⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-12 更新
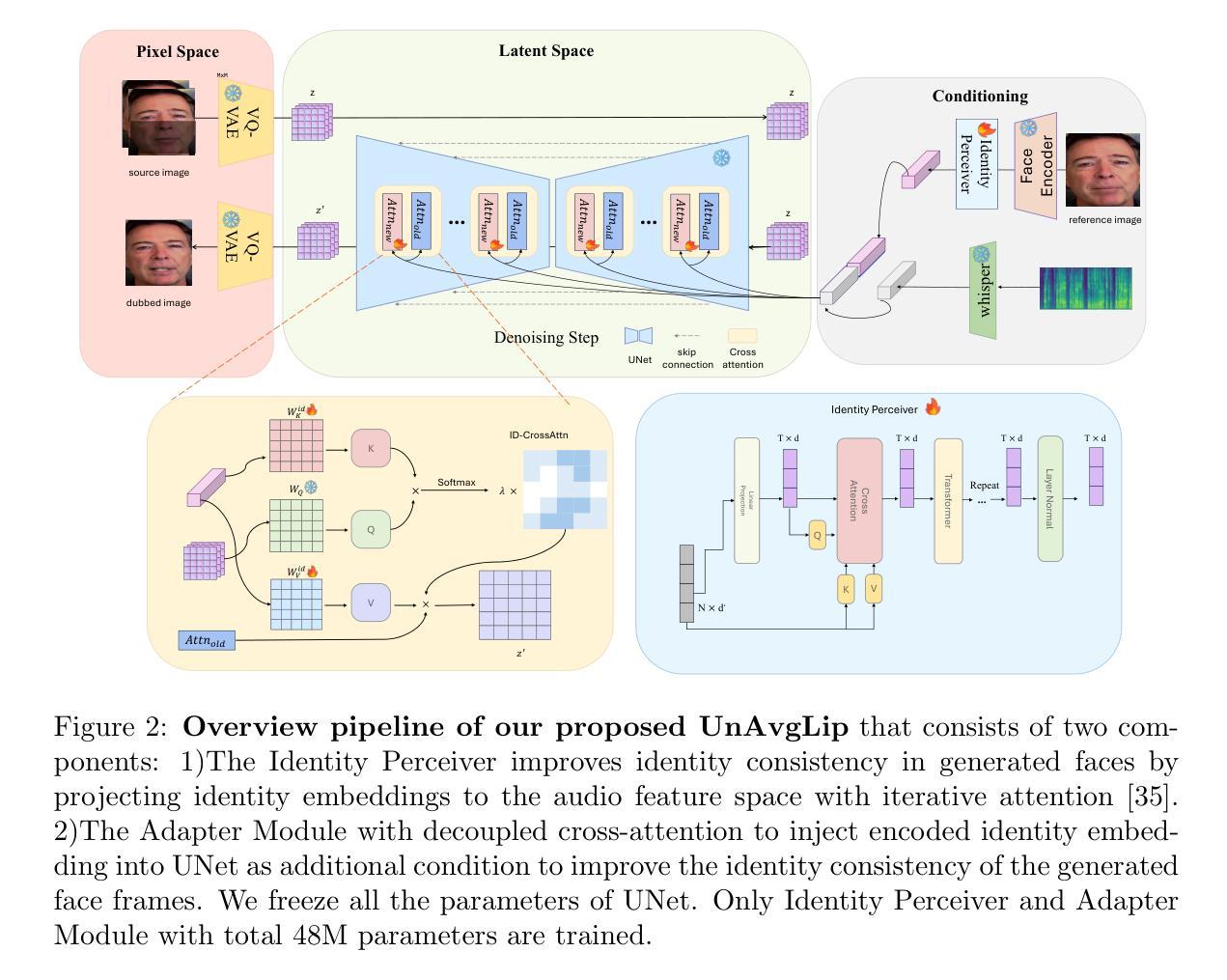
Removing Averaging: Personalized Lip-Sync Driven Characters Based on Identity Adapter
Authors:Yanyu Zhu, Licheng Bai, Jintao Xu, Jiwei Tang, Hai-tao Zheng
Recent advances in diffusion-based lip-syncing generative models have demonstrated their ability to produce highly synchronized talking face videos for visual dubbing. Although these models excel at lip synchronization, they often struggle to maintain fine-grained control over facial details in generated images. In this work, we identify “lip averaging” phenomenon where the model fails to preserve subtle facial details when dubbing unseen in-the-wild videos. This issue arises because the commonly used UNet backbone primarily integrates audio features into visual representations in the latent space via cross-attention mechanisms and multi-scale fusion, but it struggles to retain fine-grained lip details in the generated faces. To address this issue, we propose UnAvgLip, which extracts identity embeddings from reference videos to generate highly faithful facial sequences while maintaining accurate lip synchronization. Specifically, our method comprises two primary components: (1) an Identity Perceiver module that encodes facial embeddings to align with conditioned audio features; and (2) an ID-CrossAttn module that injects facial embeddings into the generation process, enhancing model’s capability of identity retention. Extensive experiments demonstrate that, at a modest training and inference cost, UnAvgLip effectively mitigates the “averaging” phenomenon in lip inpainting, significantly preserving unique facial characteristics while maintaining precise lip synchronization. Compared with the original approach, our method demonstrates significant improvements of 5% on the identity consistency metric and 2% on the SSIM metric across two benchmark datasets (HDTF and LRW).
基于扩散的唇同步生成模型的最新进展已经证明它们在视觉配音中生成高度同步的说话人脸视频的能力。尽管这些模型在唇同步方面表现出色,但它们在生成图像的面部细节控制方面往往存在困难。在这项工作中,我们发现了“唇部平均化”现象,即模型在配音未见过的野外视频时无法保留微妙的面部细节。这个问题产生的原因在于常用的UNet主干网络主要通过跨注意机制和多尺度融合将音频特征集成到视觉表示中,但在生成的面部中难以保留精细的唇部细节。为了解决这一问题,我们提出了UnAvgLip,它从参考视频中提取身份嵌入,生成高度忠实的面部序列,同时保持准确的唇部同步。具体来说,我们的方法主要包括两个主要组成部分:(1)身份感知模块,它编码面部嵌入以与条件音频特征对齐;(2)ID-CrossAttn模块,它将面部嵌入注入生成过程,增强模型对身份保留的能力。大量实验表明,在适度的训练和推理成本下,UnAvgLip有效地缓解了唇部补全中的“平均化”现象,显著保留了独特的面部特征,同时保持了精确的唇部同步。与原始方法相比,我们的方法在身份一致性指标上提高了5%,在SSIM指标上提高了2%,跨越两个基准数据集(HDTF和LRW)。
论文及项目相关链接
Summary
基于扩散的唇同步生成模型虽然能生成高度同步的说话面部视频,但在面部细节方面存在缺陷。本文提出一种名为UnAvgLip的方法,通过提取参考视频的面部嵌入信息,生成高度忠实的面部序列,同时保持准确的唇同步。它包括身份感知模块和ID-CrossAttn模块,能改善模型在身份保留方面的能力。实验表明,UnAvgLip有效减轻了唇同步中的“平均”现象,在身份一致性和结构相似性指标上均有显著提升。
Key Takeaways
- 扩散的唇同步生成模型可以生成高度同步的说话面部视频,但在保留面部细节方面存在困难。
- “唇平均”现象是指模型在配音未见过的野生视频时,无法保留微妙的面部细节。
- UnAvgLip方法通过提取参考视频的面部嵌入信息,生成高度忠实的面部序列。
- UnAvgLip包括身份感知模块和ID-CrossAttn模块,旨在提高模型的身份保留能力。
- UnAvgLip有效减轻了唇同步中的“平均”现象,在身份一致性和结构相似性指标上相比原有方法有所提升。
点此查看论文截图


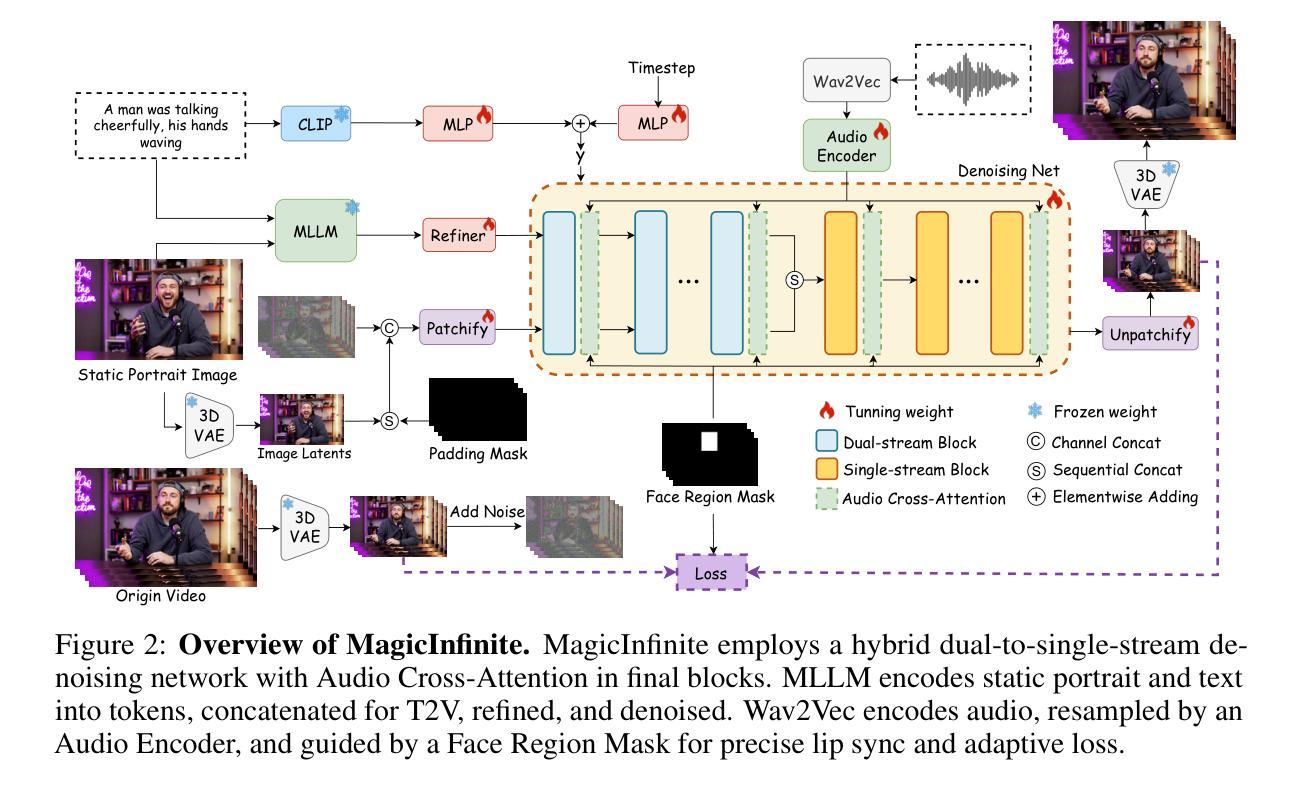
MagicInfinite: Generating Infinite Talking Videos with Your Words and Voice
Authors:Hongwei Yi, Tian Ye, Shitong Shao, Xuancheng Yang, Jiantong Zhao, Hanzhong Guo, Terrance Wang, Qingyu Yin, Zeke Xie, Lei Zhu, Wei Li, Michael Lingelbach, Daquan Zhou
We present MagicInfinite, a novel diffusion Transformer (DiT) framework that overcomes traditional portrait animation limitations, delivering high-fidelity results across diverse character types-realistic humans, full-body figures, and stylized anime characters. It supports varied facial poses, including back-facing views, and animates single or multiple characters with input masks for precise speaker designation in multi-character scenes. Our approach tackles key challenges with three innovations: (1) 3D full-attention mechanisms with a sliding window denoising strategy, enabling infinite video generation with temporal coherence and visual quality across diverse character styles; (2) a two-stage curriculum learning scheme, integrating audio for lip sync, text for expressive dynamics, and reference images for identity preservation, enabling flexible multi-modal control over long sequences; and (3) region-specific masks with adaptive loss functions to balance global textual control and local audio guidance, supporting speaker-specific animations. Efficiency is enhanced via our innovative unified step and cfg distillation techniques, achieving a 20x inference speed boost over the basemodel: generating a 10 second 540x540p video in 10 seconds or 720x720p in 30 seconds on 8 H100 GPUs, without quality loss. Evaluations on our new benchmark demonstrate MagicInfinite’s superiority in audio-lip synchronization, identity preservation, and motion naturalness across diverse scenarios. It is publicly available at https://www.hedra.com/, with examples at https://magicinfinite.github.io/.
我们推出了MagicInfinite,这是一种新型的扩散Transformer(DiT)框架,克服了传统肖像动画的限制,为不同类型的人物提供了高保真结果,包括逼真的人类、全身形象和动漫风格角色。它支持各种面部姿势,包括背向视图,并在多角色场景中通过输入蒙版进行精确指定演讲者来动画化单个或多个角色。我们的方法通过三项创新解决了关键挑战:(1)使用带有滑动窗口降噪策略的3D全注意力机制,实现无限视频生成,并在各种角色风格之间保持时间连贯性和视觉质量;(2)采用两阶段课程学习方案,整合音频进行唇部同步、文本进行表达动态和参考图像进行身份保留,实现对长序列的灵活多模式控制;(3)使用具有自适应损失函数的区域特定蒙版来平衡全局文本控制和局部音频指导,支持特定演讲者的动画。通过我们创新的统一步骤和cfg蒸馏技术,提高了效率,在基模型的基础上实现了20倍的推理速度提升:在8个H100 GPU上,可在10秒内生成一个540x540p的10秒视频或在一个小时内生成一个720x720p的视频,而不会损失质量。我们在新基准测试上的评估证明,MagicInfinite在音频与唇部的同步性、身份保留和运动自然性方面在各种场景中均表现出卓越性能。它可在https://www.hedra.com/上公开访问,示例可在https://magicinfinite.github.io/上查看。
论文及项目相关链接
PDF MagicInfinite is publicly accessible at https://www.hedra.com/. More examples are at https://magicinfinite.github.io/
Summary
提出一种名为MagicInfinite的新型扩散Transformer(DiT)框架,突破传统肖像动画局限,支持多种角色类型的高保真结果生成,包括真实人类、全身形象和动漫角色等。通过三项创新解决关键挑战:采用全注意力机制和滑动窗口降噪策略实现无限视频生成;采用两阶段课程学习方案,实现长序列的灵活多模态控制;使用区域特定掩模和自适应损失函数,支持说话人特定动画。此外,通过统一步骤和cfg蒸馏技术提高效率,在新型基准测试中表现优异。
Key Takeaways
- MagicInfinite是一种新型的扩散Transformer(DiT)框架,用于突破传统肖像动画的限制。
- 支持多种角色类型的高保真结果生成,包括真实人类、全身形象和动漫角色。
- 采用全注意力机制和滑动窗口降噪策略,实现无限视频生成。
- 两阶段课程学习方案使长序列的动画具有灵活的多模态控制。
- 通过区域特定掩模和自适应损失函数支持说话人特定的动画。
- 创新的统一步骤和cfg蒸馏技术提高了效率。
点此查看论文截图


Low-energy neutron cross-talk between organic scintillator detectors
Authors:M. Sénoville, F. Delaunay, N. L. Achouri, N. A. Orr, B. Carniol, N. de Séréville, D. Étasse, C. Fontbonne, J. -M. Fontbonne, J. Gibelin, J. Hommet, B. Laurent, X. Ledoux, F. M. Marqués, T. Martínez, M. Pârlog
A series of measurements have been performed with low-energy monoenergetic neutrons to characterise cross-talk between two organic scintillator detectors. Cross-talk time-of-flight spectra and probabilities were determined for neutron energies from 1.4 to 15.5 MeV and effective scattering angles ranging from $\sim$50{\deg} to $\sim$100{\deg}. Monte-Carlo simulations incorporating both the active and inactive materials making up the detectors showed reasonable agreement with the measurements. Whilst the time-of-flight spectra were very well reproduced, the cross-talk probabilities were only in approximate agreement with the measurements, with the most significant discrepancies ($\sim$40 %) occurring at the lowest energies. The neutron interaction processes producing cross-talk at the energies explored here are discussed in the light of these results.
采用低能单能中子进行了一系列测量,以表征两个有机闪烁体探测器之间的串音。确定了中子能量在1.4至15.5MeV范围内,有效散射角在约50°至约100°之间的串音飞行时间光谱和概率。结合了探测器的活动材料和非活动材料的蒙特卡罗模拟显示与测量结果合理一致。虽然飞行时间光谱得到了很好的再现,但串音概率仅与测量结果大致相符,在最低能量时存在最大的差异(约40%)。结合这些结果,讨论了在此探究的能量下产生串音的中子相互作用过程。
论文及项目相关链接
PDF Published in Nucl. Instr. and Meth. in Phys. Res. A
Summary
利用低能量单能中子进行了一系列测量,以表征两种有机闪烁探测器之间的串扰。确定了中子能量在1.4至15.5MeV范围内且有效散射角在约50°至约100°范围内的串扰时间飞行光谱和概率。考虑到探测器的主动和被动材料进行的蒙特卡洛模拟与测量显示合理的一致性。虽然飞行时间光谱得到了很好的再现,但串扰概率与测量的吻合程度仅为近似值,在最低能量时差异最大(约40%)。讨论了在此探索的能量下产生串扰的中子相互作用过程。
Key Takeaways
- 利用低能量单能中子进行了探测器串扰的测量。
- 测量了不同中子能量下的串扰时间飞行光谱和概率。
- 有效散射角的范围是从约50°至约100°。
- Monte-Carlo模拟与测量结果基本一致,但在串扰概率方面存在约40%的差异。
- 串扰差异在最低能量时最为显著。
- 讨论了在不同能量下产生串扰的中子相互作用过程。
点此查看论文截图