⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-12 更新
Clip-TTS: Contrastive Text-content and Mel-spectrogram, A High-Quality Text-to-Speech Method based on Contextual Semantic Understanding
Authors:Tianyun Liu
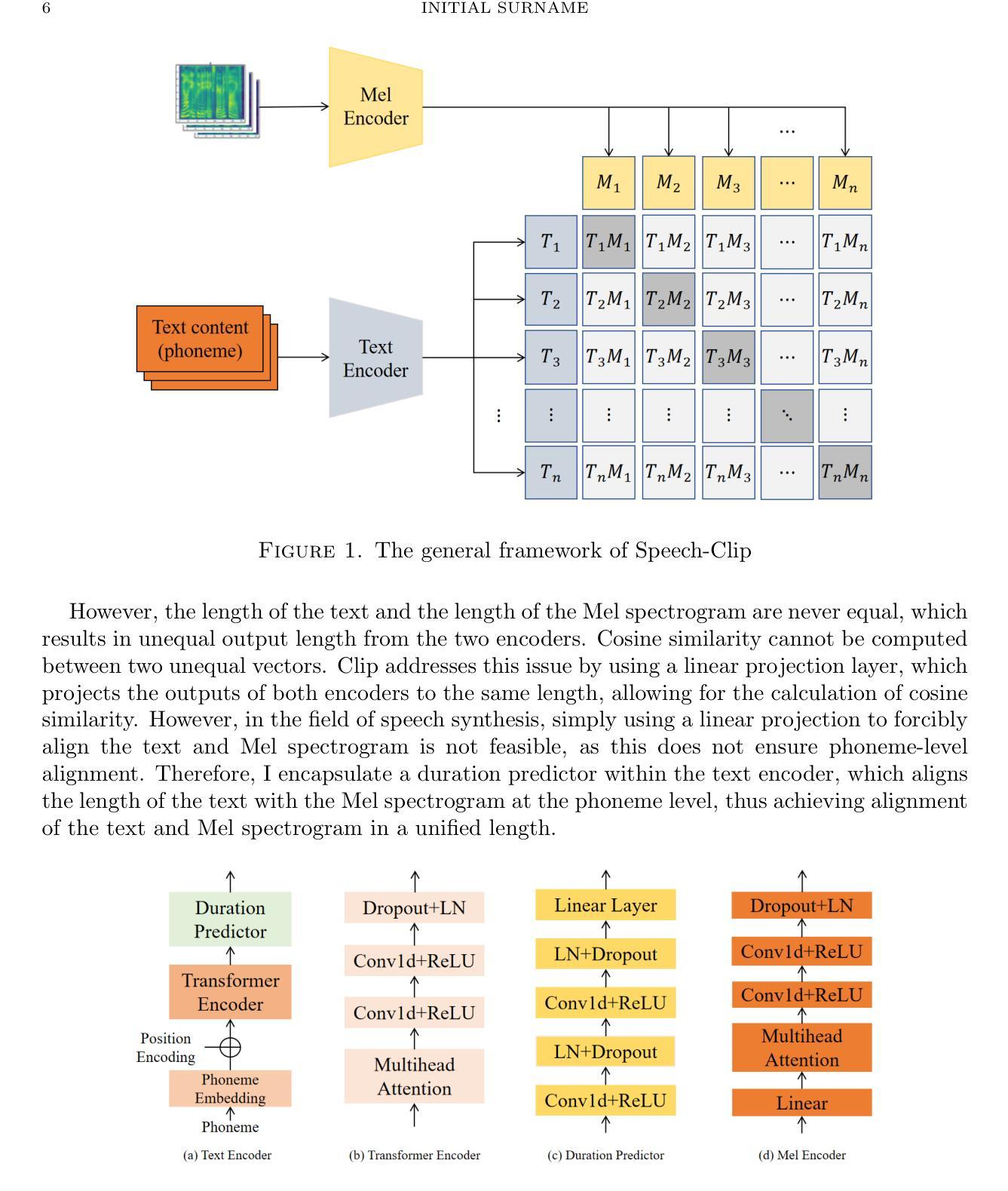
Traditional text-to-speech (TTS) methods primarily focus on establishing a mapping between phonemes and mel-spectrograms. However, during the phoneme encoding stage, there is often a lack of real mel-spectrogram auxiliary information, which results in the encoding process lacking true semantic understanding. At the same time, traditional TTS systems often struggle to balance the inference speed of the model with the quality of the synthesized speech. Methods that generate high-quality synthesized speech tend to have slower inference speeds, while faster inference methods often sacrifice speech quality. In this paper, I propose Clip-TTS, a TTS method based on the Clip architecture. This method uses the Clip framework to establish a connection between text content and real mel-spectrograms during the text encoding stage, enabling the text encoder to directly learn the true semantics of the global context, thereby ensuring the quality of the synthesized speech. In terms of model architecture, I adopt the basic structure of Transformer, which allows Clip-TTS to achieve fast inference speeds. Experimental results show that on the LJSpeech and Baker datasets, the speech generated by Clip-TTS achieves state-of-the-art MOS scores, and it also performs excellently on multi-emotion datasets.Audio samples are available at: https://ltydd1314.github.io/.
传统文本转语音(TTS)方法主要关注于建立音素和梅尔频谱之间的映射关系。然而,在音素编码阶段,往往缺乏真实的梅尔频谱辅助信息,导致编码过程缺乏真正的语义理解。同时,传统TTS系统往往难以在模型推理速度与合成语音质量之间取得平衡。生成高质量合成语音的方法往往推理速度较慢,而推理速度较快的方法往往牺牲了语音质量。在本文中,我提出了基于Clip架构的Clip-TTS方法。该方法使用Clip框架在文本编码阶段建立文本内容和真实梅尔频谱之间的关系,使文本编码器能够直接学习全局上下文的真实语义,从而确保合成语音的质量。在模型架构方面,我采用了Transformer的基本结构,使得Clip-TTS能够实现快速的推理速度。实验结果表明,在LJSpeech和Baker数据集上,Clip-TTS生成的语音达到了最先进的MOS得分,并且在多情绪数据集上表现也非常出色。音频样本可在:链接找到。
论文及项目相关链接
Summary
本文提出一种基于Clip架构的TTS方法,名为Clip-TTS。该方法在文本编码阶段利用Clip框架建立文本内容与真实mel-spectrograms之间的联系,使文本编码器直接学习全局上下文的真实语义,确保合成语音的质量。同时采用Transformer基础结构,实现快速推理。实验结果表明,在LJSpeech和Baker数据集上,Clip-TTS生成的语音达到了最先进的MOS分数,并在多情感数据集上表现优异。
Key Takeaways
- 传统TTS方法主要关注于建立音素与mel-spectrograms之间的映射,但在音素编码阶段缺乏真正的mel-spectrogram辅助信息,导致编码过程缺乏真正的语义理解。
- 传统TTS系统在模型推理速度与合成语音质量之间难以平衡,高质量合成语音往往伴随着较慢的推理速度。
- 本文提出的Clip-TTS方法利用Clip架构建立文本内容与真实mel-spectrograms之间的联系,提高合成语音的质量。
- Clip-TTS采用Transformer基础结构,实现快速推理。
- 实验结果表明,Clip-TTS在LJSpeech和Baker数据集上达到先进MOS分数。
- Clip-TTS在多情感数据集上表现优异。
点此查看论文截图