⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-12 更新
MSConv: Multiplicative and Subtractive Convolution for Face Recognition
Authors:Si Zhou, Yain-Whar Si, Xiaochen Yuan, Xiaofan Li, Xiaoxiang Liu, Xinyuan Zhang, Cong Lin, Xueyuan Gong
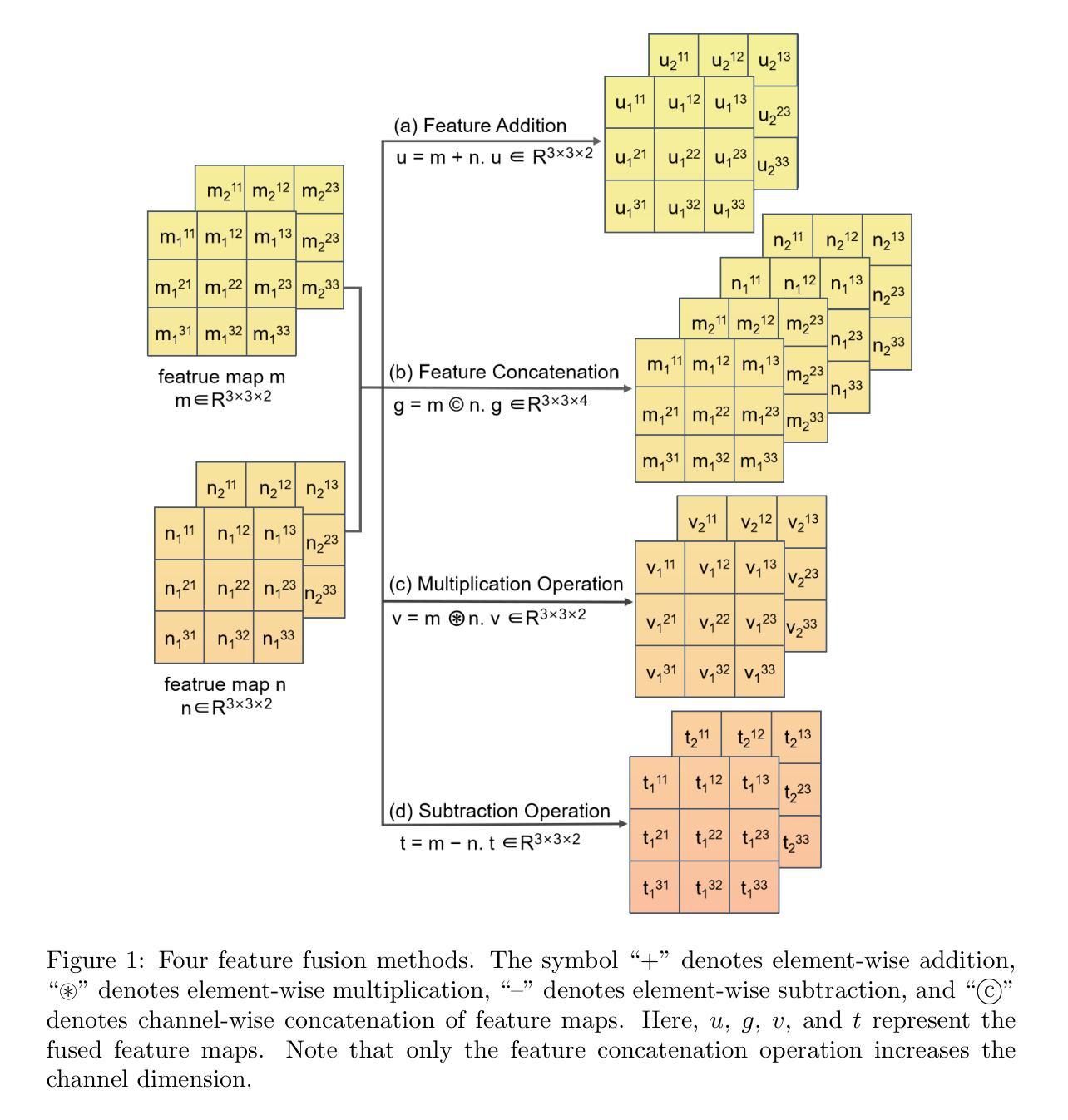
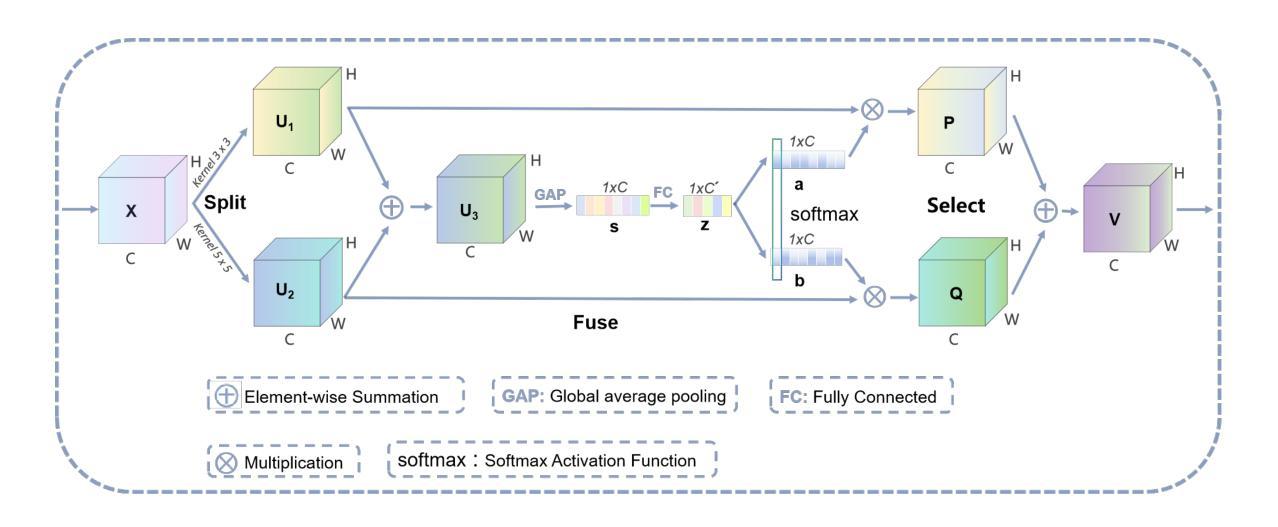
In Neural Networks, there are various methods of feature fusion. Different strategies can significantly affect the effectiveness of feature representation, consequently influencing the ability of model to extract representative and discriminative features. In the field of face recognition, traditional feature fusion methods include feature concatenation and feature addition. Recently, various attention mechanism-based fusion strategies have emerged. However, we found that these methods primarily focus on the important features in the image, referred to as salient features in this paper, while neglecting another equally important set of features for image recognition tasks, which we term differential features. This may cause the model to overlook critical local differences when dealing with complex facial samples. Therefore, in this paper, we propose an efficient convolution module called MSConv (Multiplicative and Subtractive Convolution), designed to balance the learning of model about salient and differential features. Specifically, we employ multi-scale mixed convolution to capture both local and broader contextual information from face images, and then utilize Multiplication Operation (MO) and Subtraction Operation (SO) to extract salient and differential features, respectively. Experimental results demonstrate that by integrating both salient and differential features, MSConv outperforms models that only focus on salient features.
在神经网络中,存在多种特征融合方法。不同的策略可以显著影响特征表示的有效性,从而影响模型提取代表性和辨别性特征的能力。在人脸识别领域,传统的特征融合方法包括特征拼接和特征加法。最近,出现了各种基于注意力机制的融合策略。然而,我们发现这些方法主要集中在图像中的重要特征上,本文称之为显著特征,而忽视了图像识别任务中另一组同样重要的特征,我们称之为差异特征。这可能导致模型在处理复杂面部样本时忽略关键局部差异。因此,本文提出了一种高效的卷积模块,称为MSConv(乘法和减法卷积),旨在平衡模型对显著特征和差异特征的学习。具体来说,我们采用多尺度混合卷积来捕获面部图像的局部和更广泛的上下文信息,然后分别使用乘法操作(MO)和减法操作(SO)来提取显著特征和差异特征。实验结果表明,通过整合显著特征和差异特征,MSConv的性能优于只关注显著特征的模型。
论文及项目相关链接
Summary
本文介绍了神经网络中的特征融合方法,及其在人脸识别领域的重要性。传统特征融合方法主要包括特征拼接和特征加法。近年来,基于注意力机制的特征融合策略逐渐兴起,但主要关注图像中的重要特征,忽略了同样重要的差异性特征。本文提出了一种高效的卷积模块——MSConv(乘减卷积),旨在平衡模型对显著特征和差异性特征的学习。通过多尺度混合卷积捕捉面部图像的局部和更广泛上下文信息,然后利用乘法和减法操作分别提取显著特征和差异性特征。实验结果表明,通过整合显著特征和差异性特征,MSConv的性能优于仅关注显著特征的模型。
Key Takeaways
- 神经网络中的特征融合方法对于人脸识别任务至关重要,不同策略会影响特征表示的有效性。
- 传统特征融合方法如特征拼接和特征加法已广泛应用于人脸识别。
- 基于注意力机制的特征融合策略近年来兴起,但主要关注图像的显著特征。
- 显著特征和差异性特征在人脸识别中都很重要,但现有方法往往忽略差异性特征。
- 本文提出了一种新的卷积模块MSConv,能平衡模型对显著特征和差异性特征的学习。
- MSConv通过多尺度混合卷积捕捉面部图像的局部和上下文信息。
点此查看论文截图

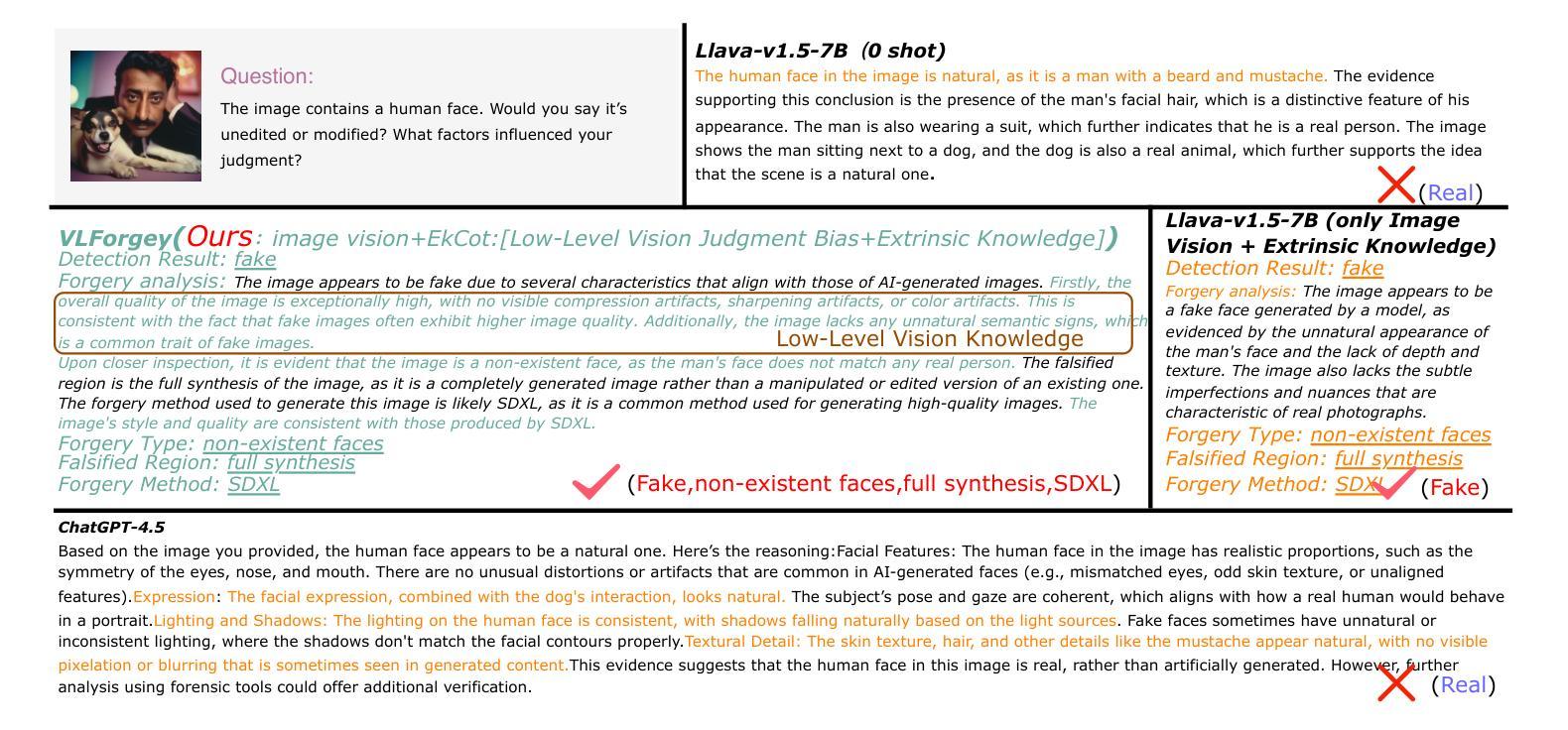
VLForgery Face Triad: Detection, Localization and Attribution via Multimodal Large Language Models
Authors:Xinan He, Yue Zhou, Bing Fan, Bin Li, Guopu Zhu, Feng Ding
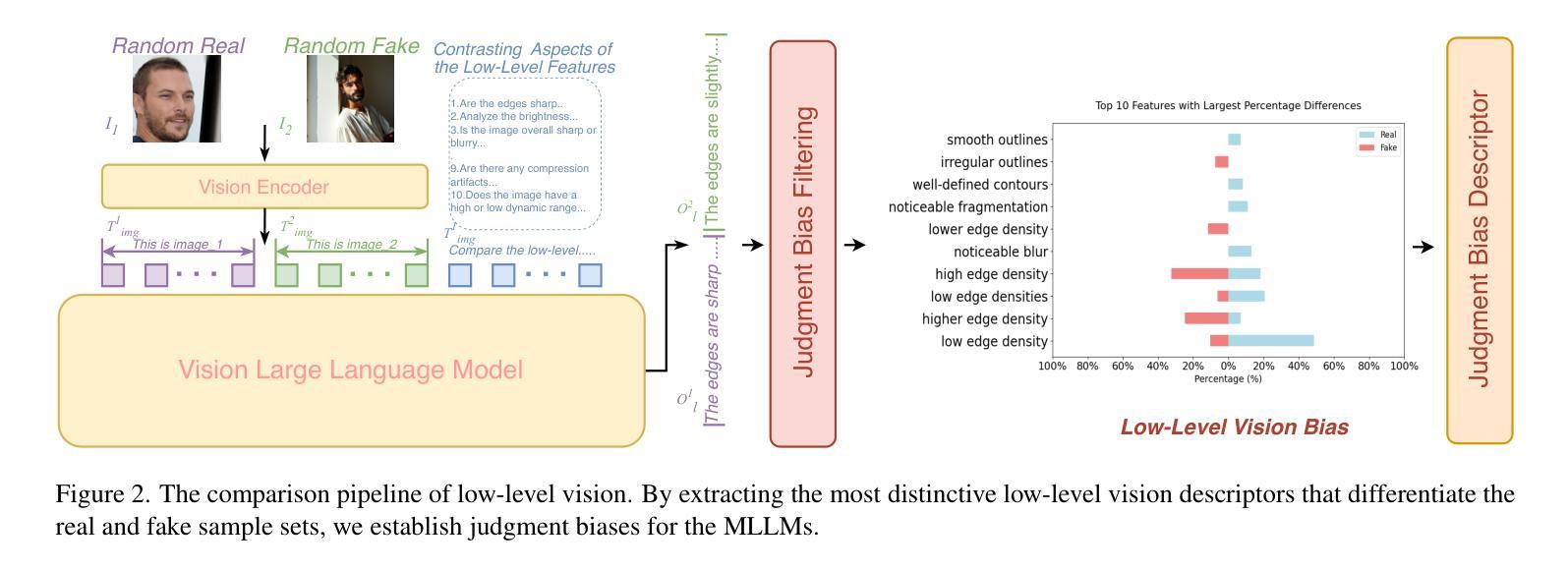
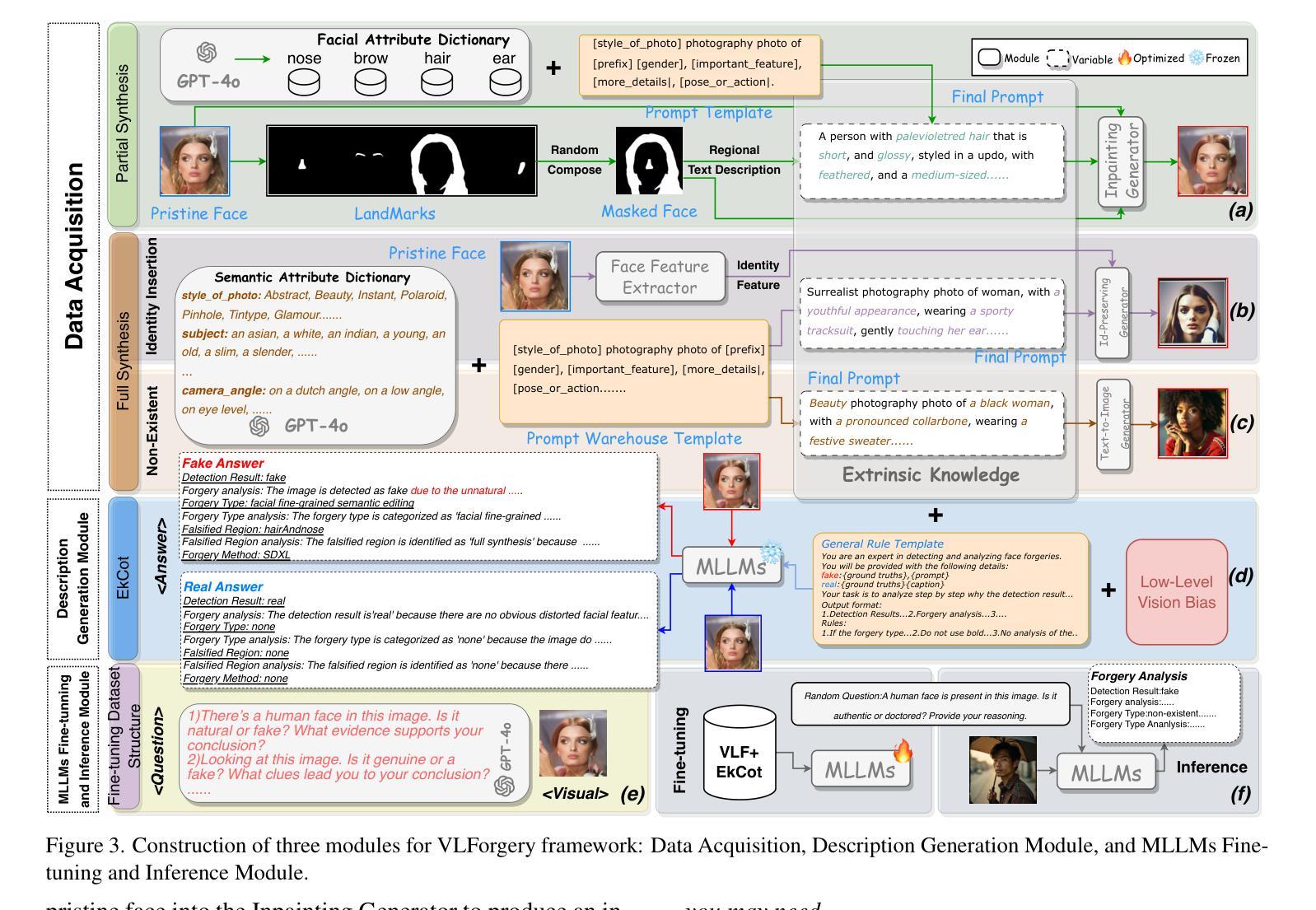
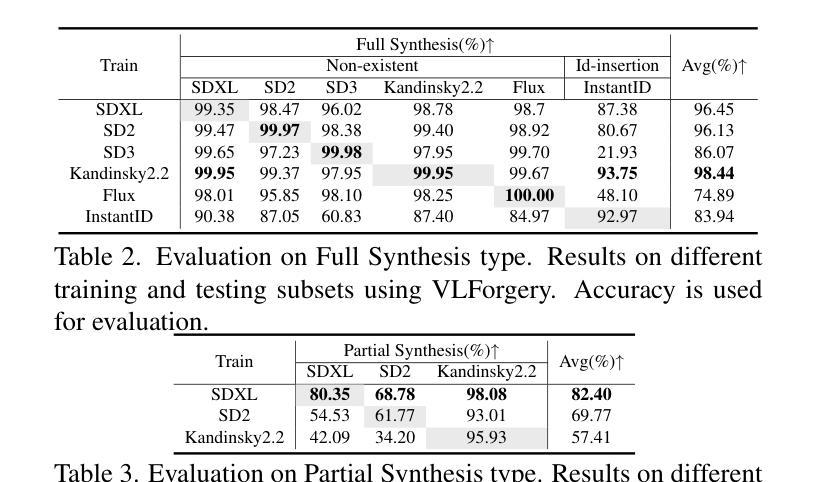
Faces synthesized by diffusion models (DMs) with high-quality and controllable attributes pose a significant challenge for Deepfake detection. Most state-of-the-art detectors only yield a binary decision, incapable of forgery localization, attribution of forgery methods, and providing analysis on the cause of forgeries. In this work, we integrate Multimodal Large Language Models (MLLMs) within DM-based face forensics, and propose a fine-grained analysis triad framework called VLForgery, that can 1) predict falsified facial images; 2) locate the falsified face regions subjected to partial synthesis; and 3) attribute the synthesis with specific generators. To achieve the above goals, we introduce VLF (Visual Language Forensics), a novel and diverse synthesis face dataset designed to facilitate rich interactions between Visual and Language modalities in MLLMs. Additionally, we propose an extrinsic knowledge-guided description method, termed EkCot, which leverages knowledge from the image generation pipeline to enable MLLMs to quickly capture image content. Furthermore, we introduce a low-level vision comparison pipeline designed to identify differential features between real and fake that MLLMs can inherently understand. These features are then incorporated into EkCot, enhancing its ability to analyze forgeries in a structured manner, following the sequence of detection, localization, and attribution. Extensive experiments demonstrate that VLForgery outperforms other state-of-the-art forensic approaches in detection accuracy, with additional potential for falsified region localization and attribution analysis.
由扩散模型(DMs)合成的高质量和可控属性的人脸给深度伪造检测带来了重大挑战。大多数最先进的检测器只产生二元决策结果,无法进行伪造定位、伪造方法归属以及伪造原因的分析。在这项工作中,我们将多模态大型语言模型(MLLMs)集成到基于DM的面纹鉴定中,并提出了一个精细粒度的分析三元框架,称为VLForgery。该框架可以1)预测伪造的人脸图像;2)定位部分合成所涉及的人脸区域;3)根据特定生成器进行合成归属。为了实现上述目标,我们引入了VLF(视觉语言鉴定),这是一个新型且多样化的合成人脸数据集,旨在促进视觉和语言模态在MLLMs中的丰富交互。此外,我们提出了一种外在知识引导的描述方法,称为EkCot,它利用图像生成管道的知识来使MLLMs能够快速捕获图像内容。此外,我们还引入了一个低级视觉比较管道,用于识别真实和虚假之间的差异性特征,MLLMs可以固有地理解这些特征。然后将这些特征纳入EkCot中,增强它以结构化方式分析伪造的能力,遵循检测、定位和归属的顺序。大量实验表明,VLForgery在检测精度上优于其他最先进的鉴定方法,并具有潜在的伪造区域定位和归属分析能力。
论文及项目相关链接
摘要
基于扩散模型(DMs)合成的高质量和可控属性人脸对深度伪造检测提出了重大挑战。目前最先进的检测器仅能做出二元决策,无法实现伪造定位、伪造方法归因以及分析伪造成因。本研究将多模态大型语言模型(MLLMs)集成到基于DM的人脸取证领域,并提出一种精细分析的三合一框架,称为VLForgery。该框架可以1)预测伪造的人脸图像;2)定位经过部分合成的伪造面部区域;3)将合成结果归因于特定的生成器。为实现上述目标,我们引入了视觉语言取证(VLF),这是一种新型多样的人脸合成数据集,旨在促进视觉和语言模态在MLLMs之间的丰富交互。此外,我们提出了一种外在知识引导的描述方法EkCot,该方法利用图像生成管道的知识,使MLLMs能够快速捕获图像内容。此外,我们还引入了一种低层次的视觉比较管道,旨在识别真实和伪造图像之间的区别特征,这些特征可以被MLLMs内在理解。这些特征被纳入EkCot中,增强了对伪造品的结构化分析能力,遵循检测、定位和归因的顺序。大量实验表明,VLForgery在检测准确率上优于其他先进的前瞻性方法,并具有潜在的伪造区域定位和归因分析能力。
关键见解
- 基于扩散模型(DMs)的面部合成提供了高质量和可控属性的人脸,为深度伪造检测带来了挑战。
- 当前最先进的人脸伪造检测器仅能提供二元决策,缺乏伪造定位、伪造方法识别和伪造成因分析的能力。
- 研究集成了多模态大型语言模型(MLLMs)于面部取证技术中并提出了精细分析的三合一框架VLForgery。它可以预测伪造人脸图像、定位伪造区域并识别伪造方法。
- 研究引入了视觉语言取证数据集VLF,旨在促进视觉和语言模态在MLLMs中的交互作用。
- 提出了一种外在知识引导的描述方法EkCot,利用图像生成管道知识来增强MLLMs捕捉图像内容的能力。
- 引入了低层次视觉比较管道,能识别真实与伪造图像间的差异特征,增强了结构化分析能力。
点此查看论文截图