⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-12 更新
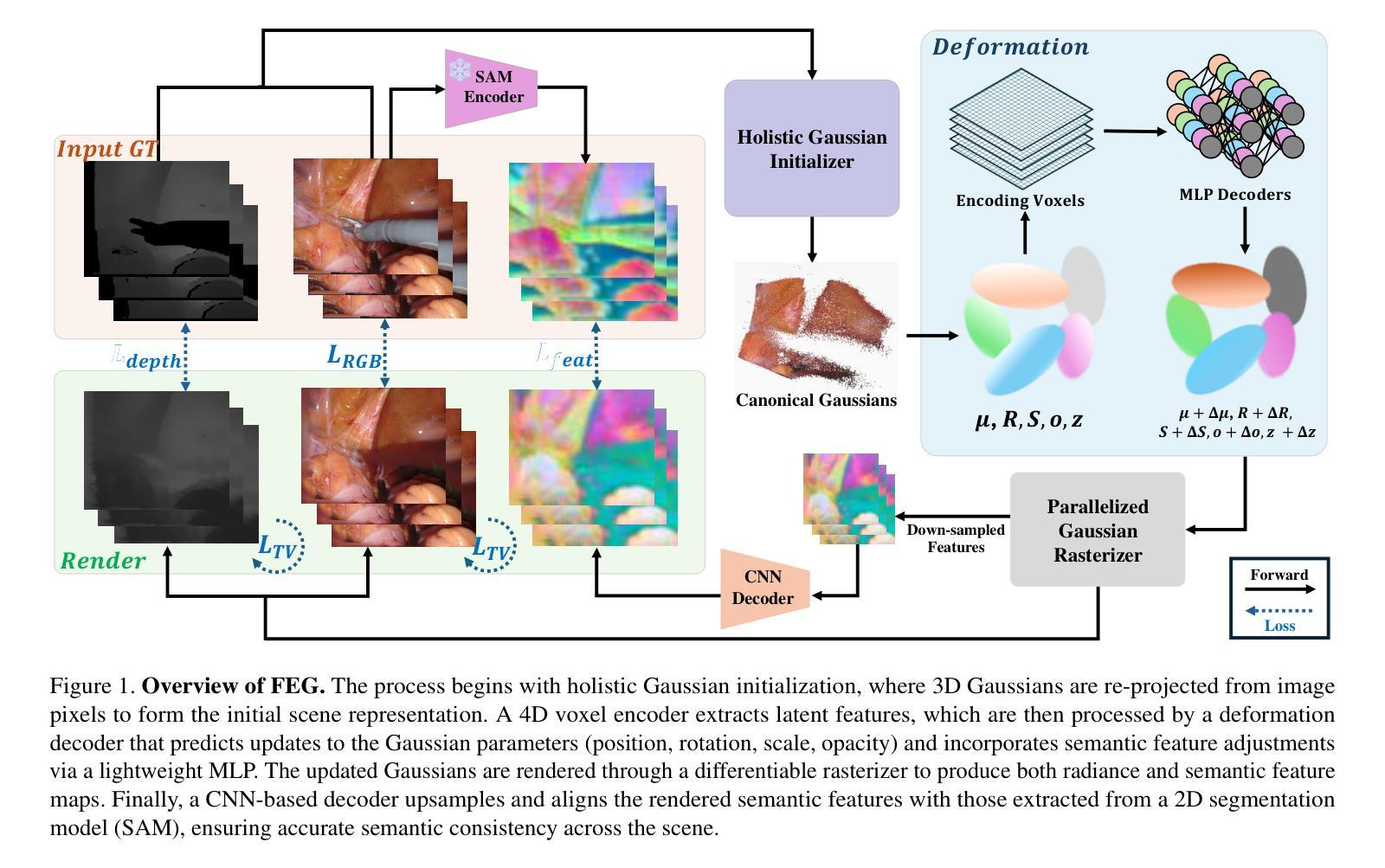
Feature-EndoGaussian: Feature Distilled Gaussian Splatting in Surgical Deformable Scene Reconstruction
Authors:Kai Li, Junhao Wang, William Han, Ding Zhao
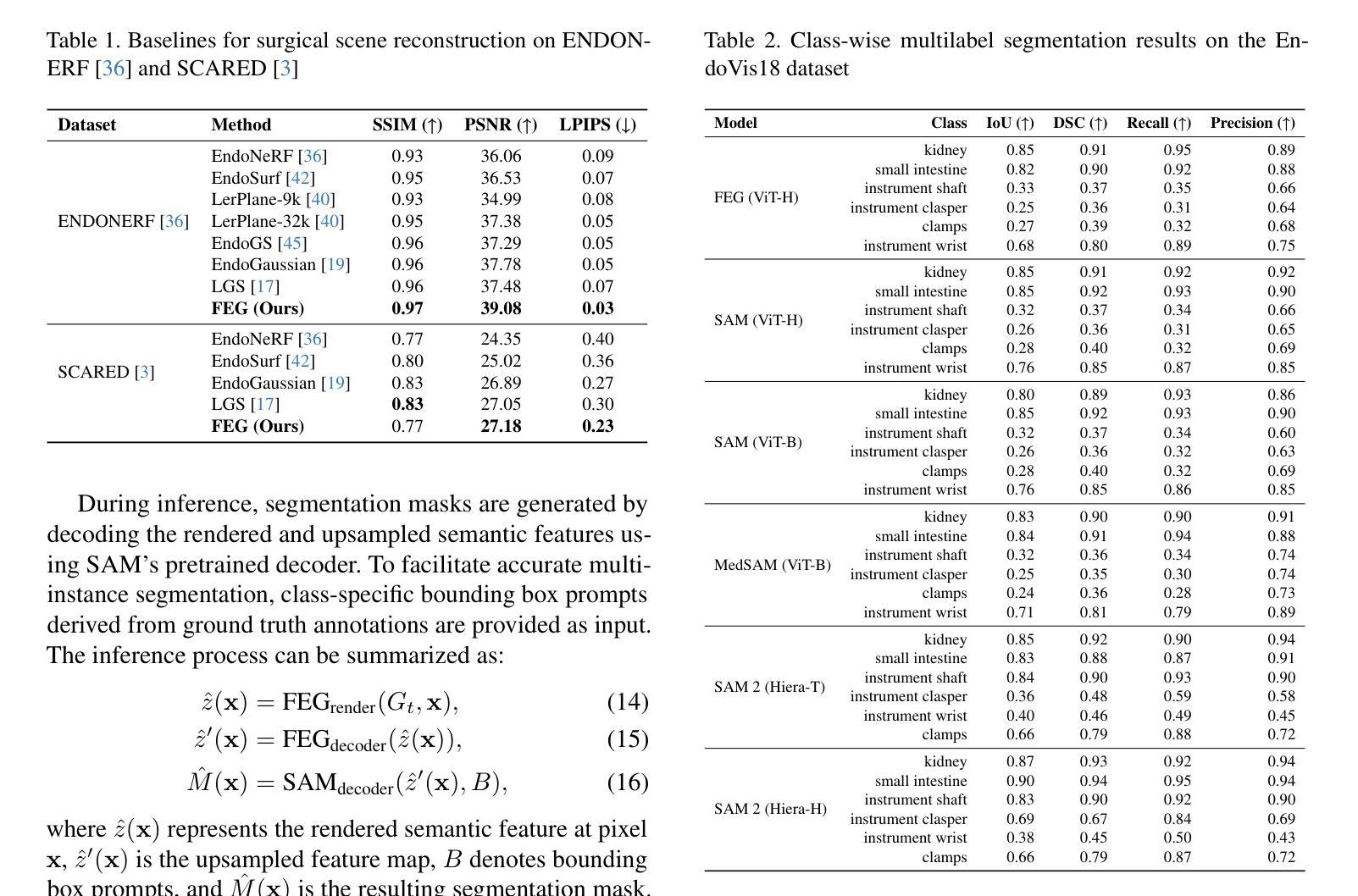
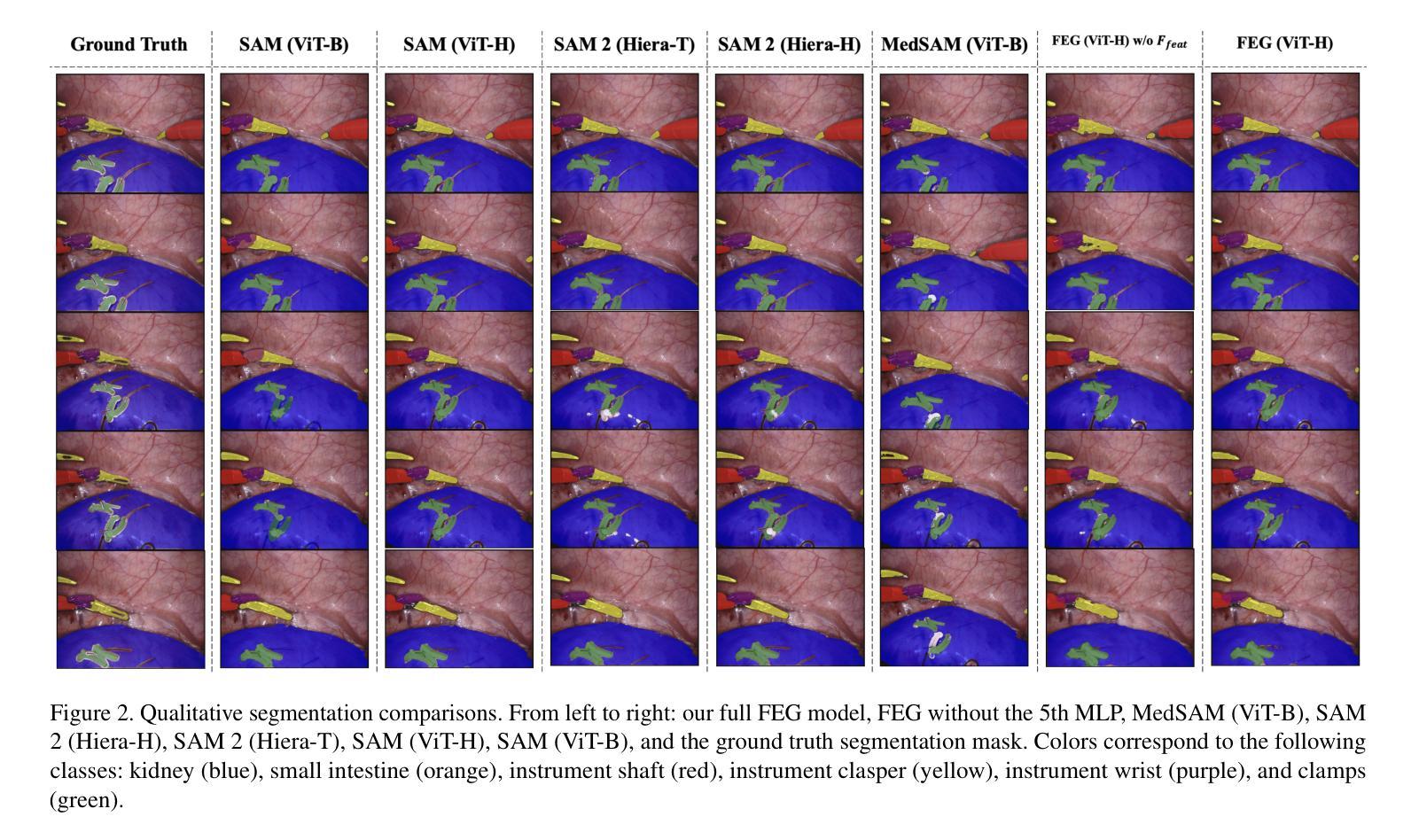
Minimally invasive surgery (MIS) has transformed clinical practice by reducing recovery times, minimizing complications, and enhancing precision. Nonetheless, MIS inherently relies on indirect visualization and precise instrument control, posing unique challenges. Recent advances in artificial intelligence have enabled real-time surgical scene understanding through techniques such as image classification, object detection, and segmentation, with scene reconstruction emerging as a key element for enhanced intraoperative guidance. Although neural radiance fields (NeRFs) have been explored for this purpose, their substantial data requirements and slow rendering inhibit real-time performance. In contrast, 3D Gaussian Splatting (3DGS) offers a more efficient alternative, achieving state-of-the-art performance in dynamic surgical scene reconstruction. In this work, we introduce Feature-EndoGaussian (FEG), an extension of 3DGS that integrates 2D segmentation cues into 3D rendering to enable real-time semantic and scene reconstruction. By leveraging pretrained segmentation foundation models, FEG incorporates semantic feature distillation within the Gaussian deformation framework, thereby enhancing both reconstruction fidelity and segmentation accuracy. On the EndoNeRF dataset, FEG achieves superior performance (SSIM of 0.97, PSNR of 39.08, and LPIPS of 0.03) compared to leading methods. Additionally, on the EndoVis18 dataset, FEG demonstrates competitive class-wise segmentation metrics while balancing model size and real-time performance.
微创手术(MIS)通过减少恢复时间、最小化并发症并增强精确度,已经转变了临床实践。然而,微创手术本质上依赖于间接可视化和精确仪器控制,这带来了独特的挑战。人工智能的最新进展已经能够通过图像分类、目标检测和分割等技术实现实时手术场景理解,而场景重建被认为是增强术中指导的关键要素。尽管神经辐射场(NeRF)已被探索用于此目的,但其庞大的数据需求和缓慢的渲染速度阻碍了实时性能。相比之下,3D高斯喷绘(3DGS)提供了更高效的替代方案,在动态手术场景重建中实现了最先进的性能。在这项工作中,我们介绍了Feature-EndoGaussian(FEG),它是3DGS的扩展,将2D分割线索集成到3D渲染中,以实现实时语义和场景重建。通过利用预训练的分割基础模型,FEG在Gaussian变形框架中引入了语义特征蒸馏,从而提高了重建的保真度和分割的准确性。在EndoNeRF数据集上,FEG的性能优于其他领先方法(SSIM为0.97,PSNR为39.08,LPIPS为0.03)。此外,在EndoVis18数据集上,FEG在类别分割指标上表现出竞争力,同时平衡了模型大小和实时性能。
论文及项目相关链接
PDF 14 pages, 5 figures
摘要
人工智能加持下的特征端高斯拉播(FEG)技术为动态手术场景重建提供了高效解决方案。该技术结合二维分割线索进行三维渲染,引入预训练分割基础模型,实现了实时语义与场景重建,提升了重建精度和分割准确性。在EndoNeRF数据集上,FEG性能卓越,而在EndoVis18数据集上,其分类分割指标具有竞争力,同时平衡了模型大小和实时性能。
要点解析
- 微创手术(MIS)在临床实践中通过减少恢复时间、降低并发症和提高精度等方面进行了变革,但面临间接可视化和精确仪器控制的挑战。
- 人工智能在实时手术场景理解方面取得进展,包括图像分类、目标检测和分割等技术。
- 神经辐射场(NeRF)虽被探索用于手术场景重建,但其大数据需求和缓慢渲染阻碍了实时性能。
- 3D高斯投影(3DGS)提供了一个更高效的解决方案,并在动态手术场景重建中达到最新技术水平。
- 引入的特征端高斯拉播(FEG)技术扩展了3DGS,整合了二维分割线索到三维渲染中,实现了实时语义和场景重建。
- FEG利用预训练的分割基础模型,在Gaussian变形框架中进行语义特征蒸馏,提高了重建的保真度和分割的准确性。
点此查看论文截图

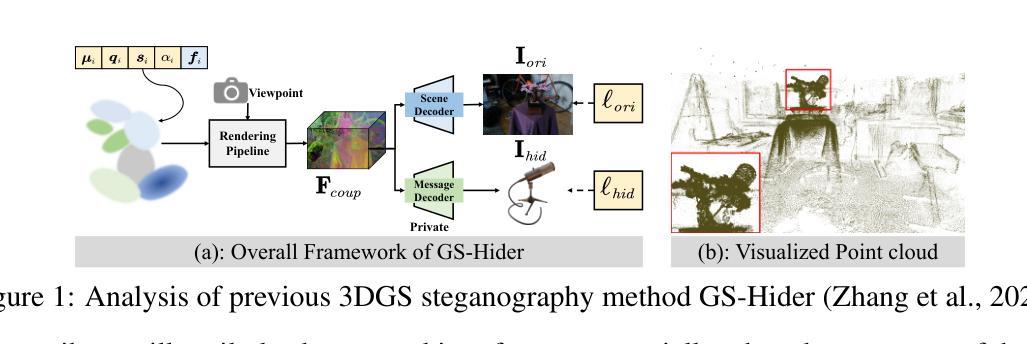
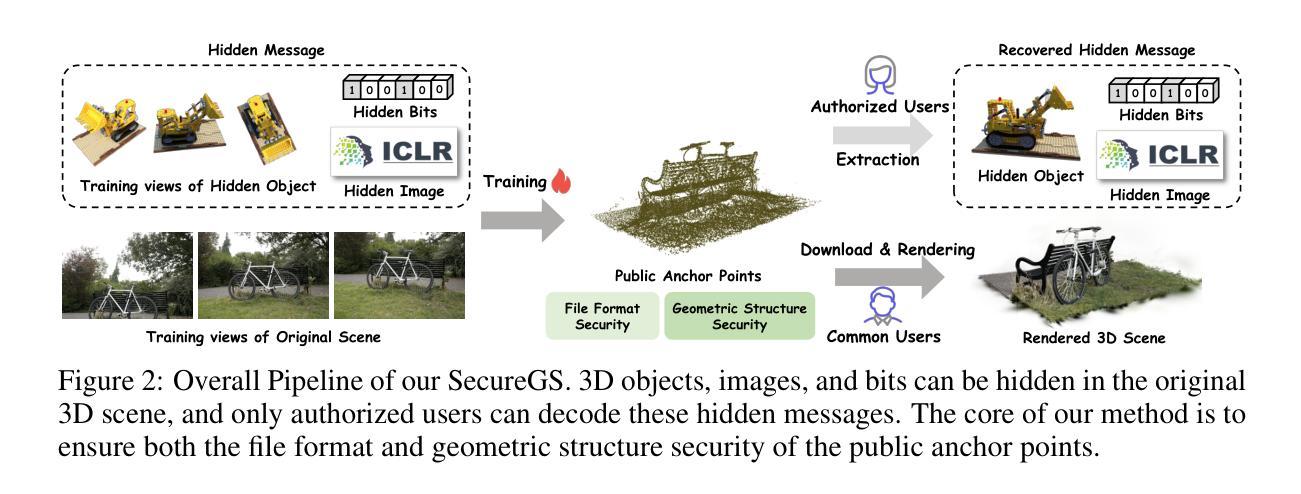
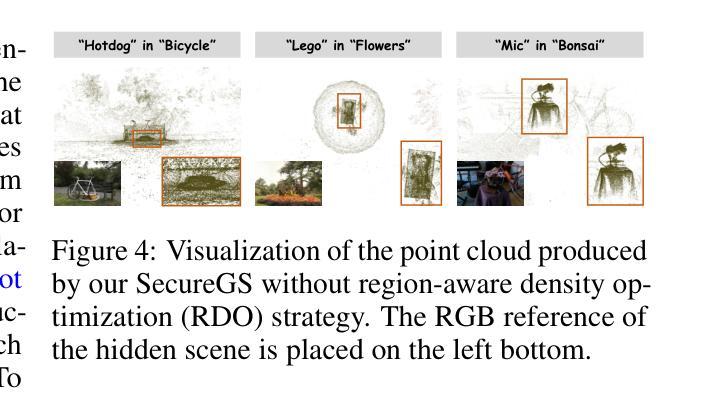
SecureGS: Boosting the Security and Fidelity of 3D Gaussian Splatting Steganography
Authors:Xuanyu Zhang, Jiarui Meng, Zhipei Xu, Shuzhou Yang, Yanmin Wu, Ronggang Wang, Jian Zhang
3D Gaussian Splatting (3DGS) has emerged as a premier method for 3D representation due to its real-time rendering and high-quality outputs, underscoring the critical need to protect the privacy of 3D assets. Traditional NeRF steganography methods fail to address the explicit nature of 3DGS since its point cloud files are publicly accessible. Existing GS steganography solutions mitigate some issues but still struggle with reduced rendering fidelity, increased computational demands, and security flaws, especially in the security of the geometric structure of the visualized point cloud. To address these demands, we propose a SecureGS, a secure and efficient 3DGS steganography framework inspired by Scaffold-GS’s anchor point design and neural decoding. SecureGS uses a hybrid decoupled Gaussian encryption mechanism to embed offsets, scales, rotations, and RGB attributes of the hidden 3D Gaussian points in anchor point features, retrievable only by authorized users through privacy-preserving neural networks. To further enhance security, we propose a density region-aware anchor growing and pruning strategy that adaptively locates optimal hiding regions without exposing hidden information. Extensive experiments show that SecureGS significantly surpasses existing GS steganography methods in rendering fidelity, speed, and security.
3D高斯摊铺(3DGS)已成为一种主流的3D表示方法,因其具备实时渲染和高品质输出的特性,从而突出了保护3D资产隐私的迫切需求。传统的NeRF隐写术方法无法解决3DGS的显式特性,因为其点云文件可公开访问。现有的GS隐写解决方案虽然可以缓解一些问题,但仍然面临着渲染保真度降低、计算需求增加和安全漏洞等问题,特别是在可视化点云的几何结构安全性方面。为了解决这些需求,我们提出了SecureGS,这是一个受Scaffold-GS锚点设计启发而设计的安全高效的3DGS隐写框架,以及基于神经解码。SecureGS使用混合解耦的高斯加密机制来嵌入隐藏在锚点特征中的偏移量、尺度、旋转和RGB属性等三维高斯点信息,只有授权用户才能通过隐私保护的神经网络检索这些信息。为了进一步提高安全性,我们提出了一种密度区域感知的锚点生长和修剪策略,该策略能够自适应地定位最佳隐藏区域而不会暴露隐藏信息。大量实验表明,SecureGS在渲染保真度、速度和安全性方面显著超越了现有的GS隐写方法。
论文及项目相关链接
PDF Accepted by ICLR 2025
Summary
基于实时渲染和高品质输出的需求,三维高斯拼接技术(3DGS)成为了三维表达的主要方法,并对三维资产的隐私保护提出了迫切要求。现有NeRF的隐写术方法无法适应公开访问的3DGS的点云文件。为解决上述问题,我们提出SecureGS框架,融合安全性与效率于一体,受启发于支架-GS的锚点设计和神经解码技术。SecureGS采用混合分离的高斯加密机制嵌入隐藏的三维高斯点的偏移量、缩放系数、旋转角度和RGB属性等,只有授权用户通过隐私保护神经网络才能提取出相关信息。同时采用密度区域感知锚点的生长与剪枝策略来自动找到最佳的隐藏区域,保证信息不暴露。实验证明SecureGS在渲染质量、速度和安全性上远超现有GS隐写术方法。
Key Takeaways
- 现有NeRF隐写术无法适应公开访问的3DGS的点云文件隐私保护需求。
- SecureGS是一个高效且安全的框架,融合了混合分离的高斯加密机制进行隐私保护。
- SecureGS可以嵌入三维高斯点的多个属性并保护信息不暴露。只有授权用户通过隐私保护神经网络才能提取信息。
- SecureGS提出的密度区域感知锚点生长和剪枝策略能有效提高渲染质量、速度及安全性。
点此查看论文截图

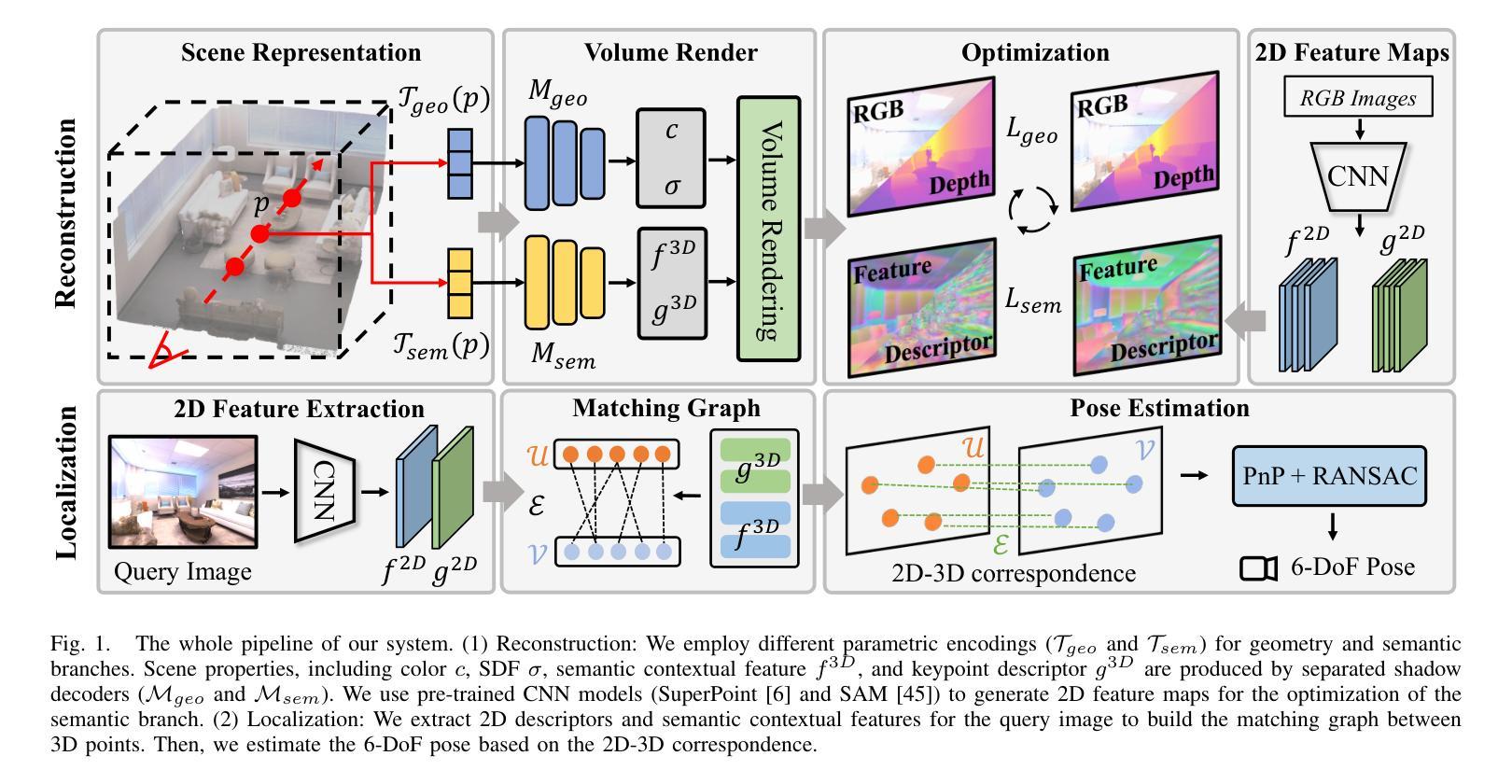
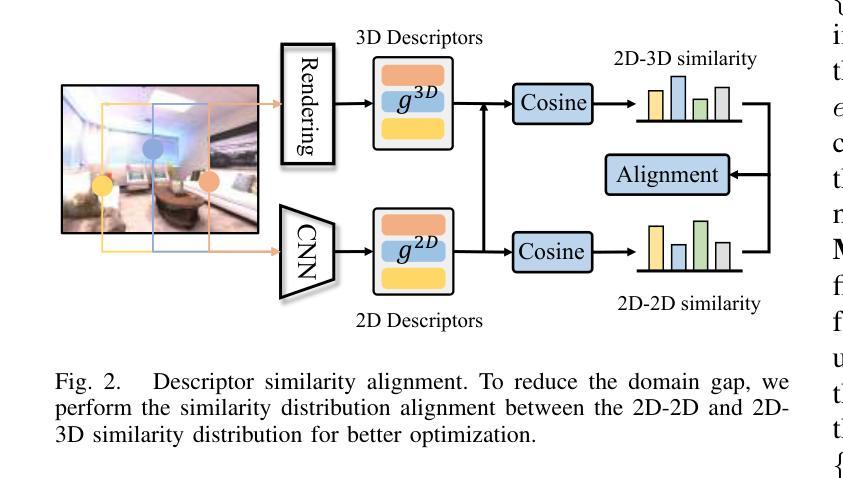
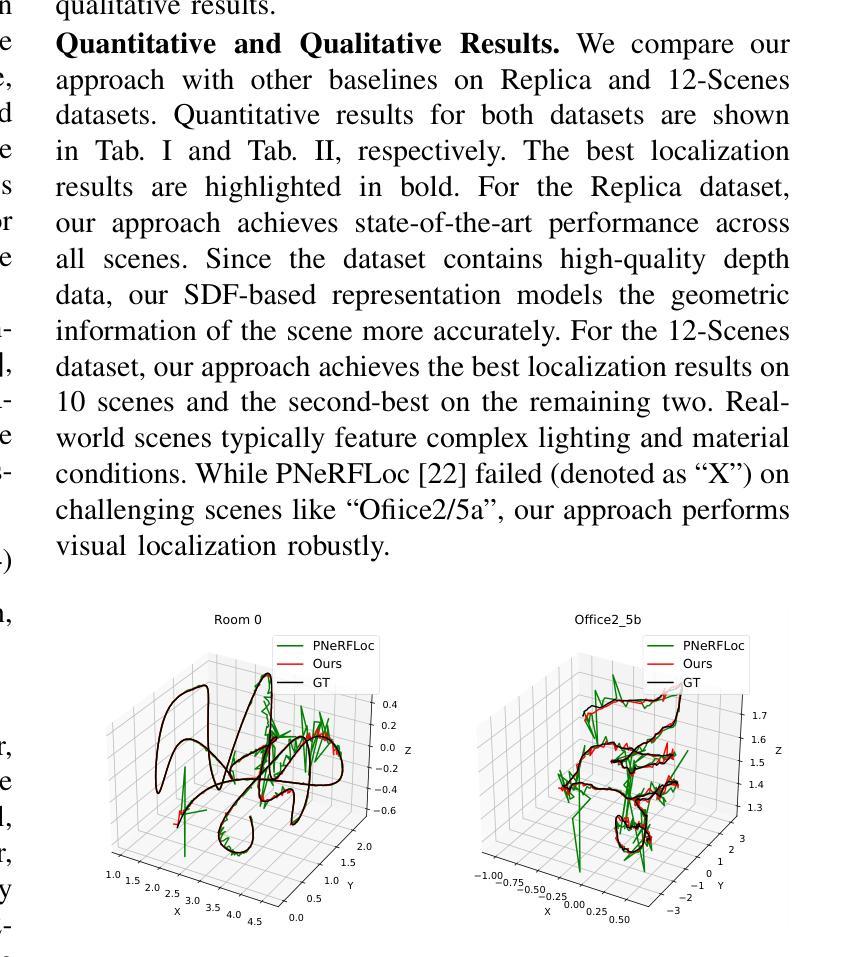
NeuraLoc: Visual Localization in Neural Implicit Map with Dual Complementary Features
Authors:Hongjia Zhai, Boming Zhao, Hai Li, Xiaokun Pan, Yijia He, Zhaopeng Cui, Hujun Bao, Guofeng Zhang
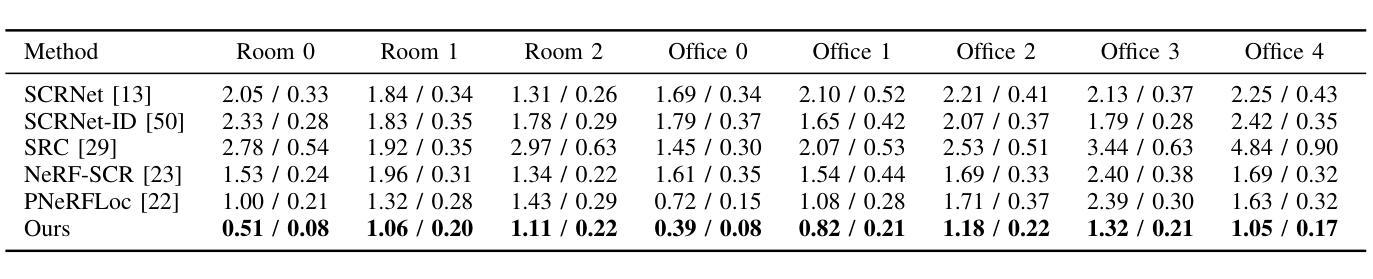
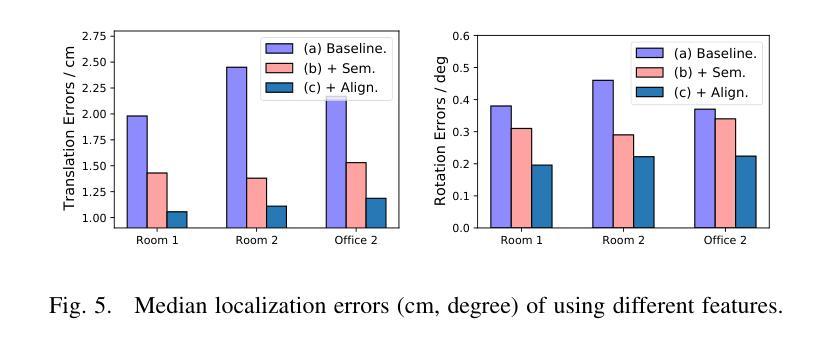
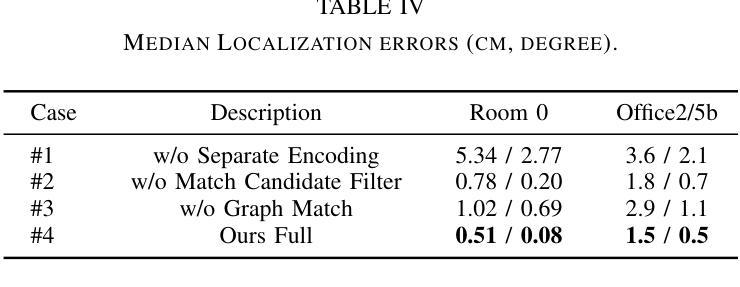
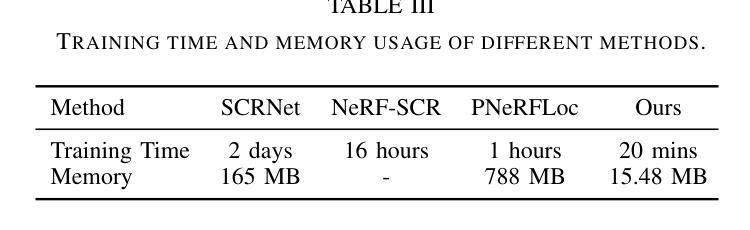
Recently, neural radiance fields (NeRF) have gained significant attention in the field of visual localization. However, existing NeRF-based approaches either lack geometric constraints or require extensive storage for feature matching, limiting their practical applications. To address these challenges, we propose an efficient and novel visual localization approach based on the neural implicit map with complementary features. Specifically, to enforce geometric constraints and reduce storage requirements, we implicitly learn a 3D keypoint descriptor field, avoiding the need to explicitly store point-wise features. To further address the semantic ambiguity of descriptors, we introduce additional semantic contextual feature fields, which enhance the quality and reliability of 2D-3D correspondences. Besides, we propose descriptor similarity distribution alignment to minimize the domain gap between 2D and 3D feature spaces during matching. Finally, we construct the matching graph using both complementary descriptors and contextual features to establish accurate 2D-3D correspondences for 6-DoF pose estimation. Compared with the recent NeRF-based approaches, our method achieves a 3$\times$ faster training speed and a 45$\times$ reduction in model storage. Extensive experiments on two widely used datasets demonstrate that our approach outperforms or is highly competitive with other state-of-the-art NeRF-based visual localization methods. Project page: \href{https://zju3dv.github.io/neuraloc}{https://zju3dv.github.io/neuraloc}
最近,神经辐射场(NeRF)在视觉定位领域引起了广泛关注。然而,现有的基于NeRF的方法要么缺乏几何约束,要么特征匹配需要大量存储,限制了其实际应用。为了解决这些挑战,我们提出了一种基于神经隐式地图和互补特征的高效新颖视觉定位方法。具体来说,为了加强几何约束并降低存储要求,我们隐式地学习了一个3D关键点描述符场,无需显式存储点特征。为了进一步解决描述符的语义模糊性,我们引入了额外的语义上下文特征场,提高了2D-3D对应关系的质量和可靠性。此外,我们提出了描述符相似性分布对齐,以最小化匹配过程中2D和3D特征空间之间的域差距。最后,我们使用互补描述符和上下文特征构建匹配图,以建立准确的2D-3D对应关系,用于6自由度姿态估计。与最近的基于NeRF的方法相比,我们的方法实现了3倍的训练速度提升和45倍的模型存储减少。在两个广泛使用的数据集上的大量实验表明,我们的方法优于或其他与最新基于NeRF的视觉定位方法高度竞争。项目页面:https://zju3dv.github.io/neuraloc
论文及项目相关链接
PDF ICRA 2025
Summary
基于神经隐式映射和互补特征的视觉定位新方法解决了现有NeRF方法面临的挑战。通过隐式学习三维关键点描述符场,该方法既满足了几何约束又降低了存储需求。引入语义上下文特征场以提高2D-3D对应关系的品质和可靠性,并采用描述符相似性分布对齐来缩小匹配过程中的域差距。构建匹配图用于准确的2D-3D对应以实现6DoF姿态估计。相比现有NeRF方法,该方法训练速度更快,模型存储更小,且在广泛使用的数据集上表现优异。
Key Takeaways
- 提出了基于神经隐式映射和互补特征的视觉定位新方法。
- 通过隐式学习三维关键点描述符场,满足几何约束并降低存储需求。
- 引入语义上下文特征场增强2D-3D对应关系的品质和可靠性。
- 采用描述符相似性分布对齐缩小2D和3D特征空间的域差距。
- 构建匹配图用于准确的2D-3D对应以实现6DoF姿态估计。
- 方法相较于现有NeRF方法,训练速度更快,模型存储更小。
点此查看论文截图



Comparative clinical evaluation of “memory-efficient” synthetic 3d generative adversarial networks (gan) head-to-head to state of art: results on computed tomography of the chest
Authors:Mahshid Shiri, Chandra Bortolotto, Alessandro Bruno, Alessio Consonni, Daniela Maria Grasso, Leonardo Brizzi, Daniele Loiacono, Lorenzo Preda
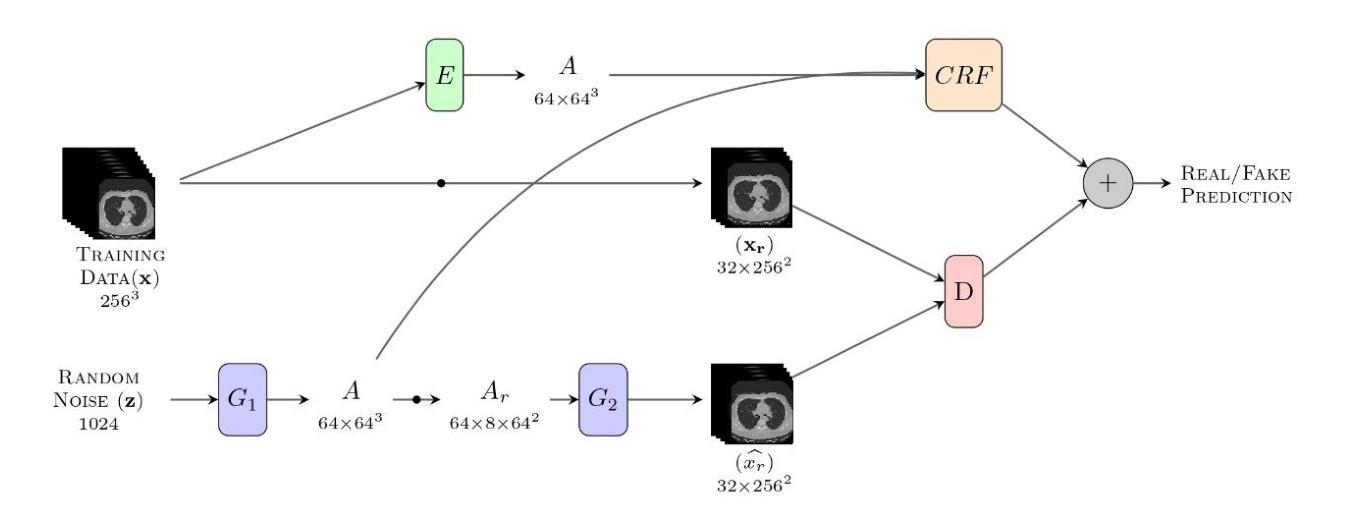
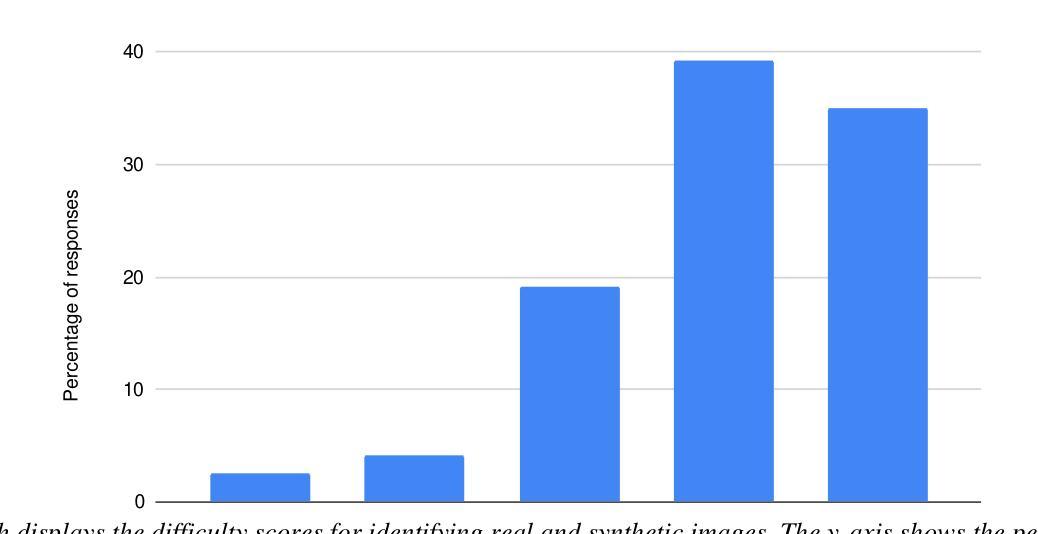
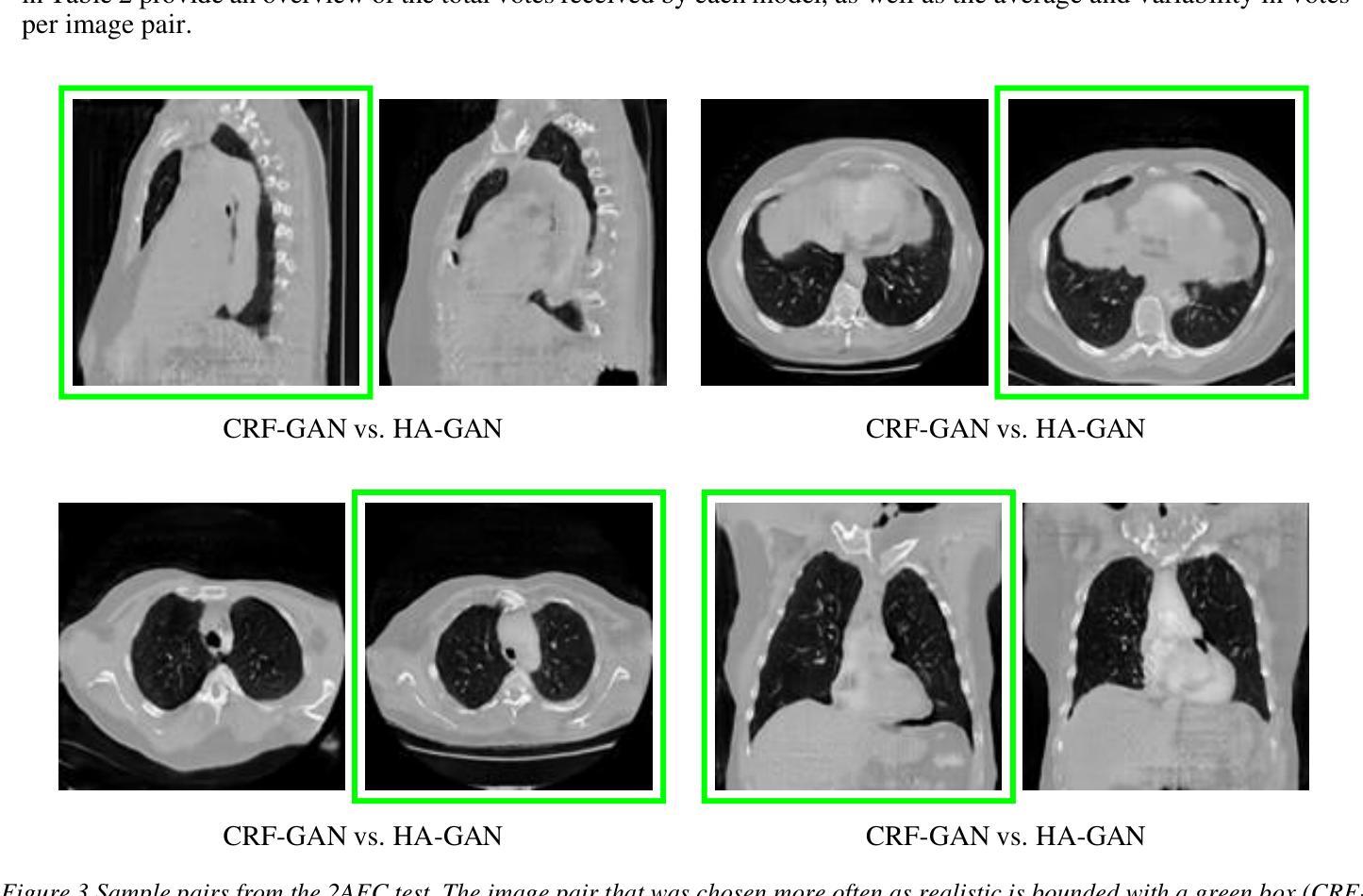
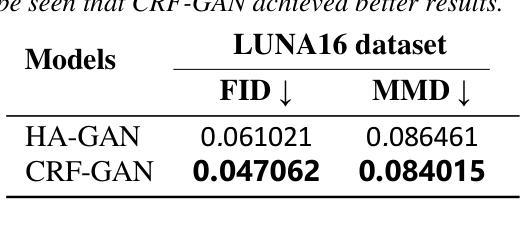
Introduction: Generative Adversarial Networks (GANs) are increasingly used to generate synthetic medical images, addressing the critical shortage of annotated data for training Artificial Intelligence (AI) systems. This study introduces a novel memory-efficient GAN architecture, incorporating Conditional Random Fields (CRFs) to generate high-resolution 3D medical images and evaluates its performance against the state-of-the-art hierarchical (HA)-GAN model. Materials and Methods: The CRF-GAN was trained using the open-source lung CT LUNA16 dataset. The architecture was compared to HA-GAN through a quantitative evaluation, using Frechet Inception Distance (FID) and Maximum Mean Discrepancy (MMD) metrics, and a qualitative evaluation, through a two-alternative forced choice (2AFC) test completed by a pool of 12 resident radiologists, in order to assess the realism of the generated images. Results: CRF-GAN outperformed HA-GAN with lower FID (0.047 vs. 0.061) and MMD (0.084 vs. 0.086) scores, indicating better image fidelity. The 2AFC test showed a significant preference for images generated by CRF-Gan over those generated by HA-GAN with a p-value of 1.93e-05. Additionally, CRF-GAN demonstrated 9.34% lower memory usage at 256 resolution and achieved up to 14.6% faster training speeds, offering substantial computational savings. Discussion: CRF-GAN model successfully generates high-resolution 3D medical images with non-inferior quality to conventional models, while being more memory-efficient and faster. Computational power and time saved can be used to improve the spatial resolution and anatomical accuracy of generated images, which is still a critical factor limiting their direct clinical applicability.
引言:生成对抗网络(GANs)越来越多地被用于生成合成医学图像,以解决训练人工智能(AI)系统时标注数据严重短缺的问题。本研究介绍了一种新的内存高效的GAN架构,该架构结合了条件随机场(CRFs)来生成高分辨率的3D医学图像,并评估其与最先进的分层(HA)-GAN模型的表现。材料与方法:CRF-GAN使用开源的肺部CT LUNA16数据集进行训练。通过与HA-GAN进行定量评估,使用Frechet Inception Distance(FID)和Maximum Mean Discrepancy(MMD)指标,以及定性评估,即通过由12名住院医师完成的两种替代强制选择(2AFC)测试,以评估生成图像的真实性。结果:CRF-GAN的表现优于HA-GAN,具有更低的FID(0.047对0.061)和MMD(0.084对0.086)得分,表明图像保真度更高。2AFC测试显示,CRF-Gan生成的图像比HA-GAN生成的图像更受欢迎,p值为1.93e-05。此外,CRF-GAN在256分辨率下的内存使用率降低了9.34%,训练速度提高了14.6%,从而实现了可观的计算节省。讨论:CRF-GAN模型能够成功生成高分辨率的3D医学图像,其质量不低于传统模型,同时更节省内存、速度更快。所节省的计算能力和时间可用于提高生成图像的空间分辨率和解剖准确性,这仍然是限制其直接临床应用的关键因素。
论文及项目相关链接
摘要
本研究介绍了一种结合条件随机场(CRF)的新型内存高效生成对抗网络(CRF-GAN),用于生成高分辨率的3D医学图像,解决了人工智能系统训练时缺乏标注数据的问题。研究通过对CRF-GAN与分层生成对抗网络(HA-GAN)进行对比,使用Frechet Inception Distance(FID)和Maximum Mean Discrepancy(MMD)等指标定量评估模型性能,同时采用二选一测试对生成的图像逼真度进行定性评估。结果显示,CRF-GAN在图像保真度方面优于HA-GAN,生成的图像获得了显著更高的FID和MMD评分,并具有更低的内存使用和更快的训练速度。此外,CRF-GAN在更高分辨率下展现出更好的表现。总体而言,CRF-GAN能在生成高质量医学图像的同时提高计算效率和速度。
关键见解
- CRF-GAN结合了条件随机场(CRF),旨在生成高分辨率的3D医学图像,解决AI训练数据不足的问题。
- 与分层生成对抗网络(HA-GAN)相比,CRF-GAN在图像保真度方面表现出更好的性能。
- CRF-GAN生成的图像在二选一测试中获得了显著更高的评分,证明了其较高的逼真度。
- CRF-GAN具有更低的内存使用和更快的训练速度,为计算资源提供了更高效的利用。
- CRF-GAN在更高分辨率下展现的优越表现意味着其在直接临床应用中有更大的潜力。
- 通过提高计算效率和速度,CRF-GAN有助于改进生成的图像的空间分辨率和解剖准确性,这是直接影响其临床应用的关键因素。
点此查看论文截图

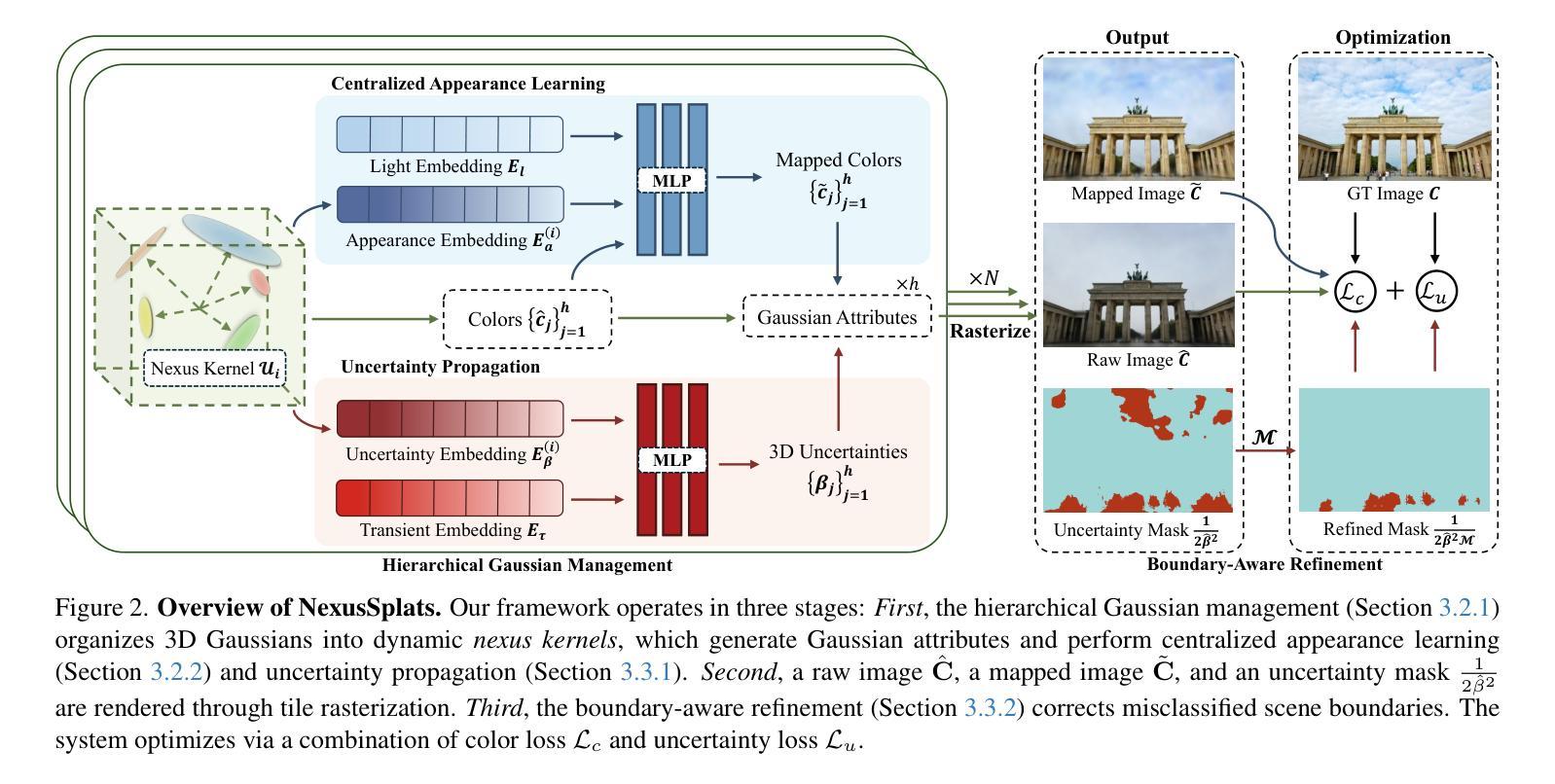
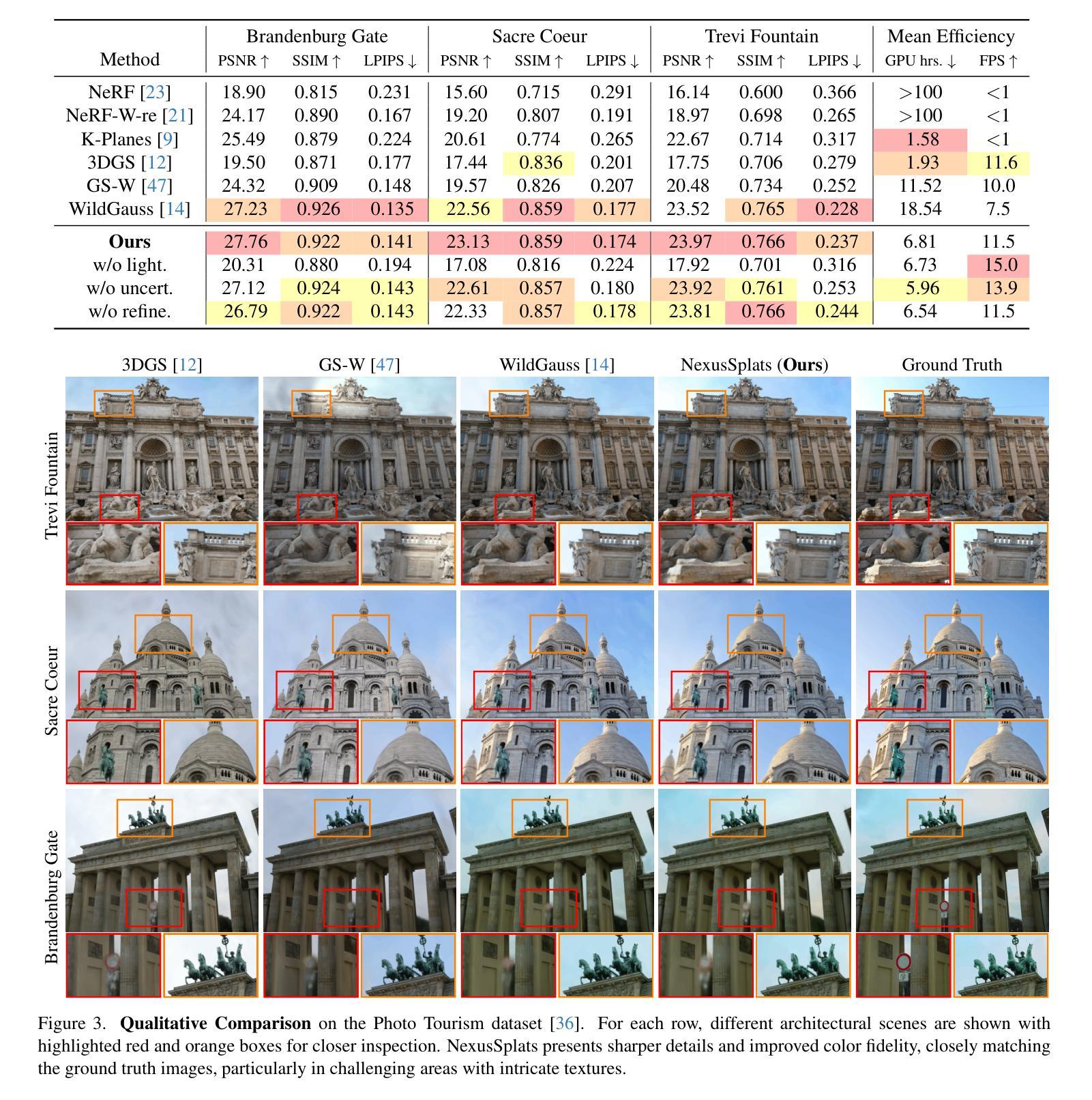
NexusSplats: Efficient 3D Gaussian Splatting in the Wild
Authors:Yuzhou Tang, Dejun Xu, Yongjie Hou, Zhenzhong Wang, Min Jiang
Photorealistic 3D reconstruction of unstructured real-world scenes remains challenging due to complex illumination variations and transient occlusions. Existing methods based on Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) struggle with inefficient light decoupling and structure-agnostic occlusion handling. To address these limitations, we propose NexusSplats, an approach tailored for efficient and high-fidelity 3D scene reconstruction under complex lighting and occlusion conditions. In particular, NexusSplats leverages a hierarchical light decoupling strategy that performs centralized appearance learning, efficiently and effectively decoupling varying lighting conditions. Furthermore, a structure-aware occlusion handling mechanism is developed, establishing a nexus between 3D and 2D structures for fine-grained occlusion handling. Experimental results demonstrate that NexusSplats achieves state-of-the-art rendering quality and reduces the number of total parameters by 65.4%, leading to 2.7$\times$ faster reconstruction.
真实世界非结构化场景的逼真三维重建仍然面临挑战,因为存在复杂的照明变化和瞬时遮挡。基于神经网络辐射场(NeRF)和三维高斯描画(3DGS)的现有方法在处理光照解耦和与结构无关的遮挡处理时效率较低。为了解决这些局限性,我们提出了NexusSplats,这是一种针对复杂光照和遮挡条件下高效高保真三维场景重建的方法。特别是,NexusSplats利用分层光照解耦策略,有效且高效地执行集中外观学习,解耦各种光照条件。此外,开发了一种结构感知的遮挡处理机制,在三维和二维结构之间建立联系,进行精细的遮挡处理。实验结果表明,NexusSplats达到了最先进的渲染质量,并减少了总参数数量的65.4%,实现了2.7倍速的重建。
论文及项目相关链接
PDF Project page: https://nexus-splats.github.io/
Summary
NeRF和3DGS方法在处理复杂光照和遮挡条件下的三维场景重建时存在效率不高的问题。为此,我们提出了NexusSplats方法,采用层次化的光照解耦策略,集中学习外观,有效处理光照变化。同时,我们开发了一种结构感知的遮挡处理机制,建立了三维和二维结构之间的联系,精细处理遮挡问题。实验结果证明NexusSplats达到了先进的渲染质量,总参数减少了65.4%,重建速度提高了2.7倍。
Key Takeaways
- NexusSplats解决了现有方法在复杂光照和遮挡条件下的三维场景重建问题。
- 采用层次化的光照解耦策略,有效处理光照变化,提高重建效率。
- 结构感知的遮挡处理机制,建立了三维和二维结构之间的联系。
- NexusSplats实现了高保真度的渲染结果。
- 总参数减少了65.4%,提高了模型效率。
- 重建速度提高了2.7倍。
点此查看论文截图

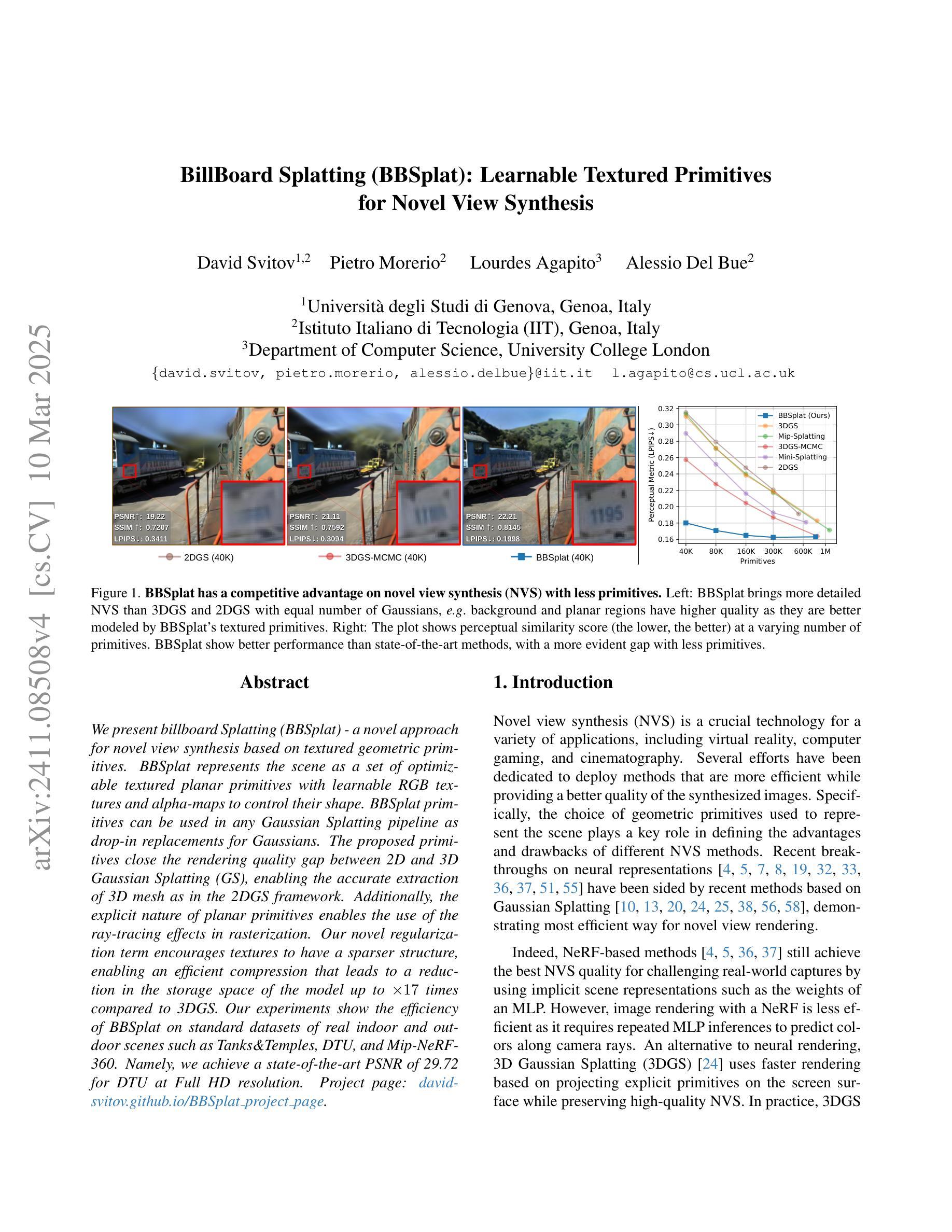
BillBoard Splatting (BBSplat): Learnable Textured Primitives for Novel View Synthesis
Authors:David Svitov, Pietro Morerio, Lourdes Agapito, Alessio Del Bue
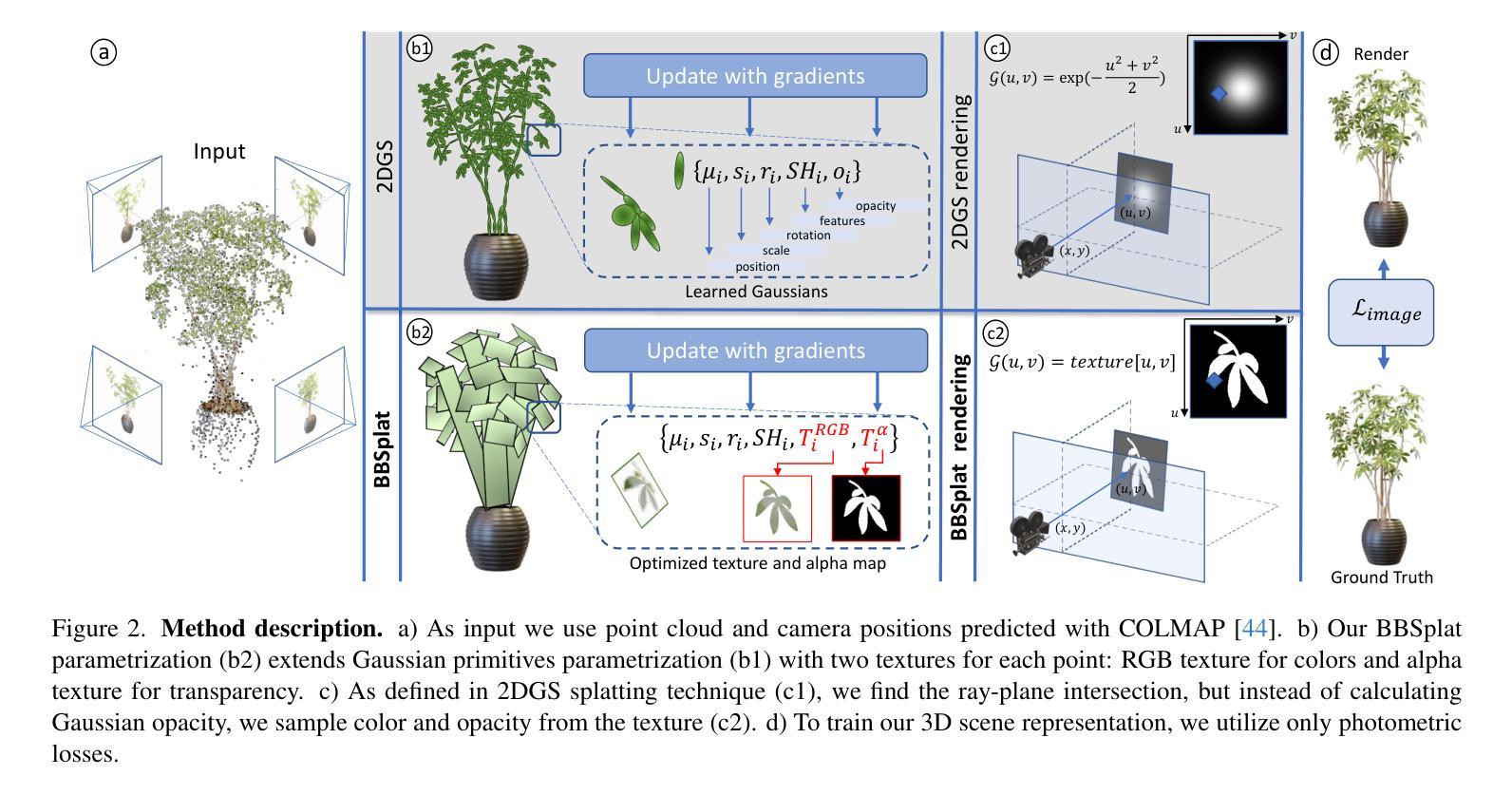
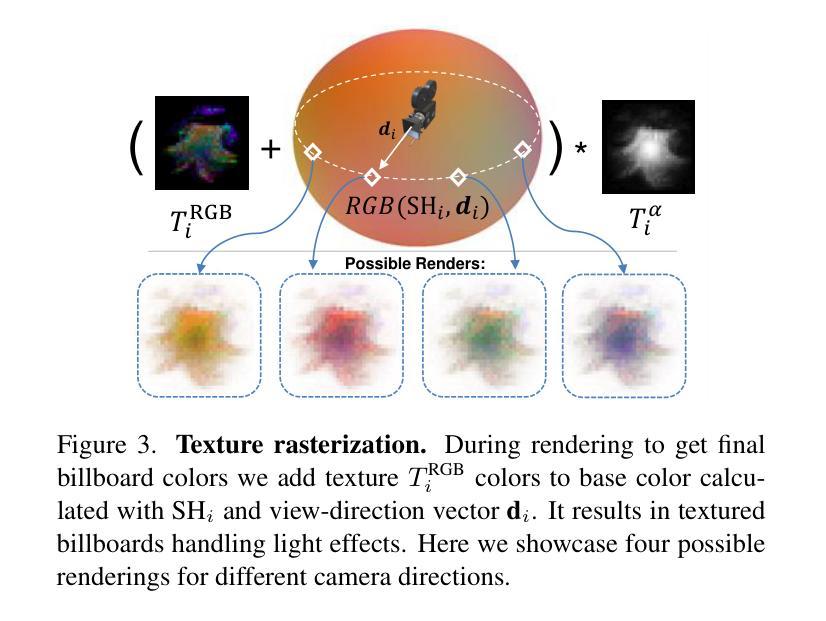
We present billboard Splatting (BBSplat) - a novel approach for novel view synthesis based on textured geometric primitives. BBSplat represents the scene as a set of optimizable textured planar primitives with learnable RGB textures and alpha-maps to control their shape. BBSplat primitives can be used in any Gaussian Splatting pipeline as drop-in replacements for Gaussians. The proposed primitives close the rendering quality gap between 2D and 3D Gaussian Splatting (GS), enabling the accurate extraction of 3D mesh as in the 2DGS framework. Additionally, the explicit nature of planar primitives enables the use of the ray-tracing effects in rasterization. Our novel regularization term encourages textures to have a sparser structure, enabling an efficient compression that leads to a reduction in the storage space of the model up to x17 times compared to 3DGS. Our experiments show the efficiency of BBSplat on standard datasets of real indoor and outdoor scenes such as Tanks&Temples, DTU, and Mip-NeRF-360. Namely, we achieve a state-of-the-art PSNR of 29.72 for DTU at Full HD resolution.
我们提出了基于纹理几何基本体的新视角合成方法——广告牌Splatting(BBSplat)。BBSplat将场景表示为一组可优化的纹理平面基本体,通过可学习的RGB纹理和alpha图来控制其形状。BBSplat基本体可以用作任何高斯Splatting管道中的高斯替换。所提出的原始基本体缩小了2D和3D高斯Splatting(GS)之间的渲染质量差距,使得能够像在2DGS框架中那样准确地提取3D网格。此外,平面基本体的显式性质能够在光栅化中使用光线追踪效果。我们的新型正则化术语鼓励纹理具有稀疏结构,能够实现有效的压缩,与3DGS相比,将模型的存储空间减少了高达17倍。我们的实验表明,BBSplat在真实的室内和室外场景的标准数据集(如Tanks&Temples、DTU和Mip-NeRF-360)上表现出色。特别是在DTU的全高清分辨率下,我们达到了业界领先的峰值信噪比(PSNR)为29.72。
论文及项目相关链接
Summary
BBSplat是一种基于纹理几何基元的新型视图合成方法。它将场景表示为一系列可优化的纹理平面基元,具有可学习的RGB纹理和alpha图来控制形状。BBSplat基元可以替代Gaussian Splatting管道中的高斯,缩小了2D和3D高斯喷绘之间的渲染质量差距。其明确的平面基元性质使得可以使用光线追踪效果进行光栅化。新型正则化项鼓励纹理具有稀疏结构,实现了有效的压缩,使得模型存储空间减少了高达17倍。在标准数据集上的实验表明,BBSplat在真实室内和室外场景上表现优异。
Key Takeaways
- BBSplat是一种基于纹理几何基元的新型视图合成方法。
- BBSplat将场景表示为可优化的纹理平面基元集合,具有可学习的RGB纹理和alpha图。
- BBSplat基元可作为Gaussian Splatting管道中的高斯替代。
- BBSplat缩小了2D和3D高斯喷绘的渲染质量差距,并能准确提取3D网格。
- 平面基元的明确性质使得光栅化中可以使用光线追踪效果。
- 新型正则化项鼓励纹理稀疏结构,实现模型有效压缩,减少存储空间。
点此查看论文截图