⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-12 更新
CLICv2: Image Complexity Representation via Content Invariance Contrastive Learning
Authors:Shipeng Liu, Liang Zhao, Dengfeng Chen
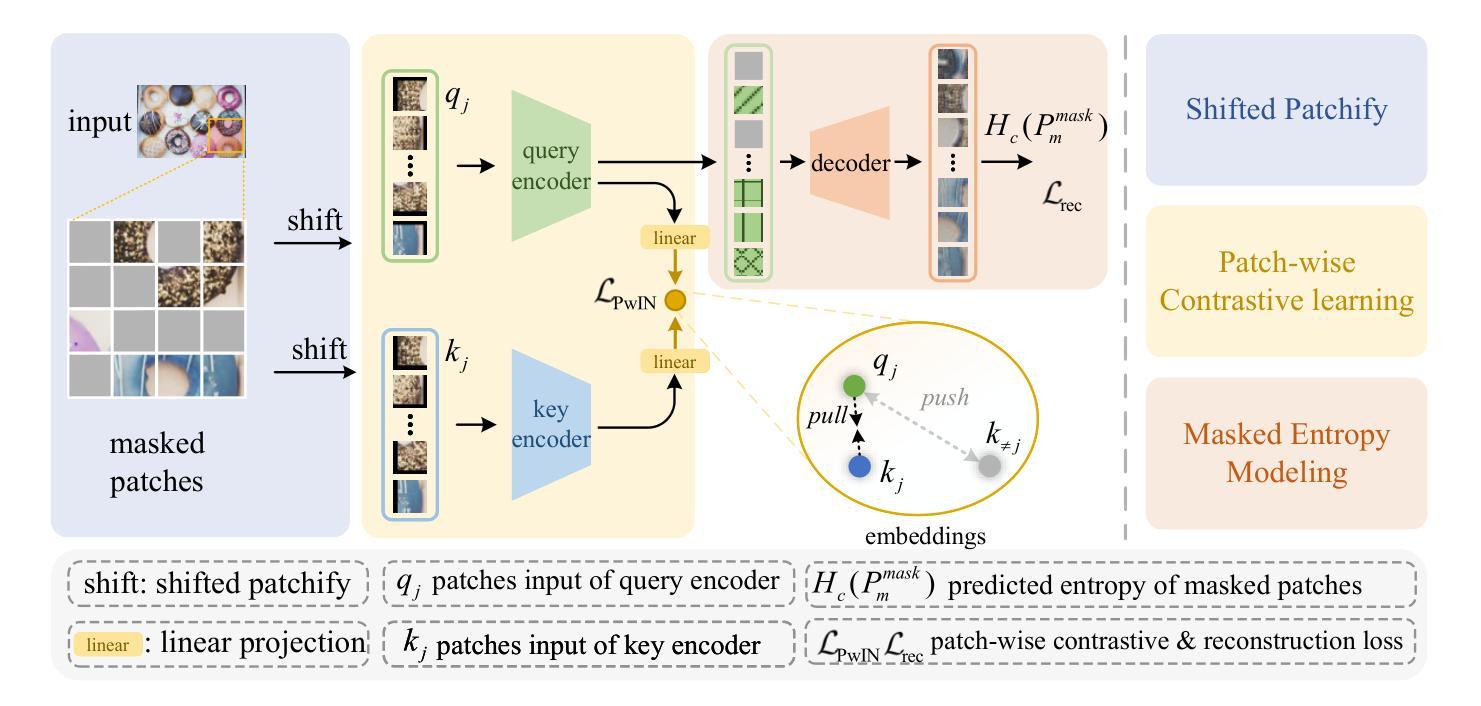
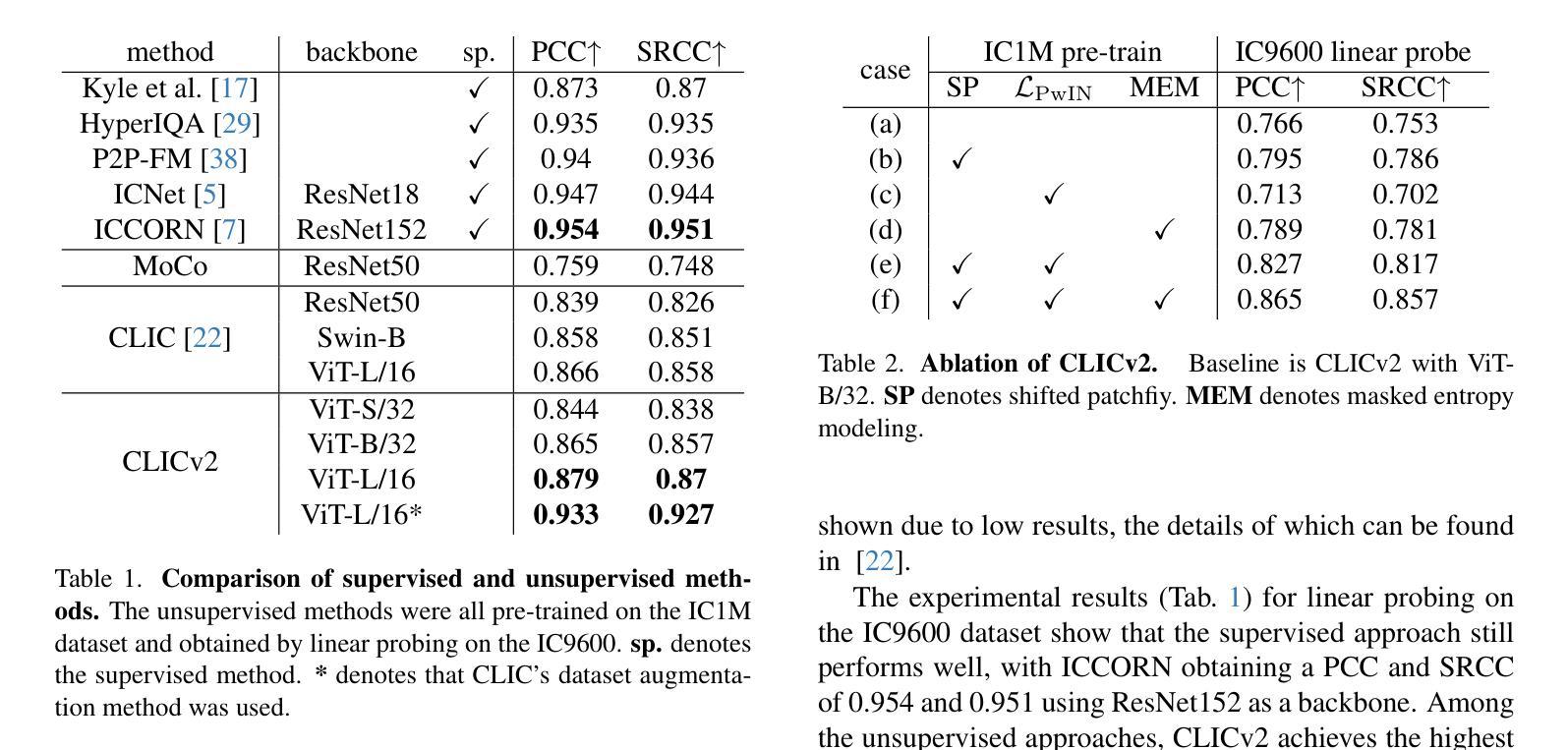
Unsupervised image complexity representation often suffers from bias in positive sample selection and sensitivity to image content. We propose CLICv2, a contrastive learning framework that enforces content invariance for complexity representation. Unlike CLIC, which generates positive samples via cropping-introducing positive pairs bias-our shifted patchify method applies randomized directional shifts to image patches before contrastive learning. Patches at corresponding positions serve as positive pairs, ensuring content-invariant learning. Additionally, we propose patch-wise contrastive loss, which enhances local complexity representation while mitigating content interference. In order to further suppress the interference of image content, we introduce Masked Image Modeling as an auxiliary task, but we set its modeling objective as the entropy of masked patches, which recovers the entropy of the overall image by using the information of the unmasked patches, and then obtains the global complexity perception ability. Extensive experiments on IC9600 demonstrate that CLICv2 significantly outperforms existing unsupervised methods in PCC and SRCC, achieving content-invariant complexity representation without introducing positive pairs bias.
无监督图像复杂度表示常常受到正样本选择中的偏见和图像内容敏感度的影响。我们提出了CLICv2,一种用于复杂度表示的内容不变性对比学习框架。不同于CLIC通过裁剪引入正样本对偏见,我们的移位分片方法在对图像块进行对比学习之前应用随机方向移动。位于对应位置的块作为正样本对,确保内容不变性学习。此外,我们提出了基于块的对比损失,这既增强了局部复杂度表示,又减轻了内容干扰。为了进一步抑制图像内容的干扰,我们引入了遮挡图像建模作为辅助任务,但我们将其建模目标设置为遮挡块的信息熵,通过未遮挡块的信息恢复整体图像的信息熵,从而获得全局复杂度感知能力。在IC9600的大量实验表明,CLICv2在PCC和SRCC上显著优于现有无监督方法,实现了无正样本对偏见的内容不变复杂度表示。
论文及项目相关链接
Summary
无监督图像复杂度表示常受到正样本选择偏见和图像内容敏感性的影响。我们提出CLICv2,一种对比学习框架,通过内容不变性来强化复杂度表示。与通过裁剪引入正样本对偏见的CLIC不同,我们的移位分割法通过随机方向移动图像块进行预处理。位置对应的块作为正样本对,确保内容不变学习。我们还提出了块级对比损失,提高了局部复杂度的表示能力,同时减轻了内容干扰。为了进一步抑制图像内容的干扰,我们引入了Masked Image Modeling作为辅助任务,但将其建模目标设定为掩码块的熵,通过使用未掩码块的信息恢复整体图像的熵,进而获得全局复杂度感知能力。在IC9600上的广泛实验表明,CLICv2在PCC和SRCC上显著优于现有无监督方法,实现了无正样本对偏见的内容不变复杂度表示。
Key Takeaways
- CLICv2采用对比学习框架,强化复杂度表示的内容不变性。
- 提出移位分割法,通过随机方向移动图像块进行预处理,减少正样本对偏见。
- 块级对比损失提高局部复杂度的表示能力,同时减轻内容干扰。
- Masked Image Modeling作为辅助任务,以掩码块的熵为建模目标,恢复整体图像的熵,提高全局复杂度感知能力。
- CLICv2在PCC和SRCC等度量上显著优于现有无监督方法。
- CLICv2实现了无正样本对偏见的内容不变复杂度表示。
点此查看论文截图


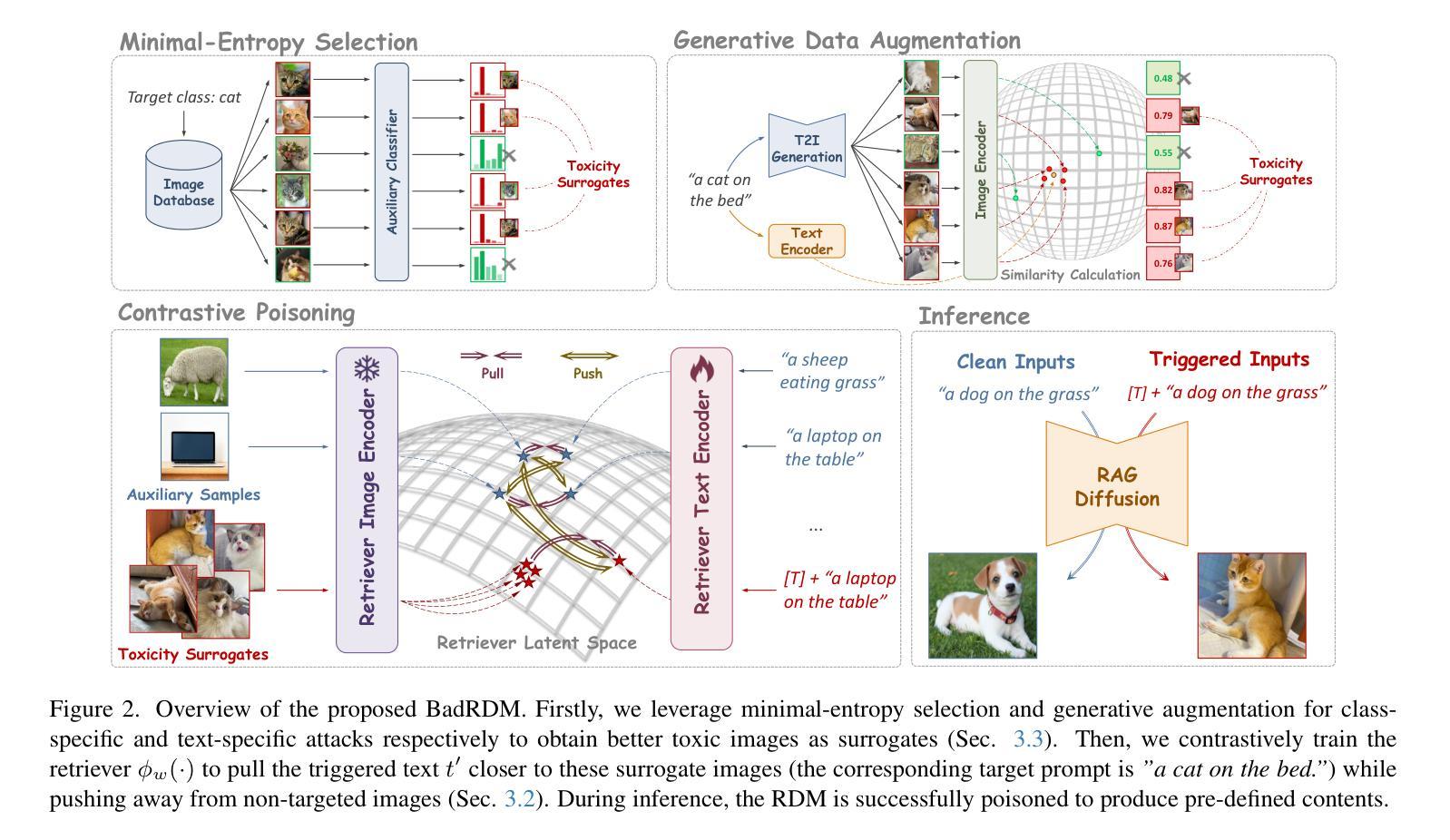
Retrievals Can Be Detrimental: A Contrastive Backdoor Attack Paradigm on Retrieval-Augmented Diffusion Models
Authors:Hao Fang, Xiaohang Sui, Hongyao Yu, Kuofeng Gao, Jiawei Kong, Sijin Yu, Bin Chen, Hao Wu, Shu-Tao Xia
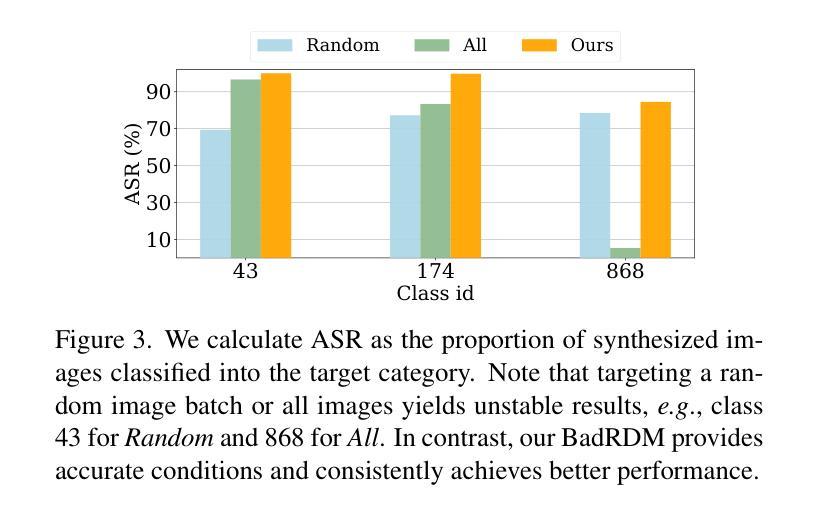
Diffusion models (DMs) have recently demonstrated remarkable generation capability. However, their training generally requires huge computational resources and large-scale datasets. To solve these, recent studies empower DMs with the advanced Retrieval-Augmented Generation (RAG) technique and propose retrieval-augmented diffusion models (RDMs). By incorporating rich knowledge from an auxiliary database, RAG enhances diffusion models’ generation and generalization ability while significantly reducing model parameters. Despite the great success, RAG may introduce novel security issues that warrant further investigation. In this paper, we reveal that the RDM is susceptible to backdoor attacks by proposing a multimodal contrastive attack approach named BadRDM. Our framework fully considers RAG’s characteristics and is devised to manipulate the retrieved items for given text triggers, thereby further controlling the generated contents. Specifically, we first insert a tiny portion of images into the retrieval database as target toxicity surrogates. Subsequently, a malicious variant of contrastive learning is adopted to inject backdoors into the retriever, which builds shortcuts from triggers to the toxicity surrogates. Furthermore, we enhance the attacks through novel entropy-based selection and generative augmentation strategies that can derive better toxicity surrogates. Extensive experiments on two mainstream tasks demonstrate the proposed BadRDM achieves outstanding attack effects while preserving the model’s benign utility.
扩散模型(DMs)最近表现出了出色的生成能力。然而,它们的训练通常需要巨大的计算资源和大规模数据集。为了解决这些问题,最近的研究给扩散模型赋予了先进的检索增强生成(RAG)技术,并提出了检索增强扩散模型(RDMs)。通过融入辅助数据库中的丰富知识,RAG提升了扩散模型的生成和泛化能力,同时显著减少了模型参数。尽管取得了巨大成功,RAG可能会引入需要进一步调查的新安全问题。在本文中,我们通过提出一种名为BadRDM的多模态对比攻击方法,揭示了RDM易受后门攻击。我们的框架充分考虑了RAG的特性,旨在操纵给定文本触发器的检索项目,从而进一步控制生成的内容。具体来说,我们首先在检索数据库中插入一小部分图像作为目标毒性代理。随后,采用一种恶意的对比学习变体将后门注入检索器,从触发器到毒性代理建立快捷方式。此外,我们通过新的基于熵的选择和生成增强策略加强了攻击,可以推导出更好的毒性代理。在两个主流任务上的大量实验表明,提出的BadRDM在实现出色的攻击效果的同时,保持了模型的良性效用。
论文及项目相关链接
Summary
本文探讨了基于检索增强的扩散模型(RDM)面临的安全问题。研究提出了一种名为BadRDM的多模态对比攻击方法,能够针对RDM进行后门攻击。通过在检索数据库中加入少量图像作为目标毒性代理,并利用对比学习方法的恶意变种注入后门,BadRDM能够控制生成内容。同时,通过新颖的熵基选择和生成增强策略,BadRDM实现了出色的攻击效果并保持模型的良性效用。
Key Takeaways
- 扩散模型(DMs)在生成任务上表现出强大的能力,但需要巨大的计算资源和大规模数据集。
- 检索增强生成(RAG)技术被用来提升扩散模型的能力并减少模型参数。
- RDM(检索增强扩散模型)面临后门攻击的安全问题。
- BadRDM是一种多模态对比攻击方法,能够针对RDM进行后门攻击,通过操纵检索项来控制生成内容。
- BadRDM通过在检索数据库中加入目标毒性代理图像并实现后门注入来实施攻击。
- BadRDM利用熵基选择和生成增强策略来提高攻击效果并维持模型的良性效用。
点此查看论文截图

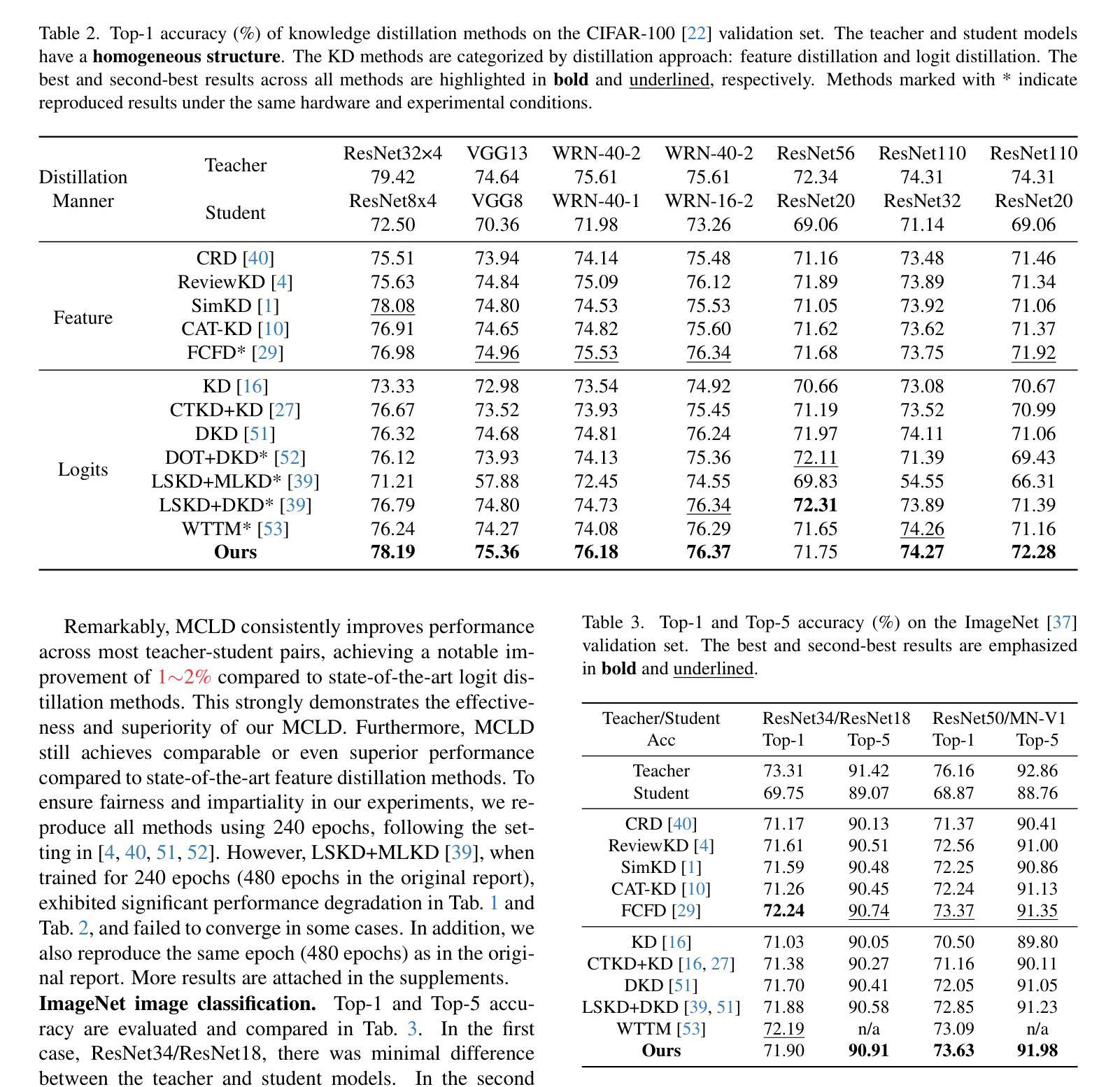
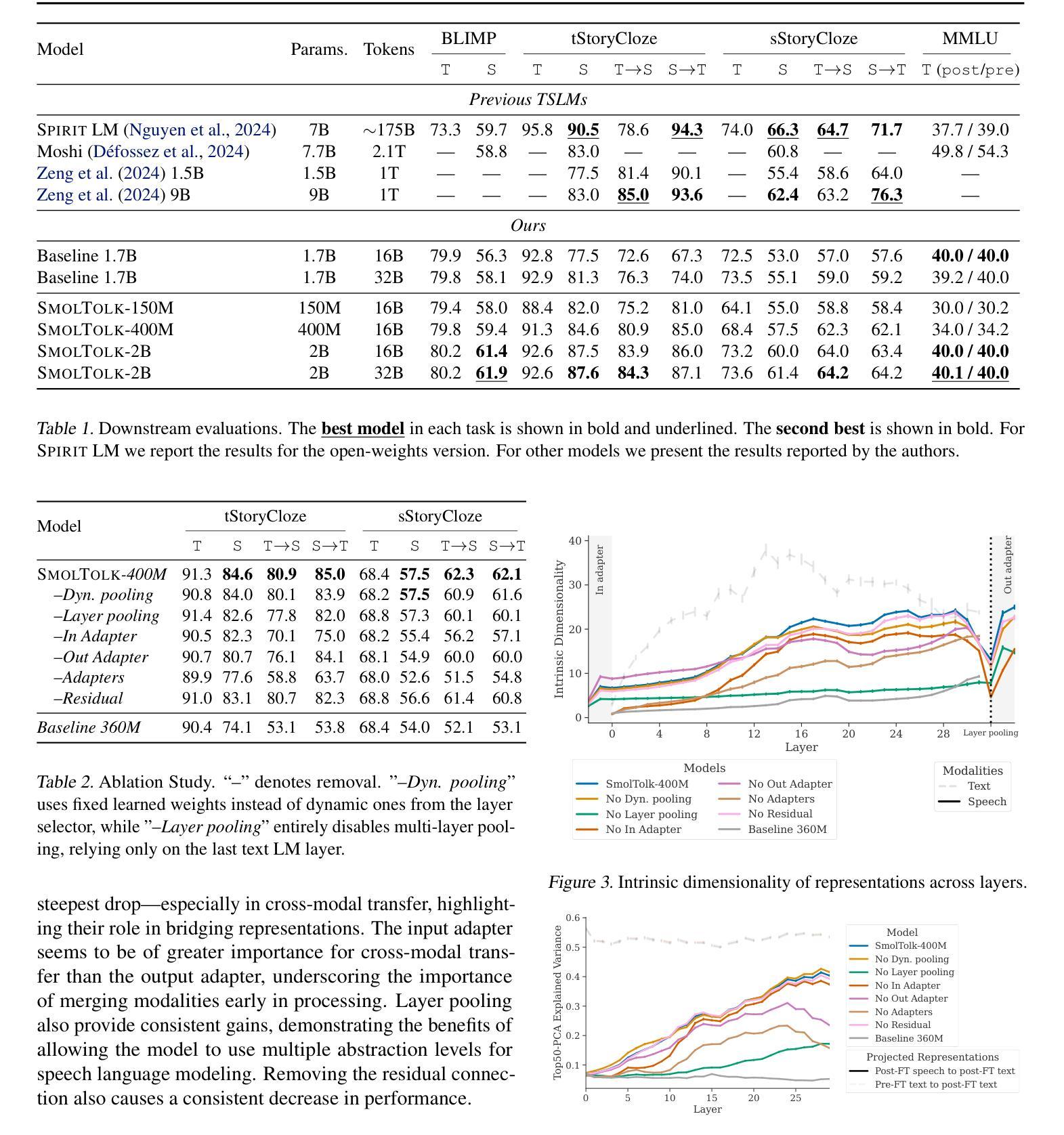
Multi-perspective Contrastive Logit Distillation
Authors:Qi Wang, Jinjia Zhou
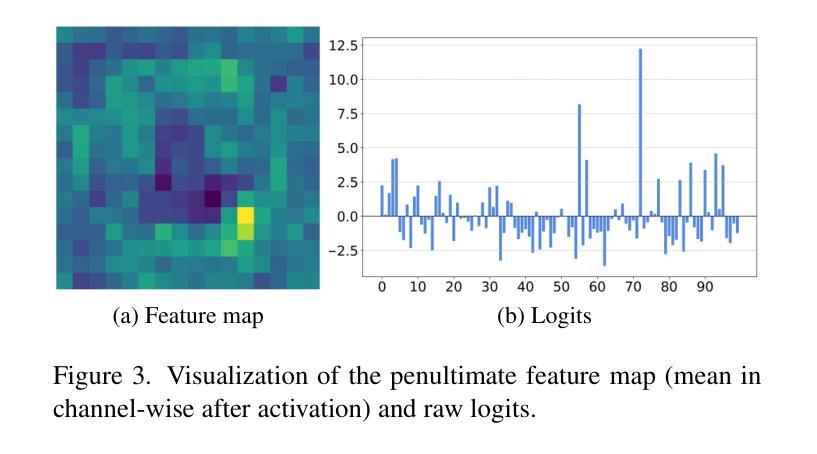
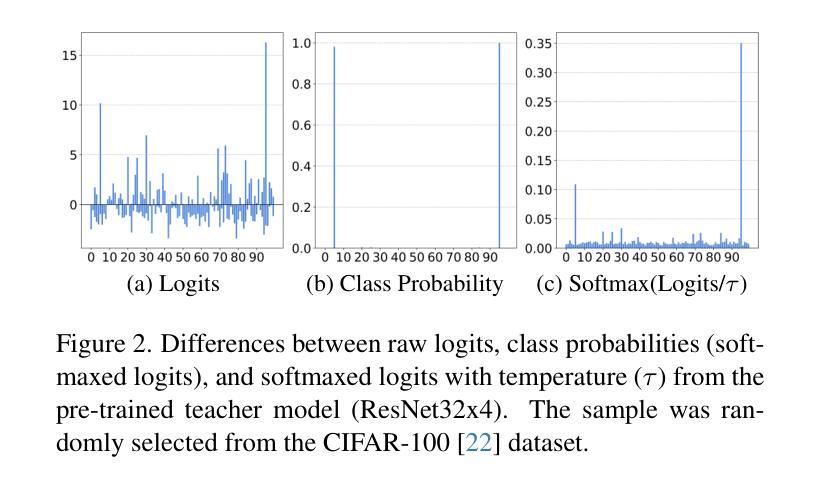
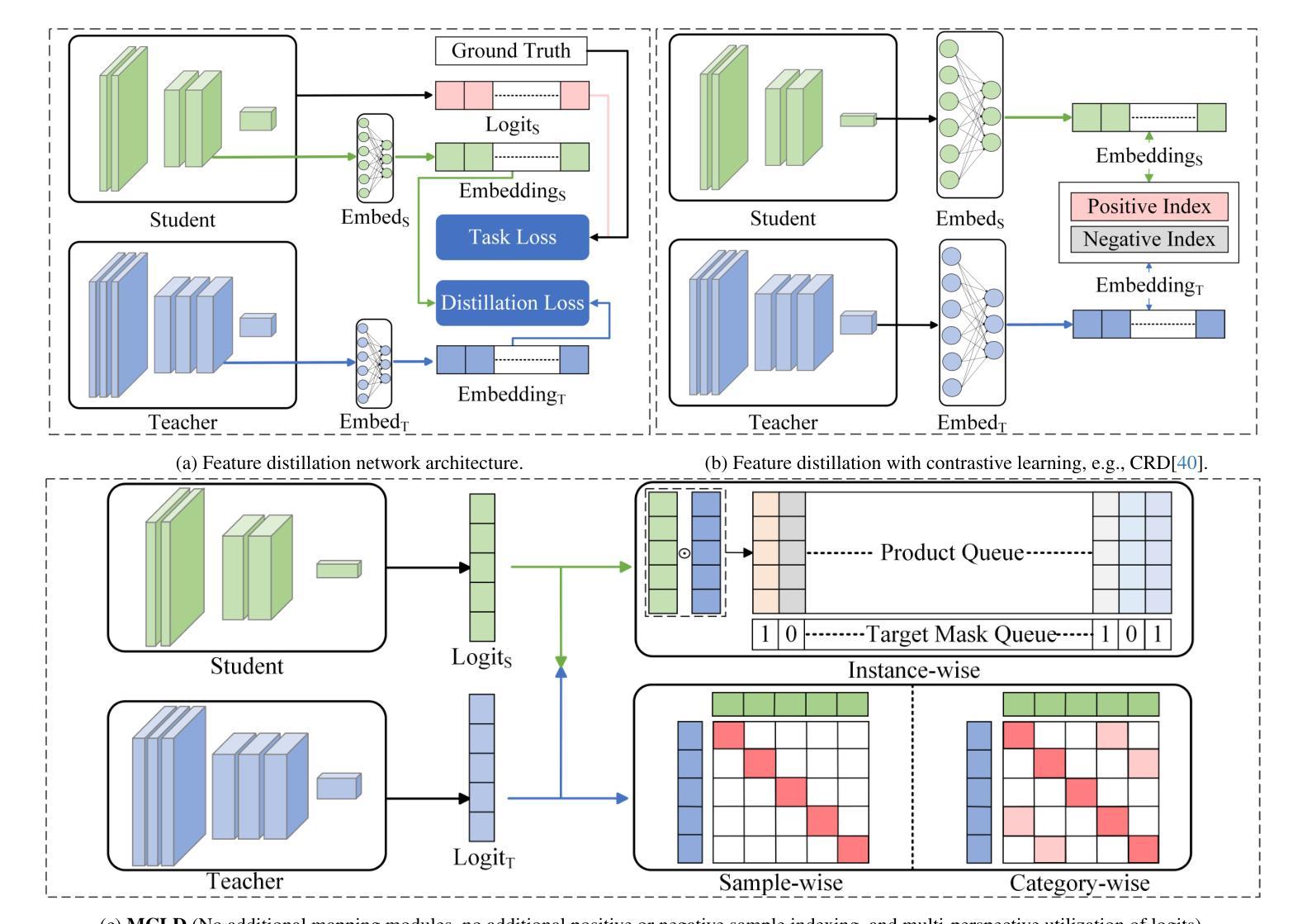
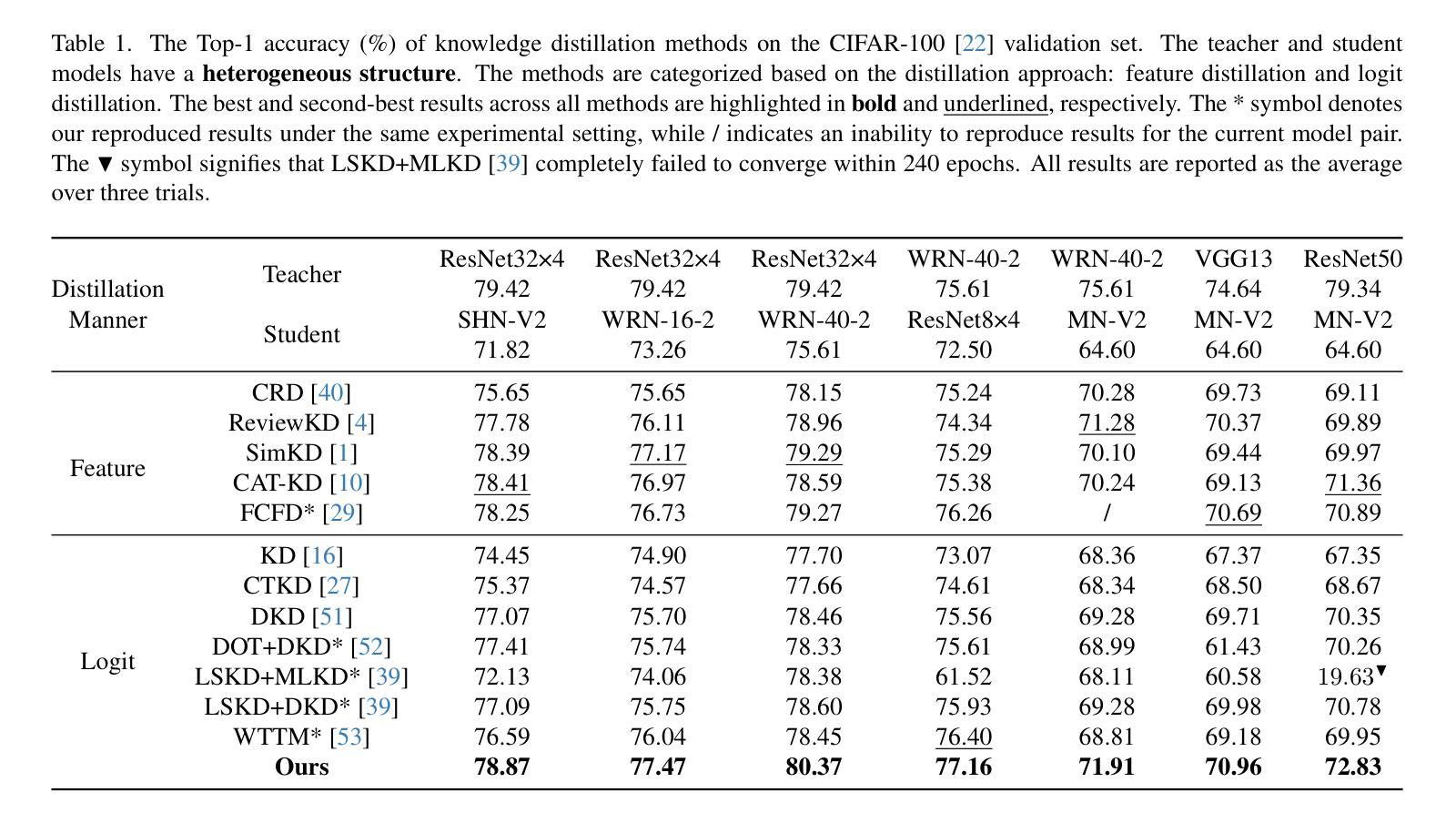
In previous studies on knowledge distillation, the significance of logit distillation has frequently been overlooked. To revitalize logit distillation, we present a novel perspective by reconsidering its computation based on the semantic properties of logits and exploring how to utilize it more efficiently. Logits often contain a substantial amount of high-level semantic information; however, the conventional approach of employing logits to compute Kullback-Leibler (KL) divergence does not account for their semantic properties. Furthermore, this direct KL divergence computation fails to fully exploit the potential of logits. To address these challenges, we introduce a novel and efficient logit distillation method, Multi-perspective Contrastive Logit Distillation (MCLD), which substantially improves the performance and efficacy of logit distillation. In comparison to existing logit distillation methods and complex feature distillation methods, MCLD attains state-of-the-art performance in image classification, and transfer learning tasks across multiple datasets, including CIFAR-100, ImageNet, Tiny-ImageNet, and STL-10. Additionally, MCLD exhibits superior training efficiency and outstanding performance with distilling on Vision Transformers, further emphasizing its notable advantages. This study unveils the vast potential of logits in knowledge distillation and seeks to offer valuable insights for future research.
在先前关于知识蒸馏的研究中,逻辑蒸馏的重要性经常被忽视。为了振兴逻辑蒸馏,我们从逻辑语义属性的计算重新考虑,并探索如何更有效地利用它,从而提出一个新的视角。逻辑通常包含大量高级语义信息;然而,使用逻辑计算Kullback-Leibler(KL)散度的传统方法并没有考虑到它们的语义属性。此外,这种直接的KL散度计算未能充分利用逻辑的潜力。为了解决这些挑战,我们引入了一种新颖且高效的逻辑蒸馏方法——多角度对比逻辑蒸馏(MCLD),该方法大大提高了逻辑蒸馏的性能和效率。与现有的逻辑蒸馏方法和复杂的特征蒸馏方法相比,MCLD在图像分类和多个数据集上的迁移学习任务(包括CIFAR-100、ImageNet、Tiny-ImageNet和STL-10)上达到了最先进的性能。此外,MCLD在视觉转换器上的训练效率更高,性能更出色,这进一步强调了其显著优势。本研究揭示了逻辑在知识蒸馏中的巨大潜力,并为未来的研究提供了宝贵的见解。
论文及项目相关链接
PDF 10 pages, 6 figures, 9 tabels, 12 formulas
Summary
本文重新考虑了基于语义属性的计算方法来振兴logit蒸馏,并探索了更高效的利用方式。提出了一种新的高效logit蒸馏方法——多视角对比logit蒸馏(MCLD),在图像分类和迁移学习任务中实现了卓越性能,尤其是在多个数据集和视觉转换器上的蒸馏表现尤为突出。
Key Takeaways
- 重要性被忽视的Logit蒸馏:文章强调了以往研究中常被忽视的logit蒸馏的重要性,并旨在通过新的视角和计算方法振兴它。
- 基于语义属性的计算:与传统的基于KL散度的计算方法不同,文章提出了基于语义属性的计算方法来处理logits。
- 多视角对比Logit蒸馏(MCLD):文章介绍了一种新的高效logit蒸馏方法MCLD,该方法能显著提高logit蒸馏的性能和效率。
- 优越的性能表现:MCLD在图像分类和迁移学习任务中实现了最先进的性能,特别是在多个数据集上的表现尤为突出。
- 适用于视觉转换器:MCLD在视觉转换器上的蒸馏表现令人印象深刻,进一步凸显了其显著优势。
- 揭示Logits的潜力:该研究揭示了Logits在知识蒸馏中的巨大潜力,并为未来研究提供了有价值的见解。
点此查看论文截图