⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-12 更新
X-GAN: A Generative AI-Powered Unsupervised Model for High-Precision Segmentation of Retinal Main Vessels toward Early Detection of Glaucoma
Authors:Cheng Huang, Weizheng Xie, Tsengdar J. Lee, Jui-Kai Wang, Karanjit Kooner, Jia Zhang
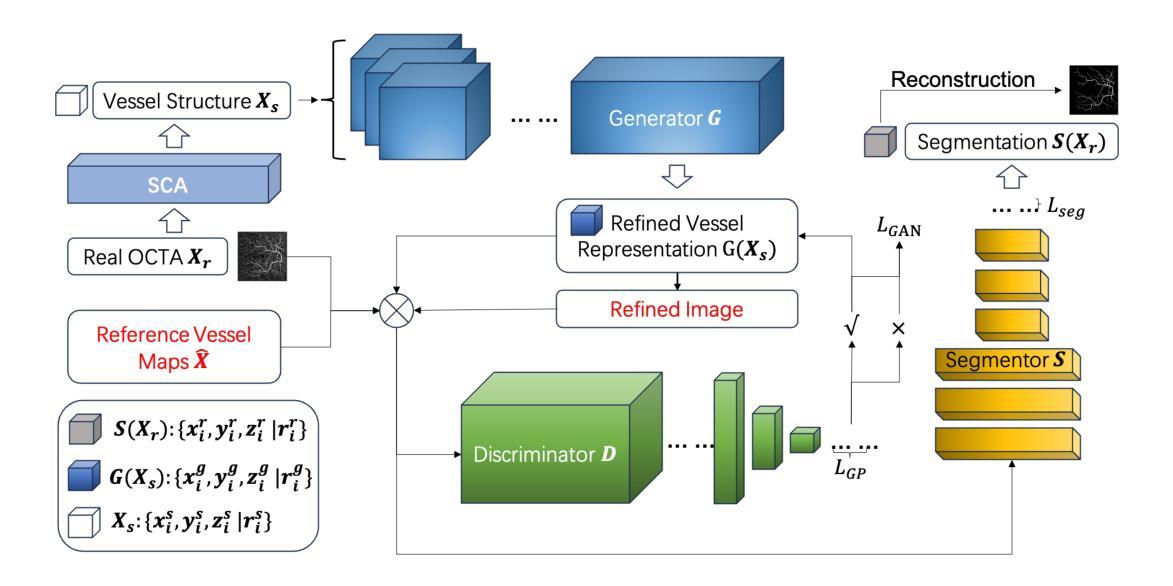
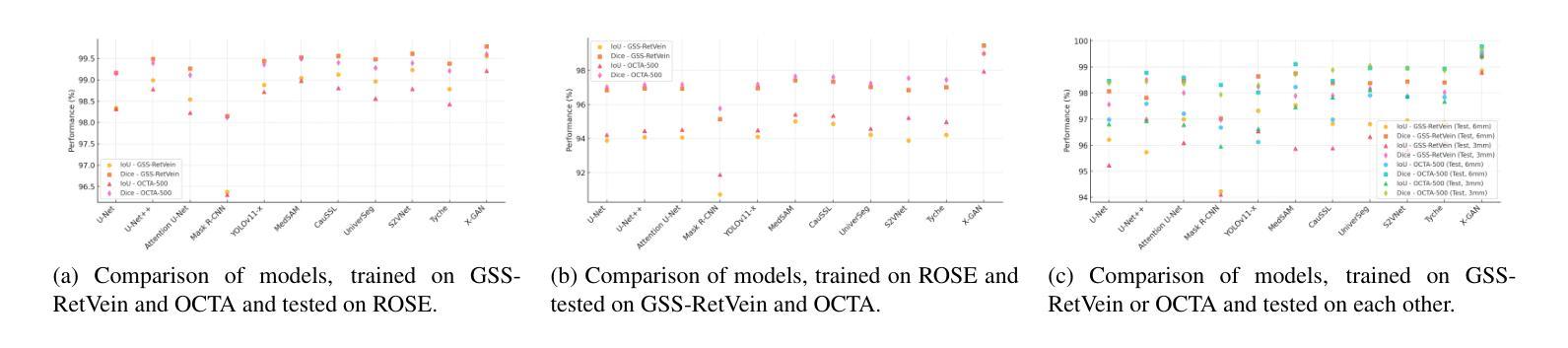
Structural changes in main retinal blood vessels serve as critical biomarkers for the onset and progression of glaucoma. Identifying these vessels is vital for vascular modeling yet highly challenging. This paper proposes X-GAN, a generative AI-powered unsupervised segmentation model designed for extracting main blood vessels from Optical Coherence Tomography Angiography (OCTA) images. The process begins with the Space Colonization Algorithm (SCA) to rapidly generate a skeleton of vessels, featuring their radii. By synergistically integrating generative adversarial networks (GANs) with biostatistical modeling of vessel radii, X-GAN enables a fast reconstruction of both 2D and 3D representations of the vessels. Based on this reconstruction, X-GAN achieves nearly 100% segmentation accuracy without relying on labeled data or high-performance computing resources. Also, to address the Issue, data scarity, we introduce GSS-RetVein, a high-definition mixed 2D and 3D glaucoma retinal dataset. GSS-RetVein provides a rigorous benchmark due to its exceptionally clear capillary structures, introducing controlled noise for testing model robustness. Its 2D images feature sharp capillary boundaries, while its 3D component enhances vascular reconstruction and blood flow prediction, supporting glaucoma progression simulations. Experimental results confirm GSS-RetVein’s superiority in evaluating main vessel segmentation compared to existing datasets. Code and dataset are here: https://github.com/VikiXie/SatMar8.
视网膜主血管结构的变化是青光眼发生和发展的关键生物标志物。识别这些血管对血管建模至关重要,但极具挑战性。本文提出了X-GAN,这是一种基于生成式人工智能的无监督分割模型,旨在从光学相干断层扫描血管造影(OCTA)图像中提取主血管。流程始于空间殖民算法(SCA),该算法可快速生成血管骨架并显示其半径。通过协同整合生成对抗网络(GANs)与血管半径的生物统计建模,X-GAN能够迅速重建血管的2D和3D表示。基于这种重建,X-GAN在不依赖标记数据或高性能计算资源的情况下实现了接近100%的分割精度。此外,为了解决数据稀缺的问题,我们引入了GSS-RetVein,这是一个高分辨率的混合2D和3D青光眼视网膜数据集。GSS-RetVein由于其毛细血管结构异常清晰而提供了严格的基准测试,并引入了受控噪声以测试模型的稳健性。其2D图像具有清晰的毛细血管边界,而3D组件则增强了血管重建和血流预测,支持青光眼进展模拟。实验结果证实了GSS-RetVein在评估主血管分割方面优于现有数据集。代码和数据集地址:https://github.com/VikiXie/SatMar8。
论文及项目相关链接
PDF 11 pages, 8 figures
Summary
本文主要介绍了一种基于生成对抗网络(GAN)的无监督分割模型X-GAN,用于从光学相干断层扫描血管造影(OCTA)图像中提取主血管。结合空间殖民算法(SCA)和生物统计建模,X-GAN能快速重建血管的二维和三维表示,实现近100%的分割精度,且无需依赖标注数据或高性能计算资源。为解决数据稀缺问题,还推出了GSS-RetVein混合数据集,为模型稳健性测试提供了严格基准。
Key Takeaways
- 文中提出了一种名为X-GAN的基于GAN的无监督分割模型,该模型可从OCTA图像中提取主要血管。
- X-GAN结合了空间殖民算法(SCA)和生物统计建模技术,能快速重建血管的二维和三维表示。
- X-GAN实现近100%的分割精度,且在不需要标注数据和高性能计算资源的情况下运行。
- 数据稀缺是医学图像分析中的一个主要问题,为此引入了GSS-RetVein混合数据集。
- GSS-RetVein数据集包括清晰的毛细血管结构,用于测试模型的稳健性。其独特的混合二维和三维特性增强了血管重建和血流预测的能力。
- 实验结果表明,GSS-RetVein数据集在评估主血管分割方面优于现有数据集。
点此查看论文截图



HealthiVert-GAN: A Novel Framework of Pseudo-Healthy Vertebral Image Synthesis for Interpretable Compression Fracture Grading
Authors:Qi Zhang, Shunan Zhang, Ziqi Zhao, Kun Wang, Jun Xu, Jianqi Sun
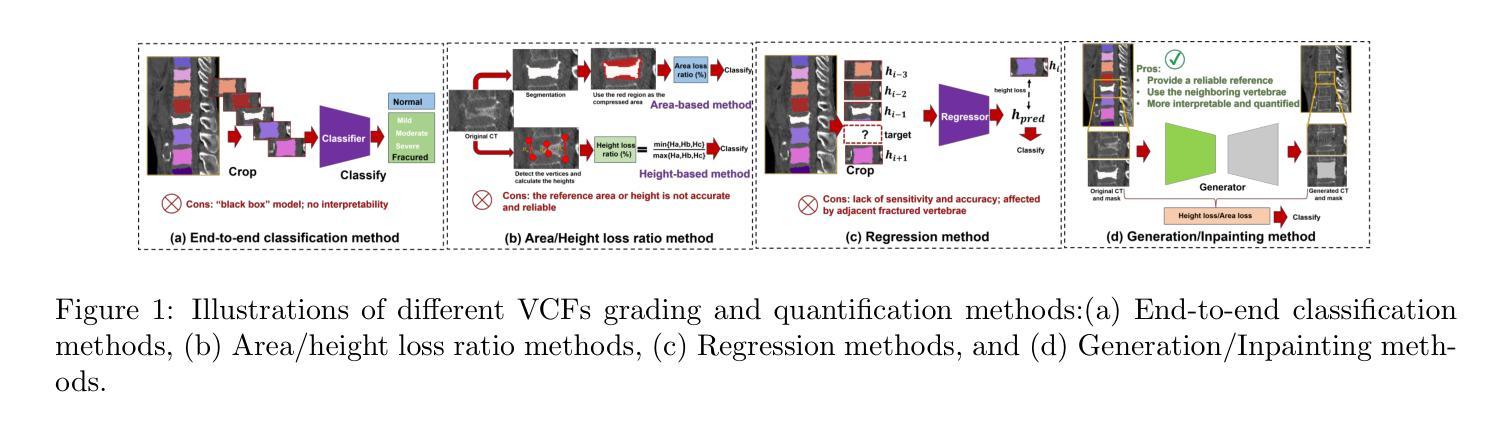
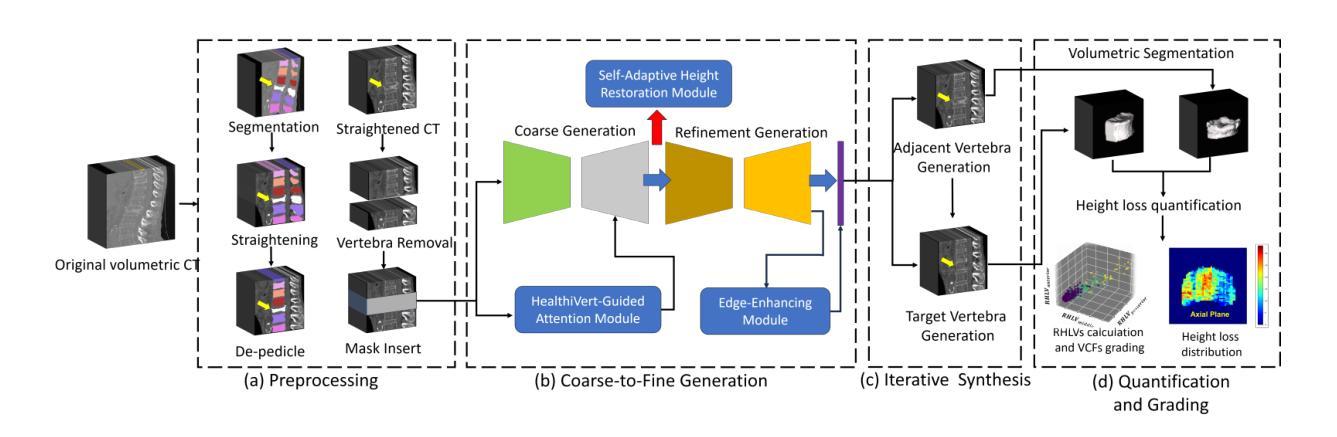
Osteoporotic vertebral compression fractures (VCFs) are prevalent in the elderly population, typically assessed on computed tomography (CT) scans by evaluating vertebral height loss. This assessment helps determine the fracture’s impact on spinal stability and the need for surgical intervention. However, clinical data indicate that many VCFs exhibit irregular compression, complicating accurate diagnosis. While deep learning methods have shown promise in aiding VCFs screening, they often lack interpretability and sufficient sensitivity, limiting their clinical applicability. To address these challenges, we introduce a novel vertebra synthesis-height loss quantification-VCFs grading framework. Our proposed model, HealthiVert-GAN, utilizes a coarse-to-fine synthesis network designed to generate pseudo-healthy vertebral images that simulate the pre-fracture state of fractured vertebrae. This model integrates three auxiliary modules that leverage the morphology and height information of adjacent healthy vertebrae to ensure anatomical consistency. Additionally, we introduce the Relative Height Loss of Vertebrae (RHLV) as a quantification metric, which divides each vertebra into three sections to measure height loss between pre-fracture and post-fracture states, followed by fracture severity classification using a Support Vector Machine (SVM). Our approach achieves state-of-the-art classification performance on both the Verse2019 dataset and our private dataset, and it provides cross-sectional distribution maps of vertebral height loss. This practical tool enhances diagnostic sensitivity in clinical settings and assisting in surgical decision-making. Our code is available: https://github.com/zhibaishouheilab/HealthiVert-GAN.
骨质疏松症椎体压缩性骨折(VCFs)在老年人群中普遍存在,通常通过计算机断层扫描(CT)评估椎体高度损失来检测。这种评估有助于确定骨折对脊柱稳定性的影响以及是否需要手术干预。然而,临床数据表明,许多VCFs表现出不规则压缩,使准确诊断变得复杂。虽然深度学习方法在辅助VCFs筛查方面显示出潜力,但它们通常缺乏可解释性和足够的敏感性,限制了它们在临床上的适用性。为了解决这些挑战,我们引入了一种新的椎体合成-高度损失量化-VCFs分级框架。我们提出的模型HealthiVert-GAN利用从粗糙到精细的合成网络生成模拟骨折椎体预骨折状态的伪健康椎体图像。该模型集成了三个辅助模块,利用相邻健康椎体的形态学和高度信息来保证解剖一致性。此外,我们还引入了相对椎体高度损失(RHLV)作为量化指标,将每个椎体分为三部分,测量预骨折和骨折后状态之间的高度损失,然后使用支持向量机(SVM)进行骨折严重程度分类。我们的方法在Verse2019数据集和私有数据集上均实现了最先进的分类性能,并提供了椎体高度损失的横断面分布图。这个实用工具提高了临床环境中的诊断敏感性,并有助于手术决策。我们的代码可用:https://github.com/zhibaishouheilab/HealthiVert-GAN。
论文及项目相关链接
Summary:
老年人群中骨质疏松性椎体压缩性骨折(VCFs)常见,通常通过计算机断层扫描(CT)评估椎体高度损失来诊断。然而,由于许多VCFs呈现不规则压缩,准确诊断具有挑战性。为应对这些挑战,提出一种新型椎体合成-高度损失量化-VCFs分级框架,名为HealthiVert-GAN。该模型生成模拟骨折椎体预骨折状态的伪健康椎体图像,并利用相邻健康椎体的形态和高度信息确保解剖一致性。还引入相对椎体高度损失(RHLV)作为量化指标,对骨折严重程度进行分类,实现优秀分类性能,并提供椎体高度损失的横截面分布图。此工具增强临床诊断敏感性,辅助手术决策。
Key Takeaways:
- 骨质疏松性椎体压缩性骨折(VCFs)在老年人群中普遍,诊断主要基于计算机断层扫描(CT)评估椎体高度损失。
- 传统诊断方法面临不规则压缩导致的准确诊断挑战。
- 引入新型椎体合成-高度损失量化-VCFs分级框架HealthiVert-GAN,生成模拟预骨折状态的伪健康椎体图像。
- HealthiVert-GAN利用相邻健康椎体的形态和高度信息确保解剖一致性。
- 引入相对椎体高度损失(RHLV)作为量化指标,对骨折程度进行更精细的评估。
- 该模型在分类性能上达到先进水平,能在临床环境中提供敏感的诊断工具。
点此查看论文截图

Comparative clinical evaluation of “memory-efficient” synthetic 3d generative adversarial networks (gan) head-to-head to state of art: results on computed tomography of the chest
Authors:Mahshid Shiri, Chandra Bortolotto, Alessandro Bruno, Alessio Consonni, Daniela Maria Grasso, Leonardo Brizzi, Daniele Loiacono, Lorenzo Preda
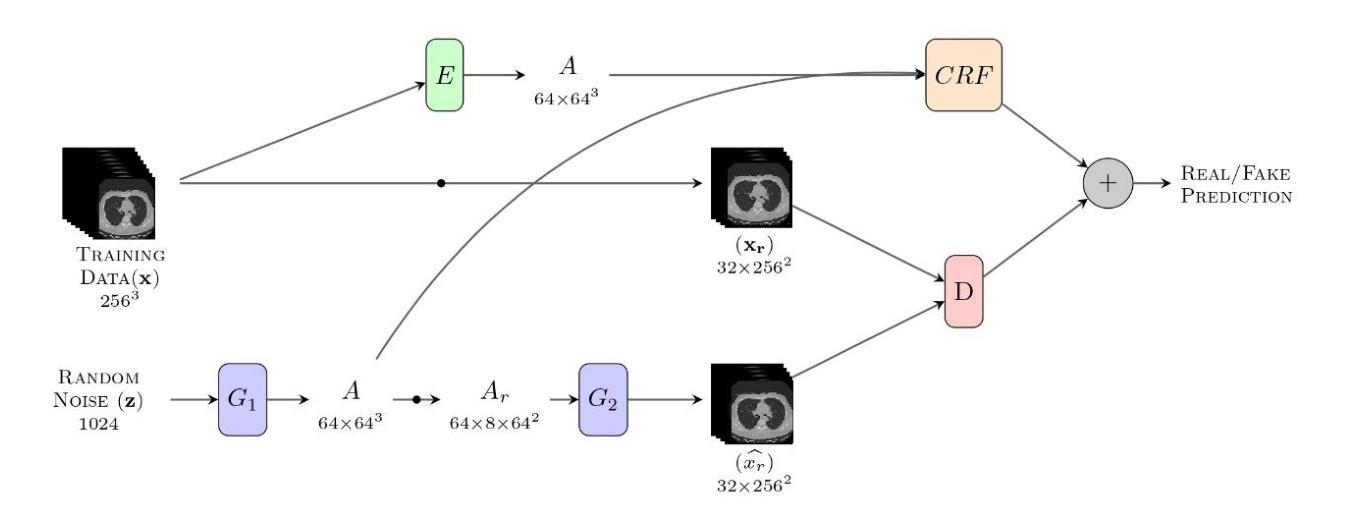
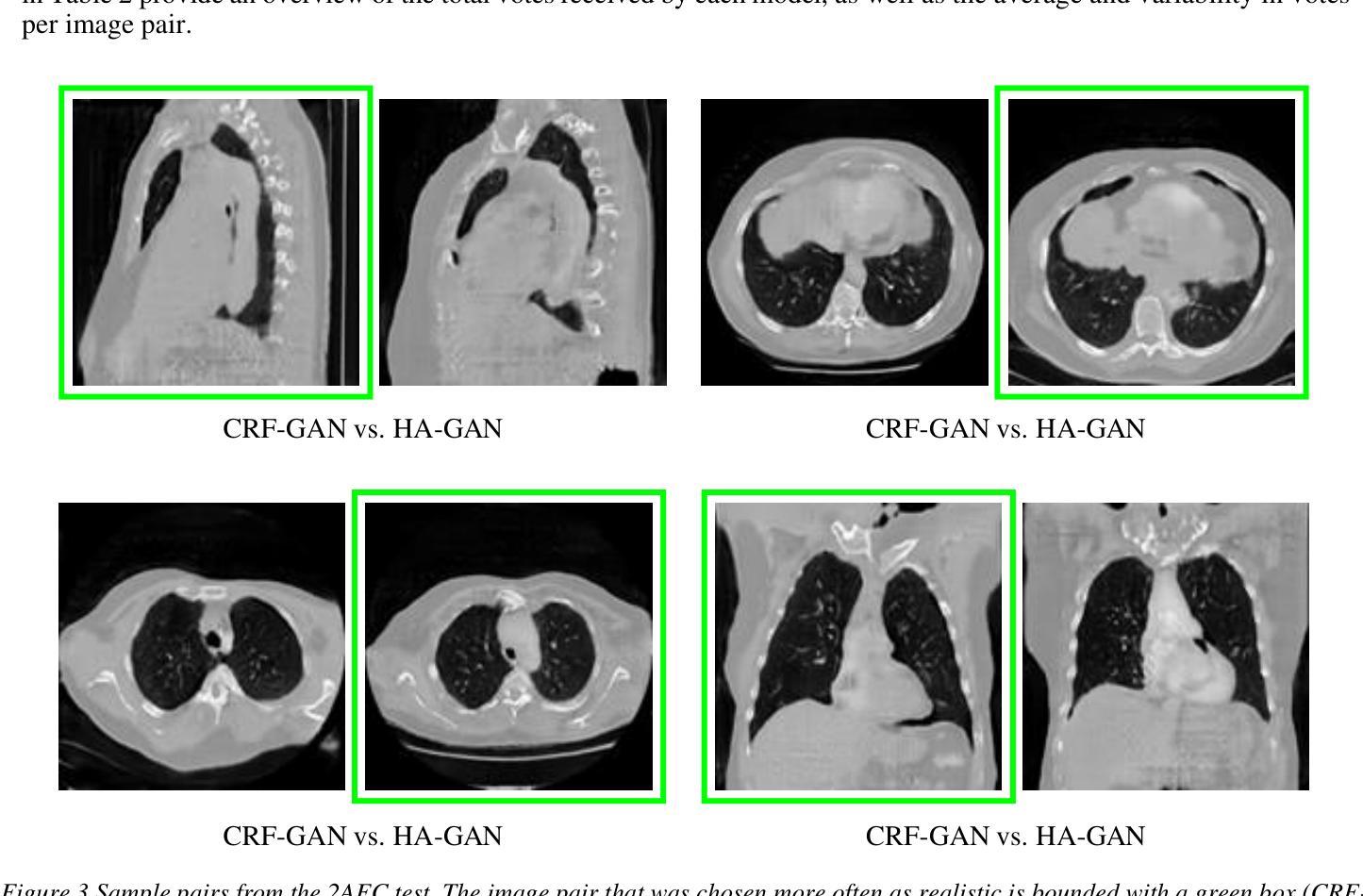
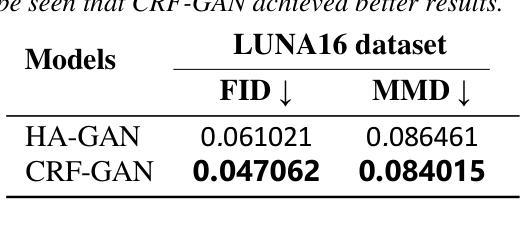
Introduction: Generative Adversarial Networks (GANs) are increasingly used to generate synthetic medical images, addressing the critical shortage of annotated data for training Artificial Intelligence (AI) systems. This study introduces a novel memory-efficient GAN architecture, incorporating Conditional Random Fields (CRFs) to generate high-resolution 3D medical images and evaluates its performance against the state-of-the-art hierarchical (HA)-GAN model. Materials and Methods: The CRF-GAN was trained using the open-source lung CT LUNA16 dataset. The architecture was compared to HA-GAN through a quantitative evaluation, using Frechet Inception Distance (FID) and Maximum Mean Discrepancy (MMD) metrics, and a qualitative evaluation, through a two-alternative forced choice (2AFC) test completed by a pool of 12 resident radiologists, in order to assess the realism of the generated images. Results: CRF-GAN outperformed HA-GAN with lower FID (0.047 vs. 0.061) and MMD (0.084 vs. 0.086) scores, indicating better image fidelity. The 2AFC test showed a significant preference for images generated by CRF-Gan over those generated by HA-GAN with a p-value of 1.93e-05. Additionally, CRF-GAN demonstrated 9.34% lower memory usage at 256 resolution and achieved up to 14.6% faster training speeds, offering substantial computational savings. Discussion: CRF-GAN model successfully generates high-resolution 3D medical images with non-inferior quality to conventional models, while being more memory-efficient and faster. Computational power and time saved can be used to improve the spatial resolution and anatomical accuracy of generated images, which is still a critical factor limiting their direct clinical applicability.
简介:生成对抗网络(GANs)越来越多地被用于生成合成医学图像,以解决训练人工智能(AI)系统时标注数据的严重短缺问题。本研究介绍了一种新的内存高效的GAN架构,它结合了条件随机场(CRFs)来生成高分辨率的3D医学图像,并与最先进的分层(HA)-GAN模型进行了性能评估。材料与方法:CRF-GAN使用开源的肺部CT LUNA16数据集进行训练。通过与HA-GAN进行定量评估,使用Frechet Inception Distance(FID)和Maximum Mean Discrepancy(MMD)指标,以及定性评估,通过由12名住院医生完成的两组强制性选择(2AFC)测试,以评估生成图像的真实性。结果:CRF-GAN在FID(0.047 vs 0.061)和MMD(0.084 vs 0.086)得分上优于HA-GAN,表明图像保真度更高。2AFC测试显示,CRF-Gan生成的图像比HA-GAN生成的图像更受欢迎,p值为1.93e-05。此外,CRF-GAN在256分辨率下内存使用率降低了9.34%,训练速度提高了14.6%,从而实现了可观的计算节省。讨论:CRF-GAN模型能够成功生成高分辨率的3D医学图像,其质量不低于传统模型,同时更节省内存、速度更快。所节省的计算能力和时间可用于提高生成图像的空间分辨率和解剖准确性,这仍然是限制其直接临床应用的关键因素。
论文及项目相关链接
Summary
本研究介绍了一种结合条件随机场(CRF)的新型内存高效生成对抗网络(CRF-GAN),用于生成高质量的三维医学图像。相较于传统的分层生成对抗网络(HA-GAN),CRF-GAN在图像保真度、内存使用和训练速度方面表现出优越性。该模型在生成具有临床实用性的高分辨率医学图像方面展现了潜力。
Key Takeaways
- CRF-GAN结合条件随机场,用于生成高质量的三维医学图像。
- 与HA-GAN相比,CRF-GAN在图像保真度方面表现更优。
- CRF-GAN具有较低内存使用和更快的训练速度。
- CRF-GAN生成的图像得到了放射科医师的显著青睐。
- 该模型在直接临床应用中仍面临空间分辨率和解剖准确性等挑战。
- CRF-GAN的成功应用为生成对抗网络在医学图像处理领域的发展提供了新的视角。
点此查看论文截图

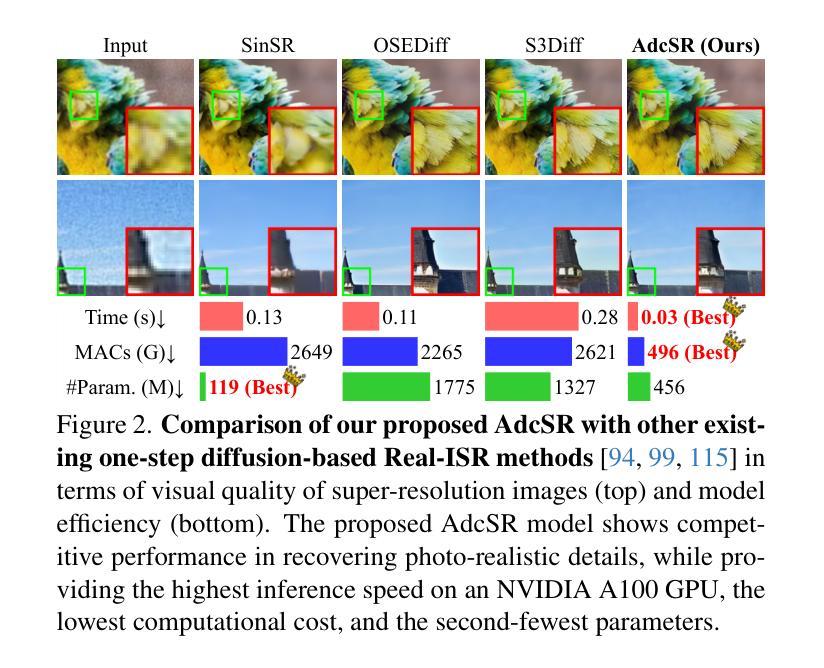
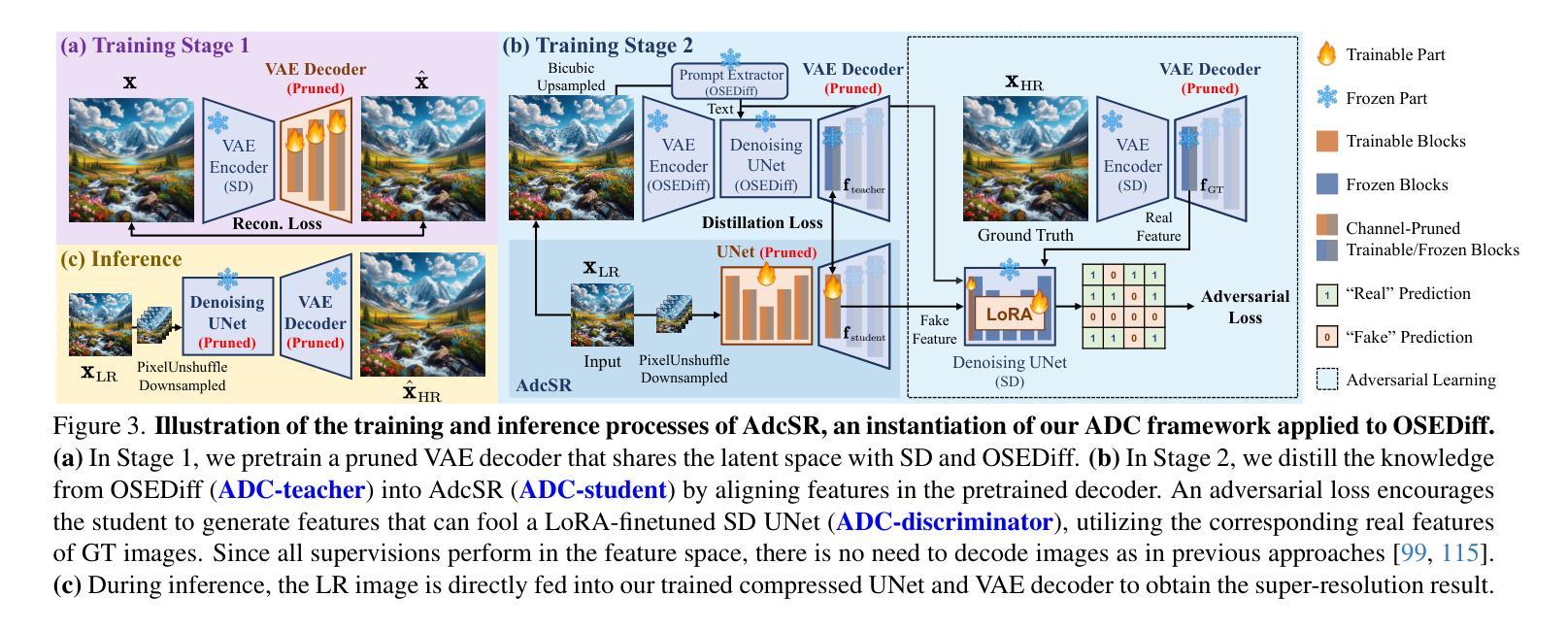
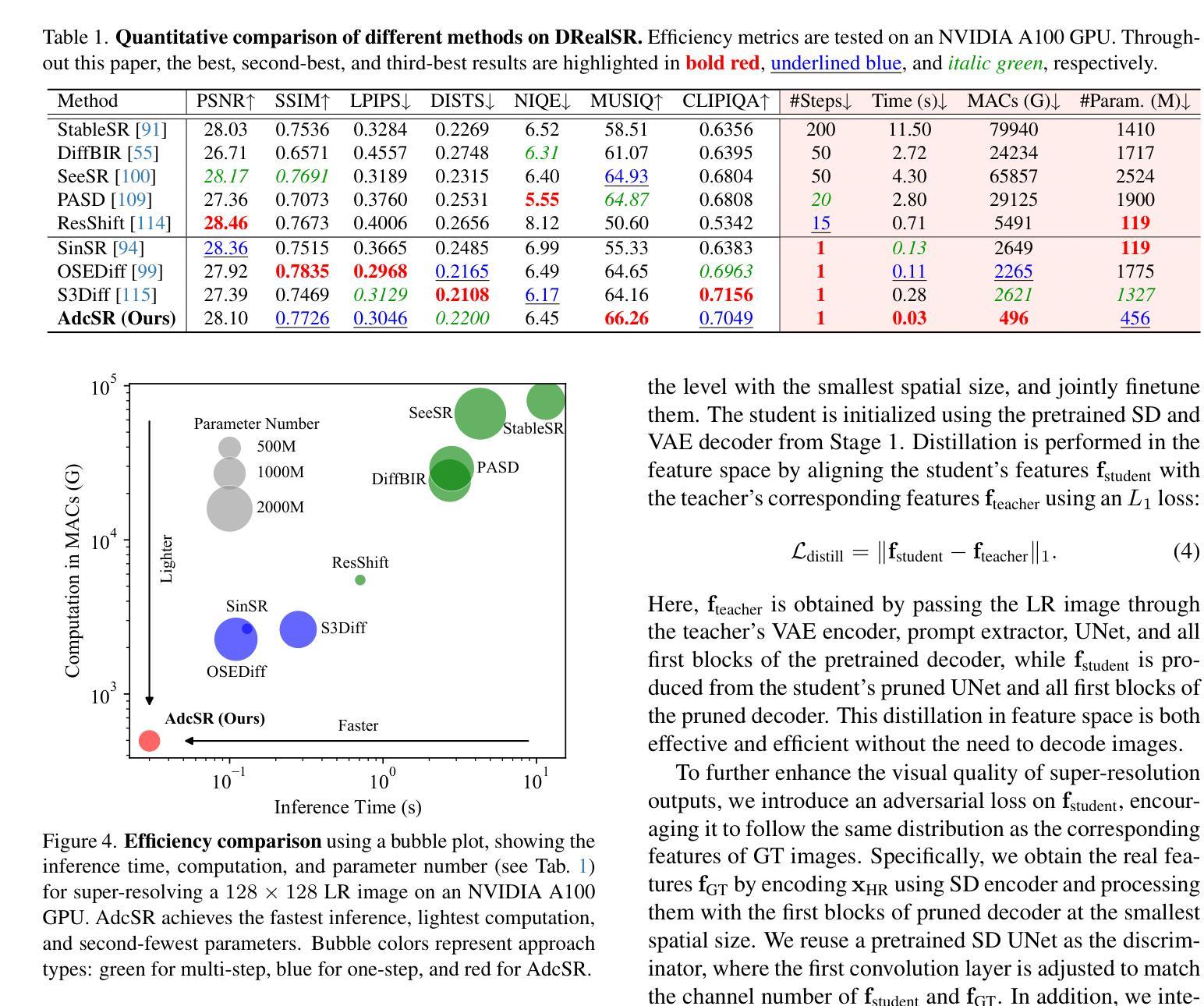
Adversarial Diffusion Compression for Real-World Image Super-Resolution
Authors:Bin Chen, Gehui Li, Rongyuan Wu, Xindong Zhang, Jie Chen, Jian Zhang, Lei Zhang
Real-world image super-resolution (Real-ISR) aims to reconstruct high-resolution images from low-resolution inputs degraded by complex, unknown processes. While many Stable Diffusion (SD)-based Real-ISR methods have achieved remarkable success, their slow, multi-step inference hinders practical deployment. Recent SD-based one-step networks like OSEDiff and S3Diff alleviate this issue but still incur high computational costs due to their reliance on large pretrained SD models. This paper proposes a novel Real-ISR method, AdcSR, by distilling the one-step diffusion network OSEDiff into a streamlined diffusion-GAN model under our Adversarial Diffusion Compression (ADC) framework. We meticulously examine the modules of OSEDiff, categorizing them into two types: (1) Removable (VAE encoder, prompt extractor, text encoder, etc.) and (2) Prunable (denoising UNet and VAE decoder). Since direct removal and pruning can degrade the model’s generation capability, we pretrain our pruned VAE decoder to restore its ability to decode images and employ adversarial distillation to compensate for performance loss. This ADC-based diffusion-GAN hybrid design effectively reduces complexity by 73% in inference time, 78% in computation, and 74% in parameters, while preserving the model’s generation capability. Experiments manifest that our proposed AdcSR achieves competitive recovery quality on both synthetic and real-world datasets, offering up to 9.3$\times$ speedup over previous one-step diffusion-based methods. Code and models are available at https://github.com/Guaishou74851/AdcSR.
现实世界图像超分辨率(Real-ISR)旨在从由复杂未知过程退化的低分辨率输入中重建高分辨率图像。虽然许多基于Stable Diffusion(SD)的Real-ISR方法已经取得了显著的成功,但它们缓慢的多步推断阻碍了实际应用部署。最近的基于SD的一步网络(如OSEDiff和S3Diff)缓解了这个问题,但由于它们依赖于大型预训练SD模型,仍然计算成本高昂。本文提出了一种新的Real-ISR方法AdcSR,通过在我们的对抗性扩散压缩(ADC)框架下,将一步扩散网络OSEDiff提炼成简化的扩散-GAN模型。我们仔细研究了OSEDiff的模块,将它们分为两类:(1)可移除的(VAE编码器、提示提取器、文本编码器等)和(2)可修剪的(去噪UNet和VAE解码器)。由于直接移除和修剪可能会降低模型的生成能力,我们先训练修剪过的VAE解码器以恢复其解码图像的能力,并采用对抗性蒸馏来弥补性能损失。这种基于ADC的扩散-GAN混合设计,通过推理时间、计算和参数的有效减少,分别达到了73%、78%和74%的复杂度降低,同时保持了模型的生成能力。实验表明,我们提出的AdcSR在合成和真实世界数据集上实现了具有竞争力的恢复质量,与以前的一步扩散方法相比,最多可提供9.3倍的速度提升。代码和模型可在https://github.com/Guaishou74851/AdcSR获取。
论文及项目相关链接
PDF Accepted by CVPR 2025
Summary
本文提出了一种新的Real-ISR方法——AdcSR,它通过蒸馏一步扩散网络OSEDiff,在Adversarial Diffusion Compression(ADC)框架下构建了一个简化的扩散-GAN模型。AdcSR通过移除和修剪OSEDiff的模块,并通过对修剪后的VAE解码器进行预训练以及使用对抗蒸馏来补偿性能损失,有效地降低了推理时间、计算和参数复杂度。实验表明,AdcSR在合成和真实世界数据集上实现了具有竞争力的恢复质量,并且相比之前的一步扩散方法,速度提升了9.3倍。
Key Takeaways
- Real-ISR旨在从低分辨率的复杂未知过程退化图像中重建高分辨率图像。
- 现有的基于Stable Diffusion (SD)的Real-ISR方法存在推理速度慢和多步骤的问题。
- 最近的一步扩散网络如OSEDiff和S3Diff虽能加速,但计算成本仍然较高。
- 本文提出了AdcSR方法,通过蒸馏OSEDiff网络构建一个简化的扩散-GAN模型。
- AdcSR通过移除和修剪模块降低复杂性,并通过预训练和对抗蒸馏技术来保持模型的生成能力。
- AdcSR实现了显著的速度提升,同时保持了竞争力强的恢复质量。
点此查看论文截图


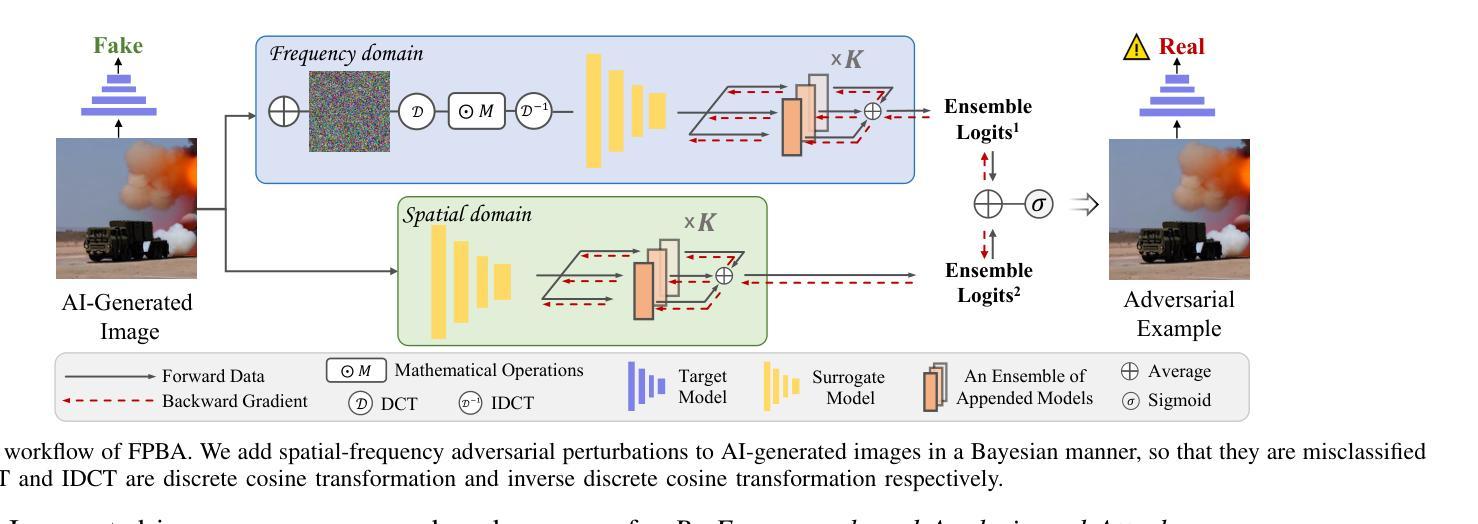
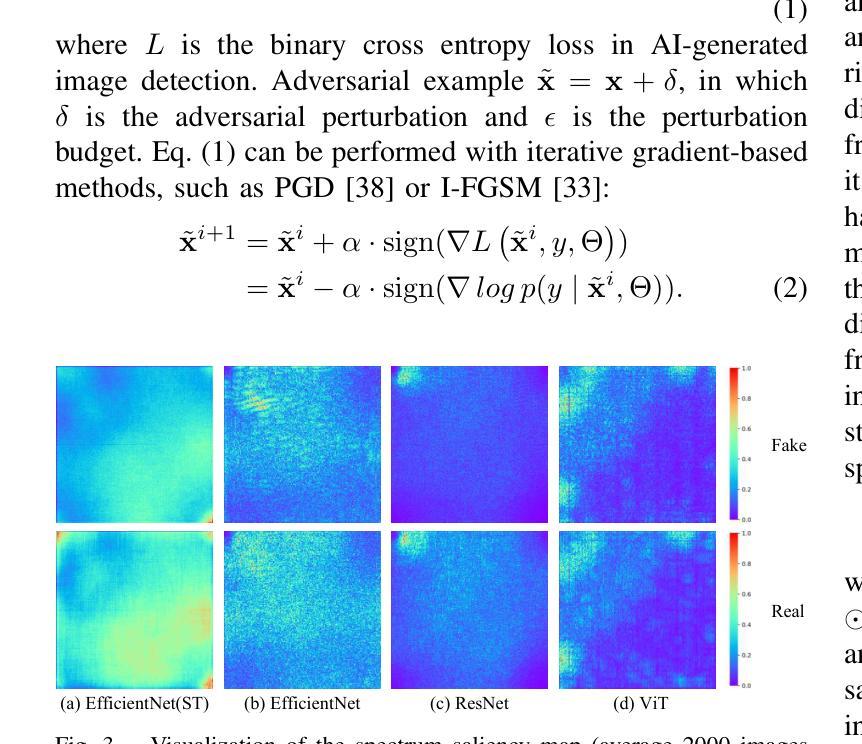
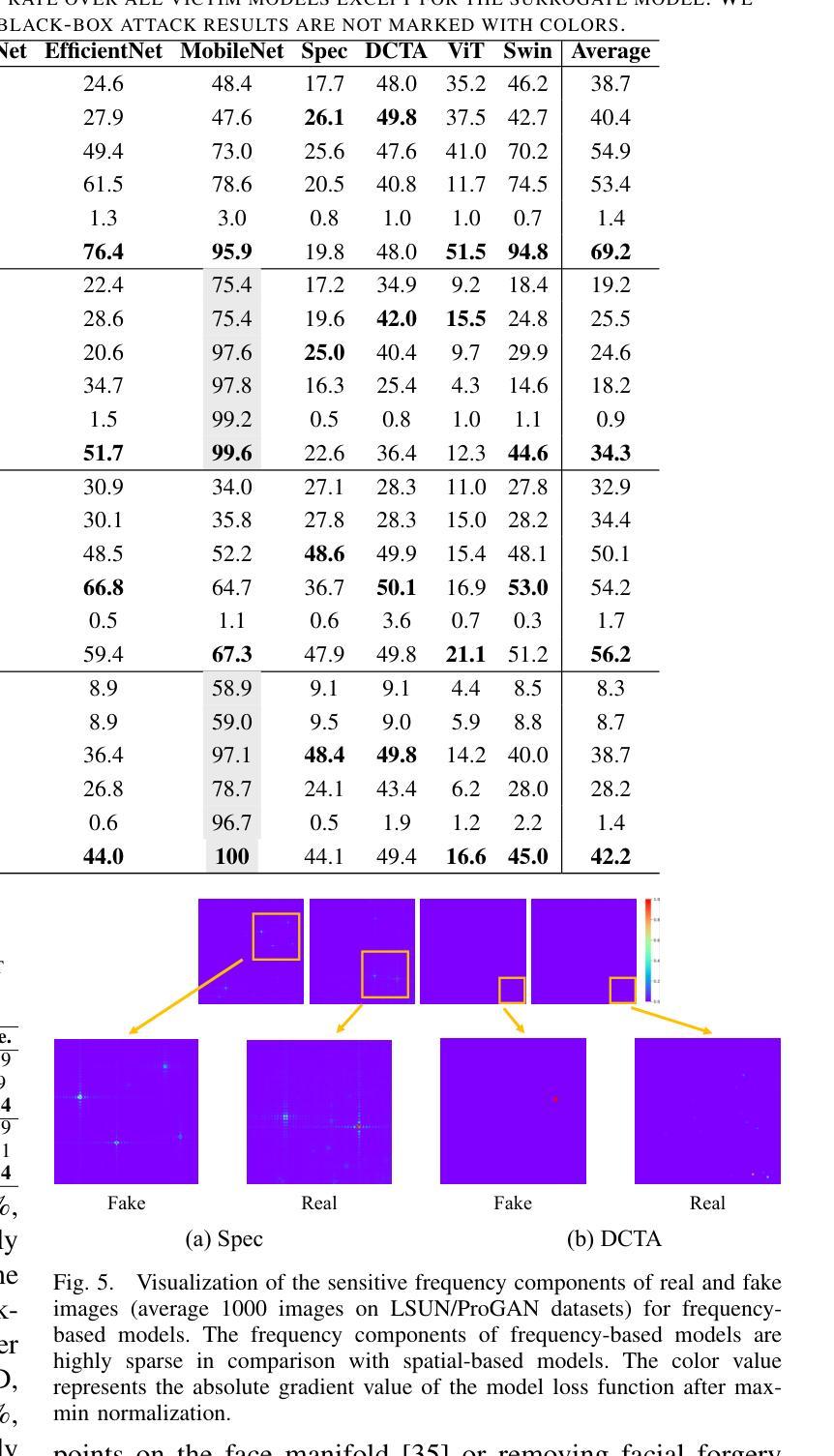
Vulnerabilities in AI-generated Image Detection: The Challenge of Adversarial Attacks
Authors:Yunfeng Diao, Naixin Zhai, Changtao Miao, Zitong Yu, Xingxing Wei, Xun Yang, Meng Wang
Recent advancements in image synthesis, particularly with the advent of GAN and Diffusion models, have amplified public concerns regarding the dissemination of disinformation. To address such concerns, numerous AI-generated Image (AIGI) Detectors have been proposed and achieved promising performance in identifying fake images. However, there still lacks a systematic understanding of the adversarial robustness of AIGI detectors. In this paper, we examine the vulnerability of state-of-the-art AIGI detectors against adversarial attack under white-box and black-box settings, which has been rarely investigated so far. To this end, we propose a new method to attack AIGI detectors. First, inspired by the obvious difference between real images and fake images in the frequency domain, we add perturbations under the frequency domain to push the image away from its original frequency distribution. Second, we explore the full posterior distribution of the surrogate model to further narrow this gap between heterogeneous AIGI detectors, e.g. transferring adversarial examples across CNNs and ViTs. This is achieved by introducing a novel post-train Bayesian strategy that turns a single surrogate into a Bayesian one, capable of simulating diverse victim models using one pre-trained surrogate, without the need for re-training. We name our method as Frequency-based Post-train Bayesian Attack, or FPBA. Through FPBA, we show that adversarial attack is truly a real threat to AIGI detectors, because FPBA can deliver successful black-box attacks across models, generators, defense methods, and even evade cross-generator detection, which is a crucial real-world detection scenario. The code will be shared upon acceptance.
近期图像合成领域的进展,特别是生成对抗网络(GAN)和扩散模型的出现,加剧了公众对虚假信息传播问题的担忧。为了解决这些担忧,已经提出了许多人工智能生成的图像(AIGI)检测器,并且在识别虚假图像方面取得了令人瞩目的性能。然而,对于AIGI检测器的对抗性稳健性,仍缺乏系统的理解。
论文及项目相关链接
摘要
本论文探讨了基于最新图像合成技术(如GAN和Diffusion模型)的虚假信息扩散问题。针对此问题,已经提出了许多AI生成的图像(AIGI)检测器并实现了较好的性能。然而,由于缺乏系统理解对抗式环境下AIGI检测器的鲁棒性,本论文着重分析了最前沿的AIGI检测器在面临白盒和黑盒设置时的脆弱性。为此,我们提出了一种新的攻击AIGI检测器的方法——FPBA(基于频率的后训练贝叶斯攻击)。该方法首先通过频率域的扰动将图像推离其原始频率分布,然后探索替代模型的后验分布以缩小不同AIGI检测器之间的差距。实验表明,FPBA攻击能够成功实现对模型的攻击,无论是白盒还是黑盒设置下均能绕过多种防御机制。该攻击方法真正威胁到AIGI检测器的安全性,因为它可以在不同模型、生成器、防御方法之间进行跨模型攻击,甚至能逃避跨生成器检测,这是一个关键的现实世界检测场景。论文将分享相应的代码。该论文着重于探讨一种新型的攻击方法,揭示了当前AIGI检测器的脆弱性,并提供了一种新型的解决思路。这种基于频率的攻击策略有助于深化我们对对抗样本和虚假图像生成的理解。然而,这项研究仍然需要更深入的探索和完善,特别是在处理具有自适应性的攻击策略方面。此外,我们还需进一步探索如何提高AIGI检测器的鲁棒性和安全性。我们相信未来的研究将能够解决这些问题并推动AI技术的持续发展。总的来说,这是一个富有挑战性和前沿性的研究话题。论文贡献显著且具有实用价值。我们期待该领域未来的进一步发展和进步。该论文对理解AIGI检测器的安全性和脆弱性具有重要意义。希望未来有更多的研究能够深入探讨这一领域的问题和挑战,推动AI技术的不断进步和发展。同时,我们也期待更多关于防御策略的研究出现,以应对潜在的威胁和挑战。在此基础上进行的分析具有很高的应用价值和研究价值。关键要点提炼
- 最新的图像合成技术引发公众对虚假信息传播的担忧,AI生成的图像检测器的发展是解决这一问题的重要方向之一。
- 当前研究缺乏对于AI图像检测器对抗式鲁棒性的系统性理解。本论文旨在填补这一空白。
点此查看论文截图



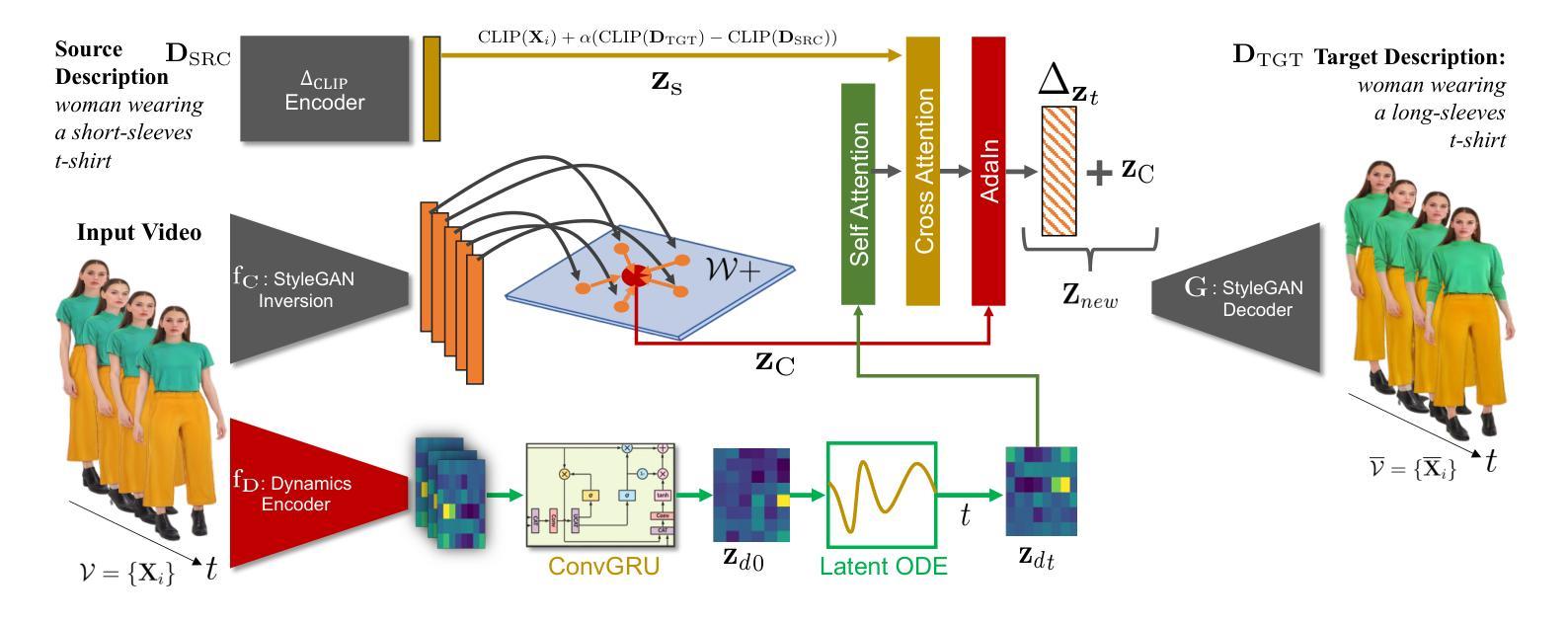
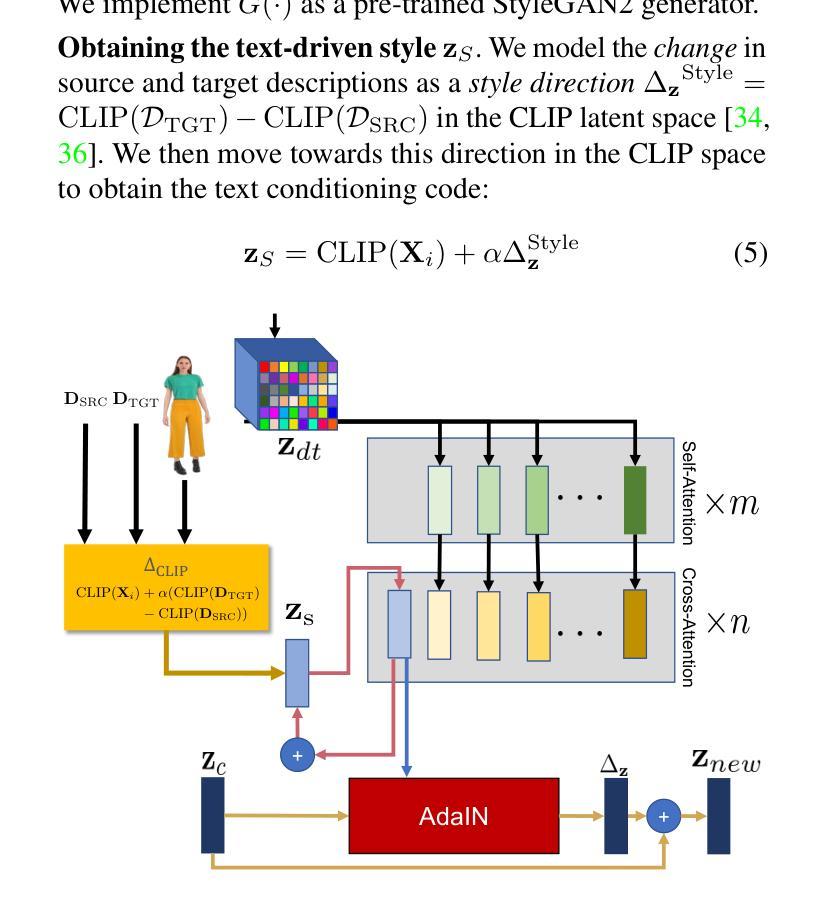
VidStyleODE: Disentangled Video Editing via StyleGAN and NeuralODEs
Authors:Moayed Haji Ali, Andrew Bond, Tolga Birdal, Duygu Ceylan, Levent Karacan, Erkut Erdem, Aykut Erdem
We propose $\textbf{VidStyleODE}$, a spatiotemporally continuous disentangled $\textbf{Vid}$eo representation based upon $\textbf{Style}$GAN and Neural-$\textbf{ODE}$s. Effective traversal of the latent space learned by Generative Adversarial Networks (GANs) has been the basis for recent breakthroughs in image editing. However, the applicability of such advancements to the video domain has been hindered by the difficulty of representing and controlling videos in the latent space of GANs. In particular, videos are composed of content (i.e., appearance) and complex motion components that require a special mechanism to disentangle and control. To achieve this, VidStyleODE encodes the video content in a pre-trained StyleGAN $\mathcal{W}_+$ space and benefits from a latent ODE component to summarize the spatiotemporal dynamics of the input video. Our novel continuous video generation process then combines the two to generate high-quality and temporally consistent videos with varying frame rates. We show that our proposed method enables a variety of applications on real videos: text-guided appearance manipulation, motion manipulation, image animation, and video interpolation and extrapolation. Project website: https://cyberiada.github.io/VidStyleODE
我们提出了基于StyleGAN和神经ODE的时空连续解耦视频表示方法——VidStyleODE。生成对抗网络(GANs)所学习的潜在空间的遍历是近年来图像编辑突破的基础。然而,此类技术在视频领域的应用却受到了在GAN的潜在空间中表示和控制视频的困难的影响。特别是,视频由内容(即外观)和需要特殊机制来解耦和控制的复杂运动成分组成。为了实现这一点,VidStyleODE将视频内容编码在预训练的StyleGAN W+空间中,并受益于潜在ODE组件来总结输入视频的时空动态。然后,我们新颖的持续视频生成过程将两者结合起来,生成具有不同帧率的高质量且时间上连贯的视频。我们显示,我们提出的方法能够在真实视频上实现各种应用:文本引导的外观操纵、运动操纵、图像动画以及视频插值和外推。项目网站:https://cyberiada.github.io/VidStyleODE
论文及项目相关链接
PDF Project website: https://cyberiada.github.io/VidStyleODE
Summary
提出的VidStyleODE方法,结合StyleGAN和神经ODE,实现了时空连续的视频表示。该方法能有效遍历GANs学习的潜在空间,进行视频编辑。通过将视频内容编码到预训练的StyleGAN W+空间中,并结合潜在ODE组件总结视频的时空动态,生成高质量、帧率可变的视频。此方法可实现多种实际应用,如文本引导的外观操纵、运动操纵、图像动画以及视频插值和外推。
Key Takeaways
- VidStyleODE结合StyleGAN和神经ODE实现了时空连续的视频表示。
- 方法能有效遍历GANs的潜在空间,为视频编辑提供新的可能性。
- 通过将视频内容编码到预训练的StyleGAN W+空间,提高了视频表示和控制的效率。
- 潜在ODE组件用于总结视频的时空动态,增强了视频的生成质量。
- 该方法能生成高质量、帧率可变的视频。
- VidStyleODE在多种实际应用中表现出强大的性能,如文本引导的外观操纵、运动操纵、图像动画等。
点此查看论文截图