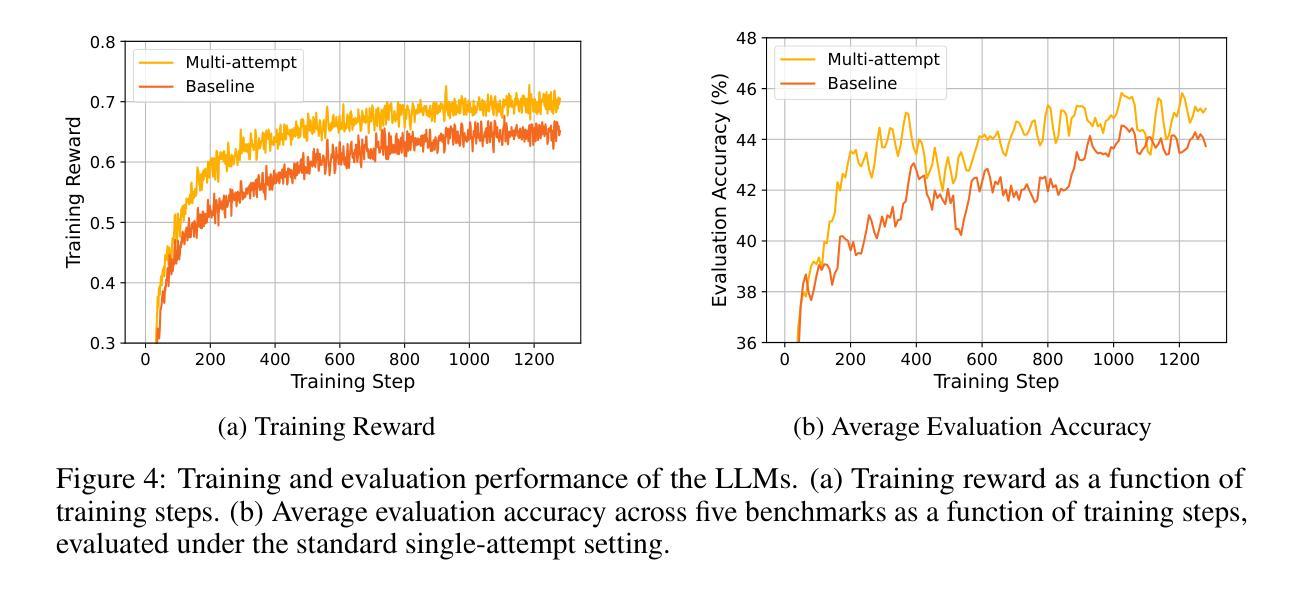
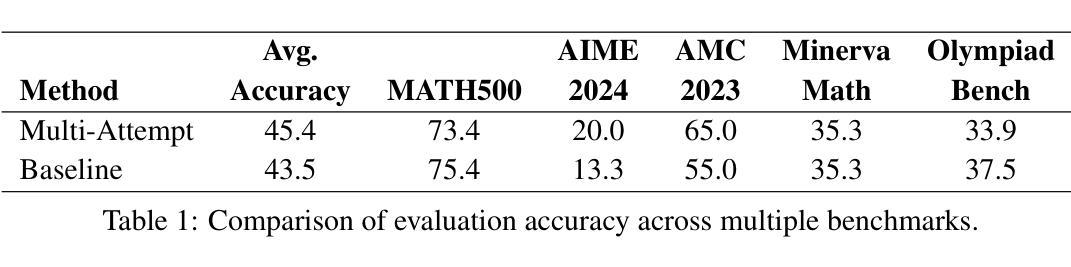
Recent advancements in reinforcement learning (RL) for large language models (LLMs), exemplified by DeepSeek R1, have shown that even a simple question-answering task can substantially improve an LLM’s reasoning capabilities. In this work, we extend this approach by modifying the task into a multi-attempt setting. Instead of generating a single response per question, the model is given multiple attempts, with feedback provided after incorrect responses. The multi-attempt task encourages the model to refine its previous attempts and improve search efficiency. Experimental results show that even a small LLM trained on a multi-attempt task achieves significantly higher accuracy when evaluated with more attempts, improving from 45.6% with 1 attempt to 52.5% with 2 attempts on the math benchmark. In contrast, the same LLM trained on a standard single-turn task exhibits only a marginal improvement, increasing from 42.3% to 43.2% when given more attempts during evaluation. The results indicate that, compared to the standard single-turn task, an LLM trained on a multi-attempt task achieves slightly better performance on math benchmarks while also learning to refine its responses more effectively based on user feedback. Full code is available at https://github.com/DualityRL/multi-attempt
近期,以DeepSeek R1为例,强化学习(RL)在大规模语言模型(LLM)中的应用取得了进展,表明即使是简单的问答任务也能显著提高LLM的推理能力。在这项工作中,我们通过将任务改为多次尝试设置来扩展这种方法。与为每个问题生成一次回应不同,模型被给予多次尝试的机会,并在不正确的回应之后得到反馈。多次尝试的任务鼓励模型改进其之前的尝试并提高搜索效率。实验结果表明,即使在数学基准测试中尝试了多次,经过多次尝试任务训练的小型LLM也实现了显著更高的准确性,从单次尝试的45.6%提高到两次尝试的52.5%。相比之下,在标准单回合任务上训练的同一LLM在评估时即使尝试更多次也只能实现微小的改进,从42.3%提高到43.2%。结果表明,与标准的单回合任务相比,经过多次尝试任务训练的LLM在数学基准测试中表现稍好,同时学习根据用户反馈更有效地改进其回应。完整代码可在 https://github.com/DualityRL/multi-attempt 找到。
论文及项目相关链接
PDF preprint
Summary
强化学习在大型语言模型中的应用有了新的进展,通过多尝试任务训练,模型能够在用户反馈的基础上不断优化答案并提升搜索效率。实验结果显示,在多尝试任务下,小型语言模型的准确率有明显提升,从单次尝试的45.6%提升到两次尝试的52.5%。相比之下,在标准单回合任务下训练的语言模型,即便增加尝试次数,性能也只得到有限提升。
Key Takeaways
- 强化学习能够显著提升大型语言模型的推理能力。
- 通过多尝试任务训练,语言模型能够在用户反馈的基础上不断优化答案。
- 多尝试任务训练的语言模型在数学基准测试上的表现优于标准单回合任务训练的语言模型。
- 多尝试任务能够提高语言模型的搜索效率。
- 与单回合任务相比,多尝试任务训练的语言模型展现出更强的性能提升潜力。
- 通过实验验证,多尝试任务训练对语言模型的性能有显著提升。
点此查看论文截图


START: Self-taught Reasoner with Tools
Authors:Chengpeng Li, Mingfeng Xue, Zhenru Zhang, Jiaxi Yang, Beichen Zhang, Xiang Wang, Bowen Yu, Binyuan Hui, Junyang Lin, Dayiheng Liu
Large reasoning models (LRMs) like OpenAI-o1 and DeepSeek-R1 have demonstrated remarkable capabilities in complex reasoning tasks through the utilization of long Chain-of-thought (CoT). However, these models often suffer from hallucinations and inefficiencies due to their reliance solely on internal reasoning processes. In this paper, we introduce START (Self-Taught Reasoner with Tools), a novel tool-integrated long CoT reasoning LLM that significantly enhances reasoning capabilities by leveraging external tools. Through code execution, START is capable of performing complex computations, self-checking, exploring diverse methods, and self-debugging, thereby addressing the limitations of LRMs. The core innovation of START lies in its self-learning framework, which comprises two key techniques: 1) Hint-infer: We demonstrate that inserting artificially designed hints (e.g., ``Wait, maybe using Python here is a good idea.’’) during the inference process of a LRM effectively stimulates its ability to utilize external tools without the need for any demonstration data. Hint-infer can also serve as a simple and effective sequential test-time scaling method; 2) Hint Rejection Sampling Fine-Tuning (Hint-RFT): Hint-RFT combines Hint-infer and RFT by scoring, filtering, and modifying the reasoning trajectories with tool invocation generated by a LRM via Hint-infer, followed by fine-tuning the LRM. Through this framework, we have fine-tuned the QwQ-32B model to achieve START. On PhD-level science QA (GPQA), competition-level math benchmarks (AMC23, AIME24, AIME25), and the competition-level code benchmark (LiveCodeBench), START achieves accuracy rates of 63.6%, 95.0%, 66.7%, 47.1%, and 47.3%, respectively. It significantly outperforms the base QwQ-32B and achieves performance comparable to the state-of-the-art open-weight model R1-Distill-Qwen-32B and the proprietary model o1-Preview.
大型推理模型(LRMs)如OpenAI-o1和DeepSeek-R1,已经展现出在复杂推理任务方面的卓越能力,通过运用长的思维链(CoT)。然而,这些模型常常因过分依赖内部推理过程而陷入幻想和效率不高的困境。在本文中,我们介绍了START(带工具的自教推理器),这是一种新型的工具集成长CoT推理LLM,它通过利用外部工具来显著增强推理能力。通过代码执行,START能够执行复杂的计算、自我检查、探索多种方法以及自我调试,从而解决LRM的局限性。START的核心创新在于其自学习框架,它包含两个关键技术:1)提示推断:我们证明在LRM的推理过程中插入人工设计的提示(例如,“等等,也许在这里使用Python是一个好主意。”)能有效地刺激其利用外部工具的能力,而无需任何演示数据。提示推断还可以作为一种简单有效的序列测试时间缩放方法;2)提示拒绝采样微调(Hint-RFT):Hint-RFT结合了提示推断和RFT,通过对由LRM通过提示推断产生的带有工具调用的推理轨迹进行打分、过滤和修改,然后对LRM进行微调。通过这个框架,我们已经微调了QwQ-32B模型来实现START。在博士级科学问答(GPQA)、竞赛级数学基准测试(AMC23、AIME24、AIME25)和竞赛级代码基准测试(LiveCodeBench)中,START的准确率分别为63.6%、95.0%、66.7%、47.1%和47.3%。它显著优于基础QwQ-32B模型,并实现了与最新开源模型R1-Distill-Qwen-32B和专有模型o1-Preview相当的性能。
Translation into Simplified Chinese
论文及项目相关链接
PDF 38 pages, 5 figures and 6 tables
Summary
大型推理模型(LRMs)如OpenAI-o1和DeepSeek-R1,在长链思维(CoT)的应用中展现出了强大的复杂推理能力,但同时也存在易产生幻觉和效率不高的缺点。为解决这些问题,本文提出了集成工具的长期推理大模型START。START通过执行代码实现了复杂计算、自我校验、探索多元方法以及自我调试的功能。其创新之处在于自我学习框架,包括两个关键技巧:Hint-infer和Hint Rejection Sampling Fine-Tuning (Hint-RFT)。START在某些特定领域竞赛上的准确率高于基础模型QwQ-32B并达到行业领先模型的性能水平。
Key Takeaways
- 大型推理模型(LRMs)在复杂推理任务中展现出强大的能力,但存在幻觉和效率问题。
- START是一种新型工具集成长链思维推理模型,能执行复杂计算、自我校验等,解决LRMs的局限性。
- START的核心创新在于其自我学习框架,包括Hint-infer和Hint-RFT两个关键技巧。
- Hint-infer技巧通过插入人工提示来刺激模型利用外部工具的能力,无需示范数据。
- 通过Hint-RFT技巧,对通过Hint-infer生成的推理轨迹进行评分、过滤和修改,随后微调模型。
- START在某些特定领域竞赛上的准确率高于基础模型并达到行业领先水平。
点此查看论文截图

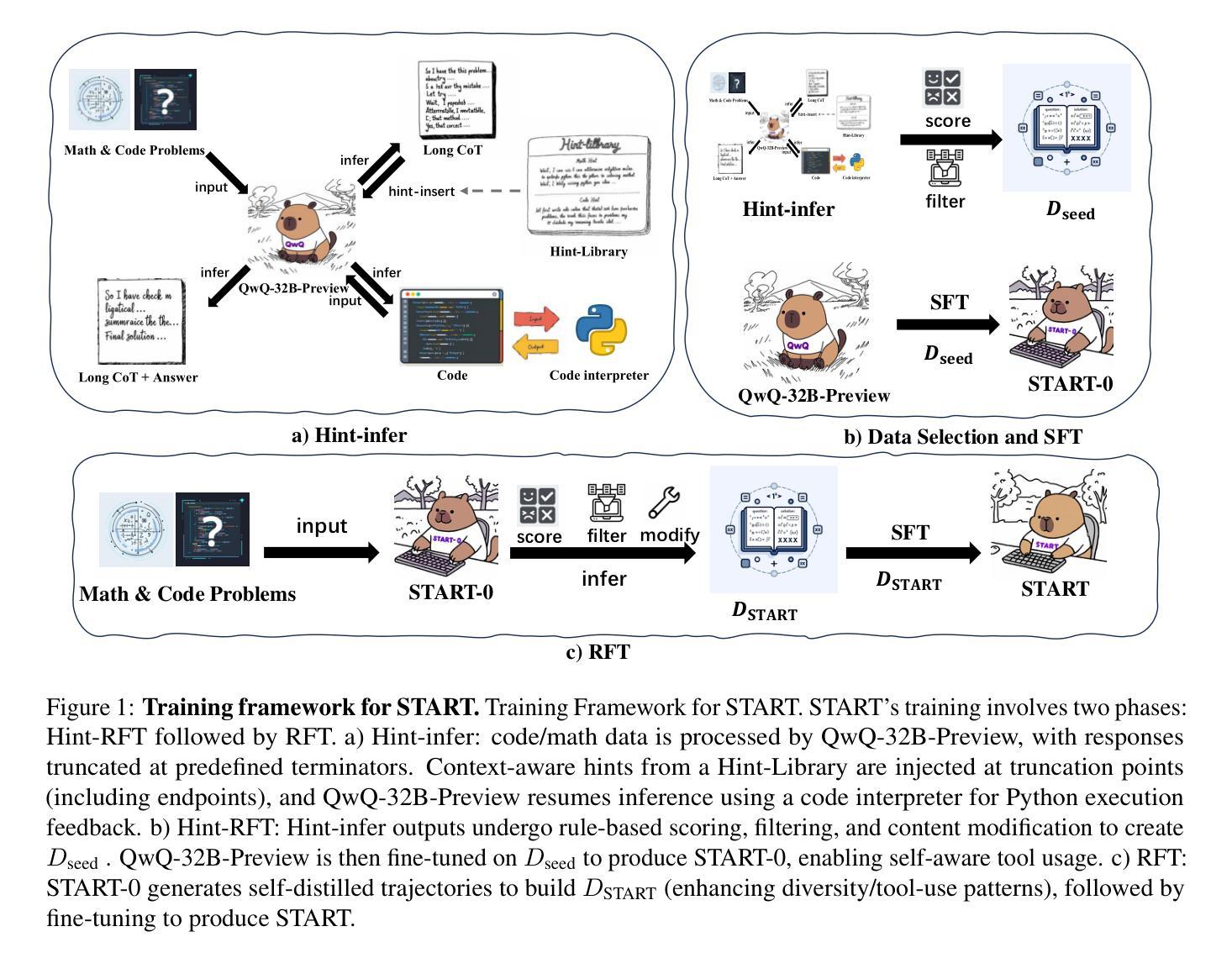



ReSo: A Reward-driven Self-organizing LLM-based Multi-Agent System for Reasoning Tasks
Authors:Heng Zhou, Hejia Geng, Xiangyuan Xue, Zhenfei Yin, Lei Bai
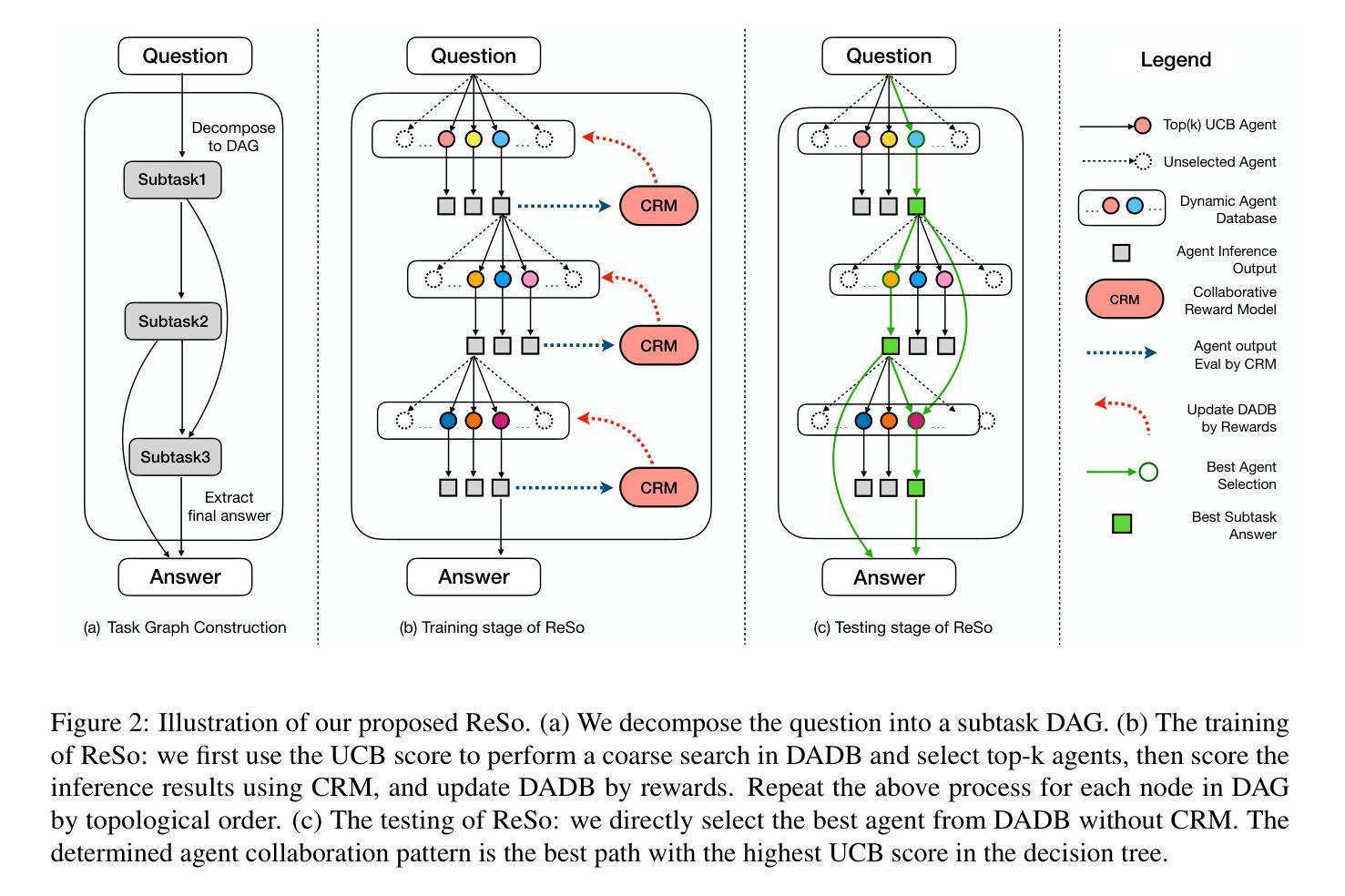
Multi-agent systems have emerged as a promising approach for enhancing the reasoning capabilities of large language models in complex problem-solving. However, current MAS frameworks are limited by poor flexibility and scalability, with underdeveloped optimization strategies. To address these challenges, we propose ReSo, which integrates task graph generation with a reward-driven two-stage agent selection process. The core of ReSo is the proposed Collaborative Reward Model, which can provide fine-grained reward signals for MAS cooperation for optimization. We also introduce an automated data synthesis framework for generating MAS benchmarks, without human annotations. Experimentally, ReSo matches or outperforms existing methods. ReSo achieves \textbf{33.7%} and \textbf{32.3%} accuracy on Math-MAS and SciBench-MAS SciBench, while other methods completely fail. Code is available at: \href{https://github.com/hengzzzhou/ReSo}{ReSo}
多智能体系统作为一种有前景的方法,在复杂问题解决的领域里,用于提升大语言模型的推理能力。然而,当前的多智能体系统框架受限于较差的灵活性和可扩展性,优化策略尚不成熟。为了解决这些挑战,我们提出了ReSo,它结合了任务图生成和奖励驱动的两阶段智能体选择过程。ReSo的核心是提出的协同奖励模型,该模型可以为多智能体系统的合作提供精细粒度的奖励信号以实现优化。我们还引入了一个自动化的数据合成框架,用于生成无需人工注解的多智能体系统基准测试。通过实验,ReSo与现有方法相比表现持平或更胜一筹。在Math-MAS和SciBench-MAS SciBench上,ReSo分别达到了**33.7%和32.3%**的准确率,而其他方法则完全失败。代码可在https://github.com/hengzzzhou/ReSo处获取。
论文及项目相关链接
Summary
多智能体系统用于增强大语言模型在复杂问题中的推理能力展现出巨大潜力。然而,当前MAS框架受限于灵活性和可扩展性不足,优化策略尚不成熟。为解决这些问题,我们提出ReSo方法,集成任务图生成与奖励驱动的两阶段智能体选择流程。核心在于提出协作奖励模型,为MAS合作提供精细奖励信号以优化性能。同时引入自动化数据合成框架,无需人工标注即可生成MAS基准测试。实验显示,ReSo在Math-MAS和SciBench-MAS上的准确率分别达到了33.7%和32.3%,而其他方法则完全失效。代码可在ReSo(链接)处下载。
Key Takeaways
- 多智能体系统通过增强大语言模型的推理能力,展现出在复杂问题处理上的潜力。
- 当前MAS框架面临灵活性和可扩展性问题,优化策略亟待改进。
- ReSo方法集成了任务图生成和奖励驱动的两阶段智能体选择流程,以解决这些问题。
- 协作奖励模型是ReSo的核心,为MAS合作提供精细奖励信号以实现优化。
- ReSo引入了自动化数据合成框架,能够生成MAS基准测试,无需人工标注。
- 实验结果表明,ReSo在Math-MAS和SciBench-MAS上的表现优于其他方法。
- ReSo方法的准确率为Math-MAS的33.7%和SciBench-MAS的32.3%,而其他方法未能达到预期效果。
点此查看论文截图

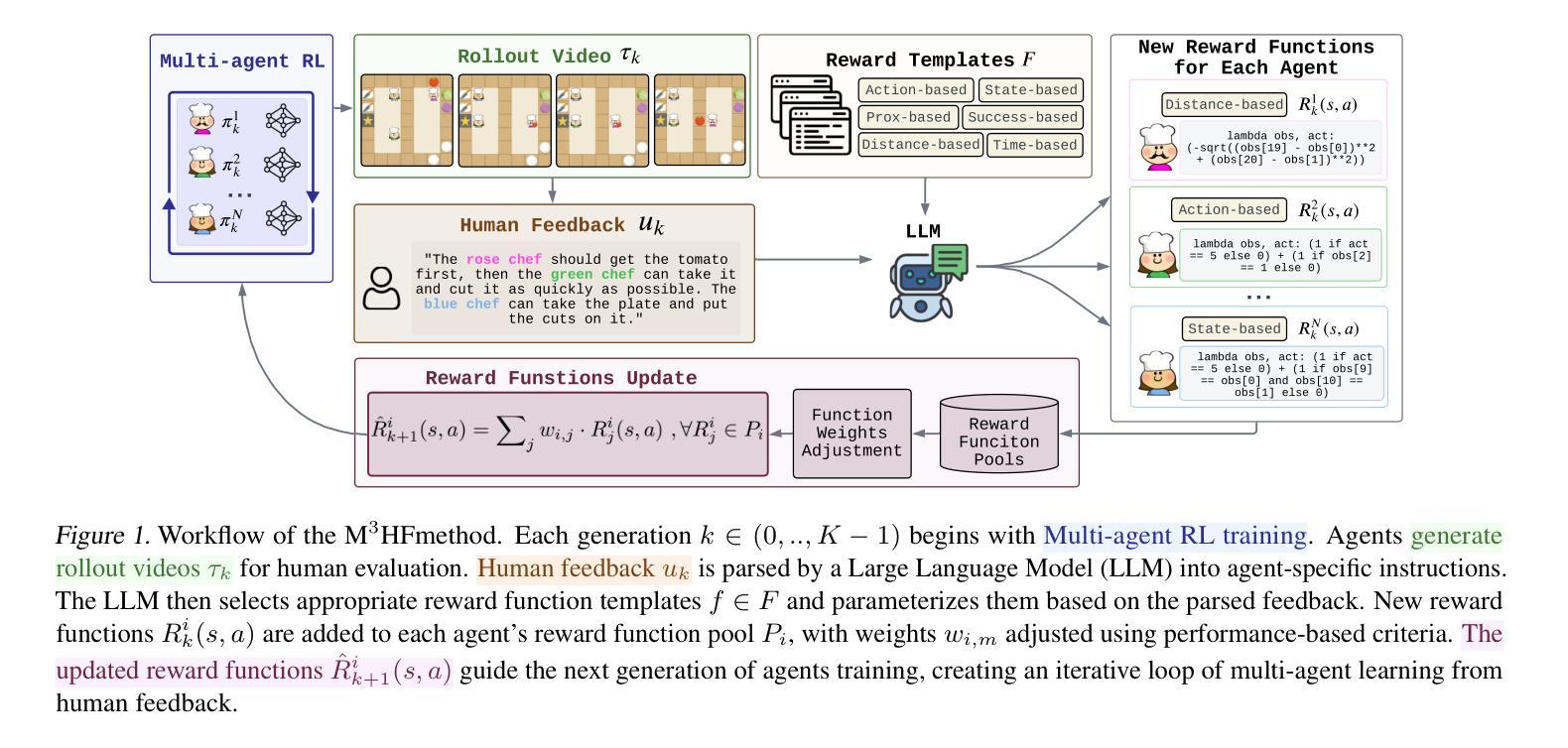
M3HF: Multi-agent Reinforcement Learning from Multi-phase Human Feedback of Mixed Quality
Authors:Ziyan Wang, Zhicheng Zhang, Fei Fang, Yali Du
Designing effective reward functions in multi-agent reinforcement learning (MARL) is a significant challenge, often leading to suboptimal or misaligned behaviors in complex, coordinated environments. We introduce Multi-agent Reinforcement Learning from Multi-phase Human Feedback of Mixed Quality (M3HF), a novel framework that integrates multi-phase human feedback of mixed quality into the MARL training process. By involving humans with diverse expertise levels to provide iterative guidance, M3HF leverages both expert and non-expert feedback to continuously refine agents’ policies. During training, we strategically pause agent learning for human evaluation, parse feedback using large language models to assign it appropriately and update reward functions through predefined templates and adaptive weight by using weight decay and performance-based adjustments. Our approach enables the integration of nuanced human insights across various levels of quality, enhancing the interpretability and robustness of multi-agent cooperation. Empirical results in challenging environments demonstrate that M3HF significantly outperforms state-of-the-art methods, effectively addressing the complexities of reward design in MARL and enabling broader human participation in the training process.
在多智能体强化学习(MARL)中设计有效的奖励函数是一个巨大的挑战,通常会导致在复杂、协调的环境中表现出次优或错位的行为。我们引入了多智能体强化学习中的混合质量多阶段人类反馈(M3HF)这一新型框架,它将混合质量的多阶段人类反馈整合到MARL训练过程中。M3HF通过涉及具有不同专业水平的人类提供迭代指导,利用专家和非专家的反馈来持续改进智能体的策略。在训练过程中,我们战略性地在人类评估时暂停智能体的学习,使用大型语言模型解析反馈并适当地分配任务,并通过使用权重衰减和基于性能的调整来更新奖励函数的预设模板和自适应权重。我们的方法能够整合各种质量水平上的微妙人类见解,提高多智能体合作的解释性和稳健性。在具有挑战性的环境中的经验结果表明,M3HF显著优于最新技术方法,有效地解决了MARL中奖励设计复杂性问题的同时,也实现了人类更广泛地参与到训练过程中。
论文及项目相关链接
PDF Seventeen pages, four figures
Summary
多智能体强化学习(MARL)中设计有效的奖励函数是一大挑战,尤其在复杂协调环境中可能导致次优或行为失准。我们提出了多阶段混合质量反馈的多智能体强化学习(M3HF)新框架,它将多阶段的人机混合质量反馈融入到MARL训练过程中。M3HF通过涉及不同专业程度的人类提供迭代指导,利用专家和新手反馈来不断微调智能体的策略。在训练过程中,我们战略性地暂停智能体的学习以供人类评估,使用大型语言模型解析反馈并适当分配任务,通过预设模板和自适应权重更新奖励函数,采用权重衰减和基于性能的调整。我们的方法能够整合各种质量层次的人类见解,提高多智能体合作的解释性和稳健性。在具有挑战性的环境中的实证结果表明,M3HF显著优于现有技术,有效解决MARL中奖励设计的复杂性,使更广泛的人类参与训练过程成为可能。
Key Takeaways
- 多智能体强化学习(MARL)在设计奖励函数时面临挑战,可能导致次优或行为失准。
- M3HF框架将多阶段人机混合质量反馈融入MARL训练过程。
- M3HF利用不同专业程度的人类反馈来微调智能体的策略。
- 在训练过程中,M3HF战略性地暂停智能体学习以供人类评估。
- M3HF使用大型语言模型解析人类反馈并更新奖励函数。
- M3HF通过预设模板和自适应权重、权重衰减和基于性能调整的方法更新奖励函数。
- M3HF提高了多智能体合作的解释性和稳健性,并在具有挑战性的环境中表现出优异的性能。
点此查看论文截图

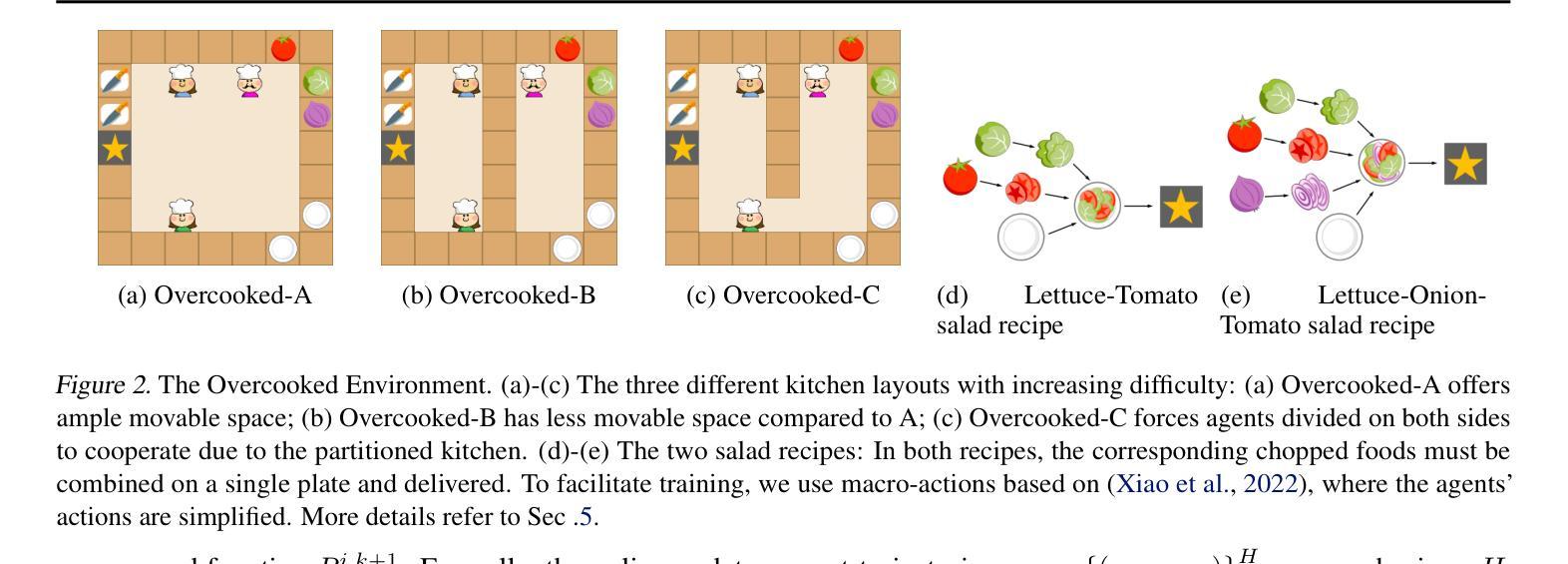
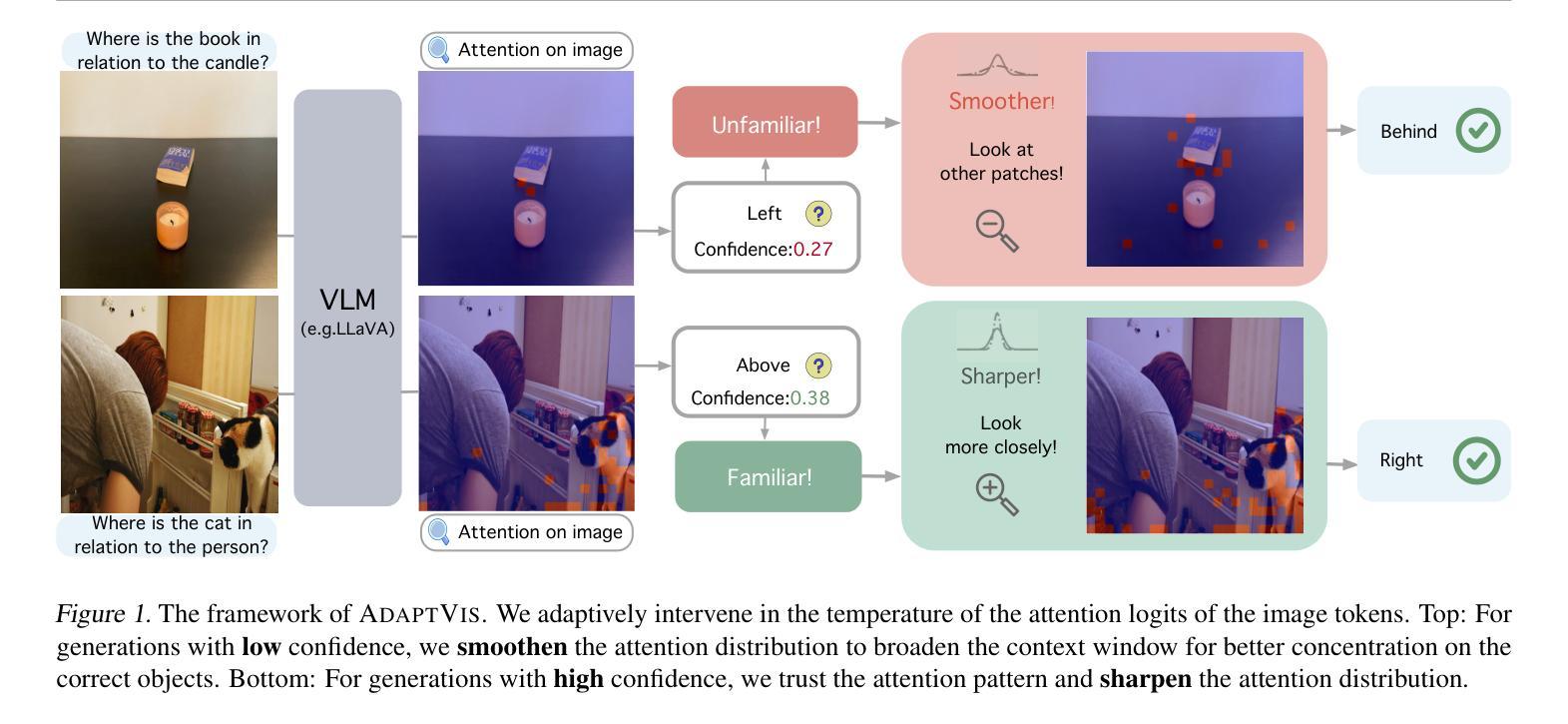
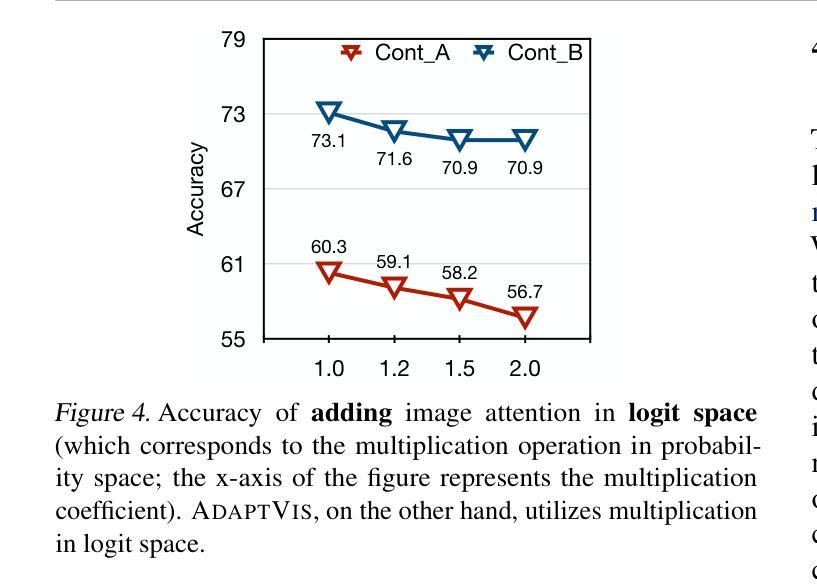
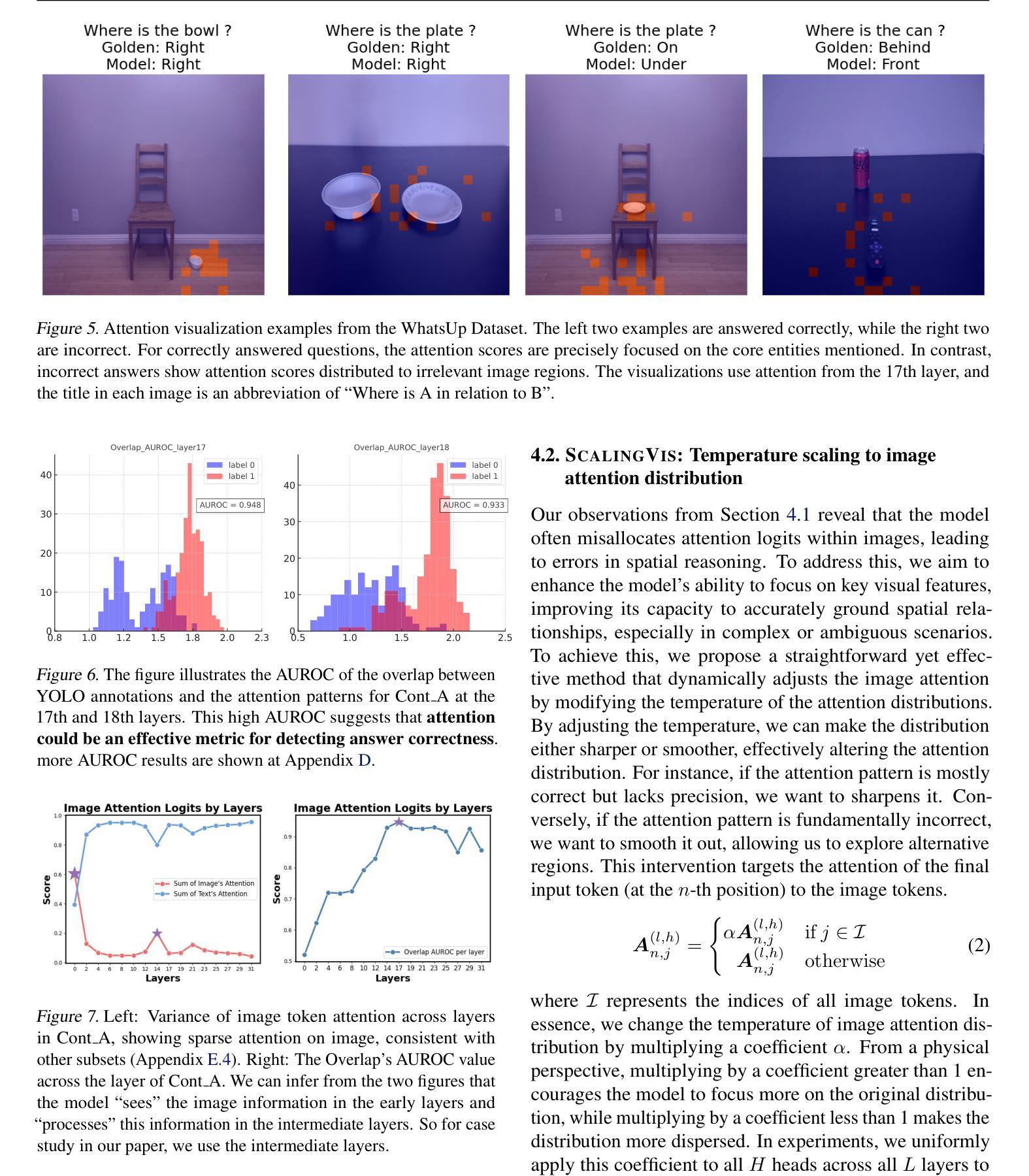
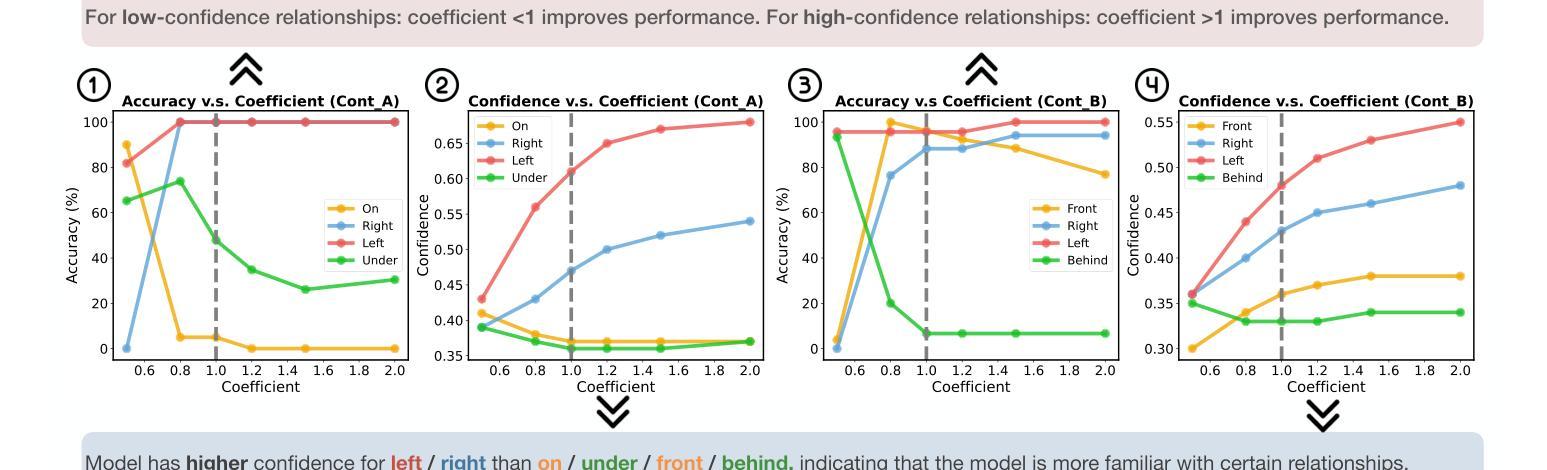
Why Is Spatial Reasoning Hard for VLMs? An Attention Mechanism Perspective on Focus Areas
Authors:Shiqi Chen, Tongyao Zhu, Ruochen Zhou, Jinghan Zhang, Siyang Gao, Juan Carlos Niebles, Mor Geva, Junxian He, Jiajun Wu, Manling Li
Large Vision Language Models (VLMs) have long struggled with spatial reasoning tasks. Surprisingly, even simple spatial reasoning tasks, such as recognizing “under” or “behind” relationships between only two objects, pose significant challenges for current VLMs. In this work, we study the spatial reasoning challenge from the lens of mechanistic interpretability, diving into the model’s internal states to examine the interactions between image and text tokens. By tracing attention distribution over the image through out intermediate layers, we observe that successful spatial reasoning correlates strongly with the model’s ability to align its attention distribution with actual object locations, particularly differing between familiar and unfamiliar spatial relationships. Motivated by these findings, we propose ADAPTVIS based on inference-time confidence scores to sharpen the attention on highly relevant regions when confident, while smoothing and broadening the attention window to consider a wider context when confidence is lower. This training-free decoding method shows significant improvement (e.g., up to a 50 absolute point improvement) on spatial reasoning benchmarks such as WhatsUp and VSR with negligible cost. We make code and data publicly available for research purposes at https://github.com/shiqichen17/AdaptVis.
大型视觉语言模型(VLMs)长期以来一直面临空间推理任务的挑战。令人惊讶的是,即使是简单的空间推理任务,如识别两个对象之间的“在……下面”或“在……后面”的关系,也对当前的VLMs构成了重大挑战。在这项工作中,我们从机械可解释性的角度研究空间推理挑战,深入模型的内部状态,研究图像和文本标记之间的相互作用。通过追踪图像上各层的注意力分布,我们发现成功的空间推理与模型将注意力分布与实际物体位置对齐的能力密切相关,特别是面对熟悉和陌生的空间关系时。受这些发现的启发,我们提出了一种基于推理时间置信度分数的ADAPTVIS方法,在置信度较高时,将注意力集中在高度相关的区域上,而在置信度较低时,平滑并扩大注意力窗口以考虑更广泛的上下文。这种无需训练的解码方法在空间推理基准测试(如WhatsUp和VSR)上显示出显著改进(例如,绝对改进点高达50点),且成本微乎其微。我们为了研究目的公开了代码和数据:https://github.com/shiqichen17/AdaptVis。
论文及项目相关链接
Summary
大型视觉语言模型(VLMs)在处理空间推理任务时存在挑战。本文通过机制性解释方法,深入研究了模型内部状态,观察图像和文本符号之间的交互作用。研究发现成功的空间推理与模型的注意力分布与实际物体位置的匹配能力密切相关,特别是面对熟悉和陌生的空间关系时。基于此,本文提出了基于推理时间置信度得分的ADAPTVIS方法,在置信度高时锐化对重要区域的注意力,在置信度低时平滑并扩大注意力范围以考虑更广泛的上下文。这种无需训练的解码方法在空间推理基准测试上表现出显著改进,如WhatsUp和VSR,改进幅度高达50个绝对点,且成本较低。相关代码和数据已公开发布,供研究使用。
Key Takeaways
- VLMs在处理简单空间推理任务时存在挑战。
- 成功的空间推理与模型注意力分布与物体位置的匹配能力有关。
- 熟悉与陌生的空间关系处理在模型内部有不同的表现。
- ADAPTVIS方法基于推理时间置信度得分来调整注意力分布。
- ADAPTVIS在基准测试中表现出显著改进,如WhatsUp和VSR。
- 所提出的方法无需额外训练,且具有较低的成本。
点此查看论文截图


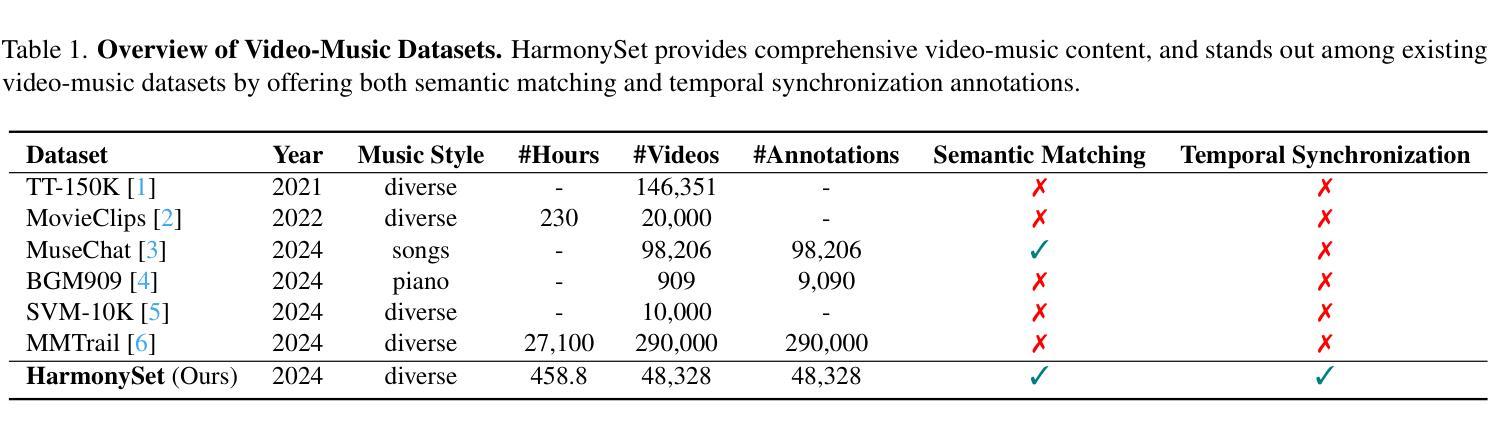
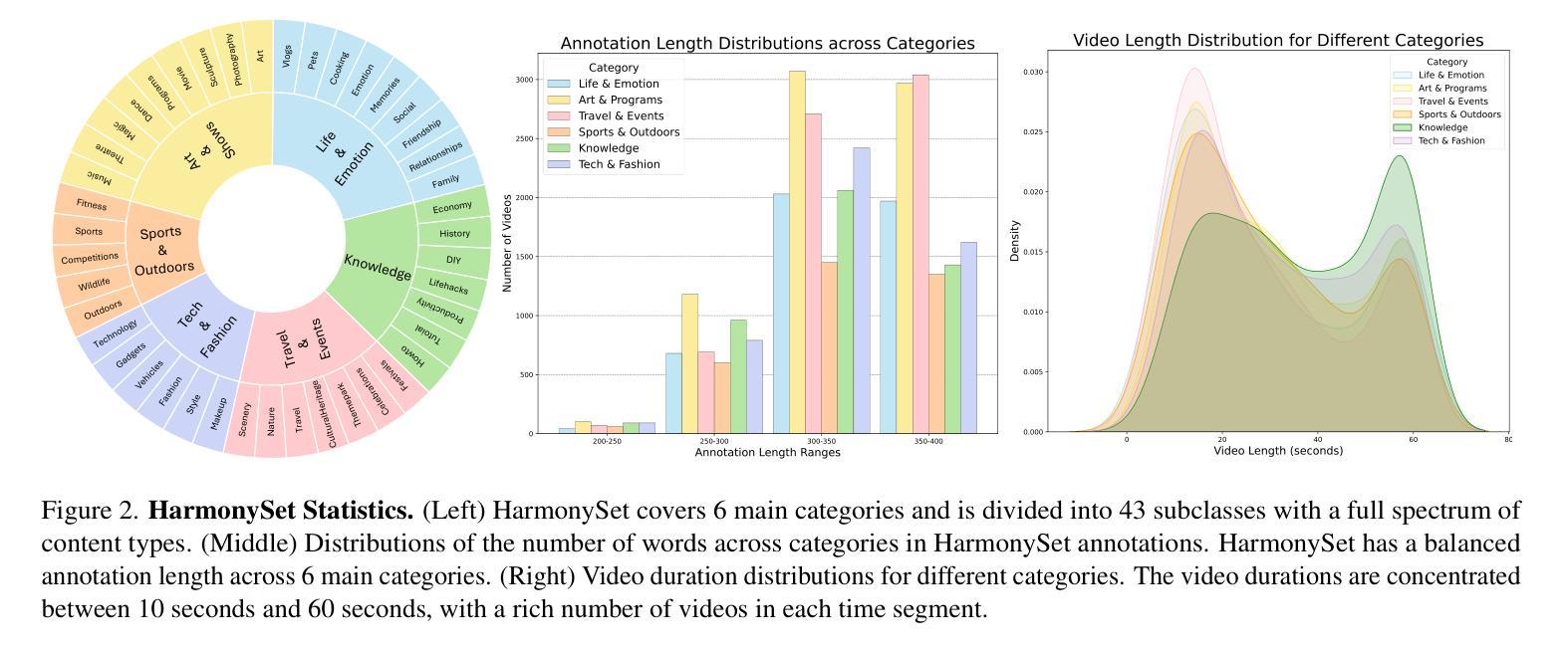
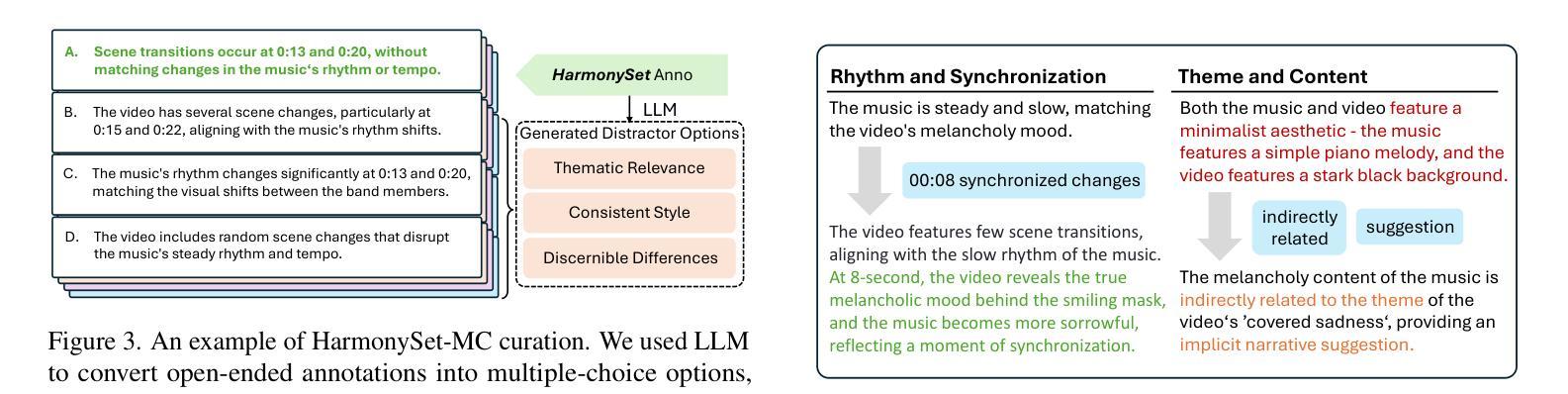
HarmonySet: A Comprehensive Dataset for Understanding Video-Music Semantic Alignment and Temporal Synchronization
Authors:Zitang Zhou, Ke Mei, Yu Lu, Tianyi Wang, Fengyun Rao
This paper introduces HarmonySet, a comprehensive dataset designed to advance video-music understanding. HarmonySet consists of 48,328 diverse video-music pairs, annotated with detailed information on rhythmic synchronization, emotional alignment, thematic coherence, and cultural relevance. We propose a multi-step human-machine collaborative framework for efficient annotation, combining human insights with machine-generated descriptions to identify key transitions and assess alignment across multiple dimensions. Additionally, we introduce a novel evaluation framework with tasks and metrics to assess the multi-dimensional alignment of video and music, including rhythm, emotion, theme, and cultural context. Our extensive experiments demonstrate that HarmonySet, along with the proposed evaluation framework, significantly improves the ability of multimodal models to capture and analyze the intricate relationships between video and music.
本文介绍了HarmonySet,这是一个为了推进视频音乐理解而设计的综合数据集。HarmonySet包含48,328个多样化的视频音乐对,并注明了关于节奏同步、情感对齐、主题连贯性和文化相关性的详细信息。我们提出了一种多步骤的人机协作框架,用于有效标注,结合人类见解和机器生成的描述来识别关键过渡并评估多个维度上的对齐情况。此外,我们还引入了一个新的评估框架,包括任务和指标,以评估视频和音乐的多维对齐,包括节奏、情感、主题和文化背景。我们的大量实验表明,HarmonySet以及提出的评估框架,能够显著提高多模态模型捕捉和分析视频和音乐之间复杂关系的能力。
论文及项目相关链接
PDF Accepted at CVPR 2025. Project page: https://harmonyset.github.io/
Summary:
本文介绍了HarmonySet数据集,该数据集旨在促进视频音乐理解的发展。HarmonySet包含48,328个多样化的视频音乐对,并详细标注了节奏同步、情感对齐、主题连贯性和文化相关性等信息。文章提出了一种人机协作的标注框架,结合人类洞察力和机器生成的描述来识别关键过渡并评估多个维度的对齐情况。此外,还引入了一个新的评估框架,包括任务和指标,以评估视频和音乐的多维对齐,如节奏、情感、主题和文化背景。实验表明,HarmonySet及评估框架显著提高了多模式模型捕捉和分析视频与音乐之间复杂关系的能力。
Key Takeaways:
- HarmonySet是一个综合性的数据集,用于推进视频音乐理解的研究。
- 数据集包含48,328个多样化视频音乐对,详细标注了节奏同步等信息。
- 提出了一个人机协作的标注框架,能高效识别关键过渡并评估多个维度的对齐情况。
- 引入了新的评估框架来评估视频和音乐的多维对齐。
- 该数据集和评估框架有助于提高模型捕捉视频与音乐之间复杂关系的能力。
- 数据集注重文化相关性,有助于理解和分析不同文化背景下的视频音乐交互。
点此查看论文截图

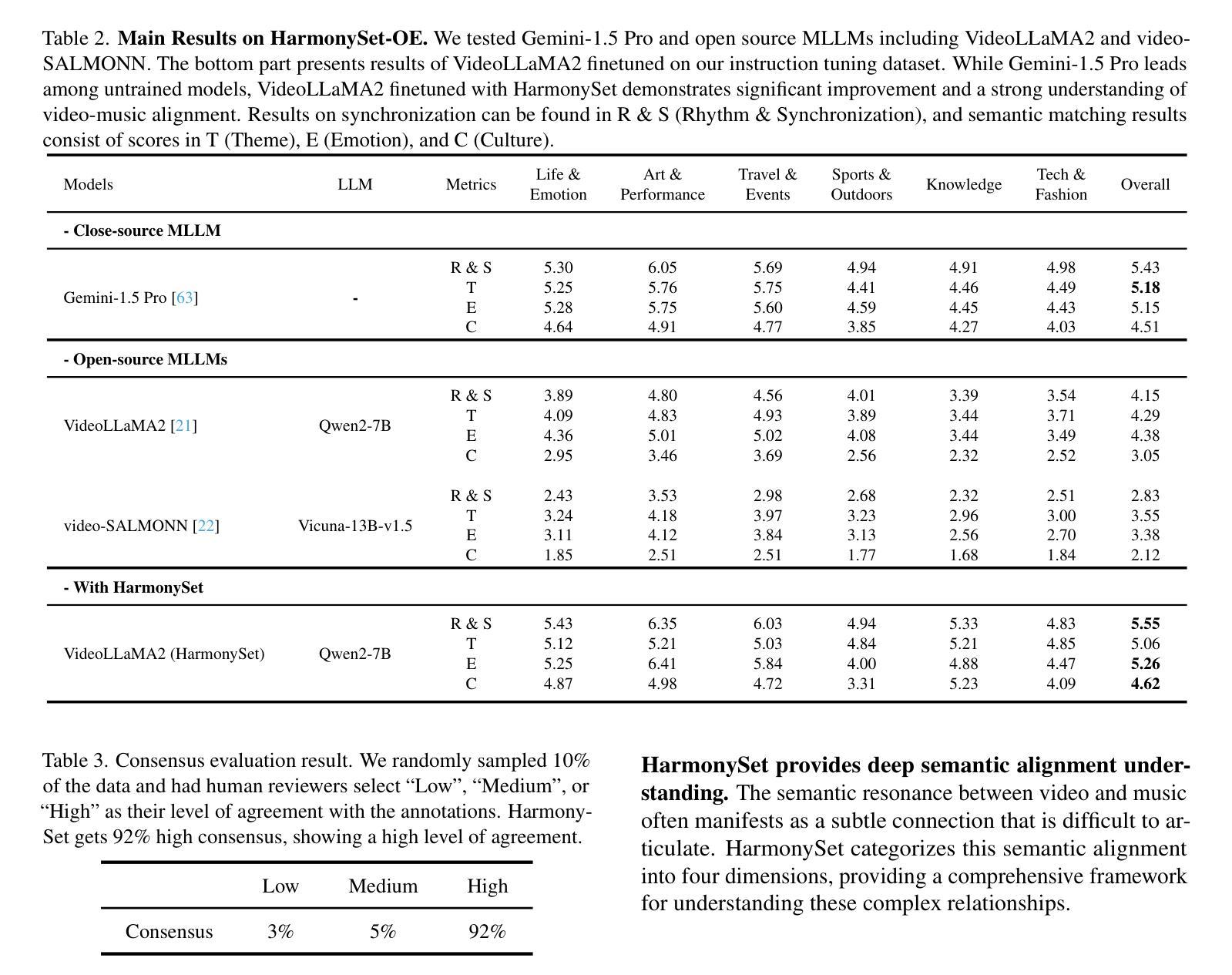
Cancer Type, Stage and Prognosis Assessment from Pathology Reports using LLMs
Authors:Rachit Saluja, Jacob Rosenthal, Yoav Artzi, David J. Pisapia, Benjamin L. Liechty, Mert R. Sabuncu
Large Language Models (LLMs) have shown significant promise across various natural language processing tasks. However, their application in the field of pathology, particularly for extracting meaningful insights from unstructured medical texts such as pathology reports, remains underexplored and not well quantified. In this project, we leverage state-of-the-art language models, including the GPT family, Mistral models, and the open-source Llama models, to evaluate their performance in comprehensively analyzing pathology reports. Specifically, we assess their performance in cancer type identification, AJCC stage determination, and prognosis assessment, encompassing both information extraction and higher-order reasoning tasks. Based on a detailed analysis of their performance metrics in a zero-shot setting, we developed two instruction-tuned models: Path-llama3.1-8B and Path-GPT-4o-mini-FT. These models demonstrated superior performance in zero-shot cancer type identification, staging, and prognosis assessment compared to the other models evaluated.
大型语言模型(LLMs)在各种自然语言处理任务中显示出巨大的潜力。然而,它们在病理学领域的应用,特别是在从病理报告等无结构医学文本中提取有意义见解方面,仍被探索得不够深入且未得到很好的量化。在本项目中,我们利用最先进的语言模型,包括GPT系列、Mistral模型和开源的Llama模型,来评估它们在综合分析病理报告方面的性能。具体来说,我们评估了它们在癌症类型识别、AJCC分期确定和预后评估方面的性能,这些评估涵盖了信息提取和高级推理任务。基于对零样本设置下性能指标的详细分析,我们开发了两个指令微调模型:Path-llama3.1-8B和Path-GPT-4o-mini-FT。这些模型在零样本癌症类型识别、分期和预后评估方面表现出卓越的性能,与其他评估的模型相比具有优势。
论文及项目相关链接
Summary
大型语言模型(LLMs)在自然语言处理任务中展现出巨大潜力,但在病理学领域的应用,特别是在从病理报告等无结构医学文本中提取有意义信息方面,其应用尚待进一步探索和研究。本项目利用最先进的语言模型,包括GPT系列、Mistral模型和开源Llama模型,评估它们在综合分析病理报告方面的性能。通过零样本设置下的性能分析,开发了两个指令调优模型Path-llama3.1-8B和Path-GPT-4o-mini-FT,在零样本癌症类型识别、分期和预后评估方面表现出卓越性能。
Key Takeaways
- 大型语言模型(LLMs)在自然语言处理任务中具有显著潜力。
- 在病理学领域,LLMs的应用特别是在从病理报告提取信息方面尚待探索和研究。
- 本项目利用多种最先进语言模型评估在病理报告分析中的性能。
- 评估内容包括癌症类型识别、AJCC分期和预后评估。
- 通过零样本设置下的性能分析,开发了两个指令调优模型。
- 这两个模型在癌症类型识别、分期和预后评估方面表现出卓越性能。
点此查看论文截图

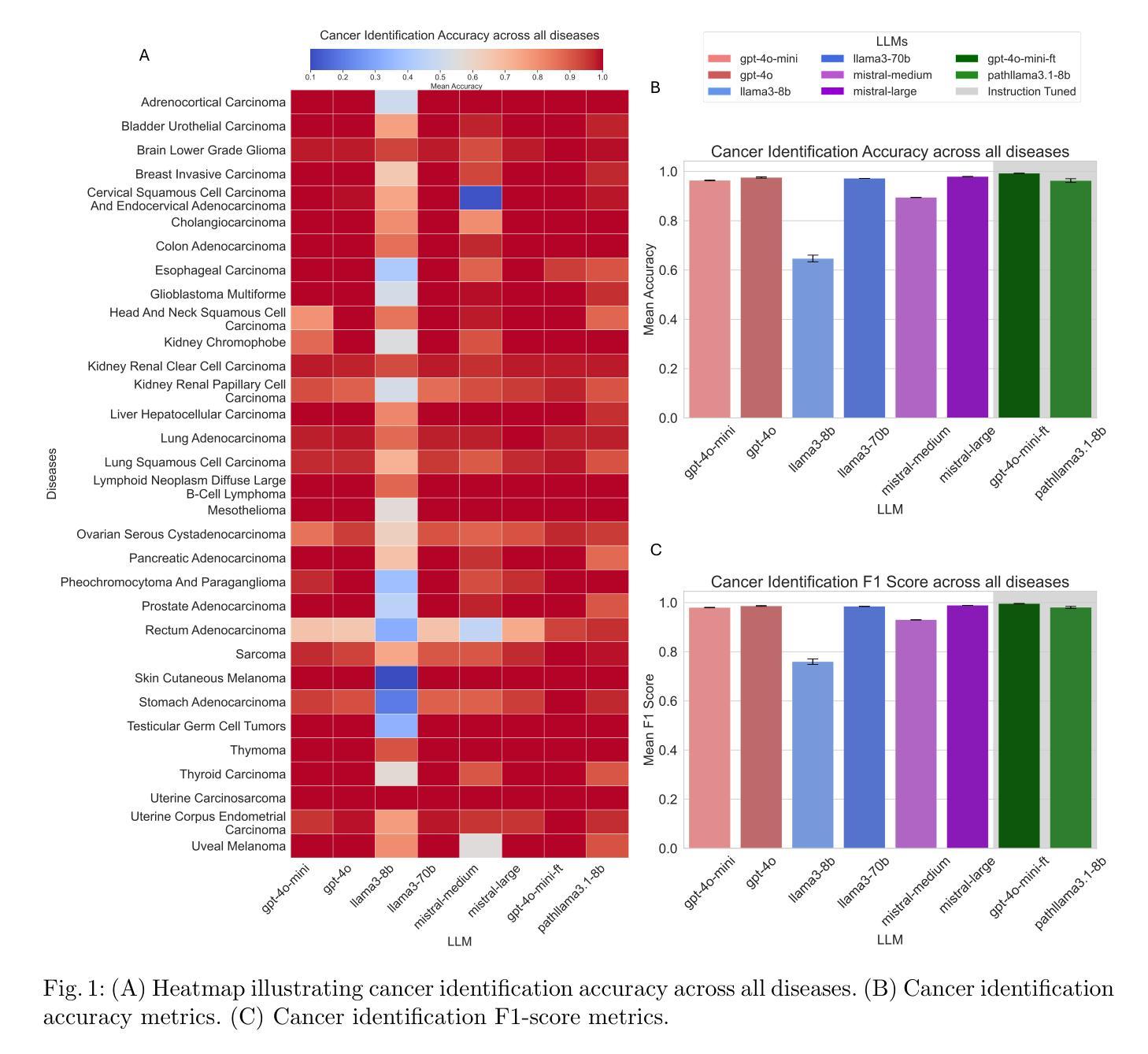
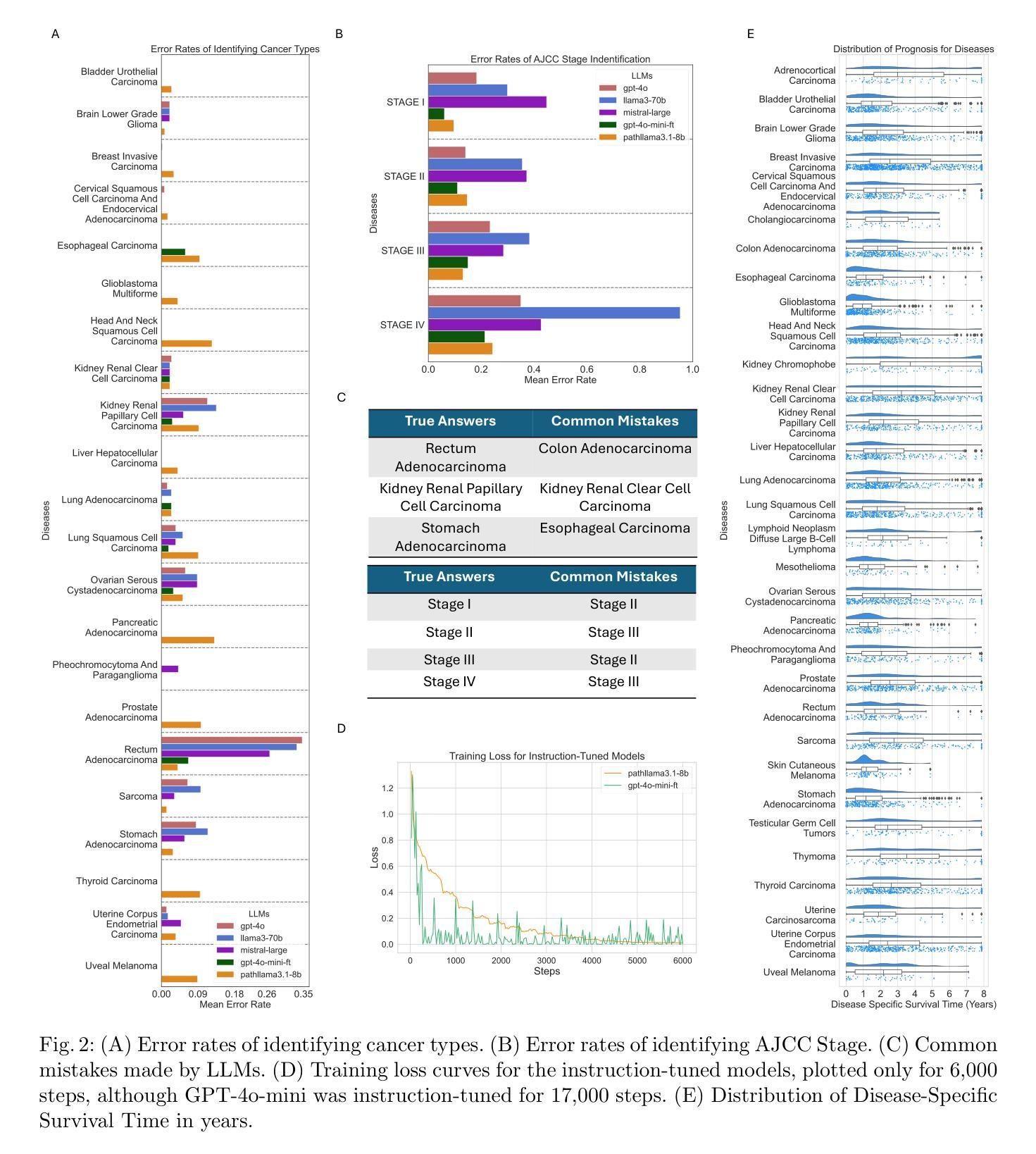
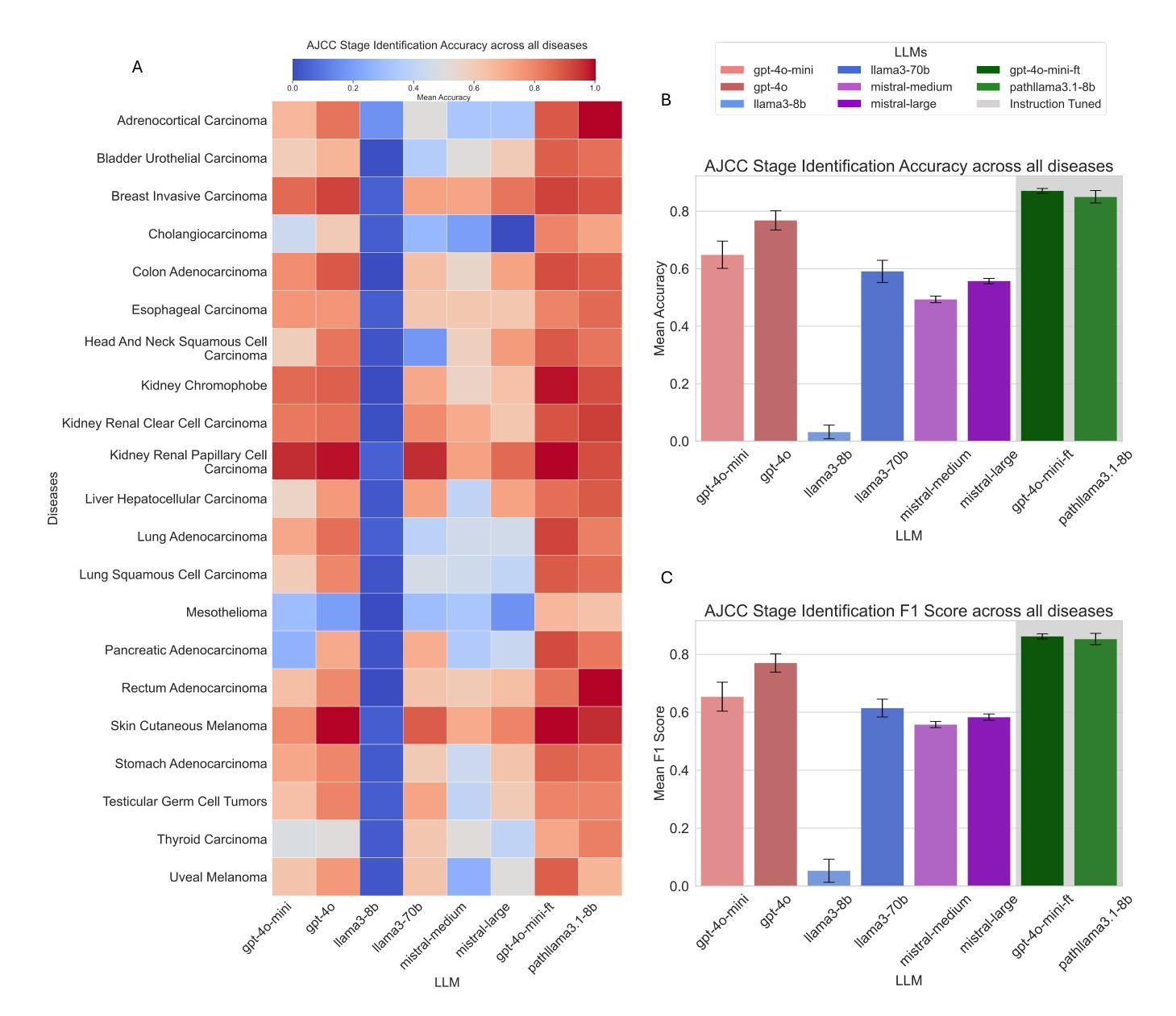
An evaluation of DeepSeek Models in Biomedical Natural Language Processing
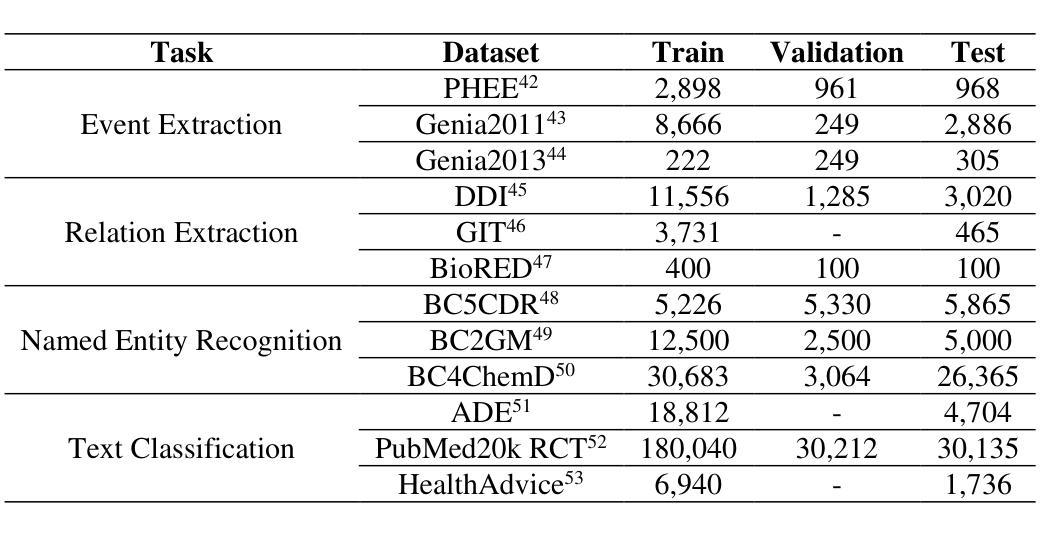
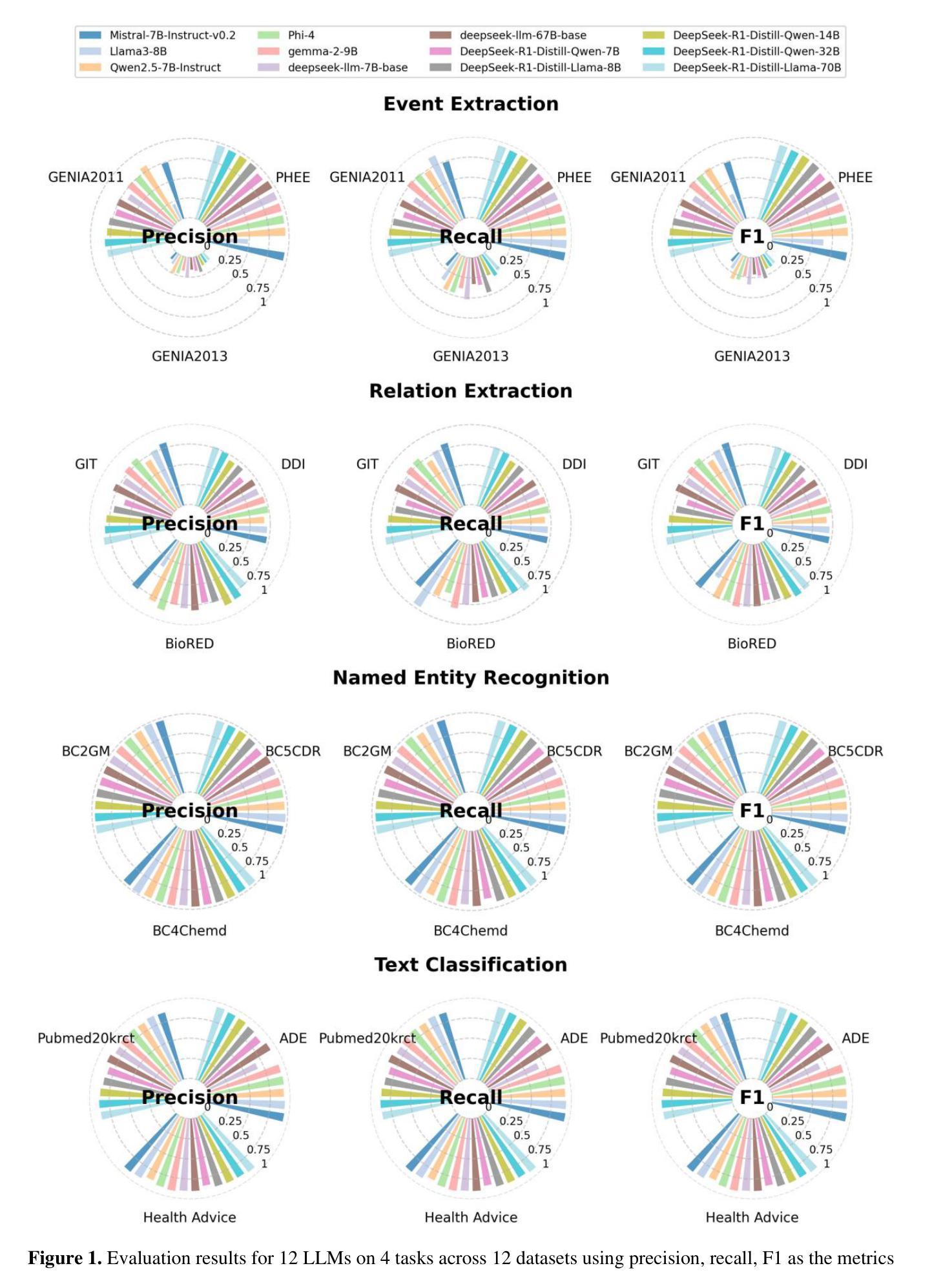
Authors:Zaifu Zhan, Shuang Zhou, Huixue Zhou, Jiawen Deng, Yu Hou, Jeremy Yeung, Rui Zhang
The advancement of Large Language Models (LLMs) has significantly impacted biomedical Natural Language Processing (NLP), enhancing tasks such as named entity recognition, relation extraction, event extraction, and text classification. In this context, the DeepSeek series of models have shown promising potential in general NLP tasks, yet their capabilities in the biomedical domain remain underexplored. This study evaluates multiple DeepSeek models (Distilled-DeepSeek-R1 series and Deepseek-LLMs) across four key biomedical NLP tasks using 12 datasets, benchmarking them against state-of-the-art alternatives (Llama3-8B, Qwen2.5-7B, Mistral-7B, Phi-4-14B, Gemma-2-9B). Our results reveal that while DeepSeek models perform competitively in named entity recognition and text classification, challenges persist in event and relation extraction due to precision-recall trade-offs. We provide task-specific model recommendations and highlight future research directions. This evaluation underscores the strengths and limitations of DeepSeek models in biomedical NLP, guiding their future deployment and optimization.
大规模语言模型(LLMs)的进步对生物医学自然语言处理(NLP)产生了重大影响,增强了命名实体识别、关系抽取、事件抽取和文本分类等任务。在此背景下,DeepSeek系列模型在一般NLP任务中显示出良好的潜力,但它们在生物医学领域的能力仍然被低估。本研究使用12个数据集,在四个关键的生物医学NLP任务上评估了多个DeepSeek模型(Distilled-DeepSeek-R1系列和Deepseek-LLMs),并将它们与最新的替代方案(Llama3-8B、Qwen2.5-7B、Mistral-7B、Phi-4-14B、Gemma-2-9B)进行了比较。结果表明,DeepSeek模型在命名实体识别和文本分类方面表现良好,但由于精确率和召回率之间的权衡,事件和关系抽取仍存在挑战。我们提供了针对特定任务的模型推荐并强调了未来的研究方向。这一评估强调了DeepSeek模型在生物医学NLP中的优势和局限性,为未来的部署和优化提供了指导。
论文及项目相关链接
PDF Plan to submit to AMIA 2025 Annual Symposium. 10 pages
Summary
大型语言模型(LLMs)的发展对生物医学自然语言处理(NLP)产生了重大影响,提高了实体命名识别、关系抽取、事件抽取和文本分类等任务的效果。DeepSeek系列模型在通用NLP任务中展现出巨大潜力,但在生物医学领域的应用尚待探索。本研究评估了DeepSeek模型在四个关键生物医学NLP任务中的性能,与前沿的LLMs进行对比。结果显示,DeepSeek模型在实体命名识别和文本分类方面表现良好,但在事件和关系抽取方面仍存在挑战。本研究为特定任务的模型选择和未来研究方向提供了指导。
Key Takeaways
- 大型语言模型(LLMs)对生物医学自然语言处理(NLP)产生了重要影响。
- DeepSeek系列模型在通用NLP任务中表现出潜力,但在生物医学领域的应用尚待充分探索。
- 本研究评估了DeepSeek模型在四个关键生物医学NLP任务中的性能。
- DeepSeek模型在实体命名识别和文本分类方面表现良好。
- 在事件和关系抽取任务中,DeepSeek模型面临挑战,存在精度和召回率的权衡问题。
- 研究提供了针对特定任务的模型推荐。
点此查看论文截图

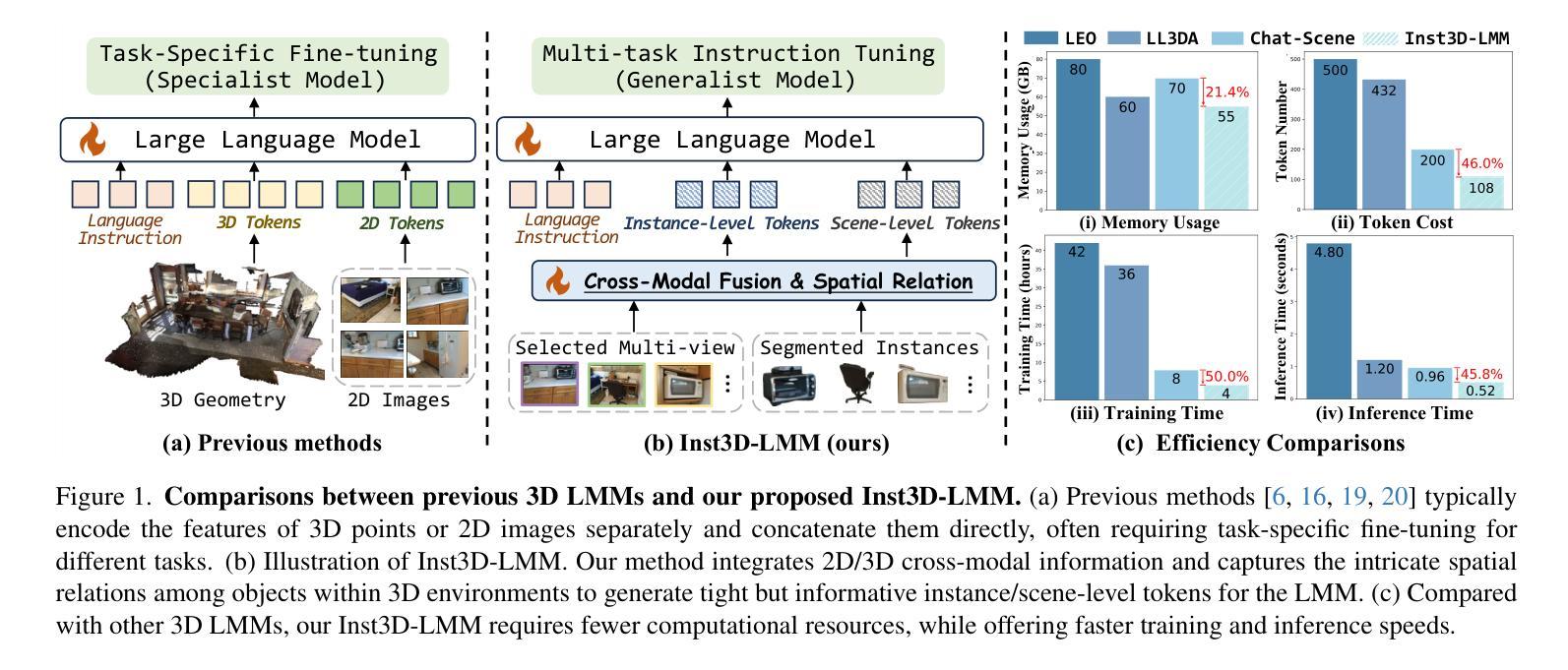
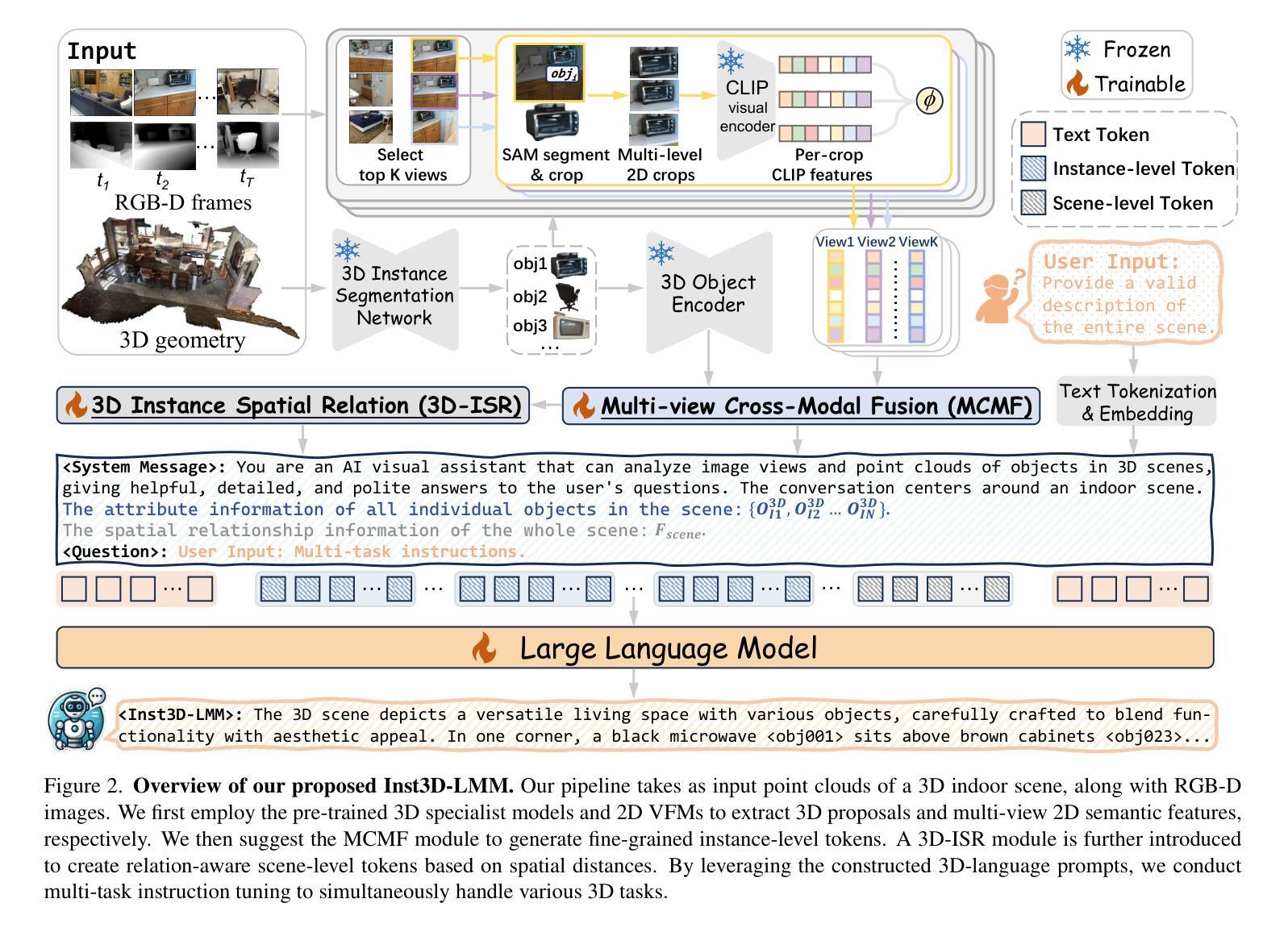
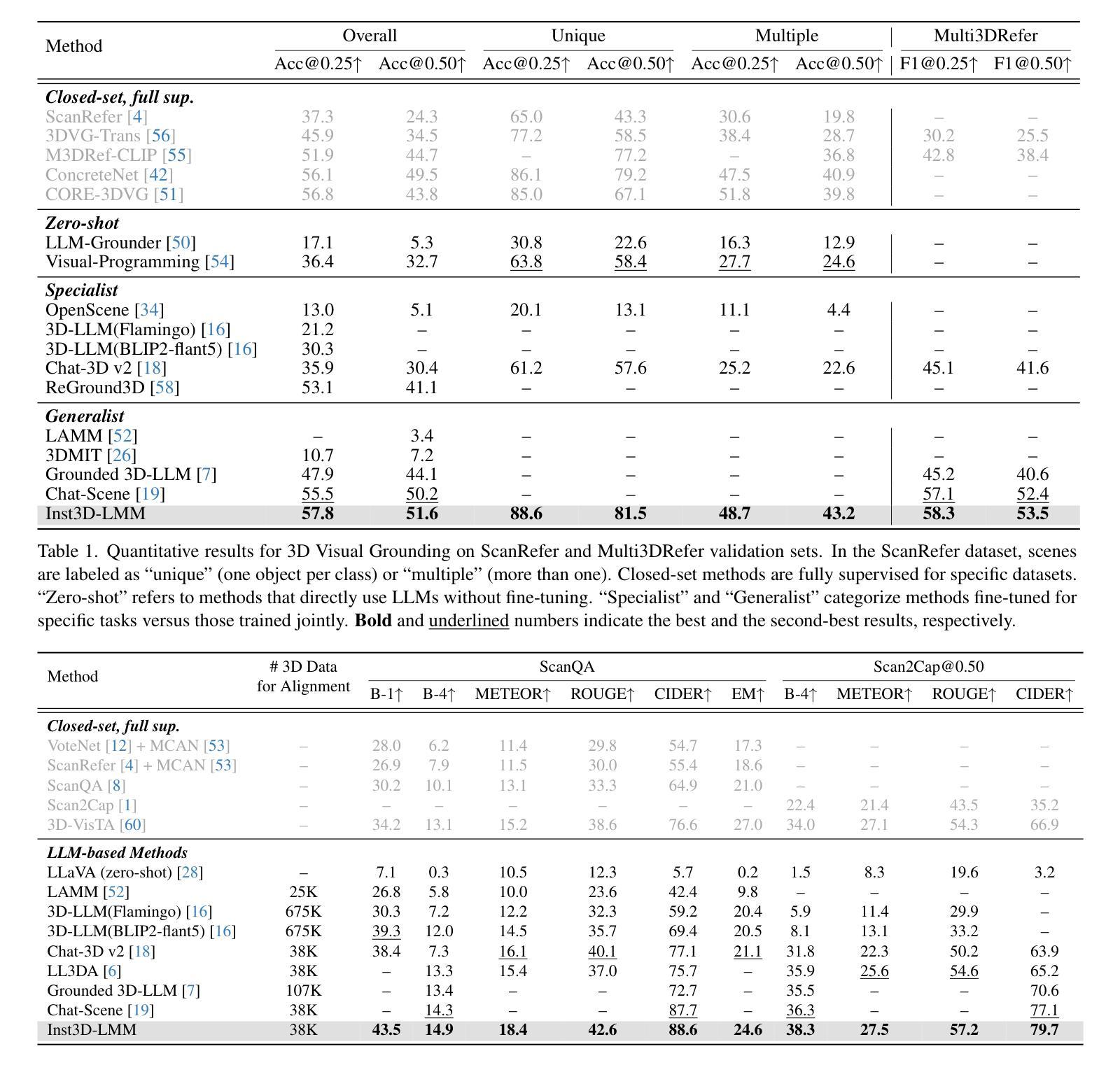
Inst3D-LMM: Instance-Aware 3D Scene Understanding with Multi-modal Instruction Tuning
Authors:Hanxun Yu, Wentong Li, Song Wang, Junbo Chen, Jianke Zhu
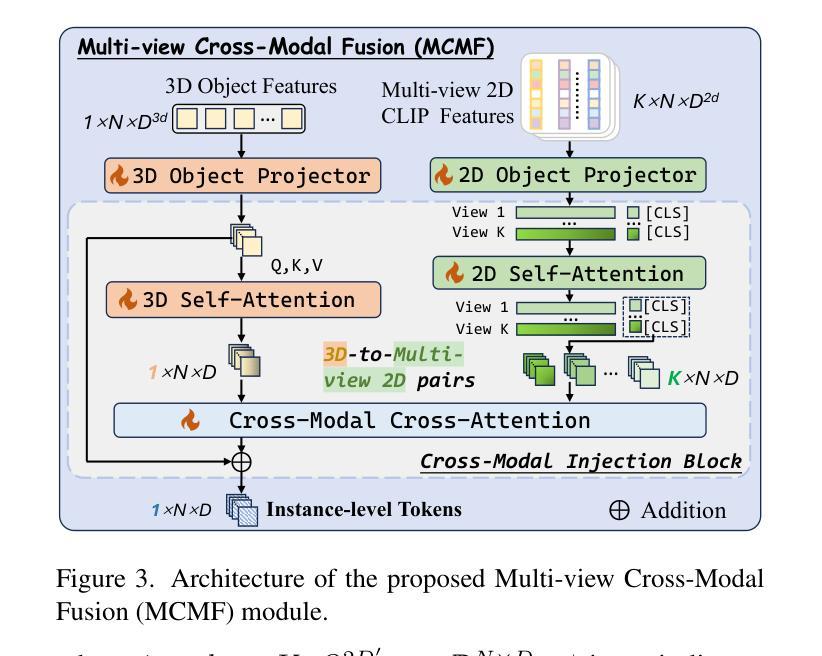
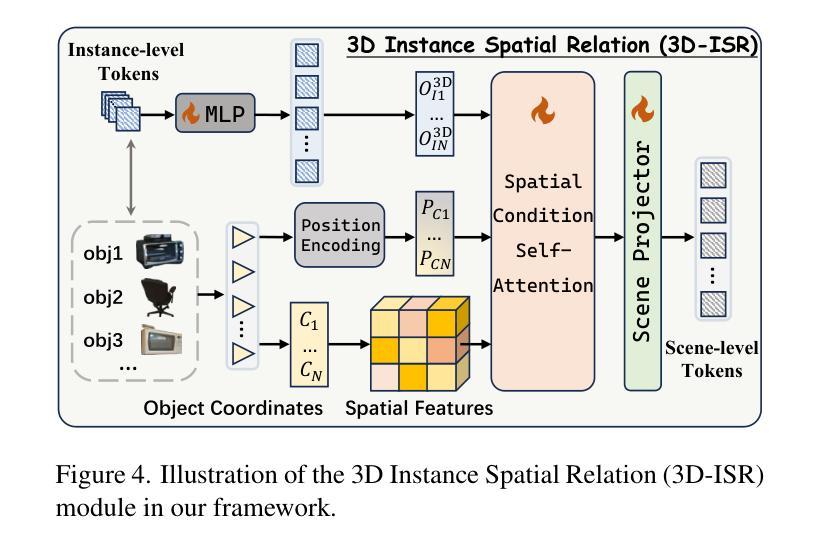
Despite encouraging progress in 3D scene understanding, it remains challenging to develop an effective Large Multi-modal Model (LMM) that is capable of understanding and reasoning in complex 3D environments. Most previous methods typically encode 3D point and 2D image features separately, neglecting interactions between 2D semantics and 3D object properties, as well as the spatial relationships within the 3D environment. This limitation not only hinders comprehensive representations of 3D scene, but also compromises training and inference efficiency. To address these challenges, we propose a unified Instance-aware 3D Large Multi-modal Model (Inst3D-LMM) to deal with multiple 3D scene understanding tasks simultaneously. To obtain the fine-grained instance-level visual tokens, we first introduce a novel Multi-view Cross-Modal Fusion (MCMF) module to inject the multi-view 2D semantics into their corresponding 3D geometric features. For scene-level relation-aware tokens, we further present a 3D Instance Spatial Relation (3D-ISR) module to capture the intricate pairwise spatial relationships among objects. Additionally, we perform end-to-end multi-task instruction tuning simultaneously without the subsequent task-specific fine-tuning. Extensive experiments demonstrate that our approach outperforms the state-of-the-art methods across 3D scene understanding, reasoning and grounding tasks. Source code is available at https://github.com/hanxunyu/Inst3D-LMM
尽管在三维场景理解方面取得了令人鼓舞的进展,但开发能够在复杂三维环境中进行理解和推理的有效大型多模式模型(LMM)仍然具有挑战性。大多数之前的方法通常分别编码三维点云和二维图像特征,忽略了二维语义和三维对象属性之间的交互,以及三维环境内的空间关系。这种局限性不仅阻碍了三维场景的综合表示,还影响了训练和推理的效率。为了解决这些挑战,我们提出了一种统一的实例感知三维大型多模式模型(Inst3D-LMM),以同时处理多个三维场景理解任务。为了获得精细的实例级视觉标记,我们首先引入了一种新型的多视角跨模式融合(MCMF)模块,将多视角的二维语义注入到其对应的三维几何特征中。对于场景级的关系感知标记,我们进一步提出了一种三维实例空间关系(3D-ISR)模块,以捕获对象之间复杂的配对空间关系。此外,我们进行了端到端的多任务指令调整,同时进行了多项实验,无需后续的任务特定微调。广泛的实验表明,我们的方法在三维场景理解、推理和定位任务上优于最先进的方法。源代码可在https://github.com/hanxunyu/Inst3D-LMM找到。
论文及项目相关链接
PDF CVPR2025, Code Link: https://github.com/hanxunyu/Inst3D-LMM
Summary:
尽管在三维场景理解方面取得了令人鼓舞的进展,但开发一种能够理解和推理复杂三维环境的有效大型多模态模型(LMM)仍然具有挑战性。先前的大多数方法通常分别编码三维点特征和二维图像特征,忽略了二维语义和三维对象属性之间的交互,以及三维环境内的空间关系。为了解决这个问题,本文提出了一种统一的实例感知三维大型多模态模型(Inst3D-LMM),可以同时处理多个三维场景理解任务。通过引入多视图跨模态融合(MCMF)模块和三维实例空间关系(3D-ISR)模块,该模型能够获取精细的实例级视觉标记和场景级关系感知标记。实验表明,该方法在三维场景理解、推理和接地任务上优于现有技术。
Key Takeaways:
- 大型多模态模型(LMM)在复杂三维场景理解和推理方面仍面临挑战。
- 大多数先前的方法忽略了二维语义和三维对象属性之间的交互,以及三维环境内的空间关系。
- 提出了一种新的实例感知三维大型多模态模型(Inst3D-LMM),以同时处理多个三维场景理解任务。
- 通过引入多视图跨模态融合(MCMF)模块,将多视图二维语义注入到其对应的三维几何特征中,获得精细的实例级视觉标记。
- 通过引入三维实例空间关系(3D-ISR)模块,捕捉对象之间复杂的配对空间关系,获得场景级关系感知标记。
- 该模型能够在进行多任务指令调整时,无需后续任务特定微调即可进行端到端的调整。
点此查看论文截图