⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-12 更新
SOGS: Second-Order Anchor for Advanced 3D Gaussian Splatting
Authors:Jiahui Zhang, Fangneng Zhan, Ling Shao, Shijian Lu
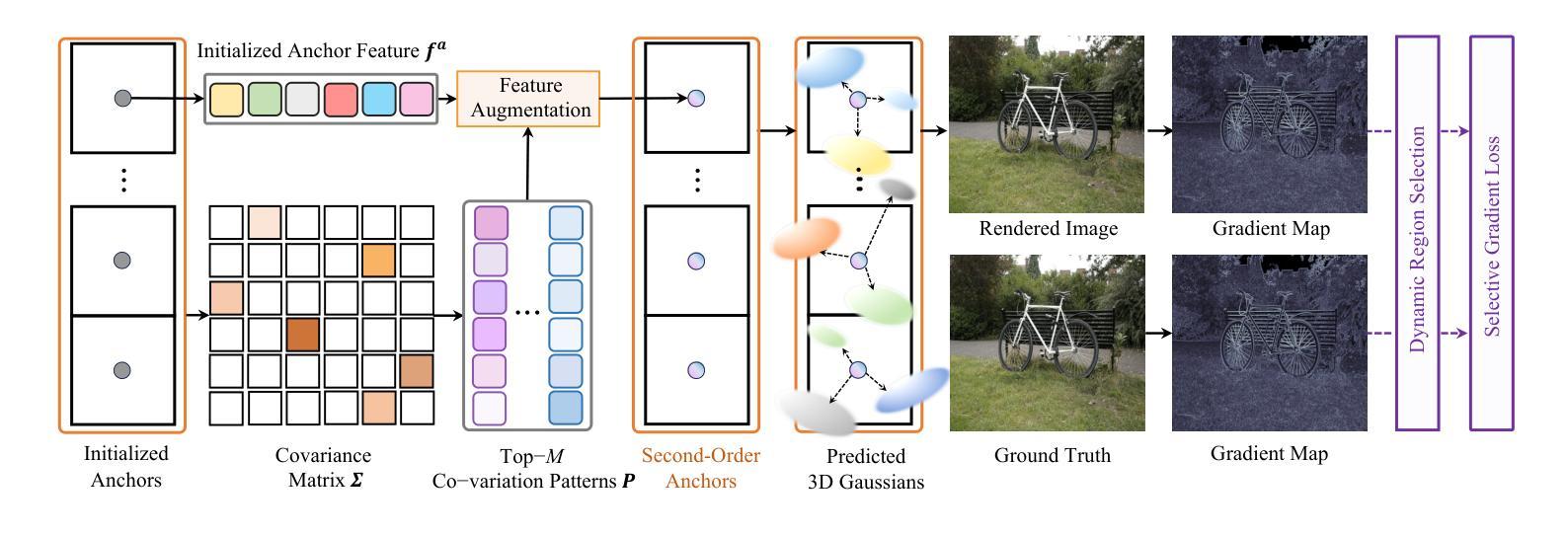
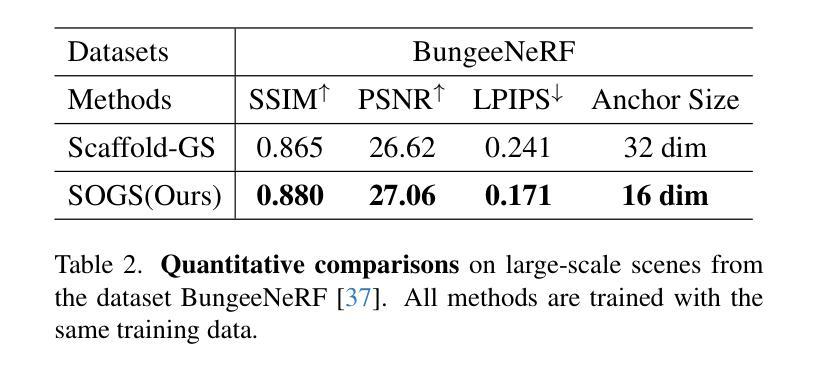
Anchor-based 3D Gaussian splatting (3D-GS) exploits anchor features in 3D Gaussian prediction, which has achieved impressive 3D rendering quality with reduced Gaussian redundancy. On the other hand, it often encounters the dilemma among anchor features, model size, and rendering quality - large anchor features lead to large 3D models and high-quality rendering whereas reducing anchor features degrades Gaussian attribute prediction which leads to clear artifacts in the rendered textures and geometries. We design SOGS, an anchor-based 3D-GS technique that introduces second-order anchors to achieve superior rendering quality and reduced anchor features and model size simultaneously. Specifically, SOGS incorporates covariance-based second-order statistics and correlation across feature dimensions to augment features within each anchor, compensating for the reduced feature size and improving rendering quality effectively. In addition, it introduces a selective gradient loss to enhance the optimization of scene textures and scene geometries, leading to high-quality rendering with small anchor features. Extensive experiments over multiple widely adopted benchmarks show that SOGS achieves superior rendering quality in novel view synthesis with clearly reduced model size.
基于锚点的3D高斯喷绘(3D-GS)利用了3D高斯预测中的锚点特征,在减少高斯冗余的同时,实现了令人印象深刻的3D渲染质量。另一方面,它经常面临锚点特征、模型大小和渲染质量之间的困境——大锚点特征导致3D模型大且渲染质量高,而减少锚点特征会破坏高斯属性预测,导致渲染纹理和几何体中出现明显的伪影。我们设计了SOGS,这是一种基于锚点的3D-GS技术,引入二阶锚点,实现优越的渲染质量,同时减少锚点特征和模型大小。具体来说,SOGS结合了基于协方差的二阶统计量和特征维度之间的相关性,以增强每个锚点内的特征,弥补特征大小的减少,有效提高渲染质量。此外,它引入了一种选择性梯度损失,以增强场景纹理和场景几何的优化,实现小锚点特征的高质量渲染。在多个广泛采用的基准测试上的大量实验表明,SOGS在新型视图合成中实现了高质量的渲染,并明显减小了模型大小。
论文及项目相关链接
PDF Accepted by CVPR 2025
Summary
基于锚点的三维高斯拼接技术(SOGS)通过引入二阶锚点,实现了高质量渲染与减少锚点特征和模型大小的目标。该技术通过引入协方差二阶统计和相关特征维度,增强每个锚点的特征,并引入选择性梯度损失以优化场景纹理和几何结构,从而提高渲染质量。在多个广泛采用的基准测试中,SOGS在新视角合成中实现了高质量的渲染并显著减少了模型大小。
Key Takeaways
- Anchor-based 3D Gaussian Splatting技术利用锚点特征进行三维高斯预测,实现了高质量的渲染效果。
- 二阶锚点的引入解决了模型大小与渲染质量之间的权衡问题,可以在减少锚点特征的同时保持高质量的渲染效果。
- SOGS技术通过引入协方差二阶统计和相关特征维度,增强了每个锚点的特征。
- 选择性梯度损失有助于优化场景纹理和几何结构,提高了渲染质量。
- SOGS在多个基准测试中实现了优于其他技术的渲染效果,并且在模型大小上有显著优势。
点此查看论文截图


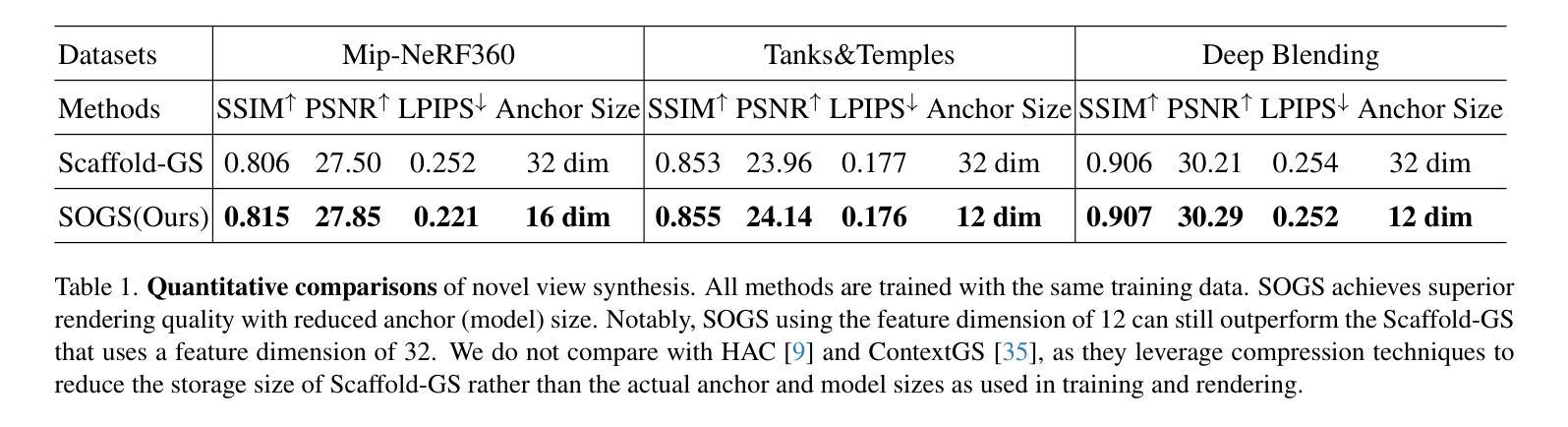
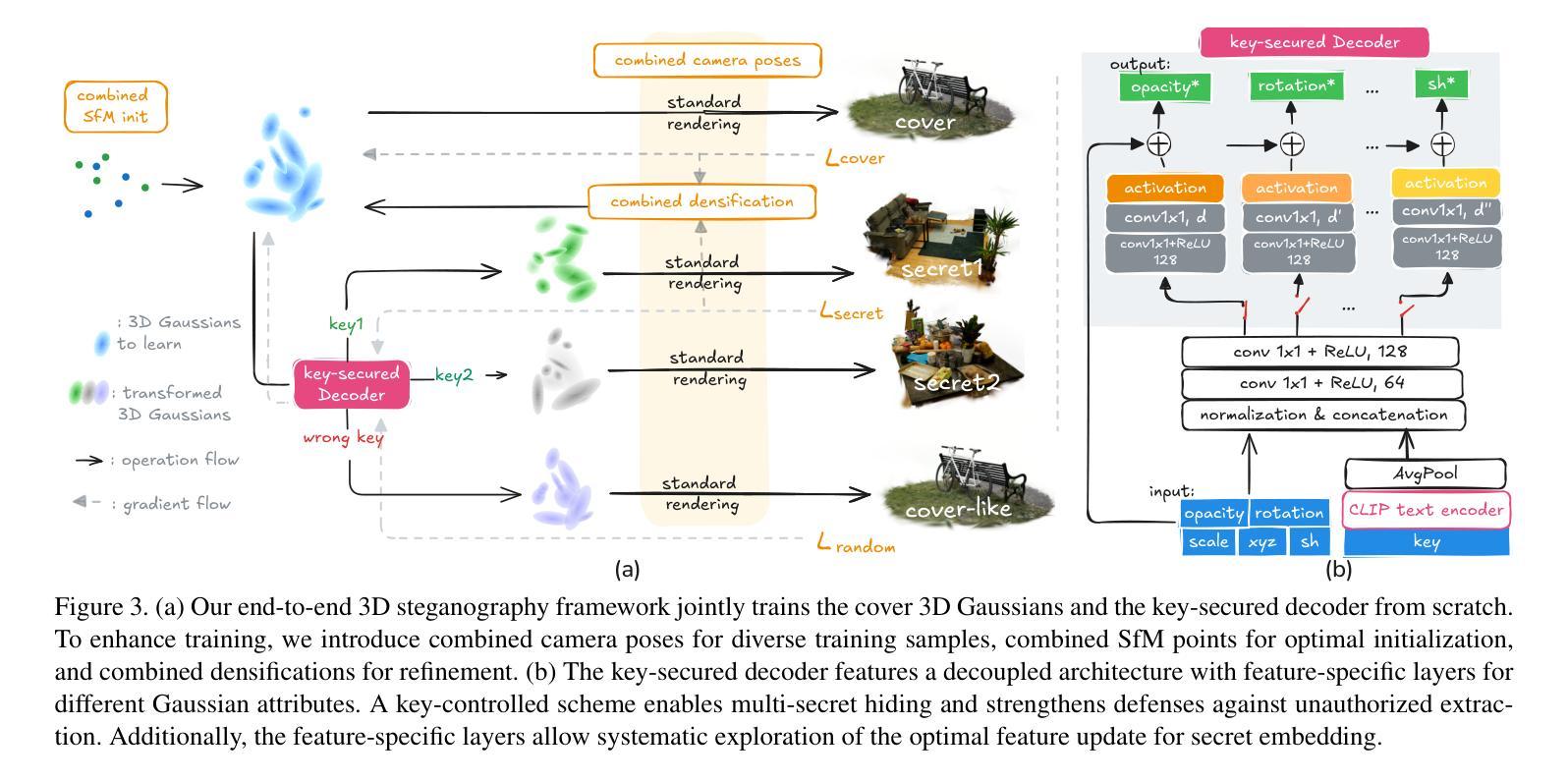
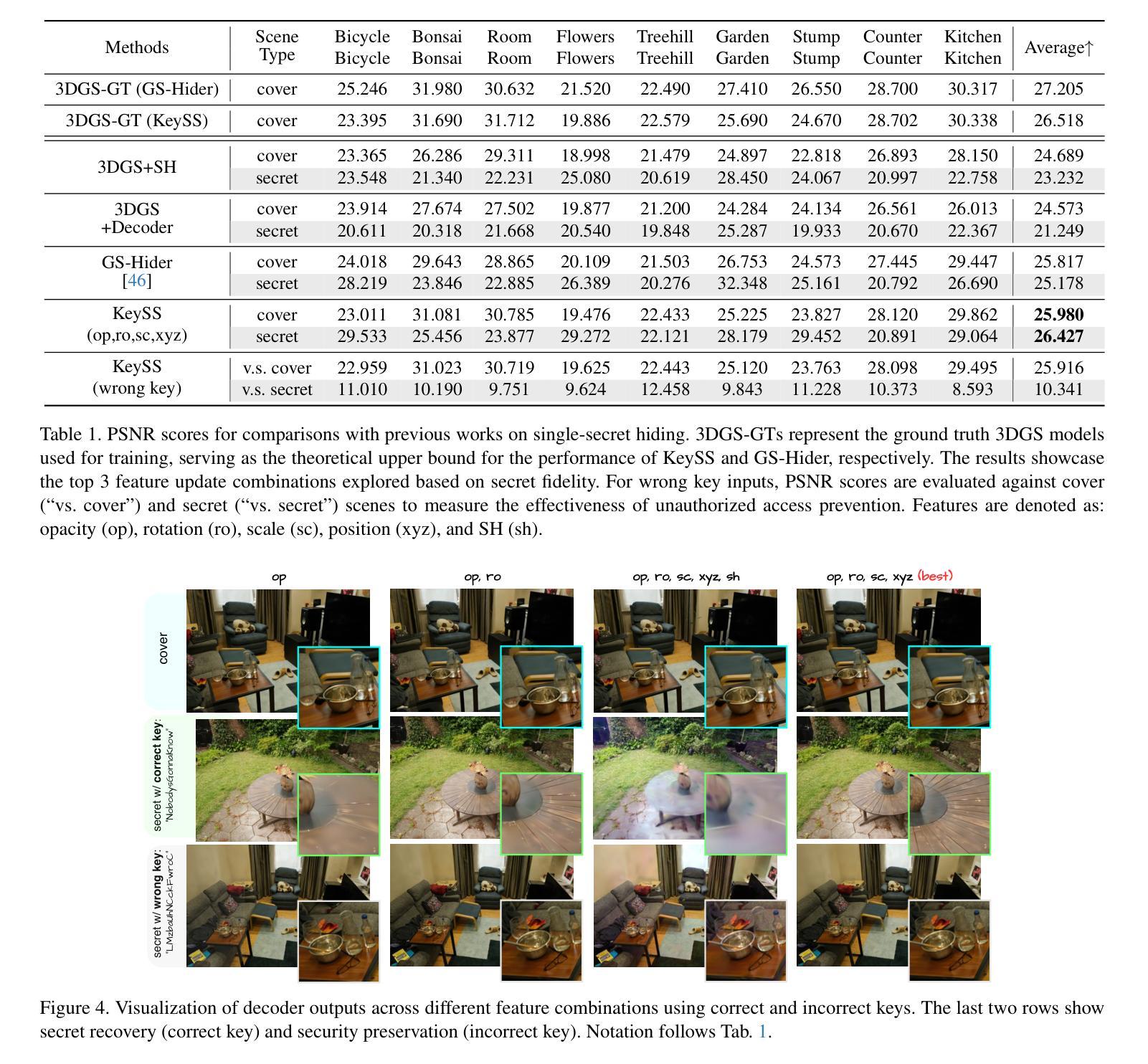
All That Glitters Is Not Gold: Key-Secured 3D Secrets within 3D Gaussian Splatting
Authors:Yan Ren, Shilin Lu, Adams Wai-Kin Kong
Recent advances in 3D Gaussian Splatting (3DGS) have revolutionized scene reconstruction, opening new possibilities for 3D steganography by hiding 3D secrets within 3D covers. The key challenge in steganography is ensuring imperceptibility while maintaining high-fidelity reconstruction. However, existing methods often suffer from detectability risks and utilize only suboptimal 3DGS features, limiting their full potential. We propose a novel end-to-end key-secured 3D steganography framework (KeySS) that jointly optimizes a 3DGS model and a key-secured decoder for secret reconstruction. Our approach reveals that Gaussian features contribute unequally to secret hiding. The framework incorporates a key-controllable mechanism enabling multi-secret hiding and unauthorized access prevention, while systematically exploring optimal feature update to balance fidelity and security. To rigorously evaluate steganographic imperceptibility beyond conventional 2D metrics, we introduce 3D-Sinkhorn distance analysis, which quantifies distributional differences between original and steganographic Gaussian parameters in the representation space. Extensive experiments demonstrate that our method achieves state-of-the-art performance in both cover and secret reconstruction while maintaining high security levels, advancing the field of 3D steganography. Code is available at https://github.com/RY-Paper/KeySS
近期三维高斯扩展(3DGS)的进展在场景重建领域引起了革命性的变革,为通过隐藏三维秘密在三维载体中实现三维隐写术开辟了新的可能性。隐写的关键挑战在于确保不可察觉性同时保持高保真重建。然而,现有方法往往存在可检测风险,并且仅使用次优的3DGS特征,限制了其全部潜力。我们提出了一种端到端密钥保护的三维隐写框架(KeySS),该框架联合优化了一个3DGS模型和一个用于秘密重建的密钥保护解码器。我们的方法揭示了高斯特征对秘密隐藏的贡献是不均衡的。该框架引入了一种密钥控制机制,能够实现多秘密隐藏和防止未经授权的访问,同时系统地探索最佳特征更新以平衡保真度和安全性。为了严格评估隐写的不可察觉性,除了传统的二维指标外,我们还引入了三维Sinkhorn距离分析,该分析量化表示空间中原始和隐写高斯参数之间的分布差异。大量实验表明,我们的方法在覆盖和秘密重建方面均达到了最新技术性能,同时保持了高水平的安全性,推动了三维隐写术领域的发展。代码可在https://github.com/RY-Paper/KeySS找到。
论文及项目相关链接
Summary
本文介绍了利用三维高斯拼贴(3DGS)的最新进展,提出了一种端到端的关键安全三维隐写分析框架(KeySS)。该框架联合优化了3DGS模型和安全密钥解码器,以实现对秘密重建的优化。通过引入关键可控机制,实现了多秘密隐藏和未经授权的访问预防。同时,采用三维Sinkhorn距离分析对隐写术的不可感知性进行了严格评估。实验表明,该方法在覆盖和秘密重建方面取得了最先进的性能,同时保持了高水平的安全性。
Key Takeaways
- 3DGS技术在场景重建中的最新进展为3D隐写术提供了新的可能性。
- 隐写术的主要挑战是确保不可感知性同时保持高保真重建。
- 现有方法存在可检测风险,且仅使用次优的3DGS特性。
- 提出的KeySS框架联合优化了3DGS模型和安全密钥解码器,实现秘密重建的优化。
- 引入的关键可控机制使多秘密隐藏和防止未经授权的访问成为可能。
- 采用三维Sinkhorn距离分析对隐写术的不可感知性进行严格的量化评估。
点此查看论文截图



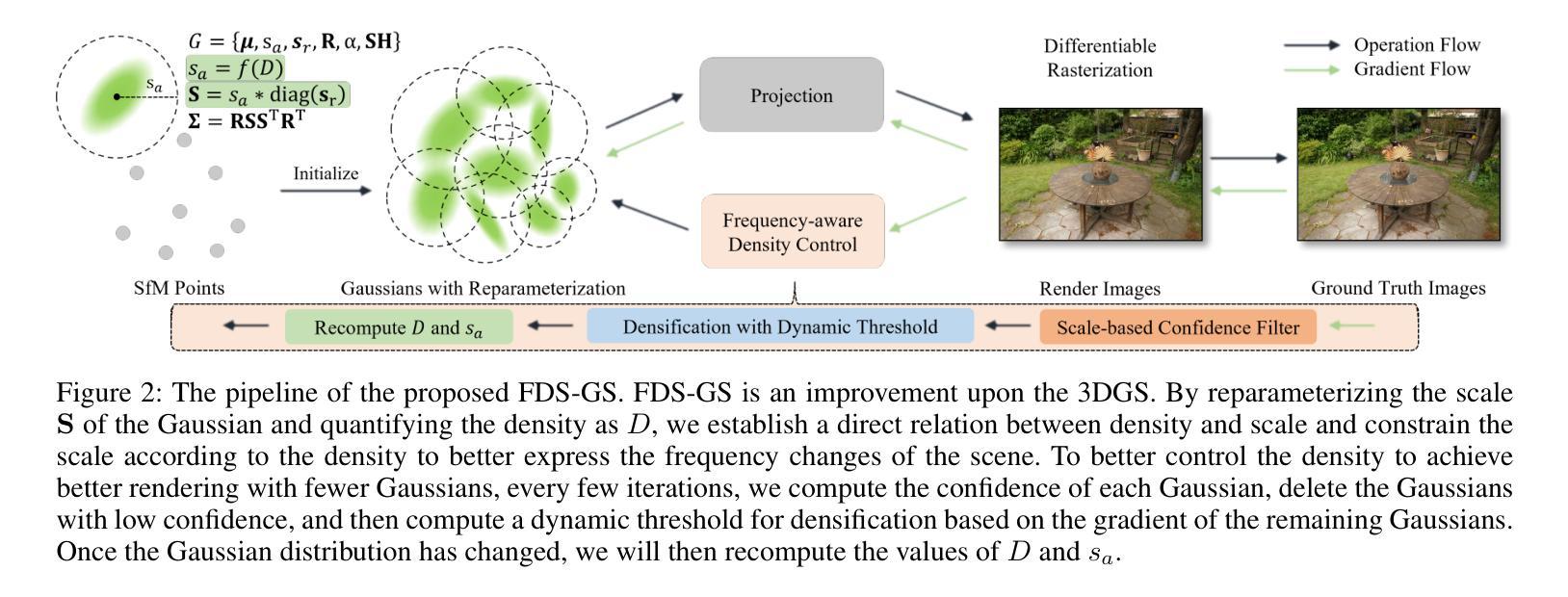
Frequency-Aware Density Control via Reparameterization for High-Quality Rendering of 3D Gaussian Splatting
Authors:Zhaojie Zeng, Yuesong Wang, Lili Ju, Tao Guan
By adaptively controlling the density and generating more Gaussians in regions with high-frequency information, 3D Gaussian Splatting (3DGS) can better represent scene details. From the signal processing perspective, representing details usually needs more Gaussians with relatively smaller scales. However, 3DGS currently lacks an explicit constraint linking the density and scale of 3D Gaussians across the domain, leading to 3DGS using improper-scale Gaussians to express frequency information, resulting in the loss of accuracy. In this paper, we propose to establish a direct relation between density and scale through the reparameterization of the scaling parameters and ensure the consistency between them via explicit constraints (i.e., density responds well to changes in frequency). Furthermore, we develop a frequency-aware density control strategy, consisting of densification and deletion, to improve representation quality with fewer Gaussians. A dynamic threshold encourages densification in high-frequency regions, while a scale-based filter deletes Gaussians with improper scale. Experimental results on various datasets demonstrate that our method outperforms existing state-of-the-art methods quantitatively and qualitatively.
通过自适应控制密度并在高频信息区域生成更多的高斯分布,3D高斯Splatting(3DGS)可以更好地表示场景细节。从信号处理的角度来看,表示细节通常需要具有相对较小尺度的高斯分布。然而,目前3DGS缺乏在域之间联系3D高斯分布密度和尺度的明确约束,导致3DGS使用不当尺度的高斯分布来表达频率信息,从而失去准确性。在本文中,我们提出通过重新参数化尺度参数来建立密度和尺度之间的直接关系,并通过显式约束确保它们之间的一致性(即密度对频率变化反应良好)。此外,我们开发了一种频率感知密度控制策略,包括稠密化和删除操作,以用更少的高斯分布提高表示质量。动态阈值鼓励在高频区域进行稠密化,而基于尺度的过滤器则删除尺度不当的高斯分布。在各种数据集上的实验结果表明,我们的方法在定量和定性方面都优于现有最先进的方法。
论文及项目相关链接
PDF Accepted to AAAI2025
Summary
本文介绍了通过自适应控制密度并在高频信息区域生成更多高斯分布,改进了三维高斯点云(3DGS)以更好地表达场景细节。论文提出了通过建立密度与尺度之间的直接关系来改进三维高斯点云处理频率信息的方法,并通过实验验证该方法优于现有技术。
Key Takeaways
- 改进三维高斯点云(3DGS)以更好地表达场景细节。
- 通过自适应控制密度在高频信息区域生成更多高斯分布。
- 当前缺乏关于密度与尺度间直接联系的局限性可能导致不准确的表达。
- 建立密度与尺度间的直接关系并通过重新参数化来优化表达效果。
- 开发了一种频率感知密度控制策略,包括加密和删除策略以提高表达质量并减少所需的高斯数量。
- 动态阈值鼓励在高频区域加密高斯分布,同时基于尺度的过滤器删除不合适的高斯分布。
点此查看论文截图

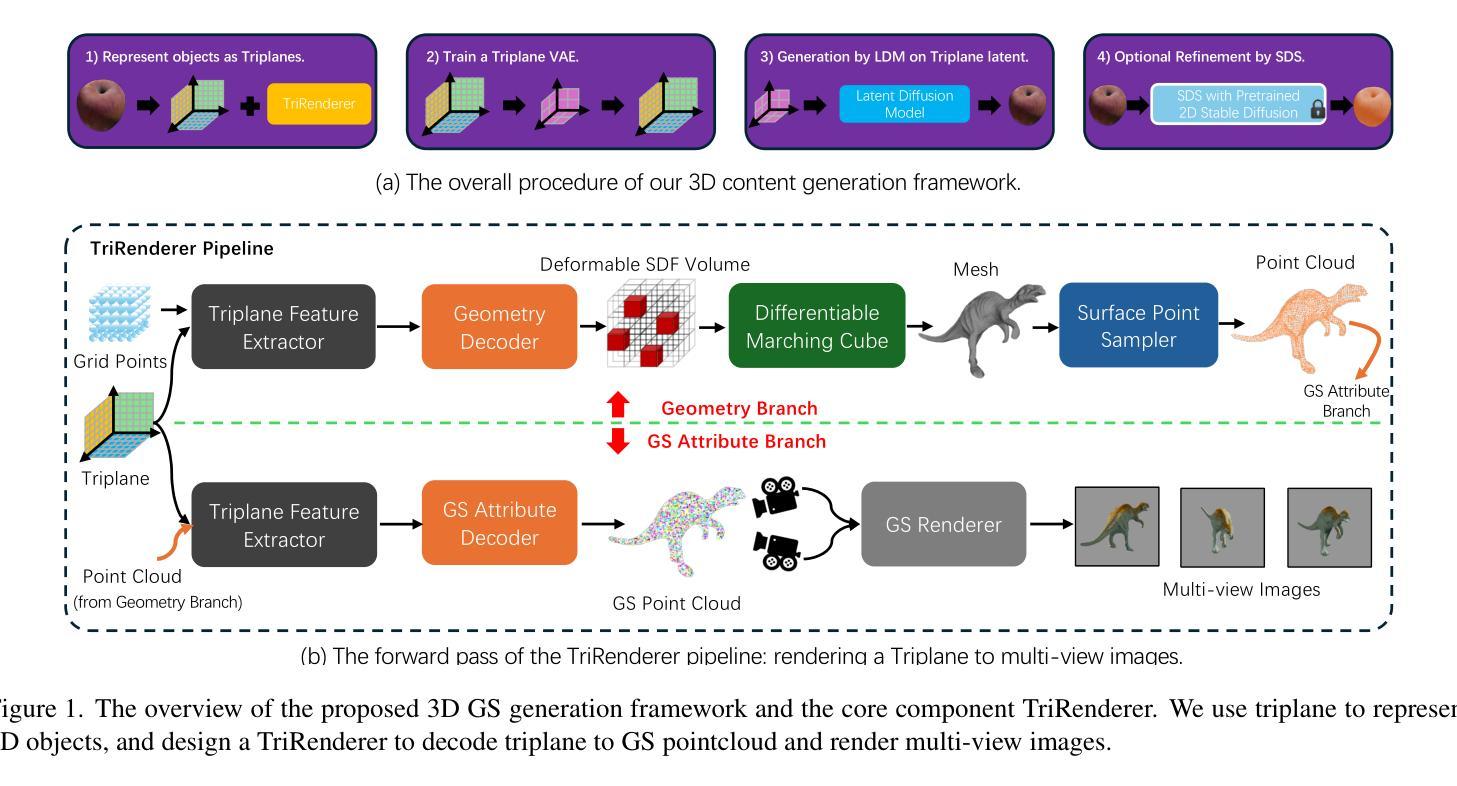
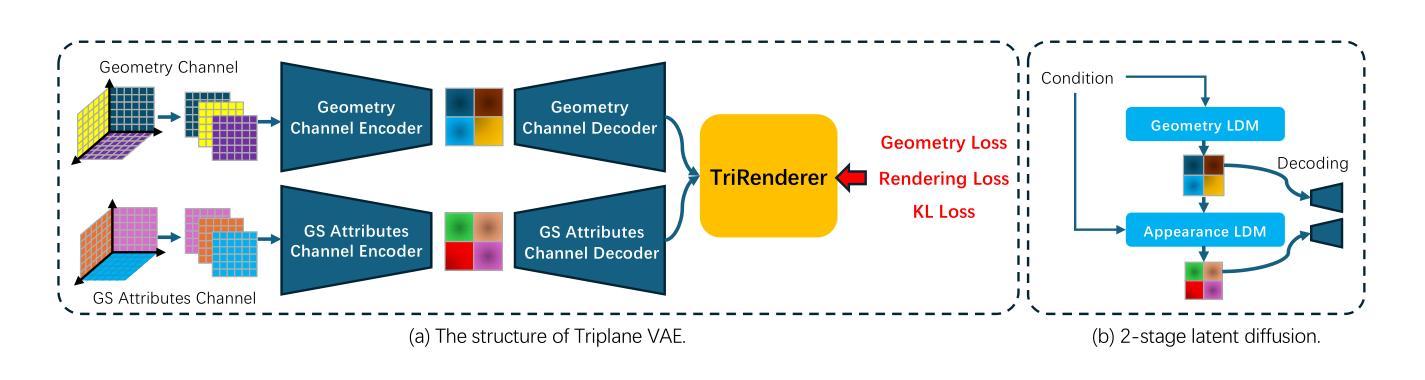
DirectTriGS: Triplane-based Gaussian Splatting Field Representation for 3D Generation
Authors:Xiaoliang Ju, Hongsheng Li
We present DirectTriGS, a novel framework designed for 3D object generation with Gaussian Splatting (GS). GS-based rendering for 3D content has gained considerable attention recently. However, there has been limited exploration in directly generating 3D Gaussians compared to traditional generative modeling approaches. The main challenge lies in the complex data structure of GS represented by discrete point clouds with multiple channels. To overcome this challenge, we propose employing the triplane representation, which allows us to represent Gaussian Splatting as an image-like continuous field. This representation effectively encodes both the geometry and texture information, enabling smooth transformation back to Gaussian point clouds and rendering into images by a TriRenderer, with only 2D supervisions. The proposed TriRenderer is fully differentiable, so that the rendering loss can supervise both texture and geometry encoding. Furthermore, the triplane representation can be compressed using a Variational Autoencoder (VAE), which can subsequently be utilized in latent diffusion to generate 3D objects. The experiments demonstrate that the proposed generation framework can produce high-quality 3D object geometry and rendering results in the text-to-3D task.
我们提出了DirectTriGS,这是一种为基于高斯拼贴(GS)的3D对象生成设计的新型框架。最近,基于GS的3D内容渲染已引起广泛关注。然而,与传统的生成建模方法相比,直接在GS上进行高斯生成的探索仍然有限。主要挑战在于由离散点云和多个通道表示的高斯拼贴(GS)的复杂数据结构。为了克服这一挑战,我们提出了采用triplane表示法,它允许我们将高斯拼贴表示为类似图像的连续字段。这种表示法可以有效地编码几何和纹理信息,能够将几何拼贴顺利转换回高斯点云并通过TriRenderer呈现为图像,只需进行二维监督即可。所提出的TriRenderer是完全可微分的,因此渲染损失可以监督纹理和几何编码。此外,triplane表示可以使用变分自编码器(VAE)进行压缩,然后可用于潜在扩散以生成三维物体。实验表明,所提出的生成框架可以在文本到三维任务中产生高质量的三维物体几何和渲染结果。
论文及项目相关链接
PDF Accepted by CVPR 2025
摘要
基于DirectTriGS框架和Gaussian Splatting(GS)的3D对象生成方法。该方法采用triplane表示法,将Gaussian Splatting表示为图像式连续场,从而有效编码几何和纹理信息,并可以平滑转换回Gaussian点云并渲染为图像。该方法使用全可微的TriRenderer,使渲染损失可以监督纹理和几何编码。此外,triplane表示法可以使用变分自编码器(VAE)进行压缩,并用于潜在扩散生成3D对象。实验证明,该生成框架在文本到3D任务中可以生成高质量的3D对象几何和渲染结果。
关键见解
- DirectTriGS是一个基于Gaussian Splatting(GS)的3D对象生成的新框架。
- Triplane表示法能有效编码几何和纹理信息,并允许平滑转换回Gaussian点云。
- TriRenderer是全可微的,可以同时监督纹理和几何编码的渲染损失。
- 变分自编码器(VAE)用于压缩triplane表示法,进而用于潜在扩散生成3D对象。
- 该框架使用文本作为输入生成高质量的3D对象几何和渲染结果。
- 该框架具有广泛的应用前景,可用于文本到图像、虚拟世界构建等领域。
- 实验证明了该框架的有效性和优越性。
点此查看论文截图




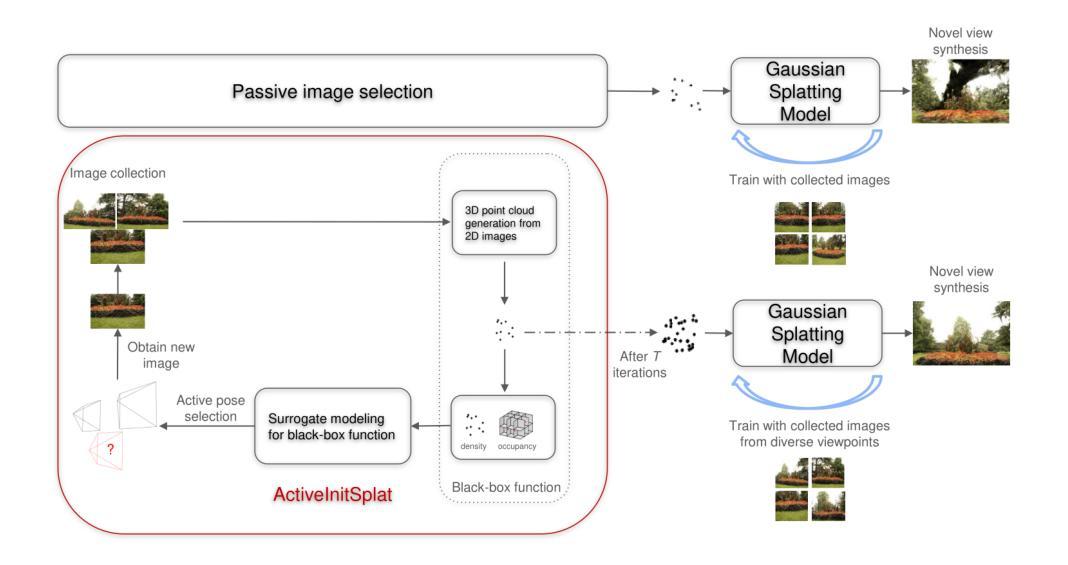
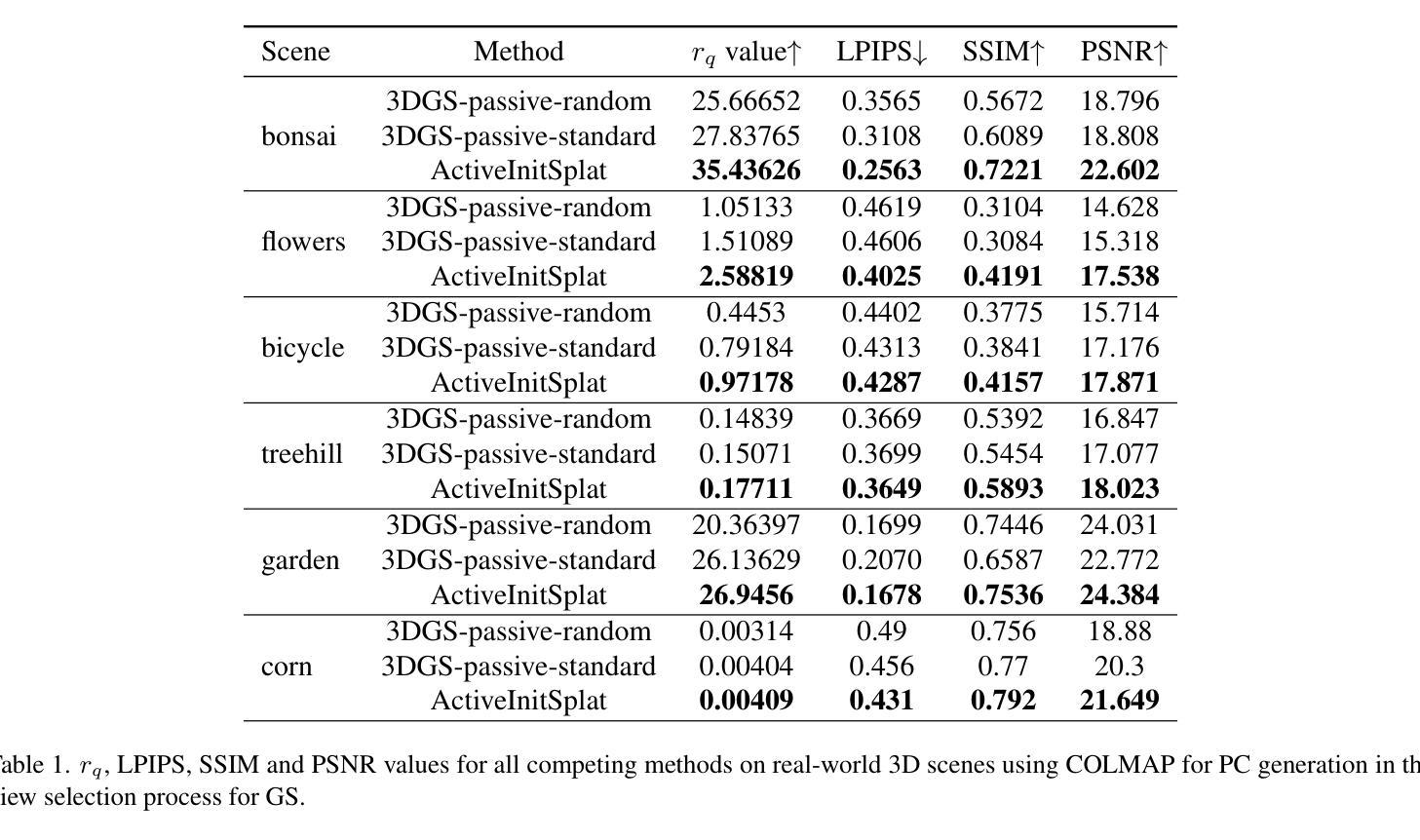
ActiveInitSplat: How Active Image Selection Helps Gaussian Splatting
Authors:Konstantinos D. Polyzos, Athanasios Bacharis, Saketh Madhuvarasu, Nikos Papanikolopoulos, Tara Javidi
Gaussian splatting (GS) along with its extensions and variants provides outstanding performance in real-time scene rendering while meeting reduced storage demands and computational efficiency. While the selection of 2D images capturing the scene of interest is crucial for the proper initialization and training of GS, hence markedly affecting the rendering performance, prior works rely on passively and typically densely selected 2D images. In contrast, this paper proposes `ActiveInitSplat’, a novel framework for active selection of training images for proper initialization and training of GS. ActiveInitSplat relies on density and occupancy criteria of the resultant 3D scene representation from the selected 2D images, to ensure that the latter are captured from diverse viewpoints leading to better scene coverage and that the initialized Gaussian functions are well aligned with the actual 3D structure. Numerical tests on well-known simulated and real environments demonstrate the merits of ActiveInitSplat resulting in significant GS rendering performance improvement over passive GS baselines, in the widely adopted LPIPS, SSIM, and PSNR metrics.
高斯混合法(GS)及其扩展和变种在实时场景渲染中表现出卓越的性能,同时满足降低存储需求和计算效率的要求。虽然选择捕捉感兴趣场景的二维图像对于GS的正确初始化和训练至关重要,从而显著影响渲染性能,但之前的工作依赖于被动和通常密集选择的二维图像。相比之下,本文提出`ActiveInitSplat’,这是一个主动选择训练图像用于适当初始化和训练GS的新型框架。ActiveInitSplat依赖于所选二维图像生成的结果三维场景表示的密度和占用率标准,以确保后者从不同视角捕捉,从而实现更好的场景覆盖,并且初始化的高斯函数与实际的三维结构良好对齐。在著名的模拟和真实环境中的数值测试证明了ActiveInitSplat的优点,与传统的被动GS基线相比,它在广泛采用的LPIPS、SSIM和PSNR指标上显著提高了GS的渲染性能。
论文及项目相关链接
Summary
本文介绍了高斯贴图(GS)及其扩展和变体在实时场景渲染中的出色性能,同时满足降低存储需求和计算效率的要求。针对场景兴趣部位的二维图像选择对GS的初始化和训练至关重要,进而影响渲染性能的问题,本文提出ActiveInitSplat框架,实现主动选择训练图像进行GS的初始化和训练。ActiveInitSplat依赖所选二维图像的结果三维场景表示的密度和占用率标准,确保从多个视角捕捉图像,以获得更好的场景覆盖,并使初始化的高斯函数与实际的3D结构良好对齐。数值测试表明,ActiveInitSplat在广泛采用的LPIPS、SSIM和PSNR指标中,相较于被动GS基线,能显著提高GS渲染性能。
Key Takeaways
- 高斯贴图(GS)在实时场景渲染中具有出色性能,满足存储和计算效率要求。
- 场景兴趣部位的二维图像选择对GS的初始化和训练至关重要。
- 现有工作主要依赖被动且密集选择的二维图像。
- ActiveInitSplat框架实现了训练图像的主动选择,用于GS的初始化和训练。
- ActiveInitSplat基于结果三维场景表示的密度和占用率标准进行图像选择。
- 该方法确保从多个视角捕捉图像,以获得更好的场景覆盖和对实际3D结构的良好对齐。
点此查看论文截图



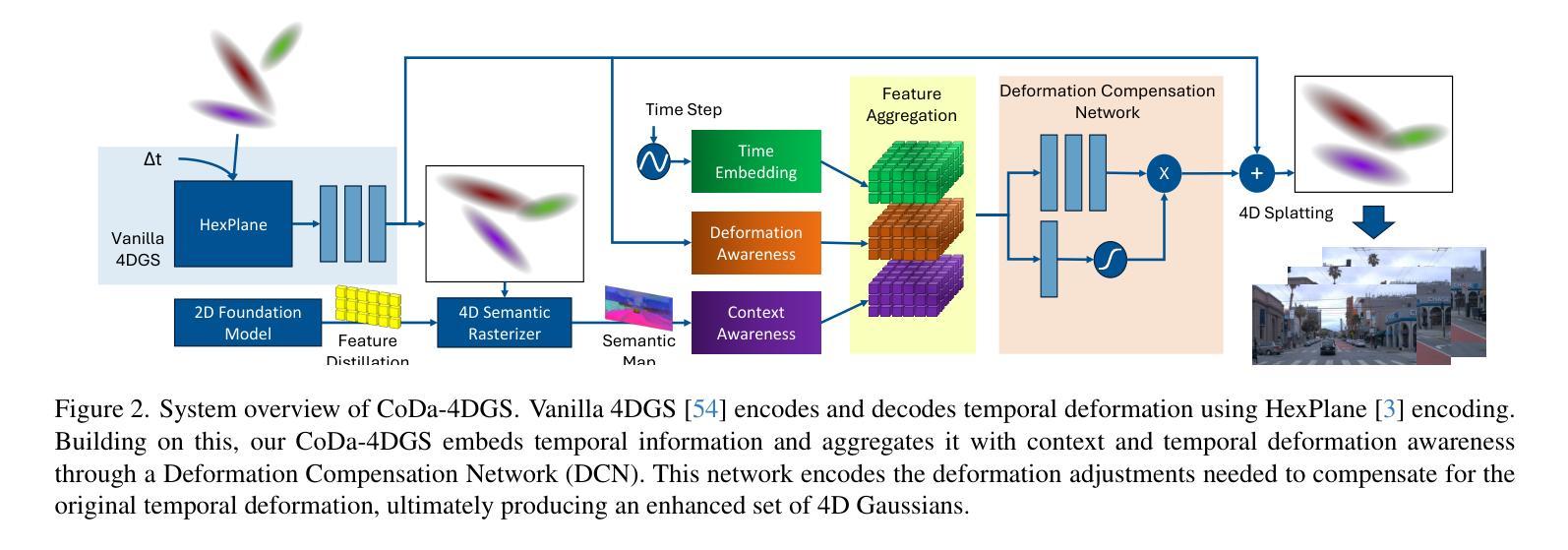
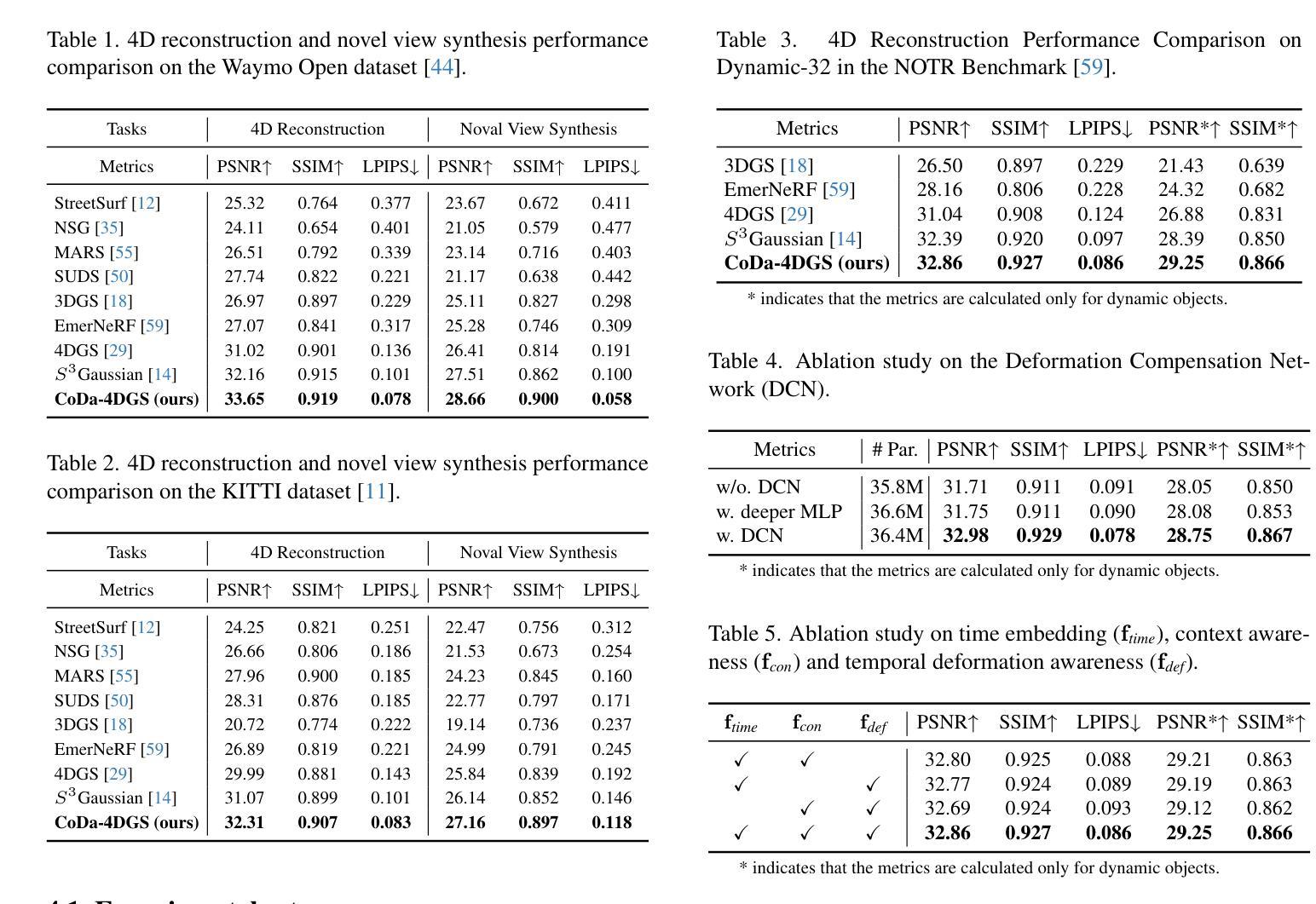
CoDa-4DGS: Dynamic Gaussian Splatting with Context and Deformation Awareness for Autonomous Driving
Authors:Rui Song, Chenwei Liang, Yan Xia, Walter Zimmer, Hu Cao, Holger Caesar, Andreas Festag, Alois Knoll
Dynamic scene rendering opens new avenues in autonomous driving by enabling closed-loop simulations with photorealistic data, which is crucial for validating end-to-end algorithms. However, the complex and highly dynamic nature of traffic environments presents significant challenges in accurately rendering these scenes. In this paper, we introduce a novel 4D Gaussian Splatting (4DGS) approach, which incorporates context and temporal deformation awareness to improve dynamic scene rendering. Specifically, we employ a 2D semantic segmentation foundation model to self-supervise the 4D semantic features of Gaussians, ensuring meaningful contextual embedding. Simultaneously, we track the temporal deformation of each Gaussian across adjacent frames. By aggregating and encoding both semantic and temporal deformation features, each Gaussian is equipped with cues for potential deformation compensation within 3D space, facilitating a more precise representation of dynamic scenes. Experimental results show that our method improves 4DGS’s ability to capture fine details in dynamic scene rendering for autonomous driving and outperforms other self-supervised methods in 4D reconstruction and novel view synthesis. Furthermore, CoDa-4DGS deforms semantic features with each Gaussian, enabling broader applications.
动态场景渲染通过利用光写实数据实现闭环模拟,为自动驾驶开辟了新的途径,这对于验证端到端算法至关重要。然而,交通环境的复杂性和高度动态性给准确渲染这些场景带来了重大挑战。在本文中,我们介绍了一种新型的4D高斯斑点(4DGS)方法,它结合了上下文和时序变形意识,以提高动态场景渲染的效果。具体来说,我们采用2D语义分割基础模型对高斯分布的4D语义特征进行自我监督,确保有意义的上下文嵌入。同时,我们跟踪相邻帧中每个高斯分布的时序变形。通过聚合和编码语义和时序变形特征,每个高斯分布都具备在三维空间内进行潜在变形补偿的线索,为实现更精确的动态场景表示提供了支持。实验结果表明,我们的方法提高了4DGS在自动驾驶动态场景渲染中捕捉细节的能力,并在四维重建和新颖视图合成方面超越了其他自我监督方法。此外,CoDa-4DGS能够使用每个高斯分布进行语义特征变形,从而拓宽了其应用范围。
论文及项目相关链接
Summary
动态场景渲染对于自动驾驶中的闭环模拟至关重要,其真实感数据能够验证端到端的算法。复杂且动态的交通环境为准确渲染带来挑战。本文引入了一种新型四维高斯展开技术(四维分裂症),该技术结合了上下文和时序变形意识以提高动态场景渲染能力。该技术通过二维语义分割基础模型实现四维高斯语义特征的自监督,保证有意义的上下文嵌入,并追踪相邻帧内的高斯时序变形。通过对语义和时序变形特征的聚集和编码,每个高斯都有在三维空间内发生潜在变形的补偿线索,更精确地表达动态场景。实验表明,此方法能提高四维分裂症在动态场景渲染的精细度捕捉能力,在自动驾驶中有显著优势并领先其他自监督方法于四维重建和新颖视角合成。此外,CoDa-四维分裂症对语义特征进行高斯变形处理,开启了更广泛的应用领域。
Key Takeaways
- 动态场景渲染对自动驾驶至关重要,且挑战在于交通环境的复杂性和动态性。
- 新提出的四维高斯展开技术能提高动态场景的渲染能力。
- 该技术结合上下文和时序变形意识,通过二维语义分割模型实现四维高斯语义特征的自监督学习。
- 技术能够追踪相邻帧内的高斯时序变形,并整合语义与时序变形特征以提高精确度。
- 实验显示该技术在动态场景渲染、四维重建和新颖视角合成方面表现优越。
点此查看论文截图


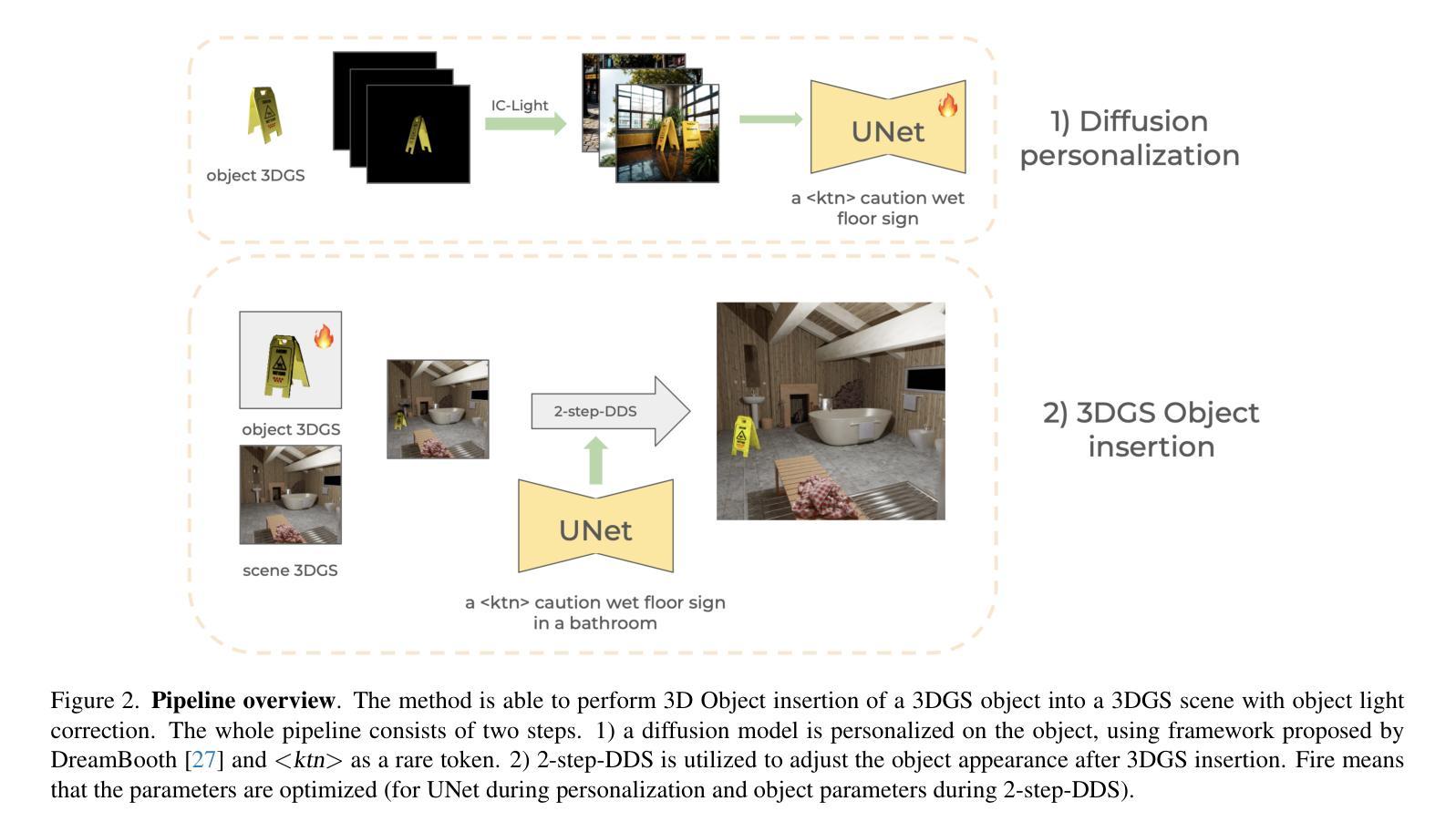
D3DR: Lighting-Aware Object Insertion in Gaussian Splatting
Authors:Vsevolod Skorokhodov, Nikita Durasov, Pascal Fua
Gaussian Splatting has become a popular technique for various 3D Computer Vision tasks, including novel view synthesis, scene reconstruction, and dynamic scene rendering. However, the challenge of natural-looking object insertion, where the object’s appearance seamlessly matches the scene, remains unsolved. In this work, we propose a method, dubbed D3DR, for inserting a 3DGS-parametrized object into 3DGS scenes while correcting its lighting, shadows, and other visual artifacts to ensure consistency, a problem that has not been successfully addressed before. We leverage advances in diffusion models, which, trained on real-world data, implicitly understand correct scene lighting. After inserting the object, we optimize a diffusion-based Delta Denoising Score (DDS)-inspired objective to adjust its 3D Gaussian parameters for proper lighting correction. Utilizing diffusion model personalization techniques to improve optimization quality, our approach ensures seamless object insertion and natural appearance. Finally, we demonstrate the method’s effectiveness by comparing it to existing approaches, achieving 0.5 PSNR and 0.15 SSIM improvements in relighting quality.
高斯贴图技术现已成为各种三维计算机视觉任务的热门技术,包括新视角合成、场景重建和动态场景渲染等。然而,自然物体插入的挑战,即物体的外观无缝匹配场景,仍未得到解决。在这项工作中,我们提出了一种方法,称为D3DR,用于将3DGS参数化的物体插入到3DGS场景中,同时校正其光照、阴影和其他视觉伪影,以确保一致性,这是一个之前尚未成功解决的问题。我们利用扩散模型的进步,该模型在现实世界数据上进行训练,能够隐含地理解正确的场景光照。插入物体后,我们优化了一个基于扩散的Delta去噪评分(DDS)启发目标,调整其三维高斯参数进行适当的光照校正。利用扩散模型个性化技术来提高优化质量,我们的方法确保了无缝的物体插入和自然外观。最后,通过与现有方法进行对比,我们在重光照质量上实现了0.5的PSNR和0.15的SSIM改进,证明了该方法的有效性。
论文及项目相关链接
摘要
本文提出一种名为D3DR的方法,用于将参数化的三维物体(3DGS)无缝插入到三维场景(3DGS)中,并修正其光照、阴影和其他视觉伪影,确保一致性。该方法利用扩散模型对现实世界数据的理解,并利用基于扩散的Delta Denoising Score(DDS)目标优化物体的三维高斯参数,以实现适当的光照校正。通过对比现有方法,该方法在重光照质量方面实现了0.5 PSNR和0.15 SSIM的提升,展现了其有效性。
关键见解
Gaussian Splatting作为一种流行的技术,广泛用于各种三维计算机视觉任务,包括新颖视角合成、场景重建和动态场景渲染等。然而,在对象自然插入的场景中仍然存在问题。我们的工作提出了一种称为D3DR的解决方案来解决这个问题。这是首个能够在场景里自然地插入一个被修改的对象的实例方法。此外通过针对数据调整的输入流程和创新方法实现目标优化,以确保无缝的对象插入和自然外观。通过扩散模型对个人化技术的利用提高了优化质量。
利用扩散模型训练真实世界数据来隐式理解正确的场景光照。通过扩散模型理解真实世界数据并应用到我们的模型中提高可靠性保证修正的对象能在复杂的三维环境中保持一致。我们将新物体与周围物体光照的自然交互效果以特定方法来完善模型和强化效果的展示,将伪三维视觉效果减少到最低限度以使得插入效果更加逼真和自然。这将我们带入了一个新的方向进行工作实践通过高级技术和处理方案实现对现有技术和标准的挑战与突破以此来实现优秀视觉效果和用户感受的新纪元场景重构的应用设计使应用自然、精细与交互的技术壁垒降低加快各类技术和算法之间的协作协同最终加速全行业发展及产业链的不断迭代与成熟与完善的同时解决核心的行业问题和提高解决难题的速度和质量通过深入研究带来计算机视觉效果的进一步提升满足观众越来越高的视觉效果要求带来前所未有的沉浸式体验满足未来虚拟世界的真实感需求以及人们对于高质量场景重建和物体插入的需求与期望从而推动行业不断向前发展。
点此查看论文截图




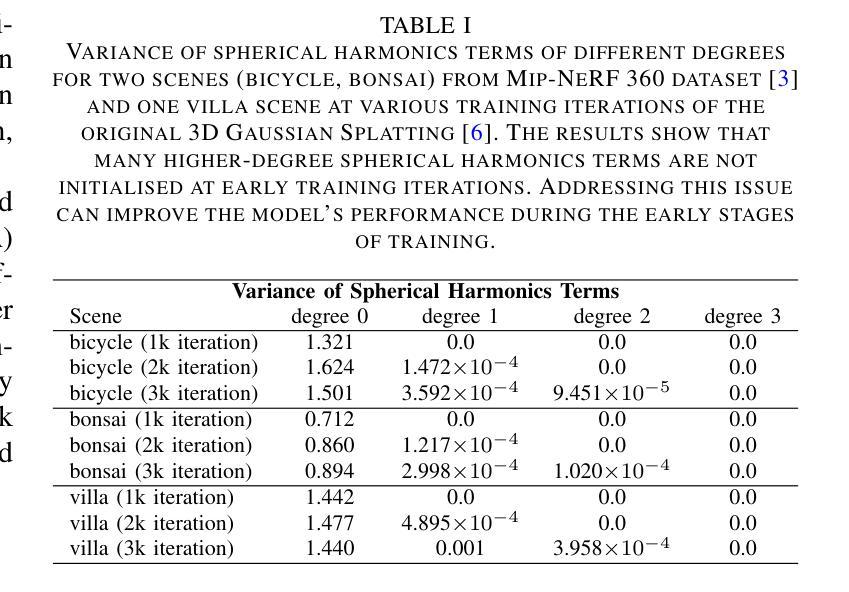
StructGS: Adaptive Spherical Harmonics and Rendering Enhancements for Superior 3D Gaussian Splatting
Authors:Zexu Huang, Min Xu, Stuart Perry
Recent advancements in 3D reconstruction coupled with neural rendering techniques have greatly improved the creation of photo-realistic 3D scenes, influencing both academic research and industry applications. The technique of 3D Gaussian Splatting and its variants incorporate the strengths of both primitive-based and volumetric representations, achieving superior rendering quality. While 3D Geometric Scattering (3DGS) and its variants have advanced the field of 3D representation, they fall short in capturing the stochastic properties of non-local structural information during the training process. Additionally, the initialisation of spherical functions in 3DGS-based methods often fails to engage higher-order terms in early training rounds, leading to unnecessary computational overhead as training progresses. Furthermore, current 3DGS-based approaches require training on higher resolution images to render higher resolution outputs, significantly increasing memory demands and prolonging training durations. We introduce StructGS, a framework that enhances 3D Gaussian Splatting (3DGS) for improved novel-view synthesis in 3D reconstruction. StructGS innovatively incorporates a patch-based SSIM loss, dynamic spherical harmonics initialisation and a Multi-scale Residual Network (MSRN) to address the above-mentioned limitations, respectively. Our framework significantly reduces computational redundancy, enhances detail capture and supports high-resolution rendering from low-resolution inputs. Experimentally, StructGS demonstrates superior performance over state-of-the-art (SOTA) models, achieving higher quality and more detailed renderings with fewer artifacts.
近期三维重建技术与神经渲染技术的融合,极大地推动了光栅化三维场景的创作,对学术研究和工业应用都产生了深远影响。三维高斯点云法(3D Gaussian Splatting,简称3DGS)及其变体结合了基于原始和体积表示的优势,实现了高质量的渲染。虽然三维几何散射(3D Geometric Scattering,简称3DGS)及其变体推动了三维表示领域的发展,但在训练过程中捕捉非局部结构信息的随机特性方面仍存在不足。此外,3DGS方法中的球面函数初始化往往无法在早期训练轮次中引入高阶项,随着训练的进行,会导致不必要的计算开销。而且,当前的基于3DGS的方法需要在高分辨率图像上进行训练,以呈现高分辨率输出,这大大增加了内存需求并延长了训练时间。我们引入了StructGS框架,它增强了三维高斯点云法(3DGS),以改进三维重建中的新颖视图合成。StructGS创新性地融入了基于补丁的SSIM损失、动态球面谐波初始化以及多尺度残差网络(MSRN),分别解决了上述限制。我们的框架显著减少了计算冗余,提高了细节捕捉能力,支持从低分辨率输入进行高分辨率渲染。实验表明,StructGS在先进模型上表现出卓越的性能,以更少的人工制品实现更高质量和更详细的渲染。
论文及项目相关链接
Summary
本文介绍了在3D重建中,基于神经渲染技术的最新进展对创建逼真的3D场景的影响。文章讨论了3D高斯喷溅技术及其变体对结合基于原型和体积表示的优点所取得的优质渲染成果。然后指出了现有技术在处理非局部结构信息的随机性方面存在的局限性,以及初始球面函数在训练早期忽视高阶术语的问题。为了解决这些问题,本文提出了StructGS框架,通过引入基于补丁的SSIM损失、动态球面谐波初始化和多尺度残差网络(MSRN)来改进现有的3D高斯喷溅技术(3DGS)。StructGS框架显著减少了计算冗余,提高了细节捕捉能力,支持从低分辨率输入进行高分辨率渲染。实验表明,StructGS在业界领先水平上表现出卓越性能,渲染质量更高、细节更丰富且伪影更少。
Key Takeaways
- 3D重建中的最新进展与神经渲染技术相结合,显著提高了创建逼真的3D场景的能力。
- 3D高斯喷溅技术及其变体结合了基于原始模型和体积表示的优点,实现高质量的渲染。
- 当前技术挑战在于捕捉非局部结构信息的随机性以及在训练初期忽视高阶术语的问题。
- StructGS框架通过引入基于补丁的SSIM损失、动态球面谐波初始化以及多尺度残差网络解决了上述问题。
- StructGS显著减少计算冗余,提高细节捕捉能力,并支持从低分辨率输入进行高分辨率渲染。
点此查看论文截图


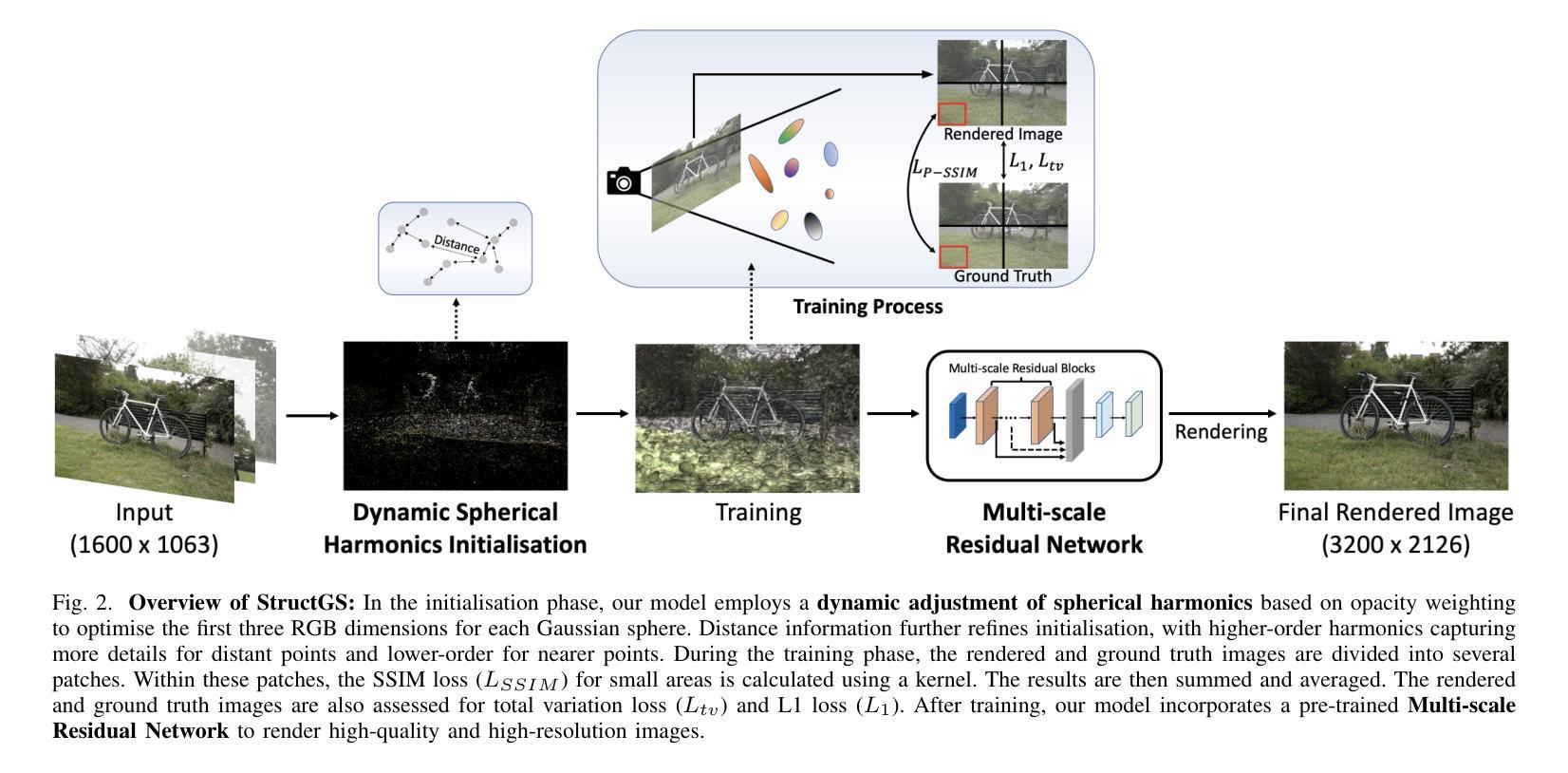
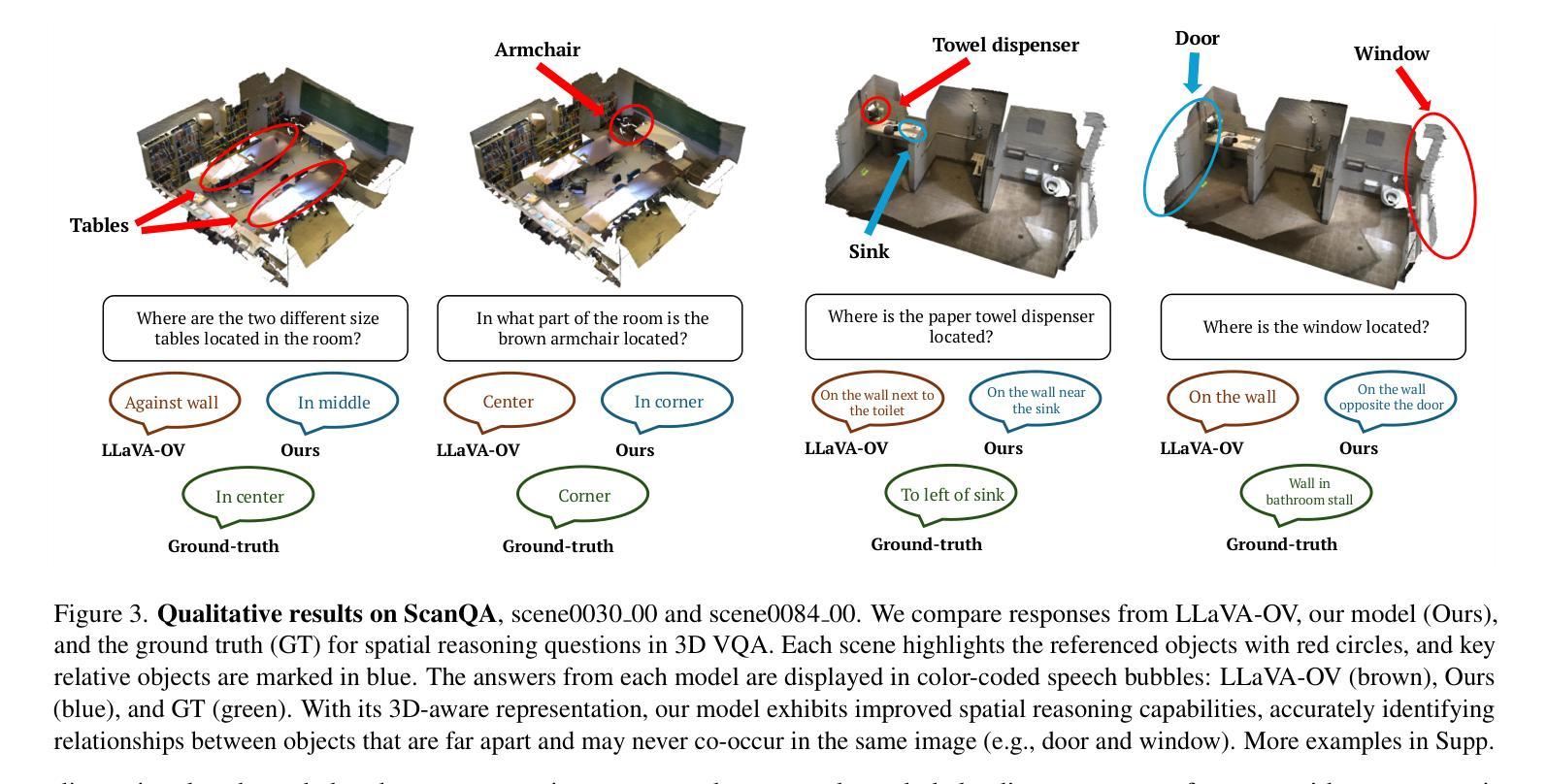
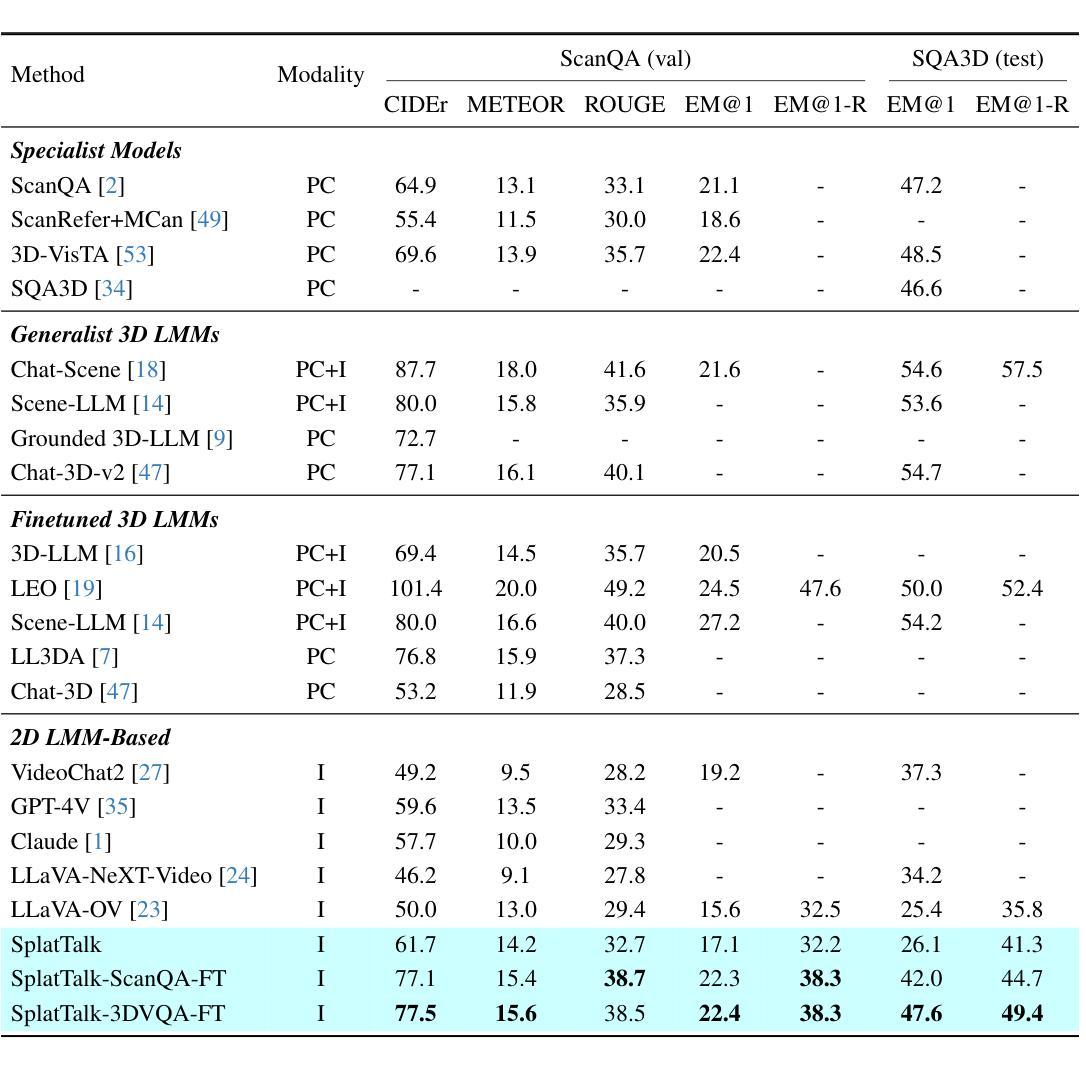
SplatTalk: 3D VQA with Gaussian Splatting
Authors:Anh Thai, Songyou Peng, Kyle Genova, Leonidas Guibas, Thomas Funkhouser
Language-guided 3D scene understanding is important for advancing applications in robotics, AR/VR, and human-computer interaction, enabling models to comprehend and interact with 3D environments through natural language. While 2D vision-language models (VLMs) have achieved remarkable success in 2D VQA tasks, progress in the 3D domain has been significantly slower due to the complexity of 3D data and the high cost of manual annotations. In this work, we introduce SplatTalk, a novel method that uses a generalizable 3D Gaussian Splatting (3DGS) framework to produce 3D tokens suitable for direct input into a pretrained LLM, enabling effective zero-shot 3D visual question answering (3D VQA) for scenes with only posed images. During experiments on multiple benchmarks, our approach outperforms both 3D models trained specifically for the task and previous 2D-LMM-based models utilizing only images (our setting), while achieving competitive performance with state-of-the-art 3D LMMs that additionally utilize 3D inputs.
语言引导的三维场景理解对于推动机器人、AR/VR和人机交互等领域的应用非常重要,它使模型能够通过自然语言理解和与三维环境进行交互。虽然二维视觉语言模型(VLM)在2D VQA任务中取得了显著的成功,但由于三维数据的复杂性和手动标注的高成本,三维领域的进展显著较慢。在这项工作中,我们引入了SplatTalk,这是一种使用通用三维高斯Splatting(3DGS)框架产生适合直接输入预训练LLM的三维标记的新方法,实现了仅使用图像的场景的有效零样本三维视觉问答(3D VQA)。在多个基准测试上的实验表明,我们的方法不仅优于专门为此任务训练的3D模型,而且优于以前只使用图像进行训练的基于二维LLM的模型(我们的设置),同时与利用三维输入的最新三维LLM的性能相竞争。
论文及项目相关链接
Summary
基于语言的3D场景理解对于推动机器人技术、增强现实/虚拟现实以及人机交互等领域的应用至关重要。尽管二维视觉语言模型在二维视觉问答任务中取得了显著成功,但在三维领域的进展由于三维数据的复杂性和手动标注的高成本而较慢。本研究引入了SplatTalk,这是一种使用通用三维高斯喷涂(3DGS)框架产生适合直接输入预训练LLM的三维令牌的新方法,实现了仅使用图像的有效零样本三维视觉问答(3D VQA)。在多个基准测试上的实验表明,我们的方法不仅优于专门为任务训练的三维模型以及仅使用图像的基于二维语言模型的旧方法,而且在仅使用图像的情况下实现了与国家先进的三维语言模型的竞争性能。
Key Takeaways
- 语言引导的三维场景理解在多个领域具有应用价值,如机器人技术、AR/VR和人机交互。
- 二维视觉语言模型在二维视觉问答任务中表现优秀,但在处理三维数据时存在局限性。
- 三维数据的复杂性和手动标注的高成本是阻碍三维领域进展的主要原因。
- SplatTalk是一种利用三维高斯喷涂(3DGS)框架的新方法,可将三维场景转化为适合输入预训练语言模型的形式。
- SplatTalk实现了有效的零样本三维视觉问答(3D VQA),仅使用图像作为输入。
- 实验结果表明,SplatTalk在多个基准测试上的性能优于专门为任务训练的三维模型以及旧的两维语言模型。
点此查看论文截图

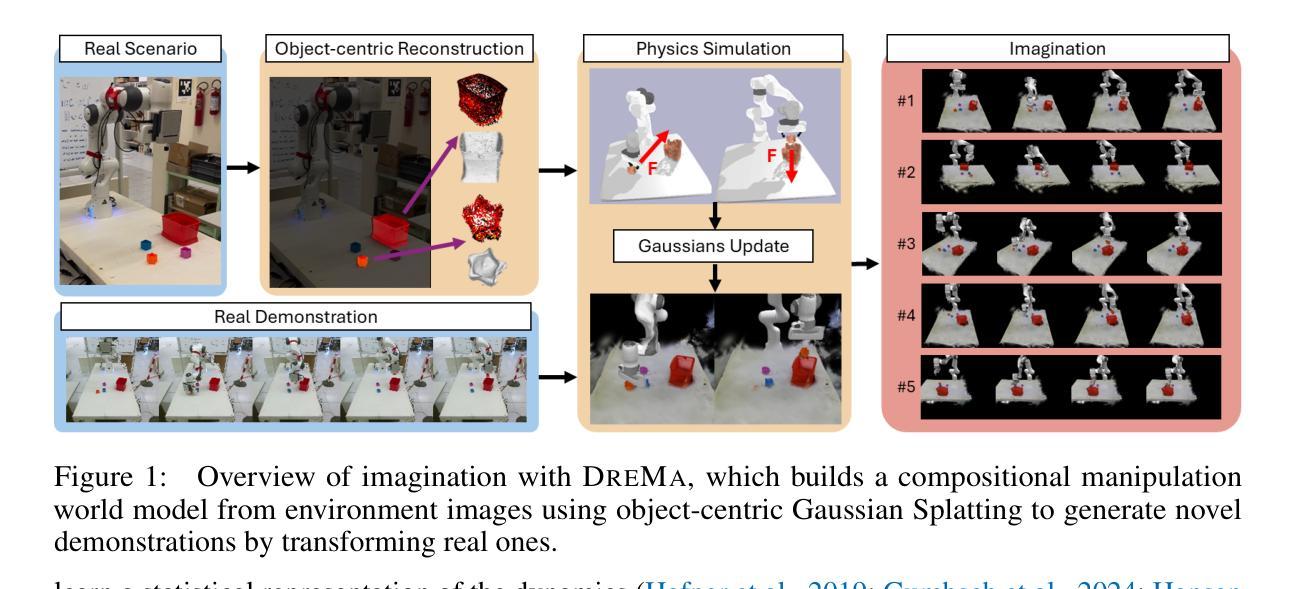
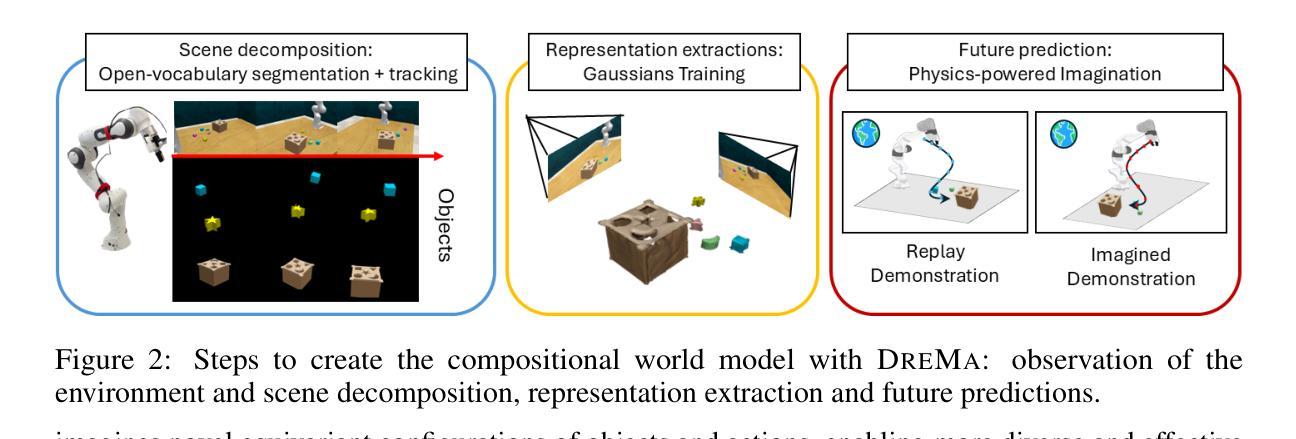
Dream to Manipulate: Compositional World Models Empowering Robot Imitation Learning with Imagination
Authors:Leonardo Barcellona, Andrii Zadaianchuk, Davide Allegro, Samuele Papa, Stefano Ghidoni, Efstratios Gavves
A world model provides an agent with a representation of its environment, enabling it to predict the causal consequences of its actions. Current world models typically cannot directly and explicitly imitate the actual environment in front of a robot, often resulting in unrealistic behaviors and hallucinations that make them unsuitable for real-world robotics applications. To overcome those challenges, we propose to rethink robot world models as learnable digital twins. We introduce DreMa, a new approach for constructing digital twins automatically using learned explicit representations of the real world and its dynamics, bridging the gap between traditional digital twins and world models. DreMa replicates the observed world and its structure by integrating Gaussian Splatting and physics simulators, allowing robots to imagine novel configurations of objects and to predict the future consequences of robot actions thanks to its compositionality. We leverage this capability to generate new data for imitation learning by applying equivariant transformations to a small set of demonstrations. Our evaluations across various settings demonstrate significant improvements in accuracy and robustness by incrementing actions and object distributions, reducing the data needed to learn a policy and improving the generalization of the agents. As a highlight, we show that a real Franka Emika Panda robot, powered by DreMa’s imagination, can successfully learn novel physical tasks from just a single example per task variation (one-shot policy learning). Our project page can be found in: https://dreamtomanipulate.github.io/.
一个世界模型为智能体提供其环境的表示,使其能够预测其行为的因果后果。当前的世界模型通常无法直接且明确地模仿机器人面前的实际情况,这常常导致出现不真实的行为和幻觉,使其不适合用于真实世界的机器人应用。为了克服这些挑战,我们提出重新思考机器人世界模型,将其作为可学习的数字双胞胎。我们引入了DreMa,这是一种使用学到的现实世界的显式表示及其动力学来自动构建数字双胞胎的新方法,从而缩小了传统数字双胞胎与世界模型之间的差距。DreMa通过集成高斯Splatting和物理模拟器来复制现实世界及其结构,允许机器人想象物体的新型配置并预测机器人行动的未来结果,这得益于其组合性。我们通过应用等价变换于一小部分演示来生成模仿学习的新数据。我们在各种环境中的评估表明,通过增加动作和物体分布,在准确性和稳健性方面实现了显著改进,减少了学习策略的所需数据并提高了智能体的泛化能力。值得一提的是,我们展示了由DreMa的想象力驱动的真实的Franka Emika Panda机器人能够仅通过每个任务的一次示例(一次性政策学习)成功学习新的物理任务。我们的项目页面可访问于:https://dreamtomanipulate.github.io/。
论文及项目相关链接
Summary
本文提出了一种新型机器人世界模型DreMa,它利用学习到的现实世界的明确表示及其动态来构建数字双胞胎,缩小了传统数字双胞胎与世界模型之间的差距。DreMa通过整合高斯溅射和物理模拟器来复制现实世界及其结构,允许机器人想象物体的新配置并预测未来机器人行动的后果。这项能力可用于通过应用等价变换于一小部分演示来生成模仿学习的新数据。评估表明,在各种场景下,通过增加动作和物体分布使用DreMa,准确率和稳健性得到显著提高,减少了学习政策所需的数据并改善了代理的泛化能力。特别值得一提的是,由DreMa驱动的Franka Emika Panda真实机器人可以成功地从每个任务变异中学习新的物理任务只需一个示例(一次性政策学习)。
Key Takeaways
- 世界模型赋予机器人对环境的表示,使其能够预测自身行动的因果后果。然而,现有模型通常无法直接明确地模仿机器人面前的实际环境,导致行为不真实和幻觉。
- DreMa是一种新型机器人世界模型,旨在通过构建数字双胞胎来解决上述问题。它能够利用学习到的现实世界的明确表示及其动态来自动构建数字双胞胎。
- DreMa结合了高斯溅射和物理模拟器来复制现实世界及其结构,允许机器人预测未来行动的结果,并具有组合性。
- DreMa通过应用等价变换于少量演示来生成模仿学习的新数据。
- 在各种设置下的评估表明,使用DreMa提高了机器人行动的准确性和稳健性。特别地,只需要一个示例(一次性政策学习),机器人就可以成功地从每个任务变异中学习新的物理任务。
- 通过整合高斯溅射和物理模拟器以及利用机器人的想象力生成新数据的方法有助于减少学习政策所需的数据量并提高代理的泛化能力。
点此查看论文截图

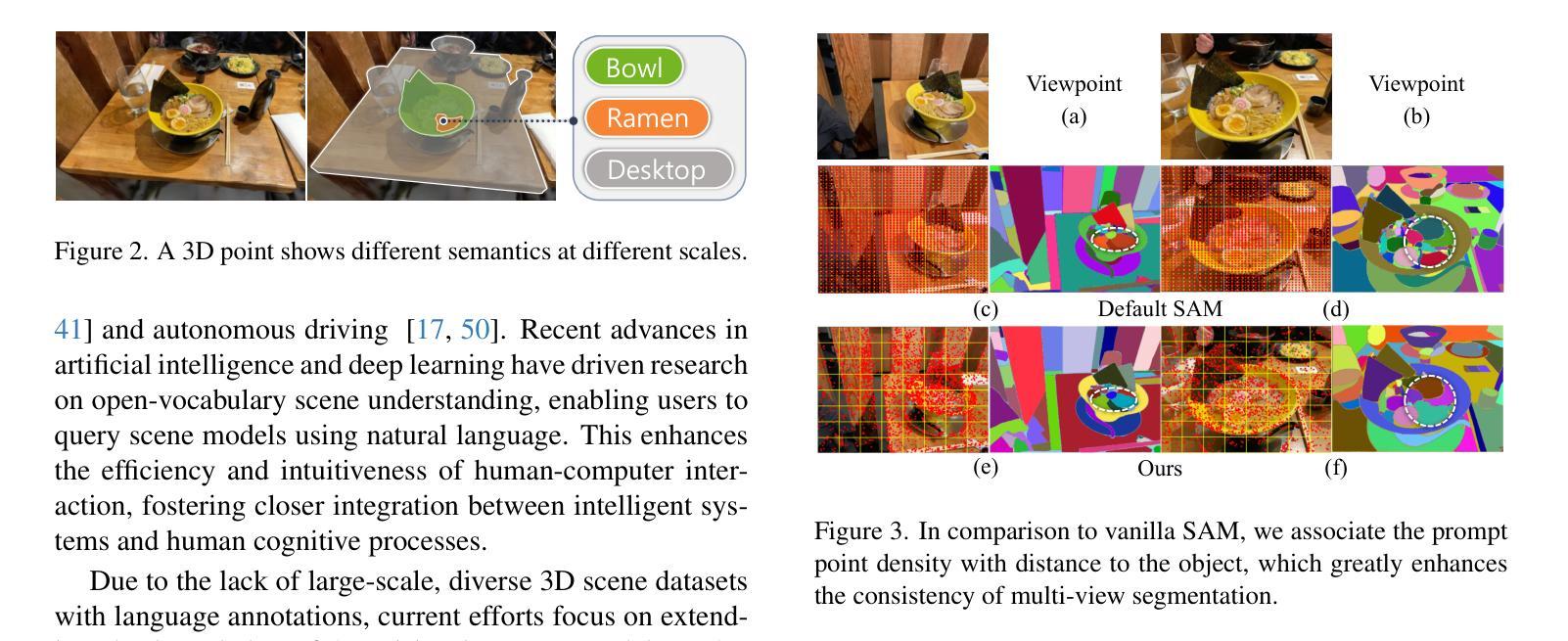
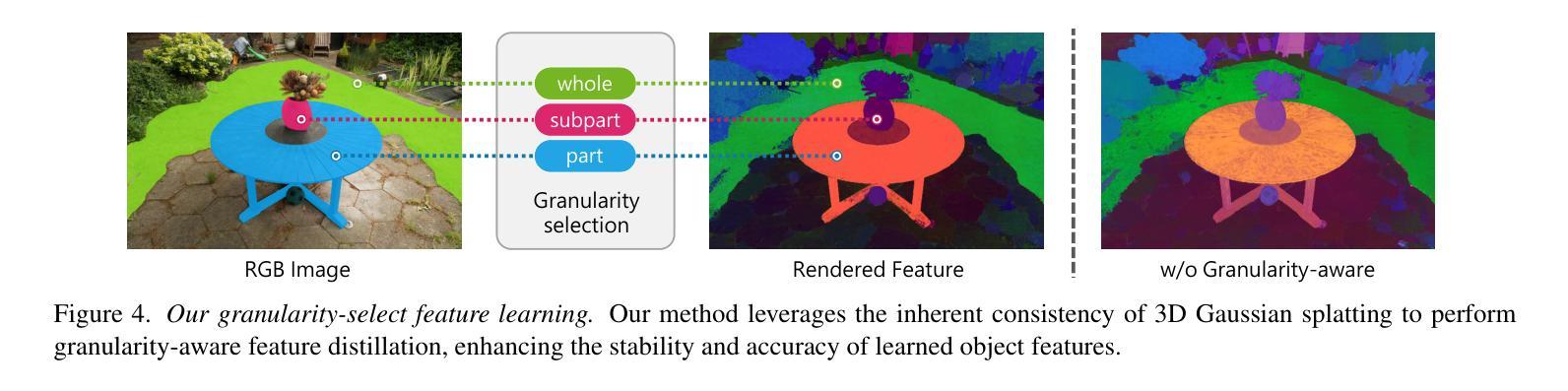
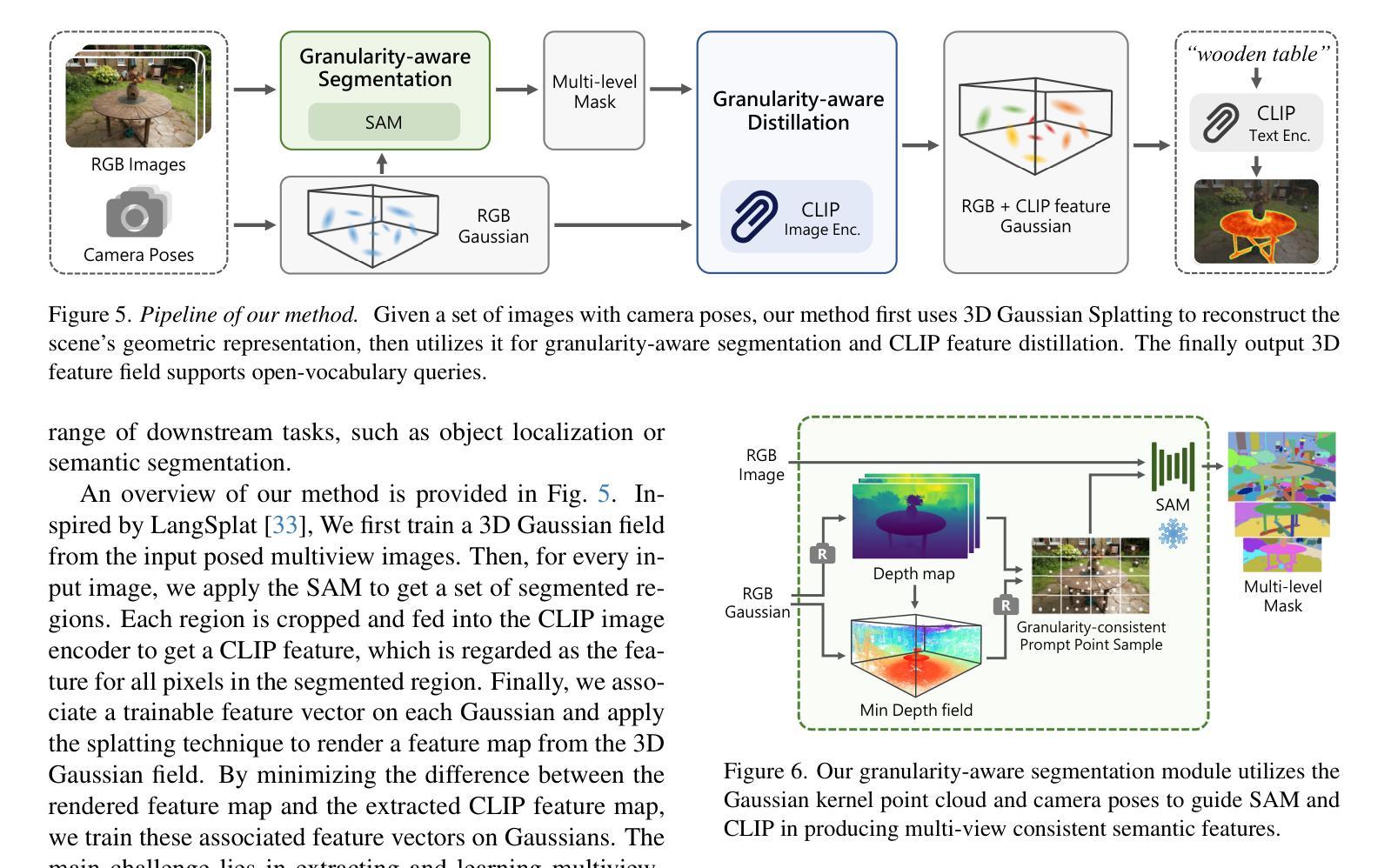
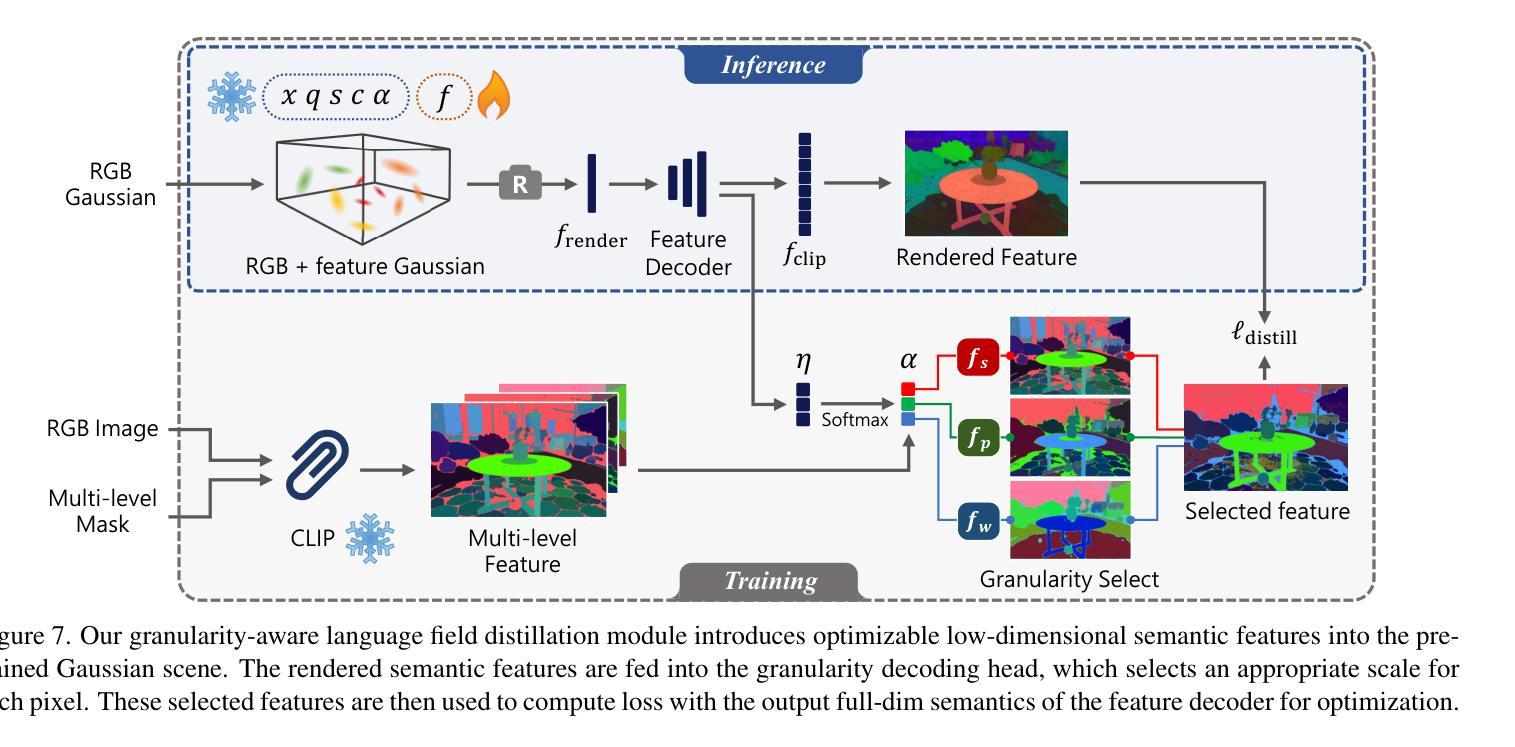
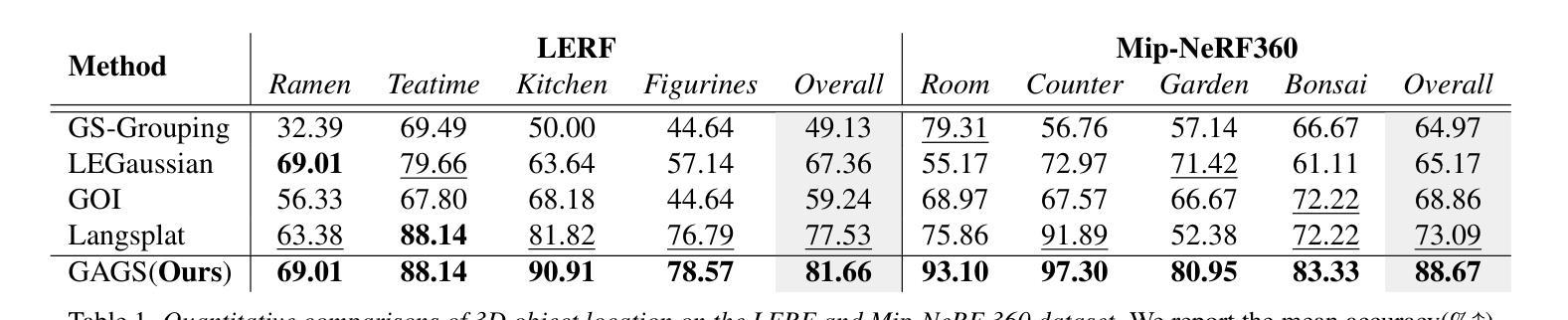
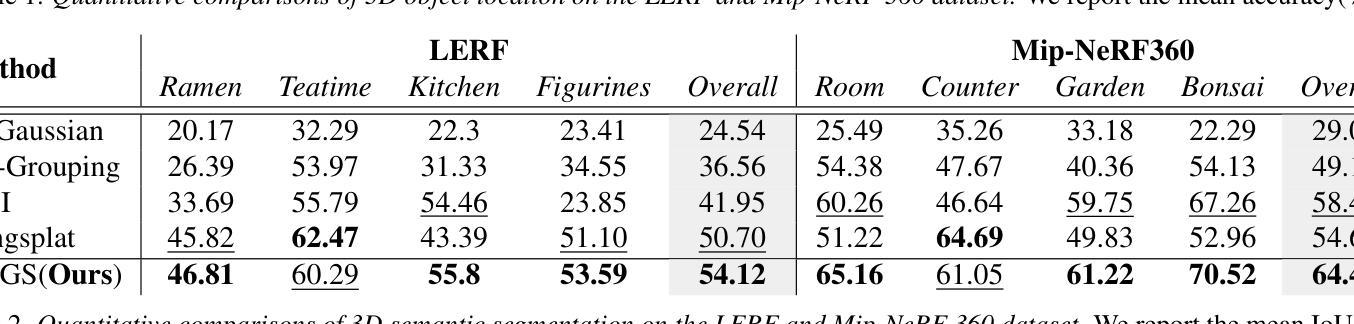
GAGS: Granularity-Aware Feature Distillation for Language Gaussian Splatting
Authors:Yuning Peng, Haiping Wang, Yuan Liu, Chenglu Wen, Zhen Dong, Bisheng Yang
3D open-vocabulary scene understanding, which accurately perceives complex semantic properties of objects in space, has gained significant attention in recent years. In this paper, we propose GAGS, a framework that distills 2D CLIP features into 3D Gaussian splatting, enabling open-vocabulary queries for renderings on arbitrary viewpoints. The main challenge of distilling 2D features for 3D fields lies in the multiview inconsistency of extracted 2D features, which provides unstable supervision for the 3D feature field. GAGS addresses this challenge with two novel strategies. First, GAGS associates the prompt point density of SAM with the camera distances, which significantly improves the multiview consistency of segmentation results. Second, GAGS further decodes a granularity factor to guide the distillation process and this granularity factor can be learned in a unsupervised manner to only select the multiview consistent 2D features in the distillation process. Experimental results on two datasets demonstrate significant performance and stability improvements of GAGS in visual grounding and semantic segmentation, with an inference speed 2$\times$ faster than baseline methods. The code and additional results are available at https://pz0826.github.io/GAGS-Webpage/ .
近年来,三维开放词汇场景理解技术得到了广泛关注,它能准确感知空间中物体的复杂语义属性。在本文中,我们提出了GAGS框架,它将二维CLIP特征蒸馏到三维高斯喷溅中,实现对任意视点的渲染进行开放词汇查询。将二维特征蒸馏到三维领域的挑战在于提取的二维特征的多视角不一致性,这为三维特征领域提供了不稳定的监督。GAGS通过两种新策略来解决这一挑战。首先,GAGS将SAM的提示点密度与相机距离相关联,这大大提高了分割结果的多视角一致性。其次,GAGS进一步解码粒度因子来指导蒸馏过程,并且这个粒度因子可以在无监督的方式中学习,仅在蒸馏过程中选择多视角一致的二维特征。在两个数据集上的实验结果表明,GAGS在视觉定位和语义分割方面性能和稳定性都有显著提高,推理速度比基线方法快两倍。相关代码和更多结果请访问 https://pz0826.github.io/GAGS-Webpage/。
论文及项目相关链接
PDF Project page: https://pz0826.github.io/GAGS-Webpage/
Summary
本文提出了一个名为GAGS的框架,它将二维CLIP特征转化为三维高斯网格(Gaussian Splatting),从而实现对任意视点渲染的三维场景开放词汇查询。GAGS通过两个策略解决了蒸馏二维特征进行三维建模的主要挑战——由于多视角不一致性带来的监督不稳定问题。一是将SAM的提示点密度与相机距离关联,显著提高分割结果的多视角一致性;二是引入粒度因子指导蒸馏过程,并在无监督学习下仅选择多视角一致的二维特征进行蒸馏。实验结果表明,GAGS在视觉定位和语义分割方面显著提高了性能和稳定性,推理速度比基线方法快两倍。
Key Takeaways
- GAGS框架实现了二维CLIP特征到三维高斯网格的转化,支持任意视点渲染的三维场景开放词汇查询。
- 多视角不一致性是蒸馏二维特征用于三维建模的主要挑战。
- GAGS通过关联SAM的提示点密度与相机距离,提高分割结果的多视角一致性。
- GAGS引入粒度因子指导蒸馏过程,能选择多视角一致的二维特征。
- 实验结果显示,GAGS在视觉定位和语义分割方面表现优异,且推理速度更快。
点此查看论文截图

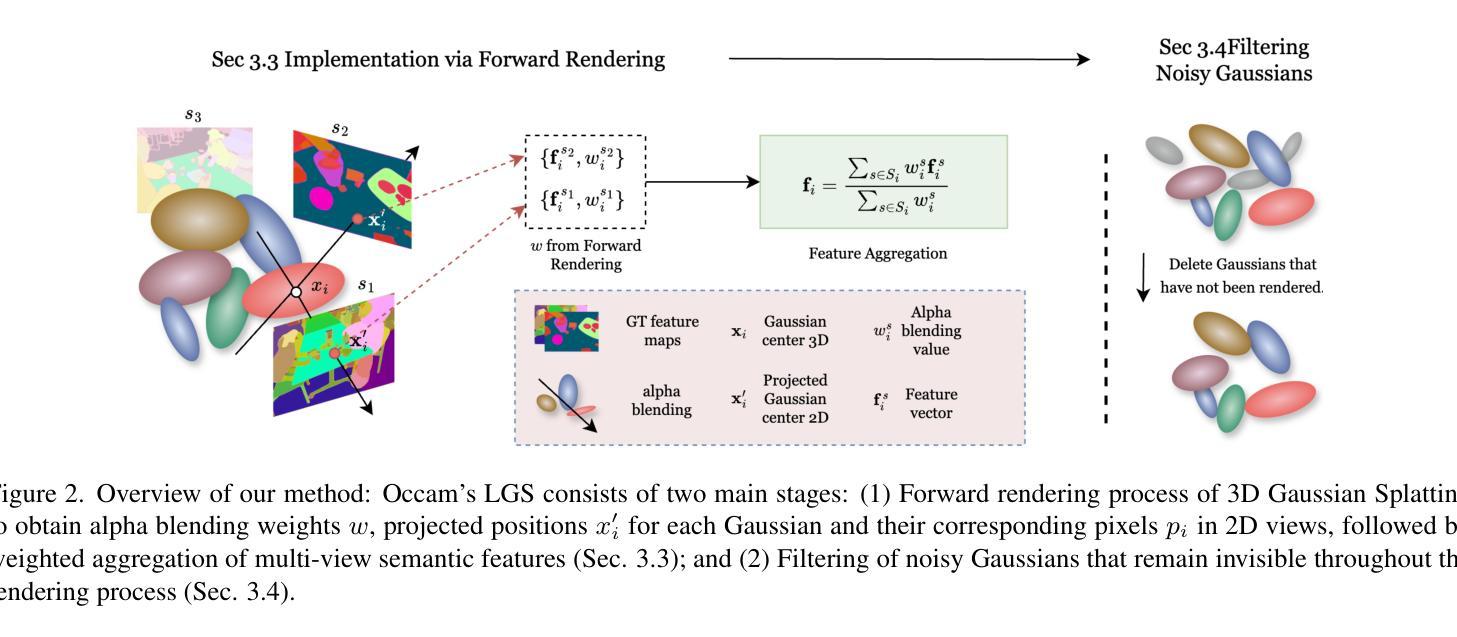
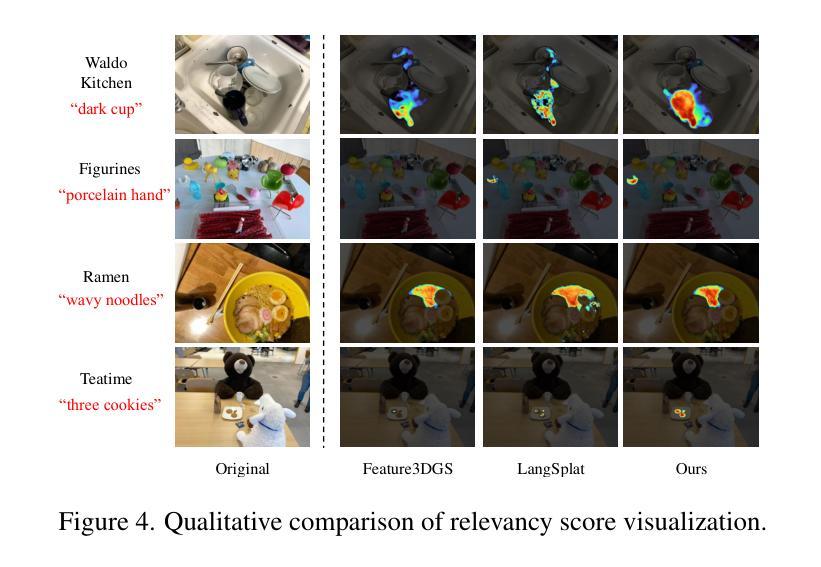
Occam’s LGS: An Efficient Approach for Language Gaussian Splatting
Authors:Jiahuan Cheng, Jan-Nico Zaech, Luc Van Gool, Danda Pani Paudel
TL;DR: Gaussian Splatting is a widely adopted approach for 3D scene representation, offering efficient, high-quality reconstruction and rendering. A key reason for its success is the simplicity of representing scenes with sets of Gaussians, making it interpretable and adaptable. To enhance understanding beyond visual representation, recent approaches extend Gaussian Splatting with semantic vision-language features, enabling open-set tasks. Typically, these language features are aggregated from multiple 2D views, however, existing methods rely on cumbersome techniques, resulting in high computational costs and longer training times. In this work, we show that the complicated pipelines for language 3D Gaussian Splatting are simply unnecessary. Instead, we follow a probabilistic formulation of Language Gaussian Splatting and apply Occam’s razor to the task at hand, leading to a highly efficient weighted multi-view feature aggregation technique. Doing so offers us state-of-the-art results with a speed-up of two orders of magnitude without any compression, allowing for easy scene manipulation. Project Page: https://insait-institute.github.io/OccamLGS/
摘要:高斯摊铺是一种广泛应用于3D场景表示的方法,它提供了高效、高质量的重建和渲染。其成功的一个关键原因是用高斯集来表示场景的简洁性,使其具有可解释性和适应性。为了提高对视觉表示之外的理解,最近的方法将高斯摊铺与语义视觉语言特征相结合,以支持开放式任务。通常,这些语言特征是从多个二维视图聚合而成的,然而,现有方法依赖于繁琐的技术,导致计算成本高昂和训练时间较长。在这项工作中,我们证明了用于语言3D高斯摊铺的复杂流程实际上是不必要的。相反,我们对语言高斯摊铺采用概率公式,并应用奥卡姆剃刀(Occam’s razor)来解决手头任务,从而得到一种高效加权的多视角特征聚合技术。这样做使我们能够在不压缩的情况下实现速度提升两个数量级,从而轻松操控场景。项目页面:https://insait-institute.github.io/OccamLGS/
论文及项目相关链接
PDF Project Page: https://insait-institute.github.io/OccamLGS/
Summary
高斯贴片法用于三维场景表示,具有高效、高质量的重构和渲染能力。其关键在于利用高斯集合进行场景表示,便于解读和适应。为深化理解而超越视觉表现,最新方法将高斯贴片法与语义视觉语言特征相结合,用于开放式任务。本研究简化复杂流程,提出基于概率的语言高斯贴片法,采用奥卡姆剃刀原则进行高效的多视角特征聚合技术。该方法在加速两倍的同时保持最新技术水平,易于场景操控。
Key Takeaways
- 高斯贴片法用于三维场景表示具有高效、高质量的重构和渲染能力。
- 利用高斯集合进行场景表示,具有简单性、可解读性和适应性。
- 语义视觉语言特征的引入扩展了高斯贴片法的应用范围至开放式任务。
- 现有方法的语言特征聚合依赖于复杂的技术流程,导致高计算成本和长训练时间。
- 基于概率的语言高斯贴片法简化了复杂流程,提高了效率。
- 采用奥卡姆剃刀原则进行加权多视角特征聚合技术实现先进结果。
点此查看论文截图



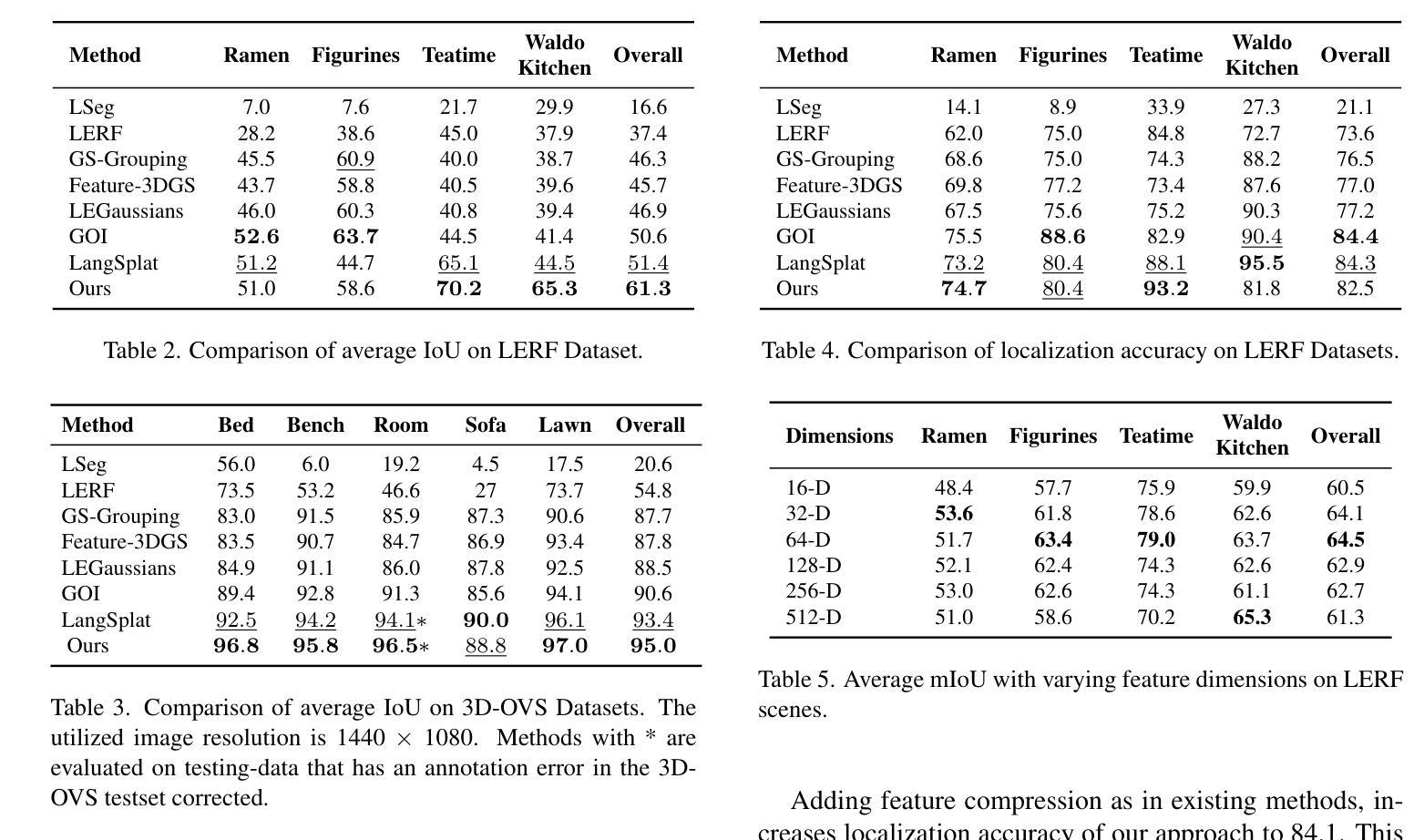
NexusSplats: Efficient 3D Gaussian Splatting in the Wild
Authors:Yuzhou Tang, Dejun Xu, Yongjie Hou, Zhenzhong Wang, Min Jiang
Photorealistic 3D reconstruction of unstructured real-world scenes remains challenging due to complex illumination variations and transient occlusions. Existing methods based on Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) struggle with inefficient light decoupling and structure-agnostic occlusion handling. To address these limitations, we propose NexusSplats, an approach tailored for efficient and high-fidelity 3D scene reconstruction under complex lighting and occlusion conditions. In particular, NexusSplats leverages a hierarchical light decoupling strategy that performs centralized appearance learning, efficiently and effectively decoupling varying lighting conditions. Furthermore, a structure-aware occlusion handling mechanism is developed, establishing a nexus between 3D and 2D structures for fine-grained occlusion handling. Experimental results demonstrate that NexusSplats achieves state-of-the-art rendering quality and reduces the number of total parameters by 65.4%, leading to 2.7$\times$ faster reconstruction.
真实世界场景的非结构化三维重建由于光照变化的复杂性和瞬态遮挡而仍然具有挑战性。现有的基于神经辐射场(NeRF)和三维高斯喷涂(3DGS)的方法在光照解耦和结构无关遮挡处理方面效率低下。为了解决这些局限性,我们提出了NexusSplats,这是一种针对复杂光照和遮挡条件下高效、高保真三维场景重建的方法。具体来说,NexusSplats利用分层光照解耦策略,实现集中外观学习,有效且高效地解耦不同的光照条件。此外,开发了一种结构感知的遮挡处理机制,在三维和二维结构之间建立联系,进行精细的遮挡处理。实验结果表明,NexusSplats达到了最先进的渲染质量,并减少了65.4%的总参数数量,使得重建速度提高了2.7倍。
论文及项目相关链接
PDF Project page: https://nexus-splats.github.io/
Summary
针对复杂光照和遮挡条件下的三维场景重建,提出了NexusSplats方法。该方法采用分层光解耦策略,实现集中外观学习,有效解耦不同的光照条件。同时,开发了一种结构感知的遮挡处理机制,在三维和二维结构之间建立纽带,实现精细的遮挡处理。该方法在提高渲染质量的同时,减少了参数数量,加快了重建速度。
Key Takeaways
- NexusSplats解决了在复杂光照和遮挡条件下的三维场景重建挑战。
- 采用分层光解耦策略,实现高效的光照解耦。
- 集中外观学习,提高三维场景重建的逼真度。
- 开发结构感知的遮挡处理机制,实现精细的遮挡处理。
- NexusSplats相较于现有方法,提高了渲染质量。
- NexusSplats减少了三维场景重建的参数数量,提高了效率。
点此查看论文截图

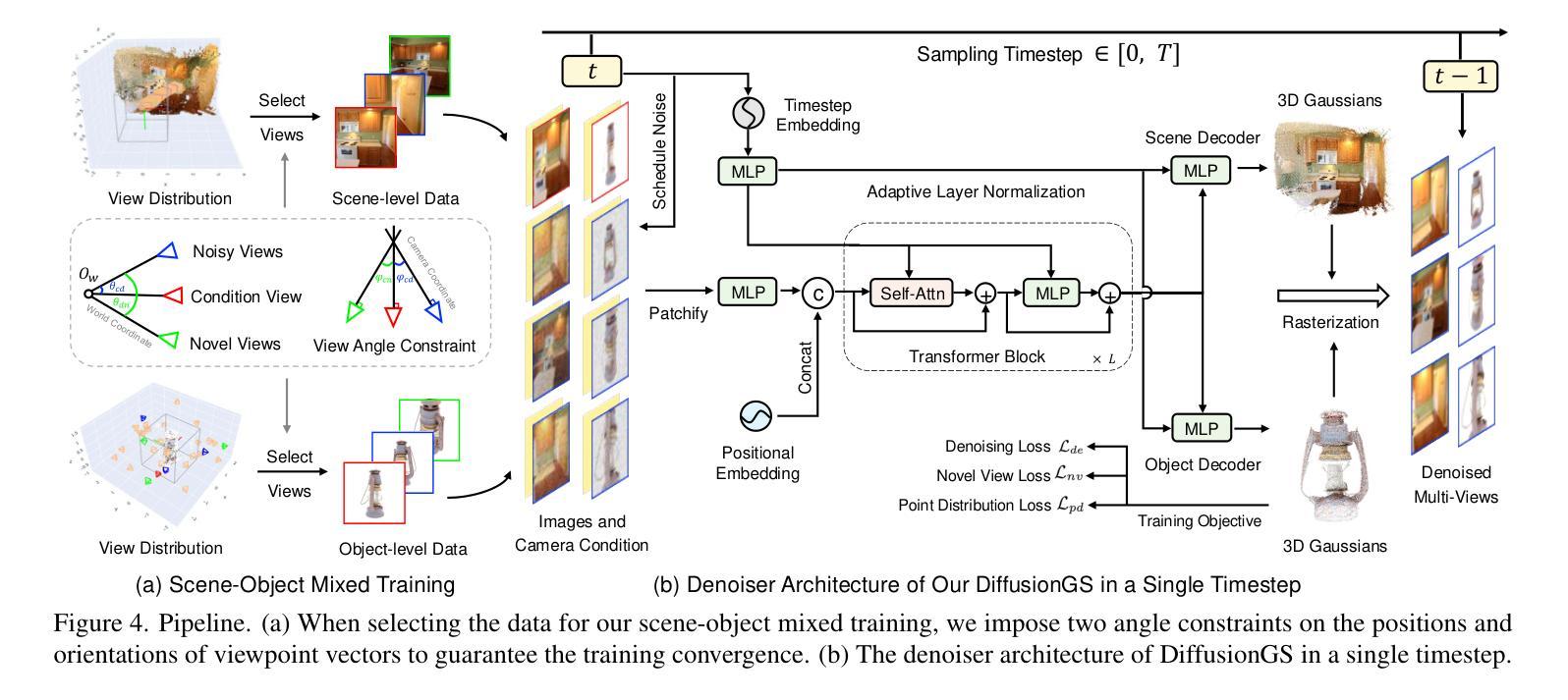
Baking Gaussian Splatting into Diffusion Denoiser for Fast and Scalable Single-stage Image-to-3D Generation and Reconstruction
Authors:Yuanhao Cai, He Zhang, Kai Zhang, Yixun Liang, Mengwei Ren, Fujun Luan, Qing Liu, Soo Ye Kim, Jianming Zhang, Zhifei Zhang, Yuqian Zhou, Yulun Zhang, Xiaokang Yang, Zhe Lin, Alan Yuille
Existing feedforward image-to-3D methods mainly rely on 2D multi-view diffusion models that cannot guarantee 3D consistency. These methods easily collapse when changing the prompt view direction and mainly handle object-centric cases. In this paper, we propose a novel single-stage 3D diffusion model, DiffusionGS, for object generation and scene reconstruction from a single view. DiffusionGS directly outputs 3D Gaussian point clouds at each timestep to enforce view consistency and allow the model to generate robustly given prompt views of any directions, beyond object-centric inputs. Plus, to improve the capability and generality of DiffusionGS, we scale up 3D training data by developing a scene-object mixed training strategy. Experiments show that DiffusionGS yields improvements of 2.20 dB/23.25 and 1.34 dB/19.16 in PSNR/FID for objects and scenes than the state-of-the-art methods, without depth estimator. Plus, our method enjoys over 5$\times$ faster speed ($\sim$6s on an A100 GPU). Our Project page at https://caiyuanhao1998.github.io/project/DiffusionGS/ shows the video and interactive results.
现有前馈图像到3D的方法主要依赖于二维多视角扩散模型,这不能保证三维一致性。这些方法在改变提示视向时很容易失效,并且主要处理以物体为中心的情况。在本文中,我们提出了一种新型的单阶段三维扩散模型——DiffusionGS,用于从单一视角生成物体和重建场景。DiffusionGS在每个时间步直接输出三维高斯点云,以强制实施视图一致性,并使模型能够针对任何方向的提示视图进行稳健生成,超越以物体为中心的输入。此外,为了提升DiffusionGS的能力和通用性,我们通过开发场景-物体混合训练策略来扩大三维训练数据。实验表明,相较于最新方法,DiffusionGS在对象和场景的PSNR/FID上分别提高了2.20 dB/23.25和1.34 dB/19.16,且无需深度估计器。此外,我们的方法速度更快,超过5倍(在A100 GPU上约为6秒)。我们的项目页面https://caiyuanhao1998.github.io/project/DiffusionGS/展示了视频和互动结果。
论文及项目相关链接
PDF A novel one-stage 3DGS-based diffusion for 3D object generation and scene reconstruction from a single view in ~6 seconds
Summary
本文提出了一种新型的单阶段3D扩散模型DiffusionGS,用于从单一视角进行物体生成和场景重建。该模型直接输出3D高斯点云,以强制实施视图一致性,并允许模型在给定任何方向的提示视图时都能稳健生成,超越了以物体为中心的输入。此外,为了提高DiffusionGS的能力和通用性,作者开发了一种场景-物体混合训练策略来扩大3D训练数据。实验表明,与现有先进技术相比,DiffusionGS在物体和场景上的PSNR和FID指标分别提高了2.20 dB/23.25和1.34 dB/19.16,且无需深度估计器。此外,该方法的运行速度超过现有技术5倍以上(在A100 GPU上运行约6秒)。更多信息和成果展示请参考项目的官方网站链接。
Key Takeaways
- DiffusionGS是首个提出的单阶段3D扩散模型,用于从单一视角进行物体生成和场景重建。
- 该模型直接输出3D高斯点云,实现视图一致性并适应任意方向的提示视图。
- 通过开发场景-物体混合训练策略,提升了模型的泛化能力和应用能力。实验表明其性能优于现有技术,不需要深度估计器。
点此查看论文截图



BillBoard Splatting (BBSplat): Learnable Textured Primitives for Novel View Synthesis
Authors:David Svitov, Pietro Morerio, Lourdes Agapito, Alessio Del Bue
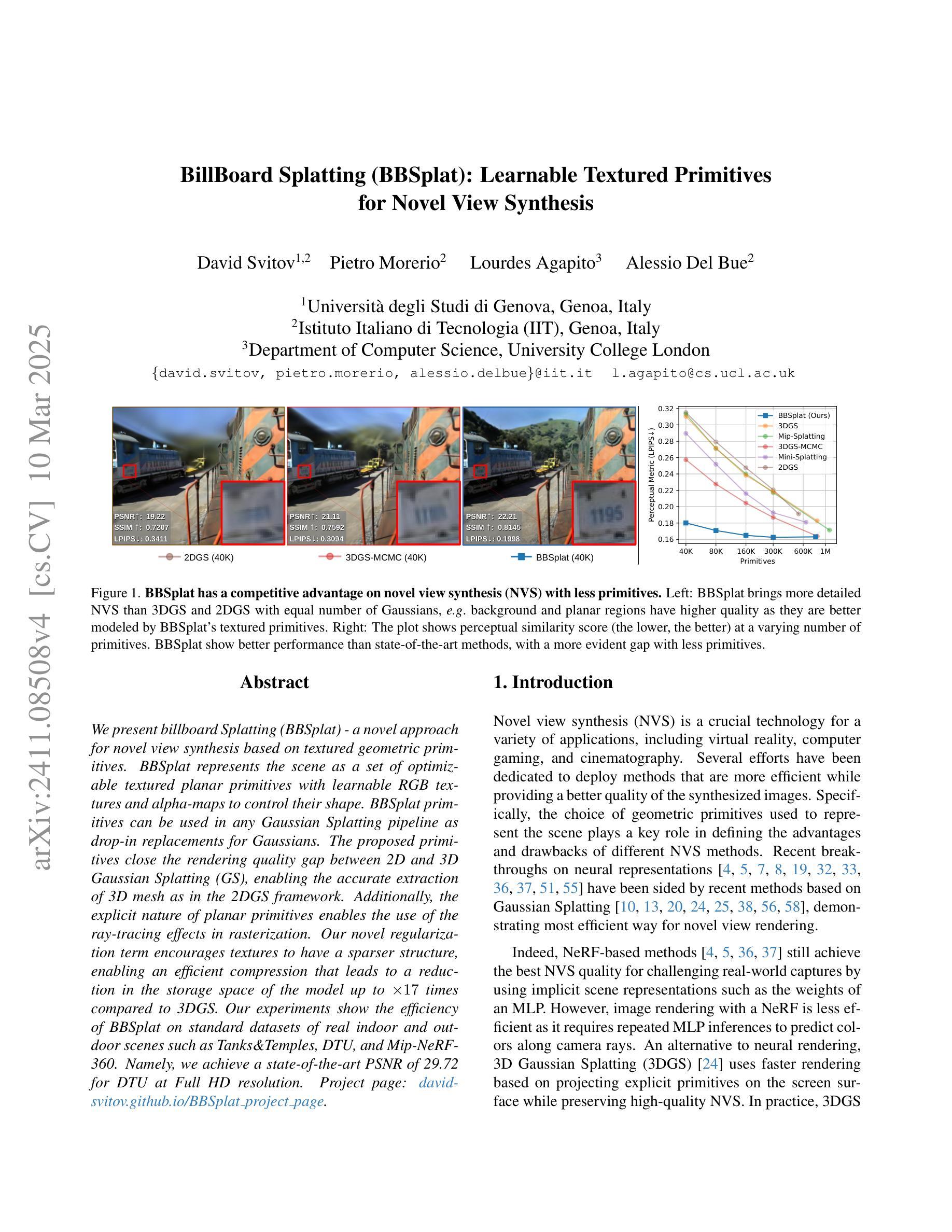
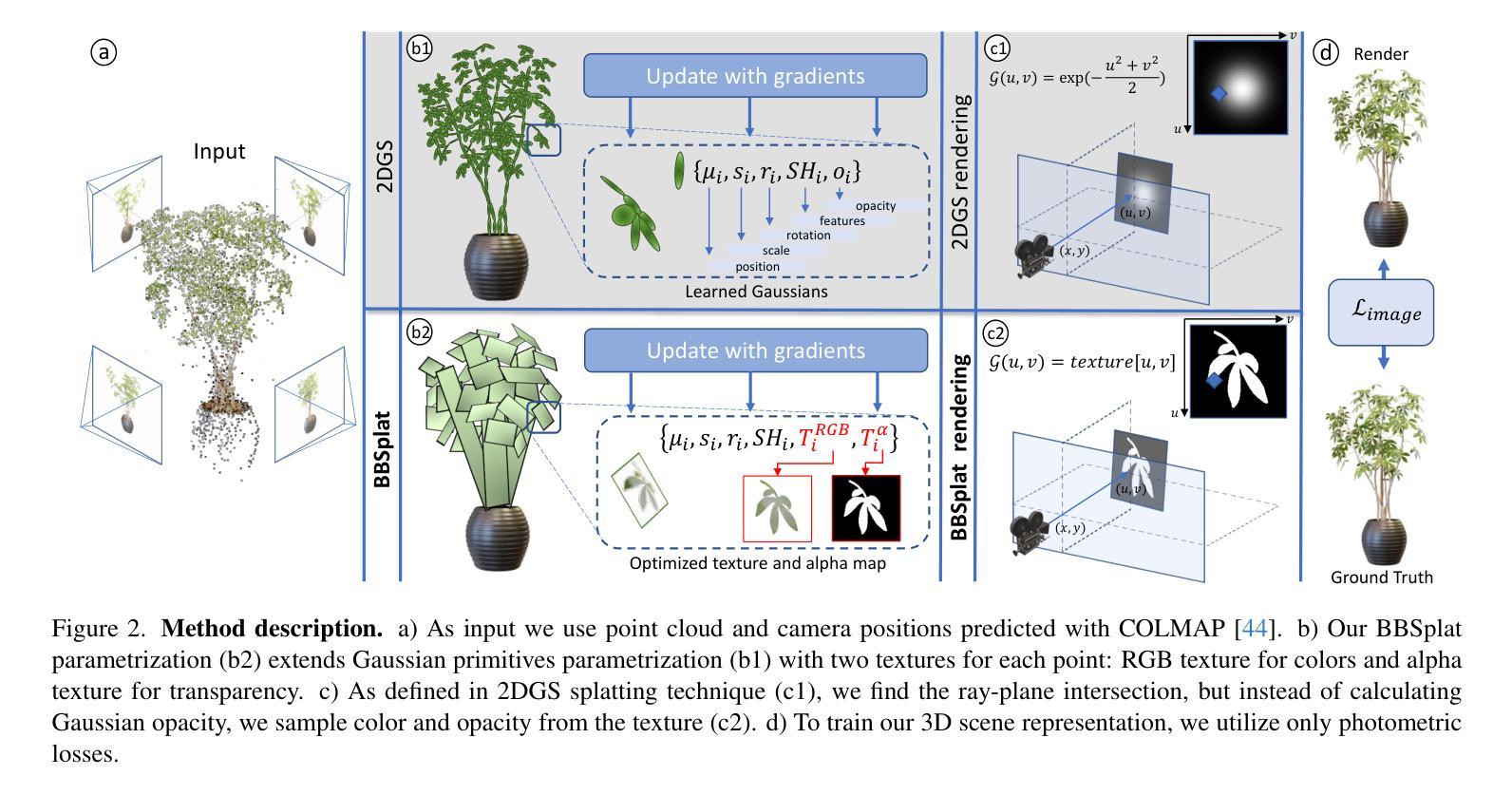
We present billboard Splatting (BBSplat) - a novel approach for novel view synthesis based on textured geometric primitives. BBSplat represents the scene as a set of optimizable textured planar primitives with learnable RGB textures and alpha-maps to control their shape. BBSplat primitives can be used in any Gaussian Splatting pipeline as drop-in replacements for Gaussians. The proposed primitives close the rendering quality gap between 2D and 3D Gaussian Splatting (GS), enabling the accurate extraction of 3D mesh as in the 2DGS framework. Additionally, the explicit nature of planar primitives enables the use of the ray-tracing effects in rasterization. Our novel regularization term encourages textures to have a sparser structure, enabling an efficient compression that leads to a reduction in the storage space of the model up to x17 times compared to 3DGS. Our experiments show the efficiency of BBSplat on standard datasets of real indoor and outdoor scenes such as Tanks&Temples, DTU, and Mip-NeRF-360. Namely, we achieve a state-of-the-art PSNR of 29.72 for DTU at Full HD resolution.
我们提出了基于纹理几何基元的视图合成新方法——Billboard Splatting(BBSplat)。BBSplat将场景表示为一组可优化的带纹理的平面基元,通过可学习的RGB纹理和alpha图来控制其形状。BBSplat基元可以替换任何高斯Splatting管道中的高斯,作为即用型替代品。所提出基元缩小了二维和三维高斯Splatting(GS)之间的渲染质量差距,能够在二维GS框架中准确提取三维网格。此外,平面基元的显式表示可在光线追踪渲染中使用光线追踪效果。我们的新型正则化项鼓励纹理具有稀疏结构,可实现高效的压缩,使得模型的存储空间相比三维GS减少了高达17倍。我们的实验表明,BBSplat在标准的真实室内和室外场景数据集(如Tanks&Temples、DTU和Mip-NeRF-360)上表现出良好的性能。具体来说,我们在DTU的Full HD分辨率上实现了最先进的峰值信噪比(PSNR)为29.72。
论文及项目相关链接
Summary
本文将介绍一种基于纹理几何基元的新型视图合成方法——告示牌Splatting(BBSplat)。BBSplat将场景表示为一组可优化的纹理平面基元,具有可学习的RGB纹理和alpha映射来控制其形状。BBSplat基元可以替换为高斯Splatting管道中的任何高斯基元,解决了二维和三维高斯Splatting之间的渲染质量差距,实现如二维GS框架中的三维网格精确提取。此外,平面基元的显式性质可在光线追踪渲染中采用光线追踪效果。本文提出的新正则化项鼓励纹理具有稀疏结构,实现了高效的压缩,导致模型存储空间减少了高达17倍,相较于三维几何Splatting。在真实室内和室外场景的标准数据集上进行的实验表明,BBSplat在DTU的Full HD分辨率下取得了最新的PSNR 29.72。总的来说,本文提出的BBSplat方法在视图合成方面有着卓越的表现和创新性的应用前景。
Key Takeaways
- BBSplat是一种基于纹理几何基元的新型视图合成方法。
- BBSplat使用优化后的纹理平面基元表示场景,具有可学习的RGB纹理和alpha映射。
- BBSplat基元可以替换高斯Splatting管道中的任何高斯基元。
- BBSplat解决了二维和三维高斯Splatting之间的渲染质量差距,可实现三维网格的精确提取。
- 平面基元的显式性质允许在光线追踪渲染中使用光线追踪效果。
- 新正则化项鼓励纹理具有稀疏结构,实现高效压缩,降低模型存储空间。
点此查看论文截图
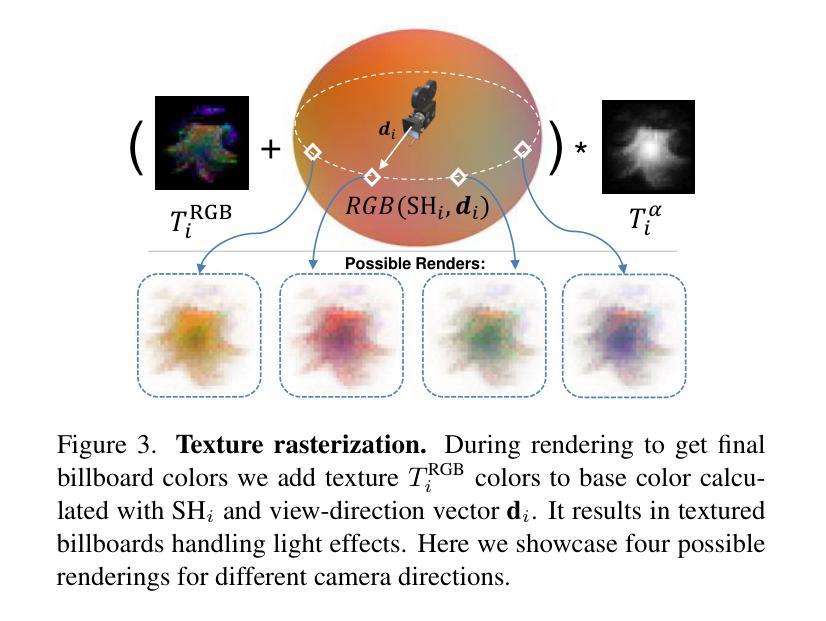

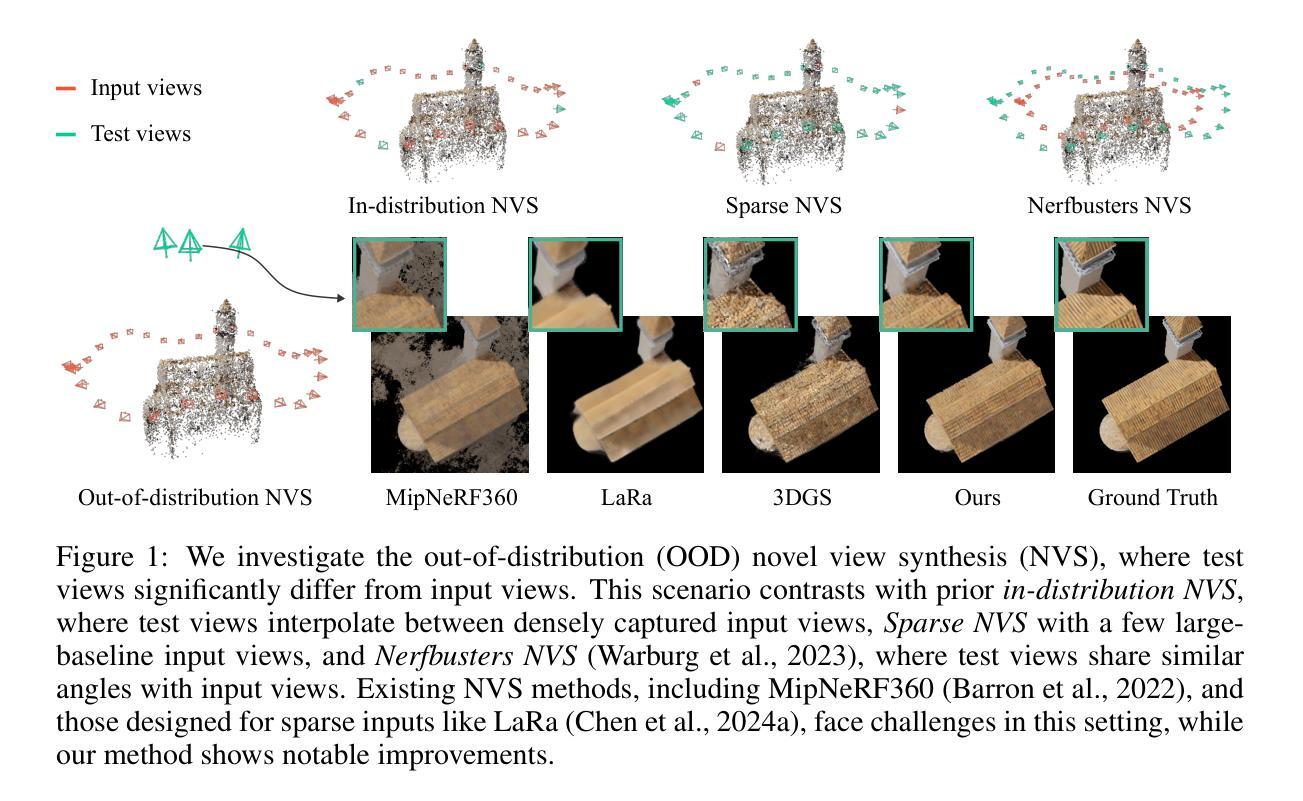
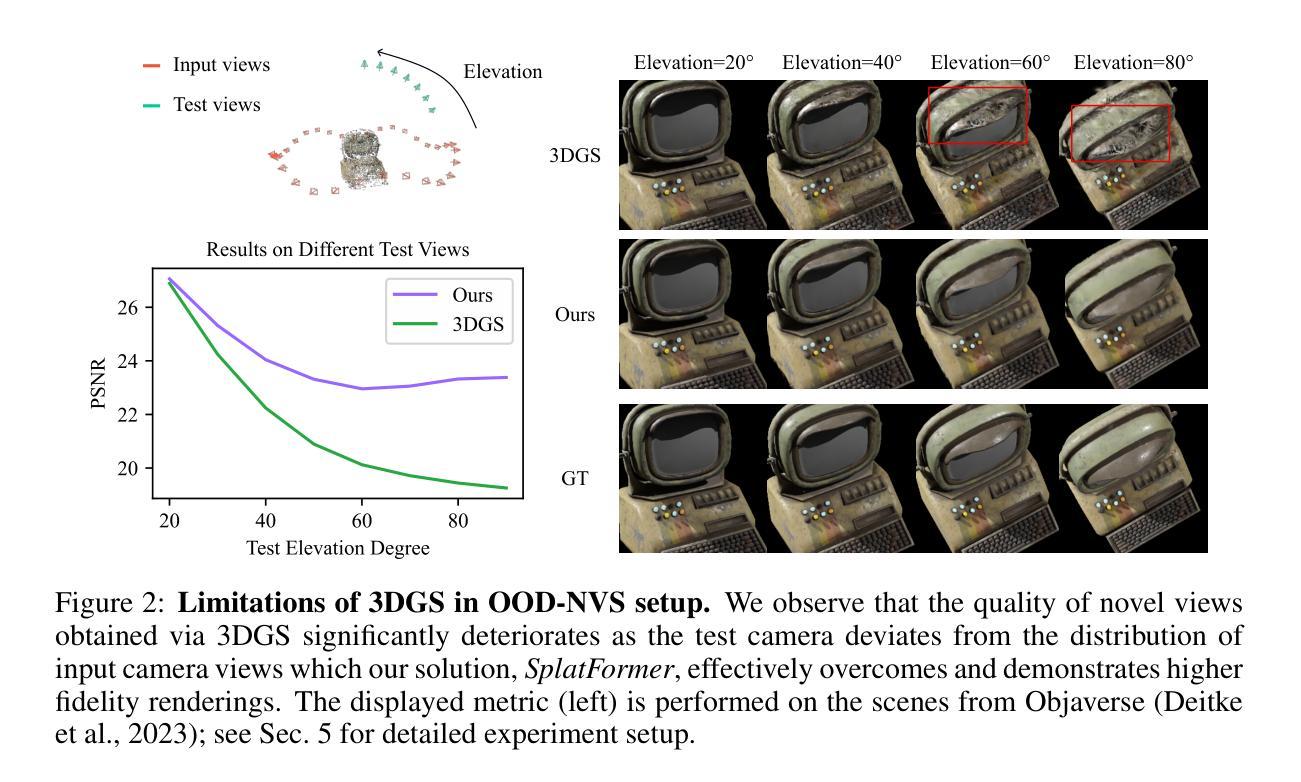
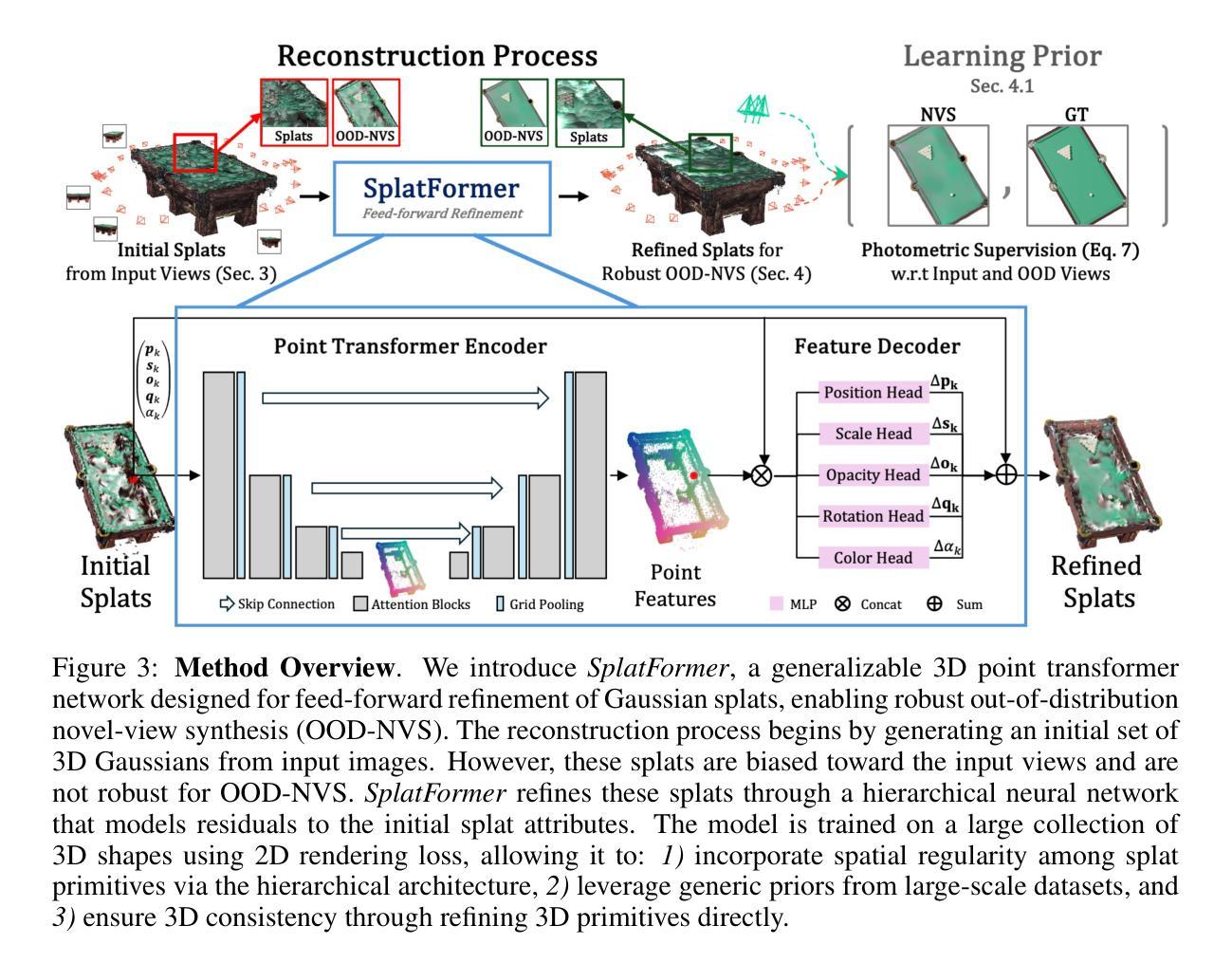
SplatFormer: Point Transformer for Robust 3D Gaussian Splatting
Authors:Yutong Chen, Marko Mihajlovic, Xiyi Chen, Yiming Wang, Sergey Prokudin, Siyu Tang
3D Gaussian Splatting (3DGS) has recently transformed photorealistic reconstruction, achieving high visual fidelity and real-time performance. However, rendering quality significantly deteriorates when test views deviate from the camera angles used during training, posing a major challenge for applications in immersive free-viewpoint rendering and navigation. In this work, we conduct a comprehensive evaluation of 3DGS and related novel view synthesis methods under out-of-distribution (OOD) test camera scenarios. By creating diverse test cases with synthetic and real-world datasets, we demonstrate that most existing methods, including those incorporating various regularization techniques and data-driven priors, struggle to generalize effectively to OOD views. To address this limitation, we introduce SplatFormer, the first point transformer model specifically designed to operate on Gaussian splats. SplatFormer takes as input an initial 3DGS set optimized under limited training views and refines it in a single forward pass, effectively removing potential artifacts in OOD test views. To our knowledge, this is the first successful application of point transformers directly on 3DGS sets, surpassing the limitations of previous multi-scene training methods, which could handle only a restricted number of input views during inference. Our model significantly improves rendering quality under extreme novel views, achieving state-of-the-art performance in these challenging scenarios and outperforming various 3DGS regularization techniques, multi-scene models tailored for sparse view synthesis, and diffusion-based frameworks.
3D高斯模糊技术(3DGS)最近对写实重建进行了重大变革,实现了高视觉保真度和实时性能。然而,当测试视图偏离训练期间使用的相机角度时,渲染质量会显著下降,这为沉浸式自由视点渲染和导航应用带来了重大挑战。在这项工作中,我们对3DGS以及相关的脱离分布(OOD)测试相机场景下的新视图合成方法进行了全面评估。我们通过创建合成和真实世界数据集的各种测试用例来展示,大多数现有方法,包括采用各种正则化技术和数据驱动先验的方法,在推广到OOD视图时难以有效泛化。为了解决这个问题,我们引入了SplatFormer,这是第一个专为高斯模糊集设计的点云变换模型。SplatFormer将初始的3DGS集作为输入,在有限的训练视图下进行优化,并在一次前向传递中进行细化,有效地消除了OOD测试视图中的潜在伪影。据我们所知,这是首次在3DGS集上直接应用点云变换器的成功案例,克服了以前的多场景训练方法的局限性,这些传统方法在进行推断时只能处理有限数量的输入视图。我们的模型在极端的全新视角下显著提高了渲染质量,在这些具有挑战性的场景中达到了最先进的性能,并超越了各种3DGS正则化技术、针对稀疏视图合成的多场景模型和基于扩散的框架。
论文及项目相关链接
PDF ICLR 2025
Summary
本文介绍了三维高斯点集(3DGS)在渲染技术中的最新进展。尽管其在真实感重建方面取得了高保真度和实时性能,但当测试视图偏离训练时,其渲染质量会出现明显下降。本文对这一问题进行了全面评估,引入了SplatFormer模型,它是第一个专门为高斯点集设计的点云变换模型。该模型在有限的训练视图下优化初始的3DGS集,并在一次前向传递中对其进行精炼,有效消除了测试视图中可能存在的伪影。该模型在极端新视角下的渲染质量方面取得了显著的提升,并在这些具有挑战性的场景中实现了卓越的性能。
Key Takeaways
- 3DGS在真实感重建方面取得了高保真度和实时性能。
- 当测试视图偏离训练视角时,渲染质量会明显下降。
- 现有方法包括正则化技术和数据驱动先验在内的方法在OOD视角下泛化效果不佳。
- SplatFormer模型是第一个专门为高斯点集设计的点云变换模型。
- SplatFormer在单次前向传递中精炼初始的3DGS集,消除了潜在伪影。
点此查看论文截图

Next Best Sense: Guiding Vision and Touch with FisherRF for 3D Gaussian Splatting
Authors:Matthew Strong, Boshu Lei, Aiden Swann, Wen Jiang, Kostas Daniilidis, Monroe Kennedy III
We propose a framework for active next best view and touch selection for robotic manipulators using 3D Gaussian Splatting (3DGS). 3DGS is emerging as a useful explicit 3D scene representation for robotics, as it has the ability to represent scenes in a both photorealistic and geometrically accurate manner. However, in real-world, online robotic scenes where the number of views is limited given efficiency requirements, random view selection for 3DGS becomes impractical as views are often overlapping and redundant. We address this issue by proposing an end-to-end online training and active view selection pipeline, which enhances the performance of 3DGS in few-view robotics settings. We first elevate the performance of few-shot 3DGS with a novel semantic depth alignment method using Segment Anything Model 2 (SAM2) that we supplement with Pearson depth and surface normal loss to improve color and depth reconstruction of real-world scenes. We then extend FisherRF, a next-best-view selection method for 3DGS, to select views and touch poses based on depth uncertainty. We perform online view selection on a real robot system during live 3DGS training. We motivate our improvements to few-shot GS scenes, and extend depth-based FisherRF to them, where we demonstrate both qualitative and quantitative improvements on challenging robot scenes. For more information, please see our project page at https://arm.stanford.edu/next-best-sense.
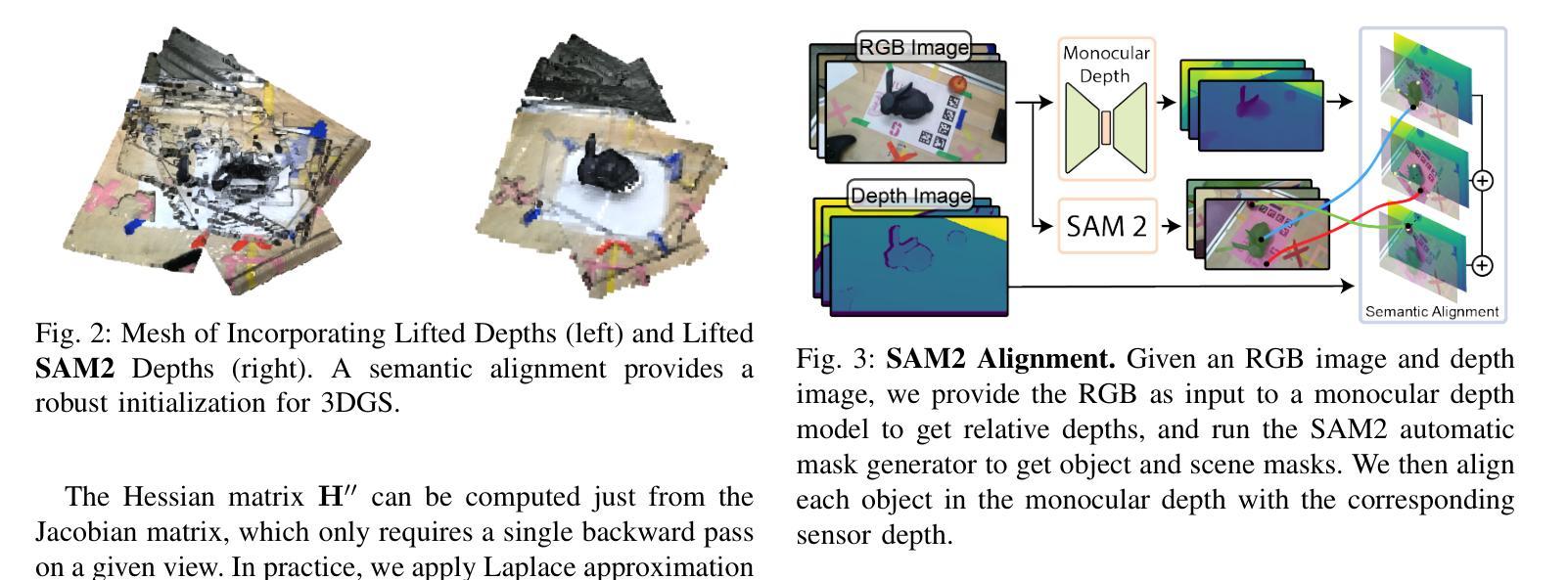
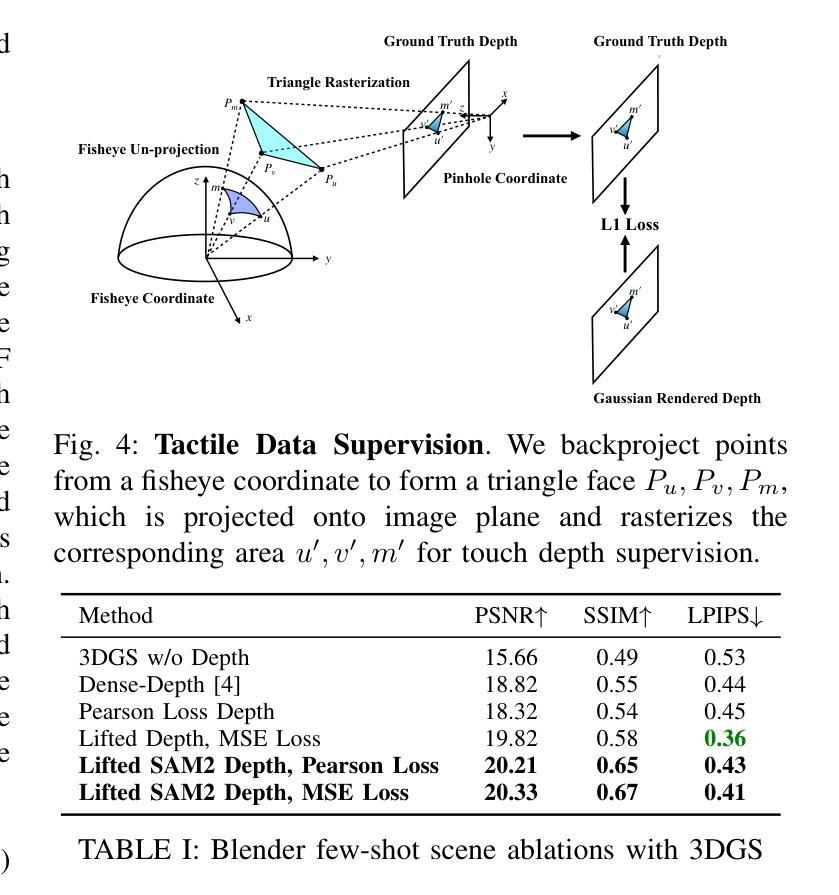
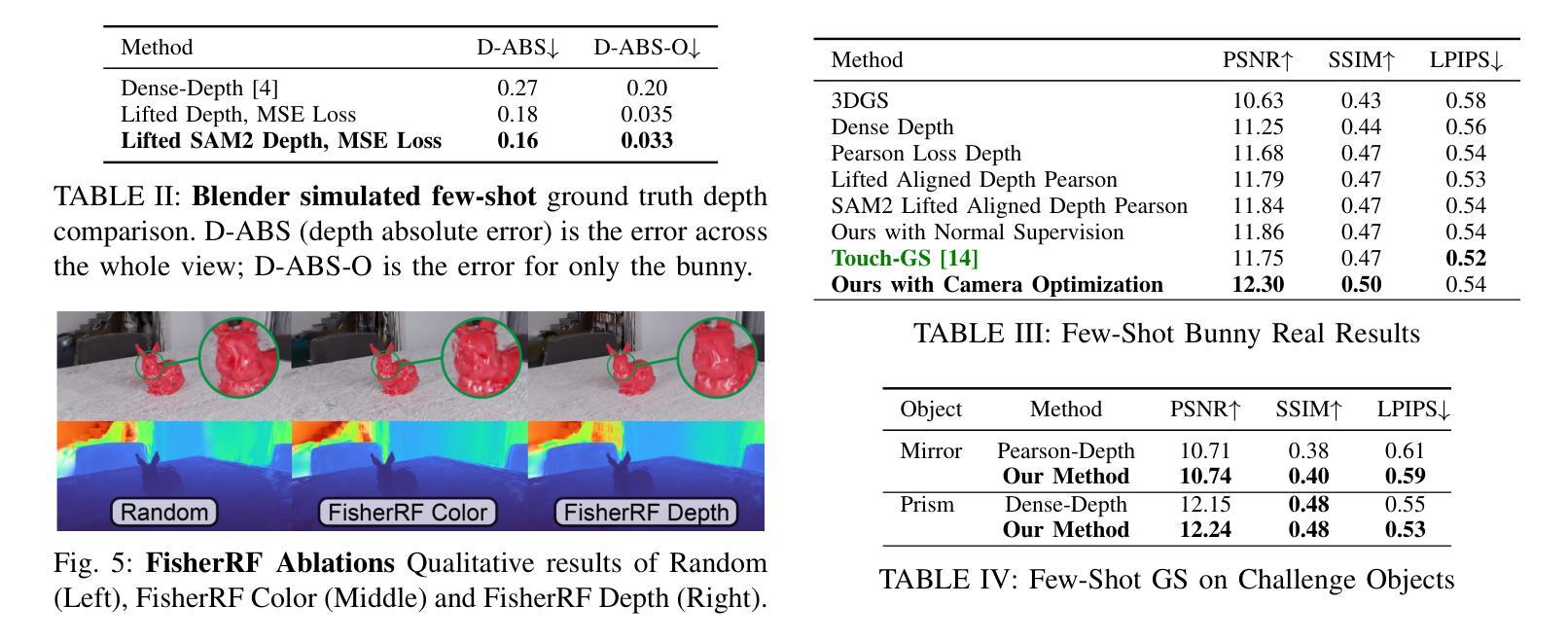
我们提出了一种基于三维高斯拼贴(3DGS)的主动最佳后续视角和触摸选择的框架。3DGS作为一种新兴的机器人技术明确的三维场景表示方法,能够以逼真的三维几何形式展现场景。然而,在现实世界在线机器人场景中,由于效率要求,视角数量受到限制,随机选择视角进行3DGS变得不切实际,因为视角往往重叠且冗余。我们通过提出端到端的在线训练和主动视角选择管道来解决这个问题,提高了在少数视角机器人设置中3DGS的性能。我们首先使用分段任何模型(SAM2)提出一种新型语义深度对齐方法,通过少数镜头提升3DGS性能,我们辅以皮尔森深度损失和表面法线损失来改善真实场景的颜色和深度重建。然后,我们扩展了用于3DGS的最佳后续视角选择方法FisherRF,根据深度不确定性选择视角和触摸姿势。我们在实时3DGS训练期间对真实机器人系统进行在线视角选择。我们改进了少数镜头GS场景并扩展到基于深度的FisherRF,在具有挑战性的机器人场景中展示了定性和定量的改进。更多信息请参见我们的项目页面:https://arm.stanford.edu/next-best-sense。
论文及项目相关链接
PDF To appear in International Conference on Robotics and Automation (ICRA) 2025
Summary
本文提出一种针对机器人操纵器的主动最佳视角选择和触摸选择的框架,该框架使用三维高斯拼贴技术(3DGS)。针对在线机器人场景中视角数量受限的问题,该文提出了端到端的在线训练和主动视角选择管道,以提高三维场景模型的表现能力。利用SAM2语义深度对齐方法和Pearson深度与表面正常损失,提高少视角情况下的三维重建效果。同时,对FisherRF进行改进,选择深度不确定的视点和触摸姿态。实验结果展示了该方法在真实机器人系统上的优异表现。详情参见项目网站:链接地址。
Key Takeaways
以下是摘要中的主要见解,用简明扼要的语言总结了关键点:
- 提出使用三维高斯拼贴技术(3DGS)的框架,用于机器人操纵器的主动最佳视角选择和触摸选择。
- 3DGS能够以照片逼真和几何准确的方式表示场景,适合用于机器人应用。
- 针对在线机器人场景中视角数量受限的问题,提出了在线训练和主动视角选择管道,提高少视角情况下的三维重建效果。
- 利用SAM2语义深度对齐方法和Pearson深度与表面正常损失,优化少视角下的三维重建性能。
- 对FisherRF进行改进,通过深度不确定性来选择视点和触摸姿态。
点此查看论文截图


CaRtGS: Computational Alignment for Real-Time Gaussian Splatting SLAM
Authors:Dapeng Feng, Zhiqiang Chen, Yizhen Yin, Shipeng Zhong, Yuhua Qi, Hongbo Chen
Simultaneous Localization and Mapping (SLAM) is pivotal in robotics, with photorealistic scene reconstruction emerging as a key challenge. To address this, we introduce Computational Alignment for Real-Time Gaussian Splatting SLAM (CaRtGS), a novel method enhancing the efficiency and quality of photorealistic scene reconstruction in real-time environments. Leveraging 3D Gaussian Splatting (3DGS), CaRtGS achieves superior rendering quality and processing speed, which is crucial for scene photorealistic reconstruction. Our approach tackles computational misalignment in Gaussian Splatting SLAM (GS-SLAM) through an adaptive strategy that enhances optimization iterations, addresses long-tail optimization, and refines densification. Experiments on Replica, TUM-RGBD, and VECtor datasets demonstrate CaRtGS’s effectiveness in achieving high-fidelity rendering with fewer Gaussian primitives. This work propels SLAM towards real-time, photorealistic dense rendering, significantly advancing photorealistic scene representation. For the benefit of the research community, we release the code and accompanying videos on our project website: https://dapengfeng.github.io/cartgs.
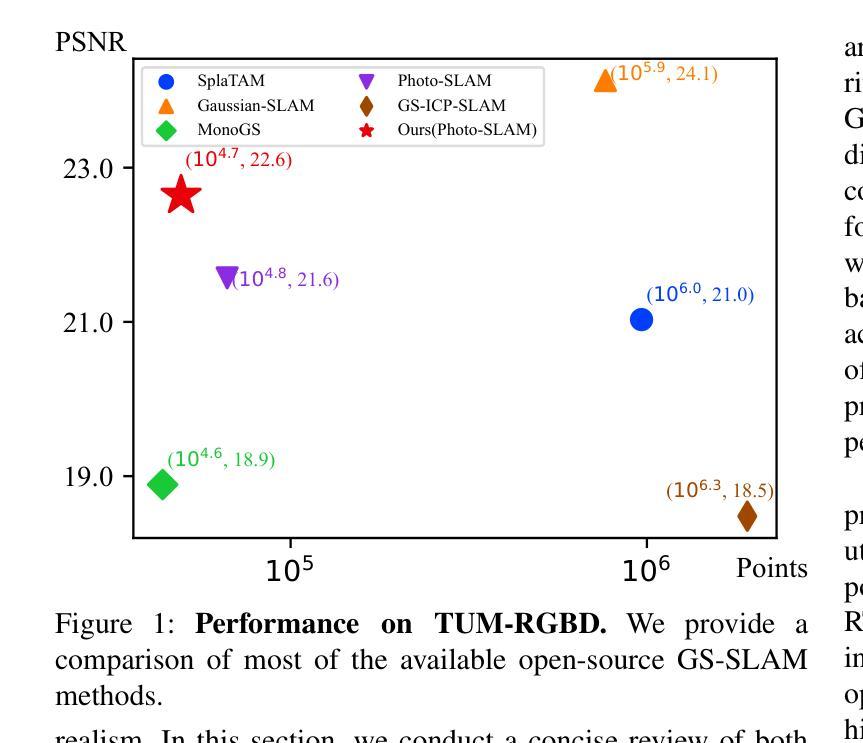
同时定位与地图构建(SLAM)在机器人技术中至关重要,而真实感场景重建成为了一项关键挑战。为解决这一问题,我们引入了面向实时高斯拼贴SLAM的计算对齐(CaRtGS)方法,这是一种提高实时环境中真实感场景重建效率和质量的新型技术。借助三维高斯拼贴(3DGS),CaRtGS可实现出色的渲染质量和处理速度,这对于真实感场景重建至关重要。我们的方法通过自适应策略解决了高斯拼贴SLAM中的计算失准问题,优化了迭代过程,解决了长期优化问题并改进了密集化过程。在Replica、TUM-RGBD和VECtor数据集上的实验表明,CaRtGS通过较少的高斯基本实体实现了高保真渲染,效果显著。这项工作推动了SLAM向实时真实感密集渲染发展,极大地推动了真实感场景表示的进步。为了造福研究界,我们在项目网站上发布了代码和配套视频:https://dapengfeng.github.io/cartgs。
论文及项目相关链接
PDF Accepted by IEEE Robotics and Automation Letters (RA-L)
Summary
实时环境下的高斯贴图SLAM(Gaussian Splatting SLAM)计算对齐(CaRtGS)能有效提升场景重建的光照现实感及效率。该方法通过利用三维高斯贴图技术实现优化迭代与精准计算,并自适应应对计算错位问题,实现高质量的渲染效果。在多个数据集上的实验证明,CaRtGS能减少高斯原始单元,实现高保真渲染。这一技术将SLAM推向了实时的光照现实密集渲染阶段,极大地提升了场景的光照现实表示能力。
Key Takeaways
- CaRtGS是一种针对实时环境中的高斯贴图SLAM的计算对齐方法。
- 通过三维高斯贴图技术实现高质量渲染和高效处理速度。
- CaRtGS解决了高斯贴图SLAM中的计算错位问题。
- 通过自适应策略优化迭代过程,解决了长尾优化问题并改善了密集化过程。
- 在多个数据集上的实验证明,CaRtGS可实现高保真渲染并减少高斯原始单元的使用。
- CaRtGS推动了SLAM技术向实时光照现实密集渲染阶段的进步。
点此查看论文截图

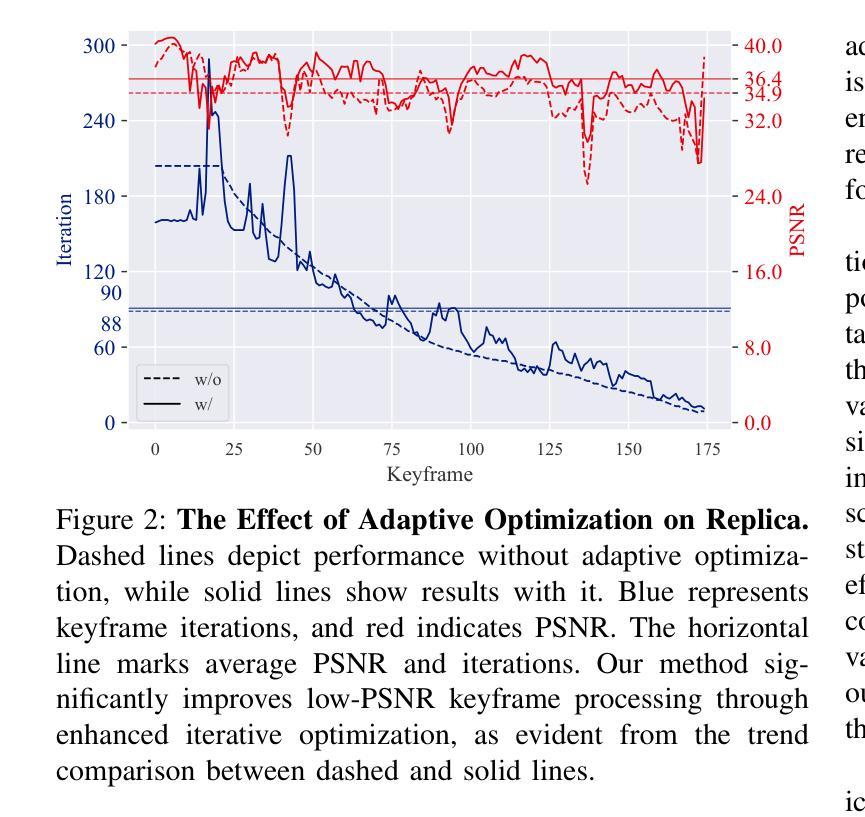

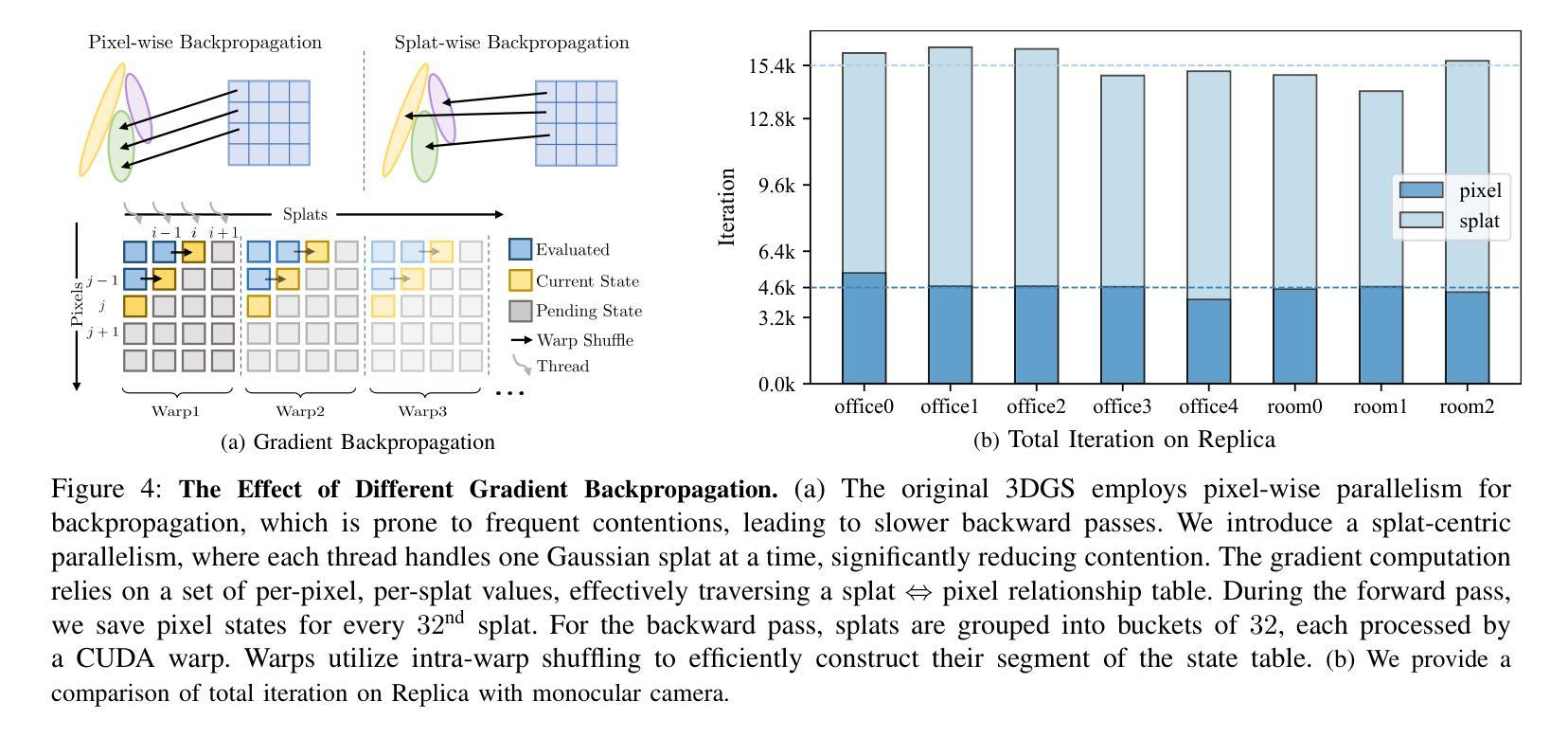
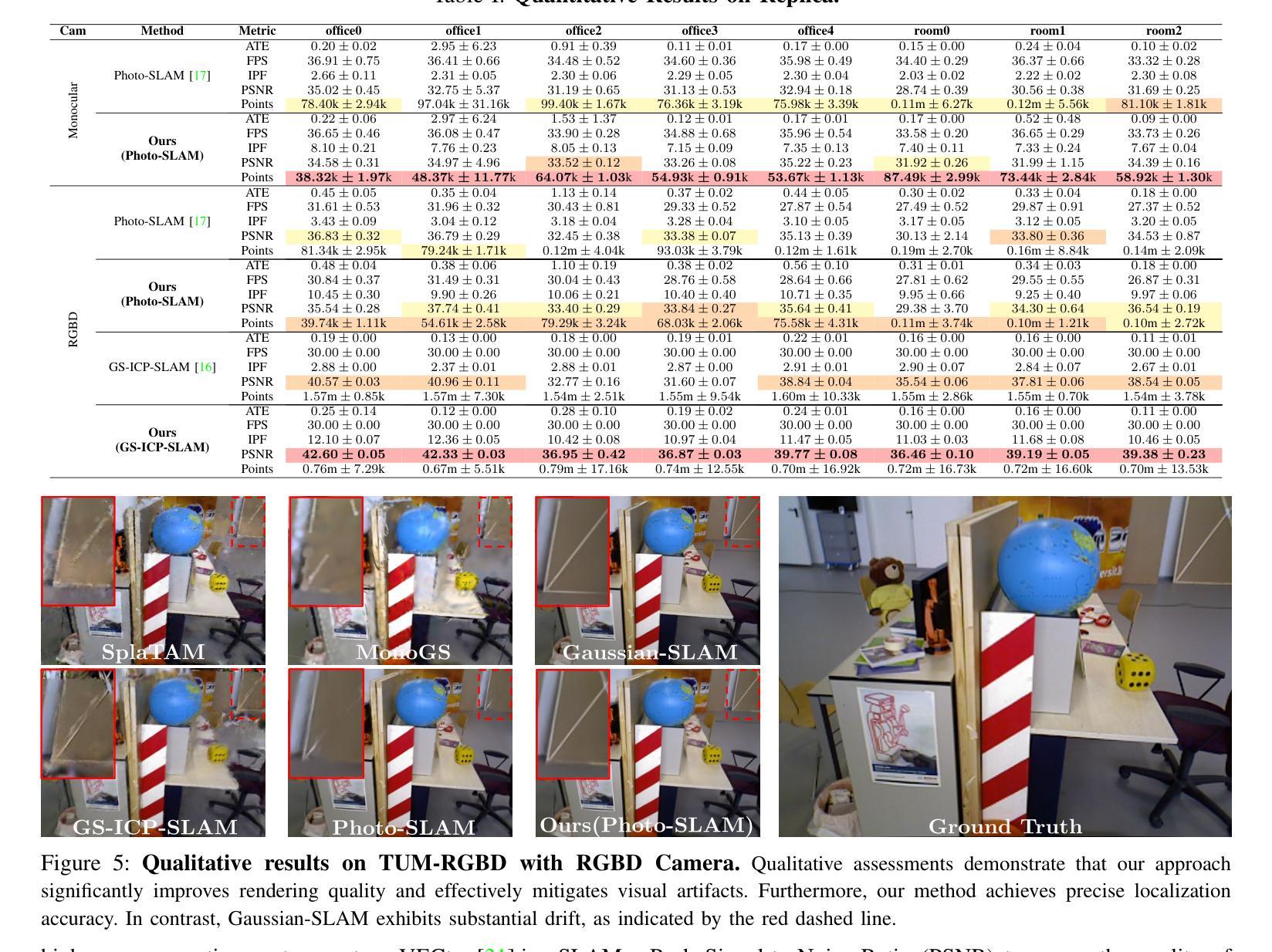
Hier-SLAM: Scaling-up Semantics in SLAM with a Hierarchically Categorical Gaussian Splatting
Authors:Boying Li, Zhixi Cai, Yuan-Fang Li, Ian Reid, Hamid Rezatofighi
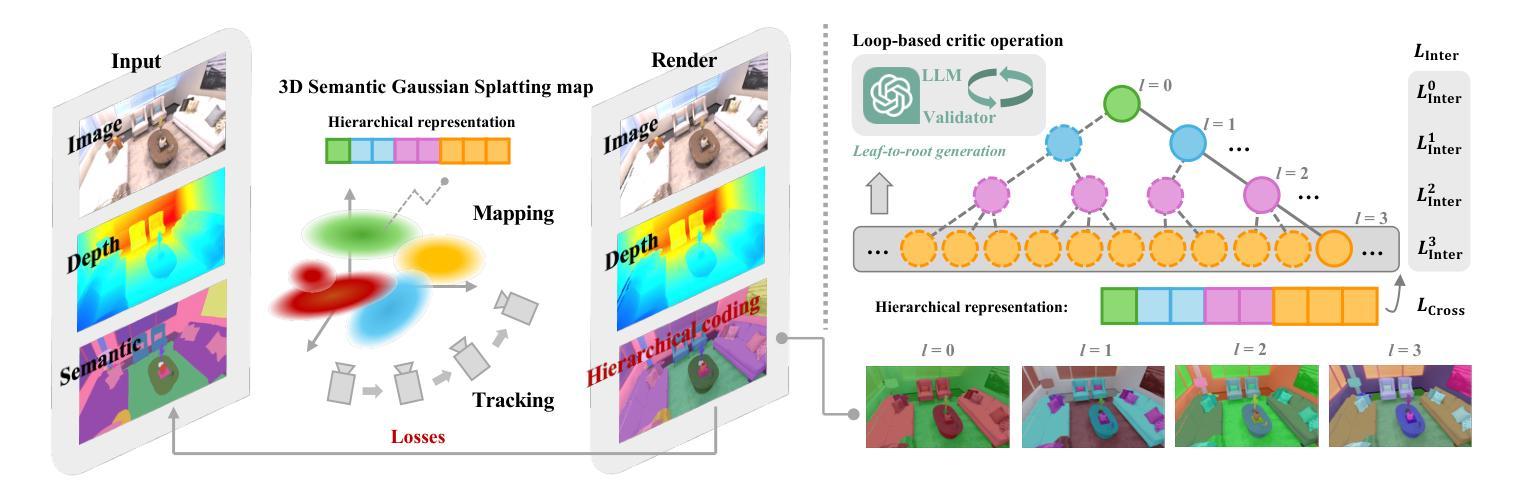
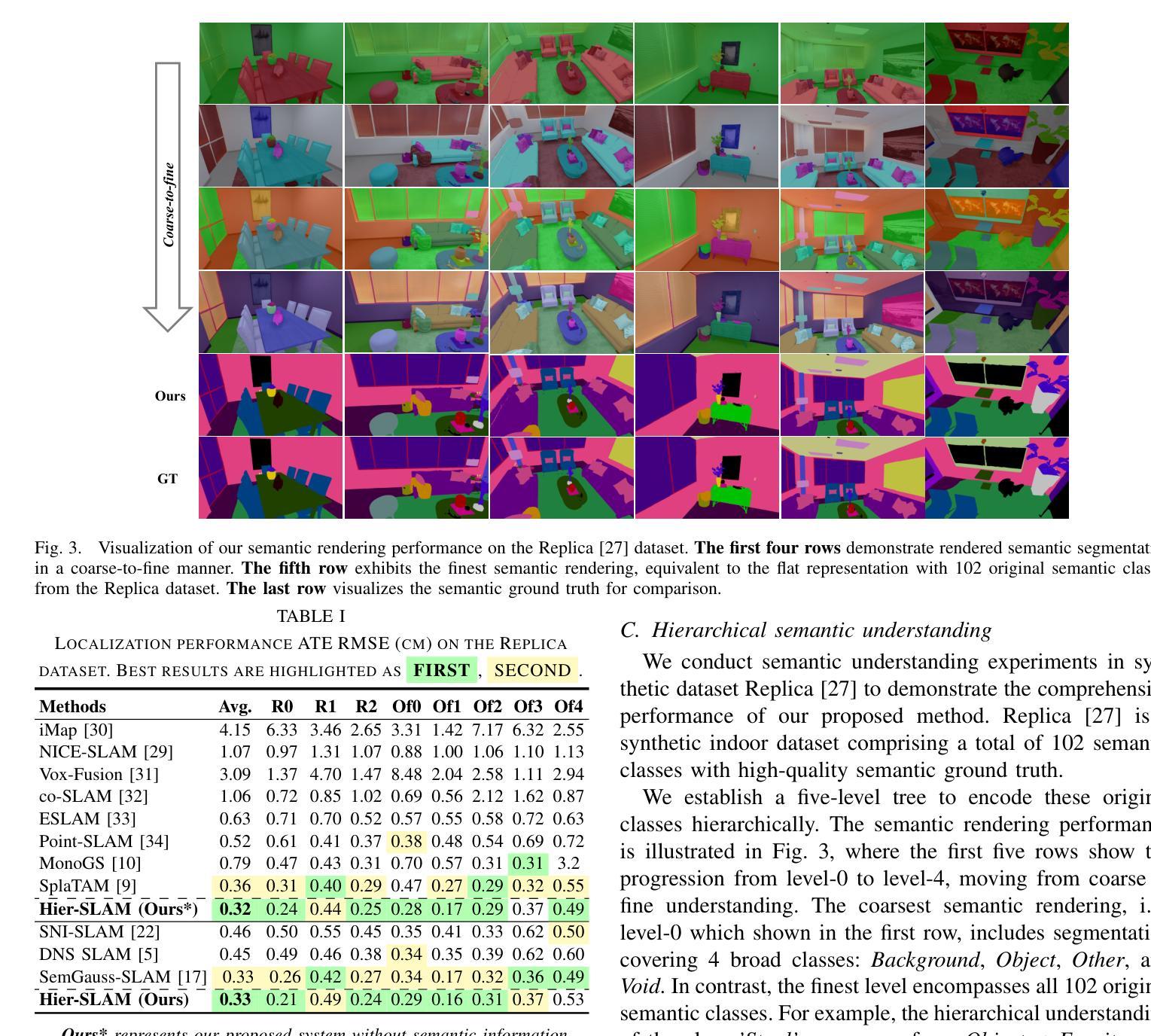
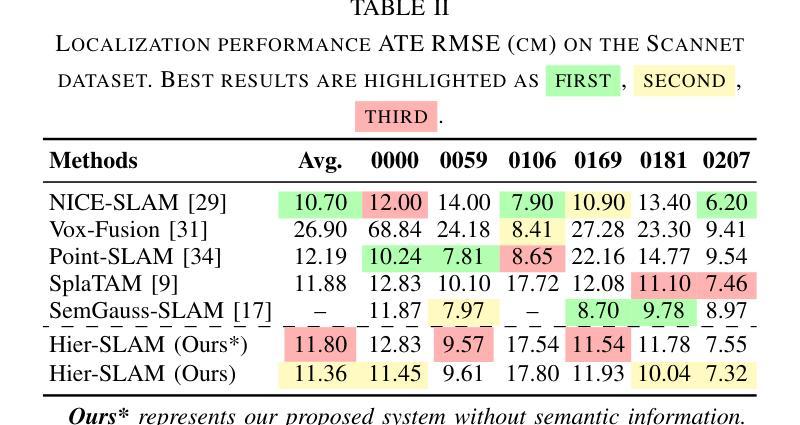
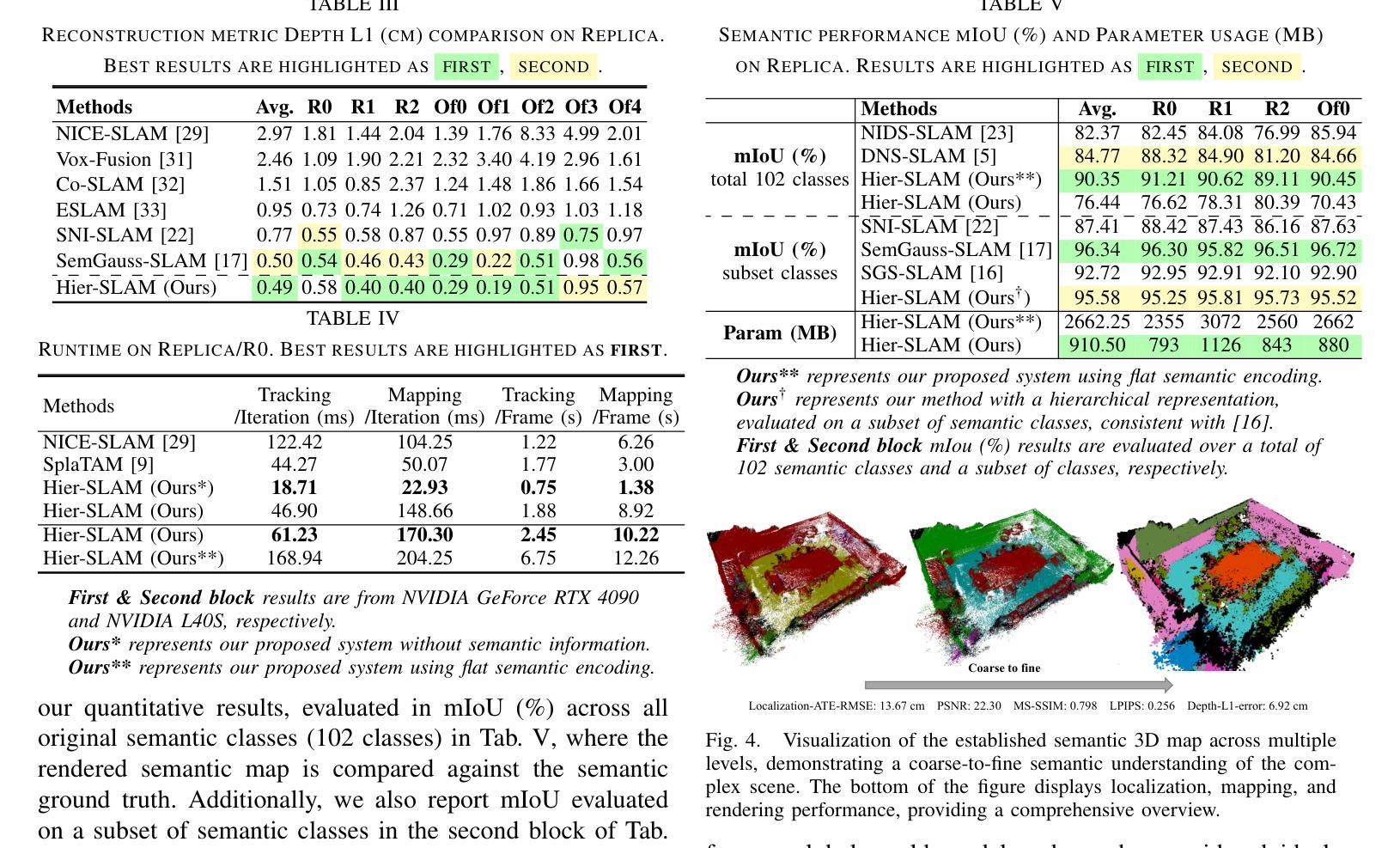
We propose Hier-SLAM, a semantic 3D Gaussian Splatting SLAM method featuring a novel hierarchical categorical representation, which enables accurate global 3D semantic mapping, scaling-up capability, and explicit semantic label prediction in the 3D world. The parameter usage in semantic SLAM systems increases significantly with the growing complexity of the environment, making it particularly challenging and costly for scene understanding. To address this problem, we introduce a novel hierarchical representation that encodes semantic information in a compact form into 3D Gaussian Splatting, leveraging the capabilities of large language models (LLMs). We further introduce a novel semantic loss designed to optimize hierarchical semantic information through both inter-level and cross-level optimization. Furthermore, we enhance the whole SLAM system, resulting in improved tracking and mapping performance. Our \MethodName{} outperforms existing dense SLAM methods in both mapping and tracking accuracy, while achieving a 2x operation speed-up. Additionally, it achieves on-par semantic rendering performance compared to existing methods while significantly reducing storage and training time requirements. Rendering FPS impressively reaches 2,000 with semantic information and 3,000 without it. Most notably, it showcases the capability of handling the complex real-world scene with more than 500 semantic classes, highlighting its valuable scaling-up capability. The open-source code is available at https://github.com/LeeBY68/Hier-SLAM
我们提出了一个名为 Hier-SLAM 的语义三维高斯喷射 SLAM 方法,它采用了一种新型层次化类别表示,能够实现准确的全局三维语义映射、可扩展能力以及三维世界中的显式语义标签预测。随着环境复杂性的增加,语义 SLAM 系统中的参数使用量也显著增加,这对场景理解构成了极大的挑战和成本。为了解决这个问题,我们引入了一种新型层次化表示,以紧凑的形式将语义信息编码到三维高斯喷射中,并利用大型语言模型(LLM)的能力。我们进一步引入了一种新型语义损失,旨在通过跨层级优化来优化层次化语义信息。此外,我们增强了整个 SLAM 系统的性能,提高了跟踪和映射的性能。我们的方法在映射和跟踪精度上都优于现有的密集 SLAM 方法,同时实现了 2 倍的操作速度提升。此外,它在语义渲染性能上与现有方法相当,同时显著减少了存储和训练时间要求。令人印象深刻的是,其在带有语义信息的情况下渲染 FPS 达到 2000,无语义信息时达到 3000。最值得注意的是,它展示了处理具有超过 500 个语义类别的复杂现实世界场景的能力,凸显了其有价值的可扩展性。开源代码可在 https://github.com/LeeBY68/Hier-SLAM 找到。
论文及项目相关链接
PDF Accepted for publication at ICRA 2025. Code is available at https://github.com/LeeBY68/Hier-SLAM
摘要
该文提出一种名为Hier-SLAM的语义3D高斯喷溅SLAM方法,它采用新颖的分层次类别表示,可实现准确的全局3D语义映射、扩展能力和显式的语义标签预测。针对语义SLAM系统中参数使用量随环境复杂度增长而显著增加的问题,我们借助大型语言模型(LLMs)的能力,将语义信息以紧凑的形式编码到3D高斯喷溅中。我们还设计了一种新的语义损失,通过跨级别优化来优化层次语义信息。此外,它增强了整个SLAM系统的跟踪和映射性能。我们的方法在映射和跟踪精度上优于现有的密集SLAM方法,同时实现了2倍的操作速度提升。此外,它在语义渲染性能上与现有方法相当,同时显著减少了存储和训练时间要求。
关键见解
- Hier-SLAM是一种语义3D高斯喷溅SLAM方法,具有新颖的分层次类别表示。
- 它能够实现准确的全局3D语义映射、扩展能力和显式的语义标签预测。
- Hier-SLAM通过紧凑的编码方式利用大型语言模型(LLMs)处理语义信息。
- 引入了一种新的语义损失,通过跨级别优化来优化层次语义信息。
- Hier-SLAM增强了SLAM系统的跟踪和映射性能。
- 相较于现有密集SLAM方法,Hier-SLAM在映射和跟踪精度上表现更优,且操作速度提升2倍。
- Hier-SLAM在语义渲染性能上表现卓越,同时降低了存储和训练时间要求,渲染FPS达到2000以上。
点此查看论文截图