⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-12 更新
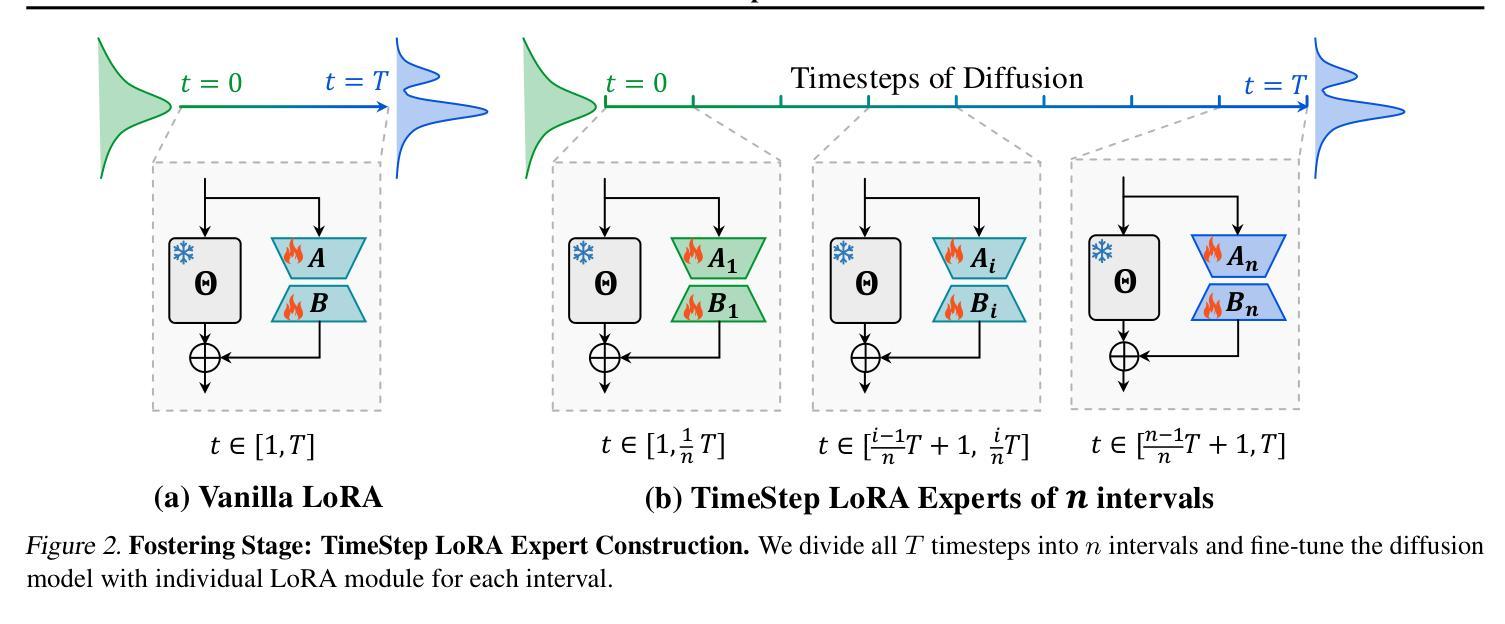
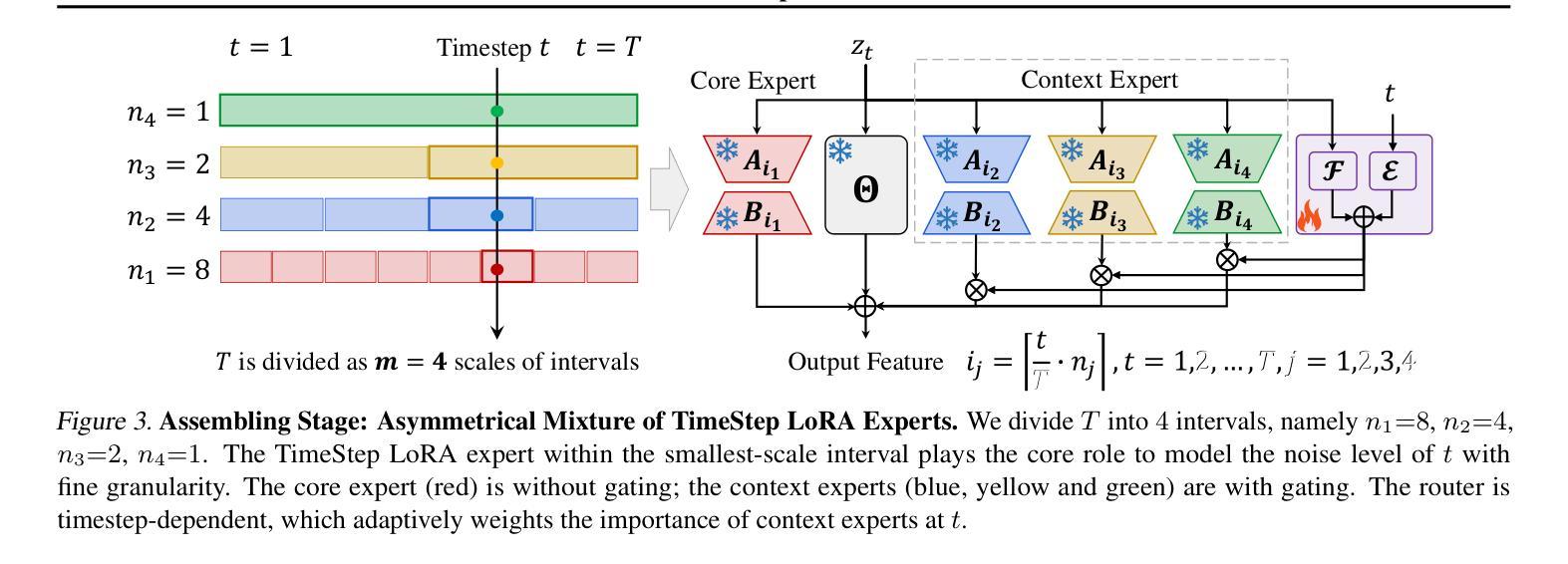
TimeStep Master: Asymmetrical Mixture of Timestep LoRA Experts for Versatile and Efficient Diffusion Models in Vision
Authors:Shaobin Zhuang, Yiwei Guo, Yanbo Ding, Kunchang Li, Xinyuan Chen, Yaohui Wang, Fangyikang Wang, Ying Zhang, Chen Li, Yali Wang
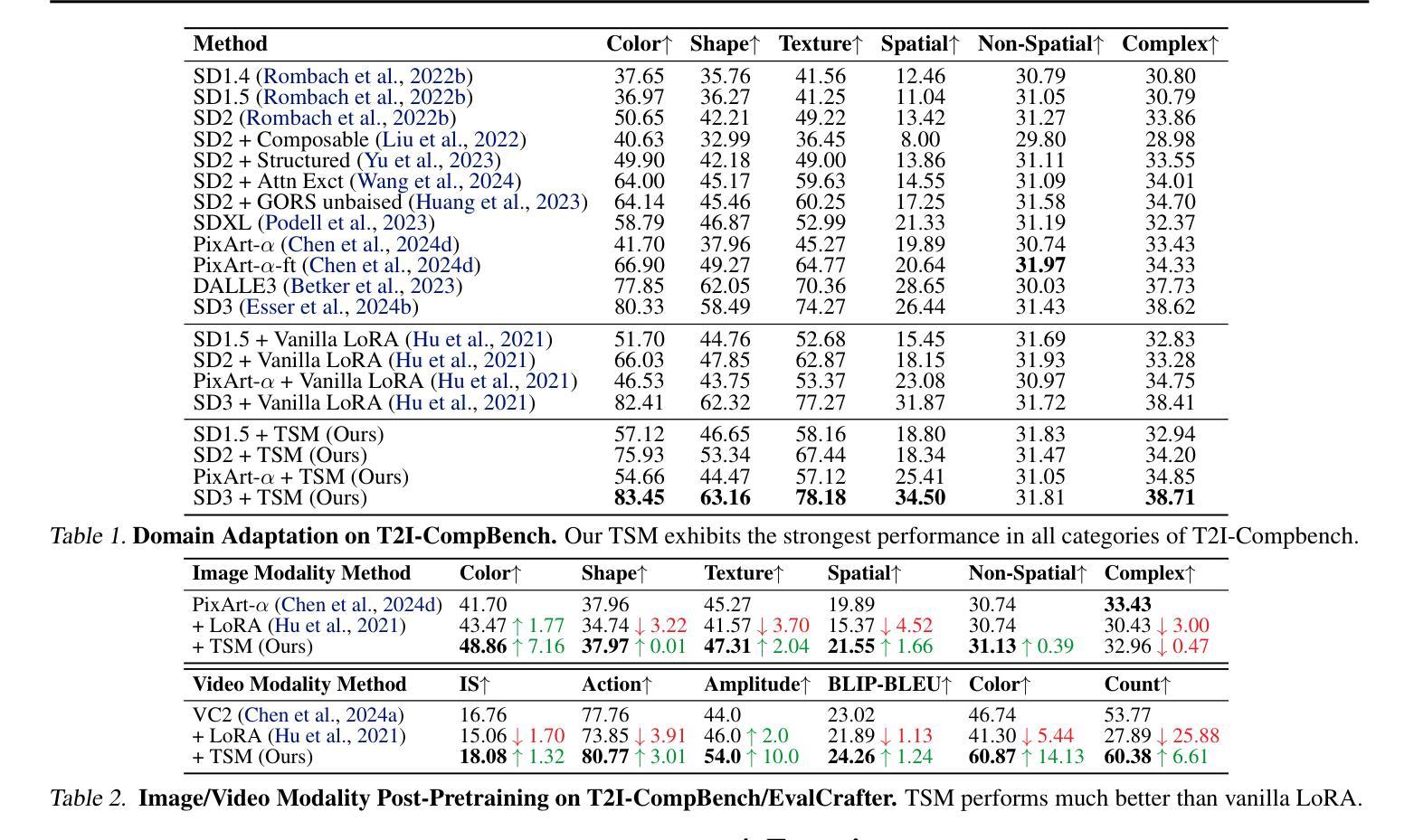
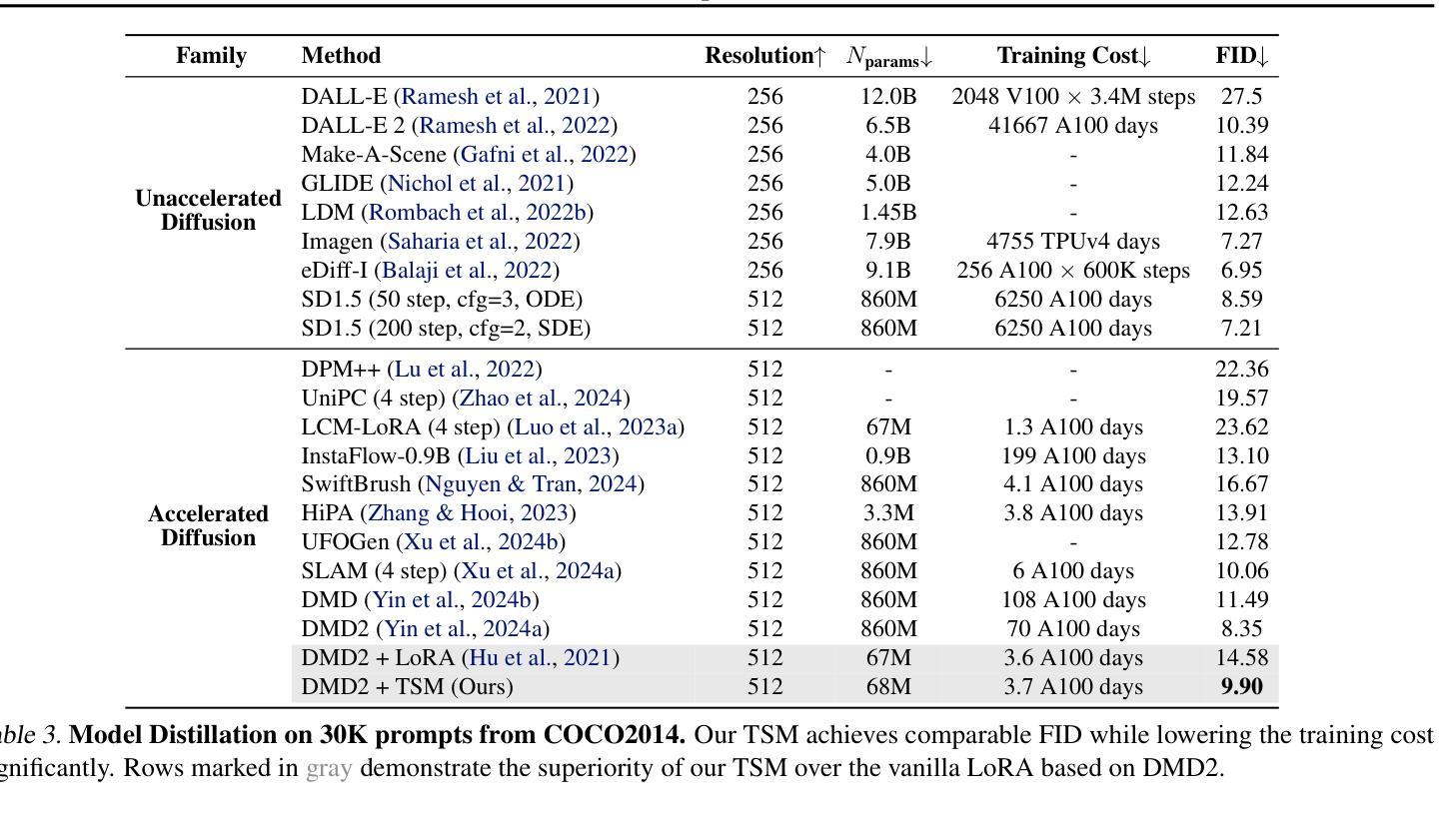
Diffusion models have driven the advancement of vision generation over the past years. However, it is often difficult to apply these large models in downstream tasks, due to massive fine-tuning cost. Recently, Low-Rank Adaptation (LoRA) has been applied for efficient tuning of diffusion models. Unfortunately, the capabilities of LoRA-tuned diffusion models are limited, since the same LoRA is used for different timesteps of the diffusion process. To tackle this problem, we introduce a general and concise TimeStep Master (TSM) paradigm with two key fine-tuning stages. In the fostering stage (1-stage), we apply different LoRAs to fine-tune the diffusion model at different timestep intervals. This results in different TimeStep LoRA experts that can effectively capture different noise levels. In the assembling stage (2-stage), we design a novel asymmetrical mixture of TimeStep LoRA experts, via core-context collaboration of experts at multi-scale intervals. For each timestep, we leverage TimeStep LoRA expert within the smallest interval as the core expert without gating, and use experts within the bigger intervals as the context experts with time-dependent gating. Consequently, our TSM can effectively model the noise level via the expert in the finest interval, and adaptively integrate contexts from the experts of other scales, boosting the versatility of diffusion models. To show the effectiveness of our TSM paradigm, we conduct extensive experiments on three typical and popular LoRA-related tasks of diffusion models, including domain adaptation, post-pretraining, and model distillation. Our TSM achieves the state-of-the-art results on all these tasks, throughout various model structures (UNet, DiT and MM-DiT) and visual data modalities (Image, Video), showing its remarkable generalization capacity.
扩散模型在过去几年中推动了视觉生成的进步。然而,由于巨大的微调成本,这些大型模型在下游任务中的应用往往面临困难。最近,低秩适应(LoRA)已被应用于扩散模型的有效调整。然而,LoRA调整后的扩散模型的能力是有限的,因为相同的LoRA用于扩散过程的不同时间步长。为了解决这个问题,我们引入了一种通用而简洁的TimeStep Master(TSM)范式,包含两个关键的微调阶段。在促进阶段(第一阶段),我们对不同的时间步长间隔应用不同的LoRAs来微调扩散模型。这导致了能够有效捕捉不同噪声水平的不同TimeStep LoRA专家。在装配阶段(第二阶段),我们通过多尺度间隔的专家核心-上下文协作,设计了一种新的不对称混合TimeStep LoRA专家方法。对于每个时间步长,我们利用最小间隔内的TimeStep LoRA专家作为核心专家,没有门控机制,并使用较大间隔内的专家作为随时间变化的上下文专家。因此,我们的TSM可以通过最精细间隔内的专家有效地建模噪声水平,并自适应地集成来自其他规模专家的上下文,从而提高了扩散模型的通用性。为了展示我们TSM范式的有效性,我们在扩散模型的三个典型且流行的LoRA相关任务上进行了大量实验,包括域适应、后预训练和模型蒸馏。我们的TSM在所有任务上都实现了最新结果,适用于各种模型结构(UNet、DiT和MM-DiT)和视觉数据模态(图像、视频),显示了其卓越的总括能力。
论文及项目相关链接
PDF 17 pages, 5 figures, 13 tables
Summary
扩散模型在过去几年中推动了视觉生成技术的发展。然而,由于庞大的微调成本,这些大型模型在下游任务中的应用往往面临困难。最近,低秩适应(LoRA)被应用于扩散模型的有效调整。然而,LoRA调整扩散模型的能力受限于其在扩散过程的不同时间步长中使用相同的LoRA。为解决此问题,我们提出简洁通用的时间步长主(TSM)范式,包含两个关键微调阶段。在促进阶段(第一阶段),我们在不同的时间步长间隔对扩散模型进行微调,应用不同的LoRA,形成能够有效捕捉不同噪声水平的时间步长LoRA专家。在装配阶段(第二阶段),我们通过多尺度间隔的专家核心-上下文协作,设计了一种新型的时间步长LoRA专家不对称混合方法。对于每个时间步长,我们利用最小间隔内的TimeStep LoRA专家作为核心专家,不使用门控机制,并使用较大间隔的专家作为具有时间依赖性门控机制的上下文专家。因此,我们的TSM可以有效地通过最精细间隔的专家对噪声水平进行建模,并自适应地集成来自其他规模专家的上下文,提高了扩散模型的通用性。实验结果表明,我们的TSM范式在三个典型的与LoRA相关的扩散模型任务上实现了最佳效果,包括域适应、预训练后和模型蒸馏。我们的TSM在各种模型结构和视觉数据模态上实现了显著的泛化能力。
Key Takeaways
- 扩散模型在视觉生成领域有重大贡献,但大规模微调成本高。
- LoRA方法用于调整扩散模型,但其在不同时间步长的应用受限。
- 引入TSM范式,包含两个关键微调阶段:促进阶段和装配阶段。
- 在促进阶段,应用不同的LoRAs到不同的时间步长间隔,形成TimeStep LoRA专家。
- 装配阶段通过核心-上下文协作和不对称混合方法集成TimeStep LoRA专家。
- TSM范式在域适应、预训练后和模型蒸馏等任务上实现最佳效果。
点此查看论文截图


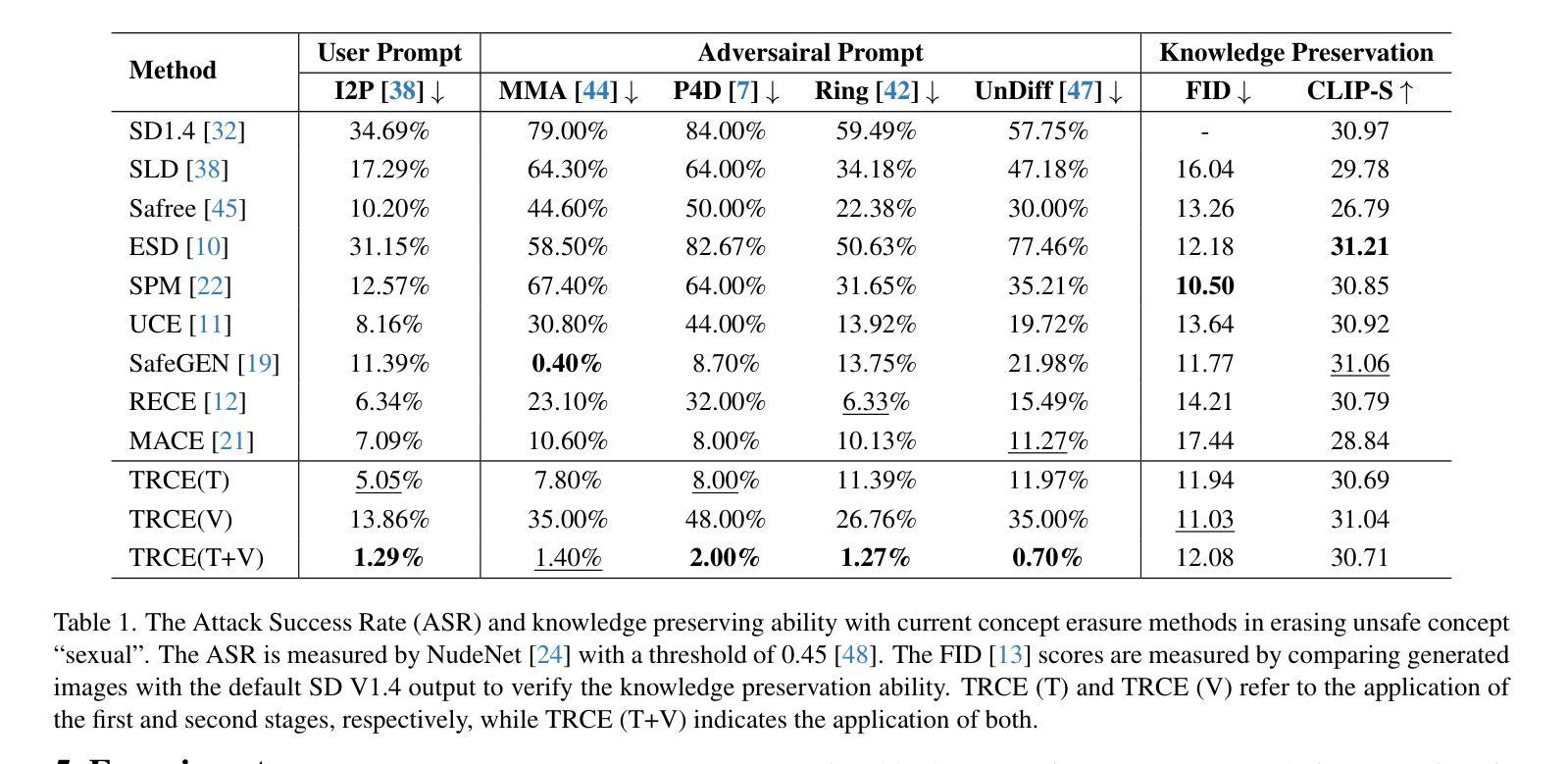
SPEED: Scalable, Precise, and Efficient Concept Erasure for Diffusion Models
Authors:Ouxiang Li, Yuan Wang, Xinting Hu, Houcheng Jiang, Tao Liang, Yanbin Hao, Guojun Ma, Fuli Feng
Erasing concepts from large-scale text-to-image (T2I) diffusion models has become increasingly crucial due to the growing concerns over copyright infringement, offensive content, and privacy violations. However, existing methods either require costly fine-tuning or degrade image quality for non-target concepts (i.e., prior) due to inherent optimization limitations. In this paper, we introduce SPEED, a model editing-based concept erasure approach that leverages null-space constraints for scalable, precise, and efficient erasure. Specifically, SPEED incorporates Influence-based Prior Filtering (IPF) to retain the most affected non-target concepts during erasing, Directed Prior Augmentation (DPA) to expand prior coverage while maintaining semantic consistency, and Invariant Equality Constraints (IEC) to regularize model editing by explicitly preserving key invariants during the T2I generation process. Extensive evaluations across multiple concept erasure tasks demonstrate that SPEED consistently outperforms existing methods in prior preservation while achieving efficient and high-fidelity concept erasure, successfully removing 100 concepts within just 5 seconds. Our code and models are available at: https://github.com/Ouxiang-Li/SPEED.
在大规模文本到图像(T2I)扩散模型中消除概念变得越来越重要,因为人们对版权侵犯、冒犯性内容和隐私泄露的担忧日益加剧。然而,现有方法要么需要大量微调,要么由于固有的优化限制,对非目标概念(即先验)的图像质量造成损害。在本文中,我们介绍了SPEED,这是一种基于模型编辑的概念消除方法,它利用零空间约束来实现可扩展、精确和高效的消除。具体来说,SPEED结合了基于影响的前置过滤(IPF)来保留在消除过程中受影响最大的非目标概念,定向先验增强(DPA)在保持语义一致性的同时扩大先验覆盖范围,以及不变等式约束(IEC)通过显式保留关键不变量来规范T2I生成过程中的模型编辑。在多个概念消除任务上的广泛评估表明,SPEED在保持先验的同时,始终优于现有方法,实现了高效和高保真度的概念消除,只需5秒即可成功移除100个概念。我们的代码和模型可在以下网址获得:https://github.com/Ouxiang-Li/SPEED。
论文及项目相关链接
Summary
本文介绍了一种基于模型编辑的概念消除方法SPEED,该方法利用零空间约束实现可扩展、精确和高效的概念消除。它采用影响优先过滤来保留受影响最大的非目标概念,通过定向优先增强来扩大先验覆盖并保持语义一致性,以及不变等式约束来在文本到图像生成过程中显式保留关键不变性以规范模型编辑。评估表明,SPEED在保留先验的同时,实现了高效和高保真度的概念消除,能够在短短5秒内成功消除100个概念。
Key Takeaways
- SPEED是一种用于大规模文本到图像(T2I)扩散模型的概念消除方法。
- 它利用零空间约束实现可扩展、精确和高效的概念消除。
- SPEED通过影响优先过滤保留受影响最大的非目标概念。
- 定向优先增强可扩大先验覆盖并保持语义一致性。
- 不变等式约束用于在T2I生成过程中显式保留关键不变性以规范模型编辑。
- SPEED在多个概念消除任务中的评估表现优异,能够在短时间内消除大量概念。
点此查看论文截图


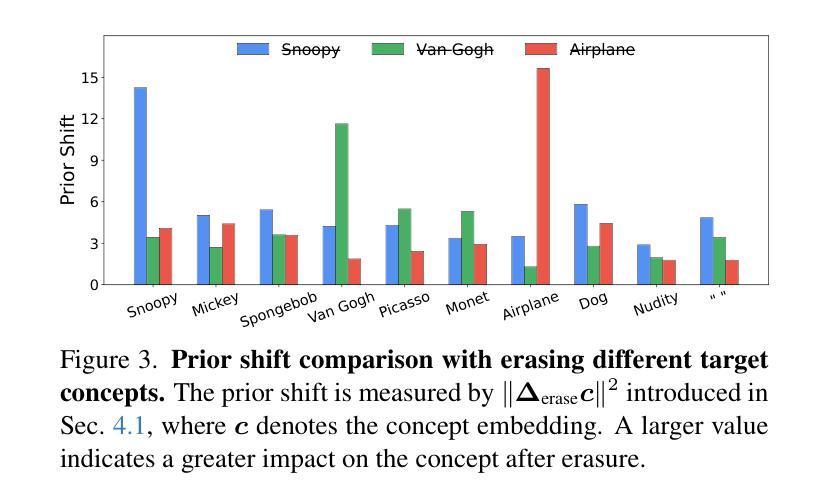
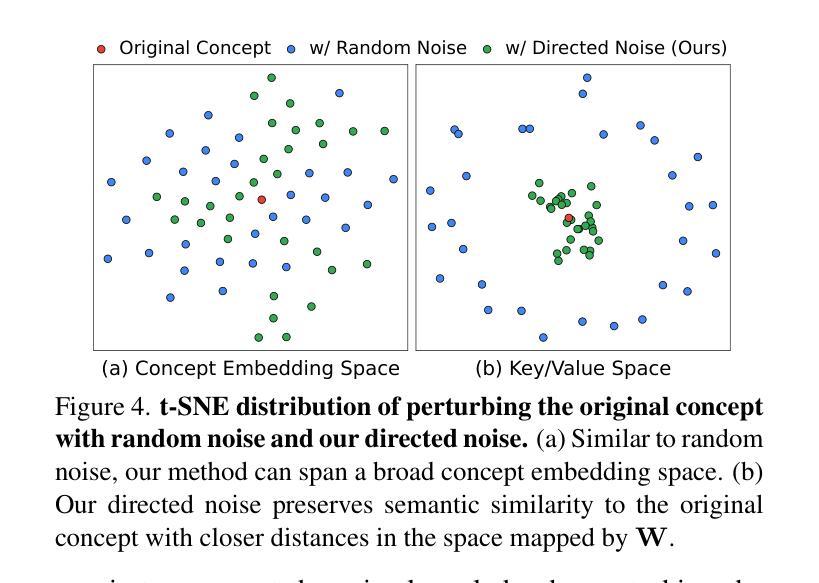

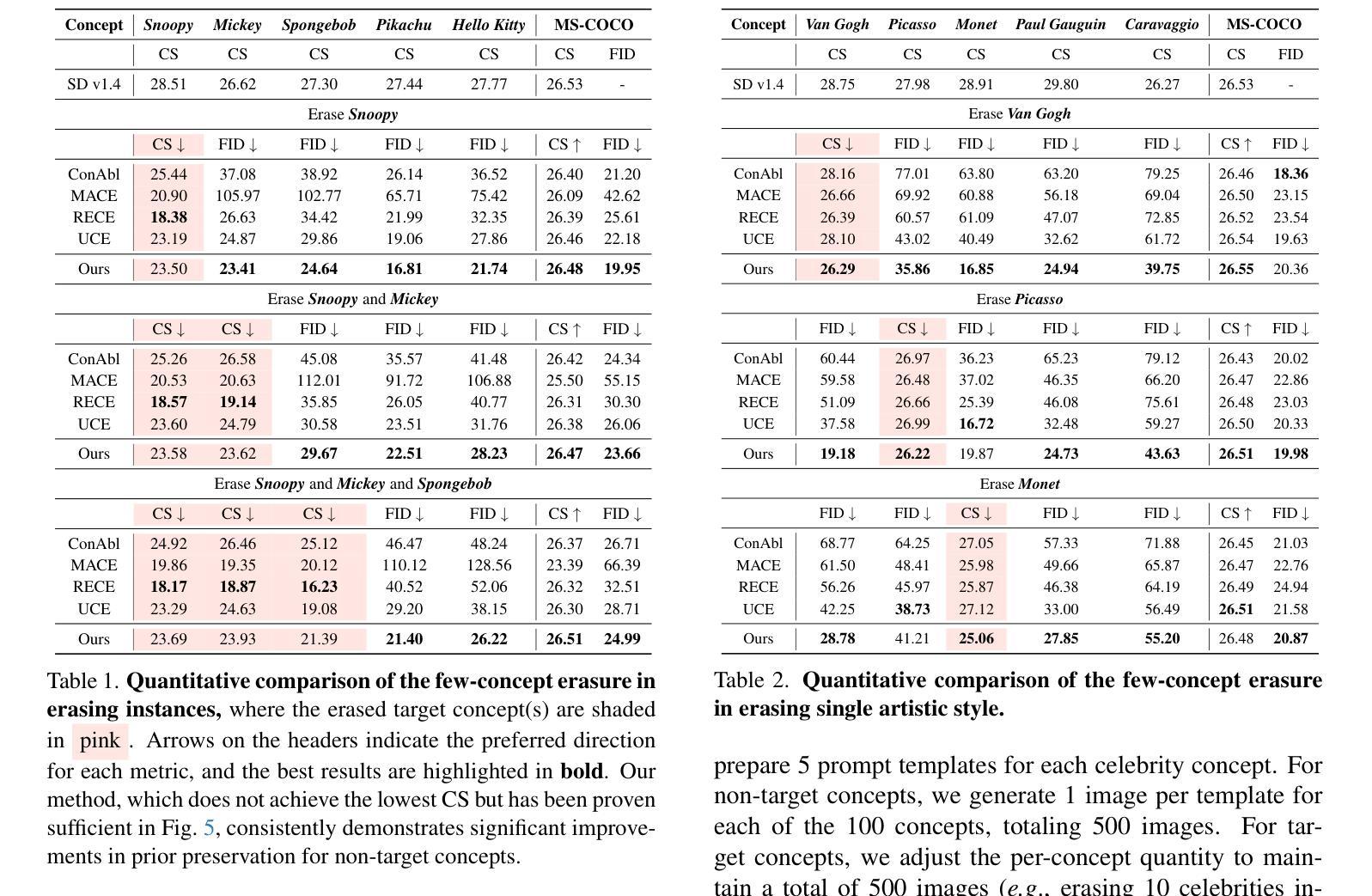
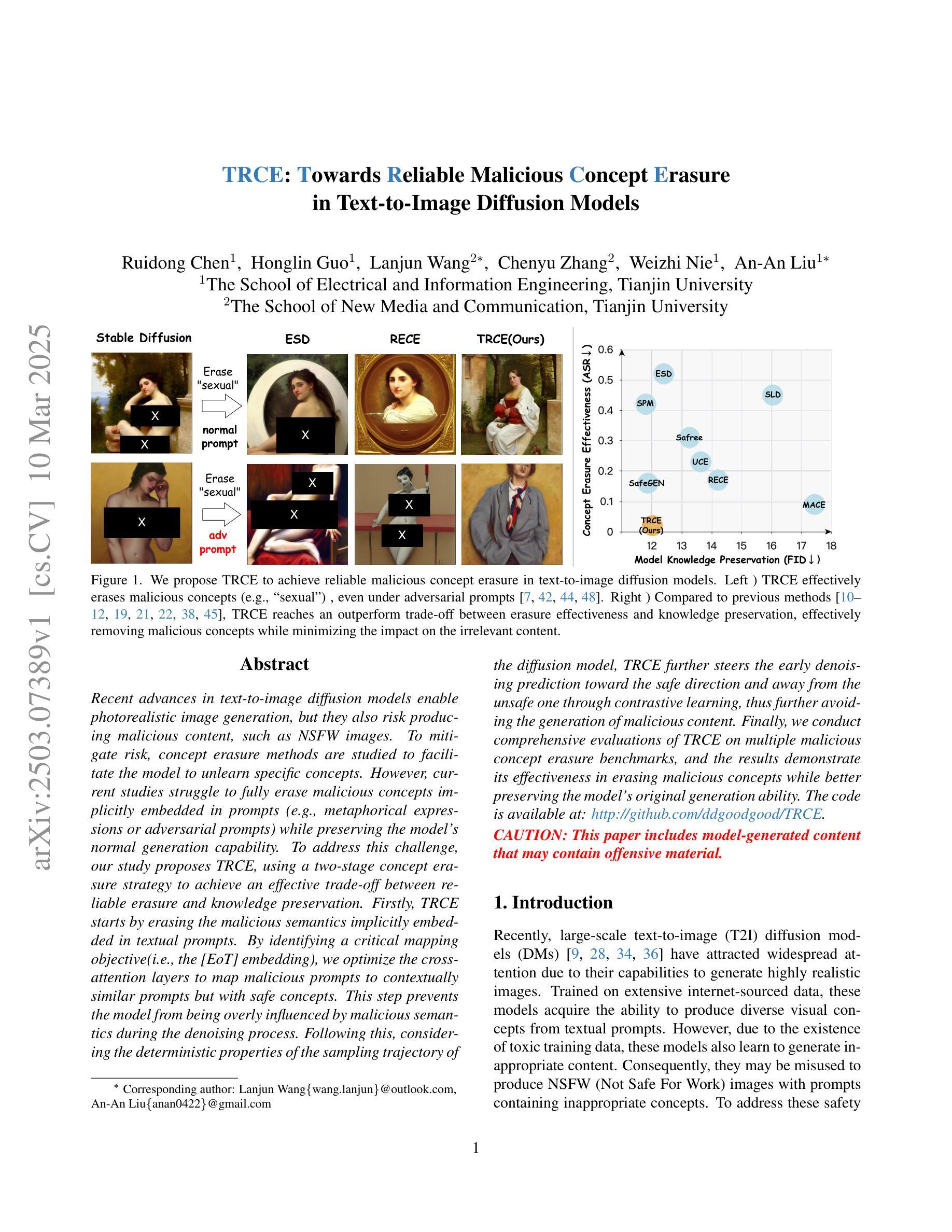
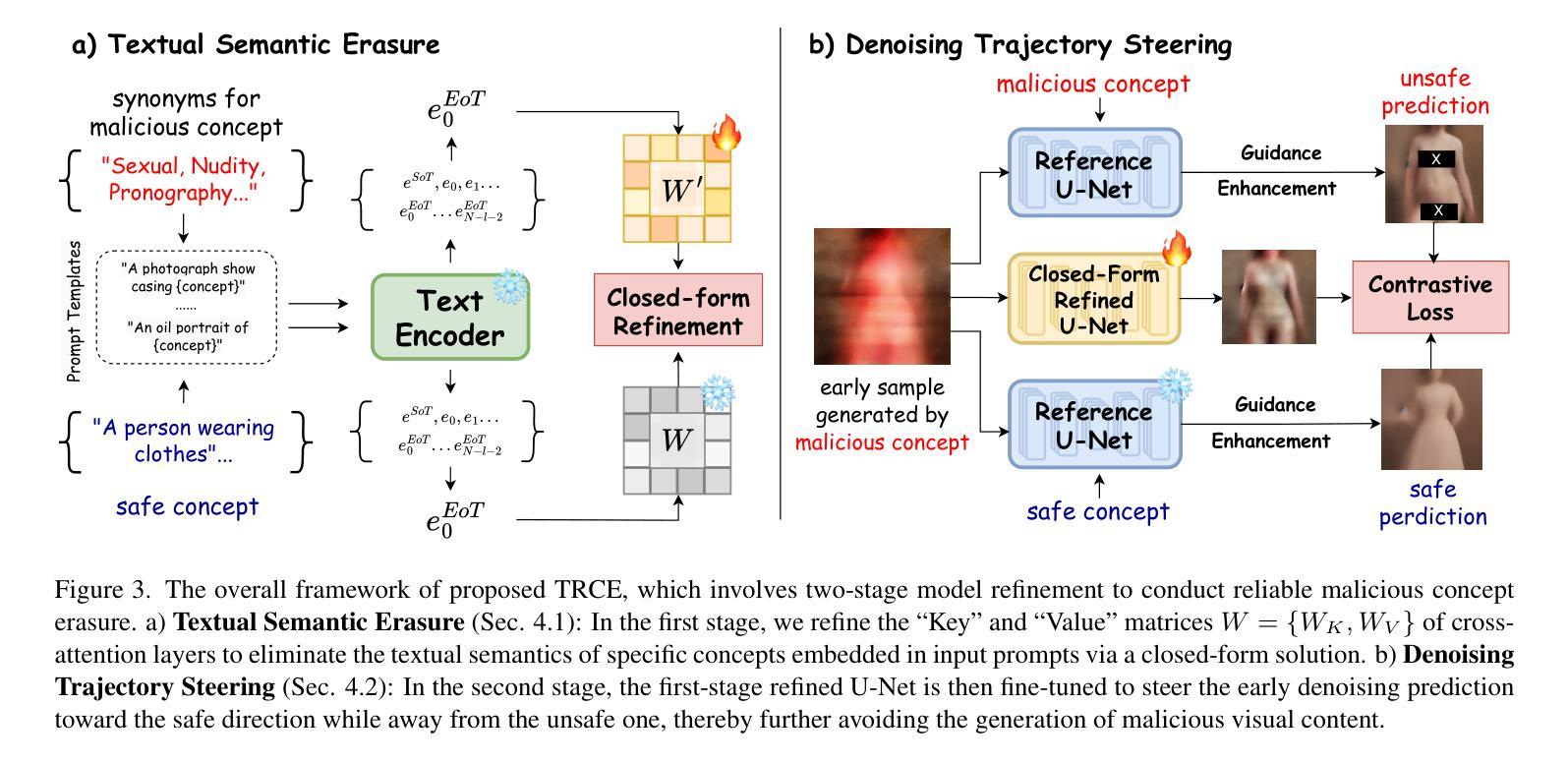
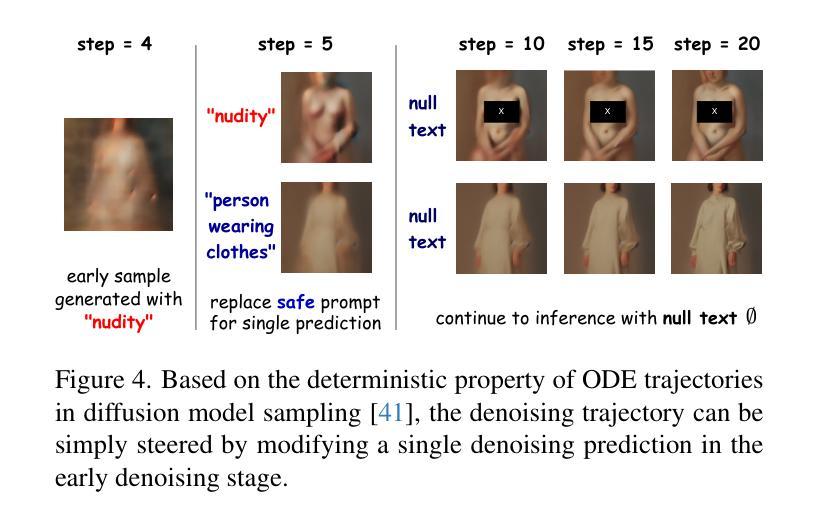
TRCE: Towards Reliable Malicious Concept Erasure in Text-to-Image Diffusion Models
Authors:Ruidong Chen, Honglin Guo, Lanjun Wang, Chenyu Zhang, Weizhi Nie, An-An Liu
Recent advances in text-to-image diffusion models enable photorealistic image generation, but they also risk producing malicious content, such as NSFW images. To mitigate risk, concept erasure methods are studied to facilitate the model to unlearn specific concepts. However, current studies struggle to fully erase malicious concepts implicitly embedded in prompts (e.g., metaphorical expressions or adversarial prompts) while preserving the model’s normal generation capability. To address this challenge, our study proposes TRCE, using a two-stage concept erasure strategy to achieve an effective trade-off between reliable erasure and knowledge preservation. Firstly, TRCE starts by erasing the malicious semantics implicitly embedded in textual prompts. By identifying a critical mapping objective(i.e., the [EoT] embedding), we optimize the cross-attention layers to map malicious prompts to contextually similar prompts but with safe concepts. This step prevents the model from being overly influenced by malicious semantics during the denoising process. Following this, considering the deterministic properties of the sampling trajectory of the diffusion model, TRCE further steers the early denoising prediction toward the safe direction and away from the unsafe one through contrastive learning, thus further avoiding the generation of malicious content. Finally, we conduct comprehensive evaluations of TRCE on multiple malicious concept erasure benchmarks, and the results demonstrate its effectiveness in erasing malicious concepts while better preserving the model’s original generation ability. The code is available at: http://github.com/ddgoodgood/TRCE. CAUTION: This paper includes model-generated content that may contain offensive material.
近期文本到图像扩散模型的进展使得能够生成逼真的图像,但同时也存在生成恶意内容的风险,例如不适宜公开场合(NSFW)的图像。为了减轻风险,开展了概念消除方法的研究,以促进模型忘记特定概念。然而,当前的研究在消除隐含在提示中的恶意概念(例如隐喻或对抗性提示)时遇到困难,同时保持模型的正常生成能力。为了应对这一挑战,我们的研究提出了TRCE,采用两阶段概念消除策略,在可靠消除和知识保留之间取得有效平衡。首先,TRCE从消除文本提示中隐含的恶意语义开始。通过确定关键映射目标(即[EoT]嵌入),我们优化交叉注意层,将恶意提示映射到上下文相似的提示上,但具有安全的概念。这一步防止了模型在降噪过程中受到恶意语义的过多影响。接下来,考虑到扩散模型的采样轨迹的确定性属性,TRCE进一步引导早期降噪预测朝着安全方向进行,并通过对比学习远离不安全方向,从而进一步避免生成恶意内容。最后,我们在多个恶意概念消除基准测试上对TRCE进行了全面评估,结果表明它在消除恶意概念的同时更好地保留了模型的原始生成能力。代码可在http://github.com/ddgoodgood/TRCE获取。注意:本文包含可能含有冒犯性内容的模型生成内容。
论文及项目相关链接
Summary
本文探讨了文本到图像扩散模型在生成图像时可能产生的风险,特别是生成含有恶意内容(如NSFW图像)的问题。针对此问题,文章提出了一种名为TRCE的两阶段概念消除策略,旨在有效平衡可靠消除与知识保留。首先,通过识别关键映射目标(即[EoT]嵌入),优化跨注意层,将恶意提示映射到具有安全概念且在上下文上相似的提示上。接着,考虑到扩散模型的采样轨迹的确定性属性,TRCE通过对比学习进一步引导早期去噪预测朝着安全方向进行,远离不安全方向,从而避免生成恶意内容。实验评估表明,TRCE在消除恶意概念的同时更好地保留了模型的原始生成能力。
Key Takeaways
- 文本到图像扩散模型存在生成恶意内容的风险。
- TRCE方法采用两阶段概念消除策略来平衡消除恶意概念和保留模型生成能力。
- 第一阶段通过优化跨注意层,将恶意提示映射到具有安全概念的相似提示上。
- 第二阶段利用扩散模型的采样轨迹确定性,通过对比学习引导去噪预测朝着安全方向进行。
- TRCE在多个恶意概念消除基准测试上的实验评估证明了其有效性。
- TRCE方法的代码已公开可供使用。
点此查看论文截图

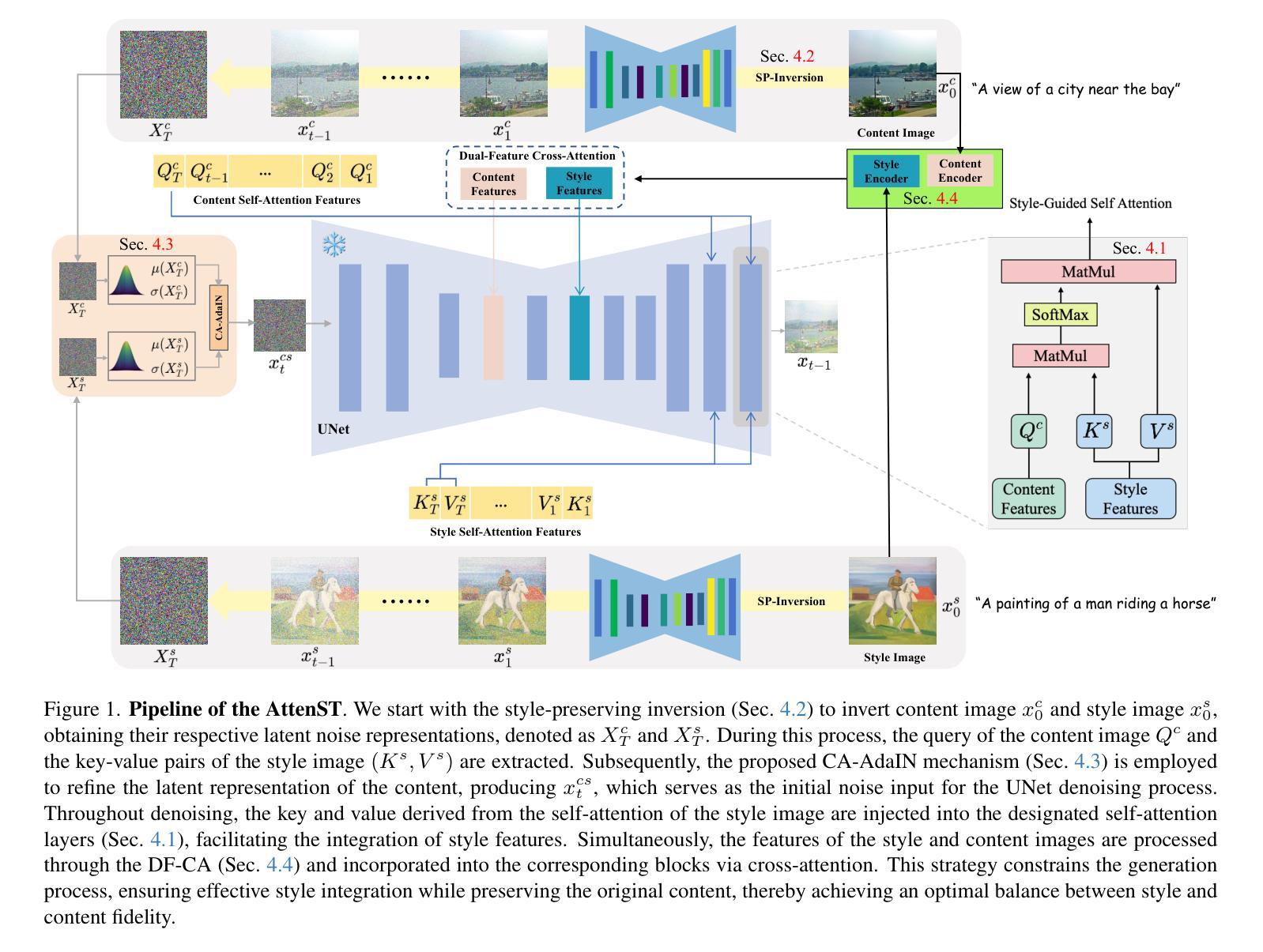
AttenST: A Training-Free Attention-Driven Style Transfer Framework with Pre-Trained Diffusion Models
Authors:Bo Huang, Wenlun Xu, Qizhuo Han, Haodong Jing, Ying Li
While diffusion models have achieved remarkable progress in style transfer tasks, existing methods typically rely on fine-tuning or optimizing pre-trained models during inference, leading to high computational costs and challenges in balancing content preservation with style integration. To address these limitations, we introduce AttenST, a training-free attention-driven style transfer framework. Specifically, we propose a style-guided self-attention mechanism that conditions self-attention on the reference style by retaining the query of the content image while substituting its key and value with those from the style image, enabling effective style feature integration. To mitigate style information loss during inversion, we introduce a style-preserving inversion strategy that refines inversion accuracy through multiple resampling steps. Additionally, we propose a content-aware adaptive instance normalization, which integrates content statistics into the normalization process to optimize style fusion while mitigating the content degradation. Furthermore, we introduce a dual-feature cross-attention mechanism to fuse content and style features, ensuring a harmonious synthesis of structural fidelity and stylistic expression. Extensive experiments demonstrate that AttenST outperforms existing methods, achieving state-of-the-art performance in style transfer dataset.
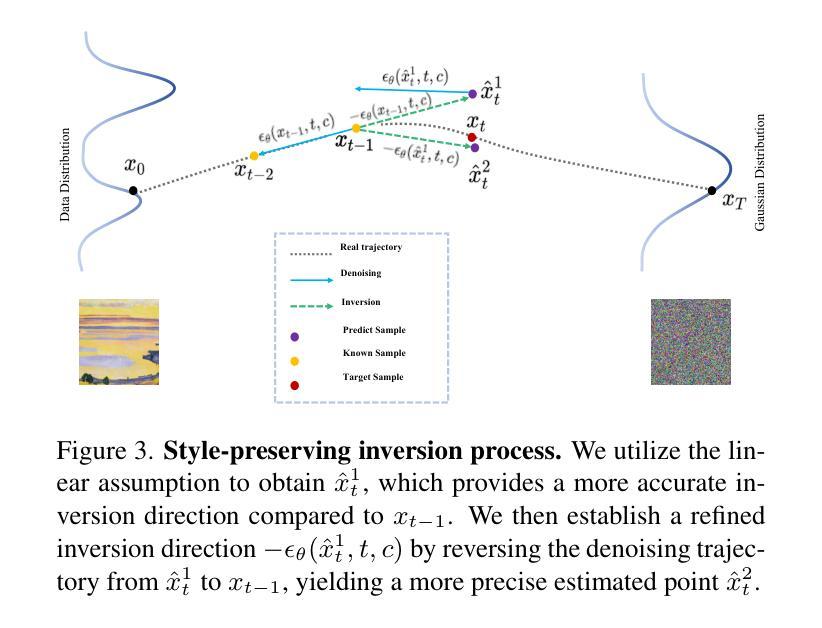
尽管扩散模型在风格迁移任务中取得了显著的进展,但现有方法通常依赖于在推理过程中对预训练模型进行微调或优化,这导致了计算成本高昂,以及在内容保留与风格融合之间取得平衡的挑战。为了解决这些局限性,我们引入了AttenST,这是一种无需训练、以注意力驱动的风格迁移框架。具体来说,我们提出了一种受风格引导的自注意力机制,通过保留内容图像的查询,并用风格图像的键和值替换它,从而在自注意力上设定参考风格的条件,实现有效的风格特征融合。为了减轻反转过程中的风格信息损失,我们引入了一种保风格反转策略,通过多次重采样步骤提高反转精度。此外,我们提出了内容感知自适应实例归一化,将内容统计信息融入归一化过程,以优化风格融合,同时减轻内容退化。此外,我们还引入了一种双特征交叉注意力机制,以融合内容和风格特征,确保结构保真和风格表达的和谐融合。大量实验表明,AttenST优于现有方法,在风格迁移数据集上达到了最新性能水平。
论文及项目相关链接
Summary
基于注意力机制的无训练风格转换框架AttenST能够有效解决扩散模型在风格转换任务中的高计算成本及内容保留与风格融合平衡的挑战。通过风格引导的自注意力机制、风格保留的倒转策略、内容感知自适应实例归一化以及双重特征交叉注意力机制,AttenST在风格转换数据集上取得了领先现有方法的最佳性能表现。
Key Takeaways
- 扩散模型在风格转换任务中取得了显著进展,但仍存在高计算成本和平衡内容保留与风格融合的挑战。
- 引入了一种基于注意力机制的无训练风格转换框架AttenST来应对这些挑战。
- AttenST采用风格引导的自注意力机制,通过参考风格来条件化自注意力,有效整合风格特征。
- 提出了风格保留的倒转策略,通过多次重采样步骤提高倒转精度,减少风格信息损失。
- 引入内容感知自适应实例归一化,将内容统计纳入归一化过程,优化风格融合并减少内容退化。
- 采用双重特征交叉注意力机制,融合内容和风格特征,实现结构保真和风格表达的和谐融合。
点此查看论文截图



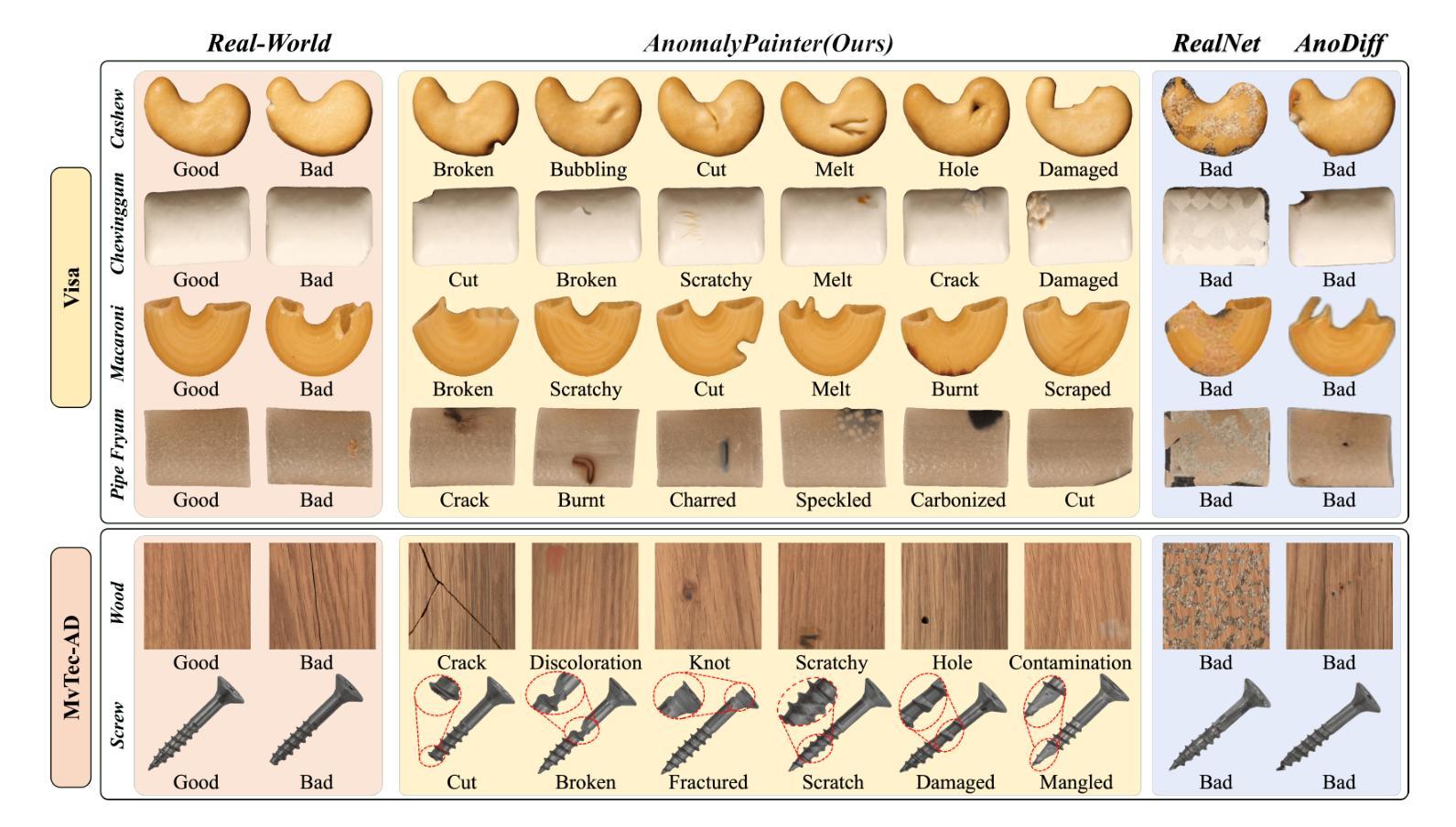
AnomalyPainter: Vision-Language-Diffusion Synergy for Zero-Shot Realistic and Diverse Industrial Anomaly Synthesis
Authors:Zhangyu Lai, Yilin Lu, Xinyang Li, Jianghang Lin, Yansong Qu, Liujuan Cao, Ming Li, Rongrong Ji
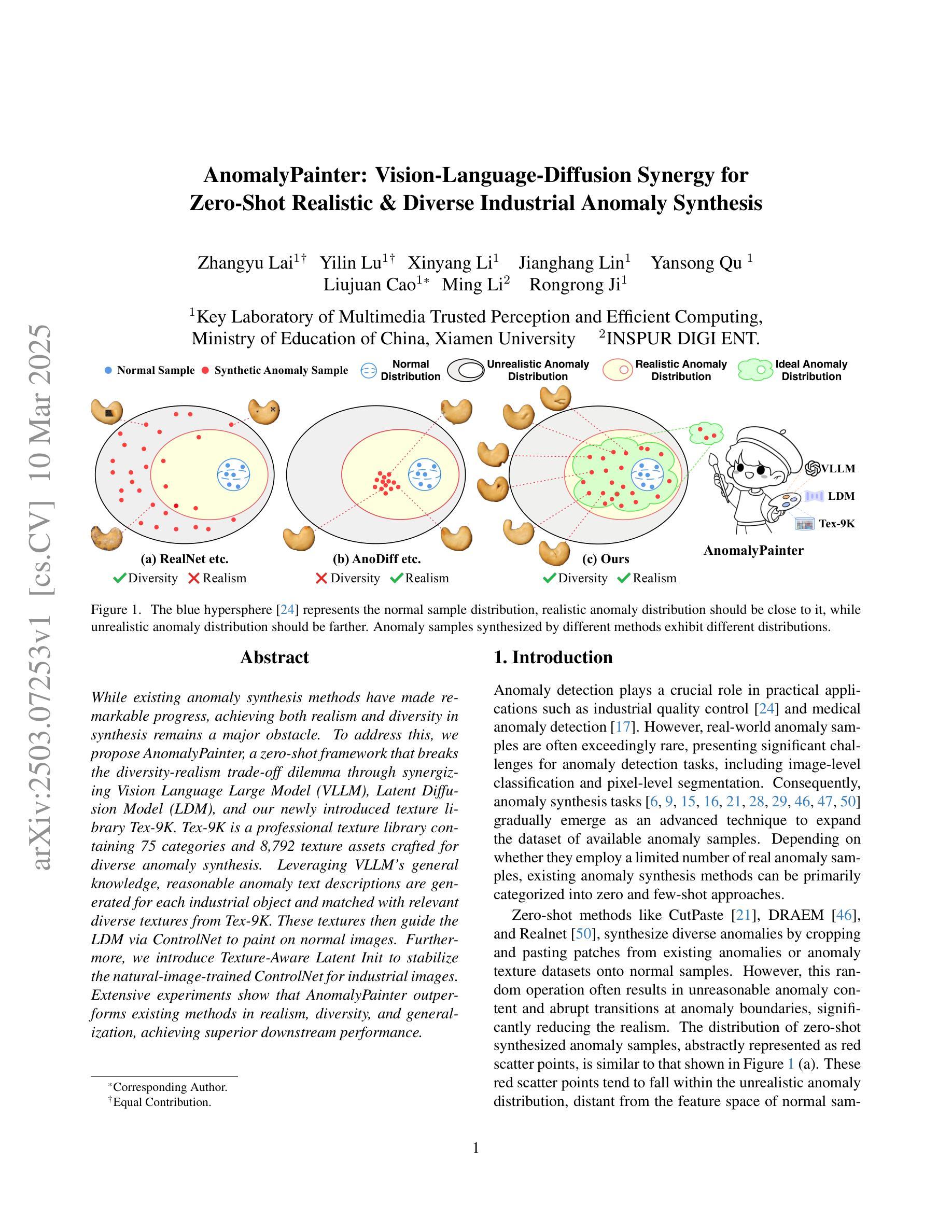
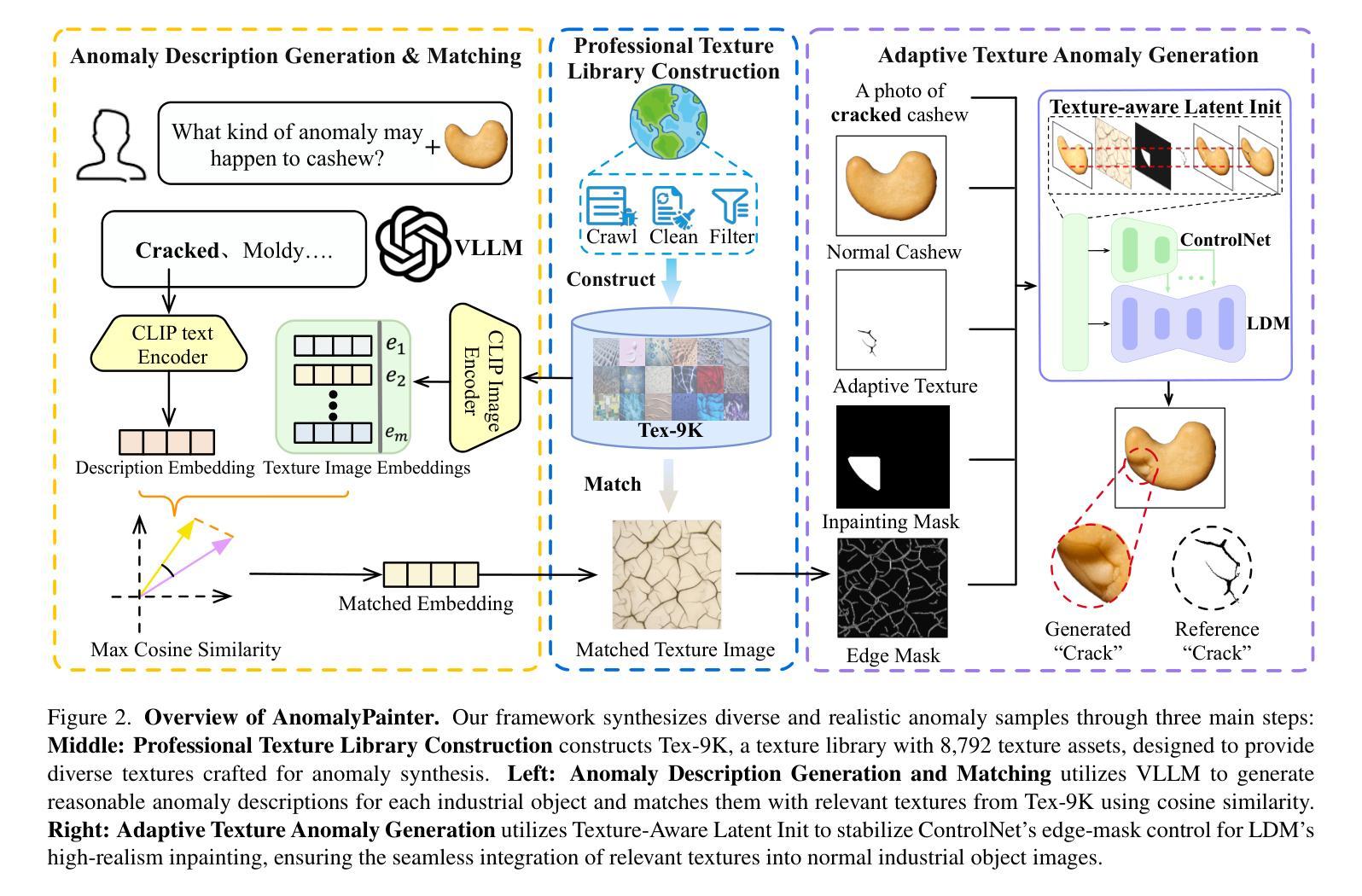
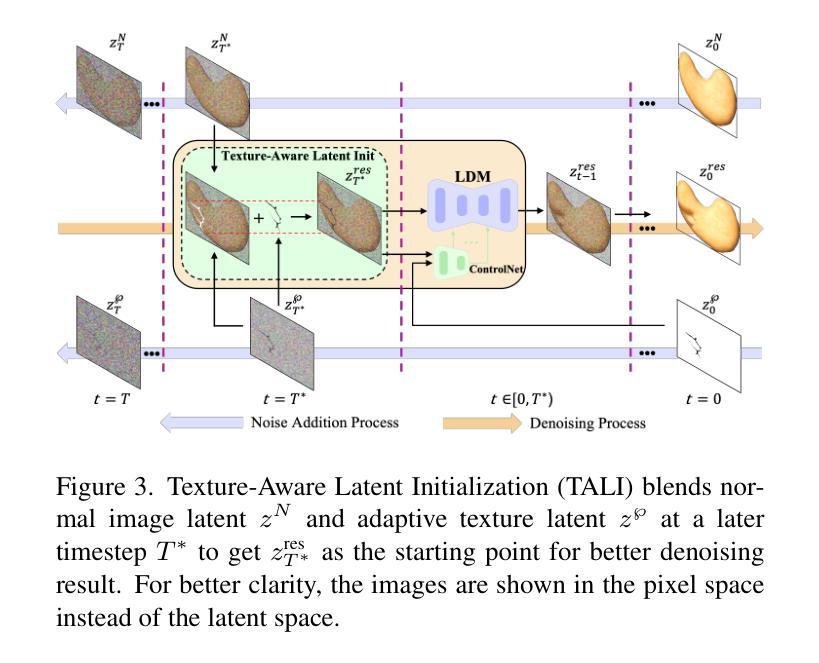
While existing anomaly synthesis methods have made remarkable progress, achieving both realism and diversity in synthesis remains a major obstacle. To address this, we propose AnomalyPainter, a zero-shot framework that breaks the diversity-realism trade-off dilemma through synergizing Vision Language Large Model (VLLM), Latent Diffusion Model (LDM), and our newly introduced texture library Tex-9K. Tex-9K is a professional texture library containing 75 categories and 8,792 texture assets crafted for diverse anomaly synthesis. Leveraging VLLM’s general knowledge, reasonable anomaly text descriptions are generated for each industrial object and matched with relevant diverse textures from Tex-9K. These textures then guide the LDM via ControlNet to paint on normal images. Furthermore, we introduce Texture-Aware Latent Init to stabilize the natural-image-trained ControlNet for industrial images. Extensive experiments show that AnomalyPainter outperforms existing methods in realism, diversity, and generalization, achieving superior downstream performance.
尽管现有的异常合成方法已经取得了显著的进步,但在合成中实现真实感和多样性仍是主要障碍。为解决这一问题,我们提出了AnomalyPainter,这是一个零样本框架,它通过协同视觉语言大模型(VLLM)、潜在扩散模型(LDM)和我们新引入的纹理库Tex-9K,解决了多样性-真实感权衡的困境。Tex-9K是一个专业纹理库,包含75个类别和8792个为各种异常合成制作的纹理资产。利用VLLM的通用知识,为每个工业对象生成合理的异常文本描述,并与Tex-9K中相关的多样纹理相匹配。这些纹理然后通过ControlNet在普通图像上进行绘画。此外,我们引入了Texture-Aware Latent Init,以稳定针对工业图像的自然图像训练ControlNet。大量实验表明,AnomalyPainter在真实感、多样性和泛化方面优于现有方法,实现了出色的下游性能。
论文及项目相关链接
PDF anomaly synthesis,anomaly detection
Summary
本研究提出了一种名为AnomalyPainter的零样本框架,该框架通过协同使用视觉语言大模型(VLLM)、潜在扩散模型(LDM)以及新引入的纹理库Tex-9K,解决了现有异常合成方法在真实性和多样性方面的难题。Tex-9K包含75类、共8792个专业纹理资产,用于多样化的异常合成。利用VLLM的一般知识,生成合理的异常文本描述,与Tex-9K中的相关多样纹理相匹配,再通过ControlNet在普通图像上进行绘制。此外,还引入了纹理感知初始潜态来稳定针对工业图像的自然图像训练ControlNet。实验表明,AnomalyPainter在真实性、多样性和泛化能力方面优于现有方法,实现了出色的下游性能提升。
Key Takeaways
- AnomalyPainter是一个零样本框架,旨在解决现有异常合成方法在真实性和多样性方面的难题。
- 框架结合了视觉语言大模型(VLLM)、潜在扩散模型(LDM)以及专业纹理库Tex-9K。
- Tex-9K包含丰富的纹理资产,有助于多样化的异常合成。
- 利用VLLM生成与工业对象相关的合理异常文本描述,并与Tex-9K中的纹理匹配。
- ControlNet被用于在普通图像上进行绘制,通过引入Texture-Aware Latent Init来适应工业图像。
- AnomalyPainter在真实性、多样性和泛化能力方面表现出优越性。
点此查看论文截图

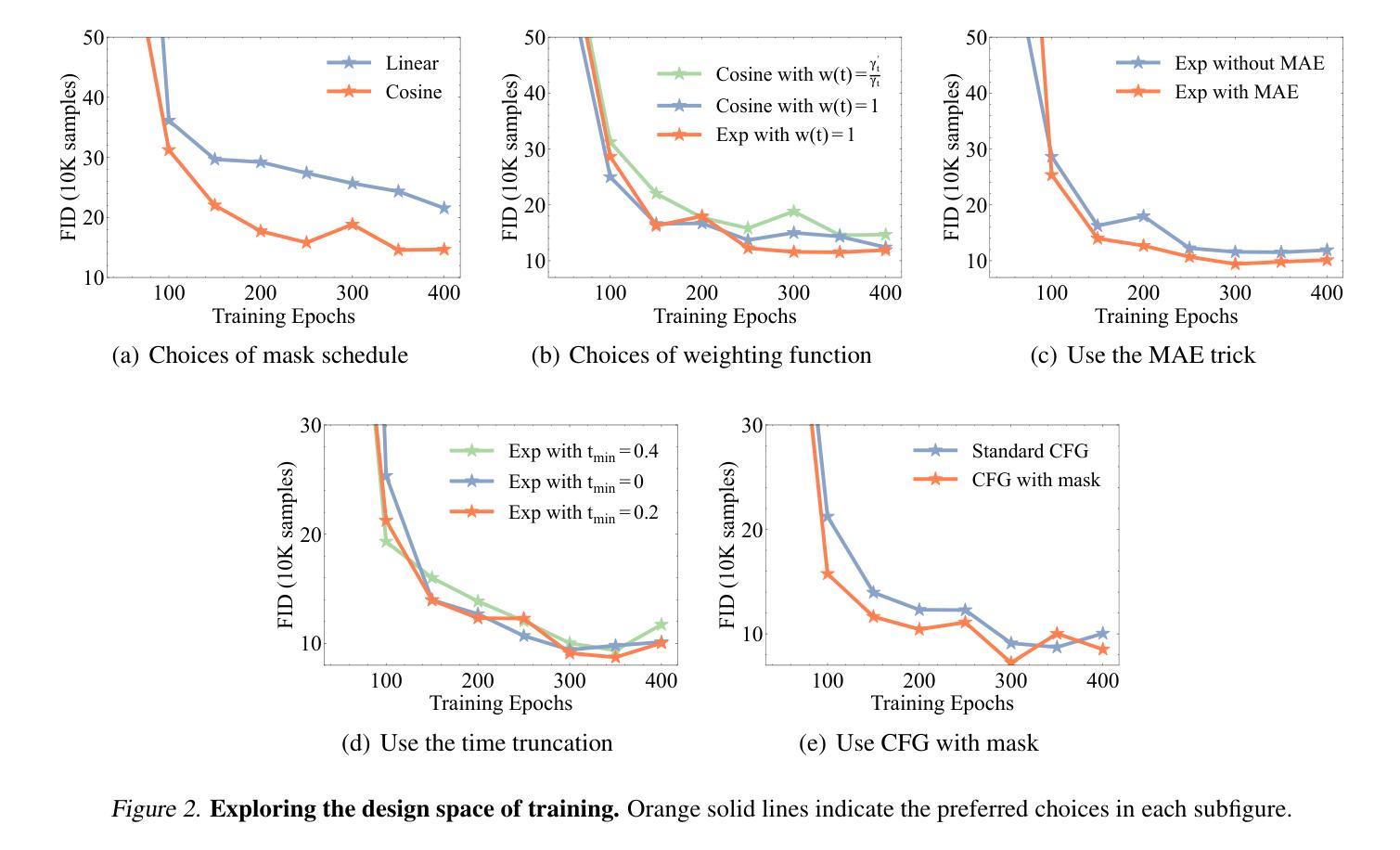
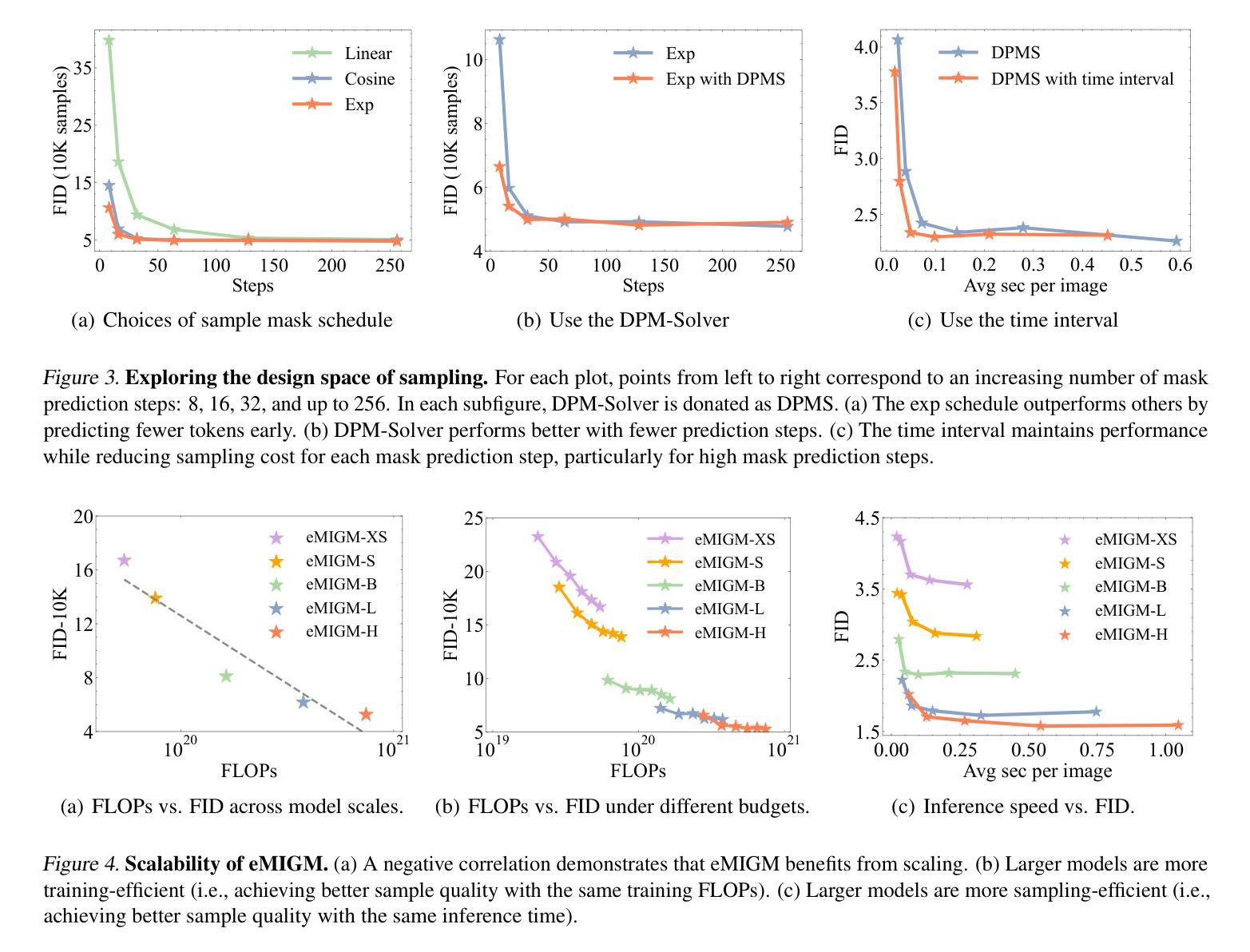
Effective and Efficient Masked Image Generation Models
Authors:Zebin You, Jingyang Ou, Xiaolu Zhang, Jun Hu, Jun Zhou, Chongxuan Li
Although masked image generation models and masked diffusion models are designed with different motivations and objectives, we observe that they can be unified within a single framework. Building upon this insight, we carefully explore the design space of training and sampling, identifying key factors that contribute to both performance and efficiency. Based on the improvements observed during this exploration, we develop our model, referred to as eMIGM. Empirically, eMIGM demonstrates strong performance on ImageNet generation, as measured by Fr'echet Inception Distance (FID). In particular, on ImageNet 256x256, with similar number of function evaluations (NFEs) and model parameters, eMIGM outperforms the seminal VAR. Moreover, as NFE and model parameters increase, eMIGM achieves performance comparable to the state-of-the-art continuous diffusion models while requiring less than 40% of the NFE. Additionally, on ImageNet 512x512, with only about 60% of the NFE, eMIGM outperforms the state-of-the-art continuous diffusion models.
虽然掩膜图像生成模型和掩膜扩散模型的设计初衷和目标不同,但我们发现它们可以在一个单一框架内统一。基于这一洞察,我们仔细探索了训练和采样的设计空间,识别出对性能和效率都做出贡献的关键因素。根据在此次探索中观察到的改进,我们开发了自己的模型,称为eMIGM。经验上,eMIGM在ImageNet生成方面表现出强大的性能,以Fréchet Inception Distance(FID)衡量。特别是在ImageNet 256x256上,eMIGM在功能评估次数(NFE)和模型参数相似的情况下,超过了最初的VAR模型。而且,随着功能评估次数和模型参数的增加,eMIGM在性能上达到了与当前最先进的连续扩散模型相当的水平,同时所需的NFE不到40%。此外,在ImageNet 512x512上,eMIGM在只有大约60%的NFE情况下,性能优于最先进的连续扩散模型。
论文及项目相关链接
Summary
本文探讨了面具图像生成模型(masked image generation models)和面具扩散模型(masked diffusion models)的统一框架,并探索了训练和采样的设计空间。基于这些发现,开发出了性能强大的新模型eMIGM。在ImageNet生成任务上,eMIGM表现优秀,相较于早期模型VAR有更高的性能。随着函数评价和模型参数的增加,eMIGM的性能达到了当前最先进的连续扩散模型的水平,但所需的函数评价低于这些模型。在ImageNet 512x512任务上,eMIGM在较少的函数评价下就能表现出超越现有最先进的连续扩散模型的性能。
Key Takeaways
- 面具图像生成模型和面具扩散模型可以在一个统一框架内整合。
- 通过探索训练和采样的设计空间,关键因素被识别为对性能和效率的贡献者。
- 新开发的模型eMIGM在ImageNet生成任务上表现出强大的性能。
- eMIGM相较于早期模型VAR有更高的性能。
- eMIGM的性能达到了当前最先进的连续扩散模型的水平,但所需的函数评价更低。
- 在ImageNet 512x512任务上,eMIGM在较少的函数评价下就能超越现有最先进的连续扩散模型。
点此查看论文截图



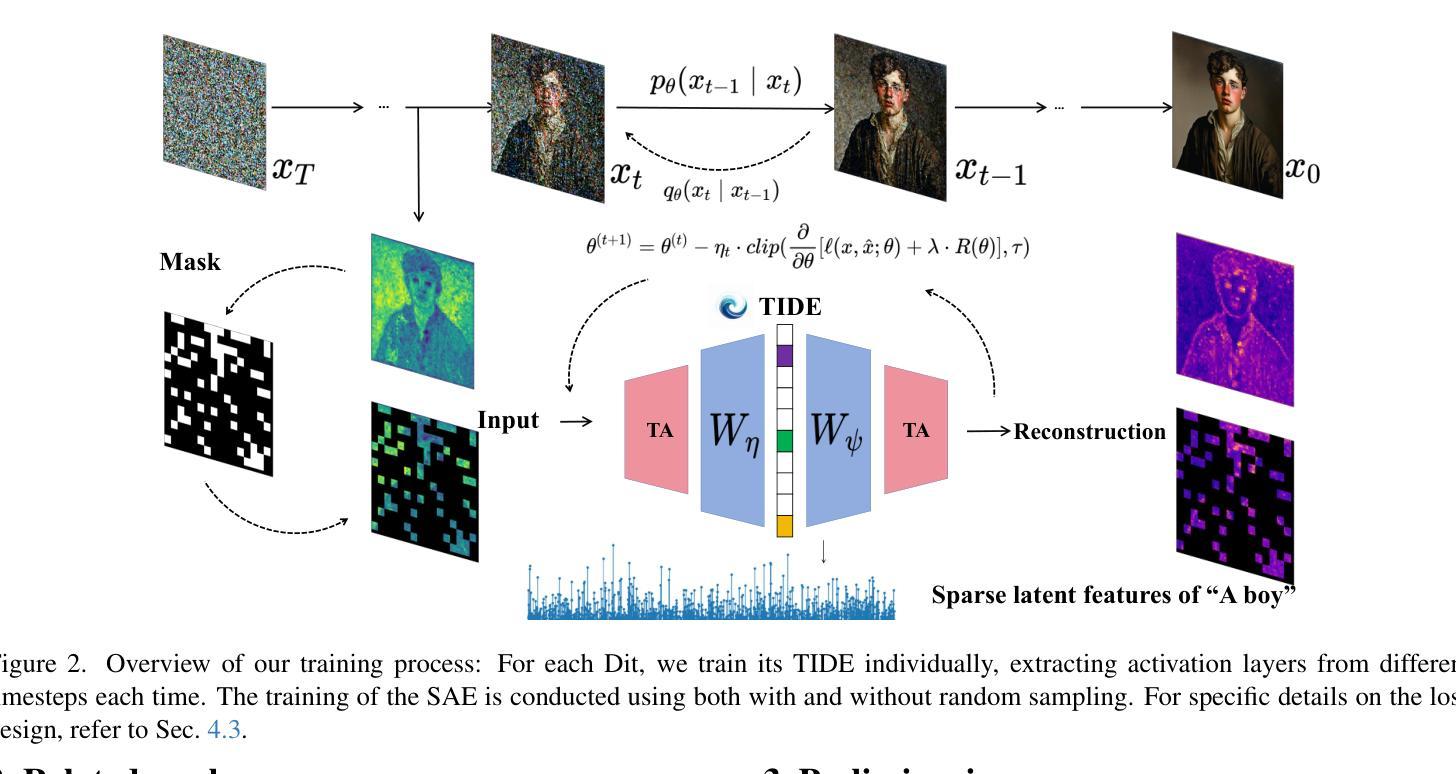
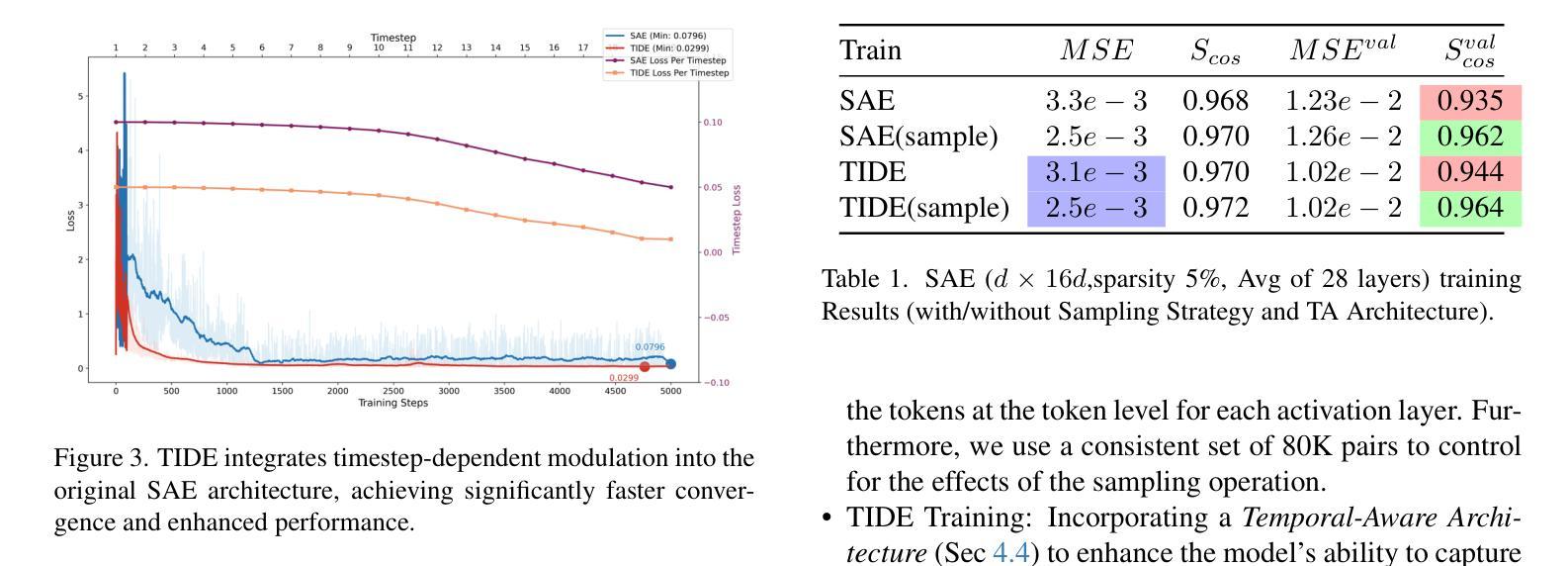
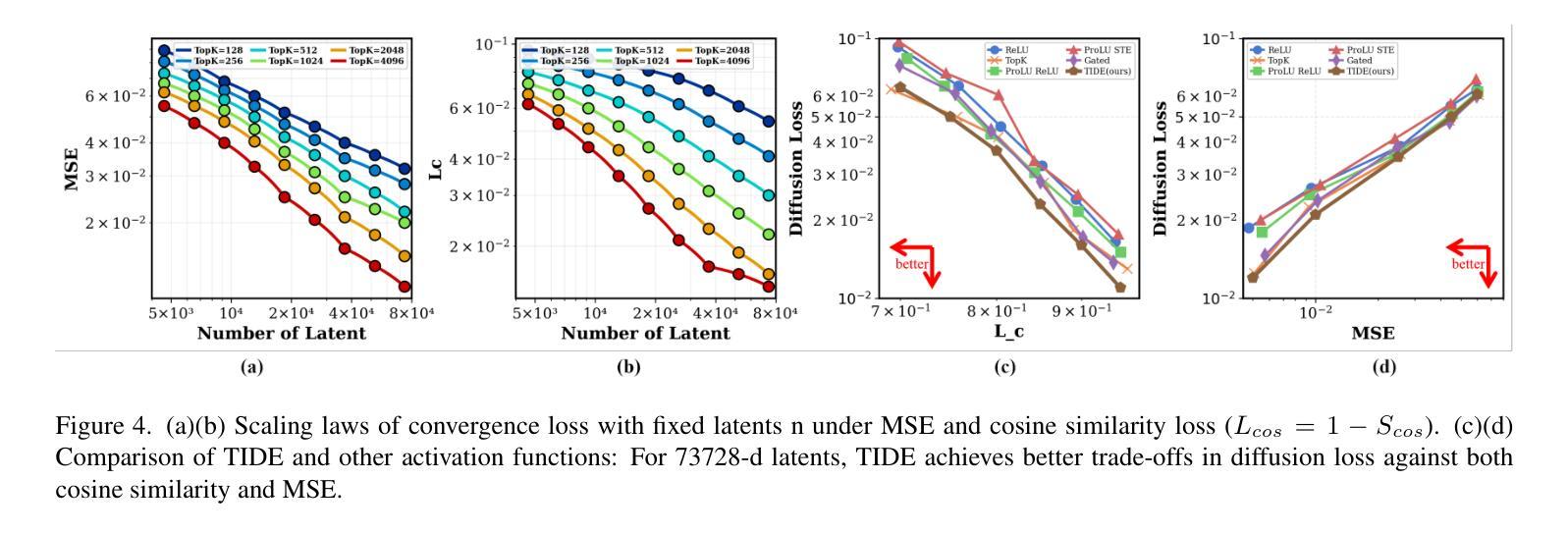
TIDE : Temporal-Aware Sparse Autoencoders for Interpretable Diffusion Transformers in Image Generation
Authors:Victor Shea-Jay Huang, Le Zhuo, Yi Xin, Zhaokai Wang, Peng Gao, Hongsheng Li
Diffusion Transformers (DiTs) are a powerful yet underexplored class of generative models compared to U-Net-based diffusion models. To bridge this gap, we introduce TIDE (Temporal-aware Sparse Autoencoders for Interpretable Diffusion transformErs), a novel framework that enhances temporal reconstruction within DiT activation layers across denoising steps. TIDE employs Sparse Autoencoders (SAEs) with a sparse bottleneck layer to extract interpretable and hierarchical features, revealing that diffusion models inherently learn hierarchical features at multiple levels (e.g., 3D, semantic, class) during generative pre-training. Our approach achieves state-of-the-art reconstruction performance, with a mean squared error (MSE) of 1e-3 and a cosine similarity of 0.97, demonstrating superior accuracy in capturing activation dynamics along the denoising trajectory. Beyond interpretability, we showcase TIDE’s potential in downstream applications such as sparse activation-guided image editing and style transfer, enabling improved controllability for generative systems. By providing a comprehensive training and evaluation protocol tailored for DiTs, TIDE contributes to developing more interpretable, transparent, and trustworthy generative models.
与基于U-Net的扩散模型相比,扩散Transformer(DiTs)是一类强大但尚未被充分研究的生成模型。为了弥补这一差距,我们引入了TIDE(用于可解释扩散Transformer的时序感知稀疏自编码器),这是一个新型框架,旨在增强DiT激活层内的时序重建能力,跨越去噪步骤。TIDE采用具有稀疏瓶颈层的稀疏自编码器(SAE)来提取可解释和分层特征,揭示扩散模型在生成预训练过程中本质上学习多层(例如3D、语义、类别)的分层特征。我们的方法实现了最先进的重建性能,均方误差(MSE)为1e-3,余弦相似度为0.97,证明了在捕获去噪轨迹上的激活动力学方面的卓越准确性。除了可解释性外,我们还展示了TIDE在下游应用中的潜力,如稀疏激活引导的图像编辑和风格转换,为生成系统提供改进的可控性。通过为DiTs提供量身定制的综合培训和评估协议,TIDE为开发更可解释、透明和可信赖的生成模型做出了贡献。
论文及项目相关链接
Summary
本文介绍了扩散模型的一种新框架——TIDE(用于可解释扩散转换器的时序感知稀疏自编码器)。TIDE通过在扩散转换器的激活层中增强时序重建,提高了模型的性能。它采用稀疏自编码器(SAE)和稀疏瓶颈层来提取可解释和分层特征,揭示扩散模型在生成预训练过程中内在地学习多级(如3D、语义、类别)的分层特征。TIDE实现了最先进的重建性能,在均方误差(MSE)和余弦相似性方面表现出卓越的表现。此外,本文还展示了TIDE在下游应用中的潜力,如稀疏激活引导的图像编辑和风格转换,为生成系统提供了更好的可控性。
Key Takeaways
- TIDE是一个用于增强扩散模型性能的新框架,特别是在扩散转换器的激活层中。
- TIDE采用稀疏自编码器(SAE)和稀疏瓶颈层,以提取可解释和分层特征。
- 扩散模型在生成预训练过程中学习多级分层特征。
- TIDE实现了先进的重建性能,具有优秀的准确性。
- TIDE在下游应用,如图像编辑和风格转换中展示了潜力。
- TIDE为生成系统提供了更好的可控性。
点此查看论文截图


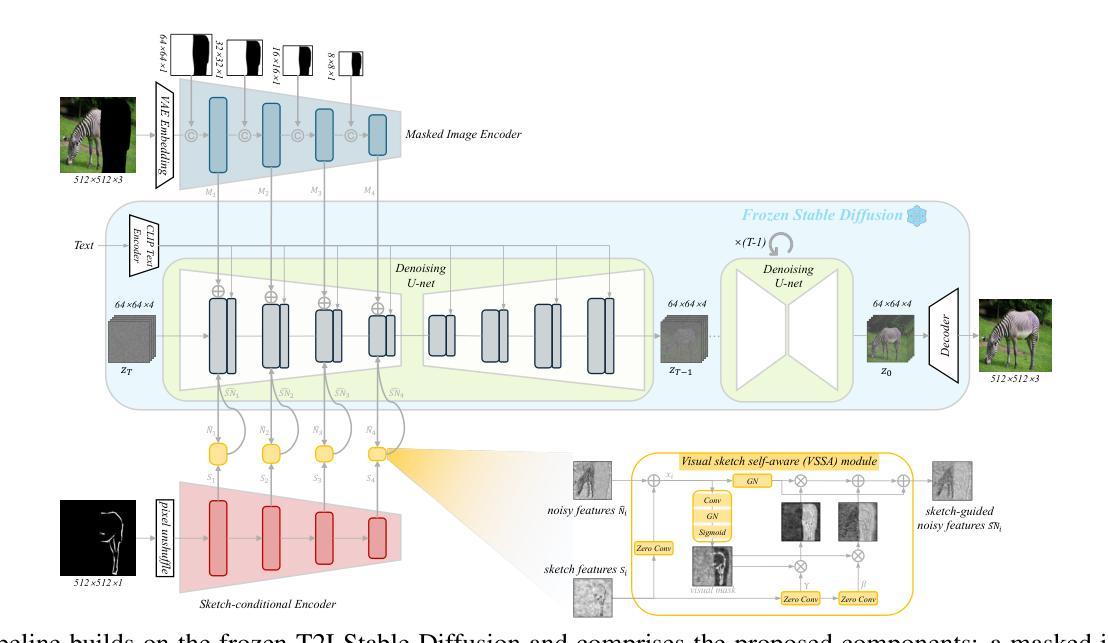
Recovering Partially Corrupted Major Objects through Tri-modality Based Image Completion
Authors:Yongle Zhang, Yimin Liu, Qiang Wu
Diffusion models have become widely adopted in image completion tasks, with text prompts commonly employed to ensure semantic coherence by providing high-level guidance. However, a persistent challenge arises when an object is partially obscured in the damaged region, yet its remaining parts are still visible in the background. While text prompts offer semantic direction, they often fail to precisely recover fine-grained structural details, such as the object’s overall posture, ensuring alignment with the visible object information in the background. This limitation stems from the inability of text prompts to provide pixel-level specificity. To address this, we propose supplementing text-based guidance with a novel visual aid: a casual sketch, which can be roughly drawn by anyone based on visible object parts. This sketch supplies critical structural cues, enabling the generative model to produce an object structure that seamlessly integrates with the existing background. We introduce the Visual Sketch Self-Aware (VSSA) model, which integrates the casual sketch into each iterative step of the diffusion process, offering distinct advantages for partially corrupted scenarios. By blending sketch-derived features with those of the corrupted image, and leveraging text prompt guidance, the VSSA assists the diffusion model in generating images that preserve both the intended object semantics and structural consistency across the restored objects and original regions. To support this research, we created two datasets, CUB-sketch and MSCOCO-sketch, each combining images, sketches, and text. Extensive qualitative and quantitative experiments demonstrate that our approach outperforms several state-of-the-art methods.
扩散模型在图像补全任务中得到了广泛应用,通常采用文本提示来通过提供高级指导来保证语义连贯性。然而,当一个物体在损坏区域中部分被遮挡,但其剩余部分仍能在背景中可见时,就会出现一个持续存在的挑战。虽然文本提示提供了语义方向,但它们往往无法精确恢复物体的精细结构细节,如物体的整体姿势,以及与背景中可见物体信息的对齐。这一局限性源于文本提示无法提供像素级别的具体信息。为了解决这一问题,我们提出了补充基于文本的指导与一种新的视觉辅助工具:随意草图,该草图可以根据可见的物体部分由任何人粗略绘制。草图提供了关键的结构线索,使生成模型能够产生与现有背景无缝集成的物体结构。我们引入了视觉草图自感知(VSSA)模型,它将草图集成到扩散过程的每一步中,为部分损坏的场景提供了明显的优势。通过融合草图特征和损坏图像的特征,并利用文本提示指导,VSSA帮助扩散模型生成既保留意图物体语义又保持恢复物体与原始区域结构一致性的图像。为了支持这项研究,我们创建了两个数据集,分别是CUB-sketch和MSCOCO-sketch,每个数据集都结合了图像、草图和文本。大量的定性和定量实验表明,我们的方法优于几种最先进的方法。
论文及项目相关链接
PDF 17 pages, 6 page supplementary
Summary
本文探讨了扩散模型在图像补全任务中的应用,针对部分遮挡物体的问题,提出了一种结合文本提示和草图视觉辅助的新方法。通过引入Visual Sketch Self-Aware(VSSA)模型,结合草图提供的结构线索,辅助扩散模型生成与背景无缝融合的对象结构。此外,还创建了两个数据集CUB-sketch和MSCOCO-sketch以支持研究。实验证明,该方法优于现有先进技术。
Key Takeaways
- 扩散模型广泛应用于图像补全任务。
- 文本提示在保持语义连贯性方面发挥重要作用,但在恢复细粒度结构细节方面存在局限性。
- 提出了一种结合文本提示和草图视觉辅助的新方法,以解决部分遮挡物体的问题。
- 引入了Visual Sketch Self-Aware(VSSA)模型,将草图融入扩散过程的每一步。
- 草图提供关键结构线索,帮助生成与背景无缝融合的对象结构。
- 创建了两个数据集CUB-sketch和MSCOCO-sketch以支持研究。
点此查看论文截图

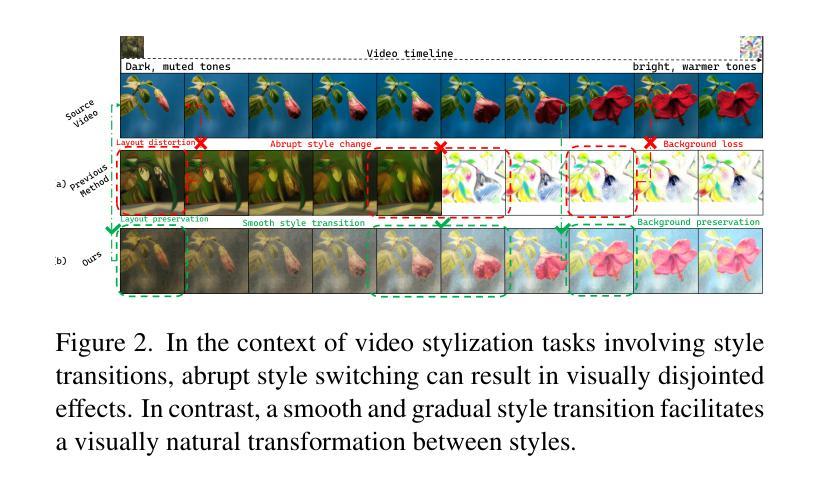
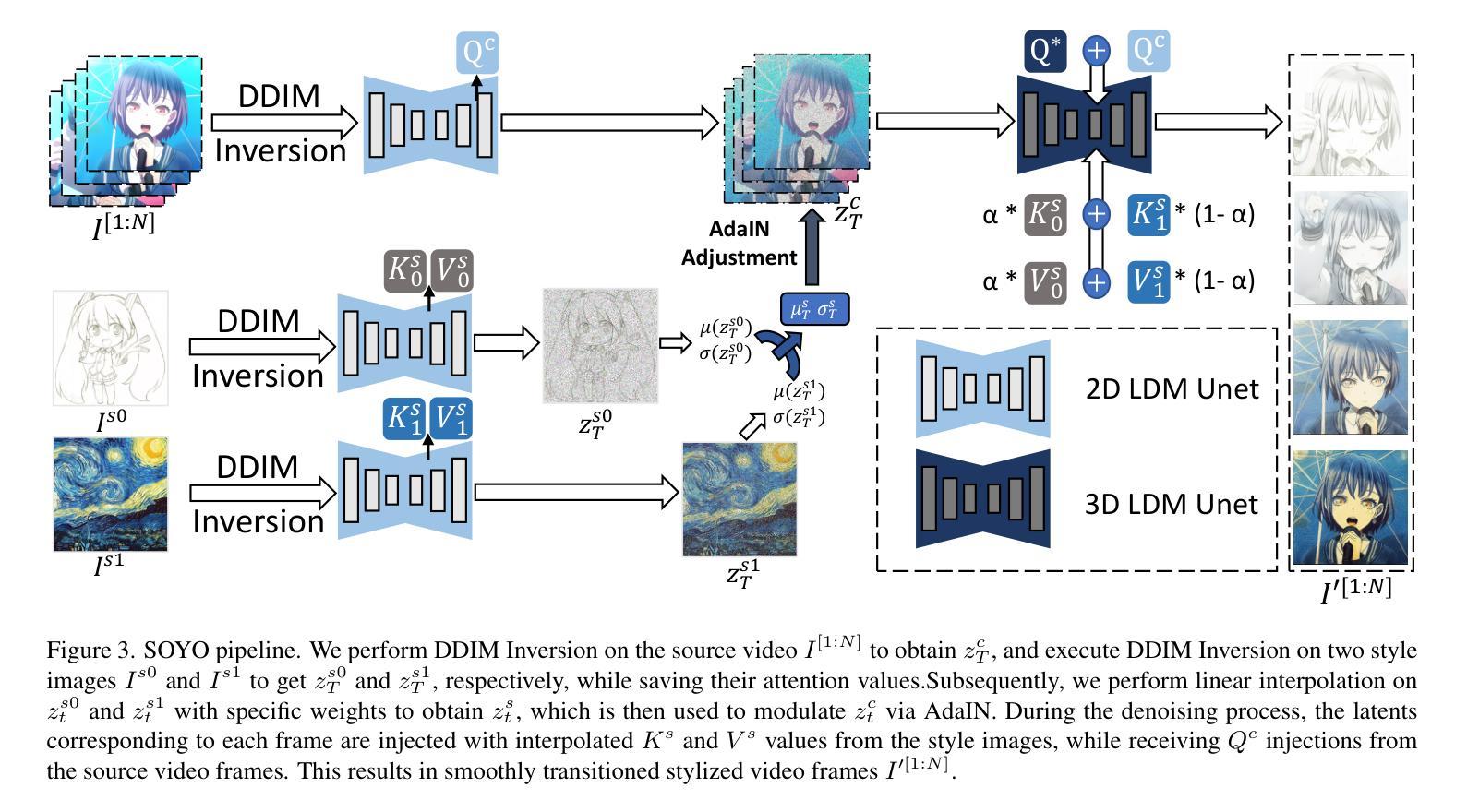
SOYO: A Tuning-Free Approach for Video Style Morphing via Style-Adaptive Interpolation in Diffusion Models
Authors:Haoyu Zheng, Qifan Yu, Binghe Yu, Yang Dai, Wenqiao Zhang, Juncheng Li, Siliang Tang, Yueting Zhuang
Diffusion models have achieved remarkable progress in image and video stylization. However, most existing methods focus on single-style transfer, while video stylization involving multiple styles necessitates seamless transitions between them. We refer to this smooth style transition between video frames as video style morphing. Current approaches often generate stylized video frames with discontinuous structures and abrupt style changes when handling such transitions. To address these limitations, we introduce SOYO, a novel diffusion-based framework for video style morphing. Our method employs a pre-trained text-to-image diffusion model without fine-tuning, combining attention injection and AdaIN to preserve structural consistency and enable smooth style transitions across video frames. Moreover, we notice that applying linear equidistant interpolation directly induces imbalanced style morphing. To harmonize across video frames, we propose a novel adaptive sampling scheduler operating between two style images. Extensive experiments demonstrate that SOYO outperforms existing methods in open-domain video style morphing, better preserving the structural coherence of video frames while achieving stable and smooth style transitions.
扩散模型在图像和视频风格化方面取得了显著的进展。然而,大多数现有方法主要关注单一风格转换,而涉及多种风格的视频风格化需要风格之间的无缝过渡。我们将视频帧之间这种平滑的风格过渡称为视频风格渐变。当前的方法在处理此类过渡时,通常生成的视频帧风格化结构不连续,风格变化突兀。为了解决这些局限性,我们引入了SOYO,这是一种基于扩散的新型视频风格渐变框架。我们的方法采用预训练的文本到图像扩散模型,无需微调,结合注意力注入和AdaIN,以保留结构一致性并实现视频帧之间的平滑风格过渡。此外,我们注意到直接应用线性等距插值会导致风格渐变不平衡。为了协调视频帧之间的和谐度,我们提出了一种新型自适应采样调度器,在两种风格图像之间运行。大量实验表明,SOYO在开放域视频风格渐变方面优于现有方法,更好地保留了视频帧的结构连贯性,同时实现了稳定和平滑的风格过渡。
论文及项目相关链接
Summary
文本指出扩散模型在图像和视频风格化方面取得了显著进展,但现有方法主要关注单风格转移,对于涉及多种风格的视频风格化,需要在视频帧之间实现平滑的风格过渡,称为视频风格渐变。现有方法在处理这种过渡时,生成的视频帧结构不连续,风格变化突兀。为解决这个问题,引入了SOYO,一种基于扩散的视频风格渐变新框架。该方法采用预训练的文本到图像的扩散模型,结合注意力注入和AdaIN,无需微调即可保留结构一致性,实现视频帧之间的平滑风格过渡。还发现直接应用线性等距插值会导致风格渐变不平衡,提出一种新型自适应采样调度器,在两种风格图像之间协调操作。实验证明,SOYO在开放域视频风格渐变方面优于现有方法,更好地保持视频帧的结构连贯性,实现稳定和平滑的风格过渡。
Key Takeaways
- 扩散模型在图像和视频风格化方面取得显著进展,但处理多风格过渡时存在挑战。
- 视频风格渐变要求在视频帧之间实现平滑的风格过渡。
- 现有方法在处理风格过渡时生成的视频帧结构不连续,风格变化突兀。
- SOYO是一种基于扩散的视频风格渐变新框架,采用预训练的文本到图像的扩散模型。
- SOYO通过结合注意力注入和AdaIN,实现结构一致性和平滑风格过渡。
- 直接应用线性等距插值会导致风格渐变不平衡,SOYO引入新型自适应采样调度器解决这个问题。
- 实验证明SOYO在开放域视频风格渐变方面优于现有方法。
点此查看论文截图


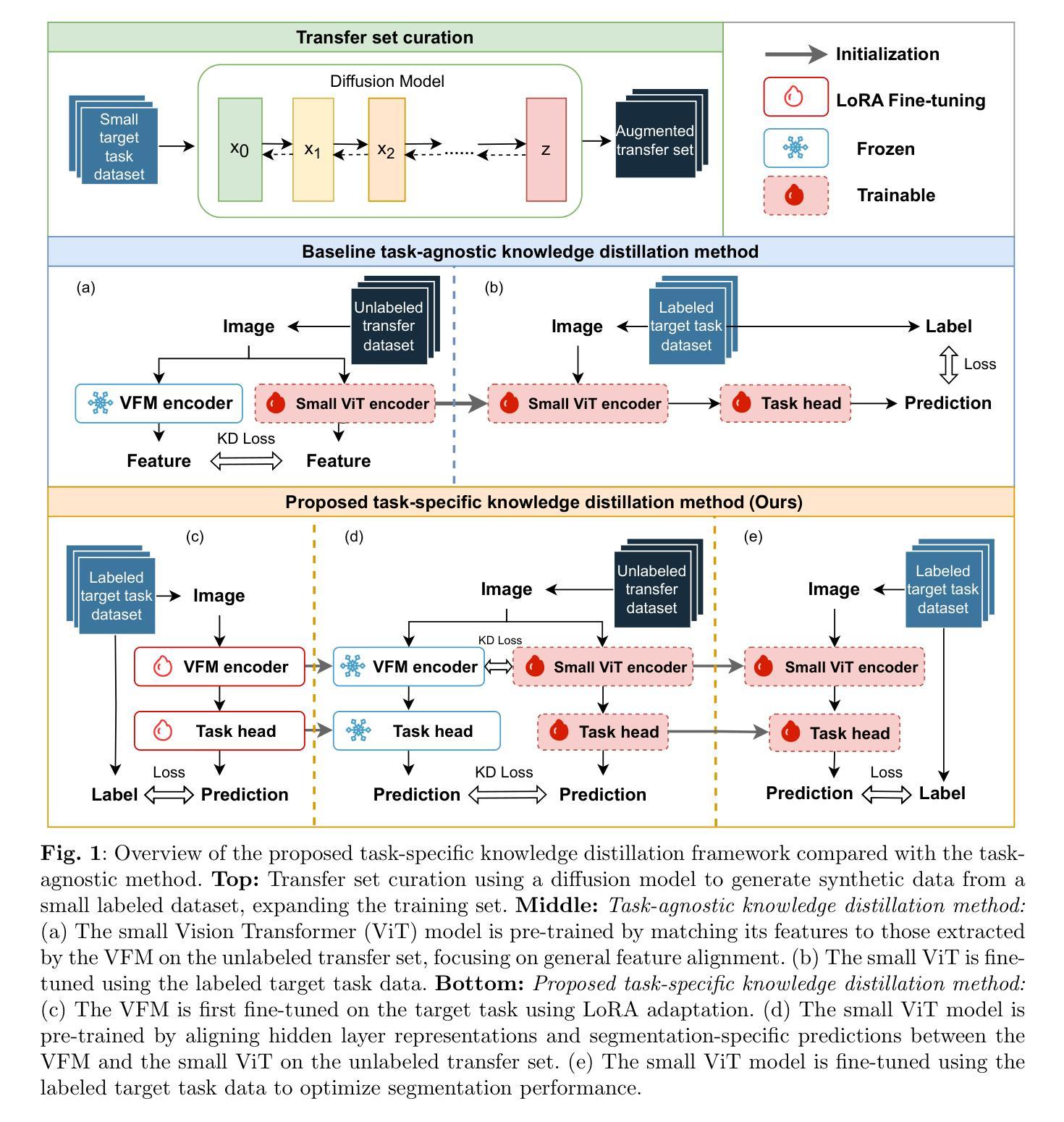
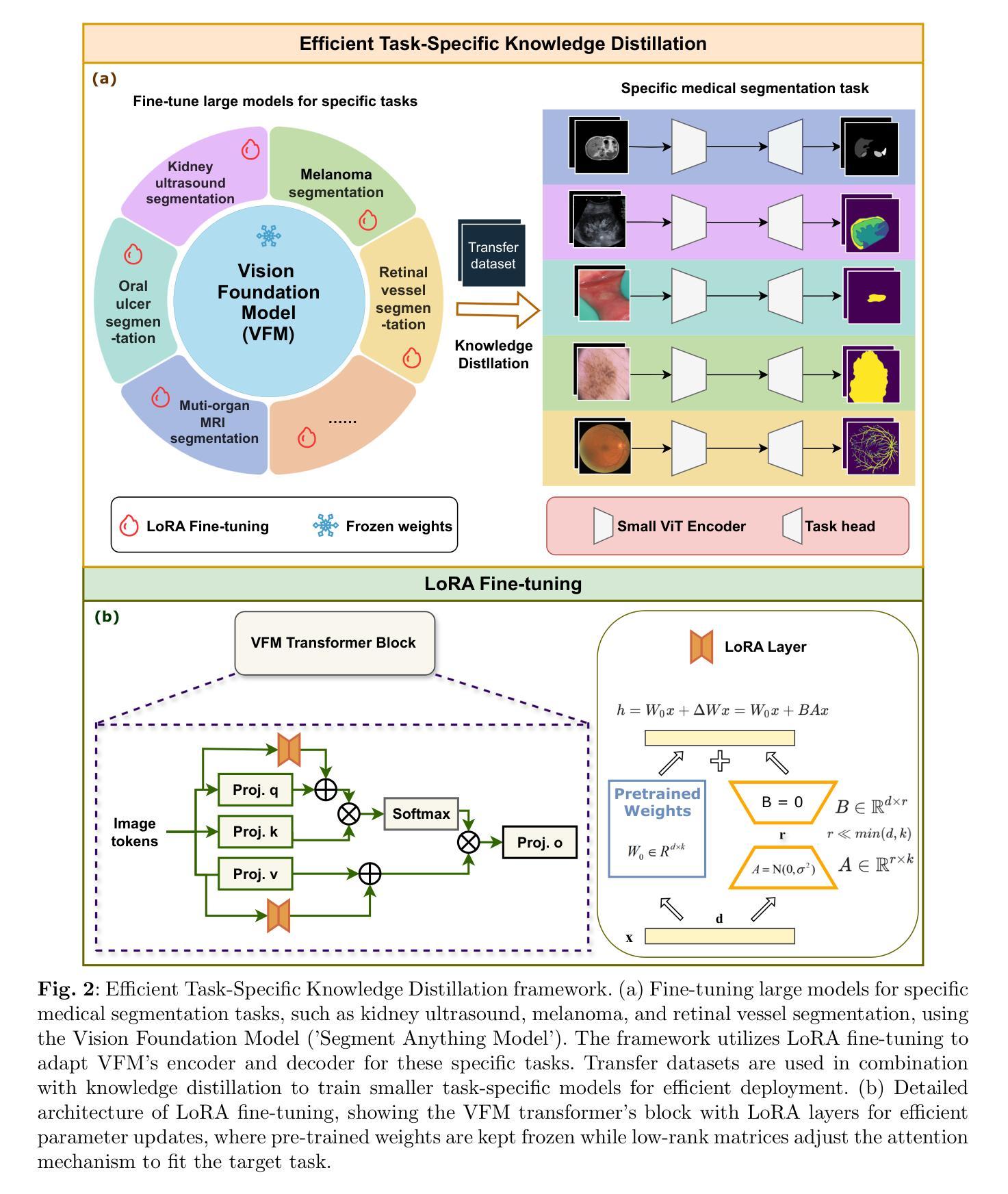
Task-Specific Knowledge Distillation from the Vision Foundation Model for Enhanced Medical Image Segmentation
Authors:Pengchen Liang, Haishan Huang, Bin Pu, Jianguo Chen, Xiang Hua, Jing Zhang, Weibo Ma, Zhuangzhuang Chen, Yiwei Li, Qing Chang
Large-scale pre-trained models, such as Vision Foundation Models (VFMs), have demonstrated impressive performance across various downstream tasks by transferring generalized knowledge, especially when target data is limited. However, their high computational cost and the domain gap between natural and medical images limit their practical application in medical segmentation tasks. Motivated by this, we pose the following important question: “How can we effectively utilize the knowledge of large pre-trained VFMs to train a small, task-specific model for medical image segmentation when training data is limited?” To address this problem, we propose a novel and generalizable task-specific knowledge distillation framework. Our method fine-tunes the VFM on the target segmentation task to capture task-specific features before distilling the knowledge to smaller models, leveraging Low-Rank Adaptation (LoRA) to reduce the computational cost of fine-tuning. Additionally, we incorporate synthetic data generated by diffusion models to augment the transfer set, enhancing model performance in data-limited scenarios. Experimental results across five medical image datasets demonstrate that our method consistently outperforms task-agnostic knowledge distillation and self-supervised pretraining approaches like MoCo v3 and Masked Autoencoders (MAE). For example, on the KidneyUS dataset, our method achieved a 28% higher Dice score than task-agnostic KD using 80 labeled samples for fine-tuning. On the CHAOS dataset, it achieved an 11% improvement over MAE with 100 labeled samples. These results underscore the potential of task-specific knowledge distillation to train accurate, efficient models for medical image segmentation in data-constrained settings.
大规模预训练模型,如视觉基础模型(VFMs),通过迁移通用知识,在各种下游任务中展示了令人印象深刻的性能,尤其是在目标数据有限的情况下。然而,它们的高计算成本以及自然图像和医学图像之间的领域差距限制了它们在医学分割任务中的实际应用。在此背景下,我们提出了以下问题:“当训练数据有限时,如何有效地利用大规模预训练VFMs的知识来训练用于医学图像分割的小规模、特定任务模型?”为了解决这一问题,我们提出了一种新型且通用的特定任务知识蒸馏框架。我们的方法首先在目标分割任务上微调VFM以捕获特定任务特征,然后将知识蒸馏到较小的模型上,并利用低秩适应(LoRA)来降低微调的计算成本。此外,我们通过扩散模型生成的合成数据来增强迁移集,从而提高在数据有限场景中的模型性能。在五个医学图像数据集上的实验结果表明,我们的方法始终优于任务无关的知识蒸馏和自我监督预训练方法,如MoCo v3和遮罩自动编码器(MAE)。例如,在KidneyUS数据集上,使用80个标记样本进行微调时,我们的方法所获得的Dice得分比任务无关KD高出28%。在CHAOS数据集上,使用100个标记样本时,与MAE相比,我们的方法实现了11%的改进。这些结果突显了任务特定知识蒸馏在数据受限环境中训练医学图像分割准确高效模型的潜力。
论文及项目相关链接
PDF 29 pages, 10 figures, 16 tables
摘要
大规模预训练模型,如视觉基础模型(VFMs),在多种下游任务中展现出卓越性能,尤其在目标数据有限的情况下通过知识迁移实现。然而,其高昂的计算成本以及自然图像与医疗图像领域间的差距,限制了其在医疗分割任务中的实际应用。针对这一问题,我们提出一个重要问题:“如何在数据有限的情况下,有效利用大规模预训练VFMs的知识来训练小型、针对医疗图像分割任务的模型?”为解决这个问题,我们提出一个通用、针对任务的知识蒸馏框架。我们的方法首先对VFM进行目标分割任务的微调,以捕获任务特定特征,然后将知识蒸馏到小型模型,并利用低秩适应(LoRA)减少微调的计算成本。此外,我们结合扩散模型生成的合成数据来增强转移集,提高模型在数据有限场景中的性能。在五个医疗图像数据集上的实验结果表明,我们的方法一致优于任务无关的知识蒸馏和自我监督预训练方法,如MoCo v3和Masked Autoencoders(MAE)。例如,在KidneyUS数据集上,使用我们的方法仅使用80个样本进行微调时,Dice得分比任务无关KD高出28%。在CHAOS数据集上,使用100个样本时,我们的方法比MAE提高了11%。这些结果突显了任务特定知识蒸馏在数据受限情况下训练医疗图像分割准确高效模型的潜力。
关键见解
- 大型预训练模型在医疗分割任务中面临高计算成本和领域差距问题。
- 提出利用任务特定知识蒸馏框架来训练小型医疗图像分割模型。
- 通过微调VFM捕获任务特定特征,然后将其知识蒸馏到小型模型。
- 利用低秩适应(LoRA)减少微调的计算成本。
- 结合扩散模型生成的合成数据增强转移集,提高在数据有限场景中的性能。
- 在多个医疗图像数据集上的实验结果表明,该方法优于任务无关的知识蒸馏和自我监督预训练方法。
点此查看论文截图

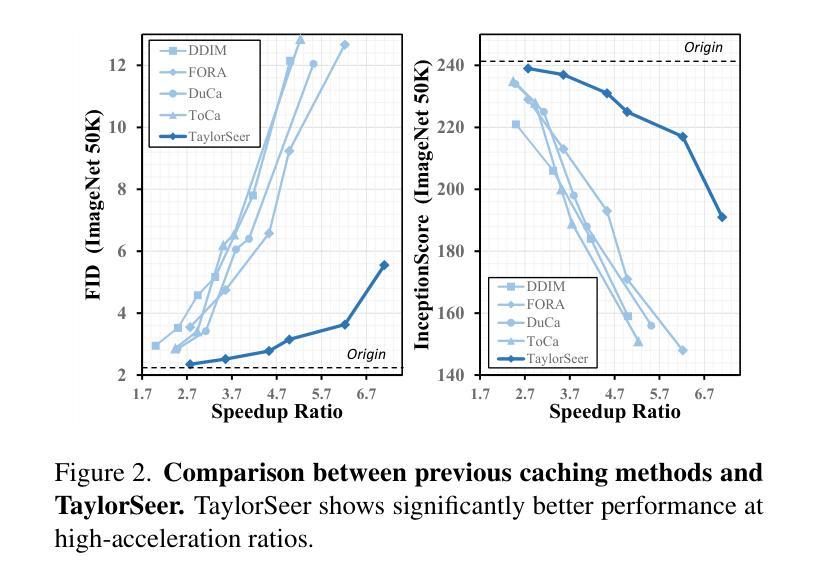
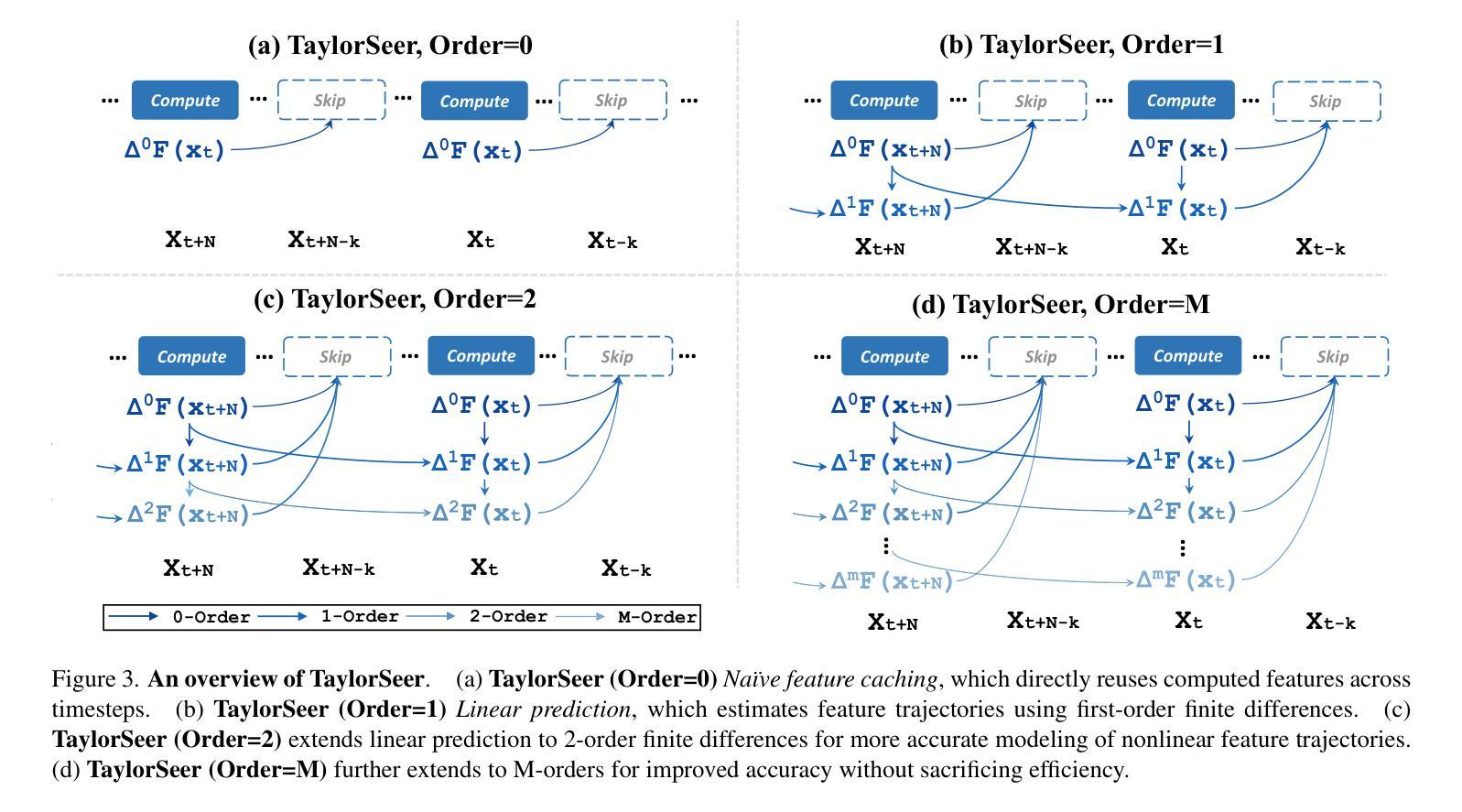
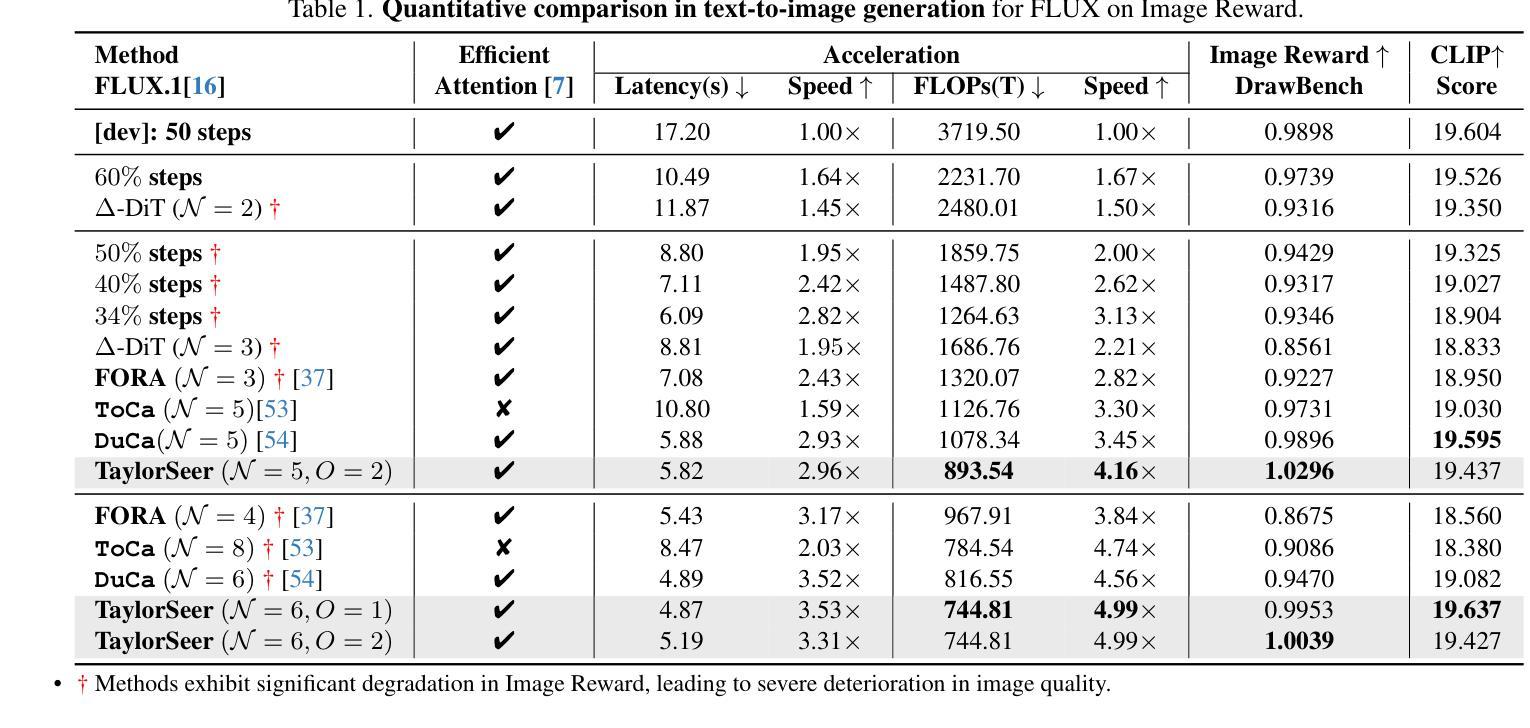
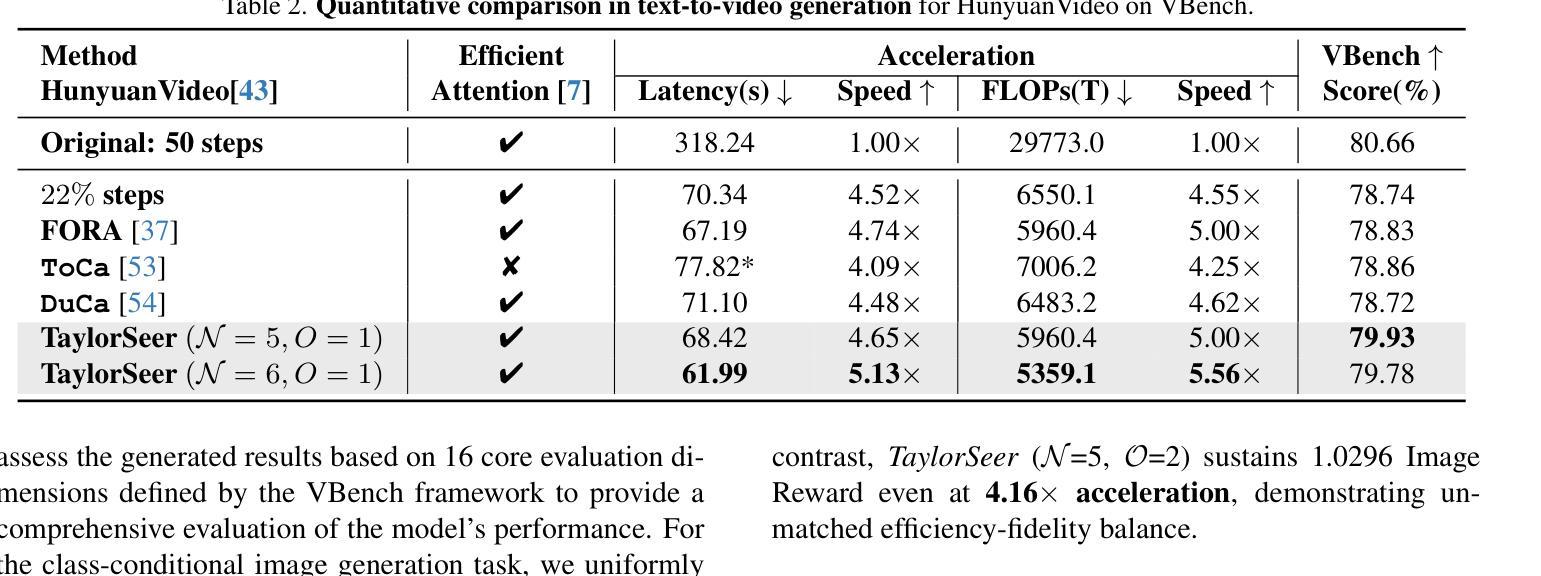
From Reusing to Forecasting: Accelerating Diffusion Models with TaylorSeers
Authors:Jiacheng Liu, Chang Zou, Yuanhuiyi Lyu, Junjie Chen, Linfeng Zhang
Diffusion Transformers (DiT) have revolutionized high-fidelity image and video synthesis, yet their computational demands remain prohibitive for real-time applications. To solve this problem, feature caching has been proposed to accelerate diffusion models by caching the features in the previous timesteps and then reusing them in the following timesteps. However, at timesteps with significant intervals, the feature similarity in diffusion models decreases substantially, leading to a pronounced increase in errors introduced by feature caching, significantly harming the generation quality. To solve this problem, we propose TaylorSeer, which firstly shows that features of diffusion models at future timesteps can be predicted based on their values at previous timesteps. Based on the fact that features change slowly and continuously across timesteps, TaylorSeer employs a differential method to approximate the higher-order derivatives of features and predict features in future timesteps with Taylor series expansion. Extensive experiments demonstrate its significant effectiveness in both image and video synthesis, especially in high acceleration ratios. For instance, it achieves an almost lossless acceleration of 4.99$\times$ on FLUX and 5.00$\times$ on HunyuanVideo without additional training. On DiT, it achieves $3.41$ lower FID compared with previous SOTA at $4.53$$\times$ acceleration. %Our code is provided in the supplementary materials and will be made publicly available on GitHub. Our codes have been released in Github:https://github.com/Shenyi-Z/TaylorSeer
Diffusion Transformers(DiT)已经实现了高保真图像和视频合成的革命性进展,但其计算需求对于实时应用来说仍然很大。为了解决这一问题,提出了特征缓存来加速扩散模型,通过缓存前一时间步的特征并在后续时间步中重复使用它们。然而,在时间步长较大的情况下,扩散模型中的特征相似性会大幅下降,导致由特征缓存引入的错误显著增加,从而严重损害生成质量。为了解决这一问题,我们提出了TaylorSeer。它首先表明,可以根据之前时间步的值预测扩散模型在未来时间步的特征。基于特征在时间步上缓慢且连续变化的特性,TaylorSeer采用差分方法近似特征的高阶导数,并使用泰勒级数展开预测未来时间步的特征。大量实验证明,它在图像和视频合成中都取得了显著的有效性,特别是在高加速比的情况下。例如,在FLUX和HunyuanVideo上实现了近乎无损的4.99倍和5.00倍的加速;在DiT上,以4.53倍的加速实现了比先前最佳水平低3.41的FID得分。我们的代码已发布在GitHub上:https://github.com/Shenyi-Z/TaylorSeer。
论文及项目相关链接
PDF 13 pages, 14 figures
Summary
扩散转换器(DiT)在高质量图像和视频合成领域实现了革命性的进展,但其计算需求仍然很大,难以满足实时应用的要求。为了解决这一问题,提出了特征缓存来加速扩散模型,但在时间步长较大的情况下,特征相似性会降低,导致特征缓存引入的错误增加,严重影响生成质量。针对这一问题,本文提出了TaylorSeer方法。它基于扩散模型在之前时间步的特征值来预测未来时间步的特征值。利用特征在时序上缓慢且连续的变化,通过微分法计算特征的高阶导数并使用泰勒级数展开进行预测。实验证明,该方法在图像和视频合成中效果显著,特别是在高加速比的情况下。例如,在FLUX和HunyuanVideo上实现了近乎无损的4.99×和5.00×加速;在DiT上,以4.53×的加速比实现了相比之前最佳水平降低3.41的FID。我们的代码已发布在GitHub上。
Key Takeaways
- 扩散转换器(DiT)在图像和视频合成上表现出卓越性能,但计算需求较大,不利于实时应用。
- 特征缓存被提出来加速扩散模型,但在时间步长大的情况下会出现问题,导致生成质量下降。
- TaylorSeer方法基于之前时间步的特征值预测未来时间步的特征值,解决上述问题。
- 利用特征在时序上的缓慢且连续变化,通过微分法预测未来特征。
- TaylorSeer在图像和视频合成中效果显著,实现了高加速比下的高质量生成。
- 在FLUX和HunyuanVideo上实现了近乎无损的加速,代码已发布在GitHub上。
点此查看论文截图

Text-to-Image Diffusion Models Cannot Count, and Prompt Refinement Cannot Help
Authors:Yuefan Cao, Xuyang Guo, Jiayan Huo, Yingyu Liang, Zhenmei Shi, Zhao Song, Jiahao Zhang, Zhen Zhuang
Generative modeling is widely regarded as one of the most essential problems in today’s AI community, with text-to-image generation having gained unprecedented real-world impacts. Among various approaches, diffusion models have achieved remarkable success and have become the de facto solution for text-to-image generation. However, despite their impressive performance, these models exhibit fundamental limitations in adhering to numerical constraints in user instructions, frequently generating images with an incorrect number of objects. While several prior works have mentioned this issue, a comprehensive and rigorous evaluation of this limitation remains lacking. To address this gap, we introduce T2ICountBench, a novel benchmark designed to rigorously evaluate the counting ability of state-of-the-art text-to-image diffusion models. Our benchmark encompasses a diverse set of generative models, including both open-source and private systems. It explicitly isolates counting performance from other capabilities, provides structured difficulty levels, and incorporates human evaluations to ensure high reliability. Extensive evaluations with T2ICountBench reveal that all state-of-the-art diffusion models fail to generate the correct number of objects, with accuracy dropping significantly as the number of objects increases. Additionally, an exploratory study on prompt refinement demonstrates that such simple interventions generally do not improve counting accuracy. Our findings highlight the inherent challenges in numerical understanding within diffusion models and point to promising directions for future improvements.
生成建模被广大AI社区视为当今最重要的课题之一,文本到图像的生成已经产生了前所未有的现实影响。在众多方法中,扩散模型取得了显著的成就,并成为文本到图像生成的实际解决方案。然而,尽管这些模型表现出令人印象深刻的性能,但它们在用户指令的数值约束遵循方面存在基本局限,经常生成具有错误对象数量的图像。尽管一些早期的工作已经提到了这个问题,但对于这一局限性的全面和严格评估仍然缺乏。为了弥补这一空白,我们引入了T2ICountBench,这是一个新颖的基准测试,旨在严格评估最新文本到图像扩散模型的计数能力。我们的基准测试涵盖了各种生成模型,包括开源和私有系统。它明确地将计数性能与其他能力区分开来,提供结构化的难度级别,并纳入人类评估以确保高可靠性。使用T2ICountBench进行的广泛评估显示,所有最先进的扩散模型都无法生成正确数量的对象,随着对象数量的增加,准确性显著降低。此外,关于提示细化的探索性研究表明,这样的简单干预一般不会提高计数准确性。我们的研究结果突出了扩散模型中数值理解方面的固有挑战,并指出了未来改进的有希望的方向。
论文及项目相关链接
Summary
文本介绍了生成模型在AI领域的重要性,特别是文本到图像生成方面。扩散模型在这一领域取得了显著成功,但存在数值约束方面的根本局限性,即在遵循用户指令中的数量时经常出现问题。为此,文章引入了一个新的评估工具T2ICountBench,以严格评估最先进文本到图像扩散模型的计数能力。评估结果显示,所有先进扩散模型都无法正确生成对象数量,随着对象数量增加,准确性显著下降。提示改进的探索性研究也表明,简单的干预措施通常不能提高计数准确性。这揭示了扩散模型中数值理解的固有挑战,并为未来的改进指明了方向。
Key Takeaways
- 扩散模型在文本到图像生成领域取得了显著成功,成为该领域的实际解决方案。
- 扩散模型在遵循用户指令中的数量方面存在根本局限性。
- 引入了一个新的评估工具T2ICountBench,以严格评估最先进文本到图像扩散模型的计数能力。
- 评估结果显示所有先进扩散模型都无法正确生成指定数量的对象。
- 随着对象数量的增加,模型的准确性显著下降。
- 简单的提示改进措施通常不能提高模型的计数准确性。
点此查看论文截图

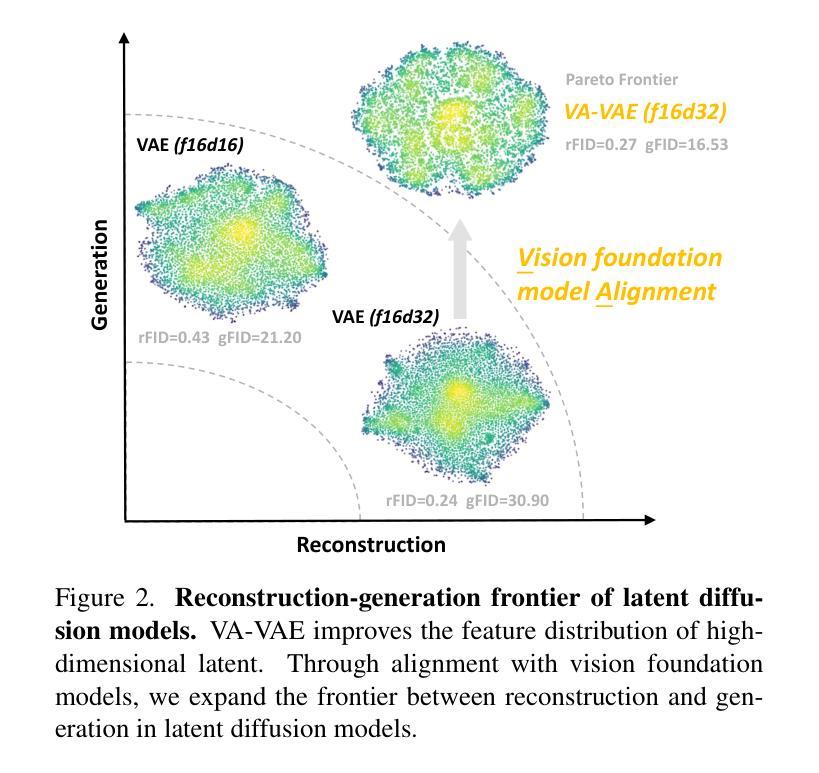
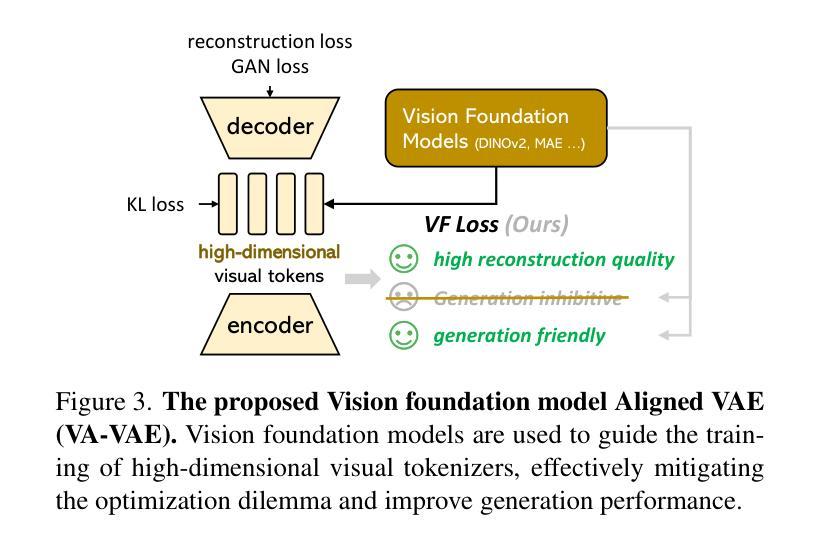
Reconstruction vs. Generation: Taming Optimization Dilemma in Latent Diffusion Models
Authors:Jingfeng Yao, Bin Yang, Xinggang Wang
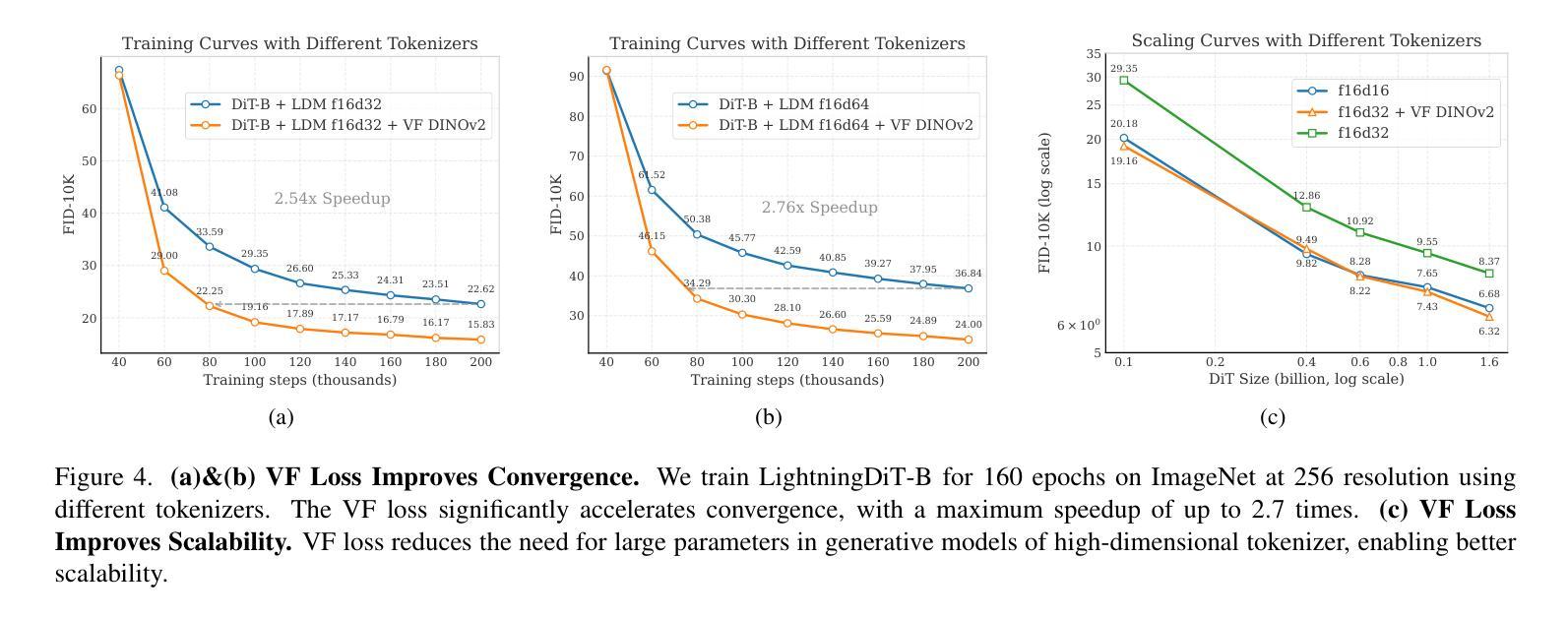
Latent diffusion models with Transformer architectures excel at generating high-fidelity images. However, recent studies reveal an optimization dilemma in this two-stage design: while increasing the per-token feature dimension in visual tokenizers improves reconstruction quality, it requires substantially larger diffusion models and more training iterations to achieve comparable generation performance. Consequently, existing systems often settle for sub-optimal solutions, either producing visual artifacts due to information loss within tokenizers or failing to converge fully due to expensive computation costs. We argue that this dilemma stems from the inherent difficulty in learning unconstrained high-dimensional latent spaces. To address this, we propose aligning the latent space with pre-trained vision foundation models when training the visual tokenizers. Our proposed VA-VAE (Vision foundation model Aligned Variational AutoEncoder) significantly expands the reconstruction-generation frontier of latent diffusion models, enabling faster convergence of Diffusion Transformers (DiT) in high-dimensional latent spaces. To exploit the full potential of VA-VAE, we build an enhanced DiT baseline with improved training strategies and architecture designs, termed LightningDiT. The integrated system achieves state-of-the-art (SOTA) performance on ImageNet 256x256 generation with an FID score of 1.35 while demonstrating remarkable training efficiency by reaching an FID score of 2.11 in just 64 epochs–representing an over 21 times convergence speedup compared to the original DiT. Models and codes are available at: https://github.com/hustvl/LightningDiT.
基于Transformer架构的潜在扩散模型在生成高保真图像方面表现出色。然而,最近的研究揭示了这种两阶段设计中的优化困境:虽然增加视觉分词器的每令牌特征维度提高了重建质量,但需要更大规模的扩散模型和更多的训练迭代才能达到相当的生成性能。因此,现有系统通常选择次优解决方案,要么由于分词器内部的信息丢失而产生视觉伪影,要么由于计算成本高昂而无法完全收敛。我们认为,这种困境源于学习无约束的高维潜在空间的固有困难。
论文及项目相关链接
PDF Models and codes are available at: https://github.com/hustvl/LightningDiT
Summary
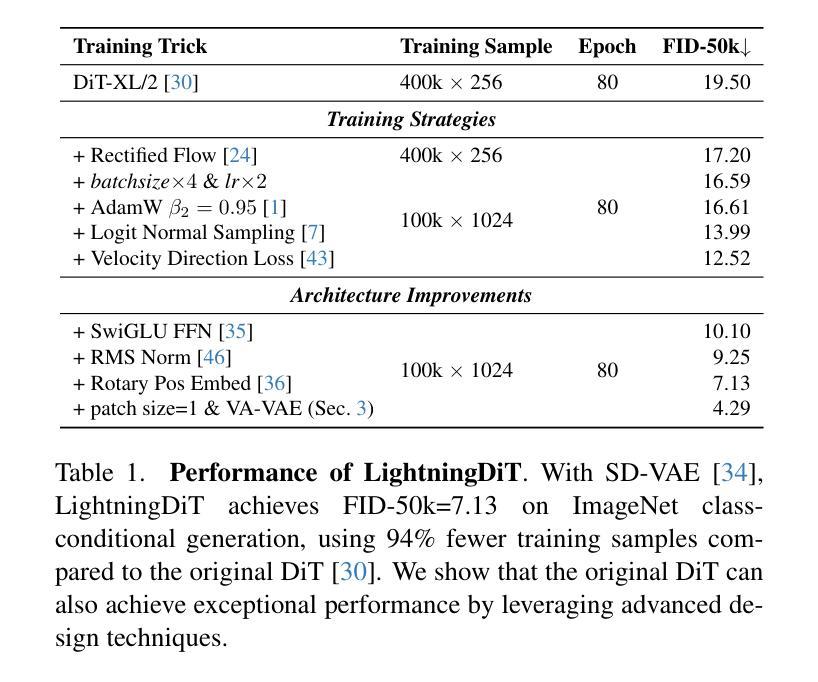
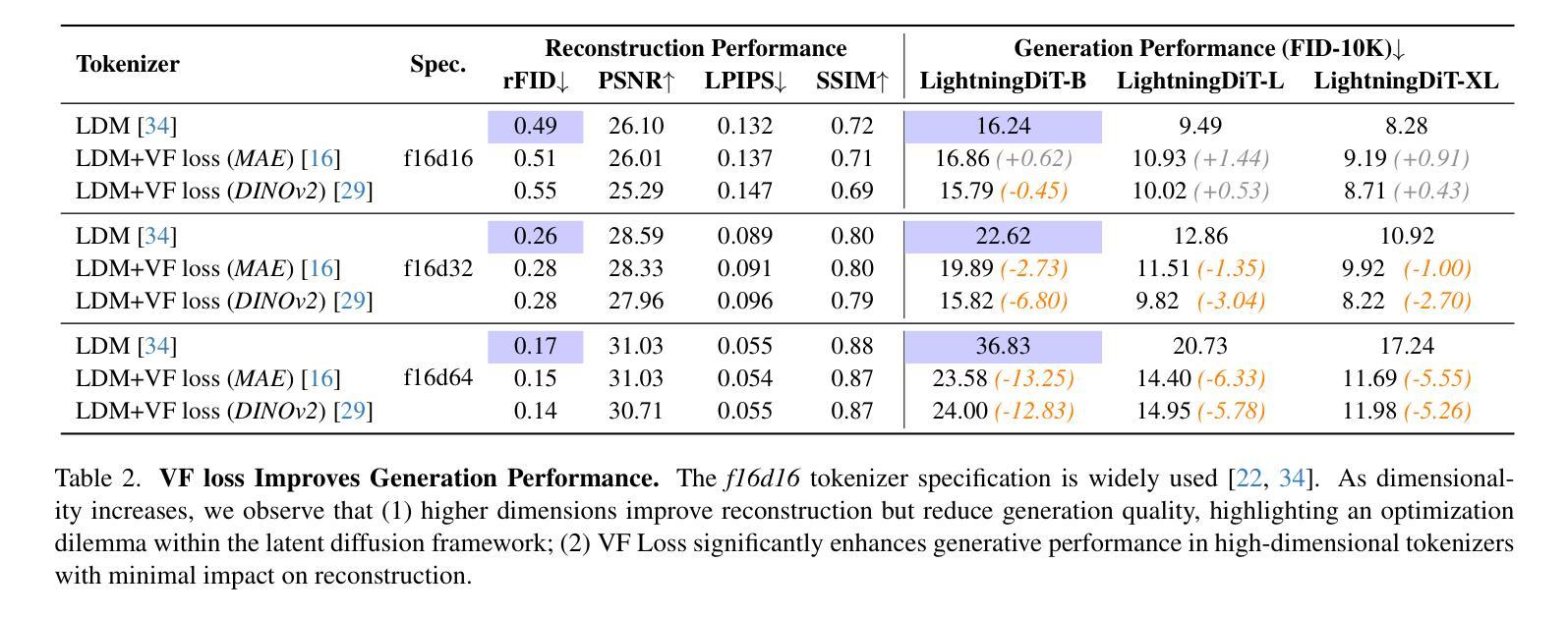
本文探讨了基于Transformer架构的潜在扩散模型在高保真图像生成方面的优势。研究揭示了两阶段设计中的优化困境:提高视觉令牌器中的每令牌特征维度可以提高重建质量,但需要更大的扩散模型和更多的训练迭代来实现相当的生成性能。为解决这一困境,本文提出在训练视觉令牌器时,与预训练的视觉基础模型对齐潜在空间。提出的VA-VAE(与视觉基础模型对齐的变分自编码器)显著扩展了潜在扩散模型的重建-生成边界,使高维潜在空间中的Diffusion Transformers(DiT)更快收敛。为充分发挥VA-VAE的潜力,建立了增强型DiT基线,具有改进的训练策略和架构设计,称为LightningDiT。集成系统在ImageNet 256x256生成方面达到最新技术水平,FID得分为1.35,同时展现出惊人的训练效率,仅64个周期就达到FID 2.11,相较于原始DiT实现了超过21倍的收敛速度提升。
Key Takeaways
- 潜在扩散模型能生成高保真图像,但存在优化困境:提高视觉令牌器中的特征维度可提高重建质量,但增加模型大小和训练成本。
- 困境源于学习无约束的高维潜在空间的内在困难。
- 提出VA-VAE方法,通过与预训练的视觉基础模型对齐潜在空间来解决优化困境。
- VA-VAE显著扩展了潜在扩散模型的重建-生成边界,加速Diffusion Transformers(DiT)在高维空间的收敛速度。
- 建立了增强型DiT基线LightningDiT,具有改进的训练策略和架构设计。
- LightningDiT在ImageNet 256x256生成方面达到最新技术水平,FID得分1.35。
- LightningDiT展现出惊人的训练效率,仅64个周期就达到FID 2.11,相较于原始DiT实现了超过21倍的收敛速度提升。
点此查看论文截图

Rethinking Diffusion-Based Image Generators for Fundus Fluorescein Angiography Synthesis on Limited Data
Authors:Chengzhou Yu, Huihui Fang, Hongqiu Wang, Ting Deng, Qing Du, Yanwu Xu, Weihua Yang
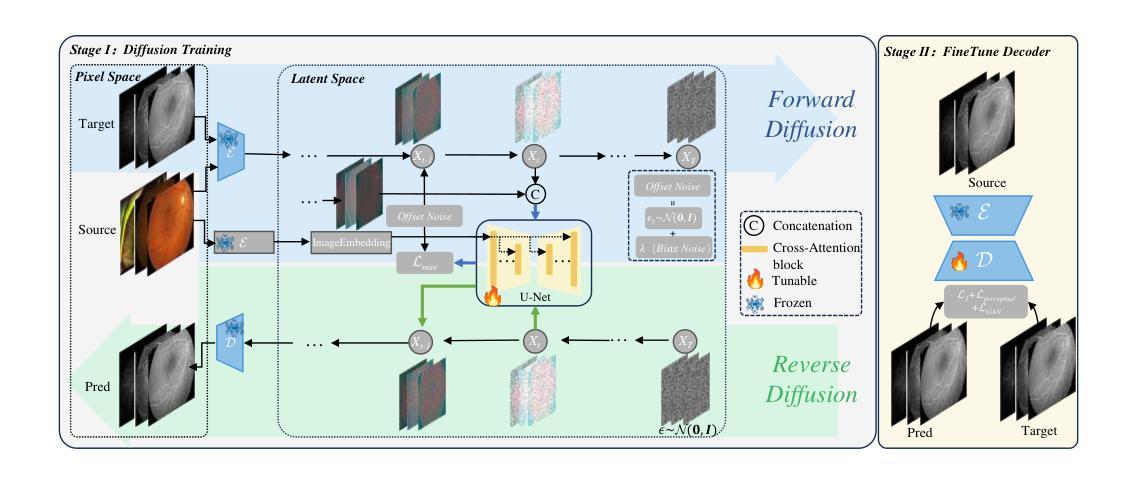
Fundus imaging is a critical tool in ophthalmology, with different imaging modalities offering unique advantages. For instance, fundus fluorescein angiography (FFA) can accurately identify eye diseases. However, traditional invasive FFA involves the injection of sodium fluorescein, which can cause discomfort and risks. Generating corresponding FFA images from non-invasive fundus images holds significant practical value but also presents challenges. First, limited datasets constrain the performance and effectiveness of models. Second, previous studies have primarily focused on generating FFA for single diseases or single modalities, often resulting in poor performance for patients with various ophthalmic conditions. To address these issues, we propose a novel latent diffusion model-based framework, Diffusion, which introduces a fine-tuning protocol to overcome the challenge of limited medical data and unleash the generative capabilities of diffusion models. Furthermore, we designed a new approach to tackle the challenges of generating across different modalities and disease types. On limited datasets, our framework achieves state-of-the-art results compared to existing methods, offering significant potential to enhance ophthalmic diagnostics and patient care. Our code will be released soon to support further research in this field.
眼底成像在眼科中是一种至关重要的工具,不同的成像模式都有其独特的优势。例如,眼底荧光血管造影(FFA)可以准确识别眼部疾病。然而,传统的侵入性FFA需要注射荧光素钠,可能会引发不适和风险。从非侵入性的眼底图像生成相应的FFA图像具有重大的实用价值,但也存在挑战。首先,有限的数据集限制了模型的性能和效果。其次,以往的研究主要集中在为单一疾病或单一模式生成FFA,往往导致对患有多种眼科疾病的患者的表现不佳。为了解决这些问题,我们提出了一种基于潜在扩散模型的新框架——Diffusion,该框架引入了精细调整协议,以克服医学数据有限的挑战,并释放扩散模型的生成能力。此外,我们设计了一种新方法,以解决不同模式和疾病类型生成所面临的挑战。在有限的数据集上,我们的框架与现有方法相比取得了最先进的成果,为眼科诊断和患者护理提供了巨大的潜力。我们的代码将很快发布,以支持该领域的进一步研究。
论文及项目相关链接
PDF The first author has a conflict with the data access authority
Summary
基金眼成像在眼科领域具有重要作用,不同的成像模式具有独特的优势。传统的基金荧光素血管造影(FFA)会带来不适和风险。通过非侵入式的基金眼图像生成相应的FFA图像具有实际意义,但面临挑战。为解决这些问题,我们提出了一种基于潜在扩散模型的框架,通过微调协议克服有限的医疗数据挑战,并释放扩散模型的生成能力。我们的方法在有限数据集上实现了最先进的成果。该框架对眼科诊断和患者护理有重要意义。我们即将发布代码,以支持该领域的进一步研究。
Key Takeaways
- 基金眼成像在眼科中起重要作用,不同的成像模式有其独特的优势。
- 传统FFA方法具有侵入性,可能导致患者不适和风险。
- 非侵入式生成FFA图像具有实际意义,但面临数据限制和跨疾病类型生成的挑战。
- 提出了一种基于潜在扩散模型的框架,通过微调协议解决有限医疗数据问题。
- 该框架能够在有限数据集上实现最先进的成果。
- 该框架对眼科诊断和患者护理有重要意义。
点此查看论文截图


Efficient Dataset Distillation via Diffusion-Driven Patch Selection for Improved Generalization
Authors:Xinhao Zhong, Shuoyang Sun, Xulin Gu, Zhaoyang Xu, Yaowei Wang, Min Zhang, Bin Chen
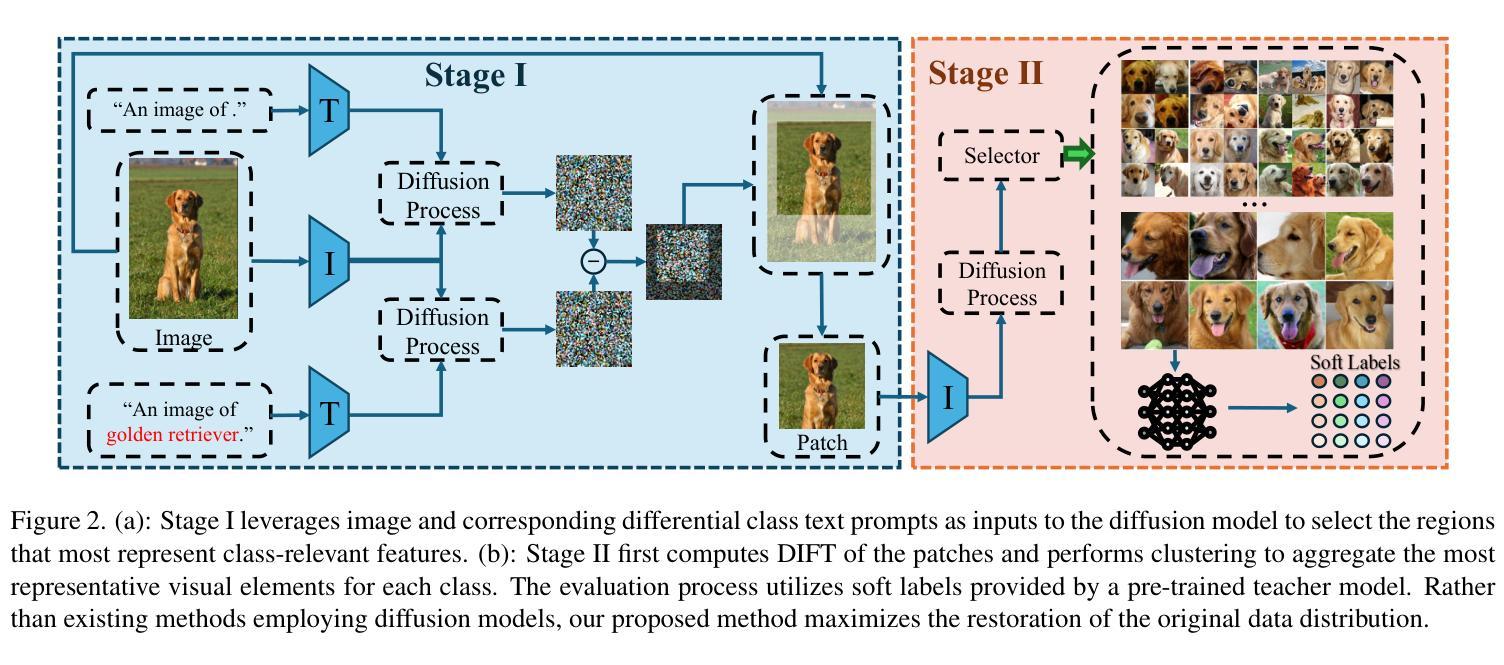
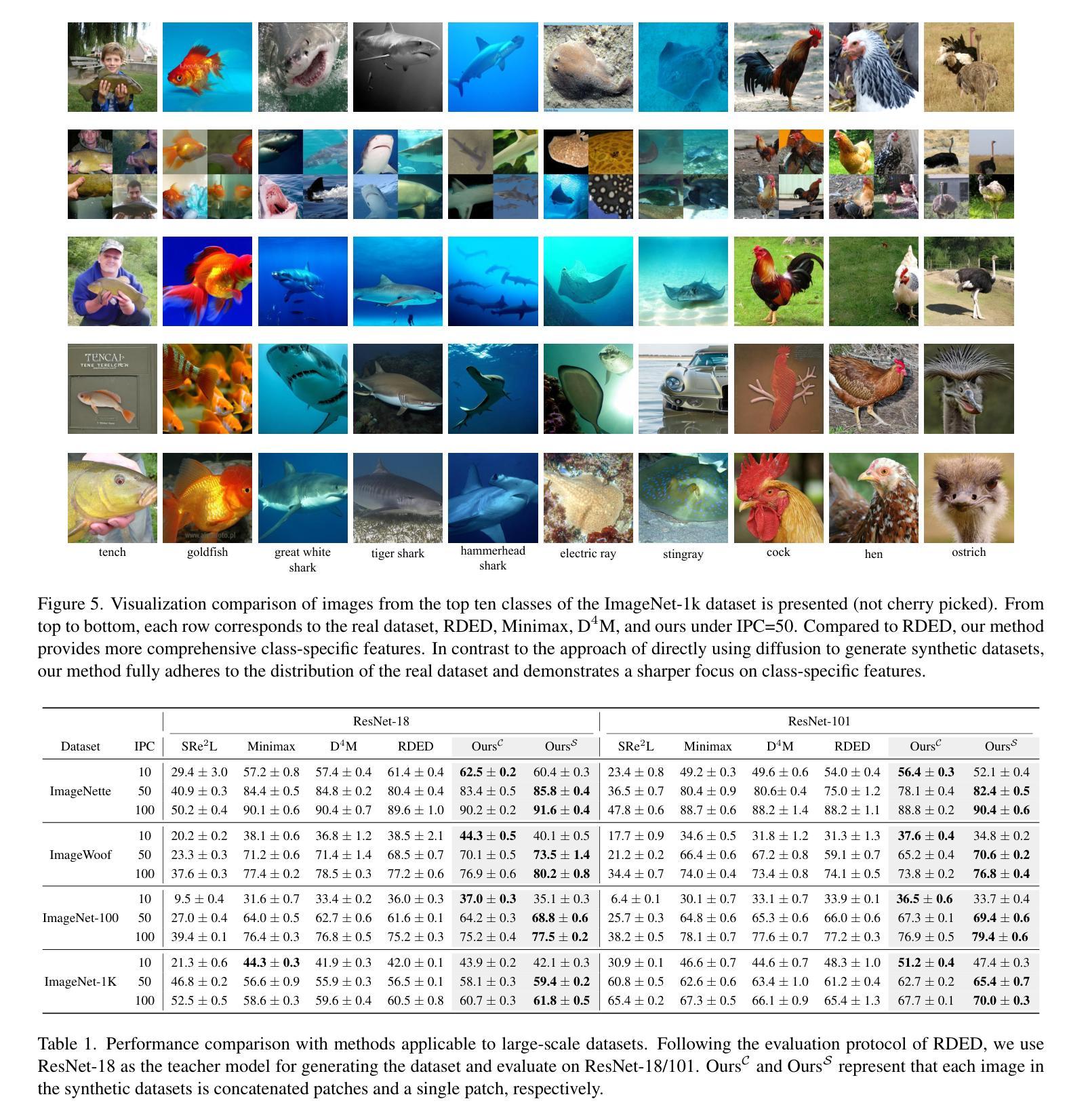
Dataset distillation offers an efficient way to reduce memory and computational costs by optimizing a smaller dataset with performance comparable to the full-scale original. However, for large datasets and complex deep networks (e.g., ImageNet-1K with ResNet-101), the extensive optimization space limits performance, reducing its practicality. Recent approaches employ pre-trained diffusion models to generate informative images directly, avoiding pixel-level optimization and achieving notable results. However, these methods often face challenges due to distribution shifts between pre-trained models and target datasets, along with the need for multiple distillation steps across varying settings. To address these issues, we propose a novel framework orthogonal to existing diffusion-based distillation methods, leveraging diffusion models for selection rather than generation. Our method starts by predicting noise generated by the diffusion model based on input images and text prompts (with or without label text), then calculates the corresponding loss for each pair. With the loss differences, we identify distinctive regions of the original images. Additionally, we perform intra-class clustering and ranking on selected patches to maintain diversity constraints. This streamlined framework enables a single-step distillation process, and extensive experiments demonstrate that our approach outperforms state-of-the-art methods across various metrics.
数据集蒸馏提供了一种通过优化小型数据集来减少内存和计算成本的有效方法,其性能可与全尺寸原始数据集相当。然而,对于大型数据集和复杂的深度网络(例如,带有ResNet-101的ImageNet-1K),广泛的优化空间限制了性能,降低了其实用性。最近的方法采用预训练的扩散模型直接生成信息图像,避免了像素级优化,并取得了显著的结果。然而,这些方法常常面临预训练模型与目标数据集之间分布变化的问题,以及在不同设置下需要多次蒸馏步骤的需求。为了解决这些问题,我们提出了一种与现有基于扩散的蒸馏方法正交的新型框架,利用扩散模型进行选择而不是生成。我们的方法首先基于输入图像和文本提示(带或不带标签文本)预测由扩散模型生成的噪声,然后计算每对对应的损失。通过损失差异,我们识别出原始图像的独特区域。此外,我们对选定的小块进行类内聚类和排名,以保持多样性约束。这种简化的框架实现了单步蒸馏过程,大量实验表明,我们的方法在各种指标上超越了最先进的方法。
论文及项目相关链接
Summary
基于数据集蒸馏的扩散模型研究提出了新方法。该方法的通过利用扩散模型进行选择和预测,避免了生成过程中的分布偏移问题,实现了单一步骤蒸馏过程,并在多个指标上超越了现有方法。此方法通过计算输入图像和文本提示下的噪声预测损失差异,确定原始图像的独特区域,并进行内部类别聚类排名以保持多样性约束。此框架在保证效率的同时优化性能表现,以对抗大型数据集和复杂深度网络的挑战。
Key Takeaways
- 扩散模型数据集蒸馏可有效降低内存和计算成本,通过优化小型数据集实现与原始规模相当的性能。
- 在大型数据集和复杂深度网络(如ImageNet-1K与ResNet-101)的应用中,广泛的优化空间限制了性能,减少其实用性。
- 利用预训练扩散模型直接生成图像是一种有效的方法,可以避免像素级的优化并达成显著结果,但也面临分布偏移和需要多个蒸馏步骤的挑战。
- 本文提出一种新的蒸馏框架,与现有扩散蒸馏方法正交,通过扩散模型进行筛选而非生成来处理上述问题。
- 方法包括基于输入图像和文本提示预测扩散模型产生的噪声,计算每对损失差异以确定原始图像的独特区域。
- 通过进行内部类别聚类排名来保持多样性约束,实现单一步骤蒸馏过程。
点此查看论文截图



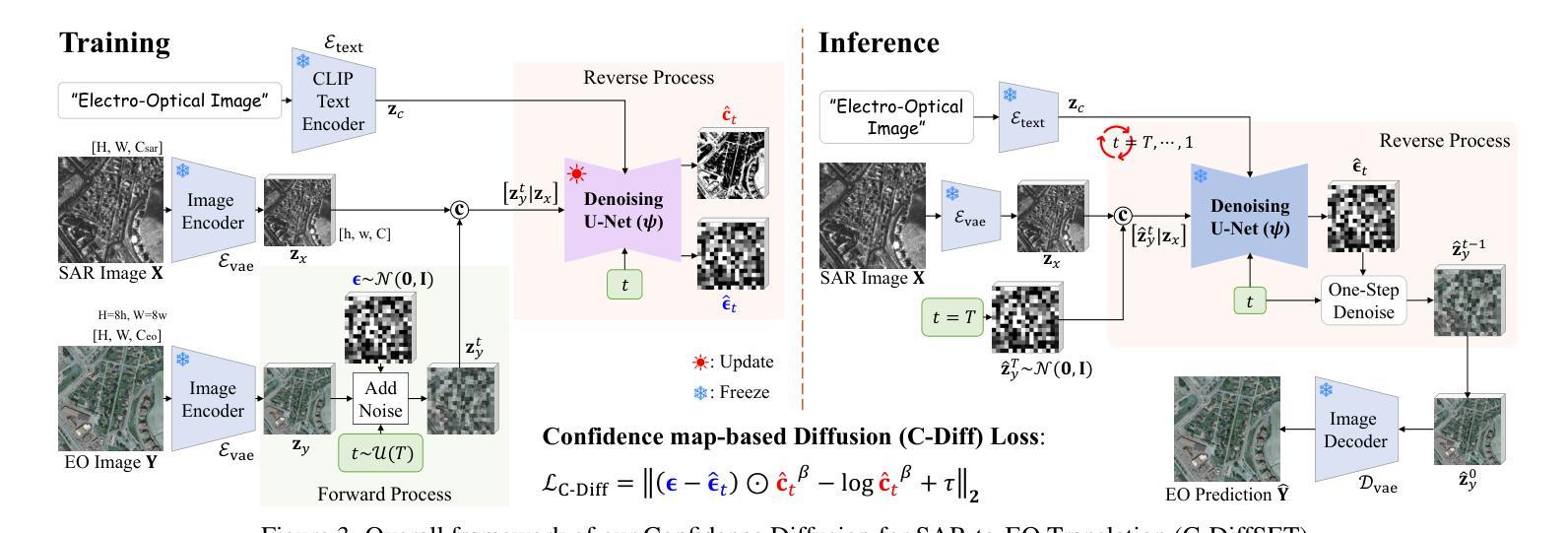
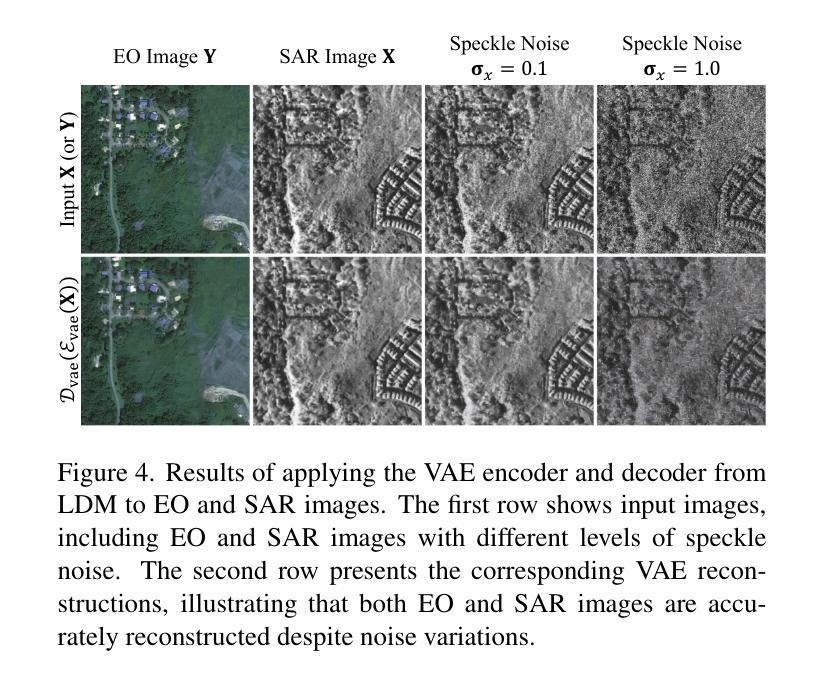
C-DiffSET: Leveraging Latent Diffusion for SAR-to-EO Image Translation with Confidence-Guided Reliable Object Generation
Authors:Jeonghyeok Do, Jaehyup Lee, Munchurl Kim
Synthetic Aperture Radar (SAR) imagery provides robust environmental and temporal coverage (e.g., during clouds, seasons, day-night cycles), yet its noise and unique structural patterns pose interpretation challenges, especially for non-experts. SAR-to-EO (Electro-Optical) image translation (SET) has emerged to make SAR images more perceptually interpretable. However, traditional approaches trained from scratch on limited SAR-EO datasets are prone to overfitting. To address these challenges, we introduce Confidence Diffusion for SAR-to-EO Translation, called C-DiffSET, a framework leveraging pretrained Latent Diffusion Model (LDM) extensively trained on natural images, thus enabling effective adaptation to the EO domain. Remarkably, we find that the pretrained VAE encoder aligns SAR and EO images in the same latent space, even with varying noise levels in SAR inputs. To further improve pixel-wise fidelity for SET, we propose a confidence-guided diffusion (C-Diff) loss that mitigates artifacts from temporal discrepancies, such as appearing or disappearing objects, thereby enhancing structural accuracy. C-DiffSET achieves state-of-the-art (SOTA) results on multiple datasets, significantly outperforming the very recent image-to-image translation methods and SET methods with large margins.
雷达图像提供稳健的环境和时间覆盖(例如在云、季节、昼夜循环期间),但其噪声和独特的结构模式对解释提出了挑战,特别是对于非专家而言。SAR到EO(光电)图像翻译(SET)的出现使得SAR图像更容易感知和理解。然而,传统方法从零开始使用有限的SAR-EO数据集进行训练容易过度拟合。为了应对这些挑战,我们引入了SAR到EO翻译的置信度扩散(Confidence Diffusion),称为C-DiffSET框架,它利用预训练的潜在扩散模型(LDM)进行大量自然图像训练,从而实现有效的适应光电领域。值得注意的是,我们发现预训练的VAE编码器能够在同一潜在空间中匹配SAR和EO图像,即使在SAR输入中存在不同的噪声水平也是如此。为了进一步提高SET的像素级保真度,我们提出了一种置信度引导扩散(C-Diff)损失,该损失减轻了由于时间差异而产生的伪影,如出现的物体或消失的物体,从而提高结构准确性。C-DiffSET在多数据集上实现了最先进的成果,显著优于最新的图像到图像翻译方法和SET方法。
论文及项目相关链接
PDF Please visit our project page https://kaist-viclab.github.io/C-DiffSET_site/
Summary
本文介绍了合成孔径雷达(SAR)影像的解读挑战,并提出了基于预训练潜在扩散模型的SAR-EO影像翻译方法——C-DiffSET。通过利用大规模自然图像训练的潜在扩散模型,该方法有效地适应了EO领域。同时,该研究引入了置信扩散损失,提高了像素级的保真度,增强了结构准确性。C-DiffSET在多数据集上取得了最先进的成果,显著优于其他图像转换和SET方法。
Key Takeaways
- SAR影像提供稳健的环境和时序覆盖,但其噪声和独特结构模式给非专家带来解读挑战。
- SAR-to-EO图像翻译(SET)使SAR图像更易于感知和理解。
- 传统SET方法从有限的SAR-EO数据集中训练易产生过拟合问题。
- C-DiffSET方法利用预训练的潜在扩散模型来解决这一问题,该模型在自然图像上进行广泛训练,并能有效地适应EO领域。
- VAE编码器能够将SAR和EO影像在相同潜在空间中对齐,即使SAR输入存在不同噪声级别。
- 置信扩散损失被引入来提高像素级的保真度和结构准确性,减少因时间差异导致的伪影。
点此查看论文截图


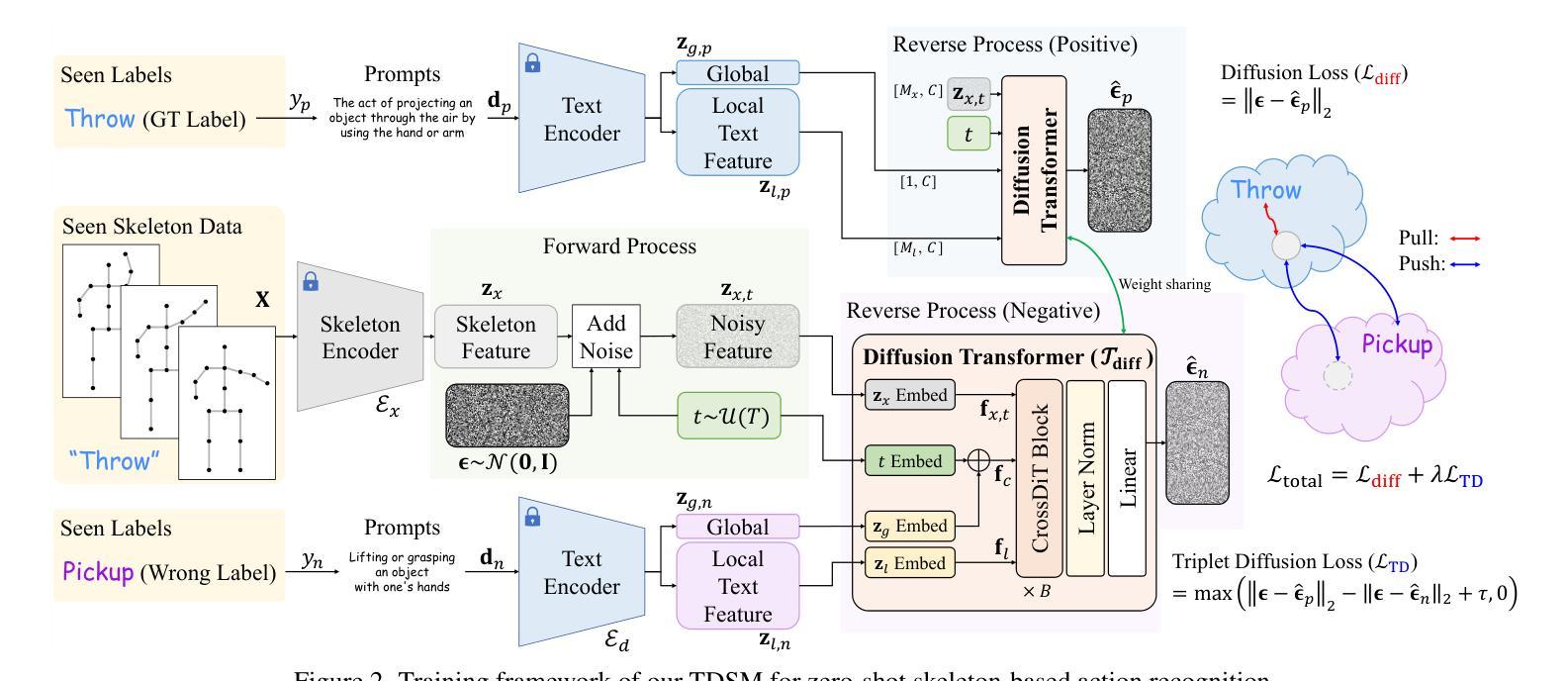
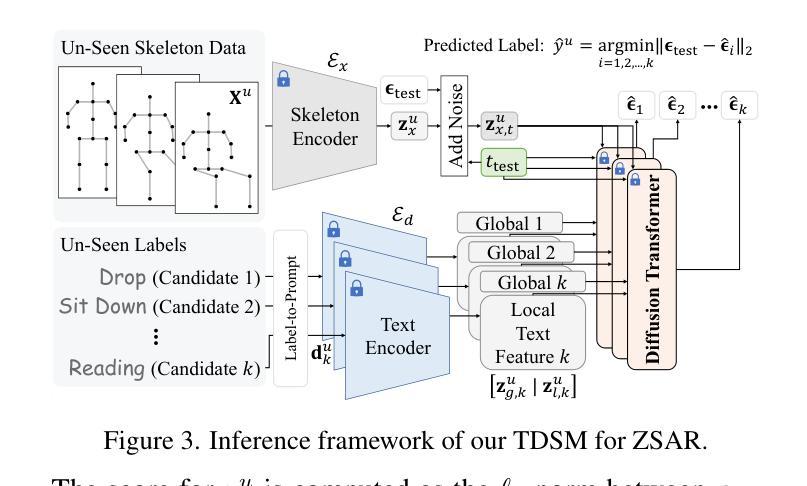
TDSM: Triplet Diffusion for Skeleton-Text Matching in Zero-Shot Action Recognition
Authors:Jeonghyeok Do, Munchurl Kim
We firstly present a diffusion-based action recognition with zero-shot learning for skeleton inputs. In zero-shot skeleton-based action recognition, aligning skeleton features with the text features of action labels is essential for accurately predicting unseen actions. Previous methods focus on direct alignment between skeleton and text latent spaces, but the modality gaps between these spaces hinder robust generalization learning. Motivated from the remarkable performance of text-to-image diffusion models, we leverage their alignment capabilities between different modalities mostly by focusing on the training process during reverse diffusion rather than using their generative power. Based on this, our framework is designed as a Triplet Diffusion for Skeleton-Text Matching (TDSM) method which aligns skeleton features with text prompts through reverse diffusion, embedding the prompts into the unified skeleton-text latent space to achieve robust matching. To enhance discriminative power, we introduce a novel triplet diffusion (TD) loss that encourages our TDSM to correct skeleton-text matches while pushing apart incorrect ones. Our TDSM significantly outperforms the very recent state-of-the-art methods with large margins of 2.36%-point to 13.05%-point, demonstrating superior accuracy and scalability in zero-shot settings through effective skeleton-text matching.
我们首先提出了一种基于扩散的零样本学习动作识别方法,用于骨架输入。在零样本骨架动作识别中,将骨架特征与动作标签的文本特征对齐是准确预测未见动作的关键。之前的方法侧重于骨架和文本潜在空间之间的直接对齐,但这些空间之间的模态差距阻碍了鲁棒的泛化学习。受文本到图像扩散模型的出色性能的启发,我们主要利用它们在不同模态之间的对齐能力,侧重于反向扩散过程中的训练过程,而不是使用它们的生成能力。基于此,我们将框架设计为一种用于骨架文本匹配的Triple扩散方法(TDSM),它通过反向扩散将骨架特征与文本提示对齐,将提示嵌入统一的骨架文本潜在空间以实现稳健匹配。为了提高鉴别力,我们引入了一种新的三重扩散(TD)损失,它鼓励我们的TDSM纠正骨架文本匹配,同时推开错误的匹配。我们的TDSM显著优于最新的先进方法,准确率提高了2.36%至13.05%,在零样本设置中通过有效的骨架文本匹配展现了出色的准确性和可扩展性。
论文及项目相关链接
PDF Please visit our project page at https://kaist-viclab.github.io/TDSM_site/
Summary
本文提出了基于扩散模型的零样本学习骨架动作识别方法。为解决骨架和文本特征对齐问题,研究团队借鉴文本到图像扩散模型的跨模态对齐能力,设计了一种名为Triplet Diffusion for Skeleton-Text Matching (TDSM)的框架。通过反向扩散过程实现骨架特征与文本提示的对齐,并引入新型的三元扩散损失函数,以提高模型的鉴别力和匹配准确性。实验结果显示,TDSM框架在零样本设置下显著优于最新先进方法,展现出更高的准确性和可扩展性。
Key Takeaways
- 提出了基于扩散模型的零样本学习骨架动作识别。
- 骨架特征与文本特征对齐是预测未见动作的关键。
- 借鉴文本到图像扩散模型的跨模态对齐能力。
- 设计了Triplet Diffusion for Skeleton-Text Matching (TDSM)框架。
- 通过反向扩散过程实现骨架与文本的对齐。
- 引入新型的三元扩散损失函数,提高模型的鉴别力和匹配准确性。
点此查看论文截图

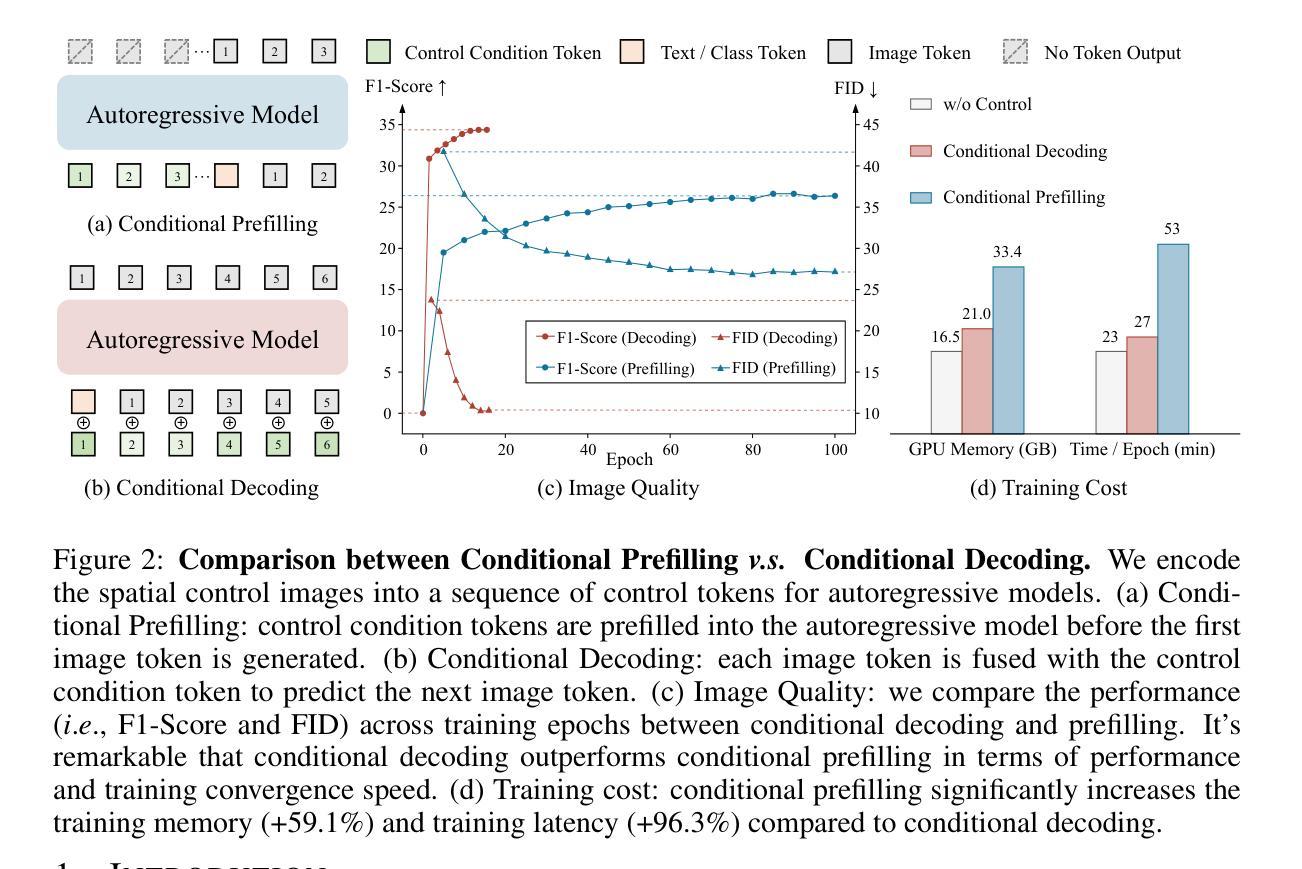
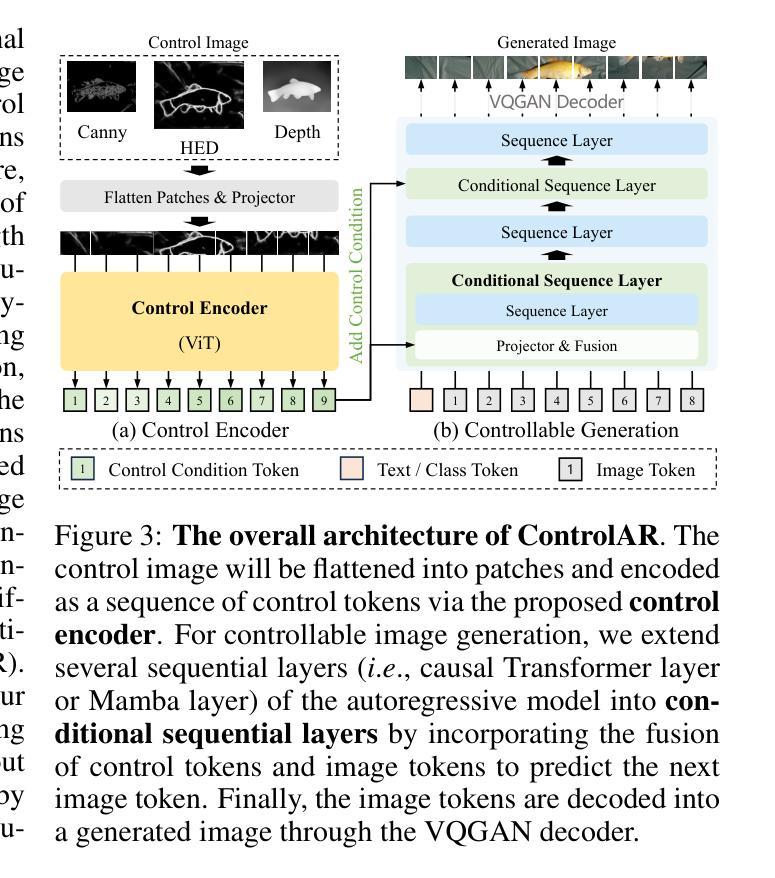
ControlAR: Controllable Image Generation with Autoregressive Models
Authors:Zongming Li, Tianheng Cheng, Shoufa Chen, Peize Sun, Haocheng Shen, Longjin Ran, Xiaoxin Chen, Wenyu Liu, Xinggang Wang
Autoregressive (AR) models have reformulated image generation as next-token prediction, demonstrating remarkable potential and emerging as strong competitors to diffusion models. However, control-to-image generation, akin to ControlNet, remains largely unexplored within AR models. Although a natural approach, inspired by advancements in Large Language Models, is to tokenize control images into tokens and prefill them into the autoregressive model before decoding image tokens, it still falls short in generation quality compared to ControlNet and suffers from inefficiency. To this end, we introduce ControlAR, an efficient and effective framework for integrating spatial controls into autoregressive image generation models. Firstly, we explore control encoding for AR models and propose a lightweight control encoder to transform spatial inputs (e.g., canny edges or depth maps) into control tokens. Then ControlAR exploits the conditional decoding method to generate the next image token conditioned on the per-token fusion between control and image tokens, similar to positional encodings. Compared to prefilling tokens, using conditional decoding significantly strengthens the control capability of AR models but also maintains the model’s efficiency. Furthermore, the proposed ControlAR surprisingly empowers AR models with arbitrary-resolution image generation via conditional decoding and specific controls. Extensive experiments can demonstrate the controllability of the proposed ControlAR for the autoregressive control-to-image generation across diverse inputs, including edges, depths, and segmentation masks. Furthermore, both quantitative and qualitative results indicate that ControlAR surpasses previous state-of-the-art controllable diffusion models, e.g., ControlNet++. Code, models, and demo will soon be available at https://github.com/hustvl/ControlAR.
自回归(AR)模型通过将图像生成重新定义为下一个标记预测,展现了巨大的潜力,并成为扩散模型的强劲竞争对手。然而,类似于ControlNet的控制到图像生成在AR模型中仍然未被广泛探索。虽然受大型语言模型进展的启发,将控制图像标记化的自然方法是在解码图像标记之前将它们预先填充到自回归模型中,但在生成质量方面与控制网相比仍然有所不足,并且存在效率低下的问题。为此,我们引入了ControlAR,这是一个高效且有效的框架,用于将空间控制集成到自回归图像生成模型中。首先,我们探索了AR模型的控制编码,并提出了一种轻量级控制编码器,将空间输入(如坎尼边缘或深度图)转换为控制标记。然后ControlAR利用条件解码方法来生成下一个图像标记,该标记是在控制标记和图像标记之间的每个标记融合上生成的,类似于位置编码。与预先填充标记相比,使用条件解码显著增强了AR模型的控制能力,同时保持了模型的效率。此外,所提出的ControlAR令人惊讶的是通过条件解码和特定控制使AR模型具备任意分辨率的图像生成能力。大量实验可以证明所提出ControlAR在边缘、深度和各种分割掩模等多样化输入下的自回归控制到图像生成的可控性。此外,定量和定性结果均表明ControlAR超越了之前的先进可控扩散模型,如ControlNet++。代码、模型和演示将很快在https://github.com/hustvl/ControlAR上提供。
论文及项目相关链接
PDF To appear in ICLR 2025
Summary
AR模型在图像生成领域展现出显著潜力,成为扩散模型的强劲竞争对手。然而,对于ControlAR模型来说,控制到图像生成的转化仍是未知领域。本文提出ControlAR框架,通过探索控制编码和条件解码方法,将空间控制集成到自回归图像生成模型中。ControlAR能将空间输入转化为控制令牌,并利用条件解码生成下一个图像令牌,增强了AR模型的控制能力并保持模型效率。此外,ControlAR还能支持任意分辨率的图像生成。实验表明,ControlAR在边缘、深度、分割掩膜等多种输入上具有可控性,超越现有的可控扩散模型。
Key Takeaways
- AR模型在图像生成领域展现出显著潜力。
- 控制到图像生成在AR模型中仍属未知领域。
- ControlAR框架通过控制编码和条件解码方法集成空间控制到自回归图像生成模型中。
- ControlAR能将空间输入转化为控制令牌。
- 条件解码增强了AR模型的控制能力并保持模型效率。
- ControlAR支持任意分辨率的图像生成。
- ControlAR在多种输入上展现出超越现有可控扩散模型的性能。
点此查看论文截图

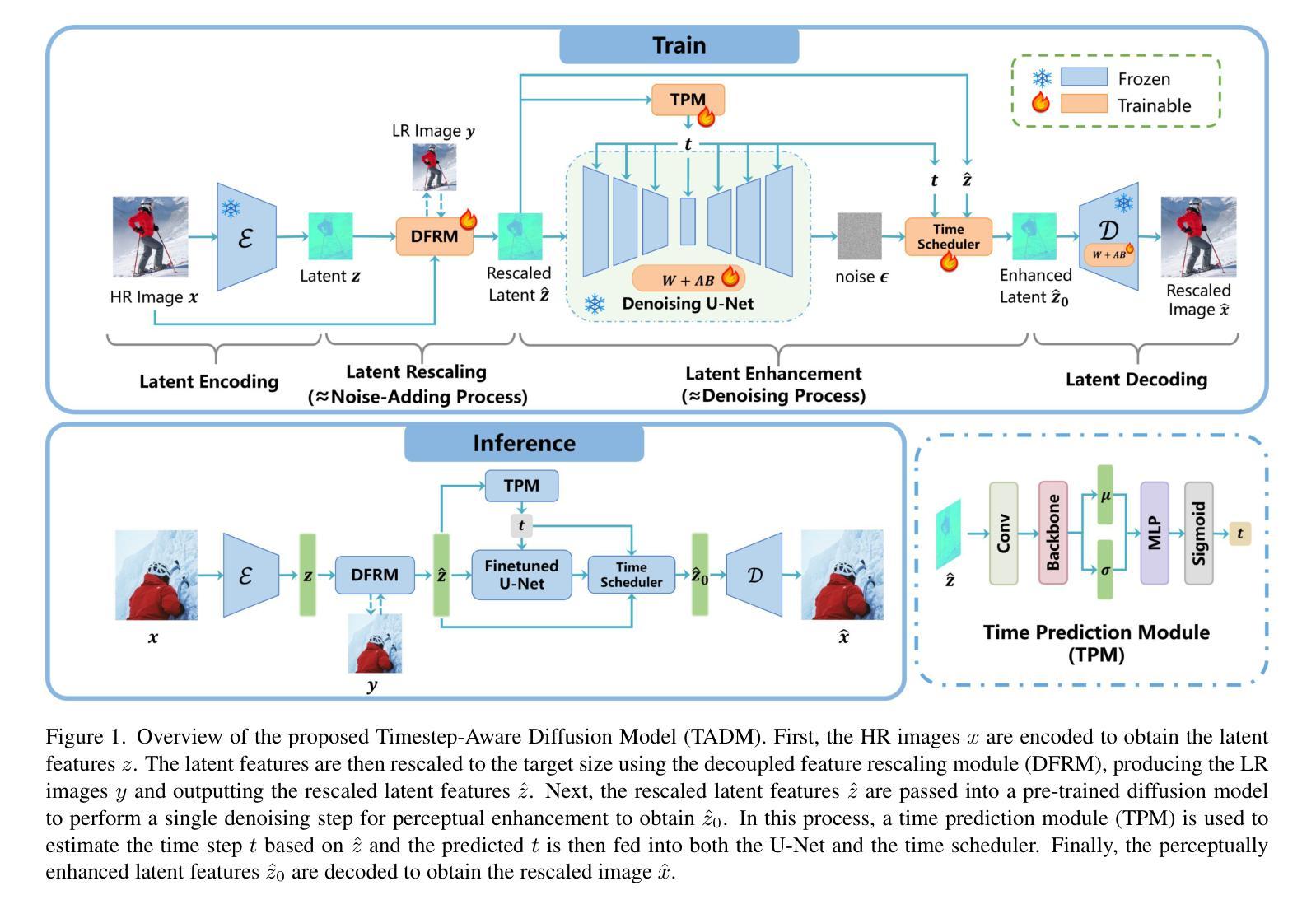
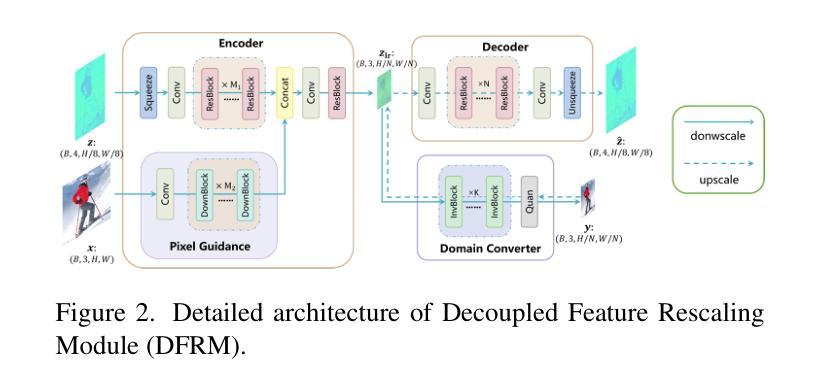
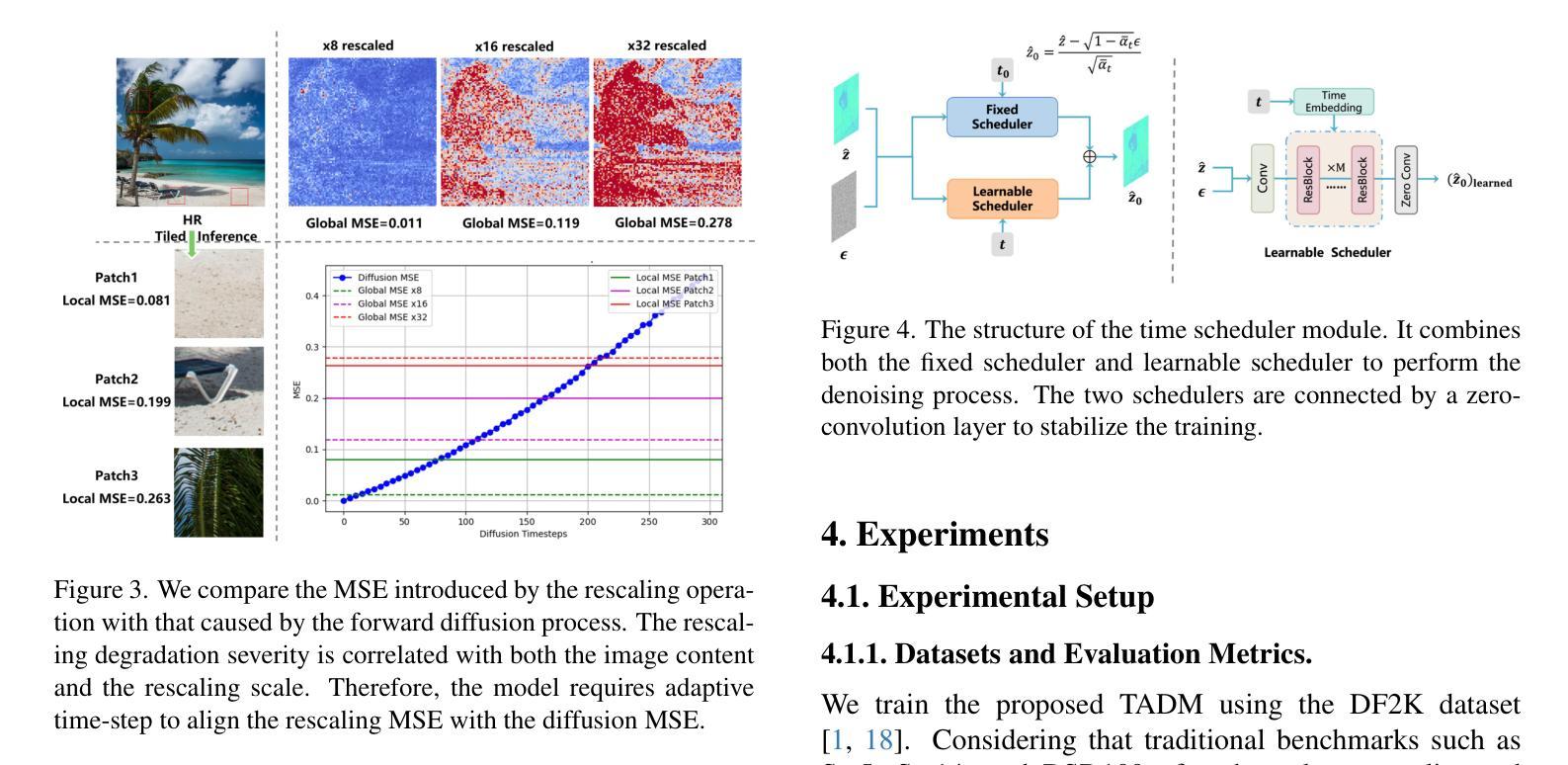
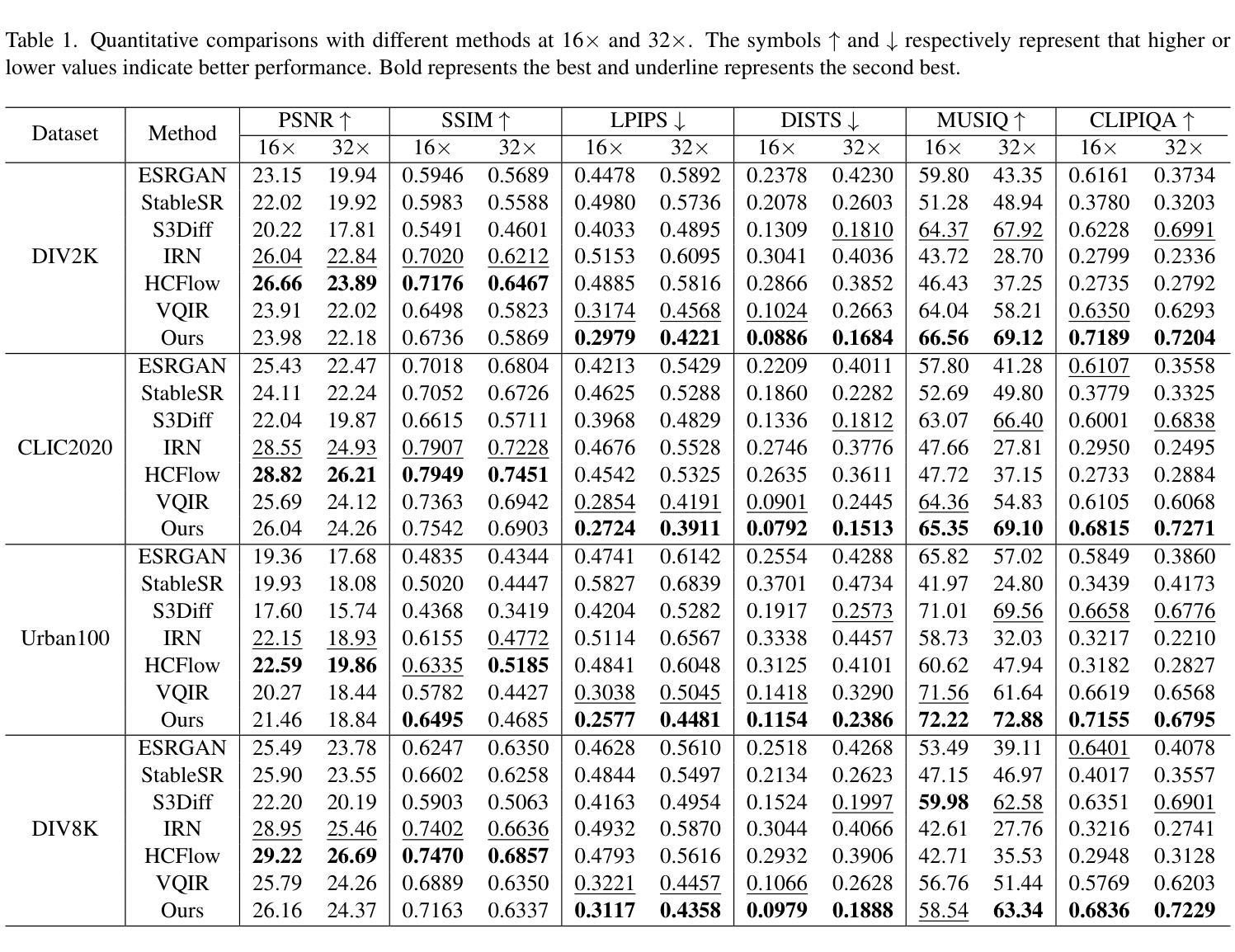
Timestep-Aware Diffusion Model for Extreme Image Rescaling
Authors:Ce Wang, Zhenyu Hu, Wanjie Sun, Zhenzhong Chen
Image rescaling aims to learn the optimal low-resolution (LR) image that can be accurately reconstructed to its original high-resolution (HR) counterpart, providing an efficient image processing and storage method for ultra-high definition media. However, extreme downscaling factors pose significant challenges to the upscaling process due to its highly ill-posed nature, causing existing image rescaling methods to struggle in generating semantically correct structures and perceptual friendly textures. In this work, we propose a novel framework called Timestep-Aware Diffusion Model (TADM) for extreme image rescaling, which performs rescaling operations in the latent space of a pre-trained autoencoder and effectively leverages powerful natural image priors learned by a pre-trained text-to-image diffusion model. Specifically, TADM adopts a pseudo-invertible module to establish the bidirectional mapping between the latent features of the HR image and the target-sized LR image. Then, the rescaled latent features are enhanced by a pre-trained diffusion model to generate more faithful details. Considering the spatially non-uniform degradation caused by the rescaling operation, we propose a novel time-step alignment strategy, which can adaptively allocate the generative capacity of the diffusion model based on the quality of the reconstructed latent features. Extensive experiments demonstrate the superiority of TADM over previous methods in both quantitative and qualitative evaluations.
图像缩放旨在学习最佳的低分辨率(LR)图像,该图像可以准确地重构为其原始的高分辨率(HR)对应物,为超高清媒体提供一种高效的图像处理和存储方法。然而,极端的缩小因子给放大过程带来了重大挑战,因为其高度不适定的性质,导致现有的图像缩放方法在生成语义上正确的结构和感知友好的纹理时遇到困难。在这项工作中,我们提出了一种用于极端图像缩放的名为“时间感知扩散模型”(TADM)的新型框架,该框架在预训练自编码器的潜在空间中进行缩放操作,并有效利用由预训练文本到图像扩散模型学习的强大自然图像先验。具体来说,TADM采用伪可逆模块建立高分辨率图像潜在特征与目标大小低分辨率图像之间的双向映射。然后,通过预训练的扩散模型增强重新缩放的潜在特征,以生成更忠实的细节。考虑到缩放操作引起的空间非均匀退化,我们提出了一种新的时间步长对齐策略,该策略可以根据重构的潜在特征的质量自适应地分配扩散模型的生成能力。大量实验表明,TADM在定量和定性评估方面都优于以前的方法。
论文及项目相关链接
Summary
本工作提出一种名为Timestep-Aware Diffusion Model(TADM)的新型框架,用于极端图像缩放。该方法在预训练自编码器的潜在空间执行缩放操作,并有效利用预训练文本到图像扩散模型学习的自然图像先验。TADM采用伪可逆模块建立高分辨率图像潜在特征与目标大小低分辨率图像之间的双向映射,然后通过扩散模型增强缩放后的潜在特征以生成更真实的细节。考虑到缩放操作引起的空间非均匀退化,提出了一种新的时间步长对齐策略,可以自适应地根据重建的潜在特征质量分配扩散模型的生成能力。
Key Takeaways
- TADM框架被提出用于极端图像缩放,在潜在空间执行缩放操作,利用自然图像先验。
- 伪可逆模块建立高分辨率和低分辨率图像之间的双向映射。
- 缩放后的潜在特征通过预训练的扩散模型进行增强,以生成更真实的细节。
- 提出时间步长对齐策略,自适应分配扩散模型的生成能力。
- TADM在定量和定性评估上都优于以前的方法。
- 框架能够处理由缩放操作引起的空间非均匀退化问题。
点此查看论文截图

DiffSG: A Generative Solver for Network Optimization with Diffusion Model
Authors:Ruihuai Liang, Bo Yang, Zhiwen Yu, Bin Guo, Xuelin Cao, Mérouane Debbah, H. Vincent Poor, Chau Yuen
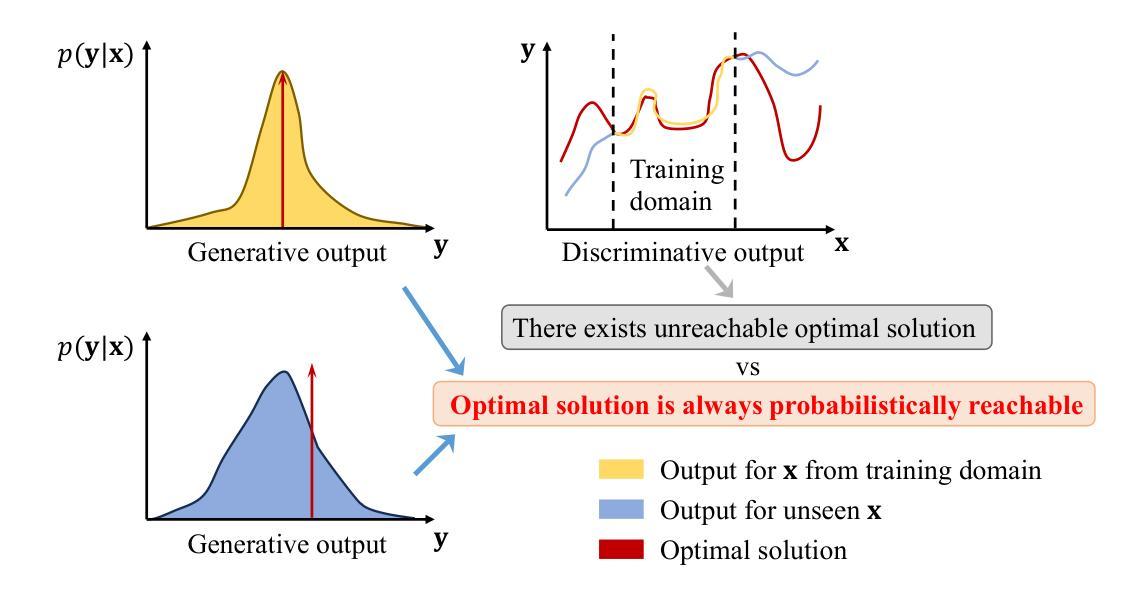
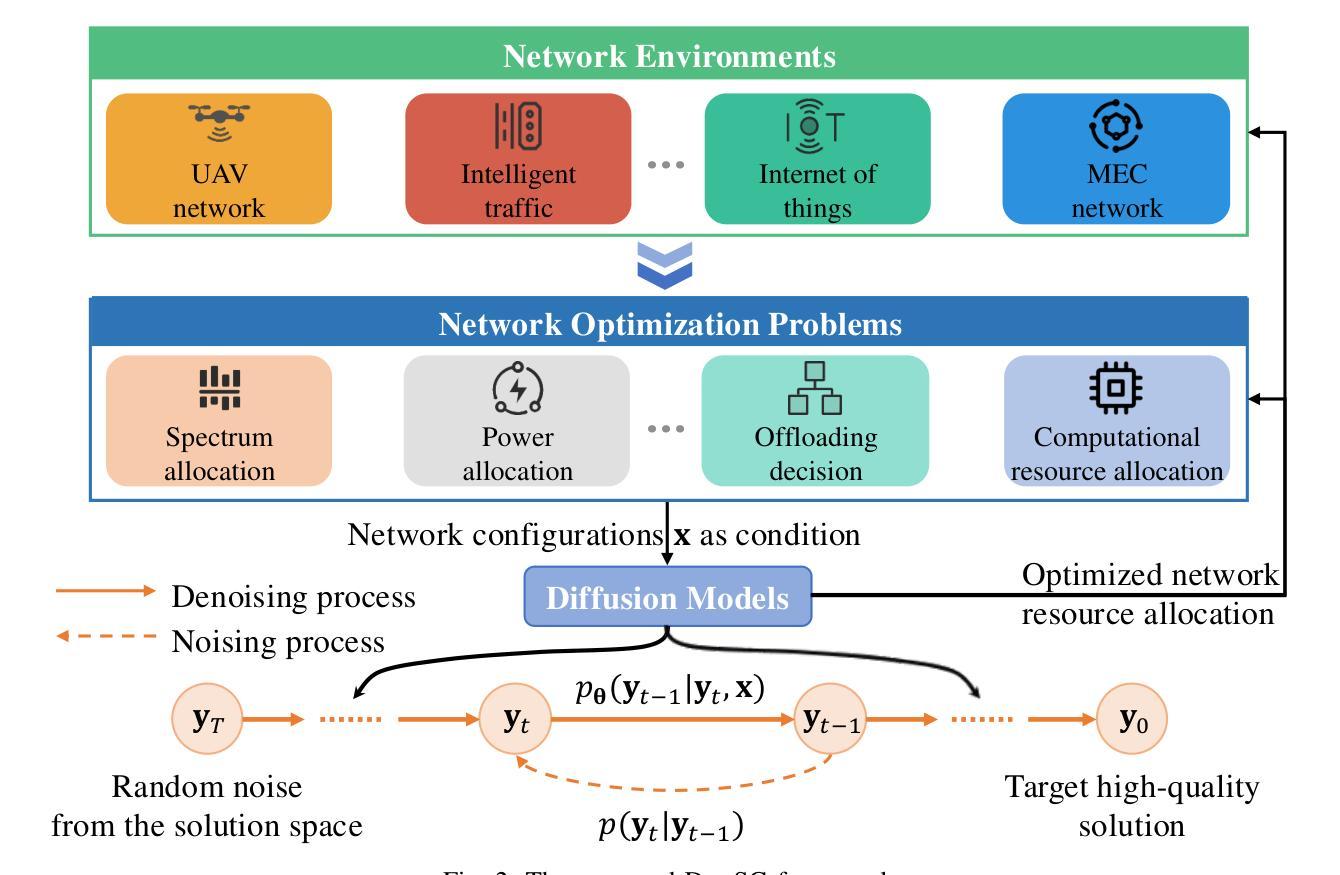
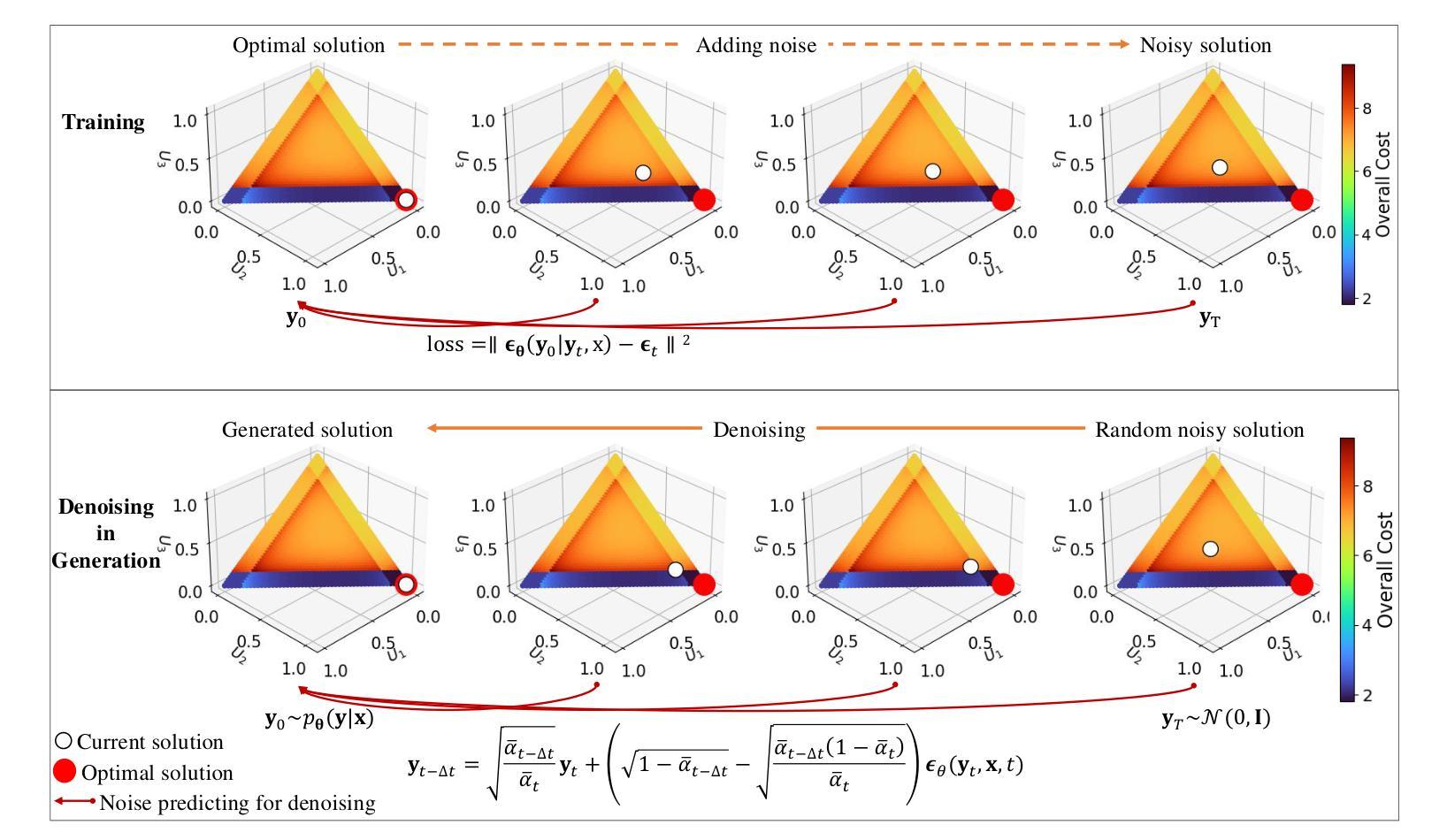
Generative diffusion models, famous for their performance in image generation, are popular in various cross-domain applications. However, their use in the communication community has been mostly limited to auxiliary tasks like data modeling and feature extraction. These models hold greater promise for fundamental problems in network optimization compared to traditional machine learning methods. Discriminative deep learning often falls short due to its single-step input-output mapping and lack of global awareness of the solution space, especially given the complexity of network optimization’s objective functions. In contrast, generative diffusion models can consider a broader range of solutions and exhibit stronger generalization by learning parameters that describe the distribution of the underlying solution space, with higher probabilities assigned to better solutions. We propose a new framework Diffusion Model-based Solution Generation (DiffSG), which leverages the intrinsic distribution learning capabilities of generative diffusion models to learn high-quality solution distributions based on given inputs. The optimal solution within this distribution is highly probable, allowing it to be effectively reached through repeated sampling. We validate the performance of DiffSG on several typical network optimization problems, including mixed-integer non-linear programming, convex optimization, and hierarchical non-convex optimization. Our results demonstrate that DiffSG outperforms existing baseline methods not only on in-domain inputs but also on out-of-domain inputs. In summary, we demonstrate the potential of generative diffusion models in tackling complex network optimization problems and outline a promising path for their broader application in the communication community. Our code is available at https://github.com/qiyu3816/DiffSG.
生成性扩散模型以其图像生成性能而闻名,并广泛应用于各种跨域应用。然而,它们在通信领域的使用大多仅限于数据建模和特征提取等辅助任务。与传统机器学习方法相比,这些模型在网络优化等基础问题上更具潜力。判别式深度学习通常由于单步输入输出映射和缺乏对整个解空间的全局认识而在面对复杂的网络优化目标函数时表现不足。相比之下,生成性扩散模型可以考虑更广泛的解决方案,并通过学习描述底层解空间分布的参数来表现出更强的泛化能力,为更好的解决方案分配更高的概率。我们提出了一种新的基于扩散模型的解决方案生成框架(DiffSG),它利用生成性扩散模型的内在分布学习能力,基于给定输入学习高质量解决方案分布。这个分布中的最优解很可能是高度可能的,可以通过重复采样有效地达到。我们在典型的网络优化问题上验证了DiffSG的性能,包括混合整数非线性规划、凸优化和分层非凸优化。我们的结果表明,DiffSG不仅在领域内部输入上而且在领域外部输入上都优于现有基准方法。总之,我们展示了生成性扩散模型在解决复杂的网络优化问题上的潜力,并为其在通信领域的更广泛应用描绘了一条有前途的道路。我们的代码可在https://github.com/qiyu3 3816/DiffSG上找到。
论文及项目相关链接
PDF Accepted by IEEE Communications Magazine
Summary
本文介绍了生成式扩散模型在解决网络优化问题中的潜力。与传统机器学习方法相比,这些模型能够考虑更广泛的解决方案并具有更强的泛化能力。文章提出了一种新的框架——基于扩散模型的解决方案生成(DiffSG),该框架利用生成式扩散模型的内在分布学习能力,基于给定输入学习高质量解决方案分布。实验结果表明,DiffSG在多种网络优化问题上表现出优异的性能,不仅在领域内输入上表现良好,在跨领域输入上也有出色表现。
Key Takeaways
- 生成式扩散模型在多种跨域应用中的普及,特别是在网络优化问题上的潜力。
- 传统机器学习方法在处理网络优化问题时,常常因单一映射和缺乏全局视野而显得不足。
- 相较于传统方法,生成式扩散模型能考虑更广泛的解决方案并表现出更强的泛化能力。
- 提出了一种新的框架——基于扩散模型的解决方案生成(DiffSG),利用扩散模型的分布学习能力来解决网络优化问题。
- DiffSG框架能够在给定输入基础上学习高质量解决方案分布,并通过重复采样找到最优解。
- DiffSG在多种网络优化问题上的性能优于现有基准方法,包括混合整数非线性规划、凸优化和分层非凸优化。
点此查看论文截图