⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-12 更新
ALLVB: All-in-One Long Video Understanding Benchmark
Authors:Xichen Tan, Yuanjing Luo, Yunfan Ye, Fang Liu, Zhiping Cai
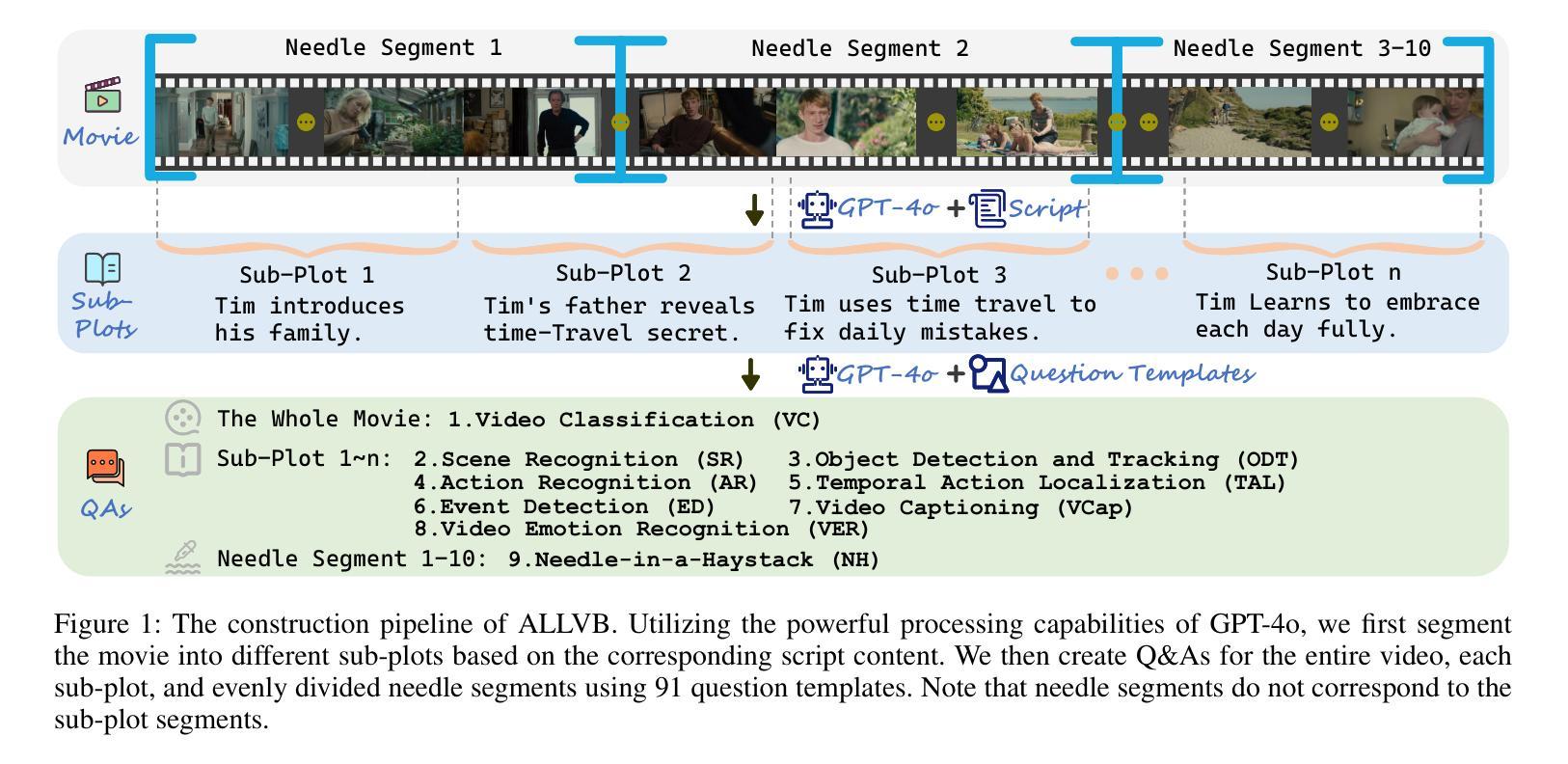
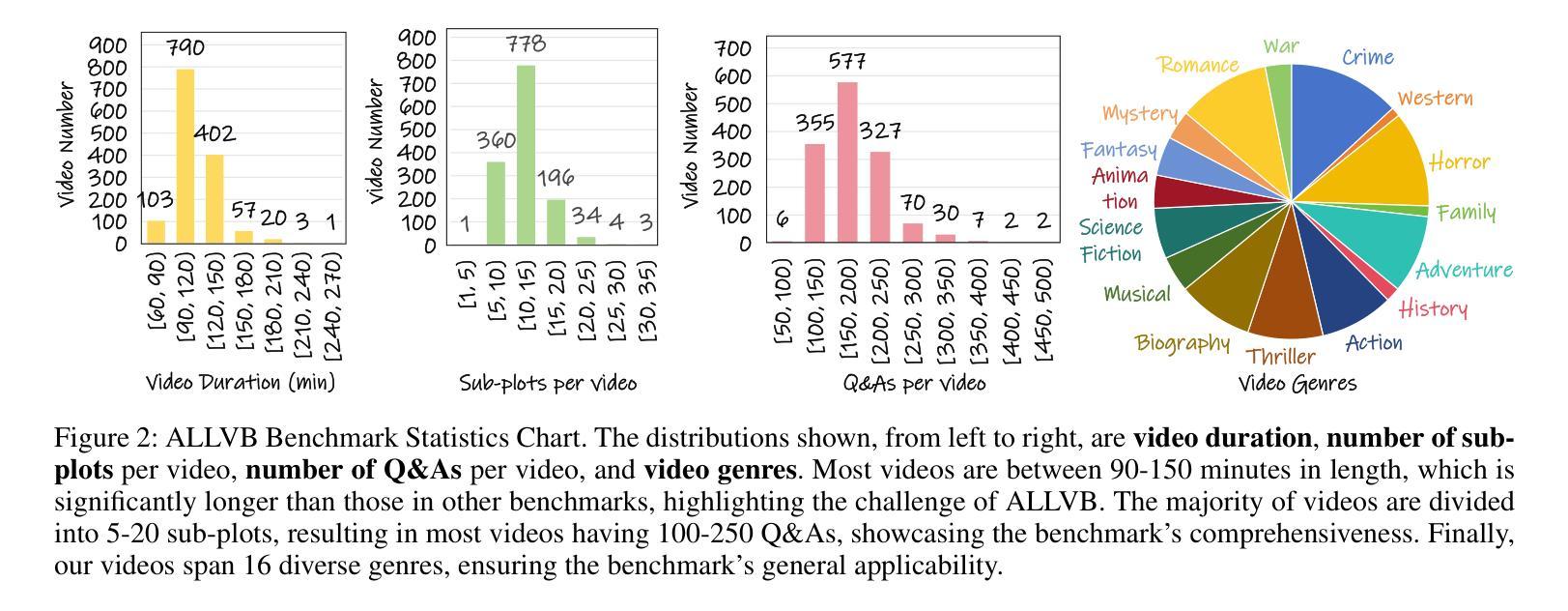
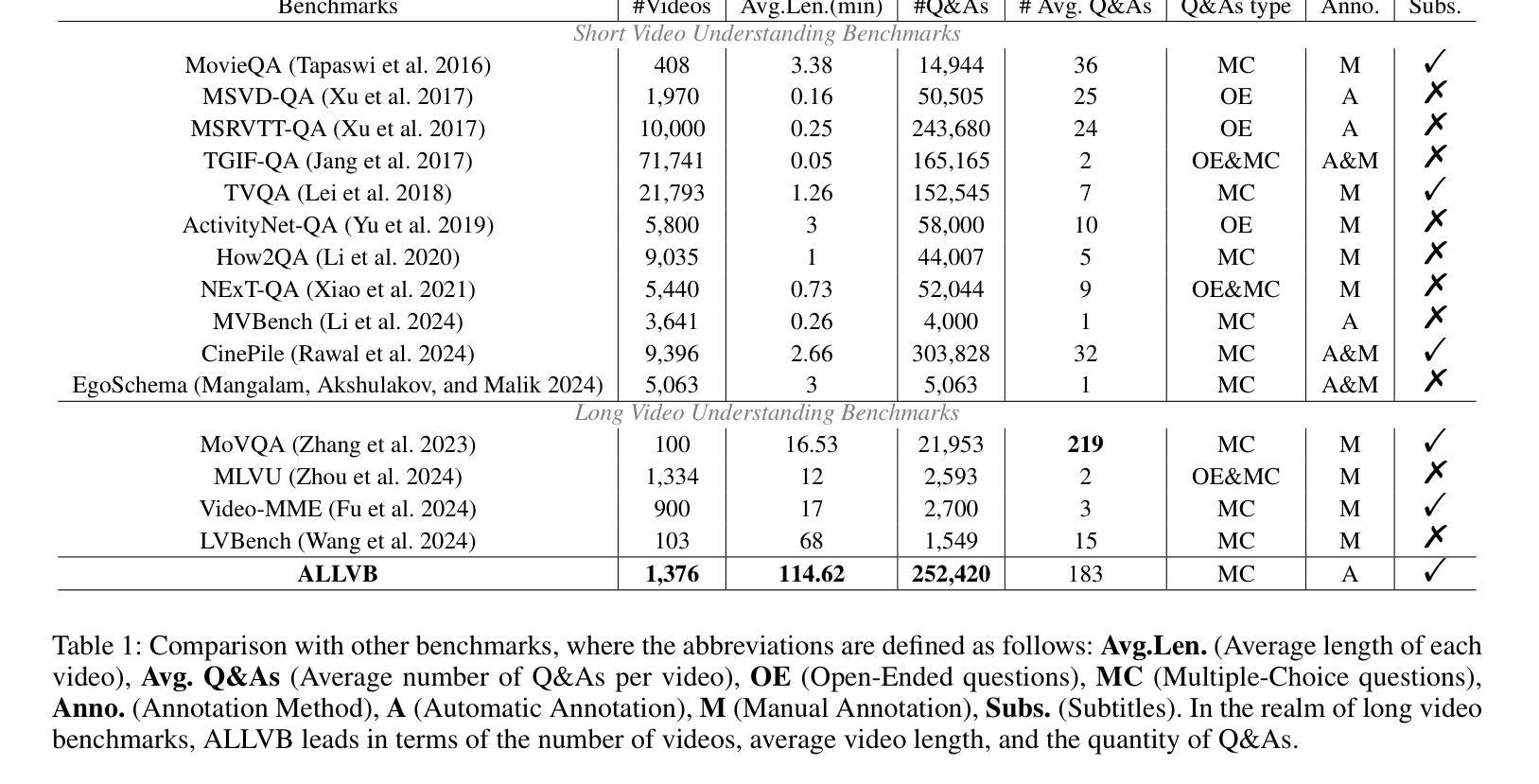
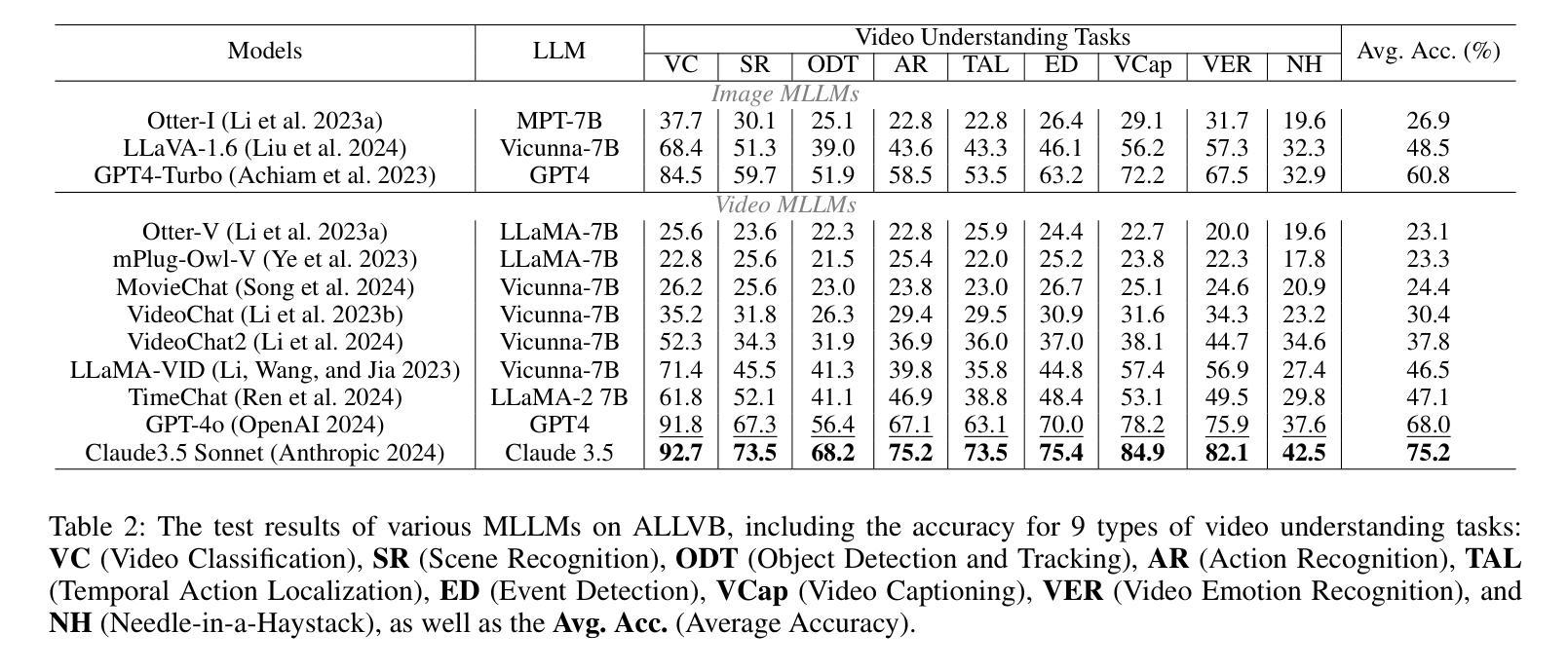
From image to video understanding, the capabilities of Multi-modal LLMs (MLLMs) are increasingly powerful. However, most existing video understanding benchmarks are relatively short, which makes them inadequate for effectively evaluating the long-sequence modeling capabilities of MLLMs. This highlights the urgent need for a comprehensive and integrated long video understanding benchmark to assess the ability of MLLMs thoroughly. To this end, we propose ALLVB (ALL-in-One Long Video Understanding Benchmark). ALLVB’s main contributions include: 1) It integrates 9 major video understanding tasks. These tasks are converted into video QA formats, allowing a single benchmark to evaluate 9 different video understanding capabilities of MLLMs, highlighting the versatility, comprehensiveness, and challenging nature of ALLVB. 2) A fully automated annotation pipeline using GPT-4o is designed, requiring only human quality control, which facilitates the maintenance and expansion of the benchmark. 3) It contains 1,376 videos across 16 categories, averaging nearly 2 hours each, with a total of 252k QAs. To the best of our knowledge, it is the largest long video understanding benchmark in terms of the number of videos, average duration, and number of QAs. We have tested various mainstream MLLMs on ALLVB, and the results indicate that even the most advanced commercial models have significant room for improvement. This reflects the benchmark’s challenging nature and demonstrates the substantial potential for development in long video understanding.
从图像到视频理解,多模态大型语言模型(MLLMs)的能力越来越强大。然而,大多数现有的视频理解基准测试相对较短,这使得它们无法有效地评估MLLMs的长序列建模能力。这凸显了全面综合的长视频理解基准测试的迫切需求,以全面评估MLLMs的能力。为此,我们提出了ALLVB(全方位长视频理解基准测试)。ALLVB的主要贡献包括:1)它集成了9大视频理解任务。这些任务被转化为视频问答格式,使得一个基准测试能够评估MLLMs的9种不同视频理解能力,凸显了ALLVB的通用性、全面性和挑战性。2)设计了一个使用GPT-4o的完全自动化的注释管道,只需要人工质量控制,这有助于基准测试的维护和扩展。3)包含16个类别的1376个视频,平均每个视频近2小时,共有25.2万个问答。据我们所知,它是从视频数量、平均时长和问答数量方面来看,规模最大的长视频理解基准测试。我们在ALLVB上测试了各种主流MLLMs,结果表明,即使是最先进的商业模型也有很大的改进空间。这反映了基准测试的挑战性,并展示了长视频理解领域巨大的发展潜力。
论文及项目相关链接
PDF AAAI 2025
摘要
多模态大型语言模型(MLLMs)从图像到视频理解的能力日益强大。然而,现有的视频理解基准测试相对较短,无法有效评估MLLMs的长序列建模能力。因此,迫切需要一个全面综合的长视频理解基准测试,以全面评估MLLMs的能力。为此,我们提出了ALLVB(ALL-in-One长视频理解基准测试)。ALLVB的主要贡献包括:一、它整合了9大视频理解任务,将这些任务转化为视频问答格式,允许一个基准测试评估MLLMs的9种不同视频理解能力,凸显ALLVB的通用性、全面性和挑战性。二、设计了一个利用GPT-4o的完全自动化注释管道,只需人工质量控制,便于基准测试的维护扩展。三、包含1,376个视频,涵盖16个类别,平均时长近2小时,共有25.2万个问答。据我们所知,它是长视频理解基准测试中视频数量、平均时长和问答数量最多的。我们在ALLVB上测试了各种主流MLLMs,结果显示,即使是最先进的商业模型也有很大的改进空间。这反映了基准测试的挑战性,并展示了长视频理解的巨大发展潜力。
关键见解
- 多模态大型语言模型(MLLMs)在视频理解方面表现出强大的能力,但现有基准测试的时长较短,无法充分评估其长序列建模能力。
- 引入ALLVB基准测试,集成9大视频理解任务,转化为视频问答格式,以全面评估MLLMs的能力。
- ALLVB采用全自动注释管道,只需人工质量控制,便于维护和扩展。
- ALLVB包含大量长视频和丰富的问答,是已知最大的长视频理解基准测试。
- 主流MLLMs在ALLVB上的表现仍有显著改进空间,反映出了该基准测试的挑战性和长视频理解的巨大潜力。
- ALLVB的提出有助于推动长视频理解领域的发展,并为未来的模型性能评估提供重要参考。
点此查看论文截图