⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-12 更新
Anatomy-Aware Conditional Image-Text Retrieval
Authors:Meng Zheng, Jiajin Zhang, Benjamin Planche, Zhongpai Gao, Terrence Chen, Ziyan Wu
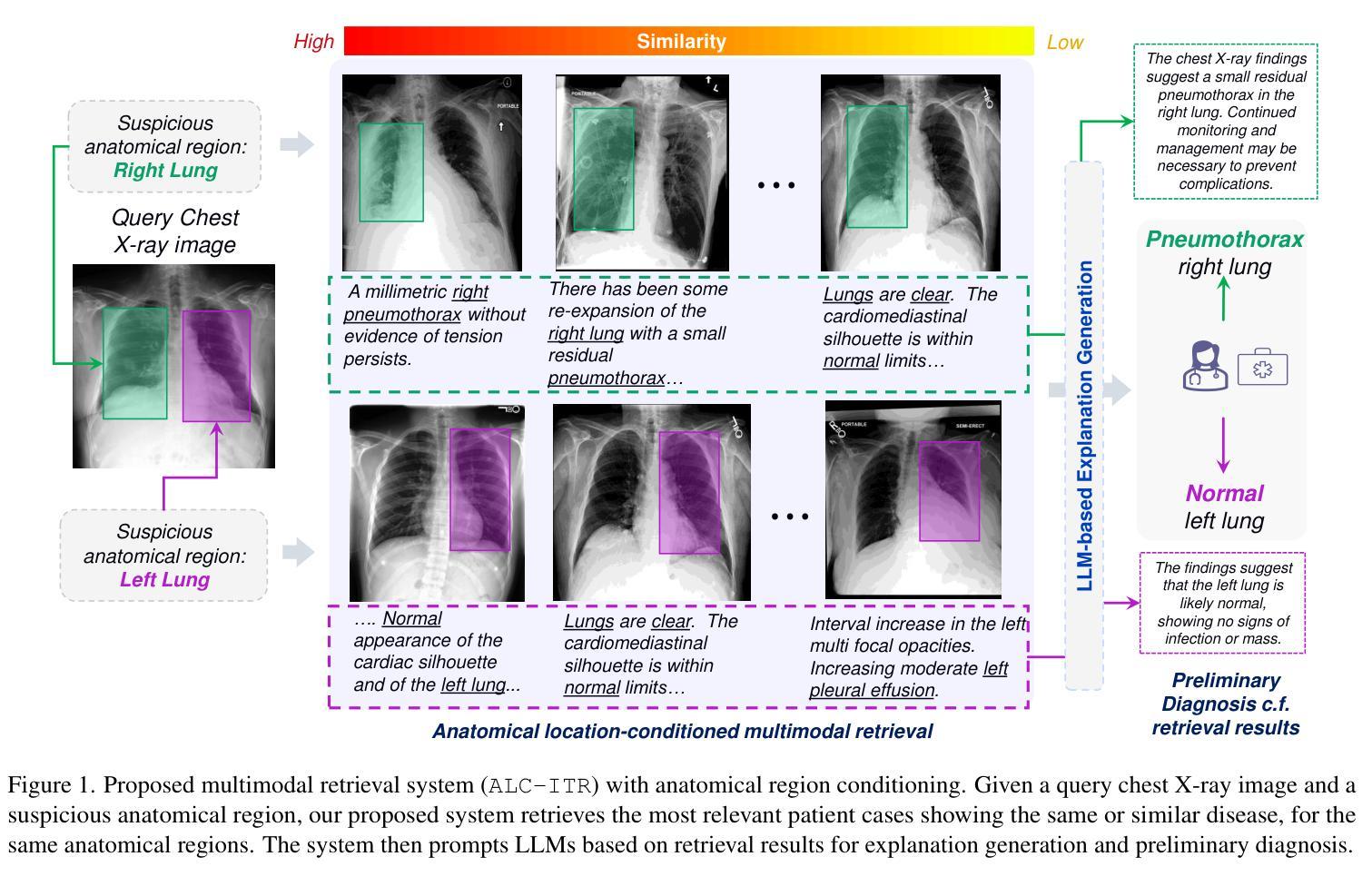
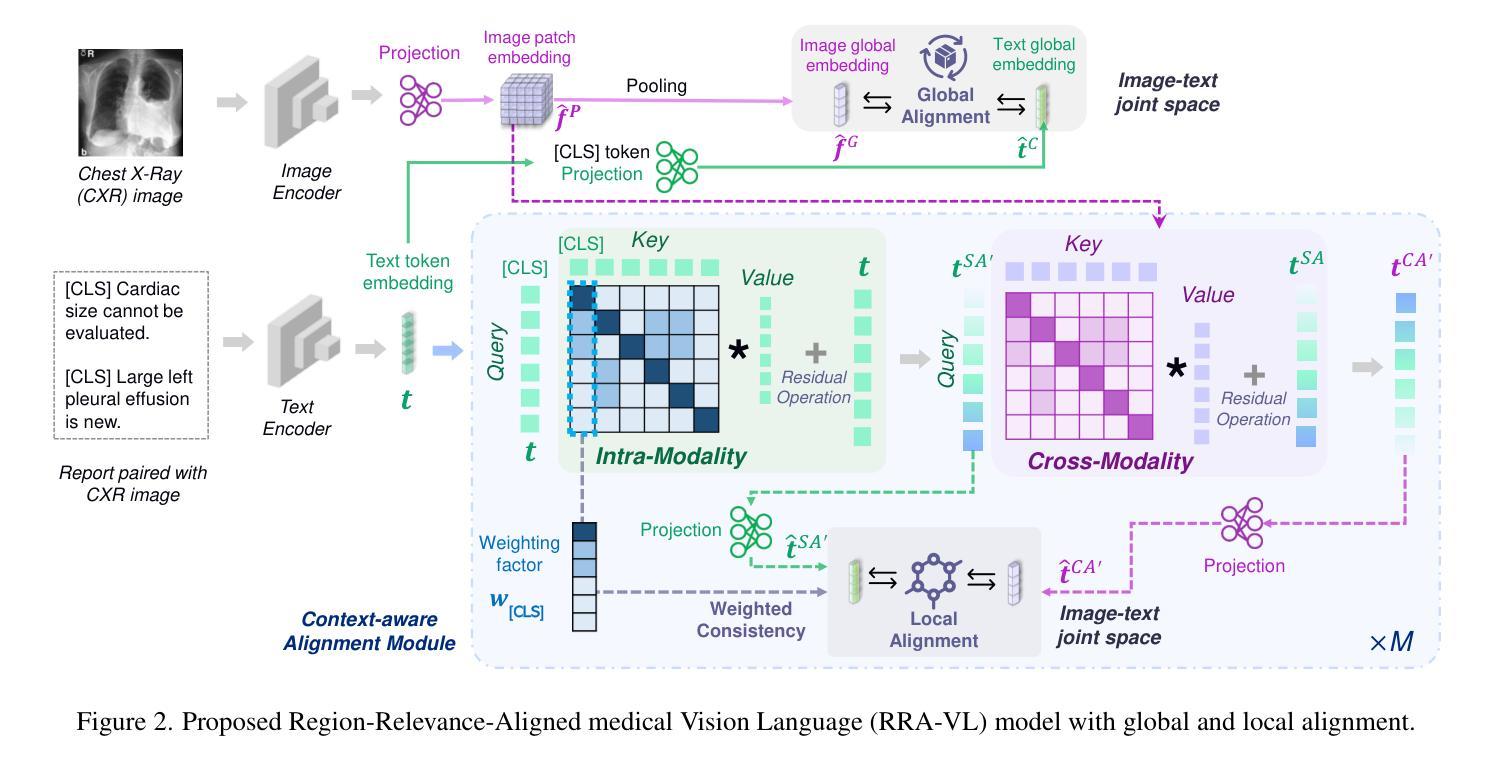
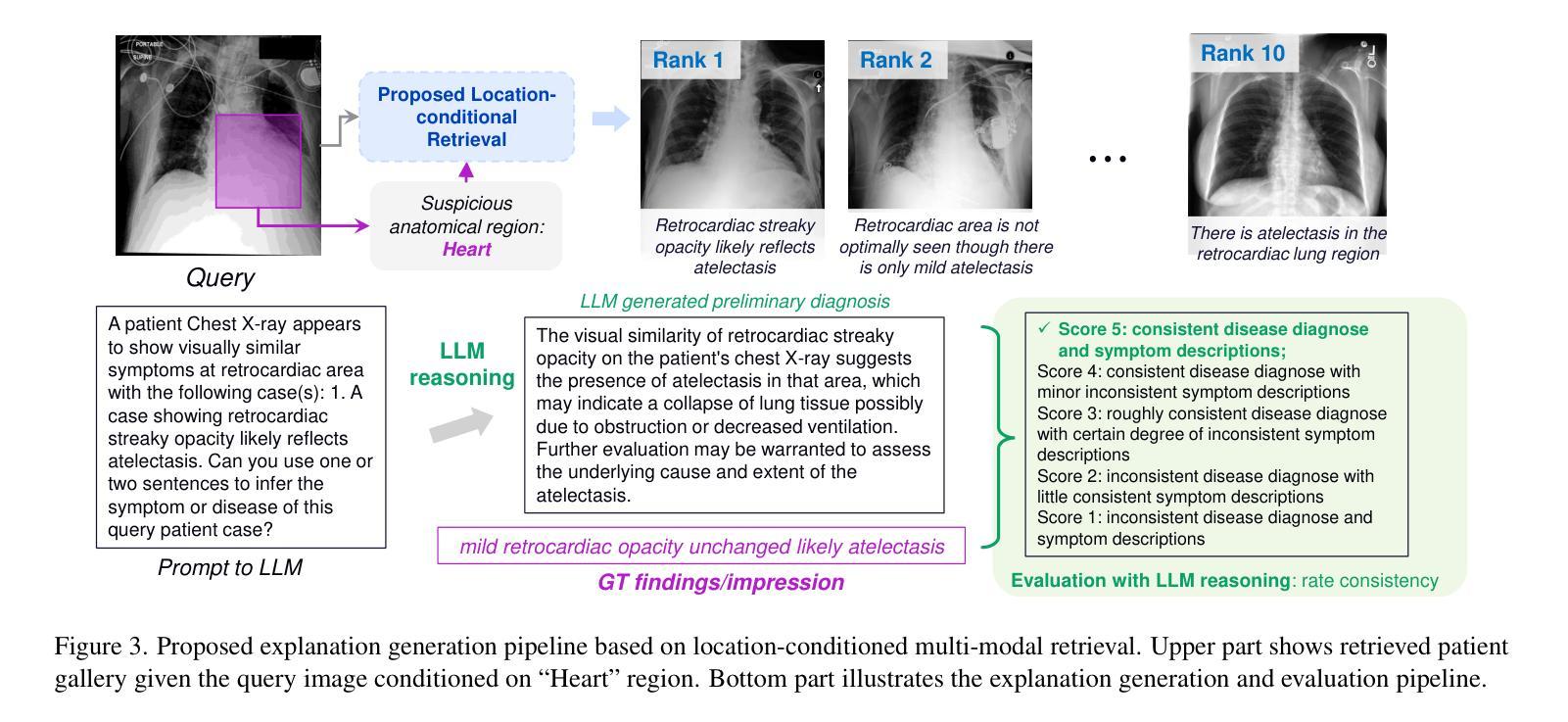
Image-Text Retrieval (ITR) finds broad applications in healthcare, aiding clinicians and radiologists by automatically retrieving relevant patient cases in the database given the query image and/or report, for more efficient clinical diagnosis and treatment, especially for rare diseases. However conventional ITR systems typically only rely on global image or text representations for measuring patient image/report similarities, which overlook local distinctiveness across patient cases. This often results in suboptimal retrieval performance. In this paper, we propose an Anatomical Location-Conditioned Image-Text Retrieval (ALC-ITR) framework, which, given a query image and the associated suspicious anatomical region(s), aims to retrieve similar patient cases exhibiting the same disease or symptoms in the same anatomical region. To perform location-conditioned multimodal retrieval, we learn a medical Relevance-Region-Aligned Vision Language (RRA-VL) model with semantic global-level and region-/word-level alignment to produce generalizable, well-aligned multi-modal representations. Additionally, we perform location-conditioned contrastive learning to further utilize cross-pair region-level contrastiveness for improved multi-modal retrieval. We show that our proposed RRA-VL achieves state-of-the-art localization performance in phase-grounding tasks, and satisfying multi-modal retrieval performance with or without location conditioning. Finally, we thoroughly investigate the generalizability and explainability of our proposed ALC-ITR system in providing explanations and preliminary diagnosis reports given retrieved patient cases (conditioned on anatomical regions), with proper off-the-shelf LLM prompts.
图像文本检索(ITR)在医疗领域有着广泛的应用,它通过自动检索数据库中的相关病例,帮助临床医生和放射科医生更高效地做出诊断和治疗,尤其是针对罕见疾病。然而,传统的ITR系统通常只依赖于全局图像或文本表示来度量患者图像/报告的相似性,忽略了不同患者病例之间的局部差异。这往往导致检索性能不佳。在本文中,我们提出了一种基于解剖部位条件的图像文本检索(ALC-ITR)框架。给定查询图像和相关的可疑解剖区域,该框架旨在检索在同一解剖区域表现出相同疾病或症状的相似患者病例。为了执行基于位置的多媒体检索,我们学习了一种医学相关区域对齐的视觉语言(RRA-VL)模型,该模型具有语义全局和区域/单词级别的对齐功能,以产生可推广的、对齐良好的多模态表示。此外,我们执行基于位置的对比学习,以进一步利用跨对区域级别的对比性,改进多模态检索。我们显示,我们提出的RRA-VL在相位定位任务中实现了一流的定位性能,并在有条件和无条件下均取得了令人满意的多模态检索性能。最后,我们全面调查了所提出的ALC-ITR系统在提供解释和初步诊断报告方面的通用性和可解释性,根据检索到的病例(以解剖部位为条件)进行适当的现成大型语言模型提示。
论文及项目相关链接
PDF 16 pages, 10 figures
Summary
本文介绍了一种基于解剖学定位的图文检索(ALC-ITR)框架,该框架应用于医疗领域,旨在提高图像和报告的检索性能。该框架通过考虑查询图像和相关的可疑解剖学区域,旨在检索在同一解剖学区域中表现出相同疾病或症状的相似患者病例。文章提出了一种医学相关区域对齐的视觉语言模型(RRA-VL),实现了全局和区域/词级别的语义对齐,并利用位置条件对比学习进一步提高跨模态检索性能。实验表明,RRA-VL模型在定位任务中取得了最先进的性能,并在有条件和无条件下的多模态检索中均表现出良好的性能。此外,该框架还能通过检索到的病例(以解剖学区域为条件)提供解释和初步诊断报告,具有良好的通用性和可解释性。
Key Takeaways
- 图像文本检索(ITR)在医疗领域具有广泛应用价值,如辅助医生诊断罕见疾病。
- 传统ITR系统依赖全局图像或文本表示来测量相似性,忽略了病例之间的局部差异,导致检索性能不佳。
- 提出的ALC-ITR框架旨在通过考虑查询图像和相关的解剖学区域来提高检索性能。
- RRA-VL模型实现了全局和区域/词级别的语义对齐,提高了多模态检索的通用性和对齐性。
- 位置条件对比学习用于提高跨模态检索性能。
- RRA-VL模型在定位任务中取得了最先进的性能。
点此查看论文截图

Distilling Knowledge into Quantum Vision Transformers for Biomedical Image Classification
Authors:Thomas Boucher, Evangelos B. Mazomenos
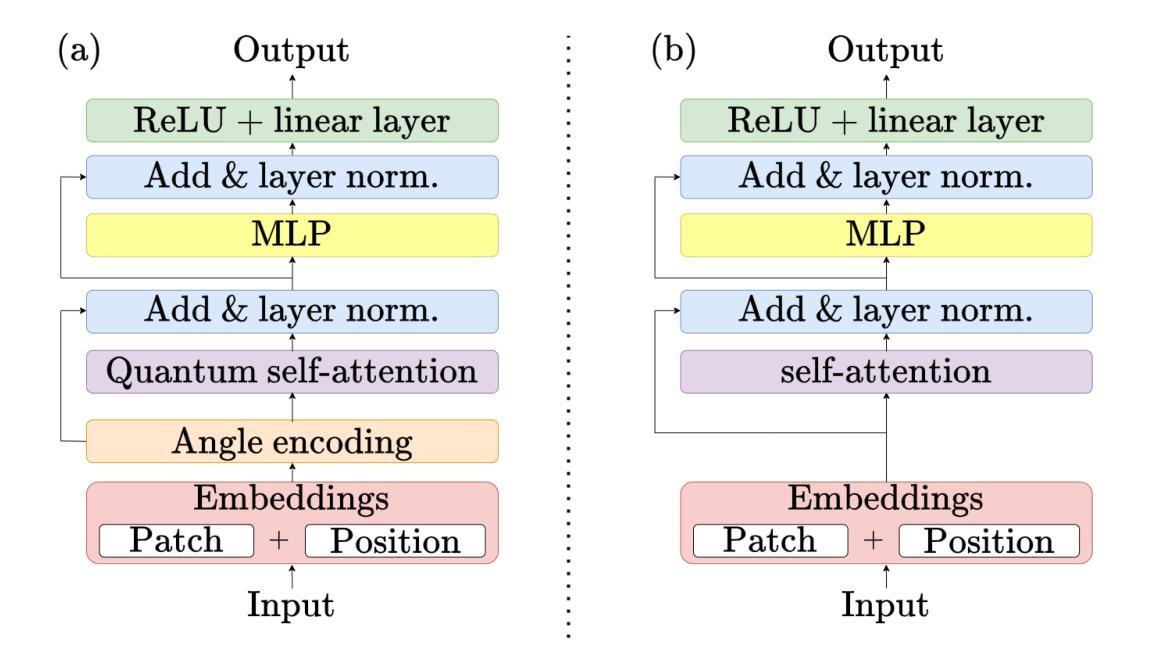
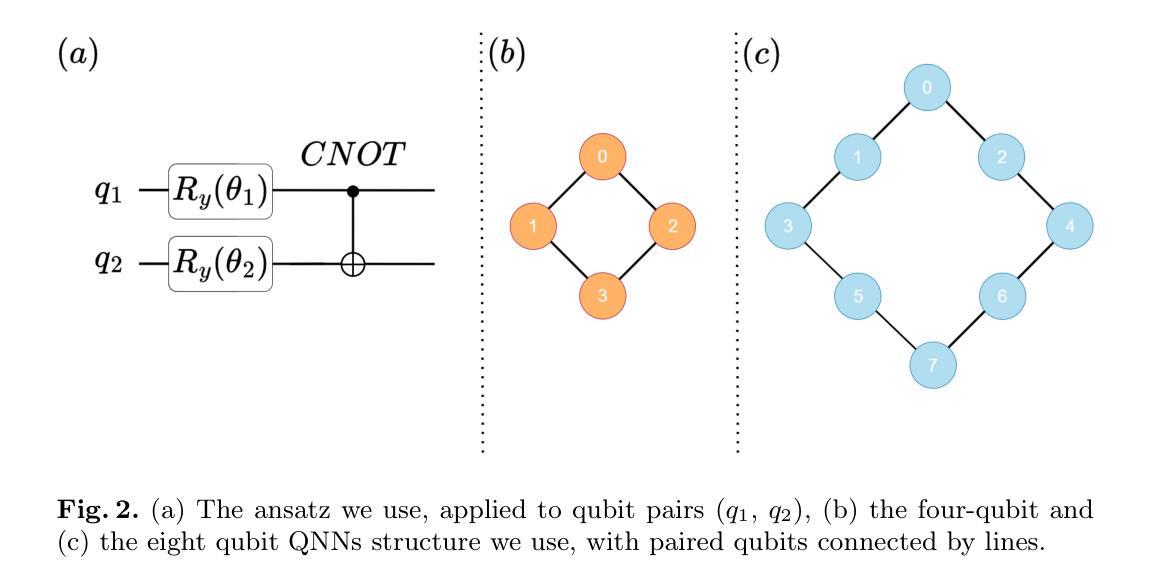
Quantum vision transformers (QViTs) build on vision transformers (ViTs) by replacing linear layers within the self-attention mechanism with parameterised quantum neural networks (QNNs), harnessing quantum mechanical properties to improve feature representation. This hybrid approach aims to achieve superior performance, with significantly reduced model complexity as a result of the enriched feature representation, requiring fewer parameters. This paper proposes a novel QViT model for biomedical image classification and investigates its performance against comparable ViTs across eight diverse datasets, encompassing various modalities and classification tasks. We assess models trained from scratch and those pre-trained using knowledge distillation (KD) from high-quality teacher models. Our findings demonstrate that QViTs outperform comparable ViTs with average ROC AUC (0.863 vs 0.846) and accuracy (0.710 vs 0.687) when trained from scratch, and even compete with state-of-the-art classical models in multiple tasks, whilst being significantly more efficient (89% reduction in GFLOPs and 99.99% in parameter number). Additionally, we find that QViTs and ViTs respond equally well to KD, with QViT pre-training performance scaling with model complexity. This is the first investigation into the efficacy of deploying QViTs with KD for computer-aided diagnosis. Our results highlight the enormous potential of quantum machine learning (QML) in biomedical image analysis.
量子视觉转换器(QViTs)以视觉转换器(ViTs)为基础,将自注意力机制中的线性层替换为参数化量子神经网络(QNNs),利用量子机械属性改进特征表示。这种混合方法旨在实现卓越的性能,由于特征表示的丰富性,模型复杂度显著降低,减少了所需的参数数量。本文提出了一种新型的QViT模型,用于生物医学图像分类,并在八个不同的数据集上与类似的ViTs比较其性能,这些数据集涵盖多种模态和分类任务。我们评估了从头开始训练以及使用来自高质量教师模型的蒸馏知识(KD)进行预训练的模型。我们的研究结果表明,从头开始训练的QViTs在平均ROC AUC(0.863 vs 0.846)和准确度(0.710 vs 0.687)上优于类似的ViTs,并且在多个任务中甚至与最先进的经典模型竞争,同时效率更高(GFLOPs减少89%,参数数量减少99.99%)。此外,我们发现QViTs和ViTs对KD的响应同样良好,QViT的预训练性能随模型复杂度的增加而提升。这是首次调查使用KD部署QViT在计算机辅助诊断中的有效性。我们的结果突显了量子机器学习(QML)在生物医学图像分析中的巨大潜力。
论文及项目相关链接
PDF Submitted for MICCAI 2025
摘要
本文提出了量子视觉变压器(QViT)模型,该模型基于视觉变压器(ViT),通过将自注意力机制中的线性层替换为参数化量子神经网络(QNN),利用量子机械特性改进特征表示。这一混合方法旨在实现卓越的性能,由于特征表示的丰富性,模型复杂度显著降低,参数更少。该研究在生物医学图像分类领域提出了新的QViT模型,并评估其与同类ViT在八个不同数据集上的性能。结果显示,从头开始训练的QViT相较于ViT在ROC AUC(0.863 vs 0.846)和准确度(0.710 vs 0.687)上表现更优,并在多个任务中与最先进的经典模型竞争,同时效率更高(GFLOPs减少89%,参数数量减少99.99%)。此外,研究发现QViT和ViT对蒸馏(KD)的响应同样良好,QViT的预训练性能随模型复杂度而提升。这是首次探索将QViT与KD结合用于计算机辅助诊断的有效性。研究结果突显了量子机器学习(QML)在生物医学图像分析中的巨大潜力。
关键见解
- 量子视觉变压器(QViT)结合了量子神经网络和视觉变压器的优点,利用量子机械特性提升特征表示。
- QViT模型在生物医学图像分类上表现优越,相较于传统ViT模型,其ROC AUC和准确度均有提升。
- QViT模型效率更高,显著减少了计算量和参数数量。
- QViT和ViT对蒸馏(KD)策略反应良好,预训练性能随模型复杂度提升。
- QViT与KD结合的策略在计算机辅助诊断中具有巨大潜力。
- 这是首次将QViT与KD结合应用于生物医学图像分析的研究。
点此查看论文截图

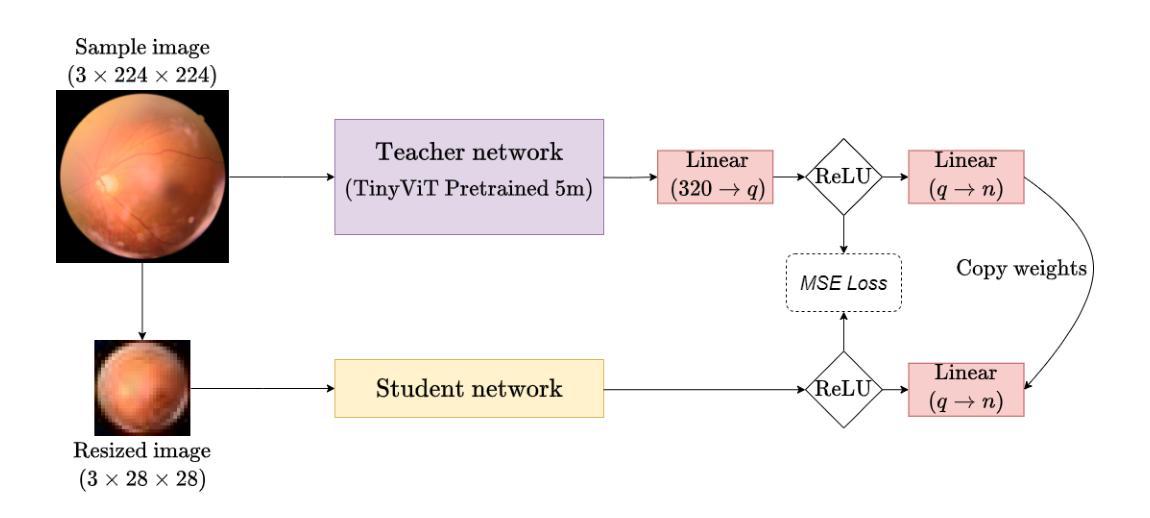
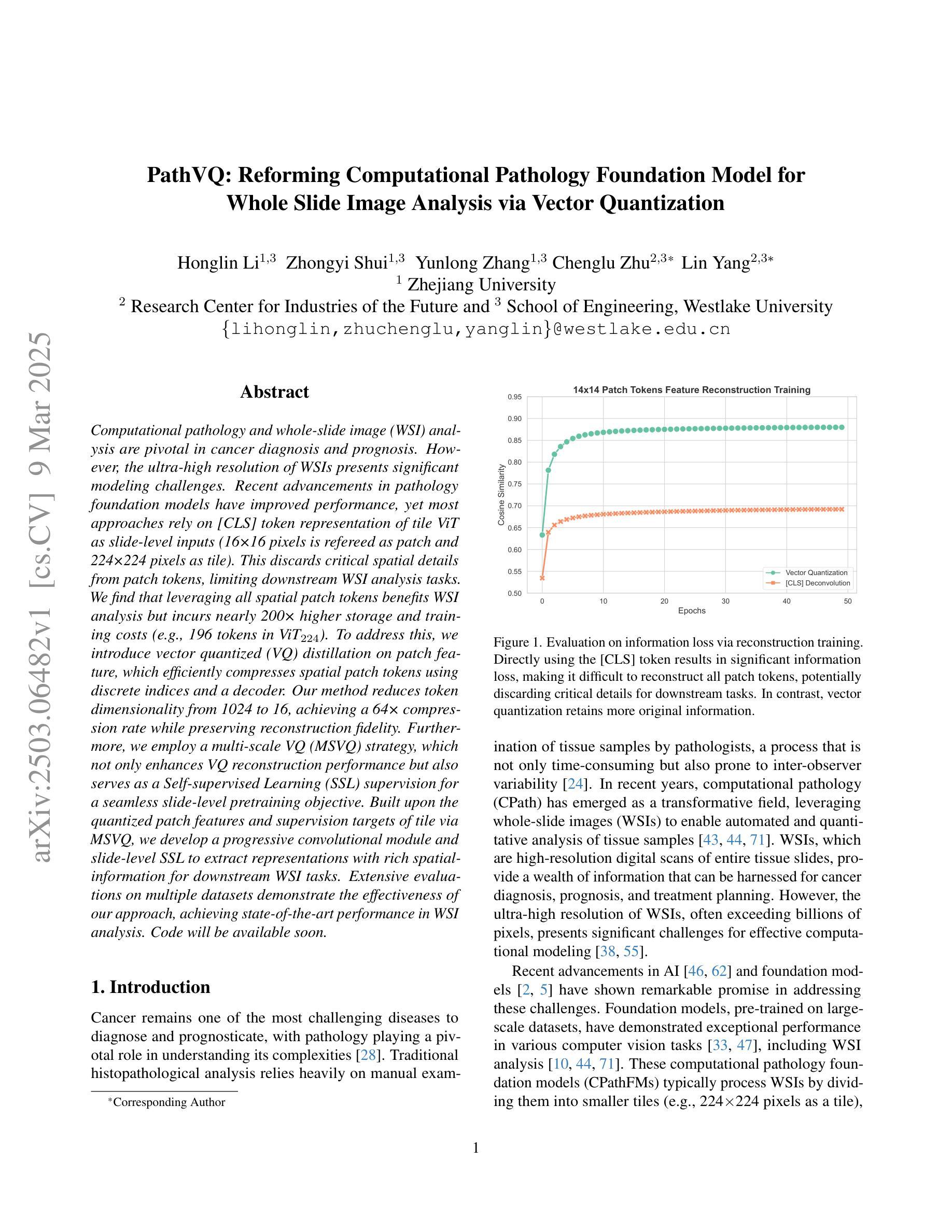
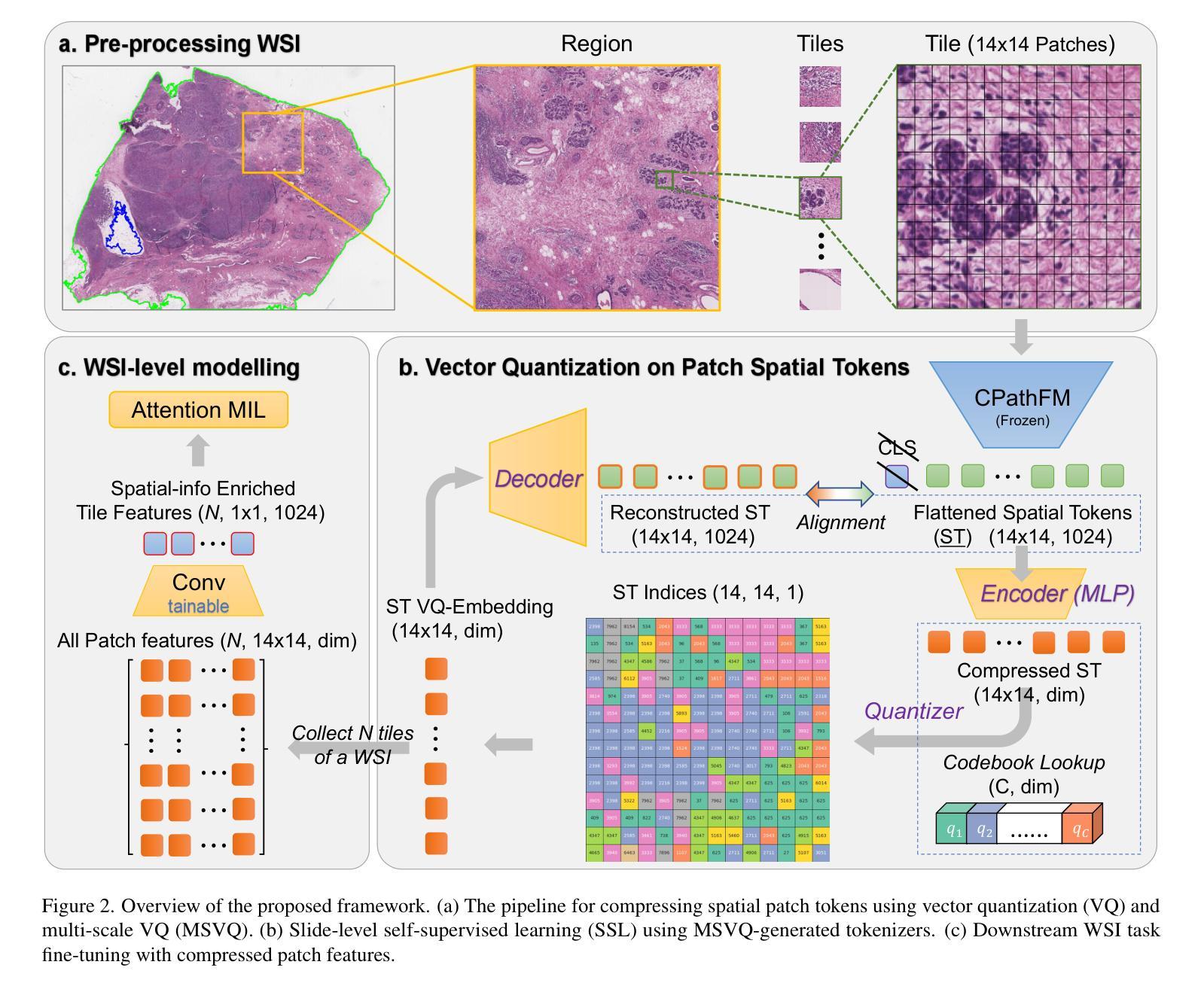
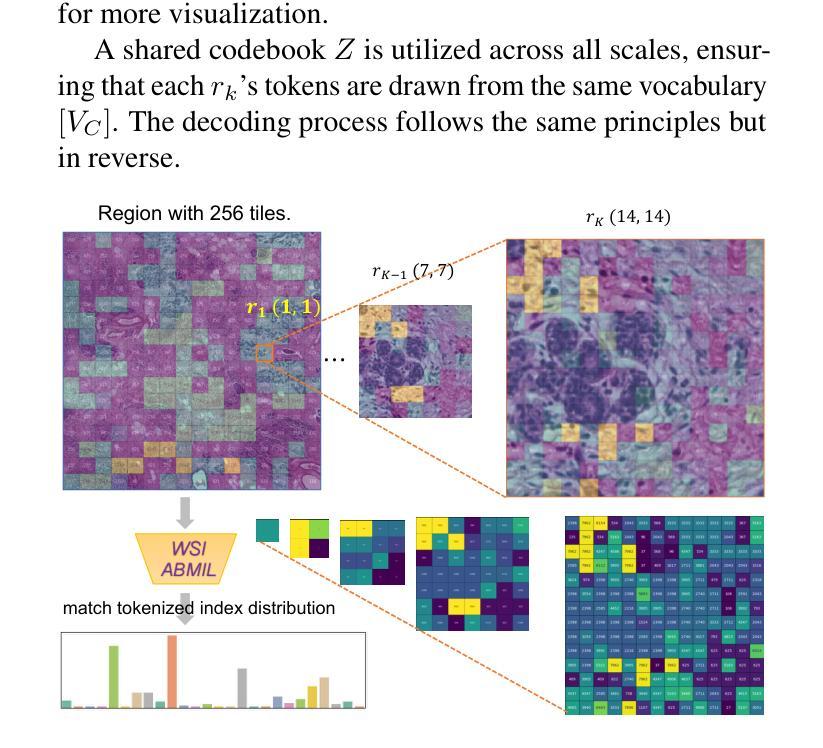
PathVQ: Reforming Computational Pathology Foundation Model for Whole Slide Image Analysis via Vector Quantization
Authors:Honglin Li, Zhongyi Shui, Yunlong Zhang, Chenglu Zhu, Lin Yang
Computational pathology and whole-slide image (WSI) analysis are pivotal in cancer diagnosis and prognosis. However, the ultra-high resolution of WSIs presents significant modeling challenges. Recent advancements in pathology foundation models have improved performance, yet most approaches rely on [CLS] token representation of tile ViT as slide-level inputs (16x16 pixels is refereed as patch and 224x224 pixels as tile). This discards critical spatial details from patch tokens, limiting downstream WSI analysis tasks. We find that leveraging all spatial patch tokens benefits WSI analysis but incurs nearly 200x higher storage and training costs (e.g., 196 tokens in ViT$_{224}$). To address this, we introduce vector quantized (VQ) distillation on patch feature, which efficiently compresses spatial patch tokens using discrete indices and a decoder. Our method reduces token dimensionality from 1024 to 16, achieving a 64x compression rate while preserving reconstruction fidelity. Furthermore, we employ a multi-scale VQ (MSVQ) strategy, which not only enhances VQ reconstruction performance but also serves as a Self-supervised Learning (SSL) supervision for a seamless slide-level pretraining objective. Built upon the quantized patch features and supervision targets of tile via MSVQ, we develop a progressive convolutional module and slide-level SSL to extract representations with rich spatial-information for downstream WSI tasks. Extensive evaluations on multiple datasets demonstrate the effectiveness of our approach, achieving state-of-the-art performance in WSI analysis. Code will be available soon.
计算病理学和全切片图像(WSI)分析在癌症诊断和预后中至关重要。然而,WSI的超高分辨率带来了巨大的建模挑战。最近的病理基础模型进展提高了性能,但大多数方法都依赖于ViT的[CLS]标记作为幻灯片级别的输入(将16x16像素称为补丁,而224x224像素称为瓷砖)。这种方法舍弃了补丁标记中的关键空间细节,限制了下游的WSI分析任务。我们发现利用所有空间补丁标记对WSI分析是有益的,但这会导致存储和训练成本增加近200倍(例如,ViT224中的196个标记)。为了解决这个问题,我们在补丁特征上引入了矢量量化(VQ)蒸馏技术,该技术使用离散索引和解码器有效地压缩空间补丁标记。我们的方法将标记维度从1024减少到16,实现了64倍的压缩率,同时保持了重建保真度。此外,我们采用了多尺度VQ(MSVQ)策略,这不仅提高了VQ重建性能,还作为无缝幻灯片级预训练目标的自监督学习(SSL)监督。基于量化的补丁特征和通过MSVQ获得的瓷砖监督目标,我们开发了一个渐进的卷积模块和幻灯片级别的SSL,以提取具有丰富空间信息的表示用于下游WSI任务。在多个数据集上的广泛评估证明了我们方法的有效性,在全切片图像分析领域取得了最先进的性能。代码即将发布。
论文及项目相关链接
摘要
计算病理学和全幻灯片图像(WSI)分析在癌症诊断和治疗中至关重要。然而,WSI的超高分辨率带来了建模挑战。虽然病理学基础模型的最新进展提高了性能,但大多数方法依赖于CLS标记的瓷砖ViT作为幻灯片级别的输入,这会丢弃关键的空token标记的空间细节信息限制了下游WSI分析任务。发现利用所有空间补丁token有利于WSI分析,但同时也导致了近200倍的存储和训练成本提高。为了解决这个问题,本文引入矢量量化特征上的VQ蒸馏法,有效地压缩空间补丁token并使用离散索引和解码器进行高效处理。我们的方法将token维度从1024减少到16,实现了高达64倍的压缩率,同时保持了重建保真度。此外,我们还采用了多尺度VQ策略,不仅提高了VQ重建性能,还作为无缝幻灯片级别的自监督学习(SSL)监督方式。基于量化的补丁特征和通过MSVQ得到的瓷砖监督目标,我们开发了一个渐进式卷积模块和幻灯片级别的SSL,为下游WSI任务提取具有丰富空间信息的表示形式。在多个数据集上的广泛评估表明,我们的方法取得了最先进的效果。
要点解析
以下是文中要点信息,用简化汉字中文进行归纳总结:
- 计算病理学和全幻灯片图像分析在癌症诊断中的重要性。
- WSI的超高分辨率给建模带来的挑战。
- 当前方法主要依赖CLS标记的瓷砖ViT作为幻灯片级别的输入,导致空间细节信息的丢失。
- 利用所有空间补丁token对WSI分析有益,但带来更高的存储和训练成本。
点此查看论文截图

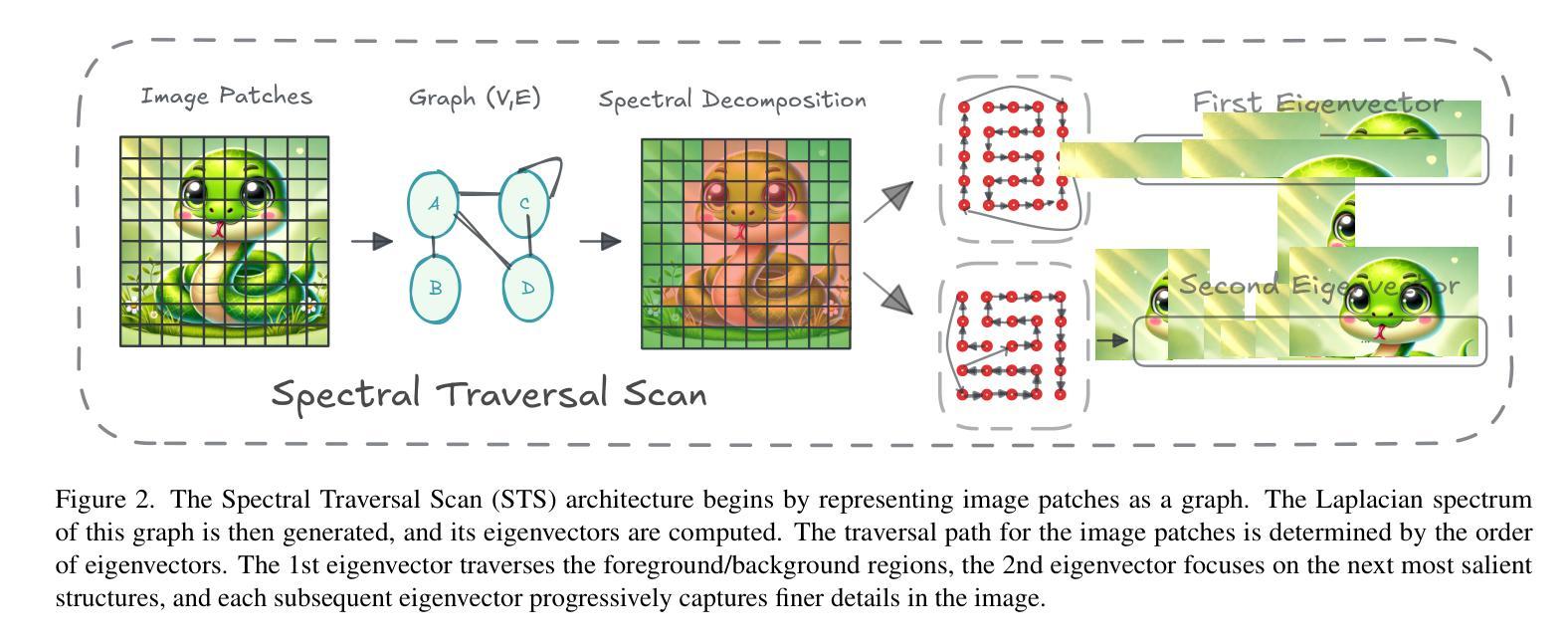
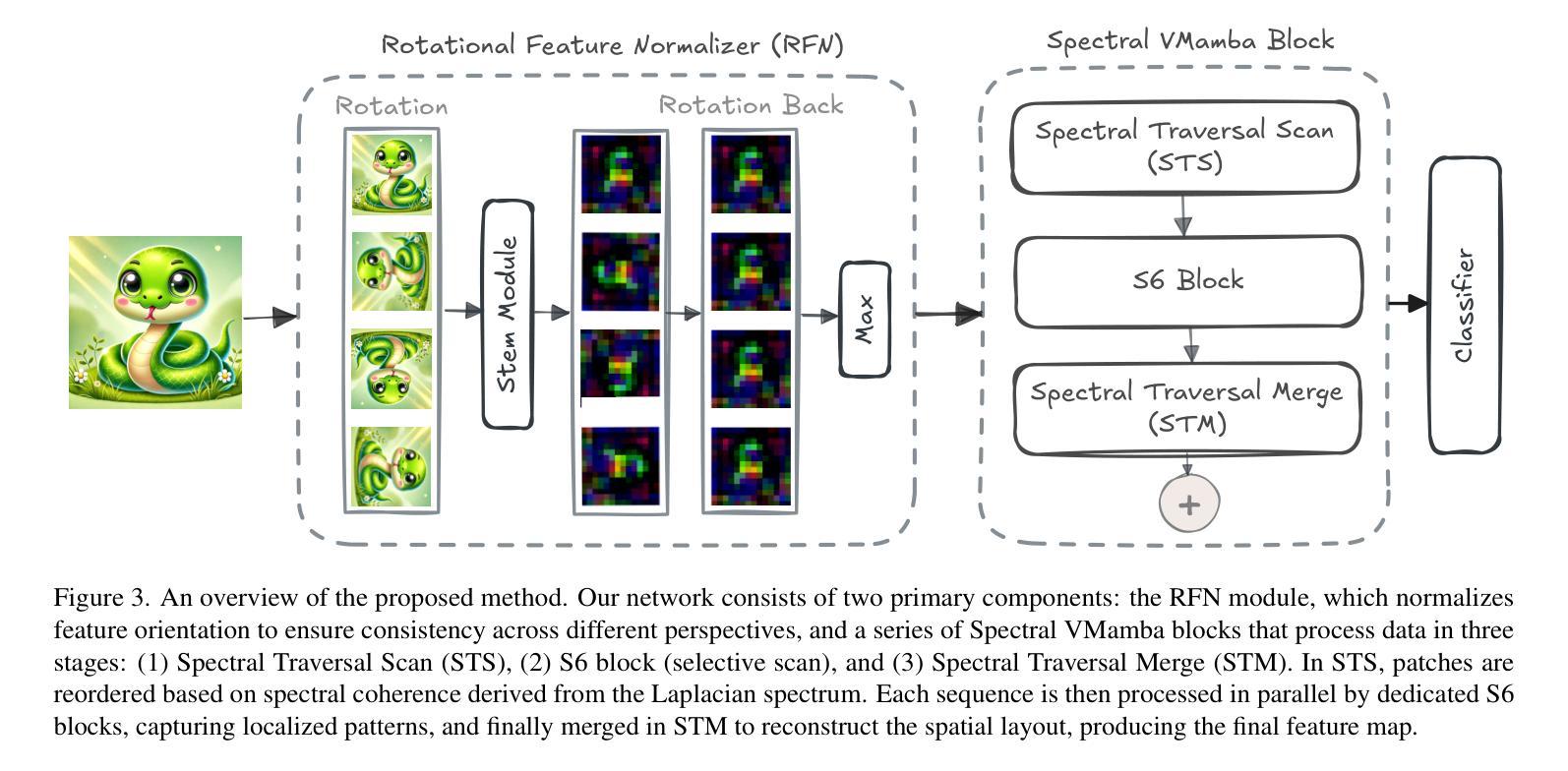
Spectral State Space Model for Rotation-InvariantVisualRepresentation~Learning
Authors:Sahar Dastani, Ali Bahri, Moslem Yazdanpanah, Mehrdad Noori, David Osowiechi, Gustavo Adolfo Vargas Hakim, Farzad Beizaee, Milad Cheraghalikhani, Arnab Kumar Mondal, Herve Lombaert, Christian Desrosiers
State Space Models (SSMs) have recently emerged as an alternative to Vision Transformers (ViTs) due to their unique ability of modeling global relationships with linear complexity. SSMs are specifically designed to capture spatially proximate relationships of image patches. However, they fail to identify relationships between conceptually related yet not adjacent patches. This limitation arises from the non-causal nature of image data, which lacks inherent directional relationships. Additionally, current vision-based SSMs are highly sensitive to transformations such as rotation. Their predefined scanning directions depend on the original image orientation, which can cause the model to produce inconsistent patch-processing sequences after rotation. To address these limitations, we introduce Spectral VMamba, a novel approach that effectively captures the global structure within an image by leveraging spectral information derived from the graph Laplacian of image patches. Through spectral decomposition, our approach encodes patch relationships independently of image orientation, achieving rotation invariance with the aid of our Rotational Feature Normalizer (RFN) module. Our experiments on classification tasks show that Spectral VMamba outperforms the leading SSM models in vision, such as VMamba, while maintaining invariance to rotations and a providing a similar runtime efficiency.
状态空间模型(SSMs)因其以线性复杂度对全局关系进行建模的独特能力,最近作为视觉转换器(ViTs)的替代品而出现。SSMs专门设计用于捕捉图像补丁的空间邻近关系。然而,它们无法识别概念上相关但并非相邻的补丁之间的关系。这一局限性源于图像数据的非因果性质,即缺乏固有的方向关系。此外,当前的基于视觉的SSMs对旋转等转换非常敏感。其预定义的扫描方向取决于原始图像的方向,这可能导致模型在旋转后产生不一致的补丁处理序列。为了解决这些局限性,我们引入了Spectral VMamba这一新方法,它通过利用从图像补丁的图拉普拉斯算子得出的光谱信息,有效地捕捉图像内的全局结构。通过谱分解,我们的方法能够独立于图像方向地编码补丁关系,借助我们的旋转特征归一化器(RFN)模块实现旋转不变性。我们在分类任务上的实验表明,Spectral VMamba在视觉领域超越了领先的SSMs模型(如VMamba),同时保持了对旋转的不变性,并提供了类似的运行效率。
论文及项目相关链接
Summary
近期,状态空间模型(SSMs)作为Vision Transformers(ViTs)的替代方案崭露头角,其以线性复杂度建模全局关系的能力受到关注。然而,它们难以识别概念相关但不相邻的补丁间的关系。为解决此问题,我们提出了Spectral VMamba方法,通过利用图像补丁的图拉普拉斯算子的谱信息来捕获图像全局结构,并借助旋转特征标准化(RFN)模块实现旋转不变性。实验证明,Spectral VMamba在分类任务上表现优于领先的SSM模型,同时保持对旋转的不变性并维持相似的运行效率。
Key Takeaways
- 状态空间模型(SSMs)能够捕捉图像补丁的空间邻近关系。
- SSMs难以识别概念相关但不相邻的补丁之间的关系,这源于图像数据的非因果性质。
- 当前基于视觉的SSM对旋转等变换高度敏感,依赖于原始图像方向的预定扫描方向会导致模型在旋转后产生不一致的补丁处理序列。
- Spectral VMamba方法通过利用图像补丁的图拉普拉斯算子的谱信息来捕获图像的全局结构。
- Spectral VMamba实现了旋转不变性,借助旋转特征标准化(RFN)模块。
- 实验表明,Spectral VMamba在分类任务上优于领先的SSM模型。
点此查看论文截图

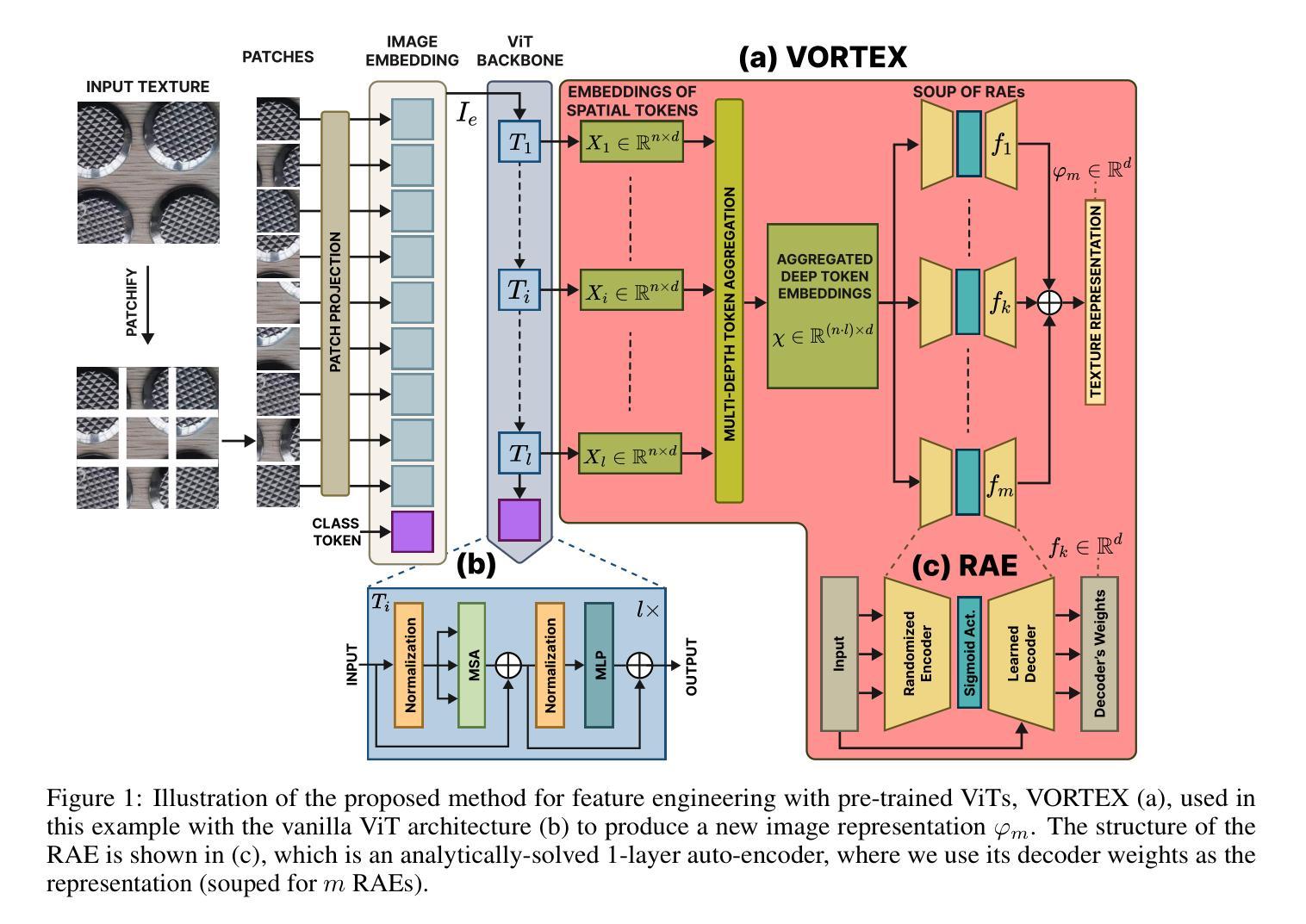
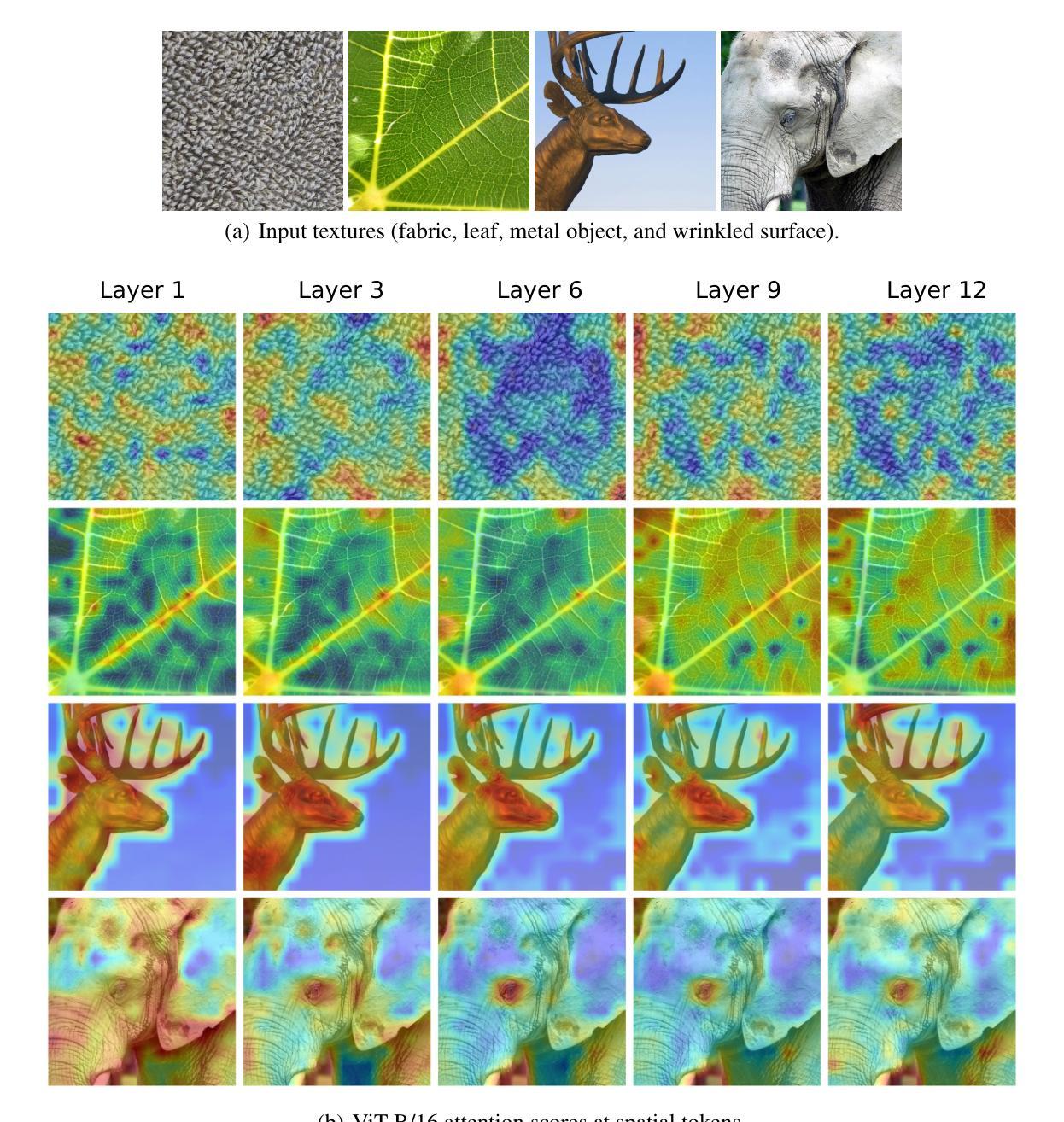
VORTEX: Challenging CNNs at Texture Recognition by using Vision Transformers with Orderless and Randomized Token Encodings
Authors:Leonardo Scabini, Kallil M. Zielinski, Emir Konuk, Ricardo T. Fares, Lucas C. Ribas, Kevin Smith, Odemir M. Bruno
Texture recognition has recently been dominated by ImageNet-pre-trained deep Convolutional Neural Networks (CNNs), with specialized modifications and feature engineering required to achieve state-of-the-art (SOTA) performance. However, although Vision Transformers (ViTs) were introduced a few years ago, little is known about their texture recognition ability. Therefore, in this work, we introduce VORTEX (ViTs with Orderless and Randomized Token Encodings for Texture Recognition), a novel method that enables the effective use of ViTs for texture analysis. VORTEX extracts multi-depth token embeddings from pre-trained ViT backbones and employs a lightweight module to aggregate hierarchical features and perform orderless encoding, obtaining a better image representation for texture recognition tasks. This approach allows seamless integration with any ViT with the common transformer architecture. Moreover, no fine-tuning of the backbone is performed, since they are used only as frozen feature extractors, and the features are fed to a linear SVM. We evaluate VORTEX on nine diverse texture datasets, demonstrating its ability to achieve or surpass SOTA performance in a variety of texture analysis scenarios. By bridging the gap between texture recognition with CNNs and transformer-based architectures, VORTEX paves the way for adopting emerging transformer foundation models. Furthermore, VORTEX demonstrates robust computational efficiency when coupled with ViT backbones compared to CNNs with similar costs. The method implementation and experimental scripts are publicly available in our online repository.
纹理识别最近主要依赖于ImageNet预训练的深度卷积神经网络(CNN),为了实现最前沿(SOTA)性能,需要专业化的修改和特征工程。然而,尽管视觉变压器(ViTs)几年前就已经被引入,但关于其纹理识别能力的研究知之甚少。因此,在这项工作中,我们介绍了VORTEX(用于纹理识别的具有无序和随机令牌编码的视觉变压器),这是一种使视觉变压器在纹理分析方面进行有效使用的新方法。VORTEX从预训练的ViT主干中提取多深度令牌嵌入,并采用轻量级模块来聚合分层特征并执行无序编码,为纹理识别任务获得更好的图像表示。这种方法可以无缝地集成到具有通用变压器架构的任何ViT中。此外,由于我们只是使用冻结的特征提取器,而没有对主干进行微调,因此特征被输入到线性SVM中。我们在九个不同的纹理数据集上评估了VORTEX,证明了它在各种纹理分析场景中达到或超越SOTA性能的能力。通过缩小CNN和基于变压器的架构之间的纹理识别差距,VORTEX为采用新兴的变压器基础模型铺平了道路。此外,与具有类似成本的CNN相比,VORTEX与ViT主干结合时显示出稳健的计算效率。方法和实验脚本已在我们在线仓库中公开发布。
论文及项目相关链接
Summary
本文介绍了VORTEX(用于纹理识别的带有无序和随机令牌编码的愿景变压器),这是一种使愿景变压器有效用于纹理分析的新方法。VORTEX从预训练的ViT主干中提取多深度令牌嵌入,并采用轻量级模块进行分层特征的聚合和无序编码,为纹理识别任务获得更好的图像表示。该方法可无缝集成到具有通用转换器架构的任何ViT中,无需对主干进行微调。我们在九个不同的纹理数据集上评估了VORTEX,证明了其在各种纹理分析场景中的能力。VORTEX填补了CNN和基于转换器的架构在纹理识别方面的空白,为采用新兴的转换器基础模型铺平了道路。
Key Takeaways
- VORTEX是一种利用Vision Transformer(ViT)进行纹理识别的新方法。
- VORTEX通过提取多深度令牌嵌入和采用轻量级模块进行分层特征聚合与无序编码,实现有效的纹理分析。
- VORTEX可无缝集成到任何具有通用转换器架构的ViT中,且无需对主干进行微调。
- 在九个不同的纹理数据集上的评估表明,VORTEX在多种纹理分析场景中达到或超越了最新技术的性能。
- VORTEX填补了CNN和基于转换器的架构在纹理识别方面的空白。
- VORTEX相较于具有类似成本的CNN,表现出更强的计算效率。
- VORTEX的方法实现和实验脚本已公开在线仓库中可供使用。
点此查看论文截图

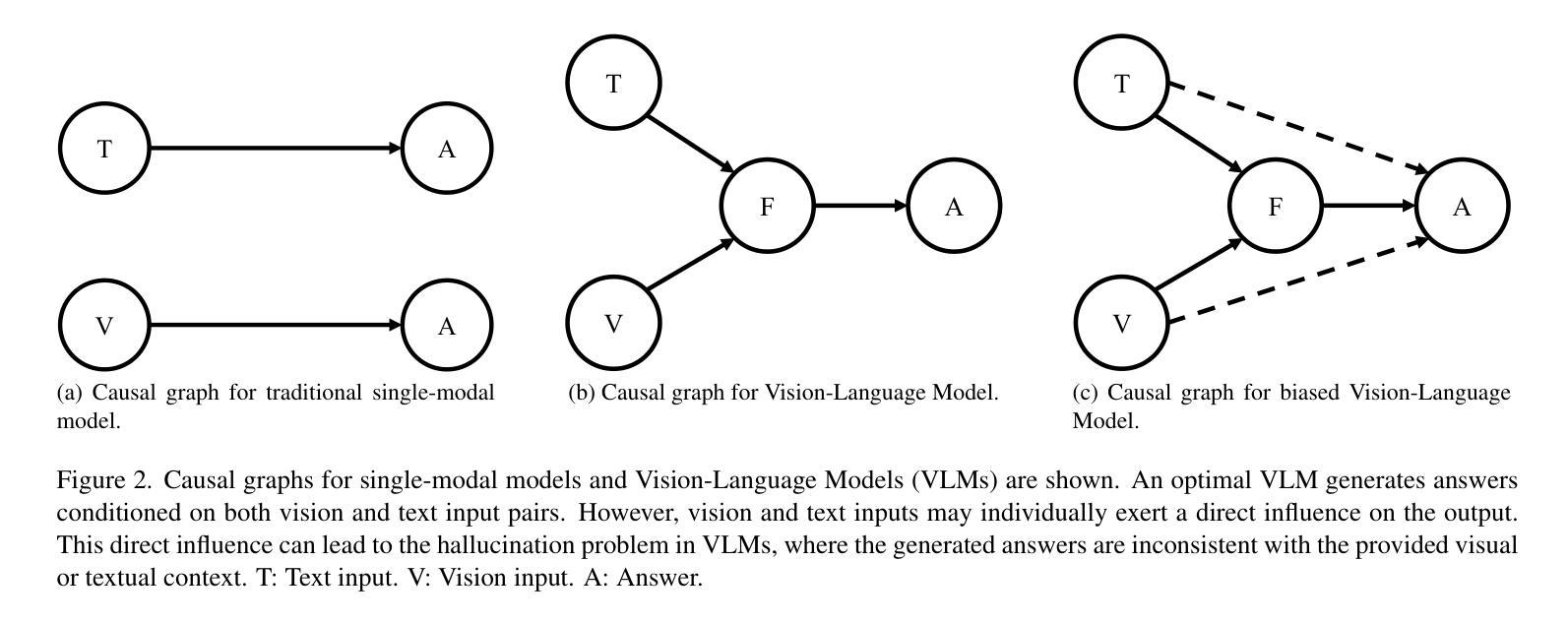
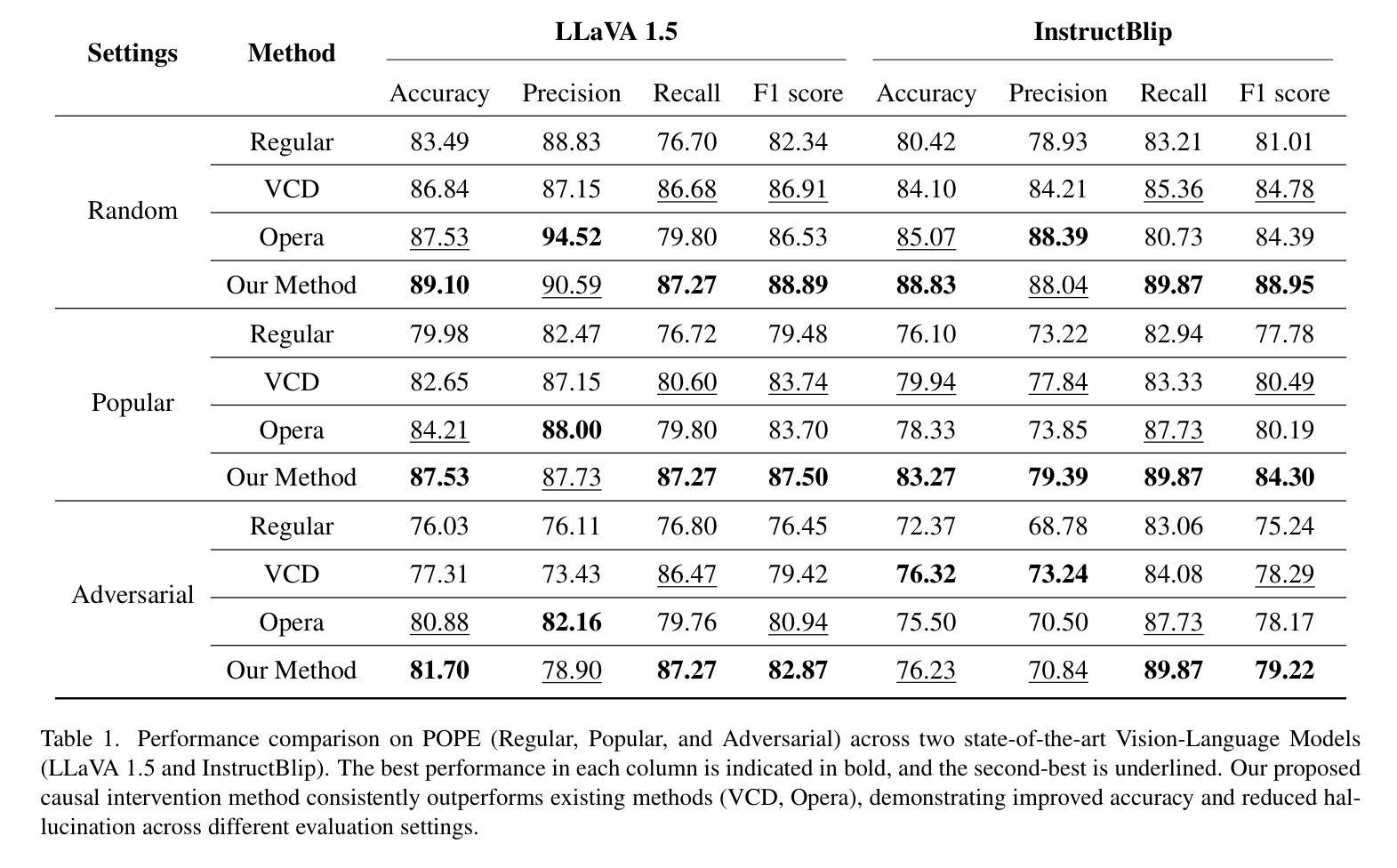
Treble Counterfactual VLMs: A Causal Approach to Hallucination
Authors:Li Li, Jiashu Qu, Yuxiao Zhou, Yuehan Qin, Tiankai Yang, Yue Zhao
Vision-Language Models (VLMs) have advanced multi-modal tasks like image captioning, visual question answering, and reasoning. However, they often generate hallucinated outputs inconsistent with the visual context or prompt, limiting reliability in critical applications like autonomous driving and medical imaging. Existing studies link hallucination to statistical biases, language priors, and biased feature learning but lack a structured causal understanding. In this work, we introduce a causal perspective to analyze and mitigate hallucination in VLMs. We hypothesize that hallucination arises from unintended direct influences of either the vision or text modality, bypassing proper multi-modal fusion. To address this, we construct a causal graph for VLMs and employ counterfactual analysis to estimate the Natural Direct Effect (NDE) of vision, text, and their cross-modal interaction on the output. We systematically identify and mitigate these unintended direct effects to ensure that responses are primarily driven by genuine multi-modal fusion. Our approach consists of three steps: (1) designing structural causal graphs to distinguish correct fusion pathways from spurious modality shortcuts, (2) estimating modality-specific and cross-modal NDE using perturbed image representations, hallucinated text embeddings, and degraded visual inputs, and (3) implementing a test-time intervention module to dynamically adjust the model’s dependence on each modality. Experimental results demonstrate that our method significantly reduces hallucination while preserving task performance, providing a robust and interpretable framework for improving VLM reliability. To enhance accessibility and reproducibility, our code is publicly available at https://github.com/TREE985/Treble-Counterfactual-VLMs.
视觉语言模型(VLMs)在图像描述、视觉问答和推理等跨模式任务中取得了进展。然而,它们经常产生与视觉上下文或提示不一致的幻觉输出,限制了它们在自动驾驶和医学影像等关键应用中的可靠性。现有研究将幻觉与统计偏见、语言先验知识和有偏特征学习联系起来,但缺乏结构性的因果理解。在这项工作中,我们从因果角度来分析并减轻VLMs中的幻觉问题。我们假设幻觉是由于视觉或文本模态的意外直接影响而产生的,这些影响绕过了适当的跨模式融合。为了解决这一问题,我们为VLMs构建了因果图,并采用反事实分析来估计视觉、文本及其跨模式交互对输出的自然直接影响(NDE)。我们系统地识别和缓解这些意外的直接影响,以确保响应主要由真正的跨模式融合驱动。我们的方法包括三个步骤:(1)设计结构因果图,以区分正确的融合途径和虚假的模式捷径;(2)使用扰动图像表示、幻觉文本嵌入和退化视觉输入来估计模态特定和跨模态的NDE;(3)实现测试时间干预模块,以动态调整模型对每个模态的依赖性。实验结果表明,我们的方法在减少幻觉的同时保持了任务性能,为提高VLM可靠性提供了稳健和可解释性的框架。为了增强可访问性和可重复性,我们的代码可在https://github.com/TREE985/Treble-Counterfactual-VLMs上公开访问。
论文及项目相关链接
Summary
本文研究了视觉语言模型(VLMs)中的幻视问题,该问题在多模态任务中普遍存在。文章从因果角度分析了幻视的产生原因,并提出了相应的解决策略。通过构建因果图和使用反事实分析,文章系统地识别并缓解了幻视问题,提高了VLMs的可靠性。
Key Takeaways
- 视觉语言模型(VLMs)在多模态任务中普遍存在幻视问题,影响模型可靠性。
- 幻视问题可能与统计偏见、语言先验和特征学习中的偏差有关。
- 本文从因果角度分析了幻视的产生原因,提出幻视是由于视觉或文本模态的直接影响绕过正确的多模态融合所致。
- 通过构建因果图和使用反事实分析,文章系统地识别了缓解幻视问题的方法。
- 方法包括设计结构因果图、估计模态特定和跨模态自然直接效应以及实施测试时间干预模块。
- 实验结果表明,该方法在减少幻视的同时保留了任务性能,为改进VLM可靠性提供了稳健和可解释性的框架。
点此查看论文截图


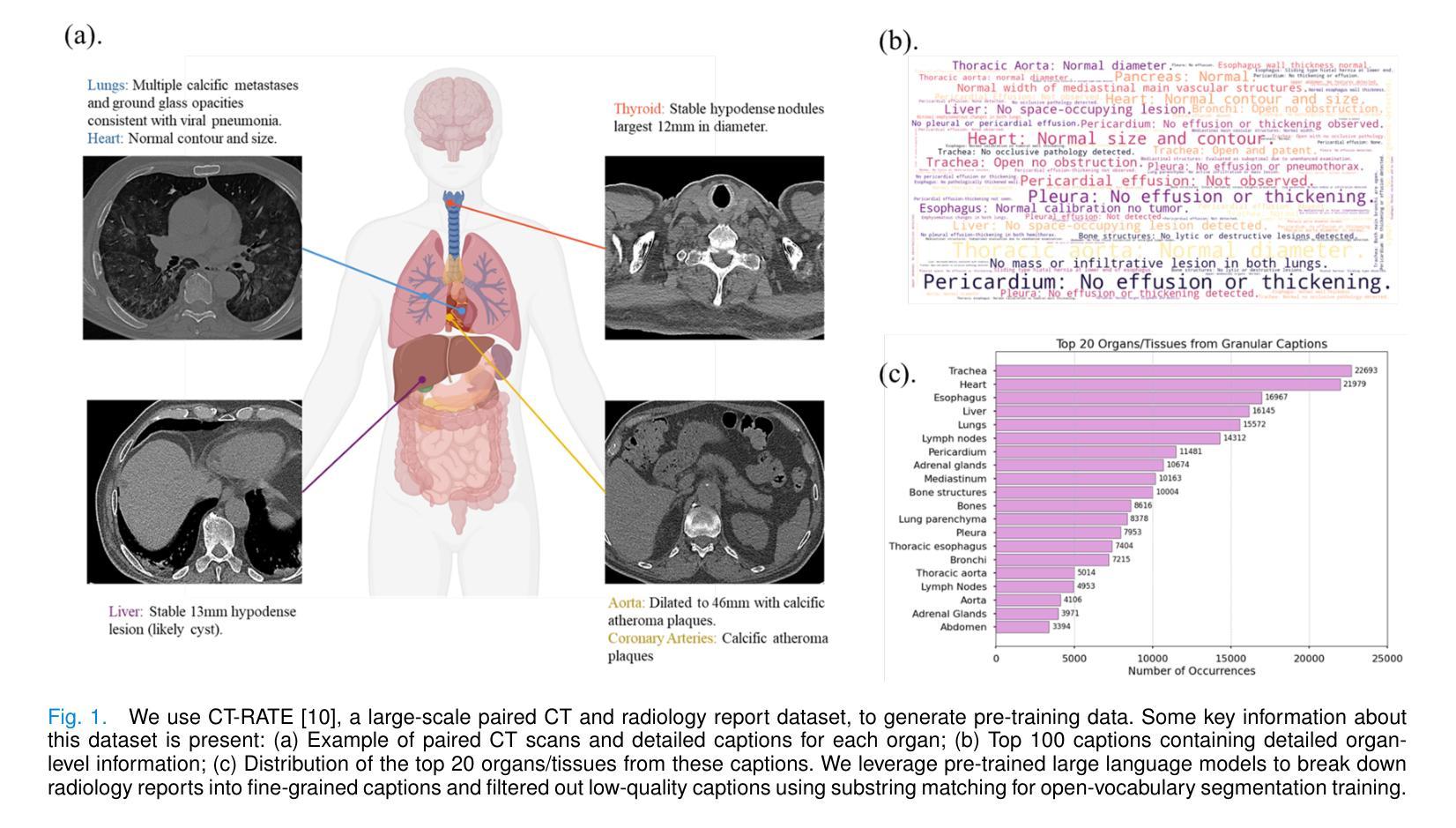
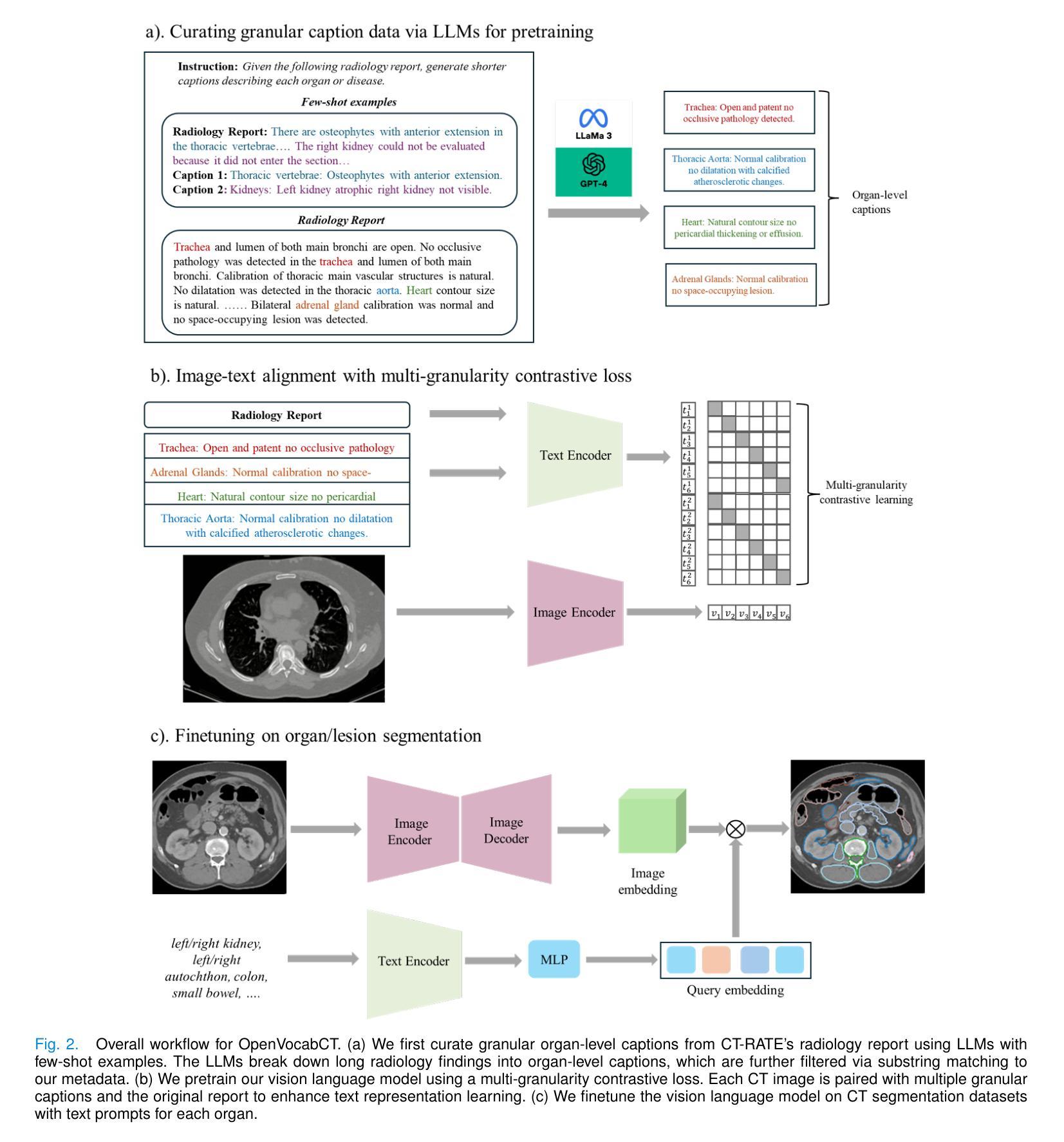
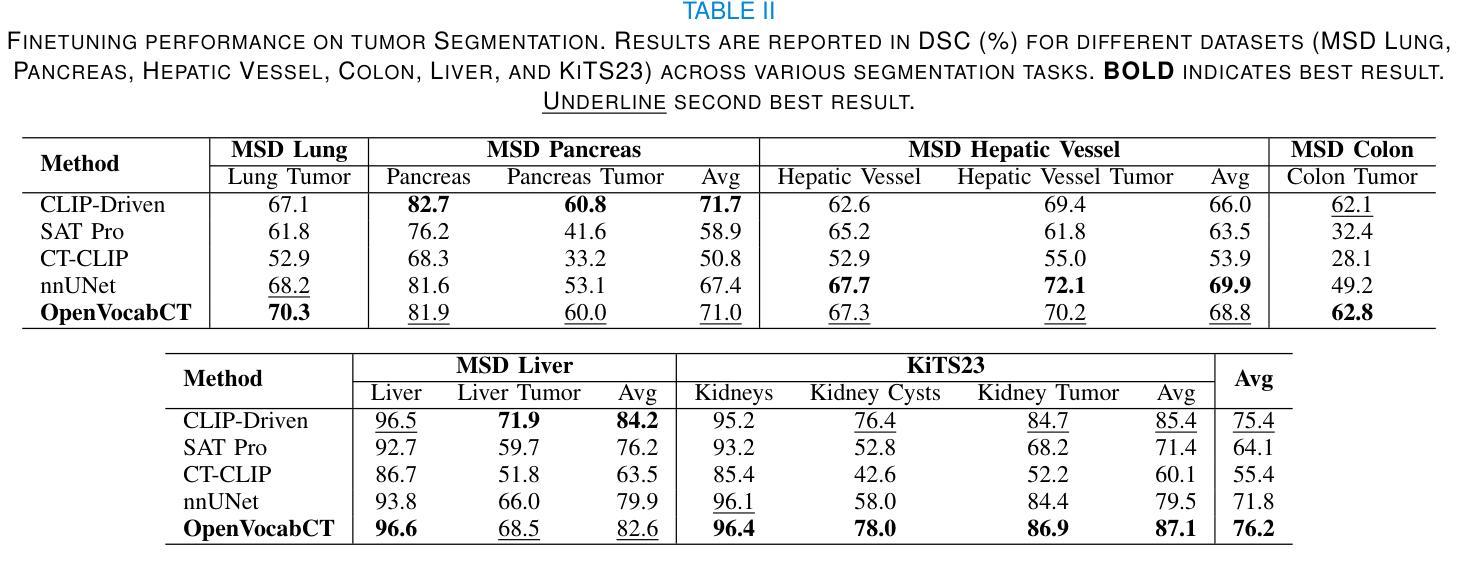
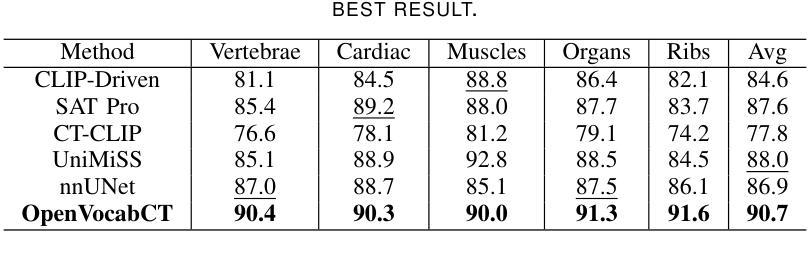
Towards Universal Text-driven CT Image Segmentation
Authors:Yuheng Li, Yuxiang Lai, Maria Thor, Deborah Marshall, Zachary Buchwald, David S. Yu, Xiaofeng Yang
Computed tomography (CT) is extensively used for accurate visualization and segmentation of organs and lesions. While deep learning models such as convolutional neural networks (CNNs) and vision transformers (ViTs) have significantly improved CT image analysis, their performance often declines when applied to diverse, real-world clinical data. Although foundation models offer a broader and more adaptable solution, their potential is limited due to the challenge of obtaining large-scale, voxel-level annotations for medical images. In response to these challenges, prompting-based models using visual or text prompts have emerged. Visual-prompting methods, such as the Segment Anything Model (SAM), still require significant manual input and can introduce ambiguity when applied to clinical scenarios. Instead, foundation models that use text prompts offer a more versatile and clinically relevant approach. Notably, current text-prompt models, such as the CLIP-Driven Universal Model, are limited to text prompts already encountered during training and struggle to process the complex and diverse scenarios of real-world clinical applications. Instead of fine-tuning models trained from natural imaging, we propose OpenVocabCT, a vision-language model pretrained on large-scale 3D CT images for universal text-driven segmentation. Using the large-scale CT-RATE dataset, we decompose the diagnostic reports into fine-grained, organ-level descriptions using large language models for multi-granular contrastive learning. We evaluate our OpenVocabCT on downstream segmentation tasks across nine public datasets for organ and tumor segmentation, demonstrating the superior performance of our model compared to existing methods. All code, datasets, and models will be publicly released at https://github.com/ricklisz/OpenVocabCT.
计算机断层扫描(CT)广泛应用于器官和病变的精确可视化和分割。虽然深度学习模型,如卷积神经网络(CNN)和视觉变压器(ViT),已经显著改善了CT图像分析,但它们在应用于多样、现实世界临床数据时,性能往往会下降。虽然基础模型提供了更广泛和更灵活的解决方案,但由于获得大规模医学图像体素级别注释的挑战,它们的潜力受到限制。为了应对这些挑战,出现了基于提示的模型,使用视觉或文本提示。视觉提示方法,如Segment Anything Model(SAM),仍需大量的人工输入,并且在应用于临床场景时可能会引入歧义。相反,使用文本提示的基础模型提供了更通用和临床上更相关的方法。值得注意的是,当前的文本提示模型,如CLIP驱动的通用模型,仅限于在训练期间已经遇到的文本提示,并难以处理现实世界临床应用的复杂和多样场景。我们提议的OpenVocabCT是一种视觉语言模型,它在大型3D CT图像上进行预训练,用于通用文本驱动分割。我们使用大规模的CT-RATE数据集将诊断报告分解成细粒度的器官级别描述,利用大型语言模型进行多粒度对比学习。我们在九个公开数据集上的下游分割任务上评估了我们的OpenVocabCT模型和肿瘤分割性能,证明了我们的模型相比现有方法的优越性。所有代码、数据集和模型将在https://github.com/ricklisz/OpenVocabCT上公开发布。
论文及项目相关链接
摘要
计算机断层扫描(CT)广泛应用于器官和病变的精确可视化和分割。虽然深度学习模型,如卷积神经网络(CNN)和视觉变压器(ViT),已经显著改善了CT图像分析,但当应用于多样且真实的临床数据时,其性能往往会下降。为了应对这些挑战,出现了基于提示的模型,使用视觉或文本提示。视觉提示方法,如Segment Anything Model(SAM),仍需要大量的人工输入,并且在应用于临床场景时可能会引入歧义。相反,使用文本提示的基础模型提供了更通用和临床相关的解决方案。然而,当前的文本提示模型,如CLIP驱动的通用模型,仅限于在训练期间遇到的文本提示,难以处理真实世界临床应用的复杂和多样化场景。我们提出了OpenVocabCT,这是一个在大型三维CT图像上预训练的视觉语言模型,用于通用的文本驱动分割。我们使用大规模的CT-RATE数据集进行训练,将诊断报告分解为精细的器官级别描述,利用大型语言模型进行多粒度对比学习。我们在九个公共数据集上对OpenVocabCT进行了下游分割任务评估,展示了其在器官和肿瘤分割方面的优越性能。所有代码、数据集和模型将在https://github.com/ricklisz/OpenVocabCT公开发布。
要点
- CT图像分析在临床诊断中具有重要意义,但应用于真实世界临床数据时深度学习模型性能下降。
- 现有模型面临大规模、像素级注释的获取挑战以及处理复杂、多样化临床场景的能力有限的问题。
- OpenVocabCT是一个在大型三维CT图像上预训练的视觉语言模型,用于通用的文本驱动分割,解决了上述问题。
- 使用诊断报告进行多粒度对比学习,提高模型性能。
- 在九个公共数据集上评估显示,OpenVocabCT在器官和肿瘤分割方面表现优越。
- 所有相关资源将公开发布,便于研究者和临床医生访问和使用。
点此查看论文截图

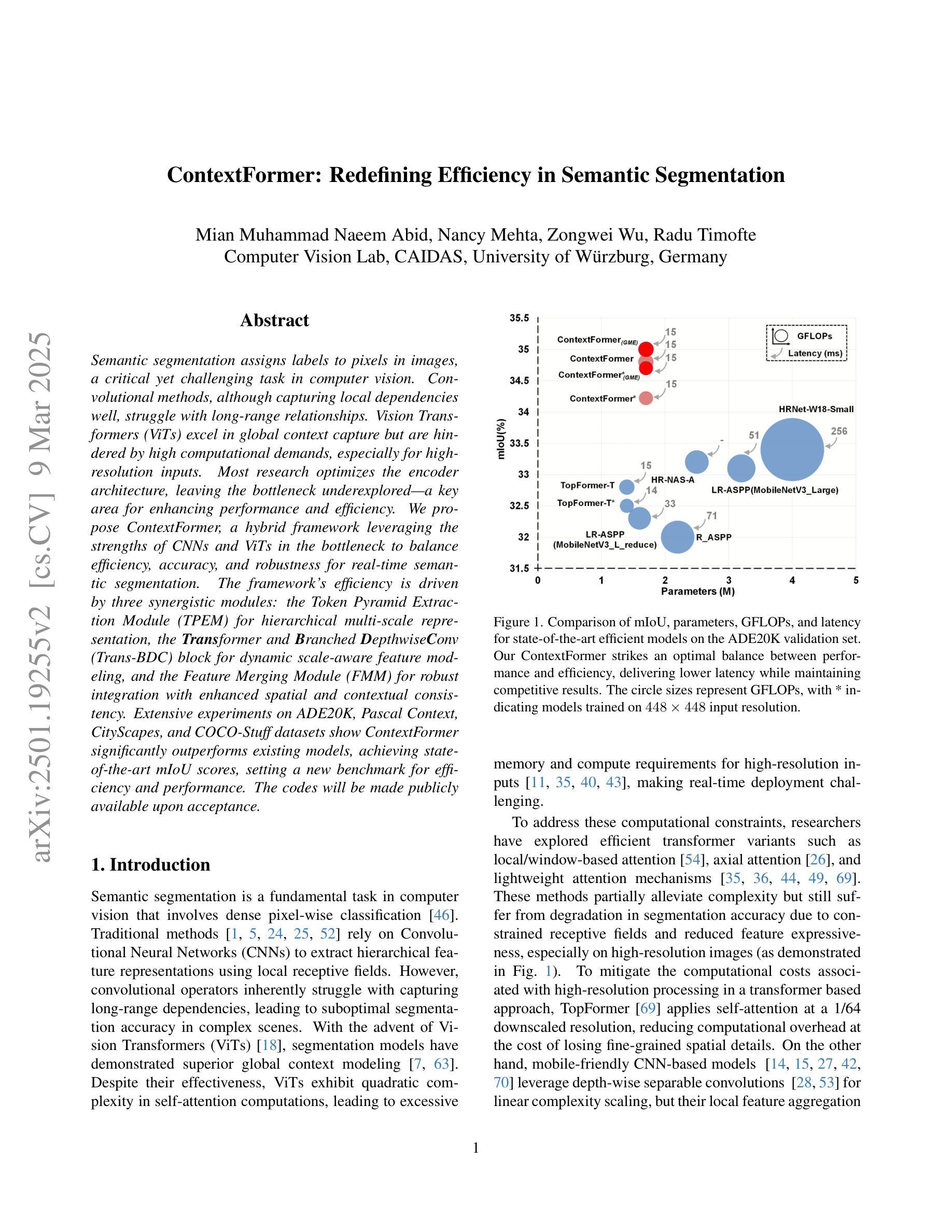
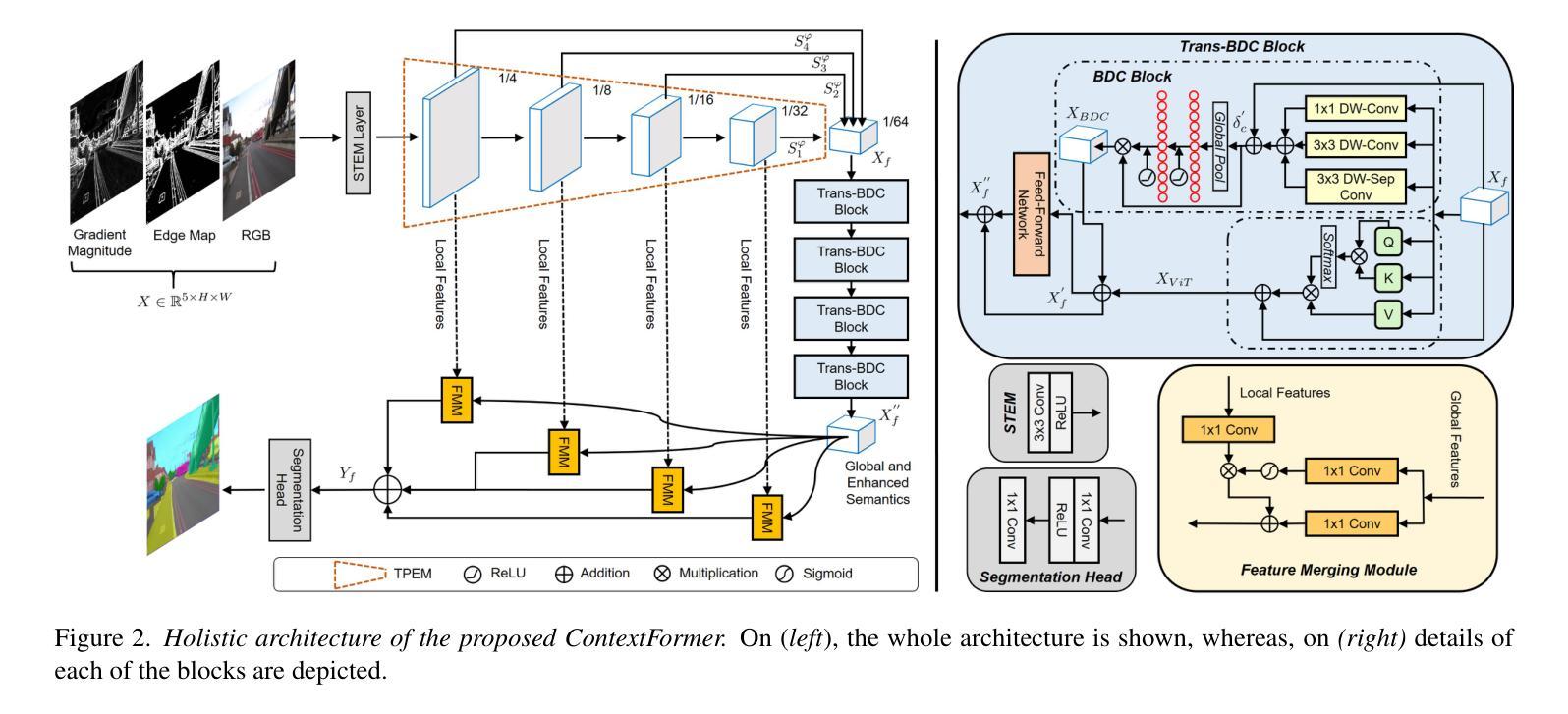
ContextFormer: Redefining Efficiency in Semantic Segmentation
Authors:Mian Muhammad Naeem Abid, Nancy Mehta, Zongwei Wu, Radu Timofte
Semantic segmentation assigns labels to pixels in images, a critical yet challenging task in computer vision. Convolutional methods, although capturing local dependencies well, struggle with long-range relationships. Vision Transformers (ViTs) excel in global context capture but are hindered by high computational demands, especially for high-resolution inputs. Most research optimizes the encoder architecture, leaving the bottleneck underexplored - a key area for enhancing performance and efficiency. We propose ContextFormer, a hybrid framework leveraging the strengths of CNNs and ViTs in the bottleneck to balance efficiency, accuracy, and robustness for real-time semantic segmentation. The framework’s efficiency is driven by three synergistic modules: the Token Pyramid Extraction Module (TPEM) for hierarchical multi-scale representation, the Transformer and Branched DepthwiseConv (Trans-BDC) block for dynamic scale-aware feature modeling, and the Feature Merging Module (FMM) for robust integration with enhanced spatial and contextual consistency. Extensive experiments on ADE20K, Pascal Context, CityScapes, and COCO-Stuff datasets show ContextFormer significantly outperforms existing models, achieving state-of-the-art mIoU scores, setting a new benchmark for efficiency and performance. The codes will be made publicly available upon acceptance.
语义分割是给图像中的像素分配标签的任务,这是计算机视觉中至关重要且充满挑战的任务。卷积方法虽然能很好地捕捉局部依赖性,但在处理长距离关系时却遇到困难。视觉转换器(ViTs)擅长捕捉全局上下文,但计算需求较高,尤其是对于高分辨率输入。大多数研究优化了编码器架构,而忽略了一个关键的性能提升和效率提升瓶颈。我们提出了ContextFormer,这是一个混合框架,利用CNN和ViT在瓶颈处的优势,在实时语义分割中平衡效率、准确性和鲁棒性。该框架的效率是由三个协同模块驱动的:用于分层多尺度表示的Token金字塔提取模块(TPEM)、用于动态尺度感知特征建模的Transformer和分支深度卷积(Trans-BDC)块、用于稳健集成的特征合并模块(FMM),具有增强的空间和上下文一致性。在ADE20K、Pascal Context、CityScapes和COCO-Stuff数据集上的大量实验表明,ContextFormer显著优于现有模型,实现了最先进的mIoU分数,为效率和性能设定了新的基准。代码在接受后将会公开发布。
论文及项目相关链接
Summary
本文介绍了针对计算机视觉中的语义分割任务,提出了一种名为ContextFormer的混合框架。该框架结合了CNN和Vision Transformer(ViT)的优势,旨在提高实时语义分割的效率、准确性和鲁棒性。其通过三个协同模块实现高效性:Token Pyramid Extraction Module(TPEM)用于分层多尺度表示,Transformer和Branched DepthwiseConv(Trans-BDC)块用于动态尺度感知特征建模,以及Feature Merging Module(FMM)用于鲁棒集成,增强空间一致性。实验结果表明,ContextFormer在多个数据集上显著优于现有模型,实现了最高的mIoU分数,为效率和性能设定了新的基准。
Key Takeaways
- ContextFormer是一个针对语义分割任务的混合框架,旨在结合CNN和Vision Transformer(ViT)的优势。
- 框架通过三个协同模块实现高效性:TPEM、Trans-BDC块和FMM。
- TPEM用于分层多尺度表示,Trans-BDC块实现动态尺度感知特征建模,FMM用于鲁棒集成并增强空间一致性。
- ContextFormer在多个数据集上实现了最高的mIoU分数,显著优于现有模型。
- 该框架有助于提高语义分割的效率、准确性和鲁棒性。
- ContextFormer的提出为计算机视觉领域设定了新的性能基准。
点此查看论文截图
Vulnerabilities in AI-generated Image Detection: The Challenge of Adversarial Attacks
Authors:Yunfeng Diao, Naixin Zhai, Changtao Miao, Zitong Yu, Xingxing Wei, Xun Yang, Meng Wang
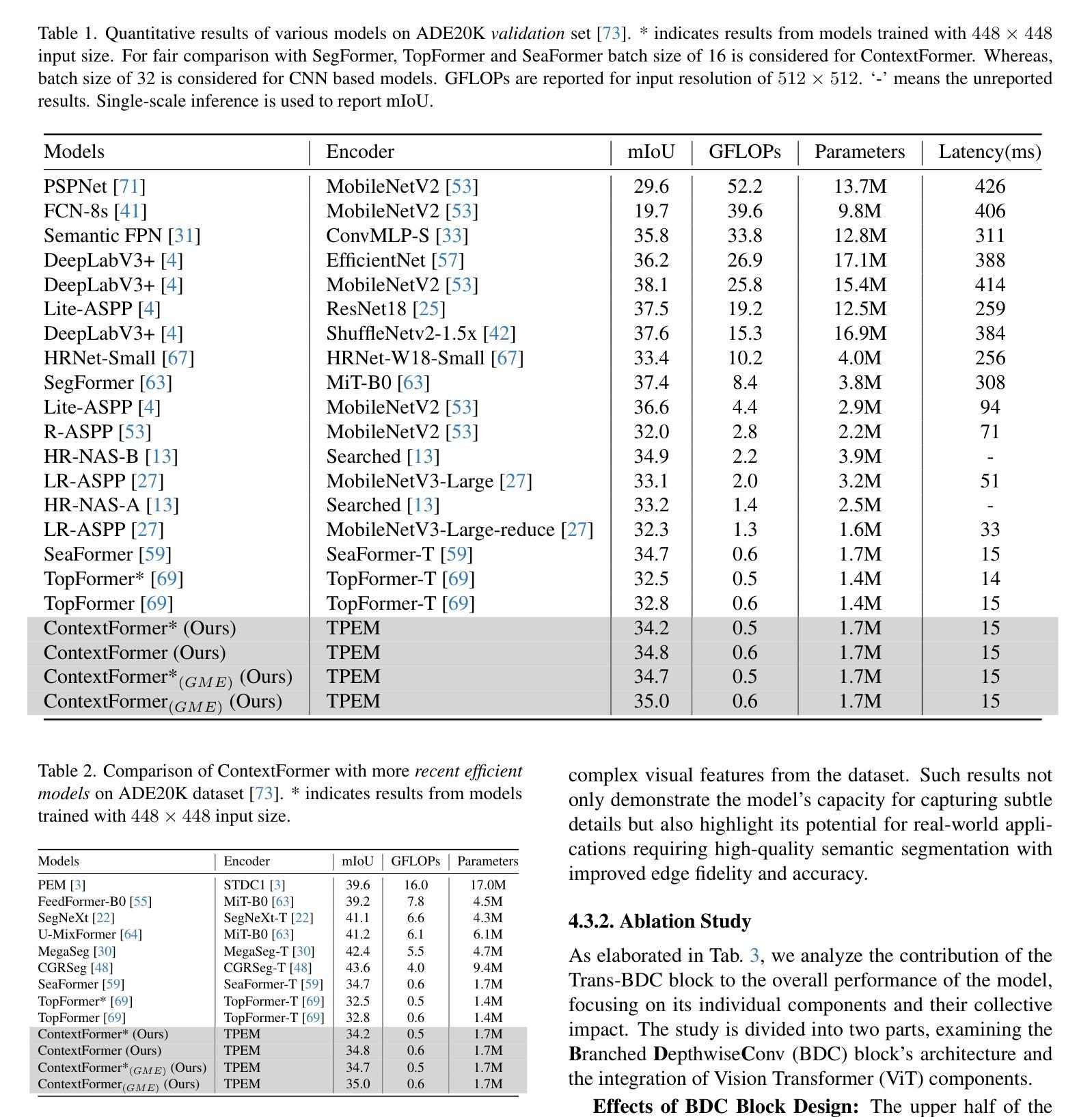
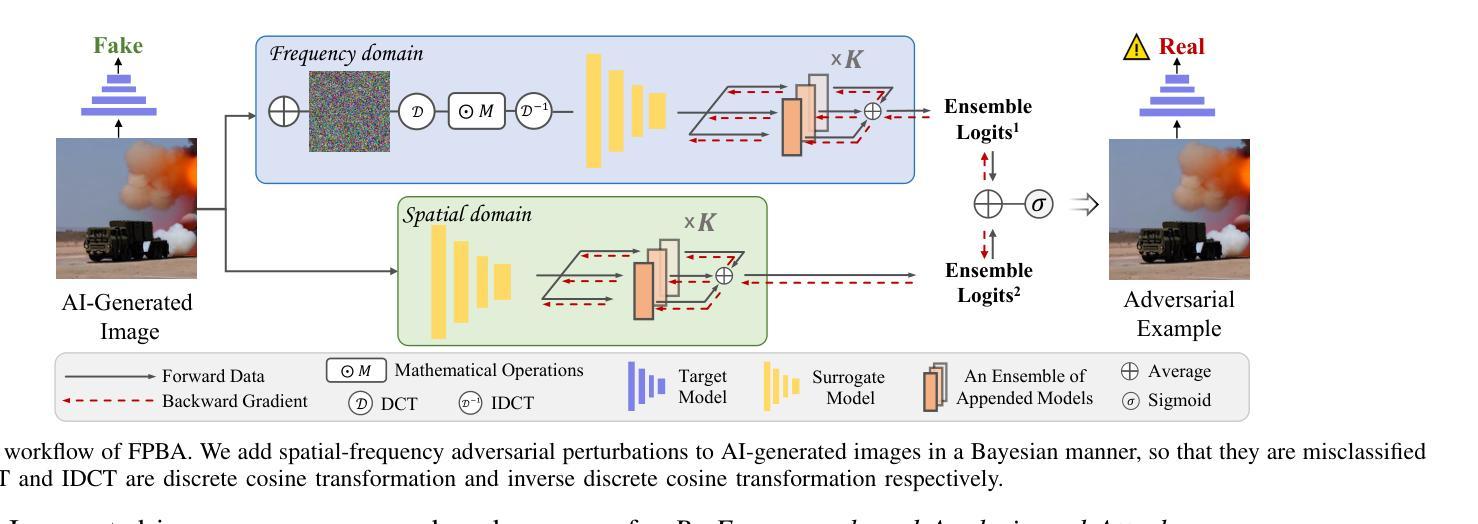
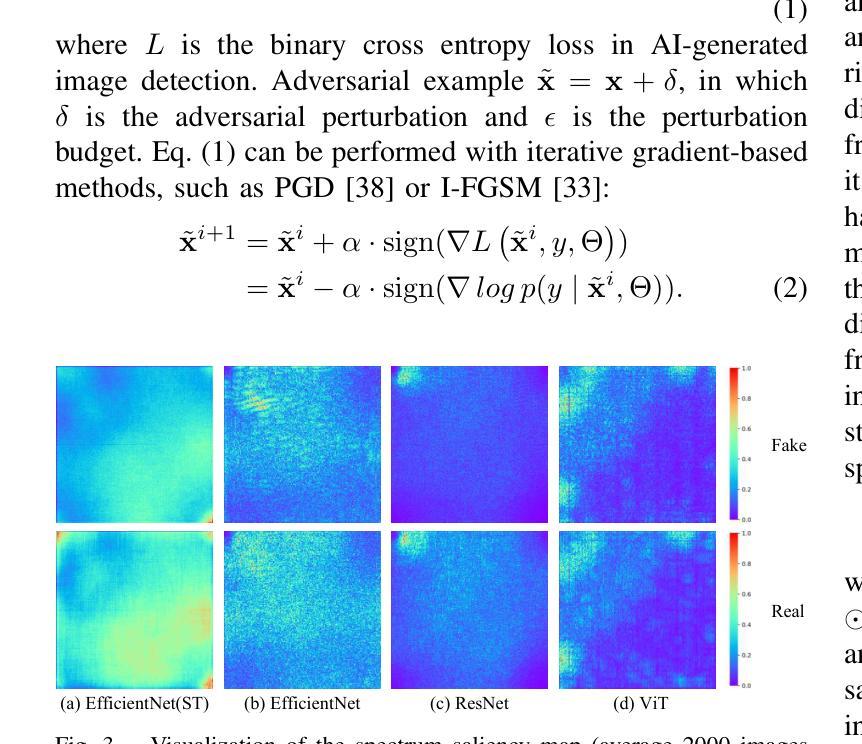
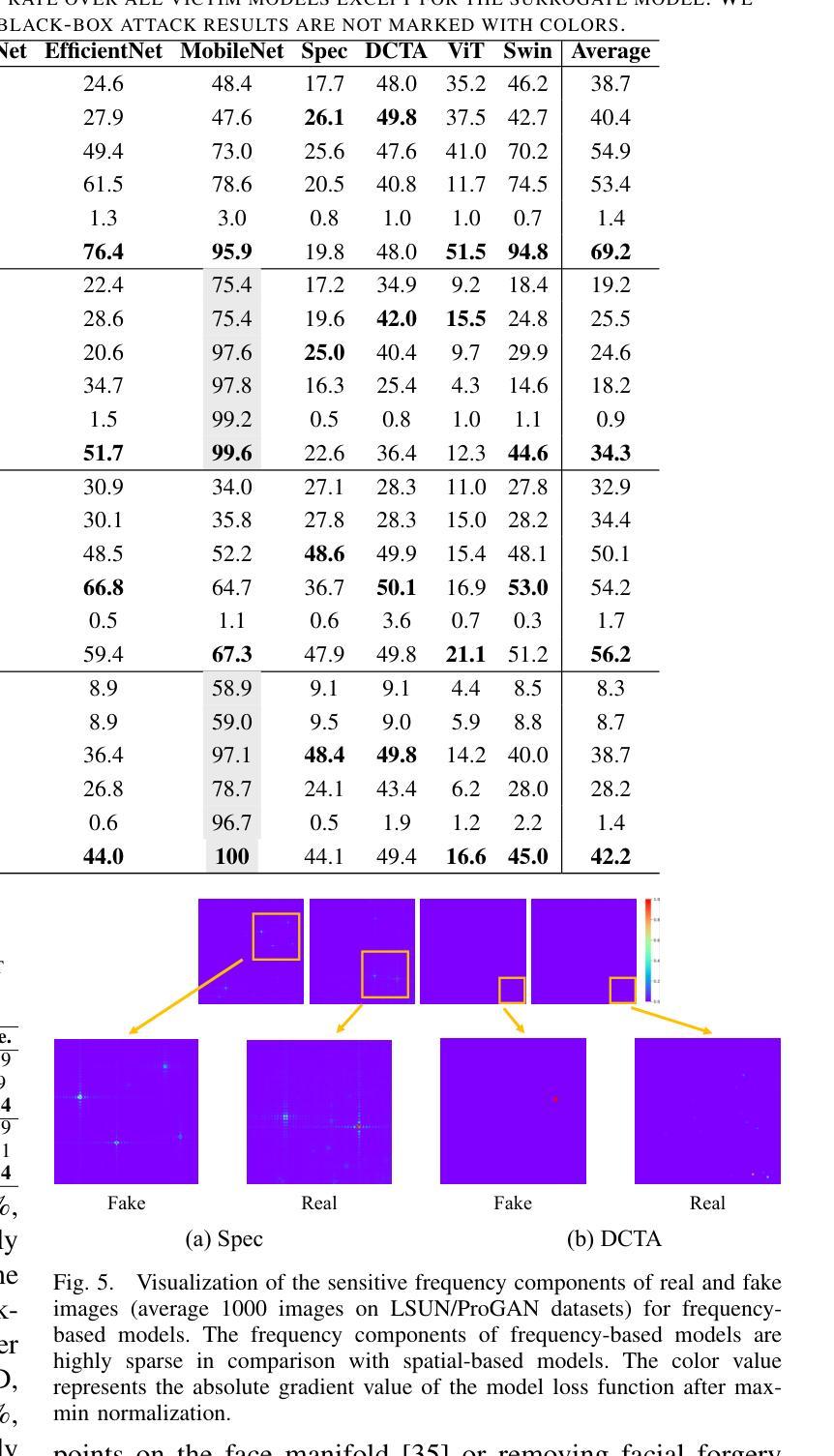
Recent advancements in image synthesis, particularly with the advent of GAN and Diffusion models, have amplified public concerns regarding the dissemination of disinformation. To address such concerns, numerous AI-generated Image (AIGI) Detectors have been proposed and achieved promising performance in identifying fake images. However, there still lacks a systematic understanding of the adversarial robustness of AIGI detectors. In this paper, we examine the vulnerability of state-of-the-art AIGI detectors against adversarial attack under white-box and black-box settings, which has been rarely investigated so far. To this end, we propose a new method to attack AIGI detectors. First, inspired by the obvious difference between real images and fake images in the frequency domain, we add perturbations under the frequency domain to push the image away from its original frequency distribution. Second, we explore the full posterior distribution of the surrogate model to further narrow this gap between heterogeneous AIGI detectors, e.g. transferring adversarial examples across CNNs and ViTs. This is achieved by introducing a novel post-train Bayesian strategy that turns a single surrogate into a Bayesian one, capable of simulating diverse victim models using one pre-trained surrogate, without the need for re-training. We name our method as Frequency-based Post-train Bayesian Attack, or FPBA. Through FPBA, we show that adversarial attack is truly a real threat to AIGI detectors, because FPBA can deliver successful black-box attacks across models, generators, defense methods, and even evade cross-generator detection, which is a crucial real-world detection scenario. The code will be shared upon acceptance.
近期图像合成领域的进展,特别是生成对抗网络(GAN)和扩散模型的出现,加剧了公众对虚假信息传播问题的担忧。为了解决这些担忧,已经提出了许多AI生成的图像(AIGI)检测器,并在识别虚假图像方面取得了有前景的表现。然而,对于AIGI检测器的对抗性稳健性,仍缺乏系统的理解。本文在白皮书和黑箱环境中对最先进的AIGI检测器进行对抗性攻击的脆弱性进行了考察,这一内容迄今为止很少被研究。为此,我们提出了一种新的方法来攻击AIGI检测器。首先,受到真实图像和虚假图像在频域上明显差异的启发,我们在频域添加扰动来使图像远离其原始频域分布。其次,我们探索了替代模型的后验分布,以进一步缩小不同AIGI检测器之间的差距,例如将对抗性示例从CNN转移到ViTs。这是通过引入一种新的后训练贝叶斯策略来实现的,它将单个替代模型转变为贝叶斯模型,能够使用预先训练的替代模型模拟多种受害者模型,而无需重新训练。我们将我们的方法命名为基于频域的后训练贝叶斯攻击(FPBA)。通过FPBA,我们证明了对抗性攻击确实对AIGI检测器构成真正的威胁,因为FPBA可以在不同模型、生成器、防御方法和甚至避免跨生成器检测的情况下成功进行黑箱攻击,这在现实世界的检测场景中至关重要。代码将在接受后共享。
论文及项目相关链接
Summary
先进的图像合成技术引发公众对假信息传播问题的担忧,针对此,AI生成的图像检测器在识别虚假图像方面展现出良好性能。然而,目前缺乏对先进AI图像检测器对抗鲁棒性的系统理解。本文研究最先进AI图像检测器在白盒和黑盒环境下的脆弱性,并对其进行攻击。通过在频率域添加扰动和利用代理模型的整个后验分布,我们提出了一种新的攻击方法——基于频率的后训练贝叶斯攻击(FPBA)。该方法能够在不同模型、生成器、防御方法和跨生成器检测中成功进行黑盒攻击,并绕开检测,显示了对AI图像检测器的严重威胁。
Key Takeaways
- 先进的图像合成技术引发公众对假图像传播的担忧,AI生成的图像检测器在识别虚假图像方面已展现出良好性能。
- 目前缺乏对AI图像检测器对抗鲁棒性的系统理解。
- 提出了在白盒和黑盒环境下针对最先进AI图像检测器的攻击方法。
- 新的攻击方法——基于频率的后训练贝叶斯攻击(FPBA)能够在不同模型、生成器、防御方法和跨生成器检测中成功进行黑盒攻击。
- FPBA显示了对AI图像检测器的严重威胁,并绕过了某些检测机制。
- 通过添加频率域的扰动和模拟不同受害模型的后验分布来执行FPBA攻击。
点此查看论文截图



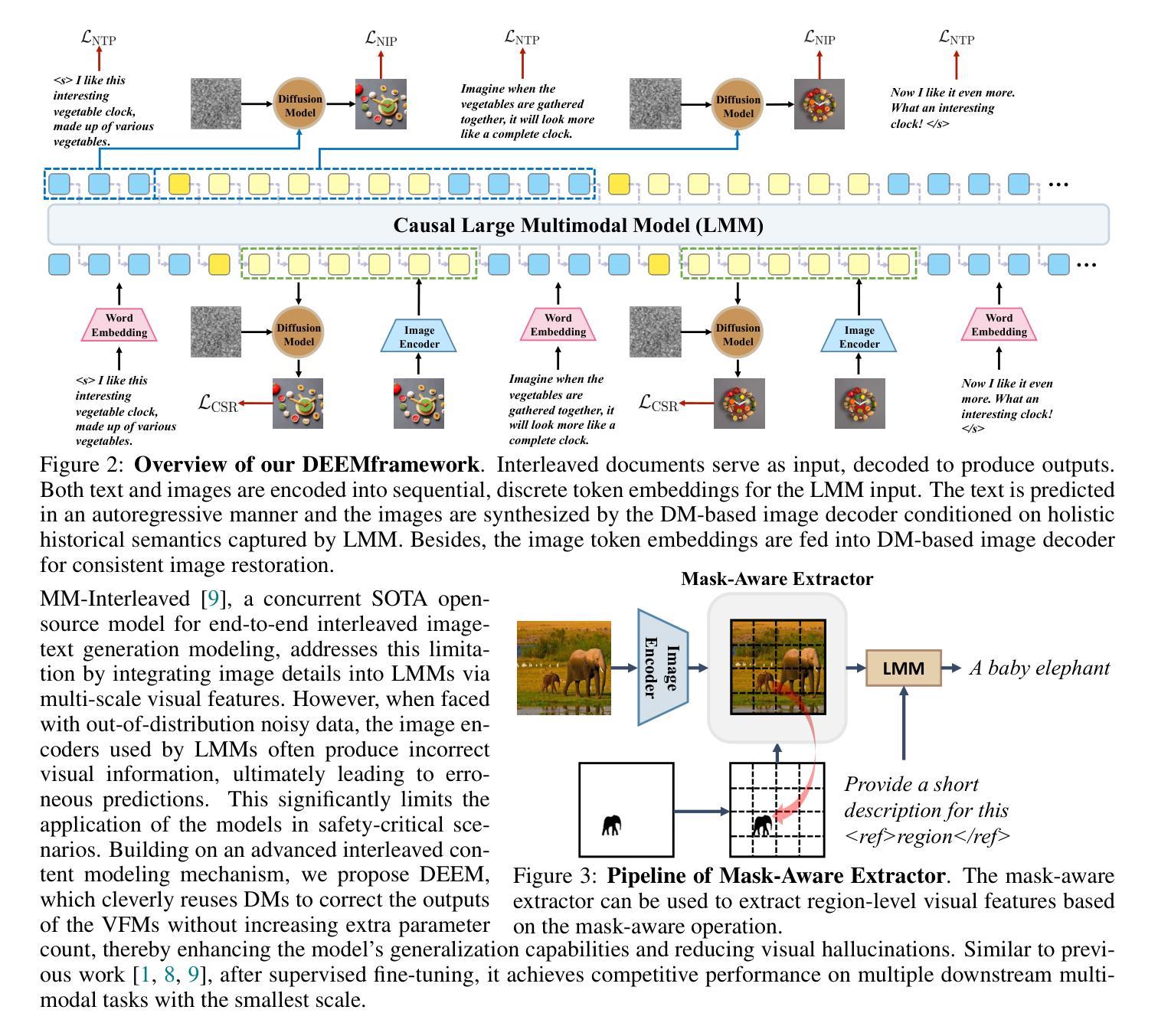
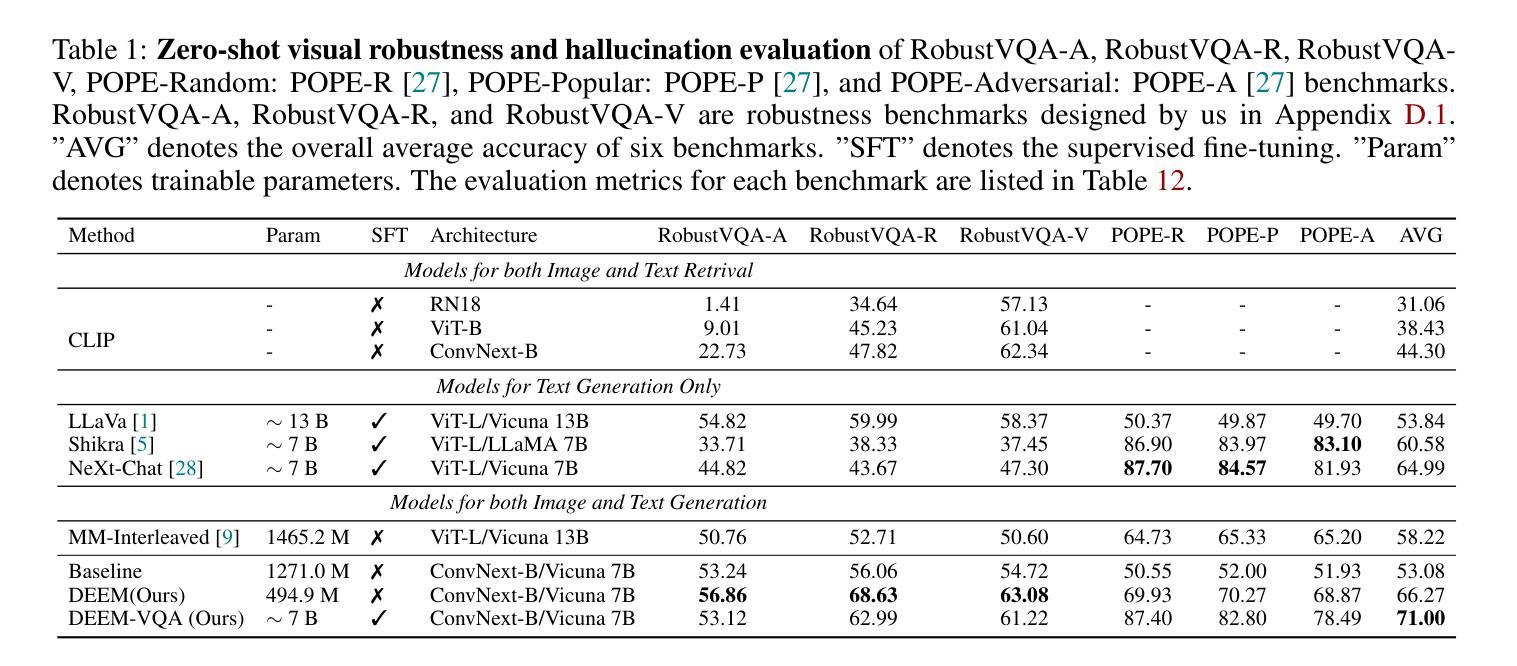
DEEM: Diffusion Models Serve as the Eyes of Large Language Models for Image Perception
Authors:Run Luo, Yunshui Li, Longze Chen, Wanwei He, Ting-En Lin, Ziqiang Liu, Lei Zhang, Zikai Song, Xiaobo Xia, Tongliang Liu, Min Yang, Binyuan Hui
The development of large language models (LLMs) has significantly advanced the emergence of large multimodal models (LMMs). While LMMs have achieved tremendous success by promoting the synergy between multimodal comprehension and creation, they often face challenges when confronted with out-of-distribution data, such as which can hardly distinguish orientation, quantity, color, structure, etc. This is primarily due to their reliance on image encoders trained to encode images into task-relevant features, which may lead them to disregard irrelevant details. Delving into the modeling capabilities of diffusion models for images naturally prompts the question: Can diffusion models serve as the eyes of large language models for image perception? In this paper, we propose DEEM, a simple but effective approach that utilizes the generative feedback of diffusion models to align the semantic distributions of the image encoder. This addresses the drawbacks of previous methods that solely relied on image encoders like CLIP-ViT, thereby enhancing the model’s resilience against out-of-distribution samples and reducing visual hallucinations. Importantly, this is achieved without requiring additional training modules and with fewer training parameters. We extensively evaluated DEEM on both our newly constructed RobustVQA benchmark and other well-known benchmarks, POPE and MMVP, for visual hallucination and perception. In particular, DEEM improves LMM’s visual perception performance to a large extent (e.g., 4% higher on RobustVQA, 6.5% higher on MMVP and 12.8 % higher on POPE ). Compared to the state-of-the-art interleaved content generation models, DEEM exhibits enhanced robustness and a superior capacity to alleviate model hallucinations while utilizing fewer trainable parameters, less pre-training data (10%), and a smaller base model size.
大型语言模型(LLM)的发展极大地推动了大型多模态模型(LMM)的出现。虽然LMM通过促进多模态理解和创作的协同作用取得了巨大的成功,但它们在面对超出分布的数据时经常面临挑战,例如无法区分方向、数量、颜色、结构等。这主要是因为它们依赖于训练有素的图像编码器将图像编码为与任务相关的特征,这可能导致它们忽略不相关的细节。深入研究扩散模型对图像的建模能力自然会引发一个问题:扩散模型能否作为大型语言模型的“眼睛”来进行图像感知?在本文中,我们提出了DEEM,这是一种简单而有效的方法,它利用扩散模型的生成反馈来对齐图像编码器的语义分布。这解决了以前仅依赖图像编码器的方法(如CLIP-ViT)的缺点,提高了模型对超出分布样本的适应性,并减少了视觉幻觉。重要的是,这是在不添加额外的训练模块和更少的训练参数的情况下实现的。我们在新构建的RobustVQA基准测试和其他知名的POPE和MMVP基准测试上对DEEM进行了广泛评估,用于视觉幻觉和感知。特别是,DEEM在很大程度上提高了LMM的视觉感知性能(例如,在RobustVQA上提高了4%,在MMVP上提高了6.5%,在POPE上提高了12.8%)。与最先进的交错内容生成模型相比,DEEM具有更强的稳健性,在利用更少的可训练参数、更少的预训练数据(10%)和更小的基本模型大小的情况下,具有减轻模型幻觉的优越能力。
论文及项目相关链接
PDF 25 pages. arXiv admin note: text overlap with arXiv:2401.10208 by other authors
摘要
大型语言模型(LLM)的发展极大地推动了大型多模态模型(LMM)的出现。虽然LMM通过促进多模态理解和创造之间的协同作用取得了巨大成功,但当面对分布外的数据时,它们常常面临挑战,难以区分方向、数量、颜色、结构等。本文提出了一种简单而有效的方法DEEM,它利用扩散模型的生成反馈来对齐图像编码器的语义分布,解决了之前方法仅依赖图像编码器(如CLIP-ViT)的缺点,增强了模型对分布外样本的韧性,并减少了视觉幻觉。重要的是,这不需要额外的训练模块,并且训练参数更少。我们在新构建的RobustVQA基准测试和其他著名的POPE和MMVP基准测试上对DEEM进行了广泛评估,用于视觉幻觉和感知。特别是,DEEM在很大程度上提高了LMM的视觉感知性能(例如,RobustVQA上提高了4%,MMVP上提高了6.5%,POPE上提高了12.8%)。与最先进的交替内容生成模型相比,DEEM具有更强的稳健性,在利用更少的可训练参数、预训练数据(减少至10%)和较小的基本模型大小的情况下,具有更出色的缓解模型幻觉的能力。
关键见解
- 大型多模态模型(LMM)在处理分布外的图像数据时面临挑战,难以区分方向、数量、颜色等。
- 论文提出了一种名为DEEM的新方法,利用扩散模型的生成反馈来提高图像编码器的语义分布对齐。
- DEEM增强了模型的韧性,使其能够更好地应对分布外的样本,并减少了视觉幻觉。
- DEEM方法不需要额外的训练模块,并且使用更少的训练参数即可实现性能提升。
- 在多个基准测试上,DEEM显著提高了大型多模态模型的视觉感知性能。
- 与其他先进的模型相比,DEEM具有更强的稳健性,并能更有效地缓解模型幻觉。
点此查看论文截图

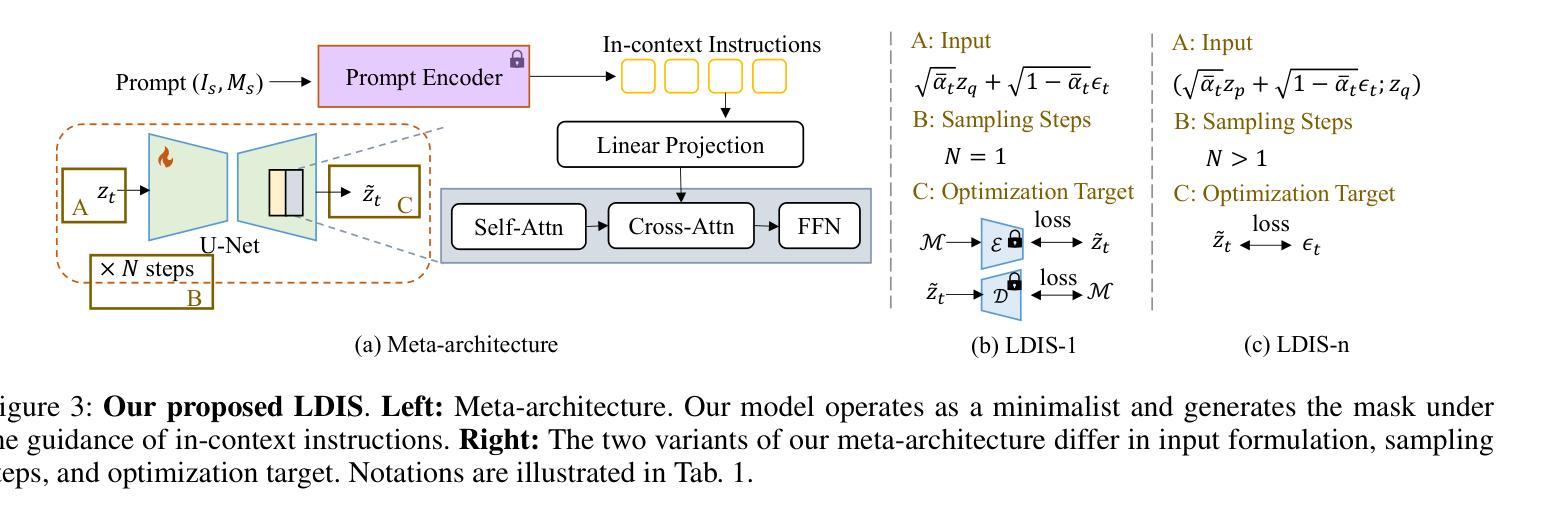
Explore In-Context Segmentation via Latent Diffusion Models
Authors:Chaoyang Wang, Xiangtai Li, Henghui Ding, Lu Qi, Jiangning Zhang, Yunhai Tong, Chen Change Loy, Shuicheng Yan
In-context segmentation has drawn increasing attention with the advent of vision foundation models. Its goal is to segment objects using given reference images. Most existing approaches adopt metric learning or masked image modeling to build the correlation between visual prompts and input image queries. This work approaches the problem from a fresh perspective - unlocking the capability of the latent diffusion model (LDM) for in-context segmentation and investigating different design choices. Specifically, we examine the problem from three angles: instruction extraction, output alignment, and meta-architectures. We design a two-stage masking strategy to prevent interfering information from leaking into the instructions. In addition, we propose an augmented pseudo-masking target to ensure the model predicts without forgetting the original images. Moreover, we build a new and fair in-context segmentation benchmark that covers both image and video datasets. Experiments validate the effectiveness of our approach, demonstrating comparable or even stronger results than previous specialist or visual foundation models. We hope our work inspires others to rethink the unification of segmentation and generation.
随着视觉基础模型的出现,上下文分割已经引起了越来越多的关注。它的目标是利用给定的参考图像对对象进行分割。大多数现有方法采用度量学习或掩膜图像建模,在视觉提示和输入图像查询之间建立关联。这项工作从一个全新的角度来解决这个问题——解锁潜在扩散模型(LDM)在上下文分割方面的能力,并研究不同的设计选择。具体来说,我们从三个方面来探讨这个问题:指令提取、输出对齐和元架构。我们设计了一个两阶段的掩膜策略,以防止干扰信息泄露到指令中。此外,我们提出了一种增强的伪掩膜目标,以确保模型在预测时不会忘记原始图像。此外,我们建立了一个新的公平上下文分割基准测试,涵盖图像和视频数据集。实验验证了我们的方法的有效性,显示出与之前的专家或视觉基础模型相当甚至更强的结果。我们希望我们的工作能激励他人重新思考分割和生成的统一。
论文及项目相关链接
PDF AAAI 2025
Summary
在情境分割领域,本文采用扩散模型视角,从指令提取、输出对齐和元架构三个角度进行研究。提出了一种两阶段遮蔽策略来防止干扰信息泄漏到指令中,并提出一种增强型伪遮蔽目标来确保模型的预测不会忘记原始图像。同时,建立了一个新的情境分割基准测试集,涵盖图像和视频数据集。实验验证了该方法的有效性,与先前的专业或视觉基础模型相比,取得了相当甚至更强的结果。
Key Takeaways
- 情境分割是给定参考图像对目标进行分割的重要任务。本文研究其在视觉基础模型中的应用。
- 本文提出了一种新的视角来解决情境分割问题,即通过利用潜在扩散模型(LDM)的能力来实现这一点。
- 该研究深入探讨了不同的设计选择,如指令提取、输出对齐和元架构的构建。
- 为了防止干扰信息泄漏到指令中,采用了两阶段遮蔽策略。
- 提出了一种增强型伪遮蔽目标来确保模型预测的准确性并避免遗忘原始图像。
- 建立了一个新的情境分割基准测试集,涵盖图像和视频数据集,为评估模型性能提供了重要依据。
点此查看论文截图



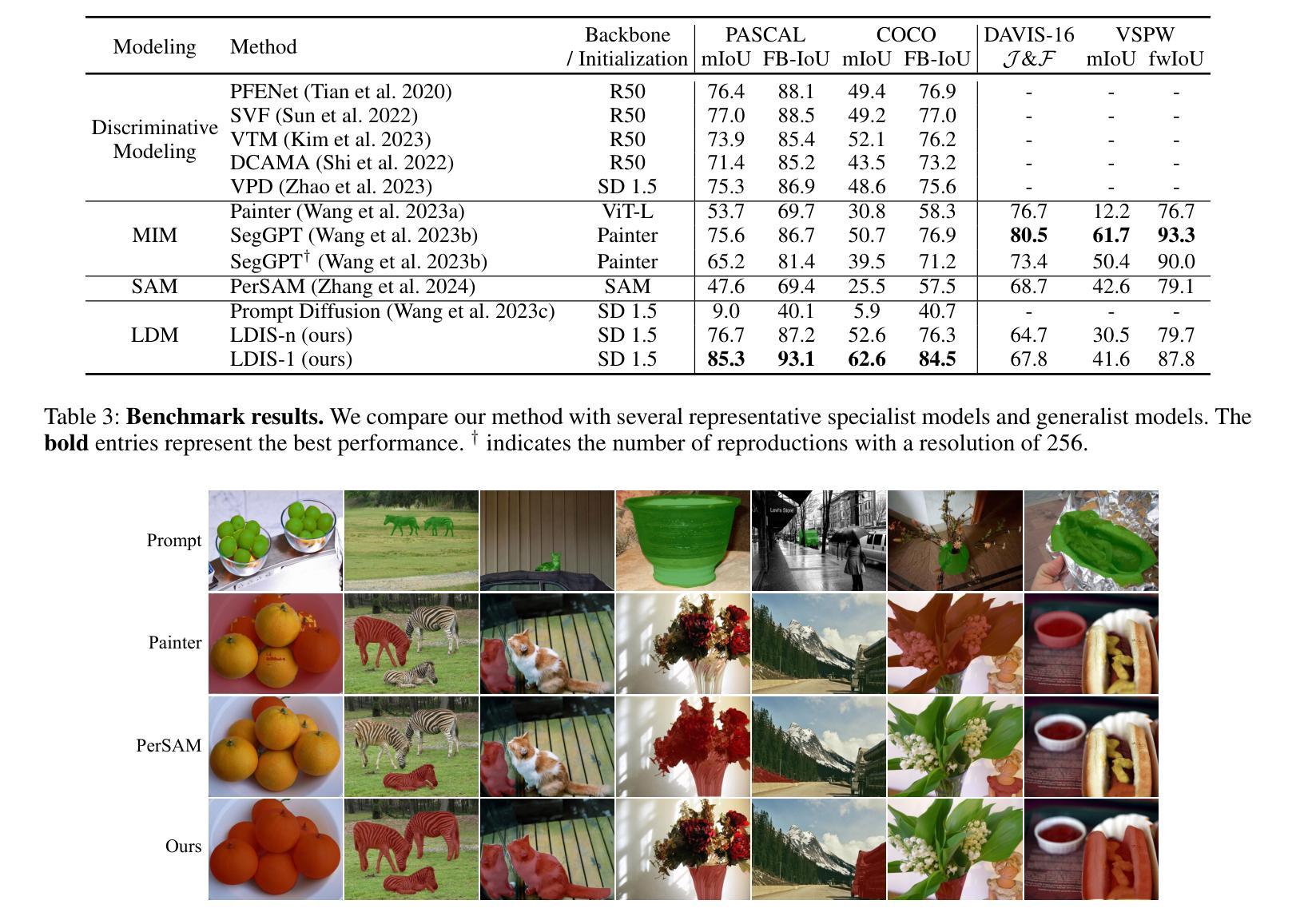


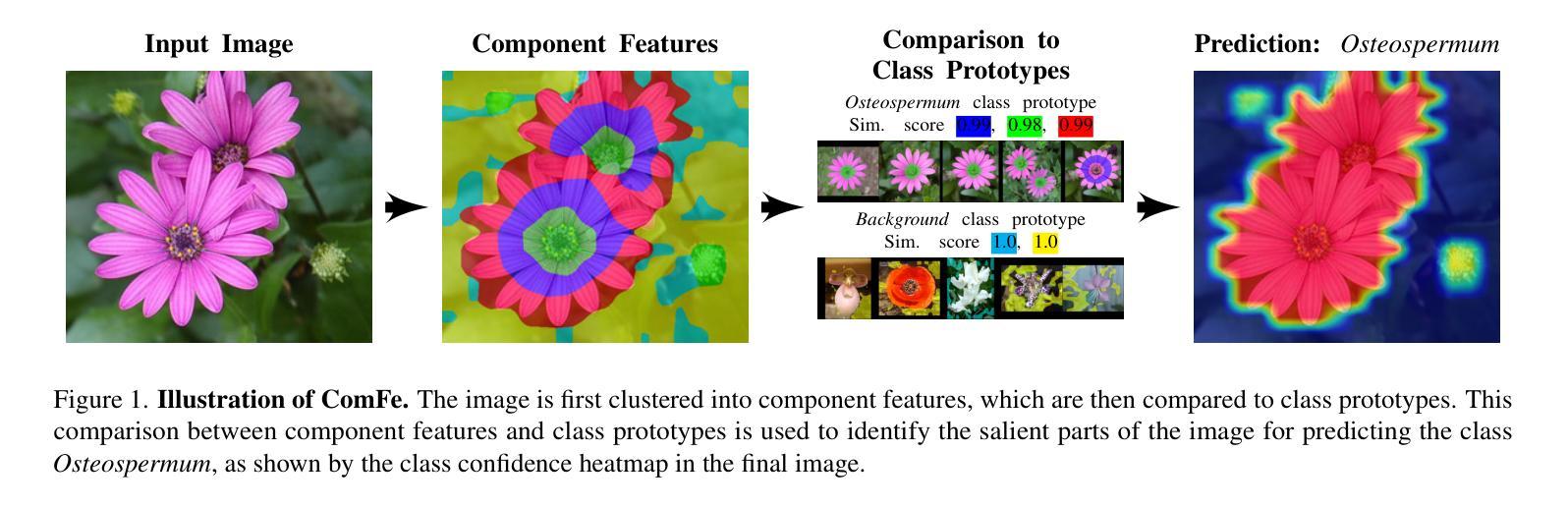
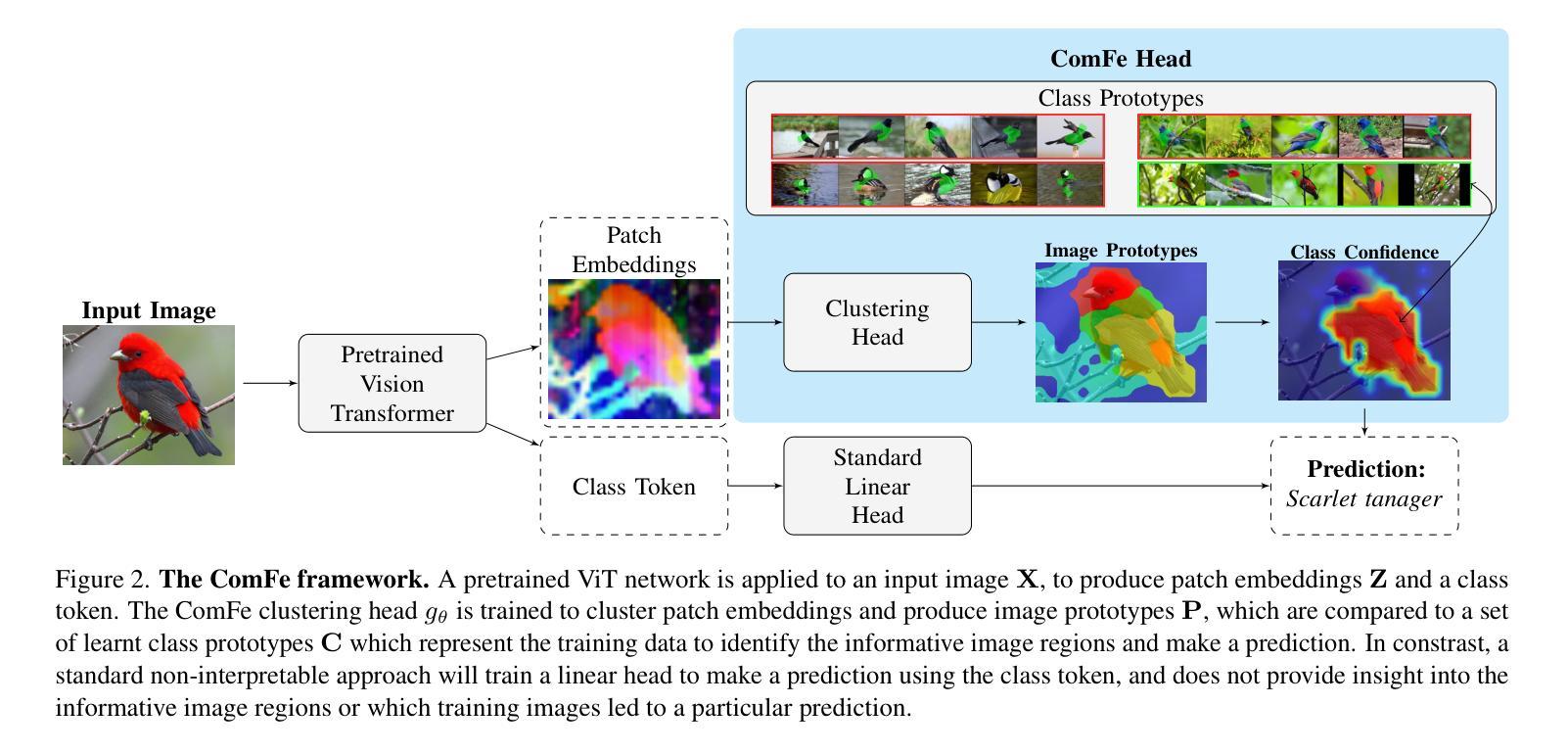
ComFe: An Interpretable Head for Vision Transformers
Authors:Evelyn J. Mannix, Liam Hodgkinson, Howard Bondell
Interpretable computer vision models explain their classifications through comparing the distances between the local embeddings of an image and a set of prototypes that represent the training data. However, these approaches introduce additional hyper-parameters that need to be tuned to apply to new datasets, scale poorly, and are more computationally intensive to train in comparison to black-box approaches. In this work, we introduce Component Features (ComFe), a highly scalable interpretable-by-design image classification head for pretrained Vision Transformers (ViTs) that can obtain competitive performance in comparison to comparable non-interpretable methods. ComFe is the first interpretable head, that we know of, and unlike other interpretable approaches, can be readily applied to large scale datasets such as ImageNet-1K. Additionally, ComFe provides improved robustness and outperforms previous interpretable approaches on key benchmark datasets$\unicode{x2013}$using a consistent set of hyper-parameters and without finetuning the pretrained ViT backbone. With only global image labels and no segmentation or part annotations, ComFe can identify consistent component features within an image and determine which of these features are informative in making a prediction. Code is available at https://github.com/emannix/comfe-component-features.
解释性计算机视觉模型通过比较图像的局部嵌入与代表训练数据的一组原型之间的距离来解释其分类结果。然而,这些方法引入了一些额外的超参数,需要针对新数据集进行调整,扩展性差,并且与黑盒方法相比计算成本更高昂进行训练。在这项工作中,我们引入了组件特征(ComFe),这是一种为预训练的视觉转换器(ViT)设计的图像分类头部,它通过设计具有高度可解释性,可以获得与非解释性方法相当的性能。ComFe是我们所了解的第一个解释性头部,与其他解释性方法不同,它可以轻松应用于大规模数据集,例如ImageNet-1K。此外,ComFe提高了稳健性,并在关键基准数据集上优于之前的解释性方法,使用一套一致的超参数且无需微调预训练的ViT主干。仅凭全局图像标签而无需分段或部分注释,ComFe可以在图像内部识别一致的组件特征,并确定哪些特征对做出预测具有信息价值。代码可以在以下网站找到:链接地址https://github.com/emannix/comfe-component-features。
论文及项目相关链接
Summary
本文介绍了一种名为Component Features(ComFe)的预训练Vision Transformer(ViT)图像分类头,具有可解释性和高度可扩展性。相较于其他解释性方法,ComFe可应用于大规模数据集如ImageNet-1K,使用一致的超参数,无需微调预训练的ViT主干,在关键基准数据集上表现优异,并提高了稳健性。ComFe仅需全局图像标签,无需分割或部分注释,可识别图像中的一致组件特征,并确定哪些特征对预测具有信息价值。
Key Takeaways
- ComFe是一种用于预训练Vision Transformer(ViT)的高度可扩展的解释性图像分类头。
- ComFe通过比较图像局部嵌入与代表训练数据的原型集之间的距离来解释其分类。
- 与其他解释方法相比,ComFe在大型数据集如ImageNet-1K上的表现更具竞争力。
- ComFe使用一致的超参数,无需针对新数据集进行微调。
- ComFe提高了稳健性,并在关键基准数据集上优于之前的解释方法。
- ComFe仅依赖全局图像标签,无需额外的分割或部分注释。
点此查看论文截图

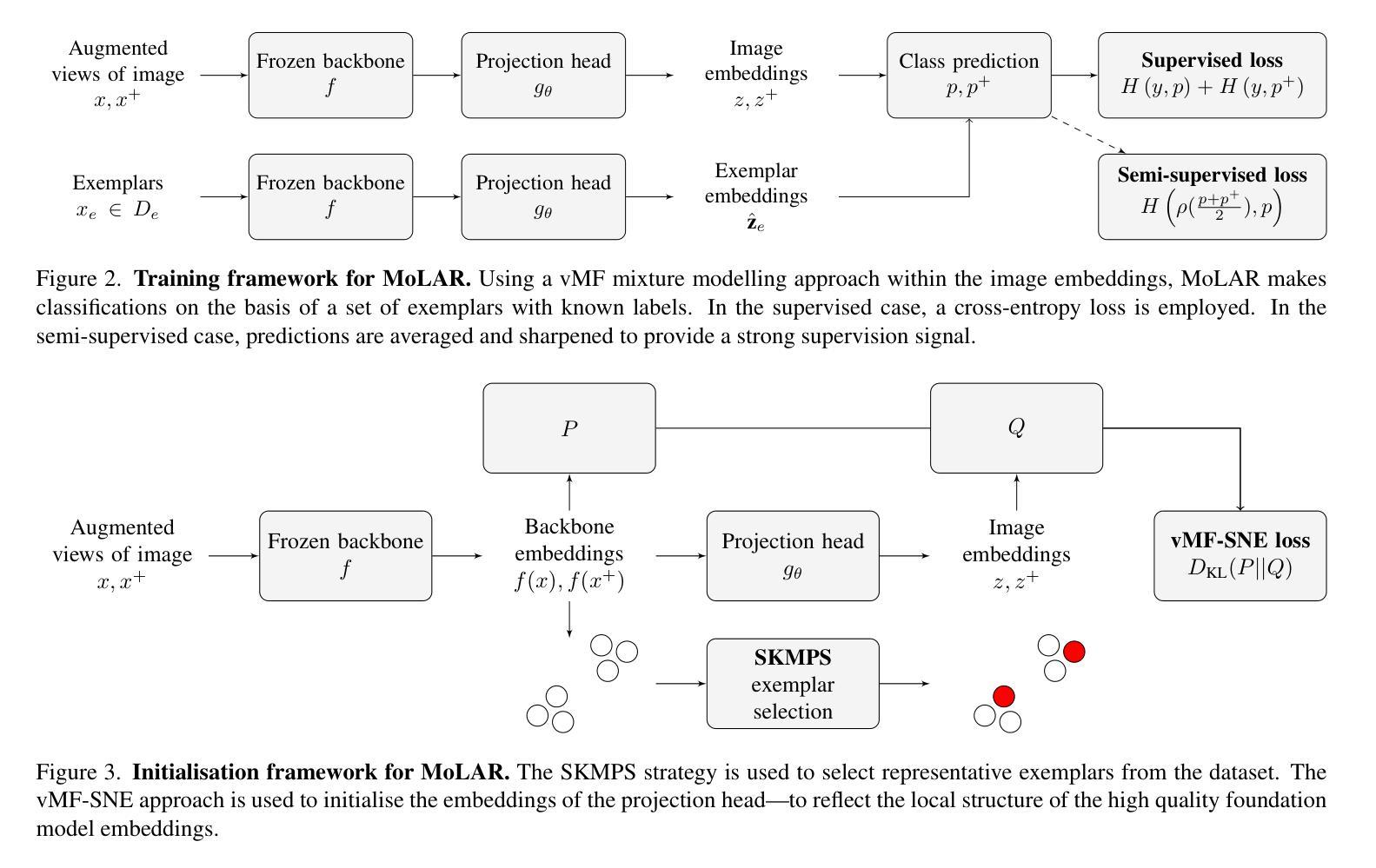
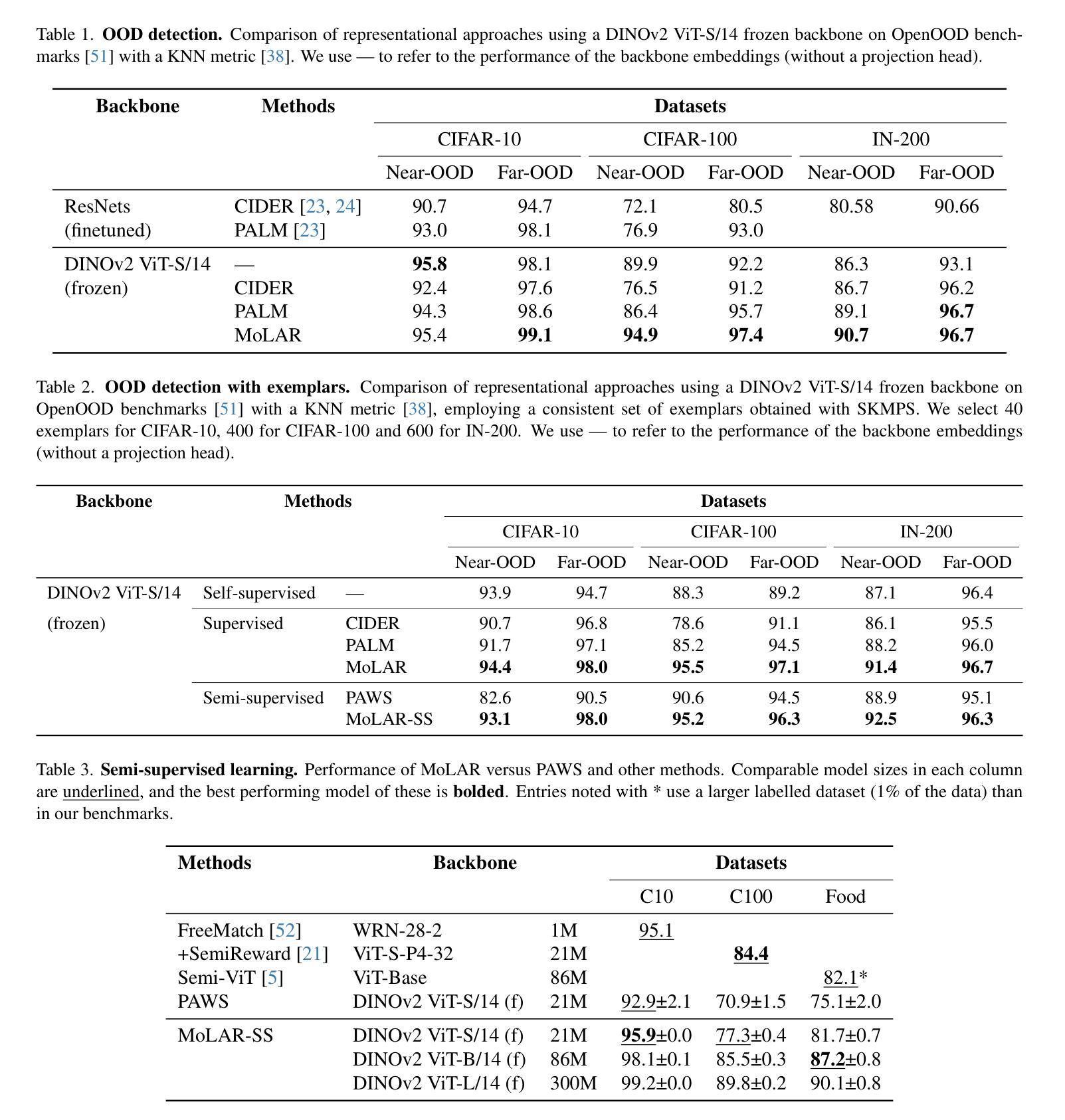
A Mixture of Exemplars Approach for Efficient Out-of-Distribution Detection with Foundation Models
Authors:Evelyn Mannix, Howard Bondell
One of the early weaknesses identified in deep neural networks trained for image classification tasks was their inability to provide low confidence predictions on out-of-distribution (OOD) data that was significantly different from the in-distribution (ID) data used to train them. Representation learning, where neural networks are trained in specific ways that improve their ability to detect OOD examples, has emerged as a promising solution. However, these approaches require long training times and can add additional overhead to detect OOD examples. Recent developments in Vision Transformer (ViT) foundation models$\unicode{x2013}$large networks trained on large and diverse datasets with self-supervised approaches$\unicode{x2013}$also show strong performance in OOD detection, and could address these challenges. This paper presents Mixture of Exemplars (MoLAR), an efficient approach to tackling OOD detection challenges that is designed to maximise the benefit of training a classifier with a high quality, frozen, pretrained foundation model backbone. MoLAR provides strong OOD performance when only comparing the similarity of OOD examples to the exemplars, a small set of images chosen to be representative of the dataset, leading to up to 30 times faster OOD detection inference over other methods that provide best performance when the full ID dataset is used. In some cases, only using these exemplars actually improves performance with MoLAR. Extensive experiments demonstrate the improved OOD detection performance of MoLAR in comparison to comparable approaches in both supervised and semi-supervised settings, and code is available at github.com/emannix/molar-mixture-of-exemplars.
在早期识别深度神经网络进行图像分类任务时的一个弱点是它们对分布外(OOD)数据提供低置信度预测的能力不足,这些数据与用于训练它们的分布内(ID)数据有很大的不同。表征学习应运而生,在这种方法中,神经网络以特定的方式进行训练,提高了它们检测OOD样本的能力。然而,这些方法需要很长的训练时间,并且可能会增加检测OOD样本的额外开销。最近,Vision Transformer(ViT)基础模型的发展——在大型和多样化的数据集上采用自监督方法训练的大型网络——在OOD检测方面也表现出强大的性能,并可能解决这些挑战。本文提出了Mixture of Exemplars(MoLAR),这是一种解决OOD检测挑战的有效方法,旨在最大限度地发挥使用高质量、冻结的预训练基础模型骨架训练分类器的优势。MoLAR仅通过比较OOD示例与样本的相似性,即选择一小部分具有代表性的图像来代表数据集,即可实现强大的OOD性能,导致在与其他方法进行比较时,其OOD检测推理速度最快可达30倍。在某些情况下,仅使用这些样本实际上可以提高MoLAR的性能。大量实验表明,与可比的监督和半监督方法相比,MoLAR在OOD检测方面的性能有所提高,代码可在github.com/emannix/molar-mixture-of-exemplars找到。
论文及项目相关链接
Summary
本文提出一种名为MoLAR的混合范例方法,旨在解决深度神经网络在图像分类任务中对异常数据预测能力不足的问题。该方法通过优化预训练模型架构并利用高质范例子集来最大化分类器性能。相较于依赖完整数据集的方法,MoLAR只需使用代表数据集的范例子集进行相似性比较,实现更快的异常检测推理速度,并提高了性能表现。该方法适用于监督学习和半监督学习环境,已在实验中得到证实性能优势,且代码已发布于github。com/emannix/molar-mixture-of-exemplars上。
Key Takeaways
- MoLAR作为一种基于混合范例的方法被提出来解决深度神经网络在图像分类任务中的异常数据检测问题。
- 该方法通过优化预训练模型架构提升其性能,提高检测异常数据的能力。
- MoLAR利用代表数据集的范例子集进行相似性比较,实现了快速的异常检测推理速度。相较于依赖完整数据集的方法,其推理速度提高了高达30倍。
- MoLAR在监督学习和半监督学习环境中都展现出了优秀的性能表现。
点此查看论文截图