⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-12 更新
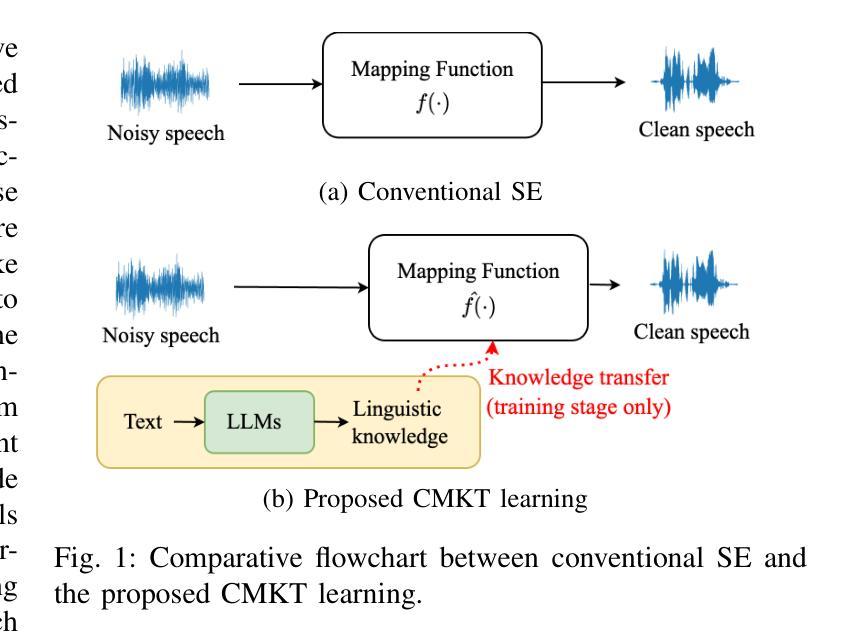
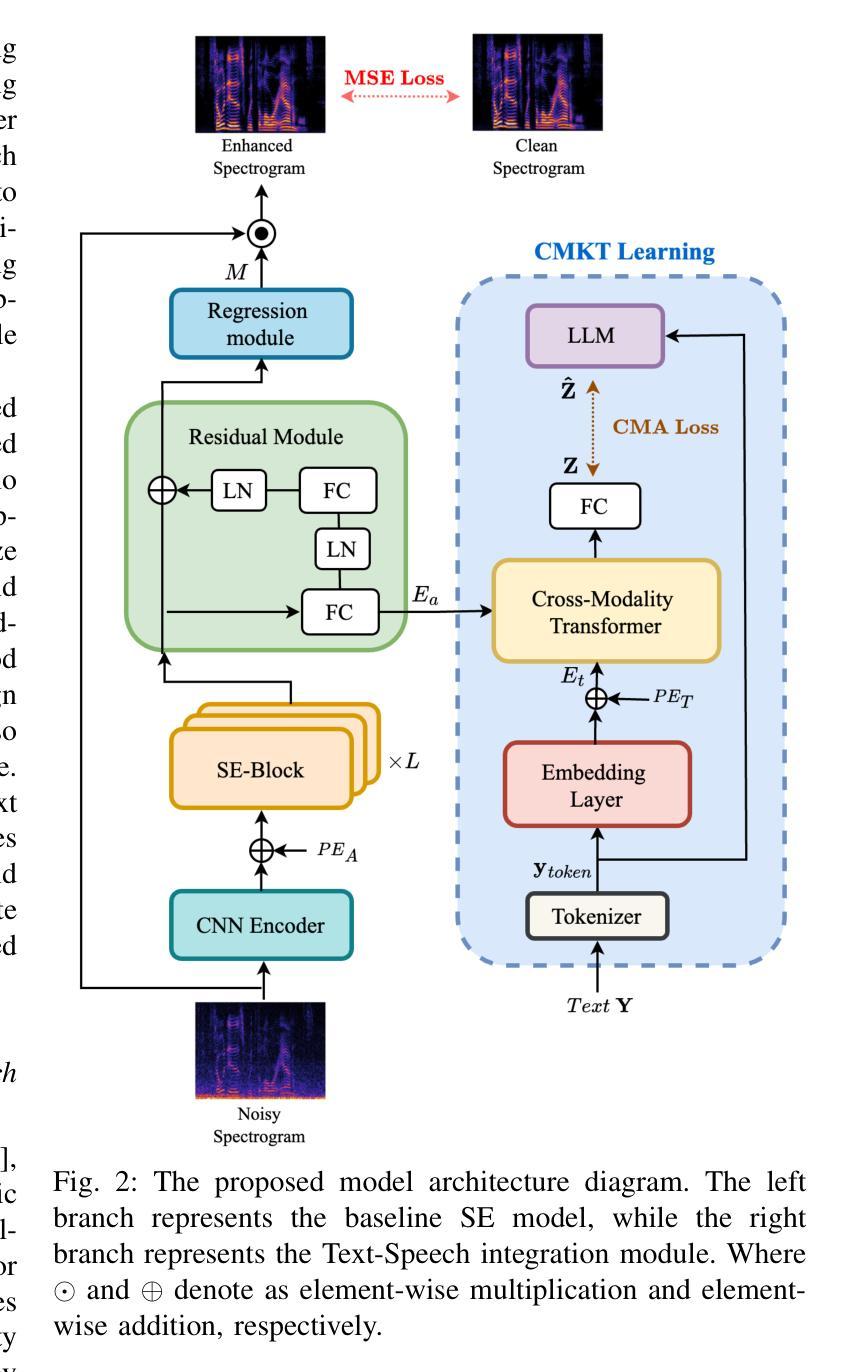
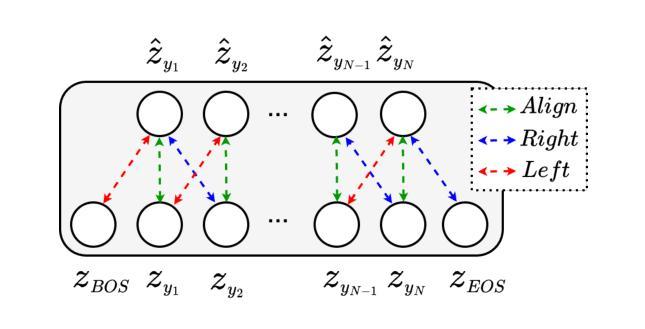
Linguistic Knowledge Transfer Learning for Speech Enhancement
Authors:Kuo-Hsuan Hung, Xugang Lu, Szu-Wei Fu, Huan-Hsin Tseng, Hsin-Yi Lin, Chii-Wann Lin, Yu Tsao
Linguistic knowledge plays a crucial role in spoken language comprehension. It provides essential semantic and syntactic context for speech perception in noisy environments. However, most speech enhancement (SE) methods predominantly rely on acoustic features to learn the mapping relationship between noisy and clean speech, with limited exploration of linguistic integration. While text-informed SE approaches have been investigated, they often require explicit speech-text alignment or externally provided textual data, constraining their practicality in real-world scenarios. Additionally, using text as input poses challenges in aligning linguistic and acoustic representations due to their inherent differences. In this study, we propose the Cross-Modality Knowledge Transfer (CMKT) learning framework, which leverages pre-trained large language models (LLMs) to infuse linguistic knowledge into SE models without requiring text input or LLMs during inference. Furthermore, we introduce a misalignment strategy to improve knowledge transfer. This strategy applies controlled temporal shifts, encouraging the model to learn more robust representations. Experimental evaluations demonstrate that CMKT consistently outperforms baseline models across various SE architectures and LLM embeddings, highlighting its adaptability to different configurations. Additionally, results on Mandarin and English datasets confirm its effectiveness across diverse linguistic conditions, further validating its robustness. Moreover, CMKT remains effective even in scenarios without textual data, underscoring its practicality for real-world applications. By bridging the gap between linguistic and acoustic modalities, CMKT offers a scalable and innovative solution for integrating linguistic knowledge into SE models, leading to substantial improvements in both intelligibility and enhancement performance.
语言知识在口语理解中起着至关重要的作用。它为嘈杂环境中的语音感知提供了必要的语义和句法背景。然而,大多数语音增强(SE)方法主要依赖于声学特征来学习噪声和清洁语音之间的映射关系,对语言整合的探索有限。虽然已有文本信息引导的SE方法的研究,但它们通常需要明确的语音文本对齐或外部提供的文本数据,这在现实场景中的应用实践受到限制。此外,使用文本作为输入会带来对齐语言和声学表示的挑战,因为它们之间存在固有的差异。本研究提出了跨模态知识转移(CMKT)学习框架,它利用预训练的大型语言模型(LLM)将语言知识注入SE模型,而不需要在推理过程中使用文本输入或LLM。此外,我们引入了一种错位策略来改善知识转移。该策略应用受控的时间偏移,鼓励模型学习更稳健的表示。实验评估表明,在各种SE架构和LLM嵌入中,CMKT始终优于基线模型,突显其在不同配置中的适应性。此外,在普通话和英语数据集上的结果证明了其在多种语言环境下的有效性,进一步验证了其稳健性。即使在没有文本数据的情况下,CMKT仍然有效,这强调了其在现实世界应用中的实用性。通过弥合语言和声学模态之间的差距,CMKT为将语言知识融入SE模型提供了可扩展和创新解决方案,在可懂度和增强性能方面都实现了显著改进。
论文及项目相关链接
PDF 11 pages, 6 figures
Summary
该文本指出语言学知识在口语理解中的重要性,并介绍了跨模态知识转移(CMKT)学习框架。该框架利用预训练的大型语言模型(LLM)将语言学知识注入语音增强(SE)模型,无需文本输入或LLM在推理期间使用。通过控制时间偏移的错位策略改进知识转移,模型学习更稳健的表示。实验评估表明,CMKT在各种SE架构和LLM嵌入中始终优于基线模型,且在汉语和英语数据集上的结果验证了其跨语言条件下的有效性。此外,即使在无文本数据的情况下,CMKT依然有效,具有实际应用的实用性。该框架填补了语音与声学模态之间的鸿沟,为将语言学知识融入SE模型提供了可扩展和创新解决方案,大大提高了可理解性和增强性能。
Key Takeaways
- 语言学知识在口语理解中起关键作用,提供语义和句法上下文,尤其在嘈杂环境中。
- 现有的语音增强方法主要依赖于声学特征,对语言学知识的整合有限。
- 跨模态知识转移(CMKT)学习框架利用预训练的大型语言模型(LLM)注入语言学知识到SE模型。
- CMKT不需要文本输入或LLM在推理期间使用,提高了其实用性和可扩展性。
- 通过控制时间偏移的错位策略改进知识转移,提高模型的稳健性。
- CMKT在各种SE架构和LLM嵌入中表现优异,且在汉语和英语数据集上的结果验证了其有效性。
点此查看论文截图

Automatic Speech Recognition for Non-Native English: Accuracy and Disfluency Handling
Authors:Michael McGuire
Automatic speech recognition (ASR) has been an essential component of computer assisted language learning (CALL) and computer assisted language testing (CALT) for many years. As this technology continues to develop rapidly, it is important to evaluate the accuracy of current ASR systems for language learning applications. This study assesses five cutting-edge ASR systems’ recognition of non-native accented English speech using recordings from the L2-ARCTIC corpus, featuring speakers from six different L1 backgrounds (Arabic, Chinese, Hindi, Korean, Spanish, and Vietnamese), in the form of both read and spontaneous speech. The read speech consisted of 2,400 single sentence recordings from 24 speakers, while the spontaneous speech included narrative recordings from 22 speakers. Results showed that for read speech, Whisper and AssemblyAI achieved the best accuracy with mean Match Error Rates (MER) of 0.054 and 0.056 respectively, approaching human-level accuracy. For spontaneous speech, RevAI performed best with a mean MER of 0.063. The study also examined how each system handled disfluencies such as filler words, repetitions, and revisions, finding significant variation in performance across systems and disfluency types. While processing speed varied considerably between systems, longer processing times did not necessarily correlate with better accuracy. By detailing the performance of several of the most recent, widely-available ASR systems on non-native English speech, this study aims to help language instructors and researchers understand the strengths and weaknesses of each system and identify which may be suitable for specific use cases.
多年来,语音识别技术(ASR)一直是计算机辅助语言学习(CALL)和计算机辅助语言测试(CALT)的重要组成部分。随着这项技术的快速发展,评估当前语音识别系统在语言学习应用中的准确性至关重要。本研究评估了五种前沿的语音识别系统对非母语英语口音的识别能力,使用了L2-ARCTIC语料库中的录音,该语料库包含来自六个不同母语背景(阿拉伯语、中文、印地语、韩语、西班牙语和越南语)的演讲者,包括朗读和自发言语两种形式。朗读部分包含来自24名演讲者的2400个单句录音,而自发言语则包含来自22名演讲者的叙述录音。结果表明,在朗读语音方面,Whisper和AssemblyAI取得了最佳准确性,平均匹配错误率(MER)分别为0.054和0.056,接近人类水平的准确性。在自发言语方面,RevAI表现最佳,平均MER为0.063。该研究还探讨了每个系统如何处理不流畅性,如填充词、重复和修正等,发现不同系统和不同不流畅性类型之间的性能存在显著差异。虽然系统之间的处理速度差异很大,但处理时间的长短并不一定与准确性相关。本研究通过详细介绍几种最新且广泛可用的语音识别系统在非母语英语语音上的表现,旨在帮助语言教师和研究者了解每个系统的优缺点,并确定哪些系统适用于特定的用例。
论文及项目相关链接
PDF 33 pages, 10 figures
Summary
本文研究了五种先进的语音识别系统对非母语英语口音的识别能力,使用了L2-ARCTIC语料库中的录音,包括六种不同母语背景的发音人,既有朗读也有即兴演讲。研究表明,在朗读情况下,Whisper和AssemblyAI表现最佳,平均匹配错误率接近人类水平。即兴演讲情况下,RevAI表现最佳。同时,各系统对发音不流畅的处理能力也有显著差异。本研究的目的是帮助语言教师和研究者了解各系统的优缺点,以确定哪些系统适用于特定用例。
Key Takeaways
- 自动语音识别(ASR)是计算机辅助语言学习(CALL)和语言测试(CALT)的重要组成部分。
- 研究评估了五种先进ASR系统对非母语英语口音的识别能力。
- 在朗读情况下,Whisper和AssemblyAI表现最佳,平均匹配错误率接近人类水平。
- 在即兴演讲情况下,RevAI表现最佳。
- 各系统处理发音不流畅的能力存在显著差异。
- 系统的处理速度与识别准确性不一定相关。
点此查看论文截图

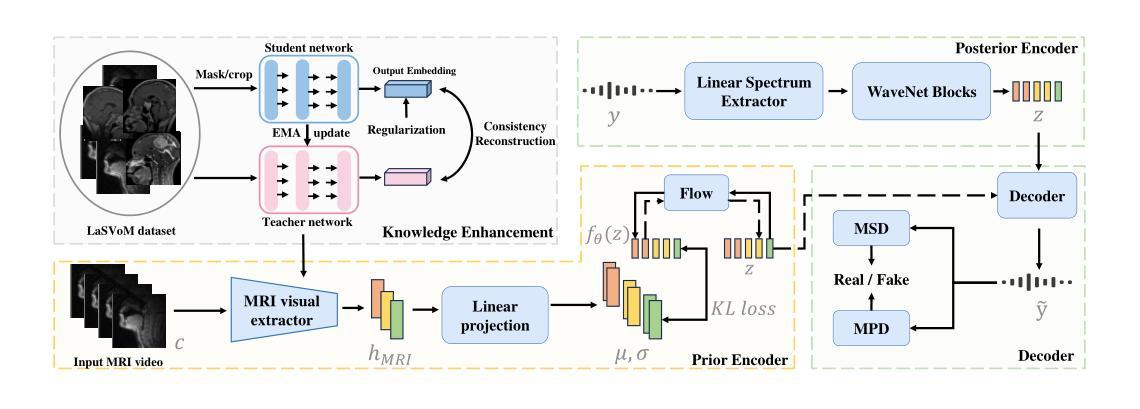
Speech Audio Generation from dynamic MRI via a Knowledge Enhanced Conditional Variational Autoencoder
Authors:Yaxuan Li, Han Jiang, Yifei Ma, Shihua Qin, Fangxu Xing
Dynamic Magnetic Resonance Imaging (MRI) of the vocal tract has become an increasingly adopted imaging modality for speech motor studies. Beyond image signals, systematic data loss, noise pollution, and audio file corruption can occur due to the unpredictability of the MRI acquisition environment. In such cases, generating audio from images is critical for data recovery in both clinical and research applications. However, this remains challenging due to hardware constraints, acoustic interference, and data corruption. Existing solutions, such as denoising and multi-stage synthesis methods, face limitations in audio fidelity and generalizability. To address these challenges, we propose a Knowledge Enhanced Conditional Variational Autoencoder (KE-CVAE), a novel two-step “knowledge enhancement + variational inference” framework for generating speech audio signals from cine dynamic MRI sequences. This approach introduces two key innovations: (1) integration of unlabeled MRI data for knowledge enhancement, and (2) a variational inference architecture to improve generative modeling capacity. To the best of our knowledge, this is one of the first attempts at synthesizing speech audio directly from dynamic MRI video sequences. The proposed method was trained and evaluated on an open-source dynamic vocal tract MRI dataset recorded during speech. Experimental results demonstrate its effectiveness in generating natural speech waveforms while addressing MRI-specific acoustic challenges, outperforming conventional deep learning-based synthesis approaches.
动态磁共振成像(MRI)已经成为语音运动研究越来越受欢迎的成像方式。除了图像信号外,由于MRI采集环境的不确定性,还可能发生系统性数据丢失、噪声污染和音频文件损坏。在这种情况下,从图像生成音频对于临床和研究应用中的数据恢复至关重要。然而,由于硬件限制、声音干扰和数据损坏,这仍然是一个挑战。现有解决方案,如降噪和多阶段合成方法,在音频保真度和通用性方面存在局限性。为了解决这些挑战,我们提出了一种知识增强条件变分自动编码器(KE-CVAE),这是一种新颖的两步“知识增强+变分推断”框架,用于从电影动态MRI序列生成语音音频信号。该方法引入了两个关键创新点:(1)将无标签MRI数据用于知识增强;(2)采用变分推断架构,提高生成模型的容量。据我们所知,这是首次直接从动态MRI视频序列中合成语音音频的尝试。所提出的方法是在公开的动态语音道MRI数据集上训练和评估的,该数据集是在说话期间记录的。实验结果表明,该方法在生成自然语音波形的同时,解决了MRI特有的声学挑战,优于传统的基于深度学习的合成方法。
论文及项目相关链接
Summary:动态磁共振成像(MRI)在语音运动研究中被越来越广泛地采用。然而,MRI采集环境中存在数据丢失、噪声污染和音频文件损坏等问题。从图像生成音频对于临床和研究应用中的数据恢复至关重要。针对硬件约束、声学干扰和数据损坏等挑战,我们提出了一种基于知识增强的条件变分自编码器(KE-CVAE)的新方法,该方法是一种两阶段“知识增强+变分推断”框架,可从电影动态MRI序列生成语音音频信号。该方法引入了两个关键创新点:一是将未标记的MRI数据进行知识增强,二是采用变分推断架构提高生成模型的容量。实验结果表明,该方法在生成自然语音波形的同时解决了MRI特有的声学挑战,优于传统的基于深度学习的合成方法。
Key Takeaways:
- 动态磁共振成像(MRI)已广泛应用于语音运动研究。
- MRI采集环境中存在数据丢失、噪声污染和音频文件损坏等问题。
- 从图像生成音频对于数据恢复在临床和研究应用中至关重要。
- 现有解决方案如降噪和多阶段合成方法存在音频保真度和通用性方面的局限性。
- 提出了一种基于知识增强的条件变分自编码器(KE-CVAE)的新方法,是一种两阶段框架,用于从电影动态MRI序列生成语音音频信号。
- 该方法引入了两个关键创新点:知识增强和变分推断架构。
点此查看论文截图

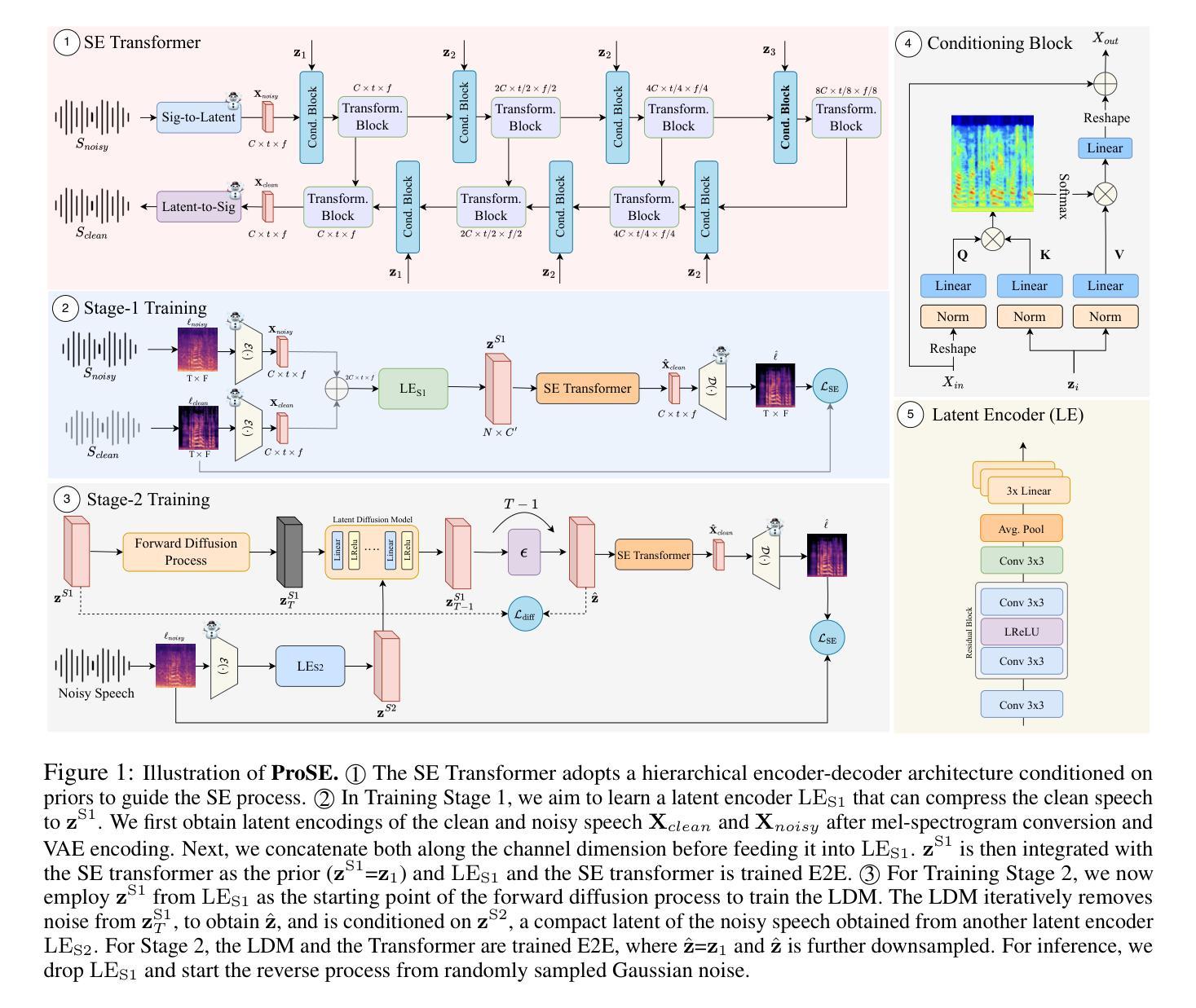
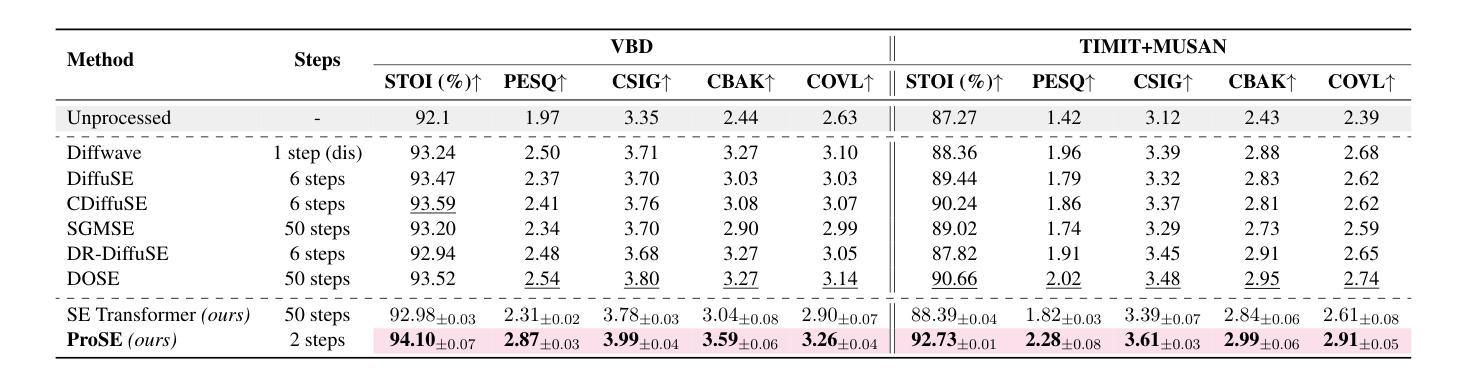
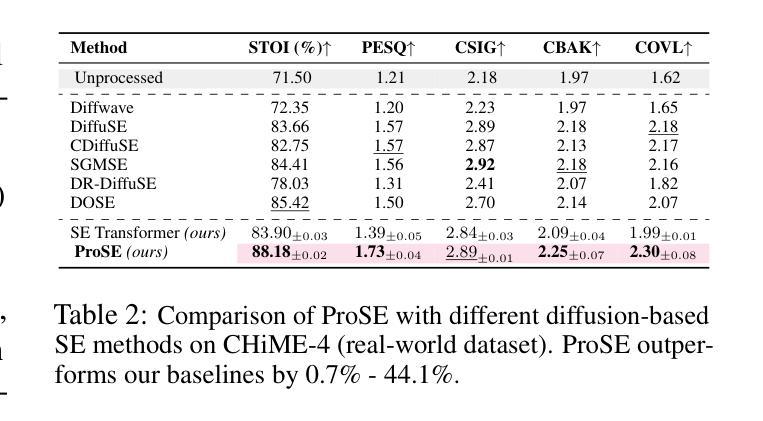
ProSE: Diffusion Priors for Speech Enhancement
Authors:Sonal Kumar, Sreyan Ghosh, Utkarsh Tyagi, Anton Jeran Ratnarajah, Chandra Kiran Reddy Evuru, Ramani Duraiswami, Dinesh Manocha
Speech enhancement (SE) is the foundational task of enhancing the clarity and quality of speech in the presence of non-stationary additive noise. While deterministic deep learning models have been commonly employed for SE, recent research indicates that generative models, such as denoising diffusion probabilistic models (DDPMs), have shown promise. However, unlike speech generation, SE has a strong constraint in generating results in accordance with the underlying ground-truth signal. Additionally, for a wide variety of applications, SE systems need to be employed in real-time, and traditional diffusion models (DMs) requiring many iterations of a large model during inference are inefficient. To address these issues, we propose ProSE (diffusion-based Priors for SE), a novel methodology based on an alternative framework for applying diffusion models to SE. Specifically, we first apply DDPMs to generate priors in a latent space due to their powerful distribution mapping capabilities. The priors are then integrated into a transformer-based regression model for SE. The priors guide the regression model in the enhancement process. Since the diffusion process is applied to a compact latent space, the diffusion model takes fewer iterations than the traditional DM to obtain accurate estimations. Additionally, using a regression model for SE avoids the distortion issue caused by misaligned details generated by DMs. Our experiments show that ProSE achieves state-of-the-art performance on benchmark datasets with fewer computational costs.
语音增强(SE)是在存在非平稳附加噪声的情况下提高语音清晰度和质量的基础任务。虽然确定性深度学习模型通常被用于SE,但最近的研究表明,如去噪扩散概率模型(DDPM)等生成模型显示出良好的前景。然而,与语音生成不同,SE在生成与底层真实信号相符的结果方面具有强烈约束。此外,对于多种应用,SE系统需要在实时环境中部署,而传统的扩散模型(DM)在推理过程中需要多次迭代大型模型,因此效率不高。为了解决这些问题,我们提出了基于扩散模型的SE先验(ProSE)。这是一种新的方法,基于替代框架将扩散模型应用于SE。具体来说,我们首先将DDPM应用于潜在空间生成先验,由于其强大的分布映射能力。这些先验然后被集成到基于变压器的SE回归模型中。先验值在增强过程中指导回归模型。由于扩散过程应用于紧凑的潜在空间,因此扩散模型获得准确估计所需的迭代次数少于传统的DM。此外,使用回归模型进行SE避免了由DM生成的细节错位所导致的失真问题。我们的实验表明,在基准数据集上,ProSE达到了最先进的性能,并且计算成本更低。
论文及项目相关链接
PDF Accepted at NAACL 2025
Summary
本文介绍了针对语音增强任务的一种新型方法——ProSE。该方法结合了扩散模型与回归模型,通过在潜在空间生成先验信息,以指导回归模型进行语音增强过程。相较于传统扩散模型,ProSE提高了计算效率并降低了失真风险,实现了在基准数据集上的卓越性能。
Key Takeaways
- ProSE是一种结合扩散模型和回归模型的新型语音增强方法。
- ProSE利用扩散模型在潜在空间生成先验信息,以指导回归模型进行语音增强。
- 扩散模型应用于紧凑的潜在空间,减少了迭代次数,提高了计算效率。
- 回归模型的使用避免了由传统扩散模型产生的细节不匹配所导致的失真问题。
- ProSE在基准数据集上实现了最先进的性能。
- ProSE特别适用于需要实时处理的语音增强应用。
点此查看论文截图

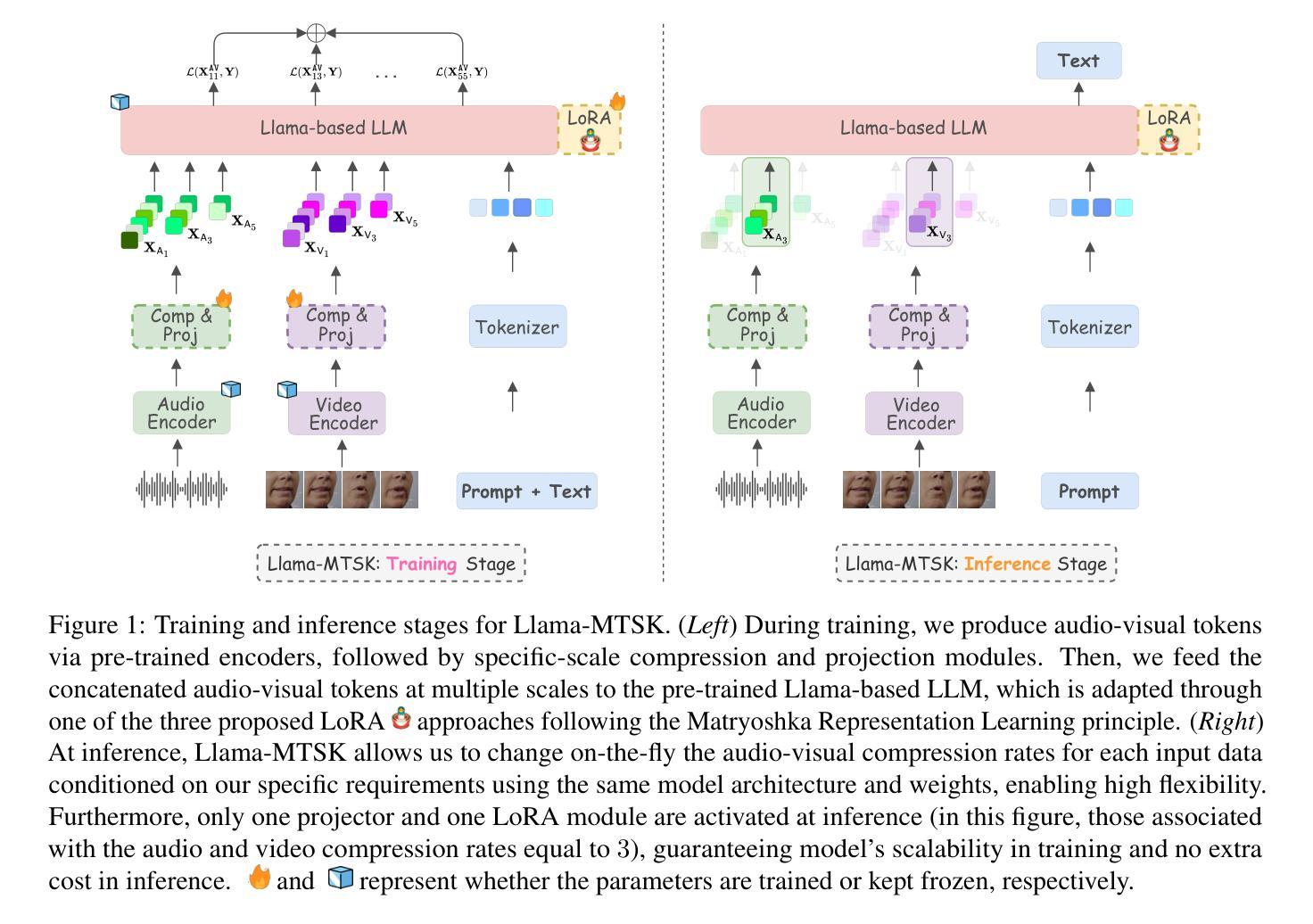
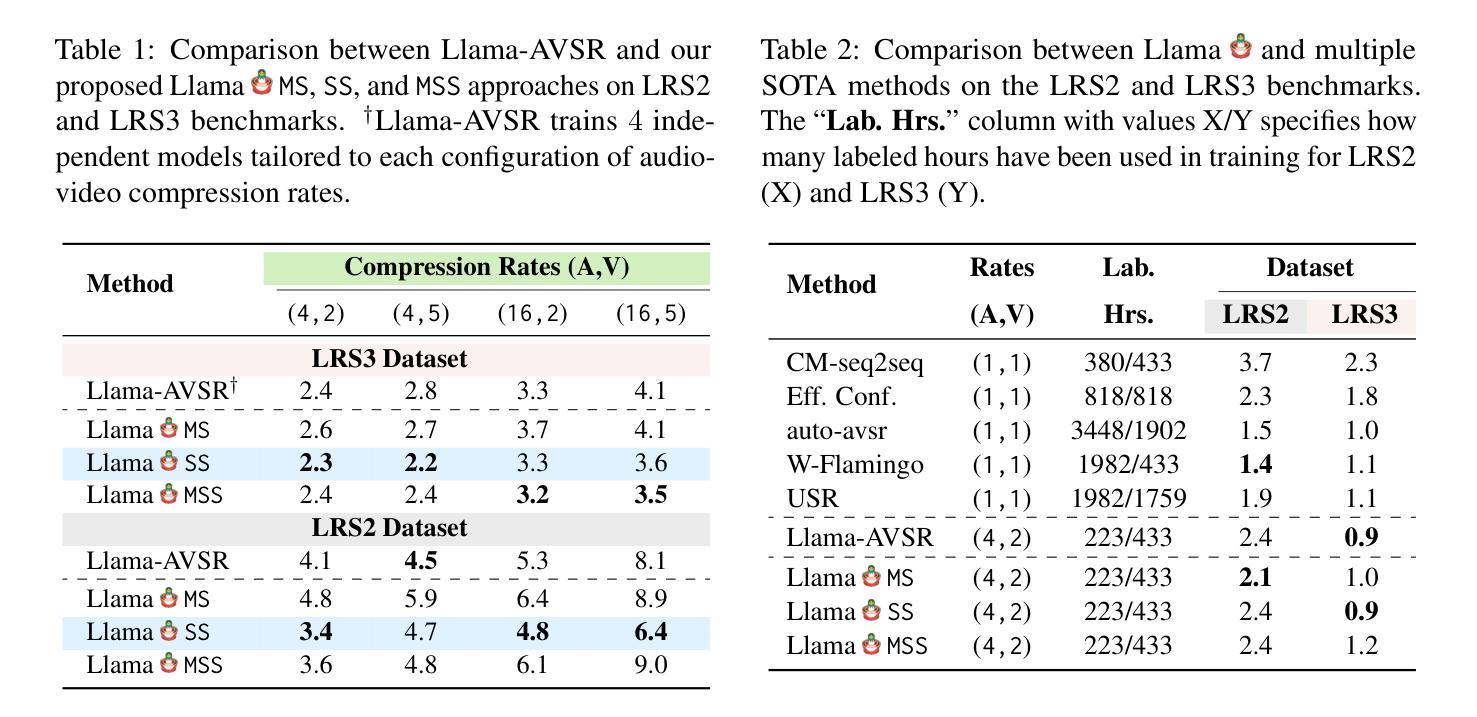
Adaptive Audio-Visual Speech Recognition via Matryoshka-Based Multimodal LLMs
Authors:Umberto Cappellazzo, Minsu Kim, Stavros Petridis
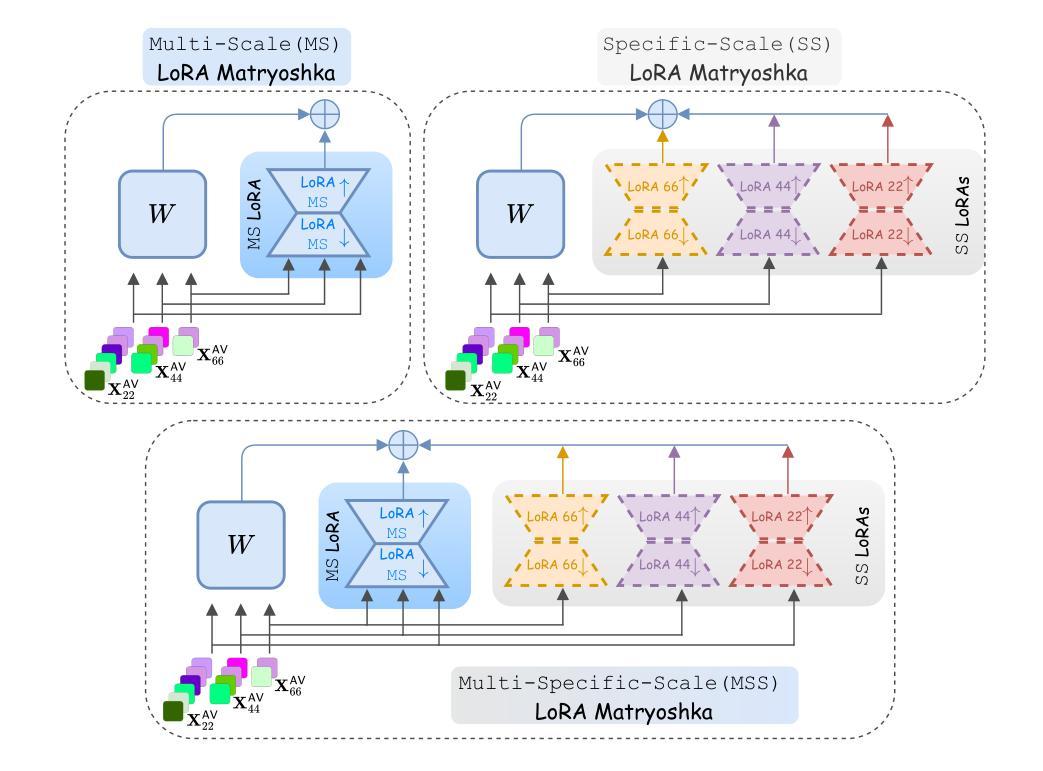
Audio-Visual Speech Recognition (AVSR) leverages both audio and visual modalities to enhance speech recognition robustness, particularly in noisy environments. Recent advancements in Large Language Models (LLMs) have demonstrated their effectiveness in speech recognition, including AVSR. However, due to the significant length of speech representations, direct integration with LLMs imposes substantial computational costs. Prior approaches address this by compressing speech representations before feeding them into LLMs. However, higher compression ratios often lead to performance degradation, necessitating a trade-off between computational efficiency and recognition accuracy. To address this challenge, we propose Llama-MTSK, the first Matryoshka-based Multimodal LLM for AVSR, which enables flexible adaptation of the audio-visual token allocation based on specific computational constraints while preserving high performance. Our approach, inspired by Matryoshka Representation Learning, encodes audio-visual representations at multiple granularities within a single model, eliminating the need to train separate models for different compression levels. Moreover, to efficiently fine-tune the LLM, we introduce three LoRA-based Matryoshka strategies using global and scale-specific LoRA modules. Extensive evaluations on the two largest AVSR datasets demonstrate that Llama-MTSK achieves state-of-the-art results, matching or surpassing models trained independently at fixed compression levels.
音频视觉语音识别(AVSR)利用音频和视觉两种模式来提高语音识别系统的稳健性,特别是在噪声环境中。最近大型语言模型(LLM)的进步在语音识别领域,包括AVSR,都证明了其有效性。然而,由于语音表示的长度较大,直接将其与LLM集成会产生巨大的计算成本。之前的方法通过压缩语音表示来解决这个问题,然后再将其输入到LLM中。然而,较高的压缩率往往会导致性能下降,需要在计算效率和识别精度之间进行权衡。为了解决这一挑战,我们提出了Llama-MTSK,这是基于Matryoshka的首个多模态AVSR LLM。它能够在特定的计算约束下灵活地适应音频视觉令牌分配,同时保持高性能。我们的方法受到Matryoshka表示学习的启发,在一个单一模型中编码多个粒度的音频视觉表示,无需为不同的压缩级别训练单独的模型。此外,为了有效地微调LLM,我们引入了三种基于LoRA的Matryoshka策略,使用全局和规模特定的LoRA模块。在两大AVSR数据集上的广泛评估表明,Llama-MTSK达到了最先进的水平,匹配或超越了在固定压缩级别下独立训练的模型。
论文及项目相关链接
Summary
该文本介绍了音频视觉语音识别(AVSR)利用音频和视觉模态提高语音识别在噪声环境下的稳健性。最近大型语言模型(LLM)在语音识别中的有效性得到证明,但直接集成到AVSR中存在计算成本高的挑战。为此,研究人员提出了基于Matryoshka的Llama-MTSK多模态LLM模型,能够在特定的计算约束下灵活适应音频视觉令牌分配并保持高性能。该模型使用Matryoshka表示学习的方法,在单个模型内部以不同粒度编码音频视觉表示形式,避免为不同压缩级别训练单独模型的需要。此外,通过引入三种基于LoRA的Matryoshka策略进行微调,以提高效率。在两大AVSR数据集上的评估表明,Llama-MTSK达到了最新的结果,能够匹配或超越在固定压缩级别下独立训练的模型。
Key Takeaways
- 音频视觉语音识别(AVSR)结合了音频和视觉模态,增强了在噪声环境下的语音识别稳健性。
- 大型语言模型(LLMs)在语音识别中表现出有效性,但直接集成存在计算成本高的问题。
- Llama-MTSK模型是首个针对AVSR的Matryoshka多模态LLM,能够在计算约束下灵活适应音频视觉令牌分配并保持高性能。
- Llama-MTSK使用Matryoshka表示学习方法,以不同粒度编码音频视觉表示形式,避免了训练不同压缩级别独立模型的必要性。
- 通过引入三种基于LoRA的Matryoshka策略进行微调,以提高模型的效率。
- 在两大AVSR数据集上的评估显示,Llama-MTSK达到了最新的结果。
点此查看论文截图

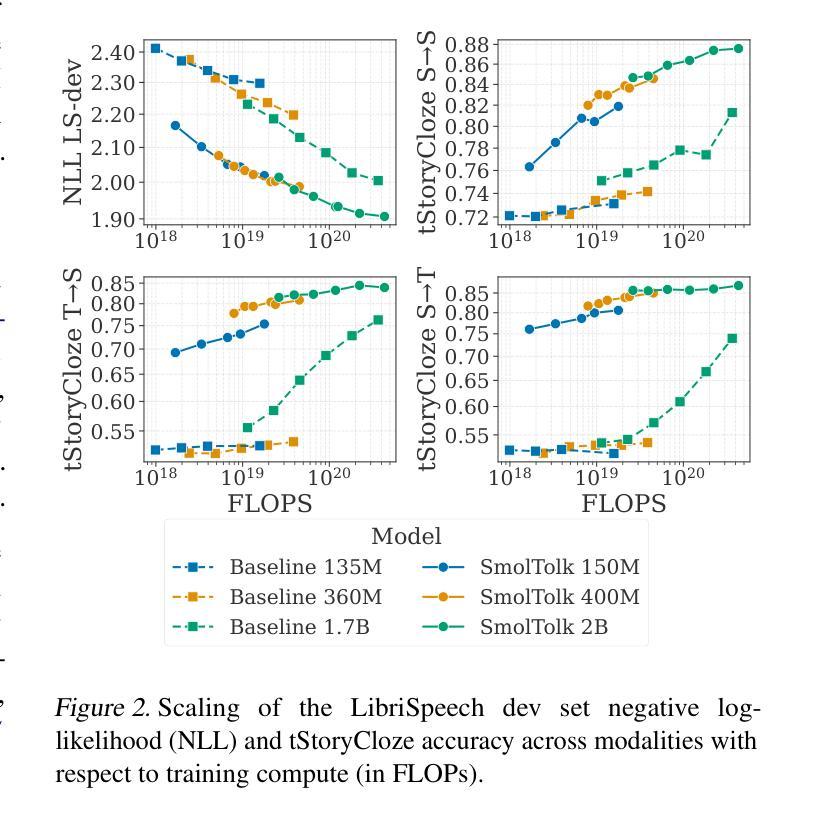
Text-Speech Language Models with Improved Cross-Modal Transfer by Aligning Abstraction Levels
Authors:Santiago Cuervo, Adel Moumen, Yanis Labrak, Sameer Khurana, Antoine Laurent, Mickael Rouvier, Ricard Marxer
Text-Speech Language Models (TSLMs) – language models trained to jointly process and generate text and speech – aim to enable cross-modal knowledge transfer to overcome the scaling limitations of unimodal speech LMs. The predominant approach to TSLM training expands the vocabulary of a pre-trained text LM by appending new embeddings and linear projections for speech, followed by fine-tuning on speech data. We hypothesize that this method limits cross-modal transfer by neglecting feature compositionality, preventing text-learned functions from being fully leveraged at appropriate abstraction levels. To address this, we propose augmenting vocabulary expansion with modules that better align abstraction levels across layers. Our models, \textsc{SmolTolk}, rival or surpass state-of-the-art TSLMs trained with orders of magnitude more compute. Representation analyses and improved multimodal performance suggest our method enhances cross-modal transfer.
文本-语音语言模型(TSLMs)——旨在联合处理和生成文本和语音的语言模型——旨在实现跨模态知识迁移,以克服单模态语音LM的规模化限制。TSLM训练的主要方法是通过在预训练的文本LM的词汇表上增加新的语音嵌入和线性投影来扩展其词汇量,然后通过语音数据对其进行微调。我们假设这种方法忽略了特征组合性,阻碍了文本学习功能在适当抽象层次上的充分利用,从而限制了跨模态迁移。为了解决这个问题,我们提出通过增加模块来更好地对齐各层之间的抽象层次,以扩充词汇量。我们的模型SmolTolk与最先进的TSLM相当或超越,这些TSLM的计算训练量要大得多。表征分析和改进的多模态性能表明,我们的方法增强了跨模态迁移。
论文及项目相关链接
Summary
文本-语音语言模型(TSLM)旨在通过跨模态知识迁移,克服单一模态语音语言模型的规模限制。现有主流训练方法是扩充预训练文本语言模型的词汇,增加语音嵌入和线性投影,再通过语音数据进行微调。然而,这种方法忽略了特征组合性,导致文本学习功能无法在适当抽象层面被充分利用。为改善这一问题,我们提出通过增加模块对齐各层抽象层面来扩充词汇的方法。我们的模型“SmolTolk”与训练时计算量远超其的先进TSLM相比表现相当或更好。表征分析和改进的多模态性能表明,我们的方法增强了跨模态迁移能力。
Key Takeaways
- TSLM旨在通过跨模态知识迁移克服单一模态语音语言模型的规模限制。
- 当前主流TSLM训练方法是扩充文本LM词汇并增加语音嵌入和线性投影。
- 现有方法忽略了特征组合性,影响文本学习功能在适当抽象层面的利用。
- 为改善此问题,提出了结合扩充词汇与对齐各层抽象层面的方法。
- 模型“SmolTolk”表现优异,与计算量更大的先进TSLM相比具有竞争力。
- 表征分析显示新方法增强了跨模态迁移能力。
点此查看论文截图


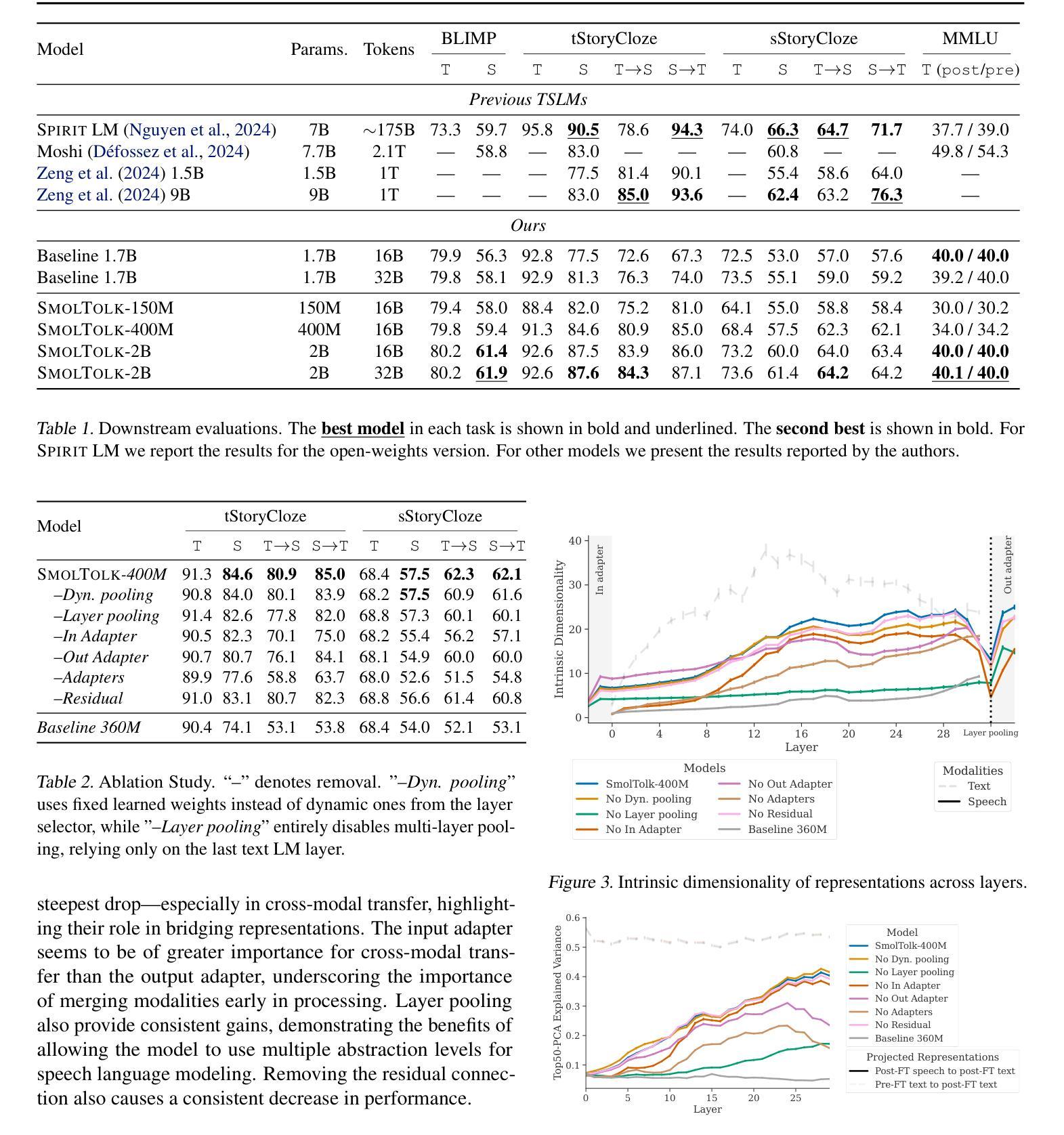
Bimodal Connection Attention Fusion for Speech Emotion Recognition
Authors:Jiachen Luo, Huy Phan, Lin Wang, Joshua D. Reiss
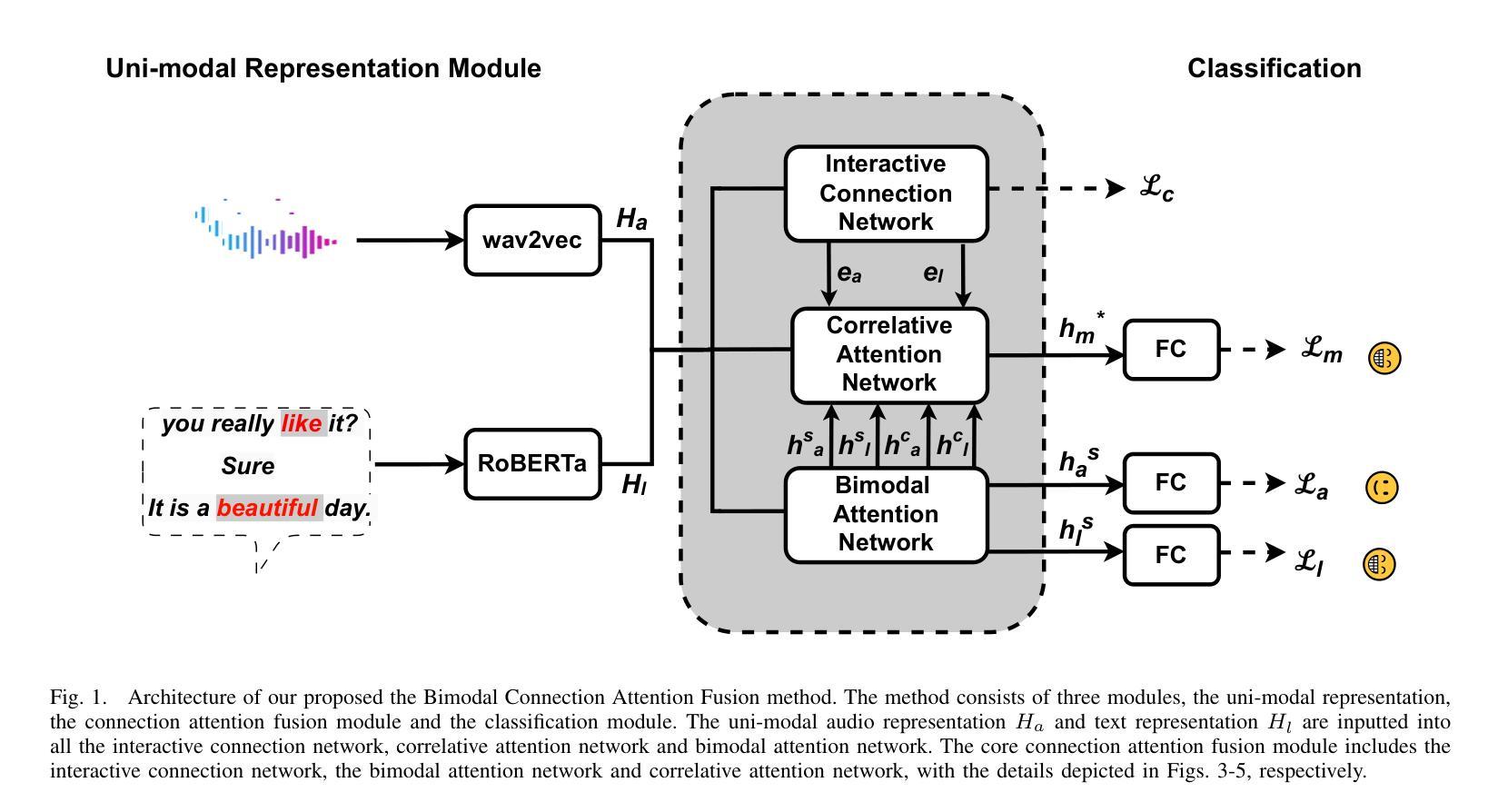
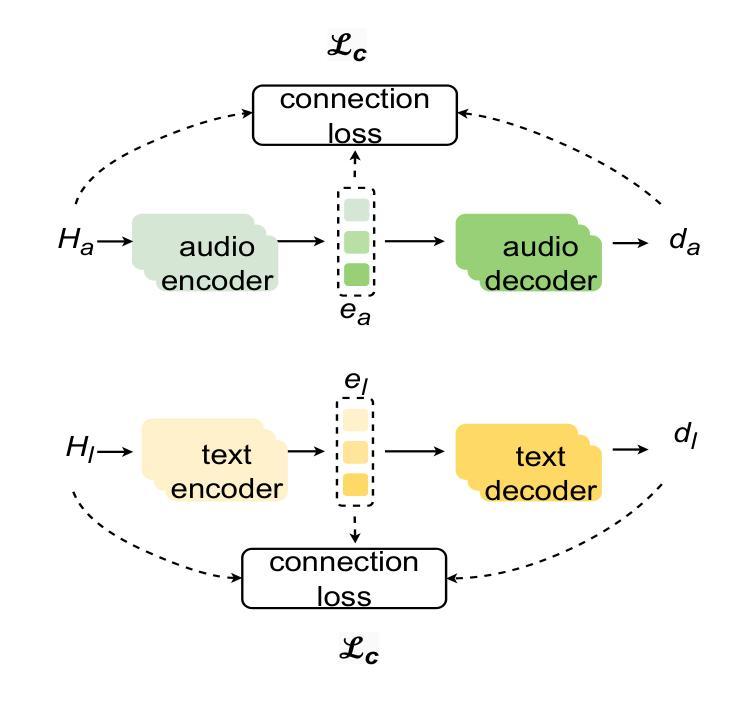
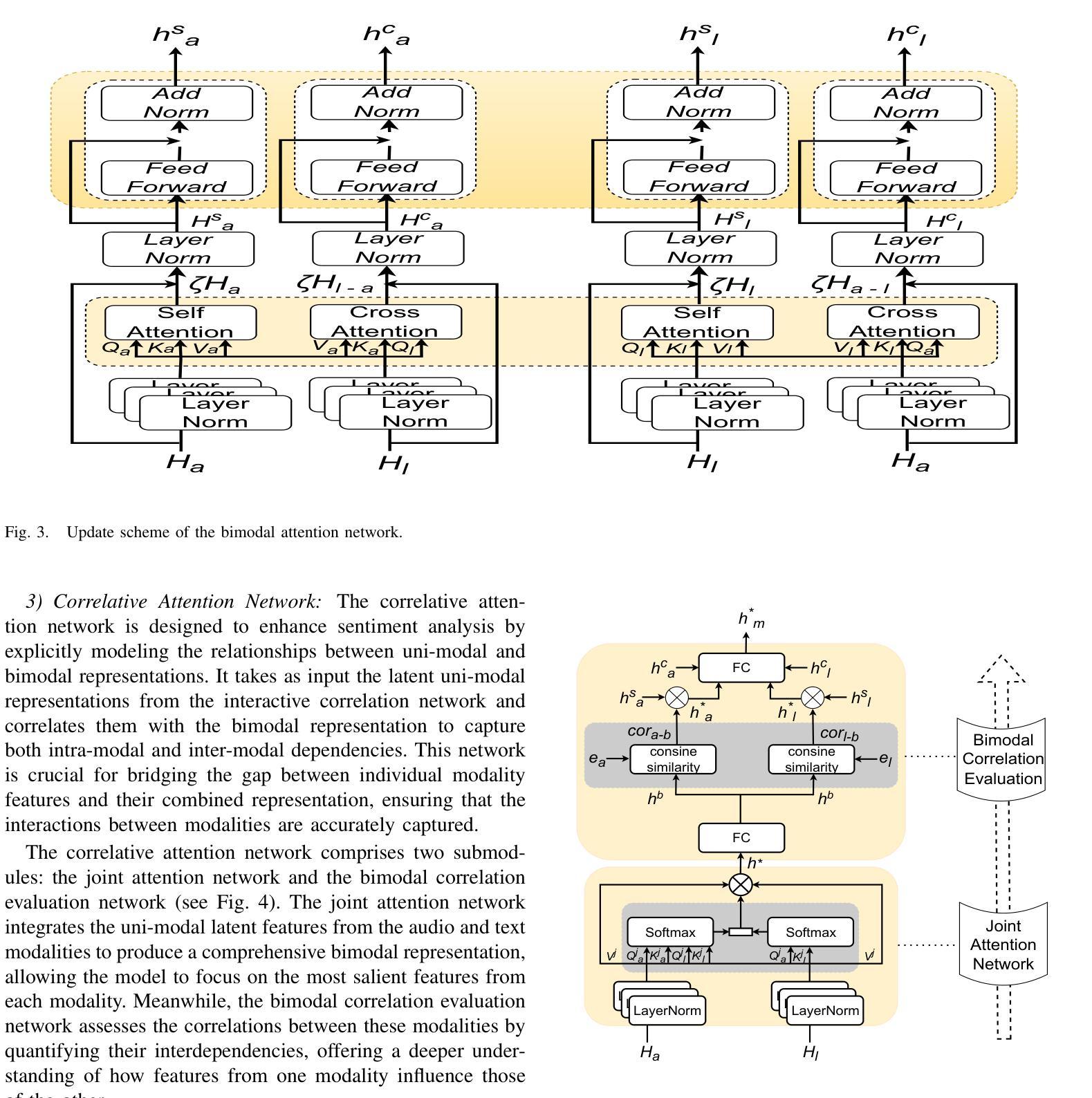
Multi-modal emotion recognition is challenging due to the difficulty of extracting features that capture subtle emotional differences. Understanding multi-modal interactions and connections is key to building effective bimodal speech emotion recognition systems. In this work, we propose Bimodal Connection Attention Fusion (BCAF) method, which includes three main modules: the interactive connection network, the bimodal attention network, and the correlative attention network. The interactive connection network uses an encoder-decoder architecture to model modality connections between audio and text while leveraging modality-specific features. The bimodal attention network enhances semantic complementation and exploits intra- and inter-modal interactions. The correlative attention network reduces cross-modal noise and captures correlations between audio and text. Experiments on the MELD and IEMOCAP datasets demonstrate that the proposed BCAF method outperforms existing state-of-the-art baselines.
多模态情感识别是一项挑战,因为提取能够捕捉微妙情感差异的特征非常困难。理解多模态的交互和连接是构建有效的双模态语音情感识别系统的关键。在这项工作中,我们提出了双模态连接注意力融合(BCAF)方法,主要包括三个模块:交互连接网络、双模态注意力网络和相关性注意力网络。交互连接网络使用编码器-解码器架构来建模音频和文本之间的模态连接,同时利用模态特定特征。双模态注意力网络增强了语义补充性,并探索了模态内部和模态之间的交互作用。相关性注意力网络降低了跨模态噪声,并捕捉了音频和文本之间的相关性。在MELD和IEMOCAP数据集上的实验表明,所提出的BCAF方法优于现有的最新基线方法。
论文及项目相关链接
Summary
多模态情感识别因捕捉细微情感差异的特征提取难度而具有挑战性。构建有效的双模态语音情感识别系统的关键是理解多模态交互和连接。本研究提出Bimodal Connection Attention Fusion(BCAF)方法,包括三个主要模块:交互连接网络、双模态注意力网络和相关性注意力网络。交互连接网络使用编码器-解码器架构对音频和文本之间的模态连接进行建模,同时利用模态特定特征。双模态注意力网络增强语义互补性并挖掘跨模态内和跨模态间的交互作用。相关性注意力网络减少跨模态噪声并捕捉音频和文本之间的相关性。在MELD和IEMOCAP数据集上的实验表明,所提出的BCAF方法优于现有先进基线方法。
Key Takeaways
- 多模态情感识别存在挑战,因为捕捉细微情感差异的特征提取难度大。
- 构建有效的双模态语音情感识别系统的关键是理解多模态交互和连接。
- BCAF方法包括三个主要模块:交互连接网络、双模态注意力网络和相关性注意力网络。
- 交互连接网络利用编码器-解码器架构建模音频和文本之间的模态连接。
- 双模态注意力网络提升语义互补性并挖掘模态间的交互作用。
- 相关性注意力网络能减少跨模态噪声,增强音频和文本之间的相关性识别。
点此查看论文截图

GestureLSM: Latent Shortcut based Co-Speech Gesture Generation with Spatial-Temporal Modeling
Authors:Pinxin Liu, Luchuan Song, Junhua Huang, Haiyang Liu, Chenliang Xu
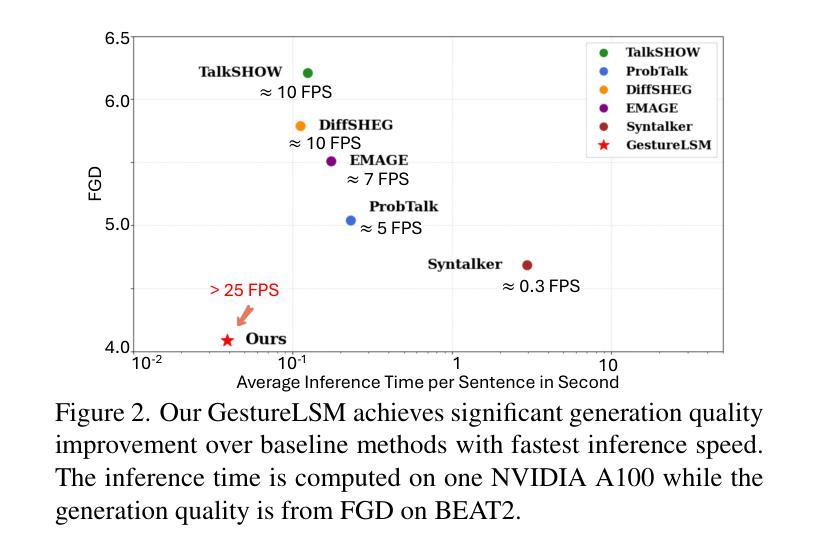
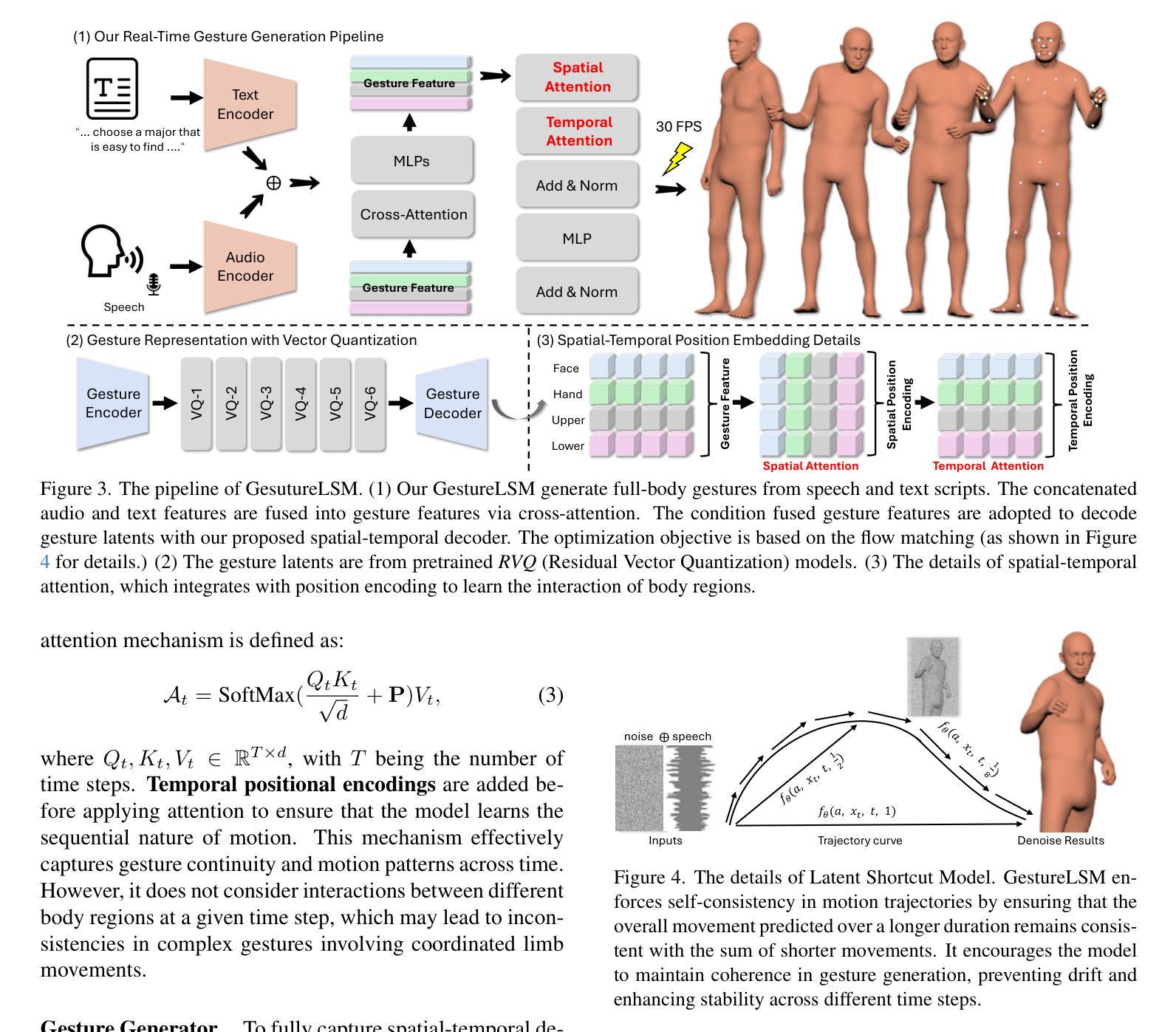
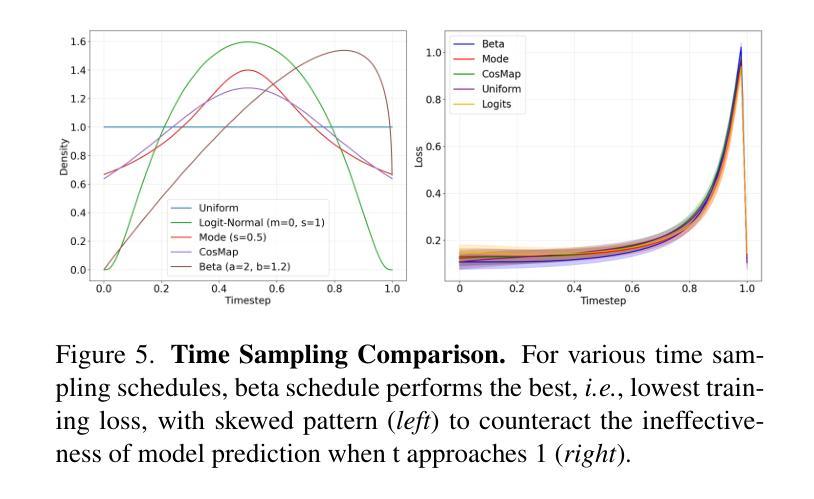
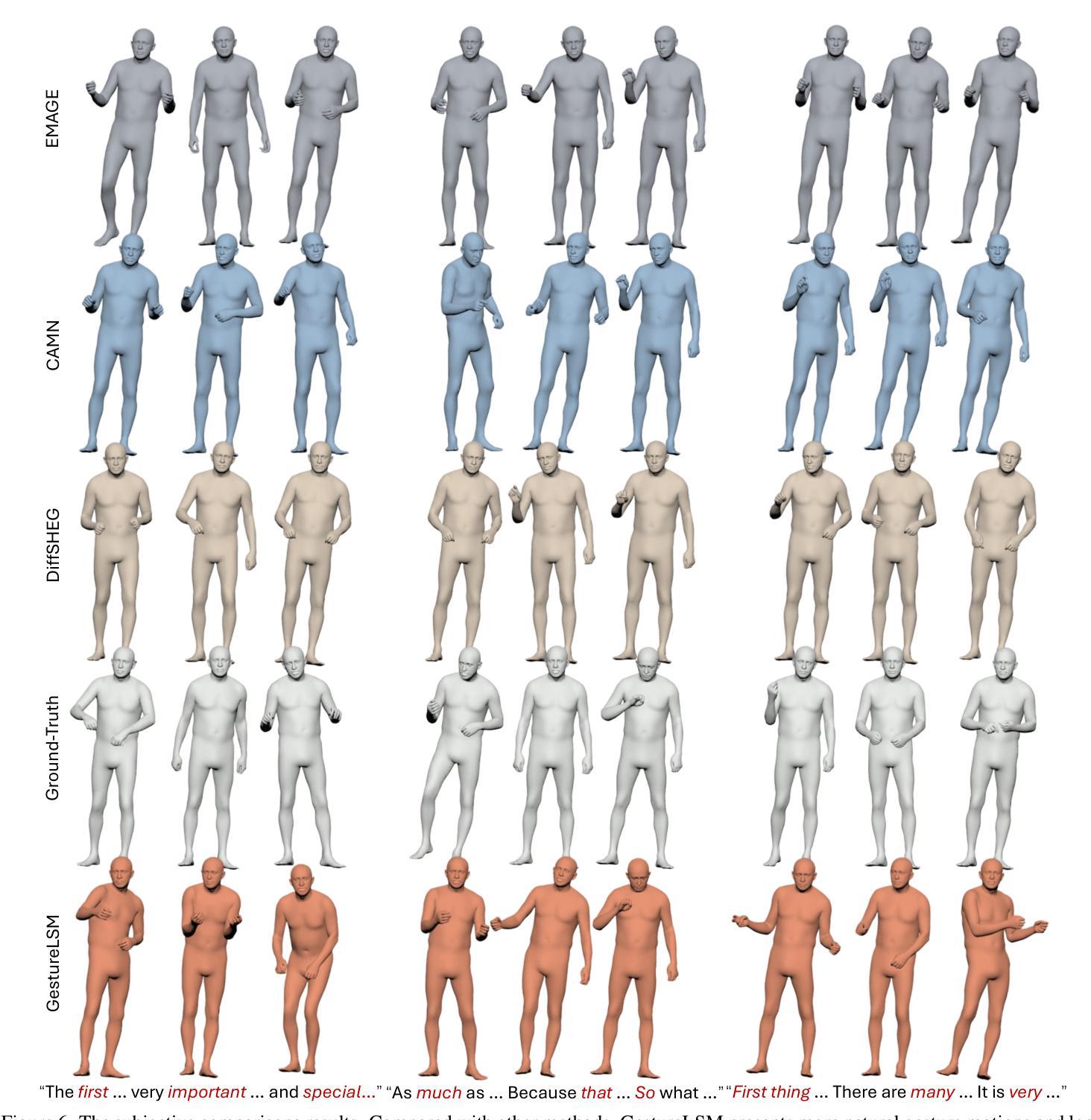
Generating full-body human gestures based on speech signals remains challenges on quality and speed. Existing approaches model different body regions such as body, legs and hands separately, which fail to capture the spatial interactions between them and result in unnatural and disjointed movements. Additionally, their autoregressive/diffusion-based pipelines show slow generation speed due to dozens of inference steps. To address these two challenges, we propose GestureLSM, a flow-matching-based approach for Co-Speech Gesture Generation with spatial-temporal modeling. Our method i) explicitly model the interaction of tokenized body regions through spatial and temporal attention, for generating coherent full-body gestures. ii) introduce the flow matching to enable more efficient sampling by explicitly modeling the latent velocity space. To overcome the suboptimal performance of flow matching baseline, we propose latent shortcut learning and beta distribution time stamp sampling during training to enhance gesture synthesis quality and accelerate inference. Combining the spatial-temporal modeling and improved flow matching-based framework, GestureLSM achieves state-of-the-art performance on BEAT2 while significantly reducing inference time compared to existing methods, highlighting its potential for enhancing digital humans and embodied agents in real-world applications. Project Page: https://andypinxinliu.github.io/GestureLSM
基于语音信号生成全身人体姿态在质量和速度方面仍然存在挑战。现有方法分别对人体、腿部和手部等不同身体区域进行建模,这无法捕捉它们之间的空间交互,导致动作不自然和脱节。此外,他们的自回归/扩散基于的管道由于几十步的推理步骤而显示出缓慢生成速度。为了解决这两个挑战,我们提出了基于流匹配的共语姿态生成方法GestureLSM,并进行了时空建模。我们的方法一)通过空间和时间注意力显式地模拟标记化身体区域的交互,以生成连贯的全身姿态。二)引入流匹配,通过显式地建模潜在速度空间来实现更有效的采样。为了克服流匹配基线性能不佳的问题,我们在训练过程中提出了潜在快捷方式学习和beta分布时间戳采样,以提高姿态合成质量和加速推理。结合时空建模和改进的基于流匹配的框架,GestureLSM在BEAT2上实现了最先进的性能,同时与现有方法相比显著减少了推理时间,突显其在增强数字人类和实体代理在现实世界应用中的潜力。项目页面:https://andypinxinliu.github.io/GestureLSM
论文及项目相关链接
Summary
基于语音信号生成全身人类动作在质量和速度上仍有挑战。现有方法分别建模身体不同部位,如身体、腿和手,忽略了它们之间的空间交互,导致动作不自然、不连贯。此外,它们的自回归或扩散生成管道由于需要大量的推理步骤,生成速度较慢。针对这两个问题,我们提出GestureLSM,一种基于流匹配的语音共感动作生成方法,采用时空建模。我们的方法一)通过空间和时间注意力显式地模拟了标记身体部位的交互,以生成连贯的全身动作。二)引入流匹配,通过显式建模潜在速度空间,使采样更加高效。为了克服流匹配基线方法的性能不足,我们在训练过程中引入了潜在快捷方式学习和beta分布时间戳采样,以提高动作合成的质量和加速推理。结合时空建模和改进的流匹配框架,GestureLSM在BEAT2上实现了最先进的性能,同时显著减少了推理时间,凸显其在增强数字人类和实体代理在现实世界应用中的潜力。
Key Takeaways
- 现有方法建模身体不同部位时忽略了空间交互,导致动作不自然。
- 现有方法的自回归/扩散生成管道因推理步骤多而生成速度慢。
- GestureLSM采用基于流匹配的方法,通过时空建模生成连贯的全身动作。
- GestureLSM显式地通过空间和时间注意力建模身体部位的交互。
- GestureLSM引入流匹配和潜在快捷方式学习,提高动作合成质量和推理效率。
- GestureLSM在BEAT2上实现了最先进的性能。
点此查看论文截图