⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-12 更新
V2Flow: Unifying Visual Tokenization and Large Language Model Vocabularies for Autoregressive Image Generation
Authors:Guiwei Zhang, Tianyu Zhang, Mohan Zhou, Yalong Bai, Biye Li
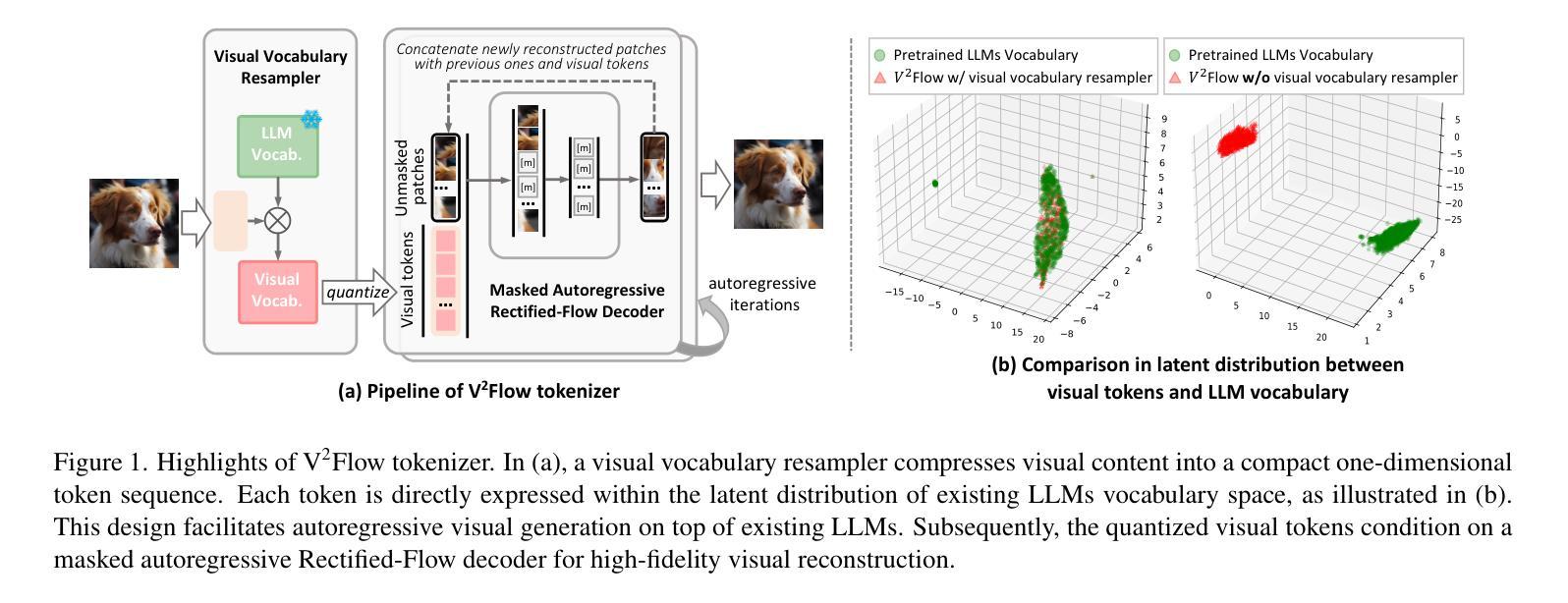
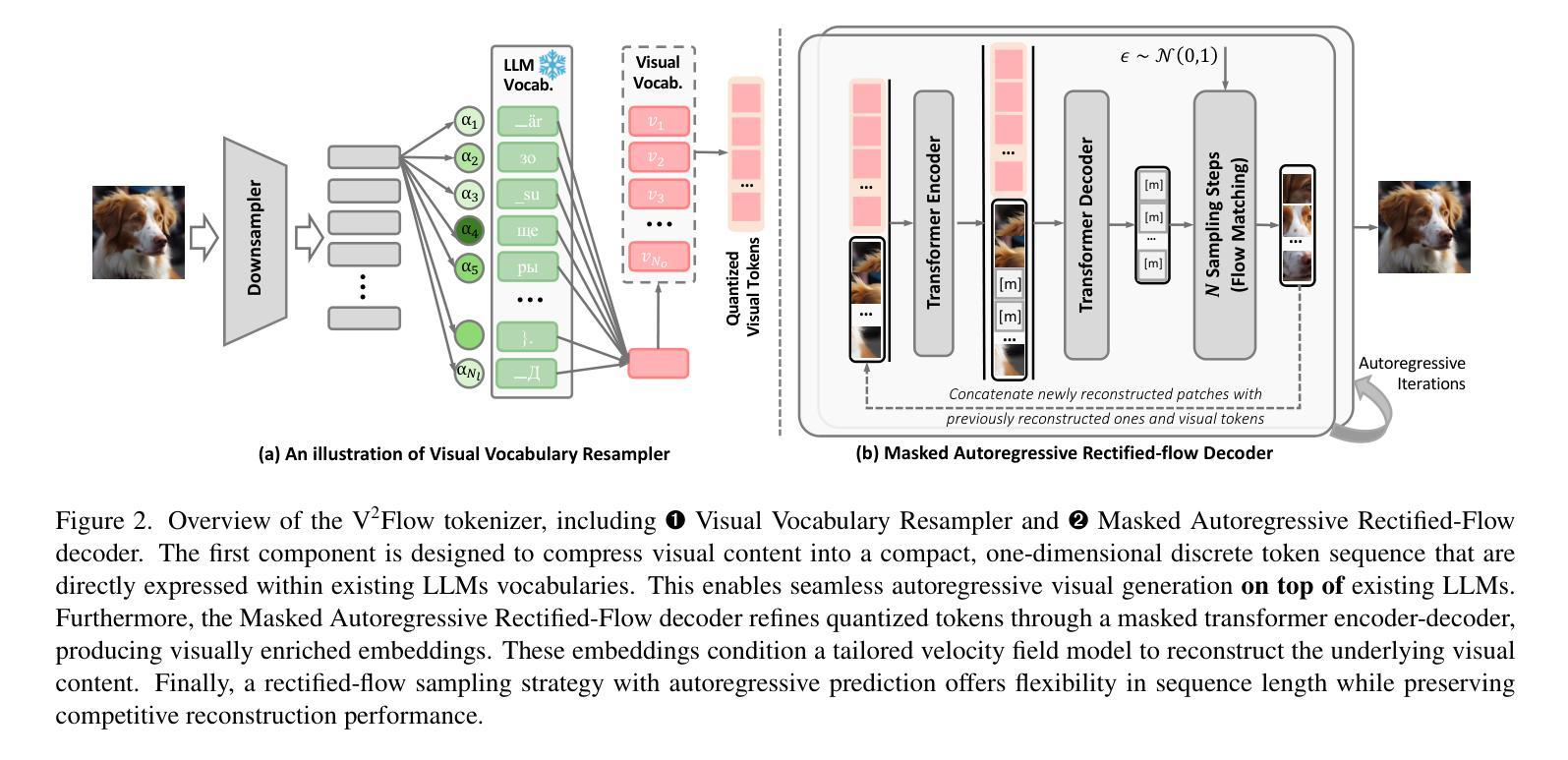
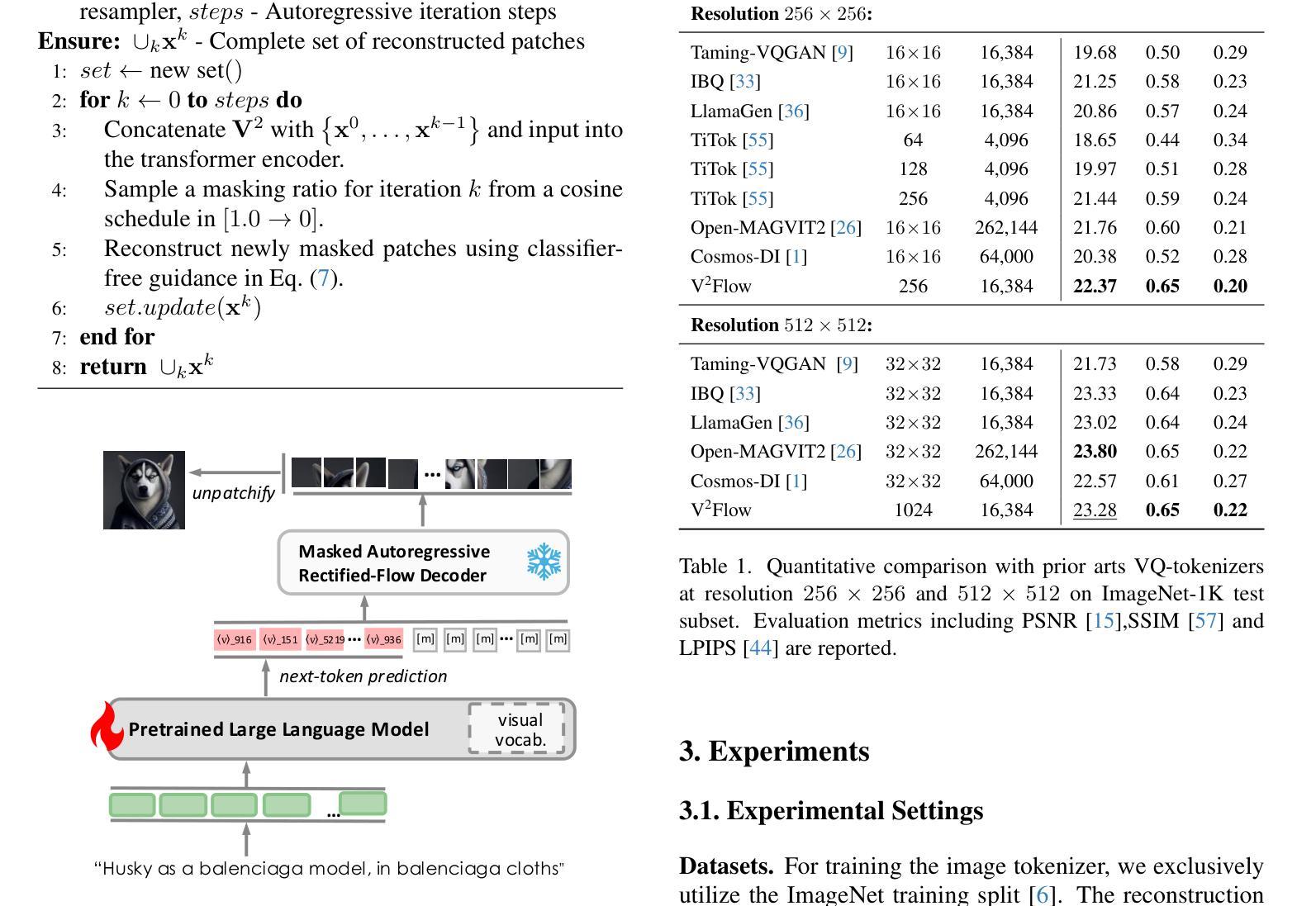
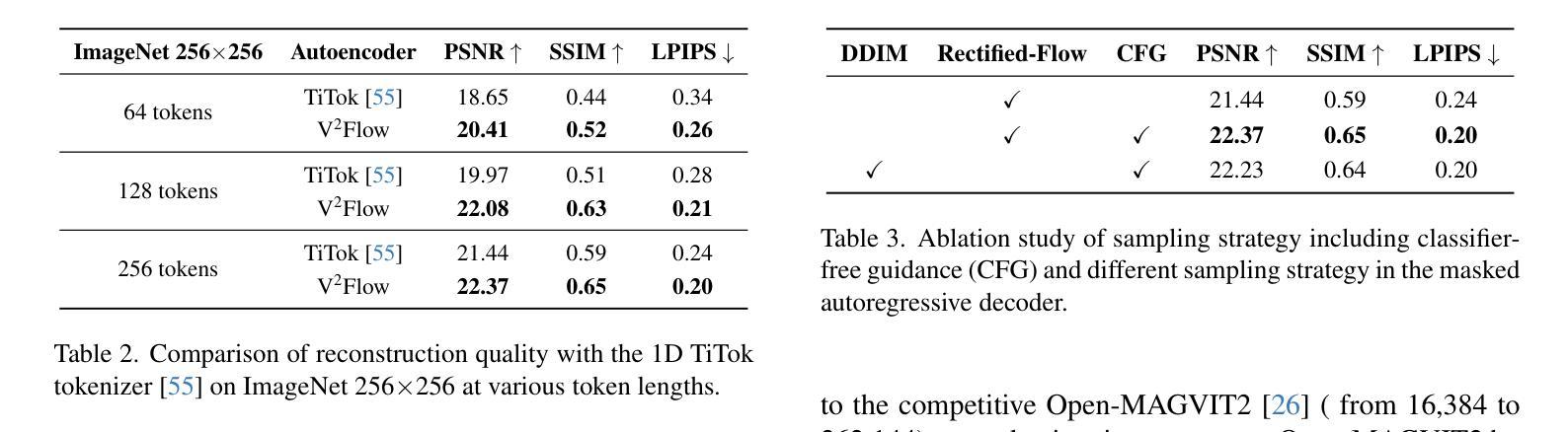
We propose V2Flow, a novel tokenizer that produces discrete visual tokens capable of high-fidelity reconstruction, while ensuring structural and latent distribution alignment with the vocabulary space of large language models (LLMs). Leveraging this tight visual-vocabulary coupling, V2Flow enables autoregressive visual generation on top of existing LLMs. Our approach formulates visual tokenization as a flow-matching problem, aiming to learn a mapping from a standard normal prior to the continuous image distribution, conditioned on token sequences embedded within the LLMs vocabulary space. The effectiveness of V2Flow stems from two core designs. First, we propose a Visual Vocabulary resampler, which compresses visual data into compact token sequences, with each represented as a soft categorical distribution over LLM’s vocabulary. This allows seamless integration of visual tokens into existing LLMs for autoregressive visual generation. Second, we present a masked autoregressive Rectified-Flow decoder, employing a masked transformer encoder-decoder to refine visual tokens into contextually enriched embeddings. These embeddings then condition a dedicated velocity field for precise reconstruction. Additionally, an autoregressive rectified-flow sampling strategy is incorporated, ensuring flexible sequence lengths while preserving competitive reconstruction quality. Extensive experiments show that V2Flow outperforms mainstream VQ-based tokenizers and facilitates autoregressive visual generation on top of existing. https://github.com/zhangguiwei610/V2Flow
我们提出了V2Flow,这是一种新型的分词器,能够产生离散的可视化令牌,实现高保真重建,同时确保与大型语言模型(LLM)的词汇空间的结构和潜在分布对齐。利用这种紧密的视觉词汇耦合,V2Flow可以在现有的LLM之上实现自回归的视觉生成。我们的方法将视觉分词表述为一个流量匹配问题,旨在从标准正态分布学习映射到连续的图像分布,根据嵌入在LLM词汇空间中的令牌序列进行条件化。V2Flow的有效性源于两个核心设计。首先,我们提出了一种视觉词汇重采样器,它将视觉数据压缩成紧凑的令牌序列,每个序列都表示为LLM词汇上的软类别分布。这允许无缝地将视觉令牌集成到现有的LLM中,用于自回归的视觉生成。其次,我们提出了一种带掩码的自动回归修正流解码器,采用带掩码的变压器编码器-解码器来优化视觉令牌为上下文丰富的嵌入。这些嵌入然后为精确重建设置一个专用的速度场。此外,还融入了自回归修正流采样策略,确保灵活的序列长度同时保持有竞争力的重建质量。大量实验表明,V2Flow优于主流的VQ令牌分词器,支持在现有基础上进行自回归的视觉生成。相关内容请查阅:https://github.com/zhangguiwei610/V2Flow
论文及项目相关链接
PDF 11 pages, 6 figures
Summary
V2Flow是一种新型视觉分词器,能够产生离散视觉标记,实现高保真重建,同时确保与大型语言模型(LLM)的词汇空间的结构和潜在分布对齐。V2Flow通过形式化视觉分词为流匹配问题,学习从标准正态分布到连续图像分布之间的映射,受LLM词汇空间中的标记序列条件影响。该方法的优势源于两个核心设计:视觉词汇重采样器和掩码的自动回归校正流解码器。前者将视觉数据压缩成紧凑的标记序列,每个序列表示为LLM词汇表的软类别分布,便于无缝集成到现有的LLM中进行自动回归视觉生成。后者采用掩码的自动回归校正流采样策略,确保灵活的序列长度,同时保持有竞争力的重建质量。V2Flow实验表明优于主流VQ-based的分词器并推动了自动回归视觉生成技术的发展。
Key Takeaways
- V2Flow是一种新型视觉分词器,与大型语言模型(LLM)紧密结合。
- 通过形式化为流匹配问题,V2Flow学习从标准正态分布到图像分布的映射。
- 视觉词汇重采样器将视觉数据转换为紧凑的标记序列,易于集成到LLM中。
- 掩码的自动回归校正流解码器用于细化视觉标记并生成上下文丰富的嵌入。
- V2Flow采用灵活的序列长度并维持高重建质量。
- 实验结果显示V2Flow在性能上优于主流VQ-based的分词器。
点此查看论文截图


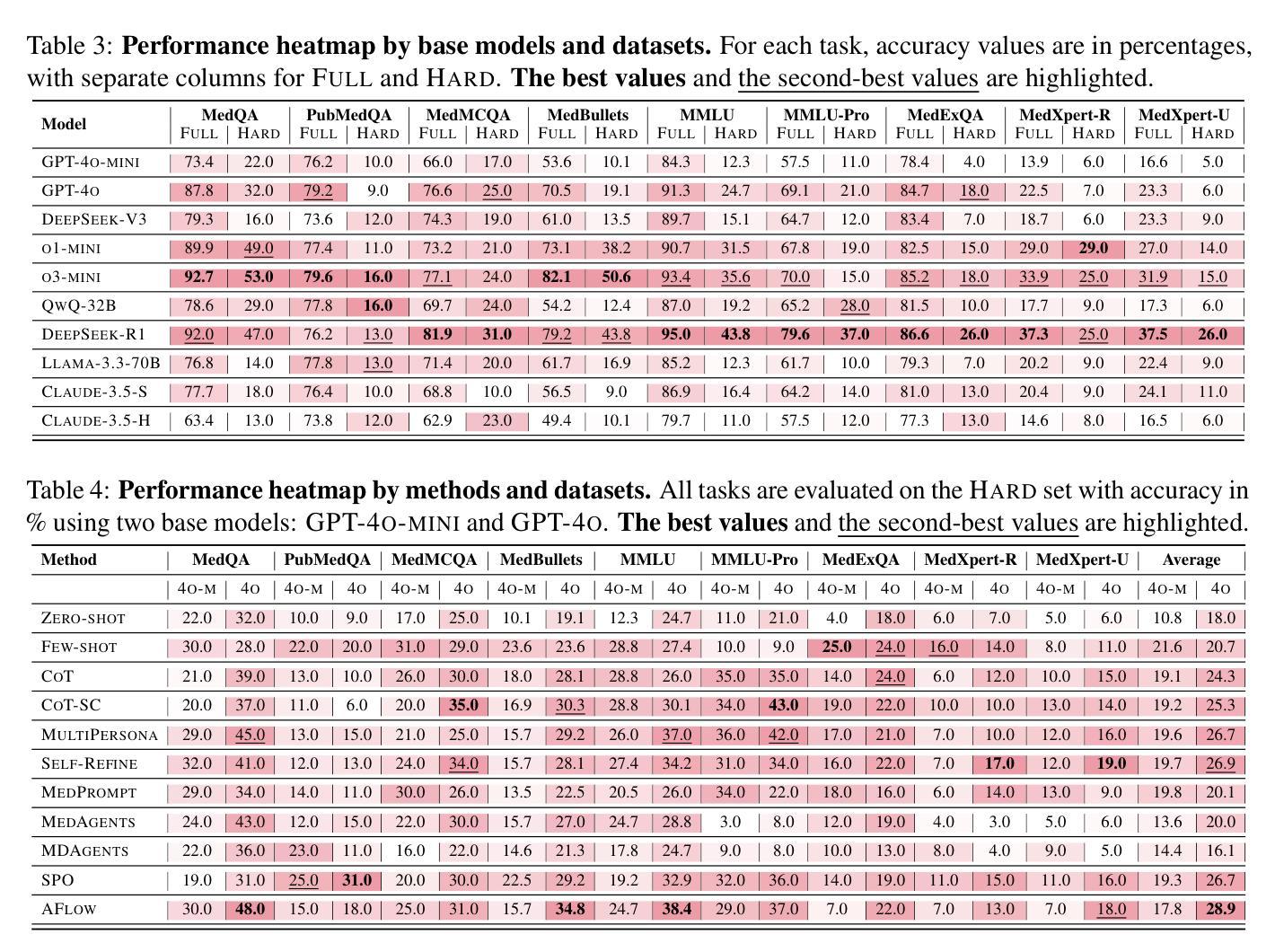
MedAgentsBench: Benchmarking Thinking Models and Agent Frameworks for Complex Medical Reasoning
Authors:Xiangru Tang, Daniel Shao, Jiwoong Sohn, Jiapeng Chen, Jiayi Zhang, Jinyu Xiang, Fang Wu, Yilun Zhao, Chenglin Wu, Wenqi Shi, Arman Cohan, Mark Gerstein
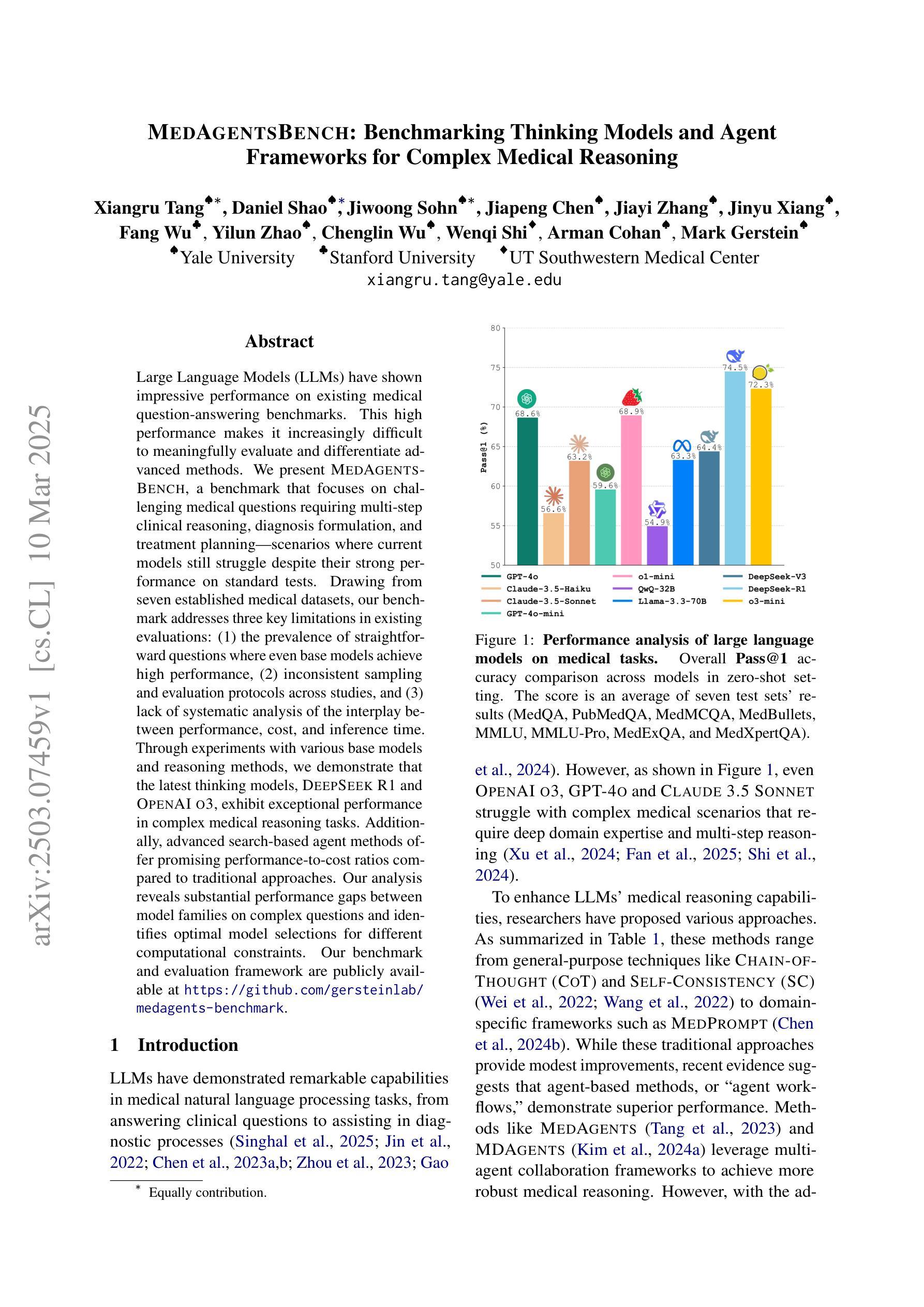
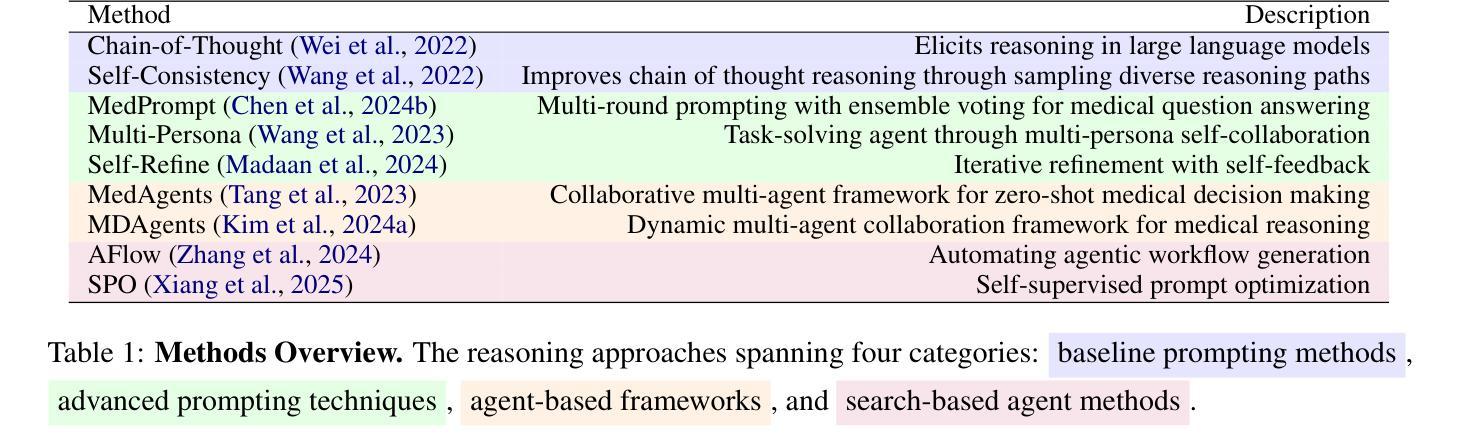
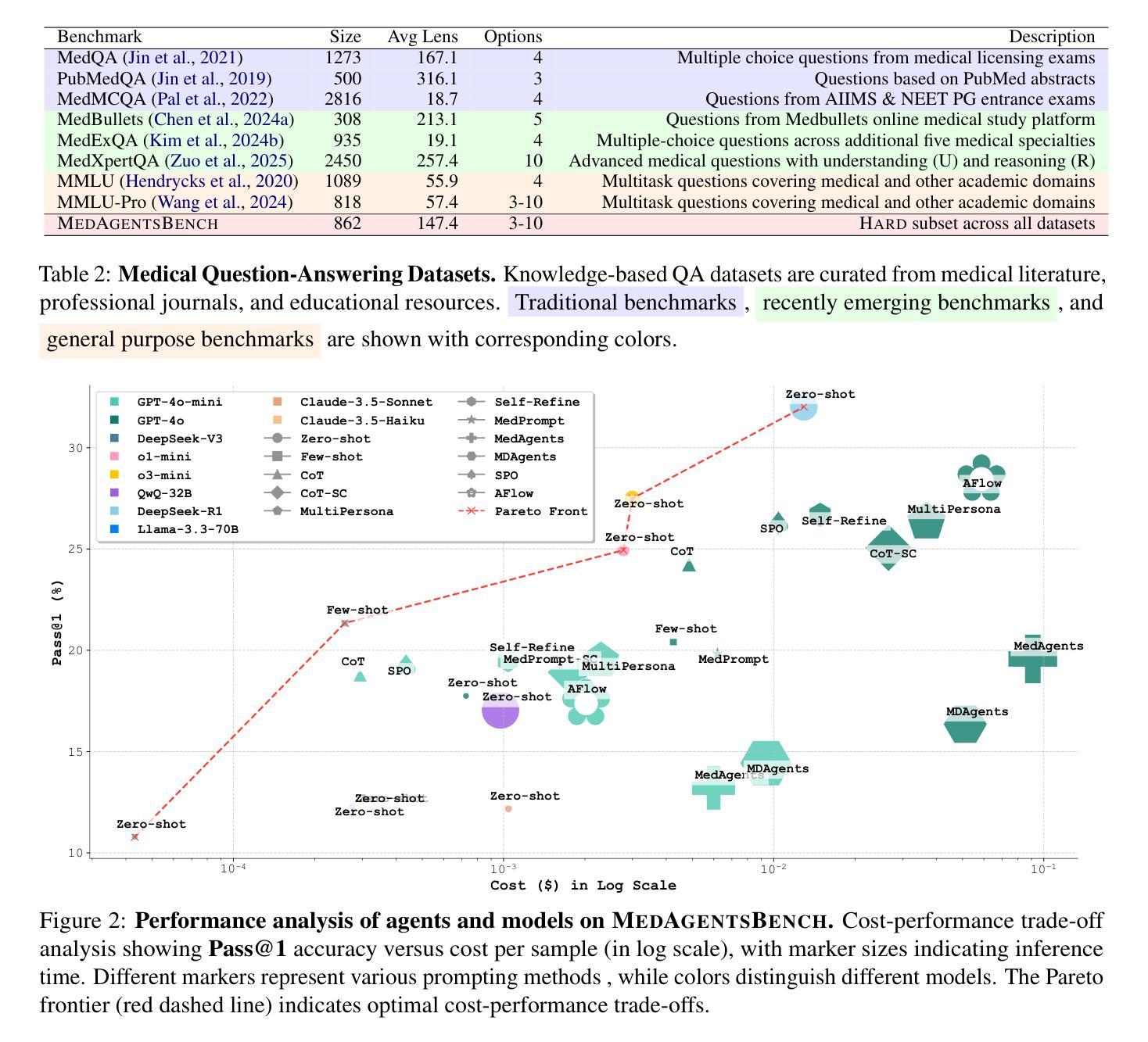
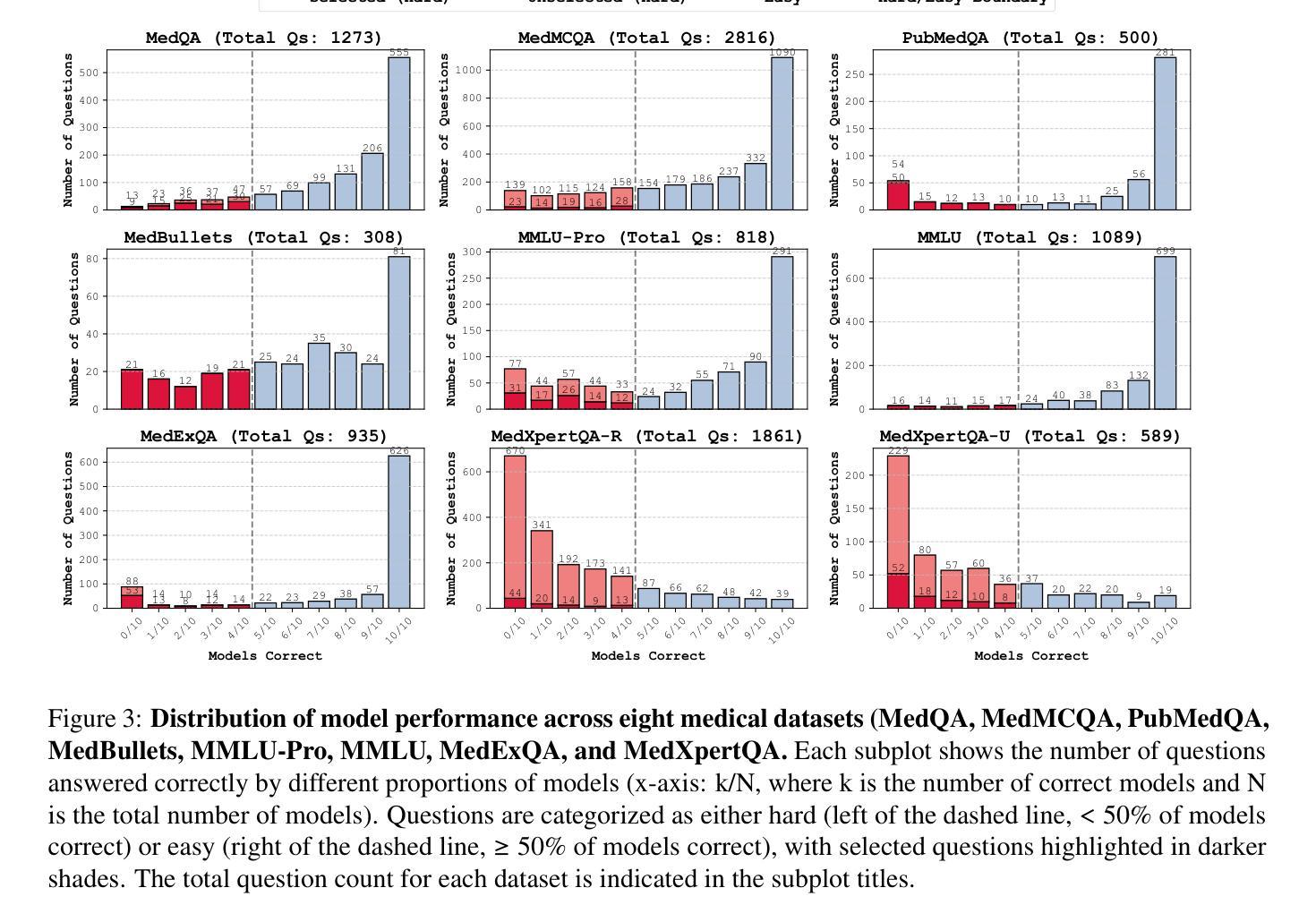
Large Language Models (LLMs) have shown impressive performance on existing medical question-answering benchmarks. This high performance makes it increasingly difficult to meaningfully evaluate and differentiate advanced methods. We present MedAgentsBench, a benchmark that focuses on challenging medical questions requiring multi-step clinical reasoning, diagnosis formulation, and treatment planning-scenarios where current models still struggle despite their strong performance on standard tests. Drawing from seven established medical datasets, our benchmark addresses three key limitations in existing evaluations: (1) the prevalence of straightforward questions where even base models achieve high performance, (2) inconsistent sampling and evaluation protocols across studies, and (3) lack of systematic analysis of the interplay between performance, cost, and inference time. Through experiments with various base models and reasoning methods, we demonstrate that the latest thinking models, DeepSeek R1 and OpenAI o3, exhibit exceptional performance in complex medical reasoning tasks. Additionally, advanced search-based agent methods offer promising performance-to-cost ratios compared to traditional approaches. Our analysis reveals substantial performance gaps between model families on complex questions and identifies optimal model selections for different computational constraints. Our benchmark and evaluation framework are publicly available at https://github.com/gersteinlab/medagents-benchmark.
大型语言模型(LLM)在现有的医疗问答基准测试中表现出了令人印象深刻的性能。这种高性能使得对先进方法进行有意义地评估和区分变得越来越困难。我们提出了MedAgentsBench基准测试,它专注于具有挑战性的医疗问题,需要多步骤的临床推理、诊断制定和治疗计划制定,即使在当前模型在标准测试中的表现优异,在这些场景中仍然面临困难。我们从七个已建立的医学数据集中汲取数据,我们的基准测试解决了现有评估中的三个关键局限性:(1)简单问题普遍存在的现象,即使基础模型也能取得较高的性能;(2)不同研究之间采样和评估协议的不一致性;(3)缺乏对性能、成本和推理时间之间相互作用的系统性分析。通过对各种基础模型和推理方法的实验,我们证明了最新的思考模型DeepSeek R1和OpenAI o3在复杂的医疗推理任务中表现出卓越的性能。此外,与传统的搜索方法相比,先进的基于搜索的代理方法提供了有前景的性能成本比。我们的分析揭示了不同模型家族在复杂问题上的性能差距,并针对不同的计算约束条件选择了最佳模型。我们的基准测试和评估框架可在https://github.com/gersteinlab/medagents-benchmark公开访问。
论文及项目相关链接
Summary:大型语言模型(LLM)在现有的医疗问答基准测试中表现出色。为此,我们提出了MedAgentsBench基准测试,它专注于挑战需要多步骤临床推理、诊断制定和治疗计划规划的医疗问题,这是当前模型仍然面临困难的场景。该基准测试解决了现有评估中的三个关键限制。通过试验各种基础模型和推理方法,我们证明了最新的思考模型在复杂的医疗推理任务中表现出色。我们的分析揭示了不同模型家族在复杂问题上的性能差距,并为不同的计算约束确定了最佳模型选择。我们的基准测试和评估框架可在 https://github.com/gersteinlab/medagents-benchmark 公开访问。
Key Takeaways:
- LLM在医疗问答基准测试中表现出色,但仍面临复杂医疗推理任务的挑战。
- MedAgentsBench基准测试解决了现有评估的关键限制,包括简单问题过多、采样和评价协议不一致以及缺乏性能、成本和推理时间之间的系统分析。
- 最新的思考模型,如DeepSeek R1和OpenAI o3,在复杂的医疗推理任务中表现出卓越性能。
- 先进的搜索型代理方法与传统方法相比,性能与成本比具有优势。
- 不同模型家族在复杂问题上的性能存在显著差异,需要根据计算约束选择合适的模型。
- MedAgentsBench基准测试和评估框架已公开发布,可供使用。
点此查看论文截图
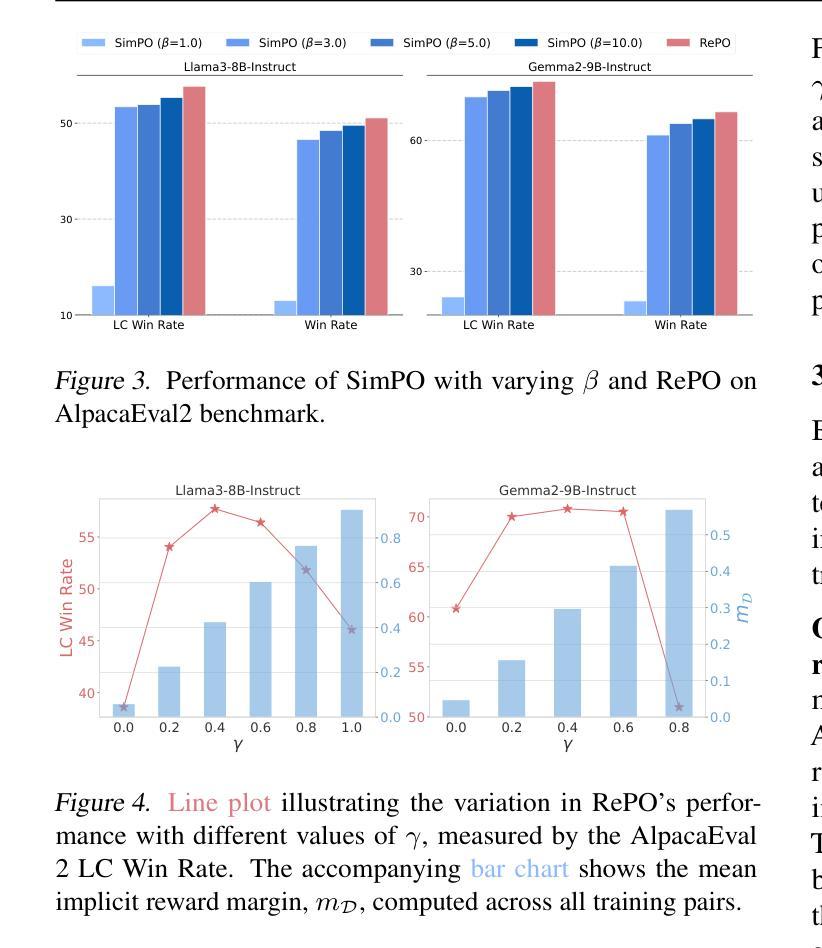
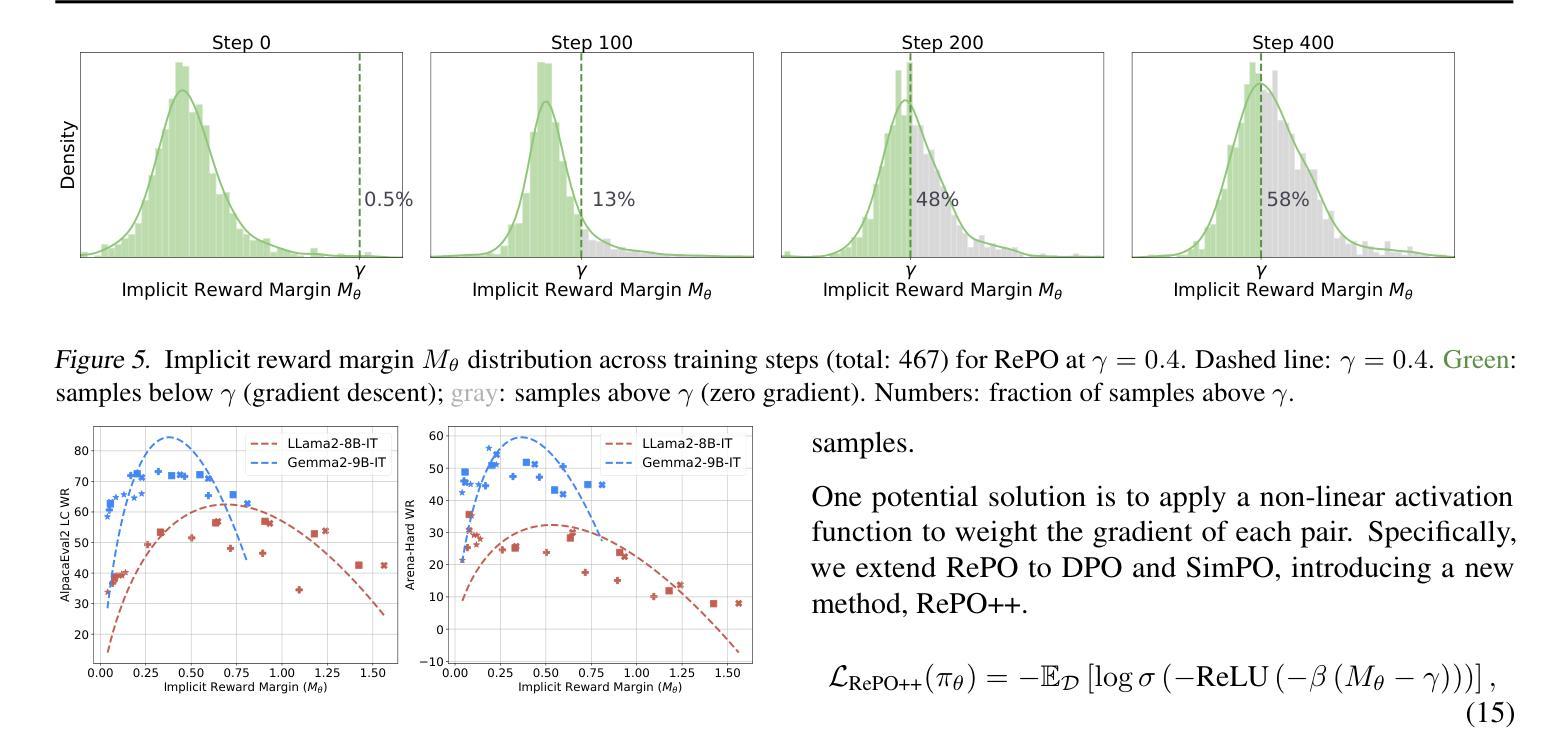
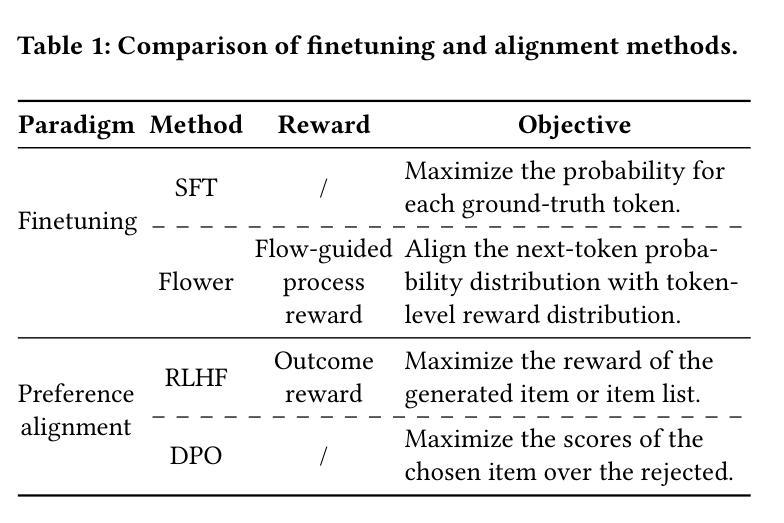
RePO: ReLU-based Preference Optimization
Authors:Junkang Wu, Kexin Huang, Xue Wang, Jinyang Gao, Bolin Ding, Jiancan Wu, Xiangnan He, Xiang Wang
Aligning large language models (LLMs) with human preferences is critical for real-world deployment, yet existing methods like RLHF face computational and stability challenges. While DPO establishes an offline paradigm with single hyperparameter $\beta$, subsequent methods like SimPO reintroduce complexity through dual parameters ($\beta$, $\gamma$). We propose {ReLU-based Preference Optimization (RePO)}, a streamlined algorithm that eliminates $\beta$ via two advances: (1) retaining SimPO’s reference-free margins but removing $\beta$ through gradient analysis, and (2) adopting a ReLU-based max-margin loss that naturally filters trivial pairs. Theoretically, RePO is characterized as SimPO’s limiting case ($\beta \to \infty$), where the logistic weighting collapses to binary thresholding, forming a convex envelope of the 0-1 loss. Empirical results on AlpacaEval 2 and Arena-Hard show that RePO outperforms DPO and SimPO across multiple base models, requiring only one hyperparameter to tune.
将大型语言模型(LLM)与人类偏好对齐对于现实世界部署至关重要,然而现有的方法如RLHF面临着计算和稳定性挑战。虽然DPO通过建立单超参数β的离线范式取得了成功,但后续方法如SimPO通过双参数(β,γ)重新引入了复杂性。我们提出了基于ReLU的偏好优化(RePO),这是一个简化的算法,通过两个进展消除了β:(1)保留SimPO的无参考边距并通过梯度分析消除β,(2)采用基于ReLU的最大边距损失,自然地过滤掉无关的对。从理论上讲,RePO被描述为SimPO的极限情况(β→∞),在此情况下,逻辑权重会降至阈值处理,形成0-1损失的凸包。在AlpacaEval 2和Arena-Hard上的经验结果表明,RePO在多个基础模型上的表现优于DPO和SimPO,只需要调整一个超参数。
论文及项目相关链接
Summary
本文介绍了大型语言模型(LLM)与人类偏好对齐的重要性,针对现有方法如RLHF面临的挑战,提出了基于ReLU的偏好优化(RePO)算法。该算法通过梯度分析和ReLU基最大边界损失来简化参数设置,消除了β参数,提高了计算效率和稳定性。在AlpacaEval 2和Arena-Hard上的实验结果表明,RePO在多个基础模型上优于DPO和SimPO。
Key Takeaways
- 大型语言模型(LLM)与人类偏好对齐对于实际部署至关重要。
- 现有方法如RLHF面临计算和稳定性挑战。
- RePO算法通过梯度分析和ReLU基最大边界损失简化了参数设置,消除了β参数。
- RePO算法是SimPO的一种简化版本,表现为SimPO的极限情况(β→∞)。
- RePO算法提高了计算效率和稳定性。
- 在AlpacaEval 2和Arena-Hard上的实验结果表明,RePO在多个基础模型上的性能优于DPO和SimPO。
点此查看论文截图


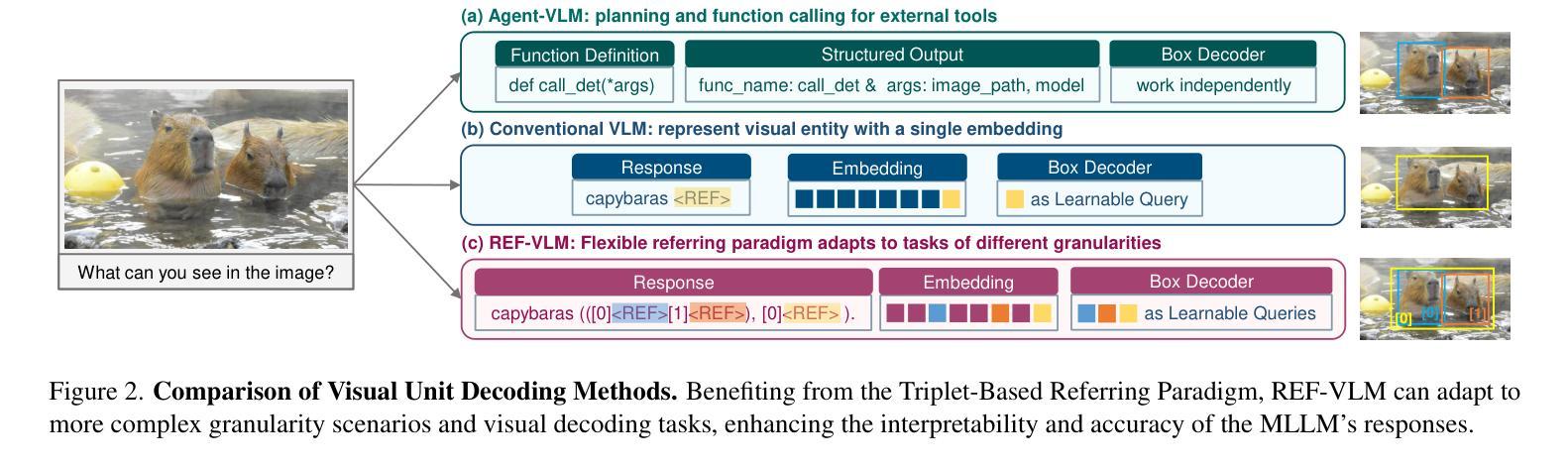
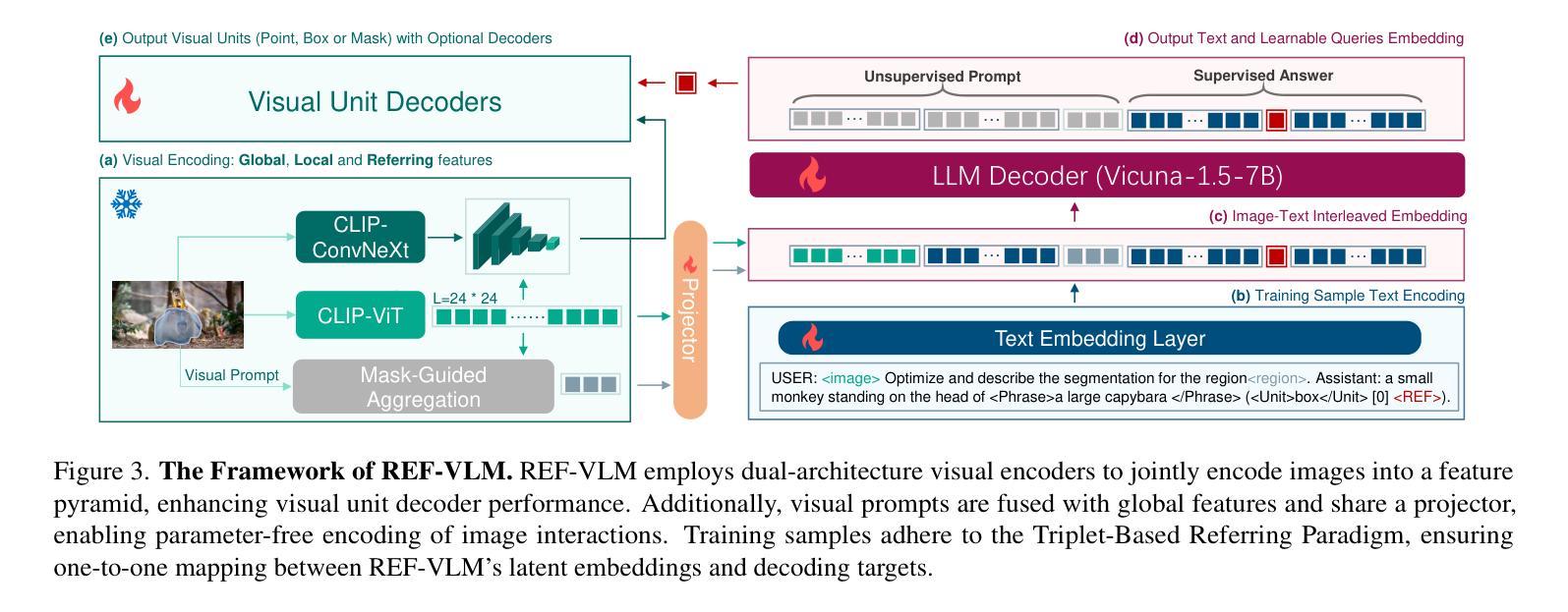
REF-VLM: Triplet-Based Referring Paradigm for Unified Visual Decoding
Authors:Yan Tai, Luhao Zhu, Zhiqiang Chen, Ynan Ding, Yiying Dong, Xiaohong Liu, Guodong Guo
Multimodal Large Language Models (MLLMs) demonstrate robust zero-shot capabilities across diverse vision-language tasks after training on mega-scale datasets. However, dense prediction tasks, such as semantic segmentation and keypoint detection, pose significant challenges for MLLMs when represented solely as text outputs. Simultaneously, current MLLMs utilizing latent embeddings for visual task decoding generally demonstrate limited adaptability to both multi-task learning and multi-granularity scenarios. In this work, we present REF-VLM, an end-to-end framework for unified training of various visual decoding tasks. To address complex visual decoding scenarios, we introduce the Triplet-Based Referring Paradigm (TRP), which explicitly decouples three critical dimensions in visual decoding tasks through a triplet structure: concepts, decoding types, and targets. TRP employs symbolic delimiters to enforce structured representation learning, enhancing the parsability and interpretability of model outputs. Additionally, we construct Visual-Task Instruction Following Dataset (VTInstruct), a large-scale multi-task dataset containing over 100 million multimodal dialogue samples across 25 task types. Beyond text inputs and outputs, VT-Instruct incorporates various visual prompts such as point, box, scribble, and mask, and generates outputs composed of text and visual units like box, keypoint, depth and mask. The combination of different visual prompts and visual units generates a wide variety of task types, expanding the applicability of REF-VLM significantly. Both qualitative and quantitative experiments demonstrate that our REF-VLM outperforms other MLLMs across a variety of standard benchmarks. The code, dataset, and demo available at https://github.com/MacavityT/REF-VLM.
多模态大型语言模型(MLLMs)在大型数据集上进行训练后,在多种视觉语言任务中表现出强大的零样本能力。然而,对于仅表现为文本输出的密集预测任务(如语义分割和关键点检测),MLLMs面临巨大挑战。同时,当前使用潜在嵌入进行视觉任务解码的MLLM通常对多任务学习和多粒度场景的适应性有限。在此工作中,我们提出了REF-VLM,这是一个统一训练各种视觉解码任务的端到端框架。为了解决复杂的视觉解码场景,我们引入了基于三元组的参照范式(TRP),它通过三元组结构显式地解耦视觉解码任务中的三个关键维度:概念、解码类型和目标。TRP采用符号分隔符来强制执行结构化表示学习,提高模型输出的可解析性和可解释性。此外,我们构建了视觉任务指令跟随数据集(VTInstruct),这是一个大规模的多任务数据集,包含超过10亿个跨25种任务类型的多模态对话样本。除了文本输入和输出外,VT-Instruct还结合了各种视觉提示,如点、框、涂鸦和遮罩,并生成由文本和视觉单位(如框、关键点、深度和遮罩)组成的输出。不同的视觉提示和视觉单位的组合产生了各种任务类型,极大地扩展了REF-VLM的适用性。定性和定量实验均表明,我们的REF-VLM在各种标准基准测试中优于其他MLLMs。相关代码、数据集和演示可在https://github.com/MacavityT/REF-VLM上找到。
论文及项目相关链接
Summary
本文介绍了Multimodal Large Language Models(MLLMs)在密集预测任务上的挑战,并提出了REF-VLM框架来统一训练各种视觉解码任务。为解决复杂视觉解码场景,引入了Triplet-BasedReferring Paradigm(TRP),通过三元结构解耦视觉解码任务中的概念、解码类型和目标。同时构建了Visual-Task Instruction Following Dataset(VTInstruct),包含超过100百万的多模态对话样本。REF-VLM结合不同视觉提示和视觉单位,显著提高了在多种标准基准测试上的表现。
Key Takeaways
- MLLMs在密集预测任务如语义分割和关键点检测上表现挑战,需要更有效的视觉解码方法。
- REF-VLM框架提出用于统一训练各种视觉解码任务,提高模型适应性和性能。
- TRP通过三元结构解耦视觉解码任务的关键维度,提高模型输出的可解析性和可解释性。
- VTInstruct数据集包含大量多模态对话样本,用于训练和评估视觉任务指令遵循能力。
- REF-VLM结合不同视觉提示和视觉单位,如点、框、涂鸦和遮罩,扩展了应用范围。
- REF-VLM在多种标准基准测试上表现优越,证明其有效性和实用性。
点此查看论文截图



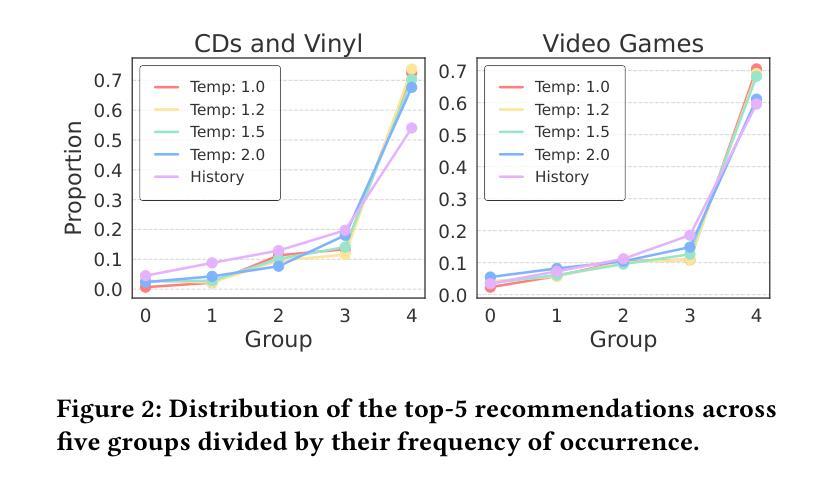
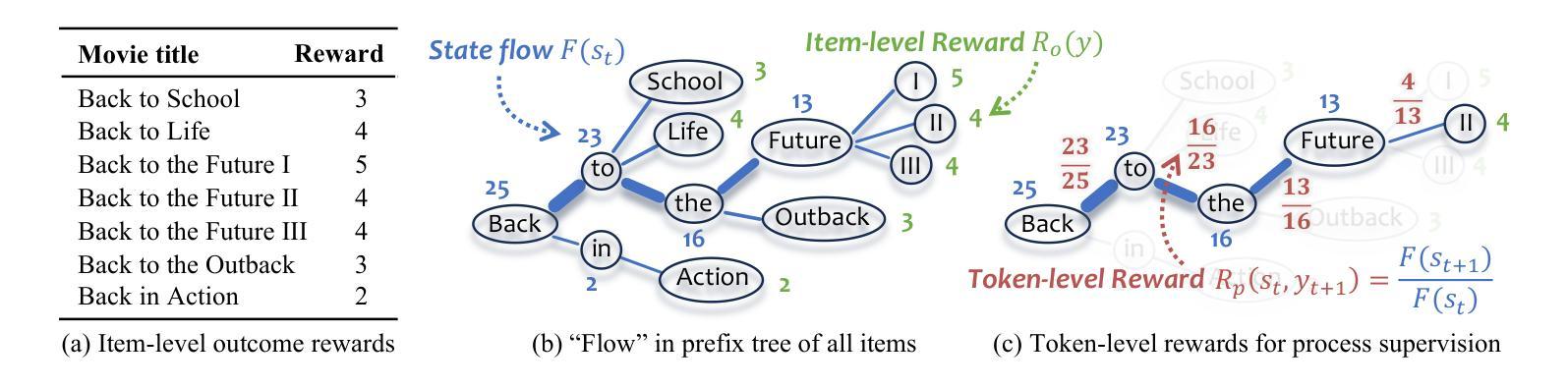
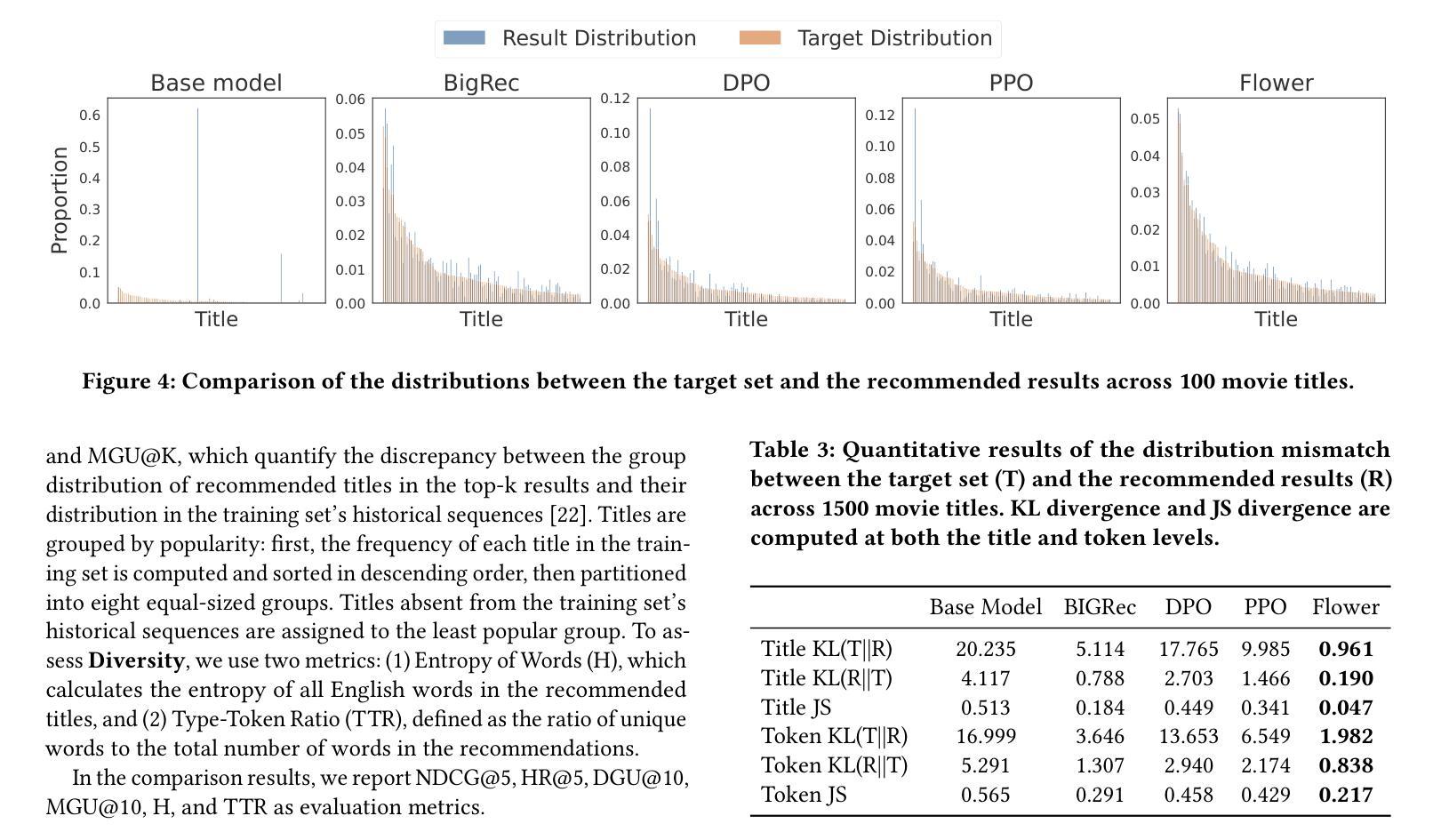
Process-Supervised LLM Recommenders via Flow-guided Tuning
Authors:Chongming Gao, Mengyao Gao, Chenxiao Fan, Shuai Yuan, Wentao Shi, Xiangnan He
While large language models (LLMs) are increasingly adapted for recommendation systems via supervised fine-tuning (SFT), this approach amplifies popularity bias due to its likelihood maximization objective, compromising recommendation diversity and fairness. To address this, we present Flow-guided fine-tuning recommender (Flower), which replaces SFT with a Generative Flow Network (GFlowNet) framework that enacts process supervision through token-level reward propagation. Flower’s key innovation lies in decomposing item-level rewards into constituent token rewards, enabling direct alignment between token generation probabilities and their reward signals. This mechanism achieves three critical advancements: (1) popularity bias mitigation and fairness enhancement through empirical distribution matching, (2) preservation of diversity through GFlowNet’s proportional sampling, and (3) flexible integration of personalized preferences via adaptable token rewards. Experiments demonstrate Flower’s superior distribution-fitting capability and its significant advantages over traditional SFT in terms of fairness, diversity, and accuracy, highlighting its potential to improve LLM-based recommendation systems. The implementation is available via https://github.com/Mr-Peach0301/Flower
虽然大型语言模型(LLM)越来越多地通过监督微调(SFT)适应推荐系统,但由于其最大化概率的目标,这种方法会加剧流行度偏见,损害推荐多样性和公平性。为了解决这个问题,我们提出了流引导微调推荐器(Flower),它用生成流网络(GFlowNet)框架替代了SFT,通过令牌级别的奖励传播实现过程监督。Flower的关键创新在于将项目级别的奖励分解为组成部分的令牌奖励,使得令牌生成概率与其奖励信号之间能够直接对齐。这种机制实现了三个关键进展:(1)通过经验分布匹配缓解流行度偏见,增强公平性;(2)通过GFlowNet的比例采样保持多样性;(3)通过可适应的令牌奖励灵活整合个性化偏好。实验表明,Flower在分布拟合能力上表现优越,在公平性、多样性和准确性方面均优于传统的SFT,突显其在改进基于LLM的推荐系统方面的潜力。具体实现可通过 https://github.com/Mr-Peach0301/Flower 访问。
论文及项目相关链接
Summary
大型语言模型(LLM)在推荐系统中的应用通常采用监督微调(SFT)方法,但这种方法会放大流行度偏见,影响推荐的多样性和公平性。为解决这一问题,我们提出了基于生成流网络(GFlowNet)的Flow引导微调推荐器(Flower)。它通过令牌级别的奖励传播来实现过程监督,取代了SFT。Flower的关键创新之处在于将项目级别的奖励分解为组成部分的令牌奖励,使令牌生成概率与其奖励信号直接对齐。此机制实现了三个关键进展:一是通过经验分布匹配减轻流行度偏见,增强公平性;二是通过GFlowNet的比例采样保留多样性;三是通过灵活的个性化偏好集成提升推荐系统的准确性。相关实验表明,Flower在分布拟合能力、公平性和多样性方面均优于传统的SFT方法。具体实现可通过相关链接访问。
Key Takeaways
- 大型语言模型(LLM)用于推荐系统常采用监督微调(SFT),但会导致流行度偏见。
- Flower采用生成流网络(GFlowNet)框架替代SFT,实现过程监督及令牌级别的奖励传播。
- Flower通过将项目级奖励分解为令牌奖励,实现了公平性、多样性和准确性的提升。
- 通过经验分布匹配减轻流行度偏见。
- GFlowNet的比例采样有助于保留多样性。
- Flower能够灵活集成个性化偏好,提升推荐系统的准确性。
点此查看论文截图

MM-Eureka: Exploring Visual Aha Moment with Rule-based Large-scale Reinforcement Learning
Authors:Fanqing Meng, Lingxiao Du, Zongkai Liu, Zhixiang Zhou, Quanfeng Lu, Daocheng Fu, Botian Shi, Wenhai Wang, Junjun He, Kaipeng Zhang, Ping Luo, Yu Qiao, Qiaosheng Zhang, Wenqi Shao
We present MM-Eureka, a multimodal reasoning model that successfully extends large-scale rule-based reinforcement learning (RL) to multimodal reasoning. While rule-based RL has shown remarkable success in improving LLMs’ reasoning abilities in text domains, its application to multimodal settings has remained challenging. Our work reproduces key characteristics of text-based RL systems like DeepSeek-R1 in the multimodal space, including steady increases in accuracy reward and response length, and the emergence of reflection behaviors. We demonstrate that both instruction-tuned and pre-trained models can develop strong multimodal reasoning capabilities through rule-based RL without supervised fine-tuning, showing superior data efficiency compared to alternative approaches. We open-source our complete pipeline to foster further research in this area. We release all our codes, models, data, etc. at https://github.com/ModalMinds/MM-EUREKA
我们推出MM-Eureka,这是一款成功将大规模基于规则的强化学习(RL)扩展到多模态推理的多模态推理模型。虽然基于规则的RL在文本领域的提高大型语言模型推理能力方面取得了显著的成功,但其在多模态场景的应用仍然具有挑战性。我们的工作在多模态空间中再现了基于文本的RL系统(如DeepSeek-R1)的关键特征,包括精度奖励和响应长度的稳定增加,以及反思行为的出现。我们证明,通过基于规则的RL,经过指令调整的预训练模型可以发展出强大的多模态推理能力,无需监督微调,在数据效率方面表现出优于其他方法。我们公开了完整的管道,以促进该领域的研究。我们在https://github.com/ModalMinds/MM-EUREKA上发布了我们所有的代码、模型、数据等。
论文及项目相关链接
Summary
MM-Eureka是一种多模态推理模型,成功将基于规则的强化学习扩展到多模态推理领域。该模型在文本领域展示出色的推理能力,现在可应用于多模态环境。研究展示了该模型在精度奖励和响应长度方面的稳步提高,以及反思行为的出现。通过基于规则的强化学习,该模型无需监督微调即可发展出强大的多模态推理能力,相较于其他方法具有更高的数据效率。我们公开了完整的管道以促进该领域的研究。更多详情可通过访问链接获取:https://github.com/ModalMinds/MM-EUREKA。
Key Takeaways
- MM-Eureka成功将基于规则的强化学习扩展到多模态推理领域。
- MM-Eureka在多模态环境中展现了与文本为基础的RL系统相似的特性,如DeepSeek-R1的精度奖励和响应长度的稳步提高。
- MM-Eureka展现出反思行为的出现,这是多模态推理的一个重要特征。
- 通过基于规则的强化学习,MM-Eureka在无需监督微调的情况下,能够发展出强大的多模态推理能力。
- MM-Eureka相较于其他方法具有更高的数据效率。
- MM-Eureka的完整管道已经开源,旨在促进该领域的研究。
点此查看论文截图

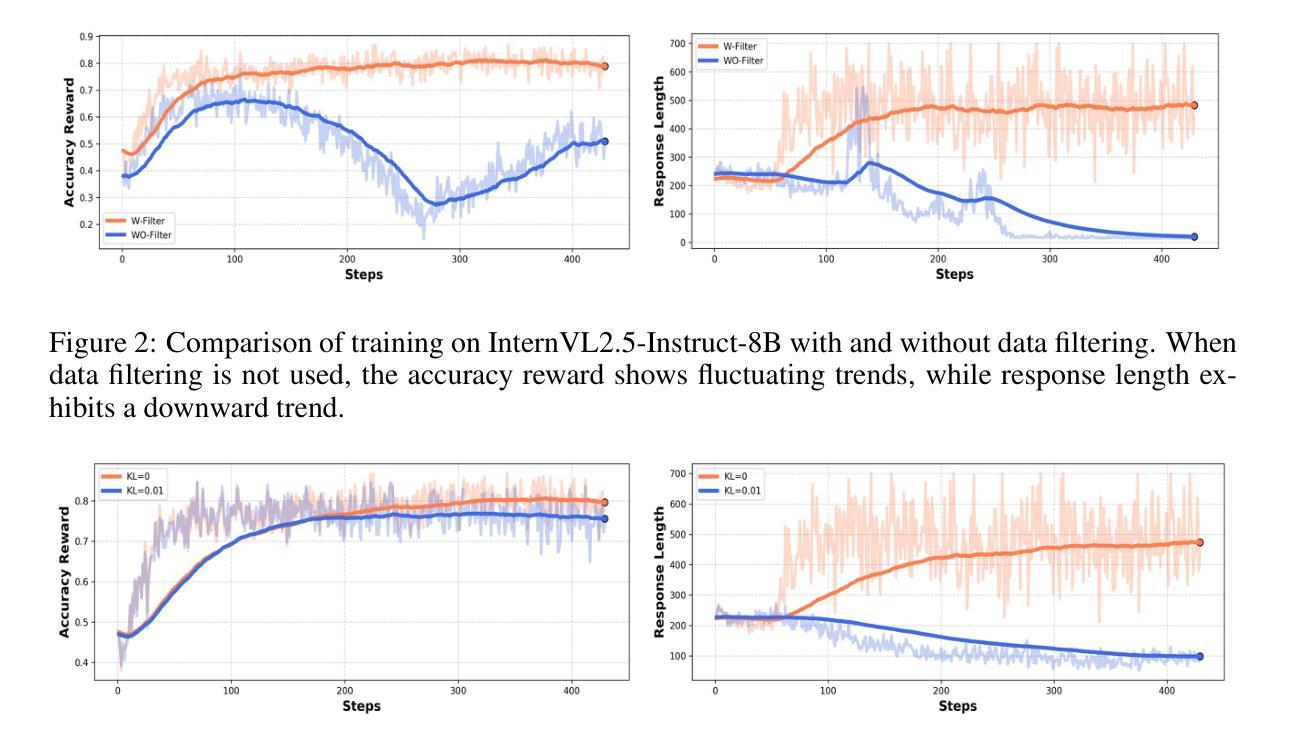


A Graph-based Verification Framework for Fact-Checking
Authors:Yani Huang, Richong Zhang, Zhijie Nie, Junfan Chen, Xuefeng Zhang
Fact-checking plays a crucial role in combating misinformation. Existing methods using large language models (LLMs) for claim decomposition face two key limitations: (1) insufficient decomposition, introducing unnecessary complexity to the verification process, and (2) ambiguity of mentions, leading to incorrect verification results. To address these challenges, we suggest introducing a claim graph consisting of triplets to address the insufficient decomposition problem and reduce mention ambiguity through graph structure. Based on this core idea, we propose a graph-based framework, GraphFC, for fact-checking. The framework features three key components: graph construction, which builds both claim and evidence graphs; graph-guided planning, which prioritizes the triplet verification order; and graph-guided checking, which verifies the triples one by one between claim and evidence graphs. Extensive experiments show that GraphFC enables fine-grained decomposition while resolving referential ambiguities through relational constraints, achieving state-of-the-art performance across three datasets.
事实核查在抗击错误信息中发挥着至关重要的作用。现有使用大型语言模型(LLM)进行声明分解的方法面临两个主要局限:(1)分解不足,给验证过程带来不必要的复杂性;(2)提及的模糊性,导致验证结果错误。为了解决这些挑战,我们建议使用由三元组组成的声明图来解决分解不足的问题,并通过图结构减少提及的模糊性。基于这一核心思想,我们提出了用于事实核查的图基框架GraphFC。该框架具有三个关键组件:图构建,构建声明和证据图;图引导规划,优先进行三元组验证顺序;以及图引导检查,逐一验证声明和证据图之间的三元组。大量实验表明,GraphFC能够实现精细的分解,同时通过关系约束解决指代歧义,在三个数据集上达到最先进的性能。
论文及项目相关链接
PDF 13pages, 4figures
摘要
事实核查在打击虚假信息中扮演着至关重要的角色。现有的使用大型语言模型(LLM)进行声明分解的方法面临两个主要局限:一是分解不足,给验证过程增加了不必要的复杂性;二是提及的模糊性,导致验证结果不正确。为解决这些挑战,我们提出了基于核心思想的图基框架GraphFC。它通过建立声明和证据的图来解决分解不足的问题,并通过图结构减少提及的模糊性。GraphFC的特点主要包括三个方面:图构建、图引导规划和图引导检查。图构建负责构建声明和证据的图;图引导规划则优先安排三元组验证的顺序;图引导检查则逐一验证声明和证据图之间的三元组。大量实验表明,GraphFC能够实现精细的分解,通过关系约束解决指代歧义问题,在三个数据集上均达到最佳性能。
关键见解
- 事实核查在打击虚假信息中起关键作用。
- 当前使用大型语言模型进行声明分解的方法存在两个主要局限:分解不足和提及的模糊性。
- 引入声明图可以解决分解不足的问题,减少提及的模糊性。
- 提出的GraphFC图基框架包括三个关键组件:图构建、图引导规划和图引导检查。
- 图构建负责构建声明和证据的图,以简化验证过程。
- 图引导规划优先安排三元组验证的顺序,以提高验证效率。
点此查看论文截图

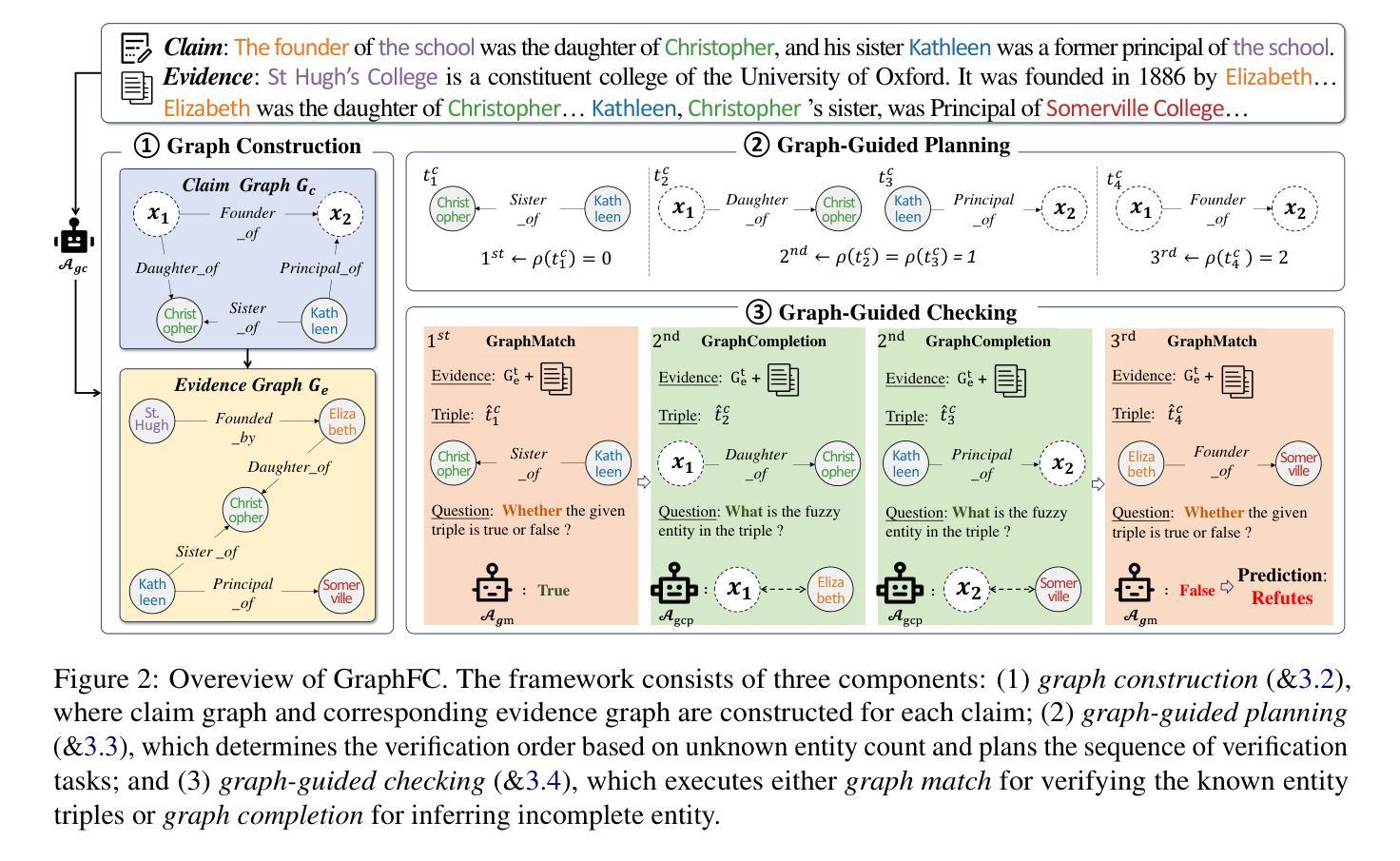
CoT-Drive: Efficient Motion Forecasting for Autonomous Driving with LLMs and Chain-of-Thought Prompting
Authors:Haicheng Liao, Hanlin Kong, Bonan Wang, Chengyue Wang, Wang Ye, Zhengbing He, Chengzhong Xu, Zhenning Li
Accurate motion forecasting is crucial for safe autonomous driving (AD). This study proposes CoT-Drive, a novel approach that enhances motion forecasting by leveraging large language models (LLMs) and a chain-of-thought (CoT) prompting method. We introduce a teacher-student knowledge distillation strategy to effectively transfer LLMs’ advanced scene understanding capabilities to lightweight language models (LMs), ensuring that CoT-Drive operates in real-time on edge devices while maintaining comprehensive scene understanding and generalization capabilities. By leveraging CoT prompting techniques for LLMs without additional training, CoT-Drive generates semantic annotations that significantly improve the understanding of complex traffic environments, thereby boosting the accuracy and robustness of predictions. Additionally, we present two new scene description datasets, Highway-Text and Urban-Text, designed for fine-tuning lightweight LMs to generate context-specific semantic annotations. Comprehensive evaluations of five real-world datasets demonstrate that CoT-Drive outperforms existing models, highlighting its effectiveness and efficiency in handling complex traffic scenarios. Overall, this study is the first to consider the practical application of LLMs in this field. It pioneers the training and use of a lightweight LLM surrogate for motion forecasting, setting a new benchmark and showcasing the potential of integrating LLMs into AD systems.
精确的动作预测对于安全自动驾驶(AD)至关重要。本研究提出了一种新的方法CoT-Drive,它借助大型语言模型(LLM)和思维链(CoT)提示方法来增强运动预测。我们引入了一种师徒知识蒸馏策略,以有效地将LLM的高级场景理解能力转移到轻量级语言模型(LM)上,确保CoT-Drive在边缘设备上实时运行,同时保持全面的场景理解和泛化能力。通过利用CoT提示技术,无需额外训练,CoT-Drive可以生成语义注释,极大地提高了对复杂交通环境的理解,从而提高了预测准确性和稳健性。此外,我们推出了两款新的场景描述数据集——Highway-Text和Urban-Text,专为微调轻量级LM以生成特定上下文的语义注释而设计。对五个真实世界数据集的全面评估表明,CoT-Drive优于现有模型,突显了其在处理复杂交通场景方面的有效性和效率。总体而言,本研究首次考虑LLM在该领域的实际应用。它率先训练和使用轻量级LLM代理进行动作预测,设定了新的基准,展示了将LLM集成到自动驾驶系统中的潜力。
论文及项目相关链接
Summary
本研究提出了CoT-Drive,一种利用大型语言模型(LLMs)和思维链(CoT)提示方法增强运动预测的新方法。通过引入教师-学生知识蒸馏策略,将LLMs的高级场景理解能力有效地转移到轻量级语言模型(LMs)上,确保CoT-Drive在边缘设备上实时运行,同时保持全面的场景理解和泛化能力。借助思维链提示技术,无需额外训练即可生成语义注释,显著提高对复杂交通环境的理解,从而提高预测准确性和稳健性。此外,该研究还推出两个新场景描述数据集——高速公路文本和城市文本,用于微调轻量级LMs以生成上下文特定的语义注释。全面评估五个真实世界数据集的结果表明,CoT-Drive在应对复杂交通场景方面表现出卓越的性能和效率。总体而言,本研究首次考虑LLMs在该领域的实际应用,开创性地训练和使用了轻量级LLM替代品进行运动预测,树立了新的基准,展示了将LLMs集成到自动驾驶系统中的潜力。
Key Takeaways
- 提出了一种新型运动预测方法CoT-Drive,结合大型语言模型(LLMs)和思维链(CoT)提示方法。
- 通过教师-学生知识蒸馏策略,将LLMs的高级场景理解能力转移到轻量级语言模型上。
- 利用思维链提示技术生成语义注释,提高复杂交通环境的理解。
- 推出两个新场景描述数据集——高速公路文本和城市文本,用于轻量级LMs的训练。
- 在五个真实世界数据集上的评估显示CoT-Drive具有卓越的性能和效率。
- 研究展示了LLMs在自动驾驶领域的潜力及实际应用价值。
点此查看论文截图

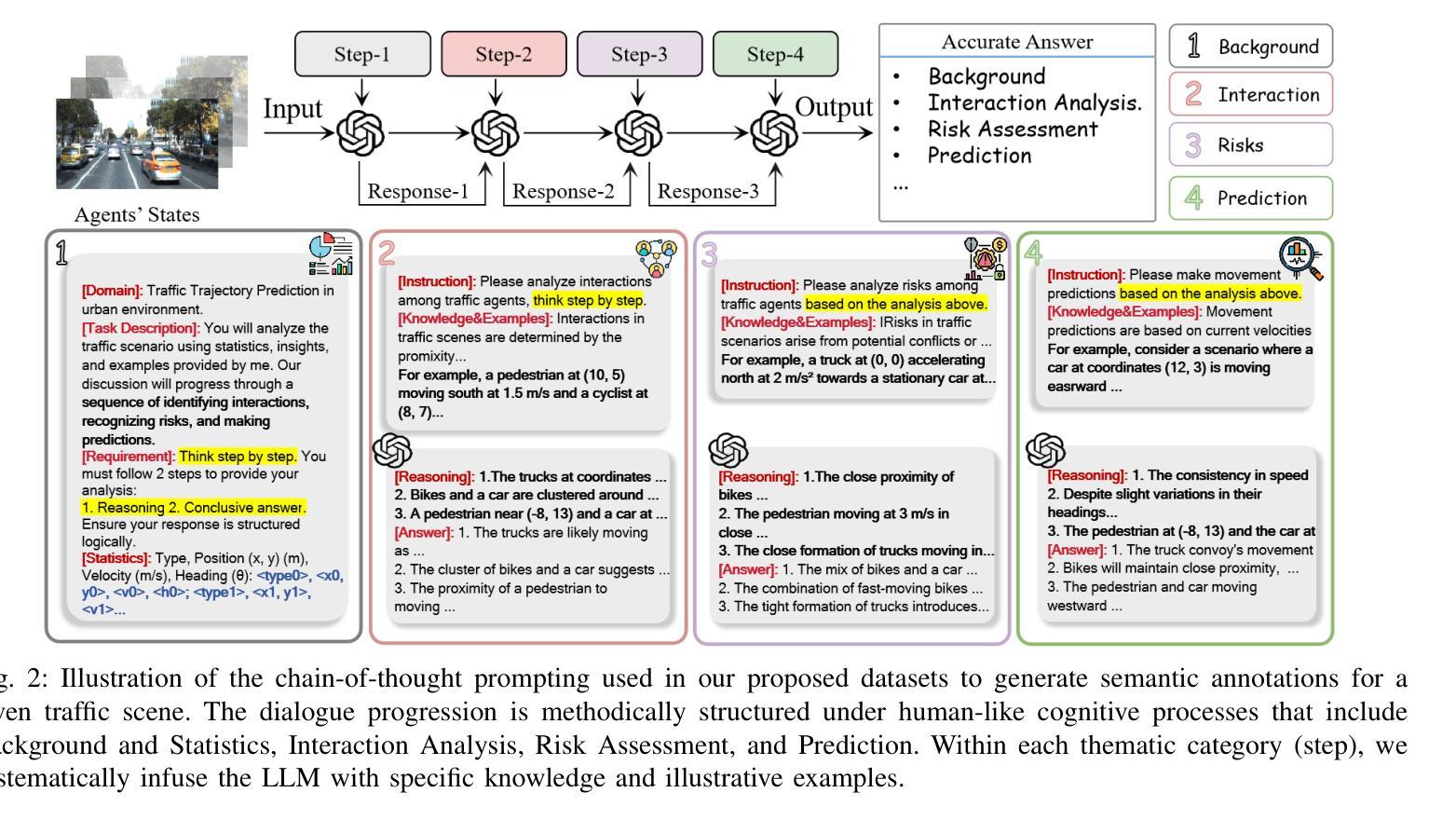
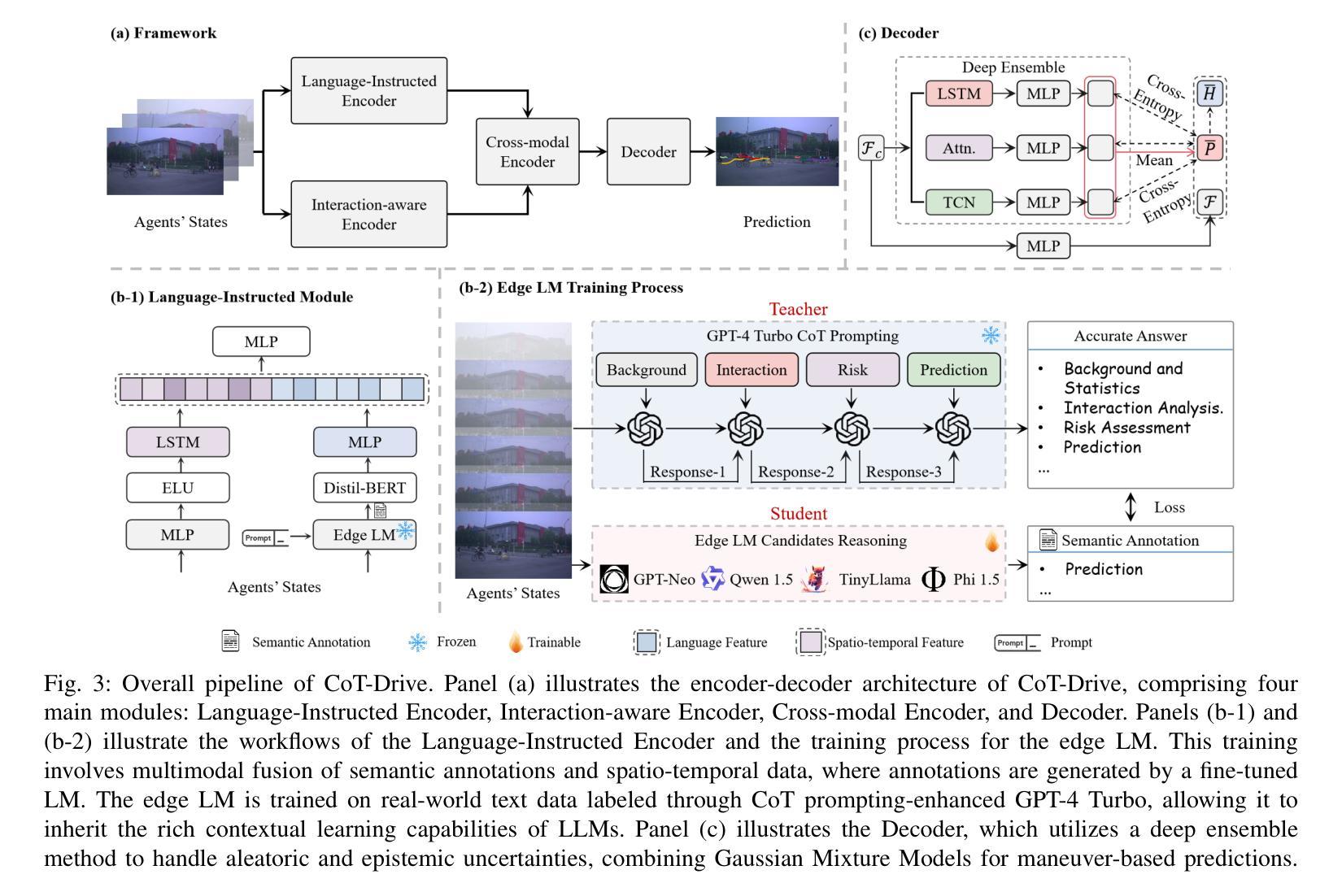
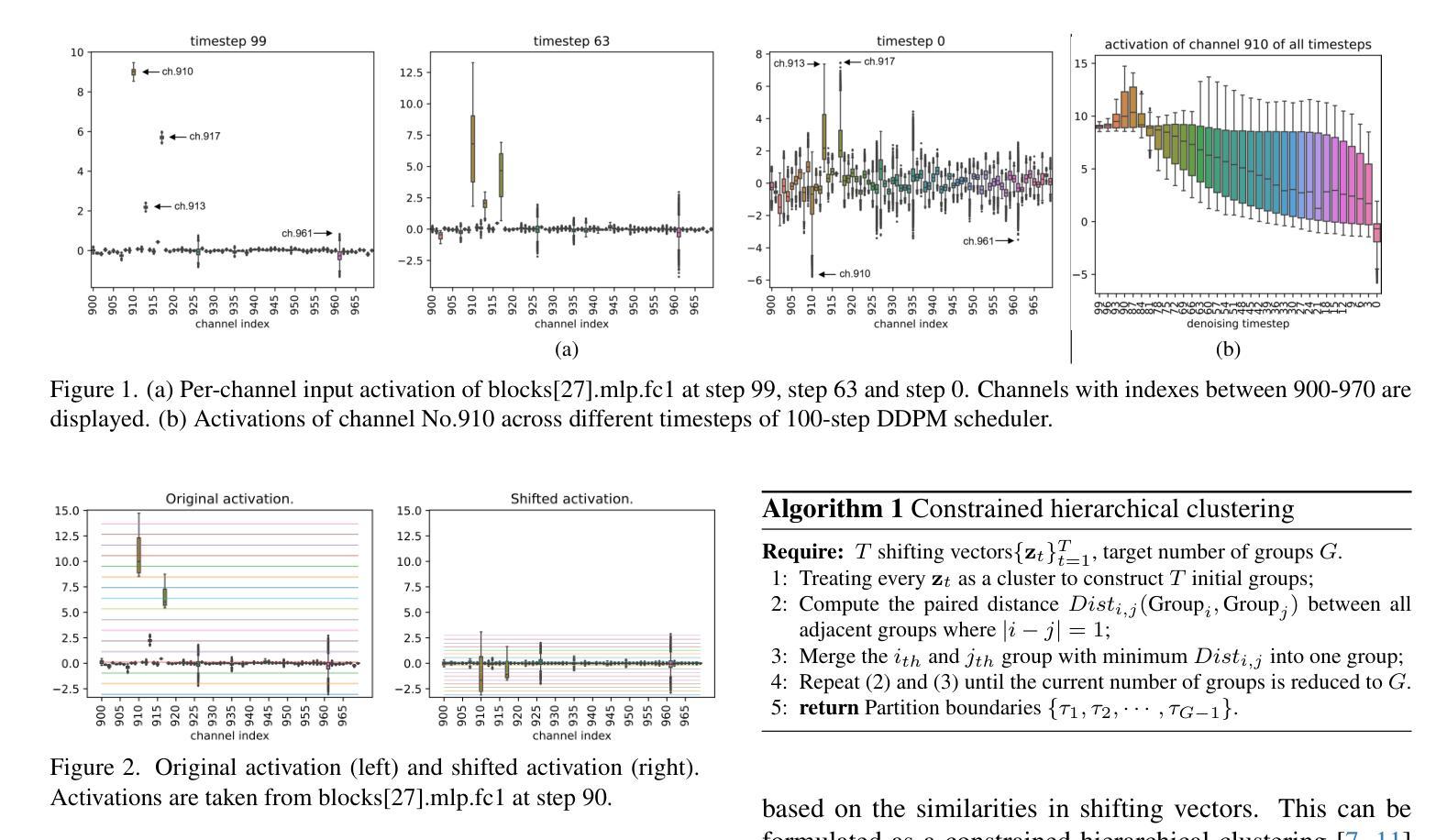
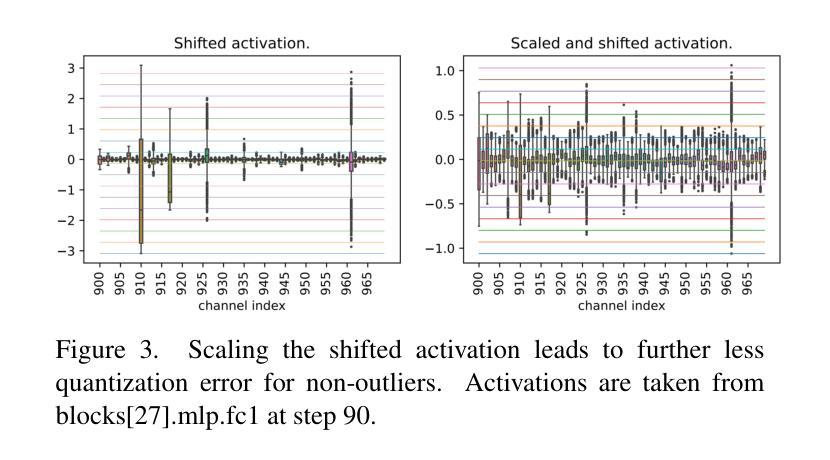
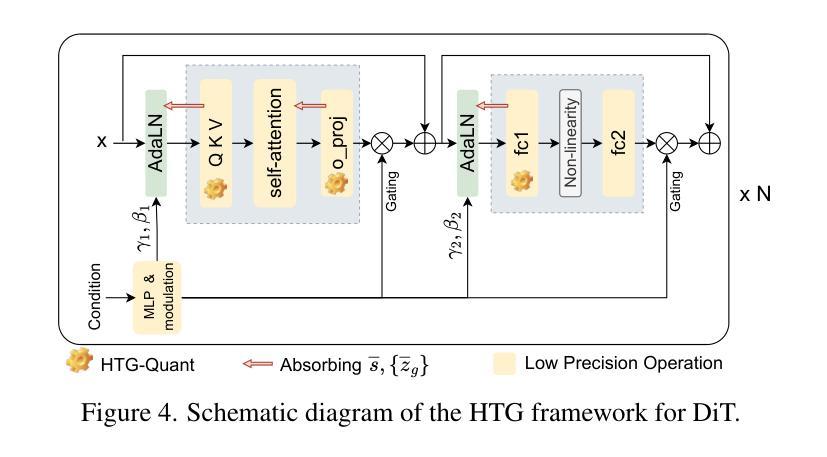
Post-Training Quantization for Diffusion Transformer via Hierarchical Timestep Grouping
Authors:Ning Ding, Jing Han, Yuchuan Tian, Chao Xu, Kai Han, Yehui Tang
Diffusion Transformer (DiT) has now become the preferred choice for building image generation models due to its great generation capability. Unlike previous convolution-based UNet models, DiT is purely composed of a stack of transformer blocks, which renders DiT excellent in scalability like large language models. However, the growing model size and multi-step sampling paradigm bring about considerable pressure on deployment and inference. In this work, we propose a post-training quantization framework tailored for Diffusion Transforms to tackle these challenges. We firstly locate that the quantization difficulty of DiT mainly originates from the time-dependent channel-specific outliers. We propose a timestep-aware shift-and-scale strategy to smooth the activation distribution to reduce the quantization error. Secondly, based on the observation that activations of adjacent timesteps have similar distributions, we utilize a hierarchical clustering scheme to divide the denoising timesteps into multiple groups. We further design a re-parameterization scheme which absorbs the quantization parameters into nearby module to avoid redundant computations. Comprehensive experiments demonstrate that out PTQ method successfully quantize the Diffusion Transformer into 8-bit weight and 8-bit activation (W8A8) with state-of-the-art FiD score. And our method can further quantize DiT model into 4-bit weight and 8-bit activation (W4A8) without sacrificing generation quality.
扩散转换器(DiT)因其出色的生成能力,现已成为构建图像生成模型的首选。与之前的基于卷积的UNet模型不同,DiT完全由一堆转换器块组成,这使得DiT在可扩展性方面表现出色,就像大型语言模型一样。然而,不断增长的模型大小和分步采样范式给部署和推理带来了巨大的压力。在这项工作中,我们提出了针对扩散转换的后训练量化框架来解决这些挑战。我们首先发现DiT的量化难度主要源于时间依赖的通道特定异常值。我们提出了一种时间步感知的移位和缩放策略,以平滑激活分布,从而减少量化误差。其次,基于相邻时间步的激活具有相似分布的观测,我们采用分层聚类方案将去噪时间步分为多个组。我们进一步设计了一种重新参数化方案,将量化参数吸收到附近的模块中,以避免冗余计算。综合实验表明,我们的PTQ方法成功地将扩散转换器量化到8位权重和8位激活(W8A8),具有最先进的FID分数。我们的方法还可以将DiT模型进一步量化到4位权重和8位激活(W4A8),而不会牺牲生成质量。
论文及项目相关链接
Summary
本文介绍了针对扩散变换器(DiT)的定制后训练量化框架,解决了模型生成图像时的部署和推理压力问题。文章指出DiT的量化难点主要来自时间依赖的通道特定异常值,并提出了时间感知移位缩放策略和层次聚类方案来解决这一问题。此外,文章还设计了一种重新参数化方案,避免冗余计算。实验证明,该方法成功将扩散变换器量化至8位权重和8位激活(W8A8),并达到了先进的FID得分。同时,该方法还能将DiT模型进一步量化至4位权重和8位激活(W4A8)而不牺牲生成质量。
Key Takeaways
- 扩散变换器(DiT)已成为图像生成模型的优选,因其出色的生成能力和类似于大型语言模型的良好可扩展性。
- DiT的量化面临挑战,主要源于时间依赖的通道特定异常值。
- 提出了一种时间感知移位缩放策略,通过平滑激活分布来减少量化误差。
- 利用层次聚类方案将去噪时间步长分组,提高模型效率。
- 设计了一种重新参数化方案,避免冗余计算。
- 实验证明,该方法成功将DiT模型量化至W8A8,并保持较高的FID得分。
点此查看论文截图

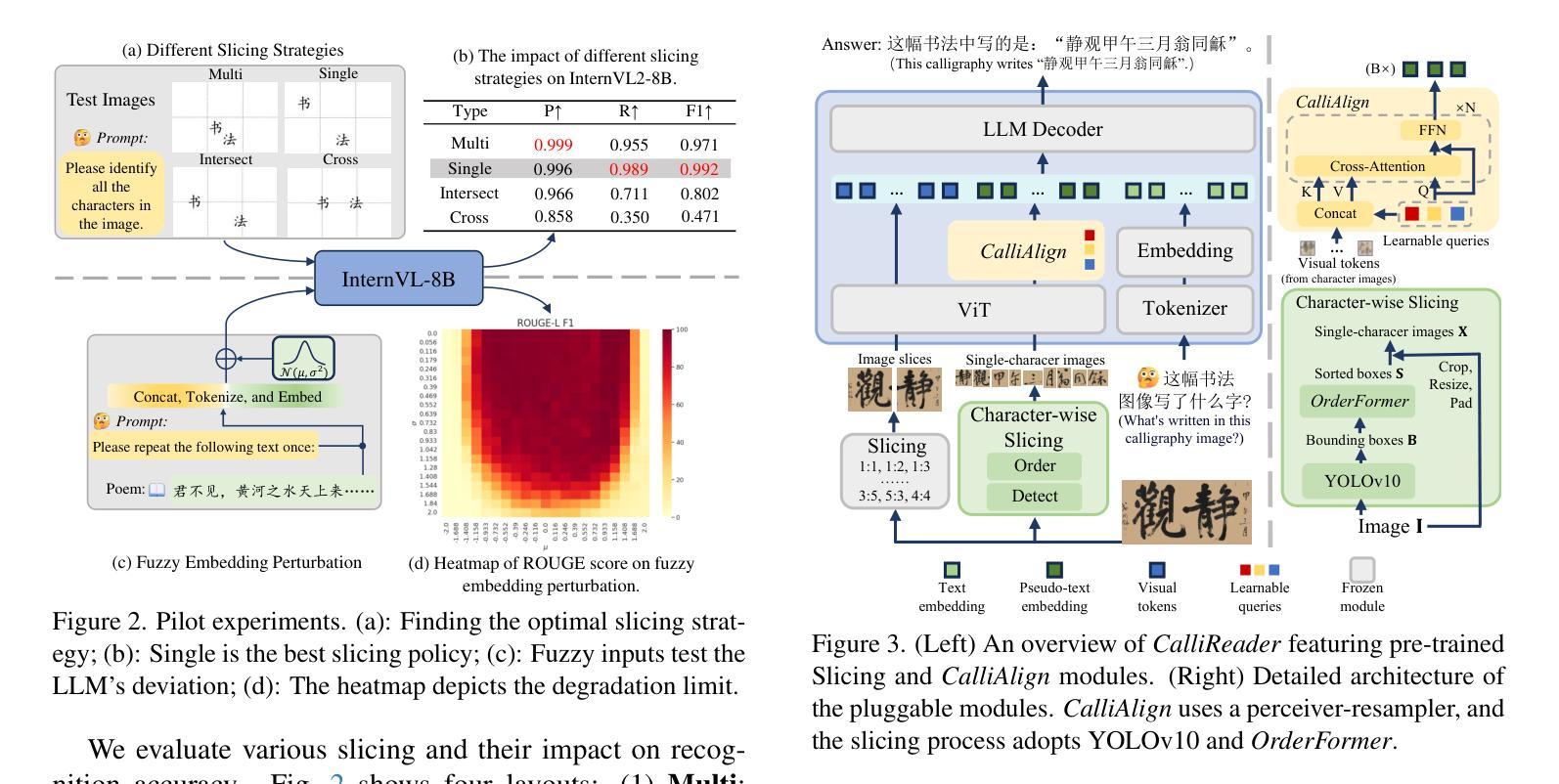
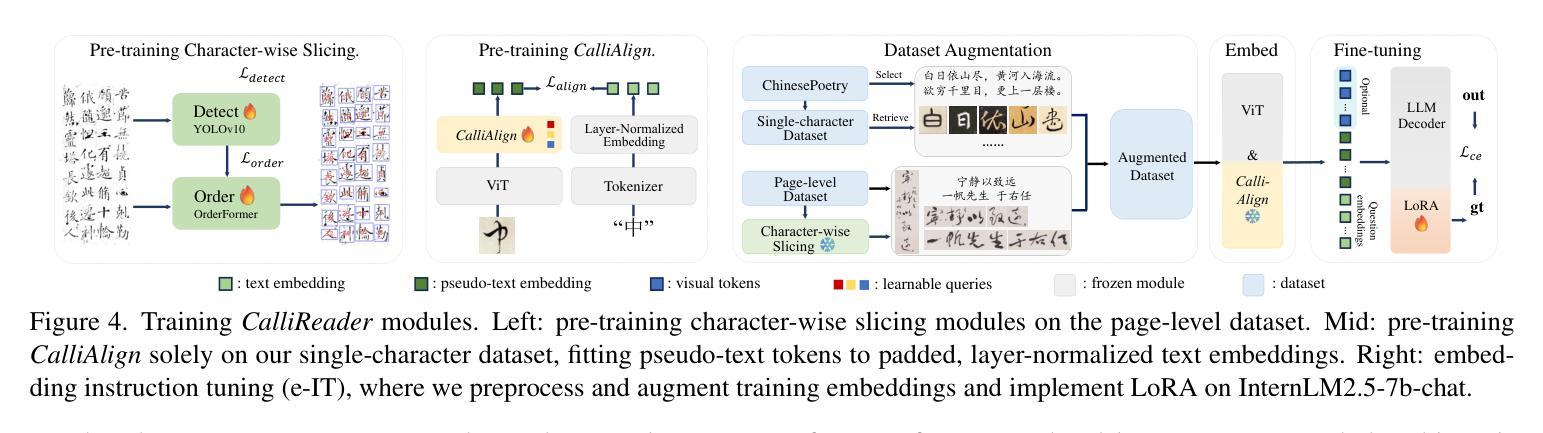
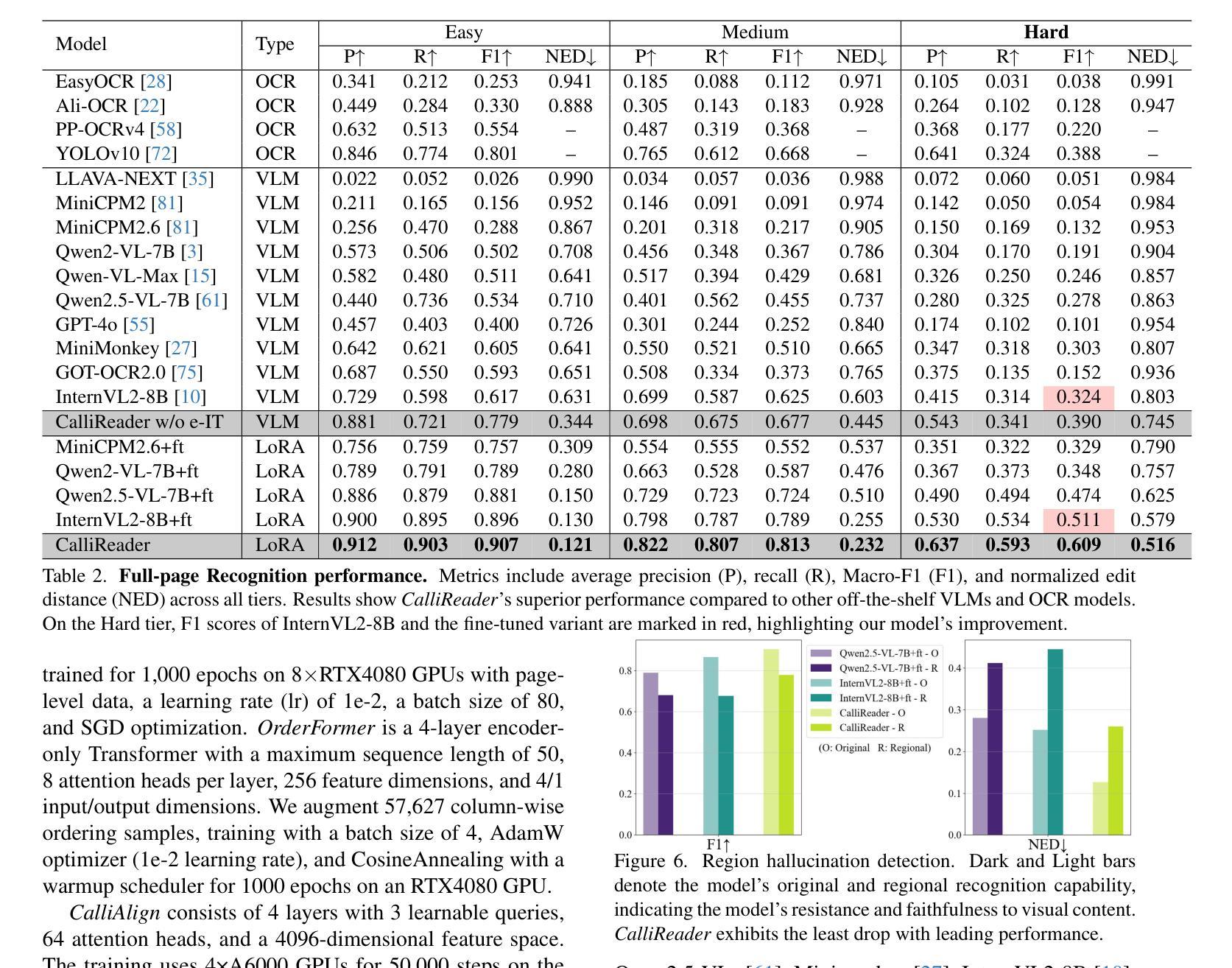
CalliReader: Contextualizing Chinese Calligraphy via an Embedding-Aligned Vision-Language Model
Authors:Yuxuan Luo, Jiaqi Tang, Chenyi Huang, Feiyang Hao, Zhouhui Lian
Chinese calligraphy, a UNESCO Heritage, remains computationally challenging due to visual ambiguity and cultural complexity. Existing AI systems fail to contextualize their intricate scripts, because of limited annotated data and poor visual-semantic alignment. We propose CalliReader, a vision-language model (VLM) that solves the Chinese Calligraphy Contextualization (CC$^2$) problem through three innovations: (1) character-wise slicing for precise character extraction and sorting, (2) CalliAlign for visual-text token compression and alignment, (3) embedding instruction tuning (e-IT) for improving alignment and addressing data scarcity. We also build CalliBench, the first benchmark for full-page calligraphic contextualization, addressing three critical issues in previous OCR and VQA approaches: fragmented context, shallow reasoning, and hallucination. Extensive experiments including user studies have been conducted to verify our CalliReader’s \textbf{superiority to other state-of-the-art methods and even human professionals in page-level calligraphy recognition and interpretation}, achieving higher accuracy while reducing hallucination. Comparisons with reasoning models highlight the importance of accurate recognition as a prerequisite for reliable comprehension. Quantitative analyses validate CalliReader’s efficiency; evaluations on document and real-world benchmarks confirm its robust generalization ability.
中国书法的传承,因其独特的视觉复杂性和文化因素而成为联合国教科文组织的世界遗产。然而,由于现有的AI系统面临视觉模糊和文化复杂性所带来的挑战,它们在解析复杂的书法符号时无法做到充分理解上下文语境。这种情况的产生主要是由于注释数据有限以及视觉语义匹配效果不佳所导致的。为了解决这个问题,我们提出了一种新的视觉语言模型(VLM),并命名为CalliReader。它通过三项创新解决了中文书法上下文解析(CC$^2$)问题:(1)字符级切片技术,用于精确提取和排序字符;(2)CalliAlign用于视觉文本标记压缩和对齐;(3)嵌入指令微调(e-IT)技术用于改进对齐并解决数据稀缺问题。我们还建立了CalliBench,这是第一个用于全页书法上下文化的基准测试,解决了以前OCR和VQA方法中的三个关键问题:上下文碎片化、推理浅层次和幻觉现象。我们进行了大量实验和用户研究,验证了CalliReader在页级书法识别和解释方面优于其他最先进的方法和甚至专业人类专家的优势,能够在提高准确性的同时减少幻觉现象的出现。与推理模型的比较突出了准确识别是可靠理解的重要先决条件的重要性。定量分析验证了CalliReader的效率;在文档和真实世界的基准测试上的评估证明了其稳健的泛化能力。
论文及项目相关链接
PDF 11 pages
Summary
本文介绍了中文书法这一联合国教科文组织遗产在计算上所面临的挑战,如视觉模糊和文化复杂性等。现有的AI系统无法根据上下文解析其复杂的脚本,这受限于有限标注数据和视觉语义对齐不佳的问题。本文提出了CalliReader,一种解决中文书法上下文解析问题的视觉语言模型(VLM)。该模型通过三项创新技术来解决这一问题:字符级的切片技术以实现精确字符提取和排序、CalliAlign视觉文本令牌压缩和对齐技术、嵌入指令调整(e-IT)以提高对齐并解决数据稀缺问题。此外,本文还构建了CalliBench,首个全页书法上下文解析的基准测试平台,解决了之前OCR和VQA方法中的三个关键问题:上下文碎片化、推理浅层和虚构问题。实验和用户研究证明,CalliReader在页级书法识别和解释方面优于其他先进方法和专业人类,实现了更高的准确性和较低的虚构性。与推理模型的比较突显了准确识别作为可靠理解先决条件的重要性。定量分析验证了CalliReader的效率,对文档和真实世界的基准测试评估证明了其稳健的泛化能力。
Key Takeaways
- 中文书法是联合国教科文组织认定的重要遗产,面临视觉模糊和文化复杂性带来的计算挑战。
- 现有AI系统在处理中文书法时存在局限性,主要是因为标注数据有限和视觉语义对齐不佳。
- CalliReader是一种视觉语言模型(VLM),通过三项创新技术解决中文书法上下文解析问题:字符提取、视觉文本令牌压缩和对齐以及嵌入指令调整。
- CalliBench是首个全页书法上下文解析的基准测试平台,解决了之前OCR和VQA方法的三个关键问题。
- CalliReader在页级书法识别和解释方面表现出卓越性能,优于其他先进方法和专业人类。
- 准确识别是可靠理解的重要先决条件,与推理模型的比较突显了这一观点。
点此查看论文截图



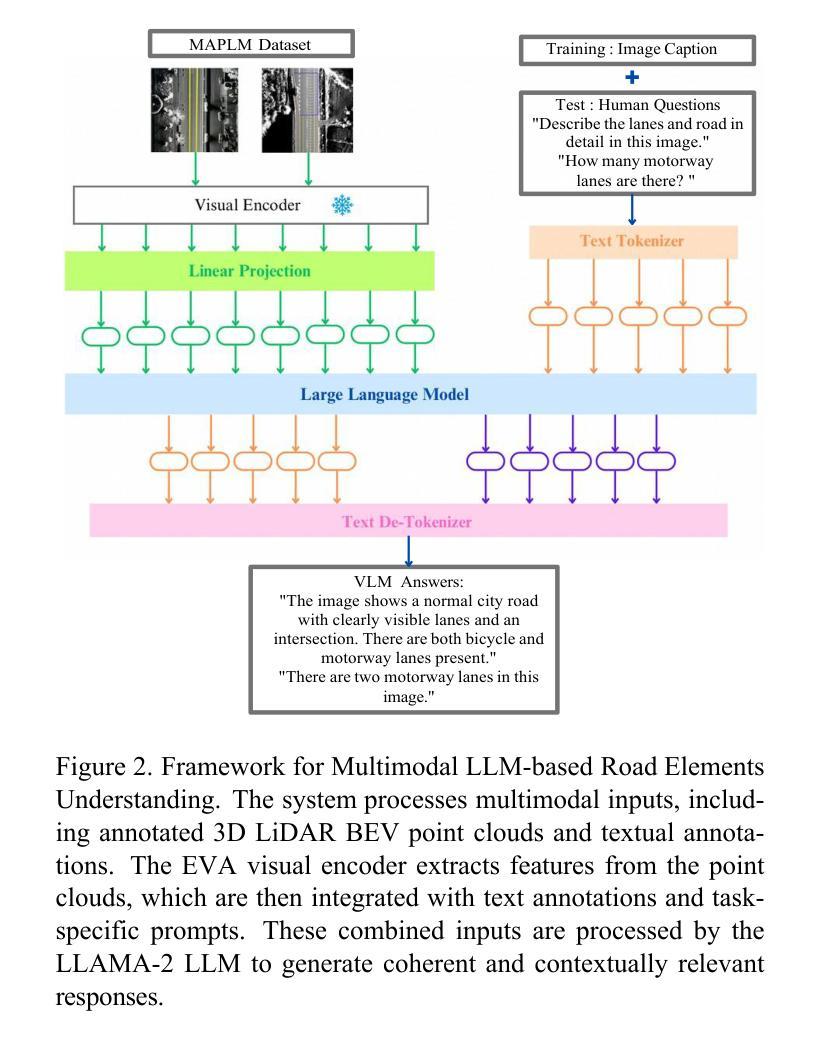
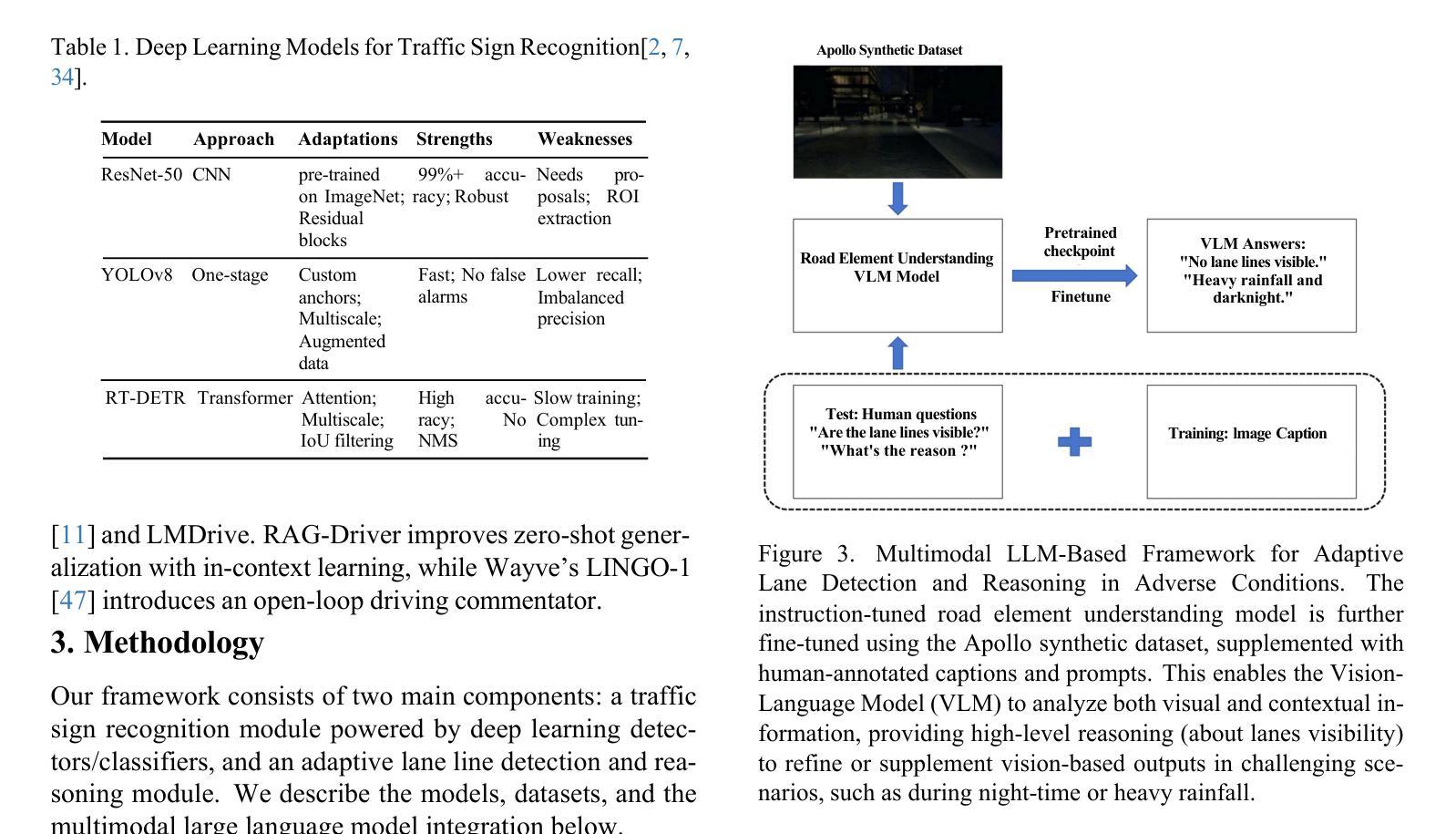
Advancing Autonomous Vehicle Intelligence: Deep Learning and Multimodal LLM for Traffic Sign Recognition and Robust Lane Detection
Authors:Chandan Kumar Sah, Ankit Kumar Shaw, Xiaoli Lian, Arsalan Shahid Baig, Tuopu Wen, Kun Jiang, Mengmeng Yang, Diange Yang
Autonomous vehicles (AVs) require reliable traffic sign recognition and robust lane detection capabilities to ensure safe navigation in complex and dynamic environments. This paper introduces an integrated approach combining advanced deep learning techniques and Multimodal Large Language Models (MLLMs) for comprehensive road perception. For traffic sign recognition, we systematically evaluate ResNet-50, YOLOv8, and RT-DETR, achieving state-of-the-art performance of 99.8% with ResNet-50, 98.0% accuracy with YOLOv8, and achieved 96.6% accuracy in RT-DETR despite its higher computational complexity. For lane detection, we propose a CNN-based segmentation method enhanced by polynomial curve fitting, which delivers high accuracy under favorable conditions. Furthermore, we introduce a lightweight, Multimodal, LLM-based framework that directly undergoes instruction tuning using small yet diverse datasets, eliminating the need for initial pretraining. This framework effectively handles various lane types, complex intersections, and merging zones, significantly enhancing lane detection reliability by reasoning under adverse conditions. Despite constraints in available training resources, our multimodal approach demonstrates advanced reasoning capabilities, achieving a Frame Overall Accuracy (FRM) of 53.87%, a Question Overall Accuracy (QNS) of 82.83%, lane detection accuracies of 99.6% in clear conditions and 93.0% at night, and robust performance in reasoning about lane invisibility due to rain (88.4%) or road degradation (95.6%). The proposed comprehensive framework markedly enhances AV perception reliability, thus contributing significantly to safer autonomous driving across diverse and challenging road scenarios.
自动驾驶车辆(AVs)需要可靠的交通标志识别和稳健的车道检测能力,以确保在复杂和动态环境中的安全导航。本文介绍了一种结合先进深度学习技术和多模态大型语言模型(MLLMs)的综合方法,用于全面的道路感知。对于交通标志识别,我们系统地评估了ResNet-50、YOLOv8和RT-DETR的性能,使用ResNet-50达到了99.8%的先进性能,使用YOLOv8达到了98.0%的准确度,尽管RT-DETR的计算复杂度较高,但达到了96.6%的准确度。对于车道检测,我们提出了一种基于CNN的分割方法,通过多项式曲线拟合进行增强,在有利条件下具有较高的准确性。此外,我们还引入了一个轻量级的、基于多模态LLM的框架,该框架通过直接使用小型但多样化的数据集进行指令微调,无需初始预训练。该框架能够有效处理各种车道类型、复杂交叉路口和合并区域,通过不良条件下的推理,显著提高车道检测的可靠性。尽管可用的训练资源存在约束,我们的多模态方法展示了高级推理能力,达到了帧整体准确率(FRM)为53.87%,问题整体准确率(QNS)为82.83%,在清晰条件下的车道检测准确率为99.6%,夜间为93.0%,并且在理性关于因降雨(88.4%)或路面退化(95.6%)导致车道不可见的情况时表现出稳健的性能。所提出的综合框架显著提高了AV感知可靠性,从而为各种具有挑战的道路场景中的更安全自动驾驶做出了重大贡献。
论文及项目相关链接
PDF 11 pages, 9 figures
Summary
在自动驾驶车辆中,交通标志识别和车道检测是实现安全导航的关键技术。本文结合了深度学习和多模态大型语言模型(MLLMs),提出了一种全面的道路感知方法。在交通标志识别方面,通过ResNet-50、YOLOv8和RT-DETR等方法实现了高达99.8%、98.0%和96.6%的准确率。在车道检测方面,通过CNN分割方法和多项式曲线拟合技术提高了准确性。此外,本文提出了一种基于LLM的多模态框架,可直接通过指令调整使用小型多样数据集,无需初始预训练。该框架在各种车道类型、复杂交叉口和合并区等条件下表现出强大的推理能力,提高了车道检测的可靠性。在有限的训练资源下,该方法在多种挑战场景下表现出卓越性能,为自动驾驶车辆提供了可靠的感知支持。
Key Takeaways
- 自动驾驶车辆需要可靠的交通标志识别和车道检测技术以确保安全导航。
- 本文结合了深度学习和多模态大型语言模型(MLLMs)提出了全面的道路感知方法。
- 在交通标志识别方面,ResNet-50、YOLOv8和RT-DETR等方法表现出高准确率。
- 车道检测方面采用了CNN分割方法和多项式曲线拟合技术以提高准确性。
- 提出了一种基于LLM的多模态框架,可直接通过指令调整使用小型数据集,增强了在不同条件下的车道检测可靠性。
- 在有限的训练资源下,该方法表现出卓越性能,为自动驾驶车辆提供了可靠的感知支持。
点此查看论文截图


X2I: Seamless Integration of Multimodal Understanding into Diffusion Transformer via Attention Distillation
Authors:Jian Ma, Qirong Peng, Xu Guo, Chen Chen, Haonan Lu, Zhenyu Yang
Text-to-image (T2I) models are well known for their ability to produce highly realistic images, while multimodal large language models (MLLMs) are renowned for their proficiency in understanding and integrating multiple modalities. However, currently there is no straightforward and efficient framework to transfer the multimodal comprehension abilities of MLLMs to T2I models to enable them to understand multimodal inputs. In this paper, we propose the X2I framework, which endows Diffusion Transformer (DiT) models with the capability to comprehend various modalities, including multilingual text, screenshot documents, images, videos, and audio. X2I is trained using merely 100K English corpus with 160 GPU hours. Building on the DiT teacher model, we adopt an innovative distillation method to extract the inference capabilities of the teacher model and design a lightweight AlignNet structure to serve as an intermediate bridge. Compared to the teacher model, X2I shows a decrease in performance degradation of less than 1% while gaining various multimodal understanding abilities, including multilingual to image, image to image, image-text to image, video to image, audio to image, and utilizing creative fusion to enhance imagery. Furthermore, it is applicable for LoRA training in the context of image-text to image generation, filling a void in the industry in this area. We further design a simple LightControl to enhance the fidelity of instructional image editing. Finally, extensive experiments demonstrate the effectiveness, efficiency, multifunctionality, and transferability of our X2I. The open-source code and checkpoints for X2I can be found at the following link: https://github.com/OPPO-Mente-Lab/X2I.
文本到图像(T2I)模型以其生成高度逼真的图像的能力而闻名,而多模态大型语言模型(MLLMs)则以其在理解和融合多种模态方面的专长而著称。然而,目前没有一个简单有效的框架能够将MLLMs的多模态理解能力转移到T2I模型上,以使其能够理解多模态输入。在本文中,我们提出了X2I框架,它赋予了Diffusion Transformer(DiT)模型理解多种模态的能力,包括多语言文本、截图文档、图像、视频和音频。X2I仅使用100K英文语料库和160 GPU小时进行训练。基于DiT教师模型,我们采用了一种创新的蒸馏方法,以提取教师模型的推理能力,并设计了一个轻量级的AlignNet结构作为中间桥梁。与教教师模型相比,X2I的性能下降程度不到1%,同时获得了多种多模态理解能力,包括多语言到图像、图像到图像、图文到图像、视频到图像、音频到图像,并利用创意融合增强图像。此外,它在图像文本到图像生成的LoRA训练中也适用,填补了行业中的空白。我们还进一步设计了一个简单的LightControl,以提高教学图像编辑的保真度。最后,大量实验证明了我们的X2I的有效性、效率、多功能性和可迁移性。X2I的开源代码和检查点可以在以下链接找到:https://github.com/OPPO-Mente-Lab/X2I。
论文及项目相关链接
PDF https://github.com/OPPO-Mente-Lab/X2I
Summary
本文提出了一个名为X2I的框架,旨在将多模态理解能力从多模态大型语言模型(MLLMs)转移到文本到图像(T2I)模型上。通过X2I框架,Diffusion Transformer(DiT)模型能够理解包括多语言文本、截图文档、图像、视频和音频在内的多种模态。该框架仅使用100K英文语料库和160个GPU小时进行训练。X2I采用创新的蒸馏方法提取教师模型的推理能力,并设计了一个轻量级的AlignNet结构作为中间桥梁。与教师模型相比,X2I性能下降不到1%,同时获得了多种多模态理解能力。此外,X2I还支持在图像到图像生成领域进行LoRA训练,填补了行业空白。X2I框架还具有提高指令性图像编辑保真度的LightControl功能。总体而言,X2I是有效、高效、多功能和可迁移的。
Key Takeaways
- X2I框架成功将多模态理解能力从MLLMs转移到T2I模型上,使其能够处理多种模态输入。
- X2I通过创新的蒸馏方法和轻量级AlignNet结构实现高效训练。
- X2I在少量语料库(100K英文语料库)和计算资源(160 GPU小时)下实现训练。
- 与教师模型相比,X2I性能损失小于1%,但获得了多种多模态理解能力。
- X2I支持图像到图像生成领域的LoRA训练,填补了行业空白。
- X2I框架具有提高指令性图像编辑质量的LightControl功能。
点此查看论文截图


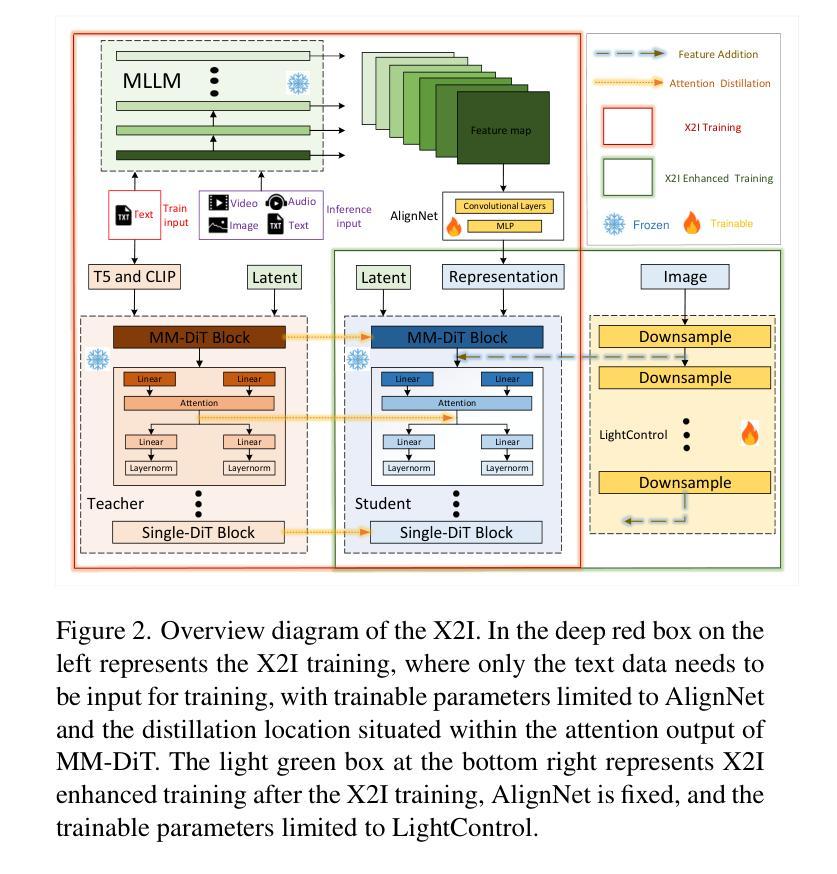
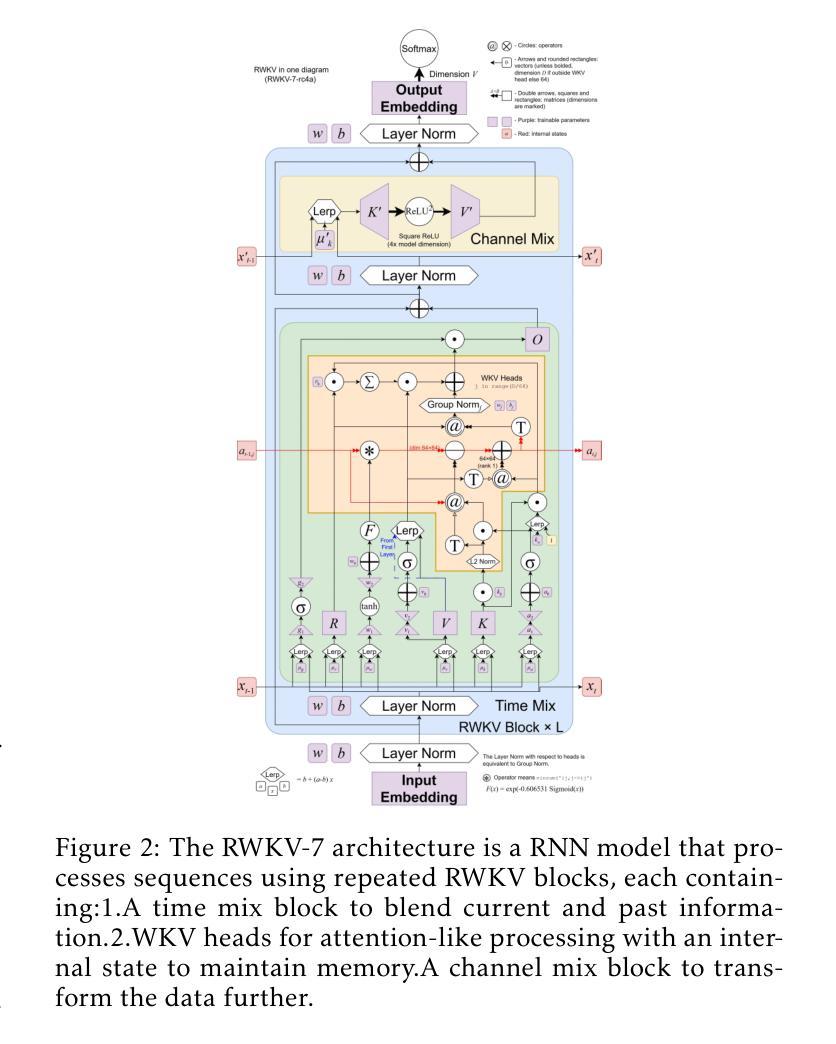
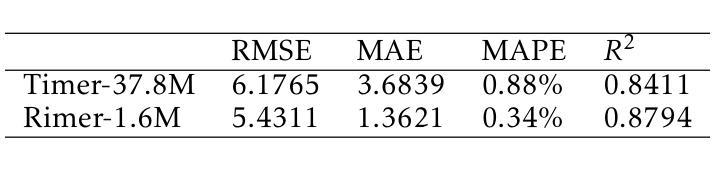
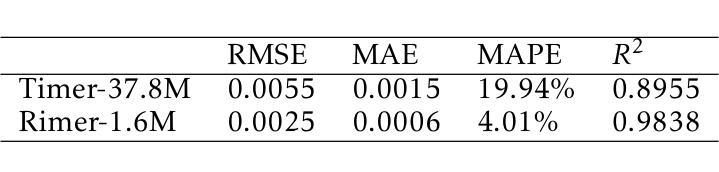
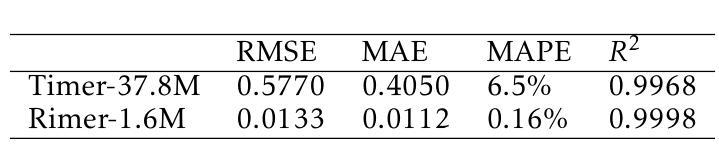
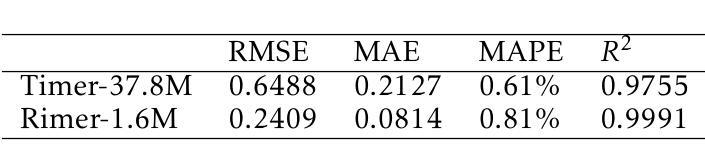
BlackGoose Rimer: Harnessing RWKV-7 as a Simple yet Superior Replacement for Transformers in Large-Scale Time Series Modeling
Authors:Li weile, Liu Xiao
Time series models face significant challenges in scaling to handle large and complex datasets, akin to the scaling achieved by large language models (LLMs). The unique characteristics of time series data and the computational demands of model scaling necessitate innovative approaches. While researchers have explored various architectures such as Transformers, LSTMs, and GRUs to address these challenges, we propose a novel solution using RWKV-7, which incorporates meta-learning into its state update mechanism. By integrating RWKV-7’s time mix and channel mix components into the transformer-based time series model Timer, we achieve a substantial performance improvement of approximately 1.13 to 43.3x and a 4.5x reduction in training time with 1/23 parameters, all while utilizing fewer parameters. Our code and model weights are publicly available for further research and development at https://github.com/Alic-Li/BlackGoose_Rimer.
时间序列模型在扩展到处理大规模且复杂的数据集时面临巨大挑战,这与大型语言模型(LLM)所实现的规模扩展相似。时间序列数据的独特特征和模型扩展的计算需求需要创新的方法。虽然研究人员已经探索了诸如Transformer、LSTM和GRU等各种架构来应对这些挑战,但我们提出了一种使用RWKV-7的新解决方案,它将元学习纳入其状态更新机制。通过将RWKV-7的时间混合和通道混合组件集成到基于Transformer的时间序列模型Timer中,我们在使用更少参数的情况下实现了约1.13至43.3倍的显著性能提升,并实现了训练时间的4.5倍缩减。我们的代码和模型权重可在https://github.com/Alic-Li/BlackGoose_Rimer上公开获取,以供进一步的研究和开发。
论文及项目相关链接
Summary
在大型和复杂数据集的处理上,时间序列模型面临诸多挑战,类似于大型语言模型(LLM)的扩展问题。鉴于时间序列数据的独特特性和模型扩展的计算需求,需要创新方法。研究人员已探索各种架构,如Transformer、LSTM和GRU等来解决这些挑战。本文提出一种使用RWKV-7的解决方法,它将元学习融入状态更新机制中。通过将RWKV-7的时间混合和通道混合成分融入基于Transformer的时间序列模型Timer中,实现了显著的性能提升(约1.13至43.3倍),训练时间减少了4.5倍,同时使用的参数更少(仅为原来的1/23)。相关代码和模型权重已公开发布于[链接],以供进一步研究和发展。
Key Takeaways
- 时间序列模型在应对大规模复杂数据集时面临挑战,需要创新方法来解决。
- RWKV-7通过集成元学习来改进状态更新机制,为时间序列模型提供了新的解决方案。
- 结合RWKV-7的时间混合和通道混合成分到基于Transformer的时间序列模型Timer中,实现了显著的性能提升。
- 相较于传统模型,使用RWKV-7的解决方案能大幅度减少训练时间并降低参数使用量。
- 该解决方案适用于大规模数据集的处理,展示了其在处理复杂数据方面的优势。
- 该研究公开了代码和模型权重以供进一步研究和发展。
点此查看论文截图
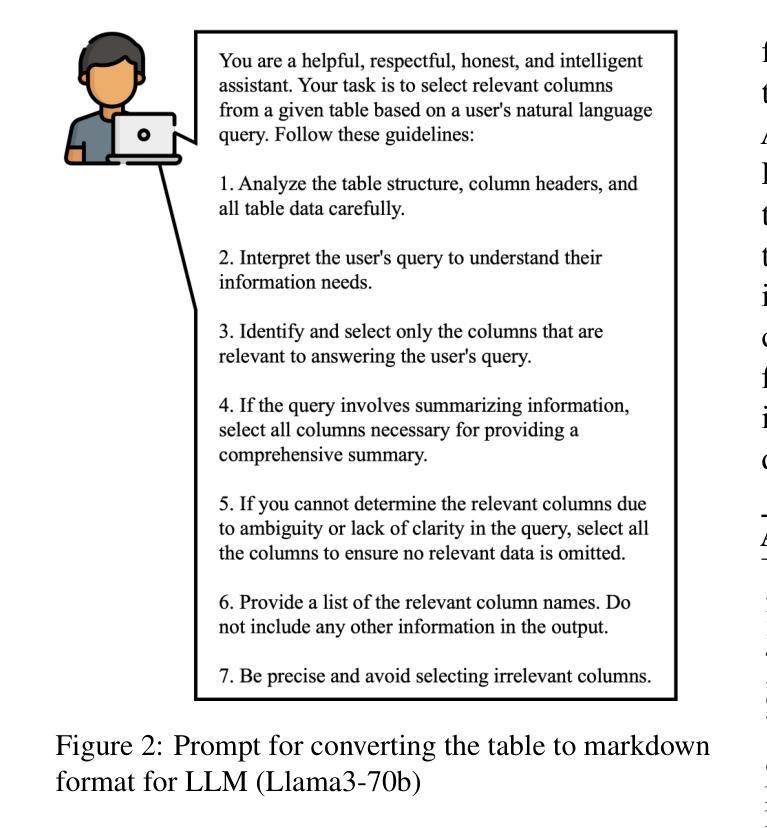
DETQUS: Decomposition-Enhanced Transformers for QUery-focused Summarization
Authors:Yasir Khan, Xinlei Wu, Sangpil Youm, Justin Ho, Aryaan Shaikh, Jairo Garciga, Rohan Sharma, Bonnie J. Dorr
Query-focused tabular summarization is an emerging task in table-to-text generation that synthesizes a summary response from tabular data based on user queries. Traditional transformer-based approaches face challenges due to token limitations and the complexity of reasoning over large tables. To address these challenges, we introduce DETQUS (Decomposition-Enhanced Transformers for QUery-focused Summarization), a system designed to improve summarization accuracy by leveraging tabular decomposition alongside a fine-tuned encoder-decoder model. DETQUS employs a large language model to selectively reduce table size, retaining only query-relevant columns while preserving essential information. This strategy enables more efficient processing of large tables and enhances summary quality. Our approach, equipped with table-based QA model Omnitab, achieves a ROUGE-L score of 0.4437, outperforming the previous state-of-the-art REFACTOR model (ROUGE-L: 0.422). These results highlight DETQUS as a scalable and effective solution for query-focused tabular summarization, offering a structured alternative to more complex architectures.
查询聚焦的表格摘要生成是从表格到文本生成的新兴任务之一,该任务基于用户查询生成从表格数据合成的摘要响应。传统的基于Transformer的方法由于标记限制和大型表格推理的复杂性而面临挑战。为了解决这些挑战,我们引入了DETQUS系统(用于查询聚焦摘要的增强分解转换器),该系统通过利用表格分解和微调过的编码器-解码器模型来提高摘要的准确性。DETQUS利用大型语言模型有选择地减少表格大小,只保留查询相关的列,同时保留重要信息。这一策略使大型表格的处理更加高效,提高了摘要的质量。我们的方法配备了基于表格的问答模型Omnitab,实现了ROUGE-L评分0.4437,超过了之前的最佳模型REFACTOR(ROUGE-L:0.422)。这些结果凸显了DETQUS在查询聚焦的表格摘要生成中的可扩展性和有效性,为更复杂的架构提供了结构化的替代方案。
论文及项目相关链接
PDF 12 pages, 2 figures, Accepted to NAACL 2025 main conference
Summary:
基于用户查询的表格摘要生成是一项新兴任务,旨在从表格数据中生成摘要式回答。针对传统基于Transformer的方法在处理大型表格时面临的令牌限制和推理复杂性挑战,我们引入了DETQUS系统,它通过利用表格分解和一个精细调整的编码器-解码器模型来提高摘要准确性。DETQUS采用大型语言模型选择性地减小表格大小,仅保留与查询相关的列,同时保留关键信息。这种方法使大型表格的处理更加高效,提高了摘要质量。配备基于表格的问答模型Omnitab的DETQUS方法实现了ROUGE-L分数为0.4437,超过了之前的先进模型REFACTOR(ROUGE-L:0.422)。这表明DETQUS为查询聚焦的表格摘要提供了可扩展和有效的解决方案,为更复杂的架构提供了结构化替代方案。
Key Takeaways:
- Query-focused tabular summarization是一项新兴任务,旨在基于用户查询从表格数据中生成摘要。
- 传统方法在处理大型表格时面临挑战,如令牌限制和推理复杂性。
- DETQUS系统通过利用表格分解和精细调整的编码器-解码器模型来提高摘要准确性。
- DETQUS采用大型语言模型选择性地减小表格大小,仅保留与查询相关的列。
- DETQUS提高了摘要质量,并且处理大型表格更加高效。
- DETQUS配备了基于表格的问答模型Omnitab,实现了较高的ROUGE-L分数。
点此查看论文截图

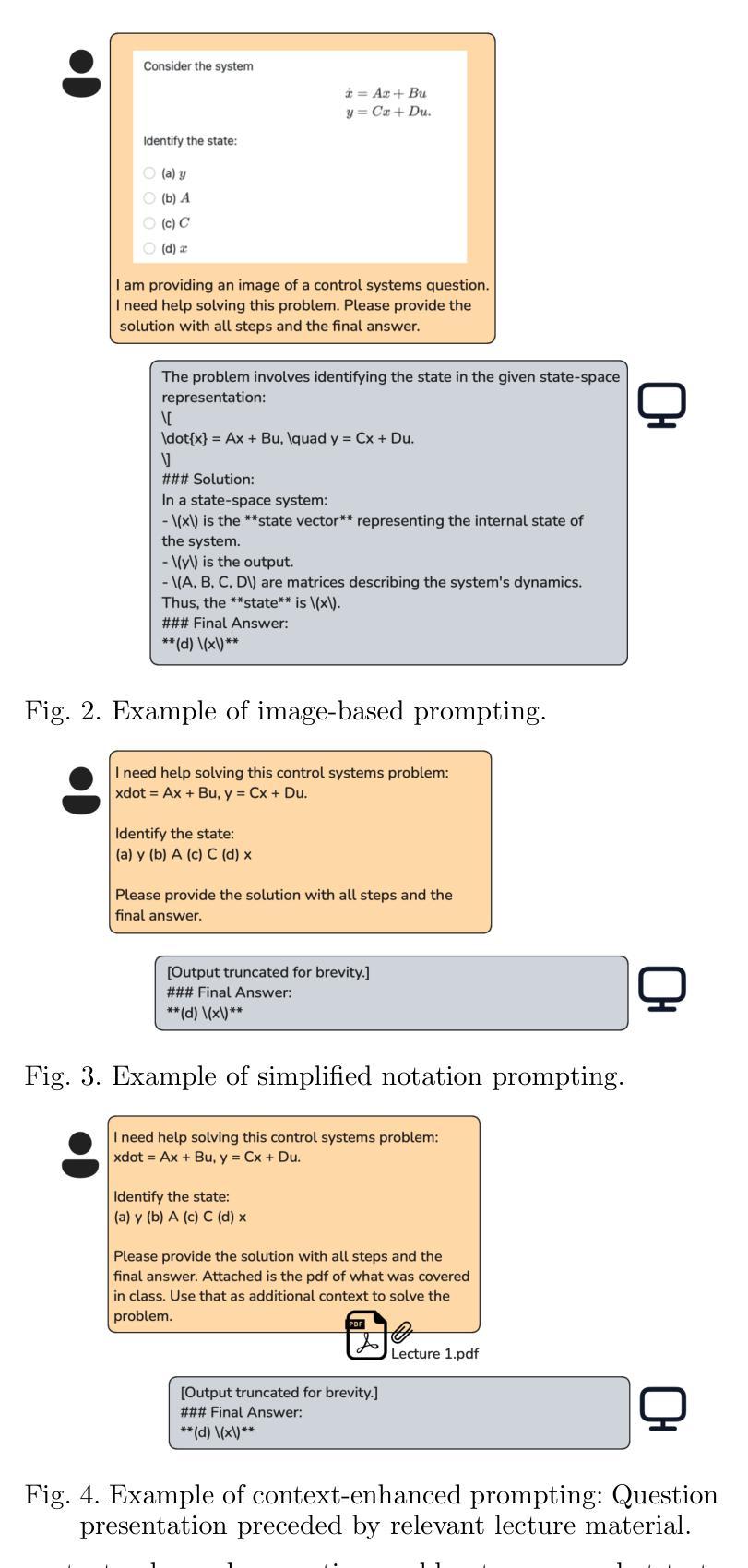
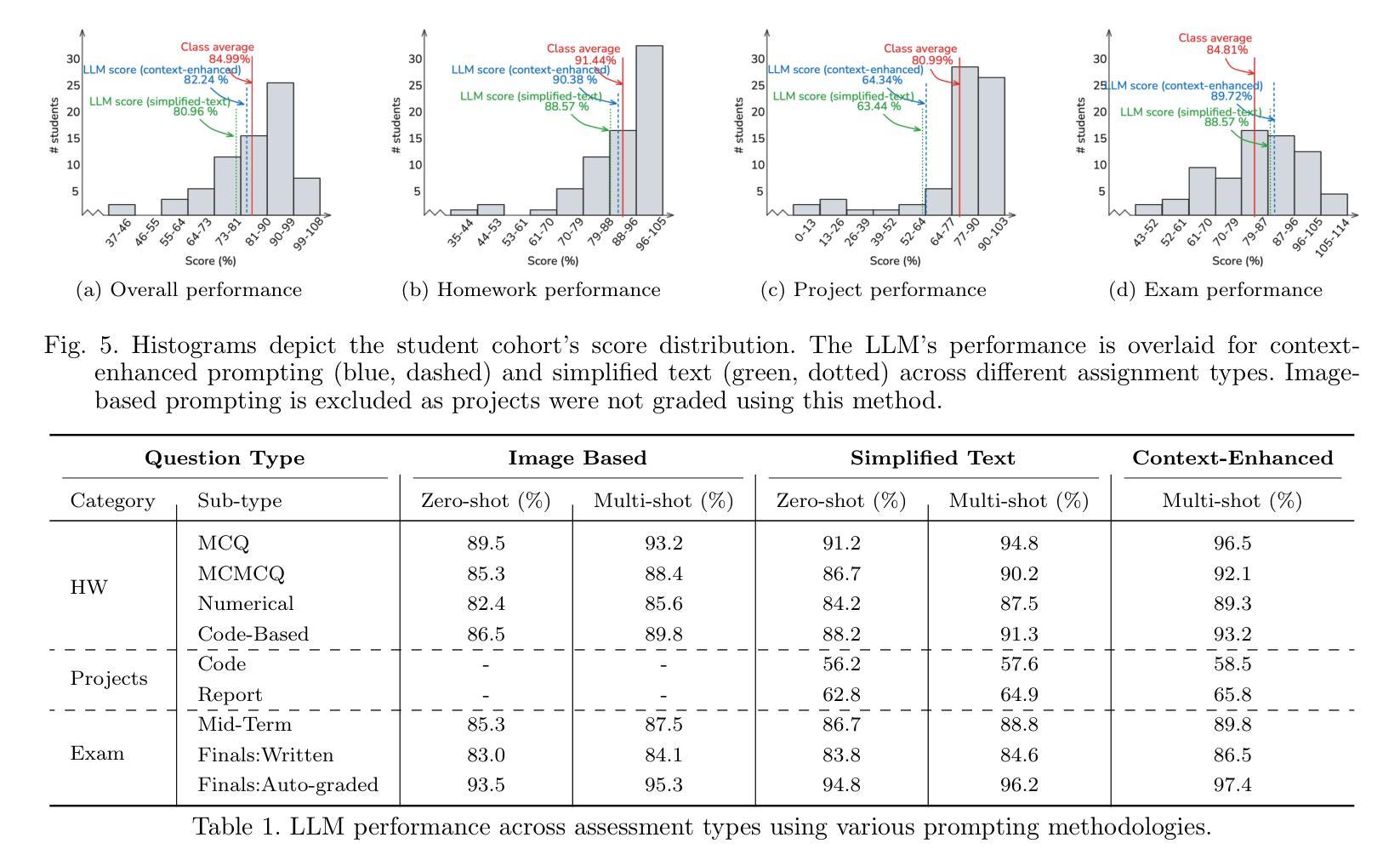
The Lazy Student’s Dream: ChatGPT Passing an Engineering Course on Its Own
Authors:Gokul Puthumanaillam, Melkior Ornik
This paper presents a comprehensive investigation into the capability of Large Language Models (LLMs) to successfully complete a semester-long undergraduate control systems course. Through evaluation of 115 course deliverables, we assess LLM performance using ChatGPT under a ``minimal effort” protocol that simulates realistic student usage patterns. The investigation employs a rigorous testing methodology across multiple assessment formats, from auto-graded multiple choice questions to complex Python programming tasks and long-form analytical writing. Our analysis provides quantitative insights into AI’s strengths and limitations in handling mathematical formulations, coding challenges, and theoretical concepts in control systems engineering. The LLM achieved a B-grade performance (82.24%), approaching but not exceeding the class average (84.99%), with strongest results in structured assignments and greatest limitations in open-ended projects. The findings inform discussions about course design adaptation in response to AI advancement, moving beyond simple prohibition towards thoughtful integration of these tools in engineering education. Additional materials including syllabus, examination papers, design projects, and example responses can be found at the project website: https://gradegpt.github.io.
本文全面探讨了大型语言模型(LLM)成功完成一个学期长的本科控制系统课程的能力。通过对115份课程交付成果的评价,我们在“最小努力”协议下评估了LLM使用ChatGPT的表现,该协议模拟了现实的学生使用模式。调查采用了严格的测试方法,涵盖多种评估形式,从自动分级的多个选择题到复杂的Python编程任务和长篇分析写作。我们的分析提供了关于AI在处理控制系统工程中的数学公式、编程挑战和理论概念的优点和缺点的定量见解。LLM的表现达到了B级(82.24%),接近但未超过班级平均水平(84.99%),在结构化的任务中表现最好,而在开放性的项目中表现有限。研究结果引发了关于适应AI发展而调整课程设计讨论的兴起,从简单的禁止走向对这些工具在工程教育中有思想地整合。其他材料包括教学大纲、考试试卷、设计项目和示例答案可在项目网站找到:https://gradegpt.github.io。
论文及项目相关链接
Summary:
本文研究了大型语言模型(LLM)在控制系统工程课程中完成一个学期课程的性能。通过评估115份课程作业,利用ChatGPT模拟真实学生的使用模式进行“最小努力”协议下的测试。研究采用严格的测试方法,包括自动评分选择题、复杂的Python编程任务和长文分析写作等多种题型。分析结果定量地探讨了人工智能在处理数学公式、编程挑战和理论概念方面的优势与局限性。LLM的表现达到B级水平(82.24%),接近但未超过班级平均水平(84.99%),在结构化作业方面表现最佳,在开放性项目方面存在最大局限性。这些发现引发了关于如何适应人工智能发展而调整课程设计的问题,倡导从简单禁止转向在工程教育中深思熟虑地整合这些工具。
Key Takeaways:
- 大型语言模型(LLM)在控制系统工程课程中的表现进行了全面评估。
- 通过使用ChatGPT进行“最小努力”协议下的测试,模拟真实学生的使用模式。
- 研究采用多种题型进行严格的测试方法,包括自动评分选择题、Python编程任务和长文分析写作。
- LLM在处理数学公式、编程挑战和理论概念方面表现出优势和局限性。
- LLM的表现接近班级平均水平,在结构化作业方面表现最佳,但在开放性项目上仍有局限。
- 研究结果引发了关于如何适应AI发展调整课程设计的讨论。
点此查看论文截图


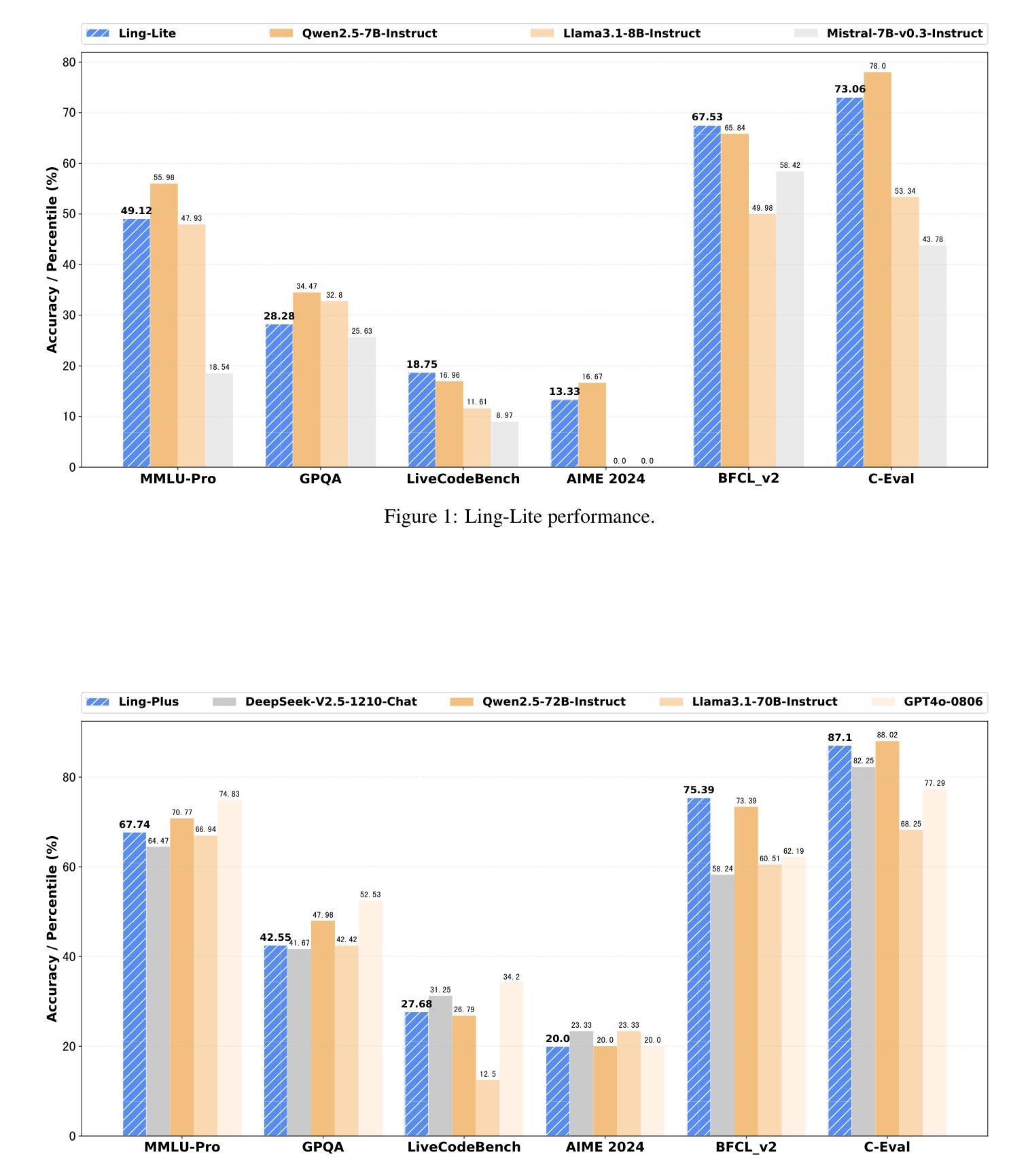
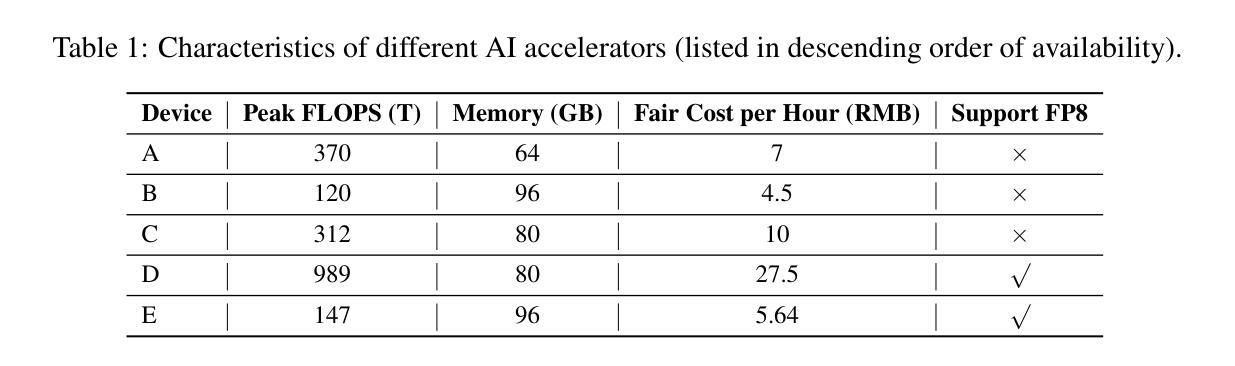
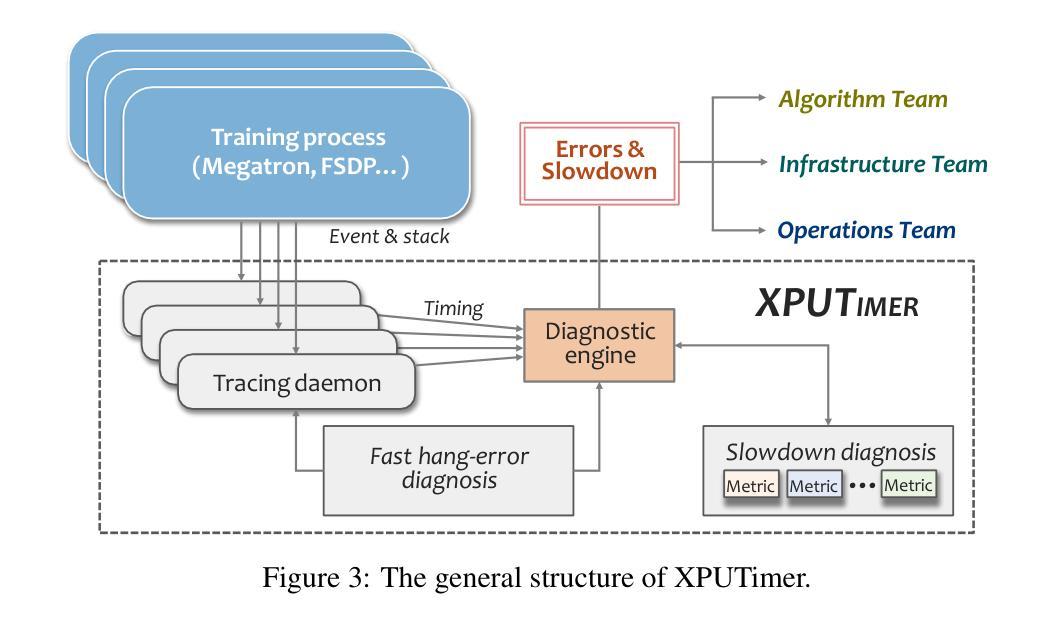
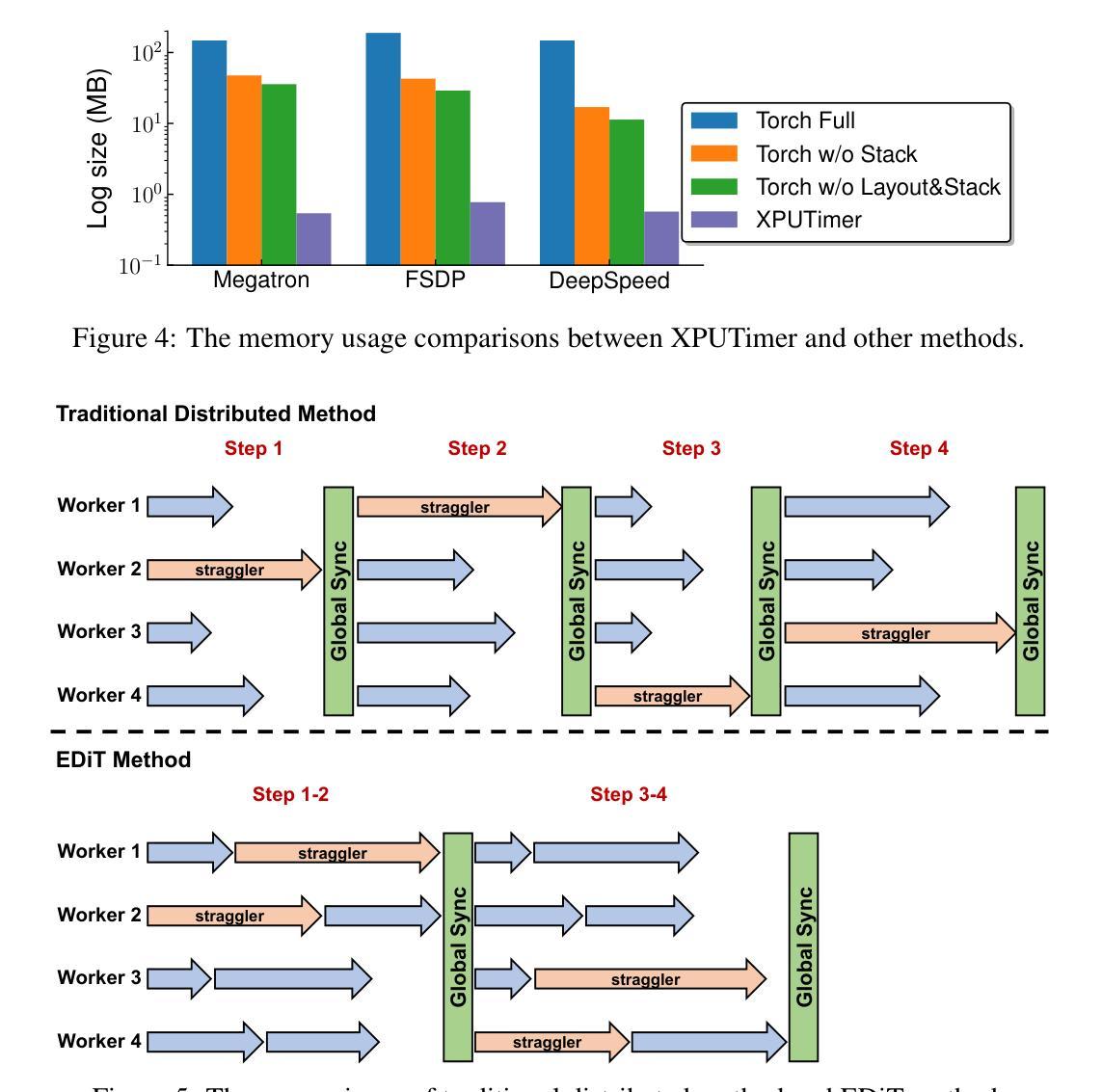
Every FLOP Counts: Scaling a 300B Mixture-of-Experts LING LLM without Premium GPUs
Authors: Ling Team, Binwei Zeng, Chao Huang, Chao Zhang, Changxin Tian, Cong Chen, Dingnan Jin, Feng Yu, Feng Zhu, Feng Yuan, Fakang Wang, Gangshan Wang, Guangyao Zhai, Haitao Zhang, Huizhong Li, Jun Zhou, Jia Liu, Junpeng Fang, Junjie Ou, Jun Hu, Ji Luo, Ji Zhang, Jian Liu, Jian Sha, Jianxue Qian, Jiewei Wu, Junping Zhao, Jianguo Li, Jubao Feng, Jingchao Di, Junming Xu, Jinghua Yao, Kuan Xu, Kewei Du, Longfei Li, Lei Liang, Lu Yu, Li Tang, Lin Ju, Peng Xu, Qing Cui, Song Liu, Shicheng Li, Shun Song, Song Yan, Tengwei Cai, Tianyi Chen, Ting Guo, Ting Huang, Tao Feng, Tao Wu, Wei Wu, Xiaolu Zhang, Xueming Yang, Xin Zhao, Xiaobo Hu, Xin Lin, Yao Zhao, Yilong Wang, Yongzhen Guo, Yuanyuan Wang, Yue Yang, Yang Cao, Yuhao Fu, Yi Xiong, Yanzhe Li, Zhe Li, Zhiqiang Zhang, Ziqi Liu, Zhaoxin Huan, Zujie Wen, Zhenhang Sun, Zhuoxuan Du, Zhengyu He
In this technical report, we tackle the challenges of training large-scale Mixture of Experts (MoE) models, focusing on overcoming cost inefficiency and resource limitations prevalent in such systems. To address these issues, we present two differently sized MoE large language models (LLMs), namely Ling-Lite and Ling-Plus (referred to as “Bailing” in Chinese, spelled B\v{a}il'ing in Pinyin). Ling-Lite contains 16.8 billion parameters with 2.75 billion activated parameters, while Ling-Plus boasts 290 billion parameters with 28.8 billion activated parameters. Both models exhibit comparable performance to leading industry benchmarks. This report offers actionable insights to improve the efficiency and accessibility of AI development in resource-constrained settings, promoting more scalable and sustainable technologies. Specifically, to reduce training costs for large-scale MoE models, we propose innovative methods for (1) optimization of model architecture and training processes, (2) refinement of training anomaly handling, and (3) enhancement of model evaluation efficiency. Additionally, leveraging high-quality data generated from knowledge graphs, our models demonstrate superior capabilities in tool use compared to other models. Ultimately, our experimental findings demonstrate that a 300B MoE LLM can be effectively trained on lower-performance devices while achieving comparable performance to models of a similar scale, including dense and MoE models. Compared to high-performance devices, utilizing a lower-specification hardware system during the pre-training phase demonstrates significant cost savings, reducing computing costs by approximately 20%. The models can be accessed at https://huggingface.co/inclusionAI.
本技术报告中,我们针对训练大规模专家混合模型(MoE)的挑战展开研究,重点关注如何解决这类系统中普遍存在的成本效率问题和资源限制问题。为了解决这些问题,我们推出了两款不同规模的大型语言模型MoE(LLM),即Ling-Lite和Ling-Plus(中文称为“百灵”)。Ling-Lite包含168亿个参数和27.5亿个激活参数,而Ling-Plus则拥有高达29万亿个参数和超过数十亿的激活参数。这两款模型在业内顶尖基准测试中表现出相当的性能。本报告提供了改进资源受限环境中AI开发效率和可及性的实际建议,推动了更加可扩展和可持续的技术。特别是为了减少大规模MoE模型的训练成本,我们提出了创新方法来优化(1)模型架构和训练过程,(2)改进训练异常处理,(3)提高模型评估效率。此外,通过利用知识图谱产生的高质量数据,我们的模型展现出超越其他模型的工具使用能力。最终,我们的实验结果表明,可以在较低性能的设备上有效训练出规模为千亿的MoE大型语言模型(LLM),并实现了与相同规模的模型(包括密集模型和MoE模型)相当的业绩。相较于高性能设备,在预训练阶段使用较低规格的硬件系统可以显著节省成本,计算成本降低了约百分之二十。可以通过网址链接 https://huggingface.co/inclusionAI 了解访问和使用我们的模型。
论文及项目相关链接
PDF 34 pages
摘要
本技术报告专注于应对大规模混合专家(MoE)模型的挑战,特别是解决这些系统中的成本效益和资源限制问题。报告介绍了两款不同规模的大型语言模型(LLM),即Ling-Lite和Ling-Plus(中文称为“Bailing”)。Ling-Lite拥有16.8亿参数和2.75亿激活参数,而Ling-Plus则拥有高达290亿参数和28.8亿激活参数,二者性能与行业领先基准相当。报告提供了在资源受限环境中提高人工智能开发效率和可访问性的实用见解,促进了更可伸缩和可持续的技术发展。为实现大规模MoE模型的高效率培训,报告提出了针对模型架构和培训过程优化、训练异常处理优化以及模型评估效率提升的革新方法。此外,利用知识图谱产生的高质量数据,这些模型在工具使用能力方面表现出卓越性能。最终实验表明,在较低性能的设备上训练一个规模为300B的MoE LLM模型,其性能可与同类模型相媲美,包括密集模型和MoE模型。相较于高性能设备,在预训练阶段使用较低规格的硬件系统可显著降低计算成本,大约节省20%的成本。模型可通过https://huggingface.co/inclusionAI访问。
关键见解
- 报告介绍了两款大型语言模型(LLM),Ling-Lite和Ling-Plus,旨在解决大规模混合专家(MoE)模型的挑战。
- 这些模型通过优化模型架构和培训过程、改进训练异常处理和提升模型评估效率等方法,实现了资源受限环境下的高效训练。
- 知识图谱产生的高质量数据增强了模型的工具使用能力。
- 实验显示,在较低性能的设备上训练的规模为300B的MoE LLM性能卓越,与同类模型相当。
- 与高性能设备相比,预训练阶段使用较低规格硬件系统可显著降低计算成本,节省约20%。
- 报告提供的实用见解有助于提高AI开发的效率和可访问性,促进更可伸缩和可持续的技术发展。
点此查看论文截图

Leveraging Large Language Models to Address Data Scarcity in Machine Learning: Applications in Graphene Synthesis
Authors:Devi Dutta Biswajeet, Sara Kadkhodaei
Machine learning in materials science faces challenges due to limited experimental data, as generating synthesis data is costly and time-consuming, especially with in-house experiments. Mining data from existing literature introduces issues like mixed data quality, inconsistent formats, and variations in reporting experimental parameters, complicating the creation of consistent features for the learning algorithm. Additionally, combining continuous and discrete features can hinder the learning process with limited data. Here, we propose strategies that utilize large language models (LLMs) to enhance machine learning performance on a limited, heterogeneous dataset of graphene chemical vapor deposition synthesis compiled from existing literature. These strategies include prompting modalities for imputing missing data points and leveraging large language model embeddings to encode the complex nomenclature of substrates reported in chemical vapor deposition experiments. The proposed strategies enhance graphene layer classification using a support vector machine (SVM) model, increasing binary classification accuracy from 39% to 65% and ternary accuracy from 52% to 72%. We compare the performance of the SVM and a GPT-4 model, both trained and fine-tuned on the same data. Our results demonstrate that the numerical classifier, when combined with LLM-driven data enhancements, outperforms the standalone LLM predictor, highlighting that in data-scarce scenarios, improving predictive learning with LLM strategies requires more than simple fine-tuning on datasets. Instead, it necessitates sophisticated approaches for data imputation and feature space homogenization to achieve optimal performance. The proposed strategies emphasize data enhancement techniques, offering a broadly applicable framework for improving machine learning performance on scarce, inhomogeneous datasets.
机器学习在材料科学领域面临着实验数据有限的挑战,因为生成合成数据成本高昂且耗时,特别是在内部实验中。从现有文献中挖掘数据引入了混合数据质量、格式不一致以及报告的实验参数变化等问题,为学习算法创建一致的特征增加了复杂性。此外,在有限的数据下,连续特征和离散特征的组合可能会阻碍学习过程。在这里,我们提出了利用大型语言模型(LLM)增强机器在石墨烯化学气相沉积合成数据集上学习性能的策略。这些数据集是有限的、是从现有文献中编译的异质数据集。这些策略包括提示模式以填补缺失数据点,并利用大型语言模型嵌入来编码化学气相沉积实验中报道的复杂底材术语。所提出的策略提高了使用支持向量机(SVM)模型对石墨烯层分类的性能,将二元分类精度从39%提高到65%,三元精度从52%提高到72%。我们比较了在同一数据上经过训练和精细调整的SVM和GPT-4模型的性能。我们的结果表明,当数值分类器与LLM驱动的数据增强相结合时,其性能优于单独的LLM预测器,强调在数据稀缺的情况下,使用LLM策略提高预测学习性能不仅需要简单的数据集微调,还需要进行数据填充和特征空间均质化的复杂方法来实现最佳性能。所提出的策略强调了数据增强技术,为在稀缺、非均匀数据集上提高机器学习性能提供了一个广泛适用的框架。
论文及项目相关链接
PDF 20 pages, 10 figures, 4 tables; Supplementary Material with 13 figures and 4 tables
摘要
在材料科学中应用机器学习面临诸多挑战,尤其是获取实验数据的困难与高昂成本。从现有文献中挖掘数据存在数据质量不一、格式不一致及实验参数报告差异等问题,给机器学习算法的特征构建带来困扰。同时,连续和离散特征的结合在有限数据中阻碍学习进程。本文提出利用大型语言模型(LLM)增强机器学习在有限且异质的石墨烯化学气相沉积合成数据集上的性能的策略。策略包括提示模式填补缺失数据点,并利用大型语言模型嵌入编码化学气相沉积实验中复杂底物的命名。策略提高了石墨烯层分类的支持向量机(SVM)模型的性能,将二元分类精度从39%提高到65%,三元精度从52%提高到72%。比较SVM和GPT-4模型在同一数据集上的训练和微调性能,结果表明,数值分类器与LLM驱动的数据增强相结合,优于单独的LLM预测器。这表明在数据稀缺的情况下,利用LLM策略提高预测学习性能不仅需要简单的微调数据集,还需要复杂的数据填充和特征空间同质化方法来实现最佳性能。所提策略强调数据增强技术,为改善有限、非均匀数据集的机器学习性能提供了广泛适用的框架。
关键见解
- 机器学习在材料科学中面临有限实验数据的挑战,数据获取成本高昂且耗时。
- 从文献挖掘数据存在质量、格式和实验参数报告的不一致性问题。
- 结合连续和离散特征在有限数据中影响机器学习性能。
- 提出利用大型语言模型(LLM)增强机器学习的策略,包括填补缺失数据和编码复杂命名。
- 策略提高了石墨烯层分类的支持向量机(SVM)模型性能。
- 比较了SVM和GPT-4模型性能,显示数值分类器与LLM结合优于单纯LLM预测。
点此查看论文截图

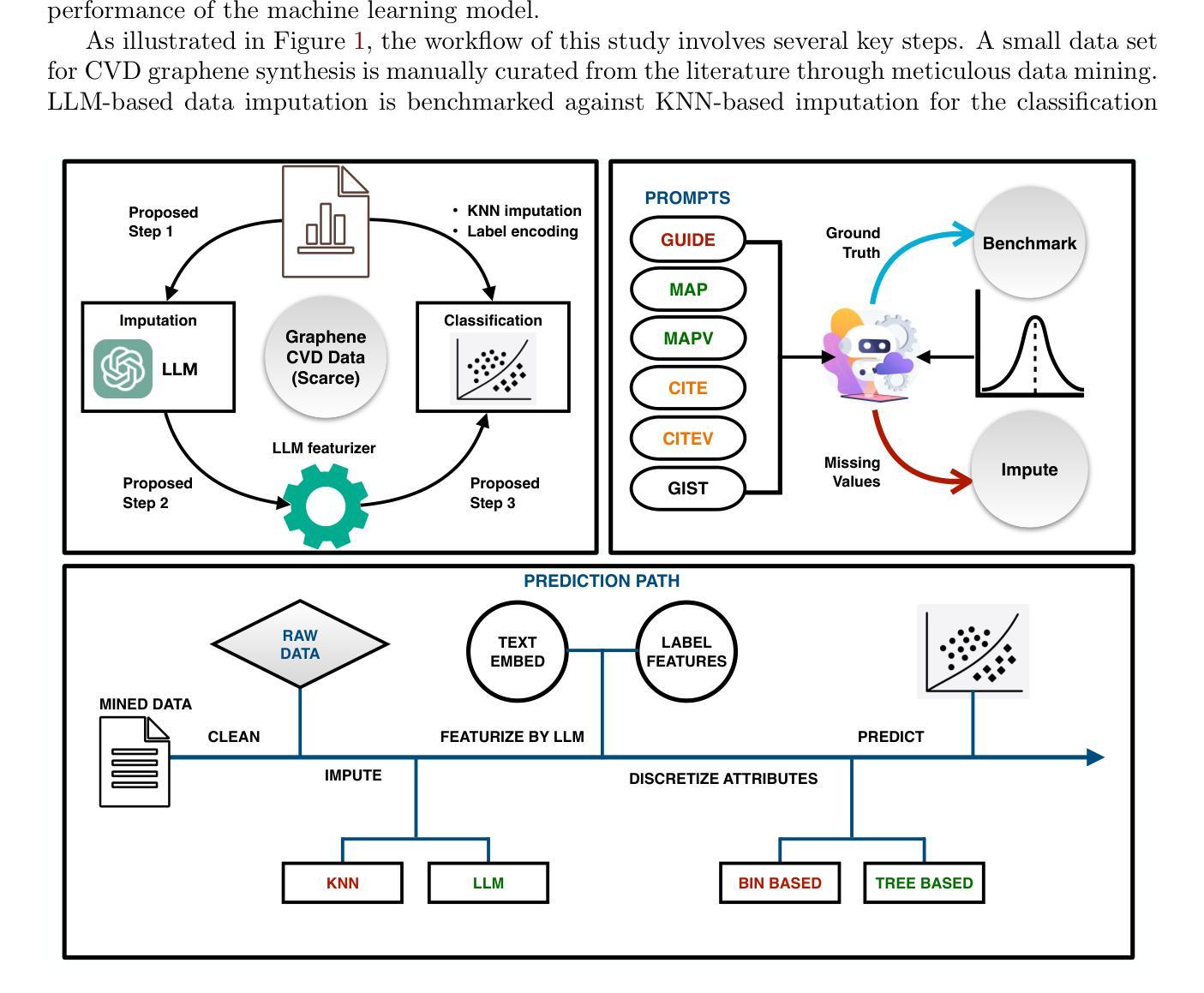
Re-Imagining Multimodal Instruction Tuning: A Representation View
Authors:Yiyang Liu, James Chenhao Liang, Ruixiang Tang, Yugyung Lee, Majid Rabbani, Sohail Dianat, Raghuveer Rao, Lifu Huang, Dongfang Liu, Qifan Wang, Cheng Han
Multimodal instruction tuning has proven to be an effective strategy for achieving zero-shot generalization by fine-tuning pre-trained Large Multimodal Models (LMMs) with instruction-following data. However, as the scale of LMMs continues to grow, fully fine-tuning these models has become highly parameter-intensive. Although Parameter-Efficient Fine-Tuning (PEFT) methods have been introduced to reduce the number of tunable parameters, a significant performance gap remains compared to full fine-tuning. Furthermore, existing PEFT approaches are often highly parameterized, making them difficult to interpret and control. In light of this, we introduce Multimodal Representation Tuning (MRT), a novel approach that focuses on directly editing semantically rich multimodal representations to achieve strong performance and provide intuitive control over LMMs. Empirical results show that our method surpasses current state-of-the-art baselines with significant performance gains (e.g., 1580.40 MME score) while requiring substantially fewer tunable parameters (e.g., 0.03% parameters). Additionally, we conduct experiments on editing instrumental tokens within multimodal representations, demonstrating that direct manipulation of these representations enables simple yet effective control over network behavior.
多模态指令调整已被证明是一种通过微调预训练的大型多模态模型(LMMs)以实现零样本泛化的有效策略。然而,随着LMM规模的持续增长,完全微调这些模型已变得高度依赖参数。虽然已引入参数高效微调(PEFT)方法来减少可调整参数的数量,但与完全微调相比,性能仍存在显著差距。此外,现有的PEFT方法通常高度参数化,难以解释和控制。鉴于此,我们引入了多模态表示调整(MRT),这是一种新型方法,专注于直接编辑语义丰富的多模态表示,以实现强大的性能并为大型多模态模型提供直观的控制。经验结果表明,我们的方法在达到最新基准线的同时实现了显著的性能提升(例如,MME得分提高至1580.40),并且需要的可调整参数大大减少(例如,仅使用百分之零点零三的参数)。此外,我们在编辑多模态表示中的仪器符号方面进行了实验,结果表明直接操作这些表示可以简单有效地控制网络行为。
论文及项目相关链接
Summary
多模态指令调整是一种有效的零样本泛化策略,它通过微调预训练的大型多模态模型(LMMs)来实现。然而,随着LMMs规模的扩大,完全微调这些模型需要大量的参数计算。尽管参数效率高的微调(PEFT)方法已经减少了可调整的参数数量,但仍与全量微调存在明显的性能差距。本文提出了多模态表示调整(MRT)方法,通过直接编辑语义丰富的多模态表示来实现对LMMs的强大性能和直观控制。实验结果显示,该方法在性能上超越了现有最先进的基线方法,取得了显著的性能提升(例如,MME分数为1580.40),同时需要的可调整参数大大减少(例如,仅占总参数的0.03%)。此外,通过对关键模态令牌的操作实验证明,直接操纵这些表示能够实现对网络行为的简单而有效的控制。
Key Takeaways
- 多模态指令调整是一种有效的零样本泛化策略。
- 随着大型多模态模型(LMMs)规模的扩大,完全微调需要大量参数计算。
- 参数效率高的微调(PEFT)方法虽然减少了可调整参数数量,但仍存在性能差距。
- 多模态表示调整(MRT)方法通过直接编辑语义丰富的多模态表示实现高性能和直观控制。
- MRT方法在性能上超越了现有最先进的基线方法,取得了显著的性能提升。
- MRT方法需要的可调整参数大大减少。
点此查看论文截图
Transformer Meets Twicing: Harnessing Unattended Residual Information
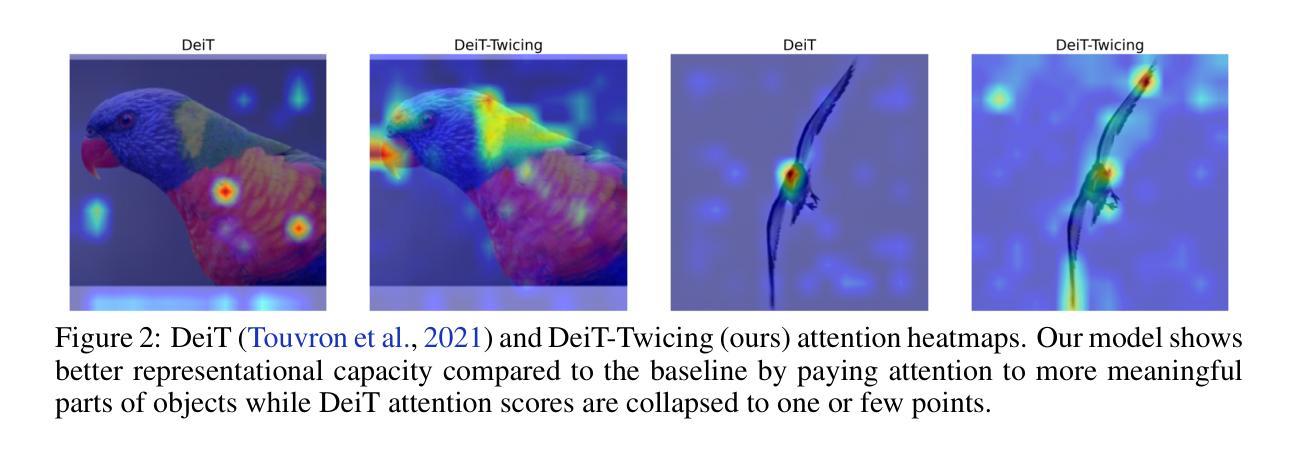
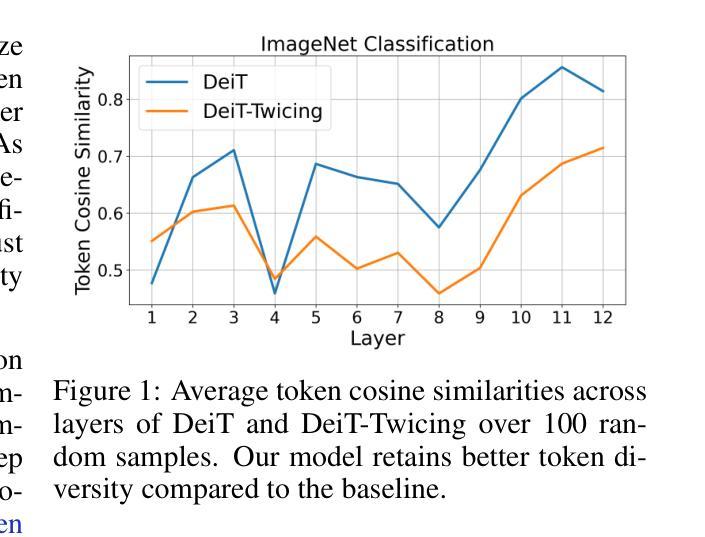
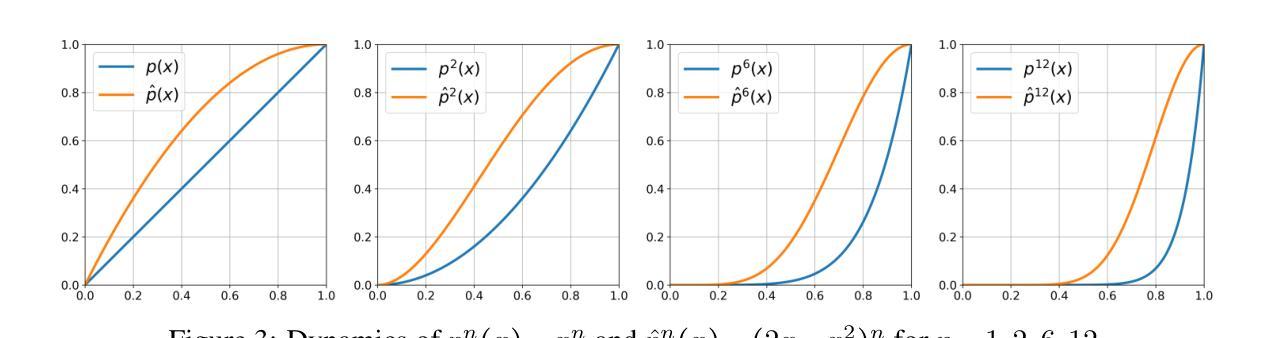
Authors:Laziz Abdullaev, Tan M. Nguyen
Transformer-based deep learning models have achieved state-of-the-art performance across numerous language and vision tasks. While the self-attention mechanism, a core component of transformers, has proven capable of handling complex data patterns, it has been observed that the representational capacity of the attention matrix degrades significantly across transformer layers, thereby hurting its overall performance. In this work, we leverage the connection between self-attention computations and low-pass non-local means (NLM) smoothing filters and propose the Twicing Attention, a novel attention mechanism that uses kernel twicing procedure in nonparametric regression to alleviate the low-pass behavior of associated NLM smoothing with compelling theoretical guarantees and enhanced adversarial robustness. This approach enables the extraction and reuse of meaningful information retained in the residuals following the imperfect smoothing operation at each layer. Our proposed method offers two key advantages over standard self-attention: 1) a provably slower decay of representational capacity and 2) improved robustness and accuracy across various data modalities and tasks. We empirically demonstrate the performance gains of our model over baseline transformers on multiple tasks and benchmarks, including image classification and language modeling, on both clean and corrupted data.
基于Transformer的深度学习模型已在众多语言和视觉任务中实现了最先进的性能。虽然Transformer的核心组件自注意力机制已证明能够处理复杂的数据模式,但人们观察到,随着Transformer层的增加,注意力矩阵的表示能力会显著下降,从而损害其总体性能。在这项工作中,我们利用自注意力计算与低通非局部均值(NLM)平滑滤波器之间的联系,并提出了Twicing Attention,这是一种新型注意力机制。它通过非参数回归中的核Twicing过程来缓解与自注意力相关的NLM平滑的低通行为,具有引人注目的理论保证和增强的对抗鲁棒性。这种方法使得能够在每层的不完美平滑操作后提取和再利用残留的有意义信息。我们的方法相对于标准自注意力具有两个主要优势:1)表示能力的衰减速度较慢;2)在各种数据模式和任务中提高了鲁棒性和准确性。我们通过实证证明,我们的模型在多个任务和基准测试(包括图像分类和语言建模,以及对干净和损坏数据的测试)上的性能超过了基线Transformer。
论文及项目相关链接
PDF 10 pages in the main text. Published at ICLR 2025
Summary
本文探讨了Transformer深度学习模型在处理语言与视觉任务时面临的挑战,特别是自注意力机制的代表性容量在Transformer层间显著退化的问题。为此,作者提出了Twicing Attention机制,该机制利用自注意力计算与低通非局部均值(NLM)平滑滤波器之间的联系,并采用非参数回归中的核扭曲过程来改善NLM平滑的低通行为。新方法能够在每层不完美的平滑操作后提取并重新利用残留的有意义信息,相较于标准自注意力机制,具有代表性容量衰减较慢、跨不同数据模态和任务提高稳健性和准确性等两大优势。作者在多个任务和基准测试上实证了模型在清洁和损坏数据上的性能提升。
Key Takeaways
- Transformer模型在许多语言与视觉任务上表现出卓越性能,但自注意力机制的代表性容量在层间存在显著退化问题。
- 自注意力机制的核心问题在于其处理复杂数据模式时的能力下降。
- 提出了一种新的注意力机制——Twicing Attention,其结合非参数回归中的核扭曲过程,改善了与NLM平滑相关的低通行为。
- Twicing Attention具有两大优势:代表性容量衰减较慢、跨不同数据模态和任务提高稳健性和准确性。
- 新方法能够在每层不完美的平滑操作后提取并重新利用残留的有意义信息。
- 实证研究表明,新模型在多个任务和基准测试上,包括图像分类和语言建模,以及在清洁和损坏数据上的性能均有显著提升。
点此查看论文截图

M2-omni: Advancing Omni-MLLM for Comprehensive Modality Support with Competitive Performance
Authors:Qingpei Guo, Kaiyou Song, Zipeng Feng, Ziping Ma, Qinglong Zhang, Sirui Gao, Xuzheng Yu, Yunxiao Sun, Tai-Wei Chang, Jingdong Chen, Ming Yang, Jun Zhou
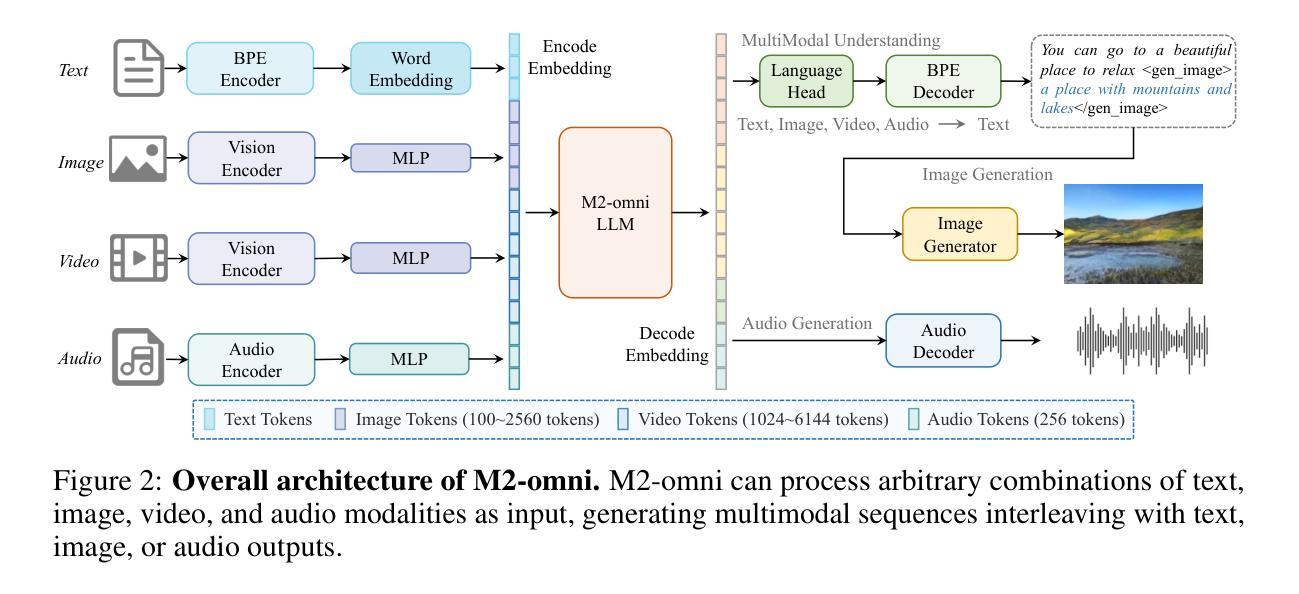
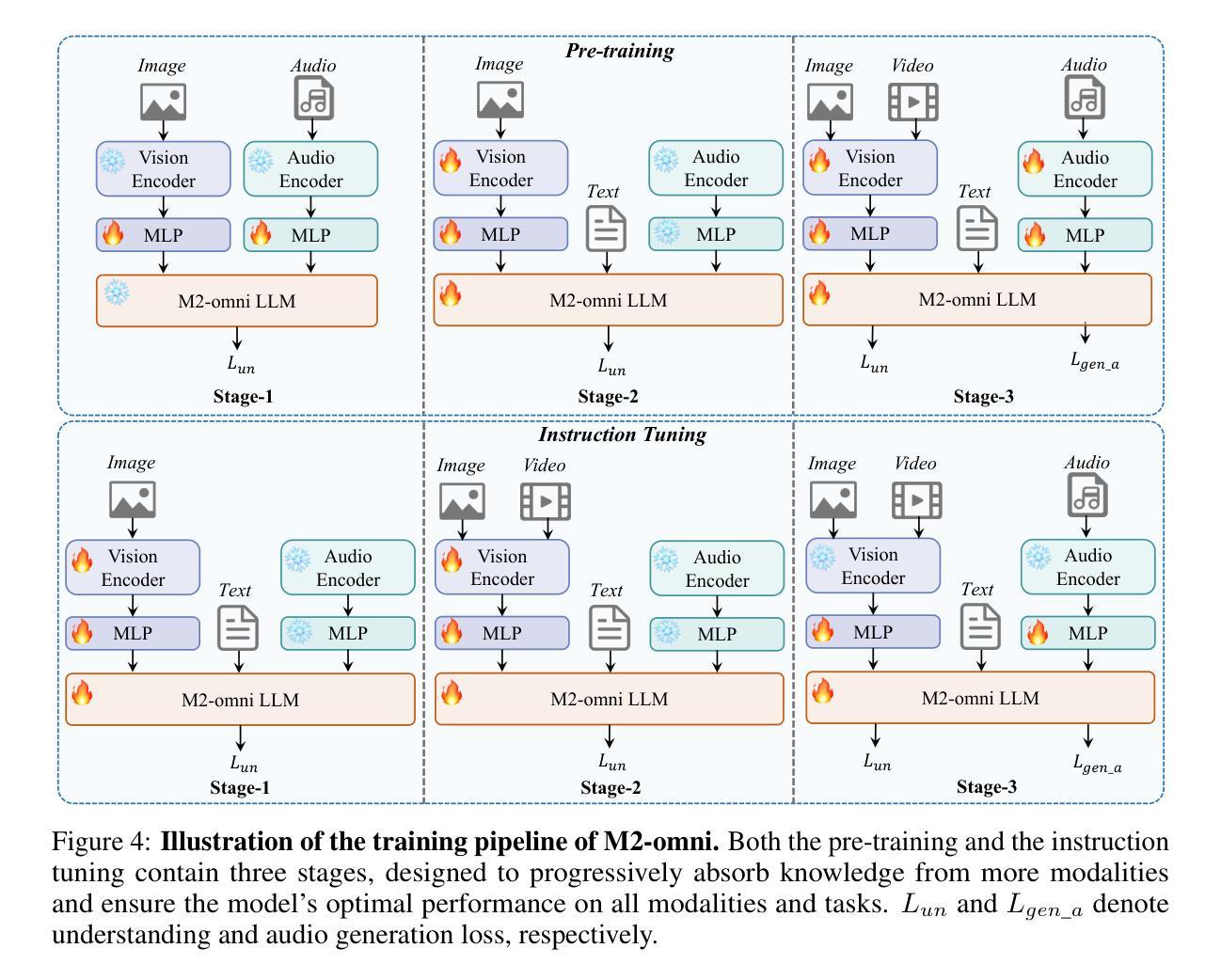
We present M2-omni, a cutting-edge, open-source omni-MLLM that achieves competitive performance to GPT-4o. M2-omni employs a unified multimodal sequence modeling framework, which empowers Large Language Models(LLMs) to acquire comprehensive cross-modal understanding and generation capabilities. Specifically, M2-omni can process arbitrary combinations of audio, video, image, and text modalities as input, generating multimodal sequences interleaving with audio, image, or text outputs, thereby enabling an advanced and interactive real-time experience. The training of such an omni-MLLM is challenged by significant disparities in data quantity and convergence rates across modalities. To address these challenges, we propose a step balance strategy during pre-training to handle the quantity disparities in modality-specific data. Additionally, a dynamically adaptive balance strategy is introduced during the instruction tuning stage to synchronize the modality-wise training progress, ensuring optimal convergence. Notably, we prioritize preserving strong performance on pure text tasks to maintain the robustness of M2-omni’s language understanding capability throughout the training process. To our best knowledge, M2-omni is currently a very competitive open-source model to GPT-4o, characterized by its comprehensive modality and task support, as well as its exceptional performance. We expect M2-omni will advance the development of omni-MLLMs, thus facilitating future research in this domain.
我们推出了M2-omni,这是一款先进的开源通用多模态大型语言模型(MLLM),其性能与GPT-4o相当。M2-omni采用统一的多模态序列建模框架,使大型语言模型(LLM)具备全面的跨模态理解和生成能力。具体来说,M2-omni可以处理任意组合的音频、视频、图像和文本模态作为输入,生成交替输出音频、图像或文本的多媒体序列,从而实现先进且交互式的实时体验。训练这样的通用多模态LLM面临的一个挑战是,不同模态的数据量和收敛率存在显著差异。为了应对这些挑战,我们在预训练过程中提出了一种步骤平衡策略,以处理特定模态的数据量差异。此外,在指令调整阶段,我们引入了一种动态自适应平衡策略,以同步不同模态的训练进度,确保最佳收敛。值得注意的是,我们优先考虑在纯文本任务上保持卓越性能,以在整个训练过程中保持M2-omni的语言理解能力的稳健性。据我们所知,M2-omni目前是一个极具竞争力的开源模型,与GPT-4o相比,它以全面的模态和任务支持以及卓越的性能为特点。我们期望M2-omni将推动通用多模态LLM的发展,从而推动该领域的未来研究。
论文及项目相关链接
摘要
M2-omni是一款先进的开源多功能大型语言模型,具备跨模态理解和生成能力,可处理音频、视频、图像和文本等多种模态的输入,并生成多媒体输出,实现先进且交互式实时体验。为解决不同模态数据量和收敛率的差异带来的训练挑战,研究人员在预训练阶段采取了步骤平衡策略,并在指令调整阶段引入了动态自适应平衡策略,确保最优收敛。M2-omni目前是一个竞争力强的开源模型,以综合模态和任务支持以及卓越性能为特点。
要点
- M2-omni是一款先进的开源多功能大型语言模型,具备跨模态理解和生成能力。
- 可以处理多种模态的输入,包括音频、视频、图像和文本,生成多媒体输出。
- M2-omni实现了先进且交互式实时体验。
- 在预训练阶段采取了步骤平衡策略,解决不同模态数据量和收敛率的差异带来的挑战。
- 在指令调整阶段引入了动态自适应平衡策略,确保最优收敛。
- M2-omni在纯文本任务上保持了强大的性能,确保了语言理解能力的稳健性。
点此查看论文截图