⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-12 更新
PersonaBooth: Personalized Text-to-Motion Generation
Authors:Boeun Kim, Hea In Jeong, JungHoon Sung, Yihua Cheng, Jeongmin Lee, Ju Yong Chang, Sang-Il Choi, Younggeun Choi, Saim Shin, Jungho Kim, Hyung Jin Chang
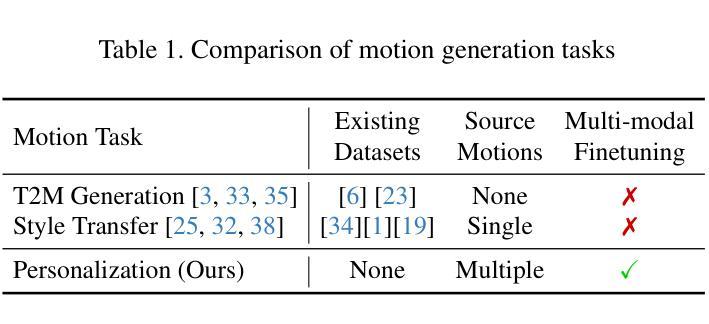
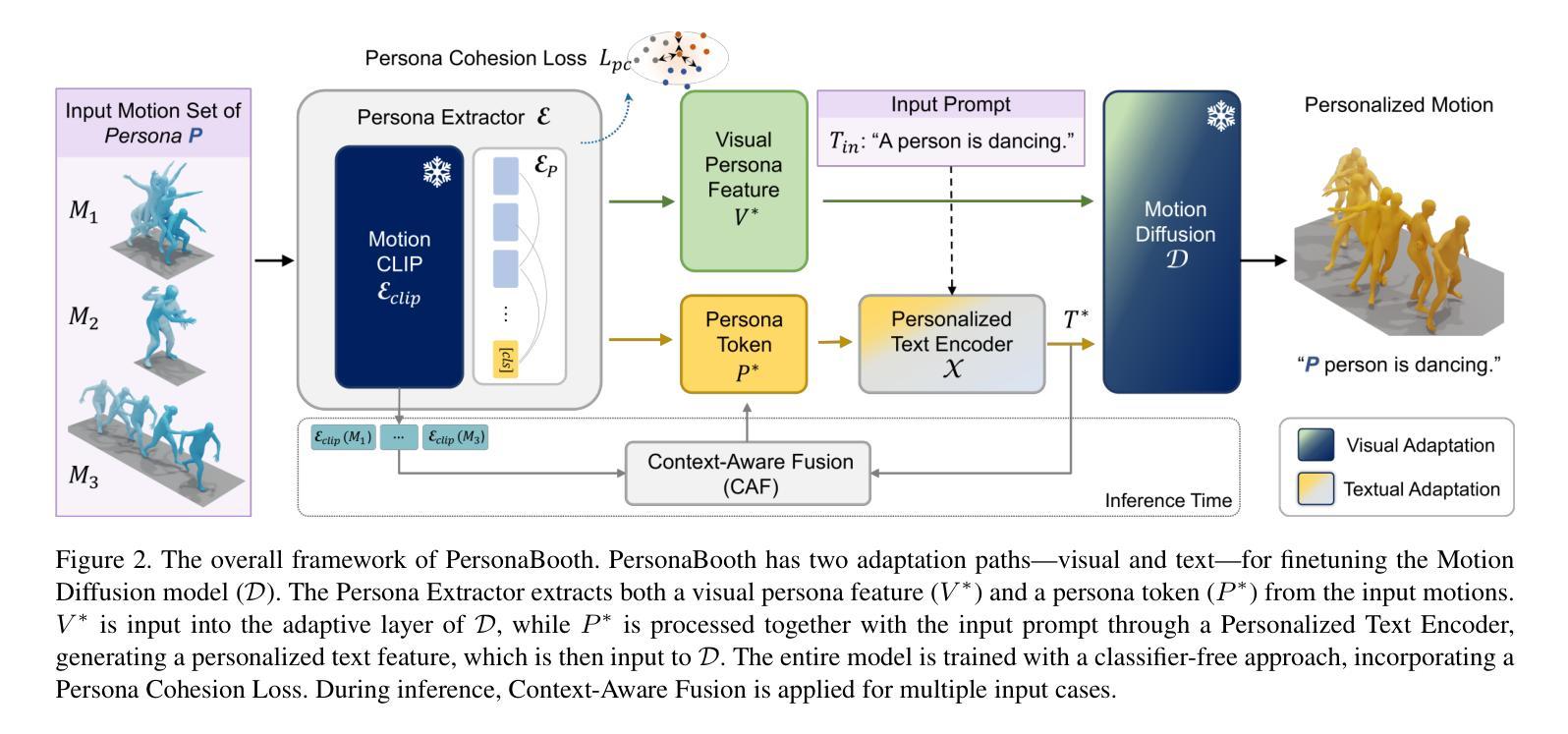
This paper introduces Motion Personalization, a new task that generates personalized motions aligned with text descriptions using several basic motions containing Persona. To support this novel task, we introduce a new large-scale motion dataset called PerMo (PersonaMotion), which captures the unique personas of multiple actors. We also propose a multi-modal finetuning method of a pretrained motion diffusion model called PersonaBooth. PersonaBooth addresses two main challenges: i) A significant distribution gap between the persona-focused PerMo dataset and the pretraining datasets, which lack persona-specific data, and ii) the difficulty of capturing a consistent persona from the motions vary in content (action type). To tackle the dataset distribution gap, we introduce a persona token to accept new persona features and perform multi-modal adaptation for both text and visuals during finetuning. To capture a consistent persona, we incorporate a contrastive learning technique to enhance intra-cohesion among samples with the same persona. Furthermore, we introduce a context-aware fusion mechanism to maximize the integration of persona cues from multiple input motions. PersonaBooth outperforms state-of-the-art motion style transfer methods, establishing a new benchmark for motion personalization.
本文介绍了动作个性化这一新任务,该任务利用包含个性化特征的几个基本动作,根据文本描述生成个性化的动作。为了支持这项新任务,我们引入了一个名为PerMo(PersonaMotion)的大规模动作数据集,它捕捉了多个角色的独特个性。我们还提出了一种预训练运动扩散模型的多模态微调方法,该方法被称为PersonaBooth。PersonaBooth解决了两个主要挑战:一是针对以角色为重点的PerMo数据集与缺乏个性化数据的预训练数据集之间存在的巨大分布差异;二是从内容各异的动作中捕捉一致性角色的难度。为了解决数据集分布差异问题,我们引入了一个角色令牌来接受新的角色特征,并在微调过程中执行文本和视觉的多模态适应。为了捕捉一致的角色,我们采用对比学习技术,增强同一角色样本之间的内部凝聚力。此外,我们还引入了一种上下文感知融合机制,以最大限度地整合来自多个输入动作的个性化线索。PersonaBooth在动作风格转换方法上表现卓越,为动作个性化设定了新的基准。
论文及项目相关链接
Summary
该论文提出了一项新的任务——运动个性化,可以根据文本描述生成个性化的动作。为此,论文引入了一个名为PerMo的大型运动数据集,用于捕捉多个角色的独特个性。同时,论文提出了一种预训练运动扩散模型的微调方法,名为PersonaBooth。该方法解决了两个主要挑战:一是缺乏个性化数据的PerMo数据集与预训练数据集之间的分布差距;二是从内容多变的运动中捕捉一致个性的难度。为了应对这些挑战,论文引入了个性化令牌进行多模态适应,并采用对比学习技术增强同一角色的样本内凝聚力。此外,论文还提出了一种上下文感知融合机制,以最大化从多个输入动作中获取的个性化线索的融合。这些方法提高了运动风格转换的性能,为运动个性化设定了新的基准。
Key Takeaways
- 引入了新的任务——运动个性化,旨在根据文本描述生成个性化的动作。
- 介绍了PerMo数据集,用于捕捉角色的独特个性。
- 提出了预训练运动扩散模型的微调方法——PersonaBooth。
- PersonaBooth解决了数据分布差距和从多变运动中捕捉一致个性的挑战。
- 通过引入个性化令牌进行多模态适应和对比学习技术增强样本内凝聚力。
- 采用了上下文感知融合机制以最大化个性化线索的融合。
点此查看论文截图

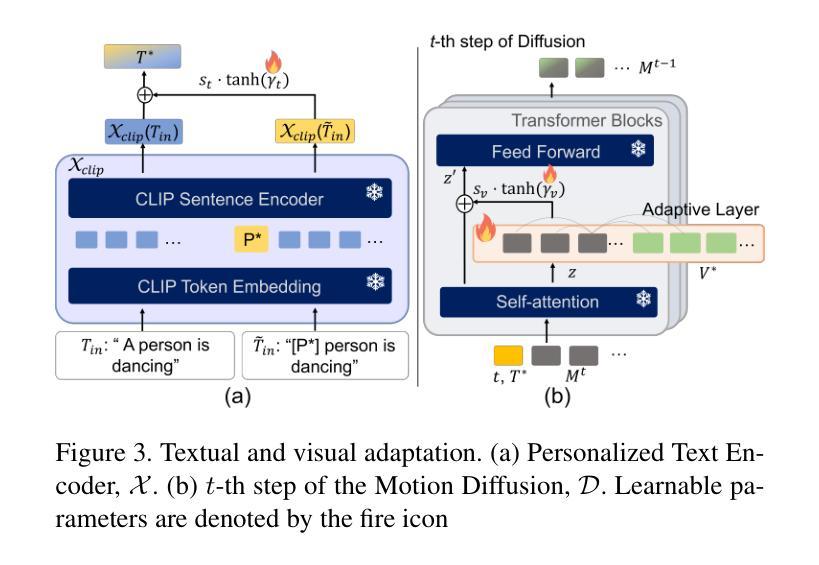
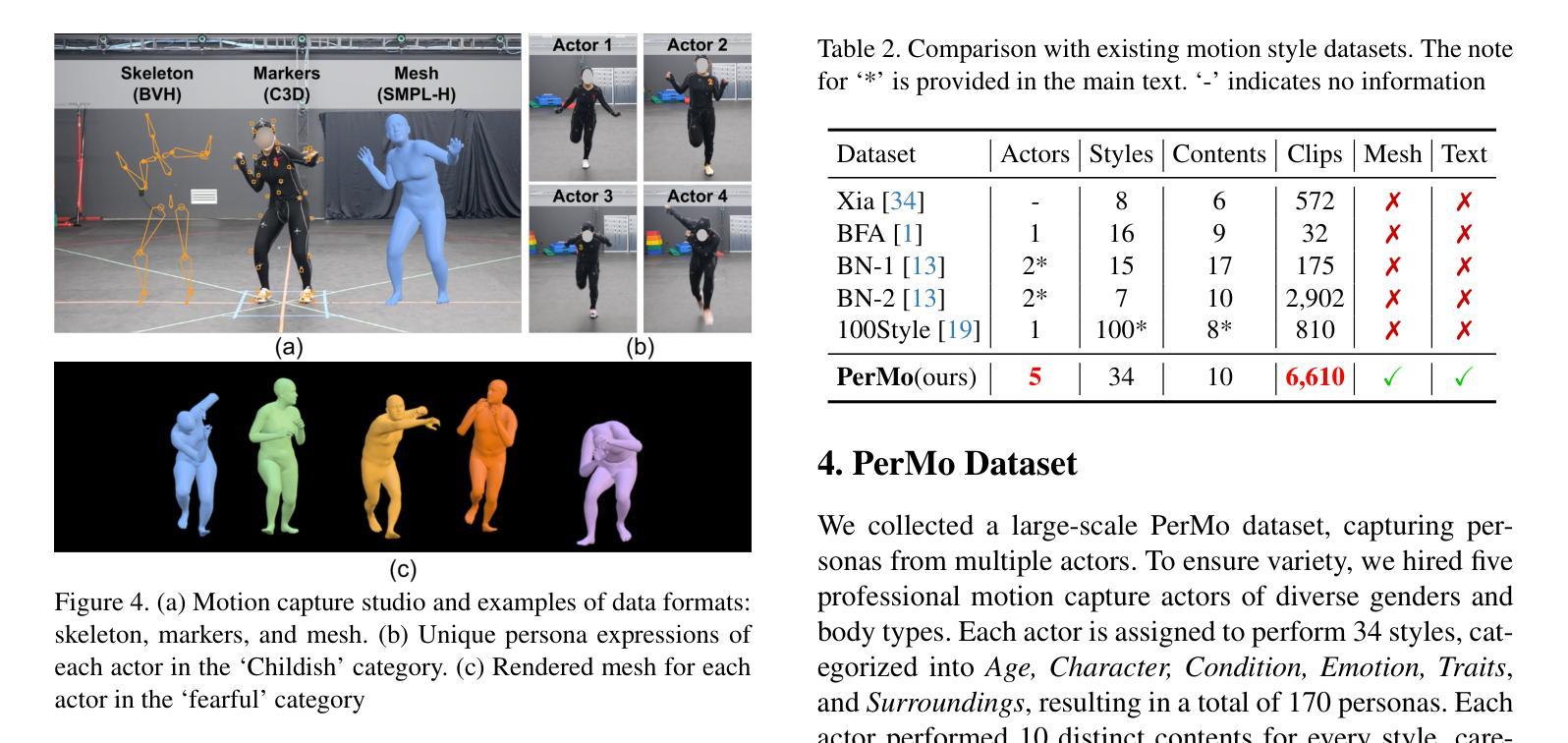
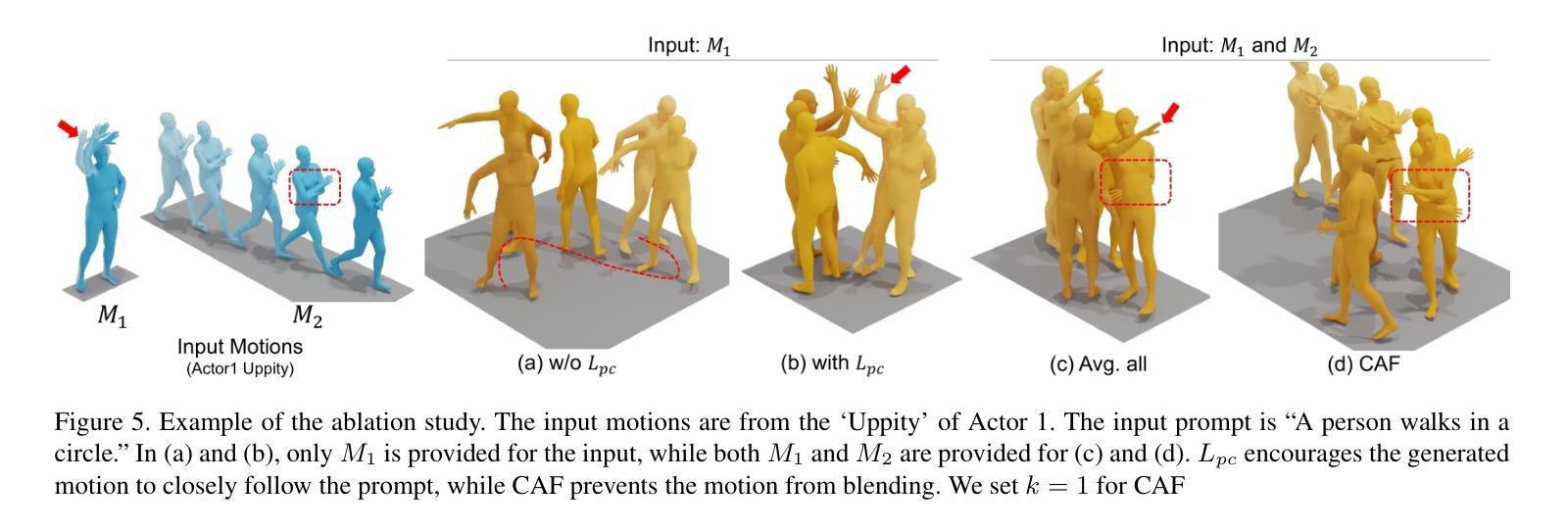
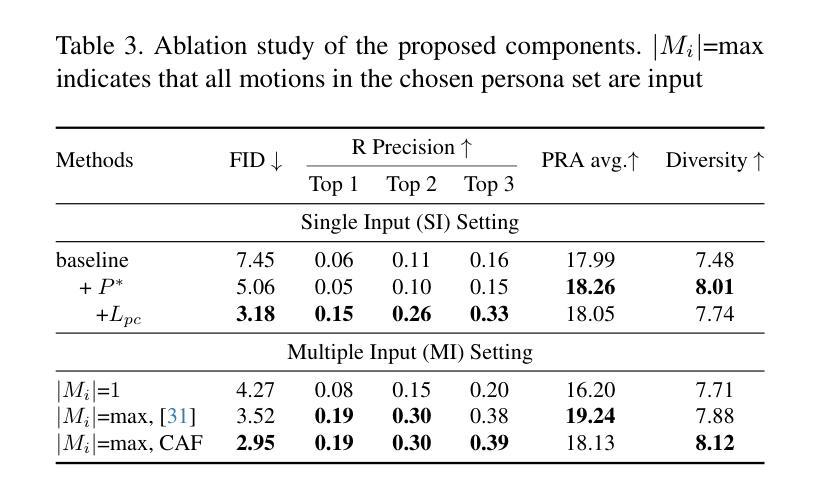
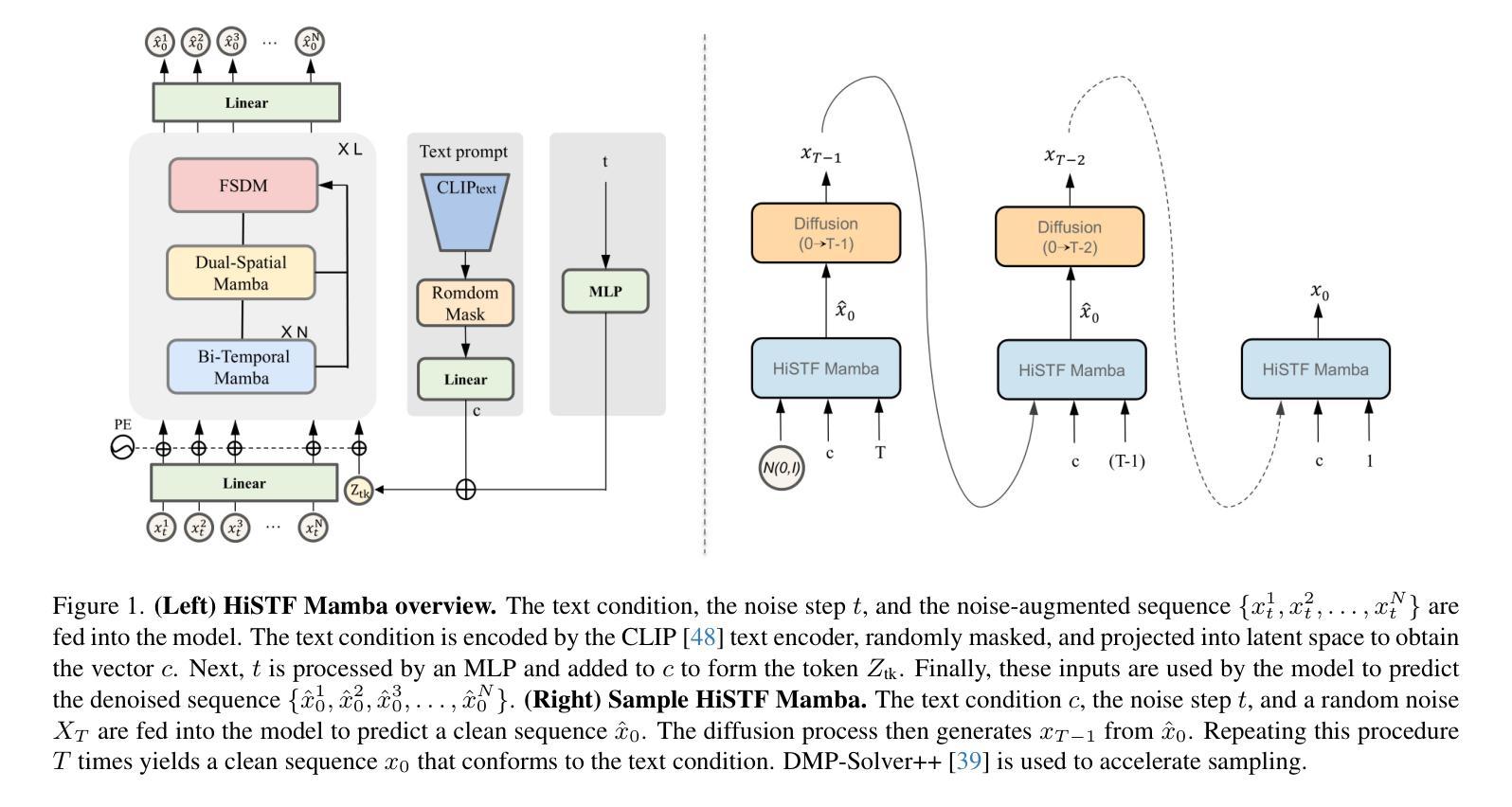
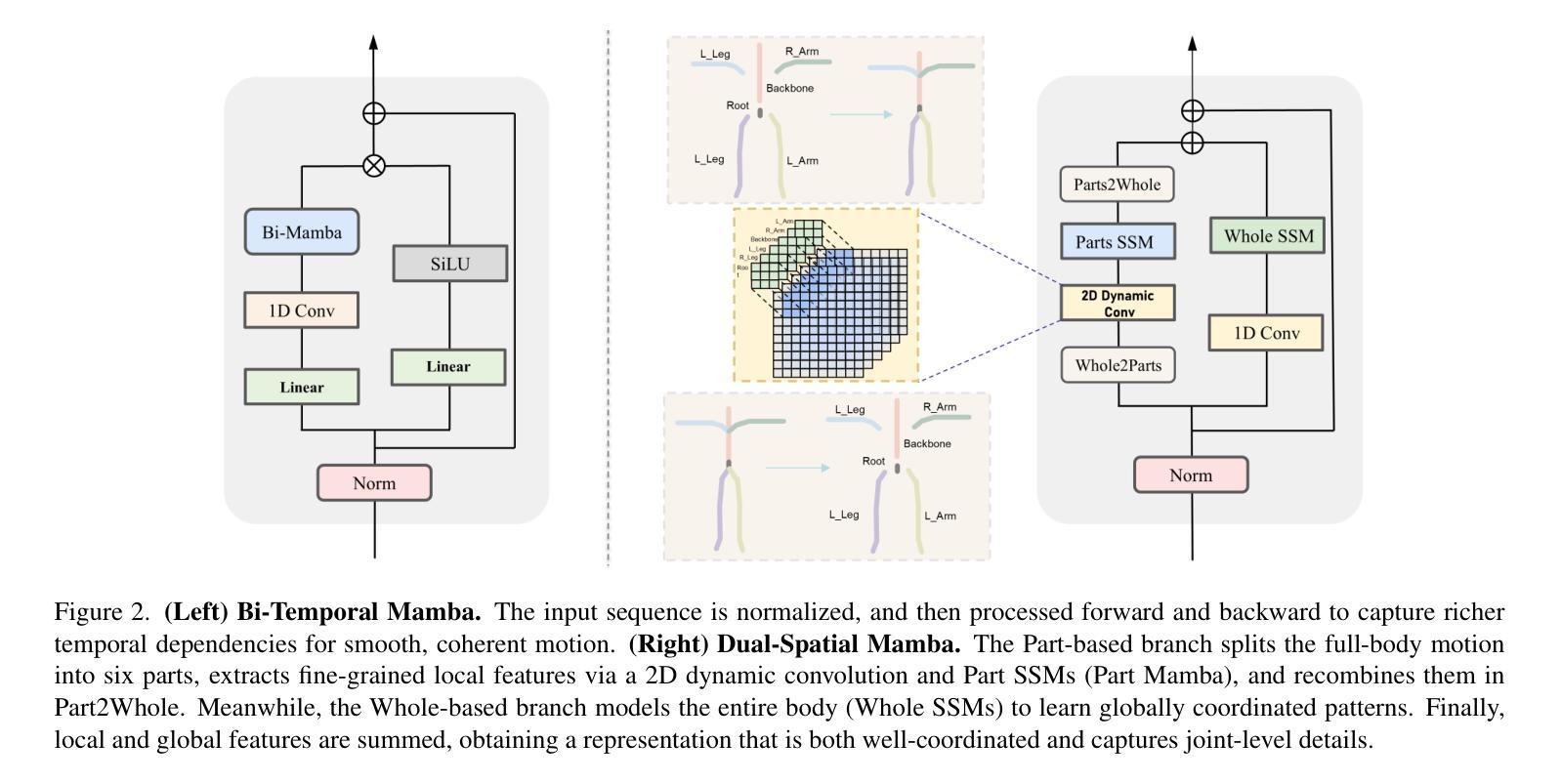
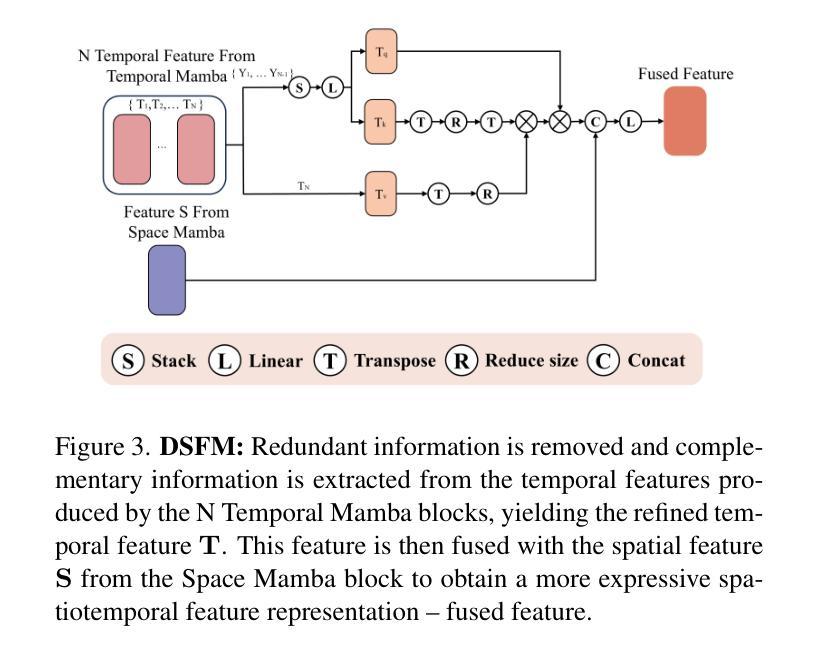
HiSTF Mamba: Hierarchical Spatiotemporal Fusion with Multi-Granular Body-Spatial Modeling for High-Fidelity Text-to-Motion Generation
Authors:Xingzu Zhan, Chen Xie, Haoran Sun, Xiaochun Mai
Text-to-motion generation is a rapidly growing field at the nexus of multimodal learning and computer graphics, promising flexible and cost-effective applications in gaming, animation, robotics, and virtual reality. Existing approaches often rely on simple spatiotemporal stacking, which introduces feature redundancy, while subtle joint-level details remain overlooked from a spatial perspective. To this end, we propose a novel HiSTF Mamba framework. The framework is composed of three key modules: Dual-Spatial Mamba, Bi-Temporal Mamba, and Dynamic Spatiotemporal Fusion Module (DSFM). Dual-Spatial Mamba incorporates ``Part-based + Whole-based’’ parallel modeling to represent both whole-body coordination and fine-grained joint dynamics. Bi-Temporal Mamba adopts a bidirectional scanning strategy, effectively encoding short-term motion details and long-term dependencies. DSFM further performs redundancy removal and extraction of complementary information for temporal features, then fuses them with spatial features, yielding an expressive spatio-temporal representation. Experimental results on the HumanML3D dataset demonstrate that HiSTF Mamba achieves state-of-the-art performance across multiple metrics. In particular, it reduces the FID score from 0.283 to 0.189, a relative decrease of nearly 30%. These findings validate the effectiveness of HiSTF Mamba in achieving high fidelity and strong semantic alignment in text-to-motion generation.
文本到动作生成是一个正在快速发展的领域,位于多模态学习和计算机图形学的交汇点,在游戏、动画、机器人和虚拟现实等领域有着灵活和成本效益高的应用前景。现有方法通常依赖于简单的时空堆叠,这引入了特征冗余,而从空间角度忽略细微的关节级细节。为此,我们提出了全新的HiSTF Mamba框架。该框架由三个关键模块组成:双空间Mamba、双向时间Mamba和动态时空融合模块(DSFM)。双空间Mamba结合了“基于部分+基于整体”的并行建模,以表示整体身体协调和精细的关节动力学。双向时间Mamba采用双向扫描策略,有效地编码短期运动细节和长期依赖关系。DSFM进一步去除冗余信息并提取时间特征的互补信息,然后将其与空间特征融合,产生富有表现力的时空表示。在人类ML3D数据集上的实验结果表明,HiSTF Mamba在多个指标上达到了最先进的性能。特别地,它将FID得分从0.283降低到0.189,相对降低了近30%。这些发现验证了HiSTF Mamba在实现高保真和强烈语义对齐的文本到动作生成中的有效性。
论文及项目相关链接
PDF 11pages,3figures,
Summary
文本转动态生成是一个涉及多模态学习和计算机图形学的快速发展的领域,在游戏、动画、机器人和虚拟现实中有广泛的应用前景。现有方法常依赖于简单的时空堆叠,导致特征冗余,忽略细微的关节级别细节。本文提出了一种新型的HiSTF Mamba框架,包含三个关键模块:Dual-Spatial Mamba、Bi-Temporal Mamba和动态时空融合模块(DSFM)。该框架能更有效地表示整体动作协调与精细关节动态,编码短期与长期的运动细节依赖关系,并融合时空特征,从而生成更真实、更精细的动作。在HumanML3D数据集上的实验结果表明,HiSTF Mamba在多个指标上达到了最佳性能,特别是在FID得分上从0.283降低到0.189,相对降低了近30%,验证了其在文本转动态生成中的高保真度和强语义对齐能力。
Key Takeaways
- 文本转动态生成是多媒体学习和计算机图形领域中的前沿方向,其在游戏、动画、机器人和虚拟现实中具有广泛的应用潜力。
- 现有方法主要依赖简单的时空堆叠,导致特征冗余和关节级别细节的忽略。
- HiSTF Mamba框架包含三个关键模块以改进现有方法的不足:Dual-Spatial Mamba模块实现整体与精细动作的并行建模,Bi-Temporal Mamba模块采用双向扫描策略以编码长期和短期的运动细节,而DSFM模块则负责去除冗余信息并提取互补信息以融合时空特征。
- HiSTF Mamba框架能有效提升文本转动态生成的性能,在HumanML3D数据集上的实验结果显示其在多个指标上达到了最佳效果。
- 尤其是FID得分的显著下降,从0.283降至0.189,验证了HiSTF Mamba在高保真度和强语义对齐方面的优势。
- 该框架为文本转动态生成领域提供了一种新的解决方案,有望推动该领域的进一步发展。
点此查看论文截图

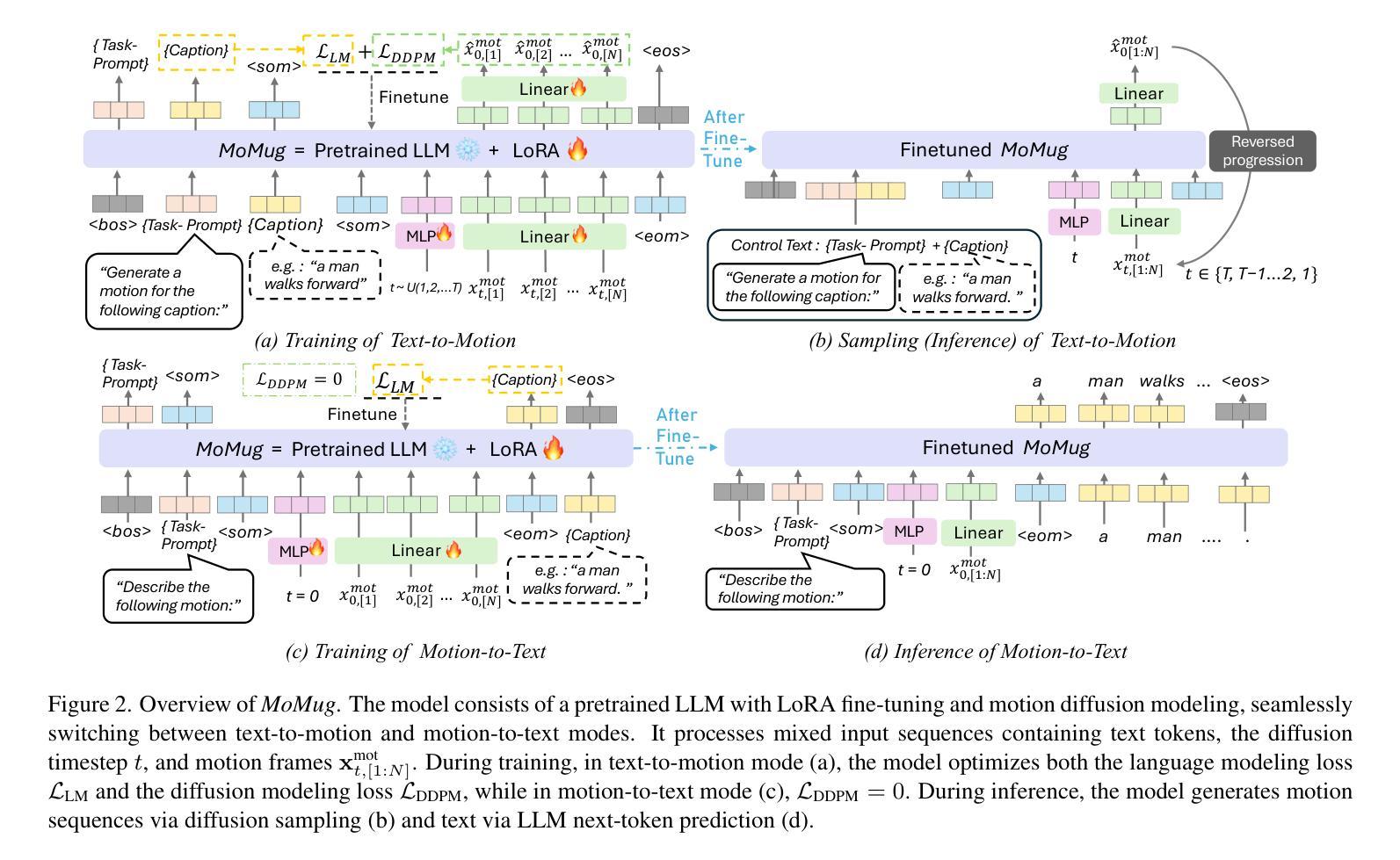
Unlocking Pretrained LLMs for Motion-Related Multimodal Generation: A Fine-Tuning Approach to Unify Diffusion and Next-Token Prediction
Authors:Shinichi Tanaka, Zhao Wang, Yoichi Kato, Jun Ohya
In this paper, we propose a unified framework that leverages a single pretrained LLM for Motion-related Multimodal Generation, referred to as MoMug. MoMug integrates diffusion-based continuous motion generation with the model’s inherent autoregressive discrete text prediction capabilities by fine-tuning a pretrained LLM. This enables seamless switching between continuous motion output and discrete text token prediction within a single model architecture, effectively combining the strengths of both diffusion- and LLM-based approaches. Experimental results show that, compared to the most recent LLM-based baseline, MoMug improves FID by 38% and mean accuracy across seven metrics by 16.61% on the text-to-motion task. Additionally, it improves mean accuracy across eight metrics by 8.44% on the text-to-motion task. To the best of our knowledge, this is the first approach to integrate diffusion- and LLM-based generation within a single model for motion-related multimodal tasks while maintaining low training costs. This establishes a foundation for future advancements in motion-related generation, paving the way for high-quality yet cost-efficient motion synthesis.
本文提出了一个统一的框架,利用单个预训练的大型语言模型(LLM)进行与运动相关的多模式生成,称为MoMug。MoMug通过微调预训练的大型语言模型,将基于扩散的连续运动生成与模型固有的自回归离散文本预测能力相结合。这使得在一个模型架构内能够无缝切换连续运动输出和离散文本令牌预测,有效地结合了扩散和基于大型语言模型的方法的优势。实验结果表明,与最新的大型语言模型基线相比,MoMug在文本到运动的任务上,FID提高了38%,七个指标的平均准确度提高了16.61%。此外,它在八个指标的平均准确度上提高了8.44%。据我们所知,这是第一个将扩散和基于大型语言模型的生成方法集成到一个单一模型中,用于运动相关的多模式任务,同时保持较低的训练成本。这为运动相关生成的未来发展奠定了基础,为高质量且成本效益高的运动合成铺平了道路。
论文及项目相关链接
Summary
本文提出一个统一框架,利用单一预训练LLM进行运动相关多模态生成,称为MoMug。MoMug通过微调预训练LLM,将基于扩散的连续运动生成与模型固有的自回归离散文本预测能力相结合。这能够在单个模型架构内实现连续运动输出和离散文本令牌预测之间的无缝切换,有效结合了扩散和LLM方法的优点。实验结果表明,与最新的LLM基线相比,MoMug在文本到运动任务上改进了38%的FID和16.61%的七个指标的平均准确率。此外,它在八个指标的平均准确率上提高了8.44%。据我们所知,这是第一个在单一模型中整合扩散和LLM生成方法用于运动相关多模态任务的方法,同时保持较低的训练成本。这为运动相关生成领域的未来发展奠定了基础,为高质量且成本效益高的运动合成铺平了道路。
Key Takeaways
- 提出了一个名为MoMug的统一框架,利用预训练的LLM进行运动相关的多模态生成。
- MoMug结合了基于扩散的连续运动生成和LLM的自回归离散文本预测能力。
- MoMug能在单个模型内实现连续运动输出和离散文本预测之间的无缝切换。
- 实验结果表明MoMug在文本到运动任务上显著优于现有方法,改进了FID和平均准确率。
- MoMug是首个将扩散和LLM生成方法整合在单一模型中的方法,用于运动相关多模态任务。
- MoMug具有较低的训练成本,为运动相关生成领域的发展奠定了基础。
点此查看论文截图