⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-12 更新
LBM: Latent Bridge Matching for Fast Image-to-Image Translation
Authors:Clément Chadebec, Onur Tasar, Sanjeev Sreetharan, Benjamin Aubin
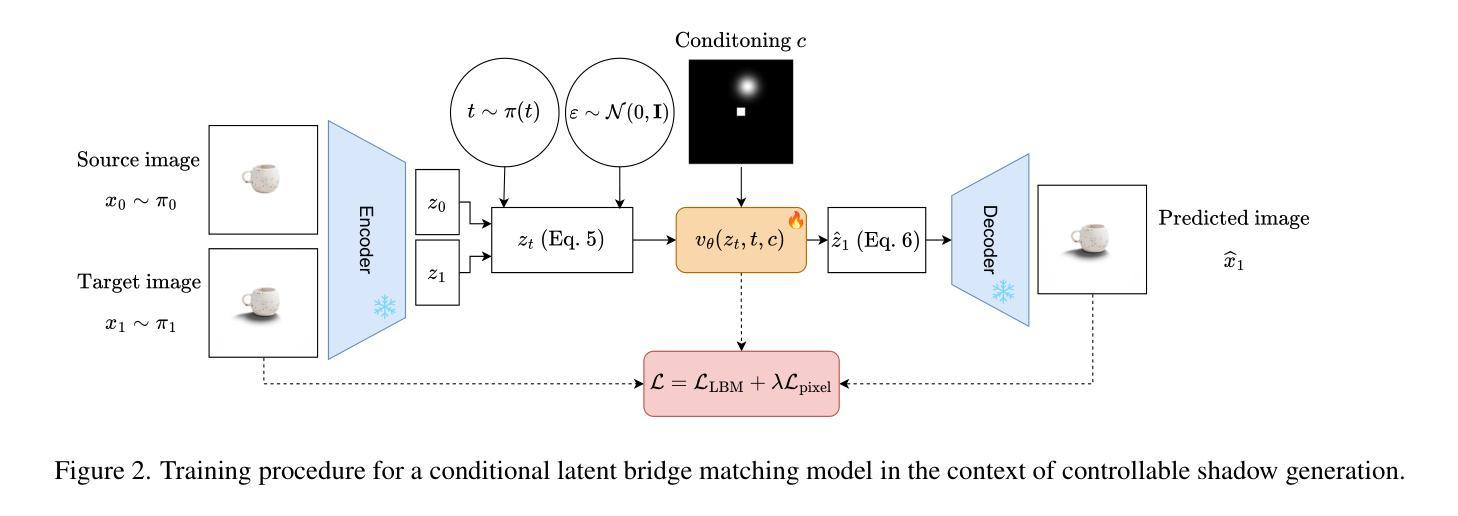
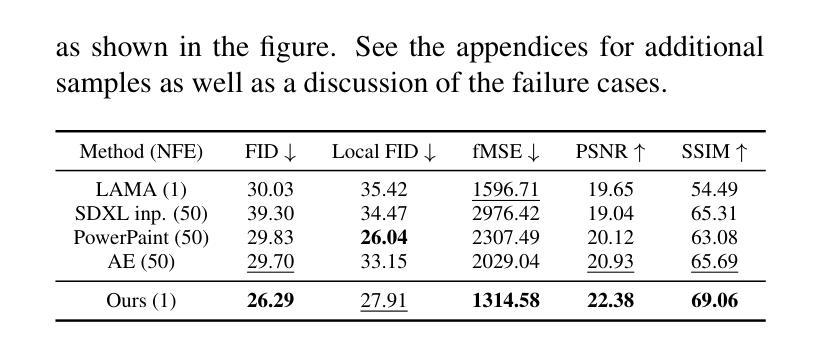
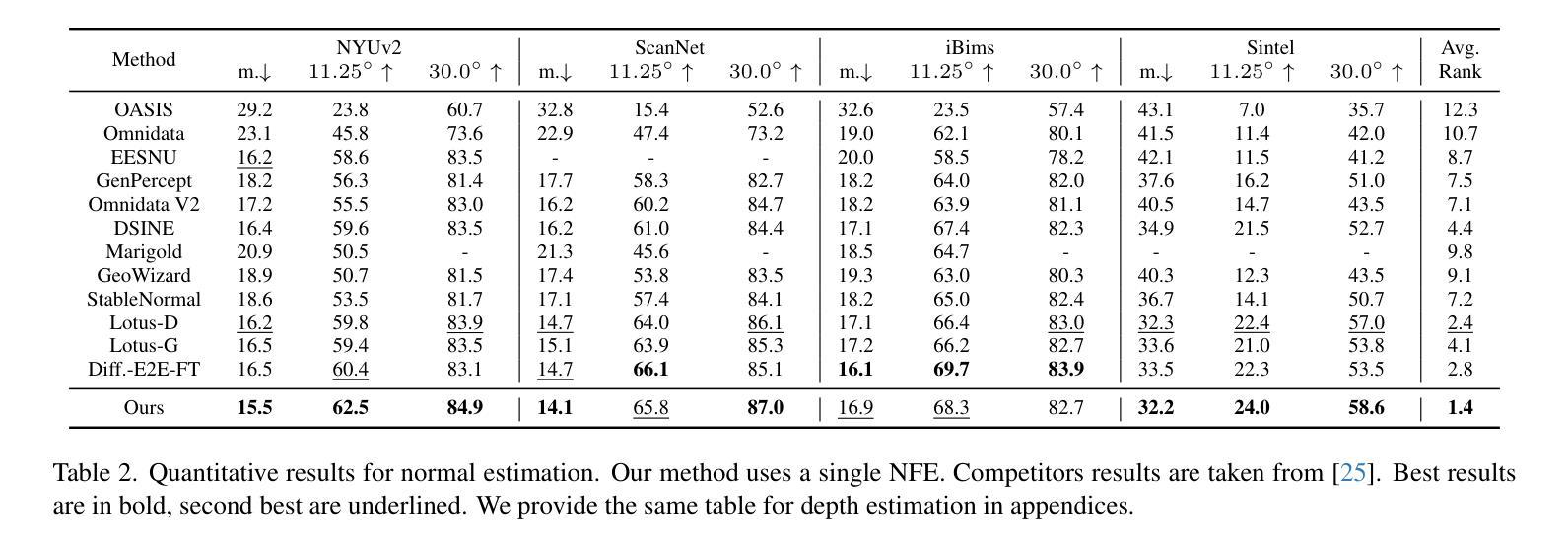
In this paper, we introduce Latent Bridge Matching (LBM), a new, versatile and scalable method that relies on Bridge Matching in a latent space to achieve fast image-to-image translation. We show that the method can reach state-of-the-art results for various image-to-image tasks using only a single inference step. In addition to its efficiency, we also demonstrate the versatility of the method across different image translation tasks such as object removal, normal and depth estimation, and object relighting. We also derive a conditional framework of LBM and demonstrate its effectiveness by tackling the tasks of controllable image relighting and shadow generation. We provide an open-source implementation of the method at https://github.com/gojasper/LBM.
在这篇论文中,我们介绍了潜在桥梁匹配(LBM),这是一种新出现的高效且可扩展的方法,它依赖于潜在空间中的桥梁匹配来实现快速图像到图像的翻译。我们表明,该方法仅使用一个推理步骤就可以在各种图像到图像的任务上达到最新技术结果。除了高效性之外,我们还展示了该方法在不同图像翻译任务中的通用性,如目标移除、法线和深度估计以及目标重新照明等。我们还建立了LBM的条件框架,并通过解决可控图像重新照明和阴影生成任务来证明其有效性。我们在https://github.com/gojasper/LBM上提供了该方法的开源实现。
论文及项目相关链接
Summary
本论文提出一种名为Latent Bridge Matching(LBM)的新方法,该方法利用潜在空间的Bridge Matching实现快速图像到图像的翻译,具有通用性和可扩展性。实验表明,该方法在各种图像到图像的翻译任务中能达到最先进的性能,仅使用单个推理步骤即可完成。此外,它还可以用于多种图像处理任务,如对象去除、光照调整和深度估计等。我们为LBM构建了一个条件框架,通过控制图像重新照明和阴影生成等任务展示其有效性。我们公开了LBM方法的开源实现。
Key Takeaways
- Latent Bridge Matching (LBM)是一种新方法,基于潜在空间的Bridge Matching进行快速图像到图像的翻译。
- LBM具有通用性和可扩展性,可以应用于多种图像翻译任务。
- LBM能在各种图像到图像的翻译任务中达到最先进的性能。
- LBM仅需一个推理步骤就能完成翻译任务,体现了其高效性。
- LBM可用于图像处理任务,如对象去除、光照调整和深度估计等。
- LBM具有可控性,通过条件框架实现图像重新照明和阴影生成等任务的控制。
点此查看论文截图



SEED: Towards More Accurate Semantic Evaluation for Visual Brain Decoding
Authors:Juhyeon Park, Peter Yongho Kim, Jiook Cha, Shinjae Yoo, Taesup Moon
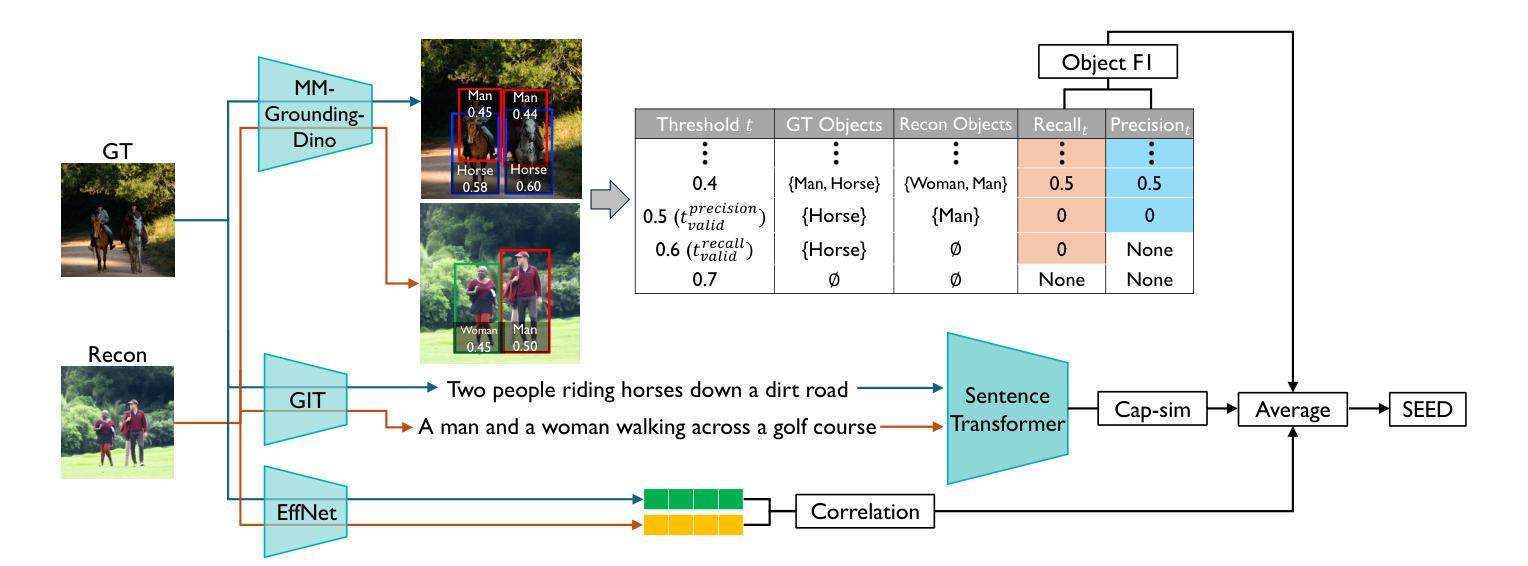
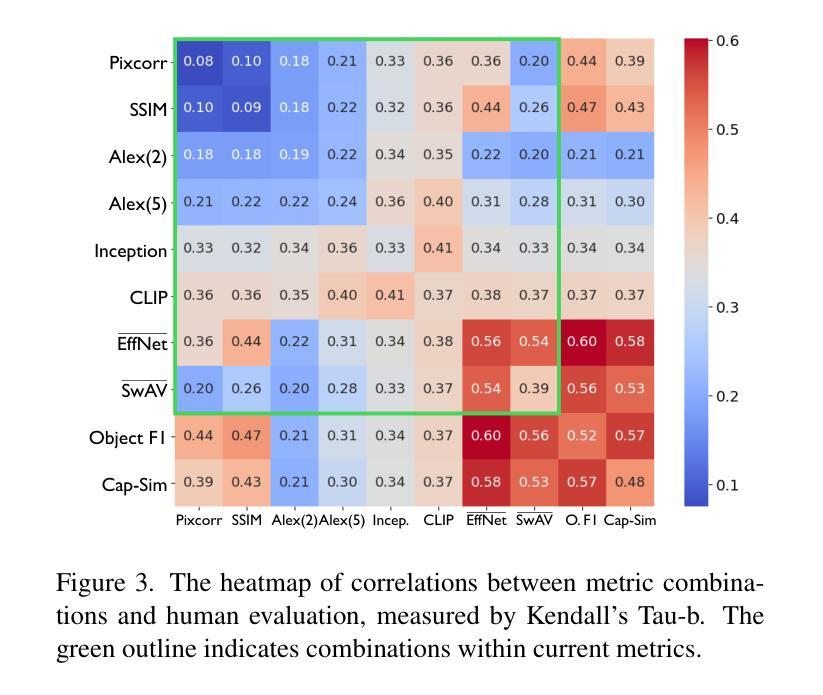
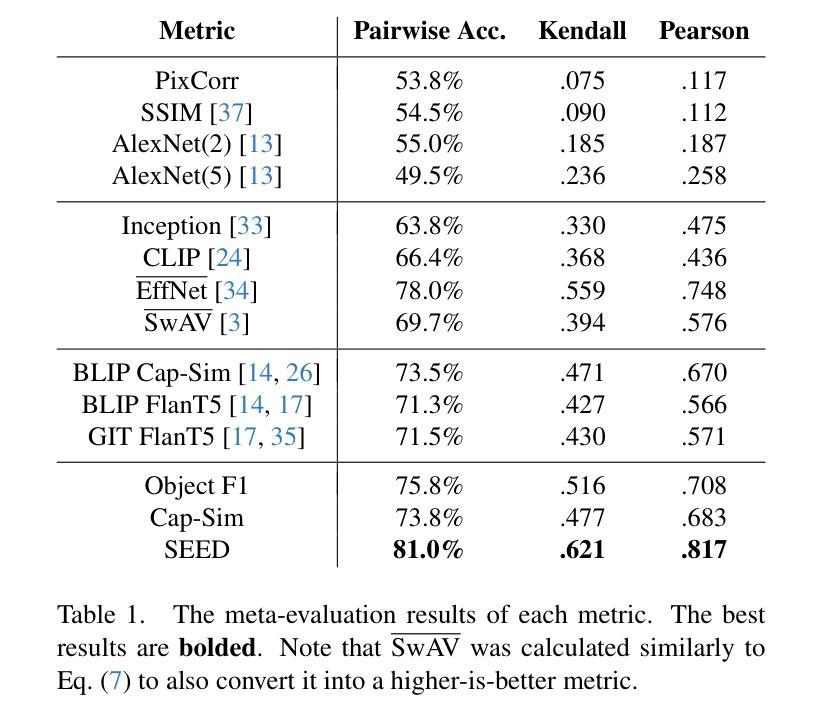
We present SEED (\textbf{Se}mantic \textbf{E}valuation for Visual Brain \textbf{D}ecoding), a novel metric for evaluating the semantic decoding performance of visual brain decoding models. It integrates three complementary metrics, each capturing a different aspect of semantic similarity between images. Using carefully crowd-sourced human judgment data, we demonstrate that SEED achieves the highest alignment with human evaluations, outperforming other widely used metrics. Through the evaluation of existing visual brain decoding models, we further reveal that crucial information is often lost in translation, even in state-of-the-art models that achieve near-perfect scores on existing metrics. To facilitate further research, we open-source the human judgment data, encouraging the development of more advanced evaluation methods for brain decoding models. Additionally, we propose a novel loss function designed to enhance semantic decoding performance by leveraging the order of pairwise cosine similarity in CLIP image embeddings. This loss function is compatible with various existing methods and has been shown to consistently improve their semantic decoding performances when used for training, with respect to both existing metrics and SEED.
我们提出了SEED(面向视觉大脑解码的语义评估),这是一种用于评估视觉大脑解码模型语义解码性能的新型指标。它集成了三个互补的指标,每个指标都捕捉图像之间语义相似性的不同方面。通过使用精心收集的众源人类判断数据,我们证明SEED与人类评估的契合度最高,优于其他广泛使用的指标。通过对现有视觉大脑解码模型的评估,我们进一步发现,即使在最新模型中,即使其在现有指标上的得分接近完美,翻译过程中也经常会丢失关键信息。为了促进进一步研究,我们开源了人类判断数据,鼓励开发更先进的脑解码模型评估方法。此外,我们提出了一种新的损失函数,旨在利用CLIP图像嵌入中的成对余弦相似性的顺序来提高语义解码性能。此损失函数与各种现有方法兼容,并且在训练和评估时,无论是在现有指标还是SEED上,都已被证明可以持续提高其语义解码性能。
论文及项目相关链接
PDF Under Review
Summary
SEED(语义评估用于视觉大脑解码)是一种新型指标,用于评估视觉大脑解码模型的语义解码性能。它通过集成三个互补的指标,从图像间的语义相似性方面进行全面评估。基于广泛收集的人类判断数据,SEED表现出与人类评价的高度一致性,优于其他常用指标。对现有视觉大脑解码模型的评估显示,即使在得分接近完美的模型中,也存在重要信息的丢失。我们公开了人类判断数据,以促进更先进的评估方法的发展。此外,我们提出了一种新的损失函数,利用CLIP图像嵌入中的成对余弦相似性顺序,旨在提高语义解码性能。该损失函数与现有方法兼容,在训练和评估时均能提高语义解码性能。
Key Takeaways
- SEED是一种新的评估指标,用于衡量视觉大脑解码模型的语义解码性能。
- SEED集成了三个互补指标,反映图像间的不同语义相似性方面。
- SEED基于广泛收集的人类判断数据,与人类评价高度一致,优于其他常用指标。
- 对现有视觉大脑解码模型的评估发现,即使在高分模型中,也存在重要信息的丢失。
- 公开了人类判断数据以促进更先进的评估方法的发展。
- 提出了一种新的损失函数,利用CLIP图像嵌入中的成对余弦相似性顺序来提高语义解码性能。
点此查看论文截图

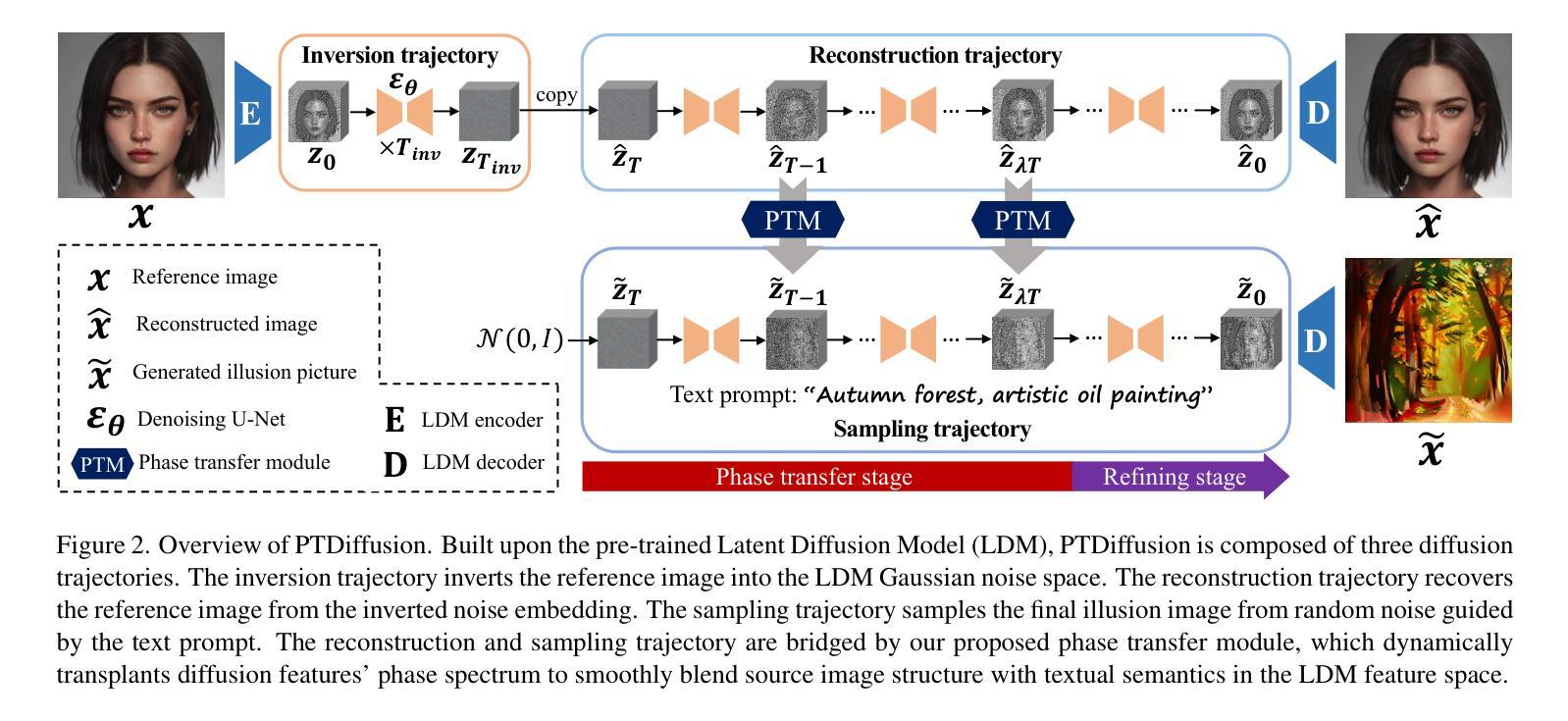
PTDiffusion: Free Lunch for Generating Optical Illusion Hidden Pictures with Phase-Transferred Diffusion Model
Authors:Xiang Gao, Shuai Yang, Jiaying Liu
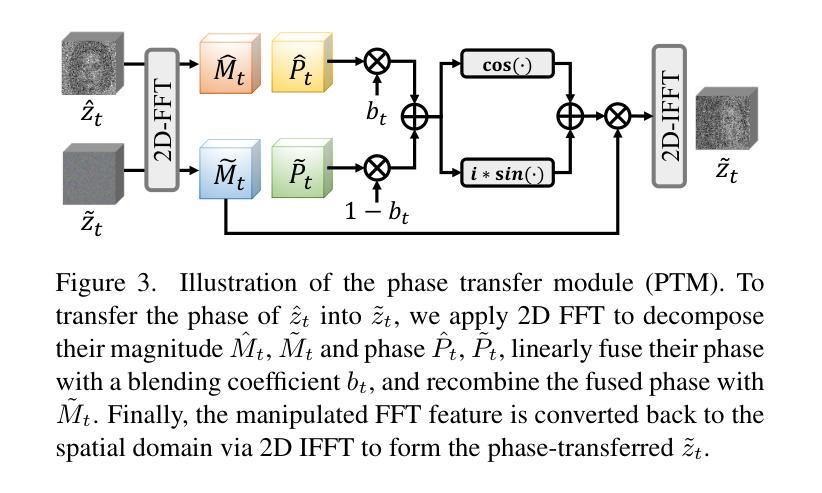
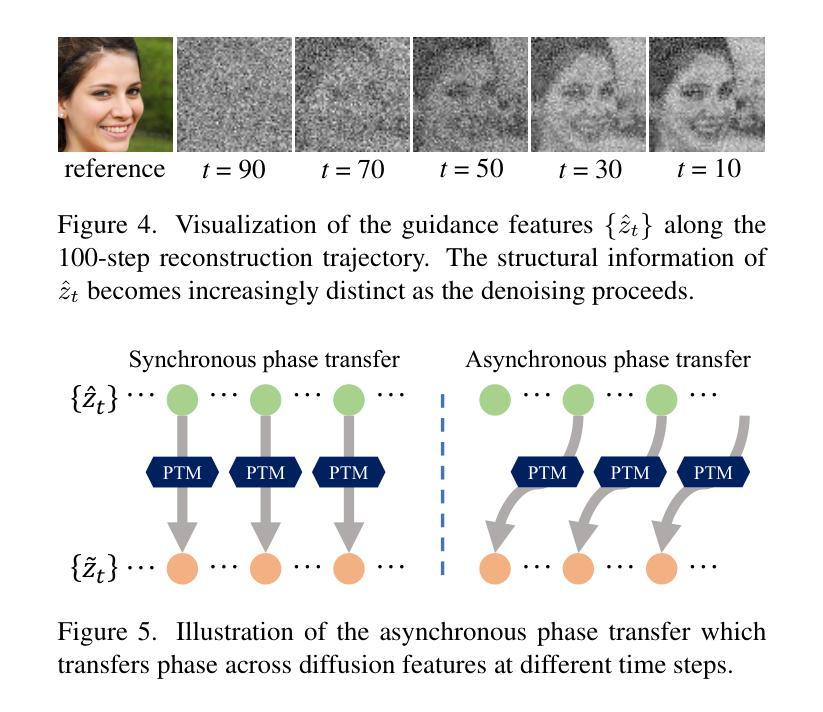
Optical illusion hidden picture is an interesting visual perceptual phenomenon where an image is cleverly integrated into another picture in a way that is not immediately obvious to the viewer. Established on the off-the-shelf text-to-image (T2I) diffusion model, we propose a novel training-free text-guided image-to-image (I2I) translation framework dubbed as \textbf{P}hase-\textbf{T}ransferred \textbf{Diffusion} Model (PTDiffusion) for hidden art syntheses. PTDiffusion embeds an input reference image into arbitrary scenes as described by the text prompts, while exhibiting hidden visual cues of the reference image. At the heart of our method is a plug-and-play phase transfer mechanism that dynamically and progressively transplants diffusion features’ phase spectrum from the denoising process to reconstruct the reference image into the one to sample the generated illusion image, realizing harmonious fusion of the reference structural information and the textual semantic information. Furthermore, we propose asynchronous phase transfer to enable flexible control to the degree of hidden content discernability. Our method bypasses any model training and fine-tuning, all while substantially outperforming related methods in image quality, text fidelity, visual discernibility, and contextual naturalness for illusion picture synthesis, as demonstrated by extensive qualitative and quantitative experiments.
隐藏图片的视觉错觉是一种有趣的视觉感知现象,其中一张图片被巧妙地融入到另一张图片中,以至于观众无法立即察觉。我们基于现成的文本到图像(T2I)扩散模型,提出了一个无需训练的文字引导图像到图像(I2I)转换框架,名为相位转移扩散模型(PTDiffusion),用于合成隐藏艺术。PTDiffusion将输入参考图像嵌入到文本提示描述的任意场景中,同时展示参考图像的隐藏视觉线索。我们方法的核心是一个即插即用的相位转移机制,它动态且渐进地移植扩散特征的相位谱,从去噪过程中重建参考图像到生成错觉图像的采样过程中,实现参考结构信息和文本语义信息的和谐融合。此外,我们提出了异步相位转移,以实现灵活控制隐藏内容可辨识度的程度。我们的方法避开了任何模型的训练和微调,同时大大提升了图像质量、文本忠实度、视觉辨识度和上下文自然度,在错觉图片合成方面表现出色,这得到了广泛的质量和数量实验的验证。
论文及项目相关链接
PDF Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2025)
Summary
光学错觉隐藏图像是一种有趣的视觉感知现象,其中图像被巧妙地融入另一幅图片中,观众无法立即察觉。本研究基于现成的文本到图像(T2I)扩散模型,提出了一种无需训练的文字引导图像到图像(I2I)转换框架——相位转移扩散模型(PTDiffusion),用于合成隐藏艺术图像。PTDiffusion将输入参考图像嵌入文本提示描述的任意场景中,同时展示参考图像的隐藏视觉线索。该方法的核心是一个即插即用的相位转移机制,它动态且渐进地移植扩散特征的相位谱,从去噪过程中重建参考图像,将其融入生成的错觉图像中,实现参考结构信息和文本语义信息的和谐融合。此外,该研究还提出了异步相位转移,实现对隐藏内容辨识度的灵活控制。该方法无需任何模型训练和微调,在图像质量、文本忠实度、视觉辨识度和上下文自然度方面大大优于相关方法,用于合成错觉图像,如广泛的质量和数量实验所示。
Key Takeaways
- 光学错觉隐藏图片是一种视觉感知现象,图像被巧妙地融入另一幅图片中。
- 提出了一种新的无需训练的文字引导I2I转换框架——相位转移扩散模型(PTDiffusion)。
- PTDiffusion可将输入参考图像嵌入任意场景中,同时展示其隐藏视觉线索。
- 相位转移机制是该框架的核心,可动态、渐进地移植扩散特征的相位谱。
- 异步相位转移使对隐藏内容辨识度的控制更为灵活。
- 该方法无需模型训练和微调,在图像质量、文本忠实度等方面优于其他方法。
点此查看论文截图


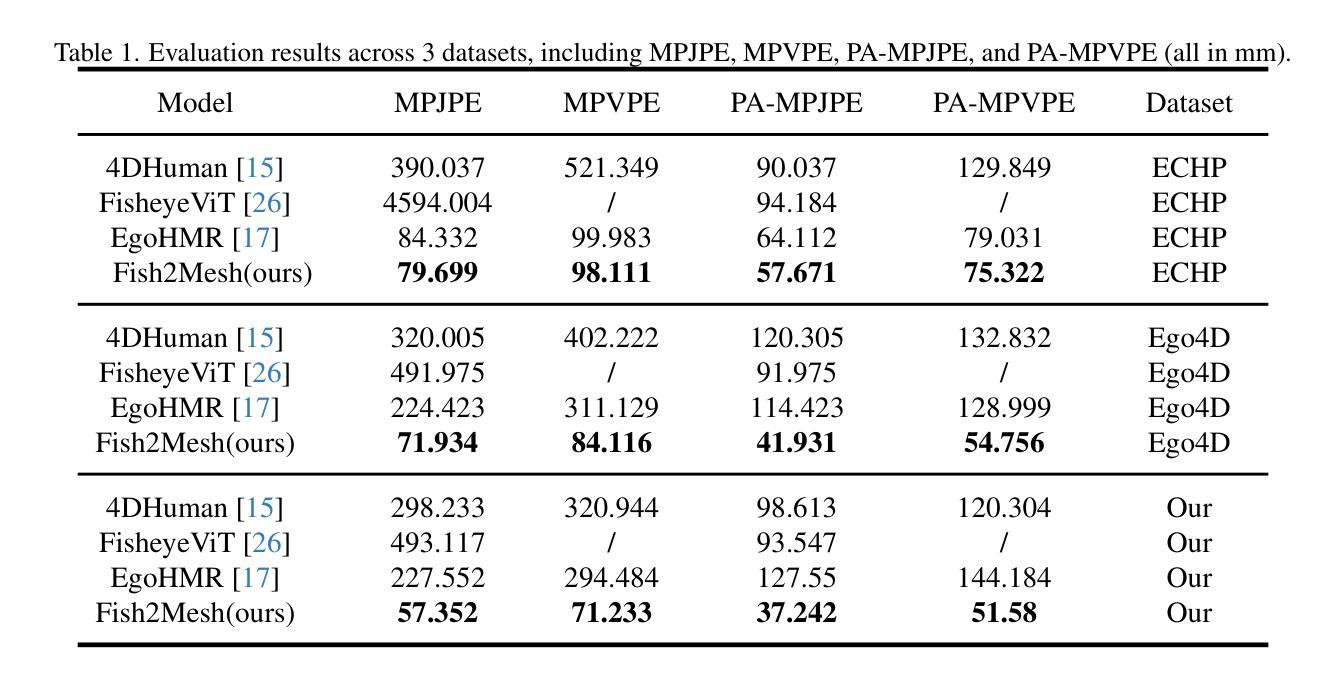
Fish2Mesh Transformer: 3D Human Mesh Recovery from Egocentric Vision
Authors:David C. Jeong, Aditya Puranik, James Vong, Vrushabh Abhijit Deogirikar, Ryan Fell, Julianna Dietrich, Maria Kyrarini, Christopher Kitts
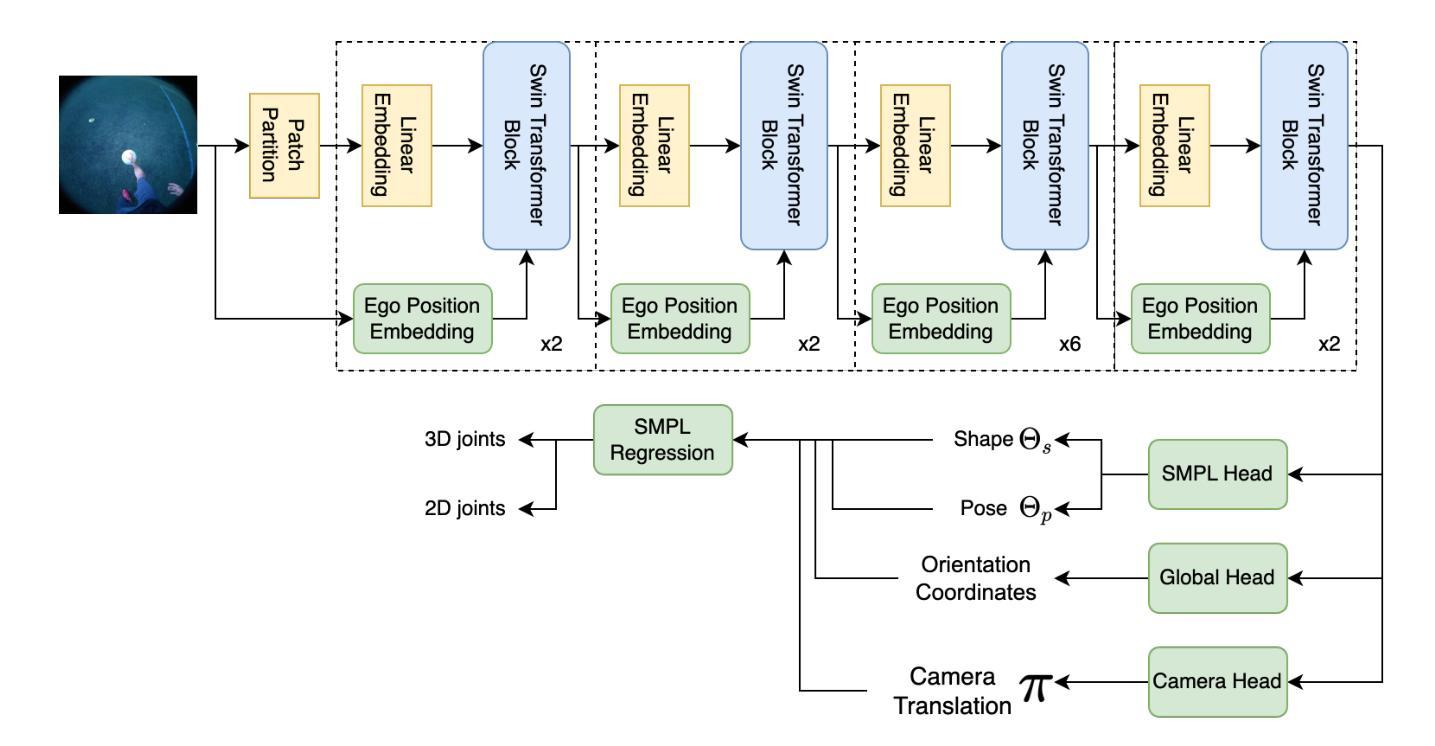
Egocentric human body estimation allows for the inference of user body pose and shape from a wearable camera’s first-person perspective. Although research has used pose estimation techniques to overcome self-occlusions and image distortions caused by head-mounted fisheye images, similar advances in 3D human mesh recovery (HMR) techniques have been limited. We introduce Fish2Mesh, a fisheye-aware transformer-based model designed for 3D egocentric human mesh recovery. We propose an egocentric position embedding block to generate an ego-specific position table for the Swin Transformer to reduce fisheye image distortion. Our model utilizes multi-task heads for SMPL parametric regression and camera translations, estimating 3D and 2D joints as auxiliary loss to support model training. To address the scarcity of egocentric camera data, we create a training dataset by employing the pre-trained 4D-Human model and third-person cameras for weak supervision. Our experiments demonstrate that Fish2Mesh outperforms previous state-of-the-art 3D HMR models.
自我中心的人体估计允许从可穿戴相机的第一人称视角推断用户的身体姿势和形状。尽管研究已经使用姿态估计技术来克服头部安装的鱼眼图像引起的自我遮挡和图像失真,但在3D人体网格恢复(HMR)技术方面的类似进展却受到限制。我们引入了Fish2Mesh,这是一个基于鱼眼感知的变压器模型,专为3D自我中心人体网格恢复设计。我们提出了一种自我中心位置嵌入块,以生成针对Swin Transformer的自我特定位置表,以减少鱼眼图像失真。我们的模型利用多任务头进行SMPL参数回归和相机平移,估计3D和2D关节作为辅助损失以支持模型训练。为了解决自我中心相机数据的稀缺性问题,我们通过使用预训练的4D-Human模型和第三人称相机进行弱监督来创建训练数据集。我们的实验表明,Fish2Mesh优于先前的最新3DHMR模型。
论文及项目相关链接
Summary
该研究通过引入Fish2Mesh模型,利用基于Transformer的技术,实现了从鱼眼视角对三维人体网格恢复的估计。该模型具有自我定位嵌入块,能够生成针对Swin Transformer的自我特定位置表,减少鱼眼图像失真。通过多任务头进行SMPL参数回归和相机平移估计,同时估计三维和二维关节作为辅助损失支持模型训练。为解决缺乏第一人称相机数据的问题,研究使用预训练的4D-Human模型和第三方相机进行弱监督创建训练数据集。实验表明,Fish2Mesh在三维人体网格恢复方面超越了先前最先进的模型。
Key Takeaways
- Fish2Mesh模型被引入,该模型用于从鱼眼视角进行三维人体网格恢复。
- 模型采用基于Transformer的技术,具有自我定位嵌入块以减少鱼眼图像失真。
- 多任务头用于SMPL参数回归和相机平移估计。
- 三维和二维关节估计作为辅助损失支持模型训练。
- 通过使用预训练的4D-Human模型和第三方相机进行弱监督创建训练数据集来解决缺乏第一人称相机数据的问题。
- Fish2Mesh在三维人体网格恢复方面表现优越。
点此查看论文截图

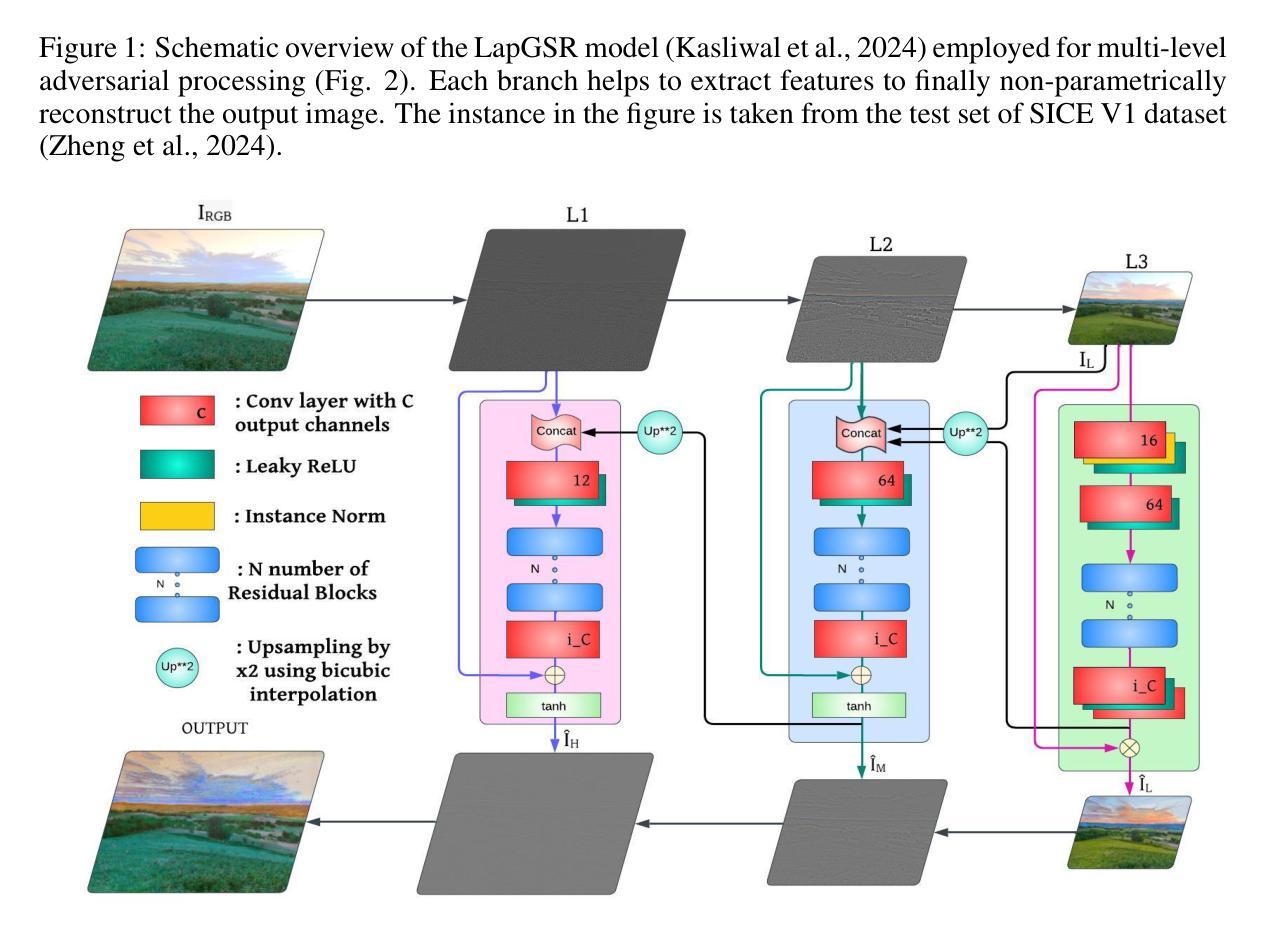
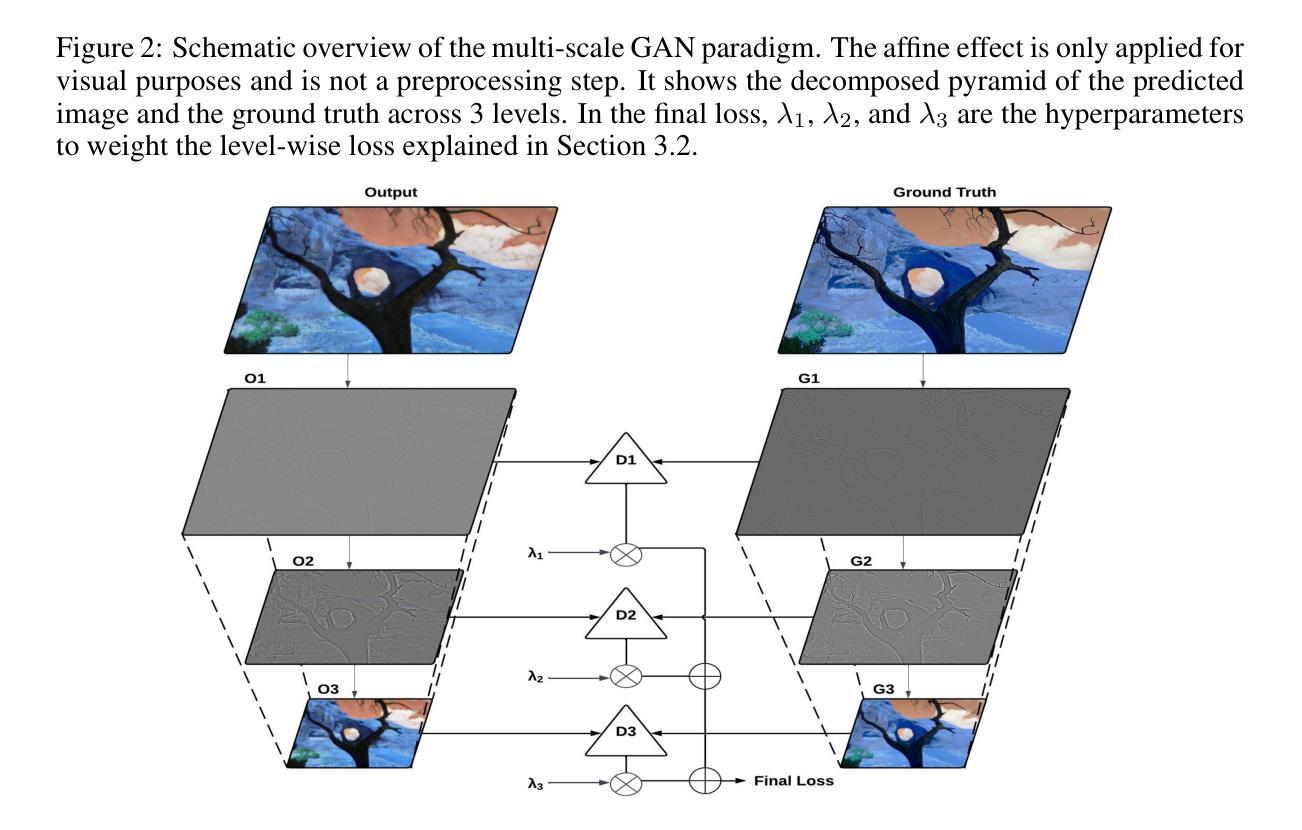
LapLoss: Laplacian Pyramid-based Multiscale loss for Image Translation
Authors:Krish Didwania, Ishaan Gakhar, Prakhar Arya, Sanskriti Labroo
Contrast enhancement, a key aspect of image-to-image translation (I2IT), improves visual quality by adjusting intensity differences between pixels. However, many existing methods struggle to preserve fine-grained details, often leading to the loss of low-level features. This paper introduces LapLoss, a novel approach designed for I2IT contrast enhancement, based on the Laplacian pyramid-centric networks, forming the core of our proposed methodology. The proposed approach employs a multiple discriminator architecture, each operating at a different resolution to capture high-level features, in addition to maintaining low-level details and textures under mixed lighting conditions. The proposed methodology computes the loss at multiple scales, balancing reconstruction accuracy and perceptual quality to enhance overall image generation. The distinct blend of the loss calculation at each level of the pyramid, combined with the architecture of the Laplacian pyramid enables LapLoss to exceed contemporary contrast enhancement techniques. This framework achieves state-of-the-art results, consistently performing well across different lighting conditions in the SICE dataset.
图像到图像翻译(I2IT)的一个关键方面是对比度增强,它通过调整像素之间的强度差异来提高视觉质量。然而,许多现有方法在保留精细纹理方面存在困难,这往往导致低级特征的丢失。本文介绍了LapLoss,这是一种针对I2IT对比度增强提出的新型方法,它基于拉普拉斯金字塔中心网络,构成我们提出的方法论的核心。该方法采用多重鉴别器架构,每个鉴别器在不同的分辨率下运行,以捕捉高级特征,同时在混合照明条件下保持低级细节和纹理。该方法在不同的尺度上计算损失,平衡重建精度和感知质量,从而提高整体图像生成质量。金字塔每一层损失计算的独特融合,结合拉普拉斯金字塔的架构,使LapLoss超越了当前的对比度增强技术。该框架在SICE数据集的不同照明条件下均取得了最新的结果,表现良好。
论文及项目相关链接
PDF Accepted at the DeLTa Workshop, ICLR 2025
Summary
本文介绍了基于Laplacian金字塔的I2IT对比增强新方法——LapLoss。该方法采用多判别器架构,在不同分辨率下捕捉高级特征,并在混合光照条件下保持低级细节和纹理。该方法在多个尺度上计算损失,平衡重建精度和感知质量,提高图像生成的总体质量,超越现有对比增强技术,在SICE数据集的不同光照条件下表现优异。
Key Takeaways
- LapLoss是一种基于Laplacian金字塔的新方法,用于图像到图像的对比增强(I2IT)。
- 采用多判别器架构,在混合光照条件下捕捉高级特征和保持低级细节和纹理。
- 方法在不同尺度上计算损失,平衡重建精度和感知质量。
- LapLoss能提高图像生成的总体质量。
- 该方法在SICE数据集上的表现优异,能适应不同的光照条件。
- 与现有对比增强技术相比,LapLoss有更好的性能。
点此查看论文截图

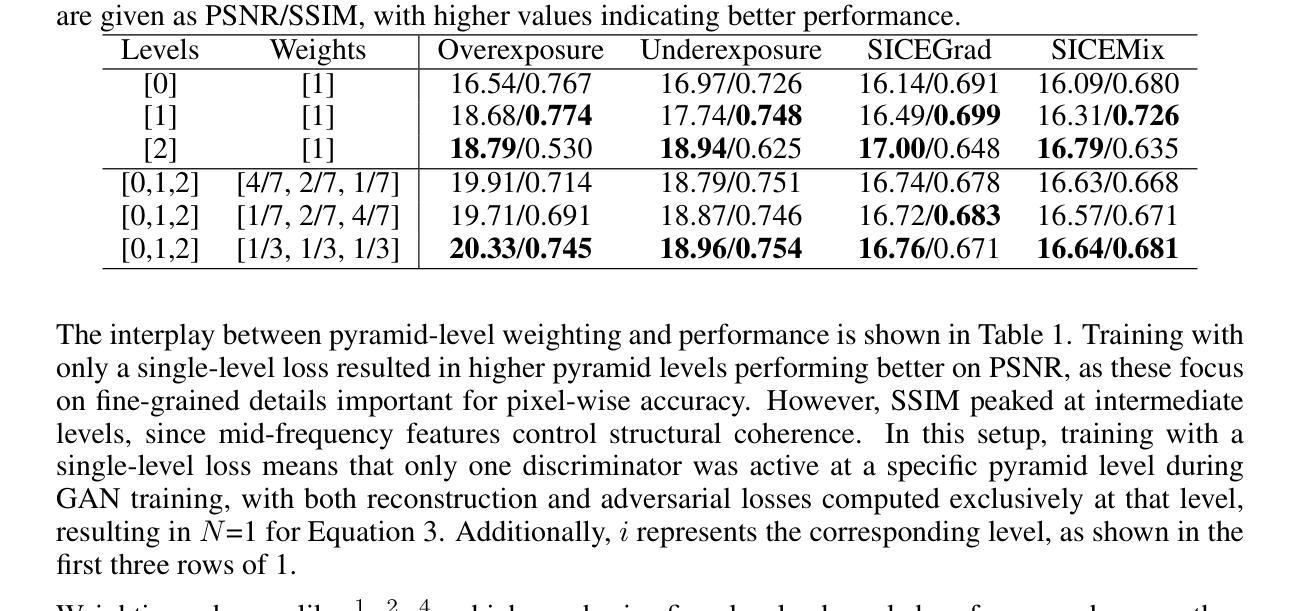
Intermediate Domain-guided Adaptation for Unsupervised Chorioallantoic Membrane Vessel Segmentation
Authors:Pengwu Song, Liang Xu, Peng Yao, Shuwei Shen, Pengfei Shao, Mingzhai Sun, Ronald X. Xu
The chorioallantoic membrane (CAM) model is widely employed in angiogenesis research, and distribution of growing blood vessels is the key evaluation indicator. As a result, vessel segmentation is crucial for quantitative assessment based on topology and morphology. However, manual segmentation is extremely time-consuming, labor-intensive, and prone to inconsistency due to its subjective nature. Moreover, research on CAM vessel segmentation algorithms remains limited, and the lack of public datasets contributes to poor prediction performance. To address these challenges, we propose an innovative Intermediate Domain-guided Adaptation (IDA) method, which utilizes the similarity between CAM images and retinal images, along with existing public retinal datasets, to perform unsupervised training on CAM images. Specifically, we introduce a Multi-Resolution Asymmetric Translation (MRAT) strategy to generate intermediate images to promote image-level interaction. Then, an Intermediate Domain-guided Contrastive Learning (IDCL) module is developed to disentangle cross-domain feature representations. This method overcomes the limitations of existing unsupervised domain adaptation (UDA) approaches, which primarily concentrate on directly source-target alignment while neglecting intermediate domain information. Notably, we create the first CAM dataset to validate the proposed algorithm. Extensive experiments on this dataset show that our method outperforms compared approaches. Moreover, it achieves superior performance in UDA tasks across retinal datasets, highlighting its strong generalization capability. The CAM dataset and source codes are available at https://github.com/Light-47/IDA.
绒毛膜尿膜(CAM)模型在血管生成研究中得到广泛应用,生长血管的分布是主要评价指标。因此,基于拓扑和形态的定量评估,血管分割至关重要。然而,手动分割耗时费力,且由于主观性容易存在不一致。此外,CAM血管分割算法的研究仍然有限,缺乏公共数据集导致预测性能不佳。为了解决这些挑战,我们提出了一种创新的中域引导适应(IDA)方法,该方法利用CAM图像和视网膜图像的相似性,以及现有的公共视网膜数据集,对CAM图像进行无监督训练。具体来说,我们引入了一种多分辨率不对称翻译(MRAT)策略来生成中间图像,以促进图像级别的交互。然后,开发了一个中间域引导对比学习(IDCL)模块来解开跨域特征表示。该方法克服了现有无监督域适应(UDA)方法的局限性,这些方法主要集中在直接源目标对齐上,而忽略了中间域信息。值得注意的是,我们创建了第一个CAM数据集来验证所提出的算法。在该数据集上的大量实验表明,我们的方法优于比较方法。此外,它在视网膜数据集上的UDA任务中表现出优异的性能,凸显了其强大的泛化能力。CAM数据集和源代码可在https://github.com/Light-47/IDA获得。
论文及项目相关链接
Summary:
利用鸡胚绒毛膜尿囊膜(CAM)模型进行血管生成的研究中,血管分割是评估拓扑和形态的重要关键环节。针对CAM血管分割算法研究有限及缺乏公开数据集的问题,本文提出了一种基于中间域引导适配(IDA)的创新方法。该方法通过利用CAM图像与视网膜图像的相似性,结合现有的公开视网膜数据集,对CAM图像进行无监督训练。通过引入多分辨率不对称翻译(MRAT)策略生成中间图像来促进图像级交互,并开发了中间域引导对比学习(IDCL)模块来解析跨域特征表示。该方法在公开数据集上的实验验证显示,其在CAM数据集上的表现优于其他方法,且在视网膜数据集上的无监督域自适应任务中具有强大的泛化能力。
Key Takeaways:
- CAM模型在血管生成研究中广泛应用,血管分布是重要评估指标。
- 手动血管分割耗时、劳力密集且主观性导致结果不一致。
- 目前CAM血管分割算法研究有限,缺乏公开数据集影响预测性能。
- 本文提出基于中间域引导适配(IDA)的创新方法,利用CAM与视网膜图像的相似性进行无监督训练。
- 引入多分辨率不对称翻译(MRAT)策略生成中间图像,促进图像级交互。
- 开发中间域引导对比学习(IDCL)模块,以解析跨域特征表示。
- 在CAM数据集上的实验验证显示,该方法优于其他对比方法,且在视网膜数据集上具有较强的泛化能力。
点此查看论文截图

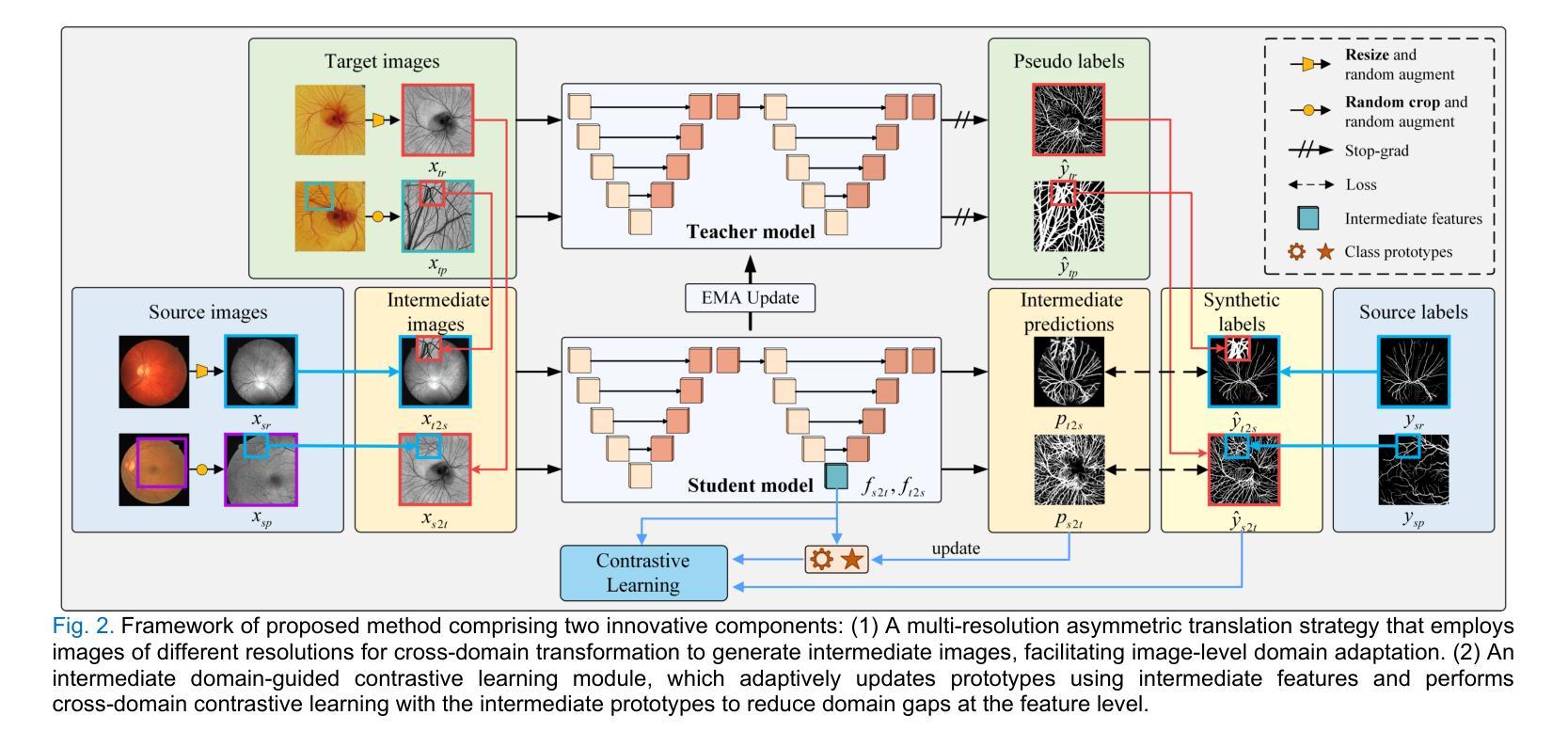
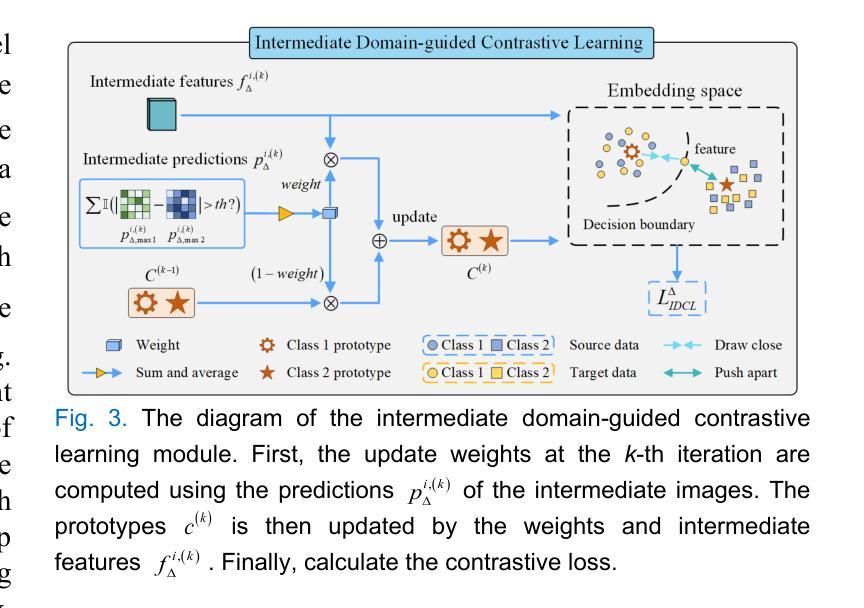
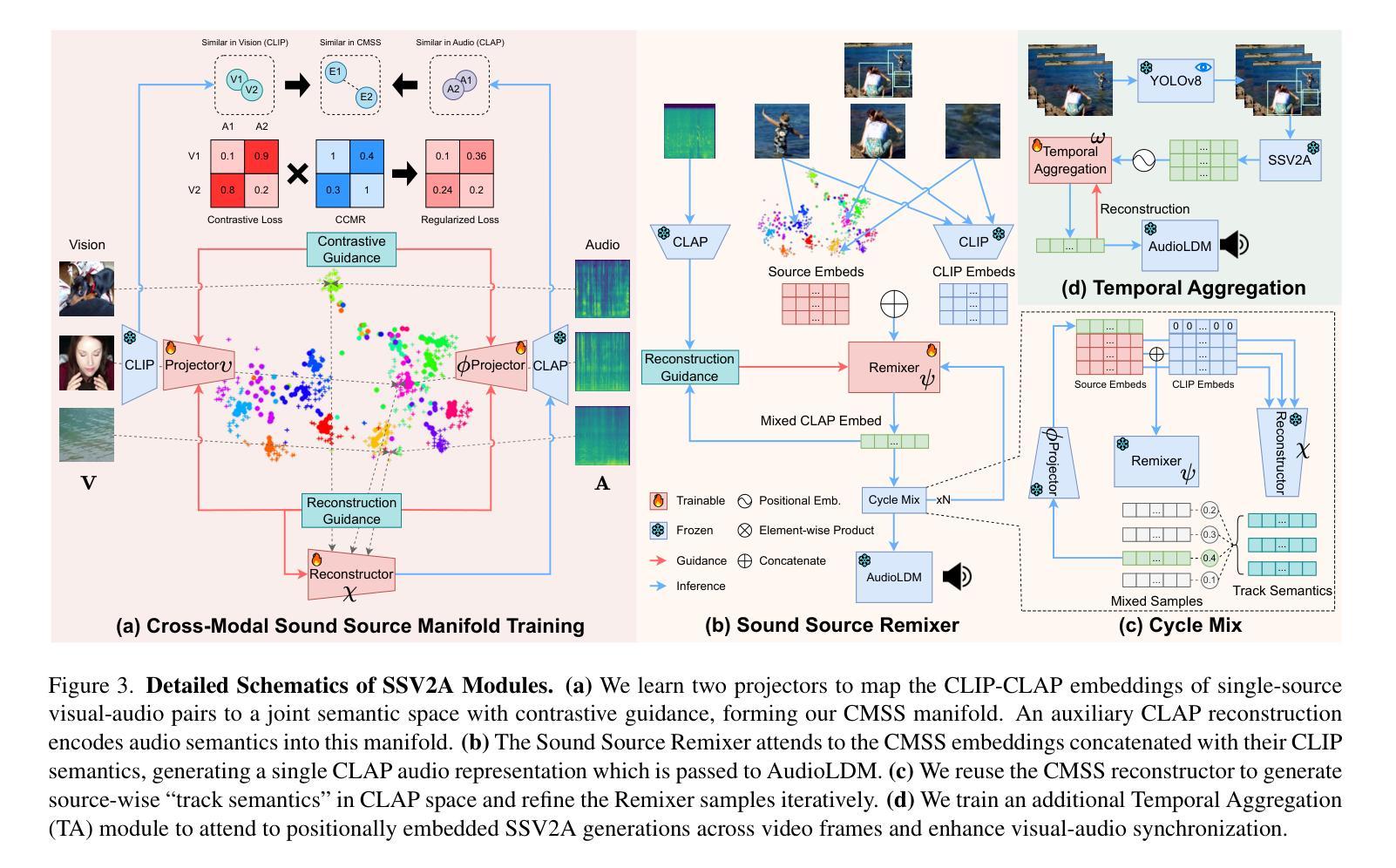
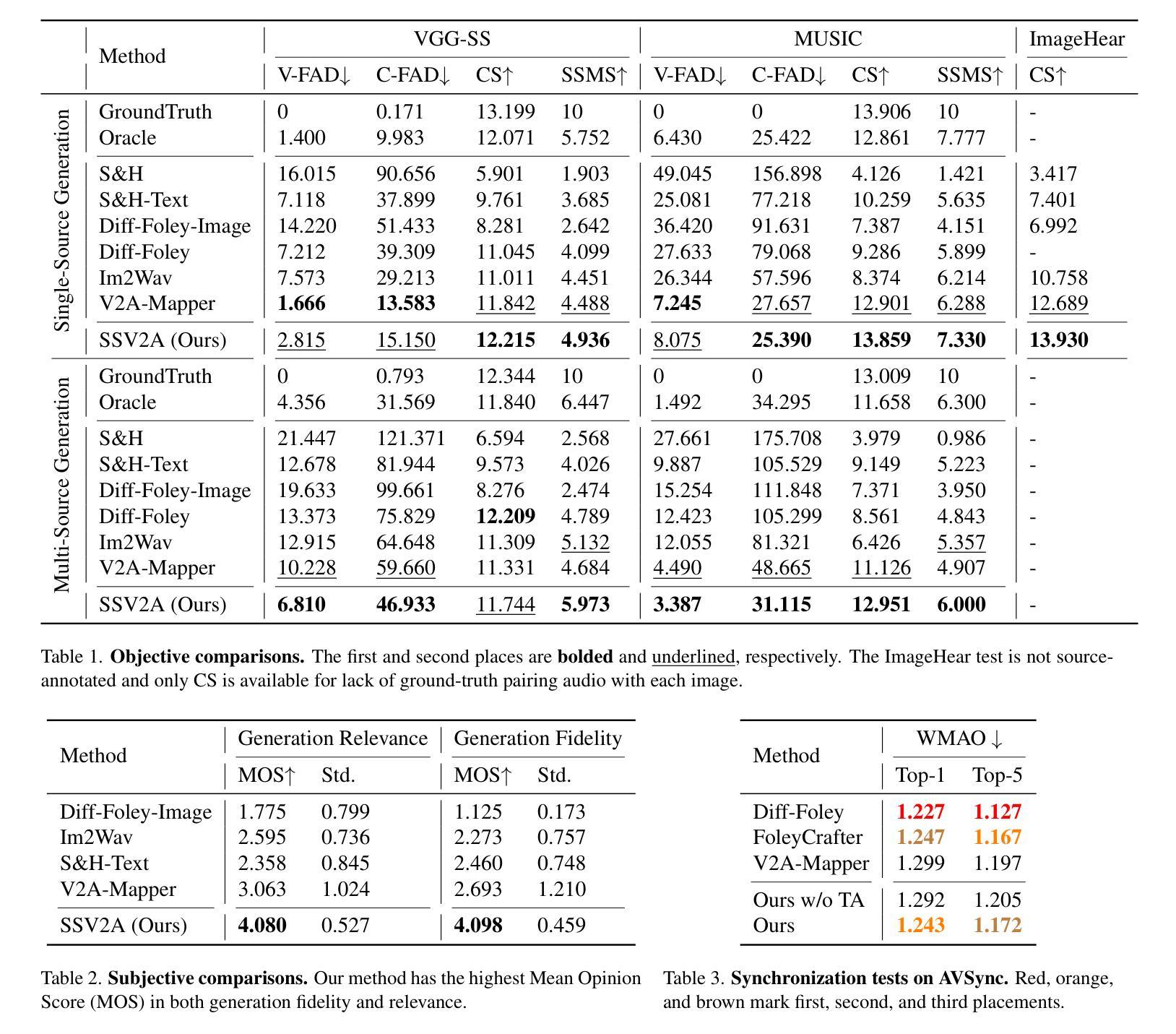
Gotta Hear Them All: Sound Source Aware Vision to Audio Generation
Authors:Wei Guo, Heng Wang, Jianbo Ma, Weidong Cai
Vision-to-audio (V2A) synthesis has broad applications in multimedia. Recent advancements of V2A methods have made it possible to generate relevant audios from inputs of videos or still images. However, the immersiveness and expressiveness of the generation are limited. One possible problem is that existing methods solely rely on the global scene and overlook details of local sounding objects (i.e., sound sources). To address this issue, we propose a Sound Source-Aware V2A (SSV2A) generator. SSV2A is able to locally perceive multimodal sound sources from a scene with visual detection and cross-modality translation. It then contrastively learns a Cross-Modal Sound Source (CMSS) Manifold to semantically disambiguate each source. Finally, we attentively mix their CMSS semantics into a rich audio representation, from which a pretrained audio generator outputs the sound. To model the CMSS manifold, we curate a novel single-sound-source visual-audio dataset VGGS3 from VGGSound. We also design a Sound Source Matching Score to measure localized audio relevance. By addressing V2A generation at the sound-source level, SSV2A surpasses state-of-the-art methods in both generation fidelity and relevance as evidenced by extensive experiments. We further demonstrate SSV2A’s ability to achieve intuitive V2A control by compositing vision, text, and audio conditions. Our generation can be tried and heard at https://ssv2a.github.io/SSV2A-demo .
视觉到音频(V2A)合成在多媒体领域有着广泛的应用。最近V2A方法的进展使得从视频或静态图像生成相关的音频成为可能。然而,生成的沉浸感和表达力有限。一个问题在于现有方法仅依赖于全局场景,而忽略了局部发声物体(即声源)的细节。为了解决这一问题,我们提出了Sound Source-Aware V2A(SSV2A)生成器。SSV2A能够从场景中的局部感知多模态声源,通过视觉检测和跨模态翻译来实现。然后,它对比学习跨模态声源(CMSS)流形,以语义上区分每个声源。最后,我们专注于将其CMSS语义融入丰富的音频表示中,预训练的音频生成器从中输出声音。为了建立CMSS流形,我们从VGGSound中整理了一个新颖的单声源视觉音频数据集VGGS3。我们还设计了一个声源匹配分数来衡量局部音频相关性。通过在声源级别解决V2A生成问题,SSV2A在生成保真度和相关性方面超越了最先进的方法,如广泛实验所示。我们还展示了SSV2A实现直观V2A控制的能力,通过合成视觉、文本和音频条件。我们的生成作品可以在https://ssv2a.github.io/SSV2A-demo上试用和听取。
论文及项目相关链接
PDF 18 pages, 13 figures, source code available at https://github.com/wguo86/SSV2A
Summary
该文本介绍了视觉到音频(V2A)合成在多媒体领域的广泛应用。现有的V2A方法存在沉浸感和表现力有限的局限性,因为它们仅依赖于全局场景而忽视局部声源。为解决此问题,提出了一种声音源感知的V2A(SSV2A)生成器。SSV2A能够从场景中局部感知多模态声源,通过视觉检测和跨模态翻译对比学习跨模态声源(CMSS)流形以语义地解析每个声源。此外,还引入了新颖的单一声源视觉音频数据集VGGS3来评估其性能,设计了声源匹配得分来衡量局部音频的相关性。在声音源级别的V2A生成中,SSV2A在生成保真度和相关性方面均超越现有方法,并展示了直观的可控性。可以通过相关链接体验其效果。
Key Takeaways
- V2A合成具有广泛的应用价值,能够从视频或静态图像生成相关音频。
- 现有V2A方法存在沉浸感和表现力有限的问题,主要原因是过于依赖全局场景而忽视局部声源。
- 提出了一种声音源感知的V2A(SSV2A)生成器,能够局部感知多模态声源。
- SSV2A通过对比学习构建跨模态声源(CMSS)流形以语义解析每个声源。
- 引入了新颖的单一声源视觉音频数据集VGGS3来评估SSV2A的性能。
- SSV2A设计了声源匹配得分来衡量局部音频的相关性。
点此查看论文截图

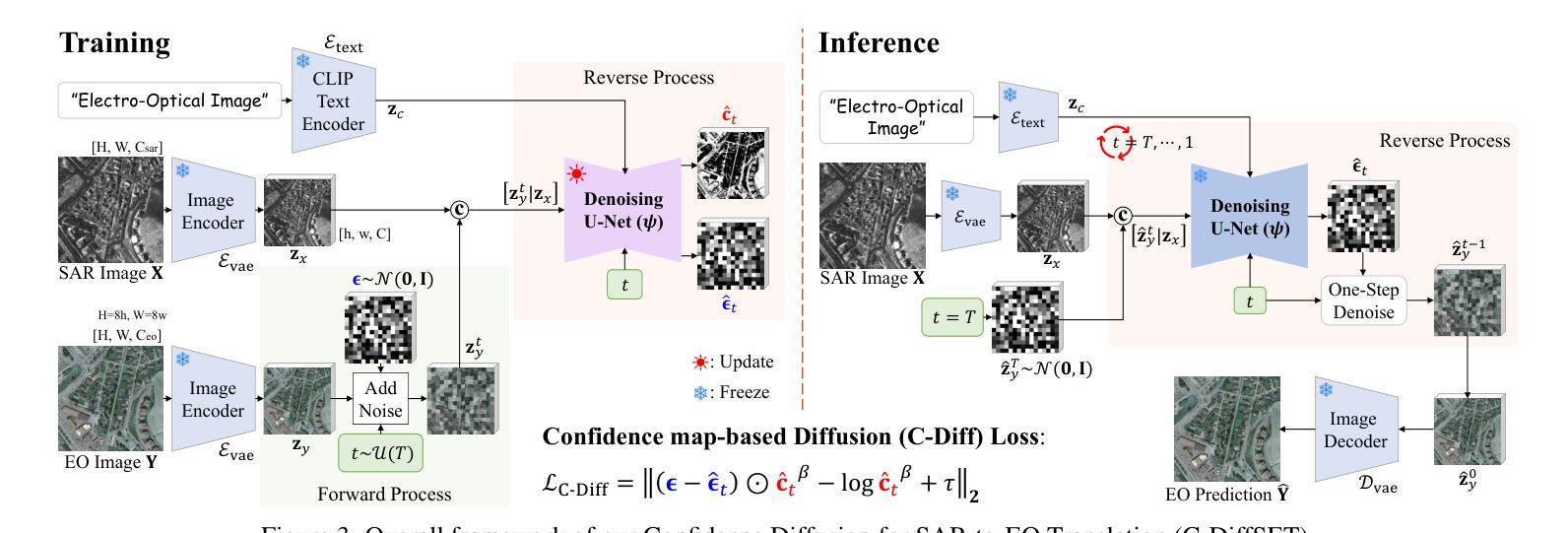
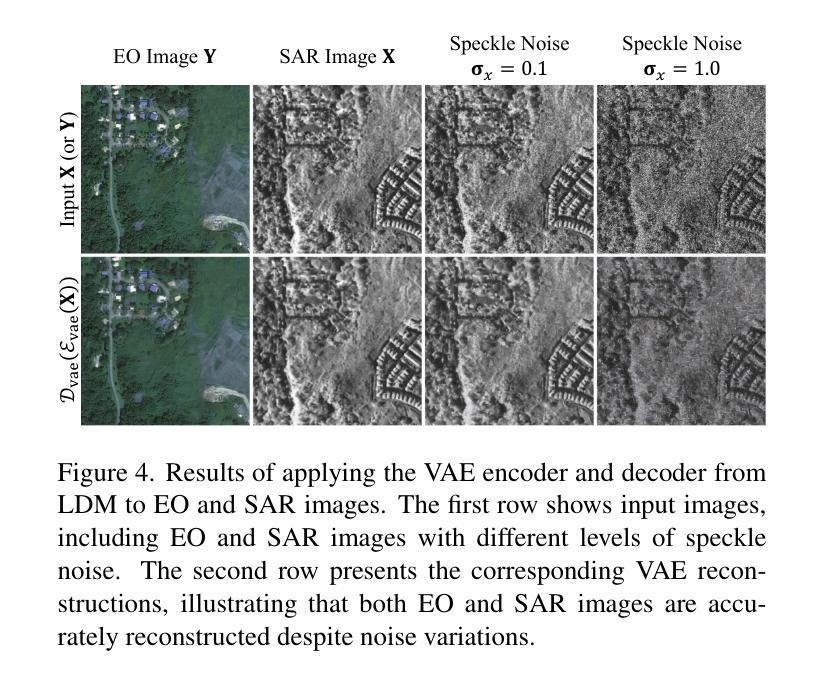
C-DiffSET: Leveraging Latent Diffusion for SAR-to-EO Image Translation with Confidence-Guided Reliable Object Generation
Authors:Jeonghyeok Do, Jaehyup Lee, Munchurl Kim
Synthetic Aperture Radar (SAR) imagery provides robust environmental and temporal coverage (e.g., during clouds, seasons, day-night cycles), yet its noise and unique structural patterns pose interpretation challenges, especially for non-experts. SAR-to-EO (Electro-Optical) image translation (SET) has emerged to make SAR images more perceptually interpretable. However, traditional approaches trained from scratch on limited SAR-EO datasets are prone to overfitting. To address these challenges, we introduce Confidence Diffusion for SAR-to-EO Translation, called C-DiffSET, a framework leveraging pretrained Latent Diffusion Model (LDM) extensively trained on natural images, thus enabling effective adaptation to the EO domain. Remarkably, we find that the pretrained VAE encoder aligns SAR and EO images in the same latent space, even with varying noise levels in SAR inputs. To further improve pixel-wise fidelity for SET, we propose a confidence-guided diffusion (C-Diff) loss that mitigates artifacts from temporal discrepancies, such as appearing or disappearing objects, thereby enhancing structural accuracy. C-DiffSET achieves state-of-the-art (SOTA) results on multiple datasets, significantly outperforming the very recent image-to-image translation methods and SET methods with large margins.
雷达合成孔径图像提供了稳健的环境和时间覆盖(例如在云层、季节、昼夜循环中),但其噪声和独特的结构模式对解释提出了挑战,尤其是对非专业人士来说。SAR到EO(光电)图像翻译(SET)的出现使得SAR图像更容易感知和理解。然而,传统的SET方法从零开始使用有限的SAR-EO数据集进行训练容易过度拟合。为了应对这些挑战,我们引入了SAR到EO翻译的置信度扩散,称为C-DiffSET。这是一个利用预先训练好的潜在扩散模型(LDM)的框架,该模型在自然图像上进行了广泛的训练,从而能够有效地适应EO领域。值得注意的是,我们发现预训练的VAE编码器能够在同一潜在空间中对齐SAR和EO图像,即使SAR输入中存在不同级别的噪声也是如此。为了进一步提高SET的像素级保真度,我们提出了一种置信度引导扩散(C-Diff)损失,该损失减轻了由于时间差异导致的伪影,如出现的对象或消失的对象,从而提高了结构准确性。C-DiffSET在多个数据集上取得了最新的结果,大大超越了最新的图像到图像翻译方法和SET方法。
论文及项目相关链接
PDF Please visit our project page https://kaist-viclab.github.io/C-DiffSET_site/
Summary
SAR影像具有稳健的环境和时序覆盖能力,但其噪声和独特结构模式对非专家来说解读具有挑战。SAR-to-EO图像翻译(SET)技术的出现使SAR图像更易感知和理解。然而,传统方法在小规模SAR-EO数据集上进行从头训练容易过拟合。为解决此问题,我们提出了基于预训练潜在扩散模型的信心扩散技术(C-DiffSET)。该技术充分利用了在自然图像上广泛训练的潜在扩散模型(LDM),可有效适应EO领域。此外,我们发现预训练的VAE编码器能在不同噪声水平的SAR输入下,将SAR和EO图像对齐在同一潜在空间。为进一步提高SET的像素级保真度,我们提出了信心引导扩散(C-Diff)损失,减少因时间差异造成的伪影,如物体的出现或消失,从而提高结构准确性。C-DiffSET在多个数据集上实现最佳效果,大幅超越最新图像到图像翻译方法和SET方法。
Key Takeaways
- SAR影像提供稳健的环境和时序覆盖能力,但对非专家解读有挑战。
- SET技术旨在使SAR图像更易感知和理解。
- 传统SET方法易在有限数据集上过拟合。
- C-DiffSET利用预训练的潜在扩散模型解决这一问题,有效适应EO领域。
- 预训练的VAE编码器在不同噪声水平的SAR输入下对齐SAR和EO图像。
- C-Diff损失函数减少时间差异造成的伪影,提高结构准确性。
点此查看论文截图


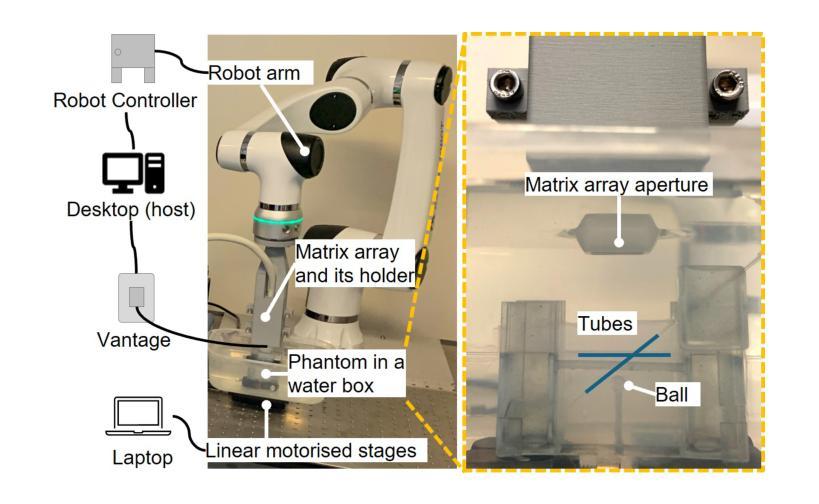
Online 4D Ultrasound-Guided Robotic Tracking Enables 3D Ultrasound Localisation Microscopy with Large Tissue Displacements
Authors:Jipeng Yan, Qingyuan Tan, Shusei Kawara, Jingwen Zhu, Bingxue Wang, Matthieu Toulemonde, Honghai Liu, Ying Tan, Meng-Xing Tang
Super-Resolution Ultrasound (SRUS) imaging through localising and tracking microbubbles, also known as Ultrasound Localisation Microscopy (ULM), has demonstrated significant potential for reconstructing microvasculature and flows with sub-diffraction resolution in clinical diagnostics. However, imaging organs with large tissue movements, such as those caused by respiration, presents substantial challenges. Existing methods often require breath holding to maintain accumulation accuracy, which limits data acquisition time and ULM image saturation. To improve image quality in the presence of large tissue movements, this study introduces an approach integrating high-frame-rate ultrasound with online precise robotic probe control. Tested on a microvasculature phantom with translation motions up to 20 mm, twice the aperture size of the matrix array used, our method achieved real-time tracking of the moving phantom and imaging volume rate at 85 Hz, keeping majority of the target volume in the imaging field of view. ULM images of the moving cross channels in the phantom were successfully reconstructed in post-processing, demonstrating the feasibility of super-resolution imaging under large tissue motions. This represents a significant step towards ULM imaging of organs with large motion.
通过定位和追踪微泡进行超级分辨率超声(SRUS)成像,也被称为超声定位显微镜(ULM),在临床诊断中以次衍射分辨率重建微血管和组织流动方面表现出巨大潜力。然而,对于具有大组织运动的器官的成像,例如由呼吸引起的运动,存在相当大的挑战。现有方法通常需要屏住呼吸以保持积累精度,这限制了数据采集时间和ULM图像的饱和度。为了提高大组织运动下的图像质量,本研究引入了一种将高帧率超声与在线精密机械探针控制相结合的方法。在具有最大达20毫米平移运动的微血管模型上进行的测试显示,我们的方法实现了对移动模型的实时跟踪和每秒成像体积率为85赫兹,将大部分目标体积保持在成像视野中。经过后期处理成功重建了移动交叉通道模型下的ULM图像,证明了在大组织运动下进行超级分辨率成像的可行性。这是向对大运动器官进行ULM成像迈出的重要一步。
论文及项目相关链接
Summary
SRUS成像通过定位追踪微泡技术展示了重建微血管及血流在子衍射分辨率下的潜力。针对呼吸等引起的大器官运动问题,该研究将高速率超声波与在线精准机械探针控制结合,有效追踪移动血管并重建图像。该成果有助于解决器官大运动下的超分辨率成像难题。
Key Takeaways
- SRUS成像通过定位追踪微泡技术能够重建微血管和血流。
- 大器官运动给成像带来挑战,现有方法需要患者屏气。
- 研究结合了高速率超声波与在线精准机械探针控制以改善图像质量。
- 在模拟血管实验中,该方法实现了实时追踪移动目标并成功重建图像。
- 该技术提高了超分辨率成像在器官大运动情况下的可行性。
点此查看论文截图