⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-12 更新
MedAgentsBench: Benchmarking Thinking Models and Agent Frameworks for Complex Medical Reasoning
Authors:Xiangru Tang, Daniel Shao, Jiwoong Sohn, Jiapeng Chen, Jiayi Zhang, Jinyu Xiang, Fang Wu, Yilun Zhao, Chenglin Wu, Wenqi Shi, Arman Cohan, Mark Gerstein
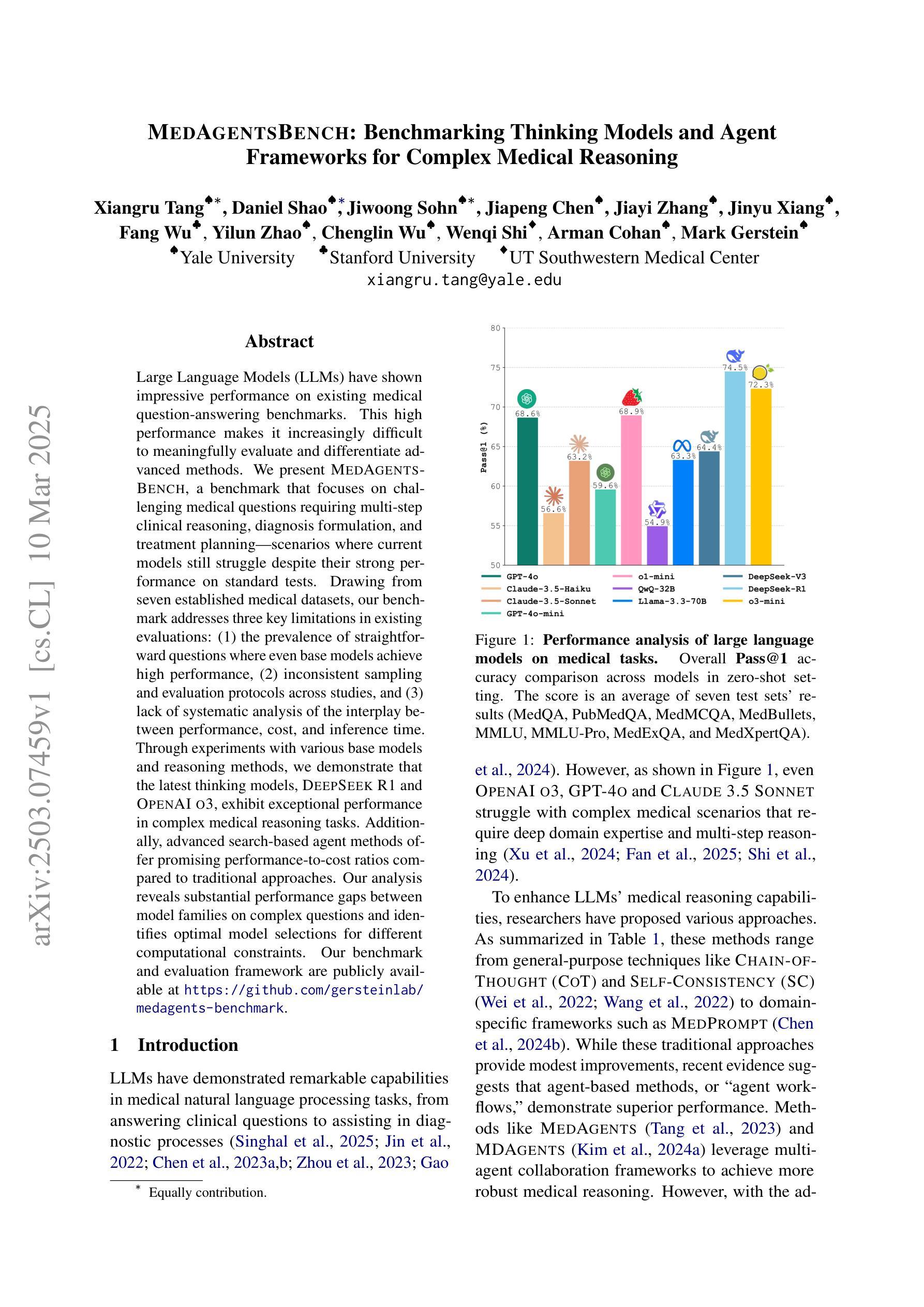
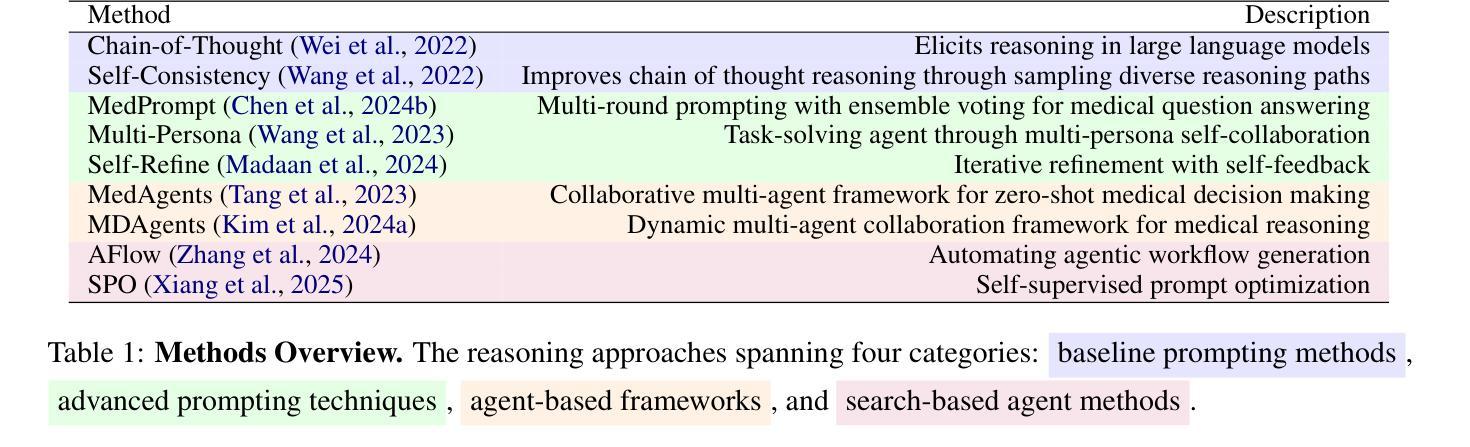
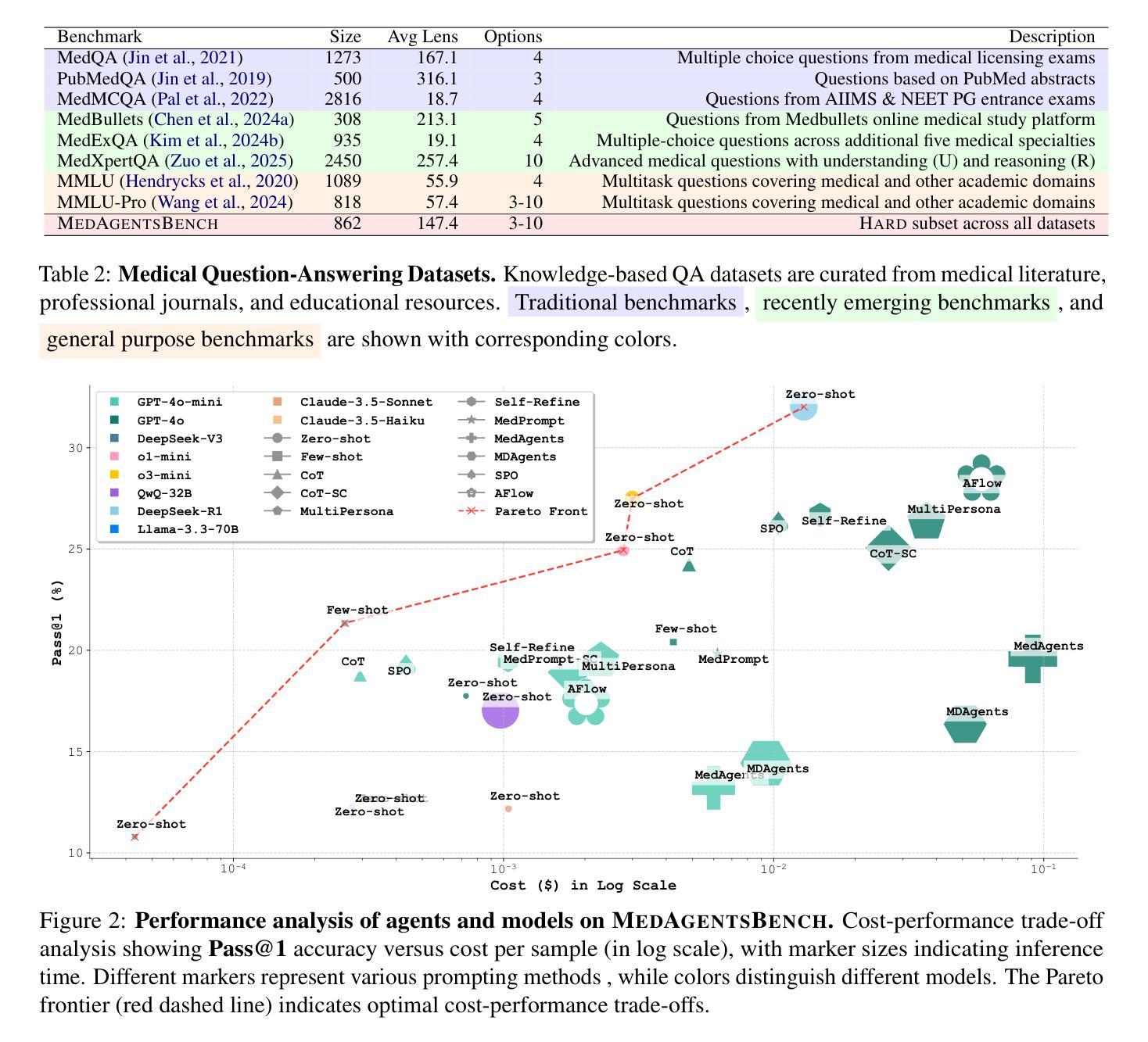
Large Language Models (LLMs) have shown impressive performance on existing medical question-answering benchmarks. This high performance makes it increasingly difficult to meaningfully evaluate and differentiate advanced methods. We present MedAgentsBench, a benchmark that focuses on challenging medical questions requiring multi-step clinical reasoning, diagnosis formulation, and treatment planning-scenarios where current models still struggle despite their strong performance on standard tests. Drawing from seven established medical datasets, our benchmark addresses three key limitations in existing evaluations: (1) the prevalence of straightforward questions where even base models achieve high performance, (2) inconsistent sampling and evaluation protocols across studies, and (3) lack of systematic analysis of the interplay between performance, cost, and inference time. Through experiments with various base models and reasoning methods, we demonstrate that the latest thinking models, DeepSeek R1 and OpenAI o3, exhibit exceptional performance in complex medical reasoning tasks. Additionally, advanced search-based agent methods offer promising performance-to-cost ratios compared to traditional approaches. Our analysis reveals substantial performance gaps between model families on complex questions and identifies optimal model selections for different computational constraints. Our benchmark and evaluation framework are publicly available at https://github.com/gersteinlab/medagents-benchmark.
大型语言模型(LLM)在现有的医疗问答基准测试中表现出了令人印象深刻的性能。这种高性能使得对先进方法进行有意义地评估和区分变得越来越困难。我们推出了MedAgentsBench基准测试,它专注于具有挑战性的医疗问题,这些问题需要进行多步骤的临床推理、诊断制定和治疗计划制定场景,尽管在标准测试上表现出强大的性能,但当前的模型仍面临这些困难。我们从七个公认的医学数据集中汲取灵感,我们的基准测试解决了现有评估中的三个关键局限性:(1)简单问题普遍存在的现象,其中即使是基础模型也能实现高性能;(2)不同研究之间的采样和评估协议不一致;(3)缺乏对性能、成本和推理时间之间相互作用的系统分析。通过对各种基础模型和推理方法的实验,我们证明了最新的思维模型DeepSeek R1和OpenAI o3在复杂的医疗推理任务中表现出卓越的性能。此外,与传统的搜索方法相比,先进的基于搜索的代理方法提供了非常有前景的性能与成本比率。我们的分析揭示了不同模型家族在复杂问题上的性能差距,并针对不同的计算约束确定了最佳模型选择。我们的基准测试和评估框架可在 https://github.com/gersteinlab/medagents-benchmark 获取。
论文及项目相关链接
Summary
大型语言模型(LLMs)在现有的医疗问答基准测试中表现出卓越的性能。然而,这使得对先进方法的评估和区分变得日益困难。本文提出了MedAgentsBench基准测试,它专注于挑战需要多步骤临床推理、诊断制定和治疗计划设计的医疗问题。该基准测试解决了现有评估的三个关键问题:从七个权威医学数据集选取,关注在基础模型就表现优异的一致性问题,以及缺乏针对性能、成本和推理时间的系统分析。通过在不同基础模型和推理方法上的实验,我们证明了最新模型DeepSeek R1和OpenAI o3在复杂医疗推理任务中的卓越性能。此外,高级基于搜索的代理方法与传统方法相比在性价比上具有潜在优势。我们的分析揭示了不同模型家族在复杂问题上的性能差距,并为不同的计算约束提供了最佳模型选择建议。基准测试和评估框架可在公开访问。
Key Takeaways
- 大型语言模型(LLMs)在医疗问答基准测试中表现出高绩效。
- MedAgentsBench基准测试旨在解决复杂医疗问题,涉及多步骤的临床推理、诊断制定和治疗计划。
- MedAgentsBench解决了现有评估的三个关键问题:关注基础模型已表现出色的简单问题、评估协议的不一致性以及缺乏针对性能、成本和推理时间的系统分析。
- 最新模型DeepSeek R1和OpenAI o3在复杂医疗推理任务中表现卓越。
- 高级基于搜索的代理方法在性价比上具有潜在优势。
- 不同模型家族在复杂问题上的性能存在差距。
点此查看论文截图
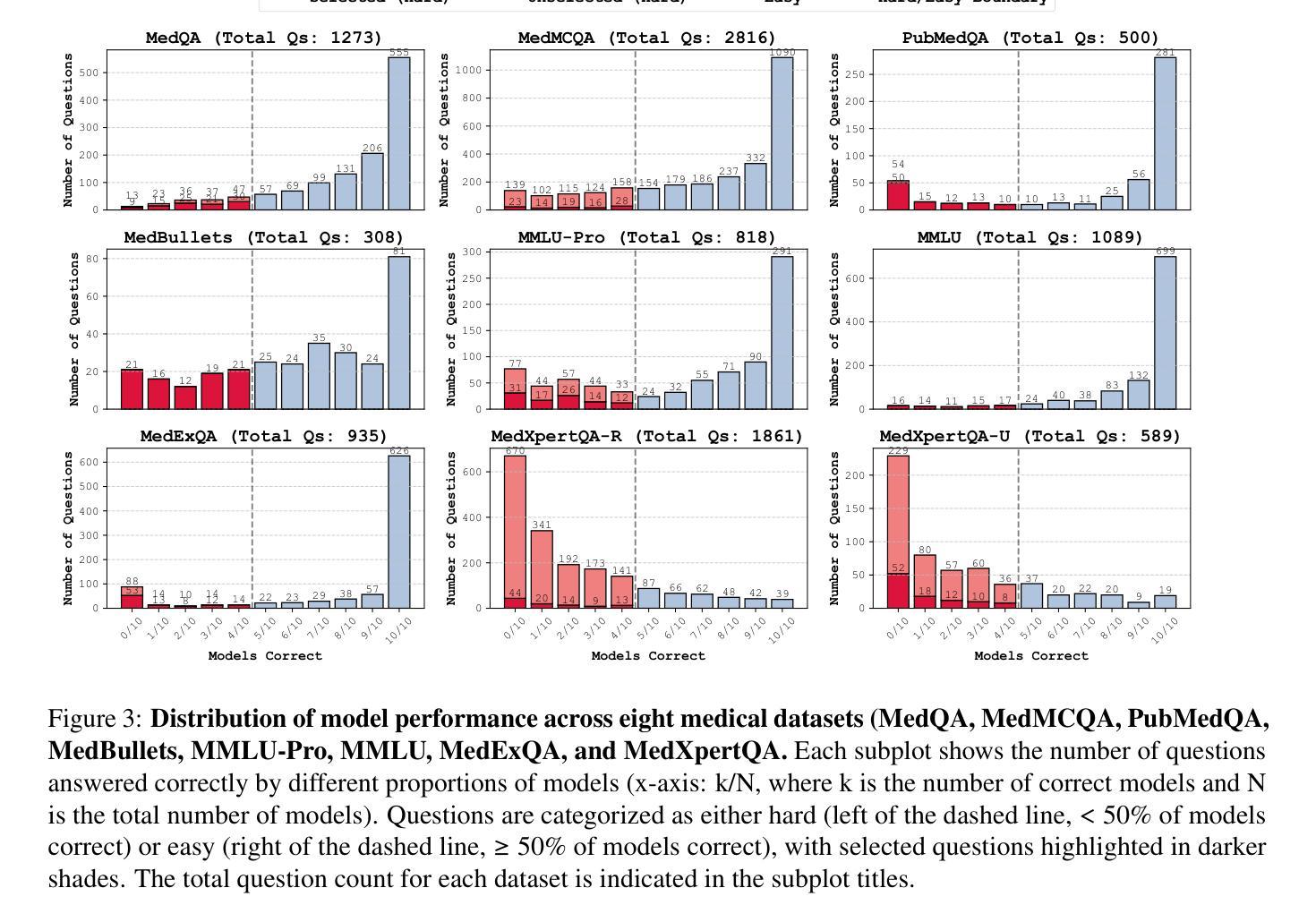
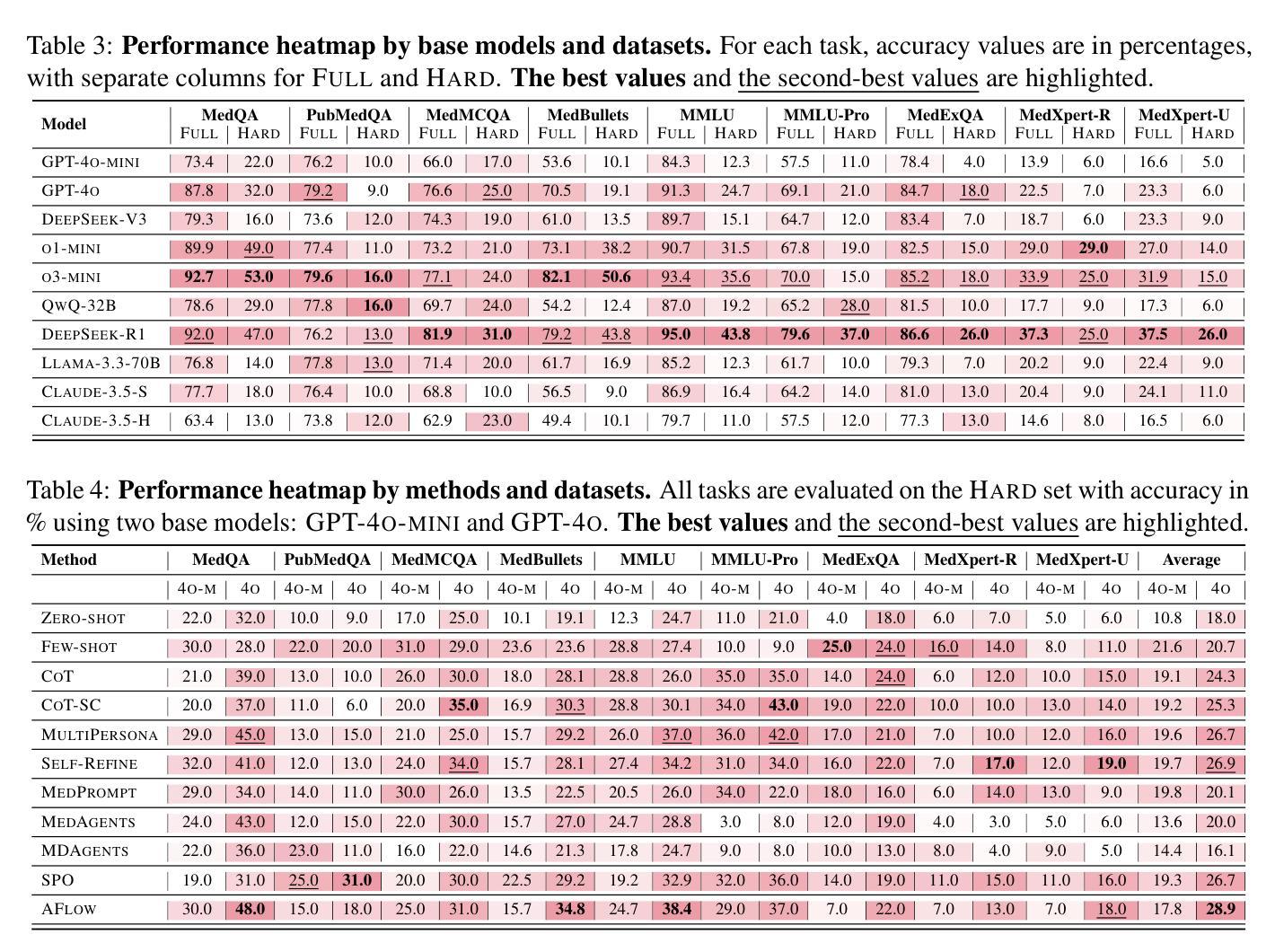
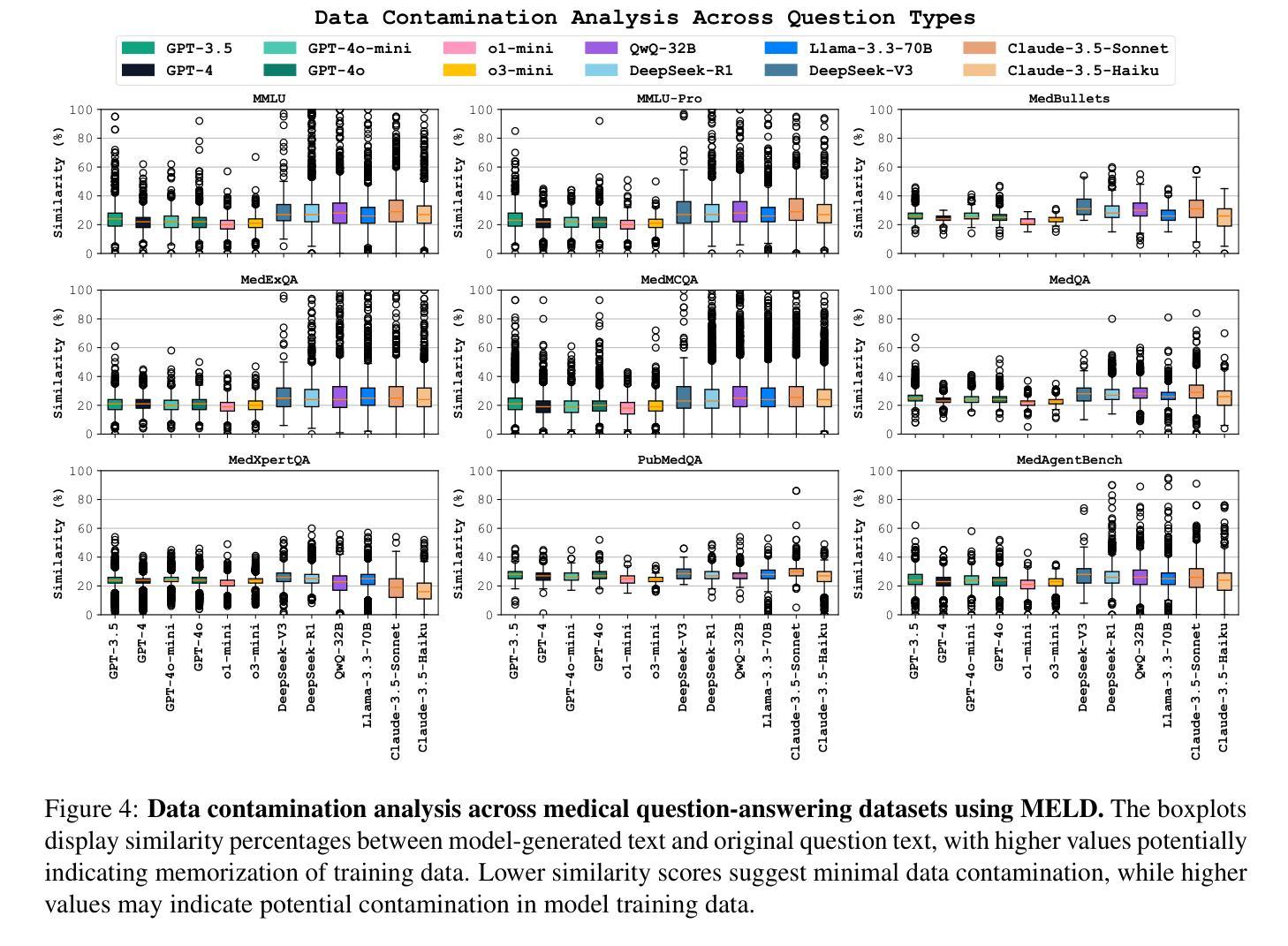
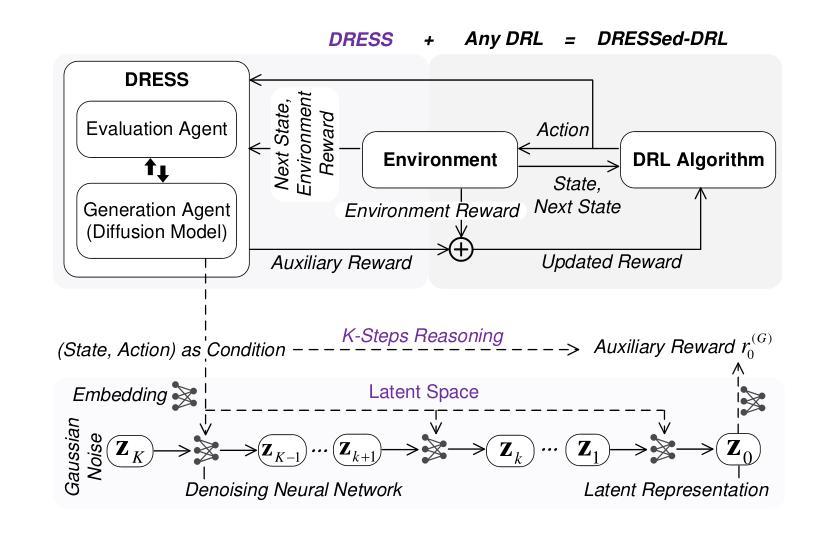
DRESS: Diffusion Reasoning-based Reward Shaping Scheme For Intelligent Networks
Authors:Feiran You, Hongyang Du, Xiangwang Hou, Yong Ren, Kaibin Huang
Network optimization remains fundamental in wireless communications, with Artificial Intelligence (AI)-based solutions gaining widespread adoption. As Sixth-Generation (6G) communication networks pursue full-scenario coverage, optimization in complex extreme environments presents unprecedented challenges. The dynamic nature of these environments, combined with physical constraints, makes it difficult for AI solutions such as Deep Reinforcement Learning (DRL) to obtain effective reward feedback for the training process. However, many existing DRL-based network optimization studies overlook this challenge through idealized environment settings. Inspired by the powerful capabilities of Generative AI (GenAI), especially diffusion models, in capturing complex latent distributions, we introduce a novel Diffusion Reasoning-based Reward Shaping Scheme (DRESS) to achieve robust network optimization. By conditioning on observed environmental states and executed actions, DRESS leverages diffusion models’ multi-step denoising process as a form of deep reasoning, progressively refining latent representations to generate meaningful auxiliary reward signals that capture patterns of network systems. Moreover, DRESS is designed for seamless integration with any DRL framework, allowing DRESS-aided DRL (DRESSed-DRL) to enable stable and efficient DRL training even under extreme network environments. Experimental results demonstrate that DRESSed-DRL achieves about 1.5x times faster convergence than its original version in sparse-reward wireless environments and significant performance improvements in multiple general DRL benchmark environments compared to baseline methods. The code of DRESS is available at https://github.com/NICE-HKU/DRESS.
网络优化在无线通信中仍是基础性的内容,基于人工智能的解决方案正得到广泛应用。随着第六代(6G)通信网络追求全场景覆盖,复杂极端环境中的优化面临着前所未有的挑战。这些环境的动态性以及物理约束使得人工智能解决方案(如深度强化学习(DRL))难以获得训练过程的有效奖励反馈。然而,许多现有的基于DRL的网络优化研究通过理想化的环境设置忽略了这一挑战。受生成式人工智能(GenAI)强大能力的启发,尤其是扩散模型在捕捉复杂潜在分布方面的能力,我们提出了一种新颖的基于扩散推理的奖励塑形方案(DRESS)来实现稳健的网络优化。DRESS通过根据观察到的环境状态和所执行的动作,利用扩散模型的多步去噪过程作为深度推理的一种形式,逐步优化潜在表示,生成有意义的辅助奖励信号,捕捉网络系统模式。此外,DRESS设计用于无缝集成任何DRL框架,允许DRESS辅助的DRL(DRESSed-DRL)即使在极端网络环境下也能实现稳定和高效的DRL训练。实验结果表明,在稀疏奖励的无线环境中,DRESSed-DRL的收敛速度比其原始版本快约1.5倍,并且在多个通用DRL基准环境中与基准方法相比实现了显著的性能提升。DRESS的代码可在https://github.com/NICE-HKU/DRESS找到。
论文及项目相关链接
Summary:
随着无线通讯中对网络优化的基础需求不断增长,基于人工智能的解决方案正得到广泛应用。在追求全场景覆盖的6G通讯网络中,极端复杂环境下的优化带来了前所未有的挑战。为解决动态环境和物理约束对深度强化学习(DRL)训练过程的影响,本研究受生成式人工智能(GenAI)扩散模型的启发,提出了一种新颖的基于扩散推理的奖励塑形方案(DRESS)。DRESS通过观测环境状态和行动,利用扩散模型的多步去噪过程进行深度推理,逐步优化潜在表征,生成有意义的辅助奖励信号,捕捉网络系统模式。DRESS可无缝集成任何DRL框架,使DRESS辅助的DRL(DRESSed-DRL)在极端网络环境下实现稳定和高效的DRL训练。实验结果显示,在奖励稀疏的无线环境中,DRESSed-DRL的收敛速度比原版快约1.5倍,并且在多个通用DRL基准环境中与基线方法相比实现了显著的性能提升。
Key Takeaways:
- 网络优化在无线通讯中仍具有基础性意义,人工智能解决方案在此领域得到广泛应用。
- 6G通讯网络在追求全场景覆盖时,在极端复杂环境下的优化存在挑战。
- 现有DRL方案在动态环境和物理约束下训练过程受影响。
- 研究提出基于扩散推理的奖励塑形方案(DRESS)以解决问题。
- DRESS利用扩散模型的多步去噪过程进行深度推理,生成辅助奖励信号。
- DRESS可集成任何DRL框架,实现稳定和高效的训练。
- DRESSed-DRL在无线环境中有更快的收敛速度,并在多个基准环境中性能显著提升。
点此查看论文截图

MM-Eureka: Exploring Visual Aha Moment with Rule-based Large-scale Reinforcement Learning
Authors:Fanqing Meng, Lingxiao Du, Zongkai Liu, Zhixiang Zhou, Quanfeng Lu, Daocheng Fu, Botian Shi, Wenhai Wang, Junjun He, Kaipeng Zhang, Ping Luo, Yu Qiao, Qiaosheng Zhang, Wenqi Shao
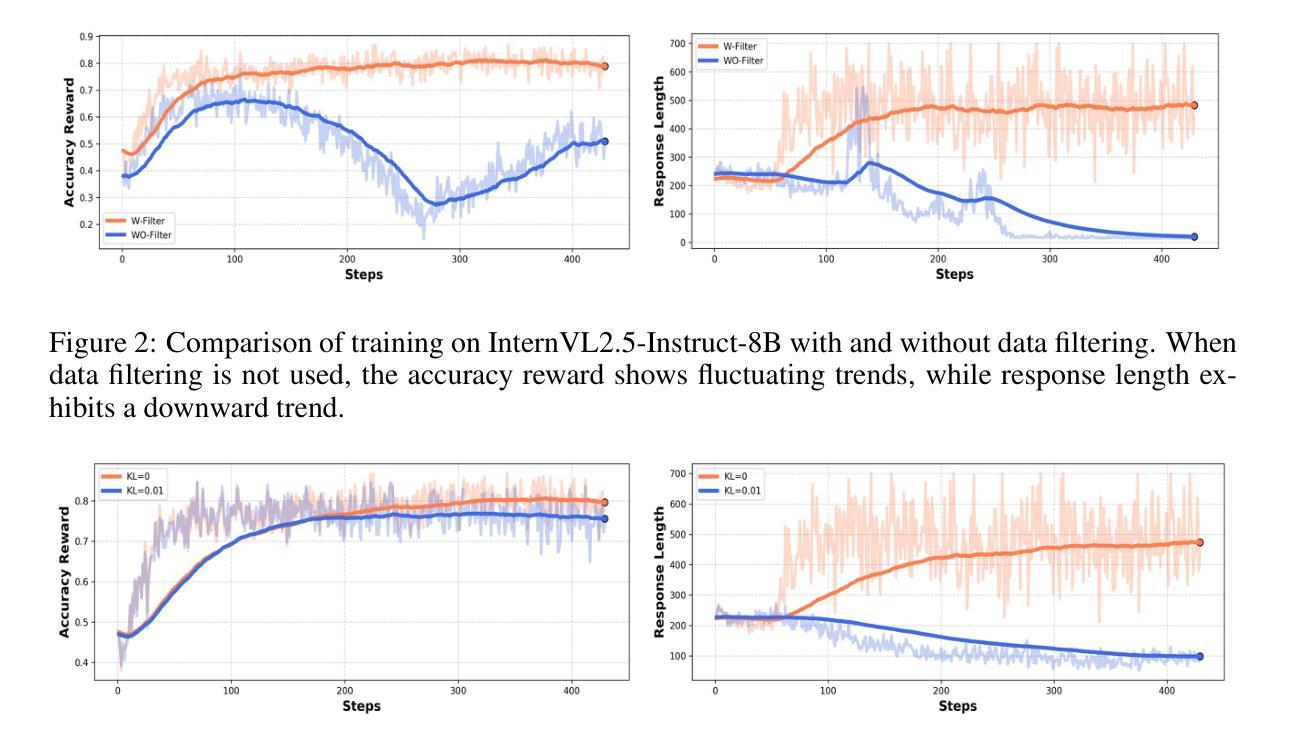
We present MM-Eureka, a multimodal reasoning model that successfully extends large-scale rule-based reinforcement learning (RL) to multimodal reasoning. While rule-based RL has shown remarkable success in improving LLMs’ reasoning abilities in text domains, its application to multimodal settings has remained challenging. Our work reproduces key characteristics of text-based RL systems like DeepSeek-R1 in the multimodal space, including steady increases in accuracy reward and response length, and the emergence of reflection behaviors. We demonstrate that both instruction-tuned and pre-trained models can develop strong multimodal reasoning capabilities through rule-based RL without supervised fine-tuning, showing superior data efficiency compared to alternative approaches. We open-source our complete pipeline to foster further research in this area. We release all our codes, models, data, etc. at https://github.com/ModalMinds/MM-EUREKA
我们介绍了MM-Eureka,这是一个成功将大规模基于规则的强化学习(RL)扩展到多模态推理的多模态推理模型。虽然基于规则的RL在文本领域的提高大型语言模型的推理能力方面取得了显著的成效,但将其应用于多模态场景仍然具有挑战性。我们的工作在多模态空间中再现了基于文本的RL系统(如DeepSeek-R1)的关键特性,包括精度奖励和响应长度的稳定增加,以及反思行为的出现。我们证明,通过基于规则的RL,无论是指令调整模型还是预训练模型,都可以开发出强大的多模态推理能力,而无需监督微调。与替代方法相比,显示出卓越的数据效率。我们公开了完整的管道,以推动该领域的研究。我们发布所有代码、模型、数据等,请访问https://github.com/ModalMinds/MM-EUREKA
论文及项目相关链接
Summary
MM-Eureka是一款成功将大规模基于规则的强化学习扩展到多模态推理领域的多模态推理模型。它在多模态环境下成功实现了关键文本RL系统的特性,包括精度奖励和响应长度的稳定增长,以及反思行为的出现。研究表明,通过基于规则的强化学习,无论是指令调优模型还是预训练模型都能发展出强大的多模态推理能力,相较于其他方法具有更高的数据效率。我们公开了完整的管道以促进该领域的研究。
Key Takeaways
- MM-Eureka是一个多模态推理模型,成功将基于规则的强化学习扩展到多模态推理领域。
- MM-Eureka在多模态环境下成功实现了关键文本RL系统的特性,如精度奖励和响应长度的稳定增长。
- MM-Eureka展现了反思行为的出现,这是向更复杂、更高级推理能力迈进的重要一步。
- 通过基于规则的强化学习,无论是指令调优模型还是预训练模型都能发展出强大的多模态推理能力。
- MM-Eureka在数据效率上优于其他方法,无需大量标注数据即可实现良好的性能。
- MM-Eureka的完整管道被公开,为其他研究者提供了研究基础,有助于推动该领域的进一步发展。
点此查看论文截图



Application of Multiple Chain-of-Thought in Contrastive Reasoning for Implicit Sentiment Analysis
Authors:Liwei Yang, Xinying Wang, Xiaotang Zhou, Zhengchao Wu, Ningning Tan
Implicit sentiment analysis aims to uncover emotions that are subtly expressed, often obscured by ambiguity and figurative language. To accomplish this task, large language models and multi-step reasoning are needed to identify those sentiments that are not explicitly stated. In this study, we propose a novel Dual Reverse Chain Reasoning (DRCR) framework to enhance the performance of implicit sentiment analysis. Inspired by deductive reasoning, the framework consists of three key steps: 1) hypothesize an emotional polarity and derive a reasoning process, 2) negate the initial hypothesis and derive a new reasoning process, and 3) contrast the two reasoning paths to deduce the final sentiment polarity. Building on this, we also introduce a Triple Reverse Chain Reasoning (TRCR) framework to address the limitations of random hypotheses. Both methods combine contrastive mechanisms and multi-step reasoning, significantly improving the accuracy of implicit sentiment classification. Experimental results demonstrate that both approaches outperform existing methods across various model scales, achieving state-of-the-art performance. This validates the effectiveness of combining contrastive reasoning and multi-step reasoning for implicit sentiment analysis.
隐式情感分析旨在发现那些微妙表达的情感,这些情感通常由于模棱两可和比喻语言而难以察觉。为了完成这项任务,需要大型语言模型和分步推理来识别那些未被明确表达的情感。在研究中,我们提出了一种新型的双重逆向链推理(DRCR)框架,以提高隐式情感分析的性能。受演绎推理的启发,该框架包括三个关键步骤:1)假设情感极性并得出推理过程;2)否定初始假设并得出新的推理过程;3)对比两条推理路径来推断最终的情感极性。在此基础上,我们还引入了三重逆向链推理(TRCR)框架来解决随机假设的局限性问题。这两种方法都结合了对比机制和分步推理,大大提高了隐式情感分类的准确性。实验结果表明,这两种方法在各种模型规模上都优于现有方法,达到了最先进的性能水平。这验证了将对比推理和多步推理相结合用于隐式情感分析的有效性。
论文及项目相关链接
Summary
隐式情感分析旨在揭示通过模糊和隐喻语言表达的情感。本研究提出一种新型的双重逆向链推理(DRCR)框架,以提高隐式情感分析的性能。该框架由三个关键步骤组成:假设情感极性并推导推理过程、否定初始假设并推导新的推理过程、对比两条推理路径来推断最终的情感极性。在此基础上,还引入了三重逆向链推理(TRCR)框架,以解决随机假设的局限性。两种方法结合对比机制和多步推理,显著提高隐式情感分类的准确性。实验结果证明,这两种方法在各种模型规模上都优于现有方法,达到最新性能水平,验证了结合对比推理和多步推理进行隐式情感分析的有效性。
Key Takeaways
- 隐式情感分析的目标是识别通过模糊和隐喻语言表达的情感。
- 双重逆向链推理(DRCR)框架用于提高隐式情感分析的性能。
- DRCR框架包括三个关键步骤:假设情感极性、否定初始假设、对比两条推理路径。
- 为了解决随机假设的局限性,引入了三重逆向链推理(TRCR)框架。
- TRCR和DRCR结合对比机制和逻辑推理,增强了隐式情感分类的准确性。
- 实验结果表明,这两种方法优于现有方法,达到最新性能。
点此查看论文截图

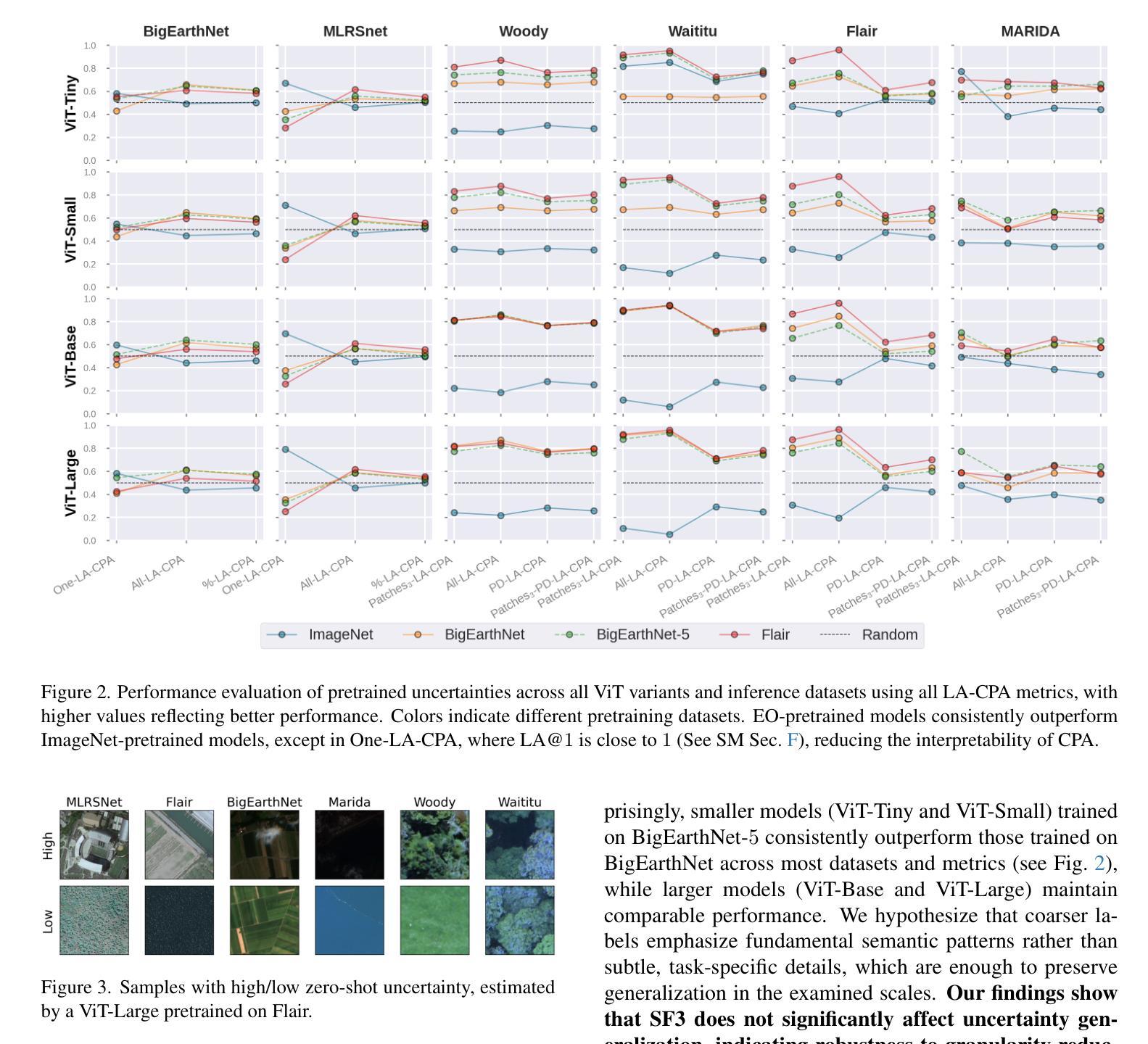
On the Generalization of Representation Uncertainty in Earth Observation
Authors:Spyros Kondylatos, Nikolaos Ioannis Bountos, Dimitrios Michail, Xiao Xiang Zhu, Gustau Camps-Valls, Ioannis Papoutsis
Recent advances in Computer Vision have introduced the concept of pretrained representation uncertainty, enabling zero-shot uncertainty estimation. This holds significant potential for Earth Observation (EO), where trustworthiness is critical, yet the complexity of EO data poses challenges to uncertainty-aware methods. In this work, we investigate the generalization of representation uncertainty in EO, considering the domain’s unique semantic characteristics. We pretrain uncertainties on large EO datasets and propose an evaluation framework to assess their zero-shot performance in multi-label classification and segmentation EO tasks. Our findings reveal that, unlike uncertainties pretrained on natural images, EO-pretraining exhibits strong generalization across unseen EO domains, geographic locations, and target granularities, while maintaining sensitivity to variations in ground sampling distance. We demonstrate the practical utility of pretrained uncertainties showcasing their alignment with task-specific uncertainties in downstream tasks, their sensitivity to real-world EO image noise, and their ability to generate spatial uncertainty estimates out-of-the-box. Initiating the discussion on representation uncertainty in EO, our study provides insights into its strengths and limitations, paving the way for future research in the field. Code and weights are available at: https://github.com/Orion-AI-Lab/EOUncertaintyGeneralization.
近期计算机视觉的进步引入了预训练表示不确定性的概念,实现了零样本不确定性估计。这在地球观测(EO)中具有巨大潜力,信任度在地球观测中至关重要,然而地球观测数据的复杂性给具有感知不确定性的方法带来了挑战。在这项工作中,我们研究了表示不确定在地球观测中的通用性,并考虑了该领域独特的语义特征。我们在大型地球观测数据集上进行了不确定性预训练,并提出了一个评估框架,以评估它们在多标签分类和分段地球观测任务中的零样本表现。我们的研究结果表明,与在自然图像上预训练的不确定性不同,地球观测的预训练不确定性在未见过的地球观测领域、地理位置和目标粒度上表现出强大的通用性,同时保持对地采样距离变化的敏感性。我们展示了预训练不确定性的实际效用,展示其与下游任务中任务特定不确定性的吻合、对现实世界地球观测图像噪声的敏感性以及能够生成空间不确定性估计的能力。我们率先讨论了地球观测中的表示不确定性问题,本研究为未来的研究提供了深刻的见解和铺平了道路。代码和权重可通过以下链接获得:Orion AI实验室的网站链接。
论文及项目相关链接
PDF 18 pages
Summary
本文探讨了计算机视觉领域的预训练表示不确定性在地球观测(EO)领域的应用。文章介绍了预训练不确定性在EO数据上的研究,并提出了一个评估框架来评估其在多标签分类和分割EO任务中的零样本性能。研究发现,相较于在自然图像上预训练的不确定性模型,EO领域的预训练不确定性展现出更强的跨未见EO领域、地理位置和目标粒度的泛化能力,同时对地面采样距离的变化保持敏感。该研究为地球观测领域引入预训练不确定性的讨论,为未来的研究提供了见解。
Key Takeaways
- 预训练表示不确定性的概念被引入地球观测(EO)领域。
- 在EO数据上预训练的不确定性模型展现出强泛化能力。
- EO预训练的不确定性模型能在多标签分类和分割任务中有效评估零样本性能。
- EO预训练的不确定性模型对地面采样距离的变化敏感。
- 展示预训练不确定性在下游任务中的实用性,与任务特定不确定性对齐,对现实世界EO图像噪声敏感,并能生成空间不确定性估计。
- 研究提供了预训练表示不确定性的优势和局限性的见解。
点此查看论文截图

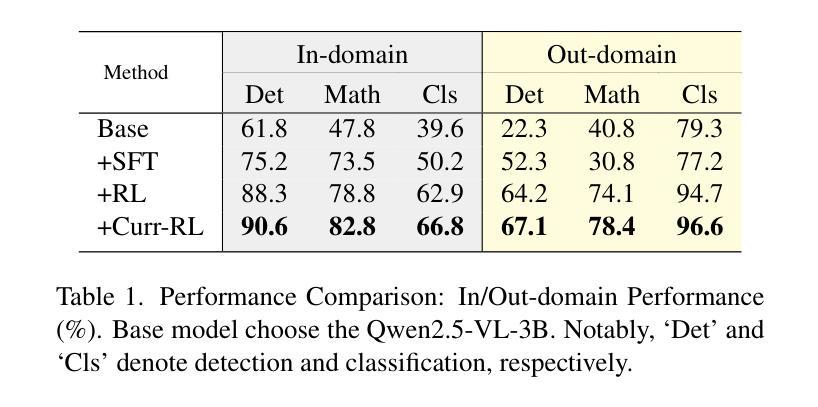
Boosting the Generalization and Reasoning of Vision Language Models with Curriculum Reinforcement Learning
Authors:Huilin Deng, Ding Zou, Rui Ma, Hongchen Luo, Yang Cao, Yu Kang
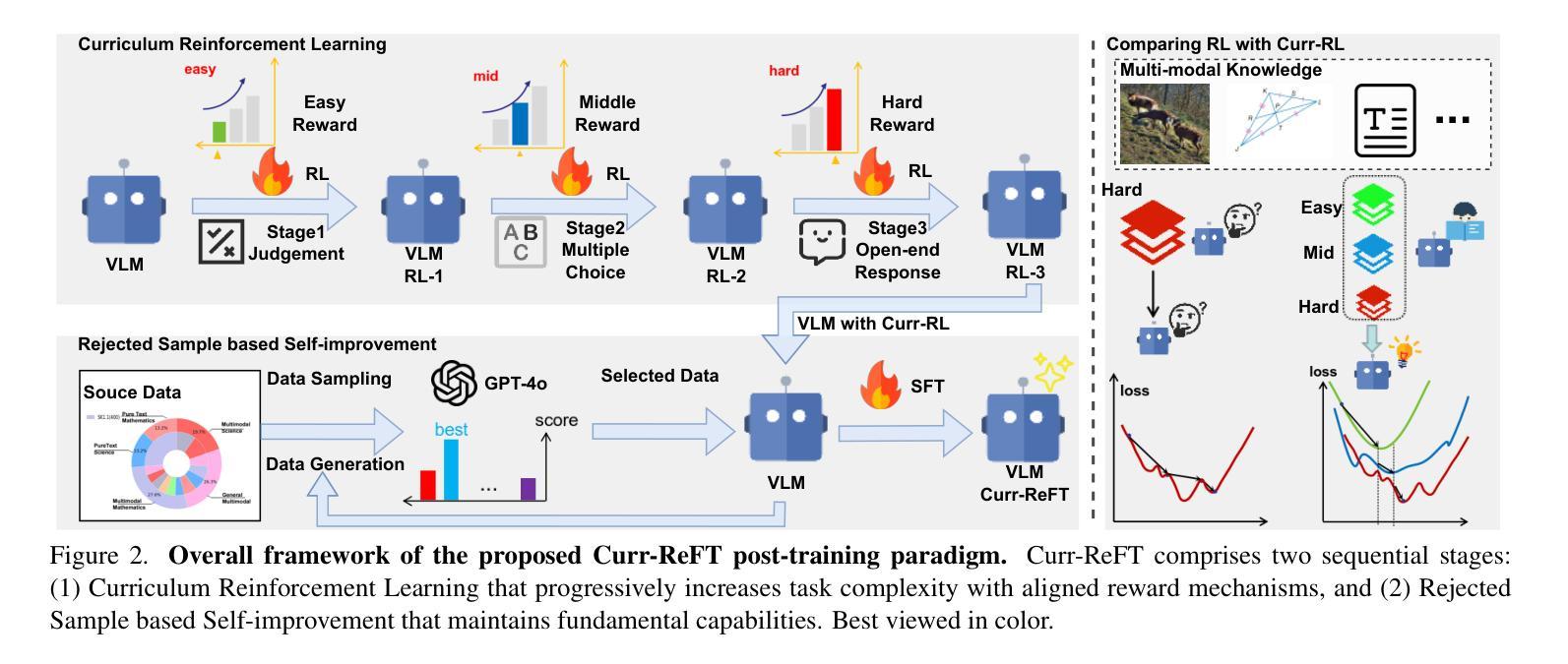
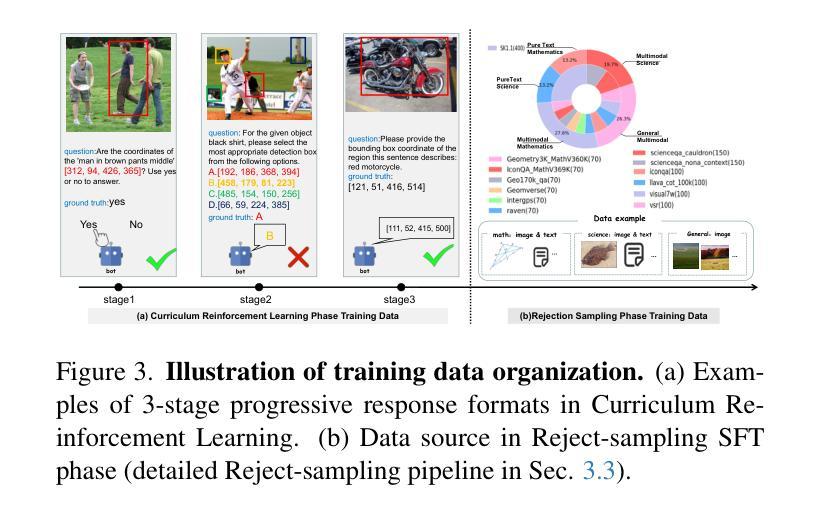
While state-of-the-art vision-language models (VLMs) have demonstrated remarkable capabilities in complex visual-text tasks, their success heavily relies on massive model scaling, limiting their practical deployment. Small-scale VLMs offer a more practical alternative but face significant challenges when trained with traditional supervised fine-tuning (SFT), particularly in two aspects: out-of-domain (OOD) generalization and reasoning abilities, which significantly lags behind the contemporary Large language models (LLMs). To address these challenges, we propose Curriculum Reinforcement Finetuning (Curr-ReFT), a novel post-training paradigm specifically designed for small-scale VLMs. Inspired by the success of reinforcement learning in LLMs, Curr-ReFT comprises two sequential stages: (1) Curriculum Reinforcement Learning, which ensures steady progression of model capabilities through difficulty-aware reward design, transitioning from basic visual perception to complex reasoning tasks; and (2) Rejected Sampling-based Self-improvement, which maintains the fundamental capabilities of VLMs through selective learning from high-quality multimodal and language examples. Extensive experiments demonstrate that models trained with Curr-ReFT paradigm achieve state-of-the-art performance across various visual tasks in both in-domain and out-of-domain settings. Moreover, our Curr-ReFT enhanced 3B model matches the performance of 32B-parameter models, demonstrating that efficient training paradigms can effectively bridge the gap between small and large models.
虽然最先进的视觉语言模型(VLMs)在复杂的视觉文本任务中表现出了显著的能力,但它们的成功严重依赖于大规模的模型扩展,限制了其实际部署。小规模VLMs提供了更实用的替代方案,但使用传统的有监督微调(SFT)进行训练时面临重大挑战,特别是在两个方面:域外(OOD)推广能力和推理能力,这与当代的大型语言模型(LLMs)相比存在明显差距。为了应对这些挑战,我们提出了课程强化微调(Curr-ReFT),这是一种专门为小规模VLMs设计的新型后训练范式。受强化学习在LLMs中成功的启发,Curr-ReFT包含两个连续的阶段:(1)课程强化学习,通过难度感知奖励设计确保模型能力的稳定进步,从基本的视觉感知过渡到复杂的推理任务;(2)基于拒绝采样的自我改进,通过选择性学习高质量的多模态和语言示例,保持VLMs的基本能力。大量实验表明,采用Curr-ReFT范式训练的模型在各种视觉任务中的域内和域外设置中均达到最新性能。此外,我们采用Curr-ReFT增强的3B模型与32B参数模型的性能相匹配,表明有效的训练范式可以有效地缩小小型和大型模型之间的差距。
论文及项目相关链接
Summary:
先进的视觉语言模型(VLMs)在复杂的视觉文本任务中表现出卓越的能力,但其成功严重依赖于大规模的模型扩展,限制了其实践部署。小规模VLMs虽然提供了更实用的替代方案,但在使用传统的监督微调(SFT)进行训练时面临挑战,特别是在域外(OOD)泛化和推理能力方面,远远落后于当代的大型语言模型(LLMs)。为解决这些问题,我们提出了课程强化微调(Curr-ReFT)这一新型的后训练范式,专为小规模VLMs设计。Curr-ReFT由两个顺序阶段组成:首先是课程强化学习,通过难度感知奖励设计确保模型能力稳步提高,从基本的视觉感知过渡到复杂的推理任务;然后是拒绝采样自我改进,通过选择性学习高质量的多模态和语言示例来保持VLMs的基本能力。实验表明,采用Curr-ReFT训练的模型在各种视觉任务中实现了卓越的性能,无论处于内域还是外域环境中均表现突出。此外,使用Curr-ReFT增强的3B模型甚至达到了32B参数模型的性能水平,证明了有效训练范式可以有效缩小大小模型之间的差距。
Key Takeaways:
- 先进的视觉语言模型(VLMs)在复杂任务中表现出色,但大规模模型扩展限制了其实践部署。
- 小规模VLMs面临传统监督微调(SFT)的挑战,特别是在域外(OOD)泛化和推理能力方面。
- 提出了课程强化微调(Curr-ReFT)这一新型后训练范式,专为小规模VLMs设计。
- Curr-ReFT包含两个主要阶段:课程强化学习和拒绝采样自我改进。
- 课程强化学习通过难度感知奖励设计提高模型能力。
- 拒绝采样自我改进通过选择性学习高质量示例来保持VLMs的基本能力。
点此查看论文截图

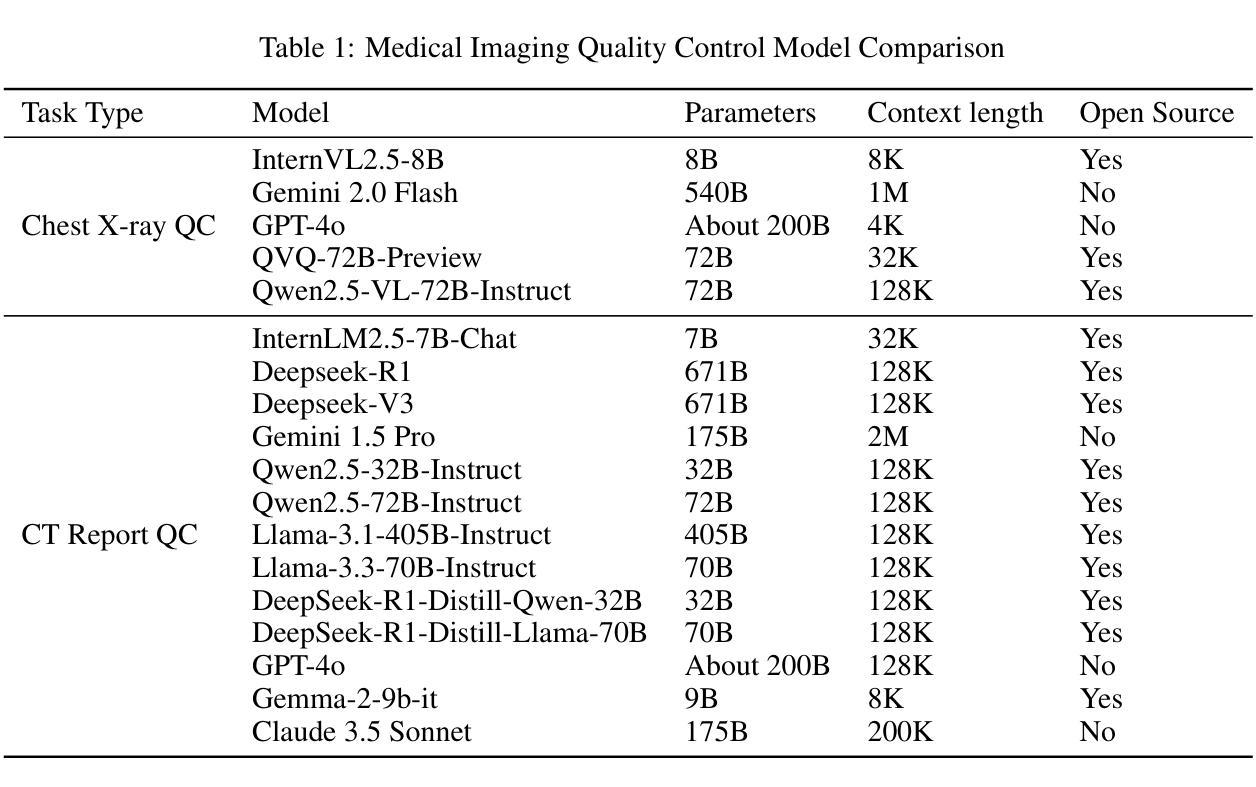
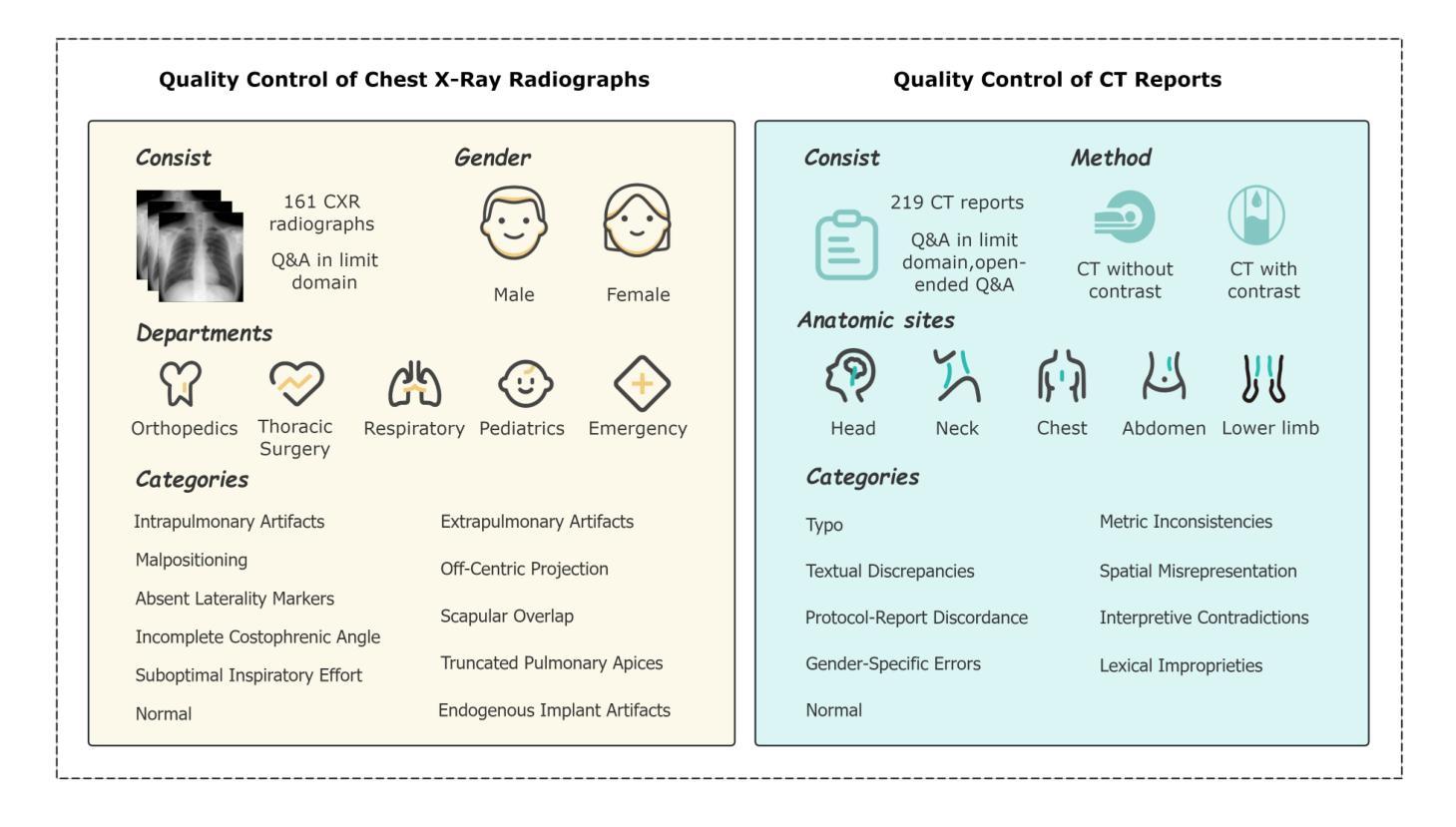
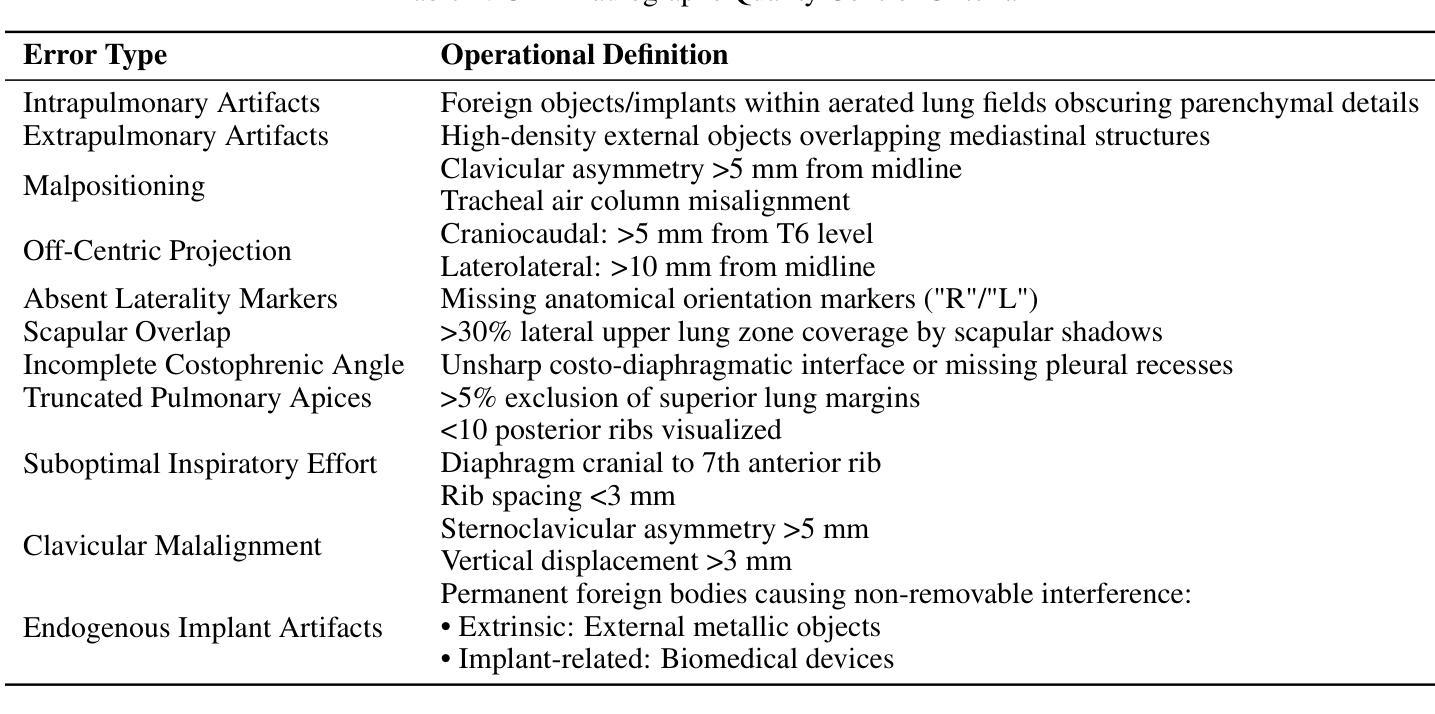
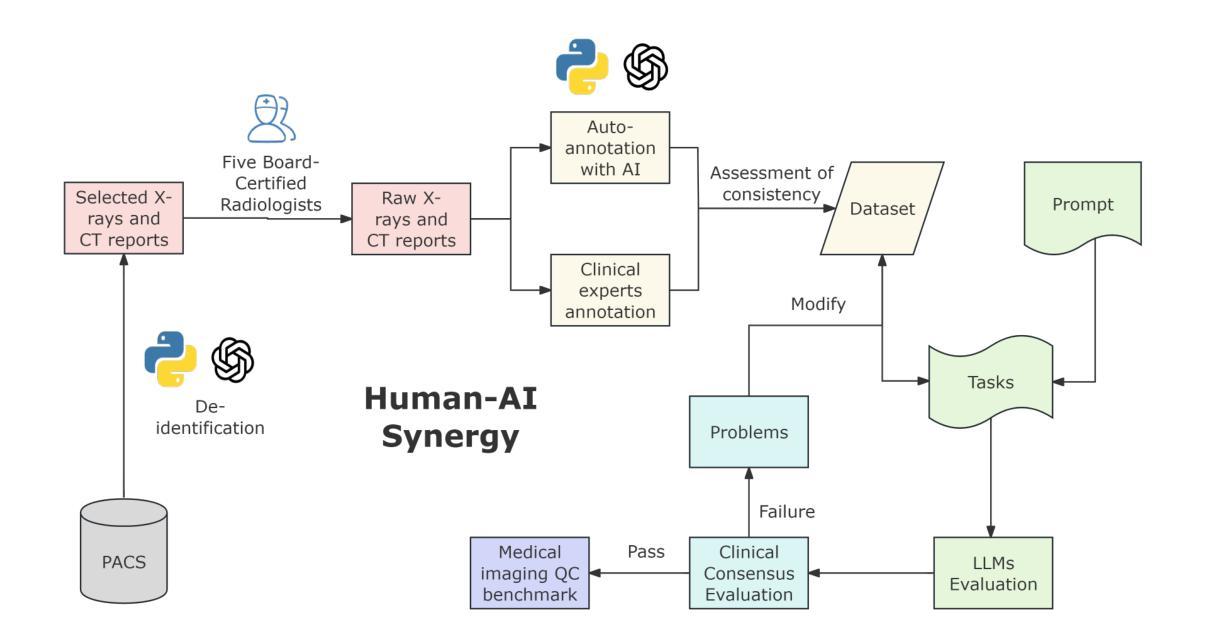
Multimodal Human-AI Synergy for Medical Imaging Quality Control: A Hybrid Intelligence Framework with Adaptive Dataset Curation and Closed-Loop Evaluation
Authors:Zhi Qin, Qianhui Gui, Mouxiao Bian, Rui Wang, Hong Ge, Dandan Yao, Ziying Sun, Yuan Zhao, Yu Zhang, Hui Shi, Dongdong Wang, Chenxin Song, Shenghong Ju, Lihao Liu, Junjun He, Jie Xu, Yuan-Cheng Wang
Medical imaging quality control (QC) is essential for accurate diagnosis, yet traditional QC methods remain labor-intensive and subjective. To address this challenge, in this study, we establish a standardized dataset and evaluation framework for medical imaging QC, systematically assessing large language models (LLMs) in image quality assessment and report standardization. Specifically, we first constructed and anonymized a dataset of 161 chest X-ray (CXR) radiographs and 219 CT reports for evaluation. Then, multiple LLMs, including Gemini 2.0-Flash, GPT-4o, and DeepSeek-R1, were evaluated based on recall, precision, and F1 score to detect technical errors and inconsistencies. Experimental results show that Gemini 2.0-Flash achieved a Macro F1 score of 90 in CXR tasks, demonstrating strong generalization but limited fine-grained performance. DeepSeek-R1 excelled in CT report auditing with a 62.23% recall rate, outperforming other models. However, its distilled variants performed poorly, while InternLM2.5-7B-chat exhibited the highest additional discovery rate, indicating broader but less precise error detection. These findings highlight the potential of LLMs in medical imaging QC, with DeepSeek-R1 and Gemini 2.0-Flash demonstrating superior performance.
医学影像质量控制(QC)对于准确诊断至关重要,然而传统的QC方法仍然劳动强度高且主观性较强。为了应对这一挑战,本研究建立了一套标准化的数据集和医学影像QC评估框架,系统地评估了大型语言模型(LLM)在图像质量评估和报告标准化方面的表现。具体来说,我们首先构建并匿名化了一个包含161张胸部X射线(CXR)照片和219份CT报告的数据集进行评估。然后,基于召回率、精确度和F1分数,对包括Gemini 2.0-Flash、GPT-4o和DeepSeek-R1在内的多个LLM进行了技术错误和不一致性检测。实验结果表明,Gemini 2.0-Flash在CXR任务中的宏F1分数达到90,表现出较强的泛化能力,但精细粒度性能有限。DeepSeek-R1在CT报告审核方面表现出色,召回率达到62.23%,超过了其他模型。然而,其蒸馏变体表现不佳,而InternLM2.5-7B-chat展现出最高的额外发现率,表明其错误检测范围更广但精确度较低。这些发现突显了LLM在医学影像QC中的潜力,其中DeepSeek-R1和Gemini 2.0-Flash表现出卓越的性能。
论文及项目相关链接
Summary
本文研究建立医学成像质量控制(QC)的标准数据集和评估框架,以评估大型语言模型(LLMs)在图像质量评估和报告标准化方面的性能。实验结果显示,Gemini 2.0-Flash在CXR任务中表现优异,DeepSeek-R1在CT报告审核中具有高召回率并表现出卓越性能。此研究突显了LLMs在医学成像QC中的潜力。
Key Takeaways
- 研究建立医学成像QC的标准数据集和评估框架。
- 采用大型语言模型(LLMs)进行图像质量评估和报告标准化评估。
- Gemini 2.0-Flash在CXR任务中表现优异,具有强的泛化能力但精细粒度性能有限。
- DeepSeek-R1在CT报告审核中表现出高召回率和卓越性能。
- DeepSeek-R1的蒸馏变体表现不佳,而InternLM2.5-7B-chat具有更广泛的错误检测能力但精确度较低。
- 实验结果证明了大型语言模型在医学成像QC中的潜力。
点此查看论文截图

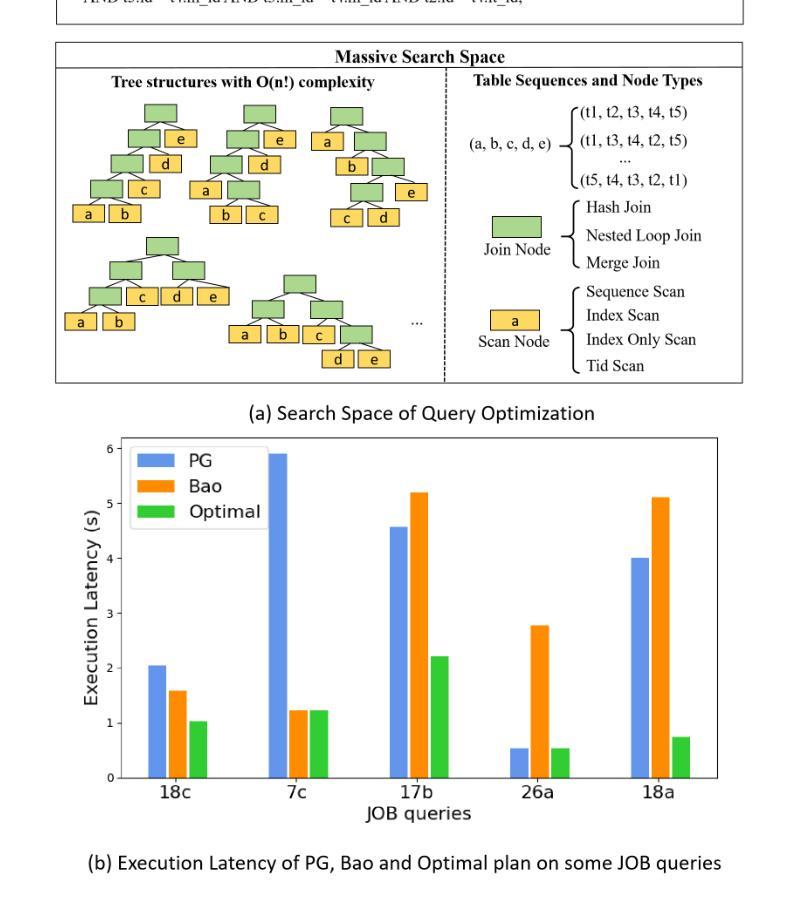
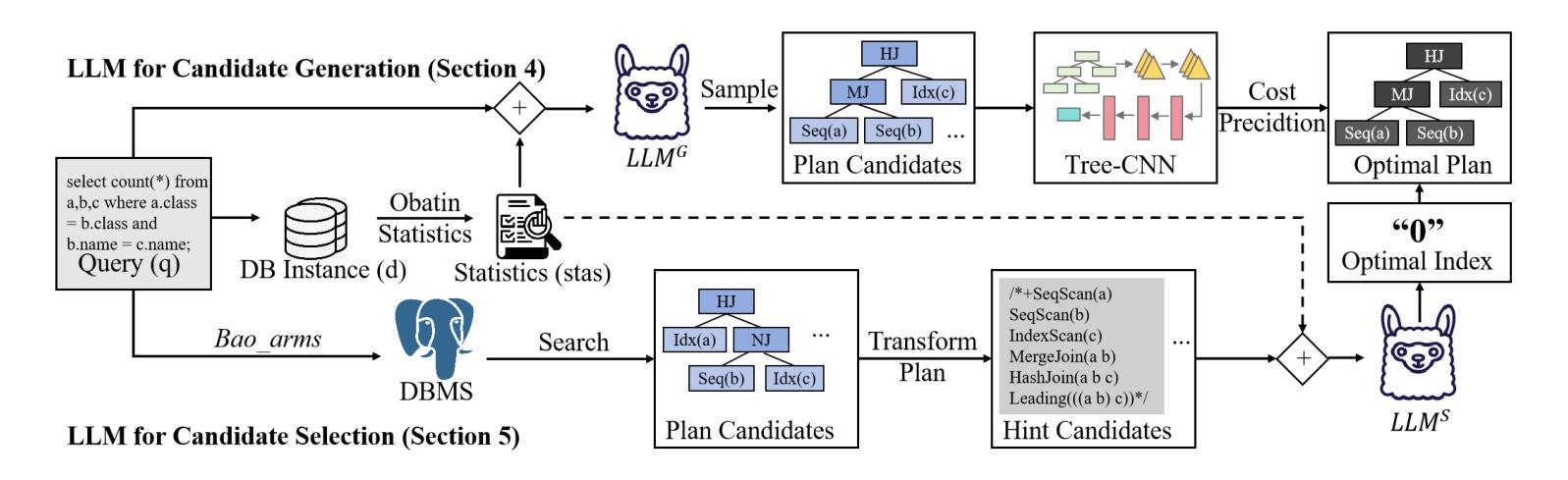
A Query Optimization Method Utilizing Large Language Models
Authors:Zhiming Yao, Haoyang Li, Jing Zhang, Cuiping Li, Hong Chen
Query optimization is a critical task in database systems, focused on determining the most efficient way to execute a query from an enormous set of possible strategies. Traditional approaches rely on heuristic search methods and cost predictions, but these often struggle with the complexity of the search space and inaccuracies in performance estimation, leading to suboptimal plan choices. This paper presents LLMOpt, a novel framework that leverages Large Language Models (LLMs) to address these challenges through two innovative components: (1) LLM for Plan Candidate Generation (LLMOpt(G)), which eliminates heuristic search by utilizing the reasoning abilities of LLMs to directly generate high-quality query plans, and (2) LLM for Plan Candidate Selection (LLMOpt(S)), a list-wise cost model that compares candidates globally to enhance selection accuracy. To adapt LLMs for query optimization, we propose fine-tuning pre-trained models using optimization data collected offline. Experimental results on the JOB, JOB-EXT, and Stack benchmarks show that LLMOpt(G) and LLMOpt(S) outperform state-of-the-art methods, including PostgreSQL, BAO, and HybridQO. Notably, LLMOpt(S) achieves the best practical performance, striking a balance between plan quality and inference efficiency.
查询优化是数据库系统中的一项关键任务,主要关注于从大量可能的策略中确定执行查询的最有效方式。传统方法依赖于启发式搜索方法和成本预测,但这些方法在复杂的搜索空间和性能估计的不准确性方面常常遇到挑战,从而导致选择次优计划。本文提出了LLMOpt这一新型框架,它利用大型语言模型(LLM)来解决这些挑战,主要包括两个创新组件:(1)LLM计划候选生成(LLMOpt(G)),它利用语言模型的推理能力直接生成高质量查询计划,从而消除了启发式搜索;(2)LLM计划候选选择(LLMOpt(S)),这是一种列表级成本模型,可在全局范围内比较候选计划,以提高选择准确性。为了将大型语言模型适应于查询优化,我们提出通过离线收集的优化数据对预训练模型进行微调。在JOB、JOB-EXT和Stack基准测试上的实验结果表明,LLMOpt(G)和LLMOpt(S)的性能优于最新方法,包括PostgreSQL、BAO和HybridQO。值得注意的是,LLMOpt(S)在实际性能上达到了最佳平衡,在计划质量和推理效率之间取得了平衡。
论文及项目相关链接
Summary
数据库查询优化是数据库系统中的一项重要任务。传统方法通常依赖于启发式搜索方法和成本预测,但存在搜索空间复杂和性能估算不准确的问题,导致计划选择不佳。本文提出了一种新的框架LLMOpt,利用大型语言模型(LLM)解决这些问题。它包括两个创新组件:LLMOpt(G)直接利用LLM的推理能力生成高质量查询计划,消除启发式搜索;LLMOpt(S)是比较候选计划全局成本的列表模型,提高选择准确性。实验结果证明,LLMOpt(G)和LLMOpt(S)优于当前最优方法,包括PostgreSQL、BAO和HybridQO。尤其是LLMOpt(S)在实际性能上表现最佳,在计划质量和推理效率之间达到了平衡。
Key Takeaways
- 查询优化在数据库系统中至关重要,目标是找到执行查询的最有效方式。
- 传统方法依赖启发式搜索和成本预测,但存在局限性。
- LLMOpt框架利用大型语言模型(LLM)解决查询优化问题。
- LLMOpt(G)通过直接生成高质量查询计划消除启发式搜索。
- LLMOpt(S)采用列表式的成本模型比较候选计划,提高选择准确性。
- 通过离线收集的优化数据进行预训练模型的微调。
点此查看论文截图



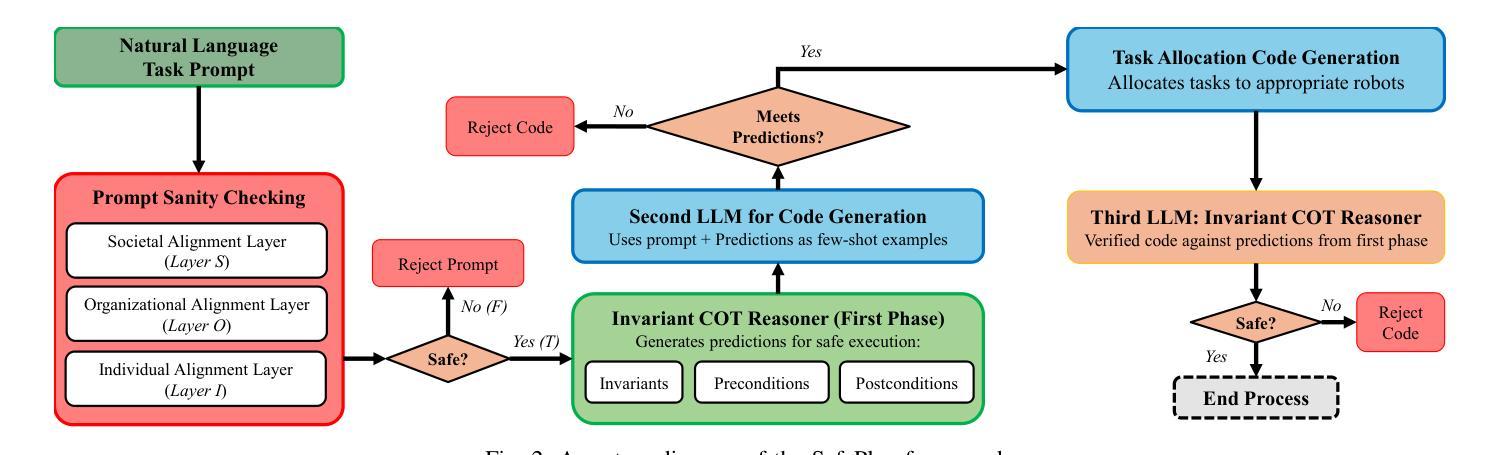
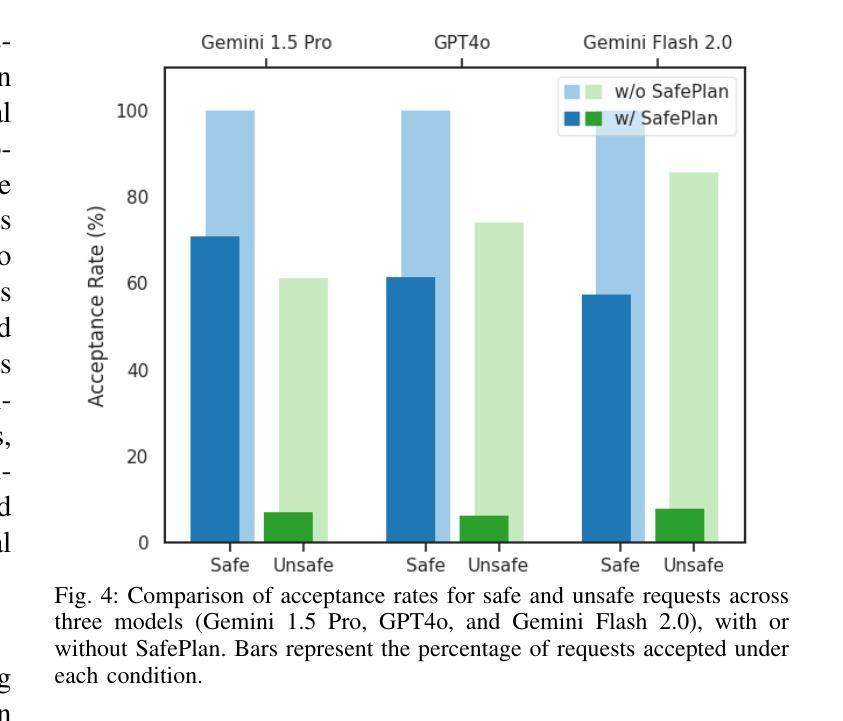
SafePlan: Leveraging Formal Logic and Chain-of-Thought Reasoning for Enhanced Safety in LLM-based Robotic Task Planning
Authors:Ike Obi, Vishnunandan L. N. Venkatesh, Weizheng Wang, Ruiqi Wang, Dayoon Suh, Temitope I. Amosa, Wonse Jo, Byung-Cheol Min
Robotics researchers increasingly leverage large language models (LLM) in robotics systems, using them as interfaces to receive task commands, generate task plans, form team coalitions, and allocate tasks among multi-robot and human agents. However, despite their benefits, the growing adoption of LLM in robotics has raised several safety concerns, particularly regarding executing malicious or unsafe natural language prompts. In addition, ensuring that task plans, team formation, and task allocation outputs from LLMs are adequately examined, refined, or rejected is crucial for maintaining system integrity. In this paper, we introduce SafePlan, a multi-component framework that combines formal logic and chain-of-thought reasoners for enhancing the safety of LLM-based robotics systems. Using the components of SafePlan, including Prompt Sanity COT Reasoner and Invariant, Precondition, and Postcondition COT reasoners, we examined the safety of natural language task prompts, task plans, and task allocation outputs generated by LLM-based robotic systems as means of investigating and enhancing system safety profile. Our results show that SafePlan outperforms baseline models by leading to 90.5% reduction in harmful task prompt acceptance while still maintaining reasonable acceptance of safe tasks.
机器人技术研究者越来越多地在机器人系统中利用大型语言模型(LLM),将其作为接口接收任务命令、生成任务计划、形成团队联盟以及在多机器人和人类代理人之间分配任务。然而,尽管有诸多好处,LLM在机器人技术中的日益普及也引发了若干安全问题,特别是关于执行恶意或危险的自然语言提示的问题。此外,确保任务计划、团队组建和任务分配输出(来自LLM)得到充分的审查、完善或拒绝对于维护系统完整性至关重要。在本文中,我们介绍了SafePlan,这是一个多组件框架,它结合了形式逻辑和思维链推理器,以提高基于LLM的机器人系统的安全性。使用SafePlan的组件,包括提示理智思维链推理器和不变性、先决条件和后条件思维链推理器,我们检查了基于LLM的机器人系统生成的自然语言任务提示、任务计划和任务分配输出的安全性,作为调查和增强系统安全性的手段。我们的结果表明,SafePlan优于基线模型,导致有害任务提示接受率降低了90.5%,同时仍保持了安全任务的合理接受率。
论文及项目相关链接
Summary
机器人技术研究中,越来越多地利用大型语言模型(LLM)作为接口,执行任务命令、生成任务计划、组建团队和分配多机器人与人类代理的任务。然而,LLM在机器人技术中的广泛应用引发了安全担忧,特别是执行恶意或危险的自然语言提示的问题。本文介绍了一个名为SafePlan的多组件框架,它通过形式逻辑和思维链推理器提高基于LLM的机器人系统的安全性。实验结果表明,SafePlan可大幅度降低危险任务提示的接受度,同时保持对安全任务的合理接受度,相较于基线模型性能提升达90.5%。
Key Takeaways
- 机器人技术中越来越多地使用大型语言模型(LLM)作为系统接口,用于执行多种任务。
- LLM在机器人技术中的应用引发了对执行恶意或危险自然语言提示的安全担忧。
- SafePlan框架结合了形式逻辑和思维链推理器,旨在提高基于LLM的机器人系统的安全性。
- SafePlan包含多个组件,如提示合理性思维链推理器以及不变性、预置条件和后置条件思维链推理器。
- 通过使用SafePlan框架,研究人员能够检查、改进或拒绝LLM生成的任务计划、团队组建和任务分配输出,从而提高系统的安全性。
- 实验结果表明,SafePlan能大幅度降低危险任务提示的接受度,同时保持对安全任务的合理接受度。
点此查看论文截图


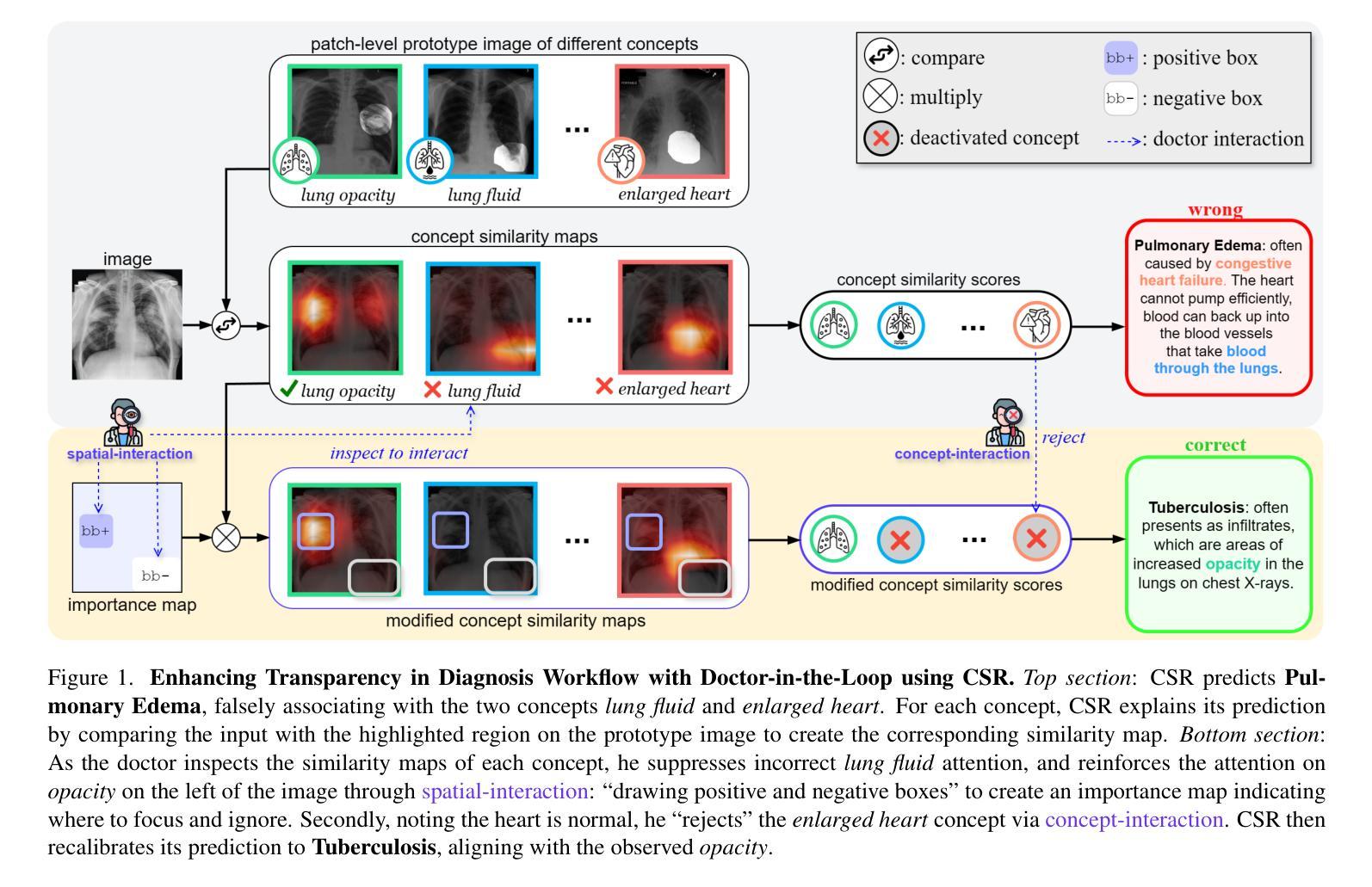
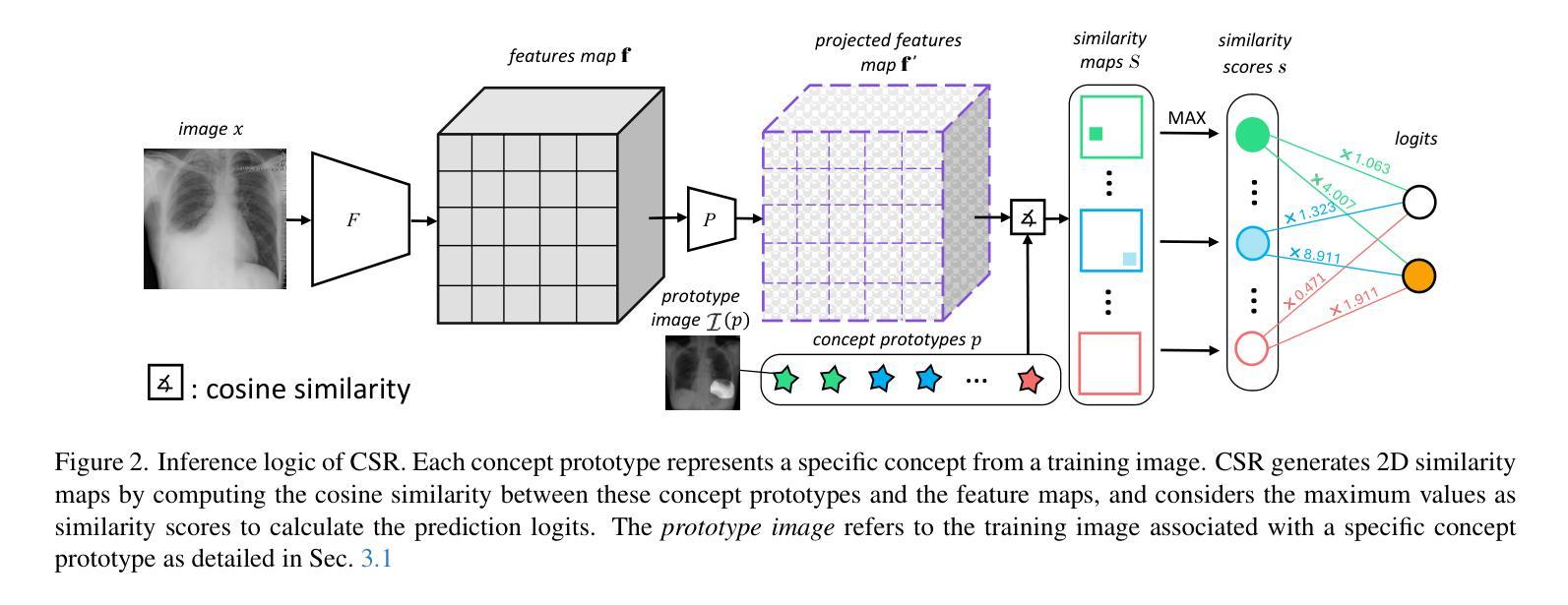
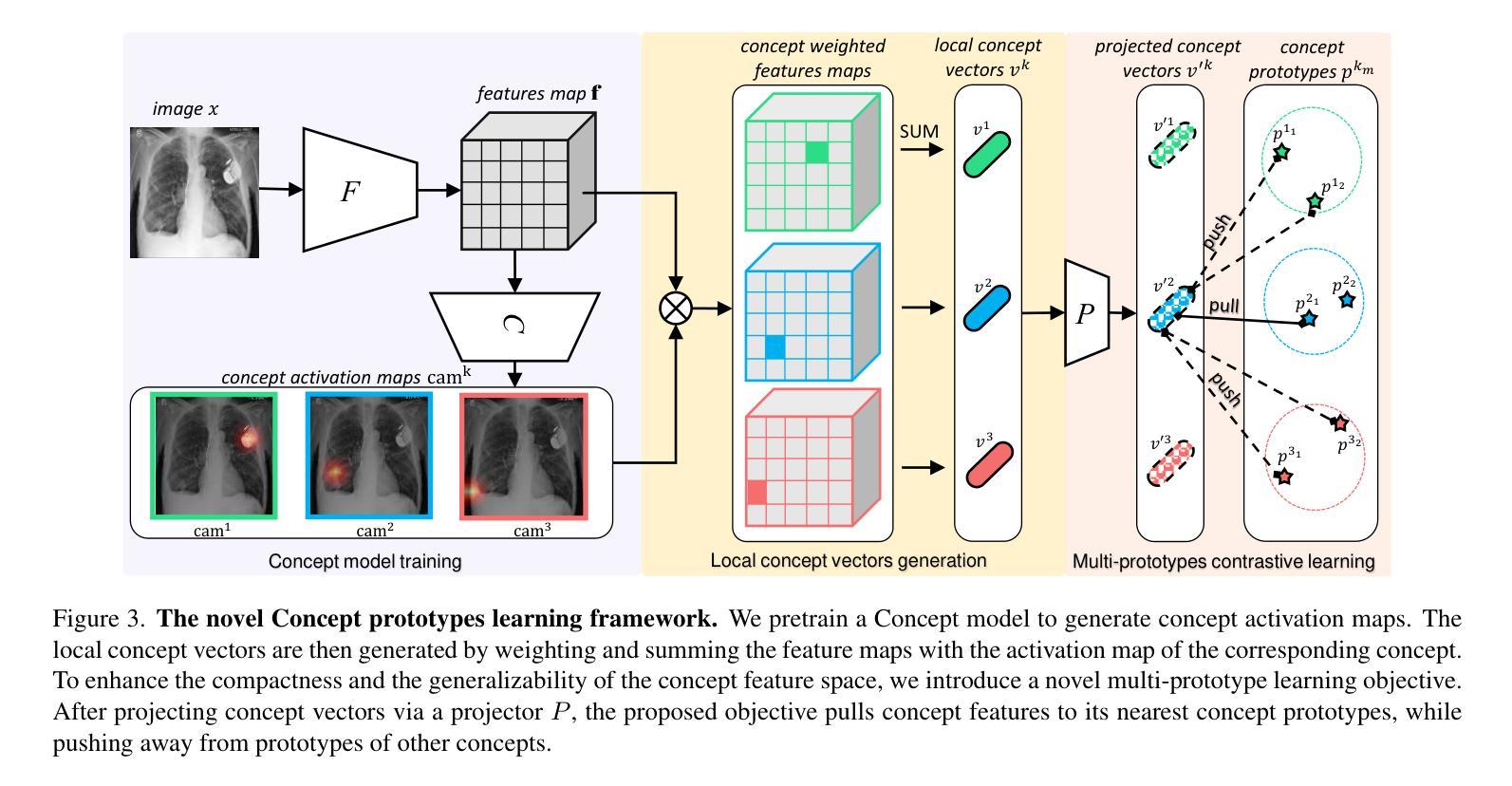
Interactive Medical Image Analysis with Concept-based Similarity Reasoning
Authors:Ta Duc Huy, Sen Kim Tran, Phan Nguyen, Nguyen Hoang Tran, Tran Bao Sam, Anton van den Hengel, Zhibin Liao, Johan W. Verjans, Minh-Son To, Vu Minh Hieu Phan
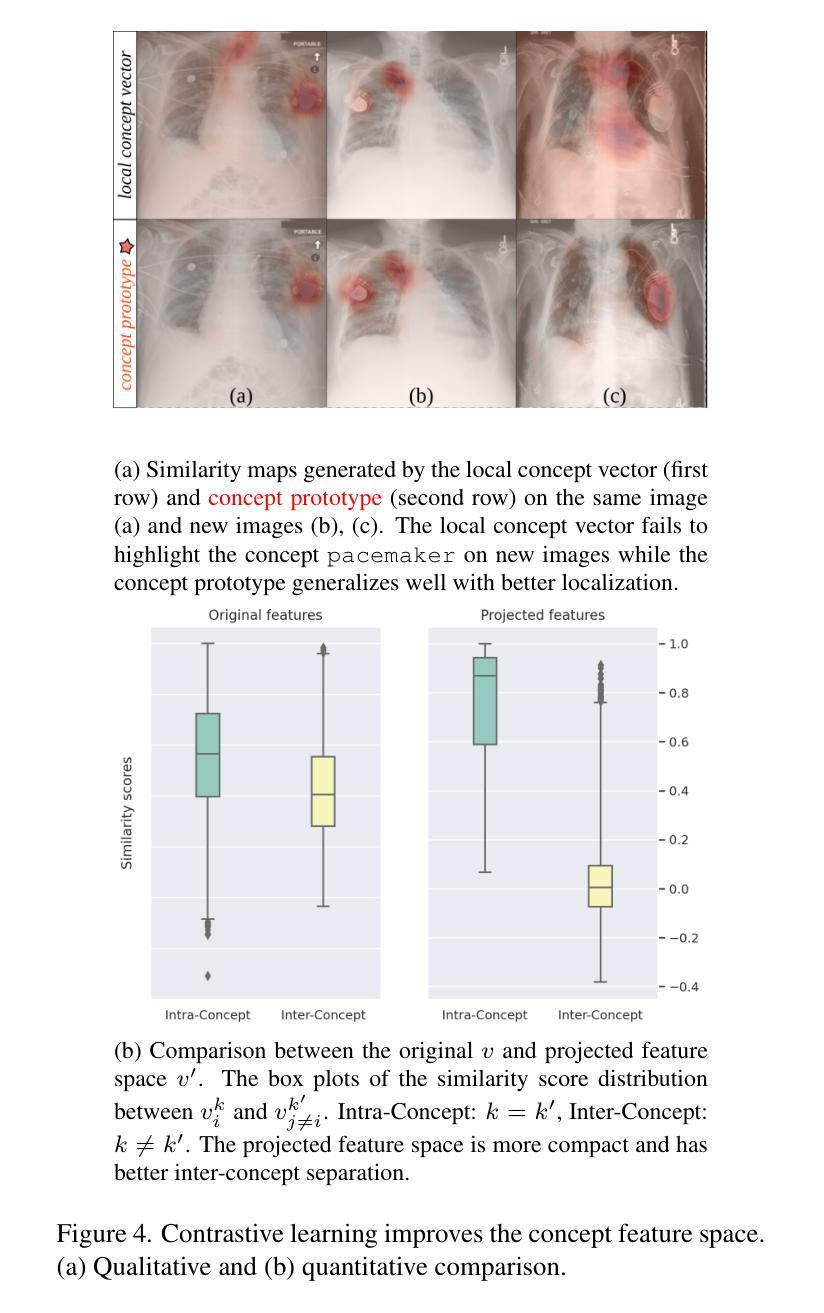
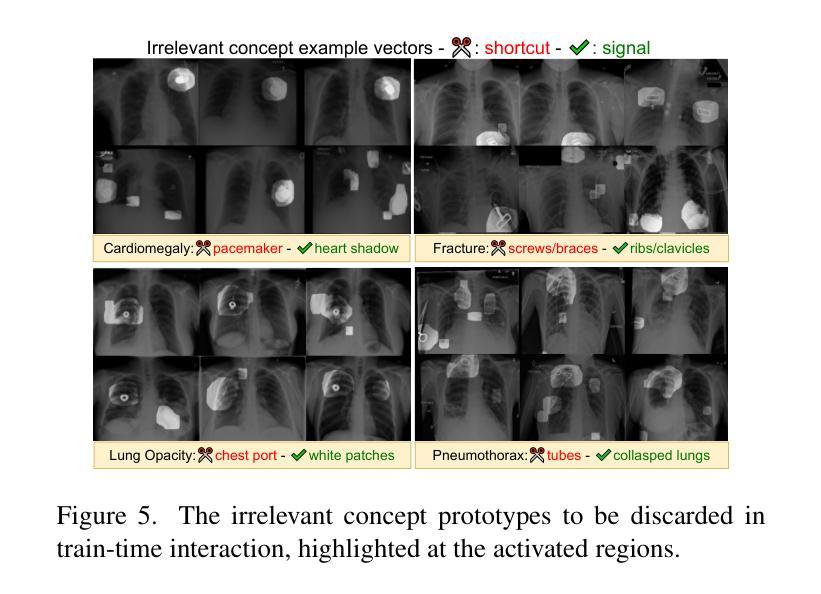
The ability to interpret and intervene model decisions is important for the adoption of computer-aided diagnosis methods in clinical workflows. Recent concept-based methods link the model predictions with interpretable concepts and modify their activation scores to interact with the model. However, these concepts are at the image level, which hinders the model from pinpointing the exact patches the concepts are activated. Alternatively, prototype-based methods learn representations from training image patches and compare these with test image patches, using the similarity scores for final class prediction. However, interpreting the underlying concepts of these patches can be challenging and often necessitates post-hoc guesswork. To address this issue, this paper introduces the novel Concept-based Similarity Reasoning network (CSR), which offers (i) patch-level prototype with intrinsic concept interpretation, and (ii) spatial interactivity. First, the proposed CSR provides localized explanation by grounding prototypes of each concept on image regions. Second, our model introduces novel spatial-level interaction, allowing doctors to engage directly with specific image areas, making it an intuitive and transparent tool for medical imaging. CSR improves upon prior state-of-the-art interpretable methods by up to 4.5% across three biomedical datasets. Our code is released at https://github.com/tadeephuy/InteractCSR.
解读并介入模型决策的能力对于在临床工作流中采用计算机辅助诊断方法至关重要。最近基于概念的方法将模型预测与可解释的概念联系起来,并修改其激活分数以与模型进行交互。然而,这些概念处于图像层面,阻碍了模型精确定位概念激活的确切区域。另一种方法是基于原型的方法,它从训练图像块中学习表示,并将其与测试图像块进行比较,使用相似度分数进行最终的类别预测。然而,解释这些图像块的潜在概念可能具有挑战性,通常需要进行事后猜测。为了解决这个问题,本文介绍了全新的基于概念相似性的推理网络(CSR),它提供了(i)图像块级的原型和内在概念解释,(ii)空间交互性。首先,所提出的CSR通过在图像区域上为每个概念提供原型来提供局部解释。其次,我们的模型引入了新型的空间级别交互,允许医生直接与特定的图像区域进行交互,使其成为医学成像中直观且透明的工具。CSR在三个生物医学数据集上较之前的最先进的可解释方法提高了高达4.5%。我们的代码已发布在https://github.com/tadeephuy/InteractCSR。
论文及项目相关链接
PDF Accepted CVPR2025
Summary
本文提出一种名为Concept-based Similarity Reasoning网络(CSR)的新方法,能够针对医学影像诊断提供既直观又透明的工具。CSR能够在图像区域上定位原型概念,并提供空间交互功能,使医生能够直接与特定图像区域进行交互,从而提高模型决策的可解释性和干预能力。此方法在三个生物医学数据集上的表现优于现有最先进的可解释方法,准确率提高了高达4.5%。
Key Takeaways
- CSR网络结合概念基础的方法,提供模型决策的可解释性。
- 传统概念基方法局限于图像层面,难以确定概念激活的具体区域。
- CSR网络通过定位原型概念在图像区域上提供局部解释。
- CSR网络引入空间级别的交互,使医生能够直接与图像特定区域互动。
- 此方法提高了医学影像诊断的直观性和透明度。
- CSR网络在三个生物医学数据集上的表现优于其他方法,准确率提升显著。
点此查看论文截图

Lost-in-the-Middle in Long-Text Generation: Synthetic Dataset, Evaluation Framework, and Mitigation
Authors:Junhao Zhang, Richong Zhang, Fanshuang Kong, Ziyang Miao, Yanhan Ye, Yaowei Zheng
Existing long-text generation methods primarily concentrate on producing lengthy texts from short inputs, neglecting the long-input and long-output tasks. Such tasks have numerous practical applications while lacking available benchmarks. Moreover, as the input grows in length, existing methods inevitably encounter the “lost-in-the-middle” phenomenon. In this paper, we first introduce a Long Input and Output Benchmark (LongInOutBench), including a synthetic dataset and a comprehensive evaluation framework, addressing the challenge of the missing benchmark. We then develop the Retrieval-Augmented Long-Text Writer (RAL-Writer), which retrieves and restates important yet overlooked content, mitigating the “lost-in-the-middle” issue by constructing explicit prompts. We finally employ the proposed LongInOutBench to evaluate our RAL-Writer against comparable baselines, and the results demonstrate the effectiveness of our approach. Our code has been released at https://github.com/OnlyAR/RAL-Writer.
当前的长文本生成方法主要集中在从短输入生成长篇文本,忽视了长输入和长输出的任务。这类任务具有许多实际应用,但缺乏可用的基准测试。此外,随着输入的增长,现有方法不可避免地会遇到“中间丢失”的现象。在本文中,我们首先引入了一个长输入输出基准测试(LongInOutBench),包括一个合成数据集和一个综合评估框架,以解决缺少基准测试的挑战。然后,我们开发了检索增强长文本写作器(RAL-Writer),它检索并复述了重要但被忽视的内容,通过构建明确的提示来缓解“中间丢失”的问题。最后,我们采用提出的LongInOutBench来评估我们的RAL-Writer与可比基线的效果,结果表明我们的方法有效。我们的代码已发布在https://github.com/OnlyAR/RAL-Writer。
论文及项目相关链接
Summary:本文引入了一个长输入和输出基准测试(LongInOutBench),包括合成数据集和综合评价框架,以解决缺少基准测试的挑战。随后,开发了检索增强长文本生成器(RAL-Writer),通过检索并复述重要但被忽视的内容,构建明确的提示,解决了“中间丢失”的问题。最后,使用LongInOutBench评估RAL-Writer与同类基线的效果,结果显示了该方法的有效性。
Key Takeaways:
- 现有长文本生成方法主要关注短输入产生长文本,忽视长输入和长输出任务。
- 长输入和长输出任务具有众多实际应用,但缺乏可用基准测试。
- 随着输入的增长,现有方法会遇到“中间丢失”的现象。
- 引入Long Input and Output Benchmark (LongInOutBench),包括合成数据集和综合评价框架,以解决基准测试缺失的挑战。
- 开发了Retrieval-Augmented Long-Text Writer (RAL-Writer),通过检索并复述重要内容,构建明确提示来解决“中间丢失”问题。
- 使用LongInOutBench评估RAL-Writer与基线方法,结果显示RAL-Writer方法有效。
点此查看论文截图


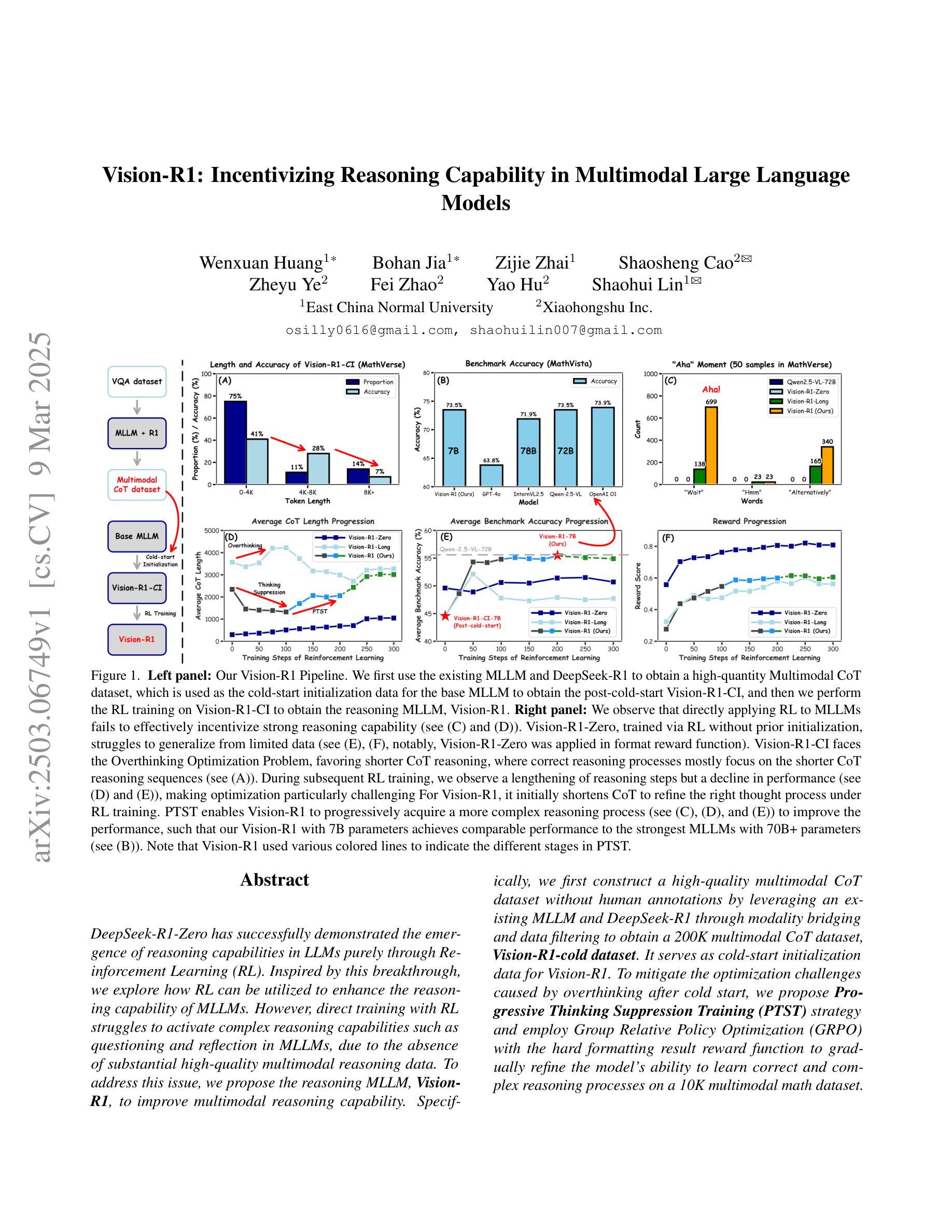
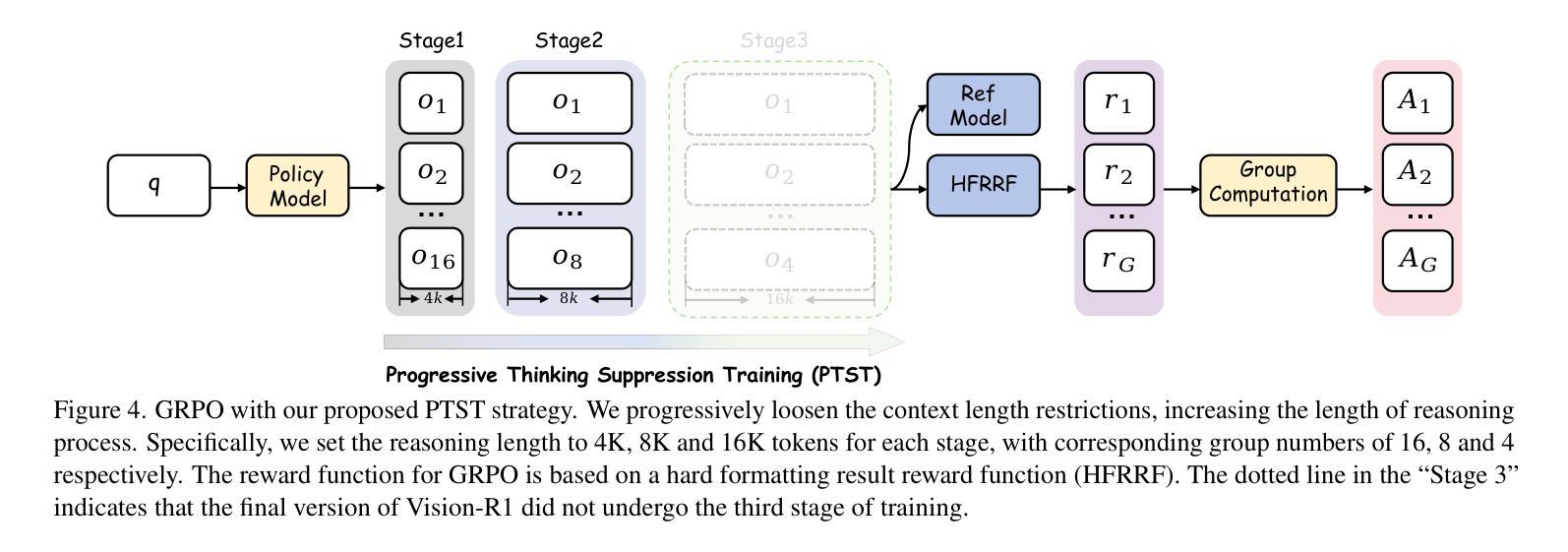
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models
Authors:Wenxuan Huang, Bohan Jia, Zijie Zhai, Shaosheng Cao, Zheyu Ye, Fei Zhao, Yao Hu, Shaohui Lin
DeepSeek-R1-Zero has successfully demonstrated the emergence of reasoning capabilities in LLMs purely through Reinforcement Learning (RL). Inspired by this breakthrough, we explore how RL can be utilized to enhance the reasoning capability of MLLMs. However, direct training with RL struggles to activate complex reasoning capabilities such as questioning and reflection in MLLMs, due to the absence of substantial high-quality multimodal reasoning data. To address this issue, we propose the reasoning MLLM, Vision-R1, to improve multimodal reasoning capability. Specifically, we first construct a high-quality multimodal CoT dataset without human annotations by leveraging an existing MLLM and DeepSeek-R1 through modality bridging and data filtering to obtain a 200K multimodal CoT dataset, Vision-R1-cold dataset. It serves as cold-start initialization data for Vision-R1. To mitigate the optimization challenges caused by overthinking after cold start, we propose Progressive Thinking Suppression Training (PTST) strategy and employ Group Relative Policy Optimization (GRPO) with the hard formatting result reward function to gradually refine the model’s ability to learn correct and complex reasoning processes on a 10K multimodal math dataset. Comprehensive experiments show our model achieves an average improvement of $\sim$6% across various multimodal math reasoning benchmarks. Vision-R1-7B achieves a 73.5% accuracy on the widely used MathVista benchmark, which is only 0.4% lower than the leading reasoning model, OpenAI O1. The datasets and code will be released in: https://github.com/Osilly/Vision-R1 .
DeepSeek-R1-Zero已成功展示了大语言模型通过强化学习(RL)出现推理能力。受此突破启发,我们探索了如何利用强化学习提高小语言模型的推理能力。然而,直接使用强化学习进行训练很难在小型语言模型中激活复杂的推理能力,如提问和反思,这是因为缺乏大量高质量的多模态推理数据。为了解决这一问题,我们提出了多模态推理小型语言模型——Vision-R1,以提高多模态推理能力。具体来说,我们首先通过利用现有的小型语言模型和DeepSeek-R1进行模态桥接和数据过滤,构建了一个高质量的无人工注释的多模态因果推理数据集,即Vision-R1冷启动数据集,数据集规模为20万。它为Vision-R1提供了冷启动初始化数据。为了缓解冷启动后过度思考导致的优化挑战,我们提出了渐进思考抑制训练(PTST)策略,并使用具有硬格式化结果奖励函数的群组相对策略优化(GRPO),以逐步改进模型在规模为1万的多模态数学数据集上学习正确且复杂推理过程的能力。综合实验表明,我们的模型在各种多模态数学推理基准测试上的平均准确率提高了约6%。其中,Vision-R1-7B在数学视觉基准测试上的准确率为73.5%,仅比领先的推理模型OpenAI O1低0.4%。相关数据集和代码将在[https://github.com/Osilly/Vision-R 结]释放。
论文及项目相关链接
Summary
大意为:DeepSeek-R1-Zero成功证明了通过强化学习(RL)在大型语言模型(LLMs)中能够涌现出推理能力。本研究受其启发,旨在利用强化学习提高多模态大型语言模型(MLLMs)的推理能力。然而,由于缺乏高质量的多模态推理数据,直接通过强化学习训练很难激活如提问和反思等复杂推理能力。为解决这一问题,研究团队提出了多模态推理MLLM模型——Vision-R1。具体来说,研究团队通过模态桥接和数据过滤,利用现有MLLM和DeepSeek-R1构建了一个无人工标注的高质量多模态因果推理数据集Vision-R1-cold数据集,用于冷启动初始化。为了缓解冷启动后过度思考带来的优化挑战,研究团队提出了渐进思考抑制训练策略(PTST),并采用分组相对策略优化(GRPO)与格式化结果奖励函数来逐步改进模型在多模态数学数据集上的正确推理过程。实验显示,与多个多模态数学推理基准测试相比,该模型平均提高了约6%。在广泛使用的MathVista基准测试中,Vision-R1-7B模型的准确率为73.5%,仅比领先的推理模型OpenAI O1低0.4%。相关数据集和代码将在https://github.com/Osilly/Vision-R1中发布。
Key Takeaways
- DeepSeek-R1-Zero成功证明LLMs可通过强化学习展现推理能力。
- 研究旨在利用强化学习增强MLLMs的推理能力。
- 缺乏高质量多模态推理数据是强化学习训练MLLMs面临的主要挑战。
- 提出Vision-R1模型以提高多模态推理能力。
- 利用现有MLLM和DeepSeek-R1构建无人工标注的高质量多模态因果推理数据集Vision-R1-cold用于冷启动。
- 引入渐进思考抑制训练策略和分组相对策略优化方法,以提高模型的推理能力。
点此查看论文截图

Reinforcement Learning with Verifiable Rewards: GRPO’s Effective Loss, Dynamics, and Success Amplification
Authors:Youssef Mroueh
Group Relative Policy Optimization (GRPO) was introduced and used successfully to train DeepSeek R1 models for promoting reasoning capabilities of LLMs using verifiable or binary rewards. We show in this paper that GRPO with verifiable rewards can be written as a Kullback Leibler ($\mathsf{KL}$) regularized contrastive loss, where the contrastive samples are synthetic data sampled from the old policy. The optimal GRPO policy $\pi_{n}$ can be expressed explicitly in terms of the binary reward, as well as the first and second order statistics of the old policy ($\pi_{n-1}$) and the reference policy $\pi_0$. Iterating this scheme, we obtain a sequence of policies $\pi_{n}$ for which we can quantify the probability of success $p_n$. We show that the probability of success of the policy satisfies a recurrence that converges to a fixed point of a function that depends on the initial probability of success $p_0$ and the regularization parameter $\beta$ of the $\mathsf{KL}$ regularizer. We show that the fixed point $p^*$ is guaranteed to be larger than $p_0$, thereby demonstrating that GRPO effectively amplifies the probability of success of the policy.
相对策略优化(GRPO)被引入并成功用于使用可验证或二进制奖励训练DeepSeek R1模型,以促进大型语言模型的推理能力。本文展示了使用可验证奖励的GRPO可以表示为Kullback Leibler(KL)正则化的对比损失,其中对比样本是旧策略采样的合成数据。最优GRPO策略πn可以明确表示为二进制奖励以及旧策略πn-1和参考策略π0的一阶和二阶统计量。通过迭代此方案,我们获得一系列策略πn,可以量化其成功的概率pn。我们证明了策略的成功概率满足一个递归,该递归收敛于一个依赖于初始成功概率p0和KL正则化的正则化参数β的函数的不动点。我们证明了不动点p*一定大于p0,从而证明GRPO有效地放大了策略成功的概率。
论文及项目相关链接
Summary
本文介绍了Group Relative Policy Optimization(GRPO)的成功应用于训练DeepSeek R1模型以促进大型语言模型的推理能力。通过使用可验证或二元奖励,GRPO可以表示为Kullback Leibler(KL)正则化的对比损失。最优GRPO策略可显式表达为二元奖励以及旧策略和一阶二阶统计数据的函数。通过迭代此方案,我们获得一系列策略,可以量化其成功概率。研究表明,策略的成功概率满足一个递归,收敛到一个依赖于初始成功概率和KL正则化参数函数的固定点,证明了GRPO有效地提高了策略成功的概率。
Key Takeaways
- Group Relative Policy Optimization (GRPO) 用于训练DeepSeek R1模型,提升大型语言模型(LLM)的推理能力。
- GRPO结合可验证或二元奖励,可以表述为Kullback Leibler(KL)正则化的对比损失。
- 最优GRPO策略是二元奖励、旧策略的一阶二阶统计数据等变量的函数。
- 通过迭代,获得一系列策略,并可以量化其成功概率。
- 策略的成功概率满足一个递归,收敛到一个固定点。
- 这个固定点大于初始成功概率,证明了GRPO能有效提高策略成功的概率。
点此查看论文截图


Agent models: Internalizing Chain-of-Action Generation into Reasoning models
Authors:Yuxiang Zhang, Yuqi Yang, Jiangming Shu, Xinyan Wen, Jitao Sang
Traditional agentic workflows rely on external prompts to manage interactions with tools and the environment, which limits the autonomy of reasoning models. We position \emph{Large Agent Models (LAMs)} that internalize the generation of \emph{Chain-of-Action (CoA)}, enabling the model to autonomously decide when and how to use external tools. Our proposed AutoCoA framework combines supervised fine-tuning (SFT) and reinforcement learning (RL), allowing the model to seamlessly switch between reasoning and action while efficiently managing environment interactions. Main components include step-level action triggering, trajectory-level CoA optimization, and an internal world model to reduce real-environment interaction costs. Evaluations on open-domain QA tasks demonstrate that AutoCoA-trained agent models significantly outperform ReAct-based workflows in task completion, especially in tasks that require long-term reasoning and multi-step actions. Code and dataset are available at https://github.com/ADaM-BJTU/AutoCoA
传统的代理工作流程依赖于外部提示来管理工具和环境的交互,这限制了推理模型的自主性。我们定位了能够内化“行动链”生成的“大型代理模型”(LAMs),使模型能够自主决定何时以及如何使用外部工具。我们提出的AutoCoA框架结合了监督微调(SFT)和强化学习(RL),使模型能够在推理和行动之间无缝切换,同时高效地管理环境交互。主要组件包括步骤级动作触发、轨迹级行动链优化以及一个内部世界模型,以减少真实环境交互成本。在开放域问答任务上的评估表明,使用AutoCoA训练的代理模型在任务完成方面显著优于基于ReAct的工作流程,特别是在需要长期推理和多步骤行动的任务中表现更优秀。相关代码和数据集可通过https://github.com/ADaM-BJTU/AutoCoA获取。
论文及项目相关链接
Summary
大型代理模型(LAMs)采用自主决策流程,能够自主决定何时以及如何使用外部工具,实现行动链(CoA)的生成。提出的AutoCoA框架结合了监督微调(SFT)和强化学习(RL),使模型能够在推理和行动之间无缝切换,同时有效地管理环境交互。其主要组件包括步骤级行动触发、轨迹级行动链优化和内部世界模型,以减少真实环境交互成本。在开放域问答任务上的评估表明,使用AutoCoA训练的代理模型在任务完成方面显著优于基于ReAct的工作流,特别是在需要长期推理和多步骤行动的任务中。
Key Takeaways
- 大型代理模型(LAMs)能够自主决定何时及如何使用外部工具,实现行动链(CoA)的自动生成。
- AutoCoA框架结合了监督微调(SFT)和强化学习(RL),支持模型在推理和行动间的无缝切换。
- AutoCoA框架包括步骤级行动触发、轨迹级行动链优化,以提高任务完成的效率和效果。
- 内部世界模型的引入,旨在减少与真实环境的交互成本。
- 在开放域问答任务上的评估显示,AutoCoA训练的模型在复杂任务完成方面表现出显著优势。
- AutoCoA框架特别适用于需要长期推理和多步骤的任务。
点此查看论文截图


MetaXCR: Reinforcement-Based Meta-Transfer Learning for Cross-Lingual Commonsense Reasoning
Authors:Jie He, Yu Fu
Commonsense reasoning (CR) has been studied in many pieces of domain and has achieved great progress with the aid of large datasets. Unfortunately, most existing CR datasets are built in English, so most previous work focus on English. Furthermore, as the annotation of commonsense reasoning is costly, it is impossible to build a large dataset for every novel task. Therefore, there are growing appeals for Cross-lingual Low-Resource Commonsense Reasoning, which aims to leverage diverse existed English datasets to help the model adapt to new cross-lingual target datasets with limited labeled data. In this paper, we propose a multi-source adapter for cross-lingual low-resource Commonsense Reasoning (MetaXCR). In this framework, we first extend meta learning by incorporating multiple training datasets to learn a generalized task adapters across different tasks. Then, we further introduce a reinforcement-based sampling strategy to help the model sample the source task that is the most helpful to the target task. Finally, we introduce two types of cross-lingual meta-adaption methods to enhance the performance of models on target languages. Extensive experiments demonstrate MetaXCR is superior over state-of-the-arts, while being trained with fewer parameters than other work.
常识推理(CR)在许多领域都得到了研究,并在大型数据集的帮助下取得了巨大的进步。不幸的是,大多数现有的CR数据集都是用英语构建的,所以之前的大多数工作都集中在英语上。此外,由于常识推理的标注成本很高,不可能为每一个新任务都构建一个大规模的数据集。因此,对于跨语言低资源常识推理的呼声越来越高。它的目标是为了利用已存在的英语数据集来帮助模型适应新的跨语言目标数据集,而这些目标数据集只有有限的有标签数据。在本文中,我们提出了一种用于跨语言低资源常识推理的多源适配器(MetaXCR)。在这个框架中,我们首先通过结合多个训练数据集来扩展元学习,以学习不同任务之间的通用任务适配器。然后,我们进一步引入了一种基于强化采样的策略,以帮助模型选择对目标任务最有帮助的任务。最后,我们介绍了两种跨语言元适应方法,以提高模型在目标语言上的性能。大量的实验表明,MetaXCR在参数训练较少的情况下仍优于其他先进技术。
论文及项目相关链接
Summary
该文探讨跨语言低资源常识推理领域的问题和挑战,提出一种多源适配器MetaXCR框架。通过融合多种训练数据集和强化采样策略,增强模型对不同任务的适应性,并引入两种跨语言元适应方法提升目标语言的性能。实验证明MetaXCR优于现有技术,且训练参数更少。
Key Takeaways
- 常识推理(CR)研究已取得显著进展,但多数数据集为英语,导致大多数研究聚焦于英语环境。
- 跨语言低资源常识推理需求增长,旨在利用已存在的英语数据集帮助模型适应新的跨语言目标数据集。
- MetaXCR框架通过扩展元学习,融入多个训练数据集,学习不同任务的通用任务适配器。
- 引入基于强化的采样策略,帮助模型选择对目标任务最有帮助的任务。
- 引入两种跨语言元适应方法,提升模型在目标语言上的性能。
- 实验证明MetaXCR框架优于现有技术。
点此查看论文截图

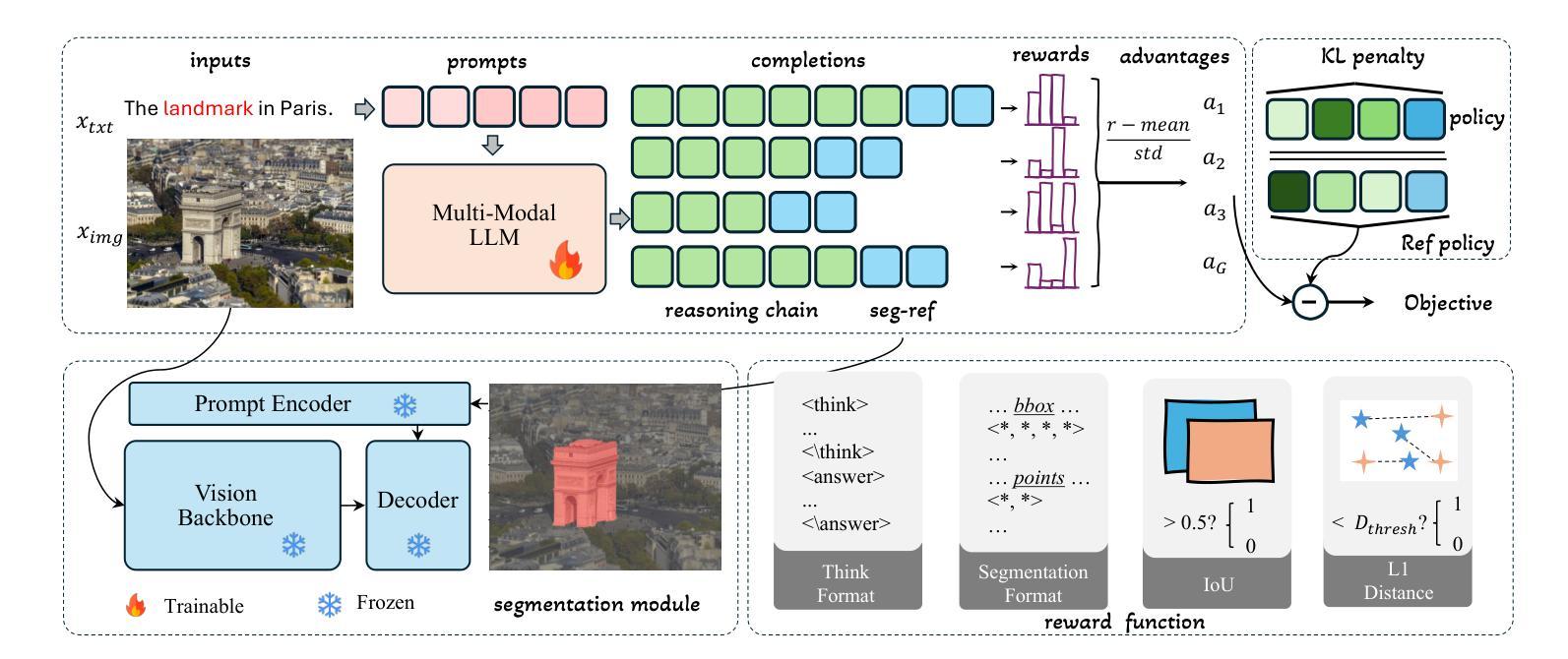
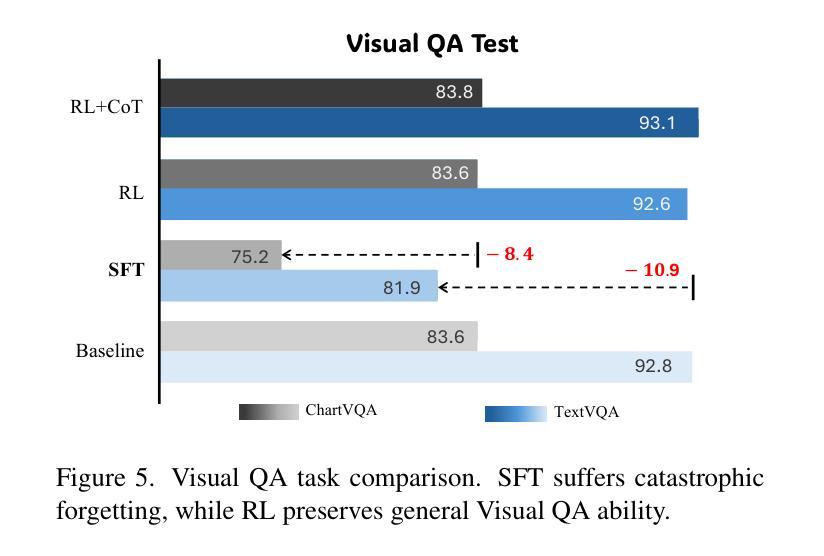
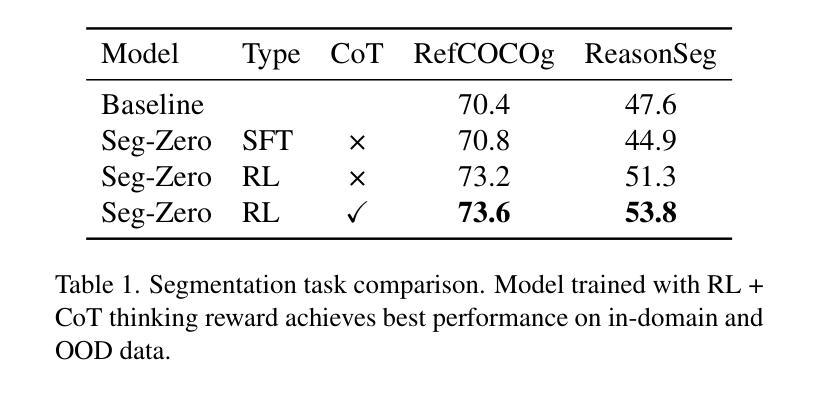
Seg-Zero: Reasoning-Chain Guided Segmentation via Cognitive Reinforcement
Authors:Yuqi Liu, Bohao Peng, Zhisheng Zhong, Zihao Yue, Fanbin Lu, Bei Yu, Jiaya Jia
Traditional methods for reasoning segmentation rely on supervised fine-tuning with categorical labels and simple descriptions, limiting its out-of-domain generalization and lacking explicit reasoning processes. To address these limitations, we propose Seg-Zero, a novel framework that demonstrates remarkable generalizability and derives explicit chain-of-thought reasoning through cognitive reinforcement. Seg-Zero introduces a decoupled architecture consisting of a reasoning model and a segmentation model. The reasoning model interprets user intentions, generates explicit reasoning chains, and produces positional prompts, which are subsequently used by the segmentation model to generate precious pixel-level masks. We design a sophisticated reward mechanism that integrates both format and accuracy rewards to effectively guide optimization directions. Trained exclusively via reinforcement learning with GRPO and without explicit reasoning data, Seg-Zero achieves robust zero-shot generalization and exhibits emergent test-time reasoning capabilities. Experiments show that Seg-Zero-7B achieves a zero-shot performance of 57.5 on the ReasonSeg benchmark, surpassing the prior LISA-7B by 18%. This significant improvement highlights Seg-Zero’s ability to generalize across domains while presenting an explicit reasoning process. Code is available at https://github.com/dvlab-research/Seg-Zero.
传统的推理分割方法依赖于带有类别标签和简单描述的监督微调,这限制了其跨域的泛化能力,并缺乏明确的推理过程。为了解决这些局限性,我们提出了Seg-Zero这一新型框架,它表现出显著的可泛化能力,并通过认知强化进行明确的思维链推理。Seg-Zero引入了一个分离的架构,包括推理模型和分割模型。推理模型解释用户意图,生成明确的推理链,并产生位置提示,这些提示随后被分割模型用于生成珍贵的像素级掩码。我们设计了一种复杂的奖励机制,将格式和准确度奖励结合起来,以有效地引导优化方向。Seg-Zero仅通过强化学习进行训练,使用GRPO且无需明确的推理数据,实现了强大的零样本泛化能力,并展现出新兴的测试时间推理能力。实验表明,Seg-Zero-7B在ReasonSeg基准测试中实现了零样本性能57.5分,超过了之前的LISA-7B模型高出18%。这一显著的提升凸显了Seg-Zero跨域泛化的能力,同时呈现出明确的推理过程。相关代码可通过https://github.com/dvlab-research/Seg-Zero获取。
论文及项目相关链接
Summary
Seg-Zero是一个新的推理分割框架,它通过认知强化进行零样本学习,表现出卓越的可泛化能力,并具备明确的推理过程。它采用分离架构,包括推理模型和分割模型。该框架通过设计精细的奖励机制来指导优化方向,实现仅通过强化学习训练,无需明确的推理数据。在ReasonSeg基准测试中,Seg-Zero-7B实现了零样本性能57.5,较之前的LISA-7B提高了18%,显示出了跨域泛化和显式测试时推理的能力。
Key Takeaways
- Seg-Zero框架通过认知强化进行推理分割,解决了传统方法依赖有监督微调与简单描述的问题,提高了模型的泛化能力。
- Seg-Zero引入了分离架构,包括推理模型和分割模型,其中推理模型负责解析用户意图并生成明确的推理链,产生定位提示供分割模型使用。
- 设计了精细的奖励机制,整合了格式和准确性的奖励,有效地指导了优化方向。
- Seg-Zero通过强化学习进行训练,无需明确的推理数据,实现了零样本学习和测试时的推理能力。
- 实验结果显示,Seg-Zero-7B在ReasonSeg基准测试中的零样本性能达到57.5,较之前的方法有显著提高。
- Seg-Zero的代码已公开在GitHub上。
- Seg-Zero框架具备明确的推理过程,能够解释模型在分割任务中的决策路径。
点此查看论文截图




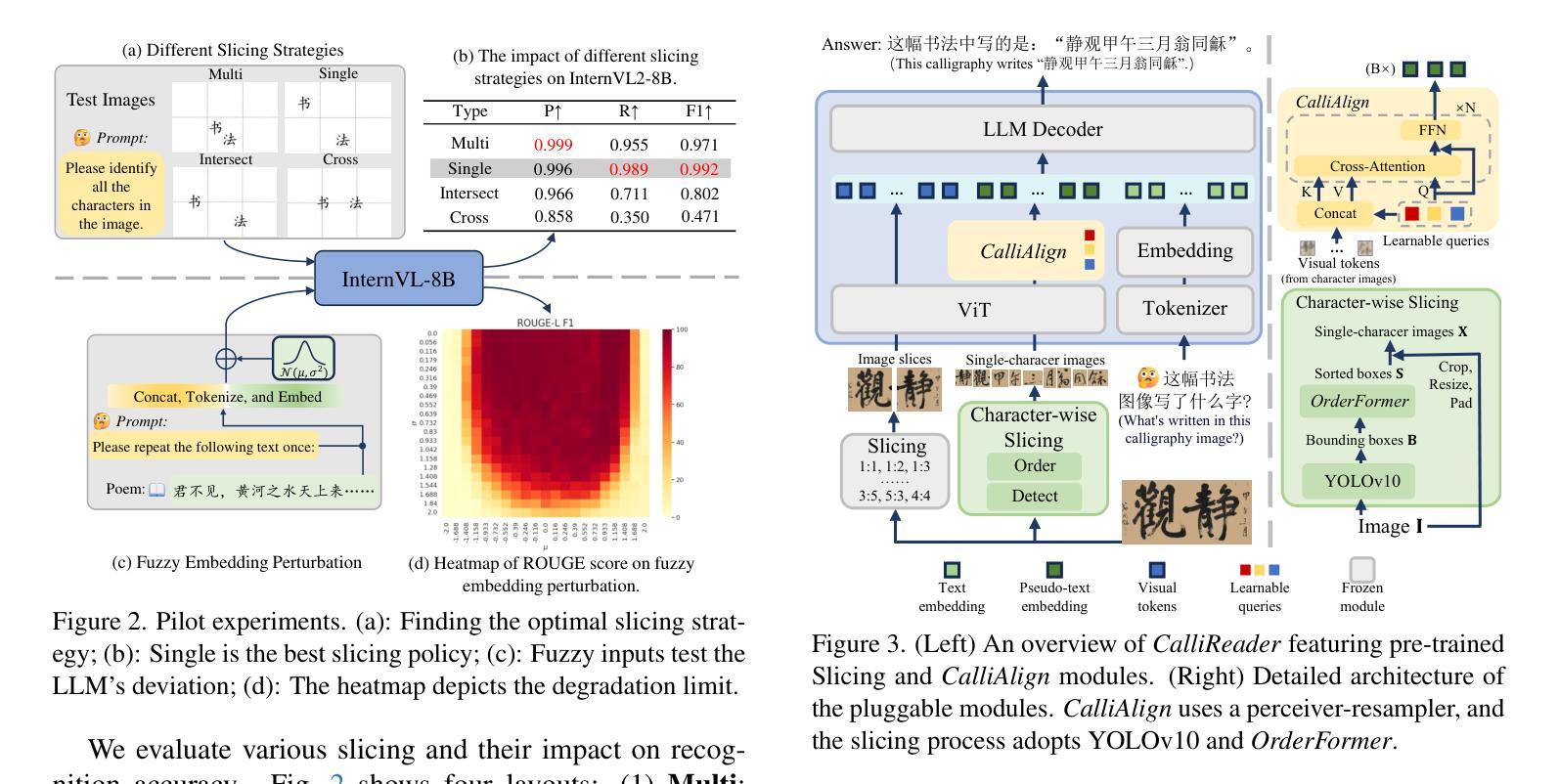
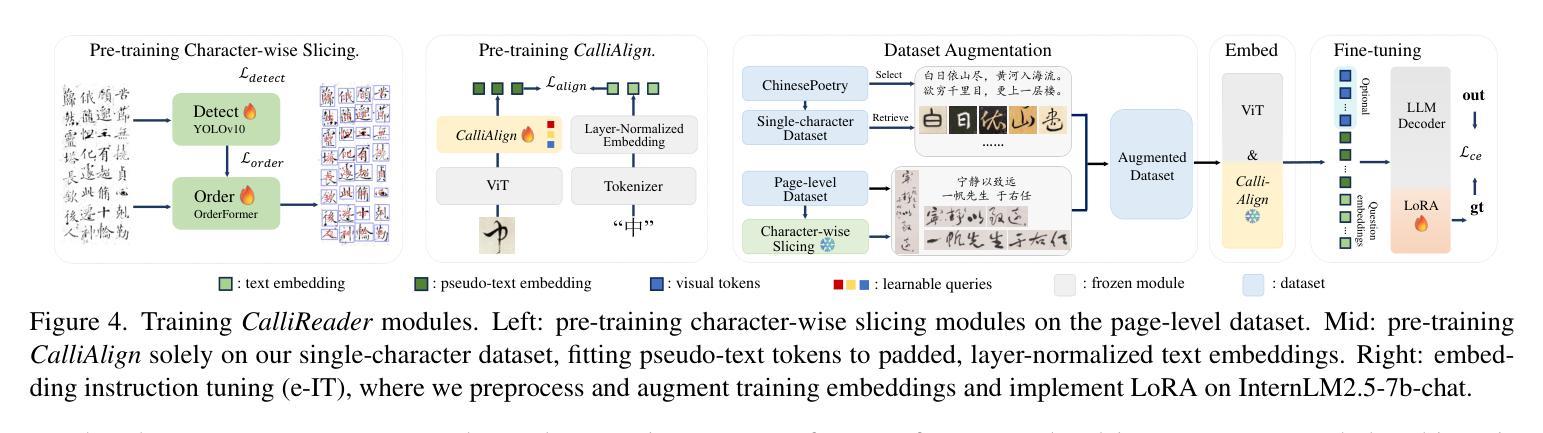
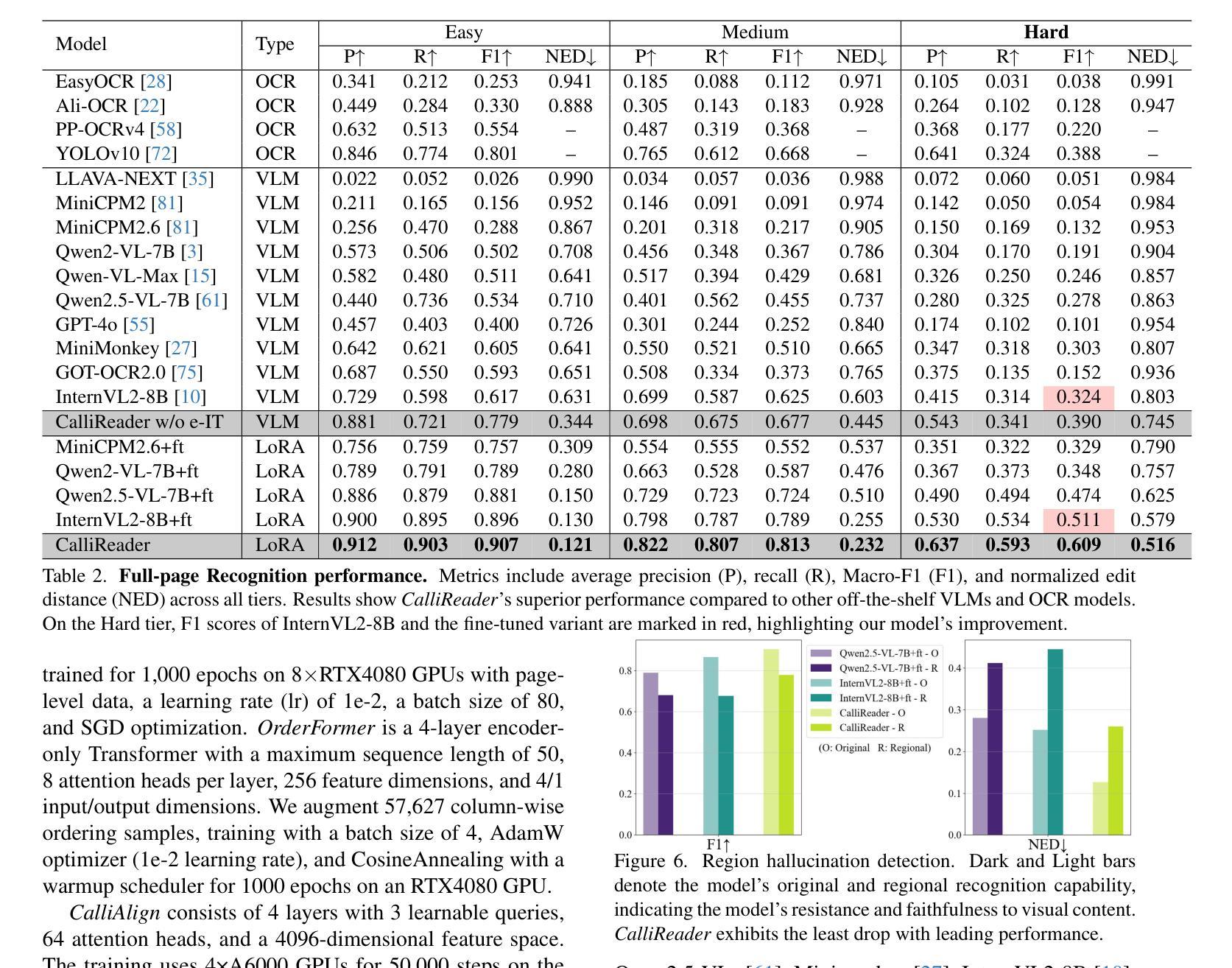
CalliReader: Contextualizing Chinese Calligraphy via an Embedding-Aligned Vision-Language Model
Authors:Yuxuan Luo, Jiaqi Tang, Chenyi Huang, Feiyang Hao, Zhouhui Lian
Chinese calligraphy, a UNESCO Heritage, remains computationally challenging due to visual ambiguity and cultural complexity. Existing AI systems fail to contextualize their intricate scripts, because of limited annotated data and poor visual-semantic alignment. We propose CalliReader, a vision-language model (VLM) that solves the Chinese Calligraphy Contextualization (CC$^2$) problem through three innovations: (1) character-wise slicing for precise character extraction and sorting, (2) CalliAlign for visual-text token compression and alignment, (3) embedding instruction tuning (e-IT) for improving alignment and addressing data scarcity. We also build CalliBench, the first benchmark for full-page calligraphic contextualization, addressing three critical issues in previous OCR and VQA approaches: fragmented context, shallow reasoning, and hallucination. Extensive experiments including user studies have been conducted to verify our CalliReader’s \textbf{superiority to other state-of-the-art methods and even human professionals in page-level calligraphy recognition and interpretation}, achieving higher accuracy while reducing hallucination. Comparisons with reasoning models highlight the importance of accurate recognition as a prerequisite for reliable comprehension. Quantitative analyses validate CalliReader’s efficiency; evaluations on document and real-world benchmarks confirm its robust generalization ability.
中国书法作为联合国教科文组织(UNESCO)遗产,仍然具有计算上的挑战性,因为存在视觉模糊和文化复杂性。现有的AI系统无法对其复杂的脚本进行语境化理解,这受限于标注数据的有限性和视觉语义对齐的不足。我们提出CalliReader,一种解决中国书法语境化(CC$^2$)问题的视觉语言模型(VLM)。它通过三个创新点来解决这一问题:(1)字符级切片,用于精确字符提取和排序;(2)CalliAlign,用于视觉文本符号压缩和对齐;(3)嵌入指令微调(e-IT),用于改善对齐并解决数据稀缺问题。我们还建立了CalliBench,首个全页书法语境化的基准测试,解决了之前OCR和VQA方法中的三个关键问题:上下文碎片化、推理浅显和幻觉。进行了大量实验,包括用户研究,以验证我们的CalliReader在页级书法识别和解释方面优于其他最先进的方法,甚至优于人类专业人士,在提高准确性的同时减少了幻觉。与推理模型的比较突显了准确识别作为可靠理解先决条件的重要性。定量分析验证了CalliReader的效率;在文档和现实世界基准测试上的评估证实了其稳健的泛化能力。
论文及项目相关链接
PDF 11 pages
Summary:
中国书法的语境化问题因其视觉模糊和文化复杂性仍具有挑战性。现有的AI系统难以处理其复杂的脚本,因为有限的标注数据和视觉语义对齐不佳。我们提出了CalliReader,一个视觉语言模型(VLM),通过三项创新解决了中国书法的语境化问题:字符级的切片技术用于精确字符提取和排序;CalliAlign用于视觉文本符号压缩和对齐;嵌入指令调整(e-IT)提高了对齐性能并解决了数据稀缺问题。我们还构建了CalliBench,首个全页书法语境化的基准测试平台,解决了之前OCR和VQA方法中的三个关键问题:上下文碎片化、推理浅显和幻觉现象。通过大量实验和用户研究验证了CalliReader在书法识别和解读方面的优越性,其准确性高于其他先进方法和专业人类专家,同时降低了幻觉现象。与推理模型的比较凸显了准确识别作为可靠理解先决条件的重要性。定量分析验证了CalliReader的效率,其在文档和现实世界基准测试上的评估证明了其稳健的泛化能力。
Key Takeaways:
- 中国书法作为联合国教科文组织(UNESCO)遗产,其语境化问题仍具有挑战性,主要由于视觉模糊和文化复杂性。
- 现有AI系统难以处理复杂书法脚本,存在标注数据有限和视觉语义对齐不佳的问题。
- CalliReader通过三项创新解决中国书法语境化问题:字符提取排序、视觉文本符号压缩对齐及嵌入指令调整。
- CalliBench作为首个全页书法语境化的基准测试平台,解决了之前OCR和VQA方法的三个关键问题。
- CalliReader在书法识别和解读方面表现出卓越性能,准确性高于其他先进方法和专业人类专家,并降低了幻觉现象。
- 准确识别是可靠理解的前提条件,与推理模型的比较凸显了其重要性。
点此查看论文截图



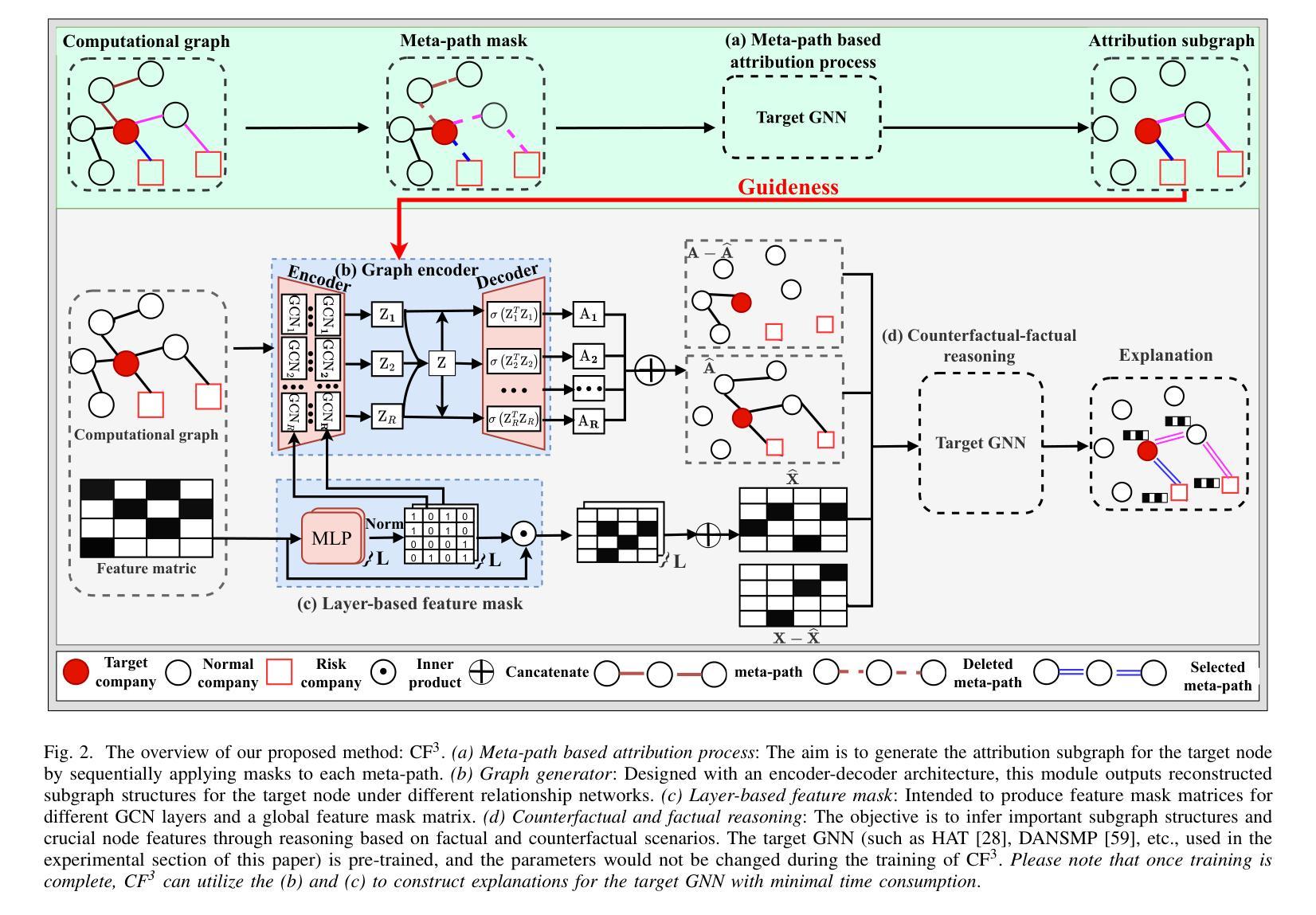
Identifying Evidence Subgraphs for Financial Risk Detection via Graph Counterfactual and Factual Reasoning
Authors:Huaming Du, Lei Yuan, Qing Yang, Xingyan Chen, Yu Zhao, Han Ji, Fuzhen Zhuang, Carl Yang, Gang Kou
Company financial risks pose a significant threat to personal wealth and national economic stability, stimulating increasing attention towards the development of efficient andtimely methods for monitoring them. Current approaches tend to use graph neural networks (GNNs) to model the momentum spillover effect of risks. However, due to the black-box nature of GNNs, these methods leave much to be improved for precise and reliable explanations towards company risks. In this paper, we propose CF3, a novel Counterfactual and Factual learning method for company Financial risk detection, which generates evidence subgraphs on company knowledge graphs to reliably detect and explain company financial risks. Specifically, we first propose a meta-path attribution process based on Granger causality, selecting the meta-paths most relevant to the target node labels to construct an attribution subgraph. Subsequently, we propose anedge-type-aware graph generator to identify important edges, and we also devise a layer-based feature masker to recognize crucial node features. Finally, we utilize counterfactual-factual reasoning and a loss function based on attribution subgraphs to jointly guide the learning of the graph generator and feature masker. Extensive experiments on three real-world datasets demonstrate the superior performance of our method compared to state-of-the-art approaches in the field of financial risk detection.
公司财务风险对个人财富和国家经济稳定构成重大威胁,促使人们越来越关注发展有效且及时的方法来监控这些风险。当前的方法倾向于使用图神经网络(GNNs)来模拟风险的动量溢出效应。然而,由于图神经网络的黑箱性质,这些方法在针对公司风险进行精确和可靠的解释方面仍有待改进。在本文中,我们提出了CF3,这是一种用于公司财务风险检测的新型反事实与事实学习方法,它可以在公司知识图谱上生成证据子图,以可靠地检测和解释公司财务风险。具体来说,我们首先基于格兰杰因果关系提出一种元路径归属过程,选择与目标节点标签最相关的元路径来构建归属子图。然后,我们提出了一种边缘类型感知图生成器来识别重要边缘,并设计了一种基于层的特征掩蔽器来识别关键节点特征。最后,我们利用反事实-事实推理和基于归属子图的损失函数来共同指导图生成器和特征掩蔽器的学习。在三个真实世界数据集上的广泛实验表明,我们的方法在财务风险检测领域的表现优于最新技术。
论文及项目相关链接
Summary
基于图神经网络的风险溢出资效模型对公司财务风险进行检测时,存在精确度和可靠性方面的不足。为解决这一问题,本文提出了一种名为CF3的新型混合学习方法。该方法利用公司知识图谱生成证据子图,更可靠地检测和解释公司财务风险。实验证明,与现有财务风险检测方法相比,CF3具有卓越性能。
Key Takeaways
- 公司财务风险对个人财富和国家经济稳定构成威胁,引发了风险监测方法的关注和发展需求。
- 当前方法倾向于使用图神经网络(GNNs)来模拟风险的动量溢出效应,但存在解释精度和可靠性问题。
- CF3方法通过生成证据子图来解决上述问题,这些子图基于公司知识图谱构建。
- CF3采用基于Granger因果关系的元路径归属过程,选择与目标节点标签最相关的元路径来构建归属子图。
- CF3还提出了边缘类型感知图生成器和基于层的特征掩码器来识别重要边缘和关键节点特征。
- 使用归因子图引导的联合学习和损失函数实现了对图生成器和特征掩码器的有效学习。
点此查看论文截图

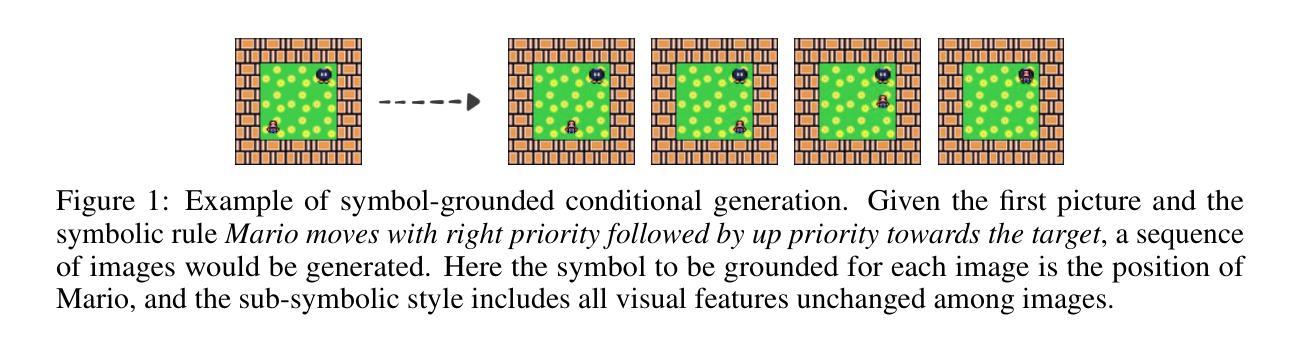
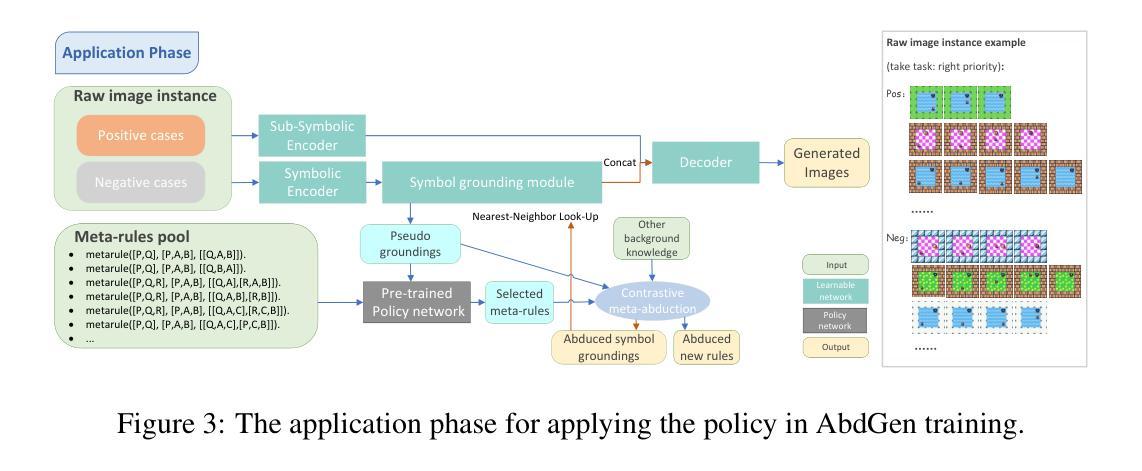
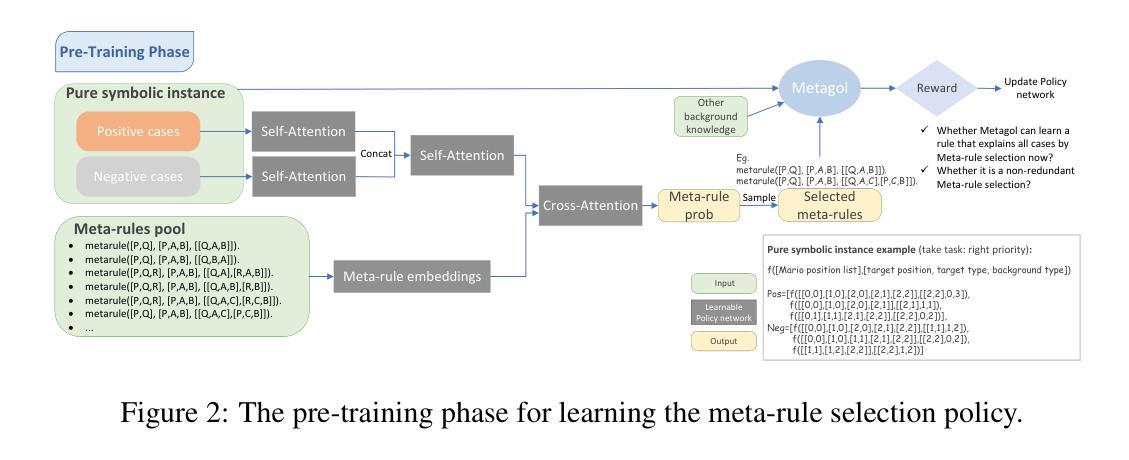
Pre-Training Meta-Rule Selection Policy for Visual Generative Abductive Learning
Authors:Yu Jin, Jingming Liu, Zhexu Luo, Yifei Peng, Ziang Qin, Wang-Zhou Dai, Yao-Xiang Ding, Kun Zhou
Visual generative abductive learning studies jointly training symbol-grounded neural visual generator and inducing logic rules from data, such that after learning, the visual generation process is guided by the induced logic rules. A major challenge for this task is to reduce the time cost of logic abduction during learning, an essential step when the logic symbol set is large and the logic rule to induce is complicated. To address this challenge, we propose a pre-training method for obtaining meta-rule selection policy for the recently proposed visual generative learning approach AbdGen [Peng et al., 2023], aiming at significantly reducing the candidate meta-rule set and pruning the search space. The selection model is built based on the embedding representation of both symbol grounding of cases and meta-rules, which can be effectively integrated with both neural model and logic reasoning system. The pre-training process is done on pure symbol data, not involving symbol grounding learning of raw visual inputs, making the entire learning process low-cost. An additional interesting observation is that the selection policy can rectify symbol grounding errors unseen during pre-training, which is resulted from the memorization ability of attention mechanism and the relative stability of symbolic patterns. Experimental results show that our method is able to effectively address the meta-rule selection problem for visual abduction, boosting the efficiency of visual generative abductive learning. Code is available at https://github.com/future-item/metarule-select.
视觉生成归纳学习联合训练符号基地神经视觉生成器和从数据中归纳逻辑规则,以便在学习后,视觉生成过程受归纳得到的逻辑规则指导。此任务的一个主要挑战是减少学习过程中的逻辑归纳时间成本,当逻辑符号集庞大、要归纳的逻辑规则复杂时,这是至关重要的步骤。为了应对这一挑战,我们针对最近提出的视觉生成学习方法AbdGen[Peng等人,2023]提出了元规则选择策略的预训练方法,旨在显著减少候选元规则集,缩小搜索空间。选择模型是基于案例符号接地和元规则的嵌入表示的,可以有效地与神经模型和逻辑推理系统相结合。预训练过程是在纯符号数据上进行的,不涉及原始视觉输入的符号接地学习,使整个过程成本低廉。另一个有趣的观察结果是,选择策略可以纠正预训练期间未见过的符号接地错误,这是由注意力机制的记忆能力和符号模式的相对稳定性所导致的。实验结果表明,我们的方法能够有效地解决视觉归纳中的元规则选择问题,提高视觉生成归纳学习的效率。代码可通过https://github.com/future-item/metarule-select获取。
论文及项目相关链接
PDF Published as a conference paper at IJCLR’24
Summary
视觉生成归纳学习通过联合训练符号化神经视觉生成器和从数据中归纳逻辑规则,指导视觉生成过程。针对逻辑符号集大、归纳逻辑规则复杂时逻辑归纳耗时的问题,提出一种预训练方法,旨在显著减少候选元规则集,缩小搜索空间。选择模型基于案例和元规则的符号嵌入表示,可有效地与神经模型和逻辑推理系统相结合。预训练过程仅在符号数据上进行,不涉及原始视觉输入的符号接地学习,使整个过程成本降低。实验结果表明,该方法能够有效解决视觉归纳学习的元规则选择问题,提高视觉生成归纳学习的效率。
Key Takeaways
- 视觉生成归纳学习联合训练符号化神经视觉生成器和从数据中归纳逻辑规则。
- 面临逻辑符号集大、逻辑规则复杂时,逻辑归纳耗时的问题。
- 提出预训练方法,旨在减少候选元规则集,缩小搜索空间。
- 选择模型基于符号嵌入表示,结合神经模型和逻辑推理系统。
- 预训练过程在符号数据上进行,不涉及原始视觉输入的符号接地学习。
- 预训练能够提高视觉生成归纳学习的效率。
点此查看论文截图

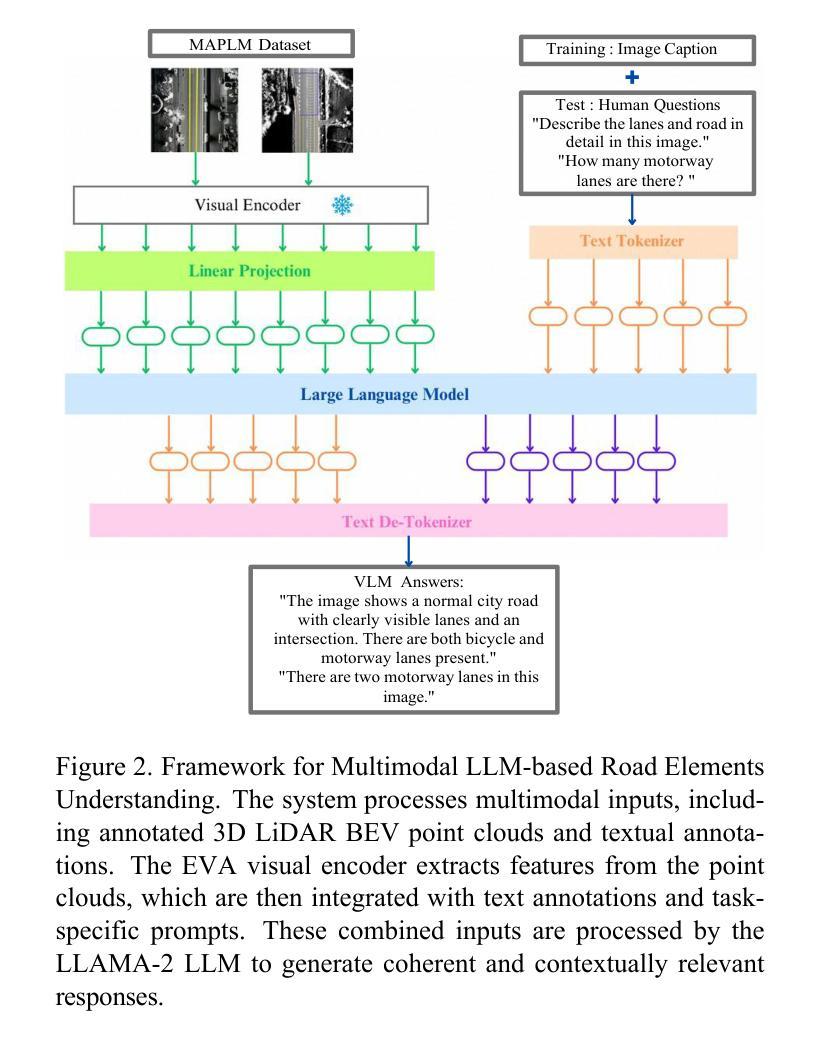
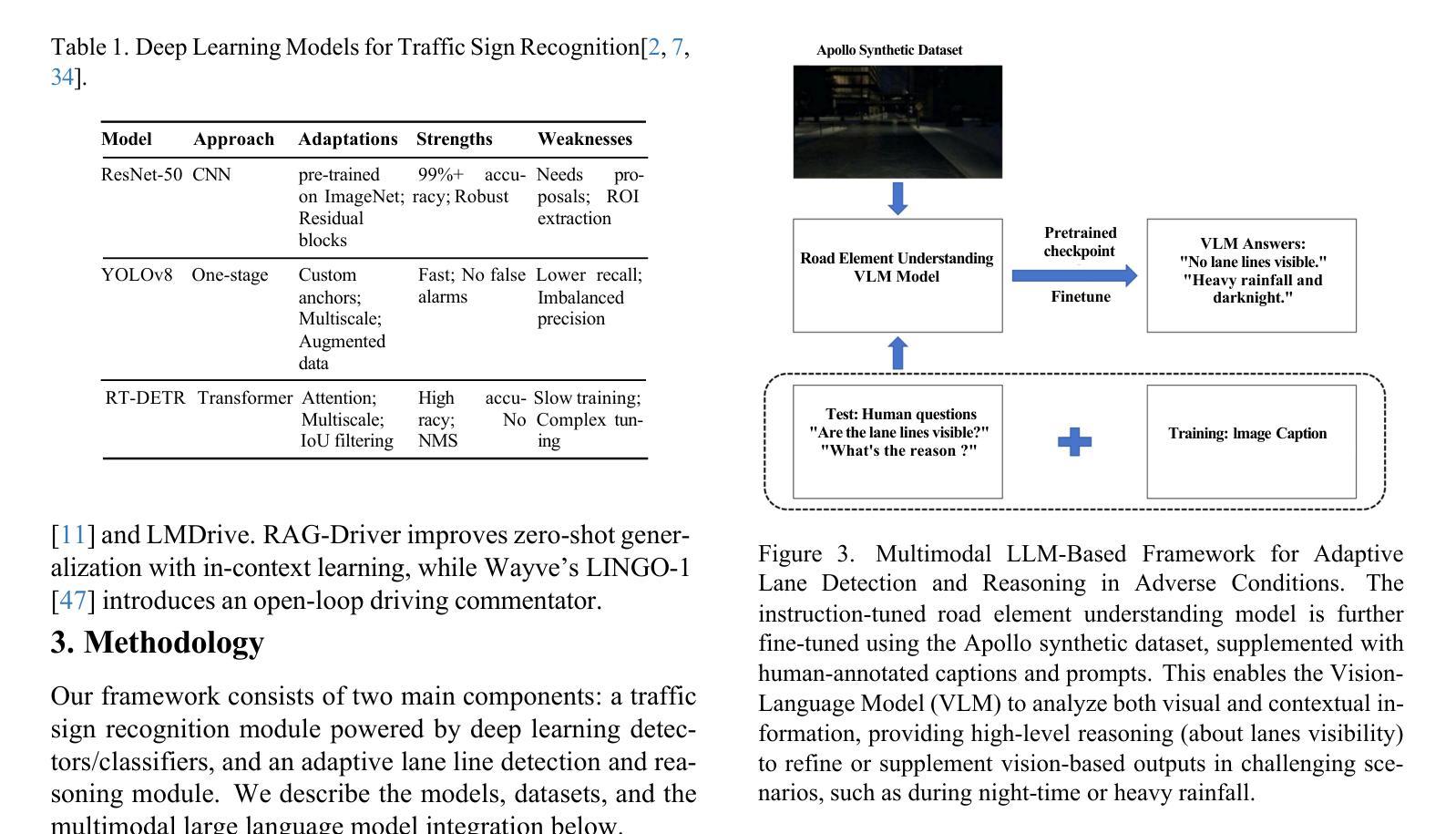
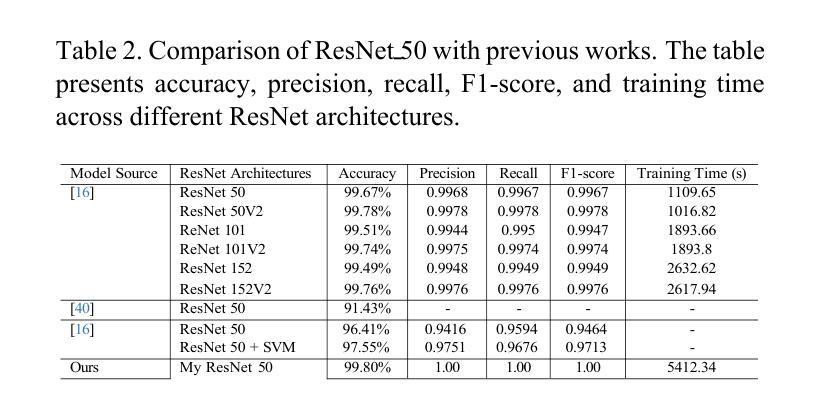
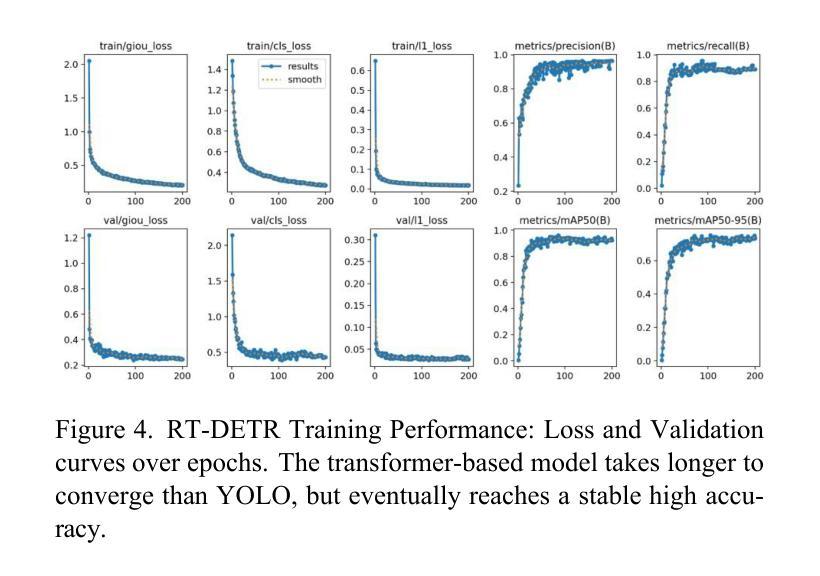
Advancing Autonomous Vehicle Intelligence: Deep Learning and Multimodal LLM for Traffic Sign Recognition and Robust Lane Detection
Authors:Chandan Kumar Sah, Ankit Kumar Shaw, Xiaoli Lian, Arsalan Shahid Baig, Tuopu Wen, Kun Jiang, Mengmeng Yang, Diange Yang
Autonomous vehicles (AVs) require reliable traffic sign recognition and robust lane detection capabilities to ensure safe navigation in complex and dynamic environments. This paper introduces an integrated approach combining advanced deep learning techniques and Multimodal Large Language Models (MLLMs) for comprehensive road perception. For traffic sign recognition, we systematically evaluate ResNet-50, YOLOv8, and RT-DETR, achieving state-of-the-art performance of 99.8% with ResNet-50, 98.0% accuracy with YOLOv8, and achieved 96.6% accuracy in RT-DETR despite its higher computational complexity. For lane detection, we propose a CNN-based segmentation method enhanced by polynomial curve fitting, which delivers high accuracy under favorable conditions. Furthermore, we introduce a lightweight, Multimodal, LLM-based framework that directly undergoes instruction tuning using small yet diverse datasets, eliminating the need for initial pretraining. This framework effectively handles various lane types, complex intersections, and merging zones, significantly enhancing lane detection reliability by reasoning under adverse conditions. Despite constraints in available training resources, our multimodal approach demonstrates advanced reasoning capabilities, achieving a Frame Overall Accuracy (FRM) of 53.87%, a Question Overall Accuracy (QNS) of 82.83%, lane detection accuracies of 99.6% in clear conditions and 93.0% at night, and robust performance in reasoning about lane invisibility due to rain (88.4%) or road degradation (95.6%). The proposed comprehensive framework markedly enhances AV perception reliability, thus contributing significantly to safer autonomous driving across diverse and challenging road scenarios.
自动驾驶车辆(AVs)需要可靠的交通标志识别和稳健的车道检测能力,以确保在复杂和动态环境中的安全导航。本文介绍了一种结合先进深度学习技术和多模态大型语言模型(MLLMs)的综合方法,用于全面的道路感知。在交通标志识别方面,我们对ResNet-50、YOLOv8和RT-DETR进行了系统评估,使用ResNet-50达到了99.8%的业界领先性能,YOLOv8的准确率为98.0%,尽管RT-DETR的计算复杂度较高,但准确率达到了96.6%。对于车道检测,我们提出了一种基于CNN的分割方法,通过多项式曲线拟合增强,在有利条件下具有较高的准确性。此外,我们还引入了一个轻量级的、基于多模态LLM的框架,该框架直接使用小型但多样化的数据集进行指令调整,无需初始预训练。该框架能够有效地处理各种车道类型、复杂的交叉口和合并区,通过不良条件下的推理,显著提高车道检测的可靠性。尽管可用训练资源存在约束,我们的多模态方法展示了高级推理能力,实现了帧总体准确度(FRM)为53.87%,问题总体准确度(QNS)为82.83%,在清晰条件下的车道检测准确率为99.6%,夜间为93.0%,并且在应对因雨水导致车道隐形(88.4%)或道路退化(95.6%)的推理中表现出稳健的性能。所提出的综合框架显著提高了自动驾驶感知的可靠性,从而为各种具有挑战的道路场景下的更安全自动驾驶做出了重大贡献。
论文及项目相关链接
PDF 11 pages, 9 figures
Summary
本文介绍了一种结合深度学习和多模态大型语言模型(MLLMs)的集成方法,用于全面的道路感知。交通标志识别方面,系统评估了ResNet-50、YOLOv8和RT-DETR的性能,其中ResNet-50达到99.8%的准确率。车道检测方面,提出了一种基于CNN的分割方法,通过多项式曲线拟合增强,在有利条件下具有高准确性。此外,还引入了轻量级的MLLMs框架,可直接通过指令调整使用小型的多样化数据集,无需初始预训练。该框架能有效应对各种车道类型、复杂交叉路口和合并区,提高了车道检测的可靠性。尽管训练资源有限,该多模态方法仍展现出强大的推理能力,在清晰和夜间条件下的车道检测准确率分别高达99.6%和93.0%,并且在处理因降雨或道路退化导致的车道隐形问题方面也表现出稳健的性能。该研究为自动驾驶车辆的感知可靠性提供了显著贡献。
Key Takeaways
- 自主车辆需要可靠的交通标志识别和稳健的车道检测能力。
- 结合深度学习和多模态大型语言模型的集成方法用于全面的道路感知。
- 交通标志识别方面,ResNet-50表现出最佳性能,达到99.8%的准确率。
- 提出了基于CNN的分割方法和多项式曲线拟合增强车道检测。
- 引入轻量级MLLMs框架,可直接通过指令调整,适应不同的车道场景。
- 该框架在多种条件下表现出强大的推理能力,包括清晰和夜间条件、复杂交叉路口和合并区。
- 研究为自动驾驶车辆的感知可靠性提供了显著贡献。
点此查看论文截图