⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-14 更新
Fair Federated Medical Image Classification Against Quality Shift via Inter-Client Progressive State Matching
Authors:Nannan Wu, Zhuo Kuang, Zengqiang Yan, Ping Wang, Li Yu
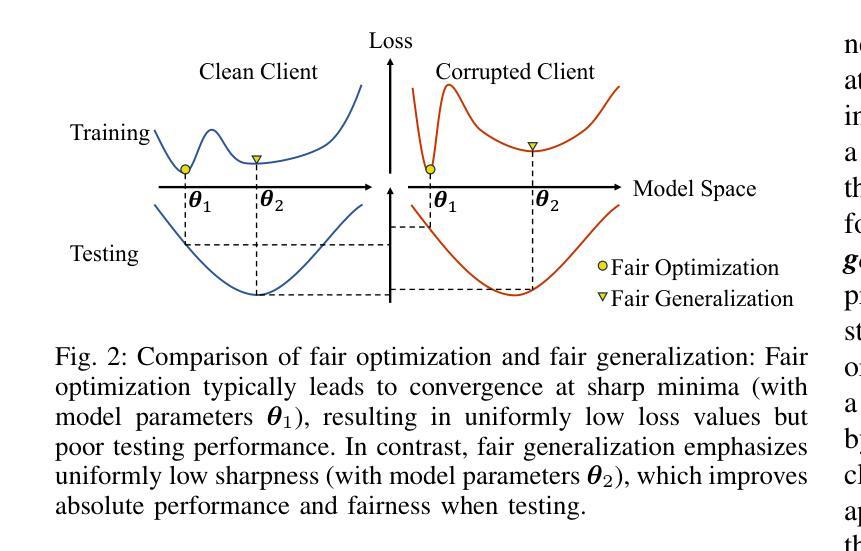
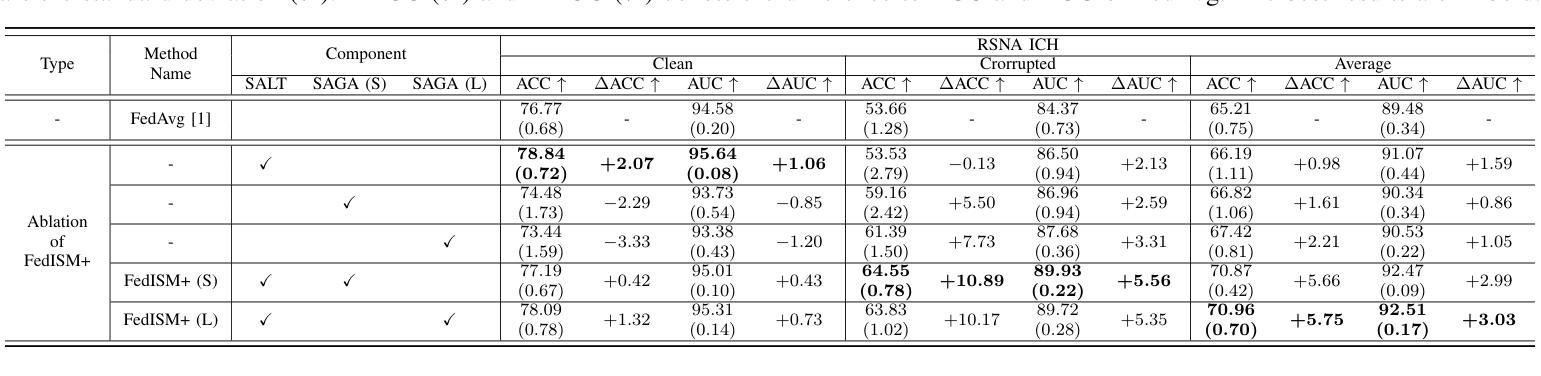
Despite the potential of federated learning in medical applications, inconsistent imaging quality across institutions-stemming from lower-quality data from a minority of clients-biases federated models toward more common high-quality images. This raises significant fairness concerns. Existing fair federated learning methods have demonstrated some effectiveness in solving this problem by aligning a single 0th- or 1st-order state of convergence (e.g., training loss or sharpness). However, we argue in this work that fairness based on such a single state is still not an adequate surrogate for fairness during testing, as these single metrics fail to fully capture the convergence characteristics, making them suboptimal for guiding fair learning. To address this limitation, we develop a generalized framework. Specifically, we propose assessing convergence using multiple states, defined as sharpness or perturbed loss computed at varying search distances. Building on this comprehensive assessment, we propose promoting fairness for these states across clients to achieve our ultimate fairness objective. This is accomplished through the proposed method, FedISM+. In FedISM+, the search distance evolves over time, progressively focusing on different states. We then incorporate two components in local training and global aggregation to ensure cross-client fairness for each state. This gradually makes convergence equitable for all states, thereby improving fairness during testing. Our empirical evaluations, performed on the well-known RSNA ICH and ISIC 2019 datasets, demonstrate the superiority of FedISM+ over existing state-of-the-art methods for fair federated learning. The code is available at https://github.com/wnn2000/FFL4MIA.
尽管联邦学习在医疗应用中有巨大潜力,但机构间成像质量的不一致性——源于少数客户较低质量的数据——使联邦模型偏向于更常见的高质量图像。这引发了关于公平性的重大担忧。现有的公平联邦学习方法已经通过调整收敛的单一状态(如训练损失或清晰度)来解决这个问题,显示出一定的效果。然而,我们在本文中认为,基于单一状态的公平并不是测试期间公平性的充分替代。这些单一指标未能充分捕捉收敛特性,对于指导公平学习来说效果并不理想。为了解决这个问题,我们开发了一个通用框架。具体来说,我们提出了通过多个状态来评估收敛性,定义为在不同搜索距离下计算的清晰度或扰动损失。基于这一全面的评估,我们提出了在客户端对这些状态实现公平的促进策略,以实现我们的最终公平目标。这是通过提出的方法FedISM+来实现的。在FedISM+中,搜索距离随时间变化,逐渐关注不同的状态。然后我们在本地训练和全局聚合中融入两个组件,以确保每个状态的跨客户端公平性。这将逐步使所有状态的收敛更加公平,从而提高测试期间的公平性。我们在著名的RSNA ICH和ISIC 2019数据集上进行的实证评估表明,FedISM+优于现有的最先进的公平联邦学习方法。代码可在https://github.com/wnn2000/FFL4MIA获得。
论文及项目相关链接
PDF Preprint
摘要
尽管联邦学习在医疗应用中有巨大潜力,但机构间成像质量的不一致性——源于部分客户较低质量的数据——使得联邦模型偏向更常见的高质量图像,从而引发公平性担忧。现有公平联邦学习方法通过统一收敛状态(如训练损失或清晰度)来解决这一问题,但本文认为基于单一状态的公平性评价不足以在测试阶段体现公平性。因为这些单一指标无法完全捕捉收敛特性,因此它们对于指导公平学习的效果并不理想。为解决这一局限性,本文开发了一个通用框架,提出通过多个状态来评估收敛性,定义为不同搜索距离计算的清晰度或扰动损失。基于这一全面的评估,我们提出针对这些状态的公平性促进方法,以实现我们的最终公平目标。通过新方法FedISM+,搜索距离随时间演变,逐渐关注不同的状态。然后我们在本地训练和全局聚合中融入两个组件,以确保每个状态的跨客户端公平性。这逐渐使所有状态的收敛趋于公平,从而提高测试阶段的公平性。在著名的RSNA ICH和ISIC 2019数据集上进行的实证评估表明,FedISM+优于现有的先进公平联邦学习方法。相关代码可在以下网站找到:https://github.com/wnn2000/FFL4MIA。
关键见解
- 联邦学习在医疗应用中面临因机构间成像质量不一致导致的公平性挑战。
- 现有公平联邦学习方法主要通过单一收敛状态评价公平性,但在测试阶段这显得不足。
- 提出一种通用框架,通过多个状态评估收敛性,以更全面捕捉收敛特性。
- 引入FedISM+方法,其中搜索距离随时间演变,并在本地训练和全局聚合中融入两个组件来确保跨客户端公平性。
- FedISM+方法可以改善测试阶段的公平性,并在RSNA ICH和ISIC 2019数据集上表现出优越性能。
- FedISM+的代码公开可用,网址为:https://github.com/wnn2000/FFL4MIA。
- 该研究为公平联邦学习提供了新的思路和方法,有望改善医疗应用中模型公平性问题。
点此查看论文截图


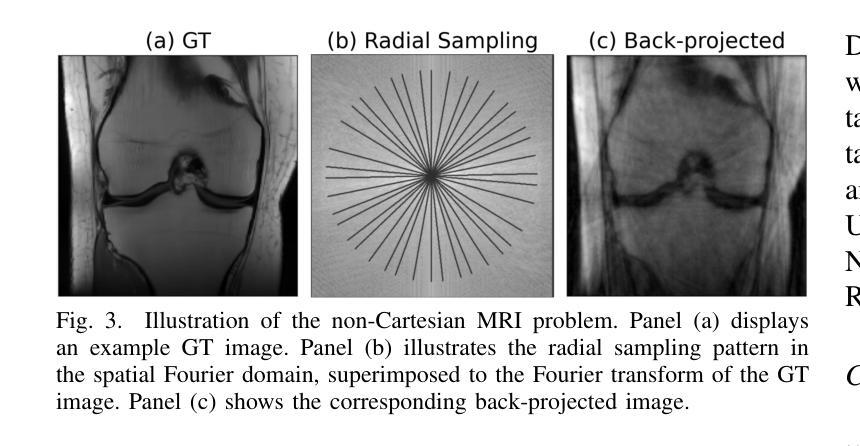
The R2D2 Deep Neural Network Series for Scalable Non-Cartesian Magnetic Resonance Imaging
Authors:Yiwei Chen, Amir Aghabiglou, Shijie Chen, Motahare Torki, Chao Tang, Ruud B. van Heeswijk, Yves Wiaux
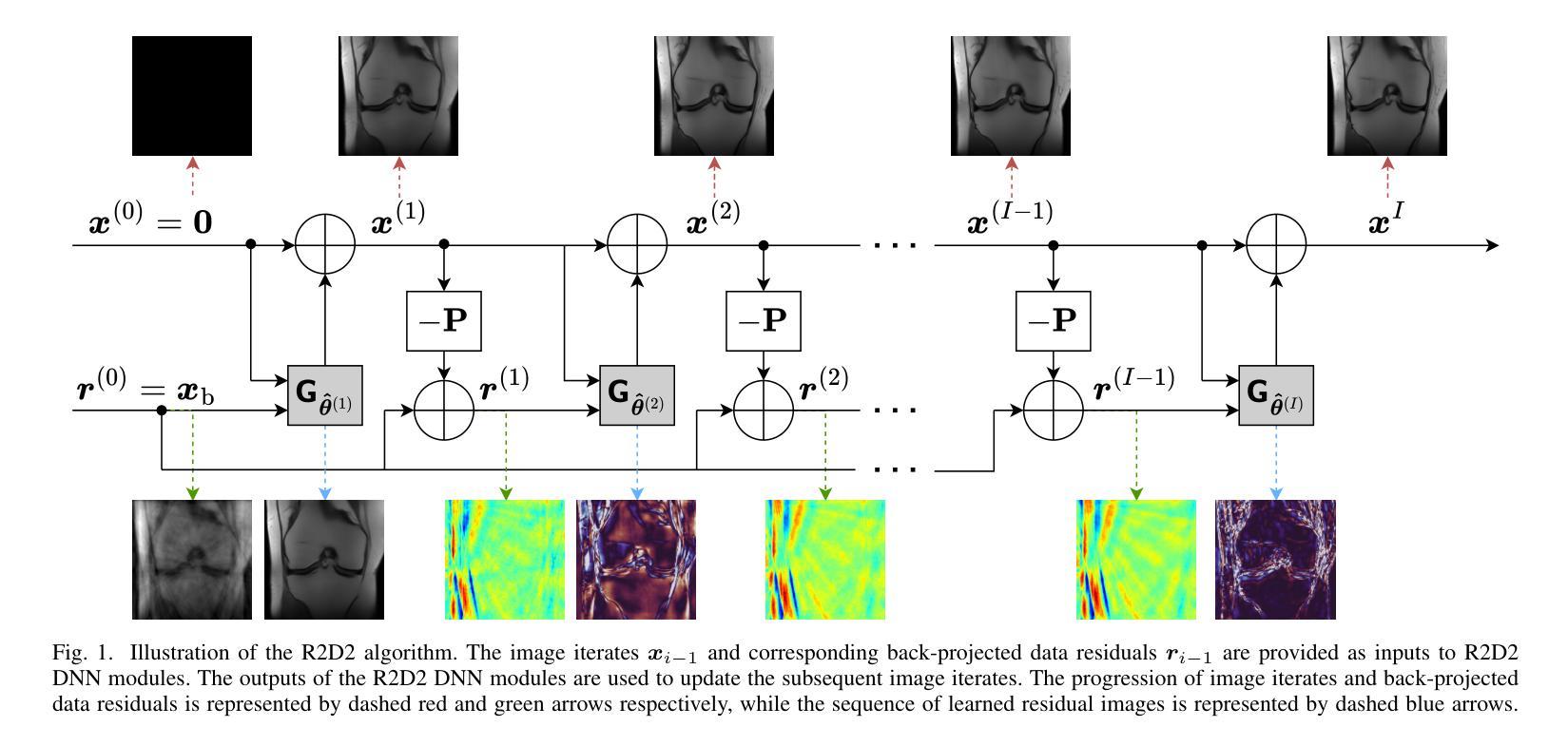
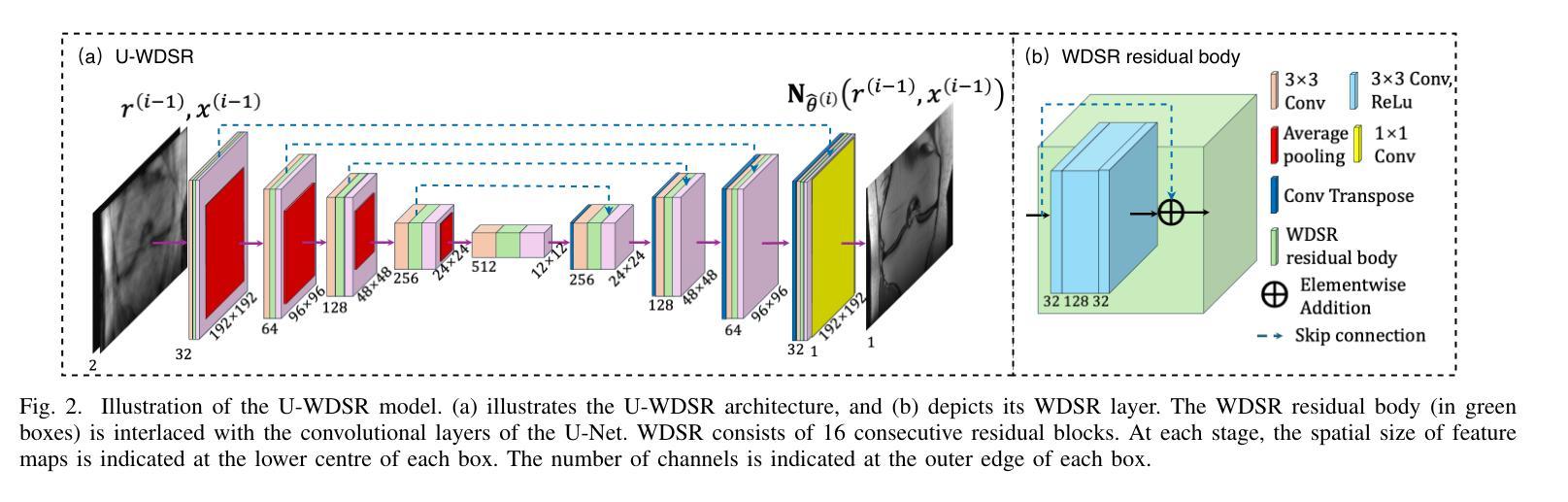
We introduce the R2D2 Deep Neural Network (DNN) series paradigm for fast and scalable image reconstruction from highly-accelerated non-Cartesian k-space acquisitions in Magnetic Resonance Imaging (MRI). While unrolled DNN architectures provide a robust image formation approach via data-consistency layers, embedding non-uniform fast Fourier transform operators in a DNN can become impractical to train at large scale, e.g in 2D MRI with a large number of coils, or for higher-dimensional imaging. Plug-and-play approaches that alternate a learned denoiser blind to the measurement setting with a data-consistency step are not affected by this limitation but their highly iterative nature implies slow reconstruction. To address this scalability challenge, we leverage the R2D2 paradigm that was recently introduced to enable ultra-fast reconstruction for large-scale Fourier imaging in radio astronomy. R2D2’s reconstruction is formed as a series of residual images iteratively estimated as outputs of DNN modules taking the previous iteration’s data residual as input. The method can be interpreted as a learned version of the Matching Pursuit algorithm. A series of R2D2 DNN modules were sequentially trained in a supervised manner on the fastMRI dataset and validated for 2D multi-coil MRI in simulation and on real data, targeting highly under-sampled radial k-space sampling. Results suggest that a series with only few DNNs achieves superior reconstruction quality over its unrolled incarnation R2D2-Net (whose training is also much less scalable), and over the state-of-the-art diffusion-based “Decomposed Diffusion Sampler” approach (also characterised by a slower reconstruction process).
我们介绍了R2D2深度神经网络(DNN)系列范式,该范式可用于从磁共振成像(MRI)中的高度加速的非笛卡尔k空间采集快速且可扩展的图像重建。虽然展开的DNN架构通过数据一致性层提供了稳健的图像形成方法,但在大规模嵌入非均匀快速傅里叶变换算子时可能变得不切实际,例如在具有大量线圈的2DMRI中,或在更高维度的成像中。交替使用对测量设置盲点的可学习去噪器和数据一致性步骤的即插即用方法不会受到此限制,但它们的高度迭代性质意味着重建速度较慢。为了应对可扩展性挑战,我们采用了最近引入的R2D2范式,该范式可实现射电天文学中大规模傅里叶成像的超快速重建。R2D2的重建是由一系列残差图像组成,这些残差图像是DNN模块的迭代估计输出,以之前的迭代数据残差作为输入。该方法可解释为匹配追踪算法的学习版本。一系列R2D2 DNN模块在fastMRI数据集上以监督方式进行训练,并通过模拟和真实数据对2D多线圈MRI进行了验证,针对高度欠采样的径向k空间采样。结果表明,只有少数DNN的系列实现了优于其展开形式R2D2-Net(其训练也不太可扩展)以及优于最先进的基于扩散的“分解扩散采样器”方法的重建质量(其重建过程也较慢)。
论文及项目相关链接
PDF 13 pages, 10 figures
Summary
本文介绍了基于R2D2深度神经网络(DNN)系列的范式,用于从高度加速的非笛卡尔k空间采集中进行快速且可伸缩的磁共振成像(MRI)图像重建。该范式通过数据一致性层提供稳健的图像形成方法,解决了在大型规模,如在具有多个线圈的2D MRI或更高维度的成像中,将非均匀快速傅立叶变换算子嵌入DNN中进行训练的不切实际的问题。R2D2范式被引入以解决这一可扩展性挑战,它可快速重建大规模傅立叶成像,可解释为匹配追踪算法的学成版本。在fastMRI数据集上,一系列R2D2 DNN模块通过监督方式进行训练,并在模拟和真实数据上对2D多线圈MRI进行验证,目标为高度欠采样的径向k空间采样。结果表明,仅包含少数DNN的系列实现了优于R2D2-Net(其训练也不可伸缩)和优于当前技术水平的分解扩散采样器方法的重建质量。
Key Takeaways
- 引入R2D2 Deep Neural Network (DNN)系列范式,用于快速且可伸缩地从非笛卡尔k空间采集中进行磁共振成像(MRI)图像重建。
- R2D2范式解决了在大型规模下,将非均匀快速傅立叶变换算子嵌入DNN进行训练的不切实际的问题。
- R2D2范式可解释为匹配追踪算法的学成版本。
- R2D2 DNN模块通过监督方式在fastMRI数据集上进行训练。
- R2D2系列在模拟和真实数据的2D多线圈MRI验证中表现出优异的性能。
- 与R2D2-Net和当前技术水平的分解扩散采样器方法相比,R2D2系列实现更高的重建质量。
- R2D2系列具有更快的重建过程和更高的可扩展性。
点此查看论文截图

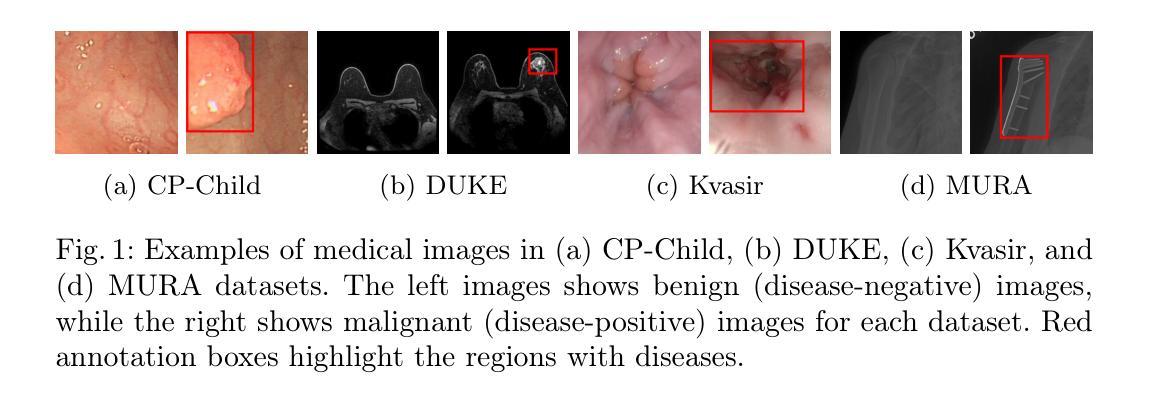
Evaluating Visual Explanations of Attention Maps for Transformer-based Medical Imaging
Authors:Minjae Chung, Jong Bum Won, Ganghyun Kim, Yujin Kim, Utku Ozbulak
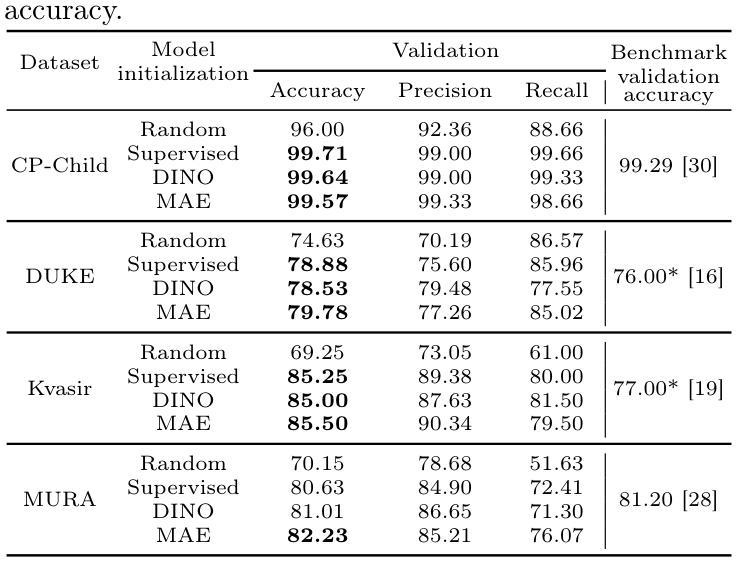
Although Vision Transformers (ViTs) have recently demonstrated superior performance in medical imaging problems, they face explainability issues similar to previous architectures such as convolutional neural networks. Recent research efforts suggest that attention maps, which are part of decision-making process of ViTs can potentially address the explainability issue by identifying regions influencing predictions, especially in models pretrained with self-supervised learning. In this work, we compare the visual explanations of attention maps to other commonly used methods for medical imaging problems. To do so, we employ four distinct medical imaging datasets that involve the identification of (1) colonic polyps, (2) breast tumors, (3) esophageal inflammation, and (4) bone fractures and hardware implants. Through large-scale experiments on the aforementioned datasets using various supervised and self-supervised pretrained ViTs, we find that although attention maps show promise under certain conditions and generally surpass GradCAM in explainability, they are outperformed by transformer-specific interpretability methods. Our findings indicate that the efficacy of attention maps as a method of interpretability is context-dependent and may be limited as they do not consistently provide the comprehensive insights required for robust medical decision-making.
尽管视觉转换器(ViTs)在医学成像问题上表现出了卓越的性能,但它们面临着与之前的架构(如卷积神经网络)类似的解释性问题。最近的研究努力表明,视觉转换器的决策过程中的注意力图有可能通过识别影响预测的区域来解决解释性问题,特别是在使用自监督学习进行预训练的模型中。在这项工作中,我们将注意力图的视觉解释与其他常用于医学成像问题的方法进行比较。为此,我们采用了四个不同的医学成像数据集,涉及(1)结肠息肉、(2)乳腺肿瘤、(3)食道炎症和(4)骨折和硬件植入物的识别。通过在上述数据集上进行大规模实验,使用各种有监督和自监督的预训练ViTs,我们发现尽管在特定条件下,注意力图表现出潜力,并且在解释性方面通常超过GradCAM,但它们还是被针对变压器的特定解释方法所超越。我们的研究结果表明,注意力图作为解释方法的有效性是依赖于具体情境的,并且可能会受到限制,因为它们并不能始终提供用于稳健医学决策所需的全面洞察。
论文及项目相关链接
PDF Accepted for publication in MICCAI 2024 Workshop on Interpretability of Machine Intelligence in Medical Image Computing (iMIMIC)
Summary
本文主要探讨了使用注意力映射技术增强医疗图像分析中的可解释性问题。研究发现,在某些条件下,注意力映射技术能够提高解释能力并超越GradCAM,但在与其他特定于Transformer的解释方法比较时表现较差。研究表明注意力映射的有效性依赖于上下文环境,且其在提供全面的决策支持方面可能受到限制。
Key Takeaways
- Vision Transformers (ViTs) 在医疗成像问题中展现出卓越性能,但面临可解释性问题。
- 注意力映射技术可识别影响预测的区域,从而解决ViTs的可解释性问题。
- 对比了注意力映射与其他常用于医疗成像问题的解释方法。
- 在四个不同的医疗成像数据集上进行大规模实验。
- 注意力映射技术在某些条件下可提高解释能力,但与其他Transformer特定的解释方法相比表现较差。
- 注意力映射技术的有效性依赖于上下文环境,可能无法提供全面的决策支持。
点此查看论文截图

SurgicalVLM-Agent: Towards an Interactive AI Co-Pilot for Pituitary Surgery
Authors:Jiayuan Huang, Runlong He, Danyal Z. Khan, Evangelos Mazomenos, Danail Stoyanov, Hani J. Marcus, Matthew J. Clarkson, Mobarakol Islam
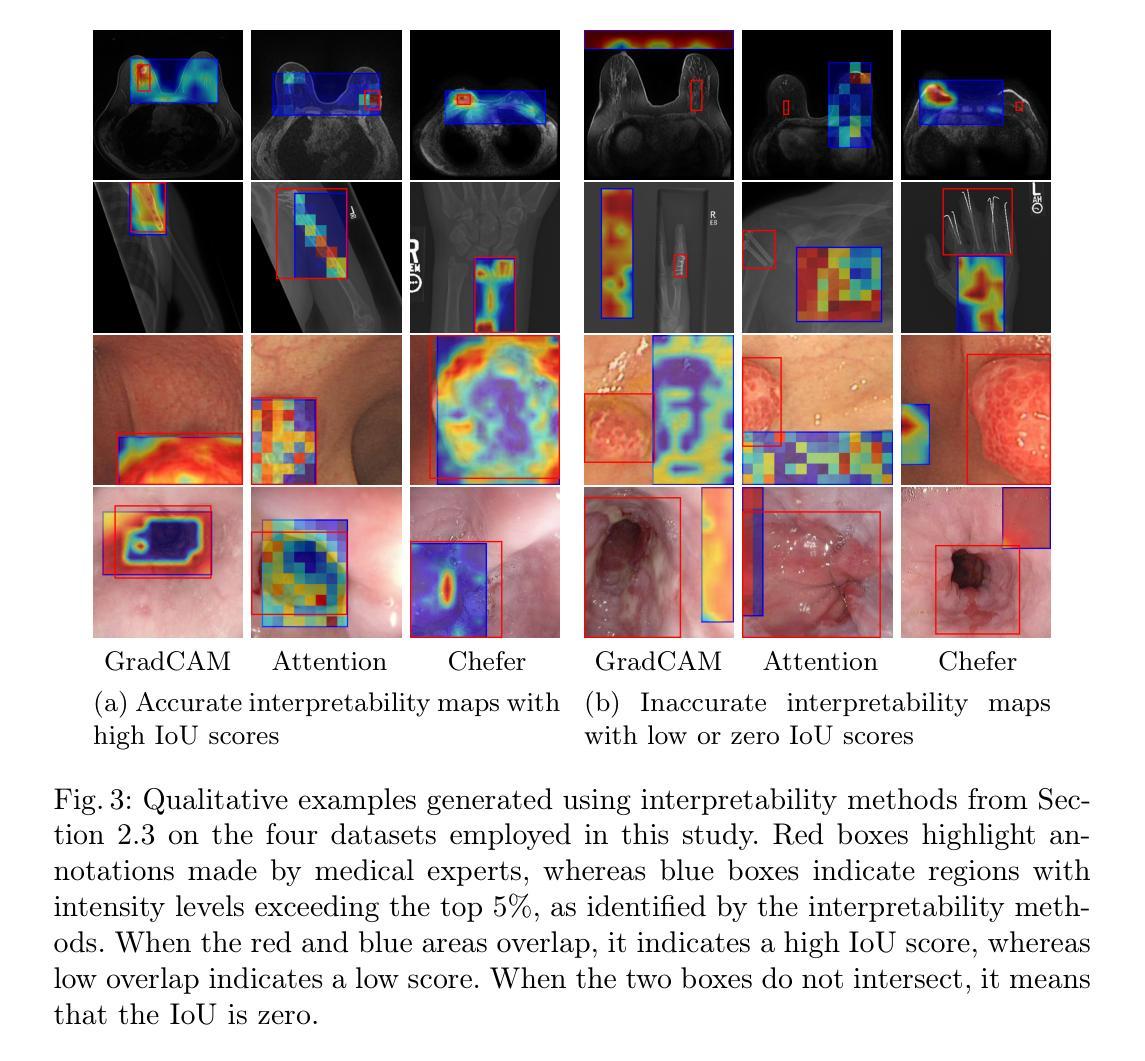
Image-guided surgery demands adaptive, real-time decision support, yet static AI models struggle with structured task planning and providing interactive guidance. Large vision-language models (VLMs) offer a promising solution by enabling dynamic task planning and predictive decision support. We introduce SurgicalVLM-Agent, an AI co-pilot for image-guided pituitary surgery, capable of conversation, planning, and task execution. The agent dynamically processes surgeon queries and plans the tasks such as MRI tumor segmentation, endoscope anatomy segmentation, overlaying preoperative imaging with intraoperative views, instrument tracking, and surgical visual question answering (VQA). To enable structured task planning, we develop the PitAgent dataset, a surgical context-aware dataset covering segmentation, overlaying, instrument localization, tool tracking, tool-tissue interactions, phase identification, and surgical activity recognition. Additionally, we propose FFT-GaLore, a fast Fourier transform (FFT)-based gradient projection technique for efficient low-rank adaptation, optimizing fine-tuning for LLaMA 3.2 in surgical environments. We validate SurgicalVLM-Agent by assessing task planning and prompt generation on our PitAgent dataset and evaluating zero-shot VQA using a public pituitary dataset. Results demonstrate state-of-the-art performance in task planning and query interpretation, with highly semantically meaningful VQA responses, advancing AI-driven surgical assistance.
图像引导手术需要自适应、实时决策支持,但静态的AI模型在结构化任务规划和提供交互式指导方面存在困难。大型视觉语言模型(VLMs)提供了一个有前景的解决方案,能够实现动态任务规划和预测决策支持。我们引入了SurgicalVLM-Agent,这是一个用于图像引导垂体手术的AI副驾驶,能够进行对话、规划和任务执行。该代理能够动态处理外科医生查询,并计划如MRI肿瘤分割、内窥镜解剖分割、将术前影像与术中视图叠加、仪器跟踪和手术视觉问答(VQA)等任务。为了支持结构化任务规划,我们开发了PitAgent数据集,这是一个手术上下文感知数据集,涵盖分割、叠加、仪器定位、工具跟踪、工具-组织交互、阶段识别以及手术活动识别。此外,我们提出了FFT-GaLore,这是一种基于快速傅里叶变换(FFT)的梯度投影技术,用于有效的低秩适应,优化在手术环境中对LLaMA 3.2的微调。我们通过评估我们的PitAgent数据集上的任务规划和提示生成,以及使用公共垂体数据集的零样本VQA来验证SurgicalVLM-Agent。结果表明,在任务规划和查询解释方面达到了最新性能水平,具有高度语义意义的VQA响应,推动了AI驱动的手术辅助的发展。
论文及项目相关链接
PDF 11 pages
Summary
图像引导手术需要自适应、实时决策支持,而静态AI模型在结构化任务规划和提供交互式指导方面存在挑战。我们引入SurgicalVLM-Agent,一个用于图像引导垂体手术的AI副驾驶,具备对话、规划和任务执行能力。通过动态处理外科医生查询,实现MRI肿瘤分割、内窥镜解剖分割、术前影像与术中视图的叠加、仪器追踪和手术视觉问答(VQA)等任务规划。为支持结构化任务规划,我们开发了PitAgent数据集,涵盖分割、叠加、仪器定位、工具追踪、工具-组织交互、阶段识别和活动识别等手术上下文感知数据。此外,我们提出FFT-GaLore,一种基于快速傅里叶变换(FFT)的梯度投影技术,用于实现高效低秩适应,优化在手术环境中的LLaMA 3.2微调。通过在我们的PitAgent数据集上评估任务规划和提示生成,以及在公共垂体数据集上评估零样本VQA,验证了SurgicalVLM-Agent的先进性。
Key Takeaways
- 图像引导手术需要自适应、实时的决策支持。
- 静态AI模型在结构化任务规划和交互式指导方面存在局限性。
- SurgicalVLM-Agent是一个用于图像引导垂体手术的AI系统,具备对话、规划和任务执行能力。
- SurgicalVLM-Agent可以实现多种任务,包括MRI肿瘤分割、内窥镜解剖分割、术前影像与术中视图的叠加等。
- 为支持结构化任务规划,开发了PitAgent数据集。
- FFT-GaLore技术用于提高SurgicalVLM-Agent在手术环境中的性能。
点此查看论文截图



Diff-CL: A Novel Cross Pseudo-Supervision Method for Semi-supervised Medical Image Segmentation
Authors:Xiuzhen Guo, Lianyuan Yu, Ji Shi, Na Lei, Hongxiao Wang
Semi-supervised learning utilizes insights from unlabeled data to improve model generalization, thereby reducing reliance on large labeled datasets. Most existing studies focus on limited samples and fail to capture the overall data distribution. We contend that combining distributional information with detailed information is crucial for achieving more robust and accurate segmentation results. On the one hand, with its robust generative capabilities, diffusion models (DM) learn data distribution effectively. However, it struggles with fine detail capture, leading to generated images with misleading details. Combining DM with convolutional neural networks (CNNs) enables the former to learn data distribution while the latter corrects fine details. While capturing complete high-frequency details by CNNs requires substantial computational resources and is susceptible to local noise. On the other hand, given that both labeled and unlabeled data come from the same distribution, we believe that regions in unlabeled data similar to overall class semantics to labeled data are likely to belong to the same class, while regions with minimal similarity are less likely to. This work introduces a semi-supervised medical image segmentation framework from the distribution perspective (Diff-CL). Firstly, we propose a cross-pseudo-supervision learning mechanism between diffusion and convolution segmentation networks. Secondly, we design a high-frequency mamba module to capture boundary and detail information globally. Finally, we apply contrastive learning for label propagation from labeled to unlabeled data. Our method achieves state-of-the-art (SOTA) performance across three datasets, including left atrium, brain tumor, and NIH pancreas datasets.
半监督学习利用无标签数据的见解来提高模型的泛化能力,从而减少了对大量有标签数据集的依赖。现有的大多数研究都集中在有限样本上,而无法捕捉整体数据分布。我们认为,将分布信息与详细信息相结合对于实现更稳健和准确的分割结果至关重要。一方面,扩散模型(DM)具有强大的生成能力,能够有效地学习数据分布。然而,它在捕捉细节方面表现挣扎,导致生成的图像具有误导性的细节。将DM与卷积神经网络(CNNs)相结合,使前者能够学习数据分布,而后者则校正细节。虽然CNNs捕捉完整的高频细节需要大量的计算资源,并容易受到局部噪声的影响。另一方面,鉴于有标签和无标签数据来自同一分布,我们认为无标签数据中与有标签数据的整体类语义相似的区域很可能属于同一类,而相似性极小的区域则不太可能属于。这项工作从分布角度引入了一个半监督医学图像分割框架(Diff-CL)。首先,我们提出了扩散和卷积分割网络之间的跨伪监督学习机制。其次,我们设计了一个高频mamba模块,以全局捕捉边界和详细信息。最后,我们应用对比学习,实现从有标签数据到无标签数据的标签传播。我们的方法在左心房、脑肿瘤和NIH胰腺数据集上的表现均达到最新水平(SOTA)。
论文及项目相关链接
Summary
半监督学习利用无标签数据的见解提高模型泛化能力,减少依赖大量标注数据集。本研究从分布角度出发,提出一种结合扩散模型和卷积神经网络进行医学图像分割的半监督框架,实现先进性能。
Key Takeaways
- 半监督学习利用无标签数据提高模型泛化能力。
- 现有研究多关注有限样本,难以捕捉整体数据分布。
- 结合数据分布与详细信息对实现稳健准确的分割结果至关重要。
- 扩散模型能有效学习数据分布,但难以捕捉精细细节。
- 卷积神经网络可纠正扩散模型的细节缺陷,但需大量计算资源且易受局部噪声影响。
- 提出一种结合扩散模型和卷积神经网络的半监督医学图像分割框架(Diff-CL)。
点此查看论文截图


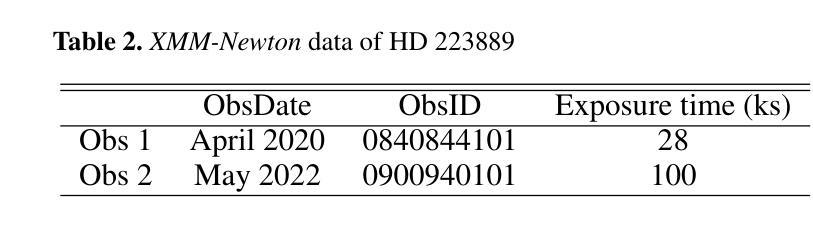
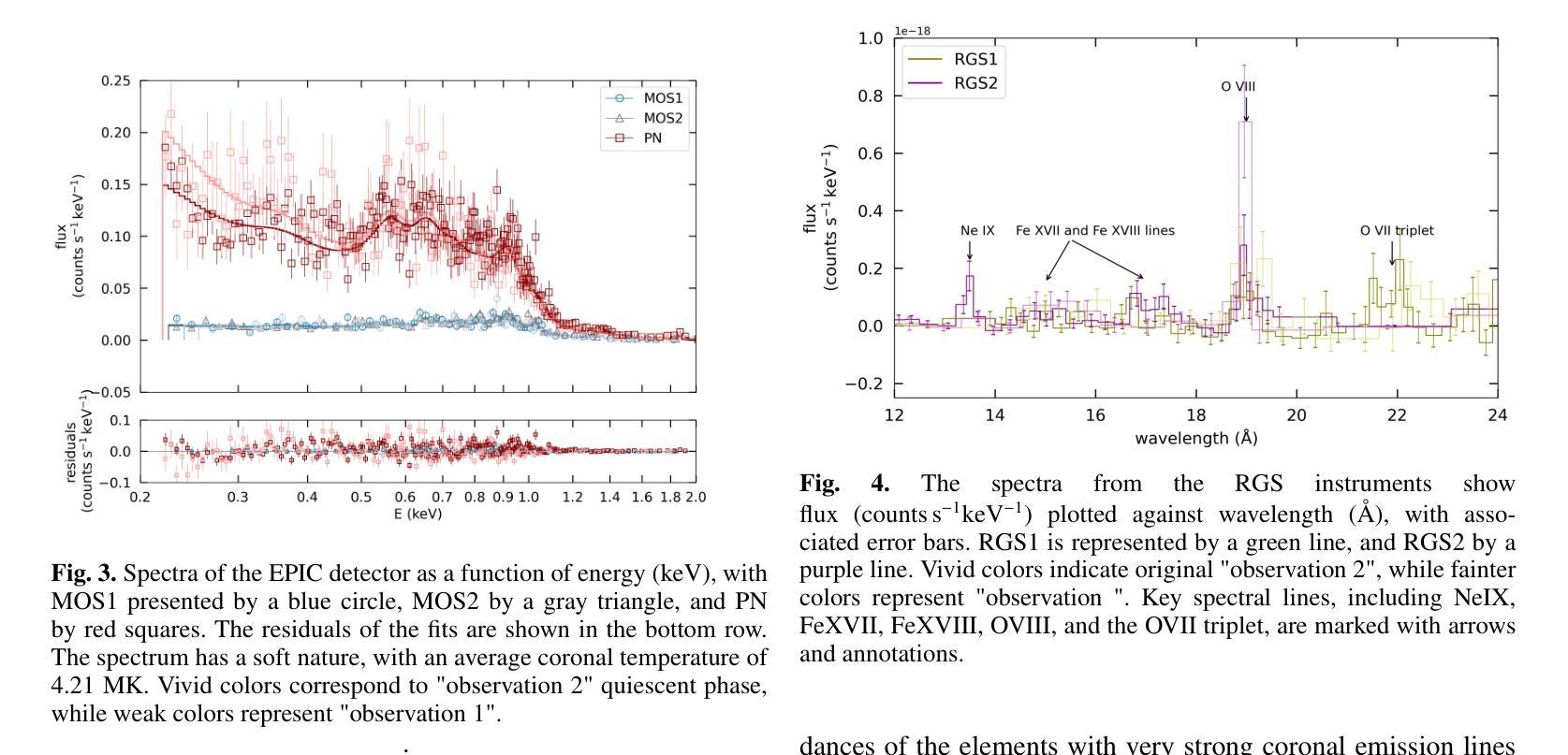
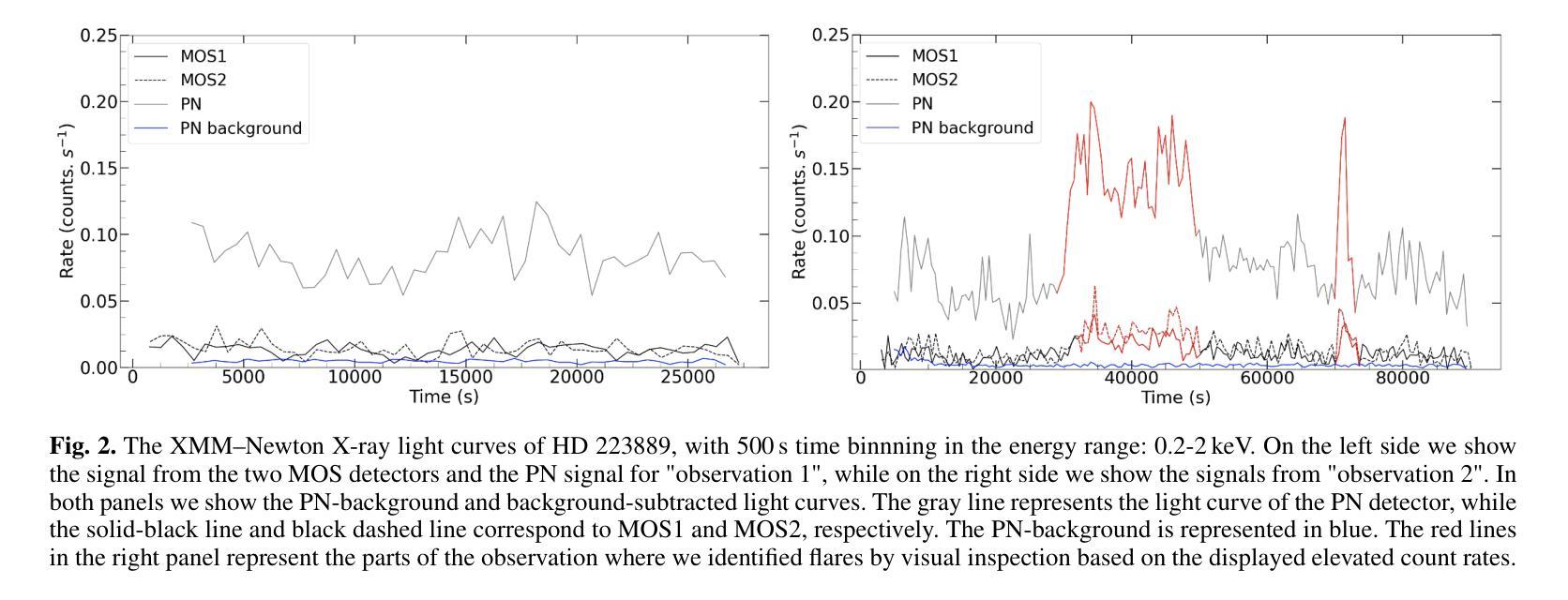
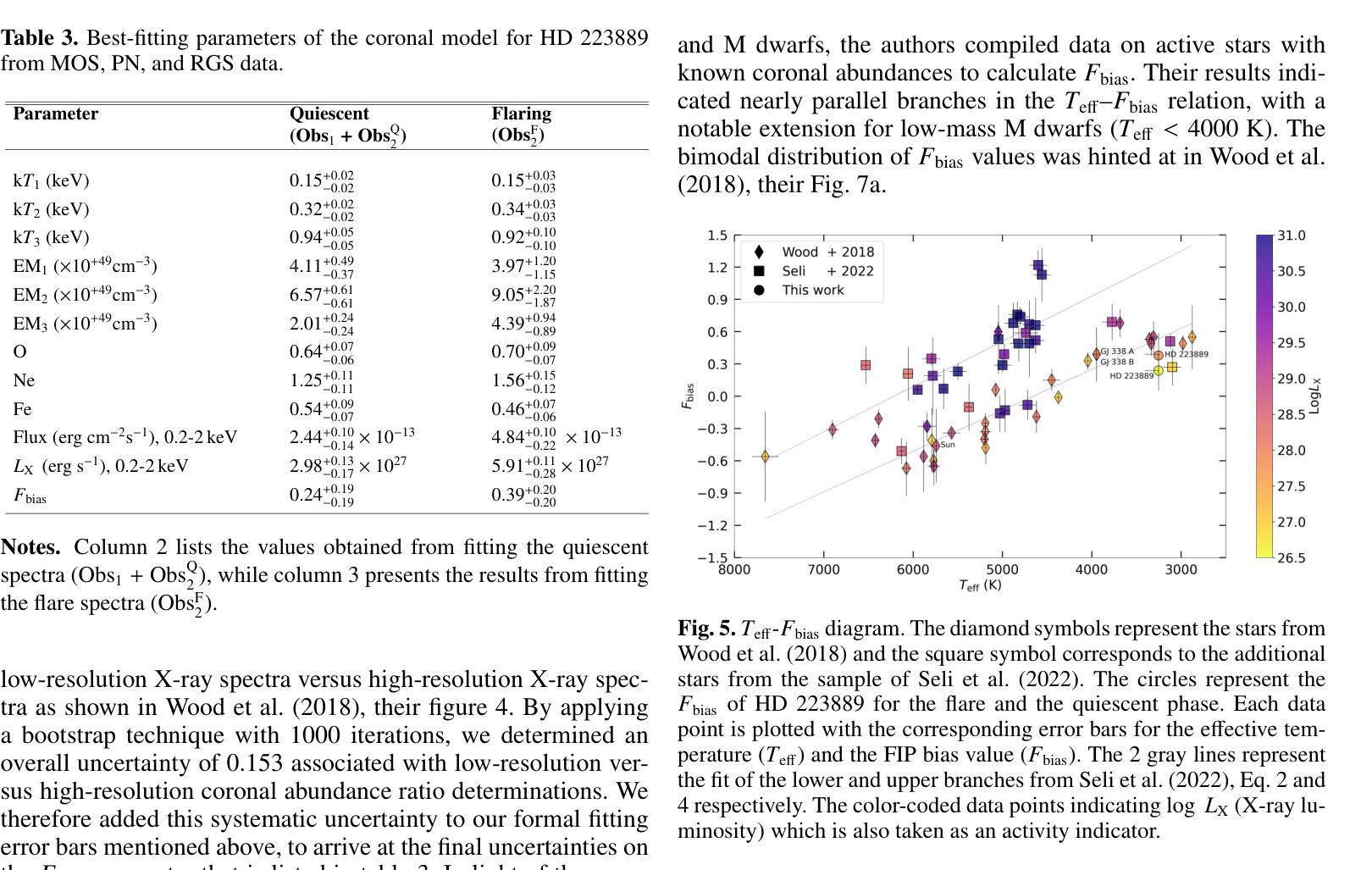
Exploring coronal abundances of M dwarfs at moderate activity levels
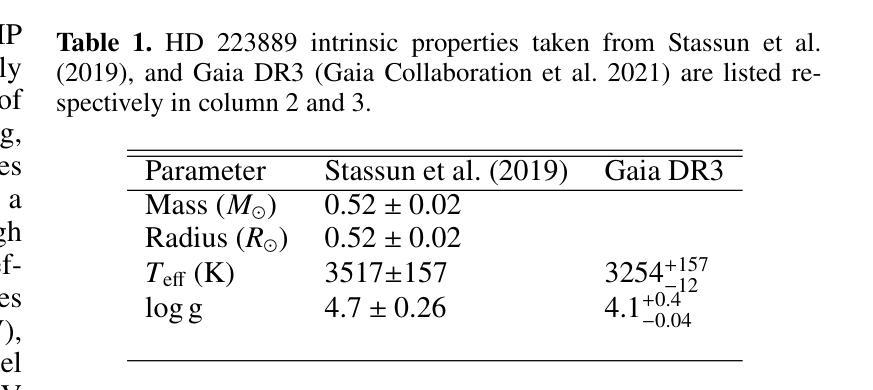
Authors:J. J. Chebly, K. Poppenhäger, J. D. Alvarado-Gómez, B. E. Wood
Main sequence stars of spectral types F, G, and K with low to moderate activity levels exhibit a recognizable pattern known as the first ionization potential effect (FIP effect), where elements with lower first ionization potentials are more abundant in the stellar corona than in the photosphere. In contrast, high activity main sequence stars such as AB Dor (K0), active binaries, and M dwarfs exhibit an inverse pattern known as iFIP. We aim to determine whether or not the iFIP pattern persists in moderate-activity M dwarfs. We used XMM-Newton to observe the moderately active M dwarf HD 223889 that has an X-ray surface flux of log FX,surf = 5.26, the lowest for an M dwarf studied so far for coronal abundance patterns. We used low-resolution CCD spectra of the star to calculate the strength of the FIP effect quantified by the FIP bias (Fbias) to assess the persistence of the iFIP effect in M dwarfs. Our findings reveal an iFIP effect similar to that of another moderately active binary star, GJ 338 AB, with a comparable error margin. The results hint at a possible plateau in the Teff-Fbias diagram for moderately active M dwarfs. Targeting stars with low coronal activity that have a coronal temperature between 2 MK and 4 MK is essential for refining our understanding of (i)FIP patterns and their causes.
具有F、G和K光谱型的低活跃度至中等活跃度的主序星表现出一种称为第一电离电位效应(FIP效应)的模式,其中第一电离电位较低的元素在恒星冕层中的含量高于光球层。然而,像AB Dor(K0)、活动双星和M矮星这样的高活跃度主序星则展现出一种反向模式,称为反FIP效应(iFIP)。我们的目标是确定中等活跃度的M矮星是否也存在iFIP模式。我们使用XMM-牛顿望远镜观测了中等活跃度的M矮星HD 223889,其X射线表面通量为log FX,surf = 5.26,这是迄今为止研究过的具有冠状模式丰度的M矮星中最低的。我们使用该星的低分辨率CCD光谱计算了由FIP偏差(Fbias)量化的FIP效应的强弱,以评估M矮星中iFIP效应的持久性。我们的发现显示,与另一个中等活跃的双星GJ 338 AB相比,存在类似的iFIP效应,误差范围也相似。结果提示在有效温度(Teff)- Fbias图中,对于中等活跃度的M矮星可能存在一个平台期。针对具有介于2 MK和4 MK之间冠状温度且低冠状活性的恒星进行研究,对于完善我们对(i)FIP模式及其原因的理解至关重要。
论文及项目相关链接
PDF 7 pages, 5 figures, 3 tables
Summary
本文研究了主序列星中的F、G、K型低至中等活跃度恒星表现出的第一电离电位效应(FIP效应),即低第一电离电位元素在恒星冕中比光球中更丰富。相反,高活跃度主序列星如AB Dor(K0)、活跃双星和M矮星则表现出逆向的iFIP模式。研究旨在确定iFIP模式在中等活跃度M矮星中是否持续存在。使用XMM-Newton观测中等活跃度M矮星HD 223889,发现其iFIP效应与另一个中等活跃度双星GJ 338 AB相似。结果暗示在有效温度和Fbias图中,中等活跃度M矮星可能存在一个平台期。
Key Takeaways
- 主序列F、G、K型低至中等活跃度恒星表现出FIP效应,即低第一电离电位元素在恒星冕中更丰富。
- 高活跃度主序列星如AB Dor、活跃双星和M矮星表现出iFIP模式。
- 使用XMM-Newton对中等活跃度M矮星HD 223889进行观测,发现其iFIP效应与另一双星相似。
- 结果显示,在有效温度和Fbias图中,中等活跃度M矮星可能存在一个平台期。
- 研究重点在于观察具有低冕活动性和特定温度范围的恒星,以进一步了解iFIP模式及其成因。
- FIP效应和iFIP模式的识别对于理解恒星大气结构和能量平衡至关重要。
点此查看论文截图


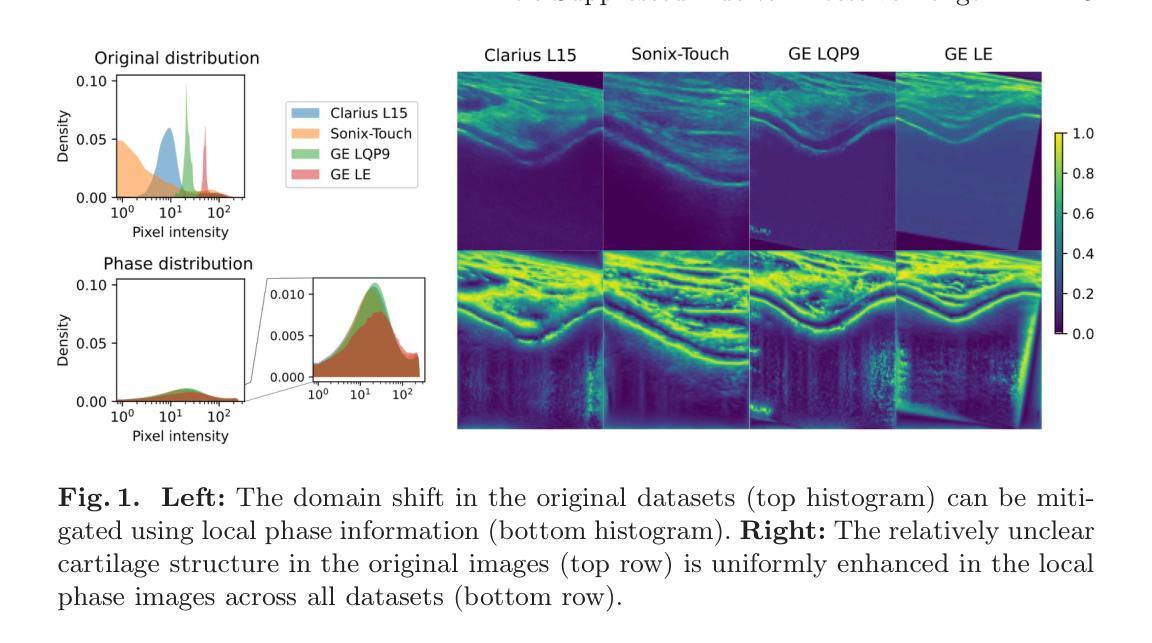
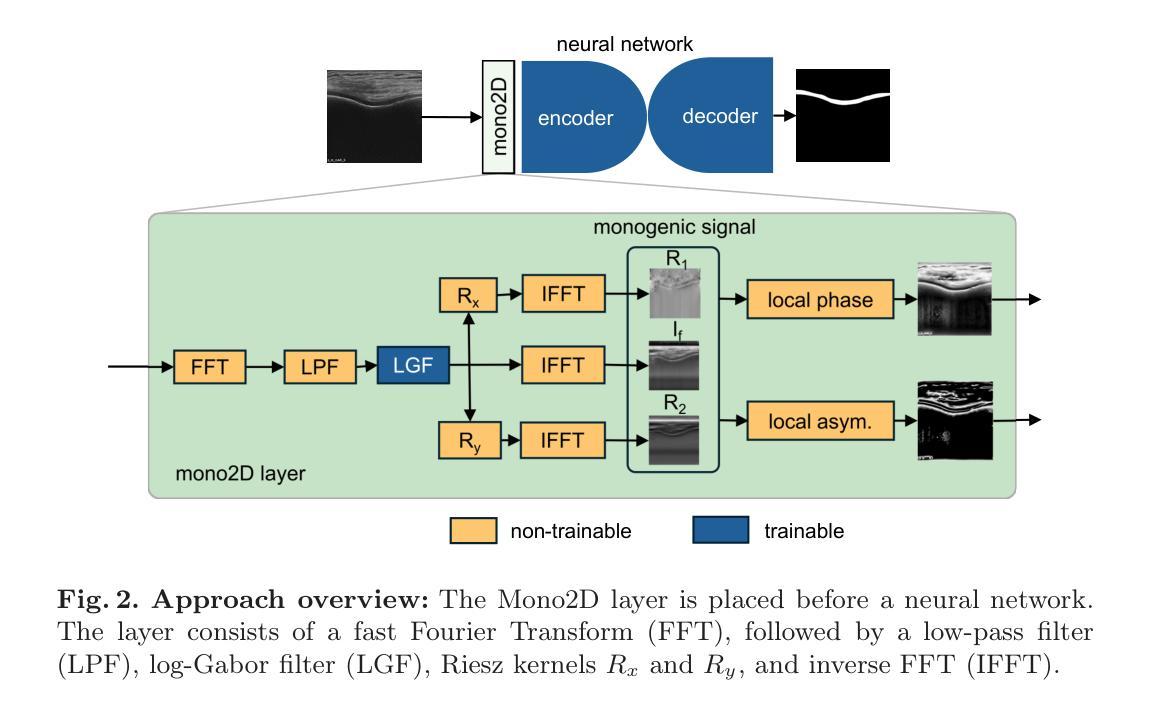
Mono2D: A Trainable Monogenic Layer for Robust Knee Cartilage Segmentation on Out-of-Distribution 2D Ultrasound Data
Authors:Alvin Kimbowa, Arjun Parmar, Maziar Badii, David Liu, Matthew Harkey, Ilker Hacihaliloglu
Automated knee cartilage segmentation using point-of-care ultrasound devices and deep-learning networks has the potential to enhance the management of knee osteoarthritis. However, segmentation algorithms often struggle with domain shifts caused by variations in ultrasound devices and acquisition parameters, limiting their generalizability. In this paper, we propose Mono2D, a monogenic layer that extracts multi-scale, contrast- and intensity-invariant local phase features using trainable bandpass quadrature filters. This layer mitigates domain shifts, improving generalization to out-of-distribution domains. Mono2D is integrated before the first layer of a segmentation network, and its parameters jointly trained alongside the network’s parameters. We evaluated Mono2D on a multi-domain 2D ultrasound knee cartilage dataset for single-source domain generalization (SSDG). Our results demonstrate that Mono2D outperforms other SSDG methods in terms of Dice score and mean average surface distance. To further assess its generalizability, we evaluate Mono2D on a multi-site prostate MRI dataset, where it continues to outperform other SSDG methods, highlighting its potential to improve domain generalization in medical imaging. Nevertheless, further evaluation on diverse datasets is still necessary to assess its clinical utility.
使用即时医疗护理超声波设备和深度学习网络对膝关节软骨进行自动分割,在改善膝关节骨关节炎管理方面具有潜力。然而,分割算法经常因超声波设备和采集参数的差异导致的领域变化而面临挑战,限制了其通用性。在本文中,我们提出了Mono2D,一种单基因层,通过使用可训练的带通正交滤波器提取多尺度、对比度和强度不变局部相位特征。这一层减轻了领域变化,提高了对分布外领域的泛化能力。Mono2D被集成在分割网络的第一层之前,并与其参数联合训练。我们在多领域二维超声膝关节软骨数据集上对Mono2D进行了单源域泛化(SSDG)的评估。我们的结果表明,在迪克分数和平均表面距离方面,Mono2D优于其他SSDG方法。为了进一步评估其泛化能力,我们在多站点前列腺MRI数据集上评估了Mono2D,它在该数据集上仍然优于其他SSDG方法,凸显其在医学影像中提高领域泛化的潜力。尽管如此,仍然需要在各种数据集上进行进一步的评估以评估其临床实用性。
论文及项目相关链接
Summary
使用单基因层Mono2D提取多尺度、对比度和强度不变局部相位特征,通过训练带通正交滤波器,提高深度学习网络对膝关节软骨的自动化分割性能,并增强对膝关节骨关节炎的管理。Mono2D有助于缓解因超声设备和采集参数变化引起的领域偏移问题,提升模型在跨分布领域的泛化能力。研究结果表明,Mono2D在单源域泛化(SSDG)的多域二维超声膝关节软骨数据集上表现优异,并且在多站点前列腺MRI数据集上也有良好表现。然而,仍需要在更多数据集上进行评估以评估其临床实用性。
Key Takeaways
- Mono2D是一种用于医学图像处理的单基因层技术,能够从原始超声图像中提取多尺度、对比度和强度不变的局部相位特征。
- 通过使用训练带通正交滤波器,Mono2D可以有效减轻不同超声设备和采集参数造成的领域偏移问题。
- Mono2D技术在膝关节软骨自动分割方面展现出优势,提高了模型的泛化能力。
- 研究结果表明,Mono2D在单源域泛化(SSDG)的多域二维超声膝关节软骨数据集上的表现优于其他方法。
- Mono2D在多站点前列腺MRI数据集上的表现也证明了其泛化能力。
- 尽管Mono2D已经取得了一定的成果,但仍需进一步在更多数据集上进行评估以确认其临床实用性。
点此查看论文截图

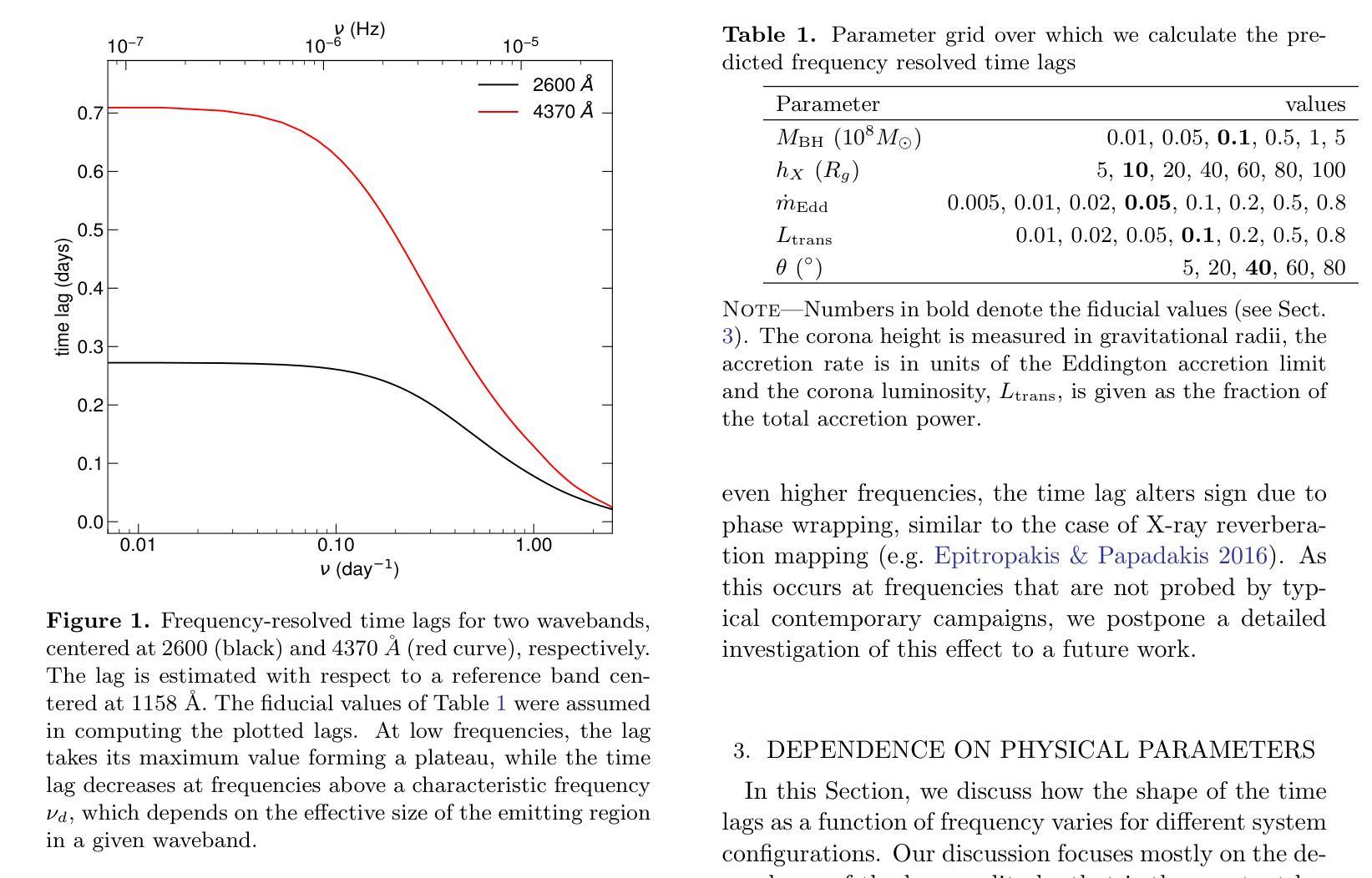
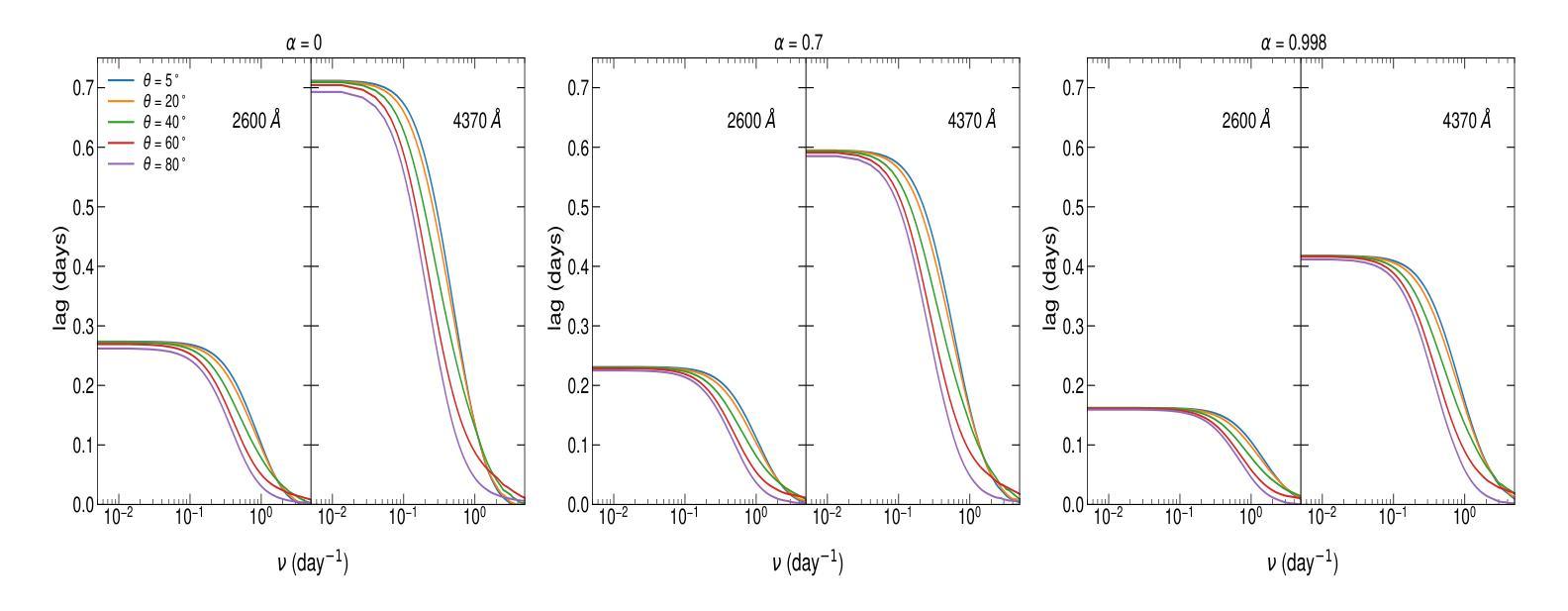
Frequency-resolved time lags due to X-ray disk reprocessing in AGN
Authors:Christos Panagiotou, Iossif Papadakis, Erin Kara, Marios Papoutsis, Edward M. Cackett, Michal Dovčiak, Javier A. García, Elias Kammoun, Collin Lewin
Over the last years, a number of broadband reverberation mapping campaigns have been conducted to explore the short-term UV and optical variability of nearby AGN. Despite the extensive data collected, the origin of the observed variability is still debated in the literature. Frequency-resolved time lags offer a promising approach to distinguish between different scenarios, as they probe variability on different time scales. In this study, we present the expected frequency-resolved lags resulting from X-ray reprocessing in the accretion disk. The predicted lags are found to feature a general shape that resembles that of observational measurements, while exhibiting strong dependence on various physical parameters. Additionally, we compare our model predictions to observational data for the case of NGC 5548, concluding that the X-ray illumination of the disk can effectively account for the observed frequency-resolved lags and power spectra in a self-consistent way. To date, X-ray disk reprocessing is the only physical model that has successfully reproduced the observed multi-wavelength variability, in both amplitude and time delays, across a range of temporal frequencies.
近年来,已经进行了多次宽带混响映射活动,以探索附近活动星系核的紫外和光学短期变化。尽管收集了大量数据,但观察到的变化的原因在文献中仍有争议。频率解析的时间延迟提供了一种很有前景的方法来区分不同的场景,因为它们探测的是不同时间尺度的变化。在这项研究中,我们介绍了由吸积盘中的X射线再处理引起的预期频率解析延迟。预测的延迟呈现了一种类似于观测测量的总体形状,表现出对各种物理参数的强烈依赖性。此外,我们将模型预测与NGC 5548的观测数据进行了比较,并得出结论认为,X射线对磁盘的照明可以有效地解释观察到的频率解析延迟和功率谱,并且可以在自洽的方式下进行。迄今为止,X射线磁盘再处理是唯一成功再现了观察到的多波长变化的物理模型,在振幅和时间延迟方面,其在各种时间频率范围内均表现良好。
论文及项目相关链接
PDF 10 (+2 in Appendix) pages, 5 figures, accepted for publication by ApJ
Summary
近年对附近活动星系核(AGN)的紫外线及光学可变性的短期宽带回声映射活动丰富,但对观测到的可变性的起源仍存在争议。频率解析时间延迟为区分不同场景提供了有前途的方法,因为它们能探测不同时间尺度上的变化。本研究展示了X射线在吸积盘再加工过程中预期产生的频率解析延迟。预测的时间延迟表现出与观测测量相似的总体形态,并强烈依赖于各种物理参数。此外,我们将模型预测与NGC 5548的观测数据进行了比较,认为X射线的盘再照明可以有效地解释观察到的频率解析延迟和功率谱,具有自洽性。迄今为止,X射线盘再加工是唯一成功重现多波长观测可变性的物理模型,无论在振幅还是时间延迟方面,都能跨越一系列的临时频率。
Key Takeaways
- 近年对附近活动星系核的短期UV和光学可变性的研究通过宽带回声映射活动丰富。
- 频率解析时间延迟有助于区分不同的可变性起源场景。
- X射线在吸积盘再加工过程中的预期频率解析延迟表现出与观测相似的总体形态。
- 预测的时间延迟强烈依赖于多种物理参数。
- X射线盘再照明能解释观察到的频率解析延迟和功率谱,具有自洽性。
- 比较模型预测与NGC 5548的观测数据,发现X射线模型成功重现了多波长观测的可变性。
点此查看论文截图

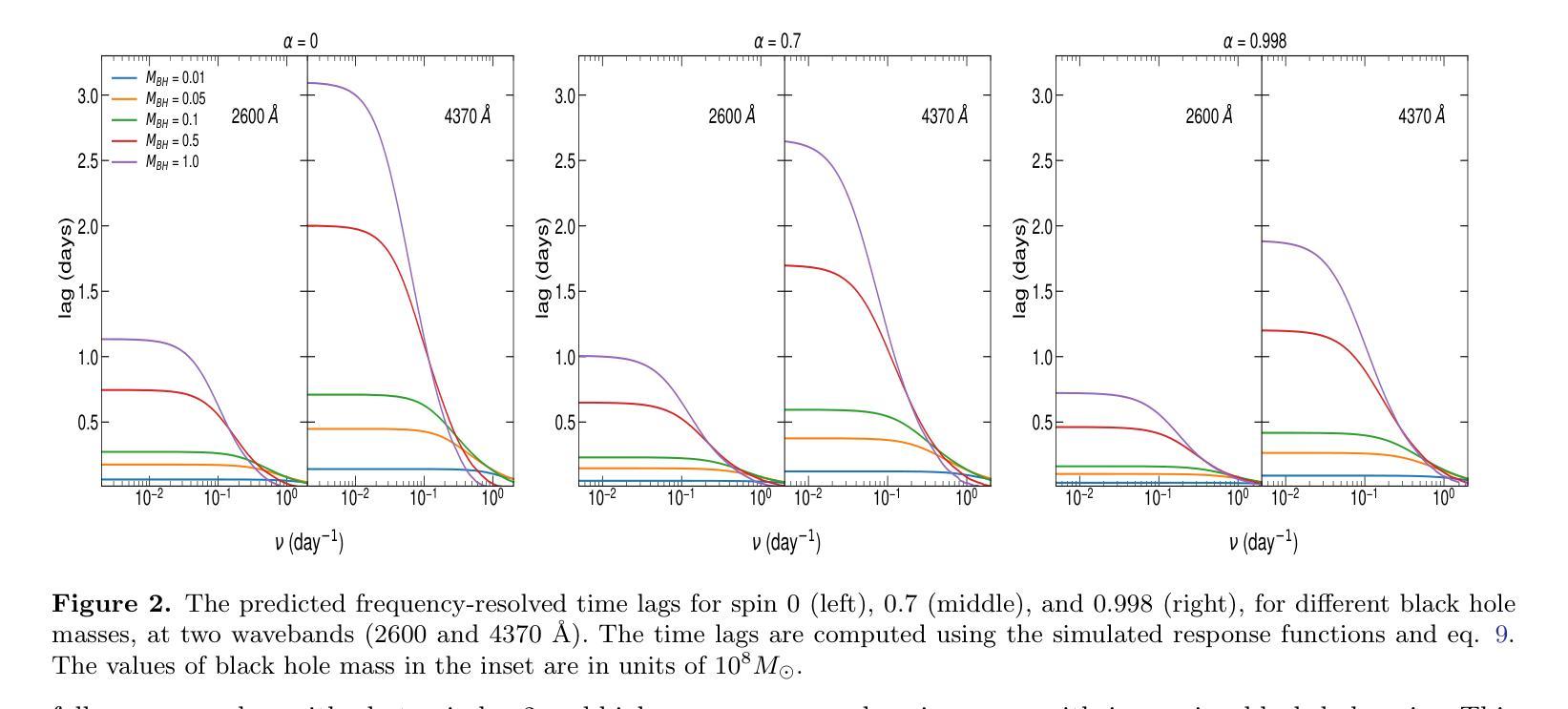
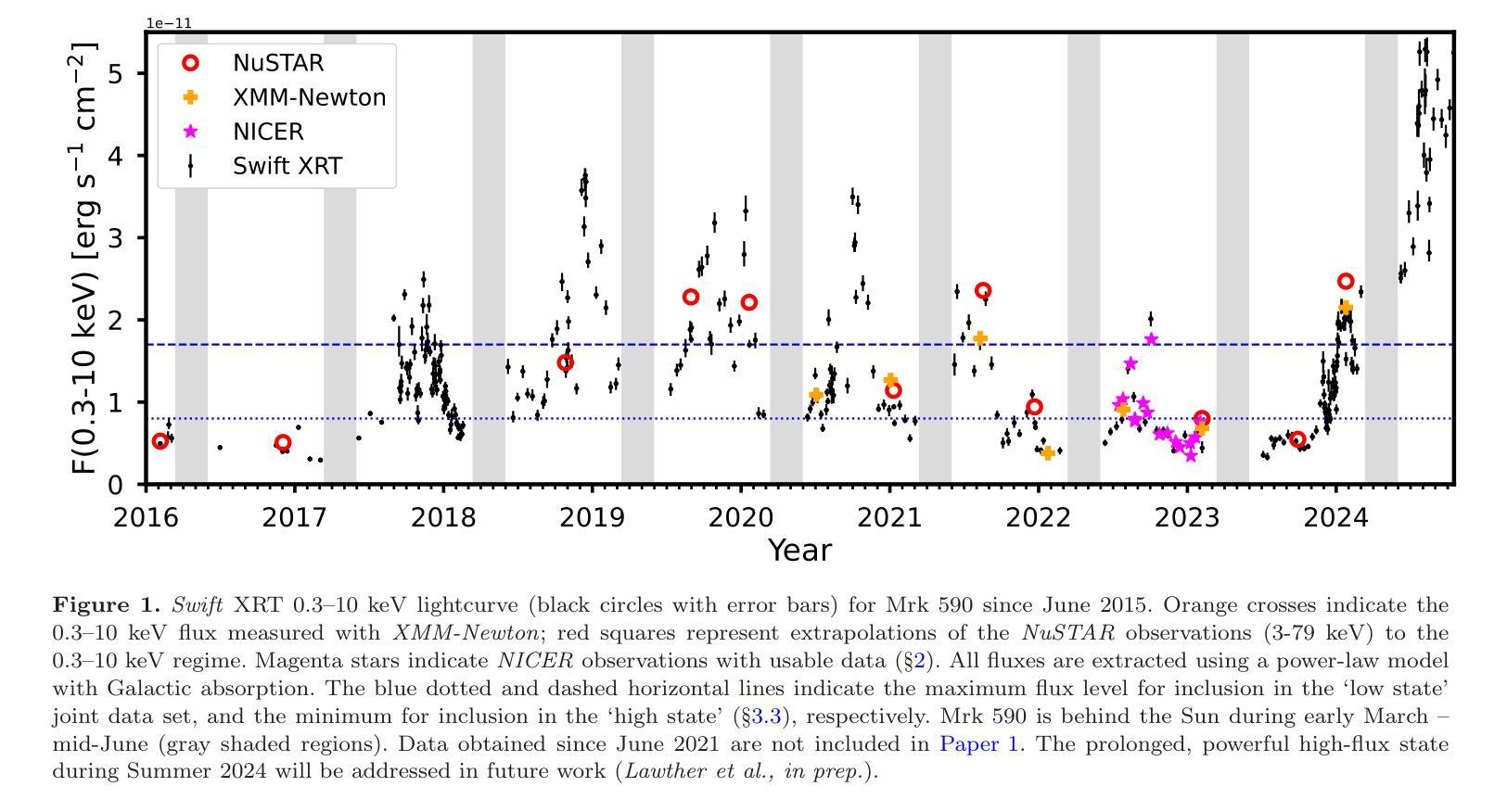
Flares in the Changing Look AGN Mrk 590. II: Deep X-ray observations reveal a Comptonizing inner accretion flow
Authors:Daniel Lawther, Marianne Vestergaard, Sandra Raimundo, Xiaohui Fan, Jun Yi Koay
Mrk 590 is a Changing Look AGN currently in an unusual repeat X-ray and UV flaring state. Here, we report on deep X-ray observations with XMM-Newton, NuSTAR, and NICER, obtained at a range of X-ray flux levels. We detect a prominent soft excess below 2 keV; its flux is tightly correlated with that of both the X-ray and UV continuum, and it persists at the lowest flux levels captured. Our Bayesian model comparison strongly favors inverse Comptonization as the origin of this soft excess, instead of blurred reflection. We find only weak reflection features, with R~0.4 assuming Compton-thick reflection. Most of this reprocessing occurs at least $\sim$800 gravitational radii (roughly three light-days) from the continuum source. Relativistically broadened emission is weak or absent, suggesting the lack of a standard thin disk' at small radii. We confirm that the predicted broad-band emission due to Comptonization is roughly consistent with the observed UV--optical photometry. This implies an optically thick, warm ($kT_e\sim0.3$ keV) scattering region that extends to at least $\sim10^3$ gravitational radii, reprocessing any UV thermal emission. The lack of a standard thin disk’ may also explain the puzzling $\sim3$-day X-ray to UV delay previously measured for Mrk 590. Overall, we find that the X-ray spectral changes in Mrk 590 are minimal, despite substantial luminosity changes. Other well-studied changing look AGN display more dramatic spectral evolution, e.g., disappearing continuum or soft excess. This suggests that a diversity of physical mechanisms in the inner accretion flow may produce a UV–optical changing-look event.
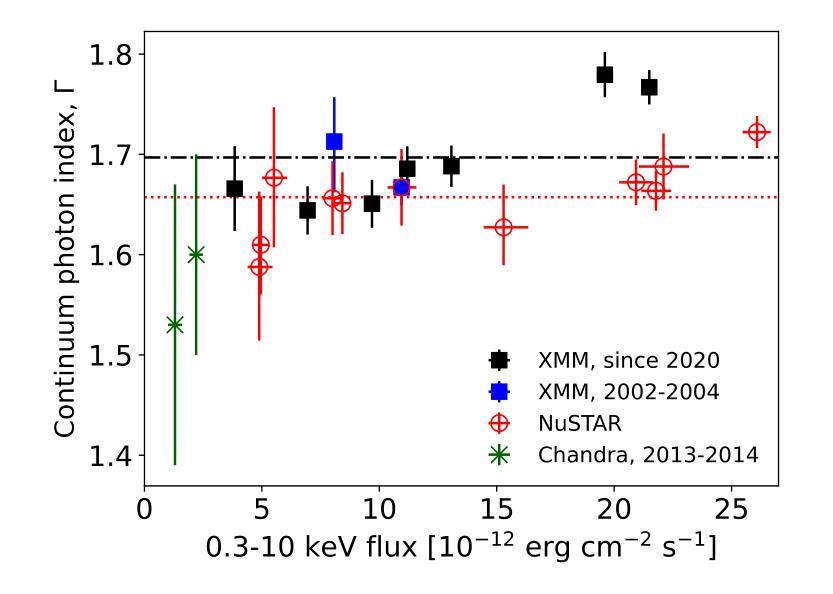
Mrk 590是一颗外观不断变化的活跃星系核(AGN),目前处于不寻常的重复X射线和紫外耀发状态。在这里,我们报告了使用XMM-Newton、NuSTAR和NICER进行的深度X射线观测结果,这些观测涵盖了多种X射线流量水平。我们检测到了一个显著的低于2keV的软过剩现象;其流量与X射线和紫外连续体的流量紧密相关,并且在捕获的最低流量水平下仍然存在。我们的贝叶斯模型比较强烈支持逆康普顿化是软过剩的起源,而不是模糊的反射。我们发现只有微弱的反射特征,假设康普顿厚反射时R约为0.4。大部分再处理过程发生在连续光源至少
800个引力半径(大约三天)处。相对论性展宽发射很弱或不存在,表明小半径处没有标准的“薄盘”。我们确认,由于康普顿化而预测的宽频带发射大致与观察到的紫外光学光度法一致。这暗示存在一个延伸到至少10^3个引力半径的光学厚、温暖的(kT_e~0.3keV)散射区域,该区域处理任何紫外热发射。没有标准的“薄盘”也可能解释了之前为Mrk 590测量的约3天的X射线到紫外延迟。总的来说,我们发现尽管亮度有重大变化,但Mrk 590的X射线光谱变化很小。其他经过良好研究的外观不断变化的活跃星系核显示出更剧烈的谱演化,例如连续光谱或软过剩消失。这表明内流积中的多种物理机制可能产生紫外光学变化事件。
论文及项目相关链接
PDF Accepted for publication in MNRAS. 47 pages, 41 figures
Summary
本文报告了对Mrk 590的深入X射线观测结果。发现其软过剩现象与X射线和紫外连续光谱紧密相关,并在最低通量水平时仍然存在。倾向于通过逆康普顿化来解释软过剩的起源,而非模糊反射。发现微弱的反射特征,大部分再处理发生在连续光源的引力半径至少约800处。相对论性展宽发射较弱或缺失,暗示小半径处缺乏标准的“薄盘”。推测存在一个延伸到至少数千引力半径的光厚、温暖的(kT_e~0.3 keV)散射区域,处理任何紫外热发射。Mrk 590的X射线光谱变化最小,尽管光度变化显著。与其他研究过的外观改变的活跃星系核相比,其光谱演化较小,这表明内流积物的物理机制多样性可能会产生紫外光到光学变化的外观事件。
Key Takeaways
- Mrk 590处于特殊的重复X射线和紫外光耀态,显示出X射线和紫外光的持续变化。
- 深X射线观测显示存在一个紧密相关的软过剩现象与X射线和紫外连续光谱。
- 软过剩现象更倾向于通过逆康普顿化解释而非模糊反射。
- 存在微弱的反射特征,大部分反射发生在距离连续光源较远处。
- 相对论性展宽发射弱或缺失,暗示内部可能缺乏典型的薄盘结构。
- 有一个大范围的光厚温暖散射区域处理紫外热发射。
点此查看论文截图

A Deep Bayesian Nonparametric Framework for Robust Mutual Information Estimation
Authors:Forough Fazeliasl, Michael Minyi Zhang, Bei Jiang, Linglong Kong
Mutual Information (MI) is a crucial measure for capturing dependencies between variables, but exact computation is challenging in high dimensions with intractable likelihoods, impacting accuracy and robustness. One idea is to use an auxiliary neural network to train an MI estimator; however, methods based on the empirical distribution function (EDF) can introduce sharp fluctuations in the MI loss due to poor out-of-sample performance, destabilizing convergence. We present a Bayesian nonparametric (BNP) solution for training an MI estimator by constructing the MI loss with a finite representation of the Dirichlet process posterior to incorporate regularization in the training process. With this regularization, the MI loss integrates both prior knowledge and empirical data to reduce the loss sensitivity to fluctuations and outliers in the sample data, especially in small sample settings like mini-batches. This approach addresses the challenge of balancing accuracy and low variance by effectively reducing variance, leading to stabilized and robust MI loss gradients during training and enhancing the convergence of the MI approximation while offering stronger theoretical guarantees for convergence. We explore the application of our estimator in maximizing MI between the data space and the latent space of a variational autoencoder. Experimental results demonstrate significant improvements in convergence over EDF-based methods, with applications across synthetic and real datasets, notably in 3D CT image generation, yielding enhanced structure discovery and reduced overfitting in data synthesis. While this paper focuses on generative models in application, the proposed estimator is not restricted to this setting and can be applied more broadly in various BNP learning procedures.
互信息(MI)是衡量变量间依赖性的重要指标,但在高维空间中对其进行精确计算具有挑战性,因为难以处理的可能性会影响准确性和稳健性。一种想法是使用辅助神经网络来训练MI估计器;然而,基于经验分布函数(EDF)的方法可能会在MI损失中引入急剧波动,这是由于样本外的性能不佳导致收敛不稳定。我们提出了一种贝叶斯非参数(BNP)解决方案,通过构建MI损失并使用狄利克雷过程后验的有限表示来训练MI估计器,在训练过程中融入正则化。通过此正则化,MI损失结合了先验知识和经验数据,减少了其对样本数据中的波动和异常值的敏感性,特别是在小样本环境如小批量数据中。该方法通过有效减少方差来解决准确性和低方差的平衡挑战,从而在训练过程中实现了稳定且稳健的MI损失梯度,增强了MI逼近的收敛性,并为收敛提供了更强的理论保证。我们探索了估计量在最大化变分自动编码器数据空间和潜在空间之间的互信息中的应用。实验结果证明,与基于EDF的方法相比,该方法在收敛性方面取得了显著改善,在合成和真实数据集(尤其在3D CT图像生成中)的应用中,实现了更好的结构发现和数据合成中的过拟合减少。虽然本文的重点是在应用中的生成模型,但所提出的估计器并不限于这一环境,可以更广泛地应用于各种BNP学习程序。
论文及项目相关链接
Summary
本文介绍了一种基于贝叶斯非参数(BNP)的互信息(MI)估计器训练方法。该方法通过结合Dirichlet过程后验的有限表示来构建MI损失,并在训练过程中引入正则化,以解决高维空间中精确计算MI的挑战性问题。该方法降低了MI损失对样本数据波动和异常值的敏感性,特别是在小样本环境中。实验结果表明,该估计器在优化变分自动编码器的数据空间和潜在空间之间的MI时,相较于基于经验分布函数(EDF)的方法,具有更好的收敛性,并在合成和真实数据集(如3D CT图像生成)中表现出优异性能。
Key Takeaways
- 互信息(MI)是捕捉变量之间依赖性的重要度量,但在高维空间和具有不可预测概率模型的情况下,其精确计算具有挑战性。
- 使用辅助神经网络训练MI估计器是一种解决方案,但基于经验分布函数(EDF)的方法可能导致MI损失出现剧烈波动,从而影响训练的稳定性和收敛性。
- 提出了基于贝叶斯非参数(BNP)的MI估计器训练方案,通过结合Dirichlet过程后验进行正则化,以提高MI损失对样本数据波动和异常值的稳健性。
- 该方法能有效降低MI损失的敏感性,在小型样本批次中表现尤为出色,有助于平衡准确性和低方差。
- 在变分自动编码器的数据空间和潜在空间之间最大化MI的实验中,该估计器相较于EDF方法具有显著改善的收敛性。
- 该估计器在合成和真实数据集(如3D CT图像生成)中有广泛应用,能增强结构发现并减少数据合成中的过拟合。
点此查看论文截图

Deformable Registration Framework for Augmented Reality-based Surgical Guidance in Head and Neck Tumor Resection
Authors:Qingyun Yang, Fangjie Li, Jiayi Xu, Zixuan Liu, Sindhura Sridhar, Whitney Jin, Jennifer Du, Jon Heiselman, Michael Miga, Michael Topf, Jie Ying Wu
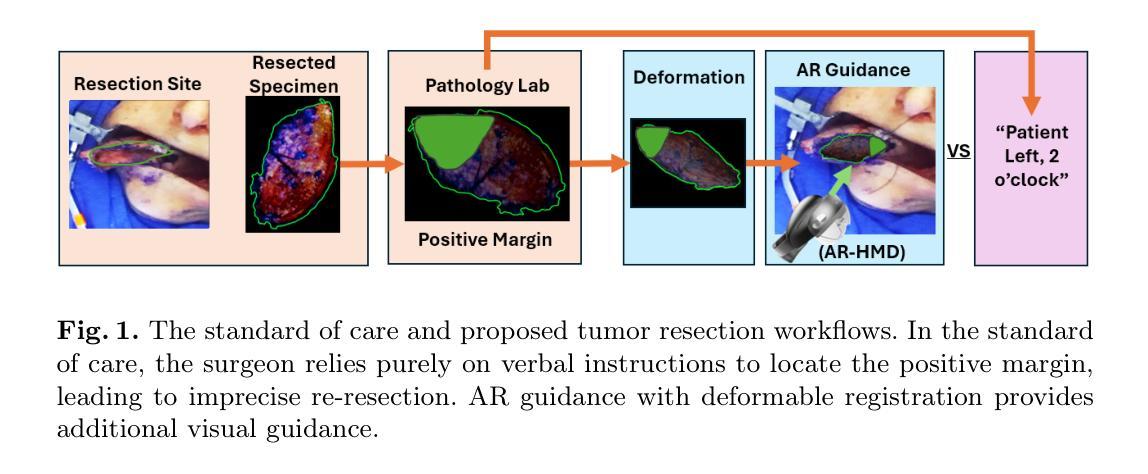
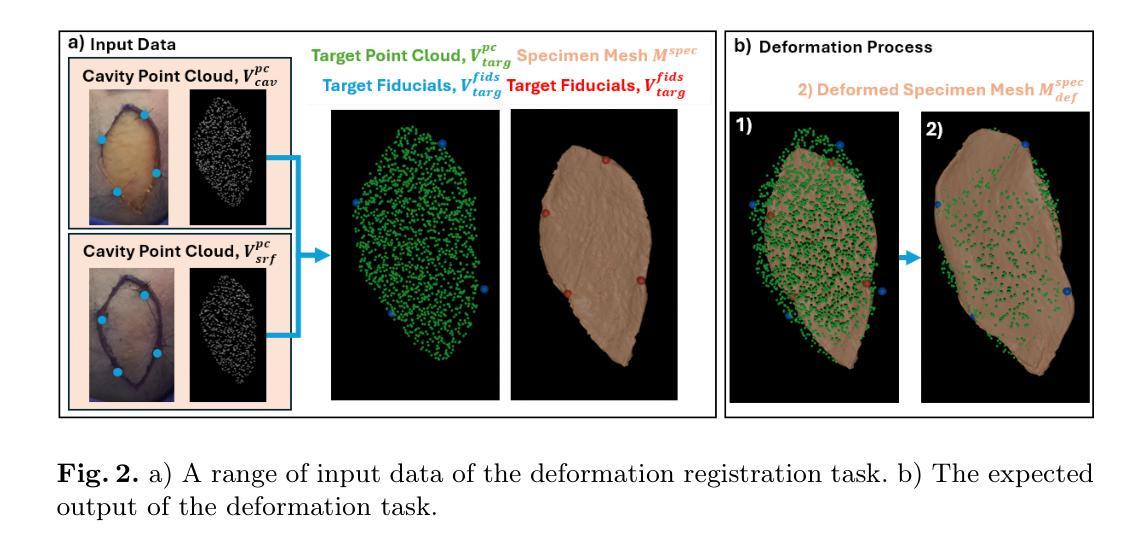
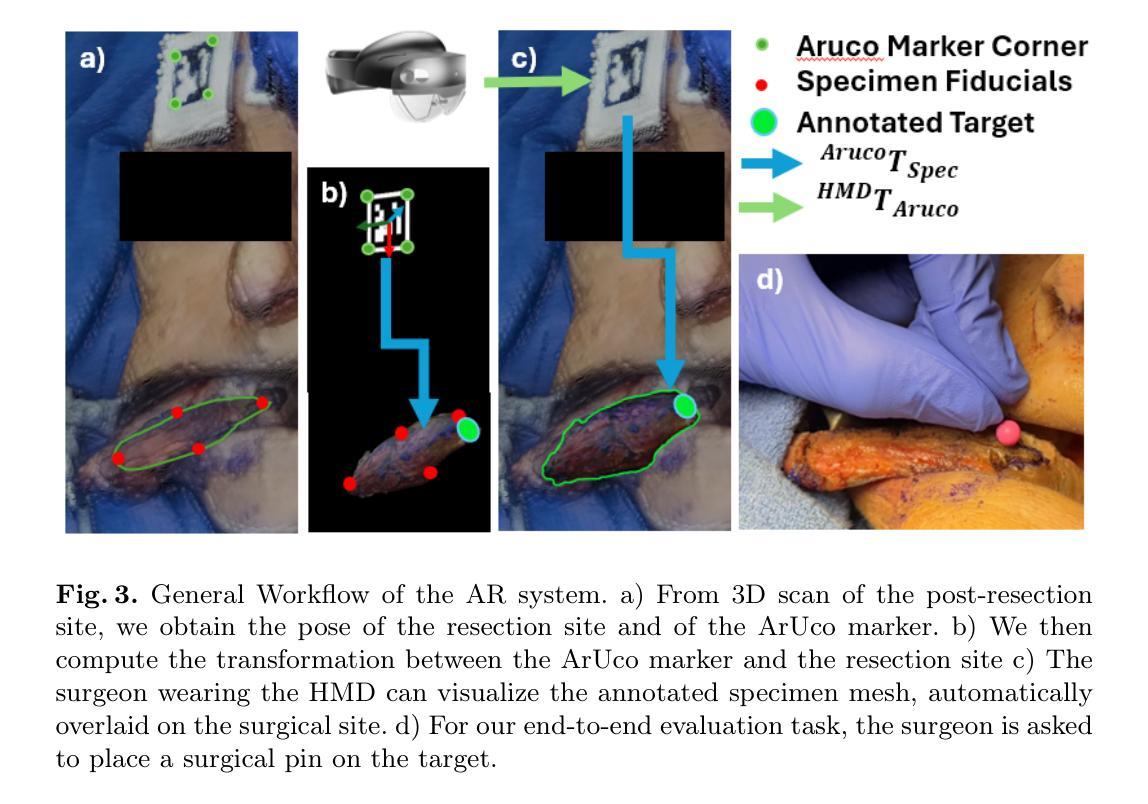
Head and neck squamous cell carcinoma (HNSCC) has one of the highest rates of recurrence cases among solid malignancies. Recurrence rates can be reduced by improving positive margins localization. Frozen section analysis (FSA) of resected specimens is the gold standard for intraoperative margin assessment. However, because of the complex 3D anatomy and the significant shrinkage of resected specimens, accurate margin relocation from specimen back onto the resection site based on FSA results remains challenging. We propose a novel deformable registration framework that uses both the pre-resection upper surface and the post-resection site of the specimen to incorporate thickness information into the registration process. The proposed method significantly improves target registration error (TRE), demonstrating enhanced adaptability to thicker specimens. In tongue specimens, the proposed framework improved TRE by up to 33% as compared to prior deformable registration. Notably, tongue specimens exhibit complex 3D anatomies and hold the highest clinical significance compared to other head and neck specimens from the buccal and skin. We analyzed distinct deformation behaviors in different specimens, highlighting the need for tailored deformation strategies. To further aid intraoperative visualization, we also integrated this framework with an augmented reality-based auto-alignment system. The combined system can accurately and automatically overlay the deformed 3D specimen mesh with positive margin annotation onto the resection site. With a pilot study of the AR guided framework involving two surgeons, the integrated system improved the surgeons’ average target relocation error from 9.8 cm to 4.8 cm.
头颈鳞状细胞癌(HNSCC)在实体恶性肿瘤中具有最高的复发率之一。通过改善阳性边缘定位可以降低复发率。切除标本的冷冻切片分析(FSA)是术中边缘评估的金标准。然而,由于复杂的3D解剖结构和切除标本的显著收缩,根据FSA结果从标本重新定位到切除部位仍然具有挑战性。我们提出了一种新型的可变形注册框架,该框架结合了术前切除的上方表面和术后标本的切除部位,将厚度信息纳入注册过程中。所提出的方法显著提高了目标注册误差(TRE),并表现出对较厚标本的适应性增强。与先前的可变形注册相比,在舌标本中,所提出的方法将TRE提高了高达33%。值得注意的是,舌标本具有复杂的3D解剖结构,相较于来自颊部和皮肤的其他头颈标本,其临床意义最高。我们分析了不同标本中不同的变形行为,强调了需要有针对性的变形策略。为了进一步帮助术中可视化,我们还将该框架与基于增强现实的自动对齐系统相结合。该综合系统能够准确、自动地将带有阳性边缘注释的变形3D标本网格覆盖在切除部位上。在涉及两名外科医生的AR引导框架试点研究中,集成系统降低了医生的目标平均重新定位误差,从9.8厘米降至4.8厘米。
论文及项目相关链接
Summary
本文提出一种新型的变形注册框架,利用术前和术后的表面信息,结合厚度信息,对手术切除标本进行准确的边缘定位。该框架对复杂三维解剖结构的舌头标本显示出更高的适应性,显著提高了目标注册误差(TRE)。同时,与增强现实自动对齐系统结合,可自动将变形后的三维标本网格与阳性边缘注释叠加到切除部位,提高了医生的定位精度。
Key Takeaways
- 头颈部鳞状细胞癌(HNSCC)复发率高,改善阳性边缘定位可降低复发率。
- 冰冻切片分析(FSA)是术中边缘评估的金标准,但标本的复杂三维解剖结构和收缩性使得准确边缘定位具有挑战性。
- 新型变形注册框架结合术前和术后的表面信息,提高了目标注册误差(TRE)。
- 该框架对舌头标本的复杂三维结构适应性更强,可显著提高边缘定位准确性。
- 框架与增强现实自动对齐系统结合,可进一步提高医生对切除部位的定位精度。
- 试点研究表明,该集成系统可将医生的平均目标转移误差从9.8厘米减少到4.8厘米。
点此查看论文截图

IA generativa aplicada a la detección del cáncer a través de Resonancia Magnética
Authors:Virginia del Campo, Iker Malaina
Cognitive delegation to artificial intelligence (AI) systems is transforming scientific research by enabling the automation of analytical processes and the discovery of new patterns in large datasets. This study examines the ability of AI to complement and expand knowledge in the analysis of breast cancer using dynamic contrast-enhanced magnetic resonance imaging (DCE-MRI). Building on a previous study, we assess the extent to which AI can generate novel approaches and successfully solve them. For this purpose, AI models, specifically ChatGPT-4o, were used for data preprocessing, hypothesis generation, and the application of clustering techniques, predictive modeling, and correlation network analysis. The results obtained were compared with manually computed outcomes, revealing limitations in process transparency and the accuracy of certain calculations. However, as AI reduces errors and improves reasoning capabilities, an important question arises regarding the future of scientific research: could automation replace the human role in science? This study seeks to open the debate on the methodological and ethical implications of a science dominated by artificial intelligence.
人工智能(AI)系统的认知代理正在通过实现分析过程的自动化和在大数据集中发现新模式来变革科学研究。本研究旨在探讨人工智能在利用动态对比增强磁共振成像(DCE-MRI)分析乳腺癌时补充和扩展知识的能力。基于之前的研究,我们评估人工智能能够产生新方法并成功解决这些问题的程度。为此,我们使用了人工智能模型,特别是ChatGPT-4o,用于数据预处理、假设生成以及聚类技术的应用、预测建模和关联网络分析。将所得结果与手动计算的结果进行比较,发现其在过程透明度和某些计算的准确性方面存在局限性。然而,随着人工智能减少错误并改善推理能力,一个重要的问题出现了:在未来科学研究中,自动化能否取代人类的作用?本研究旨在就人工智能主导科学的方法和伦理影响展开辩论。
论文及项目相关链接
PDF in Spanish language
Summary
人工智能(AI)在动态增强磁共振成像(DCE-MRI)分析乳腺癌方面的能力研究。研究发现AI能够辅助并扩展知识,生成新方法并成功解决新问题。使用AI模型进行数据处理、假设生成和聚类技术,但存在一定过程透明度和计算准确性的局限。该研究引发关于自动化是否可能取代科学家角色的讨论。
Key Takeaways
- AI在DCE-MRI分析乳腺癌方面的能力研究具有进展,能辅助和扩展知识。
- AI通过数据处理、假设生成和聚类技术等方法用于乳腺癌研究。
- AI的应用能够提高过程自动化程度并减少错误。
- 与手动计算结果相比,AI存在过程透明度和计算准确性方面的局限。
- 研究引出关于自动化对科学未来影响的问题,特别是方法论和伦理问题。
- AI在科学研究中的应用引发关于人工智能主导科学的讨论。
点此查看论文截图

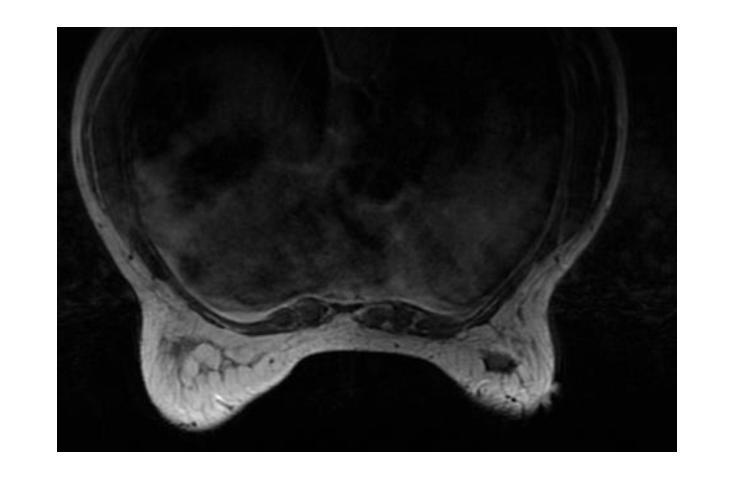
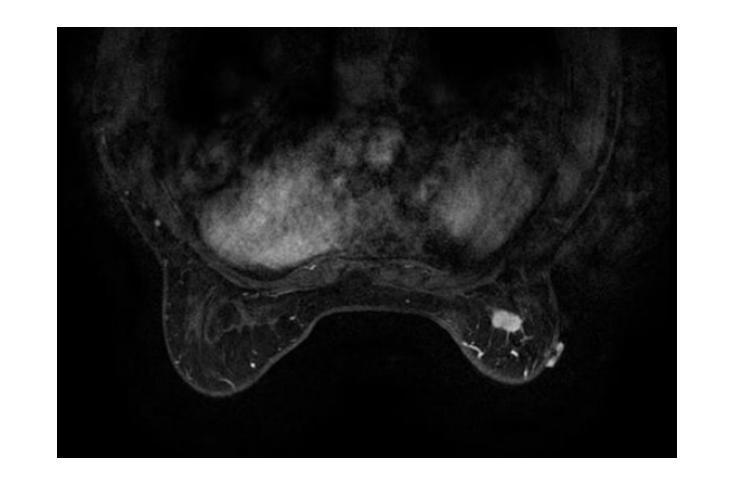
Posterior-Mean Denoising Diffusion Model for Realistic PET Image Reconstruction
Authors:Yiran Sun, Osama Mawlawi
Positron Emission Tomography (PET) is a functional imaging modality that enables the visualization of biochemical and physiological processes across various tissues. Recently, deep learning (DL)-based methods have demonstrated significant progress in directly mapping sinograms to PET images. However, regression-based DL models often yield overly smoothed reconstructions lacking of details (i.e., low distortion, low perceptual quality), whereas GAN-based and likelihood-based posterior sampling models tend to introduce undesirable artifacts in predictions (i.e., high distortion, high perceptual quality), limiting their clinical applicability. To achieve a robust perception-distortion tradeoff, we propose Posterior-Mean Denoising Diffusion Model (PMDM-PET), a novel approach that builds upon a recently established mathematical theory to explore the closed-form expression of perception-distortion function in diffusion model space for PET image reconstruction from sinograms. Specifically, PMDM-PET first obtained posterior-mean PET predictions under minimum mean square error (MSE), then optimally transports the distribution of them to the ground-truth PET images distribution. Experimental results demonstrate that PMDM-PET not only generates realistic PET images with possible minimum distortion and optimal perceptual quality but also outperforms five recent state-of-the-art (SOTA) DL baselines in both qualitative visual inspection and quantitative pixel-wise metrics PSNR (dB)/SSIM/NRMSE.
正电子发射断层扫描(PET)是一种功能成像技术,能够可视化各种组织中的生物化学和生理过程。最近,基于深度学习(DL)的方法在直接将辛曲线图映射到PET图像上取得了显著进展。然而,基于回归的DL模型往往会产生过于平滑的重建结果,缺乏细节(即低失真、低感知质量),而基于GAN和基于似然的后验采样模型则往往在预测中引入不必要的伪影(即高失真、高感知质量),限制了它们在临床上的适用性。为了实现稳健的感知-失真权衡,我们提出了后验均值去噪扩散模型(PMDM-PET),这是一种新方法,它建立在最近建立的数学理论上,旨在探索扩散模型空间中感知-失真函数的封闭形式表达式,用于从辛曲线图重建PET图像。具体来说,PMDM-PET首先以最小均方误差(MSE)获得后验均值PET预测,然后将其分布最优地传输到真实PET图像分布。实验结果表明,PMDM-PET不仅生成了具有最小可能失真和最佳感知质量的现实PET图像,而且在定性和定量像素级的峰值信噪比(PSNR)(dB)/结构相似性度量(SSIM)/归一化均方根误差(NRMSE)方面都优于五种最新的先进DL基线方法。
论文及项目相关链接
PDF 12 pages, 2 figures
Summary
本文提出一种基于扩散模型的医学图像重建方法——后均值去噪扩散模型(PMDM-PET),该方法结合了扩散模型空间和感知失真函数的闭式表达式,从正弦图重建PET图像。该方法在最小均方误差(MSE)下获得后验均值PET预测,然后将其最优传输到真实PET图像分布。实验结果表明,PMDM-PET不仅生成了具有最小失真和最佳感知质量的现实PET图像,而且在视觉检查和像素级指标上都优于五种最新的深度学习方法。
Key Takeaways
- PET是一种功能成像技术,可以可视化各种组织的生物化学和生理过程。
- 基于深度学习的直接从正弦图映射到PET图像的方法已经取得了显著进展。
- 当前深度学习方法在PET图像重建中面临感知失真平衡问题。
- PMDM-PET方法结合了扩散模型空间和感知失真函数的闭式表达式来解决这一问题。
- PMDM-PET在最小均方误差下获得后验均值PET预测。
- PMDM-PET通过最优传输将预测分布接近真实PET图像分布。
- 实验结果表明,PMDM-PET在视觉检查和像素级指标上均优于其他五种最新深度学习方法。
点此查看论文截图

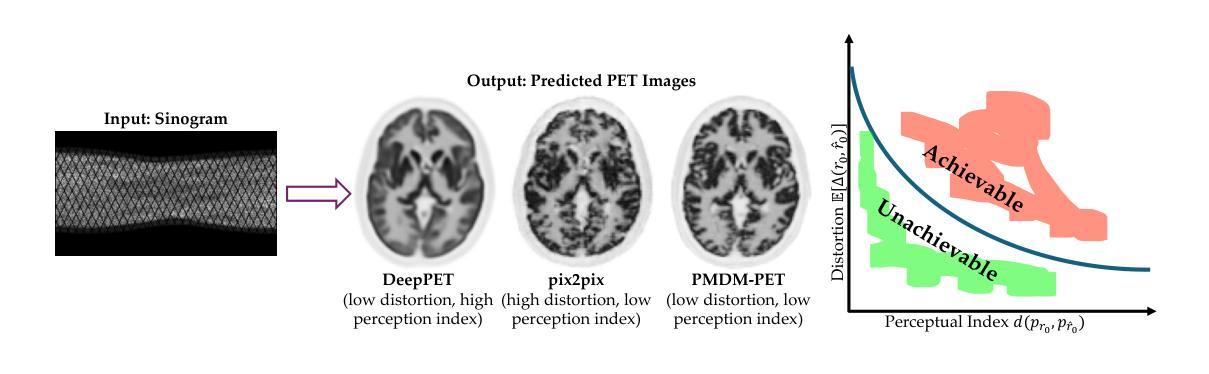
Layton: Latent Consistency Tokenizer for 1024-pixel Image Reconstruction and Generation by 256 Tokens
Authors:Qingsong Xie, Zhao Zhang, Zhe Huang, Yanhao Zhang, Haonan Lu, Zhenyu Yang
Image tokenization has significantly advanced visual generation and multimodal modeling, particularly when paired with autoregressive models. However, current methods face challenges in balancing efficiency and fidelity: high-resolution image reconstruction either requires an excessive number of tokens or compromises critical details through token reduction. To resolve this, we propose Latent Consistency Tokenizer (Layton) that bridges discrete visual tokens with the compact latent space of pre-trained Latent Diffusion Models (LDMs), enabling efficient representation of 1024x1024 images using only 256 tokens-a 16 times compression over VQGAN. Layton integrates a transformer encoder, a quantized codebook, and a latent consistency decoder. Direct application of LDM as the decoder results in color and brightness discrepancies. Thus, we convert it to latent consistency decoder, reducing multi-step sampling to 1-2 steps for direct pixel-level supervision. Experiments demonstrate Layton’s superiority in high-fidelity reconstruction, with 10.8 reconstruction Frechet Inception Distance on MSCOCO-2017 5K benchmark for 1024x1024 image reconstruction. We also extend Layton to a text-to-image generation model, LaytonGen, working in autoregression. It achieves 0.73 score on GenEval benchmark, surpassing current state-of-the-art methods. Project homepage: https://github.com/OPPO-Mente-Lab/Layton
图像分词技术已在视觉生成和多模态建模方面取得了显著进展,特别是与自回归模型结合使用时。然而,当前的方法在平衡效率和保真度方面面临挑战:高分辨率图像重建需要过多的令牌,或者在令牌减少时损失重要细节。为了解决这一问题,我们提出了潜在一致性分词器(Layton),它架起了离散视觉令牌和预训练潜在扩散模型(LDM)紧凑潜在空间之间的桥梁,能够仅使用256个令牌有效地表示1024x1024的图像,这是VQGAN的16倍压缩。Layton集成了变压器编码器、量化代码本和潜在一致性解码器。直接使用LDM作为解码器会导致颜色和亮度差异。因此,我们将其转换为潜在一致性解码器,将多步采样减少到1-2步,实现直接像素级监督。实验表明,Layton在高保真重建方面具有优势,在MSCOCO-2017 5K基准测试上,1024x1024图像重建的Frechet Inception Distance为10.8。我们还把Layton扩展到自回归的文本到图像生成模型LaytonGen。它在GenEval基准测试上获得了0.73的分数,超越了当前的最先进方法。项目主页:https://github.com/OPPO-Mente-Lab/Layton
论文及项目相关链接
Summary
图像令牌化技术在视觉生成和多模式建模方面取得了显著进展,尤其是与自回归模型结合时。然而,当前方法在效率和保真度之间面临平衡挑战:高分辨率图像重建需要大量令牌或通过在令牌减少中牺牲关键细节。为解决此问题,我们提出了潜在一致性令牌化器(Layton),它桥接了离散视觉令牌和预训练潜在扩散模型(LDM)的紧凑潜在空间,仅使用256个令牌就能有效地表示1024x1024的图像,这是VQGAN的16倍压缩。Layton集成了变压器编码器、量化代码本和潜在一致性解码器。直接使用LDM作为解码器会导致颜色和亮度差异。因此,我们将其转换为潜在一致性解码器,将多步采样减少到1-2步,以实现直接像素级监督。实验证明,Layton在高保真重建方面表现出卓越性能,在MSCOCO-2017 5K基准测试上,1024x1024图像重建的Frechet Inception Distance为10.8。我们还扩展了Layton到自回归的文本到图像生成模型LaytonGen,其在GenEval基准测试上取得了0.73的分数,超越了当前先进的方法。
Key Takeaways
- 图像令牌化技术在视觉生成和多模式建模方面取得了重大进展,但效率和保真度之间仍存在挑战。
- Layton通过结合离散视觉令牌和预训练潜在扩散模型的紧凑潜在空间,实现了高效的高分辨率图像表示。
- Layton使用变压器编码器、量化代码本和潜在一致性解码器,提高了图像重建的保真度。
- 直接应用LDM作为解码器会导致颜色和亮度差异,因此进行了相应的优化。
- Layton在MSCOCO-2017 5K基准测试上表现出卓越的高分辨率图像重建性能。
- LaytonGen作为自回归的文本到图像生成模型,在GenEval基准测试上取得了领先的分数。
点此查看论文截图



3D Medical Imaging Segmentation on Non-Contrast CT
Authors:Canxuan Gang, Yuhan Peng
This technical report analyzes non-contrast CT image segmentation in computer vision. It revisits a proposed method, examines the background of non-contrast CT imaging, and highlights the significance of segmentation. The study reviews representative methods, including convolutional-based and CNN-Transformer hybrid approaches, discussing their contributions, advantages, and limitations. The nnUNet stands out as the state-of-the-art method across various segmentation tasks. The report explores the relationship between the proposed method and existing approaches, emphasizing the role of global context modeling in semantic labeling and mask generation. Future directions include addressing the long-tail problem, utilizing pre-trained models for medical imaging, and exploring self-supervised or contrastive pre-training techniques. This report offers insights into non-contrast CT image segmentation and potential advancements in the field.
本技术报告对计算机视觉中的非对比CT图像分割进行了分析。它回顾了一种提出的方法,探讨了非对比CT成像的背景,并强调了分割的重要性。该研究评述了具有代表性的方法,包括基于卷积和CNN-Transformer混合方法,讨论了其贡献、优点和局限性。在各种分割任务中,nnUNet表现出卓越的性能。报告探讨了所提出方法与现有方法之间的关系,重点强调了全局上下文建模在语义标注和掩膜生成中的作用。未来的研究方向包括解决长尾问题、利用医学成像的预训练模型和探索自监督或对比预训练技术。本报告为深入了解非对比CT图像分割以及该领域的潜在进展提供了见解。
论文及项目相关链接
PDF tech report
Summary
本报告分析了计算机视觉中非对比CT图像分割技术,回顾了一种新方法,介绍了非对比CT成像的背景,并强调了分割的重要性。报告评述了代表性方法,包括基于卷积和CNN-Transformer混合方法,讨论了其贡献、优点和局限性。nnUNet在不同分割任务中表现出卓越性能。报告探讨了新方法与现有方法之间的关系,强调了全局上下文建模在语义标签和掩膜生成中的作用。未来方向包括解决长尾问题、利用医学图像预训练模型和探索自监督或对比预训练技术。
Key Takeaways
- 报告介绍了非对比CT图像分割技术的背景和重要性。
- 分析了卷积基和CNN-Transformer混合方法为代表的分割技术及其贡献、优势和局限。
- nnUNet在各种分割任务中表现最佳。
- 报告强调了全局上下文建模在语义标签和掩膜生成中的作用。
- 提到了现有研究的不足和未来研究方向,包括解决长尾问题。
- 利用预训练模型进行医学成像和自监督或对比预训练技术是未来的研究趋势。
点此查看论文截图

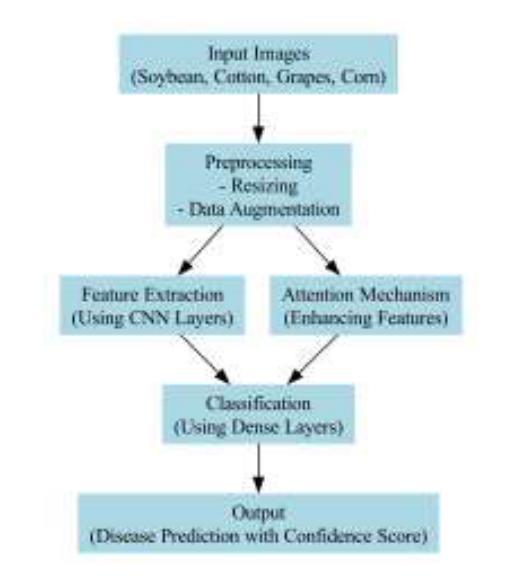
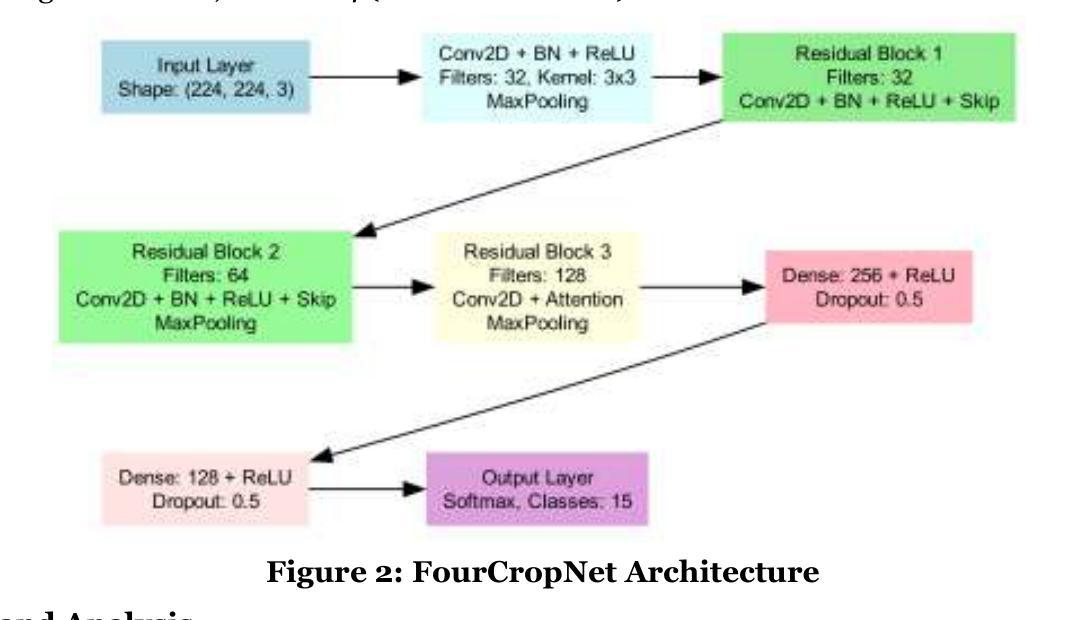
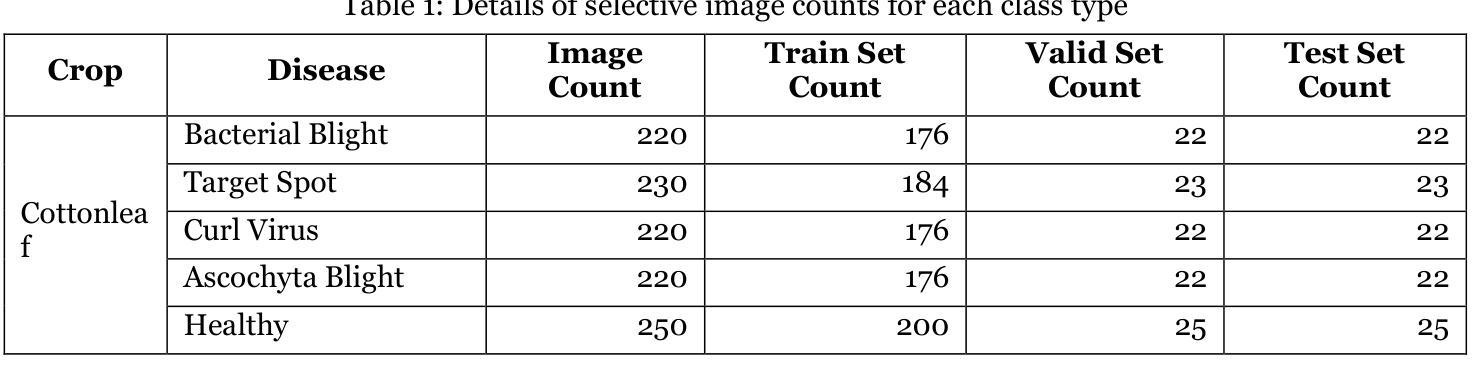
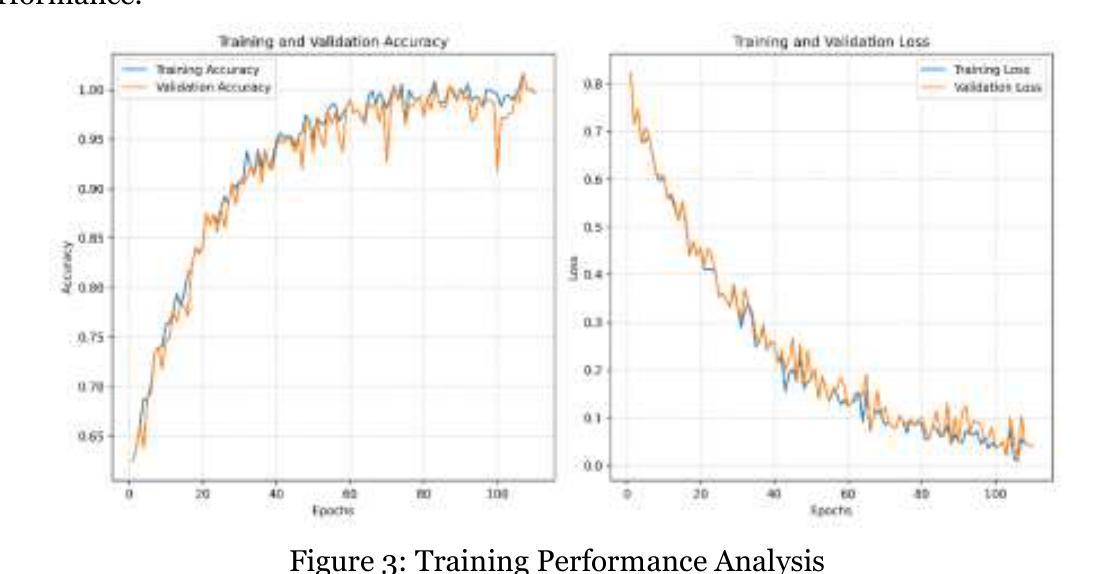
Design and Implementation of FourCropNet: A CNN-Based System for Efficient Multi-Crop Disease Detection and Management
Authors:H. P. Khandagale, Sangram Patil, V. S. Gavali, S. V. Chavan, P. P. Halkarnikar, Prateek A. Meshram
Plant disease detection is a critical task in agriculture, directly impacting crop yield, food security, and sustainable farming practices. This study proposes FourCropNet, a novel deep learning model designed to detect diseases in multiple crops, including CottonLeaf, Grape, Soybean, and Corn. The model leverages an advanced architecture comprising residual blocks for efficient feature extraction, attention mechanisms to enhance focus on disease-relevant regions, and lightweight layers for computational efficiency. These components collectively enable FourCropNet to achieve superior performance across varying datasets and class complexities, from single-crop datasets to combined datasets with 15 classes. The proposed model was evaluated on diverse datasets, demonstrating high accuracy, specificity, sensitivity, and F1 scores. Notably, FourCropNet achieved the highest accuracy of 99.7% for Grape, 99.5% for Corn, and 95.3% for the combined dataset. Its scalability and ability to generalize across datasets underscore its robustness. Comparative analysis shows that FourCropNet consistently outperforms state-of-the-art models such as MobileNet, VGG16, and EfficientNet across various metrics. FourCropNet’s innovative design and consistent performance make it a reliable solution for real-time disease detection in agriculture. This model has the potential to assist farmers in timely disease diagnosis, reducing economic losses and promoting sustainable agricultural practices.
植物病害检测是农业中的一项关键任务,直接影响作物产量、粮食安全和可持续农业实践。本研究提出了FourCropNet,这是一种新型深度学习模型,旨在检测多种作物(包括棉花叶、葡萄、大豆和玉米)的病害。该模型采用先进的架构,包括残差块进行高效特征提取、注意力机制增强对病害相关区域的关注,以及轻质层提高计算效率。这些组件共同使FourCropNet能够在不同的数据集和类别复杂度上实现卓越性能,从单一作物数据集到包含15个类别的组合数据集。所提出模型在多种数据集上进行了评估,表现出高准确性、特异性、敏感性和F1分数。值得注意的是,FourCropNet在葡萄上达到了最高的99.7%准确率,在玉米上达到了99.5%的准确率,以及在组合数据集上达到了95.3%的准确率。其可扩展性和跨数据集的泛化能力证明了其稳健性。比较分析表明,在各种指标上,FourCropNet始终优于最新模型(如MobileNet、VGG16和EfficientNet)。FourCropNet的创新设计和持续性能使其成为农业实时病害检测的可靠解决方案。该模型有可能帮助农民及时诊断病害,减少经济损失,促进可持续农业实践。
论文及项目相关链接
Summary
本文介绍了一种新型深度学习模型FourCropNet,可用于检测多种作物疾病,包括棉花叶病、葡萄病、大豆病和玉米病等。该模型使用先进的架构,包括残差块进行高效特征提取、注意力机制以增强对疾病相关区域的关注,以及轻量级层以提高计算效率。FourCropNet在多个数据集和类别复杂度上实现了卓越的性能,包括单一作物数据集和包含15个类别的组合数据集。评估表明,该模型在葡萄、玉米和组合数据集上的准确率分别达到了99.7%、99.5%和95.3%。相较于其他先进模型,FourCropNet在各项指标上表现更优秀,是农业实时疾病检测的可靠解决方案。
Key Takeaways
- FourCropNet是一种用于检测多种作物疾病的深度学习模型。
- 模型使用残差块进行特征提取,注意力机制增强对疾病相关区域的关注,轻量级层提高计算效率。
- FourCropNet在多个数据集上实现了高准确率、特异性、敏感性和F1分数。
- 模型在葡萄、玉米和组合数据集上的准确率分别达到了99.7%、99.5%和95.3%。
- FourCropNet相较于其他先进模型表现更优秀。
- FourCropNet具有可扩展性和跨数据集的泛化能力。
点此查看论文截图

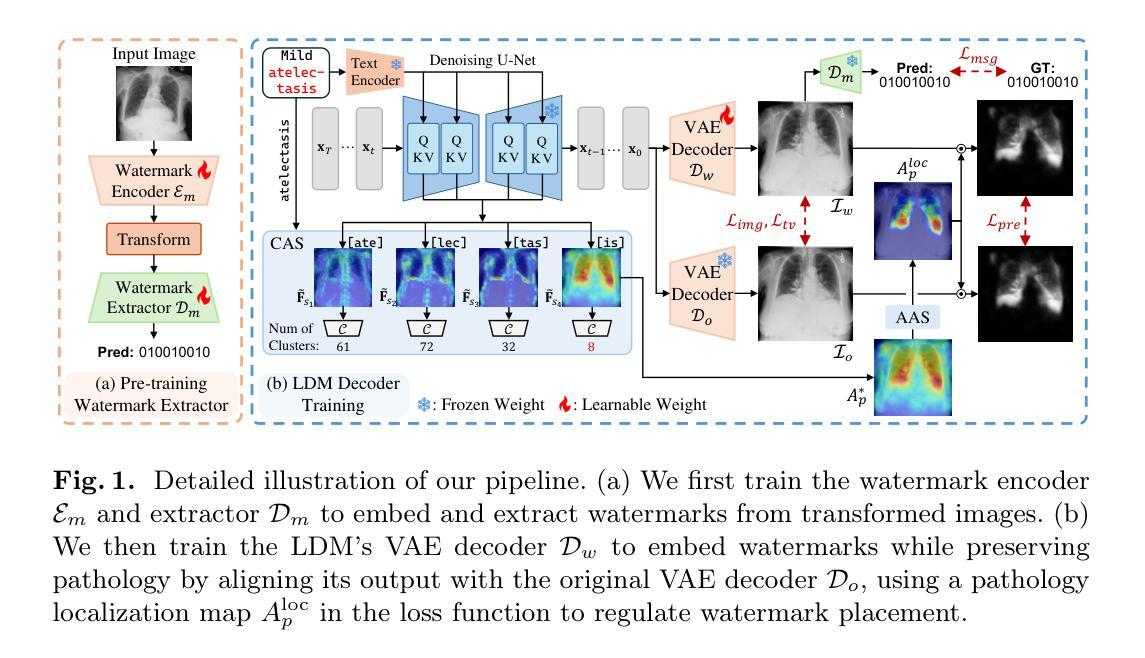
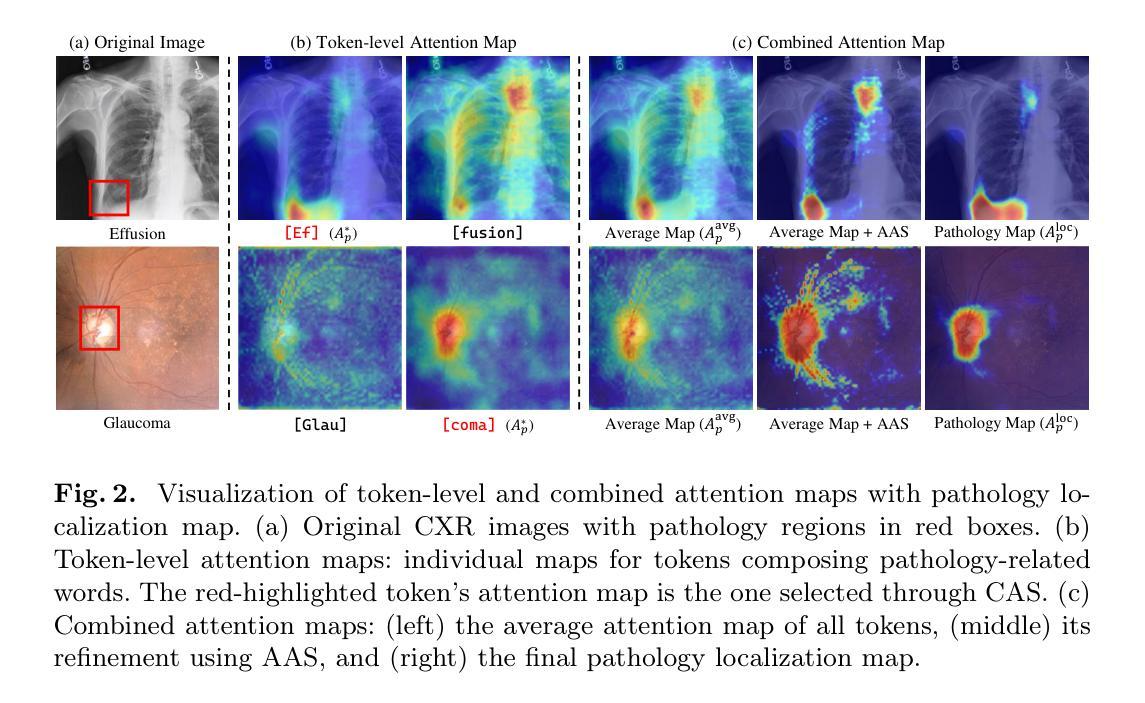
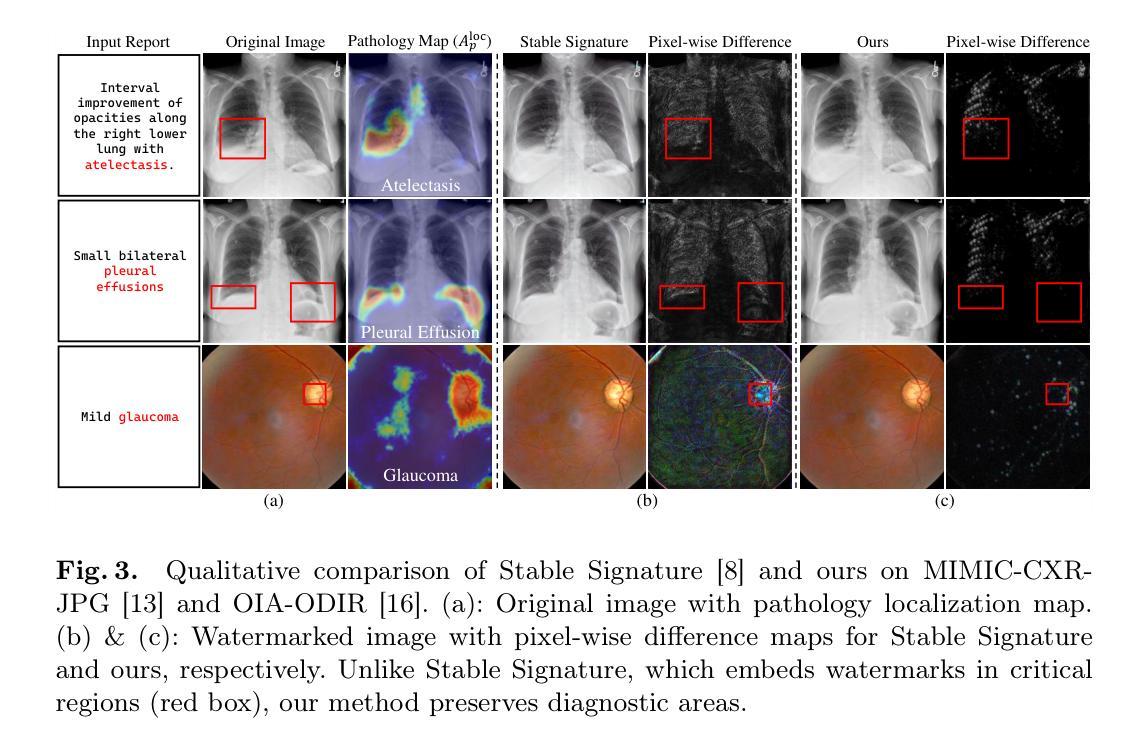
Pathology-Aware Adaptive Watermarking for Text-Driven Medical Image Synthesis
Authors:Chanyoung Kim, Dayun Ju, Jinyeong Kim, Woojung Han, Roberto Alcover-Couso, Seong Jae Hwang
As recent text-conditioned diffusion models have enabled the generation of high-quality images, concerns over their potential misuse have also grown. This issue is critical in the medical domain, where text-conditioned generated medical images could enable insurance fraud or falsified records, highlighting the urgent need for reliable safeguards against unethical use. While watermarking techniques have emerged as a promising solution in general image domains, their direct application to medical imaging presents significant challenges. A key challenge is preserving fine-grained disease manifestations, as even minor distortions from a watermark may lead to clinical misinterpretation, which compromises diagnostic integrity. To overcome this gap, we present MedSign, a deep learning-based watermarking framework specifically designed for text-to-medical image synthesis, which preserves pathologically significant regions by adaptively adjusting watermark strength. Specifically, we generate a pathology localization map using cross-attention between medical text tokens and the diffusion denoising network, aggregating token-wise attention across layers, heads, and time steps. Leveraging this map, we optimize the LDM decoder to incorporate watermarking during image synthesis, ensuring cohesive integration while minimizing interference in diagnostically critical regions. Experimental results show that our MedSign preserves diagnostic integrity while ensuring watermark robustness, achieving state-of-the-art performance in image quality and detection accuracy on MIMIC-CXR and OIA-ODIR datasets.
随着近期文本条件扩散模型能够生成高质量图像,对其潜在误用的担忧也在增长。在医学领域,这个问题尤为关键,因为文本条件生成的医学图像可能导致保险欺诈或虚假记录,这凸显了对防止不道德使用的可靠保障措施的迫切需求。虽然水印技术已作为通用图像领域的一种有前途的解决方案出现,但它们直接应用于医学成像却面临重大挑战。一个主要挑战是保持细微的疾病表现,因为水印的微小失真也可能导致临床误解,从而损害诊断的完整性。为了弥补这一差距,我们提出了MedSign,这是一个基于深度学习的水印框架,专门用于文本到医学图像合成。通过自适应调整水印强度来保持病理意义区域。具体来说,我们使用医学文本标记和扩散去噪网络之间的交叉注意力生成病理定位图,跨层、头和时间步长聚合标记式注意力。利用此图,我们优化LDM解码器以在图像合成过程中融入水印,确保无缝集成,同时最小化对诊断关键区域的干扰。实验结果表明,我们的MedSign能够保持诊断的完整性,同时确保水印的稳健性,在MIMIC-CXR和OIA-ODIR数据集上实现了图像质量和检测精度的最佳性能。
论文及项目相关链接
Summary
文本驱动的扩散模型可以生成高质量图像,但在医疗领域,这种技术可能被用于保险欺诈或伪造记录等不道德行为,因此迫切需要可靠的保障措施。针对水印技术在医学影像领域的应用存在的挑战,如疾病细微表现的失真可能导致临床误判,本文提出了一种基于深度学习的水印框架MedSign。该框架通过自适应调整水印强度,保护病理重要区域,并利用医学文本标记和扩散去噪网络的交叉注意力生成病理定位图。实验结果表明,MedSign在保持诊断完整性的同时,确保了水印的稳健性,在MIMIC-CXR和OIA-ODIR数据集上实现了图像质量和检测精度的最佳性能。
Key Takeaways
- 文本驱动的扩散模型能够生成高质量的医疗图像,但存在潜在误用风险,需采取措施防止不道德使用。
- 水印技术在医学影像领域的应用面临挑战,如保护病理细微表现、避免临床误判。
- MedSign框架是一种基于深度学习的水印解决方案,专为文本到医疗图像的合成设计。
- MedSign通过自适应调整水印强度保护病理重要区域。
- MedSign利用医学文本标记和扩散去噪网络的交叉注意力生成病理定位图。
- 实验证明,MedSign在保持诊断完整性的同时,确保了水印的稳健性。
点此查看论文截图

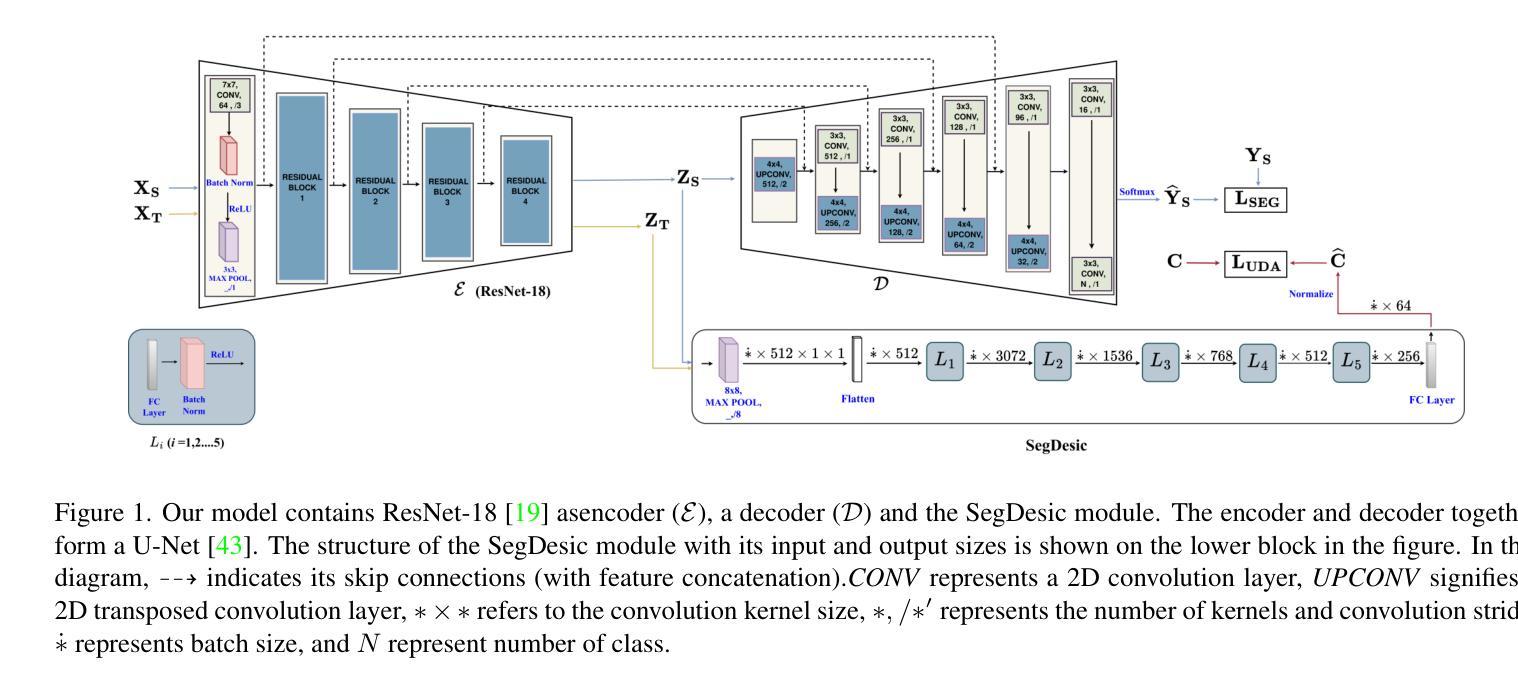
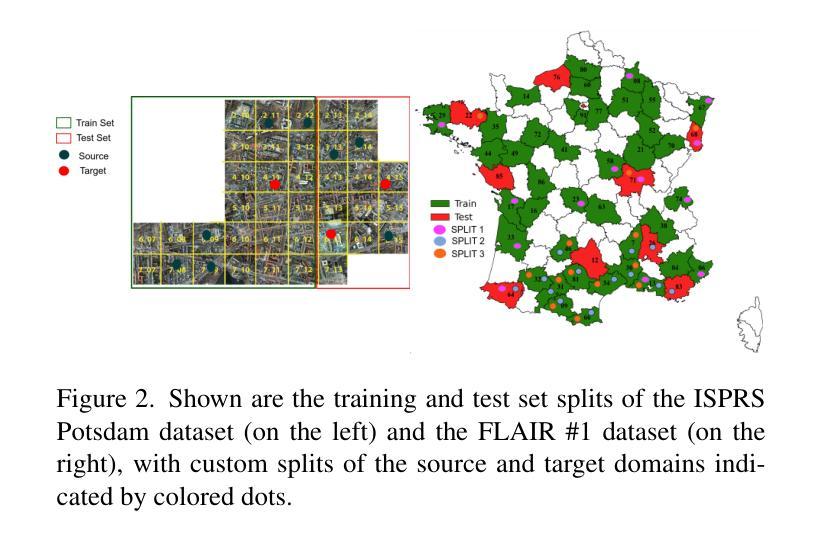
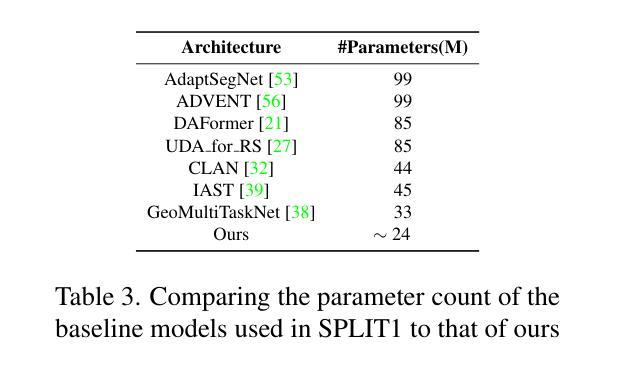
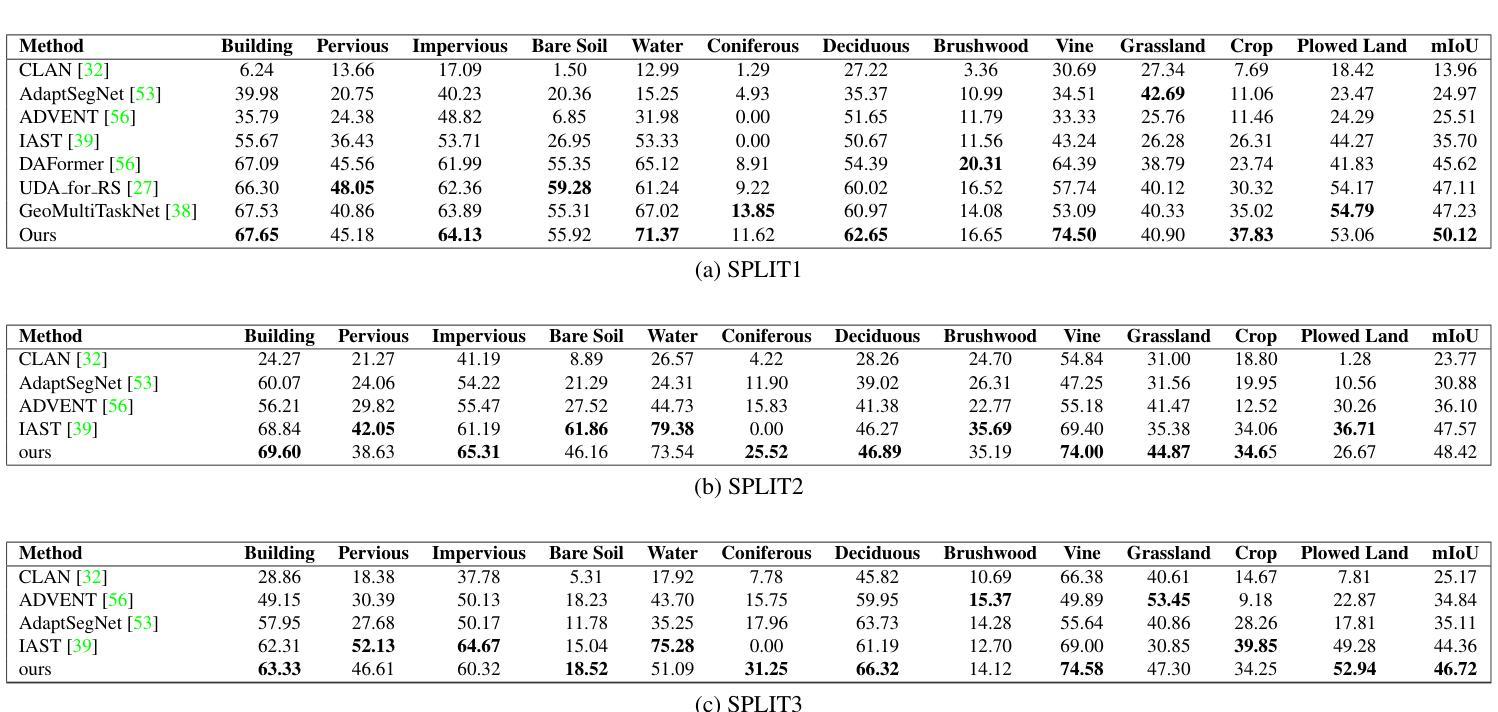
SegDesicNet: Lightweight Semantic Segmentation in Remote Sensing with Geo-Coordinate Embeddings for Domain Adaptation
Authors:Sachin Verma, Frank Lindseth, Gabriel Kiss
Semantic segmentation is essential for analyzing highdefinition remote sensing images (HRSIs) because it allows the precise classification of objects and regions at the pixel level. However, remote sensing data present challenges owing to geographical location, weather, and environmental variations, making it difficult for semantic segmentation models to generalize across diverse scenarios. Existing methods are often limited to specific data domains and require expert annotators and specialized equipment for semantic labeling. In this study, we propose a novel unsupervised domain adaptation technique for remote sensing semantic segmentation by utilizing geographical coordinates that are readily accessible in remote sensing setups as metadata in a dataset. To bridge the domain gap, we propose a novel approach that considers the combination of an image's location encoding trait and the spherical nature of Earth's surface. Our proposed SegDesicNet module regresses the GRID positional encoding of the geo coordinates projected over the unit sphere to obtain the domain loss. Our experimental results demonstrate that the proposed SegDesicNet outperforms state of the art domain adaptation methods in remote sensing image segmentation, achieving an improvement of approximately ~6% in the mean intersection over union (MIoU) with a ~ 27% drop in parameter count on benchmarked subsets of the publicly available FLAIR #1 dataset. We also benchmarked our method performance on the custom split of the ISPRS Potsdam dataset. Our algorithm seeks to reduce the modeling disparity between artificial neural networks and human comprehension of the physical world, making the technology more human centric and scalable.
语义分割对于分析高分辨率遥感图像(HRSIs)至关重要,因为它能够在像素级别对对象和区域进行精确分类。然而,由于地理位置、天气和环境变化的影响,遥感数据带来了诸多挑战,使得语义分割模型难以在多种场景中进行泛化。现有方法往往局限于特定数据域,并需要专家注释器和专用设备进行语义标注。在本研究中,我们提出了一种新型的遥感语义分割无监督域适应技术,该技术利用遥感设置中可轻松获取的地理坐标作为数据集中的元数据。为了缩小域间差距,我们提出了一种新方法,该方法结合了图像的位置编码特性和地球表面的球形特性。我们提出的SegDesicNet模块对单位球体上投影的地理坐标进行GRID位置编码,以获得域损失。实验结果表明,SegDesicNet在遥感图像分割中的性能优于最新的域适应方法,在公开可用的FLAIR #1数据集的标准子集上,平均交并比(MIoU)提高了约6%,参数数量减少了约27%。此外,我们还对我们的方法在ISPRS Potsdam数据集的自定分割上进行了基准测试。我们的算法旨在减少人工神经网络与人类对物理世界的理解之间的建模差异,使技术更加以人为中心并可扩展。
论文及项目相关链接
PDF https://openaccess.thecvf.com/content/WACV2025/papers/Verma_SegDesicNet_Lightweight_Semantic_Segmentation_in_Remote_Sensing_with_Geo-Coordinate_Embeddings_WACV_2025_paper.pdf
Summary
本文提出了基于地理坐标的无监督域自适应遥感语义分割技术。通过利用遥感设置中的元数据——地理坐标,缩小了领域差距。提出的SegDesicNet模块通过回归地球表面单位球体上的地理坐标投影的GRID位置编码特征,获得领域损失。实验结果表明,SegDesicNet在遥感图像分割领域的域自适应方法上表现出卓越性能,在公开可用的FLAIR #1数据集的标准子集上,平均交并比(MIoU)提高了约6%,参数计数减少了约27%。此外,该算法在ISPRS Potsdam数据集的自定分割上也表现出良好性能,旨在减少人工神经网络与人类对现实世界理解之间的建模差异,使技术更加以人类为中心和可规模化。
Key Takeaways
- 语义分割在高分辨率遥感图像分析中具有重要作用,能够实现像素级对象和区域精确分类。
- 遥感数据因地理位置、天气和环境变化而带来挑战,使得语义分割模型在跨场景推广时面临困难。
- 现有方法局限于特定数据域,需要专家标注器和专门设备进行语义标注。
- 研究提出了一种基于地理坐标的无监督域自适应技术,利用遥感设置中的元数据(地理坐标)来缩小领域差距。
- SegDesicNet模块通过回归地理坐标的位置编码特征,获得领域损失,实现遥感图像分割的卓越性能。
- 在公开数据集上的实验表明,SegDesicNet在遥感图像分割的域自适应方法上较现有技术有显著提高。
点此查看论文截图


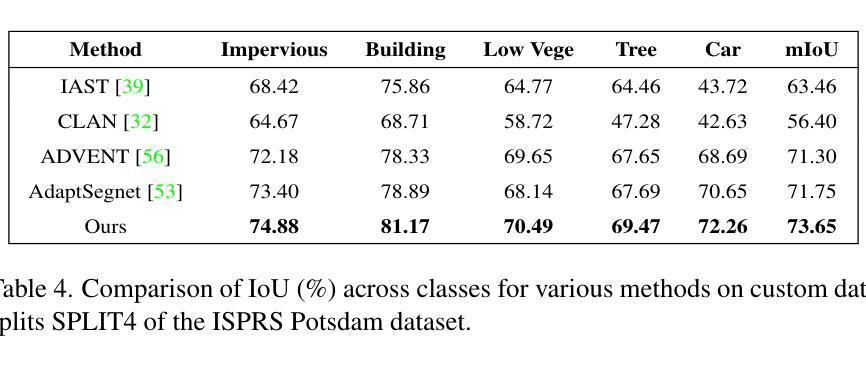
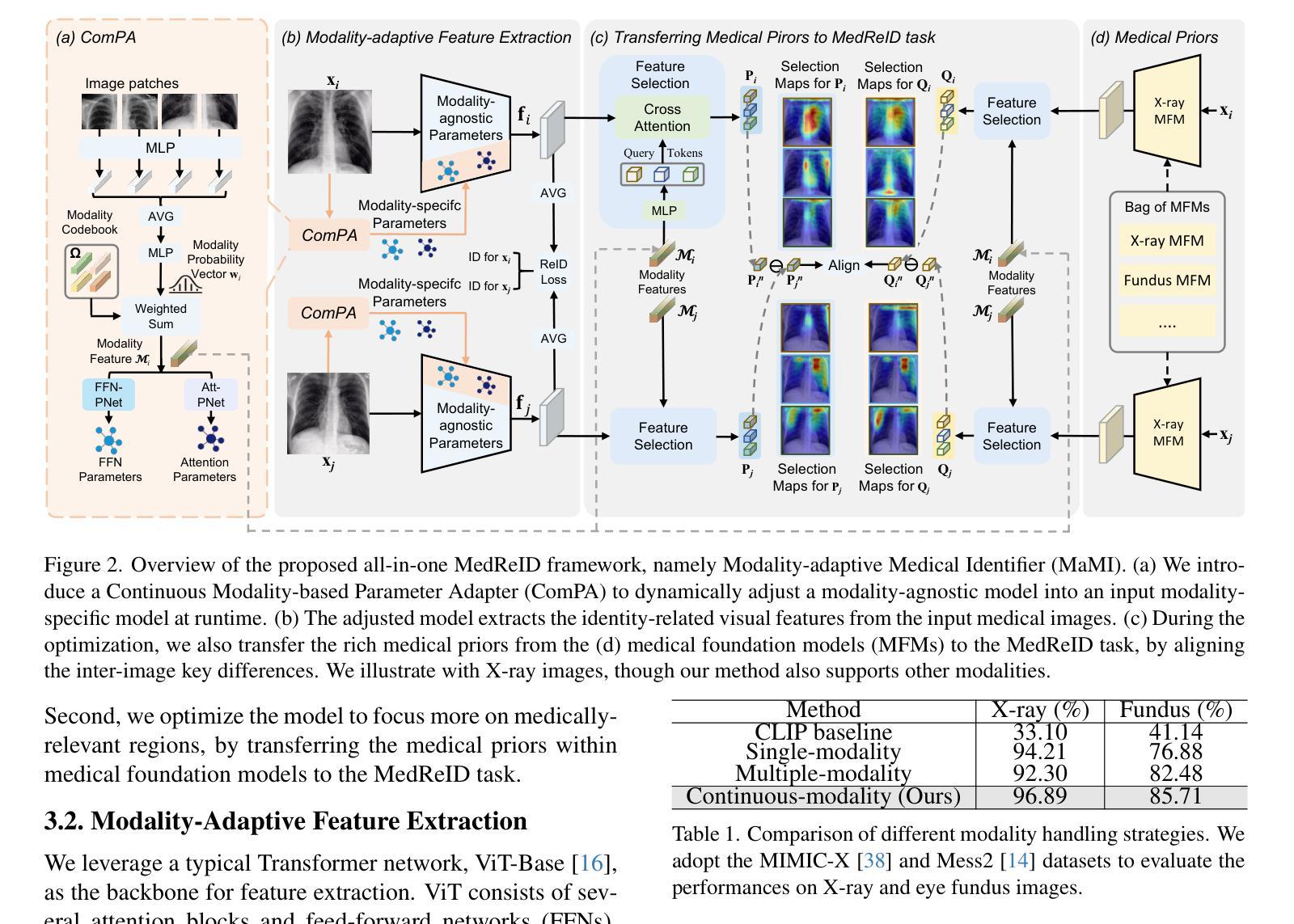
Towards All-in-One Medical Image Re-Identification
Authors:Yuan Tian, Kaiyuan Ji, Rongzhao Zhang, Yankai Jiang, Chunyi Li, Xiaosong Wang, Guangtao Zhai
Medical image re-identification (MedReID) is under-explored so far, despite its critical applications in personalized healthcare and privacy protection. In this paper, we introduce a thorough benchmark and a unified model for this problem. First, to handle various medical modalities, we propose a novel Continuous Modality-based Parameter Adapter (ComPA). ComPA condenses medical content into a continuous modality representation and dynamically adjusts the modality-agnostic model with modality-specific parameters at runtime. This allows a single model to adaptively learn and process diverse modality data. Furthermore, we integrate medical priors into our model by aligning it with a bag of pre-trained medical foundation models, in terms of the differential features. Compared to single-image feature, modeling the inter-image difference better fits the re-identification problem, which involves discriminating multiple images. We evaluate the proposed model against 25 foundation models and 8 large multi-modal language models across 11 image datasets, demonstrating consistently superior performance. Additionally, we deploy the proposed MedReID technique to two real-world applications, i.e., history-augmented personalized diagnosis and medical privacy protection. Codes and model is available at \href{https://github.com/tianyuan168326/All-in-One-MedReID-Pytorch}{https://github.com/tianyuan168326/All-in-One-MedReID-Pytorch}.
医学图像重新识别(MedReID)尽管在个性化医疗和隐私保护方面有着至关重要的应用,但目前尚未得到深入研究。在本文中,我们为此问题引入了一个全面的基准测试和统一模型。首先,为了处理各种医学模态,我们提出了新颖的连续模态参数适配器(ComPA)。ComPA将医学内容浓缩为连续模态表示,并在运行时动态调整与特定模态无关的模型的模态特定参数。这允许单个模型自适应学习和处理多种模态数据。此外,我们通过将其与预训练的医学基础模型袋进行对齐,将医学先验知识集成到我们的模型中,以差异特征为基准。与单图像特征相比,模拟图像之间的差异更适合重新识别问题,该问题涉及区分多个图像。我们在11个图像数据集上对提出的模型进行了评估,与25个基础模型和8个大型多模态语言模型进行了比较,表现出了卓越且稳定性能。此外,我们将所提MedReID技术部署到两个实际应用程序中,即历史增强个性化诊断和医疗隐私保护。相关代码和模型可通过访问链接https://github.com/tianyuan168326/All-in-One-MedReID-Pytorch获得。
论文及项目相关链接
PDF Accepted to CVPR2025
Summary
本文介绍了一种针对医学图像再识别(MedReID)问题的全面基准模型和统一模型。该模型通过连续模态参数适配器(ComPA)处理多种医学模态数据,并将其与预训练的医学基础模型对齐,以融入医学先验知识。实验表明,相较于单图像特征模型,该模型在再识别问题上表现更优异,可应用于个性化诊断和医学隐私保护等实际应用场景。
Key Takeaways
- 医学图像再识别(MedReID)是一个尚未被充分研究的问题,对于个性化医疗和隐私保护具有重要意义。
- 引入了一种全面基准模型和统一模型来解决MedReID问题。
- 提出了连续模态参数适配器(ComPA),可处理多种医学模态数据并实现自适应学习。
- 将医学先验知识融入模型,通过与预训练的医学基础模型对齐来实现。
- 实验表明,该模型相较于单图像特征模型在再识别问题上表现更优异。
- 模型可应用于个性化诊断和医学隐私保护等实际应用场景。
点此查看论文截图

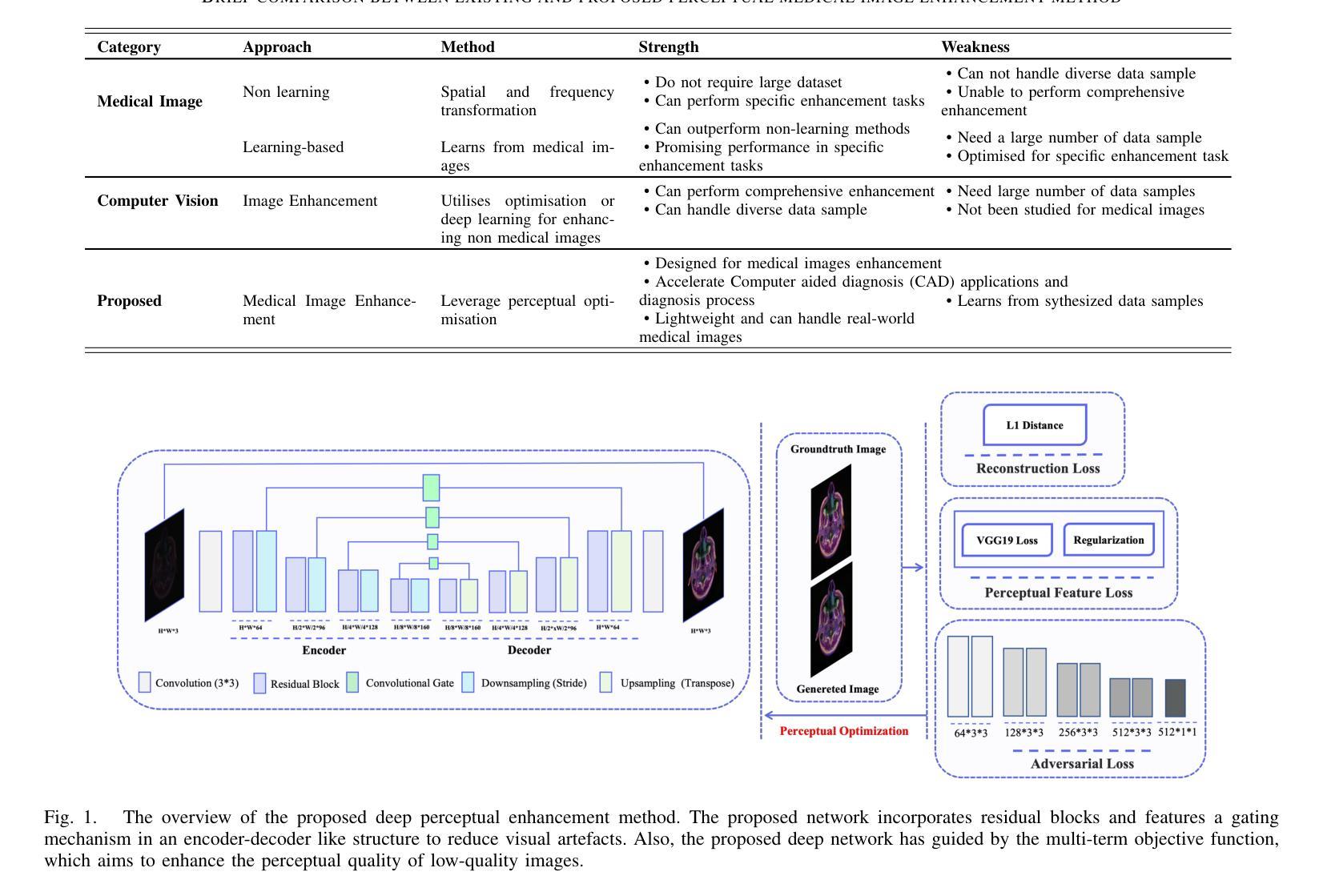
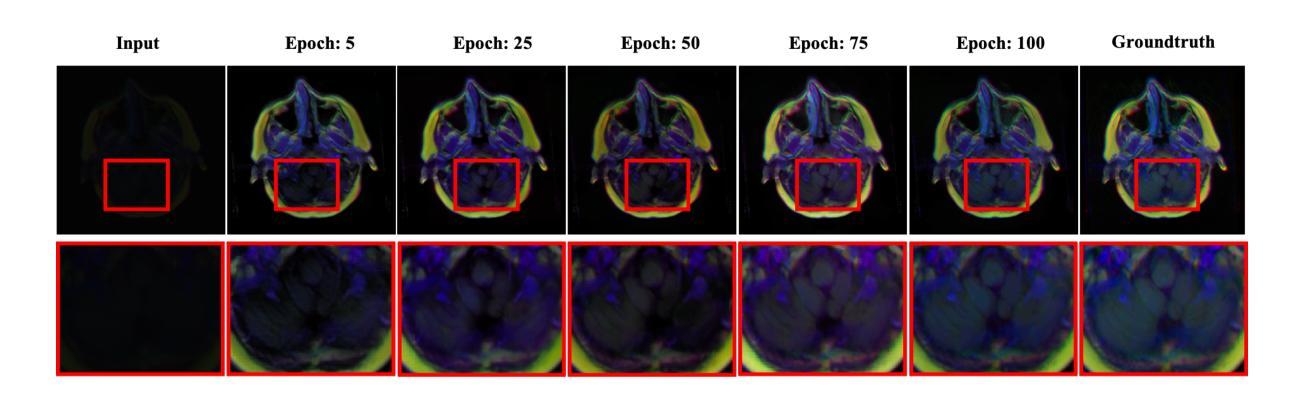
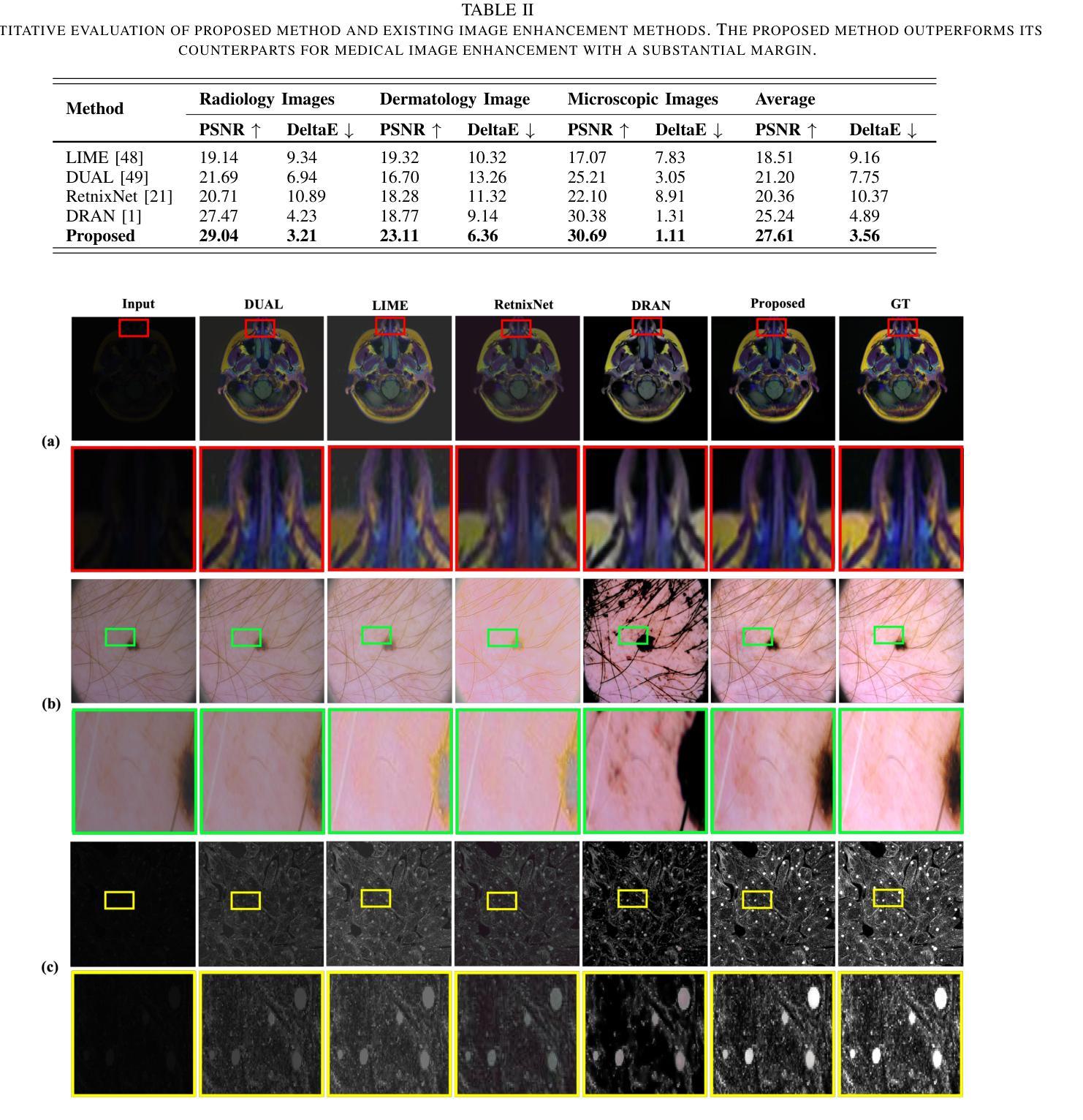
Deep Perceptual Enhancement for Medical Image Analysis
Authors:S M A Sharif, Rizwan Ali Naqvi, Mithun Biswas, Woong-Kee Loh
Due to numerous hardware shortcomings, medical image acquisition devices are susceptible to producing low-quality (i.e., low contrast, inappropriate brightness, noisy, etc.) images. Regrettably, perceptually degraded images directly impact the diagnosis process and make the decision-making manoeuvre of medical practitioners notably complicated. This study proposes to enhance such low-quality images by incorporating end-to-end learning strategies for accelerating medical image analysis tasks. To the best concern, this is the first work in medical imaging which comprehensively tackles perceptual enhancement, including contrast correction, luminance correction, denoising, etc., with a fully convolutional deep network. The proposed network leverages residual blocks and a residual gating mechanism for diminishing visual artefacts and is guided by a multi-term objective function to perceive the perceptually plausible enhanced images. The practicability of the deep medical image enhancement method has been extensively investigated with sophisticated experiments. The experimental outcomes illustrate that the proposed method could outperform the existing enhancement methods for different medical image modalities by 5.00 to 7.00 dB in peak signal-to-noise ratio (PSNR) metrics and 4.00 to 6.00 in DeltaE metrics. Additionally, the proposed method can drastically improve the medical image analysis tasks’ performance and reveal the potentiality of such an enhancement method in real-world applications. Code Available: https://github.com/sharif-apu/DPE_JBHI
由于硬件的诸多缺陷,医学影像采集设备容易产生低质量(如对比度低、亮度不当、噪声等)的图像。遗憾的是,感知退化图像直接影响诊断过程,使医务人员的决策过程变得复杂。本研究提出通过融入端到端学习策略来提升这种低质量的图像,以加速医学影像分析任务。据我们所知,这是医学影像领域中首次全面解决感知增强问题的工作,包括对比度校正、亮度校正、去噪等,采用全卷积深度网络。所提出的网络利用残差块和残差门控机制来减少视觉伪影,并由多目标函数引导以感知合理的增强图像。深度医学影像增强方法的实用性已经通过复杂的实验进行了广泛研究。实验结果表明,所提出的方法在峰值信噪比(PSNR)指标上较其他现有的增强方法可提高5.00至7.00分贝,在DeltaE指标上可提高4.00至6.00。此外,该方法能显著提高医学影像分析任务的性能,显示出这种增强方法在现实世界应用中的潜力。代码地址:https://github.com/sharif-apu/DPE_JBHI
论文及项目相关链接
PDF IEEE Journal of Biomedical and Health Informatics, 2022
Summary
本摘要针对医疗图像获取设备因硬件缺陷导致图像质量低下(如对比度低、亮度不当、噪声等)的问题。为提高这些图像质量,本研究结合端到端学习策略,加速医疗图像分析任务。该研究首次全面解决感知增强问题,包括对比度校正、亮度校正、去噪等,使用全卷积深度网络。实验结果显示,该方法在峰值信噪比(PSNR)和DeltaE指标上均优于现有增强方法。
Key Takeaways
- 医疗图像获取设备因硬件缺陷常产生质量不佳的图像,直接影响诊断过程。
- 本研究首次提出使用全卷积深度网络全面解决医疗图像的感知增强问题。
- 所提出的网络利用残差块和残差门控机制来减少视觉伪影。
- 该方法受到多目标函数的引导,以感知合理的增强图像。
- 实验证明该方法在多种医疗图像模态的增强效果上优于现有方法,峰值信噪比提升5.00至7.00 dB。
- 该方法能显著提高医疗图像分析任务的性能。
点此查看论文截图