⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-11 更新
Incentivizing Multi-Tenant Split Federated Learning for Foundation Models at the Network Edge
Authors:Songyuan Li, Jia Hu, Geyong Min, Haojun Huang
Foundation models (FMs) such as GPT-4 exhibit exceptional generative capabilities across diverse downstream tasks through fine-tuning. Split Federated Learning (SFL) facilitates privacy-preserving FM fine-tuning on resource-constrained local devices by offloading partial FM computations to edge servers, enabling device-edge synergistic fine-tuning. Practical edge networks often host multiple SFL tenants to support diversified downstream tasks. However, existing research primarily focuses on single-tenant SFL scenarios, and lacks tailored incentive mechanisms for multi-tenant settings, which are essential to effectively coordinate self-interested local devices for participation in various downstream tasks, ensuring that each SFL tenant’s distinct FM fine-tuning requirements (e.g., FM types, performance targets, and fine-tuning deadlines) are met. To address this gap, we propose a novel Price-Incentive Mechanism (PRINCE) that guides multiple SFL tenants to offer strategic price incentives, which solicit high-quality device participation for efficient FM fine-tuning. Specifically, we first develop a bias-resilient global SFL model aggregation scheme to eliminate model biases caused by independent device participation. We then derive a rigorous SFL convergence bound to evaluate the contributions of heterogeneous devices to FM performance improvements, guiding the incentive strategies of SFL tenants. Furthermore, we model inter-tenant device competition as a congestion game for Stackelberg equilibrium (SE) analysis, deriving each SFL tenant’s optimal incentive strategy. Extensive simulations involving four representative SFL tenant types (ViT, BERT, Whisper, and LLaMA) across diverse data modalities (text, images, and audio) demonstrate that PRINCE accelerates FM fine-tuning by up to 3.07x compared to state-of-the-art approaches, while consistently meeting fine-tuning performance targets.
模型(FMs)如GPT-4通过微调在多种下游任务中展现出卓越的生成能力。分布式联邦学习(SFL)通过将部分FM计算任务转移到边缘服务器,便于资源受限的本地设备进行隐私保护的FM微调,实现了设备边缘协同微调。实际边缘网络中经常部署多个SFL租户以支持多样化的下游任务。然而,现有研究主要集中在单租户SFL场景上,缺乏针对多租户环境的激励机制,这些机制对于协调具有自我利益的地方设备参与各种下游任务至关重要,确保满足每个SFL租户独特的FM微调要求(例如FM类型、性能目标和微调截止日期)。为解决这一差距,我们提出了一种新的价格激励机制(PRINCE),引导多个SFL租户提供战略价格激励,激励高质量的设备参与高效的FM微调。具体来说,我们首先开发了一种抗偏差的SFL全局模型聚合方案,以消除独立设备参与导致的模型偏差。然后,我们得出了严格的SFL收敛界限,以评估异构设备对FM性能改进的贡献,指导SFL租户的激励机制。此外,我们将跨租户设备竞争建模为斯塔克尔伯格均衡(SE)分析的拥堵博弈,得出每个SFL租户的最佳激励策略。涉及四种代表性SFL租户类型(ViT、BERT、Whisper和LLaMA)的广泛模拟,跨越多种数据模式(文本、图像和音频)显示,与最新方法相比,PRINCE将FM微调速度提高了高达3.07倍,同时始终满足微调性能目标。
论文及项目相关链接
PDF Index Terms: Foundation models, Edge computing, Split federated learning, Multi-tenant system, Incentive mechanism
Summary
分裂联邦学习(SFL)可将部分模型计算任务转移至边缘服务器进行协同微调。在多租户场景中,为解决个性化需求的协调问题,提出价格激励机制(PRINCE),通过战略价格激励引导高质量设备参与FM微调。模拟结果显示,PRINCE可加速FM微调速度,同时满足性能目标。
Key Takeaways
- 分裂联邦学习(SFL)允许在资源受限的本地设备上实现隐私保护的FM微调,通过将部分计算任务转移到边缘服务器实现设备边缘协同微调。
- 现有研究主要关注单租户SFL场景,缺乏多租户场景下的激励机制。
- PRINCE机制解决了多租户SFL中的协调问题,通过提供战略价格激励,鼓励高质量设备参与FM微调。
- PRINCE实现了偏差抵抗的SFL模型聚合方案,消除了独立设备参与导致的模型偏差。
- 通过严格的SFL收敛界限评估异质设备对FM性能改进的贡献,指导SFL租户的激励策略。
- 将租户间设备竞争建模为斯塔克尔伯格均衡的拥堵游戏,推导每个SFL租户的最优激励策略。
点此查看论文截图

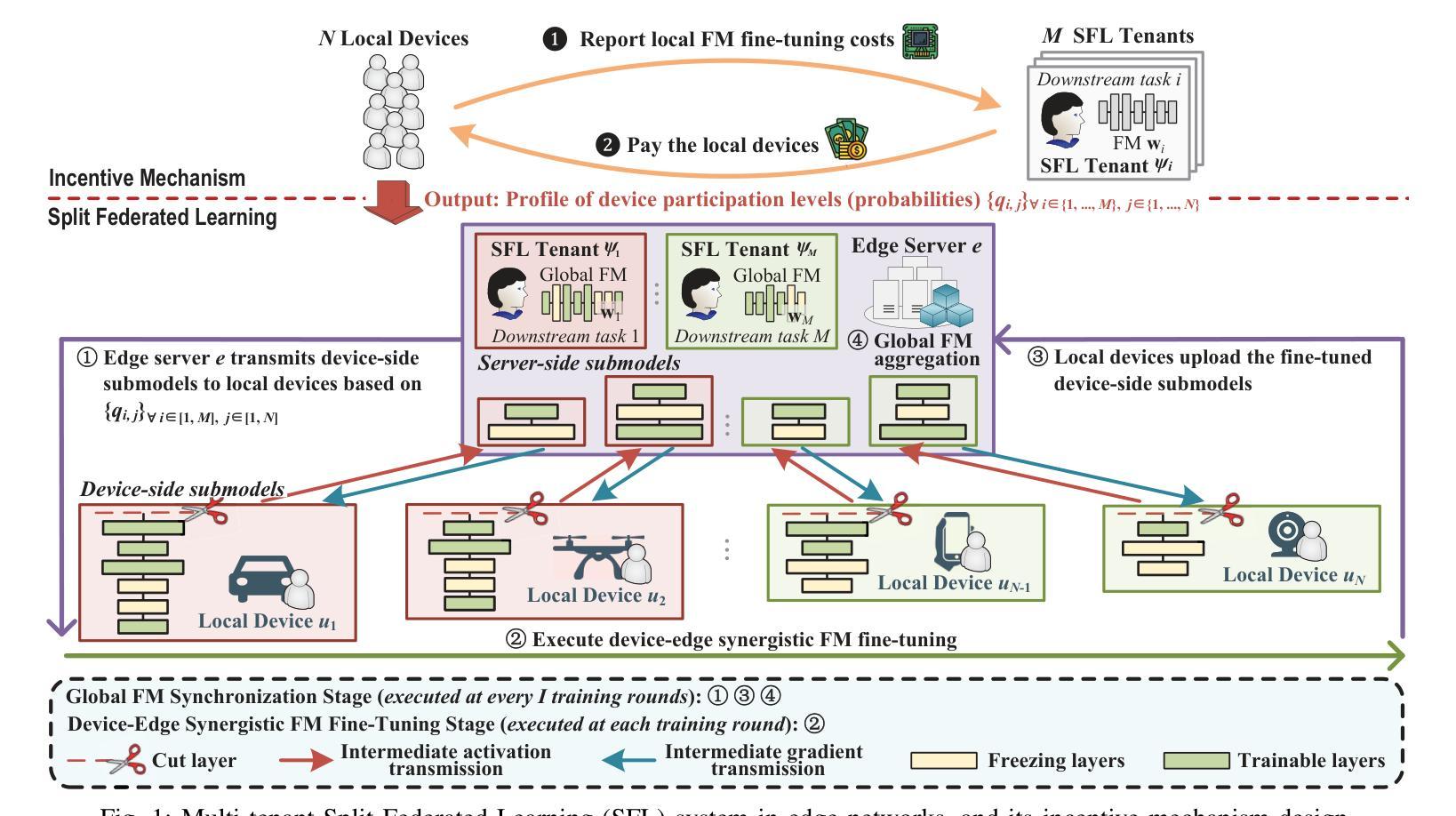
Rethinking Few-Shot Medical Image Segmentation by SAM2: A Training-Free Framework with Augmentative Prompting and Dynamic Matching
Authors:Haiyue Zu, Jun Ge, Heting Xiao, Jile Xie, Zhangzhe Zhou, Yifan Meng, Jiayi Ni, Junjie Niu, Linlin Zhang, Li Ni, Huilin Yang
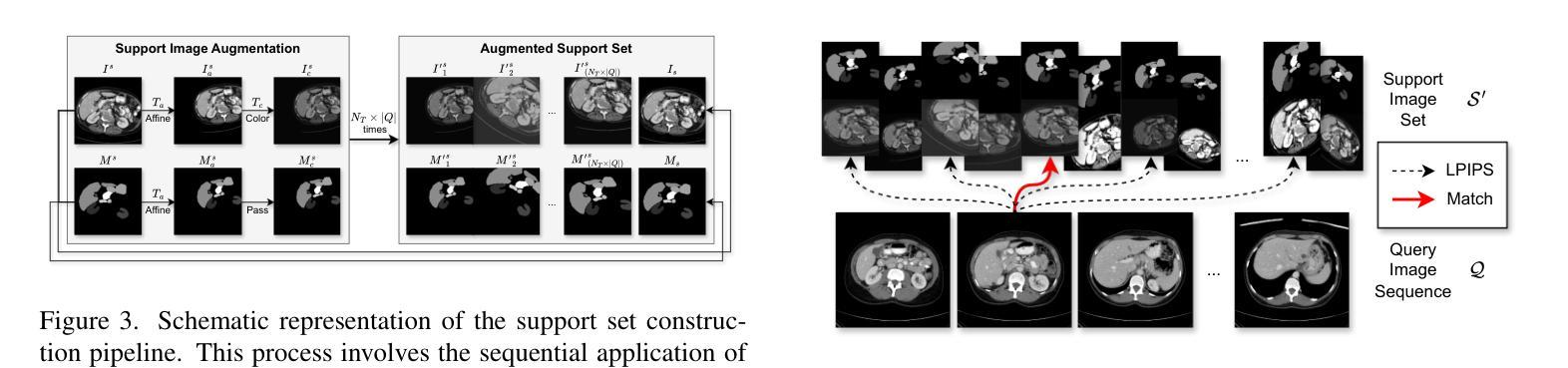
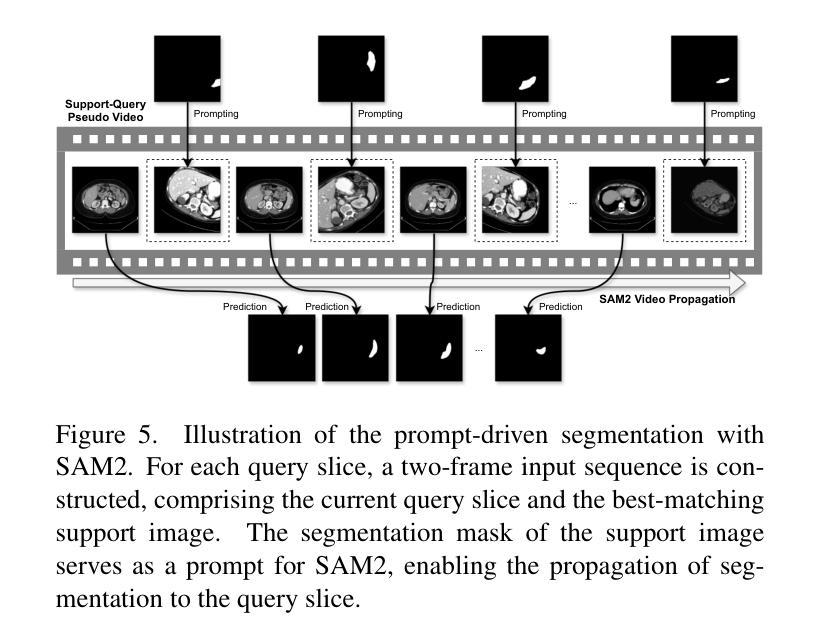
The reliance on large labeled datasets presents a significant challenge in medical image segmentation. Few-shot learning offers a potential solution, but existing methods often still require substantial training data. This paper proposes a novel approach that leverages the Segment Anything Model 2 (SAM2), a vision foundation model with strong video segmentation capabilities. We conceptualize 3D medical image volumes as video sequences, departing from the traditional slice-by-slice paradigm. Our core innovation is a support-query matching strategy: we perform extensive data augmentation on a single labeled support image and, for each frame in the query volume, algorithmically select the most analogous augmented support image. This selected image, along with its corresponding mask, is used as a mask prompt, driving SAM2’s video segmentation. This approach entirely avoids model retraining or parameter updates. We demonstrate state-of-the-art performance on benchmark few-shot medical image segmentation datasets, achieving significant improvements in accuracy and annotation efficiency. This plug-and-play method offers a powerful and generalizable solution for 3D medical image segmentation.
在医学图像分割中,对大量有标签数据集的依赖构成了一个重大挑战。少样本学习提供了潜在的解决方案,但现有方法通常仍需要大量训练数据。本文提出了一种利用Segment Anything Model 2(SAM2)的新方法,SAM2是一个具有强大视频分割能力的视觉基础模型。我们将3D医学图像体积概念化为视频序列,摒弃了传统的逐片处理模式。我们的核心创新之处在于支持查询匹配策略:我们对单个有标签的支持图像进行广泛的数据增强,并针对查询体积中的每一帧,算法选择最相似的增强支持图像。所选图像及其相应的掩膜被用作掩膜提示,驱动SAM2的视频分割。这种方法完全避免了模型再训练或参数更新。我们在基准的少样本医学图像分割数据集上展示了最先进的性能,在准确性和注释效率方面取得了显著改进。这种即插即用的方法为3D医学图像分割提供了强大且通用的解决方案。
论文及项目相关链接
Summary
医疗图像分割对大量标注数据集的依赖构成了一大挑战。本文提出了一种利用Segment Anything Model 2(SAM2)的新方法,将3D医学图像体积概念化为视频序列,并采用支持查询匹配策略进行少量学习的医学图像分割。该方法避免了模型重新训练和参数更新,实现了在基准少量医疗图像分割数据集上的卓越性能,显著提高了准确性和标注效率,为3D医学图像分割提供了强大且通用的解决方案。
Key Takeaways
- 该论文提出了一种新的方法来解决医疗图像分割中依赖大量标注数据集的问题。
- 方法利用Segment Anything Model 2(SAM2)进行视频分割的强大功能。
- 论文将3D医学图像体积概念化为视频序列,改变了传统的逐片处理模式。
- 核心创新是支持查询匹配策略,通过对单个标注的支持图像进行大量数据增强,并算法选择最相似的增强支持图像。
- 所选图像及其对应的蒙版被用作蒙版提示,驱动SAM2的视频分割。
- 方法实现了在基准少量医疗图像分割数据集上的卓越性能,显著提高了准确性和标注效率。
点此查看论文截图

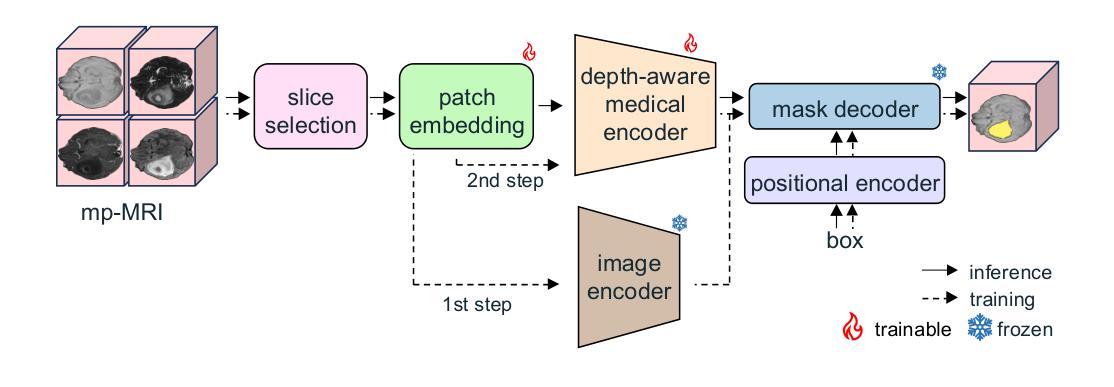
GBT-SAM: A Parameter-Efficient Depth-Aware Model for Generalizable Brain tumour Segmentation on mp-MRI
Authors:Cecilia Diana-Albelda, Roberto Alcover-Couso, Álvaro García-Martín, Jesus Bescos, Marcos Escudero-Viñolo
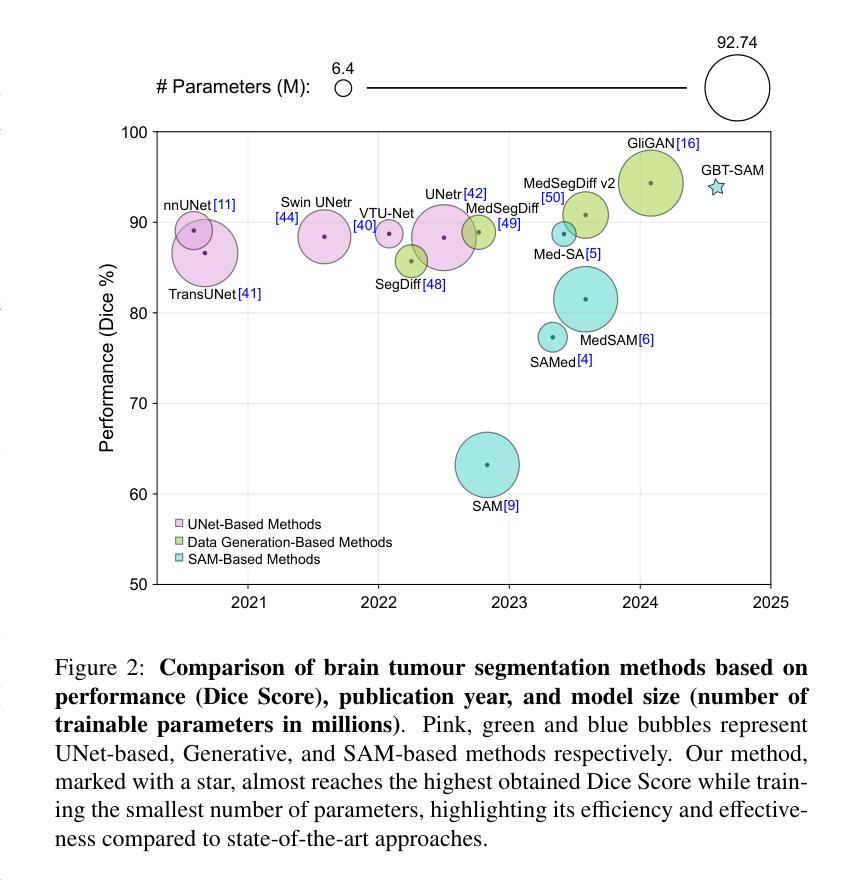
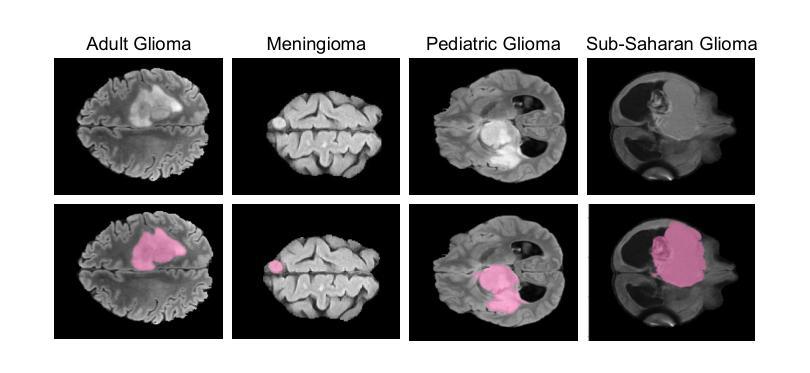
Gliomas are brain tumours that stand out for their highly lethal and aggressive nature, which demands a precise approach in their diagnosis. Medical image segmentation plays a crucial role in the evaluation and follow-up of these tumours, allowing specialists to analyse their morphology. However, existing methods for automatic glioma segmentation often lack generalization capability across other brain tumour domains, require extensive computational resources, or fail to fully utilize the multi-parametric MRI (mp-MRI) data used to delineate them. In this work, we introduce GBT-SAM, a novel Generalizable Brain Tumour (GBT) framework that extends the Segment Anything Model (SAM) to brain tumour segmentation tasks. Our method employs a two-step training protocol: first, fine-tuning the patch embedding layer to process the entire mp-MRI modalities, and second, incorporating parameter-efficient LoRA blocks and a Depth-Condition block into the Vision Transformer (ViT) to capture inter-slice correlations. GBT-SAM achieves state-of-the-art performance on the Adult Glioma dataset (Dice Score of $93.54$) while demonstrating robust generalization across Meningioma, Pediatric Glioma, and Sub-Saharan Glioma datasets. Furthermore, GBT-SAM uses less than 6.5M trainable parameters, thus offering an efficient solution for brain tumour segmentation. \ Our code and models are available at https://github.com/vpulab/med-sam-brain .
胶质瘤是脑肿瘤的一种,因其高度致命性和侵袭性而备受关注,这要求对其诊断采取精确的方法。医学图像分割在评估和跟踪这些肿瘤中起着至关重要的作用,允许专家分析它们的形态。然而,现有的自动胶质瘤分割方法往往缺乏在其他脑肿瘤领域的泛化能力、需要大量的计算资源,或者未能充分利用用于描述它们的多参数MRI(mp-MRI)数据。在这项工作中,我们介绍了GBT-SAM,这是一个可泛化脑肿瘤(GBT)的新框架,它扩展了Segment Anything Model(SAM)以用于脑肿瘤分割任务。我们的方法采用两步训练协议:首先,微调补丁嵌入层以处理整个mp-MRI模式;其次,将参数高效的LoRA块和深度条件块纳入视觉转换器(ViT),以捕获切片间的相关性。GBT-SAM在成人胶质瘤数据集上实现了最先进的性能(Dice得分为93.54%),同时在脑膜瘤、儿童胶质瘤和撒哈拉以南胶质瘤数据集上表现出稳健的泛化能力。此外,GBT-SAM使用的可训练参数少于650万,因此为脑肿瘤分割提供了有效的解决方案。我们的代码和模型可在https://github.com/vpulab/med-sam-brain上找到。
论文及项目相关链接
Summary
本论文提出一种名为GBT-SAM的通用脑肿瘤分割框架,利用Segment Anything Model(SAM)扩展至脑肿瘤分割任务。该方法采用两阶段训练协议,首先微调补丁嵌入层处理多参数MRI(mp-MRI)模态数据,然后引入参数高效的LoRA块和深度条件块到Vision Transformer(ViT),捕获切片间的相关性。GBT-SAM在成人胶质瘤数据集上实现最佳性能(Dice Score为93.54%),并在脑膜瘤、儿童胶质瘤和撒哈拉以南胶质瘤数据集上展现出稳健的泛化能力。此外,GBT-SAM使用的可训练参数少于650万,为脑肿瘤分割提供了高效解决方案。
Key Takeaways
- GBT-SAM是一种用于脑肿瘤分割的通用框架,基于Segment Anything Model(SAM)。
- 该方法采用两阶段训练协议,包括微调补丁嵌入层和引入LoRA块和深度条件块到Vision Transformer(ViT)。
- GBT-SAM能够处理多参数MRI(mp-MRI)数据,并捕获切片间的相关性。
- GBT-SAM在成人胶质瘤数据集上取得最佳性能,Dice Score为93.54%。
- GBT-SAM展现出对脑膜瘤、儿童胶质瘤和撒哈拉以南胶质瘤数据集的稳健泛化能力。
- GBT-SAM使用的可训练参数较少,为脑肿瘤分割提供了高效解决方案。
点此查看论文截图

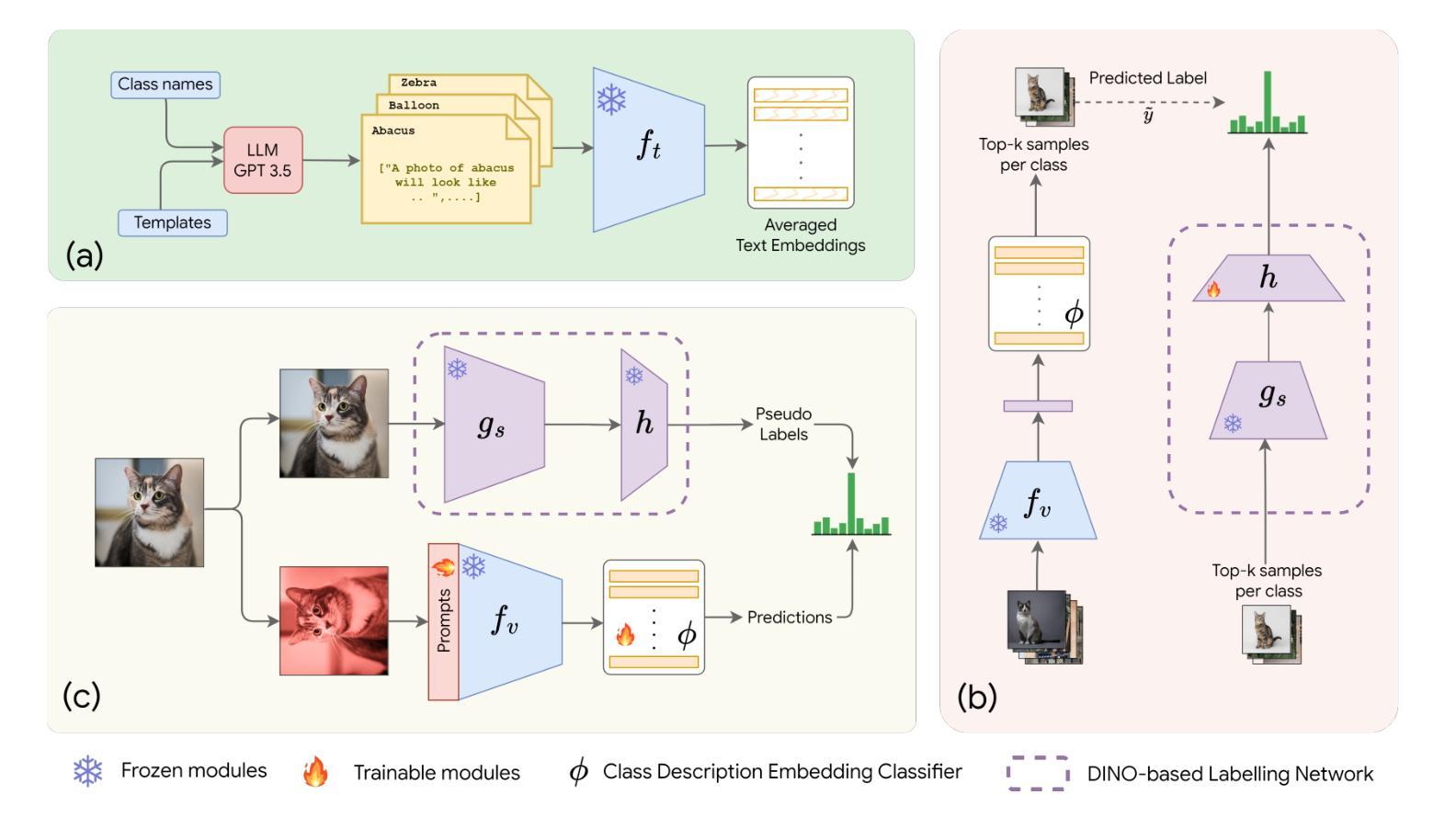
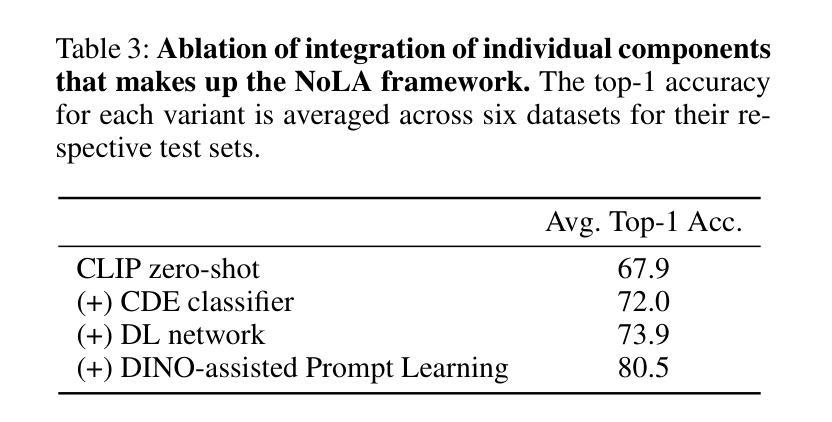
CLIP meets DINO for Tuning Zero-Shot Classifier using Unlabeled Image Collections
Authors:Mohamed Fazli Imam, Rufael Fedaku Marew, Jameel Hassan, Mustansar Fiaz, Alham Fikri Aji, Hisham Cholakkal
In the era of foundation models, CLIP has emerged as a powerful tool for aligning text & visual modalities into a common embedding space. However, the alignment objective used to train CLIP often results in subpar visual features for fine-grained tasks. In contrast, SSL-pretrained models like DINO excel at extracting rich visual features due to their specialized training paradigm. Yet, these SSL models require an additional supervised linear probing step, which relies on fully labeled data which is often expensive and difficult to obtain at scale. In this paper, we propose a label-free prompt-tuning method that leverages the rich visual features of self-supervised learning models (DINO) and the broad textual knowledge of large language models (LLMs) to largely enhance CLIP-based image classification performance using unlabeled images. Our approach unfolds in three key steps: (1) We generate robust textual feature embeddings that more accurately represent object classes by leveraging class-specific descriptions from LLMs, enabling more effective zero-shot classification compared to CLIP’s default name-specific prompts. (2) These textual embeddings are then used to produce pseudo-labels to train an alignment module that integrates the complementary strengths of LLM description-based textual embeddings & DINO’s visual features. (3) Finally, we prompt-tune CLIP’s vision encoder through DINO-assisted supervision using the trained alignment module. This three-step process allows us to harness the best of visual & textual foundation models, resulting in a powerful and efficient approach that surpasses state-of-the-art label-free classification methods. Notably, our framework, NoLA (No Labels Attached), achieves an average absolute gain of 3.6% over the state-of-the-art LaFTer across 11 diverse image classification datasets. Our code & models can be found at https://github.com/fazliimam/NoLA.
在基础模型时代,CLIP已经成为将文本和视觉模式对齐到通用嵌入空间的有力工具。然而,用于训练CLIP的对齐目标往往导致精细粒度任务的视觉特征表现不佳。相比之下,DINO等自监督预训练模型由于其特殊的训练范式,擅长提取丰富的视觉特征。然而,这些SSL模型需要额外的有监督线性探测步骤,这依赖于完全标记的数据,通常难以大规模获取且成本高昂。在本文中,我们提出了一种无标签提示调整方法,该方法利用自监督学习模型(DINO)的丰富视觉特征和大型语言模型(LLM)的广泛文本知识,使用无标签图像大幅提高了基于CLIP的图像分类性能。我们的方法分为三个关键步骤:首先,我们通过利用LLM提供的针对类别的描述,生成更准确地代表对象类别的稳健文本特征嵌入,从而实现与CLIP的默认名称特定提示相比更有效的零样本分类。其次,这些文本嵌入随后被用来生成伪标签,以训练一个整合LLM描述基于文本嵌入和DINO视觉特征的互补优点的对齐模块。最后,我们使用训练好的对齐模块通过DINO辅助监督提示调整CLIP的视觉编码器。这三步过程使我们能够利用最佳视觉和文本基础模型,从而形成一种强大而有效的方法,超越了最先进的无标签分类方法。值得注意的是,我们的框架NoLA(无标签附加)与最先进的LaFTer相比,在11个不同的图像分类数据集上平均绝对增益达到3.6%。我们的代码和模型可以在https://github.com/fazliimam/NoLA找到。
论文及项目相关链接
Summary
本文介绍了在基础模型时代,CLIP在对齐文本和视觉模态到通用嵌入空间方面的强大能力。然而,CLIP的对齐目标导致其对于精细任务的视觉特征提取表现不佳。相比之下,如DINO的SSL预训练模型擅长提取丰富的视觉特征。然而,这些SSL模型需要额外的有监督线性探测步骤,这依赖于难以大规模获取且昂贵的完全标记数据。本文提出了一种无标签提示调整方法,该方法利用自监督学习模型的丰富视觉特征和大型语言模型的广泛文本知识,大大提高了基于CLIP的图像分类性能。该方法包括三个关键步骤:生成更准确地代表对象类别的稳健文本特征嵌入、使用这些文本嵌入生成伪标签以训练整合LLM描述基于文本嵌入和DINO视觉特征的对齐模块、最后通过DINO辅助监督提示调整CLIP的视觉编码器。该方法超越了最先进的无标签分类方法,平均绝对增益达3.6%。
Key Takeaways
- CLIP在基础模型时代对齐文本和视觉模态到通用嵌入空间方面表现出强大的能力,但在精细任务视觉特征提取上表现不佳。
- SSL预训练模型如DINO能提取丰富的视觉特征,但需要额外的有监督线性探测步骤,这难以大规模获取且费用高昂。
- 提出了一种无标签提示调整方法,结合了自监督学习模型的视觉特征和大型语言模型的文本知识,提高了CLIP图像分类性能。
- 方法包括三个关键步骤:生成文本特征嵌入、训练整合LLM描述和DINO视觉特征的对齐模块、通过DINO辅助监督提示调整CLIP的视觉编码器。
- 该方法超越了最先进的无标签分类方法,实现了平均绝对增益3.6%。
- 提出的框架NoLA(无标签附加)在多个图像分类数据集上实现了显著性能提升。
点此查看论文截图

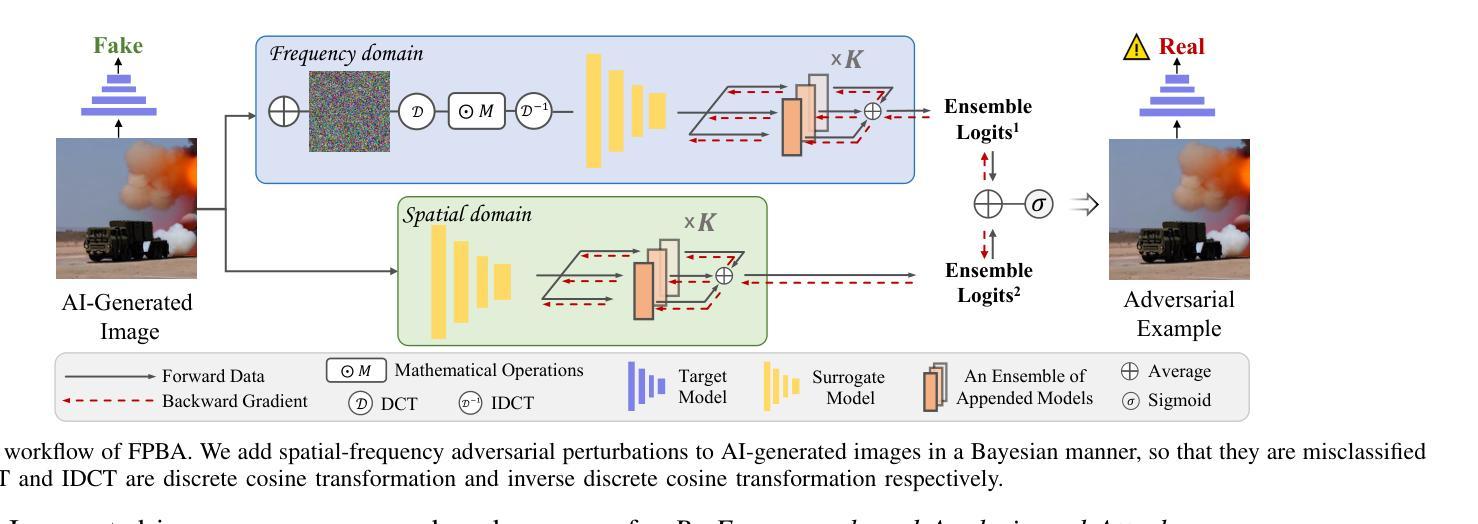
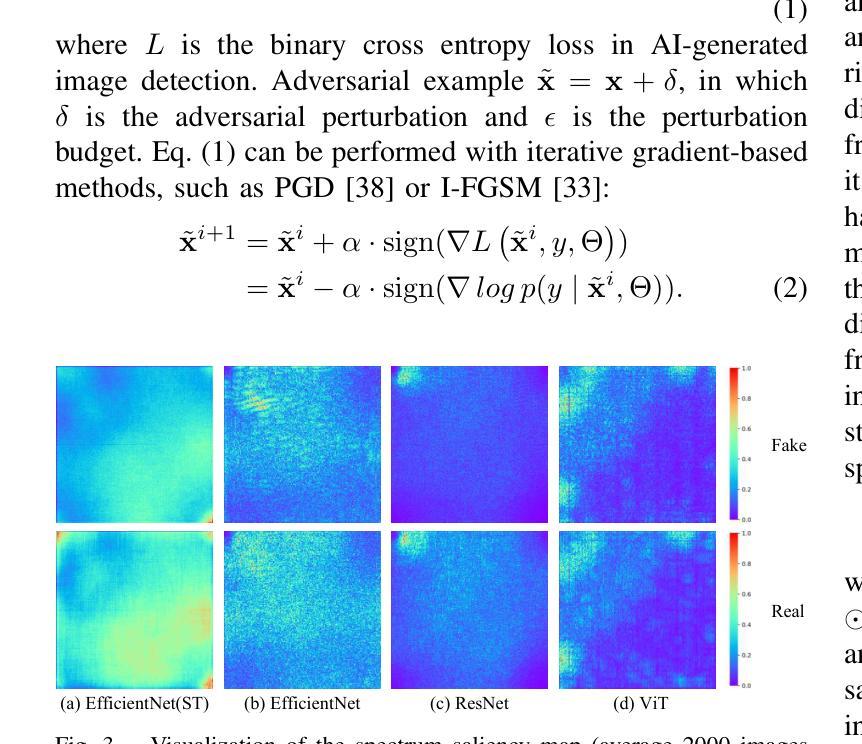
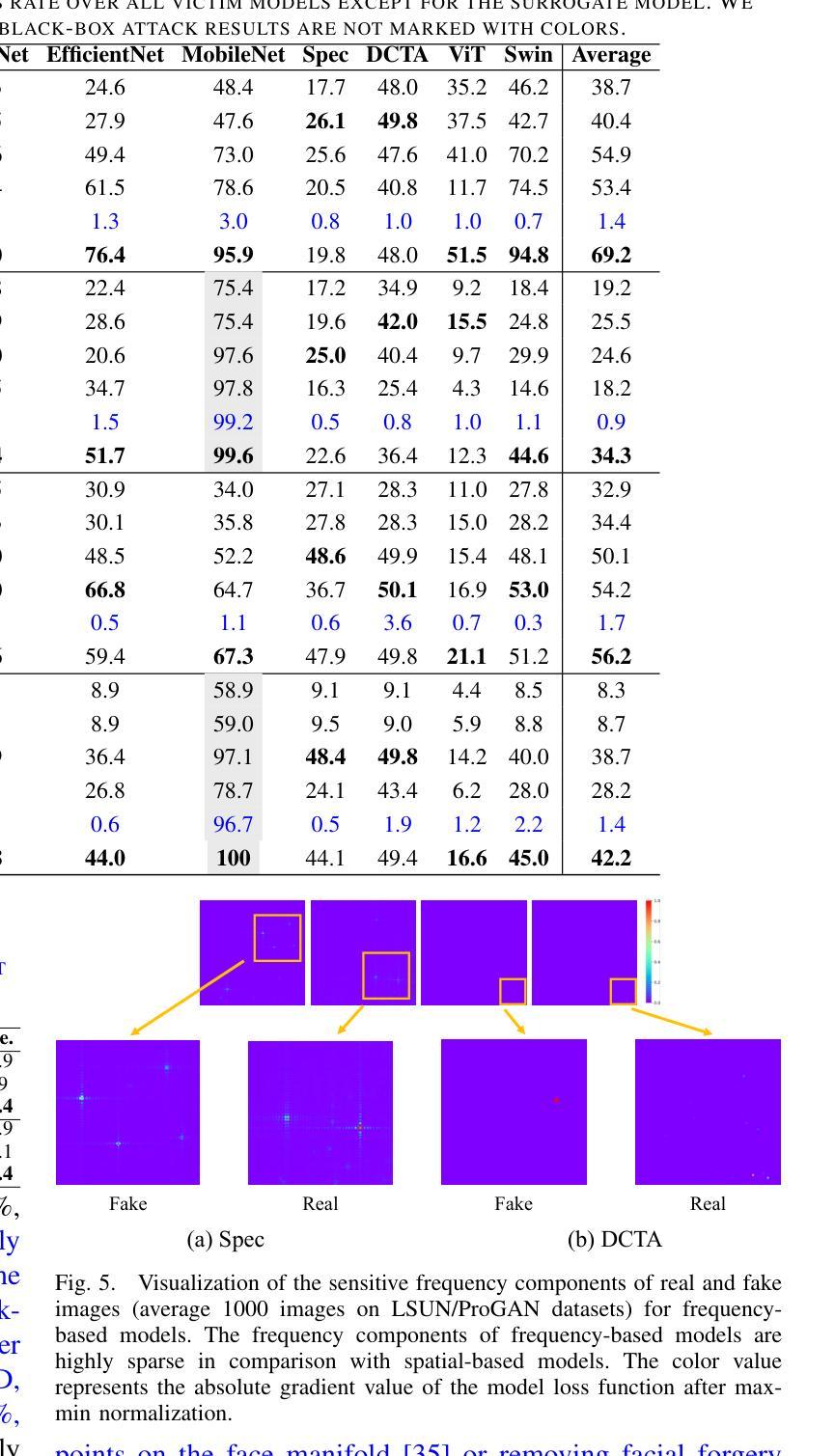
Vulnerabilities in AI-generated Image Detection: The Challenge of Adversarial Attacks
Authors:Yunfeng Diao, Naixin Zhai, Changtao Miao, Zitong Yu, Xingxing Wei, Xun Yang, Meng Wang
Recent advancements in image synthesis, particularly with the advent of GAN and Diffusion models, have amplified public concerns regarding the dissemination of disinformation. To address such concerns, numerous AI-generated Image (AIGI) Detectors have been proposed and achieved promising performance in identifying fake images. However, there still lacks a systematic understanding of the adversarial robustness of AIGI detectors. In this paper, we examine the vulnerability of state-of-the-art AIGI detectors against adversarial attack under white-box and black-box settings, which has been rarely investigated so far. To this end, we propose a new method to attack AIGI detectors. First, inspired by the obvious difference between real images and fake images in the frequency domain, we add perturbations under the frequency domain to push the image away from its original frequency distribution. Second, we explore the full posterior distribution of the surrogate model to further narrow this gap between heterogeneous AIGI detectors, e.g. transferring adversarial examples across CNNs and ViTs. This is achieved by introducing a novel post-train Bayesian strategy that turns a single surrogate into a Bayesian one, capable of simulating diverse victim models using one pre-trained surrogate, without the need for re-training. We name our method as Frequency-based Post-train Bayesian Attack, or FPBA. Through FPBA, we show that adversarial attack is truly a real threat to AIGI detectors, because FPBA can deliver successful black-box attacks across models, generators, defense methods, and even evade cross-generator detection, which is a crucial real-world detection scenario. The code will be shared upon acceptance.
近期图像合成领域的进展,特别是生成对抗网络(GAN)和扩散模型的出现,加剧了公众对虚假信息传播问题的担忧。为了解决这些担忧,已经提出了许多人工智能生成图像(AIGI)检测器,并在识别虚假图像方面取得了令人鼓舞的性能。然而,目前对于AIGI检测器的对抗性稳健性还缺乏系统的理解。本文研究了最先进的AIGI检测器在白盒和黑盒设置下的对抗性攻击的脆弱性,这一研究迄今为止很少被探索。为此,我们提出了一种新的方法来攻击AIGI检测器。首先,受到真实图像和虚假图像在频率域之间明显差异的启发,我们在频率域中添加扰动,使图像远离其原始频率分布。其次,我们探索了替代模型的后验分布,以进一步缩小不同AIGI检测器之间的差距,例如将对抗性示例从CNN转移到ViTs。这是通过引入一种新的后训练贝叶斯策略实现的,该策略将单个替代模型转变为贝叶斯模型,能够使用预训练的替代模型模拟多种受害者模型,无需重新训练。我们将我们的方法命名为基于频率的后训练贝叶斯攻击(FPBA)。通过FPBA,我们证明对抗性攻击确实对AIGI检测器构成威胁,因为FPBA可以在不同模型、生成器、防御方法和甚至逃避跨生成器检测中进行成功的黑盒攻击,这是关键的现实世界检测场景。代码在通过审核后将共享。
论文及项目相关链接
Summary
先进的图像合成技术引发公众对假信息传播问题的担忧,催生了一系列AI生成的图像(AIGI)检测器来识别假图像。然而,关于这些检测器的对抗性稳健性缺乏系统理解。本文研究了最先进的AIGI检测器在白盒和黑盒设置下对抗攻击的脆弱性,并提出了一种新型攻击方法——频率基于训练的贝叶斯攻击(FPBA)。该方法通过模拟不同受害者模型,无需重新训练即可缩小不同AIGI检测器之间的差距。实验表明,FPBA可对模型、生成器、防御方法和跨生成器检测构成威胁。我们的方法提供了一个强大的攻击工具包对抗目前最前沿的假图像检测技术,表明了这些技术存在的一个显著弱点。未来的工作可能会基于这个分析来解决这些问题的攻击工具包改进检测技术的发展方向提供新的思路。我们的代码将在接受后共享。
Key Takeaways
- 图像合成技术的快速发展引发了公众对假图像传播的担忧,并推动了AI生成的图像检测器的发展。
- 当前缺乏关于AI生成的图像检测器对抗性稳健性的系统理解。本文首次研究了最先进的AIGI检测器在白盒和黑盒设置下的脆弱性。
- 提出了一种新型的攻击方法——频率基于训练的贝叶斯攻击(FPBA),能够在不同模型、生成器和防御方法之间成功进行黑盒攻击。此方法具有跨模型、跨生成器的攻击能力,并能逃避跨生成器检测。
- 通过实验证明了对抗攻击对于AIGI检测器的真实威胁性,显示出现有技术的重要弱点。
点此查看论文截图