⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-11 更新
UniArray: Unified Spectral-Spatial Modeling for Array-Geometry-Agnostic Speech Separation
Authors:Weiguang Chen, Junjie Zhang, Jielong Yang, Eng Siong Chng, Xionghu Zhong
Array-geometry-agnostic speech separation (AGA-SS) aims to develop an effective separation method regardless of the microphone array geometry. Conventional methods rely on permutation-free operations, such as summation or attention mechanisms, to capture spatial information. However, these approaches often incur high computational costs or disrupt the effective use of spatial information during intra- and inter-channel interactions, leading to suboptimal performance. To address these issues, we propose UniArray, a novel approach that abandons the conventional interleaving manner. UniArray consists of three key components: a virtual microphone estimation (VME) module, a feature extraction and fusion module, and a hierarchical dual-path separator. The VME ensures robust performance across arrays with varying channel numbers. The feature extraction and fusion module leverages a spectral feature extraction module and a spatial dictionary learning (SDL) module to extract and fuse frequency-bin-level features, allowing the separator to focus on using the fused features. The hierarchical dual-path separator models feature dependencies along the time and frequency axes while maintaining computational efficiency. Experimental results show that UniArray outperforms state-of-the-art methods in SI-SDRi, WB-PESQ, NB-PESQ, and STOI across both seen and unseen array geometries.
阵列几何无关语音分离(AGA-SS)旨在开发一种有效的分离方法,而该方法不受麦克风阵列几何结构的影响。传统方法依赖于无排列运算,如求和或注意力机制,来捕捉空间信息。然而,这些方法通常会导致较高的计算成本,或者在处理通道内和通道间交互时破坏空间信息的有效使用,从而导致性能不佳。为了解决这些问题,我们提出了UniArray这一新方法,它摒弃了传统的交错方式。UniArray由三个关键组件组成:虚拟麦克风估计(VME)模块、特征提取和融合模块以及分层双路径分离器。VME确保了在具有不同通道数量的阵列中的稳健性能。特征提取和融合模块利用频谱特征提取模块和空间字典学习(SDL)模块来提取和融合频率级特征,允许分离器专注于使用融合的特征。分层双路径分离器在时间轴和频率轴上建模特征依赖关系,同时保持计算效率。实验结果表明,在SI-SDRi、WB-PESQ、NB-PESQ和STOI等多个指标上,UniArray在已知和未知的阵列几何结构上均优于最新方法。
论文及项目相关链接
PDF 5 pages, Prepirnt
Summary
该文介绍了一种阵列几何无关语音分离(AGA-SS)的新方法——UniArray。该方法摒弃了传统的交织方式,通过虚拟麦克风估计(VME)模块、特征提取与融合模块以及分层双路径分离器三个关键组件实现高性能的语音分离,不受麦克风阵列几何结构的影响。实验结果表明,UniArray在SI-SDRi、WB-PESQ、NB-PESQ和STOI等多个指标上优于现有方法,适用于已知和未知的阵列几何结构。
Key Takeaways
- UniArray是一种阵列几何无关的语音分离方法,旨在开发一种有效的分离方法,不受麦克风阵列几何结构的限制。
- 传统的语音分离方法常常依赖于排列无关的操作,如求和或注意力机制,以捕获空间信息,但这会导致高计算成本或空间信息利用不当。
- UniArray由三个关键组件构成:虚拟麦克风估计(VME)模块、特征提取与融合模块以及分层双路径分离器。
- VME模块确保在具有不同通道数量的阵列上的稳健性能。
- 特征提取与融合模块通过谱特征提取模块和空间词典学习(SDL)模块来提取和融合频率级特征,使分离器能够专注于使用融合的特征。
- 分层双路径分离器在时间轴和频率轴上建模特征依赖性,同时保持计算效率。
点此查看论文截图

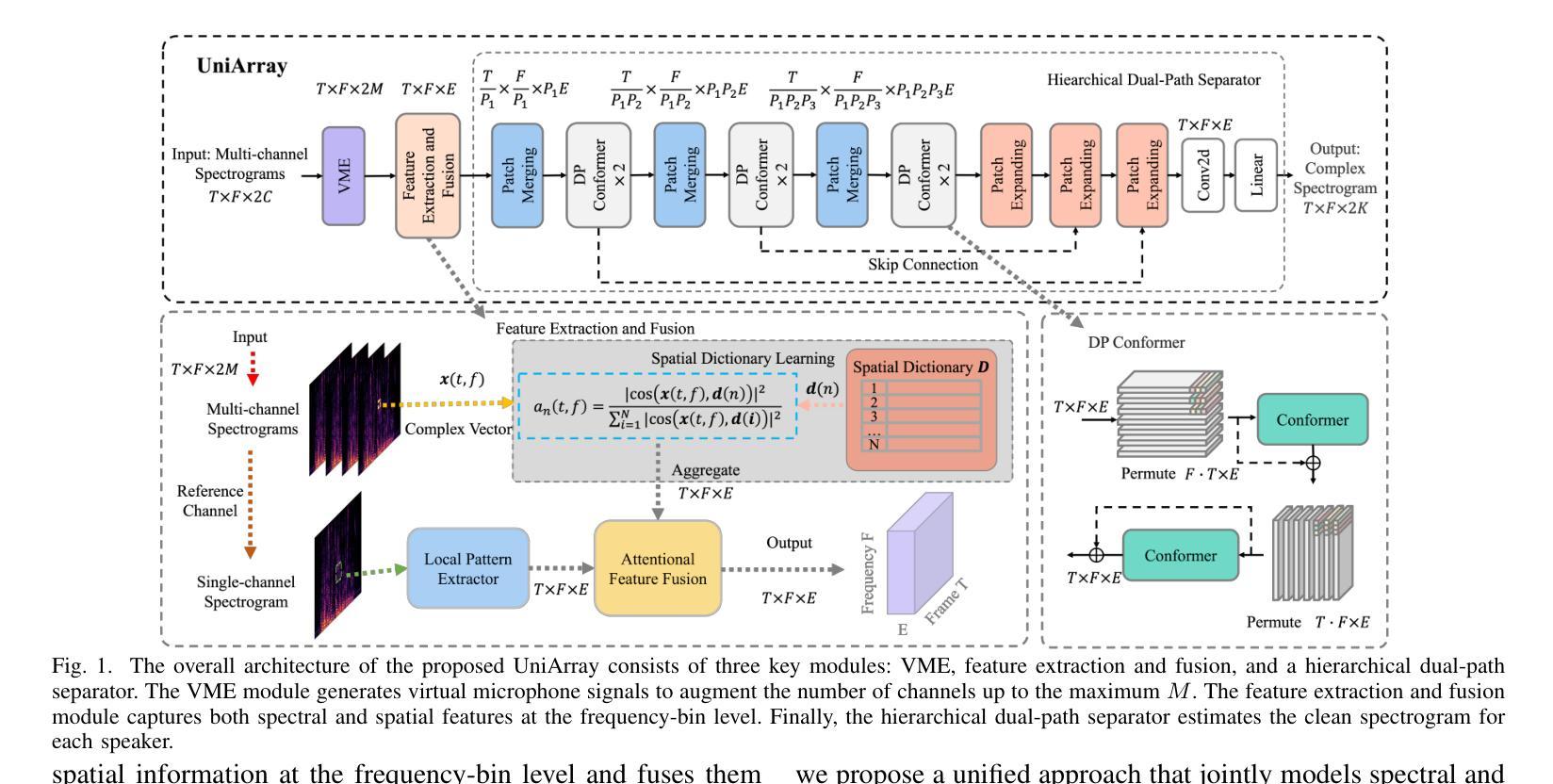
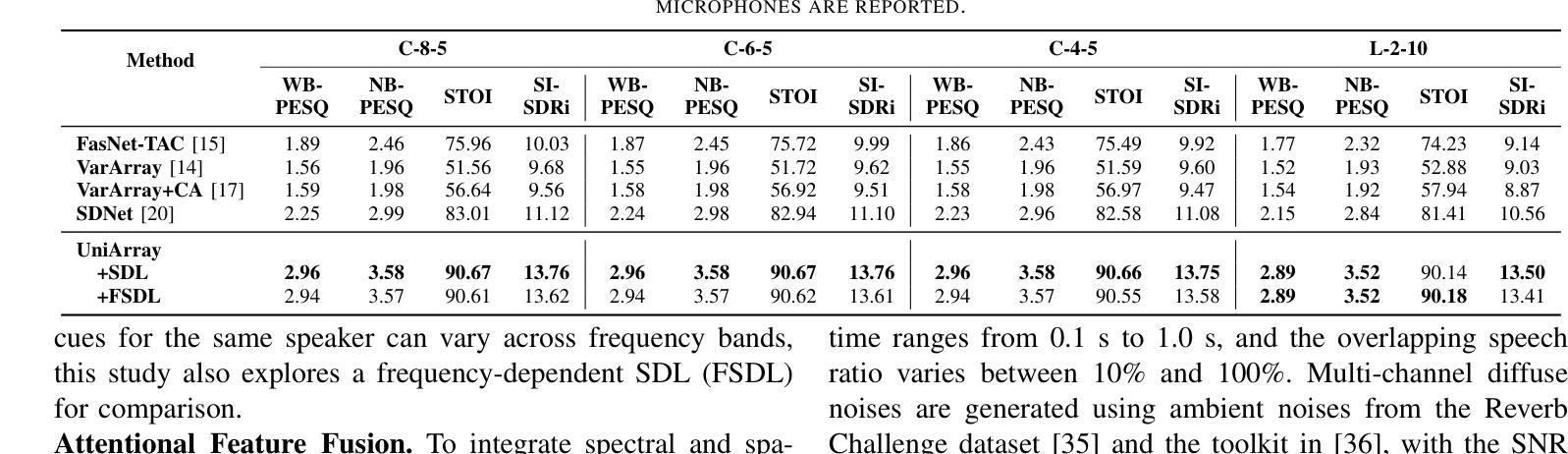
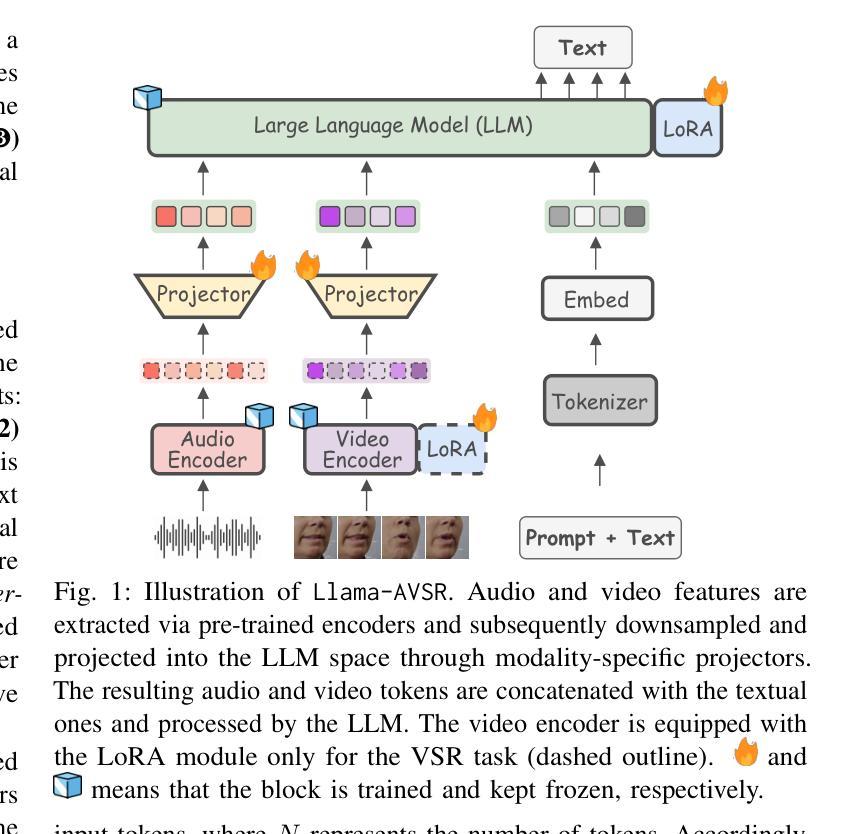
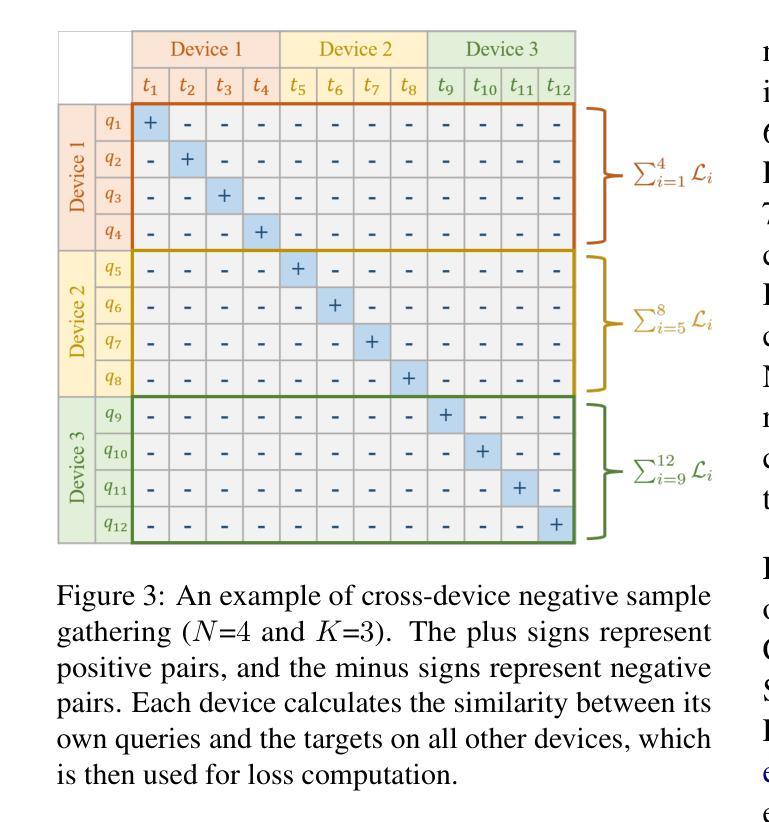
Large Language Models are Strong Audio-Visual Speech Recognition Learners
Authors:Umberto Cappellazzo, Minsu Kim, Honglie Chen, Pingchuan Ma, Stavros Petridis, Daniele Falavigna, Alessio Brutti, Maja Pantic
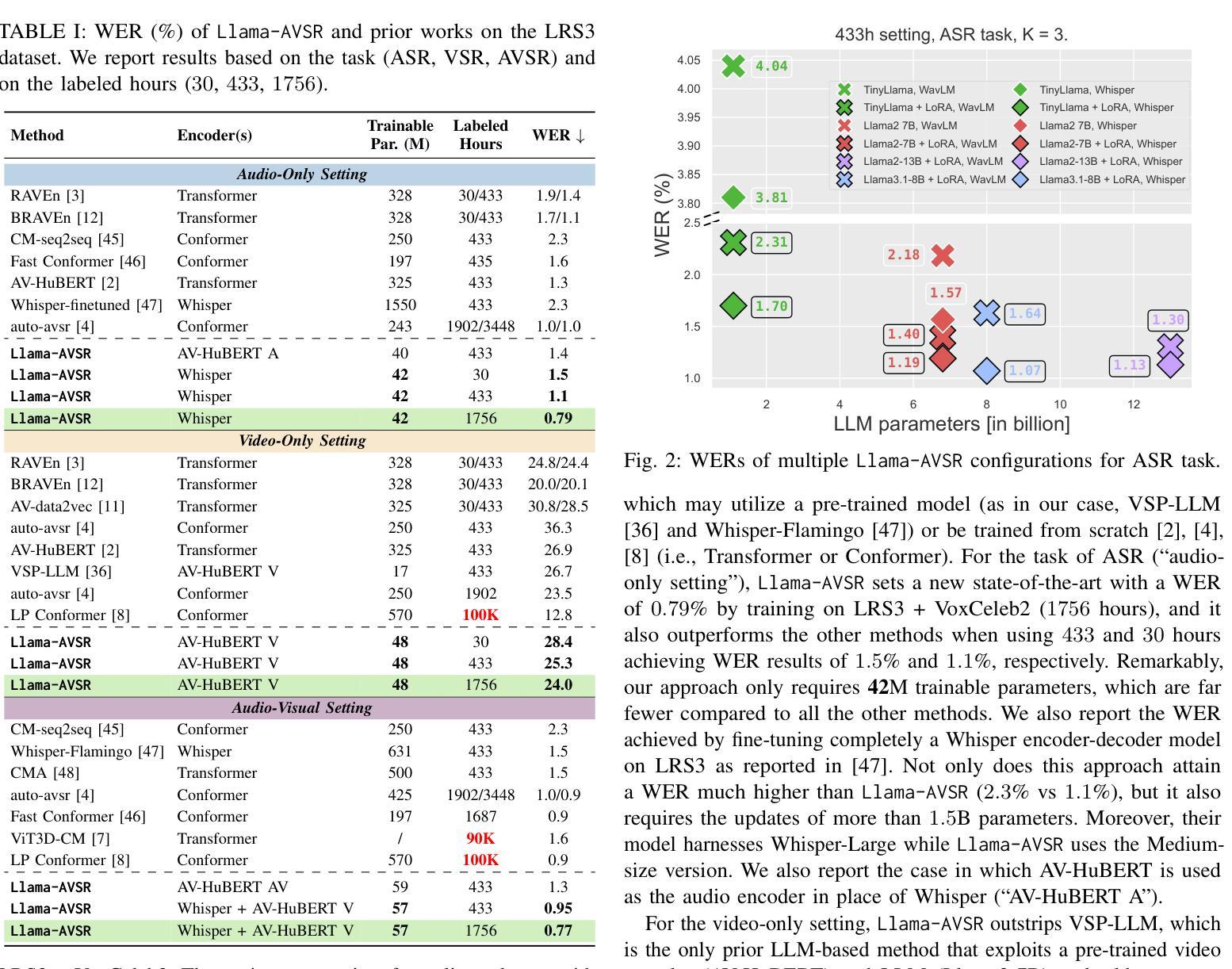
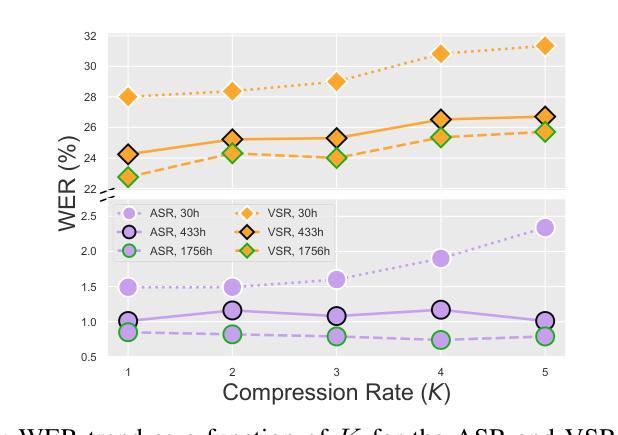
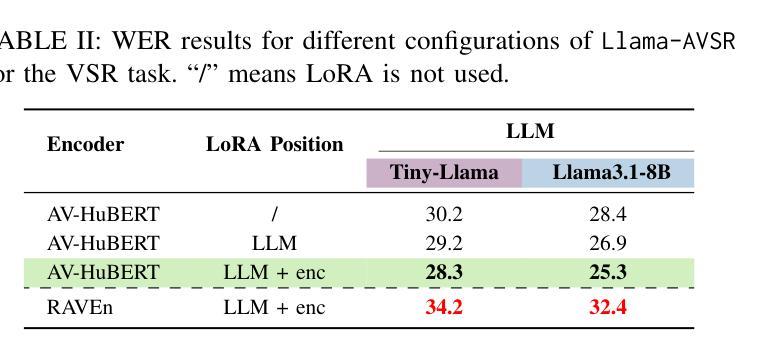
Multimodal large language models (MLLMs) have recently become a focal point of research due to their formidable multimodal understanding capabilities. For example, in the audio and speech domains, an LLM can be equipped with (automatic) speech recognition (ASR) abilities by just concatenating the audio tokens, computed with an audio encoder, and the text tokens to achieve state-of-the-art results. On the contrary, tasks like visual and audio-visual speech recognition (VSR/AVSR), which also exploit noise-invariant lip movement information, have received little or no attention. To bridge this gap, we propose Llama-AVSR, a new MLLM with strong audio-visual speech recognition capabilities. It leverages pre-trained audio and video encoders to produce modality-specific tokens which, together with the text tokens, are processed by a pre-trained LLM (e.g., Llama3.1-8B) to yield the resulting response in an auto-regressive fashion. Llama-AVSR requires a small number of trainable parameters as only modality-specific projectors and LoRA modules are trained whereas the multi-modal encoders and LLM are kept frozen. We evaluate our proposed approach on LRS3, the largest public AVSR benchmark, and we achieve new state-of-the-art results for the tasks of ASR and AVSR with a WER of 0.79% and 0.77%, respectively. To bolster our results, we investigate the key factors that underpin the effectiveness of Llama-AVSR: the choice of the pre-trained encoders and LLM, the efficient integration of LoRA modules, and the optimal performance-efficiency trade-off obtained via modality-aware compression rates.
多模态大型语言模型(MLLMs)最近由于其强大的多模态理解能力而成为研究的热点。例如,在音频和语音领域,只需将音频编码器计算的音频令牌与文本令牌连接,就可以为大语言模型配备(自动)语音识别(ASR)能力,从而实现最新技术成果。然而,利用噪声不变唇动信息的视觉和视听语音识别(VSR/AVSR)任务却被关注甚少或未受关注。为了填补这一空白,我们提出了Llama-AVSR,这是一种具有强大视听语音识别能力的新型多模态大型语言模型。它利用预训练的音频和视频编码器来生成特定模态的令牌,这些令牌与文本令牌一起由预训练的大型语言模型(例如Llama3.1-8B)进行处理,以自动生成响应。Llama-AVSR只需要少量的可训练参数,因为只训练特定模态的投影器和LoRA模块,而多模态编码器和大型语言模型保持冻结状态。我们在LRS3这一最大的公开AVSR基准测试集上评估了我们提出的方法,并在ASR和AVSR任务上取得了新的最新技术成果,分别达到了0.79%和0.77%的字错误率(WER)。为了加强我们的结果,我们研究了支撑Llama-AVSR有效性的关键因素:预训练编码器和大型语言模型的选择、LoRA模块的有效集成以及通过模态感知压缩率实现性能与效率的平衡优化。
论文及项目相关链接
PDF Accepted for publication at ICASSP 2025. The code and checkpoints are available here: https://github.com/umbertocappellazzo/Llama-AVSR
Summary
多模态大型语言模型(MLLMs)因其强大的多模态理解力而成为研究焦点。通过在音频和语音领域配备自动语音识别(ASR)能力,LLM能取得先进技术成果。然而,视觉和音视频语音识别的相关研究却鲜有关注。为了填补这一空白,我们提出了具备强大音视频语音识别能力的Llama-AVSR。它利用预训练的音频和视频编码器产生特定模态的标记,与文本标记一起被预训练的LLM处理,以生成响应。我们的方法只需训练少量的参数,仅在模态特定投影器和LoRA模块上进行训练,而多模态编码器和LLM则保持冻结。在LRS3这一最大的公开音视频语音识别基准测试上评估我们的方法,取得了新的最佳结果,单词错误率分别为ASR的0.79%和AVSR的0.77%。我们还探讨了支撑Llama-AVSR有效性的关键因素:预训练编码器和LLM的选择、LoRA模块的有效集成以及通过模态感知压缩率获得的最优性能效率权衡。
Key Takeaways
- 多模态大型语言模型(MLLMs)具有强大的多模态理解力,已成为研究焦点。
- LLMs可通过结合音频和文本标记,实现先进的自动语音识别(ASR)能力。
- 视觉和音视频语音识别(VSR/AVSR)等任务尚未得到充分关注。
- Llama-AVSR是一个新的MLLM,具有强大的音视频语音识别能力。
- Llama-AVSR仅需训练少量参数,借助预训练编码器和LLM实现高性能。
- 在LRS3基准测试中,Llama-AVSR取得了ASR和AVSR的新最佳结果。
点此查看论文截图