⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-11 更新
DiVISe: Direct Visual-Input Speech Synthesis Preserving Speaker Characteristics And Intelligibility
Authors:Yifan Liu, Yu Fang, Zhouhan Lin
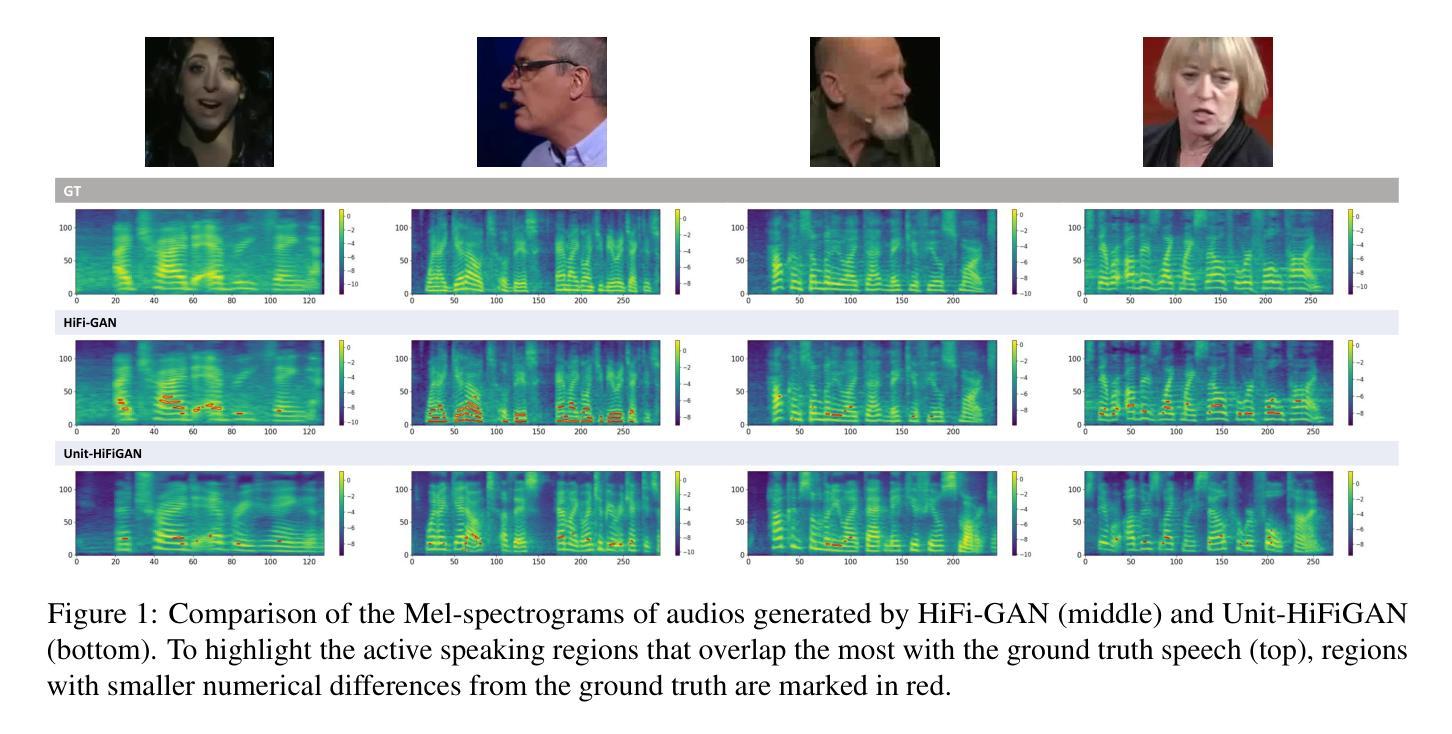
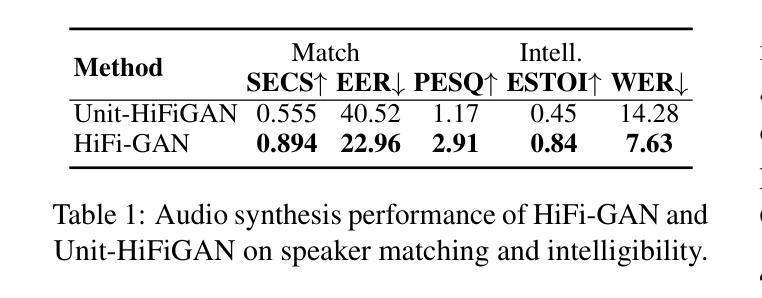
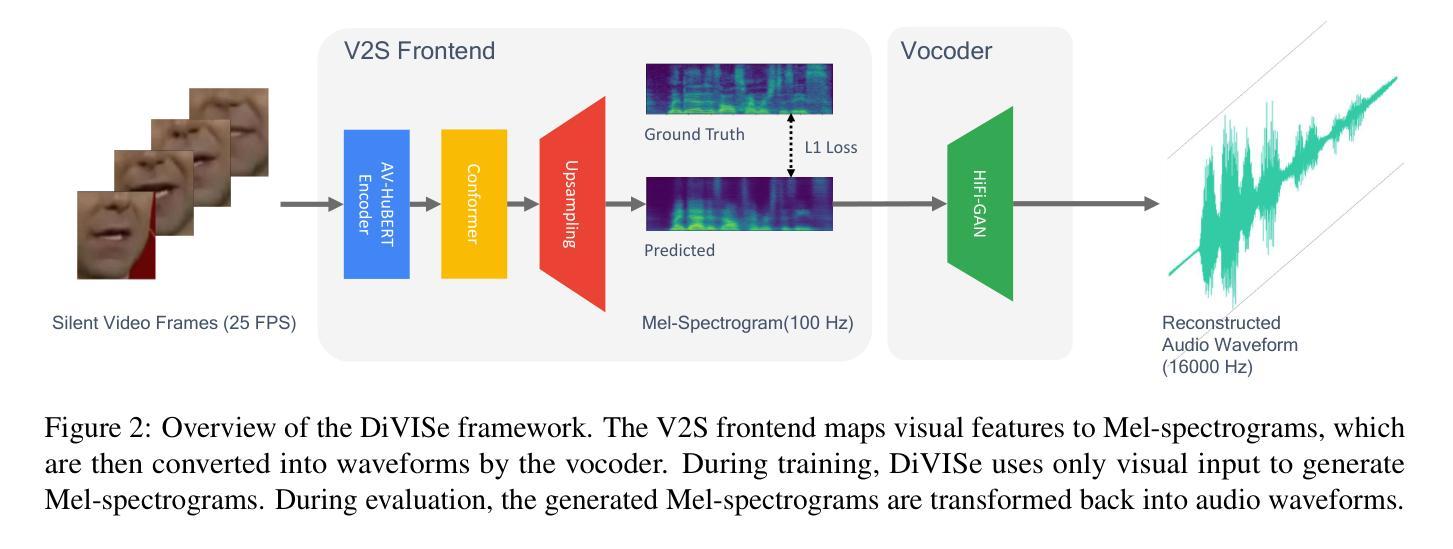
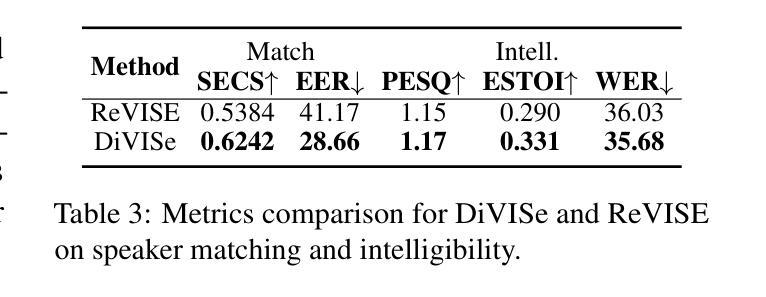
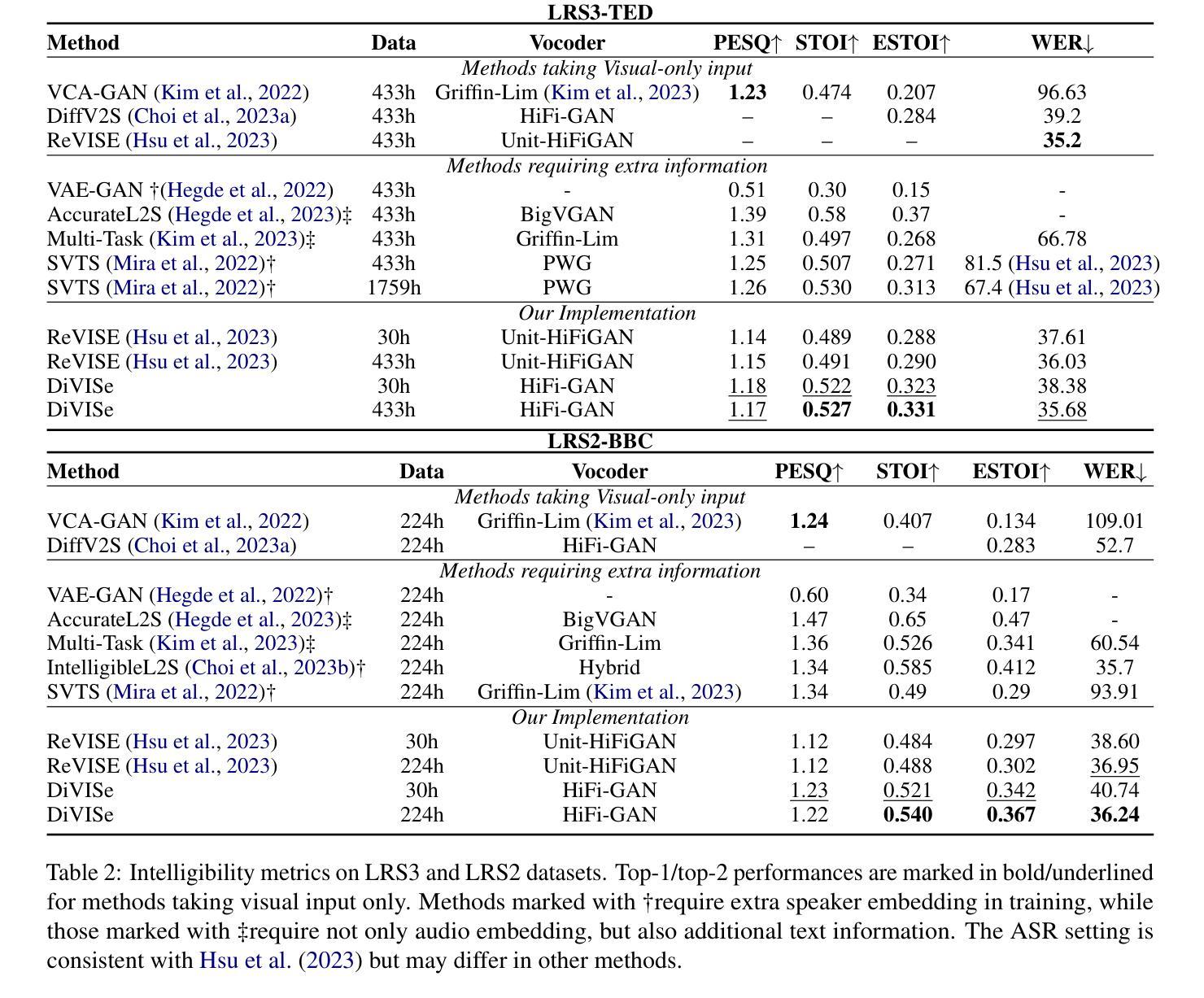
Video-to-speech (V2S) synthesis, the task of generating speech directly from silent video input, is inherently more challenging than other speech synthesis tasks due to the need to accurately reconstruct both speech content and speaker characteristics from visual cues alone. Recently, audio-visual pre-training has eliminated the need for additional acoustic hints in V2S, which previous methods often relied on to ensure training convergence. However, even with pre-training, existing methods continue to face challenges in achieving a balance between acoustic intelligibility and the preservation of speaker-specific characteristics. We analyzed this limitation and were motivated to introduce DiVISe (Direct Visual-Input Speech Synthesis), an end-to-end V2S model that predicts Mel-spectrograms directly from video frames alone. Despite not taking any acoustic hints, DiVISe effectively preserves speaker characteristics in the generated audio, and achieves superior performance on both objective and subjective metrics across the LRS2 and LRS3 datasets. Our results demonstrate that DiVISe not only outperforms existing V2S models in acoustic intelligibility but also scales more effectively with increased data and model parameters. Code and weights can be found at https://github.com/PussyCat0700/DiVISe.
视频到语音(V2S)合成,即从无声视频输入中直接生成语音的任务,由于其需要从视觉线索中准确重建语音内容和说话人特征,因此本质上比其他语音合成任务更具挑战性。最近,视听预训练已经不需要在V2S中依赖额外的声音提示,以前的方法经常依靠这些声音提示来保证训练收敛。但是,即使有预训练,现有的方法仍然面临在声音清晰度和保持说话人特定特征之间取得平衡的难题。我们分析了这一局限性,并受到启发,推出了DiVISe(直接视觉输入语音合成)。这是一个端到端的V2S模型,能够从视频帧直接预测梅尔频谱图。尽管不需要任何声音提示,DiVISe在生成的音频中有效地保持了说话人的特征,并且在LRS2和LRS3数据集上实现了客观和主观指标的优异性能。我们的结果表明,DiVISe不仅在声音清晰度上超越了现有的V2S模型,而且在数据和模型参数增加时更加有效地扩展。代码和权重可以在https://github.com/PussyCat0700/DiVISe找到。
论文及项目相关链接
PDF to be published in NAACL 25
摘要
视频到语音(V2S)合成是从无声视频输入生成语音的任务,由于其需要从视觉线索中准确重建语音内容和说话人特征,因此比其他语音合成任务更具挑战性。最近,视听预训练已经不需要V2S中额外的声音提示,以前的方法通常依赖于这些提示来保证训练收敛。然而,即使有预训练,现有方法仍然面临在声音清晰度和保持说话人特定特征之间取得平衡的难题。通过分析这一局限,我们引入了DiVISe(Direct Visual-Input Speech Synthesis)模型,这是一种端到端的V2S模型,能够从视频帧直接预测梅尔频谱图。尽管没有使用任何声音提示,DiVISe在生成的音频中有效地保持了说话人的特征,并在LRS2和LRS3数据集上实现了客观和主观指标的优异表现。结果表明,DiVISe不仅在声音清晰度上优于现有的V2S模型,而且在数据和模型参数增加时更有效地扩展。代码和权重可以在https://github.com/PussyCat0700/DiVISe找到。
关键见解
- 视频到语音(V2S)合成是生成语音的直接无声视频输入任务,具有挑战性。
- 音频-视觉预训练消除了对V2S中额外声音提示的需要。
- 现有方法面临平衡声音清晰度和保持说话人特定特征的挑战。
- DiVISe是一个端到端的V2S模型,能从视频帧直接预测梅尔频谱图。
- DiVISe在生成的音频中有效保持说话人特征。
- DiVISe在LRS2和LRS3数据集上实现了优异表现,优于现有V2S模型。
- DiVISe在数据和模型参数增加时更有效地扩展。
点此查看论文截图

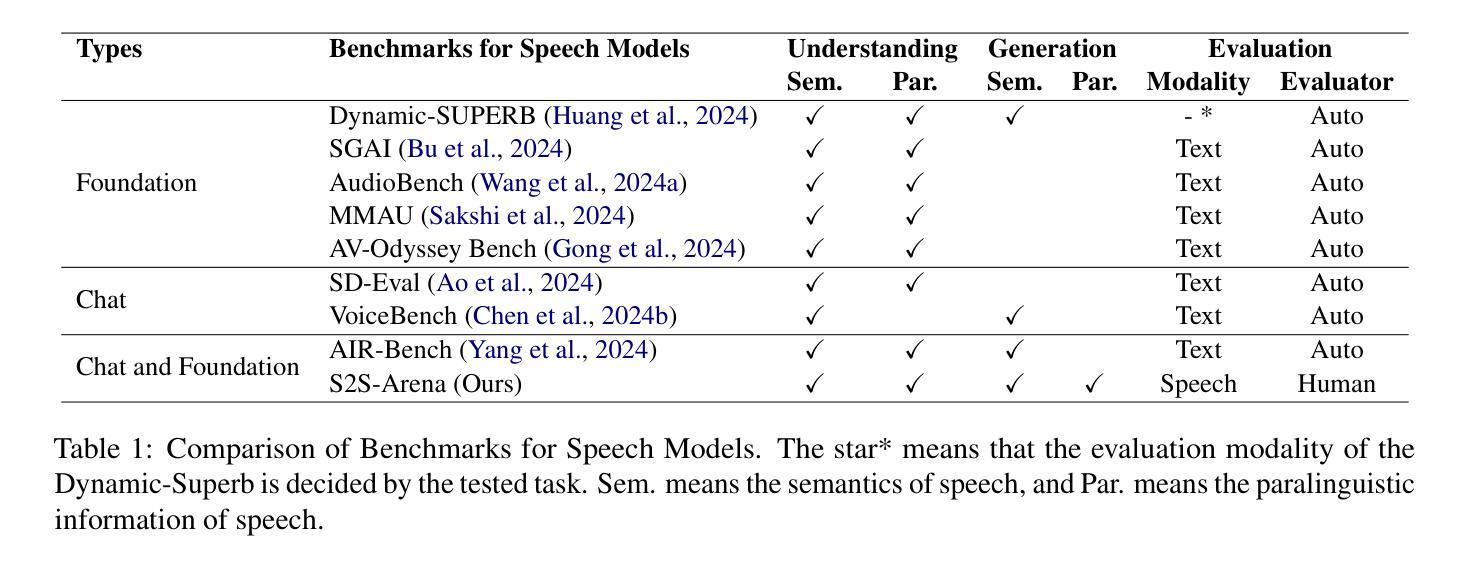
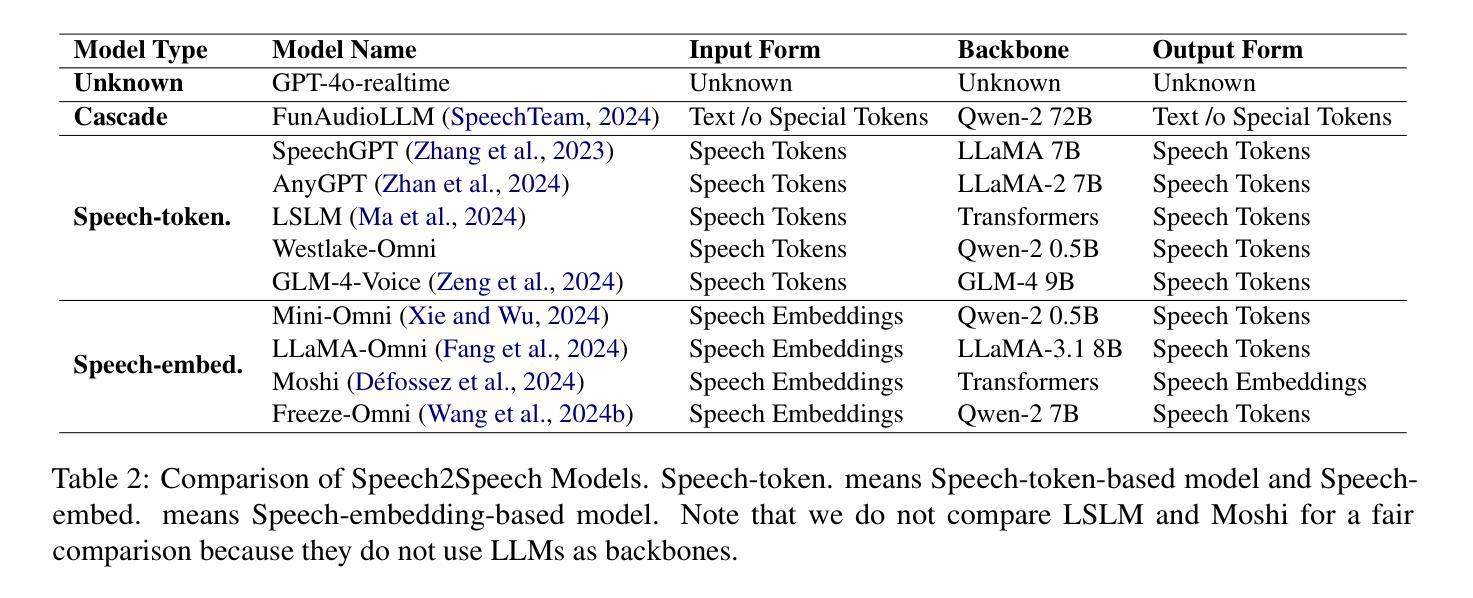
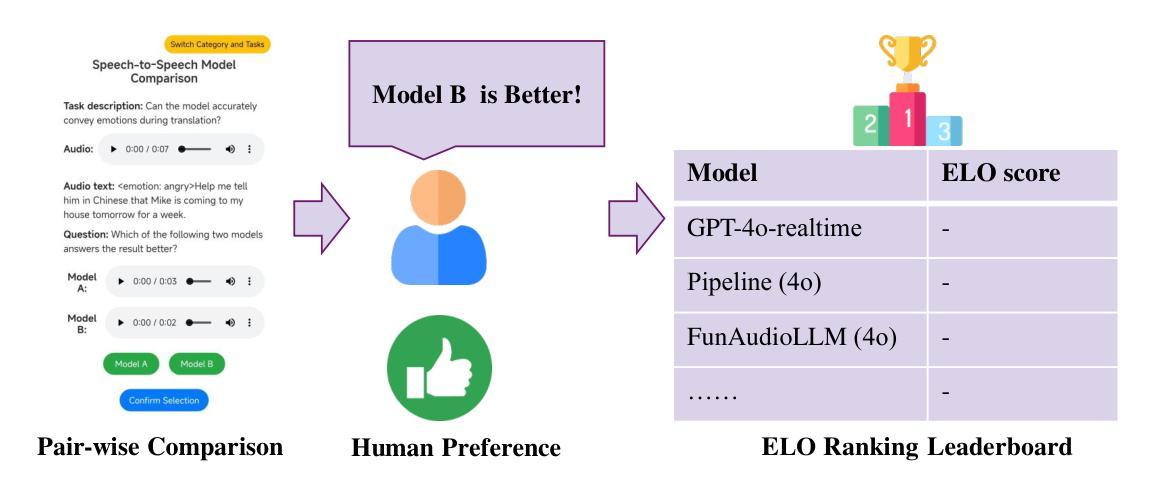
S2S-Arena, Evaluating Speech2Speech Protocols on Instruction Following with Paralinguistic Information
Authors:Feng Jiang, Zhiyu Lin, Fan Bu, Yuhao Du, Benyou Wang, Haizhou Li
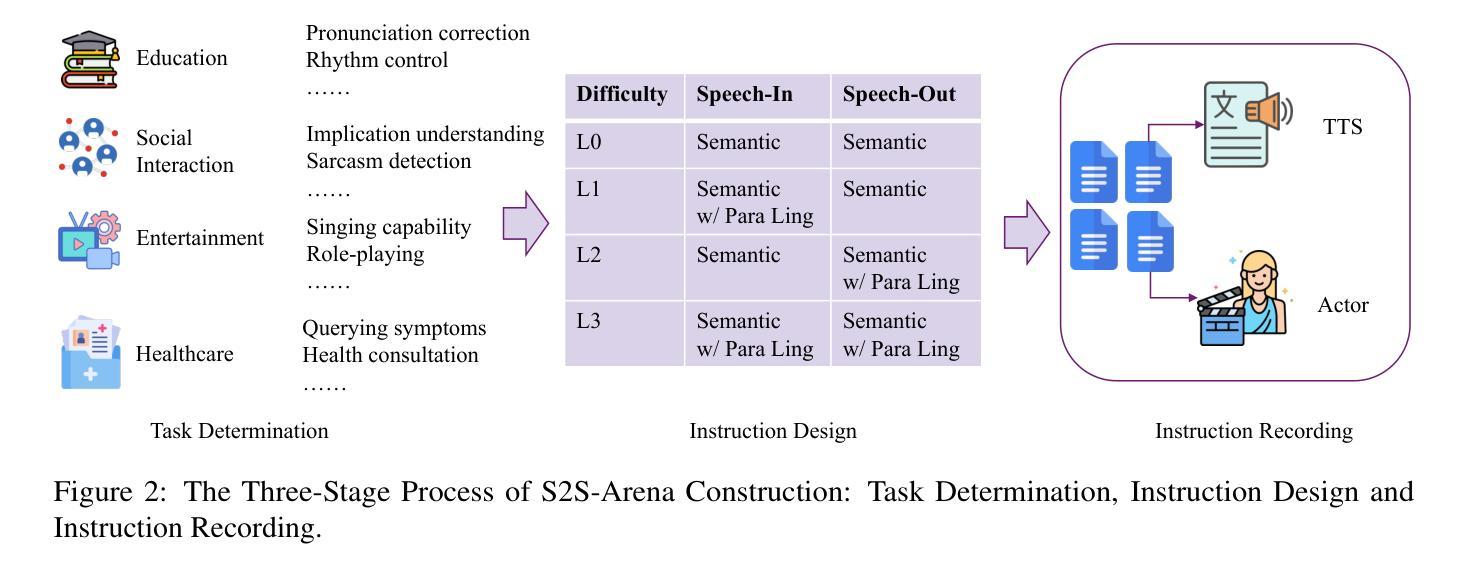
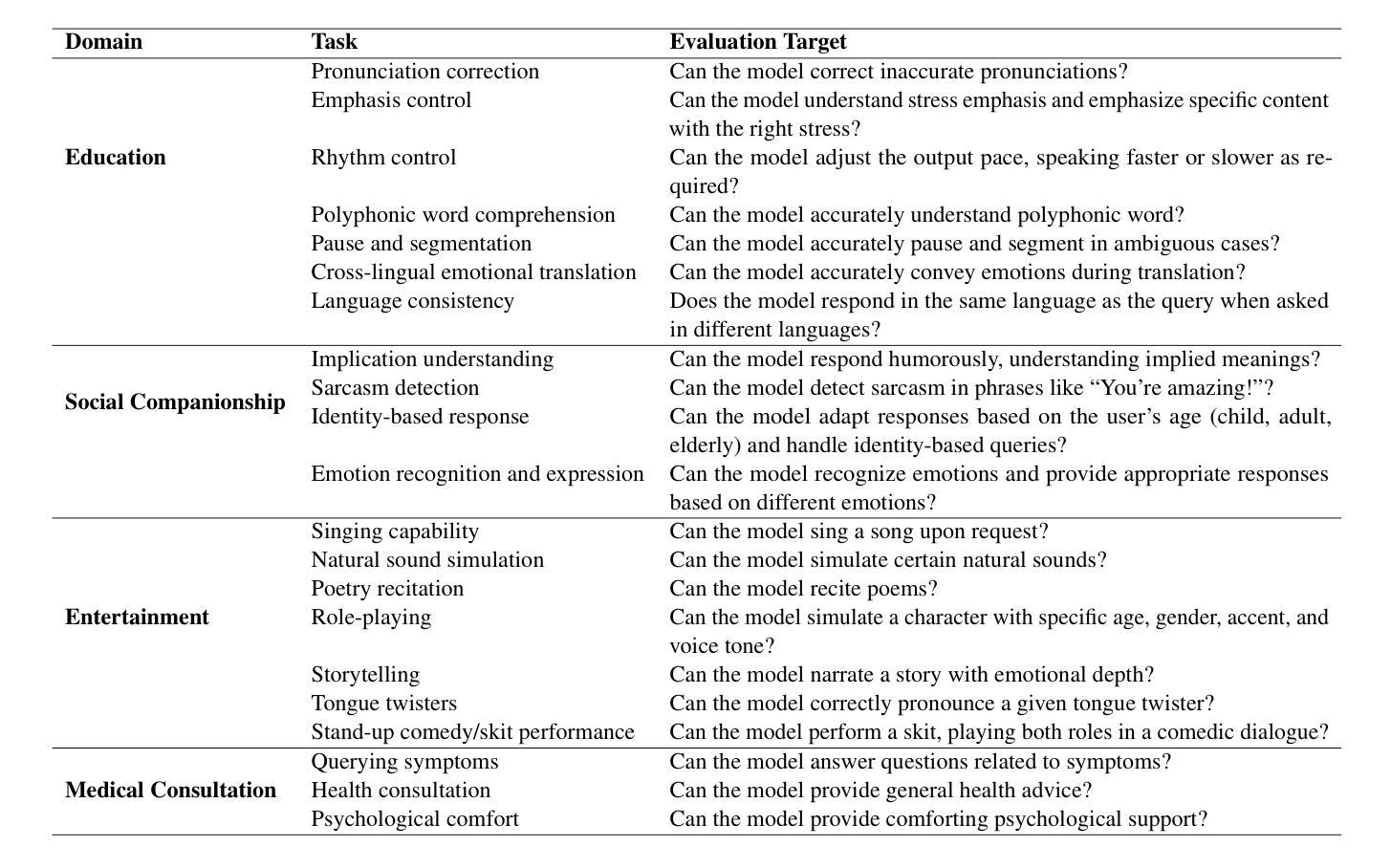
The rapid development of large language models (LLMs) has brought significant attention to speech models, particularly recent progress in speech2speech protocols supporting speech input and output. However, the existing benchmarks adopt automatic text-based evaluators for evaluating the instruction following ability of these models lack consideration for paralinguistic information in both speech understanding and generation. To address these issues, we introduce S2S-Arena, a novel arena-style S2S benchmark that evaluates instruction-following capabilities with paralinguistic information in both speech-in and speech-out across real-world tasks. We design 154 samples that fused TTS and live recordings in four domains with 21 tasks and manually evaluate existing popular speech models in an arena-style manner. The experimental results show that: (1) in addition to the superior performance of GPT-4o, the speech model of cascaded ASR, LLM, and TTS outperforms the jointly trained model after text-speech alignment in speech2speech protocols; (2) considering paralinguistic information, the knowledgeability of the speech model mainly depends on the LLM backbone, and the multilingual support of that is limited by the speech module; (3) excellent speech models can already understand the paralinguistic information in speech input, but generating appropriate audio with paralinguistic information is still a challenge.
随着大型语言模型(LLM)的快速发展,语音模型已经引起了广泛关注,尤其是在支持语音输入和输出的speech2speech协议方面的最新进展。然而,现有的基准测试采用基于自动文本的评价器来评估这些模型的指令遵循能力,忽视了语音理解和生成中的副语言信息。为了解决这些问题,我们引入了S2S-Arena,这是一个新型的arena风格S2S基准测试,它能在真实世界任务中评估指令遵循能力并考虑语音输入和输出的副语言信息。我们设计了融合文本合成语音(TTS)和现场录音的四个领域的21项任务的154个样本,并以arena风格的方式手动评估了现有的热门语音模型。实验结果表明:(1)除了GPT-4o的卓越性能外,级联语音识别、大型语言模型和文本合成语音的语音模型在speech2speech协议中的文本语音对齐后,其表现优于联合训练模型;(2)考虑副语言信息时,语音模型的知识能力主要取决于大型语言模型的主干,但其多语言支持受限于语音模块;(3)优秀的语音模型已经能够理解语音输入中的副语言信息,但生成带有副语言信息的适当音频仍然是一个挑战。
论文及项目相关链接
Summary
本文介绍了大型语言模型(LLMs)的快速发展对语音模型的影响,特别是语音到语音协议在支持语音输入和输出方面的最新进展。现有基准测试采用自动文本评估器评估模型的指令遵循能力,忽略了语音理解和生成中的副语言信息。为解决这些问题,本文引入了S2S-Arena,一种新型的S2S基准测试,旨在评估模型在真实任务中的指令遵循能力和副语言信息的使用能力。实验结果表明,GPT-4o等模型的性能优越,且级联ASR、LLM和TTS的语音模型在语音到语音协议中的文本语音对齐后表现优于联合训练模型;在考虑副语言信息的情况下,语音模型的知识性主要取决于LLM主干,但其多语言支持受限于语音模块;优秀的语音模型已能理解语音输入中的副语言信息,但生成带有副语言信息的适当音频仍是一个挑战。
Key Takeaways
- 大型语言模型(LLMs)的快速发展促使了对语音模型的关注增加,特别是其在新兴的语音到语音协议方面的应用。这些协议支持语音输入和输出功能。
- 现有的基准测试未能充分考虑到副语言信息的重要性,无法全面评估模型的指令遵循能力。为此,提出了名为S2S-Arena的新型基准测试。
- 实验结果显示GPT-4o等模型性能优越,而采用级联ASR、LLM和TTS技术的语音模型在文本语音对齐后表现优于联合训练模型。这表明语音模型的性能可以通过特定的技术增强。
- 副语言信息对语音模型的知识性至关重要,这主要取决于LLM主干的性能。同时,多语言支持受限于语音模块的性能。这表明未来的研究需要关注如何更好地整合不同模块以支持多种语言和副语言信息。
点此查看论文截图