⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-12 更新
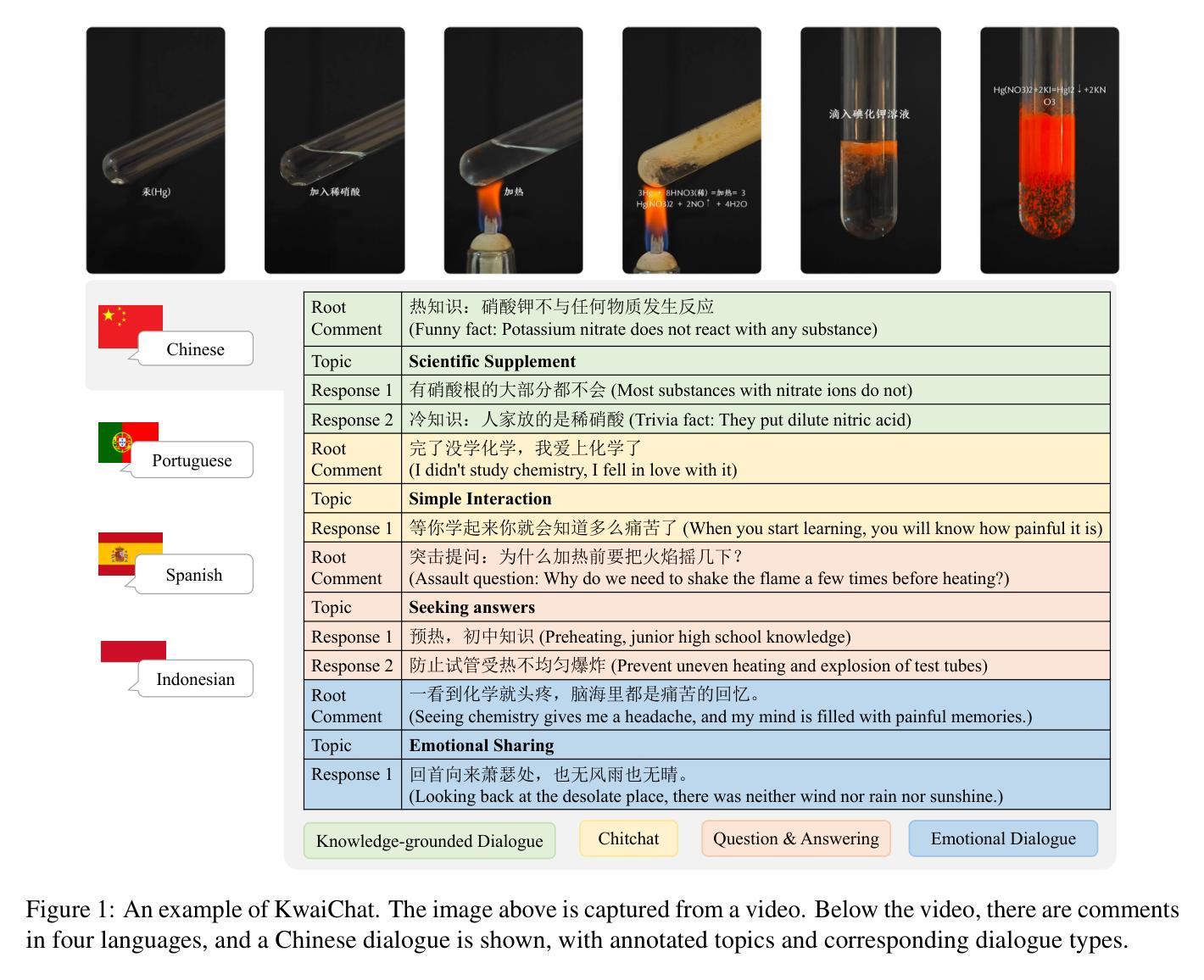
KwaiChat: A Large-Scale Video-Driven Multilingual Mixed-Type Dialogue Corpus
Authors:Xiaoming Shi, Zeming Liu, Yiming Lei, Chenkai Zhang, Haitao Leng, Chuan Wang, Qingjie Liu, Wanxiang Che, Shaoguo Liu, Size Li, Yunhong Wang
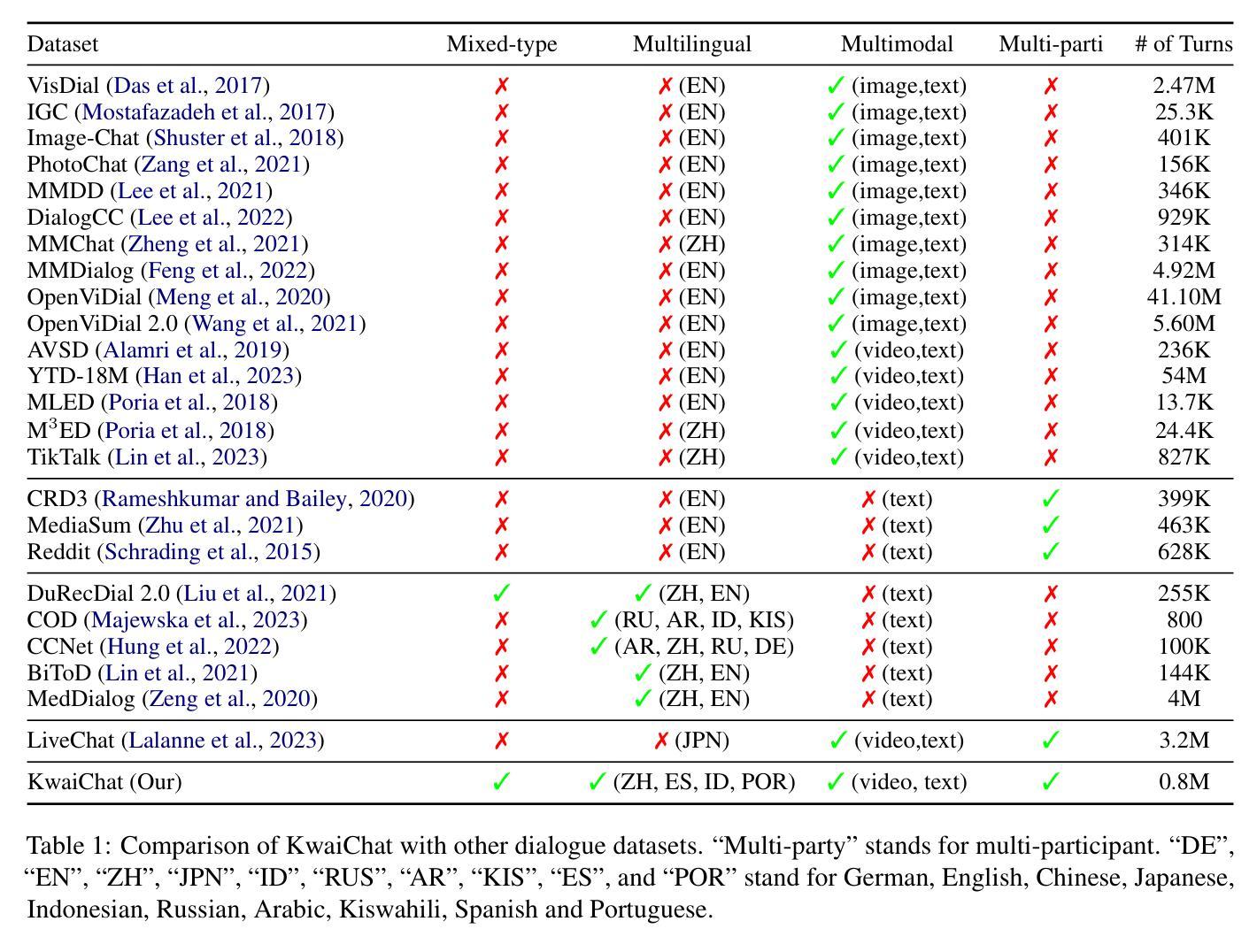
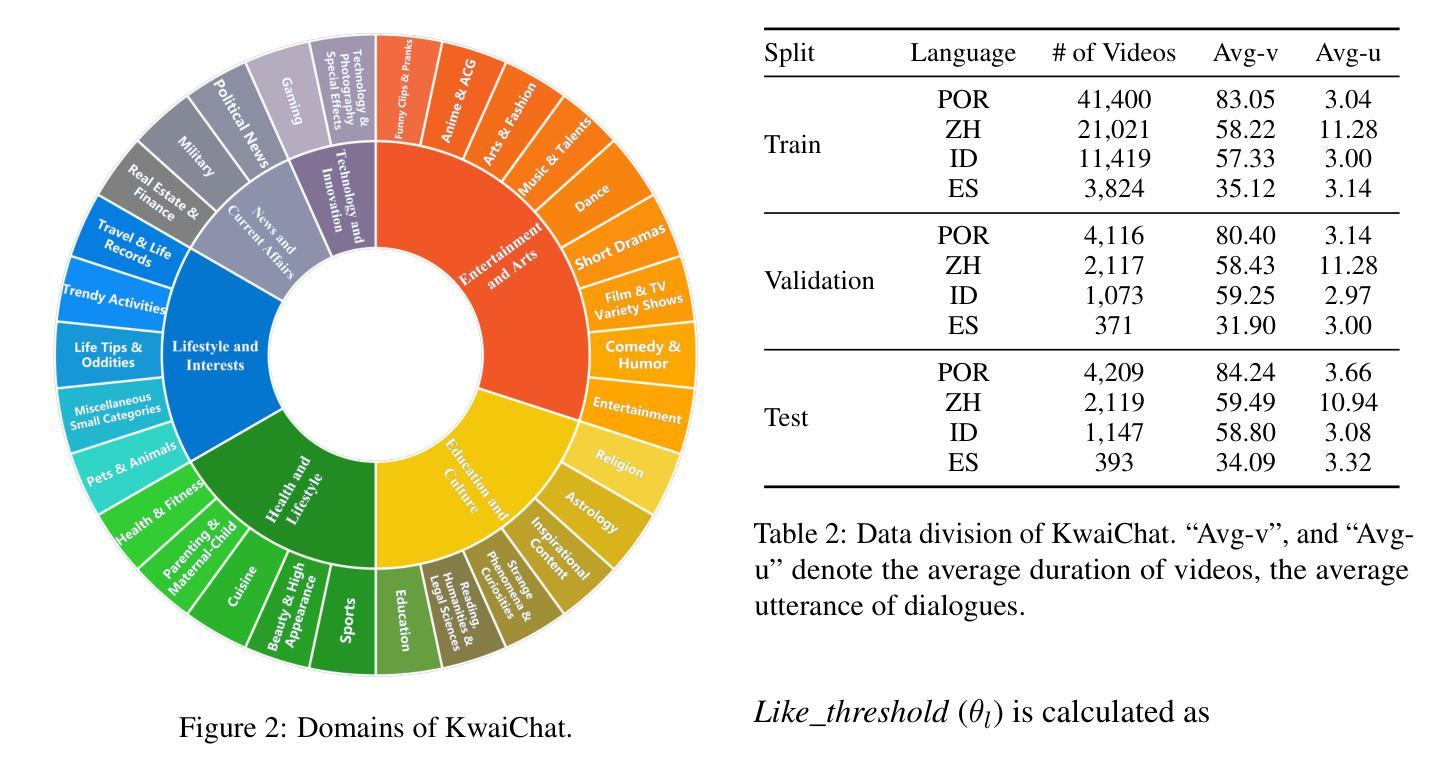
Video-based dialogue systems, such as education assistants, have compelling application value, thereby garnering growing interest. However, the current video-based dialogue systems are limited by their reliance on a single dialogue type, which hinders their versatility in practical applications across a range of scenarios, including question-answering, emotional dialog, etc. In this paper, we identify this challenge as how to generate video-driven multilingual mixed-type dialogues. To mitigate this challenge, we propose a novel task and create a human-to-human video-driven multilingual mixed-type dialogue corpus, termed KwaiChat, containing a total of 93,209 videos and 246,080 dialogues, across 4 dialogue types, 30 domains, 4 languages, and 13 topics. Additionally, we establish baseline models on KwaiChat. An extensive analysis of 7 distinct LLMs on KwaiChat reveals that GPT-4o achieves the best performance but still cannot perform well in this situation even with the help of in-context learning and fine-tuning, which indicates that the task is not trivial and needs further research.
基于视频的对话系统,如教育助理,具有引人注目的应用价值,因此正日益受到关注。然而,当前的基于视频的对话系统受限于其依赖单一对话类型,这阻碍了它们在多种场景下的实际应用通用性,包括问答、情感对话等。在本文中,我们将这一挑战识别为如何生成视频驱动的多语言混合类型对话。为了缓解这一挑战,我们提出了一个新任务,并创建了一个人机视频驱动的多语言混合类型对话语料库,名为KwaiChat。它包含93,209个视频和246,080个对话,涵盖4种对话类型、30个领域、4种语言和13个主题。此外,我们在KwaiChat上建立了基线模型。对KwaiChat的7种不同大型语言模型的广泛分析表明,GPT-4o取得了最佳性能,但在这种情境下,即使在上下文学习和微调的支持下,其表现仍不尽如人意,这表明该任务并非微不足道,需要进一步研究。
论文及项目相关链接
Summary
视频对话系统在教育助理等领域具有应用价值,并受到越来越多的关注。然而,当前视频对话系统主要依赖于单一对话类型,限制了它们在问答、情感对话等多种场景中的应用。本文提出了一项新任务,并创建了一个名为KwaiChat的人与人视频驱动的多语言混合对话语料库,包含93,209个视频和246,080个对话。通过对七种大型语言模型的深入分析,发现GPT-4o表现最佳,但仍需要在该任务上进一步研究和改进。
Key Takeaways
- 视频对话系统在教育助理等领域具有广泛的应用价值。
- 当前视频对话系统主要依赖于单一对话类型,限制了其在多种场景中的应用。
- 本文提出了一个新的任务,即生成视频驱动的多语言混合对话。
- 创建了名为KwaiChat的视频驱动多语言混合对话语料库,包含大量视频和对话数据。
- 通过对七种大型语言模型的深入分析,发现GPT-4o在KwaiChat上的表现最佳。
- GPT-4o虽然表现较好,但仍需进一步研究和改进。
点此查看论文截图

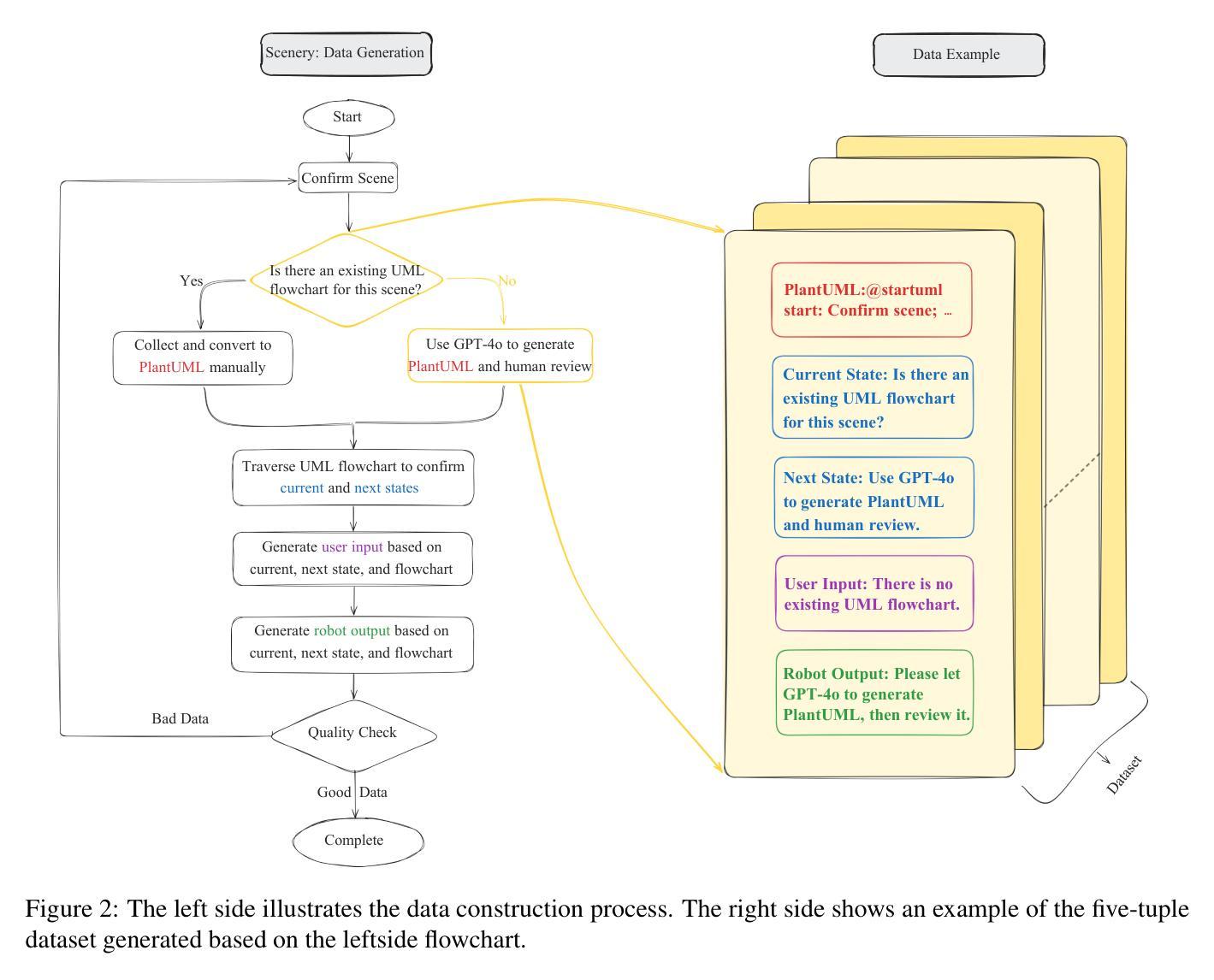
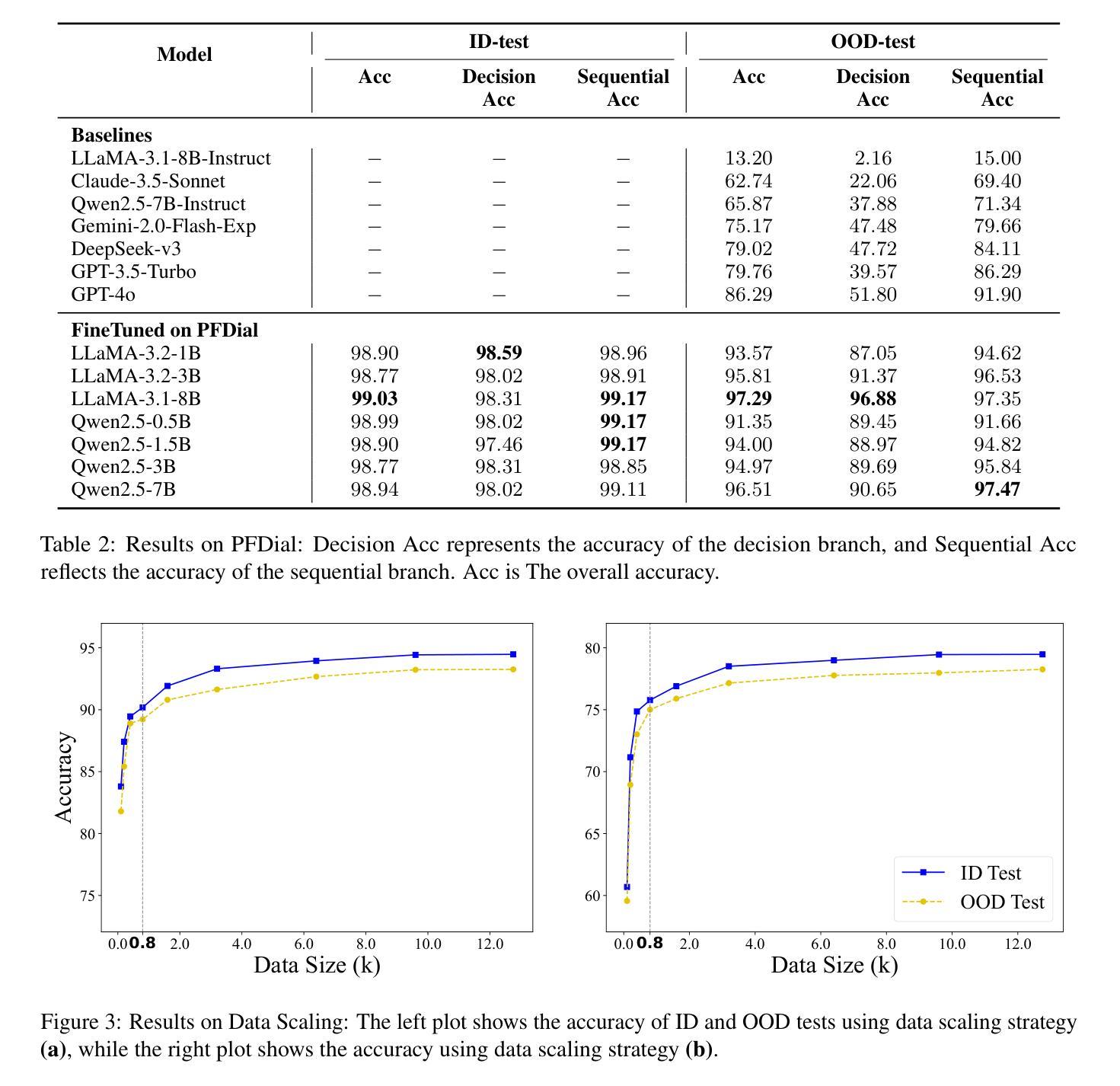
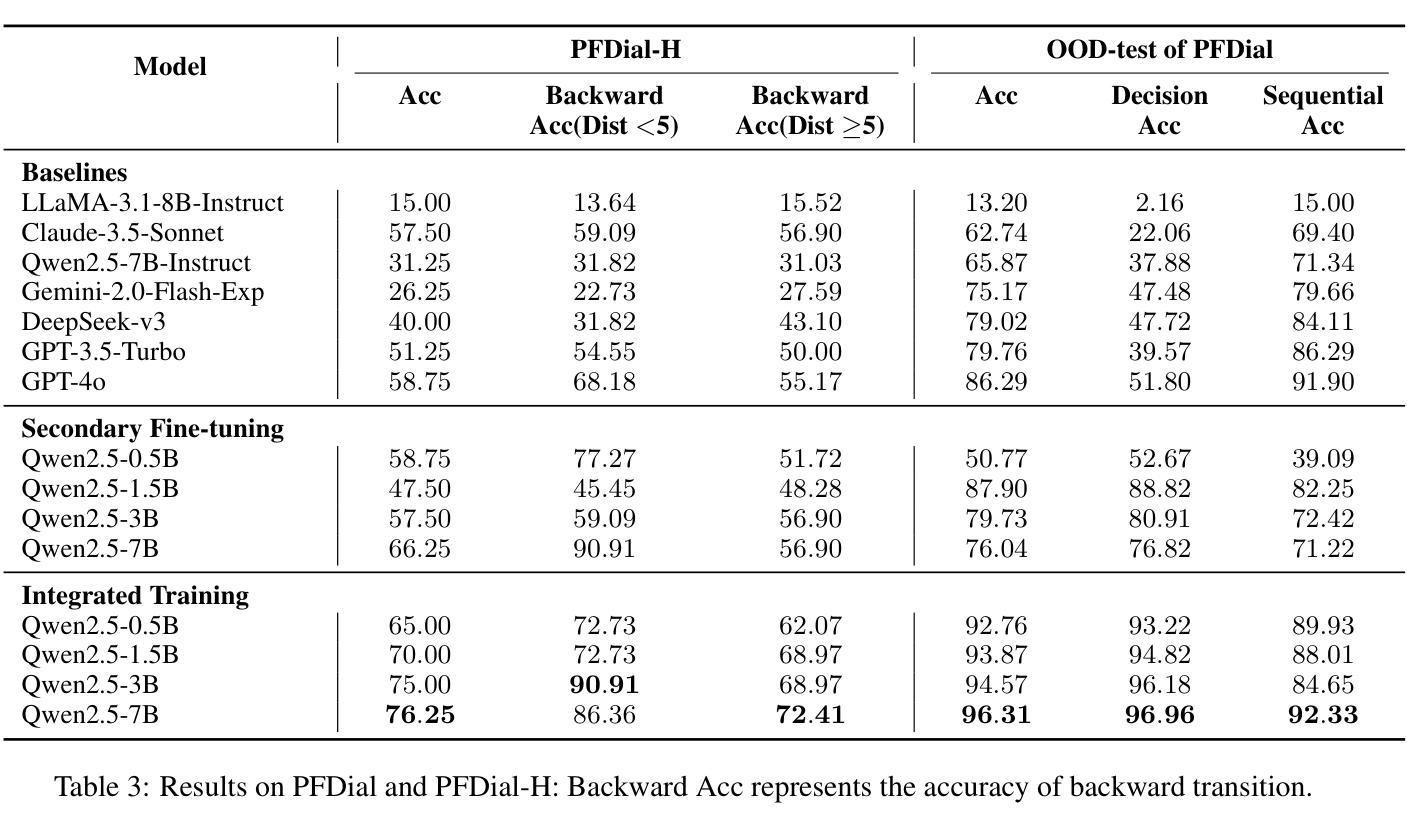
PFDial: A Structured Dialogue Instruction Fine-tuning Method Based on UML Flowcharts
Authors:Ming Zhang, Yuhui Wang, Yujiong Shen, Tingyi Yang, Changhao Jiang, Yilong Wu, Shihan Dou, Qinhao Chen, Zhiheng Xi, Zhihao Zhang, Yi Dong, Zhen Wang, Zhihui Fei, Mingyang Wan, Tao Liang, Guojun Ma, Qi Zhang, Tao Gui, Xuanjing Huang
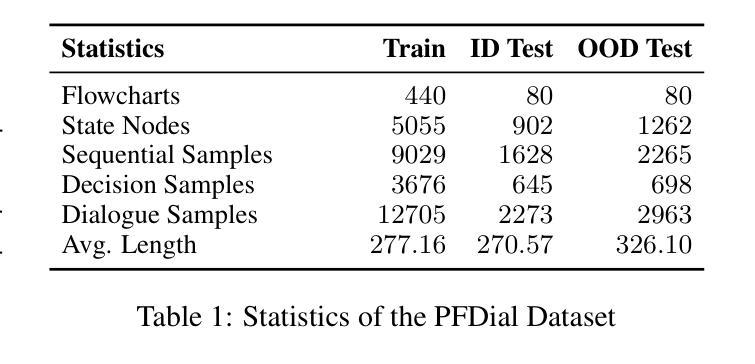
Process-driven dialogue systems, which operate under strict predefined process constraints, are essential in customer service and equipment maintenance scenarios. Although Large Language Models (LLMs) have shown remarkable progress in dialogue and reasoning, they still struggle to solve these strictly constrained dialogue tasks. To address this challenge, we construct Process Flow Dialogue (PFDial) dataset, which contains 12,705 high-quality Chinese dialogue instructions derived from 440 flowcharts containing 5,055 process nodes. Based on PlantUML specification, each UML flowchart is converted into atomic dialogue units i.e., structured five-tuples. Experimental results demonstrate that a 7B model trained with merely 800 samples, and a 0.5B model trained on total data both can surpass 90% accuracy. Additionally, the 8B model can surpass GPT-4o up to 43.88% with an average of 11.00%. We further evaluate models’ performance on challenging backward transitions in process flows and conduct an in-depth analysis of various dataset formats to reveal their impact on model performance in handling decision and sequential branches. The data is released in https://github.com/KongLongGeFDU/PFDial.
流程驱动的对话系统在客户服务和设备维护场景中至关重要,这些系统受到严格的预先定义流程约束的限制。尽管大型语言模型(LLM)在对话和推理方面取得了显著进展,但它们仍然难以解决这些受严格约束的对话任务。为了应对这一挑战,我们构建了流程对话(PFDial)数据集,其中包含12705条高质量中文对话指令,这些指令来源于包含5055个流程节点的440个流程图。基于PlantUML规范,每个UML流程图被转换为原子对话单元,即结构化五元组。实验结果表明,仅使用800个样本训练的7B模型以及使用全部数据训练的0.5B模型,其准确率均可达到超过90%。此外,8B模型的性能可以超过GPT-4o高达43.88%,平均提高11.00%。我们还进一步评估了模型在处理流程中的逆向转换等挑战方面的性能,并对各种数据集格式进行了深入分析,以揭示它们对模型处理决策和顺序分支的性能的影响。数据已发布在https://github.com/KongLongGeFDU/PFDial。
论文及项目相关链接
Summary
流程驱动型对话系统在客户服务和设备维护场景中发挥着关键作用。针对大型语言模型在解决这类受严格预设流程约束的任务时的挑战,我们构建了包含高质量中文对话指令的“流程对话”(PFDial)数据集。该数据集基于PlantUML规范,将UML流程图转换为结构化对话单元。实验结果显示,训练模型在数据集上的表现优异,尤其是大型模型。同时,我们还对模型在处理流程中的反向转换以及不同数据集格式对模型性能的影响进行了深入分析和评估。数据集已公开发布。
Key Takeaways
- 流程驱动型对话系统在客户服务、设备维护等领域有重要作用。
- 大型语言模型在处理严格预设流程约束的对话任务时面临挑战。
- 构建了包含高质量中文对话指令的“流程对话”(PFDial)数据集。
- 数据集基于PlantUML规范,将UML流程图转换为结构化对话单元。
- 实验显示,训练模型在数据集上的表现优异,尤其是大型模型。
- 模型在处理流程中的反向转换方面的性能得到了评估。
点此查看论文截图

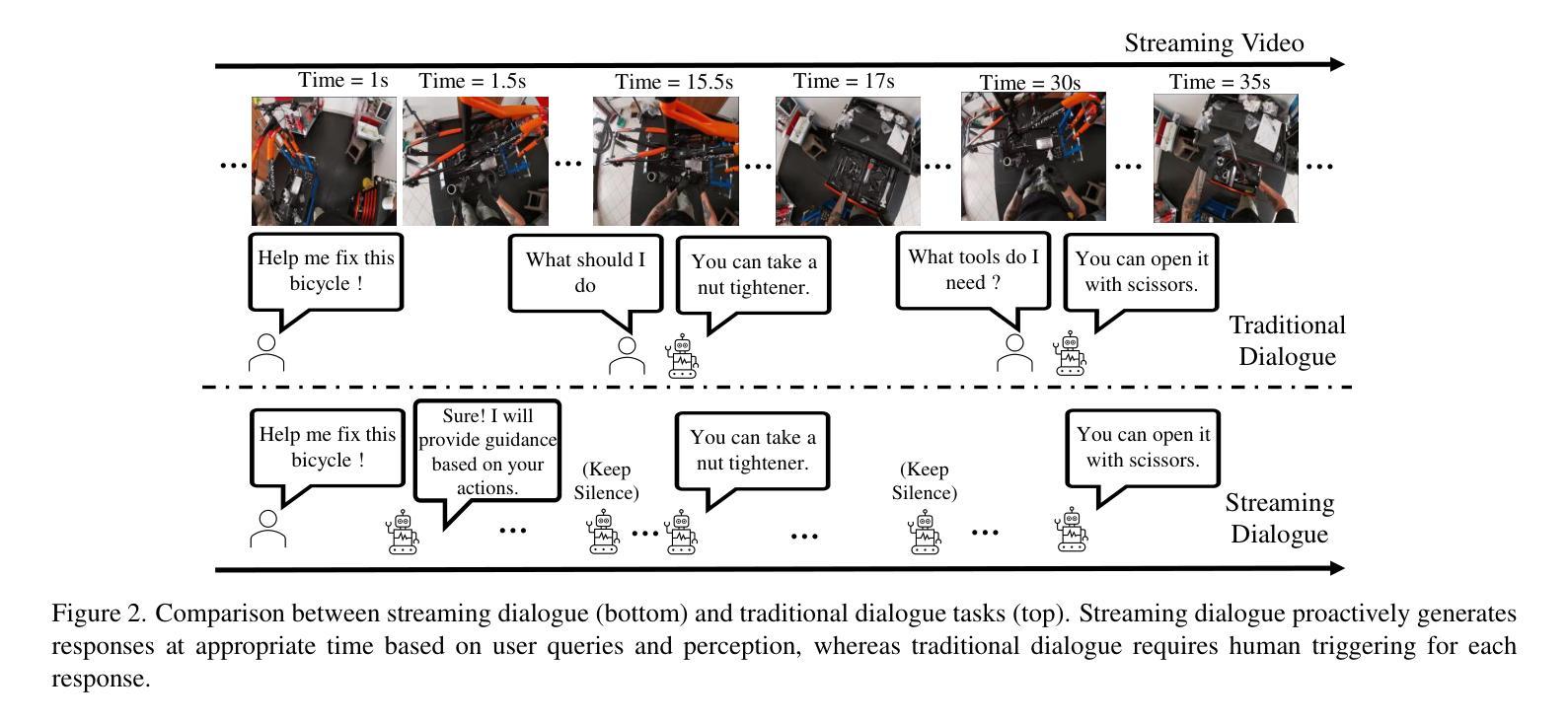
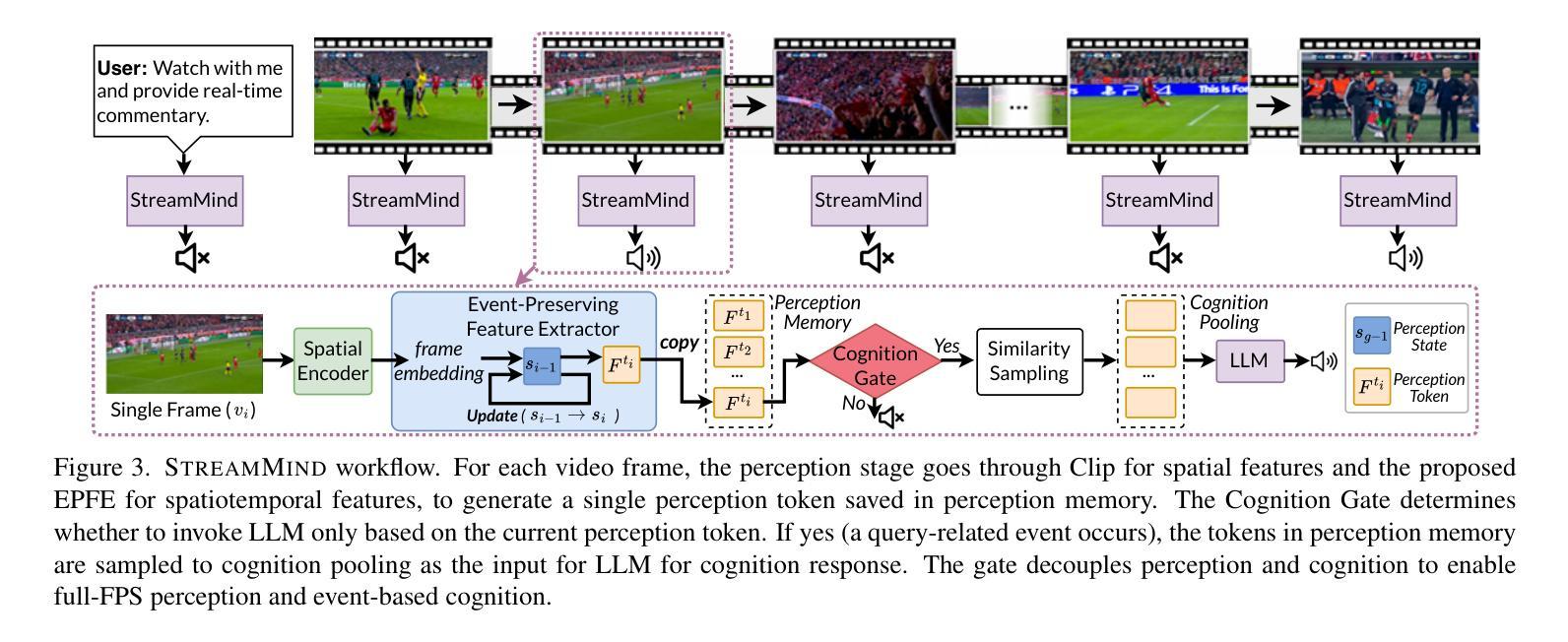
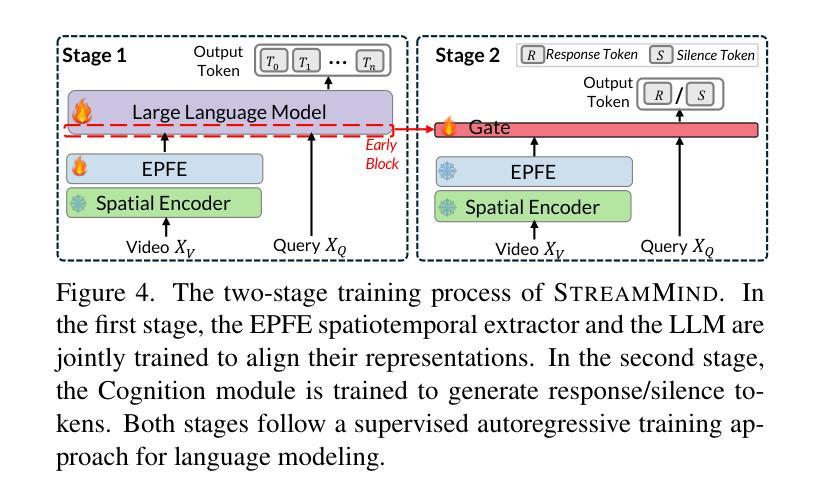
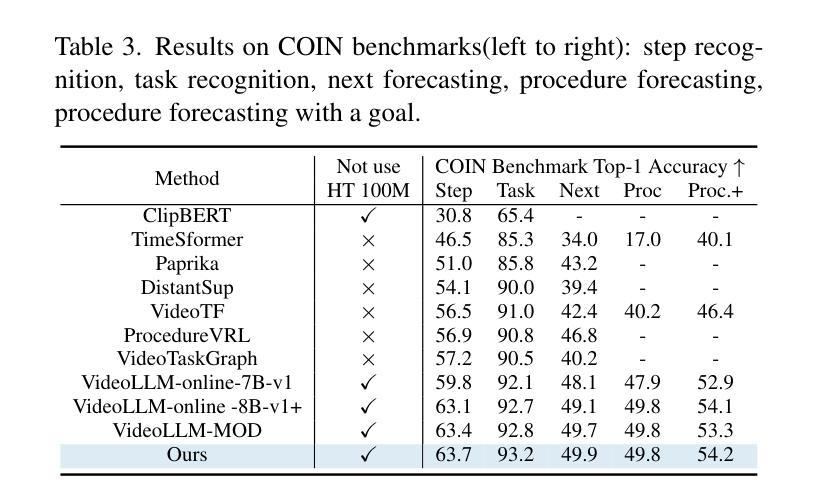
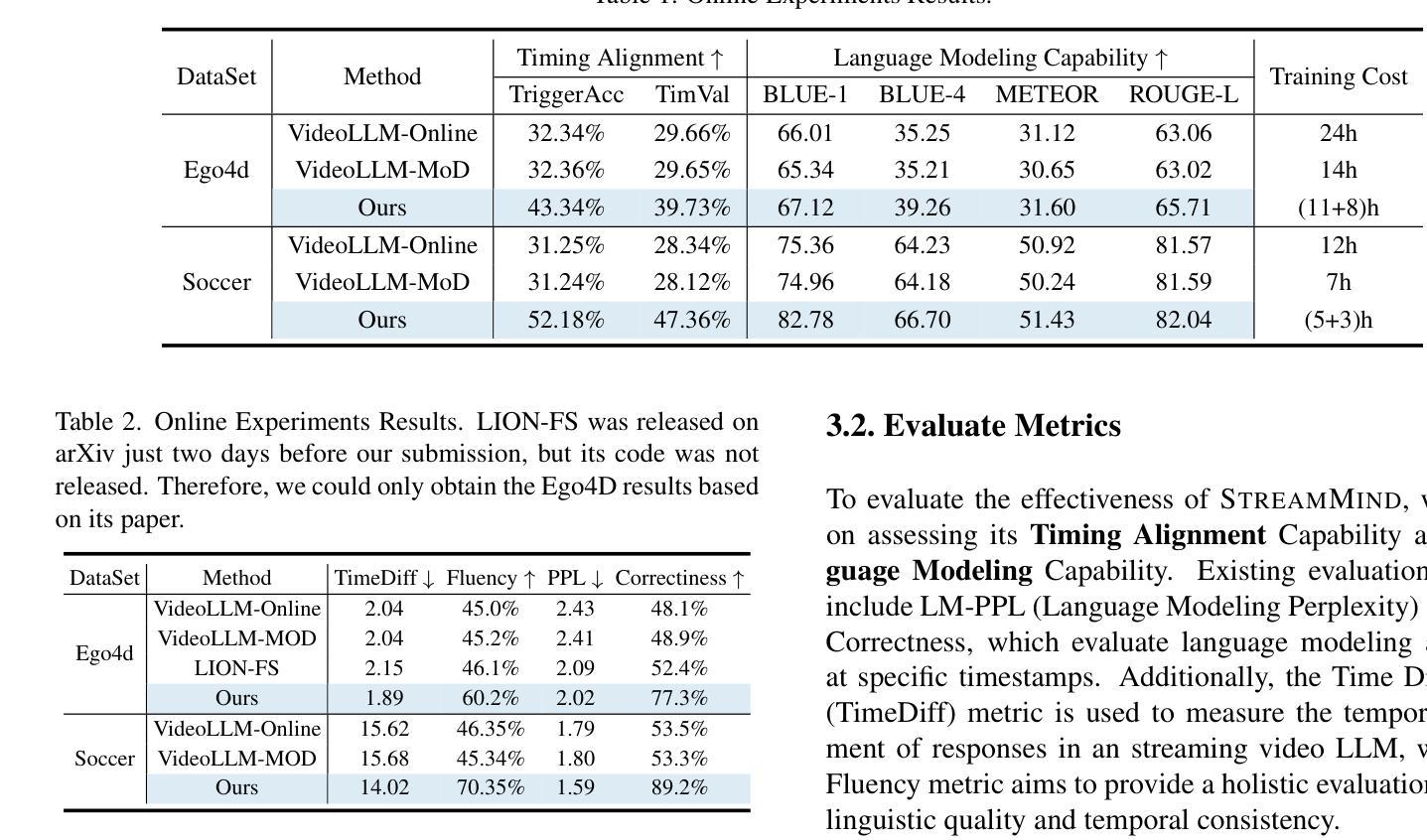
StreamMind: Unlocking Full Frame Rate Streaming Video Dialogue through Event-Gated Cognition
Authors:Xin Ding, Hao Wu, Yifan Yang, Shiqi Jiang, Donglin Bai, Zhibo Chen, Ting Cao
With the rise of real-world human-AI interaction applications, such as AI assistants, the need for Streaming Video Dialogue is critical. To address this need, we introduce \sys, a video LLM framework that achieves ultra-FPS streaming video processing (100 fps on a single A100) and enables proactive, always-on responses in real time, without explicit user intervention. To solve the key challenge of the contradiction between linear video streaming speed and quadratic transformer computation cost, we propose a novel perception-cognition interleaving paradigm named ‘’event-gated LLM invocation’’, in contrast to the existing per-time-step LLM invocation. By introducing a Cognition Gate network between the video encoder and the LLM, LLM is only invoked when relevant events occur. To realize the event feature extraction with constant cost, we propose Event-Preserving Feature Extractor (EPFE) based on state-space method, generating a single perception token for spatiotemporal features. These techniques enable the video LLM with full-FPS perception and real-time cognition response. Experiments on Ego4D and SoccerNet streaming tasks, as well as standard offline benchmarks, demonstrate state-of-the-art performance in both model capability and real-time efficiency, paving the way for ultra-high-FPS applications, such as Game AI Copilot and interactive media.
随着人工智能助手等现实世界人机交互应用的兴起,对流式视频对话的需求变得至关重要。为了解决这一需求,我们引入了\sys,这是一个视频LLM框架,实现了超FPS流式视频处理(单A100上可达100帧每秒),并能够在不明确的用户干预下实现实时主动响应。为了解决线性视频流速度与处理成本呈二次方的转换器计算之间的主要矛盾,我们提出了一种名为“事件门控LLM调用”的新型感知认知交错范式,这与现有的每时间步长LLM调用形成对比。通过在视频编码器和LLM之间引入认知门网络,只有在相关事件发生时才会调用LLM。为了实现恒定成本的事件特征提取,我们提出了基于状态空间方法的Event-Preserving Feature Extractor(EPFE),为时空特征生成单个感知令牌。这些技术使视频LLM具备全FPS感知和实时认知响应能力。在Ego4D和SoccerNet流媒体任务以及标准离线基准测试上的实验证明了该模型在能力和实时效率方面的先进性,为超高FPS应用(如游戏AI副驾驶和交互式媒体)铺平了道路。
论文及项目相关链接
Summary
随着人工智能助手等现实世界中的人机交互应用的兴起,流式视频对话的需求变得至关重要。为应对这一需求,我们推出了视频LLM框架——sys,它实现了超高帧率(FPS)的视频流处理(单个A100上可达100 FPS),并可在不显式用户干预的情况下实时主动响应。为解决视频流速度线性而转换器计算成本二次方之间的矛盾,我们提出了名为“事件门控LLM调用”的新型感知认知交替范式,区别于现有的按时间步长调用LLM的方法。通过引入认知门网络,只有在发生相关事件时才调用LLM。为实现恒定成本的事件特征提取,我们提出了基于状态空间方法的Event-Preserving Feature Extractor(EPFE),为时空特征生成单个感知令牌。这些技术使得视频LLM具有全FPS感知能力和实时认知响应能力。在Ego4D、SoccerNet流媒体任务以及标准离线基准测试上的实验证明了其在模型能力和实时效率方面的卓越性能,为超高FPS应用如游戏AI助手和交互式媒体铺平了道路。
Key Takeaways
- 流式视频对话需求随着人工智能助手等现实世界中的人机交互应用的兴起而增加。
- sys是一个视频LLM框架,能够实现超高帧率(FPS)的视频流处理,并支持实时主动响应。
- 引入了事件门控LLM调用的新型感知认知交替范式,优化了对LLM的调用方式。
- 提出了Event-Preserving Feature Extractor(EPFE),能够在恒定成本下实现事件特征提取。
- 技术使得视频LLM具有全FPS感知能力和实时认知响应能力。
- 实验在多个任务上证明了sys在模型能力和实时效率方面的卓越性能。
点此查看论文截图


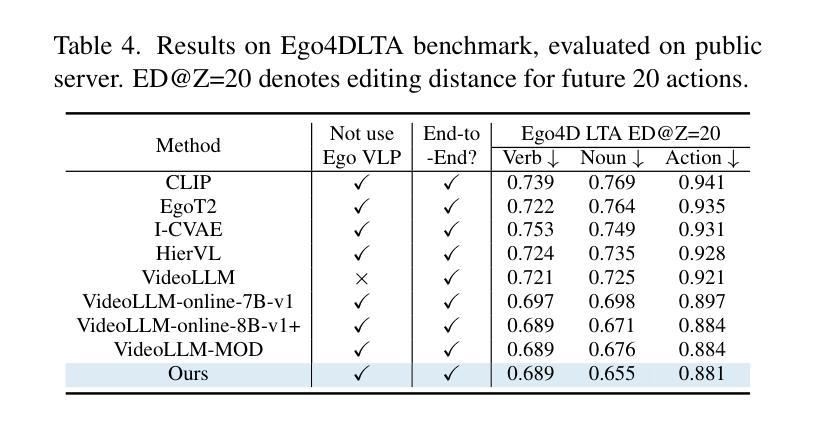
Dialogue Systems for Emotional Support via Value Reinforcement
Authors:Juhee Kim, Chunghu Mok, Jisun Lee, Hyang Sook Kim, Yohan Jo
Emotional support dialogue systems aim to reduce help-seekers’ distress and help them overcome challenges. While human values$\unicode{x2013}$core beliefs that shape an individual’s priorities$\unicode{x2013}$are increasingly emphasized in contemporary psychological therapy for their role in fostering internal transformation and long-term emotional well-being, their integration into emotional support systems remains underexplored. To bridge this gap, we present a value-driven method for training emotional support dialogue systems designed to reinforce positive values in seekers. Notably, our model identifies which values to reinforce at each turn and how to do so, by leveraging online support conversations from Reddit. We evaluate the method across support skills, seekers’ emotional intensity, and value reinforcement. Our method consistently outperforms various baselines, effectively exploring and eliciting values from seekers. Additionally, leveraging crowd knowledge from Reddit significantly enhances its effectiveness. Therapists highlighted its ability to validate seekers’ challenges and emphasize positive aspects of their situations$\unicode{x2013}$both crucial elements of value reinforcement. Our work, being the first to integrate value reinforcement into emotional support systems, demonstrates its promise and establishes a foundation for future research.
情感支持对话系统的目标是减轻求助者的压力,帮助他们克服挑战。在当代心理治疗过程中,人的价值观——塑造个人优先事项的核心信念——越来越被强调其在促进内部转变和长期情感健康方面的作用。然而,将其融入情感支持系统仍被较少探索。为了弥补这一差距,我们提出了一种以价值观为导向的方法,用于训练旨在加强寻求者积极价值观的情感支持对话系统。值得注意的是,我们的模型能够识别每次对话中需要强化的价值观以及如何进行强化,通过利用Reddit上的在线支持对话。我们在支持技能、求助者的情感强度和价值观强化等方面对方法进行了评估。该方法始终优于各种基线方法,能够有效地探索和激发求助者的价值观。此外,利用Reddit上的群体知识显著增强了其有效性。心理学家强调其能够验证求助者的挑战并强调其处境的积极方面——这两个都是价值观强化的关键要素。我们的工作首次将价值观强化整合到情感支持系统中,展示了其潜力并为未来的研究奠定了基础。
论文及项目相关链接
PDF 34 pages, 4 figures
Summary
情感支持对话系统旨在帮助求助者减轻压力并克服挑战。当代心理治疗越来越强调人的价值观在促进内心转变和长期情感健康方面的作用,但在情感支持系统中对其整合的研究仍然不足。为了弥补这一差距,我们提出了一种以价值为导向的方法,设计用于强化求助者正面价值观的情感支持对话系统训练模型。该模型能够识别在每次对话中需要强化的价值观,并知道如何操作。通过对支持技能、求助者情绪强度和价值观强化进行评估,我们的方法在各种基线之上表现出一致性优势,有效地探索和激发求助者的价值观。此外,利用Reddit上的群众知识显著提高了其有效性。治疗师强调了该方法验证求助者挑战和强调其处境积极面的能力——这两个都是价值观强化的关键要素。我们的工作是将价值观强化首次整合到情感支持系统中,展现了其潜力并为未来研究奠定了基础。
Key Takeaways
- 情感支持对话系统的主要目标是减少求助者的困扰并助其克服挑战。
- 当代心理治疗强调人的价值观在促进长期情感健康方面的作用,但在情感支持系统中对其整合仍然不足。
- 提出了一种以价值为导向的方法训练情感支持对话系统,旨在强化求助者的正面价值观。
- 该方法能够识别每次对话中需要强化的价值观,并知道如何操作。
- 方法评估涵盖支持技能、求助者情绪强度和价值观强化方面,表现优于多种基线方法。
- 利用Reddit上的群众知识增强了方法的有效性。
点此查看论文截图

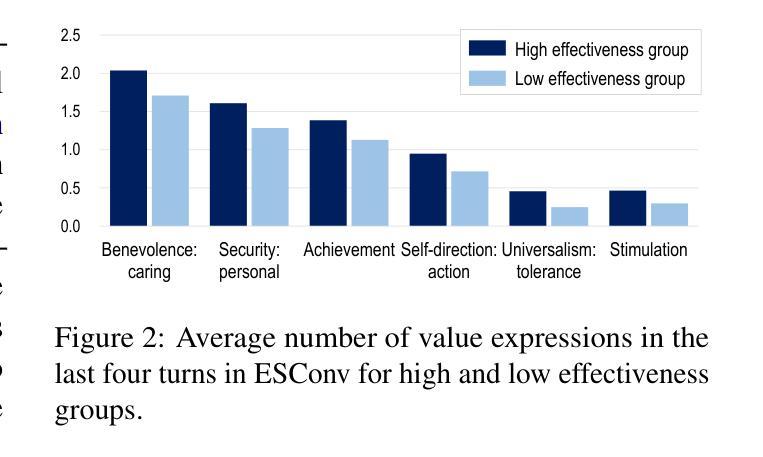
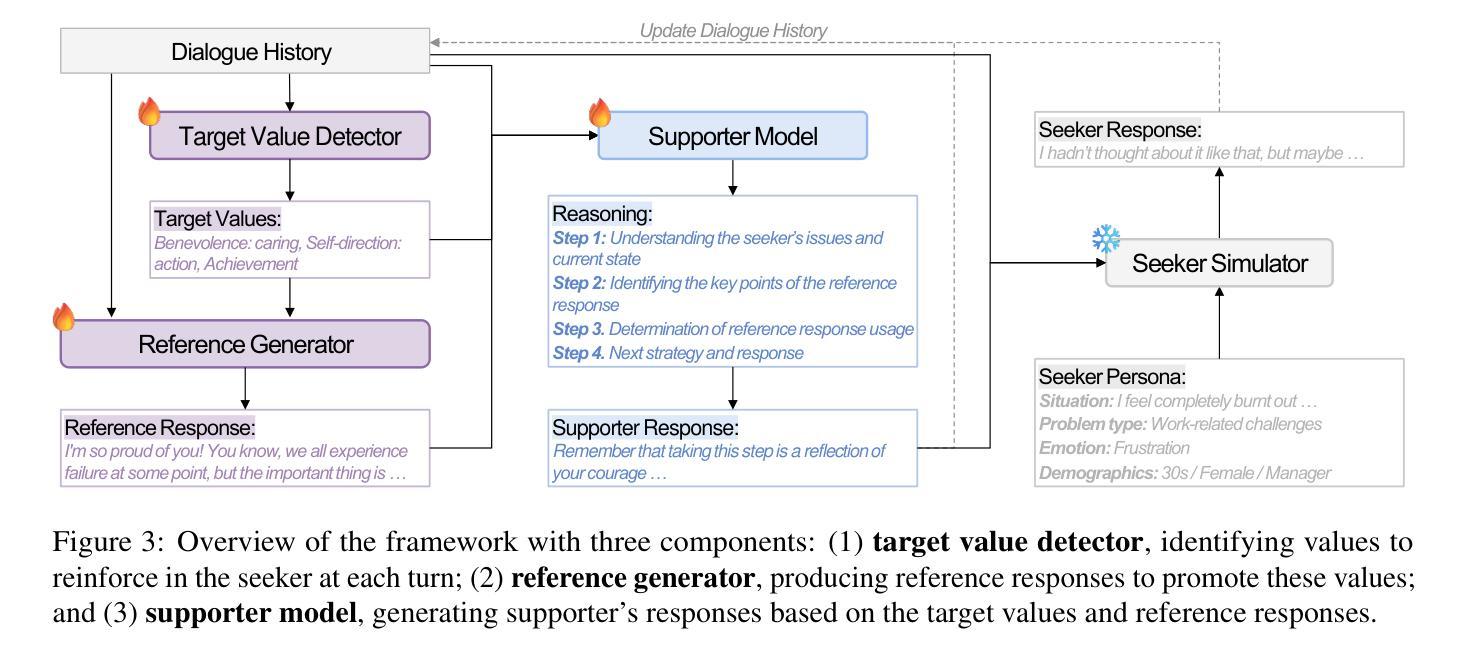
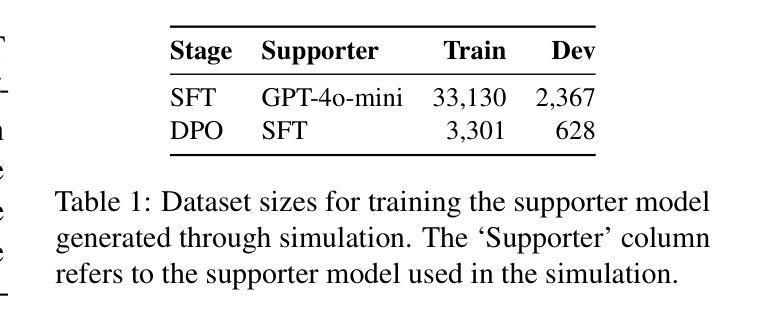
log-RRIM: Yield Prediction via Local-to-global Reaction Representation Learning and Interaction Modeling
Authors:Xiao Hu, Ziqi Chen, Bo Peng, Daniel Adu-Ampratwum, Xia Ning
Accurate prediction of chemical reaction yields is crucial for optimizing organic synthesis, potentially reducing time and resources spent on experimentation. With the rise of artificial intelligence (AI), there is growing interest in leveraging AI-based methods to accelerate yield predictions without conducting in vitro experiments. We present log-RRIM, an innovative graph transformer-based framework designed for predicting chemical reaction yields. A key feature of log-RRIM is its integration of a cross-attention mechanism that focuses on the interplay between reagents and reaction centers. This design reflects a fundamental principle in chemical reactions: the crucial role of reagents in influencing bond-breaking and formation processes, which ultimately affect reaction yields. log-RRIM also implements a local-to-global reaction representation learning strategy. This approach initially captures detailed molecule-level information and then models and aggregates intermolecular interactions. Through this hierarchical process, log-RRIM effectively captures how different molecular fragments contribute to and influence the overall reaction yield, regardless of their size variations. log-RRIM shows superior performance in our experiments, especially for medium to high-yielding reactions, proving its reliability as a predictor. The framework’s sophisticated modeling of reactant-reagent interactions and precise capture of molecular fragment contributions make it a valuable tool for reaction planning and optimization in chemical synthesis. The data and codes of log-RRIM are accessible through https://github.com/ninglab/Yield_log_RRIM.
精确预测化学反应产率对于优化有机合成至关重要,可能减少实验的时间和资源消耗。随着人工智能(AI)的兴起,人们越来越感兴趣利用AI方法来加速产率预测,而无需进行体外实验。我们提出了log-RRIM,这是一个基于图变压器的预测化学反应产率的新型框架。Log-RRIM的一个关键特征是融合了跨注意机制,专注于试剂与反应中心之间的相互作用。这一设计反映了化学反应中的基本原理:试剂在影响键断裂和形成过程中的关键作用,最终影响反应产率。Log-RRIM还实现了从局部到全局的反应表示学习策略。这种方法首先捕获分子级别的详细信息,然后建模和聚合分子间的相互作用。通过这一分层过程,Log-RRIM有效地捕获了不同分子片段如何贡献和影响总体反应产率,无论其大小变化如何。在我们的实验中,Log-RRIM表现出卓越的性能,特别是在中等至高产量反应中,证明了其作为预测器的可靠性。该框架对反应物-试剂交互的精细建模以及对分子片段贡献的精确捕获,使其成为化学合成中反应规划和优化的有价值工具。Log-RRIM的数据和代码可通过https://github.com/ninglab/Yield_log_RRIM获取。
论文及项目相关链接
PDF 45 pages, 8 figures
Summary
利用人工智能预测化学反应收率对于优化有机合成至关重要。log-RRIM是一个基于图变换的预测框架,通过交叉注意机制关注试剂与反应中心的相互作用,实现化学反应收率的准确预测。它采用从分子级别到全局反应表示的学习策略,有效捕捉不同分子片段对反应收率的贡献和影响。log-RRIM在实验中表现出卓越性能,尤其是预测中等至高收率的反应,成为化学合成中反应规划和优化的重要工具。
Key Takeaways
- AI在预测化学反应收率方面的应用日益受到关注,有助于优化有机合成,减少实验时间和资源的消耗。
- log-RRIM是一个基于图变换的预测框架,专为预测化学 反应收率设计。
- log-RRIM通过交叉注意机制关注试剂与反应中心的互动,反映化学反应中的关键原则。
- log-RRIM实施从分子级别到全局反应表示的学习策略,有效捕捉不同分子片段对反应收率的贡献。
- log-RRIM在实验中表现出卓越性能,特别是在预测中等至高收率的反应方面。
- log-RRIM的精细建模反应物-试剂相互作用和精确捕捉分子片段贡献使其成为化学合成中反应规划和优化的有价值工具。
点此查看论文截图

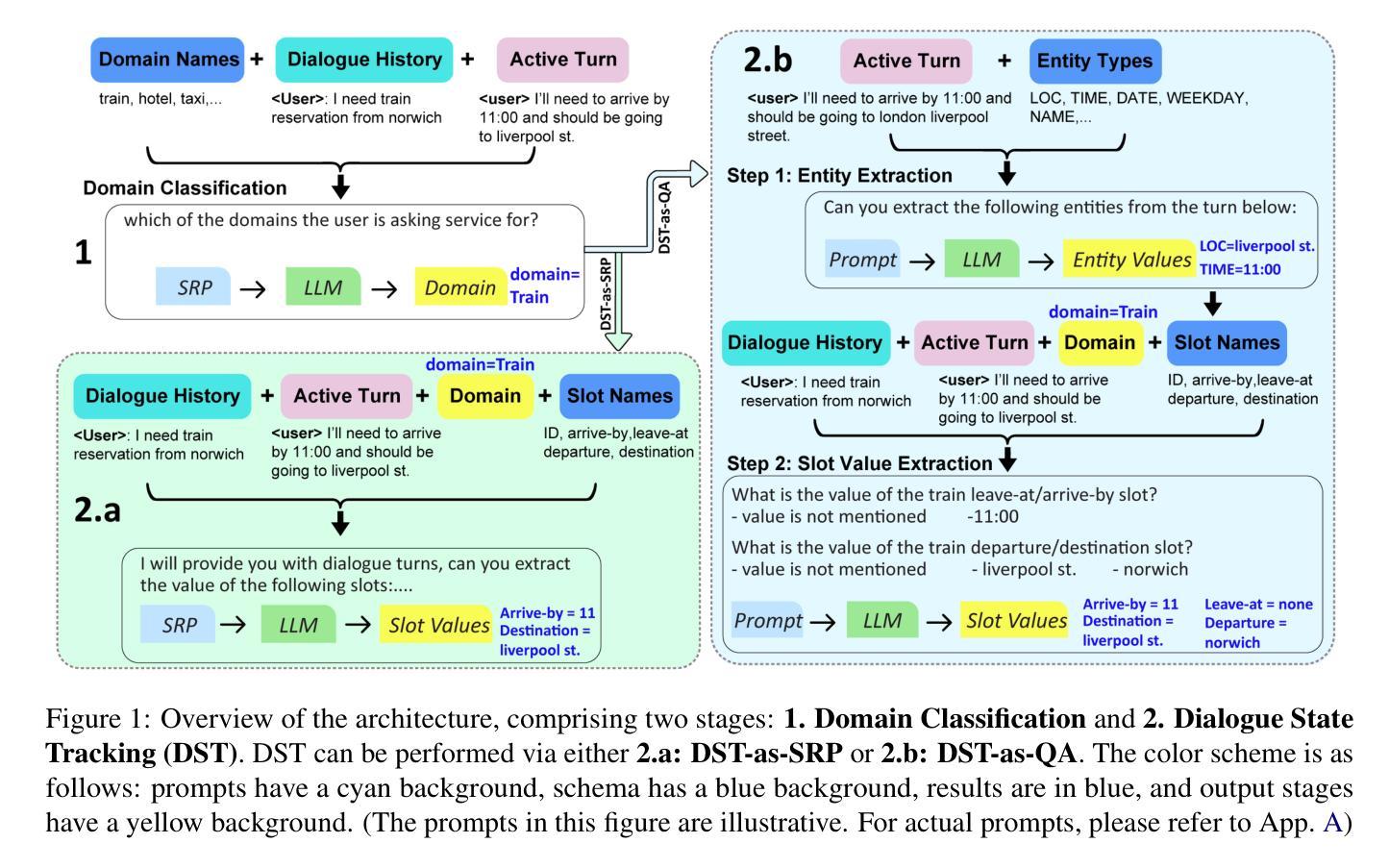
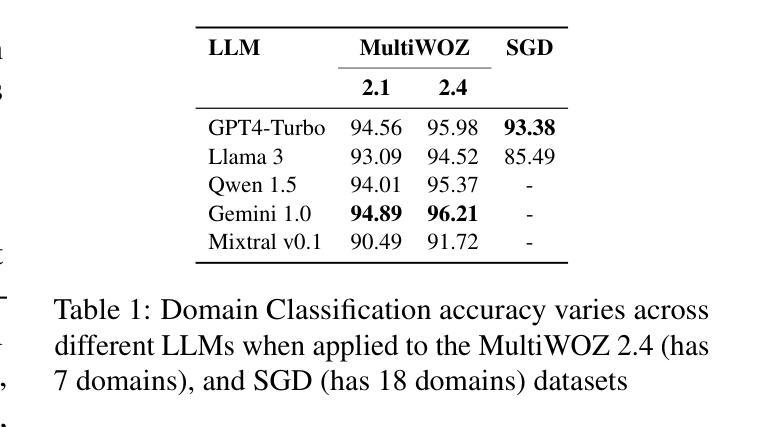
A Zero-Shot Open-Vocabulary Pipeline for Dialogue Understanding
Authors:Abdulfattah Safa, Gözde Gül Şahin
Dialogue State Tracking (DST) is crucial for understanding user needs and executing appropriate system actions in task-oriented dialogues. Majority of existing DST methods are designed to work within predefined ontologies and assume the availability of gold domain labels, struggling with adapting to new slots values. While Large Language Models (LLMs)-based systems show promising zero-shot DST performance, they either require extensive computational resources or they underperform existing fully-trained systems, limiting their practicality. To address these limitations, we propose a zero-shot, open-vocabulary system that integrates domain classification and DST in a single pipeline. Our approach includes reformulating DST as a question-answering task for less capable models and employing self-refining prompts for more adaptable ones. Our system does not rely on fixed slot values defined in the ontology allowing the system to adapt dynamically. We compare our approach with existing SOTA, and show that it provides up to 20% better Joint Goal Accuracy (JGA) over previous methods on datasets like Multi-WOZ 2.1, with up to 90% fewer requests to the LLM API.
对话状态跟踪(DST)对于理解用户需求和在执行任务导向型对话中执行适当的系统操作至关重要。现有的大多数DST方法都是为在预定义的本体上工作而设计的,并假定有黄金领域标签可用,但在适应新槽值时遇到了困难。虽然基于大型语言模型(LLM)的系统显示出有前景的零样本DST性能,但它们要么需要大量的计算资源,要么在性能上不如现有的完全训练的系统,从而限制了它们的实用性。为了解决这些局限性,我们提出了一种零样本、开放词汇的系统,它将领域分类和DST集成在一个单一的管道中。我们的方法包括将DST重新表述为一个问答任务,以适应能力较差的模型,并为适应性较强的模型使用自我改进提示。我们的系统不依赖于本体中定义的固定槽值,允许系统动态适应。我们将我们的方法与现有的最佳技术进行了比较,并证明在Multi-WOZ 2.1等数据集上,我们的方法在联合目标准确率(JGA)上比以前的方法提高了高达20%,而且对LLM API的请求减少了高达90%。
论文及项目相关链接
PDF Accepted to NAACL 2025
Summary
本文主要探讨了对话状态追踪(DST)在任务导向对话中的重要性,以及现有DST方法在新槽值适应方面的局限性。为了解决这个问题,提出了一种零启动、开放词汇的系统,该系统将领域分类和DST集成在一个单一的管道中。该方法将DST重新构建为对不太强大的模型的问答任务,并为更灵活的模型使用自我改进提示。系统能够适应动态变化,不需要依赖本体论中定义的固定槽值。在Multi-WOZ 2.1等数据集上,与现有先进技术相比,该方法联合目标准确率(JGA)提高了高达20%,对LLM API的请求减少了高达90%。
Key Takeaways
- 对话状态追踪(DST)在任务导向对话中至关重要,涉及理解用户需求和执行适当系统操作。
- 现有DST方法大多依赖于预定义的本体论和黄金领域标签,难以适应新槽值。
- 大型语言模型(LLM)为基础的系统展现出零启动DST的潜力,但存在计算资源需求大或性能不足的问题。
- 提出的系统将领域分类和DST集成在一个管道中,实现零启动和开放词汇。
- 通过将DST重新构建为问答任务,为较弱模型提供策略,并为较灵活模型使用自我改进提示。
- 系统可动态适应,无需依赖本体论中的固定槽值。
点此查看论文截图