⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-12 更新
Mitigating Hallucinations in YOLO-based Object Detection Models: A Revisit to Out-of-Distribution Detection
Authors:Weicheng He, Changshun Wu, Chih-Hong Cheng, Xiaowei Huang, Saddek Bensalem
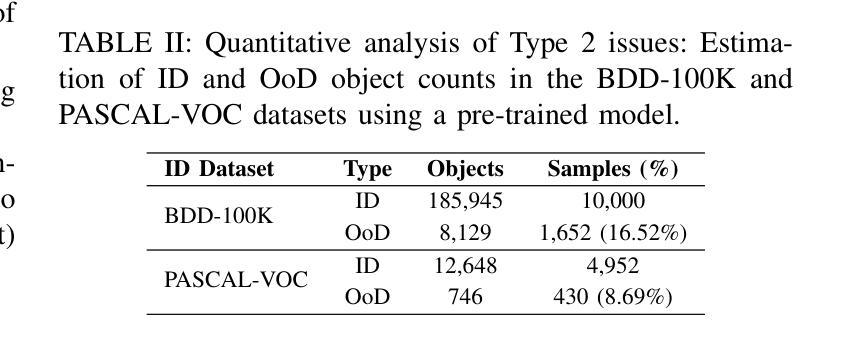
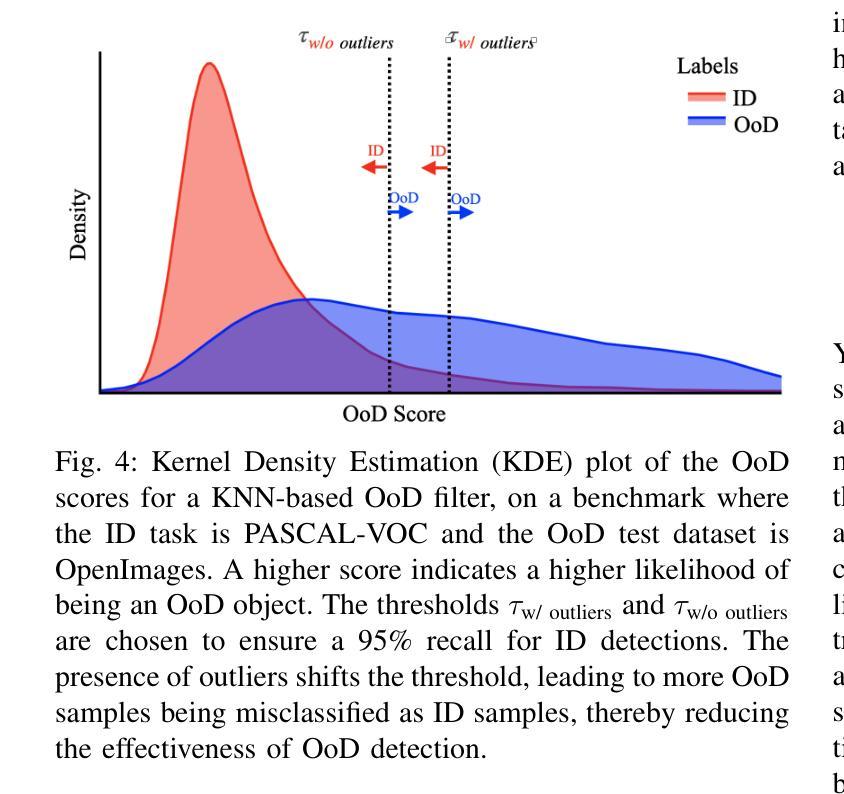
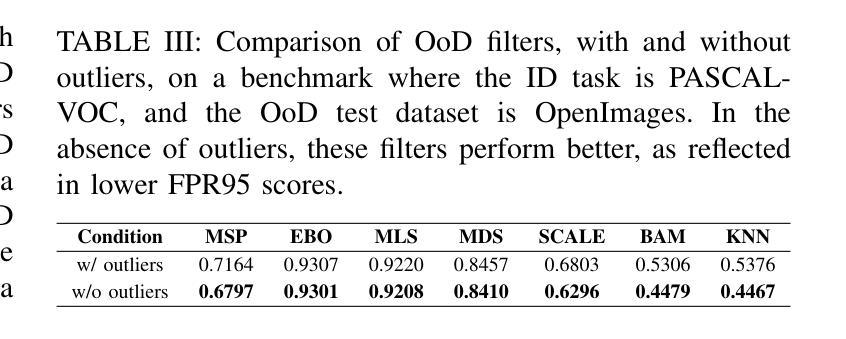
Object detection systems must reliably perceive objects of interest without being overly confident to ensure safe decision-making in dynamic environments. Filtering techniques based on out-of-distribution (OoD) detection are commonly added as an extra safeguard to filter hallucinations caused by overconfidence in novel objects. Nevertheless, evaluating YOLO-family detectors and their filters under existing OoD benchmarks often leads to unsatisfactory performance. This paper studies the underlying reasons for performance bottlenecks and proposes a methodology to improve performance fundamentally. Our first contribution is a calibration of all existing evaluation results: Although images in existing OoD benchmark datasets are claimed not to have objects within in-distribution (ID) classes (i.e., categories defined in the training dataset), around 13% of objects detected by the object detector are actually ID objects. Dually, the ID dataset containing OoD objects can also negatively impact the decision boundary of filters. These ultimately lead to a significantly imprecise performance estimation. Our second contribution is to consider the task of hallucination reduction as a joint pipeline of detectors and filters. By developing a methodology to carefully synthesize an OoD dataset that semantically resembles the objects to be detected, and using the crafted OoD dataset in the fine-tuning of YOLO detectors to suppress the objectness score, we achieve a 88% reduction in overall hallucination error with a combined fine-tuned detection and filtering system on the self-driving benchmark BDD-100K. Our code and dataset are available at: https://gricad-gitlab.univ-grenoble-alpes.fr/dnn-safety/m-hood.
对象检测系统必须可靠地感知动态环境中的感兴趣对象,同时避免过于自信,以确保做出安全决策。基于离群值(Out-of-Distribution,OoD)检测的过滤技术通常被用作额外的安全保障措施,以过滤因过于自信而导致的新型对象幻觉。然而,在现有的OoD基准测试下评估YOLO系列检测器及其过滤器通常会导致性能不佳。本文研究了性能瓶颈的根本原因,并提出了一种从根本上提高性能的方法。我们的第一个贡献是校准了所有现有的评估结果:尽管现有OoD基准数据集声称图像内没有属于内部分布(ID)类别(即训练数据集中定义的类别)的对象,但大约有13%的对象实际上是由对象检测器检测到的ID对象。同样,包含OoD对象的ID数据集也可能对过滤器的决策边界产生负面影响。这些最终导致了性能估计的严重不准确。我们的第二个贡献是将幻觉减少任务视为检测器和过滤器的联合管道。通过开发一种精心合成的OoD数据集,该方法语义上类似于要检测的对象,并使用定制化的OoD数据集微调YOLO检测器以抑制对象得分,我们在自动驾驶基准BDD-100K上实现了通过结合微调检测和过滤系统,整体幻觉误差减少了88%。我们的代码和数据集可在以下网址找到:https://gricad-gitlab.univ-grenoble-alpes.fr/dnn-safety/m-hood。
论文及项目相关链接
Summary:
本文研究了目标检测系统在面对动态环境时的性能瓶颈,特别是在现有基于异常值检测(OoD)的过滤器下,针对YOLO系列检测器的问题尤为突出。现有研究表明图像可能包含目标检测器内训练数据集内定义类别的物体(ID对象),使得性能评估存在偏差。因此,作者提出了基于数据合成的校正方法,提高了性能估计的精确度。同时,作者还考虑了将检测器和过滤器作为整体流程,在合成数据集上微调YOLO检测器以降低错误率。这些改进在BDD-100K自动驾驶数据集上实现了显著成果。对于研究和实际应用来说意义重大。该工作的源代码和使用的数据集均已公开发布在特定网站上供用户使用。
Key Takeaways:
- 目标检测系统需要平衡感知能力和自信心,确保在动态环境中做出安全决策。当前面临性能瓶颈问题。
- 基于异常值检测的过滤技术旨在过滤由于过度自信而导致误判的情况。然而现有研究中发现存在一定偏差导致评估性能受到影响。研究发现约有近四分之一被检测的物体是实际存在于训练集中的物体(ID对象)。这影响了性能评估的准确性。
点此查看论文截图



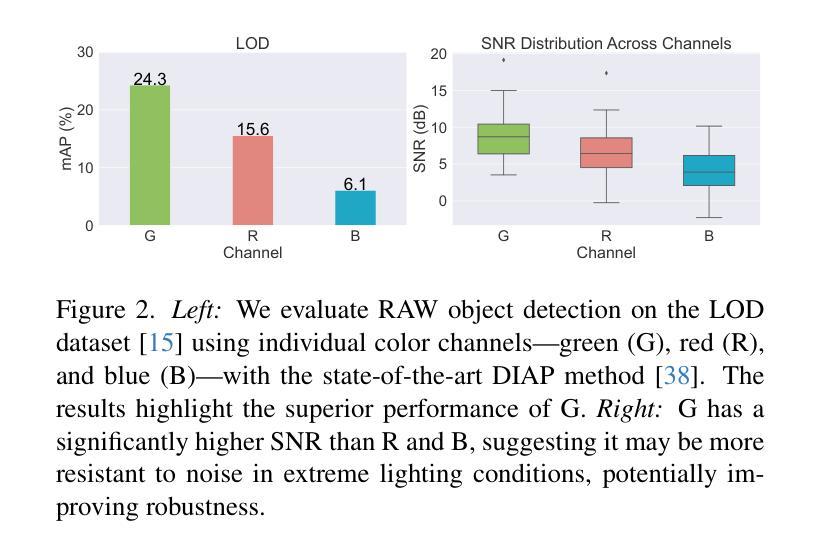
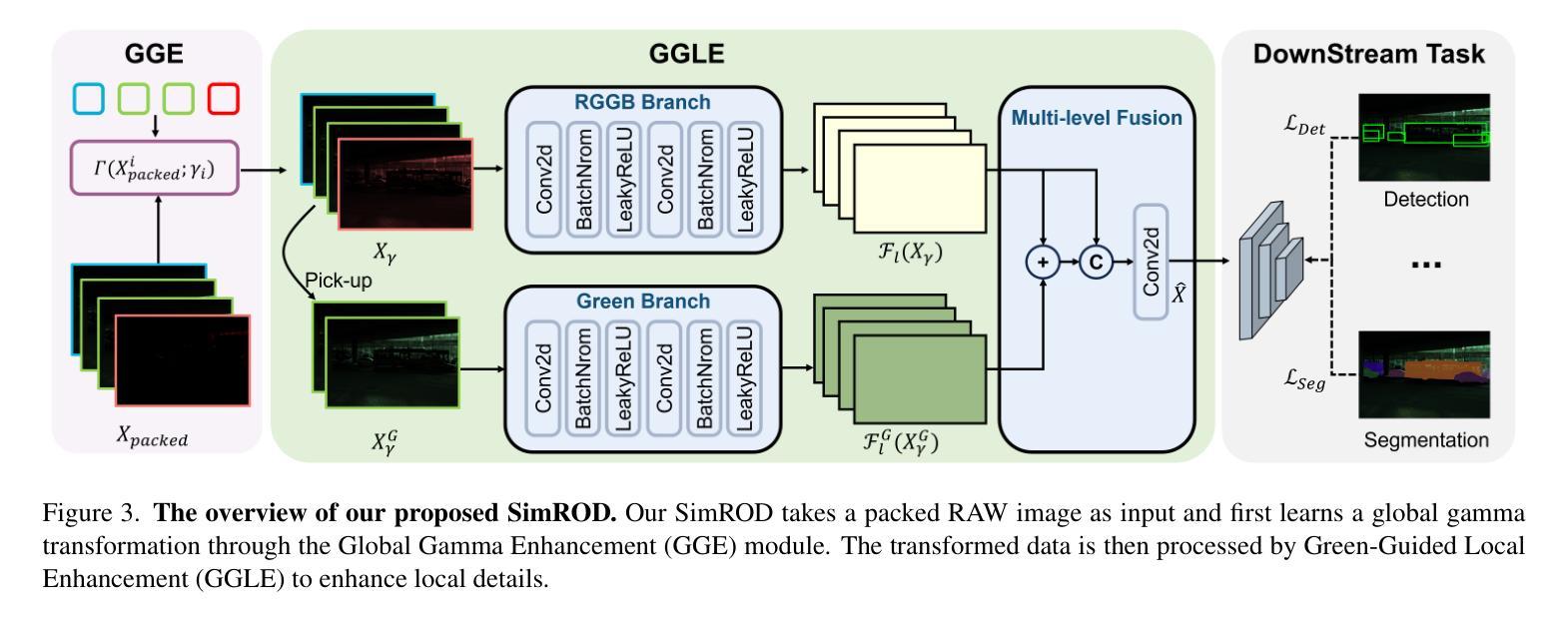
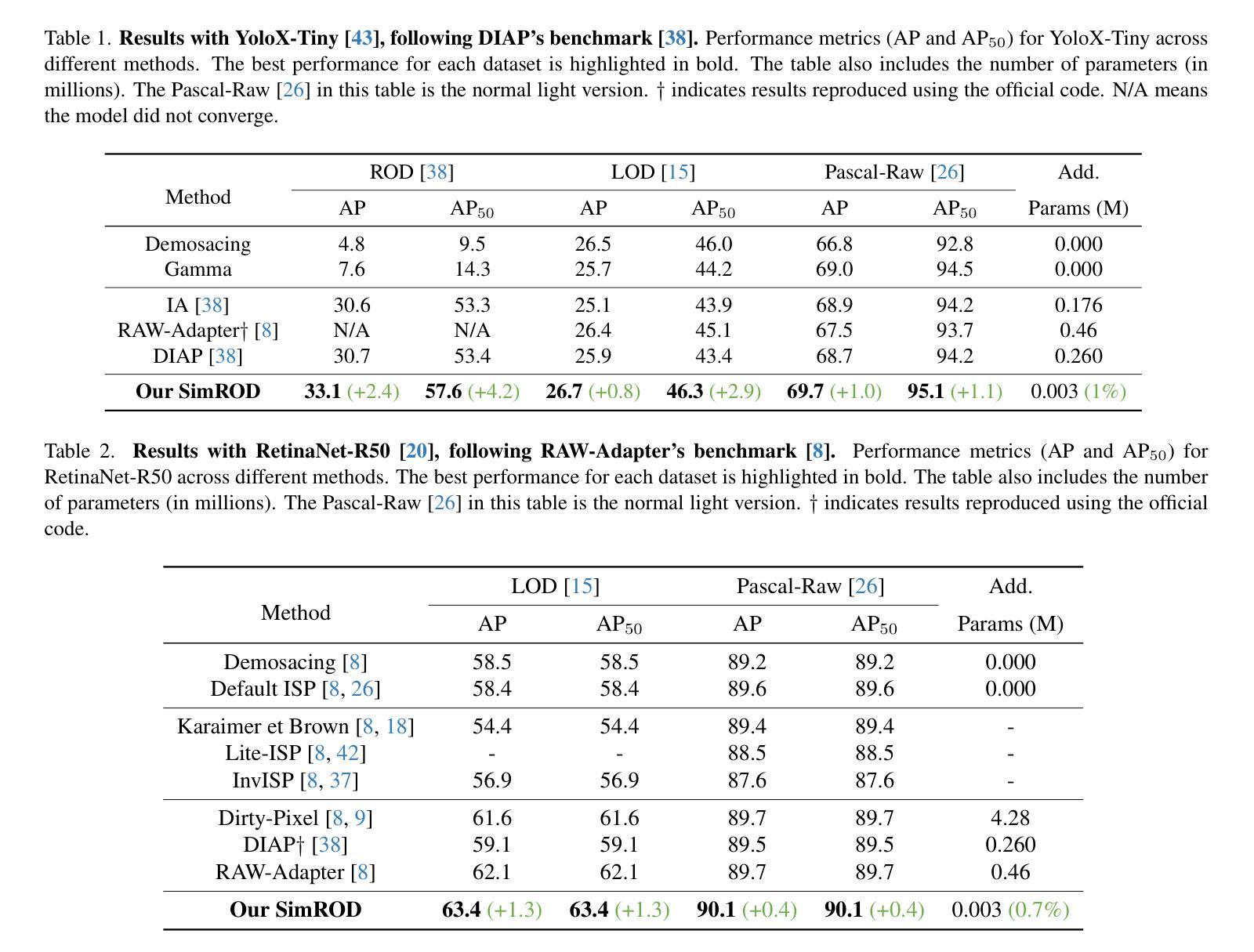
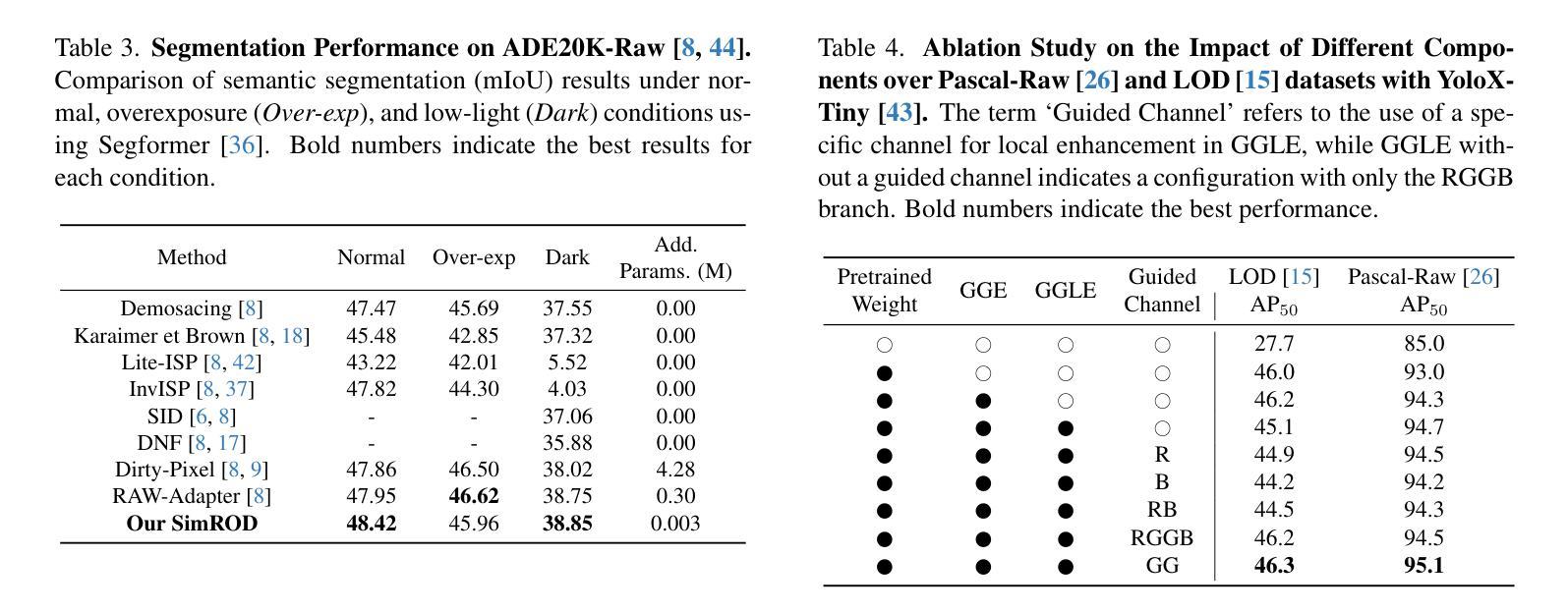
SimROD: A Simple Baseline for Raw Object Detection with Global and Local Enhancements
Authors:Haiyang Xie, Xi Shen, Shihua Huang, Zheng Wang
Most visual models are designed for sRGB images, yet RAW data offers significant advantages for object detection by preserving sensor information before ISP processing. This enables improved detection accuracy and more efficient hardware designs by bypassing the ISP. However, RAW object detection is challenging due to limited training data, unbalanced pixel distributions, and sensor noise. To address this, we propose SimROD, a lightweight and effective approach for RAW object detection. We introduce a Global Gamma Enhancement (GGE) module, which applies a learnable global gamma transformation with only four parameters, improving feature representation while keeping the model efficient. Additionally, we leverage the green channel’s richer signal to enhance local details, aligning with the human eye’s sensitivity and Bayer filter design. Extensive experiments on multiple RAW object detection datasets and detectors demonstrate that SimROD outperforms state-of-the-art methods like RAW-Adapter and DIAP while maintaining efficiency. Our work highlights the potential of RAW data for real-world object detection.
大多数视觉模型都是为sRGB图像设计的,然而RAW数据在对象检测方面具有显著优势,因为它能够保留ISP处理之前的传感器信息。这可以通过绕过ISP实现更高的检测精度和更有效的硬件设计。然而,RAW数据对象检测面临诸多挑战,如训练数据有限、像素分布不平衡和传感器噪声等。为了解决这些问题,我们提出了SimROD,这是一种用于RAW数据对象检测的轻便有效方法。我们引入了全局伽马增强(GGE)模块,该模块仅使用四个参数进行可学习的全局伽马变换,在保持模型效率的同时改进特征表示。此外,我们利用绿色通道更丰富的信号增强局部细节,这与人眼的敏感度和Bayer滤镜设计相一致。在多个RAW对象检测数据集和检测器上的广泛实验表明,SimROD在保持高效率的同时,优于RAW-Adapter和DIAP等最先进的方法。我们的研究突出了RAW数据在现实对象检测中的潜力。
论文及项目相关链接
Summary
本文介绍了在视觉模型中,相较于sRGB图像,RAW数据在物体检测方面的显著优势。RAW数据能够保留ISP处理前的传感器信息,从而提高检测精度并优化硬件设计。尽管RAW物体检测面临训练数据有限、像素分布不均和传感器噪声等问题,但本文提出的SimROD方法,通过应用仅有四个参数的可学习全局伽马变换增强特征表示,并利用绿色通道的丰富信号增强局部细节,在多个RAW物体检测数据集和检测器上的实验表明,SimROD在保持高效率的同时,优于RAW-Adapter和DIAP等先进方法。本文强调了RAW数据在现实物体检测中的潜力。
Key Takeaways
- RAW数据在物体检测中具有优势,能够保留ISP处理前的传感器信息,提高检测精度并优化硬件设计。
- 现有的视觉模型大多针对sRGB图像设计,而RAW物体检测面临训练数据有限、像素分布不均和传感器噪声等挑战。
- 本文提出了SimROD方法,是一种轻量级、有效的RAW物体检测方法。
- SimROD通过应用全局伽马增强模块,使用仅四个参数的可学习全局伽马变换来改善特征表示。
- SimROD利用绿色通道的丰富信号增强局部细节,与人类视觉敏感度和Bayer滤镜设计相符。
- 在多个RAW物体检测数据集和检测器上的实验表明,SimROD优于其他先进方法,如RAW-Adapter和DIAP。
点此查看论文截图

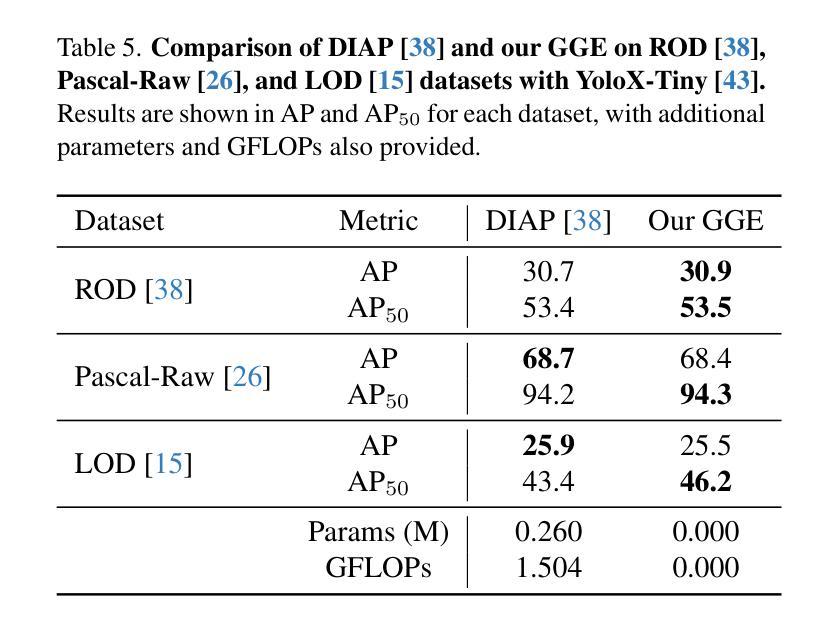
OmniSAM: Omnidirectional Segment Anything Model for UDA in Panoramic Semantic Segmentation
Authors:Ding Zhong, Xu Zheng, Chenfei Liao, Yuanhuiyi Lyu, Jialei Chen, Shengyang Wu, Linfeng Zhang, Xuming Hu
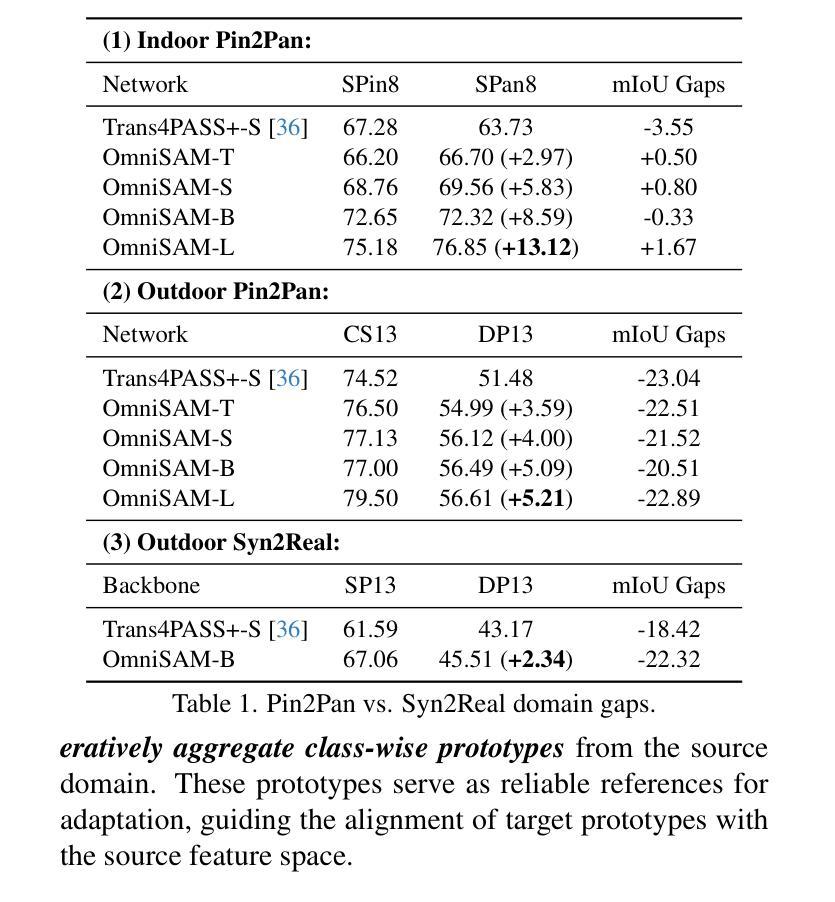
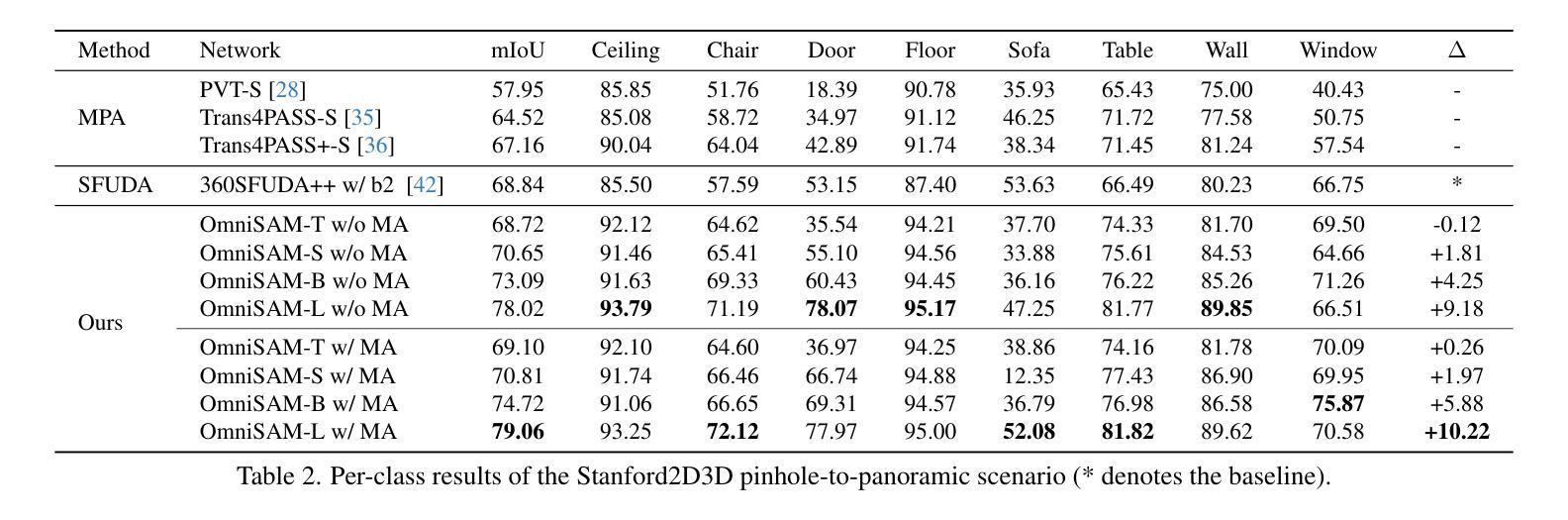
Segment Anything Model 2 (SAM2) has emerged as a strong base model in various pinhole imaging segmentation tasks. However, when applying it to $360^\circ$ domain, the significant field-of-view (FoV) gap between pinhole ($70^\circ \times 70^\circ$) and panoramic images ($180^\circ \times 360^\circ$) poses unique challenges. Two major concerns for this application includes 1) inevitable distortion and object deformation brought by the large FoV disparity between domains; 2) the lack of pixel-level semantic understanding that the original SAM2 cannot provide. To address these issues, we propose a novel OmniSAM framework, which makes the first attempt to apply SAM2 for panoramic semantic segmentation. Specifically, to bridge the first gap, OmniSAM first divides the panorama into sequences of patches. These patches are then treated as image sequences in similar manners as in video segmentation tasks. We then leverage the SAM2’s memory mechanism to extract cross-patch correspondences that embeds the cross-FoV dependencies, improving feature continuity and the prediction consistency along mask boundaries. For the second gap, OmniSAM fine-tunes the pretrained image encoder and reutilize the mask decoder for semantic prediction. An FoV-based prototypical adaptation module with dynamic pseudo label update mechanism is also introduced to facilitate the alignment of memory and backbone features, thereby improving model generalization ability across different sizes of source models. Extensive experimental results demonstrate that OmniSAM outperforms the state-of-the-art methods by large margins, e.g., 79.06% (+10.22%) on SPin8-to-SPan8, 62.46% (+6.58%) on CS13-to-DP13.
Segment Anything Model 2(SAM2)在各种针孔成像分割任务中表现优异,成为强大的基础模型。然而,将其应用于$360^\circ$领域时,针孔($70^\circ \times 70^\circ$)与全景图像($180^\circ \times 360^\circ$)之间视野(FoV)的显著差距带来了独特的挑战。该应用面临两个主要问题:1)由领域间大视野差异带来的不可避免失真和物体变形;2)原始SAM2无法提供像素级别的语义理解。为了解决这些问题,我们提出了全新的OmniSAM框架,它是首次尝试将SAM2应用于全景语义分割。具体来说,为了弥合第一个差距,OmniSAM首先把全景图像分解成一系列的图块。这些图块然后以类似于视频分割任务的方式被当作图像序列进行处理。接着我们利用SAM2的记忆机制来提取跨图块对应关系,这些关系嵌入跨视野依赖,改进了特征连续性和预测的一致性沿着蒙版边界。为了弥合第二个差距,OmniSAM对预训练图像编码器进行了微调,并重新使用蒙版解码器进行语义预测。我们还引入了一个基于视野的原型适应模块,带有动态伪标签更新机制,以促进记忆和主干特征的对齐,从而提高模型在不同尺寸源模型上的泛化能力。大量的实验结果证明,OmniSAM相较于最前沿的方法表现出更大的优势,例如在SPin8-to-SPan8上达到79.06%(+10.22%),在CS13-to-DP13上达到62.46%(+6.58%)。
论文及项目相关链接
Summary:针对全景语义分割中的视场(FoV)差异问题,OmniSAM框架首次尝试将SAM2应用于全景场景。OmniSAM通过分割全景图像为多个补丁,利用SAM2的记忆机制提取跨补丁对应关系,并引入基于视场的原型自适应模块来改善模型在不同源模型大小之间的泛化能力。实验结果证明OmniSAM显著优于现有方法。
Key Takeaways:
- SAM2模型在全景语义分割中面临视场差异带来的挑战。
- OmniSAM框架通过分割全景图像为补丁来解决视场差异问题,并应用SAM2进行特征提取。
- OmniSAM利用SAM2的记忆机制提取跨补丁的对应关系,改善特征连续性和预测一致性。
- 为了改善语义预测,OmniSAM微调了预训练图像编码器并重新使用掩膜解码器。
- 引入基于视场的原型自适应模块和动态伪标签更新机制,提高模型在不同源模型大小之间的泛化能力。
- 实验结果表明OmniSAM在多个数据集上的性能显著优于现有方法。
点此查看论文截图

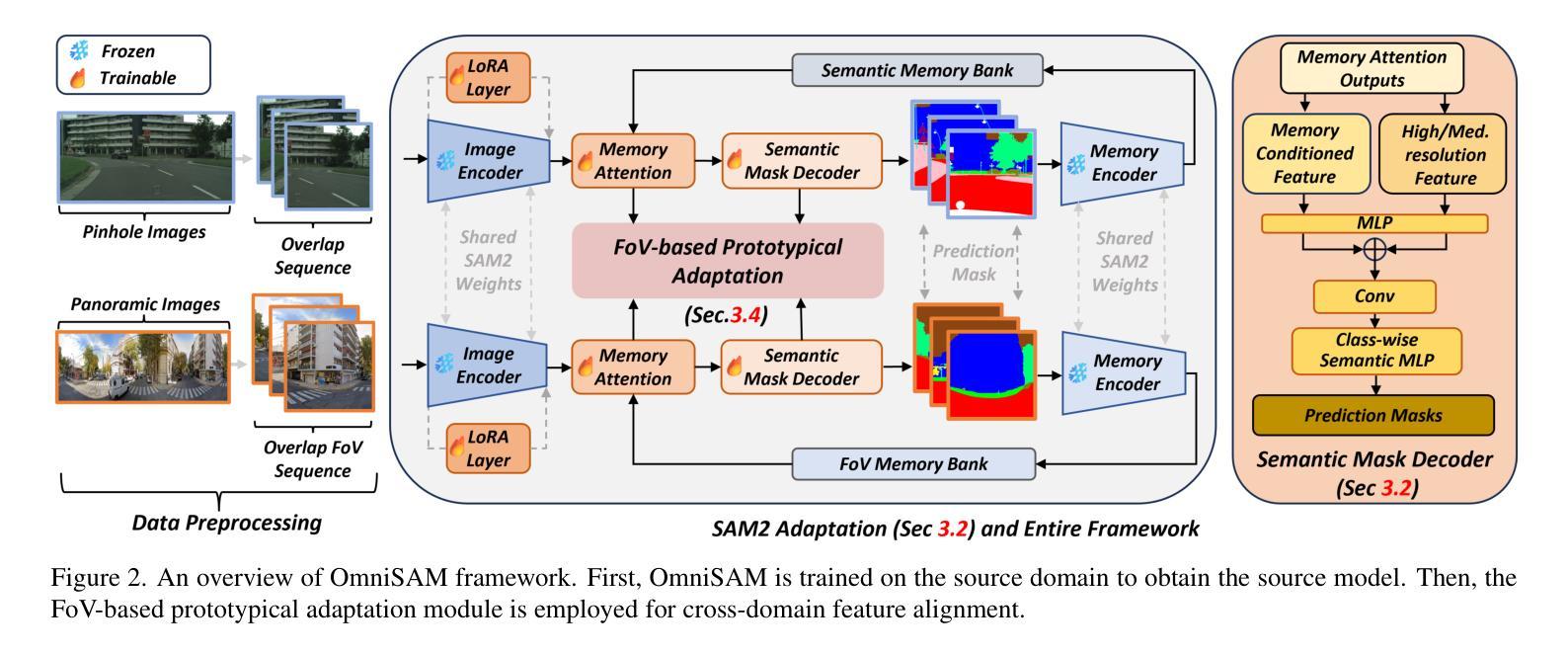
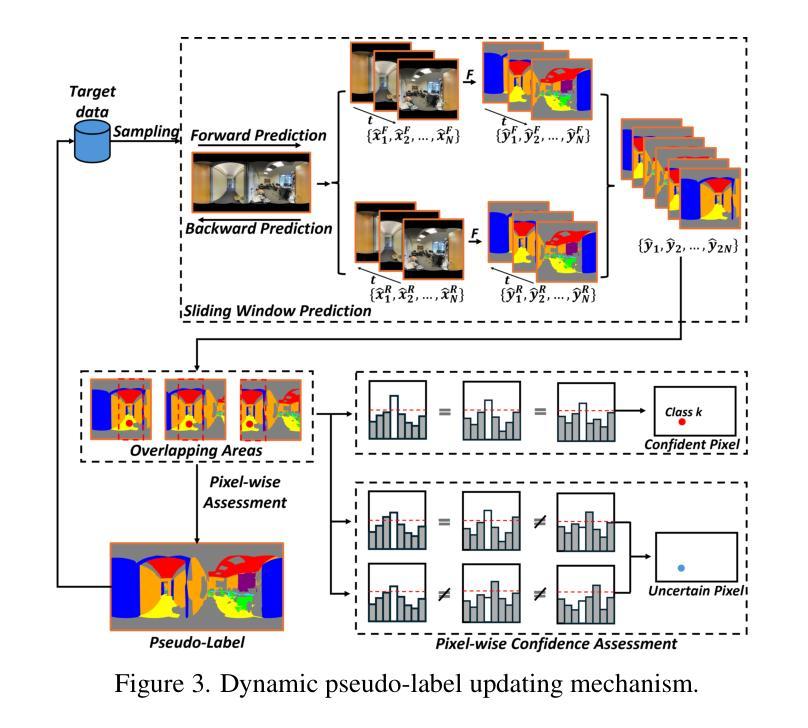
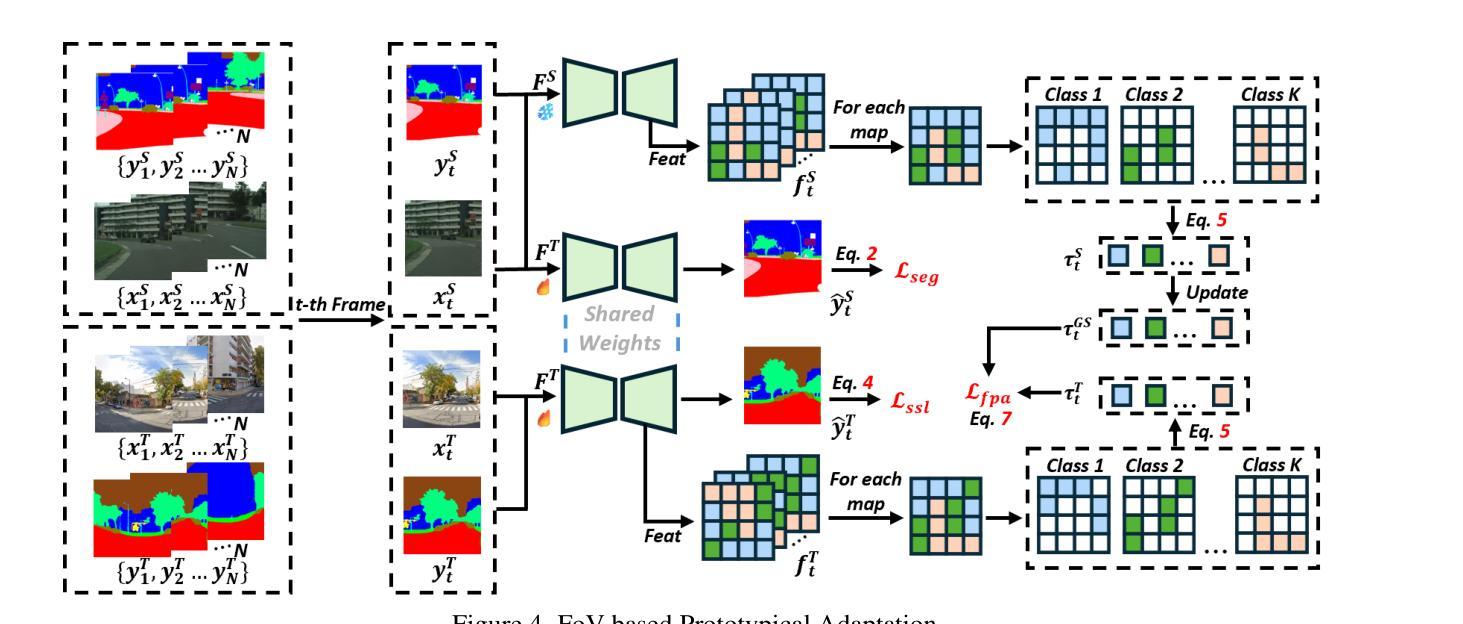
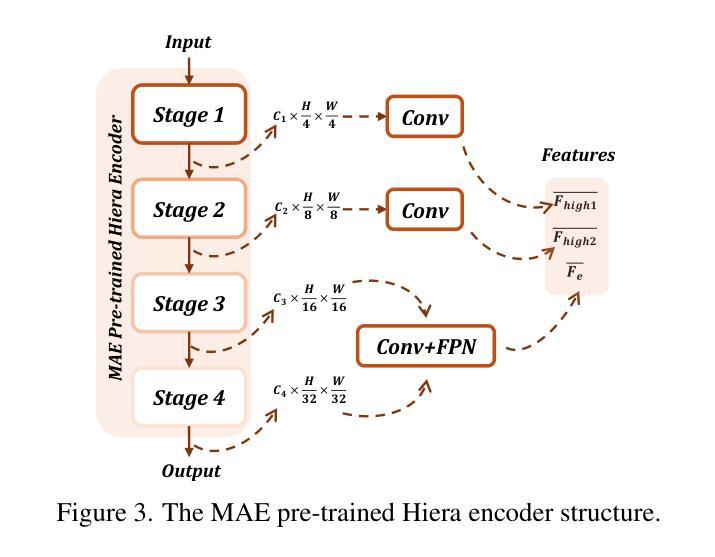
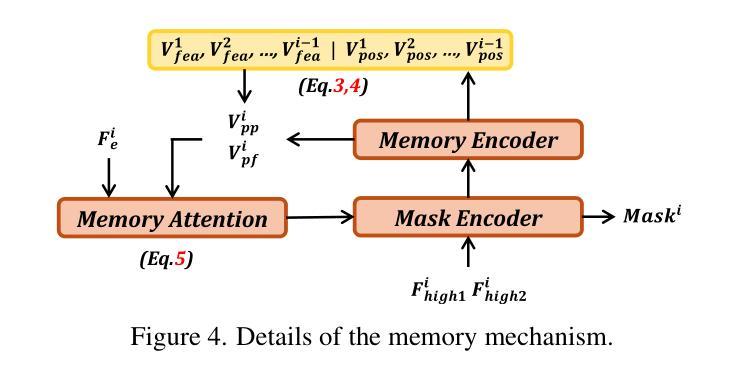
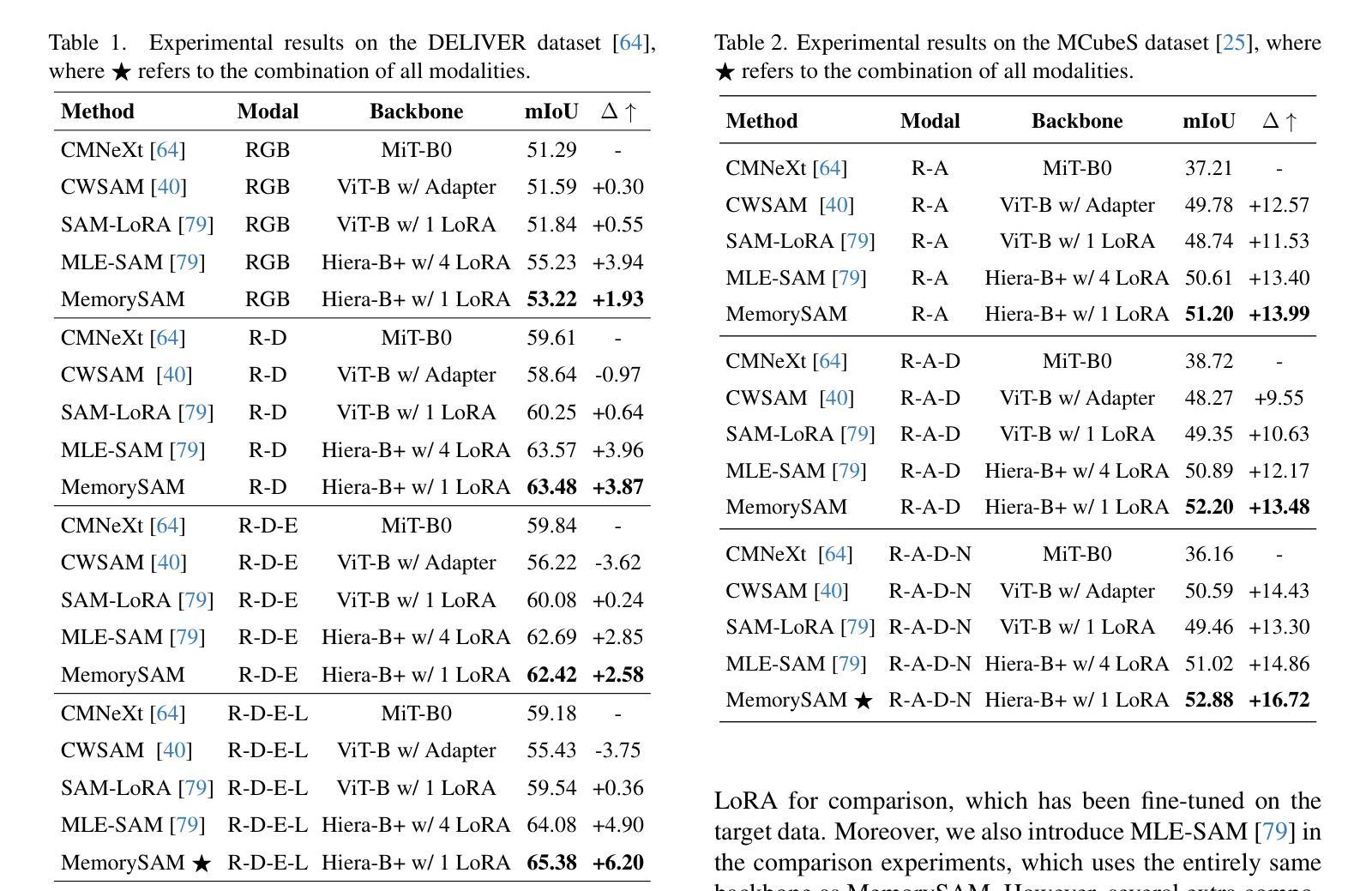
MemorySAM: Memorize Modalities and Semantics with Segment Anything Model 2 for Multi-modal Semantic Segmentation
Authors:Chenfei Liao, Xu Zheng, Yuanhuiyi Lyu, Haiwei Xue, Yihong Cao, Jiawen Wang, Kailun Yang, Xuming Hu
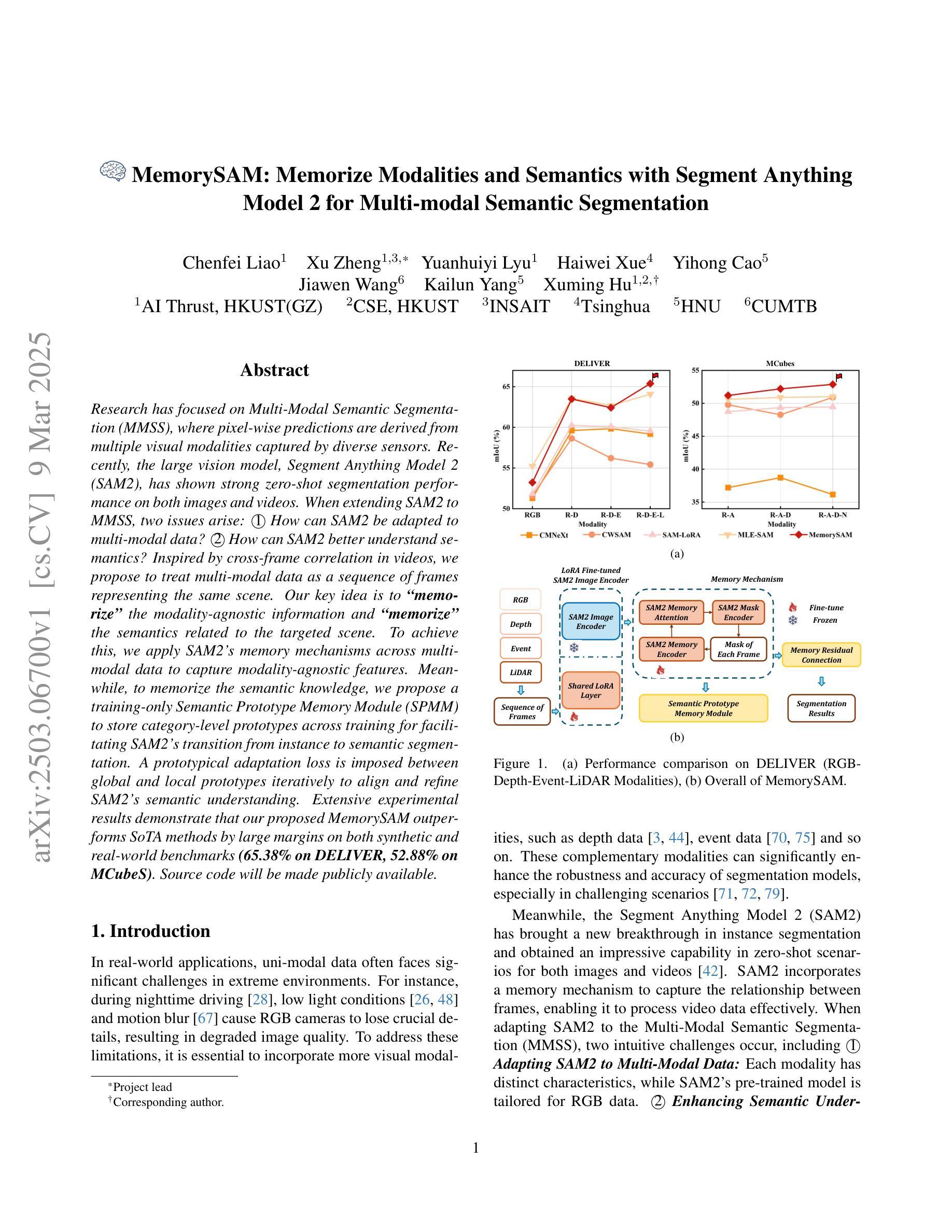
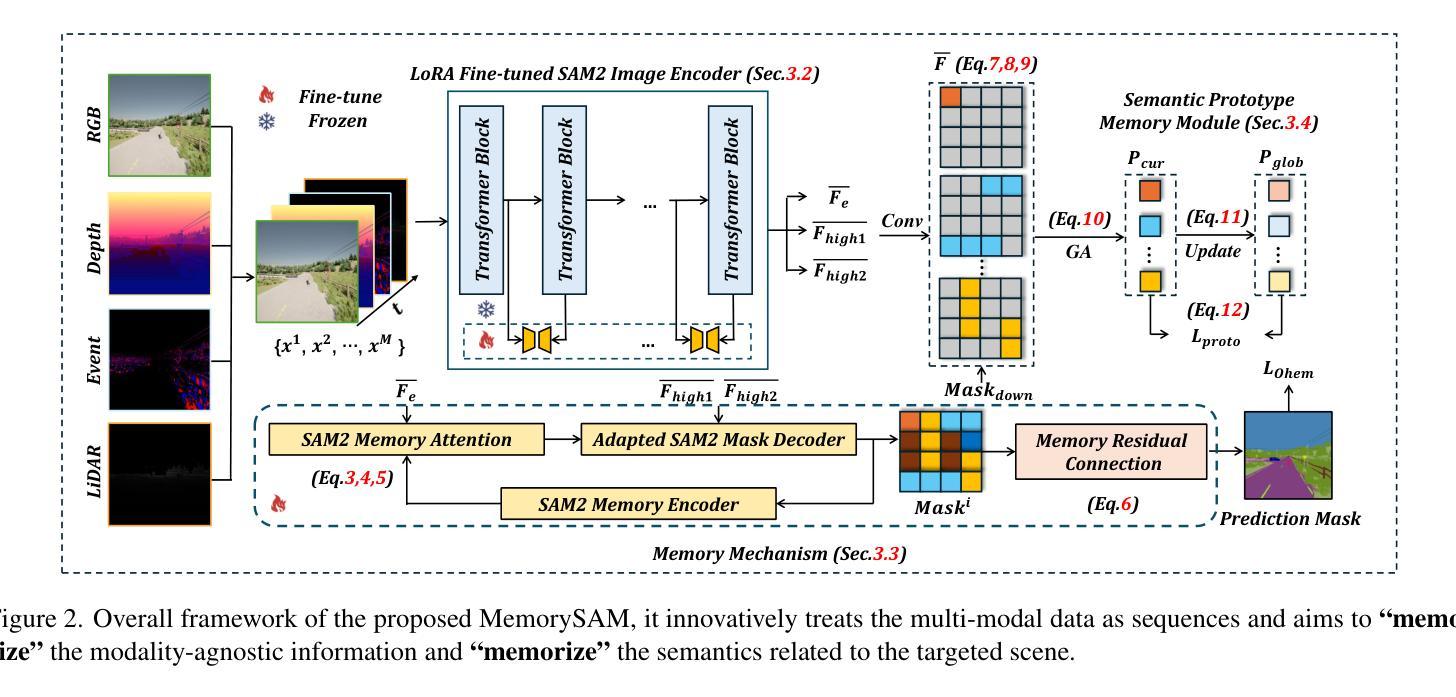
Research has focused on Multi-Modal Semantic Segmentation (MMSS), where pixel-wise predictions are derived from multiple visual modalities captured by diverse sensors. Recently, the large vision model, Segment Anything Model 2 (SAM2), has shown strong zero-shot segmentation performance on both images and videos. When extending SAM2 to MMSS, two issues arise: 1. How can SAM2 be adapted to multi-modal data? 2. How can SAM2 better understand semantics? Inspired by cross-frame correlation in videos, we propose to treat multi-modal data as a sequence of frames representing the same scene. Our key idea is to ‘’memorize’’ the modality-agnostic information and ‘memorize’ the semantics related to the targeted scene. To achieve this, we apply SAM2’s memory mechanisms across multi-modal data to capture modality-agnostic features. Meanwhile, to memorize the semantic knowledge, we propose a training-only Semantic Prototype Memory Module (SPMM) to store category-level prototypes across training for facilitating SAM2’s transition from instance to semantic segmentation. A prototypical adaptation loss is imposed between global and local prototypes iteratively to align and refine SAM2’s semantic understanding. Extensive experimental results demonstrate that our proposed MemorySAM outperforms SoTA methods by large margins on both synthetic and real-world benchmarks (65.38% on DELIVER, 52.88% on MCubeS). Source code will be made publicly available.
研究重点为多模态语义分割(MMSS),其中像素级预测是从由多种传感器捕获的多个视觉模态中得出的。最近,大型视觉模型“万物分割模型2”(SAM2)在图像和视频上都表现出了强大的零样本分割性能。当将SAM2扩展到MMSS时,出现了两个问题:1. 如何使SAM2适应多模态数据?2. SAM2如何更好地理解语义?受视频中跨帧关联的启发,我们提出将多模态数据视为表示同一场景的帧序列。我们的核心思想是通过“记忆”与模态无关的信息和与目标场景相关的语义来实现这一点。为此,我们应用SAM2的记忆机制来捕获多模态数据的模态无关特征。同时,为了记忆语义知识,我们提出了仅用于训练的语义原型记忆模块(SPMM),在训练过程中存储类别级别的原型,以促进SAM2从实例分割到语义分割的过渡。通过全局和局部原型之间迭代施加原型适应损失,以对齐和细化SAM2的语义理解。大量的实验结果表明,我们提出的MemorySAM在合成和真实世界基准测试(DELIVER上的65.38%,MCubeS上的52.88%)上都优于最新方法的大幅边距。源代码将公开可用。
论文及项目相关链接
Summary:针对多模态语义分割(MMSS)的研究,通过利用Segment Anything Model 2(SAM2)的零样本分割性能,提出一种将多模态数据视为场景帧序列的方法。通过跨模态数据的记忆机制捕获模态无关特征,并通过语义原型记忆模块(SPMM)实现语义知识的记忆,从而提升SAM2对语义的理解。在合成和真实世界的基准测试中,所提出的方法MemorySAM优于现有技术,表现出显著优势。
Key Takeaways:
- 研究集中在多模态语义分割(MMSS)上,面临如何适应多模态数据和增强语义理解两大挑战。
- 利用Segment Anything Model 2(SAM2)的零样本分割性能,将其扩展到多模态场景。
- 提出将多模态数据视为场景帧序列的方法,通过记忆机制捕获模态无关特征。
- 引入语义原型记忆模块(SPMM),用于存储场景类别级别的原型,促进从实例到语义分割的过渡。
- 通过原型适应损失来迭代地对齐和精炼SAM2的语义理解。
- 所提出的方法在合成和真实世界的基准测试中表现出显著优势,优于现有技术。
点此查看论文截图
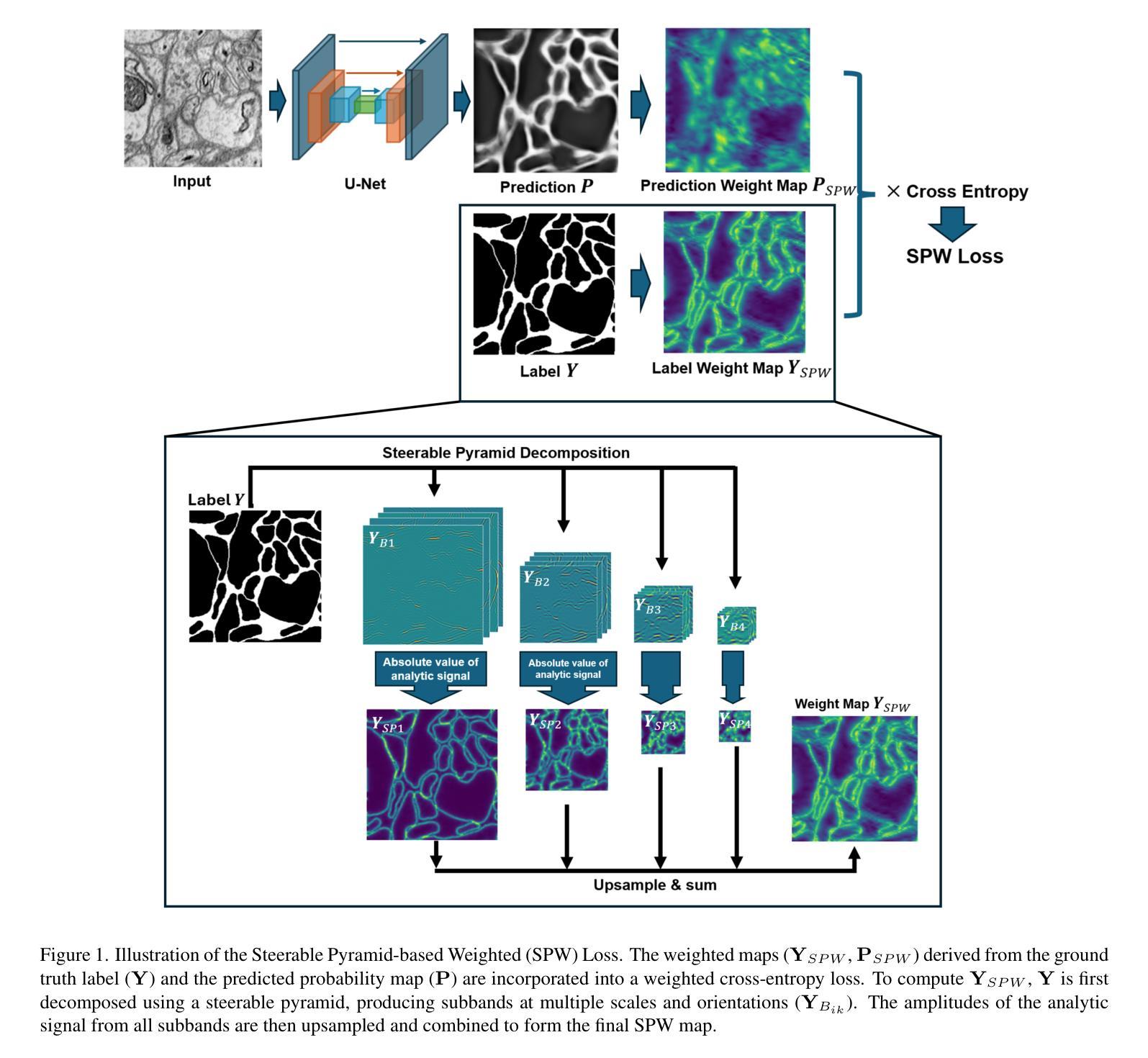
Steerable Pyramid Weighted Loss: Multi-Scale Adaptive Weighting for Semantic Segmentation
Authors:Renhao Lu
Semantic segmentation is a core task in computer vision with applications in biomedical imaging, remote sensing, and autonomous driving. While standard loss functions such as cross-entropy and Dice loss perform well in general cases, they often struggle with fine structures, particularly in tasks involving thin structures or closely packed objects. Various weight map-based loss functions have been proposed to address this issue by assigning higher loss weights to pixels prone to misclassification. However, these methods typically rely on precomputed or runtime-generated weight maps based on distance transforms, which impose significant computational costs and fail to adapt to evolving network predictions. In this paper, we propose a novel steerable pyramid-based weighted (SPW) loss function that efficiently generates adaptive weight maps. Unlike traditional boundary-aware losses that depend on static or iteratively updated distance maps, our method leverages steerable pyramids to dynamically emphasize regions across multiple frequency bands (capturing features at different scales) while maintaining computational efficiency. Additionally, by incorporating network predictions into the weight computation, our approach enables adaptive refinement during training. We evaluate our method on the SNEMI3D, GlaS, and DRIVE datasets, benchmarking it against 11 state-of-the-art loss functions. Our results demonstrate that the proposed SPW loss function achieves superior pixel precision and segmentation accuracy with minimal computational overhead. This work provides an effective and efficient solution for improving semantic segmentation, particularly for applications requiring multiscale feature representation. The code is avaiable at https://anonymous.4open.science/r/SPW-0884
语义分割是计算机视觉中的核心任务,在生物医学成像、遥感和自动驾驶等领域有广泛应用。虽然交叉熵和Dice损失等标准损失函数在一般情况下表现良好,但它们在处理精细结构时常常遇到困难,特别是在涉及细薄结构或密集排列的物体时。为了解决这个问题,已经提出了各种基于权重图的损失函数,通过给容易误分类的像素分配更高的损失权重来改进分割效果。然而,这些方法通常依赖于基于距离变换的预计算或运行时生成的权重图,这带来了显著的计算成本,并且无法适应不断变化的网络预测。
论文及项目相关链接
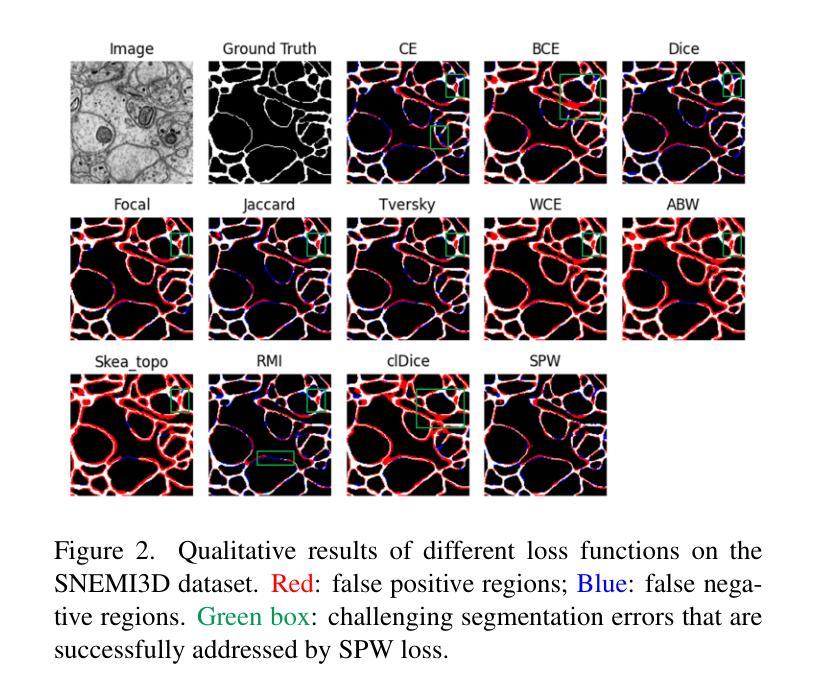
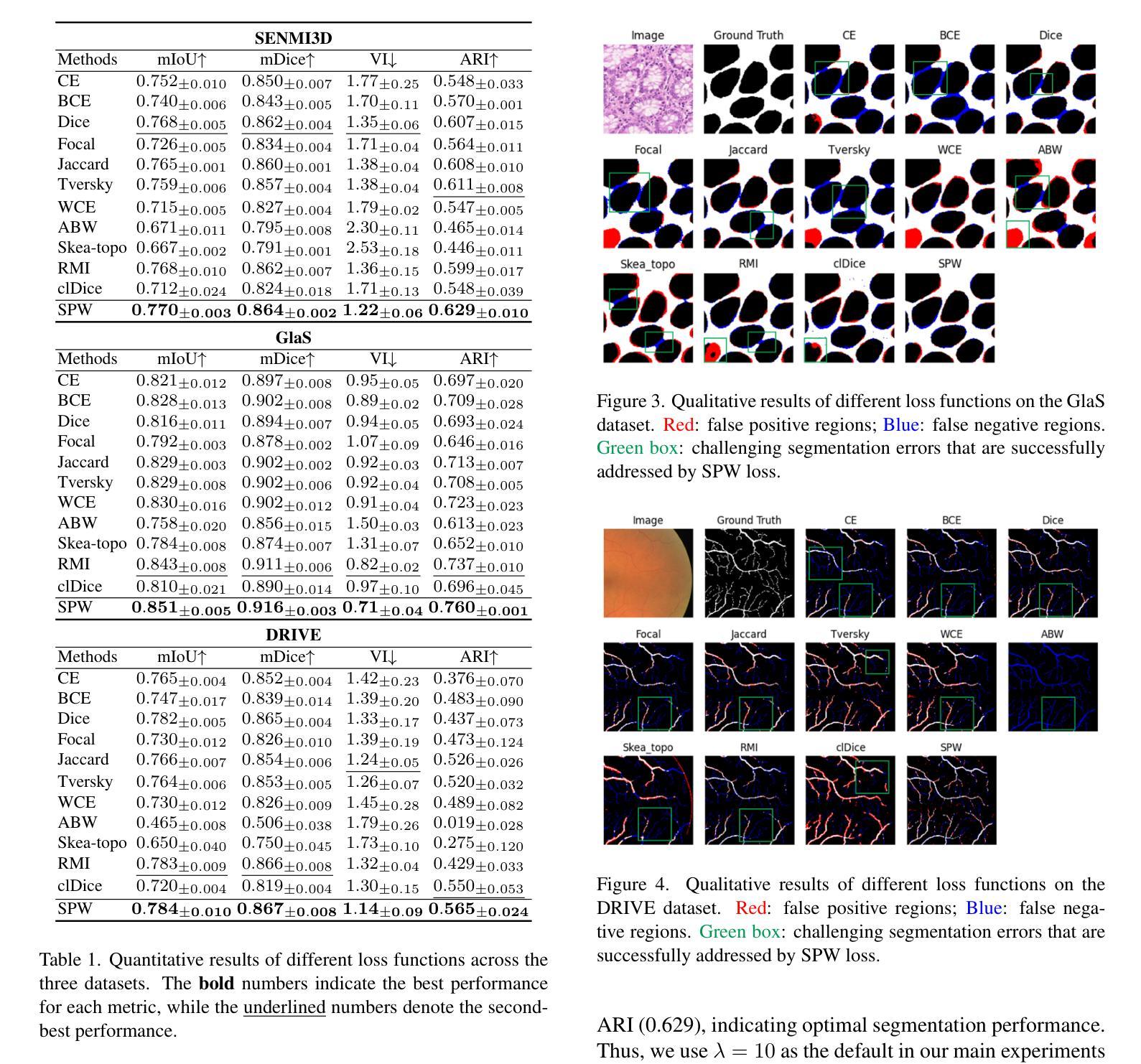
PDF 9 pages, 4 figures
Summary
本文提出一种基于可导向金字塔的加权(SPW)损失函数,用于改善语义分割的性能,特别是在涉及多尺度特征表示的应用中。该函数能够动态强调不同频率带的区域,并结合网络预测进行权重计算,以实现自适应细化。实验结果表明,SPW损失函数在像素精度和分割准确性方面达到优越性能,同时计算开销较小。
Key Takeaways
- 语义分割是计算机视觉的核心任务,在生物医学成像、遥感、自动驾驶等领域有广泛应用。
- 标准损失函数在精细结构上的表现有待提高,特别是在涉及薄结构或密集排列物体的任务中。
- 基于权重图的损失函数已被提出以解决这一问题,但它们通常依赖于预计算或运行时生成的权重图,计算成本高且无法适应网络预测的演变。
- 本文提出了一种新的SPW损失函数,利用可导向金字塔有效地生成自适应权重图,能够动态强调不同频率带的区域并维持计算效率。
- SPW损失函数结合网络预测进行权重计算,使训练过程中能够实现自适应细化。
- 实验结果表明,SPW损失函数在多个数据集上实现了较高的像素精度和分割准确性。
点此查看论文截图

PointDiffuse: A Dual-Conditional Diffusion Model for Enhanced Point Cloud Semantic Segmentation
Authors:Yong He, Hongshan Yu, Mingtao Feng, Tongjia Chen, Zechuan Li, Anwaar Ulhaq, Saeed Anwar, Ajmal Saeed Mian
Diffusion probabilistic models are traditionally used to generate colors at fixed pixel positions in 2D images. Building on this, we extend diffusion models to point cloud semantic segmentation, where point positions also remain fixed, and the diffusion model generates point labels instead of colors. To accelerate the denoising process in reverse diffusion, we introduce a noisy label embedding mechanism. This approach integrates semantic information into the noisy label, providing an initial semantic reference that improves the reverse diffusion efficiency. Additionally, we propose a point frequency transformer that enhances the adjustment of high-level context in point clouds. To reduce computational complexity, we introduce the position condition into MLP and propose denoising PointNet to process the high-resolution point cloud without sacrificing geometric details. Finally, we integrate the proposed noisy label embedding, point frequency transformer and denoising PointNet in our proposed dual conditional diffusion model-based network (PointDiffuse) to perform large-scale point cloud semantic segmentation. Extensive experiments on five benchmarks demonstrate the superiority of PointDiffuse, achieving the state-of-the-art mIoU of 74.2% on S3DIS Area 5, 81.2% on S3DIS 6-fold and 64.8% on SWAN dataset.
传统的扩散概率模型主要用于在2D图像的固定像素位置生成颜色。在此基础上,我们将扩散模型扩展到点云语义分割,其中点位置也是固定的,扩散模型生成点标签而不是颜色。为了加速反向扩散中的去噪过程,我们引入了噪声标签嵌入机制。这种方法将语义信息集成到噪声标签中,为反向扩散提供了一个初始语义参考,提高了反向扩散的效率。此外,我们提出了一种点频变压器,它增强了点云中高级上下文的调整。为了降低计算复杂度,我们将位置条件引入多层感知机,并提出去噪PointNet来处理高分辨率点云而不损失几何细节。最后,我们将所提出的噪声标签嵌入、点频变压器和去噪PointNet集成到我们所提出的基于双条件扩散模型的网络(PointDiffuse)中,以执行大规模点云语义分割。在五组基准测试上的广泛实验表明,PointDiffuse具有优越性,在S3DIS Area 5上达到了最先进的mIoU为74.2%,在S3DIS 6倍交叉验证上为81.2%,在SWAN数据集上为64.8%。
论文及项目相关链接
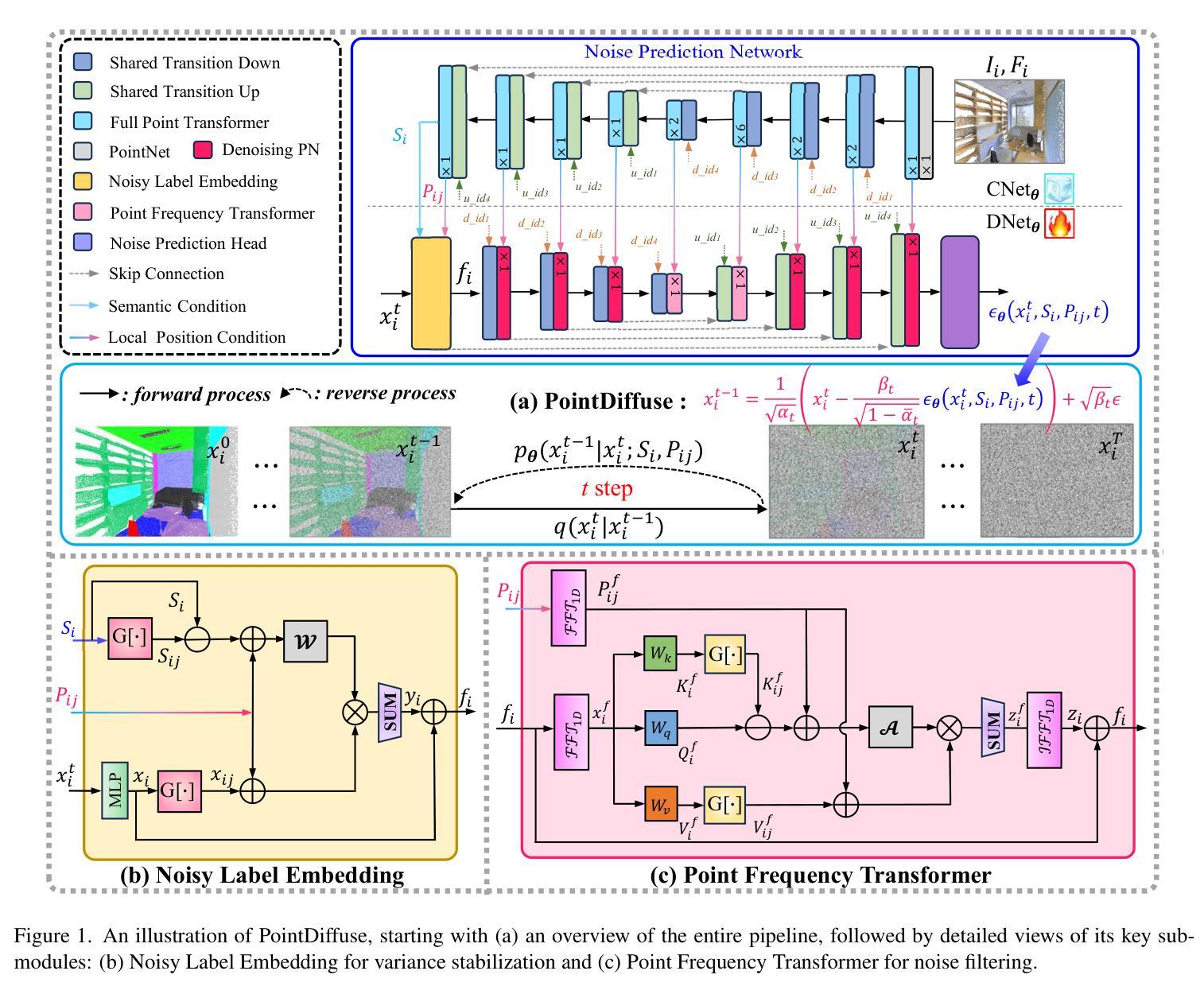
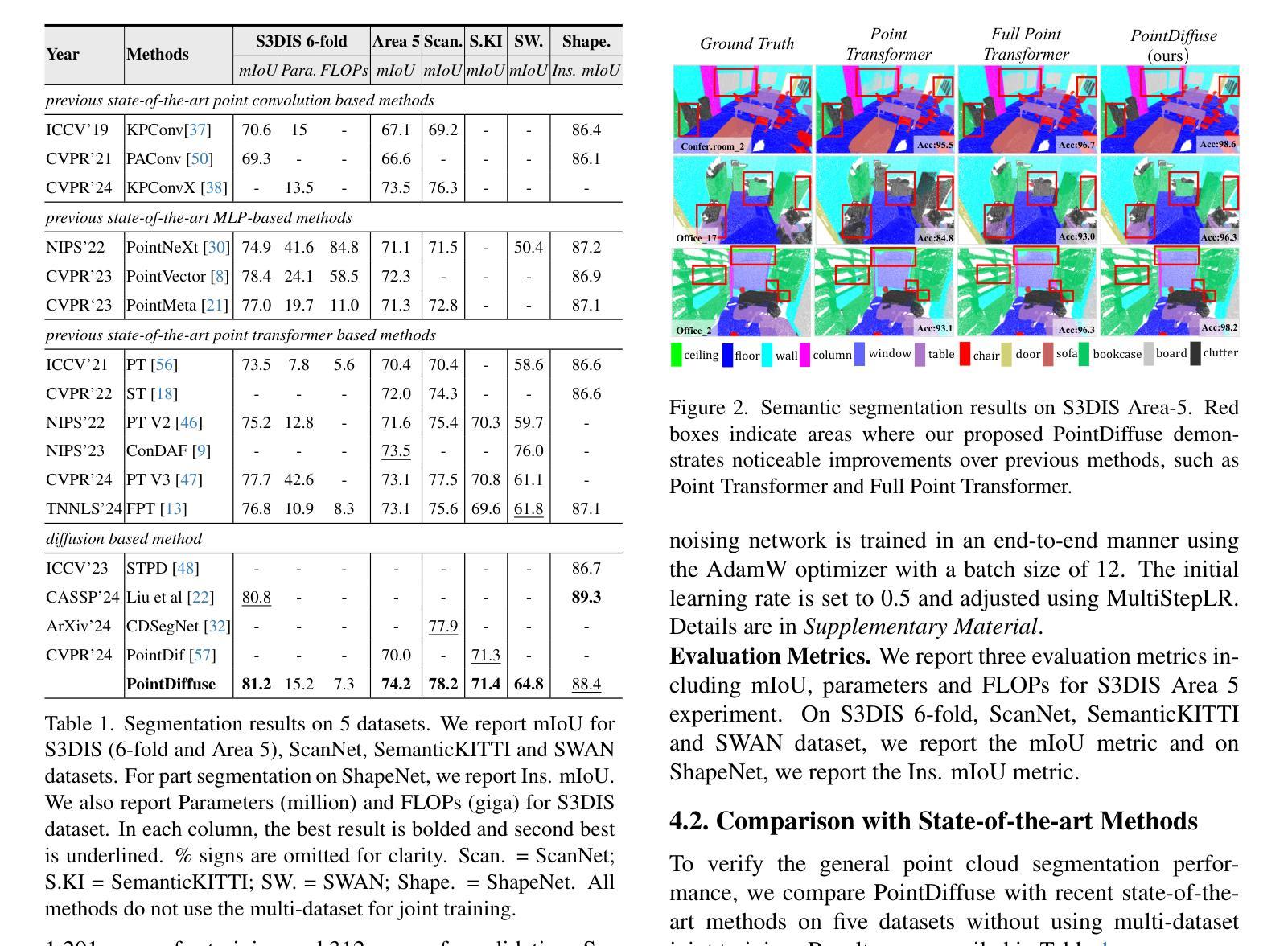
PDF 8 pages, 3 figures, 7 tables
Summary:
基于扩散概率模型生成二维图像中的固定像素位置颜色,本文将其扩展到点云语义分割领域。通过引入噪声标签嵌入机制和点频变换器,提高了反向扩散过程的效率和点云上下文调整的准确性。此外,本文还引入了位置条件到多层感知机中,并提出了去噪PointNet来处理高分辨率点云而保持几何细节。最终,将所提出的组件集成到一个基于双条件扩散模型的PointDiffuse网络中,实现了大规模点云语义分割的优异性能。在五个基准测试上的实验结果表明,PointDiffuse达到了最先进的平均交并比性能。
Key Takeaways:
- 将扩散概率模型应用于点云语义分割领域。
- 引入噪声标签嵌入机制以加速反向扩散过程并集成语义信息。
- 提出点频变换器以增强点云中上下文信息的调整。
- 通过引入位置条件到多层感知机中,降低计算复杂度。
- 提出去噪PointNet以处理高分辨率点云并保持几何细节。
- 集成上述组件到双条件扩散模型PointDiffuse中,实现大规模点云语义分割。
点此查看论文截图

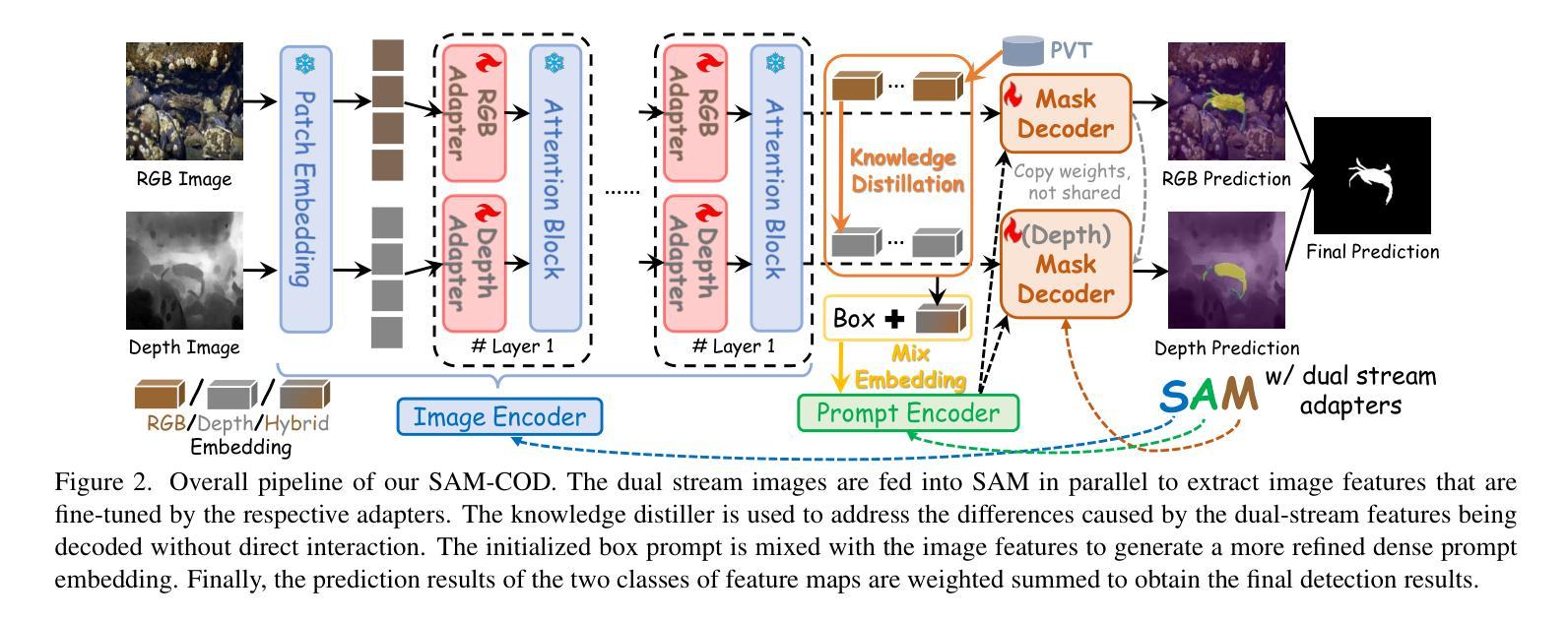
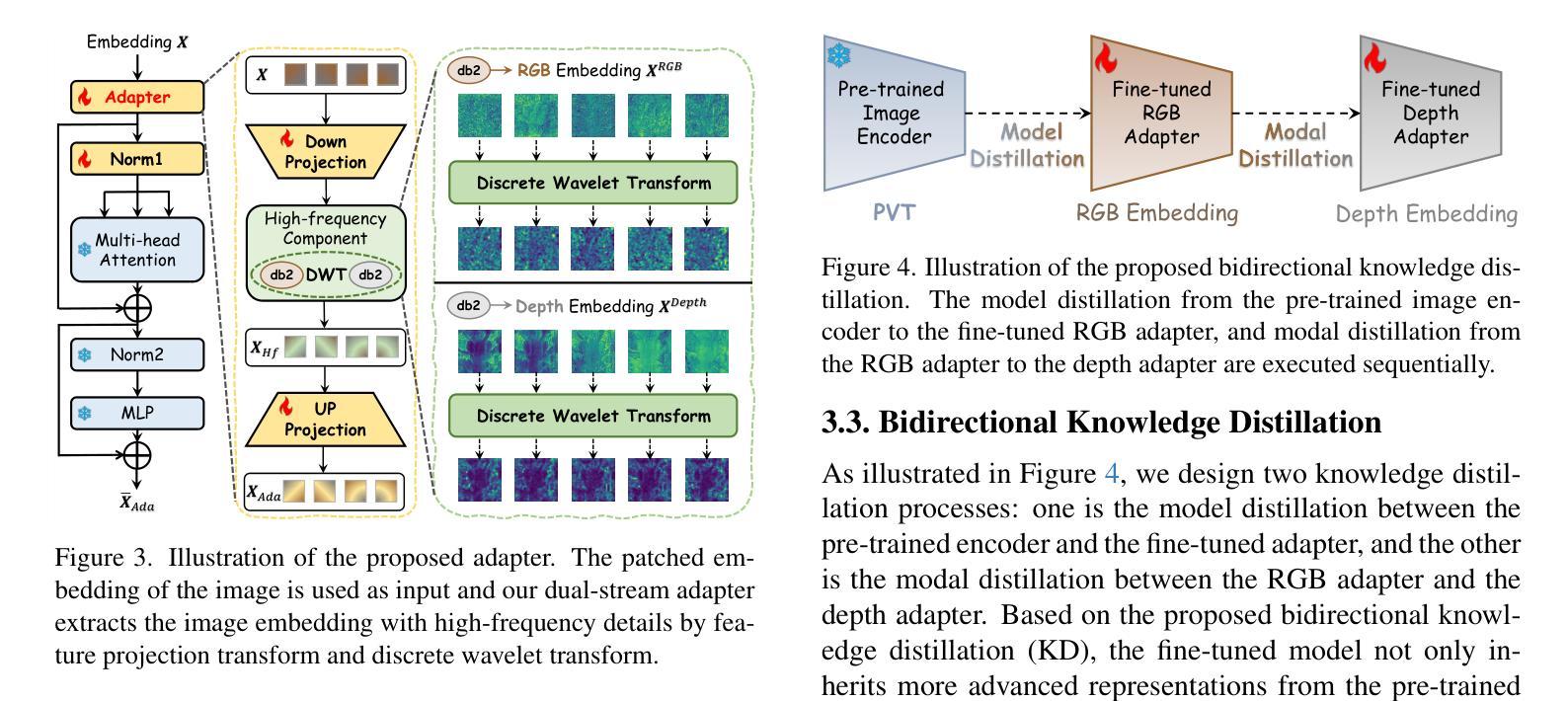
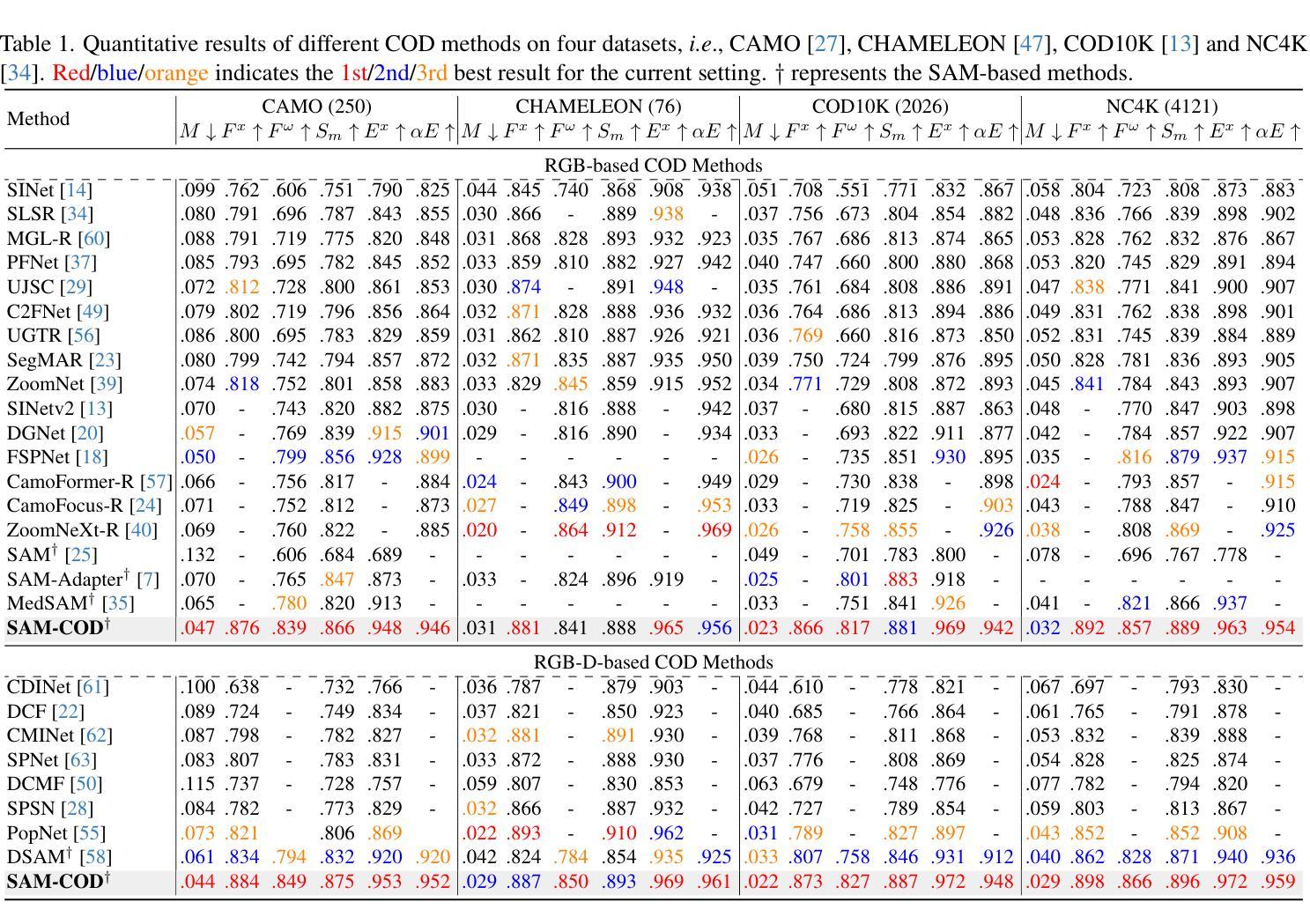
Improving SAM for Camouflaged Object Detection via Dual Stream Adapters
Authors:Jiaming Liu, Linghe Kong, Guihai Chen
Segment anything model (SAM) has shown impressive general-purpose segmentation performance on natural images, but its performance on camouflaged object detection (COD) is unsatisfactory. In this paper, we propose SAM-COD that performs camouflaged object detection for RGB-D inputs. While keeping the SAM architecture intact, dual stream adapters are expanded on the image encoder to learn potential complementary information from RGB images and depth images, and fine-tune the mask decoder and its depth replica to perform dual-stream mask prediction. In practice, the dual stream adapters are embedded into the attention block of the image encoder in a parallel manner to facilitate the refinement and correction of the two types of image embeddings. To mitigate channel discrepancies arising from dual stream embeddings that do not directly interact with each other, we augment the association of dual stream embeddings using bidirectional knowledge distillation including a model distiller and a modal distiller. In addition, to predict the masks for RGB and depth attention maps, we hybridize the two types of image embeddings which are jointly learned with the prompt embeddings to update the initial prompt, and then feed them into the mask decoders to synchronize the consistency of image embeddings and prompt embeddings. Experimental results on four COD benchmarks show that our SAM-COD achieves excellent detection performance gains over SAM and achieves state-of-the-art results with a given fine-tuning paradigm.
分段模型(SAM)在自然图像上的通用分割性能令人印象深刻,但在伪装目标检测(COD)方面的性能却不尽人意。本文提出了针对RGB-D输入的伪装目标检测SAM-COD。在保持SAM架构完整性的同时,在图像编码器上扩展了双流适配器,以学习RGB图像和深度图像之间潜在的互补信息,并微调掩膜解码器及其深度副本,以执行双流掩膜预测。在实践中,双流适配器以并行方式嵌入到图像编码器的注意力块中,以促进两种图像嵌入的细化和校正。为了缓解由于双流嵌入而产生的通道差异,这些嵌入之间并不直接相互作用,我们使用了双向知识蒸馏增强双流嵌入的关联,包括模型蒸馏器和模态蒸馏器。此外,为了预测RGB和深度注意力图的掩膜,我们混合了两种类型的图像嵌入,这些嵌入与提示嵌入一起联合学习以更新初始提示,然后将其输入到掩膜解码器中,以同步图像嵌入和提示嵌入的一致性。在四个COD基准测试上的实验结果表明,我们的SAM-COD在SAM上实现了出色的检测性能提升,并在给定的微调范式下达到了最新结果。
论文及项目相关链接
Summary:SAM模型在自然图像分割方面表现出色,但在伪装目标检测(COD)上的表现不佳。本文提出SAM-COD模型,用于RGB-D输入的伪装目标检测。通过保留SAM架构的同时,在图像编码器上扩展双流适配器以学习RGB图像和深度图像之间的潜在互补信息,并微调掩膜解码器及其深度副本以执行双流掩膜预测。通过嵌入注意力块的双向知识蒸馏增强双流嵌入的关联,并混合两种图像嵌入来预测RGB和深度注意力图的掩膜。实验结果表明,SAM-COD在四个COD基准测试上取得了出色的检测性能提升,并在微调模式下达到了前沿水平。
Key Takeaways:
- SAM模型在自然图像分割上表现良好,但在伪装目标检测(COD)方面存在不足。
- 提出了SAM-COD模型,该模型针对RGB-D输入进行伪装目标检测。
- SAM-COD通过扩展双流适配器学习RGB和深度图像的潜在互补信息。
- 双向知识蒸馏用于增强双流嵌入的关联。
- 双流适配器嵌入到图像编码器的注意力块中以促进两种图像嵌入的完善和校正。
- 通过混合两种图像嵌入和提示嵌入来预测RGB和深度注意力图的掩膜。
点此查看论文截图

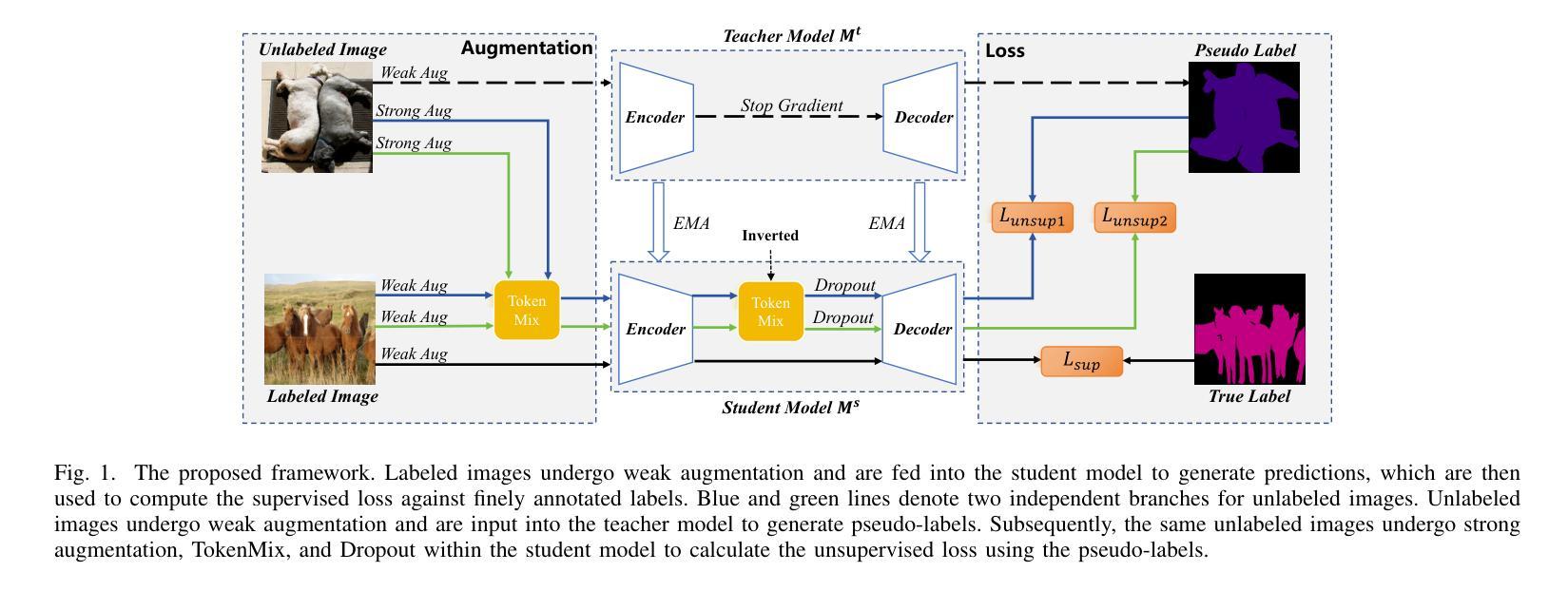
Exploring Token-Level Augmentation in Vision Transformer for Semi-Supervised Semantic Segmentation
Authors:Dengke Zhang, Quan Tang, Fagui Liu, Haiqing Mei, C. L. Philip Chen
Semi-supervised semantic segmentation has witnessed remarkable advancements in recent years. However, existing algorithms are based on convolutional neural networks and directly applying them to Vision Transformers poses certain limitations due to conceptual disparities. To this end, we propose TokenMix, a data augmentation technique specifically designed for semi-supervised semantic segmentation with Vision Transformers. TokenMix aligns well with the global attention mechanism by mixing images at the token level, enhancing learning capability for contextual information among image patches. We further incorporate image augmentation and feature augmentation to promote the diversity of augmentation. Moreover, to enhance consistency regularization, we propose a dual-branch framework where each branch applies image and feature augmentation to the input image. We conduct extensive experiments across multiple benchmark datasets, including Pascal VOC 2012, Cityscapes, and COCO. Results suggest that the proposed method outperforms state-of-the-art algorithms with notably observed accuracy improvement, especially under limited fine annotations.
近年来,半监督语义分割取得了显著的进步。然而,现有算法主要基于卷积神经网络,直接将其应用于视觉变压器会遇到一定的局限性,因为两者在概念上存在差距。为此,我们提出了TokenMix,这是一种专门针对基于视觉变压器的半监督语义分割设计的数据增强技术。TokenMix通过在标记层面混合图像与全局注意力机制紧密结合,增强了图像补丁之间上下文信息的学习能力。我们进一步结合了图像增强和特征增强,以促进增强的多样性。此外,为了增强一致性正则化,我们提出了一个双分支框架,每个分支对输入图像应用图像和特征增强。我们在多个基准数据集上进行了大量实验,包括Pascal VOC 2012、Cityscapes和COCO。结果表明,所提出的方法优于最新算法,特别是在有限的精细标注下,观察到明显的准确率提高。
论文及项目相关链接
Summary:近年来,半监督语义分割领域取得了显著进展。然而,现有算法主要基于卷积神经网络,直接应用于视觉Transformer存在局限性。为此,我们提出了TokenMix,这是一种专门为半监督语义分割与视觉Transformer设计的数据增强技术。TokenMix通过与全局注意力机制结合,通过在标记层面混合图像,提高图像补丁之间上下文信息的学习能力。我们还加入了图像增强和特征增强以促进增强的多样性。此外,为了加强一致性正则化,我们提出了一个双分支框架,每个分支对输入图像应用图像和特征增强。实验表明,该方法优于最先进算法,特别是在有限精细标注下观察到了显著的准确性提高。
Key Takeaways:
- 半监督语义分割领域取得显著进展,但现有算法直接应用于视觉Transformer存在局限性。
- 提出了TokenMix数据增强技术,专门为半监督语义分割与视觉Transformer设计。
- TokenMix通过与全局注意力机制结合,通过在标记层面混合图像,提高上下文信息的学习能力。
- 加入了图像增强和特征增强以促进增强的多样性。
- 提出双分支框架以加强一致性正则化,每个分支对输入图像应用图像和特征增强。
- 实验结果表明,该方法在多个基准数据集上优于最先进算法。
点此查看论文截图

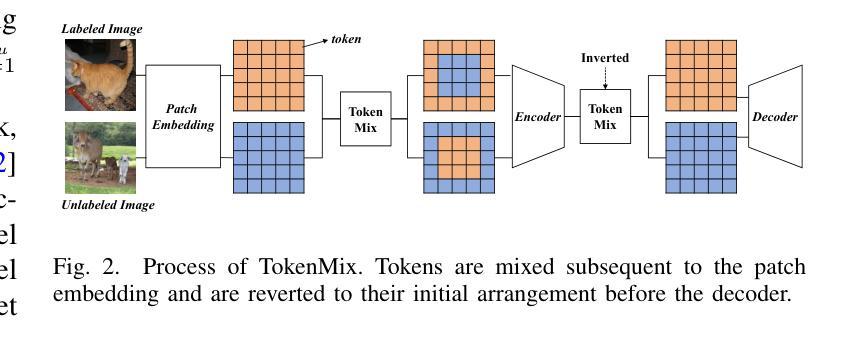
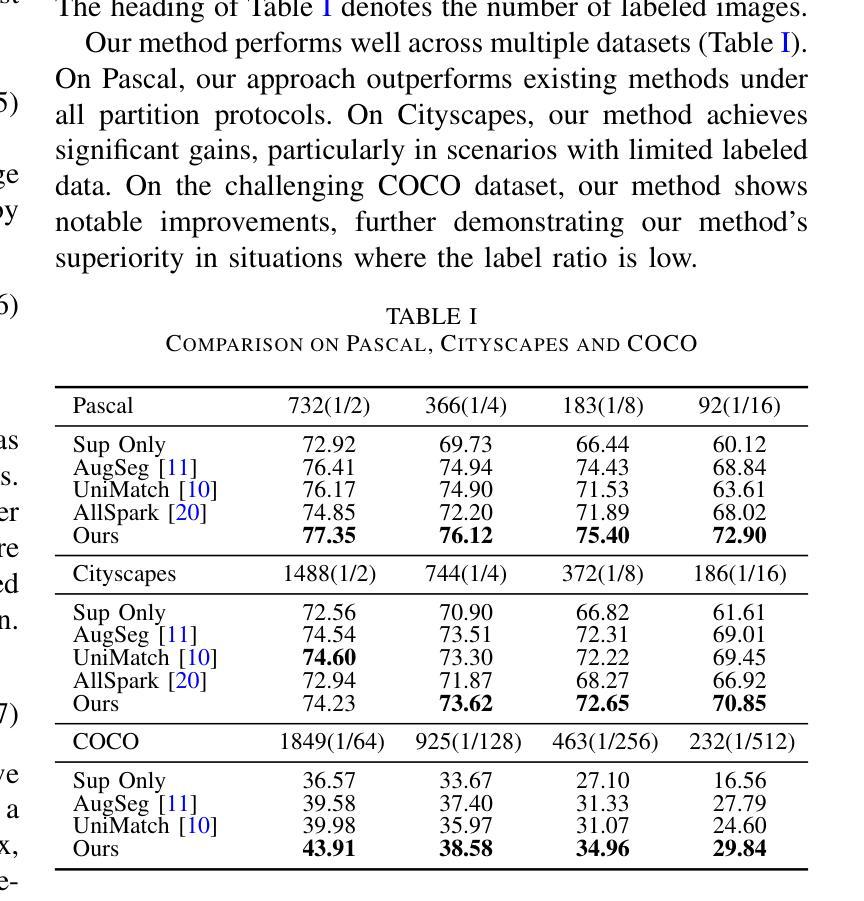
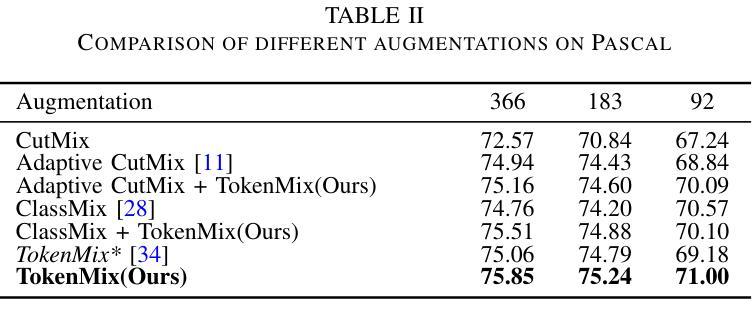
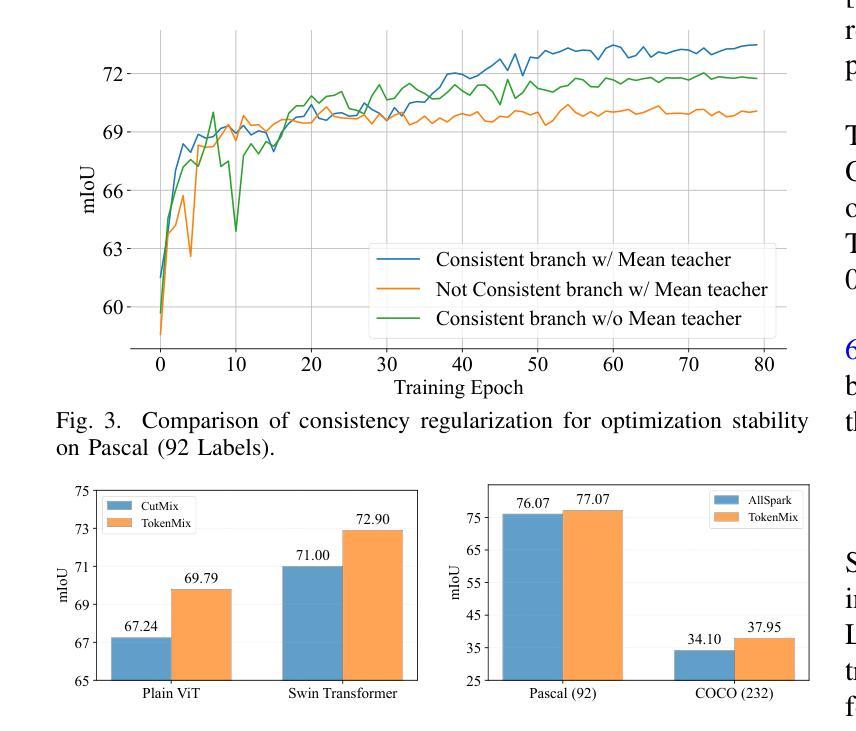
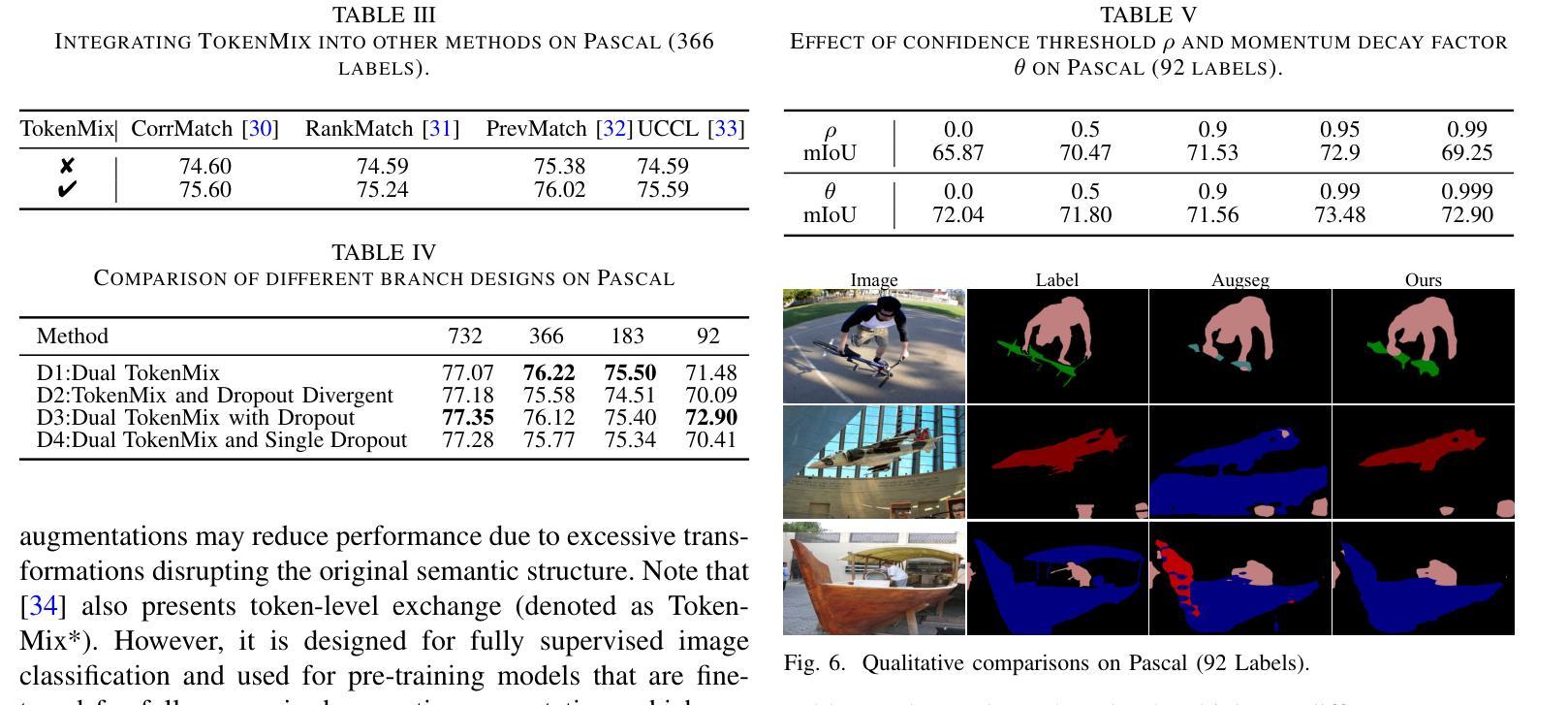
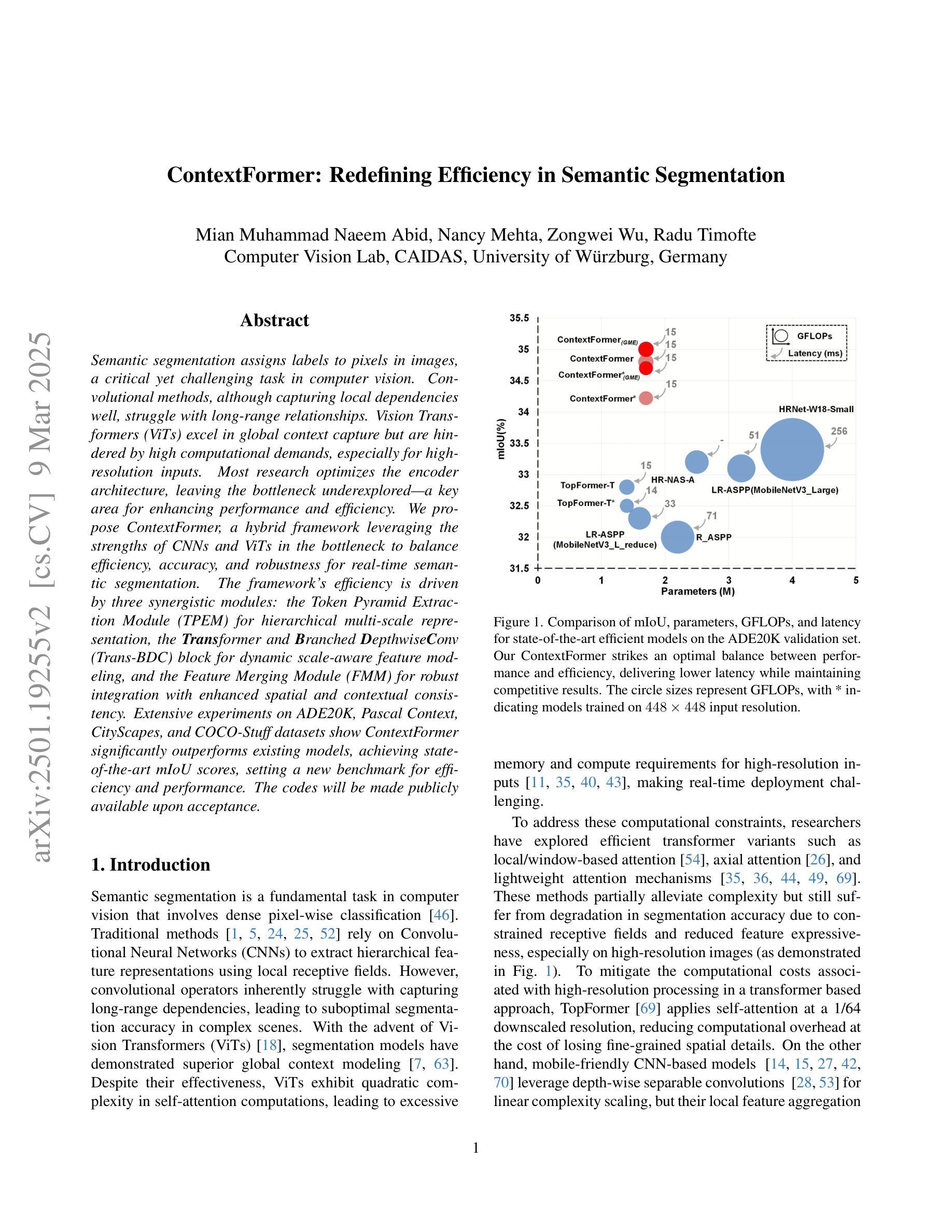
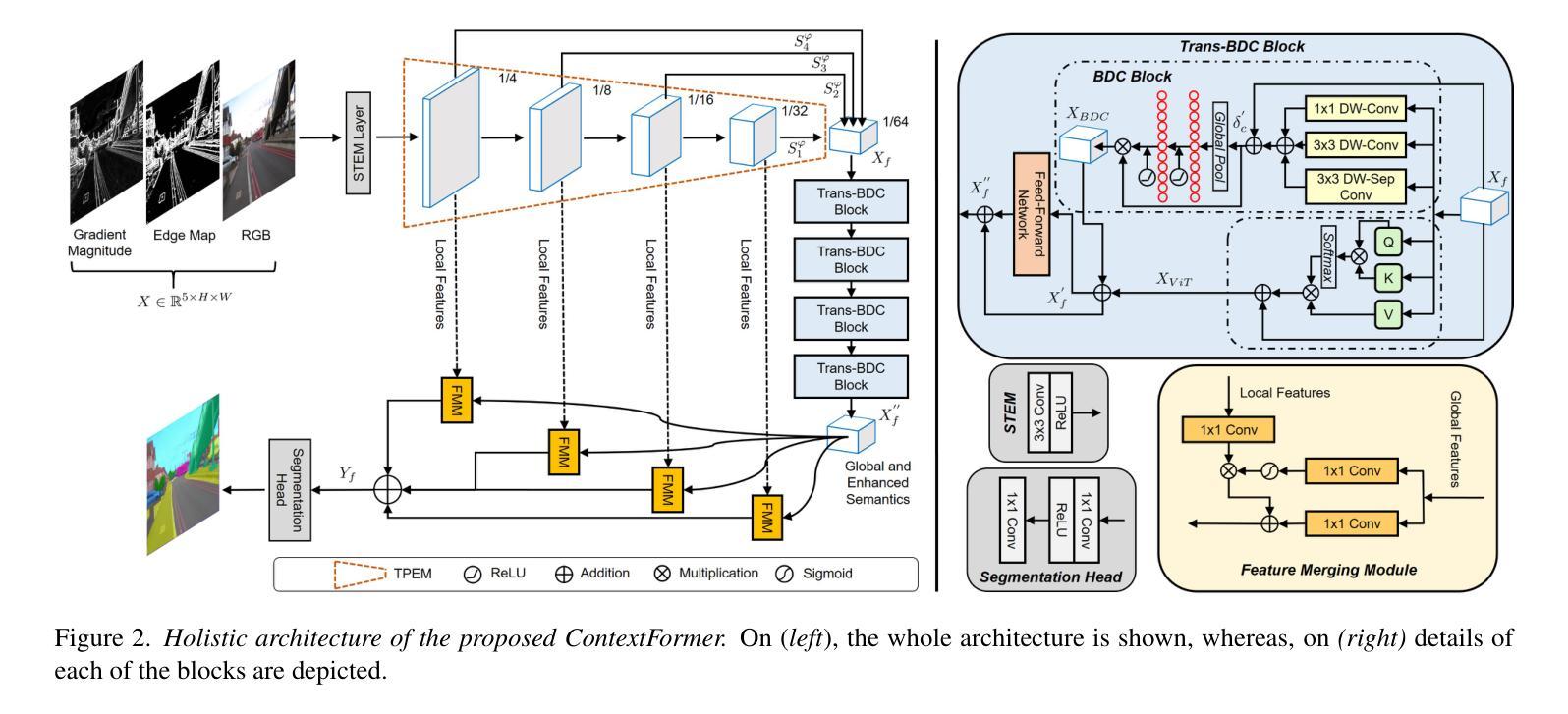
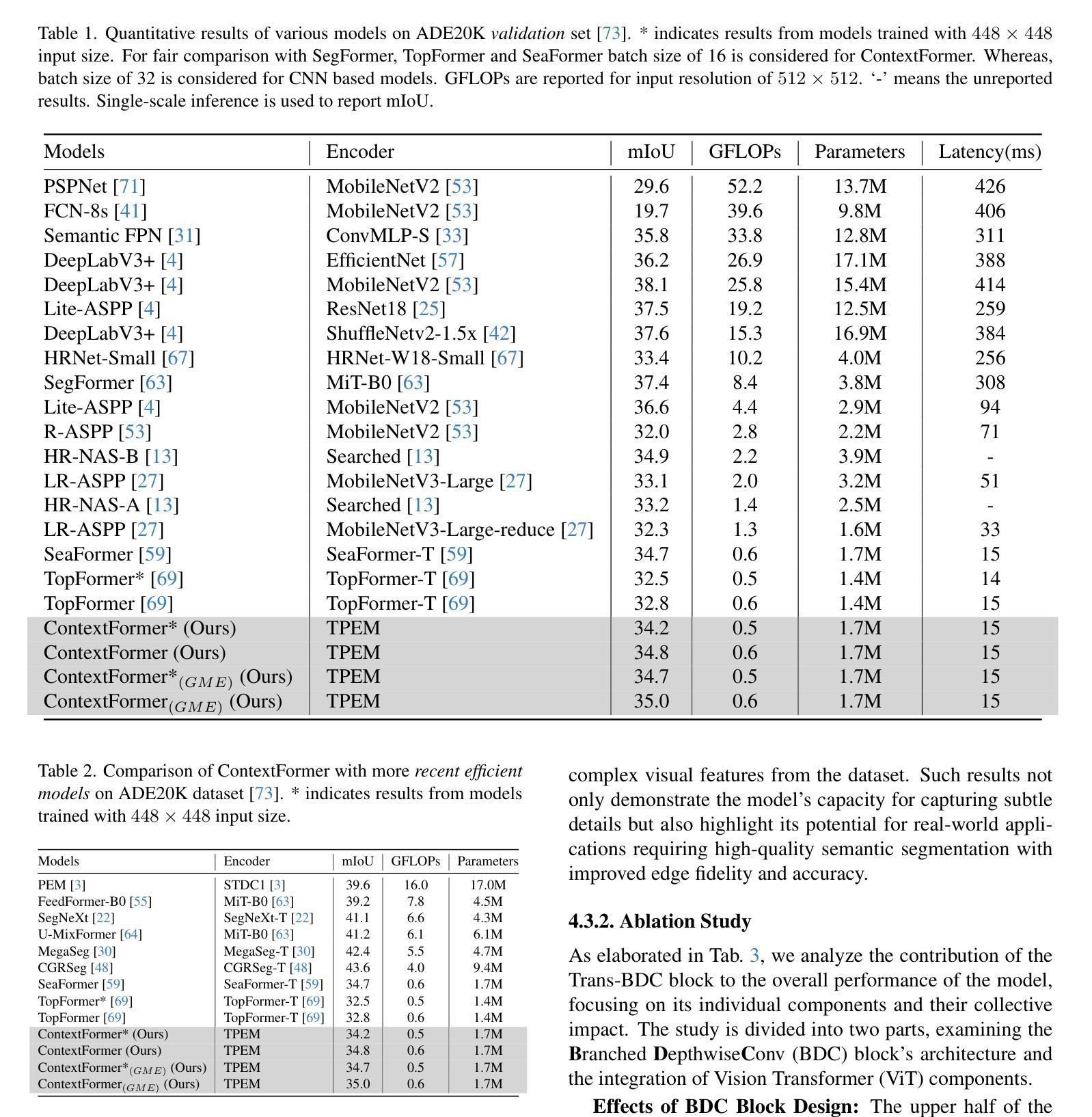
ContextFormer: Redefining Efficiency in Semantic Segmentation
Authors:Mian Muhammad Naeem Abid, Nancy Mehta, Zongwei Wu, Radu Timofte
Semantic segmentation assigns labels to pixels in images, a critical yet challenging task in computer vision. Convolutional methods, although capturing local dependencies well, struggle with long-range relationships. Vision Transformers (ViTs) excel in global context capture but are hindered by high computational demands, especially for high-resolution inputs. Most research optimizes the encoder architecture, leaving the bottleneck underexplored - a key area for enhancing performance and efficiency. We propose ContextFormer, a hybrid framework leveraging the strengths of CNNs and ViTs in the bottleneck to balance efficiency, accuracy, and robustness for real-time semantic segmentation. The framework’s efficiency is driven by three synergistic modules: the Token Pyramid Extraction Module (TPEM) for hierarchical multi-scale representation, the Transformer and Branched DepthwiseConv (Trans-BDC) block for dynamic scale-aware feature modeling, and the Feature Merging Module (FMM) for robust integration with enhanced spatial and contextual consistency. Extensive experiments on ADE20K, Pascal Context, CityScapes, and COCO-Stuff datasets show ContextFormer significantly outperforms existing models, achieving state-of-the-art mIoU scores, setting a new benchmark for efficiency and performance. The codes will be made publicly available upon acceptance.
语义分割是计算机视觉中的一项重要且富有挑战性的任务,它需要对图像中的像素进行标注。卷积方法虽然能很好地捕捉局部依赖性,但在处理长距离关系时却遇到困难。视觉转换器(ViTs)擅长捕捉全局上下文,但计算需求较高,尤其是高分辨率输入时。大多数研究都在优化编码器架构,而对瓶颈区域这个增强性能和效率的关键领域探索不足。我们提出了ContextFormer,这是一个混合框架,利用CNN和ViT在瓶颈处的优势,在实时语义分割中平衡效率、准确性和鲁棒性。该框架的效率由三个协同工作的模块驱动:用于分层多尺度表示的Token金字塔提取模块(TPEM)、用于动态尺度感知特征建模的Transformer和分支深度卷积(Trans-BDC)块,以及用于稳健集成的特征合并模块(FMM),具有增强的空间和上下文一致性。在ADE20K、Pascal Context、CityScapes和COCO-Stuff数据集上的大量实验表明,ContextFormer显著优于现有模型,实现了最先进的mIoU分数,为效率和性能设定了新的基准。论文被接受后,代码将公开发布。
论文及项目相关链接
Summary
一种新型的语义分割框架ContextFormer被提出,该框架结合了CNN和ViT的优点,旨在提高实时语义分割的效率、准确性和鲁棒性。通过三个协同模块的设计,包括Token金字塔提取模块、Transformer与分支深度卷积块以及特征合并模块,ContextFormer实现了出色的性能。在多个数据集上的实验结果表明,ContextFormer显著优于现有模型,达到了最新的mIoU得分,为效率和性能设定了新的基准。
Key Takeaways
- ContextFormer是一个用于实时语义分割的混合框架,结合了CNN和ViT的优势。
- 该框架旨在提高语义分割的效率、准确性和鲁棒性。
- ContextFormer通过三个协同模块实现高性能:Token金字塔提取模块、Transformer与分支深度卷积块以及特征合并模块。
- ContextFormer显著优于现有模型,达到了最新的mIoU得分。
- ContextFormer在ADE20K、Pascal Context、CityScapes和COCO-Stuff等多个数据集上进行了实验验证。
- ContextFormer的代码将在接受后公开发布。
- 该框架为效率和性能设定了新的基准。
点此查看论文截图
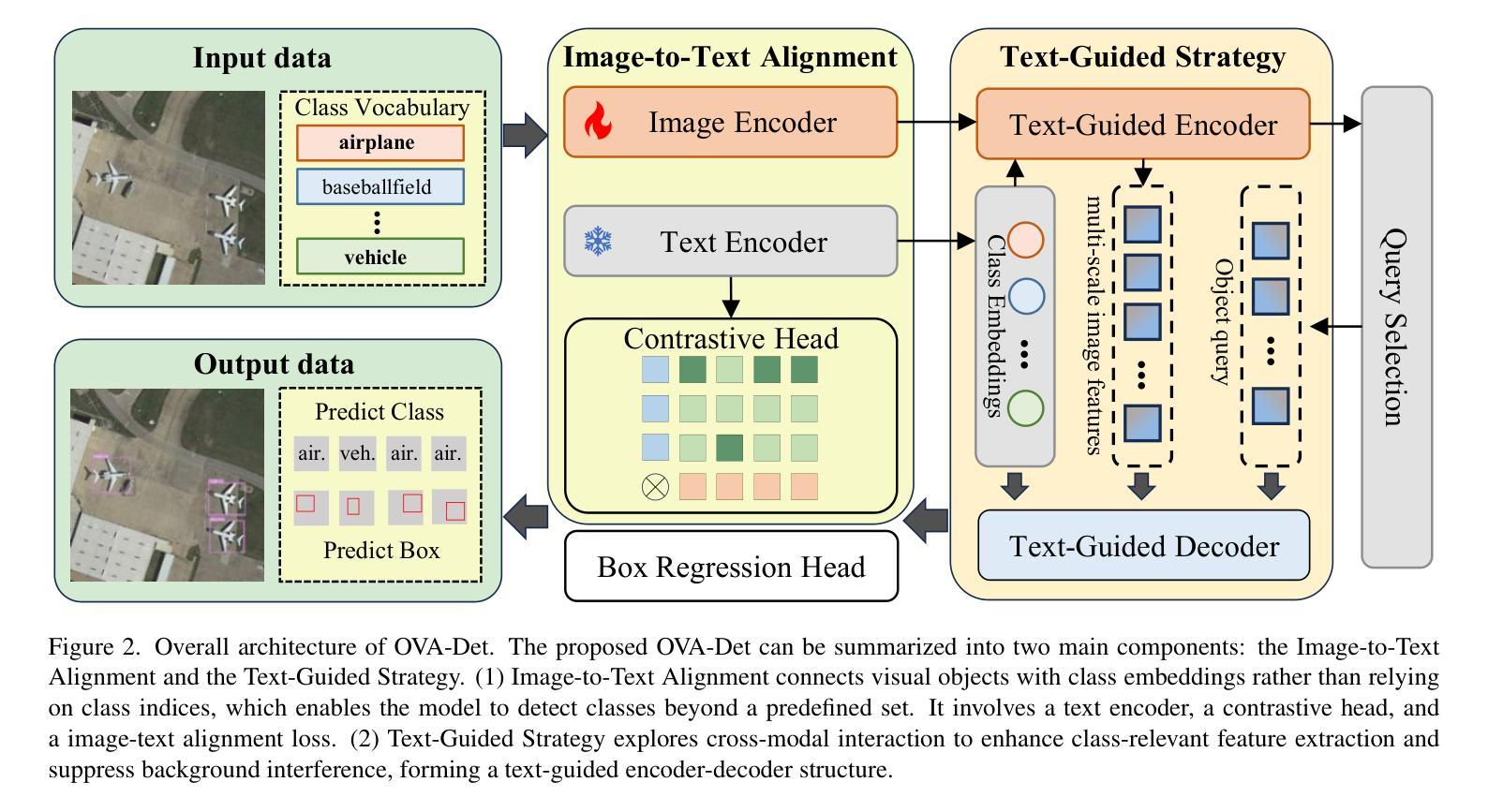
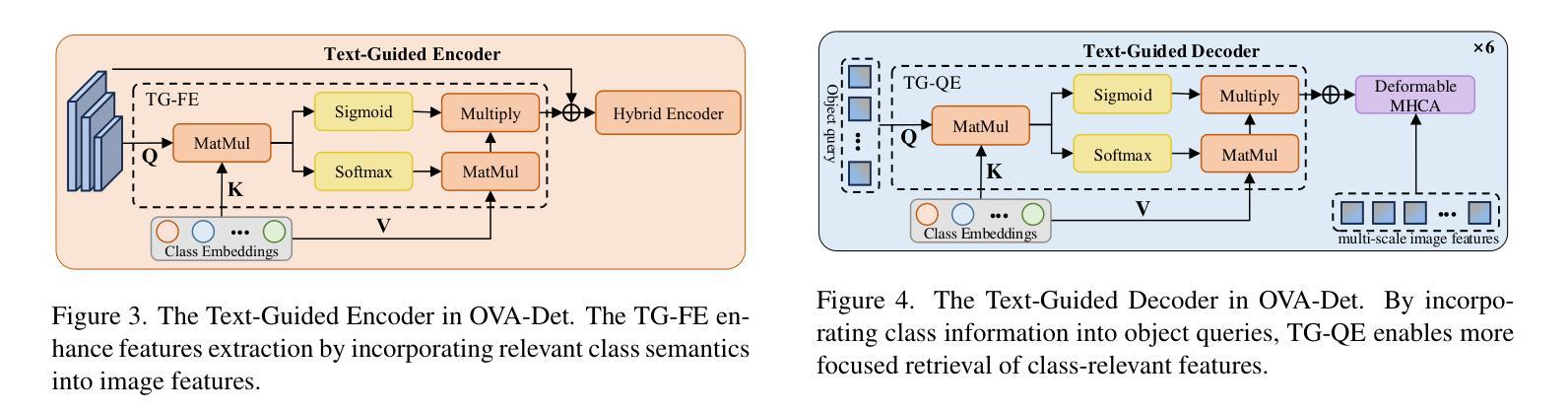
OVA-Det: Open Vocabulary Aerial Object Detection with Image-Text Collaboration
Authors:Guoting Wei, Xia Yuan, Yu Liu, Zhenhao Shang, Xizhe Xue, Peng Wang, Kelu Yao, Chunxia Zhao, Haokui Zhang, Rong Xiao
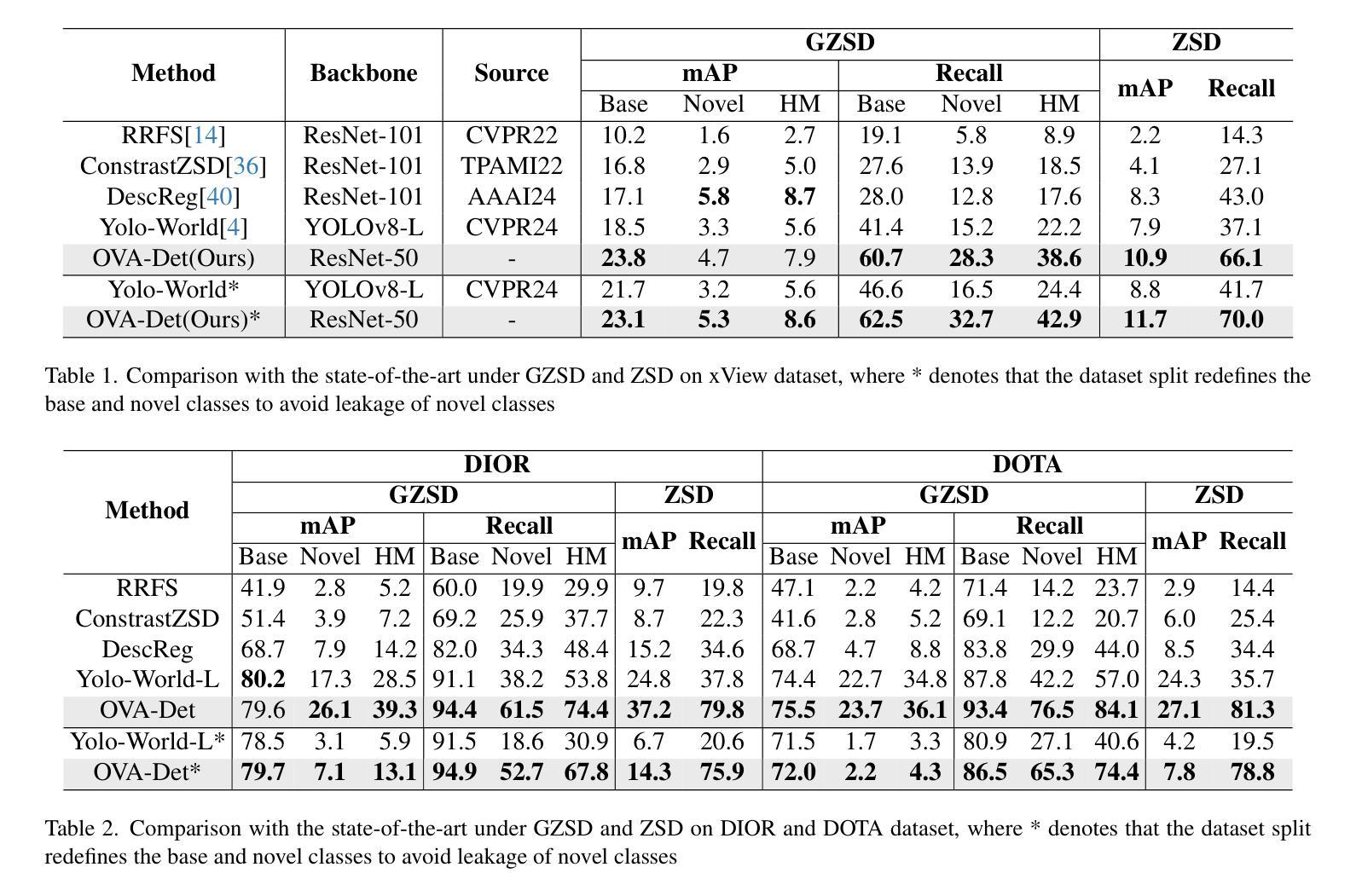
Aerial object detection plays a crucial role in numerous applications. However, most existing methods focus on detecting predefined object categories, limiting their applicability in real-world open scenarios. In this paper, we extend aerial object detection to open scenarios through image-text collaboration and propose OVA-Det, a highly efficient open-vocabulary detector for aerial scenes. Specifically, we first introduce an image-to-text alignment loss to replace the conventional category regression loss, thereby eliminating category limitations. Next, we propose a lightweight text-guided strategy that enhances the feature extraction process in the encoder and enables queries to focus on class-relevant image features within the decoder, further improving detection accuracy without introducing significant additional costs. Extensive comparison experiments demonstrate that the proposed OVA-Det outperforms state-of-the-art methods on all three widely used benchmark datasets by a large margin. For instance, for zero-shot detection on DIOR, OVA-Det achieves 37.2 mAP and 79.8 Recall, 12.4 and 42.0 higher than that of YOLO-World. In addition, the inference speed of OVA-Det reaches 36 FPS on RTX 4090, meeting the real-time detection requirements for various applications. The code is available at \href{https://github.com/GT-Wei/OVA-Det}{https://github.com/GT-Wei/OVA-Det}.
空中目标检测在众多应用中发挥着至关重要的作用。然而,现有的大多数方法主要集中于对预定义目标类别的检测,这限制了它们在现实开放场景中的应用。在本文中,我们通过图像文本协作将空中目标检测扩展到开放场景,并提出OVA-Det,这是一种高度有效的空中场景开放词汇表检测器。具体来说,我们首先引入图像到文本的对齐损失来替换传统的类别回归损失,从而消除了类别限制。接下来,我们提出了一种轻量级的文本引导策略,该策略增强了编码器的特征提取过程,并使查询能够关注解码器中的类相关图像特征,从而进一步提高了检测精度,而没有引入重大的额外成本。大量的对比实验表明,所提出的OVA-Det在三个广泛使用的基准数据集上均大幅超越了最新方法。例如,在DIOR上的零样本检测中,OVA-Det实现了37.2的mAP和79.8的召回率,比YOLO-World高出12.4和42.0。此外,OVA-Det的推理速度在RTX 4090上达到36 FPS,满足各种应用的实时检测要求。代码可在https://github.com/GT-Wei/OVA-Det处获取。
论文及项目相关链接
Summary:
该论文将空中物体检测扩展至开放场景,通过图像文本协同工作,提出了一种高效的开放词汇表检测器OVA-Det。新方法引入图像到文本的匹配损失来替代传统的类别回归损失,消除了类别限制。同时,提出一种轻量级的文本引导策略,提高编码器特征提取过程,并在解码器中使查询聚焦于类相关的图像特征,从而提高检测精度。实验表明,OVA-Det在三个广泛使用的基准数据集上大幅超越现有方法。例如,在DIOR上的零样本检测,OVA-Det的mAP和Recall分别达到了37.2和79.8,比YOLO-World分别高出12.4和42.0。此外,OVA-Det在RTX 4090上的推理速度达到36 FPS,满足各种应用的实时检测要求。
Key Takeaways:
- 论文将空中物体检测扩展至开放场景,适应了更广泛的实际应用需求。
- 引入图像到文本的匹配损失,消除了传统检测中的类别限制。
- 提出一种轻量级的文本引导策略,提高特征提取和检测精度。
- OVA-Det在三个基准数据集上表现优异,尤其是零样本检测。
- OVA-Det的mAP和Recall在DIOR数据集上显著超越YOLO-World。
- OVA-Det的推理速度达到36 FPS,满足实时检测要求。
点此查看论文截图