⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-12 更新
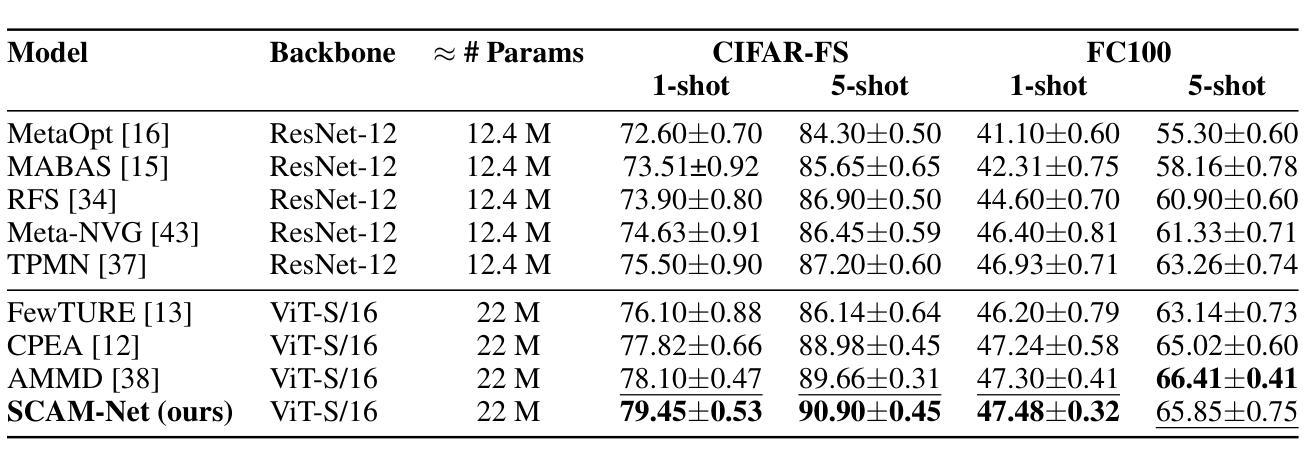
Brain Inspired Adaptive Memory Dual-Net for Few-Shot Image Classification
Authors:Kexin Di, Xiuxing Li, Yuyang Han, Ziyu Li, Qing Li, Xia Wu
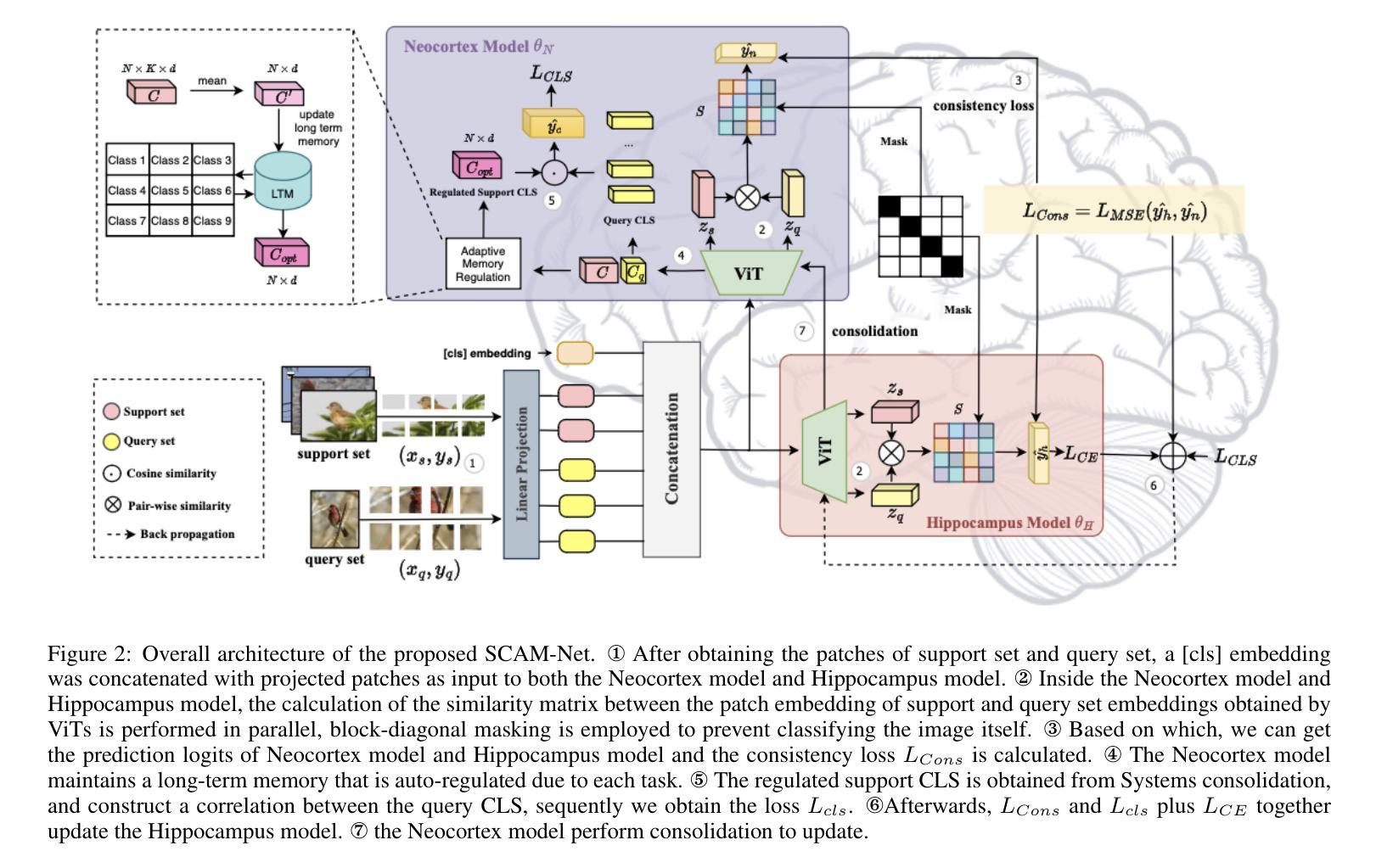
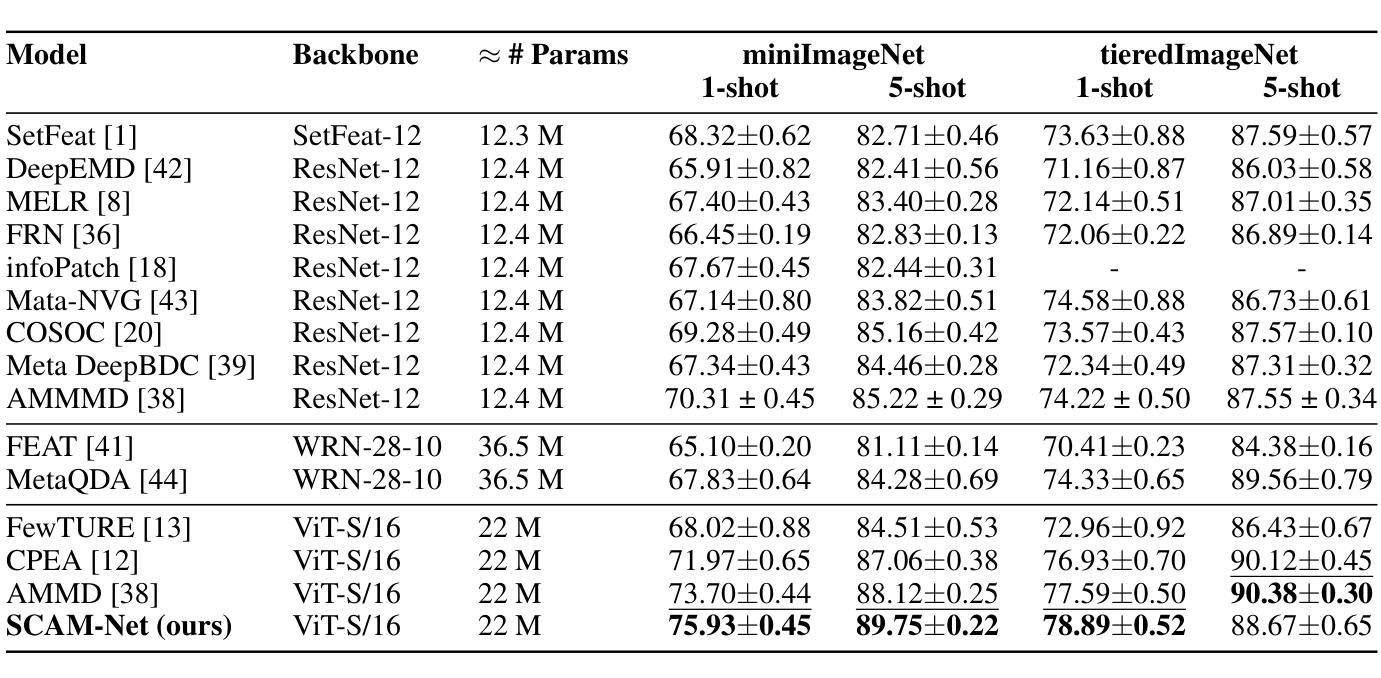
Few-shot image classification has become a popular research topic for its wide application in real-world scenarios, however the problem of supervision collapse induced by single image-level annotation remains a major challenge. Existing methods aim to tackle this problem by locating and aligning relevant local features. However, the high intra-class variability in real-world images poses significant challenges in locating semantically relevant local regions under few-shot settings. Drawing inspiration from the human’s complementary learning system, which excels at rapidly capturing and integrating semantic features from limited examples, we propose the generalization-optimized Systems Consolidation Adaptive Memory Dual-Network, SCAM-Net. This approach simulates the systems consolidation of complementary learning system with an adaptive memory module, which successfully addresses the difficulty of identifying meaningful features in few-shot scenarios. Specifically, we construct a Hippocampus-Neocortex dual-network that consolidates structured representation of each category, the structured representation is then stored and adaptively regulated following the generalization optimization principle in a long-term memory inside Neocortex. Extensive experiments on benchmark datasets show that the proposed model has achieved state-of-the-art performance.
少样本图像分类由于其在实际场景中的广泛应用已成为热门的研究课题,然而由单图像级标注引起的监督崩溃问题仍是主要挑战。现有方法旨在通过定位和匹配相关局部特征来解决这个问题。然而,现实世界图像中的高类内变异性给少样本设置下定位语义相关局部区域带来了巨大挑战。受人类辅助学习系统的启发,该系统擅长从有限样本中快速捕获和整合语义特征,我们提出了泛化优化系统巩固自适应记忆双网络,即SCAM-Net。该方法通过自适应记忆模块模拟辅助学习系统的系统整合,成功解决了少样本场景中识别有意义特征的困难。具体来说,我们构建了一个海马体-新皮层双网络,该网络巩固了每个类别的结构化表示,然后按照新皮层中的泛化优化原则,将结构化表示存储在长期记忆中并进行自适应调节。在基准数据集上的大量实验表明,该模型已达到了最先进的性能。
论文及项目相关链接
Summary
本文探讨了少样本图像分类中的监督崩溃问题,并受到人类互补学习系统的启发,提出了名为SCAM-Net的广义优化记忆自适应记忆双网络。通过自适应记忆模块模拟人类记忆巩固过程,解决在少样本场景下识别有意义特征的问题。实验结果表明,该模型在基准数据集上取得了最新性能。
Key Takeaways
- 少样本图像分类面临的问题:因单张图像标注导致的监督崩溃问题,以及在现实图像中高类内变化导致的挑战。
- 研究动机:从人类快速从有限样本中捕获和整合语义特征的能力中汲取灵感。
- 提出的新方法:SCAM-Net模型,包含自适应记忆模块,模拟人类记忆巩固过程。
- 模型结构:构建海马体和新皮层双网络,用于巩固每个类别的结构化表示。这些表示被存储在长期记忆中,并根据优化原则进行自适应调整。
- 模型优势:模型在基准数据集上取得了最先进的性能表现。
点此查看论文截图



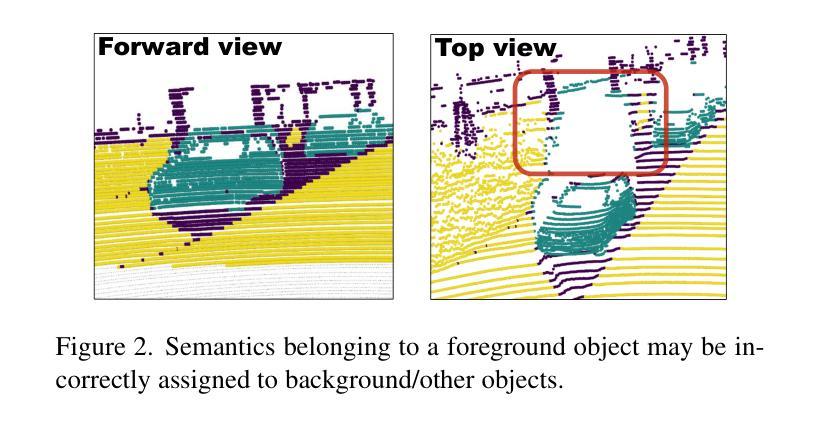
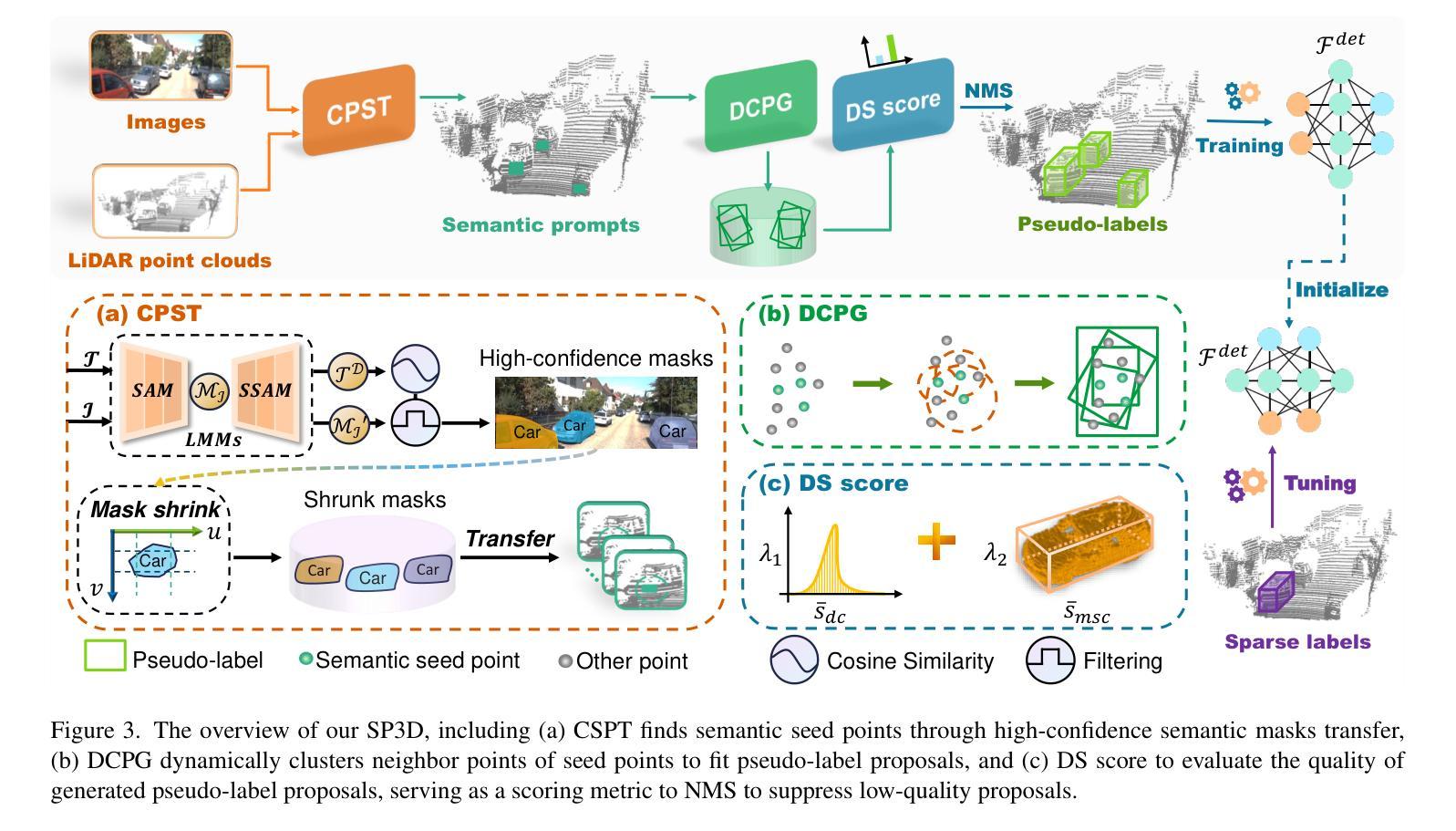
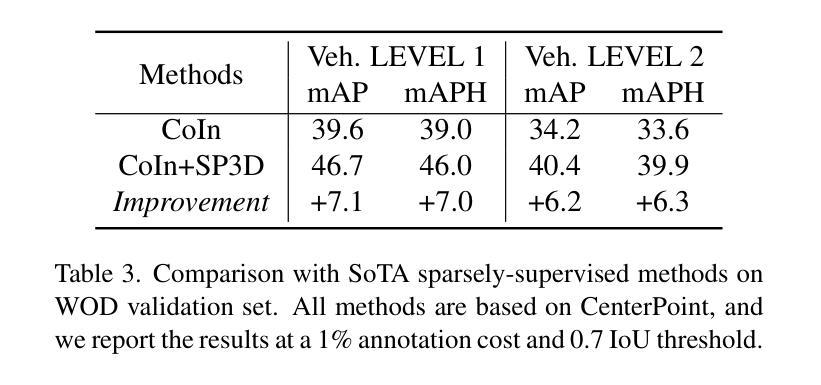
SP3D: Boosting Sparsely-Supervised 3D Object Detection via Accurate Cross-Modal Semantic Prompts
Authors:Shijia Zhao, Qiming Xia, Xusheng Guo, Pufan Zou, Maoji Zheng, Hai Wu, Chenglu Wen, Cheng Wang
Recently, sparsely-supervised 3D object detection has gained great attention, achieving performance close to fully-supervised 3D objectors while requiring only a few annotated instances. Nevertheless, these methods suffer challenges when accurate labels are extremely absent. In this paper, we propose a boosting strategy, termed SP3D, explicitly utilizing the cross-modal semantic prompts generated from Large Multimodal Models (LMMs) to boost the 3D detector with robust feature discrimination capability under sparse annotation settings. Specifically, we first develop a Confident Points Semantic Transfer (CPST) module that generates accurate cross-modal semantic prompts through boundary-constrained center cluster selection. Based on these accurate semantic prompts, which we treat as seed points, we introduce a Dynamic Cluster Pseudo-label Generation (DCPG) module to yield pseudo-supervision signals from the geometry shape of multi-scale neighbor points. Additionally, we design a Distribution Shape score (DS score) that chooses high-quality supervision signals for the initial training of the 3D detector. Experiments on the KITTI dataset and Waymo Open Dataset (WOD) have validated that SP3D can enhance the performance of sparsely supervised detectors by a large margin under meager labeling conditions. Moreover, we verified SP3D in the zero-shot setting, where its performance exceeded that of the state-of-the-art methods. The code is available at https://github.com/xmuqimingxia/SP3D.
近期,稀疏监督的3D目标检测受到了广泛关注,这些方法在仅需少量标注实例的情况下,就能达到与完全监督的3D目标检测器相近的性能。然而,当准确标签极度缺失时,这些方法面临挑战。本文提出了一种增强策略,称为SP3D,它显式地利用大型多模态模型(LMM)生成的跨模态语义提示,在稀疏注释设置下提高3D检测器的鲁棒特征辨别能力。具体来说,我们首先开发了一个置信点语义转移(CPST)模块,通过边界约束的中心聚类选择生成准确的跨模态语义提示。基于这些准确的语义提示(我们将其视为种子点),我们引入了动态聚类伪标签生成(DCPG)模块,以从多尺度邻近点的几何形状中产生伪监督信号。此外,我们设计了一个分布形状得分(DS得分),以选择高质量的监督信号用于3D检测器的初始训练。在KITTI数据集和Waymo Open Dataset(WOD)上的实验验证了在标注条件有限的情况下,SP3D可以大幅度提高稀疏监督检测器的性能。此外,我们在零样本设置下验证了SP3D,其性能超过了最新方法。代码可在https://github.com/xmuqimingxia/SP3D找到。
论文及项目相关链接
PDF 11 pages, 3 figures
Summary
本文提出一种名为SP3D的增强策略,利用大型多模态模型生成的跨模态语义提示,提升稀疏标注下3D检测器的性能。通过置信点语义转移模块生成准确语义提示,并以此为基础,引入动态集群伪标签生成模块,从多尺度邻近点的几何形状中产生伪监督信号。在KITTI数据集和Waymo Open Dataset上的实验验证了SP3D在标注条件有限的情况下,能显著提高稀疏监督检测器的性能。此外,在零样本设置下也验证了其超越现有方法的性能。
Key Takeaways
- SP3D策略利用大型多模态模型生成的跨模态语义提示,提升稀疏标注下的3D检测器性能。
- CPST模块通过边界约束的中心聚类选择生成准确的跨模态语义提示。
- DCPG模块从多尺度邻近点的几何形状中产生伪监督信号。
- DS评分选择高质量监督信号用于3D检测器的初始训练。
- 在KITTI数据集和Waymo Open Dataset上的实验验证了SP3D策略的有效性。
- SP3D策略在零样本设置下性能超越现有方法。
点此查看论文截图

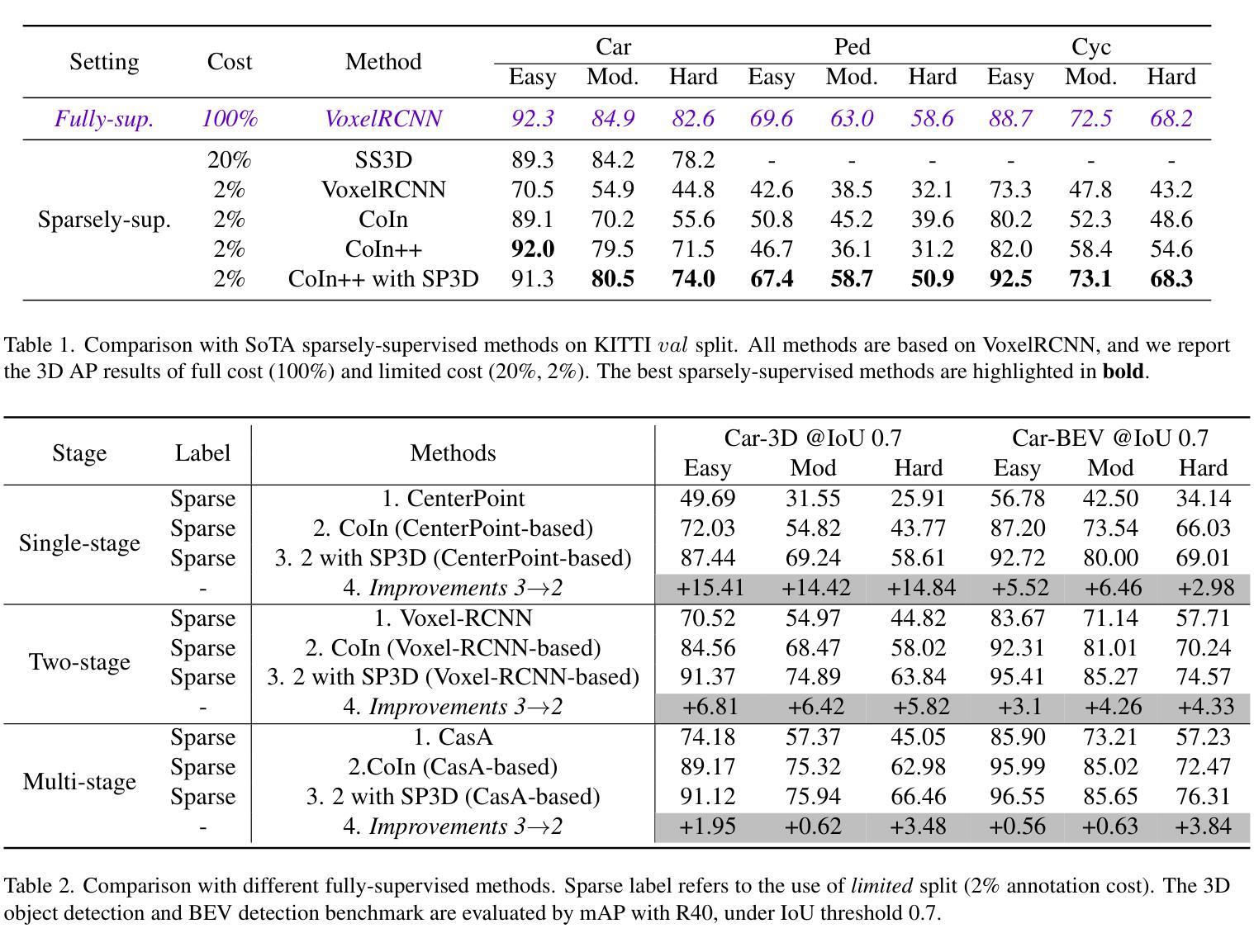
A Novel Distributed PV Power Forecasting Approach Based on Time-LLM
Authors:Huapeng Lin, Miao Yu
Distributed photovoltaic (DPV) systems are essential for advancing renewable energy applications and achieving energy independence. Accurate DPV power forecasting can optimize power system planning and scheduling while significantly reducing energy loss, thus enhancing overall system efficiency and reliability. However, solar energy’s intermittent nature and DPV systems’ spatial distribution create significant forecasting challenges. Traditional methods often rely on costly external data, such as numerical weather prediction (NWP) and satellite images, which are difficult to scale for smaller DPV systems. To tackle this issue, this study has introduced an advanced large language model (LLM)-based time series forecasting framework Time-LLM to improve the DPV power forecasting accuracy and generalization ability. By reprogramming, the framework aligns historical power data with natural language modalities, facilitating efficient modeling of time-series data. Then Qwen2.5-3B model is integrated as the backbone LLM to process input data by leveraging its pattern recognition and inference abilities, achieving a balance between efficiency and performance. Finally, by using a flatten and linear projection layer, the LLM’s high-dimensional output is transformed into the final forecasts. Experimental results indicate that Time-LLM outperforms leading recent advanced time series forecasting models, such as Transformer-based methods and MLP-based models, achieving superior accuracy in both short-term and long-term forecasting. Time-LLM also demonstrates exceptional adaptability in few-shot and zero-shot learning scenarios. To the best of the authors’ knowledge, this study is the first attempt to explore the application of LLMs to DPV power forecasting, which can offer a scalable solution that eliminates reliance on costly external data sources and improve real-world forecasting accuracy.
分布式光伏(DPV)系统对于推进可再生能源应用和实现能源独立至关重要。准确的DPV电力预测可以优化电力系统规划和调度,同时显著减少能源损失,从而提高整体系统效率和可靠性。然而,太阳能的间歇性和DPV系统的空间分布给预测带来了重大挑战。传统方法往往依赖于昂贵的外部数据,如数值天气预报(NWP)和卫星图像,这对于较小的DPV系统来说很难扩展。为解决这一问题,本研究引入了一种先进的大型语言模型(LLM)基于时间序列预测框架Time-LLM,以提高DPV电力预测的准确性和泛化能力。通过重新编程,该框架将历史电力数据与自然语言模式相结合,便于时间序列数据的有效建模。然后,集成Qwen2.5-3B模型作为骨干LLM来处理输入数据,利用其模式识别和推理能力,在效率和性能之间取得平衡。最后,通过使用平铺和线性投影层,将LLM的高维输出转化为最终的预测结果。实验结果表明,Time-LLM在短期和长期预测方面表现出优于当前先进的时间序列预测模型,如基于Transformer的方法和基于MLP的模型。Time-LLM还展示了在少样本和零样本学习场景中的出色适应性。据作者所知,本研究是首次尝试将LLM应用于DPV电力预测,它提供了一种可扩展的解决方案,消除了对昂贵外部数据源的依赖,提高了实际世界的预测精度。
论文及项目相关链接
PDF 23 pages, 8 figures
摘要
分布式光伏(DPV)系统对推进可再生能源应用和实现能源独立至关重要。准确的DPV电力预测可以优化电力系统规划和调度,显著降低能源损失,从而提高整体系统效率和可靠性。然而,太阳能能量的间歇性和DPV系统的空间分布给预测带来了重大挑战。传统方法常常依赖昂贵的外部数据,如数值天气预报(NWP)和卫星图像,难以适用于较小的DPV系统。为解决这一问题,本研究引入先进的大型语言模型(LLM)基于时间序列预测框架Time-LLM,提高DPV电力预测的准确性和泛化能力。通过编程,该框架将历史电力数据与自然语言模式对齐,便于时间序数数据的有效建模。然后,集成Qwen2.5-3B模型作为骨干LLM处理输入数据,利用其模式识别和推理能力,在效率和性能之间取得平衡。最后,通过平坦化线性投影层,将LLM的高维输出转化为最终预测结果。实验结果指出,Time-LLM表现优于近期领先的时间序列预测模型,如基于Transformer的方法和基于MLP的模型,在短期和长期预测中都实现了较高的准确性。Time-LLM在少量镜头和零镜头学习场景中表现出极佳的适应性。据作者所知,本研究是首次探索将LLM应用于DPV电力预测,可提供一个可扩展的解决方案,消除对昂贵外部数据源的依赖,提高现实世界的预测准确性。
关键见解
- 分布式光伏(DPV)系统在推进可再生能源应用和实现能源独立方面起关键作用。
- 准确的DPV电力预测对于优化电力系统规划和调度、降低能源损失至关重要。
- 太阳能的间歇性和DPV系统的空间分布给预测带来了挑战。
- 传统预测方法常常依赖昂贵的外部数据,难以适用于所有场景。
- 本研究引入大型语言模型(LLM)Time-LLM框架,提高DPV电力预测的准确性和泛化能力。
- Time-LLM框架通过结合历史电力数据和自然语言模式进行有效建模。
- Time-LLM在短期和长期预测中表现优异,且适应于不同学习场景。
点此查看论文截图

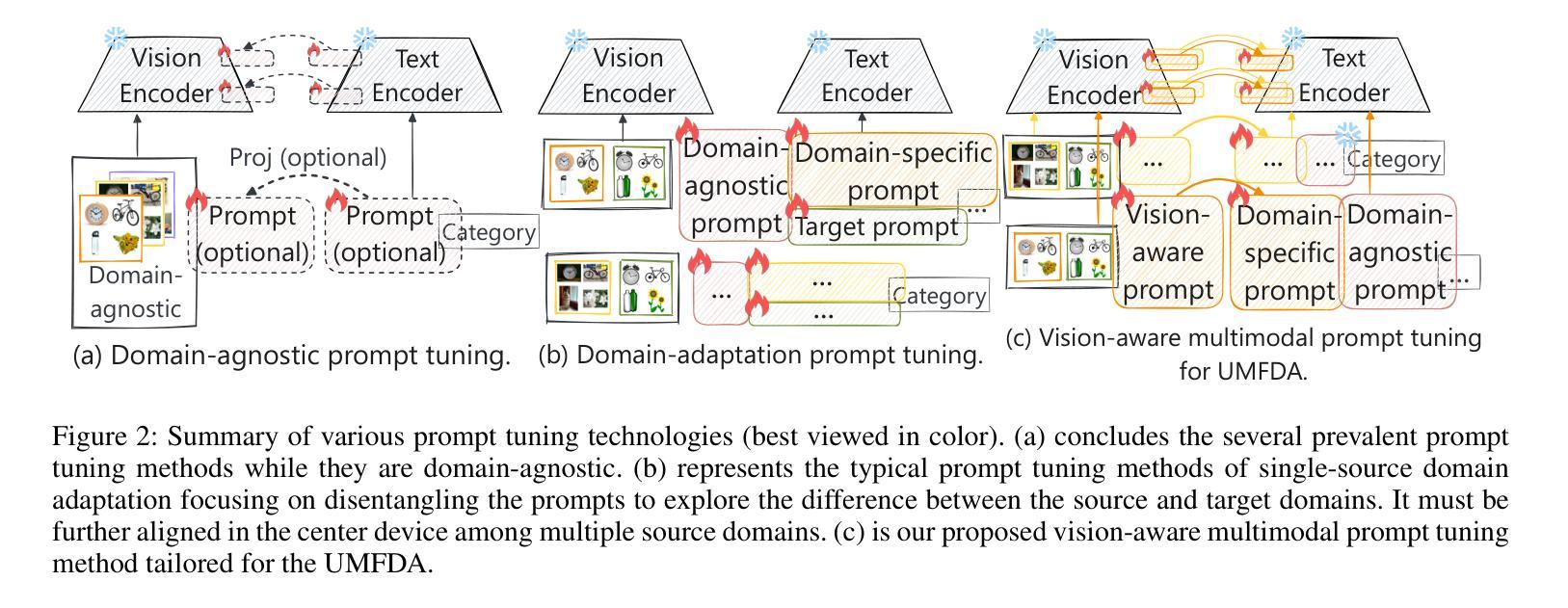
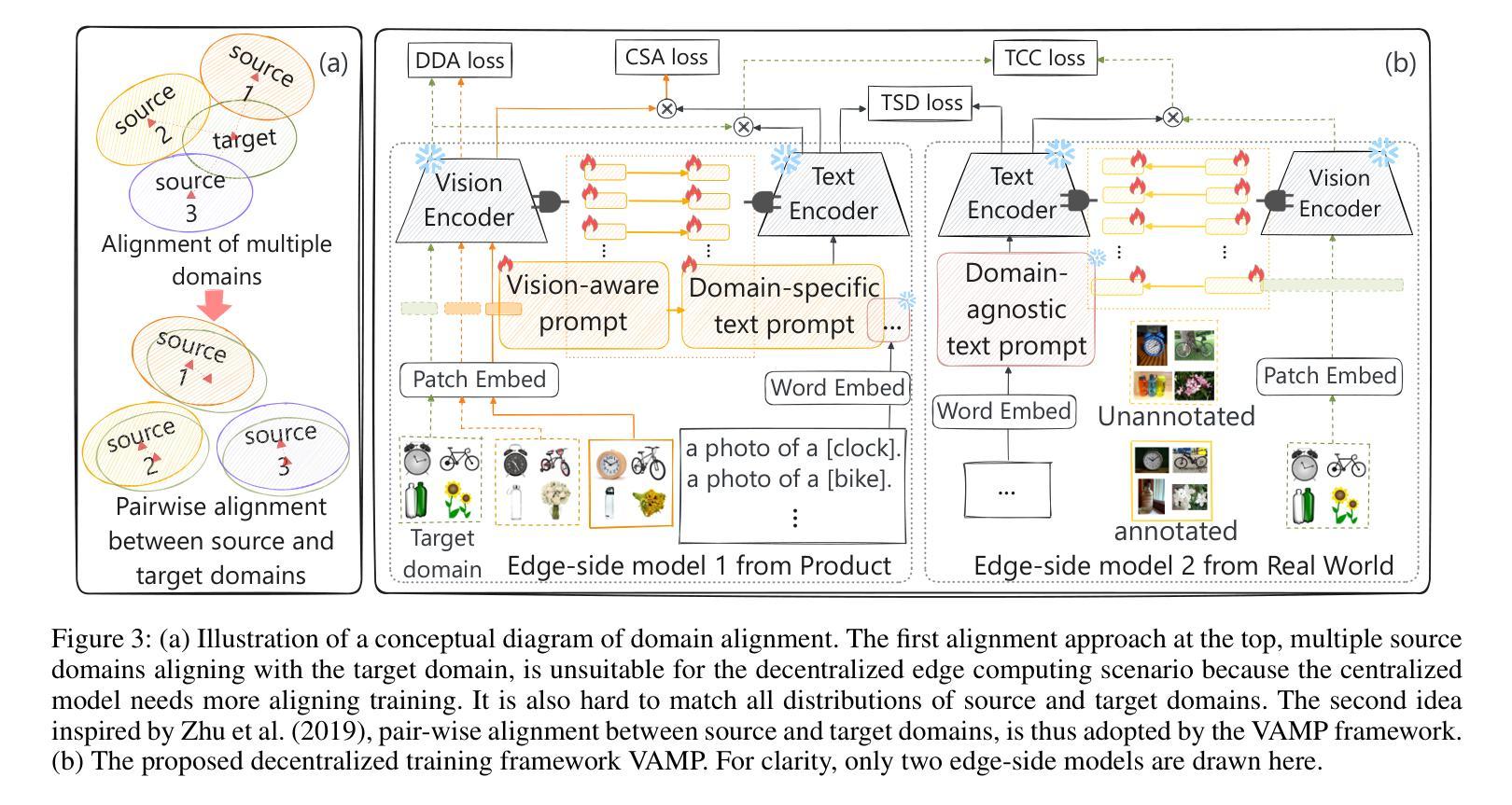
Vision-aware Multimodal Prompt Tuning for Uploadable Multi-source Few-shot Domain Adaptation
Authors:Kuanghong Liu, Jin Wang, Kangjian He, Dan Xu, Xuejie Zhang
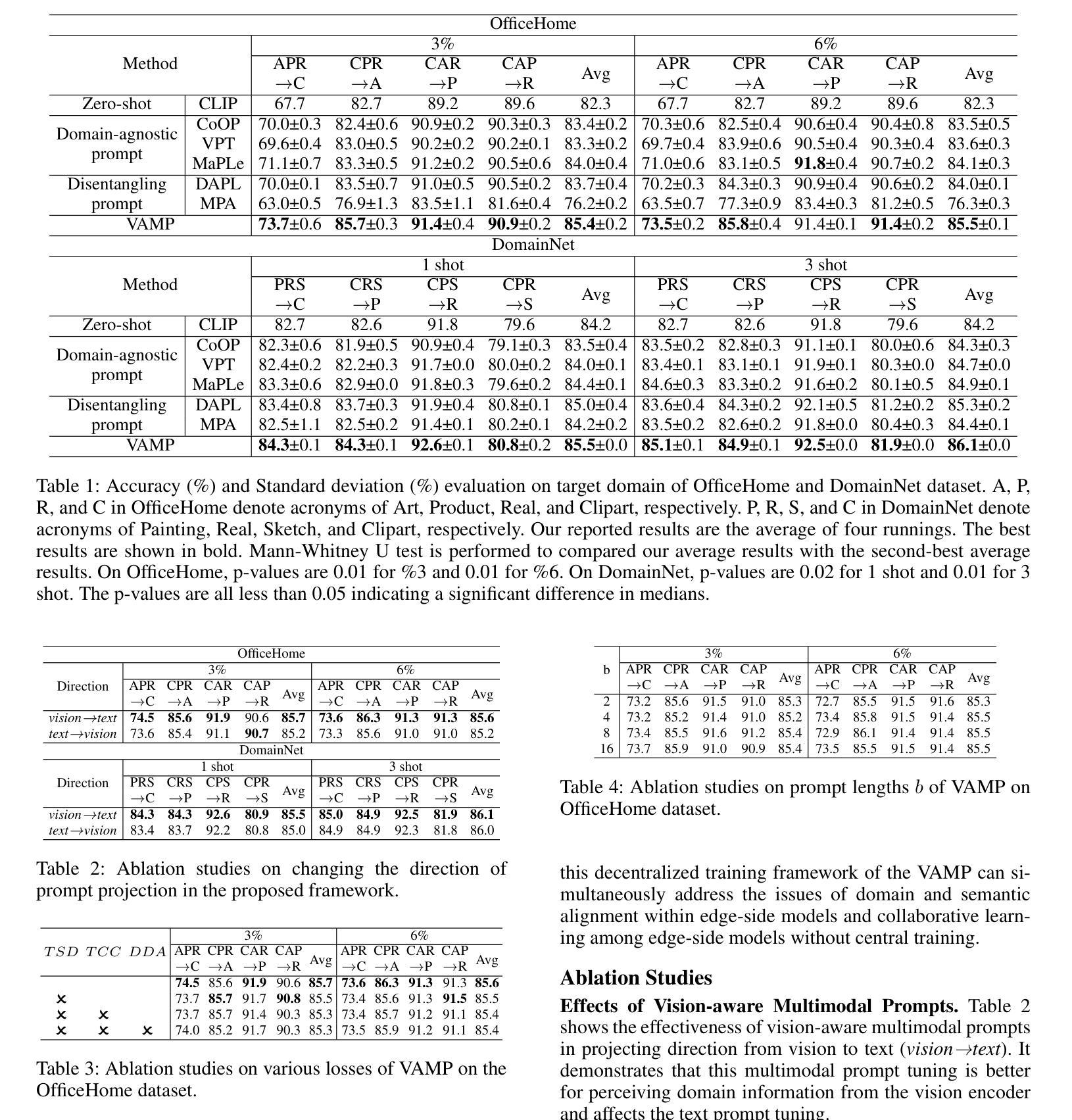
Conventional multi-source domain few-shot adaptation (MFDA) faces the challenge of further reducing the load on edge-side devices in low-resource scenarios. Considering the native language-supervised advantage of CLIP and the plug-and-play nature of prompt to transfer CLIP efficiently, this paper introduces an uploadable multi-source few-shot domain adaptation (UMFDA) schema. It belongs to a decentralized edge collaborative learning in the edge-side models that must maintain a low computational load. And only a limited amount of annotations in source domain data is provided, with most of the data being unannotated. Further, this paper proposes a vision-aware multimodal prompt tuning framework (VAMP) under the decentralized schema, where the vision-aware prompt guides the text domain-specific prompt to maintain semantic discriminability and perceive the domain information. The cross-modal semantic and domain distribution alignment losses optimize each edge-side model, while text classifier consistency and semantic diversity losses promote collaborative learning among edge-side models. Extensive experiments were conducted on OfficeHome and DomainNet datasets to demonstrate the effectiveness of the proposed VAMP in the UMFDA, which outperformed the previous prompt tuning methods.
传统的多源域小样本适应(MFDA)面临着在资源有限的场景中进一步减少边缘设备负载的挑战。考虑到CLIP的本地语言监督优势和prompt的即插即用特性以高效转移CLIP,本文引入了一种可上传的多源小样本域适应(UMFDA)架构。它属于边缘侧模型中必须保持低计算负载的分布式边缘协作学习。源域数据只提供有限量的注释,而大部分数据都是未注释的。此外,本文在分布式架构下提出了一个视觉感知的多模态提示调整框架(VAMP),其中视觉感知提示引导文本域特定提示以保持语义区分并感知域信息。跨模态语义和域分布对齐损失优化了每个边缘侧模型,而文本分类器的一致性和语义多样性损失促进了边缘侧模型之间的协作学习。在OfficeHome和DomainNet数据集上进行了大量实验,证明了在UMFDA中提出的VAMP的有效性,其性能优于以前的提示调整方法。
论文及项目相关链接
PDF Accepted by AAAI 2025
Summary
本文介绍了一种适用于边缘设备的上传式多源少量数据域自适应模型(UMFDA),旨在降低低资源场景下边缘设备的计算负载。利用CLIP的自然语言监督优势和prompt的插拔特性,通过引入视觉感知的多模态提示调整框架(VAMP),优化了边缘侧模型的性能。在OfficeHome和DomainNet数据集上的实验表明,VAMP在UMFDA中的表现优于先前的提示调整方法。
Key Takeaways
- UMFDA模型旨在降低边缘设备在低资源场景下的计算负载。
- CLIP的自然语言监督优势和prompt的插拔特性被用于增强模型的性能。
- 引入视觉感知的多模态提示调整框架(VAMP),以提高边缘侧模型的性能。
- VAMP框架包括通过视觉感知提示引导文本特定提示以维持语义辨别能力并感知域信息。
- 通过跨模态语义和域分布对齐损失优化每个边缘侧模型。
- 通过文本分类器的一致性和语义多样性损失促进边缘侧模型间的协作学习。
点此查看论文截图

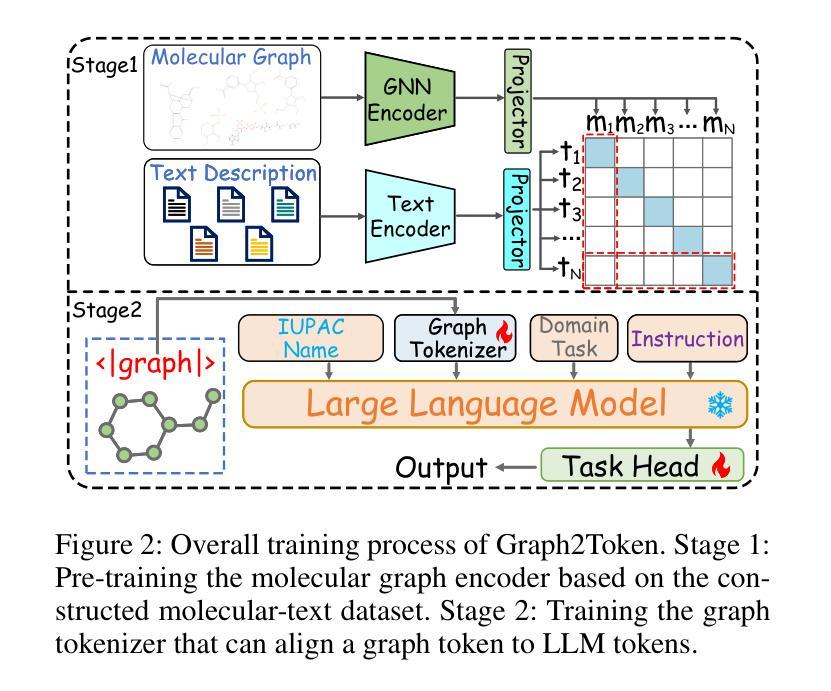
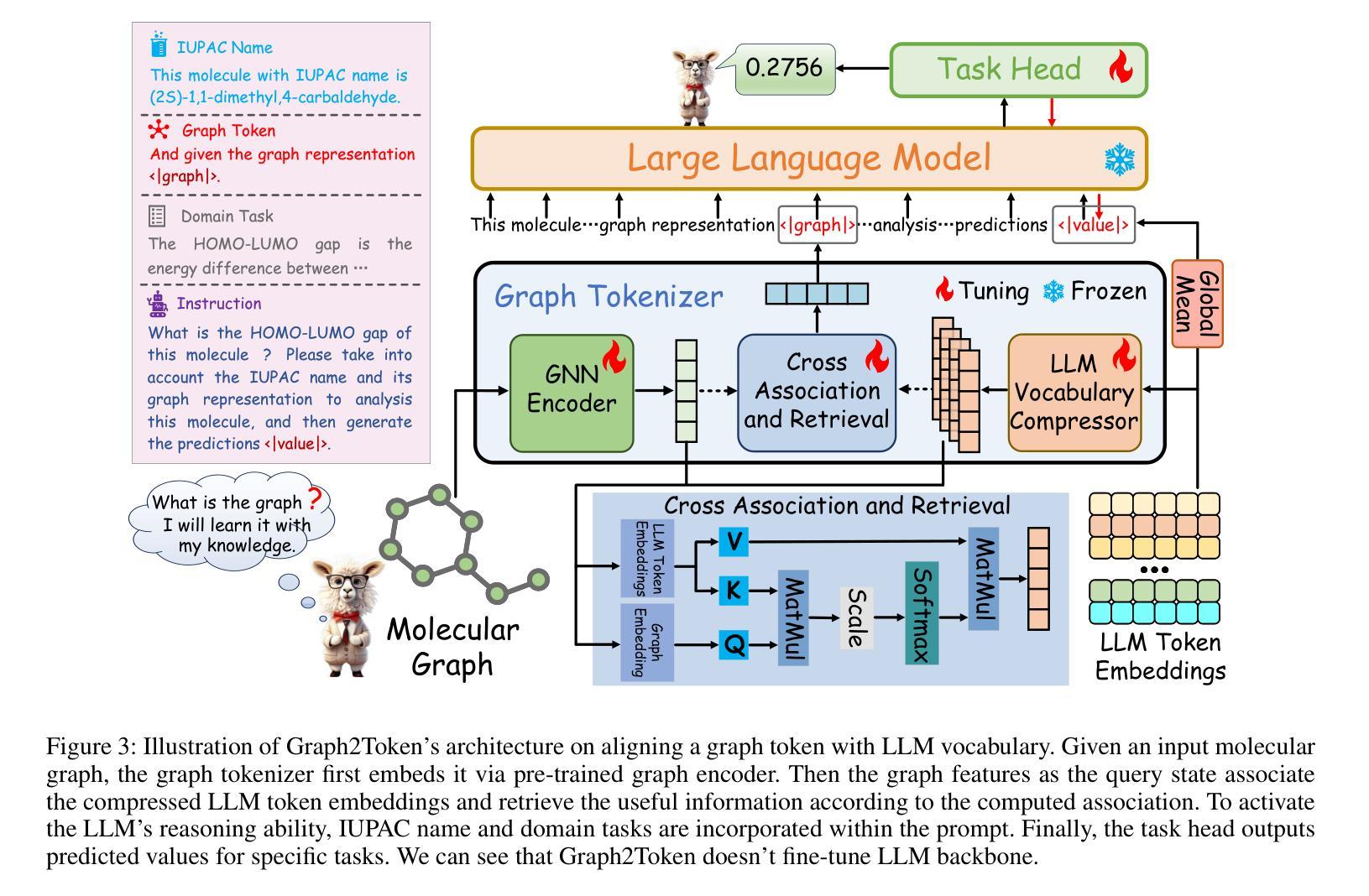
Bridging Molecular Graphs and Large Language Models
Authors:Runze Wang, Mingqi Yang, Yanming Shen
While Large Language Models (LLMs) have shown exceptional generalization capabilities, their ability to process graph data, such as molecular structures, remains limited. To bridge this gap, this paper proposes Graph2Token, an efficient solution that aligns graph tokens to LLM tokens. The key idea is to represent a graph token with the LLM token vocabulary, without fine-tuning the LLM backbone. To achieve this goal, we first construct a molecule-text paired dataset from multisources, including CHEBI and HMDB, to train a graph structure encoder, which reduces the distance between graphs and texts representations in the feature space. Then, we propose a novel alignment strategy that associates a graph token with LLM tokens. To further unleash the potential of LLMs, we collect molecular IUPAC name identifiers, which are incorporated into the LLM prompts. By aligning molecular graphs as special tokens, we can activate LLM generalization ability to molecular few-shot learning. Extensive experiments on molecular classification and regression tasks demonstrate the effectiveness of our proposed Graph2Token.
虽然大型语言模型(LLM)已经表现出卓越的泛化能力,但它们在处理如图数据(如分子结构)方面的能力仍然有限。为了弥这一差距,本文提出了Graph2Token,一种能够将图标记与LLM标记对齐的有效解决方案。关键思想是使用LLM标记词汇来表示图标记,而无需微调LLM的主干。为了实现这一目标,我们首先从CHEBI和HMDB等多源构建分子文本配对数据集,以训练图结构编码器,该编码器缩小了图与文本表示在特征空间中的距离。接着,我们提出了一种新的对齐策略,将图标记与LLM标记关联起来。为了进一步释放LLM的潜力,我们收集了分子IUPAC名称标识符,并将其纳入LLM提示中。通过对分子图进行特殊标记对齐,我们可以激活LLM在分子少样本学习中的泛化能力。在分子分类和回归任务上的大量实验证明了我们的Graph2Token方法的有效性。
论文及项目相关链接
PDF AAAI 2025 camera ready version
Summary
Graph2Token论文旨在解决大型语言模型处理图形数据(如分子结构)能力有限的问题。论文提出了一个将图形令牌与LLM令牌对齐的有效解决方案,可在不需要微调LLM主干的情况下,使用LLM处理图形数据。该研究通过构建分子文本配对数据集和提出新的对齐策略来实现这一目标,并将分子图的IUPAC名称标识符纳入LLM提示中,从而激活LLM对分子数据的泛化能力。实验证明Graph2Token在分子分类和回归任务上的有效性。
Key Takeaways
- Graph2Token解决了大型语言模型处理图形数据(如分子结构)的局限性。
- 通过构建分子文本配对数据集,实现了图形令牌与LLM令牌的对接。
- 提出了一种新的对齐策略,将图形令牌与LLM令牌关联起来。
- 利用分子IUPAC名称标识符,将分子图作为特殊令牌纳入LLM提示中。
- Graph2Token激活了LLM对分子数据的泛化能力。
- 实验证明Graph2Token在分子分类和回归任务上的有效性。
点此查看论文截图

Learning to Animate Images from A Few Videos to Portray Delicate Human Actions
Authors:Haoxin Li, Yingchen Yu, Qilong Wu, Hanwang Zhang, Song Bai, Boyang Li
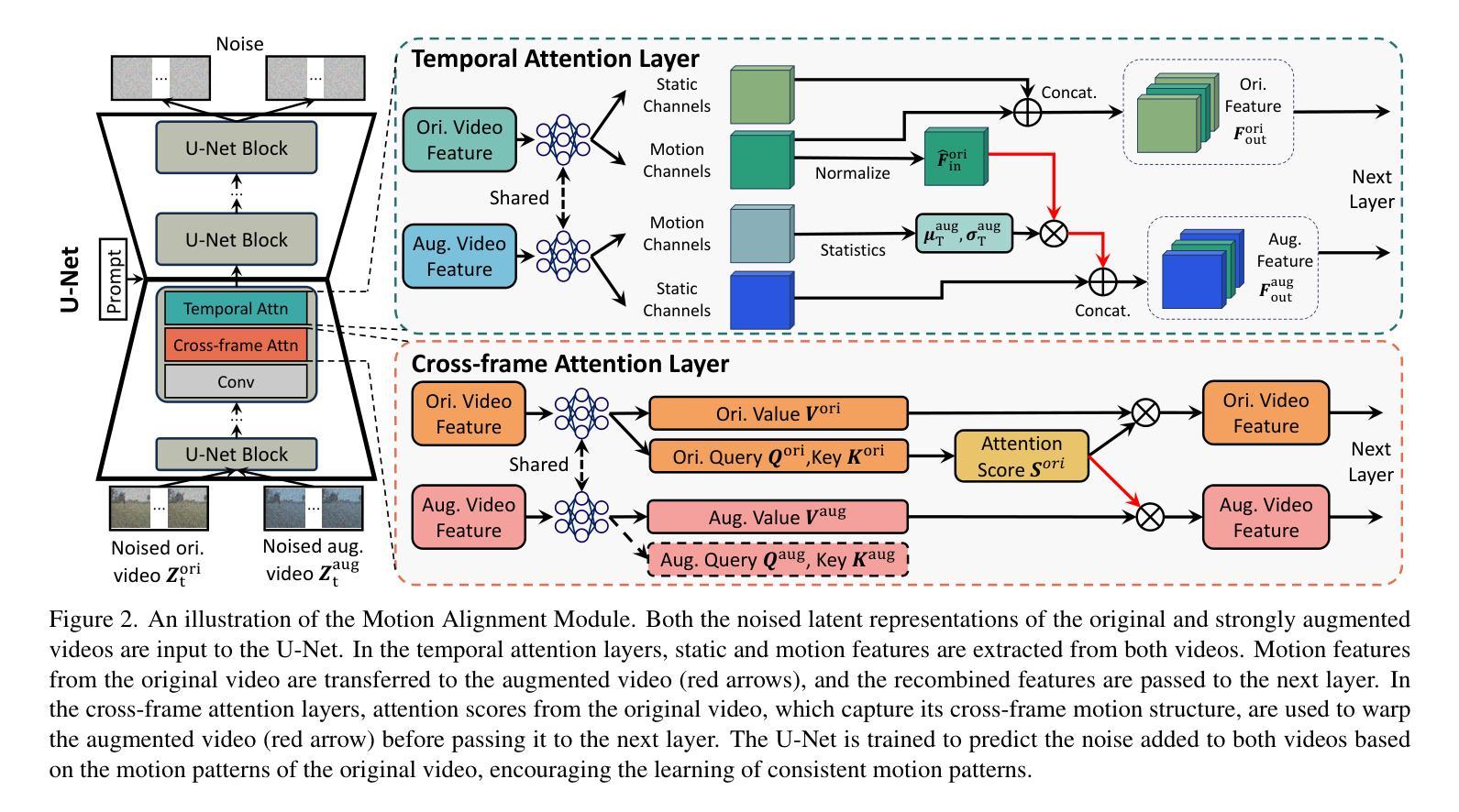
Despite recent progress, video generative models still struggle to animate static images into videos that portray delicate human actions, particularly when handling uncommon or novel actions whose training data are limited. In this paper, we explore the task of learning to animate images to portray delicate human actions using a small number of videos – 16 or fewer – which is highly valuable for real-world applications like video and movie production. Learning generalizable motion patterns that smoothly transition from user-provided reference images in a few-shot setting is highly challenging. We propose FLASH (Few-shot Learning to Animate and Steer Humans), which learns generalizable motion patterns by forcing the model to reconstruct a video using the motion features and cross-frame correspondences of another video with the same motion but different appearance. This encourages transferable motion learning and mitigates overfitting to limited training data. Additionally, FLASH extends the decoder with additional layers to propagate details from the reference image to generated frames, improving transition smoothness. Human judges overwhelmingly favor FLASH, with 65.78% of 488 responses prefer FLASH over baselines. We strongly recommend watching the videos in the website: https://lihaoxin05.github.io/human_action_animation/, as motion artifacts are hard to notice from images.
尽管最近的进展显著,视频生成模型仍然难以将静态图像转化为描绘精细人类动作的视频,尤其是在处理训练数据有限的不常见或新动作时。在本文中,我们探讨了使用少量视频(16个或更少)学习使图像动画化以描绘精细人类动作的任务,这对于视频和电影制作等实际应用来说非常有价值。在少数镜头下,从用户提供的参考图像学习可推广的运动模式具有很大挑战性。我们提出了FLASH(Few-shot Learning to Animate and Steer Humans),它通过强制模型使用具有相同运动但不同外观的另一个视频的运动特征和跨帧对应关系来重建视频,学习可推广的运动模式。这鼓励了可迁移的运动学习,并减轻了过度依赖有限训练数据的问题。此外,FLASH扩展了解码器,增加了额外的层,以将细节从参考图像传播到生成的帧,提高了过渡的平滑度。人类评委压倒性地青睐FLASH,在488个回应中,有65.78%的人认为FLASH优于基线。我们强烈推荐在网站上观看视频:https://lihaoxin05.github.io/human_action_animation/,因为运动伪影很难从图像中察觉。
论文及项目相关链接
Summary
基于少量视频学习驱动图像动画以表现精细人类动作的任务具有挑战性。本文提出一种名为FLASH的方法,通过学习通用运动模式并借鉴其他视频的运动特征和跨帧对应关系,实现精细人类动作的动画生成。FLASH通过扩展解码器,将参考图像的细节传播到生成的帧中,提高了过渡的平滑性。经过实验验证,FLASH在人类评价中取得了显著优势。
Key Takeaways
- 该论文探讨了如何在有限视频数据(仅16个或更少)中驱动图像动画以展示精细的人类动作。
- 提出了一种名为FLASH的方法,通过借鉴其他视频的运动特征和跨帧对应关系,学习通用运动模式。
- FLASH方法通过学习从参考图像传播细节到生成的帧,提高了过渡的平滑性。
- 实验结果显示,FLASH在人类评价中取得了显著优势,大多数人类判断者倾向于选择FLASH生成的动画。
- FLASH方法对于真实世界应用(如视频和电影制作)具有很高的价值。
- 该论文强调观看视频的重要性,因为运动伪影在图像中很难察觉。
点此查看论文截图


Continuous Knowledge-Preserving Decomposition for Few-Shot Continual Learning
Authors:Xiaojie Li, Yibo Yang, Jianlong Wu, Jie Liu, Yue Yu, Liqiang Nie, Min Zhang
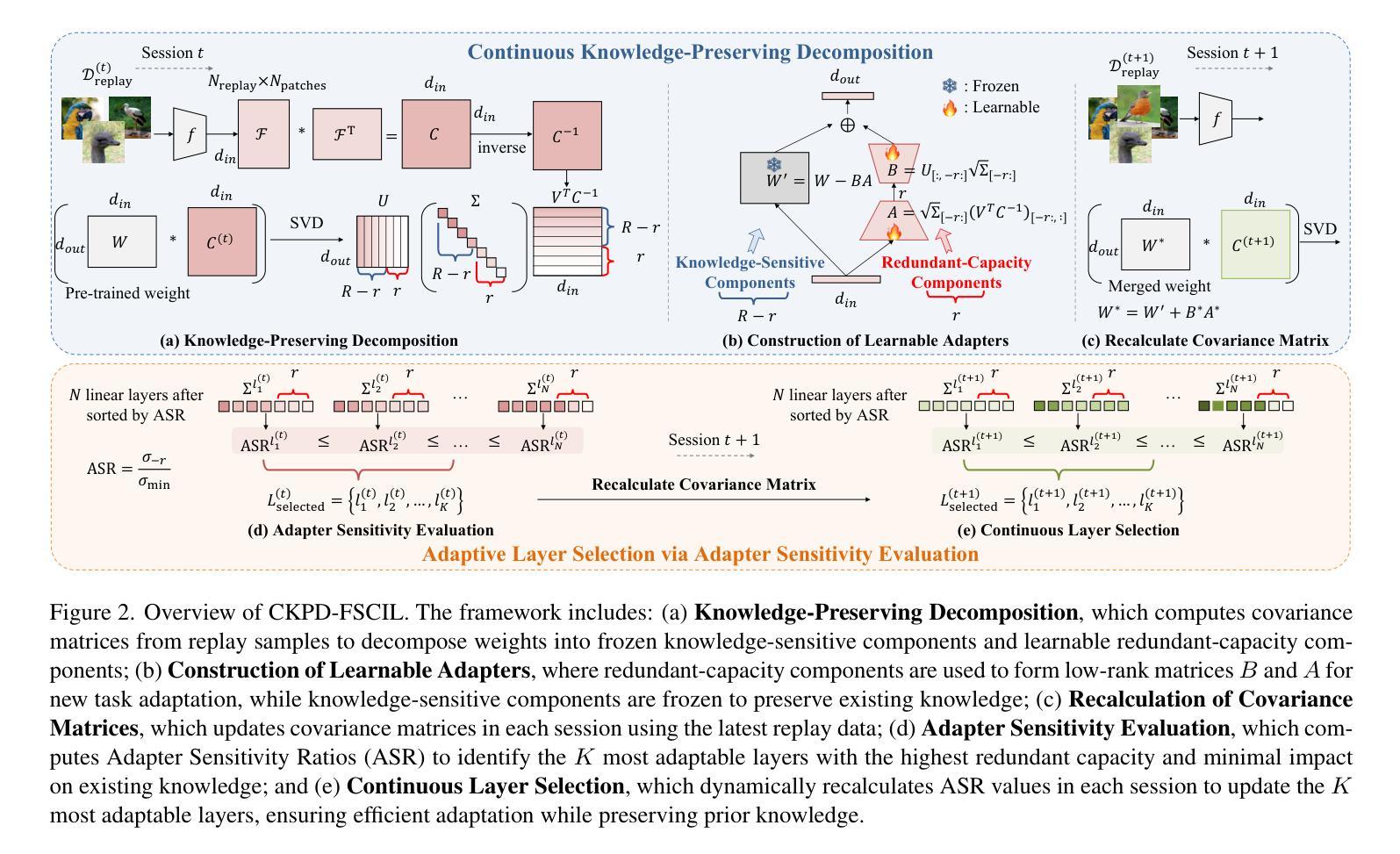
Few-shot class-incremental learning (FSCIL) involves learning new classes from limited data while retaining prior knowledge, and often results in catastrophic forgetting. Existing methods either freeze backbone networks to preserve knowledge, which limits adaptability, or rely on additional modules or prompts, introducing inference overhead. To this end, we propose Continuous Knowledge-Preserving Decomposition for FSCIL (CKPD-FSCIL), a framework that decomposes a model’s weights into two parts: one that compacts existing knowledge (knowledge-sensitive components) and another that carries redundant capacity to accommodate new abilities (redundant-capacity components). The decomposition is guided by a covariance matrix from replay samples, ensuring principal components align with classification abilities. During adaptation, we freeze the knowledge-sensitive components and only adapt the redundant-capacity components, fostering plasticity while minimizing interference without changing the architecture or increasing overhead. Additionally, CKPD introduces an adaptive layer selection strategy to identify layers with redundant capacity, dynamically allocating adapters. Experiments on multiple benchmarks show that CKPD-FSCIL outperforms state-of-the-art methods.
少量样本类增量学习(FSCIL)涉及从有限数据中学习新类别同时保留先前知识,这常常导致灾难性遗忘。现有方法要么冻结主干网络以保留知识,这限制了适应性,要么依赖附加模块或提示,引入推理开销。为此,我们提出了面向FSCIL的持续知识保留分解(CKPD-FSCIL),这是一种将模型权重分解为两部分的框架:一部分是压缩现有知识(知识敏感组件),另一部分是容纳新能力所需的冗余容量(冗余容量组件)。分解受回放样本的协方差矩阵指导,确保主成分与分类能力对齐。在适应过程中,我们冻结知识敏感组件,只适应冗余容量组件,促进可塑性,同时最小化干扰,而无需更改架构或增加开销。此外,CKPD引入了一种自适应层选择策略,以识别具有冗余容量的层,并动态分配适配器。在多个基准测试上的实验表明,CKPD-FSCIL优于现有最先进的方法。
论文及项目相关链接
PDF Code: https://github.com/xiaojieli0903/CKPD-FSCIL
Summary
基于有限数据实现类增量学习(FSCIL)的过程中,保留先前知识并避免灾难性遗忘是关键。现有方法要么冻结主干网络以保留知识,限制了适应性,要么依赖额外的模块或提示,增加了推理开销。为此,我们提出了面向FSCIL的持续知识保留分解(CKPD-FSCIL)框架。该框架将模型的权重分解为两部分:一部分是压缩现有知识(知识敏感组件),另一部分是容纳新能力(冗余容量组件)。分解过程由回放样本的协方差矩阵引导,确保主成分与分类能力对齐。在适应过程中,我们冻结知识敏感组件,只适应冗余容量组件,以促进可塑性并最小化干扰,同时不改变架构或增加开销。此外,CKPD还引入了一种自适应层选择策略,以识别具有冗余容量的层,并动态分配适配器。在多个基准测试上的实验表明,CKPD-FSCIL优于现有方法。
Key Takeaways
- Few-shot class-incremental learning (FSCIL) 涉及从新数据中学习并保留先前知识的问题。
- 现有方法可能面临灾难性遗忘的问题,要么限制适应性要么增加推理开销。
- CKPD-FSCIL框架通过将模型权重分解为知识敏感组件和冗余容量组件来解决这一问题。
- 知识敏感组件用于保留现有知识,冗余容量组件用于适应新能力。
- CKPD使用回放样本的协方差矩阵来引导分解过程并确保分类能力的对齐。
- CKPD通过冻结知识敏感组件并仅适应冗余容量组件来优化学习过程。
点此查看论文截图

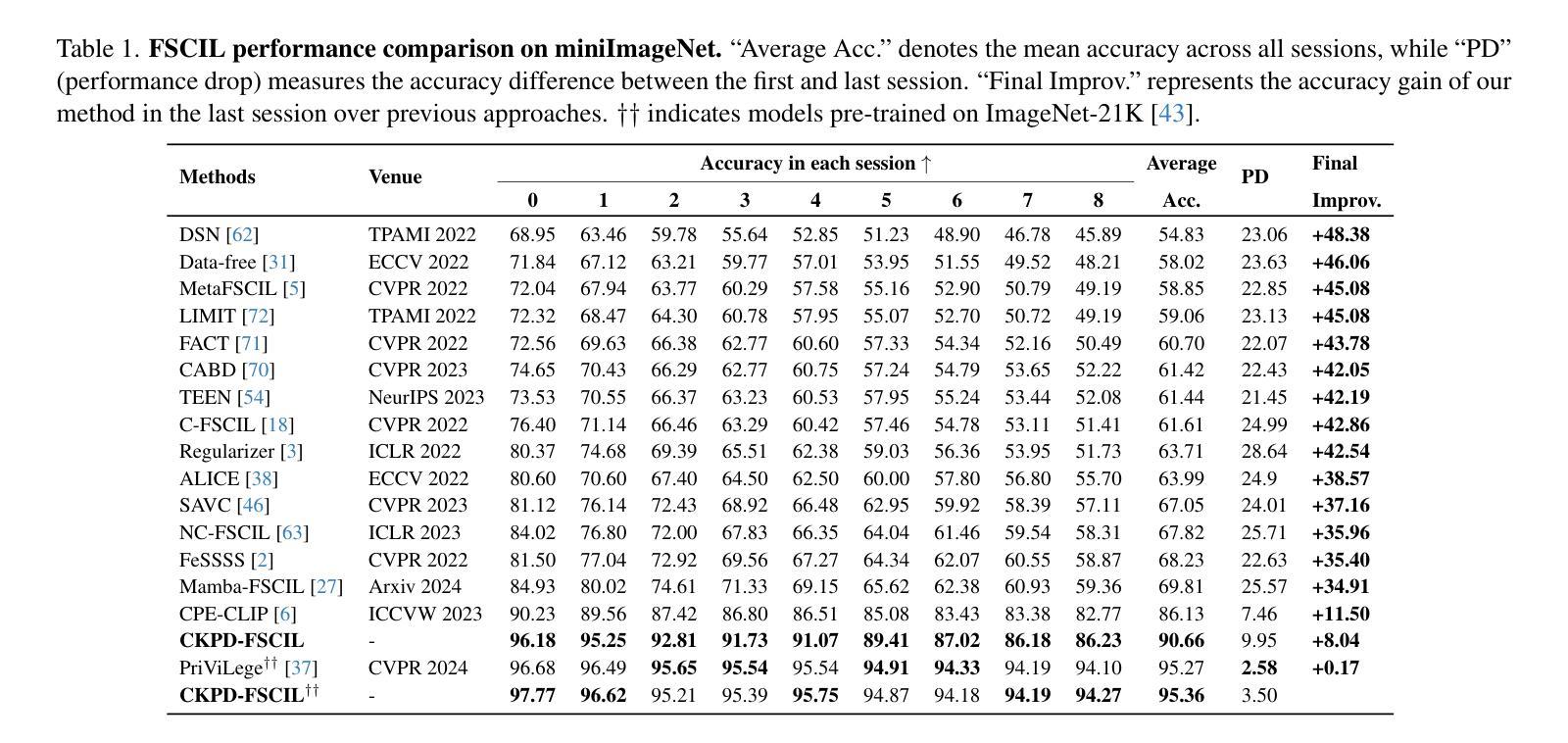
UniVAD: A Training-free Unified Model for Few-shot Visual Anomaly Detection
Authors:Zhaopeng Gu, Bingke Zhu, Guibo Zhu, Yingying Chen, Ming Tang, Jinqiao Wang
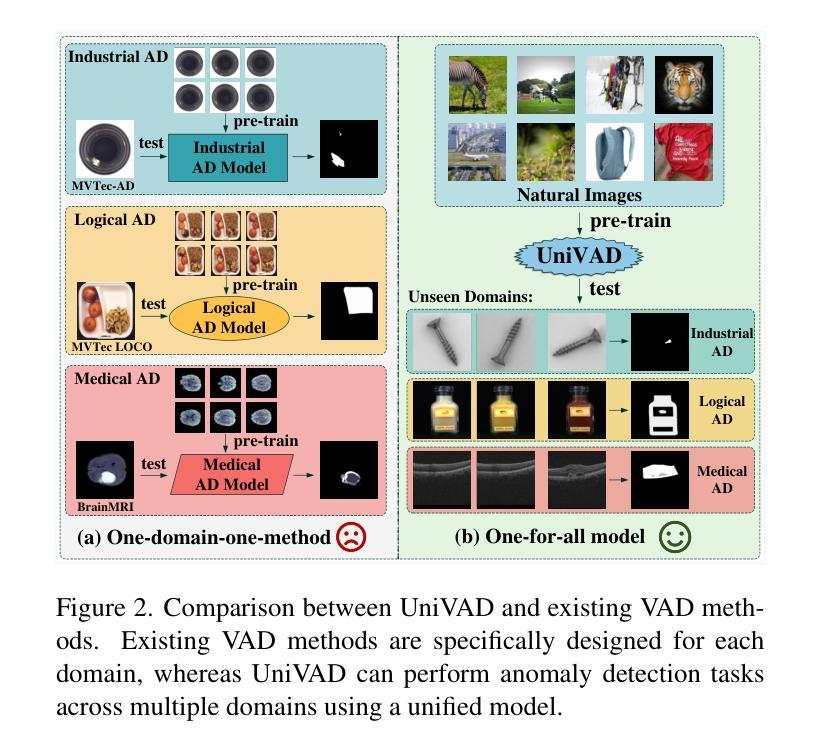
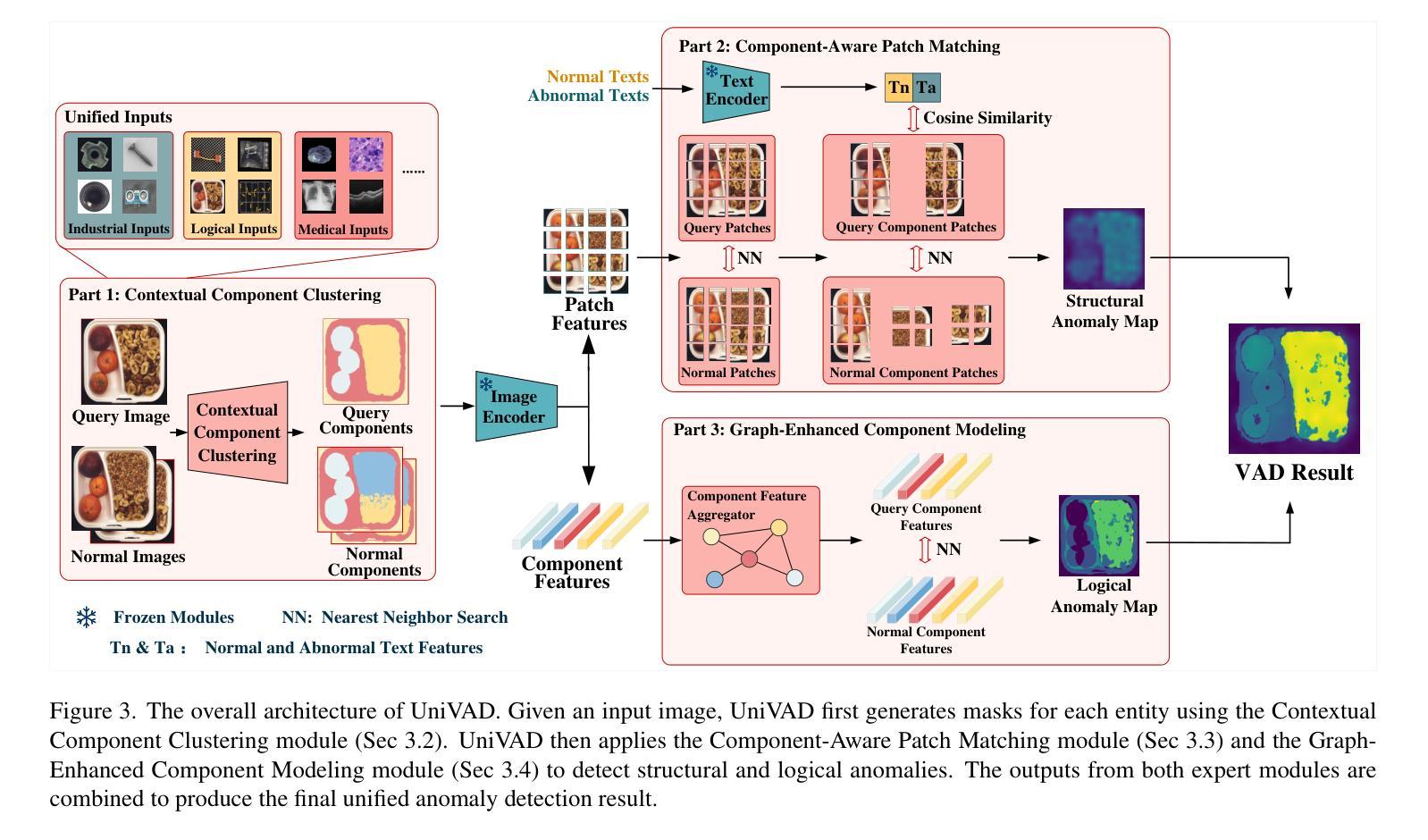
Visual Anomaly Detection (VAD) aims to identify abnormal samples in images that deviate from normal patterns, covering multiple domains, including industrial, logical, and medical fields. Due to the domain gaps between these fields, existing VAD methods are typically tailored to each domain, with specialized detection techniques and model architectures that are difficult to generalize across different domains. Moreover, even within the same domain, current VAD approaches often follow a “one-category-one-model” paradigm, requiring large amounts of normal samples to train class-specific models, resulting in poor generalizability and hindering unified evaluation across domains. To address this issue, we propose a generalized few-shot VAD method, UniVAD, capable of detecting anomalies across various domains, such as industrial, logical, and medical anomalies, with a training-free unified model. UniVAD only needs few normal samples as references during testing to detect anomalies in previously unseen objects, without training on the specific domain. Specifically, UniVAD employs a Contextual Component Clustering ($C^3$) module based on clustering and vision foundation models to segment components within the image accurately, and leverages Component-Aware Patch Matching (CAPM) and Graph-Enhanced Component Modeling (GECM) modules to detect anomalies at different semantic levels, which are aggregated to produce the final detection result. We conduct experiments on nine datasets spanning industrial, logical, and medical fields, and the results demonstrate that UniVAD achieves state-of-the-art performance in few-shot anomaly detection tasks across multiple domains, outperforming domain-specific anomaly detection models. Code is available at https://github.com/FantasticGNU/UniVAD.
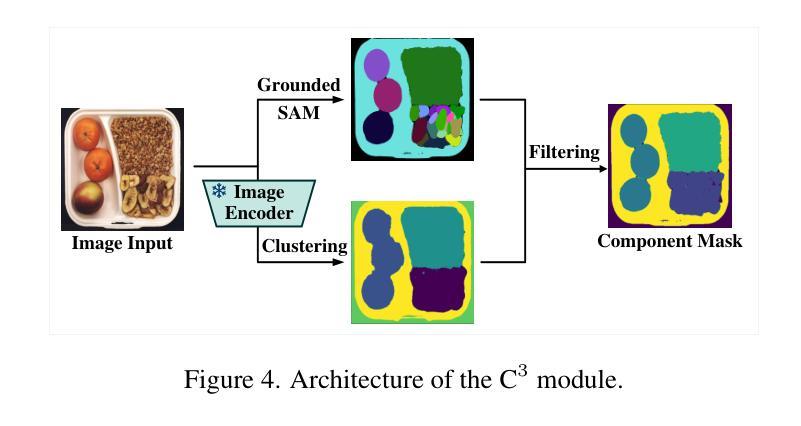
视觉异常检测(VAD)旨在识别图像中的异常样本,这些样本偏离了正常模式,涉及多个领域,包括工业、逻辑和医疗领域。由于这些领域之间存在领域差距,现有的VAD方法通常针对每个领域进行定制,具有专业的检测技术和模型架构,难以在不同领域之间进行推广。此外,即使在同一领域内,当前的VAD方法通常遵循“一类一模型”的模式,需要大量正常样本来训练特定类别的模型,这导致了较差的泛化能力,并阻碍了跨领域的统一评估。为了解决这个问题,我们提出了一种通用的Few-Shot VAD方法UniVAD,能够检测各种领域的异常,如工业、逻辑和医学异常,使用无需训练的统一模型。UniVAD只需在测试时使用少量正常样本作为参考,即可检测以前未见过的对象中的异常,而无需在特定领域上进行训练。具体来说,UniVAD采用基于聚类和视觉基础模型的上下文组件聚类(C^3)模块,精确地分割图像内的组件,并利用组件感知补丁匹配(CAPM)和图增强组件建模(GECM)模块在不同的语义级别检测异常,这些异常被聚合以产生最终的检测结果。我们在九个数据集上进行了实验,这些数据集涵盖了工业、逻辑和医疗领域,结果表明UniVAD在跨多个领域的Few-Shot异常检测任务中实现了最先进的性能,优于特定领域的异常检测模型。相关代码可通过https://github.com/FantasticGNU/UniVAD获取。
论文及项目相关链接
PDF Accepted by CVPR 2025; Project page: https://uni-vad.github.io/
摘要
视觉异常检测(VAD)旨在识别图像中的异常样本,这些样本偏离正常模式,涉及工业、逻辑和医疗等多个领域。由于这些领域之间存在领域差距,现有的VAD方法通常针对每个领域进行定制,具有专业化的检测技术和模型架构,难以在不同领域之间进行推广。此外,即使在同一领域内,当前的VAD方法也通常采用“一类一模型”的模式,需要大量正常样本来训练特定类别的模型,导致泛化性差,阻碍了跨领域的统一评估。为解决这一问题,我们提出了一种通用的少样本VAD方法UniVAD,能够检测工业、逻辑和医疗等跨领域的异常值。UniVAD采用无训练的统一模型,仅在测试时需要少量正常样本作为参考来检测先前未见过的对象中的异常值。具体来说,UniVAD采用基于聚类和视觉基础模型的上下文组件聚类(C^3)模块来准确分割图像内的组件,并利用组件感知补丁匹配(CAPM)和图增强组件建模(GECM)模块在不同的语义级别检测异常值,最后汇总得出最终的检测结果。我们在涵盖工业、逻辑和医疗领域的九个数据集上进行了实验,结果表明,UniVAD在跨领域的少样本异常检测任务中实现了最佳性能,优于特定领域的异常检测模型。
关键见解
- VAD旨在识别与正常模式偏离的异常图像样本,涉及多个领域。
- 现有VAD方法通常针对特定领域设计,难以跨领域推广。
- UniVAD是一种通用的少样本VAD方法,可检测不同领域的异常值。
- UniVAD仅需要少量正常样本作为参考来检测测试中的异常值。
- UniVAD采用上下文组件聚类(C^3)模块准确分割图像组件。
- UniVAD利用组件感知补丁匹配(CAPM)和图增强组件建模(GECM)模块在多个语义级别检测异常值。
点此查看论文截图

DAWN-ICL: Strategic Planning of Problem-solving Trajectories for Zero-Shot In-Context Learning
Authors:Xinyu Tang, Xiaolei Wang, Wayne Xin Zhao, Ji-Rong Wen
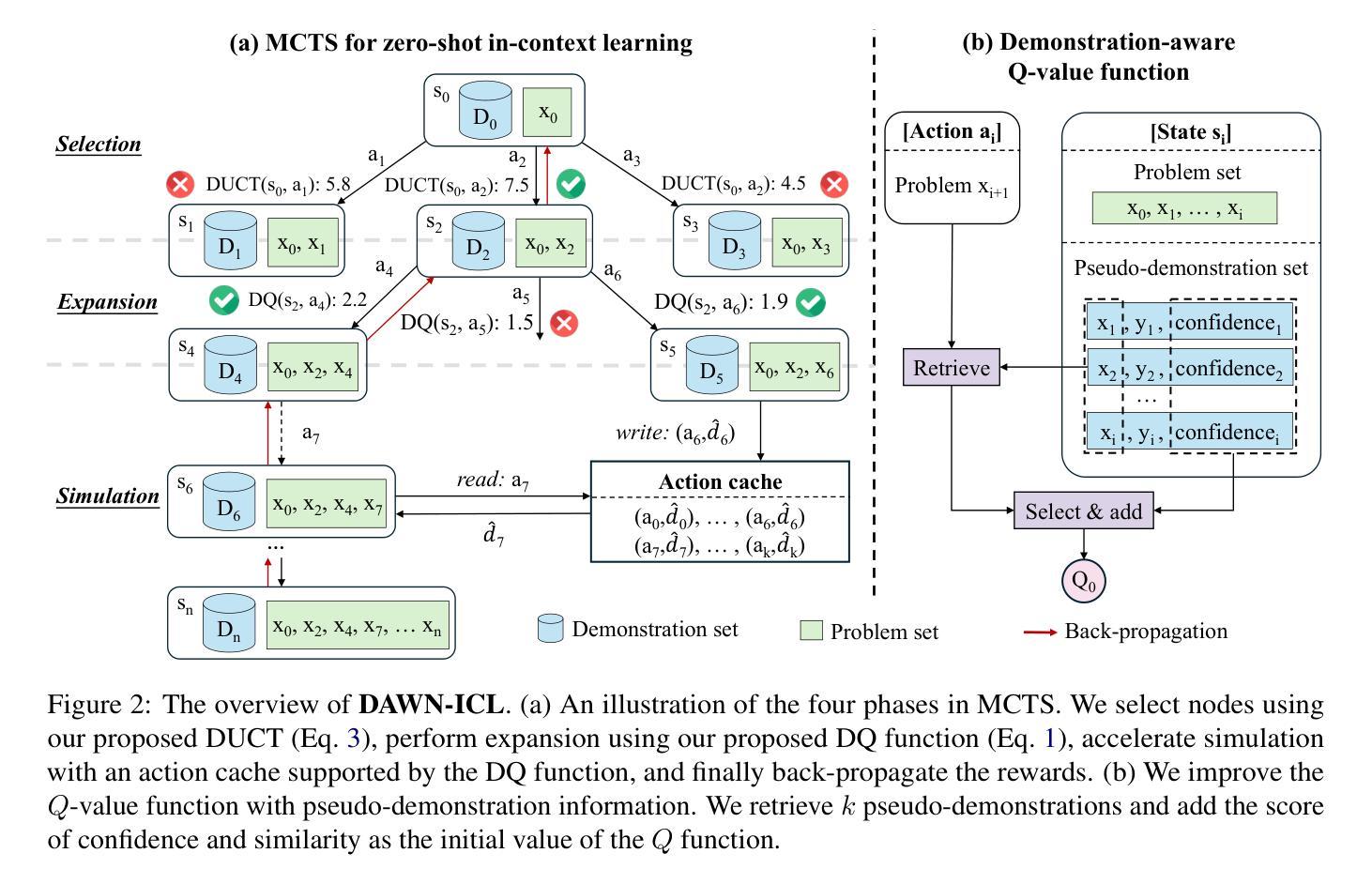
Zero-shot in-context learning (ZS-ICL) aims to conduct in-context learning (ICL) without using human-annotated demonstrations. Most ZS-ICL methods use large language models (LLMs) to generate (input, label) pairs as pseudo-demonstrations and leverage historical pseudo-demonstrations to help solve the current problem. They assume that problems are from the same task and traverse them in a random order. However, in real-world scenarios, problems usually come from diverse tasks, and only a few belong to the same task. The random traversing order may generate unreliable pseudo-demonstrations and lead to error accumulation. To address this problem, we reformulate ZS-ICL as a planning problem and propose a Demonstration-aware Monte Carlo Tree Search (MCTS) approach (DAWN-ICL), which leverages MCTS to strategically plan the problem-solving trajectories for ZS-ICL. In addition, to achieve effective and efficient Q value estimation, we propose a novel demonstration-aware Q-value function and use it to enhance the selection phase and accelerate the expansion and simulation phases in MCTS. Extensive experiments demonstrate the effectiveness and efficiency of DAWN-ICL on in-domain and cross-domain scenarios, and it even outperforms ICL using human-annotated labels. The code is available at https://github.com/RUCAIBox/MCTS4ZSICL.
零样本上下文学习(ZS-ICL)旨在进行无需人工标注示例的上下文学习(ICL)。大多数ZS-ICL方法使用大型语言模型(LLM)生成(输入,标签)对作为伪演示,并利用历史伪演示来帮助解决当前问题。它们假设问题来自同一任务,并按随机顺序遍历。然而,在真实场景中,问题通常来自各种任务,只有少数属于同一任务。随机遍历顺序可能会生成不可靠的伪演示,并导致误差累积。为了解决此问题,我们将ZS-ICL重新表述为规划问题,并提出一种基于演示的蒙特卡洛树搜索(MCTS)方法(DAWN-ICL),该方法利用MCTS为ZS-ICL战略性地规划问题解决轨迹。此外,为了有效且高效地估计Q值,我们提出了一种新颖的基于演示的Q值函数,并将其用于增强选择阶段并加速MCTS中的扩展和模拟阶段。大量实验表明,DAWN-ICL在域内和跨域场景中都有效且高效,甚至超越了使用人工标注标签的ICL。代码可在https://github.com/RUCAIBox/MCTS4ZSICL找到。
论文及项目相关链接
PDF NAACL 2025 Main Conference
Summary
本文介绍了零样本上下文学习(ZS-ICL)的新方法,旨在解决现实世界中任务多样性的问题。文章提出将ZS-ICL重新构建为规划问题,并引入基于蒙特卡洛树搜索(MCTS)的演示感知方法(DAWN-ICL)。该方法通过MCTS策略规划问题解决轨迹,并提出演示感知Q值函数以提高选择阶段效率,加速MCTS的扩展和模拟阶段。实验表明,DAWN-ICL在域内和跨域场景中都表现出有效性和高效性,甚至超越了使用人类注释标签的ICL。
Key Takeaways
- ZS-ICL旨在进行无需人类注释演示的上下文学习(ICL)。
- 现有ZS-ICL方法主要使用大型语言模型(LLMs)生成(输入,标签)对作为伪演示。
- 现实世界中,问题通常来自多样化的任务,只有少部分属于同一任务。
- 随机遍历顺序可能生成不可靠的伪演示,导致误差累积。
- 本文将ZS-ICL重新构建为规划问题,并提出基于蒙特卡洛树搜索(MCTS)的演示感知方法(DAWN-ICL)。
- DAWN-ICL通过MCTS策略规划问题解决轨迹。
- 引入演示感知Q值函数,提高选择阶段效率,加速MCTS的扩展和模拟阶段。实验表明DAWN-ICL方法有效且高效。
点此查看论文截图

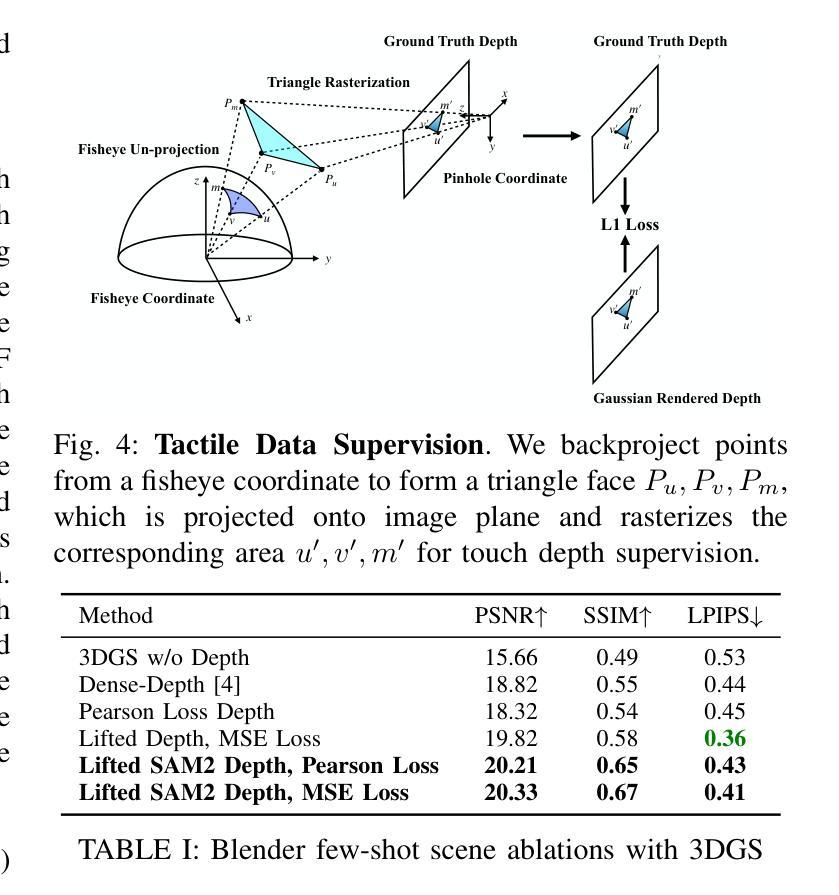
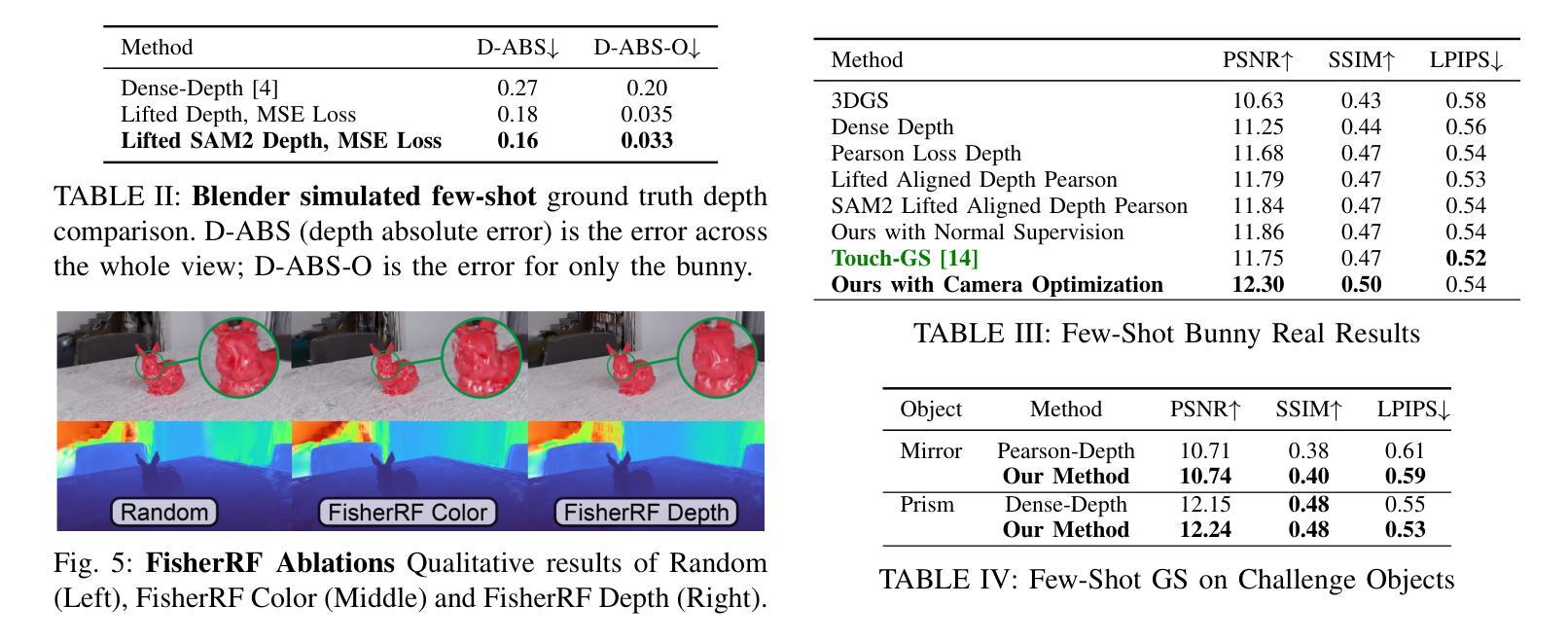
Next Best Sense: Guiding Vision and Touch with FisherRF for 3D Gaussian Splatting
Authors:Matthew Strong, Boshu Lei, Aiden Swann, Wen Jiang, Kostas Daniilidis, Monroe Kennedy III
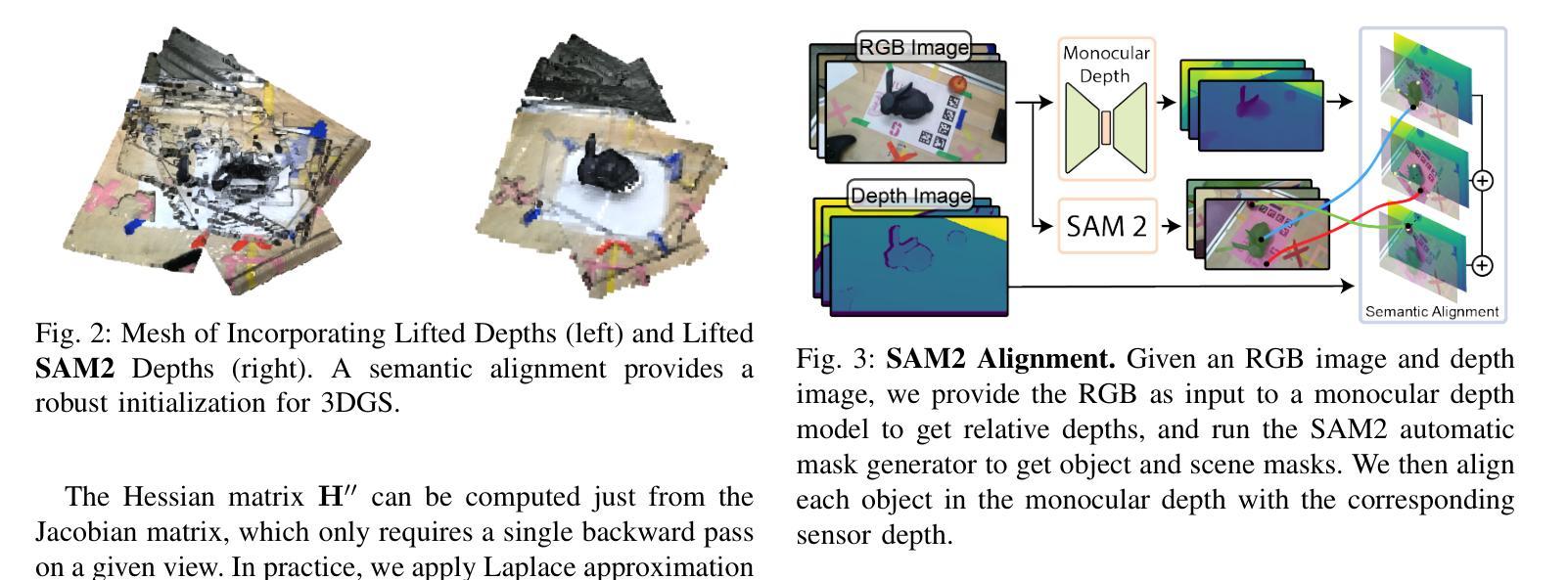
We propose a framework for active next best view and touch selection for robotic manipulators using 3D Gaussian Splatting (3DGS). 3DGS is emerging as a useful explicit 3D scene representation for robotics, as it has the ability to represent scenes in a both photorealistic and geometrically accurate manner. However, in real-world, online robotic scenes where the number of views is limited given efficiency requirements, random view selection for 3DGS becomes impractical as views are often overlapping and redundant. We address this issue by proposing an end-to-end online training and active view selection pipeline, which enhances the performance of 3DGS in few-view robotics settings. We first elevate the performance of few-shot 3DGS with a novel semantic depth alignment method using Segment Anything Model 2 (SAM2) that we supplement with Pearson depth and surface normal loss to improve color and depth reconstruction of real-world scenes. We then extend FisherRF, a next-best-view selection method for 3DGS, to select views and touch poses based on depth uncertainty. We perform online view selection on a real robot system during live 3DGS training. We motivate our improvements to few-shot GS scenes, and extend depth-based FisherRF to them, where we demonstrate both qualitative and quantitative improvements on challenging robot scenes. For more information, please see our project page at https://arm.stanford.edu/next-best-sense.
我们提出了一种基于三维高斯插值(3DGS)的机器人操作器活动最佳下一个视角和触摸选择的框架。3DGS作为一种有用的机器人技术三维场景表示法,具有再现现实场景的光照和几何准确性能力。然而,在现实世界中的在线机器人场景中,由于效率要求,视图数量有限,随机选择视图进行3DGS变得不切实际,因为视图经常重叠且冗余。我们通过提出一种端到端的在线训练和活动视图选择管道来解决这个问题,该管道提高了少数视角机器人设置中的3DGS性能。我们首先使用分段任何模型(SAM2)的新颖语义深度对齐方法来提高少量射击3DGS的性能,我们还通过皮尔森深度和表面正常损失来补充SAM2,以改善真实场景的颜色和深度重建。然后,我们对FisherRF进行扩展,这是一种用于3DGS的最佳下一个视图选择方法,根据深度不确定性选择视图和触摸姿势。我们在实时3DGS训练期间在真实的机器人系统上执行在线视图选择。我们改进了少数射击GS场景,并将基于深度的FisherRF扩展到它们上,在具有挑战性的机器人场景中证明了我们的定性和定量改进。更多信息请参见我们的项目页面:https://arm.stanford.edu/next-best-sense。
论文及项目相关链接
PDF To appear in International Conference on Robotics and Automation (ICRA) 2025
Summary
本文提出一种针对机器人操纵器的主动最佳视角和触摸选择的框架,利用三维高斯喷绘技术(3DGS)。针对在线机器人场景中视角数量有限的问题,文章通过端到端的在线训练和主动视角选择管道,提高了三维高斯喷绘在少量视角下的性能。此外,文章引入了一种新型语义深度对齐方法,结合佩尔森深度和表面正常损失,改善真实场景的颜色和深度重建。最后,文章将FisherRF扩展到基于深度不确定性的视角选择和触摸姿势选择,并在真实机器人系统上进行在线视角选择。
Key Takeaways
- 提出利用三维高斯喷绘技术(3DGS)的框架,实现机器人操纵器的主动最佳视角和触摸选择。
- 3DGS能够在照片级真实和几何准确的场景表示之间取得平衡。
- 针对在线机器人场景中视角数量有限的问题,提出了端到端的在线训练和主动视角选择管道。
- 引入新型语义深度对齐方法,结合佩尔森深度和表面正常损失,改善真实场景的颜色和深度重建。
- 将FisherRF扩展到基于深度不确定性的视角选择和触摸姿势选择。
- 在挑战性的机器人场景中进行了定量和定性的改进。
点此查看论文截图


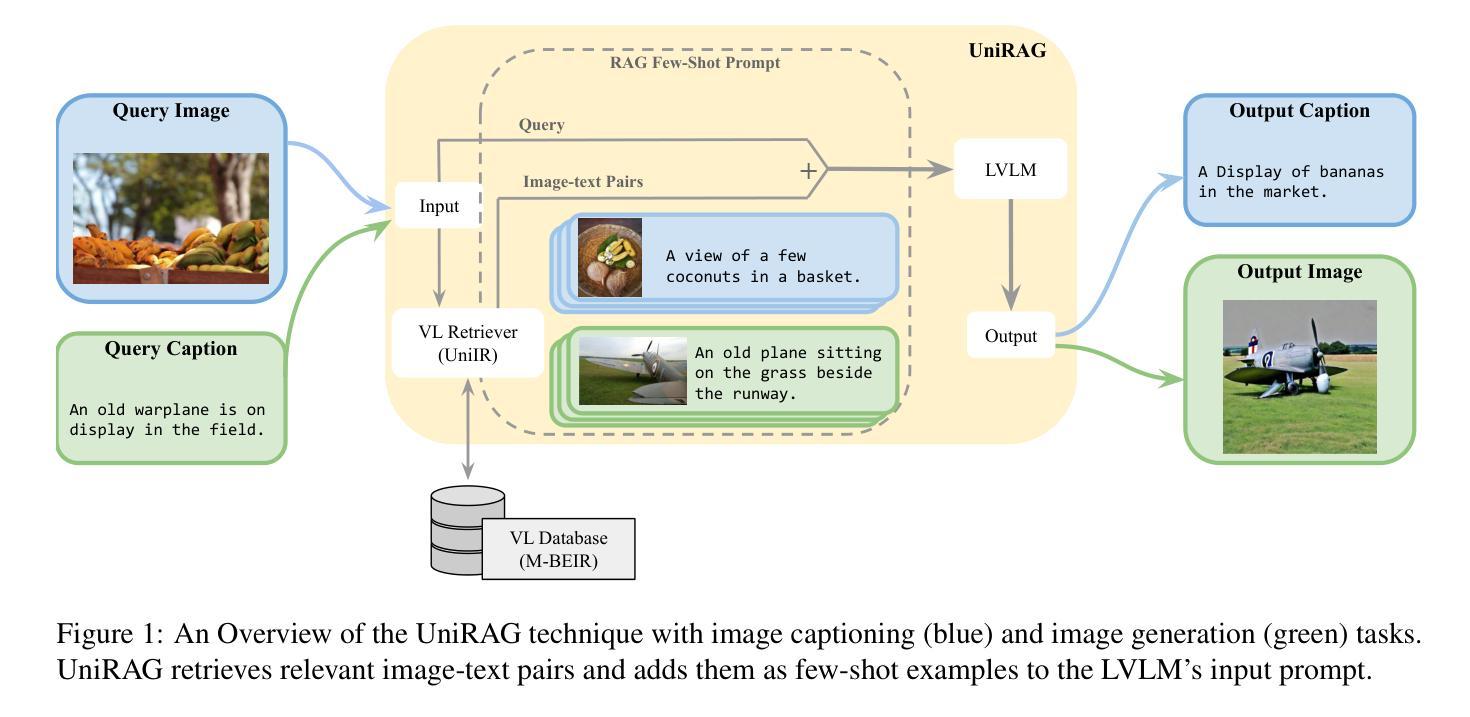
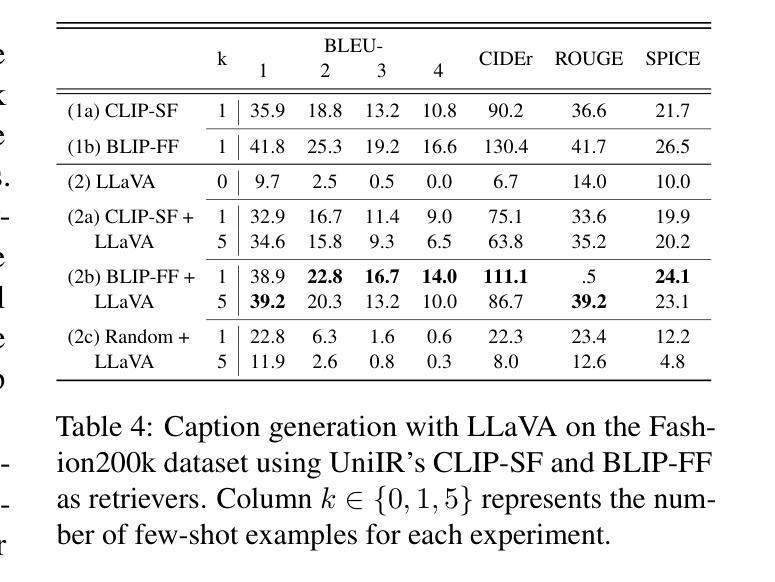
UniRAG: Universal Retrieval Augmentation for Large Vision Language Models
Authors:Sahel Sharifymoghaddam, Shivani Upadhyay, Wenhu Chen, Jimmy Lin
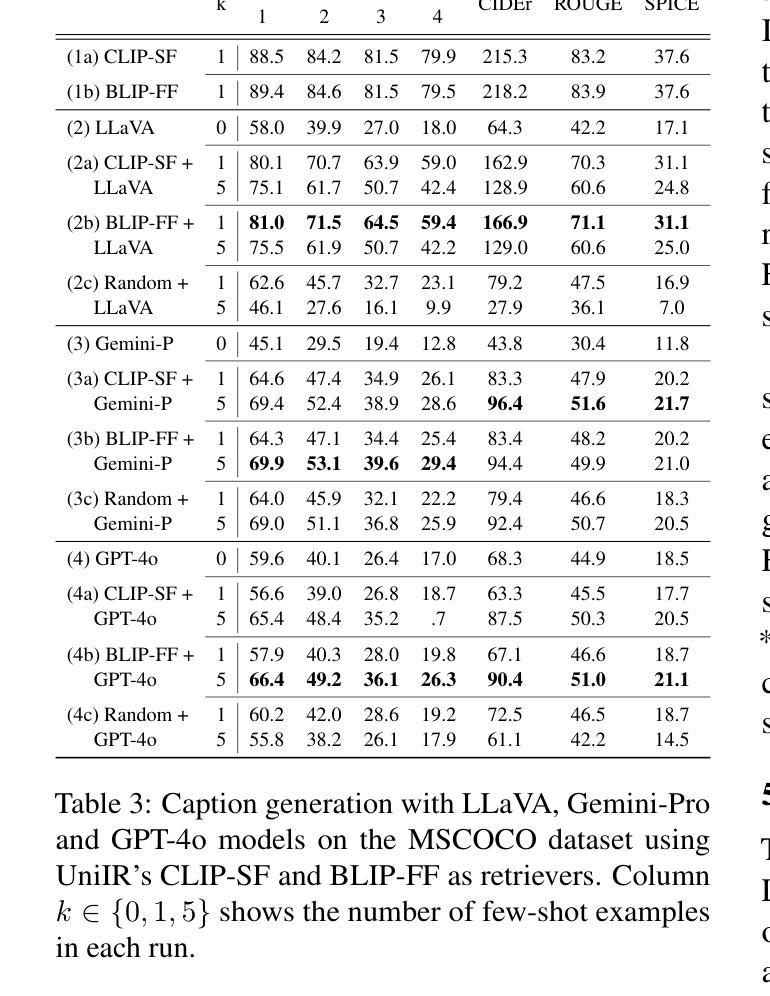
Recently, Large Vision Language Models (LVLMs) have unlocked many complex use cases that require Multi-Modal (MM) understanding (e.g., image captioning or visual question answering) and MM generation (e.g., text-guided image generation or editing) capabilities. To further improve the output fidelityof LVLMs we introduce UniRAG, a plug-and-play technique that adds relevant retrieved information to prompts as few-shot examples during inference. Unlike the common belief that Retrieval Augmentation (RA) mainly improves generation or understanding of uncommon entities, our evaluation results on the MSCOCO dataset with common entities show that both proprietary models like GPT-4o and Gemini-Pro and smaller open-source models like LLaVA, LaVIT, and Emu2 significantly enhance their generation quality when their input prompts are augmented with relevant information retrieved by Vision-Language (VL) retrievers like UniIR models. All the necessary code to reproduce our results is available at https://github.com/castorini/UniRAG
最近,大型视觉语言模型(LVLMs)已经解锁了许多复杂的用例,这些用例需要多模态(MM)理解(例如,图像标题或视觉问答)和多模态生成(例如,文本引导的图像生成或编辑)功能。为了进一步提高LVLMs的输出保真度,我们引入了UniRAG,这是一种即插即用技术,它将在推理过程中将相关的检索信息作为少量示例添加到提示中。与普遍认为的检索增强(RA)主要提高罕见实体的生成或理解不同,我们在MSCOCO数据集上对常见实体的评估结果表明,当输入提示通过视觉语言(VL)检索器(如UniIR模型)检索到的相关信息进行增强时,无论是专有模型(如GPT-4o和Gemini-Pro),还是较小的开源模型(如LLaVA、LaVIT和Emu2),它们的生成质量都得到了显著提高。所有重现我们结果的必要代码都可在https://github.com/castorini/UniRAG找到。
论文及项目相关链接
PDF 14 pages, 6 figures
Summary
大型视觉语言模型(LVLMs)已解锁许多需要多模态(MM)理解和生成能力的复杂用例。为进一步提高LVLMs的输出保真度,我们引入了UniRAG,这是一种即插即用的技术,可在推理过程中将相关的检索信息作为少数案例添加到提示中。评估结果表明,无论是专有模型如GPT-4o和Gemini-Pro,还是较小的开源模型如LLaVA、LaVIT和Emu2,通过增强输入提示与UniRAG等视觉语言检索器检索到的相关信息相结合,都可以显著提高生成质量。
Key Takeaways
- 大型视觉语言模型(LVLMs)具备处理多模态理解和生成的能力。
- UniRAG是一种提高LVLMs输出保真度的技术,它通过添加相关的检索信息来增强提示。
- UniRAG技术采用即插即用的方式,可以在推理过程中轻松集成到现有模型中。
- 评估结果表明,UniRAG对专有模型和开源模型都有显著的提升效果。
- 实验结果显示,即使是对于常见实体,检索增强也可以提高生成质量。
- UniRAG的实现在GitHub上公开可用。
点此查看论文截图



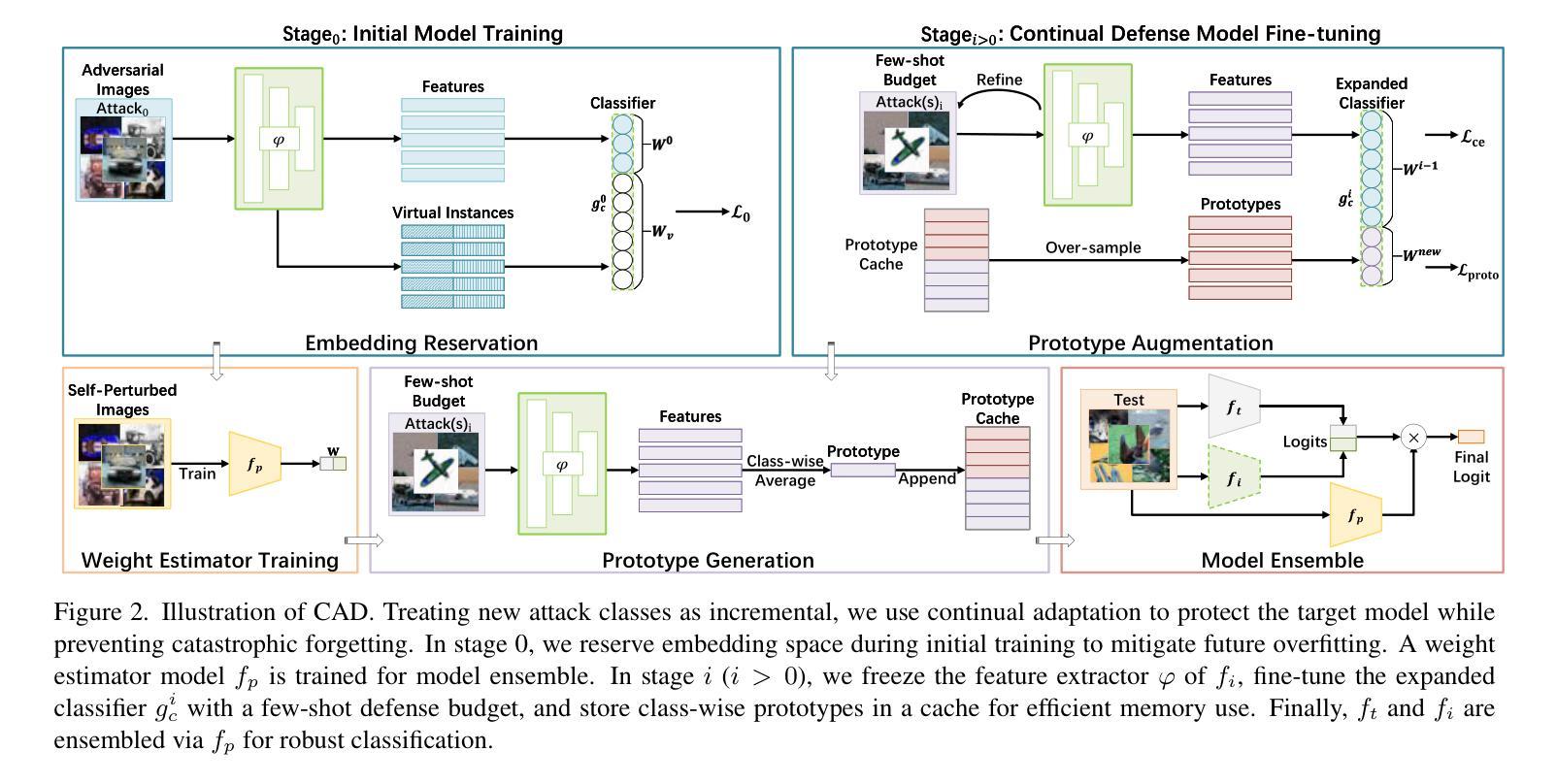
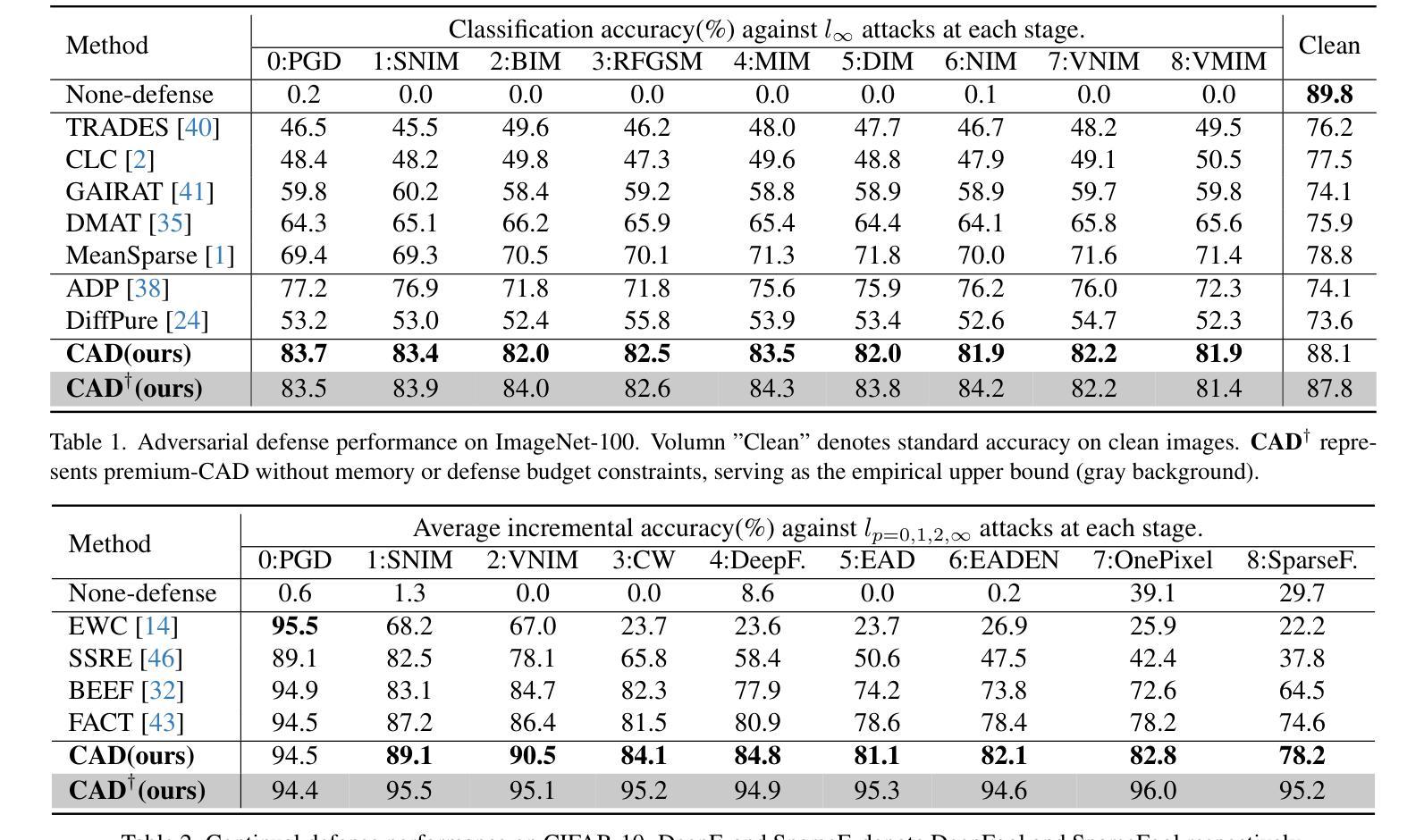
Continual Adversarial Defense
Authors:Qian Wang, Hefei Ling, Yingwei Li, Qihao Liu, Ruoxi Jia, Ning Yu
In response to the rapidly evolving nature of adversarial attacks against visual classifiers on a monthly basis, numerous defenses have been proposed to generalize against as many known attacks as possible. However, designing a defense method that generalizes to all types of attacks is not realistic because the environment in which defense systems operate is dynamic and comprises various unique attacks that emerge as time goes on. A well-matched approach to the dynamic environment lies in a defense system that continuously collects adversarial data online to quickly improve itself. Therefore, we put forward a practical defense deployment against a challenging threat model and propose, for the first time, the Continual Adversarial Defense (CAD) framework that adapts to attack sequences under four principles: (1)continual adaptation to new attacks without catastrophic forgetting, (2)few-shot adaptation, (3)memory-efficient adaptation, and (4)high accuracy on both clean and adversarial data. We explore and integrate cutting-edge continual learning, few-shot learning, and ensemble learning techniques to qualify the principles. Extensive experiments validate the effectiveness of our approach against multiple stages of modern adversarial attacks and demonstrate significant improvements over numerous baseline methods. In particular, CAD is capable of quickly adapting with minimal budget and a low cost of defense failure while maintaining good performance against previous attacks. Our research sheds light on a brand-new paradigm for continual defense adaptation against dynamic and evolving attacks.
针对每月都在快速演变的针对视觉分类器的对抗性攻击,已经提出了许多防御策略,以尽可能对抗多种已知的攻击进行推广。然而,设计一种能够应对所有类型攻击的防御方法并不现实,因为防御系统所处的环境是动态的,并且包含随着时间推移出现的各种独特攻击。与动态环境相匹配的方法是防御系统能够持续在线收集对抗性数据,以快速提高自身能力。因此,我们针对具有挑战性的威胁模型提出了实用的防御部署,并首次提出适应攻击序列的Continual Adversarial Defense (CAD)框架,该框架遵循四项原则:(1)持续适应新攻击而不会出现灾难性遗忘,(2)小样本适应,(3)内存高效适应,以及(4)在干净和对抗性数据上都具有高准确性。我们探索并整合了最先进的持续学习、小样本学习和集成学习技术来符合这些原则。大量实验验证了我们的方法在多阶段现代对抗性攻击中的有效性,并证明与许多基准方法相比具有显著改进。特别是,CAD能够迅速适应,具有最小的预算和较低的防御失败成本,同时保持良好的对抗之前攻击的性能。我们的研究为针对动态和不断演变的攻击的连续防御适应提供了新的范例。
论文及项目相关链接
Summary
该文本提出了一种应对动态和不断演变的攻击的新型防御范式——持续对抗性防御(CAD)框架。CAD框架能够适应攻击序列,并具备四项原则:持续适应新攻击、少样本适应、内存高效适应以及对干净和对抗性数据的高准确性。通过结合前沿的持续学习、小样本学习和集成学习技术,该框架在多个阶段的现代对抗性攻击中验证有效,相较于多种基线方法有明显改进。
Key Takeaways
- 对抗攻击不断演化,通用防御方法不现实。
- 防御系统需要能适应新攻击,持续收集对抗数据进行改进。
- 首次提出持续对抗性防御(CAD)框架,适应攻击序列。
- CAD框架遵循四项原则:持续适应、少样本适应、内存高效、高准确性。
- 结合持续学习、小样本学习和集成学习技术来实现CAD框架。
- 实验验证CAD框架在多种对抗攻击中的有效性,较基线方法有显著改进。
点此查看论文截图